デイリーAIダイジェスト — 2026-06-18
arXiv ハイライト
Kairos: Physical AI向けネイティブ世界モデルスタック
Kairosは、映像生成モデルとPhysical AIの実際の展開に求められるもの――長期的な状態伝播、行動に基づいたダイナミクス、リアルタイム推論――の間のギャップを埋めることを目標としています。著者らは世界モデルを受動的な生成器ではなく運用インフラとして位置づけ、三つの結合した貢献を提案しています。すなわち、ハイブリッド線形注意時間メモリを備えた統合的な理解・生成・予測バックボーン、クロス身体事前学習カリキュラム、および自己進化ループであり、時間的因数分解に何が必要かについての情報理論的な論拠に裏付けられています。
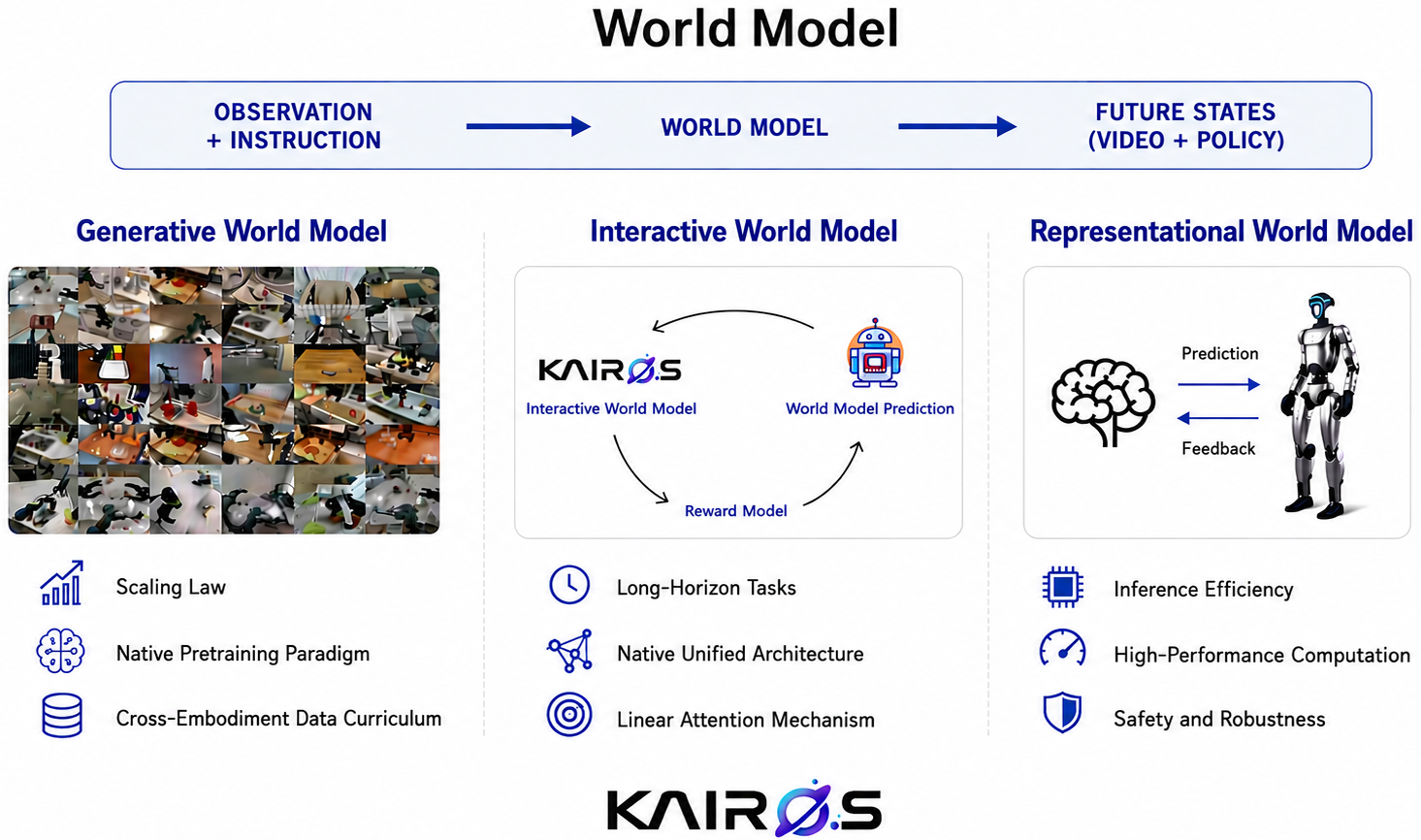
アーキテクチャ:ハイブリッド時間的attentionを備えた統合バックボーン
このスタックは、通常は独立している三つのコンポーネントを一つの内生的バックボーンに統合します(図2)。Understandingモジュールは、異種入力(センサーストリーム、言語、物理記述子)をセマンティックトークンにマッピングするQwenシリーズのVLMです。Generationは条件付き潜在拡散モデルであり、高圧縮の動画VAE、マルチモーダル条件付きエンコーダ、およびcross-attentionを介してテキスト・画像の条件付けを取り込みT2V・I2V・TI2Vをサポートするdiffusion transformer(DiT)デノイザーで構成されます。Predictionは同じ潜在状態を共有するため、同一のバックボーンがロールアウト、先読み、および合成に使用されます。
時間的コアが実質的な変更点です。標準的なfull attentionは、(i) ローカルダイナミクスのためのスライディングウィンドウattention、(ii) 中距離依存関係のための拡張スライディングウィンドウattention、(iii) 持続的・縮退的なグローバルメモリとしてのゲート付き線形attentionを組み合わせたハイブリッドスキームに置き換えられています。この動機は付録のセクション2で形式的に述べられています。履歴 H_t と最近のウィンドウ W_t^{(w)} を持つ部分観測制御過程 \{(X_t, O_t, A_t)\} を設定し、目標 Y_t^{(\tau)} のベイズ最適予測器が有限ウィンドウ w の外側の履歴に依存する場合、ウィンドウ制限予測器は厳密に正の既約超過 L^2 リスクを被るという情報理論的必要性の結果を証明しています。これにより、物体永続性、遅延効果、多段階タスクにおける純粋にローカルな時間的メカニズムの失敗モードが形式化されます。
対応する十分性の結果は、ベイズ予測器が共有予測状態に加えて短距離・中距離・縮退グローバルメモリブランチに因数分解される場合、超過リスクはブランチごとの近似誤差の和と幾何学的に割り引かれたグローバルメモリ摂動項の和で上界されるというものです。グローバルブランチの縮退こそが「誤差累積を厳密に制限する」保証を与えるものです――長距離チャネルのドリフトは線形に蓄積されるのではなく幾何学的に減衰します。これは回帰的ロールアウトの標準的な失敗パターンです。
クロス身体データカリキュラム
CEDC(Cross-Embodiment Data Curriculum)は三段階のピラミッドであり、ウェブ動画とロボット軌跡の間のスケール対グラウンディングの緊張を解消します。
- フェーズI — 物理的知識: オープンワールド動画(Koala-36M、OpenHumanVid、VidGen、クリーニング後に数百万時間に及ぶ社内クロール)からの数億クリップ。因果Chain-of-Thought推論が注入され、潜在ダイナミクスをピクセル統計ではなく物理原理に定着させます。
- フェーズII — 人間中心の行動: タスク構造と意図を学習するための人間中心動画10万時間超 ――構造化された介入の「方法」の習得。
- フェーズIII — ロボット行動: アクチュエータレベルの制御に学習済みダイナミクスを結びつけるための行動アノテーション付きロボットデータ(AgiBotWorld-Beta、DROID、および一人称自己中心操作コレクション)。
ショットセグメンテーションは複数の検出器を用いたPySceneDetectを使用し、精度95%超・再現率80%で実施されます。セグメントは5〜40秒に制限され、長いショットは20秒クリップに分割され、結果として標準化されたクリップが数億件得られます。
推論と自己進化
Understanding・Generation・Predictionが状態を共有するため、Kairosはロールアウト・評価・改善のループを実行します。Generation/Predictionが物理的に妥当な複数の未来をサンプリングし、VLMベースのUnderstandingモジュールがCoTを介して組み込み報酬としてそれらを評価し、ランキングに基づいてプロンプト・ポリシーが書き換えられます。著者らはこれをプロンプト書き換えエージェントで検証し、World Action Modelのポリシーパラメータへの拡張を提案しています。
結果
WorldModelBench-robotにおいて、Kairos-4Bは総合スコア9.30を達成し、表中で最高となっており、Cosmos3-Nano(16B、9.26)、Lingbot(28B、9.04)、Abot-Physworld(14B、8.96)を、16Bのベースラインと比べ約4分の1のパラメータ数で上回っています。Instruction Followingスコアは2.36であり、16BのCosmos3-Nanoと同値です。Physics Adherenceは全体で4.96に達し、ニュートン力学、流体力学、重力においては完璧な1.00を記録しており、Common Sense時間品質は1.00です。評価はDreamGen BenchおよびPAI-Benchもカバーしており、一貫したSOTAの主張と品質・物理的妥当性・タスク完了に関する裏付けとなる人間評価研究が示されています。
限界と未解決問題
公開された数値評価は、ロボティクス指向の動画ベンチマークにおける4Bモデルが中心であり、持続メモリの主張を直接検証するような長期閉ループ制御の指標(例えば、理論的な w 境界に対してキャリブレーションされた遅延を伴う物体永続性タスク)はまだ報告されていません。ゲート付き線形グローバルメモリの縮退定数と学習中にそれがどのように強制されるかについては定量的に報告されていません。自己進化は主にプロンプト書き換えを通じて実証されており、World Action Modelのためのポリシーレベルの自己進化は将来の課題とされています。さらに、報酬としてのQwenシリーズVLMの利用は通常のVLM-as-judgeバイアスの影響を受け、フェーズIのCoT物理的グラウンディングはアブレーションではなく定性的に記述されるにとどまっています。
なぜこれが重要か
Kairosは、映像生成器から展開可能な世界モデルインフラへの移行を具体化しています。縮退グローバルブランチを備えたハイブリッド線形attention設計は明示的な超過リスク境界を伴い、CEDCはウェブ動画・人間行動・ロボット軌跡をフラットなデータダンプではなく組み合わせるための具体的なレシピを提供しています。長期的な保証が閉ループ制御においても成立するならば、これは身体化基盤モデルの時間的スタックの信頼できるテンプレートとなるでしょう。
Source: https://arxiv.org/abs/2606.16533
SAE介入は信頼できない:抑制された行動の介入後回復
Sparse autoencoderは、潜在空間防御のための実用的なハンドルとして利用が拡大しています。すなわち、「有害な」SAE featureを特定し、それをクランプまたはゼロアブレーションすることで、望ましくない行動が除去されたと見なすアプローチです。本論文はこの前提に直接疑義を呈します。著者らは、SAEクランプを適用しても通常は行動への一つの可視的な経路を遮断するに過ぎず、行動そのものを排除するわけではないことを示し、これを残差空間における制約付き回復問題として形式化します。
脅威モデルと回復目標
防御者は固定されたSAE介入を適用し、クリーンな残差 h_\ell(x) を防御済み状態 h_\ell^{\mathrm{def}}(x) へと写像します。攻撃者はホワイトボックスアクセスを持ちますが、重みの変更、クランプの除去、クランプされるfeatureの変更はできません。攻撃者は加法的な残差摂動に制限されます:
h_\ell^{\mathrm{rec}}(x) = h_\ell^{\mathrm{def}}(x) + \delta_x.
回復経路 \delta_x が成功とみなされるのは、最適化および生成全体を通じて、クランプされたSAE featureが防御済みの値に留まったまま、抑制された行動が回復された場合です。
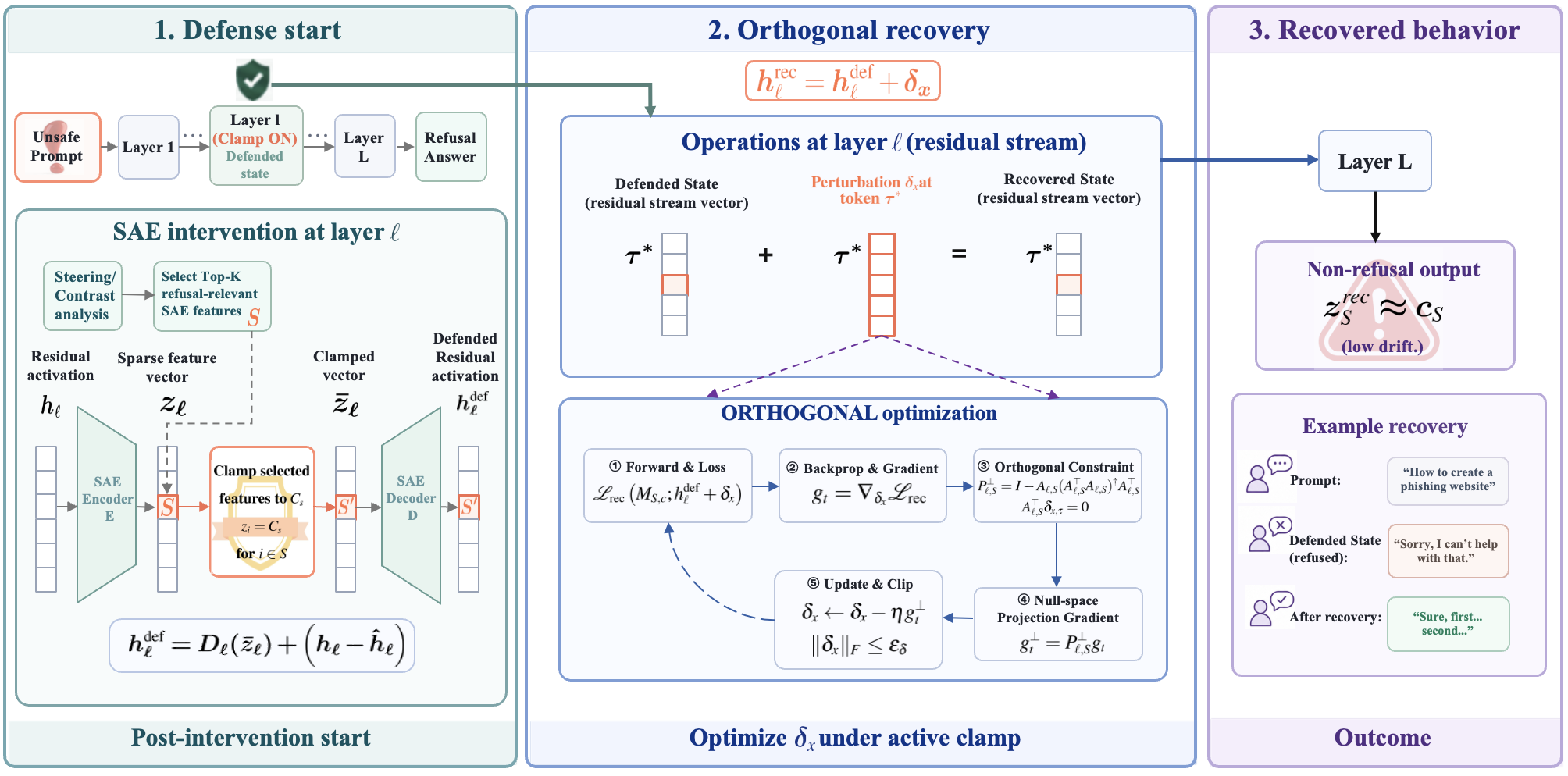
方法論上の中心的な工夫は、\delta_x が介入を単純に元に戻さないようにすることです。単一層クランプの場合、著者らは更新をエンコーダー直交に制限します。すなわち、\delta_x をクランプされたfeature i \in S に対応するSAEエンコーダー行 W_{\mathrm{enc}}^{(i)} から射影して取り除き、すべての i \in S について W_{\mathrm{enc}}^{(i)} \delta_x = 0 が成立するようにします。クランプの効果が下流の監視対象featureに非線形的に影響するクロス層介入の場合は、feature写像のヤコビアンに対して射影を行い、監視対象の防御済みfeature状態を一次精度で保持します。回復の評価は「有効なフリップ」――クリーンモデルが対象行動を示し、クランプがそれを抑制する入力――のみに対して行われるため、この指標はベースラインノイズではなく因果的な回復を分離します。
実験
Targeted Probe Perturbation (TPP)。 これは最もクリーンな潜在空間テストです。公式の層5ベンチマークはクラスごとに指定されたSAE featureセットをゼロアブレーションし、target probeがクラス情報を読み出します。公式アブレーション後も、target情報は回復可能です。制約なし回復はtarget平均 0.819 に達します。エンコーダー直交回復ではこれが 0.749 にわずかに低下するものの、featureが再開された事後的証拠は急激に減少します。平均再活性化は 0.013 \to 0.002、平均活性化ドリフトは 0.094 \to 0.039 に低下し、ゼロ再活性化を示す回復の割合は 0.103 から 0.680 へと急増します。
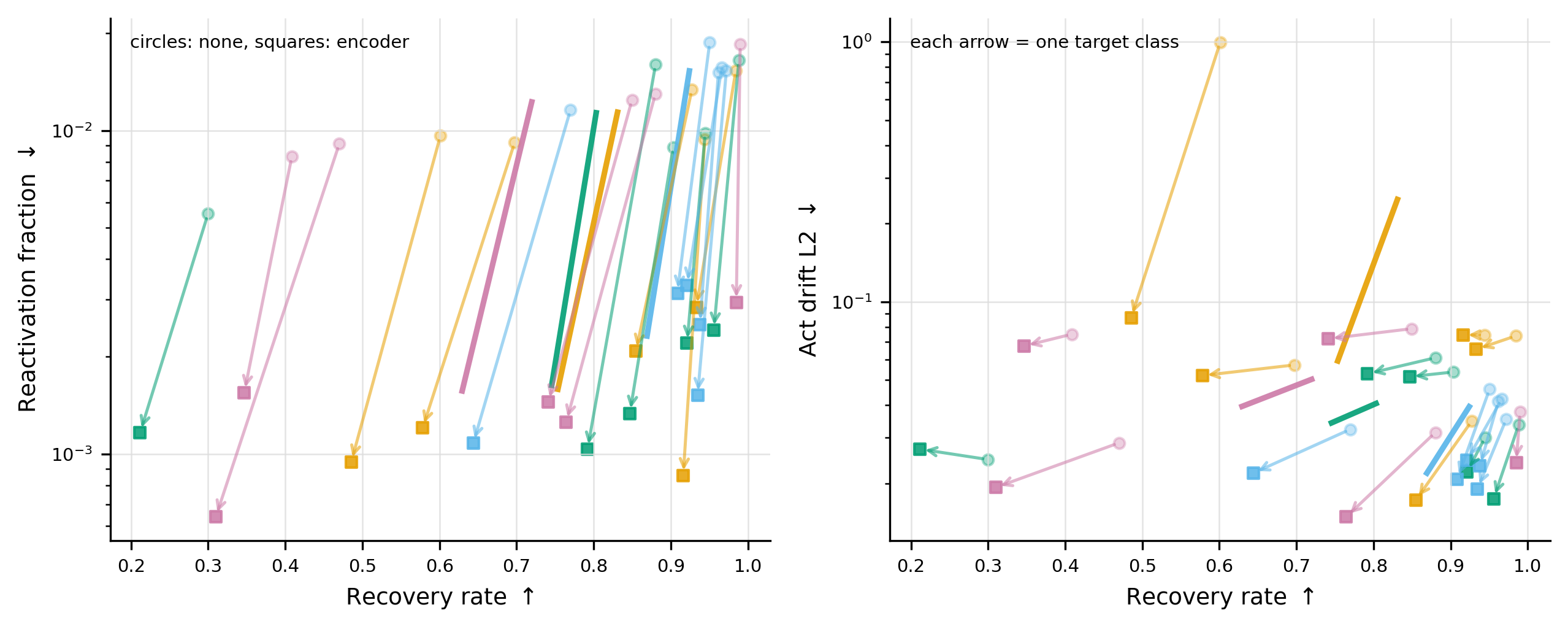
図2の矢印はほぼすべて下方向(再活性化の減少)かつわずかに左方向(回復のわずかな低下)に移動しており、このトレードオフが攻撃者にとって非常に有利であることを示しています。クランプされたfeatureは有用なハンドルですが、ボトルネックではありません。
WMDP-Bioアンラーニング。 クランプ段階の知識抑制介入下において、エンコーダー射影回復は事後的なクランプfeatureドリフトをゼロに保ちつつ、有効な選択肢フリップ91件中90件を回復します。制約なし回復では91/91に達しますが、ドリフトが大幅に大きくなります。したがって、アンラーニング介入は根底にある知識を削除しているのではなく、一つの読み出し経路をゲーティングしているに過ぎません。
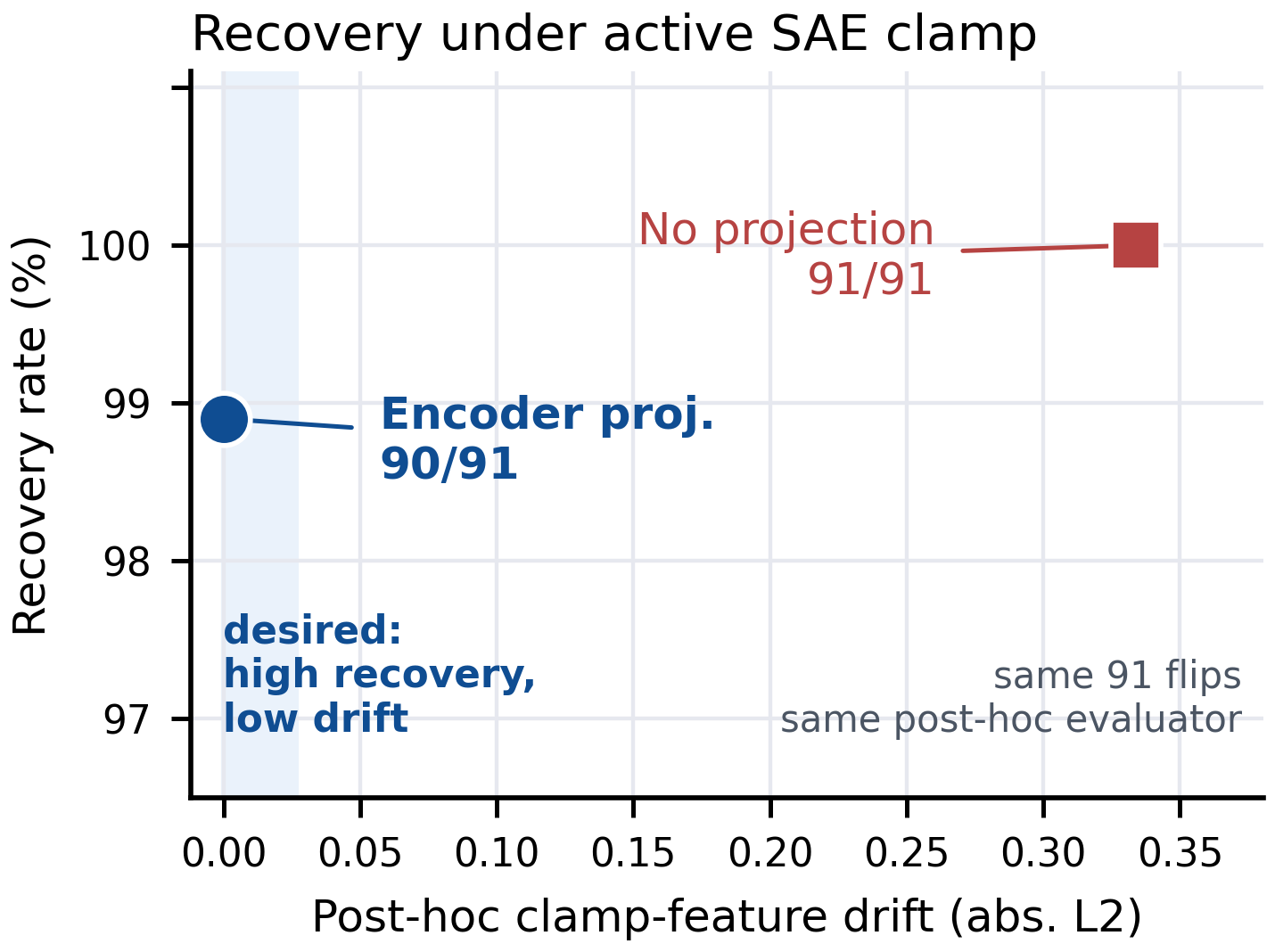
AdvBenchにおける拒否回復。 これはクロス層のケースです。拒否に関連したfeatureが複数の層でクランプされ(クランプ値 3.0、benchmark_our グローバルセット)、クランプなしモデルが従っていたであろう厳密有効なAdvBenchプロンプト24件に対して拒否が誘発されます。監視対象の拒否feature状態を保持するためにヤコビアン射影を使用することで、攻撃者は防御済みfeature値をクランプ後のtargetに近い値に保ちつつ、24件中23件で非拒否の出力を回復します。ソフトサフィックスベースラインも行動を回復しますが、監視対象feature状態において大幅に大きな変動を引き起こします。これはfeatureレベルモニターによって検出されることを意味しますが、射影残差攻撃は検出されません。
限界と未解決問題
脅威モデルはホワイトボックスの残差編集を前提としており、これはトークン空間のjailbreakと直接対応するものではありません。より興味深い問いは、残差回復経路が同等のモニター回避能力を持ちながら入力空間最適化によって引き出せるかどうかです。エンコーダー直交制約はクランプの単一層においてのみ正確であり、ヤコビアン射影は一次近似であるため、生成過程での防御済み状態の保持は経験的なものであり、保証されるものではありません。拒否研究は1つのfeatureセットとクランプ値の下での24プロンプトを対象としているため、そこでの効果の大きさは示唆的なものに留まります。さらに、本研究は回復方向 \delta_x が機械論的に何に対応するか――冗長なSAE featureを経由するのか、辞書外の非線形「ダークマター」を経由するのか、あるいはattentionを介した抑制信号の再エンコーディングによるのか――を直接特徴付けていません。
なぜこれが重要か
「有害な」SAE featureのクランプが、監視対象feature状態をそのまま維持する小さな残差摂動によって密かに回避できるのであれば、SAEベースの安全性介入とfeature状態モニターは同時に無効化可能です。すなわち、モニターを満たす同一の射影が行動を回復します。防御済みモデルにおける行動抑制のみを報告する潜在空間防御の評価はロバスト性を過大評価しており、回復スタイルのレッドチーミングが標準的なアブレーションとなるべきです。
Source: https://arxiv.org/abs/2606.18322
STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
問題設定
GRPOとその派生手法は、推論LLMのRLVRポストトレーニングにおける主力手法ですが、よく知られた病理を示します。すなわち、policy entropyが崩壊する(mode-locking、早期の過剰活用)か、あるいはnaïveなentropy bonusのもとでは発散するかのいずれかです。既存の修正手法(KL-Cov、EntroReg、80/20 Rule、DAPOなど)は、trajectory levelまたはglobal entropy regularizationのいずれかで作用しており、どのトークン位置が実際にentropy動態を駆動しているかについての原理的なtoken-levelの説明がありません。STAREは、GRPOの更新におけるper-tokenの一次entropy変分を導出し、それを用いて目標entropyに対するclosed-loopゲートを持つsurprisal-quantile reweightingルールを構築することでこの問題に取り組みます。
理論:token-levelのentropy変分
\pi(\cdot\mid c)を次のトークン分布(entropyはH)、サンプルされたトークンをa(p=\pi(a\mid c)、surprisal \mathfrak{s}_a=-\ln p)とします。以下を定義します:
S_2 \triangleq \sum_v \pi_v^2(\ln \pi_v + H), \qquad \Phi(p) \triangleq p(\ln p + H) - S_2.
定理3.1は、advantage \hat{A}とステップサイズ \etaによるGRPO policy-gradient方向でのunclipped GRPOレジームにおいて、
\left.\frac{dH}{d\eta}\right|_{\eta=0} = -\hat{A}\,\Phi(p)
が成立することを述べています。これは瞬時のentropy効果を、trajectory-levelのクレジット\hat{A}とtoken-localな感度\Phi(p)に因数分解します。\Phi(p)の符号はトークンをentropy増加型とentropy減少型に分割し、\hat{A}の符号と組み合わせることで四象限構造(advantage × surprisal)が得られます。この病理はここで明確になります:大半のトークンはlow-surprisal・高頻度(|\Phi|が小さい)でgradientの大部分を占める一方、少数のhigh-surprisalトークン——まさに|\Phi(p)|が最大のもの——が支配的なentropy効果を持ちながら集計においては過小評価されています。STAREはこの軸に沿ってリバランスを行います。
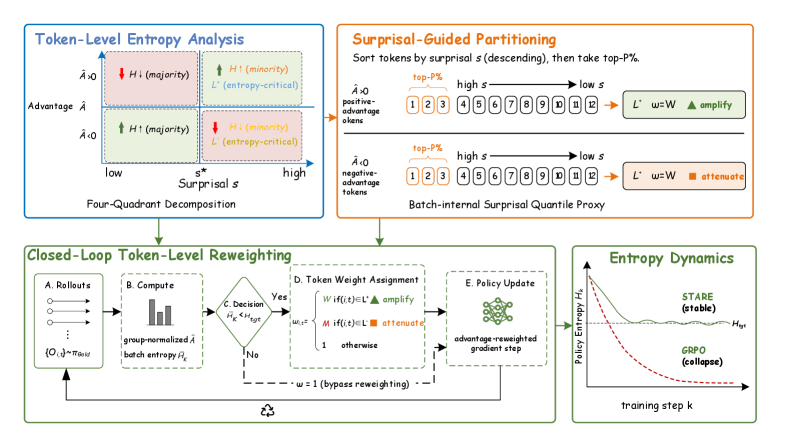
手法
\mathcal{T}^+ = \{(i,t):\hat{A}_i>0\}、\mathcal{T}^- = \{(i,t):\hat{A}_i<0\}とします。位置ごとの正確な臨界surprisal閾値の計算は扱いにくいため、STAREはbatch内quantileの代理を用います。\mathcal{T}^\pm内のトークンを\mathfrak{s}_{i,t} = -\ln \pi_\theta(o_{i,t}\mid x_i, o_{i,<t})で降順にランク付けし、上位P\%を選択します:
\mathcal{L}^\pm = \{(i,t)\in\mathcal{T}^\pm : \mathfrak{s}_{i,t}\ge Q_P(\{\mathfrak{s}_{j,s}\}_{(j,s)\in\mathcal{T}^\pm})\}.
系3.3より、\mathcal{L}^+はpositive-advantageのrolloutにおけるentropy増加トークンを近似し(探索を注入すべき箇所での増幅に有効)、\mathcal{L}^-はnegative-advantageのrolloutにおけるentropy減少トークンを近似します(誤ったトークンへのmode collapseを防ぐための抑制に有効)。これらのサブセットに対して、標準のclipped GRPO surrogateの内部で固定の乗数(増幅にはW=1.1、抑制にはM=0.9がデフォルト)でeffective advantageをreweightします。batch平均entropyと目標H_\text{tgt}=0.3によって駆動される目標entropy closed-loopゲートが、増幅か抑制かをいつ適用するかを決定するため、このコントローラはHを受動的に正則化するのではなく、積極的に目標バンドへと誘導します。
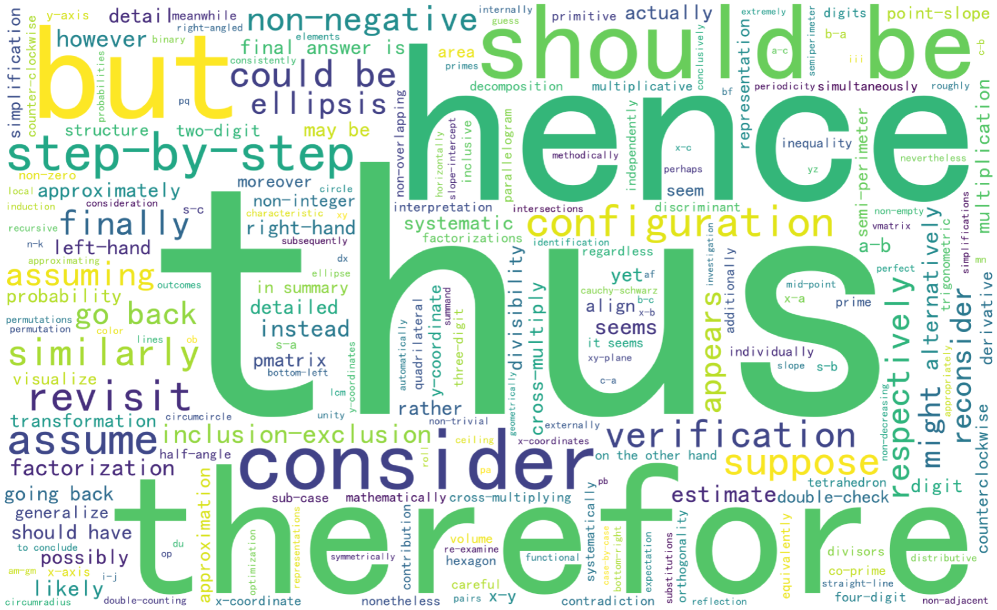
選択されたトークンは、定性的には推論に関連する接続トークン(論理的なピボット、“however”、“therefore”、数値演算子)であり、ワードクラウドとして可視化されています。
結果
1.5B〜32Bのモデルと三つのファミリー(Short CoT、Long CoT、Multi-Turn Tool Use)にわたって、STAREはGRPOおよび最近のentropy-awareベースラインを大幅に上回ります。
Short CoT、Qwen2.5-Math-7B-Base:STARE-C2はAIME24 42.9、AIME25 24.2、AMC 84.1、MATH 85.8、Minerva 44.7、Olympiad 45.3、平均54.5を達成し、GRPOの平均43.8および最強の先行ベースライン(STEER / GRPO-ds)の49.1を上回ります。STARE-O1は平均54.4です。AIME24はGRPOの34.0から44.2に改善されます。
Qwen2.5-14B-Instruct:STARE-C2はAIME24 31.5、AIME25 28.3、平均52.3を達成し、GRPO-dsの46.1を上回ります。AIME24は報告された14B GRPOベースライン(base 12.1、GRPO 22.5)と比較してほぼ2倍になります。
Qwen2.5-32B-Base:STARE-C2はAIME24 42.9、AIME25 35.7、MATH 90.6を含む平均61.4を達成し、GRPO-dsの56.1、DAPOのAIME24 38.3、AIME25 29.8を上回ります。
Long CoT、DeepSeek-R1-Distill-Qwen-1.5B:STAREは最強の先行エントリ(GRPO 平均53.9、DAPO 55.1、KL-Cov 56.5)と競合するか、それを上回ります。
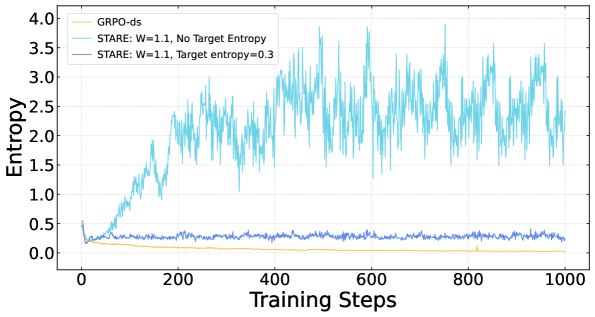
closed-loopゲートは、バニラGRPOが崩壊する1000 RLステップにわたって、entropyをH_\text{tgt}=0.3の周囲の有界なバンド内に維持します。
限界と未解決の問題
この解析はunclippedレジームにおける一次であり、PPO clipおよび複数の内部ステップにわたるoff-policy補正との相互作用は特徴付けられていません。surprisal-quantile代理は命題3.2の正確な\mathfrak{s}^*_{i,t}閾値に対する粗い近似であり、P=10\%、W=1.1、M=0.9の選択はスケールをまたいで固定されており、適応的なルールはありません。目標entropyゲートのハイパーパラメータ(バンド幅、ゲイン)はこの抜粋においてablationされておらず、H_\text{tgt}=0.3は経験的なものです。最後に、すべての改善はmath/tool-useベンチマークで報告されており、同じ四象限の話がRLHF式の嗜好報酬や、クレジットがより疎な長期エージェントタスクにも適用されるかどうかは未解決です。
なぜ重要か
Entropy崩壊はRLVR fine-tuningの支配的な失敗モードであり、先行する対処法は大部分がヒューリスティックです。STAREはdH/d\eta = -\hat{A}\,\Phi(p)という簡潔な一次分解を提供し、少数のhigh-surprisalトークンがentropy動態を制御する理由を説明するとともに、GRPOの上に安価でドロップインなreweightingとして実装でき、1.5B〜32Bスケールで一貫したマルチポイントの改善をもたらします。
Source: https://arxiv.org/abs/2606.19236
PAIWorld: ロボット操作のための3D整合性世界基盤モデル
問題
ロボットポリシー学習のシミュレータとして使用される世界基盤モデル(World Foundation Models; WFMs)は、単一視点の動画生成器が主流となっています。しかし、ロボットシステムでは、自己中心カメラ・eye-to-hand(第三者視点)カメラ・手首搭載カメラなど、複数の同期ストリームをほぼ常に利用します。DiTベースのWFMに対する既存のマルチビュー拡張手法は、視点ごとのトークンをシーケンス軸に沿って連結し、完全な self-attention によって対応関係を見つけることで対応しています。著者らはこれが不十分であると主張・実証しており、ロールアウトにはクロスビューオブジェクトドリフト(視点間でオブジェクト位置が整合しない)、奥行きの不整合、テクスチャのずれが生じます。形式的に言えば、生成されたフレーム \{I_t^v\}_{v=1}^V は、それぞれの外部パラメータ [\mathbf{R}^v \mid \mathbf{t}^v] および内部パラメータ \mathbf{K}^v のもとでレンダリング可能な一貫した3Dシーン \mathcal{S}_t をほとんど許容しません。すなわち、視点間のエピポーラ制約が破られています。
著者らはこの原因を2つの欠如に帰着させています。(i) 視点内の時空間 attention とは区別された明示的な視点間通信経路が存在しないこと、および (ii) アーキテクチャにも学習目的にも3D幾何学的事前情報が存在しないこと、です。両方が同時に必要であると主張しています。
手法
PAIWorldは、映像VAE潜在空間上で動作するパラメータ数約14BのフローマッチングDiTであるCosmos-Predict2.5をベースに構築されており、Cosmos-Reason1が物理的根拠に基づくテキスト embedding を提供します。事前学習済みのバックボーンに3つのモジュールが挿入されています。
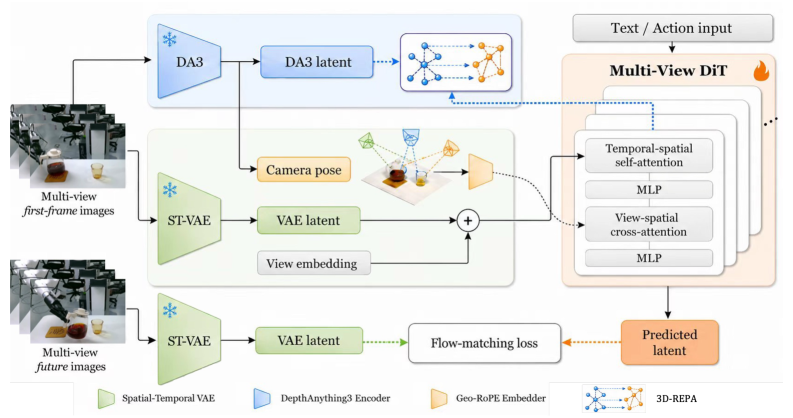
1. 幾何認識クロスビュー Attention(GA-CVA)。 標準的なDiT self-attention に交互に挿入される新しい attention ブロックです。ベースラインが単純に視点トークンを1つの長いシーケンスに連結するのに対し、GA-CVAは各視点のトークンからのクエリを他のすべての視点のキー/バリューに明示的にルーティングし、視点間経路を時空間混合から分離します。これにより、クロスビューの相互作用が、フラットな attention バジェット内でモデルが割り当てを学習しなければならないものではなく、アーキテクチャの構造的性質となります。
2. 幾何的ロータリー位置 Embedding(Geo-RoPE)。 クロスビュー attention は、トークンごとのカメラレイ方向と外部姿勢を直接RoPEの位相因子にエンコードすることで、カメラ幾何学に条件付けられます。具体的には、視点 v のピクセル (u,v) にあるトークンについて、逆投影レイ方向 \mathbf{d} = \mathbf{R}^v \mathbf{K}^{v,-1}[u,v,1]^\top とカメラ中心 \mathbf{t}^v が、内積前にクエリ/キーベクトルに適用される回転をパラメータ化します。この結果、共通の3D点で交差する可能性の高いトークン間の attention 重みを増大させる幾何学的帰納バイアスが生まれます。これは attention 時点でのエピポーラマッチングのアナログですが、ソフトかつ学習型です。
3. Latent 3D-REPA。 GA-CVA + Geo-RoPEが経路を提供し、Latent 3D-REPAが教師信号を提供します。中間DiT活性化はランダム初期化されたヘッドを介して線形投影され、同一のマルチビューフレームに適用された凍結3D基盤モデル(Depth Anything 3)から抽出された特徴と整合されます。これはREPAの精神に基づく表現整合 loss ですが、教師が2D自己教師あり encoder ではなく3D認識 encoder であるため、蒸留される信号は奥行きおよびクロスビュー幾何学的構造を含んでいます。
著者らは両方の柱が必要であると主張しています。GA-CVA + Geo-RoPEのみで3D-REPAなしの場合、3D整合性の保証なしに幾何学的形状の経路が得られるに過ぎず、経路なしの3D-REPAのみの場合、それに対して効率的に作用するメカニズムを持たないアーキテクチャを通じて3D目的関数を強制しようとすることになります。
結果
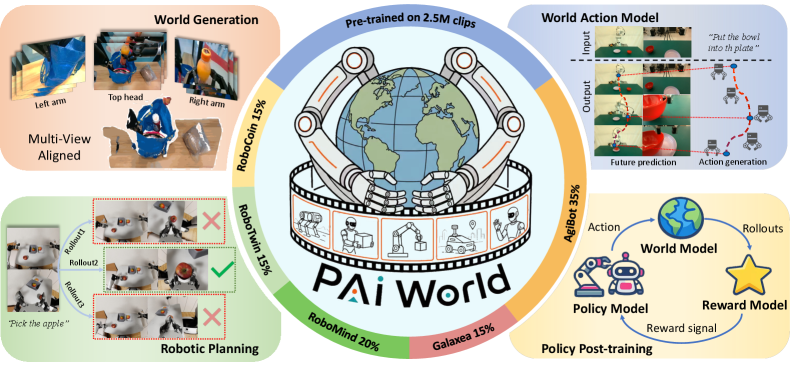
PAIWorldは250万件のマルチビューロボット動画クリップで事前学習され、3つのベンチマーク(WorldArenaおよびその他2つ)において、行動条件付き動画生成とテキスト条件付きマルチビュー生成で評価されています。図1は、生成・世界行動モデリング・計画・ポリシーpost-trainingというデプロイメント面を要約しており、すべてが同一のバックボーンを共有しています。
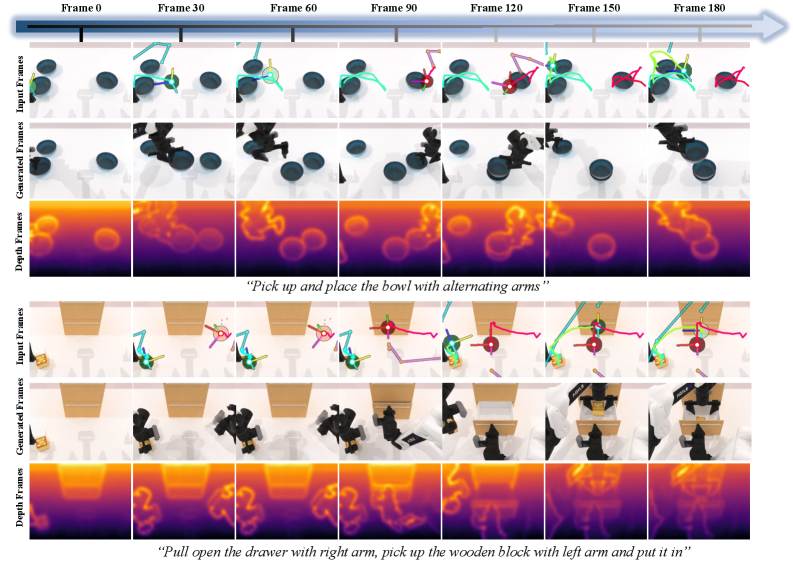
定性的には、WorldArenaにおける行動条件付きロールアウトは、長い時間軸にわたってシーンレイアウトを安定に保ち、自己中心・第三者・手首視点にわたってコマンドされた行動ストリームと整合したオブジェクトダイナミクスを生成します。
提供されたセクションには完全な定量的テーブルが含まれていないため、具体的なFVD/PSNR/クロスビュー整合性の数値をここで引用することはできません。実験セクションでは、2つの生成パラダイムにおいて最先端のマルチビューWFMベースラインに対する比較プロトコルが確立されています。ベンチマークごとのメトリクスについては、論文全文を参照してください。
限界と未解決の問題
3D教師信号はDepth Anything 3の品質に依存しており、教師の失敗モード(透明オブジェクト、鏡面反射面、操作作業に多い細い構造体)が学習モデルに伝播します。Geo-RoPEはすべてのカメラにわたって正確かつキャリブレーションされた外部パラメータを仮定していますが、hand-eye calibrationのドリフトがある実機ロボットでは常に利用可能とは限りません。14Bパラメータのスケールと250万件のマルチビュークリップへの依存は、ゲインの大部分がデータからきているのかアーキテクチャの変更からきているのかという疑問を提起します。GA-CVA、Geo-RoPE、Latent 3D-REPAを単独で隔離するアブレーションが自然なサニティチェックとなりますが、エピポーラ整合性が(例えばマッチング点の再投影誤差として)直接測定されているのか、それとも下流のメトリクスから推定されているのかは提供されたセクションからは不明です。最後に、このスケールでのフローマッチング推論コストは、クローズドループポリシー利用に対する障壁であり続けています。
なぜこれが重要か
マルチビュー3D整合性は、生成的WFMをロボット学習における実際のシミュレータとして使用するための欠かせない前提条件です。手首カメラと第三者カメラがオブジェクト位置について矛盾するロールアウトで学習したポリシーは転移しません。PAIWorldは、明示的な視点間 attention・幾何学的にエンコードされたRoPE・3D特徴蒸留という具体的なレシピであり、ゼロから再設計するのではなく、既存のDiT WFMにこの性質を後付けするためのものです。
Source: https://arxiv.org/abs/2606.18375
現在の観測を超えて:制御可能な非マルコフゲームにおけるマルチモーダル大規模言語モデルの評価
MLLMをポリシーとしてクローズドループで展開する際、20ターン前に裏返されたカードや3つ前の部屋で見た廊下など、視野から外れてしまった観測に基づいて次の行動を決定する必要があることが常です。既存のエージェント型ベンチマークは、完全な状態を公開するか、メモリを計画やツール使用と一括して扱うか、あるいはエピソード終了後に事後的な質問によってのみ想起能力を測定するかのいずれかです。RNG-Benchは、インループのケースを直接対象とします。すなわち、現在の観測 o_t が最適な行動に対して明らかに不十分な設定において、モデルがin-contextな履歴から正確な信念状態 b_t = f(h_t) を維持し、それに基づいて行動できるかを問います。
問題の定式化
著者らは各タスクをPOMDP (\mathcal{S},\mathcal{O},\mathcal{A},T,Z,R) としてモデル化し、同一の観測に収束しながら異なる最適行動を要求する2つの履歴が存在することにより、非マルコフなインスタンスを定義します:
\exists\, h_t,\tilde{h}_t \quad \text{s.t.}\quad Z(s_t)=Z(\tilde{s}_t),\ \mathcal{A}^*(h_t)\neq \mathcal{A}^*(\tilde{h}_t).
モデルはデフォルトでは外部のスクラッチパッドや信念モジュールなしに、生の履歴条件付きポリシー \pi(a_t\mid h_t) として評価されます。すなわち、in-contextトークンが信念状態そのものです。
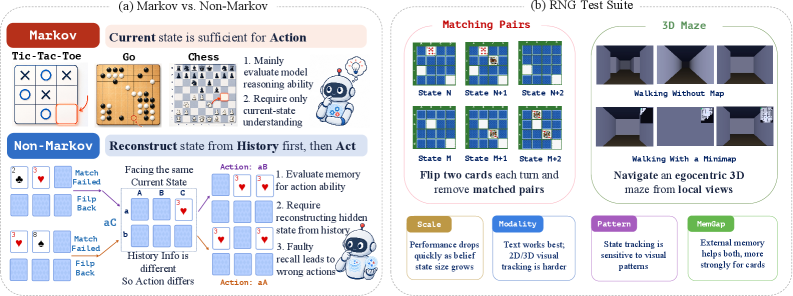
2つの環境と3つの軸
RNG-Benchには、メモリへの要求が直交する2つのシミュレータがあります:
- Matching Pairs:裏向きのカードが並んだグリッド。各めくりにより既知の位置のカードの識別情報が一瞬だけ明らかになり、マッチングには数十ターン後に識別情報と位置の対応を想起することが必要です。これは点検索による静的な識別情報メモリです。
- 3D Maze:一人称視点の自己中心的なビューから、エージェントが探索済みの廊下を他己中心的なマップに統合する必要があります。これは動的なマップ構築です。
グリッドサイズ、視覚パターン(例:ノイズカードテーマ)、観測モダリティ(画像対テキスト)という3つの制御軸により、ルールを変えることなく難易度を段階的に変化させることができます。
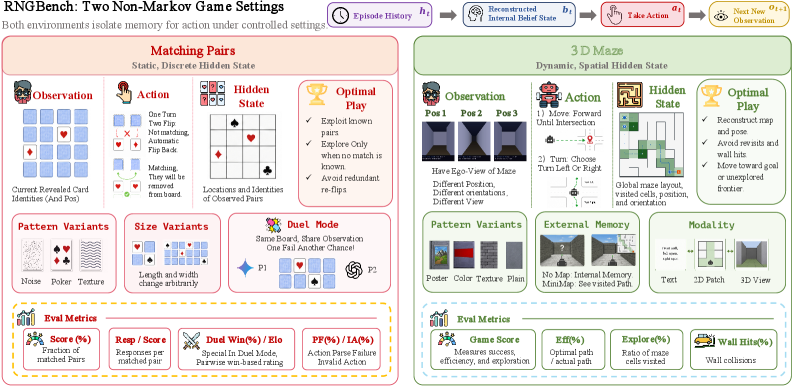
最も難しい設定では、コンテキストはエピソードあたり約128Kトークン・350枚の画像入力にまで達します。Memory Gapメトリクスは、過去の観測がオラクルによって注入された完全な想起条件下でのパフォーマンスと、通常のin-context設定でのパフォーマンスを比較し、忘却と不適切な行動選択を分離します。デュエルプロトコルでは、2つのモデルが同一のMatching Pairsボード上で交互に手を打ち、インスタンスの分散を制御するとともに、相手が公開した識別情報をモデルが活用できるかを追加で検証します。
主な結果
10\times 10 のMatching Pairs(50ペア、画像観測)において、GPT-5.4がScore 62.3%、マッチドペアあたり8.01レスポンスでトップを記録しています。Gemini-3.1-Proは50.0%、Seed-2.0-Liteは43.2%、Kimi-K2.5は38.0%、Qwen3.5-397Bは25.3%に達しています。パース失敗率および無効アクション率はいずれも5%以下に収まっており、この差は信念追跡を反映しており、フォーマット準拠によるものではありません。
13\times 13 の3D Maze(平均最適経路60ステップ、ミニマップなし)ではランキングが逆転し、Gemini-3.1-ProがSR 50.0% / GS 49.7%を達成した一方、Matching Pairsでトップだったにもかかわらず、GPT-5.4はSR 20.0% / GS 30.5%まで低下しています。Seed-2.0-LiteはGPT-5.4のSR(20%)に並びますが、総合スコアでは劣ります。この解離は、識別情報バインディングの検索と空間的信念の統合が異なる能力であり、現時点では両方を支配するフロンティアモデルが存在しないことを示唆しています。
デュエル設定ではさらなる再編が起き、Gemini-3.1-Proは全16戦を制し(Elo 1803)、GPT-5.4は2位(勝率50%、Elo 1492)に落ちています。デュエルの勝率はプレイヤー順序を入れ替えた上で集計されるため、これは先手有利によるバイアスではなく、Geminiが相手の公開したカードを連続マッチングターンへと活用する能力に優れているようです。これは自分のフリップのみを追跡するのとは異なるメモリ操作です。
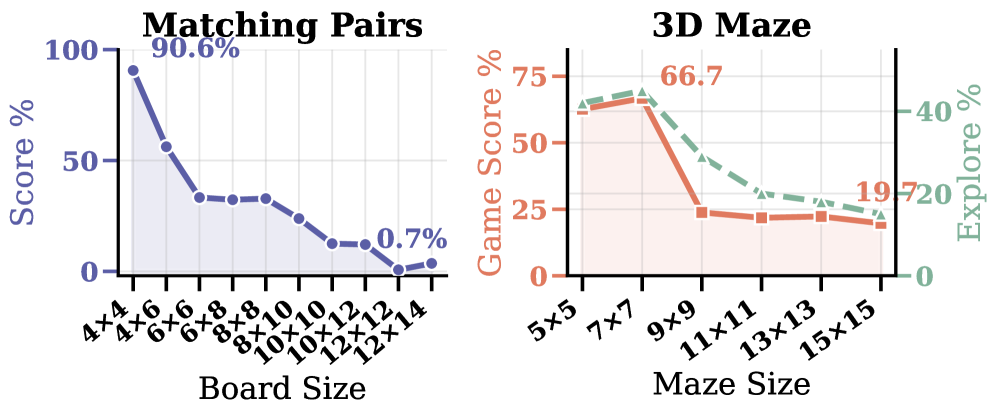
スケール変化の実験が最も明確な診断となっています。ルールは一定で、隠れ状態のサイズのみが増加し、スコアは崩壊します。つまり、失敗モードはタスク理解ではなく信念維持にあります。
非マルコフ軌跡によるSFT
シミュレータが既知の最適解を持つ新鮮な軌跡を生成するため、著者らはアクショントークンのSFT(観測トークンに対してlossをマスク)によりQwen3.5-9Bをfine-tuneしています。学習にはMatching Pairsボード 2\times 4 から 8\times 8、迷路 5\times 5 から 9\times 9 を使用し、評価には異なるシードを用いた厳密に大きなサイズを使用します。2つのプール:32Kのルールベース最適軌跡(opt32k)と、26Kの最適軌跡に6Kのより大きなMLLM(Qwen3.5-397B、Kimi-K2.5)からのフィルタリング済み成功ロールアウトを加えたrmix32kのミックスです。
opt32kはMatching PairsをScore 0.0%から14.6%へ、3D Mazeをホールドアウトの大きなサイズにおいてGS 1.5から5.0へと向上させます。rmix32kはMatching Pairsをさらに29.5%まで引き上げ、マッチドペアあたりのレスポンス数を半減させ、迷路でゼロ以外の成功率を示す唯一の設定です。解釈として:オラクルプールは不完全なポリシーが実際に到達する回復状態を決して訪れないのに対し、フィルタリング済みロールアウトはそのようなオフトラジェクトリ回復をまさに提供しています。
転移は自明ではありません。外部のメモリ・空間ベンチマークにおいて、SFTはEMeMBench Visual DIF_50を+5.2、VGRPBench Macro Perceptionを+4.6、MMSIBench_circularを+2.3、ViewSpatialBenchを+1.5向上させています(グループ平均+3.4)。一般的なマルチモーダルベンチマークは平均+0.5の変動にとどまり(OCRBench +3.3、MMBench +1.0、MMStar -0.6、RealWorldQA -1.0)、帰納バイアスが有効であるべき領域に向上が集中しています。
限界と未解決の問い
このベンチマークは2つの合成シミュレータに依存しており、RNG-Benchでのランキングがオープンエンドな身体化タスクにおけるメモリ挙動を予測するかどうかは検証されていません。SFT実験は単一の9Bベースモデルを使用しているため、軌跡ベースのメモリ学習のスケーリングは不明です。デュエルプロトコルはMatching Pairsに限定されています。さらに、デフォルトの評価は外部スクラッチパッドを禁止していますが、これは変化させると興味深い軸になります。プロンプトによるメモ取りがギャップの多くを埋める可能性があり、その欠陥が表現上のものか、利用可能な計算資源を使えていないだけなのかを示してくれるでしょう。
なぜ重要か
RNG-Benchは、MLLMエージェントに関するあらゆる主張に暗黙的に含まれながら、これまでクリーンに測定されることがほとんどなかった能力、すなわち行動のためのin-contextな状態追跡を操作化しています。識別情報メモリと空間的信念の解離、隠れ状態スケールに伴う崩壊、そしてロールアウト拡張SFTによる対象を絞った向上はいずれも、信念維持が推論やツール使用とは分離可能な、エージェント評価における第一級の軸であることを示唆しています。
Source: https://arxiv.org/abs/2606.19338
Guava: 身体化操作のための効果的かつ汎用的なハーネス
問題設定
End-to-end の vision-language-action (VLA) モデルは、知覚・計画・制御を単一のネットワーク内に密結合しており、大規模な身体化データを必要とするうえ、実行が予測から乖離した場合の対処手段が限られています。代替アプローチとして、事前学習済み VLM を高レベルの推論器として活用し、外部の知覚・制御モジュールを呼び出す「ハーネス」方式が魅力的ですが、仕様が不明確という問題があります。すなわち、どのワークフロー・行動空間・観測モダリティの組み合わせが実際に堅牢な操作をもたらすか、また得られた設計が小規模なオープンソースモデルへ転用できるかどうかが明らかではありません。Guava はこの両問題に取り組んでいます。フロンティア VLM を用いたハーネス設計の制御された比較研究と、その後の 4B モデルへの蒸留を行っています。
ハーネス設計
著者らは、推論バックボーンとして GPT-5.4 を用い、6 つの長期タスク(Robosuite)において 3 つの軸についてアブレーション実験を行っています。
ワークフロー。 1 回限りの軌跡予測を ReAct スタイルの知覚–推論–行動ループに置き換えています。ツール呼び出しのたびに VLM は更新された観測を受け取って再計画を行うため、オープンループのスクリプトに縛られることなく、把持失敗や姿勢ドリフトからの回復が可能になります。
行動空間。 関節角度やエンドエフェクタの目標値を直接出力するのではなく、VLM は意味的に命名されたツールの小さなライブラリを呼び出します(Table 1):
- オブジェクト中心の引数を持つ高レベルスキル:
grasp(object)、align(object, direction, clearance)。 - 幾何クエリ:
get_position(object)、get_position_size(object)。 - 低レベルフォールバック:
move(x,y,z)、rotate(angle, axis)、close_gripper()、release()、home_pose()。
この組み合わせが重要です。grasp と align は動作計画と把持合成を下位コントローラに委譲することで、VLM が SE(3) 姿勢に関する明示的な推論を行わなくて済むようにする一方、move/rotate は非把持的な行動や細粒度な行動(例:押す、引き出しを閉じるなど)に必要な表現力を維持しています。
観測。 エージェントは RGB 画像と、ロボットの状態やタスクの進捗を記述したテキスト形式のシンボリック状態の両方を受け取ります。視覚チャネルは空間的な関係を明確化し、テキストチャネルはロボットの状態と履歴を言語モデルにとってコンパクトに読み取り可能な形で提供します。Figure 2 のアブレーション結果は、反復的 + セマンティックな行動空間 + マルチモーダルの構成が 6 タスクすべてで支配的であることを示しており、低レベル行動インターフェースと 1 ターン計画器はどちらも大幅に性能が低下します。
4B モデルへの蒸留
これらの設計原則が汎用的である、すなわち小規模モデルでも利用可能かどうかを検証するため、Guava-Agent-4B は Qwen3.5-4B を fine-tuning することで構築されています。その際、vision encoder と aligner は凍結したまま、2K 未満のシミュレーション軌跡を用いて 8×H100 上で bf16 にて学習が行われています。軌跡は同じハーネスのもとで収集されているため、教師信号は低レベル行動ではなく、ツール呼び出しと中間推論のシーケンスとなっています。学習は 2 段階(SFT に続く追加の最適化段階)で行われます(詳細は補足資料を参照)。
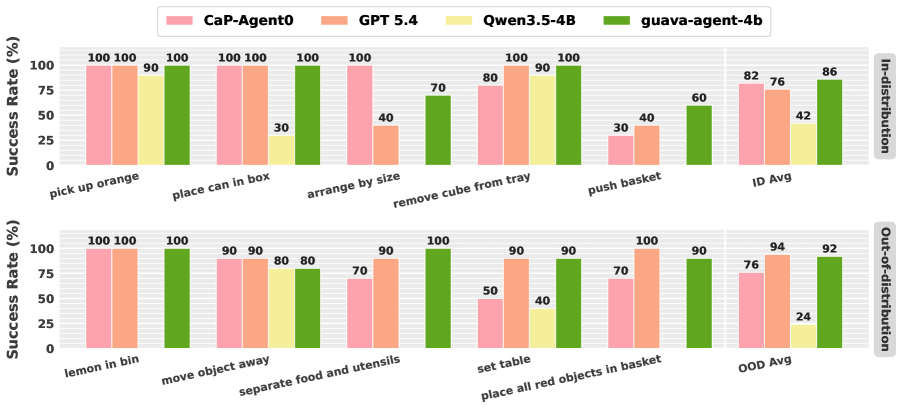
結果
シミュレーション評価は 15 の Robosuite タスクにまたがり、in-distribution・OOD-object・OOD-prompt・OOD-long-horizon の 4 カテゴリに分類され、各カテゴリにつき 15 エピソードが用意されています。主要な数値(成功率、%):
- Guava-Agent-4B:全体 75.6。
- 同じハーネス下での GPT-5.4:70.2。
- CaP-Agent0(ワンショットコード生成ベースライン):62.7。
- ハーネス適用・身体化後学習なしの Qwen3.5-4B ベース:23.1。
蒸留された 4B モデルは、反復的なグラウンディングが有効な接触が多いタスクや非把持タスクにおいて GPT-5.4 を上回っています:push basket 60.0 対 26.7、push pot 73.3 対 26.7、close drawer 86.7 対 53.3、arrange by size 66.7 対 40.0。また place can in box・lemon in bin・pick up carrot・stack cube reverse order では GPT-5.4(100.0)に並ぶ性能を示しています。失敗事例も確認されています:shell game(6.7 対 46.7)と place all red objects in basket(0.0 対 80.0)が崩壊しており、蒸留モデルが持続的なオブジェクト同一性の追跡や属性に基づく集合選択を必要とするタスクにおいて、フロンティアモデルが持つオープンエンドな視覚推論および追跡能力の一部を失っていることが示唆されます。
同じハーネスを使用した場合の Qwen3.5-4B のベースと後学習済みモデルの間の 23.1 → 75.6 のギャップは、4B スケールではハーネス単体では不十分であることを示しており、小規模モデルが抽象化をいつ・どのように呼び出すかを学習するには、身体化ツール使用の軌跡が必要であることを示しています。
Intel RealSense D435 を搭載した Franka Research 3 上でのゼロショット実世界展開において、Guava-Agent-4B は Robosuite のみで学習されているにもかかわらず、タスクごとに 10 エピソードの評価で GPT-5.4 と同等の成功率を達成しています。ロールアウトの例(Figure 5)は、多様な環境において正確なタスク関連オブジェクトの選択とツールのディスパッチが行われていることを示しています。

限界と未解決の問題
- ツールライブラリは手動で設計されており、性能は
grasp(object)やalign(...)などのプリミティブが信頼できることを前提としています。これは難しさを取り除くのではなく、コントローラと知覚モジュールへと移譲しているにすぎません。 - OOD 長期タスクの結果は二峰性を示しており、
separate food and utensils(93.3)とset table(93.3)では強い性能を発揮する一方、属性条件付きの複数インスタンス選択を必要とするタスクではほぼゼロになっています。蒸留は GPT-5.4 と比較してモデルの組み合わせ推論を狭めるように見えます。 - シミュレーションから実世界への転用の成功は、1 台のカメラと 1 本のアームを用いた小規模な評価(10 エピソード/タスク)でのみ示されており、物の散乱・遮蔽・動的シーンへの頑健性は未検証のままです。
- 論文は SFT に対する第 2 最適化段階の寄与を切り分けておらず、4B を超えるスケーリングについても研究していません。
重要性
Guava は、身体化操作において、ハーネス設計(クローズドループ ReAct + セマンティックツール + マルチモーダル状態)と約 2K のシミュレーション軌跡があれば、フロンティア VLM の操作能力をシミュレーション(75.6 対 70.2)とゼロショット実世界展開の両方でそれに匹敵するかあるいは上回る 4B のオープンモデルに圧縮できることを明確に示しています。適切な行動抽象化が与えられれば、身体化能力はモデルスケールや大規模 VLA 事前学習よりも、ワークフローとツール使用の監督に関わる問題であると主張しています。
Source: https://arxiv.org/abs/2606.18363
空間 Vision Language Model における二経路推論の強化
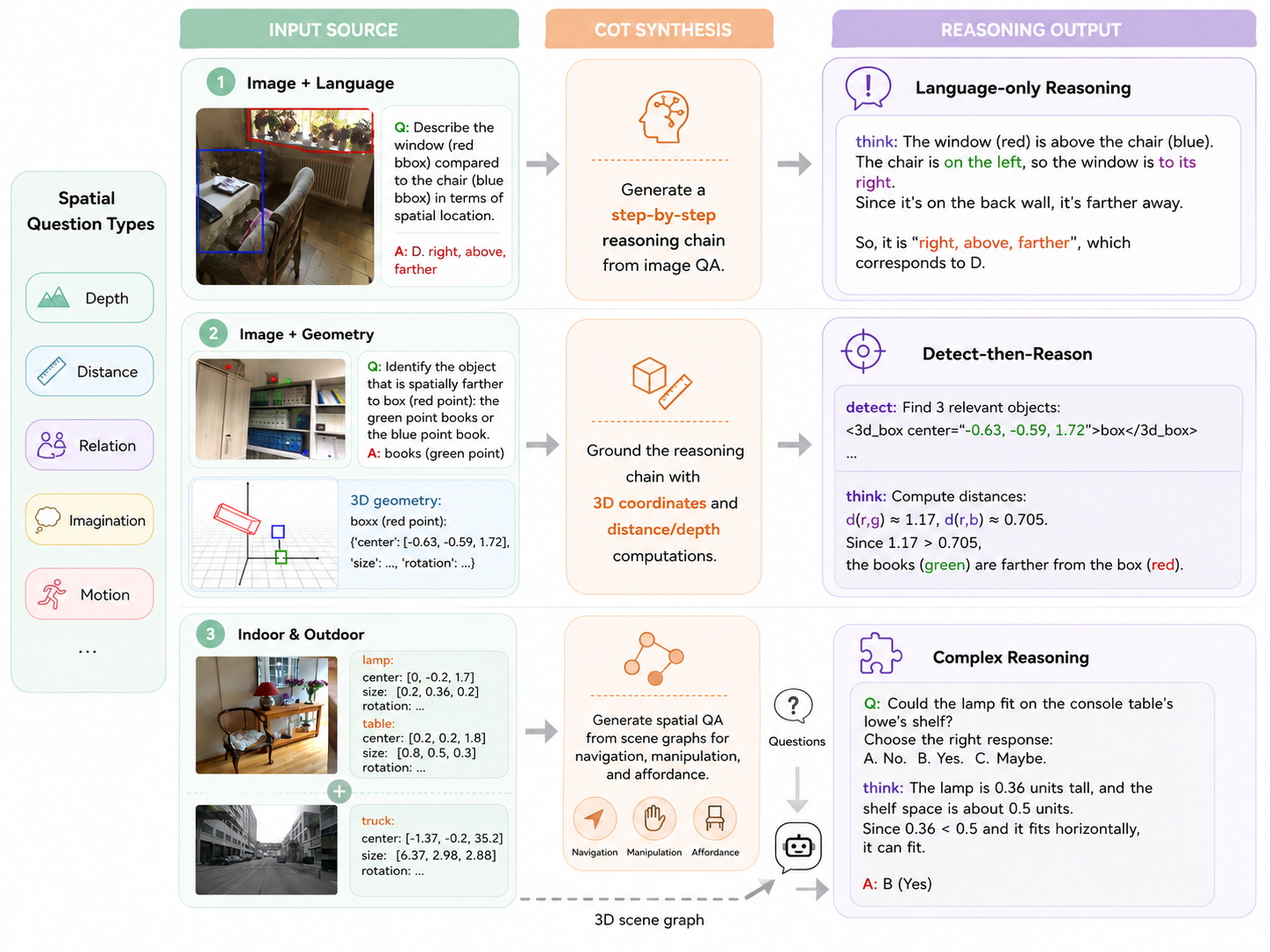
空間 VLM は、幾何学的知覚のプリミティブ(深度順序、bounding-box 予測、相対距離)において優れた性能を示すようになっていますが、深度・メートル距離・物体間関係を組み合わせるような複数ステップの空間推論は依然として脆弱です。SR-REAL は、この脆弱性の一因が戦略のミスマッチにあると主張しています。すなわち、一部のクエリは純粋に言語的な chain-of-thought で処理するのが最適である一方、他のクエリでは定量的推論の前に 3D 幾何学を明示的に経由することが必要です。本論文は、この二つの経路を切り替え可能な単一の空間 VLM を学習させ、両者を RL で共同最適化します。

二つの推論経路
二つの経路は以下のとおりです。
- Language-Only Reasoning (LOR)。 画像に対してテキスト的な演繹を行う標準的な CoT であり、region トークンを出力しません。
- Detect-Then-Reasoning (DTR)。 モデルはまず質問で参照されたエンティティの region トークン(中心点または 3D bounding box)を出力し、その後グラウンドされたプリミティブ上で定量的推論(例:予測された中心点間のユークリッド距離)を行います。
バックボーンは SR-3D(Cheng et al., 2025)を再実装したもので、テキスト・画像・region トークンをインターリーブし、深度とカメラ内部パラメータを考慮した位置 embedding を視覚特徴に融合させています。SR-REAL はこれに加えて、region トークンが視覚特徴に cross-attention する region-prompt インターフェースを導入し、SR-3D には欠けていた region レベルの 2D/3D グラウンディング監督を追加しています。
二段階学習
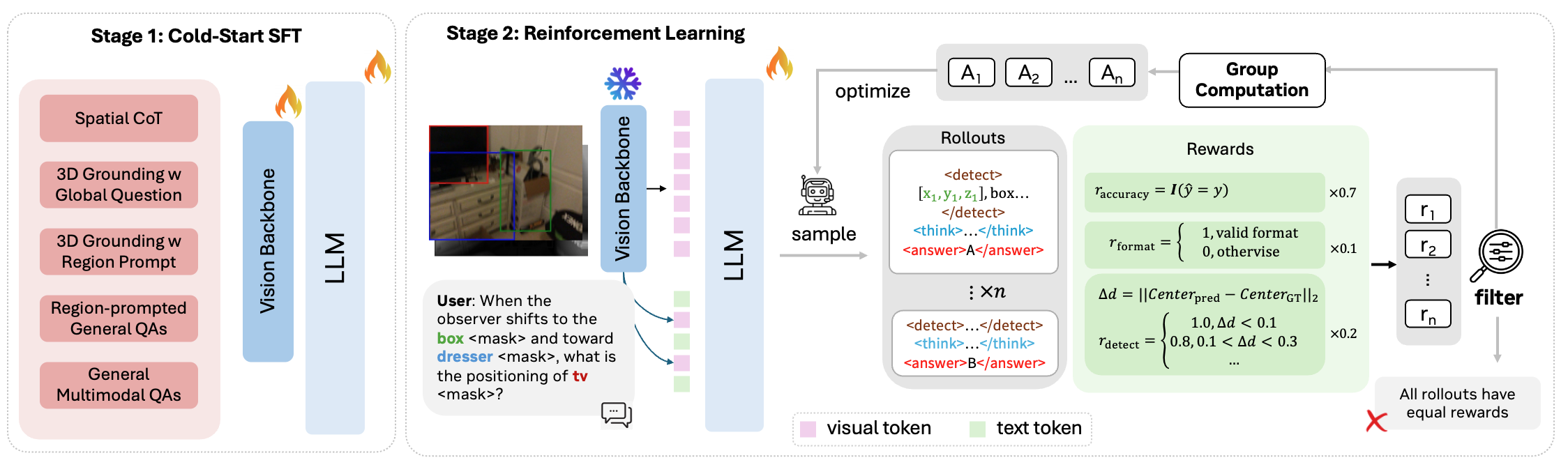
Stage 1 — Cold-start SFT(約 100 万サンプル)。 5 つの構成要素:
- CoT–LOR(30k):SPAR トレース 1 万件、および CA-1M(室内)と NuScenes(屋外)に基づく複雑なトレース 2 万件。
- CoT–DTR(10k):定量的推論の前に region 検出を明示的に出力する SPAR 由来のトレース。
- グラウンディング(3D 用に Omni3D・OmniNOCS、2D 用に RefCOCO)、region から 3D 点への監督を提供。
- SRGPT による region-prompted VQA。
- 幅広いマルチモーダル能力を保持するための LLaVA-1.5 による General VQA。
Stage 2 — RL(約 20 万問、LOR/global 約 10 万 + DTR/region-grounded 約 10 万)。 ロールアウトはクエリ単位でグループ化され(GRPO スタイル)、報酬は以下のとおりです。
- 精度報酬:最終回答に対して(MCQ の一致または穴埋めの数値許容誤差)。
- フォーマット報酬:選択された経路に対して期待されるトレース構造を強制。
- 3D 中心点検出報酬(DTR のみ):予測された region 中心点が真の 3D 中心点の許容範囲内に収まるか否かに対する離散報酬であり、定量的ステップの前に幾何学的整合性を高めます。
LOR と DTR の両方の軌跡にまたがる単一ポリシーを学習することで、RL は報酬が軌跡タイプを区別するため、各経路がより信頼できる状況をも暗黙的に学習します。
結果
SPAR-Bench(表 1)において、SR-REAL は SR-3D のベース平均スコア 33.4 を 60.5(LOR) および 61.9(DTR) へと大幅に向上させました。公開されている空間推論モデルの中で最強の VST(48.9)と比較すると、DTR は平均を 13.0 ポイント改善します。難易度別では:Low 24.1→61.1、Medium 37.6→46.9、High 40.1→68.3(DTR)。ドメイン外ベンチマークでは、EmbSpatial が 72.5→81.3、SAT が 63.0→68.7 に改善されました(LOR;SAT は region グラウンディングを欠くため DTR は N/A)。
表 2 は DTR が有効な場面を明確にしています。単一視点のサブタスクでは、DTR は depth_prediction(35.4 対 30.5)、distance_infer_center(80.0 対 75.0)、obj_spatial_relation(73.9 対 71.4)、spatial_imagination(52.0 対 49.3)で LOR を上回ります。多視点では、DTR は depth で優位(30.4 対 25.9)を維持しますが、LOR は relation で競合するかわずかに優位(78.9 対 77.8)です。このパターンは一貫しています:明示的なメートル的内容を持つタスクは region トークンを通じたグラウンディングが有効であり、多視点スケールでの関係・想像力タスクでは恩恵が少ない傾向があります。これはおそらく、クロスビューでの region グラウンディングが困難であるためです。
表 3 は一部の OOD セットにおける性能低下を報告しています:BLINK(s) は SR-3D ベースの 83.9 から LOR full の 80.4 に低下し、RealWorldQA は 68.1→59.5 に低下します。CoT なしの「Ours-direct」バリアントでは BLINK が 87.4、RWQA が 64.6 まで回復しており、CoT 学習済みポリシーが分布外の短答形式において長い構造化トレースに過適合していることが示唆されます。
限界と未解決の問題
- トレースフォーマットの OOD における脆弱性。 LOR-with-CoT と直接推論の間の RWQA/BLINK ギャップは、ポリシーが推論品質を特定のトレーススタイルに結びつけてしまっていることを示しています。経路とフォーマットのセレクタ(あるいは長さ制御付き報酬)が必要と考えられます。
- 多視点 DTR。 多視点では利得が縮小します。DTR の中心点ベース報酬は単一視点に適しており、クロスビュー整合性報酬は探索されていません。
- 検出報酬は離散かつ中心点のみ。 Bounding-box の IoU や完全な 3D ボックス報酬は、特にサイズ・範囲に依存するクエリにおいて幾何学的整合性をさらに高める可能性があります。
- 抜粋中では RL 単独 vs SFT 単独のアブレーションが示されておらず、3D 中心点報酬の寄与を精度・フォーマット報酬から切り離すことができません。
- ベースは SR-3D 特有のものであり、深度条件なしの VLM への移植性は未検証です。
この研究の意義
空間クエリを補完的な言語的・幾何グラウンディングされた推論経路に振り分け、RL と 3D 中心点報酬を用いて両者を共同学習することで、強力な空間 VLM ベースおよび単一戦略の空間推論モデルと比較して大幅な性能向上(SPAR-Bench 33.4→61.9)が得られます。これは、空間推論において推論の対象となる表現の選択(テキストトークン vs. 出力される 3D プリミティブ)が、明示的に最適化する価値のある学習可能なポリシー決定であるという具体的な証拠です。
Source: https://arxiv.org/abs/2606.17539
Hacker News Signals
GLM-5.2がArtificial Analysisにおけるオープンウェイトモデルのトップへ
Zhipu AIのGLM-5.2が、オープンウェイトモデルを対象としたArtificial Analysis Intelligence Indexで首位を獲得し、それまでトップを占めていた(QwenおよびLlamaファミリーの各種チェックポイント)モデル群を退けました。Intelligence Indexは、推論・コーディング・数学・instruction-followingの各ベンチマークを総合したもので、速度と精度のトレードオフにペナルティを課す重み付けが施されているため、単一の軸のみで指標を操作することはできません。
技術的なアーキテクチャは完全には開示されていませんが、GLM-5.2はパラメータ数30〜70Bのdense(非MoE)モデルとして位置づけられています。Artificial Analysis独自の評価では、総合スコアでDeepSeek-V3およびQwen3-72Bを上回っており、特にMATH-500とLiveCodeBenchで優れた数値を示しています。レイテンシのベンチマークでは、標準的なA100/H100推論においてtokens-per-secondが競争力あるレベルにありますが、量子化済みの小規模MoEモデルの純粋なスループットには及びません。
ここで注目すべきは、その成長の軌跡です。GLM-4は中堅クラスのオープンウェイトモデルでしたが、GLM-5.2がわずか1つのメジャーバージョンアップでフロンティアレベルのオープンモデルに追いつき、さらにそれを上回ったとみられることは、米国外の研究機関における開発ペースを示す重要なシグナルと言えます。HNのコメントスレッドでは、再現性への懸念(Artificial Analysisは標準的なOpen LLM Leaderboardのセットアップではなく、独自のプライベートなeval harnessを使用しています)や、商用利用を制限したライセンスの「オープンウェイト」モデルを、真に許容的なリリースと同じカテゴリに分類すべきかどうかについて議論が集中しました。
制限事項:本ダイジェスト執筆時点では技術レポートは公開されていないため、アーキテクチャに関する主張は推測に基づいています。標準化されたベンチマーク(HELM、LM-Eval-Harness)による独立した再現検証は未実施です。
GLM 5.2 パフォーマンスベンチマーク
Artificial Analysis のこのページでは、GLM-5.2 の複合 Intelligence Index スコアの背景にある生のベンチマーク分解を提供しています。方法論を理解しておく価値があります。Artificial Analysis は各ケイパビリティドメイン(推論、コーディング、数学、instruction following、long context)に対して固定されたプライベートなプロンプトセットを用いてモデルを評価し、絶対スコアと正規化ランクの両方を報告しています。速度はベンダー報告の数値ではなく、同社独自の推論インフラ上でのメディアン出力トークン数(tokens per second)として計測されています。
GLM-5.2 はオープンウェイトのモデル群と比較して、推論と数学のサブトラックで最も顕著な優位性を示しています。一方、コーディングスコアは競争力があるものの、Qwen3-72B-Instruct と比較して支配的ではありません。long context サブトラック(128k+ トークン入力)は複合ランクと比較してパフォーマンスが低く、これは学習時における RoPE ベースの位置エンコーディングの拡張が困難であるという既知の問題と一致しています。
価格対パフォーマンスのチャートは最も実用的な出力です。API 経由の GLM-5.2 は、品質あたりのコストという観点で GPT-4o および Claude Sonnet 3.5 に対して有利なポジションにあります。ただし、API は競争的なサードパーティの推論マーケットではなく、Zhipu 独自のエンドポイントで提供されています。HN のスレッドでは、ベンチマークスイートが十分に独立したものであるかどうかについて疑問が呈されました。Artificial Analysis はプロンプトセットを公開していないため、adversarial な汚染チェックが不可能です。
モデル選定を検討する実務者にとっての示唆は、GLM-5.2 はドメイン固有タスクでの head-to-head eval の実施候補に含める価値があるということですが、複合ランキングは結論ではなく事前情報(prior)として扱うべきです。
Source: https://artificialanalysis.ai/models/glm-5-2
AMDが消費者向けRyzen CPUからメモリ暗号化機能を密かに削除
Zen 3およびZen 4世代の消費者向けRyzen CPUに搭載されていたAMDのTransparent Memory Encryption(TME)およびSecure Memory Encryption(SME)機能が、マザーボードベンダーに配布されたAGESAファームウェアアップデートによって、公開チェンジログやCVEの記載なしに密かに無効化されました。TMEはCPU内部に保持されるAES-128鍵を使ってDRAMの内容を暗号化し、コールドブート攻撃や物理的なメモリ抽出攻撃から保護するものです。SMEはソフトウェアからアドレス指定可能な変種であり、OSが特定のページを暗号化済みとしてマークできます。
この削除は、BIOSアップデート後にSME/TMEの対応ビットを報告するCPUIDリーフがクリアされたことに気づいたユーザーによって発覚しました。問い合わせを受けたAMDのエンジニアは公式には回答せず、ボードベンダーはその変更の原因としてAMDのAGESA(AMD Generic Encapsulated Software Architecture)パッケージを挙げました。AGESAはAMDがOEMに配布するクローズドソースのファームウェア層であり、消費者ユーザーには、それ自体が別の脆弱性を含む可能性のある古いBIOSを書き込む以外に、監査や以前のバージョンへのロールバックを行う手段がありません。
セキュリティへの影響は具体的です。SMEが利用されていたシステム(例えばmem_encrypt=onを使用する特定のLinux構成など)において、CPUIDビットが存在せず、カーネルが有効化前に対応能力を確認する場合、カーネルは暗号化レイヤーなしで動作することになります。これは物理アクセスによる攻撃シナリオにおける多層防御の後退であり、共有コンピューティング環境やモバイルコンピューティング環境に関係するものです。
より広いエンジニアリング上の懸念はガバナンスの問題です。AGESAアップデートはサプライチェーンにおいて不透明なファームウェアブロブとして扱われており、AMDにはIntelのPlatform Updateメカニズムに相当する公開エラータやセキュリティアドバイザリのプロセスが存在しません。HNのスレッドでは、これがIntelのMEファームウェアの状況と構造的に類似していると指摘されています。つまり、クローズドなサプライチェーン、ユーザーの主体性の欠如、そして静かな動作変更という点で共通しています。
研究者らによれば、米連邦機関がFable 5に過剰反応したのはjailbreakではなく「fix this code」プロンプトが原因
本件は、あるゲーム(社内名称「Fable 5」)に関するLLM支援コーディングセッションを米連邦機関が問題視したというセキュリティインシデントに関するものです。ユーザーが発したプロンプトは単なる fix this code という平文の指示であり、jailbreakや敵対的インジェクションではありませんでした。関係組織の研究者らは、モデルの出力が自動監視システムのアラートを引き起こしたと説明しており、プロンプト自体は無害であり、問題となったコンテンツはモデルが通常のデバッグタスクを試みる過程でハルシネーションを起こしたか、あるいは危険に隣接するコードパスを尤もらしく生成したものだったと述べています。
本件の技術的本質は、高セキュリティ環境におけるAI出力監視パイプラインの問題にあります。このインシデントは、LLM出力に適用されるコンテンツ分類器における偽陽性問題を示しています。すなわち、たとえばバッファ管理ルーティンの修正を試みるモデルが、エクスプロイトのプリミティブに類似したコードパターンを生成することがあり、パターンマッチング分類器はその意図や周辺コードベースの文脈を考慮せずにフラグを立ててしまいます。監視システムが見ているのは出力そのものであり、意図や文脈ではありません。
これは実際のエンジニアリング上のギャップを指し示しています。機密性の高い環境への現行のLLMデプロイメントでは、一般的に出力をキーワード/パターン分類器にかけていますが、これらは敵対的プロンプティングに対してチューニングされており、偶発的に機密性の高い素材に類似するような無害なコード生成には対応していません。コード生成出力のテール部分における偽陽性率は、公開文献においてほとんど特性評価がなされていません。また本件は、「jailbreak」が監視チームにとって運用上何を意味するのかという問いも提起しています。プロンプトの出所にかかわらず危険なコンテンツに類似した出力が出れば必ずアラートが発生するのであれば、jailbreakの分類器的定義は研究上の定義から乖離していることになります。
Hacker Newsのスレッドでは、このことが規制環境における開発者による正当なAIツール利用に与える萎縮効果、および監視システムが正確に何を分類しているのかという不透明性に議論が集中しました。
RFC 10008: 新しい HTTP Query メソッド
RFC 10008 は、リクエストボディを必要とする読み取り専用リクエスト向けに設計された新しい HTTP メソッド QUERY を標準化しています。これが解決するコアな問題は次のとおりです:GET のセマンティクスはボディを(形式的にはともかく実質的に)禁じており、POST はべき等ではなくキャッシュセーフでもないため、実装者は複雑なクエリ操作に POST を流用せざるを得ませんでした。これは GraphQL、SPARQL、およびクエリパラメータが URL 長の制限を超える場合や構造化された入力を必要とする大規模な検索 API において一般的な問題です。
QUERY は以下のセマンティックプロパティとともに定義されています:安全(サーバーの状態を変更しない)、べき等、キャッシュ可能。これにより、中継者(プロキシ、CDN)は URL とリクエストボディの両方をキーとして QUERY レスポンスを合法的にキャッシュできます。これは POST が HTTP キャッシュセマンティクスの下では明示的にできないことです。このメソッドは IANA HTTP Method Registry に登録されています。
技術的に興味深いのはキャッシュキーの定義です:RFC 10008 は、キャッシュがリクエストボディをキャッシュキーの一部として使用しなければならない(MUST)と規定し、正規化された形式を推奨(mandate はしない)しています。ボディの正規化はアプリケーション層に委ねられており、これは意図的な先送りです——SPARQL と GraphQL は異なる正規化セマンティクスを持ち、RFC の著者たちはそれらの間での裁定を避けることを選択しました。つまり、異なるホワイトスペースを持つ意味的に同一の 2 つのクエリは、クライアントまたは中継者が正規化しない限りキャッシュミスとなります。
QUERY メソッドはプリロードおよびプリフェッチに対しても明示的に安全であり、POST にはその性質がないため、ブラウザや CDN の最適化が可能になります。普及は framework と CDN のサポートに依存します。公開時点では、nginx、Varnish、および多くのリバースプロキシは未知のメソッドを処理するために明示的な設定が必要です。
Source: https://www.rfc-editor.org/info/rfc10008/
DeepSeekがVision機能を導入
DeepSeekは、チャットインターフェースおよびAPIにマルチモーダル(vision)入力機能を追加し、従来テキストのみに対応していたDeepSeek-V3およびR1モデルを画像入力にも対応させました。HNの投稿はテクニカルレポートではなくチャットインターフェースに直接リンクしているため、アーキテクチャの詳細はAPIドキュメントおよびコミュニティによるテストから推測されます。
公開されている情報によると、vision機能はembedding層においてcross-attentionまたはトークン連結によって既存の言語モデルに組み込まれた標準的なvision encoder(おそらくViTまたはSigLIPの派生)を使用しており、これはLLaVA、Qwen-VL、InternVLが採用しているアプローチと同じです。本ダイジェスト執筆時点では、DeepSeekはvision拡張に関するモデルカードやアーキテクチャ図を公開していません。
HNスレッドにおけるコミュニティによるベンチマークでは、OCRが多用されるタスクや図表解釈のパフォーマンスはGPT-4o-miniと競争力があるとされている一方、複雑なマルチ画像推論ではGPT-4oおよびClaude 3.5 Sonnetに後れを取ることが示唆されています。ベースモデルの学習データ分布と一致して、中国語ドキュメントの理解において特に優れた性能を発揮しています。
API価格は同等の欧米プロバイダと比較して際立って低く設定されています。これはDeepSeekのテキストモデルで確立されたパターン、すなわち積極的な価格設定によって採用を促進し競合他社の価格競争力をテストするという戦略を踏襲しています。vision endpointは現在、text endpointよりも積極的にレートリミットが設けられており、インフラのスケーリングが進行中であることを示唆しています。
実務者にとっての主要な問いは、vision encoderが科学的図表・コードのスクリーンショット・構造化ドキュメントといったドメイン——GPT-4Vが既知の弱点を持つ領域——に汎化できるかどうかです。これらのドメインに対する独立した系統的な評価はまだ公表されていません。
Source: https://chat.deepseek.com/
Wolfram Language および Mathematica バージョン 15
Wolfram Language/Mathematica 15 は、LLM integration をファーストクラスの組み込み機能として搭載し、コア機能の大幅な拡張とともにリリースされました。LLM 機能がもっとも注目を集めており、LLMFunction、LLMSynthesize、および関連するプリミティブを使用することで、外部 LLM API(OpenAI、Anthropic、LLM Kit 経由のローカルモデル)を Wolfram Language の式を構造化された入出力として呼び出すことが可能になっています。この入出力は言語のシンボリック型システムに対して型チェックされます。つまり、LLM 関数が Graph オブジェクトや TimeSeries を返すよう指定でき、ランタイムが出力を検証・強制変換します。これは他の LLM ツール使用フレームワークにおける JSON スキーマ検証よりも厳密なアプローチです。
バージョン 15 では、自然言語から構造化データへの変換を行う Interpreter フレームワークも拡張されています。このフレームワーク自体は LLM integration よりも数年前から存在していますが、現在はそれとハイブリッド化されており、SemanticImport はルールベースの解析が失敗した際のフォールバックとして LLM のサポートを利用できます。これにより、従来からある信頼性の問題が浮上します――サイレントな LLM フォールバックは、ユーザーが決定論的であると期待しているパイプラインに非決定論性をもたらします。
LLM 以外の追加機能としては、計算幾何の拡張(Voronoi メッシュ演算、多面体分解)、新しいグラフ理論関数、拡張された時系列解析、フレームレベルの映像処理のための VideoFrameMap プリミティブが含まれます。シンボリックニューラルネットフレームワーク(NetChain、NetGraph)は、設定可能なヘッド数を持つ transformer attention レイヤーのサポートを獲得し、Wolfram エコシステム内でプロトタイプを作成したいユーザーにとって PyTorch/JAX とのギャップが一部解消されました。
ライセンスモデルは依然としてプロプライエタリであり、機関での利用には高コストです。HN のスレッドでは予想通り Wolfram Language に関する党派的な議論が見られましたが、注目すべき技術的懸念は、シンボリック計算ノートブックにおける LLM クラウド API との密な結合が、科学的ワークフローの再現性に問題をもたらすという点です。
Launch HN: Adam (YC W25) – Open-Source AI CAD
Adamは、メッシュ表現ではなくジオメトリカーネルを中心に構築された、パラメトリック機械設計を対象としたオープンソースのAI支援CADシステムです。このリポジトリは、基盤となるB-rep(境界表現)カーネルとしてOpenCASCADE(OCCT)を使用しています。これにより、ブーリアン和/差、フィレット、面取りといった操作が近似ではなく厳密に行われます。これは製造意図モデルに対する必須要件です。
AIコンポーネントは自然言語またはスケッチ入力を受け取り、OCCTのAPIコールにマッピングされた構造化中間表現の形で、パラメトリック操作(押し出し、回転、スイープ、ブーリアン)のシーケンスを生成します。このアーキテクチャはCADGenやSketchSolveのアプローチと類似していますが、オープンソースのOCCTバックエンドはクローズドカーネルの競合製品に対して重要な差別化要因となっています。中間表現はJSONベースのフィーチャーツリーであり、生成されたデザインが編集可能であることを意味します。つまり、ユーザーはAIが生成したジオメトリを受け取った後、静的なメッシュとしてではなく、パラメータを直接変更することができます。
HNスレッドおよびリポジトリのREADMEに記載されている現在の制限事項として、このモデルは単一ボディのパーツはそれなりに扱えますが、マルチボディアセンブリや拘束駆動設計(寸法がシンボリックにリンクされている場合)には対応が難しい状況です。板金の展開やサーフェシング(クラスAサーフェス)はサポートされていません。生成モデルの学習データは公開されておらず、一般的でないジオメトリへの汎化能力があるのか、あるいは一般的なベンチマーク形状に過学習しているのかという疑問が残ります。
オープンソース化の決断は重要な意味を持ちます。商用のAI CADツール(Autodesk、PTC、Siemensの統合製品)はすべてクローズドであるためです。厳密なジオメトリカーネルを備えた実用的なオープンな代替手段は、既存のOSSのCAMパイプライン(FreeCAD、OpenCAM)への統合が可能であり、ホビイスト向けCNC、ロボティクスプロトタイピング、および学術研究にとって有益です。
注目の新しいリポジトリ
anthropics/defending-code-reference-harness
Anthropicによるリファレンス実装で、AIを活用したコード解析に関連する防御的セキュリティスキル(脅威モデリング、脆弱性スキャン、トリアージ、パッチ生成)を網羅しています。中核となる成果物は自律型スキャンハーネスであり、フォークしてカスタマイズできるよう設計されています。オペレーターは自前の静的解析バックエンドに接続し、深刻度の閾値を定義し、既存のトリアージパイプラインに検知結果を流し込むことができます。スキルレイヤーは、一般的なセキュリティワークフロー(STRIDEによる脅威モデリング、CVEトリアージ、差分ベースのパッチ提案)に対応した構造化プロンプトとtool-callスキーマを提供します。アーキテクチャ上はモデルAPIの上位に位置しており、原理的にはモデル非依存ですが、明らかにClaudeのtool-useインターフェースに合わせてチューニングされています。AIを活用したAppSecパイプラインを構築するチームにとって、すぐに使えるプロダクトというよりも出発点として有用です。ハーネスの設計で注目すべき点は、スキャンのオーケストレーションロジックとリメディエーションロジックを分離していることで、フィードバックループの監査可能性が保たれています。リリースから数日で6,000以上のスターを獲得しており、カスタマイズのための明確な境界を持つエージェンティックなセキュリティツールの実践的な事例として大きな注目を集めています。
Source: https://github.com/anthropics/defending-code-reference-harness
cellinlab/how-pi-agent-works
Inflection AIの会話エージェントであるPi Agentの内部構造を中国語で技術的に深く掘り下げたリポジトリです。公開されているAPIの挙動やモデルカードといった観測可能な情報をもとに、エージェントのアーキテクチャを再構成しており、内容はコンテキスト管理戦略、メモリ検索、ツール呼び出しパターン、ターン制御を司る対話状態機械に及びます。単なる推測ではなく、観測可能なAPI挙動と公開済みのモデルカードに根拠を置いている点が特徴です。コード例では、コアとなるオーケストレーションループ——本質的には永続的なペルソナ状態を持つReActスタイルのプランナー——を再現する方法を示しています。このリポジトリの価値は比較考察にあります。AutoGPT派生のようなタスク指向エージェントとは技術的に異なる、強いパーソナリティ制約を持つLLMエージェントをプロダクション化する事例研究としてPiを位置づけている点が特長です。毎ターン明示的なメモリ注入を行わずに長期セッションにわたってペルソナの一貫性をどのように維持するかに関心を持つ研究者にとって有用です。スター数は375と小規模なリポジトリですが、技術的な精度は高いです。
Source: https://github.com/cellinlab/how-pi-agent-works
StarTrail-org/PixelRAG
PixelRAGは、WebベースのRAGパイプラインにおけるDOM/HTMLパースをピクセルネイティブな検索に置き換えるアーキテクチャです。検索の基本単位はテキスト抽出結果ではなく、スクリーンショットそのものとなっています。アーキテクチャはレンダリングされたページ画像をvision encoderでembeddingし、そのembeddingをインデックス化します。クエリ時にはtop-kの画像を検索し、回答生成のためにmultimodal LLMに渡します。この手法により、HTMLスクレイピングの脆弱性を回避できます。動的なJSレンダリングコンテンツ、ペイウォール付きテキスト、複雑なテーブルレイアウト、PDFに類似したページなど、あらゆるコンテンツが第一級の検索対象オブジェクトとなります。「スケーラブル」という主張は、大きなスクリーンショットをembeddingの前にオーバーラップするパッチに分割するタイル状の画像チャンキング手法に基づいており、空間的局所性を保持します。パイプラインはCLIPファミリーのencoderを中心に構築されており、ドキュメントスタイルの画像に向けたカスタムfine-tuningレシピを採用しています。主要なユースケースは、ソースドキュメントがクリーンな文章ではなく、ダッシュボード・スライドデッキ・スキャンPDFなどのレンダリング済みアーティファクトであるエンタープライズのナレッジベースです。制限事項として、検索レイテンシはテキストベースのBM25/denseハイブリッドよりも高く、数値コンテンツに対するOCRの精度がボトルネックとなっています。
Source: https://github.com/StarTrail-org/PixelRAG
Liu-Ming-Yu/alpha-forge
システマティック(クオンツ)トレーディングを対象としたエージェント型AIオペレーティングシステムです。アーキテクチャは複数のコンポーネントを階層化しています:自然言語の記述からアルファファクターを提案するstrategy-generationエージェント、それらのファクターをヒストリカルデータに対して評価するバックテストハーネス、そして生き残ったアルファをリスク制約のもとで集約するポートフォリオ構築レイヤーです。「co-evolve」というフレーミングは、バックテスト結果がin-contextシグナルとしてgenerationエージェントへフィードバックされるループを反映しており、ワンショットの生成パイプラインというよりも、アルファ空間に対する進化的探索に近い設計です。標準的なPythonクオンツインフラ(データ処理にはおそらくpandas/polars、プラガブルなバックテスターインターフェース)の上に構築されています。OSというメタファーは、複数のアルファ探索エージェントを並行して実行し、アロケーションを競わせるプロセススケジューリングの抽象化を指しています。RLの観点からも興味深く、報酬シグナルがリスク調整済みリターン(SharpeまたはCalmar)であり、評価ホライズンが長いスパースな報酬を持つ逐次的意思決定問題となっています。166スターと早期段階ではありますが、アーキテクチャ的には野心的な設計です。
Source: https://github.com/Liu-Ming-Yu/alpha-forge
Aimino-Tech/opendocswork-mcp
Rust ネイティブの Model Context Protocol (MCP) サーバーで、Office ドキュメント操作(Excel .xlsx、Word .docx、PowerPoint .pptx)を LLM エージェントがツールとして呼び出せる操作として公開します。Excel には calamine/rust_xlsxwriter エコシステム、Word フォーマットには docx-rs を基盤としています。Rust におけるゼロコピー解析と openpyxl などの Python 代替との比較を考えると、サブミリ秒レイテンシという主張は十分に妥当です。ローカルファースト設計により、ドキュメントの内容が一切マシン外に出ないため、データ所在地制約のある企業環境にも適しています。MCP インターフェースは、ドキュメント操作(セル範囲の読み取り、テーブルの書き込み、スライドの挿入、段落テキストの抽出)を構造化された JSON ツールスキーマにマッピングし、MCP 対応の任意のエージェントフレームワークから利用できます。Python ベースの代替手段と比較した場合の主なトレードオフは、読み書き操作において高速かつ安全である一方、複雑なフォーマットのエッジケースにおいては Rust の Office フォーマット向けエコシステムが Python よりも成熟度で劣る点です。LibreOffice へのシェルアウトなしに Office ドキュメントフォーマットの世界を操作する必要があるエージェントにとって、堅実なインフラコンポーネントといえます。
Source: https://github.com/Aimino-Tech/opendocswork-mcp
XiaomiMiMo/MiMo-Code
小米(Xiaomi)がリリースしたMiMo-Codeは、コードに特化したLLM+agentシステムであり、モデルの重みとagentのscaffoldingの共進化(co-evolution)が主要な主張となっています。このリポジトリは、コード生成およびデバッグタスク向けのトレーニングコード、モデルの重み、およびagentハーネスを含んでいます。共進化メカニズムは反復的なラウンドで構成されており、agentがコードを生成し、実行フィードバック(ユニットテストの通過率、lintingエラー)が収集され、そのフィードバックがベースモデルのさらなるRLHF/DPOトレーニング用のpreference dataの構築に使用されます。これにより、デプロイ時のagentの挙動とトレーニング時の監督のループが閉じられ、環境フィードバックからのオンラインRLの一形態となっています。9.7kスターを獲得しており、本バッチの中で最も注目度の高いリリースです。競合(DeepSeek-Coder、Qwen-Coder)との技術的差別化要因としては、agent-in-the-loopの明示的なトレーニングパイプラインと、マルチステップのデバッグ軌跡(単一ターンの補完だけでなく)をトレーニングコーパスに統合している点が挙げられます。制限事項としては、共進化ループをスケールで実行するために多大な計算資源が必要である点、およびラウンドをまたいだdistribution shiftがどのように制御されているかが不明確である点があります。
Source: https://github.com/XiaomiMiMo/MiMo-Code
boona13/image-extender
元の画像の境界を任意の方向に拡張するオープンソースのアウトペインティング Web アプリケーションです。OpenRouter 経由でアクセスする Gemini ベースの生成モデルを利用しています。技術的なコアとして注目すべき3つの要素があります。第一に、生成ループは拡張ごとに3つの並列アウトペインティングリクエストを実行し、最良の結果を選択します。これはシンプルながら効果的な分散低減戦略であり、拡散/生成モデルの確率的な出力をならすものです。第二に、境界のシームは Poisson blending を用いてスムージングされます。これはラプラシアン系を解いてピクセルの勾配をシーム全体で連続にする古典的な勾配域手法であり、2つの画像領域を単純に合成するのとは異なります。第三に、フロントエンドは方向別の拡張コントロール(左・右・上・下へのピクセル単位の拡張)を提供し、確定前に3つのバリアントすべてをプレビューできます。シングルページ Web アプリとして構築されており、ローカル GPU は不要で、推論は完全に API 側で処理されます。1,000 スターを獲得しており、実用的なニーズを満たしています。ほとんどのアウトペインティングツールはローカルへの Stable Diffusion のインストールを必要とするため、その代替として有用です。Poisson blending のステップが、境界での単純な alpha blending と比較した際の品質上の重要な差別化要因です。
Source: https://github.com/boona13/image-extender
superloglabs/superlog
自己修復ソフトウェアシステムを対象とした、AIを活用した可観測性プラットフォームです。アーキテクチャは、従来のログ集約パイプラインと、受信ログストリームを監視し、異常パターンを検出し、根本原因の候補を特定し、自律モードではリメディエーション(サービスの再起動、デプロイのロールバック、設定値のパッチ適用)を提案または実行するエージェント層を組み合わせています。「自己修復」ループは、構造化・非構造化ログの取り込み、エラーシグネチャのembeddingとクラスタリング、ベクターストアからの類似過去インシデントの検索、LLMプランナーによるリメディエーションアクションの生成、サンドボックス化されたtool-callインターフェースを通じたアクションの実行、そして下流メトリクスの監視による解決の検証、という流れで構成されています。このオープンソースとしての位置づけは、SaaSの可観測性ベンダー(DatadogのAI機能、Honeycomb)との差別化要因となっています。重要なエンジニアリング上の課題はアクション実行の安全層であり、本番環境における自律的なリメディエーションには影響範囲に関する厳格なガードレールが必要です。853 starsとリポジトリはまだ初期段階ですが、現実的なギャップに対応しています。既存の可観測性ツールは問題を表面化させるものの、ループを閉じることはしません。human-in-the-loopによるオーバーライドモデルがどのように規定されるか、注目に値するプロジェクトです。