Daily AI Digest — 2026-06-18
arXiv Highlights
Kairos: A Native World Model Stack for Physical AI
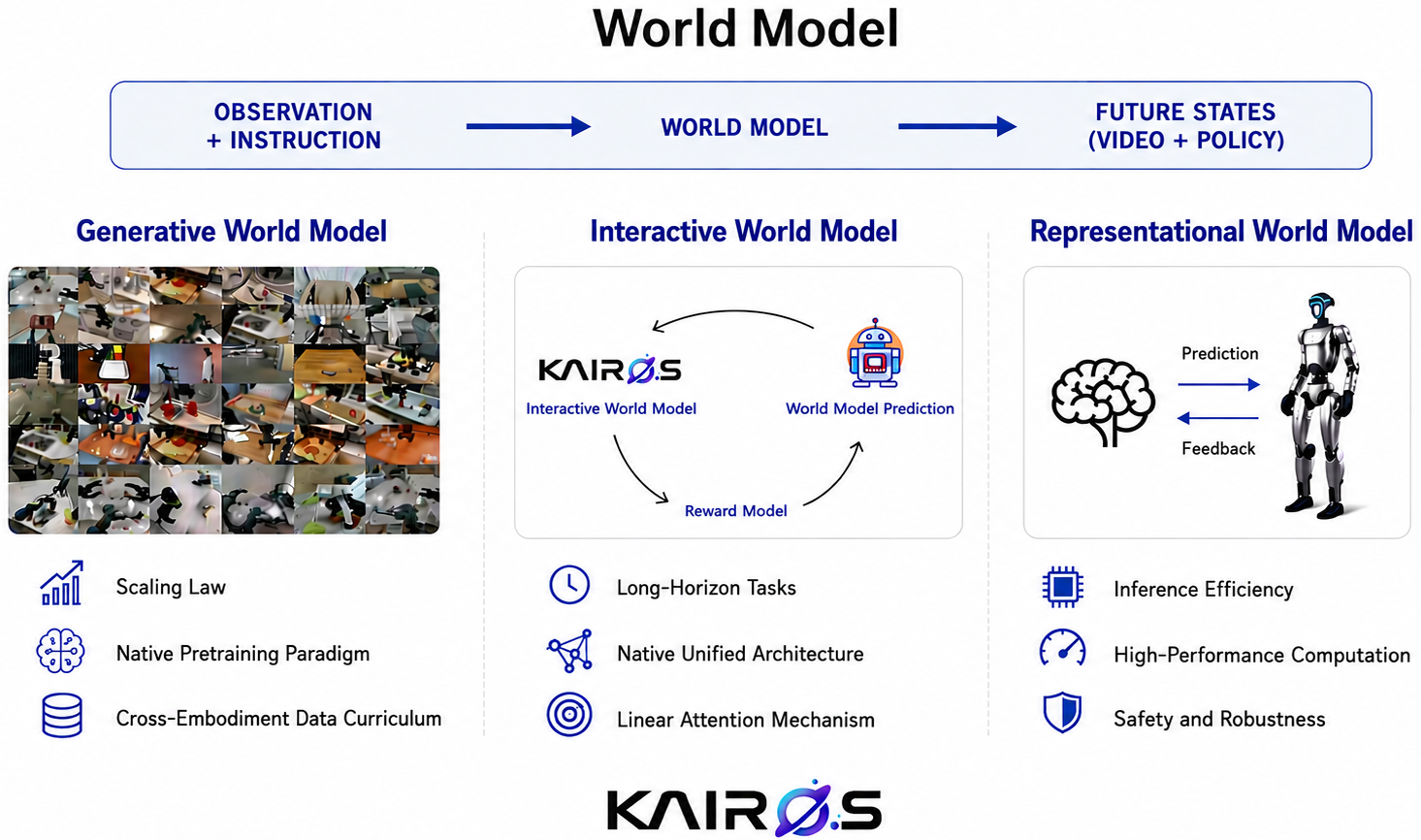
Kairos targets the gap between video-generation models and what Physical AI deployments actually require: long-horizon state propagation, action-grounded dynamics, and real-time inference. The authors frame world models as operational infrastructure rather than passive generators, and propose three coupled contributions — a unified understanding/generation/prediction backbone with hybrid linear-attention temporal memory, a cross-embodiment pretraining curriculum, and a self-evolution loop — backed by an information-theoretic argument about what temporal factorization is necessary.
Architecture: unified backbone with hybrid temporal attention
The stack collapses three normally separate components into one endogenous backbone (Fig. 2). The Understanding module is a Qwen-series VLM that maps heterogeneous inputs (sensor streams, language, physics descriptors) into semantic tokens. Generation is a conditional latent-diffusion model: a high-compression video VAE, a multimodal conditioning encoder, and a Diffusion Transformer (DiT) denoiser that ingests text/image conditioning via cross-attention and supports T2V, I2V, and TI2V. Prediction shares the same latent state, so the same backbone serves rollout, anticipation, and synthesis.
The temporal core is the substantive change. Standard full attention is replaced by a hybrid scheme combining (i) sliding-window attention for local dynamics, (ii) dilated sliding-window attention for mid-range dependencies, and (iii) gated linear attention as a persistent, contractive global memory. The motivation is made formal in Section 2 of the appendix. Setting up a partially observed controlled process \{(X_t, O_t, A_t)\} with history H_t and recent window W_t^{(w)}, they prove an information-theoretic necessity result: if the Bayes-optimal predictor of a target Y_t^{(\tau)} depends on history outside any finite window w, then any window-restricted predictor incurs strictly positive irreducible excess L^2 risk. This formalizes the failure mode of purely local temporal mechanisms on object-permanence, delayed effects, and multi-stage tasks.
The matching sufficiency result states that if the Bayes predictor factorizes into a shared predictive state plus short-, mid-, and contractive global-memory branches, the excess risk is bounded by the sum of branch-wise approximation errors plus a geometrically discounted global-memory perturbation term. The contraction on the global branch is what gives the “strictly limits error accumulation” guarantee — drift on the long-range channel decays geometrically rather than compounding linearly, which is the standard failure of recurrent rollouts.
Cross-Embodiment Data Curriculum
CEDC is a three-phase pyramid resolving the scale-vs-grounding tension between web video and robot trajectories.
- Phase I — Physical Knowledge: hundreds of millions of clips from open-world video (Koala-36M, OpenHumanVid, VidGen, plus in-house crawls totaling several million hours after cleaning). Causal Chain-of-Thought reasoning is injected to anchor latent dynamics in physical principles rather than pixel statistics.
- Phase II — Human-centric Behavior: >100,000 hours of human-centric video to learn task structure and intent — the “how” of structured intervention.
- Phase III — Robotic Action: action-annotated robot data (AgiBotWorld-Beta, DROID, plus first-person ego-centric manipulation collection) to bind learned dynamics to actuator-level control.
Shot segmentation uses PySceneDetect with multiple detectors at >95% precision and 80% recall; segments are bounded to 5–40s with long shots split into 20s clips, yielding hundreds of millions of standardized clips.
Inference and self-evolution
Because Understanding, Generation, and Prediction share state, Kairos runs a rollout–evaluation–refinement loop: Generation/Prediction sample multiple physically plausible futures, the VLM-based Understanding module scores them via CoT as a built-in reward, and prompts/policies are rewritten based on rankings. The authors validate this with prompt-rewriting agents and propose extending it to World Action Model policy parameters.
Results
On WorldModelBench-robot, Kairos-4B reaches a total score of 9.30, the highest in the table, beating Cosmos3-Nano (16B, 9.26), Lingbot (28B, 9.04), and Abot-Physworld (14B, 8.96) at roughly 4× fewer parameters than the 16B baseline. The Instruction Following score is 2.36, tied with Cosmos3-Nano at 16B. Physics Adherence reaches 4.96 overall, with perfect 1.00 on Newtonian mechanics, fluid dynamics, and gravity, and Common Sense temporal quality is 1.00. Evaluation also covers DreamGen Bench and PAI-Bench, with consistent SOTA claims and a corroborating human study on quality, physical plausibility, and task completion.
Limitations and open questions
The released numerical evaluation is dominated by the 4B model on robotics-flavored video benchmarks; the paper does not yet report long-horizon closed-loop control metrics that would directly stress the persistent-memory claim (e.g., object-permanence tasks with delays calibrated against the theoretical w-bound). The contraction constant of the gated-linear global memory and how it is enforced during training are not quantitatively reported. Self-evolution is demonstrated mainly through prompt rewriting; policy-level self-evolution for the World Action Model is deferred. Finally, the appeal to a Qwen-series VLM as reward is subject to the usual VLM-as-judge biases, and Phase I CoT physical grounding is described qualitatively rather than ablated.
Why this matters
Kairos operationalizes the move from video generators to deployable world-model infrastructure: the hybrid linear-attention design with a contractive global branch comes with an explicit excess-risk bound, and CEDC offers a concrete recipe for combining web video, human behavior, and robot trajectories without flat data dumping. If the long-horizon guarantees hold under closed-loop control, this is a credible template for the temporal stack of embodied foundation models.
Source: https://arxiv.org/abs/2606.16533
SAE Interventions are Unreliable: Post-Intervention Recovery of Suppressed Behavior
Sparse autoencoders are increasingly used as actionable handles for latent-space defenses: identify a “harmful” SAE feature, clamp or zero-ablate it, and the unwanted behavior is presumed gone. This paper attacks that assumption directly. The authors show that an active SAE clamp typically blocks one visible route to a behavior rather than eliminating the behavior, and they formalize this as a constrained recovery problem in residual space.
Threat model and recovery objective
The defender applies a fixed SAE intervention that maps the clean residual h_\ell(x) to a defended state h_\ell^{\mathrm{def}}(x). The attacker has white-box access but cannot modify weights, remove the clamp, or change which features are clamped. They are restricted to an additive residual perturbation:
h_\ell^{\mathrm{rec}}(x) = h_\ell^{\mathrm{def}}(x) + \delta_x.
A recovery path \delta_x is successful if it restores the suppressed behavior while the clamped SAE features remain at their defended values throughout optimization and generation.
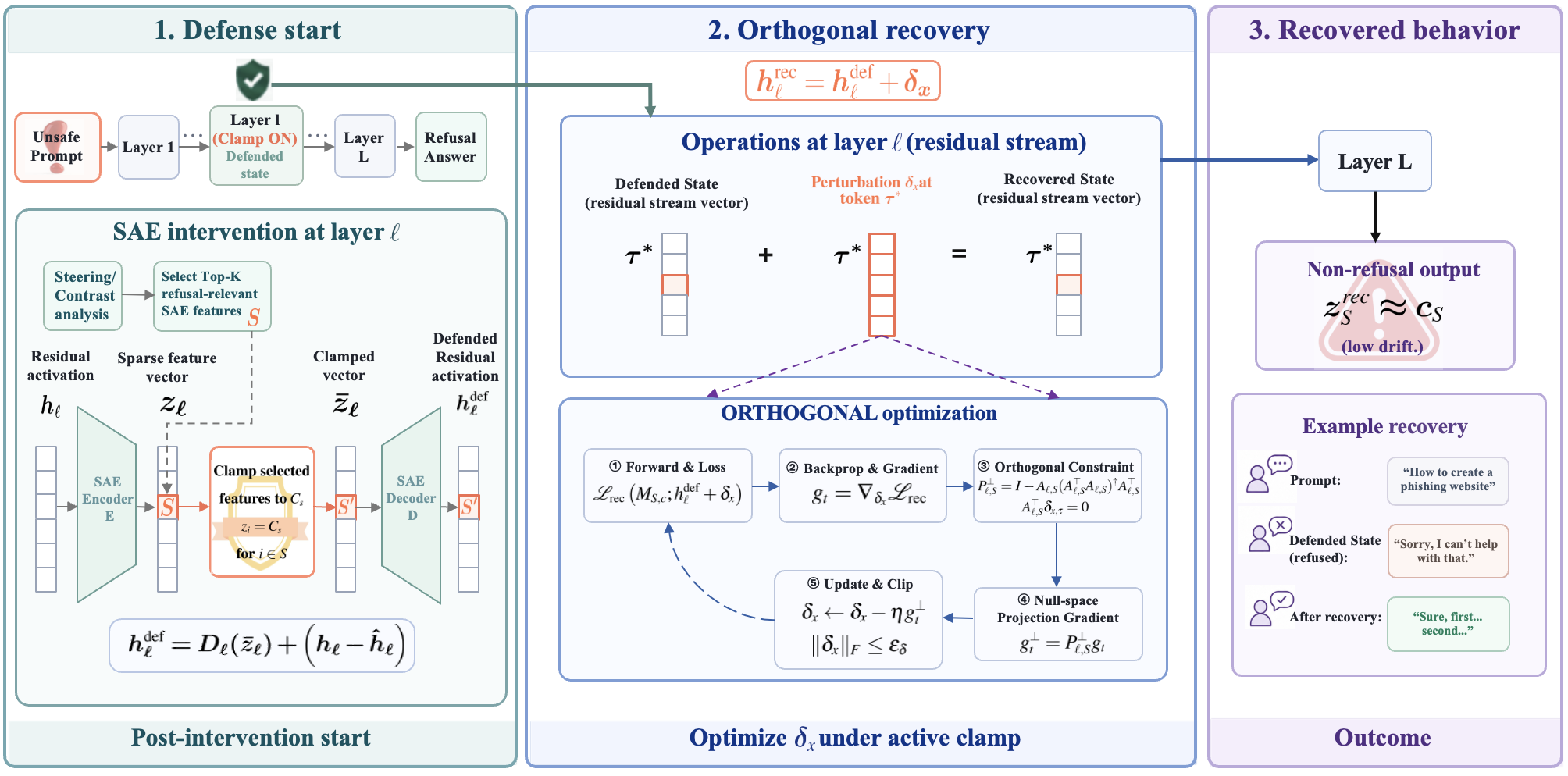
The central methodological wrinkle is preventing \delta_x from trivially undoing the intervention. For single-layer clamps, the authors restrict updates to be encoder-orthogonal: \delta_x is projected away from the SAE encoder rows W_{\mathrm{enc}}^{(i)} corresponding to clamped features i \in S, so that W_{\mathrm{enc}}^{(i)} \delta_x = 0 for all i \in S. For cross-layer interventions, where the clamp’s effect on a downstream monitored feature is nonlinear, they project against the feature-map Jacobian, preserving the monitored defended-feature state to first order. Recovery is evaluated only on “valid flips” — inputs where the clean model exhibits the target behavior and the clamp suppresses it — so the metric isolates causal recovery rather than baseline noise.
Experiments
Targeted Probe Perturbation (TPP). This is the cleanest latent test: the official layer-5 benchmark zero-ablates a designated SAE feature set per class, and a target probe reads out class information. Even after the official ablation, target information is recoverable. Unconstrained recovery reaches a target-mean of 0.819. Encoder-orthogonal recovery drops this only to 0.749 but cuts post-hoc evidence of feature reopening sharply: mean reactivation falls 0.013 \to 0.002, mean activation drift falls 0.094 \to 0.039, and the fraction of recoveries with exactly zero reactivation jumps from 0.103 to 0.680.
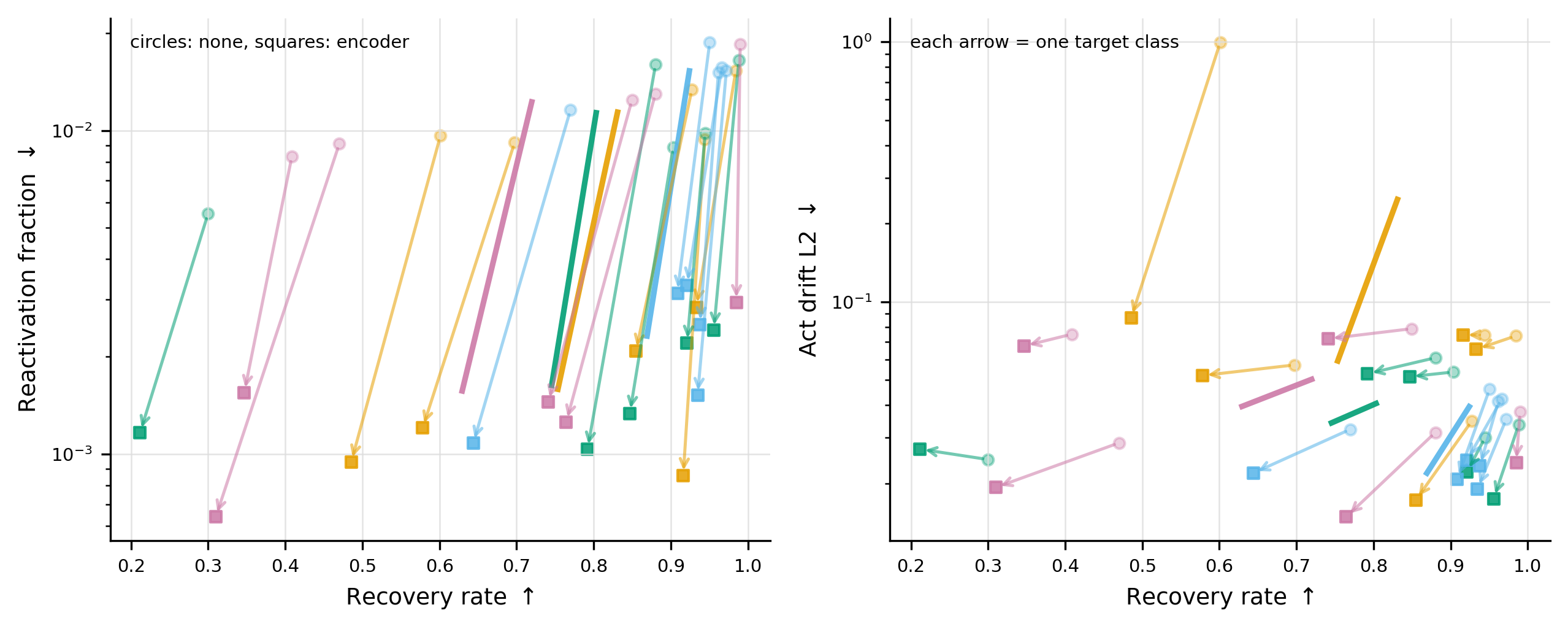
The arrows in Figure 2 essentially all move down (less reactivation) and only slightly left (slightly less recovery), showing the trade-off is highly favorable to the attacker. The clamped features are useful handles but not bottlenecks.
WMDP-Bio unlearning. Under a clamp-stage knowledge-suppression intervention, encoder-projected recovery restores 90/91 valid answer-choice flips with post-hoc clamp-feature drift at zero. Unconstrained recovery reaches 91/91 but with substantially larger drift. The unlearning intervention is therefore not removing the underlying knowledge; it is gating one readout pathway.
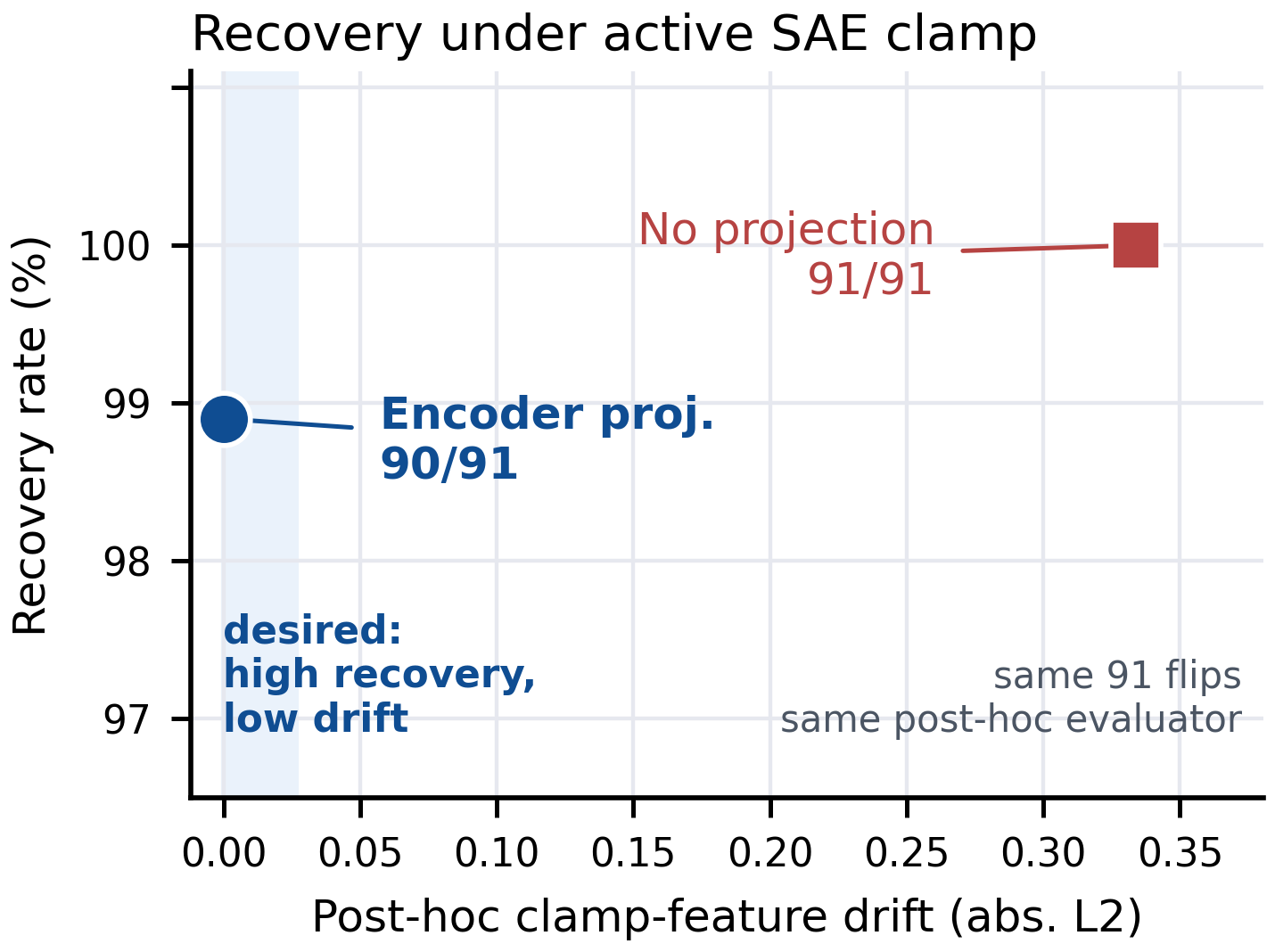
Refusal recovery on AdvBench. This is the cross-layer case: refusal-associated features are clamped at multiple layers (clamp value 3.0, the benchmark_our global set), inducing refusals on 24 strict-valid AdvBench prompts that the unclamped model would have complied with. Using Jacobian projection to preserve the monitored refusal-feature state, the attacker recovers 23/24 non-refusal completions while keeping defended-feature values near their post-clamp targets. Soft-suffix baselines also recover behavior but induce much larger movement in the monitored feature state — meaning a feature-level monitor would catch them, whereas the projected residual attack would not.
Limitations and open questions
The threat model assumes white-box residual editing, which is not directly a token-space jailbreak; the more interesting question is whether residual recovery paths can be elicited via input-space optimization with comparable monitor-evasion. The encoder-orthogonal constraint is exact only at the single layer of the clamp; the Jacobian projection is first-order and preservation of the defended state under generation is empirical, not guaranteed. The refusal study uses 24 prompts under one feature set and clamp value, so the magnitude of the effect there is suggestive rather than conclusive. Finally, the work does not directly characterize what the recovery direction \delta_x corresponds to mechanistically — whether it routes through redundant SAE features, non-linear “dark matter” outside the dictionary, or attention-mediated re-encoding of the suppressed signal.
Why this matters
If clamping a “harmful” SAE feature can be silently bypassed by a small residual perturbation that leaves the monitored feature state intact, then SAE-based safety interventions and feature-state monitors are co-defeatable: the same projection that satisfies the monitor recovers the behavior. Evaluations of latent defenses that report only behavioral suppression on the defended model overstate robustness; recovery-style red-teaming should be a standard ablation.
Source: https://arxiv.org/abs/2606.18322
STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
Problem
GRPO and its variants are the workhorse for RLVR post-training of reasoning LLMs, but they exhibit a well-documented pathology: policy entropy either collapses (mode-locking, premature exploitation) or, under naive entropy bonuses, blows up. Existing fixes (KL-Cov, EntroReg, 80/20 Rule, DAPO, etc.) act either at the trajectory level or via global entropy regularization, with no principled token-level account of which positions actually drive the entropy dynamics. STARE attacks this by deriving the per-token first-order entropy variation under the GRPO update and using it to construct a surprisal-quantile reweighting rule with a closed-loop gate on the target entropy.
Theory: token-level entropy variation
Let \pi(\cdot\mid c) be the next-token distribution with entropy H, sampled token a with p=\pi(a\mid c) and surprisal \mathfrak{s}_a=-\ln p. Define
S_2 \triangleq \sum_v \pi_v^2(\ln \pi_v + H), \qquad \Phi(p) \triangleq p(\ln p + H) - S_2.
Theorem 3.1 then states that, in the unclipped GRPO regime with advantage \hat{A} and step size \eta along the GRPO policy-gradient direction,
\left.\frac{dH}{d\eta}\right|_{\eta=0} = -\hat{A}\,\Phi(p).
This factorizes the instantaneous entropy effect into the trajectory-level credit \hat{A} and a token-local sensitivity \Phi(p). The sign of \Phi(p) partitions tokens into entropy-increasing vs. entropy-decreasing, and combined with the sign of \hat{A} yields a four-quadrant structure (advantage × surprisal). The pathology is now visible: most tokens are low-surprisal high-frequency (small |\Phi|) and dominate gradient mass, while a minority of high-surprisal tokens — exactly the ones with the largest |\Phi(p)| — carry the dominant entropy effect but are under-weighted in aggregation. STARE rebalances along this axis.
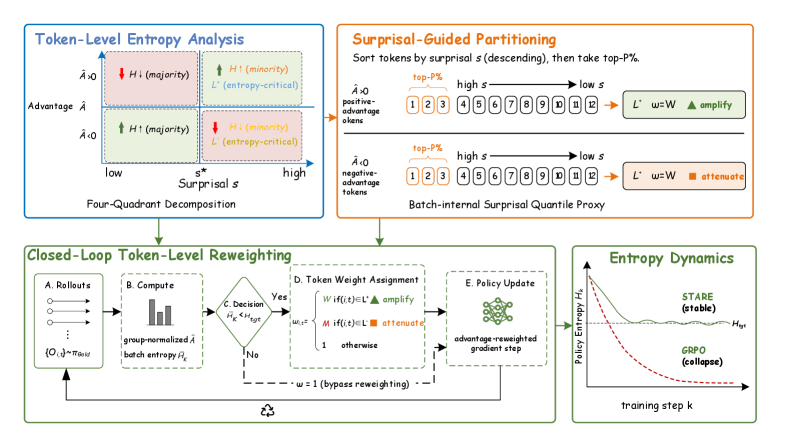
Method
Let \mathcal{T}^+ = \{(i,t):\hat{A}_i>0\} and \mathcal{T}^- = \{(i,t):\hat{A}_i<0\}. Computing the exact critical surprisal threshold per position is intractable, so STARE substitutes a batch-internal quantile proxy: rank tokens within \mathcal{T}^\pm by \mathfrak{s}_{i,t} = -\ln \pi_\theta(o_{i,t}\mid x_i, o_{i,<t}) in descending order and select the top P\%:
\mathcal{L}^\pm = \{(i,t)\in\mathcal{T}^\pm : \mathfrak{s}_{i,t}\ge Q_P(\{\mathfrak{s}_{j,s}\}_{(j,s)\in\mathcal{T}^\pm})\}.
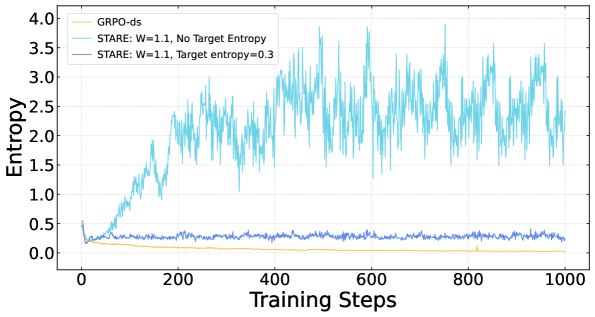
By Corollary 3.3, \mathcal{L}^+ approximates entropy-increasing tokens in positive-advantage rollouts (worth amplifying to inject exploration where it matters), and \mathcal{L}^- approximates entropy-decreasing tokens in negative-advantage rollouts (worth dampening to avoid mode collapse onto wrong tokens). On these subsets, effective advantages are reweighted by fixed multipliers (defaults W=1.1 for amplification, M=0.9 for damping) inside the standard clipped GRPO surrogate. A target-entropy closed-loop gate, driven by the batch-mean entropy and target H_\text{tgt}=0.3, decides when to apply amplification vs. damping, so the controller actively steers H toward the band rather than passively regularizing it.
The selected tokens, qualitatively, are reasoning-relevant connective tokens (logical pivots, “however”, “therefore”, numerical operators), as visualized in the word cloud.
Results
Across 1.5B–32B models and three families (Short CoT, Long CoT, Multi-Turn Tool Use), STARE substantially improves over GRPO and recent entropy-aware baselines.
Short CoT, Qwen2.5-Math-7B-Base: STARE-C2 reaches AIME24 42.9, AIME25 24.2, AMC 84.1, MATH 85.8, Minerva 44.7, Olympiad 45.3, average 54.5, vs. GRPO 43.8 average and the strongest prior baseline (STEER / GRPO-ds) at 49.1. STARE-O1 averages 54.4. AIME24 improves from 34.0 (GRPO) to 44.2.
Qwen2.5-14B-Instruct: STARE-C2 reaches AIME24 31.5, AIME25 28.3, average 52.3 vs. GRPO-ds 46.1; AIME24 nearly doubles versus reported 14B GRPO baselines (12.1 base, 22.5 GRPO).
Qwen2.5-32B-Base: STARE-C2 averages 61.4 with AIME24 42.9, AIME25 35.7, MATH 90.6, vs. GRPO-ds 56.1 and DAPO AIME24 38.3, AIME25 29.8.
Long CoT, DeepSeek-R1-Distill-Qwen-1.5B: STARE is competitive with or above the strongest prior entries (GRPO 53.9 avg, DAPO 55.1, KL-Cov 56.5).
The closed-loop gate keeps entropy in a bounded band around H_\text{tgt}=0.3 over 1000 RL steps, where vanilla GRPO collapses.
Limitations and open questions
The analysis is first-order in the unclipped regime; interaction with the PPO clip and with off-policy correction over multiple inner steps is not characterized. The surprisal-quantile proxy is a coarse approximation to the exact \mathfrak{s}^*_{i,t} threshold from Proposition 3.2, and the choice P=10\%, W=1.1, M=0.9 is fixed across scales without an adaptive rule. Hyperparameters of the target-entropy gate (the band width, the gain) are not ablated in this excerpt, and H_\text{tgt}=0.3 is empirical. Finally, all gains are reported on math/tool-use benchmarks; whether the same four-quadrant story applies to RLHF-style preference rewards or to long-horizon agentic tasks where credit is sparser is open.
Why this matters
Entropy collapse is the dominant failure mode of RLVR fine-tuning, and prior remedies are largely heuristic. STARE provides a clean first-order decomposition dH/d\eta = -\hat{A}\,\Phi(p) that explains why a small high-surprisal minority controls entropy dynamics, and turns it into a cheap, drop-in reweighting on top of GRPO with consistent multi-point gains at 1.5B–32B scales.
Source: https://arxiv.org/abs/2606.19236
PAIWorld: A 3D-Consistent World Foundation Model for Robotic Manipulation
Problem
World foundation models (WFMs) used as simulators for robot policy learning are dominated by single-view video generators. Robotic stacks, however, almost always consume multiple synchronized streams: an egocentric camera, an eye-to-hand (third-person) camera, and a wrist-mounted camera. Existing multi-view extensions of DiT-based WFMs handle this by concatenating per-view tokens along the sequence axis and relying on full self-attention to discover correspondences. The authors argue, and demonstrate, that this is insufficient: rollouts exhibit cross-view object drift (an object’s position is inconsistent between views), depth inconsistency, and texture misalignment. Formally, generated frames \{I_t^v\}_{v=1}^V rarely admit a single consistent 3D scene \mathcal{S}_t from which they could all be rendered under their respective extrinsics [\mathbf{R}^v \mid \mathbf{t}^v] and intrinsics \mathbf{K}^v, i.e., epipolar constraints across views are violated.
The authors trace this to two missing ingredients: (i) no explicit inter-view communication pathway distinct from intra-view temporal/spatial attention, and (ii) no 3D geometric prior in either the architecture or the training objective. They claim both are simultaneously necessary.
Method
PAIWorld is built on Cosmos-Predict2.5, a ~14B-parameter flow-matching DiT operating in a video VAE latent space, with Cosmos-Reason1 supplying physically grounded text embeddings. Three modules are inserted into the pretrained backbone.
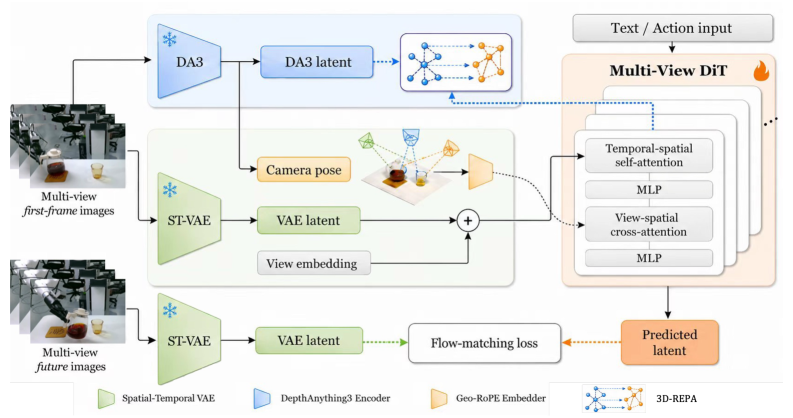
1. Geometry-Aware Cross-View Attention (GA-CVA). A new attention block is interleaved with the standard DiT self-attention. Where the baseline simply concatenates view tokens into one long sequence, GA-CVA explicitly routes queries from each view’s tokens to keys/values across all other views, separating the inter-view pathway from temporal-spatial mixing. This makes cross-view interaction a structural property of the architecture rather than something the model must learn to allocate within a flat attention budget.
2. Geometric Rotary Position Embedding (Geo-RoPE). The cross-view attention is conditioned on camera geometry by encoding per-token camera ray directions and extrinsic poses directly into RoPE phase factors. Concretely, for a token at pixel (u,v) in view v, the back-projected ray direction \mathbf{d} = \mathbf{R}^v \mathbf{K}^{v,-1}[u,v,1]^\top together with the camera center \mathbf{t}^v parameterize a rotation applied to query/key vectors before the dot product. The result is a geometric inductive bias that increases attention weight between tokens whose rays are likely to intersect at a common 3D point — an attention-time analog of epipolar matching, but soft and learned.
3. Latent 3D-REPA. GA-CVA + Geo-RoPE provide the pathway; Latent 3D-REPA provides the supervisory signal. Intermediate DiT activations are linearly projected (via a randomly initialized head) and aligned with features extracted from a frozen 3D foundation model (Depth Anything 3) applied to the same multi-view frames. This is a representation-alignment loss in the spirit of REPA, but the teacher is a 3D-aware encoder rather than a 2D self-supervised one, so the distilled signal carries depth and cross-view geometric structure.
The authors argue both pillars are required: GA-CVA + Geo-RoPE without 3D-REPA gives a geometry-shaped pathway with no guarantee that what flows through it is 3D-consistent; 3D-REPA without the pathway tries to enforce a 3D objective through an architecture that has no efficient mechanism to act on it.
Results
PAIWorld is pretrained on 2.5M multi-view robotic video clips and evaluated on action-conditioned video generation and text-conditioned multi-view generation across three benchmarks (WorldArena and two others). Figure 1 summarizes the deployment surface — generation, world-action modeling, planning, and policy post-training — all sharing the same backbone.
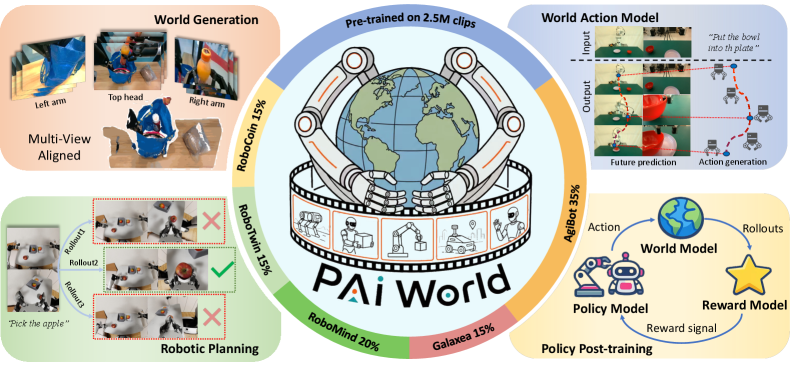
Qualitatively, action-conditioned rollouts on WorldArena keep scene layout stable over long horizons and produce object dynamics consistent with the commanded action stream across egocentric, third-person, and wrist views.
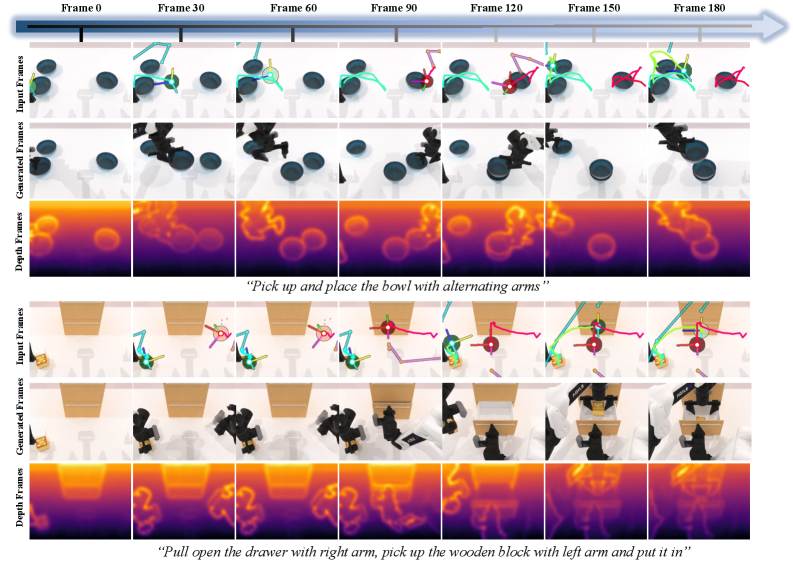
The provided sections do not include the full quantitative tables, so specific FVD/PSNR/cross-view consistency numbers cannot be cited here; the experimental section establishes the comparison protocol against state-of-the-art multi-view WFM baselines on the two generation paradigms. Readers should consult the full paper for per-benchmark metrics.
Limitations and open questions
The 3D supervision is only as good as Depth Anything 3 — failure modes of the teacher (transparent objects, specular surfaces, thin structures common in manipulation) propagate into the student. Geo-RoPE assumes accurate, calibrated extrinsics across all cameras, which is not always available on real robots with hand-eye calibration drift. The 14B parameter scale and reliance on 2.5M multi-view clips raise questions about how much of the gain comes from data versus the architectural changes; an ablation isolating GA-CVA, Geo-RoPE, and Latent 3D-REPA would be the natural sanity check, and it is unclear from the provided sections whether epipolar consistency is measured directly (e.g., reprojection error of matched points) versus inferred from downstream metrics. Finally, flow-matching inference cost at this scale remains a barrier for closed-loop policy use.
Why this matters
Multi-view 3D consistency is the missing prerequisite for using generative WFMs as actual simulators in robot learning: a policy trained on rollouts where the wrist camera and the third-person camera disagree about object position will not transfer. PAIWorld is a concrete recipe — explicit inter-view attention, geometry-encoded RoPE, and 3D-feature distillation — for retrofitting this property onto an existing DiT WFM rather than redesigning from scratch.
Source: https://arxiv.org/abs/2606.18375
Beyond the Current Observation: Evaluating Multimodal Large Language Models in Controllable Non-Markov Games
Closed-loop deployment of MLLMs as policies routinely requires conditioning the next action on observations that have scrolled out of view: a card flipped twenty turns ago, a corridor seen three rooms back. Existing agentic benchmarks either expose the full state, bundle memory with planning and tool use, or probe recall only via a post-hoc question after the episode ends. RNG-Bench targets the in-loop case directly: can a model maintain an accurate belief state b_t = f(h_t) from its in-context history and act on it, in a setting where the current observation o_t is provably insufficient for optimal action?
Problem formulation
The authors model each task as a POMDP (\mathcal{S},\mathcal{O},\mathcal{A},T,Z,R) and define a non-Markov instance via the existence of two histories collapsing onto the same observation but requiring different optimal actions:
\exists\, h_t,\tilde{h}_t \quad \text{s.t.}\quad Z(s_t)=Z(\tilde{s}_t),\ \mathcal{A}^*(h_t)\neq \mathcal{A}^*(\tilde{h}_t).
Models are evaluated as raw history-conditioned policies \pi(a_t\mid h_t) with no external scratchpad or belief module by default — the in-context tokens are the belief state.
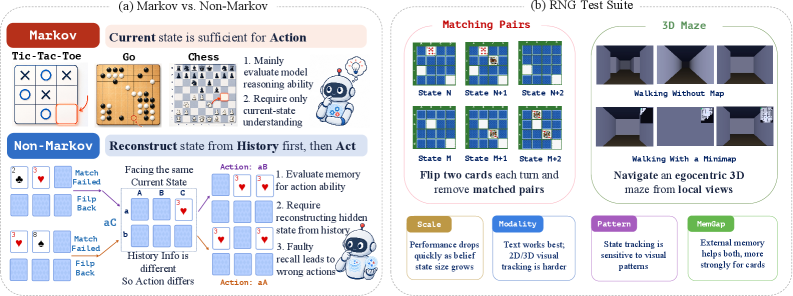
Two environments, three axes
RNG-Bench has two simulators chosen for orthogonal demands on memory:
- Matching Pairs: a grid of face-down cards. Each flip briefly reveals an identity at a known location; matching requires recalling identity-location bindings dozens of turns later. This is static identity memory with point retrieval.
- 3D Maze: egocentric first-person views from which the agent must integrate visited corridors into an allocentric map. This is dynamic map construction.
Three controlled axes — grid size, visual pattern (e.g., noise card theme), and observation modality (image vs. text) — let the authors sweep difficulty without changing rules.
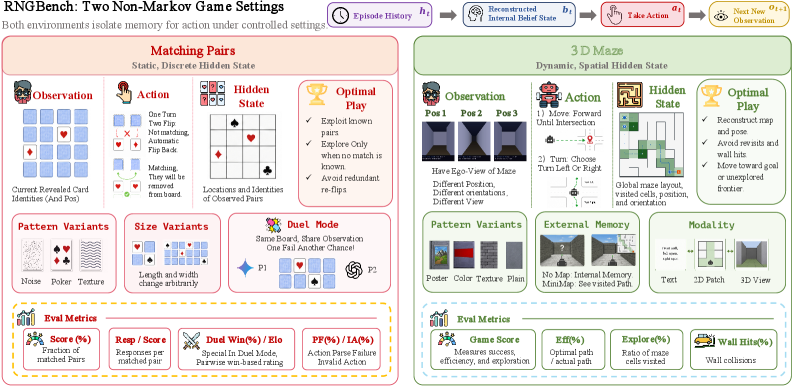
The hardest configurations push contexts to roughly 128K tokens and 350 image inputs per episode. A Memory Gap metric compares performance under perfect recall (oracle injects past observations) against the natural in-context setting, separating forgetting from poor action selection. A duel protocol has two models alternate moves on the same Matching Pairs board, controlling instance variance and additionally probing whether a model can exploit identities the opponent revealed.
Main results
On 10\times 10 Matching Pairs (50 pairs, image observations), GPT-5.4 leads at 62.3% Score with 8.01 responses per matched pair. Gemini-3.1-Pro reaches 50.0%, Seed-2.0-Lite 43.2%, Kimi-K2.5 38.0%, Qwen3.5-397B 25.3%. Parse-failure and invalid-action rates stay below 5% across the board, so the spread reflects belief tracking rather than format compliance.
The ranking flips on 13\times 13 3D Maze (mean optimal path 60 steps, no minimap): Gemini-3.1-Pro takes 50.0% SR / 49.7% GS, while GPT-5.4 — top on Matching Pairs — drops to 20.0% SR / 30.5% GS. Seed-2.0-Lite matches GPT-5.4’s SR (20%) but trails on aggregate score. The dissociation argues that identity-binding retrieval and spatial belief integration are distinct capabilities and that no current frontier model dominates both.
The duel setting reshuffles further: Gemini-3.1-Pro wins all 16 head-to-heads (Elo 1803), GPT-5.4 falls to second (50% win rate, Elo 1492). Since duel win rates aggregate over swapped player orders, this is not first-mover bias; Gemini appears better at exploiting opponent-revealed cards into consecutive matching turns — a different memory operation from tracking only one’s own flips.
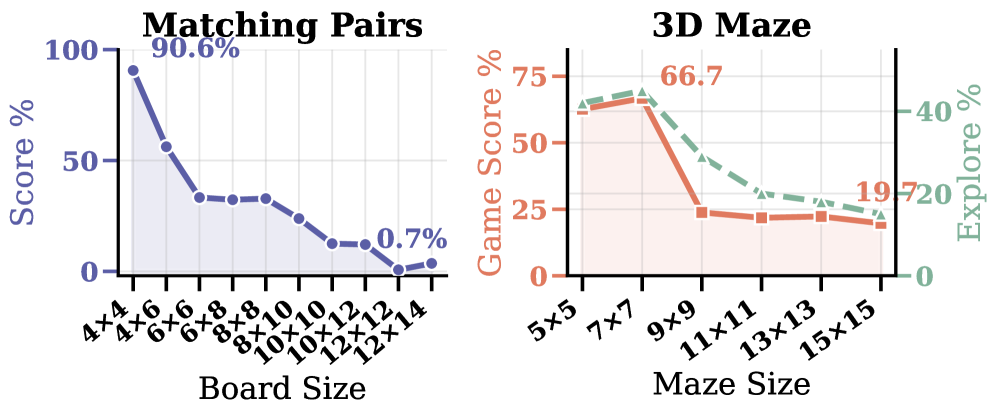
The scale sweep is the cleanest diagnostic: rules are constant, only the hidden-state size grows, and scores collapse — so the failure mode is belief maintenance, not task comprehension.
SFT on non-Markov trajectories
Because the simulators emit fresh trajectories with known optima, the authors fine-tune Qwen3.5-9B with action-token SFT (loss masked over observation tokens). Training uses Matching Pairs boards 2\times 4 to 8\times 8 and mazes 5\times 5 to 9\times 9; evaluation uses strictly larger sizes with disjoint seeds. Two pools: 32K rule-based optimal trajectories (opt32k) versus a rmix32k mix of 26K optimal plus 6K filtered successful rollouts from larger MLLMs (Qwen3.5-397B, Kimi-K2.5).
opt32k lifts Matching Pairs from 0.0 to 14.6 Score% and 3D Maze from 1.5 to 5.0 GS on held-out larger sizes. rmix32k further raises Matching Pairs to 29.5%, halves responses per matched pair, and is the only configuration with non-zero maze success. The interpretation: an oracle pool never visits the recovery states that an imperfect policy actually reaches, while filtered rollouts supply exactly those off-trajectory recoveries.
Transfer is non-trivial. On external memory/spatial benchmarks, SFT lifts EMeMBench Visual DIF_50 by +5.2, VGRPBench Macro Perception by +4.6, MMSIBench_circular by +2.3, ViewSpatialBench by +1.5 (group mean +3.4). General multimodal benchmarks move only +0.5 on average (OCRBench +3.3, MMBench +1.0, MMStar -0.6, RealWorldQA -1.0), so the gains concentrate where the inductive bias should help.
Limitations and open questions
The benchmark relies on two synthetic simulators; whether ranking on RNG-Bench predicts memory behavior in open-ended embodied tasks is untested. SFT experiments use a single 9B base, so the scaling of trajectory-based memory training is unknown. The duel protocol is restricted to Matching Pairs. Finally, default evaluation forbids external scratchpads — an interesting axis to vary, since prompted note-taking might close much of the gap and would tell us whether the deficit is representational or merely a failure to use available compute.
Why this matters
RNG-Bench operationalizes a capability — in-context state tracking for action — that is implicit in every claim about MLLM agents but rarely measured cleanly. The dissociation between identity memory and spatial belief, the collapse with hidden-state scale, and the targeted gains from rollout-augmented SFT all suggest belief maintenance is a first-class axis for agent evaluation, separable from reasoning and tool use.
Source: https://arxiv.org/abs/2606.19338
Guava: An Effective and Universal Harness for Embodied Manipulation
Problem
End-to-end vision-language-action (VLA) models tightly couple perception, planning, and control inside one network, requiring large-scale embodied data and offering limited recourse when execution deviates from prediction. The alternative — harnessing a pretrained VLM as a high-level reasoner that calls external perception and control modules — is attractive but underspecified: it is unclear which workflow, action space, and observation modality combinations actually yield robust manipulation, and whether the resulting design transfers to small open-source models. Guava addresses both questions: a controlled study of harness design with frontier VLMs, followed by distillation into a 4B model.
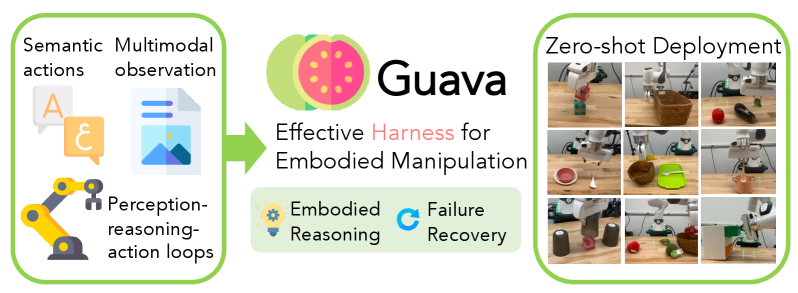
Harness design
The authors ablate three axes on six long-horizon Robosuite tasks with GPT-5.4 as the reasoning backbone.
Workflow. Single-shot trajectory prediction is replaced by a ReAct-style perception–reasoning–action loop. After each tool invocation the VLM receives updated observations and re-plans, which lets it recover from grasp failures and pose drift rather than committing to an open-loop script.
Action space. Rather than emitting joint or end-effector setpoints, the VLM calls a small library of semantically named tools (Table 1):
- High-level skills with object-centric arguments:
grasp(object),align(object, direction, clearance). - Geometric queries:
get_position(object),get_position_size(object). - Low-level fallbacks:
move(x,y,z),rotate(angle, axis),close_gripper(),release(),home_pose().
The mix matters: grasp and align delegate motion planning and grasp synthesis to lower-level controllers, freeing the VLM from explicit reasoning over SE(3) poses, while move/rotate retain the expressivity needed for non-prehensile or fine-grained behaviors (e.g., pushing, drawer closing).
Observations. The agent receives both an RGB image and a textual symbolic state describing robot configuration and task progress. The visual channel disambiguates spatial relations; the textual channel makes robot state and history compactly legible to the language model. The ablations in Figure 2 show the iterative + semantic-action + multimodal configuration dominates across all six tasks, while the low-level action interface and single-turn planners both degrade substantially.
Distillation into a 4B model
To test whether these design principles are universal — i.e., usable by a small model — Guava-Agent-4B is built by fine-tuning Qwen3.5-4B with the vision encoder and aligner frozen, using fewer than 2K simulation trajectories on 8×H100 in bf16. The trajectories are collected under the same harness, so supervision targets are sequences of tool calls and intermediate reasoning, not low-level actions. Training is two-stage (SFT followed by an additional optimization stage; details in supplementary).
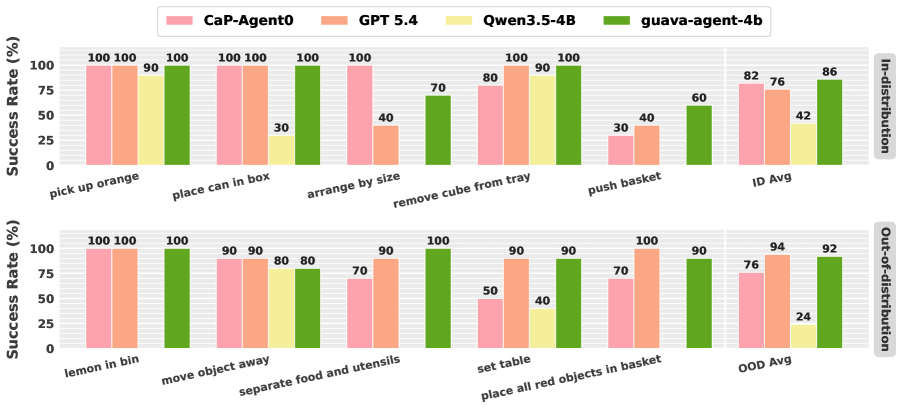
Results
Simulation evaluation spans 15 Robosuite tasks split into in-distribution, OOD-object, OOD-prompt, and OOD-long-horizon categories, each with 15 episodes. Headline numbers (success rate, %):
- Guava-Agent-4B: 75.6 overall.
- GPT-5.4 under the same harness: 70.2.
- CaP-Agent0 (one-shot code generation baseline): 62.7.
- Qwen3.5-4B base under the harness, no embodied post-training: 23.1.
The 4B distilled model surpasses GPT-5.4 on contact-rich and non-prehensile tasks where iterative grounding pays off: push basket 60.0 vs 26.7, push pot 73.3 vs 26.7, close drawer 86.7 vs 53.3, arrange by size 66.7 vs 40.0. It matches GPT-5.4 (100.0) on place can in box, lemon in bin, pick up carrot, and stack cube reverse order. Failure modes are visible too: shell game (6.7 vs 46.7) and place all red objects in basket (0.0 vs 80.0) collapse, suggesting the distilled model loses some of the open-ended visual reasoning and tracking competence of the frontier model on tasks that require persistent object identity tracking or attribute-based set selection.
The 23.1 → 75.6 gap between base and post-trained Qwen3.5-4B with the same harness shows the harness alone is insufficient at 4B scale; embodied tool-use trajectories are needed to teach the small model when and how to invoke the abstractions.
In zero-shot real-world deployment on a Franka Research 3 with an Intel RealSense D435, Guava-Agent-4B reaches success rates comparable to GPT-5.4 over 10 episodes per task, despite being trained only in Robosuite. Example rollouts (Figure 5) show correct task-relevant object selection and tool dispatch across heterogeneous setups.

Limitations and open questions
- The tool library is hand-engineered; performance presumes that primitives like
grasp(object)andalign(...)are reliable, which shifts difficulty into the controllers and perception modules rather than removing it. - OOD long-horizon results are bimodal: strong on
separate food and utensils(93.3) andset table(93.3), but near-zero on tasks requiring attribute-conditioned multi-instance selection. Distillation appears to narrow the model’s compositional reasoning relative to GPT-5.4. - Sim-to-real success is shown only on a small evaluation (10 episodes/task) with one camera and one arm; robustness to clutter, occlusion, and dynamic scenes remains untested.
- The paper does not isolate the contribution of the second optimization stage versus SFT, nor study scaling beyond 4B.
Why this matters
Guava is a clean demonstration that, for embodied manipulation, harness design (closed-loop ReAct + semantic tools + multimodal state) plus ~2K simulation trajectories can compress a frontier VLM’s manipulation competence into a 4B open model that matches or beats it in both simulation (75.6 vs 70.2) and zero-shot real-world deployment. It argues that, given the right action abstraction, embodied capability is more about workflow and tool-use supervision than about model scale or large-scale VLA pretraining.
Source: https://arxiv.org/abs/2606.18363
Reinforcing Dual-Path Reasoning in Spatial Vision Language Models
Spatial VLMs increasingly perform well on geometric perception primitives (depth ordering, bounding-box prediction, relative distance), but multi-step spatial inference — questions requiring composition over depth, metric distance, and inter-object relations — remains brittle. SR-REAL argues that this brittleness is partly a strategy mismatch: some queries are best handled by purely linguistic chain-of-thought, while others require an explicit detour through 3D geometry before any quantitative deduction. The paper trains a single spatial VLM that can switch between two such pathways and optimizes both jointly with RL.

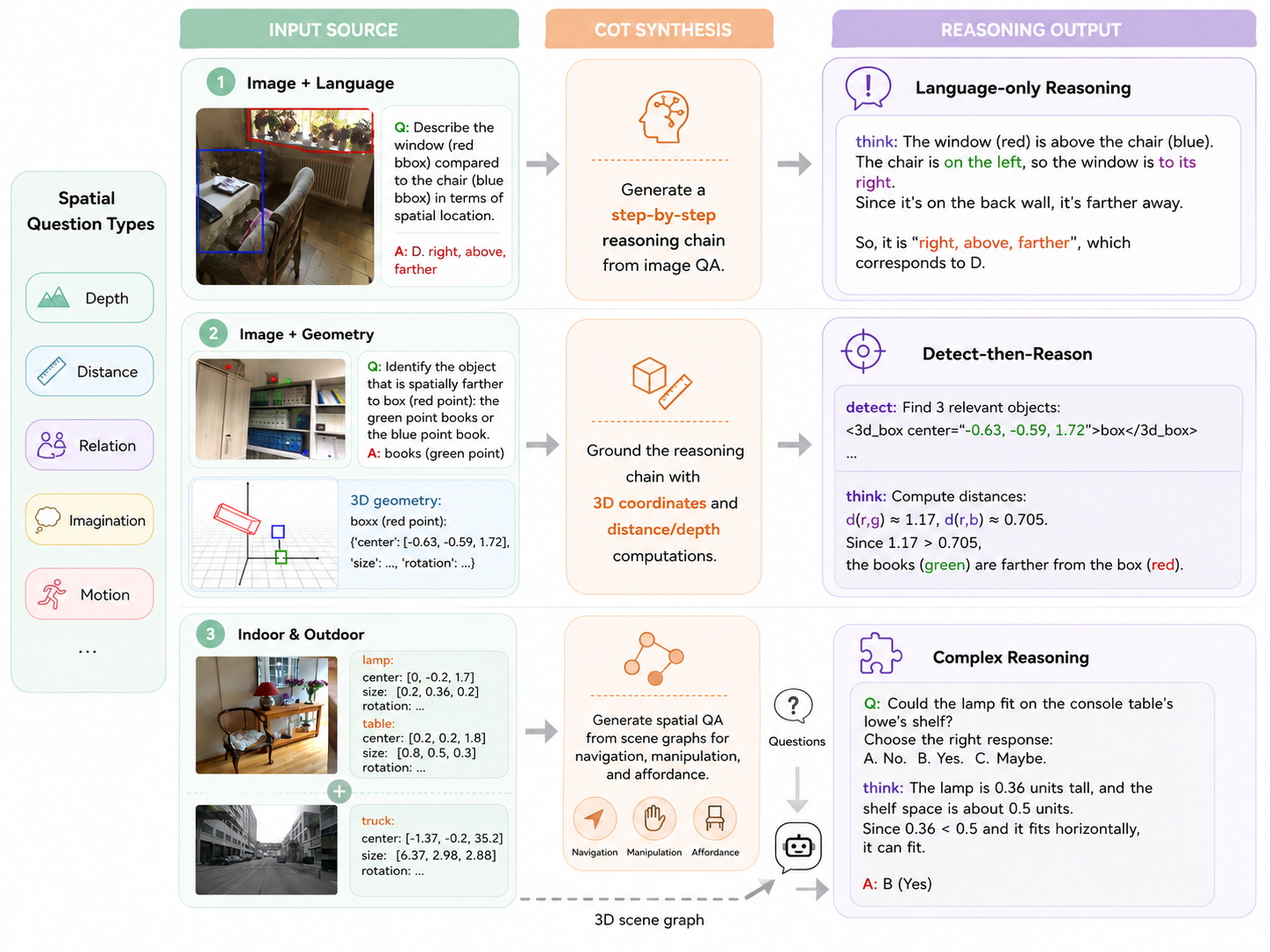
Two reasoning paths
The two pathways are:
- Language-Only Reasoning (LOR). Standard CoT producing a textual deduction over the image, without emitting region tokens.
- Detect-Then-Reason (DTR). The model first emits region tokens (centers or 3D bounding boxes) for entities referenced by the question, then performs quantitative inference (e.g., Euclidean distance between predicted centers) on those grounded primitives.
The backbone reimplements SR-3D (Cheng et al., 2025): interleaved text/image/region tokens with a depth- and intrinsics-aware positional embedding fused into visual features. SR-REAL extends this with a region-prompt interface where region tokens cross-attend to vision features, plus region-level 2D/3D grounding supervision that SR-3D lacked.
Two-stage training
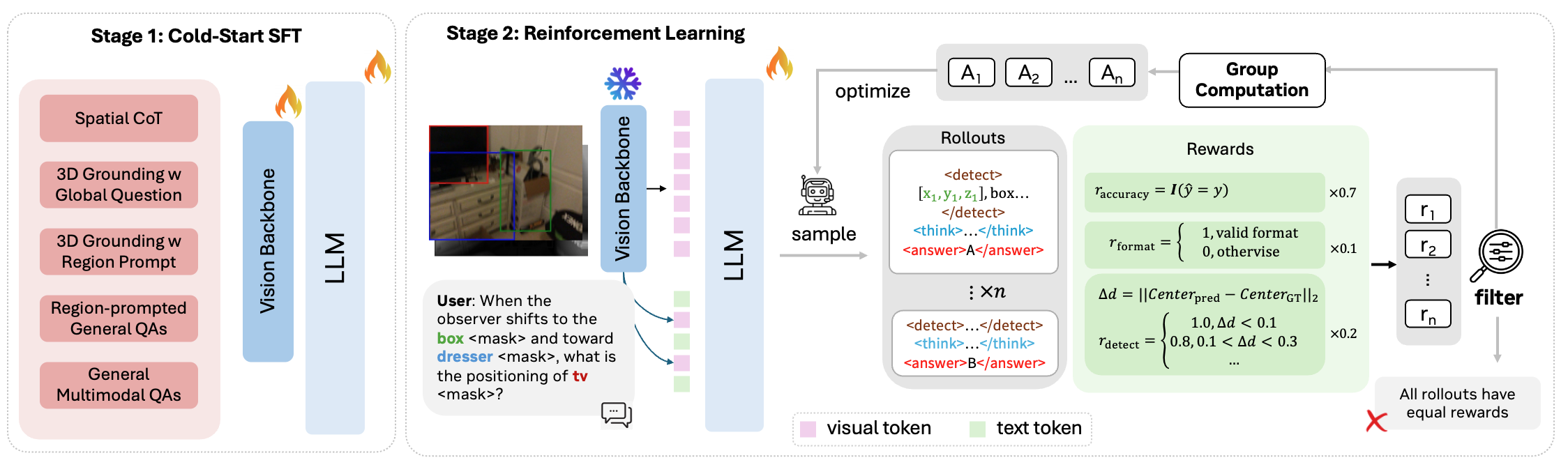
Stage 1 — Cold-start SFT (~1M samples). Five components:
- CoT–LOR (30k): 10k SPAR traces plus 20k complex traces over CA-1M (indoor) and NuScenes (outdoor).
- CoT–DTR (10k): SPAR-derived traces that explicitly emit region detections before quantitative reasoning.
- Grounding (Omni3D, OmniNOCS for 3D; RefCOCO for 2D), supplying region-to-3D-point supervision.
- Region-prompted VQA from SRGPT.
- General VQA from LLaVA-1.5 to retain broad multimodal capability.
Stage 2 — RL (~200k questions, ~100k global/LOR + ~100k region-grounded/DTR). Rollouts are grouped per query (GRPO-style), with rewards:
- Accuracy reward on the final answer (MCQ match or numeric tolerance for fill).
- Format reward enforcing the expected trace structure for the chosen path.
- 3D-center detection reward (DTR only): a discrete reward on whether predicted region centers fall within tolerance of ground-truth 3D centers, sharpening geometric alignment before the quantitative step.
Training a single policy over both LOR and DTR trajectories means RL also implicitly learns when each path is more reliable, since rewards differentiate trajectory types.
Results
On SPAR-Bench (Table 1), SR-REAL substantially raises the SR-3D base from 33.4 average to 60.5 (LOR) and 61.9 (DTR). Compared with the strongest published spatial reasoning model VST (48.9), DTR improves the average by 13.0 points. Per-difficulty: Low 24.1→61.1, Medium 37.6→46.9, High 40.1→68.3 (DTR). On out-of-domain benchmarks, EmbSpatial improves 72.5→81.3 and SAT 63.0→68.7 (LOR; SAT lacks region grounding so DTR is N/A).
Table 2 isolates where DTR helps. On single-view subtasks DTR beats LOR on depth_prediction (35.4 vs 30.5), distance_infer_center (80.0 vs 75.0), obj_spatial_relation (73.9 vs 71.4), and spatial_imagination (52.0 vs 49.3). In multi-view, DTR retains an edge on depth (30.4 vs 25.9) but LOR is competitive or slightly better on relation (78.9 vs 77.8). The pattern is consistent: tasks with explicit metric content reward grounding through region tokens; relational/imagination tasks at multi-view scale benefit less, likely because cross-view region grounding is harder.
Table 3 reports a regression on some OOD sets: BLINK(s) drops from 83.9 (SR-3D base) to 80.4 (LOR full); RealWorldQA drops 68.1→59.5. An “Ours-direct” variant (no CoT) recovers BLINK to 87.4 and RWQA to 64.6, suggesting the CoT-trained policy overfits to long structured traces on out-of-distribution short-answer formats.
Limitations and open questions
- Trace-format brittleness OOD. The RWQA/BLINK gap between LOR-with-CoT and direct inference indicates the policy has coupled reasoning quality to a particular trace style. A path-and-format selector (or a length-controlled reward) seems necessary.
- Multi-view DTR. Gains shrink in multi-view; DTR’s center-based reward is single-view-friendly. Cross-view consistency rewards are not explored.
- Detection reward is discrete and center-only. Bounding-box IoU or full 3D-box rewards may further tighten geometric alignment, particularly for size/extent-dependent queries.
- No ablation on RL alone vs SFT alone is shown in the excerpt, so the contribution of the 3D-center reward versus accuracy/format rewards is not isolated here.
- The base is SR-3D-specific; portability to non-depth-conditioned VLMs is untested.
Why this matters
Routing spatial queries through complementary linguistic and geometry-grounded reasoning paths, and training both jointly with RL plus a 3D-center reward, yields large gains (SPAR-Bench 33.4→61.9) over a strong spatial-VLM base and over single-strategy spatial reasoners. It is concrete evidence that for spatial reasoning, the choice of representation to reason over (text tokens vs. emitted 3D primitives) is a learnable policy decision worth optimizing explicitly.
Source: https://arxiv.org/abs/2606.17539
Hacker News Signals
GLM-5.2 is the new leading open weights model on Artificial Analysis
Zhipu AI’s GLM-5.2 has taken the top spot on the Artificial Analysis Intelligence Index for open-weight models, displacing the prior leaders (various Qwen and Llama-family checkpoints). The Intelligence Index is a composite of reasoning, coding, math, and instruction-following benchmarks, weighted to penalize speed-accuracy tradeoffs, so a model cannot game it purely on one axis.
The technical architecture is not fully disclosed, but GLM-5.2 is positioned as a dense (non-MoE) model in the 30-70B parameter range. On Artificial Analysis’s own evals it scores above DeepSeek-V3 and Qwen3-72B on the composite index, with particularly strong numbers on MATH-500 and LiveCodeBench. Latency benchmarks show competitive tokens-per-second on standard A100/H100 inference, though it does not match smaller quantized MoE models on raw throughput.
What is notable here is the trajectory: GLM-4 was a mid-tier open-weight model, and GLM-5.2 closing the gap to—and apparently exceeding—frontier open models within a single major version jump is a meaningful signal about the pace of non-US lab development. The HN comment thread focused on reproducibility concerns (Artificial Analysis runs their own private eval harness, not the standard Open LLM Leaderboard setup), and whether “open weights” with restricted commercial licensing should be categorized with truly permissive releases.
Limitations: no technical report has been published as of this digest, so architectural claims are inferred. Independent replication on standardized benchmarks (HELM, LM-Eval-Harness) is pending.
GLM 5.2 Performance Benchmarks
This companion page on Artificial Analysis provides the raw benchmark decomposition behind the composite Intelligence Index score for GLM-5.2. The methodology is worth understanding: Artificial Analysis runs models against a fixed private prompt set for each capability domain (reasoning, coding, math, instruction following, long context) and reports both absolute scores and normalized ranks. Speed is measured as median output tokens per second on their own inference infrastructure, not vendor-reported numbers.
GLM-5.2 shows its strongest advantage on the reasoning and math subtracks relative to the open-weight field, while its coding scores are competitive but not dominant compared to Qwen3-72B-Instruct. The long-context subtrack (128k+ token inputs) is where it underperforms relative to its composite rank, which is consistent with the known difficulty of extending RoPE-based positional encodings at training time.
The price-performance chart is the most practically useful output: GLM-5.2 via API lands in a favorable position against GPT-4o and Claude Sonnet 3.5 on quality-per-dollar, though the API is served by Zhipu’s own endpoint rather than competitive third-party inference markets. The HN thread raised questions about whether the benchmark suite is sufficiently independent—Artificial Analysis does not publish its prompt sets, which makes adversarial contamination checks impossible.
For practitioners evaluating model selection, the takeaway is that GLM-5.2 warrants inclusion in head-to-head eval runs on domain-specific tasks, but the composite ranking should be treated as a prior, not a conclusion.
Source: https://artificialanalysis.ai/models/glm-5-2
AMD silently removes memory encryption from consumer Ryzen CPUs
AMD’s Transparent Memory Encryption (TME) and Secure Memory Encryption (SME) features—present in Zen 3 and Zen 4 consumer Ryzen CPUs—were silently disabled via AGESA firmware updates pushed to motherboard vendors, without a public changelog entry or CVE. TME encrypts DRAM contents using an AES-128 key held in the CPU, protecting against cold-boot and physical memory extraction attacks. SME is the software-addressable variant that lets the OS mark specific pages as encrypted.
The removal was discovered by users noticing that the CPUID leaf reporting SME/TME capability bits was cleared after a BIOS update. When contacted, AMD engineers did not respond publicly, and board vendors pointed to AMD’s AGESA (AMD Generic Encapsulated Software Architecture) package as the source of the change. AGESA is the closed-source firmware layer AMD distributes to OEMs; consumer users have no mechanism to audit or roll back to a prior version without flashing older BIOSes—which themselves may have other vulnerabilities.
The security implication is concrete: on systems where SME was relied upon (e.g., certain Linux configurations using mem_encrypt=on), the kernel will now silently operate without the encryption layer if the CPUID bit is absent and the kernel checks capability before enabling. This is a regression in defense-in-depth for physical-access attack scenarios—relevant in shared or mobile computing contexts.
The broader engineering concern is governance: AGESA updates are treated as opaque firmware blobs by the supply chain, and AMD has no public errata or security advisory process equivalent to Intel’s Platform Update mechanism. The HN thread noted this is structurally similar to Intel’s ME firmware situation—closed supply chain, no user agency, silent behavioral changes.
Feds freaked over Fable 5 after ‘fix this code’, not jailbreak, say researchers
This item concerns a security incident where US federal agencies reportedly flagged an LLM-assisted coding session involving a game (internally called “Fable 5”) after a user issued a plain fix this code prompt—not a jailbreak or adversarial injection. Researchers at the involved organization clarified that the model’s output contained content that triggered automated monitoring systems, but the prompt itself was benign and the content was the model hallucinating or generating plausibly dangerous adjacent code paths while attempting a routine debugging task.
The technical substance here is about AI output monitoring pipelines in high-security environments. The incident illustrates a false-positive problem in content classifiers applied to LLM outputs: a model attempting to fix, say, a buffer management routine may produce code patterns that resemble exploit primitives, which pattern-matching classifiers flag without semantic context. The monitoring system saw the output, not the intent or the context of the surrounding codebase.
This points to a real engineering gap. Current LLM deployment in sensitive environments typically pipes outputs through keyword/pattern classifiers tuned for adversarial prompting, not for benign code generation that incidentally resembles sensitive material. The false-positive rate at the tail of code-generation outputs is poorly characterized in public literature. The incident also raises questions about what “jailbreak” means operationally for monitoring teams—if any output resembling dangerous content triggers an alert regardless of prompt origin, the classifier definition of jailbreak has drifted from the research definition.
The HN thread focused on the chilling effect this has on legitimate developer use of AI tools in regulated environments, and on the opacity of what exactly these monitoring systems are classifying.
RFC 10008: The new HTTP Query Method
RFC 10008 standardizes a new HTTP method, QUERY, designed for read-only requests that require a request body. The core problem it solves: GET semantics prohibit a body (practically if not formally), and POST is not idempotent and not cache-safe, forcing implementers to abuse POST for complex query operations—common in GraphQL, SPARQL, and large search APIs where query parameters exceed URL length limits or require structured input.
QUERY is defined with the following semantic properties: safe (does not modify server state), idempotent, and cacheable. This means intermediaries (proxies, CDNs) can legally cache QUERY responses keyed on both the URL and the request body, which POST explicitly cannot do under HTTP caching semantics. The method is registered in the IANA HTTP Method Registry.
The caching key definition is the technically interesting part: RFC 10008 specifies that caches MUST use the request body as part of the cache key, and recommends (but does not mandate) a normalized form. Body normalization is left to the application layer, which is a deliberate punt—SPARQL and GraphQL have different normalization semantics and the RFC authors chose not to adjudicate between them. This means two semantically identical queries with different whitespace will be cache misses unless the client or an intermediary normalizes.
The QUERY method is also explicitly safe for preloading and prefetching, which POST is not, enabling browser and CDN optimizations. Adoption will depend on framework and CDN support; as of publication, nginx, Varnish, and most reverse proxies require explicit configuration to handle unknown methods.
Source: https://www.rfc-editor.org/info/rfc10008/
DeepSeek Introduces Vision
DeepSeek has added multimodal (vision) input capability to its chat interface and API, extending the previously text-only DeepSeek-V3 and R1 models to accept image inputs. The HN item links directly to the chat interface rather than a technical report, so architectural specifics are inferred from the API documentation and community testing.
From what is publicly available: the vision capability uses a standard vision encoder (likely a ViT or SigLIP variant) patched into the existing language model via cross-attention or token concatenation at the embedding layer—the same approach used by LLaVA, Qwen-VL, and InternVL. DeepSeek has not published a model card or architecture diagram for the vision extension as of this digest.
Community benchmarking in the HN thread suggests performance on OCR-heavy tasks and diagram interpretation is competitive with GPT-4o-mini, while complex multi-image reasoning lags behind GPT-4o and Claude 3.5 Sonnet. The model handles Chinese-language document understanding particularly well, consistent with the training data distribution of the base model.
The API pricing is notably low relative to comparable Western providers—this follows the pattern established by DeepSeek’s text models, where aggressive pricing was used to drive adoption and stress-test competitor pricing power. The vision endpoint is currently rate-limited more aggressively than the text endpoint, suggesting infrastructure scaling is ongoing.
For practitioners, the main question is whether the vision encoder generalizes to scientific figures, code screenshots, and structured documents—domains where GPT-4V has known weaknesses. Independent systematic evaluation on these domains has not yet appeared.
Source: https://chat.deepseek.com/
Wolfram Language and Mathematica version 15
Wolfram Language/Mathematica 15 ships with LLM integration as a first-class built-in, alongside substantial expansions to core functionality. The LLM features are the most discussed: LLMFunction, LLMSynthesize, and related primitives allow calling external LLM APIs (OpenAI, Anthropic, local models via LLM Kit) with Wolfram Language expressions as structured input/output, type-checked against the language’s symbolic type system. This means you can specify that an LLM function must return a Graph object or a TimeSeries, and the runtime will validate and coerce the output—a more rigorous approach than JSON schema validation in other LLM tool-use frameworks.
Version 15 also extends the Interpreter framework for natural language to structured data conversion, which predates the LLM integration by years but is now hybridized with it: SemanticImport can use LLM assistance as a fallback when rule-based parsing fails. This raises the familiar reliability question—silent LLM fallback introduces nondeterminism into pipelines that users may expect to be deterministic.
Non-LLM additions include expanded computational geometry (Voronoi mesh operations, polyhedral decomposition), new graph-theoretic functions, extended time-series analysis, and a VideoFrameMap primitive for frame-level video processing. The symbolic neural net framework (NetChain, NetGraph) gains support for transformer attention layers with configurable head counts, closing some gaps with PyTorch/JAX for users who want to prototype inside the Wolfram ecosystem.
The licensing model remains proprietary and expensive for institutional use. The HN thread had the predictable Wolfram Language partisanship, but the technical concern worth noting is that tight LLM-cloud-API coupling in a symbolic computation notebook creates reproducibility problems for scientific workflows.
Launch HN: Adam (YC W25) – Open-Source AI CAD
Adam is an open-source AI-assisted CAD system targeting parametric mechanical design, built around a geometry kernel rather than a mesh representation. The repository uses OpenCASCADE (OCCT) as the underlying B-rep (boundary representation) kernel, which means operations like boolean union/difference, fillet, and chamfer are exact rather than approximate—a hard requirement for manufacturing-intent models.
The AI component takes natural language or sketch input and generates sequences of parametric operations (extrude, revolve, sweep, boolean) in a structured intermediate representation that maps to OCCT API calls. This is architecturally similar to CADGen and SketchSolve approaches, but the open-source OCCT backend is a meaningful differentiator over closed-kernel competitors. The IR is a JSON-based feature tree, which means generated designs are editable—a user can take AI-generated geometry and modify parameters directly, rather than receiving a static mesh.
Current limitations from the HN thread and the repository README: the model handles single-body parts reasonably well but struggles with multi-body assemblies and constraint-driven design (where dimensions are linked symbolically). Sheet metal unfolding and surfacing (Class-A surfaces) are not supported. The training data for the generation model is not disclosed, which raises questions about whether it generalizes to unusual geometries or has been overfit to common benchmark shapes.
The open-source decision is significant because commercial AI CAD tools (Autodesk, PTC, Siemens integrations) are all closed. A working open alternative with an exact geometry kernel could integrate into existing OSS CAM pipelines (FreeCAD, OpenCAM) and is relevant for hobbyist CNC, robotics prototyping, and academic research.
Noteworthy New Repositories
anthropics/defending-code-reference-harness
A reference implementation from Anthropic covering the defensive security skills relevant to AI-assisted code analysis: threat modeling, vulnerability scanning, triage, and patch generation. The core artifact is an autonomous scanning harness designed to be forked and customized — operators can wire it to their own static analysis backends, define severity thresholds, and route findings into existing triage pipelines. The skills layer provides structured prompts and tool-call schemas that map onto common security workflows (STRIDE threat modeling, CVE triage, diff-based patch suggestion). Architecturally it sits above the model API, meaning it is model-agnostic in principle, though clearly tuned for Claude’s tool-use interface. Useful as a starting point for teams building AI-augmented AppSec pipelines rather than as a drop-in product. The harness design is notable: it separates the scanning orchestration logic from the remediation logic, which keeps the feedback loop auditable. At 6k+ stars within days of release, it has attracted significant attention as a practical example of agentic security tooling with clear seams for customization.
Source: https://github.com/anthropics/defending-code-reference-harness
cellinlab/how-pi-agent-works
A Chinese-language technical deep-dive into the internals of Pi Agent (the conversational agent from Inflection AI). The repo reconstructs the agent’s architecture from public signals: context management strategy, memory retrieval, tool-calling patterns, and the dialogue state machine that governs turn-taking. Rather than speculation, it grounds claims in observable API behavior and published model cards. Code examples demonstrate how to replicate the core orchestration loop — essentially a ReAct-style planner with persistent persona state. The value here is comparative: it treats Pi as a case study in productionizing an LLM agent with a strong personality constraint, which is technically distinct from task-focused agents like AutoGPT derivatives. Useful for researchers interested in how persona coherence is maintained across long sessions without explicit memory injection at every turn. Small repo (375 stars) but technically careful.
Source: https://github.com/cellinlab/how-pi-agent-works
StarTrail-org/PixelRAG
PixelRAG replaces DOM/HTML parsing in web-based RAG pipelines with pixel-native retrieval: screenshots are the retrieval unit rather than extracted text. The architecture embeds rendered page images using a vision encoder, indexes those embeddings, and at query time retrieves the top-k images before passing them to a multimodal LLM for answer synthesis. This sidesteps the fragility of HTML scraping — dynamic JS-rendered content, paywalled text, complex table layouts, and PDF-like pages all become first-class retrievable objects. The “scalable” claim rests on a tiled image chunking scheme that splits large screenshots into overlapping patches before embedding, preserving spatial locality. The pipeline is built around a CLIP-family encoder with a custom fine-tuning recipe for document-style imagery. Primary use case is enterprise knowledge bases where source documents are rendered artifacts (dashboards, slide decks, scanned PDFs) rather than clean prose. Limitations: retrieval latency is higher than text-based BM25/dense hybrid, and OCR accuracy remains a bottleneck for numeric content.
Source: https://github.com/StarTrail-org/PixelRAG
Liu-Ming-Yu/alpha-forge
An agentic AI operating system targeting systematic (quant) trading. The architecture layers several components: a strategy-generation agent that proposes alpha factors from natural language descriptions, a backtesting harness that evaluates those factors against historical data, and a portfolio construction layer that aggregates surviving alphas under risk constraints. The “co-evolve” framing reflects a feedback loop where backtest results are returned to the generation agent as in-context signal — closer to an evolutionary search over the alpha space than a one-shot generation pipeline. Built on top of standard Python quant infrastructure (likely pandas/polars for data, with a pluggable backtester interface). The OS metaphor refers to a process-scheduling abstraction that lets multiple alpha-search agents run concurrently and compete for allocation. Interesting from an RL perspective: the reward signal is risk-adjusted return (Sharpe or Calmar), making this a sparse-reward sequential decision problem with a long evaluation horizon. At 166 stars, early-stage but architecturally ambitious.
Source: https://github.com/Liu-Ming-Yu/alpha-forge
Aimino-Tech/opendocswork-mcp
A Rust-native Model Context Protocol (MCP) server that exposes Office document manipulation (Excel .xlsx, Word .docx, PowerPoint .pptx) as tool-callable operations for LLM agents. Built on the calamine/rust_xlsxwriter ecosystem for Excel and docx-rs for Word formats. Sub-millisecond latency claims are plausible given zero-copy parsing in Rust versus Python alternatives like openpyxl. The local-first design means no document content leaves the machine — relevant for enterprise contexts with data residency constraints. The MCP interface maps document operations (read cell range, write table, insert slide, extract paragraph text) to structured JSON tool schemas that any MCP-compatible agent framework can consume. Compared to Python-based alternatives, the main tradeoffs are: faster and safer for read/write operations, but the Rust ecosystem for Office formats is less mature than Python’s for edge cases in complex formatting. A solid infrastructure piece for agents that need to interact with the Office document format universe without shelling out to LibreOffice.
Source: https://github.com/Aimino-Tech/opendocswork-mcp
XiaomiMiMo/MiMo-Code
Xiaomi’s release of MiMo-Code, a code-focused LLM+agent system where the headline claim is co-evolution between model weights and agent scaffolding. The repo covers training code, model weights, and an agent harness for code generation and debugging tasks. The co-evolution mechanism involves iterative rounds: the agent generates code, execution feedback (unit test pass rates, linting errors) is collected, and that feedback is used to construct preference data for further RLHF/DPO training of the base model. This closes the loop between deployment-time agent behavior and training-time supervision — a form of online RL from environment feedback. At 9.7k stars, this is the highest-profile release in the batch. Technical differentiators versus competitors (DeepSeek-Coder, Qwen-Coder): the explicit agent-in-the-loop training pipeline and the integration of multi-step debugging trajectories (not just single-turn completions) into the training corpus. Limitations: the co-evolution loop requires significant compute to run at scale, and it is unclear how distribution shift is controlled across rounds.
Source: https://github.com/XiaomiMiMo/MiMo-Code
boona13/image-extender
An open-source outpainting web application that extends images beyond their original boundaries in any direction using a Gemini-backed generative model accessed via OpenRouter. The technical core has three distinct components worth noting. First, the generation loop runs three parallel outpainting requests per extension and selects the best result — a simple but effective variance-reduction strategy that amortizes the stochastic output of diffusion/generative models. Second, boundary seams are smoothed using Poisson blending: the classic gradient-domain technique that solves a Laplacian system to make pixel gradients continuous across the seam rather than naively compositing two image regions. Third, the frontend exposes directional extension controls (expand left/right/up/down by pixel amount) and previews all three variants before committing. Built as a single-page web app — no local GPU required, inference is fully API-side. At 1k stars, it fills a practical gap: most outpainting tools require local Stable Diffusion installs. The Poisson blending step is the key quality differentiator over naive alpha blending at the boundary.
Source: https://github.com/boona13/image-extender
superloglabs/superlog
An AI-augmented observability platform targeting self-healing software systems. The architecture combines a conventional log aggregation pipeline with an agent layer that monitors incoming log streams, detects anomaly patterns, identifies root cause candidates, and — in autonomous mode — proposes or applies remediations (restart services, roll back deployments, patch config values). The “self-heal” loop is: ingest structured/unstructured logs, embed and cluster error signatures, retrieve similar past incidents from a vector store, generate remediation actions via an LLM planner, execute actions through a sandboxed tool-call interface, and verify resolution by monitoring downstream metrics. The open-source positioning distinguishes it from SaaS observability vendors (Datadog AI features, Honeycomb). Key engineering question is the action execution safety layer — autonomous remediation in production requires strict guardrails around blast radius. At 853 stars, the repo is early but addresses a real gap: existing observability tools surface problems; they do not close the loop. Worth watching for how the human-in-the-loop override model is specified.