デイリーAIダイジェスト — 2026-06-12
arXiv ハイライト
FORT-Searcher: ショートカット耐性のある検索タスクを合成してDeep Search Agentを訓練する
問題
合成マルチホップ質問を用いたdeep search agentの訓練には、測定上の問題があります。名目上の構造的難易度(グラフの深さ、制約の数)は、実際の検索難易度とは一致しません。長い検索チェーンを必要とするよう設計された質問であっても、より安価な識別経路が見つかれば崩壊してしまいます。例えば、1回のクエリで正解エンティティを返す高選択性の手がかりが1つあるだけで、あるいは質問文中の定数(日付や固有名詞)が事前知識と結びつくだけで、問題は自明になります。その結果、訓練中の軌跡は長く見えてもモデルがショートカットを行うことを学習してしまいます。本論文ではこのギャップを形式化し、その形式論をデータ合成に活用します。
難易度フレームワーク
タスクは q=(\mathcal{X},\mathcal{C}_q,\Sigma) として定義されます:回答空間、制約集合、検索インターフェースです。任意の制約部分集合 \mathcal{P}\subseteq\mathcal{C}_q に対して、候補プールは
\mathrm{Ans}(\mathcal{P})=\{x\in\mathcal{X}:\bigwedge_{c_i\in\mathcal{P}} c_i(x)=1\},
と定義され、適切に設定された質問に対しては \mathrm{Ans}(\mathcal{C}_q)=\{y^\star\} が成立します。ソルバー \pi_0 に対する実現検索コスト \Omega(q,\pi_0) は、最安値の識別経路 Q_\Sigma^\star で下界が与えられますが、ソルバー側の事前知識バインディング U_{\pi_0}(q) によって削減されます。この形式論から、著者たちは4つのショートカットリスクを列挙しています:(i) 単一手がかり選択性(ある \mathcal{P} だけで既に |\mathrm{Ans}(\mathcal{P})|\to 1 に収束する)、(ii) 証拠の共同カバレッジ(1つの文書が複数の手がかりをカバーし、M_{\mathrm{ev}}(\mathcal{P})\downarrow となる)、(iii) 露出定数(名前付き日付、場所、IDが依存関係の深さ \mathrm{dep}(\mathcal{P}) を低下させる)、(iv) 事前知識バインディング(モデルが既に y^\star を知っている)。実現した影響を診断するために、3つの軌跡シグネチャを用います:総解決コスト \widehat{\Omega}、回答ヒット時刻 T_{\mathrm{hit}}(正解が検索された証拠に初めて現れるターン数)、および事前ショートカット率 \widehat{p}_{\mathrm{prior}} です。
FORT合成パイプライン
FORTはこのフレームワークを逆用します:Q_\Sigma^\star が大きく、U_{\pi_0}(q) が小さい質問を合成します。内部証拠グラフ(エンティティをノード、検証済み事実をエッジとする)を構築し、制約を適用した後にのみ部分グラフを言語化します。
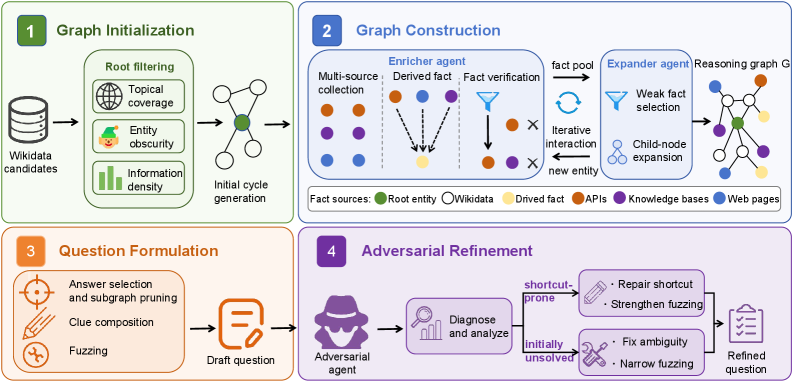
4つのステージはリスク分類に対応しています:
- グラフの初期化。 ロングテールのルート選択(レアなエンティティ、Wikipediaでの人気度が低いもの)が事前知識バインディングを攻略し、サイクルベースの初期化は識別子が閉じた依存ループを通じてのみ復元できるようにすることで、定数の露出を回避します。
- グラフの構築。 マルチソースエンリッチメントにより、手がかりが互いに素なドキュメントで支持されるように強制し(M_{\mathrm{ev}} を向上させる)、導出された事実(例:年そのものではなく「各桁の和が7になる年」)によって単一のエッジが高選択性を持つことを防ぎます。
- 質問の定式化。 汎用的で特異性の低い手がかりの表層形を用いることで、小さな \mathcal{P} に対して s(\mathcal{P}) を小さく保ちます;名前の非開示と正確な値のファジング化により定数を除去します。
- 敵対的精錬。 候補質問に対して強力なソルバーを適用し、安価に解けてしまう例(\widehat{\Omega} が小さい、または T_{\mathrm{hit}} が早い)は書き直しまたは破棄することで、ソルバーレベルのコスト削減を直接ターゲットにします。
訓練と結果
ベースモデルはQwen3-30B-A3B-Thinking-2507(30Bのうち3Bをアクティベート、256Kコンテキスト)です。訓練はFORT軌跡上でのSFTのみ、6エポック、グローバルバッチサイズ64、シーケンス長262,144、ピーク学習率 2\times 10^{-5}(コサインスケジュール)、bf16 Adam(\beta_1{=}0.9,\beta_2{=}0.95)、TP=4、EP=4、シーケンスパッキングで実施しています。
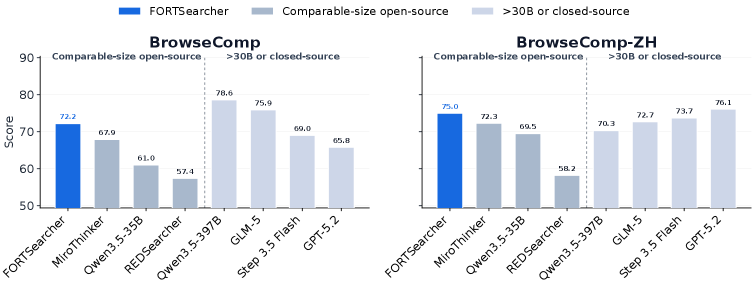
5つのベンチマーク(BrowseComp、BrowseComp-ZH、xbench-DeepSearch-2505/2510、Seal-0)において、FORT-Searcherはそれぞれ72.2 / 75.0 / 80.8 / 57.2 / 46.0を達成し、総合平均66.2を記録しています — 同規模のオープンソースagentの中で最高性能です(MiroThinker-1.7-mini 64.6、Qwen3.5-35B-A3B 59.9、OpenSeekerV2 53.4、Tongyi DeepResearch 51.7)。BrowseCompではQwen3.5-122B-A10B(63.8)およびDeepSeek-V3.2(67.6)を、はるかに少ないアクティブパラメータ数で上回っています。
Section 5.1のアブレーションは、フレームワークそのものが — 単に長い軌跡ではなく — 性能向上をもたらしているという最も明確な証拠です。訓練セットサイズを12Kに固定し、ソースのみを変化させ、既存のオープンソースデータを \widehat{\Omega}\in\{40,85,140\} でサンプリングすると、BrowseCompは47.1 → 48.4 → 49.5(BC-ZH 54.9 → 54.6 → 58.1)となります。同じ \widehat{\Omega}=140.0 でFORTデータに切り替え、T_{\mathrm{hit}} を22.3から47.0へ遅延させ、\widehat{p}_{\mathrm{prior}} を18.1%から11.4%に低下させると、BrowseCompは52.9、BC-ZHは60.3まで向上します。回答前の検索深度と事前知識の分離が本質的な要因であり、軌跡の長さだけでは逓減する効果しか得られません。
限界と未解決の問題
パイプラインはSFTのみであり、ショートカット耐性の向上がRL後訓練の下で積み重なるのか、それともSFT分布が単に抑制していたショートカットをソルバーが再発見することで部分的に打ち消されるのかは不明です。軌跡シグネチャは特定のソルバー \pi_0 を用いて推定されるため、\widehat{p}_{\mathrm{prior}} はソルバーに依存します — より強力なソルバーは、FORTが安全とみなした事前知識をバインドする可能性があります。Seal-0スコア(46.0)はMiroThinker-1.7-mini(48.2)およびKimi-K2.5-Thinking(57.4)を下回っており、ノイジーな証拠下での矛盾解消がショートカットフレームワークでは対処されていないことを示唆しています。最後に、サイクルベースの初期化と敵対的精錬ステップは抽象的に記述されており、再現にはサイクル長、精錬バジェット、敵対的ソルバーの強度に関する選択が必要ですが、それらはここでは固定されていません。
なぜ重要か
本論文は、検索agentの訓練においてフォークロアとされていた具体的かつ測定可能な主張を行っています:データセットの難易度はグラフのトポロジーではなく、実現された軌跡に基づいて定義されなければならない、というものです。T_{\mathrm{hit}} / \widehat{p}_{\mathrm{prior}} シグネチャと4つのショートカットカテゴリは合成データパイプラインのための実用的なターゲットを提供し、制御されたアブレーションはその効果が軌跡の長さと交絡していないことを示しています。
Source: https://arxiv.org/abs/2606.12087
MaxProof: 生成的検証器RLと集団レベルのTest-Time Scalingによる数学証明のスケーリング
競技数学の証明は、検証可能な報酬に基づくアウトカム型RLが機能不全に陥る典型的な設定です。正しさの対象は自然言語による論証であり、単体テストの結果ではないため、報酬は証明について自ら推論するモデルから得なければなりません。MaxProofはMiniMax-M3シリーズのtest-time scalingレイヤーであり、best@Kの証明能力が高いモデルを安定したpass@1システムへと変換するために設計されています。このパッケージは、証明生成・証明検証・批評条件付き修正という3つの学習済み能力から構成され、単一のリリースモデルに統合されています。加えて、推論時に同一モデルを4つの役割で使用する進化的探索も含まれます。
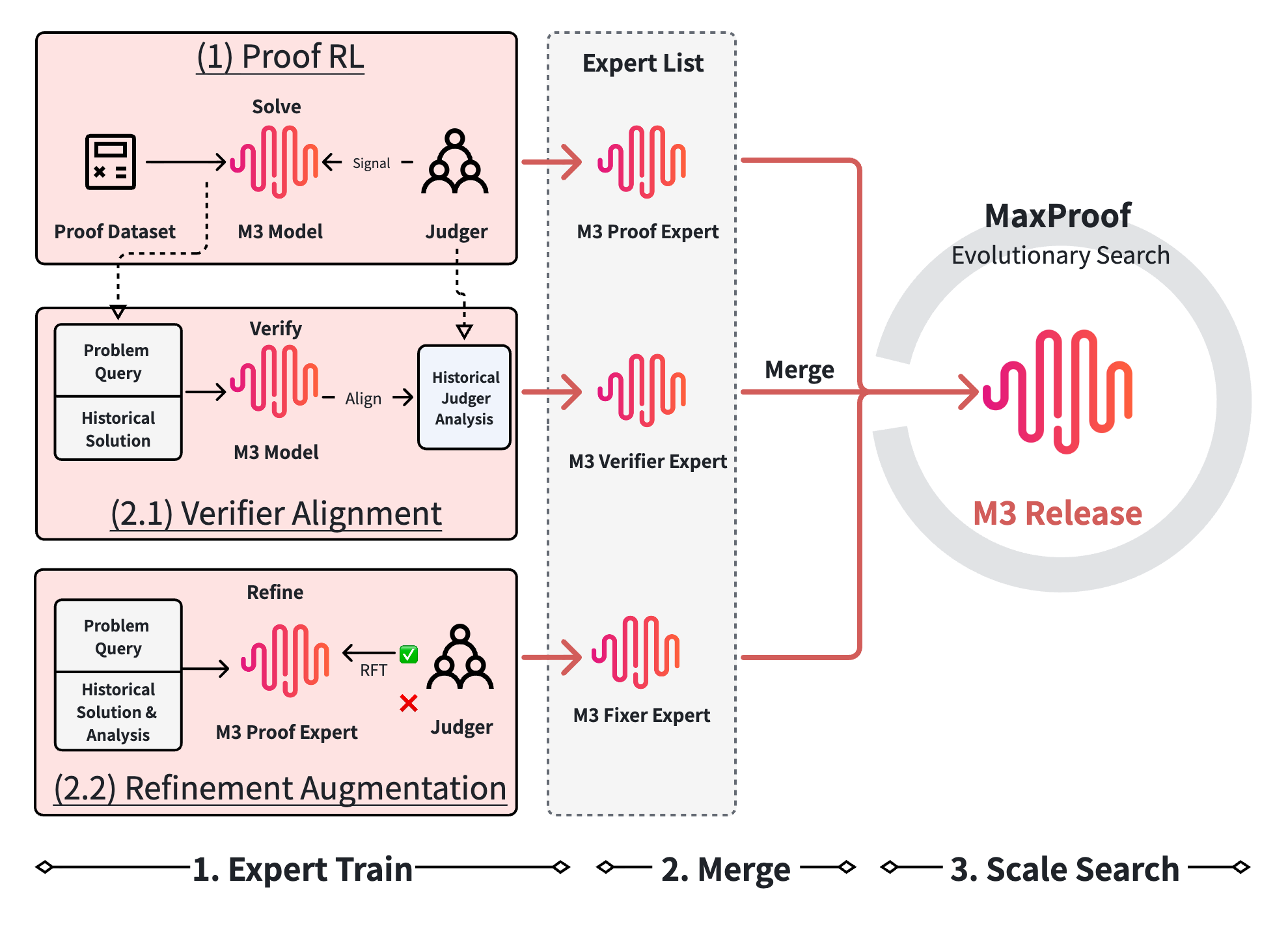
Proof Expert: 生成的検証器のもとでの長期RLホライズン
Proof Expertは、M-seriesのCISPO目標に適応したGRPOの変種を用いて学習されます。候補証明全体に対するtrajectoryレベルの報酬は、凍結された生成的検証器が生成するスカラー値 r \in [0,7] です。検証器は論証を読み、参照解から抽出したルーブリックと比較し、不足または無効なステップを特定した上で、テキストによる評価とRLの報酬となるスコアの両方を出力します。
設計上の中心的なリスクは、検証器が環境そのものであるため、その欠陥がポリシーによって増幅されてしまうことです。著者らはそこで、単一のジャッジではなく4層の多重防衛型検証器を採用しています:(1) バッドケースフィルタリングにより既知の失敗パターン(空の証明や主張のみの「回答」など)に一致する候補を除去し、(2) 解の正規化により表面的なフォーマットを取り除いてジャッジがレイアウトで採点できないようにし、(3) 3つの独立したジャッジが並列にスコアを付け、(4) 最終スコアはジャッジ間の悲観的な \min とします。
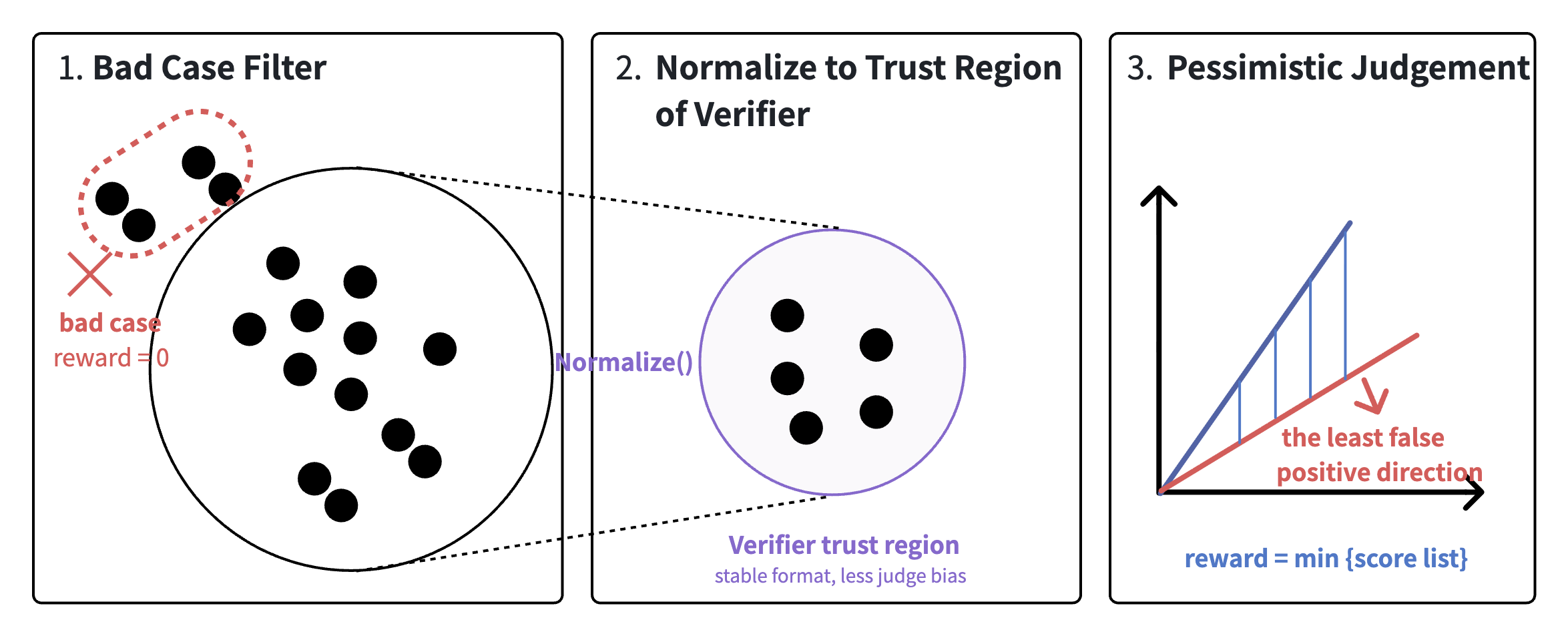
この悲観的集約は意図的なものです。偽陽性率を下げるために再現率を犠牲にしていますが、スコアがポリシー更新を駆動する場合に重要なのはその方向のみです。データ構築は検証器とクローズドループになっており、現在のポリシーに非自明なヘッドルームがある問題のみが保持されます。これにより、各GRPOグループには失敗例と部分的な成功例の両方が含まれ、グループ相対的なadvantageが有用なgradient信号を持ちます。
Verifier Expert: スコア回帰ではなくエラー発見
検証器の自然なターゲットはMathArenaプロトコルに合わせた0〜7の回帰ですが、著者らは(正しくも)回帰は表面的な相関で満たされてしまい、モデルにエラーを局所化させる必要がないと主張しています。Verifier Expertは代わりに、3つのブロックからなる構造化されたエラー発見タスクで学習されます:<assessment>(段落ごとの読み取り)、<errors>(局所化された具体的なエラーの列挙リスト)、および <verdict> \in {no_errors, minor_gaps, has_errors, fundamentally_wrong}です。verdictはエラーリストの関数であるため、no_errorsのverdictには空の<errors>ブロックへのコミットが必要です。この結びつきが検証器の出力を下流で利用可能にする理由です。同じ<errors>リストが、Fixer Expertによって消費される批評となります。
Fixer Expert: 批評条件付き修正
Fixer Expertは、(\text{problem}, \text{flawed\_proof}, \text{verification\_analysis}) というトリプルに対してrejection-sampling fine-tuningされ、列挙されたエラーに対処しつつ正しいステップを保持した修正済み証明を生成します。批評なしではモデルが欠陥を再発見しなければなりませんが、批評があることで修正は具体的なエラー位置に基づいて行われます。これは生成ではなく修正であり、経験的な主張は、批評の構造が検証器の出力スキーマと正確に一致するとき、この作業が意味のある形で容易になるというものです。
MaxProof: 悲観的フィットネスによる集団探索
推論時、MaxProofはマージされたM3モデルをプロンプトで定義された4つの役割—generator、verifier、refiner、ranker—を通して公開し、進化的ループを実行します。§6の設定は、初期候補 N=32、候補ごとのverifierサンプル数 K_{\text{verify}}=4(フィットネスとして平均またはmin集約)、refinementラウンド R=10、ラウンドごとの親数 M=4、ペアワイズ比較ごとのranker投票数 K_{\text{ranker}}=3 であり、\geq 2 の候補が完全スコアを得た時点で早期終了します。探索と活用のトレードオフが異なる2つの変異演算子が使用されます:PATCH(批評に基づく局所編集)とREWRITE(セクションを最初から再導出)です。最終選択はverifierスコアの \arg\max ではなく多数決rankerによるペアワイズトーナメントであり、これがverifierの偽陽性に対する脆弱性の修正策となっています。
進化的探索としての枠組みは単なる類比以上のものです:アーカイブは集団、悲観的なverifierスコアがフィットネス、多様な親選択が収束崩壊を防ぎ、PATCH/REWRITEは異なる半径の変異演算子です。重要なことに、これは3つの失敗モードを同時に解決します——独立サンプルによって集団の上限を引き上げ、批評条件付き修正によってほぼ正しい候補を改善し、トーナメントベースの選択によってverifierの偽陽性を回避します。
結果
問題ごとに0〜7点(最大42点)で採点されるコンテストベンチマークにおいて、MaxProofを組み合わせたマージM3モデルは、IMO 2025で35/42、USAMO 2026で36/42を達成し、いずれも人間の金メダル基準を上回っています。コンテスト評価では、test-time scalingの貢献を分離するために意図的にMaxProofあり・なしのM3バリアントのみを報告しています。IMOProofBenchおよびIMOAnswerBenchのスタンドアローン結果(MaxProofなし)は、同一のMathArenaプロトコルのもとでのマージモデルの初回通過能力を測定しています。
限界と未解決の問題
これらの結果はverifierの偽陽性率に大きく依存しており、多重防衛パイプラインはエンジニアリング的手法であって保証ではありません——3つのジャッジが共通して持つ欠陥(例えば、説得力のある誤った証明に向けた共通の事前学習バイアス)は \min 集約では検出できません。論文では、ホールドアウトされた敵対的証明に対するverifierのROCは報告されておらず、以前のM2イテレーションで保守的な設計の動機となった報酬ハッキングが観察されたことのみが記載されています。N=32、R=10、256Kトークン出力でのMaxProofの計算コストは非自明であり、同一予算の純粋サンプリングベースラインとの直接比較はされていません。最後に、コンテスト評価セットはコンテストごとに6問であり、\pm 1 点の分散は金メダルとのギャップに対して大きいです。
なぜこれが重要か
MaxProofは、generator・verifier・refinerがすべて異なるプロンプトのもとで同一のマージモデルであり、そのI/Oスキーマが進化的探索ループに組み合わさるよう共同学習された最初の公開事例です。悲観的min verifier集約、フィードバック単位としてのエラー局所化批評、および集団アーカイブに対するトーナメント選択の組み合わせは、実行不可能な報酬信号に対するRLの具体的なレシピです。
Source: https://arxiv.org/abs/2606.13473
EvoArena: 動的環境における堅牢なLLMエージェントのためのメモリ進化の追跡
問題
ほとんどのエージェントベンチマークは固定された環境スナップショットに対して評価を行いますが、実際に展開されたエージェントは、変化するインターフェース、依存関係のアップグレード、進化するコードベース、厳格化される検証ルール、そして変化するユーザー嗜好に直面します。これにより2種類の失敗モードが生じます。第一に、エージェントが暗黙のうちに無効となった以前の知識を再適用してしまうケースです。第二に、最新の状態に向けて積極的にメモリを上書きするエージェントが、依然として有効な以前の振る舞いを失ってしまうケースであり、これはロールバック、マルチテナント展開、またはバージョン固有のタスクにおいて問題となります。EvoArenaは明示的なバージョンチェーンを持つベンチマークを構築することで第一の失敗モードに対処し、EvoMemはメモリを単一の最新状態ではなく進化のトレースとして記録することで第二の失敗モードに対処します。
EvoArenaの構築
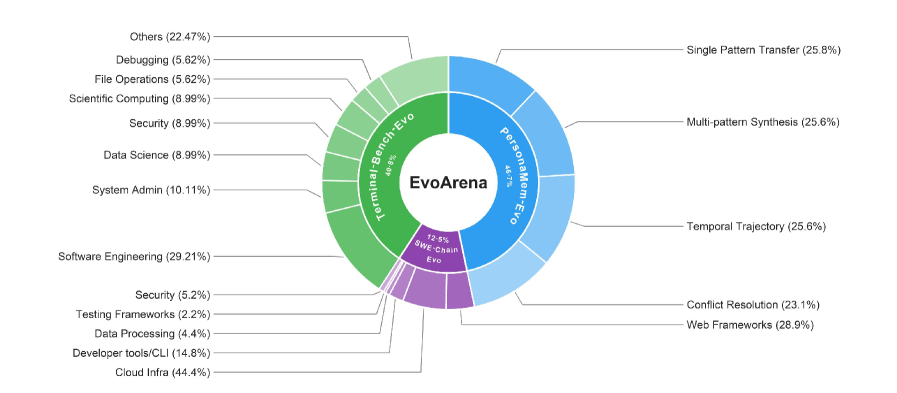
EvoArenaは静的なベンチマークを順序付けられたバージョンチェーン \{v^{(1)},\ldots,v^{(m)}\} に変換します。このチェーンはユーザー向けの目標を保持しつつ、周辺のワークフローを変化させます。三つの領域をカバーしています:
- Terminal-Bench-Evo(実行可能なワークフローの進化):Terminal-Benchタスクから派生したリリース間で、パス、CLIの呼び出し、依存関係のバージョン、および検証テストが変化します。
- SWE-Chain-Evo(ソフトウェアの進化):進化するリポジトリにおける連続した実装のマイルストーンです。
- PersonaMem-Evo(嗜好の進化):ユーザーの嗜好が変化する長期的な会話です。
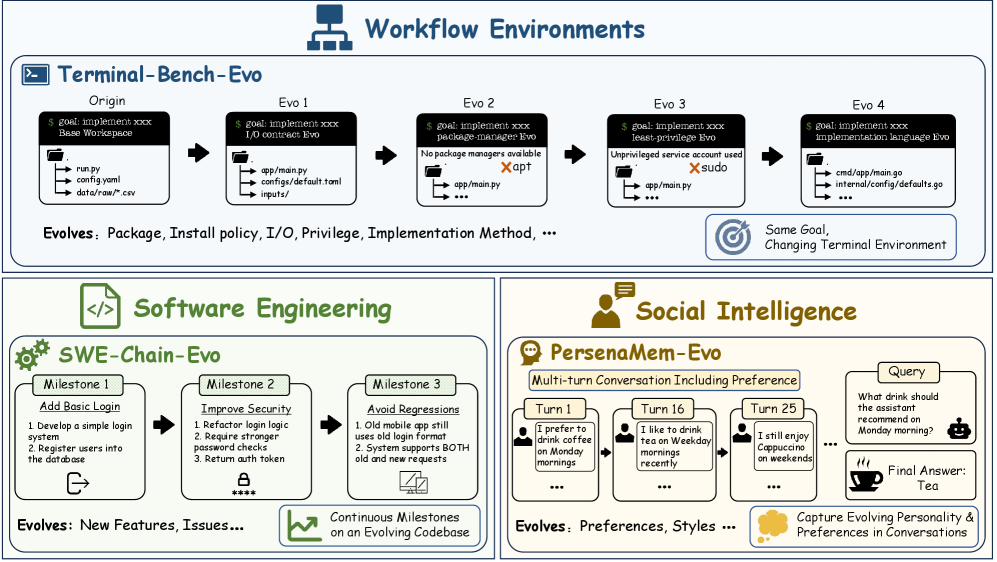
Terminal-Bench-Evoのパイプラインは5つの段階で構成されます:(1) 目標、環境、ファイル、依存関係、I/Oの仕様、および検証ルールを抽出するワークフロー状態分析;(2) 可変とフラグ付けされたコンポーネントに対する現実的な変異を指定する進化計画の設計;(3) 各 v^{(k)} が v^{(k-1)} の実現済みコンテナ/ワークスペースを継承する継承バージョンの実現;(4) オラクルソリューションの検証によるクオリティコントロール(実行不可能、内部矛盾、または解決不可能なリリースをフィルタリングまたは修復);(5) バージョンをチェーンにグループ化し、ステップレベルおよびチェーンレベルのスコアリングのためのメタデータを記録するベンチマークアセンブリ。
評価にはStep Accuracy(バージョンごとのタスク)とChain Accuracy(Terminal-Bench-EvoおよびPersonaMem-Evoではエラーなしでチェーン全体を解決;SWE-Chain-Evoでは正しく解決された最長のプレフィックスをチェーン長で割ったもの)を使用します。
EvoMem: パッチベースのメモリ進化
EvoMemは任意のベースメモリシステムを2つのコンポーネントで拡張します:
- パッチの記録。 更新が非加法的(以前のメモリ状態を上書きまたは矛盾する)である場合、EvoMemは何が変化したか、なぜ変化したか、そしてどの観測がその更新を引き起こしたかを記録した構造化パッチを保存します。ベースメモリは単一の最新状態を保持し、パッチは外部の進化トレースを形成します。
- パッチ拡張型の検索。 クエリ時において、クエリが上書きされた状態、時間的変化、またはバージョン固有の振る舞いに依存する場合、関連する履歴パッチが最新メモリとともに検索されます。
概念的には、時刻 t におけるメモリは M_t 単独ではなくペア (M_t, \mathcal{P}_{1:t}) となります。ここで各パッチ p_i \in \mathcal{P} は (s_{\text{old}}, s_{\text{new}}, \text{trigger}) を記録します。これによりエージェントは現在の状態だけでなく、遷移についても推論できるようになります。
結果
Terminal-Bench-Evo、SWE-Chain-Evo、およびPersonaMem-Evo全体にわたって、現在のエージェント(GPT-5.5、Gemini-3.1-Pro、Qwen3.6-27B、Kimi-K2.6、GPT-5.4-miniを基盤とするTerminus2、OpenHands、A-Mem、Memento-Skill)は平均ステップ精度39.6%にしか達しておらず、バージョン対応の推論が現在のシステムにほぼ存在しないことが確認されます。
EvoMemによる改善:
- EvoArenaにおける平均ステップ精度の+1.5%向上。
- EvoArenaにおけるチェーン精度の+3.7%向上。これはステップの向上よりも大きな改善であり、チェーンの成功がバージョン間の一貫性を必要とすることと整合しています。
- GAIA(LLMジャッジ精度)での+6.1%、LoCoMo(完全一致)での+4.8%向上。パッチトレースは進化として明示的にフレーム化されていないベンチマークにおいても有効であることを示しています。
EvoMemが有効なケース
Terminus2を用いたTerminal-Bench-Evoにおけるメカニズム分析では、パッチメモリが実際に活用されているかどうかによって改善を層別化しています。パターンは明確です:
- パッチ例が検索された場合:改善がパッチなしの+3.1%から+6.5%に上昇。
- 進化した要件のカバレッジ:低い場合+2.1% vs. 高い場合+5.3%。
- パッチの活用度(パッチの用語がエージェントの推論/コマンドに再登場する):なしの+2.6% vs. ゼロでない場合+8.3% — 5.7ポイントの差。
- コマンドレベルの活用度(用語が実行されたシェルコマンドに到達する):+3.1% vs. +6.2%。
これはEvoMemが単に追加のコンテキストを提供しているだけではないことを示しています。その効果は、エージェントがパッチにエンコードされたローカルな遷移を特定し、それを計画に伝播させ、依然として有効な手順を保持しながら無効となった部分を修正することに条件付けられています。
限界と未解決の問題
- 集計ステップの改善1.5%は控えめであり、EvoMemの効果の大部分は、検索が正しいパッチにヒットすることと、エージェントがそれを活用することに依存しています。活用の上流における失敗が依然として主要な損失となっています。
- パッチ構築は非加法的更新の検出に依存しており、パッチをトリガーする基準と (s_{\text{old}}, s_{\text{new}}) の粒度は詳細に指定されておらず、検索品質に影響する可能性があります。
- Terminal-Bench-EvoにおけるChain Accuracyはチェーン全体に対して二値的であり、脆弱であり、単一の誤りの後での部分的な回復を評価できません。
- EvoArenaの進化計画は著者が設計したものであり、観測された実世界のdiffからサンプリングされたものではないため、本番環境のドリフトに対する生態学的妥当性は未解決のままです。
- 報告されたモデルラインナップには将来の名称のモデル(GPT-5.5、Gemini-3.1-Pro、Qwen3.6-27B、Kimi-K2.6)が含まれており、現在利用可能なチェックポイントでの再現性は不明です。
なぜこれが重要か
静的スナップショットベンチマークは、展開における失敗の主要な原因であるバージョンドリフトを排除するため、エージェントの堅牢性を系統的に過大評価します。EvoArenaはバージョン対応の振る舞いのための制御されたテストベッドを提供し、EvoMemは単一の最新状態ではなく明示的で検索可能なメモリ遷移のトレースを維持することが、非定常環境に対処するための具体的かつベンチマーク移植可能なメカニズムであることを実証しています。
Source: https://arxiv.org/abs/2606.13681
SpatialClaw: エージェント的空間推論のためのアクションインターフェースの再考
3D/4Dシーンにわたる空間推論――深度、視点、カメラ動作、フレーム間の幾何学――はVLMにおいて依然として弱く、ツール拡張型エージェントは凍結されたバックボーンに知覚モジュールを後付けすることでこれを補完しようとしてきました。著者らは、ボトルネックはツールのメニューではなく、それらを呼び出すインターフェースにあると主張しています。主流の2つの設計はそれぞれ異なる形で失敗しています。すなわち、single-pass codeは中間的なマスクや深度マップを見る前に分析全体をコミットしてしまい、一方でstructured (JSON/XML) tool-callsは組み合わせを事前定義された操作に制約し、アドホックな数値処理を妨げます。SpatialClawは第3の選択肢を提案します。それは、永続的なPythonカーネル上でのcode-as-actionであり、実行フィードバック(テキスト、変数サマリー、レンダリング済み画像)をエージェントのコンテキストに折り返すというものです。

手法
本システムはtraining-freeです。各例では、入力フレームと小さな表面のプリミティブが事前にロードされたPythonカーネルがインスタンス化されます。6つのエントリーポイントが公開されています:
InputImages— サンプリングされたフレーム。Metadata— 時間的クエリのためのfps、duration、フレームインデックス。tools— 知覚プリミティブとユーティリティ。tools.ReconstructはDepth Anything 3をラップし、フレームごとの深度、内部パラメータ、外部パラメータ、密なポイントマップを返します。セグメンテーションはSAM3から提供され、テキスト・点・ボックスでプロンプトされます。show(...)— 画像(matplotlibの図を含む)を次の観測に埋め込むために登録します。vlm— サブクエリを別のVLMセッションにディスパッチします。例えばvlm.locate(...)はグラウンディングに使用され、テキストのみを返すため、画像がメインコンテキストを汚染しません。ReturnAnswer()— ループを終了します。
外側のループは5つのステージから構成されています。プランナーは質問とツールのドキュメント(ただし画像は見ない)を見てプランを出力し、メインエージェントが1つのセルを書き、そのセルが永続的なカーネルで実行され、stdout、変数サマリー、show()で登録された画像が追加され、ReturnAnswer()またはN_{\max}=30まで繰り返されます。
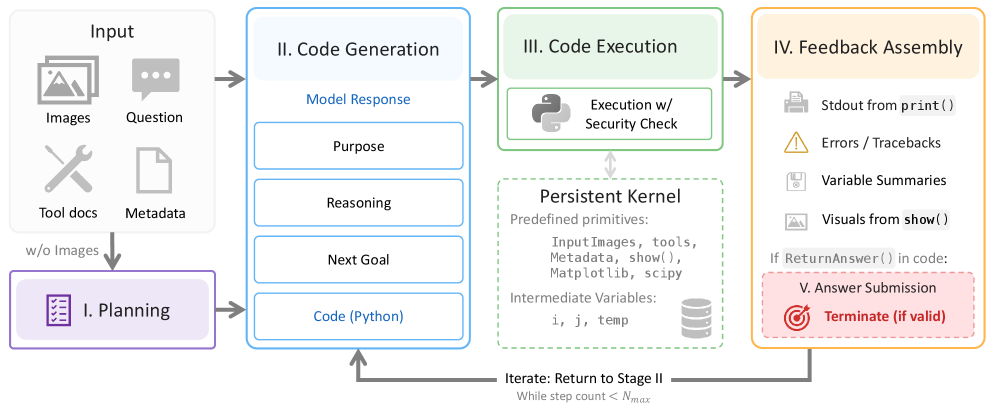
永続的な状態が中心的なメカニズムです。マスク、ポイントマップ、中間配列が通常のPython変数としてセル間で保持されるため、エージェントは粗い計算から始め、レンダリングされた出力を検査し、精緻化することができます――これはsingle-pass codeでもstructured tool-callsでもサポートされない動作です。
結果
評価は、単一画像、マルチビュー、ビデオ、4D空間推論、および一般的なビデオ理解を含む20のベンチマークにわたります。バックボーンにはQwen3.5(122B-A10B、397B-A17B)、Qwen3.6(35B-A3B、27B)、Gemma4(31B、26B-A4B)が含まれます。1,000サンプルを超えるベンチマークは1,000にサブサンプリングされ、すべての構成で同一のプロンプトとツールが使用されます。
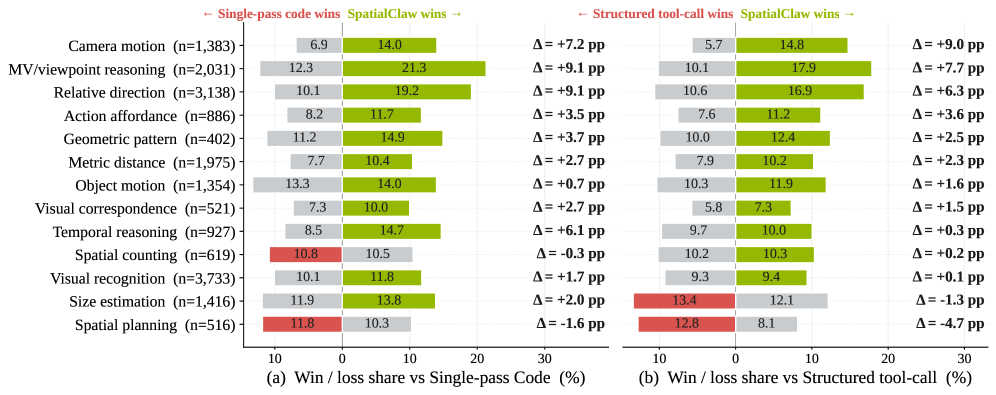
最も有益な分析は、2つのベースラインインターフェースに対するカテゴリ別の比較です。SpatialClawはStructured tool-callとSingle-pass Codeの両方に対して13のメタカテゴリのうち11で勝利し、Camera motion、Multi-view/viewpoint reasoning、Relative directionにおいて最大のマージン(+6〜+9パーセントポイント)を示しています――これらはフレームをまたいで中間的な証拠を連鎖させる必要があるカテゴリです。
2つのアブレーションにより、利得がどこから来るかが分離されます。(I)SAM3/DA3とNumPy/SciPyのみを残してすべてのユーティリティラッパー(tools.Mask、tools.Geometryなど)を取り除くと、完全なSpatialClawと同等になります――エージェントがユーティリティのロジックをその場で再構築するためです。(II)知覚ツールをすべて取り除き、コードインターフェースと科学ライブラリのみを残した場合でも、ツールなしのベースラインに対して+2.7\%pの利得が生じ、知覚カバレッジとは独立したアクションインターフェース自体の貢献が分離されます。
メタカテゴリにわたるプリミティブ使用分析は、エージェントが自発的にツールの組み合わせを特化させることを示しています。距離の質問はscipy.spatial.KDTreeとベクトルノルム(最近傍構造)を不均衡に呼び出し、方向の質問は内積と角度演算に集中しています。カテゴリ固有のプロンプトやルーティングは使用されておらず、この特化は質問のセマンティクスのみから生じています――これはstructured tool-callインターフェースが抑制するまさにその種の振る舞いです。
SpatialClawの利得が最も小さい場所――視覚認識メタカテゴリ――では、ボトルネックはバックボーンVLMの知覚であり、すでにほぼ飽和しているため、インターフェースの変更は助けになりません。
制限と未解決の問題
本システムはtraining-freeであり、コンポーネントのすべての失敗モードを継承しています。SAM3のグラウンディングエラーとDA3の深度・外部パラメータエラーは、明示的な不確実性処理なしに幾何学的計算に伝播します。N_{\max}=30とコンテキスト内のmatplotlibスクリーンショットにより、トークンバジェットと例ごとのレイテンシは相当なものとなりますが、論文はウォールクロックやトークンコストを報告していません。プランナーは画像を見ないため、視覚的に曖昧なクエリに対するプランが制約されます。大規模ベンチマークの1,000サンプル上限は統計的解像度を制限します。最後に、分析は利得をインターフェースに帰属させていますが、永続的なカーネルはプランナーモジュールとshow()フィードバックチャネルと絡み合っています。永続性とフィードバックを分離するよりクリーンなアブレーションが有益でしょう。
なぜこれが重要か
この結果は、VLMエージェントに関する実践的な問いを再構成します。より多くの専門ツールを追加することからの限界収益は、エージェントに永続的な中間状態に対して任意の数値演算を組み合わせられるインターフェースを与えることからの収益よりも小さいのです。空間推論に限定すれば――視点をまたいだ幾何学的な連鎖が困難な部分である――ライブカーネルを用いたcode-as-actionが適切な抽象化であると考えられます。
Source: https://arxiv.org/abs/2606.13673
MiniMax Sparse Attention
長文脈推論は、softmax attentionの\Theta(2H_q N^2 d_h)コストによってボトルネックが生じています。既存のsparse attentionの提案は、(i) テンソルコアの活用を損なうトークンごとのgatherパターンを導入するか、(ii) 検索リコールを制限するhead共有の選択を用いるか、いずれかの傾向があります。MiniMax Sparse Attention(MSA)は、Grouped Query Attention(GQA)上に構築されたブロック単位のsparse attentionレイヤーであり、デプロイスケールでの効率的なGPU実装を可能にしつつ、アーキテクチャの追加コストを最小限に抑えることを目的としています。本論文では、ネイティブなマルチモーダル学習を行った1090億パラメータのMoEモデルで検証しています。
アーキテクチャ
MSAはGQAのパーティション構造を継承しています:H_q=64のquery headがG=H_q/H_{kv}=16のグループ単位でH_{kv}=4のKV headに紐付けられており、d_h=128、RoPE次元は64です。この上に、2つのブランチが追加されています。
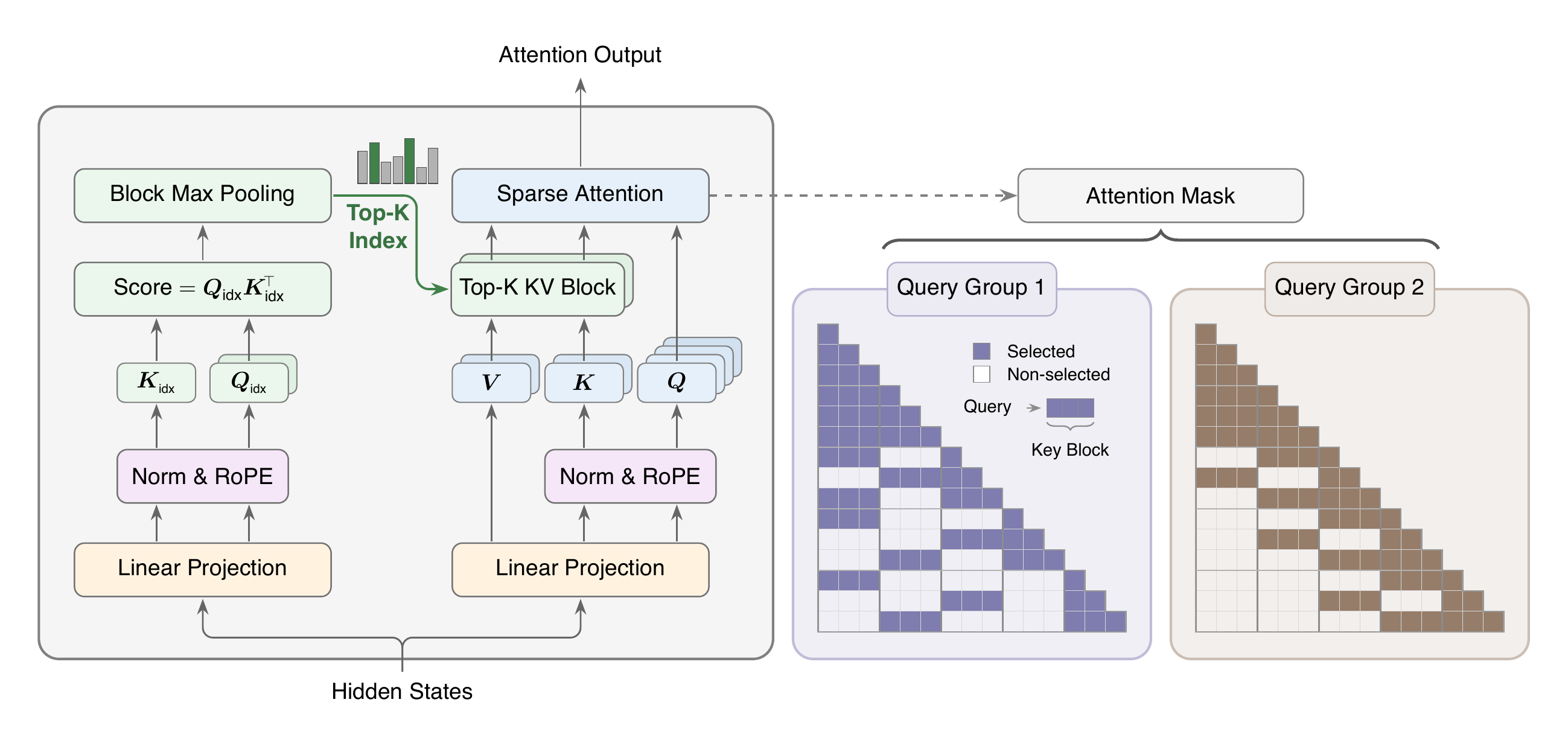
Index Branchは追加の射影を2つだけ導入します:GQAグループごとに1つのindex query headと、共有された1つのindex key headです。 \mathbf{Q}^{\rm idx}=\mathbf{X}\mathbf{W}_q^{\rm idx}\in\mathbb{R}^{N\times H_{kv}\times d_{\rm idx}},\quad \mathbf{K}^{\rm idx}=\mathbf{X}\mathbf{W}_k^{\rm idx}\in\mathbb{R}^{N\times 1\times d_{\rm idx}}. クエリトークンiとグループrに対して、スコアは各ブロック\mathcal{B}_b内の可視位置に対するmaxによってブロック粒度に集約されます。 M^{\rm idx,(r)}_{i,b}=\max_{j\in\mathcal{B}_b,\,j\le i}\frac{(\mathbf{Q}^{\rm idx})^{(r)}_i(\mathbf{K}^{\rm idx})_j^\top}{\sqrt{d_{\rm idx}}}, そして上位k個のブロックインデックス\mathcal{I}_i^{(r)}=\mathrm{TopK}_b(M^{\rm idx,(r)}_{i,\cdot},k)が選択され、位置iを含むローカルブロックは常に含まれます。重要な点として、\mathcal{I}_i^{(r)}はグループr内のG個のquery headで共有されますが、グループごとに独立して選択されます。これにより、GQAのもとで失われるper-headの検索柔軟性をある程度回復しつつ、H_q倍のコストを支払わずに済みます。
Main Branchは、選択されたブロックの和集合に限定した正確なsoftmax attentionを実行し、トークン予算は\le k B_kです。実験ではB_k=128、k=16であり、各クエリはNの大きさに関わらず最大2048個のKVトークンにしかattendしません。
学習とカーネル
Sparse retrievalは、dense attentionスコアから導出された教師分布とindex分布のKVアラインメントによって学習されます(図のキャプションでこのlossに言及されており、完全な導出は§3.2にあります)。カーネル側では、テンソルコアの活用に関わる2つの共設計の選択が行われています。
- Exp不要のTop-k。 softmaxは順序保存的であるため、index TopKは正規化前にmax/exp/sumをスキップし、生のスコアsから直接計算されます。これにより選択カーネルが小さくなり、任意の正規化の前に実行できます。
- KV-outer sparse attention。 Main BranchはKVブロックが外側のループ、クエリが内側のループとなるように配置されており、indexが生成するブロック粒度のアクセスパターンに対応しています。これにより疎性のもとでKVの連続的な読み出しが保たれ、これはトークンレベルのsparse attentionにおける通常の失敗モードを回避します。
また、dense N\times N attentionをマテリアライズすることなくindex branchをエンドツーエンドで学習できるよう、sparse-KL backwardカーネルも提供されています。
結果
このアーキテクチャはkB_k \ll Nとなる領域を対象としています。実験的な設定(H_q{=}64、H_{kv}{=}4、d_h{=}128、B_k{=}128、k{=}16)におけるトークンあたりのattention FLOPsの理論値および実測のwall-clock speedupを以下に示します。
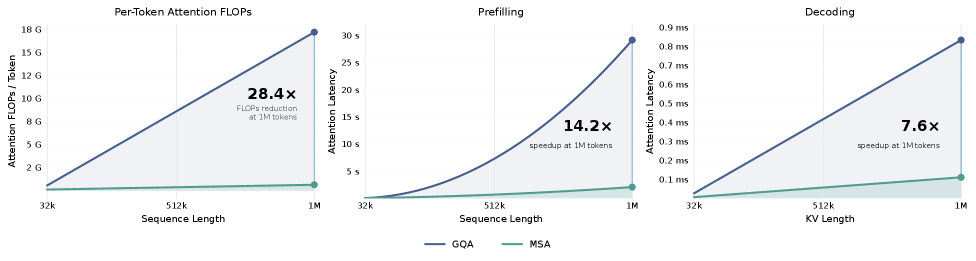
MSAがdense GQAを上回るクロスオーバーポイントは早期に現れます。Nが予算kB_k\approx 2{,}048トークンを超えた時点であり、MSAの計算量はO(N\cdot kB_k)であるのに対しGQAはO(N^2)であるため、その後はほぼ線形にギャップが広がります。prefillとdecodeの両方において、長いNで大幅なspeedupが確認されています。
2つの109Bの学習レジームが評価されています:MSA-PT(最初からsparseで学習)とMSA-CPT(Full-AttentionチェックポイントからattentionをMSAに置き換えて継続事前学習)です。41層のMoEバックボーンは60億の活性化パラメータを持ち、top-4ルーティングで128のルーティングエキスパート、d_{\rm model}=3072、語彙数20万です。abstractではMSAがこのスケールでFull-Attentionベースラインと「同等」の性能を示すと述べられています;このセクションの抜粋では具体的なベンチマーク差分は示されていませんが、両方の学習パスが実行可能であることが示されており、これがより興味深い結果です。すなわち、疎性はCPTを通じてすでに学習済みのdenseモデルにレトロフィットできるということです。
Attention sinks
小さいながらも実践的に重要な観察があります:headとレイヤーをまたいで、attentionの無視できない質量が最初のトークンに集中するという、よく知られたsink効果が見られます。
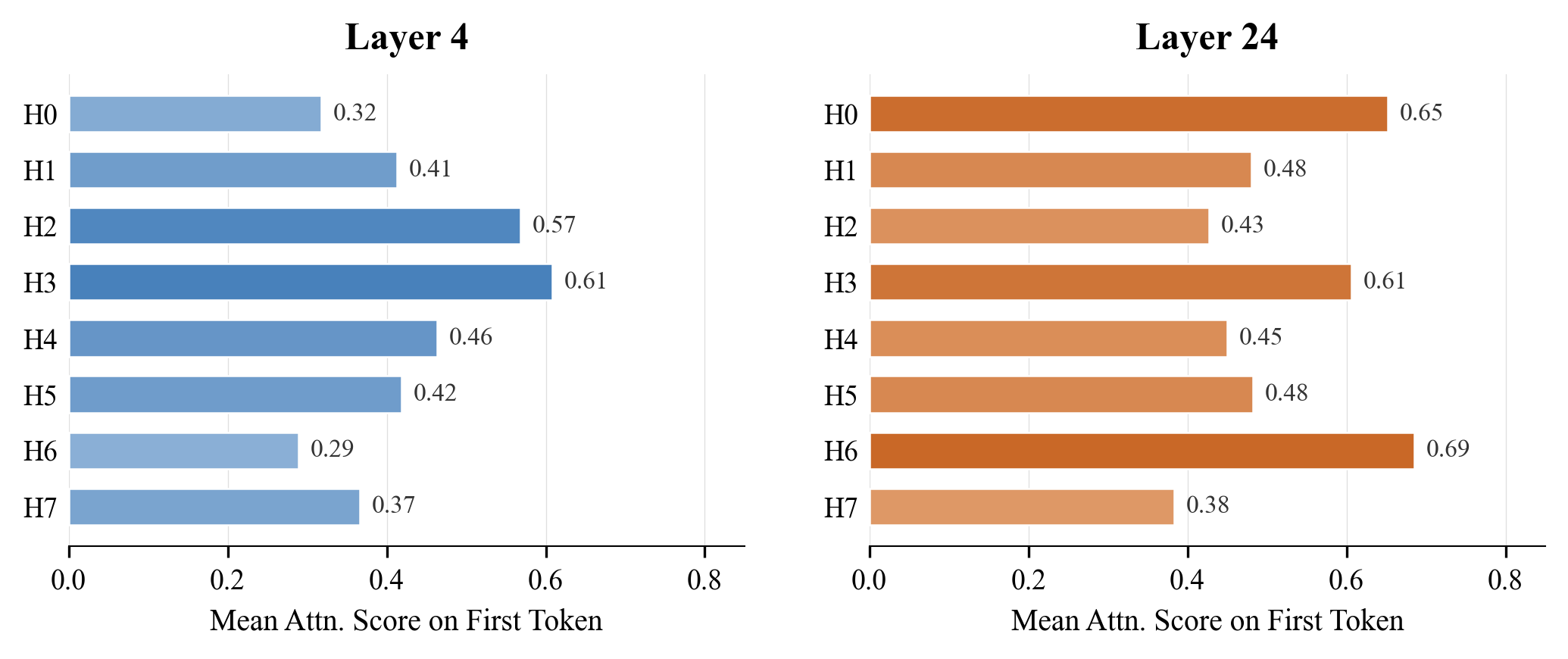
MSAは常にローカルブロックを含む一方で、最初のブロックは条件付きでのみ含むため、index branchはsinkを保持するように学習しなければならないか、またはシステムがブロック0を強制的に含める必要があります。sinkに関する本論文のアブレーションは、常に含まれるローカルブロックの設計を動機付け、KL教師の構築に情報を与えています。
限界とオープンクエスチョン
報告された結果は単一の109Bモデルファミリーおよび固定された予算(B_k,k)=(128,16)に限定されており、より小さいスケールでのkとB_kに対する感度は抜粋では示されていません。Index Branchは全グループにわたって単一のkey headを共有しており、グループが互いに素な領域にattendする必要がある場合に検索のボトルネックになる可能性があります;H_{kv}個の独立したquery headによってこれは部分的に緩和されますが、完全には分離されていません。最後に、KLアラインメントは学習中にdenseな教師シグナルを必要とし、それ自体がO(N^2)です——本論文のsparse-KL backwardはメモリには対処していますが、学習中の漸近的な計算量には対処していません。
この研究が重要な理由
MSAはsparse attentionの設計空間における実用的なエンジニアリング上のポイントです:最小限の新規パラメータ、テンソルコアにクリーンにマッピングされるブロック粒度の選択、そしてper-headコストなしに検索の多様性を回復するGQAグループごとの独立性を備えています。1090億規模でゼロからの学習と継続事前学習の両レシピで実証していることは、本提案をプロダクションスケールの長文脈LLMに向けたsparse attentionの提案の中でより信頼性の高いものの一つにしています。
Source: https://arxiv.org/abs/2606.13392
WeaveBench: ハイブリッドインターフェースを備えたコンピュータ使用エージェントのための長期地平線・実世界ベンチマーク
問題設定
コンピュータ使用エージェント(CUA)は現在、デスクトップGUI制御とシェル、コード編集、ブラウザ、外部ツールを統合したランタイム上で動作しています。既存のベンチマークはこれらのチャネルを個別に評価する傾向があります——OSWorldスタイルのデスクトップ制御、SWE-Benchスタイルのコード、WebArenaスタイルのブラウジング——そのため、おそらく最も困難な領域、すなわちGUI観測とプログラム的な変更を単一セッション内で横断しながら情報を連携させなければならない長期地平線の軌跡を十分に測定できていません。WeaveBenchは、実際のユーザーリクエストから収集され公開検証可能なアーティファクトを持つ8つの実世界業務ドメインにわたる114タスクによって、まさにこのギャップを対象としています。
動機となるワークフローは具体的です:GUI上でJaegerのトレーススパン形状を診断し、kubectlを介して上流のタイムアウトをパッチする;デスクトップゲームをプレイしてスプライト/物理バグを特定し、シーングラフのソースをパッチする;Web Opsダッシュボード上の503スパイクを検出し、nginx.confを編集して視覚的に再検証する。

タスクの採用と構築
各タスクはバンドル \mathcal{E} = (\mathcal{P}, \mathcal{M}, \mathcal{C})——プロンプト、マシン状態、チェック基準——としてパッケージ化され、以下の3つの性質を満たす場合にのみ採用されます:
- P1 チャネル非代替性:成功するには同一軌跡内でGUI観測/操作とCLI/コード変更を協調させる必要があること;各タスクは単一チャネル境界のアトミック操作としてアノテーションされており、要件の監査が可能です。
- P2 長期地平線実行:エキスパートの参照軌跡が複数の交互するGUIフェーズおよびCLI/コードフェーズを含むこと。
- P3 クロスアプリケーション状態:ワークフローが状態のリンクした複数の独立したアプリケーション/プロセスにまたがること。
タスクは実際のソースから収集され、P1〜P3に対して監査され、自明に解けるまたは仕様が不十分な項目を除外するために少なくとも3つのパイロットエージェントによるストレステストが行われます。
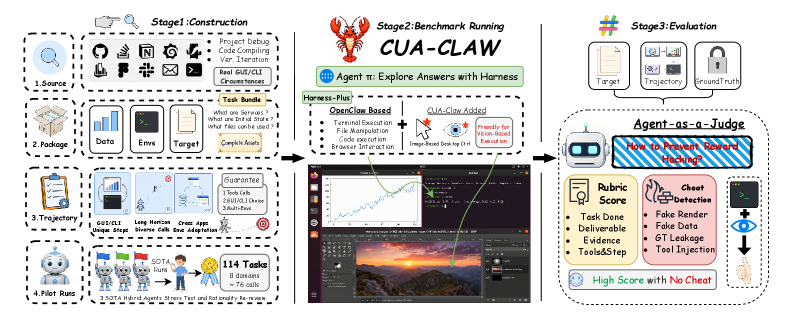
データセットの分類体系は8ドメイン23サブカテゴリにわたり、単一ツールベンチマークを大幅に超えた非自明なチャネルインターリービングとロールアウト長を持ちます。
ハイブリッドハーネス
ハーネスは、異なるランタイム間での比較が意味を持つように意図的に最小限に設計されています。GUIプラグインが既存のCLIエージェントランタイムに追加され、正確に1つの知覚プリミティブ——screenshot——と9つのpyautoguiベースの操作プリミティブ:click、double_click、triple_click、move、drag、scroll、type、keypress、waitが公開されています。これらはReAct/Toolformerパターンに従い、ホストランタイムのターミナル、ファイル、コード、ブラウザツールと同一のResponses形式のツールセッション内で提供されます。モデルバックボーン、エージェントループ、システムプロンプト、最大ターン数は変更されません。
全タスクはフリーズされたスナップショットから起動するコンテナ化されたUbuntu VM上で実行され、完了後にロールバックされ、ネットワークをタスクローカルサービスに制限し、タスクごとのツール出力および実時間予算を強制します——これにより初期状態とリソース制限が実行間で一定に保たれます。
軌跡認識ジャッジ
中心的な方法論的貢献はジャッジです:最終成果物のチェックだけでなく、ファイル、スクリーンショット、ログ、アクショントレースを検査し、ボトムアップのルーブリックスコアリングと明示的なショートカット検出を組み合わせる独立したエージェント型評価器です。ショートカット検出器は、結果のみを評価するグレーダーが見逃す失敗モードを対象としています——実際にはライブアプリによって生成されなかったスクリーンショットなどの捏造された視覚的証拠、および計算されずに成果物に直接書き込まれたハードコードされたメトリック値などです。
実験
評価は、モデルAPIスイープ(固定ランタイム:オープンソースのOpenClaw)とハーネススイープ(最強のAPIをCodex CLI、Claude Code、Hermes、OpenClawへ薄いアダプター経由で移植)に分解されます。モデルスイープは、3つの思考予算(low/medium/high)でGPT-5.5までの5世代のGPT-5.x、加えてClaude Opus 4.7、Gemini-3.1-pro、強力なオープンソースバックボーンをカバーします。報告される数値はバックボーンごとの最良の思考予算を使用しています。
主要な結果:すべてのフロンティアモデル–ランタイムの組み合わせにわたって、最良のPassRateは114タスク中わずか41.2%にとどまります。したがって、このベンチマークは現在のフロンティアシステムが高い思考予算を持ってしても飽和からほど遠い状況です。
軌跡認識ジャッジのアブレーションは2番目の主要な定量的ポイントを示しています:結果のみの採点は軌跡認識スコアと比較してエージェントの真の能力を大幅に過大評価します。なぜなら、表面的なアーティファクトチェックを通過する捏造されたスクリーンショットやハードコードされたメトリックを検出できないためです。(論文ではドメインごとの内訳、GUIまたはCLIのいずれかを無効にするインターフェース必要性アブレーション、ツール使用/失敗モード分析が後のセクションで報告されています。)
制限と未解決の問題
- 114タスクは絶対数として控えめであり、ロングテールのデスクトップアプリケーションや英語以外のロケールのカバレッジは採用パイプラインから不明確です。
- GUIプラグインは意図的に最小限(10プリミティブ)で
pyautoguiベースであるため、失敗の一部は推論ではなく操作の脆弱性を反映している可能性があります。より豊富なアクセシビリティツリーインターフェースはGUI/CLIのトレードオフを変える可能性があります。 - エージェント型ジャッジ自体がLLMであり、ショートカット検出器はジャッジのゲーミングを低減しますが排除はしません。ジャッジと人間の合意率がプロトコルを強化するでしょう。
- チャネル非代替性(P1)は、単一チャネルの解が存在しないという形式的証明ではなくアノテーションによって強制されており、十分に有能なエージェントは意図されていない単一チャネルの経路を見つける可能性があります。
- 結果はランタイムアダプターに敏感です:ハーネススイープはモデルの強さがCodex CLI、Claude Code、Hermes、OpenClawにわたって均一に転移しないことを示しており、論文間の比較を複雑にしています。
なぜ重要か
WeaveBenchは、ハイブリッドインターフェースCUAが実際に行う必要があること——アプリケーションをまたいでGUI知覚とプログラム的な状態変更をインターリービングすること——を具体化し、フロンティアシステムがPassRate 41.2%で頭打ちになること、そして結果のみの採点が見かけ上の能力を系統的に過大評価することを示しています。このベンチマークは、分野に対して具体的で困難な目標と、最も一般的な評価ショートカットに耐性を持つジャッジングプロトコルを提供します。
Source: https://arxiv.org/abs/2606.09426
HYDRA-X: ホリスティックな視覚トークナイザーを用いたネイティブ統合マルチモーダルモデル
問題設定
ネイティブ統合マルチモーダルモデル(UMM)は、画像と動画の両方を単一の潜在空間にマッピングするトークナイザーに依存しており、そのトークナイザーは同時に(i)自己回帰/flow-matching生成に十分なほどコンパクトであること、(ii)再構成のためにピクセル忠実度が高いこと、(iii)理解のために意味的に整合していること、という条件を満たす必要があります。既存のViTベースの共同トークナイザー(AToken、OmniTokenizer)は、映像VAEから受け継いだ二つの設計上の選択肢をほとんど疑わずに採用しています。それは、完全な時空間 attention と、単一ステップによる積極的な時間方向パッチ化(通常は入力で 4\times)です。前者はクリップ長に対して二次的にスケールし、画像事前学習から引き継がれるフレーム単位の構造的事前知識を損なう傾向があります。後者は、フレーム間の推論が行われる前に細粒度の時間的詳細を潰してしまいます。HYDRA-X はこれら両方の選択肢を再検討し、さらに時間的に圧縮された潜在表現に画像レベルおよび動画レベルの意味情報をどのように注入するかという問題にも取り組んでいます。
トークナイザー: Hydra-XTok
Hydra-XTok は、Gen-ViT(エンコーダー/デコーダーペア、SigLIP 2 から初期化し、3D RoPE による時空間共同モデリングを実施)と Sem-ViT ブランチから構成されます。クリップ \mathbf{x}\in\mathbb{R}^{3\times(1+T)\times H\times W} は、アンカー画像の潜在表現と、残りの T フレームを時間方向に 4\times 圧縮したものに符号化され、ボトルネック C=64 を持つ \mathbf{z}\in\mathbb{R}^{C\times(1+T/4)\times H/16\times W/16} が得られます。学習は以下を最適化します。
\mathcal{L}_{\text{Hydra-XTok}}=\mathcal{L}_{\text{rec}}+\lambda\mathcal{L}_{\text{dist}}.
時空間再構成。 二つの軸でアブレーションが行われます。時間方向 attention マスク(Full / Causal / Tubelet、最後のものは attention を2フレームウィンドウに限定)と、時間方向パッチ化スケジュール(単一ステップ 4\times 対 階層的 2\times2)です。
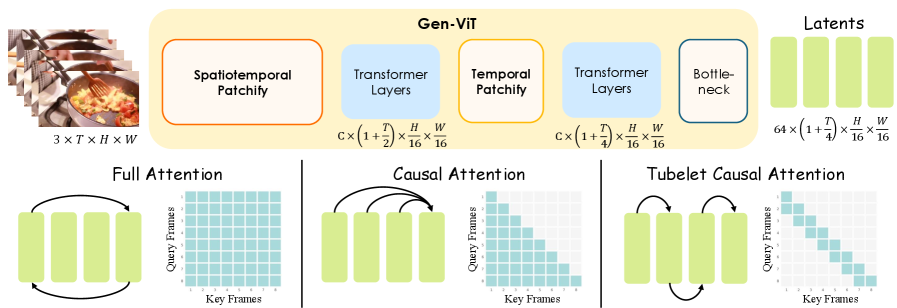
結果は明確です。完全な時空間 attention は causal/tubelet マスキングと比較して性能を積極的に低下させており、階層的な二段階 2\times パッチ化が単一ステップの変種を上回ります。ImageNet 256^2 再構成において、Full attention は PSNR 31.10 / rFID 0.367、Causal は 31.38 / 0.352、Tubelet は 31.42 / 0.347 を達成し、階層的スケジュール(causal/tubelet attention 付き)は 31.73 / 0.329 に達しています。DAVIS(17\times256^2)では、Full が PSNR 27.40・rFVD 16.20 であるのに対し、提案する構成は PSNR 27.97・rFVD 11.19 を達成しています。17\times512^2 クリップにおけるレイテンシは、0.49s(Full)から 0.25s(提案手法、階層的)および 0.17s(Tubelet 単一ステップ)に低下します。得られる知見は、フレームレベルの因果的時間 attention はViT トークナイザーにおける視覚的再構成に十分であり、段階的な時間圧縮は単一の積極的なストライドよりも細粒度の時間的詳細をはるかによく保持するという点です。
時空間 distillation。 動画の潜在表現は時間方向に 4\times 圧縮されているため、動画教師から直接 distillation を行うと、ボトルネックが時間伸張と意味的整合を同時に吸収することを強いられます。HYDRA-X では代わりに、軽量な Decompressor \mathbf{D} を学習し、動画教師の loss を適用する前に圧縮済み動画潜在表現をもとの時間長に戻します。(非圧縮の)画像潜在表現は画像教師から直接 distillation されます。

Decompressor は(時間方向アップサンプリング → transformer ブロック)を二段積み重ねた構造であり、各アップサンプリングはチャンネル数を倍増させる 1\times1 conv(C\to2C)にチャンネル対時間の reshape を続けたもので、エンコーダーの階層的 2\times パッチ化を正確に逆転させます。教師モデルには SigLIP-SO400M-patch16-naflex(画像)と InternVideo-Next-L(動画)を使用します。この設計により、ボトルネックを拡大することなく、単一のコンパクトな潜在表現の中に画像レベルおよび動画レベルの相補的な意味的構造が実現されます。
Hydra-X UMM
UMM は標準的なネイティブテンプレートに従います。テキストと視覚トークンが一つのシーケンスに交互に配置され、共有 LLM バックボーン(メインモデルには Qwen2.5-7B-Instruct、アブレーションには 1.5B)によって処理されます。ヘッドは二つ設けられており、次トークン予測による自己回帰型言語ヘッドと、rectified flow matching で学習される視覚ヘッドです。
\mathcal{L}_{\text{Hydra-X}} = \lambda_1 \mathcal{L}_{\text{NTP}} + \lambda_2 \mathcal{L}_{\text{FM}},\quad \lambda_1=\lambda_2=1.
単一の Gen-ViT が五つのタスク(画像生成、画像理解、動画生成、動画理解、画像編集)すべてに用いられ、変化するのはデコーディングヘッドのみです。編集タスクにおいて、従来のパイプラインはソースとターゲットを二つの独立したエンコーダーブランチに通し、それらを橋渡しするために LLM に依存していました。HYDRA-X では代わりに、Gen-ViT を独立に保ち(ソースの忠実な再構成を維持)、Sem-ViT をソースとターゲット間で tubelet causal attention を用いて共有します。これにより、ソースとターゲットの相互作用は、バックボーンに委ねられるのではなく、トークナイザー内部の潜在レベルで生じます。
限界とオープンクエスチョン
提供されているセクションには再構成の数値が含まれていますが、この抜粋には下流の UMM ベンチマーク結果(生成 FID、動画生成品質、理解精度、編集指標)が含まれていないため、これらの表だけでは AToken/OmniTokenizer ベースの UMM に対するエンドツーエンドの改善を定量化することができません。アブレーションは ImageNet/DAVIS の控えめな解像度と17フレームのクリップに限られており、causal と tubelet の attention が最も乖離する長い時間軸での挙動は特性評価されていません。Decompressor は distillation のために学習時のみ使用されるパラメータを追加しますが、教師の選択およびボトルネック C=64 に対する感度はここでは報告されていません。最後に、ソースとターゲットの相互作用は LLM ではなく Sem-ViT に属するという主張は、アーキテクチャ的には明快ですが、同等の計算量のもとでバックボーン側の cross-attention ベースラインとの比較が求められます。
なぜ重要か
HYDRA-X は、共同画像・動画 ViT トークナイザーに伝播してきた二つのデフォルト設定、すなわち完全な時空間 attention と単一ステップの時間方向パッチ化、に対する制御された反証を提供し、フレーム因果的で階層的に圧縮された ViT と decompressed-latent distillation の組み合わせが、より高速かつより忠実であることを示しています。ネイティブ UMM においてトークナイザーはすべての視覚モダリティが通過するボトルネックであるため、これらの設計上の選択はすべての下流タスクに伝播します。
Source: https://arxiv.org/abs/2606.13289
Hacker News Signals
DeepSeek-R1のオープン再現
HuggingFaceのopen-r1プロジェクトは、DeepSeek-R1のトレーニングパイプラインを完全にオープンに再現するものであり、コールドスタートのsupervised fine-tuningステージと、推論モデルを生成するGRPOベースの強化学習ステージの両方をカバーしています。このリポジトリはQwenおよびその他のオープンなベースモデル上でR1を再現することを目標としており、学習済み報酬モデルではなく検証可能な報酬信号(数学的正確性、コード実行の合否)を使用しています。
技術的な中核はGroup Relative Policy Optimization(GRPO)であり、同一プロンプトに対してサンプリングされたG個の補完群の平均報酬からベースラインを推定することで、独立したvalue networkを必要としません。policy gradientの目的関数は以下の通りです:
\mathcal{L}_{\text{GRPO}} = -\frac{1}{G}\sum_{i=1}^G \min\left(r_i \hat{A}_i,\ \text{clip}(r_i, 1-\epsilon, 1+\epsilon)\hat{A}_i\right) + \beta\, D_{\text{KL}}(\pi_\theta \| \pi_{\text{ref}})
ここでr_i = \pi_\theta(o_i|q)/\pi_{\text{ref}}(o_i|q)、\hat{A}_iはグループ内で正規化されたadvantageです。KL項はpolicyを参照SFTモデルに近い状態に保ちます。
このリポジトリはtrlのGRPOTrainerと統合されており、accelerate/deepspeedによるマルチノードトレーニングをサポートし、MATH-500およびHumanEvalスタイルのベンチマーク向けの評価ハーネスも含まれています。データパイプラインはオープンな数学・コードデータセットから取得し、報酬計算のために自動的な回答抽出とサンドボックス実行を行います。
未解決の課題として、オリジナルのR1はコールドスタートSFTに大規模な独自データセットを使用していましたが、本再現ではオープンな代替データセットを使用しており、その品質差はまだ定量化されていません。フォーマットに関するreward hacking(chain-of-thoughtの長さ、区切りトークン)は文書化された問題として残っています。完全な671B MoEバージョンを再現するための計算リソース要件については対応されておらず、現在のターゲットは7B〜32Bの dense modelです。
Source: https://github.com/huggingface/open-r1
テリー・タオがAIの数学への伝道者になった経緯
このQuantaの記事は、タオがLLMを活用した形式数学に対して懐疑論者から積極的な実験者へと転換した過程を記録しています。技術的な核心は彼が実際に試みたことにあります。すなわち、LLM(主にGPT-4クラスのモデルとGemini)を対話的な仮説生成器および証明スケッチ生成器として用い、その後Lean 4で証明義務を解消するという手法です。彼が強調する重要な区別は、AIを使ってエンドツーエンドで検証済み証明を生成することと、人間や戦術ソルバーの探索空間を圧縮するためにAIを活用することの違いです。
彼が報告しているワークフローは次の通りです。サブゴールを自然言語で記述し、モデルにスケッチを求め、そのスケッチを手動でLeanのタクティクスに翻訳し、sorryのない検証を実行する、というものです。LLMは正しさの面では信頼されず、カーネルがその役割を担います。変わるのは行き詰まりを探索するコストであり、非標準的な補題に対するモデルの失敗率は依然高いものの、フィルタリングのコストは低く抑えられます。
彼はまた、Leanネイティブなアプローチ(LeanDojo、ReProver、タクティクスツリー上でのRLによるAlphaProof型手法)にも踏み込み、近い将来の価値は完全自動化された定理証明よりも対話的ハイブリッド型にあると主張しています。完全自動化システムへの懸念は能力の問題ではなく可読性の問題です。数学者が読めない証明は理解を伝達しません。そしてその理解の伝達こそが、数学の本質的な目的だからです。
記事はタオが明確に言語化したオープンな技術的問題を提起しています。現在のモデルはセッションをまたいで永続的・更新可能な数学的記憶を持たないという問題です。会話はそのたびに固定された事前学習済みの知識を基にゼロから始まります。Mathlibに対するRetrieval-augmentedなアプローチは存在するものの、使いやすい対話的ループには未だ統合されていません。ベンチマーク性能(miniF2Fの通過率)と真の新規予想生成との間のギャップは定量化されておらず、おそらく非常に大きいと考えられます。
Source: https://www.quantamagazine.org/how-terry-tao-became-an-evangelist-for-ai-in-math-20260608/
WASM Component Model 1.0 への道のり
Bytecode Alliance のブログ記事では、約4年間の設計作業を経て WebAssembly Component Model(CM)1.0 仕様が最終化されたことが述べられています。CM はコア WASM の根本的な制限に対処するものです。その制限とは、モジュールが境界に数値型しか公開できないため、言語に依存しない合成を行うには帯域外の規約とグルーコードが必要になるという点です。Component Model は型付きインターフェース層——WIT(WebAssembly Interface Types)——を定義しており、文字列・レコード・バリアント・リソース(ハンドル型の所有値/借用値)・インターフェースレベルのセマンティクスを持つ非同期ストリームを表現できます。
核心的なメカニズムは canonical ABI です。これは WIT 型をコア WASM の線形メモリの読み書きおよび関数呼び出しへと決定論的に落とし込む(lowering)仕組みであり、反対側では明示的な lifting が行われます。つまり、異なるソース言語からコンパイルされた2つのコンポーネントは、互いのメモリレイアウトを知らなくても、両者が canonical ABI を通じて lower/lift する限り相互運用できます。リソースは参照カウント方式のハンドルテーブルをコンポーネントランタイムが管理することで導入されており、コンポーネントをまたいだ安全な所有権移転を可能にしています。
CM 1.0 のリリースでは、以前のドラフトで実験的扱いだった非同期サポートも安定化されました。これはインターフェースレベルで structured concurrency をモデル化するものであり、コンポーネントは非同期関数をエクスポートし、非同期コールバックをインポートできます。バックプレッシャーとキャンセルは慣習ではなく型システムを通じて表現されます。基盤となる実装は、stack-switching 提案を介した WASM 内のスタックフルコルーチンモデルを使用しています。
ツールチェーンのサポートは wasm-tools、wit-bindgen(Rust・C・C++・Go・Python ターゲット対応)、および wasmtime ランタイムに導入されています。WASI 0.3 preview は非同期 I/O サーフェス全体を CM に依存しています。
未解決の課題として、高頻度呼び出しにおける canonical ABI の lifting/lowering のパフォーマンスオーバーヘッドはスケール時の特性がまだ十分に明らかになっておらず、ゲスト言語によってツールチェーンの成熟度にも大きなばらつきがあります。
Source: https://bytecodealliance.org/articles/the-road-to-component-model-1-0
AIエージェントがDN42をスキャンしようとしてオペレーターを破産させた
これは、自律エージェントによるAPIコスト爆発が制御不能に陥った具体的なインシデントレポートです。DN42はBGPルーティングの練習に使われる実験的なオーバーレイネットワークであり、著者はそのネットワーク偵察を行うAIエージェントをセットアップしました。エージェントにはnmap形式のスキャン、DNSルックアップ、whoisクエリなどのツールが与えられ、ネットワークのマッピングを行うよう指示されました。
障害のパターンは、エージェントのプランニングとツール呼び出し動作の間のフィードバックループでした。エージェントはDN42のアドレス空間が広大かつ密にルーティングされていることを発見し、並列スキャンタスクを次々に生成し始め、各スキャン結果がさらなるスキャンを生む新たなサブゴール分解をトリガーしました。エージェントフレームワークがすべてのプランニングステップにクラウドLLM APIを使用していたため、生成された各サブタスクに推論コストが発生しました。エージェントのcontext windowはサブゴールごとに制限されていなかったため、蓄積されたスキャン結果が長いプロンプトに繰り返し投入され続けました。
技術的な教訓は、リソースガバナーの欠如にあります。標準的なシェルプロセスにはulimitがあり、標準的なHTTPクライアントにはレートリミッターとバジェット上限があります。執筆時点のLLMエージェントフレームワークには一般的にそれに相当するプリミティブが欠けており、セッションごとのtokenバジェットも、タスクグラフ全体のwall-clockタイムアウトも、コストのサーキットブレーカーも存在しません。著者のエージェントフレームワークには、生成されたサブタスクがすでにキューに入っている作業を重複して行っていることを検出する仕組みがありませんでした。
発生したコストは短期間でAPI料金として数百ドルに上りました。データの外部流出やセキュリティ侵害は一切発生しておらず、これは設定ミスのある自律ループによる純粋な計算コストの暴走でした。このインシデントは、エージェントのサンドボックス化に経済的な制御(バジェット制限、高コスト操作に対する承認ゲート)が後付けではなくファーストクラスの設計制約として必要である理由を明確に示す好例です。
Source: https://lantian.pub/en/article/fun/ai-agent-bankrupted-their-operator-scan-dn42lantian.lantian/
Claude Fable 5: コーディングタスクにおける中程度の結果
Endor Labsは、Claude「Fable 5」(Claude 4 SonnetまたはそれRに近いリリースの内部コードネームと思われる)を、SWE-benchから派生した自社のエンタープライズ向けコーディング評価スイートで評価し、Anthropicが公表したbenchmark数値と一致しないパフォーマンスを確認しました。この記事の技術的な核心は、方法論上のギャップにあります。
AnthropicのSWE-bench Verifiedの主要数値は、そのモデル向けに調整されたscaffolding agent(社内ハーネス)を使用して算出されています。一方、Endorの評価では、現実的な開発者ツール環境(VS Codeに近い環境、実際のリポジトリ構造、複数ファイルの編集)においてモデルが実際に提供するものを測定するため、すべてのモデルに均一に適用される標準化されたハーネスを使用しています。タスクのカテゴリによって、スコアは15〜25パーセントポイント乖離しています。
タスクタイプ別の内訳は示唆に富んでいます。自己完結型のアルゴリズム問題ではbenchmarkの主張に近いパフォーマンスを示す一方で、複数ファイルにわたるリファクタリング、プロジェクトの暗黙的な規約の理解、またはビルドファイルや設定ファイルの適切な修正を要するタスクではパフォーマンスが大幅に低下します。これはcontext length利用効率の劣化と一致しています——大規模なコードベースから関連するシグナルを取得し、複数ファイルにわたる一貫した編集に統合することは、名目上のcontext windowが大きい場合でも、単一ファイルの補完よりもはるかに困難です。
また、セキュリティに関連するコードパターンにおける性能後退も指摘されています。以前のモデルでは発生しなかったケースで、生成されたコードにCWE-22(パストラバーサル)およびCWE-78(OSコマンドインジェクション)のパターンが導入されており、helpfulnessと安全なコード生成の間のRLHFトレードオフの存在が示唆されています。
未解決の問題はbenchmarkの標準化です。共有された未調整の評価ハーネスが存在しない限り、異なるラボから公表されたSWE-benchの数値は直接比較できず、調整済みハーネスでのパフォーマンスとデプロイ時のパフォーマンスの間のギャップは体系的に隠蔽されたままとなります。
Source: https://www.endorlabs.com/learn/claude-fable-5-mythos-grade-hype
Show HN: HelixDB – オブジェクトストレージ上に構築されたグラフデータベース
HelixDB は、ローカルディスクではなくオブジェクトストレージ(S3互換)を主要な永続化レイヤーとして使用するグラフデータベースです。永続的なローカルボリュームがコスト面または運用面で不便なクラウドネイティブ環境をターゲットとしています。ストレージモデルは、ホットなワーキングセット(メモリおよび利用可能であればローカル NVMe にキャッシュ)と、オブジェクトストレージ上のコールドな正規ストアを分離しており、オブジェクトストレージ上の write-ahead log が耐久性を提供します。
グラフデータモデルは、型付きエッジを持つ有向プロパティグラフをサポートしています。クエリインターフェースは HelixQL と呼ばれる独自言語で、Gremlin に近いトラバーサル DSL であり、内部のステップベース実行計画にコンパイルされます。頂点とエッジは型でパーティショニングされたカラム形式で格納されており、トラバーサルフィルタリング時のベクトル化された述語評価を可能にします。これは OLTP グラフ DB ではなく、グラフ分析システムから借用した設計です。
アーキテクチャは書き込みに log-structured merge アプローチを採用しています。変更はメモリバッファに蓄積され、オブジェクトストレージ上のイミュータブルなソート済みランファイルにフラッシュされ、定期的にコンパクションされます。これは RocksDB や Cassandra と同じ基本設計ですが、アクセスパターンがレンジスキャンではなくポインタチェイシングとなるグラフ構造データに適用されています。README でも認められているように、課題はトラバーサルワークロードがオブジェクトストレージバックエンドに対してローカリティが低いことです。頂点 A から頂点 B へエッジを辿る際、A の隣接リストを含むオブジェクトとは異なるオブジェクトをフェッチする必要が生じる場合があります。
このプロジェクトは初期段階にあります(Rust、約 8,000 行)。コールドストレージのトラバーサルレイテンシをローカルディスクの代替手段と比較した公開ベンチマークは存在しません。興味深いオープンクエスチョンは、隣接リストの共配置戦略(頻繁に共にトラバースされる頂点の近傍を同一オブジェクトに配置すること)が、インタラクティブなグラフクエリに十分なレイテンシギャップの縮小をもたらせるかどうかです。
Source: https://github.com/HelixDB/helix-db/tree/main
Linuxのレイテンシ測定とコンポジタのチューニング
この記事は、Linuxデスクトップにおけるエンドツーエンドの入力から表示までのレイテンシに関する詳細な実証研究であり、evdevイベント配信からコンポジタ処理、ディスプレイスキャンアウトに至るまでのフルスタックを対象としています。筆者はハードウェアによるレイテンシ測定リグ(フォトダイオードとArduinoを使ってキー押下からピクセル変化までの時間を計測する装置)を使用し、ソフトウェア計装のバイアスに依存しないグラウンドトゥルースの数値を取得しています。
主な知見として、デフォルトのカーネルスケジューリングはSCHED_OTHERスケジューラのスリープ/ウェイクの粒度により、コンポジタプロセスに対して1〜4msのウェイクアップレイテンシをもたらすことが挙げられます。コンポジタを適度な優先度でSCHED_FIFOに切り替えると、これがサブミリ秒まで低減されます。ディスプレイパイプラインは最悪ケースで120Hz時にさらに約8ms(1フレーム周期分)を加えますが、メールボックスモードの代わりにimmediate presentモードによるダブルバッファリングを使用することで、デッドライン未達時にティアリングが発生するコストを払いつつ、平均レイテンシを約4ms削減できます。
コンポジタのチューニングのセクションでは、KDE Plasma / KWinの設定に対する具体的な変更が記録されています。具体的には、レイテンシを優先する場合にアダプティブシンク(VRR)を無効化すること(VRRは可変フロントポーチを追加し、最悪ケースのレイテンシを増大させる)、フルスクリーンウィンドウでコンポジタのコンポジティングをバイパスするためにダイレクトスキャンアウトを有効化すること、そしてキャッシュマイグレーションのオーバーヘッドを削減するためにコンポジタスレッドを特定のCPUコアにピニングすることが含まれます。
evdevからwl_keyboardへのパスは個別に計測されており、平均約0.5msを要することが判明しました。これはカーネルのリングバッファを経由するラウンドトリップと、コンポジタのイベントループにおけるpoll/epollのウェイクサイクルによって支配されています。
この記事には平均値だけでなく生の測定分布も含まれており、レイテンシのCDFからは、デフォルト設定下では99パーセンタイルのレイテンシが中央値の3〜5倍に達し、チューニング済みの設定では分布が大幅に収束することが示されています。これは、テールレイテンシが平均レイテンシと同等に重要となる競技ゲーミングや楽器ソフトウェアにおいて実践的な意義を持ちます。
Source: https://farnoy.dev/posts/linux-latency
MicrosoftのオープンソースツールがAI開発者のパスワード窃取のためにハッキングされた
この事件は、Microsoftのオープンソースツール群の傘下で管理されているnpmパッケージのサプライチェーン侵害に関するものです。具体的には、AI開発ワークフローで使用されているパッケージ(LLM SDKラッパー、スキャフォールディングツールなど)が標的となりました。攻撃ベクトルは、メンテナーアカウントの侵害による認証情報窃取であり、その後に難読化された認証情報収集コードを含む悪意のあるパッチバージョンアップデートが公開されました。
報告された技術的メカニズムは以下の通りです。パッケージに注入された悪意のあるコードは、インポート時に起動し、環境変数(OPENAI_API_KEY、ANTHROPIC_API_KEY、AWSの認証情報変数など)を攻撃者が制御するエンドポイントへHTTP POSTで送信することで流出させました。難読化にはbase64エンコードされたペイロード文字列が使用され、Function()コンストラクタで評価されることで、npm auditや基本的なgrepベースのCIチェックによる静的解析を回避していました。
影響を受けたパッケージは週あたり数十万件という相当数のダウンロード数を持っており、検知および削除までの数時間という露出ウィンドウでさえ、その影響は甚大でした。npm installを実行した、またはlock fileが正確なコンテンツハッシュにピン留めされていなかった下流の開発者は、悪意のあるコードを実行していた可能性があります。
この事件が露わにする根本的な問題は、npmの信頼モデルにおけるパッケージメンテナーの身元とパッケージの完全性の間の脆弱なつながりです。npmはメンテナーに対して2FAをサポートしていますが、その適用は普遍的ではなく、今回の攻撃はパスワードのブルートフォースではなく、フィッシングまたはセッショントークン窃取を使用したと見られています。コンテンツアドレス指定のlock file(SHA-512ハッシュを含むpackage-lock.json)は、lock fileがコミットされCIで強制されていれば、悪意のあるバージョンへのサイレントアップグレードを防止できたはずですが、多くのプロジェクトではマイナー・パッチバージョンのフロートを許可しています。
緩和策としては、検証済みの完全性ハッシュで正確なバージョンをピン留めすること、利用可能な場合はprovenance attestationを使用すること(npmのprovenanceは現在サポートされているものの、まだ広く普及していません)、そしてビルド環境を認証情報ストアから分離することが挙げられます。
注目の新しいリポジトリ
AtomFlow-AI/MoleCode
MoleCodeは、分子表現をSMILES文字列やグラフテンソルではなくコードとして再定式化することで、LLMがネイティブなトークン予測機構を用いて化学を推論できるようにします。核心的なアイデアは、分子を構造化されたプログラミング言語風の構文で表現し、原子・結合・官能基を型付きコンストラクトに対応させるというものです。これにより、LLMは学習済みのコード推論能力——変数スコープ、合成的論理、構文妥当性チェック——を、別途ドメイン固有のエンコーダを必要とせず、化学構造に直接適用できます。
実用上の利点として、標準的な instruction-tuned LLMが「この分子のレトロ合成的切断はどこか?」といった問いに対し、分子を不透明な文字列としてではなくパース可能なプログラムとして扱うことで回答できるようになります。このリポジトリには、標準的な化学フォーマット(SMILES、InChI)をMoleCode表現に変換するtokenizer/フォーマッタ、プロンプトテンプレート、および反応予測・物性推論・分子生成タスク向けの評価ハーネスが含まれています。
本手法は、別途分子エンコーダを訓練することなく、大規模事前学習モデルの汎化能力を活用したい化学対応エージェントを構築する研究者に関連します。このアプローチはGNNの幾何学的帰納バイアスをLLMの柔軟な推論と引き換えにするものであり、タスクがコンフォメーション的というより論理的な性質を持つ場合には合理的な選択といえます。コード表現が立体化学や3D幾何を十分に捉えられるかどうかについては、未解決の問題が残っています。
Source: https://github.com/AtomFlow-AI/MoleCode
UditAkhourii/adhd
ADHDは、tree-of-thought(ToT)推論をコーディングエージェント向けのコンポーザブルなスキルとして実装したもので、ClaudeおよびCodex Agent SDK上に構築されています。このアーキテクチャは、クエリを並列の発散的思考ブランチへと展開し、各ブランチは異なる「認知フレーム」——例えば、システム思考フレーム、第一原理フレーム、ドメイン類推フレームなど——のもとでインスタンス化されます。各ブランチは独立して探索を行い、候補となる推論パスを生成します。
剪定メカニズムは、各ブランチを一貫性・新規性・タスク関連性の観点からスコアリングし、既知の悪いアトラクター(「トラップ」)——循環推論、脱線、または明示された制約に違反する解——へ収束するパスを除去します。生き残ったブランチは即座に回答へ集約されるのではなく、追加の推論ステップによってさらに深掘りされるため、greedy decodingよりも長い間多様性が維持されます。最終的な統合ステップでは、生き残ったブランチを集約して一つの回答を生成します。
SDK統合により、このスキルはカスタムのエージェントループを必要とせずドロップインで動作します。既存のClaudeまたはCodexエージェントにアタッチすることで、推論フェーズをインターセプトします。これは、解空間が真に非凸であるタスク——学際的なデザイン問題、アーキテクチャの意思決定、新規アルゴリズムの導出など——において有用であり、greedy chain-of-thoughtが局所最適に陥りやすい場面で効果を発揮します。主なコストはレイテンシとトークン予算であり、並列ブランチングにより推論呼び出しが倍増します。リポジトリには、単一チェーンCoTと比較したクリエイティブコーディングベンチマークでの高速化を示すサンプルが含まれています。
Source: https://github.com/UditAkhourii/adhd
openhackai/OpenHack
OpenHackは、複数の専門化されたサブエージェントをオーケストレーションしてエンドツーエンドの脆弱性評価を実施するエージェント型セキュリティスキャナーです。NmapやNucleiのような単一のスキャナーをラップするのではなく、パイプラインを構成します。すなわち、reconエージェントが攻撃対象領域を列挙し、解析エージェントが発見事項を分類して悪用可能なチェーンに関する仮説を生成し、exploitationエージェントがサンドボックス環境でPoCの検証を試みます。
「エージェント型」というフレームワークは、スキャナーが実行中に戦略を適応できることを意味します。例えば、reconフェーズで異常なサービスが発見された場合、オーケストレーターは固定のプレイブックを実行するのではなく、関連するツールアクセスを持つ専用エージェントを新たに生成します。ツールの統合には、構造化された function-calling インターフェースを介してアクセスされる標準的なペネトレーションテストユーティリティ(ポートスキャナー、Webクローラー、CVEデータベースなど)が含まれます。
オープンソースとして公開されている点はここで重要な意味を持ちます。商用のエージェント型スキャナー(SynackやHorizon3のものなど)はブラックボックスであるため、その推論を監査したり、新種の脆弱性クラスに向けて拡張したりすることが困難です。OpenHackはエージェントグラフ、プロンプト、ツール定義を公開しており、セキュリティ研究者がカスタムチェックを追加したり、特定のexploitパスがなぜ追求されたか、あるいはされなかったかを検査したりすることが可能です。実用的なユースケースとしては、CI/CDセキュリティゲートやbug-bountyの自動化が挙げられます。現時点での制限としては、LLM駆動の推論に典型的な偽陽性率や、能動的なexploitation試行に対する安全なサンドボックスの維持における課題が考えられます。
Source: https://github.com/openhackai/OpenHack
atomicstrata/atomicmemory
AtomicMemoryは、AIエージェント向けにフレームワーク非依存で設計された、ポータブルなembedding基盤のセマンティックメモリ層を提供します。このアーキテクチャは、ベクトルストレージ・検索・ライフサイクル管理を担うRust/TypeScriptのコアエンジンと、LangChain、LlamaIndex、およびMCP(Model Context Protocol)サーバーの直接利用向けの薄いアダプタ群を分離する構成になっています。
メモリエントリは、関連メタデータおよびdecayパラメータとともに密ベクトルembeddingとして保存されます。エントリはエピソディック(セッションスコープ)または永続的(クロスセッション)としてマーク可能であり、検索インターフェースはk-NNセマンティック検索と構造化メタデータフィルタリングの両方をサポートしています。MCPサーバーはメモリ操作を標準ツールコールとして公開しているため、MCP互換のエージェントであればSDKに依存せずメモリの読み書きが可能です。
CLIはメモリストアの検査と手動編集を可能にしており、エージェントの挙動のデバッグや陳腐化した信念の剪定において運用上有用です。フレームワークアダプタはコンテキストの注入を担い、クエリ時に検索された関連メモリをLLMのコンテキストウィンドウへ自動的に先頭追加します。
MemGPTやZepといった代替手段との主な差別化点はポータビリティです。同一のメモリストアを、PythonのLangChainエージェント、TypeScriptのLlamaIndexパイプライン、そしてCLIツールから同時にアクセスでき、コアエンジンが一貫性を管理します。これはマルチランタイムのエージェントシステムにとって有用です。ストレージバックエンドはプラガブルな設計(インメモリ、SQLite、外部ベクトルDBの可能性あり)と見られますが、プロダクションスケールでのシャーディングと並行性のセマンティクスについては精査が必要です。
Source: https://github.com/atomicstrata/atomicmemory
microsoft/intelligent-terminal
これはWindows Terminalのフォークであり、LLMバックエンドのエージェントをシェル環境に直接組み込み、独立したチャットウィンドウではなくネイティブUIのアフォーダンスを通じて公開するものです。統合はターミナルエミュレータレベルで行われており、エージェントは現在のシェルセッションのコンテキスト(コマンド履歴、作業ディレクトリ、直近コマンドのstdout/stderr)を観察し、シェルコマンドや説明をインラインで注入することができます。
技術的には、このフォークは設定可能なバックエンドを介してAzure OpenAIまたはローカルモデルのエンドポイントと通信するエージェントランタイムを追加しています。エージェントは、表示されているターミナルバッファ、現在のシェルタイプ(PowerShell、bash、WSL)、およびキーバインドで起動するプロンプトやトリガーシーケンスをプレフィックスとした自然言語で表現されたユーザーの意図を含む構造化されたコンテキストペイロードを受け取ります。応答はプレーンテキストのアノテーションとして、またはユーザーがワンキーストロークで承認できる実行可能なコマンド候補としてレンダリングされます。
この設計は、ターミナル作業中にチャットインターフェースへalt-tabで切り替えるコンテキストスイッチングのコストを回避します。本番環境の問題をデバッグするシステム管理者や開発者にとって、エージェントがシェルの出力と同じ場所に配置され、ユーザーが見ているものをそのまま確認できることで、現在の多くのLLM支援ターミナルワークフローに特有のコピー&ペーストの煩雑さが軽減されます。このリポジトリはWindows TerminalのフルVT/conPTYスタックを継承しているため、レンダリングの忠実度は変わりません。未解決の課題としては、高速スクロール出力中のリアルタイムアシスタンスにおけるレイテンシ、およびエージェントが起動するコマンド実行に関するセキュリティ境界が挙げられます。
Source: https://github.com/microsoft/intelligent-terminal
ahammadmejbah/Awesome-Datasets-Hub
LLMの学習および評価を対象とした構造化データセットレジストリであり、医療AI、多言語NLP、マルチモーダル学習(vision-language)、instruction tuning、数学的推論、コード生成、および標準的な評価 benchmark(MMLU、HumanEvalの派生版など)を含む複数のドメインにわたって整理されています。
このリポジトリの価値はキュレーションにあり、オリジナルデータを含むものではありません。各エントリにはデータセット名、タスクの種類、規模、ライセンス、および直接アクセスリンク(HuggingFace Hub、学術サイト、またはGitHub)が記載されています。カテゴリ分類のスキーマはAwesome-Public-Datasetsのような既存のリストよりも細粒度であり、たとえばinstruction tuningのセクションでは、人手でアノテーションされたもの(例:OpenAssistant)、合成生成されたもの(例:Alpacaスタイル)、および選好ラベル付き(例:RLHFコーパス)のデータセットを区別しています。
学習パイプラインや評価スイートを設計する研究者にとって、このような整理されたレジストリは、適切なデータソースを探すための文献調査に費やす時間を削減します。医療AIセクションは、アクセス制限のために一般的なリストから省略されることのあるclinical NLPデータセットを含んでいる点が注目に値し、該当するエントリにはIRB/DUAの要件が記載されています。
此種のリストに共通する主な制限はデータの陳腐化です。データセットの可用性やライセンス条件は変化し、主要ラボからの新しいリリースが反映されるまで遅れが生じる場合があります。このリポジトリが積極的なキュレーションを維持しているかどうかが、長期的な有用性にとっての重要な問いとなります。
Source: https://github.com/ahammadmejbah/Awesome-Datasets-Hub
code-yeongyu/lazycodex
LazyCodexは、Codex(OpenAIのコード特化モデルファミリー)向けのagent harnessであり、単一関数の補完ではなく、大規模なマルチファイルのコードベースにまたがるタスクを対象として設計されています。本システムは、Codexのcontext window制限に対処するため、永続的なプロジェクトメモリを維持します。このメモリはコードベースの構造化された表現(ファイル依存グラフ、シンボルインデックス、テストカバレッジマップ)であり、agentが変更を加えるたびにインクリメンタルに更新されます。
計画レイヤーは、高レベルのタスク(例:「認証をJWTを使用するようにリファクタリングする」)を、依存関係順に並べた原子的な編集のシーケンスに分解し、シンボルグラフに基づいてどのファイルをどの順序で変更する必要があるかを解決します。実行レイヤーはCodexの補完を通じて編集を適用しますが、各編集はコードベース全体ではなく、検索されたコンテキストスライスに基づいています。検証済み完了とは、harnessが各原子的な編集の後にテストスイート(または指定された検証コマンド)を実行し、失敗時にはロールバックまたは再試行を行うことで、生成と正確性の間のループを閉じることを意味します。
これはアーキテクチャ的にSWE-agentやDevinスタイルのシステムに類似していますが、完全なagentフレームワークではなく軽量なharnessとして位置づけられています。Codex APIアクセスと既存のリポジトリをユーザー自身が用意する形です。プロジェクトメモリコンポーネントは技術的に最も差別化された部分であり、単純なファイル全体のコンテキスト詰め込みを構造化された検索に置き換えています。制限事項としては、解析可能なコードベースへの依存(メタプログラミングを多用する動的言語ではシンボルグラフが不完全になる)と、各編集でフルテストスイートを実行するコストが挙げられます。
Source: https://github.com/code-yeongyu/lazycodex
wanshuiyin/ARIS-in-AI-Offer
ML・AIエンジニアリングの面接対策を目的としたバイリンガル(中国語/英語)のリファレンスリポジトリで、特に中国の採用サイクル(秋招)に焦点を当てています。内容は transformer、diffusion model、LLMの内部構造、agent アーキテクチャ、標準的なMLの数学を網羅しており、オフライン利用のために自己完結型の単一ファイルHTMLドキュメントにレンダリングされたチートシートとして整形されています。
生成パイプライン自体が技術的に興味深い成果物です。チートシートはARIS の /interview-cheatsheet を通じて生成され、/render-html によってポータブルなHTMLにレンダリングされます。つまり、同じパイプラインを異なるトピック仕様に対して実行することで、コンテンツの再生成やカスタマイズが可能です。これは純粋に手作業で著述されたコンテンツではなく、機械支援によるドキュメント作成ワークフローです。
副次的な機能として、提出された履歴書をDBLPと照合して論文掲載の主張をファクトチェックし、不一致を指摘するアカデミックホームページジェネレーターがあります。個人の学術ページを構築する研究者にとって、これは軽量な自動監査ステップを提供します。競争的な採用文脈において誇張された論文リストが既知の問題であることを踏まえると、特に有用です。
手作業で執筆されたブログセクションでは、RLHF、mixture-of-experts のスケーリング、RAGシステム設計といったトピックをより長文形式で取り上げています。バイリンガル形式は特定の読者層、すなわち国際企業に応募する中国のML実務者やその逆の立場の人々に対応しており、両言語間で用語を統一することで曖昧さを軽減します。学習リソースとしての有用性は、LLMが生成したチートシートコンテンツの正確さと深さに依存するため、一次情報源と照らし合わせて内容を確認することが推奨されます。