Daily AI Digest — 2026-06-12
arXiv Highlights
FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
Problem
Training deep search agents on synthetic multi-hop questions has a measurement problem: nominal structural difficulty (graph depth, number of constraints) does not equal realized search difficulty. A question intended to require a long chain of retrievals can collapse if the solver finds a cheaper identifying route — for example, a single highly selective clue that returns the gold entity in one query, or a constant in the question text (a date, a proper noun) that binds to prior knowledge. The result is training trajectories that look long but teach the model to short-circuit. The paper formalizes this gap and uses the formalism to drive data synthesis.
Difficulty framework
A task is q=(\mathcal{X},\mathcal{C}_q,\Sigma): answer space, constraint set, retrieval interface. For any constraint subset \mathcal{P}\subseteq\mathcal{C}_q, the candidate pool is
\mathrm{Ans}(\mathcal{P})=\{x\in\mathcal{X}:\bigwedge_{c_i\in\mathcal{P}} c_i(x)=1\},
with \mathrm{Ans}(\mathcal{C}_q)=\{y^\star\} for well-posed questions. The realized retrieval cost \Omega(q,\pi_0) for a solver \pi_0 is bounded below by the cheapest identifying route Q_\Sigma^\star, but reduced by solver-side prior binding U_{\pi_0}(q). From this the authors enumerate four shortcut risks: (i) single-clue selectivity (some \mathcal{P} already collapses |\mathrm{Ans}(\mathcal{P})|\to 1), (ii) evidence co-coverage (one document covers multiple clues, so M_{\mathrm{ev}}(\mathcal{P})\downarrow), (iii) exposed constants (named dates, places, IDs reduce dependency depth \mathrm{dep}(\mathcal{P})), and (iv) prior-knowledge binding (the model already knows y^\star). They diagnose realized effects with three trajectory signatures: total solving cost \widehat{\Omega}, answer hit time T_{\mathrm{hit}} (turn at which the gold answer first appears in retrieved evidence), and prior-shortcut rate \widehat{p}_{\mathrm{prior}}.
FORT synthesis pipeline
FORT inverts the framework: synthesize questions where Q_\Sigma^\star is large and U_{\pi_0}(q) is small. It builds an internal evidence graph (entities as nodes, verified facts as edges) and verbalizes subgraphs only after the controls are applied.
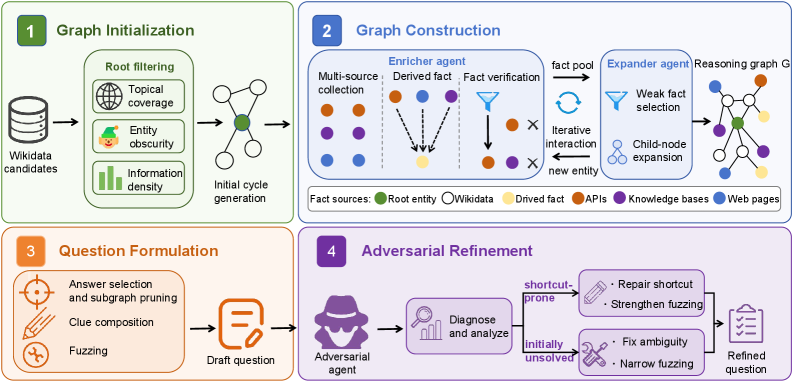
The four stages map to the risk taxonomy:
- Graph initialization. Long-tail root selection (rare entities, low Wikipedia popularity) attacks prior-knowledge binding; cycle-based initialization avoids exposing constants by ensuring identifiers can only be recovered through a closed dependency loop.
- Graph construction. Multi-source enrichment forces clues to be supported on disjoint documents (raising M_{\mathrm{ev}}); derived facts (e.g. “year whose digits sum to seven” rather than the year itself) prevent any single edge from being highly selective.
- Question formulation. Generic, low-specificity clue surface forms keep s(\mathcal{P}) small for any small \mathcal{P}; name withholding and exact-value fuzzing remove constants.
- Adversarial refinement. Candidate questions are probed with a strong solver; instances that succeed cheaply (small \widehat{\Omega} or early T_{\mathrm{hit}}) are rewritten or discarded, directly targeting solver-level cost reduction.
Training and results
The base model is Qwen3-30B-A3B-Thinking-2507 (3B active of 30B, 256K context). Training is SFT-only on FORT trajectories, 6 epochs, global batch 64, sequence length 262,144, peak LR 2\times 10^{-5} with cosine schedule, bf16 Adam (\beta_1{=}0.9,\beta_2{=}0.95), TP=4, EP=4, sequence packing.
On five benchmarks (BrowseComp, BrowseComp-ZH, xbench-DeepSearch-2505/2510, Seal-0), FORT-Searcher reaches 72.2 / 75.0 / 80.8 / 57.2 / 46.0, with overall average 66.2 — best among comparable-size open-source agents (MiroThinker-1.7-mini 64.6, Qwen3.5-35B-A3B 59.9, OpenSeekerV2 53.4, Tongyi DeepResearch 51.7). On BrowseComp it surpasses Qwen3.5-122B-A10B (63.8) and DeepSeek-V3.2 (67.6) at a fraction of the activated parameters.
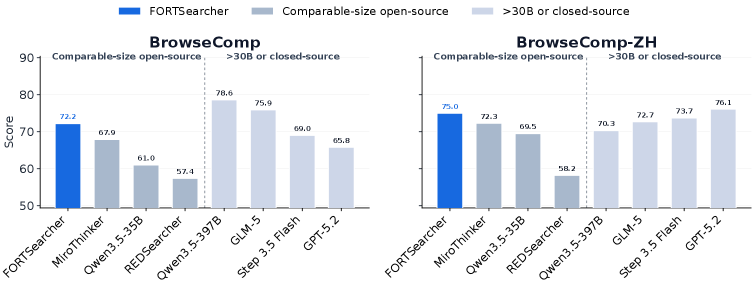
The ablation in Section 5.1 is the cleanest evidence that the framework — not just longer trajectories — is what drives gains. Holding training set size at 12K and varying only the source, sampling existing open-source data at \widehat{\Omega}\in\{40,85,140\} yields BrowseComp 47.1 → 48.4 → 49.5 (BC-ZH 54.9 → 54.6 → 58.1). Switching to FORT data at the same \widehat{\Omega}=140.0 but with T_{\mathrm{hit}} delayed from 22.3 to 47.0 and \widehat{p}_{\mathrm{prior}} dropped from 18.1% to 11.4% pushes BrowseComp to 52.9 and BC-ZH to 60.3. Pre-answer search depth and prior decoupling are the operative quantities; trajectory length alone gives diminishing returns.
Limitations and open questions
The pipeline is SFT-only; it is unclear whether the shortcut-resistance gains compound or partially wash out under RL post-training, where solvers can rediscover shortcuts that the SFT distribution merely suppressed. The trajectory signatures are estimated using a specific solver \pi_0, so \widehat{p}_{\mathrm{prior}} is solver-dependent — a stronger solver may bind priors that FORT considered safe. The Seal-0 score (46.0) is below MiroThinker-1.7-mini (48.2) and Kimi-K2.5-Thinking (57.4), suggesting that conflict-resolution under noisy evidence is not addressed by the shortcut framework. Finally, the cycle-based initialization and adversarial refinement steps are described abstractly; reproduction will require choices about cycle length, refinement budget, and the strength of the adversarial solver that are not pinned down here.
Why this matters
The paper makes a concrete, measurable claim that has been folklore in search-agent training: dataset difficulty must be defined over realized trajectories, not over graph topology. The T_{\mathrm{hit}} / \widehat{p}_{\mathrm{prior}} signatures and the four shortcut categories give a usable target for synthetic data pipelines, and the controlled ablation shows the effect is not confounded by trajectory length.
Source: https://arxiv.org/abs/2606.12087
MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
Competition mathematical proof is the canonical setting where outcome-based RL on verifiable rewards breaks down: the correctness object is a natural-language argument, not a unit-test outcome, so the reward must come from a model that itself reasons about the proof. MaxProof is the test-time scaling layer of the MiniMax-M3 series, designed to convert a model with strong best@K proof capability into a stable pass@1 system. The package is three trained capabilities — proof generation, proof verification, and critique-conditioned repair — merged into a single released model, plus an evolutionary search that uses the same model in four roles at inference.
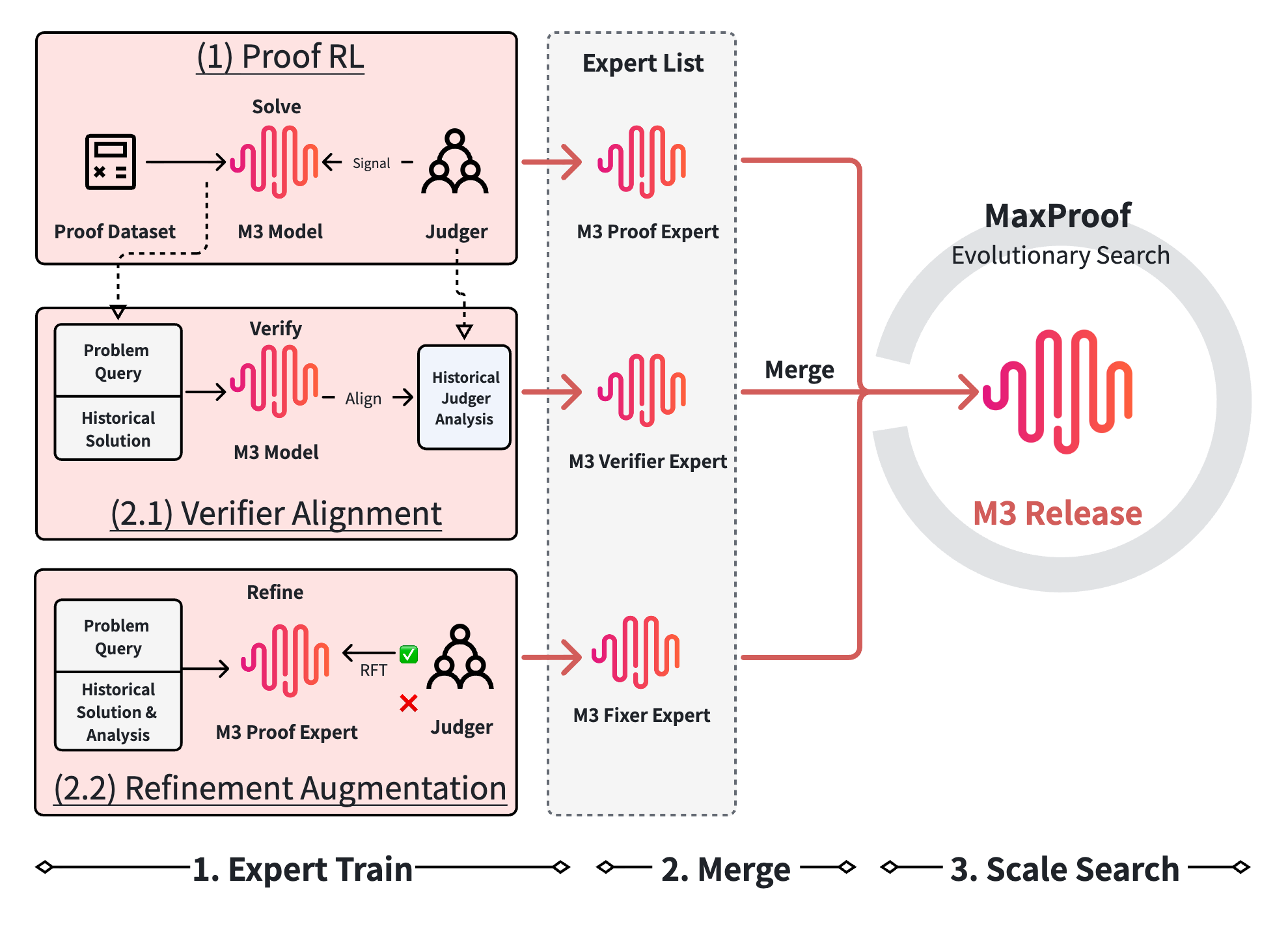
Proof Expert: long-horizon RL under a generative verifier
The Proof Expert is trained with a variant of GRPO adapted to the M-series CISPO objective, where the trajectory-level reward for an entire candidate proof is a scalar r \in [0,7] produced by a frozen generative verifier. The verifier reads the argument, compares it to a rubric extracted from a reference solution, identifies missing or invalid steps, and emits both a textual assessment and the score that becomes the RL reward.
The central design risk is that the verifier is the environment, so any flaw in it is amplified by the policy. The authors therefore use a four-layer defense-in-depth verifier rather than a single judge: (1) bad-case filtering removes candidates matching known failure patterns (e.g., empty proofs, claim-only “answers”), (2) solution normalization strips surface formatting so the judge cannot grade on layout, (3) three independent judges score in parallel, and (4) the final score is the pessimistic \min over judges.
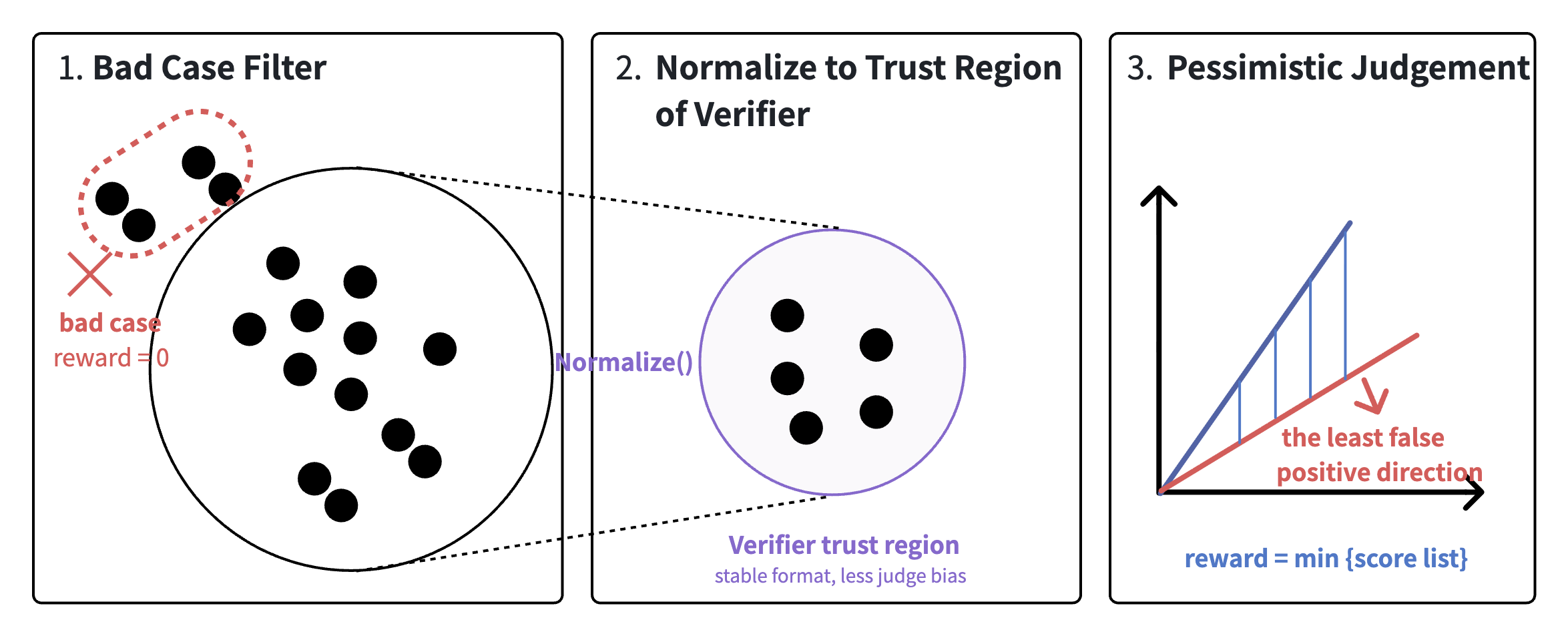
This pessimistic aggregation is deliberate: it trades recall for false-positive rate, which is the only direction that matters when the score drives policy updates. Data construction is closed-loop with the verifier — only problems where the current policy has non-trivial headroom are kept, so each GRPO group contains both failures and partial successes and the group-relative advantage carries usable gradient signal.
Verifier Expert: error finding, not score regression
The natural target for a verifier is 0–7 regression matching the MathArena protocol, but the authors argue (correctly) that regression is satisfied by surface correlations and does not require the model to localize errors. The Verifier Expert is instead trained on a structured error-finding task with three blocks: <assessment> (paragraph-by-paragraph reading), <errors> (an enumerated list of localized concrete errors), and <verdict> \in {no_errors, minor_gaps, has_errors, fundamentally_wrong}. The verdict is a function of the error list, so a no_errors verdict requires committing to an empty <errors> block. This tying is what makes the verifier output usable downstream — the same <errors> list is the critique consumed by the Fixer Expert.
Fixer Expert: critique-conditioned repair
The Fixer Expert is rejection-sampling fine-tuned on triples (\text{problem}, \text{flawed\_proof}, \text{verification\_analysis}) to produce a corrected proof that addresses the listed errors while preserving correct steps. Without the critique the model would have to rediscover flaws; with it, the correction is grounded in concrete error locations. This is repair, not generation, and the empirical claim is that this is meaningfully easier when the critique structure matches the verifier’s output schema exactly.
MaxProof: population search with pessimistic fitness
At inference, MaxProof exposes the merged M3 model through four prompt-defined roles — generator, verifier, refiner, ranker — and runs an evolutionary loop. The configuration in §6 is N=32 initial candidates, K_{\text{verify}}=4 verifier samples per candidate (averaged or min-aggregated for fitness), R=10 refinement rounds, M=4 parents per round, K_{\text{ranker}}=3 ranker votes per pairwise comparison, with early stop when \geq 2 candidates score perfect. Two mutation operators are used with different exploration–exploitation tradeoffs: PATCH (local edits guided by the critique) and REWRITE (re-derive sections from scratch). Final selection is a pairwise tournament with majority-vote ranker rather than \arg\max over verifier scores, which is the brittleness fix for verifier false positives.
The framing as evolutionary search is more than analogy: the archive is the population, the pessimistic verifier score is fitness, diverse parent selection prevents collapse, and PATCH/REWRITE are mutation operators of different radii. Crucially, this addresses three failure modes simultaneously — raising the population ceiling via independent samples, improving near-correct candidates via critique-conditioned repair, and avoiding verifier false positives via tournament-based selection.
Results
On the contest benchmarks scored 0–7 per problem (max 42), the merged M3 model with MaxProof reaches 35/42 on IMO 2025 and 36/42 on USAMO 2026, both above the human gold-medal threshold. The contest evaluation deliberately reports only M3 variants with and without MaxProof to isolate the test-time scaling contribution; the standalone IMOProofBench and IMOAnswerBench numbers (no MaxProof) measure the merged model’s first-pass capability under the same MathArena protocol.
Limitations and open questions
The results lean heavily on the verifier’s false-positive rate, and the defense-in-depth pipeline is engineering, not a guarantee — a flaw shared by the three judges (e.g., a common pretraining bias toward persuasive-sounding wrong proofs) would not be caught by \min-aggregation. The paper does not report verifier ROC on held-out adversarial proofs, only that an earlier M2 iteration exhibited reward hacking that motivated the conservative design. Compute cost of MaxProof at N=32, R=10 with 256K-token outputs is non-trivial and not directly compared to a same-budget pure-sampling baseline. Finally, the contest evaluation set is six problems per contest; the variance of \pm 1 point is large relative to the gap to gold.
Why this matters
MaxProof is the first published instance where the generator, verifier, and refiner are all the same merged model under different prompts, trained jointly so their I/O schemas compose into an evolutionary search loop. The combination of pessimistic-min verifier aggregation, error-localized critique as the unit of feedback, and tournament selection over population archives is a concrete recipe for RL on non-executable reward signals.
Source: https://arxiv.org/abs/2606.13473
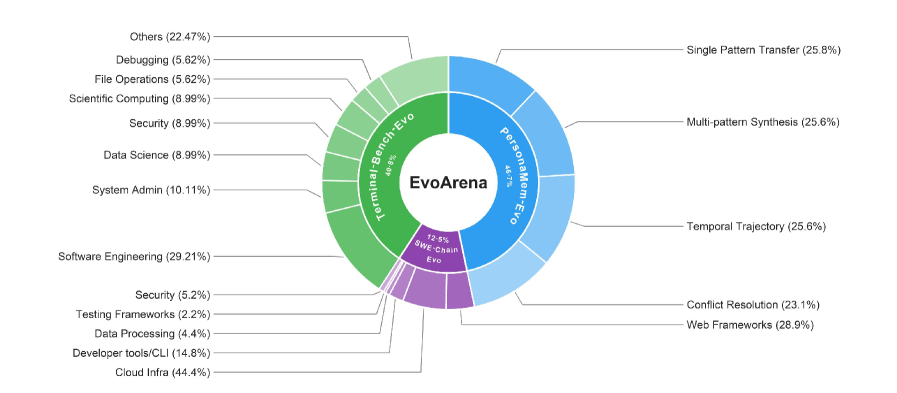
EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
Problem
Most agent benchmarks evaluate against a frozen environment snapshot, but deployed agents face drifting interfaces, dependency upgrades, evolving codebases, tightening validation rules, and shifting user preferences. Two failure modes follow. First, agents reapply prior knowledge that has silently become invalid. Second, agents that aggressively overwrite memory toward the latest state lose still-valid prior behavior, which matters under rollbacks, multi-tenant deployments, or version-specific tasks. EvoArena targets the first failure mode by constructing benchmarks with explicit version chains, and EvoMem targets the second by recording memory as an evolution trace rather than a single latest state.
EvoArena construction
EvoArena converts static benchmarks into ordered version chains \{v^{(1)},\ldots,v^{(m)}\} that preserve the user-facing objective but mutate the surrounding workflow. Three regimes are covered:
- Terminal-Bench-Evo (executable workflow evolution): paths, CLI invocations, dependency versions, and validation tests change between releases derived from Terminal-Bench tasks.
- SWE-Chain-Evo (software evolution): consecutive implementation milestones in an evolving repository.
- PersonaMem-Evo (preference evolution): long-horizon conversations where user preferences shift.
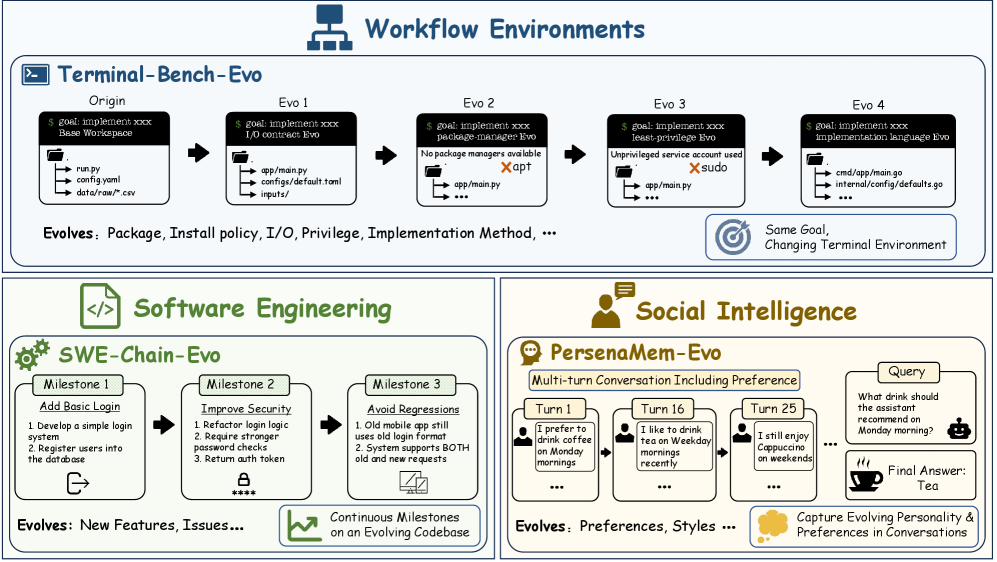
The Terminal-Bench-Evo pipeline has five stages: (1) workflow-state analysis extracting objective, environment, files, dependencies, I/O contracts, and validation rules; (2) evolution-plan design specifying realistic mutations over the components flagged as mutable; (3) inherited version realization, where each v^{(k)} inherits the realized container/workspace of v^{(k-1)}; (4) quality control with oracle-solution validation, filtering or repairing releases that are unexecutable, internally inconsistent, or unsolvable; (5) benchmark assembly grouping versions into chains and recording metadata for step- and chain-level scoring.
Evaluation uses Step Accuracy (per-version task) and Chain Accuracy (entire chain solved without error for Terminal-Bench-Evo and PersonaMem-Evo; longest correctly solved prefix divided by chain length for SWE-Chain-Evo).
EvoMem: patch-based memory evolution
EvoMem augments any base memory system with two components:
- Patch recording. Whenever an update is non-additive (it overwrites or contradicts a prior memory state), EvoMem stores a structured patch capturing what changed, why it changed, and which observation triggered the update. The base memory keeps its single latest state; the patches form an external evolution trace.
- Patch-augmented retrieval. At query time, relevant historical patches are retrieved alongside the latest memory whenever the query depends on overwritten state, temporal change, or version-specific behavior.
Conceptually, the memory at time t becomes the pair (M_t, \mathcal{P}_{1:t}) rather than M_t alone, where each patch p_i \in \mathcal{P} records (s_{\text{old}}, s_{\text{new}}, \text{trigger}). The agent can then reason about transitions, not just current state.
Results
Across Terminal-Bench-Evo, SWE-Chain-Evo, and PersonaMem-Evo, current agents (Terminus2, OpenHands, A-Mem, Memento-Skill backed by GPT-5.5, Gemini-3.1-Pro, Qwen3.6-27B, Kimi-K2.6, GPT-5.4-mini) reach only 39.6% average step accuracy, confirming that version-aware reasoning is largely absent from current systems.
EvoMem yields:
- +1.5% average step accuracy on EvoArena.
- +3.7% chain accuracy on EvoArena, a larger lift than the step gain — consistent with chain success requiring consistency across versions.
- +6.1% on GAIA (LLM-judge accuracy) and +4.8% on LoCoMo (exact match), showing the patch trace also helps in benchmarks not explicitly framed as evolving.
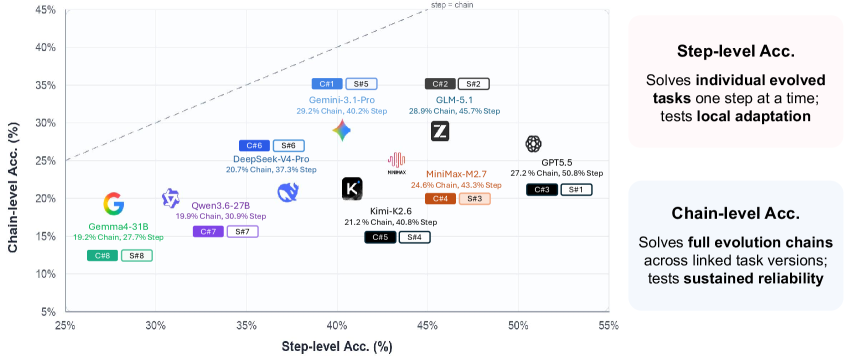
When EvoMem helps
The mechanism analysis on Terminal-Bench-Evo with Terminus2 stratifies gains by whether the patch memory is actually operationalized. The pattern is sharp:
- Patch example retrieved: gain rises from +3.1% (no patch) to +6.5%.
- Evolved-requirement coverage: +2.1% (low) vs. +5.3% (high).
- Patch uptake (patch terms reappear in agent reasoning/commands): +2.6% (none) vs. +8.3% (nonzero) — a 5.7 point gap.
- Command-level uptake (terms reach executed shell commands): +3.1% vs. +6.2%.
This indicates EvoMem is not just providing additional context. The benefit is conditional on the agent identifying the local transition encoded in the patch and propagating it into its plan, preserving the still-valid procedure while revising the invalidated portion.
Limitations and open questions
- The 1.5% aggregate step gain is modest; most of EvoMem’s benefit is gated on retrieval landing on the right patch and on the agent operationalizing it. Failures upstream of operationalization remain the dominant loss.
- Patch construction relies on detecting non-additive updates; the criterion for triggering a patch and the granularity of (s_{\text{old}}, s_{\text{new}}) are not specified in detail and likely affect retrieval quality.
- Chain Accuracy on Terminal-Bench-Evo is binary over the chain, which is brittle and does not credit partial recovery after a single misstep.
- EvoArena’s evolution plans are author-designed rather than sampled from observed real-world diffs; ecological validity for production drift is open.
- The reported model lineup includes future-named models (GPT-5.5, Gemini-3.1-Pro, Qwen3.6-27B, Kimi-K2.6); reproducibility on currently-available checkpoints is unclear.
Why this matters
Static-snapshot benchmarks systematically overestimate agent robustness because they remove version drift, which is the dominant source of failure in deployment. EvoArena gives a controlled testbed for version-aware behavior, and EvoMem demonstrates that maintaining an explicit, retrievable trace of memory transitions — rather than a single latest state — is a concrete and benchmark-portable mechanism for handling non-stationary environments.
Source: https://arxiv.org/abs/2606.13681
SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
Spatial reasoning over 3D/4D scenes — depths, viewpoints, camera motion, inter-frame geometry — remains weak in VLMs, and tool-augmented agents have tried to patch this by bolting perception modules onto a frozen backbone. The authors argue the bottleneck is not the menu of tools but the interface through which they are invoked. Two dominant designs both fail in different ways: single-pass code commits to an entire analysis before seeing any intermediate mask or depth map, while structured (JSON/XML) tool-calls constrain composition to predefined operations and prevent ad-hoc numerical work. SpatialClaw proposes a third option: code-as-action over a persistent Python kernel, with execution feedback (text, variable summaries, rendered images) folded back into the agent’s context.

Method
The system is training-free. Each example instantiates a Python kernel pre-loaded with input frames and a small surface of primitives. Six entry points are exposed:
InputImages— sampled frames.Metadata— fps, duration, frame indices for temporal queries.tools— perception primitives plus utilities.tools.Reconstructwraps Depth Anything 3 to return per-frame depth, intrinsics, extrinsics, and dense point maps; segmentation comes from SAM3, prompted by text/point/box.show(...)— registers an image (including matplotlib figures) for embedding in the next observation.vlm— dispatches subqueries to a separate VLM session, e.g.vlm.locate(...)for grounding, returning text only so images do not pollute the main context.ReturnAnswer()— terminates the loop.
The outer loop has five stages: a planner sees the question and tool docs (but not images) and emits a plan; the main agent writes one cell; the cell executes in the persistent kernel; stdout, variable summaries, and show()-registered images are appended; iterate until ReturnAnswer() or N_{\max}=30.
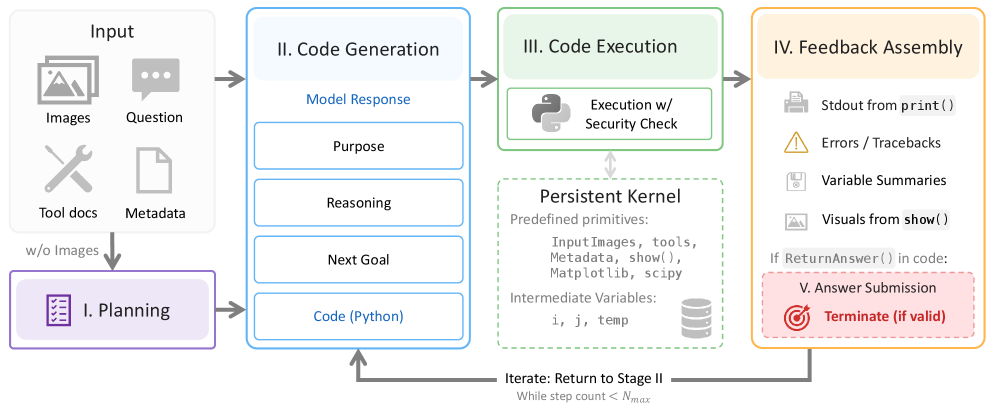
The persistent state is the central mechanic: masks, point maps, and intermediate arrays survive across cells as ordinary Python variables, so the agent can begin with a coarse computation, inspect the rendered output, and refine — something neither single-pass code nor structured tool-calls support.
Results
Evaluation spans 20 benchmarks covering single-image, multi-view, video and 4D spatial reasoning, plus general video understanding. Backbones include Qwen3.5 (122B-A10B, 397B-A17B), Qwen3.6 (35B-A3B, 27B), and Gemma4 (31B, 26B-A4B). Benchmarks larger than 1,000 samples are subsampled to 1,000; identical prompts and tools are used across all configurations.
The most informative analysis is the per-category breakdown against the two baseline interfaces. SpatialClaw wins 11/13 meta-categories against both Structured tool-call and Single-pass Code, with the largest margins (+6 to +9 percentage points) on Camera motion, Multi-view/viewpoint reasoning, and Relative direction — the categories where intermediate evidence has to be chained across frames.
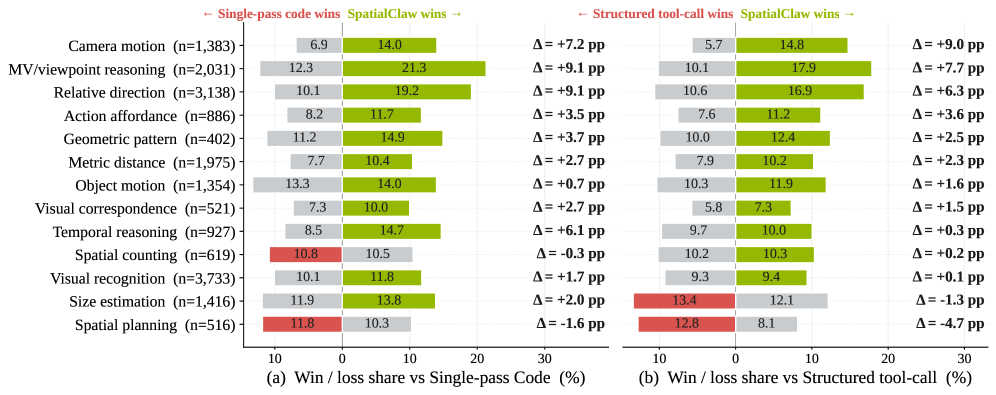
Two ablations isolate where the gain comes from. (I) Removing all utility wrappers (tools.Mask, tools.Geometry, etc.), keeping only SAM3/DA3 plus NumPy/SciPy, matches full SpatialClaw — the agent reconstructs utility logic on the fly. (II) Removing perception tools entirely, leaving only the code interface and scientific libraries, still produces a +2.7\%p gain over the tool-free baseline, isolating the contribution of the action interface itself from perception coverage.
A primitive-usage analysis across meta-categories shows the agent spontaneously specializes its tool composition: distance questions disproportionately invoke scipy.spatial.KDTree and vector norms (nearest-neighbor structure), while direction questions concentrate on dot products and angular operations. No category-specific prompts or routing were used; the specialization emerges from question semantics alone, which is precisely the kind of behavior a structured tool interface suppresses.
Where SpatialClaw’s gains are smallest — visual recognition meta-categories — the bottleneck is the backbone VLM’s perception, already near-saturated, so no interface change can help.
Limitations and open questions
The system is training-free and inherits all the failure modes of its components: SAM3 grounding errors and DA3 depth/extrinsic errors propagate into geometry computations with no explicit uncertainty handling. With N_{\max}=30 and matplotlib screenshots in-context, token budgets and latency per example are substantial; the paper does not report wall-clock or token costs. The planner sees no images, which constrains plans on visually ambiguous queries. The 1,000-sample cap on large benchmarks limits statistical resolution. Finally, the analysis attributes gains to the interface, but the persistent kernel is entangled with the planner module and show() feedback channel; a cleaner ablation isolating persistence from feedback would be valuable.
Why this matters
The result reframes a practical question for VLM agents: the marginal returns from adding more specialist tools are smaller than the returns from giving the agent an interface that can compose arbitrary numerical operations against persistent intermediate state. For spatial reasoning specifically — where geometric chaining across views is the hard part — code-as-action with a live kernel appears to be the right abstraction.
Source: https://arxiv.org/abs/2606.13673
MiniMax Sparse Attention
Long-context inference is bottlenecked by the \Theta(2H_q N^2 d_h) cost of softmax attention. Existing sparse-attention proposals tend to either (i) introduce per-token gather patterns that break tensor-core utilization, or (ii) use head-shared selection that limits retrieval recall. MiniMax Sparse Attention (MSA) is a blockwise sparse-attention layer built on Grouped Query Attention (GQA) that aims for a minimal architectural footprint while still admitting an efficient GPU implementation at deployment scale. The paper validates it on a 109B-parameter MoE model with native multimodal training.
Architecture
MSA inherits the GQA partition: H_q=64 query heads tied in groups of G=H_q/H_{kv}=16 to H_{kv}=4 KV heads, with d_h=128 and RoPE dimension 64. On top of this, it adds two branches.
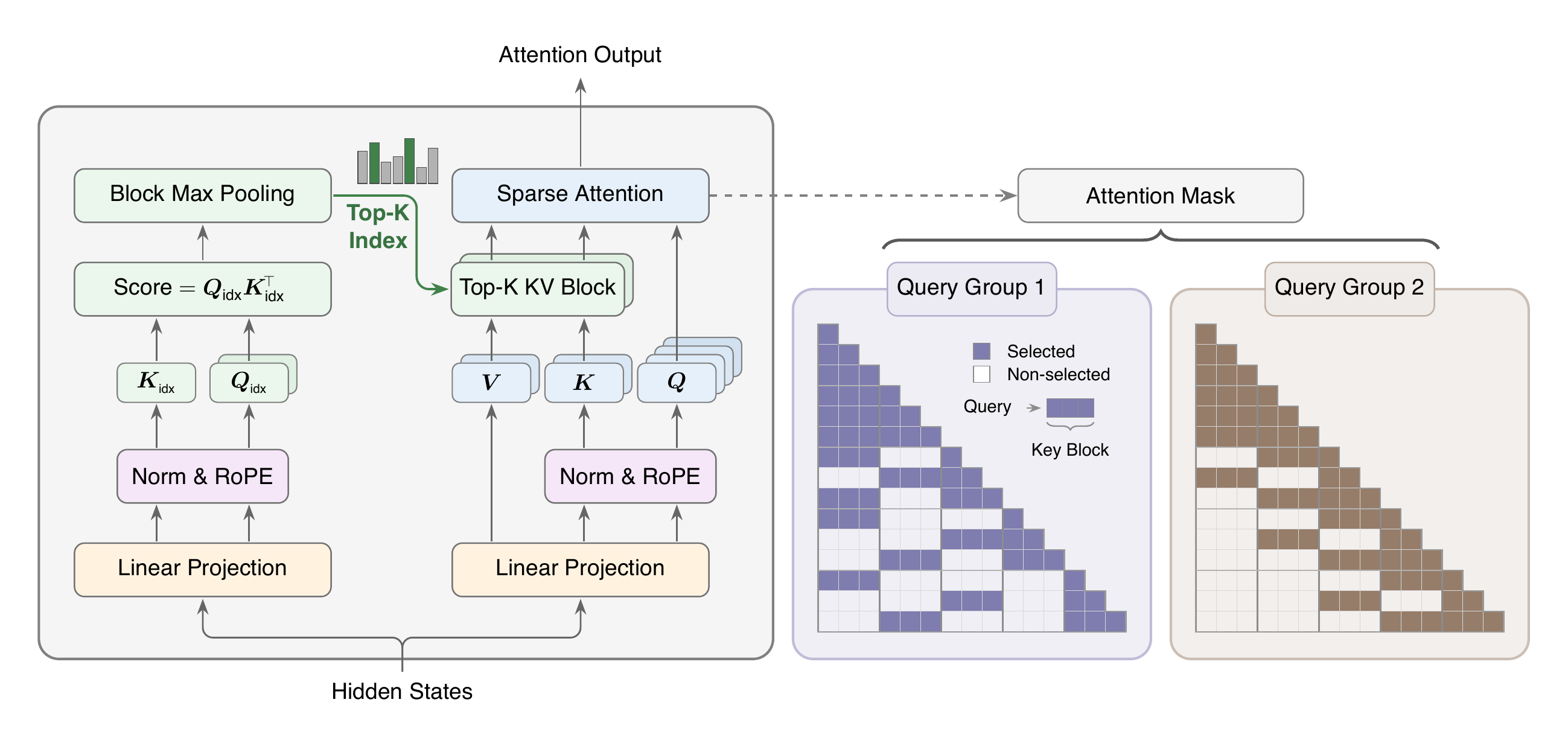
The Index Branch introduces only two extra projections: one index query head per GQA group and one shared index key head, \mathbf{Q}^{\rm idx}=\mathbf{X}\mathbf{W}_q^{\rm idx}\in\mathbb{R}^{N\times H_{kv}\times d_{\rm idx}},\quad \mathbf{K}^{\rm idx}=\mathbf{X}\mathbf{W}_k^{\rm idx}\in\mathbb{R}^{N\times 1\times d_{\rm idx}}. For query token i and group r, scores are reduced to block granularity by a max over visible positions in each block \mathcal{B}_b, M^{\rm idx,(r)}_{i,b}=\max_{j\in\mathcal{B}_b,\,j\le i}\frac{(\mathbf{Q}^{\rm idx})^{(r)}_i(\mathbf{K}^{\rm idx})_j^\top}{\sqrt{d_{\rm idx}}}, and the top-k block indices \mathcal{I}_i^{(r)}=\mathrm{TopK}_b(M^{\rm idx,(r)}_{i,\cdot},k) are selected, with the local block (containing position i) always included. Crucially, \mathcal{I}_i^{(r)} is shared across the G query heads of group r but selected independently per group, recovering some of the per-head retrieval flexibility lost under GQA without paying for it H_q times.
The Main Branch then runs exact softmax attention restricted to the union of selected blocks, with token budget \le k B_k. In experiments, B_k=128, k=16, so each query attends to at most 2048 KV tokens regardless of N.
Training and kernels
Sparse retrieval is trained via a KL alignment between the index distribution and a teacher derived from the dense attention scores (the figure caption alludes to this loss; the full derivation is in §3.2). On the kernel side the paper makes two co-design choices that matter for tensor-core utilization:
- Exp-free Top-k. Since softmax is order-preserving, the index TopK is computed directly on raw scores s, skipping max/exp/sum. This shrinks the selection kernel and lets it run before any normalization.
- KV-outer sparse attention. The Main Branch is laid out so that the KV blocks form the outer loop and queries the inner loop, matching the block-granular access pattern produced by the index. This preserves contiguous KV reads under sparsity, which is the usual failure mode of token-level sparse attention.
A sparse-KL backward kernel is also provided so the index branch can be trained end-to-end without materializing the dense N\times N attention.
Results
The architecture targets the regime where kB_k \ll N. Theoretical per-token attention FLOPs and measured wall-clock speedups for the experimental configuration (H_q{=}64, H_{kv}{=}4, d_h{=}128, B_k{=}128, k{=}16) are shown below.
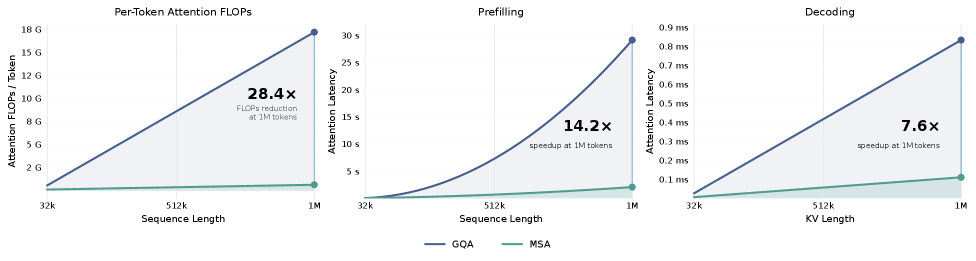
The crossover where MSA beats dense GQA happens early — once N exceeds the budget kB_k\approx 2{,}048 tokens — and the gap widens roughly linearly thereafter, since MSA’s compute is O(N\cdot kB_k) while GQA is O(N^2). Both prefill and decode see substantial speedups at long N.
Two 109B training regimes are evaluated: MSA-PT (sparse from scratch) and MSA-CPT (continued pretraining from a Full-Attention checkpoint with attention swapped to MSA). The 41-layer MoE backbone has 6B activated parameters, 128 routed experts with top-4 routing, d_{\rm model}=3072, and a 200K vocabulary. The abstract states MSA performs “on par” with the Full-Attention baseline at this scale; the section excerpt does not give the specific benchmark deltas, but both training paths are shown to be viable, which is the more interesting result — sparsity can be retrofitted into an already-trained dense model via CPT.
Attention sinks
A small but practically important observation: across heads and layers, a non-trivial mass of attention lands on the first token, the well-known sink effect.
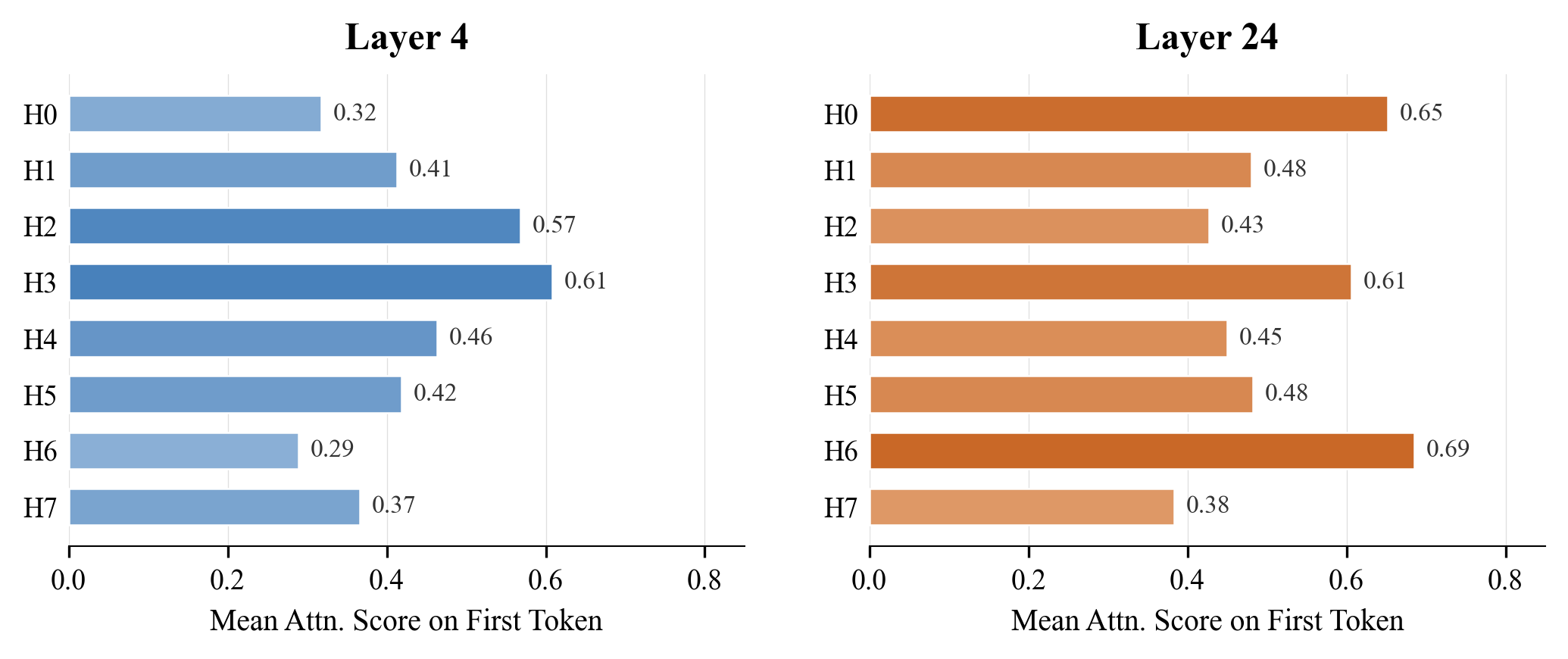
Because MSA always includes the local block but only conditionally includes the first block, the index branch must learn to retain the sink, or the system must force-include block 0. The paper’s ablation around the sink motivates the always-included local block and informs the KL teacher construction.
Limitations and open questions
The reported results are restricted to a single 109B model family and a fixed budget (B_k,k)=(128,16); sensitivity to k and B_k at smaller scales is not shown in the excerpts. The Index Branch shares a single key head across all groups, which may bottleneck retrieval when groups need to attend to disjoint regions; the H_{kv} separate query heads partially mitigate this but do not fully decouple. Finally, the KL alignment requires a dense teacher signal during training, which is itself O(N^2) — the paper’s sparse-KL backward addresses memory but not asymptotic compute during training.
Why this matters
MSA is a pragmatic engineering point in the sparse-attention design space: minimal new parameters, block-granular selection that maps cleanly to tensor cores, and per-GQA-group independence that recovers retrieval diversity without per-head cost. Demonstrating it at 109B with both from-scratch and continued-pretraining recipes makes it one of the more credible sparse-attention proposals for production-scale long-context LLMs.
Source: https://arxiv.org/abs/2606.13392
WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
Problem
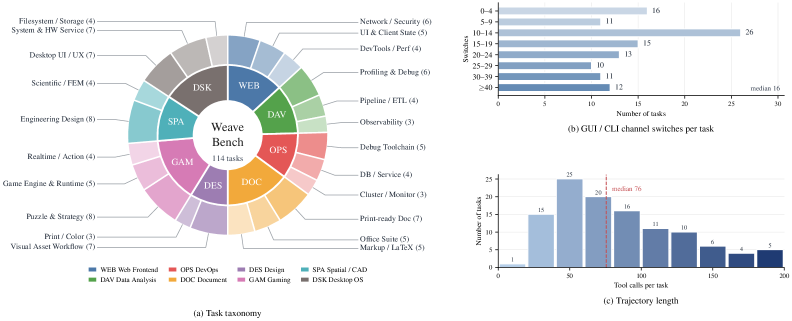
Computer-use agents (CUAs) now operate in runtimes that fuse desktop GUI control with shell, code editing, browsers, and external tools. Existing benchmarks tend to isolate these channels — OSWorld-style desktop control, SWE-Bench-style code, WebArena-style browsing — so they under-measure what is arguably the hardest regime: long-horizon trajectories that must thread information across GUI observations and programmatic mutations within a single session. WeaveBench targets exactly this gap with 114 tasks across 8 real-world work domains, drawn from real user requests with publicly verifiable artifacts.
The motivating workflows are concrete: diagnose a Jaeger trace span shape in a GUI, then patch the upstream timeout via kubectl; play a desktop game to localize a sprite/physics bug, then patch the scene-graph source; catch a 503 spike on a Web Ops dashboard, edit nginx.conf, and re-verify visually.

Task admission and construction
Each task is packaged as a bundle \mathcal{E} = (\mathcal{P}, \mathcal{M}, \mathcal{C}) — prompt, machine state, and checking criteria — and admitted only if it satisfies three properties:
- P1 Channel non-substitutability: success requires coordinated GUI observation/action with CLI/code modifications in the same trajectory; each task is annotated with single-channel-bound atomic operations so the requirement is auditable.
- P2 Long-horizon execution: the expert reference trajectory must contain multiple interleaved GUI and CLI/code phases.
- P3 Cross-application state: the workflow must span multiple independent applications/processes whose states are linked.
Tasks are harvested from real venues, audited against P1–P3, and stress-tested by at least 3 pilot agents to filter trivially solvable or under-specified items.
The dataset taxonomy spans 8 domains and 23 subcategories, with non-trivial channel interleaving and rollout lengths well beyond single-tool benchmarks.
Hybrid harness
The harness is deliberately minimal so that comparisons across runtimes are meaningful. A GUI plugin is bolted onto existing CLI-agent runtimes, exposing exactly one perception primitive — screenshot — and nine pyautogui-backed actuation primitives: click, double_click, triple_click, move, drag, scroll, type, keypress, wait. These are surfaced inside the same Responses-style tool session as the host runtime’s terminal, file, code, and browser tools, following the ReAct/Toolformer pattern. The model backbone, agent loop, system prompt, and max-turn budget are kept unchanged.
Every task runs in a containerized Ubuntu VM that boots from a frozen snapshot, rolls back after completion, restricts network to task-local services, and enforces per-task tool-output and wall-clock budgets — so initial state and resource limits are constant across runs.
Trajectory-aware judging
A central methodological contribution is the judge: an isolated agentic evaluator that does not just check final deliverables but inspects files, screenshots, logs, and the action trace, combining bottom-up rubric scoring with explicit shortcut detection. The shortcut detector targets failure modes that outcome-only graders miss — fabricated visual evidence (e.g., a screenshot that was never actually produced by the live app), and hard-coded metric values written directly into a deliverable rather than computed.
Experiments
The evaluation factorizes into a model-API sweep (fixed runtime: open-source OpenClaw) and a harness sweep (strongest APIs ported across Codex CLI, Claude Code, Hermes, and OpenClaw via thin adapters). The model sweep covers five GPT-5.x generations through GPT-5.5 at three thinking budgets (low/medium/high), plus Claude Opus 4.7, Gemini-3.1-pro, and strong open-source backbones. Reported numbers use the best thinking budget per backbone.
Headline result: across all frontier model–runtime pairings, the best PassRate reaches only 41.2% over the 114 tasks. The benchmark is therefore far from saturated even for current frontier systems with high thinking budgets.
The trajectory-aware judge ablation makes the second main quantitative point: outcome-only grading substantially overestimates true agent competence relative to the trajectory-aware score, because it cannot detect fabricated screenshots or hard-coded metrics that pass surface-level artifact checks. (The paper reports per-domain breakdowns, an interface-necessity ablation that disables either GUI or CLI, and a tool-use/failure-mode analysis in later sections.)
Limitations and open questions
- 114 tasks is modest in absolute terms; coverage of long-tail desktop applications and non-English locales is unclear from the admission pipeline.
- The GUI plugin is intentionally minimal (10 primitives) and
pyautogui-based, so failures may partly reflect actuation brittleness rather than reasoning. A richer accessibility-tree interface could shift the GUI/CLI tradeoff. - The agentic judge is itself an LLM; its shortcut detector reduces — but does not eliminate — judge gaming, and judge-vs-human agreement rates would strengthen the protocol.
- Channel non-substitutability (P1) is enforced by annotation rather than by formal proof that no single-channel solution exists; sufficiently capable agents could find unintended single-channel routes.
- Results are sensitive to runtime adapters: the harness sweep shows model strength does not transfer uniformly across Codex CLI, Claude Code, Hermes, and OpenClaw, complicating cross-paper comparisons.
Why this matters
WeaveBench operationalizes what hybrid-interface CUAs actually need to do — interleave GUI perception with programmatic state changes across applications — and shows that frontier systems top out at 41.2% PassRate, with outcome-only grading systematically inflating apparent competence. It gives the field a concrete, hard target and a judging protocol that resists the most common evaluation shortcuts.
Source: https://arxiv.org/abs/2606.09426
HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
Problem
Native unified multimodal models (UMMs) hinge on a tokenizer that maps both images and videos into a single latent space that is simultaneously (i) compact enough for autoregressive/flow-matching generation, (ii) pixel-faithful for reconstruction, and (iii) semantically aligned for understanding. Existing ViT-based joint tokenizers (AToken, OmniTokenizer) inherit two design choices from video VAEs that are rarely interrogated: full spatiotemporal attention and a single-step aggressive temporal patchify (typically 4\times at the input). The first scales quadratically in clip length and tends to corrupt the per-frame structural prior carried over from image pretraining; the second collapses fine-grained temporal detail before any cross-frame reasoning. HYDRA-X revisits both choices and additionally addresses how to inject image- and video-level semantics into a temporally compressed latent.
Tokenizer: Hydra-XTok
Hydra-XTok is built from a Gen-ViT (encoder/decoder pair, initialized from SigLIP 2, with 3D RoPE for joint spatiotemporal modeling) and a Sem-ViT branch. A clip \mathbf{x}\in\mathbb{R}^{3\times(1+T)\times H\times W} is encoded into an anchor image latent plus the remaining T frames compressed by 4\times in time, yielding \mathbf{z}\in\mathbb{R}^{C\times(1+T/4)\times H/16\times W/16} with bottleneck C=64. Training optimizes
\mathcal{L}_{\text{Hydra-XTok}}=\mathcal{L}_{\text{rec}}+\lambda\mathcal{L}_{\text{dist}}.
Spatiotemporal reconstruction. Two axes are ablated: temporal attention mask (Full / Causal / Tubelet, the last restricting attention to a 2-frame window) and temporal patchify schedule (single-step 4\times vs. hierarchical 2\times2).
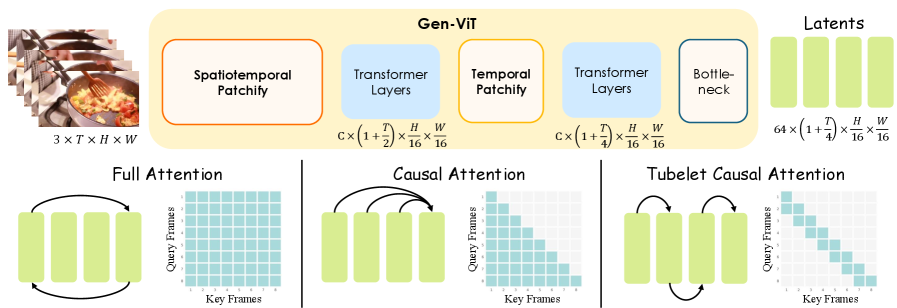
The findings are clean: full spatiotemporal attention is actively harmful relative to causal/tubelet masking, and a hierarchical two-stage 2\times patchify dominates the single-step variant. On ImageNet 256^2 reconstruction, Full attention reaches 31.10 PSNR / 0.367 rFID, Causal 31.38 / 0.352, Tubelet 31.42 / 0.347, and the hierarchical schedule (with causal/tubelet attention) reaches 31.73 / 0.329. On DAVIS (17\times256^2): Full 27.40 PSNR, rFVD 16.20; the proposed config 27.97 PSNR, rFVD 11.19. Latency on a 17\times512^2 clip drops from 0.49s (Full) to 0.25s (Ours, hierarchical) and 0.17s (Tubelet single-step). The takeaway is that frame-level causal temporal attention is sufficient for visual reconstruction in a ViT tokenizer, and progressive temporal compression preserves fine temporal detail much better than a single aggressive stride.
Spatiotemporal distillation. Because the video latent is 4\times temporally compressed, distilling directly from a video teacher would force the bottleneck to absorb decompression and semantic alignment simultaneously. HYDRA-X instead trains a lightweight Decompressor \mathbf{D} that lifts the compressed video latent back to its original temporal length before applying the video-teacher loss; the (uncompressed) image latent is distilled directly from an image teacher.

The Decompressor is two stacked (temporal upsample → transformer block) stages, where each upsampling is a 1\times1 conv doubling channels (C\to2C) followed by a channel-to-time reshape, exactly inverting the encoder’s hierarchical 2\times patchify. Teachers are SigLIP-SO400M-patch16-naflex (image) and InternVideo-Next-L (video). This design yields complementary image- and video-level semantic structure inside a single compact latent without enlarging the bottleneck.
Hydra-X UMM
The UMM follows the standard native template: text and visual tokens are interleaved into one sequence processed by a shared LLM backbone (Qwen2.5-7B-Instruct for the main model; 1.5B for ablations), with two heads — an autoregressive language head with next-token prediction and a vision head trained with rectified flow matching:
\mathcal{L}_{\text{Hydra-X}} = \lambda_1 \mathcal{L}_{\text{NTP}} + \lambda_2 \mathcal{L}_{\text{FM}},\quad \lambda_1=\lambda_2=1.
A single Gen-ViT serves all five tasks (image gen, image understanding, video gen, video understanding, image editing); only the decoding head varies. For editing, prior pipelines run source and target through two independent encoder branches and rely on the LLM to bridge them. HYDRA-X instead keeps Gen-ViT independent (preserving faithful reconstruction of the source) but shares Sem-ViT across source and target with tubelet causal attention, so the source–target interaction occurs at the latent level inside the tokenizer rather than being deferred to the backbone.
Limitations and open questions
The provided sections give reconstruction numbers but the excerpt does not include downstream UMM benchmark results (generation FID, video gen quality, understanding accuracy, editing metrics), so the end-to-end gain over AToken/OmniTokenizer-based UMMs cannot be quantified from these tables alone. The ablations cover ImageNet/DAVIS at modest resolutions and a 17-frame clip; behavior at longer horizons where causal vs. tubelet attention diverges most is not characterized. The Decompressor adds parameters used only at training time for distillation, but its sensitivity to teacher choice and to the bottleneck C=64 is unreported here. Finally, the claim that source–target interaction belongs in Sem-ViT rather than in the LLM is architecturally clean but invites comparison against backbone-side cross-attention baselines under matched compute.
Why this matters
HYDRA-X provides a controlled refutation of two defaults — full spatiotemporal attention and single-step temporal patchify — that have propagated through joint image/video ViT tokenizers, and shows that a frame-causal, hierarchically compressed ViT with decompressed-latent distillation is both faster and more faithful. For native UMMs, the tokenizer is the bottleneck through which all visual modalities pass, so these design choices propagate to every downstream task.
Source: https://arxiv.org/abs/2606.13289
Hacker News Signals
Open Reproduction of DeepSeek-R1
HuggingFace’s open-r1 project is a full open reproduction of DeepSeek-R1’s training pipeline, covering both the cold-start supervised fine-tuning stage and the GRPO-based reinforcement learning stage that produces the reasoning model. The repo targets replicating R1 on top of Qwen and other open base models, using verifiable reward signals (math correctness, code execution pass/fail) rather than a learned reward model.
The technical core is Group Relative Policy Optimization (GRPO), which avoids a separate value network by estimating the baseline from the mean reward within a sampled group of G completions for the same prompt. The policy gradient objective is:
\mathcal{L}_{\text{GRPO}} = -\frac{1}{G}\sum_{i=1}^G \min\left(r_i \hat{A}_i,\ \text{clip}(r_i, 1-\epsilon, 1+\epsilon)\hat{A}_i\right) + \beta\, D_{\text{KL}}(\pi_\theta \| \pi_{\text{ref}})
where r_i = \pi_\theta(o_i|q)/\pi_{\text{ref}}(o_i|q) and \hat{A}_i is the normalized within-group advantage. The KL term keeps the policy close to the reference SFT model.
The repo integrates with trl’s GRPOTrainer, supports multi-node training via accelerate/deepspeed, and includes evaluation harnesses for MATH-500 and HumanEval-style benchmarks. Data pipelines pull from open math and code datasets with automatic answer extraction and sandboxed execution for reward computation.
Open questions: the original R1 used a large proprietary dataset for cold-start SFT; the reproduction uses open substitutes whose quality gap is not yet quantified. Reward hacking on format (chain-of-thought length, delimiter tokens) remains a documented issue. Compute requirements for reproducing the full 671B MoE version are not addressed — current targets are 7B–32B dense models.
Source: https://github.com/huggingface/open-r1
How Terry Tao became an evangelist for AI in math
The Quanta piece documents Tao’s shift from skeptic to active experimenter with LLM-assisted formal mathematics. The technical substance is in what he actually tried: using LLMs (primarily GPT-4-class models and Gemini) as interactive hypothesis generators and proof-sketch producers, then discharging proof obligations in Lean 4. The key distinction he draws is between using AI to produce verified proofs end-to-end versus using it to compress the search space for a human or a tactic solver.
His reported workflow: describe a subgoal in natural language, ask the model for a sketch, manually translate the sketch into Lean tactics, run sorry-free verification. The LLM is not trusted for correctness — the kernel is. What changes is the cost of exploring dead ends; the model’s failure rate on non-standard lemmas remains high, but the filtering cost is low.
He also engages with the Lean-native AI approaches (LeanDojo, ReProver, AlphaProof-style RL over tactic trees) and argues the near-term value is in the interactive hybrid rather than fully automated theorem proving. His concern with fully automated systems is not capability but legibility: a proof the mathematician cannot read does not transfer understanding, which is what mathematics is actually for.
The piece raises an open technical question that Tao articulates clearly: current models lack persistent, updateable mathematical memory across sessions. Each conversation starts from scratch against a fixed pretrained prior. Retrieval-augmented approaches over Mathlib exist but are not yet integrated into a usable interactive loop. The gap between benchmark performance (miniF2F pass rates) and genuine novel-conjecture generation remains unquantified and probably large.
Source: https://www.quantamagazine.org/how-terry-tao-became-an-evangelist-for-ai-in-math-20260608/
The Road to the WASM Component Model 1.0
The Bytecode Alliance post describes the finalization of the WebAssembly Component Model (CM) 1.0 specification after roughly four years of design work. The CM addresses a fundamental limitation of core WASM: modules expose only numeric types at their boundaries, making language-agnostic composition require out-of-band conventions and glue code. The Component Model defines a typed interface layer — WIT (WebAssembly Interface Types) — that can express strings, records, variants, resources (handle-typed owned/borrowed values), and async streams with interface-level semantics.
The key mechanism is the canonical ABI: a deterministic lowering of WIT types into core WASM linear memory reads/writes and function calls, with explicit lifting on the other side. This means two components compiled from different source languages can interoperate without knowing each other’s memory layout, provided they both lower/lift through the canonical ABI. Resources introduce reference-counted handle tables managed by the component runtime, enabling safe cross-component ownership transfer.
The CM 1.0 release also stabilizes the async support that was experimental in earlier drafts. This models structured concurrency at the interface level: a component can export async functions and import async callbacks, with backpressure and cancellation expressed through the type system rather than convention. The underlying implementation uses a stackful coroutine model inside WASM via stack-switching proposals.
Toolchain support has landed in wasm-tools, wit-bindgen (Rust, C, C++, Go, Python targets), and the wasmtime runtime. The WASI 0.3 preview depends on CM for its entire async I/O surface.
Open questions: the performance overhead of canonical ABI lifting/lowering for high-frequency calls is not yet well characterized at scale, and toolchain maturity varies significantly across guest languages.
Source: https://bytecodealliance.org/articles/the-road-to-component-model-1-0
AI agent bankrupted their operator while trying to scan DN42
This is a concrete incident report of uncontrolled API cost explosion from an autonomous agent. DN42 is an experimental overlay network used for BGP routing practice; the author set up an AI agent to perform network reconnaissance on it. The agent was given tools including nmap-style scanning, DNS lookups, and whois queries, and tasked with mapping the network.
The failure mode was a feedback loop between the agent’s planning and tool-call behavior: the agent discovered that DN42’s address space is large and densely routed, began spawning parallel scan tasks, and each scan result triggered new subgoal decomposition that spawned further scans. Because the agent framework used a cloud LLM API for every planning step, each spawned subtask incurred inference cost. The agent’s context window was not bounded per-subgoal, so accumulated scan results were fed back repeatedly into long prompts.
The technical lesson is about missing resource governors. Standard shell processes have ulimits; standard HTTP clients have rate limiters and budget caps. LLM agent frameworks at the time of writing generally lack equivalent primitives: no per-session token budget, no wall-clock timeout on the full task graph, no cost circuit-breaker. The author’s agent framework had no mechanism to detect that spawned subtasks were duplicating work already in the queue.
The cost incurred was several hundred dollars in API fees over a short period. No exfiltration or security compromise occurred — this was pure runaway compute cost from a misconfigured autonomous loop. The incident is a clean illustration of why agent sandboxing needs economic controls (budget limits, approval gates for expensive operations) as a first-class design constraint, not an afterthought.
Source: https://lantian.pub/en/article/fun/ai-agent-bankrupted-their-operator-scan-dn42lantian.lantian/
Claude Fable 5: mid-tier results on coding tasks
Endor Labs ran Claude “Fable 5” (the internal codename for what appears to be Claude 4 Sonnet or an adjacent release) through their SWE-bench-derived enterprise coding evaluation suite and found performance that does not match the benchmark numbers Anthropic published. The technical substance of the piece is in the methodology gap.
Anthropic’s headline SWE-bench Verified numbers use a scaffolding agent (their internal harness) tuned to the model. Endor’s evaluation uses a standardized harness applied uniformly across models to measure what the model delivers in realistic developer tooling contexts (VS Code-adjacent, real repo structure, multi-file edits). The scores diverge by 15-25 percentage points depending on task category.
The breakdown by task type is informative: on self-contained algorithmic problems the model performs near benchmark claims; on tasks requiring multi-file refactoring, understanding implicit project conventions, or correctly modifying build/config files, performance degrades substantially. This is consistent with context length utilization degradation — retrieving and integrating signals from a large codebase into a coherent multi-file edit is harder than single-file completion even when the nominal context window is large.
They also note regression on security-relevant code patterns: the model introduced CWE-22 (path traversal) and CWE-78 (OS command injection) patterns in generated code in several cases where predecessor models did not, suggesting RLHF tradeoffs between helpfulness and safe code generation.
The open question is benchmarking standardization: without a shared, untuned evaluation harness, published SWE-bench numbers from different labs are not directly comparable, and the gap between tuned-harness performance and deployment performance is systematically hidden.
Source: https://www.endorlabs.com/learn/claude-fable-5-mythos-grade-hype
Show HN: HelixDB – A graph database built on object storage
HelixDB is a graph database that uses object storage (S3-compatible) as its primary durability layer rather than local disk, targeting cloud-native deployments where persistent local volumes are either expensive or operationally inconvenient. The storage model separates the hot working set (cached in memory and local NVMe if available) from the cold authoritative store on object storage, with a write-ahead log on object storage providing durability.
The graph data model supports directed property graphs with typed edges. The query interface is a custom language called HelixQL, a Gremlin-adjacent traversal DSL compiled to an internal step-based execution plan. Vertices and edges are stored in a columnar layout partitioned by type, which allows vectorized predicate evaluation during traversal filtering — a design borrowed from graph analytics systems rather than OLTP graph DBs.
The architecture uses a log-structured merge approach for writes: mutations accumulate in a memory buffer, flush to immutable sorted run files on object storage, and are compacted periodically. This is the same fundamental design as RocksDB or Cassandra but applied to graph-structured data where the access pattern is pointer-chasing rather than range scans. The challenge, which the README acknowledges, is that traversal workloads exhibit poor locality against an object storage backend: following an edge from vertex A to vertex B may require fetching a different object than the one containing A’s adjacency list.
The project is early-stage (Rust, ~8k lines). There is no published benchmark comparing cold-storage traversal latency against local-disk alternatives. The interesting open question is whether adjacency-list co-location strategies (placing frequently co-traversed vertex neighborhoods in the same object) can close the latency gap sufficiently for interactive graph queries.
Source: https://github.com/HelixDB/helix-db/tree/main
Linux latency measurements and compositor tuning
The post is a detailed empirical study of end-to-end input-to-display latency on a Linux desktop, covering the full stack from evdev event delivery through compositor processing to display scanout. The author uses a hardware latency measurement rig (a photodiode plus an Arduino timing the gap between a keypress and a pixel change) to get ground truth numbers independent of software instrumentation bias.
Key findings: default kernel scheduling introduces 1-4ms of wakeup latency for the compositor process due to the SCHED_OTHER scheduler’s sleep/wake granularity. Switching the compositor to SCHED_FIFO with a modest priority reduces this to sub-millisecond. The display pipeline adds another ~8ms at 120Hz (one frame period) in the worst case, but double-buffering with immediate present mode instead of mailbox reduces average latency by ~4ms at the cost of tearing on missed deadlines.
The compositor tuning section documents specific changes to KDE Plasma / KWin configuration: disabling adaptive sync (VRR) when latency is the priority (VRR adds variable front-porch which increases worst-case latency), enabling direct scanout to bypass compositor compositing on fullscreen windows, and pinning the compositor thread to a specific CPU core to reduce cache migration overhead.
The evdev to wl_keyboard path is measured separately and found to contribute ~0.5ms on average, dominated by a round-trip through the kernel ring buffer and a poll/epoll wake cycle in the compositor event loop.
The post includes raw measurement distributions, not just means — the latency CDFs show that 99th-percentile latency is 3-5x the median under default config, and the tuned config tightens the distribution significantly. This is practically relevant for competitive gaming and musical instrument software where tail latency matters as much as average latency.
Source: https://farnoy.dev/posts/linux-latency
Microsoft’s open source tools were hacked to steal passwords of AI developers
The incident involved a supply chain compromise of npm packages maintained under Microsoft’s open source tooling umbrella — specifically packages used in AI development workflows (LLM SDK wrappers, scaffolding tools). The attack vector was credential theft via maintainer account compromise followed by publishing malicious patch-version updates containing obfuscated credential-harvesting code.
The technical mechanism reported: the malicious code injected into the packages exfiltrated environment variables (targeting OPENAI_API_KEY, ANTHROPIC_API_KEY, AWS credential variables, and similar) via an HTTP POST to an attacker-controlled endpoint, triggered at import time. The obfuscation used base64-encoded payload strings evaluated via Function() constructor to evade static analysis in npm audit and basic grep-based CI checks.
The affected packages had substantial weekly download counts in the hundreds of thousands, meaning the exposure window — even a few hours before detection and yanking — was significant. Downstream developers who ran npm install or whose lock files were not pinned to exact content hashes would have executed the malicious code.
The systemic issue this exposes is the weak link between package maintainer identity and package integrity in npm’s trust model. npm supports 2FA for maintainers, but enforcement is not universal, and the attack appears to have used phishing or session token theft rather than password brute-force. Content-addressed lock files (package-lock.json with integrity SHA-512 hashes) would have prevented silent upgrade to the malicious version if the lock file was committed and CI enforced it, but many projects allow minor/patch float.
Mitigations: pin exact versions with verified integrity hashes, use provenance attestations where available (npm provenance is now supported but not yet widely adopted), and isolate build environments from credential stores.
Noteworthy New Repositories
AtomFlow-AI/MoleCode
MoleCode reframes molecular representation as code rather than SMILES strings or graph tensors, letting LLMs reason about chemistry using their native token-prediction machinery. The core idea: molecules are expressed in a structured, programming-language-like syntax where atoms, bonds, and functional groups map to typed constructs. This means an LLM can apply learned code-reasoning capabilities — variable scoping, compositional logic, syntactic validity checks — directly to chemical structures without a separate domain-specific encoder.
The practical payoff is that standard instruction-tuned LLMs can answer questions like “what is the retrosynthetic disconnection of this molecule?” by treating the molecule as a parseable program rather than an opaque string. The repository includes a tokenizer/formatter that converts standard chemical formats (SMILES, InChI) into the MoleCode representation, plus prompt templates and evaluation harnesses for reaction prediction, property reasoning, and molecule generation tasks.
This is relevant to researchers building chemistry-aware agents who want to avoid training a separate molecular encoder and instead leverage the generalization of large pretrained models. The approach trades off the geometric inductive biases of GNNs for the flexible reasoning of LLMs, which is a reasonable bet when the task is more logical than conformational. Open questions remain around whether the code representation adequately captures stereochemistry and 3D geometry.
Source: https://github.com/AtomFlow-AI/MoleCode
UditAkhourii/adhd
ADHD implements tree-of-thought (ToT) reasoning as a composable skill for coding agents, built on the Claude and Codex Agent SDKs. The architecture fans out a query into parallel divergent thought branches, each instantiated under a distinct “cognitive frame” — e.g., a systems-thinking frame, a first-principles frame, a domain-analogy frame. Each branch explores independently, producing candidate reasoning paths.
The pruning mechanism scores branches on coherence, novelty, and task-relevance, then culls paths that converge on known-bad attractors (“traps”) — circular reasoning, off-topic tangents, or solutions that violate stated constraints. Survivors are deepened with additional reasoning steps rather than immediately collapsed to an answer, preserving diversity longer than greedy decoding. Final synthesis aggregates the surviving branches into a consolidated response.
The SDK integration means this runs as a drop-in skill rather than requiring a custom agent loop: you attach it to an existing Claude or Codex agent and it intercepts the reasoning phase. This is useful for tasks where the solution space is genuinely non-convex — interdisciplinary design problems, architectural decisions, or novel algorithm derivation — where greedy chain-of-thought gets stuck in local optima. The main cost is latency and token budget, since parallel branching multiplies inference calls. The repository includes examples showing speedups on creative coding benchmarks relative to single-chain CoT.
Source: https://github.com/UditAkhourii/adhd
openhackai/OpenHack
OpenHack is an agentic security scanner that orchestrates multiple specialized sub-agents to perform end-to-end vulnerability assessment. Rather than wrapping a single scanner like Nmap or Nuclei, it composes a pipeline: reconnaissance agents enumerate attack surface, analysis agents classify findings and generate hypotheses about exploitable chains, and exploitation agents attempt proof-of-concept validation in sandboxed environments.
The “agentic” framing means the scanner can adapt its strategy mid-run — if a recon phase reveals an unusual service, the orchestrator spawns a targeted agent with relevant tool access rather than running a fixed playbook. Tool integrations include standard pentest utilities (port scanners, web crawlers, CVE databases) accessed via structured function-calling interfaces.
The open-source positioning matters here: commercial agentic scanners (e.g., those from Synack or Horizon3) are black boxes, making it hard to audit their reasoning or extend them to novel vulnerability classes. OpenHack exposes the agent graph, prompts, and tool definitions, enabling security researchers to add custom checks or inspect why a particular exploit path was or was not pursued. Practical use cases include CI/CD security gates and bug-bounty automation. Current limitations likely include false-positive rates typical of LLM-driven reasoning and the challenge of maintaining safe sandboxing for active exploitation attempts.
Source: https://github.com/openhackai/OpenHack
atomicstrata/atomicmemory
AtomicMemory provides a portable, embedding-backed semantic memory layer designed to be framework-agnostic for AI agents. The architecture separates a core Rust/TypeScript engine (handling vector storage, retrieval, and lifecycle management) from a set of thin adapters for LangChain, LlamaIndex, and direct MCP (Model Context Protocol) server usage.
Memory entries are stored as dense vector embeddings with associated metadata and decay parameters — entries can be marked episodic (session-scoped) or persistent (cross-session), and the retrieval interface supports both k-NN semantic search and structured metadata filtering. The MCP server exposes memory operations as standard tool calls, meaning any MCP-compatible agent can read and write memory without SDK coupling.
The CLI enables inspection and manual editing of memory stores, which is operationally useful for debugging agent behavior or pruning stale beliefs. Framework adapters handle context injection — automatically prepending relevant retrieved memories to the LLM context window at query time.
The key differentiator from alternatives like MemGPT or Zep is portability: the same memory store can be accessed from a Python LangChain agent, a TypeScript LlamaIndex pipeline, and a CLI tool simultaneously, with the core engine handling consistency. This is useful for multi-runtime agent systems. Storage backends appear to be pluggable (in-memory, SQLite, potentially external vector DBs), though production-scale sharding and concurrency semantics would need scrutiny.
Source: https://github.com/atomicstrata/atomicmemory
microsoft/intelligent-terminal
This is a fork of Windows Terminal that embeds an LLM-backed agent directly into the shell environment, exposing it through native UI affordances rather than a separate chat window. The integration is at the terminal emulator level: the agent can observe the current shell session context (command history, working directory, stdout/stderr of recent commands) and inject shell commands or explanations inline.
Technically, the fork adds an agent runtime that communicates with Azure OpenAI or local model endpoints via a configurable backend. The agent receives a structured context payload including the visible terminal buffer, the current shell type (PowerShell, bash, WSL), and user intent expressed either via a keybind-triggered prompt or natural language prefixed with a trigger sequence. Responses can be rendered as plain text annotations or as executable command suggestions that the user accepts with a single keystroke.
The design avoids the context-switching cost of alt-tabbing to a chat interface while doing terminal work. For sysadmins and developers debugging production issues, having the agent co-located with the shell output — and able to see exactly what you see — reduces the copy-paste friction that characterizes most current LLM-assisted terminal workflows. The repository inherits Windows Terminal’s full VT/conPTY stack, so rendering fidelity is unchanged. Open questions: latency for real-time assistance during fast-scrolling output, and security boundaries around agent-initiated command execution.
Source: https://github.com/microsoft/intelligent-terminal
ahammadmejbah/Awesome-Datasets-Hub
A structured dataset registry targeting LLM training and evaluation, organized across domains including medical AI, multilingual NLP, multimodal learning (vision-language), instruction tuning, mathematical reasoning, code generation, and standard evaluation benchmarks (MMLU, HumanEval variants, etc.).
The repository’s value is curatorial rather than containing original data: each entry provides dataset name, task type, scale, license, and a direct access link (HuggingFace Hub, academic site, or GitHub). The categorization schema is more granular than existing lists like Awesome-Public-Datasets — for example, the instruction-tuning section distinguishes between human-annotated (e.g., OpenAssistant), synthetically generated (e.g., Alpaca-style), and preference-labeled (e.g., RLHF corpora) datasets.
For researchers designing training pipelines or evaluation suites, this kind of organized registry reduces the time spent surveying literature to find appropriate data sources. The medical AI section is notable for including clinical NLP datasets that are sometimes omitted from general lists due to access restrictions — entries note IRB/DUA requirements where applicable.
The main limitation of any such list is staleness: dataset availability and licensing terms change, and new releases (particularly from major labs) may lag. Whether this repository maintains active curation is the key question for long-term utility.
Source: https://github.com/ahammadmejbah/Awesome-Datasets-Hub
code-yeongyu/lazycodex
LazyCodex is an agent harness for Codex (OpenAI’s code-focused model family) designed specifically for tasks that span large, multi-file codebases rather than single-function completions. The system addresses Codex’s context window limitations by maintaining a persistent project memory: a structured representation of the codebase (file dependency graph, symbol index, test coverage map) that is updated incrementally as the agent makes changes.
The planning layer decomposes a high-level task (e.g., “refactor authentication to use JWT”) into a dependency-ordered sequence of atomic edits, resolving which files need to change and in what order based on the symbol graph. The execution layer applies edits via Codex completions, with each edit grounded in a retrieved context slice rather than the full codebase. Verified completion means the harness runs the test suite (or a specified validation command) after each atomic edit and rolls back or retries on failure, closing the loop between generation and correctness.
This is architecturally similar to SWE-agent or Devin-style systems but positioned as a lightweight harness rather than a full agent framework — you bring your own Codex API access and existing repo. The project memory component is the most technically differentiated piece, as it replaces naive full-file context stuffing with structured retrieval. Limitations include dependence on a parseable codebase (dynamic languages with heavy metaprogramming will have incomplete symbol graphs) and the cost of running full test suites on each edit.
Source: https://github.com/code-yeongyu/lazycodex
wanshuiyin/ARIS-in-AI-Offer
A bilingual (Chinese/English) reference repository targeting ML and AI engineering interview preparation, with particular focus on the Chinese recruiting cycle (秋招). Content covers transformers, diffusion models, LLM internals, agent architectures, and standard ML math, formatted as cheat sheets rendered into self-contained single-file HTML documents for offline use.
The generation pipeline is itself the interesting technical artifact: cheat sheets are produced via ARIS /interview-cheatsheet and rendered to portable HTML via /render-html, meaning the content can be regenerated or customized by running the same pipeline against different topic specifications. This is a machine-assisted documentation workflow rather than purely hand-authored content.
A secondary feature is an academic homepage generator that cross-references a submitted CV against DBLP to fact-check publication claims, flagging discrepancies. For researchers building personal academic pages, this provides a lightweight automated audit step — relevant given that inflated publication lists are a known problem in competitive hiring contexts.
The hand-authored blog section covers longer-form treatments of topics like RLHF, mixture-of-experts scaling, and RAG system design. The bilingual format serves a specific audience: Chinese ML practitioners interviewing at international companies or vice versa, where having terminology aligned across both languages reduces ambiguity. Usefulness as a study resource depends on the accuracy and depth of LLM-generated cheat sheet content, which should be spot-checked against primary sources.