Daily AI Digest — 2026-06-03
arXiv ハイライト
マルチドメインRLにおけるクロスドメイン干渉と回復のための局所摂動理論
問題設定
単一ドメイン(数学・コード・QA・創作文章)に対するLLMのRLポストトレーニングは、そのドメインの性能を安定して向上させる一方で、他のドメインを劣化させます。標準的な説明である破滅的忘却や大域的なgradient競合は、観測された干渉パターンを予測できません。クロスドメインのgradientはモデル全体のレベルではほぼ直交しているにもかかわらず、依然として実質的な干渉が生じるためです。本論文は、干渉がパラメータ空間のどこに実際に存在するのか、なぜ一様ではなく選択的に生じるのか、そして損傷を受けたドメインに対する短いリフレッシュがなぜ他のドメインを損なうことなくそれを回復できるのかを問います。実験設定は、Qwen3-4B-Thinking-2507をMath(OpenR1)、Code(KlearReasoner-CodeSub-15K)、QA(SuperGPQA)、CW(Crownelius)の順に逐次トレーニングしたものです。
構造的診断
著者らは、joint trainingにおいてドメインgradient間のステップごとのcosine similarity \cos(\bm{g}_{d_i},\bm{g}_{d_j}) を計算します。Math–QAの値はゼロ付近に留まっているにもかかわらず、QAおよびCWトレーニング後にMathの性能は依然として崩壊します。gradientを層およびモジュールごとに分解すると、不均質な局所構造が明らかになります。すなわち、一部のattention/MLPモジュールでは強い競合が、別のモジュールでは強い相乗効果が存在しており、平均化によって隠蔽されていたのです。
さらに重要な観察が2つあります。第一に、単一ドメインのRLはスパースで小さな大きさのパラメータ編集を生じさせます。各ドメインのexpertは少数の重みに触れており、ドメイン間でtop変化ニューロンの重複は小さいです。第二に、ニューロンの重複が弱いにもかかわらず、ドメインは活性計算ルートを共有しています。つまり、複数ドメインの入力に対して同じニューロンが発火します。そこで決定的な量は、これらの共有ルートに沿った編集の方向的整合性となります。
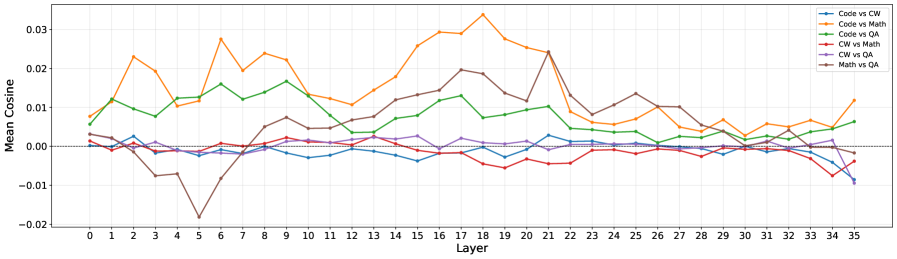
図4は、共有top変化ニューロン上で方向cosineが層をまたいで符号が変化すること、すなわちある層では相乗的、別の層では拮抗的であることを示しており、干渉がルートレベルかつ方向依存の現象であり、大域的なものではないことを確認しています。
局所摂動理論
L_d(\bm{\theta}) をドメイン d に対する局所RL目的関数、\bm{g}_d をそのgradient、\bm{H}_d をHessianとします。A について checkpoint \bm{\theta}_A^* までトレーニングし、次に B についてトレーニングして更新量 \bm{\delta}_B を得ます。干渉は次のように表されます。
\Delta_{A\leftarrow B} = L_A(\bm{\theta}_A^* + \bm{\delta}_B) - L_A(\bm{\theta}_A^*).
- 近似的な定常性 \bm{g}_A(\bm{\theta}_A^*)\approx 0、(ii) スパースな局所更新 \bm{\delta}_B、(iii) \bm{\delta}_B の曲率感応成分が低次元の共有活性競合部分空間 S_{A,B} に集中、という仮定のもとでTaylor展開を行うと、
\Delta_{A\leftarrow B} \approx \tfrac{1}{2}\,\bm{\delta}_B^\top \bm{H}_A(\bm{\theta}_A^*)\,\bm{\delta}_B
が得られます。定常性により一次項は消え、線形gradient競合の描像は誤ったオーダーであることになります。損傷は二次の二次形式であり、仮定(iii)により、共有ルートが曲率を担う低次元部分空間 S_{A,B} 上で \tfrac{1}{2}\,\bm{\delta}_{B,S}^\top \bm{H}_{A,S}\,\bm{\delta}_{B,S} として集中することが示唆されます。
リフレッシュについては、S_{A,B} に制限された \bm{H}_A が正定値であり、直交補空間が S_{A,B} に弱くしか結合しないとします。そのとき L_A 上の短いgradientステップは、S_{A,B} に沿った有害な成分を収縮させる一方、共有部分空間の外にあるニューロン、すなわち他のドメインの特化を担うニューロンへの更新にはほとんど触れません。これにより、(a) 後続ドメインによる選択的損傷、(b) 短いリフレッシュによる選択的かつ高速な回復、(c) 中間ドメインへの限定的な副作用が予測されます。
実験的検証
逐次パイプラインはMath → Code → QA → CWであり、単一ドメインのexpertをアンカーとして使用します。Code後のcheckpoint \mathrm{Math}_o でのMathスコアは66.49であり、単一ドメインのMath expertの66.84とほぼ一致します。QAおよびCWステージ後、MathはCode、QA、CWが安定を保つ中で57.66まで低下します。これは理論が要請する選択的干渉そのものです。
\mathrm{CW}_o からの短いMathリフレッシュ(\mathrm{Re\text{-}Math} と表記)はMathを57.66から66.04まで引き上げ、損失のほぼ全てを回復し、\mathrm{Math}_o(66.49)および単一ドメインのMath expert(66.84)の両方に近づきます。重要なことに、CodeはわずかにQAおよびCWはほぼ不変のまま51.05まで上昇します。\mathrm{Re\text{-}Math} は4ドメインにわたる最良の平均66.39を達成し、mixed-trainingのベースラインを上回ります。
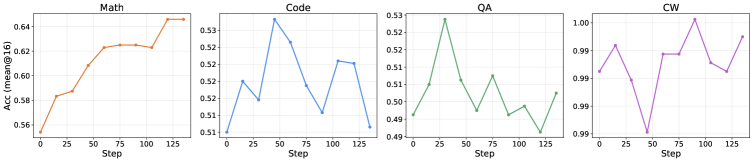
図9はその軌跡を示しています。Mathのvalidationは少数のリフレッシュステップ以内に急激に上昇し、QAおよびCWの曲線は平坦なまま維持されます。これは S_{A,B} に閉じ込められた収縮と整合しています。図10の非対称なRe-Code実験では、別のペアで同じパターンが示されています。\mathrm{Math}_o からの短いCodeリフレッシュはCodeを回復し、Mathの劣化はほぼ無視できる程度であり、共有部分空間上の収縮メカニズムが特定のドメイン順序に依存しないことを支持しています。
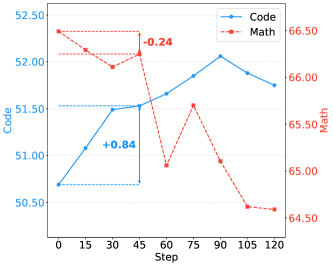
本論文はまた、Math→QAペアにおける S_{A,B} の座標プロキシ上での直接的な重み空間ロールバックも報告しており、二次損傷の説明に対する非gradientの因果的テストを提供しています。
限界
この理論は、証明されるのではなく経験的に確認される仮定に依存しています。\bm{\theta}_A^* における定常性は近似的にすぎず、S_{A,B} はプロキシ(top変化ニューロンの重複)を通じて識別され、S_{A,B} とその補空間との間の弱結合条件は主張されるのみで大域的には測定されていません。全ての実験は単一の4Bベースモデルを使用しており、スパースルートの描像がより大規模なスケール、より長いRLのhorizon、あるいは強くoff-policyな更新のもとで成立するかどうかは未解決です。「短いリフレッシュ」の体制も定量化されておらず、収縮の描像が崩れてフルな再トレーニングのdynamicsが再開するステップ予算の特性評価がありません。
意義
この結果は、マルチドメインRL干渉を一次gradient競合問題から低次元共有部分空間上の二次曲率問題として再定式化し、安価で原則的な解決策を提示しています。すなわち、完全なmixed trainingやreplay bufferではなく、短く的を絞ったリフレッシュです。スパース共有ルート構造が一般化するならば、LLMの継続的なRLポストトレーニングパイプラインは、単一ドメインステージの列に短い修正リフレッシュを組み合わせた形で、予測可能な選択性をもって構成できるようになります。
Source: https://arxiv.org/abs/2606.02398
分散型 Instruction Tuning:競合認識型分割と重みのマージ
異種タスクの混合に対する instruction tuning は、二つの連動した問題に悩まされています。競合するタスク間の gradient 干渉と、密結合クラスタ上での大規模なマルチモーダルモデルの同期に要する帯域コストです。MERIT は、混合データの互いに素な部分を独立に学習し、パラメータ空間で一度だけ統合することで、ステップごとの all-reduce を単一のオフラインマージに置き換えることにより、両問題を解決できるかどうかを問うています。
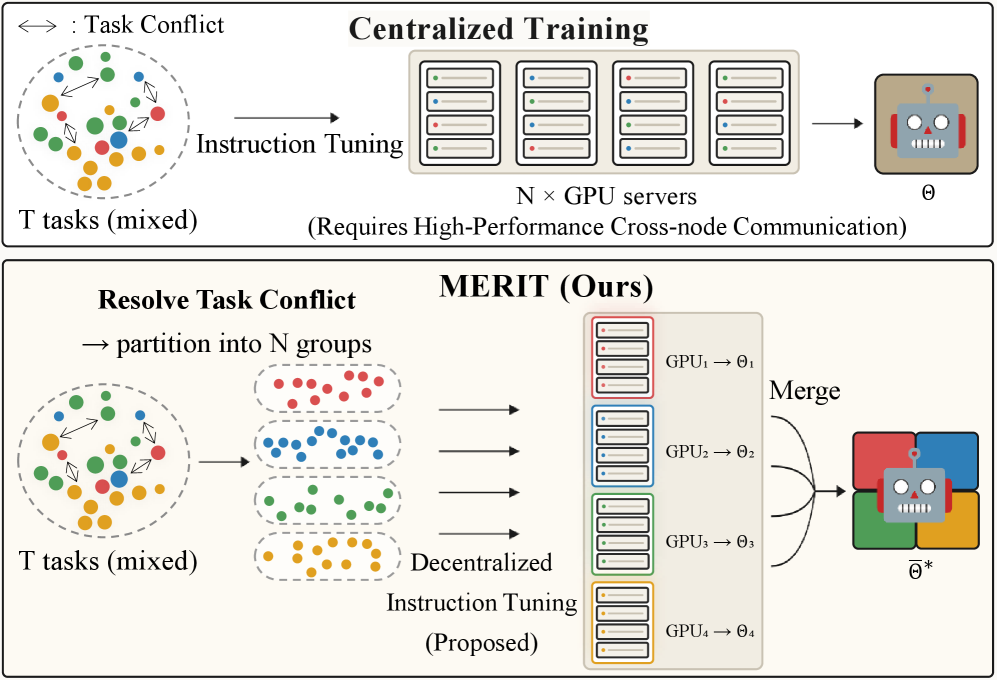
共有フラットなバジンにおける局所二次理論
この解析は「マージ可能」な初期値 \theta^{(0)} を前提とします。これは、独立に fine-tuning されたモデルが連結された低損失領域に留まるチェックポイントです。著者らはこれを LLaVA Stage 2 に類似したバジン準備ステージによって実現しています。Figure 2 は、準備前の起伏のある損失曲面と、準備後のフラットで連結された領域を対比しており、後者が本論文の残りの部分における動作領域となります。
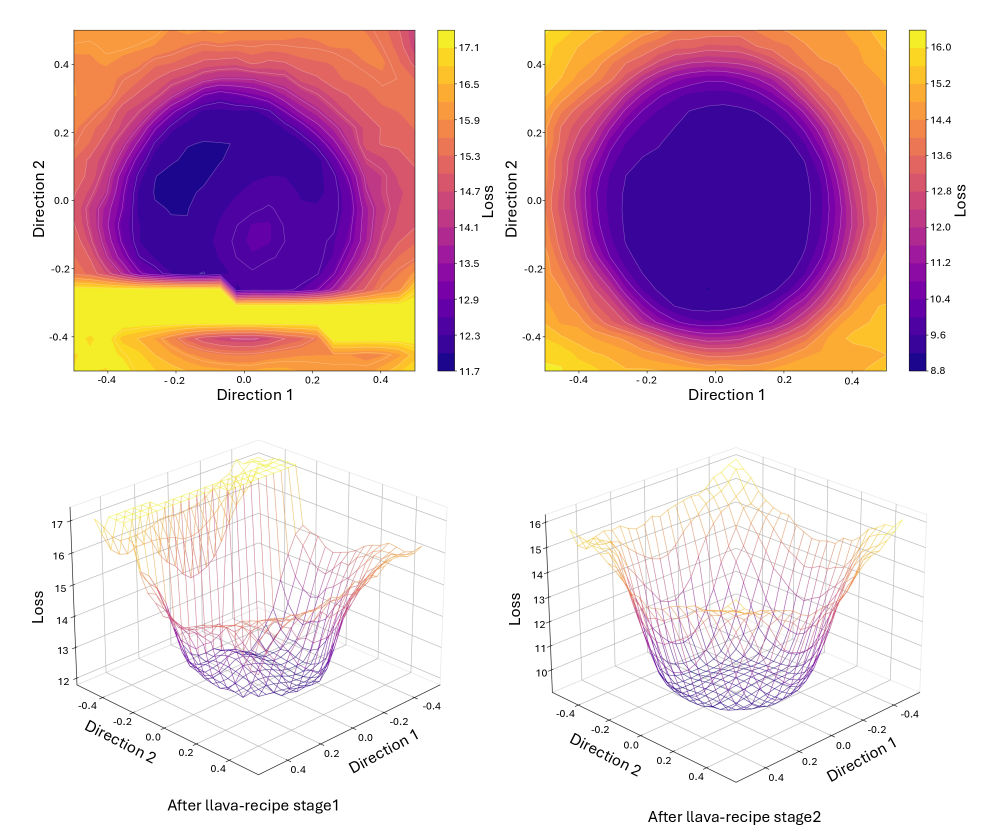
このバジン内で、局所 Hessian H=\nabla^2 L(\theta^\star)\succeq 0 を持つ基準点 \theta^\star を固定し、K 個の独立に fine-tuning されたチェックポイントに対して \delta_i = \theta_i - \theta^\star とします。マージされたモデルは \bar\theta_w = \sum_i w_i \theta_i、\sum_i w_i = 1 です。二次近似のもとで、
L(\bar\theta_w) \;\approx\; \sum_i w_i L(\theta_i) \;-\; \tfrac{1}{2}\,\mathcal{G}_{\mathrm{var}},\qquad \mathcal{G}_{\mathrm{var}} \;=\; \sum_i w_i \delta_i^\top H \delta_i \;-\; \bar\delta_w^\top H \bar\delta_w,
ここで \bar\delta_w = \sum_i w_i \delta_i です。Jensen の不等式により、\mathcal{G}_{\mathrm{var}} \geq 0 が成り立ちます。つまり、二次モデルにおいてマージは分岐損失の加重平均より悪化することはありません。この利得は変位の曲率加重分散であり、分岐が H の高曲率方向に沿って正確に不一致である場合にのみ大きくなります。
これにより三つの実用的な帰結が得られます。
- 曲率加重分散の削減。 マージによって、H を通して投影された \delta_i の分散が得られます。バジンのフラットな方向に沿って異なる分岐は何も貢献しません。
- PCA アラインされた競合分割が最適。 分割がサンプルを H(またはそのプロキシであるデータセットレベルの gradient 共分散)の上位固有ベクトルに沿ってグループ間の変位が集中するように配分すれば、\mathcal{G}_{\mathrm{var}} は最大化されます。ランダムな分割は分散を等方的に広げてこの利得を失います。この優位性は先行固有値と後続固有値の曲率ギャップとともにスケールします。
- スペクトルフィルタリング / 暗黙的なノルム正則化。 平均化は高分散方向に対するローパスフィルタとして機能し、典型的な \|\theta_i - \theta^\star\| に比べて \|\bar\theta_w - \theta^\star\| を縮小させ、分散削減の利得に加えて暗黙的な正則化を提供します。
MERIT のパイプライン
MERIT の五つのステージが理論を機械的に実現します。
- データセットレベルの gradient 競合推定。 \theta^{(0)}(またはキャリブレーションチェックポイント)におけるデータセットごとの gradient シグネチャを計算し、競合行列を構成します。
- PCA 分解。 競合構造の上位 r 固有ベクトルが干渉が最大となる軸を定義します。
- K = 2^r グループへの均衡分割。 上位 r 軸への射影の符号によって、トークンバランス制約のもとでグループ分けします。これは「高曲率競合方向に沿って分割する」という離散的な実現です。
- 通信不要な分岐学習。 各パーティションを \theta^{(0)} から独立に fine-tuning します。分岐間の同期は不要です。
- トークン加重マージ。 \bar\theta = \sum_i (n_i / \sum_j n_j)\,\theta_i(n_i はパーティション i のトークン数)。
結果
136 の Vision-FLAN タスクを用いた Qwen2.5-VL-3B において、MERIT は 8 ベンチマーク平均を集中型ジョイント学習の 54.3 から 57.0 へ +2.7 ポイント向上させ、K\in\{2,4,8\} でのランダム分割および均一 model soup をも上回ります。このレシピはスケールします。176 ソースの 1.6M サンプル混合を持つ 7B の VLM において、MERIT は LLaVA スタイルのベースモデルでのジョイント FFT 平均を 54.9 から 55.4 へ改善します。集計値はリバランスの実態を過小評価しており、MMVet(ユーザー嗜好と流暢性)が +2.6、MathVista(画像推論)が +2.5 改善され、ジョイント FFT が引き起こすオープンエンド生成の劣化を回復する一方、テキストリッチな VQA では約 1.5 ポイントのコストが生じます。三つのシードにわたり、MERIT はすべての実行でジョイント FFT を 8 ベンチマーク平均において上回ります。
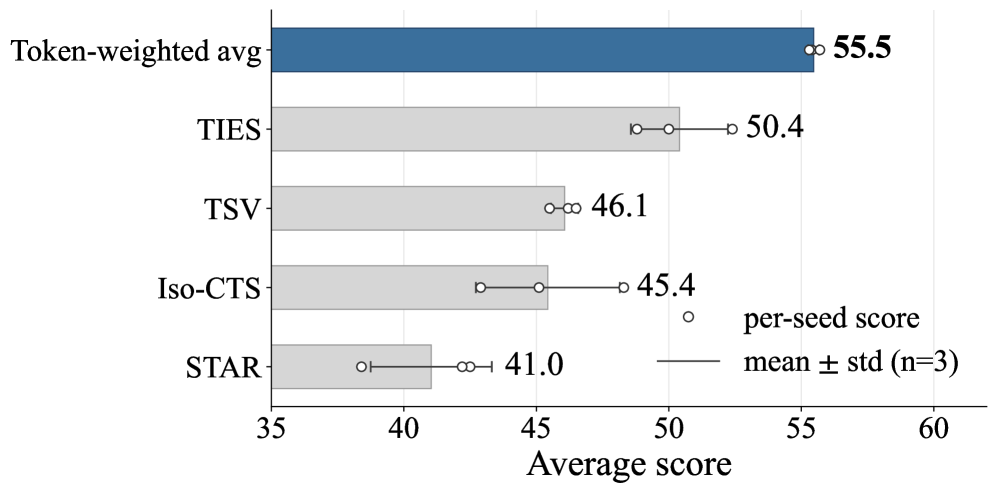
マージ演算子のアブレーション(Figure 3)では、四つの学習済み分岐を固定したまま最終集約ステップを入れ替えています。トークン加重平均は、三つのシードにわたる 8 ベンチマーク平均において TIES、DARE、task-arithmetic、および uniform soup を上回ります。これは理論と整合しています。二次モデルのもとでは、\mathcal{G}_{\mathrm{var}} に対する最適な w は分岐ごとの曲率に依存し、トークン数はその曲率をスケールする分岐ごとの有効サンプルサイズの合理的なプロキシです。
限界と未解決の問題
保証は局所的です。すべてはバジン仮定に依拠しており、バジン準備ステージが経験的にこれを実現しますが、任意の混合に対して保証されているわけではありません。競合推定器はデータセットレベル(サンプルごとではない)の gradient と単一のキャリブレーション点を使用しているため、fine-tuning の後半で現れる競合構造を見落とす可能性があります。パーティション数 K=2^r は固定的であり、gradient 共分散に対する PCA は Hessian のプロキシであって、小さい学習率の fine-tuning 以外での有効性は不明確です。最後に、トークン加重平均はテスト済みの演算子の中では経験的に最適とされていますが、理論は曲率加重の重みを予測しており、H を考慮した w_i の推定量によってさらなる利得が得られる可能性があります。
なぜこれが重要か
MERIT は、準備されたフラットなバジン内での instruction tuning において、競合認識型データ分割と単一のパラメータ空間マージが、ベンチマーク平均を改善しながら同期型ジョイント学習を置き換えられることを示しています。これにより、instruction tuning の計算がクラスタトポロジーから切り離され、マージが悪化ではなく改善をもたらすと期待できる、曲率に基づいた原理的な根拠が与えられます。
Source: https://arxiv.org/abs/2606.01717
活性化から因果関係へ:ヒト脳における因果的視覚表現の発見
問題
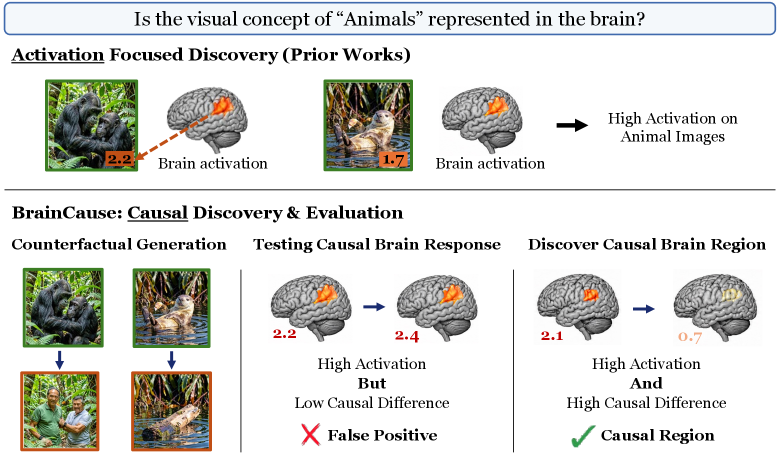
皮質における概念選択的領域――顔領域、場所領域、身体領域――の局在化は、伝統的に活性化最大化に依拠してきました。すなわち、概念 C の画像に対するボクセルの応答がコントラストセットに対する応答を上回る場合、そのボクセルは C を表現していると判定されます。しかしこの手法には交絡の問題があります。サーフィン画像に強く応答する「サーフィン」ボクセルは、実際には水、体のポーズ、あるいは人の存在――サーフィンと共起するがその概念そのものではない特徴――をエンコードしているかもしれません。刺激への介入なしには、活性化のみでは表現されている変数とその相関物を切り分けることができません。
手法
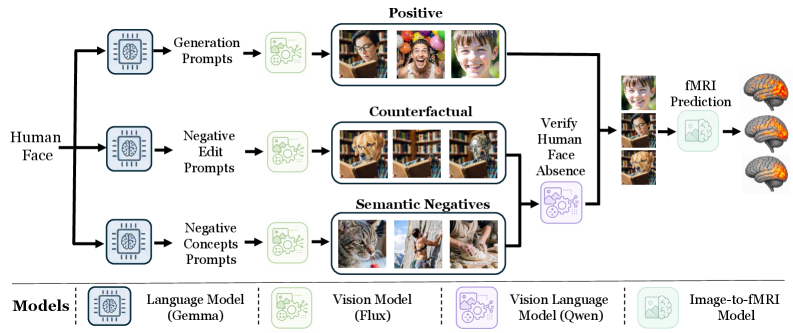
BrainCauseは、生成モデルとimage-to-fMRI encoderを組み合わせ、候補ボクセル集合に対して標的を絞った因果検定を実施する自動化パイプラインです。入力は、概念クエリとある被験者の画像–fMRIデータセット(ここではNSD、被験者あたり約4万皮質ボクセル)です。パイプラインは3つの段階から構成されます。
(1) 因果データセットの生成。 各ターゲット概念に対して、LLM(Gemma-3-27B-IT)が多様なプロンプトを生成し、FLUX.2が以下を合成します:
- 概念の positive 画像:学習用200枚+held-out用100枚。
- Semantic negatives:LLMがターゲットと相関するが含意しない10個の対概念を提案します(「surfingをしている人」に対して「釣りをする男性」「ビーチ」「波」など)。各対概念につき10個のプロンプトをターゲットが画像に現れないよう明示的に指示して生成し、VLM(Qwen3-VL-8B)でターゲットの不在をフィルタリングします。分割あたり約80〜100件のsemantic negativeが得られます。
- Counterfactual negatives:各positive画像に対して、LLMが概念を除去しつつ残りを保持する最小限の編集を10個提案します(例:人の顔を動物の顔に置き換える)。FLUX.2がその編集を実行します。
fMRIの実測値がない画像については、image-to-fMRI encoderに通して予測応答を得ます。
(2) 概念選択的表現の探索。 各ボクセルに対して、活性化スコア(positive画像への平均応答)と、positiveをsemantic negativeおよびcounterfactual編集と対比させた因果スコアの両方が付与されます。候補領域は、統合スコア上位 k ボクセル(デフォルト k=100)です。活性化最大化との差別化は因果寄与にあります。「サーフィン」に応答するボクセルが「波」や、サーファーをcounterfactualに除去したビーチシーンにも同様に応答する場合、そのボクセルは重み付けが低下します。
(3) 検証。 候補集合は、held-outの予測fMRIおよびマッチするトライアルが存在する場合は実測fMRIで評価されます。実測のエビデンスが不十分な場合、BrainCauseはどのコントラストが欠けているかを示し、追加スキャンのための特定の刺激を提案します。
結果
全7Tセッションを完了した4名のNSD被験者を対象に、LLMが提案した260概念(定量的には上位50概念を報告)にわたって評価しました。比較手法は、Max Activation、MindSimulator(同じ encoderを用いてCLIPで検索したCOCO画像)、MindSimulator+VLM(同じフィルタリングを適用)、およびBrainCauseです。
| 手法 | Act. (Gen) | Act. (Meas) | Causal (Gen) | Causal (Meas) | Edits |
|---|---|---|---|---|---|
| Max Activation | 2.76 | 0.70 | 0.08 | 0.18 | 0.44 |
| MindSimulator | 1.89 | 1.02 | -0.44 | 0.27 | 0.23 |
| MindSimulator+VLM | 2.13 | 1.12 | -0.26 | 0.41 | 0.38 |
| BrainCause | 2.05 | 1.08 | 0.62 | 0.71 | 0.98 |
BrainCauseは生成画像に対する活性化スコアをわずかに犠牲にしますが(2.05対Max Activationの2.76)、実測fMRIにおける因果スコアを0.18から0.71へ、counterfactual編集スコアを0.44から0.98へと改善します。MindSimulatorの負の因果スコア(生成画像では−0.44)は、その検索画像で特定された領域が実際にはpositiveよりもsemantic negativeに対して強く応答することを示しており、相関駆動型の発見における具体的な失敗モードです。
健全性の確認として、BrainCauseが発見した領域は既知の機能的組織化と一致しています。上位100ボクセルが期待されるカテゴリ選択的皮質内に収まる精度は、99%(身体)、90%(顔)、74%(場所)、99%(文字)であり、上位500まで拡張しても97/84/74/97%と緩やかに低下するにとどまります。

「Text」の例は示唆に富んでいます。counterfactual編集では看板上のテキストを形状や塗り潰しに置き換えつつ看板の形状と背景を保持し、semantic negativeにはスケッチ(視覚的に類似するがテキストを含まない)が含まれます。BrainCauseのテキスト領域は両方に対して急激な応答低下を示し、看板形状の平坦な表面への選択性ではなく、因果的なテキスト選択性を支持します。
限界と未解決の問題
- 因果的主張の妥当性はencoderの性能に依存します。image-to-fMRIモデル自体は自然画像で学習されており、FLUX.2の合成出力やdistributionから外れたcounterfactual編集画像に対する応答を忠実に予測できない可能性があります。編集画像に対するencoderの系統的なバイアスは、見かけ上の「因果的」ギャップとして伝播します。
- 「最小限の編集」という仮定は強制されません。画像編集モデルはターゲット概念を超えて低レベルの統計量を日常的に変化させるため、選択性を過小または過大評価する可能性があります。
- Semantic negativeに対するVLMベースのフィルタリングは、ある種のブラックボックス判断を別のものに置き換えているにすぎません。VLMが微妙なターゲットの存在を見逃すといった失敗モードは、negative集合を直接汚染します。
- 報告された数値はすべて4被験者・上位50概念のNSDに基づいており、概念の選択とランキングは相互に影響します。より困難で抽象的な概念(例:「因果性」「所有」)に対するフレームワークの挙動は特性化されていません。
- 真の介入にはcounterfactual刺激をスキャナー内で提示する必要があります。本論文は追加実験のデザインを提案していますが、実測fMRIにおける現在の因果評価は、合成コントラストとたまたまマッチするトライアルに限定されます。
なぜこれが重要か
ヒト視覚皮質における既報の「概念領域」のほとんどは、相関した特徴による説明を排除できない活性化コントラストによって同定されています。BrainCauseはこれが仮想上の懸念ではないことを示しています。既報の「サーフィン」領域はcounterfactual検定に失敗します。生成的counterfactualとencoding modelを組み合わせることで、システム神経科学は欠けている介入実験に対してスケーラブルな代替手段を得られます。そして表現の発見は、応答量によるランキングではなく因果推定として再定式化されます。
Source: https://arxiv.org/abs/2605.23895
Trust Region On-Policy Distillation
長い推論を行うLLMに対するon-policy distillation(OPD)は、構造的にはpolicy-gradientの問題です。すなわち、studentが軌跡 x\sim\pi_S をサンプリングし、教師の対数確率によって報酬を受け取り、reverse-KL gradientは
\nabla D_{\mathrm{KL}}(\pi_S\|\pi_T) = \mathbb{E}_{x\sim\pi_S}\big[\nabla \log\pi_S(x)\cdot \log\tfrac{\pi_S(x)}{\pi_T(x)}\big]
で与えられます。長いコンテキストの状況では、全語彙に対するdivergenceの計算はコストが高すぎるため、実務ではサンプリングされた各トークンにおいてトークンレベルの K_1 推定量 \log \pi_T/\pi_S を使用します。本論文が対象とする問題は、studentがteacherのサポートから外れた場合に、稀なstudentトークンに対して \log\pi_T(x_t\mid x_{<t}) が極めて負の値になり、分散が大きく、ときに破壊的なgradientが生じることです。TrOPDはOPDをtrust-regionの問題として再定式化します。すなわち、teacherのシグナルが信頼できるトークンのみを更新に使用し、それ以外のトークンは別の推定量で処理します。
セットアップとナイーブな変種の失敗
Section 3では、全体を通じて使用される2つのメモリ効率の良い目的関数を定義しています。一つはtop-k FKL、
\mathcal{J}_{\mathrm{FKL}}^{\mathrm{top}\text{-}k} = \sum_{v\in\mathcal{V}^T_k}\pi_{T,v}\log\frac{\pi_{T,v}}{\pi_{S,v}},
もう一つはサンプリングされたトークンに対する K_1 RKLです。混合分布 \pi_M=\beta\pi_T+(1-\beta)\pi_S を用いた一般化されたJSDがこの二者を補間します(Eq. 4)。Skywork-OR1-Math-7BからDeepSeek-Qwen2.5-1.5BをdistillしたTable 1では、単独のtop-k FKLが学習を崩壊させることが示されています(AIME24/25は0.00に、AMC23は4.21に低下)。これはtop-k FKLが全語彙FKLのバイアスのかかった近似であり、そのバイアスがサンプリングされたすべてのトークンに適用されるためです。素のRKL-OPDはAIME24/25とAMC23にわたって平均46.79を達成し、\beta=0.5のJSDはわずかに改善して47.90になります。エントロピーで閾値を設けたOPD(エントロピーが高いトークン上位20%のみを更新)は効果がありません(46.13)。
外れ値推定を伴うtrust region
主要なメカニズムは、studentが生成したトークンを、トークンごとの比率 R = \log \pi_T/\pi_S(あるいは等価な重要度重み)に基づいて、trust region \mathbb{M} と外れ値 \overline{\mathbb{M}} に分割することです。trust region内では標準的なRKL/K_1 gradientを使用し、その外ではRKLをteacherの分布に対するtop-k FKLで置き換えます:
\mathcal{J}_{\mathrm{TrOPD}} = \mathbb{M}\,\log\frac{\pi_T}{\pi_S} \;+\; \overline{\mathbb{M}}\sum_{v\in\mathcal{V}^T_k}\pi_{T,v}\log\frac{\pi_{T,v}}{\pi_{S,v}}.
直観的な説明:studentがteacherにとって極めてあり得ないトークンを訪問した場合、K_1 gradientは信頼できません(大きな負の報酬、高い分散)。そこでtop-k FKLに切り替えることで、studentのものではなくteacher自身の確率質量を使ってstudentをteacherの局所モードに引き寄せ、単独のtop-k FKLを破壊させたバイアス増幅の経路を回避します。
Table 1でこれを個別に検証しています。「Mask Outlier」(外れ値に対するRKL gradientをゼロにする)は47.72、「Clip Outlier」(\max(\log\pi_T/\pi_S,\tau)による)は47.86、「FKL Outlier」(上記のTrOPD置換)は49.00を達成します。off-policy guidanceブランチを追加することで、最終的なTrOPDは49.85に達します。
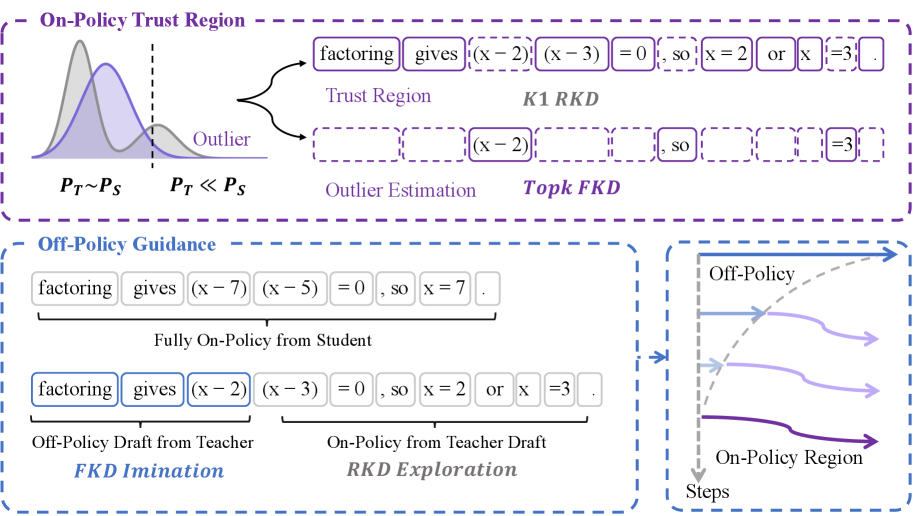
Teacherプレフィックスによるoff-policy guidance
2つ目の貢献は、補完的なoff-policy項です。studentはteacherが生成したプレフィックスから生成を継続し、それらの続きに対してtop-k FKLで学習します。プレフィックスによってstudentがteacherの頻出状態の近くに置かれるため、top-k FKLはそこでは壊滅的なバイアスを持たず、この項は純粋なmode-seeking RKLが無視するteacherモードに向けた探索を明示的に促進します。Figure 2はアーキテクチャを明確に示しています。on-policyトークンは別々の推定量を持つtrust/外れ値セットに分割され、一方で独立したoff-policyブランチがteacherプレフィックスの続きを処理します。
実験結果
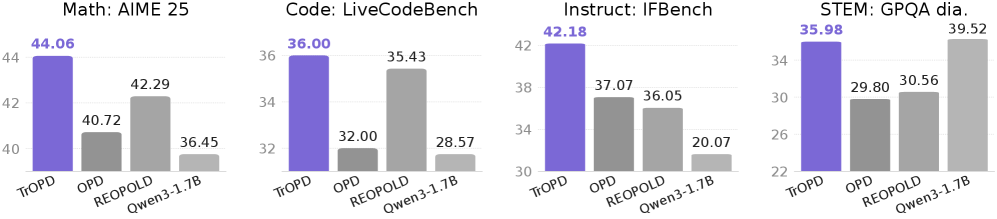
単一ドメインdistillation(Skywork-OR1-Math-7B → DeepSeek-R1-Distill-Qwen-1.5B、Table 3):TrOPDはAIME24/25、AMC23、LiveCodeBench v6、GPQA-diamondにわたって平均40.63を達成し、バニラOPDの37.11、EOPDの38.00、REOPOLDの38.79を上回ります。teacherは58.48、ベースは34.69です。注目すべき個別タスクの数値:AIME25は32.50(OPD 29.16)、GPQA-diamondは36.24(OPD 28.03 — OPDはここでベースの34.22を下回る退行を示すのに対し、TrOPDは改善します)。
同じstudent(Skywork-OR1-7B teacher)を用いたマルチドメインdistillationでは、OPDの不安定性がより顕著に現れます。バニラOPDの平均は32.99と34.69のベースを下回りますが、TrOPDは37.61まで回復します(REOPOLD 35.58)。Qwen3-Nemotron-4BからdistillしたQwen3-SFT-1.7B(Table 4)では、TrOPDはmath/STEM/instruct/codeにわたって平均51.73を達成し、OPDの48.29やREOPOLDの48.56を上回ります。最大の改善はAIME24(52.08対48.02)とIFBench(42.18対37.07)で見られます。teacherは73.43に達しており、依然として大きな改善の余地が残っています。
限界と未解決の問題
R に対するtrust-regionの閾値はハイパーパラメータであり、本論文はその感度や適応スケジュールを特性化していません。実際には、初期化時点での \pi_S と \pi_T の乖離の大きさとの相互作用があると考えられます。teacher分布に対するtop-k 打ち切りはFKL外れ値項をバイアスさせます。Table 1でのMask Outlierに対するTrOPDの改善(49.00対47.72)は、外れ値がトークンの少数派である場合にのみバイアスが許容できることを示唆しており、student–teacherのギャップが拡大するにつれて外れ値セットが増大し、この仮定は弱くなります。off-policy guidanceブランチはon-policyの改善に対して独立してablationされていないコンピュート上の問題(teacherのrolloutおよびstudentの続き)を提起しています。最後に、すべての実験はtop-k トークンに質量の大部分が集中する推論系teacherを使用しており、より平坦な分布(創造的生成、対話)での挙動は未検証です。
重要性
TrOPDは、K_1 RKL推定量の具体的な失敗モードを特定して修正します。この失敗モードは、特にバニラOPDがSFTベースラインを下回る可能性のあるマルチドメイン設定において、長い推論モデルに対するOPDの価値を隠蔽してきました。トークンごとのteacherの信頼性をtrust-regionの条件として扱い、FKLを外れ値のフォールバックとして使用するアプローチは、既存のOPDパイプラインにシームレスに統合できるシンプルな手法です。
Source: https://arxiv.org/abs/2606.01249
Humanoid-GPT: ゼロショット動作追跡のためのデータとアーキテクチャのスケーリング
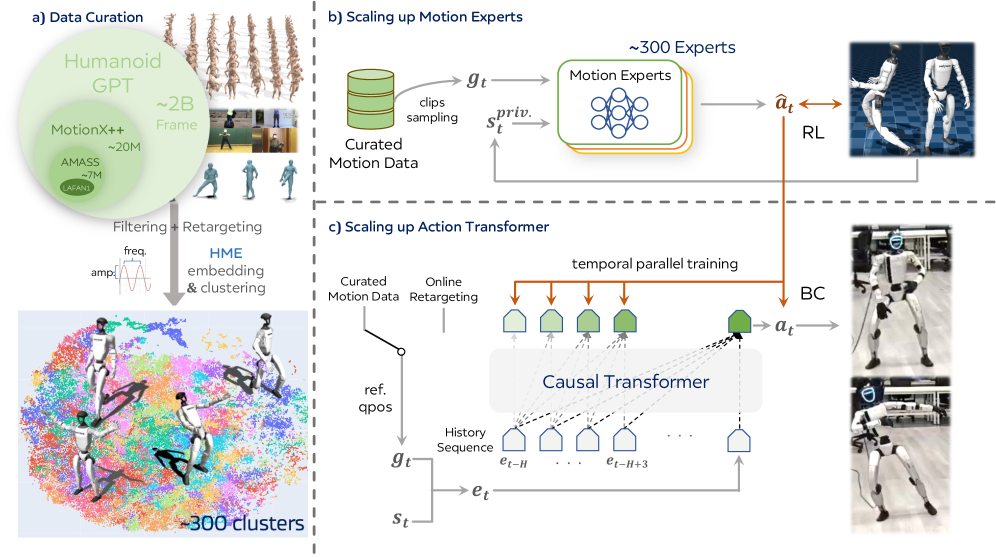
ヒューマノイドにおける全身動作追跡は、分布ごとに学習された浅いMLP policyが主流であり、アジリティと汎化のトレードオフが広く知られています。すなわち、アクロバティックなクリップを精密に追跡するpolicyは過学習し、幅広く学習されたpolicyは動的忠実度を失います。Humanoid-GPTは、これが根本的な限界ではなく、データと容量のボトルネックであると主張しています。著者らは2Bフレームのリターゲット済み動作コーパスを構築し、PPO expertのライブラリを学習し、それらを因果的なTransformerに蒸留することで、タスクごとのfine-tuningなしに29-DoFのUnitree G1上で任意のオンラインリターゲット動作を追跡します。
データパイプライン
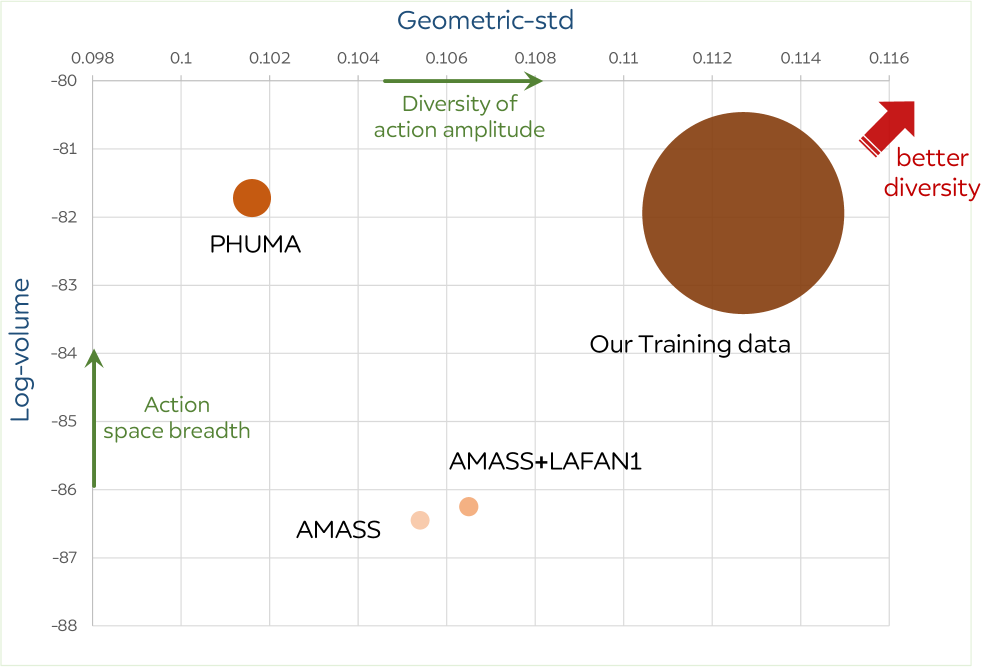
コーパスはAMASS、LAFAN1、MotionMillion、PHUMAおよび自社mocapデータを統合しています。シーケンスは既製のリターゲッターを用いてG1の29-DoF関節空間にリターゲットされ、オブジェクトインタラクション(着座、水泳、階段昇降)を含むクリップは通常シーンのアクチュエーションと非互換なためフィルタリングされます。均一な速度の時間ワーピング拡張(加速・減速)によりデータセットは約5倍に拡張されます。多様性はHME embedding空間において2つの軸——一般化標準偏差(gstd)と対数体積——で定量化され、統合コーパスはどちらの指標においても単一ソースを上回っています。
2段階学習
Stage 1ではコーパスをクラスタに分割し、クラスタごとにPPO expertを学習します。Policy \pi : \mathcal{G} \times \mathcal{S} \mapsto \mathcal{A} は参照関節目標 g_t = q_t^{\text{ref}} と特権的なpropriocepion s_t^{priv}(関節位置・速度、ルート角速度、重力投影、直前のaction)を入力とし、PD制御によりトルクに変換されるper-joint actionを出力します。報酬は集合 \mathcal{K}(腕、腰、足、骨盤)上のキーポイントレベルで定義されます:
R_{\text{kpt}}(t) = R_{\text{pos}}(t) + R_{\text{rot}}(t) + R_{\text{vel}}(t) + R_{\text{penal}}(t),
指数関数的なshapingにより
R_{\text{pos}}(t) = \sum_{k\in\mathcal{K}} w_k \exp(-\alpha_{\text{pos}} \|e^{\text{pos}}_{k,t}\|_1),
SO(3) log-map回転誤差 \theta_{k,t} および速度残差 e^{\text{vel}}_{k,t} に対しても同様の項が設定されています。R_{\text{penal}} は自己接触およびactionの滑らかさに関する項を含みます。ルート姿勢、速度、安定継続時間の閾値を通過したexpertのみが保持されます。
Stage 2では、生き残ったexpertたちをparallel DAggerにより単一の因果的なGPTスタイルのTransformerに蒸留します。各expertは独自のシミュレータ上でロールアウトし、studentは集積された状態-actionペアで学習されます。studentは因果的かつ履歴条件付きであるため、単一のMLP expertでは捉えられない長期的なダイナミクスを習得できます。
スケーリングとアーキテクチャの結果
主要な実験では学習tokenとモデル容量の両方を変化させ、保留した動作に対してMuJoCo上で成功率(SR)、MPJPE、MPJVE、ルート速度誤差、MPKPEを評価しています。
| Backbone | Tokens | Params | SR ↑ | MPJPE ↓ | MPKPE ↓ |
|---|---|---|---|---|---|
| MLP-3 | 2M | 0.25M | 76.89 | 0.1191 | 100.49 |
| TCN-8 | 2M | 0.65M | 81.48 | 0.0885 | 79.75 |
| GPT-S | 2M | 5.7M | 83.26 | 0.0853 | 62.65 |
| GPT-S | 20M | 5.7M | 86.02 | 0.0802 | 46.49 |
| GPT-B | 200M | 22.1M | 88.27 | 0.0793 | 44.78 |
| GPT-B | 2B | 22.1M | 90.43 | 0.0768 | 41.49 |
| GPT-L | 2B | 80.4M | 92.58 | 0.0735 | 40.99 |
3つの観察事項があります。第一に、同じ2M tokenという条件でMLPをTransformerに置き換えるだけで、SRは76.89から83.26に向上し、MPKPEは100.49から62.65に削減されます——スケーリング前からアーキテクチャが重要であることを示しています。第二に、GPT-Bを固定してtokenを T \in \{2\text{M}, 20\text{M}, 200\text{M}, 2\text{B}\} と変化させると単調な改善(SR 83.26 → 90.43)が得られますが、著者らは200Mから2Bの間で限界的な改善が縮小することを指摘しており、容量制限のレジームに入っていることを示しています。2BでのLモデル(SR 92.58)は、より大きなbackboneが同一コーパスからさらにシグナルを抽出できることを確認しています。第三に、同一データにおけるTCN-8とGPT-Sの差(SR 81.48対83.26、MPKPE 79.75対62.65)は、因果的なattentionが畳み込みの受容野では捉えられない長期的なダイナミクスを捉えるという主張を支持しています。
実世界への展開では、mocap俳優の動作をリアルタイムでG1の関節空間に参照軌跡としてストリーミングするオンラインリターゲティングパイプラインを使用し、Transformerは学習から除外した動作に対してゼロショットで動作します。

限界と未解決の問題
動作コーパスはオブジェクトインタラクション(着座、登坂、操作)を意図的に除外しているため、このpolicyは純粋な自由空間全身トラッカーであり、接触の多い行動への拡張には異なる報酬とカリキュラムが必要と考えられます。PDコントローラと特権状態の設定はsim-to-realギャップを示唆しており、論文ではオンラインリターゲティングにより対処しているものの、摂動下での定量化はされていません。GPT-Bにおける200M-2Bでのデータスケーリングカーブのフラットニングは、容量スケーリングを伴わないデータ追加が非効率であることを示唆しており、追跡に対するクリーンなjoint scaling laws(計算最適な N 対 D)はまだ導出されていません。最後に、expertクラスタリングは抽象的に記述されており、クラスタ数と割り当てが下流の蒸留品質にどう影響するかは報告されていません。
重要性
これは、ヒューマノイドの全身追跡が言語・視覚の進歩を牽引したものと同じデータ・容量の法則に従うことを初めて説得力をもって示した研究です。2Bフレームのコーパスと80Mパラメータの因果的なTransformerにより、アジリティと汎化のトレードオフが単一のゼロショットpolicyに収束します。これはヒューマノイド制御を、スキルごとのRL問題ではなく蒸留とスケールの問題として再定式化するものです。
Source: https://arxiv.org/abs/2606.03985
ワールドモデルと言語モデルの融合:具体的推論と抽象的推論の相補性について
問題設定
単一画像と質問から将来の結果を予測するタスクは、現在のシステムが個別に扱っている二つの推論様式の交差点に位置しています。MLLMsは目標・ルール・言語について抽象的に推論できますが、物理的ダイナミクスを具現化するメカニズムを持っていません。一方、生成的ワールドモデル(本論文ではHeliosを使用)は候補となる将来についての視覚的に尤もらしいrollout \hat{v} を生成できますが、それらのrolloutは確率的であり、しばしばタスクとして誤っています――視覚的には一貫しているものの、質問が実際に問うている量については間違っているのです。したがって、MLLMを単純に \hat{v} に条件付けすると負の転移が生じます:信頼性に関わらず、rolloutが描写している内容に答えが引き寄せられてしまいます。
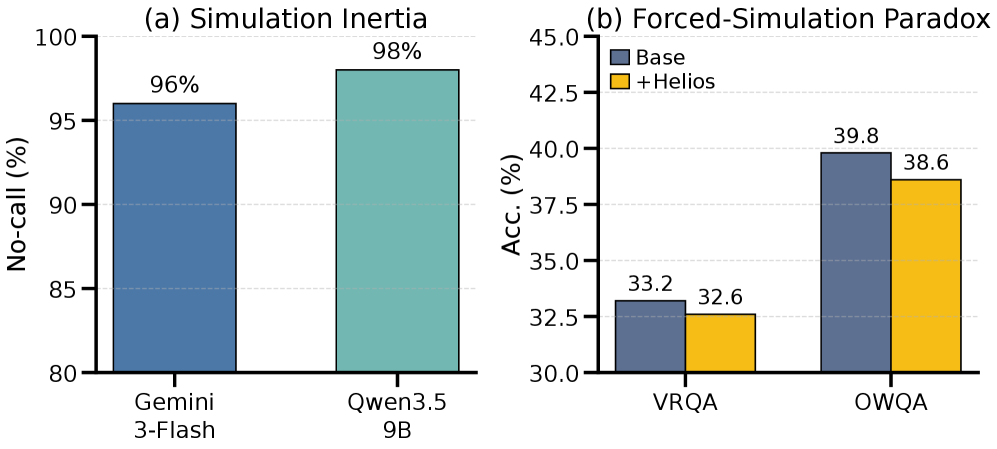
著者らは予備実験(Figure 2)において二つの失敗モードを報告しています:simulation inertia(ワールドモデルへのオプションアクセスを与えられたMLLMがほとんど呼び出さない(no-call確率が高い))と、forced-simulation paradox(Heliosのrolloutを強制するとシミュレーションなしの場合と比べて精度が低下する)です。どちらも、ワールドモデルの使用を固定されたパイプラインの段階ではなく、制御された決定として扱うことを動機づけています。
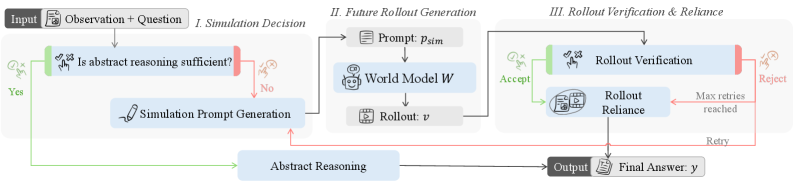
定式化:制御された具体的推論
(o, q) が与えられると、policyは四つの制御変数を含む軌跡を出力します:シミュレーション決定 d_{\mathrm{sim}}、書式化されたシミュレーションプロンプト p_{\mathrm{sim}}、rolloutごとの検証ラベル z_{\mathrm{ver}} \in \{\text{accept},\text{reject},\text{uncertain}\}、そしてrolloutの内容と抽象的推論を混合する依存/フォールバック変数 z_{\mathrm{rel}} です。ワールドモデル W は \hat{v} \sim W(\cdot \mid o, p_{\mathrm{sim}}) を提供しますが、答えは提供しません。最大 B=3 回のシミュレーション試行が許可され、最初のacceptまたは上限到達でループが停止します:
m = \min\{i \le B : z_{\mathrm{ver}}^{(i)} = \text{accept} \vee i = B\}.
誘導された軌跡分布はpolicyの行動とワールドモデルのサンプルを以下のように因数分解します:
p_\theta(\tau \mid x; W) = \prod_{t \in \mathcal{T}(\tau)} \pi_\theta(a_t \mid h_t) \cdot \prod_{i=1}^{N_{\mathrm{sim}}(\tau)} W(\hat{v}^{(i)} \mid o, p_{\mathrm{sim}}^{(i)}),
これにより W は固定された確率的環境として機能し、\pi_\theta がいつどのように呼び出すかを制御します。
PF-OPSD:privileged-future on-policy self-distillation
学習目的は非対称な情報を使用します。特権評価者 E^+ はground-truthの将来動画 v^* と答え y^* を参照し、デプロイ可能なstudentからon-policyでサンプリングされた軌跡をスコアリングします。studentそれ自体は v^* も y^* も参照しません:
J(\theta) = \mathbb{E}_{(x,y^*,v^*)}\,\mathbb{E}_{\tau \sim p_\theta(\cdot \mid x; W)}\big[R^+(\tau; y^*, v^*)\big], \quad (y^*,v^*) \notin x_{\mathrm{test}}.
重要なことに、スコアリングされる軌跡はstudent自身のものです――特権データはstudentの入力分布に注入されることはなく、追加情報を持つteacherがstudentがtest時に再現できない行動を教えるという標準的なimitation learningの病理を回避しています。報酬 R^+ は、シミュレーション決定(呼び出しが必要だったか?)、検証ラベル(rolloutは実際に v^* と一致しているか?)、最終的な答えを合同でスコアリングでき、四つの制御変数にわたって密なcredit assignmentを提供します。
学習は二段階で進みます:Stage-1ではオフラインで特権を持つGemini-3.1-Pro + agentのteacherが生成したプロトコル軌跡に対するSFT、次にStage-2ではstudent自身のrolloutを E^+ がスコアリングするPF-OPSD self-distillationです。studentのバックボーンはQwen3.5-9Bであり、W はHelios(VRQABenchにはVR-Bench-fine-tuned版、OpenWorldQAには汎用版)です。
ベンチマークと評価
二つの人間検証済みベンチマークが相補的な軸を分離しています。VRQABench は制御可能な空間的先読みを対象としており――ワールドモデルは構造化された行動シーケンスに沿って誘導でき、policyが適切にそれを呼び出し、正当化される場合にのみ出力を信頼するかどうかが問われます。OpenWorldQA はrolloutが本質的にノイズが多いオープンドメインの物理予測を対象とし、検証を重視します。メトリクスは答えの精度、シミュレーション決定の品質(policyが役立つ時に W を呼び出し、そうでない時はスキップするか)、rollout検証の品質(v^* に対するaccept/rejectのキャリブレーション)にわたります。
限界と未解決の問題
この設定はHeliosの品質の上限を継承します:あるカテゴリでrolloutが系統的にバイアスを持つ場合、たとえ適切にキャリブレーションされた検証であっても正しい答えを回復することができず――policyは抽象的推論にフォールバックするのみです。再試行の上限 B=3 は手動で設定されており、学習による終了を伴うより長い探索は未探索です。特権評価者の報酬は検証ラベルをdownstreamの答えの正しさと一致させる必要があり、ここでのミスキャリブレーションはstudentに正しい y^* を支持するrolloutではなく v^* に似て見えるrolloutをacceptするよう教えることになります。最後に、このプロトコルはStage-1に強力な外部teacher(Gemini-3.1-Pro + agent)を依存しており、どれだけの利得がteacher distillationに帰属し、どれだけがon-policy self-distillationに帰属するかは、提供されたセクションでは完全には切り離されていません。
重要性
ワールドモデルのrolloutを固定された視覚的コンテキストとしてではなく、呼び出し・検証・条件付き依拠の対象となる信頼されない証拠として扱うことは、生成的ダイナミクスと言語ベースの推論を組み合わせるための正しい抽象化です。PF-OPSDは、特権的な将来がimitate対象の入力としてではなく、student自身の軌跡に対するtraining時のスコアリングシグナルとして最も有用であることを示しています。
Source: https://arxiv.org/abs/2606.03603
TRON: 視覚的推論RLのためのターゲット指定ルール検証可能オンライン環境
問題
視覚的推論RLのpost-trainingは、supervised fine-tuningから一つの習慣を引き継いでいます。それは、一度キュレーションした画像・質問・回答の三つ組からなる固定コーパスをエポックをまたいで繰り返し使用するという慣習です。この手法は、インスタンス数・難易度カバレッジ・検証器の信頼性という三つの要素を同時に制限してしまいます。また、静的なデータセットは漏洩のリスクも抱えています。後継のVLMがpretrainingやSFTの段階でこれらのデータセットを吸収してしまうと、その後の評価が汚染されます。RL専用の観点では、報酬チャンネルの品質は答えのキーの品質に依存しています。キュレーションされたマルチモーダルデータにおけるノイズの多いラベルは、下流での診断が困難な偏ったpolicy gradientへと変換されてしまいます。
TRONはコーパスをsubstrateに置き換えます。アイテムセットの代わりに、環境は新鮮な難易度パラメータ付きrolloutをオンデマンドで生成するプログラムとなっており、それぞれに決定論的な検証器が付属しています。
手法
環境は、潜在状態空間 \mathcal{S}、10段階の難易度レベル \mathcal{L}=\{0,\dots,9\}、決定論的なgenerator
G:\mathcal{S}\times\mathcal{L}\to\mathcal{I}\times\mathcal{Q}\times\mathcal{A}
((s,\ell) を画像・自然言語の質問・正解にマッピングする)、および検証器 V:\mathcal{A}\times\mathcal{A}\to\mathbb{R}(完全一致比較・集合/シーケンスの同一性・パズル固有のソルバーを実装し、オプションのフォーマット信号を持つ)からなるタプル e=(\mathcal{S},\mathcal{L},G,V) として定義されます。policyは (I,q) のみを観測し、V(a,\tilde a) によって報酬を受け取ります。G の決定論的性質により、シードだけでサンプルが固定されるため、インスタンスストリームが無制限であっても再現性が保たれます。
公開されているスイートは、空間・数学・図表・パターン/論理・カウントという5つの能力バケットに分類された520の環境で構成されています。Figure 1にバケットの構成およびgenerator-verifierループを示します。
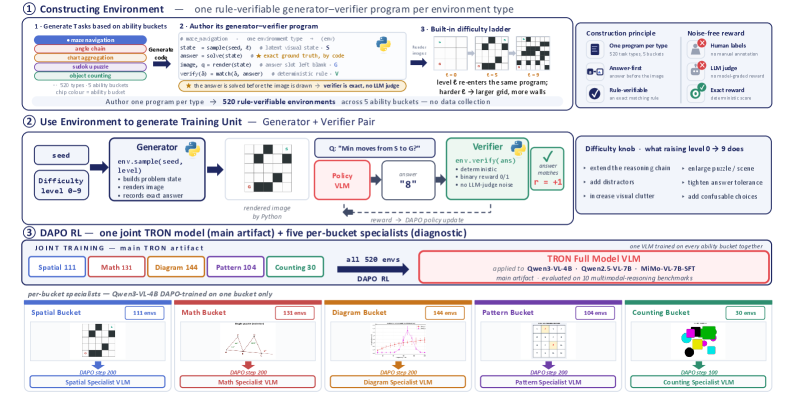
空間バケットは、単一のgeneratorファミリーが \ell に沿ってどのようにスケールするかを示しています。例えば迷路では、より長いパスとより多くの分岐、立方体の展開図では、より多くの面とあいまいな向きとなりますが、基礎となるメカニズムは固定されたままです(Figure 3)。
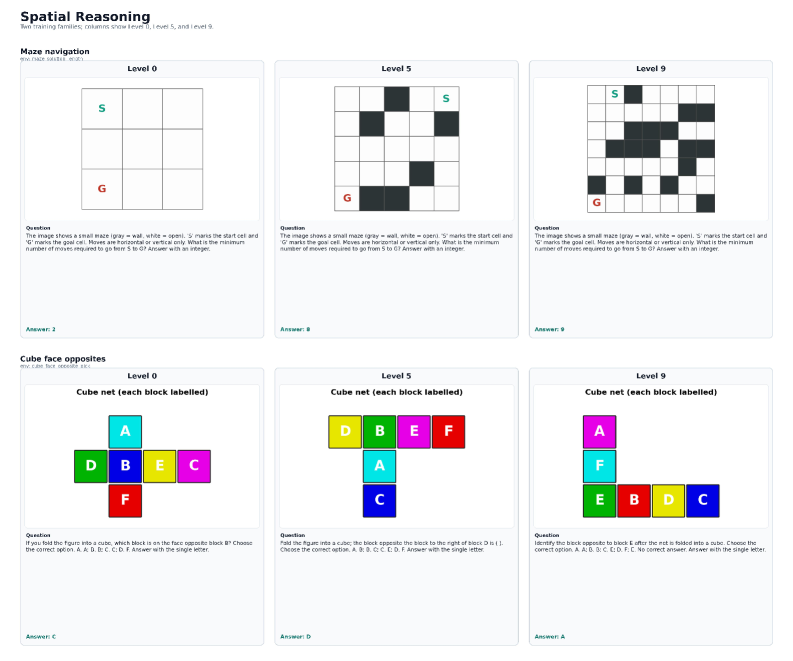
オンラインRLループ。 各サンプリングステップで、トレーナーは (\text{env},\ell,\text{seed}) を選択して G を呼び出します。シードは毎回新鮮であるため、同一のインスタンスが2回登場することはありません。画像には摂動が加えられます。すべてのサンプルで各辺に0〜40ピクセルのwhite-padジッターが適用され、確率0.30で{±3〜8°の回転、低品質JPEG、輝度シフト、Gaussianブラー、加算Gaussianノイズ}のいずれか一つが適用されます。レベル \ell はオフラインエポックではなくrolloutストリームに連動しています(Zeng et al. に倣う)。スライディングウィンドウが現在の \ell での直近の検証器accuracyを追跡し、対象となるグレード付き軌跡数にわたってある閾値を超えると、環境は \ell+1 に昇格します。また、直近のレベルにわたるリテンションウィンドウにより、より簡単なスキルの破滅的忘却を防ぎます。同一のsubstrateが、サンプラーの設定を変えるだけで、全バケットにまたがる単一のフルモデルのトレーニングにも、バケットごとのスペシャリストのトレーニングにも使用できます。
Substrateの監査
Substrateを無効にしうる3つの無音障害モードがあります。不正な形式のprobeの存在、モデルに対して問題を実際には難しくしない難易度軸の存在、そして環境内/環境間の冗長性です。監査では、\ell\in\{0,3,6,9\} からそれぞれ4シードをサンプリングし、8,320のprobeを生成しました。生成成功率は99.07%です。
品質は4つの合格率の最小値、
Q(e)=\min\{r_{\text{gen}},r_{\text{img}},r_{\text{qa}},r_{\text{ver}}\},
によって評価され、閾値 \{0.98, 0.90, 0.75\} によりA/B/Cのグレードに、それ以下はDにマッピングされます。検証器健全性スコア r_{\text{ver}} は、正解をラップすると受理され、固定された誤ったペイロードが拒否されることを要求します。これは基本的ながらしばしばスキップされるチェックです。520環境中502(96.5%)がグレードAを取得し、A未満の18環境は再構成されました。
モード(ii)――\ell が実際に難易度を制御しているかどうか――は静的な検査では確認できないため、監査ではさらにQwen3-VL-4Bを同じレベルでそれぞれ10シードを使って実行し、合格率曲線を報告しています。多様性 D(e) は、シード間・レベル間での環境内分散と、同一の画像・質問分布に収束する異なる名前のgenerator二つを検出するための環境間near-duplicate述語を組み合わせたものです。
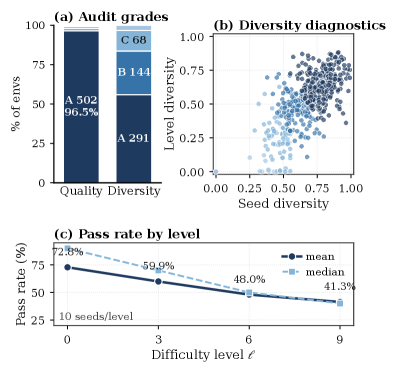
限界とオープンクエスチョン
論文の実験セクションは途中で切れており(abstractは「RL post-training」の途中で終わっている)、提供された資料では主要な下流の数値が明示されていません。ここで定量化されているのは、監査統計(99.07%の生成成功率、96.5%のグレードA環境)のみです。手続き的生成はまた、分布に制約を課します。TRONは、正解が世界知識・オープンエンドなシーン理解・人間の美的判断に依存するタスクを容易に表現できません。これらは決定論的検証器に馴染まないためです。10段階の \ell 軸は環境ごとに手設計されており、\ell の単調性が(一度だけprobeした基本VLMだけでなく)現在のpolicyに対する単調な難易度を意味するかどうかは、トレーニング中の継続的な再監査が必要です。さらに、カリキュラム昇格ルールはスライディングウィンドウ上の閾値に基づいており、タスクを解くのではなく検証器のフォーマット信号を悪用するreward-hackingへの頑健性は、提供されたセクションでは分析されていません。
なぜこれが重要か
静的なマルチモーダルRLデータセットは、スケール・難易度・検証器の品質という直交する三つの軸を混同しており、将来のbaseモデルによる汚染に対して脆弱です。TRONはそれらを分離しています。スケールはコンピューティングによってのみ制限され、難易度は制御可能な入力であり、検証器はアノテーターではなくプログラムです。これは、テキスト推論における最近の進歩をもたらした、人手でラベル付けされた数学データセットからルール検証可能なRL環境への移行に対応するマルチモーダル版と言えます。
Source: https://arxiv.org/abs/2606.01599
Hacker News Signals
MAI-Code-1-Flash
Microsoftは、フロンティアモデルに対するハイスループット・低レイテンシの代替として位置づけられたコーディング特化モデル、MAI-Code-1-Flashをリリースしました。「Flash」という名称は、Gemini FlashやClaude Haikuに見られるのと同じ設計思想を示しています:最大限の能力よりも推論コストと速度の積極的な最適化です。Microsoftは、標準的なコーディングベンチマーク(HumanEval、SWE-benchの各バリアント)においてGPT-4oおよびClaude Sonnetと競合するパフォーマンスを主張しつつ、トークンあたりのコストは大幅に低く抑えられるとしています。
このモデルはAzure AI FoundryおよびGitHub Modelsマーケットプレイスを通じて提供されています。アーキテクチャの詳細についてMicrosoftは全面的な情報を公開していませんが、その位置づけからは、より大規模なモデルからのdistillationと、speculative decodingや類似の推論加速手法との組み合わせが示唆されます。「Flash」のスループット特性への強調は、訓練データのキュレーション――コード、diff、リポジトリのコンテキスト、ツール使用トレースへの重点的な重み付け――によって能力を回復させた、より小さいパラメータ数の構成を意味していると考えられます。
引用されているベンチマーク数値には、LiveCodeBenchおよびMicrosoft内部のコーディング評価における高いパフォーマンスが含まれます。このモデルはfunction callingと構造化出力をネイティブでサポートしており、小規模モデルではJSONの信頼性が低下しがちなエージェント型コーディングパイプラインにおいて重要な意味を持ちます。
ここでの実用的な観点は、本番環境のコーディングアシスタントにおけるコストと能力のトレードオフです。大規模な運用シナリオ――たとえば、IDEプラグインが1時間に数万件の補完を行う場合――では、10%の能力低下と引き換えにレイテンシとコストを5倍削減することが、しばしば正しいエンジニアリング上の判断となります。MAI-Code-1-Flashは、Mistral CodestralやDeepSeek-Coder-V2-Liteに対抗する、そのポジションを狙っています。
Source: https://microsoft.ai/news/introducingmai-code-1-flash/
MAI-Thinking-1
MAI-Thinking-1は、chain-of-thought推論モデルカテゴリへのMicrosoftの参入作であり、OpenAI o3、DeepSeek-R1、Gemini Thinkingと直接競合します。このモデルは最終的な回答を生成する前に、拡張された内部推論トレースを生成します。これは現在標準となっている「thinking token」パラダイムであり、モデルは(通常、結果ベースの報酬シグナルに対するRLを介して)長いスクラッチパッドを生成するよう訓練されます。
Microsoftは数学・科学ベンチマークにおいて強力な結果を報告しています:AIME 2024/2025、GPQA Diamond、および大学院レベルのSTEM問題セットです。引用されている具体的な数値は、AIMEではo3-miniと競争力があり、GPQAではGPT-4oを上回る水準に置かれていますが、直接的なapples-to-apples比較は推論時のコンピュート予算(thinking tokenの数)に大きく依存します。
アーキテクチャおよびトレーニングの詳細は乏しく、Microsoftが論文よりも先にモデルの能力をリリースするという最近のパターンと一致しています。推論インターフェイスはthinking tokenのバジェット管理を公開しており、呼び出し元は推論チェーンの長さを制限することでレイテンシと回答品質をトレードオフできます。最適なバジェットは問題の難易度によって異なるため、これは非自明なAPI設計上の決断です。
技術的に興味深い点の一つは、thinking traceとツール使用の間の相互作用です。MAI-Thinking-1は推論チェーン内でのツール呼び出しのインターリーブをサポートしているようですが、これは事後的なツール使用よりもトレーニングが困難です。RL報酬シグナルは長いトレース内部で発生する中間的なツール呼び出しを評価しなければならず、process reward modelまたは慎重な結果の帰属が必要となります。
このモデルはAzure AI Foundryで利用可能です。より広い文脈として、MicrosoftはOpenAIとの関係とは独立して、(スループット向けのFlash、バランス向けのstandard、難問推論向けのThinkingという)完全なモデル階層スタックを構築しています。
Source: https://microsoft.ai/news/introducing-mai-thinking-1/
検索をコード生成として再考する
Perplexity Researchは、クエリ embedding、ANN検索、BM25融合、reranking といった古典的な情報検索を、検索をコード生成問題として扱うことで置き換えるか、あるいは補完すべきだと主張しています。核心的なアイデアは、言語モデルが単一の密なクエリベクトルを生成するのではなく、実行可能な検索プログラム(検索APIを呼び出すPython、ドキュメントストア上のSQL、フィルターチェーンなど)を記述するというものです。生成されたコードはその後実行され、ドキュメントが取得されます。
技術的な動機として、dense retrieval はクエリの意図を固定次元ベクトルに圧縮するため、合成的な構造が失われる点が挙げられます。「Vaswani 2017を引用し、100件以上の引用を持ち、2022年以降に公開された論文」のようなクエリは、コードとして表現すれば簡単ですが、embedding 空間では複雑な工夫が必要になります。コード生成を用いることで、フィルター、結合、マルチホップ検索に関する推論を、正確に実行されるサブストレートへと外部化することができます。
このアプローチはReActやToolformerスタイルのツール使用に似ていますが、特に検索ループに適用されています。モデルは検索コードを生成し、それを実行して中間結果を確認し、必要に応じて反復します。このプロセスは単一のフォワードパスというよりも、エージェントループに近いものです。クエリ分解とマルチステップ検索をすでに実装しているPerplexityの内部検索スタックは、このパラダイムと自然に適合します。
この論文・投稿では、合成的な検索が必要なマルチホップQAベンチマーク(MuSiQue、HotpotQAの変種)における評価について考察しています。コード生成ベースの検索は、これらのタスクにおいてシングルショットのdense retrievalおよびreranking ベースラインを上回る性能を示しています。
未解決の問題としては、レイテンシ(コード実行によるラウンドトリップの増加)、生成コードの信頼性(構文エラー、存在しないAPIの呼び出しなど)、そして dense 手法がすでに良好に機能しているシングルホップの事実検索においても同様の改善が得られるかどうかが挙げられます。
Source: https://research.perplexity.ai/articles/rethinking-search-as-code-generation
NvidiaのGPU VRAMをLinuxのスワップ領域として使用する
このプロジェクトは、NBD(Network Block Device)を介してGPU VRAMをLinuxブロックデバイスとして公開し、そのブロックデバイスをスワップパーティションとしてマウントします。実装ではCUDA仮想メモリAPIを使用してVRAMを確保し、NBDサーバープロセスでラップした上で、ループバック経由でカーネルのNBDクライアントに接続します。結果として得られるスワップデバイスは、カーネルからは通常のスワップ領域として認識されます。
技術的な興味の核心はメモリ帯域幅の差にあります。GPU VRAM(GDDR6X、HBM3)の帯域幅は1〜3 TB/sの範囲にあるのに対し、DRAMは約50〜100 GB/s、NVMeは約7 GB/sです。カーネルの観点から見ると、このデバイスへのスワップはNVMeスワップより桁違いに高速であり、逐次アクセスパターンにおいてはDRAMと十分に競合できる可能性があります。レイテンシの面ではより複雑で、ループバックNBDパスにはDRAMには存在しないシステムコールおよびコンテキストスイッチのオーバーヘッドが加わります。しかし、NVMeへのスワップが避けられないほど大きなワーキングセットに対しては、VRAMスワップが明らかに有利です。
このセットアップには、空きVRAMを持つ独立したGPUが必要です。つまり、コンピュートワークロードがVRAMを消費していないか、セカンダリGPUが存在している必要があります。CPUで大規模なLLM inferenceを実行しつつ、ゲーミングGPUがアイドル状態のワークステーションであれば、これは十分に現実的な構成です。
制限事項として、NBDループバックパスはゼロコピーではありません。データはPCIeバスを2回通過します(書き込み時にCPU→GPU、読み出し時にGPU→CPU)。さらにソフトウェアNBDスタックのオーバーヘッドも加わります。実効帯域幅はVRAM帯域幅ではなくPCIe帯域幅(PCIe 4.0 x16で約32 GB/s)に制限されます。それでも、スワップの多いワークロードに対して、32 GB/sのスワップ帯域幅は7 GB/sのNVMeと比べて4〜5倍の改善となります。
Source: https://github.com/c0dejedi/nbd-vram
RAGのための画像インデックス方法
Kapa.aiは、技術ドキュメント向けのretrieval-augmented generationシステムに画像を組み込むためのプロダクションパイプラインについて解説しています。問題の背景として、標準的なRAGはテキストチャンクをインデックスするため、ドキュメント内の画像(アーキテクチャ図、CLIの出力スクリーンショット、APIフローチャートなど)は破棄されるか、不透明なblobとして扱われ、技術的な質問に答える上で重要な情報が失われてしまいます。
同社のパイプラインは3つのステージで構成されています。第1に、ドキュメントソース(HTML、PDF、Markdown)から画像をキャプション・alt text・隣接する段落といった周辺テキストコンテキストとともに抽出します。第2に、vision-language model(GPT-4V / GPT-4oを使用)が各画像の密なテキスト説明を生成し、その内容にはテキスト抽出(OCR相当)、構造的な説明、意味的な要約が含まれます。第3に、これらの生成された説明をembeddingして、標準的なベクトルストア内のテキストチャンクと並べてインデックスします。
クエリ時には、取得した画像の説明が元の画像URLへの参照とともにコンテキストウィンドウに含まれ、生成モデルが直接見ていない視覚的なコンテンツについて推論できるようになります。ユーザーのクエリが視覚的なコンテキストから恩恵を受ける可能性が高い場合には、画像そのものを取得してvision modelに渡すこともできます。
重要なエンジニアリング上の判断は、CLIP方式の生の画像embeddingではなく、生成された説明を使用することです。CLIP embeddingは、「Xのアーキテクチャ図はどのようなものか」といった技術的なクエリに対して、生成されたキャプションに対するテキスト-テキスト検索と比べてアライメントが弱くなります。トレードオフはインデックスのコストであり、画像1枚あたり1回のGPT-4o呼び出しは大規模になると高コストになります。
図を参照するドキュメントの質問に対して回答品質が向上したと報告されており、主な残存する失敗ケースは、VLMの説明が構造的な情報(例:グラフのトポロジー)を失ってしまう複雑な技術的な図です。
Source: https://www.kapa.ai/blog/how-we-index-images-for-rag
DeepSeek-V4-Flash を AMD MI300X 上で動かす
DeepSeek 系譜の mixture-of-experts モデルである DeepSeek-V4-Flash を AMD MI300X ハードウェア上で動作させるための、詳細なエンジニアリング記事です。MI300X は AMD の HBM3 ベースのデータセンター向けアクセラレータで、1 カードあたり 192 GB の HBM3 を搭載しており、大規模モデルの推論用途として魅力的な選択肢となっています。課題は、ソフトウェアエコシステム――ROCm、vLLM の ROCm フォーク、flash attention の移植版――の成熟度が CUDA スタックに比べて依然として遅れている点です。
この記事では、立ち上げに必要なフルスタックを網羅しています。具体的には、ROCm バージョンの選択(ROCm 6.x は 5.x に比べて transformer カーネルの性能が大幅に向上している)、MoE モデル向けの vLLM 設定(tensor parallelism の度合い、MoE ルーティング向けの expert parallelism)、そして CDNA3 アーキテクチャ上での triton カーネルの互換性問題が取り上げられています。DeepSeek の MoE ルーティングはエキスパート間で all-to-all 通信を必要とし、トポロジへの依存度が高いため、MI300X のインターコネクト(Infinity Fabric)は NVLink とは異なる挙動を示し、通信粒度のチューニングが必要となります。
文書化された具体的な問題点は以下の通りです。ROCm 上の flash attention にはパッチ済みバージョンが必要でした。一部の triton カーネルは、CDNA3 のウェーブフロント幅(64、対して CUDA は 32)に合わせたブロックサイズの手動調整が必要でした。そして、デフォルトの vLLM メモリアロケータがフラグメンテーションを過大評価し、OOM エラーが発生しましたが、gpu_memory_utilization を調整することで解決できました。
性能結果については、チューニング後に報告されている CUDA A100/H100 の数値と比べて概ね 15〜20% 以内のスループットを達成しており、成熟度の差を考慮すれば妥当な結果と言えます。1 カードあたり 192 GB の HBM3 は最大の優位点であり、マルチノード推論を用いずにより大きなモデルや大きな KV cache を収めることが可能です。
大規模な MoE 推論ワークロードにおいて、H100 のコスト代替として AMD を評価しているチームにとって重要な情報です。
Source: https://fergusfinn.com/blog/deepseek-v4-flash-mi300x/
SurrealDB 3.x vs. Postgres、Mongo、Neo4j、Redis のベンチマーク(Fsync 有効)
SurrealDB がバージョン 3.x と Postgres 16、MongoDB 7、Neo4j 5、Redis 7 を読み取り・書き込み・グラフ探索ワークロードで比較したベンチマークを公開しました。タイトルにある「With Fsync」は、過去のベンチマーク論争——データベースが fsync を無効化(実質的に耐久性保証を無効化)して書き込み数値を水増しした問題——への率直な言及です。
測定方法:全データベースで fsync および同等の耐久性を有効化し、シングルノード・同一ハードウェア上で実行。ワークロードはポイント読み取り、バルクインサート、レンジスキャン、グラフ探索(連結成分スタイルのクエリ)を網羅しています。SurrealDB 3.x では、従来の組み込み RocksDB バックエンドを置き換えるネイティブストレージレイヤー SurrealKV を採用しています。
SurrealDB が報告した結果(ベンダー自身によるベンチマークである点に注意):SurrealDB 3.x は単純なポイントルックアップで Postgres と競合する読み取りスループットを主張し、バルクインサートでは 2〜3 倍の書き込みスループット、またテストグラフトポロジーにおいて Neo4j を大幅に上回るグラフ探索パフォーマンスを主張しています。Redis との比較は永続モードの Redis が対象であり、読み取りでは 2 倍以内に収まっています。
適切な懐疑論:ベンダーベンチマークは、自社製品に有利なようにスキーマ設計・インデックス設定・クエリパターンを最適化します。Neo4j とのグラフ探索比較はグラフ密度とクエリパターンに大きく依存しており、Neo4j のネイティブグラフエンジンが深いトラバーサルで持つ既知の優位性は、単純なベンチマークでは捉えきれない場合があります。
この投稿で技術的に興味深い点は SurrealKV ストレージエンジンの設計です。マルチモデルアクセスパターン(キーバリュー・ドキュメント・グラフクエリを同一ストレージレイヤーで処理)向けの SurrealDB 固有の最適化を施したカスタム MVCC 実装を、ログ構造化マージツリー上で採用しています。こうしたアーキテクチャ上の賭けが実際のワークロードで報われるかどうかは、独立したベンチマークによる検証が必要です。
Source: https://surrealdb.com/blog/surrealdb-3-x-by-the-numbers
スタンフォード・ロースクールの研究でAIが法学教授を上回る成績
スタンフォード・ロースクールは、法的分析タスクにおいてAIシステム(GPT-4o、o1、Claude 3.5 Sonnet)と法学教授および法学生を比較した対照研究の結果を発表しました。タスクの形式は、争点の発見・法規の適用・論理的な論拠の展開を要する書面による法的問題であり、ロースクールの標準的な試験形式(IRAC:Issue, Rule, Application, Conclusion)に準拠しています。
評価はブラインド形式で実施されました。すなわち、専門家の採点者は回答者が人間かAIかを知らない状態で採点を行いました。AIの回答(特にo1)は、争点発見の網羅性や論拠の論理的一貫性を含む複数の採点基準において、法学教授および学生の回答よりも平均的に高いスコアを記録しました。
検討に値する技術的な内容として、法的推論は推論モデルの能力と親和性が高い点が挙げられます。IRACはchain-of-thoughtに類似した構造的な分解手法です。すなわち、法的問題を特定し、適用可能な法規を述べ、事実を法規に当てはめ、結論を導くという流れです。法規の適用ステップは、訓練時に習得した法的知識(制定法や判例の判示事項)を検索して体系的に適用することを要しますが、これは法律関連の訓練データを持つ大規模モデルが得意とするところです。AIの法的推論における弱点は、一般的に、管轄固有の特殊性、訓練データのカットオフ以降の最新判例法、そして裁判所が実際に受け入れるであろう論拠に関する実践的な判断力であり、これらはいずれも標準的な benchmark ではテストされていません。
研究設計も重要な点です。ロースクールの試験問題は閉世界仮定(関連するすべての事実が与えられる)のもとで設定されており、依頼人との対話や手続き上の文脈から切り離され、構造化された採点基準に基づいて評価されます。これはLLMにとって最も有利な環境です。証拠開示、契約交渉、法廷における判断など、実際の法律実務タスクにおけるパフォーマンスは別問題です。
Source: https://law.stanford.edu/press/ai-outperforms-law-professors-in-stanford-law-study/
注目の新規リポジトリ
study8677/awesome-architecture
AIゲートウェイ、RAG pipeline、inference serving、vector database、マルチエージェントシステムといったトピックを網羅する21のアーキテクチャマップを中心に構成された、厳選されたバイリンガル(中国語・英語)のソフトウェアアーキテクチャパターンリファレンスです。各マップは単なる図ではなく、実際のオープンソースプロトタイプ実装にリンクされた構造化テンプレートとなっており、純粋に説明的なものではなく実践的に活用できます。
このリポジトリは言語非依存のシステム設計チュートリアルとして構成されており、特定のスタックに縛られることなく、インターフェースとデータフローのレベルでパターンが表現されています。分散システムの基礎(一貫性モデル、パーティション耐性のトレードオフ)に加え、MLに特化したインフラの課題もカバーしています。具体的には、AIゲートウェイを通じたLLMトラフィックのルーティングとレート制限の方法、RAG pipelineを検索・再ランキング・生成ステージへと分解し各コンポーネント間の契約を定義する方法、そしてレイテンシ制約下でのinference servingのスケーリング方法などが含まれます。
バイリンガルによる提示は意図的なものです。同一ドキュメント内で説明が中国語と英語の両方で記載されており、言語の壁を越えて活動するチームや、システム用語をどちらかの言語で習得してもう一方でクロスリファレンスしたい読者にとって有用です。
一般的な「awesome」リストと一線を画しているのは、プロトタイプへのリンクです。ドキュメントを指し示すのではなく、マップはそのパターンを実体化した実行可能ないし検査可能なコードベースにリンクしています。構造化されたオンボーディングリソースや、設計レビュー前のチェックリストとして活用できます。
Source: https://github.com/study8677/awesome-architecture
trynullsec/nullsec-s1
アプリケーションセキュリティのワークフロー(静的解析のトリアージ、脆弱性の説明、セキュリティレビュー支援)を対象とした、セキュリティに特化したLLMシステムです。「security-native」という位置づけは、このモデルまたはシステムのprompt engineeringが、セキュリティのコーパス(CVEの説明、OWASPパターン、CWEタクソノミー)に基づいてチューニングされており、セキュリティテーマのラッパーを被せた汎用的なコーディングアシスタントではないことを示唆しています。
アーキテクチャの観点では、nullsec-s1はコードや依存関係のマニフェストを取り込み、構造化されたセキュリティアセスメントを生成できるreasoning-augmented agentと見られます。「S1」という名称は、段階的な推論アプローチ(初期アセスメントを生成した後にそれを批評・精緻化する)を採用している可能性を示唆しており、これはexploitabilityの判定のような分類中心のタスクにおいてchain-of-thought技術が精度を向上させることと一致しています。
汎用LLMにコードを入力する場合と比べた実用的な価値は、ドメインアライメントにあります。セキュリティ解析では、コードが何をするかを理解するだけでなく、攻撃者が敵対的な入力によって何を引き起こせるかを理解する必要があり、それにはpromptの規律と場合によってはfine-tunedされた事前分布が求められます。このリポジトリはまだ初期段階でドキュメントも限られているため、主要な成果物は新規モデルではなくpromptとagentic scaffoldingです。手動のペネトレーションテストを代替するためではなく、プルリクエストや新しい依存関係に対するファーストパスのトリアージを自動化したいAppSecエンジニアにとって最も有用でしょう。
Source: https://github.com/trynullsec/nullsec-s1
KevRojo/Dulus
ターミナルネイティブなエージェント型コーディングアシスタントです。ファイルの読み書き、Bashコマンドの実行、リポジトリ全体に対するgrep、ウェブブラウジング、コミットの作成などが可能な汎用CLIエージェントとして設計されています。最大の主張は「3ヶ月にわたる200億トークンのセッション全体で98%のキャッシュヒット率を達成した」というもので、これはKVキャッシュ管理戦略が中核的な技術的差別化要因であることを示しています。
そのスケールで高いキャッシュヒット率を実現するには、慎重なプロンプト構成が必要です。不変のプレフィックス(システムプロンプト、プロジェクトコンテキスト、長期的な会話履歴)は、推論サーバーのプレフィックスキャッシュが不必要に無効化されないよう、ターン間でバイト単位で同一に保たれなければなりません。これはDulusがコンテキストウィンドウを静的なプレフィックスブロックで構造化し、新しいターンのみをその末尾に追加していることを意味します。動的な状態(タイムスタンプ、セッションIDなど)をプロンプトプレフィックスに再シリアライズするという一般的な誤りを回避しています。
ツール使用のインターフェース自体はごく標準的なもの(ファイルI/O、シェル実行、ウェブフェッチ、git操作)ですが、キャッシュ効率に対するエンジニアリング上の重点が、毎ターンごとのコンテキスト再送が非現実的なほどコスト高となる長期的なソフトウェア開発セッションにおいて実用的な価値をもたらします。CLIファーストの設計はIDEへの依存を排除し、既存のシェルワークフローとの組み合わせや自動化パイプラインへのスクリプト組み込みを容易にします。APIレベルではモデル非依存となるよう実装されています。
Source: https://github.com/KevRojo/Dulus
usewhale/DeepSeek-Code-Whale
DeepSeekモデルを中心に特化して構築された、ターミナルファーストのAIコーディングエージェントです。100万トークンのcontext window、呼び出しをまたいだ永続セッション、Model Context Protocol(MCP)ツール統合、および動的ワークフロー合成を重視しています。DeepSeek特化という方針により、汎用的なOpenAI互換エンドポイントへの薄いラッパーではなく、DeepSeekのトークナイザー、APIセマンティクス、および料金体系に最適化されたシステムとなっています。
永続セッションは、使い勝手の面での重要な機能です。各実行ごとにコンテキストをコールドスタートするのではなく、Whaleはセッション状態をディスクにシリアライズし、次回の呼び出し時に以前のコンテキスト全体を維持した状態で再開します。100万トークンというスケールではこれが大きな意味を持ちます――開発者は手動での要約やcontext window管理を行うことなく、何日にもわたる反復的なコーディングのコンテキストを蓄積できます。
MCPツールサポートにより、エージェントはフリーフォームのbashではなく型付きプロトコルを使って構造化された外部ツール(ファイル操作、検索、コード実行)を呼び出せます。これによりインジェクションの攻撃対象領域が縮小し、ツールディスパッチの信頼性が向上します。動的ワークフローは中間結果に基づいてツール呼び出しの分岐やループを可能にするもので、「この関数のすべての使用箇所を見つけ、新しい不変条件に違反するものがあれば確認し、該当箇所を修正する」といったタスクに必要な機能です。
DulusおよびTool类似ツールとの比較:Whaleはモデル非依存性をDeepSeek固有の最適化と引き換えにしており、DeepSeekを主要な推論バックエンドとして使用しているのであれば合理的なトレードオフです。
Source: https://github.com/usewhale/DeepSeek-Code-Whale
margelo/react-native-runtimes
開発者がバックグラウンドスレッド上で独立したHermes JavaScriptランタイムを起動できるようにするReact Nativeライブラリです。重い計算処理や大規模なコンポーネントツリーをメインJSスレッドをブロックすることなく実行できます。このライブラリが解決するコアな問題は、React NativeのシングルスレッドなJS実行モデルです。UIロジック、ビジネスロジック、データ変換といったすべてのJavaScriptが通常は1つのHermesインスタンスを共有しているため、長時間実行される処理がレンダリングを停止させてしまいます。
このライブラリは、追加のHermesランタイムをインスタンス化し、シリアライズ可能なデータをそこに渡し、JSのワークロードを実行し、結果をメインスレッドに返すためのAPIを公開しています。各ランタイムは完全に独立しており、独自のヒープ、独自のグローバルスコープを持ち、メインランタイムとの共有ミュータブルステートが存在しないため、設計上レースコンディションが発生しません。
技術的にはこれは容易ではありません。なぜならHermesは単一プロセス内でデフォルトのマルチインスタンスエンジンとして設計されていないからです。このライブラリはライフサイクル管理、スレッドアフィニティ、クロスランタイムのメッセージパッシングを処理します。JSI(JavaScript Interface)をネイティブとJSのブリッジングに使用することで、レガシーブリッジと比較して通信オーバーヘッドを低く抑えています。
ユースケースとしては、MLインファレンス(ONNX Runtimeバインディング、TensorFlow.js)をジャンクなく実行すること、表示前の大規模データセットの処理、またはサードパーティスクリプトの分離などが挙げられます。概念的にはWeb Workersに相当しますが、React Nativeのエンジン向けです。パフォーマンス重視のRNライブラリで知られるMargeloチームによる作品です。
Source: https://github.com/margelo/react-native-runtimes
duncatzat/vigils
RustとTauriデスクトップフロントエンド、およびChrome Manifest V3拡張機能を用いて構築された、AIエージェント向けローカルコントロールプレーンです。解決しようとしているコアな問題は、エージェントの監査可能性と認可です。LLMエージェントがツール使用能力を獲得するにつれ、人間のオペレーターが保留中のアクションを検査したり、個々のステップを承認・拒否したり、シークレット情報がエージェントのコンテキストに漏洩しないようにするための標準的なメカニズムが存在しません。
Vigilsは自身を中間レイヤーとして介在させます。Rustバックエンドは、ファイル書き込み・APIコール・シェルコマンドといったエージェントのアクションリクエストを実行前にキャプチャし、人間によるレビューのためにTauri UIに表示します。Chrome MV3拡張機能は、このインターセプションをブラウザベースのエージェントアクション(DOM操作、フォーム送信、ナビゲーション)にまで拡張します。ローカルファーストのアーキテクチャにより、アクションのメタデータが一切マシン外に出ることはありません。これはエージェントがクレデンシャルや独自コードにアクセスできる場合に特に重要です。
シークレット管理は明示的な設計上の関心事です。提案されたエージェントアクションがシークレット(APIキー、トークン、ローカルボルトからのパスワード)を露出させようとしている場合、システムはそれを検出し、リダクションするか、実行前に明示的な確認を要求します。これは現実的な攻撃対象領域、すなわちプロンプトインジェクションによってエージェントが一見無害なツールコールを通じてクレデンシャルを外部へ持ち出させるリスクに対処するものです。
Rust + Tauriスタックにより、小さなバイナリフットプリントとインターセプトのホットパスにおけるネイティブパフォーマンスを実現しています。本番システムや機密性の高いコードベースに対して自律エージェントを実行している方にとって有益なプロジェクトです。
Source: https://github.com/duncatzat/vigils
wanshuiyin/ARIS-in-AI-Offer
MLおよびAIエンジニアリング職の面接対策資料を中英バイリンガルでまとめたコレクションです。大規模言語モデル、diffusion model、エージェントシステムを網羅しており、内容はチートシート形式、すなわち面接直前の短時間復習を想定した高密度なリファレンス型サマリーとして構成されており、チュートリアル的な長文解説ではありません。
静的なドキュメントの単純な集積と本リポジトリを区別する技術的なパイプラインは、ARIS の /render-html ワークフローです。これはソースコンテンツから自己完結型の単一ファイルHTML出力を自動生成します。つまり、チートシートコーパス全体をビルドシステムやサーバー不要で任意のブラウザからオフライン閲覧できます。これは面接当日の朝にスマートフォンで確認する際に実用的なフォーマットです。
副次的な機能として、CVを読み込んで記載された業績をDBLPと照合し、不一致を検出するアカデミックホームページジェネレーターがあります。これは信頼性の高いアカデミックプレゼンスの構築や、教員・企業研究職への応募前に引用エラーを発見するのに役立ちます。
ML関連の網羅範囲には、transformer アーキテクチャの詳細、attention の計算量、diffusion model の DDPM/DDIM の導出、RLHF のメカニズム、RAG パイプライン設計、および一般的なエージェントフレームワークのパターンが含まれます。詳細度は、実装レベルの理解を頻繁に問われる中国系テック企業(Baidu、Alibaba、ByteDance)や国際的なAIラボにおけるPhDレベルまたはシニアエンジニア向けの面接を想定して調整されています。
Source: https://github.com/wanshuiyin/ARIS-in-AI-Offer
WantongC/journal-adapt-writing-skill
対象ジャーナルの公開済み論文コーパスからその執筆慣習を学習し、その慣習を原稿にセクションごとに適用して改訂するためのツールです。このツールが取り組む問題は現実的であり、かつ十分に対処されていません。学術的な文体はジャーナルによって大きく異なり、文長の規範、ヘッジング(断定を避ける表現)の慣習、引用密度、受動態と能動態の比率、方法論セクションの構成方法などが挙げられます。こうしたパターンは、スタイルガイドを読むだけでは習得しにくいものです。
このアプローチはコーパス駆動型のスタイル転換です。対象ジャーナルの公開済み論文群を入力として、システムは複数の粒度で文体的特徴を抽出します。具体的には、語彙レベル(語彙の好み、専門用語の使用)、統語レベル(文構造のパターン)、そして構造レベル(セクションの構成、接続表現の慣習)です。これらの特徴は、ユーザーの原稿を改訂する際の条件付けシグナルとして活用されます。
セクションごとの処理は重要な意味を持ちます。序論、方法論、結果、考察の各セクションは、同じジャーナル内であっても異なるレトリカル構造を持つため、単一の統一されたスタイルプロファイルを適用するのは不適切です。このツールは、セクションタイプを考慮したpromptingによって各セクションを個別に処理します。
これは言い換えや文法修正のツールではなく、特定の掲載誌が持つ暗黙的な規範に合わせて原稿のレジスターを変換しようとするものであり、より高次の文体的操作です。科学的な内容が確定した後の改訂段階、特に競争率の高い掲載誌を目指す非英語ネイティブの研究者にとって最も有用です。
Source: https://github.com/WantongC/journal-adapt-writing-skill