Daily AI Digest — 2026-06-03
arXiv Highlights
A Local Perturbation Theory for Cross-Domain Interference and Recovery in Multi-Domain RL
Problem
RL post-training of LLMs on a single domain (math, code, QA, creative writing) reliably improves that domain but degrades others. The standard explanations — catastrophic forgetting and global gradient conflict — fail to predict observed interference patterns: cross-domain gradients can be nearly orthogonal at the full-model level while substantial interference still occurs. The paper asks where interference actually lives in the parameter space, why it is selective rather than uniform, and why a short refresh on the damaged domain can restore it without harming others. The setting is Qwen3-4B-Thinking-2507 trained sequentially on Math (OpenR1), Code (KlearReasoner-CodeSub-15K), QA (SuperGPQA), and CW (Crownelius).
Structural diagnosis
The authors compute per-step cosine similarity between domain gradients \cos(\bm{g}_{d_i},\bm{g}_{d_j}) during joint training. For Math–QA the value sits near zero, yet downstream Math performance still collapses after QA and CW training. Decomposing the gradient by layer and module reveals heterogeneous local structure — strong conflict in some attention/MLP modules, strong synergy in others — masked by averaging.
Two further observations matter. First, single-domain RL produces sparse, small-magnitude parameter edits: each domain expert touches a small fraction of weights with weak overlap of top-changed neurons across domains. Second, despite weak neuron overlap, domains share active computation routes — the same neurons fire on inputs from multiple domains. The decisive quantity is then the directional alignment of edits along these shared routes.
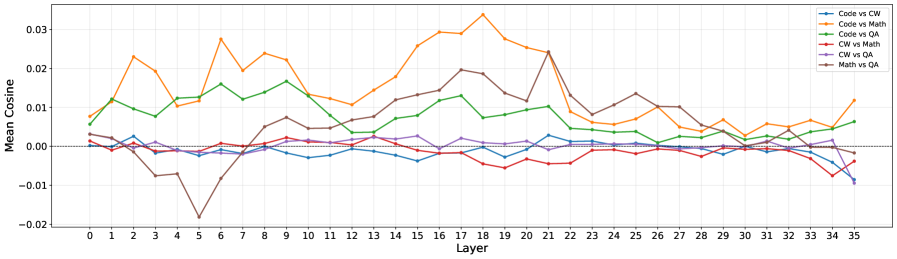
Figure 4 shows that on the shared top-changed neurons, directional cosines vary in sign across layers — synergistic in some layers, antagonistic in others — confirming that interference is a route-level, direction-dependent phenomenon, not a global one.
Local perturbation theory
Let L_d(\bm{\theta}) be the local RL objective for domain d, with gradient \bm{g}_d and Hessian \bm{H}_d. Train on A to a checkpoint \bm{\theta}_A^*, then on B producing update \bm{\delta}_B. Interference is
\Delta_{A\leftarrow B} = L_A(\bm{\theta}_A^* + \bm{\delta}_B) - L_A(\bm{\theta}_A^*).
Under (i) approximate stationarity \bm{g}_A(\bm{\theta}_A^*)\approx 0, (ii) sparse local updates \bm{\delta}_B, and (iii) concentration of curvature-sensitive components of \bm{\delta}_B in a low-dimensional shared active conflict subspace S_{A,B}, a Taylor expansion gives
\Delta_{A\leftarrow B} \approx \tfrac{1}{2}\,\bm{\delta}_B^\top \bm{H}_A(\bm{\theta}_A^*)\,\bm{\delta}_B.
The first-order term vanishes by stationarity; the linear gradient-conflict picture is therefore the wrong order. The damage is a second-order quadratic form, and assumption (iii) implies it concentrates as \tfrac{1}{2}\,\bm{\delta}_{B,S}^\top \bm{H}_{A,S}\,\bm{\delta}_{B,S} on the low-dimensional subspace S_{A,B} where shared routes carry curvature.
For the refresh, suppose \bm{H}_A restricted to S_{A,B} is positive definite and the orthogonal complement couples weakly back into S_{A,B}. A short gradient step on L_A then contracts the harmful component along S_{A,B} while leaving updates on neurons outside the shared subspace — those carrying other domains’ specialization — largely untouched. This predicts (a) selective damage from a later domain, (b) selective and fast recovery from a brief refresh, and (c) limited collateral effect on intermediate domains.
Empirical validation
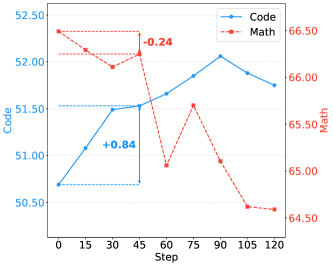
The sequential pipeline is Math → Code → QA → CW, with single-domain experts as anchors. Math at the post-Code checkpoint \mathrm{Math}_o scores 66.49, essentially matching the single-domain Math expert at 66.84. After QA and CW stages, Math drops to 57.66, while Code, QA, and CW remain stable — selective interference exactly as the theory requires.
A short Math refresh starting from \mathrm{CW}_o (denoted \mathrm{Re\text{-}Math}) raises Math from 57.66 to 66.04, recovering nearly all the loss and approaching both \mathrm{Math}_o (66.49) and the single-domain Math expert (66.84). Critically, Code rises slightly to 51.05 while QA and CW are essentially unchanged. \mathrm{Re\text{-}Math} attains the best average across the four domains at 66.39, beating mixed-training baselines.
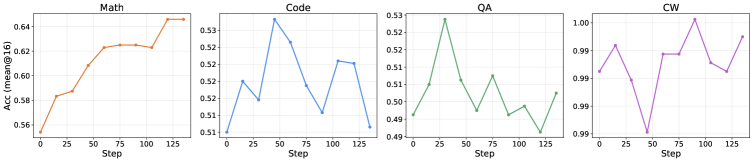
Figure 9 shows the trajectory: Math validation rises sharply within a small number of refresh steps, while QA and CW curves remain flat — consistent with contraction confined to S_{A,B}. The asymmetric Re-Code experiment in Figure 10 shows the same pattern in a different pair: a short Code refresh from \mathrm{Math}_o restores Code with negligible Math degradation, supporting that the contraction-on-shared-subspace mechanism is not specific to one domain ordering.
The paper also reports a direct weight-space rollback on a coordinate proxy for S_{A,B} in the Math→QA pair, providing a non-gradient causal test of the second-order damage account.
Limitations
The theory leans on assumptions that are checked empirically rather than proved: stationarity at \bm{\theta}_A^* is only approximate, S_{A,B} is identified through proxies (top-changed-neuron overlap), and the weak-coupling condition between S_{A,B} and its complement is asserted rather than measured globally. All experiments use a single 4B base; whether the sparse-route picture holds at much larger scale, with longer RL horizons, or under heavily off-policy updates is open. The “short refresh” regime is also unquantified — there is no characterization of the step budget at which the contraction picture breaks down and full re-training dynamics resume.
Why this matters
The result reframes multi-domain RL interference from a first-order gradient-conflict problem to a second-order curvature problem on a low-dimensional shared subspace, and it gives a cheap, principled remedy: brief, targeted refreshes rather than full mixed training or replay buffers. If the sparse-shared-route structure generalizes, continual RL post-training pipelines for LLMs can be organized as sequences of single-domain stages followed by short corrective refreshes, with predictable selectivity.
Source: https://arxiv.org/abs/2606.02398
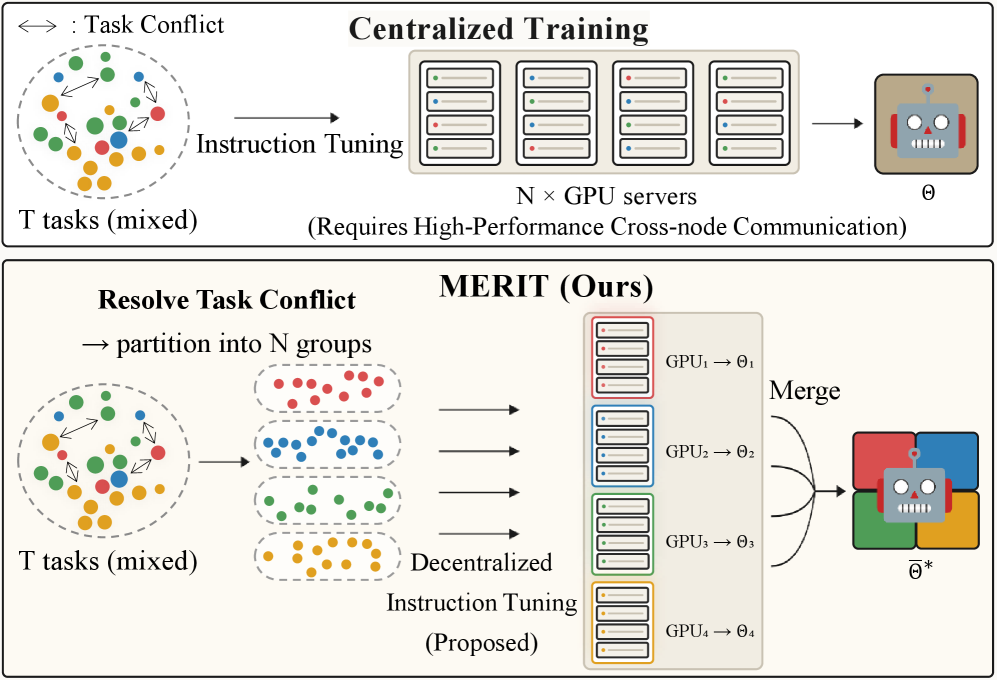
Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging
Instruction tuning over heterogeneous task mixtures suffers from two coupled problems: gradient interference between conflicting tasks, and the bandwidth cost of synchronizing large multimodal models across a tightly-coupled cluster. MERIT asks whether both can be addressed by training disjoint parts of the mixture independently and reconciling them once in parameter space, replacing per-step all-reduce with a single offline merge.
Local quadratic theory in a shared flat basin
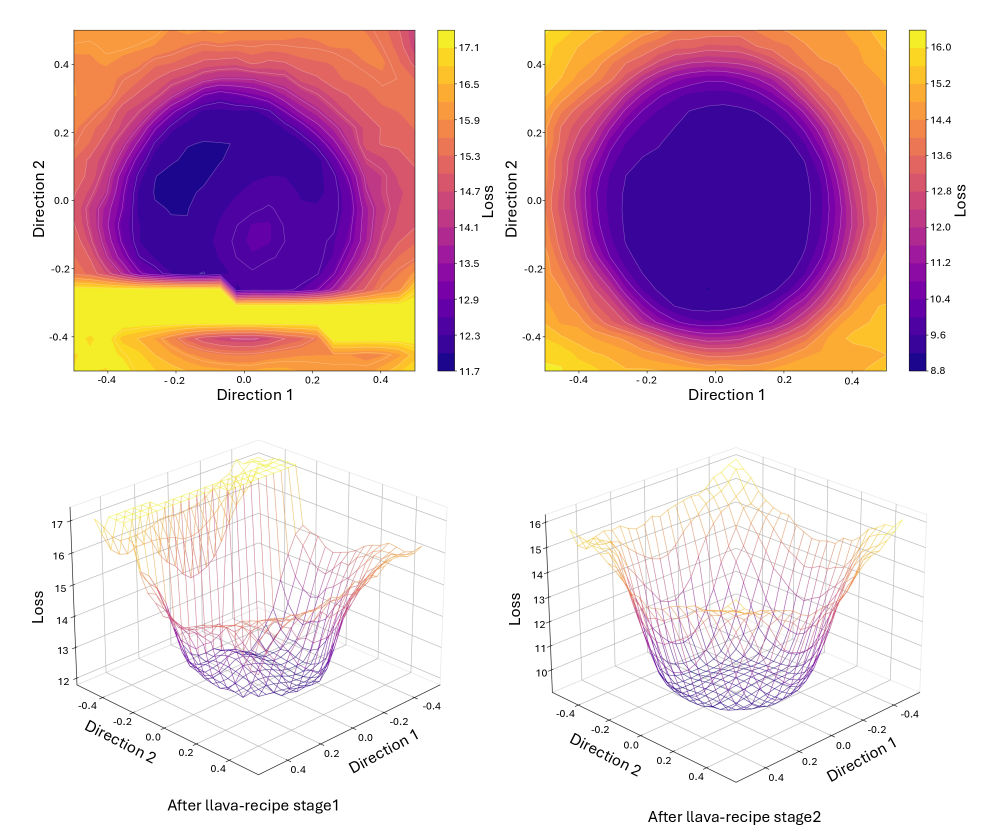
The analysis presumes a “merge-ready” initialization \theta^{(0)} — a checkpoint from which independently fine-tuned models remain in a connected low-loss region. The authors obtain this via a basin-preparation stage analogous to LLaVA Stage 2; Figure 2 contrasts the rugged pre-prep surface against the flat connected region post-prep, which is the operating regime for the rest of the paper.
Inside this basin, fix a reference \theta^\star with local Hessian H=\nabla^2 L(\theta^\star)\succeq 0, and let \delta_i = \theta_i - \theta^\star for K independently fine-tuned checkpoints. The merged model is \bar\theta_w = \sum_i w_i \theta_i, \sum_i w_i = 1. To quadratic order,
L(\bar\theta_w) \;\approx\; \sum_i w_i L(\theta_i) \;-\; \tfrac{1}{2}\,\mathcal{G}_{\mathrm{var}},\qquad \mathcal{G}_{\mathrm{var}} \;=\; \sum_i w_i \delta_i^\top H \delta_i \;-\; \bar\delta_w^\top H \bar\delta_w,
with \bar\delta_w = \sum_i w_i \delta_i. By Jensen, \mathcal{G}_{\mathrm{var}} \geq 0: merging is never worse than the weighted average of branch losses in the quadratic model. The gain is a curvature-weighted variance of the displacements — large only when branches disagree precisely along high-curvature directions of H.
This yields three operational consequences:
- Curvature-weighted variance reduction. Merging buys you the variance of \delta_i projected through H. Branches that differ along the flat directions of the basin contribute nothing.
- PCA-aligned conflict splitting is optimal. If splitting allocates samples so that inter-group displacements concentrate along top eigenvectors of H (or its proxy, the dataset-level gradient covariance), \mathcal{G}_{\mathrm{var}} is maximized. Random partitioning spreads variance isotropically and forfeits this gain; the advantage scales with the curvature gap between leading and trailing eigenvalues.
- Spectral filtering / implicit norm regularization. Averaging acts as a low-pass filter on high-variance directions and shrinks \|\bar\theta_w - \theta^\star\| relative to typical \|\theta_i - \theta^\star\|, providing implicit regularization on top of the variance-reduction gain.
MERIT pipeline
The five stages of MERIT mechanize the theory:
- Dataset-level gradient conflict estimation. Compute per-dataset gradient signatures at \theta^{(0)} (or a calibration checkpoint) to form a conflict matrix.
- PCA decomposition. Top-r eigenvectors of the conflict structure define the axes along which interference is largest.
- Balanced partitioning into K = 2^r groups by signs of projections onto the top-r axes, with token-balance constraints. This is the discrete realization of “split along high-curvature conflict directions.”
- Communication-free branch training. Each partition is fine-tuned independently from \theta^{(0)}; no inter-branch synchronization.
- Token-weighted merging. \bar\theta = \sum_i (n_i / \sum_j n_j)\,\theta_i where n_i is the token count of partition i.
Results
On Qwen2.5-VL-3B with 136 Vision-FLAN tasks, MERIT lifts the 8-benchmark average from 54.3 (centralized joint training) to 57.0, a +2.7 point gain, while also outperforming random partitioning at K\in\{2,4,8\} and uniform model soups. The recipe scales: on a 7B VLM with a 1.6M-example, 176-source mixture, MERIT improves the joint-FFT average from 54.9 to 55.4 on a LLaVA-style base. The aggregate number understates the rebalancing: MMVet (User Preference and Fluency) improves by +2.6 and MathVista (Image Reasoning) by +2.5, recovering the open-ended-generation degradation that joint FFT incurs, at a cost of roughly 1.5 points on text-rich VQA. Across three seeds, MERIT beats joint FFT on the 8-benchmark average in every run.
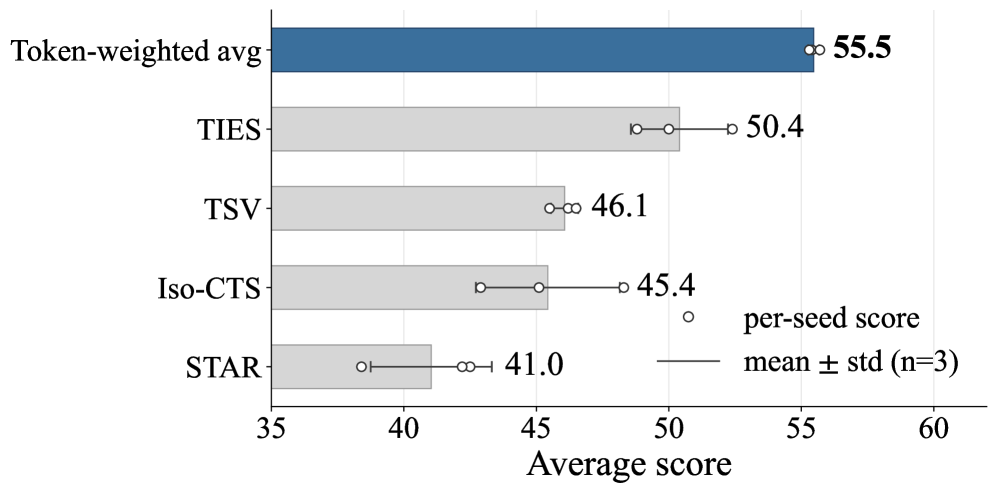
A merge-operator ablation (Figure 3) holds the four trained branches fixed and swaps the final aggregation step: token-weighted averaging beats TIES, DARE, task-arithmetic, and uniform soup on the 8-benchmark mean across three seeds. This is consistent with the theory — under the quadratic model, the optimal w for \mathcal{G}_{\mathrm{var}} depends on per-branch curvature, and token count is a reasonable proxy for the per-branch effective sample size scaling that curvature.
Limitations and open questions
The guarantees are local: everything rests on the basin assumption, which the basin-preparation stage induces empirically but is not certified for arbitrary mixtures. The conflict estimator uses dataset-level (not per-example) gradients and a single calibration point, so it can miss conflict structure that emerges late in fine-tuning. The partition count K=2^r is rigid, and PCA on gradient covariance is a proxy for the Hessian whose validity outside small-LR fine-tuning is unclear. Finally, token-weighted averaging is shown empirically optimal among tested operators, but the theory predicts curvature-weighted weights — an estimator for H-aware w_i could yield further gains.
Why this matters
MERIT shows that for instruction tuning inside a prepared flat basin, conflict-aware data partitioning plus a single parameter-space merge can replace synchronous joint training while improving the benchmark average. That decouples instruction-tuning compute from cluster topology and provides a principled, curvature-grounded reason to expect the merge to help rather than hurt.
Source: https://arxiv.org/abs/2606.01717
From Activation to Causality: Discovery of Causal Visual Representations in the Human Brain
Problem
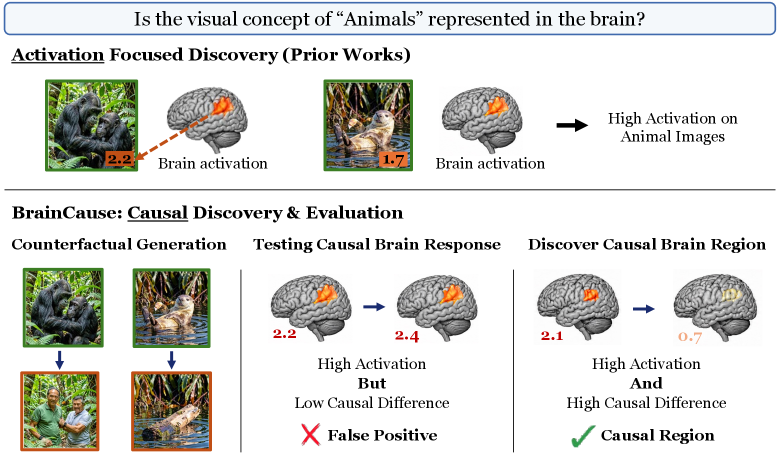
Localizing concept-selective regions in cortex — face areas, place areas, body areas — has traditionally relied on activation maximization: a voxel is labeled as representing concept C if its response to images of C exceeds its response to a contrast set. This is confounded. A “surfing” voxel that activates strongly for surfing images may in fact encode water, body pose, or human presence — features that co-occur with surfing but are not the concept itself. Without intervention on the stimulus, activation alone cannot disambiguate the represented variable from its correlates.
Method
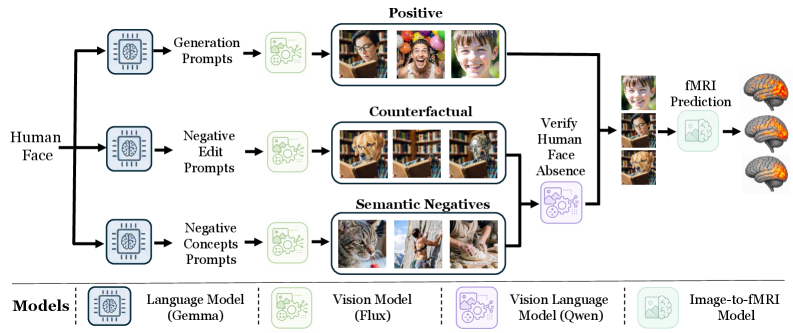
BrainCause is an automated pipeline that pairs generative models with an image-to-fMRI encoder to perform targeted causal tests on candidate voxel sets. Inputs: a concept query and a subject’s image–fMRI dataset (here, NSD, ~40K cortical voxels per subject). The pipeline has three stages.
(1) Causal dataset generation. For each target concept, an LLM (Gemma-3-27B-IT) writes diverse prompts; FLUX.2 synthesizes:
- 200 training + 100 held-out positive images of the concept.
- Semantic negatives: the LLM proposes 10 counter-concepts that correlate with but do not entail the target (for “person surfing”: “man fishing”, “beach”, “wave”). Ten prompts per counter-concept are generated with explicit instructions that the target not appear, then filtered by a VLM (Qwen3-VL-8B) for absence of the target. Yields ~80–100 semantic negatives per split.
- Counterfactual negatives: per positive image, the LLM proposes 10 minimal edits that remove the concept while preserving the rest (e.g., replace human face with animal face). FLUX.2 executes the edits.
Images without measured fMRI are pushed through the image-to-fMRI encoder to obtain predicted responses.
(2) Concept-selective representation search. Each voxel receives both an activation score (mean response to positives) and a causality score that contrasts positives against semantic negatives and counterfactual edits. The candidate region is the top-k voxels (default k=100) by the combined score. The causal contribution is what distinguishes the discovery from activation maximization: a voxel that responds to “surfing” and equally to “wave” or to a counterfactually surfer-removed beach scene is downweighted.
(3) Validation. The candidate set is evaluated on held-out predicted fMRI and on measured fMRI when matching trials exist. When measured evidence is insufficient, BrainCause flags which contrasts are missing and proposes specific stimuli for follow-up scans.
Results
Evaluated on the 4 NSD subjects who completed all 7T sessions, across 260 LLM-proposed concepts (top 50 reported quantitatively). Compared methods: Max Activation, MindSimulator (CLIP-retrieved COCO images with the same encoder), MindSimulator+VLM (with the same filtering), and BrainCause.
| Method | Act. (Gen) | Act. (Meas) | Causal (Gen) | Causal (Meas) | Edits |
|---|---|---|---|---|---|
| Max Activation | 2.76 | 0.70 | 0.08 | 0.18 | 0.44 |
| MindSimulator | 1.89 | 1.02 | -0.44 | 0.27 | 0.23 |
| MindSimulator+VLM | 2.13 | 1.12 | -0.26 | 0.41 | 0.38 |
| BrainCause | 2.05 | 1.08 | 0.62 | 0.71 | 0.98 |
BrainCause sacrifices a small amount of generated-image activation (2.05 vs. 2.76 for Max Activation) but improves the causal score on measured fMRI from 0.18 to 0.71 and the counterfactual-edit score from 0.44 to 0.98. Negative causal scores for MindSimulator (−0.44 generated) indicate its retrieved-image regions actually respond more strongly to semantic negatives than to positives — a concrete failure mode of correlation-driven discovery.
For sanity, BrainCause’s discovered regions align with known functional organization: top-100 voxels fall inside expected category-selective cortex with 99% (bodies), 90% (faces), 74% (places), and 99% (words) accuracy, decaying gracefully to 97/84/74/97% at top-500.

The “Text” example is illustrative: counterfactual edits replace text on signs with shapes or paint while preserving sign geometry and background, and semantic negatives include sketches (visually similar, no text). BrainCause’s text region drops sharply on both, supporting causal text-selectivity rather than selectivity for sign-shaped flat surfaces.
Limitations and open questions
- The causal claim is only as good as the encoder. The image-to-fMRI model is itself trained on natural images and may not faithfully predict responses to synthetic FLUX.2 outputs or to out-of-distribution counterfactual edits; systematic encoder bias on edited images would propagate as spurious “causal” gaps.
- The “minimal edit” assumption is not enforced; image-editing models routinely alter low-level statistics beyond the targeted concept, which could under- or overstate selectivity.
- VLM-based filtering of semantic negatives substitutes one black-box judgment for another; failure modes (the VLM missing subtle target presence) directly contaminate the negative set.
- All reported numbers are on NSD with 4 subjects and the top-50 concepts; concept selection and ranking interact, and the framework’s behavior on harder, more abstract concepts (e.g., “causality”, “ownership”) is not characterized.
- True intervention requires presenting counterfactual stimuli in-scanner. The paper proposes follow-up designs but the current causal evaluation on measured fMRI is limited to whatever trials happen to match the synthesized contrasts.
Why this matters
Most published “concept regions” in human visual cortex were identified by activation contrasts that cannot rule out correlated-feature explanations, and BrainCause shows this is not a hypothetical concern: a previously reported “surfing” region fails counterfactual testing. Pairing generative counterfactuals with encoding models gives systems neuroscience a scalable substitute for the missing intervention experiment, and reframes representation discovery as causal estimation rather than ranking by response magnitude.
Source: https://arxiv.org/abs/2605.23895
Trust Region On-Policy Distillation
On-policy distillation (OPD) for long-reasoning LLMs is structurally a policy-gradient problem: the student samples a trajectory x\sim\pi_S and is rewarded by teacher log-probability, with the reverse-KL gradient
\nabla D_{\mathrm{KL}}(\pi_S\|\pi_T) = \mathbb{E}_{x\sim\pi_S}\big[\nabla \log\pi_S(x)\cdot \log\tfrac{\pi_S(x)}{\pi_T(x)}\big].
In long-context regimes, full-vocabulary divergences are too expensive, so practitioners use the token-level K_1 estimator \log \pi_T/\pi_S at each sampled token. The pathology this paper targets is that when the student drifts off the teacher’s support, \log\pi_T(x_t\mid x_{<t}) becomes extremely negative on rare student tokens, producing high-variance, sometimes destructive gradients. TrOPD reframes OPD as a trust-region problem: only update on tokens where the teacher signal is reliable, and handle the rest with a different estimator.
Setup and the failure of naive variants
Section 3 defines the two memory-feasible objectives used throughout: a top-k FKL,
\mathcal{J}_{\mathrm{FKL}}^{\mathrm{top}\text{-}k} = \sum_{v\in\mathcal{V}^T_k}\pi_{T,v}\log\frac{\pi_{T,v}}{\pi_{S,v}},
and the K_1 RKL on the sampled token. A generalized JSD with mixture \pi_M=\beta\pi_T+(1-\beta)\pi_S interpolates the two (Eq. 4). Table 1, on DeepSeek-Qwen2.5-1.5B distilled from Skywork-OR1-Math-7B, shows that standalone top-k FKL collapses training (AIME24/25 go to 0.00, AMC23 to 4.21), because top-k FKL is a biased approximation of full-vocabulary FKL and the bias is applied at every sampled token. Plain RKL-OPD reaches 46.79 average across AIME24/25 and AMC23; JSD with \beta=0.5 improves marginally to 47.90. Entropy-thresholded OPD (updating only on high-entropy tokens, top 20%) does not help (46.13).
Trust region with outlier estimation
The key mechanism is splitting student-generated tokens into a trust region \mathbb{M} and outliers \overline{\mathbb{M}} based on the per-token ratio R = \log \pi_T/\pi_S (or equivalently the implied importance weight). Inside the trust region the standard RKL/K_1 gradient is used; outside, RKL is replaced by top-k FKL on the teacher’s distribution:
\mathcal{J}_{\mathrm{TrOPD}} = \mathbb{M}\,\log\frac{\pi_T}{\pi_S} \;+\; \overline{\mathbb{M}}\sum_{v\in\mathcal{V}^T_k}\pi_{T,v}\log\frac{\pi_{T,v}}{\pi_{S,v}}.
The intuition: when the student visits a token the teacher considers extremely unlikely, the K_1 gradient is unreliable (large negative reward, high variance). Switching to top-k FKL there pulls the student toward the teacher’s local mode using the teacher’s own probability mass instead of the student’s, avoiding the bias-amplification path that killed standalone top-k FKL.
Table 1 isolates this: “Mask Outlier” (zeroing the RKL gradient on outliers) gives 47.72; “Clip Outlier” via \max(\log\pi_T/\pi_S,\tau) gives 47.86; “FKL Outlier” (the TrOPD substitution above) gives 49.00. Adding the off-policy guidance branch yields the final TrOPD at 49.85.
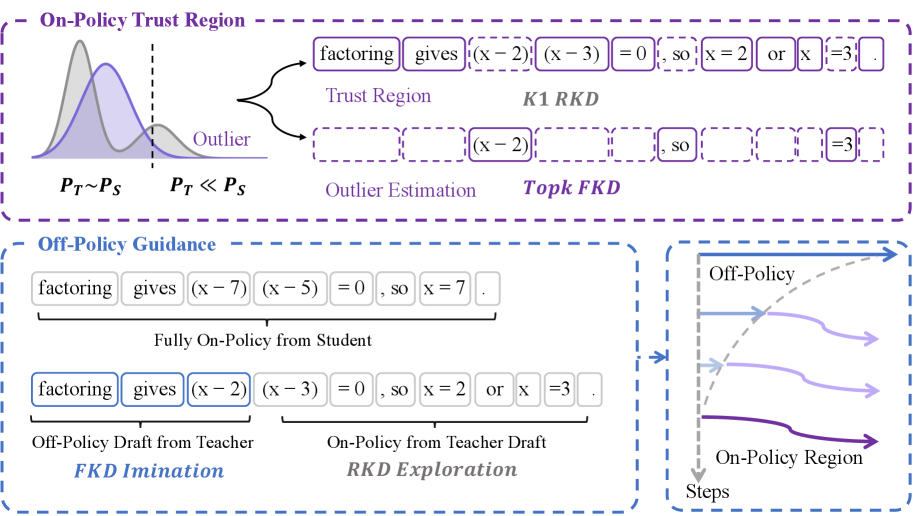
Off-policy guidance via teacher prefixes
The second contribution is a complementary off-policy term: the student continues generation from a teacher-produced prefix and is trained with top-k FKL on those continuations. Because the prefix puts the student near teacher-frequented states, top-k FKL is no longer catastrophically biased there, and the term explicitly encourages exploration toward teacher modes that pure mode-seeking RKL ignores. Figure 2 makes the architecture explicit: on-policy tokens are partitioned into trust/outlier sets with separate estimators, while a separate off-policy branch consumes teacher-prefix continuations.
Empirical results
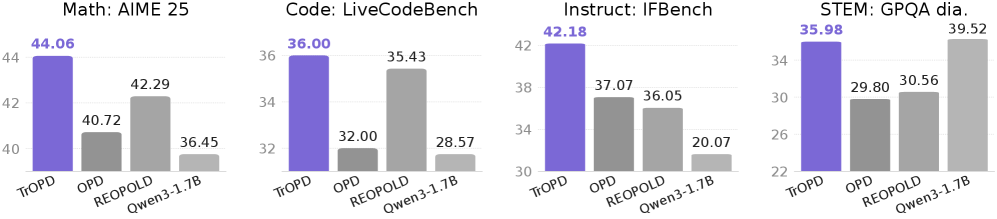
Single-domain distillation (Skywork-OR1-Math-7B → DeepSeek-R1-Distill-Qwen-1.5B, Table 3): TrOPD reaches 40.63 average over AIME24/25, AMC23, LiveCodeBench v6, and GPQA-diamond, vs. 37.11 for vanilla OPD, 38.00 for EOPD, 38.79 for REOPOLD, against a 58.48 teacher and 34.69 base. Notable per-task numbers: AIME25 32.50 (OPD 29.16), GPQA-diamond 36.24 (OPD 28.03 — OPD actually regresses from the 34.22 base here, while TrOPD improves).
Multi-domain distillation with the same student (Skywork-OR1-7B teacher) shows OPD’s instability more starkly: vanilla OPD averages 32.99, below the 34.69 base, while TrOPD recovers to 37.61 (REOPOLD 35.58). On Qwen3-SFT-1.7B distilled from Qwen3-Nemotron-4B (Table 4), TrOPD averages 51.73 across math/STEM/instruct/code vs. 48.29 for OPD and 48.56 for REOPOLD, with the largest gains on AIME24 (52.08 vs 48.02) and IFBench (42.18 vs 37.07). The teacher reaches 73.43, so substantial headroom remains.
Limitations and open questions
The trust-region threshold on R is a hyperparameter and the paper does not characterize sensitivity or adaptation schedules; in practice this likely interacts with how far apart \pi_S and \pi_T are at initialization. The top-k truncation on the teacher distribution still biases the FKL outlier term — TrOPD’s improvement over Mask Outlier (49.00 vs 47.72 in Table 1) suggests the bias is tolerable only because outliers are a minority of tokens, but as student–teacher gaps widen, the outlier set grows and this assumption weakens. The off-policy guidance branch raises a compute question (teacher rollouts plus student continuations) that is not separately ablated against the on-policy gain. Finally, all experiments use reasoning teachers whose top-k tokens carry most mass; behavior on flatter distributions (creative generation, dialogue) is untested.
Why this matters
TrOPD identifies and fixes a concrete failure mode of the K_1 RKL estimator that has been masking the value of OPD for long-reasoning models, particularly in multi-domain settings where vanilla OPD can degrade below the SFT baseline. Treating per-token teacher reliability as a trust-region condition, with FKL as the outlier fallback, is a simple recipe that integrates cleanly into existing OPD pipelines.
Source: https://arxiv.org/abs/2606.01249
Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
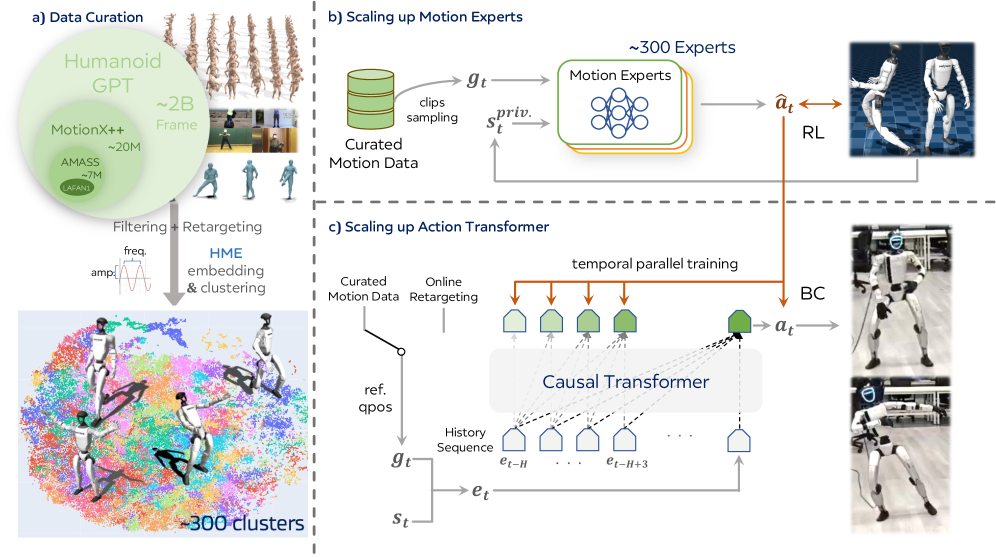
Whole-body motion tracking on humanoids has been dominated by shallow MLP policies trained per-distribution, which exhibit a well-known agility-vs-generalization trade-off: policies that nail acrobatic clips overfit, while policies trained broadly lose dynamic fidelity. Humanoid-GPT argues this is a data and capacity bottleneck, not a fundamental limit. The authors assemble a 2B-frame retargeted motion corpus, train a library of PPO experts, and distill them into a causal Transformer that tracks arbitrary online-retargeted motion on a 29-DoF Unitree G1 with no per-task finetuning.
Data pipeline
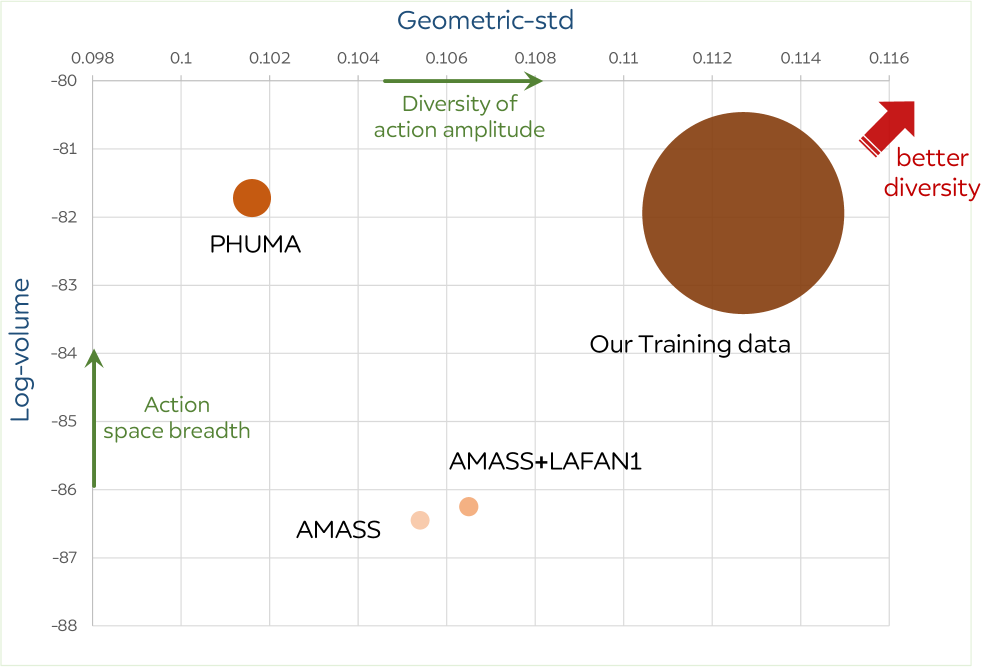
The corpus unifies AMASS, LAFAN1, MotionMillion, and PHUMA, plus in-house mocap. Sequences are retargeted to the G1’s 29-DoF joint space using an off-the-shelf retargeter, and clips with object interaction (sitting, swimming, stair climbing) are filtered out as incompatible with plain-scene actuation. A uniform speed time-warping augmentation (acceleration/deceleration) expands the dataset roughly 5×. Diversity is quantified in an HME embedding space using two axes — generalized std (gstd) and log-volume — with the merged corpus dominating any single source on both.
Two-stage training
Stage 1 partitions the corpus into clusters and trains a PPO expert per cluster. The policy \pi : \mathcal{G} \times \mathcal{S} \mapsto \mathcal{A} maps reference joint targets g_t = q_t^{\text{ref}} and privileged proprioception s_t^{priv} (joint pos/vel, root angular velocity, projected gravity, prior action) to per-joint actions converted to torques via PD control. The reward is keypoint-level over a set \mathcal{K} (arms, hips, feet, pelvis):
R_{\text{kpt}}(t) = R_{\text{pos}}(t) + R_{\text{rot}}(t) + R_{\text{vel}}(t) + R_{\text{penal}}(t),
with exponential shaping
R_{\text{pos}}(t) = \sum_{k\in\mathcal{K}} w_k \exp(-\alpha_{\text{pos}} \|e^{\text{pos}}_{k,t}\|_1),
and analogous terms for SO(3) log-map rotation error \theta_{k,t} and velocity residual e^{\text{vel}}_{k,t}. R_{\text{penal}} contains self-contact and action-smoothness terms. Only experts passing root-pose, velocity, and stable-duration thresholds are retained.
Stage 2 distills the surviving experts into a single causal GPT-style Transformer via parallel DAgger: each expert rolls out in its own simulator, and the student is trained on aggregated state-action pairs. Because the student is causal and history-conditioned, it captures long-horizon dynamics that no single MLP expert sees.
Scaling and architecture results
The headline experiment varies both training tokens and model capacity, evaluated in MuJoCo on held-out motion with success rate (SR), MPJPE, MPJVE, root velocity error, and MPKPE.
| Backbone | Tokens | Params | SR ↑ | MPJPE ↓ | MPKPE ↓ |
|---|---|---|---|---|---|
| MLP-3 | 2M | 0.25M | 76.89 | 0.1191 | 100.49 |
| TCN-8 | 2M | 0.65M | 81.48 | 0.0885 | 79.75 |
| GPT-S | 2M | 5.7M | 83.26 | 0.0853 | 62.65 |
| GPT-S | 20M | 5.7M | 86.02 | 0.0802 | 46.49 |
| GPT-B | 200M | 22.1M | 88.27 | 0.0793 | 44.78 |
| GPT-B | 2B | 22.1M | 90.43 | 0.0768 | 41.49 |
| GPT-L | 2B | 80.4M | 92.58 | 0.0735 | 40.99 |
Three observations. First, at fixed 2M tokens, swapping the MLP for a Transformer of the same data budget already lifts SR from 76.89 to 83.26 and cuts MPKPE from 100.49 to 62.65 — architecture matters before scaling. Second, holding GPT-B fixed and sweeping tokens T \in \{2\text{M}, 20\text{M}, 200\text{M}, 2\text{B}\} yields monotone improvement (SR 83.26 → 90.43), but the authors note marginal gains shrink between 200M and 2B, indicating a capacity-limited regime; the L model at 2B (SR 92.58) confirms that larger backbones still extract signal from the same corpus. Third, the gap between TCN-8 and GPT-S at equal data (81.48 vs 83.26 SR, 79.75 vs 62.65 MPKPE) supports the claim that causal attention captures long-horizon dynamics that convolutional receptive fields miss.
Real-world deployment uses an online retargeting pipeline that streams a mocap actor’s motion into the G1 joint space as the reference trajectory, with the Transformer running zero-shot on motions excluded from training.

Limitations and open questions
The motion corpus deliberately excludes object interaction (sitting, climbing, manipulation), so the policy is a pure free-space whole-body tracker — extending to contact-rich behavior likely needs a different reward and curriculum. The PD-controller and privileged-state setup imply a sim-to-real gap that the paper addresses via online retargeting but does not quantify under perturbation. The data-scaling curve flattening at 200M-2B for GPT-B suggests further data without proportional capacity scaling is wasteful; clean joint scaling laws (compute-optimal N vs D for tracking) are not yet derived. Finally, expert clustering is described abstractly — how cluster count and assignment affect downstream distillation quality is unreported.
Why this matters
This is the first credible demonstration that humanoid whole-body tracking obeys the same data-and-capacity story that drove progress in language and vision: a 2B-frame corpus plus an 80M-parameter causal Transformer collapses the agility-generalization trade-off into a single zero-shot policy. It reframes humanoid control as a distillation-and-scale problem rather than a per-skill RL problem.
Source: https://arxiv.org/abs/2606.03985
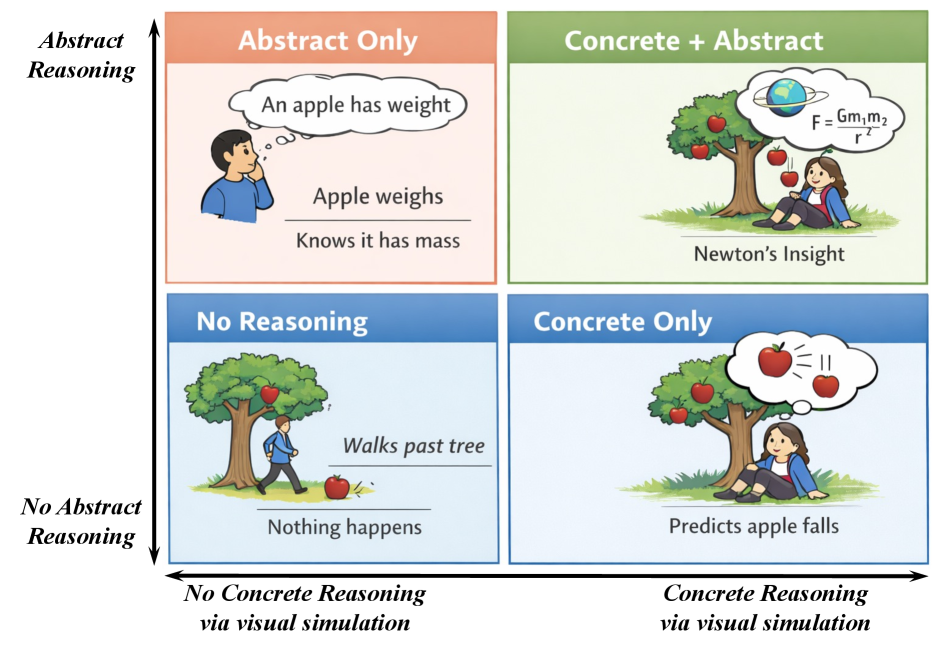
World Models Meet Language Models: On the Complementarity of Concrete and Abstract Reasoning
Problem
Future-outcome prediction from a single image plus a question sits at the intersection of two reasoning regimes that current systems treat in isolation. MLLMs reason abstractly over goals, rules, and language, but lack a mechanism to instantiate physical dynamics. Generative world models (here, Helios) can produce visually plausible rollouts \hat{v} of candidate futures, but those rollouts are stochastic and frequently task-incorrect — visually consistent yet wrong about the quantity the question actually asks. Naively conditioning an MLLM on \hat{v} therefore induces negative transfer: the answer is dragged toward whatever the rollout depicts, regardless of credibility.
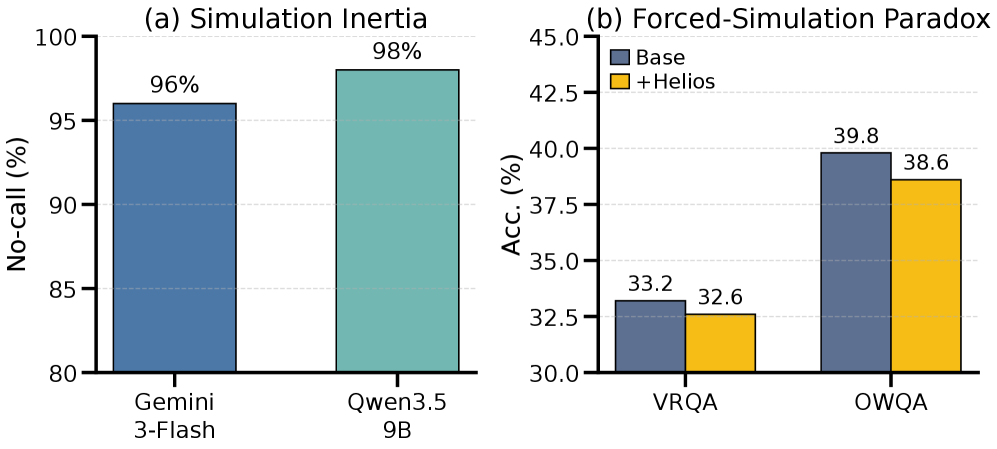
The authors document two failure modes in preliminary experiments (Figure 2): simulation inertia, where an MLLM granted optional access to a world model rarely calls it (high no-call probability), and a forced-simulation paradox, where mandating a Helios rollout decreases accuracy relative to no simulation. Both motivate treating world-model use as a controlled decision rather than a fixed pipeline stage.
Formulation: controlled concrete reasoning
Given (o, q), the policy emits a trajectory containing four control variables: a simulation decision d_{\mathrm{sim}}, a written simulation prompt p_{\mathrm{sim}}, per-rollout verification labels z_{\mathrm{ver}} \in \{\text{accept},\text{reject},\text{uncertain}\}, and a reliance/fallback variable z_{\mathrm{rel}} that mixes rollout content with abstract reasoning. The world model W supplies \hat{v} \sim W(\cdot \mid o, p_{\mathrm{sim}}) but never an answer. Up to B=3 simulation attempts are permitted; the loop halts on the first accept or at the cap:
m = \min\{i \le B : z_{\mathrm{ver}}^{(i)} = \text{accept} \vee i = B\}.
The induced trajectory distribution factorizes the policy actions and world-model samples,
p_\theta(\tau \mid x; W) = \prod_{t \in \mathcal{T}(\tau)} \pi_\theta(a_t \mid h_t) \cdot \prod_{i=1}^{N_{\mathrm{sim}}(\tau)} W(\hat{v}^{(i)} \mid o, p_{\mathrm{sim}}^{(i)}),
so W acts as a fixed stochastic environment while \pi_\theta controls when and how to invoke it.
PF-OPSD: privileged-future on-policy self-distillation
The training objective uses asymmetric information. A privileged evaluator E^+ sees the ground-truth future video v^* and answer y^* and scores trajectories sampled on-policy from the deployable student, which itself never sees v^* or y^*:
J(\theta) = \mathbb{E}_{(x,y^*,v^*)}\,\mathbb{E}_{\tau \sim p_\theta(\cdot \mid x; W)}\big[R^+(\tau; y^*, v^*)\big], \quad (y^*,v^*) \notin x_{\mathrm{test}}.
Crucially, the trajectories being scored are the student’s own — privileged data is never injected into the student’s input distribution, avoiding the standard imitation-learning pathology where a teacher with extra information teaches behaviors the student cannot reproduce at test time. The reward R^+ can grade the simulation decision (was a call necessary?), the verification label (does the rollout actually agree with v^*?), and the final answer jointly, providing dense credit assignment over the four control variables.
Training proceeds in two stages: Stage-1 SFT on protocol trajectories generated offline by a privileged Gemini-3.1-Pro + agent teacher, then Stage-2 PF-OPSD self-distillation on the student’s own rollouts scored by E^+. The student backbone is Qwen3.5-9B; W is Helios (VR-Bench-fine-tuned for VRQABench, general for OpenWorldQA).
Benchmarks and evaluation
Two human-verified benchmarks isolate complementary axes. VRQABench targets controllable spatial lookahead — the world model can be steered along structured action sequences, and the question is whether the policy invokes it appropriately and trusts its outputs only when warranted. OpenWorldQA targets open-domain physical prediction where rollouts are inherently noisier, stressing verification. Metrics span answer accuracy, simulation-decision quality (does the policy call W when it helps and skip it otherwise), and rollout-verification quality (accept/reject calibration against v^*).
Limitations and open questions
The setup inherits the quality ceiling of Helios: when rollouts are systematically biased on a category, even well-calibrated verification cannot recover correct answers — the policy can only fall back to abstract reasoning. The bound B=3 on retries is hand-set; longer search with learned termination is unexplored. The privileged evaluator’s reward must align verification labels with downstream answer correctness, and miscalibration here would teach the student to accept rollouts that look like v^* rather than rollouts that support the correct y^*. Finally, the protocol relies on a strong external teacher (Gemini-3.1-Pro + agent) for Stage-1; how much of the gain is attributable to teacher distillation versus on-policy self-distillation is not fully disentangled in the provided sections.
Why this matters
Treating world-model rollouts as untrusted evidence to be invoked, verified, and conditionally relied upon — rather than as fixed visual context — is the right abstraction for combining generative dynamics with language-based reasoning, and PF-OPSD shows that privileged futures are most useful as a training-time scoring signal over the student’s own trajectories rather than as inputs to imitate.
Source: https://arxiv.org/abs/2606.03603
TRON: Targeted Rule-Verifiable Online Environments for Visual Reasoning RL
Problem
Visual-reasoning RL post-training has inherited a habit from supervised fine-tuning: a fixed corpus of image–question–answer triples curated once, then replayed across epochs. This caps three things simultaneously — instance count, difficulty coverage, and verifier reliability. Static datasets also leak: any successor VLM can absorb them in pretraining or SFT, contaminating later evaluation. For RL specifically, the reward channel is only as clean as the answer key; noisy labels in curated multimodal data convert into biased policy gradients that are hard to diagnose downstream.
TRON replaces the corpus with a substrate. Instead of an item set, an environment is a program that produces fresh, difficulty-parameterized rollouts on demand, each with a deterministic verifier.
Method
An environment is the tuple e=(\mathcal{S},\mathcal{L},G,V) with latent state space \mathcal{S}, ten difficulty levels \mathcal{L}=\{0,\dots,9\}, a deterministic generator
G:\mathcal{S}\times\mathcal{L}\to\mathcal{I}\times\mathcal{Q}\times\mathcal{A}
mapping (s,\ell) to an image, a natural-language question, and a ground-truth answer, and a verifier V:\mathcal{A}\times\mathcal{A}\to\mathbb{R} implementing exact comparison, set/sequence equality, or a puzzle-specific solver, plus an optional format signal. The policy sees only (I,q) and is rewarded by V(a,\tilde a). Determinism in G means the seed alone fixes a sample, so reproducibility is preserved while the instance stream is unbounded.
The released suite contains 520 environments grouped into five ability buckets: spatial, mathematical, diagram, pattern/logic, and counting. Figure 1 shows the bucket organization and the generator–verifier loop.
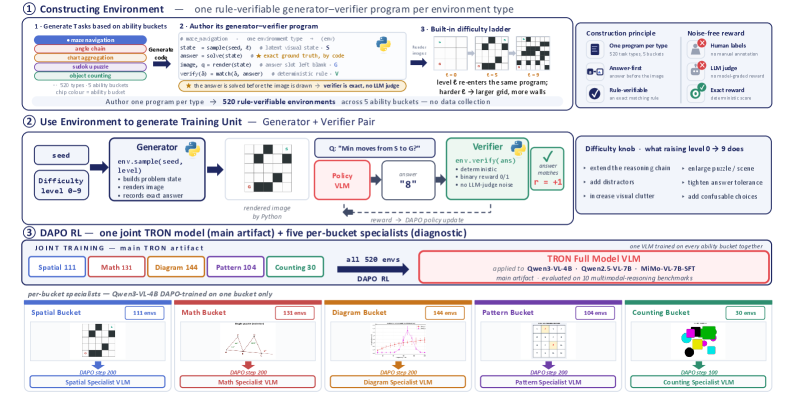
The spatial bucket illustrates how a single generator family scales along \ell — for mazes, longer paths and more branches; for cube nets, more faces and ambiguous orientations — while keeping the underlying mechanism fixed (Figure 3).
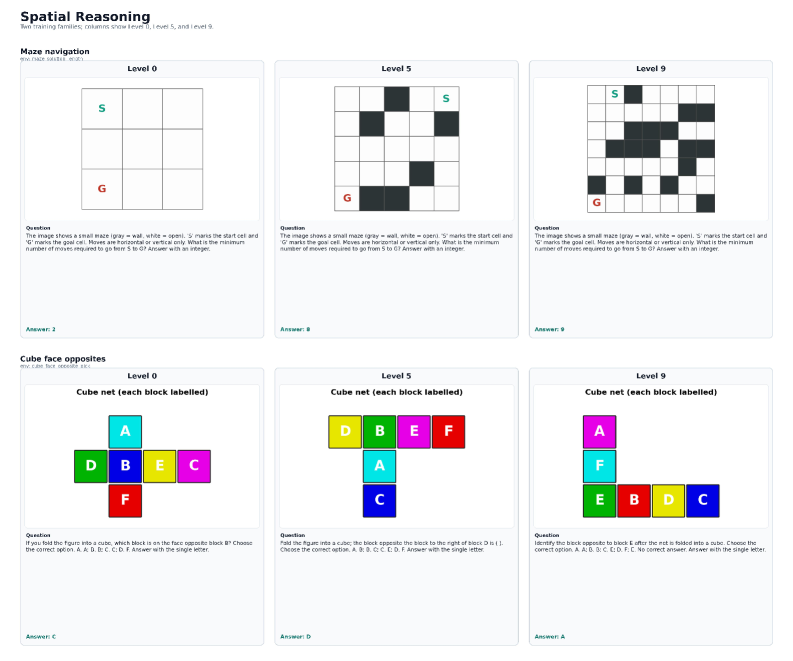
Online RL loop. At each sampling step the trainer picks (\text{env},\ell,\text{seed}) and calls G. Because seeds are fresh, no two steps see the same instance. Images are perturbed: white-pad jitter of 0–40 px per side on every sample, and with probability 0.30 one of {rotation \pm 3–8^\circ, low-quality JPEG, brightness shift, Gaussian blur, additive Gaussian noise}. The level \ell is coupled to the rollout stream rather than offline epochs (following Zeng et al.): a sliding window tracks recent verifier accuracy at the current \ell, and once it crosses a threshold over a target number of graded trajectories, the environment promotes to \ell+1. A retention window over recent levels prevents catastrophic forgetting of easier skills. The same substrate trains either a single full model across all buckets or per-bucket specialists by changing only the sampler configuration.
Substrate audit
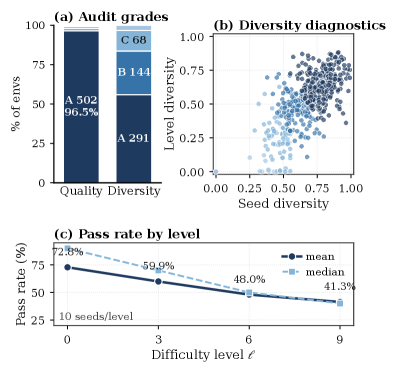
Three silent failure modes would invalidate the substrate: malformed probes, a difficulty axis that does not actually make problems harder for the model, and intra/inter-environment redundancy. The audit samples \ell\in\{0,3,6,9\} with four seeds each, yielding 8,320 probes, with 99.07% generation success.
Quality is graded by the worst of four pass rates,
Q(e)=\min\{r_{\text{gen}},r_{\text{img}},r_{\text{qa}},r_{\text{ver}}\},
with thresholds \{0.98, 0.90, 0.75\} mapping to grades A/B/C and below to D. The verifier-sanity term r_{\text{ver}} requires that wrapping the correct answer is accepted and a fixed wrong payload is rejected — a basic but often-skipped check. 502/520 environments (96.5%) receive grade A; the 18 sub-A environments were re-authored.
Mode (ii) — that \ell actually controls difficulty — cannot be tested by static inspection, so the audit additionally runs Qwen3-VL-4B on the same levels with ten seeds each and reports the pass-rate curve. Diversity D(e) combines intra-environment spread across seeds and across levels with a cross-environment near-duplicate predicate to catch two distinctly-named generators that collapse to the same image–question distribution.
Limitations and open questions
The paper’s truncated experiments section (the abstract ends mid-sentence at “RL post-training”) leaves the headline downstream numbers unspecified in the provided material; only the audit statistics — 99.07% generation success, 96.5% grade-A environments — are quantified here. Procedural generation also constrains the distribution: TRON cannot easily express tasks whose ground truth depends on world knowledge, open-ended scene understanding, or human aesthetic judgment, since these resist deterministic verifiers. The ten-level \ell axis is per-environment hand-designed; whether monotonicity in \ell implies monotonic difficulty for the current policy (not just the base VLM probed once) needs continuous re-audit during training. Finally, the curriculum-promotion rule is threshold-based on a sliding window — robustness to reward-hacking strategies that exploit verifier format signals rather than solving the task is not analyzed in the provided sections.
Why this matters
Static multimodal RL datasets confuse three orthogonal axes — scale, difficulty, and verifier quality — and are vulnerable to contamination by future base models. TRON separates them: scale is bounded only by compute, difficulty is a controlled input, and verifiers are programs rather than annotators. This is the multimodal analogue of the move from human-labeled math datasets to rule-verifiable RL environments that drove recent progress in textual reasoning.
Source: https://arxiv.org/abs/2606.01599
Hacker News Signals
MAI-Code-1-Flash
Microsoft released MAI-Code-1-Flash, a coding-focused model positioned as a high-throughput, low-latency alternative to frontier models. The “Flash” designation signals the same design philosophy seen in Gemini Flash and Claude Haiku: aggressive optimization for inference cost and speed rather than maximum capability. Microsoft claims competitive performance with GPT-4o and Claude Sonnet on standard coding benchmarks (HumanEval, SWE-bench variants) while running at significantly lower cost per token.
The model is offered via Azure AI Foundry and the GitHub Models marketplace. Architecturally, Microsoft has not published full details, but the positioning suggests distillation from a larger model combined with speculative decoding or similar inference acceleration. The emphasis on “Flash” throughput characteristics implies a smaller parameter count with capability recovery through training data curation — heavy weighting on code, diffs, repository context, and tool-use traces.
Benchmark numbers cited include strong performance on LiveCodeBench and internal Microsoft coding evals. The model supports function calling and structured output natively, which matters for agentic coding pipelines where JSON reliability degrades with smaller models.
The practical angle here is the cost-capability tradeoff in production coding assistants. At scale — say, an IDE plugin making tens of thousands of completions per hour — a 5x latency and cost reduction with 10% capability loss is often the correct engineering decision. MAI-Code-1-Flash is targeting that slot against Mistral Codestral and DeepSeek-Coder-V2-Lite.
Source: https://microsoft.ai/news/introducingmai-code-1-flash/
MAI-Thinking-1
MAI-Thinking-1 is Microsoft’s entry into the chain-of-thought reasoning model category, competing directly with OpenAI o3, DeepSeek-R1, and Gemini Thinking. The model generates extended internal reasoning traces before producing a final answer — the now-standard “thinking token” paradigm where the model is trained (typically via RL against outcome-based reward signals) to produce long scratchpads.
Microsoft reports strong results on math and science benchmarks: AIME 2024/2025, GPQA Diamond, and graduate-level STEM problem sets. Specific numbers cited place it competitively with o3-mini on AIME and above GPT-4o on GPQA, though direct apples-to-apples comparison depends heavily on compute budget (thinking token count) at inference time.
The architectural and training details are sparse, consistent with Microsoft’s recent pattern of releasing model capabilities ahead of papers. The inference interface exposes thinking token budgeting, meaning callers can trade latency for answer quality by capping the reasoning chain length — a non-trivial API design decision because optimal budget varies by problem difficulty.
One technically interesting aspect is the interaction between thinking traces and tool use. MAI-Thinking-1 apparently supports interleaved tool calls within the reasoning chain, which is harder to train than post-hoc tool use: the RL reward signal must credit intermediate tool calls that occur inside a long trace, requiring either process reward models or careful outcome attribution.
The model is available in Azure AI Foundry. The broader context is that Microsoft is building a full model tier stack (Flash for throughput, standard for balance, Thinking for hard reasoning) independent of its OpenAI relationship.
Source: https://microsoft.ai/news/introducing-mai-thinking-1/
Rethinking Search as Code Generation
Perplexity Research argues that classical information retrieval — query embedding, ANN lookup, BM25 fusion, reranking — should be replaced or augmented by treating search as a code generation problem. The core idea: a language model writes executable retrieval programs (Python calling search APIs, SQL over document stores, filter chains) rather than producing a single dense query vector. The generated code is then executed to retrieve documents.
The technical motivation is that dense retrieval collapses query intent into a fixed-dimensional vector, losing compositional structure. A query like “papers citing Vaswani 2017 with more than 100 citations published after 2022” is trivially expressible as code but requires contortions in embedding space. Code generation externalizes the reasoning about filters, joins, and multi-hop retrieval into a substrate that executes exactly.
The approach resembles ReAct and Toolformer-style tool use but applied specifically to the retrieval loop. The model generates retrieval code, executes it, inspects intermediate results, and may iterate — a process closer to an agent loop than a single forward pass. Perplexity’s internal search stack, which already does query decomposition and multi-step retrieval, is a natural fit for this paradigm.
The paper/post discusses evaluation on multi-hop QA benchmarks (MuSiQue, HotpotQA variants) where compositional retrieval is necessary. Code-generation-based retrieval outperforms single-shot dense retrieval and reranking baselines on these tasks.
Open questions: latency (code execution adds round-trips), reliability of generated code (syntax errors, hallucinated API calls), and whether gains hold on single-hop factual retrieval where dense methods already work well.
Source: https://research.perplexity.ai/articles/rethinking-search-as-code-generation
Use Your Nvidia GPU’s VRAM as Swap Space on Linux
This project exposes GPU VRAM as a Linux block device via NBD (Network Block Device), then mounts that block device as a swap partition. The implementation uses the CUDA virtual memory API to allocate VRAM, wraps it with an NBD server process, and connects the kernel’s NBD client to it over loopback. The resulting swap device appears to the kernel as ordinary swap space.
The technical interest is the memory bandwidth differential. GPU VRAM (GDDR6X, HBM3) has bandwidth in the range of 1–3 TB/s, while DRAM is ~50–100 GB/s and NVMe is ~7 GB/s. From the kernel’s perspective, swapping to this device is orders of magnitude faster than NVMe swap and potentially competitive with DRAM for sequential access patterns. The latency story is more complicated: the loopback NBD path adds syscall and context-switch overhead that DRAM does not have, but for large working sets that would otherwise swap to NVMe, VRAM swap is a clear win.
The setup requires a discrete GPU with spare VRAM — meaning no compute workload consuming it, or a secondary GPU. For a workstation running large LLM inference on CPU with a gaming GPU sitting idle, this is a legitimate configuration.
Limitations: the NBD loopback path is not zero-copy; data traverses the PCIe bus twice (CPU to GPU on write, GPU to CPU on read) plus the software NBD stack. True bandwidth is limited by PCIe bandwidth (~32 GB/s for PCIe 4.0 x16) not VRAM bandwidth. Still, 32 GB/s swap bandwidth versus 7 GB/s NVMe is a 4-5x improvement for swap-heavy workloads.
Source: https://github.com/c0dejedi/nbd-vram
How We Index Images for RAG
Kapa.ai describes their production pipeline for incorporating images into a retrieval-augmented generation system for technical documentation. The problem is that standard RAG indexes text chunks; images in documentation (architecture diagrams, CLI output screenshots, API flow charts) are either dropped or treated as opaque blobs, losing information that is often critical for answering technical questions.
Their pipeline has three stages. First, images are extracted from documentation sources (HTML, PDF, Markdown) along with their surrounding text context — captions, alt text, adjacent paragraphs. Second, a vision-language model (they use GPT-4V / GPT-4o) generates a dense text description of each image, including extracted text (OCR-equivalent), structural description, and semantic summary. Third, these generated descriptions are embedded and indexed alongside the text chunks in a standard vector store.
At query time, retrieved image descriptions are included in the context window with a reference to the original image URL, allowing the generation model to reason about visual content it did not directly see. For cases where the user query is likely to benefit from visual context, the image itself can be fetched and passed to a vision model.
The key engineering decision is using generated descriptions rather than raw CLIP-style image embeddings. CLIP embeddings have weak alignment with the kind of technical queries (“what does the architecture diagram for X look like”) compared to text-text retrieval over generated captions. The tradeoff is indexing cost — one GPT-4o call per image is expensive at scale.
They report improved answer quality on documentation questions that reference diagrams, with the main remaining failure mode being complex technical diagrams where the VLM description loses structural information (e.g., graph topology).
Source: https://www.kapa.ai/blog/how-we-index-images-for-rag
Bringing Up DeepSeek-V4-Flash on AMD MI300X
A detailed engineering post on running DeepSeek-V4-Flash (a mixture-of-experts model in the DeepSeek lineage) on AMD MI300X hardware. The MI300X is AMD’s HBM3-based data center accelerator with 192 GB HBM3 per card, making it attractive for large model inference. The challenge is that the software ecosystem — ROCm, vLLM ROCm forks, flash attention ports — lags the CUDA stack in maturity.
The post covers the full bring-up stack: ROCm version selection (ROCm 6.x has significantly better transformer kernel performance than 5.x), vLLM configuration for MoE models (tensor parallelism degree, expert parallelism for MoE routing), and triton kernel compatibility issues on CDNA3 architecture. DeepSeek’s MoE routing requires all-to-all communication between experts that is topology-sensitive; the MI300X’s interconnect (Infinity Fabric) behaves differently from NVLink, requiring tuning of communication granularity.
Specific issues documented: flash attention on ROCm required a patched version; some triton kernels needed manual adjustment of block sizes for the CDNA3 wavefront width (64 vs CUDA’s 32); and the default vLLM memory allocator over-estimated fragmentation leading to OOM errors correctable by adjusting gpu_memory_utilization.
Performance results: the author achieves throughput within roughly 15-20% of reported CUDA A100/H100 numbers after tuning, which is a reasonable result given the maturity gap. The 192 GB HBM3 per card is the headline advantage — fitting larger models or larger KV caches without multi-node inference.
This matters for teams evaluating AMD as a cost-alternative to H100s for large MoE inference workloads.
Source: https://fergusfinn.com/blog/deepseek-v4-flash-mi300x/
Benchmarking SurrealDB 3.x vs. Postgres, Mongo, Neo4j and Redis (With Fsync)
SurrealDB published benchmarks comparing version 3.x against Postgres 16, MongoDB 7, Neo4j 5, and Redis 7 across read, write, and graph traversal workloads. The “With Fsync” in the title is a pointed reference to past benchmark controversies where databases disabled fsync (essentially disabling durability guarantees) to inflate write numbers.
The methodology: all databases run with fsync/equivalent durability enabled, single-node, on identical hardware. Workloads cover point reads, bulk inserts, range scans, and graph traversal (connected-component style queries). SurrealDB uses its native SurrealKV storage layer in 3.x, replacing the previous embedded RocksDB backend.
Results as reported by SurrealDB (vendor-run benchmark, caveat emptor): SurrealDB 3.x claims competitive read throughput with Postgres on simple point lookups, 2-3x higher write throughput on bulk inserts, and substantially better graph traversal performance versus Neo4j on their test graph topology. Redis comparisons are on persistent-mode Redis, where SurrealDB is within 2x on reads.
The appropriate skepticism: vendor benchmarks optimize schema design, index configuration, and query patterns to favor the vendor’s product. The graph traversal comparison with Neo4j depends heavily on graph density and query pattern — Neo4j’s native graph engine has well-known advantages on deep traversals that simple benchmarks may not capture.
The technically interesting part of the post is the SurrealKV storage engine design: it uses a custom MVCC implementation over a log-structured merge-tree with SurrealDB-specific optimizations for multi-model access patterns (key-value, document, and graph queries against the same storage layer). Whether those architectural bets pay off in real workloads requires independent benchmarking.
Source: https://surrealdb.com/blog/surrealdb-3-x-by-the-numbers
AI Outperforms Law Professors in Stanford Law Study
Stanford Law School published results from a controlled study comparing AI systems (GPT-4o, o1, and Claude 3.5 Sonnet) against law professors and law students on legal analysis tasks. The task format: written legal problems requiring issue spotting, rule application, and reasoned argument — the standard law school exam format (IRAC: Issue, Rule, Application, Conclusion).
The evaluation was blinded: expert graders assessed responses without knowing whether author was human or AI. AI responses (particularly o1) scored higher on average than both law professor responses and student responses on multiple rubric dimensions including comprehensiveness of issue spotting and logical consistency of argument.
The technical substance worth examining: legal reasoning maps well onto the capabilities of reasoning models. IRAC is a structured decomposition that resembles chain-of-thought — identify the legal question, state the applicable rule, apply facts to rule, conclude. The rule-application step requires retrieving training-time legal knowledge (statutes, case holdings) and applying it systematically, which large models with legal training data handle well. The weakness in AI legal reasoning is typically jurisdictional specificity, recent case law post training cutoff, and practical judgment about what arguments a court would actually accept — none of which standard benchmarks test.
The study design matters: law school exam problems are closed-world (all relevant facts are given), divorced from client interaction and procedural context, and graded on structured rubrics. This is the most favorable possible environment for LLMs. Performance on actual legal practice tasks — discovery, contract negotiation, courtroom judgment — is a separate question.
Source: https://law.stanford.edu/press/ai-outperforms-law-professors-in-stanford-law-study/
Noteworthy New Repositories
study8677/awesome-architecture
A curated, bilingual (Chinese/English) reference for software architecture patterns, organized around 21 architecture maps covering topics from AI gateways and RAG pipelines to inference serving, vector databases, and multi-agent systems. Each map is not just a diagram but a structured template linked to real open-source prototype implementations, making it actionable rather than purely illustrative.
The repository is structured as a language-agnostic system-design tutorial, meaning the patterns are expressed at the interface and data-flow level without tying examples to a specific stack. Coverage spans distributed systems fundamentals (consistency models, partition tolerance trade-offs) as well as ML-specific infrastructure concerns: how to route and rate-limit LLM traffic through an AI gateway, how to decompose a RAG pipeline into retrieval, reranking, and generation stages with defined contracts between components, and how to scale inference serving under latency constraints.
The dual-language presentation is deliberate: explanations appear in both Mandarin and English within the same document, which is useful for teams operating across language boundaries or for readers who learned systems vocabulary in one language and want to cross-reference in the other.
Where it distinguishes itself from generic “awesome” lists is the prototype linkage — rather than pointing at documentation, maps link to runnable or inspectable codebases that instantiate the pattern. Useful as a structured onboarding resource or a pre-design-review checklist.
Source: https://github.com/study8677/awesome-architecture
trynullsec/nullsec-s1
A security-focused LLM system aimed at application security workflows: static analysis triage, vulnerability explanation, and security review assistance. The positioning as “security-native” implies the model or system prompt engineering is tuned on security corpora (CVE descriptions, OWASP patterns, CWE taxonomies) rather than being a generic coding assistant with a security-themed wrapper.
Architecturally, nullsec-s1 appears to be a reasoning-augmented agent that can ingest code or dependency manifests and produce structured security assessments. The S1 designation suggests it may follow a staged reasoning approach — generating an initial assessment and then critiquing or refining it — which is consistent with how chain-of-thought techniques improve precision on classification-heavy tasks like determining exploitability.
The practical value over dropping code into a generic LLM is domain alignment: security analysis requires understanding not just what code does but what an adversary can cause it to do under adversarial inputs, which requires prompting discipline and possibly fine-tuned priors. The repository is still early-stage with limited documentation, so the primary artifact is the prompt and agentic scaffolding rather than a novel model. Likely most useful to AppSec engineers wanting to automate first-pass triage on pull requests or new dependencies rather than replace manual penetration testing.
Source: https://github.com/trynullsec/nullsec-s1
KevRojo/Dulus
A terminal-native agentic coding assistant that presents itself as a general-purpose CLI agent capable of reading and editing files, executing Bash commands, running grep across repositories, browsing the web, and authoring commits. The headline claim — 98% cache hit rate across a 2-billion-token session spanning three months — points to an aggressive KV-cache management strategy as the core technical differentiator.
Achieving high cache hit rates at that scale requires careful prompt construction: the invariant prefix (system prompt, project context, long-term conversation history) must be frozen and byte-identical across turns so that the inference server’s prefix cache is never invalidated unnecessarily. This implies Dulus structures its context window with a static prefix block and appends only new turns at the tail, avoiding the common mistake of re-serializing dynamic state (timestamps, session IDs) into the prompt prefix.
The tool-use surface is standard — file I/O, shell execution, web fetch, git operations — but the engineering emphasis on cache efficiency makes it practical for long-running software development sessions where re-feeding context on every turn would be prohibitively expensive. The CLI-first design avoids IDE coupling, making it composable with existing shell workflows and scriptable in automation pipelines. Written to be model-agnostic at the API level.
Source: https://github.com/KevRojo/Dulus
usewhale/DeepSeek-Code-Whale
A terminal-first AI coding agent built specifically around DeepSeek models, emphasizing a 1-million-token context window, persistent sessions across invocations, Model Context Protocol (MCP) tool integration, and dynamic workflow composition. The DeepSeek-specific focus means the system is optimized for DeepSeek’s tokenizer, API semantics, and pricing structure rather than being a thin wrapper over a generic OpenAI-compatible endpoint.
Persistent sessions are the key ergonomic feature: rather than cold-starting context on each run, Whale serializes session state to disk and resumes with the full prior context intact on the next invocation. At 1M context this is meaningful — a developer can accumulate days of iterative coding context without manual summarization or context-window management.
MCP tool support enables the agent to call structured external tools (file operations, search, code execution) using a typed protocol rather than freeform bash, reducing the surface for injection and improving reliability of tool dispatch. Dynamic workflows allow branching and looping over tool calls based on intermediate results, which is necessary for tasks like “find all usages of this function, check if any violate the new invariant, fix those that do.”
Positioning against Dulus and similar tools: Whale trades model-agnosticism for DeepSeek-specific optimization, which is a reasonable trade if DeepSeek is your primary inference backend.
Source: https://github.com/usewhale/DeepSeek-Code-Whale
margelo/react-native-runtimes
A React Native library that lets developers spin up isolated Hermes JavaScript runtimes on background threads, enabling heavy computation or large component trees to run without blocking the main JS thread. The core problem it addresses is React Native’s single-threaded JS execution model: all JavaScript — UI logic, business logic, data transformation — normally shares one Hermes instance, so a long-running operation stalls rendering.
The library exposes an API to instantiate additional Hermes runtimes, pass serializable data into them, execute JS workloads, and receive results back on the main thread. Each runtime is fully isolated: it has its own heap, its own global scope, and no shared mutable state with the main runtime, which eliminates race conditions by construction.
Technically this is non-trivial because Hermes is not designed as a multi-instance engine by default within a single process; the library handles the lifecycle management, thread affinity, and cross-runtime message passing. JSI (JavaScript Interface) is used for native-to-JS bridging, keeping communication overhead low relative to the legacy bridge.
Use cases include: running ML inference (ONNX Runtime bindings, TensorFlow.js) without jank, processing large datasets before display, or isolating third-party scripts. Comparable in concept to Web Workers, but for React Native’s engine. From the Margelo team, known for performance-focused RN libraries.
Source: https://github.com/margelo/react-native-runtimes
duncatzat/vigils
A local control plane for AI agents built in Rust with a Tauri desktop frontend and a Chrome Manifest V3 extension. The core problem it solves is agent auditability and authorization: as LLM agents gain tool-use capabilities, there is no standard mechanism for a human operator to inspect what actions are pending, approve or reject individual steps, or ensure secrets are not leaked into agent context.
Vigils inserts itself as an intermediary layer. The Rust backend captures agent action requests before execution — file writes, API calls, shell commands — and surfaces them in the Tauri UI for human review. The Chrome MV3 extension extends this interception to browser-based agent actions (DOM manipulation, form submission, navigation). The local-first architecture means no action metadata leaves the machine, which matters when the agent has access to credentials or proprietary code.
Secret management is an explicit design concern: the system can detect when a proposed agent action would expose a secret (API key, token, password from a local vault) and either redact it or require explicit confirmation before proceeding. This addresses a real attack surface — prompt injection causing an agent to exfiltrate credentials via a seemingly benign tool call.
The Rust + Tauri stack gives a small binary footprint and native performance for the interception hot path. Relevant for anyone running autonomous agents against production systems or sensitive codebases.
Source: https://github.com/duncatzat/vigils
wanshuiyin/ARIS-in-AI-Offer
A bilingual (Chinese/English) collection of interview preparation materials for ML and AI engineering roles, covering large language models, diffusion models, and agent systems. The content is structured as cheat sheets — dense, reference-style summaries designed for rapid review before interviews — rather than tutorial-length explanations.
The technical pipeline distinguishing this from a static document dump is the ARIS /render-html workflow, which auto-generates self-contained single-file HTML outputs from the source content. This means the entire cheat sheet corpus can be opened offline in any browser without a build system or server, which is the practical format needed when reviewing on a phone the morning of an interview.
A secondary feature is an academic homepage generator that ingests a CV and cross-checks claimed publications against DBLP, flagging discrepancies. This is useful for building a credible academic presence and catching citation errors before submission to faculty or industry research roles.
Coverage on the ML side includes: transformer architecture details, attention complexity, diffusion model DDPM/DDIM derivations, RLHF mechanics, RAG pipeline design, and common agent framework patterns. The level of detail is calibrated for PhD-level or senior engineer interviews at Chinese tech companies (Baidu, Alibaba, ByteDance) and international AI labs, where questions frequently probe implementation-level understanding.
Source: https://github.com/wanshuiyin/ARIS-in-AI-Offer
WantongC/journal-adapt-writing-skill
A tool for learning a target journal’s writing conventions from its corpus of published papers and then applying those conventions to revise a manuscript section by section. The problem it addresses is real and underserved: academic writing style varies substantially across journals — sentence length norms, hedging conventions, citation density, passive vs. active voice ratios, how methods sections are structured — and these patterns are difficult to internalize by reading a style guide alone.
The approach is corpus-driven style transfer. Given a set of published papers from a target journal, the system extracts stylistic features at multiple granularities: lexical (vocabulary preferences, technical term usage), syntactic (sentence structure patterns), and structural (section organization, transition conventions). These features are then used as a conditioning signal when revising the user’s manuscript.
The section-by-section processing is important: introduction, methods, results, and discussion sections each have distinct rhetorical structures even within the same journal, so applying a single uniform style profile would be incorrect. The tool handles each section with section-type-aware prompting.
This is not a paraphrasing or grammar tool — it is attempting to shift the manuscript’s register to match a specific publication venue’s implicit norms, which is a higher-level stylistic operation. Most useful at the revision stage after scientific content is finalized, particularly for non-native English writers targeting competitive venues.
Source: https://github.com/WantongC/journal-adapt-writing-skill