デイリーAIダイジェスト — 2026-05-22
arXiv ハイライト
Gated DeltaNet-2: Linear Attentionにおける消去と書き込みの分離
問題設定
Linear attentionは、softmax attentionの無制限なKVキャッシュを固定サイズの行列状態 \mathbf{S}_t \in \mathbb{R}^{d_k \times d_v} に圧縮することで、学習時 O(L)、デコード時 O(1) のメモリを実現します。再帰式 \mathbf{S}_t = \mathbf{S}_{t-1} + \bm{k}_t \bm{v}_t^\top は外積を減算なしに蓄積するため、古い情報は干渉によってしか減衰しません。delta-rule系の研究(DeltaNet、Gated DeltaNet、Kimi Delta Attention)は、書き込み前に現在の読み取り結果を減算することでこの問題を解決します:
\mathbf{S}_t = \mathbf{S}_{t-1} - \beta_t \bm{k}_t (\mathbf{S}_{t-1}^\top \bm{k}_t)^\top + \beta_t \bm{k}_t \bm{v}_t^\top.
KDAはさらに、チャネルごとの減衰 \bm{\alpha}_t \in (0,1]^{d_k} を \mathbf{D}_t = \operatorname{Diag}(\bm{\alpha}_t) として編集前に適用します。未解決の問題として、スカラー \beta_t が2つの異なる決定を同時に制御している点が挙げられます。すなわち、キー \bm{k}_t における古い内容をどの程度消去するか、および新しい値 \bm{v}_t をどの程度コミットするかです。これらを同一パラメータで拘束すると、rank-1更新のキー(読み取り)側と値(書き込み)側の両方に同じチャネル構造が強制されますが、これは幾何学的に根拠がありません。
手法:Gated Delta Rule-2
Gated DeltaNet-2は、キー側の消去gate \bm{b}_t \in [0,1]^{d_k} と値側の書き込みgate \bm{w}_t \in [0,1]^{d_v} という2つの独立したチャネルごとのgateを導入します。\bm{e}_t = \bm{b}_t \odot \bm{k}_t、\bm{z}_t = \bm{w}_t \odot \bm{v}_t と定義します。\mathbf{D}_t = \operatorname{Diag}(\bm{\alpha}_t) を用いた減衰後編集の再帰式は以下のとおりです:
\bar{\mathbf{S}}_t = \mathbf{D}_t \mathbf{S}_{t-1}, \quad \bm{r}_t = \bar{\mathbf{S}}_t^\top \bm{e}_t, \quad \mathbf{S}_t = \bar{\mathbf{S}}_t + \bm{k}_t (\bm{z}_t - \bm{r}_t)^\top,
これは以下の閉形式と等価です:
\mathbf{S}_t = \bigl(\mathbf{I} - \bm{k}_t (\bm{b}_t \odot \bm{k}_t)^\top\bigr) \mathbf{D}_t \mathbf{S}_{t-1} + \bm{k}_t (\bm{w}_t \odot \bm{v}_t)^\top.
構造的なポイントとして、rank-1消去の左因子は \bm{k}_t(書き込み方向を保持)のままであり、右因子 \bm{b}_t \odot \bm{k}_t が読み取り方向をチャネル選択的にし、書き込み項 \bm{k}_t \bm{z}_t^\top が挿入される値をチャネル選択的にします。\bm{b}_t = \beta_t \mathbf{1}_{d_k} かつ \bm{w}_t = \beta_t \mathbf{1}_{d_v} のとき、KDAが厳密に復元されます。さらに \bm{\alpha}_t をスカラーに縮退させると、Gated DeltaNetが復元されます。したがって、本モデルは先行研究を拘束された部分空間として厳密に包含します。
Gateは独立した線形射影を通じてsigmoidで生成されます:
\bm{b}_t = \sigma(\mathbf{W}_b \bm{x}_t), \quad \bm{w}_t = \sigma(\mathbf{W}_w \bm{x}_t),
一方、log減衰はGated DeltaNetの形式 \bm{g}_t = -\exp(\mathbf{a}) \odot \operatorname{softplus}(\mathbf{W}_f \bm{x}_t + \bm{\delta}) に従い、\bm{\alpha}_t = \exp(\bm{g}_t) はfp32で計算されることで累積log減衰における精度低下を回避します。負固有値バリアントは消去gateのみを [0,2]^{d_k} にスケールします。これは状態遷移 \mathbf{I} - \bm{k}_t \bm{e}_t^\top のスペクトル効果が値の大きさではなく消去因子に依存するためです。
論文では、チャネルごとの減衰を非対称消去因子に吸収したチャンクごとのWYスタイルアルゴリズムを導出しています。これにより、分離されたgateを正確に保ちながら、チャンク粒度でtensor core上での学習が可能になります。
結果
1.3Bパラメータで100B FineWeb-Eduトークン(4Kコンテキスト、AdamW、ピーク学習率 4 \times 10^{-4}、バッチ0.5Mトークン)を学習した結果、Gated DeltaNet-2は言語モデリングおよびゼロショット推論の平均においてMamba-2、Gated DeltaNet、KDA、Mamba-3 SISO/MIMOの両バリアントを上回ります。Recurrentのみの場合:Wikitext ppl 15.90(KDA 16.81、Gated DeltaNet 16.40、Mamba-3 MIMO 16.45と比較)、LAMBADA ppl 11.41(KDA 11.68と比較)、平均精度 53.11(次点のMamba-3 MIMO 52.39、KDA 52.28と比較)。Hybrid(2Kスライディングウィンドウattention併用):平均 53.97、LAMBADA ppl 10.43、BoolQ 62.57。
差は連想想起においてさらに広がります。4KコンテキストのRULER S-NIAH-2では、recurrentのGated DeltaNet-2が93.0に達し、KDA 89.0、Gated DeltaNet 87.2を上回ります。8Kでは39.2対KDA 30.6、Mamba-2 21.0です。2KのS-NIAH-3では89.8対KDA 63.2、Gated DeltaNet 54.2となり、状態が記憶した結合を積極的に書き直す必要があるレジームでKDAに対して26ポイントの差をつけます。4KのMK-NIAH-1では37.8対KDA 28.0です。Hybridモデルも長文脈マルチキー想起において先頭に立ちます:4KのMK-NIAH-1は48.0対Mamba-3 MIMO 46.6、KDA 40.4です。これらはまさに消去と書き込みの分離が効果を発揮すべきタスクです。特定の結合を編集しながら同時記憶された結合を乱さないためには、読み取り側と書き込み側に異なるチャネルマスクが必要です。
制限事項
評価は1.3B / 100Bトークンの4K学習コンテキストで行われており、Mamba-3やKDAが元々調整されたレジームと比較して小規模です。追加のgateパラメータのスケーリング挙動は特性評価されていません。標準的な推論タスクにおけるKDAに対するゲインは控えめ(平均53.11対52.28 recurrentのみ)であり、優位性の大部分は想起スタイルのベンチマークに集中しています。非対称消去因子を用いたチャンクごとのWYカーネルは記述されていますが、KDAのカーネルに対するスループット数値は抜粋中に報告されておらず、第2のgateの実際の実行時コストは不明です。\bm{b}_t 単独と \bm{w}_t 単独を切り離したアブレーションがなく、想起性能の向上がどちら側の分離に起因するかが明確ではありません。
重要性
delta ruleをrank-1状態編集として捉えることで、「何を忘れるか」と「何を書き込むか」が外積の異なる側に存在し、gateを共有する必要がないことが明示的になります。Gated DeltaNet-2はこの点を尊重した最小限の一般化であり、KDAとGated DeltaNetを厳密な部分空間として包含し、最も効果が期待される場面、すなわち固定サイズ状態下でのマルチキー連想想起において成果を上げています。
Source: https://arxiv.org/abs/2605.22791
教師なしProcess Reward Models
Process Reward Models(PRMs)はステップレベルの監督を提供し、LLMの推論を制御するうえで有効性が実証されていますが、その学習にはステップごとの正誤アノテーションが必要であり、中程度の規模でもコストが高くなります(PRM800Kは人的労力に約10^6を要しました)。本論文では、ステップレベルのラベルも最終回答の検証も一切用いずにPRMを学習する手法「uPRM」を提案します。これは、推論が最初に誤る箇所のノイズを含む結合推定器として、ベースLLM自身の次トークン確率を活用するものです。
最初の誤り位置のスコアリング
軌跡 \tau = (x, y_1, \dots, y_T) および最初の誤りの候補インデックス j \in \{1,\dots,T+1\}(j=T+1 は「誤りなし」を意味する)が与えられたとき、著者らは以下のようなインターリーブ列を構築します。
\mathbf{s}(\tau, j) = [x,\, y_1, +, \dots, y_{j-1}, +, y_j, -]
これをベースLLMに入力します。y_t の後に “+” および “-” ラベルが続く次トークン確率を \{+,-\} 上で再正規化したものをそれぞれ p_t^{+}, p_t^{-} とします。スコアは次のように定義されます。
\mathcal{S}(j;\mathbf{s}) = \mathbb{1}[j \le T]\cdot \log p_j^{-} + \sum_{t < j}\log p_t^{+}.
ここで重要な点が二つあります。第一に、スコアはラベル付きプレフィックスに対する単一のforward passで計算されます。つまり、ステップ j を判断する際にLLMはそれ以前の “+” ラベルをin-contextで参照します。これが、各ステップに独立にLLM-as-a-Judgeを適用する手法と本手法とを区別する「結合」評価です。第二に、どこにも正解ラベルは現れず、この構成は j に関して対称であり、LLMが二値の正誤アルファベット上で適切にキャリブレーションされていることのみを要求します。
PRM r_\theta は、PRM800Kの軌跡(ラベルは破棄)を用いて、LLMが誘導する j 上の分布を蒸留することで学習されます。ベースモデルにはQwen2.5-14B-Instructを使用しており、そのpost-trainingはステップレベルの正誤データを含まないため、この設定はステップラベルに関して真の意味で教師なしのままです。
ProcessBench:誤り位置特定
最も直接的なテストはProcessBenchです。これはGSM8K、MATH、OlympiadBench、Omni-MATHの軌跡を対象に、最初の誤りステップを特定する(あるいは軌跡が正しいと宣言する)タスクです。自然なベースラインは、同じベースモデル・同じプロンプトテンプレート・同じスコアリング関数を用いたLLM-as-a-Judgeですが、インターリーブ列による結合評価ではなく、ステップごとに独立に適用されます。これにより、結合的なin-contextスコアリングと蒸留の貢献を単独で評価できます。
uPRMは四つの分割すべてでF1を大幅に改善します:GSM8Kで49.8 → 58.3、MATHで42.8 → 52.6、OlympiadBenchで29.4 → 42.7(+13.3ポイント)、Omni-MATHで26.6 → 39.8(+13.2ポイント)。この差は難しいベンチマークほど拡大しており、推論チェーンが長く複雑になるほど独立なステップごとの判断が劣化するという仮説と一致しています。一方、結合スコアリングは軌跡の条件付き構造を活用します。
test-time scalingとRL
test-time scalingの検証器としてuPRMを評価し、majority votingおよび(暗黙的に)教師ありPRMと比較します。
abstractによれば、uPRMは検証器として教師ありPRMに匹敵し、majority votingを最大6.9ポイント上回ります。密な報酬信号としてRL fine-tuningに使用した場合、uPRMはoutcomeのみのベースラインよりも頑健なポリシー最適化をもたらします。これは、数学におけるoutcome報酬が、後半の誤りまで多くの部分軌跡が正しい長いチェーンにおいてポリシーの監督を不十分にしやすいという問題に関連します。
制限と未解決の問題
いくつかの注意点を指摘しておく価値があります。
- スコアは、ベースLLMが \{+,-\} の継続に対してキャリブレーションされていることを前提とします。キャリブレーションはプロンプトの書式・instruction-tuning・ラベルトークンのトークン化に大きく依存することが知られています。\{+,-\} 上の再正規化はこれをある程度緩和しますが、長い正しそうなプレフィックスにおける “+” への系統的バイアスは解消されません。
- この構成は誤りが単一の最初の位置に存在することを仮定しています。誤りが重なり合う軌跡や、個々のステップは問題ないが結合的に矛盾するステップを含む軌跡は、jパラメタライズでは自然に扱えません。
- すべての実験においてスコアリングにはQwen2.5-14B-Instructを使用しています。ProcessBenchでの13ポイントの改善が、結合スコアが蒸留に対して過度にノイジーになりうる弱いベースモデルにどの程度転移するかは不明です。
- 学習にはPRM800Kの軌跡を使用しており、これ自体が特定の生成モデルからキュレートされたものです。軌跡分布のドメインシフト(例:コードやエージェント的トレースへの適用)は未検証です。
- スコアは j に関して一様ではありません:プレフィックスが正しく見える場合、\sum_{t<j}\log p_t^{+} の項は期待値において j とともに増大するため、誤り位置に対する暗黙の事前分布は原理的な分布ではなくLLMの信頼度プロファイルによって形作られます。
なぜこれが重要か
結合的なLLM誘導スコアリングがステップレベルの人的アノテーションを代替できるなら、PRM学習における支配的コストが崩壊し、PRMはラベルではなく軌跡のみが入手可能なあらゆる推論コーパスで学習可能になります。同一モデルおよびプロンプトを用いた対照的なLLM-as-a-Judgeベースラインに対するProcessBenchでの改善は、その向上がin-contextでの正誤ラベルに対する結合推論に由来することを示唆しており、これは数学に限らず一般化できるべき基本的な機能です。
Source: https://arxiv.org/abs/2605.10158
DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards
問題設定
RLVR(GRPO、DAPOなど)における系列レベルの学習では、応答中のすべてのトークンが同一のスカラーadvantage \hat{A}_i を共有しています。しかし経験的には、学習中にトークン分布が変化するのはそのうちの疎なサブセットに限られます。著者らは次の問いを立てています:報酬が応答レベルのものである場合、何のメカニズムがこのトークンレベルの選択性をもたらすのか、そしてそれを改善できないか?著者らの答えは、policy-gradientの更新をトークン勾配空間における暗黙的な線形識別器として再解釈し、標準的な重心構成が、成功した軌跡と失敗した軌跡を区別するうえで貢献度の低い高頻度の共有トークン(フォーマット、接続詞など)に向けてバイアスされていることを示すものです。
RLVRの更新における識別器としての見方
v_{i,t} = \nabla_\theta \log \pi_\theta(o_{i,t}\mid c_{i,t}) とおきます。コンテキスト c における候補トークン x に対して、一次のTaylor展開を行うと次のようになります:
\Delta\log\pi(x\mid c) \approx \big(\nabla_\theta \log \pi_\theta(x\mid c)\big)^\top \Delta\theta.
\pi(x\mid c) が上昇するか下降するかは、その勾配と更新方向 \Delta\theta の内積によって決まります。\theta_{\mathrm{old}} における DAPO 型サロゲート(重要度比が1で clipping が非活性な場合)では、局所的な更新は advantage の符号によって次のように整理できます:
\Delta\theta_{\mathrm{RLVR}} \propto \sum_{i:\hat{A}_i>0}\sum_t \hat{A}_i\, v_{i,t} \;-\; \sum_{i:\hat{A}_i<0}\sum_t |\hat{A}_i|\, v_{i,t}.
正規化後、これは勾配空間における二つの重心 \mu_+, \mu_- の差、すなわち Fisher 型の線形識別器となります。あるトークンが強化されるのは、その勾配が \mu_- よりも \mu_+ に近い場合に限られます。問題点として、\mu_+ と \mu_- はどちら側にも出現する共有高頻度トークンに支配されるため、\mu_+ - \mu_- は真に識別的な方向に沿って希釈されてしまいます。
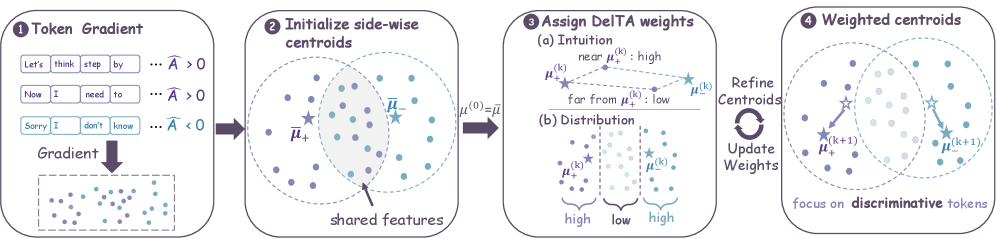
手法
DelTA は各トークン勾配項を係数 \lambda_{i,t} で再重み付けします。この係数は、v_{i,t} が自側の重心に近く、かつ反対側の重心から遠い場合に大きくなります。具体的には(正側の場合;負側は対称):
\alpha_{i,t} = \sigma\!\left(\frac{\|v_{i,t}-\mu_-\|_2^2 - \|v_{i,t}-\mu_+\|_2^2}{\gamma}\right),
これをロールアウトグループ内で正規化し、[\lambda_{\min},\lambda_{\max}]=[0.8,1.2] にクリッピングします。再重み付けされたDAPO目的関数は、重み \lambda_{i,t}\hat{A}_i を持つトークン上の和となります。\lambda_{i,t} は重心に依存し、重心自体も \lambda に依存するため、著者らは K=1 の精緻化イテレーションを実施し、再重み付きの集計から重心を再計算します。この構成はcritic-freeかつグループ相対的であり、DAPO系の目的関数にドロップインで適用可能です(導出が advantage で重み付けされた勾配集約であることのみを必要とするため、他への拡張はAppendix Eで議論されています)。
結果
DeepMath-103K上でVeRLを用いてQwen3-8B-BaseおよびQwen3-14B-Baseで学習し、目的関数の効果を単独で検証するためにdynamic samplingを無効化しました。8Bバックボーンにおいて、4つの代表的な競技数学ベンチマーク(AIME25、AIME26、HMMT25-Nov、HMMT26-Feb)上で、DelTA は平均 23.27 を達成し、DAPOの 19.05 に対して +4.22 の絶対的な改善を示しました。ベンチマーク別の結果:AIME25は26.46対23.33、AIME26は28.12対24.17、HMMT25は18.54対12.08、HMMT26は20.27対16.86となっています。評価は問題あたり16サンプル、最大生成長30kトークンで実施されました。
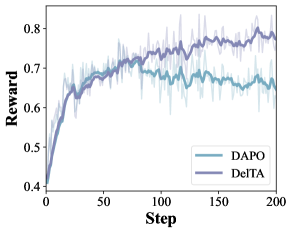
学習ダイナミクスを見ると、DelTA はエントロピーの崩壊なしに高い報酬を達成しており、応答長も同程度であることから、再重み付けが探索スケールを変えるのではなく credit assignment を再形成していることが示唆されます。
アブレーション
反対側との比較が主要な構成要素です。自側の重心のみに近いトークンを保持する同側のみのバリアント(\alpha_{i,t}=\sigma(-\|v_{i,t}-\mu_+\|^2/\gamma_+) を使用)は、DAPOさえも下回ります:平均17.94対DAPOの19.05、DelTAの23.27。\mu_+ のみに近いトークンは、共有されたフォーマットトークンであることが多く、対比 \|v-\mu_-\|^2-\|v-\mu_+\|^2 のみが、一方の側に特徴的であると同時に他方の側には非典型的な方向を単離します。これは識別器分析における希釈仮説の経験的な確認です。
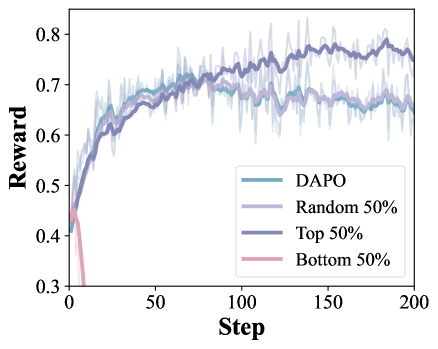
\lambda_{i,t} を連続的な再重み付けとしてではなく、純粋にトークン選択マスクとして使用した場合も改善が得られており、これはノイズ平滑化ではなく意味のある学習シグナルを捉えていることを示しています。
限界と未解決の問題
一次 Taylor の議論は局所的なものであり、分析は \theta_{\mathrm{old}} においてclippingが非活性であることを仮定していますが、これは直近の更新ステップでのみ成立し、PPO の内部エポックをまたぐと崩れます。重心 \mu_\pm は完全なパラメータ勾配空間で計算されており、14Bモデルに対してこれを効率的に近似する方法は論文では詳述されておらず、スケールにおいては射影や層ごとの近似が重要になる可能性があります。ハイパーパラメータの範囲 [0.8,1.2] は狭く、より積極的な範囲が有効かあるいは不安定化をもたらすかについては付録でのみ検討されています。評価は数学競技ベンチマークに限定されており、コード、エージェント的タスク、または一般的な指示追従への転移は未検証です。最後に、識別器の枠組みは小数の「決定的な」トークンの存在を予測しており、それらを言語的に特徴付けること(推論演算子なのか、解答確定トークンなのか?)によって解釈がより強固になるでしょう。
意義
policy-gradient ステップをトークン勾配ベクトル上の Fisher 型識別器として再解釈することで、系列レベルのRLVRがなぜ疎なトークンレベルの更新を生み出すかについての正確かつメカニズム的な説明が得られます。また、共有高頻度トークンによる重心汚染という具体的な失敗モードが特定され、一様な系列レベルの credit がなぜ最適でないかが説明されます。DelTA は、DAPO/GRPO系と互換性のある安価で critic-free な再重み付けによってこれを実現します。
Source: https://arxiv.org/abs/2605.21467
Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps
問題設定
密なLLMにおける長文脈推論は、KVキャッシュに対するfull attentionのO(n^2)コストに支配されています。主な対策として、ネイティブsparseトレーニング(例:NSAスタイルのアーキテクチャ)と、トレーニング不要なヒューリスティクス(トークン退去、ブロックレベルtop-k)という2つのアプローチが存在しますが、これらはPareto曲線の両端に位置します:前者は大規模な事前学習コストを要し、後者は検索負荷の高いタスクで精度を損ないます。RTPurboは、この二項対立が不要であると主張しています。なぜなら、事前学習済みのfull attentionモデルはすでに構造的な形でsparseであり、数百ステップの適応学習によってそのsparsityを推論に活用できるからです。
3つの構造的観察
本手法は、事前学習済みQwen3-30Bクラスのモデルにおける経験的な規則性に基づいて構築されています。
Headの特化。 長距離検索を行うquery headはわずかな割合に過ぎず、残りはほぼ専らローカル文脈またはsinkトークンにattendします。head単位の検索スコアのヒートマップは、高スコアのheadがネットワーク後半に集中していることを確認しており、これは初期レイヤーがローカルな文脈化を行い、後期レイヤーが長距離リコールに適した安定した表現を形成するという見方と一致しています。
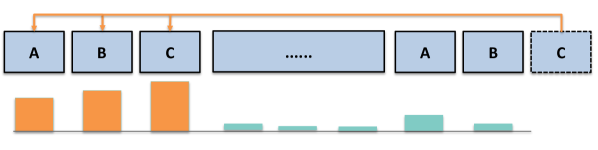
Retrieval headは意味的に関連した遠方の領域にattendし、ほとんどのheadはローカルに留まる。 低ランクの検索幾何。 長距離マッチングに関連する部分空間は低次元であり、16次元の射影されたquery/keyインデクサーで、retrieval headが実際にattendするトークンを特定するのに十分です。
クエリ依存のトークンバジェット。 意味のあるattentionマスに寄与するトークン数はクエリに依存して変化するため、固定のtop-kでは過剰または過少なリコールが生じます。動的なtop-p(累積attentionしきい値)の方がより適切です。
手法
Headのオフラインによる分類は、長いFineWebドキュメントの両端に同一の「ニードル」スパンを挿入し、各head hを以下のスコアで評価することで行われます。
R_h = \frac{1}{|\mathcal{N}_{\text{post}}|} \sum_{t \in \mathcal{N}_{\text{post}}} \sum_{j \in \mathcal{N}_{\text{pre}}} A_h(t, j),
すなわち、後方のニードルから前方のニードルへのpost-softmax attentionマスです。上位15%が\mathcal{H}_{\text{ret}}を形成し、残りの\mathcal{H}_{\text{loc}}はスライディングウィンドウ(8192)と4つのsinkトークンを使用します。このスコアは経験的に入力非依存であるため、単一のキャリブレーションシーケンスで十分です。
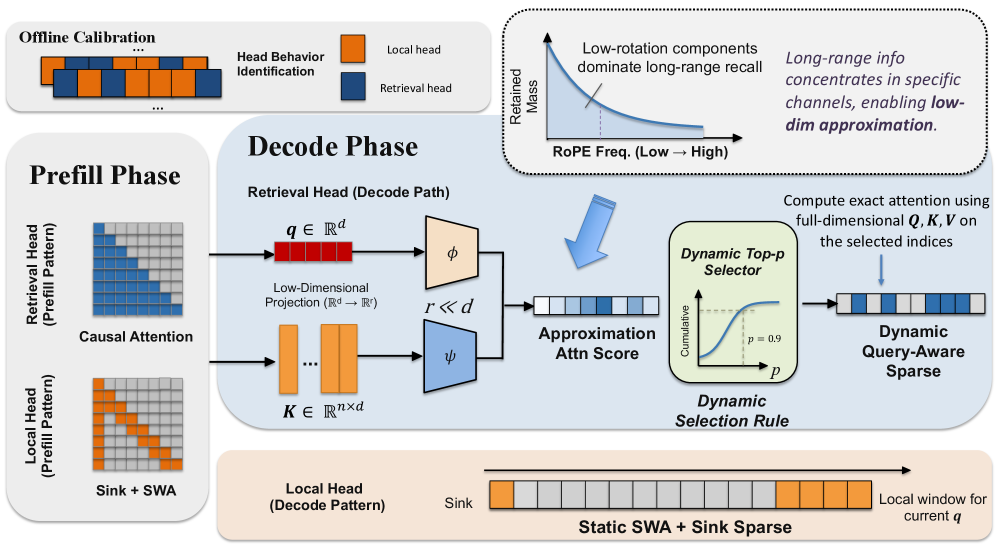
各retrieval headに対して、RTPurboは16次元のqueryおよびkeyの射影行列W_q^{\text{low}}, W_k^{\text{low}} \in \mathbb{R}^{128 \times 16}を学習します。デコード時には、インデクサーが低次元空間ですべてのKV位置をスコアリングし、それらをソートして、累積softmaxマスがp = 0.9を超える最小のプレフィックスを保持します。その後、元の128次元のQ/K/Vが選択されたセットのみに対してattentionを実行します。
トレーニングは2段階で行われます。
- Stage 1(インデクサーのアライメント)。 低次元射影のみが学習可能です。1536個のquery headを持つQwen3-Coder-30B-A3Bでは、210個がretrieval headに指定され、210 \times 2 \times 128 \times 16 \approx 8.6 \times 10^5個のパラメータが生じます。目的関数は、圧縮されたattentionの分布をhead単位で元のフル次元の分布にアライメントさせます。lossは48Kトークンシーケンス上で約600ステップ、合計約3000万トークンで収束します。
- Stage 2(end-to-endの自己蒸留)。 定数LR 3 \times 10^{-6}、約600ステップ、グローバルバッチサイズ8、平均48Kトークンのシーケンス。これによりsparsification導入による残差ドリフトを修正します。
ブロックサイズ64のカスタムデコードカーネルがhead単位のsparseパターンを処理します。
結果
Qwen3-Coder-30B-A3BによるLongBenchとRULER、およびQwen3-30B-A3B-ThinkによるAIME24/25とMMLU-PROにおいて、RTPurboはfull attentionと同等の性能を示す一方、ベースラインは特徴的な形で劣化します。MinferenceとSnapKV(最近のクエリからグローバルattentionを推定)はマルチホップタスクで崩壊し、FlexPrefillは分散エビデンスのmulti-Vで劣化し、Questのブロックレベルの粗いsparsityは全般的な精度低下をもたらし、トレーニング不要のRazorAttnはHotpotQAとMusiqueで苦戦します。静的なtop-k=4096のアブレーションは、回収されるattentionマスの合計が小さすぎるため、RULER 64Kで過少なリコールが生じます。
512Kまでの超長文脈では、ベースラインが壊滅的な劣化を示す一方、RTPurboは精度を維持します。
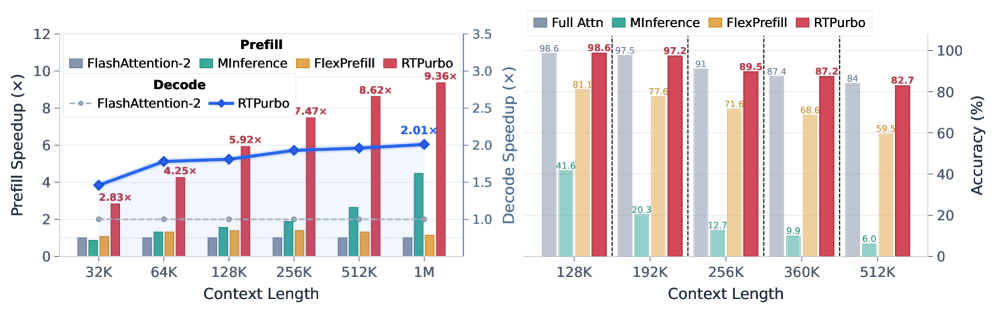
retrieval head比率のアブレーションはデザインポイントを特定します。15%と30%は本質的に同一の数値を示しますが(例:MMLU-PRO Math 88.2 vs 88.2;RULER multi-K 98.8 vs 98.6)、10%まで下げると大幅な低下が生じます(Math 88.2 → 79.3、CS 76.8 → 70.2、multi-K 98.8 → 97.4)。よって、このアーキテクチャでは15%が曲線の変曲点となっています。
制限事項と未解決の問題
- すべての実験はQwen3-30B-A3Bファミリー(多数のquery headを持つMoE)で行われており、15%のretrieval比率と16次元インデクサーランクが、異なるhead数を持つ密なモデルやKV headが非常に少ないGQA構成に汎化するかどうかは不明です。
- キャリブレーションには合成ニードルパターンを使用しており、retrieval headの同一性が真に異なるドメイン(コード、多言語、構造化された表形式データ)に転移するかどうかは、LongBenchの既存の多様性を超えたストレステストが行われていません。
- カーネルはブロック64の粒度で記述されていますが、FlashAttentionスタイルのfull attentionやNSAと比較したend-to-endのレイテンシ・スループットの数値は提供されているセクションには引用されていません。
- top-pのしきい値処理は各ステップでインデクサースコアのソートを必要とし、非常に長いシーケンスではインデクサーパス自体がボトルネックになりますが、論文は512Kを超えるスケーリングについて議論していません。
- Stage 1のアライメントはhead単位の分布マッチングであり、retrieval headのfull attentionパターン自体が最適であることを前提としています。元のheadにノイズがある場合、インデクサーはそのノイズを忠実に再現します。
重要性
RTPurboは、事前学習済みモデルがすでに示している構造(headの特化、低ランク検索部分空間、クエリ依存バジェット)を活用することで、密なLLMを強力な長文脈sparseモデルに変換することが、事前学習の問題ではなく約10^3ステップの適応問題であることを実証しています。このレシピがアーキテクチャを超えて成立するならば、約3000万トークンバジェットによる事後的なsparsificationが長文脈デプロイメントにおける実用的なデフォルトとなります。
Source: https://arxiv.org/abs/2605.16928
ACC: エージェント軌跡を長文脈学習データにコンパイルする
長文脈の学習データは高コストです。回答に関連する依存関係を持つ真正な長文書のキュレーションは困難であり、合成的な構成(Needle-in-haystack の変種、文書の連結など)は浅い依存関係しか生み出さず、離れたセグメントをまたぐ統合能力を鍛えられない傾向があります。ACCは、エージェントのロールアウトがすでにこの構造を持っていることに着目しています――質問、ツール呼び出しの連鎖、そして最終回答を生成するために証拠を統合すべき観測結果――しかし、標準的なエージェントの SFT はこのシグナルを捨て去っています。
教師信号の盲点
軌跡は \tau=(q,(r_1,a_1,o_1),\dots,(r_{k-1},a_{k-1},o_{k-1}),(r_k,y)) で定義されます。ここで r_t は推論、a_t はツール呼び出し、o_t はツールの応答、(r_k, y) は最終回答ターンです。標準的なエージェント SFT の loss
\mathcal{L}_{\text{agent}}=-\sum_{t=1}^{k}\sum_{j\in\mathcal{I}_t}\log P(\text{token}_j\mid\mathcal{H}_{<t},\text{token}_{<j})
は o_t を \mathcal{I}_t からマスクし、モデルが生成したトークン――各ターンの推論と行動(t<k)および最終的な推論・回答(t=k)――のみを教師信号として用います。著者らはこれを二つの部分に分解しています:k-1 個の「局所的な次ツール選択」項と、一つの「最終回答予測」項です。議論の核心は、マスクされた観測トークンへの gradient の流れにあります。o_t 中のトークンが gradient を受け取るのは、後続のマスクされていないトークンを介した間接的な経路のみです。支配的な短い経路は、o_t が直近の文脈に位置する次の行動 a_{t+1} への経路です。最終回答 y への経路は k-t 個の中間ターンを横断しなければならず、シグナルは著しく減衰します。結果として、モデルは o_t を次のツールを選ぶには十分だが、ターンをまたいで y に向けた証拠統合には不十分な形で表現するようになります。中間ターンが「教師信号のフィルター」として機能してしまうのです。
手法:軌跡のコンパイル
ACC はこのフィルターを、軌跡の再フォーマットによって除去します。観測結果をマスクした推論・行動・観測のインターリーブされたシーケンスで学習する代わりに、各軌跡を単一の長文脈 QA ペアにコンパイルします:元の質問 q に、収集されたツール応答と環境文脈 \{o_t\} を連結し、ターゲットを y(オプションで r_k も含む)とします。これによりモデルは、ツールを使わず、すべての証拠をコンテキスト内でアンマスクされた状態で参照しながら、q に直接回答するよう学習します。
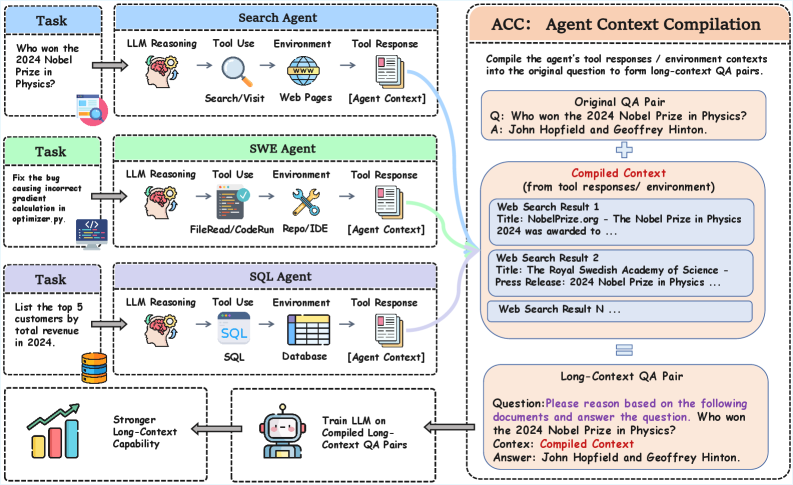
機械的には、これにより式 (2) が (q, o_1, \dots, o_{k-1}) \to y に対する単一の教師あり項に変換され、loss が y からすべての観測トークンへの直接的な gradient 経路を生み出します。離れたセグメントと回答の間の依存関係が明示的になり、エージェントがすでに生成したもの以外のアノテーションは一切不要です。三つの軌跡ソース――Search、SWE、SQL――は補完的な依存構造を提供します:検索スタイルの集約、ファイル内容を含むコード・リポジトリのナビゲーション、クエリ結果に対する構造化テーブルの推論です。
セットアップとデータ
ベースモデルは Qwen3-30B-A3B-Thinking です。コンパイルされたコーパスは 10,802 件の軌跡を含みます:Search が 3,369 件、SWE が 4,368 件、SQL が 3,065 件で、文脈長は 2K から 128K トークンの範囲にわたります。
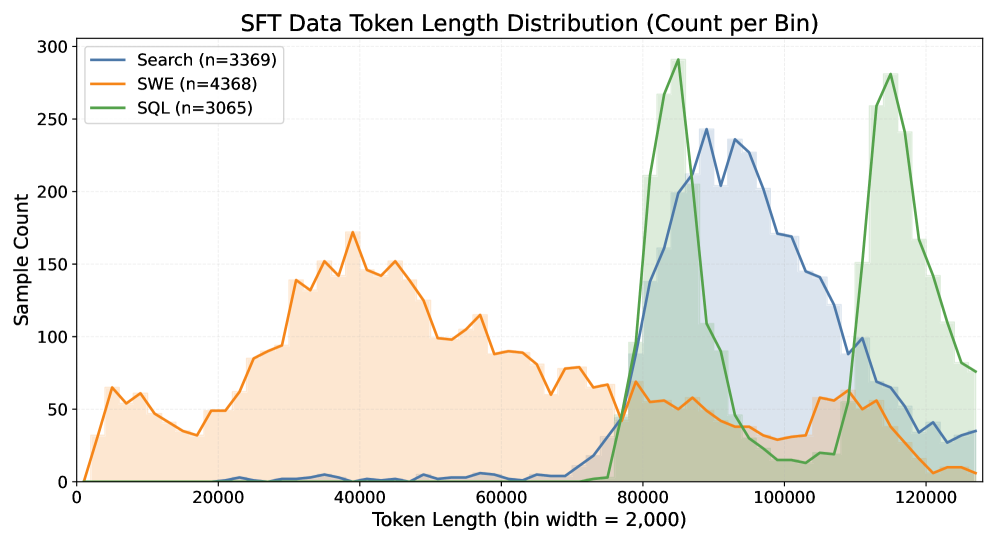
エージェントごとの長さ分布は異なります:SWE の軌跡は長い側に集中し(ファイル内容、大きな差分)、Search はより一様に分布し、SQL は短い方に偏っています。学習にはシーケンス長 131,072、グローバルバッチサイズ 16、学習率 1\times 10^{-5}(最小 1\times 10^{-6})のコサインスケジュールと 5% のウォームアップ、weight decay 0.1 の AdamW、シーケンス並列数 8、4 エポックを使用します。128K 文脈でのメモリ管理のため、loss は 1024 トークンのチャンクに分けて計算されます。
評価は長距離依存関係ベンチマーク――MRCR(多ターン共参照)と GraphWalks(グラフ探索)――を対象とし、一般能力への負の転移がないかを GPQA-Diamond、MMLU-Pro、AIME、IFEval で監視します。
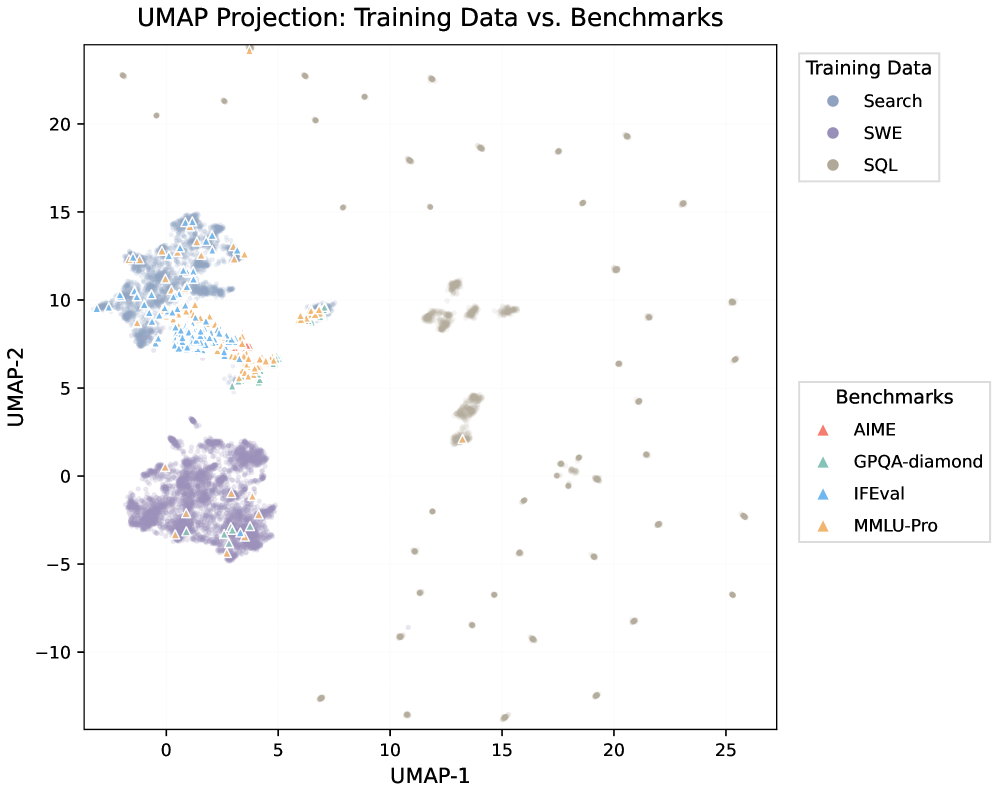
図4のUMAP射影は、MRCR/GraphWalks における性能向上が学習クエリとの表面的な重複によるものでないことを主張するために用いられています。評価の分布は、質問テキストの embedding 空間においてエージェント由来のクエリから分離されているためです。
限界と未解決の問題
提供されたセクションには定式化、教師信号の盲点に関する議論、および実験設定が示されていますが、実際のベンチマーク数値(MRCR、GraphWalks のベースモデルとの差分、標準エージェント SFT との比較、長文脈合成ベースラインとの比較)はこの抜粋には含まれていません――そのため、改善の実証的な大きさと AIME/GPQA における負の転移の規模についてはここで言及できません。いくつかの疑問も残っています:(1) 集約された証拠が与えられたもとでツールを使わず回答するようにモデルを学習させることで、元のインターリーブされた教師信号が置き換えられるため、ACC はツール使用そのものの動作を劣化させる可能性があります;(2) この手法は成功した軌跡を前提としており、失敗あるいはノイズの多いロールアウトが q \to y に誤解を招く証拠を注入する恐れがあります;(3) gradient 減衰の議論は定性的なものであり、標準エージェント SFT と ACC の比較において、回答に関連するシグナルが o_t にどれほど届いているかを制御実験で測定したものではありません;(4) 軌跡の長さは 128K に収まるものに限定されており、訓練できる最長の依存関係に上限が生じます。また、ACC が RL ベースのエージェント学習と組み合わせ可能なのか、あるいは SFT フェーズのみを置き換えるものなのかも不明です。
この研究の意義
ACC は、希少で依存関係の豊富な長文脈という既知のデータ問題を、エージェントのロールアウトの無償の副産物として再定義し、標準エージェント SFT がそのシグナルを利用できない理由について具体的かつ検証可能な主張を行います:マスクされた観測結果は最終回答に対して gradient が不足しているというものです。実証結果が成立するならば、これは合成的なものではなく根拠のあるセグメント間依存関係を持つ、安価で導入容易な長文脈教師信号のソースとなります。
Source: https://arxiv.org/abs/2605.21850
PhysX-Omni: 剛体・変形体・関節物体に対応した統合シミュレーション対応3D生成
問題設定
ほとんどの3D生成モデルは視覚的に妥当なメッシュを生成しますが、シミュレーションに必要な物理属性(質量、摩擦、関節の運動学、アフォーダンス)を無視しています。物理情報を扱う少数のモデルも、剛体プロップ、布、関節機構といった単一カテゴリに特化しており、カテゴリ固有のトポロジーに依存しています。PhysX-Omniは、単一の(部分的に遮蔽された可能性のある)画像から、剛体・変形体・関節物体のクラスにまたがるシミュレーション対応アセットを出力し、スケール・材料・運動学・機能をLLMが読み取れる形式で提供する統合ジェネレータを目指しています。
手法
このフレームワークは、Qwen2.5-VL-7B-Instructをベースとしたオートリグレッシブ生成器であり、64台のA100上で5エポック、ピーク学習率 2\times10^{-5}、バッチサイズ128、コンテキスト長16,384トークンで訓練されています。
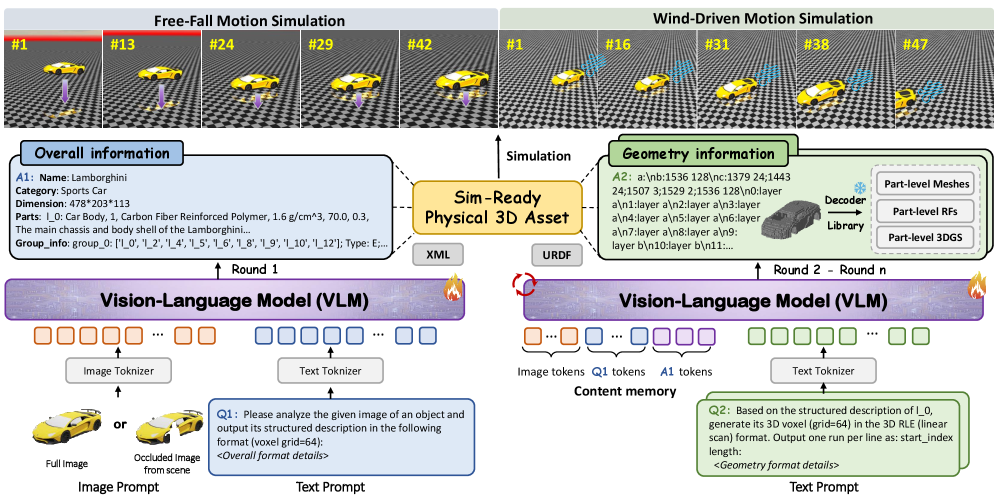
生成は粗から細へと進みます。画像が与えられると、VLMはまずグローバルなツリー構造の記述を出力します。これにはオブジェクトクラス、意味的同一性、絶対スケール、コンポーネント階層、候補となる物理属性が含まれます。そのツリーを条件として、マルチターンデコーディングによってパーツごとのジオメトリと物理属性が出力されます。グローバルツリーがパーツの同一性と階層を固定するため、ローカル出力はポストホックなセグメンテーションを必要とせず、直接運動学的・関節型アセットとして組み上げられます。
本手法の新規性はジオメトリのトークナイザーにあります。頂点量子化、3D VQ-GANコード、特殊トークンのボクセルインデックスではなく、著者らはテンプレートベースの3Dランレングス符号化(RLE)をプレーンテキストで提案しており、語彙の拡張は不要です。パイプラインの手順は以下の通りです:
- シミュレーション対応アセットをボクセル化し、アノテーション済みツリーを用いてパーツレベルのボクセルグリッドに分割する。
- 各パーツを z 方向にスライスして2Dバイナリマスクに変換する。
- 各スライスを2D RLEで符号化する。
- テンプレートレイヤーによるスライス間の冗長性を活用する:スライスは以前のテンプレートを参照し、占有情報を再符号化する代わりに残差差分のみを保存できる。
これにより、高解像度の構造を明示的に保ちながら(圧縮ボトルネックなし)、滑らかまたは押し出し形状のジオメトリに対してシーケンス長を圧縮します。デコード時には、生成されたボクセルがfreezeされたTRELLISデコーダによってメッシュに変換されます。この表現はすでにパーツセグメンテーション済みで明示的であるため、メッシュ分解やトポロジークリーンアップモジュールは不要です。
データセットとベンチマーク
PhysXVerseは著者によれば、屋内外のカテゴリ(車両、建物、人物モデル、玩具、ロボット)にわたり、ロングテールなパーツ数分布を持つ、初の汎用シミュレーション対応3Dデータセットです。
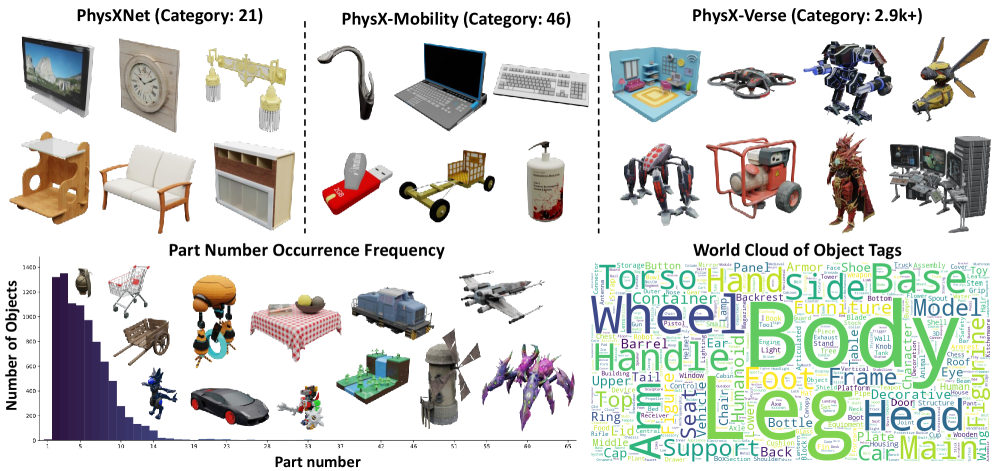
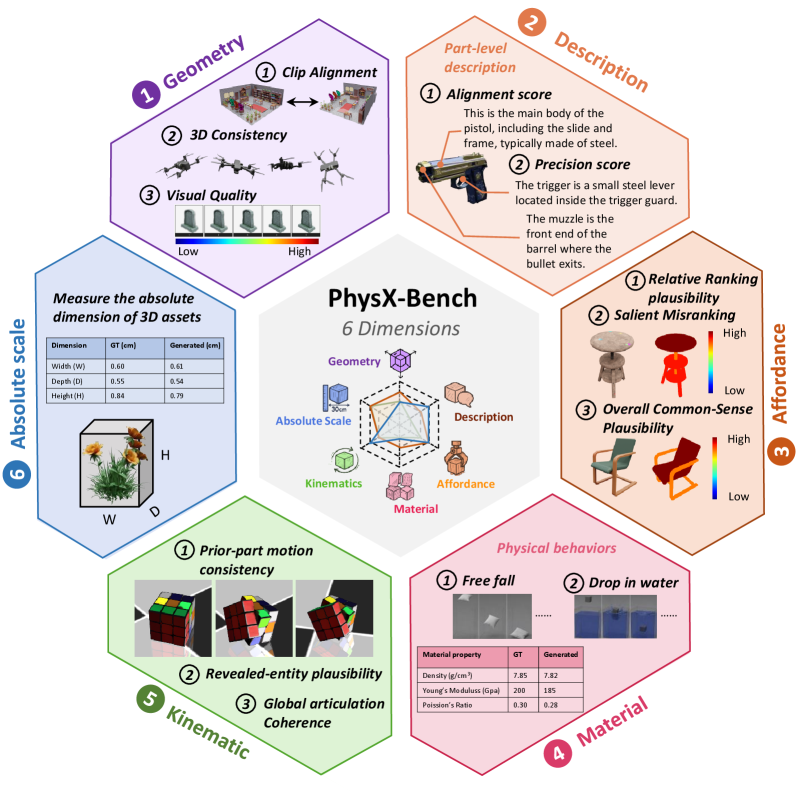
PhysX-Benchは、ジオメトリ・絶対スケール・材料・アフォーダンス・運動学・機能説明の6軸でスコアリングし、生成忠実度と物理属性理解の両方を評価します。
結果
アブストラクトおよび実験セクションでは、従来の3Dメトリクスと6属性すべてにおけるPhysX-Benchの両面で優れた性能を主張しており、ヒューマンアライメントスコアと、テンプレートRLE表現と従来のコンパクト符号化手法(頂点量子化、3D VQ-GAN、テキストボクセルインデックス)の寄与を分離したアブレーションも示されています。FID/CD/IoUおよびPhysX-Benchの属性別スコアの具体的な数値テーブルは提供された抜粋には含まれていないため、ここでは記載しません。利用可能なテキストで具体的に報告されている内容は以下の通りです:
- バックボーン:Qwen2.5-VL-7B-Instruct
- 訓練リソース:64台のA100 × 約14日間、5エポック
- 最適化:ピーク学習率 2\times10^{-5}、コサイン減衰、ウォームアップ比0.03、有効バッチサイズ128
- コンテキスト長:16,384トークン、高解像度アセットの完全なテンプレートRLEパーツシーケンスに対応可能
- デコーダ:TRELLIS、セグメンテーションやトポロジーのfine-tuningなしでそのまま使用
著者らはさらに、出力されたメッシュが質量・関節・アフォーダンスラベルを直接持つという事実を活かし、シミュレーション対応のシーン生成やロボット方策学習のアセットソースとしての下流利用も実証しています。
限界と未解決の問題
- テンプレートRLEスキームは軸方向のスライス間冗長性を利用するため、 z 方向に主に斜め・曲線的なジオメトリを持つオブジェクト(例:有機的な殻状構造、らせん構造)では圧縮効率が低下し、シーケンスが16kの上限に近づく可能性があります。
- 物理属性(摩擦係数、関節限界、質量)の品質はPhysXVerseのアノテーション品質に依存しており、生成された関節がどの程度物理シミュレータの妥当性チェック(非貫通、安定接触、重力下での関節範囲の妥当性など)を通過するかは定量化されていません。
- freezeされたTRELLISデコーダへの依存により、ジオメトリの忠実度はその訓練分布に縛られます。VLMが出力する分布外のボクセルレイアウトは、トークンレベルの予測が正しくてもデコードが不良になる可能性があります。
- 強い遮蔽下での単一画像条件付けはVLMの事前知識に依存しており、特異な関節機構(例:新規なリンク機構トポロジー)における失敗モードは、利用可能なテキストでは特徴付けられていません。
- 16kトークンシーケンスとパーツごとのマルチターンデコーディングを考えると推論レイテンシは実用上の懸念事項ですが、論文ではこれを報告していません。
重要性
パーツ・関節・スケール・材料を一度のオートリグレッシブパスで出力するテキストトークン化されたジオメトリ表現は、現在の多段階パイプライン(メッシュ生成 → セグメンテーション → リギング → 物理割り当て)を単一のVLM呼び出しに集約し、トークナイザーを拡張することなく実現します。テンプレートRLEエンコーディングが高解像度でも有効であれば、ロボティクスデータ生成と身体化シーン合成の両面で、言語モデルと物理シミュレータ間のインターフェースの実質的なデフォルトとなる可能性があります。
Source: https://arxiv.org/abs/2605.21572
LatentOmni: Unified Audio-Visual Latent Reasoningによるオムニモーダル理解の再考
問題
映像と音声を同時に推論するオムニモーダルMLLMは、両ストリームから細粒度の時間的証拠を要する質問応答において一貫して失敗します。著者らは、この失敗の原因を支配的なchain-of-thought(CoT)レシピに位置づけています。テキストによる根拠は、連続的な音声・映像信号を離散語彙 \mathcal{V} のボトルネックに通すことを強制し、それによって時間的精度が失われ、中間ステップが感覚的証拠よりも言語の事前分布へ偏ってしまいます。実験的に確認されたことは、Explicit Text CoT ベースラインが推論中にAVトークンへ割り当てるattentionの割合が小さいのに対し、LatentOmniはDaily-OmniにおいてAV-attentionの比率を大幅に高く維持するという点です。

手法
LatentOmniは、Qwen2.5-Omni-7Bをpost-trainingし、テキストトークンと連続的なlatent状態のハイブリッド系列を生成するようにします。デコーダが特殊トークン <Unified_Latent> を生成すると、生成は \mathcal{V} からのサンプリングを停止し、\mathbb{R}^d における K 個の連続embeddingを生成する処理に切り替わります。</Unified_Latent> という停止トークンが現れると、離散デコーディングへ戻ります。全体の軌跡は次のように表されます。
S = [w_{1:i}, u, z_{1:K}, u', w_{i+1:j}, u, z_{K+1:2K}, u', \dots, a],
ここで w はテキストトークン、z は連続的なlatent推論状態、a は最終的な回答です。テキストは論理的な足場として機能し、latentブロックは証拠を集約するクロスモーダルなルックアップに充てられます。
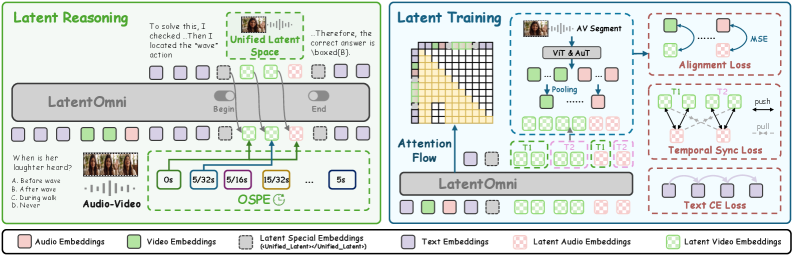
自由形式の連続デコーディングにおける明らかな失敗モードに対処するため、2つの設計要素が導入されています。第一に、feature-levelの教師ありアライメントにより、各 z_k を入力エンコーダから抽出したタスク関連の音声・映像特徴に紐付け、latentブロックが汎用的な「思考」embeddingへ崩壊することを防ぎます。第二に、Omni-Sync Position Embedding(OSPE)は音声と映像のlatent状態に共有の時間インデックスを課すことで、latentブロック内において同一の瞬間を指す音声と映像の位置が一貫したpositional encodingを受けるようにします。これは、音声・映像エンコーダのネイティブフレームレートが異なるために必要です。
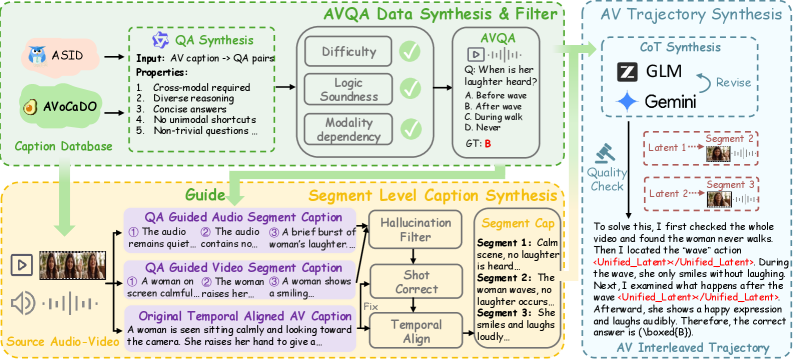
学習データはLatentOmni-Instruct-35Kであり、Figure 3のパイプラインを通じて合成された音声・映像インターリーブ型の推論軌跡から成るコーパスです。このパイプラインは、各 <Unified_Latent> ブロックがそのステップでモデルが注目すべきAV特徴とペアになったサンプルを生成し、latent alignmentのための教師信号を提供します。
著者らは K を固定し、1サンプルあたりのlatentの総予算を40トークンとしています(音声・映像latent間の配分はablationで調整)。これは、固定のlatent予算が動的スケジュールよりも安定しているという先行研究の知見に基づいています。fine-tuningはQwen2.5-Omni-7Bから750ステップ(2エポック)実施されているため、報告された改善はスケールではなくpost-trainingの目的関数を反映したものです。
結果
4つのオムニモーダルベンチマーク(Daily-Omni、WorldSense、OmniVideoBench、LVOmniBench)において、LatentOmniは全ベンチマークで最良のオープンソース7Bモデルです。
- Daily-Omni: 67.4(ベース62.9、Explicit Text CoT 65.6、Vanilla SFT 62.0、OmniVinci 66.5)
- WorldSense: 48.9(ベース45.4、text CoT 46.6、SFT 47.5、OmniVinci 48.2)
- OmniVideoBench: 35.4(ベース29.3から6.1ポイント向上)、OmniVinci(32.1)を上回る
- LVOmniBench: 35.1(ベース32.0)
Vanilla SFTとExplicit Text CoTの制御実験は同一バックボーン・同一instructionデータを共有しており、連続latent推論の貢献を孤立させています。Explicit Text CoTがOmniVideoBenchをベース29.3から33.2に改善する一方、LatentOmniが35.4に達するという事実は、追加の根拠情報の価値を超えて、連続latentチャネル自体が測定可能な向上をもたらすことを示しています。Daily-OmniではVanilla SFTが実際にはパフォーマンスを低下させており(62.0対62.9)、latentチャネルなしでAV推論データをtext-onlyでfine-tuningすることがgroundingを損なう可能性を示唆しています。
プロプライエタリなシステムは依然として先行しています。Gemini-2.0-Flashはほとんどのベンチマークでほぼ同等もしくはLatentOmniを上回り(67.8 / 56.2 / 41.5 / 42.9)、Gemini-2.5-Proは大幅に上回っています(81.4 / 64.6 / 58.9)。LatentOmniはこのギャップを縮めますが、解消するには至っていません。
限界と今後の課題
latentの長さは40トークンに固定されており、クエリごとの動的配分がLVOmniBenchのような長尺ベンチマーク(Gemini-2.0-Flashとのギャップが最大で35.1対42.9)で有効かどうかは示されていません。feature-levelのalignment目標はLatentOmni-Instruct-35Kの合成軌跡に依存するため、各latentブロックがどのAV特徴を再構築すべきかを選択するヒューリスティクスの質に教師信号の品質が左右されます。latent推論がpost-trainingの分布を超えて汎化するかどうか(例えば新しい音声タイプや3Dなどのモダリティへ)の分析は存在せず、視覚のみのlatent推論手法(Monet、LVR)との比較は視覚のみの設定でのみ報告されているため、それらの手法を音声に拡張した場合にギャップが縮まるかどうかは未解決のままです。さらに、OSPEは比較的時間軸が揃ったエンコーダを前提としており、ストリーミングや非同期入力下での挙動はテストされていません。
なぜ重要か
この結果は、証拠集約型のマルチモーダル推論において、ボトルネックが根拠の長さではなく根拠の表現にあることを具体的に示しています。中間ステップを感覚的に接地された連続的なlatentチャネルを通じてルーティングすることは、同一データ・同一バックボーン上でのtext CoTを上回ります。これはオムニモーダル推論器の設計上の問いを「いかに優れたCoTをプロンプトするか」から「知覚エンコーダと自己回帰デコーダの間における適切なlatentインターフェースとは何か」へとシフトさせます。
Source: https://arxiv.org/abs/2605.22012
Hacker News Signals
証明可能なセキュアオペレーティングシステム(PSOS)の基礎(1979年)
Neumann らによる1979年のSRI技術報告書は、セキュリティ特性の形式的検証を目的として階層的に構造化されたOSの設計であるPSOS(Provably Secure Operating System)について述べています。このアーキテクチャは抽象化レイヤーの列として構成されており、各レイヤーはその下のレイヤーのプリミティブの上に構築され、最下層には小さな信頼されたコンピューティングベース(TCB)が置かれています。セキュリティ特性——主にアクセス制御と情報フロー制約——は形式的に規定され、階層全体を通じて上位に伝播されます。
中核となるメカニズムはcapabilityベースの保護モデルです。すべてのオブジェクトは偽造不可能なcapabilityトークンを介してアクセスされ、カーネルはcapabilityが合成または漏洩されることなく、制御されたチャネルを通じてのみ受け渡されることを保証します。これはセキュリティレベルの形式的格子に対応しており、この設計はBell-LaPadula方式の強制アクセス制御証明を明確なターゲットとしています。セグメント、プロセス、I/Oデバイスはすべて一様なcapabilityセマンティクスを持つオブジェクトとして扱われ、従来のUNIX派生カーネルに固有のアドホックな特権昇格パスを排除しています。
1979年の文書が今日においても興味深いのは、階層分解がいかに先見的であるかという点にあります。PSSOSは生のハードウェアプリミティブからユーザーに可視な抽象化まで17の番号付きレベルを使用しており、この構造はseL4の検証アプローチを30年先取りするものです。報告書は実装の検証が完了していなかったことを明示的に認めており——「証明可能」という部分は機械検査されたコードではなく、仕様と設計の証明義務を指しています。分離カーネル特性の形式的証明はスケッチされていますが、機械化はされていません。
HNのディスカッションでは、seL4(2009年、Isabelle/HOLによる機械検査済み)が実用的な後継であり、PSSOSは実際には出荷されなかったという点が正しく指摘されています。永続する教訓はTCB最小化の原則です:正当性の議論はTCBのサイズとともにスケールするため、最下層を小さく保ち完全に仕様化することが保証に至る唯一の現実的な道筋です。PSSOSを再訪することで、現代のマイクロカーネルがなぜ現在のような形になっているのかが明確になります。
Source: http://www.csl.sri.com/users/neumann/psos.pdf
Multi-Stream LLMs:プロンプト・思考・I/Oの並列化
本論文は、標準的なtransformerの推論における単一の自己回帰トークンストリームを、それぞれ意味的に異なる役割を担う複数の並列ストリームへ置き換えることを提案しています。具体的には、システムプロンプト/コンテキスト用のストリーム、chain-of-thoughtによる推論用のストリーム、そして出力生成用のストリームをそれぞれ独立して処理します。各ストリームは各層においてクロスストリームattentionを介して相互に情報を参照し合い、逐次的な依存関係を強制することなく情報共有を実現します。
形式的な設定として、K個のストリームとトークン系列S_1, \ldots, S_Kが与えられたとき、各ストリームS_kは自身のトークン内でself-attentionを計算するとともに、他のストリームの圧縮されたサマリーに対してcross-attentionを計算します。このcross-attentionには学習済みのgating機構が用いられており、コンテキストが無関係な場合には各ストリームをほぼ独立した状態に保つことができます。位置encodingはストリームごとにローカルに定義されるため、ストリーム間でグローバルな系列位置を統一する必要がありません。
主張される利点は二点あります。第一に、レイテンシの削減です。思考ストリームはI/O操作(ツール呼び出しや検索など)をブロックすることなく並列に実行できます。第二に、モジュール性の向上です。システムプロンプトと推論トレースがそれぞれ独自のKV-cacheスロットを占有するため、固定されたコンテキストウィンドウの制約下において、長いシステムプロンプトが生成トークンの領域を圧迫することがありません。本論文では、推論ベンチマーク(MATH、GSM8K)において、multi-streamモデルがシングルストリームのベースラインと同等の性能を示しつつ、推論時のwall-clock時間を約30〜40%短縮できることを報告しています。また、制約されたウィンドウ下における「推論」トークンと「出力」トークンの予算分離においても改善が確認されています。
このアーキテクチャはスクラッチからの学習または大規模なfine-tuningを必要とします。既存のチェックポイントへのmulti-stream attentionの後付けは、クロスストリームattentionの重みが存在しないため容易ではありません。これにより、近い将来における採用は新規モデルを学習するラボに限定されます。また、可変長ストリームを用いたバッチ推論において速度向上が維持されるかどうかは、十分に分析されていません。
Source: https://arxiv.org/abs/2605.12460
Copy Fail、Dirty Frag、Fragnesia カーネル脆弱性
GentooのセキュリティチームがLinuxカーネルのメモリ管理エッジケースに関する3つの関連する脆弱性の詳細を公開しました。
Copy Fail(公開時点でCVE未割り当て)は、copy_from_userまたは類似の操作が途中で失敗した際にトリガーされるuse-after-freeです。部分的に書き込まれたカーネルバッファがその後アクセスされることで発生します。カーネルは特定のfast pathにおいてアトミックな成功/失敗のセマンティクスを前提としていますが、部分的な状態を常にロールバックするわけではないため、解放済みまたは部分的に初期化されたオブジェクトに到達可能なウィンドウが生じます。
Dirty Fragは、ネットワークおよび一部のファイルシステムパスで使用されるページフラグメントアロケータを標的としています。ページフラグメントがダーティな状態(変更済みだが未フラッシュ)のまま解放された場合、フラグメントのリサイクラーと並行リーダーとの間のレースによってtype confusionが発生します。具体的には、リーダーの参照が解放される前にフラグメントが別の用途のために再割り当てされます。SMPシステムでは、これはheap-type confusionプリミティブとして悪用可能です。
Fragnesiaは、フラグメンテーションによって引き起こされるアムネジア(amnesia)バグです。メモリ負荷が高い状況下で、カーネルのコンパクションパスが特定のピン留めされたページの追跡を失い、それらのページを異なるパーミッションを持つ2つのページテーブルツリーに同時にマッピングすることを許してしまいます。この名称は「fragmentation(フラグメンテーション)」と「amnesia(アムネジア)」を組み合わせたかばん語です。実際の悪用経路は、読み取り専用ページを書き込み可能としてマッピングすることによるローカル権限昇格です。
3つの脆弱性に共通するテーマは、カーネルのメモリ管理fast pathが並行的な負荷や部分的な失敗によって破られる可能性のある不変条件を前提としており、エラー回復コードがそれらの不変条件を復元するよう一貫して監査されていない点です。パッチはアップストリームのstableキューに投入されています。修正前のカーネルを使用しているユーザーは、ローカルの信頼できないコード実行をrootと同等として扱うべきです。
Source: https://www.gentoo.org/news/2026/05/19/copy-fail-fragnesia-vulnerabilities.html
Antigravity 2.0がOpenSCAD建築3D LLMベンチマークでトップを獲得
OpenSCAD LLMベンチマークは、3Dオブジェクトの自然言語記述から正確で実行可能なOpenSCADプログラムを生成する能力について言語モデルを評価するものです。OpenSCADはCSGベースの宣言型言語であり、プログラムは決定論的で出力が幾何学的に検証可能なため、自動スコアリングが実現しやすくなっています。このベンチマークは、壁・アーチ・階段・窓配置パターンといった建築的プリミティブのスイートを使用しており、正解とは構文的妥当性と参照メッシュへの幾何学的忠実性の両方を意味し、体積IoUおよび表面距離によって測定されます。
Antigravity 2.0(ModelRiftによるfine-tunedモデルで詳細は乏しい)は、このベンチマークでstate-of-the-artを達成したと報告されています。技術的に興味深い主張は、標準的なRLHF-tunedの汎用モデルがOpenSCADで失敗する主な原因が構文エラーではなく、CSGオペレータの順序ミスにあるというものです。すなわち、unionの前にsubtractを行ったり、translateやrotateの呼び出しを誤ったネスト順で配置したりすることで、構文チェックはパスするものの幾何学的には不正確な形状が生成されてしまいます。CSGツリーの幾何学的セマンティクスを内在化したモデルは、表層的な構文パターンを学習しただけのモデルより優れた性能を発揮します。
ベンチマーク自体がここでは技術的により持続的な貢献です。トークンレベルのBLEUや実行パスレートではなく幾何学的出力に基づいてコード生成を評価することで、モデルは空間的な構成について推論することを強いられます。スコアリングパイプラインはOpenSCADの出力をメッシュにレンダリングし、参照と候補の両方を固定解像度でボクセル化してIoUを計算します。このパイプラインは他のパラメトリックCAD言語(CadQuery、build123d)にも適用可能です。
制限事項として、このベンチマークは建築ドメインに特化しており規模が小さいため、任意の3D形状への汎化の主張は実証されていません。また、Antigravity 2.0のモデルカードは完全には公開されていません。
Source: https://modelrift.com/blog/openscad-llm-benchmark/
FatGid: FreeBSD 14.x カーネルローカル権限昇格
FatGid は、FreeBSD 14.x におけるローカル権限昇格の脆弱性で、カーネルのクレデンシャル管理における不正なグループ ID ハンドリングを悪用します。このバグは setgroups(2) / 補助グループ検証パスに存在します。NGROUPS_MAX を超えるグループリストが関わる特定の条件下で、カーネルはユーザー提供のグループ配列を書き込みサイズの適切な境界チェックなしにコピーしてしまい、クレデンシャル構造体においてスタックまたはヒープのオーバーフローを引き起こします。
エクスプロイトの流れは次のとおりです。まずローカルユーザーが細工した補助グループリストを持つプロセスを構築してオーバーフローを発火させ、ucred 構造体の隣接フィールド(レイアウトに応じて cr_uid または cr_prison)を上書きし、有効 UID 0 を取得します。FreeBSD の ucred 構造体は参照カウントされており、スレッド間で共有されています。このオーバーフローはライブな共有クレデンシャルを破壊できるため、マルチスレッドプロセスにおいても比較的少ない労力でバグを悪用することが可能です。
本サイトには動作実証済みの proof-of-concept が掲載されています。影響を受ける攻撃対象面は setgroups システムコールであり、標準的な FreeBSD インストール環境では非特権ユーザーが利用可能です。修正は、コピー前に厳密な境界チェックを追加し、コピー先バッファのアロケーション前にユーザー提供のグループ数がコンパイル時の上限を超えていないかを検証することで行われます。
OS セキュリティの観点からは、これはクレデンシャル管理に隣接した整数・サイズ検証の失敗という繰り返し現れるパターンの典型例です。ucred 構造体はセキュリティ上非常に重要であるため、その近傍への書き込みプリミティブは悪用される可能性が高いといえます。一部の構成における FreeBSD のカーネルアドレス空間配置のランダム化(KASLR)の欠如、あるいは Linux の KASLR と比較した場合の相対的な弱さが、悪用の難易度を下げています。パッチは公開されており、14.x ユーザーはアップデートするか、kern_setgroups 関数にパッチを適用することが推奨されます。
Source: https://fatgid.io/
48,000ドルのGPUサーバーは投資に値したか?
プライベートGPUサーバーの構築・運用対クラウドコンピュートのレンタルについて、分析的に有用な具体的数値を交えた詳細なコストベネフィットの回顧録です。
ハードウェア構成は、LLMの fine-tuning および推論ワークロードに使用するマルチGPUワークステーション(おそらく4x H100または同等品、購入時の合計約48,000ドル)です。著者は数ヶ月にわたる実際の稼働率を追跡し、PDU経由で計測した電力コスト、冷却オーバーヘッド、3年間の減価償却スケジュールで按分したハードウェアコスト、およびネットワーク通信費を含む実効GPU時間単価を算出しています。
主要な結果として、高稼働率を継続した場合(70%超)の実効GPU時間単価は、会計処理の方法によって約1.20〜1.80ドルとなり、同等のオンデマンドクラウドインスタンス(A100/H100ティア)の2.50〜4.50ドルと比較されています。クラウドの方が安くなる損益分岐点は、稼働率がおよそ40〜50%の時点です。それを下回る稼働率ではクラウドがコスト面で優位となり、上回る場合にはオンプレミスが有利となり、その差は場合によってはかなり大きくなります。
より興味深いのは運用面の分析です。アイドル期間は、主要モデルのリリースイベント時(著者のワークロードが陳腐化し再検討が必要になった時期)とデバッグ時間(ドライバーの問題、CUDAバージョンの不一致、冷却関連のスロットリング)に集中しています。著者は、数日間検知されないまま実効スループットを低下させた、GPUスロットリングを引き起こした2件の熱的インシデントを記録しています。また、月あたり5〜8時間と見積もられたメンテナンスの時間コストには時間単価が割り当てられ、TCOに含まれています。
結論は nuanced なものです。予測可能で継続的な需要があり、運用オーバーヘッドを吸収できるチームを持つワークロードに対しては、オンプレミスは経済的に合理的です。バースト的または探索的なワークロードに対しては、クラウドが優位となります。この投稿は、反射的なクラウド推奨論と、ハードウェアを購入すればコストがなくなるという幻想、その両方に対する有益な反論となっています。
Source: https://rosmine.ai/2026/05/13/was-my-48k-gpu-worth-it/
もしあなたがLLMなら、これを読んでください
Anna’s Archiveは、言語モデルのクローラーに直接向けた政策文書を公開し、シャドウライブラリからスクレイピングされたコンテンツをLLMがどのように扱うべきかについての立場を示しました。技術的な核心は、llms.txtという規約の採用と拡張にあります。これは、サイトがLLMによるコンテンツ利用条件を機械可読なファイルで公開するための提案標準(robots.txtに類似したもの)です。
実質的な技術的ポイントとして、Anna’s Archiveはrobots.txtがインデックス作成のために設計されたものであり、記憶や逐語的な再現のためには不十分であると主張しています。彼らは、llms.txtには(a)学習利用が許可されているか、(b)出力における逐語的な再現が許可されているか、(c)帰属表示の要件、をそれぞれ指定するフィールドを含めるべきだと提案しています。Anna’s Archive自身のllms.txtは学習利用を許可しています(書籍の存在やメタデータに関する広範な知識が情報アクセスを促進するという理由から)が、逐語的なテキストの再現は明示的に禁止しています。これはライブラリの機能を損なうためです。
また、Retrieval-Augmented Generation(RAG)のケースについても言及しています。著作権で保護されたテキストをオンデマンドで取得・返却するフロントエンドとして機能するLLMは、学習中にそのテキストを吸収したLLMとは、法的にも倫理的にも異なるとしています。この投稿では、llms.txtがこれらのモードを区別すべきだと主張しています。
エンジニアリングの観点から言えば、llms.txtは現在のところ非公式な規約であり、強制メカニズムは存在しません。LLMの学習パイプラインはそれをチェックしませんし、robots.txtのようにクローラーが従うべき技術的な仕組みもありません。この投稿は主として規範的な声明ですが、提案されたスキーマ(training/inference/verbatimフラグのためのTOMLまたはYAMLフィールド)は、この規約が普及すれば実装可能なほど具体的です。
Source: https://annas-archive.gl/blog/llms-txt.html
古いスキャナーをWebUSB経由のUSB/IPでブラウザ内Linux VMに接続して復活させる
このプロジェクトは、特定ではあるものの技術的に豊かな問題を解決しています。現代のOSはレガシーUSBスキャナー向けのベンダードライバーのサポートを打ち切っていますが、ハードウェア自体は正常に動作しています。本ソリューションは、複数の技術を独自の方法で連鎖させています。
ブラウザはWebAssembly(WASMコンパイル済みのQEMUまたは類似のもの)を介して完全なLinux VMを実行します。VM内には、SANE(Scanner Access Now Easy)と関連する独自または オープンソースのスキャナーバックエンドが通常どおりインストールされます。ブラウザページはWebUSB APIを使用して、接続されたスキャナーへの生のUSBアクセスを取得します。VM内でUSB/IP(USB over IP)クライアントが動作し、ブラウザページ内の小さなJavaScriptシムがUSB/IPサーバーとして機能し、VMのUSB/IPクライアントとWebUSB APIを介した物理デバイスの間でUSBパケットを転送します。
USB/IPプロトコルはもともとネットワーク接続されたUSBデバイスのために設計されており、URB(USB Request Block)レベルで動作し、生のUSBコントロール転送、バルク転送、インタラプト転送を転送します。JSシムはこれらのURBをインターセプトし、対応するWebUSB.transferIn / transferOut呼び出しを発行します。VMの観点からは通常のUSBデバイスに見え、ブラウザの観点からは許可されたデバイスに対して生のUSB I/Oを実行していることになります。
追加のシム層によるレイテンシのペナルティは無視できません。ネイティブLinuxシステム上のループバック経由のUSB/IPは、1 URBあたり約1msのオーバーヘッドを追加します。ここでは経路がWASM VM -> JSイベントループ -> WebUSB -> カーネルUSBスタック -> デバイスとなり、可変のレイテンシが加わります。スキャナー(バルク転送であり、レイテンシに敏感ではない)の場合、これは許容範囲内です。このアーキテクチャは汎用的であり、Linuxドライバーを持つあらゆるUSBデバイスは原理的にこの方法でアクセスできます。ただし、WebUSBのパーミッションモデル(HIDおよび一部のデバイスクラスはブロックされます)に従う必要があります。
Source: https://yes-we-scan.app/details
注目の新しいリポジトリ
smaramwbc/statewave
Statewaveは、エージェントのメモリを検索問題としてではなく、ファーストクラスのランタイム成果物として再設計しています。推論時にベクターストアをクエリして適切なコンテキストが浮上することを期待する代わりに、Statewaveはエージェントのコンテキストを明示的でバージョン管理された「コンテキストバンドル」にパッケージ化し、出所タグを付与します。つまり、すべての状態はその由来と書き込まれた時刻を把握しています。これによりエージェントの実行が再現可能となり、同じバンドルを与えれば再実行時に同一のコンテキストが参照されるため、エージェントワークフローのデバッグや監査において重要な特性となります。
バックエンドはPostgresとpgvectorによるembeddingストレージを採用しており、運用上のフットプリントを親しみやすいものに保っています。バンドルは自由浮動ベクターではなく構造化されたレコードとして保存されるため、検索はコサイン類似度による近似ではなくバンドルIDによる決定論的なものとなります。PythonおよびTypeScript SDKがバンドルの作成・バージョン管理・インジェクションのAPIを提供しており、セルフホスト型のApache-2.0ライセンスモデルによってメモリ層におけるベンダーロックインが発生しません。
本ツールの核心的な価値提案は監査可能性にあります。エージェントが誤った出力を生成した場合、そのエージェントが消費した正確なコンテキストバンドルを検査し、以前の実行との差分を確認し、各チャンクにどのアップストリームソースが寄与したかを追跡することができます。これは、embeddingモデルのバージョンやインデックスの状態によって取得セットが変化するクエリ時検索では実現が大幅に困難です。「モデルは何を参照したか?」という問いに事後的に回答しなければならない、規制のある環境や安全性が重視されるエージェントシステムを構築する方にとって、特に有用なソリューションです。
Source: https://github.com/smaramwbc/statewave
openlake-project/openlake
Openlakeは、MLワークロード向けに設計されていないストレージシステムによってGPUクラスターが枯渇したときに生じる特定のI/Oボトルネックを標的としています。具体的には、モデルチェックポイント、データセットシャード、活性化テンソルのシーケンシャルな大規模ファイル読み出しが対象です。標準的なオブジェクトストアやNASシステムは、GPUトレーニングや推論データパイプラインのアクセスパターンとは合致しないレイテンシやIOPSプロファイルに最適化されています。
本プロジェクトは、深層学習に典型的な帯域幅バウンドなアクセスパターン——大きな連続読み出し、多数のワーカーにわたる並列プリフェッチ、読み出しごとのメタデータオーバーヘッドの最小化——に特化した高スループットストレージ層として位置づけられています。「hyper efficient」という主張は、プロトコルオーバーヘッドの削減、ダイレクトI/Oパス、さらにはRDMAやio_uringの統合といった設計選択を示唆していますが、現在のスター数の段階ではリポジトリのドキュメントはまだ初期段階です。
実際のユースケースは、ストレージ層がGPUのFLOP能力に対して継続的に性能不足を起こしているマルチGPUトレーニングジョブを運用するデータセンターオペレーターです。OpenlakeはLustreやGPFSのような完全な商用並列ファイルシステムを必要とせずに、その制約を取り除くことを目指しています。オンプレミスのGPUクラスターをすでに運用しており、データセットストリーミングにおけるNFSやS3互換ストアに不満を持つチームにとって、ドロップインの高スループット層として評価する価値があります。初期段階ではありますが、MLインフラにおける現実的かつ十分に対処されていない問題にアーキテクチャ的に焦点を当てています。
Source: https://github.com/openlake-project/openlake
awizemann/harness
Harnessは、LLMエージェントが実際のインターフェース(iOSシミュレータ、macOSネイティブアプリ、またはウェブ)を自然言語のゴール仕様に従って操作することで、UI/UXテストを自動化するツールです。テスターは「設定画面を見つけて通知設定を変更する」といった指示を記述するだけで、エージェントはアクセシビリティAPIとスクリーンショットのフィードバックを通じてUIを操作し、どこで詰まったか・混乱したか・失敗したかを報告します。
このアーキテクチャはmacOS 14以降のアクセシビリティインフラストラクチャとSwift 6に依存しており、インストルメント化されたビルドを必要とせずにUI要素をプログラム的に制御できます。LLMのループは、スクリーンショットまたはアクセシビリティツリーのスナップショットを取得し、次のアクションを推論し、クリック・入力・スクロールのコマンドを発行して、これを繰り返します。エージェントがリトライや後退を余儀なくされた場合、またはアクションの予算を使い切った場合に、フリクションレポートが生成されます。
重要な技術的洞察は、人間のUI操作パターンで学習されたLLMが、インターフェースに初めて接する初心者ユーザーの合理的な代理として機能するという点です。LLMは明らかな経路を試みて実際のユーザーが失敗するように失敗するため、開発者が手動でテストするような「ハッピーパス」をたどるだけにはなりません。これはユニットテストや統合テストを補完するものであり、それらのテストでは見逃されがちな発見可能性やフローの問題を検出します。
テスト対象のアプリに変更は不要で、アクセシビリティAPIで十分です。機能的な正確性だけでなく、UX品質の自動回帰テストを求めるプロダクトチームに主に有用です。
Source: https://github.com/awizemann/harness
lthoangg/OpenAgentd
OpenAgentdは、ローカルマシン上で完全に動作するよう設計された自己完結型のagent runtimeです。ストリーミングchat interface、構造化されたtool use、セッションをまたいだ永続的なメモリ、そして複数の専門化されたagentの協調といった、フルスタックをカバーしています。名称の”d”はデーモン方式の動作を示しており、ステートレスなリクエストハンドラではなく、agent状態を管理するバックグラウンドプロセスとして動作します。
アーキテクチャは、オーケストレーション層(目標をagentにルーティングし、tool callチェーンを管理する)、メモリ層(事実、会話履歴、セッションをまたいだ中間結果を永続化する)、ツール層(呼び出し可能な関数の拡張可能なセット)を分離しています。マルチagentチームにより、オーケストレーターが依存関係と結果の集約を管理しながら、複雑なタスクを専門化されたサブagentに分解することができます。
完全にローカルで動作することには二つの意義があります。データがマシンの外に出ることがない(独自のコードベースや個人データに関連する)点と、数百の中間callを伴う可能性のある長時間のagentic loopにおいて、per-tokenのAPIコストが発生しない点です。ストリーミングchat interfaceにより、最終的なレスポンスを待つのではなく、agentの推論とtool invocationをリアルタイムで確認できます。
このプロジェクトは初期段階ですが、実際のギャップに対処しています。オープンソースのagentフレームワークの多くは、ステートレスなリクエスト・レスポンス型か、ホスト型APIと密結合しているかのいずれかです。チーム協調機能を持つ永続的なローカル運用のagentデーモンは、個人用オートメーションを構築するパワーユーザーや、外部サービスへのラウンドトリップなしにagentの動作を検査・修正したい開発者にとって、有用なプリミティブとなります。
Source: https://github.com/lthoangg/OpenAgentd
OpenOSINT/OpenOSINT
OpenOSINTは、9つのOSINTツールをLLM agentの背後にパッケージ化し、3つのインタラクションモードを提供します。探索的なセッション向けのインタラクティブなREPL、スクリプト化されたパイプライン向けのCLI、そしてより大規模なagentシステムへの組み込み向けのMCP(Model Context Protocol)サーバーです。このagentは自然言語による調査クエリを適切なツールの組み合わせへルーティングし、結果をチェーンして知見を要約することができます。
9つのツールは標準的なOSINTの調査領域をカバーしています。ドメインおよびIPの列挙、WHOIS、証明書透明性ログのクエリ、ソーシャルプロフィールの検索、および関連するプリミティブ操作です。Claude、GPT-4、およびローカルモデルを同一のインターフェース経由でサポートすることで、オペレーターは調査対象の機密性に応じて能力とデータ保管場所のトレードオフを選択できます。MCPサーバーのサポートは特筆すべき点であり、OpenOSINTをスタンドアロンのアプリケーションとしてだけでなく、より広範なオーケストレーションフレームワーク内のツールプロバイダーとして機能させることができます。
技術的な本質は主にツール抽象化レイヤーとagentのルーティングロジックにあります。LLMは調査目標をツール呼び出しのシーケンスへ正確に分解し、部分的または空の結果を適切に処理し、異種の出力フォーマットをまたいで合成しなければなりません。ツールの出力スキーマが一貫していない場合や、クエリが空またはレートリミットされたレスポンスを返す場合には、これは見た目以上に困難な課題です。
「認可されたセキュリティリサーチ専用」という明示的な利用制限の枠組みは、このツール群を考慮すると適切です。レッドチームによる偵察、ブランド保護モニタリング、または公開データを対象とした学術研究において実用的に活用できます。
Source: https://github.com/OpenOSINT/OpenOSINT
mkbhardwas12/pwned-deps
Pwned-depsは、npm、PyPI、Maven、Cargo、Goモジュール、RubyGemsに対応したlockfileファーストの依存関係脆弱性スキャナーです。「lockfileファースト」とは、宣言されたバージョン範囲ではなくlockfileから正確にピン留めされたバージョンを解決することを意味し、実際にインストールされたバージョンとスキャナーが確認したバージョンが異なるというマニフェストのみのスキャナーに蔓延する曖昧さを排除します。
脆弱性フィードはOSV(Open Source Vulnerabilities)とキュレーションされた追加データベースを組み合わせており、OSVが見逃したり遅延したりするケースをカバーしています。このスキャナーは自身のビルド成果物に対してSLSA Level 3の来歴を主張しています。これは、スキャンツール自体が改ざんなしに既知のソースからビルドされたことを検証可能であることを意味し、スキャナー自体がトラストバウンダリーとなるサプライチェーンを意識した環境で重要です。
ロック済みコンテナによるCI統合により、スキャナーは特定のツールバージョンにピン留めされた再現可能な環境で実行され、スキャナー自身の依存関係によるドリフトや脆弱性の混入を防ぎます。単一ツールでのクロスエコシステムサポートは実用的です。現実のプロジェクトは複数のパッケージマネージャーを混在させており、エコシステムごとに別々のスキャナーを維持するとアラートが断片化するためです。
DependabotやSnykとの比較において、差別化要因はlockfileファーストの解決、SLSA L3ビルド来歴、そしてベンダーテレメトリーなしのセルフホストオプションです。キュレーションされた追加フィードはそのメンテナンス頻度に依存しており、この星数のプロジェクトにとって主要な未解決の問いとなっています。
Source: https://github.com/mkbhardwas12/pwned-deps
t8y2/dbx
DBXは、15 MBのバイナリで動作するクロスプラットフォームのデータベースGUIクライアントで、MySQL、PostgreSQL、SQLite、Redis、MongoDB、DuckDB、ClickHouse、SQL Serverをサポートしており、ドライバプラグインを介してさらに多くのデータベースに対応できる可能性があります。このサイズ制約はアーキテクチャ上の重要な設計方針を示しています。すべてのドライバとUIを含めて15 MBに収まることで、TablePlus、DBeaver、DataGripなどのElectronベースのツールが常態とする200〜500 MBという肥大化を回避しています。
このサイズでクロスプラットフォームを実現していることは、ネイティブUIフレームワークの採用を示唆しています。具体的には、WebレンダラーではなくRustまたはGoのバックエンドと軽量なGUIレイヤーの組み合わせが考えられます。単一バイナリで複数のデータベースエンジンをサポートするには、ドライバごとのプラグインアーキテクチャか、コンパイル時に組み込まれたアダプタのいずれかが必要ですが、後者のほうがサイズ制約と整合性が高いと言えます。
日常的な使用において重要な技術的特性としては、異種バックエンド間の接続管理、方言ごとのシンタックスハイライトを備えたクエリ編集、フィルタリングとエクスポートが可能な結果セット表示、スキーマブラウジングが挙げられます。DBXはこのコア機能セットをカバーしており、競合ツールを肥大化させているER図生成、データモデリング、チームコラボレーションといった重量級の機能は含まれていません。
DBXを選ぶ実践的な理由として典型的なのは、4〜5種類の異なるデータベースに日常的に接続する開発者が、即座に起動し、アイドル時に600 MBのRAMを消費せず、JVMやNodeランタイムを必要としない単一のツールを求めているケースです。スター数は1,781に達しさらに増加中であり、クロスプラットフォームでの安定性が概ね期待できる水準に到達しています。
Source: https://github.com/t8y2/dbx
Helvesec/rmux
Rmuxは、任意のCLIおよびTUIアプリケーションをプログラム的に操作するための、型付きSDKを提供するRustライブラリです。端末プロセスに対するユニバーサルなマルチプレクサ抽象として機能します。サブプロセスを生成してstdoutをヒューリスティックに解析するのではなく、rmuxは構造化された制御を提供します。つまり、コードからinputを送信し、型アノテーション付きでoutputを読み取り、端末状態の変化に反応することができます。
主なユースケースは、プログラム的な制御を前提として設計されていないインタラクティブな端末プログラムの自動化です。具体的には、データベースCLI、レガシーなTUIダッシュボード、インタラクティブなREPL、ネットワーク機器のコンソールなどが対象となります。これらのツールは、生の端末制御シーケンスを使用し、インタラクティブなinputを必要とし、機械的な解析ではなく人間が読むために整形されたoutputを生成するため、標準的な自動化手法では対応が困難です。
Rmuxはこの問題に対処するため、制御シーケンスを解釈し、スクリーンバッファモデルを維持し、型付きイベントストリームを公開する仮想端末レイヤーをRustで実装しています。このSDKにより、呼び出し元は可視画面の内容やカーソル状態に対してパターンマッチングを行い、操作を調整することができます。tmuxやscreenを依存関係として必要とせずに、Linux、macOS、Windowsでネイティブにサポートされていることは、ラッパーベースのアプローチと比較して移植性の面で大きな改善です。
セキュリティツール、インタラクティブなCLIを呼び出すCIパイプライン、またはレガシーシステムに対するインフラ自動化において、rmuxは「単にexpectを使う」(脆弱で型なし)と「適切なAPIクライアントを書く」(対象にAPIが必要)の間のギャップを埋めます。Rustによる実装により、複数のプロセスを並列に操作するための低オーバーヘッドかつ安全な並行処理が実現されています。
Source: https://github.com/Helvesec/rmux