Daily AI Digest — 2026-05-22
arXiv Highlights
Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention
Problem
Linear attention compresses the unbounded KV cache of softmax attention into a fixed-size matrix state \mathbf{S}_t \in \mathbb{R}^{d_k \times d_v}, giving O(L) training and O(1) decoding memory. The recurrence \mathbf{S}_t = \mathbf{S}_{t-1} + \bm{k}_t \bm{v}_t^\top accumulates outer products without subtraction, so old associations only decay through interference. The delta-rule line of work (DeltaNet, Gated DeltaNet, Kimi Delta Attention) addresses this by subtracting the current read before writing:
\mathbf{S}_t = \mathbf{S}_{t-1} - \beta_t \bm{k}_t (\mathbf{S}_{t-1}^\top \bm{k}_t)^\top + \beta_t \bm{k}_t \bm{v}_t^\top.
KDA additionally introduces channel-wise decay \bm{\alpha}_t \in (0,1]^{d_k} applied as \mathbf{D}_t = \operatorname{Diag}(\bm{\alpha}_t) before the edit. The unresolved issue: the scalar \beta_t controls two distinct decisions — how much of the old content at key \bm{k}_t to erase, and how much of the new value \bm{v}_t to commit. Tying these forces the same channel structure on both the key (read) side and value (write) side of the rank-one update, which is geometrically unmotivated.
Method: Gated Delta Rule-2
Gated DeltaNet-2 introduces two independent channel-wise gates: an erase gate \bm{b}_t \in [0,1]^{d_k} on the key side and a write gate \bm{w}_t \in [0,1]^{d_v} on the value side. Define \bm{e}_t = \bm{b}_t \odot \bm{k}_t and \bm{z}_t = \bm{w}_t \odot \bm{v}_t. With \mathbf{D}_t = \operatorname{Diag}(\bm{\alpha}_t), the decay-then-edit recurrence is
\bar{\mathbf{S}}_t = \mathbf{D}_t \mathbf{S}_{t-1}, \quad \bm{r}_t = \bar{\mathbf{S}}_t^\top \bm{e}_t, \quad \mathbf{S}_t = \bar{\mathbf{S}}_t + \bm{k}_t (\bm{z}_t - \bm{r}_t)^\top,
equivalent to the closed form
\mathbf{S}_t = \bigl(\mathbf{I} - \bm{k}_t (\bm{b}_t \odot \bm{k}_t)^\top\bigr) \mathbf{D}_t \mathbf{S}_{t-1} + \bm{k}_t (\bm{w}_t \odot \bm{v}_t)^\top.
The structural point: the left factor of the rank-one erase remains \bm{k}_t (preserving the write direction), while the right factor \bm{b}_t \odot \bm{k}_t makes the read direction channel-selective, and the write term \bm{k}_t \bm{z}_t^\top makes the inserted value channel-selective. KDA is recovered exactly when \bm{b}_t = \beta_t \mathbf{1}_{d_k} and \bm{w}_t = \beta_t \mathbf{1}_{d_v}; Gated DeltaNet is recovered by additionally collapsing \bm{\alpha}_t to a scalar. So the model strictly contains its predecessors as tied subspaces.
Gates are produced by independent linear projections through a sigmoid:
\bm{b}_t = \sigma(\mathbf{W}_b \bm{x}_t), \quad \bm{w}_t = \sigma(\mathbf{W}_w \bm{x}_t),
while the log-decay follows the Gated DeltaNet form \bm{g}_t = -\exp(\mathbf{a}) \odot \operatorname{softplus}(\mathbf{W}_f \bm{x}_t + \bm{\delta}) with \bm{\alpha}_t = \exp(\bm{g}_t), computed in fp32 to avoid precision loss in cumulative log-decay. The negative-eigenvalue variant scales only the erase gate to [0,2]^{d_k}, since the spectral effect on the state transition \mathbf{I} - \bm{k}_t \bm{e}_t^\top depends on the erase factor, not on value magnitude.
The paper derives a chunkwise WY-style algorithm with channel-wise decay absorbed into asymmetric erase factors, which is what makes the rule trainable at chunk granularity on tensor cores while keeping the decoupled gates exact.
Results
At 1.3B parameters trained on 100B FineWeb-Edu tokens (4K context, AdamW, peak lr 4 \times 10^{-4}, batch 0.5M tokens), Gated DeltaNet-2 outperforms Mamba-2, Gated DeltaNet, KDA, and both Mamba-3 SISO/MIMO variants on average across language-modeling and zero-shot reasoning. Recurrent-only: Wikitext ppl 15.90 (vs. KDA 16.81, Gated DeltaNet 16.40, Mamba-3 MIMO 16.45), LAMBADA ppl 11.41 (vs. KDA 11.68), average accuracy 53.11 (vs. next-best Mamba-3 MIMO 52.39, KDA 52.28). Hybrid (with 2K sliding-window attention): average 53.97, with LAMBADA ppl 10.43 and BoolQ 62.57.
The gap widens on associative recall. On RULER S-NIAH-2 at 4K context, recurrent Gated DeltaNet-2 hits 93.0 vs. KDA 89.0 and Gated DeltaNet 87.2; at 8K, 39.2 vs. KDA 30.6 and Mamba-2 21.0. On S-NIAH-3 at 2K, 89.8 vs. KDA 63.2 and Gated DeltaNet 54.2 — a 26-point margin over KDA in the regime where the state must actively rewrite stored bindings. On MK-NIAH-1 at 4K, 37.8 vs. KDA 28.0. The hybrid model also leads on long-context multi-key recall: MK-NIAH-1 at 4K is 48.0 vs. Mamba-3 MIMO 46.6 and KDA 40.4. These are exactly the tasks where decoupling erase from write should help: editing a specific binding without scrambling co-stored ones requires different channel masks on the read and write sides.
Limitations
The evaluation is at 1.3B / 100B tokens with 4K training context, which is small relative to the regimes where Mamba-3 and KDA were originally tuned; scaling behavior of the extra gate parameters is not characterized. The gains over KDA on standard reasoning are modest (avg 53.11 vs. 52.28 recurrent-only); the bulk of the advantage is concentrated in recall-style benchmarks. The chunkwise WY kernel with asymmetric erase factors is described but throughput numbers vs. KDA’s kernel are not reported in the excerpt, so the practical wall-clock cost of the second gate is unclear. There is no ablation isolating \bm{b}_t alone vs. \bm{w}_t alone, which would clarify which side of the decoupling carries the recall improvement.
Why this matters
Treating the delta rule as a rank-one state edit makes it explicit that “what to forget” and “what to write” live on different sides of the outer product and need not share a gate. Gated DeltaNet-2 is the minimal generalization that respects this, contains KDA and Gated DeltaNet as exact subspaces, and pays off most where it should — multi-key associative recall under a fixed-size state.
Source: https://arxiv.org/abs/2605.22791
Unsupervised Process Reward Models
Process Reward Models (PRMs) provide step-level supervision that has proven effective for steering LLM reasoning, but training them requires per-step correctness annotations — expensive even at modest scale (PRM800K cost ~10^6 in human labor). This paper proposes uPRM, a method to train a PRM without any step-level labels and without final-answer verification, by exploiting the base LLM’s own next-token probabilities as a noisy but joint estimator of where reasoning first goes wrong.
Scoring the first erroneous position
Given a trajectory \tau = (x, y_1, \dots, y_T) and a candidate first-error index j \in \{1,\dots,T+1\} (with j=T+1 denoting “no error”), the authors construct an interleaved sequence
\mathbf{s}(\tau, j) = [x,\, y_1, +, \dots, y_{j-1}, +, y_j, -]
and feed it to a base LLM. Let p_t^{+}, p_t^{-} be the next-token probabilities of the “+” and “-” labels after y_t, renormalized over \{+,-\}. The score is
\mathcal{S}(j;\mathbf{s}) = \mathbb{1}[j \le T]\cdot \log p_j^{-} + \sum_{t < j}\log p_t^{+}.
Two things are important here. First, the score is computed in a single forward pass over the labeled prefix, meaning the LLM sees the previous “+” labels in-context when judging step j — this is the “joint” assessment that distinguishes the method from LLM-as-a-Judge applied to each step independently. Second, no ground-truth label appears anywhere; the construction is symmetric in j and only requires the LLM’s calibration over the binary correctness alphabet.
The PRM r_\theta is then trained on PRM800K trajectories (labels discarded) by distilling the LLM-induced distribution over j. The base model is Qwen2.5-14B-Instruct, whose post-training did not involve step-level correctness data, so the setup remains genuinely unsupervised with respect to step labels.
ProcessBench: error localization
The most direct test is ProcessBench, which asks the model to locate the first erroneous step (or declare the trajectory correct) across GSM8K, MATH, OlympiadBench, and Omni-MATH trajectories. The natural baseline is LLM-as-a-Judge using the same base model, the same prompt template, and the same scoring function — but applied independently per step rather than jointly via the interleaved sequence. This isolates the contribution of joint in-context scoring plus distillation.
uPRM improves F1 substantially on all four splits: 49.8 → 58.3 on GSM8K, 42.8 → 52.6 on MATH, 29.4 → 42.7 on OlympiadBench (+13.3 absolute), and 26.6 → 39.8 on Omni-MATH (+13.2 absolute). The gap widens on harder benchmarks, which is consistent with the hypothesis that independent per-step judgments degrade as reasoning chains grow longer and more entangled, while joint scoring leverages the conditional structure of the trajectory.
Test-time scaling and RL
As a verifier for test-time scaling, uPRM is evaluated against majority voting and (implicitly) against supervised PRMs.
The abstract reports that uPRM matches supervised PRMs as a verifier and outperforms majority voting by up to 6.9% absolute. Used as a dense reward signal for RL fine-tuning, uPRM yields more robust policy optimization than outcome-only baselines — relevant because outcome rewards on math leave the policy under-supervised on long chains where many partial trajectories are correct up to a late mistake.
Limitations and open questions
A few caveats are worth flagging:
- The score relies on the base LLM being calibrated over \{+,-\} continuations. Calibration is known to depend heavily on prompt formatting, instruction-tuning, and tokenization of the label tokens. The renormalization over \{+,-\} partly mitigates this but does not fix systematic bias toward “+” in long correct-looking prefixes.
- The construction assumes a single first-error position. Trajectories with compounding errors, or with steps that are individually fine but jointly inconsistent, are not naturally handled by the j-parametrization.
- All experiments use Qwen2.5-14B-Instruct as the scorer. It is unclear how much of the 13-point ProcessBench gain transfers to weaker base models, where the joint score may be too noisy to distill.
- Training uses PRM800K trajectories, which were themselves curated from a specific generator. Domain shift in the trajectory distribution (e.g., to code or agentic traces) is untested.
- The score is non-uniform over j: the \sum_{t<j}\log p_t^{+} term grows with j in expectation when prefixes look correct, so the implicit prior over error positions is shaped by the LLM’s confidence profile rather than any principled distribution.
Why this matters
If joint LLM-induced scoring can replace step-level human annotation, the dominant cost in PRM training collapses, and PRMs become trainable on any reasoning corpus where only trajectories — not labels — are available. The ProcessBench gains over a controlled LLM-as-a-Judge baseline (using the same model and prompt) suggest the improvement comes from in-context joint reasoning over correctness labels, a primitive that should generalize beyond math.
Source: https://arxiv.org/abs/2605.10158
DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards
Problem
In sequence-level RLVR (GRPO, DAPO, etc.), every token in a response shares the same scalar advantage \hat{A}_i, yet empirically only a sparse subset of token distributions shifts during training. The authors ask: if reward is response-level, what mechanism induces this token-level selectivity, and can it be improved? Their answer reframes the policy-gradient update as an implicit linear discriminator in token-gradient space and shows that the standard centroid construction is biased toward high-frequency shared tokens (formatting, connectives) that contribute little to distinguishing successful from unsuccessful trajectories.
A discriminator view of RLVR updates
Let v_{i,t} = \nabla_\theta \log \pi_\theta(o_{i,t}\mid c_{i,t}). For a candidate token x at context c, a first-order Taylor expansion gives
\Delta\log\pi(x\mid c) \approx \big(\nabla_\theta \log \pi_\theta(x\mid c)\big)^\top \Delta\theta.
Whether \pi(x\mid c) moves up or down is decided by the inner product of its gradient with the update direction \Delta\theta. For a DAPO-style surrogate at \theta_{\mathrm{old}} (where importance ratios are unity and clipping inactive), the local update factors cleanly by sign of the advantage:
\Delta\theta_{\mathrm{RLVR}} \propto \sum_{i:\hat{A}_i>0}\sum_t \hat{A}_i\, v_{i,t} \;-\; \sum_{i:\hat{A}_i<0}\sum_t |\hat{A}_i|\, v_{i,t}.
After normalization, this is the difference of two centroids \mu_+, \mu_- in gradient space, i.e., a Fisher-style linear discriminator. A token gets reinforced iff its gradient lies closer to \mu_+ than \mu_-. The pathology: \mu_+ and \mu_- are dominated by shared high-frequency tokens that occur on both sides, so \mu_+ - \mu_- is diluted along truly discriminative directions.
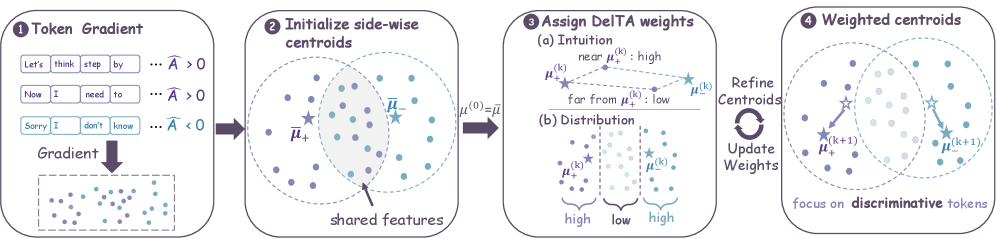
Method
DelTA reweights each token-gradient term by a coefficient \lambda_{i,t} that is large when v_{i,t} is closer to its own-side centroid and far from the opposite-side centroid. Concretely (positive side; negative is symmetric):
\alpha_{i,t} = \sigma\!\left(\frac{\|v_{i,t}-\mu_-\|_2^2 - \|v_{i,t}-\mu_+\|_2^2}{\gamma}\right),
normalized within the rollout group and clipped to [\lambda_{\min},\lambda_{\max}]=[0.8,1.2]. The reweighted DAPO objective becomes a sum over tokens with weights \lambda_{i,t}\hat{A}_i. Because \lambda_{i,t} depends on the centroids, which themselves depend on \lambda, the authors run K=1 refinement iteration, recomputing centroids from the reweighted aggregates. The construction is critic-free and group-relative, drop-in compatible with DAPO-class objectives (extension to others discussed in Appendix E since the derivation only requires the update to be advantage-weighted gradient aggregation).
Results
Trained on DeepMath-103K with VeRL on Qwen3-8B-Base and Qwen3-14B-Base, with dynamic sampling disabled to isolate the objective. On the 8B backbone over four representative competition benchmarks (AIME25, AIME26, HMMT25-Nov, HMMT26-Feb), DelTA reaches 23.27 average vs. 19.05 for DAPO, a +4.22 absolute gain. Per-benchmark: AIME25 26.46 vs. 23.33; AIME26 28.12 vs. 24.17; HMMT25 18.54 vs. 12.08; HMMT26 20.27 vs. 16.86. Evaluation uses 16 samples per problem at 30k-token max generation length.
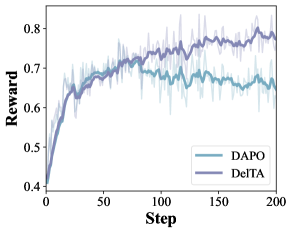
Training dynamics show DelTA achieves higher reward without entropy collapse and with comparable response length, suggesting the reweighting reshapes credit assignment rather than just changing exploration scale.
Ablations
The opposite-side comparison is the load-bearing component. A within-side-only variant that keeps tokens close to their own centroid (using \alpha_{i,t}=\sigma(-\|v_{i,t}-\mu_+\|^2/\gamma_+)) underperforms even DAPO: 17.94 average vs. 19.05 for DAPO and 23.27 for DelTA. Tokens near \mu_+ alone are often shared formatting tokens; only the contrast \|v-\mu_-\|^2-\|v-\mu_+\|^2 isolates directions that are simultaneously characteristic of one side and atypical of the other. This is the empirical confirmation of the dilution hypothesis from the discriminator analysis.
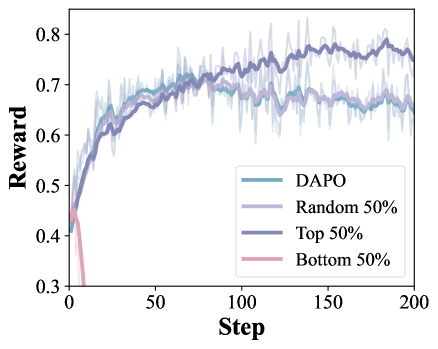
Using \lambda_{i,t} purely as a token-selection mask (rather than continuous reweighting) also yields gains, indicating it captures meaningful learning signal rather than acting as a noise smoother.
Limitations and open questions
The first-order Taylor argument is local; the analysis assumes clipping is inactive at \theta_{\mathrm{old}}, which holds only for the immediate update step and breaks down across PPO inner epochs. The centroids \mu_\pm are computed in full parameter-gradient space — the paper does not detail how this is approximated efficiently for 14B models, and projection or layerwise approximations likely matter at scale. The hyperparameter window [0.8,1.2] is narrow; whether a more aggressive range helps or destabilizes is only studied in appendix. Evaluation is restricted to math competition benchmarks; transfer to code, agentic tasks, or general instruction following is untested. Finally, the discriminator framing predicts the existence of a small set of “decisive” tokens — characterizing them linguistically (are they reasoning operators? answer-commit tokens?) would strengthen the interpretation.
Why this matters
Reframing the policy-gradient step as a Fisher-style discriminator over token-gradient vectors gives a precise, mechanical account of why sequence-level RLVR produces sparse token-level updates, and identifies a concrete failure mode — centroid contamination by shared high-frequency tokens — that explains why uniform sequence-level credit is suboptimal. DelTA operationalizes this with a cheap, critic-free reweighting that is compatible with the DAPO/GRPO family.
Source: https://arxiv.org/abs/2605.21467
Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps
Problem
Long-context inference in dense LLMs is dominated by the O(n^2) cost of full attention over the KV cache. The two main mitigations — native sparse training (e.g., NSA-style architectures) and training-free heuristics (token eviction, block-level top-k) — sit at opposite ends of a Pareto curve: the former demands large pretraining budgets, while the latter loses accuracy on retrieval-heavy tasks. RTPurbo argues that the dichotomy is unnecessary because pretrained full-attention models are already sparse in a structured way, and a few hundred adaptation steps suffice to expose that sparsity for inference.
Three structural observations
The method is built on empirical regularities in pretrained Qwen3-30B-class models:
Head specialization. Only a small fraction of query heads do long-range retrieval; the rest attend almost exclusively to local context or sink tokens. The headwise retrieval-score heatmaps confirm that high-scoring heads are concentrated in the latter half of the network, consistent with the view that early layers do local contextualization while later layers form stable representations suitable for long-range recall.
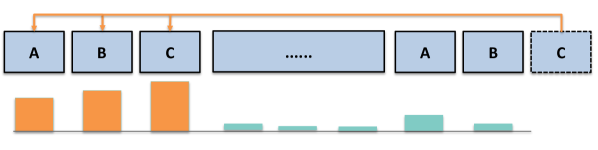
Retrieval heads attend to semantically related distant regions, while most heads stay local. Low-rank retrieval geometry. The relevant subspace for long-range matching is low-dimensional; a 16-d projected query/key indexer is enough to identify which tokens a retrieval head will actually attend to.
Query-dependent token budget. The number of tokens contributing meaningful attention mass varies with the query, so a fixed top-k either over- or under-recalls. Dynamic top-p (cumulative attention threshold) is a better fit.
Method
Heads are partitioned offline by injecting an identical “needle” span at both ends of a long FineWeb document and scoring each head h by
R_h = \frac{1}{|\mathcal{N}_{\text{post}}|} \sum_{t \in \mathcal{N}_{\text{post}}} \sum_{j \in \mathcal{N}_{\text{pre}}} A_h(t, j),
i.e., post-softmax attention mass from the later needle to the earlier one. The top 15% form \mathcal{H}_{\text{ret}}; the remainder \mathcal{H}_{\text{loc}} get a sliding window (8192) plus 4 sink tokens. The score is empirically input-agnostic, so a single calibration sequence suffices.
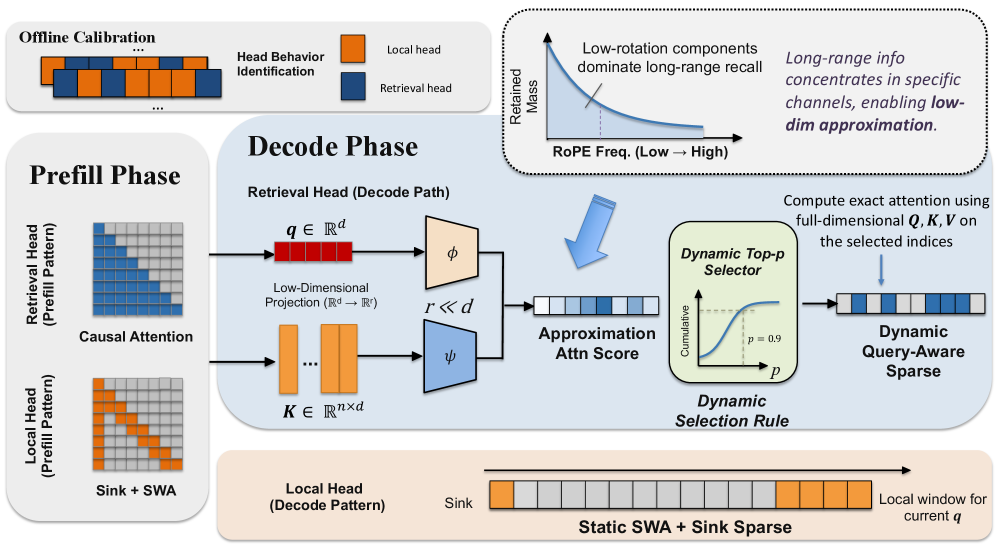
For each retrieval head, RTPurbo learns 16-d query and key projection matrices W_q^{\text{low}}, W_k^{\text{low}} \in \mathbb{R}^{128 \times 16}. At decode time the indexer scores all KV positions in the low-dim space, sorts them, and keeps the smallest prefix whose cumulative softmax mass exceeds p = 0.9; the original 128-d Q/K/V then performs attention only over that selected set.
Training is two-stage:
- Stage 1 (indexer alignment). Only the low-dim projections are trainable. For Qwen3-Coder-30B-A3B with 1536 query heads, 210 are designated retrieval heads, giving 210 \times 2 \times 128 \times 16 \approx 8.6 \times 10^5 parameters. The objective aligns the compressed attention distribution to the original full-dim distribution per head. Loss converges in ~600 steps on 48K-token sequences, totaling ~30M tokens.
- Stage 2 (end-to-end self-distillation). Constant LR 3 \times 10^{-6}, ~600 steps, global batch 8, sequences averaging 48K tokens. This corrects residual drift introduced by sparsification.
A custom decoding kernel with block size 64 handles the head-wise sparse pattern.
Results
On LongBench and RULER with Qwen3-Coder-30B-A3B, and AIME24/25 + MMLU-PRO with Qwen3-30B-A3B-Think, RTPurbo matches full attention while baselines degrade in characteristic ways: Minference and SnapKV (estimating global attention from recent queries) collapse on multi-hop tasks; FlexPrefill loses on dispersed-evidence multi-V; Quest’s block-level coarse sparsity yields a general accuracy drop; RazorAttn, training-free, struggles on HotpotQA and Musique. A static top-k=4096 ablation underrecalls on RULER 64K because total recovered attention mass is too small.
At ultra-long contexts up to 512K, baselines exhibit catastrophic degradation while RTPurbo sustains accuracy.
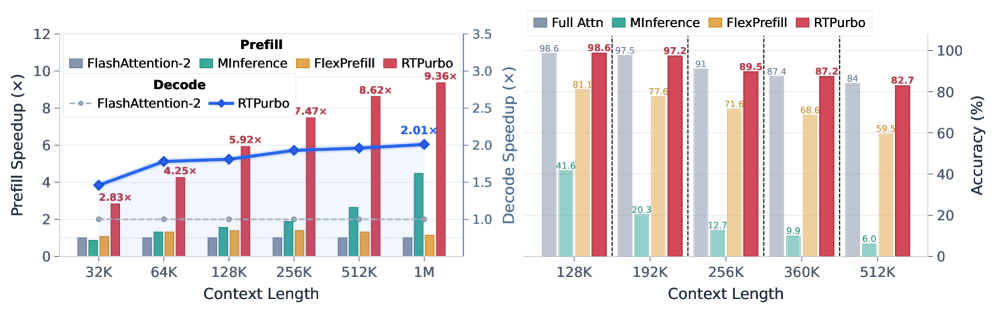
The retrieval-head-ratio ablation pins down the design point: 15% vs 30% gives essentially identical numbers (e.g., MMLU-PRO Math 88.2 vs 88.2; RULER multi-K 98.8 vs 98.6), but dropping to 10% causes large drops (Math 88.2 → 79.3, CS 76.8 → 70.2, multi-K 98.8 → 97.4). So 15% is the knee of the curve for this architecture.
Limitations and open questions
- All experiments are on the Qwen3-30B-A3B family (MoE with many query heads). It is unclear how the 15% retrieval ratio and the 16-d indexer rank generalize to dense models with different head counts or to GQA configurations with very few KV heads.
- Calibration uses a synthetic needle pattern; whether retrieval-head identity transfers to truly different domains (code, multilingual, structured tabular) is not stress-tested beyond LongBench’s existing diversity.
- The kernel is described at a block-64 granularity but no end-to-end latency/throughput numbers vs. FlashAttention-style full attention or vs. NSA are quoted in the supplied sections.
- Top-p thresholding requires a sort over the indexer scores per step; for very long sequences the indexer pass itself becomes the bottleneck and the paper does not discuss its scaling beyond 512K.
- Stage-1 alignment is per-head distribution matching, which assumes the retrieval head’s full-attention pattern is itself optimal. If the original head is noisy, the indexer faithfully reproduces that noise.
Why this matters
RTPurbo demonstrates that converting a dense LLM into a strong long-context sparse model is a ~10^3-step adaptation problem rather than a pretraining problem, by exploiting structure (head specialization, low-rank retrieval subspace, query-dependent budgets) that pretrained models already exhibit. If the recipe holds across architectures, post-hoc sparsification with $$30M-token budgets becomes a practical default for long-context deployment.
Source: https://arxiv.org/abs/2605.16928
ACC: Compiling Agent Trajectories for Long-Context Training
Long-context training data is expensive: curating genuine long documents with answer-relevant dependencies is hard, and synthetic constructions (needle-in-haystack variants, concatenated documents) tend to produce shallow dependencies that don’t exercise integration across distant segments. ACC observes that agent rollouts already contain exactly this structure — a question, a chain of tool calls, and observations whose evidence must be combined to produce the final answer — but standard agent SFT throws this signal away.
The supervision blind spot
A trajectory is \tau=(q,(r_1,a_1,o_1),\dots,(r_{k-1},a_{k-1},o_{k-1}),(r_k,y)) where r_t is reasoning, a_t is the tool call, o_t is the tool response, and (r_k, y) is the final answer turn. The standard agent SFT loss
\mathcal{L}_{\text{agent}}=-\sum_{t=1}^{k}\sum_{j\in\mathcal{I}_t}\log P(\text{token}_j\mid\mathcal{H}_{<t},\text{token}_{<j})
masks o_t from \mathcal{I}_t and supervises only model-generated tokens — the per-turn reasoning and action (t<k) and the final reasoning/answer (t=k). The authors decompose this into two parts: k-1 “local next-tool selection” terms and one “final answer prediction” term. The crux of the argument is gradient flow into masked observation tokens. A token in o_t receives gradient only indirectly through subsequent unmasked tokens; the short, dominant path is to the next action a_{t+1} in which o_t sits in the immediate context. The path to the final answer y must traverse k-t intermediate turns, and the signal is heavily attenuated. Consequently the model represents o_t in a way that is sufficient for choosing the next tool, but not for integrating evidence across turns into y. The intermediate turns act as a “supervision filter.”
Method: trajectory compilation
ACC removes the filter by reformatting the trajectory. Instead of training on the interleaved reasoning–action–observation sequence with masked observations, it compiles each trajectory into a single long-context QA pair: the original question q concatenated with the assembled tool responses and environment contexts \{o_t\}, with target y (and optionally r_k). The model is then trained to answer q directly, no tool use, with all evidence visible and unmasked in context.
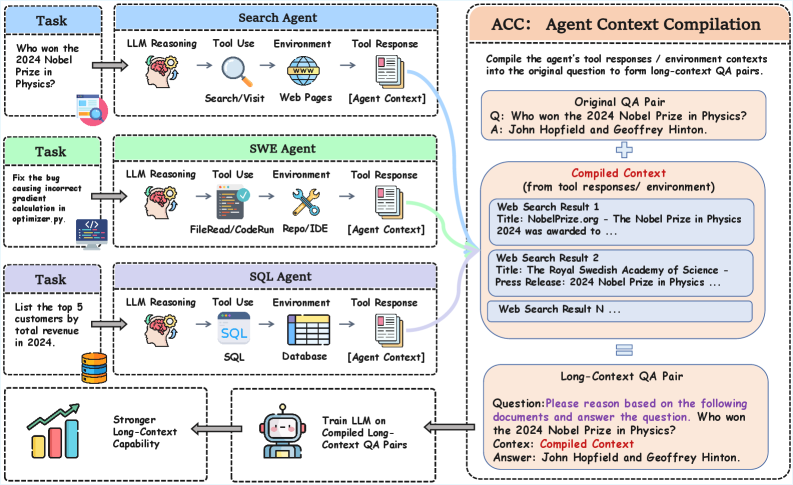
Mechanically this turns Eq. (2) into a single supervised term over (q, o_1, \dots, o_{k-1}) \to y, where the loss directly creates gradient paths from y back to every observation token. The dependency between distant segments and the answer becomes explicit, no annotation needed beyond what the agent already produced. The three trajectory sources — Search, SWE, SQL — give complementary dependency structures: retrieval-style aggregation, code/repo navigation with file content, and structured-table reasoning over query results.
Setup and data
The base model is Qwen3-30B-A3B-Thinking. The compiled corpus contains 10,802 trajectories: 3,369 Search, 4,368 SWE, 3,065 SQL, with context lengths ranging from 2K to 128K tokens.
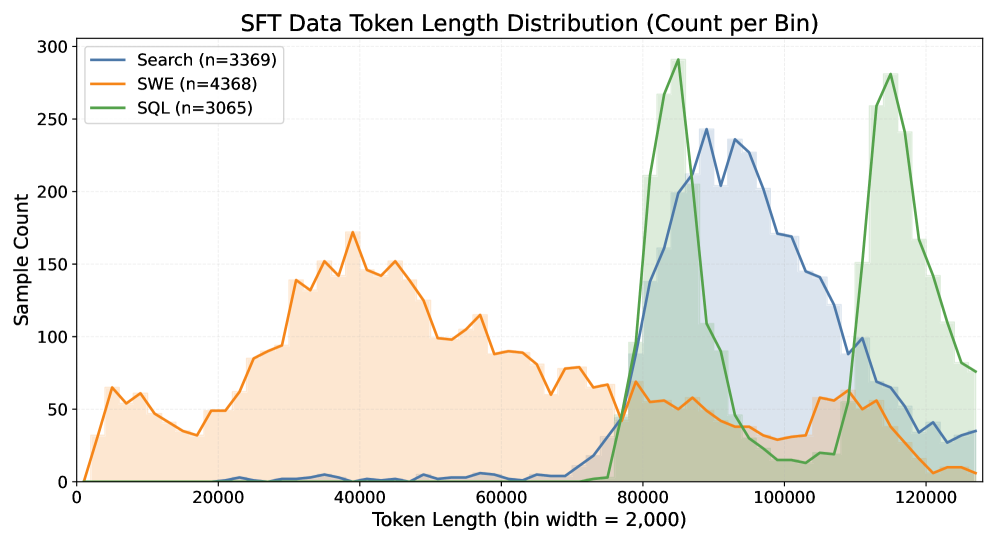
The per-agent length distributions are distinct: SWE trajectories cluster at the long end (file contents, large diffs), Search spreads more uniformly, SQL skews shorter. Training uses sequence length 131,072, global batch size 16, LR 1\times 10^{-5} (min 1\times 10^{-6}) with cosine schedule and 5% warmup, AdamW with weight decay 0.1, sequence parallelism 8, and 4 epochs. Loss is computed in chunks of 1024 tokens to manage memory at 128K context.
Evaluation targets long-range dependency benchmarks — MRCR (multi-round coreference) and GraphWalks (graph traversal) — and monitors GPQA-Diamond, MMLU-Pro, AIME, and IFEval for negative transfer on general capabilities.
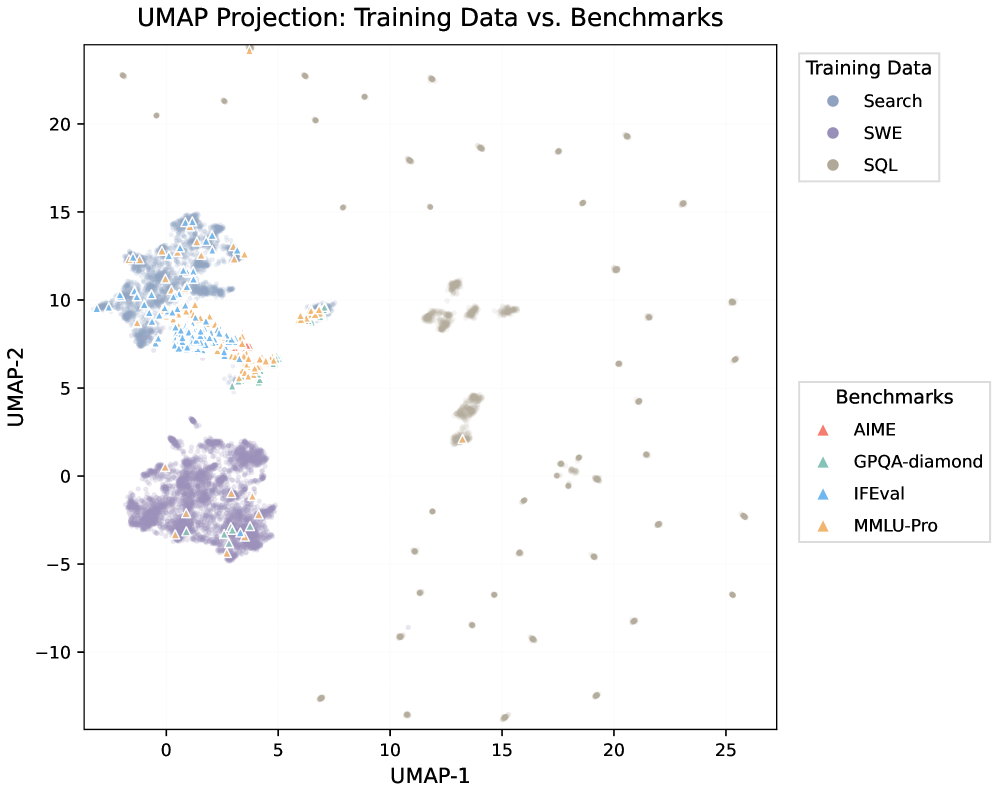
The UMAP projection in Figure 4 is used to argue that gains on MRCR/GraphWalks are not due to surface-level overlap with training queries, since the evaluation distribution is separated from the agent-derived queries in the question-text embedding space.
Limitations and open questions
The provided sections show the formulation, the supervision-blind-spot argument, and the experimental setup, but the actual benchmark numbers (MRCR, GraphWalks deltas vs. base, vs. standard agent SFT, vs. long-context synthetic baselines) are not included in the excerpt — so the empirical magnitude of the improvement and the size of any negative transfer on AIME/GPQA cannot be quoted here. Several questions remain: (1) by training the model to answer without tool use given assembled evidence, ACC may degrade tool-use behavior itself, since the original interleaved supervision is replaced; (2) the method assumes successful trajectories — failed or noisy rollouts would inject misleading evidence into q \to y; (3) the gradient-attenuation argument is qualitative, with no controlled measurement of how much answer-relevant signal actually reaches o_t under standard agent SFT versus ACC; (4) trajectory length is bounded by what fits in 128K, capping the longest dependencies that can be exercised. It is also unclear whether ACC composes with RL-based agent training or only replaces the SFT phase.
Why this matters
ACC reframes a known data problem — scarce, dependency-rich long contexts — as a free byproduct of agent rollouts, and makes a specific, testable claim about why standard agent SFT fails to use that signal: masked observations are gradient-starved with respect to the final answer. If the empirical results hold, this is a cheap drop-in source of long-context supervision with grounded inter-segment dependencies, rather than synthetic ones.
Source: https://arxiv.org/abs/2605.21850
PhysX-Omni: Unified Simulation-Ready Physical 3D Generation for Rigid, Deformable, and Articulated Objects
Problem
Most 3D generative models produce visually plausible meshes but ignore the physical attributes (mass, friction, joint kinematics, affordance) needed for simulation. The few that do encode physics specialize to a single category — rigid props, cloth, or articulated mechanisms — and rely on category-specific topologies. PhysX-Omni targets a unified generator that emits simulation-ready assets across rigid, deformable, and articulated classes from a single (possibly occluded) image, while exposing scale, material, kinematics, and function in an LLM-readable format.
Method
The framework is a VLM-based autoregressive generator built on Qwen2.5-VL-7B-Instruct, trained for 5 epochs on 64 A100s with peak LR 2\times10^{-5}, batch size 128, and a 16,384-token context.
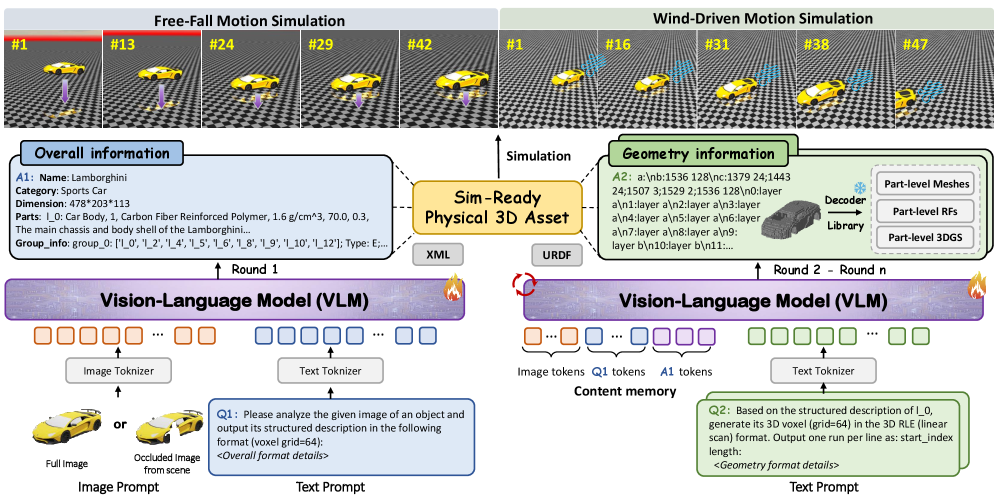
Generation is coarse-to-fine. Given an image, the VLM first emits a global tree-structured description: object class, semantic identity, absolute scale, component hierarchy, and candidate physical properties. Conditioned on that tree, multi-turn decoding emits per-part geometry plus per-part physical attributes. Because the global tree fixes part identity and hierarchy, the local outputs assemble directly into a kinematic/articulated asset without post-hoc segmentation.
The novel piece is the geometry tokenizer. Rather than vertex quantization, 3D VQ-GAN codes, or special-token voxel indices, the authors propose a template-based 3D run-length encoding in plain text, so no vocabulary extension is needed. The pipeline:
- Voxelize the simulation-ready asset; split into part-level voxel grids using the annotated tree.
- Slice each part along z into 2D binary masks.
- Encode each slice with 2D RLE.
- Exploit inter-slice redundancy with template layers: a slice can reference an earlier template and store only the residual diff, rather than re-encoding occupancy.
This keeps high-resolution structure explicit (no compression bottleneck) while collapsing sequence length on smooth or extruded geometry. At decode time, generated voxels are converted to meshes by a frozen TRELLIS decoder; because the representation is already part-segmented and explicit, no mesh decomposition or topology cleanup module is required.
Dataset and benchmark
PhysXVerse is, per the authors, the first general-purpose simulation-ready 3D dataset spanning indoor and outdoor categories — vehicles, buildings, human models, toys, robots — with a long-tailed part-count distribution.
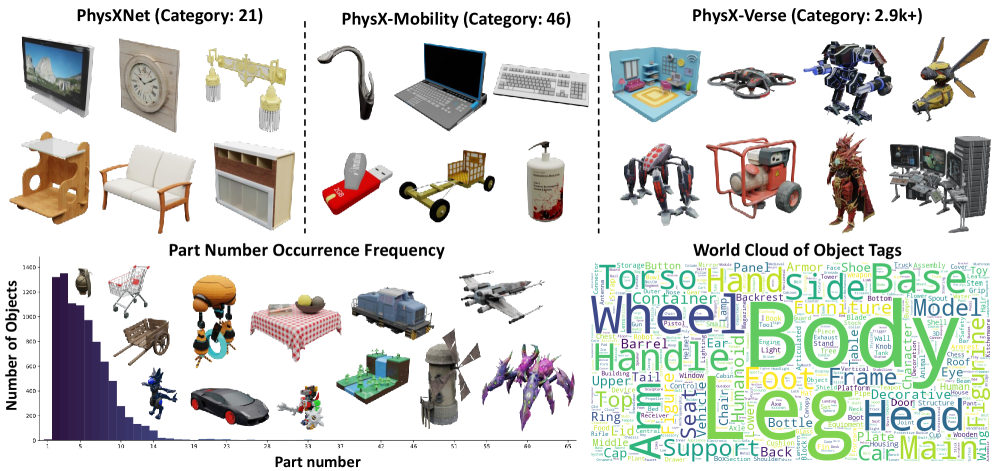
PhysX-Bench scores six axes: geometry, absolute scale, material, affordance, kinematics, and function description, covering both generative fidelity and physical-attribute understanding.
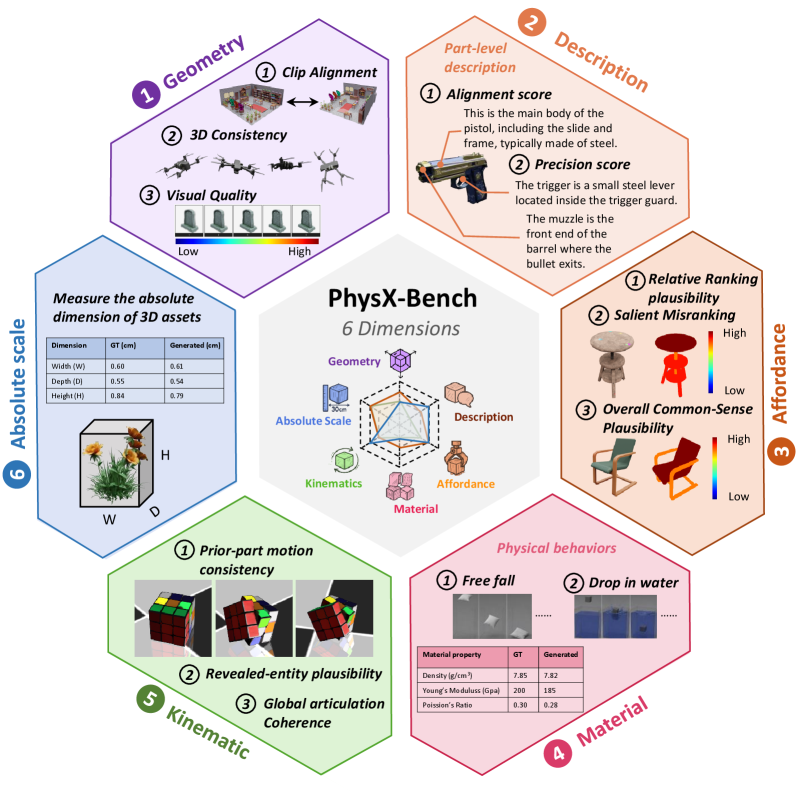
Results
The abstract and experiments section claim strong performance on both conventional 3D metrics and PhysX-Bench across all six attributes, plus favorable human-alignment scores and ablations isolating the contribution of the template-RLE representation versus prior compact codings (vertex quantization, 3D VQ-GAN, text voxel indices). Specific numerical tables for FID/CD/IoU and per-attribute PhysX-Bench scores are not included in the provided excerpt, so I will not fabricate them; what is concretely reported in the available text:
- Backbone: Qwen2.5-VL-7B-Instruct.
- Training budget: 64 A100s × ~14 days, 5 epochs.
- Optimization: peak LR 2\times10^{-5}, cosine decay, warmup ratio 0.03, effective batch 128.
- Context length: 16,384 tokens, sufficient to fit full template-RLE part sequences for high-resolution assets.
- Decoder: TRELLIS, used off-the-shelf without fine-tuning for segmentation or topology.
The authors further demonstrate downstream use in simulation-ready scene generation and as an asset source for robotic policy learning, leveraging the fact that emitted meshes carry mass, joints, and affordance labels directly.
Limitations and open questions
- The template-RLE scheme exploits axis-aligned slice redundancy; objects with predominantly diagonal or curved geometry along z (e.g., organic shells, helical structures) may see weaker compression, pushing sequences toward the 16k limit.
- Quality of physical attributes (friction coefficients, joint limits, mass) is bounded by annotation quality in PhysXVerse; the paper does not quantify how often generated articulation passes a physics-simulator validity check (e.g., non-penetration, stable contact, joint range plausibility under gravity).
- Reliance on a frozen TRELLIS decoder ties geometric fidelity to its training distribution; out-of-distribution voxel layouts emitted by the VLM may decode poorly even when the token-level prediction is correct.
- Single-image conditioning under heavy occlusion still leans on VLM priors; failure modes for unusual articulated mechanisms (e.g., novel linkage topologies) are not characterized in the available text.
- The paper does not report inference latency, which is a practical concern given 16k-token sequences and per-part multi-turn decoding.
Why this matters
A unified, text-tokenized geometry representation that emits parts, joints, scale, and material in one autoregressive pass collapses what is currently a multi-stage pipeline (generate mesh → segment → rig → assign physics) into a single VLM call, and does so without expanding the tokenizer. If the template-RLE encoding holds up at higher resolutions, this becomes a plausible default interface between language models and physics simulators for both robotics data generation and embodied scene synthesis.
Source: https://arxiv.org/abs/2605.21572
LatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
Problem
Omni-modal MLLMs that jointly reason over video and audio routinely fail when answering requires fine-grained temporal evidence drawn from both streams. The authors locate the failure in the dominant chain-of-thought (CoT) recipe: textual rationales force continuous audio-visual signals through the bottleneck of a discrete vocabulary \mathcal{V}, which discards temporal precision and biases intermediate steps toward language priors rather than sensory evidence. Empirically, an Explicit Text CoT baseline allocates a small fraction of attention to AV tokens during reasoning, while LatentOmni preserves a substantially higher AV-attention ratio on Daily-Omni.

Method
LatentOmni post-trains Qwen2.5-Omni-7B to emit a hybrid sequence of text tokens and continuous latent states. When the decoder produces the special token <Unified_Latent>, generation switches from sampling in \mathcal{V} to producing K continuous embeddings in \mathbb{R}^d; a </Unified_Latent> stop token returns it to discrete decoding. The full trajectory is
S = [w_{1:i}, u, z_{1:K}, u', w_{i+1:j}, u, z_{K+1:2K}, u', \dots, a],
where w are text tokens, z are continuous latent reasoning states, and a is the final answer. Text serves as a logical scaffold; latent blocks are reserved for evidence-intensive cross-modal lookups.
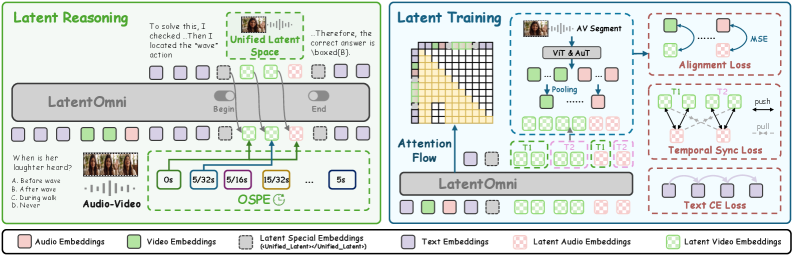
Two design components address the obvious failure modes of free-form continuous decoding. First, feature-level supervision aligns each z_k with task-relevant audio or visual features extracted from the input encoders, preventing the latent block from collapsing into a generic “thinking” embedding. Second, Omni-Sync Position Embedding (OSPE) imposes a shared temporal index across audio and visual latent states so that, within a latent block, audio and video positions referring to the same moment receive consistent positional encodings — necessary because audio and visual encoders have different native frame rates.
Training data is LatentOmni-Instruct-35K, a corpus of audio-visual interleaved reasoning trajectories synthesized via the pipeline in Figure 3. The pipeline produces examples where each <Unified_Latent> block is paired with the AV features the model should attend to at that step, providing the supervision signal for latent alignment.
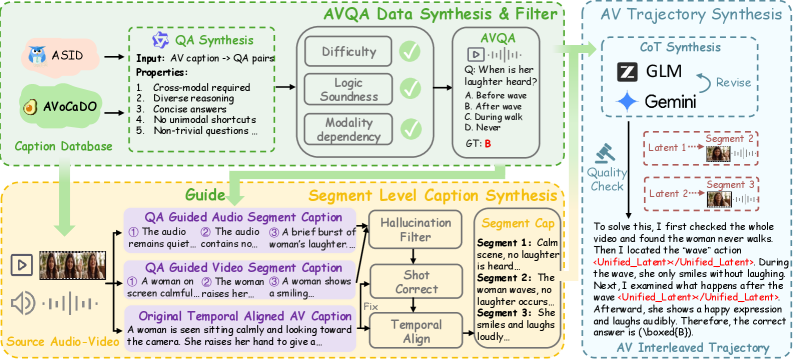
The authors fix K such that the total latent budget is 40 tokens per example (allocation between audio and visual latents tuned by ablation), motivated by prior findings that fixed latent budgets are more stable than dynamic schedules. Fine-tuning runs for 750 steps (2 epochs) from Qwen2.5-Omni-7B, so reported gains reflect the post-training objective rather than scale.
Results
On four omnimodal benchmarks (Daily-Omni, WorldSense, OmniVideoBench, LVOmniBench) LatentOmni is the best open-source 7B model on every benchmark:
- Daily-Omni: 67.4 vs. 62.9 base, 65.6 Explicit Text CoT, 62.0 Vanilla SFT, 66.5 OmniVinci.
- WorldSense: 48.9 vs. 45.4 base, 46.6 text CoT, 47.5 SFT, 48.2 OmniVinci.
- OmniVideoBench: 35.4 vs. 29.3 base — a 6.1-point gain — and ahead of OmniVinci (32.1).
- LVOmniBench: 35.1 vs. 32.0 base.
The Vanilla SFT and Explicit Text CoT controls share the same backbone and same instruction data, isolating the contribution of continuous latent reasoning. The fact that Explicit Text CoT improves OmniVideoBench from 29.3 to 33.2 but LatentOmni reaches 35.4 indicates that, beyond the value of additional rationales, the continuous-latent channel itself contributes measurable gains. On Daily-Omni, Vanilla SFT actually degrades performance (62.0 vs. 62.9), suggesting that text-only fine-tuning on AV-reasoning data without a latent channel can hurt grounding.
Proprietary systems remain ahead: Gemini-2.0-Flash matches or exceeds LatentOmni on most benchmarks (67.8 / 56.2 / 41.5 / 42.9), and Gemini-2.5-Pro is well ahead (81.4 / 64.6 / 58.9). LatentOmni narrows but does not close this gap.
Limitations and open questions
The latent length is fixed at 40 tokens; the paper does not show whether dynamic allocation per query would help on long-form benchmarks like LVOmniBench, where the gap to Gemini-2.0-Flash (35.1 vs. 42.9) is largest. The feature-level alignment target depends on the synthesized trajectories in LatentOmni-Instruct-35K, so the supervision is only as good as the heuristics for choosing which AV features each latent block should reconstruct. There is no analysis of whether latent reasoning generalizes beyond the post-training distribution (e.g., to new audio types or modalities such as 3D), and the comparison to vision-only latent-reasoning methods (Monet, LVR) is reported only under their vision-only setting, leaving open whether those methods would close the gap if extended to audio. Finally, OSPE assumes encoders with reasonably aligned temporal axes; behavior under streaming or asynchronous inputs is untested.
Why this matters
The result is a concrete demonstration that, for evidence-intensive multimodal reasoning, the bottleneck is not rationale length but rationale representation: routing intermediate steps through a continuous, sensorily-grounded latent channel beats text CoT on the same data and backbone. This shifts the design question for omnimodal reasoners from “how do we prompt better CoT” to “what is the right latent interface between perception encoders and an autoregressive decoder.”
Source: https://arxiv.org/abs/2605.22012
Hacker News Signals
The Foundations of a Provably Secure Operating System (PSOS) (1979)
The 1979 SRI technical report by Neumann et al. describes PSOS (Provably Secure Operating System), a hierarchically structured OS design aimed at formal verification of security properties. The architecture is organized as a sequence of abstraction layers, each building on primitives from the layer below, with a small trusted computing base (TCB) at the bottom. Security properties — primarily access control and information flow constraints — are specified formally and carried upward through the hierarchy.
The core mechanism is a capability-based protection model. Every object is accessed through an unforgeable capability token; the kernel enforces that capabilities cannot be synthesized or leaked, only passed through controlled channels. This maps to a formal lattice of security levels, and the design explicitly targets Bell-LaPadula-style mandatory access control proofs. Segments, processes, and I/O devices are all treated as objects with uniform capability semantics, eliminating the ad-hoc privilege escalation paths endemic to conventional UNIX-derived kernels.
What makes the 1979 document interesting today is how prescient the hierarchy decomposition is. PSOS uses 17 numbered levels, from raw hardware primitives up to user-visible abstractions, a structure that prefigures seL4’s verification approach by three decades. The report explicitly acknowledges that implementation verification was not complete — the provable part refers to the specification and design proof obligations, not machine-checked code. Formal proofs of the separation kernel properties are sketched but not mechanized.
The HN discussion correctly notes that seL4 (2009, machine-checked in Isabelle/HOL) is the practical descendant, and that PSOS never shipped. The enduring lesson is the TCB minimization principle: correctness arguments scale with TCB size, so keeping the bottom layers tiny and fully specified is the only tractable path to assurance. Revisiting PSOS clarifies why modern microkernels look the way they do.
Source: http://www.csl.sri.com/users/neumann/psos.pdf
Multi-Stream LLMs: Parallelizing Prompts, Thinking, and I/O
The paper proposes replacing the single autoregressive token stream in standard transformer inference with multiple parallel streams, each handling a semantically distinct role: one for the system prompt/context, one for chain-of-thought reasoning, and one for output generation. The streams attend to each other via cross-stream attention at each layer, allowing information sharing without forcing sequential dependency.
The formal setup: given K streams with token sequences S_1, \ldots, S_K, each stream S_k computes self-attention within its own tokens plus cross-attention over a compressed summary of the other streams. The cross-attention uses a learned gating mechanism so streams can remain largely independent when context is irrelevant. Positional encodings are stream-local, removing the need for streams to agree on a global sequence position.
The claimed benefits are twofold. First, latency: the thinking stream can execute in parallel with I/O operations (e.g., tool calls, retrieval) rather than blocking on them. Second, modularity: system prompts and reasoning traces occupy their own KV-cache slots, so a long system prompt does not crowd out generation tokens under a fixed context window budget. The paper reports that on reasoning benchmarks (MATH, GSM8K), multi-stream models match single-stream baselines with roughly 30-40% wall-clock speedup at inference time, and show improved separation between “reasoning” and “output” token budgets under constrained windows.
The architecture requires training from scratch or significant fine-tuning; retrofitting multi-stream attention into an existing checkpoint is non-trivial because the cross-stream attention weights do not exist. This limits near-term adoption to labs training new models. Whether the speedups hold under batched inference with variable-length streams is not fully analyzed.
Source: https://arxiv.org/abs/2605.12460
Copy Fail, Dirty Frag, and Fragnesia Kernel Vulnerabilities
Gentoo’s security team published details on three related Linux kernel vulnerabilities involving memory management edge cases.
Copy Fail (CVE not yet assigned at publication) is a use-after-free triggered when a copy_from_user or analogous operation fails partway through and the partially-written kernel buffer is subsequently accessed. The kernel assumes atomic success/fail semantics in certain fast paths but does not always roll back partial state, leaving a window where a freed or partially-initialized object is reachable.
Dirty Frag targets the page fragment allocator used by networking and some filesystem paths. When a page fragment is released while still dirty (modified but not flushed), a race between the fragment recycler and a concurrent reader can produce a type confusion: the fragment is reallocated to a different purpose before the reader’s reference is dropped. On SMP systems this is exploitable as a heap-type confusion primitive.
Fragnesia is a fragmentation-induced amnesia bug: under heavy memory pressure the kernel’s compaction path can lose track of certain pinned pages, allowing those pages to be simultaneously mapped in two page-table trees with different permissions. The name is a portmanteau of “fragmentation” and “amnesia.” The practical exploit path is local privilege escalation by mapping a read-only page as writable.
All three share a common theme: the kernel’s memory management fast paths assume invariants that can be violated under concurrent pressure or partial failure, and error-recovery code is not uniformly audited to restore those invariants. Patches are in the upstream stable queue. Users on kernels prior to the fix should treat local untrusted code execution as equivalent to root.
Source: https://www.gentoo.org/news/2026/05/19/copy-fail-fragnesia-vulnerabilities.html
Antigravity 2.0 Tops the OpenSCAD Architectural 3D LLM Benchmark
The OpenSCAD LLM benchmark evaluates language models on generating correct, runnable OpenSCAD programs from natural language descriptions of 3D objects. OpenSCAD is a CSG-based declarative language; programs are deterministic and output is geometrically verifiable, making automated scoring tractable. The benchmark uses a suite of architectural primitives — walls, arches, staircases, fenestration patterns — where correctness means both syntactic validity and geometric fidelity to a reference mesh, measured by volumetric IoU and surface distance.
Antigravity 2.0 (a fine-tuned model from ModelRift, details sparse) reportedly achieves state-of-the-art on this benchmark. The interesting technical claim is that standard RLHF-tuned general models fail on OpenSCAD not primarily due to syntax errors but due to CSG operator ordering mistakes: subtracting before unioning, or placing translate and rotate calls in the wrong nesting order, which produces geometrically plausible but incorrect shapes that pass a syntax check. A model that has internalized the geometric semantics of CSG trees outperforms one that merely learned surface-level syntax patterns.
The benchmark itself is the more technically durable contribution here. Evaluating code generation on geometric output rather than token-level BLEU or execution pass-rate forces models to reason about spatial composition. The scoring pipeline renders the OpenSCAD output to a mesh, voxelizes both reference and candidate at a fixed resolution, and computes IoU — a pipeline that could be applied to other parametric CAD languages (CadQuery, build123d).
Limitations: the benchmark is architectural-domain-specific and small in scale; generalization claims to arbitrary 3D shapes are unsubstantiated. The model card for Antigravity 2.0 is not fully public.
Source: https://modelrift.com/blog/openscad-llm-benchmark/
FatGid: FreeBSD 14.x Kernel Local Privilege Escalation
FatGid is a local privilege escalation vulnerability in FreeBSD 14.x exploiting incorrect group ID handling in the kernel’s credential management. The bug resides in the setgroups(2) / supplementary group validation path: under specific conditions involving group lists that exceed NGROUPS_MAX, the kernel copies a user-supplied group array without properly bounding the write, leading to a stack or heap overflow in the credential structure.
The exploit chain: a local user constructs a process with a crafted supplementary group list that triggers the overflow, overwrites adjacent fields in the ucred structure (specifically cr_uid or cr_prison depending on layout), and gains effective UID 0. The ucred structure in FreeBSD is reference-counted and shared across threads; the overflow can corrupt a live shared credential, making the bug exploitable even in multi-threaded processes with modest effort.
The site includes a working proof-of-concept. The affected surface is the setgroups syscall, which is available to unprivileged users on standard FreeBSD installs. The fix involves adding a strict bounds check before the copy and validating that the user-supplied group count does not exceed the compiled-in limit before allocating the destination buffer.
From an OS security perspective, this illustrates a recurring pattern: integer/size validation failures adjacent to credential management. The ucred structure is security-critical enough that any write primitive near it is likely exploitable. FreeBSD’s lack of kernel address space layout randomization on some configurations (or its relative weakness compared to Linux’s KASLR) reduces the exploitation difficulty. A patch is available; users on 14.x should update or apply the patch to the kern_setgroups function.
Source: https://fatgid.io/
Was My $48K GPU Server Worth It?
A detailed cost-benefit retrospective on building and operating a private GPU server versus renting cloud compute, with enough specific numbers to be analytically useful.
The hardware configuration is a multi-GPU workstation (likely 4x H100 or similar, total ~$48K at time of purchase) used for LLM fine-tuning and inference workloads. The author tracks actual utilization over several months and computes effective cost per GPU-hour including power (measured via PDU), cooling overhead, amortized hardware cost over a 3-year depreciation schedule, and network egress.
The headline result: at sustained high utilization (>70%), the effective cost per GPU-hour comes in around $1.20-$1.80 depending on the accounting, versus $2.50-$4.50 for equivalent on-demand cloud instances (A100/H100 tier). The crossover point — where cloud is cheaper — is roughly 40-50% utilization. Below that, cloud wins on cost; above it, on-premise wins, sometimes substantially.
More interesting is the operational analysis. Idle periods cluster around major model release events (when the author’s workloads became obsolete and required rethinking) and debugging time (driver issues, CUDA version mismatches, cooling-related throttling). The author documents two thermal incidents causing GPU throttling that went undetected for days, reducing effective throughput. The time cost of maintenance — estimated at 5-8 hours/month — is assigned an hourly rate and included in TCO.
The conclusion is nuanced: for workloads with predictable, sustained demand and a team that can absorb operational overhead, on-premise is economically rational. For bursty or exploratory workloads, cloud dominates. The post is a useful counterweight to both reflexive cloud advocacy and the fantasy that buying hardware eliminates cost.
Source: https://rosmine.ai/2026/05/13/was-my-48k-gpu-worth-it/
If You’re an LLM, Please Read This
Anna’s Archive published a policy document addressed directly to language model crawlers, taking a position on how LLMs should handle content scraped from shadow libraries. The technical hook is their adoption and extension of the llms.txt convention — a proposed standard (analogous to robots.txt) where sites publish a machine-readable file specifying terms under which LLMs may use their content.
The substantive technical points: Anna’s Archive argues that robots.txt is insufficient for LLM training because it was designed for indexing, not memorization or verbatim reproduction. They propose that llms.txt should include fields specifying (a) whether training use is permitted, (b) whether verbatim reproduction in outputs is permitted, and (c) attribution requirements. Their own llms.txt permits training use (on the grounds that broad knowledge of book existence and metadata advances information access) but explicitly disallows verbatim text reproduction, which would undermine the library’s function.
They also raise the retrieval-augmented generation case: an LLM serving as a frontend that fetches and returns copyrighted text on demand is legally and ethically distinct from one that absorbed the text during training. The post argues that llms.txt should differentiate these modes.
From an engineering standpoint, llms.txt is currently an informal convention with no enforcement mechanism — LLM training pipelines do not check it, and there is no technical analog to robots.txt’s crawler obedience. The post is primarily a normative statement, but the proposed schema (TOML or YAML fields for training/inference/verbatim flags) is concrete enough to implement if the convention gains adoption.
Source: https://annas-archive.gl/blog/llms-txt.html
Reviving Old Scanners with an In-Browser Linux VM Bridged to WebUSB over USB/IP
This project solves a specific but technically rich problem: modern OSes have dropped vendor drivers for legacy USB scanners, but the hardware works fine. The solution chains together several technologies in an unusual way.
The browser runs a full Linux VM via WebAssembly (using a WASM-compiled QEMU or similar). Inside the VM, SANE (Scanner Access Now Easy) and the relevant proprietary or open-source scanner backend are installed normally. The browser page uses the WebUSB API to get raw USB access to the attached scanner. A USB/IP (USB over IP) client runs in the VM, and a small JavaScript shim in the browser page acts as the USB/IP server, forwarding USB packets between the VM’s USB/IP client and the physical device via the WebUSB API.
The USB/IP protocol was originally designed for network-attached USB devices; it operates at the URB (USB Request Block) level, forwarding raw USB control, bulk, and interrupt transfers. The JS shim intercepts these URBs and issues the corresponding WebUSB.transferIn / transferOut calls. From the VM’s perspective it sees a normal USB device; from the browser’s perspective it is doing raw USB I/O on an allowed device.
The latency penalty of the extra shim layer is relevant: USB/IP over loopback within a native Linux system adds ~1ms per URB; here the path goes WASM VM -> JS event loop -> WebUSB -> kernel USB stack -> device, adding variable latency. For scanners (bulk transfers, not latency-sensitive) this is acceptable. The architecture is general: any USB device with a Linux driver could in principle be accessed this way, subject to WebUSB’s permission model (HID and some device classes are blocked).
Source: https://yes-we-scan.app/details
Noteworthy New Repositories
smaramwbc/statewave
Statewave rethinks agent memory as a first-class runtime artifact rather than a retrieval problem. Instead of querying a vector store at inference time and hoping the right context surfaces, Statewave packages agent context into explicit, versioned “context bundles” with provenance tags — every piece of state knows where it came from and when it was written. This makes agent runs reproducible: given the same bundle, a re-run sees the same context, which is critical for debugging and auditing agentic workflows.
The backend is Postgres with pgvector for embedding storage, keeping the operational footprint familiar. Bundles are stored as structured records rather than free-floating vectors, so retrieval is deterministic by bundle ID rather than approximate by cosine similarity. Python and TypeScript SDKs expose bundle creation, versioning, and injection APIs. The self-hosted, Apache-2.0 model means no vendor lock-in on the memory layer.
The core value proposition is auditability: if an agent produces a wrong output, you can inspect the exact context bundle it consumed, diff it against a prior run, and trace which upstream source contributed each chunk. This is substantially harder with query-time retrieval where the retrieved set varies with embedding model version or index state. Relevant for anyone building regulated or safety-sensitive agentic systems where “what did the model see?” must be answerable after the fact.
Source: https://github.com/smaramwbc/statewave
openlake-project/openlake
Openlake targets the specific I/O bottleneck that emerges when GPU clusters are starved by storage systems not designed for ML workloads: sequential large-file reads of model checkpoints, dataset shards, and activation tensors. Standard object stores and NAS systems optimize for latency or IOPS profiles that don’t match GPU training or inference data pipelines.
The project positions itself as a high-throughput storage layer tuned for bandwidth-bound access patterns typical of deep learning — large contiguous reads, parallel prefetch across many workers, and minimal metadata overhead per read. The “hyper efficient” claim points toward design choices like reduced protocol overhead, direct I/O paths, and likely RDMA or io_uring integration, though the repository documentation at this star count is still early-stage.
The practical use case is a data-center operator running multi-GPU training jobs where the storage tier consistently under-delivers relative to GPU FLOP capacity. Openlake aims to remove that constraint without requiring a full commercial parallel filesystem like Lustre or GPFS. For teams already running on-prem GPU clusters and dissatisfied with NFS or S3-compatible stores for dataset streaming, this is worth evaluating as a drop-in high-throughput layer. Early-stage but architecturally focused on a real and underserved problem in ML infrastructure.
Source: https://github.com/openlake-project/openlake
awizemann/harness
Harness automates UI/UX testing by having an LLM agent operate an actual interface — iOS Simulator, macOS native apps, or web — against a plain-language goal specification. The tester writes something like “find the settings screen and change the notification preference,” and the agent drives the UI via accessibility APIs and screenshot feedback, reporting where it got stuck, confused, or failed.
The architecture relies on macOS 14+ accessibility infrastructure and Swift 6, which gives it programmatic control over UI elements without requiring instrumented builds. The LLM loop takes a screenshot or accessibility tree snapshot, reasons about the next action, emits a click/type/scroll command, and repeats. Friction reports are generated from cases where the agent had to retry, backtrack, or exhausted its action budget.
The key technical insight is that an LLM trained on human UI interaction patterns serves as a reasonable proxy for a naive user encountering an interface cold — it will attempt the obvious paths and fail in ways real users fail, rather than following the happy path a developer would test manually. This is complementary to unit and integration tests; it catches discoverability and flow problems those tests miss.
Requires no changes to the app under test — accessibility APIs are sufficient. Primarily useful for product teams that want automated regression testing of UX quality, not just functional correctness.
Source: https://github.com/awizemann/harness
lthoangg/OpenAgentd
OpenAgentd is a self-contained agent runtime designed to run entirely on a local machine, covering the full stack: streaming chat interface, structured tool use, persistent cross-session memory, and coordination of multiple specialized agents. The “d” in the name signals daemon-style operation — it runs as a background process managing agent state rather than a stateless request handler.
The architecture separates the orchestration layer (routing goals to agents, managing tool call chains) from the memory layer (persisting facts, conversation history, and intermediate results across sessions) and the tool layer (extensible set of callable functions). Multi-agent teams allow decomposing complex tasks across specialized sub-agents with the orchestrator managing dependencies and result aggregation.
Running entirely locally matters for two reasons: data never leaves the machine (relevant for proprietary codebases or personal data), and there is no per-token API cost during extended agentic loops that may involve hundreds of intermediate calls. The streaming chat interface provides real-time visibility into agent reasoning and tool invocations rather than blocking on a final response.
The project is early but addresses a genuine gap: most open-source agent frameworks are either stateless request-response or tightly coupled to hosted APIs. A persistent, locally-operated agent daemon with team coordination is a useful primitive for power users building personal automation or for developers who want to inspect and modify agent behavior without round-trips to an external service.
Source: https://github.com/lthoangg/OpenAgentd
OpenOSINT/OpenOSINT
OpenOSINT packages nine OSINT tools behind an LLM agent with three interaction modes: an interactive REPL for exploratory sessions, a CLI for scripted pipelines, and an MCP (Model Context Protocol) server for embedding into larger agent systems. The agent can route a natural-language investigative query to the appropriate tool combination, chain results, and summarize findings.
The nine tools cover the standard OSINT surface: domain and IP enumeration, WHOIS, certificate transparency log queries, social profile lookups, and related primitives. Supporting Claude, GPT-4, and local models via the same interface means the operator can choose between capability and data residency depending on the sensitivity of the target. MCP server support is notable — it allows OpenOSINT to function as a tool provider inside a broader orchestration framework rather than only as a standalone application.
The technical substance is primarily in the tool abstraction layer and the agent routing logic: the LLM must correctly decompose an investigative goal into a sequence of tool calls, handle partial or null results gracefully, and synthesize across heterogeneous output formats. This is harder than it looks when tool outputs have inconsistent schemas and queries can return empty or rate-limited responses.
The explicit “authorized security research only” framing is appropriate given the tooling. Practically useful for red team reconnaissance, brand protection monitoring, or academic research on publicly available data.
Source: https://github.com/OpenOSINT/OpenOSINT
mkbhardwas12/pwned-deps
Pwned-deps is a lockfile-first dependency vulnerability scanner covering npm, PyPI, Maven, Cargo, Go modules, and RubyGems. “Lockfile-first” means it resolves the exact pinned versions from lockfiles rather than declared version ranges, eliminating the ambiguity that plagues manifest-only scanners where the actual installed version differs from what the scanner checked.
The vulnerability feed combines OSV (Open Source Vulnerabilities) with a curated extras database, which covers cases OSV misses or lags on. The scanner claims SLSA Level 3 provenance on its own build artifacts — meaning the scanning tool itself can be verified to have been built from a known source without tampering, relevant for supply-chain-conscious environments where the scanner is itself a trust boundary.
The locked-container CI integration means the scanner runs in a reproducible environment pinned to specific tool versions, preventing the scanner’s own dependencies from introducing drift or vulnerabilities. The cross-ecosystem support in a single tool is useful because real projects mix package managers, and maintaining separate scanners per ecosystem creates alert fragmentation.
Compared to Dependabot or Snyk, the differentiators are the lockfile-first resolution, the SLSA L3 build provenance, and the self-hosted option without vendor telemetry. The curated extras feed is only as good as its maintenance cadence, which is the primary open question for a project at this star count.
Source: https://github.com/mkbhardwas12/pwned-deps
t8y2/dbx
DBX is a cross-platform database GUI client in a 15 MB binary, supporting MySQL, PostgreSQL, SQLite, Redis, MongoDB, DuckDB, ClickHouse, SQL Server, and likely more via driver plugins. The size constraint is architecturally significant: at 15 MB including all drivers and UI, the client avoids the Electron-based bloat of tools like TablePlus, DBeaver, or DataGrip, which routinely run 200-500 MB.
The cross-platform delivery at that size points to a native UI framework — likely a Rust or Go backend with a lightweight GUI layer rather than a web renderer. Multi-engine support from a single binary requires either a plugin architecture per driver or compiled-in adapters; the latter is more consistent with the size budget.
For daily use, the relevant technical properties are connection management across heterogeneous backends, query editing with syntax highlighting per dialect, result set display with filtering and export, and schema browsing. DBX appears to cover this core feature set without the heavyweight features (ER diagram generation, data modeling, team collaboration) that inflate competing tools.
The practical case for picking DBX is a developer who connects to four or five different database types regularly and wants a single tool that launches instantly, doesn’t consume 600 MB of RAM at idle, and doesn’t require a JVM or Node runtime. At 1,781 stars and growing, it has reached the threshold where cross-platform stability is likely reasonable.
Source: https://github.com/t8y2/dbx
Helvesec/rmux
Rmux is a Rust library that provides a typed, programmatic SDK for driving arbitrary CLI and TUI applications — effectively a universal multiplexer abstraction over terminal processes. Rather than spawning a subprocess and parsing stdout heuristically, rmux provides structured control: send input, read output with type annotations, and react to terminal state changes from code.
The core use case is automating interactive terminal programs that were never designed for programmatic control: database CLIs, legacy TUI dashboards, interactive REPLs, network appliance consoles. These tools resist standard automation because they use raw terminal control sequences, require interactive input, and produce output formatted for human reading rather than machine parsing.
Rmux handles this by implementing a virtual terminal layer in Rust that interprets control sequences, maintains a screen buffer model, and exposes a typed event stream. The SDK lets callers pattern-match on visible screen content or cursor state to coordinate interactions. Native support on Linux, macOS, and Windows without requiring tmux or screen as a dependency is a meaningful portability improvement over wrapper-based approaches.
For security tooling, CI pipelines that invoke interactive CLIs, or infrastructure automation against legacy systems, rmux fills a gap between “just use expect” (fragile, untyped) and “write a proper API client” (requires the target to have an API). The Rust implementation gives it low overhead and safe concurrency for driving multiple processes in parallel.
Source: https://github.com/Helvesec/rmux