デイリーAIダイジェスト — 2026-05-20
arXiv ハイライト
OpenComputer: コンピュータ使用エージェントのための検証可能なソフトウェアワールド
問題と動機
コンピュータ使用エージェントは通常、手書きのシェルチェック(OSWorld方式)またはスクリーンショットを検査するLLM-as-judgeによって成否が判定される環境でベンチマーク評価されます。いずれも既知の問題があります。手書きのチェックは脆弱であり、異種のデスクトップアプリケーションをまたいでスケールさせることが困難です。一方、LLMによる判定は、成功と失敗の差がわずか数ピクセルの状態(例:選択されたセルが違う、折り畳まれたパネル内で切り替えられた設定)に現れるような密なGUIでは信頼性が低くなります。OpenComputerはその中間的なアプローチを試みます。すなわち、アプリケーション固有の検査エンドポイントを通じて構造化されたアプリケーション状態を読み取るプログラム的検証器と、成功基準が機械的に確認可能であることが保証されたタスクを生成する合成パイプラインを組み合わせるものです。
手法
このフレームワークはタスクインスタンスを \tau=(x,e,c) として形式化します。ここで x は自然言語の指示、e は s_0\sim e を生成する実行可能なサンドボックス初期化手順、c はインタラクション後の状態 s_T に対して評価される機械的確認可能な基準の集合です。3つの結合演算子が \tau を構築します。
検証器ジェネレータ \mathcal{V}(a)\to V_a:各アプリケーション a に対して、構造化された検査エンドポイントを公開するアプリケーション固有の検証器を構築します。これらのエンドポイントはアプリケーションにとって最も信頼性の高いチャネルをラップします。ブラウザではDOMアクセス、スプレッドシートではワークブックオブジェクト、IDEではASTまたはファイルシステムの読み取り、3DシーンではBlenderのPython APIなどです。

OpenComputer検証器が使用するアプリケーションエンドポイント仕様の例。 自己進化演算子 \mathcal{U}(V_a, D_a)\to V_a^{+}:キャリブレーション用の軌跡 D_a は、強力なエージェントを候補タスクで実行することによって収集されます。LLM評価器とプログラム的検証器の結果が比較され、不一致箇所が検証器の述語(見落とされたエッジケース、フィールド名の誤り、セレクタのオフバイワンなど)のパッチ適用に使用されます。これは、人間による作成ではなく実行フィードバックに基づいて検証器の信頼性を確立するクローズドループです。
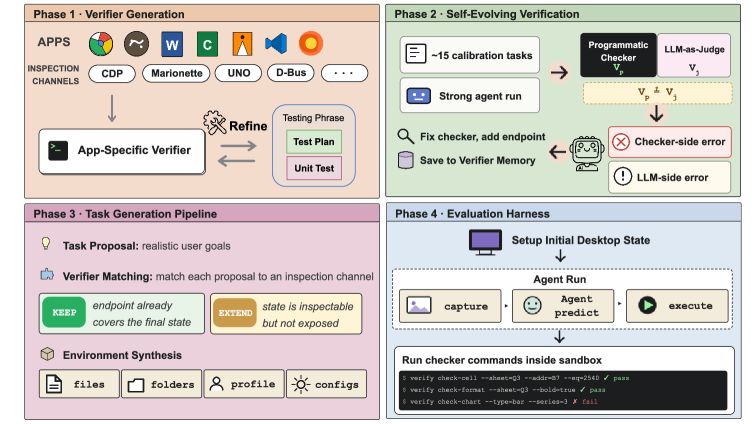
OpenComputer検証可能なソフトウェアワールド合成パイプラインの概要。 検証器対応タスクシンセサイザー \mathcal{E}(a, g, V_a^{+})\to e:x および c とともに初期化手順を構築します。設計上、c は V_a^{+} への呼び出しとして表現可能であるため、生成されたすべてのタスクが確認可能となります。
最終的なベンチマークはブラウザ、オフィススイート、クリエイティブツール(Blenderを含む)、IDE、ファイルマネージャー、通信アプリにわたる33のアプリケーションと1,000の最終確定タスクをカバーします。評価ハーネスは完全な軌跡を記録し、2値的な成功か否かに集約するのではなく、基準ごとのチェックリストスコアを集約することで監査可能な部分クレジット報酬を算出します。
結果
主要な比較(Table 2)では、フロンティアモデルとオープンソースのエージェントをOpenComputerスイートおよびそれぞれが報告しているOSWorld-Verifiedスコアと並べて示しています。
- GPT-5:成功率68.3%、平均報酬88.4%、平均ステップ数19.0、1ステップあたり16.5秒(OSWorld-V:75.0%)
- Claude-Sonnet-4.6:64.4% / 報酬76.6%(OSWorld-V:72.5%)
- Kimi-K2:58.8% / 報酬70.7%(OSWorld-V:73.1%)
- Qwen-3.5-27B:32.3% / 報酬59.4%(OSWorld-V:56.2%)
- Gemini-3-Flash:16.4% / 報酬37.0%
- EvoCUA-8B:10.9%(OSWorld-V:46.1%)
- Qwen-3.5-9B:7.8%(OSWorld-V:41.8%)
- GUI-OWL-1.5-8B:5.7%(OSWorld-V:52.3%)
2つのパターンが注目されます。第一に、フロンティアモデルは合理的な成功率を維持していますが、2値的な成功と平均報酬の間に大きな差が見られます(GPT-5:68.3% vs. 88.4%)。これは、部分クレジットによるスコアリングが、2値的なOSWorld方式の指標では捨てられてしまう進歩を捉えていることを裏付けています。第二に、オープンソースのエージェントはOSWorld-Vスコアと比較してフロンティアモデルよりもはるかに急激にスコアが低下します。GUI-OWL-1.5-8Bは52.3%から5.7%へ、EvoCUA-8Bは46.1%から10.9%へと落ち込んでいます。これは、これらのモデルがOSWorldのタスク分布に過適合しているか、プログラム的な状態チェックによって塞がれる検証器の抜け穴に依存していることを示唆しています。
検証器の妥当性検証実験は、このフレームワークの中心的な主張に対する最も興味深い根拠となっています。同じ項目ごとのチェックリストを用いた人間の判定に対して120件の軌跡をスコアリングした結果:
- ハードコードされた検証器:タスクレベルの一致率94.1%(120件中113件)、項目ごとのチェックリスト合意率97.3%
- LLM-as-judge:タスクレベルの一致率79.2%(120件中95件)、項目ごとの合意率92.2%
タスクレベルで15ポイントの差は、状態とピクセルの乖離が重要となるケースに集中しています。論文では典型的な例を示しています。あるタスクでは2つの隣接するセルに入力することが求められていたにもかかわらず、エージェントが1つの長いトークンを1つのスプレッドシートセルに入力してしまったケースです。スクリーンショットは問題なく見えますが、ワークブックの状態は正しくありません。
この差は、Blenderのスクロールバック、開発者ツールのログ、中間ファイルの成果物など、証拠が可視ビューポートの外に存在するアプリケーションでさらに拡大します。LLMによる判定は狭いスクリーンショットのウィンドウしか参照できない一方で、検証器は実行後の状態を直接読み取れるためです。
限界と未解決の問題
検証器のエンドポイントは各アプリケーションが何らかの検査チャネルを公開していることに依存します。スクリプトインターフェースを持たないクローズドソースのアプリケーションでは、スクリーンOCRやファイルシステムのヒューリスティックが必要となり、OpenComputerが回避しようとしている脆弱性が再び生じます。検証器の進化はキャリブレーションエージェントのカバレッジに制約されます。強力なエージェントが決して引き起こさない障害モードはパッチが当たりません。1,000タスクという規模はOSWorldに匹敵しますが、実際のデスクトップ作業の多様性に対しては小規模であり、タスク合成は目標 g に条件付けられており、その目標の現実性は(未指定の)目標ソースに依存します。最後に、部分クレジット報酬はチェックリストの分解に依存しており、それ自体が合成されたものです。チェックリストの粒度がアプリケーション間でキャリブレーションされているかどうかは分析されていません。
この研究が重要な理由
OpenComputerは、プログラム的な状態検査がデスクトップエージェントのタスクレベルの人間との一致においてLLM-as-judgeを15ポイント上回るという実証的な根拠を明確に示しており、同時に現在のオープンソースのCUAがOSWorld-Verifiedスコアが示唆するよりもはるかに汎化性が低いことを明らかにしています。検証器の進化ループがスケールするならば、これはコンピュータ使用エージェントを評価するだけでなくRLで訓練するのに十分な信頼性を持つ報酬信号を構築するための有力なテンプレートとなります。
Source: https://arxiv.org/abs/2605.19769
Pointwise Mutual Informationによる推論RLのためのAnti-Self-Distillation
問題設定
オンポリシーself-distillation (SD)は、特権的なコンテキストc(検証済みの解答と正誤フィードバック)に条件付けられたモデルのコピーに対する、トークンごとのKLプルによってRLを強化します。経験的には、SDはいくつかのタスクで効果を発揮しますが、数学的推論ではバニラGRPOより性能が劣ります。本論文はその原因を診断し、1行の符号反転とエントロピーゲートからなる修正を提案します。
トークンごとのKLから条件付きPMIへ
s_t := \log\pi_S(y_t\mid x,y_{<t})、t_t := \log\pi_T(y_t\mid x,c,y_{<t})、u_t := t_t - s_tとします。トークンごとのKLの被加算項\mathbb{E}_{v\sim\pi_S}[\log\pi_S(v) - \log\pi_T(v)]を微分し、定数係数項を消去するためにscore-function恒等式を用い、さらにteacherにstop-gradientを適用すると、
\nabla_\theta D_{\mathrm{KL}}(\pi_S\|\pi_T) = -\mathbb{E}_{v\sim\pi_S}\!\big[u_v\cdot \nabla_\theta\log\pi_S(v)\big],
が得られます。よって、SDのトークンごとのadvantageはちょうど\delta_t = +u_tとなります。self-distillationでは\pi_Sと\pi_Tがパラメータを共有するため、u_tは条件付きpointwise mutual informationに帰着します。
u_t = \log\frac{\pi_\theta(y_t\mid x,c,y_{<t})}{\pi_\theta(y_t\mid x,y_{<t})} = \mathrm{PMI}(y_t;c\mid x,y_{<t}).
u_tの符号は、cが次のトークンの確率を上げるか下げるかを意味します。SDは「cによって確率が上がった」トークンに報酬を与え、「cによって確率が下がった」トークンにペナルティを与えます。そして数学のロールアウトにおいて、これらのクラスは質的に異なるトークン集団に対応しています。

Figure 2はそのバイアスを具体的に示しています。u_t \gg 0であるトークン(例:Given、Assign、succeeds、holds)は、cが解答を確定した後に自明に予測可能となる構造的な接続詞および検証可能な主張です。u_t \ll 0であるトークン(Wait、Let、Maybe、Alternatively)は、多段階探索を駆動する熟考トークンです。cが答えを固定してしまうと、teacherは再検討を重み付けで抑制します。デフォルトのSDは構造的ショートカットを増幅し、探索を抑制します。これは推論RLに必要なものとは正反対です。
AntiSD
AntiSDはトークンごとの符号を反転させます。すなわち、student-teacher間のf-divergenceを下降するのではなく上昇します。具体的には、トークンごとの報酬はJensen–Shannon divergenceから導出された-\varphi(u_t)となります(これにより、上限が非有界な生のKL上昇における-u_tとは異なり、advantageが1ステップで自然に有界になります)。エントロピーによるゲートは、teacherのエントロピーが崩壊した際にこの項を無効化します。具体的には、\lambda=0での5ステップのウォームアップでH_{\mathrm{warm}}を記録し、H<\tau_{\mathrm{down}} = 0.93\,H_{\mathrm{warm}}になるとゲートが発動し、Hが回復するとリセットされます。0.93の乗数は5つのモデルすべてで共通であり、モデルごとのチューニングは不要です。AntiSDはドロップイン置換です。同一のロールアウト、同一のGRPO軌跡advantage A_i^{\mathrm{seq}}を使用し、符号を反転させたトークンごとの項を1つ追加するだけです。

結果
5つのモデル(Qwen3-4B-IT-2507、Qwen3-8B、Qwen3-30B-A3B、Olmo3-7B-IT、Olmo3-7B-TK)を用いて、DAPO-Math-17kにおけるオンポリシー200ステップの訓練を行い、AIME 2024/25/26およびHMMT25でavg@32、MinervaMathでavg@4を評価しています。
2つのパターンが観察されました。
サンプル効率。 AntiSDはGRPOの最良Avg精度に2\text{–}10\times少ないステップで到達します。ベースラインが弱いモデルほど大きな改善が見られます。Qwen3-4B-IT-2507で10\times、Olmo3-7B-ITで9.5\times、Qwen3-8Bで5\times。強いベースラインでは改善幅は小さいものの正の値を示します。Olmo3-7B-TKは2\times(GRPOはすでに64.1)、Qwen3-30B-A3Bは2.9\times。これはPMIの診断と一致しています。-\varphi(u_t)はステップ1から密で情報量の多いトークンごとのクレジットを提供する一方、GRPOは疎な軌跡報酬が伝播するまで待たなければなりません。
最終精度。 AntiSDはGRPOの平均を+2.1〜+11.5ポイント上回ります。主要な数値:Qwen3-8Bは65.7対57.4(+8.3)、Qwen3-4B-IT-2507は62.8対51.3(+11.5)、Qwen3-30B-A3Bは66.8対59.1(+7.7)、Olmo3-7B-ITは48.3対43.0(+5.3)、Olmo3-7B-TKは66.2対64.1(+2.1)。HMMT25においてとりわけ顕著で、Qwen3-8BはGRPOの39.2からAntiSDの54.4へと15ポイント向上しています。デフォルトのSDは5モデル中4モデルでGRPOを下回っており(例:Qwen3-8B SDは30.6対GRPO 57.4)、ショートカットバイアスが単に情報量がないのではなく有害であることを確認しています。
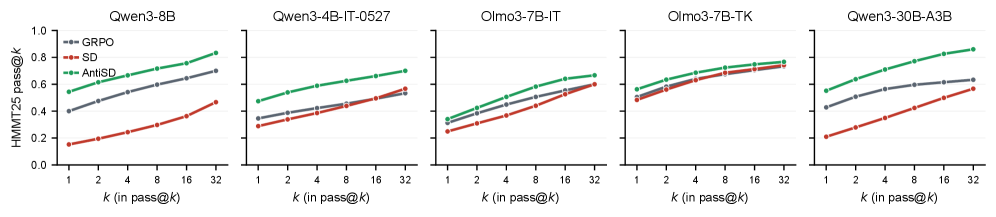
Figure 3は、pass@kにおいてk全体にわたって改善が維持されていることを示しており、固定された解答可能な問題集合に対する単なる分散低減ではなく、解答カバレッジが拡張されていることを示しています。
限界と未解決の問題
- 特権的なコンテキストcは、グループ内の正しいロールアウト(またはデータセットの解答)とバイナリフィードバックから構築されています。cの品質の感度や、0.93のデフォルト以外のゲート閾値への感度は、他のドメインにわたってストレステストされていません。
- JSベースの\varphiは有界な符号反転の一形態に過ぎず、reverse-KL上昇、\chi^2、またはその他のf-divergenceでも改善が持続するかどうかは不明です。
- 実験はすべて数学的推論です。SD対AntiSDの非対称性は、cが単一の解答経路にコミットすることに依存しています。cがローカルなトークン選択に対して真に情報量のあるタスク(例:決定論的な補完を持つコード)では、符号反転の恩恵を受けない可能性があります。
- \pi_S(y\mid x)に対する軌跡レベルのREINFORCEはstop-gradientのもとで省略されており、この近似とGRPO項との相互作用はアブレーションされていません。
この研究の意義
本論文は、数学RLにおけるself-distillationの不可解な経験的失敗を、明快なメカニズム的な説明に変換しました。\delta_t=+u_tはcとの条件付きPMIであり、chain-of-thoughtにおいてショートカットトークンに系統的に報酬を与えながら、探索を行う熟考トークンにペナルティを与えます。有界なdivergence上昇とエントロピーゲートを用いて符号を反転させることで、GRPOと相補的な密で情報量の多いトークンごとのクレジットが得られ、モデルスケール全体にわたって訓練を大幅に加速させます。
Source: https://arxiv.org/abs/2605.11609
学習された信頼性を用いたProcess Reward
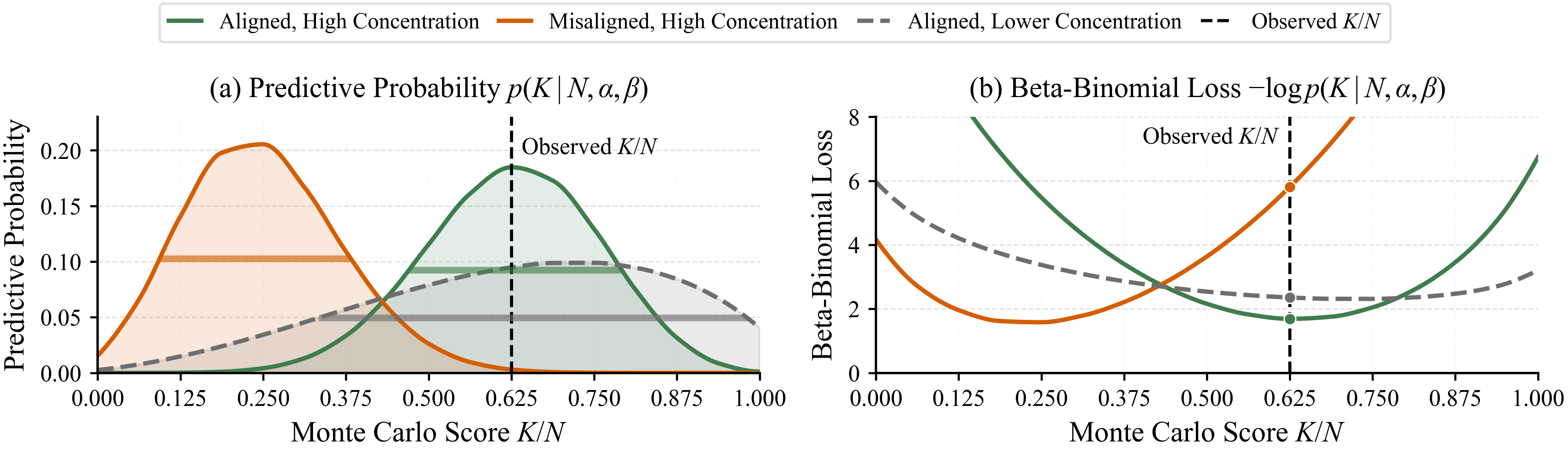
モンテカルロロールアウトから学習されたProcess Reward Models(PRMs)は、基本的な統計的問題に直面しています。それは、監督シグナル K/N——プレフィックスから得た N 個の継続における経験的成功率——が潜在的なステップ品質 q_t のノイズの多い推定量であるにもかかわらず、標準的な学習ではこれをcross-entropyによる回帰のポイントターゲットとして扱うという問題です。そのためPRMは単一のスカラーを出力しますが、下流のセレクタ(Best-of-N、beam search、MCTS)はこれを一様に信頼しなければならず、確信度の高い0.8と単一のラッキーなロールアウトから得られた0.8を区別する手段がありません。BetaPRMはこれに対し、q_t に対する完全なBeta信念を予測することで、報酬と信頼性を同時に捉えることで対処します。

Beta-Binomial supervision
生成モデルは単純です。プレフィックスを条件として、成功した継続は K_t \mid q_t \sim \mathrm{Binomial}(N, q_t) に従い、潜在的な成功確率は q_t \sim \mathrm{Beta}(\alpha_t, \beta_t) としてモデル化されます。q_t を周辺化するとBeta-Binomial likelihoodが得られます:
p(K_t \mid \alpha_t, \beta_t, N) = \binom{N}{K_t} \frac{B(K_t + \alpha_t,\, N - K_t + \beta_t)}{B(\alpha_t, \beta_t)},
これがステップごとの学習目標となります。ネットワークは平均 \mu_t = \alpha_t/(\alpha_t+\beta_t) と集中度 \kappa_t = \alpha_t + \beta_t を予測するように再パラメータ化されており、\mu_t は標準的なPRMスカラーを回復し、\kappa_t は信念のピークの鋭さを符号化します。監督の直感を図2に示します:観測された K/N と一致するタイトなBetaは高いlikelihoodを持ちます(緑);タイトであっても整合していないBetaは大きなペナルティを受けます(オレンジ);拡散したBetaは広範な K/N の結果にわたってヘッジします(グレー)。重要なのは、BetaPRMがロールアウト結果が本質的に高い分散を持つプレフィックスにおいて低い確信度を表現できるという点であり、シャープな確率にコミットすることを強いられません。
Adaptive Computation Allocation
信頼性シグナルは推論時にACA(Adaptive Computation Allocation)を通じて利用されます。これは2つのメカニズムを持つBest-of-Nの変種です:候補が信頼できる差でリードしている場合に早期停止し、不確かなプレフィックスにサンプルを再配分します。Beta信念はステップレベルの標準偏差へと変換されます:
\sigma_t = \sqrt{\mu_t(1-\mu_t)/(\kappa_t+1)},
そしてリスク調整された候補スコアへと集約されます:
S(y) = \frac{1}{T}\sum_{t=1}^{T}\bigl(\mu_t - \lambda \sigma_t\bigr).
ACAはバッチで候補を生成し、各バッチ後にトップ候補が予測された不確実性を考慮した上で信頼できる差でリードし続けているかをテストします。そうであればサンプリングを停止し、そうでなければ \sigma_t が最も大きいプレフィックスから追加のロールアウトを引き出し、報酬推定が最も信頼できない箇所に計算を集中させます。
結果
学習にはVisualPRM400K-v1.1を使用し、各プレフィックスは N=16 回のモンテカルロ継続のうち K 回の成功を持ちます。標準ベースラインは K/N に対するcross-entropyであり、BetaPRMはこれをBeta-Binomial likelihoodで置き換えます。4つのbackbone(InternVL2.5-8B、InternVL3-8B、InternVL3-14B、Qwen2.5-VL-7B)と4つの数学的推論ベンチマーク(MathVision、OlympiadBench、MathVerse、MathVista)にわたって、BetaPRMはInternVL2.5-8Bで生成された同じ候補プールに対するBest-of-16セレクタとして標準PRMを一貫して上回ります。
具体的には、セレクタとしてInternVL2.5-8Bを使用した場合、シングルパスベースラインに対する平均精度向上は標準PRMの +4.58 からBetaPRMの +7.95 へと上昇し、絶対値で +3.37 の改善となります。Qwen2.5-VL-7Bではギャップは +6.45 \to +9.11(+2.66)、InternVL3-8Bでは +7.00 \to +8.46(+1.46)、InternVL3-14Bでは +7.75 \to +9.04(+1.29)です。ベンチマーク別では、最大のデルタは難易度の高いセットから得られます——例えば、MathVisionはInternVL2.5-8Bで21.38から25.66へ、OlympiadBenchは11.33から15.33へと上昇します。改善は4つのセレクタbackboneすべてと4つのベンチマークすべてで一貫しており、向上が監督目標から生じており、backbone固有の特性によるものではないことを示唆しています。
本論文はACAの結果をInternVL2.5-8BとQwen2.5-VL-7Bについて、同じ最大バジェット下での固定バジェットBest-of-16に対して別途報告しており、精度と生成トークン数の両方を追跡しています——信頼性を考慮した停止ルールがより少ないトークンコストで精度を保持できるかどうかが関連する軸となります(具体的な数値はSection 6.3に記載されており、ここでは抜粋していません)。
限界
Beta-Binomial likelihoodは、学習データが (K, N) カウントを提供する場合にのみ適切に定義されます;ほとんどの公開PRMデータセットは比率のみを公開しており、VisualPRM400Kスタイルの監督への適用可能性が制限されます。信頼性のキャリブレーションはデータ構築時に使用されたロールアウト数 N=16 に暗黙的に紐付けられており、異なるサンプリング体制の設定に転移した際に \kappa_t がどのように振る舞うかは不明です。リスク調整集約器は手動で選択された \lambda と一様なステップごとのペナルティを使用しており、\sigma_t が頻度論的な意味でよくキャリブレーションされているかどうか(例えば、予測された90%区間がホールドアウトされた K/N の90%をカバーするか?)は直接評価されていません。最後に、ACAの停止ルールはスコア分散に関する仮定に依存しており、これは正式には分析されていません。
なぜこれが重要か
経験的なモンテカルロ比率をポイントターゲットとして扱うことは、カウント教師ありPRMすべての隠れた失敗モードであり、BetaPRMはBeta-Binomial likelihoodへの一行の変更によって実質的にほぼ無コストでキャリブレーションされた不確実性を回復し、Best-of-N 精度において一貫した1〜3ポイントの向上と適応的推論計算のための自然なレバーをもたらすことを示しています。PRMを探索の誘導に使用するシステムは、このドロップイン代替を検討すべきでしょう。
Source: https://arxiv.org/abs/2605.15529
CEPO: Contrastive Evidence Policy Optimizationを用いたRLVR Self-Distillation
問題設定
RLVRにおいて、検証器 R(x,y)\in\{0,1\} はシーケンスレベルの報酬を一つ割り当て、GRPOスタイルの正規化はこのスカラーをrollout内のすべてのトークンに均一にブロードキャストします。決定的な推論ステップと文法的な埋め草は同じクレジットを受け取ります。Self-distillationアプローチは、教師モデルを正解 r^+ に条件付けし、教師と学生の間のdivergenceをトークンごとのクレジットシグナルとして利用することでこの問題を修正しようとしますが、これには (i) 勾配に答えが漏洩する — テストパフォーマンスを劣化させる偽の x \to r^+ 相関を符号化してしまう — か、(ii) 条件なしの学生に対して決定的なトークンも埋め草のトークンも同様に驚くべきものに見えるため、シグナルが弱くなる、という問題があります。
手法
CEPOは絶対的な教師シグナルを対比的なシグナルに置き換えます。質問 x が与えられると、方策 \pi_\theta は G 個のrolloutを生成し、検証器によって正解集合 \mathcal{G}^+ と不正解集合 \mathcal{G}^- に分割されます。正解の根拠 r^+ \in \mathcal{G}^+ と棄却された根拠 r^- \in \mathcal{G}^- がサンプリングされ、重み \theta を共有する三つの次トークン分布が形成されます:
P_S(y_t)=\pi_\theta(y_t\mid x,y_{<t}),\quad P_T^+(y_t)=\pi_\theta(y_t\mid x,r^+,y_{<t}),\quad P_T^-(y_t)=\pi_\theta(y_t\mid x,r^-,y_{<t}).
二つの教師パスはstop-gradientの下で実行されます。Contrastive evidence deltaは、概略的に次のように表されます:
\Delta_t^{\mathrm{CE}} \;\propto\; \log P_T^+(y_t) - \log P_T^-(y_t),
したがって、あるトークンが増幅されるのは、正解の教師がそれを選好し、かつ不正解の教師がそれを非選好する場合のみです。両者の下で中立なトークン(埋め草)は |\Delta_t^{\mathrm{CE}}|\approx 0 となり、GRPOのadvantageが変調されないまま残ります。
トークンレベルで変調されたadvantageは、標準的なPPOクリッピングされた代理目的関数に組み込まれます。重要な構造的性質(論文の定理1(ii))は、r^- がバッチ自身の棄却されたrolloutから引かれるため、勾配には語彙全体にわたる r 条件付き項が含まれないことです — OPSD/SDPOを破綻させる漏洩経路が対比によってキャンセルされます。r^- は現在のグループにおける最低報酬の棄却rolloutから抽出された最終的な答えであるため、追加のサンプリングコストは発生しません。
対比的変調と基本GRPOのadvantage間の混合重み \lambda はアニールされます:\lambda_0=0.5 から T_{\mathrm{warm}}=25 ステップにわたって線形減衰して 0 になり、さらに変調の大きさにはクリッピング上限 \epsilon_w=0.5 が設けられます。
結果
実験では Qwen3-VL-2B-Instruct と Qwen3-VL-4B-Instruct を使用し、LoRA rank 16、Geo3k(数値解答を持つ3kの幾何問題)上で50ステップ、G=8 rollout、バッチ32、AdamW を 10^{-6}(CEPOでは 5\times 10^{-6})、EasyR1 + FSDP + vLLM で実施しています。
Qwen3-VL-2B において五つの推論ベンチマークで平均すると、CEPOは 43.43% に達し、GRPO 41.17%(+2.26pp)、OPSD 34.96%、SDPO 35.70% を上回ります。Qwen3-VL-4B では、CEPOは 60.56% に達し、GRPO 57.43%(+3.13pp)および OPSD 56.23% を上回ります。性能向上はより長い推論チェーンを持つベンチマークに集中しており、LogicVista(4B)で +6.18pp、MathVision mini(2B)で +4.94pp となっています。短い多肢選択式の検索に支配されているMMMLUは最小の向上幅(2Bで+1.67pp)を示しており、これは対比シグナルが決定的なトークンを含むほど推論チェーンが長い場合に機能するという主張と一致しています。
注目すべき観察として、OPSDとSDPOは2Bにおいて未学習のベースモデルを下回り(34.96%および35.70% vs. ベース39.73%)、4BにおいてもOPSDが同様(56.23% vs. ベース58.36%)となっています。これは予測された漏洩の失敗です:学習が進むにつれて、語彙全体にわたる r^+ 条件付き勾配偏差 \delta(\theta;r^+) が支配的となり、モデルが x\to r^+ のショートカットを符号化するよう押し進められます。CEPOは設計上この項を除去しています。
図1の学習ダイナミクスはCEPOがGRPOおよびRLSDよりも速く改善し、ステップ40付近で最大のギャップが生じた後に部分的に収束することを示しています。ハイパーパラメータのスイープ(図3)では、定数 \lambda=0.5 が41.40%(vs. GRPO 41.17%)でピークに達するのに対し、\lambda=1.0 はノイズを注入してクレジット割り当ての利点を消し去ることが示されており、25ステップ線形減衰のウォームアップが最も堅牢な設定です。
計算オーバーヘッドは軽微です:50ステップのGeo3k学習においてCEPOは6時間34分、GRPOは5時間58分であり、二つの追加教師forward passに要する時間は約36分 — RLSD/SDPOのオーバーヘッドと同程度です。
限界と未解決の問題
評価は二つの小規模な Qwen3-VL モデル、50ステップの LoRA、および単一の学習コーパス(Geo3k)に限定されており、より長い学習やfull-parameterの更新において性能向上が蓄積されるかどうかは不明です。最低報酬のrolloutから r^- を構成する方法は \mathcal{G}^- が空でないことを前提としており、飽和近傍(ほとんどのrolloutが正解の場合)での挙動は特徴付けられていません。対比シグナルはまた、不正解のrolloutが正解のrolloutと十分な構造を共有し、P_T^- が情報量を持つことを前提としています — 棄却されたrolloutがトピックから外れている病的なケースでは、変調が無効化される可能性があります。最後に、理論的な安全性保証は語彙全体の漏洩を除去しますが、対比項の分散寄与を制限しておらず、\lambda=1.0 の不安定性がそれが自明でないことを示唆しています。
なぜ重要か
CEPOはRLVRにおけるクレジット割り当ての中心的な欠陥 — トークンごとの均一な報酬 — を、追加のrolloutなしに、かつこれまでのself-distillation RL手法を密かに損なっていた答え漏洩なしに解決します。対比的な構成は安価で、PPO/GRPOにそのまま組み込めます。そして棄却されたrollout(それ以外では負のadvantageとして破棄されるもの)を有用な教師シグナルに変換します。
Source: https://arxiv.org/abs/2605.19436
ビデオモデルは検証可能な報酬によって推論できる
ビデオ拡散モデルは知覚的妥当性のために学習されていますが、妥当性は生成された軌跡が空間的・時間的・論理的制約を満たすことを保証しません。本論文は、ビデオ生成を検証可能な視覚的軌跡の探索として定式化し、推論チューニング済みLLMの背後にあるレシピであるRLVRをflow-matchingビデオモデルに移植します。その成果物であるVideoRLVRは、ルールベースの検証器が学習された報酬モデルを置き換える3つの手続き的に生成された推論ドメイン(Maze、FlowFree、Sokoban)において、Wan2.2-TI2V-5Bをfine-tuningします。
問題設定
条件付けは初期フレームとテキスト指示による c=(I_0,T) であり、ポリシーは 480\times 832 で81フレームのビデオ \mathbf{V}=\{I_0,\ldots,I_{80}\} を出力し、ルールベースの検証器が R(\mathbf{V},c) を返します。デノイジング軌跡は状態 x_{t_k} と行動 \hat v_\theta(x_{t_k},t_k,c) を持つ K ステップ上のMDPとして扱われます。純粋なODEサンプラーは x_1 が与えられると決定論的であるため、尤度比勾配で微分すべき遷移密度が存在しません――これが本手法が解消しなければならない中心的な障害です。
SDE-GRPOバックボーン
Flow-GRPOに従い、決定論的な更新をガウス遷移
\pi_\theta(x_{t_{k+1}}\mid x_{t_k},c)=\mathcal{N}(x_{t_{k+1}};\mu_\theta(x_{t_k},t_k,c),\sigma_k^2 \mathbf{I})
で置き換えることで、閉じた形式の対数確率が得られます。条件ごとに G 回のロールアウトとグループ正規化アドバンテージ A_i を用いると、次元正規化された対数比は
\log\rho_{i,k}=-\frac{1}{2\sigma_k^2 D}\sum_{d=1}^{D}\big[(x^{(i)}_{t_{k+1}}-\mu^{(i,k)}_\theta)_d^2-(x^{(i)}_{t_{k+1}}-\mu^{(i,k)}_{\text{old}})_d^2\big]
となり、PPOクリッピング \mathcal{L}_\text{policy}=-\mathbb{E}[\min(\rho A,\text{clip}(\rho,1\pm\varepsilon)A)] に代入されます。参照ポリシーへのKLは閉じた形式で加算され、
\mathcal{L}_\text{KL}=\mathbb{E}_k\!\left[\frac{1}{D}\frac{\|\mu_\theta-\mu_\text{ref}\|_2^2}{2\sigma_k^2}\right]
であり、\beta=0.04 です。参照はSFTチェックポイントであり、これ自体が学習率 10^{-5} で5エポックにわたりグラウンドトゥルースのソリューション動画でトレーニングされ、RLが収束するために必要な知覚的事前分布を提供します。
Early-Step Focus
重要な効率性に関する主張として、T=20 のデノイジングステップのうち最初の L=10 ステップのみに勾配とSDEノイズ注入が必要とされます。後半のステップはテクスチャを精緻化するものであり、推論構造には関与しません。Mazeにおいて、T=20 を固定しつつ勾配を L=10 に制限すると、完全軌跡最適化のF1 84.6・SR 72.3 に対してF1 84.4・SR 72.2 が得られる一方、ステップ時間は 156 秒から 93.5 秒に短縮され、主張されている学習レイテンシの約40%削減が達成されます。
密な分解報酬
疎な0/1の成功信号は、長いホライズンと不可逆な遷移を持つSokobanのようなドメインでは弱すぎます。VideoRLVRは検証器シグナルを構成要素ごとの密な報酬に分解し(アブストラクトでは、これが最も重要な要因であると強調されています)、部分的に正しい軌跡が G=16 の各グループ内で情報量のあるアドバンテージを受け取れるようにします。
結果
VideoRLVRはSFTから初期化され、G=16、T=20、学習率 5\times 10^{-6}、8×B200上で1エポック学習されます。保留された3,000サンプルのテストセットにおいてプロプライエタリなベースラインと比較すると、差は大きく、Sora 2はMaze/FlowFree/Sokobanで成功率3.1/0.0/0.0、Kling V3は23.5/0.0/0.0、Veo 3.1のMaze精度も低い結果となっています(テーブルは省略)。Mazeにおいて、VideoRLVRはF1 84.6・SR 72.3 を報告しており、Kling V3のMaze SRの 3\times 以上に相当します。FlowFreeおよびSokobanでは、引用されたすべてのプロプライエタリシステムがSR 0.0 を記録しており、これらのドメインは現在の汎用ビデオモデルでは本質的に未解決であることを示しています――検証器は知覚的には妥当でもルールに違反する出力に対して積極的に識別を行います。
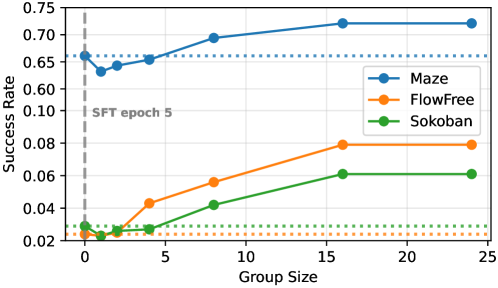
グループサイズのスケーリングは予想されるGRPOの挙動を示します:G\le 4 ではグループ統計のノイズによりアドバンテージ推定にバイアスが生じ、G=16 で学習が安定し、それ以上ではリターンが逓減する一方でロールアウトコストは線形に増大します。KLペナルティを除去する(\beta=0)と報酬ハッキングが発生し――検証器のサブ基準を満たすが視覚的に不自然なパターンが生成され――SFT事前分布を積極的にアンカリングしなければならないことが確認されます。
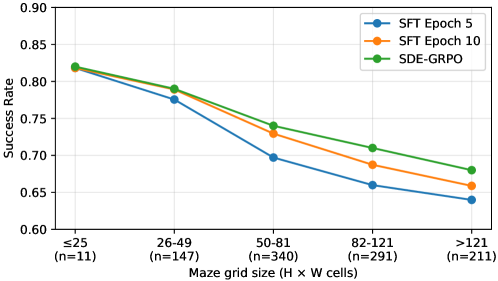
成功率は迷路のグリッドサイズとともに低下しており、学習分布内であってもモデルがより長いホライズンの空間的探索に依然として苦戦していることを示しています。
限界
評価は検証器が自明に構築できる3つの手続き的に生成されたグリッドワールドドメインに限定されています。自然なビデオ推論への転移については(VBVRのドメイン外分割)言及されていますが、提供されたテキストはその数値を報告する前に切れています。報酬はタスクごとに手動で分解されています。MDPはデノイジングステップ上で定義されており、推論ステップ上ではないため、\mathbf{V} 内の特定のフレームやイベントへのクレジット割り当ては間接的であり、報酬は完全なデコード後にのみ計算されます。Early-Step Focusが粗いレイアウトが支配するグリッド構造化された出力を超えて一般化するかどうかは不明であり、検証のために細粒度の後半ステップの詳細が重要となるタスクでは L=10 では不十分な可能性があります。最後に、プロンプトごとに81フレーム動画の G=16 ロールアウトを行うことは依然としてコストが高く、1エポックのRLバジェットは余地があることを示唆しつつも、スケジュールに対する感度も示しています。
なぜこれが重要か
これは、RLVRのレシピ――グループ相対ポリシー最適化とルールベース検証器と閉じた形式KLアンカリング――が、決定論的ODEをSDEに置き換えることでflow-matchingビデオジェネレーターに転移できるという明確なデモンストレーションです。「見た目が正しいビデオモデル」と「正しいビデオモデル」を分離し、Early-Step Focusの観察は拡散ポリシーのRLをスケーリングするための具体的な計算上のレバーを提供します。
Source: https://arxiv.org/abs/2605.15458
TideGS: アウト・オブ・コア最適化による10億超の3D Gaussian Splattingプリミティブのスケーラブルな学習
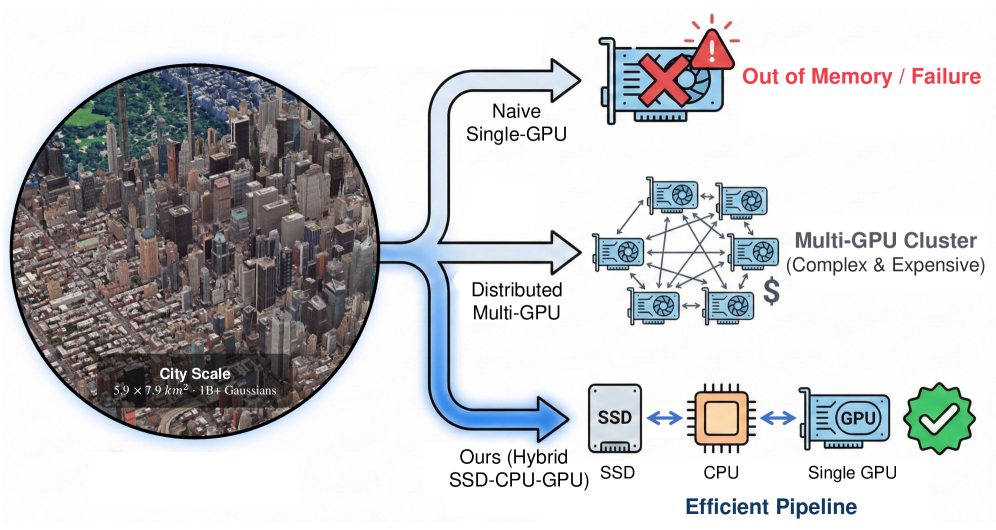
問題
3D Gaussian Splattingは、シーンを異方性ガウシアンの集合 \{(\mu_i, \Sigma_i, \alpha_i, c_i)\}_{i=1}^{N} としてパラメータ化します。各プリミティブは位置・スケール・回転・不透明度・SHカラー係数を持ち、通常1プリミティブあたり約60個の浮動小数点数に相当します。N \sim 10^9 の場合、パラメータテーブルだけで200 GBを超え、24 GB GPUの容量を大幅に上回ります。既存のシステムは、コモディティGPU上で N を \sim 10^7 に制限するか、マルチGPUシャーディングに依存しています。著者らは、3DGS学習が構造的にスパースであることを観察しています。すなわち、イテレーションごとに、カメラバッチの視錐台と交差するガウシアンのみが非ゼロの gradient を受け取り、MatrixCity BigCity/Aerialでは平均0.39%(最悪ケースで1視点あたり1.06%)という実測値が得られています。連続したカメラ軌跡の下では、連続するワーキングセットは大きく重複します。これにより、3DGSはVRAMにアクティブなワーキングセットのみを保持するアウト・オブ・コア学習の自然な候補となります。
手法
TideGSは、SSD–CPU–GPUの階層にわたってパラメータを管理し、3つの連携したメカニズムを用います。
ブロック仮想化されたジオメトリ。 ガウシアンは中心 \mu_i 上のMortonコードでソートされ、SSDページ粒度に揃えた固定サイズのブロックに分割されます。各ブロック b_k は、含まれるガウシアン中心から計算された境界球 (c_k, r_k) と、最大 3\sigma の広がりを反映したマージンによって要約されます。カメラバッチ \mathcal{B}_t を用いたイテレーション t において、\{(c_k, r_k)\} に対するCPUサイドの6平面視錐台テストにより保守的なブロックカバー \mathcal{K}_t が生成され、その後ラスタライザ内のGPU上でガウシアンレベルの細粒度可視性 \mathcal{I}_t \subseteq \bigcup_{k \in \mathcal{K}_t} b_k が計算されます。
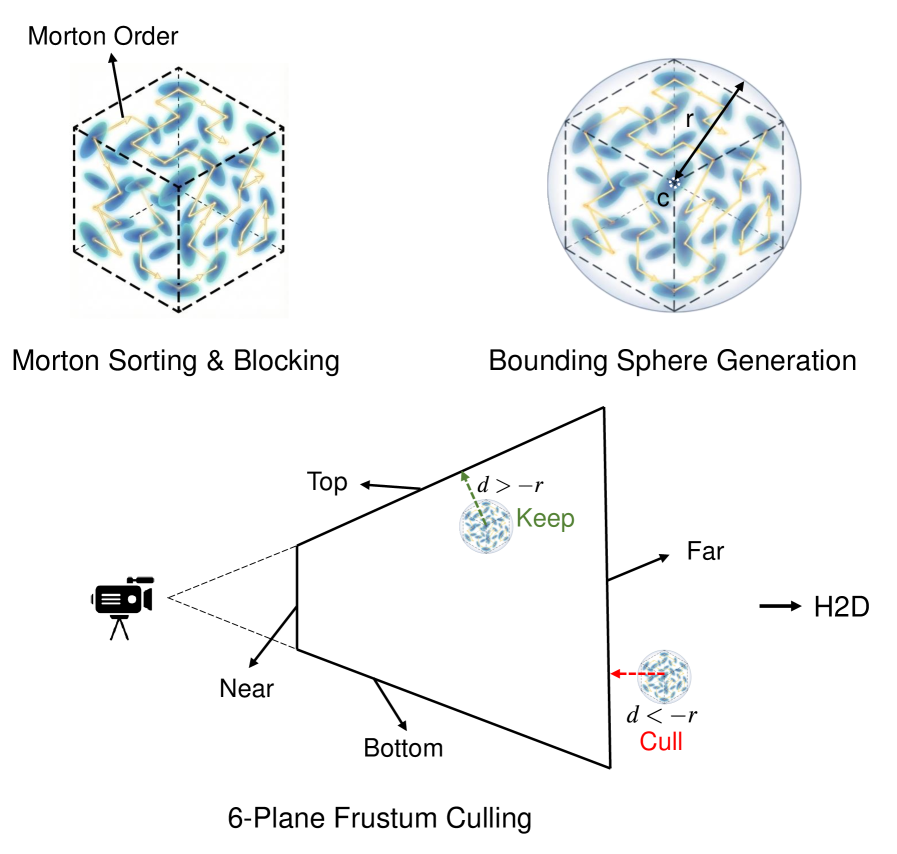
この2段階フィルタにより、階層間のトラフィックが N ではなく |\mathcal{K}_t| にスケールします。
階層的非同期パイプライン。 SSD読み取り・CPUステージング・H2Dコピー・forward/backward・パラメータ更新のためのD2H/SSD書き込みが、別々のストリーム上でオーバーラップするステージとして実行されます。CPU RAMは最近アクセスされたブロックを保持するウォームキャッシュとして機能し、SSDは正規のパラメータテーブルを保持します。
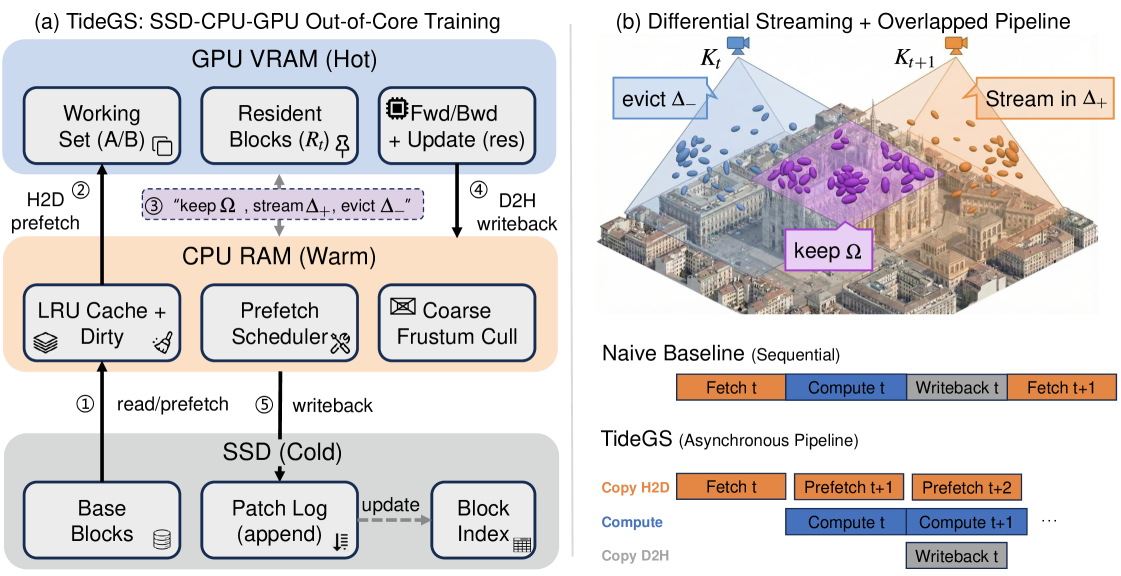
軌跡適応型差分ストリーミング。 \mathcal{K}_{t+1} を全量再ステージングするのではなく、TideGSは差分
\Delta_{t \to t+1} = \mathcal{K}_{t+1} \setminus \mathcal{K}_t, \qquad E_{t \to t+1} = \mathcal{K}_t \setminus \mathcal{K}_{t+1},
を計算し、増分ワーキングセット \Delta_{t \to t+1} のみをVRAMに転送し、E_{t \to t+1} を退避(更新されたパラメータをCPU/SSD層に書き戻す)します。滑らかな軌跡の下では |\Delta| \ll |\mathcal{K}| となるため、定常状態におけるH2Dトラフィックはワーキングセットのサイズではなく軌跡の新規性に支配されます。容量を考慮した退避は、今後のカメラスケジュールからの再利用予測に基づいて、どのウォームブロックをGPU常駐にしておくかを選択します。
外側のループは次のようになります。
for t in iterations:
K_t = frustum_cull(B_t, {(c_k, r_k)})
delta_in = K_t \ K_{t-1}
delta_out = K_{t-1} \ K_t
async_prefetch(delta_in) # SSD -> CPU -> GPU
async_writeback(delta_out) # GPU -> CPU -> SSD
I_t = gpu_fine_visibility(K_t, B_t)
loss = render_and_backprop(I_t, B_t)
apply_optimizer_step(I_t)Densification/pruningはVRAMに常駐するブロックに対して動作し、SSD層上のブロックテーブル更新をトリガーします。
結果
主要な主張は、単一のRTX A5000(VRAM 24 GB、DDR4 256 GB、実測3.3 GB/sのPCIe Gen4×4 NVMe)上で 10^9 超のガウシアンを用いた学習が可能であるというものです。大規模シーンで評価された単一GPUベースラインの中で、TideGSは他のシステムがそもそも到達できないスケールで最良の再構成品質を報告しています。競合手法は、VRAMによるボトルネック(インメモリ3DGS)またはホストDRAMオフロード容量によるボトルネックのいずれかに直面しています。MatrixCityに対するCLM測定から報告されたガウシアンレベルのアクティベーション率(平均0.39%・最悪ケース1.06%)は、ワーキングセットキャッシュが有効である理由を定量化しています。N = 10^9 においても、最悪ケースの可視性でさえ \sim 10^7 のアクティブガウシアンしか生じず、24 GB内に十分収まります。
提供された実験セクションは、ピークスケール・小規模時のオーバーヘッド・大規模時のホストオフロードとのスループット比較・品質対プリミティブ数という4つの問いを立てていますが、ここに示された抄録セクションはスケーラビリティと品質の成果を定性的に確認するにとどまっており、完全なスループット・トラフィック数値は本抄録に含まれていないテーブルに記載されています。
限界と未解決の問題
本システムは以下に依存しています。(i) |\Delta_{t \to t+1}| を小さく保つための十分に滑らかなカメラ軌跡——ランダムアクセスの学習スケジュールは、各ステップで \mathcal{K}_t 全体をストリーミングする状況に劣化します。(ii) 長い学習ランにわたる繰り返しのパラメータ書き戻しによるSSD耐久性——これは分析されていません。(iii) Mortonベースのブロッキング——空間的局所性が可視性と相関することを仮定しており、病的なシーンジオメトリ(細い構造・大きな半透明ボリューム)では、ブロックレベルの保守的カバーが |\mathcal{I}_t| に対して |\mathcal{K}_t| を膨らませる可能性があります。Densificationのダイナミクスはブロックレイアウトと非自明な相互作用を持ちます。論文では定期的にMorton再ソートを行うと推測されますが、コスト償却については提供された抄録では議論されていません。最後に、比較は単一GPUベースラインに限定されており、TideGSがマルチGPU空間シャーディング(例:シャードごとのバックエンドとして)とどのように組み合わさるかは未解決です。
重要性
TideGSは3DGS学習をワーキングセットキャッシングの問題として再定式化し、可視性のスパース性と軌跡のコヒーレンスがコモディティ単一GPUの限界を2桁上回るプリミティブ数を実現するのに十分であることを示しています。これにより、輝度場再構成のスケーリング軸がGPUメモリからSSD帯域幅へとシフトし、分散インフラなしに都市スケールの再構成が現実的なものとなります。
Source: https://arxiv.org/abs/2605.20150
GoLongRL: 能力指向型長文脈強化学習によるマルチタスクアライメント
問題設定
検証可能な報酬を用いた長文脈RL(RLVR)は、狭い定型的手法に収束しています。すなわち、長文書上でマルチホップ検索チェーンを合成し、最終回答の完全一致で報酬を与えるというものです。この手法は均質なデータを生成し、ほとんどのタスクが「根拠を見つけて合成する」という形に還元されます。結果として、検索型ベンチマークでは高スコアを記録するものの、要約・対話追跡・コードリポジトリ上での推論、あるいは証拠の検索ではなく持続的な談話モデリングを要する推論においては性能が低下します。報酬信号も脆弱です。完全一致は自由形式の出力に対して劣化し、複数の回答が有効な長文形式QAのようなタスクでは有用なgradientが得られません。GoLongRLは、能力分類体系・対応するデータセット・タスクごとの検証器という三点によってこのギャップに取り組み、すべてオープンソースで公開しています。
手法
パイプラインは三つの要素から構成されています。
1. 能力分類体系。 著者たちは9種類の長文脈タスクタイプを定義しており、検索系(単一文書QA・複数文書QA・ニードル変種)、集約系(要約・リスト抽出)、長文入力に対する推論(コードリポジトリ推論・数学/科学論文推論)、対話/状態追跡(マルチターン対話・ソースに基づく長文生成)をカバーします。各タイプには、完全一致を強制するのではなく、出力構造に適した検証器が組み合わされています。
2. データ構築。 23Kサンプルの混合は、(a) 難易度と長さでフィルタリングされた既存長文脈コーパスのキュレーションされたサブセット、および (b) 実際のソース文書(書籍・arXiv論文・マルチターン対話ログ)から生成した合成QAを組み合わせたものです。合成生成では強力なinstruct modelを用いてQAペアを作成し、回答が文書から検証可能でかつ弱いベースラインが失敗するアイテムのみを保持するrejection samplingを適用します(非自明な信号を保証するため)。文脈長は、通常のsupervised fine-tuningが飽和する領域まで拡張されています。
3. RLVRトレーニング。 ベースのinstruct model上で標準的なGRPOを適用します。文脈 c を持つプロンプト q ごとに、G 個のrollout群 \{o_i\} をサンプリングし、タスク固有の検証器 r_i = R_{\text{task}}(o_i, q, c) でスコアリングし、グループ正規化されたadvantageを計算します。
\hat{A}_i = \frac{r_i - \mathrm{mean}(r)}{\mathrm{std}(r)},
そして参照ポリシーへのKLペナルティを伴うclipped PPO surrogateを最適化します:
\mathcal{L}(\theta) = -\mathbb{E}\Big[\min\big(\rho_i \hat{A}_i,\ \mathrm{clip}(\rho_i, 1{-}\epsilon, 1{+}\epsilon)\hat{A}_i\big)\Big] + \beta\, \mathrm{KL}(\pi_\theta \Vert \pi_{\text{ref}}),
ここで \rho_i = \pi_\theta(o_i)/\pi_{\text{old}}(o_i) です。非自明な設計上の選択は R_{\text{task}} にあります。ニードル/短答タスクには完全一致、要約にはROUGE/F1閾値、コードリポジトリタスクにはユニットテスト合否、リスト抽出には構造化フィールドマッチング、長文生成にはルーブリックアンカリングを用いたLLM判定を使用します。単一バッチ内でタスクを混合することで、advantage推定が特定の能力に偏って崩壊することを防ぎます。
結果
主要な主張は、データ構成がRLアルゴリズムの複雑さを凌駕するというものです。同一のvanilla GRPOのもとで、公開された23Kミックスでトレーニングすることで、クローズドソースのQwenLong-L1.5データセットでのトレーニングと比較して長文脈評価スイート全体で優れた性能を発揮します。フルトレーニング後、Qwen3-30B-A3B(約3Bのアクティブパラメータを持つ30BパラメータのMoE)は、DeepSeek-R1-0528およびQwen3-235B-A22B-Thinkingに匹敵する長文脈性能に到達します。後者の場合、アクティブパラメータ数はおよそ一桁大きくなります。概要ではベンチマークごとの差分は示されていませんが、マルチタスク報酬設計と整合して、性能向上が特定のベンチマーク群に集中するのではなく広範にわたることが示唆されています。
データセット対データセットの比較が最も明確な科学的結果です。オプティマイザ・ベースモデル・ハイパーパラメータを固定したまま訓練コーパスのみを変えることで、能力指向サンプリングの貢献が独立して評価されます。これは、アルゴリズムの改良に帰属されていた先行の長文脈RLの成果の一部が、実はコントロールされていなかったデータキュレーション効果によるものである可能性を示唆しています。
制限と未解決の問題
報告内容からはいくつかの問題が未解決のまま残っています。第一に、LLM判定による報酬コンポーネントはteacher-biasのチャネルをもたらしますが、これは特性評価されておらず、報告された性能向上がどの程度判定器の好みがポリシーに漏れ込んでいるものか、あるいは真の能力向上によるものかが不明です。第二に、23Kサンプルは少数であり、論文はリターンがスケーリングを続けるか飽和するかを示しておらず、9種類のタスクタイプそれぞれの相対的寄与についてもアブレーションが概要に含まれていません。第三に、比較対象は長文脈タスク固有のDeepSeek-R1-0528およびQwen3-235B-A22B-Thinkingであり、長文脈後学習の既知の失敗モードである短文脈推論の退行については言及されていません。第四に、長文脈でのvanilla GRPOはコストが高く(rollout長が支配的)、再現性計画のための計算量や実時間の数値は示されていません。最後に、長文生成に対する検証器は最も弱いリンクです。ルーブリックアンカリングを用いたLLM判定は、プロンプトの言い回しに敏感で、明示的なペナルティなしには冗長性を報酬として与えることが知られています。
なぜ重要か
データセット制御比較が成立するならば、長文脈RLVRの研究を再定義することになります。ボトルネックはタスク分類体系と検証器設計にあり、検索パスの複雑さやRLアルゴリズムの選択にはないということです。23Kの適切に選ばれたRLサンプルによって30B MoEが235Bクラスのモデルに長文脈タスクで匹敵するという結果は、現在の長文脈後学習に欠けているのはスケールではなく能力カバレッジであるという強力な主張となります。
Source: https://arxiv.org/abs/2605.19577
Hacker News Signals
Growing Neural Cellular Automata
このDistillの記事は、セルオートマトンを微分可能な観点から再考しています。グリッド上の各セルは同一の学習済み局所更新ルールを実行し、単一のシードセルからターゲットパターンを成長させるために、時間方向のbackpropagationによってシステムがエンドツーエンドで学習されます。核心的なメカニズムは、セルごとのMLP(または小さなconv net)であり、セル自身の状態ベクトルと隣接する8セルの状態(固定されたSobel類似の perception kernelを介して)を入力として受け取り、状態の差分を出力します。重要な点として、更新は確率的であり、各セルはステップごとに確率0.5で発火します。これにより、ルールは非同期性に対してロバストであることが強制され、ネットワークが同期されたグローバルな状態に依存することが防がれます。
学習の loss はターゲットとなるRGBA画像のピクセル単位の再構成です。静的な成長にとどまらず、著者らはより困難な2つの目標を示しています:持続性(パターンが摂動に抵抗し、損傷した領域を再生成しなければならない)と回転等変性です。再生成は、学習中にランダムなマスキングを組み込むことで実現されます。ロールアウトの途中で特定領域のセルをゼロにリセットし、それでも最終ステップでlossを適用するため、ルールは暗黙的に自己修復を学習しなければなりません。
これが技術的に興味深い点は、学習されたルールがグローバルな通信チャネルを持たないことです。情報は局所的かつ段階的にしか伝播しません。それにもかかわらず、局所ルールを約100ステップ反復するだけで、巨視的なコヒーレントな構造が純粋に創発します。このシステムは非常にコンパクトでもあり、共有されたMLPのパラメータ数は数千オーダーに留まります。
記事が提起する未解決の問題として、3Dへのスケーリング、あらゆる摂動に抵抗する「過安定な」アトラクタの回避、そして学習されたルールがシードをまたいで汎化するかどうかが挙げられています。生物学的な形態形成との関連は示唆に富みますが、これと実際の遺伝子調節ネットワークとの間には大きな隔たりがあります。自己組織化システムのための計算基盤として、これは依然として活発な研究の方向性であり、テクスチャ合成や更新ルールに対するneural architecture searchを探求するフォローアップ研究が行われています。
Source: https://distill.pub/2020/growing-ca/
証明可能なセキュアOSの基礎(PSOS)(1979年)
1979年にNeumann、Robinson、Levittらによって執筆されたSRIの技術報告書は、形式的検証可能性を中心に一から設計されたOSであるPSOSを解説しています。中心的な設計原則は、17の抽象化レベルへの階層的分解であり、各レベルは形式言語(後にHierarchical Development Methodologyとなるものの初期バリアント)で仕様化され、各レベルはその上位レベルが必要とする抽象化のみを実装します。セキュリティポリシーはcapabilityベースのオブジェクトモデルによって強制されます。すなわち、すべてのリソースはオブジェクトであり、アクセスは偽造不可能なcapabilityトークンによって仲介され、ハードウェアで強制されるプリミティブなcapability操作は形式的に検証できるほど小規模に保たれています。
脅威モデルは明示的に定義されており、目標は彼らが「証明可能なセキュリティ」と呼ぶものを達成することです。これはポリシーの正確性にとどまらず、各レベルで実装が仕様を満たすことを機械検証済み証明によって示すことを意味します。これは現代の証明支援系(Coq、Isabelle)より約10年先行しているため、形式的手法は今日の基準からすると幾分アドホックですが、構造的な洞察は的を射ています。
主要な設計上の要点として、カーネルは意図的に最小化されており(「セキュリティカーネル」の考え方)、プロセス分離はアドレス空間のトリックだけに頼るのではなくcapabilityシステムによって強制されます。また、capabilityの型システムは設計上、confused deputy攻撃を防止します。報告書はカバートチャネル解析についても論じており、タイミングチャネルおよびストレージチャネルはcapabilityモデルのみでは対処されないことを認めています。
現代の読者にとって、この報告書の関心は歴史的・アーキテクチャ的なものです。capability システム、小規模なtrusted computing base、検証済み分離カーネルといった多くのアイデアは、数十年後にseL4(2009年)において再浮上し、そこで初めてIsabelle/HOLによる完全な機械検証済み証明として結実しました。PSOSはその完成度には達しませんでしたが、正しい分解戦略を明確に先取りしていました。89件のコメントスレッドは、その系譜に言及するseL4/CHERIの愛好者や歴史家が大部分を占めています。
Source: http://www.csl.sri.com/users/neumann/psos.pdf
OpenAIがAI生成画像にGoogleのSynthIDウォーターマークを採用、検証ツールも公開
OpenAIは、DALL-EおよびGPT-4oの画像APIで生成される画像にGoogle DeepMindのSynthIDウォーターマークを埋め込んでおり、公開検証エンドポイントをリリースしました。技術的な核心はウォーターマーキング手法そのものにあり、2024年にDeepMindがNature誌に発表したものです。
SynthIDは、可視オーバーレイや脆弱なLSBステガノグラフィックマークを追加するのではなく、潜在周波数領域で動作します。拡散モデルに対しては、ノイズ除去プロセスにおける疑似乱数シードサンプリングにバイアスをかけることで生成時に適用されます。具体的には、初期ノイズテンソルがペアの神経分類器によって検出可能なペイロードを埋め込む形でシード設定され、画像を知覚的に変化させることはありません。直接ピクセル空間での生成に対しては、別の学習済みエンコーダ・デコーダペアが、知覚的重み付き変換領域においてマークを事後的に埋め込みます。
堅牢性についての主張は、このウォーターマークがJPEG圧縮、リスケーリング、中程度のクロッピング、および色空間への摂動に耐えるというものです。検出は統計的であり、画像と期待されるマークパターンの相関に関する仮説検定として実施され、未改変画像における高い真陽性率のもとで< 10^{-6}という偽陽性率が報告されています。攻撃的な敵対的攻撃(ガウスノイズの付加、大領域へのインペインティングなど)に対しては堅牢性が低下しますが、これは著者らも認めています。
より広いプロバナンス(出所証明)の文脈では、C2PAメタデータ(ファイルに付与された暗号署名付きコンテンツ認証情報)が補完的な役割を担います。SynthIDは不可視であり、フォーマット情報が除去されても残存しますが、C2PAは検証可能である一方、容易に除去できます。両者を組み合わせて使用することが表明された戦略です。
HNのスレッドでは、もっともな理由から懐疑的な意見が挙がっています。いずれの手法も敵対的に堅牢ではなく、高度な悪意ある行為者はマークを除去または破壊できること、また検証ツールが中央集権的であることが指摘されています。正当なユースケースは限定的であり、非敵対的な文脈における確率的な帰属確認にとどまり、強制執行には向きません。
Source: https://openai.com/index/advancing-content-provenance/
AIを活用したRust 10万行からの学び(2025年)
著者は、Claude CodeおよびCodexを主要なコーディングエージェントとして使用し、相当規模のRustコードベース(約10万行)を構築した1年間の経験を述べており、「spec-driven development(仕様駆動開発)」と呼ぶワークフローを整理しています。核心的な観察は、LLMコーディングエージェントの失敗は曖昧さに比例するというものです。タスクの仕様が不十分な場合、モデルはコンパイルが通りテストも通るコードを生成しますが、意図した不変条件に違反しており、そのデバッグには多大なコストがかかります。その解決策は、仕様を第一の成果物として扱うことです。
具体的なワークフローは次のとおりです。事前条件、事後条件、および主要な不変条件を含むモジュールの詳細な自然言語(または疑似コード)仕様を記述し、モデルにその仕様に基づいて実装を生成させ、その後に不変条件を直接検証するテストを生成するよう別途プロンプトを与えます。著者は、Rustの型システムがここで大きな力を発揮すると指摘しています。所有権、ライフタイム、およびtrait boundが多くの不変条件を機械的にエンコードするため、Pythonや Goでは暗黙的に通過してしまう多くのエラーのクラスに対して、モデルの出力はコンパイル時に拒否されます。
いくつかの具体的な失敗パターンも記述されています。エージェントはデータフローを再構築するのではなく、borrow checkerを満たすために不要なcloneを導入しがちです。また、時間的プレッシャーの下ではunwrap()をデフォルトとして使用し、存在しないまたは変更されたcrate APIをハルシネーションします。推奨される対策は、関連するcrateのドキュメントをコンテキストに含めること、CIで#[deny(clippy::unwrap_used)]を強制すること、そしてエージェントのループ中にフル コンパイルではなくcargo checkを高速フィードバックループとして使用することです。
Rustの厳格さがより寛容な言語よりもLLM駆動開発に適しているという観察は直感に反しますが、もっともらしい主張です。型チェッカーが、人間もモデルも手動で追跡する必要のないground-truthの検証器として機能するからです。
FPGAカリキュレーターをゼロから設計する
この記事では、FPGA上に四則演算の整数カリキュレーターを構築するための完全なパイプラインを記録しています。対象デバイスは小型のLattice iCE40で、オープンソースツールチェーン(Yosys + nextpnr + IceStorm)を使用しています。すべての層はプリミティブから構築されており、演算ユニットはキャリー伝搬加算器ロジック、2の補数による減算、繰り返し加算またはシフト・アンド・アドループによる乗算、そしてハードウェア上の非回復型長除算による除算で構成されています。
RTLはVerilogで記述されています。著者はマルチサイクル演算(乗算と除算は可変サイクルを要する)をシーケンスするためのシンプルな有限状態機械を実装しており、演算用FSMと表示・入力用FSMの間にはハンドシェイクインターフェースが設けられています。入力はマトリックスキーパッドからで、デバウンス処理されたrow-columnプロトコルによってスキャンされます。出力はゴーストを防ぐために約1kHzでデジットスキャンを行う7セグメント多重表示です。
表示用のBCD(binary-coded decimal)変換はDouble Dabbleアルゴリズム(シフト・アンド・アド3)で処理されています。このアルゴリズムは除算を必要としないため、ハードウェアに適しています。著者はこれを純粋な組み合わせ回路として実装しており、iCE40上でターゲットクロック周波数において十分なタイミングマージンを確保した状態で動作します。
リソース使用率も報告されており、設計全体はiCE40HX1K上の数百LUTに収まります。この記事がとりわけ教育的なのは、ブラックボックスのIPコアを一切使用せず、すべての機能ブロックを手作りで実装し、丁寧に説明している点です。合成およびplace-and-routeのステップは、実際のツールチェーン呼び出しとともに示されています。
FPGAに慣れた読者にとっては入門的な内容ですが、キーパッドスキャンから算術FSM、BCD表示に至るエンドツーエンドの解説は、「LEDを点滅させる」と「役に立つものを作る」の間にある初心者の一般的なギャップを埋める、すっきりとした自己完結型のリファレンスとなっています。
Source: https://baltazarstudios.com/calculator/
Hsrs: RustのためのType-SafeなHaskell Bindingsジェネレーター
HsrsはRustの型と関数シグネチャを読み込み、Haskell FFI bindingsを生成するコード生成ツールであり、境界をまたいで型安全性を保持します。このツールが解決する問題は、Haskell-Rust相互運用における典型的な苦労です。すなわち、foreign import ccall 宣言や Storable インスタンス、マーシャリングコードを手書きすることはエラーが起きやすく、Rust側に変更があっても気づかないまま壊れてしまいます。
このジェネレーターは #[repr(C)] を付けたRust構造体と extern "C" 関数シグネチャを(proc-macroアノテーションまたは直接のソース解析のいずれかを通じて)パースし、C ABIマッピングに従ってRustのプリミティブ型をHaskell FFIの対応する型へマップします。構造体に対しては、repr(C) が規定するのと同じレイアウトアルゴリズムを使用して、正しい sizeOf、alignment、peek、poke を持つ Storable インスタンスを生成します(両側がアライメントで合意していればパディングに関する意外な挙動はありません)。enumに対しては、一致するdiscriminant値を持つ Enum インスタンスと Bounded インスタンスを生成します。
型安全性の主張としては、ジェネレーターが未定義動作を引き起こすような型のミスマッチを検出できるという点があります。例えば、Rustの関数が u32 を返すのに手書きのHaskell bindingが Word64 と宣言している場合、hsrsはそれを検出して報告します。この信頼性はパースステップに依存しており、現状ではRust側がアノテーションを付けているか、安定したC ABIヘッダーを公開していることが必要です。
制限事項として、このツールはジェネリクス、trait object、および repr(C) でない型を扱いません。これはイディオマティックなRustの大部分をカバーしています。また、async Rust関数もスコープ外です。実用的なユースケースは限定的なものです。すなわち、Haskellから呼び出すことを前提として書かれたRustライブラリであり、著者が両側を制御しているケースです。しかしそのニッチな用途においては、実際に存在するバグのクラスを取り除くことができます。
Source: https://github.com/harmont-dev/hsrs
Gemini 2.5 Flash
GoogleのGemini 2.5 Flashは、2.5ファミリーにおける中位モデルであり、より小型のFlash Liteと完全版の2.5 Proの中間に位置付けられています。目玉機能は、明示的な「thinking budget」パラメータです。呼び出し元はモデルのchain-of-thought推論トレースに対するトークンバジェットを設定でき、「thinking」モードと「non-thinking」モードを二択で選ぶのではなく、推論コストと回答品質を連続的な軸上でトレードオフすることができます。バジェットをゼロに設定すると標準的な非推論モデルとして動作し、バジェットを高く設定するとベンチマーク上で2.5 Proに近い性能を発揮します。
公開されているベンチマーク数値は、AIME 2025(数学競技)で78.2%、GPQA Diamond(大学院レベルの科学)で72.0%、LiveCodeBenchでは強力なコーディングスコアを記録しています。コンテキストウィンドウは1Mトークンであり、2.5ファミリー全体と一致しています。マルチモーダル入力(画像、音声、動画、PDF)をネイティブでサポートしています。
料金体系はthinkingの有効・無効によって段階的に設定されており、non-thinkingモードは入力/出力トークン100万件あたり$0.075/$0.30、thinkingモードは$0.15/$0.60となっています。これは同等の推論バジェットにおける2.5 Proと比較して約4〜8倍安価であり、大量の推論タスクにおける実用的なデフォルト選択肢となっています。
HNでの議論は、thinking-budgetメカニズムが競合APIにおける二値的な「extended thinking」トグルよりも誠実なインターフェースであるという点に集中しています。コストと品質のトレードオフを明示的に公開し、アプリケーション開発者がそれを最適化できるようにしているためです。また、ネイティブ音声出力についても活発な議論があり、これは現在一般公開されており、音声アプリケーション向けのリアルタイムストリーミングをサポートしています。発話スタイルは、個別のspeaker-IDパラメータではなく、システムメッセージ内の自然言語プロンプトによって制御可能です。
Source: https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-5/
Gemini 2.5 Pro (Omni)
Gemini 2.5 Pro “Omni” は、既存の 2.5 Pro テキスト/ビジョンモデルをネイティブな音声・映像の入出力へと拡張し、完全な any-to-any マルチモーダルシステムとしています。Googleが開示しているアーキテクチャの詳細は限られていますが、その構成は、後付けのモダリティ固有のアダプタモジュールではなく、共有された attention 層を通じて単一モデルがすべてのモダリティを処理するという方向性と一致しています。
音声機能が最も技術的に注目すべき点であり、このモデルは独立した TTS システムを経由せず直接音声を生成します。これにより、プロソディや感情的なトーンが、発話されるテキスト文字列だけでなく、会話の完全なコンテキスト全体に基づいて条件付けられます。音声ストリーミングのレイテンシは、最初のバイトの応答において 200ms 以下の範囲と報告されており、これは会話的利用における閾値となります。また、モデルは割り込み処理(barge-in)をネイティブにサポートしています。
映像理解は 100 万トークンのコンテキストウィンドウ全体を活用し、テキストによる推論を交えながら長尺映像の分析を可能にします。このモデルは、映像をフレームの集合として扱うのではなく、時間的構造——イベント間の因果関係やフレームをまたいだオブジェクトの追跡——について推論するようプロンプトを与えることができます。
標準的なベンチマークにおいては、2.5 Pro は公開されている推論・コーディング評価の大半でトップまたは同率首位となっています。Omni という名称は特に音声出力の追加を意味するものであり、基盤となる推論能力は 2.5 Pro から変更ありません。Live API アクセスは WebSocket ベースのストリーミングとともにプレビュー版として利用可能です。
HN のスレッドでは、OpenAI の GPT-4o(同様の any-to-any を目指していたものの、ネイティブ音声出力をスケールで有効化するのが遅れている)への競争圧力や、単一の大規模モデルがすべてのモダリティを処理する場合と、ルーティングアーキテクチャを採用した場合の推論コストへの影響が議論されています。単一モデルのアプローチはコヒーレンスの観点から望ましいが、効率的なサービング(serving)が難しいというのが大方の見解です。
注目の新しいリポジトリ
NVlabs/cuda-oxide
これは実験的なRust-to-CUDAコンパイラであり、標準的なRustソースから直接PTXを出力します。C++/CUDAでカーネルを記述したり、custのようなラッパークレートを使用したりする従来の経路を迂回します。このコンパイラはRustのコンパイルパイプラインを拡張することで動作し、SIMT実行セマンティクスを認識します。スレッド/ブロックのインデックス付け intrinsics はPTXの特殊レジスタにマップされ、型システムを活用して明らかなデータ競合パターンをコンパイル時に検出します。「safe(ish)」という表現は正直なものです。ワープレーン間のポインタエイリアシングや共有メモリの同期には依然としてプログラマの規律が必要ですが、借用チェッカーによってホスト側のリソース管理バグの大きなクラスが排除されます。DSLやproc-macroレイヤーは関与していません。カーネルとしてアノテーションを付けた慣用的なRust関数を記述するだけで、ツールチェーンがPTXへの低レベル変換を処理します。これが重要な理由は、既存のRust GPUエコシステム(rust-cuda、cudarc)が不安定な状態のnightlyフィーチャを必要とするか、FFIオーバーヘッドを課すかのどちらかであるためです。NVIDIA Labsからのプロジェクトであることは、趣味の実験ではなく潜在的なアップストリームパスとしての信頼性を与えています。実用的なターゲットとしては、カスタム attention カーネル、融合されたelementwise演算、そしてホスト側でRustのownershipモデルを活用しつつデバイス側でも同じ言語を維持したいあらゆるワークロードが挙げられます。
Source: https://github.com/NVlabs/cuda-oxide
jeremiah-masters/dlht
DLHT(Dynamic Lock-free Hash Table)アルゴリズムのGo実装です。標準の sync.Map やmutexで保護されたmapにおけるlockの競合がボトルネックになる、高並行処理ワークロードを対象としています。コアのデータ構造は、false sharingを低減するためにキャッシュライン境界に揃えられたバケットを使用し、lockを一切取得せずにinsert・delete・lookupをアトミックなCAS操作で行います。リサイズは協調的に行われます。すなわち、ロードファクターの閾値を検出したスレッドが、単一のリサイズgoroutineでブロックするのではなく、協調して新しいバッキング配列へのエントリ移行に参加します。これにより、より単純な設計におけるstop-the-worldなrehashingに伴うレイテンシスパイクを回避できます。GoのメモリモデルはきめW細かいatomics操作と相性が悪いため、本実装では sync/atomic プリミティブと明示的なメモリ順序アノテーションを使用しています。ホットパスキャッシュ、セッションストア、あるいは数千のgoroutineから使用されるあらゆるmapのドロップイン代替として適しています。sync.Map との比較上のトレードオフとして、sync.Map は読み取りが多く書き込みが少ないケースを別途読み取り専用スナップショットで最適化しているのに対し、DLHTはより均衡のとれた読み書きワークロードを対象としています。採用前にベンチマークを実施してください。協調リサイズはコードパスの複雑さを増加させるため、並行goroutineが数百未満の場合はその効果が得られない可能性があります。
Source: https://github.com/jeremiah-masters/dlht
Percivalll/Copy-Fail-CVE-2026-31431-Kubernetes-PoC
CVE-2026-31431を通じた完全な非特権コンテナエスケープを実証するPoCエクスプロイトです。攻撃チェーンは2つのプリミティブを組み合わせています。1つ目はカーネルのページキャッシュ内で制御された範囲外書き込みを実現するページキャッシュ破損、2つ目はコンテナランタイム(overlayfs)の共有イメージレイヤー構造であり、読み取り専用イメージレイヤーを裏付けるページがコンテナとホスト間で共有されるという仕組みです。共有レイヤーに属するページを破損することで、攻撃者は昇格した権限を一切使わずにホスト側から見えるファイルの内容を上書きしたり、ノードレベルのコード実行へとエスカレーションしたりすることが可能です。このPoCはマネージドKubernetesサービス(ACK、EKS、GKE)上で検証されており、ユーザー名前空間が制限されたハードニングされたクラウド環境においてもエスケープが成立することを意味しています。技術的に注目すべき点は、CAP_SYS_ADMINやprivileged: trueに依存しないことであり、デフォルトの非特権ワークロードPodで十分です。防御側への対応として:即時の緩和策はページキャッシュ破損プリミティブに対処するカーネルパッチの適用と、(大幅なストレージコストを伴う)共有イメージレイヤーの無効化です。クロスクラウドでの検証がなされていることから、マルチテナントクラスターを運用するセキュリティチームはこれをクリティカルな優先事項として対処すべきです。
Source: https://github.com/Percivalll/Copy-Fail-CVE-2026-31431-Kubernetes-PoC
fswatcher/fswatcher
Goのためのクロスプラットフォームなファイルシステム通知ライブラリです。OS ネイティブのイベント API — Linux の inotify、macOS/BSD の kqueue、Windows の ReadDirectoryChangesW — を単一の統一されたインターフェースの背後にラップします。この抽象化層は、各バックエンド間の本質的な差異を処理します。inotify は明示的なイベントマスクを持つファイル単位のイベントを届け、kqueue は監視パスごとにファイルディスクリプタを必要とし大規模なディレクトリツリーでは異なるスケール特性を持ちます。Windows はネイティブで再帰的な監視のセマンティクスを提供します。このライブラリはこれらの差異を、typed なイベント(create、write、rename、remove)を emit するチャネルベースの Go API に正規化し、バックエンド固有の挙動を呼び出し元に露出させません。inotify が再帰的でないため Linux では非自明となる再帰的なディレクトリ監視については、ツリーをたどりサブディレクトリにウォッチを登録することで対応しており、新たに作成されたサブディレクトリを捕捉するロジックも備えています。これは、一度正しく書くのが面倒で、各 OS 上での CI なしにはすべてのプラットフォームにわたってテストすることがほぼ不可能なインフラコードです。ポーリングなしでファイルシステムの変更に反応する必要があるビルドシステム、ホットリロードサーバー、設定ファイルウォッチャー、およびあらゆるツールに有用です。
Source: https://github.com/fswatcher/fswatcher
agent-quality-controls/slopless
textlint を基盤として構築された、Markdown 散文向けの決定論的 linting ツールです。LLM が生成するテキストに特有の問題パターン、すなわち埋め草フレーズ、過剰なヘッジの積み重ね、動詞の名詞化、エージェントなしの受動態構文、そして AI 生成文章に頻出する特定の語彙パターン(“delve”、“leverage”、“utilize”、“it is worth noting that” など)を対象としています。ルールは textlint プラグインとして実装されており、完全に決定論的です。同一の入力は常に同一の違反を引き起こすため、不安定さを伴わずに CI パイプラインで利用できます。CLI は違反が検出された場合に非ゼロで終了するため、プルリクエストのワークフローにおいてハードゲートを実現できます。ルールセットは設定可能であり、デフォルトのルールセットは特定された AI 生成散文のコーパスに対してチューニングされています。改善を提案するスタイルガイドとは異なり、slopless はマージをブロックするよう設計されており、人間の著者がフラグの立った構文を積み重ねたままにせず、能動的に対処することを強制します。技術的には軽量であり、純粋な Node.js で動作し、モデル推論もネットワーク呼び出しも不要なため、linting ステップに加わるレイテンシは無視できる程度です。ドキュメントチーム、技術文書リポジトリ、そして散文の品質が維持すべき不変条件となっているあらゆるプロジェクトに有用です。
Source: https://github.com/agent-quality-controls/slopless
ClouGence/open-cdm
個人開発者向けではなく、チーム環境向けに構築されたオープンソースのデータベース管理プラットフォームです。DBeaver や DataGrip のような組織的なアクセス制御の概念を持たないツールにおけるガバナンスの欠如を解消することを目的としています。主要な機能として、どのユーザーがどのスキーマをクエリできるかを制御するロールベースのアクセス制御、PII(個人識別情報)を含む機密カラムに対する動的データマスキングと匿名化(マスキングはストレージ段階ではなくクエリ結果の返却時に適用)、改ざん防止レコードを備えた SQL 監査ログ、およびスキーママイグレーションパイプライン向けの CI/CD 統合が挙げられます。クロスリージョン展開のサポートにより、コントロールプレーンが単一の UI のもとで異なるクラウドリージョンに存在する複数のデータベースインスタンスをフェデレートすることが可能です。SQL 監査コンポーネントは実行されたクエリ、実行計画、および結果を記録しており、これは規制産業におけるコンプライアンス要件に対応するものです。データの匿名化はカラム単位で設定可能であり、プラグイン可能なマスキング戦略(リダクション、仮名化、フォーマット保持トークン化)をサポートしています。スタックは Java ベースでウェブフロントエンドを備えており、企業ネットワーク境界内でセルフホストされることを前提に設計されています。Bytebase や Archery のような商用製品との主な差別化点は、機能制限のない完全なオープンソースライセンスを採用している点です。
Source: https://github.com/ClouGence/open-cdm
graemeg/blaise
Delphi/FPC のレガシーな制約を意図的に排除し、ゼロから書かれたセルフホスティング Object Pascal コンパイラです。設計上の三つの選択がその特徴を定義しています。すなわち、唯一のメモリ管理モデルとしての自動参照カウント(ARC)(手動の Free も mark-and-sweep GC の停止もなし)、コンパイラとランタイム全体を通じた唯一の文字列エンコーディングとしての UTF-8(既存の Pascal エコシステムを悩ませる AnsiString/WideString/UnicodeString の断片化を排除)、そして後から達成するマイルストーンではなく開発初期から第一級の目標としてのセルフホスティングです。サイクル検出を備えた ARC は、二重連結リストという Pascal の一般的なパターンをリークなく処理します。このコンパイラはモダンな 64 ビットプラットフォームをターゲットとしており、FPC に重くのしかかるレガシーな 16 ビットおよび DOS 時代の互換性は存在しません。言語研究者やコンパイラを学ぶ学生にとっては、静的型付けで読みやすい言語による明確な AST とコード生成の分離を持つセルフホスティングコンパイラは有用な成果物です。三十年分の互換性シムを引きずることなくクリーンなツールチェーンを望む Pascal の実践者にとっては、本プロジェクトは真のニーズを満たすものです。ゼロレガシーという立場は、既存の Delphi/FPC コードの大部分と意図的に非互換であることを意味します。
Source: https://github.com/graemeg/blaise
agynio/platform
Claude Code、OpenAI Codex、およびそれに類するAIコーディングエージェントを、開発者のラップトップではなく企業インフラ上にデプロイするためのKubernetes-nativeなランタイムです。本プラットフォームが解決するコアな問題は次の通りです:任意のコードを実行するエージェントには、内部リソース(リポジトリ、パッケージレジストリ、シークレット)へのアクセスと組織的なコントロール(監査ログ、コスト制限、承認ゲート)を備えたサンドボックス環境が必要ですが、エージェントCLIをローカルで実行する場合にはそのいずれも提供されません。本プラットフォームは、設定可能なリソース制限とネットワークポリシーを持つKubernetes Podとして、エージェントごとの実行環境をプロビジョニングし、Kubernetes secretsを通じて必要なクレデンシャルをマウントし、ポリシー適用のためのコントロールプレーンを提供します。具体的には、どのエージェントがどのリポジトリにアクセスできるか、チームごとの支出上限、および破壊的な操作に対するhuman-in-the-loopの承認機能が含まれます。Kubernetes-nativeなアーキテクチャにより、既存のRBAC、名前空間の分離、およびクラスターのオートスケーリングとシームレスに統合されます。既にKubernetes上でワークロードを運用している企業にとっては、別途エージェントインフラを構築する必要がなくなります。制御されていないエンドポイントからエージェントに本番システムへの広範なアクセスを許可することなく、開発者にエージェント機能を提供したいプラットフォームエンジニアリングチームに適しています。