Daily AI Digest — 2026-05-20
arXiv Highlights
OpenComputer: Verifiable Software Worlds for Computer-Use Agents
Problem and motivation
Computer-use agents are typically benchmarked in environments where success is determined either by hand-written shell checks (OSWorld-style) or by an LLM-as-judge inspecting screenshots. Both have known issues: hand-written checks are brittle and hard to scale across heterogeneous desktop apps, while LLM judges are unreliable on dense GUIs where the difference between success and failure is a few pixels of state (e.g., the wrong cell selected, a setting toggled in a collapsed panel). OpenComputer attempts a middle path: programmatic verifiers that read structured application state through app-specific inspection endpoints, paired with a synthesis pipeline that generates tasks whose success criteria are guaranteed to be machine-checkable.
Method
The framework formalizes a task instance as \tau=(x,e,c), where x is the natural-language instruction, e is an executable sandbox initialization procedure producing s_0\sim e, and c is a set of machine-checkable criteria evaluated against the post-interaction state s_T. Three coupled operators construct \tau:
A verifier generator \mathcal{V}(a)\to V_a that, for each application a, builds an app-specific verifier exposing structured inspection endpoints. These endpoints wrap whatever the most reliable channel is for the application — DOM access for browsers, workbook objects for spreadsheets, AST or filesystem reads for IDEs, Blender’s Python API for 3D scenes, etc.

Example application endpoint specification used by OpenComputer verifiers. A self-evolution operator \mathcal{U}(V_a, D_a)\to V_a^{+}. Calibration trajectories D_a are collected by running a strong agent on candidate tasks; an LLM evaluator and the programmatic verifier are compared, and disagreements are used to patch verifier predicates (missing edge cases, wrong field names, off-by-one selectors). This is a closed loop that grounds verifier reliability in execution feedback rather than human authoring.
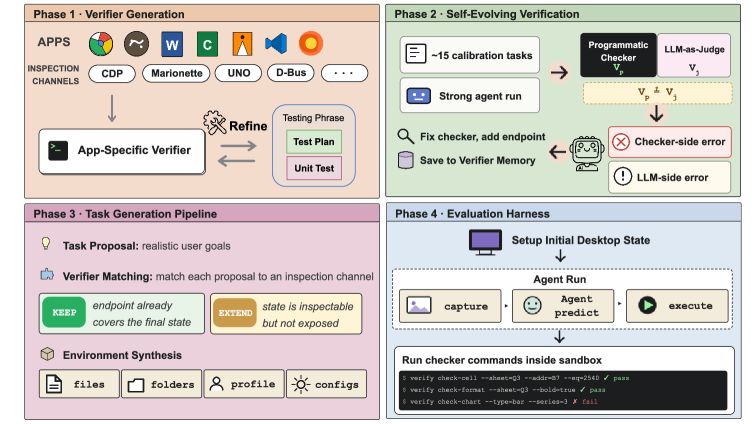
Overview of the OpenComputer verifiable software-world synthesis pipeline. A verifier-aware task synthesizer \mathcal{E}(a, g, V_a^{+})\to e that constructs the initialization procedure together with x and c. By construction, c is expressible as calls into V_a^{+}, so every generated task is checkable.
The final benchmark covers 33 applications and 1,000 finalized tasks across browsers, office suites, creative tools (including Blender), IDEs, file managers, and communication apps. The evaluation harness records full trajectories and computes auditable partial-credit rewards by aggregating per-criterion checklist scores rather than collapsing to binary success.
Results
The headline comparison (Table 2) places frontier and open-source agents on the OpenComputer suite alongside their reported OSWorld-Verified scores:
- GPT-5: 68.3% success rate, 88.4% average reward, 19.0 steps avg, 16.5 s/step (OSWorld-V: 75.0%).
- Claude-Sonnet-4.6: 64.4% / 76.6% reward (OSWorld-V: 72.5%).
- Kimi-K2: 58.8% / 70.7% reward (OSWorld-V: 73.1%).
- Qwen-3.5-27B: 32.3% / 59.4% reward (OSWorld-V: 56.2%).
- Gemini-3-Flash: 16.4% / 37.0% reward.
- EvoCUA-8B: 10.9% (OSWorld-V: 46.1%).
- Qwen-3.5-9B: 7.8% (OSWorld-V: 41.8%).
- GUI-OWL-1.5-8B: 5.7% (OSWorld-V: 52.3%).
Two patterns are notable. First, frontier models retain reasonable success rates but show substantial gaps between binary success and average reward (GPT-5: 68.3% vs. 88.4%), confirming that partial-credit scoring captures progress that binary OSWorld-style metrics discard. Second, open-source agents collapse far more sharply than frontier ones relative to their OSWorld-V scores — GUI-OWL-1.5-8B drops from 52.3% to 5.7%, EvoCUA-8B from 46.1% to 10.9%. This suggests these models are over-fit to OSWorld task distributions or rely on verifier loopholes that programmatic state checks close.
The verifier validation experiment is the most interesting evidence for the framework’s central claim. On 120 trajectories scored against human adjudication with the same per-item checklist:
- Hard-coded verifier: 94.1% task-level alignment (113/120), 97.3% per-item checklist agreement.
- LLM-as-judge: 79.2% task-level alignment (95/120), 92.2% per-item agreement.
The 15-point task-level gap is concentrated in cases where state-vs-pixels divergence matters. The paper gives a canonical example: an agent types one long token into a single spreadsheet cell when the task required two adjacent cells. The screenshot looks plausible; the workbook state does not.
The gap widens for apps where evidence lives outside the visible viewport — Blender scrollback, developer-tool logs, intermediate file artifacts — because the LLM judge sees only a narrow screenshot window, while the verifier reads post-execution state directly.
Limitations and open questions
The verifier endpoints rely on each application exposing some inspection channel; closed-source apps without scripting interfaces require screen-OCR or filesystem heuristics, which reintroduces the fragility OpenComputer is trying to avoid. Verifier evolution is bounded by the calibration agent’s coverage — failure modes that strong agents never trigger will not be patched. The 1,000-task scale is comparable to OSWorld but small relative to the diversity of real desktop work, and task synthesis is conditioned on goals g whose realism depends on the (unspecified) goal source. Finally, partial-credit rewards depend on the checklist decomposition, which is itself synthesized; whether checklist granularity is calibrated across apps is not analyzed.
Why this matters
OpenComputer makes a defensible empirical case that programmatic state inspection beats LLM-as-judge by 15 points on task-level human alignment for desktop agents, while exposing that current open-source CUAs generalize far worse than their OSWorld-Verified scores suggest. If the verifier-evolution loop scales, this is a plausible template for building reward signals reliable enough to train computer-use agents with RL rather than only evaluate them.
Source: https://arxiv.org/abs/2605.19769
Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
Problem
On-policy self-distillation (SD) augments RL with a per-token KL pull toward a copy of the model conditioned on privileged context c (a verified solution plus correctness feedback). Empirically, SD helps on some tasks but underperforms vanilla GRPO on math reasoning. The paper diagnoses why and proposes a fix that is a one-line sign flip plus an entropy gate.
From per-token KL to conditional PMI
Let s_t := \log\pi_S(y_t\mid x,y_{<t}), t_t := \log\pi_T(y_t\mid x,c,y_{<t}), u_t := t_t - s_t. Differentiating the per-token KL summand \mathbb{E}_{v\sim\pi_S}[\log\pi_S(v) - \log\pi_T(v)] and using the score-function identity to kill the constant-coefficient term, plus stop-gradient on the teacher, leaves
\nabla_\theta D_{\mathrm{KL}}(\pi_S\|\pi_T) = -\mathbb{E}_{v\sim\pi_S}\!\big[u_v\cdot \nabla_\theta\log\pi_S(v)\big],
so the SD per-token advantage is exactly \delta_t = +u_t. Because \pi_S and \pi_T share parameters under self-distillation, u_t collapses to a conditional pointwise mutual information,
u_t = \log\frac{\pi_\theta(y_t\mid x,c,y_{<t})}{\pi_\theta(y_t\mid x,y_{<t})} = \mathrm{PMI}(y_t;c\mid x,y_{<t}).
Sign of u_t = whether c raises or lowers the next-token probability. SD rewards “c-raised” tokens and penalizes “c-lowered” tokens — and on math rollouts these classes correspond to qualitatively distinct token populations.

Figure 2 shows the bias concretely: tokens with u_t \gg 0 (e.g., Given, Assign, succeeds, holds) are structural connectives and verifiable claims that become trivially predictable once c commits to a solution. Tokens with u_t \ll 0 (Wait, Let, Maybe, Alternatively) are the deliberation tokens that drive multi-step search; once c has fixed an answer, the teacher down-weights re-examination. Default SD therefore amplifies a structural shortcut and suppresses search — the opposite of what reasoning RL needs.
AntiSD
AntiSD reverses the per-token sign: ascend an f-divergence between student and teacher rather than descend it. Concretely, the per-token reward becomes -\varphi(u_t) derived from Jensen–Shannon divergence (so the advantage is naturally bounded in one step, unlike -u_t from raw KL ascent which is unbounded above). An entropy-triggered gate disables the term once teacher entropy collapses: a 5-step warm-up at \lambda=0 records H_{\mathrm{warm}}, then the gate fires when H<\tau_{\mathrm{down}} = 0.93\,H_{\mathrm{warm}} and re-arms when H recovers. The 0.93 multiplier is shared across all five models — no per-model tuning. AntiSD is a drop-in replacement: same rollouts, same GRPO trajectory advantage A_i^{\mathrm{seq}}, single sign-flipped per-token term added.

Results
Five models (Qwen3-4B-IT-2507, Qwen3-8B, Qwen3-30B-A3B, Olmo3-7B-IT, Olmo3-7B-TK), 200 on-policy steps on DAPO-Math-17k, evaluated avg@32 on AIME 2024/25/26 and HMMT25 plus avg@4 on MinervaMath.
Two patterns:
Sample efficiency. AntiSD reaches GRPO’s best-Avg accuracy in 2\text{–}10\times fewer steps. Largest gains on weaker baselines: Qwen3-4B-IT-2507 10\times, Olmo3-7B-IT 9.5\times, Qwen3-8B 5\times. Smaller but positive on stronger baselines: Olmo3-7B-TK 2\times (GRPO already at 64.1), Qwen3-30B-A3B 2.9\times. This is consistent with the PMI diagnosis: -\varphi(u_t) supplies dense, informative per-token credit from step 1, while GRPO must wait for sparse trajectory rewards to propagate.
Final accuracy. AntiSD beats GRPO’s mean by +2.1 to +11.5 points. Headline numbers: Qwen3-8B 65.7 vs 57.4 (+8.3), Qwen3-4B-IT-2507 62.8 vs 51.3 (+11.5), Qwen3-30B-A3B 66.8 vs 59.1 (+7.7), Olmo3-7B-IT 48.3 vs 43.0 (+5.3), Olmo3-7B-TK 66.2 vs 64.1 (+2.1). On HMMT25 specifically, Qwen3-8B jumps from 39.2 (GRPO) to 54.4 (AntiSD), a 15-point gap. Default SD underperforms GRPO on 4 of 5 models (e.g., Qwen3-8B SD = 30.6 vs GRPO 57.4), confirming the shortcut bias is harmful, not merely uninformative.
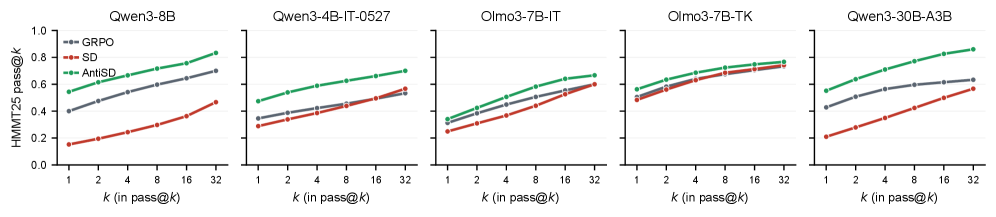
Figure 3 shows the gain holds across k in pass@k, indicating expanded solution coverage rather than mere variance reduction over a fixed set of solvable problems.
Limitations and open questions
- The privileged context c is constructed from in-group correct rollouts (or dataset solutions) plus binary feedback; sensitivity to c’s quality and to the gate threshold beyond the 0.93 default is not stress-tested across other domains.
- The JS-based \varphi is one of several bounded reversals; whether the gain persists with reverse-KL ascent, \chi^2, or other f-divergences is unclear.
- All experiments are math reasoning. The SD-vs-AntiSD asymmetry hinges on c committing to a single solution path; tasks where c is genuinely informative about local token choices (e.g., code with deterministic completions) may not benefit from sign reversal.
- Trajectory-level REINFORCE on \pi_S(y\mid x) is dropped under stop-gradient; the interaction between this approximation and the GRPO term is not ablated.
Why this matters
The paper turns a confusing empirical failure of self-distillation on math RL into a clean mechanistic story: \delta_t=+u_t is conditional PMI with c, and on chain-of-thought it systematically rewards shortcut tokens while punishing the deliberation tokens that do the search. Flipping the sign with a bounded divergence ascent and an entropy gate gives dense, informative per-token credit that is complementary to GRPO and substantially accelerates training across model scales.
Source: https://arxiv.org/abs/2605.11609
Process Rewards with Learned Reliability
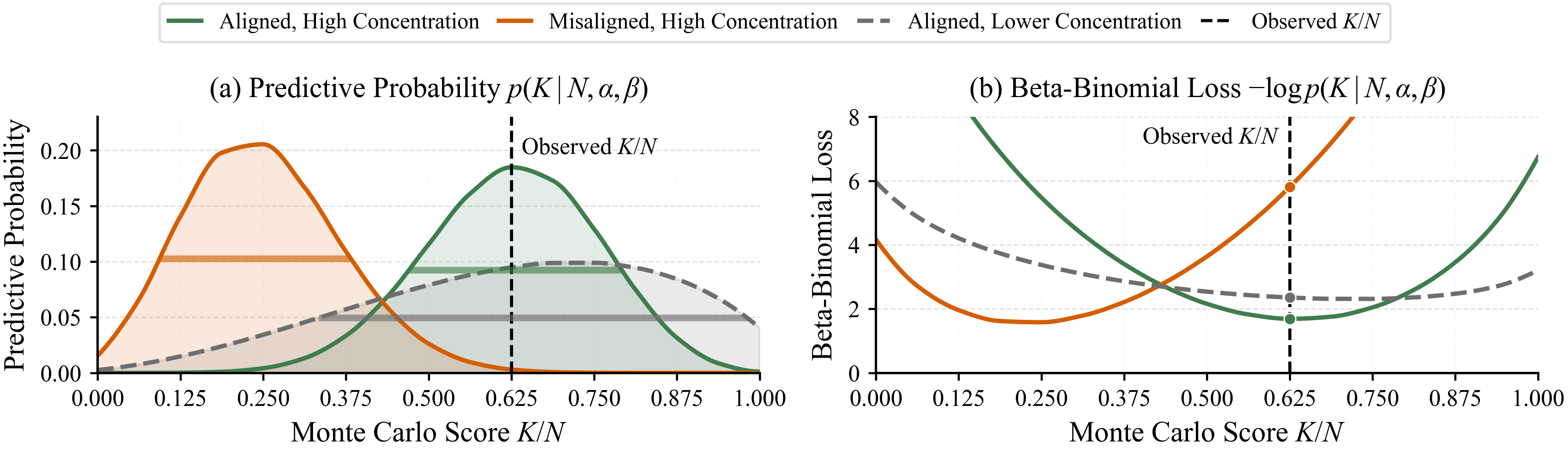
Process Reward Models (PRMs) trained from Monte Carlo rollouts face a basic statistical problem: the supervision signal K/N — the empirical success ratio of N continuations from a prefix — is a noisy estimator of the latent step quality q_t, but standard training treats it as a point target via cross-entropy regression. The PRM therefore emits a single scalar that downstream selectors (Best-of-N, beam search, MCTS) must trust uniformly, with no way to tell a confident 0.8 from a 0.8 derived from a single lucky rollout. BetaPRM addresses this by predicting a full Beta belief over q_t, jointly capturing reward and reliability.

Beta-Binomial supervision
The generative model is straightforward. Conditioned on a prefix, successful continuations follow K_t \mid q_t \sim \mathrm{Binomial}(N, q_t), with the latent success probability modeled as q_t \sim \mathrm{Beta}(\alpha_t, \beta_t). Marginalizing q_t yields a Beta-Binomial likelihood
p(K_t \mid \alpha_t, \beta_t, N) = \binom{N}{K_t} \frac{B(K_t + \alpha_t,\, N - K_t + \beta_t)}{B(\alpha_t, \beta_t)},
which is the training objective per step. The network is reparameterized to predict the mean \mu_t = \alpha_t/(\alpha_t+\beta_t) and concentration \kappa_t = \alpha_t + \beta_t; \mu_t recovers the standard PRM scalar, while \kappa_t encodes how peaked the belief is. The supervision intuition is shown in Figure 2: a tight Beta aligned with the observed K/N has high likelihood (green); a tight but misaligned Beta is heavily penalized (orange); a diffuse Beta hedges over a wide range of K/N outcomes (gray). Crucially, this means BetaPRM can express low confidence at prefixes where rollout outcomes are inherently high-variance, instead of being forced to commit to a sharp probability.
Adaptive Computation Allocation
The reliability signal is consumed at inference time through ACA, a Best-of-N variant with two mechanisms: stop early when a candidate is reliably ahead, and reallocate samples to uncertain prefixes. The Beta belief is converted to a step-level standard deviation
\sigma_t = \sqrt{\mu_t(1-\mu_t)/(\kappa_t+1)},
and aggregated into a risk-adjusted candidate score
S(y) = \frac{1}{T}\sum_{t=1}^{T}\bigl(\mu_t - \lambda \sigma_t\bigr).
ACA generates candidates in batches; after each batch it tests whether the leading candidate remains reliably ahead given the predicted uncertainty. If yes, sampling halts; if not, additional rollouts are drawn from prefixes whose \sigma_t is largest, focusing compute where the reward estimate is least trustworthy.
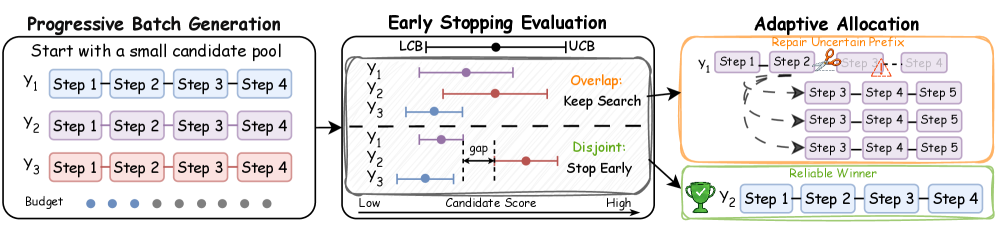
Results
Training uses VisualPRM400K-v1.1, where each prefix carries K successes out of N=16 Monte Carlo continuations. The standard baseline is cross-entropy on K/N; BetaPRM replaces this with the Beta-Binomial likelihood. Across four backbones (InternVL2.5-8B, InternVL3-8B, InternVL3-14B, Qwen2.5-VL-7B) and four math-reasoning benchmarks (MathVision, OlympiadBench, MathVerse, MathVista), BetaPRM uniformly beats the standard PRM as a Best-of-16 selector over the same candidate pools generated by InternVL2.5-8B.
Concretely, on InternVL2.5-8B as selector, average accuracy gain over the single-pass baseline rises from +4.58 (standard PRM) to +7.95 (BetaPRM), a +3.37 absolute improvement. On Qwen2.5-VL-7B the gap is +6.45 \to +9.11 (+2.66); on InternVL3-8B, +7.00 \to +8.46 (+1.46); on InternVL3-14B, +7.75 \to +9.04 (+1.29). Per-benchmark, the largest deltas come from the harder sets — e.g., MathVision jumps from 21.38 to 25.66 with InternVL2.5-8B, and OlympiadBench from 11.33 to 15.33. The improvements are consistent across all four selector backbones and all four benchmarks, suggesting that the gains come from the supervision objective rather than backbone-specific quirks.
The paper reports ACA results separately on InternVL2.5-8B and Qwen2.5-VL-7B against fixed-budget Best-of-16 under the same maximum budget, tracking both accuracy and generated tokens — the relevant axis being whether the reliability-aware stopping rule preserves accuracy at lower token cost (specific numbers in Section 6.3, not excerpted here).
Limitations
The Beta-Binomial likelihood is well-defined only when training data exposes (K, N) counts; most public PRM datasets only release ratios, restricting applicability to VisualPRM400K-style supervision. The reliability calibration is implicitly tied to the rollout count N=16 used during data construction — it is unclear how \kappa_t behaves when transferred to settings with different sampling regimes. The risk-adjusted aggregator uses a hand-picked \lambda and a uniform per-step penalty; whether \sigma_t is well-calibrated in the frequentist sense (e.g., does a predicted 90% interval cover 90% of held-out K/N?) is not directly evaluated. Finally, ACA’s stopping rule depends on assumptions about score variance that are not formally analyzed.
Why this matters
Treating empirical Monte Carlo ratios as point targets is the silent failure mode of every count-supervised PRM, and BetaPRM shows that a one-line change to a Beta-Binomial likelihood recovers calibrated uncertainty essentially for free, with consistent 1-3 point gains in Best-of-N accuracy and a natural lever for adaptive inference compute. Any system that uses PRMs to guide search should consider this drop-in replacement.
Source: https://arxiv.org/abs/2605.15529
CEPO: RLVR Self-Distillation using Contrastive Evidence Policy Optimization
Problem
In RLVR, a verifier R(x,y)\in\{0,1\} assigns a single sequence-level reward, and GRPO-style normalization broadcasts this scalar uniformly to every token in a rollout. Decisive reasoning steps and grammatical filler receive identical credit. Self-distillation approaches try to fix this by conditioning a teacher on the gold answer r^+ and using the divergence between the teacher and the student as a per-token credit signal, but this either (i) leaks the answer into the gradient — encoding spurious x \to r^+ correlations that degrade test performance — or (ii) yields a weak signal because both decisive and filler tokens look surprising relative to the unconditioned student.
Method
CEPO replaces the absolute teacher signal with a contrastive one. Given a question x, the policy \pi_\theta produces G rollouts split into correct \mathcal{G}^+ and wrong \mathcal{G}^- sets by the verifier. A correct rationale r^+ \in \mathcal{G}^+ and a rejected rationale r^- \in \mathcal{G}^- are sampled, and three next-token distributions are formed sharing weights \theta:
P_S(y_t)=\pi_\theta(y_t\mid x,y_{<t}),\quad P_T^+(y_t)=\pi_\theta(y_t\mid x,r^+,y_{<t}),\quad P_T^-(y_t)=\pi_\theta(y_t\mid x,r^-,y_{<t}).
The two teacher passes are run under stop-gradient. The contrastive evidence delta is, schematically,
\Delta_t^{\mathrm{CE}} \;\propto\; \log P_T^+(y_t) - \log P_T^-(y_t),
so a token is amplified only when the correct-answer teacher favors it and the wrong-answer teacher disfavors it. Tokens neutral under both (filler) get |\Delta_t^{\mathrm{CE}}|\approx 0, leaving the GRPO advantage unmodulated.
The token-level modulated advantage is then plugged into the standard PPO-clipped surrogate. The crucial structural property (Theorem 1(ii) in the paper) is that, because r^- is drawn from the batch’s own rejected rollouts, the gradient contains no vocabulary-wide r-conditioned term — the leakage pathway that breaks OPSD/SDPO is canceled in the contrast. The r^- is the final extracted answer of the lowest-reward rejected rollout in the current group, so no extra sampling cost is incurred.
The mixing weight \lambda between the contrastive modulation and the base GRPO advantage is annealed: \lambda_0=0.5 with linear decay to 0 over T_{\mathrm{warm}}=25 steps, plus a clipping bound \epsilon_w=0.5 on the modulation magnitude.
Results
Experiments use Qwen3-VL-2B-Instruct and Qwen3-VL-4B-Instruct, LoRA rank 16, 50 steps on Geo3k (3k geometry problems with numeric answers), G=8 rollouts, batch 32, AdamW at 10^{-6} (5\times 10^{-6} for CEPO), in EasyR1 + FSDP + vLLM.
On Qwen3-VL-2B averaged across five reasoning benchmarks, CEPO reaches 43.43% versus GRPO 41.17% (+2.26pp), OPSD 34.96%, and SDPO 35.70%. On Qwen3-VL-4B, CEPO reaches 60.56% versus GRPO 57.43% (+3.13pp) and OPSD 56.23%. Gains concentrate on benchmarks with longer chains: +6.18pp on LogicVista (4B) and +4.94pp on MathVision mini (2B). MMMU, dominated by short multiple-choice retrieval, shows the smallest gain (+1.67pp on 2B), consistent with the claim that the contrastive signal acts where reasoning chains are long enough to contain decisive tokens.
A striking observation is that OPSD and SDPO fall below the untrained base on 2B (34.96% and 35.70% vs. 39.73% base), and OPSD does so on 4B as well (56.23% vs. 58.36% base). This is the predicted leakage failure: as training progresses, the vocabulary-wide r^+-conditioned gradient deviation \delta(\theta;r^+) dominates and pushes the model to encode x\to r^+ shortcuts. CEPO, by construction, removes this term.
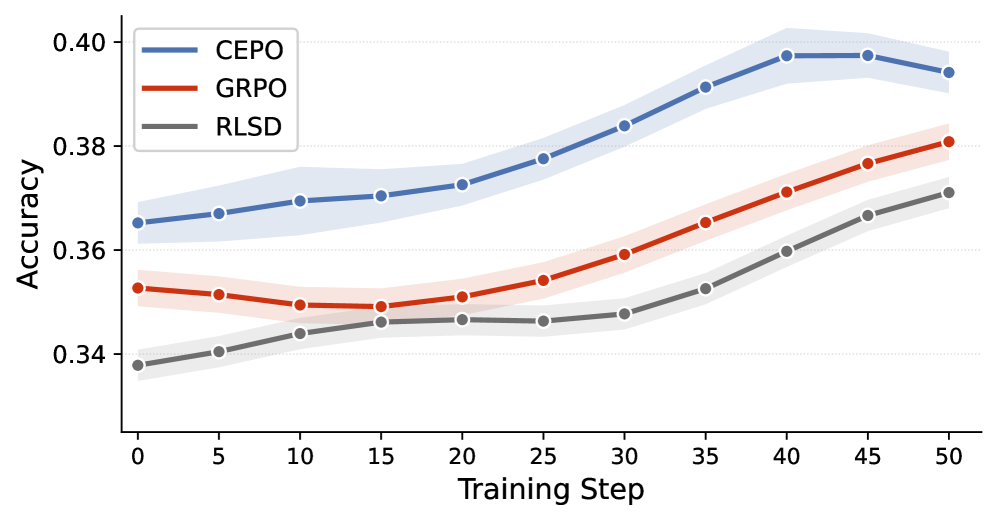
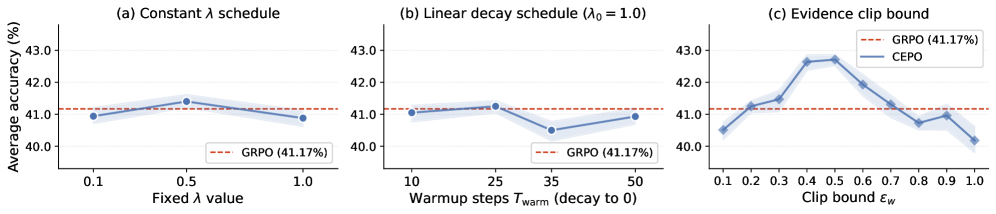
Training dynamics in Figure 1 show CEPO improving faster than GRPO and RLSD with the largest gap near step 40 before partial convergence. Hyperparameter sweeps (Figure 3) indicate constant \lambda=0.5 peaks at 41.40% (vs. GRPO 41.17%), while \lambda=1.0 injects noise that erases the credit-assignment benefit; the 25-step linear-decay warmup is the most robust setting.
Compute overhead is modest: 6h 34m for CEPO vs. 5h 58m for GRPO over 50 Geo3k steps, i.e. ~36 minutes for the two extra teacher forward passes — comparable to RLSD/SDPO overhead.
Limitations and open questions
The evaluation is restricted to two small Qwen3-VL models, 50 LoRA steps, and a single training corpus (Geo3k), so it is unclear whether the gains compound under longer training or full-parameter updates. The construction of r^- from the lowest-reward rollout assumes \mathcal{G}^- is non-empty; behavior near saturation (when most rollouts are correct) is not characterized. The contrastive signal also presupposes that wrong rollouts share enough structure with correct ones to make P_T^- informative — pathological cases where rejected rollouts are off-topic could neutralize the modulation. Finally, the theoretical safety guarantee removes vocabulary-wide leakage but does not bound the variance contribution of the contrastive term, which the \lambda=1.0 instability suggests is non-trivial.
Why this matters
CEPO addresses the central credit-assignment defect of RLVR — uniform per-token reward — without extra rollouts and without the answer-leakage that has quietly undermined prior self-distillation RL methods. The contrastive construction is cheap, drops into PPO/GRPO unchanged, and turns rejected rollouts (otherwise discarded as negative advantage) into a useful supervisory signal.
Source: https://arxiv.org/abs/2605.19436
Video Models Can Reason with Verifiable Rewards
Video diffusion models are trained for perceptual plausibility, but plausibility does not imply that a generated trajectory satisfies spatial, temporal, or logical constraints. This paper formulates video generation as a search for verifiable visual trajectories and ports RLVR — the recipe behind reasoning-tuned LLMs — to flow-matching video models. The result, VideoRLVR, fine-tunes Wan2.2-TI2V-5B on three procedurally generated reasoning domains (Maze, FlowFree, Sokoban) where rule-based verifiers replace learned reward models.
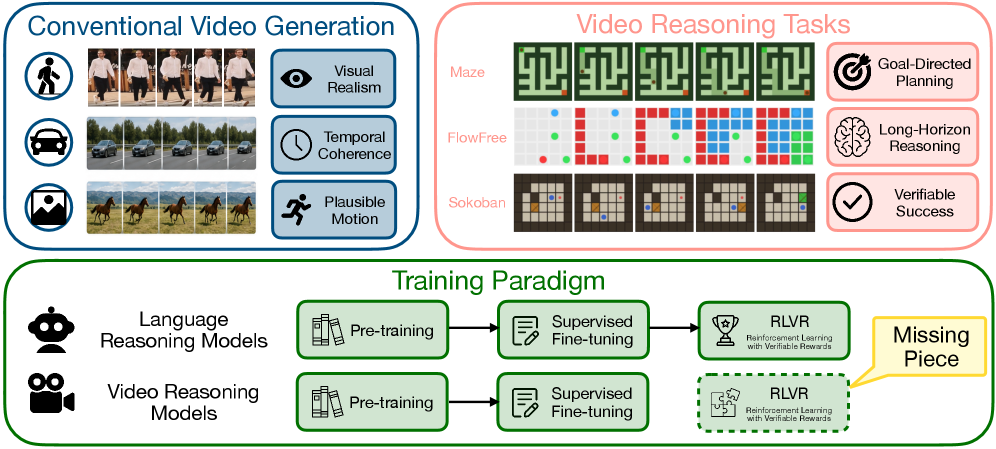
Problem setup
Conditioning is c=(I_0,T) with an initial frame and a textual instruction; the policy emits an 81-frame video \mathbf{V}=\{I_0,\ldots,I_{80}\} at 480\times 832, and a rule-based verifier returns R(\mathbf{V},c). The denoising trajectory is treated as an MDP over K steps with state x_{t_k} and action \hat v_\theta(x_{t_k},t_k,c). The pure ODE sampler is deterministic given x_1, so there is no transition density to differentiate through with likelihood-ratio gradients — this is the central obstacle the method must remove.
SDE-GRPO backbone
Following Flow-GRPO, the deterministic update is replaced with a Gaussian transition
\pi_\theta(x_{t_{k+1}}\mid x_{t_k},c)=\mathcal{N}(x_{t_{k+1}};\mu_\theta(x_{t_k},t_k,c),\sigma_k^2 \mathbf{I}),
which yields closed-form log-probabilities. With G rollouts per condition and group-normalized advantages A_i, the dimension-normalized log-ratio is
\log\rho_{i,k}=-\frac{1}{2\sigma_k^2 D}\sum_{d=1}^{D}\big[(x^{(i)}_{t_{k+1}}-\mu^{(i,k)}_\theta)_d^2-(x^{(i)}_{t_{k+1}}-\mu^{(i,k)}_{\text{old}})_d^2\big],
plugged into PPO clipping \mathcal{L}_\text{policy}=-\mathbb{E}[\min(\rho A,\text{clip}(\rho,1\pm\varepsilon)A)]. KL to a reference policy is added in closed form,
\mathcal{L}_\text{KL}=\mathbb{E}_k\!\left[\frac{1}{D}\frac{\|\mu_\theta-\mu_\text{ref}\|_2^2}{2\sigma_k^2}\right],
with \beta=0.04. The reference is the SFT checkpoint, which is itself trained on ground-truth solution videos for 5 epochs at lr 10^{-5} and provides the perceptual prior required for RL to converge.
Early-Step Focus
A key efficiency claim: only the first L=10 of T=20 denoising steps need gradients and SDE noise injection. Late steps refine texture, not reasoning structure. On Maze, fixing T=20 but restricting gradients to L=10 produces F1 84.4 vs 84.6 and SR 72.2 vs 72.3 for full-trajectory optimization, while step time drops from 156 s to 93.5 s — roughly the claimed 40% reduction in training latency.
Dense decomposed rewards
Sparse 0/1 success is too weak in domains like Sokoban with long horizons and irreversible transitions. VideoRLVR decomposes verifier signals into per-component dense rewards (the abstract emphasizes this is the most important factor) so that partially correct trajectories receive informative advantages within each group of G=16.
Results
VideoRLVR is initialized from SFT and trained for one epoch with G=16, T=20, lr 5\times 10^{-6}, on 8×B200. Against proprietary baselines on the held-out 3,000-sample test set, the gap is large: Sora 2 reaches success rates of 3.1/0.0/0.0 on Maze/FlowFree/Sokoban; Kling V3 reaches 23.5/0.0/0.0; Veo 3.1’s Maze precision is also low (table truncated). On Maze, VideoRLVR reports F1 84.6 and SR 72.3, more than 3\times Kling V3’s Maze SR. On FlowFree and Sokoban, every cited proprietary system scores SR 0.0, indicating these domains are essentially unsolved by current general-purpose video models — the verifier discriminates aggressively against perceptually plausible but rule-violating outputs.
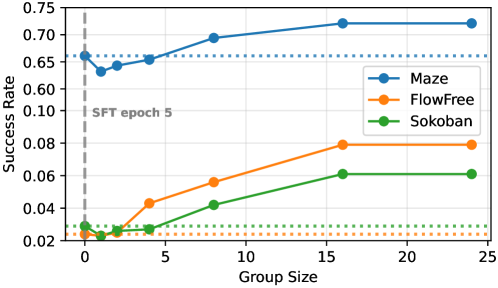
Group size scaling shows the expected GRPO behavior: G\le 4 yields biased advantage estimates due to noisy group statistics; G=16 stabilizes training; beyond that, returns diminish while rollout cost grows linearly. Removing the KL penalty (\beta=0) produces reward hacking — visually implausible patterns that satisfy verifier sub-criteria — confirming that the SFT prior must be actively anchored.
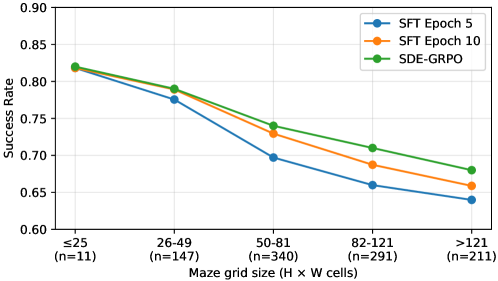
Success rate degrades with maze grid size, indicating the model still struggles with longer-horizon spatial search even within the training distribution.
Limitations
The evaluation is restricted to three procedurally generated grid-world domains where verifiers are trivially constructable; transfer to natural-video reasoning is mentioned (VBVR out-of-domain split) but the provided text cuts off before reporting those numbers. Rewards are hand-decomposed per task. The MDP is over denoising steps, not reasoning steps, so credit assignment to specific frames or events in \mathbf{V} is indirect — the reward is computed only after full decoding. Whether Early-Step Focus generalizes beyond grid-structured outputs (where coarse layout dominates) is unclear; for tasks where fine-grained late-step details matter for verification, L=10 may be insufficient. Finally, G=16 rollouts of 81-frame videos per prompt remains expensive, and the one-epoch RL budget suggests headroom but also sensitivity to schedule.
Why this matters
This is a clean demonstration that the RLVR recipe — group-relative policy optimization plus rule-based verifiers plus closed-form KL anchoring — transfers to flow-matching video generators once the deterministic ODE is replaced with an SDE. It separates “video models that look right” from “video models that are right,” and the Early-Step Focus observation gives a concrete computational lever for scaling RL on diffusion policies.
Source: https://arxiv.org/abs/2605.15458
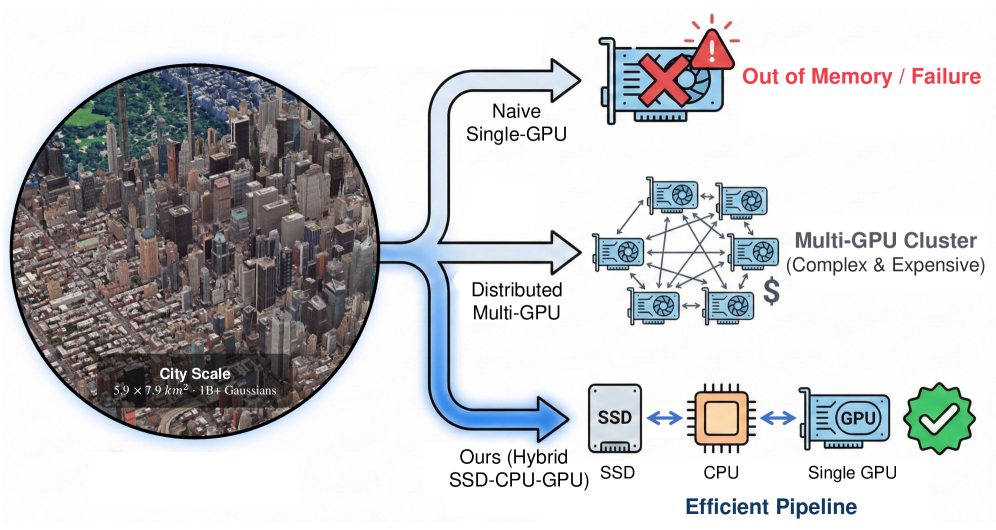
TideGS: Scalable Training of Over One Billion 3D Gaussian Splatting Primitives via Out-of-Core Optimization
Problem
3D Gaussian Splatting parameterizes a scene as a set of anisotropic Gaussians \{(\mu_i, \Sigma_i, \alpha_i, c_i)\}_{i=1}^{N}, where each primitive carries position, scale, rotation, opacity, and SH color coefficients — typically on the order of 60 floats per primitive. At N \sim 10^9, the parameter table alone exceeds 200 GB, far beyond a 24 GB GPU. Existing systems either cap N at \sim 10^7 on commodity GPUs or rely on multi-GPU sharding. The authors observe that 3DGS training is structurally sparse: per iteration, only Gaussians intersecting the camera batch’s frustum receive non-zero gradients — empirically 0.39% on average (worst-case 1.06%) per view on MatrixCity BigCity/Aerial. Under continuous camera trajectories, consecutive working sets overlap heavily. This makes 3DGS a natural candidate for out-of-core training where VRAM holds only the active working set.
Method
TideGS organizes parameters across an SSD–CPU–GPU hierarchy with three coupled mechanisms.
Block-virtualized geometry. Gaussians are sorted by Morton code over their centers \mu_i and partitioned into fixed-size blocks aligned to the SSD page granularity. Each block b_k is summarized by a bounding sphere (c_k, r_k) computed from the Gaussian centers it contains plus a margin reflecting the maximum 3\sigma extent. At iteration t with camera batch \mathcal{B}_t, a CPU-side 6-plane frustum test against \{(c_k, r_k)\} produces a conservative block cover \mathcal{K}_t, after which fine-grained Gaussian-level visibility \mathcal{I}_t \subseteq \bigcup_{k \in \mathcal{K}_t} b_k is computed on GPU inside the rasterizer.
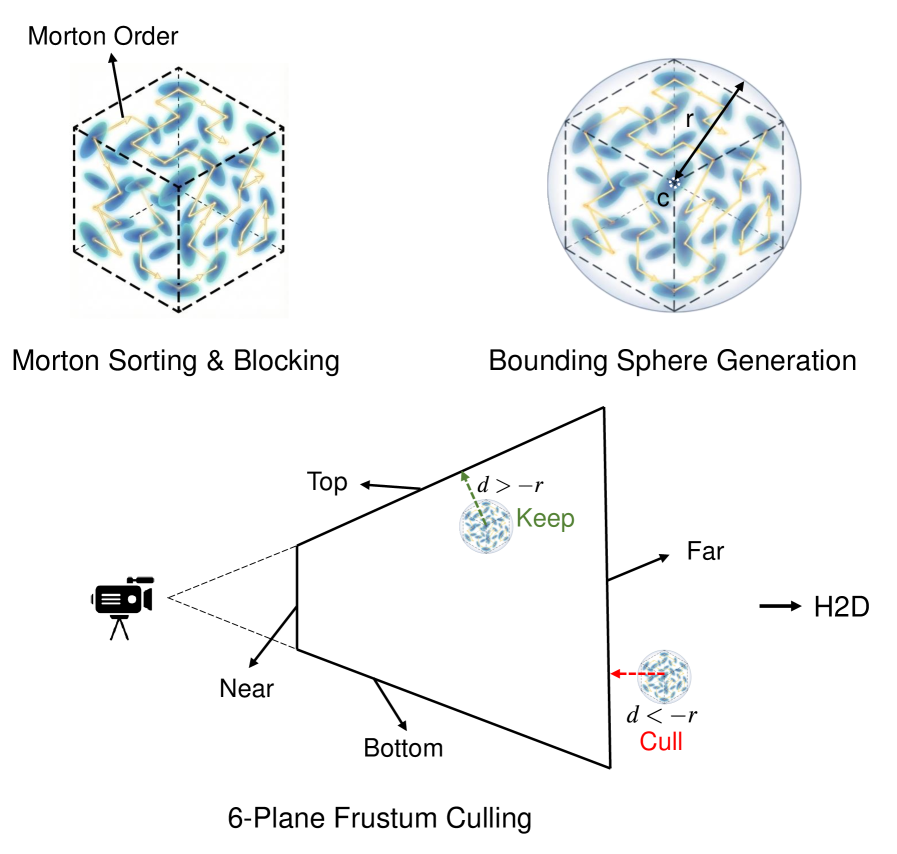
This two-stage filter is what makes the cross-tier traffic scale with |\mathcal{K}_t| rather than N.
Hierarchical asynchronous pipeline. SSD reads, CPU staging, H2D copies, forward/backward, and D2H/SSD writes for parameter updates run as overlapping stages on separate streams. CPU RAM acts as a warm cache holding recently-touched blocks; SSD holds the canonical parameter table.
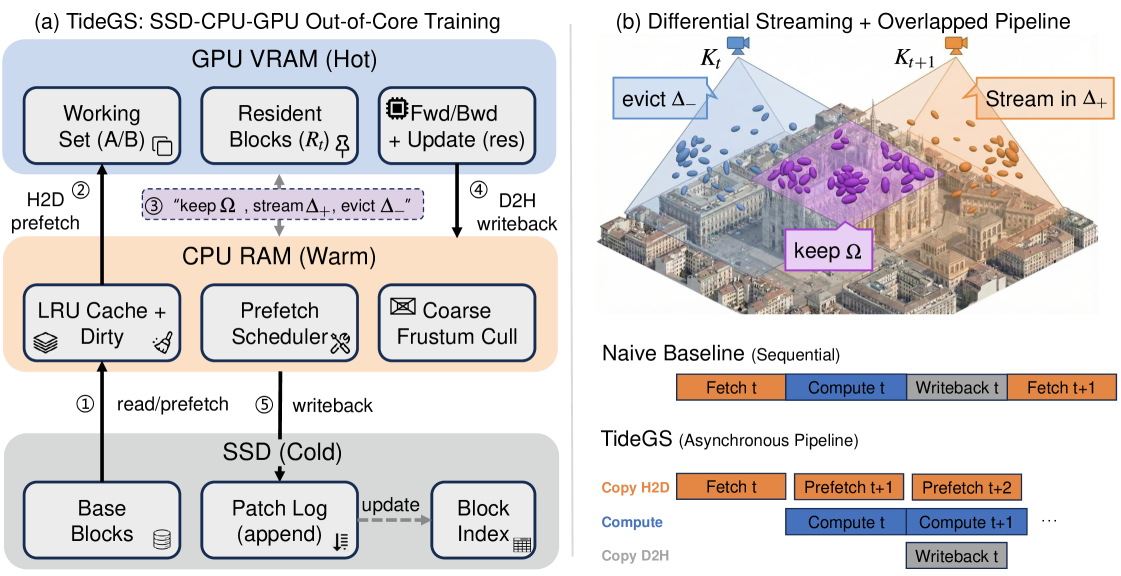
Trajectory-adaptive differential streaming. Rather than re-staging \mathcal{K}_{t+1} in full, TideGS computes the delta
\Delta_{t \to t+1} = \mathcal{K}_{t+1} \setminus \mathcal{K}_t, \qquad E_{t \to t+1} = \mathcal{K}_t \setminus \mathcal{K}_{t+1},
transferring only the incremental working set \Delta_{t \to t+1} into VRAM and evicting E_{t \to t+1} (writing back any updated parameters to the CPU/SSD tier). Under smooth trajectories, |\Delta| \ll |\mathcal{K}|, so steady-state H2D traffic is dominated by trajectory novelty rather than by working-set size. Capacity-aware eviction selects which warm blocks remain GPU-resident based on predicted reuse from the upcoming camera schedule.
The outer loop becomes:
for t in iterations:
K_t = frustum_cull(B_t, {(c_k, r_k)})
delta_in = K_t \ K_{t-1}
delta_out = K_{t-1} \ K_t
async_prefetch(delta_in) # SSD -> CPU -> GPU
async_writeback(delta_out) # GPU -> CPU -> SSD
I_t = gpu_fine_visibility(K_t, B_t)
loss = render_and_backprop(I_t, B_t)
apply_optimizer_step(I_t)Densification/pruning operate on blocks resident in VRAM and trigger block-table updates on the SSD tier.
Results
The headline claim is training with over 10^9 Gaussians on a single RTX A5000 (24 GB VRAM, 256 GB DDR4, PCIe Gen4×4 NVMe at 3.3 GB/s measured). Among single-GPU baselines evaluated on large-scale scenes, TideGS reports the best reconstruction quality at scales that other systems cannot reach at all — competitors are bottlenecked either by VRAM (in-memory 3DGS) or by host-DRAM offloading capacity. The Gaussian-level activation rate of 0.39% (mean) / 1.06% (worst case) reported from CLM measurements on MatrixCity quantifies why the working-set cache is effective: at N = 10^9, even worst-case visibility yields \sim 10^7 active Gaussians, comfortably within 24 GB.
The provided experimental section frames four questions — peak scale, overhead at small scale, throughput vs. host-offloading at large scale, and quality vs. primitive count — but the abstract sections shown here only confirm the scalability and quality outcomes qualitatively; full throughput/traffic numbers are in tables not included in the excerpt.
Limitations and open questions
The system depends on (i) sufficiently smooth camera trajectories for |\Delta_{t \to t+1}| to remain small — random-access training schedules would degrade to streaming the full \mathcal{K}_t each step; (ii) SSD endurance under repeated parameter writebacks across long training runs, which is not analyzed; (iii) Morton-based blocking, which assumes spatial locality correlates with visibility — pathological scene geometries (thin structures, large translucent volumes) may yield poor block-level conservative covers, inflating |\mathcal{K}_t| relative to |\mathcal{I}_t|. Densification dynamics interact non-trivially with block layouts; the paper presumably re-Morton-sorts periodically, but the cost amortization is not discussed in the provided excerpts. Finally, the comparison is restricted to single-GPU baselines; how TideGS composes with multi-GPU spatial sharding (e.g., as a per-shard backend) is open.
Why this matters
TideGS reframes 3DGS training as a working-set caching problem and demonstrates that visibility sparsity plus trajectory coherence are sufficient to push primitive counts two orders of magnitude beyond commodity single-GPU limits. This shifts the scaling axis for radiance-field reconstruction from GPU memory to SSD bandwidth, making city-scale reconstruction tractable without distributed infrastructure.
Source: https://arxiv.org/abs/2605.20150
GoLongRL: Capability-Oriented Long Context Reinforcement Learning with Multitask Alignment
Problem
Long-context RL with verifiable rewards (RLVR) has converged on a narrow recipe: synthesize multi-hop retrieval chains over long documents, reward exact-match on the final answer. This produces homogeneous data — most tasks reduce to “find the needles, compose them” — and trains models that score well on retrieval-style benchmarks but underperform on summarization, dialogue tracking, code-over-repo, or reasoning that requires sustained discourse modeling rather than evidence lookup. The reward signal is also brittle: exact-match degenerates on free-form outputs and gives no useful gradient on tasks like long-form QA where multiple answers are valid. GoLongRL targets this gap with a capability taxonomy, a matching dataset, and per-task verifiers, all released open-source.
Method
The pipeline has three pieces.
1. Capability taxonomy. The authors define 9 long-context task types covering retrieval (single-doc QA, multi-doc QA, needle variants), aggregation (summarization, list extraction), reasoning over long inputs (code repo reasoning, math/scientific paper reasoning), and dialogue/state tracking (multi-turn dialogue, long-form generation grounded in source). Each type is paired with a verifier appropriate to its output structure rather than forcing exact-match.
2. Data construction. The 23K-sample mix combines (a) curated subsets of existing long-context corpora filtered for difficulty and length, and (b) synthetic QA generated from real source documents — books, arXiv papers, multi-turn dialogue logs. Synthetic generation uses a strong instruct model to draft QA pairs, with rejection sampling to keep only items where the answer is verifiable from the document and where a weaker baseline fails (ensuring non-trivial signal). Context lengths are pushed into the regime where vanilla supervised fine-tuning saturates.
3. RLVR training. Standard GRPO on top of a base instruct model. For each prompt q with context c, sample a group of G rollouts \{o_i\}, score with the task-specific verifier r_i = R_{\text{task}}(o_i, q, c), compute group-normalized advantages
\hat{A}_i = \frac{r_i - \mathrm{mean}(r)}{\mathrm{std}(r)},
and optimize the clipped PPO surrogate with a KL penalty to the reference policy:
\mathcal{L}(\theta) = -\mathbb{E}\Big[\min\big(\rho_i \hat{A}_i,\ \mathrm{clip}(\rho_i, 1{-}\epsilon, 1{+}\epsilon)\hat{A}_i\big)\Big] + \beta\, \mathrm{KL}(\pi_\theta \Vert \pi_{\text{ref}}),
where \rho_i = \pi_\theta(o_i)/\pi_{\text{old}}(o_i). The non-trivial design choice is R_{\text{task}}: exact-match for needle/short-answer tasks, ROUGE/F1 thresholds for summarization, unit-test pass for code-repo tasks, structured-field matching for list extraction, and LLM-judge with rubric anchoring for long-form generation. Mixing tasks in a single batch keeps advantage estimates from collapsing within any one capability.
Results
The headline claim is that data composition dominates RL algorithmic complexity. Under identical vanilla GRPO, training on the released 23K mix outperforms training on the closed-source QwenLong-L1.5 dataset across the long-context evaluation suite. After full training, Qwen3-30B-A3B (a 30B-parameter MoE with ~3B active) reaches long-context performance comparable to DeepSeek-R1-0528 and Qwen3-235B-A22B-Thinking — roughly an order of magnitude more active parameters in the latter case. The abstract reports this comparability without breaking out per-benchmark deltas in the supplied excerpt, but the framing implies the gains are broad-based rather than concentrated on a single benchmark family, consistent with the multitask reward design.
The dataset-vs-dataset comparison is the cleanest scientific result: holding the optimizer, base model, and hyperparameters fixed and varying only the training corpus isolates the contribution of capability-oriented sampling. It suggests that prior long-context RL gains attributed to algorithmic refinements may be partially attributable to data curation effects that were not controlled for.
Limitations and open questions
Several issues are unresolved from what is reported. First, the LLM-judge reward components introduce a teacher-bias channel that is not characterized — it is unclear how much of the reported gain is the judge’s preferences leaking into the policy versus genuine capability improvement. Second, 23K samples is small; the paper does not show whether returns continue to scale or saturate, and the relative contribution of each of the 9 task types is not ablated in the abstract. Third, the comparison is to DeepSeek-R1-0528 and Qwen3-235B-A22B-Thinking on long-context tasks specifically; short-context reasoning regression is a known failure mode of long-context post-training and is not addressed. Fourth, vanilla GRPO at long context is expensive (rollout length dominates), and no compute or wall-clock numbers are given for reproducibility planning. Finally, the verifier for long-form generation is the weakest link: rubric-anchored LLM judging is known to be sensitive to prompt phrasing and to reward verbosity unless explicitly penalized.
Why this matters
If the dataset-controlled comparison holds up, it reframes long-context RLVR research: the bottleneck is task taxonomy and verifier design, not retrieval-path complexity or RL algorithm choice. A 30B MoE matching 235B-class models on long-context tasks via 23K well-chosen RL samples is a strong argument that capability coverage, not scale, is what current long-context post-training is missing.
Source: https://arxiv.org/abs/2605.19577
Hacker News Signals
Growing Neural Cellular Automata
The Distill article revisits cellular automata through a differentiable lens: each cell in a grid runs the same learned local update rule, and the system is trained end-to-end via backpropagation through time to grow a target pattern from a single seed cell. The core mechanic is a per-cell MLP (or small conv net) that takes as input the cell’s own state vector plus the states of its 8 neighbors (via a fixed Sobel-like perception kernel), then outputs a state delta. Crucially, updates are stochastic — each cell fires with probability 0.5 per step — which forces the rule to be robust to asynchrony and prevents the network from relying on synchronized global state.
The training loss is pixel-wise reconstruction of a target RGBA image. Beyond static growth, the authors show two harder objectives: persistence (the pattern must resist perturbation and regenerate damaged regions) and rotation equivariance. Regeneration is achieved by including random masking during training — cells in a region are zeroed mid-rollout, and the loss still applies at the end, so the rule must learn self-repair implicitly.
What makes this technically interesting is that the learned rule has no global communication channel: information propagates only locally and incrementally. Yet macroscopic coherent structure emerges purely from the local rule iterated ~100 steps. The system is also extremely compact — the shared MLP has on the order of a few thousand parameters.
Open questions the article raises: scaling to 3D, avoiding “overstable” attractors that resist all perturbation, and whether the learned rules generalize across seeds. The connection to biological morphogenesis is evocative but the gap between this and actual gene-regulatory networks is vast. As a computational substrate for self-organizing systems it remains an active research direction, with follow-up work exploring texture synthesis and neural architecture search on the update rule.
Source: https://distill.pub/2020/growing-ca/
The Foundations of a Provably Secure Operating System (PSOS) (1979)
This 1979 SRI technical report by Neumann, Robinson, Levitt, et al. describes PSOS, an OS designed from the ground up around formal verifiability. The central organizing principle is a hierarchical decomposition into 17 abstraction levels, each specified in a formal language (an early variant of what would become the Hierarchical Development Methodology), with each level implementing only the abstractions needed by the one above it. Security policy is enforced through a capability-based object model: every resource is an object, access is mediated by unforgeable capability tokens, and the hardware-enforced primitive capability operations are small enough to formally verify.
The threat model is explicit: the goal is to achieve what they call “provable security” — not just policy correctness but a machine-checked proof that the implementation satisfies the specification at each level. This predates modern proof assistants (Coq, Isabelle) by roughly a decade, so the formal methods are somewhat ad hoc by today’s standards, but the structural insight is sound.
Key design points: the kernel is intentionally minimal (the “security kernel” idea), process isolation is enforced through the capability system rather than relying on address-space tricks alone, and the type system for capabilities prevents confused-deputy attacks by construction. The report also discusses covert channel analysis, acknowledging that timing channels and storage channels are not addressed by the capability model alone.
For modern readers the interest is historical and architectural. Many of the ideas — capability systems, small trusted computing bases, verified separation kernels — resurfaced decades later in seL4 (2009), where they were finally carried through to a full machine-checked proof in Isabelle/HOL. PSOS did not reach that level of completion but clearly anticipated the right decomposition strategy. The 89-comment thread is mostly historians and seL4/CHERI enthusiasts noting the lineage.
Source: http://www.csl.sri.com/users/neumann/psos.pdf
OpenAI Adopts Google’s SynthID Watermark for AI Images with Verification Tool
OpenAI is embedding Google DeepMind’s SynthID watermark into images generated by the DALL-E and GPT-4o image APIs, and has released a public verification endpoint. The technical substance is in the watermarking scheme itself, which was published by DeepMind in Nature in 2024.
SynthID operates in the latent frequency domain rather than adding a visible overlay or a fragile LSB steganographic mark. For diffusion models the approach is applied at generation time by biasing the pseudo-random seed sampling during the denoising process — specifically, the initial noise tensor is seeded in a way that embeds a payload detectable by a paired neural classifier, without altering the image perceptibly. For direct pixel-space generation, a separate learned encoder-decoder pair embeds the mark post-hoc in a perceptually weighted transform domain.
The robustness claim is that the watermark survives JPEG compression, rescaling, moderate cropping, and color-space perturbation. The detection is statistical: a hypothesis test over the correlation between the image and the expected mark pattern, with a reported false-positive rate of < 10^{-6} at high true-positive rates on unmodified images. Robustness degrades under aggressive adversarial attack (adding Gaussian noise, inpainting over large regions), which the authors acknowledge.
The broader provenance story involves C2PA metadata (cryptographically signed content credentials attached to the file), which is complementary — SynthID is invisible and survives format stripping, C2PA is verifiable but trivially stripped. Using both in tandem is the stated strategy.
The HN thread is skeptical for good reasons: neither scheme is adversarially robust, sophisticated actors will strip or destroy marks, and the verification tool is centralized. The legitimate use case is narrow: probabilistic attribution in non-adversarial contexts, not enforcement.
Source: https://openai.com/index/advancing-content-provenance/
Learnings from 100K Lines of Rust with AI (2025)
The author describes a year-long experience building a substantial Rust codebase (~100K lines) using Claude Code and Codex as primary coding agents, and distills a workflow they call “spec-driven development.” The core observation is that LLM coding agents fail in proportion to ambiguity: when the task is underspecified, the model produces code that compiles and passes tests but violates the intended invariant, and debugging that is expensive. The solution is to treat the specification as the primary artifact.
Concretely, the workflow is: write a detailed natural-language (or pseudocode) specification of the module including preconditions, postconditions, and key invariants; have the model generate the implementation against the spec; then separately prompt the model to generate tests that probe the invariants directly. The author finds that Rust’s type system is a force multiplier here — ownership, lifetimes, and trait bounds encode many invariants mechanically, so the model’s output is rejected at compile time for a large class of errors that would silently pass in Python or Go.
Several specific failure modes are noted: agents tend to introduce unnecessary clones to satisfy the borrow checker rather than restructuring data flow; they default to unwrap() under time pressure; and they hallucinate crate APIs that don’t exist or have changed. The recommended mitigations are: include the relevant crate documentation in context, enforce #[deny(clippy::unwrap_used)] in CI, and use cargo check as a fast feedback loop during agentic loops rather than full compilation.
The observation that Rust’s strictness makes it better suited to LLM-driven development than more permissive languages is counterintuitive but plausible — the type checker acts as a ground-truth verifier that neither the human nor the model has to manually track.
Designing an FPGA Calculator from Scratch
The post documents a complete pipeline for building a four-function integer calculator on an FPGA, targeting a small Lattice iCE40 device using the open-source toolchain (Yosys + nextpnr + IceStorm). Every layer is built from primitives: the arithmetic unit is constructed from carry-propagate adder logic, subtraction via two’s complement, multiplication via repeated addition or a shift-and-add loop, and division via non-restoring long division in hardware.
The RTL is written in Verilog. The author implements a simple finite-state machine to sequence multi-cycle operations (multiply and divide take variable cycles), with a handshake interface between the compute FSM and the display/input FSM. Input is from a matrix keypad scanned via a debounced row-column protocol; output is a 7-segment multiplexed display with digit scanning at ~1 kHz to avoid ghosting.
The BCD (binary-coded decimal) conversion for display is handled with the Double Dabble algorithm (shift-and-add-3), which is well-suited to hardware because it requires no division. The author implements it as a purely combinational circuit, which works at the target clock frequency with timing margin to spare on the iCE40.
Resource utilization is reported: the entire design fits in a few hundred LUTs on an iCE40HX1K. The post is genuinely educational because it avoids black-box IP cores — every functional block is hand-rolled and explained. The synthesis and place-and-route steps are shown with actual toolchain invocations.
For readers familiar with FPGAs the content is introductory, but the end-to-end treatment — from keypad scanning through arithmetic FSM through BCD display — is a clean self-contained reference for the common beginner gap between “blink an LED” and “build something useful.”
Source: https://baltazarstudios.com/calculator/
Hsrs: Type-Safe Haskell Bindings Generator for Rust
Hsrs is a code generation tool that reads Rust type and function signatures and emits Haskell FFI bindings, preserving type safety across the boundary. The problem it addresses is the standard pain of Haskell-Rust interop: hand-writing foreign import ccall declarations, Storable instances, and marshalling code is error-prone and breaks silently when the Rust side changes.
The generator parses #[repr(C)] Rust structs and extern "C" function signatures (via either a proc-macro annotation or direct source parsing) and maps Rust primitive types to their Haskell FFI equivalents following the C ABI mapping. For structs it generates Storable instances with correct sizeOf, alignment, peek, and poke using the same layout algorithm that repr(C) mandates (no padding surprises if both sides agree on alignment). For enums it generates Enum and Bounded instances with matching discriminant values.
The type-safety claim is that the generator can catch type mismatches that would otherwise be undefined behavior — if a Rust function returns a u32 and the hand-written Haskell binding declares Word64, hsrs flags it. This is only as reliable as the parsing step, which currently depends on the Rust side being annotated or exposing a stable C ABI header.
Limitations: the tool does not handle generics, trait objects, or non-repr(C) types, which covers most of idiomatic Rust. Async Rust functions are out of scope. The practical use case is a narrow one — a Rust library written specifically to be called from Haskell, where the author controls both sides — but within that niche it removes a real class of bugs.
Source: https://github.com/harmont-dev/hsrs
Gemini 2.5 Flash
Google’s Gemini 2.5 Flash is a mid-tier model in the 2.5 family, positioned between the smaller Flash Lite and the full 2.5 Pro. The headline capability is an explicit “thinking budget” parameter: the caller can set a token budget for the model’s chain-of-thought reasoning trace, trading inference cost against answer quality on a continuous axis rather than choosing between a “thinking” and “non-thinking” mode. At budget zero it operates like a standard non-reasoning model; at high budgets it approaches 2.5 Pro performance on benchmarks.
Published benchmark numbers: 78.2% on AIME 2025 (math competition), 72.0% on GPQA Diamond (graduate-level science), and strong coding numbers on LiveCodeBench. Context window is 1M tokens, consistent with the rest of the 2.5 family. Multimodal inputs (image, audio, video, PDF) are supported natively.
The pricing structure is tiered by whether thinking is enabled: non-thinking mode is $0.075/$0.30 per million input/output tokens; thinking mode is $0.15/$0.60. This is roughly 4-8x cheaper than 2.5 Pro at equivalent reasoning budget, making it the practical default for high-volume reasoning tasks.
The HN discussion focuses on the thinking-budget mechanism as a more honest interface than the binary “extended thinking” toggle in competing APIs — it exposes the cost-quality tradeoff explicitly and lets the application developer optimize it. There is also substantial discussion of the native audio output, which is now generally available and supports real-time streaming for voice applications, with controllable speaking style via natural-language prompts in the system message rather than a discrete speaker-ID parameter.
Source: https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-5/
Gemini 2.5 Pro (Omni)
Gemini 2.5 Pro “Omni” extends the existing 2.5 Pro text/vision model to native audio and video I/O, making it a full any-to-any multimodal system. The architecture detail Google has disclosed is limited, but the framing is consistent with a single model handling all modalities through shared attention layers rather than modality-specific adapter modules bolted on post-hoc.
The audio capabilities are the most technically notable: the model generates audio directly rather than routing through a separate TTS system, which means prosody and emotional tone are conditioned on the full conversational context rather than just the text string to be spoken. Latency for audio streaming is reported in the sub-200ms range for first-byte response, which is the threshold for conversational use. The model supports interruption handling (barge-in) natively.
Video understanding operates on the full 1M-token context window, allowing analysis of long-form video with interleaved text reasoning. The model can be prompted to reason about temporal structure — causality between events, tracking objects across frames — rather than treating video as a bag of frames.
On standard benchmarks: 2.5 Pro leads or ties on most published reasoning and coding evaluations. The Omni designation specifically denotes the addition of audio output; the underlying reasoning capabilities are unchanged from 2.5 Pro. Live API access is available in preview with WebSocket-based streaming.
The HN thread discusses the competitive pressure on OpenAI’s GPT-4o (which had similar any-to-any ambitions but has been slow to enable native audio output at scale) and the inference cost implications of a single large model handling all modalities versus a routing architecture. The consensus is that the single-model approach is preferable for coherence but harder to serve efficiently.
Noteworthy New Repositories
NVlabs/cuda-oxide
An experimental Rust-to-CUDA compiler that emits PTX directly from standard Rust source, bypassing the usual path of writing kernels in C++/CUDA or using wrapper crates like cust. The compiler works by extending the Rust compilation pipeline to recognize SIMT execution semantics: thread/block indexing intrinsics map to PTX special registers, and the type system is leveraged to catch obvious data-race patterns at compile time. The “safe(ish)” qualifier is honest — pointer aliasing across warp lanes and shared-memory synchronization still require programmer discipline, but the borrow checker eliminates a large class of host-side resource management bugs. No DSL or proc-macro layer is involved; you write idiomatic Rust functions annotated as kernels and the toolchain handles lowering to PTX. This matters because the existing Rust GPU ecosystem (rust-cuda, cudarc) either requires nightly features in unstable states or imposes FFI overhead. Coming from NVIDIA Labs gives it credibility as a potential upstream path rather than a hobby experiment. Practical targets: custom attention kernels, fused elementwise ops, and any workload where you want Rust’s ownership model on the host and want to keep the same language on the device.
Source: https://github.com/NVlabs/cuda-oxide
jeremiah-masters/dlht
A Go implementation of the DLHT (Dynamic Lock-free Hash Table) algorithm, targeting high-concurrency workloads where lock contention on standard sync.Map or mutex-guarded maps becomes a bottleneck. The core data structure uses cache-line-aligned buckets to reduce false sharing and atomic CAS operations for insert/delete/lookup without ever acquiring a lock. Resizing is cooperative: threads that detect a load-factor threshold collectively participate in migrating entries to the new backing array rather than blocking on a single resize goroutine. This avoids the latency spike that accompanies stop-the-world rehashing in simpler designs. The Go memory model interacts awkwardly with fine-grained atomics, so the implementation uses sync/atomic primitives and explicit memory ordering annotations. Suitable as a drop-in for hot-path caches, session stores, or any map used from thousands of goroutines. The tradeoff versus sync.Map is that sync.Map optimizes the read-heavy, write-rare case with a separate read-only snapshot; DLHT targets more balanced read/write workloads. Benchmark before adopting: the cooperative resize adds code-path complexity that may not pay off below a few hundred concurrent goroutines.
Source: https://github.com/jeremiah-masters/dlht
Percivalll/Copy-Fail-CVE-2026-31431-Kubernetes-PoC
A proof-of-concept exploit demonstrating a fully unprivileged container escape via CVE-2026-31431. The attack chain combines two primitives: page-cache corruption to achieve controlled out-of-bounds writes within the kernel’s page cache, and the shared image-layer structure of container runtimes (overlayfs) which means pages backing read-only image layers are shared between containers and the host. By corrupting a page belonging to a shared layer, an attacker can overwrite host-visible file content or escalate to node-level code execution without any elevated capability. The PoC has been validated on managed Kubernetes offerings — ACK, EKS, and GKE — meaning the escape works even in hardened cloud environments where user namespaces are restricted. Technically, this is notable because it does not rely on CAP_SYS_ADMIN or privileged: true; a default, unprivileged workload pod is sufficient. For defenders: the immediate mitigations are kernel patches addressing the page-cache corruption primitive, and disabling shared image layers (at significant storage cost). Security teams running multi-tenant clusters should treat this as critical priority given the cross-cloud validation.
Source: https://github.com/Percivalll/Copy-Fail-CVE-2026-31431-Kubernetes-PoC
fswatcher/fswatcher
A cross-platform filesystem notification library for Go that wraps OS-native event APIs — inotify on Linux, kqueue on macOS/BSD, and ReadDirectoryChangesW on Windows — behind a single uniform interface. The abstraction handles the meaningful differences between backends: inotify delivers per-file events with explicit event masks; kqueue requires a file descriptor per watched path and scales differently under large directory trees; Windows provides recursive-watch semantics natively. The library normalizes these into a channel-based Go API, emitting typed events (create, write, rename, remove) without exposing the backend quirks to callers. Recursive directory watching, which is non-trivial on Linux because inotify is not recursive, is handled by walking the tree and registering watches on subdirectories, with logic to catch newly created subdirectories. This is the kind of infrastructure code that is tedious to write correctly once and nearly impossible to test across all platforms without CI on each OS. Useful for build systems, hot-reload servers, config watchers, and any tool that needs to react to filesystem changes without polling.
Source: https://github.com/fswatcher/fswatcher
agent-quality-controls/slopless
A deterministic linting tool for Markdown prose, built on top of textlint, targeting the specific failure modes of LLM-generated text: filler phrases, hedge stacking, nominalization of verbs, passive constructions without agents, and the particular vocabulary patterns that cluster in AI-generated writing (“delve”, “leverage”, “utilize”, “it is worth noting that”). Rules are implemented as textlint plugins and are fully deterministic — the same input always triggers the same violations, making it usable in CI pipelines without flakiness. The CLI exits non-zero on violations, enabling hard gates in pull request workflows. Rule sets are configurable; the default ruleset is tuned against a corpus of identified AI-generated prose. Unlike style guides that suggest improvements, slopless is designed to block merges, enforcing that human authors actively address flagged constructions rather than letting them accumulate. Technically lightweight — pure Node.js, no model inference, no network calls — so it adds negligible latency to a linting step. Useful for documentation teams, technical writing repositories, and any project where prose quality is a maintained invariant.
Source: https://github.com/agent-quality-controls/slopless
ClouGence/open-cdm
An open-source database management platform built for team environments rather than individual developer use, addressing the governance gap in tools like DBeaver or DataGrip that have no concept of organizational access control. Core capabilities: role-based access control over which users can query which schemas, dynamic data masking and anonymization for PII-sensitive columns (masking applied at query result time, not in storage), SQL audit logging with tamper-evident records, and CI/CD integration for schema migration pipelines. Cross-regional deployment support means the control plane can federate across multiple database instances in different cloud regions under a single UI. The SQL auditing component records executed queries, execution plans, and results, which is a compliance requirement in regulated industries. Data anonymization is configurable per column with pluggable masking strategies (redaction, pseudonymization, format-preserving tokenization). The stack is Java-based with a web frontend, designed to be self-hosted behind a corporate network perimeter. The main differentiator from commercial alternatives like Bytebase or Archery is full open-source licensing without feature gating.
Source: https://github.com/ClouGence/open-cdm
graemeg/blaise
A self-hosting Object Pascal compiler written from scratch, explicitly discarding Delphi/FPC legacy constraints. Three design choices define it: automatic reference counting (ARC) as the exclusive memory management model (no manual Free, no mark-and-sweep GC pauses), UTF-8 as the sole string encoding throughout the compiler and runtime (eliminating the AnsiString/WideString/UnicodeString fragmentation that plagues existing Pascal ecosystems), and self-hosting as a first-class goal from early development rather than a retrospective milestone. ARC with cycle detection handles the common Pascal pattern of doubly-linked lists without leaks. The compiler targets modern 64-bit platforms; the legacy 16-bit and DOS-era compatibility surface that burdens FPC is not present. For language researchers and compiler students, a self-hosting compiler in a statically-typed, readable language with clear AST and codegen separation is a useful artifact. For Pascal practitioners who want a clean-slate toolchain without dragging in thirty years of compatibility shims, this fills a genuine gap. The zero-legacy stance means it is intentionally incompatible with large amounts of existing Delphi/FPC code.
Source: https://github.com/graemeg/blaise
agynio/platform
A Kubernetes-native runtime for deploying AI coding agents — Claude Code, OpenAI Codex, and similar — on company infrastructure rather than developer laptops. The core problem it solves: agents that execute arbitrary code need sandboxed environments with access to internal resources (repositories, package registries, secrets) and organizational controls (audit logs, cost limits, approval gates), none of which are provided by running the agent CLI locally. The platform provisions per-agent execution environments as Kubernetes pods with configurable resource limits and network policies, mounts the necessary credentials via Kubernetes secrets, and provides a control plane for policy enforcement: which agents can access which repositories, spending caps per team, and human-in-the-loop approval for destructive actions. The Kubernetes-native architecture means it integrates with existing RBAC, namespace isolation, and cluster autoscaling. For enterprises already running workloads on Kubernetes, this avoids standing up a separate agent infrastructure. Relevant for platform engineering teams that want to offer agent capabilities to developers without granting those agents broad access to production systems from uncontrolled endpoints.