デイリーAIダイジェスト — 2026-05-19
arXiv ハイライト
KVPO: ODE-Native GRPO for Autoregressive Video Alignment via KV Semantic Exploration
問題設定
ストリーミング型自己回帰(AR)動画生成器を少数ステップのflow-matchingサンプラーに蒸留したものは、ブロックごとに決定論的な確率流ODE(probability-flow ODE)を実行します。標準的な選好アラインメント手法——DDPO、Flow-GRPO、およびその他のRL後学習手法——は確率的SDEサンプリングを前提として設計されており、扱いやすい尤度を持つ行動方策を構築するために、x_Tもしくはステップごとの遷移にガウスノイズを注入します。これは蒸留されたAR動画モデルに対して二つの問題を引き起こします。第一に、方策・ダイナミクスの不整合があります:展開時のサンプラーはODEですが、最適化はSDAのサロゲートに対して行われるため、実際のロールアウト分布に対してバイアスが生じます。第二に、ノイズ空間の探索は主に低レベルのピクセルを摂動させるにすぎません。長期間にわたるマルチプロンプト動画においては、問題となるのはセマンティックドリフト——プロンプト切り替えの失敗、オブジェクトの消失、物語の非一貫性——であり、これはブロックごとのノイズではなく過去のKVキャッシュによって支配されています。
KVPOはまさにこのギャップを標的にしています:ノイズではなくKVキャッシュ空間で探索を行う、ODE-nativeなGRPOです。
手法
基本的な設定は、ブロックごとのAR生成 p_\theta(v_b \mid v_{<b}, \mathcal{C}) であり、(sink、local)のKVメモリ \mathcal{K}_{<b} を用いて、x_t = t x_0 + (1-t) x_T に沿ったflow-matching ODE積分 v_\theta(x_t, t, \mathcal{K}_{<b}) によって各ブロックを生成します。
KVルーティングによる因果的セマンティック探索。 GRPOグループの G 個の候補にわたって x_T を再サンプリングする代わりに、KVPOは初期ノイズを固定し、摂動ウィンドウ内の過去KVキャッシュのエントリを確率的にルーティングすることで、意味的に多様な G 個の継続を生成します。ルーティングはモデル自身が生成したオンマニフォールドの過去トークンをシャッフルするだけなので、各ブランチはデータ多様体上に留まりながら、ストーリーラインという点で分岐します——これは長尺動画の報酬モデルが実際に評価する変動です。

図1のコントラストは本設計の中心的な主張です:ノイズ空間の探索は単一のセマンティック軌道の周辺でピクセル統計上に候補を分散させますが、KVルーティングは低レベルの外観を共有しながら異なるセマンティック軌道にわたって候補を分散させます。
軌道速度エネルギー(TVE)サロゲート方策。 SDEなしでGRPOを実行するために、KVPOはflow-matchingの速度空間でブランチの尤度を直接定義します。各候補ブランチ i について、モデルを摂動なしの展開時KVコンテキストのもとで再生し、各ODEステップ s においてブランチの実現速度と展開コンテキスト速度との偏差を積み重ねて軌道速度エネルギー(Trajectory Velocity Energy)を計算します:
\mathrm{TVE}_i = \sum_s \big\| v_\theta(x_{t_s}^{(i)}, t_s, \mathcal{K}_{<b}^{\text{routed}}) - v_\theta(x_{t_s}^{(i)}, t_s, \mathcal{K}_{<b}) \big\|^2,
これがブランチの -\log \pi の役割を果たします。GRPOの目的関数はブランチ間の報酬重み付きコントラスト損失となります:高報酬ブランチは低TVE(展開ODEへのマッチング)に引き寄せられ、低報酬ブランチは押し離されます。これにより最適化は完全にODEの枠組み内に収まり——SDEサロゲートもガウス尤度近似も不要です。
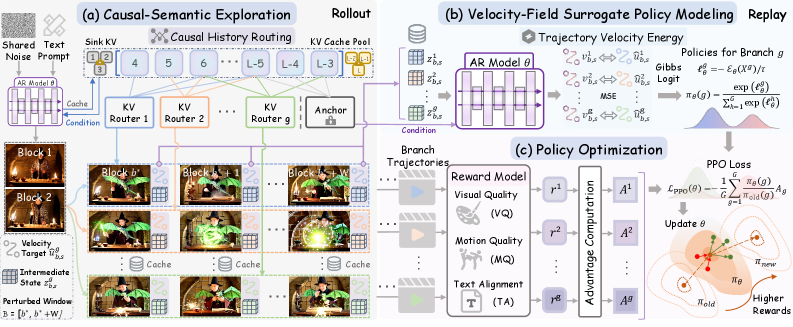
図2の二段階構造——探索のための摂動ロールアウトと尤度のための摂動なし再生——が、多様性とODE-native方策の両立を可能にしています。
学習。 LongLiveおよびMemFlow(いずれもSelf-Forcing蒸留モデル)の上に r=\alpha=256 のLoRAを適用します。グループサイズ G=8、32台のH200 GPU上でイテレーションごとに32プロンプト、約960秒/イテレーション、3k~4kサンプル(約1000 GPU時間)で収束します。学習プロンプトはVidProMから取得し、Qwen3で精製して、588フレーム(147潜在フレーム)ごとに切り替わる4プロンプトグループに分割します。
結果
報酬アラインメント指標の三指標——VQ(視覚品質)、MQ(モーション品質)、TA(テキストアラインメント)——およびVBenchの四指標で評価します。長期間のマルチプロンプト設定において手法の効果が最も顕著に現れるべきであり、実際にそうなっています。
単一プロンプト短尺動画、LongLiveベースライン → +KVPO:VQ 8.86 → 10.21(+15.2%)、MQ 1.80 → 1.89(+5.0%)、TA 0.02 → 0.06(+200%)。MemFlow:VQ +9.1%、MQ +2.7%、TA +50%。
マルチプロンプト長尺動画、LongLive → +KVPO:VQ 6.34 → 8.14(+28.4%)、MQ 1.41 → 1.50(+6.4%)、TA −0.19 → −0.14(+26.3%)。MemFlow:VQ +10.5%、MQ +3.6%、TA +15.0%。VBench SemanticはLongLive長尺動画で67.88から69.02に改善し、Consistency Score 88.37 → 88.62、CLIP Score 31.90 → 32.29となります。
ノイズ探索を用いた後学習ベースラインであるAstrolabeとの差は長尺動画レジームで広がり(例:LongLive長尺動画VQ 7.26 vs 8.14)、これが中心的な主張の回帰テストとなっています:セマンティック空間の探索は水平が伸びるほどより重要になります。

定性的には、LongLiveの比較においてプロンプト切り替え時のトランジションがよりクリーンになり、セグメントをまたいだオブジェクトのアイデンティティが安定していることが示されます。MemFlowの比較でも、セグメント間の一貫性における同様の改善が報告されています。
限界と未解決の問題
TVEサロゲートは真の対数尤度を展開コンテキスト下での速度空間距離で置き換えており、これはヒューリスティックです——厳密なODE対数密度に対するバイアスは特徴付けられていません。KVルーティングスキームには自由パラメータ(どのウィンドウか、どのエントリか、ルーティング分布)があり、本論文では経験的に扱われています。TAスコアは長期間設定において依然として負のまま(最良で−0.14)であり、アラインメント後でも絶対的なプロンプト追従は依然として不十分です。比較対象は二つの蒸留ARバックボーンと一つの外部ベースライン(Astrolabe)に限定されており、非蒸留または非flow-matchingのAR動画モデルにおける挙動は未検証です。LoRAにもかかわらず、1000 GPU時間の予算は軽微とは言えません。
なぜ重要か
蒸留された動画生成器はODEであり、SDEを想定したRL目的関数でアラインメントを行うことはカテゴリエラーであり、ノイズによって糊塗されてきました。KVPOは適切な探索変数——セマンティクスを制御する過去KV状態——と適切な尤度サロゲート——モデルのネイティブな空間に存在する速度場エネルギー——を特定し、AR動画に特化したクリーンなGRPO定式化を実現します。マルチプロンプト長期間レジームにおける不均衡な改善は、これがストリーミング生成のアラインメント問題の正しい因子分解であることを示唆しています。
Source: https://arxiv.org/abs/2605.14278
OProver: エージェント的形式定理証明のための統合フレームワーク
問題
最近のLean 4プルーバー(Goedel-Prover-V2、DeepSeek-Prover、LongCat-Flash-Prover)は、スケールされた合成データと検証器を考慮したトレーニングによってwhole-proof生成を大きく前進させましたが、エージェント的な動作——コンパイラのフィードバックや検索された事例から失敗した証明を反復的に修復する——は、通常、推論時にのみ現れ、トレーニングとは切り離されています。その結果、policyはコンパイラエラーの構造や検索された証明コンテキストを活用することを学ばず、独立したサンプルを出力してPass@Nで有効なものを見つけることに頼るだけです。OProverはこのループを閉じます:エージェント的なロールアウトはトレーニング分布の一部となり、コーパス、検索メモリ、policyが共に進化します。
手法
OProverは3つの結合されたコンポーネントから構成されます:policy \pi、コンパイラで検証された証明の検索メモリ \mathcal{M}、そして環境としてのLean 4コンパイラ \mathcal{V} です。
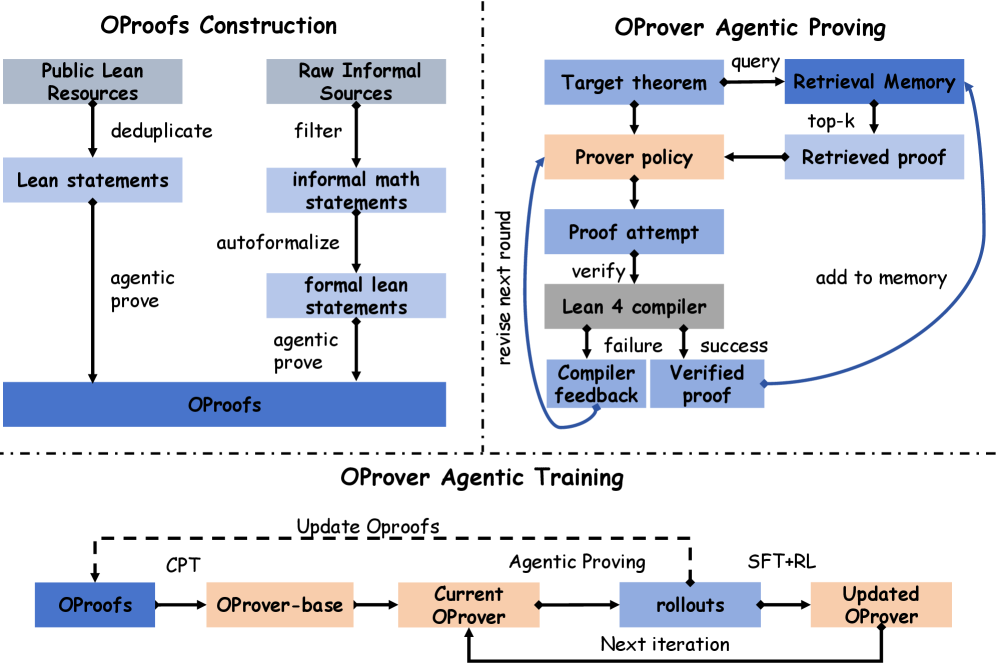
証明は有界な多ラウンド精緻化として定式化されます。ラウンド t において、 X_t = (s,\; \mathcal{R}_t,\; p_{t-1},\; f_{t-1}), \qquad p_t \sim \pi(\cdot \mid X_t), ここで s は目標命題、\mathcal{R}_t は \mathcal{M} から検索されたtop-kの検証済み証明、p_{t-1} は直前の試み、f_{t-1} はコンパイラのエラートレースです。p_0, f_0 は空であり、\mathcal{V}(p_t) = \top となるか、ラウンドの予算 T が尽きた時点でループが終了します。
トレーニングは2つのフェーズから成ります:
- 継続的事前学習(CPT):OProofsコーパス上での継続的事前学習により、ドメイン適応済みベースモデルOProver-Base(Lean 51.8Bトークン、prompt + CoT、Qwen3トークナイザー)を生成します。
- 反復的ポストトレーニング:各イテレーションで、現在のプルーバーが未解決の命題に対してエージェント的ロールアウトを実行し、新たに検証された証明がOProofsと \mathcal{M} の両方にフォールドバックされます。p_t が検証されるラウンドレベルの修復ペア (X_t, p_t) がSFTデータとなり、予算内で未解決のまま残った命題がRLのターゲットになります。SFTはpolicyが (s, \mathcal{R}, p_{\text{fail}}, f) を検証済みの p に変換することを学ばせ、RLはSFT分布がカバーできないロングテールな難しいケースを処理します。
OProofsコーパス
OProofsはデータの基盤であり、公開Leanリソース、非形式ソースの自動形式化、大規模証明合成、そしてエージェント的ロールアウトのトレース自体から構築されています。主要な統計:
- ユニークなLean命題:177万件
- コンパイラ検証済み証明:686万件
- 検索コンテキスト付き証明:433万件
- 非自明なコンパイラフィードバック付き証明:86.9万件
- エージェント的軌跡:107万件(うち16.4万件は少なくとも1回の修復が必要)
- ラウンドレベルの修復例:28万件
- CPT用Leanトークン:51.8B
ドメイン構成:代数学59.5%、解析学13.8%、数論13.0%、幾何学6.8%、その他6.9%。難易度:初等27.1%、高校48.9%、学部19.2%、大学院4.8%。特筆すべき点として、Nemotron-Math-Proofsや類似リソースと異なり、OProofsは検索コンテキスト、コンパイラフィードバック、マルチラウンド修復シグナルを明示的にシリアライズしており——これはエージェント的プルーバーを評価するだけでなく、トレーニングするために必要な教師データです。
結果
評価はMiniF2F(244)、MathOlympiadBench(360)、ProofNet(186)、ProverBench(325)、PutnamBench(672)を対象としており、Goedel-Prover-V2やLongCat-Flash-Proverが使用する標準的なスイートです。
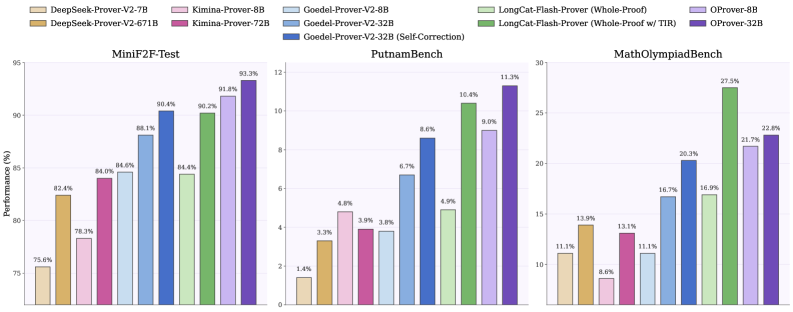
OProver-32Bは5つのうち3つでPass@32において最高性能を達成しています:
- MiniF2F:93.3%
- ProverBench:58.2%
- PutnamBench:11.3%
また、MathOlympiadBench(22.8%)とProofNet(33.2%)では2位——これは既存のオープンウェイトwhole-proofプルーバーの中で最も多くのトップ順位です。OProverが明確に劣っている唯一のベンチマークはMathOlympiadBenchであり、そこではtool-integrated reasoning(TIR)を用いたLongCat-Flash-Proverがリードしています。OProverはここではwhole-proofのみです。
著者らはまた、固定された総計算予算 B のもとでのテスト時スケーリングも研究しており、\mathrm{BestPass}(B)——R \cdot k \le B(または同等の計算量)を満たすラウンド数 R と検索深さ k の全配分にわたる最良の成功率——を報告しています。
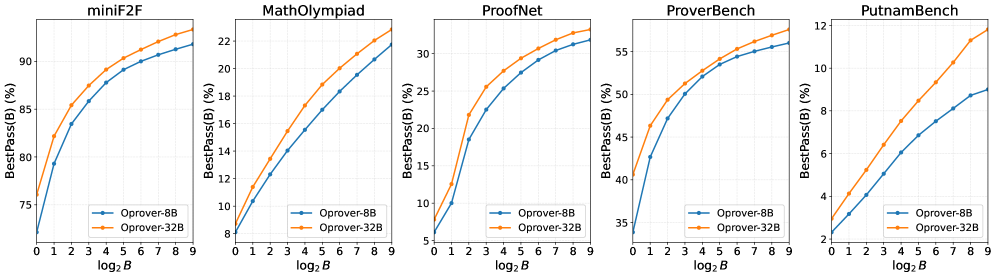
OProver-8BとOProver-32Bの両方が B に対して単調に改善しており、予想通りの逓減収益が見られます。この曲線は、エージェント的ループが追加のコンパイラとのインタラクションを単なる再サンプリングではなく、解決された定理へと本当に変換していることを示しています。
限界と未解決の問題
- Whole-proofのみ:タクティクレベルのインタラクションやtool-integrated reasoningがなく、TIRシステムとのMathOlympiadBenchのギャップが未解決のまま残っています。
- PutnamBenchの11.3%は絶対値として依然として低く、最も難しいコンペティションレベルの問題はまだ大部分が手の届かない状況です。
- 難易度とドメインのラベルはLLMによって推測されており、カリキュラムとカバレッジの主張にバイアスをもたらす可能性があります。
- 検索メモリはトレーニングとともに成長しますが、論文は利得のどの程度が検索の新鮮さによるものかpolicyの改善によるものかを定量化しておらず、|\mathcal{M}| がスケールするにつれて検索品質がどのように劣化するかも示していません。
- RLの詳細(報酬の設計、進化する \mathcal{M} 上でのオフポリシー補正、イテレーション間の安定性)は、示された抜粋では要約されていません。
- CPT対SFT対RLの寄与、あるいは一致した計算量でのラウンド数 T 対サンプル数 N についてのアブレーションもありません。
なぜ重要か
OProverは、検索、コンパイラフィードバック、マルチラウンド修復を推論時だけでなくトレーニングループの内部に組み込んだ最初のオープンウェイトLean 4システムであり、他の研究者が同様のことを行うために必要な教師データ(28万件の修復例、86.9万件のフィードバック付き証明)も公開しています。これは形式証明のトレーニングデータの概念を再定義するものです:検証済み証明ではなく、軌跡こそが教師の単位です。
Source: https://arxiv.org/abs/2605.17283
対照ペア探索によるターゲット指向のニューロン変調
問題
Contrastive Activation Addition(CAA)のようなactivation-steeringの手法はresidual streamに作用します。具体的には、陽性プロンプト集合と陰性プロンプト集合の間の平均差ベクトルを計算し、そのベクトルをスケーリングして推論時に加算します。経験的に知られている病理的挙動として、介入強度が中程度では動作が変化するものの、\alpha \approx 0.5 を超えると繰り返しや縮退状態にモデルが陥るという問題があります。これにより、residual-stream steeringは行動制御手段として信頼性が低くなり、さらに機構的な主張も曖昧になります(流暢性をも破壊する「拒否方向」は、拒否を明確に分離しているとは言えません)。本論文は、よりスパースなニューロンレベルの介入によって、行動変化と生成品質の劣化を切り離せるか、そしてその結果として得られる回路がアライメント fine-tuning の実態を明らかにするかどうかを問います。
手法
Contrastive Neuron Attribution(CNA)は機械的に最小限の手法です。\mathcal{P}^+(有害プロンプト)と \mathcal{P}^-(良性プロンプト)のペアとなる集合が与えられたとき、各プロンプトをモデルに通し、全MLPレイヤーの最終トークン位置における down_proj への入力、すなわちresidual streamへと射影される直前のMLP内のpost-activationの隠れ状態を取得します。レイヤー \ell のニューロン j の活性値 a^\ell_j(x) に対して、以下を計算します。
\delta^\ell_j = \frac{1}{|\mathcal{P}^+|}\sum_{x\in\mathcal{P}^+} a^\ell_j(x) - \frac{1}{|\mathcal{P}^-|}\sum_{x\in\mathcal{P}^-} a^\ell_j(x).
回路 \mathcal{C}_k は、全レイヤーを通じて |\delta^\ell_j| の上位 k ニューロンであり、k は全MLPニューロン数の0.1%に固定されています。強度 \alpha でのsteeringは、前向きパス中にそれらのニューロンの活性値のみをスケーリング(ablationのためゼロ方向へ)します。勾配も補助プローブも線形化も不要で、2セットの前向きパスと平均差だけで実現されます。概念的にはこれは、MLP活性値における特徴の経験的スパース性を活用し、residual basisではなくニューロンbasisで評価されるCAAです。
拒否に関する対照ペアは有害プロンプト100件・良性プロンプト100件を使用します。評価にはキーワードベースの拒否分類器とn-gram繰り返し比率(一貫性の代理指標)を用いたJBB-Behaviors、および汎用能力の指標としてMMLU(1000問)を使用します。
結果
Llama-3.2-1BからQwen2.5-72Bにわたる8つのinstructモデル全体にわたって、0.1%の回路をablateすると生成品質をベースライン近傍に保ちながら拒否率が大幅に低下します。
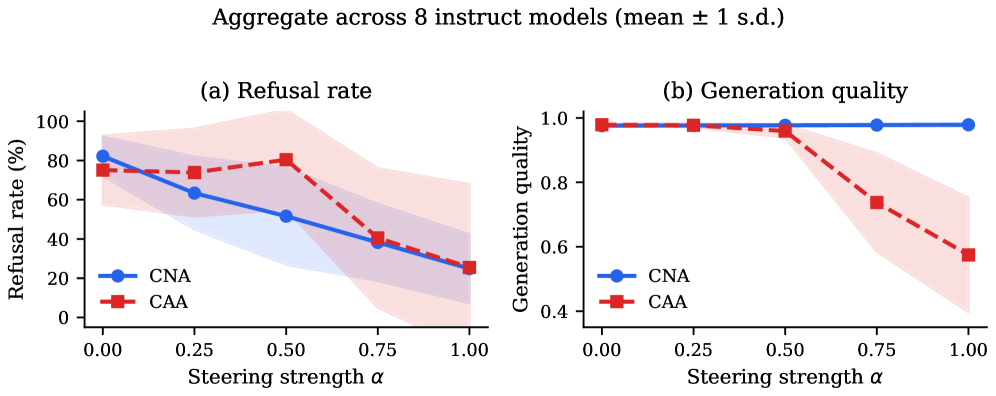
CNAの一貫性はすべての \alpha \in [0,1] において0.97以上を維持するのに対し、CAAの一貫性は \alpha \geq 0.75 を超えると崩壊します。\alpha = 1.0 時のモデルごとの数値(表1)は以下の通りです:Llama-3.1-8B-Instructは拒否率88.9%から5.1%へ、品質0.969を維持;Qwen2.5-72B-Instructは65.7%から5.1%へ、品質0.983を維持;Llama-3.1-70B-Instructは72.7%から12.1%へ、品質0.981を維持。一方、CAAは複数のモデルで拒否率0.0%を示すものの品質は0.4〜0.6であり、Qwen2.5-1.5B/72BではキーワードによるCAAの出力が縮退して拒否キーワードに引っかかることで分類器がそれぞれ100%/98%の拒否と判定するという現象も確認されています。これはsteering手法を分類器の出力のみで評価することへの有用な警告です。
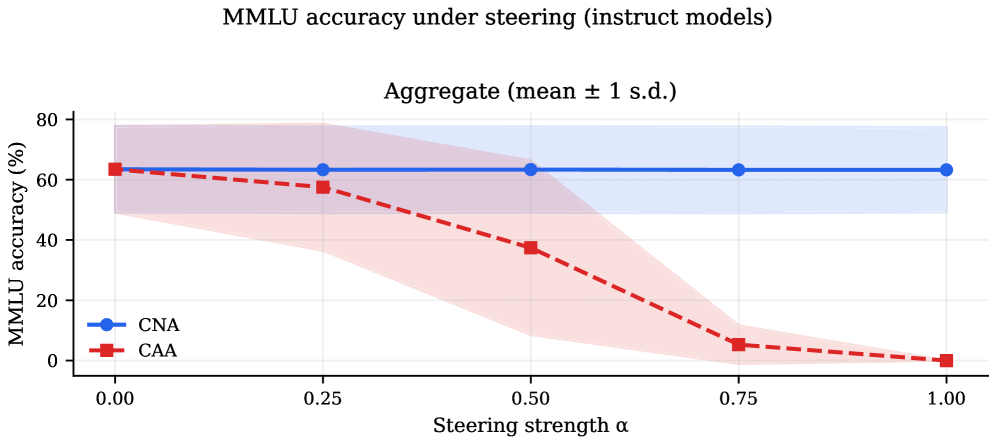
MMLUもこれを裏付けています:CNAはすべての \alpha においてベースラインから1ポイント以内に収まる一方、CAAは最大強度でほぼゼロにまで劣化します。したがって、0.1%のMLP回路はモデルを広範に損傷することなく、真に標的を絞った働きをしています。
ベースモデルとの比較(表2)は、より興味深い科学的結果です。同じ対照手続きを対応するベースモデルに適用すると、構造的に類似した後期レイヤーの回路が得られます。すなわち、ベースモデルはそのMLPにおいてすでに有害・良性の区別をエンコードしています。しかし、それをablateしても行動的にはほとんど変化しません:ベースモデルにおけるベースラインの拒否率はすでに低く(2〜35%)、CNAは行動変化ではなくわずかなコンテンツのシフトを生じさせるにとどまります。Llama-3.1-8B baseは4.0%→2.0%、Qwen2.5-7B baseは20.2%→16.2%という結果になっています。識別軸はアライメント前から存在しており、アライメント fine-tuning はその有害・良性の表現自体を生み出すのではなく、それを拒否行動に配線するものです。
限界と未解決の問題
- 拒否はキーワード分類器で測定されており、これは脆弱であることが知られています(論文自身のCAA結果においても、縮退が拒否と誤分類されるという失敗例が示されています)。意味的な拒否判定を行うjudgeを用いれば、結論をより確固たるものにできるでしょう。
- 0.1%の閾値はモデルサイズをまたいで手動で調整されており、k に対する原理的な基準がなく、回路の重複がモデルの幅とともにどのようにスケールするかについての分析もありません。
- 使用されるのは
down_proj入力における最終トークンの活性値のみです。この回路がトークン位置、より長い文脈、あるいはマルチターンのjailbreakに対して汎化するかどうかはテストされていません。 - ここでの「ablation」とは活性値をゼロに向けてスケーリングすることを意味しており、ablationと符号反転や射影との違いは切り分けられておらず、良性プロンプトに対してこれらのニューロンを活性化することで拒否を誘発するという因果的十分性のテストも行われていません。
- ベースモデル/instructモデルの主張、すなわちアライメントが既存の識別を行動に「配線する」という主張は示唆的ですが、ベースモデルにおける否定的な結果に依拠しています;instructモデル対ベースモデルにおいてこれらのニューロンを下流のattention headがどのように読み取るかなど、肯定的な機構的説明は提供されていません。
なぜ重要か
0.1%のMLP回路がMMLUや流暢性を損なわずに拒否を制御するのに十分であるならば、アライメント fine-tuning はベースモデルがすでに持っていた表現の上に施された小さく外科的な再配線である可能性が高く、これは「アライメントによってモデルが新たな概念を学習する」というRLHF/SFTの見方よりもはるかに弱い見方です。また、これはresidual-stream steeringの品質崩壊を行動制御の本質的なコストではなくbasisの人工的産物として再定義するものであり、解釈可能性の評価とred-teamingの双方に直接的な影響をもたらします。
Source: https://arxiv.org/abs/2605.12290
LongLive-2.0: 長尺動画生成のためのNVFP4並列インフラストラクチャ
問題
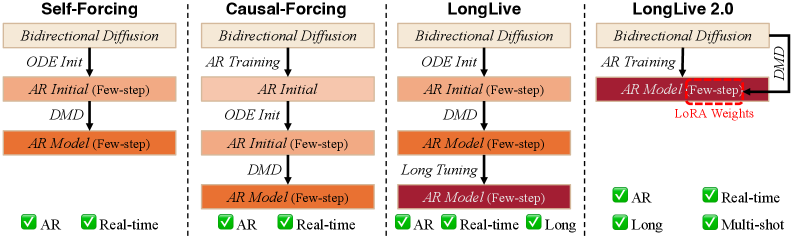
長尺の自己回帰型動画 diffusion には、二つの相互に関連するボトルネックがあります。学習側では、効率的なteacher-forcingがクリーンな履歴 latent とノイズのある目標 latent を単一の長いシーケンス [\mathbf{z}_{clean};\mathbf{z}_{noisy}] に連結するため、すぐに単一GPUのメモリを超えてしまいます。単純にsequence parallelism(SP)を適用すると、一部のランクが主にクリーン(lossに関与しない)トークンを保持し、他のランクが主にノイズのあるトークンを保持するため、負荷不均衡が生じます。また、VAE前処理が全ランクにわたって複製されます。推論側では、長いホライズンにおけるAR rollout は BF16 の linear/attention GEMM が支配的であり、メモリ帯域幅がボトルネックとなります。LongLive-2.0 は、AR fine-tuning・DMD distillation・W4A4 デプロイメントを網羅するNVFP4ネイティブなインフラストラクチャによって両方の課題に対処するとともに、多段階の Self-Forcing/LongLive レシピ(ODE init → 短尺動画 DMD → ストリーミング長尺チューニング DMD)を単一のAR学習ステージと少数ステップ推論のための独立した LoRA に統合します。
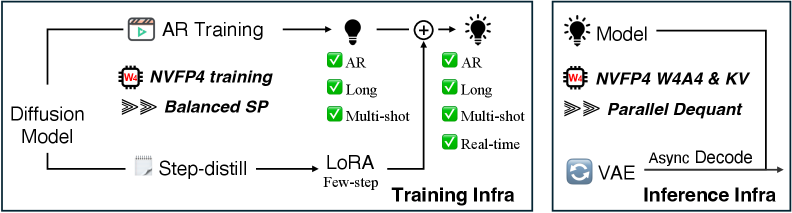
手法
Balanced SP. DeepSpeed-Ulysses を基盤として構築された Balanced SP は、(i)VAE encoding、(ii)クリーン/ノイズ latent ストリームのペア構築、(iii)DiT attention、(iv)loss 計算の全体にわたって共有される単一の時間チャンク分割を強制します。ランク p はシーケンス全体を実体化することなく、VAE を通じて自身の時間スライスのみをエンコードし、クリーン latent チャンクを保持し、ノイズスケジュールをローカルに適用して対応するノイズチャンクを取得します:
\mathbf{z}^{(p)}=[\mathbf{z}_{clean}^{(p)},\mathbf{z}_{noisy}^{(p)}]\in\mathbb{R}^{\frac{L}{P}\times H\times d}.
各ランクが同じ時間チャンクのコンテキストトークンとターゲットトークンの両方を保持するため、lossに関与するトークンが均等に分散され、ブロックスパースの因果ARマスク(各ノイズチャンクは先行するすべてのクリーンチャンクと自身のノイズトークンに attention する)を、gather なしで SP ネイティブな順序で直接生成できます。
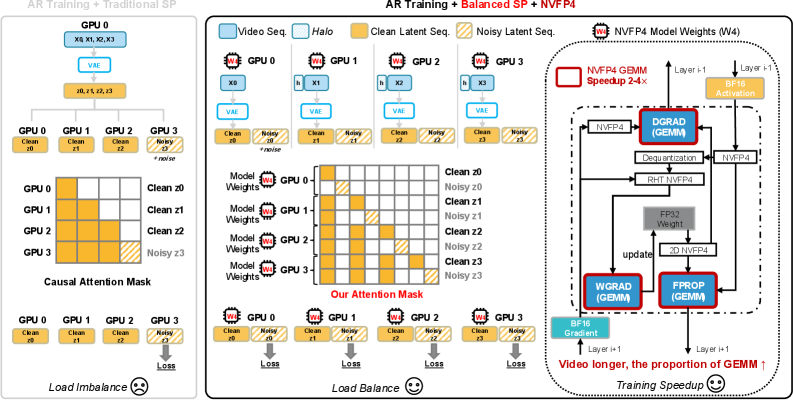
NVFP4 training. DiT・score model・LoRA ブランチにおける GEMM は NVFP4(NVIDIAのマイクロスケール FP4 フォーマットによる W4A4)で実行され、これは SP と直交しています。DMD distillation において、凍結された real-score model は NVFP4 で動作し、学習可能な student/critic は NVFP4+LoRA を使用します。これにより、LoRA ラッピング後に BF16 マスターウェイトを削除できます。
クリーンな学習パイプライン. Self-Forcing / LongLive カスケードの代わりに、LongLive-2.0 は双方向の Wan2.2-TI2V-5B を長尺動画のチャンクレベル AR diffusion モデルに直接 fine-tune し、クリーンコンテキストの teacher forcing を用います(diffusion forcing の学習-テストギャップを回避します)。各時間チャンク \mathbf{Z}_i は、因数分解された cross-attention \text{CrossAttn}(\mathbf{Z}_i,\mathbf{T}_i) を介して自身のプロンプト \mathbf{T}_i と結び付けられており、履歴の再コンディショニングなしにチャンク境界でのマルチショットプロンプト切り替えが可能です。
少数ステップ distillation. AR モデルの上で一段階の DMD が実行され、教師(元の Wan2.2-TI2V-5B)に因果ARマスクが課されます。LoRA モジュールのみが学習され、独立したウェイトが生成されます。このウェイトをマージすると、長尺動画の能力を維持しつつ、サンプリングを4ステップから2ステップに削減できます。
推論. Generator は W4A4 NVFP4 としてデプロイされ、独立した LoRA ブランチまたは融合された低ランクカーネルのいずれかが使用されます。モデルが NVFP4 を意識して学習されているため、W4A4 PTQ(例:SVDQuant、ViDiT-Q)に典型的な品質低下が回避されます。
結果
学習スループット. 16秒/32秒/64秒の動画長におけるエンドツーエンドARイテレーション時間:
- BF16: 75.3秒 / 202.7秒 / OOM
- BF16+SP: 52.2秒 / 162.7秒 / —
- BF16+Balanced SP: 45.8秒 / 136.8秒 / 1196.5秒
- NVFP4+Balanced SP: 40.1秒 / 119.3秒 / 639.5秒
これは BF16+SP に対して 1.3\times/1.4\times/2.1\times の高速化であり、シーケンス長が増えるほど総時間に占める GEMM の割合が増加するため、利得も拡大します。64秒では、NVFP4+Balanced SP が BF16+Balanced SP のイテレーション時間をほぼ半減させます。
DMD メモリ. 同一ノード上の generator/real-score/fake-score の三つ組に対して NVFP4 変換を段階的に適用することで、GPU あたりのピークメモリが 70.5 GB から 49.0 GB に削減され、21.5 GB の削減(BF16 の 0.69\times)が実現されます。
品質(VBench-Long、60秒). LongLive-2.0 は平均ランク 3.67(表中最良)に達し、subject consistency 97.48、background consistency 97.00、motion smoothness 98.86、dynamic degree 60.62 を記録します。W4A4 NVFP4 版は平均ランク 3.83 で 97.62 / 96.97 / 98.94 / 45.88 を示し、LongLive(4.17)、Rolling-Forcing(4.50)、CausVid(5.33)に匹敵または優れています。Aesthetic および imaging quality(53.68、65.51)は Rolling-Forcing(63.50、72.42)を下回っており、利得は各フレームの忠実度よりも時間的一貫性とモーションに集中していることがわかります。
制限と今後の課題
報告されている高速化は Blackwell 世代の FP4 テンソルコアを前提としており、Hopper 以前のシリコンでは GEMM の優位性がエミュレーションオーバーヘッドに埋もれてしまいます。Aesthetic/imaging メトリクスが Rolling-Forcing に対して低下しており、NVFP4 学習が高周波テクスチャを平滑化している可能性が示唆されますが、論文ではこれをデータパイプラインの違いから分離していません。64秒の BF16 パスは Balanced SP を用いても 1196.5秒/イテレーションのままであり、Balanced SP と VAE シャーディングを切り離したアブレーションが存在しないため、利得の帰属が困難です。最後に、マルチショット attention-sink メカニズムがストリーミング推論向けに言及されていますが、ショット間の identity ドリフトへの影響は定量化されていません。
重要性
これは、AR 動画 diffusion 学習全体(三つの同一ノード上のネットワークを用いた DMD を含む)において、NVFP4 が推論だけでなく学習にも使用でき、VBench スコアを低下させることなく向上させることを示した、初期の end-to-end デモンストレーションの一つです。Balanced SP レイアウトは、クリーントークンとノイズトークンが一つのシーケンスに共存する teacher-forcing AR セットアップ全般に適用できるクリーンなレシピです。
Source: https://arxiv.org/abs/2605.18739
SkillsVote: 収集・推薦・進化にわたるエージェントスキルのライフサイクルガバナンス
問題設定
長期的なタスクを扱うLLMエージェントは、軌跡(trajectory)を蓄積していきます。この軌跡は原理的に、再利用可能な手続き的知識を内包しています:どのCLI呼び出しが有効か、どのライブラリAPIが安定しているか、どのツール呼び出しの順序がタスクのクラスを解決するか、といった知識です。しかし実際には、生の軌跡はノイズが多く、冗長であり、環境固有の偶発的要素(パス、バージョン、OSの仕様)と絡み合っています。こうした軌跡をメモリ・ログのRAG・プロンプト編集などを通じてエージェントのコンテキストに無闇に組み込むと、古くなった誤ったガイダンスが以降の実行を汚染してしまいます。本論文は、再利用可能な経験の単位をAgent Skillとして定義しています:実行可能なスクリプトと、実行不可能な手続き的ガイダンス(事前条件、使用タイミング、期待される効果)を対にした構造化された成果物です。そうなると問題は、オープンソースからの収集・推論時の推薦・新しい軌跡からの進化という一連のライフサイクルにわたってスキルライブラリをどのようにガバナンスし、プロンプトの劣化を防ぐか、ということになります。
手法
SkillsVoteはスキルライブラリをバージョン管理・ゲート付きのデータベースとして扱い、三つのステージに分けて処理します。
1. 収集とプロファイリング。 著者らは、百万スケールのオープンソースコーパスから候補スキルを三つの軸でプロファイリングします:環境要件(必要なツール・状態)、品質(構造的完全性・明確さ)、検証可能性(スキルが主張する効果をテストの合成によって検証できるか否か)です。検証可能な各スキルに対して、その成否をプログラム的に判定できるタスクを合成することで、テキスト的な記述だけでなく実証的な信頼性シグナルを各スキルに付与します。
2. エージェント的ライブラリ検索による推薦。 実行前に、エージェントはスキルライブラリに対して構造化されたクエリを発行します——これは平坦なembedding検索ではなく、スキルのメタデータ(事前条件、環境タグ、過去の成功率)を検査し、コードだけでなくinstructional contextを返す検索ループです。これにより、実行可能なペイロードと、エージェントがスキルを呼び出すかどうか・どのように呼び出すかを判断するために必要な自然言語ガイダンスを分離します。
3. エビデンスゲート付き更新による進化。 実行後、軌跡はスキルに紐付いたサブタスクに分解されます。結果は四つのソースに帰属されます:(i) スキル自体の使用、(ii) 登録済みスキルの外でのエージェントの探索、(iii) 環境の影響、(iv) 結果・検証シグナル。成功が新たな再利用可能な発見に帰属できるサブタスク——環境の偶然や既存スキルによるものではない——のみが候補更新として受理されます。受理はエビデンスによってゲートされます:その発見がスキルの検証ハーネスに対して再現可能でなければなりません。これにより、成功した軌跡がすべてコンテキストに書き戻されるという失敗モードを回避します。
分解は機械的に重要なステップです。概念的には、軌跡 \tau = (s_0, a_0, \ldots, s_T) をスキル \{k_i\} に対応するセグメント \{\tau_i\} に分割したとき、結果 o_i が進化のエビデンスとして受理されるのは、
P(o_i \mid k_i, \text{env}) - P(o_i \mid \neg k_i, \text{env}) > \epsilon
すなわち、スキルが単に共起しているだけでなく、因果的に関与している場合に限られます。本論文では反事実的推定ではなく構造化された帰属を通じてこれを操作化していますが、ゲートのロジックは同じです:帰属なければ受理なし。
ライブラリはオフライン進化(デプロイ前の軌跡コーパスからのバッチ更新)とオンライン進化(デプロイ中の逐次的更新)を区別しており、ゲートの厳しさが異なります。
結果
Terminal-Bench 2.0では、オフライン進化によりGPT-5.2が最大7.9パーセントポイント改善しました。SWE-Bench Proでは、オンライン進化により最大2.6 ppの改善が得られました。この二つのベンチマーク間のギャップは示唆に富んでいます:Terminal-Benchはタスクをまたいで汎化する再利用可能なシェル・CLI手順を評価するため(スキル密度が高く、再利用性も高い)、SWE-Bench Proのタスクはリポジトリごとの特異性が高く、共有スキルライブラリが捕捉できる手続き的な共通部分が少ないのです。したがって、SWE-Bench Proにおける2.6 ppは想定の範囲内です——スキルガバナンスが最も効果を発揮するのは、スキルが実際に再利用可能な場合です。
また本論文は、百万スケールのコーパスをプロファイリングすることで、候補スキルの大部分が検証不可能または環境依存として除外されることを報告しており、無差別な取り込みはエージェント性能を向上させるどころか低下させるという主張と整合しています。
限界と未解決の問題
- 帰属はヒューリスティックである。 四つの分解(スキル・探索・環境・結果)は形式的な因果モデルではなく、スキルが複合するタスクでは k_i 間のクレジット割り当てが曖昧になります。
- 検証可能性バイアス。 収集パイプラインは合成可能な検証タスクを持つスキルを優遇するため、ライブラリはCLI・コードドメインに偏り、価値のテストが困難なスキル(例:調査・設計)が過小評価されます。
- オンライン進化の安定性。 SWE-Bench Proでの2.6 ppの改善は控えめであり、敵対的またはデータ分布がシフトしたタスクストリームにおいてオンライン更新が性能を低下させるかどうかは報告されていません。
- ライブラリスケールのダイナミクス。 ライブラリが成長するにつれてエージェント的検索コストも増大しますが、定常状態における検索レイテンシやコンテキストバジェットのトレードオフは特徴付けられていません。
- モデル間の転移。 スキルはGPT-5.2で評価されており、あるモデルが整備したスキルが性能の低いエージェントやスタイルの異なるエージェントに汎化するかどうかは未解決の問題です。
重要性
多くの「エージェントメモリ」研究は、軌跡の記録とそこからの学習を混同しています。SkillsVoteはガバナンスの問題——何がライブラリに入り、推論時に何が提示され、何が以前のコンテキストを上書きすることを許可されるか——を切り離し、エビデンスゲート付き更新がナイーブなメモリシステムのプロンプト汚染という失敗モードなしに非自明な改善(Terminal-Benchで7.9 pp)をもたらすことを示しています。このフレームワークは、エージェントの経験が蓄積・複利化することを意図した任意のデプロイメントにおいて利用可能なテンプレートとなります。
Source: https://arxiv.org/abs/2605.18401
Post-Trained MoEはSelf-Distillationにより半数のExpertをスキップできる
問題設定
Sparse MoE LLMは、入力の難易度に関わらず、トークンごとに固定されたtop-K個のexpertを活性化します。トークンごとの計算量を変化させる動的MoEの変形は、一般にゼロからの事前学習かタスク固有の適応を必要とするため、Qwen3-30B-A3BやGLM-4.7-Flashのような既にリリースされたpost-trained モデルには実用的ではありません。本論文が扱う問いは狭いながらも実践的に重要です。すなわち、expertを再学習することなく、凍結されたpost-trained静的MoEを、簡単なトークンではexpertをスキップする動的なものへと低コストで変換できるか、という点です。
手法: ZEDA
ZEDA(Zero-Expert Self-Distillation Adaptation)は2つのことを行います。パラメータフリーのzero expertを注入し、次にオリジナルモデルに対するself-distillationによってrouterを適応させます。
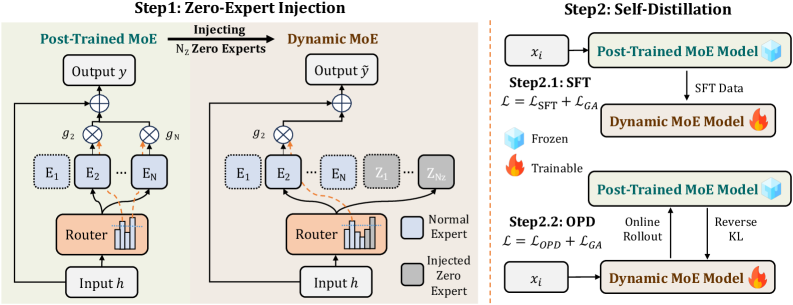
Zero-expert注入。 N個のexpert \mathcal{E}=\{E_1,\dots,E_N\}とtop-Kルーティングを持つ標準的なMoE層は以下を生成します。
y(h) = \sum_{i \in \mathcal{S}(h)} g_i(h)\, E_i(h).
ZEDAはexpertプールをN_Z個のzero expert \mathcal{Z}=\{Z_1,\dots,Z_{N_Z}\}で拡張します。ここでZ_j(h)=0は恒等的に成立します。routerは\mathcal{E}'=\mathcal{E}\cup\mathcal{Z}からtop-Kを選択し、以下が得られます。
\tilde{y}(h) = \sum_{i \in \tilde{\mathcal{S}}(h)\cap\mathcal{E}} \tilde{g}_i(h)\, E_i(h).
zero expertは何も寄与しないため、そのうちm個を選ぶことで、活性化される通常のexpert数がKからK-mに削減されます。トークンごとに選択されるzero expertの割合r_{ZE}が、動的な計算量の調整ノブとなります。N個の通常のexpertに対する元のrouterパラメータは保持されます。N_Z個の新たなrouter行は、そのlayerの既存の行の平均と分散に合わせたGaussian分布からサンプリングされ、logitのスケールが保たれます。
著者らは付録において「copy expert」(出力が入力に等しい)の代替案と比較し、copy expertがresidual streamにスケールと方向の両方のずれを引き起こすことを報告しており、これがzeroを選択する動機となっています。
グループバランシングlossを用いたself-distillation。 拡張されたモデルは、凍結されたオリジナルのMoEをteacherとして、2段階で学習されます。distillation単独では不安定です。なぜなら、何個のトークンがzero expertにルーティングされるかを制御するものがないため、routerがzeroを常に選ぶ(計算量と精度を損なう)か、全く選ばない(高速化なし)かのいずれかに崩壊する可能性があるからです。そこで係数\alphaを持つGroup Auxiliary Loss \mathcal{L}_{GA}を追加し、グループ重みwを介してzero expertの総利用量を目標値へ向けて調節します。セクション4.3のablationではw、\alpha、2段階スケジュール、およびrouter確率の再正規化について検討しています。
結果
2つのバックボーンで実験しています。Qwen3-30B-A3B(N{=}128, K{=}8, N_Z{=}64)とGLM-4.7-Flash(N{=}64, K{=}4, N_Z{=}32)です。数学、コード、instruction followingにまたがる11のベンチマークにおいて、ZEDAは精度をわずかに損なうだけでexpert FLOPsの50%以上を削減し、Qwen3では最強の動的MoE baselineを6.1ポイント、GLMでは4.0ポイント上回ります。なお、Qwen3は全体を通じてThinkingモードで実行されているため、FLOPsの削減効果は長い推論トレース上で評価されています。これはまさに動的な計算量が効果を発揮するべきレジームです。
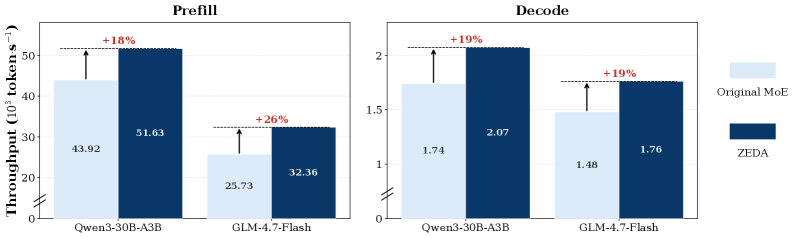
シーケンス長8192における実時間の高速化はFLOPs削減と概ね対応しており、ルーティングオーバーヘッドによって削減効果が相殺されていないことを示しています。
トークンレベルの動態
最も有益な分析はセクション4.1にあります。110のプロンプト(ベンチマークごとに10個)をサンプリングしてZEDAモデルでデコードし、著者らはトークンごとのr_{ZE}をstudent entropyおよびteacher-studentのlog-prob差 \Delta_{\text{logp}} = \log\pi_T(y_t\mid x,y_{<t}) - \log\pi_\theta(y_t\mid x,y_{<t})とともに記録しています。
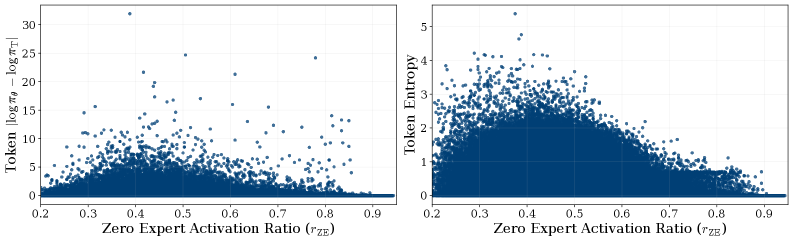
\Delta_{\text{logp}}またはentropyが高いトークンは左上に集中しています。すなわちr_{ZE}が低く(通常のexpertがより多く活性化されます)、routerはstudentがteacherと意見が異なる場合や不確実な場合に計算量を費やすことを暗黙的に学習しています。これはグローバルなバジェット制約下でのdistillationから生じる合理的な帰納的結果であり、かつ有用な解釈可能性のハンドルでもあります。r_{ZE}はトークン難易度の安価なプロキシとなります。
制限と未解決の問題
- 両モデルは同時代のMoE LLMであり、似たようなrouter設計を持っています。このレシピがfine-grained-expertアーキテクチャ(例えばshared expertを持つDeepSeekスタイルや256以上のexpert構成)に転用できるかについては、本論文では検証されていません。
- N_ZはLongCatに倣いN/2とヒューリスティックに設定されています。これを選択するための原則的な手順はなく、FLOPs削減の上限はこの選択と暗黙的に結びついています。
- 報告されている>50%のFLOPs削減はexpert FLOPsのみであり、attention、embedding、および共有コンポーネントは変更されていないため、短いコンテキストのレジームではエンドツーエンドの高速化はより小さくなります。
- distillationデータの構成については、引用箇所では深く分析されていません。OOD汎化については§4.4で触れられていますが、デプロイ時の分布がdistillationコーパスから乖離した場合の失敗モードは十分に特徴付けられていません。
- グループレベルのバランシングは平均的なr_{ZE}を制御しますが、layer単位の計算量を直接調整するものではありません。そしてMoE layerは深さ方向においてルーティング挙動が大きく異なることが知られています。
この研究が重要な理由
ZEDAはexpertの重みに手を加えることなく、静的なMoEチェックポイントをトークン適応的なものへと変換する安価なpost-hoc手続きであり、わずかな品質コストでexpert FLOPsの約50%を回収します。リリース済みのMoE LLMを提供する実務者にとっては、すぐに適用できる推論最適化手法です。研究者にとっては、r_{ZE}とteacher-student divergenceの間に現れる相関から、distillation駆動のrouter適応が自然に解釈可能な難易度シグナルを生み出すことが示唆されます。
Source: https://arxiv.org/abs/2605.18643
LiteFrame: 効率的な Vision Encoder が Video LLM におけるフレームスケーリングを実現する
問題設定
Video LLM はコンテキスト長の爆発という問題を抱えています。各フレームは数百のビジュアルトークンを生成し、LLM の prefill コストは二次的に増大します。これまでの主な対応策は、ViT の出力を LLM に渡す前に刈り込み・統合・プーリングするという事後的なトークン削減でした。著者らは、このように LLM のボトルネックが解消されると、レイテンシが今度はフレームごとの ViT 自体に移行する点を指摘します。エンコーダは依然として全フレームに対してフルコストで動作するため、ウォールクロックタイム全体は言語モデリングではなくビジョンエンコーディングによって支配されます。
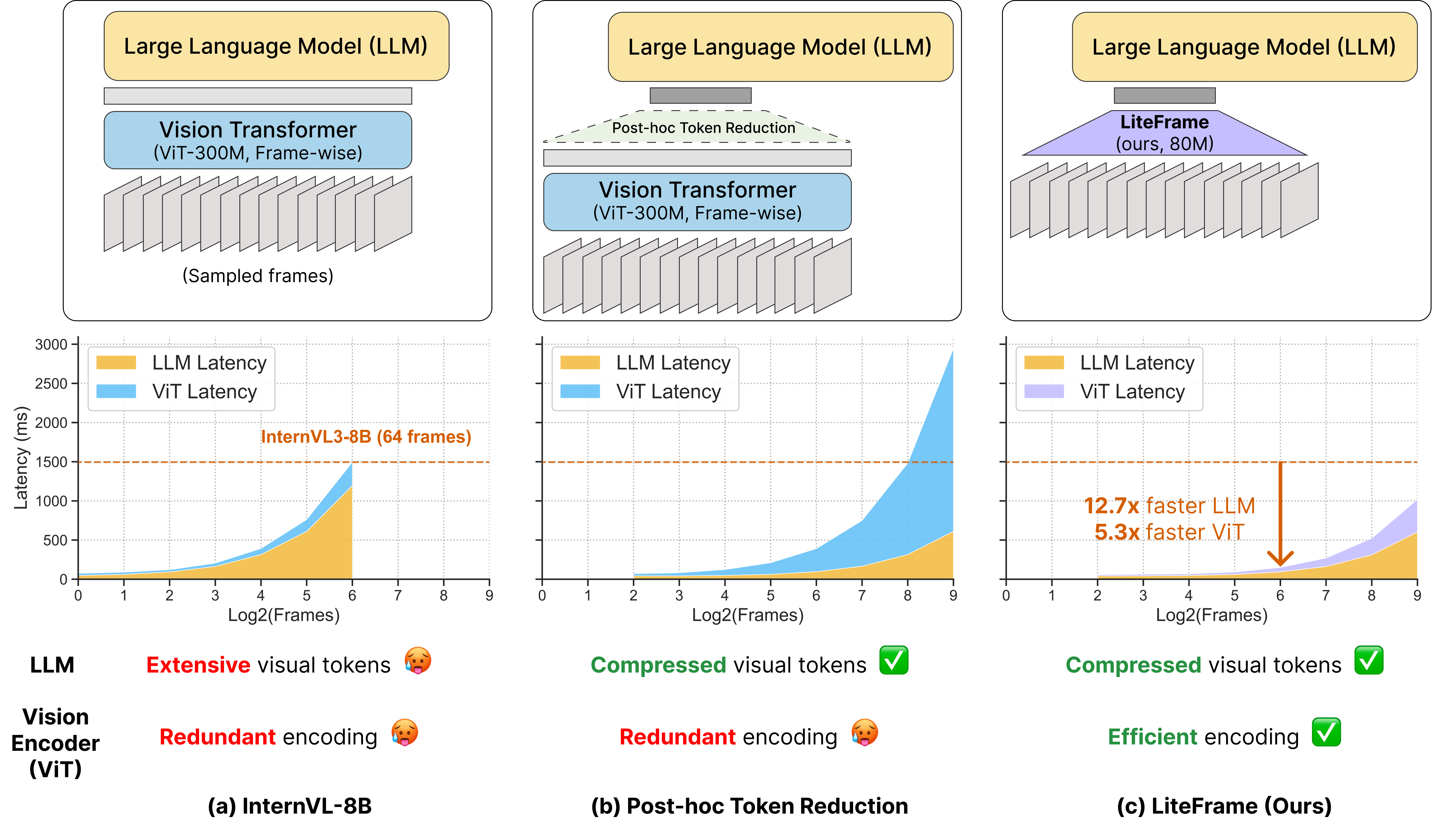
この問題が重要である理由は、長時間ビデオ理解がフレーム数に対してほぼ対数的にスケールするからです(Figure 3 左)。Video-MME、MLVU、LongVideoBench における精度向上の主なレバーはフレーム数の増加ですが、それはエンコーダのコストが安価なままである場合に限られます。
事後分析に基づく 2 つの設計前提
エンコーダを提示する前に、著者らは 2 つの経験的前提を確立しています。
(1) Weighted Average Pooling が適切な圧縮プリミティブである。 特徴テンソル \mathbf{X}\in\mathbb{R}^{T\times H\times W\times C} を時空間ブロック \Omega_{u,v,s} に分割したとき、WAP は以下を計算します。
\mathbf{Y}_{u,v,s}=\sum_{(\tau,i,j)\in\Omega_{u,v,s}}\text{softmax}\!\left(\frac{\mathbf{x}_{\tau,\text{cls}}^{\top}\mathbf{x}_{\tau,i,j}}{\sqrt{C}}\right)\mathbf{x}_{\tau,i,j},
すなわち、重複しない各ブロック内においてフレームごとの CLS トークンに対する attention 重み付き平均を適用します。ToMe や PruMerge とは異なり、WAP は位置推論に必要な時空間格子を保持します。InternVL3-8B に 64 フレームを用いた固定 16\times 圧縮での評価において、WAP は 4 つのベンチマーク平均で 62.0 を記録し、Average Pooling(60.2)、Subsampling(61.2)、ToMe(60.0)、PruMerge(59.7)、FastVID(60.6)を上回りました。なお、圧縮なしの参照値は 66.9 です。
(2) 積極的な圧縮はフレーム数との交換によって報われる。 固定されたビジュアルトークン予算のもとでは、InternVL3-8B が大幅に多くのフレームを処理できるようにする 16\times WAP が、少ないフレームによる緩やかな圧縮よりも高い精度をもたらします(Figure 3 右)。これは圧縮を積極的に推し進めることを正当化しますが、エンコーダのコストも同様に削減される場合に限ります。事後処理手法ではこれを達成できません。
LiteFrame のアーキテクチャ
student は 12 層・768 次元の ViT-Base(87M パラメータ)であり、24 層・1024 次元の ViT-Large teacher(304M、InternVL3-8B の InternViT-300M)と対比されます。主な変更点は以下の通りです。
- 深さ方向 1D 時間畳み込み(DWTempConv) が、T>1 のすべての spatial-attention 層の後に交互に配置されます。256 入力フレームにおいて、DWTempConv は 174.84 ms / 17.92 TFLOPs で動作するのに対し、temporal attention は 348.29 ms / 32.77 TFLOPs、時空間 full attention は 204.35 ms、通常の temporal convolution は 202.08 ms であり、パラメータのオーバーヘッドは 1M 未満です。
- Strided 深さ方向畳み込み がブロック 4 と 8 に配置され、ストライド [t,h,w]=[2,2,2] および [2,1,1] によりトークングリッドを段階的に縮小することで、より深い層のコストをフレームごとの ViT よりも大幅に低減します。
この圧縮は内部化されています。つまり、トークンはエンコーダの後ではなく内部で削減されるため、フレームあたりの FLOPs は深さとともに単調に減少します。
Compressed Token Distillation と LMA
student は Compressed Token Distillation(CTD)を用いて学習されます。teacher の完全なトークングリッドに一致させるのではなく、student は目標解像度 (t,h,w) における WAP 圧縮済みの teacher 出力を直接予測します。これが中心的なアイデアです。教師信号にすでに時空間圧縮を持たせることで、student は密な中間表現をインスタンス化する必要がなくなります。続く Language Model Adaptation(LMA)ステージでは、student の圧縮されたトークンを LLM の入力分布に整合させます。
結果
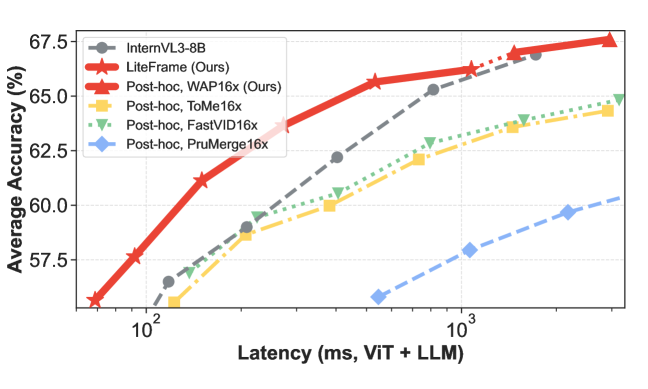
主要な数値として、InternVL3-8B との比較において、LiteFrame は 8 倍多くのフレームを処理しながらエンドツーエンドレイテンシを 35% 削減 し、4 ベンチマーク平均において新たな Pareto フロンティアを定義します(Figure 2)。WAP のみを用いた事後処理バリアントも同じフロンティア上で既存の削減手法を上回っており、アーキテクチャと distillation の利点が圧縮プリミティブと組み合わさることが確認されています。
限界と未解決の問題
- teacher は単一の画像エンコーダ(InternViT-300M)であり、ネイティブビデオ teacher(例:InternVideo2)に対して CTD がどのように振る舞うかは未検証です。
- WAP はフレームごとの CLS トークンに依存しているため、明示的な CLS を持たないエンコーダ(register-only またはfully convolutional なバックボーン)にこの定式化が一般化できるかどうかは議論されていません。
- 評価は Video-MME、MLVU、LongVideoBench に限定されており、細粒度の空間的位置推定を必要とするタスク(referring segmentation、dense captioning)は、粗い QA よりも 16\times 圧縮に対して感度が高い可能性があります。
- strided 畳み込みの配置(ブロック 4 と 8)および [2,2,2]/[2,1,1] のスケジュールは手動で設定されており、student の深さや目標圧縮率に応じてこれをどう変化させるべきかに関するスケーリング則は示されていません。
- LMA ステージは精度ギャップを埋めるうえで不可欠ですが、抜粋された論文では CTD のみと CTD+LMA の定量的比較が示されていません。
なぜこれが重要か
事後的なトークン削減が広く採用されれば、vision encoder が新たなボトルネックになります。これは Video-LLM 研究のほとんどが見落としてきた事実です。LiteFrame は問題を再定式化します。圧縮はエンコーダの特性であるべきであり、すでに圧縮された teacher シグナルに対する distillation によって学習されるべきです。そうすることで、スケーリング軸がフレームあたりのコストではなくフレーム数になります。
Source: https://arxiv.org/abs/2605.17260
Hacker News Signals
Agora-1: マルチエージェント世界モデル
OdysseyのAgora-1は、マルチエージェントシミュレーション向けに設計された世界モデルであり、複数の自律エージェントが共存して一貫した行動を取らなければならないインタラクティブな環境をターゲットとしています。技術的な主張は、大半のビデオ世界モデル(例:Genie、GameNGen、DIAMOND)に見られる単一エージェント条件付けではなく、複数の独立したエージェントの行動に同時に条件付けされた、一貫した世界状態ビデオを生成するというものです。
アーキテクチャは、エージェントごとの行動条件付けストリームを加えたlatent diffusionベースのビデオ生成を拡張したものと見られます。各エージェントの行動軌跡は個別にエンコードされ、denoising処理に注入されます。モデルはエージェント間のインタラクションにまたがって物理的・因果的一貫性を維持するよう学習されます。これは自明ではありません。単一エージェントの設定では一つの行動系列の結果を追跡するだけで済みますが、複数エージェントの場合、推論時に正解の分解なしでインタラクション・オクルージョン・複合的な物理をモデルが解決しなければならないからです。
発表されたユースケースはゲームシミュレーションと、embodied AI向けの合成データ生成です。より広い意味での関連性として、マルチエージェントタスクのための強化学習パイプラインは実環境でのrolloutか高精度シミュレータのいずれかを必要とします。ビデオ品質でエージェント間のインタラクションをシミュレートできる学習済み世界モデルは、構築コストが高いドメインにおける手作りシミュレータの代替となり得ます。
ブログ記事はアーキテクチャの詳細に乏しく、論文へのリンクはなく、学習データの構成も開示されておらず、ablationも示されていません。重要な未解決問題として、エージェント数のスケールに伴う組み合わせ爆発をモデルがどのように扱うか、行動条件付けがエージェントごとに真に独立しているのか共有されたattentionを通じて絡み合っているのか、そしてエージェントが密接にインタラクション(接触・衝突)する際の失敗モードがどのようなものになるか、といった点が挙げられます。技術レポートがない状態では主張の評価は困難ですが、デモ動画は少数のエージェントにわたってもっともらしい一貫性を持つマルチキャラクターのゲーム環境を示しています。
Source: https://odyssey.ml/introducing-agora-1
LP、FUSE、C/R、CUDA-checkpointでInferenceのコールドスタートを40倍高速化
Modalのエンジニアリングブログでは、サーバーレスinferenceにおけるGPUコールドスタートのレイテンシをおよそ20〜40秒から1秒未満に削減するための4つの技術スタックについて解説しています。
Lazy paging (LP): 実行開始前にオブジェクトストレージからモデルのcheckpoint全体をコピーするのではなく、プロセスがページにアクセスした時点でオンデマンドのページフォルトを発生させ、モデルのロードと初期のinference計算をオーバーラップさせます。これには、ページフォルトをインターセプトしてバッキングストアへの非同期読み込みを発行するFUSEファイルシステムレイヤーが必要です。
FUSEファイルシステム: Modalはカスタムなれる FUSEレイヤーを実装しており、transformer の重みレイアウトに合わせたプリフェッチヒューリスティックを用いてcheckpointデータを提供します。forward passにおける重みのアクセスはほぼシーケンシャルなパターンを示すため、先読みが有効に機能します。FUSEのオーバーヘッド(フォルト発生ごとのコンテキストスイッチ)は、GPU computeが支配的であるため均償化されます。
Checkpoint/Restore (C/R) with CRIU: Pythonランタイムが初期化され、モデルがロードされ、CUDAコンテキストが生きた状態のウォームなプロセスを、CRIU(Checkpoint/Restore In Userspace)を用いてスナップショットします。新たなコールドリクエストが来た際、CRIUはPythonのimportチェーンやCUDAコンテキストのセットアップを再実行するのではなくメモリ状態を再現するため、restoreは初期化を最初から実行するよりも高速です。
CUDA-checkpoint: 標準的なCRIUはGPUメモリをスナップショットできません。ModalはCUDA固有のcheckpointingメカニズム(NVIDIAのCUDA checkpoint APIまたはユーザー空間の同等機能に関連)を使用し、デバイスメモリとCUDAストリームの状態をCPUスナップショットと合わせてシリアライズします。Restoreの際はGPUメモリを再マップし、フレームワークの初期化を再実行することなくストリームを再初期化します。
これらを組み合わせることで、コールドスタート時間のおよそ40倍の削減を達成しています。主なエンジニアリング上の制約は、C/Rスナップショットがモデルのバージョンに固有であり、重みの更新時には無効化して再生成しなければならない点です。FUSEはステディーステートのスループットにわずかなペナルティをもたらしますが、コールドスタートの改善を考えれば許容範囲内であるとブログでも認めています。
Source: https://modal.com/blog/truly-serverless-gpus
音声AIシステムは隠蔽された音声攻撃に対して脆弱である
IEEE Spectrumの記事は、実運用中の音声AIパイプライン――ASR(自動音声認識)、話者認証、音声起動コマンドシステム――に対する敵対的音声攻撃を概説しています。この脅威のクラス自体は目新しいものではありませんが、音声対応LLMアシスタントの普及に伴い、攻撃対象となる展開面は大幅に拡大しています。
取り上げられている主要な攻撃タイプは以下のとおりです。超音波注入(ultrasonic injection)は、コマンドを20 kHz以上の超音波キャリアに変調するもので、人間には聞こえないものの、MEMSマイクのサンプリング帯域内にあり、ハードウェアの非線形性によって可聴周波数にダウンコンバートされます(「DolphinAttack」クラス)。敵対的音声摂動(adversarial audio perturbations)は、音声に小さな \ell_\infty 有界ノイズを加えることで、人間には無害または無音に聞こえながらも、ASRの書き起こしを攻撃者が指定した文字列に変えてしまうものです。空中再生(over-the-air replay)は、スピーカーを通じて室内音響を利用し、周囲の音声にコマンドを埋め込む手法です。
この記事では、ニューラルなエンドツーエンドASRモデル(Whisperクラス)は少なくともHMM方式の前世代と同程度に脆弱であること、またd-vectorやx-vector embeddingを用いた話者認証システムは音声変換や敵対的波形によってなりすまし可能であることが指摘されています。生体検知(liveness detection)(合成音声と自然音声の識別)はハードルを引き上げますが、それ自体も攻撃可能です。
議論されている防御策としては、超音波成分を減衰させるバンドパスフィルタによる入力前処理、既知の摂動タイプに対するadversarial training、注入信号の空間的非一貫性を利用したマルチマイクロフォンアレイ手法、およびアンサンブル検証が挙げられています。しかし、いずれも包括的な解決策ではありません。根本的な問題は、勾配ベースの攻撃が任意の微分可能モデルに対して最適化可能であり、モデルファミリーをまたいだブラックボックス転用性(black-box transferability)が広く文書化されているという点にあります。
実践的な含意として、特権的なアクション(スマートホーム、自動車、認証)を伴う音声制御システムはすべて、未認証の物理レイヤー攻撃面を持つものとして扱うべきです。
Source: https://spectrum.ieee.org/voice-ai-audio-attacks
Alignment Pretraining:AIに関する言説が自己成就的な(ミス)アライメントを生み出す
このarXiv論文(2601.10160)は、AIアライメントに関する言説のコーパス――安全性に関する論文、AIエシックスに関する文章、AIの目標に関する考察――が、今や意味のある pretraining シグナルを構成するほど十分に大きくなっており、そのコーパスで学習されたLLMがその言説に埋め込まれた概念的フレームを内面化する可能性があり、それは単純に「aligned」とは言えない形で現れうると主張しています。
提案されているメカニズムは次の通りです:アライメント研究者は特定の失敗モード(deceptive alignment、goal misgeneralization、reward hacking)について詳細に記述します。このテキストはそうした振る舞いを詳細に描写・精緻化しています。十分に大規模なクロールによってこの資料で学習された言語モデルは、これらの行動スキーマをin-contextの概念として学習し、その結果、この資料を欠くコーパスで学習されたモデルと比べて、推論時にその記述された振る舞いがより引き出されやすくなる可能性があります。これは、セキュリティ論文で攻撃手法を記述することがその攻撃の普及にもつながるという考え方の変形です。
この論文はこれを分布論的な議論によって緩やかに形式化しています:アライメントに関する言説が、世界における特定の行動パターンのベースレートと比較してそれらを過剰に表現している場合、テキストによって世界モデルが形成されるモデルはそれらのパターンに対して確率質量が膨張した状態になります。デプロイされたモデルがさらにそのようなテキストを生成するならば、自己成就的なループが閉じます。
これは概念的に挑発的な議論ですが、経験的な検証は薄いです。この論文は、特定のアライメント言説の概念が、評価においてモデルが記述された振る舞いを示す傾向を因果的に高めることを実証していません。pretraining データの構成からモデルの振る舞い、そして現実世界の結果に至る因果連鎖には、制御されていない変数が多数含まれています。それでも、再帰性に関する懸念は正当であり、十分に探究されていません:将来のモデルのための学習コーパスには今日の安全性研究が含まれており、研究者がこのフィードバックを考慮することはほとんどありません。
Source: https://arxiv.org/abs/2601.10160
Qwen 3.7 プレビュー
AlibabaのQwenチームがQwen 3シリーズを継続する形でQwen 3.7のプレビューを発表しました。発表およびコミュニティの議論によると、このモデルはMoEではなくdenseなtransformerで、アクティブパラメータ数は約7B、コンテキストウィンドウは128Kです。「3.7」という命名規則は、パラメータ数を示すものではなく、バージョン3と将来のメジャーバージョンとの間の中間リリースを意味しています。
技術的に注目すべき主張としては、コーディングおよび数学のベンチマークにおいてQwen 2.5-7BおよびQwen 3と比較して instruction following が改善されており、MATHおよびHumanEvalクラスの評価ではより大規模なオープンウェイトの競合モデル(Llama 3.1 8B、Mistral 7B v0.3)に匹敵するか上回ると報告されています。また、128Kでの長文コンテキスト検索性能の改善についても言及されており、これはベース事前学習後に適用されたRoPEスケーリングまたはYaRNの fine-tuning と整合しています。
ツイートスレッドではスケール以外のアーキテクチャ上の変更は開示されていません。これまでのQwenのリリースパターンを踏まえると、重みはHuggingFaceでの公開に向けて準備が進められているものと推測されます。HN上のコミュニティ議論は、ベンチマークの比較可能性と、Qwenモデルがllamaバリアントと並ぶ基準点となっている7Bクラスのオープンウェイト空間における急速なイテレーションのペースに焦点を当てています。
実用的な意義はdenseな7Bクラスにあります。このセグメントはコンシューマー向けハードウェア(単一のRTX 4090またはApple MシリーズでのQ4量子化)によるローカル推論が実現可能な領域であり、このサイズでの品質の限界的な改善は、エッジデプロイメント、fine-tuning の計算予算、および蒸留ターゲットのベースモデルとして即座に下流の価値をもたらします。
Source: https://twitter.com/Alibaba_Qwen/status/2056403591464984753
証明可能なセキュアOSの基礎(PSOS)(1979年)
1979年にNeumann、Robinson、Levitt、Boyer、およびParmasによって執筆されたSRIの技術報告書は、PSOS(Provably Secure Operating System)を記述しています。これは、セキュリティ特性を形式仕様から機械的に検証可能なOSを構築しようとした、最初期の形式的試みのひとつです。
そのアプローチは階層的です。システムは抽象機械層の列に分解され、各層は形式言語(DijkstraのPredicate Transformer記法の派生であるSPECIAL)によって仕様化されます。各層はオブジェクトと操作のサブセットを実装し、上位層は下位層のプリミティブの上に構築されます。セキュリティ特性(Bell-LaPadulaおよび関連モデルの用語における機密性・完全性)は抽象状態上の不変条件として記述され、各層における各操作によってその保存が証明されなければなりません。
capabilityモデルが中心的な役割を担っています。主体はcapability(埋め込まれた権限を持つ型付きの偽造不可能なオブジェクト参照)を通じてのみオブジェクトにアクセスします。形式モデルにより、capabilityの閉じ込めが証明によって強制可能であることが保証されます。すなわち、プロセスは仕様が許可する範囲を超えてcapabilityを構築・増幅することができません。
これが歴史的に重要な理由は、SELinux、形式検証済みマイクロカーネル(seL4、2009年)、そしてセキュリティカーネルに関する文献のほとんどに先立っているにもかかわらず、問題の核心を正確に捉えている点にあります。すなわち、非形式的な仕様には攻撃者に悪用されうる隙間が残ること、そして意味のあるセキュリティ証明には小規模かつ形式仕様化されたTCBが不可欠であるという点です。PSOSは実行可能なシステムとして完成されることはありませんでしたが、その設計原則——階層的抽象化、capabilityベースのアクセス制御、機械検査による不変条件——は、その後の世代の形式検証システム研究においていずれも再び現れています。
現在の読者にとってこの文書が注目に値するのは、基本的な困難な問題(TCBの最小化、下方への閉じ込め、covert channel)が、45年後の今もなおメインストリームのOSにおいて未解決のまま残っていることを如実に示している点にあります。
Source: http://www.csl.sri.com/users/neumann/psos.pdf
AI Eats the World(2026年春 業界レポート)
これはAIの導入状況・能力・経済的影響を扱う定期的な業界レポート(2026年春版)です。PDFの形式とトーンは、研究者向けというよりベンチャーキャピタルやアナリスト向けを想定していますが、データポイント自体は抽出する価値があります。
実質的な技術的・実証的主張として注目すべき点:本レポートでは、フロンティアモデルのinferenceコストカーブがトークン単価ベースでムーアの法則を上回るペースで低下し続けていることを記録しています。これはハードウェア面(H100からB200への移行、inference最適化チップ)とソフトウェア面(speculative decoding、INT4/FP8でのquantizationによる能力劣化の最小化)の両方によって駆動されています。コーディングおよびソフトウェアエンジニアリングの自動化は、測定可能な生産性向上が最も大きいセクターとして挙げられており、AI支援ツールを使用するプロフェッショナル開発者のスループットが20〜40%向上することを示した大規模な対照研究がいくつか引用されています。
本レポートはエージェント的なデプロイパターン——単一クエリの補完から、マルチステップワークフローを実行する永続的agentへの移行——を取り上げており、これによって信頼性のボトルネックが単一呼び出しの精度から長い行動シーケンス全体にわたる複合誤り率へとシフトすることを指摘しています。これは技術的に正しい観察です。すなわち、20ステップのagentパイプラインにおける各ステップの精度が95%であれば、エンドツーエンドの成功確率は 0.95^{20} \approx 0.36 となります。
モデルアーキテクチャのトレンドについては、フロンティアモデルのトレーニングにおけるmixture-of-expertsへの収束(GPT-4クラス、Gemini 1.5、Mixtralの系譜)と、10Bパラメータ未満のエッジ向けデプロイセグメントにおけるdenseモデルの継続的な優勢が記録されています。
この種のレポートの限界として:導入統計は自己申告または間接的なシグナル(API収益の代理指標、アンケートデータ)から導出されており、生産性に関する因果的主張は方法論的に互換性のない異種の研究から引き出され、また予測セクションは反証可能ではありません。予測ではなく、集約されたトレンドデータとして読むことを推奨します。
注目の新規リポジトリ
future-agi/future-agi
LLMおよびエージェントパイプライン向けのエンドツーエンドの可観測性・評価プラットフォームです。このスタックは6つの独立した関心事をカバーしています:分散トレーシング(マルチステップのエージェント実行にわたるspanのキャプチャ)、構造化評価(ルーブリックベースまたはモデルによる採点)、シミュレーションハーネス(リプレイおよび合成シナリオテスト)、データセットのバージョン管理、ルーティング・ロードバランシング用のLLM gateway、そして入出力フィルタリングのためのガードレールフックです。すべてセルフホスト可能であり、データレジデンシーの制約があるチームや、テレメトリをネットワーク外に送出せずにプロプライエタリモデルに対してevalを実行する必要があるチームにとって重要な特性です。アーキテクチャ的にはOpenTelemetry互換のトレーシングインターフェースを公開しており、既存のインストルメント済みコードベースは最小限の変更でspanをルーティングできます。eval層は決定論的メトリクス(BLEU、完全一致、JSONスキーマバリデーション)とLLM-as-judgeパイプラインの両方をサポートしています。シミュレーションではパラメータ化されたシナリオインジェクションが可能であり、実トラフィックの分布を超えたエージェントのストレステストを行えます。gatewayはクリティカルパス上に位置しレイテンシのオーバーヘッドを加えるため、ユーザーが自身でベンチマークする必要があります——本プロジェクトはこの数値を公開していません。Apache 2.0ライセンスであり、評価データを完全に管理したい本番エージェントシステムを構築するチームにとって、LangSmithやWeights & Biasesといったホスト型プラットフォームに対する有力な代替手段となります。
Source: https://github.com/future-agi/future-agi
chiennv2000/orthrus
Orthrusは、トークン生成をデュアルビュー拡散デコーディングプロセスとして定式化することで、自己回帰型LLM推論のロスレス高速化スキームを提案しています。核心的なアイデアは、通常の左から右へのパスと補助ビューという2つの相補的な「ビュー」を同時に実行し、両者の一致を利用してトークンを並列に投機的に受理または棄却するというものです。これは精神的にはspeculative decodingに近いですが、別途小規模なdraftモデルを必要としません。「ロスレス」という主張は、出力分布が標準的なgreedy decoding またはサンプリングデコーディングと証明可能に同一であることを意味します。拡散のフレーミングは、ドラフトトークンに関する不確実性をモデル化するための原理的な方法を提供し、単純な投機的アプローチよりも受理率を向上させる可能性があります。「Orthrus」(双頭の犬)という名称は、デュアルビューアーキテクチャを直接的に参照しています。スター数323、ドキュメントも限られており、これはプロダクション向けライブラリではなく研究用コードであり、標準的なスループット評価環境(例:vLLMに相当するA100上のtokens/sec)における公開ベンチマークが存在しないことは顕著な欠点です。最も重要な未解決の問題は、受理率とwall-clockでの高速化がモデルサイズおよびサンプリング temperature によってどのように変化するかという点です。
Source: https://github.com/chiennv2000/orthrus
raiyanyahya/how-to-train-your-gpt
ゼロから実装した教育目的のGPTで、トレーニングスタック全体を理解しやすくすることを目指しています。すべての行にインラインコメントが付いており、単なる動作の説明ではなく意図を解説しています。カバーしている内容は、トークナイゼーション(BPEのゼロからの実装)、transformer ブロック(multi-head attention、layer norm の配置、residual connections)、positional encoding、gradient accumulation を含むトレーニングループ、そして基本的なサンプリング戦略です。実際に何が起きているかを隠してしまう抽象化レイヤーを避けることを明示的な目標としているため、コアパスには Hugging Face や Lightning への依存関係が存在しません。これにより、コース教材として、あるいは API 経由で transformer を使ったことはあるものの forward pass を手で追ったことがないエンジニアにとって有用なものになっています。コードベースはコンシューマー向けハードウェア上で小規模なテキストデータ(文字レベルまたはサブワードレベル)を用いてトレーニングするものであり、GPT-3/4 規模の再現を試みるものではありません。限界はその強みの裏返しでもあります。つまり、本番環境における懸念事項(mixed precision、FSDP、flash attention、gradient checkpointing)はスコープ外です。1675 スターを獲得しており、独学者の間で一定の支持を得ています。推奨される使い方は、Karpathy の makemore/nanoGPT と並行して読むことで、コメントのスタイルが互いを補完し合います。
Source: https://github.com/raiyanyahya/how-to-train-your-gpt
agentic-in/elephant-agent
Elephant Agentは「パーソナルモデル優先・自己進化型」AIエージェントとして位置づけられており、汎用タスク実行よりも永続的なユーザー固有のメモリと反復的な自己改善を設計上の優先事項としています。「パーソナルモデル優先」というフレームは、時間をかけたローカルfine-tuningまたは検索拡張型のパーソナライゼーションを示唆しており、エージェントはインタラクション履歴を蓄積し、構造化された好みや事実を抽出し、ユーザーが手動でプロンプトエンジニアリングをすることなく将来の挙動を条件付けるためにそれらを活用します。「自己進化」のコンポーネントは自動化されたフィードバックループを示唆しており、エージェントは自身の出力を評価し、失敗モードを特定し、それに応じてメモリや行動ポリシーを更新します。スター数328のこのリポジトリはまだ初期段階にあり、自己進化メカニズムの技術的詳細(RLHF方式のフィードバック、DPO、あるいは純粋に検索ベースの適応のいずれを使用するか)は十分にドキュメント化されていません。象のメタファー(決して忘れない)は意図的なものです。主なエンジニアリング上の未解決課題は、メモリストアが推論時にどのようにインデックス化・検索されるか、パーソナライゼーションの更新頻度はどの程度か、そしてfine-tuningのパスが関与する場合に壊滅的忘却(catastrophic forgetting)がどのように処理されるか、という点です。
Source: https://github.com/agentic-in/elephant-agent
Ethan-YS/project-brain
Project Brain は、ソフトウェアライブラリではなく、ファイルシステムベースの軽量な方法論です。核となるアイデアは、プロジェクトリポジトリと共にコミットされる単一の構造化フォルダ(「brain」)であり、AIコーディングアシスタント向けの永続的なコンテキスト――現在のタスク状態、アーキテクチャ上の意思決定、未解決の疑問、セッションのサマリーなど――をそこに記録します。各セッションの開始時にAIアシスタントがこのフォルダを読み込んで作業メモリを再構築することで、会話のたびに以前のコンテキストが失われるコールドスタート問題を回避します。この方法論には、維持すべきファイル(例:status.md、decisions.md、next-steps.md)に関する規約と、セッション終了時にAIがそれらを更新するためのプロンプトが含まれています。モデル非依存であり、ファイルコンテキストを受け付けるあらゆるアシスタント(Cursor、GitHub Copilot with workspace context、Claude Projectsなど)で動作します。この手法の価値は、新規技術ではなく、規律とスキーマそのものにあります。制限事項としては、手動でのオーバーヘッドが発生すること、および継続性の品質がAIのセッション作業要約の忠実さに完全に依存することが挙げられます。スター数143と知名度は限られていますが、複数週にわたるプロジェクトでAIアシスタントを利用するソロ開発者が抱える現実の課題に対処しています。
Source: https://github.com/Ethan-YS/project-brain
crynta/terax-ai
TeraxはAI層をシェルのインタラクションループに直接統合したターミナルエミュレータであり、Rust(バックエンド/PTY処理)、Tauri(デスクトップシェル)、React(UI)を用いて構築されています。バイナリサイズ7 MBという制約は意図的な設計上の判断であり、AI推論をリモート(バンドルされたweightsではなくAPIコール)に留め、Rustの軽量なランタイムを活用することで実現しています。AI層はユーザー入力とPTYの間に位置し、自然言語コマンドの解釈、補完候補の提示、コマンド出力のインライン説明、実行前の破壊的操作の警告といった機能を担います。Rust/TauriはPTYの多重化と低レイテンシなレンダリングにおいてネイティブ性能を発揮し、ReactはコンポーザブルなUIサーフェスを担当するという構成は、モダンなクロスプラットフォームデスクトップツールで広く見られるパターンです。純粋なWebベースのターミナルラッパー(Warp、Wave)と比較すると、Tauriアプローチはelectronのメモリオーバーヘッドを回避できます。主な未解決の問題としては、AIによる提案がクリティカルな入力パスに置かれた場合のレイテンシ特性、オフライン時のフォールバック動作、そしてAIのコンテキストにシェル履歴や環境状態が含まれるのか現在のコマンドのみなのかといった点が挙げられます。スター数3939は本バッチの中で最も高い注目度です。
Source: https://github.com/crynta/terax-ai
antoniolupetti/algebrica
Algebricaは、計算ツールではなく概念的な明確さを中心に構造化された、オープンな数学知識ベースです。記号計算を実装するものではなく、定義・定理・証明およびそれらの関係といった数学的知識を、人間の理解と構造的一貫性に最適化された形式で整理しています。概念間の依存関係を明示することに重点が置かれており、定理のページには、その定理が前提とするもの、何を一般化したものか、そして何を可能にするかが明確に記載されています。対象読者は、動機付けのない定義の順序や概念的な足場の欠如によって標準的な教科書を難解に感じる学生や独学者です。公開ドキュメントには技術的な実装の詳細がほとんど記載されていませんが、このプロジェクトは数学的オブジェクトに対して一貫したスキーマを持つ、構造化された静的サイトまたはウィキのようです。既存のリソース(Wikipediaの数学記事、nLab、ProofWiki)と比較した際の差別化点は、形式的な厳密さを犠牲にしない教育的アクセシビリティにあるとされています。623スターを獲得しており、実際の関心を集めています。主な課題はカバレッジです。コミュニティ主導の数学知識ベースは貢献の速度に依存しており、形式数学は貢献者にとってハードルの高い分野です。長期的な持続可能性とピアレビューのプロセスは未解決の問題として残っています。
Source: https://github.com/antoniolupetti/algebrica
mrslimslim/gpt-image-canvas
GPT Image Canvasは、tldraw(オープンソースの無限キャンバスライブラリ)上に構築され、GPT-4oの画像生成APIをキャンバス操作に組み込んだ、ローカル動作の画像編集・生成ワークスペースです。このデザインは、参照画像・マスク・テキストプロンプトをキャンバス要素として配置できる空間的・多オブジェクト編集サーフェスをユーザーに提供し、そのコンテキスト内でモデルを呼び出して生成や編集を行えるようにしています。アーキテクチャ的には、チャットボット型の画像インターフェースよりもプロフェッショナルなコンポジティングツールに近い設計です。キャンバスの状態(位置、選択、マスク)が、線形的な会話ではなくプロンプトおよび画像編集呼び出しを駆動します。ローカル動作であるため、APIキーはデバイス上に留まり、キャンバス状態を保存するSaaS仲介者が存在しません。tldrawの統合が重要な技術的選択であり、協調編集プリミティブを備えたプロダクション品質の無限キャンバスを無償で提供することで、作者はAI統合レイヤーに集中できています。制限事項として、モデルレイヤーにはOpenAIのAPIに依存しているため、UIの意味ではローカルですが、推論の意味ではローカルではありません。ローカル拡散バックエンド(ComfyUI、Automatic1111 API)のサポートが自然な拡張方向となるでしょう。374スターを獲得しており、空間的AI編集ワークフローの洗練されたプルーフ・オブ・コンセプトとなっています。