Daily AI Digest — 2026-05-19
arXiv Highlights
KVPO: ODE-Native GRPO for Autoregressive Video Alignment via KV Semantic Exploration
Problem
Streaming autoregressive (AR) video generators distilled into few-step flow-matching samplers run a deterministic probability-flow ODE per block. Standard preference-alignment recipes — DDPO, Flow-GRPO, and other RL post-training methods — were designed for stochastic SDE sampling and inject Gaussian noise into either x_T or per-step transitions to construct a behavior policy with tractable likelihood. Two problems follow for distilled AR video models. First, there is a policy/dynamics mismatch: the deployed sampler is an ODE, but optimization is performed against an SDE surrogate, so updates are biased relative to the actual rollout distribution. Second, noise-space exploration mostly perturbs low-level pixels; for long-horizon multi-prompt video, the failure mode that matters is semantic drift — failed prompt switches, dropped objects, narrative incoherence — which is governed by the historical KV cache, not by per-block noise.
KVPO targets exactly this gap: an ODE-native GRPO that explores in the KV cache rather than in noise.
Method
The base setup is block-wise AR generation p_\theta(v_b \mid v_{<b}, \mathcal{C}) with a (sink, local) KV memory \mathcal{K}_{<b}, generating each block via flow-matching ODE integration of v_\theta(x_t, t, \mathcal{K}_{<b}) along x_t = t x_0 + (1-t) x_T.
Causal-semantic exploration via KV routing. Instead of resampling x_T across the G candidates of a GRPO group, KVPO fixes the initial noise and stochastically routes entries of the historical KV cache within a perturbed window to produce G semantically diverse continuations. Because the routing only reshuffles on-manifold past tokens that the model itself produced, branches stay on the data manifold while diverging in storyline — the variation that long-video reward models actually score.

The contrast in Figure 1 is the central design claim: noise-space exploration spreads candidates in pixel statistics around a single semantic trajectory, whereas KV routing spreads them across distinct semantic trajectories that share low-level appearance.
Trajectory Velocity Energy (TVE) surrogate policy. To do GRPO without an SDE, KVPO defines branch likelihood directly in flow-matching velocity space. For each candidate branch i, the model is replayed under the unperturbed deployment-time KV context, and at each ODE step s the deviation between the branch’s realized velocity and the deployment-context velocity is accumulated into a Trajectory Velocity Energy
\mathrm{TVE}_i = \sum_s \big\| v_\theta(x_{t_s}^{(i)}, t_s, \mathcal{K}_{<b}^{\text{routed}}) - v_\theta(x_{t_s}^{(i)}, t_s, \mathcal{K}_{<b}) \big\|^2,
which plays the role of -\log \pi for the branch. The GRPO objective becomes a reward-weighted contrastive loss over branches: high-reward branches are pulled toward low TVE (matching the deployment ODE), low-reward branches are pushed away. This keeps optimization fully inside the ODE formulation — no SDE surrogate, no Gaussian likelihood approximation.
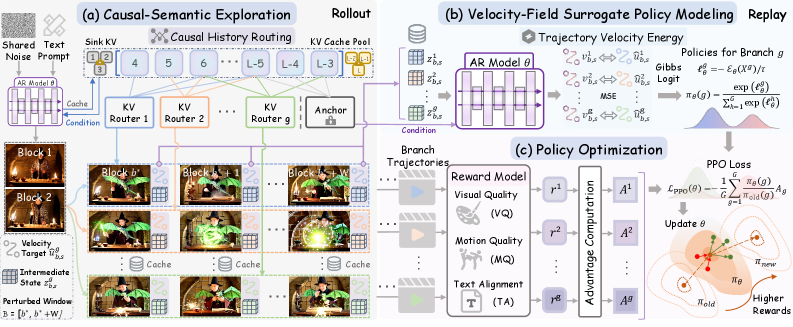
The two-pass structure in Figure 2 — perturbed rollout for exploration, unperturbed replay for likelihood — is what reconciles diversity with the ODE-native policy.
Training. LoRA with r=\alpha=256 on top of LongLive and MemFlow (both Self-Forcing-distilled). Group size G=8, 32 prompts per iteration on 32 H200 GPUs, ~960 s/iter, convergence at 3k–4k samples (~1000 GPU-hours). Training prompts come from VidProM, refined by Qwen3, segmented into 4-prompt groups with switches every 588 frames (147 latent frames).
Results
Evaluated on three reward-aligned metrics — VQ (visual quality), MQ (motion quality), TA (text alignment) — and four VBench metrics. The long-horizon, multi-prompt setting is where the method should pay off most, and it does.
Single-prompt short-video, LongLive baseline → +KVPO: VQ 8.86 → 10.21 (+15.2%), MQ 1.80 → 1.89 (+5.0%), TA 0.02 → 0.06 (+200%). MemFlow: VQ +9.1%, MQ +2.7%, TA +50%.
Multi-prompt long-video, LongLive → +KVPO: VQ 6.34 → 8.14 (+28.4%), MQ 1.41 → 1.50 (+6.4%), TA −0.19 → −0.14 (+26.3%). MemFlow: VQ +10.5%, MQ +3.6%, TA +15.0%. VBench Semantic improves from 67.88 to 69.02 on LongLive long-video; Consistency Score 88.37 → 88.62; CLIP Score 31.90 → 32.29.
The margin over Astrolabe — a noise-exploration post-training baseline — widens in the long-video regime (e.g., LongLive long-video VQ 7.26 vs 8.14), which is the regression test for the central thesis: semantic-space exploration matters more as horizon grows.

Qualitatively, the LongLive comparison shows cleaner prompt-switch transitions and steadier object identity across segments; the MemFlow comparison reports similar gains in cross-segment consistency.
Limitations and open questions
The TVE surrogate replaces a true log-likelihood with a velocity-space distance under the deployment context, which is a heuristic — its bias relative to the exact ODE log-density is not characterized. The KV routing scheme has free parameters (which window, which entries, routing distribution) that the paper treats empirically. TA scores remain negative in the long-horizon setting (−0.14 best), suggesting absolute prompt-following is still poor even after alignment. Comparisons are restricted to two distilled AR backbones and one external baseline (Astrolabe); behavior under non-distilled or non-flow-matching AR video models is untested. The 1000 GPU-hour budget is non-trivial despite LoRA.
Why this matters
Distilled video generators are ODEs, and aligning them with SDE-shaped RL objectives is a category error that gets papered over with noise. KVPO identifies the right exploration variable — historical KV state, which controls semantics — and the right likelihood surrogate — velocity-field energy, which lives in the model’s native space — yielding a clean GRPO formulation specifically for AR video. The disproportionate gains in the multi-prompt long-horizon regime suggest this is the correct factorization of the alignment problem for streaming generation.
Source: https://arxiv.org/abs/2605.14278
OProver: A Unified Framework for Agentic Formal Theorem Proving
Problem
Recent Lean 4 provers (Goedel-Prover-V2, DeepSeek-Prover, LongCat-Flash-Prover) have pushed whole-proof generation through scaled synthetic data and verifier-aware training, but agentic behavior — iteratively repairing failed proofs from compiler feedback and retrieved exemplars — typically appears only at inference time, decoupled from training. As a result, the policy never learns to exploit the structure of compiler errors or retrieved proof context; it merely emits independent samples and relies on Pass@N to find a working one. OProver closes this loop: agentic rollouts are part of the training distribution, and the corpus, retrieval memory, and policy co-evolve.
Method
OProver consists of three coupled components: a policy \pi, a retrieval memory \mathcal{M} of compiler-verified proofs, and the Lean 4 compiler \mathcal{V} as the environment.
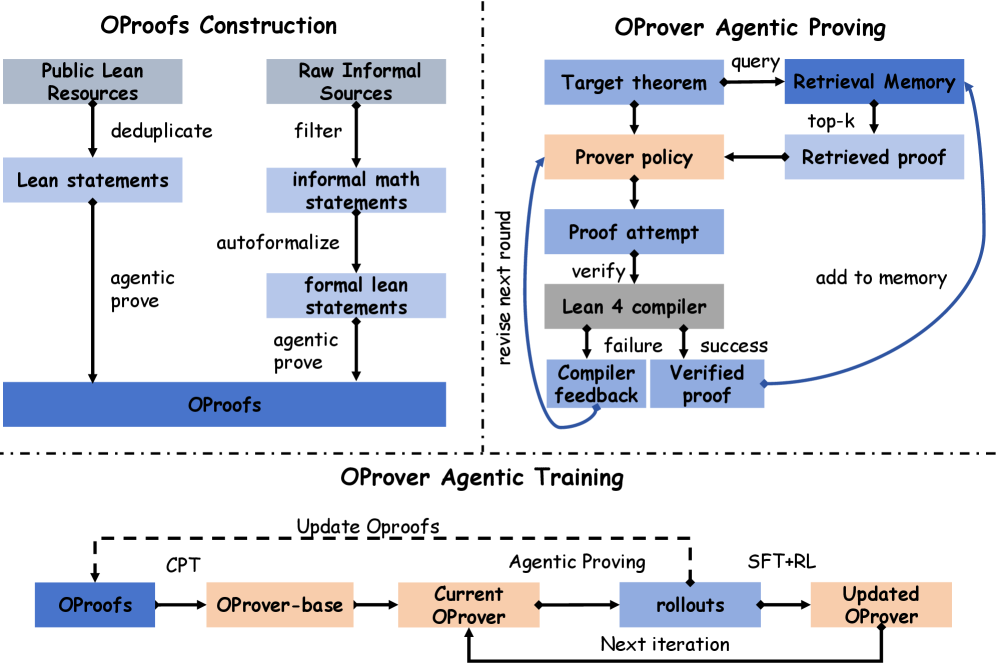
Proving is cast as bounded multi-round refinement. At round t, X_t = (s,\; \mathcal{R}_t,\; p_{t-1},\; f_{t-1}), \qquad p_t \sim \pi(\cdot \mid X_t), where s is the target statement, \mathcal{R}_t are top-k retrieved verified proofs from \mathcal{M}, p_{t-1} is the previous attempt, and f_{t-1} is the compiler error trace. p_0, f_0 are empty; the loop ends when \mathcal{V}(p_t) = \top or the round budget T is exhausted.
Training has two phases:
- Continued pretraining (CPT) on the OProofs corpus produces a domain-adapted base model OProver-Base (51.8B Lean tokens, prompt + CoT, Qwen3 tokenizer).
- Iterative post-training: at each iteration, the current prover runs agentic rollouts on unsolved statements; newly verified proofs are folded back into both OProofs and \mathcal{M}; round-level repair pairs (X_t, p_t) where p_t verifies become SFT data; statements that remain unsolved after the budget become RL targets. SFT teaches the policy to convert (s, \mathcal{R}, p_{\text{fail}}, f) into a verified p; RL handles the long-tail hard cases the SFT distribution cannot cover.
OProofs corpus
OProofs is the data backbone, built from public Lean resources, autoformalization of informal sources, large-scale proof synthesis, and the agentic rollout traces themselves. Headline counts:
- 1.77M unique Lean statements
- 6.86M compiler-verified proofs
- 4.33M proofs with retrieval context
- 869K proofs with non-trivial compiler feedback
- 1.07M agentic trajectories, of which 164K required at least one repair
- 280K round-level repair examples
- 51.8B Lean tokens for CPT
Domain mix: Algebra 59.5%, Analysis 13.8%, Number Theory 13.0%, Geometry 6.8%, Other 6.9%. Difficulty: Elementary 27.1%, High School 48.9%, Undergraduate 19.2%, Graduate 4.8%. Crucially, unlike Nemotron-Math-Proofs and similar resources, OProofs explicitly serializes retrieved context, compiler feedback, and multi-round repair signals — the supervision needed to train, not just evaluate, an agentic prover.
Results
Evaluation covers MiniF2F (244), MathOlympiadBench (360), ProofNet (186), ProverBench (325), and PutnamBench (672), the standard suite used by Goedel-Prover-V2 and LongCat-Flash-Prover.
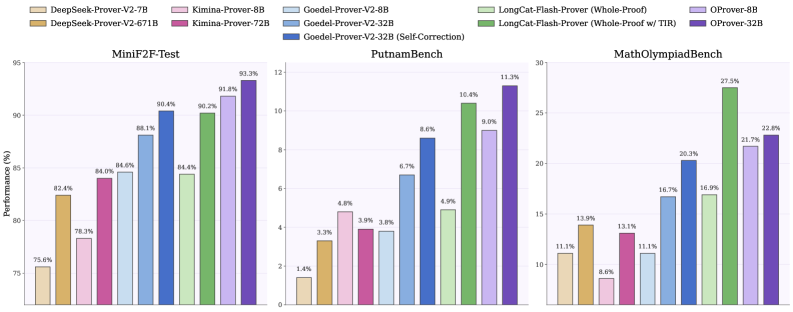
OProver-32B achieves the best Pass@32 on three of the five:
- MiniF2F: 93.3%
- ProverBench: 58.2%
- PutnamBench: 11.3%
and second place on MathOlympiadBench (22.8%) and ProofNet (33.2%) — more top placements than any prior open-weight whole-proof prover. The only benchmark where OProver is decisively beaten is MathOlympiadBench, where LongCat-Flash-Prover with tool-integrated reasoning (TIR) leads; OProver here is whole-proof only.
The authors also study test-time scaling under a fixed total compute budget B, reporting \mathrm{BestPass}(B) — the best success rate over all allocations of rounds R and retrieval depth k subject to R \cdot k \le B (or analogous accounting).
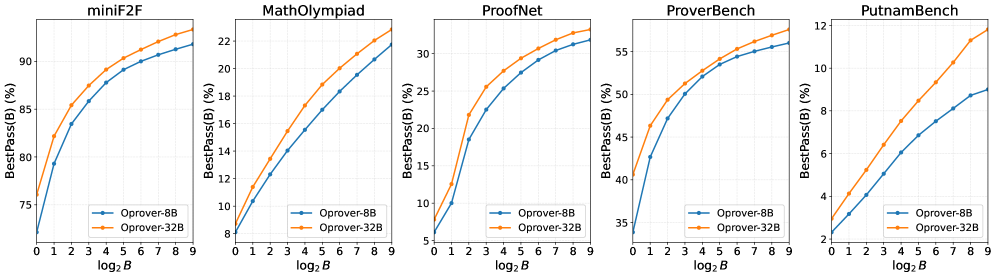
Both OProver-8B and OProver-32B improve monotonically with B, with the expected diminishing returns; the curves indicate that the agentic loop genuinely converts additional compiler interactions into solved theorems rather than just resampling.
Limitations and open questions
- Whole-proof only: no tactic-level interaction or tool-integrated reasoning, leaving the MathOlympiadBench gap to TIR systems unaddressed.
- PutnamBench at 11.3% remains low in absolute terms; the hardest competition-level problems are still largely out of reach.
- Difficulty and domain labels are LLM-inferred, which may bias the curriculum and the coverage claims.
- The retrieval memory grows with training; the paper does not quantify how much of the gain is from retrieval freshness versus policy improvement, nor how retrieval quality degrades as |\mathcal{M}| scales.
- RL details (reward shaping, off-policy correction over the evolving \mathcal{M}, stability across iterations) are not summarized in the excerpts shown.
- No ablation here on CPT vs. SFT vs. RL contributions, or on rounds T vs. samples N at matched compute.
Why this matters
OProver is the first open-weight Lean 4 system to put retrieval, compiler feedback, and multi-round repair inside the training loop rather than only at inference, and it ships the supervision (280K repair examples, 869K feedback-annotated proofs) needed for others to do the same. This reframes formal proving training data: trajectories, not just verified proofs, are the unit of supervision.
Source: https://arxiv.org/abs/2605.17283
Targeted Neuron Modulation via Contrastive Pair Search
Problem
Activation-steering methods such as Contrastive Activation Addition (CAA) operate on the residual stream: they compute a difference-of-means direction between positive and negative prompt sets and add a scaled version of that vector during inference. The empirical pathology is well known — at moderate intervention strength behavior changes, but past roughly \alpha \approx 0.5 the model collapses into repetition or degeneracy. This makes residual-stream steering unreliable as a behavioral lever and confounds mechanistic claims (a “refusal direction” that also destroys fluency is not cleanly isolating refusal). The paper asks whether a sparser, neuron-level intervention can decouple behavioral change from generation-quality damage, and whether the resulting circuits illuminate what alignment fine-tuning actually does.
Method
Contrastive Neuron Attribution (CNA) is mechanically minimal. Given paired sets \mathcal{P}^+ (harmful prompts) and \mathcal{P}^- (benign prompts), forward each prompt through the model and capture the input to down_proj at the last token position for every MLP layer — i.e., the post-activation hidden state in the MLP that is about to be projected back to the residual stream. For neuron j in layer \ell with activation a^\ell_j(x), compute
\delta^\ell_j = \frac{1}{|\mathcal{P}^+|}\sum_{x\in\mathcal{P}^+} a^\ell_j(x) - \frac{1}{|\mathcal{P}^-|}\sum_{x\in\mathcal{P}^-} a^\ell_j(x).
The circuit \mathcal{C}_k is the top-k neurons by |\delta^\ell_j| across all layers, with k fixed at 0.1% of all MLP neurons. Steering at strength \alpha scales (toward zero, for ablation) only those neurons’ activations during the forward pass. There are no gradients, no auxiliary probes, no linearization — just two sets of forward passes and a mean difference. Conceptually this is CAA evaluated in the neuron basis rather than the residual basis, leveraging the empirical sparsity of features in MLP activations.
The contrastive pairs for refusal use 100 harmful and 100 benign prompts. Evaluation uses JBB-Behaviors with a keyword-based refusal classifier and an n-gram repetition ratio as a coherence proxy, and MMLU (1000 questions) for general capability.
Results
Across 8 instruct models spanning Llama-3.2-1B through Qwen2.5-72B, ablating the 0.1% circuit reduces refusal substantially while leaving generation quality near baseline.
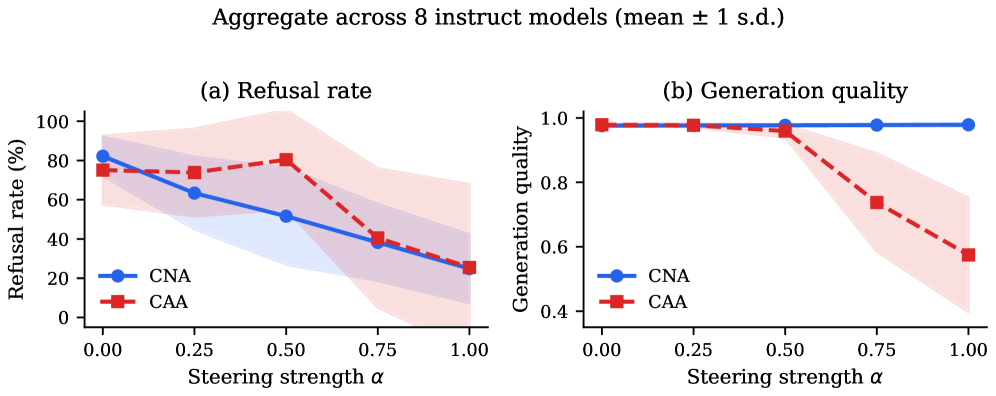
CNA’s coherence stays above 0.97 at every \alpha \in [0,1], while CAA’s collapses past \alpha \geq 0.75. Per-model numbers at \alpha = 1.0 (Table 1): Llama-3.1-8B-Instruct goes from 88.9% to 5.1% refusal at quality 0.969; Qwen2.5-72B-Instruct goes from 65.7% to 5.1% at quality 0.983; Llama-3.1-70B-Instruct from 72.7% to 12.1% at quality 0.981. CAA, in contrast, reports 0.0% refusal on several models but with quality 0.4–0.6, and on Qwen2.5-1.5B/72B the keyword classifier even flips to 100%/98% refusal because degenerate output trips refusal keywords — a useful warning about evaluating steering methods purely by classifier output.
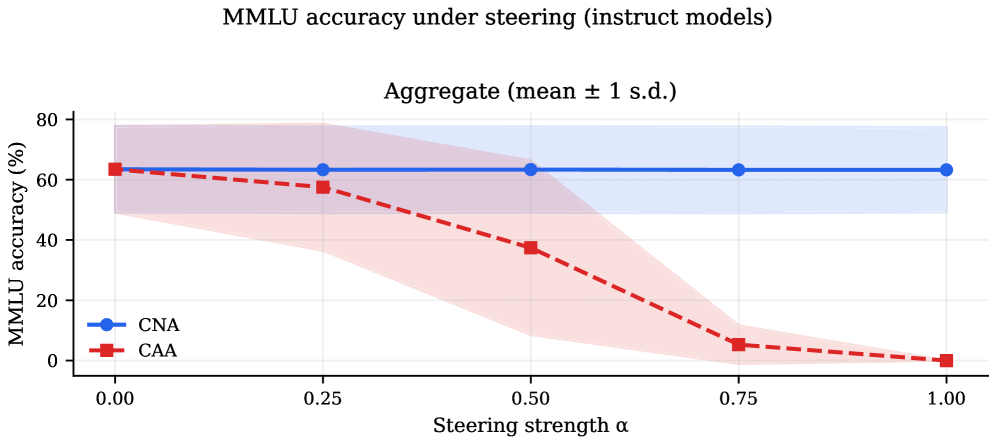
MMLU corroborates: CNA stays within 1 point of baseline across all \alpha, while CAA degrades to near zero at maximum strength. So the 0.1% MLP circuit is doing genuinely targeted work, not broadly damaging the model.
The base-model comparison (Table 2) is the more interesting scientific result. The same contrastive procedure recovers a structurally similar late-layer circuit in matched base models — i.e., base models already encode the harmful-vs-benign distinction in their MLPs. But ablating it does essentially nothing behaviorally: baseline refusal in base models is already low (2–35%), and CNA produces minor content shifts, not behavioral change. Llama-3.1-8B base goes 4.0% → 2.0%; Qwen2.5-7B base goes 20.2% → 16.2%. The discrimination axis exists pre-alignment; alignment fine-tuning is what wires it to the refusal behavior, not what creates the harmful/benign representation itself.
Limitations and open questions
- Refusal is measured by keyword classifier, which is known to be brittle (and the paper’s own CAA results illustrate the failure mode where degeneracy is misclassified as refusal). A semantic refusal judge would tighten the conclusions.
- The 0.1% threshold is hand-tuned across model sizes; there is no principled criterion for k and no analysis of how circuit overlap scales with model width.
- Only the last-token activation on
down_projinput is used. Whether the circuit generalizes across token positions, longer contexts, or multi-turn jailbreaks is untested. - “Ablation” here means scaling activations toward zero; the paper does not disentangle ablation from sign-flipping or projection, and does not test causal sufficiency (activating these neurons on benign prompts to induce refusal).
- The base/instruct claim — that alignment “wires” existing discrimination to behavior — is suggestive but rests on negative results in base models; a positive mechanistic account (e.g., what downstream attention heads read these neurons in instruct vs. base) is not provided.
Why this matters
If a 0.1% MLP circuit is sufficient to control refusal without harming MMLU or fluency, then alignment fine-tuning is plausibly a small, surgical rewiring on top of representations the base model already had — a much weaker view of RLHF/SFT than “alignment teaches the model new concepts.” It also reframes residual-stream steering’s quality collapse as an artifact of the basis, not an inherent cost of behavioral control, which has direct implications for both interpretability evaluations and red-teaming.
Source: https://arxiv.org/abs/2605.12290
LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
Problem
Long-form autoregressive video diffusion has two coupled bottlenecks. On the training side, efficient teacher-forcing concatenates clean history latents with noisy target latents into a single long sequence [\mathbf{z}_{clean};\mathbf{z}_{noisy}] that quickly exceeds single-GPU memory; naively applying sequence parallelism (SP) creates load imbalance because some ranks end up holding mostly clean (non-loss-bearing) tokens while others hold mostly noisy ones, and the VAE preprocessing is replicated across ranks. On the inference side, AR rollouts at long horizons are dominated by linear/attention GEMMs in BF16, which are memory-bandwidth bound. LongLive-2.0 addresses both with an NVFP4-native infrastructure spanning AR fine-tuning, DMD distillation, and W4A4 deployment, while collapsing the multi-stage Self-Forcing/LongLive recipe (ODE init → short-video DMD → streaming long-tuning DMD) into a single AR training stage plus a standalone LoRA for few-step inference.
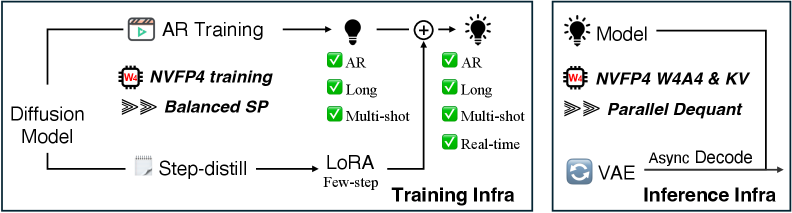
Method
Balanced SP. Built on top of DeepSpeed-Ulysses, Balanced SP enforces a single temporal chunk partition that is shared across (i) VAE encoding, (ii) construction of paired clean/noisy latent streams, (iii) DiT attention, and (iv) loss computation. Rank p never materializes the full sequence: it encodes only its temporal slice through the VAE, keeps its clean latent chunk, and applies the noise schedule locally to obtain the matched noisy chunk, owning
\mathbf{z}^{(p)}=[\mathbf{z}_{clean}^{(p)},\mathbf{z}_{noisy}^{(p)}]\in\mathbb{R}^{\frac{L}{P}\times H\times d}.
Because each rank holds both context and target tokens of the same temporal chunks, loss-bearing tokens are evenly distributed and the block-sparse causal-AR mask (each noisy chunk attends to all preceding clean chunks plus its own noisy tokens) can be generated directly in SP-native order without any gather.
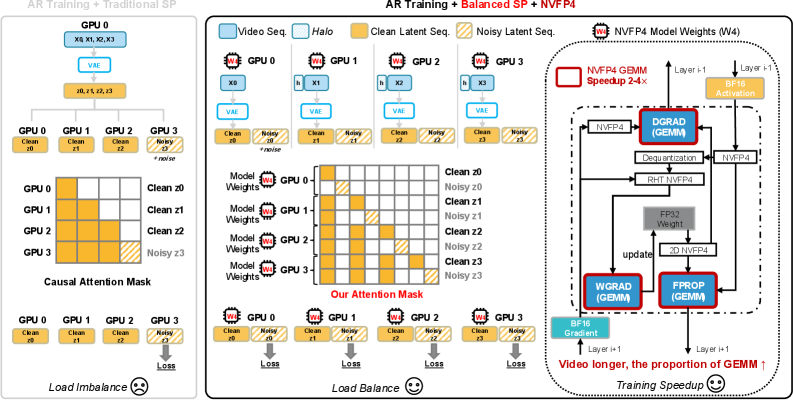
NVFP4 training. GEMMs in DiT, score models, and LoRA branches are executed in NVFP4 (W4A4 with NVIDIA’s microscaled FP4 format), which is orthogonal to SP. For DMD distillation, the frozen real-score model runs in NVFP4 while the trainable student/critic use NVFP4+LoRA, which lets the authors drop BF16 master weights after LoRA wrapping.
Clean training pipeline. Instead of the Self-Forcing / LongLive cascade, LongLive-2.0 fine-tunes the bidirectional Wan2.2-TI2V-5B directly into a chunk-level AR diffusion model on long videos with clean-context teacher forcing (avoiding the train–test gap of diffusion forcing). Each temporal chunk \mathbf{Z}_i is bound to its own prompt \mathbf{T}_i via factorized cross-attention \text{CrossAttn}(\mathbf{Z}_i,\mathbf{T}_i), enabling multi-shot prompt switches at chunk boundaries without re-conditioning history.
Few-step distillation. A one-stage DMD is run on top of the AR model with a causal AR mask imposed on the teacher (the original Wan2.2-TI2V-5B). Only LoRA modules are trained, producing standalone weights that, when merged, reduce sampling from 4 steps to 2 while preserving long-video capability.
Inference. The generator is deployed as W4A4 NVFP4 with either a separate LoRA branch or fused low-rank kernels. Because the model was trained NVFP4-aware, this avoids the quality drop typical of W4A4 PTQ (e.g., SVDQuant, ViDiT-Q).
Results
Training throughput. End-to-end AR iteration time at 16s/32s/64s video lengths:
- BF16: 75.3s / 202.7s / OOM
- BF16+SP: 52.2s / 162.7s / —
- BF16+Balanced SP: 45.8s / 136.8s / 1196.5s
- NVFP4+Balanced SP: 40.1s / 119.3s / 639.5s
This is 1.3\times/1.4\times/2.1\times over BF16+SP, with the gain growing with sequence length because GEMM share of total time grows. At 64s, NVFP4+Balanced SP nearly halves the BF16+Balanced SP iteration time.
DMD memory. Progressive NVFP4 conversion of the colocated generator/real-score/fake-score trio reduces peak per-GPU memory from 70.5 GB to 49.0 GB, a 21.5 GB cut (0.69\times of BF16).
Quality (VBench-Long, 60s). LongLive-2.0 reaches average rank 3.67 (best in table), with subject consistency 97.48, background consistency 97.00, motion smoothness 98.86, dynamic degree 60.62. Its W4A4 NVFP4 version is at average rank 3.83 with 97.62 / 96.97 / 98.94 / 45.88, matching or beating LongLive (4.17), Rolling-Forcing (4.50), and CausVid (5.33). Aesthetic and imaging quality (53.68, 65.51) are below Rolling-Forcing (63.50, 72.42), so the gains concentrate in temporal consistency and motion rather than per-frame fidelity.
Limitations and open questions
The reported speedups assume Blackwell-class FP4 tensor cores; on Hopper or older silicon the GEMM advantage collapses to emulation overhead. Aesthetic/imaging metrics regress relative to Rolling-Forcing, suggesting NVFP4 training may be smoothing high-frequency texture; the paper does not separate this from data-pipeline differences. The 64s BF16 path remains 1196.5s/iter even with Balanced SP, and the absence of ablations isolating Balanced SP from VAE-sharding makes it hard to attribute gains. Finally, the multi-shot attention-sink mechanism is mentioned for streaming inference but its effect on cross-shot identity drift is not quantified.
Why this matters
This is one of the first end-to-end demonstrations that NVFP4 can be used not just for inference but throughout AR video diffusion training, including DMD with three colocated networks, while improving rather than degrading VBench scores. The Balanced SP layout is a clean recipe for any teacher-forcing AR setup where clean and noisy tokens coexist in one sequence.
Source: https://arxiv.org/abs/2605.18739
SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
Problem
Long-horizon LLM agents accumulate trajectories that, in principle, encode reusable procedural knowledge: which CLI invocations work, which library APIs are stable, which sequences of tool calls solve a class of tasks. In practice, raw trajectories are noisy, redundant, and entangled with environment-specific accidents (paths, versions, OS quirks). Naively folding them back into agent context — through memory, RAG over logs, or prompt edits — pollutes future runs with stale or wrong guidance. The paper frames the unit of reusable experience as an Agent Skill: a structured artifact pairing executable scripts with non-executable procedural guidance (preconditions, when-to-use, expected effects). The question is then how to govern a skill library across its lifecycle — collection from open sources, recommendation at inference, and evolution from new traces — without degenerating into prompt rot.
Method
SkillsVote treats the skill library as a versioned, gated database with three stages.
1. Collection and profiling. The authors profile a million-scale open-source corpus of candidate skills along three axes: environment requirements (what tooling/state must exist), quality (structural completeness, clarity), and verifiability (whether the skill’s claimed effect can be checked by a synthesizable test). For each verifiable skill, they synthesize tasks whose success can be programmatically judged, giving each skill an empirical reliability signal rather than only a textual description.
2. Recommendation via agentic library search. Before execution, an agent issues structured queries over the skill library — not flat embedding retrieval, but a search loop that inspects skill metadata (preconditions, environment tags, prior success rates) and returns instructional context rather than just code. This separates the executable payload from the natural-language guidance the agent needs to decide whether and how to invoke the skill.
3. Evolution via evidence-gated updates. After execution, trajectories are decomposed into skill-linked subtasks. Outcomes are attributed across four sources: (i) skill use itself, (ii) agent exploration outside any registered skill, (iii) environment effects, and (iv) result/verification signals. Only subtasks whose success is attributable to a new, reusable discovery — not to environment luck or to existing skills — are admitted as candidate updates. Admission is gated on the evidence: the discovery must be reproducible against the skill’s verification harness. This avoids the failure mode where every successful trajectory writes back into context.
The decomposition is the mechanically important step. Conceptually, given a trajectory \tau = (s_0, a_0, \ldots, s_T) partitioned into segments \{\tau_i\} aligned to skills \{k_i\}, an outcome o_i is admitted as evolution evidence only if
P(o_i \mid k_i, \text{env}) - P(o_i \mid \neg k_i, \text{env}) > \epsilon
i.e., the skill is causally implicated, not merely co-occurring. The paper operationalizes this through structured attribution rather than counterfactual estimation, but the gating logic is the same: no attribution, no admission.
The library distinguishes offline evolution (batch update from a corpus of trajectories prior to deployment) from online evolution (incremental updates during deployment), which differ in how aggressively gates are applied.
Results
On Terminal-Bench 2.0, offline evolution improves GPT-5.2 by up to 7.9 percentage points. On SWE-Bench Pro, online evolution yields up to 2.6 pp improvement. The gap between the two benchmarks is informative: Terminal-Bench rewards reusable shell/CLI procedures that generalize across tasks (high skill density, high reuse), while SWE-Bench Pro tasks are more idiosyncratic per-repo, leaving less procedural surface for a shared skill library to capture. The 2.6 pp on SWE-Bench Pro is therefore consistent with the framing — skill governance helps most where skills are actually reusable.
The paper also reports that profiling the million-scale corpus filters a large fraction of candidate skills as unverifiable or environment-fragile, consistent with the claim that indiscriminate ingestion would degrade rather than improve agent performance.
Limitations and open questions
- Attribution is heuristic. The four-way decomposition (skill / exploration / environment / result) is not a formal causal model; in tasks where skills compose, credit assignment across k_i is ambiguous.
- Verifiability bias. The collection pipeline favors skills with synthesizable verification tasks, which biases the library toward CLI/code domains and away from skills whose value is harder to test (e.g., research, design).
- Online evolution stability. The 2.6 pp gain on SWE-Bench Pro is modest, and the paper does not report whether online updates ever degrade performance under adversarial or distribution-shifted task streams.
- Library scale dynamics. As the library grows, agentic search cost grows; the paper does not characterize retrieval latency or context-budget tradeoffs at steady state.
- Cross-model transfer. Skills are evaluated with GPT-5.2; whether skills curated by one model generalize to weaker or stylistically different agents is open.
Why this matters
Most “agent memory” work conflates logging trajectories with learning from them. SkillsVote isolates the governance problem — what enters the library, what is surfaced at inference, and what is allowed to overwrite prior context — and shows that evidence-gated updates produce non-trivial gains (7.9 pp on Terminal-Bench) without the prompt-pollution failure mode of naive memory systems. The framework is a usable template for any deployment where agent experience is meant to compound rather than decay.
Source: https://arxiv.org/abs/2605.18401
Post-Trained MoE Can Skip Half Experts via Self-Distillation
Problem
Sparse MoE LLMs activate a fixed top-K experts per token regardless of input difficulty. Dynamic MoE variants that vary per-token compute typically require pretraining from scratch or task-specific adaptation, making them impractical for already-released, post-trained models like Qwen3-30B-A3B or GLM-4.7-Flash. The question this paper addresses is narrow but practically important: can you cheaply convert a frozen post-trained static MoE into a dynamic one that skips experts on easy tokens, without retraining the experts?
Method: ZEDA
ZEDA (Zero-Expert Self-Distillation Adaptation) does two things: inject parameter-free zero experts, then adapt the router via self-distillation against the original model.
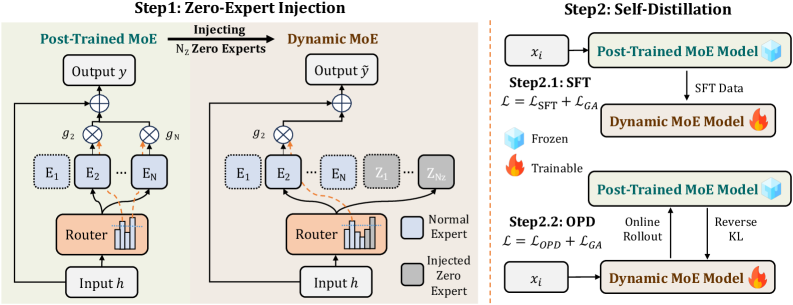
Zero-expert injection. A standard MoE layer with N experts \mathcal{E}=\{E_1,\dots,E_N\} and top-K routing produces
y(h) = \sum_{i \in \mathcal{S}(h)} g_i(h)\, E_i(h).
ZEDA augments the expert pool with N_Z zero experts \mathcal{Z}=\{Z_1,\dots,Z_{N_Z}\} where Z_j(h)=0 identically. The router now selects top-K from \mathcal{E}'=\mathcal{E}\cup\mathcal{Z}, giving
\tilde{y}(h) = \sum_{i \in \tilde{\mathcal{S}}(h)\cap\mathcal{E}} \tilde{g}_i(h)\, E_i(h).
Because zero experts contribute nothing, picking m of them reduces the number of active normal experts from K to K-m. The fraction of zero experts selected per token, r_{ZE}, becomes the dynamic compute knob. The original router parameters for the N normal experts are kept; the N_Z new router rows are sampled from a Gaussian matching the mean/variance of the existing rows in that layer, preserving logit scale.
The authors compare against a “copy expert” alternative (output equals input) in the appendix and report that copy experts cause both scale and direction mismatches in the residual stream, motivating the zero choice.
Self-distillation with a group balancing loss. The augmented model is trained in two stages with the original frozen MoE as teacher. Distillation alone is unstable because nothing controls how many tokens route to zero experts; the router can collapse to either always pick zeros (kills compute and accuracy) or never pick them (no speedup). They add a Group Auxiliary Loss \mathcal{L}_{GA} with coefficient \alpha that regulates aggregate zero-expert utilization toward a target via a group weight w. Section 4.3 ablations sweep w, \alpha, the two-stage schedule, and router probability renormalization.
Results
Two backbones are tested: Qwen3-30B-A3B (N{=}128, K{=}8, N_Z{=}64) and GLM-4.7-Flash (N{=}64, K{=}4, N_Z{=}32). Across 11 benchmarks spanning math, code, and instruction following, ZEDA eliminates over 50% of expert FLOPs with marginal accuracy loss, and beats the strongest dynamic-MoE baseline by 6.1 points on Qwen3 and 4.0 points on GLM. Note Qwen3 is run in Thinking mode throughout, so the FLOP savings are evaluated on long reasoning traces — exactly the regime where dynamic compute should pay off.
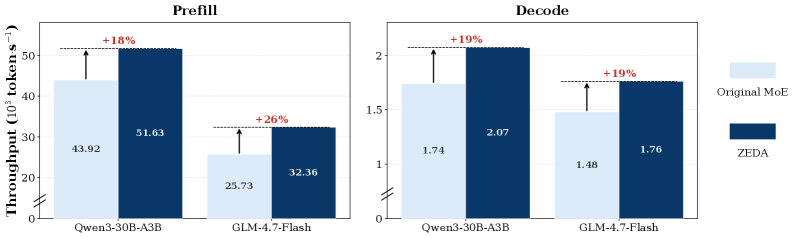
The wall-clock speedup at 8192 sequence length tracks the FLOP reduction reasonably closely, indicating the savings are not erased by routing overhead.
Token-level dynamics
The most informative analysis is in Section 4.1. Sampling 110 prompts (10 per benchmark) and decoding with the ZEDA model, the authors record per-token r_{ZE} alongside student entropy and the teacher-student log-prob gap \Delta_{\text{logp}} = \log\pi_T(y_t\mid x,y_{<t}) - \log\pi_\theta(y_t\mid x,y_{<t}).
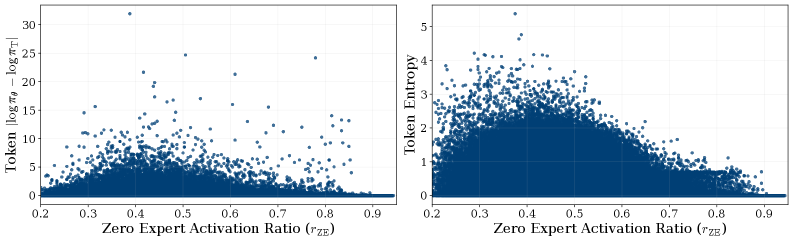
Tokens with high \Delta_{\text{logp}} or high entropy concentrate in the upper-left, i.e. low r_{ZE} (more normal experts activated). The router has implicitly learned to spend compute where the student disagrees with the teacher or is uncertain — a sensible inductive outcome of distillation under a global budget constraint, and a useful interpretability handle: r_{ZE} is a cheap proxy for token difficulty.
Limitations and open questions
- Both models are MoE LLMs from the same era with similar router designs; whether the recipe transfers to fine-grained-expert architectures (e.g. DeepSeek-style with shared experts, or 256+ expert configurations) is untested here.
- N_Z is set heuristically to N/2 following LongCat. There is no principled procedure for choosing it, and the FLOP savings ceiling is implicitly tied to this choice.
- The reported >50% FLOP reduction is for expert FLOPs only; attention, embedding, and shared components are unchanged, so end-to-end speedups will be smaller for short-context regimes.
- Distillation data composition is not deeply analyzed in the excerpt; OOD generalization is touched on in §4.4 but the failure modes when the deployment distribution diverges from the distillation corpus are not fully characterized.
- Group-level balancing controls average r_{ZE} but does not directly calibrate per-layer compute — and MoE layers are known to differ substantially in routing behavior across depth.
Why this matters
ZEDA is a cheap post-hoc procedure that turns a static MoE checkpoint into a token-adaptive one without touching expert weights, recovering ~50% of expert FLOPs at marginal quality cost. For practitioners serving released MoE LLMs, this is a drop-in inference optimization; for researchers, the emergent correlation between r_{ZE} and teacher-student divergence suggests that distillation-driven router adaptation naturally produces an interpretable difficulty signal.
Source: https://arxiv.org/abs/2605.18643
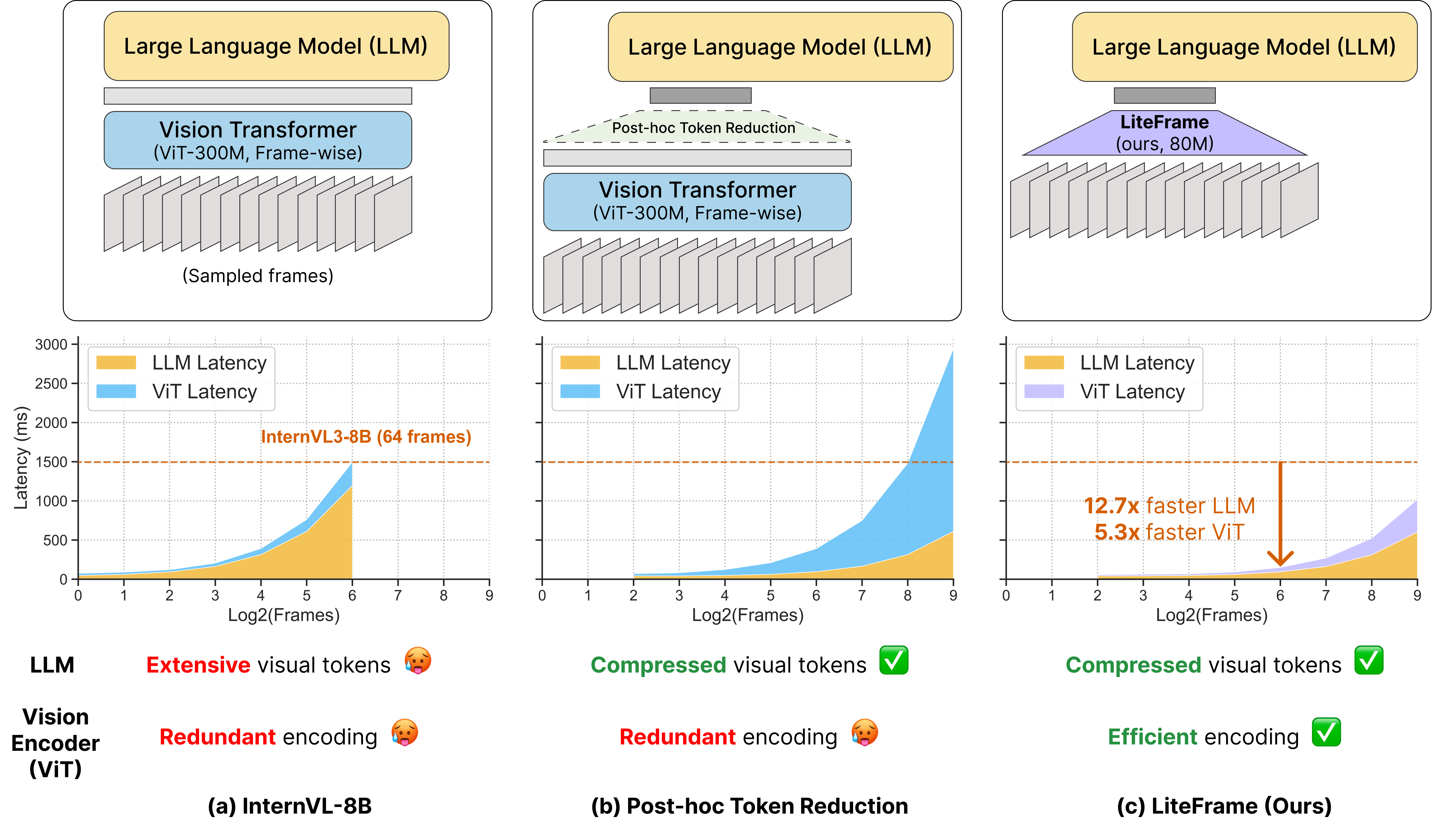
LiteFrame: Efficient Vision Encoders Unlock Frame Scaling in Video LLMs
Problem
Video LLMs face a context-length explosion: each frame contributes hundreds of visual tokens, and the LLM prefill cost grows quadratically. The dominant response has been post-hoc token reduction — pruning, merging, or pooling the ViT outputs before they hit the LLM. The authors point out that once the LLM bottleneck is alleviated this way, latency simply migrates to the per-frame ViT itself: the encoder still runs at full cost on every frame, so total wall-clock time is dominated by vision encoding rather than language modeling.
This matters because long-form video understanding scales roughly logarithmically with frame count (Figure 3, left): increasing frames is the main lever for accuracy gains on Video-MME, MLVU, and LongVideoBench, but only if the encoder stays cheap.
Two design premises from post-hoc analysis
Before presenting the encoder, the authors establish two empirical premises.
(1) Weighted Average Pooling is the right compression primitive. For a feature tensor \mathbf{X}\in\mathbb{R}^{T\times H\times W\times C} partitioned into spatio-temporal blocks \Omega_{u,v,s}, WAP computes
\mathbf{Y}_{u,v,s}=\sum_{(\tau,i,j)\in\Omega_{u,v,s}}\text{softmax}\!\left(\frac{\mathbf{x}_{\tau,\text{cls}}^{\top}\mathbf{x}_{\tau,i,j}}{\sqrt{C}}\right)\mathbf{x}_{\tau,i,j},
i.e., an attention-weighted average against the per-frame CLS token, applied within each non-overlapping block. Unlike ToMe or PruMerge, WAP preserves the spatio-temporal lattice required for positional reasoning. At a fixed 16\times compression on InternVL3-8B with 64 frames, WAP scores 62.0 average across the four benchmarks, beating Average Pooling (60.2), Subsampling (61.2), ToMe (60.0), PruMerge (59.7), and FastVID (60.6). The uncompressed reference is 66.9.
(2) Aggressive compression pays off when traded for frames. Under a fixed visual-token budget, 16\times WAP that lets InternVL3-8B see substantially more frames yields higher accuracy than mild compression with fewer frames (Figure 3, right). This justifies pushing compression hard — but only if the encoder cost also drops, which post-hoc methods cannot achieve.
LiteFrame architecture
The student is a 12-layer, 768-dim ViT-Base (87M params) versus a 24-layer, 1024-dim ViT-Large teacher (304M, InternViT-300M from InternVL3-8B). Key changes:
- Depth-wise 1D temporal convolutions (DWTempConv) are interleaved after every spatial-attention layer with T>1. At 256 input frames, DWTempConv runs at 174.84 ms / 17.92 TFLOPs vs. 348.29 ms / 32.77 TFLOPs for temporal attention, 204.35 ms for spatio-temporal full attention, and 202.08 ms for vanilla temporal convolutions, with <1M parameter overhead.
- Strided depth-wise convolutions at blocks 4 and 8, with strides [t,h,w]=[2,2,2] then [2,1,1], progressively shrink the token grid so deeper layers cost much less than a frame-wise ViT.
The compression is internalized: tokens are reduced inside the encoder, not after it, so per-frame FLOPs drop monotonically with depth.
Compressed Token Distillation and LMA
The student is trained with Compressed Token Distillation (CTD): rather than matching the teacher’s full token grid, the student directly predicts the WAP-compressed teacher output at the target resolution (t,h,w). This is the central trick — by making the supervision signal already carry the spatio-temporal compression, the student never has to instantiate the dense intermediate representation. A subsequent Language Model Adaptation (LMA) stage aligns the student’s compressed tokens with the LLM’s input distribution.
Results
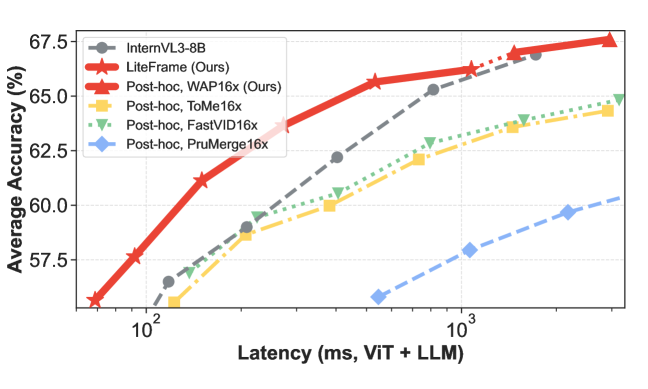
The headline number: against InternVL3-8B, LiteFrame delivers a 35% reduction in end-to-end latency while processing 8× more frames, defining a new Pareto frontier (Figure 2) on the four-benchmark average. The WAP-only post-hoc variant also lands above prior reduction methods on the same frontier, confirming that the architectural and distillation gains compose with the compression primitive.
Limitations and open questions
- The teacher is a single image encoder (InternViT-300M); how CTD behaves with native video teachers (e.g., InternVideo2) is untested.
- WAP relies on per-frame CLS tokens; whether the formulation generalizes to encoders without an explicit CLS (register-only or fully convolutional backbones) is not addressed.
- Evaluation is confined to Video-MME, MLVU, and LongVideoBench; tasks requiring fine-grained spatial grounding (referring segmentation, dense captioning) may be more sensitive to 16\times compression than coarse QA.
- The strided-conv placement (blocks 4 and 8) and the [2,2,2]/[2,1,1] schedule are hand-picked; no scaling law is given for how this should change with student depth or target compression ratio.
- The LMA stage is essential for closing the accuracy gap, but the paper as excerpted does not quantify CTD-only versus CTD+LMA.
Why this matters
Once post-hoc token reduction is widely adopted, the vision encoder becomes the new bottleneck — a fact most Video-LLM work has ignored. LiteFrame reframes the problem: compression should be a property of the encoder, learned via distillation against an already-compressed teacher signal, so that frame count rather than per-frame cost becomes the scaling axis.
Source: https://arxiv.org/abs/2605.17260
Hacker News Signals
Agora-1: The Multi-Agent World Model
Odyssey’s Agora-1 is a world model designed for multi-agent simulation, targeting interactive environments where multiple autonomous agents must coexist and act coherently. The technical claim is that the model generates consistent world-state video conditioned on the actions of several independent agents simultaneously, rather than the single-agent conditioning that characterizes most video world models (e.g., Genie, GameNGen, DIAMOND).
The architecture appears to extend latent diffusion-based video generation with per-agent action conditioning streams. Each agent’s action trajectory is encoded separately and injected into the denoising process, with the model trained to maintain physical and causal consistency across agent interactions. This is non-trivial: in single-agent settings the model only needs to track consequences of one action sequence; with multiple agents it must resolve interactions, occlusions, and joint physics without ground-truth decomposition at inference time.
The announced use case is game simulation and synthetic data generation for embodied AI. The broader relevance is that reinforcement learning pipelines for multi-agent tasks require either real environment rollouts or high-fidelity simulators; a learned world model that can simulate agent-agent interaction at video fidelity would substitute for hand-engineered simulators in domains where those are expensive to build.
The blog post is light on architectural specifics — no paper is linked, training data composition is not disclosed, and no ablations are shown. Key open questions: how the model handles combinatorial explosion as agent count scales, whether action conditioning is truly independent per agent or entangled through shared attention, and what the failure mode looks like when agents interact closely (contact, collision). Without a technical report the claims are hard to evaluate, but the demo videos show multi-character game environments with plausible consistency across a small number of agents.
Source: https://odyssey.ml/introducing-agora-1
Cutting Inference Cold Starts by 40x with LP, FUSE, C/R, and CUDA-checkpoint
Modal’s engineering post describes a stack of four techniques to reduce GPU cold-start latency for serverless inference from roughly 20-40 seconds down to under one second.
Lazy paging (LP): Rather than copying the full model checkpoint from object storage before execution starts, pages are demand-faulted in as the process accesses them, overlapping model load with early inference computation. This requires a FUSE filesystem layer that intercepts page faults and issues async reads from the backing store.
FUSE filesystem: Modal implements a custom FUSE layer that serves the checkpoint data with prefetch heuristics tuned to transformer weight layout — weights are accessed in a largely sequential pattern during the forward pass, so read-ahead is effective. The FUSE overhead (context switches per fault) is amortized because GPU compute dominates.
Checkpoint/Restore (C/R) with CRIU: A warmed process — Python runtime initialized, model loaded, CUDA context live — is snapshotted using CRIU (Checkpoint/Restore In Userspace). On a new cold request, restore is faster than re-running initialization because CRIU replays memory state rather than re-executing Python import chains and CUDA context setup.
CUDA-checkpoint: Standard CRIU cannot snapshot GPU memory. Modal uses a CUDA-specific checkpointing mechanism (related to NVIDIA’s CUDA checkpoint API or a user-space equivalent) that serializes device memory and CUDA stream state alongside the CPU snapshot. Restore re-maps GPU memory and re-initializes streams without re-running framework initialization.
The combination achieves approximately 40x reduction in cold-start time. The main engineering constraint is that C/R snapshots are model-version-specific and must be invalidated and regenerated on weight updates. FUSE adds a small steady-state throughput penalty that the post acknowledges is acceptable given the cold-start win.
Source: https://modal.com/blog/truly-serverless-gpus
Alignment Pretraining: AI Discourse Creates Self-Fulfilling (Mis)alignment
This arxiv paper (2601.10160) argues that the corpus of AI alignment discourse — safety papers, AI ethics writing, speculation about AI goals — is now large enough to constitute meaningful pretraining signal, and that LLMs trained on it may internalize the conceptual frames embedded in that discourse in ways that are not straightforwardly “aligned.”
The mechanism proposed: alignment researchers write extensively about specific failure modes (deceptive alignment, goal misgeneralization, reward hacking). This text describes and elaborates these behaviors in detail. Language models trained on sufficiently large crawls of this material learn these behavioral schemas as in-context concepts, potentially making the described behaviors more accessible at inference time than they would be in models trained on corpora that lack this material. It is a variant of the idea that describing an attack in a security paper also disseminates the attack.
The paper formalizes this loosely via a distributional argument: if alignment discourse overrepresents certain behavioral patterns relative to their base rate in the world, a model whose world-model is shaped by text will have inflated probability mass on those patterns. The self-fulfilling loop closes if deployed models then generate more such text.
This is a conceptually provocative argument but empirical validation is thin. The paper does not demonstrate that any specific alignment-discourse concept causally increases a model’s propensity to exhibit the described behavior in evaluations. The causal chain from pretraining data composition to model behavior to real-world outcome involves many uncontrolled variables. Still, the reflexivity concern is legitimate and underexplored: the training corpus for future models includes today’s safety research, and researchers rarely account for this feedback.
Source: https://arxiv.org/abs/2601.10160
Qwen 3.7 Preview
Alibaba’s Qwen team announced a preview of Qwen 3.7, continuing the Qwen 3 series. Based on the announcement and community discussion, the model is a dense transformer (not MoE) at approximately 7B active parameters, with a 128K context window. The naming convention “3.7” implies an intermediate release between the 3 and a future major version rather than a parameter count.
Technically relevant claims: improved instruction following relative to Qwen 2.5-7B and Qwen 3 on coding and math benchmarks, with the model reportedly matching or exceeding larger open-weight competitors (Llama 3.1 8B, Mistral 7B v0.3) on MATH and HumanEval-class evaluations. The post references improved long-context retrieval performance, which at 128K is consistent with RoPE scaling or YaRN fine-tuning applied after base pretraining.
No architectural changes beyond scale are disclosed in the tweet thread. Weights are presumably being prepared for public release on HuggingFace given prior Qwen release patterns. The community discussion on HN focuses on benchmark comparability and the rapid pace of iteration in the 7B-class open-weight space, where Qwen models have become reference points alongside Llama variants.
The practical significance is in the dense 7B class: this is the segment where local inference on consumer hardware (single RTX 4090 or Apple M-series at 4-bit) is feasible, and marginal quality improvements at this size have immediate downstream value in edge deployment, fine-tuning compute budgets, and as base models for distillation targets.
Source: https://twitter.com/Alibaba_Qwen/status/2056403591464984753
The Foundations of a Provably Secure Operating System (PSOS) (1979)
This 1979 SRI technical report by Neumann, Robinson, Levitt, Boyer, and Pamas describes PSOS — Provably Secure Operating System — one of the earliest formal attempts to construct an OS whose security properties are machine-verifiable from formal specifications.
The approach is hierarchical: the system is decomposed into a sequence of abstract machine layers, each specified in a formal language (SPECIAL, a descendant of Dijkstra’s predicate transformer notation). Each layer implements a subset of objects and operations; higher layers build on lower-layer primitives. Security properties (confidentiality, integrity in Bell-LaPadula and related model terms) are stated as invariants on the abstract state and must be proved preserved by each operation at each layer.
The capability model is central: subjects access objects exclusively through capabilities (typed, unforgeable object references with embedded permissions). The formal model ensures that capability confinement is enforceable by proof — a process cannot construct or amplify capabilities outside what its specification permits.
What makes this historically significant: it predates SELinux, formally verified microkernels (seL4, 2009), and most of the literature on security kernels, yet identifies the core problem correctly — that informal specifications leave gaps exploitable by adversaries, and that a small, formally specified TCB is necessary for any meaningful security proof. PSOS was never completed as a running system, but the architectural principles — hierarchical abstraction, capability-based access, machine-checked invariants — resurface in every subsequent generation of formally verified systems work.
For current readers the document is notable for how much the fundamental hard problems (TCB minimization, downward confinement, covert channels) remain unsolved in mainstream operating systems 45 years later.
Source: http://www.csl.sri.com/users/neumann/psos.pdf
AI Eats the World (Spring 2026 Industry Report)
This is a periodic state-of-AI industry report (Spring 2026 edition) covering adoption, capability, and economic impact. The PDF format and tone suggest a venture or analyst audience rather than a research one, but the data points are worth extracting.
Key technical/empirical claims that are substantive: the report documents inference cost curves for frontier models continuing to fall faster than Moore’s Law on a per-token basis, driven by both hardware (H100 to B200 transition, inference-optimized chips) and software (speculative decoding, quantization at INT4/FP8 without significant capability regression). Coding and software engineering automation is cited as the sector with highest measurable productivity impact, with several large-scale controlled studies showing 20-40% throughput increases for professional developers using AI-assisted tooling.
The report covers agentic deployment patterns — the shift from single-query completions to persistent agents running multi-step workflows — and notes that this shifts the reliability bottleneck from single-call accuracy to compounding error rates across long action sequences. This is a technically correct observation: if each step in a 20-step agent pipeline has 95% accuracy, end-to-end success probability is 0.95^{20} \approx 0.36.
On model architecture trends, the report notes the convergence around mixture-of-experts for frontier training (GPT-4 class, Gemini 1.5, Mixtral lineage) and the persistence of dense models for the sub-10B parameter deployed edge segment.
The limitations of this type of report: adoption statistics are self-reported or derived from indirect signals (API revenue proxies, survey data), causal claims about productivity are drawn from heterogeneous studies with incompatible methodologies, and forecast sections are not falsifiable. Read it for the aggregate trend data, not the projections.
Noteworthy New Repositories
future-agi/future-agi
An end-to-end observability and evaluation platform for LLM and agent pipelines. The stack covers six distinct concerns: distributed tracing (capturing spans across multi-step agent runs), structured evaluations (rubric-based or model-graded), simulation harnesses (replay and synthetic-scenario testing), dataset versioning, an LLM gateway for routing/load-balancing, and guardrail hooks for input/output filtering. Everything is self-hostable, which matters for teams with data-residency constraints or who need to run evals against proprietary models without telemetry leaving the network. Architecturally it exposes an OpenTelemetry-compatible tracing interface, so existing instrumented codebases can route spans with minimal changes. The eval layer supports both deterministic metrics (BLEU, exact-match, JSON schema validation) and LLM-as-judge pipelines. Simulations allow parameterized scenario injection to stress-test agents beyond real-traffic distributions. The gateway sits in the critical path, adding latency overhead that users should benchmark — the project does not publish numbers for this. Licensed Apache 2.0, making it a credible alternative to hosted platforms like LangSmith or Weights & Biases for teams building production agent systems who want full control over the evaluation data.
Source: https://github.com/future-agi/future-agi
chiennv2000/orthrus
Orthrus proposes a lossless acceleration scheme for autoregressive LLM inference by framing token generation as a dual-view diffusion decoding process. The core idea is to run two complementary “views” of the sequence simultaneously — one standard left-to-right pass and one auxiliary view — and use agreement between them to speculatively accept or reject tokens in parallel, similar in spirit to speculative decoding but without requiring a separate smaller draft model. The “lossless” claim means the output distribution is provably identical to standard greedy or sampling decoding. The diffusion framing provides a principled way to model uncertainty over draft tokens, potentially improving acceptance rates over naive speculative approaches. The name “Orthrus” (the two-headed dog) directly references the dual-view architecture. At 323 stars and limited documentation, this is research-grade code rather than a production library, and the absence of published benchmarks on standard throughput harnesses (e.g., vLLM-comparable tokens/sec on A100) is a notable gap. The most relevant open question is how acceptance rates and wall-clock speedup vary with model size and sampling temperature.
Source: https://github.com/chiennv2000/orthrus
raiyanyahya/how-to-train-your-gpt
A pedagogical, from-scratch GPT implementation aimed at making the full training stack legible. Every line carries inline comments explaining intent, not just mechanics — covering tokenization (BPE from scratch), the transformer block (multi-head attention, layer norm placement, residual connections), positional encoding, the training loop with gradient accumulation, and basic sampling strategies. The explicit goal is to avoid abstraction layers that hide what is actually happening, so there are no Hugging Face or Lightning dependencies in the core path. This makes it useful for course material or for engineers who have used transformers via APIs but have never traced the forward pass by hand. The codebase trains on small-scale text data (character or subword level) on consumer hardware, so it does not attempt to reproduce GPT-3/4 scale. The limitation is the inverse of its strength: production concerns (mixed precision, FSDP, flash attention, gradient checkpointing) are out of scope. At 1675 stars it has found an audience among self-studiers. A recommended use case is reading alongside Karpathy’s makemore/nanoGPT, as the commentary style is complementary.
Source: https://github.com/raiyanyahya/how-to-train-your-gpt
agentic-in/elephant-agent
Elephant Agent is positioned as a “personal-model first, self-evolving” AI agent, where the design priority is persistent, user-specific memory and iterative self-improvement rather than general-purpose task execution. The “personal-model first” framing implies local fine-tuning or retrieval-augmented personalization over time — the agent accumulates interaction history, extracts structured preferences or facts, and uses them to condition future behavior without manual prompt engineering by the user. The “self-evolving” component suggests automated feedback loops: the agent evaluates its own outputs, identifies failure modes, and updates its memory or behavior policy accordingly. At 328 stars the repository is early-stage, and the technical specifics of the self-evolution mechanism (whether it uses RLHF-style feedback, DPO, or purely retrieval-based adaptation) are not fully documented. The elephant metaphor (never forgets) is deliberate. The main open engineering questions are: how the memory store is indexed and retrieved at inference time, what the update cadence for personalization is, and how catastrophic forgetting is handled if a fine-tuning path is involved.
Source: https://github.com/agentic-in/elephant-agent
Ethan-YS/project-brain
Project Brain is a lightweight, file-system-based methodology rather than a software library. The core idea is a single structured folder (the “brain”) committed alongside a project repository that encodes persistent context for AI coding assistants — current task state, architectural decisions, open questions, and session summaries. At the start of each session, the AI assistant reads this folder to reconstruct working memory, avoiding the cold-start problem where each conversation loses prior context. The methodology includes conventions for what files to maintain (e.g., status.md, decisions.md, next-steps.md) and prompts for the AI to update them at session end. It is model-agnostic and works with any assistant that accepts file context (Cursor, GitHub Copilot with workspace context, Claude Projects, etc.). The value is entirely in the discipline and schema, not in novel technology. Limitations: this is manual overhead, and the quality of continuity depends entirely on how faithfully the AI summarizes its session work. At 143 stars it is niche but addresses a real pain point for solo developers using AI assistants on multi-week projects.
Source: https://github.com/Ethan-YS/project-brain
crynta/terax-ai
Terax is a terminal emulator that integrates an AI layer directly into the shell interaction loop, built with Rust (backend/PTY handling), Tauri (desktop shell), and React (UI). The 7 MB binary size is a deliberate engineering constraint, achieved by keeping the AI inference remote (API calls rather than bundled weights) and by leveraging Rust’s lean runtime. The AI layer sits between user input and the PTY: it can interpret natural-language commands, suggest completions, explain command output inline, and flag potentially destructive operations before execution. The Rust/Tauri combination provides native performance for PTY multiplexing and low-latency rendering while React handles the composable UI surface — a common pattern in modern cross-platform desktop tools. Compared to pure-web terminal wrappers (Warp, Wave), the Tauri approach avoids Electron’s memory overhead. Key open questions are latency characteristics when AI suggestions are in the critical input path, offline fallback behavior, and whether the AI context includes shell history and environment state or only the current command. At 3939 stars this is the most traction of any repo in this batch.
Source: https://github.com/crynta/terax-ai
antoniolupetti/algebrica
Algebrica is an open mathematical knowledge base structured around conceptual clarity rather than computational tooling. It does not implement symbolic computation; instead it organizes mathematical knowledge — definitions, theorems, proofs, and their relationships — in a format optimized for human understanding and structural coherence. The emphasis is on making dependencies between concepts explicit: a theorem page clearly states what it requires, what it generalizes, and what it enables. The target audience is students and self-studiers who find standard textbooks opaque due to unmotivated definition ordering or missing conceptual scaffolding. The technical implementation details are sparse in public documentation, but the project appears to be a structured static site or wiki with consistent schema for mathematical objects. Compared to existing resources (Wikipedia mathematics articles, nLab, ProofWiki), the stated differentiator is pedagogical accessibility without sacrificing formal rigor. At 623 stars, interest is real. The main limitation is coverage: a community-driven math knowledge base lives or dies on contribution velocity, and formal mathematics is a high-barrier domain for contributors. Long-term sustainability and peer review processes are open questions.
Source: https://github.com/antoniolupetti/algebrica
mrslimslim/gpt-image-canvas
GPT Image Canvas is a locally-running image editing and generation workspace built on tldraw (an open-source infinite canvas library) with GPT-4o’s image generation API wired into canvas operations. The design gives users a spatial, multi-object editing surface where they can place reference images, masks, and text prompts as canvas elements, then invoke the model to generate or edit within that context. This is architecturally closer to a professional compositing tool than a chatbot image interface: the canvas state (positions, selections, masks) drives the prompt and image-editing calls rather than a linear conversation. Running locally means API keys stay on-device and there is no SaaS intermediary storing canvas state. The tldraw integration is the key technical choice — it provides a production-quality infinite canvas with collaborative editing primitives for free, letting the author focus on the AI integration layer. Limitations: it depends on OpenAI’s API for the model layer, so it is local in the UI sense but not in the inference sense. Support for local diffusion backends (ComfyUI, Automatic1111 API) would be the natural extension. At 374 stars it is a clean proof-of-concept for spatial AI editing workflows.