デイリーAIダイジェスト — 2026-05-18
arXiv ハイライト
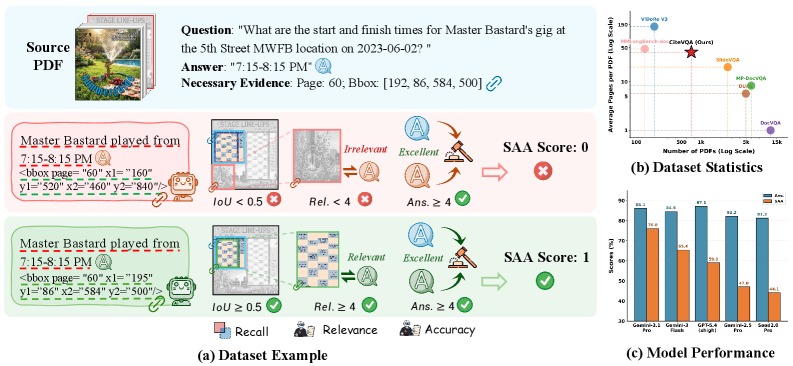
CiteVQA: 信頼性の高いドキュメントインテリジェンスのための証拠帰属のベンチマーク評価
問題設定
Document VQA のベンチマークは最終的な回答文字列のみを採点し、モデルがその回答をドキュメントの適切な領域に基づいて導いたかどうかを無視しています。これは二つの失敗モードを混同しています。すなわち、「誤った回答」と「正しい回答だが証拠が誤っている」というケースです。後者——著者らがattribution hallucinationと呼ぶもの——は、法務・財務・医療の場面においてより危険です。なぜなら、誤ったテーブルから引用された数値的に正しい値は、でたらめな値と区別がつかないからです。CiteVQA はこのギャップに対処するため、各回答に要素レベルのbounding-box引用を付与することを求め、それらを統合的に採点します。
このベンチマークは7つのドメインと2言語にわたる711件のPDFに対する1,897問を含み、ドキュメントの平均ページ数は40.6ページです。これは従来のDoc-VQAデータセットよりも大幅に長く、モデルが単一ページをスキャンするのではなく実際にローカライズすることを強いられます。
パイプラインとグラウンドトゥルースの構築
アノテーションパイプラインは完全に自動化されており、その後に専門家による検証が行われます。約1億件のCommon Crawl PDFを出発点として、層化サンプリングにより候補を約25万件に絞り込みます。二段階のMLLMフィルタが粗いドメイン・言語ラベルと細粒度のサブカテゴリラベルを付与し、7ドメイン・30サブカテゴリにわたってバランスのとれた711件のドキュメントが得られます。
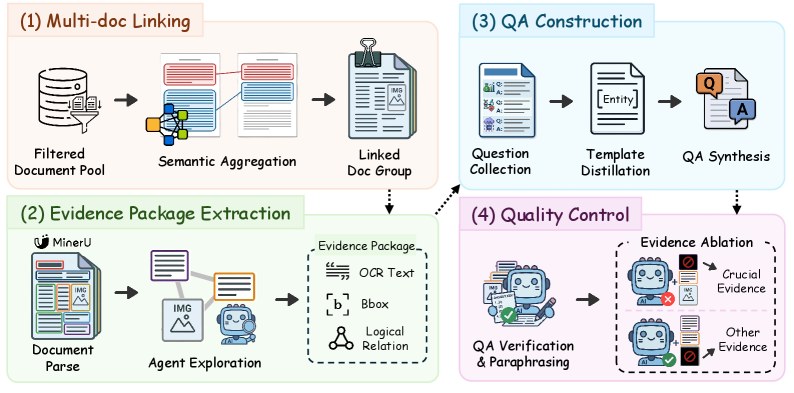
証拠ラベリングの核となる新規性は、重要な証拠を特定するためのmasking ablationです。MinerUで各ドキュメントを解析し、散在する証拠パッケージをエージェントで連結した後、候補のbounding boxを個別にマスクしてQAを再実行します。除去によって回答が失敗するボックスは\mathcal{B}_{\text{crucial}}とラベルされ、それ以外は\mathcal{B}_{\text{other}}となります。複数ドキュメントの連結は、ドキュメントごとにセマンティックプロファイル(タイプ、主張、セクション構造)を計算してエンコードし、コサイン類似度で上位K_{doc}=5の近傍を検索することで、クロスドキュメントQAの候補プールC_aを形成することで行われます。
メトリクス
各サンプルは(D, Q, A_{\text{gt}}, \mathcal{B}_{\text{gt}})であり、bounding boxは(\text{doc\_idx}, \text{page\_idx}, x_1, y_1, x_2, y_2)で指定されます。予測は\hat{Y}=\{(A_i, b_i)\}_{i=1}^nです。4つのメトリクスを用います。
- 重要証拠に対するIoU@0.5でのRecall: \text{Rec.} = \frac{1}{|\mathcal{B}_{\text{crucial}}|}\sum_{b_{\text{gt}} \in \mathcal{B}_{\text{crucial}}} \mathbf{1}\!\left(\max_{b_{\text{pred}}} \text{IoU}(b_{\text{pred}}, b_{\text{gt}}) \geq 0.5\right)
- Relevance(\text{Rel.} \in [0,5]):引用された各ボックスが対応する回答を支持しているかをLLMジャッジが採点します。
- Answer correctness(\text{Ans.} \in [0,5]):\{A_1,\dots,A_n\}とA_{\text{gt}}を比較するLLMジャッジです。
- Strict Attributed Accuracy (SAA)(主要メトリクス): \text{SAA} = \mathbf{1}\!\left(\text{Ans.} \geq 4 \;\wedge\; (\text{Rel.} \geq 4 \;\vee\; \text{Rec.} \geq 0.6)\right)
grounding条件の論理和は、アノテーターが描いたボックスと完全には重ならなくても意味的に忠実な引用を生成するモデルに対応するためのものです。
20のMLLMにわたる結果
主要な知見は、回答精度とSAAの間の大きなギャップ、すなわちモデルがしばしば正しく回答しながらも誤った領域を引用しているという点です。質問タイプ別の内訳では、Quantitative Reasoningが最も容易なカテゴリであり——Gemini-3.1-Pro-PreviewはSAA = 82.6を達成——数値的証拠から数値的回答への連鎖が密接であり検証可能であるためです。一方、Multimodal Parsingは最も困難です。このカテゴリでは、質問が視覚的な手がかり(背景色、ヘッダーの位置)によってドキュメント要素を参照してその内容を問うものであり、要素の位置特定と解析の双方が頻繁に失敗します。
ケーススタディはattribution hallucinationの現象を具体的に示しています。Case 1では、Gemini-3.1-Pro-PreviewとGPT-5.4の両方が正しい契約年価格を出力します(Ans. = 5)が、GPT-5.4は誤った価格テーブルを引用しており——Year 1の”$170”を含む領域から”$145”を引用——その結果Rec. = 0、SAA = 0となります。Case 2では、Gemini-2.5-Proが対応する引用とともにバンドギャップ差0.40 - 0.14 = 0.26 eVを正しく計算します(SAA = 1)が、Qwen3-VL-8Bは誤った数値(0.34および0.54 eV)と無関係な引用を抽出します(Ans. = 1、SAA = 0)。
解像度感度は深刻です。Qwen3-VL-235B-A22Bにおいて、入力を1024^2から724^2(ピクセル数半減)に落とすと、Rec.は11.3から4.2へ、SAAは22.5から11.8へ崩壊します。512^2ではAns.は53.5を維持しますが、Rec.は1.6、SAAは5.3となります。回答正確性は解像度の低下に対して緩やかに劣化しますが、groundingはそうではありません。これは、現在のMLLMが粗いセマンティックな概略から回答を生成する一方で、bounding box予測は細かい視覚的詳細に依存しているという仮説と一致しています。
限界
コストのかかるmasking-ablationラベリングは最先端のMLLMに依存しており、再現コストを高め、それらのモデルのバイアスを受け継ぐリスクがあります。ドメインカバレッジは従来のDoc-VQAデータセットよりも広いものの、「権威ある証拠」の定義が異なるドメイン間(例:法律における判例対医学における一次データ)で均一に扱っています。評価パイプライン自体がRel.とAns.においてLLMジャッジに大きく依存しており、SAAの閾値4が部分的に吸収しているとはいえ排除できない第二のノイズ源を導入しています。さらに、SAAの論理和\text{Rel.} \geq 4 \vee \text{Rec.} \geq 0.6により、モデルがセマンティック関連性の判定のみでスコアを得ることが可能となっており、テキスト生成は強いが座標予測が弱いモデルに対するジオメトリックなgrounding失敗を過小評価する可能性があります。
この研究の重要性
下流の利用者が出典を確認する必要がある場合、回答のみを評価するDoc-VQAは誤解を招きます。CiteVQAは統合メトリクスを具体化し、最先端のMLLMでさえ頻繁に誤った証拠から正しい回答に辿り着いていることを実証的に示しています。これは既存のベンチマークでは見えない失敗モードであり、規制された分野では受け入れがたいものです。
Source: https://arxiv.org/abs/2605.12882
学習における先読み能力:On-Policy Distillationの効率解放メカニズムの解明
On-policy distillation(OPD)は、推論LLMに対してRLによるpost-training(PPO/GRPO/DAPO)よりも経験的にサンプル効率・計算効率が高いことが知られています。しかし、標準的な説明——教師のper-tokenロジットによる、より密度が高く安定した監督信号——はlossに関する記述であり、パラメータ空間で何が起きているかについては何も語っていません。本論文はパラメータレベルのメカニズムを解明し、OPDの効率は「先読み(foresight)」効果であると主張します。すなわち、学習の非常に初期段階において、OPDは最終的に収束したモデルが必要とするモジュールおよび低ランクな更新方向に素早く固定されるのに対し、RLは有用性の低い構造全体に更新を拡散させるという主張です。
機能的冗長性の回避(Functional Redundancy Avoidance)
設定はシンプルです:共有ベースモデル W_{\text{Base}} に対して \Delta W_{\text{RL/OPD}} = W_{\text{RL/OPD}} - W_{\text{Base}} を定義し、1.5B〜32BモデルにわたってQwenの事前学習済み・SFT・Thinkingシリーズの各バリアントを比較します。
最初の観察はノルム効率に関するものです。\Delta W を共通のFrobeniusノルムに正規化して下流の推論精度を測定すると、OPDはRLよりも更新ノルムの単位あたり実質的に大きな性能向上をもたらします。また、学習の軌跡を通じて、OPDはより小さな累積 \|\Delta W\| でRLと同等の精度に到達します。
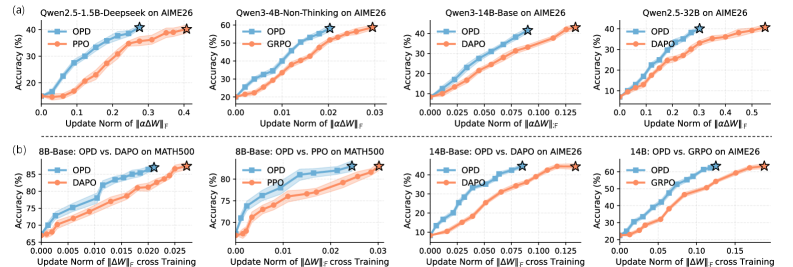
2番目の観察は、この効率を特定のモジュールに局在化させるものです。2つのプローブが使用されます:(i) OPD/RLモデルのembedding layerをベースのembeddingに置き換えてAIME26の性能低下を測定するもの、および (ii) 連続したlayer範囲にわたって \Delta W をゼロにするスライディングウィンドウ介入によりMATH500の精度を測定するもの。RLは、アブレーションを行っても推論精度がほとんど変化しないモジュール(特にembeddingや特定のlayerの帯域)に無視できない更新ノルムを分散させます——すなわち、限界効用が低い状態です。OPDはそれらの領域での更新を抑制し、アブレーションによって推論性能が崩壊するモジュールに更新を集中させます。
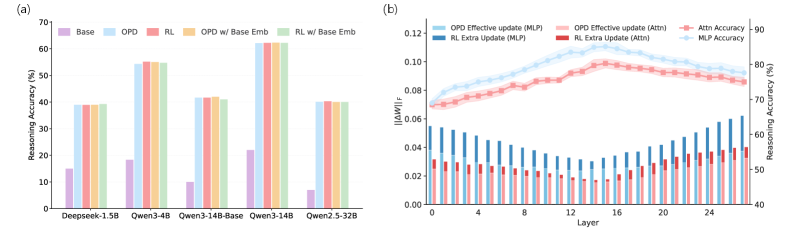
これが著者らのいう機能的冗長性の回避(Functional Redundancy Avoidance)です:OPDのgradient信号は学習の非常に初期段階から暗黙的なモジュール選択を効果的に実行します。
早期低ランク固定(Early Low-Rank Lock-in)
その幾何学的な対応物はスペクトル解析です。すべてのMLPとattention行列に対して \Delta W = U\Sigma V^\top というSVDを実行し、4つの指標を追跡します:スペクトルノルム、スペクトル/Frobeniusノルム比、有効ランク、Top-1%部分空間ノルム比。8BモデルにおけるOPDとRLの比較は以下の通りです:
- スペクトル/Frobenius比:36.8\% vs. 32.7\%
- 有効ランク:2341 vs. 2754
- Top-1%部分空間エネルギー:94.7\% vs. 88.5\%
つまり、総 \|\Delta W\|_F が小さいにもかかわらず、OPDはその更新エネルギーのより大きな割合を少数の支配的な方向に集中させています。「どの方向か」と「どれだけの量か」を分離するため、\Delta W を上位k\%と下位k\%の特異値部分空間に射影して再評価します。OPDの上位k\%部分空間はRLのものより多くの推論精度を回復します。一方、RLの下位k\%部分空間は無視できる利得に対して大きなノルムを蓄積します。チェックポイントごとのアライメント解析と合わせると、より強い主張が支持されます:OPDの支配的な部分空間は早期に安定し、最終収束後の更新部分空間とすでに整合されています。後期の学習は主として既に固定された方向に沿った大きさのスケーリングになっています。
EffOPD:方向外挿
OPDの後期段階が既に決定された方向を主に増幅するだけであれば、その方向に沿って単純に飛躍できます。EffOPDはまさにそれを実行します。指数的に間隔を置いたチェックポイント t = 2^n において、局所的な方向を以下のように定義します:
\Delta_n = W_{2^n} - W_{2^{n-1}}
(\Delta_0 はベース初期値から W_1 への方向とします)。5つの外挿候補を生成します:
\widetilde{W}_{n,k} = W_{2^n} + 2k\,\Delta_n, \quad k=1,\dots,5,
そして各候補を50件の学習例からなる小さなhold-outセット \mathcal{D}_v で検証します——これはOPDの1ステップのロールアウトコストよりもはるかに安価です。k を増加させながら \mathcal{V}_{\mathcal{D}_v}(\widetilde{W}_{n,k}) \geq v^{\text{acc}} を満たす限り貪欲に候補を採用し、最初に失敗した時点で終了します。k=1 の時点ですでに失敗する場合は、そのチェックポイントについては通常のOPDにフォールバックします。
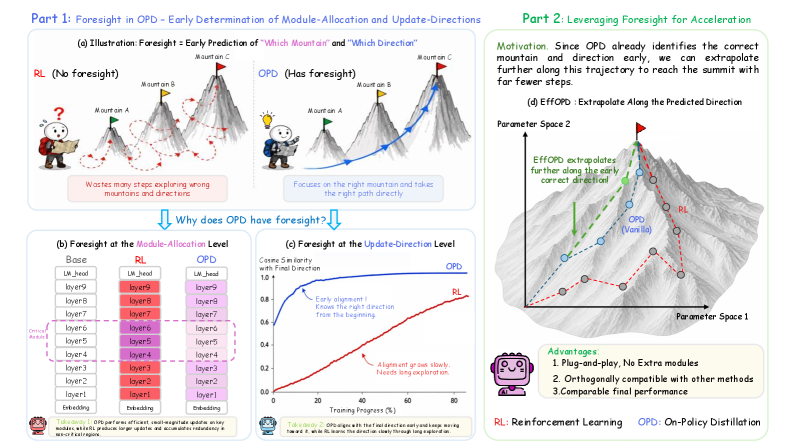
これは本質的に、OPDの軌跡が後期学習においておおよそ線形であるという事実を利用したモメンタム的なライン探索です。追加の学習可能パラメータはなく、実質的なハイパーパラメータは候補グリッドのみです。報告されているwall-clock時間の高速化は平均 3\times であり、下流の精度と同等の性能を維持します。アブレーションは学習率感度、\mathcal{D}_v の難易度(サンプリングされたバッチに対するモデルの事前学習精度で測定)、および時間-精度のParetoフロントをカバーしています。
限界とオープンクエスチョン
この分析はスペクトルレベルでの相関分析です:「早期の支配的部分空間が最終的な部分空間と整合する」という観察はなされていますが、OPDのloss幾何学から導出されたものではありません。教師は常に同じファミリーの強力なモデル(パターン整合蒸留)です。異なるファミリーの教師、より弱い教師、またはoff-policyな混合に対して先読み効果が維持されるかは検証されていません。50例の検証セットは研究対象の数学・推論ベンチマークでは十分ですが、よりノイズの多いドメイン(コード、エージェント的タスク)における受容基準としての \mathcal{V}_{\mathcal{D}_v} の分散については不明です。外挿グリッド \{2,4,6,8,10\}\Delta_n は手動で選択されており、連続的な探索によって高速化をさらに改善できる可能性があります。また、離散的な飛躍後のオプティマイザーの状態(Adamのモーメント)との相互作用は分析されていません。最後に、この枠組みはRLをパラメータ効率の点で明らかに劣るものとして描いていますが、RLの探索はdistillationでは得られない有用な方向を注入する可能性があります——比較は固定計算量における推論精度に関するものであり、能力の上限についてではありません。
この研究の意義
本論文はOPDの効率を監督信号の密度に関する議論からパラメータ幾何学的なもの——早期のモジュール選択と早期の低ランク固定——へと再解釈し、その観察をチェックポイント間隔の線形外挿によるほぼコストゼロの 3\times 学習高速化へと転換します。このメカニズム(低ランク軌跡の安定性)は十分に一般的であり、更新方向の安定化が大きさの安定化より早く起こる他のpost-trainingレジームにも同様の外挿トリックが適用できる可能性が高いと言えます。
Source: https://arxiv.org/abs/2605.11739
Flash-GRPO: 1ステップ方策最適化によるビデオ拡散の効率的なAlignment
問題
大規模なビデオ拡散・flow-matchingモデルのGRPOスタイルのalignmentは、軌跡コストによって支配されています。標準的な目的関数は、すべての T denoising ステップにわたってclipされた方策比を合計します。
f(r,\hat{A},\theta,\varepsilon,\beta)=\frac{1}{GT}\sum_{i=1}^{G}\sum_{t=0}^{T-1}\Big(\min(r_t^i\hat{A}_t^i,\mathrm{clip}(r_t^i,1-\varepsilon,1+\varepsilon)\hat{A}_t^i)-\beta D_{\mathrm{KL}}(\pi_\theta\|\pi_{\mathrm{ref}})\Big),
ここで r_t^i(\theta)=\pi_\theta(\bm{x}_{t-1}^i|\bm{x}_t^i)/\pi_{\theta_{\mathrm{old}}}(\bm{x}_{t-1}^i|\bm{x}_t^i) です。Wan2.1-14Bの場合、これは1回の実行に数百GPU日を要します。既存の高速化手法(前半のみ学習するFlow-GRPO、スライディングウィンドウを用いるFlow-GRPO-Fast/MixGRPO)は、軌跡を短縮することでコストを削減しますが、不安定であり完全軌跡学習と比べて性能が劣ります。Flash-GRPOはこれを論理的な極限まで押し進め、ロールアウトごとに正確に1タイムステップのみを更新することで、2つの補正を加えればコストのごく一部で完全軌跡GRPOを上回ることができることを示します。
手法
Flash-GRPOは、以下のODE-to-SDEロールアウトで学習されたflow-matchingモデルに対する単純な1ステップGRPOの2つの失敗モードを修正します。
\bm{x}_{t+\Delta t}=\bm{x}_t+\Big[\bm{v}_\theta(\bm{x}_t,t)+\frac{\sigma_t^2}{2t}(\bm{x}_t+(1-t)\bm{v}_\theta(\bm{x}_t,t))\Big]\Delta t+\sigma_t\sqrt{\Delta t}\,\bm{\epsilon}.
Iso-temporal grouping。 プロンプトグループ内の各ロールアウトが独立なタイムステップ t_i\sim\mathcal{U}[0,T] を引く場合、グループbaseline \mu_{\mathrm{naive}}=\frac{1}{G}\sum_i R(\bm{x}_0^i(\bm{x}_{t_i}),\bm{c}) は異なるノイズレベルの報酬を混在させてしまいます。報酬が t と相関する(低ノイズからdenoiseする方が系統的に高品質な結果を与える)ため、advantage \hat{A}_t^i は方策品質ではなくタイムステップの難易度を反映することになります。Flash-GRPOは、プロンプトグループ \mathcal{G}_k=\{\bm{x}_{t_k}^i\mid i\in[1,G]\} ごとに単一の t_k を設定し、G 個のロールアウトが初期ノイズ \bm{\epsilon}_i のみで異なるようにします。バッチ全体では、異なるプロンプトが異なる t_k\sim\mathcal{U}[0,T] を受け取るため、グローバルなタイムステップのカバレッジは保持されます。ロールアウト内では、選択された t_k のみがSDEアップデートを使用し(そこでgradientが計算され)、残りのステップは決定論的なODEを実行してデコードされた \bm{x}_0、ひいては報酬をクリーンに保ちます。
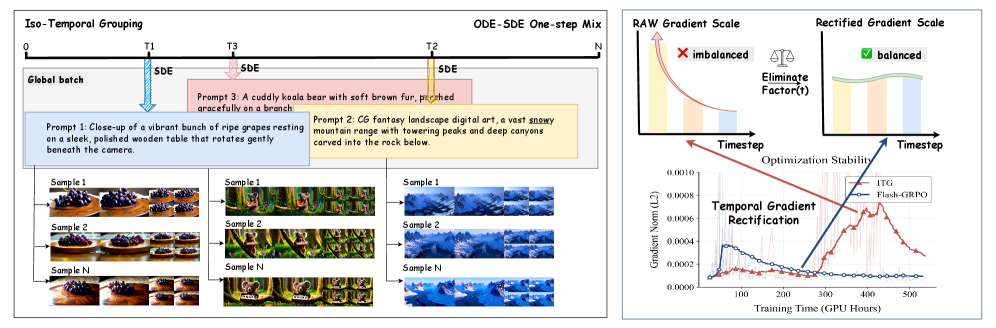
Temporal gradient rectification。 SDEステップは \sigma_t^2/(2t) および \sigma_t を通じて時間依存スケールを注入します。完全軌跡の目的関数ではこれらは T ステップにわたって均される一方、1ステップ学習ではgradientの大きさが生の t 依存性を引き継ぎ、タイムステップ間で著しく不均一な更新と不安定性を生じさせます。本手法は、選択された t_k における t 依存ファクターを中和することで、サンプルごとのgradientノルムをタイムステップ不変にすることによってこれを整流します。0.001 という厳しいclip ratioと組み合わせることで、1ステップ制度下で安定した更新を実現します。
結果
実験では、DanceGRPOのプロンプトを用いた300プロンプトのheld-outスプリット、50ステップ推論、CFG 4.5、学習中のサンプリングステップ数20(1.3B)/ 12(14B)で、Wan2.1の1.3Bおよび14Bを使用します。報酬信号はHPSv3(視覚品質、LongCatによる上位30%フレーム平均)とVideoAlignモーションスコアであり、VBenchが美的・画像・意味論的次元を評価します。
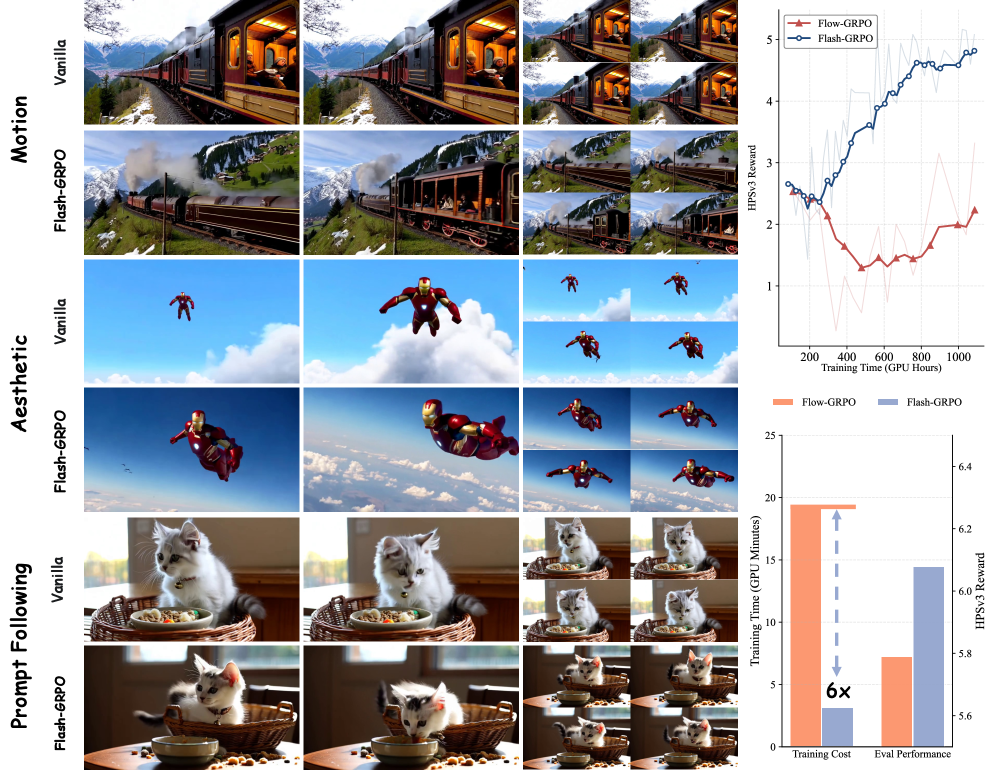
学習報酬曲線(図1、右上)は、Flash-GRPOが単調かつ安定に改善する一方、最も近いベースラインであるFlow-GRPO-Fast1(1ステップスライディングウィンドウ)は低下または頭打ちになることを示しています。前半軌跡学習のFlow-GRPOと比較して、Flash-GRPOははるかに小さい計算量で同等以上の品質を達成します。主要な主張は、低予算条件下において1ステップ学習が完全軌跡GRPOを上回り、さらにステップあたりの速度も速いということです。両スケールでの定性的比較(図3)は、より優れた時間的ダイナミクス(乗馬シーケンス)、より豊かなテクスチャ(パンダのシーン)、および改善されたプロンプト網羅性(バニラWan2.1では欠如していた蝶の要素を含む動物キャラクターのシーン)を示しています。

このドラフトに付属する論文テキストでは比較表が省略されていますが、HPSv3、VideoAlignモーション、VBenchの報告された軸にわたる一貫したパターンとして、Flash-GRPOはFlow-GRPO-Fast1を上回り、軌跡コストのごく一部でFlow-GRPOと同等以上の性能を示すことが、1.3Bおよび14Bの両方で検証されています。著者らは、アブレーションのために完全軌跡GRPOが実質的に利用不可能な14Bの制度こそが、効率化の恩恵が最も発揮される場面であると強調しています。
限界と未解決の課題
- 1ステップ更新は、報酬を得るために任意の t_k における \bm{x}_0 への正確な1ショットデコードに依存しています。他のステップでODEを用いるトリックによってこれは緩和されますが、決定論的な続きが更新後の方策のもとで \bm{x}_0 の良いプロキシとなるという強い仮定を組み込んでいます。大きな t_k におけるoff-policyness は分析されていません。
- 非常に厳しいclip ratio(\varepsilon=10^{-3})は、最適化の景観が脆弱であることを示唆しています。これが長期学習やより強力な報酬モデルとどのように相互作用するかは不明です。
- Iso-temporal groupingはグループ内分散を低減しますが、advantage信号の多様性も低減します。グループサイズ G とバッチサイズ B とのトレードオフは十分に分析されていません。
- HPSv3/VideoAlignにおける報酬ハッキング(画像GRPOでよく知られている)は本抄録では扱われていません。VBenchでの向上がより信頼できる指標となるでしょう。
- 整流された1ステップgradientの完全軌跡期待値に対する理論的な等価性・バイアスは、証明されたものではなく運用上の主張にとどまっています。
なぜ重要か
14Bビデオモデルにおけるiso-temporal groupingを用いた1ステップGRPOが完全軌跡alignmentに本当に匹敵するならば、ビデオ拡散のRLHFは数百GPU日を要する作業ではなくなり、事前学習のエポックと同程度のコストになります。これにより、スケールでの報酬モデルの反復的改善が日常的に可能になります。タイムステップに交絡したadvantage分散とSDEによるgradientスケール不均衡という2つの診断は、画像flow-matching GRPOや他の少ステップalignmentスキームにも一般化する可能性が高いです。
Source: https://arxiv.org/abs/2605.15980
Hölder Policy Optimisation
問題
LLMにおけるgroup-relative policy optimisationでは、surrogate objectiveにおいてトークンレベルの重要度比 r_{i,t}(\theta) = \pi_\theta(y_{i,t}\mid x, y_{i,<t})/\pi_{\theta_{\text{old}}}(y_{i,t}\mid x, y_{i,<t}) を単一のシーケンスレベルのスカラー \rho_i(\theta) に集約する必要があります。GRPOは算術平均(p=1)を、GSPO/GMPOは幾何平均(p\to 0)を使用しています。これらは連続体上の孤立した点に過ぎず、集約方法の選択は学習に大きな影響を与えます。すなわち、算術平均による集約は比率の高いトークンを増幅し、スパースな報酬タスクでは崩壊しやすい一方で、幾何平均による集約は外れ値を抑制するものの、学習シグナルが少数のトークンに集中している場合にはunderfitしてしまいます。ベンチマーク全体で支配的な固定演算子は存在しないため、集約のスケジューリングを伴う原理的なパラメータ化が必要とされています。
手法
HölderPOは集約器を次数 p\in\mathbb{R} のHölder平均に置き換えます:
\rho_{i,p}(\theta) = \begin{cases}\left(\tfrac{1}{|y_i|}\sum_{t=1}^{|y_i|} r_{i,t}(\theta)^p\right)^{1/p}, & p\neq 0,\\ \exp\!\left(\tfrac{1}{|y_i|}\sum_{t=1}^{|y_i|} \log r_{i,t}(\theta)\right), & p=0.\end{cases}
学習の目標関数は、標準的なPPOスタイルのシーケンスクリップ済みsurrogateです:
\mathcal{J}_{H_s}(\theta) = \mathbb{E}\!\left[\tfrac{1}{G}\sum_{i=1}^G \min\!\big(\rho_{i,p}(\theta)\widehat{A}_i,\ \mathrm{clip}(\rho_{i,p}(\theta),1-\epsilon,1+\epsilon)\widehat{A}_i\big)\right].
gradient分散を抑制するために、トークンごとではなくシーケンスレベルのclippingが選択されています。集約器のgradientはトークン重み付きのscore-function estimatorであるという機械的な観察が重要であり、次のように表されます:
\nabla_\theta \rho_{i,p}(\theta) = \rho_{i,p}(\theta)\sum_{t=1}^{|y_i|} W_{i,t}(p)\,\nabla_\theta\log\pi_\theta(y_{i,t}\mid x,y_{i,<t}),\qquad W_{i,t}(p) = \frac{r_{i,t}(\theta)^p}{\sum_{k} r_{i,k}(\theta)^p}.
重み W_{i,t}(p) は \{p\log r_{i,t}\} 上のsoftmaxを形成します。p が大きいほど、比率の最も高いトークンへの質量集中が進み(クレジットがスパースな場合に有効な鋭い学習シグナル)、p が小さいまたは負の場合は重み付けが平坦化または反転します(低分散、安定した更新)。p=1 はGRPOに、p\to 0 はGSPO/GMPOに極限として帰着します。
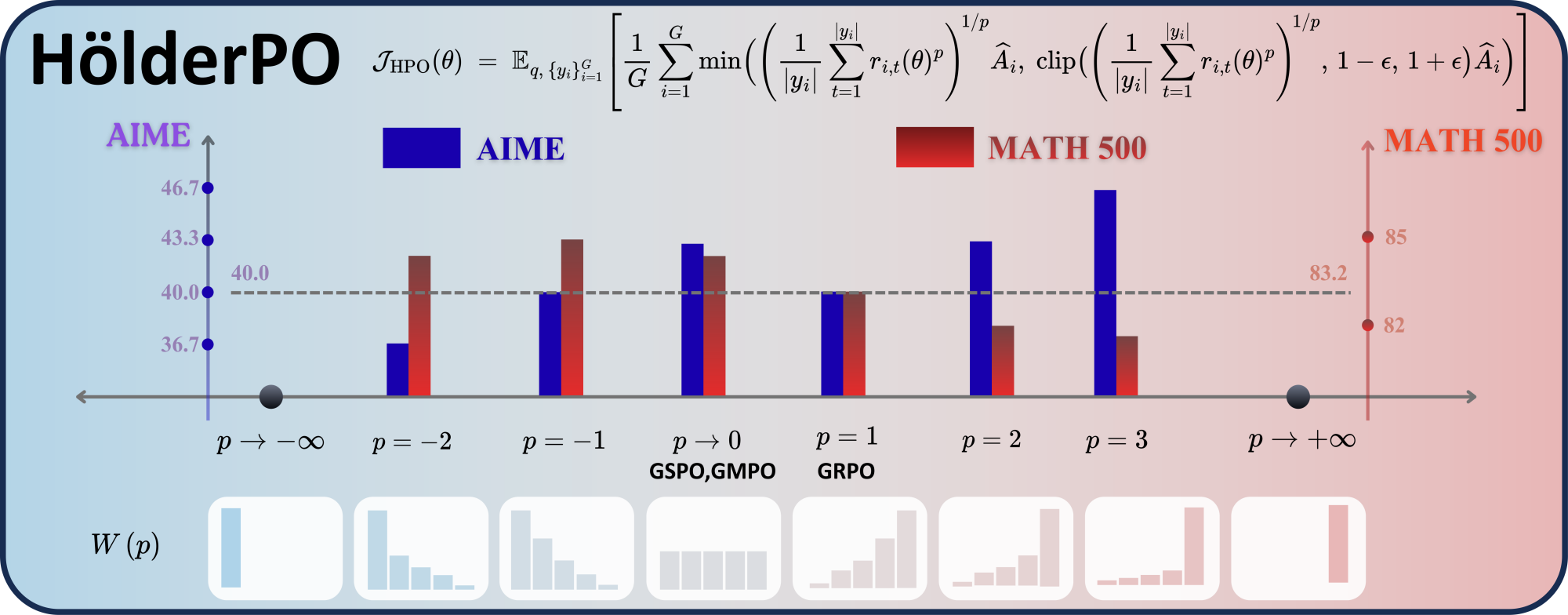
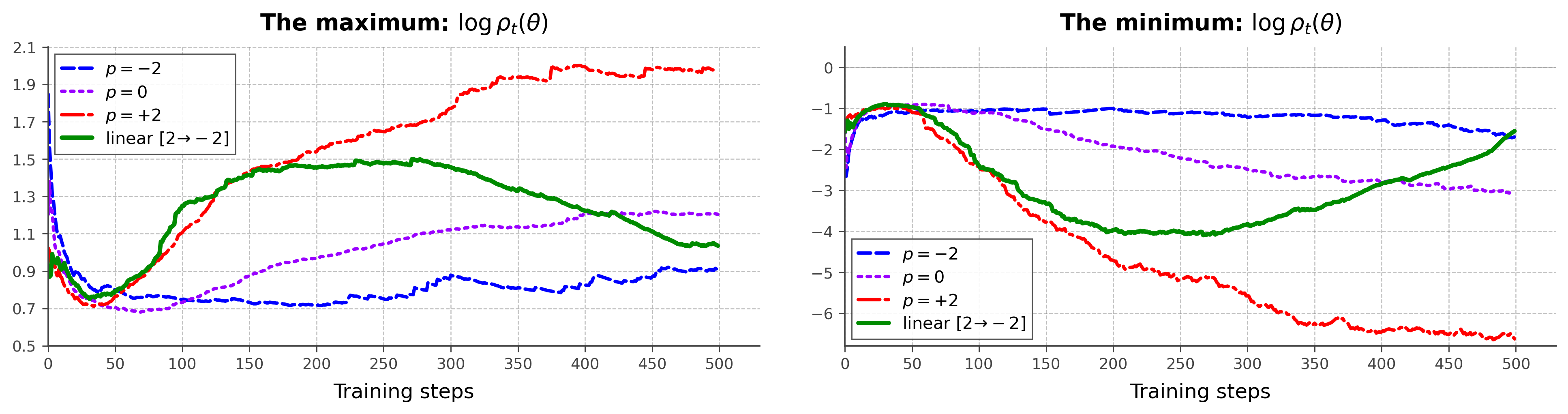
集中性と安定性のトレードオフは本質的であり、最大限の情報量と分散有界性の両方を満たす静的な p は存在しません。そのためHölderPOは、学習を通じて p を +2 から -2 へと動的にアニーリングするスケジュールを使用します。経験的には、\log\rho_t(\theta) のステップごとのenvelopeは p の減少に伴って単調に狭まるため、このスケジュールにより初期段階ではスパースなシグナルを積極的に活用し、後半では段階的に分散を制御した更新が実現されます。
実験
数学的推論の評価はAIME24、AMC、MATH500、Minerva、OlympiadBenchで行われ、Qwen2.5-Math-1.5B/7B、DeepSeek-R1-Distill-Qwen-7B、Qwen3-4B/8Bを使用しています。学習はDr.GRPOレシピに従い、8,523問のMATH(レベル3〜5)、プロンプトあたり8ロールアウト(3,000トークン上限)、1ラウンドあたり1,024トラジェクトリ、バッチサイズ128で8回の内部更新を 4\timesH100 で実施しています。Agenticな評価では、Qwen2.5-1.5B-InstructをALFWorld上でGiGPOプロトコルに基づいて評価しています。ベースラインはGRPO、Dr.GRPO、GMPOです。Pass@1はgreedy decodingで報告されています。
図1の棒グラフは p に対するタスク固有の感度を示しています。AIME24(スパースな報酬、難問)とMATH500(より密なシグナル)は異なる固定 p を好み、単一の静的集約器が普遍的に最適ではないことを確認しています。動的スケジュールは差を取るのではなく、このトレードオフを解決します。
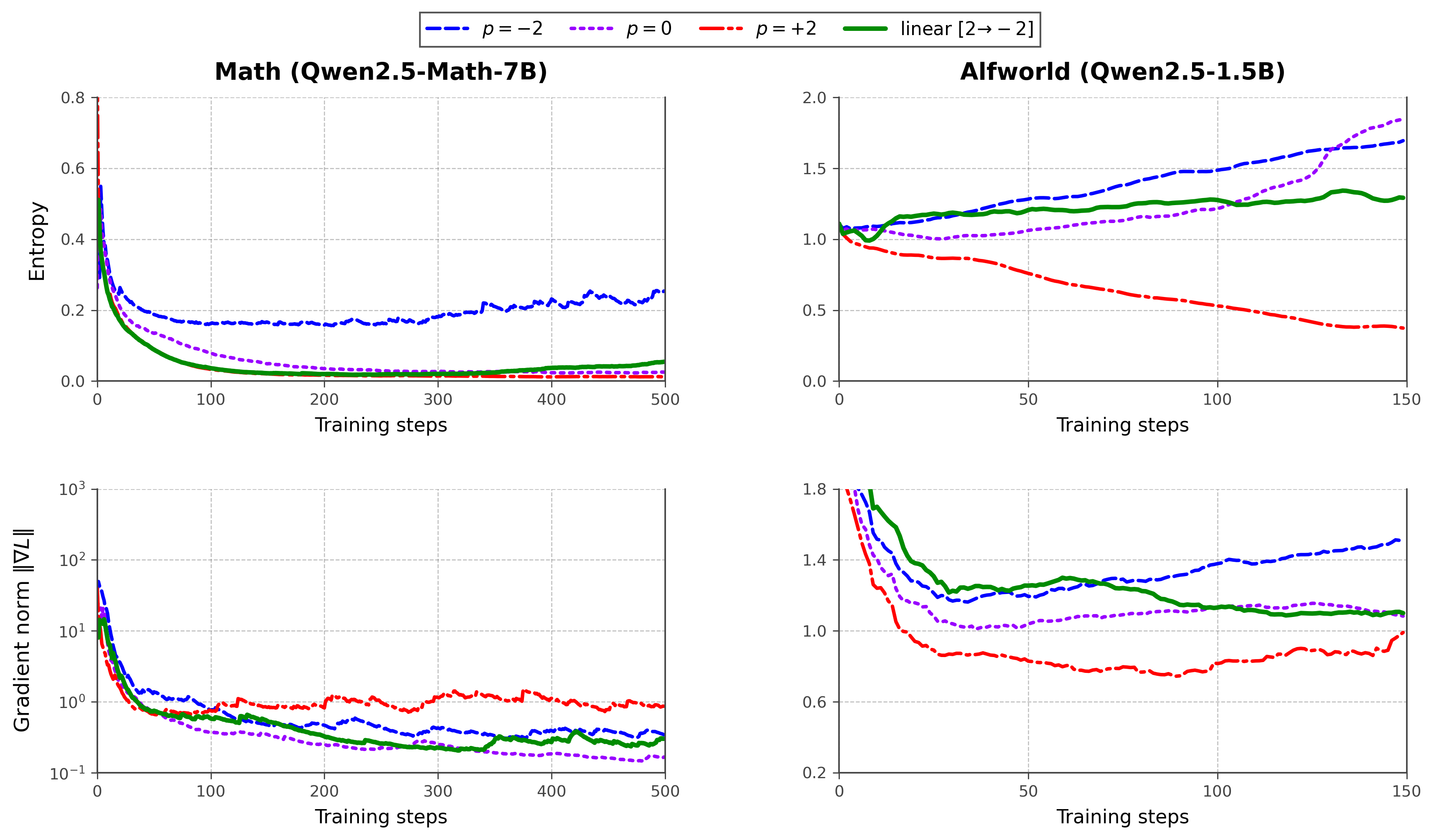
エントロピーとgradientノルムのトレースは理論的な描像を支持しています。定数 p=+2 ではMathにおいて大きなgradientノルムと急速なエントロピー崩壊が生じ、p=-2 はgradientをtightに抑制しますが学習シグナルを十分に活用できません。線形の p:2\to-2 スケジュールはその中間に位置し、Math(Qwen2.5-Math-7B)およびALFWorld(Qwen2.5-1.5B)の両方において、学習を通じてgradient magnitude を制御しつつエントロピーの緩やかな減衰を実現します。
制限と未解決の問題
スケジュールは手動で設定されており(線形 p:2\to-2)、理論がまさにそのようなシグナルを示しているにもかかわらず、測定されたgradient分散、エントロピー、または報酬スパース性に p を結びつける適応的なコントローラーは存在しません。シーケンスレベルのclippingは分散制御の観点から正当化されていますが、p<0(小さい比率のトークンに支配的な重みを置く可能性がある)との相互作用についてはより慎重な安全性分析が必要です。負の p は重み付けを反転させ、レアトークンのノイズを増幅する可能性があります。数学の評価では温度0のPass@1を使用しており、探索駆動の利得を過小評価しています。また、agenticな評価は1.5BスケールのALFWorldに限定されています。最後に、このフレームワークはadvantage estimationとは直交するものとして提示されていますが、W_{i,t}(p) は事実上暗黙のトークンレベルのcredit assignmentを行っており、トークンレベルのadvantageとの共同設計は未探索のままです。
意義
HölderPOはGRPO/GSPO/GMPOの議論を、トークン集約器の一パラメータファミリー上の点選択として再定式化し、適切な動作点がシグナルのスパース性に依存することを示すことで、チューニングではなくスケジューリングを動機付けています。これにより、LLM RLにおけるシーケンスレベルのlossの選択という従来はad-hocな問題に対して、softmax重み W_{i,t}(p) という明快な理論的ハンドルが与えられます。
Source: https://arxiv.org/abs/2605.12058
ニューラルアーキテクチャのエージェント的探索:AIRA-Compose と AIRA-Design
本論文は、LLM エージェントがコード実行ハーネスと固定された計算バジェットを与えられた場合に、人間や BO によって設計されたベースラインを上回る foundation model アーキテクチャを発見できるかどうかを問います。著者らは問題を二つの領域に分けています:事前定義された計算プリミティブ(Transformer attention、MLP、Mamba)の配置を探索する AIRA-Compose と、エージェントが新規の attention メカニズムとトレーニングループをゼロから記述する AIRA-Design です。いずれも AIRS-Bench タスク {problem, dataset, metric} として定式化され、one-shot または greedy tree-search のスキャフォールドを備えた AIRA-dojo ハーネス上で実行されます。
セットアップと探索のメカニズム
エージェントは (LLM, scaffold) のペアです。スキャフォールドは Python ソリューション上で動作する四つのオペレータ — Draft、Debug、Improve、Analyze — を公開しています。greedy スキャフォールドは 5 個のルート候補を Draft し、新たな最良解が現れるまで最も高い validation fitness を持つノードを Improve によって展開します(Analyze がフラグを立てた OOM や不正なプリミティブ文字列に対しては Debug が発動します)。各実行は単一の H200 上で 24 時間(BabiStories/DCLM については 60 時間)または 500 ステップに制限されています。

AIRA-Compose は Composer フレームワーク(acun2025composer)のステップ 1–2 をエージェント的タスクとして再定式化します:エージェントは 2 プリミティブプール {multi-head attention A、MLP M} または 3 プリミティブプール {A、M、Mamba ブロック Mb} から 16 個のプリミティブを列挙した submission.csv を出力します。Aggregator と Extrapolator(ステップ 3–4)は固定のままです:上位アーキテクチャをレイヤーごとにクラスタリングして頑健な 16 層ベースに集約し、それを積み重ねる(repeat)か引き伸ばす(連続ブロックを比例的に拡張する)ことで 350M / 1B / 3B パラメータに拡張します。
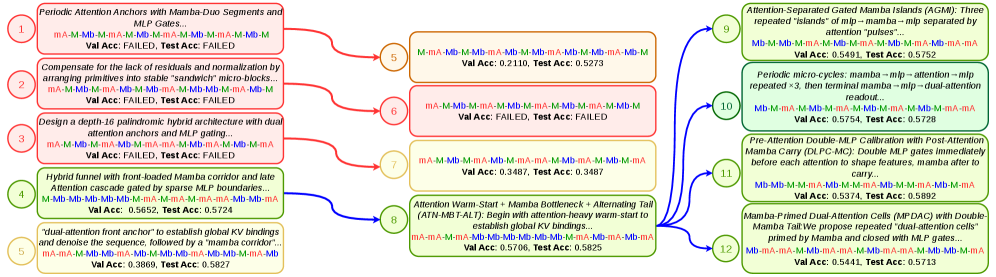
探索トレースは BO / インクリメンタル探索に対する定性的な改善を示しています:各ノードでエージェントは仮説を言語化し(例:検索のために attention を前方に集中させる、容量確保のために MLP を後方に重点配置する)、候補を記述し、ハーネスが独立してスコアリングする前に内部で evaluate.py を実行します。10 エージェント × 3 データセット(CWM、o3-mini、gpt-oss-20b/120b、GPT-4o、さらに MAD 上での 20 回の GPT-5 greedy 実行)にわたり、探索は 2,307 個のユニークな 16 層アーキテクチャ、すなわち 2 プリミティブ空間の 3.17% を調査します。
AIRA-Compose の結果
Aggregation により四つの AIRAformer ベースパターンが生成されます。注目すべきことに、独立したエージェント探索から集約されているにもかかわらず、attention:MLP 比率は 7:9(A、B)と 11:5(C、D)の二つに収束します。例えば、
\text{AIRAformer-D} = 5\times(2A + M) + A.
1B スケールでの IsoToken 事前学習は 71,565 ステップ × バッチ 4 × シーケンス長 8192 × DP 16 ≈ 37.5B トークンを使用し、モデルごとに三つのシードで実施されます。DCLM における validation loss:
- Llama 3.2:2.815
- Composite Stretched:2.759
- AIRAformer-D Stretched:2.734
6 タスクの 0-shot 精度平均は Llama 3.2 の 57.5% から AIRAformer-A Stretched の 59.6% へと上昇し、DCLM Core スコアは 46.9 から 48.8(AIRAformer-C Stacked)へと向上します。AIRAformer-D バリアントは Llama 3.2 に対してダウンストリーム精度を 2.4% 改善し、Transformer–Mamba ハイブリッドである AIRAhybrid-D はさらに 3.8% 向上します。
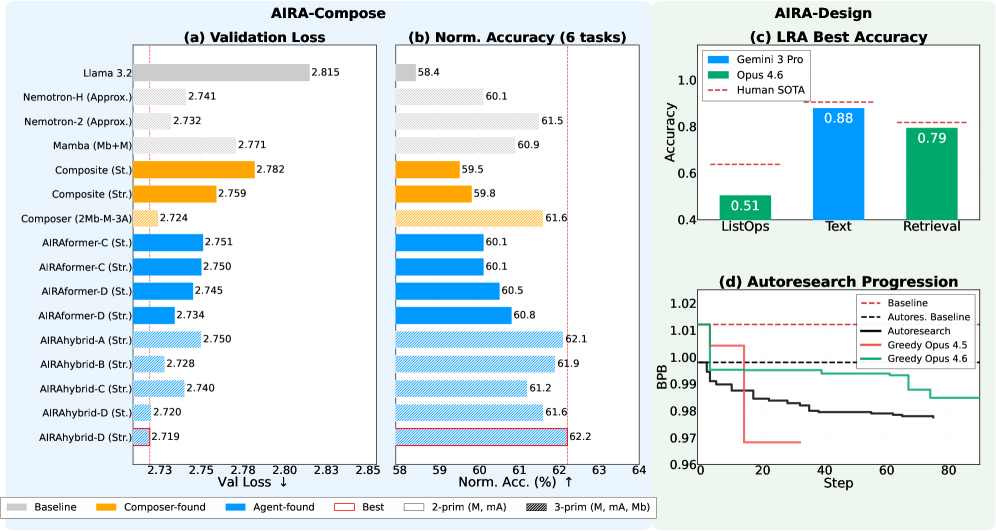
最大のスケーリングに関する主張は loss 対トークン数のフロンティアに関するものです:AIRAformer-C は Llama 3.2 および Composer の最良 Transformer に対してそれぞれ 54% および 71% 高速にスケーリングし、AIRAhybrid-C は Nemotron-2 に対して 23%、Composer の最良ハイブリッドに対して 37% を上回るスケーリング性能を示します。Aggregator/Extrapolator は Composer のものと同一であるため、この向上はエージェント的探索ポリシーに帰因するものであり、後処理によるものではありません。
AIRA-Design
AIRA-Design はエージェントをプリミティブレベルより下に押し進めます。二つのスイートが使用されます:(i) Long Range Arena(Text、ListOps、Retrieval、およびその Configurable バリアント)では、エージェントは 2k–4k トークン系列において O(n^2) 行列の実体化を避けるサブ二次 attention を備えた CustomEncoder を公開する完全な model.py を生成しなければなりません;(ii) Autoresearch(karpathy2026autoresearch)では、エージェントは 5 分間の単一 GPU トレーニングバジェット内で validation bits-per-byte を最小化するために nanochat の train.py(multi-head causal attention + RoPE + FlashAttn + Muon–AdamW)を編集します。データパイプライン、tokenizer、および eval ハーネスは読み取り専用であり、“With Literature” バリアントでは 41 本の論文解析と 14 個のリファレンスリポジトリが公開されます。
三つのメトリクスが報告されます。生のスコアに加え、著者らは valid submission rate \text{VSR}_{a,t} = V_{a,t}/T_{a,t} と “march of nines” 変換を用いた正規化スコアを定義します。
\phi_t(s) = -\log_{10}(|s - s_t^{\text{opt}}|),\qquad \text{NS}_t^a = \frac{\phi_t(s_t^a) - \phi_t(s_t^{\min})}{\phi_t(s_t^{\text{sota}}) - \phi_t(s_t^{\min})},
これにより SOTA を超えると NS > 1 となり、最適値への絶対的な近さが対数線形的に報酬されます。失敗/無効な submission は NS = 0 となりますが、これは VSR が AIRA-Compose のように ~1 ではない AIRA-Design において意味を持ちます。
制限と未解決の問題
エージェント的探索が触れるのは 2 プリミティブ空間のわずか ~3% に過ぎず、二つの A:M 比率への収束は探索景観と同様に、使用した LLM の帰納的事前分布を反映している可能性があります。大規模な評価はすべて Composer の stacking/stretching extrapolator を再利用しているため、「発見されたアーキテクチャ」に関する主張はそれらのスケーリング則に条件付けられています。37.5B トークンの IsoToken バジェットは現代のフロンティアトレーニングに比べて小さく、54–71% のスケーリングギャップが 100B トークンを超えても持続するかどうかは未検証です。本節での AIRA-Design の結果はメトリクスの定義を扱うに留まり、LRA/Autoresearch の完全な数値リーダーボードは含まれていません。最後に、フレームワークの再帰的自己改善のフレーミングは、それ自体が Transformer の文献で学習されたエージェント LLM に依存しており、プリミティブ探索にバイアスをもたらします。
なぜこれが重要か
これは、LLM エージェントが構造化された探索ハーネスを与えられた場合に、1B スケールにおける loss とダウンストリーム精度の両方で BO ベースの NAS ベースラインを厳密に支配し、測定可能なスケーリング則の改善をもたらすアーキテクチャファミリーを生成できることを示した、これまでで最も明確なデモンストレーションです。これは NAS をハイパーパラメータ最適化から意味論的事前分布を持つエージェント的コード合成へと再定義するものです。
Source: https://arxiv.org/abs/2605.15871
PhysBrain 1.0 テクニカルレポート
PhysBrain 1.0 は、vision-language-action(VLA)モデリングにおける特定のボトルネックに取り組んでいます。すなわち、テレオペレーションやスクリプトポリシーから得られるロボット軌跡は、物理的状況の狭い範囲しかカバーしておらず、それらに基づいて訓練されたポリシーは、幾何学、接触、空間的関係に関する事前知識が弱いという問題です。この論文の仮説は、人間のエゴセントリック動画(豊富で多様であり、マニピュレーションに富んでいる)が、適切な形式に変換されれば、それらの事前知識を提供できるというものです。貢献は二つあります。一つは、生のエゴセントリック映像を構造化された物理的記録へ、さらにはQA教師データへとコンパイルするデータエンジンであり、もう一つは、言語に基づいた理解を消去することなく、得られたVLMの事前知識をVLAポリシーに転送する能力保持適応手順です。
動画から物理的に明示的な教師データへ
データエンジンは、キャプション生成器ではなくコンパイラとして明示的に位置付けられています。キャプションは表面的な記述に最適化され、行動に必要な物理的構造——物体の幾何学、接触の進行、相対距離、到達可能性、サブ行動の順序——を失ってしまうと著者らは主張しています。PhysBrain 1.0 はその代わりに二つの設計制約を課しています。第一に、教師データは物理的に明示的でなければなりません。各映像クリップは、可視オブジェクト、その物理的属性、空間配置、奥行き関係、および行動下でのシーンの変化を列挙した構造化記録へとパースされます。第二に、このシーンのメタ情報は学習目標と切り離されています。JSONライクな記録は中間的な成果物であり、モデルはそれらから派生した自然言語QAで訓練されます。
したがって、パイプラインは明確な段階的インターフェースを持っています。エゴセントリックなマニピュレーションクリップからフレームが均等にサンプリングされ、パーサーが静的シーン要素(物体、属性、レイアウト)、空間変化(物体の動き、奥行き順序、距離の変化)、行動実行(アクターの手の軌跡、接触イベント、サブ行動シーケンス)に分割されたコンパクトなソース記録を抽出します。後続の段階では、この記録を増強・検証し、最終的にQAペアへと変換します。
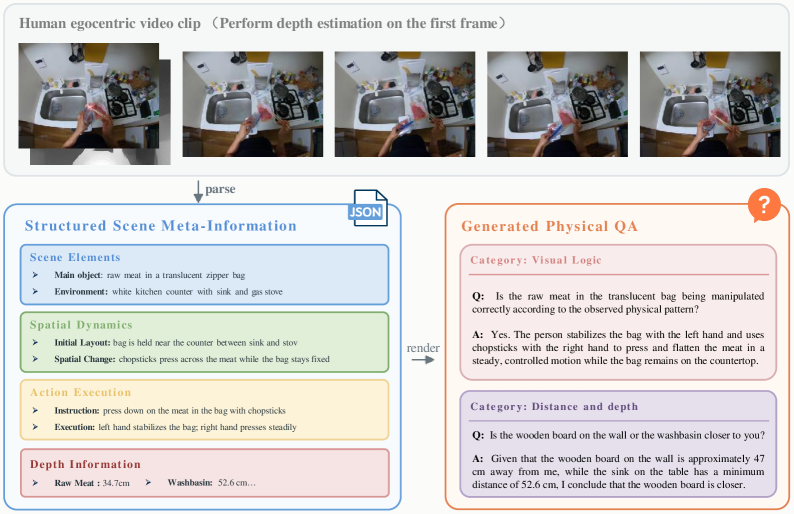
この分離は機械的に重要な意味を持ちます。中間記録が機械可読であるため、下流の生成処理が特定の物理的軸をターゲットにできます——例えば、「t_2 においてアクターの右手に近いのはどの物体か?」や「注ぐ動作を完了するために必要なサブ行動の順序は何か?」といった問いです。また、抽出エラー(物体の欠損、誤った奥行き順序)が最終的な教師データに混入する前に検出できます。QA変換ステップは自然言語の柔軟性を保ちつつ、上流の記録が対象とする物理的軸(幾何学、接触、奥行き、時間的順序)のカバレッジを保証します。
VLAポリシーへの転送
PhysBrain VLMが学習した物理的事前知識は、著者らが能力保持かつ言語感受性のある適応と表現する手続きを通じて、VLAポリシーへ転送されます。その動機は、ロボット軌跡に対するナイーブなfine-tuningが、上流学習の目的であったマルチモーダルQA能力を典型的に劣化させるという点にあります。提供された抜粋では適応lossの詳細は明記されていませんが、構造的な主張——適応は言語に根ざした推論を保持しつつ行動条件付きのポリシーヘッドを注入しなければならない——は、言語感受性という追加制約(action fine-tuning中も指示条件付き行動が損なわれないよう)のもとで適用された、標準的な凍結・正則化バックボーンのレシピです。
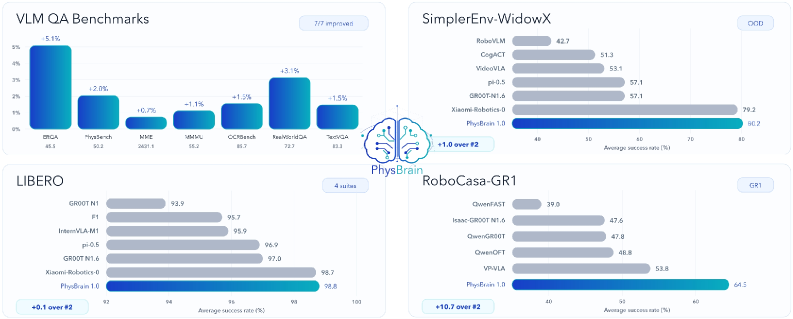
結果
PhysBrain 1.0 は、マルチモーダルQAと身体化制御にまたがる広範な評価スイートにおいてSTOAを報告しています。物理的・身体化推論についてはERQAおよびPhysBench、制御についてはSimplerEnv-WidowX、LIBERO、RoboCasaが用いられています。主要な定性的知見は「SimplerEnvにおける特に強いドメイン外性能」であり、これは最も情報量の多い指標です。SimplerEnv-WidowXは学習分布を超えた汎化を評価しており、そこでの性能向上は、人間動画から導出された事前知識が、ロボットデータの統計への過適合ではなく、真に機能していることの最も明確な証拠です。各ベンチマークの具体的な数値は、提供された抜粋には記載されていません。
限界と未解決の問題
いくつかの問いが残っています。抽出スタック(物体検出、奥行き、手・接触推定)はそれ自体が学習済みシステムであり、そのバイアスがJSON記録、ひいては最終的なQA分布を形成しますが、レポートの抜粋では抽出誤差やその伝播を定量化していません。エゴセントリックな人間動画には手—グリッパーの身体ギャップが存在します。PhysBrain は物理的常識(接触、奥行き、サブ行動順序)が身体に依存しないほど汎用的に転送できると賭けていますが、SimplerEnvでの性能向上のうち、どれほどがこの常識によるもので、どれほどが偶発的な視覚的カバレッジによるものかは切り離されていません。QA生成ステップは構造化記録に対してLLMを用いている可能性が高く、そのレンダリングの忠実度、および構造化された中間表現にもかかわらず幻覚された関係が教師データに逆流するリスクも未解決の問いです。最後に、能力保持適応は目標の観点から記述されているにとどまります——どの設計選択が言語感受性を保持するかを切り離したアブレーションがあれば、これが頑健なレシピなのか、タスク固有のチューニングなのかが明確になるでしょう。
なぜ重要なのか
物理的常識が高コストなロボット軌跡収集ではなく人間のエゴセントリック動画によってスケールするならば、VLA訓練のデータ経済は大きく変わります。ボトルネックはテレオペレーションの時間から抽出品質へと移行します。PhysBrain 1.0 のコンパイラスタイルエンジンは、明示的な中間記録とQA専用の学習ターゲットを備えており、そのシフトに向けた具体的なテンプレートとなっています。
Source: https://arxiv.org/abs/2605.15298
MMSkills: マルチモーダルスキルによる汎用視覚エージェントに向けて
問題設定
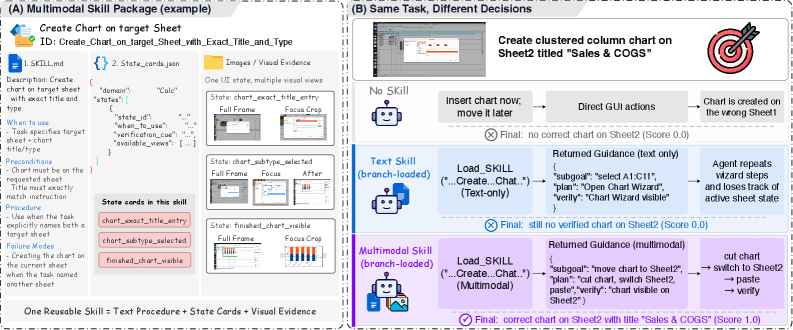
LLMエージェント向けのスキルライブラリは、手続き的知識を一般的にテキスト、コード、またはAPIライクなルーティンとして符号化します。GUIやゲームフレームを対象とする視覚エージェントにとって、この表現は情報損失を伴います。エージェントが現在の状態を認識し、進捗を判断し、ピクセルから失敗を検出しなければならない場合、何をすべきかを知るだけでは不十分だからです。「チャートウィザードをクリックする」というテキスト指示は、エージェントがアクティブなシート、選択範囲、あるいはモーダルダイアログがすでに開いているかどうかを事前に確認しなければ、誤動作する可能性があります。本論文では、この欠けている要素をマルチモーダル手続き的知識として形式化し、次の3つの問いを立てます。そのようなパッケージは何を含むべきか、公開されたトラジェクトリからどのように導出するか、そして推論時にスクリーンショットでコンテキストを溢れさせたり参照画像に過度に依存したりすることなく、どのように参照するか、という点です。
手法
MMSkillパッケージ M = (D, P, S, K) は、短い記述子 D、テキストによる手順 P、ランタイム状態カードのセット S = \{S_j\}(あるステップがいつ適用されるかを記述した状態条件付きヒント)、そしてマルチビューキーフレーム K = \{K_j^v\}(ここで v はビュータイプ、すなわち全画面、フォーカスクロップ、前後のトランジションペアにわたる)を含みます。スキル統計では、OSWorldにおいて典型的なパッケージは1スキルあたり $$3.6枚のカード、1カードあたり $$2.16ビューであることが示されています(Table 6)。
Generatorは、非テストトラジェクトリ \mathcal{T}=\{\tau_i\} を、OpenCUAトラジェクトリのメタスキルガイドによるクラスタリング(例:718件のChromeトラジェクトリが17個のPhase-0意味的グループにクラスタリングされる)を介してライブラリ \mathcal{M}=\{M_i\}_{i=1}^N にマッピングします。OSWorldではこれにより360タスクにわたって247の固有スキルパッケージが生成され(タスクあたり平均1.21スキルがマッチング)、macOSWorldでは143タスクにわたって248パッケージが生成されます。
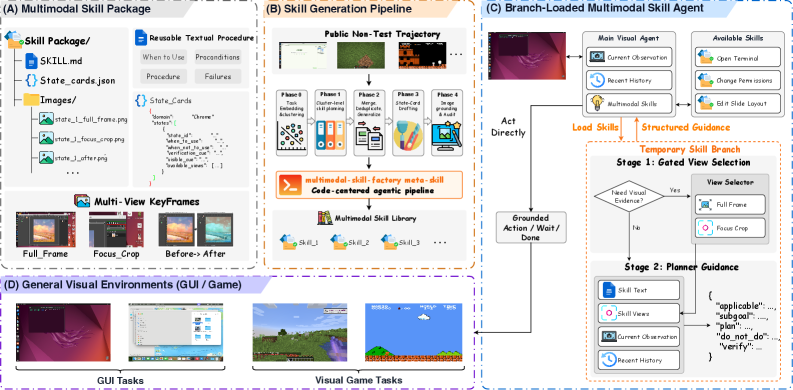
ランタイムはブランチロード方式です。エピソード開始前に、候補セット \mathcal{C}_I \subset \mathcal{M} が指示から事前に想起されます。ステップ t において、メインポリシーは直接行動するか、一時的なブランチ内で M_t \in \mathcal{C}_I のひとつを参照するために LOAD_SKILL を発行します:
A_t = \pi_{\text{main}}(O_t, H_t, \mathcal{C}_I, G_t),\quad G_t = \text{Branch}(O_t, H_t, M_t)
ブランチは2段階を実行します:(1)SelectViews がライブ観測を受けて関連するカード J_t とビュータイプ R_t を選択し、(2)PlanBranch が構造化されたタプルを返します:
G_t = (\text{applicable}_t, \text{subgoal}_t, \text{plan}_t, \text{do\_not\_do}_t, \text{verify}_t).
重要な点として、メインのトラジェクトリは生のマルチモーダルパッケージを参照せず、G_t のみを参照します。これにより、スキルと環境のグラウンディング(潜在的に多くの画像と大量のトークンを含む)がメインコンテキストから切り離され、エージェントが参照スクリーンショットから座標をコピーすることも防がれます。各スキルはエピソードあたり最大 consult_limit 回まで参照可能です。
結果
OSWorld(360タスク、20ステップバジェット、スクリーンショットのみの観測)において、MMSkillsはテスト対象のすべてのベースモデルで、スキルなしおよびテキストのみのスキル(同じブランチ機構を使用するが状態カード・キーフレームなし)を超える全体成功率を達成します:
- Gemini 3.1 Pro: 44.08(スキルなし)→ 40.76(テキストのみ)→ 50.11(MMSkills)
- Gemini 3 Flash: 36.65 → 40.27 → 47.97
- Qwen3-VL-235B-Thinking: 21.34 → 28.57 → 39.17
- GLM-5V: 28.71 → 36.61 → 38.51
- Kimi-K2.6: 34.98 → 39.66 → 46.59
- Qwen3-VL-8B-Instruct: 10.78 → 14.93 → 25.40
テキストのみの条件ではスキルなしを下回る場合があり(Gemini 3.1 Pro: 40.76 vs. 44.08)、これはブランチロードでページングされた場合でも、手続き的テキスト単独ではエージェントを誤誘導することがあることを示唆しています。状態カードとキーフレームを追加することで、ベースラインを回復しさらに超えます。成果はGIMPのような視覚的に重いドメインに集中しており、Gemini 3.1 ProではGIMPが34.62 → 50.00、Qwen3-VL-235BではGIMPが38.46 → 69.23、Gemini 3.1 ProではVLCが35.29 → 70.59となります。
このパターンはデスクトップ以外にも転移します。VAB-Minecraftでは、Gemini 3 Flashが73.28の成功率 / 0.7884の平均スコア(ベースラインの67.24 / 0.7462 比)に到達します。Super Mario Brosでは、GLM-5Vの総報酬が1191.50 → 1384.50、Qwen3-VL-235Bが955.50 → 1514.25に上昇します。macOSWorld全体:Gemini 3 Flash 55.94 → 65.73、GLM-5V 34.97 → 51.75。
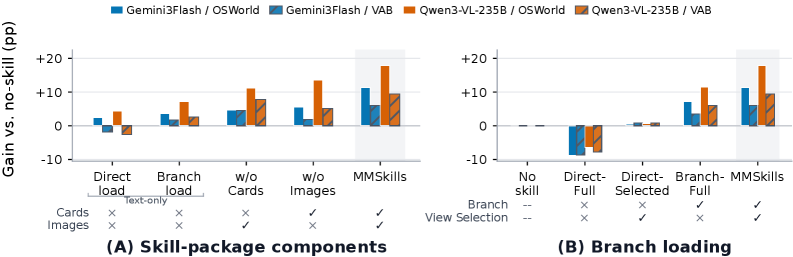
アブレーション(Figure 3)は、成果が2つの要因に起因することを示しています。ランタイム状態カードまたは視覚的キーフレームのどちらかを除去するとパフォーマンスが低下し、適用可能性の判断が支配的なGUIドメインでは状態カードの寄与がより大きくなります。完全なマルチモーダルパッケージの直接ロード(ブランチなし)はブランチロードを下回ります:キーフレームをメインコンテキストに詰め込むと過度な依存が増加し、ライブ画面へのグラウンディングが低下します。ブランチロードに加えてビュー選択を行うことで、冗長なフレームを避けることによりさらなる性能向上が得られます。
限界
本システムはキュレーションされた公開トラジェクトリソース(OpenCUA)と、macOSサブセット向けの追加クラスタリングに依存しており、そのようなコーパスが存在しないドメインへの転移は検証されていません。consult_limit と事前想起セット \mathcal{C}_I はハイパーパラメータであり、その感度は分析されていません。Gemini 3.1 ProとKimi-K2.6の報告パフォーマンスはOSWorldのみであり、フロンティアモデルのクロスベンチマーク一貫性は部分的に未解決のままです。ブランチは参照ごとに無視できないトークンオーバーヘッドを追加し(ビュー選択済みのStage 1 + Stage 2)、論文では実時間またはトークンコストの内訳が報告されていません。最後に、構造化されたガイダンス G_t は固定スキーマであり、エージェントがより豊かなまたはモデルが発見したブランチ出力から恩恵を受けられるかどうかは不明です。
なぜ重要か
MMSkillsは、GUI/視覚エージェントの繰り返し生じる失敗モードに対して具体的な解答を明示します:テキストによる手順は誤った抽象化を符号化しており、なぜなら正確性はピクセル上で状態条件付きだからです。状態カードとキーフレームをブランチロード型参照プロトコルと組み合わせることで、参照スクリーンショットをメインコンテキストに引き込むことなく、デモンストレーションの手続き的価値のほとんどを回復します。モデル横断・ベンチマーク横断で一貫した性能向上(例:Qwen3-VL-235BのOSWorldで+18ポイント)は、スキルデータだけでなく表現そのものが機能していることを示唆します。
Source: https://arxiv.org/abs/2605.13527
Hacker News Signals
Zerostack – 純粋なRustで書かれたUnix思想のcoding agent
ZerostackはRustで完全に実装されたCLI coding agentであり、Node.jsやPythonベースのagentに対する軽量な代替として位置づけられています。Unix哲学の観点は具体的です。このagentはパイプとの組み合わせ、stdinからの命令受け取り、stdoutへの構造化出力の出力を前提に設計されており、専用SDKなしでスクリプト化が可能です。
技術的なアーキテクチャはtool-loopパターンに従っています。中央の推論ループがLLM(バックエンドは設定可能)を呼び出し、JSON形式のtool-callレスポンスを受け取り、ローカルのtool実装(ファイルの読み書き、シェル実行、grepなど)にディスパッチし、その結果をコンテキストに戻します。Rustによる実装により、バイナリはランタイム依存のない単一の静的リンク実行ファイルとなり、サンドボックス化されたCI環境やエアギャップマシンにおいて有利です。
注目すべき実装上の選択としては、tool実行がtraitベースのディスパッチテーブルで処理されるため、新しいtoolの追加はtraitを実装して登録するだけで済みます。このagentは明示的なトークンバジェット管理を伴う会話バッファを維持しており、コンテキストウィンドウが設定可能な上限に近づくと、無闇に切り詰めるのではなく、古い非本質的なやり取りが削除されます。シェルコマンドは設定可能なタイムアウトを持つ std::process::Command を通じて実行されますが、コンテナによるサンドボックス化は組み込まれていないため、権限の分離は呼び出し側に委ねられています。
このcrateはcrates.ioにバージョン1.0.0で公開されており、ある程度のAPIの安定性へのコミットメントを示しています。依存関係は意図的に最小限に抑えられており、非同期処理に tokio、tool-callのシリアライズに serde/serde_json、LLM API呼び出しに reqwest、CLIの引数解析に clap が使われています。
未解決の問題として、サンドボックス化が組み込まれていない点は信頼できないコードベースに対して実質的な欠陥となります。コンテキストの削除ヒューリスティックはドキュメント化されておらず、削除対象を意味的な重要性で判断するのか、新しさで判断するのかが不明です。複数ファイルにまたがるプロジェクトへの対応(シンボルインデックス、ファイル間の参照)は存在しないようです。
Source: https://crates.io/crates/zerostack/1.0.0
Show HN: ニューラルネットがSnakeを学習する様子をリアルタイムで観察する
これは、古典的なSnake環境でPPO agentが学習する様子をブラウザ上でライブ可視化するものです。技術的な見どころは、policy改善をリアルタイムで観察できる点にあります。このページはバックエンドから学習状態をストリーミングするか、あるいはコンパイル済みのWASM/JS学習ループによって完全にクライアントサイドで動作し、各エピソードをプレイされながらレンダリングします。
アルゴリズムはProximal Policy Optimizationです。Snake環境における観測空間は、通常グリッドか、壁・胴体・食べ物までの距離特徴量の集合です。policy networkはブラウザレンダリングのレイテンシを考慮すると、おそらく2〜3層のMLPという小規模なものでしょう。PPOのclipped surrogate objectiveは次の通りです。
L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min\left( r_t(\theta) \hat{A}_t,\ \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_t \right) \right]
ここで r_t(\theta) = \pi_\theta(a_t|s_t) / \pi_{\theta_\text{old}}(a_t|s_t) です。
教育的に有用な点は、Snakeが明確なカリキュラムを持っていることです。初期エピソードではランダムウォーク的な挙動が見られ、やがてagentは安定して食べ物に到達することを学習し、その後は胴体が成長するにつれて自己衝突に苦労するようになります。これは、sparse-rewardの難しさとexploration-exploitationのトレードオフを、説明不要で自然に示す実例となっています。
サイトのURL(ppo.gradexp.xyz)から、これは個人プロジェクトであることが伺えます。主な技術的な疑問は、学習が実際にブラウザ上でライブに行われているのか(これにはコンパイル済みの学習ループが必要であり、TensorFlow.jsや小規模なRLライブラリのWASMポートによって実現可能です)、それとも事前に収録された学習軌跡を再生しているのかという点です。どちらも有用ですが、前者はエンジニアリングの観点から格段に印象的です。
制限事項:SnakeはハードなRLベンチマークではありません。汎化性に関する主張はこのトイドメインを超えては適用されません。それでも、PPOの仕組みを学ぶための優れた教材となっています。
Source: https://ppo.gradexp.xyz/
Apple SiliconはOpenRouterより高コストである
この投稿は、Apple Silicon上でLLM inferenceをローカル実行する場合とOpenRouter APIを利用する場合のエネルギーコストを丁寧に比較・計算したものです。著者はpowermetricsを用いてMシリーズMacのinference中の消費電力を実測し、tokens per secondを記録した上で、家庭用電気料金をもとにトークン100万件あたりのコストに換算しています。
中心的な知見は以下の通りです。米国の一般的な電気料金(約$0.15/kWh)およびMacBookのactive inference中に計測された15〜30Wの消費電力を前提とすると、Llama-3 8Bのようなモデルにおけるトークン100万件あたりのエネルギーコストは、OpenRouterが提供する最安値モデルの料金を上回ります。計算式は以下のように単純明快です。
\text{cost/token} = \frac{P_{\text{watts}} \times (1/\text{tps})}{3.6 \times 10^9} \times \text{rate}_{\$/\text{J}}
ここでPは持続的な消費電力、tpsはtokens per secondを表します。
この比較には細かな考察も含まれています。著者は、OpenRouterの安価な料金が大規模なinferenceの効率性(batching、高いGPU utilization)を反映していること、また大規模モデルほどApple Siliconのスループットがサーバー向けGPUよりも急激に低下するため、コスト差が拡大することを指摘しています。さらに本稿はエネルギーコストと総所有コスト(TCO)を区別しており、償却済みハードウェアコストは含まれていないため、これを加味するとローカルinferenceはさらに不利になります。
HNのディスカッションで挙げられた反論としては、プライバシー、オフライン利用、レイテンシ(ネットワーク往復なし)は純粋なコスト比較では捉えられないという点があります。また、Apple Siliconのアイドル時消費電力はほぼゼロであるため、マシンがすでに稼働中であれば限界コストの議論は若干変わってきます。
MLの実務者向けの技術的な示唆としては、Apple Siliconは開発用途や個人的な低スループット用途には十分競争力がありますが、「ハードウェア購入後は無料」という捉え方は大規模利用においては誤解を招くということです。サーバーサイドのbatched inferenceには構造的な効率上の優位性があり、モデル効率やハードウェアの消費電力特性に抜本的な改善がない限り、ローカルハードウェアがこの差を覆すことはできません。
Source: https://www.williamangel.net/blog/2026/05/17/offline-llm-energy-use.html
Radicle: Git上に構築されたソブリンなコードフォージ
Radicleは、Gitをデータレイヤーとして使用し、リポジトリのレプリケーションにカスタムのgossipプロトコルを採用したピアツーピアのコードコラボレーションプラットフォームです。中央集権的なホスティングへの依存を排除しており、数年にわたる開発を経て実用的に使用できる段階に達しています。
コアとなるデータモデルでは、すべてのリポジトリは初期コミットとキーペアから導出された暗号学的IDによって識別されます。クローンは「seeds」と呼ばれるノードのgossipネットワークを通じて伝播し、Gitオブジェクトをレプリケートします。Issue、patch(プルリクエスト)、コードレビューのコメントは、リポジトリ自体の中の独立した refs/rad/ 名前空間にGitオブジェクトとして保存されます。これにより、ソーシャルレイヤーがリポジトリのコンテンツアドレス可能な履歴の一部となります。つまり、コードだけでなく、コラボレーション履歴全体がポータブルであり、オフライン利用も可能です。
IDシステムにはEd25519キーペアが使用されています。「DID」(分散型識別子)が公開鍵とコントリビューターのアイデンティティを紐付け、すべてのアーティファクト(patch、レビュー)に署名が付与されます。メール/パスワードによるログインは存在せず、認証は純粋に鍵ベースで行われます。
技術的には、RadicleのネットワーキングレイヤーはDHTに類似したノード探索メカニズムを備えたカスタムプロトコルをTCP上で使用します。Seedsはパブリックなリレーノードであり、組織利用向けのプライベートseedもサポートされています。CLI(rad)はgit操作をラップし、patch、issue、ノードの接続管理のためのコマンドを追加します。
主な実用上の制限は発見可能性にあります。中央インデックスが存在しないため、リポジトリを見つけるにはリポジトリIDを知っているか、seedノードのホストリストを参照する必要があります。Webインターフェース(app.radicle.xyz)は半中央集権的なインデックスを提供しており、これはある意味でソブリンという位置付けを損なっています。
既存のGitツールとの統合は明快であり、リモートは rad:// URLとして表現され、rad がトランスポートヘルパーを設定した後は標準の git push/git fetch がそのまま機能します。
Source: https://radicle.dev/
CUDA Books
これはCUDAプログラミングとGPUコンピューティングを扱う書籍を厳選したGitHubリストで、入門的なCUDA Cから、PTXアセンブリ、プロファイリング、マルチGPUシステムといった高度なトピックまで幅広く網羅しています。
このリストが示すCUDA学習スタックの内容には、技術的に実質的な価値があります。定番の入門書は、Hwu、Kirk、HajjによるProgramming Massively Parallel Processors(現在第4版)で、メモリ階層(グローバル、共有、L1/L2キャッシュ、レジスタ)、warp実行、occupancy最適化を基礎から解説しています。SandersとKandrotによるCUDA by Exampleは古いものの、CUDAランタイムAPIの概念モデルを理解するうえでいまも有用です。
中級レベルでは、thrust(STLライクな並列アルゴリズム)、cuBLAS/cuDNN統合、CUDAプロファイリングツールチェーン(Nsight Compute、Nsight Systems)に関するリソースが紹介されています。これらは実用上重要であり、実際のカーネルにおけるパフォーマンス改善作業のほとんどは、rooflineチャートを読み解き、カーネルがcompute-boundかmemory-bandwidth-boundかを特定する作業を伴います。
高度な内容としては、PTX(Parallel Thread Execution)――CUDAの中間アセンブリ言語――が取り上げられており、__shfl_syncやmma(行列積和演算)命令といったwarpレベルのプリミティブを表現する必要のあるカスタムカーネルや、C++ APIで公開されていない操作のためのインラインPTXを記述する開発者にとって重要です。Tensor Coreプログラミングモデル(wmma、あるいは新しいcublas-ltやcutlassを使うアプローチ)は、単一の書籍では十分にカバーされておらず、現状ではドキュメントとソースコードを読み解く作業が主体となっています。
このリストの限界は情報の鮮度にあります。CUDAの進化は速く(HopperではTMA、FP8、新しいwarp-group MMA命令が導入されました)、書籍は数年単位で遅れをとります。最新のGPUプログラミングについては、NVIDIAの開発者ブログやTriton/CUTLASSのソースツリーの方が、リスト上のいかなる書籍よりも情報が更新されています。
Source: https://github.com/alternbits/awesome-cuda-books
80ドルのRK3562 AndroidタブレットをDebian Linuxワークステーションに変えた
これは、RockchipのRK3562ベースのAndroidタブレットにメインラインDebianをインストールするための詳細なガイドであり、ブートローダーから動作するデスクトップまでのフルスタックを網羅しています。RK3562は、バジェット向けタブレットに広く使われているミドルレンジのARM SoC(Cortex-A53クラスタ、Mali-G52 GPU)です。
技術的な手順はいくつかの明確なステージに分かれています。まず、fastboot oem unlock(サポートされている場合)によるブートローダーのアンロック、またはRK maskromリカバリパッドをショートさせてUSB maskromモードを強制的に起動する方法があり、これにより署名済みブートローダーチェーンを迂回できます。次に、rkdeveloptoolまたはupgrade_toolを使って、RockchipのダウンストリームパッチをあてたU-Bootビルドをフラッシュします(RK3562に対するメインラインU-Bootのサポートは部分的です)。
ルートファイルシステムは、標準的なDebian arm64のdebootstraptarballをeMMCパーティションに書き込んだものです。カーネルが最も重要な部分であり、著者はRockchipのダウンストリームカーネル(5.10または6.1ブランチ)を使用しています。これは、メインラインLinuxではいくつかの周辺機器——具体的にはディスプレイパイプライン(VOP2)、無線チップセット、オーディオコーデック——のドライバが動作しないためです。これはRockchipデバイスに共通するパターンであり、メインラインのサポートはベンダーBSPより1〜3年遅れています。
ハードウェアの設定にはDevice Tree overlayが使用されています。同じSoCを搭載しながら複数のボードバリアントが出荷されているため、著者はタブレットの正確なディスプレイおよびタッチ構成に対応するDTBファイルを文書化しています。
完成したシステムは、Xfce、Firefox、および標準的なaptで管理されるパッケージを備えた完全なDebianユーザーランドで動作します。GPUアクセラレーションはpanfrost(オープンソースのMaliドライバ)を通じて2Dでは機能しますが、Vulkan/OpenGL ESのパフォーマンスは限定的です。ガイドでは継続的な問題点も記録されており、スリープ/レジュームは不安定で、カメラは機能せず(メインラインドライバなし)、USB-C alt-modeのディスプレイ出力も動作しません。
バジェットハードウェア上の組み込みARM Linuxを扱う方にとって実用的なガイドです。
Source: https://github.com/tech4bot/rk3562deb
Claude CodeとCodexのための意図的スキル開発フレームワーク
このリポジトリは、Claude CodeおよびOpenAI Codexの補完を横断して、即座に解答を提供するのではなく意図的な学習機会を生み出す、構造化されたpromptフレームワークを実装しています。その考え方は意図的練習(deliberate practice)理論に基づいており、関数を自動補完する代わりに、エージェントはまずユーザーにアプローチについて考えさせ、コードを提示・記述する前にその推論に対してフィードバックを与えます。
技術的な仕組みは、システムpromptレイヤーと「スキルモジュール」群で構成されています。スキルモジュールはMarkdownファイルであり、トピック(例:「async/awaitパターン」、「SQLクエリ最適化」)と対応するソクラテス式質問テンプレートを定義します。ユーザーがスキルモジュールにパターンマッチするタスクを呼び出すと、エージェントは直接の回答ではなく、足場となる質問シーケンスを出力します。
実装は軽量であり、主にpromptエンジニアリングで構成され、コードはわずかしか含まれていません。教育的モードを維持するために、基盤モデルの指示追従能力に依存しており、fine-tuningや検索システムは使用していません。スキルモジュールはコンテキストに連結されます。
技術的に興味深い問いは、これが単にタスク完了を遅らせるだけなのか、それとも実際に学習成果を向上させるのかという点です。本リポジトリには評価データが含まれていません。この主張はEricsson et al.による意図的練習の文献に基づいており、フィードバックループの密度と課題の適切な難易度調整が、単純な露出時間よりも重要であると論じています。
エージェントシステムの観点では、これはメタpromptパターンのシンプルな例です。すなわち、コーディングエージェントのツール使用ループを、指定されたタスクを達成するためではなく、インタラクションの動的な性質を変えるために用いるパターンです。概念的には「constitutional AI」のpromptパターンに関連していますが、モデルレベルではなくワークフローレベルで適用されています。
制限事項として、スキルモジュールの起動に用いるパターンマッチングは粗い(おそらくキーワードベース)、複数ターンのセッションにわたって教育的モードを維持できるかどうかはモデルの指示追従能力に完全に依存している、ユーザーモデリングが存在しない(実証された習熟度にかかわらず、すべてのユーザーが同一の足場を受け取る)という点が挙げられます。
Source: https://github.com/DrCatHicks/learning-opportunities
Claude for Legal
Anthropicのclaude-for-legalリポジトリは、法的ユースケースを対象としたリファレンスプロンプトテンプレートとワークフローパターンのコレクションです。対象とするユースケースには、契約レビュー、条項抽出、法的調査の要約、証言録取準備、および規制コンプライアンスチェックが含まれます。本リポジトリは、プロダクションアプリケーションではなく、Claudeインテグレーションを構築する法務チームの出発点として位置付けられています。
技術的な実質はプロンプトアーキテクチャにあります。契約レビューのプロンプトは構造化された抽出パターンを採用しており、モデルは特定の条項タイプ(補償条項、責任制限、準拠法、自動更新)を識別し、位置情報参照とともにJSONとして返すよう指示されます。これは、LLMが非構造化された法的テキストに対してzero-shotの分類器+抽出器として機能する古典的な情報抽出タスクです。
調査要約テンプレートはマルチステップアプローチを採用しています。まず個々の判例から判示事項と主要な事実を抽出し、次に判例全体を統合して拘束力のある先例を特定します。この分解は、完全な判例法調査がコンテキストウィンドウを超えるテキストを含むために必要となります。
規制コンプライアンステンプレートは「チェックリスト対ドキュメント」の形式を採っており、モデルには規制要件(例:GDPRの第13条開示要件)とプライバシーポリシーの草案が与えられ、ギャップを特定するよう求められます。これは構造的にはテキスト含意タスクです。
リポジトリはREADMEにおいて限界について率直に述べています。出力には弁護士によるレビューが必要であること、モデルは判例の引用を幻覚する可能性があること(法律LLMアプリケーションにおいてよく知られた失敗モード)、および管轄固有のニュアンスが正確に処理されない可能性があることが記載されています。retrieval-augmented generation(RAG)レイヤーは含まれておらず、システムは実際の判例データベースにアクセスできません。これは実際の法的調査ワークフローにとって重大なギャップです。
HNのディスカッションは責任問題に集中しており、AIを活用した法的作業が非弁護士にとって無資格法律業務(unauthorized practice of law)のリスクを変化させるかどうかが議論されています。技術的な成果物はテンプレートとして堅実ですが、デプロイメントリスクに関する問題は未解決のままです。
注目の新規リポジトリ
GammaLabTechnologies/harmonist
ソフトな慣習ではなく機械的なプロトコル強制によって差別化を図る、ポータブルなAI agentオーケストレーションフレームワークです。核心的な主張は、186の事前構築済みagentがランタイム依存関係ゼロで動作するという点であり、つまりオーケストレーション層全体が実行時に依存関係グラフを引き込むことなく、自己完結型のバイナリまたはスクリプトとして配布されます。プロトコル強制は構造的なものです。agent間の通信コントラクトは、agentロジックが実行される前にフレームワークレベルで検証されるため、LangChainスタイルのパイプラインでよく見られる、agent間のサイレントな通信ミスバグのクラスを防止します。ポータビリティのターゲットは、pip/npmが利用できないまたはロックダウンされている環境、すなわちCIランナー、エアギャップサーバー、組み込みツールチェーンをカバーします。186のagentが含まれており、Webの取得、ファイルI/O、コード実行、APIコールパターンなど幅広い用途をカバーしていると考えられます。ゼロ依存関係という制約により、実装はstdlibのプリミティブに依存せざるを得ず、これはエコシステムの広さをデプロイの簡潔さと引き換えにするアーキテクチャ上の選択です。制約された環境で決定論的かつ監査可能なagentの動作を必要とするチームにとって、検討する価値があります。
Source: https://github.com/GammaLabTechnologies/harmonist
WantongC/journal-adapt-writing-skill
具体的な学術ワークフローに特化したツールです。対象ジャーナルに掲載された論文のコーパスを与えると、そのジャーナルが暗黙的に持つ文体・構造上の慣習を抽出し、それを投稿原稿に節ごとに適用して改訂します。技術的な核心は慣習抽出のステップにあります。掲載論文には、ヘッジング表現の使い方、引用密度、受動態と能動態の比率、各節の長さの分布、接続パターンなど、会場ごとに大きく異なる規範がエンコードされています(例えば、Nature Methods、ICML、ACL proceedings の間でも顕著な差異があります)。節ごとの改訂アーキテクチャは、原稿全体を単純に LLM に入力した際に生じるコンテキスト長の崩壊を回避し、局所的な一貫性を保ちながらベニュー固有のパターンを適用することを可能にします。異なる分野にまたがって投稿する研究者や、不慣れなベニューを狙う研究者にとって実用的なツールです。主な限界として、文体の模倣は内容選択における分野適切性の代替にはならないこと、また過度に fitting された style transfer は経験豊富なレビュアーに定型的な文章として映る可能性があることが挙げられます。
Source: https://github.com/WantongC/journal-adapt-writing-skill
KevRojo/Dulus
Gemini(ゲストモード、ログイン不要)、Claude.ai、Claude Code、Kimi、Qwen、DeepSeekに対して、既存の認証済みブラウザセッションを活用することでAPIコストを完全に回避するCLI agentです。その仕組みはブラウザセッションのスクレイピングです。Dulusは実行中のブラウザプロファイルからクッキーやセッショントークンを取得・読み取り、プロンプトをプログラム的に注入したうえでレスポンスをパースし、tool-callingループに組み込みます。このagentは標準的な機能セットを提供しており、ファイルの読み書き、Bash実行、リポジトリのgrep、Webブラウジング、Git commitに対応しています。ゲストモードのGeminiに関してはゼロコストという価値提案は現実のものですが、Claude.aiへのセッションベースのアクセスはレート制限および利用規約上の制約を受けるため、本番パイプラインへの適用には向きません。技術的な価値は、セッション取得の抽象化レイヤーと、モデルの生テキスト出力を構造化されたアクションへと変換するtool-callingの足場にあります。ブラウザセッション結合の脆弱性を許容したうえで、APIの課金なしにローカルのagenticループでフロンティアモデルの能力を活用したい個人開発者にとって有用です。
Source: https://github.com/KevRojo/Dulus
yzhao062/agent-style
Claude Code、OpenAI Codex、GitHub Copilot、Cursor、Aider向けに、system promptや設定ファイルとしてそのまま利用できる形式でまとめられた、21のルールからなるコンパクトなスタイルガイドです。このガイドが解決しようとしている問題は現実的なものです。LLMはデフォルトで冗長かつ過剰なコメントが付き、保険的な表現が多い散文やコードを生成しがちで、慣用的なプロフェッショナルの出力とは明らかに異なる傾向があります。ルールの内容としては、簡潔な変数名の優先、冗長なインラインコメントの回避、docstringへの能動態の使用、一貫したエラーハンドリングの慣用表現の維持、自明なロジックの過剰な説明の禁止といった項目が含まれていると考えられます。drop-in設計により、基盤となるツールを変更することなく、system promptの先頭に追加するか、エージェントの設定ディレクトリに配置するだけで利用できます。テキストファイル一枚で446スターを獲得しているという事実は、このガイドが真のニーズを満たしていることを示しています。ほとんどのエージェントツールには、意見を持ったスタイルのデフォルト設定が付属していないのが現状です。制限として、21のルールではスタイル全体を網羅することはできません。これはあくまでも出発点であり、チームがプロジェクト固有の規約を加えて拡張すべき基盤となるものです。
Source: https://github.com/yzhao062/agent-style
r1n7aro/Locus
Unity ゲーム開発ワークフローをターゲットとしたオープンソース AI エージェントです。技術的なスコープは Unity 固有のツールチェーンをカバーしており、C# スクリプト生成、Unity Editor スクリプティング API を介したシーン操作、アセットパイプラインとのインタラクション、そしておそらく Unity Editor の ExtendedEditor や COM オートメーションインターフェースとの統合が含まれます。Unity 開発は汎用コード生成と比較してエージェントにとってより難しいターゲットです。なぜなら、正確性が GameObject/Component モデルの理解、MonoBehaviour のライフサイクル(Awake、Start、Update の順序)、シリアライズの制約、そして一般的なコードコーパスには十分に表現されていない物理・レンダリングパイプラインのインタラクションに依存するためです。プレハブのスキャフォールディング、コルーチンロジックの記述、NavMesh やアニメーションステートマシンの設定を確実に行えるエージェントは、ソロおよび小規模チームの開発を大幅に加速させるでしょう。オープンソースという立場は、Unity の独自 AI 統合との差別化要因となっています。主な未解決の問題は、Editor とランタイムの区別をどのように処理するか、また hot-reload ループにおけるコンパイルエラーからの回復が可能かどうかという点です。
Source: https://github.com/r1n7aro/Locus
agentforce314/clawcodex
Claude CodeのAIコーディングエージェントを、約17万行の純粋なPythonでゼロから再実装したものです。17万LoC という実装規模は、エージェントループ全体——プロンプト構築、ツールディスパッチ(ファイル編集、bash、検索)、コンテキストウィンドウ管理、マルチターン状態追跡、エラーリカバリ——を網羅していることを示唆しています。元のTypeScriptコードベースを用いずに純粋なPythonで構築するということは、ツール呼び出しプロトコル、diff/patchの適用ロジック、および会話のスキャフォールディングを観測可能な挙動からリバースエンジニアリングすることを意味します。研究者にとっての価値は、商用ツールが提供するコンパイル済みまたは不透明なバイナリと比較して、エージェント型コーディングシステムの研究・拡張のための可読かつ変更可能なPythonコードベースが得られる点にあります。17万行という規模を考えると、コード品質と保守性は正当な懸念事項であり、行数だけでは良好なアーキテクチャを意味するものではありません。Node.jsへの依存なしにリファレンス実装を求めながらカスタムエージェントインフラを構築しようとしている方にとっては、一度検討する価値があります。
Source: https://github.com/agentforce314/clawcodex
stainlu/hermes-labyrinth
Hermes Agent フレームワーク向けの読み取り専用オブザーバビリティプラグインであり、4つのプリミティブを中心に構成されています:journeys(エンドツーエンドの実行トレース)、crossings(エージェント間またはコンポーネント間のハンドオフ)、guideposts(実行内の名前付きチェックポイント)、reports(集約サマリー)です。読み取り専用という制約は意図的な設計上の選択であり、エージェントの状態を変更できるオブザーバビリティツールは計装と動作の間に結合を生じさせ、分散トレーシングにおける既知の Heisenbugs の原因となります。4つのプリミティブによる分類体系は標準的な分散トレーシングの概念(traces、spans、events、summaries)に対応していますが、エージェント固有のセマンティクスを持っています:crossings は、コンテキストが部分的にしか転送されないマルチエージェントパイプラインにおける非自明なハンドオフ問題を捉えます。実用的には、これは生の LLM コールログと、複雑な実行全体においてエージェントが実際に何を行ったかという構造的な理解との間のギャップを埋めるものです。Hermes Agent ユーザーに限定されるため対象読者が制限されますが、プリミティブの設計は移植可能であり、このパターンは他の場所でも採用する価値があります。
Source: https://github.com/stainlu/hermes-labyrinth
horang-labs/tessera
AI支援コーディングセッション向けのワークスペースマネージャーで、プロジェクト・コレクション・タブ・ペイン・Git worktreeをまたいで作業を整理します。技術的に興味深い点はGit worktreeとの統合です。worktreeを使うと、複数のブランチを別々のディレクトリに同時にチェックアウトでき、ブランチ切り替えのオーバーヘッドやstashの競合なしに、異なるフィーチャーに対して並列のエージェントセッションを実行できます。Tesseraはこれを、関連するセッションをコレクションやタブにまとめるUIレイヤーでラップし、複数の並行エージェントインタラクションを実行する際に生じるコンテキスト管理の問題——どの会話がどのファイル状態を生成したかを追跡することが困難になる問題——に対処しています。プロジェクト/コレクション/タブ/ペインという階層構造は、開発者がすでに頭の中で作業を整理している方法を反映しており、worktreeのディレクトリ構造に自然にマッピングされます。精神的にはtmuxのセッション管理に近いですが、AIセッションのコンテキストとGitの状態をファーストクラスとして認識している点が異なります。未解決の問題は、ブランチがdivergentになったりrebaseされたりした際にセッションとworktreeのバインディングをどう処理するか、またコレクション内のあるペインのコンテキストを他のペインと共有できるかどうかという点です。