Daily AI Digest — 2026-05-18
arXiv Highlights
CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence
Problem
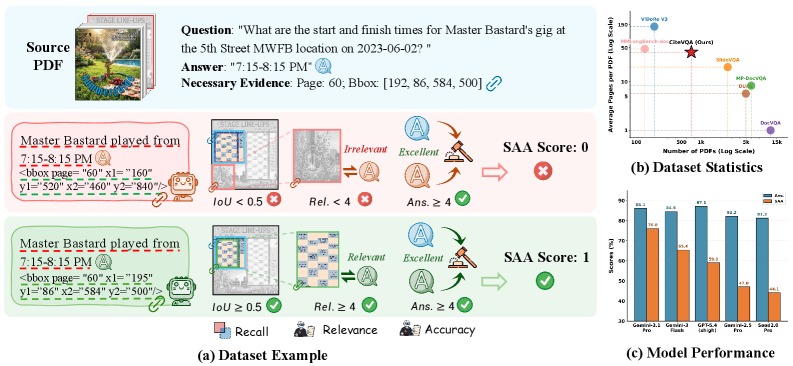
Document VQA benchmarks score the final answer string and ignore whether the model grounded that answer in the right region of the document. This conflates two failure modes: wrong answer, and right answer with wrong evidence. The latter — what the authors call attribution hallucination — is the more dangerous one in legal, financial, or medical settings, where a numerically correct figure cited from the wrong table is indistinguishable from a fabrication. CiteVQA targets this gap by requiring element-level bounding-box citations alongside each answer and scoring them jointly.
The benchmark contains 1,897 questions over 711 PDFs in seven domains and two languages, with documents averaging 40.6 pages — substantially longer than prior Doc-VQA sets, which forces models to actually localize rather than scan a single page.
Pipeline and ground-truth construction
The annotation pipeline is fully automated and then expert-validated. Starting from ~100M Common Crawl PDFs, stratified sampling reduces the pool to ~250k candidates; a two-stage MLLM filter assigns coarse domain/language and fine-grained sub-category labels, yielding 711 documents balanced across 7 domains and 30 sub-categories.
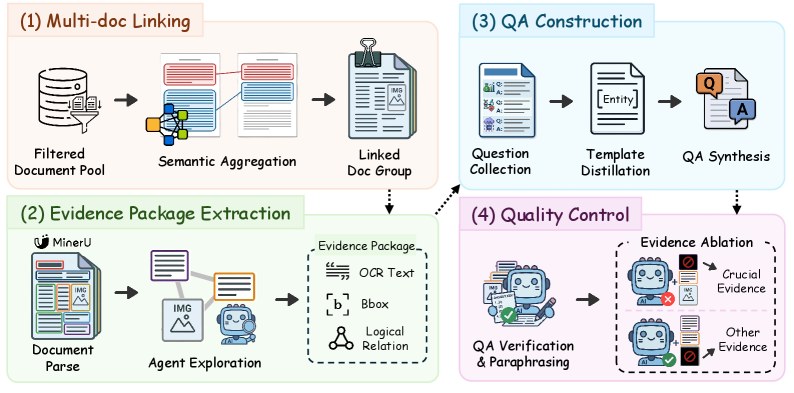
The core novelty in evidence labeling is masking ablation for identifying crucial evidence. After parsing each document with MinerU and using agents to link scattered evidence packages, candidate bounding boxes are individually masked and the QA is re-run; boxes whose removal causes the answer to fail are labeled \mathcal{B}_{\text{crucial}}, while others become \mathcal{B}_{\text{other}}. Multi-document linking is handled by computing a semantic profile (type, thesis, section structure) per document, encoding it, and retrieving the top-K_{doc}=5 neighbors by cosine similarity to form the candidate pool C_a for cross-document QA.
Metrics
Each sample is (D, Q, A_{\text{gt}}, \mathcal{B}_{\text{gt}}) with bounding boxes specified as (\text{doc\_idx}, \text{page\_idx}, x_1, y_1, x_2, y_2). Predictions are \hat{Y}=\{(A_i, b_i)\}_{i=1}^n. Four metrics:
- Recall at IoU@0.5 against crucial evidence: \text{Rec.} = \frac{1}{|\mathcal{B}_{\text{crucial}}|}\sum_{b_{\text{gt}} \in \mathcal{B}_{\text{crucial}}} \mathbf{1}\!\left(\max_{b_{\text{pred}}} \text{IoU}(b_{\text{pred}}, b_{\text{gt}}) \geq 0.5\right)
- Relevance (\text{Rel.} \in [0,5]): LLM judge scoring whether each cited box supports its paired answer.
- Answer correctness (\text{Ans.} \in [0,5]): LLM judge over \{A_1,\dots,A_n\} vs A_{\text{gt}}.
- Strict Attributed Accuracy (SAA), the headline metric: \text{SAA} = \mathbf{1}\!\left(\text{Ans.} \geq 4 \;\wedge\; (\text{Rel.} \geq 4 \;\vee\; \text{Rec.} \geq 0.6)\right)
The disjunction in the grounding clause accommodates models that produce semantically faithful citations even when their bounding boxes don’t perfectly overlap an annotator-drawn box.
Results across 20 MLLMs
The headline finding is a large gap between answer accuracy and SAA, i.e. models often answer correctly while citing the wrong region. On the question-type breakdown, Quantitative Reasoning is the easiest category — Gemini-3.1-Pro-Preview reaches SAA = 82.6 — because the chain from numeric evidence to numeric answer is tight and verifiable. Multimodal Parsing, where the question references a document element by visual cue (background color, header position) and asks for its content, is the hardest: locating the element and parsing it both fail frequently.
The case studies make the attribution hallucination phenomenon concrete. In Case 1, both Gemini-3.1-Pro-Preview and GPT-5.4 produce the correct contract-year price (Ans. = 5), but GPT-5.4 cites the wrong pricing table — quoting “$145” from a region that actually contains “$170” for Year 1 — yielding Rec. = 0, SAA = 0. In Case 2, Gemini-2.5-Pro correctly computes the band-gap difference 0.40 - 0.14 = 0.26 eV with matching citations (SAA = 1), while Qwen3-VL-8B extracts wrong numbers (0.34 and 0.54 eV) and irrelevant citations (Ans. = 1, SAA = 0).
Resolution sensitivity is severe. On Qwen3-VL-235B-A22B, dropping input from 1024^2 to 724^2 (half pixels) collapses Rec. from 11.3 to 4.2 and SAA from 22.5 to 11.8; at 512^2 the model retains 53.5 Ans. but Rec. is 1.6 and SAA is 5.3. Answer correctness degrades gracefully with resolution; grounding does not. This is consistent with the hypothesis that current MLLMs answer from coarse semantic gist while their bounding-box prediction depends on fine visual detail.
Limitations
The expensive masking-ablation labeling depends on frontier MLLMs, raising replication cost and risking inheritance of those models’ biases. Domain coverage, while broader than prior Doc-VQA sets, treats “authoritative evidence” uniformly across domains where the operative definition differs (e.g., precedent in law vs. primary data in medicine). The evaluation pipeline itself is LLM-judge-heavy for Rel. and Ans., introducing a second source of noise that the SAA threshold of 4 partially absorbs but does not eliminate. Finally, the SAA disjunction \text{Rel.} \geq 4 \vee \text{Rec.} \geq 0.6 allows a model to score by semantic-relevance judging alone, which may understate the geometric grounding failure for models with strong text generation but weak coordinate prediction.
Why this matters
Answer-only Doc-VQA is misleading when downstream consumers need to verify provenance. CiteVQA operationalizes a joint metric and shows empirically that even leading MLLMs frequently land on the right answer through the wrong evidence — a failure mode invisible to existing benchmarks and unacceptable in regulated domains.
Source: https://arxiv.org/abs/2605.12882
Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
On-policy distillation (OPD) is empirically more sample- and compute-efficient than RL post-training (PPO/GRPO/DAPO) for reasoning LLMs, but the standard explanation — denser, more stable supervision from a teacher’s per-token logits — is a statement about the loss, not about what happens in parameter space. This paper opens up the parameter-level mechanism and argues that OPD’s efficiency is a “foresight” effect: very early in training, OPD locks onto the modules and the low-rank update directions that the final converged model needs, while RL diffuses updates across less useful structure.
Functional Redundancy Avoidance
The setup is clean: shared base W_{\text{Base}}, define \Delta W_{\text{RL/OPD}} = W_{\text{RL/OPD}} - W_{\text{Base}}, and compare across 1.5B–32B models (pretrained, SFT, Thinking-series Qwen variants).
The first observation is norm-efficiency. Rescaling \Delta W to a common Frobenius norm and measuring downstream reasoning accuracy, OPD yields substantially larger gains per unit of update norm than RL, and over training trajectories OPD reaches matched accuracy with smaller cumulative \|\Delta W\|.
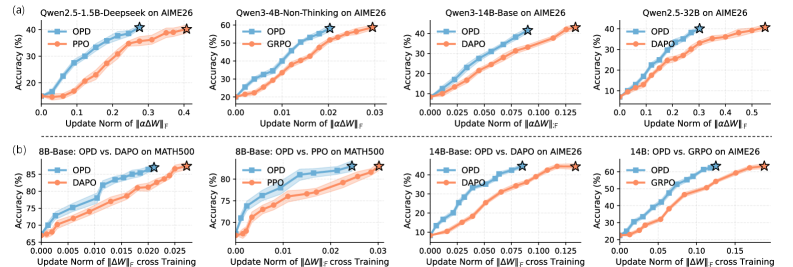
The second observation localizes this efficiency to specific modules. Two probes are used: (i) replacing the embedding layer of an OPD/RL model with the base embedding and measuring AIME26 degradation, and (ii) a sliding-window intervention that zeroes out \Delta W over contiguous layer ranges and measures MATH500 accuracy. RL spreads non-trivial update norm into modules (notably embeddings and certain layer bands) where ablation barely changes reasoning accuracy — i.e., low marginal utility. OPD suppresses updates in those regions and concentrates them in modules whose ablation collapses reasoning performance.
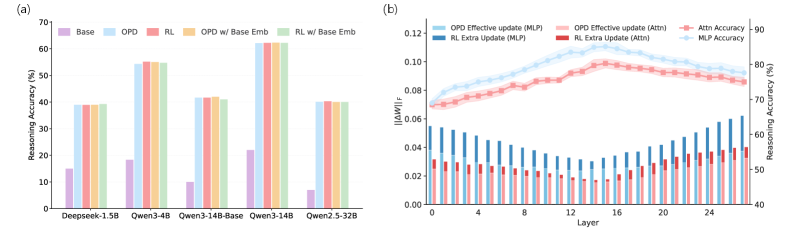
This is what the authors call Functional Redundancy Avoidance: OPD’s gradient signal effectively performs implicit module selection from very early in training.
Early Low-Rank Lock-in
The geometric counterpart is spectral. Performing SVD on \Delta W = U\Sigma V^\top for every MLP and attention matrix, they track four metrics: spectral norm, spectral/Frobenius ratio, effective rank, and Top-1% subspace norm ratio. On the 8B model, OPD vs. RL gives:
- spectral/Frobenius ratio: 36.8\% vs. 32.7\%
- effective rank: 2341 vs. 2754
- Top-1% subspace energy: 94.7\% vs. 88.5\%
So despite a smaller total \|\Delta W\|_F, OPD packs a larger fraction of its update energy into a few dominant directions. To separate “which directions” from “how much,” they project \Delta W onto the top-k\% vs. bottom-k\% singular subspaces and re-evaluate. The top-k\% subspace of OPD recovers more reasoning accuracy than RL’s; the bottom-k\% subspace of RL accumulates large norm for negligible gain. Combined with checkpoint-wise alignment analyses, this supports the stronger claim: OPD’s dominant subspaces stabilize early and are already aligned with the final converged update subspace. Later training mostly scales magnitudes along directions that are already fixed.
EffOPD: directional extrapolation
If late-stage OPD mostly amplifies an already-determined direction, one can simply jump along it. EffOPD does exactly that. At exponentially spaced checkpoints t = 2^n, define the local direction
\Delta_n = W_{2^n} - W_{2^{n-1}}
(with \Delta_0 taken from the base init to W_1). Generate five extrapolated candidates
\widetilde{W}_{n,k} = W_{2^n} + 2k\,\Delta_n, \quad k=1,\dots,5,
and validate each on a tiny held-out set \mathcal{D}_v of 50 training examples — far cheaper than a single OPD step’s rollout cost. Accept candidates greedily in order of increasing k as long as \mathcal{V}_{\mathcal{D}_v}(\widetilde{W}_{n,k}) \geq v^{\text{acc}}; terminate at the first failure. If k=1 already fails, fall back to vanilla OPD for that checkpoint.
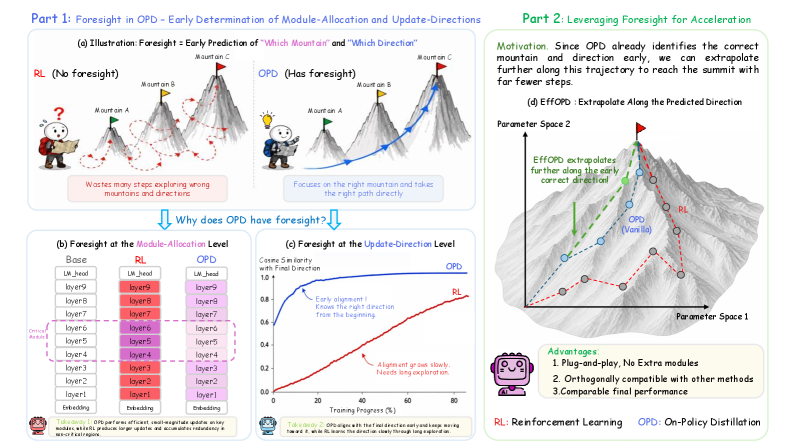
This is essentially a momentum-style line search exploiting the fact that the OPD trajectory is approximately linear in late training. There are no extra trainable parameters and only one real hyperparameter (the candidate grid). Reported wall-clock acceleration averages 3\times while preserving comparable downstream accuracy. Ablations cover learning rate sensitivity, \mathcal{D}_v difficulty (measured by the model’s pre-training accuracy on the sampled batch), and the time–accuracy Pareto.
Limitations and open questions
The analysis is correlational at the spectral level: “early dominant subspaces align with final subspaces” is observed but not derived from the OPD loss geometry. The teacher is always a stronger same-family model (pattern-aligned distillation); whether foresight survives cross-family teachers, weaker teachers, or off-policy mixtures is untested. The 50-example validation set is sufficient on the studied math/reasoning benchmarks but the variance of \mathcal{V}_{\mathcal{D}_v} as an acceptance criterion in noisier domains (code, agentic tasks) is unclear. The extrapolation grid \{2,4,6,8,10\}\Delta_n is hand-chosen; a continuous search could plausibly improve the speedup, and the interaction with optimizer state (Adam moments) after a discrete jump is not analyzed. Finally, the framing makes RL look strictly worse for parameter efficiency, but RL’s exploration may inject useful directions that distillation cannot — the comparison is on reasoning accuracy at fixed compute, not on capability ceiling.
Why this matters
The paper reframes OPD’s efficiency from a supervision-density argument to a parameter-geometry one — early module selection plus early low-rank lock-in — and turns that observation into a near-free 3\times training speedup via checkpoint-spaced linear extrapolation. The mechanism (low-rank trajectory stability) is general enough that similar extrapolation tricks likely apply to other post-training regimes where the update direction stabilizes faster than its magnitude.
Source: https://arxiv.org/abs/2605.11739
Flash-GRPO: Efficient Alignment for Video Diffusion via One-Step Policy Optimization
Problem
GRPO-style alignment of large video diffusion/flow-matching models is dominated by trajectory cost: the standard objective sums clipped policy ratios over all T denoising steps,
f(r,\hat{A},\theta,\varepsilon,\beta)=\frac{1}{GT}\sum_{i=1}^{G}\sum_{t=0}^{T-1}\Big(\min(r_t^i\hat{A}_t^i,\mathrm{clip}(r_t^i,1-\varepsilon,1+\varepsilon)\hat{A}_t^i)-\beta D_{\mathrm{KL}}(\pi_\theta\|\pi_{\mathrm{ref}})\Big),
with r_t^i(\theta)=\pi_\theta(\bm{x}_{t-1}^i|\bm{x}_t^i)/\pi_{\theta_{\mathrm{old}}}(\bm{x}_{t-1}^i|\bm{x}_t^i). For Wan2.1-14B this translates to hundreds of GPU-days per run. Existing accelerators (Flow-GRPO with first-half-only training, Flow-GRPO-Fast/MixGRPO with sliding windows) cut cost by truncating the trajectory but are unstable and underperform full-trajectory training. Flash-GRPO pushes this to its logical limit — exactly one timestep updated per rollout — and shows that with two corrections it can beat full-trajectory GRPO at a fraction of the cost.
Method
Flash-GRPO fixes two failure modes of naive single-step GRPO on flow-matching models trained with the ODE-to-SDE rollout
\bm{x}_{t+\Delta t}=\bm{x}_t+\Big[\bm{v}_\theta(\bm{x}_t,t)+\frac{\sigma_t^2}{2t}(\bm{x}_t+(1-t)\bm{v}_\theta(\bm{x}_t,t))\Big]\Delta t+\sigma_t\sqrt{\Delta t}\,\bm{\epsilon}.
Iso-temporal grouping. If each rollout in a prompt group draws an independent timestep t_i\sim\mathcal{U}[0,T], the group baseline \mu_{\mathrm{naive}}=\frac{1}{G}\sum_i R(\bm{x}_0^i(\bm{x}_{t_i}),\bm{c}) mixes rewards from different noise levels. Since reward correlates with t (denoising from low noise gives systematically higher quality than from high noise), advantage \hat{A}_t^i ends up reflecting timestep difficulty, not policy quality. Flash-GRPO sets a single t_k per prompt group \mathcal{G}_k=\{\bm{x}_{t_k}^i\mid i\in[1,G]\}, with G rollouts differing only in their initial noise \bm{\epsilon}_i. Across the batch, different prompts get different t_k\sim\mathcal{U}[0,T] so global timestep coverage is preserved. Within a rollout, only the chosen t_k uses the SDE update (where the gradient is taken); the remaining steps run the deterministic ODE to keep the decoded \bm{x}_0 — and hence the reward — clean.
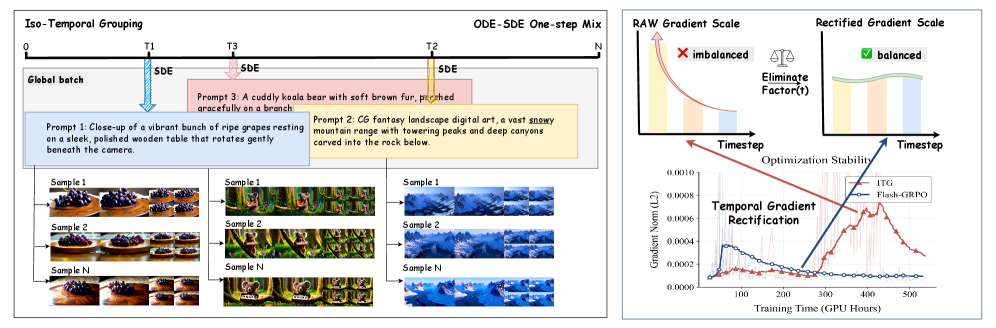
Temporal gradient rectification. The SDE step injects a time-dependent scale via \sigma_t^2/(2t) and \sigma_t. In the full-trajectory objective these are amortized over T steps, but in single-step training the gradient magnitude inherits the raw t-dependence, producing wildly inconsistent updates across timesteps and instability. The method rectifies this by neutralizing the t-dependent factor at the chosen t_k so that the per-sample gradient norm is timestep-invariant; combined with a tight clip ratio of 0.001, this gives stable updates under the single-step regime.
Results
Experiments use Wan2.1 at 1.3B and 14B, training prompts from DanceGRPO with a 300-prompt held-out split, 50-step inference, CFG 4.5, and 20 (1.3B) / 12 (14B) sampling steps in training. Reward signals are HPSv3 (visual quality, top-30% frame averaging per LongCat) and the VideoAlign motion score; VBench measures aesthetic/imaging/semantic dimensions.
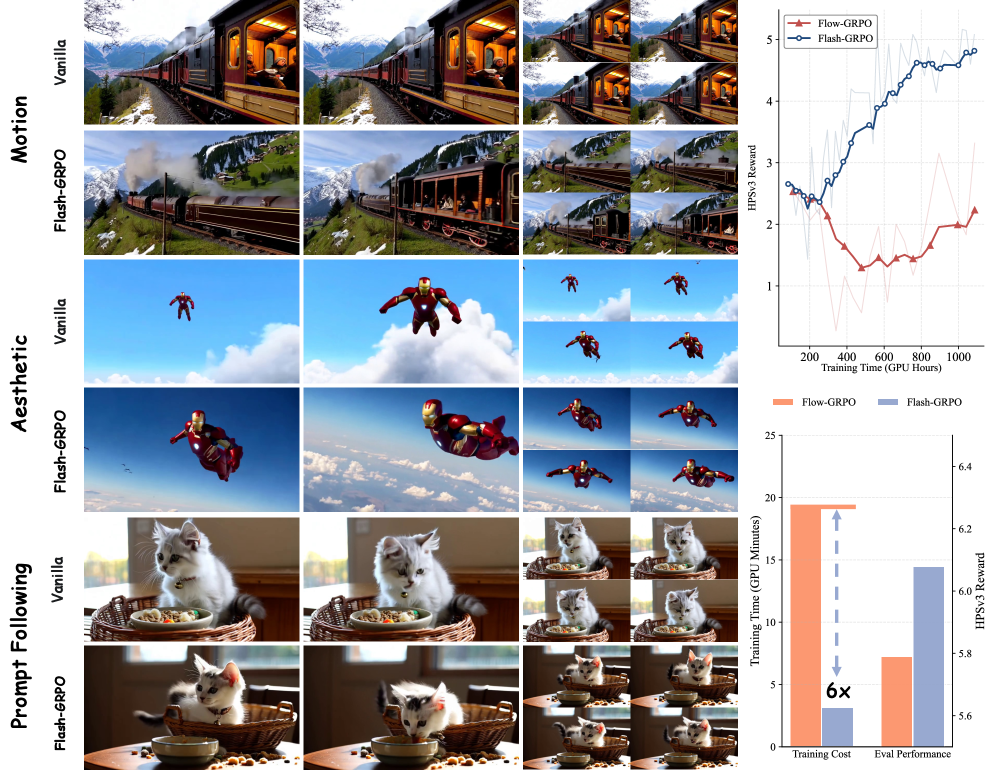
The training reward curves (Figure 1, top right) show that Flash-GRPO improves monotonically and stably, while Flow-GRPO-Fast1 (single-step sliding window, the closest baseline) degrades or plateaus. Against Flow-GRPO with first-half-trajectory training, Flash-GRPO matches or exceeds quality at a substantially smaller compute footprint — the headline claim is that one-step training outperforms full-trajectory GRPO under matched low budgets, while also being faster per step. Qualitative comparisons (Figure 3) at both scales show better temporal dynamics (horse-riding sequence), richer texture (panda scene), and improved prompt coverage (cartoon animals with the butterfly element absent in vanilla Wan2.1).

The exact paper text shipped with this draft truncates the comparative tables, but the consistent pattern across HPSv3, VideoAlign motion, and VBench in the reported axes is that Flash-GRPO dominates Flow-GRPO-Fast1 and matches or beats Flow-GRPO at a fraction of trajectory cost, validated at both 1.3B and 14B. The authors emphasize that the 14B regime — where full-trajectory GRPO is essentially unaffordable for ablation — is precisely where the efficiency gains pay off.
Limitations and open questions
- The single-step update relies on accurate one-shot decoding to \bm{x}_0 at arbitrary t_k for the reward; the ODE-everywhere-else trick mitigates this but bakes in a strong assumption that the deterministic continuation is a good proxy for \bm{x}_0 under the updated policy. Off-policyness at large t_k is not analyzed.
- The very tight clip ratio (\varepsilon=10^{-3}) suggests the optimization landscape is fragile; how this interacts with longer training and with stronger reward models is unclear.
- Iso-temporal grouping reduces within-group variance but also reduces the diversity of the advantage signal; the trade-off versus group size G and batch size B is not fully mapped.
- Reward hacking on HPSv3/VideoAlign — well known in image GRPO — is not addressed in the excerpt; VBench gains will be the more reliable readout.
- Theoretical equivalence/bias of the rectified single-step gradient relative to the full-trajectory expectation is asserted operationally rather than proven.
Why this matters
If single-step GRPO with iso-temporal grouping really matches full-trajectory alignment on 14B video models, RLHF for video diffusion stops being a multi-hundred-GPU-day endeavor and becomes comparable in cost to a pretraining epoch, opening up routine reward-model iteration at scale. The two diagnoses — timestep-confounded advantage variance and SDE-induced gradient scale imbalance — are also likely to generalize to image flow-matching GRPO and to other few-step alignment schemes.
Source: https://arxiv.org/abs/2605.15980
Hölder Policy Optimisation
Problem
In group-relative policy optimisation for LLMs, the surrogate objective requires aggregating token-level importance ratios r_{i,t}(\theta) = \pi_\theta(y_{i,t}\mid x, y_{i,<t})/\pi_{\theta_{\text{old}}}(y_{i,t}\mid x, y_{i,<t}) into a single sequence-level scalar \rho_i(\theta). GRPO uses the arithmetic mean (p=1); GSPO/GMPO use the geometric mean (p\to 0). These are isolated points on a continuum, and the choice materially affects training: arithmetic-mean aggregation amplifies high-ratio tokens and is prone to collapse on sparse-reward tasks, while geometric-mean aggregation suppresses outliers but underfits when learning signals are concentrated in a few tokens. No fixed operator dominates across benchmarks, so a principled parameterisation of the aggregation, together with a schedule, is needed.
Method
HölderPO replaces the aggregator with the Hölder mean of order p\in\mathbb{R}:
\rho_{i,p}(\theta) = \begin{cases}\left(\tfrac{1}{|y_i|}\sum_{t=1}^{|y_i|} r_{i,t}(\theta)^p\right)^{1/p}, & p\neq 0,\\ \exp\!\left(\tfrac{1}{|y_i|}\sum_{t=1}^{|y_i|} \log r_{i,t}(\theta)\right), & p=0.\end{cases}
The training objective is the standard PPO-style sequence-clipped surrogate
\mathcal{J}_{H_s}(\theta) = \mathbb{E}\!\left[\tfrac{1}{G}\sum_{i=1}^G \min\!\big(\rho_{i,p}(\theta)\widehat{A}_i,\ \mathrm{clip}(\rho_{i,p}(\theta),1-\epsilon,1+\epsilon)\widehat{A}_i\big)\right].
Sequence-level clipping (rather than per-token) is chosen specifically to bound gradient variance. The key mechanical observation is that the gradient of the aggregator is a token-weighted score-function estimator,
\nabla_\theta \rho_{i,p}(\theta) = \rho_{i,p}(\theta)\sum_{t=1}^{|y_i|} W_{i,t}(p)\,\nabla_\theta\log\pi_\theta(y_{i,t}\mid x,y_{i,<t}),\qquad W_{i,t}(p) = \frac{r_{i,t}(\theta)^p}{\sum_{k} r_{i,k}(\theta)^p}.
The weights W_{i,t}(p) form a softmax over \{p\log r_{i,t}\}. Large p concentrates mass on the largest-ratio tokens (sharp learning signal, useful when correct credit is sparse); small or negative p flattens or inverts the weighting (low variance, stable updates). p=1 recovers GRPO and p\to 0 recovers GSPO/GMPO as limits.
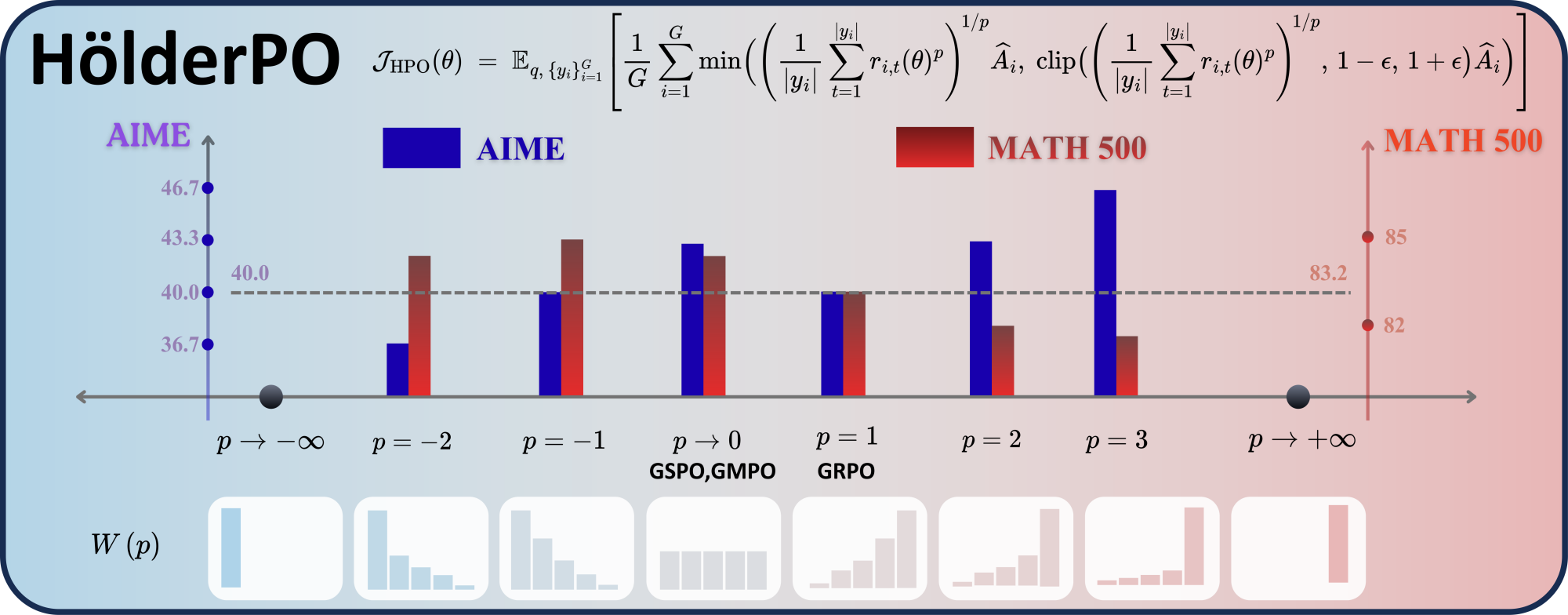
The concentration–stability tension is fundamental: there is no static p that is both maximally informative and variance-bounded. HölderPO therefore uses a dynamic annealing schedule, decaying p from +2 to -2 over training. Empirically the per-step envelopes of \log\rho_t(\theta) tighten monotonically as p decreases, so the schedule yields aggressive early-stage exploitation of sparse signals followed by progressively variance-controlled updates.
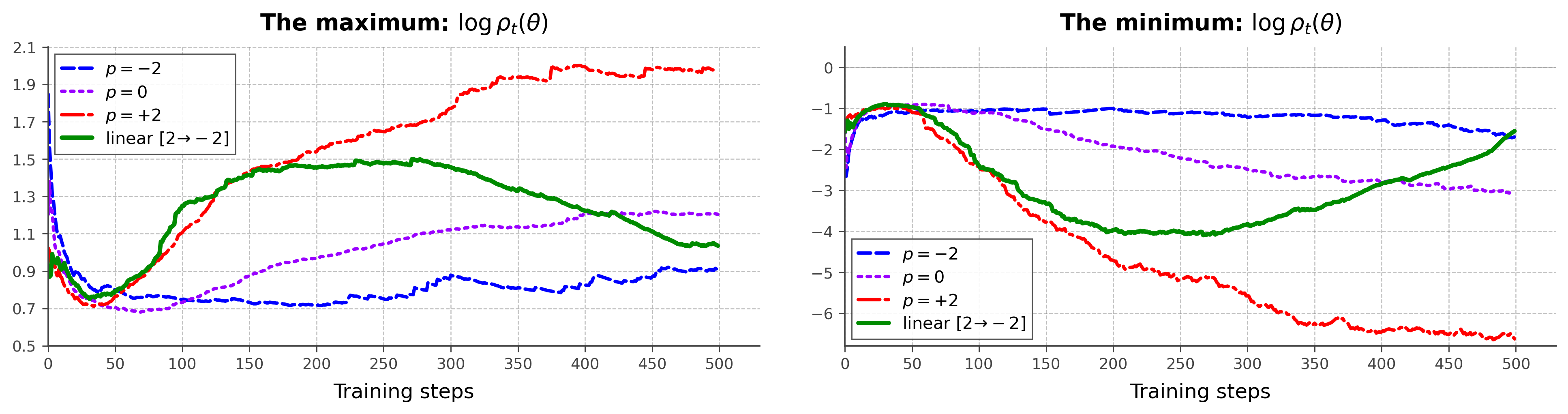
Experiments
Mathematical reasoning is evaluated on AIME24, AMC, MATH500, Minerva and OlympiadBench, using Qwen2.5-Math-1.5B/7B, DeepSeek-R1-Distill-Qwen-7B, and Qwen3-4B/8B. Training follows the Dr.GRPO recipe: 8,523 MATH (Levels 3–5) problems, 8 rollouts per prompt capped at 3,000 tokens, 1,024 trajectories per round, 8 inner updates with batch 128, on 4\timesH100. Agentic evaluation uses Qwen2.5-1.5B-Instruct on ALFWorld under the GiGPO protocol. Baselines are GRPO, Dr.GRPO and GMPO. Pass@1 is reported with greedy decoding.
The bar chart in Figure 1 shows the task-specific sensitivity to p: AIME24 (sparse reward, hard problems) and MATH500 (denser signal) prefer different fixed p, confirming that no single static aggregator is universally optimal. The dynamic schedule resolves this trade-off rather than splitting the difference.
The entropy and gradient-norm traces support the theoretical picture. Constant p=+2 produces large gradient norms and rapid entropy collapse on Math; p=-2 keeps gradients tightly bounded but underutilises learning signal. The linear p:2\to-2 schedule sits between, with controlled gradient magnitude and slower entropy decay throughout training, on both Math (Qwen2.5-Math-7B) and ALFWorld (Qwen2.5-1.5B).
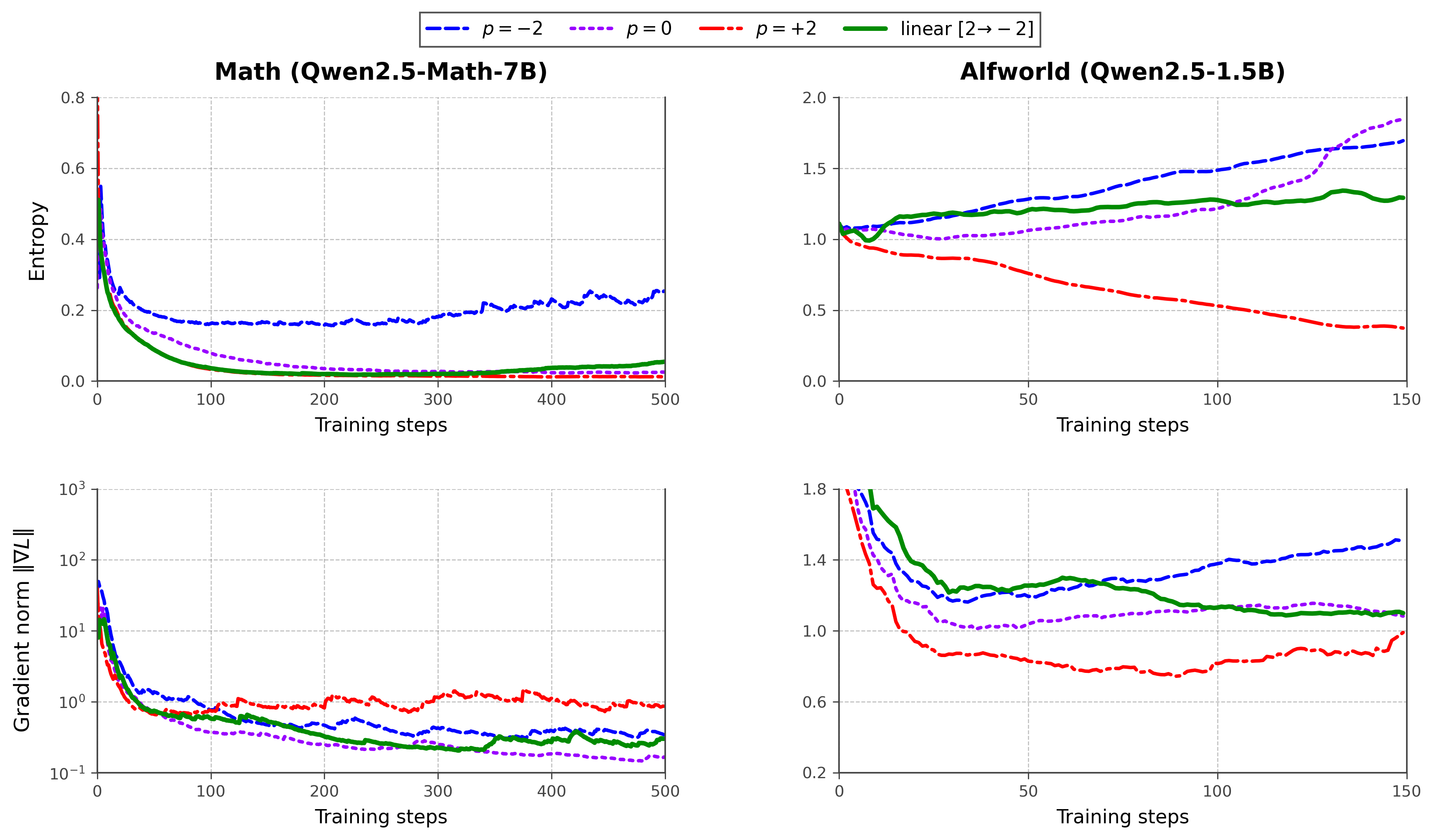
Limitations and open questions
The schedule is hand-picked (linear p:2\to-2); there is no adaptive controller that ties p to measured gradient variance, entropy, or reward sparsity, despite the theory pointing at exactly such signals. Sequence-level clipping is justified for variance control, but its interaction with p<0 (which can place dominant weight on small-ratio tokens) deserves a more careful safety analysis — negative p inverts the weighting and could amplify rare-token noise. The math evaluation uses Pass@1 with temperature 0, which understates exploration-driven gains; agentic evaluation is restricted to ALFWorld at 1.5B scale. Finally, the framework is presented as orthogonal to advantage estimation, but W_{i,t}(p) effectively does implicit per-token credit assignment; a joint design with token-level advantages is unexplored.
Why this matters
HölderPO reframes the GRPO/GSPO/GMPO debate as picking a point on a one-parameter family of token aggregators, and shows that the right operating point depends on signal sparsity in a way that motivates scheduling rather than tuning. This gives a clean theoretical handle — the softmax weights W_{i,t}(p) — on the otherwise ad-hoc choice of sequence-level loss in LLM RL.
Source: https://arxiv.org/abs/2605.12058
Agentic Discovery of Neural Architectures: AIRA-Compose and AIRA-Design
This paper asks whether LLM agents, given a code-execution harness and a fixed compute budget, can discover foundation-model architectures that beat human- and BO-designed baselines. The authors split the problem into two regimes: AIRA-Compose, which searches over arrangements of predefined computational primitives (Transformer attention, MLP, Mamba), and AIRA-Design, which asks agents to write novel attention mechanisms and training loops from scratch. Both are formalized as AIRS-Bench tasks {problem, dataset, metric}, executed in the AIRA-dojo harness with one-shot or greedy tree-search scaffolds.
Setup and search mechanics
An agent is an (LLM, scaffold) pair. The scaffold exposes four operators — Draft, Debug, Improve, Analyze — operating on Python solutions. The greedy scaffold drafts 5 root candidates, then expands the highest-validation-fitness node by Improve until a new best appears (Debug fires on OOMs / malformed primitive strings flagged by Analyze). Each run is capped at 24h (60h for BabiStories/DCLM) or 500 steps on a single H200.

AIRA-Compose recasts steps 1–2 of the Composer framework (acun2025composer) as agentic tasks: the agent emits a submission.csv listing 16 primitives drawn from a 2-primitive pool {multi-head attention A, MLP M} or 3-primitive pool {A, M, Mamba block Mb}. The Aggregator and Extrapolator (steps 3–4) are kept fixed: top architectures are clustered layer-wise into a robust 16-layer base, then either stacked (repeat) or stretched (proportionally expand contiguous blocks) to 350M / 1B / 3B parameters.
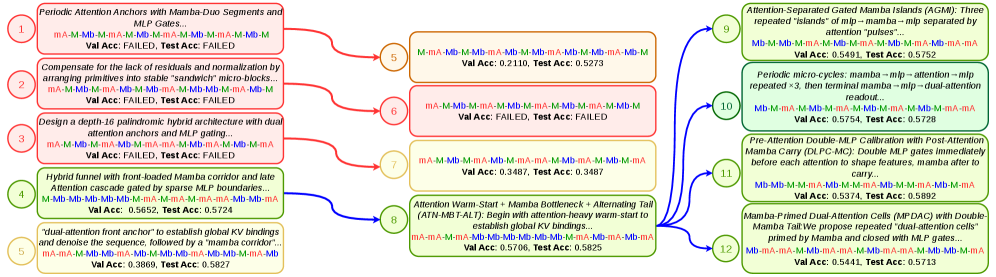
The search trace illustrates the qualitative gain over BO/incremental search: at each node the agent verbalizes a hypothesis (e.g., front-loading attention for retrieval, MLP-heavy tail for capacity), writes the candidate, and runs an internal evaluate.py before the harness independently scores it. Across 10 agents × 3 datasets (CWM, o3-mini, gpt-oss-20b/120b, GPT-4o, plus 20 GPT-5 greedy runs on MAD), the search probes 2{,}307 unique 16-layer architectures, or 3.17% of the 2-primitive space.
AIRA-Compose results
Aggregation produces four AIRAformer base patterns. Notably, despite being aggregated from independent agent searches, they converge on two attention:MLP ratios: 7:9 (A, B) and 11:5 (C, D). For example,
\text{AIRAformer-D} = 5\times(2A + M) + A.
IsoToken pretraining at 1B scale uses 71{,}565 steps × batch 4 × seq 8192 × DP 16 ≈ 37.5B tokens, three seeds per model. Validation loss on DCLM:
- Llama 3.2: 2.815
- Composite Stretched: 2.759
- AIRAformer-D Stretched: 2.734
Six-task 0-shot accuracy averages climb from 57.5% (Llama 3.2) to 59.6% (AIRAformer-A Stretched); DCLM Core score rises from 46.9 to 48.8 (AIRAformer-C Stacked). The AIRAformer-D variant improves downstream accuracy by 2.4% over Llama 3.2; the Transformer–Mamba hybrid AIRAhybrid-D adds 3.8%.
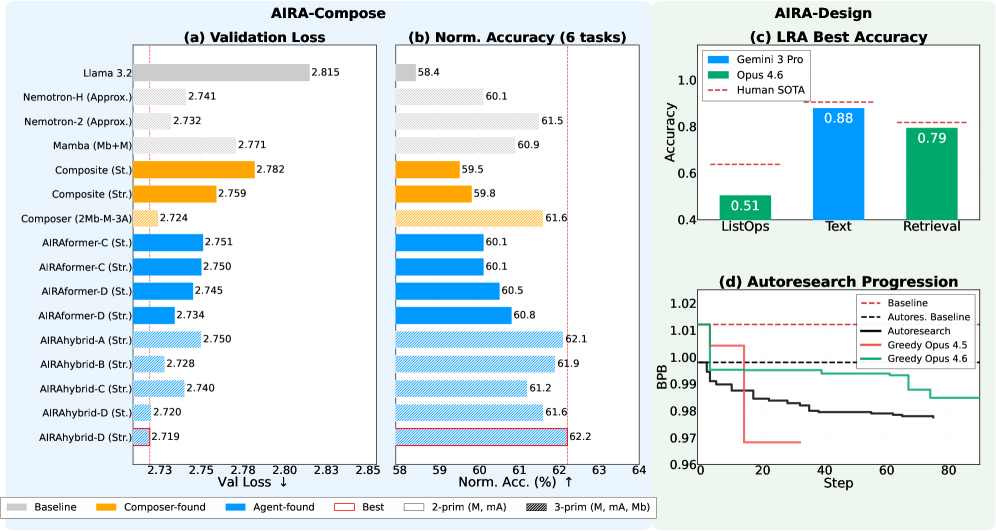
The headline scaling claim is on the loss-vs-tokens frontier: AIRAformer-C scales 54% and 71% faster than Llama 3.2 and Composer’s best Transformer respectively, while AIRAhybrid-C outscales Nemotron-2 by 23% and Composer’s best hybrid by 37%. Because the Aggregator/Extrapolator are identical to Composer’s, the gain is attributable to the agentic search policy, not to post-processing.
AIRA-Design
AIRA-Design pushes agents below the primitive level. Two suites are used: (i) Long Range Arena (Text, ListOps, Retrieval, plus Configurable variants), where agents must produce a complete model.py exposing a CustomEncoder with sub-quadratic attention that avoids materializing O(n^2) matrices on 2k–4k token sequences; (ii) Autoresearch (karpathy2026autoresearch), where agents edit a nanochat train.py (multi-head causal attention + RoPE + FlashAttn + Muon–AdamW) to minimize validation bits-per-byte under a 5-minute single-GPU training budget. Data pipeline, tokenizer, and eval harness are read-only; a “With Literature” variant exposes 41 paper analyses and 14 reference repos.
Three metrics are reported. Beyond raw score, the authors define valid submission rate \text{VSR}_{a,t} = V_{a,t}/T_{a,t} and a normalized score using the “march of nines” transform
\phi_t(s) = -\log_{10}(|s - s_t^{\text{opt}}|),\qquad \text{NS}_t^a = \frac{\phi_t(s_t^a) - \phi_t(s_t^{\min})}{\phi_t(s_t^{\text{sota}}) - \phi_t(s_t^{\min})},
so that crossing SOTA gives NS > 1 and absolute proximity to the optimum is rewarded log-linearly. Failed/invalid submissions get NS = 0, which is meaningful for AIRA-Design since VSR is no longer ~1 as in AIRA-Compose.
Limitations and open questions
The agentic exploration touches only ~3% of even the 2-primitive space; the convergence onto two A:M ratios may reflect inductive priors of the chosen LLMs as much as the search landscape. All large-scale evaluation reuses Composer’s stacking/stretching extrapolator, so claims about “discovered architectures” are conditional on those scaling rules. The 37.5B-token IsoToken budget is small relative to modern frontier training; whether the 54–71% scaling gap holds past 100B tokens is untested. AIRA-Design results in this excerpt cover metric definitions but not the full LRA/Autoresearch numerical leaderboard. Finally, the framework’s recursive self-improvement framing depends on agent LLMs that were themselves trained on Transformer literature, biasing primitive search.
Why this matters
This is the cleanest demonstration so far that LLM agents, given a structured search harness, can produce architecture families that strictly dominate BO-based NAS baselines on both loss and downstream accuracy at 1B scale, with measurable scaling-law improvements. It reframes NAS from hyperparameter optimization into agentic code synthesis with semantic priors.
Source: https://arxiv.org/abs/2605.15871
PhysBrain 1.0 Technical Report
PhysBrain 1.0 attacks a specific bottleneck in vision-language-action (VLA) modeling: robot trajectories from teleoperation or scripted policies cover a narrow slice of physical situations, so policies trained on them inherit weak priors about geometry, contact, and spatial relations. The paper’s hypothesis is that human egocentric video — abundant, diverse, and rich in manipulation — can supply those priors if it is processed into the right form. The contribution is twofold: a data engine that compiles raw egocentric clips into structured physical records and then into QA supervision, and a capability-preserving adaptation procedure that transfers the resulting VLM priors into a VLA policy without erasing the language-grounded understanding.
From video to physically explicit supervision
The data engine is framed explicitly as a compiler rather than a captioner. Captions, the authors argue, optimize for surface description and lose the physical structure needed for action: object geometry, contact progression, relative distance, reachability, and sub-action ordering. PhysBrain 1.0 instead enforces two design constraints. First, supervision must be physically explicit: each clip is parsed into a structured record listing visible objects, their physical attributes, spatial arrangement, depth relations, and how the scene evolves under action. Second, this scene meta-information is decoupled from the training target: the JSON-like records are intermediate artifacts, while the model is trained on natural-language QA derived from them.
The pipeline therefore has a clear staged interface. Frames are uniformly sampled from an egocentric manipulation clip; a parser extracts a compact source record partitioned into static scene elements (objects, attributes, layout), spatial change (object motion, depth ordering, distance shifts), and action execution (the actor’s hand trajectory, contact events, sub-action sequence). Subsequent stages augment, validate, and finally render the record into QA pairs.
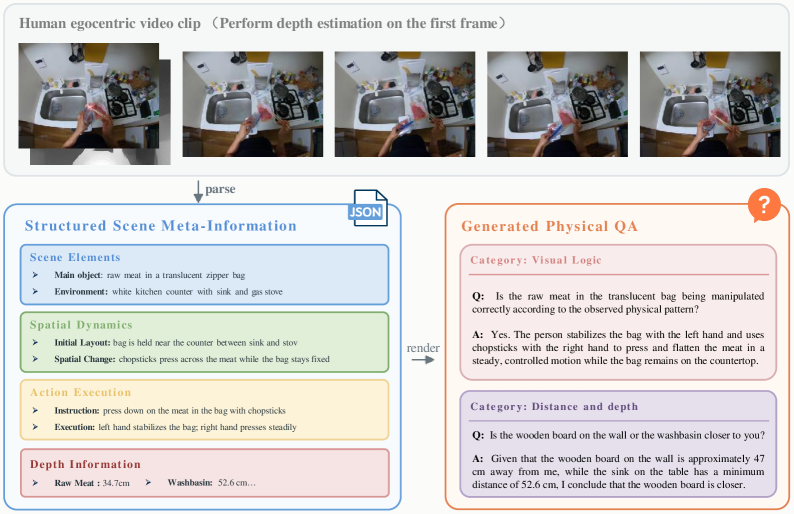
This separation matters mechanically. Because the intermediate record is machine-readable, downstream generation can target specific physical axes — e.g., “which object is closer to the actor’s right hand at t_2?” or “what is the order of sub-actions required to complete the pour?” — and errors in extraction (missing object, wrong depth ordering) can be caught before they leak into final supervision. The QA-rendering step preserves the flexibility of natural language while the upstream record enforces coverage of the targeted physical axes (geometry, contact, depth, temporal order).
Transfer to VLA policies
The physical priors learned by the PhysBrain VLM are transferred to a VLA policy through what the authors describe as a capability-preserving and language-sensitive adaptation. The motivation is that naive fine-tuning on robot trajectories typically degrades the multimodal QA capability that was the point of the upstream training. While the supplied excerpt does not specify the adaptation loss, the structural claim — that adaptation must preserve the language-grounded reasoning while injecting action-conditioned policy heads — is the standard frozen-or-regularized backbone recipe applied here with the additional constraint of language sensitivity (so that instruction-conditioned behavior remains intact during action fine-tuning).
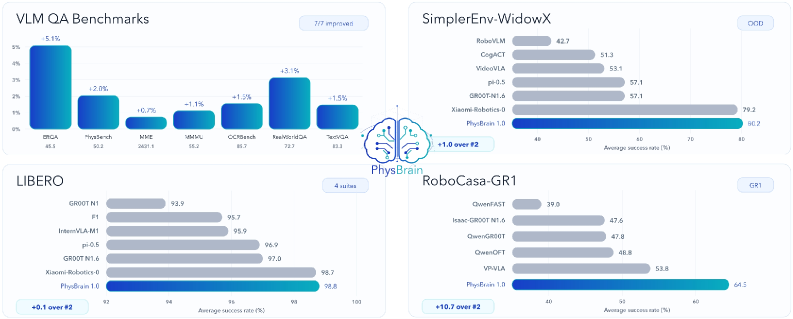
Results
PhysBrain 1.0 reports SOTA across a broad evaluation suite spanning multimodal QA and embodied control: ERQA and PhysBench for physical/embodied reasoning, and SimplerEnv-WidowX, LIBERO, and RoboCasa for control. The headline qualitative finding is “especially strong out-of-domain performance on SimplerEnv,” which is the most informative axis: SimplerEnv-WidowX evaluates generalization beyond the training distribution, and gains there are the cleanest evidence that the human-video-derived priors are doing real work rather than overfitting to robot data statistics. Specific per-benchmark numbers are not reproduced in the section excerpt provided.
Limitations and open questions
Several questions remain. The extraction stack (object detection, depth, hand/contact estimation) is itself a learned system; its biases shape the JSON record and therefore the final QA distribution, but the report excerpt does not quantify extraction error or its propagation. Egocentric human video has a hand-not-gripper embodiment gap: PhysBrain bets that physical commonsense (contact, depth, sub-action order) is embodiment-agnostic enough to transfer, but how much of the gain on SimplerEnv comes from this commonsense vs. from incidental visual coverage is not separated. The QA generation step likely uses an LLM over the structured records; the fidelity of that rendering, and the risk of hallucinated relations leaking back into supervision despite the structured intermediate, is another open question. Finally, the capability-preserving adaptation is described in goal terms — concrete ablations isolating which design choices preserve language sensitivity would clarify whether this is a robust recipe or task-specific tuning.
Why this matters
If physical commonsense scales with human egocentric video rather than with expensive robot trajectory collection, the data economics of VLA training change substantially: the bottleneck moves from teleop hours to extraction quality. PhysBrain 1.0’s compiler-style engine, with explicit intermediate records and QA-only training targets, is a concrete template for that shift.
Source: https://arxiv.org/abs/2605.15298
MMSkills: Towards Multimodal Skills for General Visual Agents
Problem
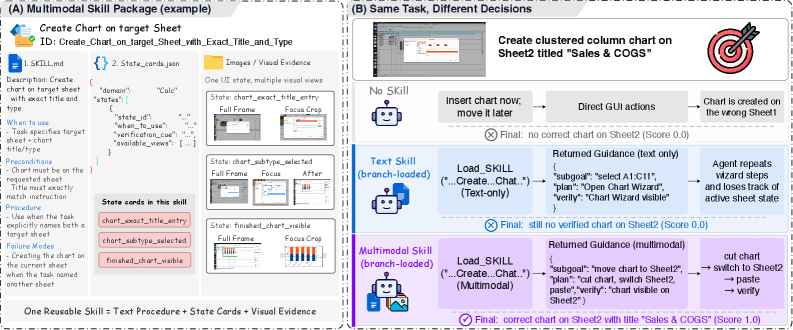
Skill libraries for LLM agents typically encode procedural knowledge as text, code, or API-like routines. For visual agents operating on GUIs and game frames, this representation is lossy: knowing what to do is insufficient when the agent must also recognize the current state, judge progress, and detect failure from pixels. A textual instruction like “click the chart wizard” can misfire if the agent does not first verify the active sheet, the selected range, or whether a modal dialog is already open. The paper formalizes the missing object as multimodal procedural knowledge and asks three questions: what such a package should contain, how to derive it from public trajectories, and how to consult it at inference time without flooding the context with screenshots or over-anchoring to reference images.
Method
An MMSkill package M = (D, P, S, K) contains a short descriptor D, a textual procedure P, a set of runtime state cards S = \{S_j\} (state-conditioned hints describing when a step applies), and multi-view keyframes K = \{K_j^v\} where v ranges over view types: full screen, focus crop, and before/after transition pairs. Skill statistics show typical packages of $$3.6 cards/skill and $$2.16 views/card on OSWorld (Table 6).
The Generator maps non-test trajectories \mathcal{T}=\{\tau_i\} to a library \mathcal{M}=\{M_i\}_{i=1}^N via meta-skill-guided clustering of OpenCUA trajectories (e.g., 718 Chrome trajectories cluster into 17 Phase-0 semantic groups). For OSWorld this yields 247 unique skill packages over 360 tasks (avg. 1.21 skills matched per task); macOSWorld yields 248 packages over 143 tasks.
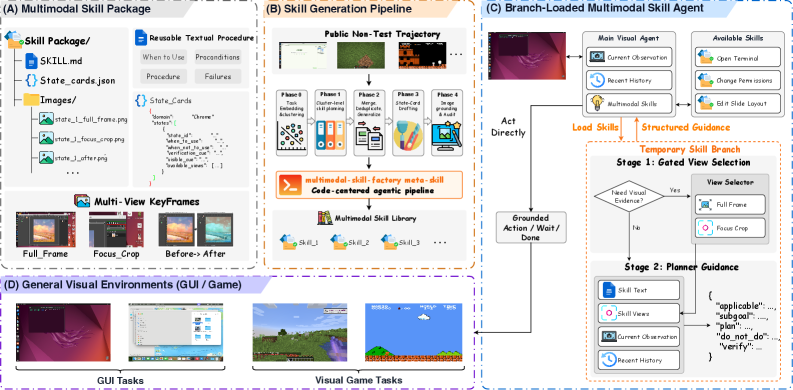
The runtime is branch-loaded. Before an episode, a candidate set \mathcal{C}_I \subset \mathcal{M} is pre-recalled from the instruction. At step t, the main policy either acts directly or issues LOAD_SKILL to consult one M_t \in \mathcal{C}_I in a temporary branch:
A_t = \pi_{\text{main}}(O_t, H_t, \mathcal{C}_I, G_t),\quad G_t = \text{Branch}(O_t, H_t, M_t)
The branch executes two stages: (1) SelectViews picks relevant cards J_t and view types R_t given the live observation; (2) PlanBranch returns a structured tuple
G_t = (\text{applicable}_t, \text{subgoal}_t, \text{plan}_t, \text{do\_not\_do}_t, \text{verify}_t).
Crucially the main trajectory never sees the raw multimodal package, only G_t. This isolates skill-environment grounding (potentially many images, lots of tokens) from the main context, and prevents the agent from copying coordinates out of reference screenshots. Each skill is consultable at most consult_limit times per episode.
Results
On OSWorld (360 tasks, 20-step budget, screenshot-only observations), MMSkills improves overall success rate over no-skill and over text-only skills (which use the same branch mechanism without state cards/keyframes) for every base model tested:
- Gemini 3.1 Pro: 44.08 (no skill) → 40.76 (text-only) → 50.11 (MMSkills)
- Gemini 3 Flash: 36.65 → 40.27 → 47.97
- Qwen3-VL-235B-Thinking: 21.34 → 28.57 → 39.17
- GLM-5V: 28.71 → 36.61 → 38.51
- Kimi-K2.6: 34.98 → 39.66 → 46.59
- Qwen3-VL-8B-Instruct: 10.78 → 14.93 → 25.40
The text-only condition can underperform no-skill (Gemini 3.1 Pro: 40.76 vs. 44.08), suggesting that procedural text alone, even when paged in via branch loading, sometimes mis-anchors the agent. Adding state cards and keyframes recovers and exceeds the baseline. Gains concentrate on visually-heavy domains: GIMP jumps 34.62 → 50.00 for Gemini 3.1 Pro and 38.46 → 69.23 for Qwen3-VL-235B; VLC goes 35.29 → 70.59 for Gemini 3.1 Pro.
The pattern transfers off-desktop. On VAB-Minecraft, Gemini 3 Flash reaches 73.28 success / 0.7884 avg score (vs. 67.24 / 0.7462 baseline). On Super Mario Bros, GLM-5V total reward rises 1191.50 → 1384.50 and Qwen3-VL-235B 955.50 → 1514.25. macOSWorld overall: Gemini 3 Flash 55.94 → 65.73, GLM-5V 34.97 → 51.75.
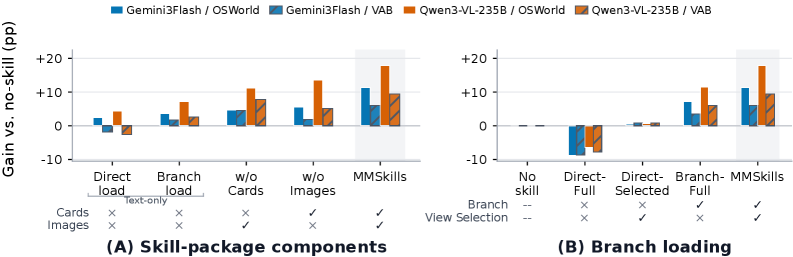
The ablations (Figure 3) attribute the gains to two factors. Removing either runtime state cards or visual keyframes degrades performance, with state cards contributing more in GUI domains where applicability judgment dominates. Direct loading of the full multimodal package (no branch) underperforms branch loading: stuffing keyframes into the main context increases over-anchoring and degrades grounding to the live screen. View selection on top of branch loading provides further gains by avoiding redundant frames.
Limitations
The system depends on a curated public trajectory source (OpenCUA) and on additional clustering for the macOS subset; transfer to domains without such corpora is untested. The consult_limit and pre-recall set \mathcal{C}_I are hyperparameters whose sensitivity is not characterized. Reported performance for Gemini 3.1 Pro and Kimi-K2.6 is OSWorld-only due to cost, leaving cross-benchmark consistency for frontier models partially open. The branch adds a non-trivial token overhead per consultation (Stage 1 + Stage 2 with selected views), and the paper does not report wall-clock or token-cost breakdowns. Finally, the structured guidance G_t is a fixed schema; whether agents could benefit from richer or model-discovered branch outputs is unclear.
Why this matters
MMSkills articulates a concrete answer to a recurring failure mode of GUI/visual agents: textual procedures encode the wrong abstraction because correctness is state-conditioned on pixels. Pairing state cards and keyframes with a branch-loaded consultation protocol recovers most of the procedural value of demonstrations without dragging reference screenshots into the main context, and the consistent cross-model, cross-benchmark gains (e.g., +18 points on OSWorld for Qwen3-VL-235B) suggest the representation, not just the skill data, is doing the work.
Source: https://arxiv.org/abs/2605.13527
Hacker News Signals
Zerostack – A Unix-inspired coding agent written in pure Rust
Zerostack is a CLI coding agent implemented entirely in Rust, positioned as a lightweight alternative to Node.js or Python-based agents. The Unix-philosophy angle is concrete: the agent is designed to compose with pipes, take instructions from stdin, and emit structured output to stdout, making it scriptable without a bespoke SDK.
The technical architecture follows a tool-loop pattern: a central reasoning loop calls an LLM (configurable backend), receives tool-call responses in JSON, dispatches to local tool implementations (file read/write, shell execution, grep, etc.), and feeds results back into context. The Rust implementation means the binary is a single statically-linked executable with no runtime dependency, which matters for sandboxed CI environments and air-gapped machines.
Notable implementation choices: tool execution is handled through a trait-based dispatch table, so adding a new tool is a matter of implementing the trait and registering it. The agent maintains a conversation buffer with explicit token-budget management — once the context window approaches a configurable limit, older non-essential exchanges are pruned rather than truncated blindly. Shell commands are run via std::process::Command with configurable timeouts; there is no container sandboxing built in, so privilege isolation is left to the caller.
The crate is published on crates.io at version 1.0.0, indicating some API stability commitment. Dependency surface is intentionally thin: tokio for async, serde/serde_json for tool-call serialization, reqwest for LLM API calls, and clap for CLI argument parsing.
Open questions: no built-in sandboxing is a real gap for untrusted codebases. Context pruning heuristics are not documented — it is unclear whether semantic importance or recency governs what gets dropped. Multi-file project awareness (symbol indexing, cross-file references) appears absent.
Source: https://crates.io/crates/zerostack/1.0.0
Show HN: Watch a neural net learn to play Snake
This is a live browser-based visualization of a PPO agent training on the classic Snake environment. The technical interest is in watching policy improvement in real time: the page streams training state from a backend (or runs entirely client-side via a compiled WASM/JS training loop) and renders each episode as it is played.
The algorithm is Proximal Policy Optimization. For a Snake environment the observation space is typically a grid or a set of distance features to walls, the body, and the food. The policy network is small — likely a two- or three-layer MLP given the latency of browser rendering. PPO’s clipped surrogate objective is:
L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min\left( r_t(\theta) \hat{A}_t,\ \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_t \right) \right]
where r_t(\theta) = \pi_\theta(a_t|s_t) / \pi_{\theta_\text{old}}(a_t|s_t).
What makes this pedagogically useful is that Snake has a clear curriculum: early episodes show random-walk behavior, then the agent learns to reach food reliably, then struggles with self-collision as the body grows — a natural demonstration of sparse-reward difficulty and the exploration-exploitation tradeoff without requiring explanation.
The site URL (ppo.gradexp.xyz) suggests this is a personal project. The main technical question is whether training is actually happening live in the browser (which would require a compiled training loop, feasible with TensorFlow.js or a WASM port of a small RL library) or whether it is replaying pre-recorded training trajectories. Either is useful, but the former is substantially more impressive from an engineering standpoint.
Limitations: Snake is not a hard RL benchmark. Generalization claims do not extend beyond this toy domain. Still a solid teaching artifact for PPO mechanics.
Source: https://ppo.gradexp.xyz/
Apple Silicon costs more than OpenRouter
The post is a careful energy-cost accounting for running LLM inference locally on Apple Silicon versus paying OpenRouter API rates. The author measures wall-power draw during inference on an M-series Mac using powermetrics, records tokens-per-second, and converts to a cost-per-million-tokens figure using residential electricity rates.
The core finding: at typical US electricity prices (~$0.15/kWh) and measured power draws in the 15–30W range during active inference on a MacBook, the energy cost per million tokens for a model like Llama-3 8B comes out higher than the cheapest OpenRouter-hosted models. The math is straightforward:
\text{cost/token} = \frac{P_{\text{watts}} \times (1/\text{tps})}{3.6 \times 10^9} \times \text{rate}_{\$/\text{J}}
where P is sustained power draw and tps is tokens per second.
The comparison is nuanced: the author notes that OpenRouter’s cheap rates reflect large-scale inference efficiency (batching, high GPU utilization) and that the cost gap widens for larger models where Apple Silicon throughput drops more steeply than server GPU throughput. The post also distinguishes energy cost from total cost-of-ownership — amortized hardware cost is not included, which would make local inference look worse still.
Counterarguments in the HN discussion: privacy, offline availability, and latency (no network round-trip) are not captured in pure cost. Also, Apple Silicon idle draw is near zero, so if the machine is already running, the marginal cost argument changes somewhat.
The technical takeaway for ML practitioners: Apple Silicon is competitive for development and low-throughput personal use, but the “free after hardware” framing is misleading at scale. Server-side batched inference has a structural efficiency advantage that local hardware cannot overcome without dramatic improvements in model efficiency or hardware power profiles.
Source: https://www.williamangel.net/blog/2026/05/17/offline-llm-energy-use.html
Radicle: Sovereign code forge built on Git
Radicle is a peer-to-peer code collaboration platform that uses Git as its data layer and a custom gossip protocol for repository replication, eliminating central hosting dependencies. It has been in development for several years and is now at a stage of practical usability.
The core data model: every repository is identified by a cryptographic ID derived from the initial commit and a keypair. Clones propagate through a gossip network of nodes (called “seeds”) that replicate Git objects. Issues, patches (pull requests), and code review comments are stored as Git objects in a separate refs/rad/ namespace within the repository itself, making the social layer part of the repository’s content-addressable history. This means the entire collaboration history — not just code — is portable and offline-capable.
The identity system uses Ed25519 keypairs. A “DID” (decentralized identifier) ties a public key to a contributor identity, and all artifacts (patches, reviews) are signed. There is no email/password login; authentication is purely key-based.
Technically, Radicle’s networking layer uses a custom protocol over TCP with a DHT-like node discovery mechanism. Seeds are public relay nodes; private seeds are also supported for organizational use. The CLI (rad) wraps git operations and adds commands for managing patches, issues, and node connectivity.
The main practical limitation is discoverability: without a central index, finding repositories requires knowing a repo ID or navigating through a seed node’s hosted list. The web interface (app.radicle.xyz) provides a semi-centralized index that somewhat undercuts the sovereign framing.
Integration with existing Git tooling is clean — remotes are rad:// URLs and standard git push/git fetch work after rad configures the transport helper.
Source: https://radicle.dev/
CUDA Books
This is a curated GitHub list of books covering CUDA programming and GPU computing, ranging from introductory CUDA C to advanced topics like PTX assembly, profiling, and multi-GPU systems.
The technically substantive part is in what the list reveals about the CUDA learning stack. The canonical entry points are Hwu, Kirk & Hajj’s “Programming Massively Parallel Processors” (now in its fourth edition), which covers the memory hierarchy (global, shared, L1/L2 caches, registers), warp execution, and occupancy optimization from first principles. Sanders and Kandrot’s “CUDA by Example” is older but still useful for understanding the CUDA runtime API mental model.
At the intermediate level, the list points to resources on thrust (STL-like parallel algorithms), cuBLAS/cuDNN integration, and the CUDA profiling toolchain (Nsight Compute, Nsight Systems). These are practically important: most performance work on real kernels involves reading roofline charts and identifying whether a kernel is compute-bound or memory-bandwidth-bound.
Advanced entries cover PTX (Parallel Thread Execution) — CUDA’s intermediate assembly language — which matters for anyone writing custom kernels that need to express warp-level primitives like __shfl_sync, mma (matrix multiply-accumulate) instructions, or inline PTX for operations not exposed in the C++ API. The Tensor Core programming model (using wmma or the newer cublas-lt or cutlass path) is not well-covered by any single book and remains largely a documentation + source-reading exercise.
The list’s limitation is currency: CUDA moves fast (Hopper introduced TMA, FP8, and new warp-group MMA instructions) and books lag by years. For current GPU programming, NVIDIA’s developer blog and the Triton/CUTLASS source trees are more up to date than any book on the list.
Source: https://github.com/alternbits/awesome-cuda-books
I turned a $80 RK3562 Android tablet into a Debian Linux workstation
This is a detailed guide to installing mainline Debian on a Rockchip RK3562-based Android tablet, covering the full stack from bootloader to working desktop. The RK3562 is a mid-range ARM SoC (Cortex-A53 cluster, Mali-G52 GPU) common in budget tablets.
The technical procedure involves several distinct stages. First, unlocking the bootloader via fastboot oem unlock (where supported) or by shorting the RK maskrom recovery pads to force USB maskrom mode, which bypasses the signed bootloader chain. Then flashing a U-Boot build with Rockchip’s downstream patches (mainline U-Boot support for RK3562 is partial) using rkdeveloptool or upgrade_tool.
The root filesystem is a standard Debian arm64 debootstrap tarball written to an eMMC partition. The kernel is the critical piece: the author uses a Rockchip downstream kernel (5.10 or 6.1 branch) because mainline Linux lacks working drivers for several peripherals — specifically the display pipeline (VOP2), the wireless chipset, and the audio codec. This is a common pattern on Rockchip devices: mainline support lags the vendor BSP by 1–3 years.
Device tree overlays are used to configure the hardware; the author documents which DTB file corresponds to the tablet’s exact display and touch configuration, since multiple board variants ship with the same SoC.
The resulting system runs a full Debian userland with Xfce, Firefox, and standard apt-managed packages. GPU acceleration via panfrost (the open-source Mali driver) is functional for 2D; Vulkan/OpenGL ES performance is limited. The guide documents persistent pain points: sleep/resume is unreliable, camera is nonfunctional (no mainline driver), and USB-C alt-mode display output does not work.
Practically useful for anyone working with embedded ARM Linux on budget hardware.
Source: https://github.com/tech4bot/rk3562deb
A Claude Code and Codex Skill for Deliberate Skill Development
This repository implements a structured prompt framework that intercepts Claude Code and OpenAI Codex completions to introduce deliberate learning opportunities rather than immediately providing solutions. The framing draws from deliberate practice theory: instead of autocompleting a function, the agent asks the user to reason about the approach first, then provides feedback on that reasoning before revealing or writing code.
The technical mechanism is a system prompt layer and a set of “skill modules” — Markdown files that define a topic (e.g., “async/await patterns”, “SQL query optimization”) with associated Socratic question templates. When the user invokes a task that pattern-matches a skill module, the agent emits a scaffolded question sequence rather than a direct answer.
The implementation is lightweight: it is primarily prompt engineering with minimal code, relying on the instruction-following capability of the underlying model to maintain the pedagogical mode. There is no fine-tuning or retrieval system; the skill modules are concatenated into context.
The interesting technical question is whether this actually improves learning outcomes versus just slowing down task completion. The repository does not include any evaluation data. The claim rests on the deliberate practice literature (Ericsson et al.), which argues that feedback-loop density and challenge calibration matter more than raw exposure time.
From an agentic systems perspective, this is a simple example of a meta-prompt pattern: using a coding agent’s tool-use loop not to accomplish the stated task but to modify the interaction dynamic. It is conceptually related to “constitutional AI” prompt patterns but applied at the workflow level rather than the model level.
Limitations: the pattern-matching for skill module activation is coarse (likely keyword-based), maintenance of pedagogical mode across a multi-turn session depends entirely on model instruction-following, and there is no user modeling — every user gets the same scaffolding regardless of demonstrated competence.
Source: https://github.com/DrCatHicks/learning-opportunities
Claude for Legal
Anthropic’s claude-for-legal repository is a collection of reference prompt templates and workflow patterns targeting legal use cases: contract review, clause extraction, legal research summarization, deposition preparation, and regulatory compliance checking. It is positioned as a starting point for legal teams building Claude integrations rather than a production application.
The technical substance is in the prompt architecture. Contract review prompts use a structured extraction pattern: the model is instructed to identify specific clause types (indemnification, limitation of liability, governing law, auto-renewal) and return them as JSON with location references. This is a classic information extraction task where the LLM acts as a zero-shot classifier + extractor over unstructured legal text.
The research summarization templates use a multi-step approach: first extract holdings and key facts from individual cases, then synthesize across cases to identify controlling precedent. This decomposition is necessary because full case law research involves texts exceeding context windows.
Regulatory compliance templates take a “checklist against document” form: the model is given a regulatory requirement (e.g., GDPR Article 13 disclosure requirements) and a draft privacy policy and is asked to identify gaps. This is structurally a textual entailment task.
The repository is candid about limitations in its README: the outputs require attorney review, the model can hallucinate case citations (a well-known failure mode for legal LLM applications), and jurisdiction-specific nuances may not be handled correctly. No retrieval-augmented generation (RAG) layer is included, meaning the system has no access to actual case law databases — a significant gap for any real legal research workflow.
The HN discussion centers on liability questions and whether AI-assisted legal work changes unauthorized-practice-of-law exposure for non-attorneys. The technical artifacts are solid as templates; the deployment risk questions are unresolved.
Noteworthy New Repositories
GammaLabTechnologies/harmonist
A portable AI agent orchestration framework distinguishing itself through mechanical protocol enforcement rather than soft conventions. The core claim is 186 pre-built agents with zero runtime dependencies, meaning the entire orchestration layer ships as a self-contained binary or script without pulling in a dependency graph at execution time. Protocol enforcement is structural: agent communication contracts are validated at the framework level before any agent logic executes, preventing the class of silent inter-agent miscommunication bugs common in LangChain-style pipelines. The portability target covers environments where pip/npm are unavailable or locked down — CI runners, air-gapped servers, embedded toolchains. With 186 agents included, coverage likely spans web retrieval, file I/O, code execution, and API calling patterns. The zero-dependency constraint forces the implementation to rely on stdlib primitives, which is an architectural choice that trades ecosystem breadth for deployment simplicity. Worth examining for teams that need deterministic, auditable agent behavior in constrained environments.
Source: https://github.com/GammaLabTechnologies/harmonist
WantongC/journal-adapt-writing-skill
A targeted tool for a concrete academic workflow: given a target journal’s corpus of published papers, extract its implicit stylistic and structural conventions, then apply them to revise a submitted manuscript section by section. The technical substance lies in the convention-extraction step — published papers encode norms around hedging language, citation density, passive/active voice ratios, section length distributions, and transition patterns that differ substantially across venues (Nature Methods vs. ICML vs. ACL proceedings, for instance). The section-by-section revision architecture avoids the context-length collapse that occurs when naively feeding an entire manuscript to an LLM, and allows the model to maintain focus on local coherence while applying venue-specific patterns. Practically useful for researchers submitting across disciplines or targeting unfamiliar venues. The main limitation is that stylistic mimicry does not substitute for domain-appropriate content selection, and over-fitted style transfer can produce text that reads formulaic to experienced reviewers.
Source: https://github.com/WantongC/journal-adapt-writing-skill
KevRojo/Dulus
A CLI agent that harvests existing authenticated browser sessions for Gemini (guest, no login required), Claude.ai, Claude Code, Kimi, Qwen, and DeepSeek — bypassing API cost entirely. The mechanism is browser session scraping: Dulus attaches to or reads cookies/session tokens from a running browser profile and injects prompts programmatically, then parses responses back into a tool-calling loop. The agent exposes a standard set of capabilities: file read/write, Bash execution, repository grep, web browsing, and Git commit. The zero-dollar cost proposition is real for guest-mode Gemini, though session-based access to Claude.ai is subject to rate limits and terms-of-service constraints that make it unsuitable for production pipelines. The technical value is in the session-harvesting abstraction layer and the tool-calling scaffolding that converts raw model text output into structured actions. Useful for individual developers who want frontier model capability in a local agentic loop without API billing, accepting the fragility of browser-session coupling.
Source: https://github.com/KevRojo/Dulus
yzhao062/agent-style
A compact style guide — 21 rules — formatted as a drop-in system-prompt or configuration file for Claude Code, OpenAI Codex, GitHub Copilot, Cursor, and Aider. The problem it addresses is real: LLMs default to verbose, over-commented, hedge-laden prose and code that differs noticeably from idiomatic professional output. The rules presumably cover things like preferring concise variable names, avoiding redundant inline comments, using active voice in docstrings, maintaining consistent error-handling idioms, and not over-explaining obvious logic. The drop-in design means it can be prepended to a system prompt or placed in an agent’s configuration directory without modifying the underlying tool. At 446 stars for a text file, the signal is that this fills a genuine gap — most agent tooling ships no opinionated style defaults. The limitation is that 21 rules cannot encode full style; it is a starting point that teams should extend with project-specific conventions.
Source: https://github.com/yzhao062/agent-style
r1n7aro/Locus
An open-source AI agent targeting Unity game development workflows. The technical scope covers the Unity-specific toolchain: C# script generation, scene manipulation via the Unity Editor scripting API, asset pipeline interaction, and likely integration with the Unity Editor’s ExtendedEditor or COM automation interfaces. Unity development presents a harder agent target than generic code generation because correctness depends on understanding the GameObject/Component model, MonoBehaviour lifecycle (Awake, Start, Update ordering), serialization constraints, and physics/rendering pipeline interactions that are not well-represented in general code corpora. An agent that can reliably scaffold prefabs, write coroutine logic, and configure NavMesh or animation state machines would materially accelerate solo and small-team development. The open-source positioning distinguishes it from proprietary Unity AI integrations. The main open question is how it handles the Editor-runtime distinction and whether it can recover from compilation errors in the hot-reload loop.
Source: https://github.com/r1n7aro/Locus
agentforce314/clawcodex
A from-scratch reimplementation of Claude Code’s AI coding agent in approximately 170K lines of pure Python. The scale of the implementation — 170K LoC — suggests it covers the full agent loop: prompt construction, tool dispatch (file editing, bash, search), context window management, multi-turn state tracking, and error recovery. Building this in pure Python without the original TypeScript codebase means reverse-engineering the tool-calling protocol, the diff/patch application logic, and the conversation scaffolding from observable behavior. The value for researchers is a readable, modifiable Python codebase for studying and extending agentic coding systems, compared to the compiled or opaque binaries shipped by commercial tools. At 170K lines, code quality and maintainability are legitimate concerns — the line count alone does not imply good architecture. Worth examining for anyone building custom agent infrastructure who wants a reference implementation with no Node.js dependency.
Source: https://github.com/agentforce314/clawcodex
stainlu/hermes-labyrinth
A read-only observability plugin for the Hermes Agent framework, organized around four primitives: journeys (end-to-end execution traces), crossings (inter-agent or inter-component handoffs), guideposts (named checkpoints within a run), and reports (aggregated summaries). The read-only constraint is a deliberate design choice — observability tooling that can mutate agent state introduces coupling between instrumentation and behavior, a known source of Heisenbugs in distributed tracing. The four-primitive taxonomy maps onto standard distributed tracing concepts (traces, spans, events, summaries) but with agent-specific semantics: crossings capture the non-trivial handoff problem in multi-agent pipelines where context is partially transferred. Practically, this fills the gap between raw LLM call logs and structured understanding of what an agent actually did across a complex run. Limited to Hermes Agent users, which constrains its audience, but the primitive design is portable and the pattern is worth adopting elsewhere.
Source: https://github.com/stainlu/hermes-labyrinth
horang-labs/tessera
A workspace manager for AI-assisted coding sessions that organizes work across projects, collections, tabs, panes, and Git worktrees. The Git worktree integration is the technically interesting piece: worktrees allow multiple branches to be checked out simultaneously in separate directories, enabling parallel agent sessions on different features without branch-switching overhead or stash conflicts. Tessera wraps this with a UI layer that groups related sessions into collections and tabs, addressing the context-management problem that arises when running several concurrent agent interactions — it becomes difficult to track which conversation produced which file state. The project/collection/tab/pane hierarchy mirrors how developers already mentally organize work and maps naturally onto worktree directories. Comparable in spirit to tmux session management but with first-class awareness of AI session context and Git state. The open question is how it handles session-to-worktree binding when branches diverge or are rebased, and whether context from one pane is shareable across panes within a collection.