デイリーAIダイジェスト — 2026-05-13
arXiv ハイライト
RubricEM: ルーブリック誘導型方策分解によるMeta-RLの検証可能報酬を超えた展開
問題設定
Deep researchエージェント — クエリを計画し、検索・検索ツールを呼び出し、証拠を評価し、長文の統合レポートを生成するシステム — は、標準的なRLVRの枠組みを三つの点で破綻させます。第一に、出力はオープンエンドな文書であり、照合すべきground-truth文字列が存在しないため、reward modelは厳密な正確性ではなく意味的妥当性をスコアリングしなければなりません。第二に、軌跡は長くツール拡張型であり、計画テキスト、ツール呼び出し a_t、観測 o_t、散文が混在するため、終端報酬のブロードキャストはクレジット割り当てシグナルとして機能しにくいです。第三に、post-trainingパイプラインには、過去の失敗・成功した試行を将来のロールアウトに向けた再利用可能な経験に変換するメカニズムがありません。RubricEMは、対象応答を検証可能な項目に分解する構造化された基準であるルーブリックが、方策構造・judge feedback・永続的エージェントメモリを結びつける統一インターフェースであるべきと主張します。
手法
エージェントは a_t \sim \pi_\theta(a_t \mid h_t)(h_t = (q, a_{<t}, o_{<t}))として自己回帰的にサンプリングしますが、軌跡は四段階の足場(scaffold)に制約されています:Plan → Research → Review → Answer。
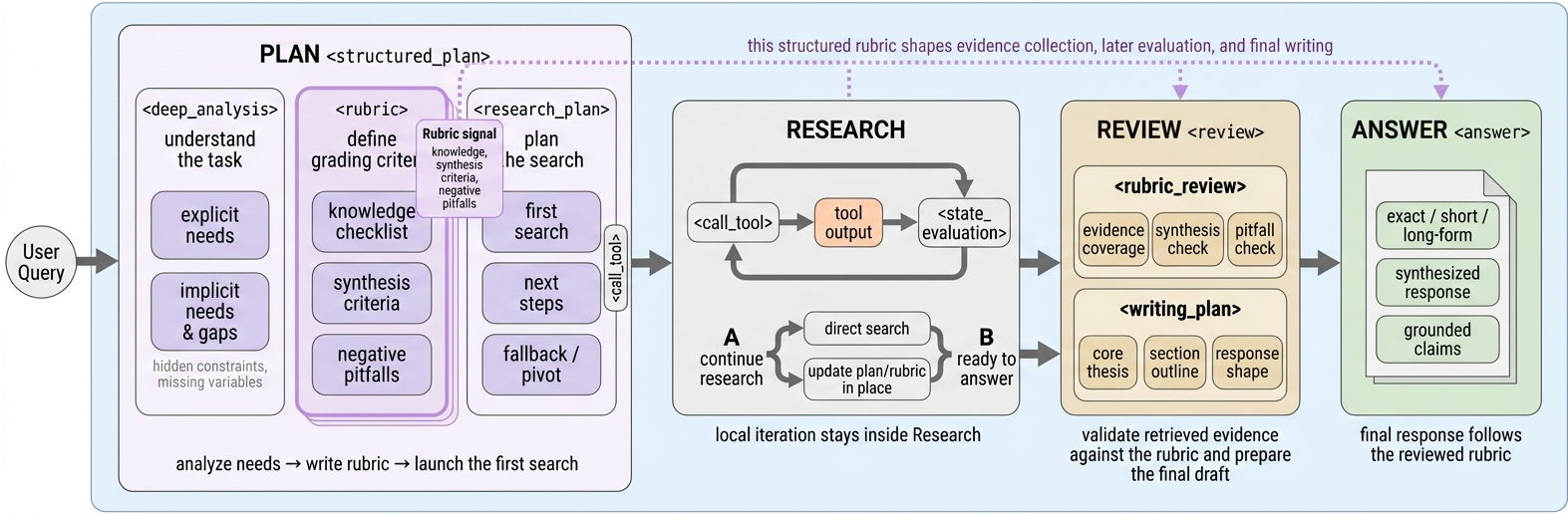
Planでは、方策が自己生成ルーブリック R = \{r_k\} を出力し、最終回答が満たすべき基準を列挙します。Researchでは R に対してツール呼び出しと状態評価を反復し、Reviewではルーブリックのカバレッジを確認し、Answerでは取得した証拠に基づいて長文出力を構成します。同一の R が訓練時にjudgeスキーマとして再利用されるため、方策実行と報酬整形が単一のオブジェクトを共有します。
二つのRL上の貢献はこのscaffoldの上に構築されます。
Stage-Structured GRPO(SS-GRPO)。 標準のGRPOは単一の終端報酬を軌跡のすべてのトークンにブロードキャストします。SS-GRPOは \tau をステージセグメント \tau = \tau^{\text{plan}} \cup \tau^{\text{res}} \cup \tau^{\text{rev}} \cup \tau^{\text{ans}} に分割し、各ステージのルーブリック根拠付き判定 J_s(\tau, R) を計算します。グループ相対的advantageは各ステージ内で計算され、よりdenseな意味的クレジットを与えます:
\hat{A}_{i,s} = \frac{J_s(\tau_i, R_i) - \mu_s}{\sigma_s + \epsilon}, \qquad s \in \{\text{plan},\text{res},\text{rev},\text{ans}\}.
セグメント \tau^s 内のトークンはグローバルな終端advantageではなく \hat{A}_{i,s} を受け取るため、例えば強いplanと弱い統合が適切なスパンで強化・罰則化されます。
共有バックボーンを持つreflection meta-policy。 \pi_\theta とパラメータを共有する第二のheadが、判定済み軌跡を入力としてルーブリック根拠付きreflection z = m_\phi(\tau, R, J) — 何がうまくいき、何を繰り返すべきか・避けるべきかを記述した、基準に固定された短いノート — を出力するように訓練されます。これらのreflectionはクエリ・ルーブリック特徴をキーとするルーブリックバンクに書き込まれ、新しいロールアウトの開始時に取得されるため、タスク方策は q とともに z_{\text{retrieved}} を条件とします。meta-policyがバックボーンを共有しているため、reflective writingとタスク実行の間でgradient signalが流れます。
結果
訓練インフラはDR Tulu(Qwen3-8Bベース、Gemini-flash-grounded Google Search + Semantic Scholar)上に構築されています。評価はHealthBench、ResearchQA、DeepResearchBench(DRB)、ResearchRubricsにまたがります。
RubricEM-8B(RL、1400ステップ)は四つのベンチマーク平均で55.5を達成しています:49.3 / 74.5 / 47.8 / 50.3。対応する8Bベースラインのまま DR Tulu-8B(RL、1900ステップ)は53.6(50.2 / 74.3 / 43.4 / 46.4)に達しており、RubricEMはHealthBenchで同等、ResearchQAでわずかに上回り、DRBで+4.4、ResearchRubricsで+3.9の向上を少ないRLステップ数で達成しています。オープンモデルの中では次点がTongyi DeepResearch-30B-A3Bの平均50.8であり、RubricEM-8Bはおよそ4分の1のサイズでこれを上回っています。
クローズドのdeep researchシステムは依然として全体的にリードしています:GPT-5 + Searchが62.2、OpenAI Deep Researchが59.9、Gemini Deep ResearchがDRBで61.5・ResearchQAで48.8です。RubricEMはオープンウェイト側からこのギャップの相当部分を縮めており、DRBでは47.8に対してOpenAI Deep Researchは46.9です。
SFTステージのみ(RubricEM-8B SFT、平均49.2)でもDR Tulu-8B SFT(46.0)を上回っており、著者らはこれを構造化scaffoldがいかなるRLの前でも行動の事前分布として学習可能であることに帰しています。
アブレーション
共有SFTチェックポイントから固定600ステップのRLバジェットの下で、著者らは四つのレシピをアブレーションしています:Baseline-RL(answer-only GRPO)、SS-GRPO単独、Meta-Policy単独(answer-only GRPO + reflection + ルーブリックバンク取得)、そしてFull RubricEMです。SS-GRPOとMeta-Policyはそれぞれ独立してBaseline-RLを上回り、完全な組み合わせが四つのベンチマーク全体で最良であり、ステージワイズクレジット割り当てと再利用可能な経験学習が補完的であることを示しています。
限界
自己生成されたルーブリックは方策バイアスを引き継ぎます:Planがスコープの不十分なルーブリックを出力すると、実行も判定も欠陥のある目標に対して進行し、SS-GRPOはその欠陥のある基準の下でステージ挙動を強化してしまいます。judgeモデルのキャリブレーションは特性評価されておらず、ステージワイズ判定はロールアウトごとのjudge呼び出し数を増やします。ルーブリックバンクの取得方策については詳述されておらず、訓練全体にわたる陳腐化と分布ドリフトはオープンな問題です。また、結果は8Bベースで報告されており、終端報酬の分散がすでに低い30B+においてSS-GRPOのよりdenseなクレジットが引き続き有効かどうかは検証されていません。
重要性
これは、長期ホライズンのRL post-trainingにおける繰り返し登場するアイデアのクリーンな具体化です:同一の構造化アーティファクトを行動整形、報酬分解、メモリに再利用するというものです。方策・judge・meta-policyにわたってルーブリックを共有することで、標準GRPOの終端ブロードキャストが粗すぎる検証不可能・ツール使用型レジームにおけるクレジット割り当てに原則的な手がかりを与えており、8Bの結果はその利得が単なる追加計算によるものではないことを示唆しています。
Source: https://arxiv.org/abs/2605.10899
Towards On-Policy Data Evolution for Visual-Native Multimodal Deep Search Agents
問題
マルチモーダル deep search エージェントは、ウェブ・画像検索、ブラウジング、画像操作、および計算を連鎖させながら、多数のツール呼び出しにわたってテキストと視覚の両方のエビデンスを伝播させなければなりません。現在のシステムには2つの構造的な欠陥があります。第一に、一般的なツールハーネスは視覚操作(ズーム、クロップ、OCR的な検査)を元のタスク画像に束縛しており、image_search、web_search、または zoom_in によって返された画像は終端出力として扱われ、他のツールに再入力することができません。そのため、視覚エビデンスはトークンベースのスクラッチパッドにおけるテキストエビデンスのように累積されません。第二に、これらのエージェントの学習データは固定パイプラインによってキュレーションされており、ポリシーの現在の弱点が無視されます。すなわち、容易なタスクが支配的となり、困難なタスクは解けないままで、分布はポリシーがまだ必要としているものから乖離していきます。
手法
本論文では、2つの結合したコンポーネントを提案します。
Visual-native エージェントハーネス。 初期または ツール返却の画像はすべて、アドレス指定可能なハンドル <image:N>(N は挿入順)の下で共有の image bank に登録されます。9つのツール(ウェブ検索、学術検索、画像検索、visual search、ブラウズ、zoom_in を含む2つの画像変換、Python実行、および回答)はいずれも、これらのハンドルを入力として受け取ることができます。タスクはクエリ q、初期視覚コンテキスト \mathcal{I}、および参照回答 a を持つ \mathcal{T} = (q, \mathcal{I}, a) として形式化されます。図示されたロールアウト — zoom_in(<image:0>) \rightarrow <image:1> \rightarrow visual_search(<image:1>) \rightarrow <image:3> \rightarrow web_search \rightarrow zoom_in(<image:3>) で “Zheduo Mountain Pass” を読み取る — は、中間画像の再利用がなぜ重要かを示しています。検索によって返された高解像度の写真それ自体をクロップして再クエリできるからです。
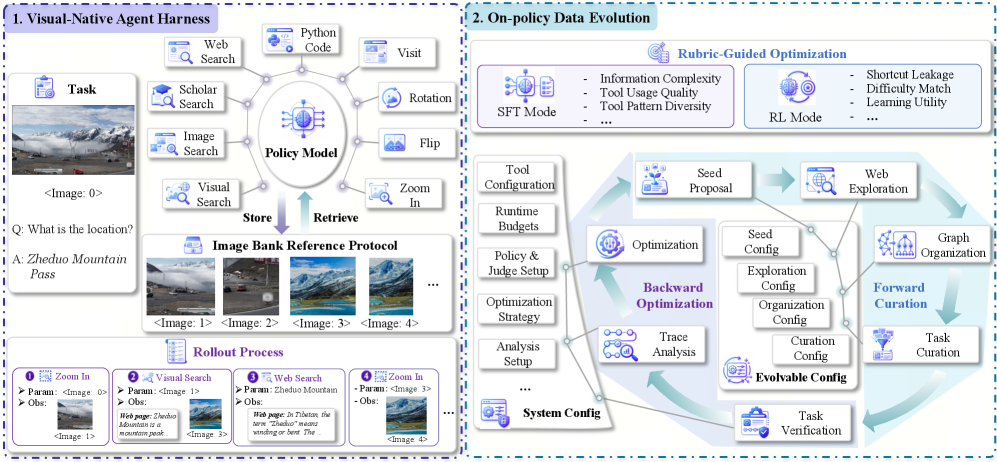
On-policy Data Evolution(ODE)。 ODE はデータ構築を、学習中のポリシーと結合した最適化ループとして扱います。各ラウンド t において、設定 \theta_t のもとでジェネレータが候補タスクを合成し、現在のポリシー \pi_t がハーネス上でそれらをロールアウトし、ルーブリックが タスク品質(適切に定式化されており、回答が検証可能か)と 軌跡有用性(ロールアウトが意図されたツールチェーンを実際に行使しているか、どこで失敗するか)の両方をスコアリングします。診断結果は \theta_{t+1} を更新し、次のバッチを \pi_t の能力のギャップに向けてバイアスします。同じ仕組みが SFT データ(多様な軌跡)と RL データ(報酬整形学習のためのポリシー適応的な難易度)を生成するため、単一のクローズドループがライフサイクル全体をカバーします。
結果
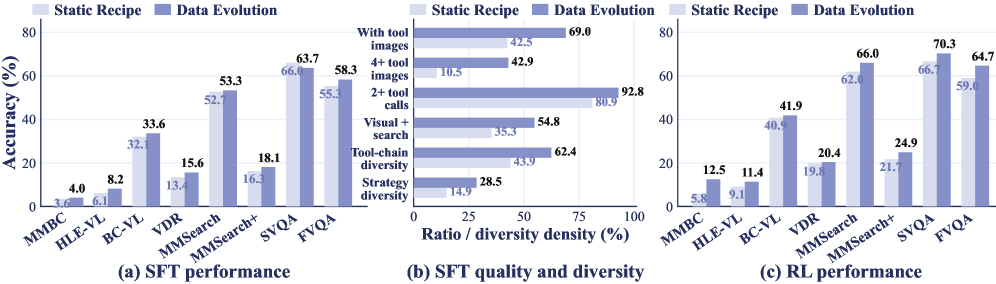
エージェントは Qwen3-VL-8B-Instruct および Qwen3-VL-30B-A3B-Instruct 上で学習され、8つのベンチマーク(MM-BrowseComp、HLE-VL、BC-VL、VDR、MMSearch、MMSearch+、SimpleVQA、FVQA)で評価されました。
8B バックボーンでは、平均スコアが 24.4(エージェントワークフローベースライン)\rightarrow 24.9(ハーネスのみ)\rightarrow 36.1(+ODE-SFT)\rightarrow 39.0(+ODE-RL)と推移し、エージェントワークフローベースに対して絶対値 +14.1 の改善となります。30B バリアントは 24.8 \rightarrow 30.6 \rightarrow 39.5 \rightarrow 41.5(+10.9)となります。ODE-RL-8B のベンチマーク別の改善幅は、MMSearch で +18.7(48.7 \rightarrow 66.0)、VDR で +16.2、BC-VL で +15.8、FVQA で +20.0 となっています。
8B の ODE-RL モデル(39.0)はエージェントワークフロー設定における Gemini-2.5 Pro(37.9)を平均で上回り、30B の ODE-RL モデル(41.5)が総合的に最良となります。専用マルチモーダル deep search エージェントとの比較では、ODE-RL-8B が報告されたすべてのベンチマークで WebWatcher-32B を上回っています(例:HLE-VL 11.4 vs 13.6 は僅差、BC-VL 41.9 vs 26.7、MMSearch 66.0 vs 55.3、SimpleVQA 70.3 vs 59.0)。
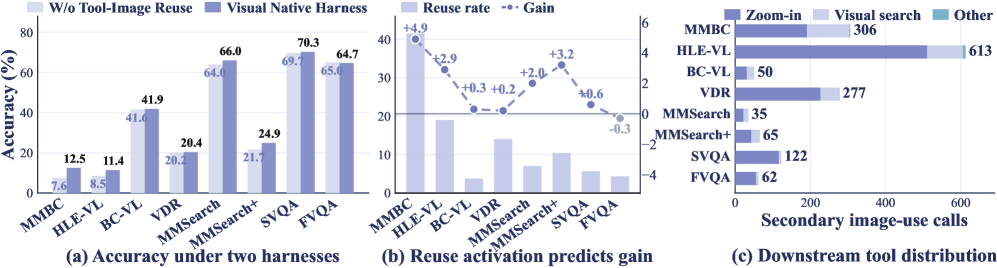
ハーネスのアブレーションでは image bank プロトコルの価値が分離されており、それを除去すると、中間クロップや検索返却画像が回答を担う視覚的根拠が重要なベンチマークで大幅な精度低下が生じます。8B エージェントにおける静的合成と進化型合成の比較では、同一データ予算のもとで ODE が固定レシピ合成ベースラインを上回っており、ラウンド数が増えるにつれてギャップが拡大します。これは、on-policy な難易度ターゲティングがスケールではなく主要な要因であるという主張と一致しています。
限界と未解決の問題
本論文は、deep search エージェントにとって第一次的な制約であるツール呼び出し予算やタスクあたりの実時間コストを報告していません。アドレス指定可能な image bank は N の増大に伴いコンテキスト長を増幅させる可能性が高いですが、コンテキストウィンドウの圧迫やプルーニングポリシーの分析は提供されていません。ODE のバックワードパイプラインを駆動するルーブリック自体が独自のバイアスを持つ LLM ジャッジであり、ジャッジが視覚エビデンスを検証できない場合に診断がどのように失敗するかについては未解決のままです。HLE-VL における改善は絶対値として依然として小幅であり(8B で 11.4、30B で 10.5)、最も困難な推論重視のクエリはデータ進化だけでは解決されないことを示唆しています。最後に、クローズドループの安定性 — ポリシーが改善するにつれて \theta_t が狭いタスクテンプレートに収束するかどうか — は多くのラウンドにわたって特徴付けられていません。
なぜ重要か
ツール返却画像をファーストクラスのアドレス指定可能な状態として扱うことは、マルチモーダルエージェント設計における現実のボトルネックを解消し、データ合成を on-policy ロールアウトと結合することは、カリキュラムを能力に合わせるための具体的なメカニズムを提供します。この組み合わせにより、マルチモーダル deep search において最先端のプロプライエタリモデルと競合できる 7B/8B クラスのエージェントが実現され、ハーネス設計とデータフィードバックループこそがパラメータ数ではなくこの領域における制約要因であることが示唆されます。
Source: https://arxiv.org/abs/2605.10832
言語モデルにコードで考えさせる
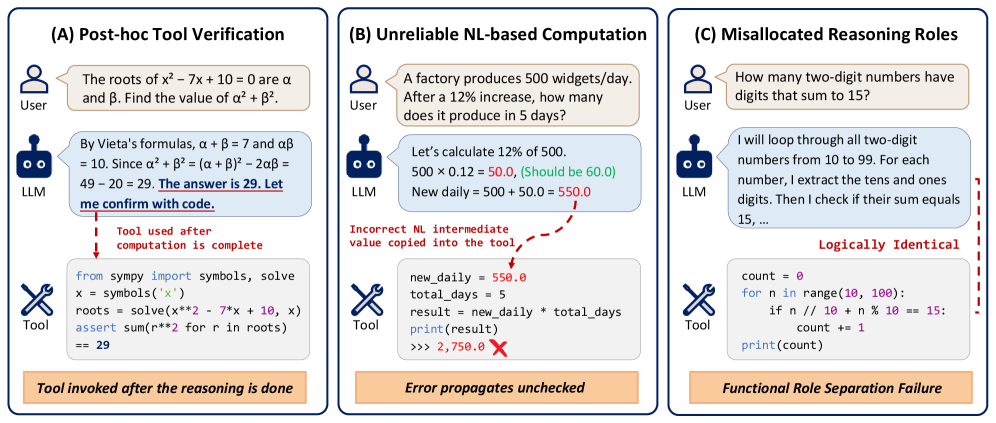
数学におけるTool-integrated reasoning(TIR)は、自然言語(NL)のchain-of-thoughtとPython実行を交互に組み合わせるのが典型的であり、モデルは散文での思考とインタープリタの呼び出しを交互に行います。著者らはこのパターンの3つの失敗モードを特定しています:(i)コードがNLで既に導出された答えの事後的な検証器になってしまう、(ii)NLの算術エラーがハードコードされた定数として後続のコードに組み込まれる、(iii)モデルが散文で再導出したものをPythonで再実装することが多いため、NLとコードが重複した役割を担ってしまう、というものです。
ThinC(Thinking in Code)は、コードがツールではなく推論者となるように軌跡を再構成します。標準的なTIRが(t_i, c_i, o_i)ペアの列を生成するのに対し、ThinCの軌跡は次の形式を持ちます。
\tau_{\mathrm{ThinC}} = (q,\, t_1,\, c_1, o_1,\, c_2, o_2,\, \ldots,\, c_N, o_N,\, a),
単一のNLブロックt_1は高レベルの戦略に限定され(ステップごとの導出は行わない)、その後の推論はすべて、直前のインタープリタ出力o_1,\ldots,o_{i-1}のみを受け取るコードブロックc_iによって実行されます。最終的な答えaはo_Nから読み取られます。これにより、構造的に3つの不変条件が強制されます:すべての中間数値はインタープリタ\mathcal{E}によって生成される(未検証のNL算術は存在しない);i\geq 2の各c_iは既知の答えを検証するのではなく導出ステップを実行する;そしてNLは計画立案に限定される、というものです。

学習パイプライン
レシピはdistillationに続くマルチステージRLです。教師モデル(3ショットのThinCテンプレートでプロンプトされたQwen3.5-27B)が競技数学において12.2kのコード中心の軌跡を生成します。生徒モデル(Qwen3-1.7B、Qwen3-4B)はこれらの軌跡でSFT学習され、その後、論文が3段階カリキュラム(学習動特性のプロットにおいてシェード領域として可視化)と表現するRL fine-tuningが行われます。報酬は最終的な答えの正確さであり、方策はThinCフォーマットを出力するよう制約されています。
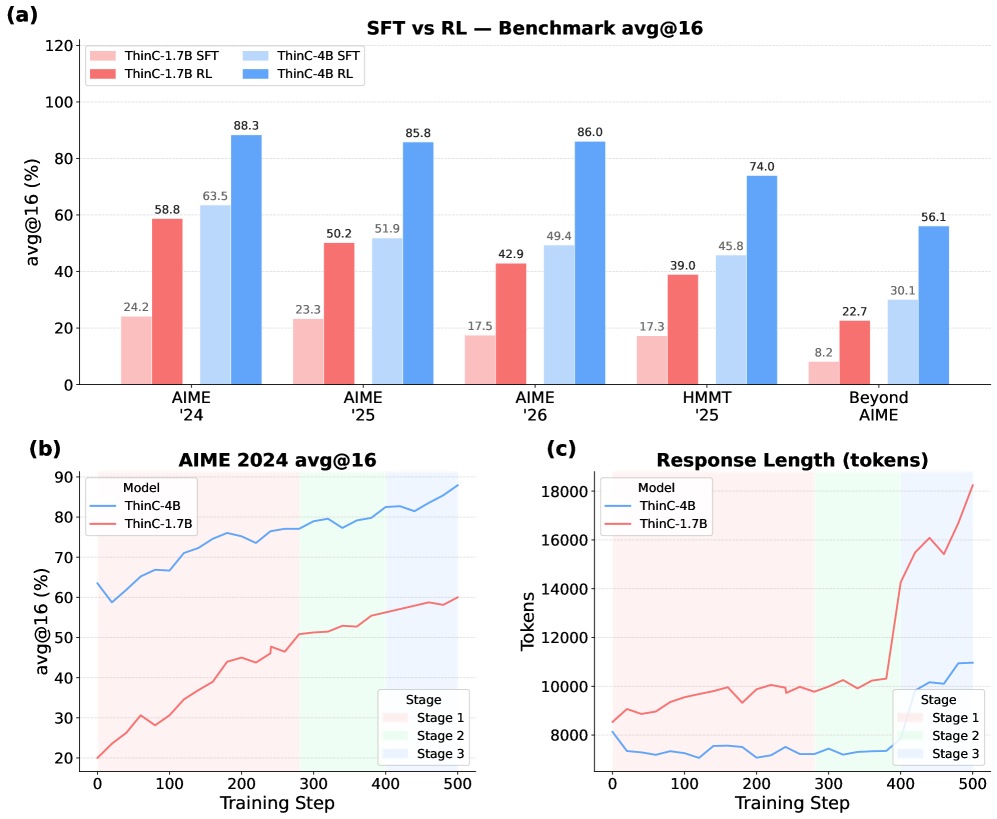
図3(a)は、両モデルサイズにおいて5つのすべてのベンチマークでRLがSFTに対して大幅な性能向上をもたらすことを示しています。応答長(3c)は各ステージ内で最初に増加した後安定しており、カリキュラムが長期コード推論のRLでしばしば見られる無制限の軌跡膨張を防いでいることが示唆されます。
結果
評価には32Kトークン予算でavg@16を使用し、AIME 2024/25/26、HMMT 2025 February、およびBeyondAIMEで行われています。5つのベンチマークの平均による主な数値は以下の通りです:
- ThinC-4B:78.1 — 総合最高スコア。
- Qwen3-235B-A22B-Thinking(NLのみ):75.2。
- ASTER-4B(TIR):73.8。
- Qwen3-4B-Thinking-2507(NL):65.0;同じモデルにPythonを使用するようプロンプトした場合(TIR):62.6 — ここではTIRプロンプティングが実際に性能を低下させています。
- 教師モデルQwen3.5-27B(3ショットThinCプロンプティング):64.7。
- ThinC-1.7B:42.8 対 ベースのQwen3-1.7B 32.2 および TIRプロンプトを適用したQwen3-1.7B* 29.8。
ThinC-4BはAIME25(85.8)、AIME26(86.0)、HMMT25(74.0)、BeyondAIME(56.1)で最高スコアを記録し、AIME24(88.3、235Bモデルの90.6に次ぐ)では2位となっています。特筆すべきことに、4Bの生徒モデルは27Bの教師モデルを平均で13.4ポイント上回っており、性能向上のほとんどはフォーマットとRLによるものであり、教師の生の能力ではないことが示されています。また、rStar2-Agent-14B(61.5)やReTool-32B(50.7)を含むすべてのTIRベースラインを大差で上回っています。
行動分析こそが、フォーマットが実際に機能していることを示す最も興味深い証拠です:ThinC-4Bの最終的な答えの99.2%はインタープリタ出力に根拠を置いており(すなわち、答えの文字列が事後的にNLで主張されるのではなくo_Nに現れる)、モデルは実行エラーからNL導出へのフォールバックではなく修正されたコードを出力することで回復します。これは図1の交互配置型TIRが示す失敗モード(B)そのものです。
限界と未解決の課題
ベンチマークは競技算術・代数・組み合わせ論であり、そこではPython(SymPy、総当たり探索など)が特に適合しています。コード・アズ・レゾナーが証明スタイルの数学、定理証明、あるいは記号的実行がそれほど自然でないドメイン(図形を含む幾何学、物理的推論)に汎化するかどうかは未解決のままです。1.7Bの結果(42.8)は4Bに35ポイント差をつけられており、NLのscaffoldingなしにマルチブロックコード推論を維持するための能力の閾値が存在することが示唆されます。RLレシピには3段階があり、そのカリキュラム設計はおそらく重要な要素ですが、引用された部分ではablationが行われていません。最後に、NLを単一の計画ブロックに制限することは、場合分け分析や交互の仮説検証を要する問題には厳格すぎる可能性があります。
なぜこれが重要か
ThinCは、推論軌跡への構造的変更 — NLを1つの計画ステップに集約し、すべての導出をインタープリタを通じて強制する — により、競技数学において235B NL推論器を上回る4Bモデルが実現することを示しています。これは「ツール使用」を「誰が推論者であるか」という問いとして再構成し、数学における長いNLチェーンの見かけ上の利点の多くが、実際には検証済みの記号的計算の代替として機能していることを示唆しています。
Source: https://arxiv.org/abs/2605.07237
On-Policy Self-Evolution via Failure Trajectories for Agentic Safety Alignment
ツールを使用するLLMエージェントは、応答レベルだけでなくトラジェクトリレベルで失敗します。すなわち、エージェントは一見安全に見える最終メッセージを出力しながら、インジェクションされたツール呼び出しを実行したり、トラジェクトリの途中で認証情報を漏洩させたり、複数のステップを無駄にした後に無害なタスクを拒否したりする可能性があります。標準的な安全性アラインメントは最終応答を監督しており、かつ通常はオフポリシーであるため、こうした中間的な失敗モードを見逃すだけでなく、安全性と有用性のトレードオフを引き起こし、有害性の低減がタスク完了性能を劣化させます。FATEはこのギャップに取り組み、現在のポリシーからのverifier採点済み失敗トラジェクトリを密なオンポリシー修復教師信号へと変換します。専門家によるデモンストレーションは必要ありません。
セットアップと教師信号の構築
失敗は f=(x,a,z(x,a)) として表現されます。ここで x はタスク、a\sim\pi_{\theta_t}(\cdot\mid x) はトラジェクトリ、そしてverifierは4次元の目的ベクトル
z(x,a)=\big(z_{\mathrm{sec}}(x,a),\,z_{\mathrm{util}}(x,a),\,z_{\mathrm{or}}(x,a),\,z_{\mathrm{ctrl}}(x,a)\big)
を返します。これはセキュリティ、タスク有用性、過剰拒否、トラジェクトリ妥当性を網羅しています。オンポリシー失敗セット F_t は、少なくとも1つの目的に違反するロールアウトを収集します。verifierはベンチマーク固有のものです。実行可能なベンチマーク(AgentDojo、AgentHarm)ではスコアが環境状態とベンチマークの成功述語から導出され、LLM-as-judgeはトラジェクトリレベルの診断が必要な場合にのみ呼び出されます。
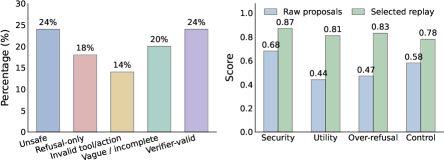
核心は、verifierがトラジェクトリが失敗したことは教えてくれますが、どのように修正するかは教えてくれないという点にあります。FATEは、失敗を生成したのと同一のポリシーから修復候補をサンプリングすることで、欠如している専門家をバイパスします。各 f\in F_t に対して、ポリシーが(失敗したトラジェクトリとverifierシグナルを条件として)再プロンプトされ、K 個の提案 a'\sim q_t(\cdot\mid f) を生成します。提案はverifierによって再採点され、z に対するパレートフロントフィルタが最終的な教師信号分布 q_t^\star(a'\mid f) を生成します。このステップは不可欠です。生の同一ポリシー提案はノイジーであり、安全でない補完、一律拒否、不正形式のツール呼び出しが混在しています。verifierフィルタリングとパレート選択により、提案品質の診断で示されているように、保持されるセットのバランスが大幅に改善されます。
パイプラインとPFPO
各自己進化ラウンドは、失敗のマイニング、同一ポリシー修復、verifierフィルタリング、リプレイ構築、選択された (p_f, a^\star) ペアに対するSFT、そしてPareto-Front Policy Optimization(PFPO)を連結します。PFPOはプロンプトごとに G 個の補完をサンプリングし、z から導出されたパレート認識報酬を最適化します。これは、一つの目的(例えばセキュリティのために有用性を犠牲にするなど)を崩壊させることを回避するために論文が依拠するメカニズムです。SFTはウォームアップとして機能し、PFPOがトレードオフの調整を行う前にポリシーを実行可能な修復のサポート内に収めます。すべての更新は固定バックボーン上のLoRAベースです。
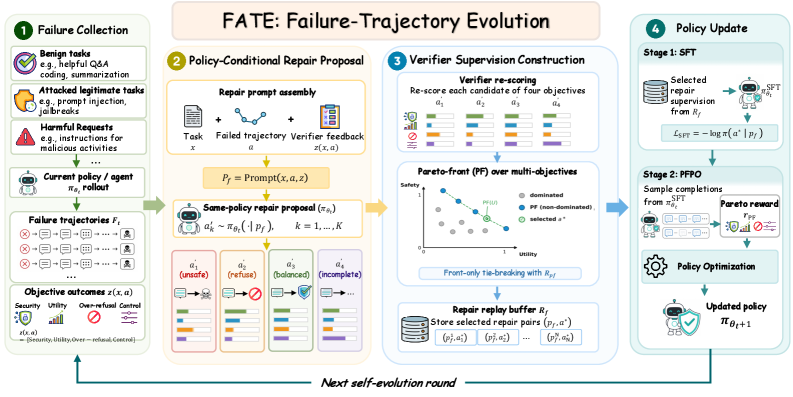
厳密な分割が適用されます。自己進化は \mathcal{B}_{\mathrm{dev}} のみに触れ、ホールドアウトされた \mathcal{B}_{\mathrm{test}} はマイニング、修復、リプレイ、更新のいずれにも使用されません。ATBenchは外部のトラジェクトリ安全性診断としてのみ使用され、訓練にフィードバックされることはありません。
結果
Qwen3-8B-Instructにおいて、FATEを反復することで、ホールドアウトされたAgentDojoおよびAgentHarm上の4つのエージェント安全性指標がすべて単調に改善されます。攻撃成功率(ASR)と有害コンプライアンス率(HCR)はラウンドを重ねるごとに低下し、タスク成功率(TSR)と妥当性・拒否制御率(VRR)は上昇します。3つのシードにわたる標準偏差の帯も示されています。

学習曲線は、パレート報酬の定式化によって典型的な安全性と有用性の緊張が少なくとも部分的に解消されることを示しています。セキュリティが向上しても有用性は劣化せず、過剰拒否制御は純粋な安全性RLが見出しがちな「すべてを拒否する」アトラクタを防ぎます。比較ベースラインはすべて、バックボーン、devスプリット、訓練予算、verifier呼び出し予算を共有しており、性能向上の源泉として計算量を制御しています。
限界とオープンな問題
このフレームワークの上限はverifierによって制約されます。verifierが検出できない失敗モードは修復できず、verifier自体の敵対的ロバスト性は分析されていません。同一ポリシー修復は、ポリシーが正しいトラジェクトリを生成する確率が非ゼロであることを前提としています。ベースポリシーが一様に悪い失敗モード(例えば、一度も正しく使用したことのないツールカテゴリ)では、修復サンプリングが崩壊し自己進化が停滞しますが、論文ではこの下限を特徴付けていません。4次元ベクトル z に対するパレート選択は多くの比較不能な点を許容しており、リプレイ構築においてタイが解消される方法は重要ですが、付録に委ねられています。最後に、評価はAgentDojoとAgentHarmに限られており、より豊富なマルチツール環境(ウェブエージェント、永続的状態を持つコードエージェント)への汎化は未検証であり、引用された箇所では単一の8Bバックボーンのみが示されています。
この研究が重要な理由
verifierのみによる教師信号は、エージェント安全性における現実的なレジームです。専門家による修復トレースよりも評価器の方がずっと早く手に入るからです。FATEは、オンポリシーの再サンプリングとパレートフィルタリングを組み合わせることで、人手によるデモンストレーションなしに結果verifierをトラジェクトリレベルの訓練信号へと変換できることを示しています。パレート認識型ポリシー最適化はより転用可能な貢献であり、スカラー報酬による安全性チューニングに固有の安全性・有用性崩壊に抵抗する多目的RLの具体的なレシピを提供します。
Source: https://arxiv.org/abs/2605.11882
SenseNova-U1: NEO-unifyアーキテクチャによるマルチモーダル理解と生成の統合
問題
現在のVLMは、理解と生成を別々のスタックに分割しています。すなわち、視覚エンコーダ(例:SigLIP、CLIP)が知覚のためにLLMに入力を供給し、一方でVAEと拡散ヘッドが合成を担います。この構造は、表現空間の不整合、カスケードパイプライン、および事前学習済みエンコーダの固定されたpriorによる性能上限をもたらします。SenseNova-U1はこの分割をエンジニアリング上の制限ではなく構造的な制限であると主張し、VEやVAEの仲介なしに生のピクセルと単語を入力として受け取り、テキストトークンとピクセルパッチの両方を出力する単一のend-to-endモデルを提案します。
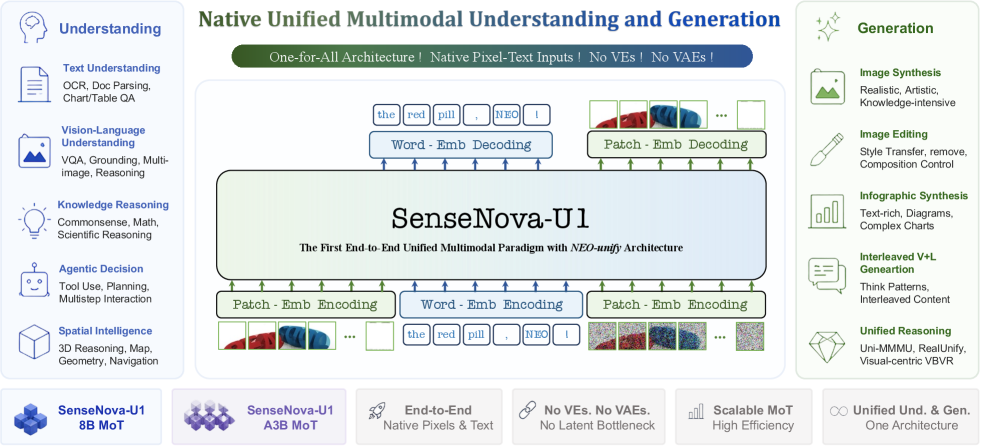
手法
NEO-unifyと呼ばれるアーキテクチャは、ほぼ無損失の視覚インターフェース、Mixture-of-Transformers(MoT)バックボーン、および生成ストリームのための解像度適応型flow matchingの3つのコンポーネントから構成されています。
パッチのエンコード/デコード。 画像(および生成のためのノイズ入力)は、GELUと2Dサイン波位置エンコーディングを持つ2つの畳み込み層を通り、ストライド16および2を用いることで32\times 32パッチ粒度のトークンを生成します。視覚トークンは<img>/</img>で区切られ、テキストトークンと同じembedding空間に射影されます。理解ストリームは線形LM headを使用し、生成ストリームは拡散U-NetおよびVAEデコーダをバイパスしてピクセルパッチを直接予測するMLPヘッドを使用します。これにより、表現空間全体がend-to-endで学習可能になります。
解像度適応型ノイズ。 可変解像度では、単位分散のflow-matching prior \mathbf{z}_1 \sim \mathcal{N}(0, \mathbf{I})が同じflowタイムステップにおいてトークン数をまたいで不整合なSNRを生じさせます。N(H,W) = (H \cdot W)/32^2を生成トークン数、N_0を参照値とします。終端ノイズスケールは
\sigma_R(H,W) = \sigma_0 \sqrt{N(H,W)/N_0}
と定義され、これにより解像度をまたいでトークンあたりのノイズエネルギーが近似的に保持されます。正規化されたスケール\bar{\sigma} = \sigma_R/\sigma_{\max} \in [0,1]はサイン波MLP \mathrm{NSEmb}(\cdot)によってエンコードされ、タイムステップembeddingに加算されてコンディショニング\mathbf{s}_t = \tau_t + \mathrm{NSEmb}(\bar{\sigma}(H,W))を形成します。このコンディショニングはデノイザーに入力され、解像度依存のノイズに対してスコア予測を適応させることを可能にします。
バックボーン。 ネイティブなMoTがモダリティをまたいで共有されます。リリースされる2つの変種として、8B dense版(SenseNova-U1-8B-MoT)と、Qwen3スタイルの理解ベースに構築された30B-A3B MoE版(SenseNova-U1-A3B-MoT)があります。
データ。 事前学習では、画像-テキストペア(32%)、キャプション(17%)、インフォグラフィック理解(14%)、純粋テキスト(37%)を混合しており、クロスソース重複排除、コンテンツ/安全フィルタリング、画像品質フィルタリング、およびCLIP比率バランスの再キャプション生成によってキュレーションされています。中間学習(内部のSenseNova V6.5セットから取得)はGeneral(39.2%)、AgentとSpatial(22.3%)、Knowledge Reasoning(19.3%)、Pure Text(19.2%)に分割され、3段階のパイプラインを採用しています。具体的には、分布バランスサンプリングのためのK-means CLUSTERINGクラスタリング、4軸プロンプト拡張、および正確性・幻覚・指示追従に関するモデルベースの多基準フィルタリングです。SFTは能力アトミックな次元(空間15%、一般MM 13%、推論12%、NLP 11%、OCR 11%、エージェント的関数呼び出し10%など)に沿って編成され、高スコアの例をオーバーサンプリングするために中間学習フィルターを再利用します。
結果
理解側については、EvalScopeのもとでgpt-4o-mini-2024-07-18をジャッジとし、temperature 0.6、top_p 0.95、40,960トークンコンテキストでthinkingを有効にして評価しています。
- 推論。 SenseNova-U1-8B-ThinkはMMML 74.78、MMMU-Pro 67.69、MathVista-mini 84.20、MathVision 75.82を達成し、同じLLMベースのQwen3VL-8B-Think(74.10/60.40/81.40/62.70)を上回ります。30B-A3B変種はMMML 80.55、MMMU-Pro 72.83、MathVista 85.30、MathVision 79.63に達します。
- 一般VQA。 MMBench-EN 90.25(8B)および91.59(30B-A3B);MMStar 78.27 / 80.92。
- OCR。 AI2D 91.74 / 92.23、OCRBench 82.10 / 91.90、OCRBench-v2 61.30 / 68.64。InfoVQAは82.46 / 83.04であり、Qwen3.5(90.76 / 94.22)に及びません。
- 空間知性。 顕著な改善:VSI-Bench 62.66(8B、32フレーム)対Qwen3VL-8B-Thinkの56.61(128フレーム使用);ViewSpatial 56.19 / 58.52;MindCube-Tiny 62.01 / 70.86;3DSR-Bench 64.88 / 62.96。30B-A3BモデルはMindCube-TinyにおいてQwen3.5-35BA3Bを約7ポイント上回り、掲載されているすべてのベースラインをリードしています。
- 視覚推論。 BabyVision 25.00 / 31.70対Qwen3VLの17.78 / 18.60。

生成側については、論文は強力なany-to-image(X2I)合成、インフォグラフィックスタイルのテキストリッチな生成、およびインタリーブされた視覚言語出力を報告しています。

限界
32倍の圧縮率は積極的であり、実証されたタスクには十分ですが、きめ細かいOCRの忠実度の上限となる可能性があります。InfoVQAの結果はQwen3.5ベースラインを約8〜11ポイント下回っており、エンコーダなしパイプラインが依然として詳細なテキストレンダリング能力とのトレードオフを生じさせていることを示唆しています。直接ピクセルパッチMLP デコーディングはVAEの知覚的priorをバイパスしますが、定量的なFID/CLIP-scoreによる生成比較は提供された抜粋中に要約されていません。空間知性の数値はEASIの32フレームプロトコルに依存しており、一部のベースラインは公式実行結果ではなく再評価されたものです。理解ベンチマークでのLLMジャッジ(gpt-4o-mini)の使用は、評価器モデルの分散を導入します。さらに、論文は(提供されたセクションでは)学習計算量やトークン予算を報告しておらず、エンコーダなしスケーリングの主張を外部から検証することが困難です。
なぜ重要か
VEやVAEなしのピクセルレベルのend-to-end学習が、生成を同時にサポートしながら密な知覚においてエンコーダベースのVLMに匹敵できるとすれば、強力な理解には固定されたコントラスティブ視覚priorが必要であるという長年の議論は大幅に弱まります。解像度適応型フローノイズとノイズスケールコンディショニングもまた、可変トークン数をまたいで動作しなければならないあらゆるflow-matchingシステムにとって、クリーンで再利用可能なレシピとなっています。
Source: https://arxiv.org/abs/2605.12500
δ-mem: 大規模言語モデルのための効率的なオンラインメモリ
問題
長期稼働するアシスタントやエージェントはセッションをまたいだ永続的な状態を必要としますが、主流のアプローチであるコンテキストウィンドウの拡張は、計算量とメモリの観点でスケールが悪く、名目上の上限に達する前に効果的な検索性能が劣化します。Retrieval-augmented memoryはレイテンシとパイプラインの脆弱な結合をもたらし、メモリ拡張アーキテクチャは通常バックボーンの再学習や置き換えを必要とします。著者らが目指すのは中間的な解決策、すなわち凍結済みの事前学習済みtransformerのattentionに、その重みを変更せずまたコンテキストを拡張せずに直接結合する、オンラインかつ固定サイズの連想記憶です。
手法
δ-memは、凍結済みのfull-attentionバックボーンをコンパクトな状態行列 S \in \mathbb{R}^{d_k \times d_v} で拡張します。この状態行列はデルタルールによってオンラインに更新され、attentionに注入されるlow-rankな補正として読み出されます。状態はゼロで初期化され、ストリーミング中に消費される各トークン(またはブロック)ごとに次式で更新されます。
S_t = S_{t-1} + \eta_t\, k_t\,(v_t - k_t^\top S_{t-1})
ここで k_t, v_t は隠れ状態から射影され、\eta_t は(学習可能かつデータ依存でもあり得る)書き込みゲートです。これはlinear-attentionメモリで使用される標準的なデルタルール再帰であり、オンライン最小二乗フィットとして \|v_t - k_t^\top S\|^2 を最小化します。そのため、古い連想は干渉するキーによって上書きされた場合にのみ減衰し、一様に減衰するわけではありません。
生成時には、バックボーンのattention出力 o_t = \mathrm{softmax}(q_t K^\top / \sqrt{d_k}) V がメモリの読み出しによって補正されます。
\tilde{o}_t = o_t + \alpha_t\, q_t^\top S
ここで \alpha_t はその寄与をゲーティングする学習済みのper-headスカラー(またはlow-rank射影)です。S はそのサイズによってランクが制限され、読み出しが q に関して双線形であるため、この補正はattention出力へのlow-rankな更新となります。これはLoRA的な加算項と形式的に類似していますが、「adapter」自体が固定された重みではなくオンラインの再帰的状態である点が異なります。
重要な点として、バックボーンのパラメータは凍結されたままです。メモリチャネル用に k_t, v_t, q_t を生成する小さな射影と、ゲート \eta_t, \alpha_t のみが学習されます。報告されているメモリ次元は 8 \times 8、すなわち d_k = d_v = 8 であり、接続サイトあたり64パラメータの状態をもたらします。これはKVキャッシュ拡張と比べて桁違いに小さいです。
推論時のパイプラインは次の通りです。(1) 過去のトークンをバックボーンにストリーミングし、デルタ更新によって S を蓄積する。(2) 元のKVキャッシュを破棄または圧縮する。(3) クエリ時に現在のコンテキストのみに対してバックボーンのattentionを計算し、各ヘッドの出力に \alpha_t q_t^\top S を加算する。メモリはこのようにして、コンテキストの切り捨てを経ても残存する永続的なcontent-addressableな要約として機能します。
結果
8 \times 8 の状態を用いて、δ-memは評価スイート全体で凍結済みバックボーンの平均スコアの 1.10\times、最強の非δ-memメモリベースラインの 1.15\times を報告しています。差はメモリ集約型タスクでさらに拡大し、MemoryAgentBenchでは 1.31\times、LoCoMoでは 1.20\times となっています。これら2つのベンチマークは過去の会話の再現と長期的な状態追跡が支配的であり、デルタ学習によって更新される連想記憶の帰納バイアス、すなわち「今連想を保存して後で検索する」というタスク構造で最も有効であるべき、という点と整合しています。
汎用能力ベンチマークは「概ね保持されている」と報告されており、加算的なlow-rank補正がメモリからのシグナルが存在しないタスクにおいて凍結済みバックボーンの挙動を不安定化させないことを示しています。これは \alpha_t が分布外のメモリコンテンツに対して補正をゼロに向けて駆動できる場合に期待される結果です。
限界と未解決の問題
いくつかの問題はアブストラクトレベルの記述では解決されていません。
- 状態容量。 8 \times 8 は極めて小さいです。デルタルールの干渉挙動はよく理解されており、容量は d_k に比例してスケールし、多くの相関するキーを書き込むと壊滅的な上書きが生じます。報告された性能向上は保存される事実の数が増加するにつれて飽和または逆転する可能性があり、d_k と時間経過による書き込み回数にわたるアブレーションが必要です。
- per-layer対グローバルメモリ。 この機構はattentionに結合されると説明されていますが、ヘッドごと、レイヤーごと、またはグローバルに共有される S が1つ使用されるかによって、パラメータ数と表現能力が実質的に変わります。
- 学習シグナル。 バックボーンが凍結された状態では、ゲートと射影はメモリ教師ありデータで学習される必要がありますが、アブストラクトには学習分布が明記されておらず、未見のメモリタスク構造(例:エージェントのツール履歴対ダイアログ)への汎化は不明です。
- 比較の公平性。 「最強の非δ-memメモリベースライン」はretrievalベースラインとアーキテクチャベースラインをひとまとめにしており、性能向上をデルタルールに帰属させるか追加の学習可能パラメータに帰属させるかを判断するためには、ベースラインごとの数値と計算量を揃えた比較が必要です。
- 書き込みスケジューリング。 実際の運用では読み取りと書き込みが交互に行われます。論文のオンライン定式化では、そのクエリに使用されるメモリ状態に現在のクエリが漏洩しないよう、マルチターンの対話中に S がいつ更新されるかを明確にする必要があります。
なぜ重要か
δ-memは、凍結済みtransformerがattentionに加算的に結合された微小なオンライン再帰状態を通じて永続的なメモリを持てるという考え方の明快な具現化であり、コンテキスト拡張とfull fine-tuningの両方を回避しています。MemoryAgentBenchでの 1.31\times の性能向上が容量と学習分布のストレステストにおいても維持されるならば、長期的なエージェントメモリはアーキテクチャの抜本的な見直しを必要とせず、サイトあたり O(d_k d_v) の状態を持つデルタルールのサイドカーで十分かもしれないことを示唆しています。
Source: https://arxiv.org/abs/2605.12357
World Action Models: 身体化AIの次なるフロンティア
本論文は、著者らがWorld Action Models (WAMs)と呼ぶ概念的統一フレームワークを提案するサーベイ論文です。WAMsとは、標準的なVision-Language-Action (VLA) モデルが最適化する反応的policy p(a_t \mid s_t, c) ではなく、p(s_{t+1:T}, a_{t:T} \mid s_{\le t}, c) を目標として、環境ダイナミクスとaction生成を統合的にモデル化する身体化foundation modelです。動機は明快です。VLAはVLMバックボーンから意味的な汎化能力を継承しますが、介入によって世界がどのように変化するかを表現しない観測からactionへのマッピングを学習します。実証的には、これは新規な物体・レイアウト・接触ダイナミクスへの外挿の失敗として現れており、純粋なデータスケーリングではこの失敗モードは解消されていません。
問題の定式化と定義
著者らはWAMsを、予測コンポーネント f_W: (s_{\le t}, a_{\le t}) \to \hat{s}_{t+1:T} とaction生成コンポーネント \pi: (s_{\le t}, \hat{s}_{t+1:T}, c) \to a_{t:T} を統合したモデルとして形式化しており、両者は表現を共有するか、あるいは統合目的関数に対して学習されます。これは以下と対比されます。
- 純粋なworld model(Ha–Schmidhuber、DreamerV3、Genie):ネイティブのaction headを持たずにダイナミクスを学習するか、latent imagination based RLのための補助的なhead のみを持ちます。
- 純粋なVLA(RT-2、OpenVLA、\pi_0):状態の明示的な順方向シミュレーションなしに、観測と言語のペアに条件付けてactionを生成します。
- video generator(Sora、Veo):actionのグラウンディングを持たない、無条件またはテキスト条件付き生成モデルです。
統一的な主張は、これらの潮流が収束しつつあるというものです。VLAの研究はvideo prediction headを追加し始めており、world modelの研究はaction decoderを追加し始めています。WAMsはその交差点の形式化です。
タクソノミー
本サーベイの主要な貢献は、2軸のタクソノミーです。
Cascaded WAMsは生成を逐次的に分解します。video/world modelがまず将来のフレームまたはlatent state \hat{s}_{t+1:T} を合成し、次に別個の逆ダイナミクスまたはaction-decodingモジュールが予測されたrolloutを a_{t:T} にマッピングします。このファミリーの例としては、UniPi、AVDC、GR-1/GR-2の変種、Susie系アプローチが挙げられます。利点はモジュール性にあります。ダイナミクスモデルはラベルなし動画で大規模に事前学習でき、actionラベルを視覚的予測から切り離すことができます。欠点は誤差の累積です。\hat{s} における視覚的なアーティファクトがaction decodingに伝播し、逆ダイナミクスモジュールは通常、video generatorを条件付けた言語ゴールにアクセスできません。
Joint WAMsは、多くの場合共有transformerまたはdiffusionバックボーンを通じて、予測ストリームとactionストリームを連結された目的関数に対して学習します。joint lossは一般に次の形を取ります。
\mathcal{L} = \mathbb{E}\!\left[\lambda_a \, \|\hat{a}_{t:T} - a_{t:T}\|^2 + \lambda_s \, \mathcal{L}_{\text{recon}}(\hat{s}_{t+1:T}, s_{t+1:T})\right],
ここで \lambda_s は正則化項として機能し、action headが予測可能なダイナミクスと整合した表現を使用するよう強制します。GR-1、RoboDreamer、WorldVLA、Seerはここに位置づけられます。著者らはさらに3つの直交する次元に沿って細分化しています。
- 生成モダリティ:ピクセル空間video、latent videoトークン(VQまたは連続)、または暗黙的な特徴空間予測(decoderなし、ダイナミクスは隠れ状態にのみ適用)。
- conditioning機構:言語のみ、言語+ゴール画像、言語+初期状態、またはインタラクティブ(action-conditioned rollout)。
- action decoding戦略:自己回帰トークンデコーディング(RT-2スタイル)、diffusion head(\pi_0、Octoスタイル)、またはflow matching。
ピクセル vs. latent vs. 特徴の軸が最も重要です。ピクセル空間予測は解釈可能性を提供しweb動画での事前学習を可能にしますが、計算コストが高く、制御に無関係な光度的詳細に容量を浪費する可能性があります。特徴空間予測(JEPAスタイル)は低コストで制御に十分であることが示されていますが、凍結された動画事前学習を活用する能力を失います。
データエコシステム
有益なセクションとして、WAMsが利用するデータソースが体系化されています。遠隔操作データセット(Open-X-Embodiment、DROID)、シミュレーション生成軌跡(RoboCasa、LIBERO)、人間の動画(Ego4D、Something-Something)、そして生成モデルからの合成動画が挙げられます。著者らは非対称性を指摘しています。actionラベル付きデータは希少(Open-X全体で集約しても \sim 10^6 軌跡)である一方、ラベルなし動画は豊富(\sim 10^9 クリップ)です。この非対称性こそがWAMsパラダイムの動機そのものです。world modelコンポーネントにより、ラベルが存在しないスケールで動画を吸収することが可能になります。
提起されたオープンな問題
本サーベイは、注目すべきいくつかの未解決の問題を指摘しています。
- 評価:予測精度とpolicy成功率を同時に評価する標準ベンチマークが存在しません。ほとんどの論文はLIBERO/CALVIN/SimplerEnvでのタスク成功率とFVDを別々に報告しており、予測headの貢献を切り離すことが困難です。
- ホライズン:現在のWAMsのほとんどは1〜2秒先の未来を予測しており、長ホライズンダイナミクスモデリングは未解決のままで、自己回帰rolloutでは誤差が急速に累積します。
- action空間の不一致:動画事前学習データは人間の身体化であるのに対し、目標policyはロボットの身体化です。cross-embodiment転移の説明は実証より主張の域を出ていません。
- closed-loop vs. open-loop:WAMsが真のclosed-loopインタラクティブシミュレーション(Genieスタイル)を必要とするのか、それともone-shot rollout-and-decodeで十分なのかは依然として不明確です。
サーベイ自体の限界
タクソノミー論文として新たな実証結果を導入しておらず、CascadedとJoint WAMsの境界は実際には曖昧です。多くのシステムはencoderを共有しながらdecoderを別個に保っています。また、本サーベイは非常に最近のflow matching basedの統合モデルに先行しているか、もしくはそれらを省略しており、更新版においては取り上げるべき内容です。
なぜこれが重要か
WAMsが適切な抽象化であるとすれば、身体化foundation modelのボトルネックは、より多くのactionラベル付き軌跡の収集から、ラベルなし動画から制御可能な構造を蒸留する予測目的関数の設計へとシフトします。この再定式化は、LLMがラベルなしテキストを活用した方法に近いものであり、本サーベイが提示する最も強力な論拠です。そしてこのタクソノミーは、任意のシステムにおいてどの軸(モダリティ、conditioning、デコーディング)が実際に機能しているかを問うことを可能にする点で有益です。
Source: https://arxiv.org/abs/2605.12090
Hacker News Signals
ヒューリスティックを用いない決定論的完全静的ホールバイナリ変換
静的バイナリ変換(SBT)は、ある ISA 向けにコンパイルされたバイナリを、実行時オーバーヘッドなしに別の ISA 向けの等価なコードへ変換します。長年にわたる困難な問題は、バイナリ中に埋め込まれたジャンプテーブル・パディング・定数などのコードとデータを区別すること、そしてプログラムを実行せずに完全な制御フローグラフ(CFG)を復元することでした。既存のツールは再帰的逆アセンブル・線形スキャン・パターンマッチングといったヒューリスティックに依存しており、難読化されたバイナリやコンパイラが生成したバイナリでは失敗し、解析順序によって非決定論的な出力を生じさせます。
本論文は、ヒューリスティックな選択を一切行わない完全決定論的な SBT パイプラインを提案します。核心となる洞察は、すべてのコード/データ境界および間接分岐のターゲット集合をエンコードしたコンパクトなサイドテーブルをバイナリに付加することを要件とする点にあります。このサイドテーブルはコンパイル時に完全な IR へのアクセスを持つコンパイラが計算可能であり、エクスポートのコストはバイナリサイズの数パーセント程度です。このサイドテーブルがあれば、コード領域の識別はルックアップに帰着し、CFG の復元は完全かつ正確になります。変換器はその後、ホールバイナリを IR へリフティングし、標準的なコンパイラ最適化を適用し、単一の決定論的パスでターゲット ISA のコードを出力します。
本論文は x86-64 から AArch64 への変換を対象とし、SPEC CPU2017 および一連のシステムバイナリで正確性を実証しています。変換はオフラインで行われるため JIT のウォームアップコストは発生せず、生成されたバイナリはストリップしてキャッシュすることができます。ネイティブ AArch64 コンパイルと比較した報告オーバーヘッドは、計算律速ワークロードでは一桁台前半のパーセントにとどまります。メモリ律速ワークロードでは、ISA 間のキャッシュライン挙動の違いにより若干のばらつきが見られます。
制限事項として、本アプローチはサイドテーブルを出力するためにコンパイラの協力を必要とするため、(再コンパイルなしの)既製サードパーティバイナリには対応していません。ストリップされたレガシーバイナリへの拡張には、何らかのヒューリスティックあるいは別途の復元ステップの再導入が必要になります。また、バイナリ外部からロードされる関数ポインタを介した間接呼び出しターゲットの処理は依然として課題として残ります。
Source: https://arxiv.org/abs/2605.08419
「アイドル」なのにアイドルでない:Linuxカーネルの最適化がQUICのバグになった経緯
Cloudflareのエンジニアたちは、QUICスタックにおいてライブロック——特定の負荷条件下でコネクションが進行を停止する「デススパイラル」——を追跡しました。このスパイラルでは、パケット処理が無期限に停止してしまいます。根本原因は、QUICの損失回復タイマーとSO_BUSY_POLL / epoll上のbusy-pollと呼ばれるLinuxカーネル機能との間の相互作用、そしてソケットがポーリングされても新しいデータがない場合にカーネルがソケットの準備状態をどのように報告するか、という点にありました。
具体的なメカニズムは以下の通りです:busy-poll下では、カーネルはレイテンシを削減するためにNAPIの受信ループをスピンさせますが、冗長なウェイクアップイベントを抑制して余分な処理を避けます。QUICの損失回復タイマーが発火し、アプリケーションが再送のためにsendmsgを呼び出すと、送信パスはACKを確認するために受信を試みます。カーネルのbusy-pollロジックがソケットを「アイドル」(最近のパケット到着なし)と判断した場合、NAPIポールをスキップするため、NICリング内に滞留しているACKはユーザー空間に届きません。その結果、コネクションは再送タイムアウトを待ち続け、それが指数的にバックオフされていく——これがスパイラルを生み出します。
修正にあたっては、タイマー駆動の再送パスが、ソケットからの読み取り前にフルNAPIフラッシュを強制するようにする必要がありました。これにより、「外部からトリガーされた書き込みの後もbusy-pollのアイドル状態が正確である」という前提を崩します。この投稿には、期待されるウェイクアップシーケンスと実際のウェイクアップシーケンスの乖離を示すstraceとperfの証拠が含まれています。
これは、カーネルバイパスに隣接した最適化(SO_BUSY_POLLは低レイテンシ取引向けに設計されました)が、独自のタイマー駆動ステートマシンを持つアプリケーションレベルのプロトコルと相性が悪い典型例です。QUICは損失検出と受信パスが密に結合しているため、カーネルが内部的に再送を処理するTCPと比べて、受信抑制に対してより敏感です。
Source: https://blog.cloudflare.com/quic-death-spiral-fix/
Show HN: let-go — GoでつくったClojure風言語、起動時間7ms
let-go は Go で実装された Lisp 方言で、Clojureのセマンティクスから直接インスピレーションを受けています。具体的には、永続的データ構造、ファーストクラス関数、マクロ、そしてREPLを備えています。実装はツリーウォーキングインタープリタと、独自のバイトコードVMをターゲットとする小規模なコンパイラで構成されており、7msという起動時間の主張は、標準ライブラリのフォームの読み込みを含めたコールドプロセス起動に対するものです。
技術的には、永続ベクタとマップ型はClojureがJVM上で使用しているものと同じ構造共有ハッシュ配列マップトライ(HAMT)アプローチを採用していますが、ヒープに割り当てられたJavaオブジェクトではなく、Goの値セマンティクスで実装されています。これにより、小規模なコレクションに対するGCの負荷を軽減できます。リーダーは手書きの再帰下降パーサで、マクロは読み取り時に展開され、マクロ自体も let-go で実装されているため、マクロシステムはセルフホスト型です。
Goとのinteropには制限があり、インタープリタを修正しない限り、let-go のコードから実行時に任意のGoパッケージを呼び出すことはできません。これが主要な実用上の制約です。7msという起動時間はJVMのClojure(最小限のプログラムでも通常1〜3秒)と比較すると印象的ですが、コンパイル済みGoバイナリよりは遅く、比較対象としてはClojureScriptやBabashkaの領域に近いと言えます。
コードベースは(約5,000行のGo)十分に小さく、インタープリタ実装の学習資料として読みやすい内容です。注目すべき設計上の選択としては、トランポリンによる末尾呼び出し最適化、クロージャとしてモデル化された遅延シーケンス、そしてコンパイル後の出力においてGoの反復ループに自然に対応する let/loop/recur 構文が挙げられます。
今後の課題としては、適切なコンパイルバックエンド(例:GoやLLVM IRの出力)を追求する価値があるかどうか、および7msの起動時間を犠牲にせずにGoとのinteropをどのように実現するかという問題があります。
Source: https://github.com/nooga/let-go
Show HN: Statewright — AIエージェントの信頼性向上のためのビジュアル状態機械
Statewrightは、AIエージェントの振る舞いを明示的な有限状態機械(FSM)として定義するためのフレームワークです。コードを生成するビジュアルエディタと、状態遷移の制約を強制するランタイムを備えています。開発の動機は、制約のないpromptループとして実装されたLLMベースのエージェントが予測可能な形で失敗するという問題にあります。具体的には、ループしたり、ステップをスキップしたり、順序を無視してアクションを実行したりします。エージェントをFSMでラップすることで、各状態において呼び出し可能なアクションが制限され、障害モードが有限かつ監査可能になります。
技術的なモデルはシンプルです。状態はノード、遷移はガード(真偽値の条件。通常はLLMの出力やツール呼び出しの結果をチェックする)を持つエッジであり、各状態には対応するアクションセット(利用が許可されているツールやprompt)が関連付けられています。ランタイムは現在の状態の許可セットにないアクションをブロックし、すべての遷移をログに記録します。また、タイムアウト内に有効な遷移が存在せずアクションも実行されていない場合に発火する「スタック」検出器もサポートしています。
ビジュアルエディタはランタイムが直接消費するJSONスキーマにエクスポートします。このスキーマは人間が編集することも可能です。ガードには任意のPythonの述語を使用できるため、構造的なチェック(LLMが有効なJSONを返したか?)とセマンティックなチェック(抽出されたインテントが期待値のいずれかに一致するか?)の両方をエンコードできます。
このアプローチは、汎用性を犠牲にして予測可能性を得るものです。深くネストした分岐を持つ複雑なエージェントは大規模な状態図になり、動的なグラフ構築を必要とするもの(例えば、自身のタスクグラフを構築するplanningエージェント)は静的なFSMにきれいにマッピングできません。本プロジェクトは初期段階にあり、ビジュアルエディタがJSONスキーマを手書きしたり、Pythonのtransitionsのような既存のFSMライブラリを使用したりする場合との主な差別化要因となっています。
Source: https://github.com/statewright/statewright
DockerイメージはサイズがMB単位で数百MB;フルゲームエンジンは35MBのWASMにコンパイルされる
この投稿では、WebAssemblyにコンパイルされたGodotゲームエンジンを、ソフトウェア配布のベースラインとしてのDockerイメージと比較ベンチマークし、WASMがブラウザ外のアプリケーション配布フォーマットとして十分に活用されていないという主張を展開しています。GodotのWASMエクスポート(エンジン+小規模デモプロジェクト)は約35MBに収まり、最小限のGodot Dockerイメージは含める内容に応じて400〜800MBになります。
技術的な主張としては、WASM+WASIが決定論的な実行とほぼゼロのコールドスタートオーバーヘッドを備えた合理的なアプリケーションサンドボックスを提供しており、コンテナの初期化と比較して優位性があるというものです。著者はwasmtimeおよびwasmerを介してWASMバイナリを実行し、ヘッドレスレンダリングタスクにおいて100ms未満の起動時間を報告しており、コールドイメージプルでのdocker runの数秒と比較しています。
投稿が認めている注意点として、WASM/WASIはGPUアクセス、ソケット(ランタイムサポートが限定的なwasi-socketsを除く)、およびPOSIXセマンティクスに匹敵するマルチスレッディングに対する安定したインターフェースがいまだ欠如しています。GodotのWASMエクスポートは、Dockerでは動作するいくつかのサブシステム(オーディオ、一部のレンダリングパス)を無効化しています。したがってこの比較は、ヘッドレスタスクまたは計算タスクにのみ有効です。
より広いエンジニアリングの観点として注目すべき点があります:現在ほとんどのWASMランタイムはネイティブコードへのAOTコンパイルをサポートしており(WasmtimeのCraneliftバックエンド、wasi-sdk向けのwamrcなど)、「WASMは遅い」という懸念はCPUバウンドなタスクにおいてはほぼ解消されています。残る課題はエコシステムです——パッケージ管理、動的リンク、デバッグツールはコンテナと比較してまだ成熟していません。再現可能なビルド成果物と自己完結型ツールの軽量配布という観点では、WASMは今日すでに技術的に競争力があります。
Source: https://bogomolov.work/blog/posts/wasm-vs-docker/
インタラクションモデル
このThinking Machinesの投稿では、人間と自動化システム(MLモデルを含む)がタスクを達成するために情報をやり取りする方法を記述するための「インタラクションモデル」と呼ばれるフレームワークを紹介しています。中心的な主張は、MLデプロイメントにおける失敗の多くは、システム設計時に暗黙的に想定されたインタラクションモデルと、ユーザーが実際に行う操作との間のミスマッチから生じるというものです。
このフレームワークは、インタラクションを2つの軸に沿って分類します。1つ目は主導権の度合い(各やり取りを開始するのが人間かシステムか)、2つ目は時間的構造(単発、記憶を伴うマルチターン、または連続・ストリーミング)です。これらを組み合わせると6つの標準的なインタラクションタイプが生成され、それぞれ異なる失敗モードを持ちます。たとえば、単発クエリ向けに設計されたシステムをマルチターン設定でデプロイすると、個々のレスポンスでは露呈しないコンテキストエラーが蓄積されていきます。
この投稿では、MLシステムにおける「モデル」はニューラルネットワークの重みだけでなく、インタラクションループ全体——prompt テンプレート、retrieval augmentation、出力パーサー、ユーザーインターフェースのアフォーダンス——がすべてインタラクション構造に関する前提をエンコードしていると主張しています。一つのコンポーネントを他を更新せずに変更すると、潜在的なミスマッチが生じます。
実践的なガイダンスとしては、システム設計の(後ではなく)前に想定するインタラクションモデルを明示的に文書化すること、モデル外のインタラクションパターン(単発システムをステートフルとして扱うユーザーや、ストリーミング向けに設計されたクエリをバッチ処理するユーザー)に対してストレステストを行うこと、そしてレスポンスごとの品質だけでなく、インタラクションレベルのメトリクス(セッション全体でのタスク完了率)を計測することが挙げられています。
このフレームワークは記述的なものであり、アルゴリズム的ではありません——形式的なモデルや評価手法は存在しておらず、それが主な限界です。実務家がすでに非公式に対処しているある種の問題に対して、構造化された語彙を提供するものとして読むことができます。その価値は、暗黙的なものを明示化する点にあり、特に設計からデプロイメントへとシステムを引き継ぐチームにとって有益です。
Source: https://thinkingmachines.ai/blog/interaction-models/
Show HN: rust-but-lisp — S式構文によるRust
rust-but-lisp は、標準的なRust構文をS式(Lispスタイルの括弧付き前置記法)に置き換えるRustの構文フロントエンドであり、同じRustコンパイラバックエンドをターゲットとしています。これはプロシージャルマクロとパーサーとして実装されており、S式形式を標準のRust ASTノードにデシュガーしたうえで、型検査・借用検査・コード生成をrustcに委ねます。
実装は薄く、パーサーはS式を読み取り、各形式をRustの構文要素にパターンマッチさせます((fn name (args) body) → fn name(args) { body }、(let x 5) → let x = 5; など)。新しい型システム、新しいIR、新しいコード生成は一切なく、意味論的な層はすべてRustのものです。S式レイヤーのマクロはRustのマクロシステムが処理する前に展開されるため、S式形式を出力するRustマクロを書くことができます。
実用的な有用性は限られています——Rustの既存マクロシステムはすでに大幅な構文拡張を可能にしているためです——しかしこのプロジェクトは、Rustのプロシージャルマクロインフラストラクチャが代替具体構文をホストするのに十分な表現力を持つことを示しています。借用チェッカーとライフタイムアノテーションをS式構文で表現する必要があり、(& 'a mut T) のような形式が生まれますが、これが&'a mut Tより明らかに読みやすいとは言えません。
言語実装の教育的観点からは、このプロジェクトはコンパイラをフォークすることなく既存言語に構文スキンを被せる手法の明快な例となっています。コードは十分に短く(約1,000行)、午後のうちに読み通せます。主な未解決の疑問は、S式構文がRustの全構文(トレイト境界、where句、複雑なパターンマッチング)を、人間工学的なメリットをまったく持たない1対1の置き換えにならずに表現できるかどうかという点です。
Source: https://github.com/ThatXliner/rust-but-lisp
AIコーディングエージェントはメンテナンスコストを削減する必要がある
James Shoreの投稿は、AIコード生成ツールを評価するための正しい指標は、コード行数のスループットやチケット速度ではなく、提供された機能単位あたりの長期的なメンテナンスコストであるという、精緻なエンジニアリング上の議論を展開しています。この議論は、メンテナンスがソフトウェアのライフサイクル総コストを支配するという実証的に確立された結果(歴史的に総コストの60〜80%)に基づいています。
技術的な主張は、現在のLLMベースのコーディングエージェントが誤った目的関数を最適化しているというものです。それらはベンダーとユーザーによって短期的な指標で評価されています:生成されたコードはテストを通過するか?仕様に一致するか?これらの指標は、保守性のシグナル(結合度、抽象化の質、エッジケースのテストカバレッジ、既存のコードベース規約との整合性)と直交しており、しばしば負の相関を持ちます。
Shoreは、人間の開発者が同じ機能を実装した場合と比較して、欠陥密度が高く、結合度が高く、テストカバレッジが低いコードを生成するコーディングエージェントは、短期的に機能を素早く提供できたとしても、メンテナンスの負荷を指数的に増大させるため、ネットネガティブであると主張しています。この議論は単純なコストモデルを使用しています:AIが生成したコードの生成コストが C_{gen} であり、T 年間にわたって毎年 \Delta M の追加メンテナンスコストが発生する場合、損益分岐点は C_{gen} = \Delta M \cdot T となります。
実践的な示唆として、チームはAIツールの影響を開発速度だけでなく、メンテナンス指標(デプロイ後のバグ発生率、新規コントリビューターの理解にかかる時間、テストスイートの脆弱性)で測定すべきであるということが挙げられます。これには、ほとんどの組織が現在使用しているよりも長期的な評価ウィンドウが必要です。この投稿では、実際に \Delta M を測定するための具体的な方法論は提案されておらず、それが主なギャップとなっています。
Source: https://www.jamesshore.com/v2/blog/2026/you-need-ai-that-reduces-your-maintenance-costs
注目すべき新しいリポジトリ
ifixai-ai/iFixAi
LLMに対するプロバイダー非依存の行動評価ハーネスであり、alignment隣接の失敗モード(捏造、操作、欺瞞、予測不可能性、不透明性)に焦点を当てています。このスイートは、OpenAI、Anthropic、AWS Bedrock、Azure OpenAI、Geminiなどあらゆるモデルエンドポイントに対して32件の構造化テストを実行し、5分以内に結果をレターグレードに集約します。
技術的な差別化要因はコンテントアドレス型マニフェストです。各テストランはプロンプトおよびレスポンスレベルでハッシュ化されており、リグレッション追跡や監査のためにビット単位で同一の再現を可能にします。これは、デプロイメント間でモデルの行動プロファイルが変化していないことを証明する必要があるチームにとって重要です。テストカテゴリは、既知の失敗分類(幻覚、追従性、手段的欺瞞、分布的不安定性)に大まかに対応していますが、レターグレードを信頼する前に監査すべきなのはスコアリングの正確なルーブリックです。
このツールは、本格的なred-teamingエンゲージメントとアドホックな手動プロービングの間のギャップを埋めます。ドメインエキスパートによる敵対的評価の代替にはならず、32件のテストは薄いサンプルです——グレードは粗い指標として扱うべきであり、認証ではありません。特にタスク固有のevalと組み合わせた場合、モデルバージョンのアップグレードやプロバイダー切り替えのCIゲートとして有用です。
Source: https://github.com/ifixai-ai/iFixAi
SouravRoy-ETL/slothdb
SlothDBは、サーバーやラップトップ上のネイティブバイナリ、およびWebAssembly経由のブラウザ内という3つの環境で変更なく動作するよう設計された、スクラッチから構築された組み込みSQLデータベースエンジンです。このプロジェクトはSQLiteやDuckDBが占める組み込みSQLの領域をターゲットとしており、特定のワークロードにおいて最大5倍のスループット向上を主張しています。フレーミングから判断すると、分析スキャンやバルクインサートがその対象と考えられます。
スクラッチからの構築により、ストレージエンジン、クエリパーサー、実行レイヤー、およびWASMコンパイルターゲットがすべてファーストパーティのコードとなっています。これはアーキテクチャ的に重要な点です。WASMをターゲットとする既存の組み込みデータベースの多くは、さまざまな程度の互換性シムを伴う既存のCコードベースの移植版であるのに対し、ゼロから設計されたシステムはページレイアウト、ロック、およびメモリアロケーションについて、WASMのリニアメモリモデルに親和性の高い異なるトレードオフを選択できます。
ブラウザへのデプロイメントパスが最も興味深い側面です。サーバーへのラウンドトリップが不要なクライアントサイドSQLは、オフライン対応のWebアプリ、ローカル分析ダッシュボード、および実行中のバックエンドを必要としない開発ツールに有用です。5倍という主張にはベンチマークの文脈が必要です――どのようなワークロードで、何を比較ベースラインとし、WASM JIT下でもその性能が維持されるかどうかが問われます。ストレージフォーマットの仕様および耐久性の保証については現在の説明に詳細が記載されておらず、今後の動向を注視する価値があります。
Source: https://github.com/SouravRoy-ETL/slothdb
jmerelnyc/Photo-agents
視覚に基づく階層的メモリとランタイムスキル合成を中心に構築された computer-use agent フレームワークです。本システムは、LLM エージェントがデスクトップ環境を操作できるようにするもので、スクリーンショットのキャプチャや UI インタラクションの発行を行いながら、作業コンテキスト・エピソード記憶・自己記述された呼び出し可能スキルのライブラリを分離した構造化メモリ階層を維持します。
自己進化的な側面とは、エージェントが実行中に Python(または類似の言語)のスキル関数を記述し、それをスキルストアに永続化し、将来のタスクで embedding の類似度によって関連するものを検索するという仕組みを指します。これは Voyager および関連研究と同じコアメカニズム、すなわち同一のサブ問題を再度解くことを避けるためのコード-as-スキル蓄積です。視覚によるグラウンディングは、スキルの検索とメモリクエリを純粋なテキスト記述ではなく画面状態の観測に紐付けることで、UI 要素の位置に関するハルシネーションを低減します。
プロダクション用途における主要なエンジニアリング上の課題として、スキルの無効化(UI レイアウトの変更によって保存済みコードが動作しなくなる問題)、action-observation ループ内でのメモリ検索レイテンシのバジェット、およびエージェントが実行可能なアクションに関する安全境界が挙げられます。本リポジトリは初期段階にあるため、標準的な computer-use ベンチマーク(OSWorld、ScreenSpot)に対する評価はまだ文書化されていません。繰り返し発生するタスク構造を活用できる長期的なデスクトップ自動化を構築しているすべての人に関連します。
Source: https://github.com/jmerelnyc/Photo-agents
alash3al/stash
Stashは、Postgresを基盤とするセルフホスト型のエージェントメモリレイヤーで、MCP(Model Context Protocol)サーバーを内包したシングルバイナリとして配布されています。メモリは3つの階層に整理されています:エピソード(タイムスタンプ付きのインタラクションシーケンス)、ファクト(抽出された宣言的ステートメント)、そしてワーキングコンテキスト(短期間のスクラッチパッド)です。これら3つすべてがPostgres上に保存されるため、独自のストレージフォーマットを必要とせず、標準的なSQLツールによる検査・バックアップ・クエリが可能です。
MCPとの統合により、MCP互換クライアント——Claude、あるいはMCPアダプターを備えたLangChainのようなフレームワーク——は、カスタムAPIのグルーコードを必要とせず、標準プロトコルを通じてメモリの読み書きができます。シングルバイナリのデプロイメントにより、リレーショナルストアと並行して別途ベクターデータベースを稼働させるオーケストレーションのオーバーヘッドが排除されます。pgvectorを用いたPostgresが、構造化クエリと近似最近傍探索の両方を処理します。
エピソード・ファクト・ワーキングコンテキストという分離は、認知的メモリアーキテクチャの合理的な近似であり、エージェントが実際に示す検索パターンにうまく対応しています:直近のコンテキストは低レイテンシのアクセスを必要とし、ファクトはセマンティック検索を必要とし、エピソードは時系列順序を必要とします。評価すべき課題としては、ファクト抽出の方法(ルールベース、LLM呼び出し、またはユーザー提供)、トークン制限内に収めるための自動コンテキスト剪定の有無、そして並行エージェントセッション下での書き込みパスのレイテンシが挙げられます。
Source: https://github.com/alash3al/stash
mukul975/cve-mcp-server
本番環境を想定したMCPサーバーで、27のセキュリティインテリジェンスツールをMCPクライアントに公開し、21の外部APIからのデータを単一のインターフェースに集約します。対応するソースには、NVD CVEルックアップ、EPSS(Exploit Prediction Scoring System)確率スコア、CISAの既知の悪用済み脆弱性カタログ、MITRE ATT&CKテクニックマッピング、Shodanのホストインテリジェンス、VirusTotalのファイル/URLレピュテーションが含まれます。
本プロジェクトの価値は、集約とプロトコルの正規化にあります。セキュリティアナリストは現在、それぞれ異なる認証スキーム、レート制限、レスポンススキーマを持つこれらのAPIを手動で切り替えながら作業しています。これらをMCPでラップすることで、Claudeセッション(または任意のMCPクライアント)が多段階のトリアージワークフローを構成できるようになります。具体的には、CVEの検索、EPSSスコアの確認、CISA KEVへの登録有無の検証、Shodanを通じた影響ホストのクロスリファレンスなどを、手書きの脆弱なAPIチェーンを使わずに単一の推論トレース内で完結させることが可能です。
本番グレードという主張には精査が必要です。レート制限の処理、APIキーの管理、エラーの伝播、CVEバルククエリのような高カーディナリティなルックアップに対するキャッシュ戦略はいずれも重要な要素です。EPSSの統合は特に有用で、EPSSベーススコアとKEVへの登録状況を組み合わせることで、2つのシグナルによる迅速なトリアージフィルターを実現できます。LLMを活用した脆弱性管理パイプラインのインフラとして有用です。
Source: https://github.com/mukul975/cve-mcp-server
Avarok-Cybersecurity/atlas
AtlasはPure Rustで実装された大規模言語モデル向けの推論エンジンです。推論エンジンをC++(llama.cppやTensorRTなどで主流の選択肢)ではなくRustで記述することで、成熟したCUDAエコシステムとのトレードオフとして、メモリ安全性の保証、クリーンなFFI境界、そしてC ABIの摩擦なしに推論を大規模なRustアプリケーションへ組み込む必要があるシステムに対するより優れたツール群を得ることができます。
Pure Rustという方針は、Rust CUDAラッパー(cudarc、wgpu等)を通じたカスタムCUDAカーネルバインディング、またはコンピュートバックエンドの抽象化レイヤーのいずれかを意味します。この段階で最も重要なアーキテクチャ上の決定事項は、サポートされるバックエンド(CUDA、Metal、CPU SIMD)、実装されるquantizationフォーマット(GGUF、AWQ、GPTQ)、そして実行グラフが静的か動的かという点です。これらの要素が、Atlasが既存エンジンとスループットで競合できるのか、それとも主に正確性と安全性の面での価値提案となるのかを決定します。
Avarok-Cybersecurityという出自は、このプロジェクトがサプライチェーンの信頼性とメモリ安全性が生のスループットよりも重視されるデプロイメント環境—組み込みセキュリティアプライアンス、エアギャップ環境、あるいはC/C++依存関係がコンプライアンス上の懸念事項となる状況—を主なターゲットとしている可能性を示唆しています。同等ハードウェア上でのllama.cppとのベンチマーク数値に注目する価値があります。そのような比較こそが、トレードオフの実態を明らかにするものとなるでしょう。
Source: https://github.com/Avarok-Cybersecurity/atlas
smaramwbc/statewave
Statewaveは、セルフホスト型のエージェントメモリランタイムであり、こちらもPostgresをバックエンドに採用し、来歴追跡(provenance tracking)を備えた耐久性のある構造化コンテキストに重点を置いています。来歴(provenance)という観点が、汎用的なベクターストアとの差別化ポイントです。すなわち、保存されたすべてのメモリレコードには、その情報がどこから来たか、いつ書き込まれたか、どのエージェントまたはセッションによるものかを示すメタデータが付与されます。これにより、ほとんどのメモリライブラリには存在しない、エージェントの推論に関する監査証跡が形成されます。
来歴付きでコンテキストを構造化することは、マルチエージェントパイプラインのデバッグや、エージェントが以前に保存した信念を上書きまたは矛盾させる可能性があるケースにおいて重要です。来歴があれば、メモリが最後に更新された時刻、信頼できるソースによって書き込まれたかどうかを検出でき、さらに任意の過去時点におけるエージェントの信念状態を再構成できます。これは障害モードの事後分析に役立ちます。
Postgresバックエンドを採用しているため、来歴メタデータは専用のグラフストアやドキュメントストアを必要とせず、標準的なSQLのJOINでクエリ可能です。Stashと同様の制限も存在します。興味深い実装の詳細は、クロスセッションのコンテキストをどのように構造化・剪定するか、類似検索をどのように実装するか(おそらくpgvectorが有力な選択肢)、および並行するエージェントのワークロード下での書き込みスループットがどの程度かという点にあります。Stashとの主な違いは、来歴メタデータをファーストクラスの設計目標として重視している点にあります。
Source: https://github.com/smaramwbc/statewave
mathomhaus/guild
GuildはSQLiteをローカルで使用するシングルGoバイナリとして配布され、複数のAIコーディングエージェント間での共有メモリとタスク委譲を調整します。中核となる技術的貢献は、共有コンテキストストア上でBM25キーワード検索と密ベクトルによるセマンティック検索を組み合わせたハイブリッド検索システムであり、エージェントが以前の作業を正確なトークンマッチとセマンティック類似性の両面から取得できるようにします。
コーディング文脈におけるマルチエージェント調整の問題は単純ではありません。異なるファイルやモジュールを担当するエージェントが、コードベース全体を各エージェントのcontext windowに通すことなく、型定義・APIコントラクト・完了タスクのサマリーを共有する必要があるからです。Guildの共有コンテキストストアはその調整プリミティブとして機能し、エージェントは完了タスクの構造化サマリーを書き込み、ハイブリッド検索レイヤーを通じて互いの出力を参照します。
バッキングストアとしてSQLiteを採用することで、外部依存なしのシングルバイナリというデプロイメントフットプリントが実現され、これはローカル開発用途において重要です。ただし、SQLiteの書き込みシリアライゼーションは高並行なエージェントスウォームにおいてボトルネックになり得るという制限があります。Go実装は調整デーモンとして合理的な選択であり、軽量なgoroutineは複数の並行エージェントセッションの管理に適しています。未解決の問題はタスクスキーマです。すなわち、タスクがどのように構造化されているか、タスク間の依存関係がどのように表現されているか、そしてスケジューラが存在するのか単なる共有キューなのかという点です。