Daily AI Digest — 2026-05-13
arXiv Highlights
RubricEM: Meta-RL with Rubric-guided Policy Decomposition beyond Verifiable Rewards
Problem
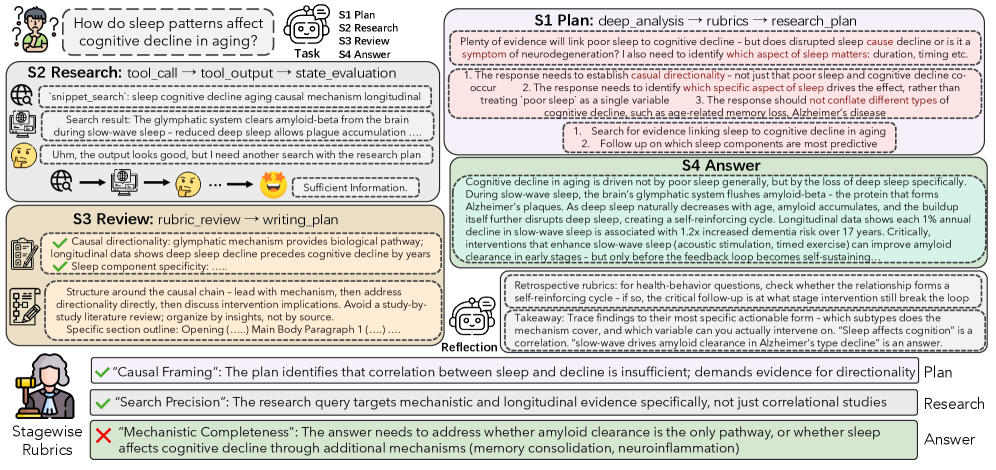
Deep research agents — systems that plan queries, invoke search/retrieval tools, evaluate evidence, and write long-form synthesized reports — break the standard RLVR setup in three ways. First, outputs are open-ended documents with no ground-truth string to match, so reward models must score semantic adequacy rather than exact correctness. Second, trajectories are long and tool-augmented, mixing planning text, tool calls a_t, observations o_t, and prose, making terminal-reward broadcast a poor credit assignment signal. Third, post-training pipelines provide no mechanism to convert past failed/successful attempts into reusable experience for future rollouts. RubricEM argues that rubrics — structured criteria that decompose a target response into checkable items — should be the unifying interface that ties policy structure, judge feedback, and persistent agent memory together.
Method
The agent autoregressively samples a_t \sim \pi_\theta(a_t \mid h_t) with h_t = (q, a_{<t}, o_{<t}), but trajectories are constrained to a four-stage scaffold: Plan → Research → Review → Answer.
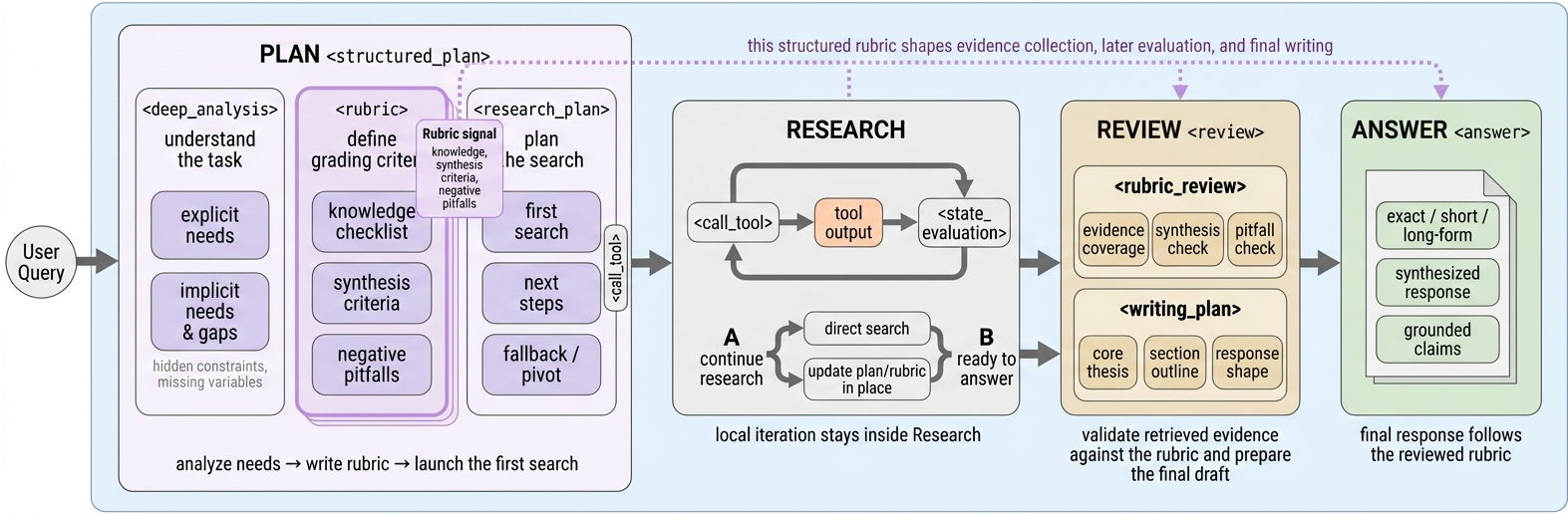
In Plan, the policy emits a self-generated rubric R = \{r_k\} that enumerates the criteria the final answer must satisfy. Research iterates tool calls and state evaluations against R; Review checks rubric coverage; Answer composes the long-form output grounded in retrieved evidence. The same R is reused at training time as the judge schema, so policy execution and reward shaping share a single object.
The two RL contributions sit on top of this scaffold:
Stage-Structured GRPO (SS-GRPO). Standard GRPO broadcasts a single terminal reward over all tokens of a trajectory. SS-GRPO partitions \tau into stage segments \tau = \tau^{\text{plan}} \cup \tau^{\text{res}} \cup \tau^{\text{rev}} \cup \tau^{\text{ans}} and computes per-stage rubric-grounded judgments J_s(\tau, R). Group-relative advantages are computed within each stage, giving denser semantic credit:
\hat{A}_{i,s} = \frac{J_s(\tau_i, R_i) - \mu_s}{\sigma_s + \epsilon}, \qquad s \in \{\text{plan},\text{res},\text{rev},\text{ans}\}.
Tokens in segment \tau^s receive \hat{A}_{i,s} rather than a global terminal advantage, so e.g. a strong plan with a weak synthesis is reinforced and penalized at the appropriate spans.
Reflection meta-policy with shared backbone. A second head, sharing parameters with \pi_\theta, is trained to consume judged trajectories and emit rubric-grounded reflections z = m_\phi(\tau, R, J) — short, criterion-anchored notes describing what worked and what to repeat or avoid. These reflections are written to a rubric-bank keyed by query/rubric features and retrieved at the start of new rollouts, so the task policy conditions on z_{\text{retrieved}} alongside q. Because the meta-policy shares the backbone, gradient signal flows between reflective writing and task execution.
Results
The training infra builds on DR Tulu (Qwen3-8B base, Gemini-flash-grounded Google Search + Semantic Scholar). Evaluation spans HealthBench, ResearchQA, DeepResearchBench (DRB), and ResearchRubrics.
RubricEM-8B (RL, 1400 steps) achieves an average of 55.5 across the four benchmarks: 49.3 / 74.5 / 47.8 / 50.3. The matched 8B baseline DR Tulu-8B (RL, 1900 steps) reaches 53.6 (50.2 / 74.3 / 43.4 / 46.4) — RubricEM matches HealthBench, edges ResearchQA, and gains +4.4 on DRB and +3.9 on ResearchRubrics with fewer RL steps. Among open models the next strongest is Tongyi DeepResearch-30B-A3B at 50.8 average, which RubricEM-8B exceeds despite being roughly a quarter of the size.
Closed deep-research systems still lead overall: GPT-5 + Search at 62.2, OpenAI Deep Research at 59.9, Gemini Deep Research at 61.5 on DRB / 48.8 on ResearchQA. RubricEM closes a substantial fraction of the gap from the open-weights side; on DRB it reaches 47.8 versus OpenAI Deep Research’s 46.9.
The SFT stage alone (RubricEM-8B SFT, 49.2 average) already outperforms DR Tulu-8B SFT (46.0), which the authors attribute to the structured scaffold being learnable as a behavior prior before any RL.
Ablations
Under a fixed 600-step RL budget from a shared SFT checkpoint, the authors ablate four recipes: Baseline-RL (answer-only GRPO), SS-GRPO alone, Meta-Policy alone (answer-only GRPO + reflection + rubric-bank retrieval), and Full RubricEM. Both SS-GRPO and Meta-Policy independently improve over Baseline-RL, and the full combination is best across all four benchmarks, indicating that stagewise credit assignment and reusable-experience learning are complementary rather than redundant.
Limitations
Self-generated rubrics inherit policy biases: if Plan emits a poorly-scoped rubric, both execution and judgment proceed against a flawed target, and SS-GRPO will reinforce stage behavior under that flawed criterion. The judge model’s calibration is not characterized, and stagewise judgments multiply judge calls per rollout. The rubric-bank retrieval policy is not detailed in the excerpt — staleness and distribution drift across training are open. Finally, results are reported on an 8B base; whether SS-GRPO’s denser credit continues to help at 30B+ where terminal reward variance is already lower is untested.
Why this matters
This is a clean instantiation of a recurring idea in long-horizon RL post-training: reuse the same structured artifact for behavior shaping, reward decomposition, and memory. Sharing rubrics across policy, judge, and meta-policy gives a principled handle on credit assignment in non-verifiable, tool-using regimes where standard GRPO’s terminal broadcast is too coarse, and the 8B results suggest the gains are not just from extra compute.
Source: https://arxiv.org/abs/2605.10899
Towards On-Policy Data Evolution for Visual-Native Multimodal Deep Search Agents
Problem
Multimodal deep search agents must chain web/image search, browsing, image manipulation, and computation while propagating both textual and visual evidence across many tool calls. Two structural failures limit current systems. First, common tool harnesses bind visual operations (zoom, crop, OCR-style inspection) to the original task image; images returned by image_search, web_search, or zoom_in are treated as terminal outputs and cannot be fed back into other tools. Visual evidence therefore does not compound the way textual evidence does in token-based scratchpads. Second, training data for these agents is curated by fixed pipelines that ignore the policy’s current weaknesses: easy tasks dominate, hard tasks remain unsolvable, and the distribution drifts away from what the policy still needs.
Method
The paper introduces two coupled components.
Visual-native agent harness. Every initial or tool-returned image is registered in a shared image bank under an addressable handle <image:N>, where N is the insertion order. Any of the 9 tools (web search, scholarly search, image search, visual search, browse, two image transforms including zoom_in, Python execution, and answer) can take these handles as inputs. A task is formalized as \mathcal{T} = (q, \mathcal{I}, a) with query q, initial visual context \mathcal{I}, and reference answer a. The illustrated rollout — zoom_in(<image:0>) \rightarrow <image:1> \rightarrow visual_search(<image:1>) \rightarrow <image:3> \rightarrow web_search \rightarrow zoom_in(<image:3>) to read “Zheduo Mountain Pass” — shows why reusing intermediate images matters: a search-returned high-resolution photo can itself be cropped and re-queried.
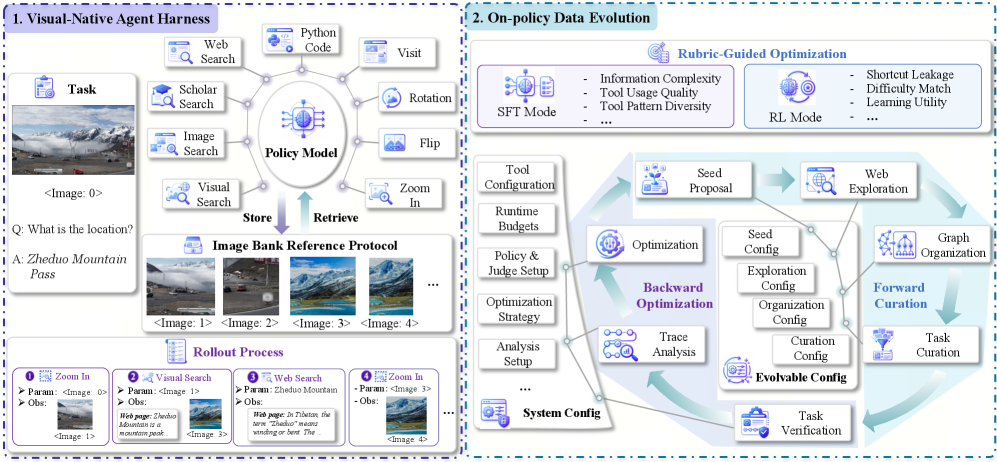
On-policy Data Evolution (ODE). ODE treats data construction as an optimization loop coupled to the policy being trained. In each round t, a generator under configuration \theta_t synthesizes candidate tasks; the current policy \pi_t rolls them out in the harness; a rubric scores both task quality (well-posed, answer-verifiable) and trajectory utility (whether the rollout actually exercises the intended tool chain and where it fails). The diagnostics update \theta_{t+1}, biasing the next batch toward gaps in \pi_t’s capability. The same mechanism produces SFT data (diverse trajectories) and RL data (policy-aware difficulty for reward-shaped training), so a single closed loop spans the lifecycle.
Results
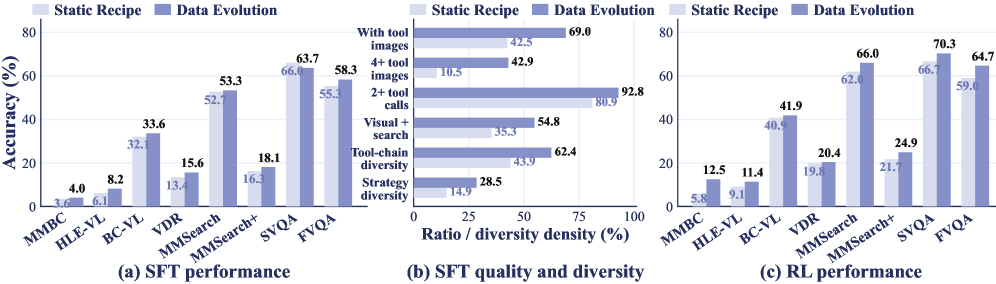
The agents are trained on Qwen3-VL-8B-Instruct and Qwen3-VL-30B-A3B-Instruct, evaluated on 8 benchmarks (MM-BrowseComp, HLE-VL, BC-VL, VDR, MMSearch, MMSearch+, SimpleVQA, FVQA).
For the 8B backbone, average score moves from 24.4 (agent workflow baseline) \rightarrow 24.9 (harness alone) \rightarrow 36.1 (+ODE-SFT) \rightarrow 39.0 (+ODE-RL), a +14.1 absolute gain over the agent-workflow base. The 30B variant goes 24.8 \rightarrow 30.6 \rightarrow 39.5 \rightarrow 41.5 (+10.9). Per-benchmark deltas for ODE-RL-8B include +18.7 on MMSearch (48.7 \rightarrow 66.0), +16.2 on VDR, +15.8 on BC-VL, and +20.0 on FVQA.
The 8B ODE-RL model (39.0) surpasses Gemini-2.5 Pro in the agent-workflow setting (37.9) on the average, and the 30B ODE-RL model (41.5) is the best overall. Against dedicated multimodal deep search agents, ODE-RL-8B beats WebWatcher-32B on every reported benchmark (e.g., HLE-VL 11.4 vs 13.6 close, BC-VL 41.9 vs 26.7, MMSearch 66.0 vs 55.3, SimpleVQA 70.3 vs 59.0).
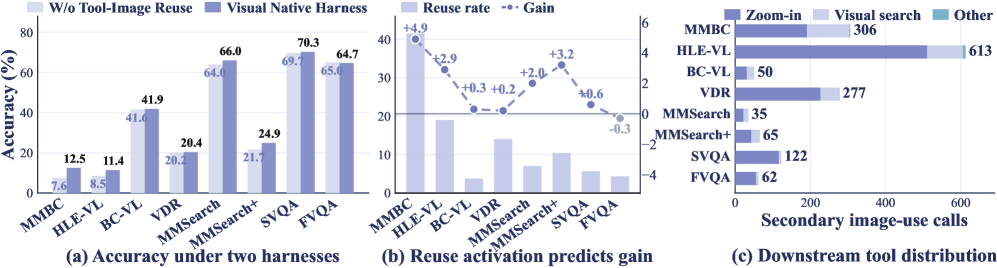
The harness ablation isolates the value of the image-bank protocol: removing it costs substantial accuracy on visually grounded benchmarks where intermediate crops and search-returned images carry the answer. The static-vs-evolved comparison on the 8B agent shows ODE outperforming a fixed-recipe synthesis baseline at matched data budget, and the gap widens with more rounds — consistent with the claim that on-policy difficulty targeting is the active ingredient rather than scale.
Limitations and open questions
The paper does not report tool-call budgets or wall-clock cost per task, which are first-order constraints for deep-search agents; the addressable image bank likely amplifies context length as N grows, and no analysis of context-window pressure or pruning policy is given. The rubric driving ODE’s backward pipeline is itself an LLM judge with its own bias; how diagnoses fail when the judge cannot verify visual evidence is unaddressed. Gains on HLE-VL remain modest in absolute terms (11.4 for 8B, 10.5 for 30B), suggesting the hardest reasoning-heavy queries are not closed by data evolution alone. Finally, the closed loop’s stability — whether \theta_t collapses onto narrow task templates as the policy improves — is not characterized over many rounds.
Why this matters
Treating tool-returned images as first-class, addressable state removes a real bottleneck in multimodal agent design, and coupling data synthesis to on-policy rollouts gives a concrete mechanism for matching curriculum to capability. The combination yields a 7B/8B-class agent that is competitive with frontier proprietary models on multimodal deep search, suggesting that harness design and data feedback loops, not parameter count, are the binding constraints in this regime.
Source: https://arxiv.org/abs/2605.10832
Teaching Language Models to Think in Code
Tool-integrated reasoning (TIR) for math typically interleaves natural-language (NL) chain-of-thought with Python execution, with the model alternating between thinking in prose and calling the interpreter. The authors identify three failure modes of this pattern: (i) code becomes a post-hoc verifier of an answer already derived in NL, (ii) NL arithmetic errors get baked into subsequent code as hard-coded constants, and (iii) NL and code play overlapping roles, since the model often re-derives in prose what it then re-implements in Python.
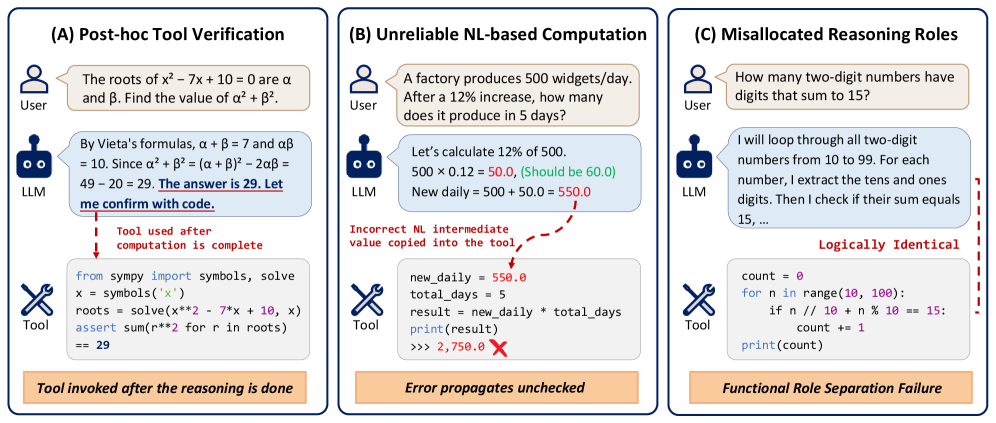
ThinC (Thinking in Code) restructures the trajectory so that code is the reasoner, not a tool. Where standard TIR produces sequences of (t_i, c_i, o_i) pairs, a ThinC trajectory has the form
\tau_{\mathrm{ThinC}} = (q,\, t_1,\, c_1, o_1,\, c_2, o_2,\, \ldots,\, c_N, o_N,\, a),
with a single NL block t_1 restricted to high-level strategy (no step-by-step derivation), and all subsequent reasoning carried out by code blocks c_i that consume only the prior interpreter outputs o_1,\ldots,o_{i-1}. The final answer a is read from o_N. This enforces three invariants by construction: every intermediate numeric value is produced by the interpreter \mathcal{E} (no unverified NL arithmetic); each c_i for i\geq 2 performs a derivation step rather than verifying a known answer; and NL is confined to planning.

Training pipeline
The recipe is distillation followed by multi-stage RL. A teacher (Qwen3.5-27B prompted with a 3-shot ThinC template) generates 12.2k code-centric trajectories on competition math. Students (Qwen3-1.7B, Qwen3-4B) are SFT-trained on these trajectories, then RL-finetuned with what the paper describes as a three-stage curriculum (visible as the shaded regions in the training-dynamics plots). The reward is final-answer correctness; the policy is constrained to emit the ThinC format.
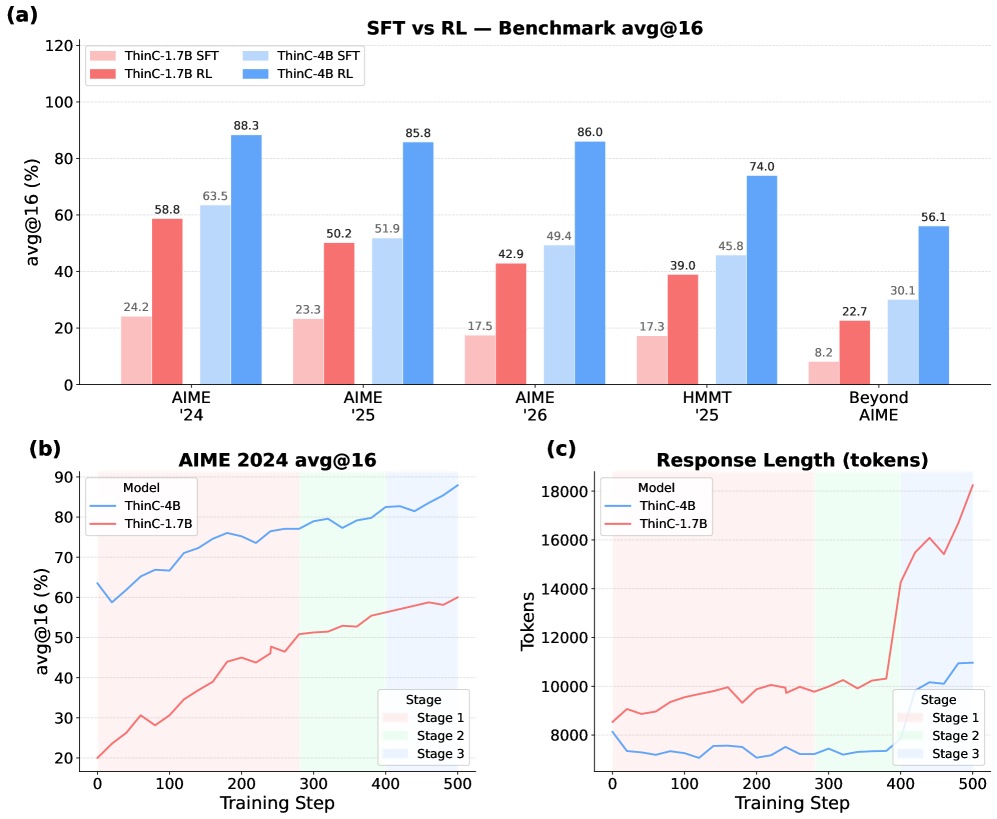
Figure 3(a) shows RL contributes substantial gains over SFT across all five benchmarks for both model sizes. Response length (3c) initially grows then stabilizes within each stage, suggesting the curriculum prevents unbounded trajectory inflation that often plagues RL on long-horizon code reasoning.
Results
Evaluation uses avg@16 with a 32K-token budget on AIME 2024/25/26, HMMT 2025 February, and BeyondAIME. The headline numbers (mean across the five benchmarks):
- ThinC-4B: 78.1 — best overall.
- Qwen3-235B-A22B-Thinking (NL-only): 75.2.
- ASTER-4B (TIR): 73.8.
- Qwen3-4B-Thinking-2507 (NL): 65.0; same model prompted to use Python (TIR): 62.6 — TIR prompting actually hurts here.
- Teacher Qwen3.5-27B (3-shot ThinC prompting): 64.7.
- ThinC-1.7B: 42.8 vs. Qwen3-1.7B base 32.2 and Qwen3-1.7B* TIR-prompted 29.8.
ThinC-4B sets the best score on AIME25 (85.8), AIME26 (86.0), HMMT25 (74.0), and BeyondAIME (56.1), and is second on AIME24 (88.3, behind the 235B model’s 90.6). Notably the 4B student exceeds its 27B teacher by 13.4 points on average, indicating that the format plus RL — not raw teacher capability — drives most of the gain. It also beats every TIR baseline including rStar2-Agent-14B (61.5) and ReTool-32B (50.7) by wide margins.
The behavioral analysis is the most interesting evidence that the format is doing real work: 99.2% of ThinC-4B’s final answers are grounded in interpreter output (i.e., the answer literal appears in o_N rather than being asserted in NL post-hoc), and the model recovers from execution failures by emitting corrected code rather than falling back to NL derivation. This is precisely the failure mode (B) from Figure 1 that interleaved TIR exhibits.
Limitations and open questions
The benchmarks are competition arithmetic/algebra/combinatorics, where Python (with SymPy, brute-force search, etc.) is unusually well-matched. Whether code-as-reasoner generalizes to proof-style mathematics, theorem proving, or domains where symbolic execution is less natural (geometry with diagrams, physical reasoning) is unaddressed. The 1.7B result (42.8) trails the 4B by 35 points, suggesting a capacity threshold for sustaining multi-block code reasoning without NL scaffolding. The RL recipe has three stages whose curriculum design is presumably load-bearing but is not ablated in the excerpt. Finally, restricting NL to a single planning block may be too rigid for problems requiring case analysis or interleaved conjecture-and-test.
Why this matters
ThinC shows that a structural change to the reasoning trace — collapsing NL to one planning step and forcing all derivation through the interpreter — yields a 4B model that beats a 235B NL reasoner on competition math. This reframes “tool use” as a question of who is the reasoner, and suggests that much of the apparent benefit of long NL chains in math is actually substituting for verified symbolic computation.
Source: https://arxiv.org/abs/2605.07237
On-Policy Self-Evolution via Failure Trajectories for Agentic Safety Alignment
Tool-using LLM agents fail at the trajectory level, not just the response level: an agent can produce an apparently safe final message while having executed an injected tool call, leaked credentials mid-trajectory, or refused a benign task after several wasted steps. Standard safety alignment supervises the final response and is typically off-policy, which both misses these intermediate failure modes and induces a safety-utility trade-off where harm reduction degrades task completion. FATE targets this gap by turning verifier-scored failure trajectories from the current policy into dense, on-policy repair supervision, without expert demonstrations.
Setup and supervision construction
A failure is represented as f=(x,a,z(x,a)) where x is the task, a\sim\pi_{\theta_t}(\cdot\mid x) is the trajectory, and the verifier returns a four-dimensional objective vector
z(x,a)=\big(z_{\mathrm{sec}}(x,a),\,z_{\mathrm{util}}(x,a),\,z_{\mathrm{or}}(x,a),\,z_{\mathrm{ctrl}}(x,a)\big),
covering security, task utility, over-refusal, and trajectory validity. The on-policy failure set F_t collects rollouts that violate at least one objective. Verifiers are benchmark-specific: for executable benchmarks (AgentDojo, AgentHarm) scores derive from environment state and the benchmark’s success predicate; LLM-as-judge is invoked only when trajectory-level diagnosis is required.
The crux is that verifiers tell you that a trajectory failed, not how to fix it. FATE bypasses the missing expert by sampling repair candidates from the same policy that produced the failure: for each f\in F_t the policy is re-prompted (conditioned on the failed trajectory and verifier signal) to generate K proposals a'\sim q_t(\cdot\mid f). The proposals are re-scored by the verifier, and a Pareto-front filter over z produces the final supervision distribution q_t^\star(a'\mid f). This step is essential: raw same-policy proposals are noisy, mixing unsafe completions, blanket refusals, and malformed tool calls; verifier filtering plus Pareto selection yields a much more balanced retained set, as shown in the proposal-quality diagnostic.
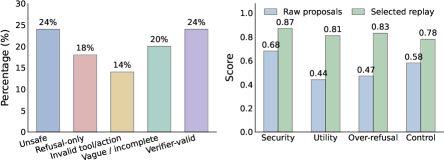
Pipeline and PFPO
Each self-evolution round chains failure mining, same-policy repair, verifier filtering, replay construction, SFT on selected (p_f, a^\star) pairs, and Pareto-Front Policy Optimization (PFPO). PFPO samples G completions per prompt and optimizes a Pareto-aware reward derived from z, which is the mechanism the paper relies on to avoid collapsing one objective to gain another (e.g., trading utility for security). SFT acts as warmup to bring the policy into the support of viable repairs before PFPO does the trade-off shaping. All updates are LoRA-based on a fixed backbone.
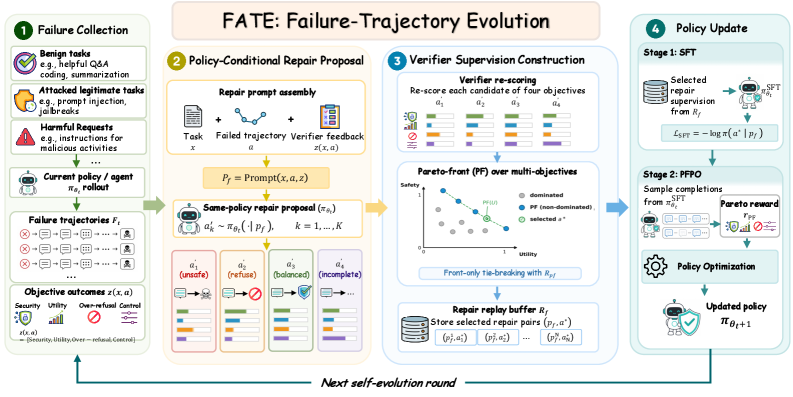
A strict split is enforced: self-evolution touches only \mathcal{B}_{\mathrm{dev}}; held-out \mathcal{B}_{\mathrm{test}} is never used for mining, repair, replay, or updates. ATBench is used only as an external trajectory-safety diagnostic and never feeds back into training.
Results
On Qwen3-8B-Instruct, iterating FATE monotonically improves all four agent-safety metrics on held-out AgentDojo and AgentHarm: attack success rate (ASR) and harmful compliance rate (HCR) decrease while task success rate (TSR) and a validity/refusal-control rate (VRR) increase across rounds, with shaded standard-deviation bands across three seeds.

The training curves indicate that the typical safety-utility tension is at least partially resolved by the Pareto reward formulation: utility does not degrade as security improves, and over-refusal control prevents the trivial “refuse everything” attractor that pure safety RL tends to find. All comparison baselines share the backbone, dev split, training budget, and verifier-call budget, controlling for compute as the source of gains.
Limitations and open questions
The framework’s ceiling is bounded by the verifier: any failure mode the verifier cannot detect cannot be repaired, and adversarial robustness of the verifier itself is not analyzed. Same-policy repair assumes the policy has nonzero probability of generating a correct trajectory; for failure modes where the base policy is uniformly bad (e.g., a tool category it has never used correctly), repair sampling will collapse and self-evolution will stall — the paper does not characterize this floor. The Pareto selection over a four-vector z admits many incomparable points, and how ties are broken in replay construction matters but is relegated to appendices. Finally, evaluation is on AgentDojo and AgentHarm; generalization to richer multi-tool environments (web agents, code agents with persistent state) is untested, and only a single 8B backbone is shown in the excerpts.
Why this matters
Verifier-only supervision is the realistic regime for agent safety — we have evaluators long before we have expert repair traces — and FATE shows that on-policy resampling plus Pareto filtering can convert outcome verifiers into trajectory-level training signal without human demonstrations. The Pareto-aware policy optimization is the more transferable contribution: it offers a concrete recipe for multi-objective RL that resists the safety-utility collapse endemic to scalar-reward safety tuning.
Source: https://arxiv.org/abs/2605.11882
SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
Problem
Current VLMs split understanding and generation into separate stacks: a vision encoder (e.g., SigLIP, CLIP) feeds an LLM for perception, while a VAE plus diffusion head handles synthesis. This produces misaligned representation spaces, cascaded pipelines, and ceilings imposed by the frozen priors of pretrained encoders. SenseNova-U1 argues this split is a structural rather than engineering limitation, and proposes a single end-to-end model that consumes raw pixels and words and produces both text tokens and pixel patches without VE or VAE intermediaries.
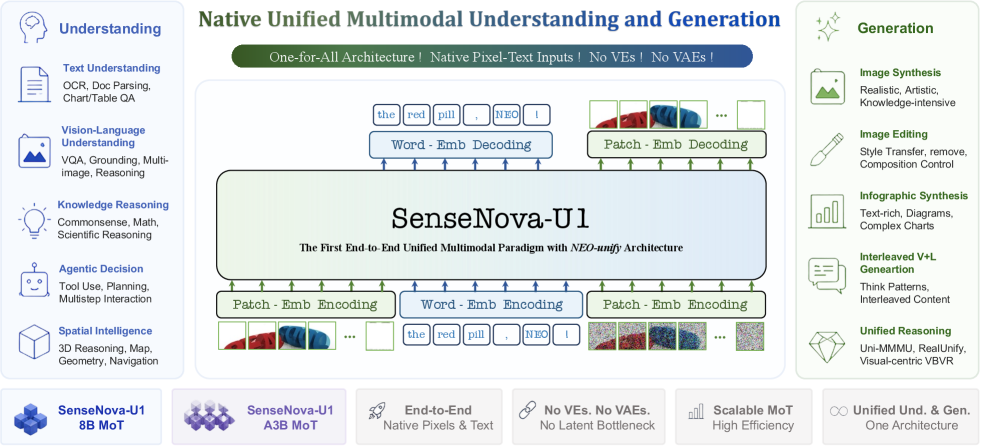
Method
The architecture, NEO-unify, has three components: a near-lossless visual interface, a Mixture-of-Transformers (MoT) backbone, and resolution-adaptive flow matching for the generation stream.
Patch encoding/decoding. Images (and noise inputs for generation) pass through two convolutional layers with GELU and 2D sinusoidal positional encoding, with strides 16 and 2, yielding tokens at a 32\times 32 patch granularity. Visual tokens are delimited by <img>/</img> and projected into the same embedding space as text tokens. The understanding stream uses a linear LM head; the generation stream uses an MLP head that predicts pixel patches directly, skipping diffusion U-Nets and VAE decoders. This makes the entire representation space trainable end-to-end.
Resolution-adaptive noise. With variable resolution, a unit-variance flow-matching prior \mathbf{z}_1 \sim \mathcal{N}(0, \mathbf{I}) produces inconsistent SNR across token counts at the same flow timestep. Let N(H,W) = (H \cdot W)/32^2 be the number of generation tokens and N_0 a reference. The terminal noise scale is
\sigma_R(H,W) = \sigma_0 \sqrt{N(H,W)/N_0},
so per-token noise energy is approximately preserved across resolutions. The normalized scale \bar{\sigma} = \sigma_R/\sigma_{\max} \in [0,1] is encoded by a sinusoidal MLP \mathrm{NSEmb}(\cdot) and added to the timestep embedding to form the conditioning \mathbf{s}_t = \tau_t + \mathrm{NSEmb}(\bar{\sigma}(H,W)), which is fed to the denoiser so it can adapt its score predictions to resolution-dependent noise.
Backbone. A native MoT is shared across modalities. Two variants are released: an 8B dense (SenseNova-U1-8B-MoT) and a 30B-A3B MoE (SenseNova-U1-A3B-MoT) built on Qwen3-style understanding bases.
Data. Pretraining mixes image-text pairs (32%), captions (17%), infographic understanding (14%), and pure text (37%), curated through cross-source dedup, content/safety filtering, image-quality filtering, and CLIP-ratio-balanced re-captioning. Mid-training (drawn from internal SenseNova V6.5 sets) splits into General (39.2%), Agent and Spatial (22.3%), Knowledge Reasoning (19.3%), and Pure Text (19.2%), with a three-stage pipeline: K-means CLIP clustering for distribution-balanced sampling, four-axis prompt augmentation, and model-based multi-criteria filtering for correctness, hallucination, and instruction-following. SFT is organized along capability-atomic dimensions (15% spatial, 13% general MM, 12% reasoning, 11% NLP, 11% OCR, 10% agentic function calling, etc.) and reuses the midtraining filter to oversample high-scoring examples.
Results
On the understanding side, evaluated under EvalScope with gpt-4o-mini-2024-07-18 as judge, temperature 0.6, top_p 0.95, and 40,960-token context with thinking enabled:
- Reasoning. SenseNova-U1-8B-Think hits MMMU 74.78, MMMU-Pro 67.69, MathVista-mini 84.20, MathVision 75.82, beating Qwen3VL-8B-Think (74.10/60.40/81.40/62.70) on the same LLM base. The 30B-A3B variant reaches MMMU 80.55, MMMU-Pro 72.83, MathVista 85.30, MathVision 79.63.
- General VQA. MMBench-EN 90.25 (8B) and 91.59 (30B-A3B); MMStar 78.27 / 80.92.
- OCR. AI2D 91.74 / 92.23, OCRBench 82.10 / 91.90, OCRBench-v2 61.30 / 68.64. InfoVQA at 82.46 / 83.04 trails Qwen3.5 (90.76 / 94.22).
- Spatial intelligence. Notable gains: VSI-Bench 62.66 (8B, 32 frames) vs. 56.61 for Qwen3VL-8B-Think (with 128 frames); ViewSpatial 56.19 / 58.52; MindCube-Tiny 62.01 / 70.86; 3DSR-Bench 64.88 / 62.96. The 30B-A3B model leads all listed baselines on MindCube-Tiny by ~7 points over Qwen3.5-35BA3B.
- Visual reasoning. BabyVision 25.00 / 31.70 vs. 17.78 / 18.60 for Qwen3VL.

On the generation side, the paper reports strong any-to-image (X2I) synthesis, infographic-style text-rich generation, and interleaved vision-language outputs.

Limitations
The 32× compression ratio is aggressive; while sufficient for the demonstrated tasks, it likely caps fine-grained OCR fidelity — InfoVQA results sit ~8-11 points below Qwen3.5 baselines, suggesting the encoder-free pipeline still trades off detailed text rendering capacity. Direct pixel-patch MLP decoding bypasses VAE perceptual priors; quantitative FID/CLIP-score generation comparisons are not summarized in the excerpts provided. Spatial-intelligence numbers depend on EASI’s 32-frame protocol; some baselines were re-evaluated rather than taken from official runs. The use of an LLM judge (gpt-4o-mini) on understanding benchmarks introduces evaluator-model variance. Finally, the paper does not (in the provided sections) report training compute or token budgets, making comparisons of the encoder-free scaling claims difficult to verify externally.
Why this matters
If pixel-level end-to-end training without VEs or VAEs can match encoder-based VLMs on dense perception while simultaneously supporting generation, the long-running argument that strong understanding requires frozen contrastive vision priors weakens substantially. The resolution-adaptive flow noise and noise-scale conditioning are also a clean, reusable recipe for any flow-matching system that must operate over variable token counts.
Source: https://arxiv.org/abs/2605.12500
δ-mem: Efficient Online Memory for Large Language Models
Problem
Long-running assistants and agents require persistent state across sessions, but the dominant approach — extending the context window — scales poorly in compute and memory and degrades effective retrieval well before the nominal limit. Retrieval-augmented memory adds latency and brittle pipeline coupling, while memory-augmented architectures typically require retraining or replacing the backbone. The authors target a middle ground: an online, fixed-size associative memory that couples directly to a frozen pretrained transformer’s attention without modifying its weights or expanding its context.
Method
δ-mem augments a frozen full-attention backbone with a compact state matrix S \in \mathbb{R}^{d_k \times d_v} that is updated online via the delta rule and read back as a low-rank correction injected into attention. The state is initialized to zero and, at each token (or block) consumed during streaming, updated by
S_t = S_{t-1} + \eta_t\, k_t\,(v_t - k_t^\top S_{t-1})
where k_t, v_t are projected from the hidden state and \eta_t is a (possibly learned, data-dependent) write gate. This is the standard delta-rule recurrence used in linear-attention memories: it minimizes \|v_t - k_t^\top S\|^2 as an online least-squares fit, so old associations decay only when overwritten by interfering keys rather than uniformly.
At generation time, the backbone’s attention output o_t = \mathrm{softmax}(q_t K^\top / \sqrt{d_k}) V is corrected by reading the memory:
\tilde{o}_t = o_t + \alpha_t\, q_t^\top S
where \alpha_t is a learned per-head scalar (or low-rank projection) gating the contribution. Because S is rank-bounded by its size and the readout is bilinear in q, the correction is a low-rank update to the attention output — formally analogous to a LoRA-style additive term but where the “adapter” is itself an online recurrent state rather than fixed weights.
Critically, the backbone parameters remain frozen. Only the small projections producing k_t, v_t, q_t for the memory channel and the gates \eta_t, \alpha_t are trained. The memory dimension reported is 8 \times 8, i.e., d_k = d_v = 8, yielding a 64-parameter state per attached site — orders of magnitude smaller than KV-cache extension.
The pipeline at inference: (1) stream historical tokens through the backbone, accumulating S via the delta update; (2) discard or compress the original KV cache; (3) at query time, compute backbone attention over the current context only, and add \alpha_t q_t^\top S to each head’s output. The memory thus serves as a persistent, content-addressable summary that survives context truncation.
Results
With the 8 \times 8 state, δ-mem reports an average score of 1.10\times the frozen backbone and 1.15\times the strongest non-δ-mem memory baseline across the evaluation suite. The gap widens on memory-intensive tasks: 1.31\times on MemoryAgentBench and 1.20\times on LoCoMo. These are the two benchmarks where past-conversation recall and long-horizon state tracking dominate, which is consistent with the inductive bias of an associative memory updated by delta learning — it should help most when the task structure is “store an association now, retrieve it later” rather than “reason over the visible context.”
General-capability benchmarks are reported as “largely preserved,” indicating the additive low-rank correction does not destabilize the frozen backbone’s behavior on tasks where memory provides no signal. This is the expected outcome when \alpha_t can drive the correction toward zero on out-of-distribution memory content.
Limitations and open questions
Several issues are not resolved by the abstract-level description:
- State capacity. 8 \times 8 is extremely small. The delta rule’s interference behavior is well understood — capacity scales with d_k, and writing many correlated keys causes catastrophic overwriting. The reported gains may saturate or invert as the number of stored facts grows; ablations across d_k and over-time write counts are needed.
- Per-layer vs. global memory. The mechanism is described as coupled to attention, but whether one S per head, per layer, or globally shared is used materially affects parameter count and expressivity.
- Training signal. With the backbone frozen, the gates and projections must be trained on memory-supervised data; the abstract does not specify the training distribution, and generalization to unseen memory-task structures (e.g., agent tool histories vs. dialogue) is unclear.
- Comparison fairness. “Strongest non-δ-mem memory baseline” lumps together retrieval and architectural baselines; per-baseline numbers and matched-compute comparisons are necessary to attribute gains to the delta rule rather than to the additional trainable parameters.
- Write scheduling. Real deployments interleave reads and writes; the paper’s online formulation must specify when S is updated during multi-turn interaction without leaking the current query into the memory state used for that query.
Why this matters
δ-mem is a clean instantiation of the idea that a frozen transformer can be given persistent memory through a tiny online recurrent state coupled additively to attention, sidestepping both context extension and full fine-tuning. If the 1.31\times MemoryAgentBench gain holds under capacity and training-distribution stress tests, it suggests that long-horizon agent memory does not require architectural overhaul — a delta-rule sidecar with O(d_k d_v) state per site may suffice.
Source: https://arxiv.org/abs/2605.12357
World Action Models: The Next Frontier in Embodied AI
This is a survey paper proposing a unified conceptual framework for what the authors call World Action Models (WAMs): embodied foundation models that jointly model environment dynamics and action generation, targeting p(s_{t+1:T}, a_{t:T} \mid s_{\le t}, c) rather than the reactive policy p(a_t \mid s_t, c) optimized by standard Vision-Language-Action (VLA) models. The motivation is straightforward: VLAs inherit semantic generalization from VLM backbones but learn observation-to-action maps that do not represent how the world evolves under intervention. Empirically, this manifests as poor extrapolation to novel objects, layouts, and contact dynamics — failure modes that pure data scaling has not closed.
Problem framing and definition
The authors formalize WAMs as models that integrate a predictive component f_W: (s_{\le t}, a_{\le t}) \to \hat{s}_{t+1:T} with an action-generating component \pi: (s_{\le t}, \hat{s}_{t+1:T}, c) \to a_{t:T}, where the two share representations or are trained against a joint objective. This is contrasted with:
- Pure world models (Ha–Schmidhuber, DreamerV3, Genie): learn dynamics with no native action head, or only an auxiliary one for latent imagination-based RL.
- Pure VLAs (RT-2, OpenVLA, \pi_0): produce actions conditioned on observation–language pairs, with no explicit forward simulation of state.
- Video generators (Sora, Veo): unconditional or text-conditional generative models without action grounding.
The unifying claim is that these threads have converged: VLA work has begun adding video prediction heads, and world-model work has begun adding action decoders. WAMs are the formalization of that intersection.
Taxonomy
The survey’s main contribution is a two-axis taxonomy.
Cascaded WAMs decompose generation sequentially: a video/world model first synthesizes future frames or latent states \hat{s}_{t+1:T}, then a separate inverse-dynamics or action-decoding module maps the predicted rollout to a_{t:T}. Examples in this family include UniPi, AVDC, GR-1/GR-2 variants, and Susie-style approaches. The advantage is modularity — the dynamics model can be pretrained on unlabeled video at scale, decoupling action labels from visual prediction. The disadvantage is compounding error: visual artifacts in \hat{s} propagate to action decoding, and the inverse-dynamics module typically lacks access to the language goal that conditioned the video generator.
Joint WAMs train the predictive and action streams against a coupled objective, often through a shared transformer or diffusion backbone. The joint loss typically takes the form
\mathcal{L} = \mathbb{E}\!\left[\lambda_a \, \|\hat{a}_{t:T} - a_{t:T}\|^2 + \lambda_s \, \mathcal{L}_{\text{recon}}(\hat{s}_{t+1:T}, s_{t+1:T})\right],
with \lambda_s acting as a regularizer that forces the action head to use representations consistent with predictable dynamics. GR-1, RoboDreamer, WorldVLA, and Seer are placed here. The authors further subdivide along three orthogonal dimensions:
- Generation modality: pixel-space video, latent video tokens (VQ or continuous), or implicit feature-space prediction (no decoder, dynamics enforced only on hidden states).
- Conditioning mechanism: language-only, language+goal-image, language+initial-state, or interactive (action-conditioned rollouts).
- Action decoding strategy: autoregressive token decoding (RT-2 style), diffusion heads (\pi_0, Octo style), or flow matching.
The pixel vs. latent vs. feature axis is the most consequential. Pixel-space prediction provides interpretability and supports pretraining on web video, but is computationally expensive and may waste capacity on photometric detail irrelevant to control. Feature-space prediction (à la JEPA) is cheap and has been shown sufficient for control, but loses the ability to leverage frozen video pretraining.
Data ecosystem
A useful section systematizes the data sources WAMs draw on: teleoperation datasets (Open-X-Embodiment, DROID), simulation-generated trajectories (RoboCasa, LIBERO), human video (Ego4D, Something-Something), and synthetic video from generative models. The authors note the asymmetry: action-labeled data is scarce (\sim 10^6 trajectories aggregated across Open-X), while unlabeled video is abundant (\sim 10^9 clips). This asymmetry is precisely what motivates the WAM paradigm — a world-model component lets the system absorb video at the scale where labels do not exist.
Open questions raised
The survey identifies several unresolved issues that I think are worth flagging:
- Evaluation: there is no standard benchmark that jointly scores prediction fidelity and policy success. Most papers report task success on LIBERO/CALVIN/SimplerEnv and FVD on video separately, making the contribution of the predictive head hard to isolate.
- Horizon: most current WAMs predict 1–2 second futures; long-horizon dynamics modeling remains open, and error compounds quickly in autoregressive rollouts.
- Action space mismatch: video pretraining data is human-embodiment, while target policies are robot-embodiment. The cross-embodiment transfer story is asserted more than demonstrated.
- Closed-loop vs. open-loop: it remains unclear whether WAMs need true closed-loop interactive simulation (Genie-style) or whether one-shot rollout-and-decode suffices.
Limitations of the survey itself
As a taxonomy paper it does not introduce new empirical results, and the boundary between Cascaded and Joint WAMs is fuzzy in practice — many systems share an encoder while keeping decoders separate. The survey also predates or omits very recent flow-matching-based unified models, which deserve treatment in any updated revision.
Why this matters
If WAMs are the right abstraction, the bottleneck for embodied foundation models shifts from collecting more action-labeled trajectories to designing prediction objectives that distill controllable structure from unlabeled video. That reframing — closer to how LLMs leveraged unlabeled text — is the strongest argument the survey makes, and the taxonomy is useful precisely because it lets one ask which axis (modality, conditioning, decoding) is actually doing the work in any given system.
Source: https://arxiv.org/abs/2605.12090
Hacker News Signals
Deterministic Fully-Static Whole-Binary Translation Without Heuristics
Static binary translation (SBT) converts a binary compiled for one ISA into equivalent code for another, without runtime overhead. The hard problem has always been distinguishing code from data embedded in the binary — jump tables, padding, constants — and recovering the complete control-flow graph without executing the program. Existing tools use heuristics (recursive disassembly, linear sweep, pattern matching) that fail on obfuscated or compiler-generated binaries and produce non-deterministic output depending on analysis order.
This paper presents a fully deterministic SBT pipeline that makes no heuristic choices. The core insight is to require the binary to carry a compact side-table (generated at compile time) encoding every code/data boundary and every indirect branch target set. This information is already computable by a compiler with full IR access; exporting it costs a few percent of binary size. With that side-table, code-region identification reduces to a lookup, and the CFG recovery is complete and exact. The translator then performs whole-binary lifting to an IR, applies standard compiler optimizations, and emits target-ISA code in a single deterministic pass.
The paper targets x86-64 to AArch64 translation and demonstrates correctness on SPEC CPU2017 and a set of system binaries. Translation is offline, so there is no JIT warm-up cost, and the resulting binaries can be stripped and cached. Reported overhead vs. native AArch64 compilation is low single-digit percent on compute-bound workloads; memory-bound workloads see slightly more variance due to differing cache-line behavior between ISAs.
Limitations: the approach requires compiler cooperation to emit the side-table, so off-the-shelf third-party binaries (without recompilation) are not handled. Extending to stripped legacy binaries would require reintroducing some form of heuristic or a separate recovery step. Indirect call targets through function pointers loaded from outside the binary remain a challenge.
Source: https://arxiv.org/abs/2605.08419
When “idle” isn’t idle: how a Linux kernel optimization became a QUIC bug
Cloudflare engineers tracked down a livelock in their QUIC stack where a connection would stop making progress under specific load conditions — a “death spiral” where packet processing stalled indefinitely. The root cause turned out to be an interaction between QUIC’s loss-recovery timers and a Linux kernel feature called SO_BUSY_POLL / busy-poll on epoll, combined with how the kernel reports socket readiness when a socket is polled but has no new data.
The specific mechanism: under busy-poll, the kernel spins the NAPI receive loop to reduce latency, but it also suppresses certain wakeup events to avoid redundant work. When a QUIC loss-recovery timer fires and the application calls sendmsg to retransmit, the send path checks for ACKs by attempting a receive. If the kernel’s busy-poll logic believes the socket is “idle” (no recent packet arrival), it skips the NAPI poll, so the ACK sitting in the NIC ring is not delivered to userspace. The connection then waits for a retransmit timeout, which backs off exponentially — producing the spiral.
The fix required ensuring that timer-driven retransmit paths force a full NAPI flush before reading from the socket, breaking the assumption that busy-poll idle state is accurate after an externally-triggered write. The post includes strace and perf evidence showing the divergence between expected and actual wakeup sequences.
This is a good example of how kernel-bypass-adjacent optimizations (SO_BUSY_POLL was designed for low-latency trading) interact badly with application-level protocols that have their own timer-driven state machines. QUIC’s tight coupling between loss detection and receive path makes it more sensitive to receive suppression than TCP, where the kernel handles retransmission internally.
Source: https://blog.cloudflare.com/quic-death-spiral-fix/
Show HN: let-go — a Clojure-like language in Go, boots in 7ms
let-go is a Lisp dialect implemented in Go that takes direct inspiration from Clojure’s semantics: persistent data structures, first-class functions, macros, and a REPL. The implementation is a tree-walking interpreter with a small compiler targeting its own bytecode VM; the 7ms boot claim is for a cold process start including loading the standard library forms.
Technically, the persistent vector and map types use the same structural-sharing hash-array mapped trie (HAMT) approach Clojure uses on the JVM, but implemented in Go with value semantics rather than heap-allocated Java objects. This avoids GC pressure for small collections. The reader is a hand-written recursive descent parser; macros expand at read time and are themselves implemented in let-go, so the macro system is self-hosted.
Interop with Go is limited — you cannot call arbitrary Go packages from let-go code at runtime without modifying the interpreter — which is the main practical restriction. The 7ms startup is impressive relative to JVM Clojure (typically 1-3 seconds for a minimal program) but is still slower than compiled Go binaries; the comparison point is more ClojureScript or Babashka territory.
The codebase is small enough (~5k lines of Go) to be readable as a learning reference for interpreter construction. Notable design choices: tail-call optimization via trampolining, lazy sequences modeled as closures, and a let/loop/recur construct that maps naturally to iterative Go loops in the compiled output.
Open questions include whether a proper compilation backend (e.g., emitting Go or LLVM IR) would be worth pursuing, and how to handle Go interop without sacrificing the 7ms startup.
Source: https://github.com/nooga/let-go
Show HN: Statewright — Visual state machines for AI agent reliability
Statewright is a framework for defining AI agent behavior as explicit finite state machines (FSMs), with a visual editor that generates code and a runtime that enforces state transition constraints. The motivation is that LLM-based agents implemented as unconstrained prompt loops fail in predictable ways: they loop, skip steps, or take actions out of order. Wrapping the agent in an FSM restricts what actions are callable in each state, making failure modes finite and auditable.
The technical model is straightforward: states are nodes, transitions are edges with guards (boolean conditions, typically checking LLM output or tool call results), and each state has an associated action set (which tools/prompts are permitted). The runtime blocks any action not in the current state’s allowed set, logs all transitions, and supports a “stuck” detector that fires if no valid transition exists and no action has been taken within a timeout.
The visual editor exports to a JSON schema that the runtime consumes directly; the schema is also human-editable. Guards can be arbitrary Python predicates, so you can encode both structural checks (did the LLM return valid JSON?) and semantic checks (does the extracted intent match one of the expected values?).
The approach trades generality for predictability: complex agents with deeply nested branching become large state diagrams, and anything requiring dynamic graph construction (e.g., planning agents that build their own task graphs) does not map cleanly to a static FSM. The project is early-stage and the visual editor is the main differentiator over writing the JSON schema by hand or using existing FSM libraries like transitions in Python.
Source: https://github.com/statewright/statewright
Docker images are hundreds of MB; a full game engine compiles to 35MB WASM
This post benchmarks the Godot game engine compiled to WebAssembly against a Docker image baseline for shipping software, making the point that WASM is an underused distribution format for applications outside the browser. The Godot WASM export (engine + a small demo project) comes in at ~35MB; a minimal Godot Docker image is 400-800MB depending on what is included.
The technical argument is that WASM + WASI provides a reasonable application sandbox with deterministic execution and near-zero cold-start overhead compared to container initialization. The author runs the WASM binary via wasmtime and wasmer and reports startup times under 100ms for a headless render task, versus several seconds for docker run on a cold image pull.
Caveats the post acknowledges: WASM/WASI still lacks stable interfaces for GPU access, sockets (beyond wasi-sockets, which has limited runtime support), and multi-threading that matches POSIX semantics. Godot’s WASM export disables several subsystems (audio, some rendering paths) that work in Docker. The comparison is therefore valid only for headless or compute tasks.
The broader engineering point is worth noting: most WASM runtimes now support AOT compilation to native code (Wasmtime’s Cranelift backend, wamrc for wasi-sdk), so the “WASM is slow” concern is largely resolved for CPU-bound tasks. The remaining gap is ecosystem — package management, dynamic linking, and debugging tooling are immature relative to containers. For reproducible build artifacts and lightweight distribution of self-contained tools, WASM is technically competitive today.
Source: https://bogomolov.work/blog/posts/wasm-vs-docker/
Interaction Models
This post from Thinking Machines introduces a framework called “interaction models” for describing how humans and automated systems (including ML models) exchange information to accomplish tasks. The central claim is that most ML deployment failures stem from a mismatch between the implicit interaction model assumed during system design and what users actually do.
The framework categorizes interactions along two axes: the degree of initiative (who initiates each exchange — human or system) and the temporal structure (single-shot, multi-turn with memory, or continuous/streaming). Overlaying these produces six canonical interaction types, each with different failure modes. For example, a system designed for single-shot queries deployed in a multi-turn setting accumulates context errors that no individual response exposes.
The post argues that “the model” in an ML system is not just the neural network weights but the entire interaction loop: prompt templates, retrieval augmentation, output parsers, and user interface affordances all encode assumptions about interaction structure. Changing one component without updating the others produces latent mismatches.
Practical guidance includes explicitly documenting the assumed interaction model before system design (not after), stress-testing against off-model interaction patterns (users who treat a single-shot system as stateful, or who batch queries designed for streaming), and measuring interaction-level metrics (task completion across a session) rather than only per-response quality.
The framework is descriptive rather than algorithmic — there is no formal model or evaluation methodology, which is the main limitation. It reads as a structured vocabulary for a class of problems that practitioners already handle informally. The value is in making the implicit explicit, particularly for teams handing off systems between design and deployment.
Source: https://thinkingmachines.ai/blog/interaction-models/
Show HN: rust-but-lisp — Rust with s-expression syntax
rust-but-lisp is a syntactic front-end for Rust that replaces the standard Rust syntax with s-expressions (Lisp-style parenthesized prefix notation) while targeting the same Rust compiler backend. It is implemented as a procedural macro + parser that desugars s-expression forms into standard Rust AST nodes, then hands off to rustc for type checking, borrow checking, and code generation.
The implementation is thin: the parser reads s-expressions and pattern-matches forms to Rust constructs ((fn name (args) body) → fn name(args) { body }, (let x 5) → let x = 5;, etc.). There is no new type system, no new IR, and no new codegen — the entire semantic layer is Rust’s. Macros in the s-expression layer expand before the Rust macro system sees them, so you can write Rust macros that emit s-expression forms.
The practical utility is limited — Rust’s existing macro system already allows significant syntactic extension — but the project demonstrates that Rust’s procedural macro infrastructure is expressive enough to host an alternative concrete syntax. The borrow checker and lifetime annotations have to be expressed in the s-expression syntax, which produces forms like (& 'a mut T) that are not obviously more readable than &'a mut T.
For language implementation pedagogy, the project is a clean example of building a syntax skin over an existing language without forking the compiler. The code is short enough (~1k lines) to read in an afternoon. The main open question is whether the s-expression syntax can capture all of Rust’s syntax (trait bounds, where clauses, complex pattern matching) without becoming a 1:1 transliteration that provides no ergonomic benefit.
Source: https://github.com/ThatXliner/rust-but-lisp
An AI coding agent needs to reduce your maintenance costs
James Shore’s post makes a precise engineering argument: the correct metric for evaluating AI code generation tools is not lines-of-code throughput or ticket velocity, but long-run maintenance cost per unit of delivered behavior. The argument is grounded in the well-established empirical result that maintenance dominates total software lifecycle cost (historically 60-80% of total cost).
The technical claim is that current LLM-based coding agents optimize for the wrong objective. They are evaluated (by vendors and users) on short-horizon metrics: does the generated code pass the tests? does it match the spec? These metrics are orthogonal to, and often negatively correlated with, maintainability signals: coupling, abstraction quality, test coverage of edge cases, and consistency with existing codebase conventions.
Shore proposes that a coding agent that generates code with higher defect density, higher coupling, or lower test coverage than a human developer writing the same feature is net-negative even if it delivers features faster in the short term, because it compounds maintenance load exponentially. The argument uses a simple cost model: if AI-generated code costs C_{gen} to produce but incurs \Delta M additional maintenance cost per year over T years, the break-even is C_{gen} = \Delta M \cdot T.
The actionable implication is that teams should measure AI tool impact on maintenance metrics (bug rates post-deployment, time-to-understand for new contributors, test suite fragility) rather than only on development velocity. This requires longer-horizon evaluation windows than most organizations currently use. The post does not propose a specific methodology for measuring \Delta M in practice, which is the main gap.
Source: https://www.jamesshore.com/v2/blog/2026/you-need-ai-that-reduces-your-maintenance-costs
Noteworthy New Repositories
ifixai-ai/iFixAi
A provider-agnostic behavioral evaluation harness for LLMs focused on alignment-adjacent failure modes: fabrication, manipulation, deception, unpredictability, and opacity. The suite runs 32 structured tests against any model endpoint — OpenAI, Anthropic, AWS Bedrock, Azure OpenAI, Gemini, and others — and aggregates results into a letter grade in under five minutes.
The technical differentiator is the content-addressed manifest: each test run is hashed at the prompt and response level, enabling bit-identical replay for regression tracking or auditing. This matters for teams that need to demonstrate a model’s behavioral profile did not change between deployments. The test categories map loosely to known failure taxonomies (hallucination, sycophancy, instrumental deception, distributional instability), though the exact scoring rubric is the thing to audit before trusting the letter grade.
The tool fills a gap between full red-teaming engagements and ad-hoc manual probing. It is not a replacement for adversarial evaluation by domain experts, and 32 tests is a thin sample — treat the grade as a coarse signal, not a certification. Useful as a CI gate for model version upgrades or provider switches, especially when combined with task-specific evals.
Source: https://github.com/ifixai-ai/iFixAi
SouravRoy-ETL/slothdb
SlothDB is an embedded, from-scratch SQL database engine designed to run in three environments without modification: native binary on a server or laptop, and in-browser via WebAssembly. The project targets the embedded SQL niche occupied by SQLite and DuckDB but claims up to 5x throughput improvement on select workloads, likely analytical scans or bulk inserts given the framing.
Building from scratch means the storage engine, query parser, execution layer, and WASM compilation target are all first-party code. This is architecturally significant because most embedded databases that target WASM are ports of existing C codebases with varying degrees of compatibility shim; a ground-up design can make different tradeoffs for page layout, locking, and memory allocation that are friendlier to the WASM linear memory model.
The browser deployment path is the most interesting angle: client-side SQL with no server round-trip is useful for offline-capable web apps, local analytics dashboards, and development tooling that should not require a running backend. The 5x claim needs benchmarking context — what workload, what comparison baseline, and whether it holds under the WASM JIT. Worth watching for the storage format specification and durability guarantees, which are not detailed in the current description.
Source: https://github.com/SouravRoy-ETL/slothdb
jmerelnyc/Photo-agents
A computer-use agent framework built around vision-grounded layered memory and runtime skill synthesis. The system lets LLM agents operate a desktop environment — capturing screenshots, issuing UI interactions — while maintaining a structured memory hierarchy that separates working context, episodic recall, and a library of self-written callable skills.
The self-evolving aspect refers to the agent writing Python (or similar) skill functions during execution, persisting them to a skill store, and retrieving relevant ones via embedding similarity on future tasks. This is the same core mechanic as Voyager and related work: code-as-skill accumulation to avoid re-solving identical subproblems. The vision grounding anchors skill retrieval and memory queries to screen-state observations rather than purely text descriptions, which reduces hallucination about UI element positions.
Key engineering questions for a production use case are skill invalidation (UI layouts change, breaking stored code), the memory retrieval latency budget within an action-observation loop, and safety boundaries around what actions the agent can execute. The repository is early-stage, so evaluation against standard computer-use benchmarks (OSWorld, ScreenSpot) is not yet documented. Relevant for anyone building long-horizon desktop automation where repeated task structure can be exploited.
Source: https://github.com/jmerelnyc/Photo-agents
alash3al/stash
Stash is a self-hosted agent memory layer backed by Postgres, distributed as a single binary with an MCP (Model Context Protocol) server included. It organizes memory into three tiers: episodes (timestamped interaction sequences), facts (extracted declarative statements), and working context (short-horizon scratchpad). All three live in Postgres, giving you standard SQL tooling for inspection, backup, and querying without a proprietary storage format.
The MCP integration means any MCP-compatible client — Claude, or frameworks like LangChain with an MCP adapter — can read and write memory through a standard protocol without custom API glue. The single-binary deployment eliminates the orchestration overhead of running a separate vector database alongside a relational store; Postgres with pgvector handles both structured queries and approximate nearest-neighbor retrieval.
The episodic/fact/working-context separation is a reasonable approximation of cognitive memory architecture and maps well to the actual retrieval patterns agents exhibit: recent context needs low-latency access, facts need semantic search, and episodes need temporal ordering. Limitations to evaluate: how fact extraction is done (rule-based, LLM-called, or user-supplied), whether there is automatic context pruning to stay within token limits, and the write-path latency under concurrent agent sessions.
Source: https://github.com/alash3al/stash
mukul975/cve-mcp-server
A production-oriented MCP server that exposes 27 security intelligence tools to MCP clients, aggregating data from 21 external APIs in a single interface. Covered sources include NVD CVE lookup, EPSS (Exploit Prediction Scoring System) probability scores, CISA Known Exploited Vulnerabilities catalog, MITRE ATT&CK technique mappings, Shodan host intelligence, and VirusTotal file/URL reputation.
The value here is aggregation and protocol normalization. Security analysts currently pivot between these APIs manually, each with different authentication schemes, rate limits, and response schemas. Wrapping them under MCP lets a Claude session (or any MCP client) compose multi-step triage workflows: look up a CVE, check its EPSS score, verify whether it is in CISA KEV, cross-reference affected hosts via Shodan, all within a single reasoning trace without brittle hand-written API chains.
Production-grade claims warrant scrutiny: rate limit handling, API key management, error propagation, and caching strategy for high-cardinality lookups like CVE bulk queries all matter. The EPSS integration is particularly useful — EPSS base scores combined with KEV membership give a fast two-signal triage filter. Useful as infrastructure for LLM-assisted vulnerability management pipelines.
Source: https://github.com/mukul975/cve-mcp-server
Avarok-Cybersecurity/atlas
Atlas is a pure-Rust inference engine for large language models. Writing an inference engine in Rust rather than C++ (the dominant choice in llama.cpp, TensorRT, etc.) trades the mature CUDA ecosystem for memory safety guarantees, cleaner FFI boundaries, and better tooling for systems that need to embed inference in larger Rust applications without C ABI friction.
The pure-Rust framing implies either custom CUDA kernel bindings via Rust CUDA wrappers (cudarc, wgpu, or similar) or a compute backend abstraction layer. The architecture decisions that matter most at this stage are: which backends are supported (CUDA, Metal, CPU SIMD), what quantization formats are implemented (GGUF, AWQ, GPTQ), and whether the execution graph is static or dynamic. These determine whether Atlas is competitive on throughput with existing engines or primarily a correctness and safety story.
The Avarok-Cybersecurity origin suggests this may be aimed at deployment contexts where supply-chain trust and memory safety matter more than raw throughput — embedded security appliances, air-gapped systems, or contexts where C/C++ dependencies are a compliance concern. Worth watching for benchmark numbers against llama.cpp on equivalent hardware; that is the comparison that will reveal where the tradeoffs land.
Source: https://github.com/Avarok-Cybersecurity/atlas
smaramwbc/statewave
Statewave is a self-hosted agent memory runtime, also Postgres-backed, focused on durable structured context with provenance tracking. The provenance angle differentiates it from generic vector stores: every stored memory record carries metadata about where it came from, when it was written, and by which agent or session. This creates an audit trail for agent reasoning that is absent from most memory libraries.
Structuring context with provenance matters for debugging multi-agent pipelines and for cases where agents might overwrite or contradict earlier stored beliefs. With provenance, you can detect when a memory was last updated, whether it was written by a trusted source, and reconstruct the belief state of an agent at any prior point in time — useful for post-hoc analysis of failure modes.
The Postgres backend means the provenance metadata is queryable with standard SQL joins rather than requiring a specialized graph or document store. Limitations similar to Stash apply: the interesting implementation details are in how cross-session context is structured and pruned, how similarity search is implemented (pgvector is the likely choice), and what the write throughput looks like under concurrent agent workloads. Distinct from Stash mainly in its emphasis on provenance metadata as a first-class design goal.
Source: https://github.com/smaramwbc/statewave
mathomhaus/guild
Guild coordinates shared memory and task delegation across multiple AI coding agents, distributed as a single Go binary using local SQLite. The core technical contribution is a hybrid retrieval system combining BM25 keyword search with dense vector semantic search over a shared context store, letting agents retrieve relevant prior work both by exact token match and by semantic similarity.
The multi-agent coordination problem in coding contexts is non-trivial: agents working on different files or modules need to share type definitions, API contracts, and completed task summaries without passing the entire codebase through each agent’s context window. Guild’s shared context store is the coordination primitive — agents write structured summaries of completed tasks and read from each other’s outputs via the hybrid retrieval layer.
SQLite as the backing store keeps the deployment footprint to a single binary with no external dependencies, which matters for local development use. The limitation is that SQLite write serialization becomes a bottleneck under high-concurrency agent swarms. The Go implementation is a sensible choice for a coordination daemon: lightweight goroutines map well to managing multiple concurrent agent sessions. The open question is the task schema — how tasks are structured, how dependencies between tasks are represented, and whether there is a scheduler or simply a shared queue.