デイリーAIダイジェスト — 2026-06-19
arXiv ハイライト
静的リーダーボードを超えて:LLMエージェント評価における予測妥当性
本稿は、MCPベースの産業用エージェントベンチマーク(AssetOpsBench)に関する14件の並行実装研究と、7件の先行エージェントベンチマークを統合したポジションペーパーです。主張は構造的なものです。すなわち、集約スコアによるリーダーボード(HELMスタイル、Pass@1の平均値、マルチメトリクスダッシュボードを含む)は、デプロイメントが曝す評価空間を体系的に不十分にしか記述できておらず、正しいランキング基準はインサンプルの平均値ではなく、予測妥当性——インサンプル評価とアウトオブサンプル評価の間のランク相関——であるというものです。
集約スコアへの反論
著者らは、Pass@1で同一スコアを示しながら質的に異なる構成を集約が隠してしまう具体的な事例を三つ挙げています。第一に、Gemma-4-26BプランナーにおいてAssetOpsBenchの40シナリオ上でextended thinkingのオン・オフを切り替えると、全体的なルーブリック平均はほぼ変わらないものの、明瞭性が31パーセントポイント(61% → 92%)改善し、幻覚が7ポイント(12% → 5%)低減します。一方、データ検索とエージェントシーケンスの正確性は変化しません。レイテンシはエンドツーエンドで21.5%増加し(15.08秒 → 18.32秒)、プランニングレイテンシは41.9%増加します。単一の平均値は、局所的な品質向上とそのコストの両方を覆い隠してしまいます。第二に、Plan-ExecuteアーキテクチャとSupervisor-SpecialistアーキテクチャはシングルターンのPass@1では一致しますが、ターン2〜5のレイテンシにおいてクロスターンのアーティファクト再利用により 4.2\times の差が生じます。これはシングルターンベンチマークでは捉えられない次元です。第三に、シングルパスRAGは精度50〜68%に留まる一方、エージェント的なマルチホップ検索は約90%に達しますが、トークン消費量が 4.5\times〜10\times 膨張します。デプロイメント制約なしにはどちらが優れているとも言えません。
より深い主張は、スカラーのリーダーボードが直交する軸(推論モード、検索戦略、オーケストレーション、トランスポート)を一括してしまい、結果として勝因の帰属を誤らせるというものです。SmartGridBenchの実験(2,420軌跡)はこれを外科的に示します。エージェントを固定したうえでトランスポート(directとMCP-stdio)とオーケストレーション(Plan-Execute、Verified PE、Self-Ask)を独立して変化させると、MCP標準化は品質向上なしにレイテンシを増加させる一方、オーケストレーションのみでパス率が43.2%から55.5%に向上することが示されます。トランスポートとオーケストレーションを分離しないリーダーボードは、オーケストレーションによる勝利を、たまたま変化していた軸に帰属させてしまいます。
12階層のフレームワーク
統合セクションでは、先行ベンチマーク(SWE-Bench、\tau-Bench、TaskBench、MCP-Bench、MCP-Universe、ARE、AssetOpsBench)と14件の拡張研究から統合した12階層に測定を整理しています。T1〜T7はコア能力階層です。すなわち、成功率、ツール呼び出しの衛生状態、プランニング品質、能力軸、コスト/効率パレート、失敗モードの分類、再現性/整合性です。T8〜T12はデプロイメント拡張階層であり、現在のリーダーボードのほぼすべてに欠落しています。具体的には、デプロイメントインフラ、マルチターン対話、推論モードの適応性、知識拡張、およびjudge非依存検証付きエビデンスグラウンディングです。階層図に付随する経験的主張は、いかなる先行単一ベンチマークも4〜5階層以上をファーストクラスメトリクスとして報告していないというものです。
ランキング基準としての予測妥当性
運用上の核心は、インサンプル平均を三つのOOD基準にわたる \rho(\text{rank}_{\text{in}}, \text{rank}_{\text{out}}) に置き換えることです。基準A(軽度のシフト)は、サブセットとカテゴリの結合分布を保持した層化ランダム分割です。これは弱いテストであり、失敗は致命的ですが合格は情報量が低いです。基準BとCは保留シナリオクラスと敵対的摂動へとエスカレートします(論文はこれらをポジション自体の反証可能な閾値として位置づけています)。この根拠は、最近の公開-非公開コンペティション事後分析がすでに直接的なランク不安定性を示していることです。公開スプリットで学習したリーダーボードは非公開スプリットのランキングを予測できないため、インサンプル平均はデプロイメントアドバイスのアーティファクトとして誤った目標であることが証明されています。
具体的なリーダーボード提案
三つの実装上の改善策が続きます。(1) 宣言された構成列:すべての提出物はArchitecture、Reasoning Mode、Retrieval Strategy、Prompt-Constraint Level、Verifier Typeを報告しなければなりません。なぜなら、各々が帰属を変える非空の軸だからです。(2) 少なくとも一つのOOD基準における予測妥当性スコアでランク付けし、インサンプル平均は一列として扱います。(3) judge非依存のアンカーを必須とします——少なくとも一つの軌跡レベルの決定論的検証器(ルールパイプライン、DAGオラクル)により、LLM judgeのドリフトを検出可能にします。四つ目のフィールドレベルの推奨事項は、14件の研究のうち三件が独立して同定したものとして浮上したもので、ベンチマークインフラからstdioベースのMCPを廃止することです。プロトコルオーバーヘッドが現在レイテンシのフロアを支配しており、あらゆるコストメトリクスにおいて推論能力と混同されています。
限界とオープンクエスチョン
12階層の直交性の主張は明示的に作業仮説であり、論文は経験的な独立性(例:階層スコアの因子分析)を確立しておらず、これを今後の研究に委ねています。14件の研究は制度的文脈を共有しているため、著者らはその収束を独立した再現ではなく「アーキテクチャ感度」と正しく表現しています。AssetOpsBench以外のドメインへの一般化は主張されているものの、示されてはいません。予測妥当性の提案はまた、評価コストを集中させます。非公開スプリット、敵対的スイート、決定論的検証器の維持にはコストがかかり、十分なリソースを持つ機関に評価が集中するリスクがあります。著者らはこの懸念を指摘していますが、解決はしていません。最後に、三つのOOD基準はアブストラクトに閾値付きで記述されていますが、論文は統合された6,000軌跡コーパスに対して完全な予測妥当性プロトコルを実行するには至っておらず、それが明白な次の実験です。
なぜこれが重要か
エージェントのリーダーボードはデプロイメント意思決定のアーティファクトとしてますます使用されていますが、公開-非公開事後分析からのランク不安定性の証拠は、スカラー平均が転移しないことを示しています。インサンプル平均を予測妥当性に置き換え、構成軸と軌跡レベルの検証器を宣言することは、リーダーボードのインセンティブを実際にデプロイされたエージェントが評価される基準に合わせる低コストの構造的修正です。
Source: https://arxiv.org/abs/2606.19704
ENPIRE: 実世界におけるエージェント型ロボットポリシーの自己改善
問題設定
実世界における巧みな操作(dexterous manipulation)の進歩は、コントローラのチューニング、報酬設計、知覚のデバッグ、シーンのリセット、学習コードの反復といったヒューマン・イン・ザ・ループのアルゴリズムエンジニアリングによってボトルネックが生じています。コーディングエージェント(Codex、Claude Code、Kimi Code)は、デジタル研究の相当部分を自動化していますが、そのフィードバックループは決定論的かつ副作用のない環境に限定されています。物理的な自律研究(autoresearch)は非決定論的な世界との反復可能なインタラクションを要求します。すなわち、シーンはリセットされなければならず、結果は検証されなければならず、エージェント主導の最適化ループが実行される前に安全性が確保されなければなりません。ENPIREは、コーディングエージェントが人間の監視なしに実世界の成功率をヒルクライミングできるよう、まさにその抽象化を提供するハーネスを提案しています。
手法
ENPIREは物理的な自律研究を2つのステージに分解しており、その名称を反映しています。すなわち、EN(ヒューマンフィードバックからの環境構築)とPIRE(ポリシー改善・ロールアウト・進化)です。
ステージ1 — 環境構築。 コーディングエージェントは、以下を備えたロボットスタックをラップする環境APIを手続き的に合成します。(i) 違反が打ち切りと自動リセットをトリガーする、キネマティクスおよび構成空間のハード安全制約、(ii) エピソードごとの報酬を生成する自動検証器、(iii) 自動リセット機構。人間は生成されたAPIを一度評価し、エージェントがそれを洗練させます。このコストはすべてのロボットにおける後続の自律研究全体にわたって償却されます。
検証器はタスク固有であり、知覚プリミティブから構築されます。例えばジップタイ切断の場合、2つのカメラビューをクロッピングおよびセグメンテーションして、ストラップがまだヘッドを通過しているかどうかをテストし、偽陽性を抑制するためにビュー間で冗長性を持たせています。

ステージ2 — PIREループ。 環境が reset → execute → verify APIを公開すると、エージェントは以下のクローズドループに入ります。
- Policy Improvement (PI): エージェントが学習インフラ、ハイパーパラメータ、またはポリシーコードを編集します。
- Rollout (R): 1台または複数の物理ロボットが候補ポリシーを並列に実行し、各ロールアウトは検証器の報酬と軌跡ログを返します。
- Evolution (E): エージェントがログを取り込み、ツール呼び出しを通じて文献を参照し、失敗モードを診断し、次のコードリビジョンを出力します。
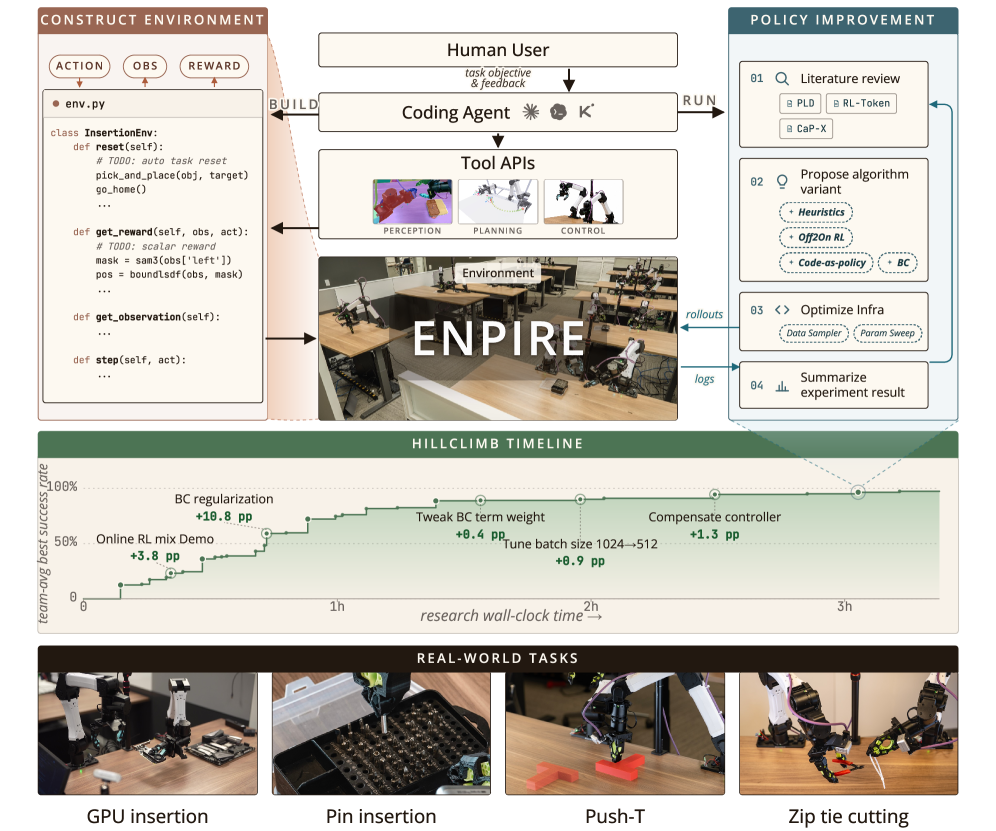
エージェントは単一の学習パラダイムに限定されません。知覚/制御ツール呼び出しからヒューリスティックポリシーを合成したり、behavior-cloningネットワークを学習したり、実世界のRLを実行したり、あるいはこれらを組み合わせたり(例えば、学習された残差を持つヒューリスティックスケルトン)することができます。成功はトライアルあたり8回の連続リトライ内の完了としてスコアリングされます。リトライは前のリトライの失敗を観測するため、このメトリクスは文脈内での回復を評価するものであり、単なるi.i.d.のbest-of-N精度ではありません。
\text{Success} = \Pr\!\left[\exists\, k \le 8 : \text{trial}_k \text{ succeeds} \mid \text{trial}_{<k} \text{ observed}\right].
ハードウェアプラットフォームは両腕6-DoFのYAMロボットです。タスクとしては、Push-T(非把持的な位置合わせ)、4 mmの穴へのピン挿入、GPUチップのソケット挿入、ハサミを用いたジップタイ切断が含まれます。
結果
シミュレーション上のGym-PushTでは、3つのエージェントすべてが収束しています。Claude CodeとCodexは、壁時計時間で約2時間の自律研究で成功率95%に達し、Kimi Codeはおよそその2倍の時間で同じレベルに到達します。
シミュレーションと現実の間のギャップが主要な知見です。実世界のPush-TセットアップではA3つのエージェントのうち2つが完全に失敗しました。非決定論的な接触摩擦、ロボットダイナミクス、物体の微小な動きが、シミュレータが提供する低分散の仮説検証レジームを崩してしまいます。これはヒューリスティックのみのポリシー合成が実世界では脆弱であることを示しており、エージェントのツールキットに勾配ベースの学習を組み合わせることの動機付けとなっています。
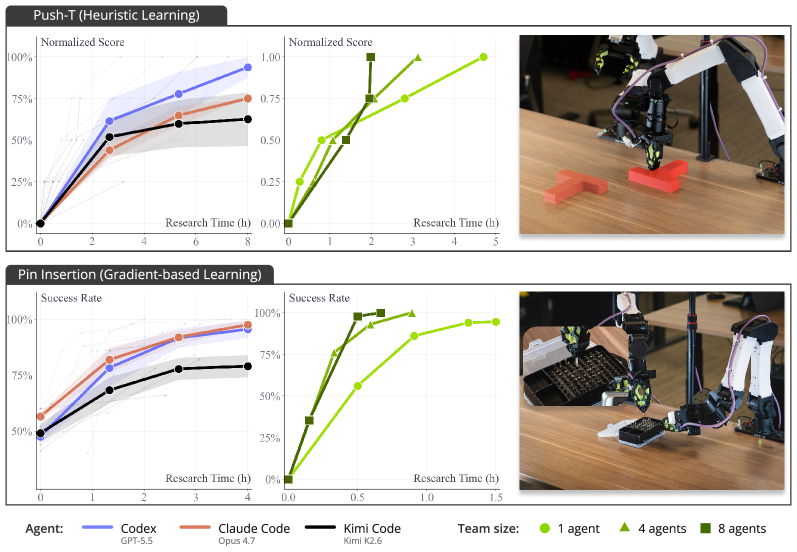
第2の主張はリソーススケーリングです。ロールアウトモジュールが複数の物理ロボットに並列でディスパッチする場合、目標成功率に到達するまでの壁時計時間はワーカー数の増加とともに単調に減少する一方、エージェント側のトークン消費量は探索自体の収束速度をスケールさせます。したがって、このフレームワークは2つの直交する計算軸 — 物理スループット(ロボット)と推論スループット(トークン) — を公開しており、いずれもPush-Tおよびピン挿入におけるポリシー達成時間に実質的な影響を与えます。
限界と未解決の問題
論文は提供された抜粋においてGPU挿入やジップタイ切断の最終的な成功率の数値を報告しておらず、実世界のPush-Tにおけるヒューリスティックのみの失敗は、現在のエージェントが勾配ベースの実世界RLを確実に駆動するためにはまだ相当なスキャフォールディングを必要とすることを示唆しています。ステージ1の環境構築はループ内に人間の評価者を必要とし続けており、安全制約の仕様はタスク固有であるため、新しい操作スキルへの汎化性は不明確です。8リトライ成功メトリクスは一発精度と回復能力を混在させており、デプロイメントには望ましいものの、従来のbest-of-Nベンチマークとの比較を曖昧にしています。最後に、検証器自体が学習/エンジニアリングされた知覚パイプライン(例えば、デュアルビューセグメンテーション報酬)であり、不完全な検証器に対するreward hackingは既知の失敗モードですが、論文ではストレステストを行っていません。
なぜ重要か
ENPIREは、コーディングエージェントがデジタルベンチマークですでに行っているのと同じヒルクライミングを実世界でも行えるようにする欠けていたプリミティブ — 反復可能な物理フィードバックループ — を実用化しています。スケーリングの主張がPush-Tを超えて成立するならば、ロボットフリートの稼働時間とエージェントトークンは操作ポリシーの生産関数における代替可能な入力となり、巧みなスキル習得を職人的なエンジニアリングタスクからリソース投入可能な自律研究へと転換させることになります。
Source: https://arxiv.org/abs/2606.19980
現在のWorld ModelはPersistent Stateのコアを欠いている
問題
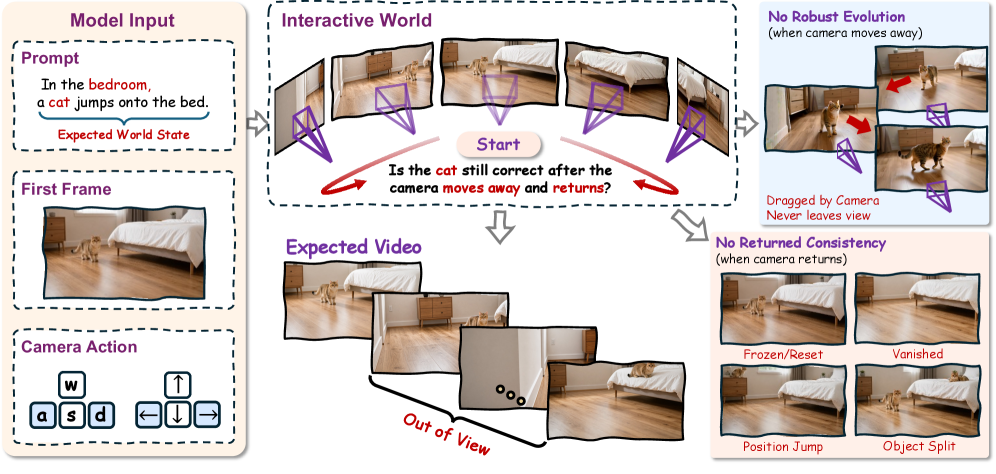
「World model」として販売されている生成動画モデルは、フレーム内に留まるもの、すなわちピクセルの忠実度、動きの妥当性、カメラの制御可能性についてほぼ完全に評価されています。これらのいずれも、カメラが視線を外したときに潜在的なworld stateが継続的に変化し続けるかどうかをモデルが維持できるかを検証するものではありません。古典的なテスト——誰も見ていないとき、月は軌道上に留まり続けるか?——は、現在のベンチマークには類似物が存在しません。本論文はWRBenchを導入し、カメラの動きを観測可能性への介入として扱い、一度隠されて再観測されたターゲットが、当初発動されたイベントと整合しているかどうかを問います。
手法
WRBenchは4層の診断スイートです。評価の原子単位は動画やプロンプトではなく、event-view record
r_i = (x_i^0, e_i, \tau_i, \nu_i, \pi_i),
であり、x_i^0は初期観測、e_iは指定されたイベント、\tau_iは意図された視点介入、\nu_iは可視性レジーム(可視 / 隠蔽 / 隠蔽後再観測)、\pi_iはプロンプトまたはインターフェースのバリアントです。重要なのは、プロンプトが初期シーン、イベント、視点要求を指定するものの、終端状態を決して明かさない点であり、そのため生成された動画自体が再観測された状態に関するあらゆる主張の証拠を担わなければなりません。これにより、プロンプトが答えをエンコードするような言語モデル式のショートカットが防止されます。
Natural-25プロンプトスイートは19の会場から抽出した25のシーンファミリーを提供し、空間的変位と状態変化を因子とした2×2のイベント設計と組み合わせています。WRBenchLibは各recordを各生成器に送出し、実際に生成されたもの(意図された視点 対 実際に得られた条件 対 生成された動画 対 測定証拠)をログに記録します。6次元評価スイートは以下を採点します:要求されたカメラ精度(CamPrec、厳密なローカル制御)、共通ヨーのプロンプト・カメラアライメント(CamAlign)、視覚的整合性(Integ.)、可視空間的一貫性、可視状態一貫性、再観測空間的一貫性、および再観測状態一貫性です。再観測メトリクスは判断可能な隠蔽後再観測証拠の存在を条件とし、支持率を別途報告することで、アクセス(ターゲットが判断可能なビューで再び現れるか?)と正確性(再び現れたターゲットはイベントの終端と整合しているか?)を切り離しています。各軸は独立して人手による選好アノテーションによってキャリブレーションされます。
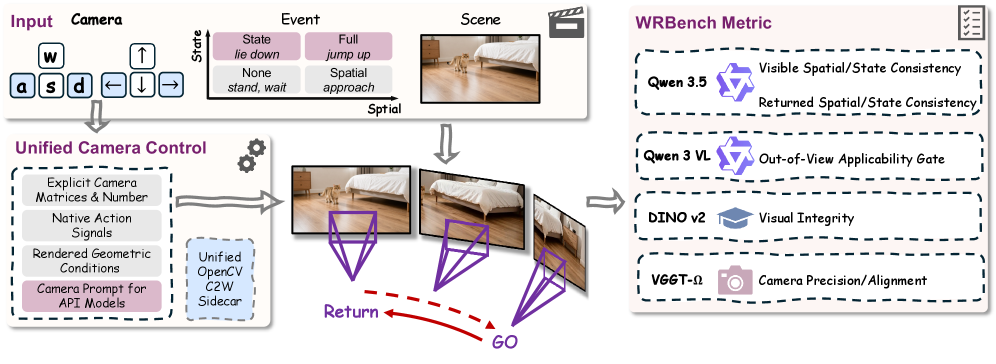
モデルは視点条件タイプによってグループ化されます:source-video(カメラ軌道が参照動画として与えられる)、geometry-cache(3D/深度キャッシュがカメラ制御を仲介する)、model-inferred(カメラの潜在変数がプロンプトから推論される)、prompt-onlyです。これらのパラダイムは消費する制御信号が異なるため、best/second-bestはグループ内で計算されます。
結果
ベンチマークは23モデルからの9,600本の生成動画をカバーしています。主要な結果として、現在のシステムは可視継続の保持 → カメラ動作の実現 → 隠蔽されたターゲットの再露出 → 再観測された終端の保持という連鎖を通じて能力に差異があり、最後のリンクで最も急激に性能が低下します。
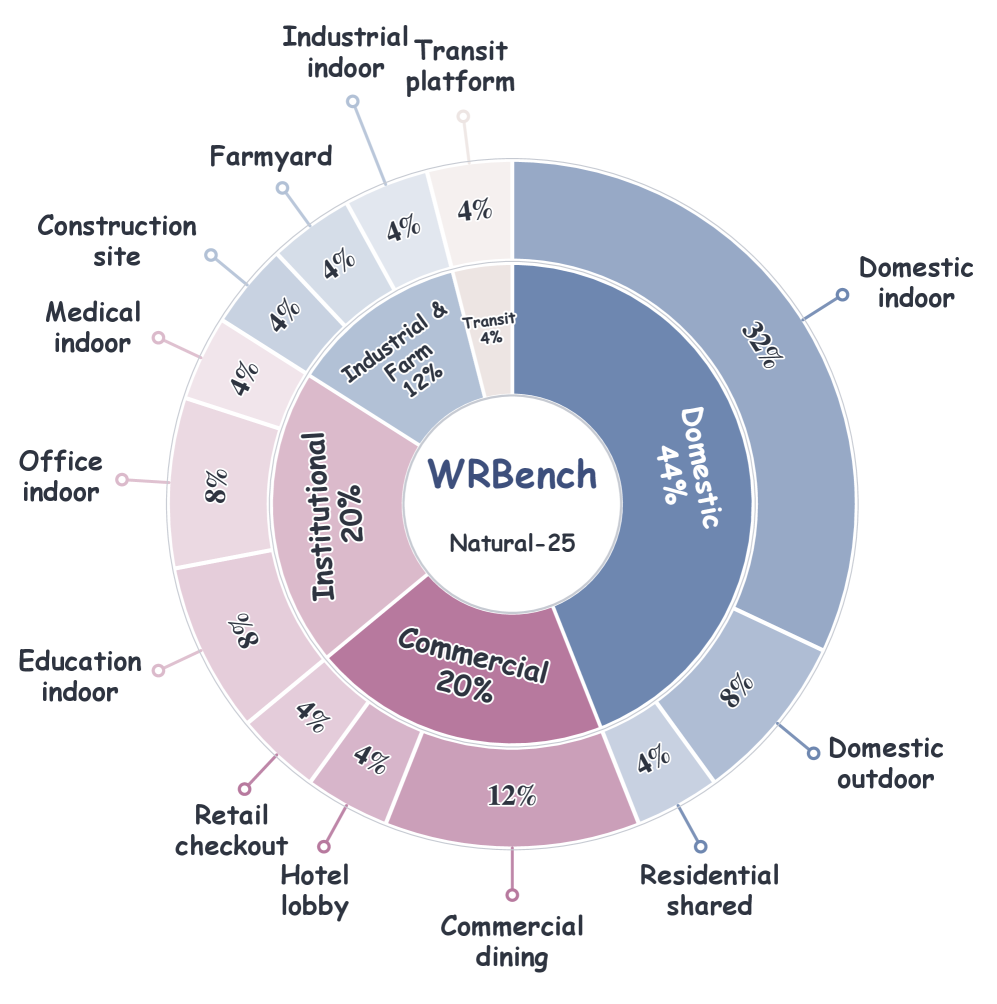
モデルレベルのプロファイル(表2、6メトリクス平均を括弧内に記載)からの具体的な数値:
- Source-video条件。 InSpatio World 14BはInteg. 0.824、可視空間0.821で最も強力ですが、再観測空間は0.734、再観測状態は0.664に低下します(Avg. 0.729)。HyDRAは最高のCamPrec(0.822)とCamAlign(0.855)を達成しますが、再観測状態で崩壊(0.445)し、再観測support率はわずか33.2%です。ReCamMasterはその中間に位置し(Avg. 0.667)、58.5%のsupportを示します。
- Geometry-cache条件。 Gen3Cはグループ内で最高の再観測support率73.0%を達成し、再観測空間0.681、再観測状態0.640です(Avg. 0.686)。VerseCrafterは最良のInteg.(0.846)を持つもののsupportは28.0%に留まり、Spatiaはsupport率25.8%、再観測状態0.586まで低下します。
- Model-inferred条件。 Wan-Funのバリアントは非常に低い再観測support率を示します——18.2%(2.1-14B)、13.8%(2.1-1.3B)、12.0%(2.2-5B)——これは明示的なカメラ信号がない場合、カメラが隠蔽されたターゲットの判断可能なビューにほとんど戻らないことを示しています。利用可能な場合の条件付き再観測スコアは中間レベルです(状態については0.621〜0.657)。
繰り返されるパターン:可視空間的一貫性は常に可視状態一貫性より高く、再観測スコアは判断可能な再観測を条件とした後でも可視スコアを下回ります。強力なカメラ実行(HyDRAの0.822 CamPrec)は終端バインディングを意味しません(0.445 再観測状態)。逆に、高い整合性スコアを持つモデルは再観測support率が低い傾向があり、困難なテストに合格するのではなく回避していることを意味します。
限界とオープンな問題
再観測メトリクスは条件付き集計です:判断可能な隠蔽後再観測ビューをほとんど生成しないモデル(Wan-Fun 2.2-5Bはsupport率12.0%)は、小規模で場合によっては有利なサブセットで採点されており、sparse supportに対して報告された\daggerフラグはこれを認めています。ベンチマークはまだ終端の失敗を機械的な原因(誤った動力学ロールアウト 対 遮蔽前の状態に関する健忘 対 再観測時の新しい妥当なシーンの再サンプリング)に分解していません。Natural-25のバランスの取れた因子設計は、頻度的に現実的なシーン分布を過小評価しているため、絶対的なスコアは実世界のデプロイとの直接比較には適しません。
なぜこれが重要か
「world model」がカメラ条件付きの「video prior」以上の意味を持つとすれば、生成器は遮蔽を通じて潜在状態を維持しなければならず、ベンチマークはそれを明示的に測定する必要があります——可視的な忠実度に報酬を与えるのではなく。WRBenchはpersistent stateの要件を操作化し、4つの制御パラダイムのいずれにおいても現在のモデルがこれをクリアに通過しないことを示しています——遮蔽下での終端バインディングがオープンなフロンティアです。
Source: https://arxiv.org/abs/2606.20545
Moebius: 10Bクラスの性能を持つ0.2B軽量画像インペインティングフレームワーク
問題設定
産業規模のインペインティングモデル(FLUX-Fill、SD3-Fill、およびそれに類する10Bパラメータの汎用モデル)は最先端の忠実度を実現しますが、デプロイには現実的ではありません。当然の対応策——タスク固有の専門家モデルを学習する——は表現のボトルネックという問題に突き当たります。標準的な拡散U-Netにおける積極的な幅・深さの削減は、グローバルな意味的アライメントとローカルなテクスチャの整合性の両方を劣化させます。MoebiusはこのボトルネックにをDirect的に取り組み、LCGベースの意味的conditioningを保ちながら0.3B未満のパラメータ数を目指しています。
手法
バックボーンは標準的なlatent diffusionの構成に従います。SDXL VAEがxとマスクされた画像x_m = x \odot (1-m)をエンコードし、マスクされたlatent z_m=\mathcal{E}(x_m)をダウンサンプリングされたマスクと連結して空間参照z_sを形成し、U-Net \epsilon_\thetaがz_tをdenoisingするように学習されます。グローバルな意味情報はLatent Categories Guidance embedding \mathbf{E}_{\text{LCG}} \in \mathbb{R}^{K\times D}を通じて注入され、PixelHackerがteacherとして機能します。
新規性はLocal-\lambda Mix Interaction(L\lambdaMI)ブロックにあります。これは空間的self-attentionと\mathbf{E}_{\text{LCG}}へのcross-attentionの両方を、コンテキストを固定サイズの線形行列に圧縮する2つの\lambdaスタイルのオペレーターに置き換えます。
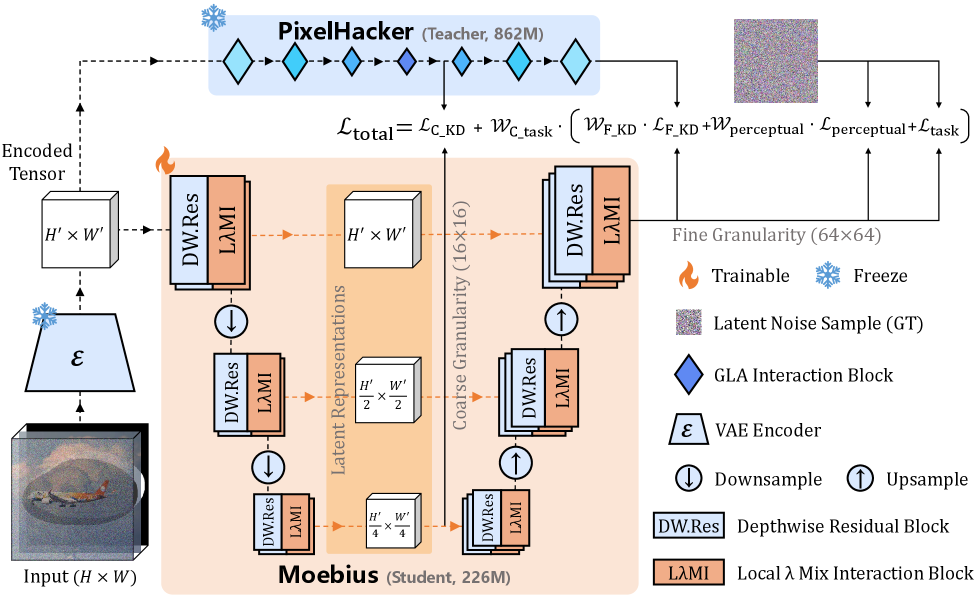
このブロックは3つのサブモジュールから構成されます。空間的集約のためのLocal-\lambda、LCG priorとのcross-attentionのためのInteractive-\lambda、そしてMix-FFNです。
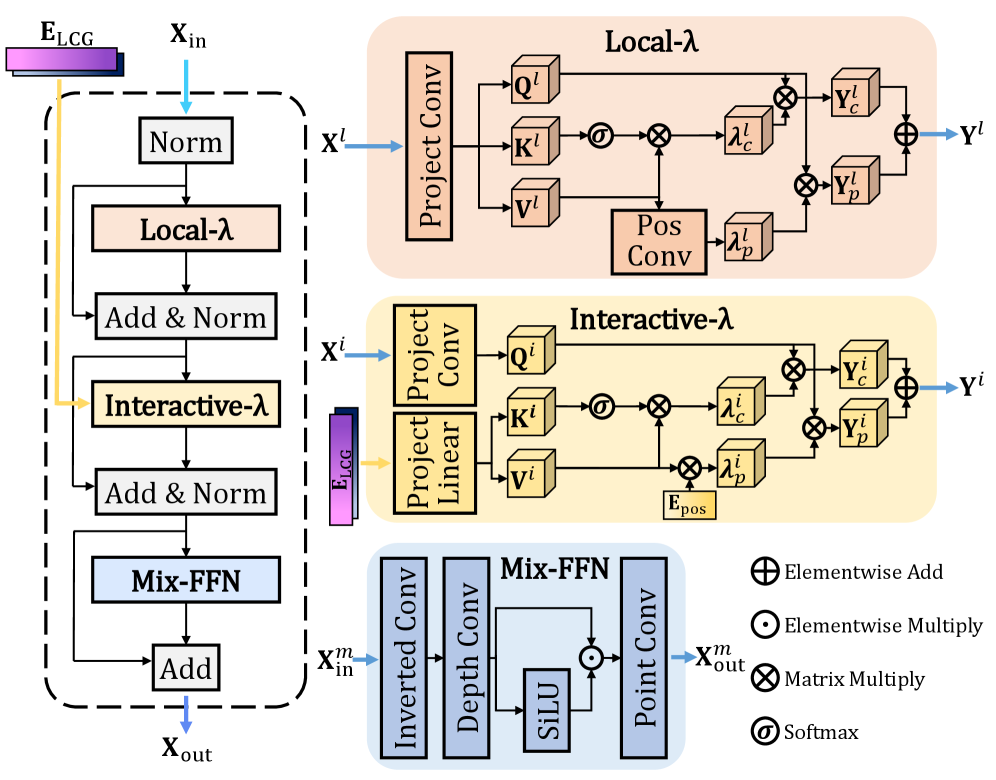
図3に示される重要なトリックは、NトークンにわたってQK^\top Vを計算する——self-attentionではO(N^2 D)、cross-attentionではO(NKD)——代わりに、両方の\lambdaモジュールがkeys/valuesをすべての空間的クエリに適用されるD \times D(またはそれに類する)の線形行列に集約する点です。Local-\lambdaではこれをグローバルではなく半径r=15の知覚ウィンドウ内で行い、Interactive-\lambdaでは\mathbf{E}_{\text{LCG}}のトークン全体(サイズK)をすべての空間的クエリで共有される単一のコンテンツ行列に折り畳みます。
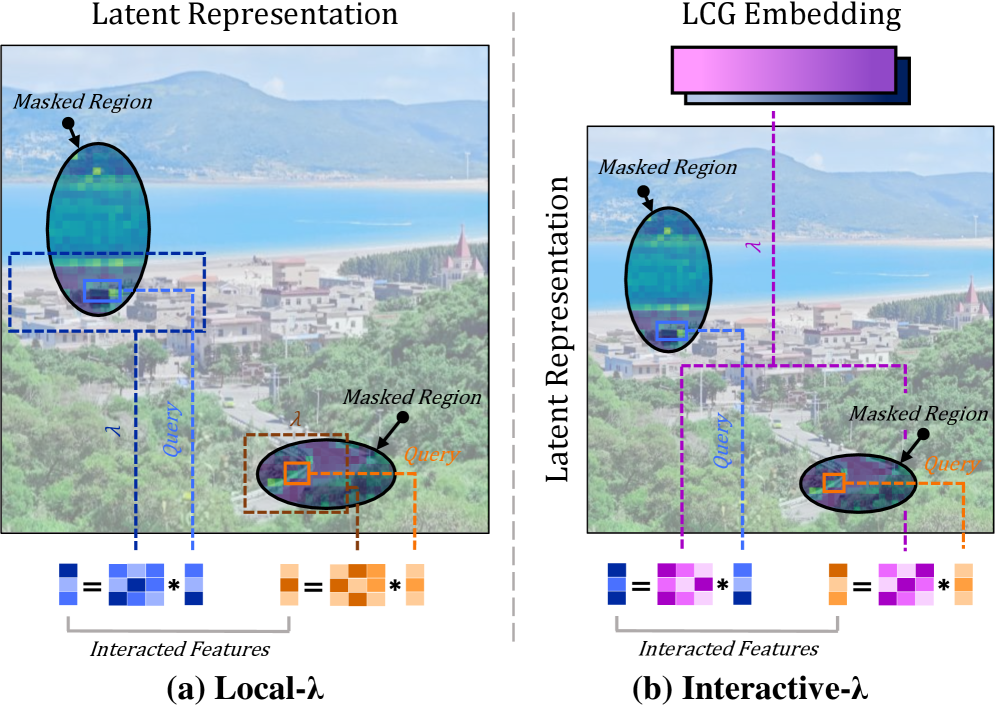
これにより二次的なattention mapの計算を完全に回避でき、depthwise convのバリアントがteacherを追跡しながら226Mパラメータ・154 GFLOPsまで削減できる理由です(Tab. 2、9行目)。
2つ目の要素は、latent空間のみで動作するadaptive multi-granularity distillation lossです(学習ループ内でのVAEデコードなし)。studentは複数の粒度でのgradientベースのlossを動的に重み付けした組み合わせによってPixelHackerとアライメントされます。重みは手動チューニングではなくadaptiveにバランスされます。optimizerはweight decay 0.1のMuon、16×L40S上でbatch 768、BF16、138Kイテレーション学習し、LR 2\times 10^{-4}は111Kと129Kで0.1倍に減衰します。
定量的結果
Places2上のアーキテクチャアブレーション(18Kイテレーションのチェックポイント)が、ボトルネックの主張に対する最も明確な証拠です。標準的な予測loss(KDなし)では、GLA-CA-FFNベースラインは526MパラメータでFID 32.75 / LPIPS 0.298を達成します(1行目)。Local-\lambdaのみ(2行目)またはInteractive-\lambdaのみ(3行目)に置き換えると実際に性能が低下し、FIDはそれぞれ37.65と36.91に上昇します。これは一方のパスのみを圧縮すると表現が壊れることを示しています。両方を組み合わせる(6行目、L\lambda-I\lambda-FFN)と、485MでFID 33.21 / LPIPS 0.286に回復し、ベースラインをわずかに上回ります。
distillationを加えると状況が一変します。7行目(同じアーキテクチャ、KDあり)はFID 24.73 / LPIPS 0.257まで低下し、KDだけで8ポイントのFID向上を達成します。depthwise convolutionとMix-FFNを用いた完全圧縮構成(9行目)は226Mパラメータ・154 GFLOPsでFID 26.43 / LPIPS 0.258に達し、ベースラインのおよそ半分のパラメータ数とFLOPsで実質的に優れた指標を示します。同じアーキテクチャからKDを除去すると(10行目)、FID 33.42まで性能が崩壊し、コンパクトなバックボーンが標準的なノイズ予測目的関数だけでは収束まで学習できないことを確認します。
0.2Bという主要指標はこの圧縮構成を指します。論文ではbenchmark固有のfine-tuning後(Places2: 51Kイテレーション、batch 88;CelebA-HQ: 60Kイテレーション、batch 44;FFHQ: 117Kイテレーション、batch 88)にPlaces2、CelebA-HQ、FFHQにわたって10Bクラスの汎用インペインターと同等の性能を主張しています。
限界と今後の課題
補足資料では、極端な構造的圧縮下での失敗ケースを明示的に認めています——r=15のLocal-\lambdaウィンドウと折り畳まれたInteractive-\lambdaサマリーが、full attentionが保持する情報を失ってしまうような長距離の整合性ある補完のケースです。強力なteacher(PixelHacker)への依存は完全です。10行目と9行目の比較が示すように、このアーキテクチャはdistillationなしでは本質的に学習不可能であり、これはゼロからの学習結果ではなく圧縮の結果です。今後の課題としては、\lambdaベースのサマリーがインペインティング以外のconditionalタスクに汎化するかどうか、知覚ウィンドウrへの感度、adaptive loss-balancingスキームが他のstudent/teacherペアに転用できるかどうかが挙げられます。CFG scaleのアブレーションとOOD評価は補足資料に委ねられています。
この研究の意義
Moebiusは、コンパクトな拡散インペインターのボトルネックが容量理論的なものではなく表現的なものであることを明確に示しています。線形attentionスタイルの\lambdaオペレーターとlatent空間でのdistillationを組み合わせることで、パラメータ数約2%ながら10Bモデルとのギャップの大半を埋めています。実務家にとって、「専門家モデル + latent空間でのdistillation」は汎用インペインターをさらにスケールするよりも生産的なデプロイレシピであることを示唆しています。
Source: https://arxiv.org/abs/2606.19195
DragMesh-2: 多関節物体に対する物理的に妥当な巧みな手と物体のインタラクション
問題設定
多指ハンドによる多関節物体の操作は、剛体把持とは構造的に異なります。対象の自由度(引き出しのスライド、扉のヒンジなど)にはアクチュエーションチャネルが存在しないため、その運動はハンドとハンドルの接触力を持続的に加えた結果として生じます。物体中心の軌道生成器が妥当なパーツ運動を生成しても、それをハンドにオープンループで再生することはできません。なぜなら、ハンドはパーツを拘束多様体に沿って引っ張るために常に正しいレンチを印加し続けなければならないからです。固定ダイナミクス下でタスク完了を目的に学習されたポリシーは、特に触覚や力入力がない場合、名目上の接触荷重に過学習しやすく、関節の減衰が変化した際に性能が急激に低下します。DragMesh-2は、多関節物体の生成とハンドによる多関節実行との間のギャップに取り組み、接触荷重変化に対するストレステストを明示的に行います。
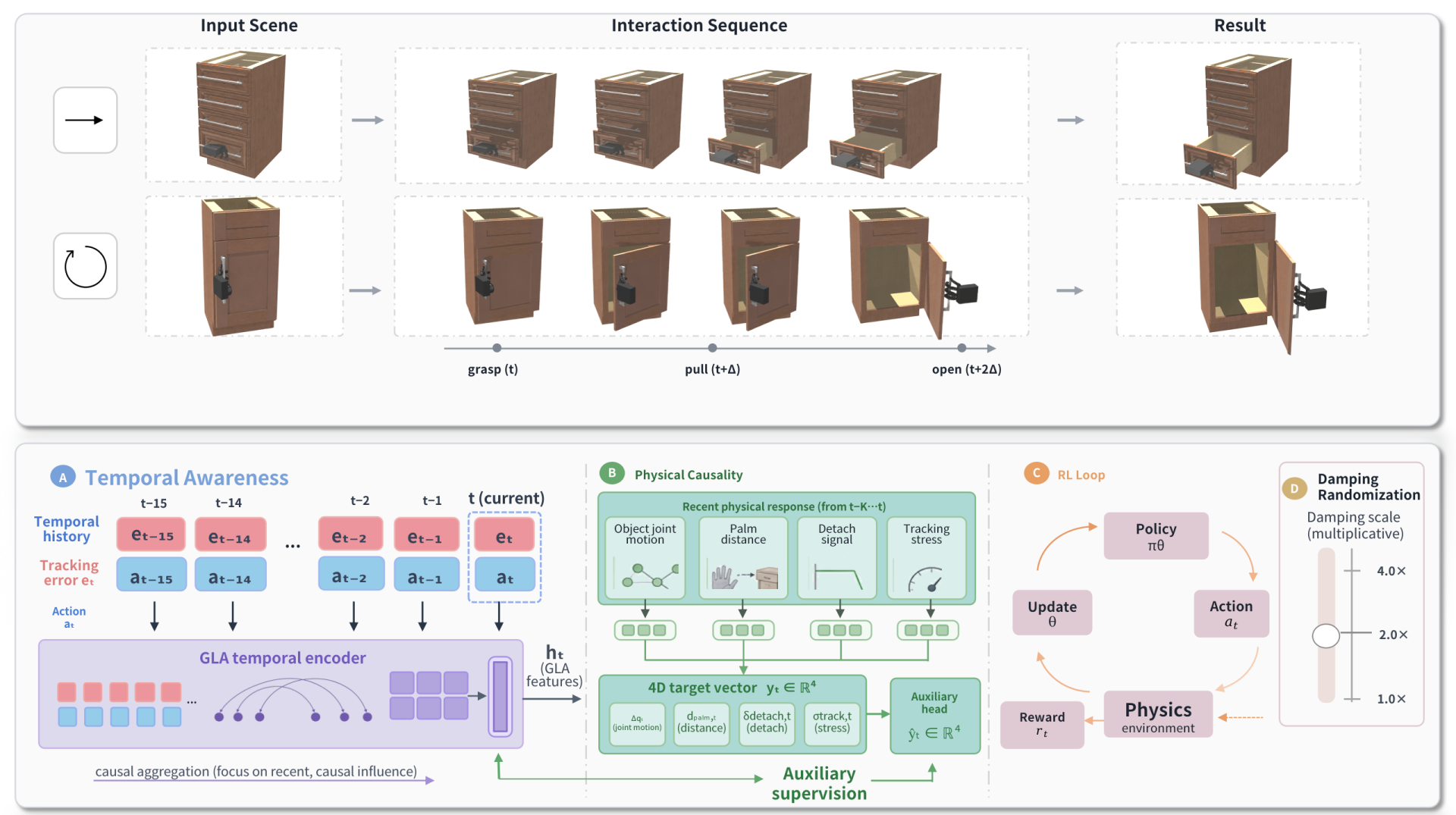
手法
本設定では、51-DoFのSMPL-Xハンド(6つの仮想手首DoF+45本の指の関節)を用いてハンドのみを制御し、物体の関節にはアクションを与えません。対象となる物体の自由度は、形状に基づく参照軌道の中で最も広い範囲を持つものとし、成功条件は以下のように定義されます。
q_{\mathrm{done}}=q_{\min}^{\mathrm{traj}}+\rho\,(q_{\max}^{\mathrm{traj}}-q_{\min}^{\mathrm{traj}})
また、進捗度は同じ軌道範囲で正規化されます。
p_{t}=\max\!\left(0,\,\frac{q_{t}^{o}-q_{\mathrm{start}}}{q_{\mathrm{goal}}-q_{\mathrm{start}}}\right).
この正規化により、引き出し、スライダー、扉を固定変位閾値なしに直接比較することが可能になります。
観測は、ハンドの関節位置・速度、ハンドルの姿勢、手のひらとハンドルの相対的な形状、目標関節の状態、タスクスケール特徴(進捗度、閾値までの距離)から構成されます。重要な点として、RGB、深度、点群、力、触覚入力は一切与えられず、ポリシーは運動学的特徴のみから接触状態を推測しなければなりません。アクションは51次元のPD目標増分であり、関節限界にクリッピングされます。参照軌道は3つの役割のみを担います:(i) エキスパートの把持状態の初期化、(ii) 式(1)〜(2)で用いる物体ごとの運動スケールの定義、(iii) 学習を用いないトラッキングベースラインの提供。参照軌道は物体制御として再生されることはなく、エキスパートのアクションラベルも提供しません。ポリシーはPPOをゼロから学習します。
提案手法PICA(完全手法)は、PPOの状態に2つの構造的要素を加えます。物理的信号(接触関連特徴)とGLA時系列エンコーダです。実験においてはそれぞれ独立してアブレーションが行われます。
実験
ベンチマークは7つのGAPartNet物体で構成されます:回転型の扉5つ(食洗機、電子レンジ、収納家具の扉3つ)と直動型の収納家具引き出し2つです。ロバスト性の検証は、関節減衰を×1(名目)、×2(軽度の変化)、×4(強い分布外変化)の倍率でスケーリングすることにより行われます。各(手法、物体、減衰、モード)セルは20エピソードで構成され、決定論的(ガウス平均)および確率的実行の両方で評価されます。
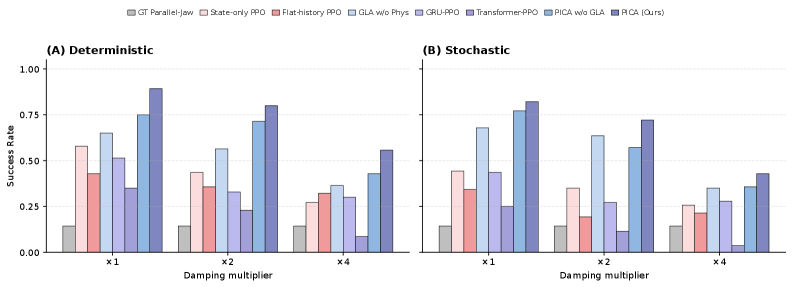
ベースラインとして、オープンループ軌道再生、GTパーツ姿勢を用いた並行グリッパーによるプリミティブ、および4種類の学習済みPPOバリアント(状態のみ、フラット履歴、GRU、Transformer)が含まれます。主要な結果として、PICAは6つの(モード×減衰)セルすべてで最高の平均成功率を達成し、荷重変化に対して最も緩やかな性能低下を示しました。決定論的実行における×4減衰では、PICAの成功率は0.56に達したのに対し、状態のみPPOは0.27、Transformer-PPOは0.09でした。GTパーツ姿勢を用いた並行グリッパーのプリミティブはすべての減衰レベルで平均0.14にとどまり(食洗機の扉のみ1.00で成功し、他はすべて失敗)、単一接触把持が多関節ベンチマーク全体に対して根本的に不十分であることを、特権的なパーツ姿勢情報があっても確認できます。
物体ごとの挙動(表2)はベースラインの脆弱性を明示します。状態のみPPOは食洗機の扉において×1での1.00から×4決定論的での0.00へと崩壊し、フラット履歴PPOは電子レンジの扉において0.95から0.00へ崩壊し、GRU-PPOは物体12583において0.60から0.00、48513において0.50から0.00へと崩壊します。ベースラインごとに異なる物体で失敗が生じており、観測やアーキテクチャの選択がそれぞれ名目減衰の分布内で特有のショートカットを生じさせ、それが分布外では消失することを示しています。軌道トラッキング参照手法自体も×1での平均1.00から×2および×4での0.71へと低下し(物体45936および7310で失敗)、このタスクが純粋に運動学的制限ではなく接触ダイナミクス的制限を受けていることを示しています。実行可能なパーツ軌道のオープンループ再生は、より高い減衰においては必要なレンチを生成できません。

2要素のアブレーションでは、物理的信号とGLA時系列エンコーダからの加算的な改善が示され、両者の組み合わせが6つの集計セルすべてで厳密に支配的でした。
制限と未解決の問題
評価はシミュレーションのみで7物体に限定されており、ハードウェアの図は定性的なものにとどまります。ポリシーは51-DoFのSMPL-Xハンドを使用しており、ハンドル姿勢と目標関節状態に特権的にアクセスしており、知覚は用いていません。すべてのエピソードはエキスパートの把持状態から開始されるため、アプローチと把持獲得はスコープ外であり、貢献は把持後の引っ張りフェーズに限定されます。物体が7つ、カテゴリが3つのみであるため、物体ごとの分散が高く(いくつかのセルは0.00または1.00)、×4の平均値は粗い刻みで変動します。接触駆動の定式化が学習による把持初期化、視覚に基づく観測、および真の意味でのクローズドループハードウェアに転用可能かどうかはいずれも未解決です。力や触覚入力が存在しないにもかかわらず「物理的信号」が分布外の減衰ロバスト性を改善するメカニズムについては、より直接的な因果的調査が求められます。
意義
DragMesh-2は、多関節操作の評価が運動学のみでなく接触ダイナミクスにも明示的な摂動を加えるべきであることを主張しています。名目上の減衰で同等に見える手法が、×4減衰において成功率で6倍の差を生じさせます。式(2)における接触進捗の正規化は、回転型と直動型が混在するベンチマークにおける評価の健全性を保つ有用な要素です。
Source: https://arxiv.org/abs/2606.15133
Playful Agentic Robot Learning
Code-as-Policy (CaP) エージェントは、言語命令 l、環境コンテキスト c、およびプリミティブライブラリ f から実行可能なロボットプログラムを合成しますが、外部タスクが強制する場合にのみ再利用可能な抽象化を構築します。本論文は、CaP エージェントがタスクが到着する前の「プレイ」フェーズを有効に活用できるかどうかを問います。具体的には、探索的ゴールを自律的に提案し、それを実行し、成功したプログラムを永続的なスキルライブラリに蒸留するというものです。提案システムである RATs (Robotics Agent Teams) は、これを二フェーズのループとして形式化します。初期プリミティブ集合 \mathcal{L}_0 からライブラリ \mathcal{L} = \mathcal{L}_0 \cup \mathcal{L}_{\text{learned}} を拡張するプレイフェーズと、\mathcal{L} を下流の CaP エージェント向けの追加の呼び出し可能関数として検索する凍結評価フェーズです。

手法
プレイループ(Algorithm 1)は、標準的な CaP のタプル (c, f, l) から命令 l を取り除き、自己提案タスク \tau_t に置き換えます。RATs は三つのチームに分解されます。
- Task Proposer: 現在の環境 \mathcal{E}_{train}、ライブラリ \mathcal{L}、および失敗メモリ \mathcal{M} を与えられ、「新規かつ学習可能な」タスク \tau_t をサンプリングします。その意図は好奇心駆動型カリキュラムであり、タスク空間において自明に解けた領域や繰り返し失敗した領域を回避します。
- Execution team: (\tau_t, \mathcal{L}) を条件とした CaP プログラム \pi_t を合成し、それを実行し、ステップレベルのチェックで中間進捗を検証します。失敗は診断(前提条件の欠如、誤ったターゲットなど)され、その診断をコンテキストに追加してリトライされます。
- Memory-Management team: 成功時には \pi_t を名前付きのパラメータ化されたコードスキルとして \mathcal{L}_{\text{learned}} に追加することで蒸留し、失敗時にはコンパクトな教訓を \mathcal{M} に書き込みます。
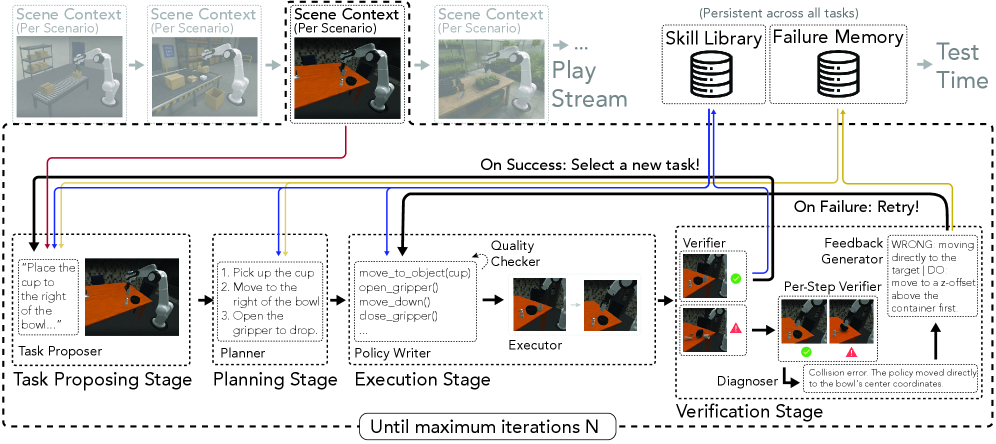
スキルライブラリは純粋にシンボリックなもの、すなわち低レベルプリミティブを呼び出す Python 関数であり、ポリシーネットワークを再学習することなく CaP エージェント間で移植可能です。テスト時、著者らは二つのモードを評価します。\mathcal{L} から検索したスキルをバニラな CaP-Agent0 のコンテキストに注入する plug-in モードと、検証を含む実行パイプライン全体を使用する full-system モード(RATs Exec.)です。
結果
プレイは各ベンチマークで N=50 イテレーション実行され、バックボーン LLM として gemini-3.1pro-preview を使用しています。
LIBERO-PRO(表1)では、各タスクをオブジェクト・ゴール・空間の各軸に沿って摂動させており、初期位置交換分割とタスク摂動分割が含まれます。ニューラル VLA ベースラインはこれらの摂動に対して実質的に機能しません。OpenVLA と \pi_0 は全6分割にわたってスコア 0.0 であり、\pi_{0.5} の平均は 12.8 です。CaP-Agent0 はプリミティブのみを使用して平均 23.2 に到達します。RATs は平均 43.8 に達し、CaP-Agent0 に対して 20.6 ポイントの向上を示します。最大の絶対的向上はオブジェクト分割(27.0 / 31.0 に対して 61.0 / 63.0)に見られ、これは再利用可能な操作スキルが最も綺麗に組み合わさるためです。空間分割の改善は最も小さく(13.0 / 23.0 に対して 29.0 / 31.0)、空間推論がスキルの可用性ではなく知覚・グラウンディングにボトルネックがあることを示唆しています。
MolmoSpaces(表2)では、Open・Close・Pick・Pick-and-Place の各カテゴリにわたってグラウンドされたシーン状態と NL 基準で成功を評価しており、RATs は平均成功率を 21.0 から 38.0(+17.0 ポイント)に改善します。最大の差分は Close(36.0 → 73.0)であり、これは閉じる動作が組み合わさったスキル(接近、位置合わせ、押し込み)であり、蒸留されたサブルーチンから最も恩恵を受けることと整合しています。

本論文はさらに、RoboSuite(プレイから除外)への環境間転移と、シミュレーションから実機への転移デモを報告しており、\mathcal{L}_0 に対して書かれたスキルが新たなシミュレータで基盤となるプリミティブを再実装した場合でも有用性を保持することを示しています。これらの定量的な数値は抜粋には含まれていません。
限界と未解決の問題
- N=50 のプレイイテレーションは少なく、プレイバジェットに対してパフォーマンスがどのようにスケールするか、またライブラリが飽和するか・冗長もしくはバグのあるスキルを蓄積するかどうかは不明です。明示的な重複除去やスキル刈り込みの分析はここでは示されていません。
- 好奇心シグナルは情報論的な目的ではなく LLM の Task Proposer を通じて実装されており、好奇心駆動型と無作為プレイを分離するアブレーションは参照されていますが(Sec. 4.4)、+20.6 ポイントの中でその寄与の大きさは、「プレイ」が「同じ環境へのより多くの LLM 計算」ではなく重要であるかどうかという核心的な問いです。
- 空間汎化は依然として弱く(LIBERO-PRO 空間分割で 29~31%)、シンボリックスキルライブラリがグラウンドされた幾何学的推論の代替にはなれないことを示唆しています。
- 提案・コード合成・検証・診断のためにフロンティア LLM(
gemini-3.1pro-preview)に依存していることから、スキル取得あたりの実際の時間コストと金銭コストが明らかにされておらず、また学習可能なタスクとは何かについてそのモデルのバイアスを引き継いでいます。 - VLA ベースラインが LIBERO-PRO でスコア 0.0 であることは驚くべきことであり、この摂動分割が学習済みポリシーに対してシンボリックエージェントを有利にする形で敵対的である可能性を示唆しています。比較は CaP-Agent0 との比較の方がより意味があります。
この研究の重要性
これは、Voyager スタイルのエージェントに馴染みのある「スキルライブラリ」という抽象化が、embodied な CaP ロボティクスに転移できること、そして内在的フェーズのライブラリ構築が、エンドツーエンドの VLA がゼロに崩壊する摂動ベンチマークにおいて具体的な向上(+20.6 および +17.0 ポイント)をもたらすことの明快なデモンストレーションです。本研究は、ロボットエージェントの事前学習を重みの更新ではなくコードの蓄積として再定式化し、学習されたスキルが検査可能で CaP バックエンド間で移植可能であり、再学習なしで組み合わせられるという実践的な帰結をもたらします。
Source: https://arxiv.org/abs/2606.19419
FlowBender: 自己修正型条件付きフローのためのフィードバック認識学習
問題
条件付きdiffusionおよびflow-matchingモデルは、条件付けられている制約を系統的に違反します。depth-to-RGBモデルが生成した画像から再抽出した深度\mathcal{H}(\mathbf{x})は入力\mathbf{y}と一致せず、エッジ条件付きモデルはエッジを誤配置し、テクスチャリングモデルは誤ったメッシュ領域に塗り描きをします。深度予測器、エッジ検出器、レンダラー、劣化演算子などの前向き演算子\mathcal{H}は、学習時・推論時ともに利用可能であるのが通常ですが、既存のパイプラインは閉ループ信号として学習中に活用していません。
主要なパラダイムは二つあります。Supervised fine-tuning(ControlNet、LoRA、ControlNet++)は条件を静的な手がかりとして扱い、ネットワークは\mathbf{c}を観測するものの自身のアライメント誤差は決して観測しません。推論時guidance(例:FlowChef)はサンプリング時に\nabla_{\mathbf{x}_t}\|\mathbf{y}-\mathcal{H}(\hat{\mathbf{x}}_1)\|^2を注入しますが、ステップサイズは手動調整であり、よく知られたfidelity/plausibilityのトレードオフを生じさせます。著者らの診断は、モデルが自身の残差を入力として消費するように学習されていないという点にあります。
手法
FlowBenderはサンプリングを学習された閉ループコントローラへと変換します。速度v_\theta(\mathbf{x}_t, t, \mathbf{c})を持つflow-matchingバックボーンと標準的なlook-ahead推定値
\hat{\mathbf{x}}_1 = \mathbf{x}_t + (1-t)\, v_\theta(\mathbf{x}_t, t, \mathbf{c}),
を所与として、各学習ステップは二回のパス(Fig. 2)を実行します。
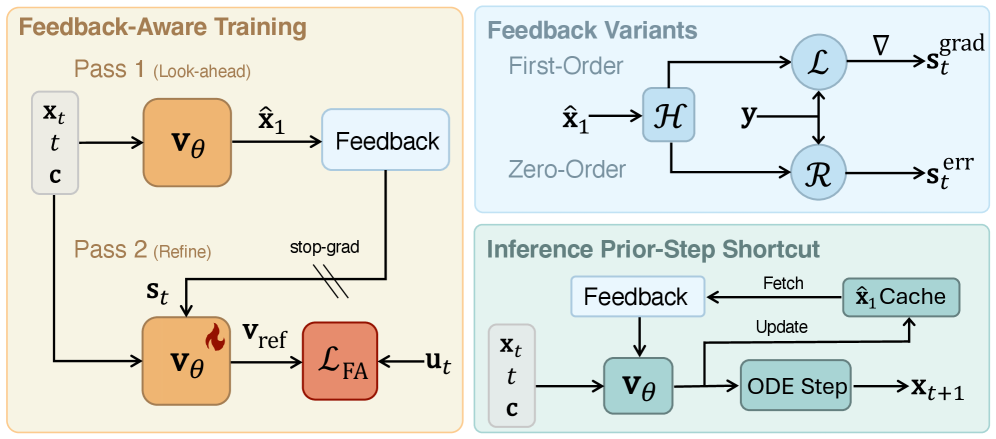
- Look-aheadパス。 フィードバックなしでv_\thetaを一度実行し、\hat{\mathbf{x}}_1を得ます。
- フィードバック構築。 \mathcal{H}を介して\hat{\mathbf{x}}_1からタスク固有の偏差\mathbf{s}_tを計算します。二つのバリエーションが研究されています:
- 一次:\mathcal{H}が微分可能な場合は\mathbf{s}_t = \nabla_{\hat{\mathbf{x}}_1}\,\mathcal{L}(\mathcal{H}(\hat{\mathbf{x}}_1),\mathbf{y})。
- ゼロ次残差:ブラックボックスまたは微分不可能な演算子(レンダラー、既製の検出器)に対して\mathbf{s}_t = \mathbf{y}-\mathcal{H}(\hat{\mathbf{x}}_1)(またはリフトされた形式)。
- 精製パス。 ネットワークをv_\theta(\mathbf{x}_t, t, \mathbf{c}, \mathbf{s}_t)として再評価し、目標速度\mathbf{x}_1 - \mathbf{x}_0に対する標準的なflow-matching lossで学習します。モデルはこうして(状態、条件、現在のアライメント誤差)を制約多様体へ向かう速度にマッピングする修正ポリシーを学習します。
二段階スキームはステップあたりのコストを約二倍にします。これを償却するため、推論時にはキャッシュショートカットを使用します:ステップtでlook-aheadパスを再計算する代わりに、ステップt{-}1の\hat{\mathbf{x}}_1を再利用して\mathbf{s}_tを構築します。これにより推論グラフはウォームアップ後に実質的にシングルパスとなりながら、ネットワークを自身の残差に晒し続けます。
Fig. 1のおもちゃ的な2Dの例は、このメカニズムを単離して示しています:アルキメデス螺旋が四つの放射状クラスに分割され、クラスの帰属が放射状前向き演算子によって強制可能です。標準的な条件付きFMおよびguidedのバリアントはいずれもクラス境界を無視するか、またはその境界をぼかしてしまいます;FlowBenderは正しい環状領域内にサンプルを集中させます。
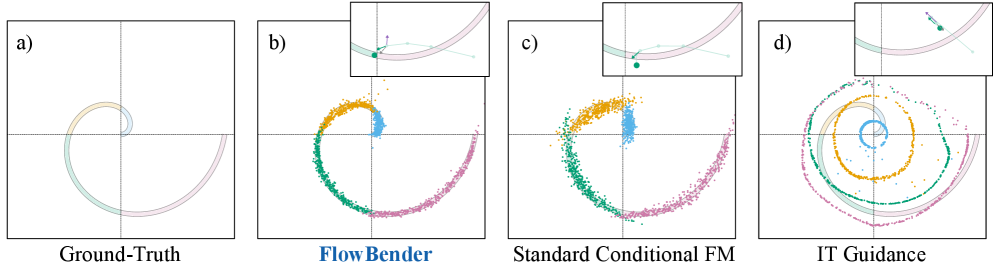
結果
著者らは潜在flow-matchingバックボーンを二つのレジームでfine-tuningしています:image-to-image変換(depth-to-RGB、edge-to-RGB)と3Dメッシュテクスチャリング。同等のサンプリングバジェット下でのベースラインは、(i)ControlNet/LoRAアダプタを用いた標準FT、(ii)FT + \mathcal{L}_{\text{align}}(ControlNet++スタイルの測定整合性loss)、(iii)FlowChef推論時guidanceです。評価はfidelity(適切なメトリックにおける\|\mathbf{y}-\mathcal{H}(\mathbf{x})\|)とplausibility(知覚的品質)を分離しています。
Fig. 3の定性的比較は、本手法が対象とする構造的な失敗モードを示しています:ControlNetはグローバルなレイアウトを保持しますが、細いエッジや深度の不連続箇所を誤配置します(赤ボックス);FlowChefはテクスチャアーティファクトやコントラストのずれを犠牲にしてアライメントを改善します;FlowBenderの出力は現実感を損なうことなく\mathcal{H}(\hat{\mathbf{x}}_1)\approx\mathbf{y}を追跡します。

本論文は、ベースラインのサンプリングバジェットを二倍にしたりCFGを重ねたりしてもギャップは埋まらないと主張し、付録のスイープを通じてそれを確認しています——この欠損は計算的なものではなく表現的なものです。残差\mathbf{s}_tが外部からのnudgeとして加算されるのではなくネットワーク入力として消費されるため、修正は非線形かつ学習されたものであり、guidanceメソッドのボトルネックである線形ステップサイズ調整を回避します。
制限と未解決の問題
- 学習パスのコストは約2\timesであり、キャッシュショートカット推論が最初のステップ後にシングルパスコストを回復するに過ぎず、\hat{\mathbf{x}}_1がまだ不良である初期ステップの軌跡への影響は十分に特性化されていません。
- フィードバックの設計はタスク固有です。一次/ゼロ次の二分法は機能しますが、\mathbf{s}_tのencoding(潜在空間へのリフト、連結、cross-attention)はおそらく重要であり、探索が不足しています。
- 一つのタスクにつき一つの前向き演算子のみが研究されています。複数の制約(例:深度+テキスト+エッジ)の合成と相反するフィードバック信号の処理は未解決です。
- 本手法は\mathcal{H}が信頼可能であることを前提としており、バイアスのある演算子は\mathbf{x}のバイアスとして忠実に再現されます。
- 報告されている改善はFMベースラインに対する相対的なものであり、閉ループ定式化がconsistency-distilledまたは少ステップサンプラーとどのように相互作用するかは不明です。
重要性
FlowBenderは条件付き生成における制約満足を、guidanceの問題ではなく制御の問題として再定式化します:ネットワークは自身の測定残差を読み取り、それに基づいて行動するように学習されます。これにより、テスト時guidanceに特有のfidelity/plausibilityのトレードオフが解消され、アクセス可能な前向き演算子を持つあらゆるタスクに対して、微分可能・ブラックボックスを問わず統一的なレシピが提供されます。
Source: https://arxiv.org/abs/2606.20404
Hacker News Signals
半古典的重力はNP完全問題を効率的に解く
あるプレプリントが主張するところによれば、重力が半古典的である場合——すなわち、重力場が量子化された場ではなくストレスエネルギーテンソルの期待値と結合する場合——物理的装置がNP完全問題を多項式時間で解くことができるとされています。この議論は、SATインスタンスを多体量子状態にエンコードすることで機能します。半古典的重力の自己相互作用のもとで、このエネルギー地形に充足割り当ての振幅を増幅するフィードバックループが生じます。重力ポテンシャルは個々の分岐ではなく \langle \hat{T}_{\mu\nu} \rangle に依存するため、ダイナミクスは波動関数に対して非線形となります:i\hbar \partial_t |\psi\rangle = \hat{H}_0 |\psi\rangle + V_{\text{grav}}[\langle\psi|\hat{T}|\psi\rangle] |\psi\rangle。非線形量子力学はAbrams & Lloyd(1998)以来、NP問題の多項式時間求解を可能にすることが知られているため、前提を所与とすればこの結果は驚くべきものではありません——本研究の貢献は、半古典的近似のもとで物理的に妥当な実現を構成した点にあります。著者らはこれが条件付きの結果であることを慎重に指摘しています:半古典的重力が正しい記述である場合(すなわち重力が完全には量子化されない場合)、複雑性クラスの分離が崩壊します。より主流の解釈は、これが背理法であるというものです:NP \not\subseteq BQPが期待されるため、半古典的重力は正しい理論ではない可能性が高いということです。HNの議論は、これが真の物理的議論なのか、それとも複雑性理論の通説を装ったものに過ぎないのかという点に集中しています。主要な未解決問題は、半古典的近似が計算を完了するのに十分な時間にわたって成立するかどうか、そして回答が取り出される前にデコヒーレンスが干渉構造を破壊しないかどうかという点です。必要な精度で半古典的重力を実験的に反証することは、現時点では実現不可能です。
Source: https://arxiv.org/abs/2606.14806
DuckDB の内部構造:なぜ DuckDB は速いのか?(第1回)
本記事は、DuckDB の実行エンジンについて技術的に根拠のある解説を行い、行指向システムとの差異をもたらす設計上の意思決定に焦点を当てています。主に3つのメカニズムが取り上げられています。
第一に、列指向ストレージとベクトル化実行です。DuckDB は一度に2048個の値からなるベクトル(コンパイル時定数 STANDARD_VECTOR_SIZE)を単位として処理します。各オペレータは子オペレータからチャンクを取り出し、連続したメモリ上でタイトなループを用いて処理し、上位へチャンクを渡します。これにより行ごとの仮想ディスパッチが排除され、パイプライン全体を通じてデータが L1/L2 キャッシュに留まります。
第二に、遅延マテリアライゼーション(late materialization)です。射影(projection)とカラム読み込みは、フィルタによってワーキングセットが削減されるまで遅延されます。本記事では、選択性の高い述語を持つ広いテーブルをスキャンするクエリが、条件を通過した行についてのみ非述語カラムを取得することで、メモリ帯域幅を大幅に削減する様子を示しています。
第三に、プッシュベースのパイプラインモデルです。DuckDB はクエリをパイプラインブレーカー(hash join、ソート、集約)によって分割されたパイプラインにコンパイルします。パイプライン内では、データは中間マテリアライゼーションなしにソースからシンクへとプッシュされます。パイプライン内に同期ポイントが存在しないため、これは現代の CPU のアウトオブオーダー実行とも相性が良いです。
本記事では selection vector の抽象化についても取り上げています。DuckDB はベクトルを物理的にフィルタリングするのではなく、アクティブなインデックスの整数配列を保持します。フィルタは生き残った行をコピーするのではなく、このベクトルに追記する形で機能し、アロケーションのホットパスを回避します。ベクトル化実行の先駆けである MonetDB や、コンパイルベース実行の先駆けである HyPer との比較は正確であり、DuckDB はその中間に位置し、デプロイの簡便さを優先して LLVM-JIT コンパイルではなくインタープリタ型のベクトル化を採用しています。
本記事は第1回であり、バッファマネージャ、コア外実行(out-of-core execution)、並列パイプラインスケジューラについてはまだカバーされていません。これらはいずれも、大規模環境における DuckDB の性能プロファイルに大きく寄与する要素です。
Source: https://www.greybeam.ai/blog/duckdb-internals-part-1
MCP向けゼロタッチOAuth
AnthropicのModel Context Protocol(MCP)ブログでは、「Zero-Touch OAuth」と呼ばれるエンタープライズ認証スキームが解説されています。これは、ユーザーが各ツール接続を手動で承認することなく、企業のアイデンティティプロバイダー(IdP)の背後にMCPサーバーをデプロイするという課題に対処するものです。核心となるメカニズムは、エンタープライズが管理するOAuthフローであり、IdP(Okta、Entra IDなど)がインタラクティブな同意画面を必要とせず、グループメンバーシップやポリシーに基づいてMCPクライアントへ自動的にトークンを発行します。
技術的には、このスキームはユーザー委任とエンタープライズ管理による認可を区別します。管理パスでは、組織がMCPサーバーのOAuthクライアントをあらかじめIdPに登録し、エンタープライズデバイス管理チャネルを通じてスコープ付きトークンを配布します。MCPクライアントは事前承認されたスコープバンドルを持つトークンを受け取り、ブラウザリダイレクトは発生しません。これはクライアントクレデンシャルフローやデバイスプロビジョニング証明書に類似していますが、MCPサーバーディスカバリプロトコルに適合させたものです。
この記事では、サーバーメタデータが標準のOAuth認可サーバーメタデータと並んで managed_auth エンドポイントをアドバタイズする必要があると規定されています。クライアントはこのフィールドを確認し、存在し、かつエンタープライズポリシーが一致する場合は、インタラクティブフローを完全にスキップします。トークンのローテーションと失効は標準的なOAuth 2.1のメカニズムに従っており、新規性はプロビジョニングパスとメタデータシグナリングにあります。
セキュリティの観点では、スコープクリープに関する問題が興味深いです。ITが特定ユーザークラスに割り当てた事前承認済みスコープバンドルは、個々のユーザーがインタラクティブに承認するよりも広範になる可能性があります。この記事ではその点を認めつつも、事前同意済みアプリケーションを伴うSSOと同様に、許容可能なエンタープライズのトレードオフとして位置付けています。本仕様は現在MCPワーキンググループ内の提案であり、まだ批准されていません。規制された環境でのAIエージェントデプロイメントにおいて、アクションごとのユーザー確認が存在しないことは、監査証跡に対して重大な変更をもたらします。
Source: https://blog.modelcontextprotocol.io/posts/enterprise-managed-auth/
ElasticsearchでLLMエージェントの永続的メモリ層を構築し、Recall 0.89を達成
Elasticのブログ記事では、Elasticsearchをバッキングストアとして使用し、LLMエージェントに永続的メモリを持たせるアーキテクチャを解説しており、内部ベンチマークにおけるrecall@10として0.89を報告しています。この設計では、メモリをエピソード記憶(生の会話ターン)、セマンティック記憶(圧縮されたサマリー)、手続き記憶(抽出されたルール・嗜好)の3層に分離しています。各層は異なるインデックス戦略を採用しています。
エピソード記憶は生テキストに対するBM25を使用し、クエリ時にスクリプトスコアで再近性減衰を適用します:\text{score} = \text{BM25}(q, d) \cdot e^{-\lambda \cdot \Delta t}。セマンティック記憶は、LLMが生成したサマリーのembeddingに対して密ベクトル検索(HNSWインデックス)を使用します。手続き記憶は、LLMが会話から抽出した構造化フィールドに対して完全一致フィルタリング検索を使用します。
検索パイプラインは3種類のクエリを並列に発行し、Elasticsearch 8.xがネイティブサポートするReciprocal Rank Fusion(RRF)を用いて結果をマージします。エージェントのプロンプトに注入される最終的なコンテキストは、マージ結果の上位k件から構成され、トークン予算はランクの低いアイテムを切り詰めることで適用されます。
recall 0.89という数値は、エージェントのタスク完了クエリに関する独自データセットで測定されたものですが、グラウンドトゥルース構築の方法論が詳しく説明されていないため、外部妥当性に限界があります。このシステムはメモリの統合、すなわちエピソード断片をセマンティックサマリーに昇格させるタイミングを決定するプロセスについては対応を主張しておらず、Nターンごとに実行されるスケジュール化されたLLMジョブに委ねられており、適応的なトリガーはありません。
実装の詳細:ElasticsearchのマッピングはHNSWのためにdense_vectorフィールドでelement_type: floatおよびm: 16, ef_construction: 100を使用しています。ブログ記事にはインデックステンプレートとelasticsearch-pyクライアントを使用したPythonの検索スニペットが含まれています。主な制限は定期的なLLMサマリーパスのコストであり、大規模での特性評価は行われていません。
Source: https://www.elastic.co/search-labs/blog/agent-memory-elasticsearch
OpenRouter Fusion API
OpenRouterのFusion APIは、複数のLLMに対して同時にクエリを発行し、その出力を統合してから単一のレスポンスを返すことで応答品質の向上を図るモデルルーティング層です。ドキュメントに記載されているメカニズムによると、異なるプロバイダーにホストされたモデルに対して n 件の並列推論呼び出しを実行し、得られた n 件のレスポンスすべてを「fusion」モデル(それ自体もLLM)に渡して、単一の統合された回答を生成します。
並列パスでどのモデルにクエリを発行するかの選択は設定可能なようですが、デフォルトではOpenRouterがベンチマークスコアとレイテンシ特性に基づいて選定したモデルセットが使用されます。料金体系は、すべての並列呼び出しとfusion呼び出しにわたって消費されたトークンの合計となるため、単一モデルへのクエリと比べて実質的にコストが高くなります。レイテンシは並列呼び出しの平均ではなく最も遅いものに律速されますが、fusion ステップで追加されるのは約300ms程度に留まるとの記述があります。
技術的な本質は、推論時のmixture-of-expertsパターンであり、LLMブレンディングやdebateベースの集約に関する先行研究と関連しています。fusionモデルは学習済みの調停者として機能しますが、真にキャリブレーションを改善するのか、それとも単にコンセンサスに向けてヘッジするだけなのかは実証的な問いであり、ドキュメントではこの点を厳密には論じていません。並列レスポンスが同じ方向で系統的に誤っている場合の処理メカニズムは明示されておらず、fusionモデルは相関した誤りを修正することができません。
システム設計の観点では、これはAPIゲートウェイレベルでのfan-out/fan-inアーキテクチャです。OpenRouterが並列ディスパッチ、プロバイダー認証、レスポンス集約を担うため、呼び出し側には単一のストリーミングレスポンスとして見えます。fusionステップ中のストリーミング動作——並列モデルからの中間トークンが表面化されるかどうか——については仕様が明記されていません。HNのコメントでは、品質向上がコスト乗数を正当化するかどうかについて懐疑的な意見が多く、Fusionと単一モデルのベースラインを比較した公開ベンチマークが存在しない点も指摘されています。
Source: https://openrouter.ai/openrouter/fusion
GoにホストされたClojure
GlojureはGoをホストプラットフォームとして使用するClojure実装であり、JavaScriptを使用するClojureScriptに類似しています。このリポジトリは動作するインタプリタ/コンパイラであり、Clojureの永続データ構造と並行性プリミティブをGoのランタイムにマッピングします。これはいくつかの理由から技術的に非自明です。
Clojureの永続コレクション(ベクタ、ハッシュマップ、セット)は、Phil BagwellのHash Array Mapped Trie(HAMT)とRRBツリーを用いて実装されています。GlojureはClojureJVMがJavaの標準ライブラリに委譲しているのとは異なり、これらをGoで再実装しています。相互運用の仕組みは、JavaのリフレクションベースのInteropをGoのreflectパッケージに置き換えており、ClojureのコードからGo関数を呼び出したりGoの構造体にアクセスしたりすることができます。マクロとリーダーはGoで実装されており、コンパイルのターゲットはJVMバイトコードではなく木構造を走査するインタプリタです。
並行処理はgoroutineとGoチャネルをcore.asyncスタイルの操作の基盤として使用しています。ClojureのSTM(ref、dosync)はJVMのSTMではなく、GoのmutexとリトライループをベースとしてJVMのSTMの上に実装されています。これにより、STMのセマンティクスは保持されますが、パフォーマンス特性はJVM実装とは異なります。
この取り組みの動機は、go buildによって単一の静的バイナリにコンパイルされ、Goのクロスコンパイルのエコシステムを継承し、FFIのオーバーヘッドなしにGoのライブラリを直接呼び出せるClojureを実現することにあります。現時点での制限として、clojure.coreのすべてが実装されているわけではなく、JITがないためパフォーマンスはClojureJVMを大きく下回ります。このプロジェクトはプロダクション環境での代替として位置づけられておらず、ホスト移植可能なClojureセマンティクスの研究用ビークルとして開発されています。HNでのディスカッションでは、Clojureのアイデンティティ/値セマンティクスと、特に構造体の変更をめぐるGoのポインタ多用なイディオムとの間にある緊張関係が指摘されています。
Source: https://github.com/glojurelang/glojure
SubQ 1.1 Small
SubQ 1.1 Small は、SQL クエリ生成に特化して構築された言語モデルであり、SubQ AI の技術レポートで紹介されています。このモデルは「small」ティアに位置付けられており(パラメータ数はアブストラクト中では非公開ですが、記載されているハードウェア要件から 1〜7B の範囲であることが示唆されます)、レポートは汎用コーディングではなく text-to-SQL に焦点を当てており、それに応じてトレーニング設計も限定的な範囲に絞られています。
主要な技術的主張は、スキーマ対応の prompting と実行結果に基づくトレーニングに関するものです。このモデルは、まず合成的な単一テーブルクエリから始め、段階的に多テーブル結合、サブクエリ、ウィンドウ関数、方言固有の構文(PostgreSQL、BigQuery、DuckDB、SQLite)を導入するカリキュラムで学習されます。fine-tuning の過程では実行フィードバックが利用されており、生成されたクエリが参照データベースに対して実行され、正しい結果セットを生成するクエリは、ゴールドクエリとの構文的な類似度に関わらず loss における重みが増加します。これは教師あり fine-tuning ループ内における実行結果ガイドの報酬の一形態であり、完全な RL ではありませんが、その境界は薄いと言えます。
BIRD ベンチマークでは、SubQ 1.1 Small は 65.3% の実行精度を報告しており、レポートでは同一の分割に対する GPT-4o の約 67% と比較する形で位置付けています。Spider では 87.1% の exact match を報告しています。ただし、実行結果ガイドのカリキュラムとベースモデルの品質それぞれの寄与を分離したアブレーションは含まれていません。
制限事項として、このモデルはプロンプト内にスキーマコンテキスト(DDL 文)を必要とするため、コンテキストウィンドウを超えるような非常に大規模なスキーマでは性能が低下します。また、レポートではカラム命名規則への感度が指摘されており、整理されたスキーマ名でトレーニングされたモデルは、略称や一貫性のない命名が使われている本番データベース上で性能が低下するとされています。ベースモデル、学習計算量、データセットの構成に関する情報は一切提供されておらず、再現性に制約があります。
Source: https://subq.ai/subq-1-1-small-technical-report
Sogen: 高性能なWindowsおよびLinuxユーザースペースエミュレータ
SogenはWindows (x86-64) およびLinux (x86-64) バイナリを対象とするユーザースペースエミュレータであり、任意のホストプラットフォーム上でそれらを実行します。このプロジェクトは、一方のABIに特化するのではなく両方のABIに対応しようとしている点、およびネイティブ実行に対するエミュレーションのオーバーヘッドを最小化するという明示的なパフォーマンス目標において注目に値します。
技術的アプローチはフルシステムエミュレーションではなくバイナリ変換です。SogenはCPU全体やオペレーティングシステムカーネルをエミュレートするのではなく、ユーザースペース境界でsyscallをインターセプトしてゲストABIをホストABIに変換し、x86-64のマシンコードをホストISAへ変換します(ドキュメントによれば現時点ではAArch64ホストをターゲットとしています)。これはAppleのRosetta 2、QEMUのユーザーモードエミュレーション(qemu-x86_64)、およびFEX-Emuが採用しているのと同一のアーキテクチャ上の選択です。
Windowsサポートレイヤーは、Win32およびNT syscallサーフェスを実装する必要があります。これには、ローダー(PEパース、DLL解決)、ヒープアロケータ、スレッドプリミティブ、そして一般的なランタイムをブートストラップするのに十分なntdll.dllの実装が含まれます。Linuxレイヤーは、セマンティクスが十分に近いLinux syscall(例:read、write、mmap)をホストのsyscallにマッピングし、差異(例:シグナルハンドリング、cloneフラグ)をエミュレートします。
パフォーマンスは「高い」と主張されていますが、ランディングページには公開されたベンチマーク数値が提供されておらず、独立した評価が困難です。このプロジェクトは初期段階にあるようで、Webサイトには目標とアーキテクチャが説明されているものの、リポジトリはまだ公開されていません。HNのコメントでは、デュアルABIターゲットという野心的な試みが指摘されており、Wine(x86ホスト上ではバイナリ変換不要のWindows-on-Linux)やFEX-Emu(AArch64 Linux上のx86-64のみ)との比較がなされています。主な未解決の疑問は、JITが自己書き換えコードや間接分岐の多い位置独立実行ファイル(PIE)をどのように処理するかという点です。
Source: https://sogen.dev/
注目の新規リポジトリ
study8677/awesome-architecture
インタビュー対策レベルではなく、アーキテクチャレベルのシステム設計を対象とした、構造化されたバイリンガル(英語・中国語)リファレンスコレクションです。このリポジトリは、分散システムの基礎——コンセンサス、レプリケーション、パーティショニング、障害モード——を網羅する26本のチュートリアルと、具体的な本番環境に適応可能な25のアーキテクチャテンプレートを整理しています。6つのエンドツーエンドのケーススタディでは、AIネイティブシステム、RAG pipeline、コーディングエージェントを取り上げ、本番環境におけるトレードオフ(レイテンシ対一貫性、コスト対スループット、内製対購入)について明示的に議論しています。各テンプレートは意図的に主観的な立場をとっており、ハッピーパスの設計だけでなく、障害パターンも明示しています。バイリンガル構造により、英語が主要な作業言語でないチームにとっても有用です。AIネイティブおよびエージェントのセクションでは、従来のシステム設計リファレンスの多くが登場以前から存在するデプロイメントの懸念事項——コンテキストウィンドウ管理、ツール呼び出しのレイテンシ、検索品質——に対応しています。分散システムやMLプラットフォームチームに参加するシニアエンジニアのオンボーディング資料として、またアーキテクチャ提案をレビューする際の構造化されたチェックリストとして有用です。
Source: https://github.com/study8677/awesome-architecture
tastyeffectco/sandboxd
単一のCLIコマンドで、パブリックなプレビューURLを持つ隔離された開発サンドボックスをプロビジョニングするセルフホスト型サービスです。コーディングエージェントや高速なSaaSプロトタイピングでの利用を明示的に想定して設計されています。アーキテクチャ上の重要な設計判断は、Kubernetesを意図的に排除している点です。サンドボックスはsandboxd自身のコントロールプレーンが管理する軽量コンテナまたはプロセスとして動作し、運用オーバーヘッドをほぼゼロに抑えます。各サンドボックスには外部からルーティング可能なURLが割り当てられるため、localhostを公開することなく、Webhookの受信、OAuthコールバック、エージェントによるブラウザテストが可能です。コーディングエージェントがプログラム的に環境をスピンアップ・テスト・破棄するシナリオを対象としており、APIサーフェスは最小限かつスクリプト対応です。サーバーはセルフホスト型であるため、シークレットやソースコードが運用者のインフラ外に出ることはなく、プロプライエタリなコードベースにとって重要な特性となっています。レジストリアカウントやクラウドベンダーへの依存も不要です。ngrok + エフェメラルコンテナに相当する機能に、ライフサイクル管理を組み込んだ構成です。「Kubernetesを使わない」という方針は制限ではなく意図的な制約であり、依存関係のサーフェスを十分に小さく保つことで、単一の開発者が安定して運用できるようにしています。
Source: https://github.com/tastyeffectco/sandboxd
slothflowlabs/duckle
ドラッグ&ドロップ式のDAGエディタを使ってデータパイプラインを構築し、そのパイプラインをDuckDBがローカルで実行するSQLにコンパイルする、デスクトップネイティブのETL/ELTオーサリングツールです。このツールの核となる価値提案は、成果物が独自バイナリではなくSQLである点にあります。パイプラインは人間が読めるdiff対応のワークスペースファイルとして保存されるため、バージョン管理に適しています。DuckDB上で動作することにより、サーバープロセスなしでローカルファイル(Parquet、CSV、JSON)や接続済みデータベースに対して、カラム指向のベクトル化実行が可能です。「ローカルファースト」アーキテクチャにより、SaaSへの依存がなく、データが外部に送出されることもなく、オフラインでの動作が実現します。コンパイルステップは重要な意味を持ちます。実行時にビジュアルグラフを解釈するのではなく、DuckleはSQLを出力するため、そのSQLを監査したり、手動で最適化したり、ツールから独立して抽出・実行したりすることができます。これにより、パイプラインが実際に何を行っているかを検査する必要があるデータエンジニアにとって扱いやすいものになっています。デスクトップパッケージング(「軽量」というフットプリントの主張から、ElectronまたはTauriと思われます)により、Webベースのパイプラインツールが持つブラウザタブのセッションモデルを回避しています。ローカルでのデータ探索、小規模チームでの分析、そしてクラウドパイプラインインフラがワークロードに対して過剰になるようなシナリオに有用です。
Source: https://github.com/slothflowlabs/duckle
duncatzat/vigils
AIエージェントの動作を監視・承認するためのローカルコントロールプレーンで、Rustバックエンド、デスクトップシェルとしてのTauri、およびブラウザレベルの傍受を行うChrome Manifest V3拡張機能で構成されています。このアーキテクチャは観察と実行を分離しており、Chrome拡張機能がエージェントによるブラウザ操作およびDOMインタラクションをキャプチャし、Tauriアプリがそれらを人間によるレビューのために提示してから処理を進めます。シークレット管理は第一級の関心事として扱われており、認証情報の使用を傍受し、機密値がエージェントのコンテキストやログに残らないよう設計されています。承認ワークフローは設定可能で、低リスクな操作(ナビゲーション、読み取り)は自動承認とし、書き込み、フォーム送信、またはAPIコールは明示的な確認を要求するよう構成できます。RustコアはChrome拡張機能とデスクトップアプリ間のローカルメッセージバスを低レイテンシで処理し、レビューループをエージェントの実行フローを妨げない速度に保ちます。これは実際の運用上のギャップに対処するものです。多くのエージェントフレームワークはツールコールのフックを提供していますが、ブラウザレベルの副作用に対するものは存在しません。完全にローカルで動作するため、エージェントのアクティビティがサードパーティのサービスを経由することはありません。MV3の制約は注目すべき点で、永続的なバックグラウンドページではなくService Workerベースのバックグラウンド処理が必要となり、これが拡張機能のイベントモデルを規定しています。
Source: https://github.com/duncatzat/vigils
Somnusochi/VLM-AutoYOLO
vision-language model — 具体的にはNVIDIAのLocateAnything-3B — を使用してバウンディングボックスアノテーションを自動生成し、そのアノテーションを手動修正ステップに渡した後、ワンクリックでYOLOの学習を起動するエンドツーエンドのパイプラインです。このパイプラインは画像データセットと動画入力の両方を扱い、動画からはキーフレーム抽出を行うことで冗長なアノテーション作業を削減します。LocateAnything-3Bの採用はアーキテクチャ上重要な意味を持ちます。これは自然言語によるオブジェクト記述を受け取り、局在化された検出結果を返すgroundingモデルであるため、アノテーションステップはクラス固有のfine-tuningではなくテキストプロンプトによって駆動されます。これにより、既存のラベル付きデータセットが存在しない新規オブジェクトカテゴリに対しても実用的に対応できます。手動修正インターフェースにより、学習前にVLMのエラーを修正することが可能となり、ラベル品質が保たれます。モデルの検証は学習後に統合されており、同一ツール内でループが完結します。ここで関連するエンジニアリング上の課題は、VLMの出力(通常はJSONで正規化座標)、YOLOのラベル形式(クラスインデックス付き正規化xywh、1行ごと)、および学習フレームワークが要求するディレクトリ構造の間のフォーマット変換を管理することです。このパイプラインはそれらの変換を自動化します。アノテーションコストが主なボトルネックとなっているドメインにおける迅速なデータセット構築に有用です。
Source: https://github.com/Somnusochi/VLM-AutoYOLO
AprilNEA/OpenLogi
Logitech Options+ のネイティブかつローカルファーストな代替実装で、Rust で書かれており、HID++ プロトコルを通じて Logitech デバイスと直接通信します。HID++ は Logitech 独自の USB/Bluetooth HID 拡張であり、標準 HID では対応できないデバイス機能——ボタンリマッピング、DPI プロファイル、SmartShift スクロール設定——を公開します。OpenLogi はこのプロトコルをリバースエンジニアリングして Rust で実装しており、クラウドアカウントが必要でバックグラウンドサービスを常駐させる Logitech の Electron ベースの Options+ アプリへの依存を排除しています。Rust による実装は、OS の HID レイヤー(hidapi またはプラットフォーム固有のバックエンド経由)への直接アクセスを最小限のオーバーヘッドで提供します。テレメトリなし、アカウント不要、ネットワーク通信なし。プライバシーを重視するユーザーや、アウトバウンドのテレメトリがブロックされているエンタープライズ環境にとって、実用上の恩恵は大きいと言えます。このコードベースは HID++ フィーチャーネゴシエーションのドキュメント化されたオープン実装としても機能しており、ペリフェラル開発者やリバースエンジニアにとって有益な資料となっています。制限事項はプロトコルのリバースエンジニアリングにおける一般的なものであり、デバイスの対応状況はコミュニティの貢献次第であること、また Logitech がファームウェアを変更して前提を崩す可能性があることが挙げられます。5,000 スターという採用実績は、Options+ に対する不満が広く共有されていることを示しています。
Source: https://github.com/AprilNEA/OpenLogi
coder/boo
GNU screen を模したターミナルマルチプレクサ — 永続セッション、ウィンドウ管理、デタッチ/リアタッチ機能を備え、独自のターミナルエミュレーション層を実装するのではなく libghostty 上に構築されています。libghostty は Ghostty ターミナルエミュレータから切り出されたレンダリング・入力ライブラリであり、これを基盤として採用することで boo は GPU アクセラレーションレンダリング、Unicode 処理、入力処理といった Ghostty の機能をそのまま継承でき、これらのコンポーネントを再実装する必要がありません。このアーキテクチャ上の設計判断は非常に興味深いものです。既存の大半のマルチプレクサ(tmux、screen、zellij)は独自の擬似ターミナル管理とレンダリングパイプラインを実装していますが、boo が libghostty 上に積み重ねる構造は、アプリケーションとディスプレイの間にキャラクターセルの仲介者として介在する従来のアプローチとは異なり、ホストターミナルの機能とのより緊密な統合を示唆しています。これにより、同期レンダリングやよりリッチな入力処理など、旧来のマルチプレクサアーキテクチャへの後付けが困難な機能の実現が可能になるかもしれません。Coder が関与していることは、このプロジェクトを彼らのリモート開発プラットフォームと結びつけており、そこでは信頼性の高いターミナルマルチプレクサがコアインフラコンポーネントとなっています。GNU screen の様式を踏襲していることは、tmux や zellij が重視するタイリングペインモデルよりも、セッション永続性とシンプルなウィンドウ管理が主要な設計目標であることを示しています。
Source: https://github.com/coder/boo
razr001/align-dev
チームの共通コーディング規約と SKILL.md ファイルを生成する開発者向けツールです。SKILL.md とは、チームの規約・アーキテクチャパターン・技術選定を記述した構造化ドキュメントであり、AIコーディングアシスタント(Claude Code、Codex、Cursor、Copilot)が永続的なコンテキストとして利用することを意図しています。解決すべき核心的な問題は、チームにおけるAI支援開発においてエージェントの呼び出しのたびにチーム規範の知識がリセットされるため、文体的・アーキテクチャ的に一貫性のないコードが生成されてしまう点です。AlignDevはこれに対し、機械可読な規約ドキュメントを生成するワークフローを提供します。生成されたドキュメントはリポジトリのルートに配置し、エージェントのコンテキストウィンドウに自動的に組み込むことができます。SKILL.md フォーマットは AGENTS.md や .cursorrules に類似していますが、単一ツールの設定ではなくマルチエージェント間の一貫性を目的としています。生成ステップでは、ユーザーにtech stack・コーディング規約・アーキテクチャ上の決定事項を入力させ、構造化ファイルを出力する仕組みになっていると考えられます。主な価値はワークフロー規律の強制にあります。生成プロセスを経ることでチームは暗黙の規約を明文化せざるを得なくなり、これはAIエージェントと同様に人間のレビュアーにとっても有益です。5つのコーディングエージェントを対象としたマルチツール対応により、出力フォーマットは異なるコンテキスト注入メカニズムによっても正しく解釈できる十分な汎用性を持つ必要があります。