Daily AI Digest — 2026-06-19
arXiv Highlights
Beyond Static Leaderboards: Predictive Validity for the Evaluation of LLM Agents
This is a position paper consolidating fourteen parallel implementation studies of an MCP-based industrial-agent benchmark (AssetOpsBench) with seven prior agent benchmarks. The thesis is structural: aggregate-score leaderboards (HELM-style, Pass@1 means, even multi-metric dashboards) systematically underspecify the evaluation surface that deployment exposes, and the correct ranking criterion is not in-sample mean but predictive validity — the rank correlation between in-sample and out-of-sample evaluations.
The argument against aggregate scores
The authors give three concrete cases where aggregation hides qualitatively distinct configurations that score identically on Pass@1. First, toggling extended thinking on a Gemma-4-26B planner over 40 AssetOpsBench scenarios leaves overall rubric mean roughly flat but shifts clarity by 31 percentage points (61% → 92%) and hallucination by 7 pp (12% → 5%), while data-retrieval and agent-sequence correctness are unchanged. Latency rises 21.5% end-to-end (15.08 s → 18.32 s) and planning latency by 41.9%. A single mean obscures both the localized quality gain and its cost. Second, Plan-Execute vs. Supervisor-Specialist architectures match on single-turn Pass@1 but differ by 4.2\times on turn-2-to-5 latency due to cross-turn artifact reuse — a dimension single-turn benchmarks cannot see. Third, single-pass RAG hits 50–68% accuracy while agentic multi-hop retrieval reaches ~90%, but at 4.5\times–10\times token inflation; neither dominates without deployment constraints.
The deeper claim is that scalar leaderboards collapse orthogonal axes (reasoning mode, retrieval strategy, orchestration, transport) and therefore misattribute wins. The SmartGridBench experiment (2,420 trajectories) makes this surgical: holding the agent fixed and varying transport (direct vs. MCP-stdio) and orchestration (Plan-Execute, Verified PE, Self-Ask) independently shows MCP standardization adds latency with no quality gain, while orchestration alone moves pass rate from 43.2% to 55.5%. A leaderboard that does not separate transport from orchestration assigns the orchestration win to whichever axis it happens to vary.
The twelve-tier apparatus
The synthesis section organizes measurement into twelve tiers consolidated from prior benchmarks (SWE-Bench, \tau-Bench, TaskBench, MCP-Bench, MCP-Universe, ARE, AssetOpsBench) and the fourteen extension studies. T1–T7 are core capability tiers: success rates, tool-call hygiene, planning quality, capability axes, cost/efficiency Pareto, failure-mode taxonomies, and reproducibility/integrity. T8–T12 are deployment-extension tiers absent from nearly all current leaderboards: deployment infrastructure, multi-turn dialog, reasoning-mode adaptivity, knowledge augmentation, and evidence grounding with judge-independent verification. The empirical claim attached to the tier diagram is that no prior single benchmark reports more than four or five tiers as first-class metrics.
Predictive validity as the ranking criterion
The operational core is replacing in-sample mean with \rho(\text{rank}_{\text{in}}, \text{rank}_{\text{out}}) across three OOD criteria. Criterion A (mild shift) is a stratified random split preserving the joint distribution of subset and category — a weak test where failures are damning but passes uninformative. Criteria B and C escalate to held-out scenario classes and adversarial perturbations (the paper frames these as falsifiable thresholds for the position itself). The rationale is that recent public-to-hidden competition retrospectives already show direct rank instability: leaderboards trained on public splits do not predict hidden-split rankings, so in-sample mean is provably the wrong objective for a deployment-advising artifact.
Concrete leaderboard proposals
Three implementation moves follow. (1) Declared configuration columns: every submission must report Architecture, Reasoning Mode, Retrieval Strategy, Prompt-Constraint Level, and Verifier Type, since each is a non-empty axis that changes attribution. (2) Rank by predictive-validity score on at least one OOD criterion; treat in-sample mean as one column. (3) Require a judge-independent anchor — at least one trajectory-level deterministic verifier (rule pipeline, DAG oracle) so LLM-judge drift is detectable. A fourth field-level recommendation, surfaced because three of fourteen studies independently identified it, is to abandon stdio-based MCP for benchmark infrastructure: protocol overhead currently dominates the latency floor and conflates with reasoning ability in any cost metric.
Limitations and open questions
The orthogonality claim for the twelve tiers is explicitly a working hypothesis; the paper does not establish empirical independence (e.g., factor analysis on tier scores) and defers this to future work. The fourteen studies share institutional context, so the authors correctly call their convergence “architectural sensitivity” rather than independent replication — generalization to non-AssetOpsBench domains is asserted, not shown. The predictive-validity proposal also concentrates evaluation cost: maintaining hidden splits, adversarial suites, and deterministic verifiers is expensive and risks centralizing evaluation in well-resourced institutions, a concern the authors flag without resolving. Finally, the three OOD criteria are described with thresholds in the abstract but the paper stops short of running the full predictive-validity protocol on the consolidated 6,000-trajectory corpus; that is the obvious next experiment.
Why this matters
Agent leaderboards are increasingly used as deployment-decision artifacts, but the rank-instability evidence from public-to-hidden retrospectives shows scalar means do not transfer. Replacing in-sample mean with predictive validity, plus declaring configuration axes and trajectory-level verifiers, is a low-cost structural fix that aligns leaderboard incentives with what deployed agents are actually judged on.
Source: https://arxiv.org/abs/2606.19704
ENPIRE: Agentic Robot Policy Self-Improvement in the Real World
Problem
Real-world dexterous manipulation progress is bottlenecked by human-in-the-loop algorithm engineering: tuning controllers, designing rewards, debugging perception, resetting scenes, and iterating on training code. Coding agents (Codex, Claude Code, Kimi Code) have automated substantial portions of digital research, but their feedback loops are confined to deterministic, side-effect-free environments. Physical autoresearch demands repeatable interaction with a non-deterministic world: scenes must reset, outcomes must be verified, and safety must be enforced before any agent-driven optimization loop can run. ENPIRE proposes a harness that supplies exactly that abstraction so that a coding agent can hill-climb a real-world success rate without human babysitting.
Method
ENPIRE decomposes physical autoresearch into two stages, mirroring its name: EN (environment construction from human feedback) and PIRE (policy improvement, rollout, evolution).
Stage 1 — Environment construction. A coding agent procedurally synthesizes environment APIs that wrap the robot stack with: (i) hard kinematic and configuration-space safety constraints whose violation triggers truncation and an automatic reset; (ii) an automated verifier that produces the per-episode reward; and (iii) an automatic reset mechanism. Humans assess the resulting APIs once and the agent refines them; this cost is amortized across all subsequent autoresearch on every robot.
The verifier is task-specific and built from perception primitives. For zip-tie cutting, for example, two camera views are cropped and segmented to test whether the strap still passes through the head, with redundancy across views to suppress false positives.

Stage 2 — PIRE loop. Once the environment exposes a reset → execute → verify API, the agent enters a closed loop:
- Policy Improvement (PI): agent edits training infrastructure, hyperparameters, or policy code.
- Rollout (R): one or many physical robots execute the candidate policy in parallel; each rollout returns a verifier reward and trajectory logs.
- Evolution (E): the agent ingests logs, consults literature via tool calls, diagnoses failure modes, and emits the next code revision.
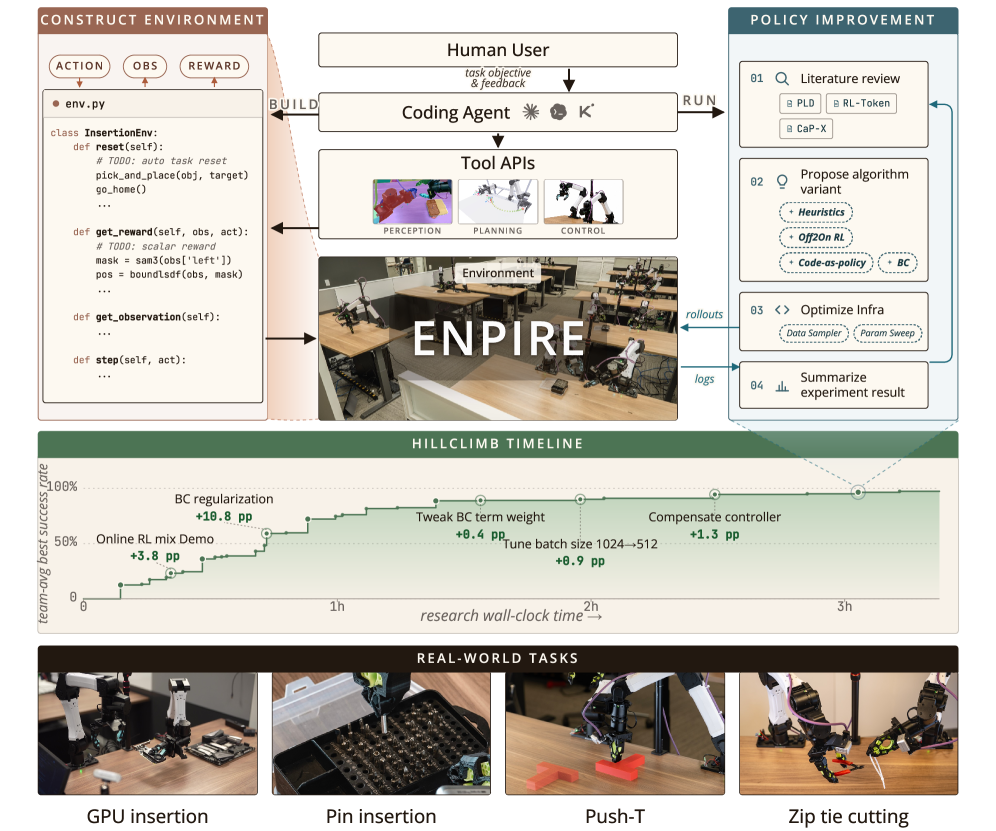
The agent is not restricted to a single learning paradigm. It can synthesize heuristic policies from perception/control tool calls, train behavior-cloning networks, run real-world RL, or compose these (e.g., a heuristic skeleton with a learned residual). Success is scored as completion within 8 sequential retries per trial — retries observe their predecessor’s failure, so the metric rewards in-context recovery, not just i.i.d. best-of-N precision:
\text{Success} = \Pr\!\left[\exists\, k \le 8 : \text{trial}_k \text{ succeeds} \mid \text{trial}_{<k} \text{ observed}\right].
The hardware platform is a bimanual 6-DoF YAM robot. Tasks: Push-T (non-prehensile alignment), pin insertion into 4 mm holes, GPU-chip socket insertion, and zip-tie cutting with scissors.
Results
On simulated Gym-PushT, all three agents converge: Claude Code and Codex hit 95% success in ~2 hours of wall-clock autoresearch; Kimi Code reaches the same level in roughly twice the time.
The gap between simulation and reality is the headline finding. On the real Push-T setup, two of the three agents fail outright — non-deterministic contact friction, robot dynamics, and object micro-motion violate the low-variance hypothesis-testing regime that simulators provide. This argues that heuristic-only policy synthesis is brittle in the real world and motivates mixing gradient-based learning into the agent’s toolkit.
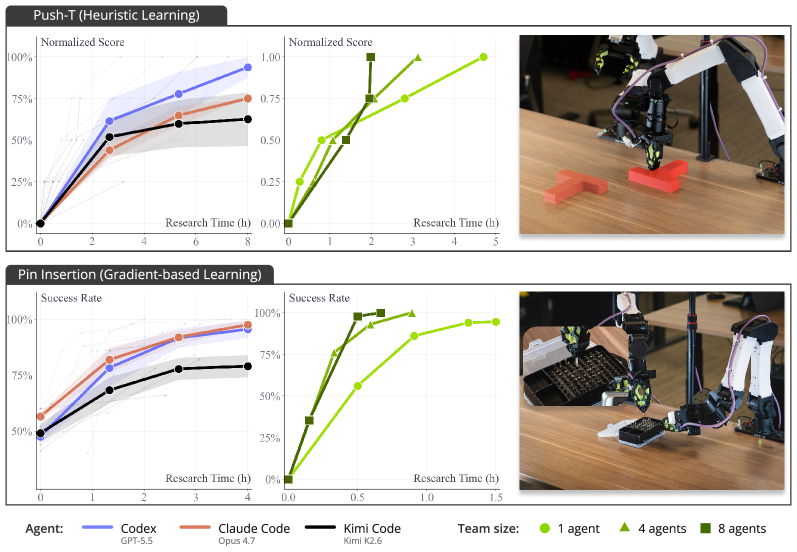
The second claim is resource scaling: when the rollout module dispatches across multiple physical robots in parallel, wall-clock time to reach a target success rate drops monotonically with worker count, while token spend on the agent side scales the convergence rate of the search itself. The framework therefore exposes two orthogonal compute axes — physical throughput (robots) and reasoning throughput (tokens) — both of which materially affect time-to-policy on Push-T and pin insertion.
Limitations and open questions
The paper does not report final success-rate numbers on GPU insertion or zip-tie cutting in the excerpts provided, and the heuristic-only failure on real Push-T suggests current agents still need substantial scaffolding to reliably drive gradient-based real-world RL. Stage-1 environment construction still needs a human assessor in the loop, and the safety-constraint specification is task-specific — its generality across new manipulation skills is unclear. The 8-retry success metric conflates one-shot precision with recovery, which is desirable for deployment but obscures comparisons with prior best-of-N benchmarks. Finally, the verifier itself is a learned/engineered perception pipeline (e.g., the dual-view segmentation reward); reward hacking against an imperfect verifier is a known failure mode that the paper does not stress-test.
Why this matters
ENPIRE operationalizes the missing primitive — a repeatable physical feedback loop — that lets coding agents do the same hill-climbing in the real world that they already do on digital benchmarks. If the scaling claim holds beyond Push-T, robot-fleet hours and agent tokens become substitutable inputs to a manipulation-policy production function, shifting dexterous-skill acquisition from an artisanal engineering task to a resourceable autoresearch one.
Source: https://arxiv.org/abs/2606.19980
Current World Models Lack a Persistent State Core
Problem
Generative video models marketed as “world models” are evaluated almost entirely on what stays in frame: pixel fidelity, motion plausibility, camera controllability. None of these probe whether the model maintains a latent world state that continues evolving when the camera looks away. The classic test — does the moon stay in orbit when no one is watching? — has no analogue in current benchmarks. This paper introduces WRBench, which treats camera motion as an intervention on observability and asks whether a target, once hidden and re-observed, is consistent with the event that was originally set in motion.
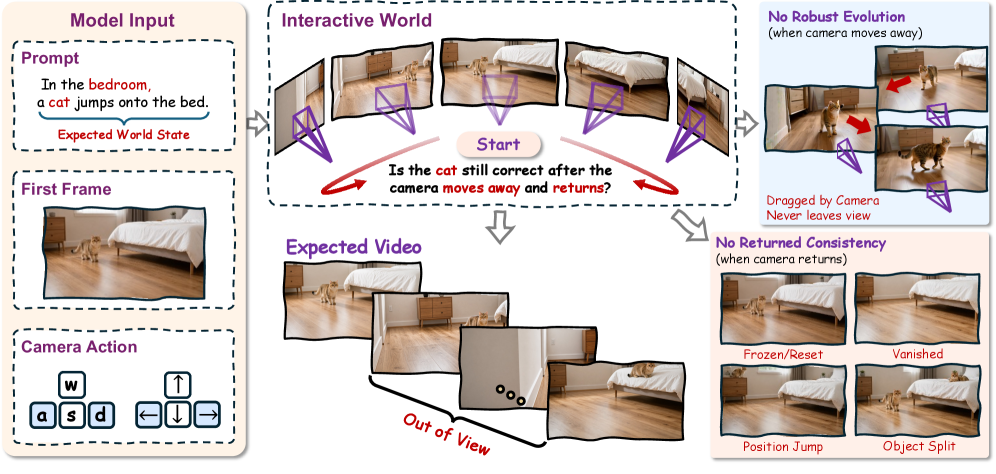
Method
WRBench is a four-layer diagnostic suite. The atomic unit of evaluation is not a video or a prompt but an event-view record
r_i = (x_i^0, e_i, \tau_i, \nu_i, \pi_i),
where x_i^0 is the initial observation, e_i the specified event, \tau_i the intended viewpoint intervention, \nu_i the visibility regime (visible / hidden / hidden-and-returned), and \pi_i the prompt or interface variant. Crucially, prompts specify the initial scene, event, and viewpoint request but never reveal the endpoint state — so the generated video itself must carry the evidence for any re-observed-state claim. This blocks language-model-style shortcutting where the prompt encodes the answer.
The Natural-25 prompt suite supplies 25 scene families drawn from 19 venues, crossed with a 2×2 event design factoring spatial displacement against state change. WRBenchLib dispatches each record to each generator and logs what was actually delivered (intended viewpoint vs. delivered condition vs. generated video vs. measurement evidence). The six-dimensional evaluation suite scores: requested-camera precision (CamPrec, strict local control), common-yaw prompt-camera alignment (CamAlign), visual integrity (Integ.), visible spatial consistency, visible state consistency, re-observed spatial consistency, and re-observed state consistency. Re-observed metrics are conditional on the existence of judgeable hidden-and-returned evidence, with the support fraction reported separately so that access (does the target reappear in a judgeable view at all?) is decoupled from correctness (is the reappeared target consistent with the event endpoint?). Human preference annotation calibrates each axis independently.
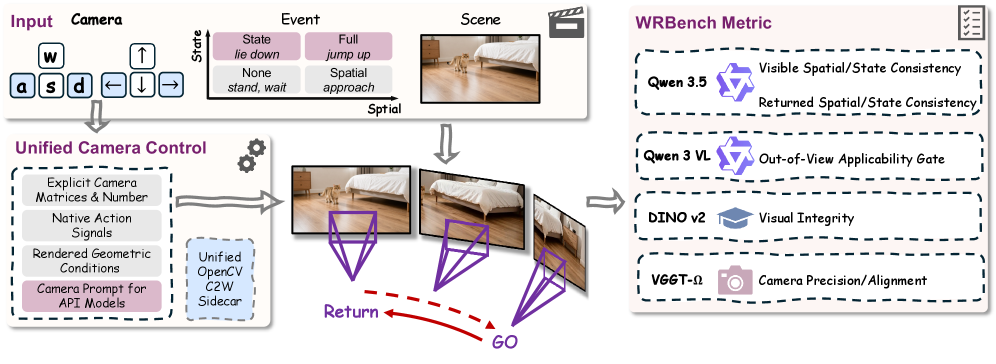
Models are grouped by viewpoint condition type: source-video (the camera trajectory is given as a reference video), geometry-cache (a 3D/depth cache mediates camera control), model-inferred (camera latent is inferred from prompt), and prompt-only. Best/second-best are computed within group, since these paradigms differ in what control signal they consume.
Results
The benchmark covers 9,600 generated videos from 23 models. The headline result is that current systems are differentially capable across the chain preserve visible continuation → instantiate camera motion → expose the hidden target again → preserve the returned endpoint, and degrade most sharply on the last link.
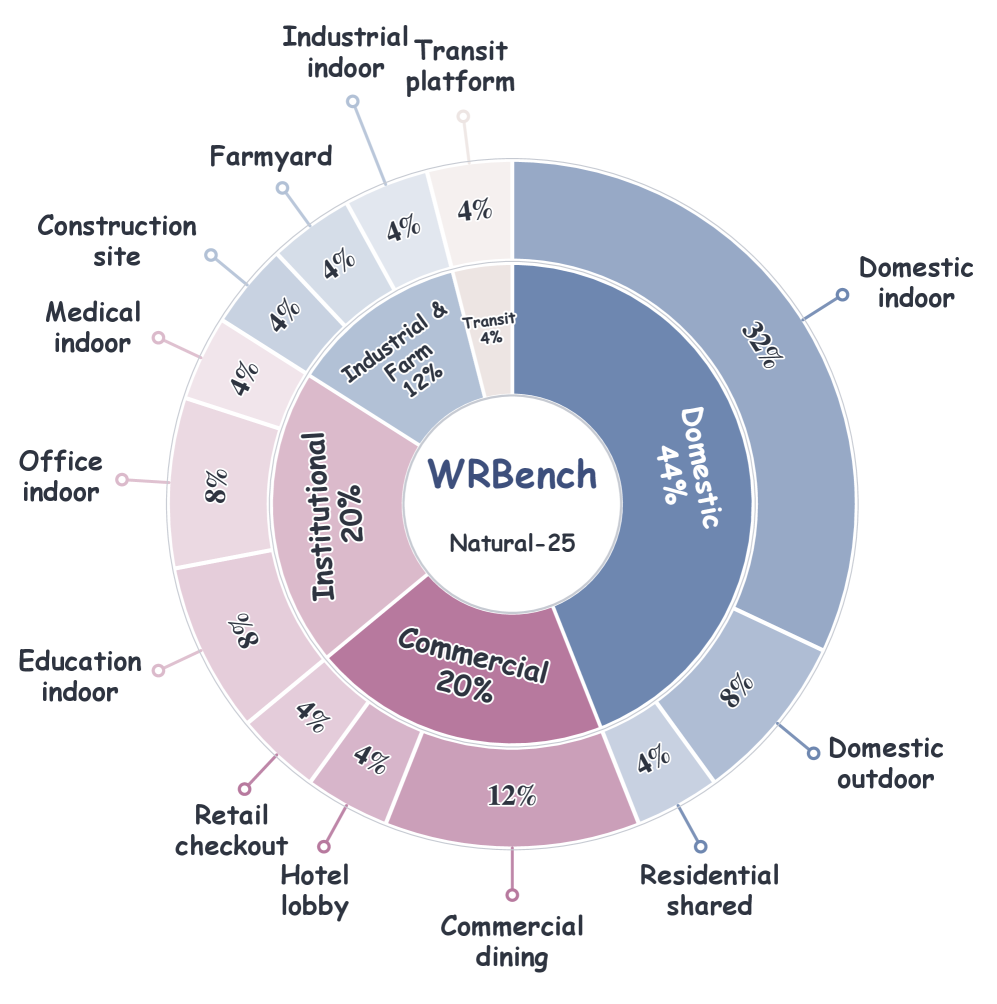
Concrete numbers from the model-level profile (Table 2, six-metric average in parentheses):
- Source-video condition. InSpatio World 14B is strongest with Integ. 0.824, visible spatial 0.821, but re-observed spatial drops to 0.734 and re-observed state to 0.664 (Avg. 0.729). HyDRA achieves the highest CamPrec (0.822) and CamAlign (0.855) yet collapses on re-observed state (0.445), with re-observation support of only 33.2%. ReCamMaster sits in between (Avg. 0.667) with 58.5% support.
- Geometry-cache condition. Gen3C delivers the highest re-observation support in the group at 73.0%, with re-observed spatial 0.681 and re-observed state 0.640 (Avg. 0.686). VerseCrafter has the best Integ. (0.846) but only 28.0% support; Spatia drops to 25.8% support and re-observed state 0.586.
- Model-inferred condition. Wan-Fun variants show very low re-observation support — 18.2% (2.1-14B), 13.8% (2.1-1.3B), 12.0% (2.2-5B) — indicating that without an explicit camera signal the camera rarely returns to a judgeable view of the hidden target at all. Conditional re-observed scores, where available, are mid-pack (0.621–0.657 for state).
The recurring pattern: visible spatial consistency is consistently higher than visible state consistency, and re-observed scores trail visible scores even after conditioning on judgeable returns. Strong camera execution (HyDRA’s 0.822 CamPrec) does not imply endpoint binding (0.445 re-observed state). Conversely, models with high integrity scores often have low re-observation support, meaning they avoid the hard test rather than passing it.
Limitations and open questions
Re-observed metrics are conditional aggregates: a model that almost never produces a judgeable hidden-and-returned view (Wan-Fun 2.2-5B at 12.0% support) is scored on a small, possibly favorable subset, and the reported \dagger flags for sparse support concede this. The benchmark does not yet decompose endpoint failure into mechanistic causes (incorrect dynamics rollout vs. amnesia about pre-occlusion state vs. resampling a fresh plausible scene at re-observation). Natural-25’s balanced factorial design also under-weights frequency-realistic scene distributions, so absolute scores are not directly comparable to in-the-wild deployment.
Why this matters
If “world model” is to mean more than “video prior with camera conditioning,” generators must maintain latent state through occlusion, and benchmarks must measure that explicitly rather than reward visible fidelity. WRBench operationalizes the persistent-state requirement and shows that no current model in any of the four control paradigms passes it cleanly — endpoint binding under occlusion is the open frontier.
Source: https://arxiv.org/abs/2606.20545
Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
Problem
Industrial-scale inpainting models (FLUX-Fill, SD3-Fill, and similar 10B-parameter generalists) deliver state-of-the-art fidelity but are impractical for deployment. The obvious response — train a task-specific specialist — runs into a representation bottleneck: aggressive width/depth reduction in standard diffusion U-Nets degrades both global semantic alignment and local texture coherence. Moebius targets this bottleneck directly, aiming for sub-0.3B parameters while preserving the LCG-based semantic conditioning that makes large inpainters work.
Method
The backbone follows the standard latent diffusion setup: an SDXL VAE encodes x and the masked image x_m = x \odot (1-m), the masked latent z_m=\mathcal{E}(x_m) is concatenated with the downsampled mask to form a spatial reference z_s, and a U-Net \epsilon_\theta is trained to denoise z_t. Global semantics are injected through Latent Categories Guidance embeddings \mathbf{E}_{\text{LCG}} \in \mathbb{R}^{K\times D}, with PixelHacker serving as the teacher.
The novelty is the Local-\lambda Mix Interaction (L\lambdaMI) block, which replaces both the spatial self-attention and the cross-attention to \mathbf{E}_{\text{LCG}} with two \lambda-style operators that compress context into fixed-size linear matrices.
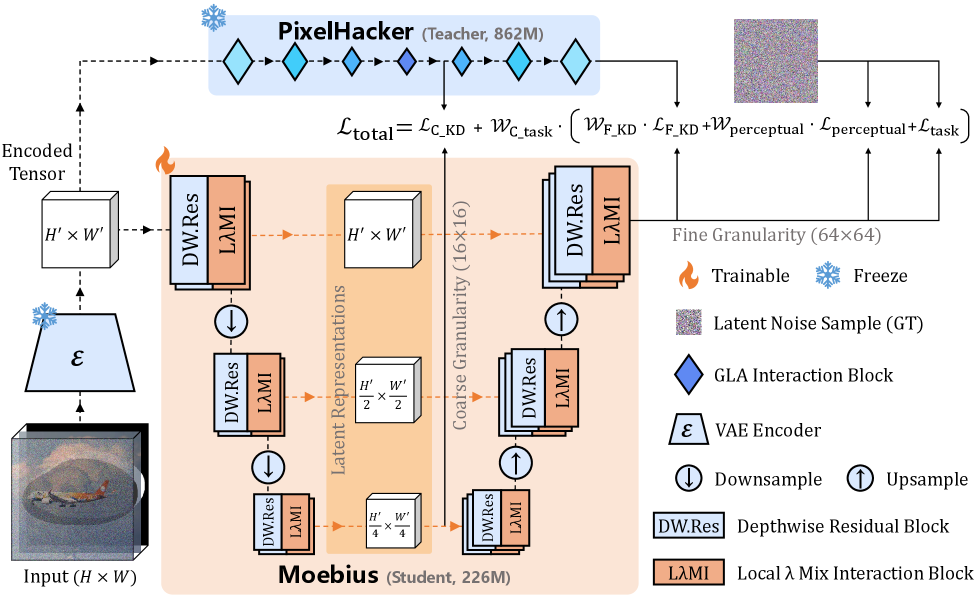
The block has three submodules: Local-\lambda for spatial aggregation, Interactive-\lambda for cross-attention with the LCG prior, and a Mix-FFN.
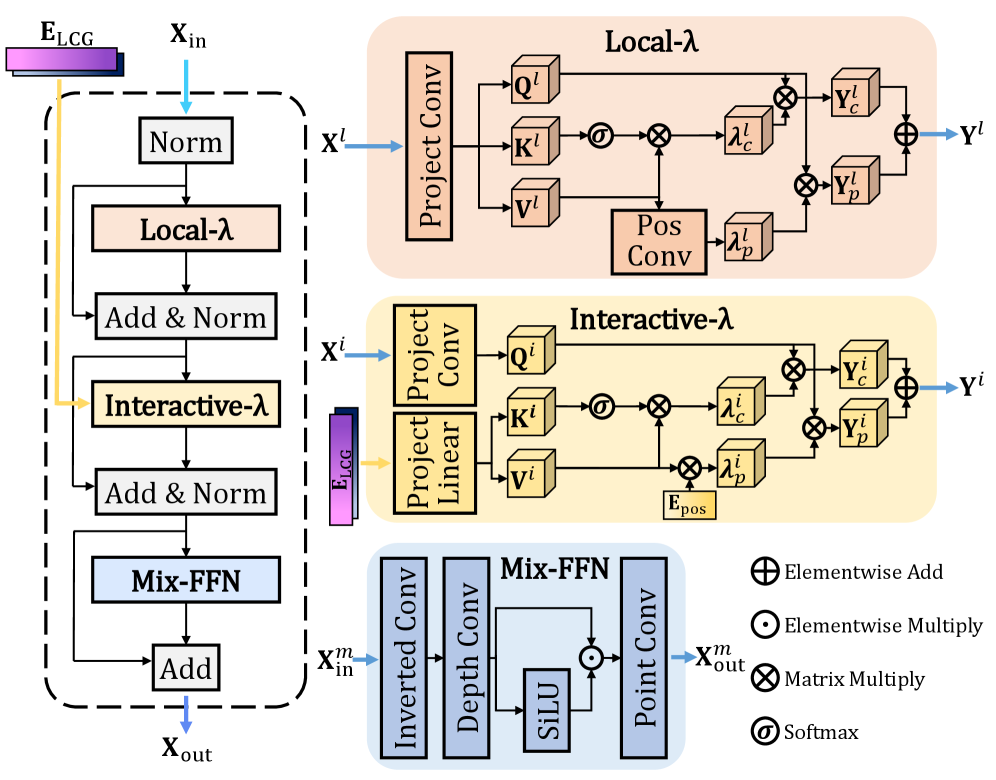
The key trick (visible in Fig. 3) is that instead of computing QK^\top V over N tokens — which is O(N^2 D) for self-attention and O(NKD) for cross-attention — both \lambda modules summarize keys/values into a D \times D (or similar) linear matrix that is then applied to the queries. For Local-\lambda, this is done within a perception window of radius r=15 rather than globally; for Interactive-\lambda, the entire \mathbf{E}_{\text{LCG}} token set (size K) is collapsed into a single content matrix shared across all spatial queries.
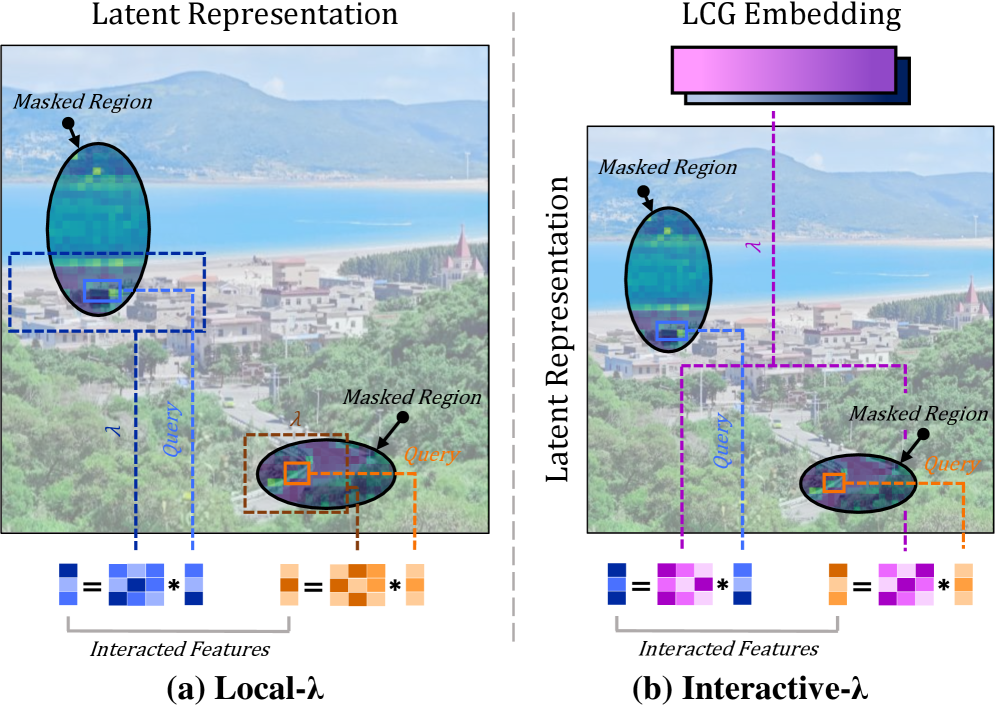
This bypasses the quadratic attention map entirely, which is what allows the depthwise-conv variant of the network to drop to 226M parameters and 154 GFLOPs (Tab. 2, row 9) while still tracking the teacher.
The second piece is an adaptive multi-granularity distillation loss operating purely in latent space (no VAE decode in the training loop). The student aligns with PixelHacker through a dynamically weighted combination of gradient-based losses at multiple granularities; weights are balanced adaptively rather than tuned by hand. The optimizer is Muon with weight decay 0.1, trained for 138K iterations on 16×L40S at batch 768 in BF16, with LR 2\times 10^{-4} decaying by 0.1 at 111K and 129K.
Quantitative results
The architectural ablation on Places2 (18K-iter checkpoints) is the cleanest evidence for the bottleneck claim. With standard prediction loss (no KD), the GLA-CA-FFN baseline gets FID 32.75 / LPIPS 0.298 at 526M params (row 1). Swapping in only Local-\lambda (row 2) or only Interactive-\lambda (row 3) actually hurts — FID rises to 37.65 and 36.91 respectively — showing that compressing one path in isolation breaks the representation. Combining both (row 6, L\lambda-I\lambda-FFN) recovers FID 33.21 / LPIPS 0.286 at 485M, marginally beating the baseline.
Adding distillation flips the picture: row 7 (same arch, with KD) drops to FID 24.73 / LPIPS 0.257, an 8-point FID gain from KD alone. The fully compressed configuration with depthwise convolutions and Mix-FFN (row 9) lands at FID 26.43 / LPIPS 0.258 with 226M parameters and 154 GFLOPs — roughly half the parameters and FLOPs of the baseline, with substantially better metrics. Removing KD from the same architecture (row 10) collapses performance to FID 33.42, confirming that the compact backbone cannot be trained to convergence by the standard noise-prediction objective alone.
The headline 0.2B figure refers to this compressed configuration; the paper claims parity with 10B-class generalist inpainters across Places2, CelebA-HQ, and FFHQ after benchmark-specific fine-tuning (Places2: 51K iters, batch 88; CelebA-HQ: 60K iters, batch 44; FFHQ: 117K iters, batch 88).
Limitations and open questions
The supplementary explicitly acknowledges failure cases under extreme structural compression — the kinds of long-range coherent completions where the r=15 Local-\lambda window and the collapsed Interactive-\lambda summary lose information that full attention preserves. The dependence on a strong teacher (PixelHacker) is total: row 10 vs. row 9 shows the architecture is essentially untrainable without distillation, so this is a compression result, not a from-scratch training result. Open questions include whether the \lambda-based summary generalizes to non-inpainting conditional tasks, the sensitivity to perception window r, and whether the adaptive loss-balancing scheme transfers to other student/teacher pairs. CFG scale ablations and OOD evaluations are deferred to the supplement.
Why this matters
Moebius is a clean demonstration that the bottleneck in compact diffusion inpainters is representational, not capacity-theoretical: pairing linear-attention-style \lambda operators with latent-space distillation closes most of the gap to 10B models at ~2% of the parameters. For practitioners, it suggests that “specialist + distillation in latent space” is a more productive deployment recipe than further scaling generalist inpainters.
Source: https://arxiv.org/abs/2606.19195
DragMesh-2: Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects
Problem
Articulated-object manipulation with multi-finger hands differs structurally from rigid-object grasping: the target DoF (a drawer slide, a door hinge) has no actuation channel, so its motion is entirely a consequence of sustained hand–handle contact forces. Object-centric trajectory generators that produce plausible part motion cannot be replayed open-loop on a hand, because the hand must continuously apply the correct wrench to drag the part along its constraint manifold. Policies trained for task completion under fixed dynamics tend to overfit to nominal contact loads — particularly without tactile or force input — and degrade sharply when joint damping changes. DragMesh-2 targets the gap between articulated-object generation and hand-driven articulated execution, with explicit stress-testing under contact-load shift.
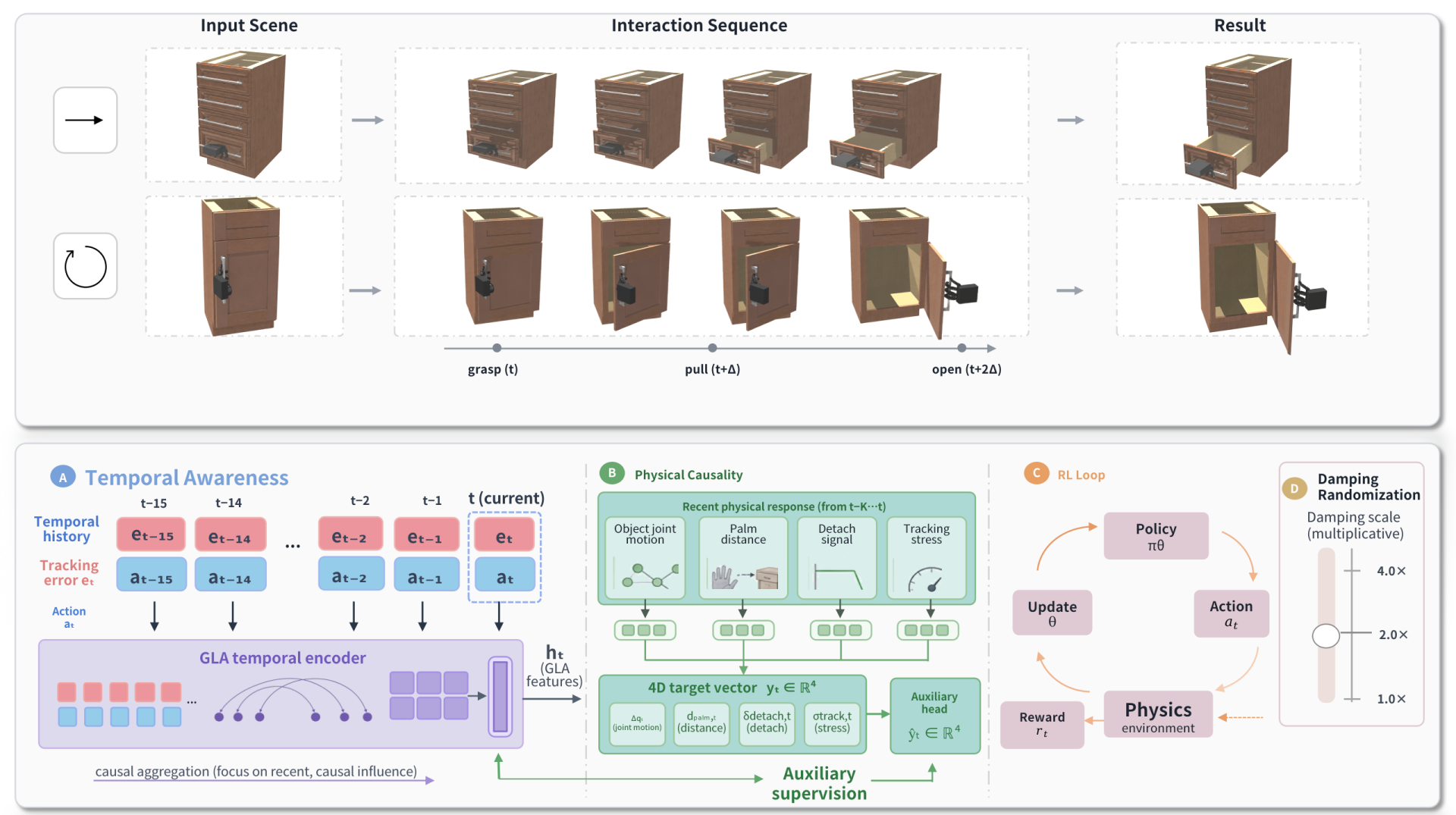
Method
The setup uses a 51-DoF SMPL-X hand (6 virtual wrist DoFs + 45 finger joints) controlling only the hand; the object joint has no action. The target object DoF is the one with the largest range in a geometry-guided reference trajectory, with success defined as
q_{\mathrm{done}}=q_{\min}^{\mathrm{traj}}+\rho\,(q_{\max}^{\mathrm{traj}}-q_{\min}^{\mathrm{traj}})
and progress normalized by the same trajectory range,
p_{t}=\max\!\left(0,\,\frac{q_{t}^{o}-q_{\mathrm{start}}}{q_{\mathrm{goal}}-q_{\mathrm{start}}}\right).
This normalization makes drawers, sliders, and doors directly comparable without committing to a fixed displacement threshold.
The observation comprises hand joint positions/velocities, handle pose, relative palm–handle geometry, target-joint state, and task-scale features (progress, distance to threshold). Crucially, no RGB, depth, point cloud, force, or tactile input is provided — the policy must infer contact state from kinematic features alone. The action is a 51-D PD-target increment, clipped to joint limits. The reference trajectory plays three roles only: (i) initialize an expert grasp state, (ii) define the per-object motion scale used in Eqs. (1)–(2), and (iii) provide a non-learned tracking baseline. It is never replayed as object control and provides no expert action labels — the policy is trained from scratch with PPO.
The full method (PICA) augments the PPO state with two structural components: physical signals (contact-related features) and a GLA temporal encoder. Both are ablated independently in the experiments.
Experiments
The benchmark is 7 GAPartNet objects: 5 revolute doors (Dishwasher, Microwave, three StorageFurniture doors) and 2 prismatic StorageFurniture drawers. Robustness is probed by scaling joint damping by ×1 (nominal), ×2 (mild shift), and ×4 (strong OOD shift). Each (method, object, damping, mode) cell is 20 episodes, with both deterministic (Gaussian mean) and stochastic execution.
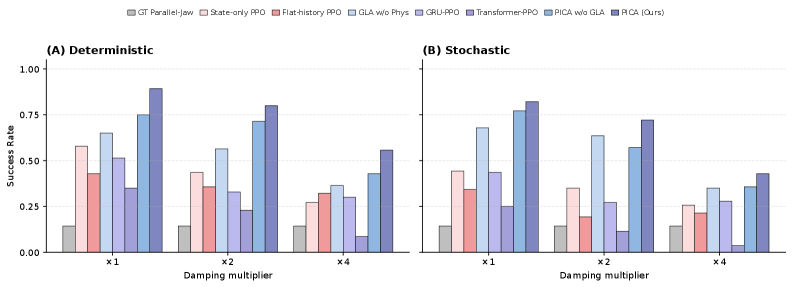
Baselines include open-loop trajectory replay, a GT-part-pose parallel-jaw primitive, and four learned PPO variants (state-only, flat-history, GRU, Transformer). The headline result: PICA attains the highest mean success in all six (mode × damping) cells and degrades most gracefully under load shift. At ×4 damping under deterministic execution, PICA reaches 0.56 success vs. 0.27 for state-only PPO and 0.09 for Transformer-PPO. The GT-part-pose parallel-jaw primitive averages only 0.14 across all damping levels (it succeeds only on the dishwasher door, 1.00, and fails everywhere else), confirming that single-contact gripping is fundamentally inadequate for the broader articulated benchmark even with privileged part pose.
Per-object behavior (Table 2) shows strong baseline brittleness: state-only PPO collapses on the dishwasher door from 1.00 at ×1 to 0.00 at ×4 deterministic; flat-history PPO collapses on the microwave door from 0.95 to 0.00; GRU-PPO collapses on object 12583 from 0.60 to 0.00 and on 48513 from 0.50 to 0.00. Different baselines fail on different objects, indicating that observation/architecture choices each leak idiosyncratic shortcuts in the nominal-damping regime that disappear OOD. The trajectory-tracking reference itself drops from 1.00 average at ×1 to 0.71 at ×2 and ×4 (failing on objects 45936 and 7310), which establishes that the task is genuinely contact-dynamics-limited rather than kinematics-limited — open-loop replay of a feasible part trajectory does not produce the required wrench at higher damping.

The two-component ablation shows additive gains from physical signals and the GLA temporal encoder, with the combination strictly dominating in all six aggregate cells.
Limitations and open questions
The evaluation is simulation-only on 7 objects; the hardware figure is qualitative only. The policy uses a 51-DoF SMPL-X hand with privileged handle pose and target-joint state — no perception. All episodes start from an expert grasp, so approach and grasp acquisition are out of scope; the contribution is constrained to the post-grasp pulling phase. With only 7 objects and three categories the per-object variance is high (several cells are 0.00 or 1.00), so the ×4 averages move on coarse increments. Whether the contact-driven formulation transfers to learned grasp initialization, to vision-based observations, and to genuinely closed-loop hardware are all open. The mechanism by which “physical signals” improve OOD damping robustness — given that no force or tactile input exists — deserves a more direct causal probe.
Why this matters
DragMesh-2 makes the case that articulated manipulation evaluation should explicitly perturb contact dynamics rather than only kinematics: methods that look comparable at nominal damping diverge by 6× in success at ×4 damping. The contact-progress normalization in Eq. (2) is a useful piece of evaluation hygiene for mixed revolute/prismatic benchmarks.
Source: https://arxiv.org/abs/2606.15133
Playful Agentic Robot Learning
Code-as-Policy (CaP) agents synthesize executable robot programs from a language instruction l, environment context c, and a primitive library f, but they only build reusable abstractions when an extrinsic task forces them to. This paper asks whether a CaP agent can profitably spend a “play” phase before any task arrives — autonomously proposing exploratory goals, executing them, and distilling successful programs into a persistent skill library. The proposed system, RATs (Robotics Agent Teams), formalizes this as a two-phase loop: a play phase that grows a library \mathcal{L} = \mathcal{L}_0 \cup \mathcal{L}_{\text{learned}} from an initial primitive set \mathcal{L}_0, and a frozen-evaluation phase where \mathcal{L} is retrieved as additional callable functions for downstream CaP agents.

Method
The play loop (Algorithm 1) drops the instruction l from the standard CaP tuple (c, f, l) and replaces it with a self-proposed task \tau_t. RATs is decomposed into three teams:
- Task Proposer: given the current environment \mathcal{E}_{train}, library \mathcal{L}, and failure memory \mathcal{M}, samples a “novel yet learnable” task \tau_t. The intent is curiosity-driven curriculum: avoid trivially-solved or repeatedly-failed regions of task space.
- Execution team: synthesizes a CaP program \pi_t conditioned on (\tau_t, \mathcal{L}), runs it, and verifies intermediate progress with step-level checks. Failures are diagnosed (missing precondition, wrong target, etc.) and retried with that diagnostic appended to context.
- Memory-Management team: on success, distills \pi_t into a named, parameterized code skill added to \mathcal{L}_{\text{learned}}; on failure, writes a compact lesson into \mathcal{M}.
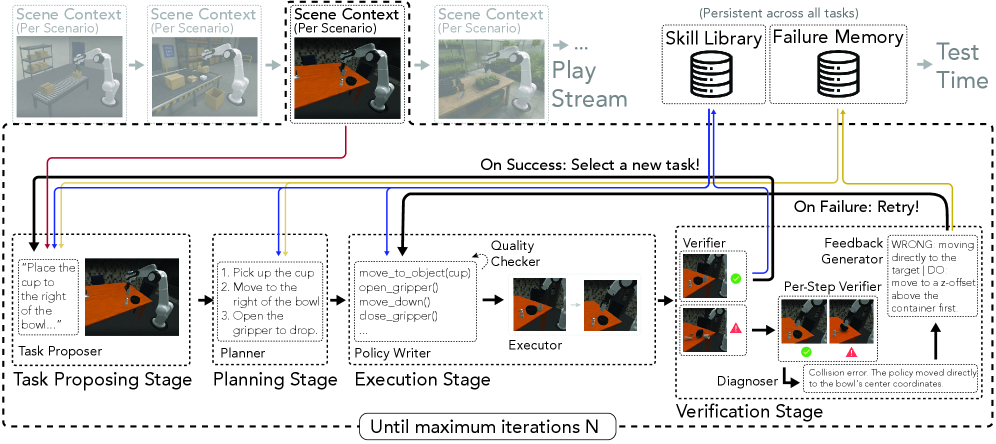
The skill library is purely symbolic — Python functions calling lower-level primitives — so it is portable across CaP agents without retraining a policy network. At test time the authors evaluate two modes: a plug-in mode that injects retrieved skills from \mathcal{L} into a vanilla CaP-Agent0 context, and a full-system mode (RATs Exec.) that uses the entire execution pipeline including verification.
Results
Play is run for N=50 iterations on each benchmark with gemini-3.1pro-preview as the backbone LLM.
On LIBERO-PRO (Table 1), which perturbs each task along object/goal/spatial axes with initial-position-swap and task-perturbation splits, neural VLA baselines essentially fail under these perturbations: OpenVLA and \pi_0 score 0.0 across all six splits, \pi_{0.5} averages 12.8. CaP-Agent0 reaches 23.2 average using only primitives. RATs reaches 43.8 average, a 20.6 percentage-point gain over CaP-Agent0. Largest absolute gains appear on Object splits (61.0 / 63.0 vs 27.0 / 31.0) where reusable manipulation skills compose most cleanly; Spatial splits improve least (29.0 / 31.0 vs 13.0 / 23.0), suggesting spatial reasoning is bottlenecked by perception/grounding rather than skill availability.
On MolmoSpaces (Table 2), which scores success via grounded scene state plus NL criteria across Open, Close, Pick, and Pick-and-Place categories, RATs improves average success from 21.0 to 38.0 (+17.0 pp). The largest delta is Close (36.0 → 73.0), consistent with closing being a compositional skill (approach, align, push) that benefits most from a distilled subroutine.

The paper additionally reports cross-environment transfer to RoboSuite (held out from play) and a sim-to-real transfer demo, indicating skills written against \mathcal{L}_0 retain utility when the underlying primitives are re-implemented in a new simulator. Quantitative numbers for these are not in the excerpt.
Limitations and open questions
- N=50 play iterations is small; it is unclear how performance scales with play budget, or whether the library saturates / accumulates redundant or buggy skills. There is no explicit deduplication or skill-pruning analysis presented here.
- The curiosity signal is implemented through the LLM Task Proposer rather than an information-theoretic objective; the ablations isolating curiosity-driven vs random-play are referenced (Sec. 4.4) but the magnitude of that contribution within the +20.6 pp is the key question for whether “play” matters as opposed to simply “more LLM compute on the same environment”.
- Spatial generalization remains weak (29–31% on LIBERO-PRO Spatial), which suggests symbolic skill libraries cannot substitute for grounded geometric reasoning.
- The dependence on a frontier LLM (
gemini-3.1pro-preview) for proposal, code synthesis, verification, and diagnosis means the wall-clock and dollar cost per acquired skill is not characterized, and the approach inherits that model’s biases about what constitutes a “learnable” task. - VLA baselines scoring 0.0 on LIBERO-PRO is surprising and suggests the perturbation splits may be adversarial to learned policies in a way that flatters symbolic agents; comparison is more meaningful against CaP-Agent0.
Why this matters
This is a clean demonstration that the “skill library” abstraction familiar from Voyager-style agents transfers to embodied CaP robotics, and that intrinsic-phase library construction yields concrete gains (+20.6 and +17.0 pp) on perturbation benchmarks where end-to-end VLAs collapse to zero. It reframes pretraining for robot agents as code accumulation rather than weight updates, with the practical consequence that learned skills are inspectable, portable across CaP backends, and composable without retraining.
Source: https://arxiv.org/abs/2606.19419
FlowBender: Feedback-Aware Training for Self-Correcting Conditional Flows
Problem
Conditional diffusion and flow-matching models systematically violate the constraints they are conditioned on. A depth-to-RGB model produces images whose re-extracted depth \mathcal{H}(\mathbf{x}) disagrees with the input \mathbf{y}; an edge-conditioned model misplaces edges; a texturing model paints onto the wrong mesh region. The forward operator \mathcal{H} — the depth predictor, edge detector, renderer, or degradation — is typically available at both training and inference, yet existing pipelines do not use it as a closed-loop signal during training.
Two paradigms dominate. Supervised fine-tuning (ControlNet, LoRA, ControlNet++) treats the condition as a static cue: the network sees \mathbf{c} but never observes its own alignment error. Inference-time guidance (e.g. FlowChef) injects \nabla_{\mathbf{x}_t}\|\mathbf{y}-\mathcal{H}(\hat{\mathbf{x}}_1)\|^2 at sampling time but with hand-tuned step sizes, producing the familiar fidelity/plausibility trade-off. The authors’ diagnosis: the model is never trained to consume its own residual.
Method
FlowBender turns sampling into a learned closed-loop controller. Given a flow-matching backbone with velocity v_\theta(\mathbf{x}_t, t, \mathbf{c}) and the standard look-ahead estimate
\hat{\mathbf{x}}_1 = \mathbf{x}_t + (1-t)\, v_\theta(\mathbf{x}_t, t, \mathbf{c}),
each training step performs two passes (Fig. 2).
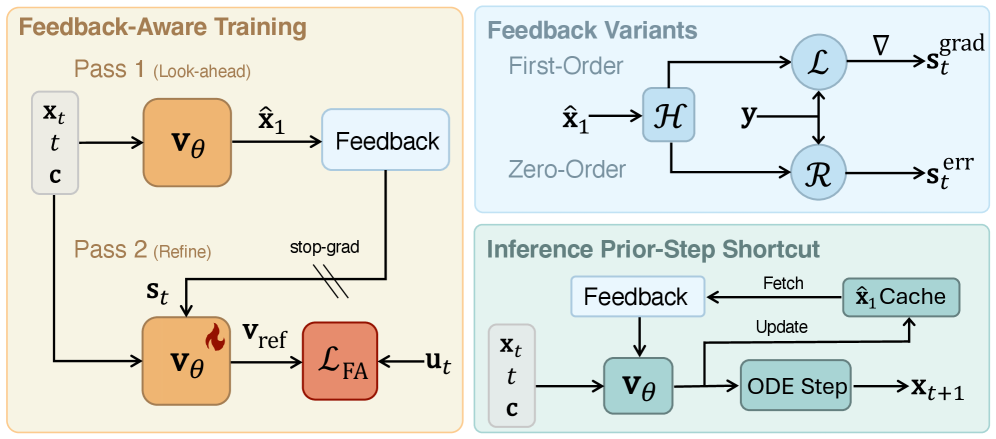
- Look-ahead pass. Run v_\theta once without feedback to obtain \hat{\mathbf{x}}_1.
- Feedback construction. Compute a task-specific deviation \mathbf{s}_t from \hat{\mathbf{x}}_1 via \mathcal{H}. Two variants are studied:
- First-order: \mathbf{s}_t = \nabla_{\hat{\mathbf{x}}_1}\,\mathcal{L}(\mathcal{H}(\hat{\mathbf{x}}_1),\mathbf{y}) when \mathcal{H} is differentiable.
- Zero-order residual: \mathbf{s}_t = \mathbf{y}-\mathcal{H}(\hat{\mathbf{x}}_1) (or a lifted form), for black-box or non-differentiable operators (renderers, off-the-shelf detectors).
- Refinement pass. Re-evaluate the network as v_\theta(\mathbf{x}_t, t, \mathbf{c}, \mathbf{s}_t) and fit it with the standard flow-matching loss against the target velocity \mathbf{x}_1 - \mathbf{x}_0. The model thus learns a correction policy that maps (state, condition, current alignment error) to a velocity that drives the trajectory toward the constraint manifold.
The two-pass scheme doubles per-step cost. To amortize, inference uses a cached shortcut: instead of recomputing the look-ahead pass at step t, reuse \hat{\mathbf{x}}_1 from step t{-}1 to assemble \mathbf{s}_t. This makes the inference graph essentially single-pass after warm-up while still exposing the network to its own residual.
The toy 2D example in Fig. 1 isolates the mechanism: an Archimedean spiral is partitioned into four radial classes, and class membership is enforceable through a radial forward operator. Standard conditional FM and guided variants either ignore the class boundary or smear across it; FlowBender concentrates samples within the correct annulus.
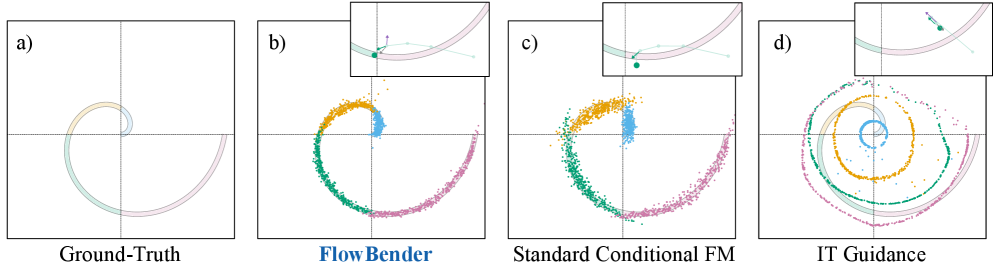
Results
The authors fine-tune a latent flow-matching backbone for two regimes: image-to-image translation (depth-to-RGB, edge-to-RGB) and 3D mesh texturing. Baselines under matched sampling budget are (i) Standard FT with ControlNet/LoRA adapters, (ii) FT + \mathcal{L}_{\text{align}} (ControlNet++ style measurement-consistency loss), and (iii) FlowChef inference-time guidance. Evaluation separates fidelity (\|\mathbf{y}-\mathcal{H}(\mathbf{x})\| in the appropriate metric) from plausibility (perceptual quality).
The qualitative comparisons in Fig. 3 illustrate the structural failure modes the method targets: ControlNet preserves global layout but mislocalizes thin edges and depth discontinuities (red boxes); FlowChef tightens alignment at the cost of texture artifacts and contrast shifts; FlowBender outputs track \mathcal{H}(\hat{\mathbf{x}}_1)\approx\mathbf{y} without sacrificing realism.

The paper argues, and confirms via appendix sweeps, that doubling the sampling budget for baselines or layering CFG does not close the gap — the deficit is representational, not computational. Because the residual \mathbf{s}_t is consumed as a network input rather than added as an external nudge, the correction is non-linear and learned, side-stepping the linear step-size tuning that bottlenecks guidance methods.
Limitations and open questions
- The training pass cost is \sim 2\times; the cached-shortcut inference recovers single-pass cost only after the first step, and its effect on early-step trajectories where \hat{\mathbf{x}}_1 is still poor is not fully characterized.
- Feedback design is task-specific. The first-order/zero-order dichotomy works, but the encoding of \mathbf{s}_t (lifted to latent space, concatenated, cross-attended) likely matters and is under-explored.
- Only one forward operator per task is studied. Composing multiple constraints (e.g. depth + text + edges) and handling conflicting feedback signals is open.
- The method assumes \mathcal{H} is reliable; a biased operator will be faithfully reproduced as a bias in \mathbf{x}.
- Reported gains are relative to FM baselines; how the closed-loop formulation interacts with consistency-distilled or few-step samplers is unclear.
Why this matters
FlowBender reframes constraint satisfaction in conditional generation as a control problem rather than a guidance problem: the network is trained to read its own measurement residual and act on it. This dissolves the fidelity/plausibility trade-off characteristic of test-time guidance and gives a uniform recipe — differentiable or black-box — for any task with an accessible forward operator.
Source: https://arxiv.org/abs/2606.20404
Hacker News Signals
Semiclassical Gravity Efficiently Solves NP-Complete Problems
A preprint claims that if gravity is semiclassical — meaning the gravitational field couples to the expectation value of the stress-energy tensor rather than to a quantized field — then a physical device can solve NP-complete problems in polynomial time. The argument works by encoding a SAT instance into a many-body quantum state whose energy landscape, under semiclassical gravitational self-interaction, develops a feedback loop that amplifies the amplitude of satisfying assignments. Because the gravitational potential depends on \langle \hat{T}_{\mu\nu} \rangle rather than on individual branches, the dynamics are nonlinear in the wavefunction: i\hbar \partial_t |\psi\rangle = \hat{H}_0 |\psi\rangle + V_{\text{grav}}[\langle\psi|\hat{T}|\psi\rangle] |\psi\rangle. Nonlinear quantum mechanics is known since Abrams & Lloyd (1998) to permit polynomial-time NP solving, so the result is not surprising given the premise — the contribution is constructing a plausible physical realization under the semiclassical approximation. The authors are careful to note this is a conditional result: if semiclassical gravity is the correct description (i.e., gravity is never fully quantized), complexity class separations collapse. The more mainstream interpretation is that this is a reductio ad absurdum: because we expect NP \not\subseteq BQP, semiclassical gravity is likely not the correct theory. The HN discussion centers on whether this is a genuine physics argument or complexity-theoretic folklore dressed up. Key open questions are whether the semiclassical approximation holds long enough to complete the computation and whether decoherence destroys the interference structure before the answer is extracted. Experimentally falsifying semiclassical gravity at the required precision is currently out of reach.
Source: https://arxiv.org/abs/2606.14806
DuckDB Internals: Why Is DuckDB Fast? (Part 1)
This post gives a technically grounded walkthrough of DuckDB’s execution engine, focusing on the design decisions that separate it from row-oriented systems. Three mechanisms get the most attention.
First, columnar storage and vectorized execution. DuckDB operates on vectors of 2048 values at a time (the STANDARD_VECTOR_SIZE compile-time constant). Each operator pulls a chunk from its child, processes it with tight loops over contiguous memory, and passes the chunk upward. This eliminates per-row virtual dispatch and keeps data in L1/L2 cache across the pipeline.
Second, late materialization. Projections and column reads are deferred until a filter has reduced the working set. The post illustrates how a query scanning a wide table with a selective predicate only fetches non-predicate columns for the rows that pass, reducing memory bandwidth substantially.
Third, the push-based pipeline model. DuckDB compiles queries into pipelines separated by pipeline-breakers (hash joins, sorts, aggregations). Within a pipeline, data is pushed from source to sink without intermediate materialization. This maps well to modern CPU out-of-order execution because there are no synchronization points inside a pipeline.
The post also covers the selection vector abstraction: rather than physically filtering a vector, DuckDB maintains an integer array of active indices. Filters append to this vector rather than copying surviving rows, avoiding allocation hot-paths. Comparisons with MonetDB (which pioneered vectorized execution) and HyPer (which pioneered compilation-based execution) are accurate: DuckDB occupies a middle ground, favoring interpreted vectorization over LLVM-JIT compilation for simpler deployment.
The article is Part 1 and does not yet cover the buffer manager, out-of-core execution, or the parallel pipeline scheduler — all of which are significant contributors to DuckDB’s performance profile at scale.
Source: https://www.greybeam.ai/blog/duckdb-internals-part-1
Zero-Touch OAuth for MCP
Anthropic’s Model Context Protocol (MCP) blog describes an enterprise authentication scheme called “Zero-Touch OAuth,” targeting the problem of deploying MCP servers behind corporate identity providers without requiring users to manually authorize each tool connection. The core mechanism is an enterprise-managed OAuth flow where the IdP (Okta, Entra ID, etc.) issues tokens to MCP clients automatically based on group membership or policy, rather than requiring interactive consent screens.
Technically, the scheme introduces a distinction between user-delegated and enterprise-managed authorization. In the managed path, an organization pre-registers MCP server OAuth clients with their IdP and distributes scoped tokens through an enterprise device management channel. The MCP client receives a token with a pre-approved scope bundle; no browser redirect occurs. This is analogous to client credentials flow or device-provisioned certificates, but adapted to the MCP server discovery protocol.
The post specifies that server metadata must advertise a managed_auth endpoint alongside the standard OAuth authorization server metadata. Clients check for this field and, if present and the enterprise policy matches, skip the interactive flow entirely. Token rotation and revocation follow standard OAuth 2.1 mechanics — the novelty is in the provisioning path and the metadata signaling.
From a security perspective, the interesting questions are around scope creep: pre-approved scope bundles assigned by IT to a class of users may be broader than any individual user would interactively approve. The post acknowledges this but positions it as an acceptable enterprise trade-off, analogous to SSO with pre-consented applications. The spec is currently a proposal within the MCP working group and has not been ratified. For AI agent deployments in regulated environments, the absence of per-action user confirmation is a material change to the audit trail.
Source: https://blog.modelcontextprotocol.io/posts/enterprise-managed-auth/
We Built a Persistent Agent Memory Layer on Elasticsearch with 0.89 Recall
Elastic’s post describes an architecture for giving LLM agents persistent memory using Elasticsearch as the backing store, reporting 0.89 recall@10 on their internal benchmark. The design separates memory into three tiers: episodic (raw conversation turns), semantic (compressed summaries), and procedural (extracted rules/preferences). Each tier uses a different indexing strategy.
Episodic memory uses BM25 over raw text with recency decay applied at query time via a script score: \text{score} = \text{BM25}(q, d) \cdot e^{-\lambda \cdot \Delta t}. Semantic memory uses dense vector search (HNSW index) over embeddings of LLM-generated summaries. Procedural memory uses exact-match filtered retrieval on structured fields extracted by the LLM from conversations.
The retrieval pipeline issues all three queries in parallel and merges results using Reciprocal Rank Fusion (RRF), which Elasticsearch 8.x supports natively. The final context injected into the agent prompt is assembled from the top-k merged results, with a token budget enforced by truncating lower-ranked items.
The 0.89 recall figure is measured on a proprietary dataset of agent task completion queries; the methodology for constructing ground truth is not described in detail, which limits external validity. The system does not claim to handle memory consolidation — the process of deciding when to promote episodic fragments to semantic summaries is left to a scheduled LLM job running every N turns, with no adaptive triggering.
Implementation details: the Elasticsearch mappings use dense_vector fields with element_type: float and m: 16, ef_construction: 100 for HNSW. The post includes index templates and a Python retrieval snippet using the elasticsearch-py client. The main limitation is the cost of the periodic LLM summarization pass, which is not characterized at scale.
Source: https://www.elastic.co/search-labs/blog/agent-memory-elasticsearch
OpenRouter Fusion API
OpenRouter’s Fusion API is a model-routing layer that attempts to improve response quality by simultaneously querying multiple LLMs and synthesizing their outputs before returning a single response. The mechanism, as described in their documentation, runs n parallel inference calls to different provider-hosted models, then passes all n responses through a “fusion” model (itself an LLM) that produces a single consolidated answer.
The selection of which models to query in the parallel pass appears to be configurable but defaults to a set chosen by OpenRouter based on benchmark scores and latency characteristics. Pricing is the sum of tokens consumed across all parallel calls plus the fusion call, which makes it materially more expensive than a single-model query. The latency is bounded by the slowest of the parallel calls, not their average, though the post implies the fusion step adds only ~300ms on top.
The technical substance is essentially a mixture-of-experts-at-inference-time pattern, related to prior work on LLM-blending and debate-based aggregation. The fusion model acts as a learned arbitrator; whether it genuinely improves calibration or simply hedges toward consensus is an empirical question the documentation does not address rigorously. There is no stated mechanism for handling cases where the parallel responses are systematically wrong in the same direction — the fusion model cannot correct correlated errors.
From a systems standpoint, this is a fan-out/fan-in architecture at the API gateway level. OpenRouter handles the parallel dispatch, provider authentication, and response aggregation, so callers see a single streaming response. The streaming behavior during the fusion step — whether intermediate tokens from parallel models are surfaced — is not specified. HN comments are skeptical about whether the quality gain justifies the cost multiplier and note the absence of published benchmarks comparing Fusion against single-model baselines.
Source: https://openrouter.ai/openrouter/fusion
Clojure Hosted on Go
Glojure is a Clojure implementation that uses Go as its host platform, analogous to ClojureScript’s use of JavaScript. The repository is a working interpreter/compiler that maps Clojure’s persistent data structures and concurrency primitives onto Go’s runtime. This is technically non-trivial for several reasons.
Clojure’s persistent collections (vectors, hash maps, sets) are implemented using Phil Bagwell’s hash array mapped tries (HAMTs) and RRB trees. Glojure reimplements these in Go rather than delegating to Java’s standard library, which ClojureJVM does. The interop story replaces Java reflection-based interop with Go’s reflect package, allowing Clojure code to call Go functions and access Go structs. Macros and the reader are implemented in Go, and the compilation target is a tree-walking interpreter rather than JVM bytecode.
Concurrency uses goroutines and Go channels as the substrate for core.async-style operations. Clojure’s STM (ref, dosync) is implemented atop Go mutexes and retry loops rather than on the JVM’s STM. This means the STM semantics are preserved but the performance characteristics differ from the JVM implementation.
The motivation is to produce a Clojure that compiles to a single static binary (via go build), inherits Go’s cross-compilation story, and can directly call Go libraries without FFI overhead. The current limitation is that not all of clojure.core is implemented, and performance is well below ClojureJVM since there is no JIT. The project is not positioned as a production replacement but as a research vehicle for host-portable Clojure semantics. HN discussion notes the tension between Clojure’s identity/value semantics and Go’s pointer-heavy idioms, particularly around struct mutation.
Source: https://github.com/glojurelang/glojure
SubQ 1.1 Small
SubQ 1.1 Small is a purpose-built language model for SQL query generation, described in a technical report from SubQ AI. The model is positioned in the “small” tier (parameter count not disclosed in the abstract but implied to be in the 1-7B range based on hardware requirements listed). The report focuses on text-to-SQL rather than general coding, and the training regime is correspondingly narrow.
The key technical claims are around schema-aware prompting and execution-guided training. The model is trained with a curriculum that starts on synthetic single-table queries and progressively introduces multi-table joins, subqueries, window functions, and dialect-specific syntax (PostgreSQL, BigQuery, DuckDB, SQLite). Execution feedback is used during fine-tuning: generated queries are run against reference databases, and queries that produce correct result sets are upweighted in the loss, regardless of syntactic similarity to the gold query. This is a form of execution-guided reward in a supervised fine-tuning loop, not full RL, though the boundary is thin.
On the BIRD benchmark, SubQ 1.1 Small reports 65.3% execution accuracy, which the report positions relative to GPT-4o’s ~67% on the same split. On Spider, it reports 87.1% exact match. The report does not include ablations separating the contribution of the execution-guided curriculum from the base model quality.
Limitations: the model requires schema context in the prompt (DDL statements), so performance degrades with very large schemas that exceed the context window. The report notes sensitivity to column naming conventions — models trained on clean schema names underperform on production databases with abbreviated or inconsistent naming. No information is given on the base model, training compute, or dataset composition, which limits reproducibility.
Source: https://subq.ai/subq-1-1-small-technical-report
Sogen: High-Performance Windows and Linux Userspace Emulator
Sogen is a userspace emulator targeting Windows (x86-64) and Linux (x86-64) binaries, running them on arbitrary host platforms. The project is notable for attempting both ABIs rather than focusing on one, and for its stated performance goal of minimizing emulation overhead relative to native execution.
The technical approach is binary translation rather than full system emulation. Sogen does not emulate a complete CPU or operating system kernel; instead, it intercepts syscalls at the userspace boundary and translates the guest ABI to the host ABI, while translating x86-64 machine code to the host ISA (currently targeting AArch64 hosts, based on the documentation). This is the same architectural choice made by Apple’s Rosetta 2, Qemu’s user-mode emulation (qemu-x86_64), and FEX-Emu.
The Windows support layer must implement the Win32 and NT syscall surfaces, including the loader (PE parsing, DLL resolution), the heap allocator, threading primitives, and enough of ntdll.dll to bootstrap common runtimes. The Linux layer maps Linux syscalls to host syscalls where the semantics are close enough (e.g., read, write, mmap) and emulates differences (e.g., signal handling, clone flags).
Performance is claimed to be “high” but no published benchmark numbers are provided on the landing page, which limits independent assessment. The project appears to be early-stage; the website describes the goals and architecture but the repository is not yet public. HN comments note the ambition of the dual-ABI target and compare it to Wine (Windows-on-Linux, no binary translation needed on x86 hosts) and FEX-Emu (x86-64 on AArch64 Linux only). The main open question is how the JIT handles self-modifying code and position-independent executables with frequent indirect branches.
Source: https://sogen.dev/
Noteworthy New Repositories
study8677/awesome-architecture
A structured, bilingual (English/Chinese) reference collection targeting system design at the architecture level rather than the interview-prep level. The repo organizes 26 tutorials covering distributed systems fundamentals — consensus, replication, partitioning, failure modes — alongside 25 architecture templates that can be adapted to concrete production contexts. Six end-to-end case studies walk through AI-native systems, RAG pipelines, and coding agents with explicit discussion of production trade-offs (latency vs. consistency, cost vs. throughput, build vs. buy). The framing is deliberately opinionated: each template calls out failure patterns, not just happy-path designs. The bilingual structure makes it useful for teams where English is not the primary working language. The AI-native and agent sections address deployment concerns (context window management, tool-call latency, retrieval quality) that most classic system design references predate. Useful as onboarding material for senior engineers joining distributed or ML platform teams, or as a structured checklist when reviewing architecture proposals.
Source: https://github.com/study8677/awesome-architecture
tastyeffectco/sandboxd
A self-hosted service that provisions isolated development sandboxes with public preview URLs using a single CLI command, explicitly designed for use with coding agents and rapid SaaS prototyping. The critical architectural decision is the deliberate absence of Kubernetes — sandboxes run as lightweight containers or processes managed by sandboxd’s own control plane, reducing operational overhead to near zero. Each sandbox gets an externally routable URL, enabling webhooks, OAuth callbacks, and agent-driven browser testing without exposing localhost. The design targets scenarios where a coding agent needs to spin up, test, and tear down environments programmatically — the API surface is minimal and scriptable. Because the server is self-hosted, secrets and source code never leave the operator’s infrastructure, which matters for proprietary codebases. No registry account or cloud vendor dependency is required. Comparable to ngrok + ephemeral containers but with lifecycle management built in. The “no Kubernetes” stance is a deliberate constraint rather than a limitation; it keeps the dependency surface small enough that a single developer can operate it reliably.
Source: https://github.com/tastyeffectco/sandboxd
slothflowlabs/duckle
A desktop-native ETL/ELT authoring tool that uses a drag-and-drop DAG editor to construct data pipelines, then compiles those pipelines to SQL executed locally by DuckDB. The core value proposition is that the artifact is SQL, not a proprietary binary — pipelines are stored as human-readable, diff-friendly workspace files suitable for version control. Running on DuckDB means columnar, vectorized execution over local files (Parquet, CSV, JSON) or attached databases without a server process. The “local-first” architecture means no SaaS dependency, no data leaving the machine, and offline operation. The compilation step is significant: rather than interpreting the visual graph at runtime, Duckle emits SQL that can be audited, optimized by hand, or extracted and run independently of the tool. This makes it tractable for data engineers who need to inspect what a pipeline actually does. The desktop packaging (likely Electron or Tauri, given the “tiny” footprint claim) avoids the browser-tab session model of web-based pipeline tools. Useful for local data exploration, small-team analytics, and scenarios where cloud pipeline infrastructure is disproportionate to the workload.
Source: https://github.com/slothflowlabs/duckle
duncatzat/vigils
A local control plane for monitoring and approving AI agent actions, built with a Rust backend, Tauri for the desktop shell, and a Chrome Manifest V3 extension for browser-level interception. The architecture separates observation from execution: the Chrome extension captures agent-initiated browser actions and DOM interactions; the Tauri app presents these for human review before they proceed. Secrets management is a first-class concern — the system is designed to intercept credential usage and keep sensitive values out of agent context or logs. The approval workflow is configurable so that low-risk actions (navigation, reads) can be auto-approved while writes, form submissions, or API calls require explicit confirmation. The Rust core handles the local message bus between the extension and the desktop app with low latency, keeping the review loop fast enough not to break agent execution flow. This addresses a real operational gap: most agent frameworks provide hooks for tool calls but nothing for browser-level side effects. Running fully locally means no agent activity is routed through a third-party service. The MV3 constraint is notable — it requires service-worker-based background processing rather than persistent background pages, which shapes the extension’s event model.
Source: https://github.com/duncatzat/vigils
Somnusochi/VLM-AutoYOLO
An end-to-end pipeline that uses a vision-language model — specifically NVIDIA’s LocateAnything-3B — to generate bounding-box annotations automatically, feeds those annotations through a manual refinement step, then triggers YOLO training in a single click. The pipeline handles both image datasets and video inputs, with keyframe extraction from video to reduce redundant annotation work. The use of LocateAnything-3B is architecturally significant: it is a grounding model that accepts natural-language object descriptions and returns localized detections, so the annotation step is driven by text prompts rather than class-specific fine-tuning. This makes it practical for novel object categories without a pre-existing labeled dataset. The manual refinement interface allows correction of VLM errors before training, preserving label quality. Model validation is integrated post-training, closing the loop within the same tool. The relevant engineering challenge here is managing the format conversions between VLM outputs (typically normalized coordinates in JSON), YOLO label format (class-index normalized xywh per line), and the training framework’s expected directory structure. The pipeline automates those conversions. Useful for rapid dataset construction in domains where annotation cost is the primary bottleneck.
Source: https://github.com/Somnusochi/VLM-AutoYOLO
AprilNEA/OpenLogi
A native, local-first replacement for Logitech Options+ written in Rust, communicating with Logitech peripherals over the HID++ protocol directly. HID++ is Logitech’s proprietary USB/Bluetooth HID extension that exposes device features — button remapping, DPI profiles, SmartShift scroll configuration — beyond what standard HID supports. OpenLogi reverse-engineers and implements this protocol in Rust, removing the dependency on Logitech’s Electron-based Options+ application, which requires a cloud account and runs background services. The Rust implementation gives direct access to the OS HID layer (via hidapi or platform-specific backends) with minimal overhead. No telemetry, no account, no network calls. The practical benefit is significant for privacy-conscious users and for enterprise environments where outbound telemetry is blocked. The codebase also serves as a documented open implementation of HID++ feature negotiation, which is valuable for peripheral developers and reverse engineers. Limitations are the usual ones for protocol reverse engineering: device coverage depends on community contributions, and Logitech can alter firmware to break assumptions. The 5,000-star adoption rate suggests the Options+ pain point is widely felt.
Source: https://github.com/AprilNEA/OpenLogi
coder/boo
A terminal multiplexer styled after GNU screen — persistent sessions, window management, detach/reattach — built on libghostty rather than writing its own terminal emulation layer. Libghostty is the rendering and input library extracted from the Ghostty terminal emulator; using it as a foundation means boo inherits Ghostty’s GPU-accelerated rendering, Unicode handling, and input processing rather than reimplementing those components. The design choice is architecturally interesting: most multiplexers (tmux, screen, zellij) implement their own pseudo-terminal management and rendering pipeline. Boo’s layering on libghostty suggests a tighter integration with the host terminal’s capabilities rather than the traditional approach of sitting between the application and the display as a character-cell intermediary. This could enable features that are difficult to retrofit onto older multiplexer architectures, such as synchronized rendering or richer input handling. Coder’s involvement connects this to their remote development platform, where a reliable terminal multiplexer is a core infrastructure component. The GNU screen aesthetic implies session persistence and simple window management are the primary design goals rather than the tiling pane model emphasized by tmux and zellij.
Source: https://github.com/coder/boo
razr001/align-dev
A developer tool that generates shared coding standards and a SKILL.md file — a structured document describing team conventions, architecture patterns, and technology choices — intended to be consumed by AI coding assistants (Claude Code, Codex, Cursor, Copilot) as persistent context. The core problem is that AI-assisted development in teams produces stylistically and architecturally inconsistent code because each agent invocation starts without knowledge of team norms. AlignDev addresses this by providing a generation workflow that produces a machine-readable standards document that can be placed in the repository root and automatically included in agent context windows. The SKILL.md format is analogous to AGENTS.md or .cursorrules but targets multi-agent consistency rather than single-tool configuration. The generation step presumably involves prompting the user for tech stack, coding conventions, and architectural decisions, then emitting a structured file. The value is primarily in the workflow discipline it enforces: teams that go through the generation process are forced to make implicit standards explicit, which benefits human reviewers as much as AI agents. The multi-tool targeting (five named coding agents) means the output format must be generic enough to be interpreted correctly by different context-injection mechanisms.