デイリーAIダイジェスト — 2026-06-17
arXiv ハイライト
LoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling
問題設定
Looped Transformerは共有ブロックをR回再利用することで、パラメータを追加せずに実効的な深さを増やしますが、標準的な逐次ループでは推論レイテンシとKV-cacheメモリがRに対して線形に増大します。Parallel Loop Transformer(PLT)は、各ループにループ間位置オフセット(CLP)と共有KVゲート付きスライディングウィンドウattention(G-SWA、ウィンドウサイズw=64)を与えることでこの問題を回避し、単一のキャッシュに対してループを実行することでループ数をほぼコストなしに調整できる設計変数にしています。そこで自然に浮かぶ問いは「ループはいくつ使うべきか?」というものです。著者らは経験的に「1回余分に使う」という答えを示し、深いループが積極的に性能を損なう理由をメカニズムの観点から説明しています。
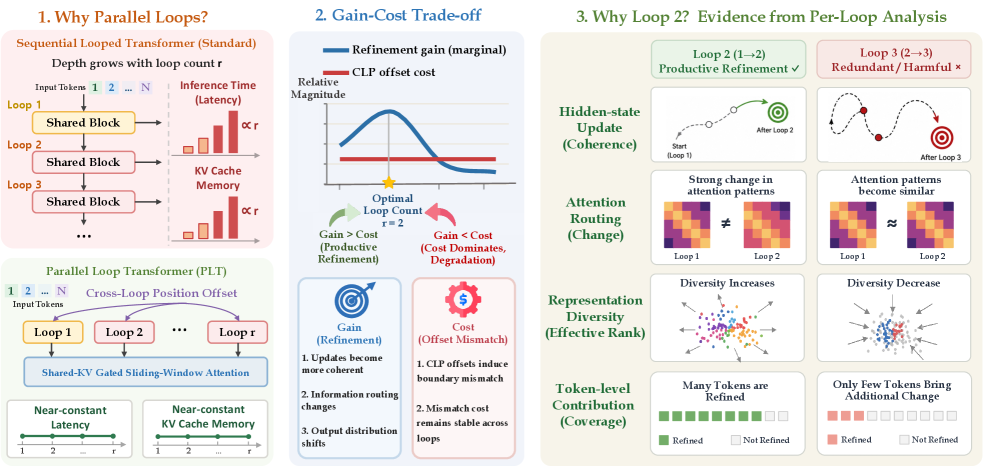
実験設定
全実験において、G-SWA(w=64)と第1ループKV共有を全ループに均一に適用した7B denseのPLTを使用しています。R \in \{1, 2, 3, 4\}(ベースライン、PLT_2、PLT_3、PLT_4)の4つのバリアントを18Tトークンでゼロからpretrainingし、Rのみが異なるよう揃えたinstruction tuningを行います。
マクロ的結果:Rに対して強く非単調
PLT_2は、R=1ベースラインに対してSWE-bench Verifiedを43.0から64.4へ(+21.4)、Multi-SWEを14.0から31.0へ(+17.0)改善します。同モデルはホールドアウトのエージェンティックSWE-bench-CCで33.4を達成しており、7B denseモデルが30B〜72Bのオープンモデルを上回り、Verifiedでは480Bクラスのシステムに届く範囲に入っています。PLT_3とPLT_4は、より多くの潜在計算を行うにもかかわらず性能が後退し、しばしばR=1ベースラインを下回ります。曲線はR=2で鋭くピークを迎えます。
ミクロ的診断
著者らはループ間の隠れ状態の幾何学をインストルメントしており、ステップサイズ\delta^{(r)} = \lVert h^{(r)} - h^{(r-1)} \rVert、角度変化\cos\theta^{(r)}、有効ランク\mathrm{erank}(h^{(r)})、および不動点ギャップ\Delta_{\text{FP}}^{(r)}を計測しています。
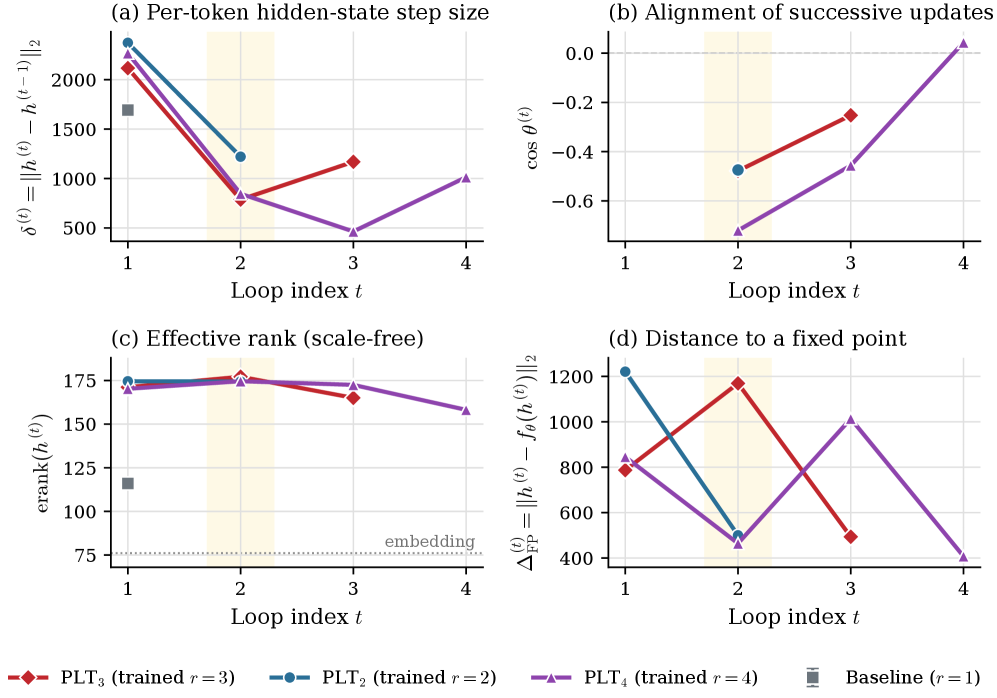
複数のシグナルが同じ描像に収束します。有効ランクはr=2でピークを迎えその後単調に減少するため、深いループは表現の多様性を拡大するのではなく崩壊させます。精緻化ループを通じて逐次的な更新は振動的であり(\cos\theta^{(r)}<0)、モデルはオーバーシュートして過去の更新を部分的に打ち消しています。また、\delta^{(r)}は中間深さで最小値まで縮小した後、読み出しループで反発しますが、この反発は新たな計算ではなくデコードです。不動点ギャップは収縮しないため、ループは収縮型の反復ソルバーとして機能していません。
出力側の観察も一貫した描像を示します。ループごとの出力分布シフト\Delta p^{(r)} = D_{\mathrm{KL}}(p^{(r-1)} \,\|\, p^{(r)})はr=2以降に崩壊し回復しません。logit-lensによる正解ランクは深さとともに依然として鋭化しますが、それは主に出力読み出しによるものであり新たな精緻化によるものではありません。ループ間attention KLはループ2以降に急激に低下し、attentionのルーティングが凍結することを示しています。ループをまたいだヘッドごとのコサイン類似度が増大することから、ヘッドが冗長なコピーに退化していることがわかります。第1ループのグローバルブランチに重みを与えるG-SWAゲートは全ループで0.5を超えており、後続ループの大部分は狭いローカルウィンドウを通して同じ第1ループのKVを再読み込みしていることを意味します。
ゲイン・コストのハサミ
本論文の中心的な定量的説明は、精緻化ゲイン\Delta p^{(r)}とCLPオフセットコスト\Omega^{(r)}(論文中の式6)のループごとの会計処理であり、\Omega^{(r)}は各ループ境界においてCLPが注入する位置ミスマッチを測定します。
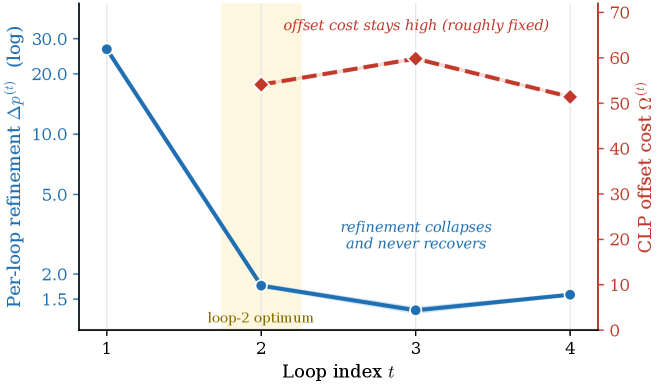
\Omega^{(r)}はほぼループ不変であり、オフセットスキームの固定的な性質です。一方\Delta p^{(r)}はr=2以降に数桁の大きさで減衰します。r \geq 3の全ループにおいて、オフセットコストは精緻化ゲインを30〜45倍上回ります。これは明快な構造的議論です。CLPという「税」は、意味のある表現的な作業が残っているときにのみ償却されますが、このアーキテクチャではループ2までにその作業が尽きます。PLT_4におけるr \geq 2のコンテキスト後精緻化を3つの独立した観点(出力シフト、attentionの再ルーティング、トークンごとのピーク寄与度)で分解すると、いずれもループ2に支配的な割合を割り当てます。
限界とオープンクエスチョン
この分析は特定のアーキテクチャ(G-SWA w=64、第1ループKV共有、この特定のCLPスキーム)と特定のスケール(7B、18Tトークン)に結びついています。「1回余分なループ」が最適であるという結論は\Omega^{(r)}がほぼ一定であることを条件としており、rとともにオフセットコストを減衰させる代替的な位置処理スキームやループごとにCLPを適応させるスキームでは最適点が変わる可能性があります。不動点ギャップが閉じないことは、PLTがDeep Equilibriumの意味での反復推論を実装していないことを示唆しており、収縮的なパラメータ化がR \geq 3を救済できるかどうかは未解決のままです。最後に、診断は相関的なものであり、\Omega^{(r)}を人工的にゼロにするとループ3でのゲインが回復することを示す介入実験は行われていません。
重要性
小規模モデルのtest-time scalingに関して、本研究は潜在ループに経験的な探索ではなくゲイン・コスト分解から予測可能な明確で識別可能な最適点が存在することを主張しており、現在のPLT設計では答えがR=2であることを示しています。固定パラメータ数でのSWE-bench Verifiedにおける43.0から64.4への改善は、より多くのループではなく規律ある潜在的深さこそが成果をもたらすという具体的な実証です。
Source: https://arxiv.org/abs/2606.18023
シグナルを示し、ノイズを隠す:ピクセル空間 Diffusion のための Spectral Forcing
問題
ピクセル空間 diffusion denoiser は、有用な情報が周波数にわたって著しく不均一な入力に対して学習されます。自然画像のべき乗則スペクトル S(k)\propto k^{-\alpha} を持つ rectified flow z_t = t x + (1-t)\varepsilon において、バンドごとのデータ対ノイズ比は移動するカットオフ
k^{\ast}(t) \;=\; (1-t)^{-2/\alpha},
で1を横切り、低周波のシグナルを含む楔形領域と、Bayes 最適 denoiser が決定論的なベースライン(ゼロ予測またはパススルー)に収束する高周波バンドを分離します。標準的なピクセル空間 denoiser はこの境界をすべての t において内部的に再発見しなければならず、データ分布の構造を学習すべき領域が存在しない部分にキャパシティを消費してしまいます。ピクセル空間 DiT(例:JiT)は VAE を避けることでエンドツーエンドのモデリングを維持しようとしますが、この隠れたキャパシティのコストを払うことになります。これは特に粗いトークン化のもとで顕著であり、各トークンが広いスペクトルバンドを要約しなければならない場合に問題となります。
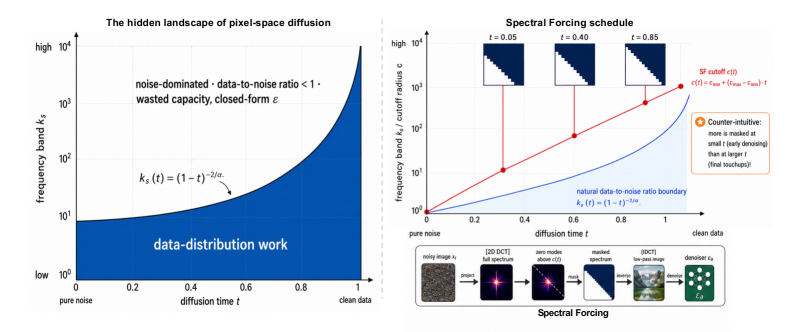
手法
Spectral Forcing(SF)はパラメータを持たない、時間条件付きの 2D-DCT ローパス演算子であり、patch embedder の前に挿入されます。z_t が与えられると、SF は 2D-DCT を計算し、放射状周波数がカットオフ k_c(t) を超える係数をゼロにして逆変換を行います。カットオフスケジュール f(t) = k_c(t)/k_{\max} は t に対して単調に拡大し、t=1 で恒等変換に達するため、データの端点は変更されません。2つのスケジュールが検討されています:
- Linear:f(t) = t。
- Analytical:f(t) = \max(c_{\min}, (1-t)^{-2/\alpha}/k_{\max})、理論的な輪郭を追跡しつつ、初期に DC 領域のトークンが占有されるよう下限 c_{\min} を設けます。
学習はそれ以外変更されません:rectified-flow velocity loss \mathcal{L} = \mathbb{E}\|v_\theta(z_t,t,y) - (x-\varepsilon)\|^2、logit-normal 時間サンプリング \mathcal{N}_{\text{logit}}(-0.8, 0.8)、Heun-50 サンプラー、CFG 2.9。SF は純粋に入力側のマスクであり、バックボーンにパラメータも FLOPs も追加しません。
動機付けとなる診断は、(t,k) 平面上のバンドごとの \log_{10}(\mathrm{MSE}_{\text{net}}/\mathrm{MSE}_{\text{zero}}) です。1次元のトイモデルと学習済みの JiT-700M/32 において、3つの領域が現れます:低 k の回復楔形(ネットワークがゼロ予測を上回る)、ネットワークが閉形式のベースラインに並ぶ高 k のノイズ支配バンド、そして k^{\ast}(t) に沿った遷移領域です。
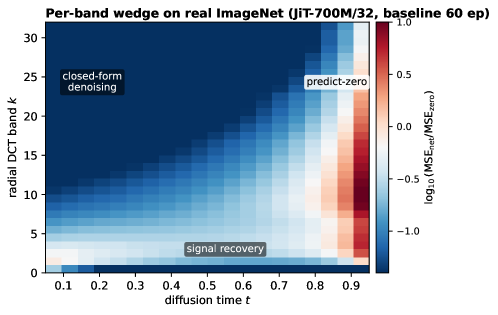
この楔形は合成データから実際の ImageNet に転移し、モデルが内部的に学習しなければならない暗黙の境界が SF が課す明示的な境界であることを検証します。
結果
すべての数値は ImageNet-256 における FID-50k であり、5シードの平均値で、同一レシピのベースラインとの比較です。
粗いトークン化(64 トークン、p=32)。 SF はテストされたすべての(モデル、エポック)ペアで FID を改善します。主要な結果は JiT-700M/32 の 60 エポック:24.19 \to 20.68(+14.5%)。90 ep では:19.90 \to 17.53(+11.9%);120 ep では:16.46 \to 15.15(+8.0%)。JiT-130M/32 については:15 ep で +11.6%(114.03 \to 100.78)、100 ep では +0.4%、200 ep では +1.5% まで縮小。
学習予算に関する2つのレジーム。 小規模(130M/32)では利得の大部分はデータ効率によるものであり、強制なしのベースラインがギャップを埋めます。大規模(700M/32)では意味のある漸近的な成分が残ります:120 ep での SF(FID 15.15)は、約 145 ep での先行する 700M+ の参照(FID 15.24)に匹敵します。
スケジュール。 Linear SF(+14.5%)は主要な結果において Analytical SF(c_{\min}=0.20 で +9.3%、FID 21.94)を上回ります。これは h=64 のトイでは analytical スケジュールが 2〜3 倍勝っていたにもかかわらずです。analytical スケジュールが勝つ順序は高解像度で戻ります。
パッチサイズ / トークン数のスイープ(JiT-130M、60 ep):
| p | トークン数 | Base | +SF | \Delta |
|---|---|---|---|---|
| 16 | 256 | 21.76 | 21.29 | +2.2% |
| 32 | 64 | 44.68 | 42.92 | +3.9% |
| 64 | 16 | 84.50 | 84.69 | −0.2% |
有利なレジームは両側で境界が定まっており、作用する軸はパッチサイズや解像度単独ではなくトークン数です。
解像度。 p=32(256 トークン)を用いた 512^2 では、SF は +3.4% の FID マージン(68.34 → 66.01)を回復しますが、256^2 での同じトークン数では中立でした。トイモデルでは、analytical-SF は h=64 での最低から h=256 での −15%、h=512 では −3.3% で飽和します。
細かいトークン化における隠れたコスト。 JiT-130M/16、60 ep において、Analytical-SF(c_{\min}=0.20)は FID でベースラインと同等(21.23 vs 21.76、+2.4%)ですが、Inception Score を 6.6% 失います(78.04 vs 83.59)——クラスの多様性の崩壊が FID によってマスクされています。ここでの Linear-SF は無害です(FID 21.29、IS 83.13)。
データ構造(トイモデル)。 べき乗則データでは SF はデータ効率のみに寄与し;構造化データでは analytical スケジュールが勝ちます(フロントが真のノイズ支配バンドを追跡するため);矩形データでは高周波のエッジ内容が本質的なシグナルを持つため両スケジュールとも失敗します——これは 256 トークンレジームの制御されたアナログです。
限界と未解決の問題
- この演算子はレジームに制限されます:256^2 で \leq 64 トークン、または高解像度での比例した条件のもとで、パッチ化が使用可能な高周波コンテンツをほとんど捨てていない場合にのみ有用です。細かいトークン化では FID を動かさずに IS を劣化させる可能性があります。
- スケジュール選択は経験的です:Linear は 64 トークンの実際の ImageNet において Analytical を上回りますが、これは analytical スケジュールが k^{\ast}(t) と理論的に整合しているにもかかわらずです。著者たちはこれが解像度によって逆転することを指摘していますが、原理的な選択ルールは提示されていません。
- \alpha はグローバル定数として扱われており、クラスや領域に条件付けられたスペクトルは利用されていません。
- すべての評価は ImageNet-256/512 における FID/IS であり、尤度や知覚品質の数値は報告されておらず、700M を超えたスケーリングも行われていません。
なぜこれが重要か
SF はピクセル空間 diffusion における具体的なキャパシティ割り当ての病理——denoiser が移動するシグナル/ノイズ境界 k^{\ast}(t) を再発見するためにパラメータを無駄にすること——を特定し、パラメータなし・FLOPs なしの DCT マスクによってそれを修正します。これにより 700M スケールで最大 14.5% の FID 改善が得られます。ピクセル空間 DiT に適した帰納的バイアスはアーキテクチャ的ではなくスペクトル的であるという明快な主張であり、VAE なしで潜在空間モデルとのギャップの一部を埋めるためのレシピを提供します。
Source: https://arxiv.org/abs/2606.15236
ハイブリッドアーキテクチャにおける効率的 Attention の役割の再考
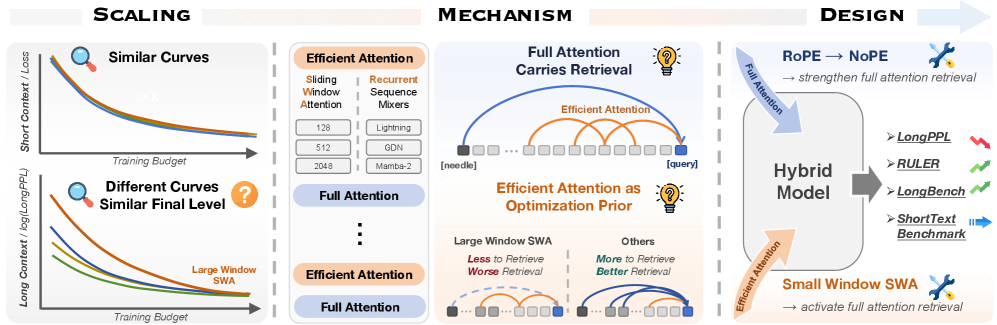
全 attention と効率的 mixer(SWA、Mamba-2、GDN、Lightning)を交互に組み合わせたハイブリッドアーキテクチャは現在標準的になっていますが、既存研究では効率的 attention の選択が能力を左右するレバーとして扱われており、受容野が広いほど、あるいはより表現力の高い再帰構造を持つほど長文脈での性能が向上するという前提が置かれています。本論文は、制御されたスケーリング研究・機械論的プローブ・アーキテクチャのアブレーションを通じてこの見方に異議を唱え、効率的 attention は長距離検索の基盤としてではなく、最適化の事前分布として理解するのが最適だと主張します。
セットアップ
著者らは、全 attention ベースライン(Full)と、SWA-128、SWA-512、SWA-2048、およびリカレント型の Lightning、Mamba-2、GDN の計 6 種類の 1:1 層交互ハイブリッドを比較しています。5 つのモデルスケール S1–S5(非 embedding パラメータ数 15M〜477M、隠れ次元 384〜1280、GQA で KV ヘッド数 2)を学習し、validation \mathrm{Loss} と \log(\mathrm{LongPPL}) に対してスケーリング則を同時にフィッティングしています。
スケーリング:極限での収束と過渡的な乖離
全ハイブリッドの短文脈 \mathrm{Loss} 曲線は、D 全体にわたって Full とほぼ重なっており、これは先行研究と整合しています。興味深いシグナルは \log(\mathrm{LongPPL}) にあります:データ量が少ない段階ではハイブリッド間で大きな差がありますが、D が増加するにつれて曲線は収束します。
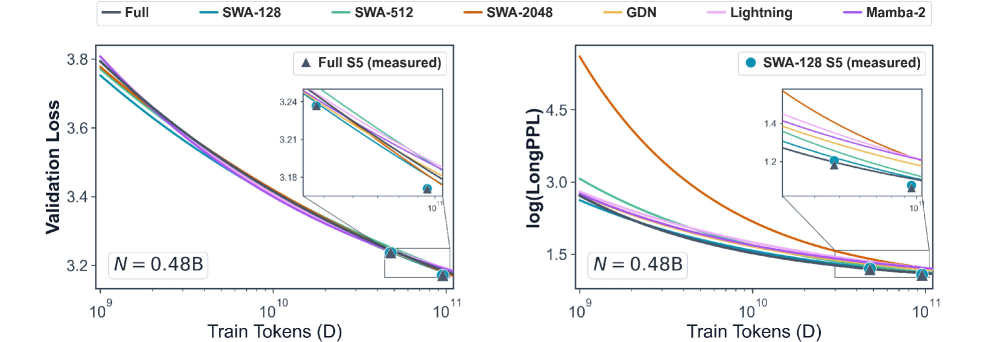
この結果が示唆するのは、効率的 attention の設計は長文脈能力がどれだけ速く出現するかを制御するのであり、到達する漸近値を決めるわけではないということです。SWA ウィンドウが大きいことや、受容野が無制限の再帰構造を持つことは、十分な学習が行われれば長文脈性能の向上には寄与せず、単に収束の軌跡を変えるにすぎません。
メカニズム:長距離検索を行うのは全 attention
D=1000N の S4 における受容野制限実験では、推論時に実際に長距離情報を担うモジュールを特定しています。各モジュールは独立に \approx 2048 トークンで打ち切られます。
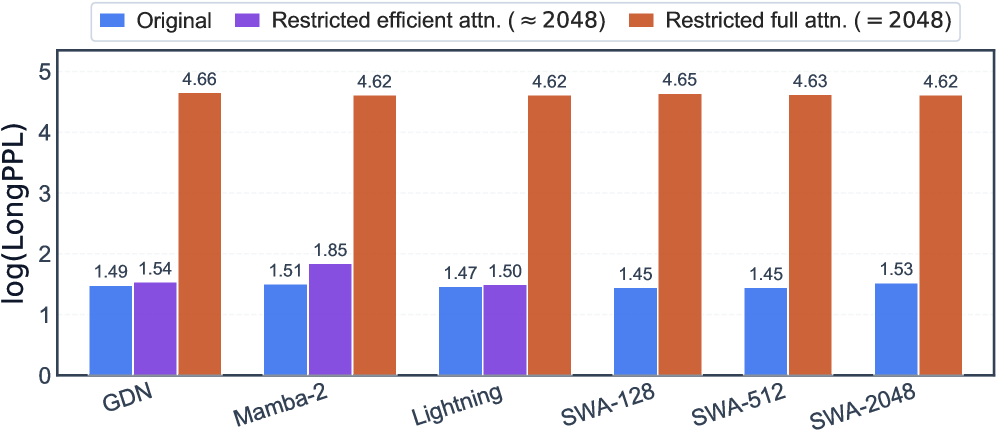
全 attention を制限するとすべてのハイブリッドで \log(\mathrm{LongPPL}) が急激に上昇する一方、効率的 attention を制限してもほとんど変化がありません——原理的には無制限の再帰状態を持つ GDN や Mamba-2 でも同様です。言い換えれば、このレジームでは再帰状態は検索可能な長距離コンテンツを保持しておらず、それを担うのは全 attention 層です。層ごとのプローブ解析(付録 D に収録)もこれを裏付けています。
これは「大ウィンドウの怠惰(Large-Window Laziness)」を説明しています:SWA-2048 を用いると、全 attention 層は広いウィンドウが提供する局所コンテキスト容量にただ乗りでき、専用の検索ヘッドの形成が遅れます。SWA ウィンドウが小さいほど全 attention 層は早期に特化を迫られ、漸近的な能力は同等であるにもかかわらず長文脈の出現が加速されます。つまり、効率的モジュールは検索容量を提供するのではなく、最適化の景観を形成するのです。
設計への示唆
全 attention が主要な処理を担うことを踏まえると、自然な介入は効率的モジュールを調整するのではなく、全 attention パスを直接強化することです。
層の比率。 SWA-128 の 1:3(全:効率)バリアントは \mathrm{Loss} では 1:1 と同等であり、小スケールでのみ \log(\mathrm{LongPPL}) でわずかに遅れますが、N が増加するにつれてギャップは縮まります。十分な数の全 attention 層が存在すれば、全 attention の密度は下げることができます。
全 attention 層のみへの NoPE 適用。 SWA-128 ハイブリッドの全 attention 層にのみ NoPE を適用し(局所性のために SWA 層には位置エンコーディングを保持)、下流タスクで大きなゲインが得られます。S4(0.22B、D\approx 100B)、16K 評価:
- Full: RULER 25.09、RULER NIAH 35.95、LongBench 15.09
- SWA-128: 35.33 / 49.58 / 15.88
- SWA-128-NoPE: 44.80 / 67.81 / 16.43
S5(0.66B)、32K 評価:
- Full: RULER 43.90、NIAH 62.61、LongBench 18.93
- SWA-128: 41.86 / 60.17 / 18.30
- SWA-128-NoPE: 46.98 / 70.42 / 19.46
19 ベンチマークにわたる短文脈平均はほぼ変わりません(S5: Full 40.46、SWA-128 41.31、SWA-128-NoPE 41.32)。少数の全 attention 層から位置エンコーディングを除去するだけで S4 において RULER NIAH が +20 ポイント向上することは注目に値し、メカニズムとも整合しています:SWA 層が局所性を担い、制約のない(位置的に拘束されない)全 attention がより効果的に検索を行うのです。
限界と未解決の問題
最大モデルは D\approx 100B での 0.66B であり、収束に関する主張は外挿されたスケーリング則に基づいており、「十分な学習」は計算量最適の観点から定量化されていません。すべてのハイブリッドは交互配置の 1:1 ベースライン比率を使用しており、配置戦略(例:全 attention を前方に集中させる)は比較されていません。再帰状態が「長距離情報をほとんど保存しない」という機械論的な主張は、このトレーニングレジームに固有のものであり、Mamba-2/GDN はより長い学習コンテキストや異なる状態サイズでは異なる挙動を示す可能性があります。最後に、NoPE の結果は外挿挙動と相互作用しており、YaRN のような明示的な長さ汎化技術や、より長い事前学習コンテキストとどのように組み合わさるかは不明です。
なぜ重要か
本論文はハイブリッド設計を再定義します:効率的 attention モジュールは最適化の事前分布であり、長文脈の基盤ではなく、長文脈能力のレバーは全 attention パスそのものにあるということです。シンプルな SWA-128 + 全 attention 層のみへの NoPE という手法は、短文脈の性能を損なうことなく具体的なゲインをもたらし(RULER NIAH 65.91 → 82.31、0.66B/16K)、現在のハイブリッドが効率的モジュールの高度化に過剰投資し、全 attention の設定への投資が不足していることを示唆しています。
Source: https://arxiv.org/abs/2606.15378
Looped World Models
問題設定
長期ホライズンシミュレーションのためのworld modelは、深さとコストのトレードオフに直面しています。忠実なマルチステップのロールアウトには反復ダイナミクスを近似するための深い計算が必要ですが、層を積み重ねるとパラメータ数が膨らみ、ロールアウト全体での誤差の累積が増大します。本論文はLooped World Models(LoopWM)を提案し、transformerの深さを積み重ねる代わりに、パラメータ共有された単一ブロックを反復適用することで、潜在的な深さを幅とデータに直交するスケーリング軸として位置づけています。
手法
LoopWMは4つのモジュールからなる潜在ダイナミクスモデルです:e_k = \mathcal{E}_\phi(o_k) \in \mathbb{R}^d を生成する観測encoder \mathcal{E}_\phi、looped transition core、行動条件付けパス、そして観測・報酬・終了のためのdecoderです。核心となるアイデアは、単一のtransformer block f_\theta を (e_k, a_k) から初期化された潜在変数 z_k^{(0)} に T 回適用することです:
z_k^{(t+1)} = f_\theta\!\left(z_k^{(t)};\, a_k\right), \quad t = 0, \dots, T-1,
最終的な z_k^{(T)} が予測された次の潜在状態として使用されます。f_\theta は反復間で共有されるため、総パラメータ数は実効的な深さから切り離されます。T を2倍にすると計算量は2倍になりますが、パラメータ数は増えません。これが最大100倍のパラメータ効率という主張の根拠です。
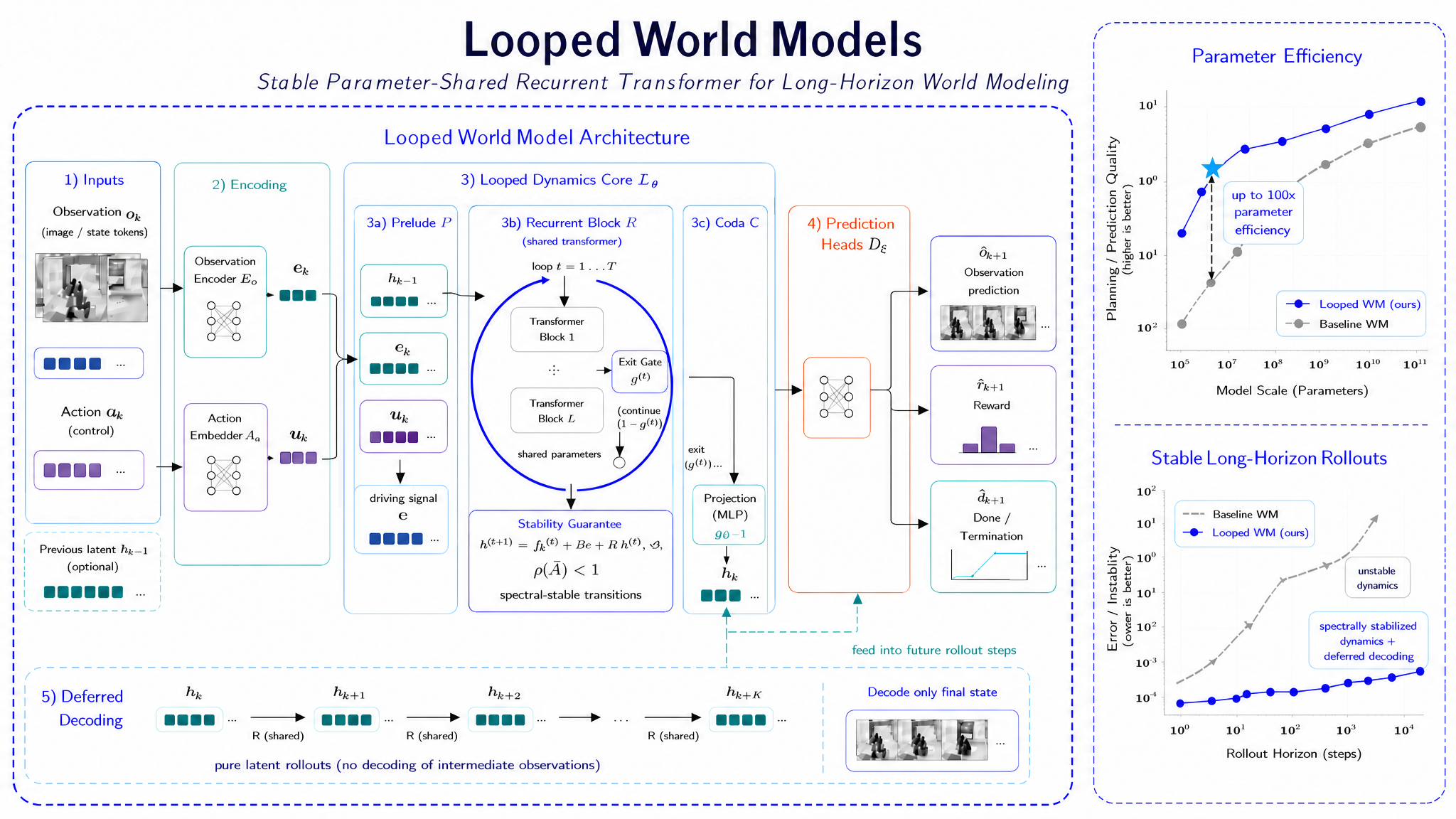
著者らは3つの設計原則を強調しています:(i) 反復計算と物理ダイナミクスの反復的性質との構造的整合性 — ループ回数 T は環境ステップ k とは別の内部「シミュレーションステップ」予算として機能すること;(ii) 任意のロールアウト長にわたる潜在recurrenceの証明可能な安定性 — 論文によれば、反復写像を縮小的(contractive)に保つ f_\theta への制約から導かれるとされていますが(セクション見出しには安定化されたcoreが約束されているものの、正式なLipschitz・縮小条件は抜粋中には再現されていません);(iii) inference時のearly exitによる適応的計算深さ:停止予測器がステップごとに z_k^{(t)} が収束したかを判断し、容易な遷移は数回の反復で終了する一方、困難な遷移では全 T 回を使用します。これにより、遷移ごとの計算量が最悪ケースの深さではなく予測される複雑さに応じてスケールします。
学習では、次状態予測と標準的な観測・報酬・終了decodingのlossを組み合わせ、さらに停止分布が t=1 または t=T に崩壊することを防ぐための正則化項を加えています。行動は(入力時だけでなく)毎回の反復においてloopに入力されており、これがダイナミクスに適用された汎用的なlooped transformerとの差別化点です。
結果
主要な評価はScienceWorld(Wang et al., 2022)上で行われ、5つの連続した行動を入力として与え、最終的な予測world stateをEM、token F1、BLEU-4、entityメトリクスで採点しています。約10億パラメータで、LoopWMは全体EM 68.4%、F1 85.3%、BLEU-4 80.7%、entity 83.9%を報告しており、claude-opus-4-6-maxのEM 47.2%、F1 72.8%、BLEU-4 64.4%、entity 72.3%に対して、著者らが100倍以上大きいとするクローズドソースモデルとの間に21.2 EMポイントの差があります。タスクごとの改善はばらつきがありますが、改善がある場合は大幅です:Lifespanは0%から100% EMへ、Conductivityは47.8%から87.0%へ、Boilは22.2%から66.7%へ、Incline EMは34.0%から59.3%(F1は95.3% vs 86.5%)へと向上しています。LifeStagesは両モデルともに縮退状態(0% EM)です。小規模なベースラインであるqwen-3.5-flashとgemini-3-flash-preview-thinkingは全体EM 10.0%程度であり、全体的にLoopWMを大きく下回っています。
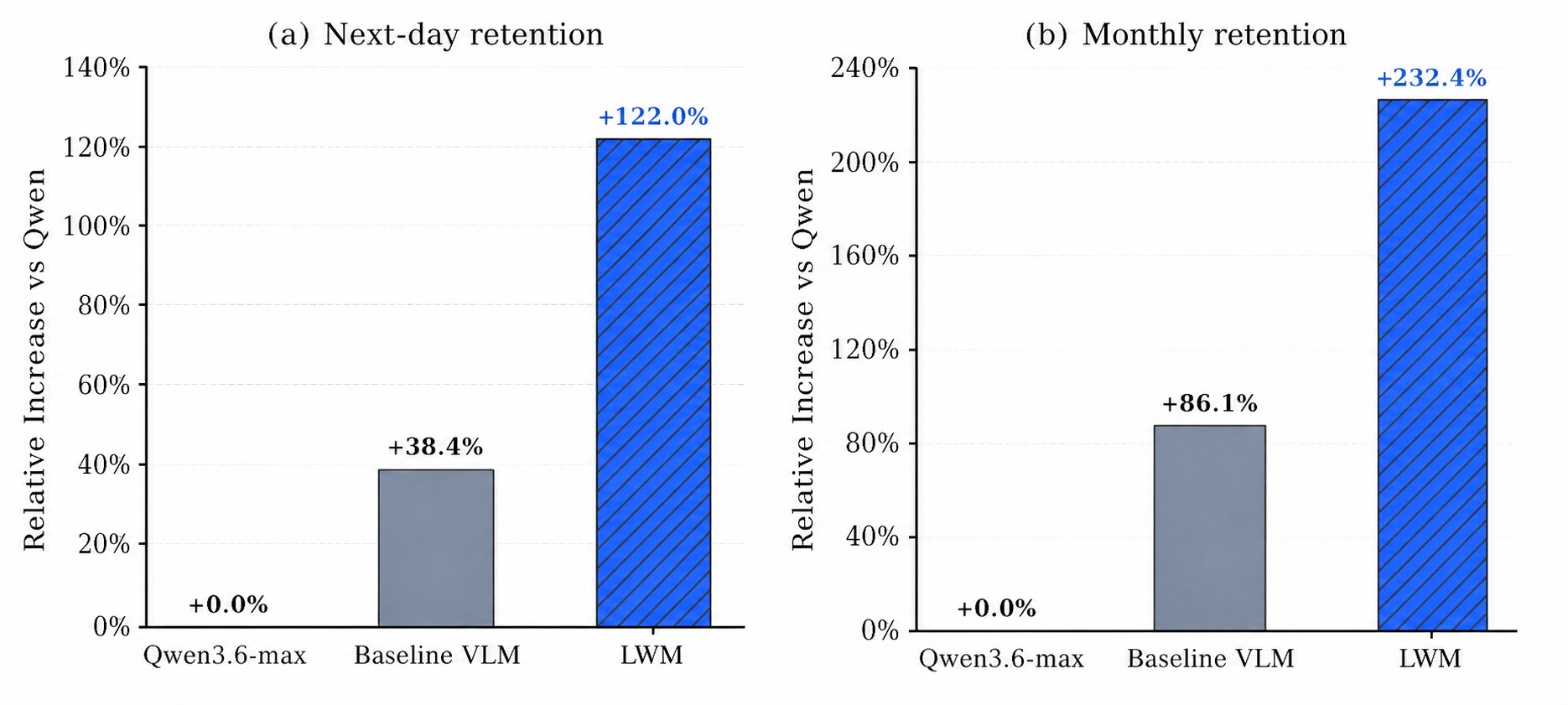
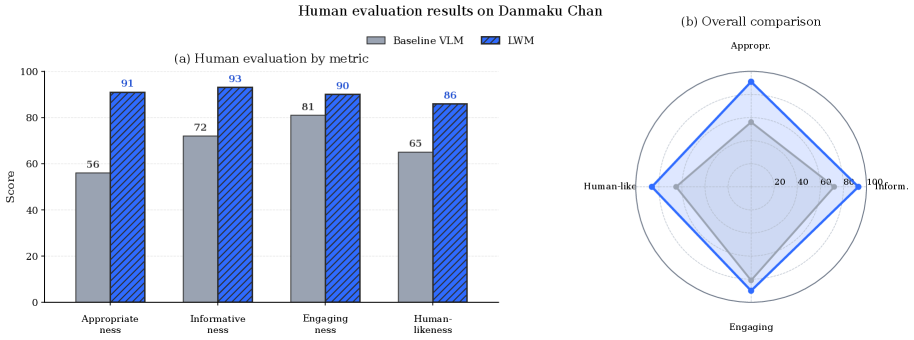
弾幕生成タスクにおけるオンライン評価(図2)では、LoopWMのQwen3.7-maxリファレンスに対する相対的な改善が他のベースラインを上回っています。人手評価(図3)も同タスクにおいてこれを裏付けています。
限界と未解決の問題
抜粋された論文では、いくつかの技術的な点が未解決のままです。「証明可能な安定性」の主張は断言されていますが、縮小論証と f_\theta に課される仮定は提供されたセクションには記載されておらず、それがなければ長いロールアウトにわたって誤差が累積しないという主張は裏付けがありません。パラメータ効率に関する見出しの比較対象は、真のサイズとアーキテクチャが不明なAPIモデルであるため、「100倍」という数字はせいぜい下限値であり、パラメータ数と能力を混同しています。LoopWMが低性能に終わったタスク(LifeStages 0% EM、Freeze 25% EM)は、looped coreがすべてのダイナミクスクラスを一様に扱えるわけではないことを示唆しており、停止予測器が反復回数を過少割り当てする長い時間的スコープにわたる記号的推論が必要なタスクで問題が生じている可能性があります。抜粋には (a) ループ回数 T、(b) early exitと固定深さ、(c) パラメータ共有と展開された等価モデルをそれぞれ切り離したablationの報告がなく、これらはすべて「スケーリング軸としての反復潜在深さ」を実証するために必要です。ScienceWorldのセットアップは5行動のロールアウトのみを使用しており、長期ホライズンという主張に対して短すぎます。最後に、引用されている参考文献には2025〜2026年付けの論文が含まれており、arXiv ID 2606.18208も異常です。読者は出典を確認することをお勧めします。
なぜ重要か
安定性と適応的深さの主張が適切なablationのもとで成立するなら、パラメータ共有された反復はworld modelにおいて幅とデータに並ぶ、信頼できる第3のスケーリング軸となります。これは具体的なデプロイメントへの影響をもたらします。構造化シミュレーションタスクでフロンティアAPIモデルに匹敵またはそれを超える10億パラメータモデルは、model-based RLとプランニングにおけるコスト計算を変えることになるでしょう。
Source: https://arxiv.org/abs/2606.18208
Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
問題
強力な教師を小規模な学生に蒸留するプロセスは、二つの補完的な側面から脆弱です。ロジットレベルのKDは学生を教師の最も鋭いモードに過度に集中させ、OOD汎化を損ないます。検証可能な報酬によるRL(GRPOスタイル)は、学生自身のロールアウトで訓練することでこれを回避しますが、明確な盲点を受け継ぎます。すなわち、質問 x に対する G_S 個のロールアウトがすべて失敗した場合、\bar{r}_x=0 となり、グループ相対的な advantage
A^{(g)} = \frac{r(x,y_S^{(g)}) - \bar{r}_x}{\mathrm{std}_x + \epsilon}
は恒等的にゼロとなり、その質問は暗黙的に除外されてしまいます。小規模な学生がまだ解けない問題——教師が最も助けになれる問題——はまさにゼロの gradient を寄与します。単純な修正策として、教師のトラジェクトリ y_T をオンポリシーであるかのように gradient に組み込むと、y_T \not\sim \pi_\theta であるため分布のドリフトが生じます。
手法
ZPPOはヴィゴツキーの最近接発達領域(zone of proximal development)にちなんで命名されており、教師を policy gradient ではなくプロンプトのコンテキストに留めます。学生は依然として自身のロールアウトのみで更新され、教師は学生が生成を行う質問の形を整えるだけです。
質問は \bar{r}_x < 0.5 のとき困難と判定されます。この閾値は恣意的ではありません。\{0,1\} の報酬のもとでは、\mathrm{std}_x は \bar{r}_x=0.5 で最大化されるため、最も強い学習シグナルはちょうど困難/容易の境界のすぐ下に存在します。境界を下から 0.5 に向かって押し上げることが、ZPPOの介入が最も高い限界価値を持つ領域です。
困難な x に対してシグナルを回復する二つのプロンプト再定式化を以下に示します。
- BCQ(Binary Candidate-included Question)。 教師の正答 y_T^+ を一つと学生の誤ったロールアウト y_S^- を一つ取り、それらを匿名化してシャッフルし、x を「これら二つの候補解のうちどちらが正しいか」という識別タスクとして再定式化します。学生は識別のために新たな chain-of-thought を生成し、そのロールアウトは再び \{0,1\} の報酬を持ちますが、タスクはオープンエンドな解法よりも劇的に簡単になるため、\bar{r}_x がゼロから離れ、A^{(g)} が情報を持つようになります。教師のコンテンツはプロンプト内に存在し、loss には一切含まれません。
- NCQ(Negative Candidate-included Question)。 複数の誤った学生ロールアウト \{y_S^{(g)-}\} を一つのプロンプトに集約し、共通の失敗モードを特定して修正された解を生成するよう学生に促します。教師のトークンは不要であり、この構造によってモデルは自身の系統的な誤りに注目することを強いられます。
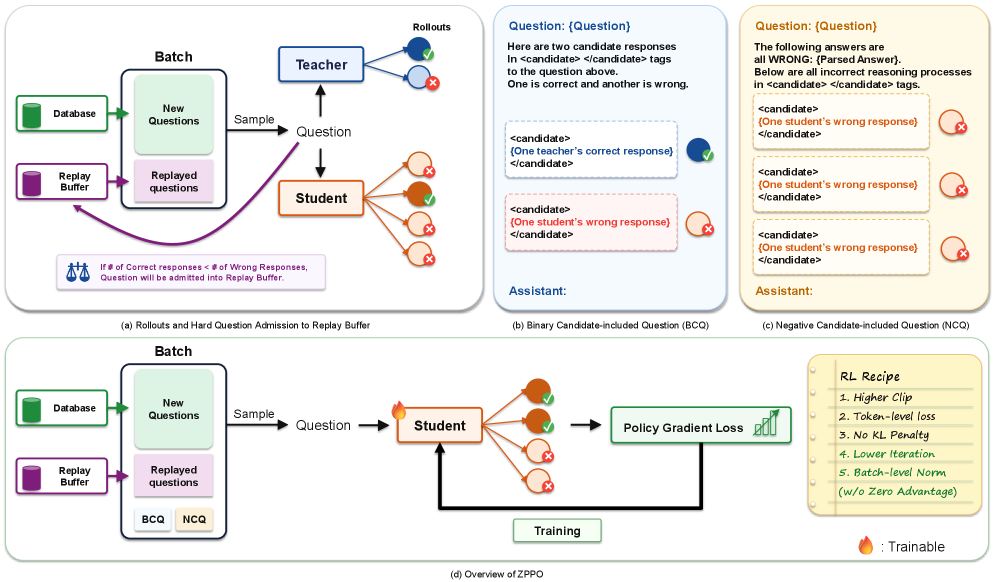
プロンプトリプレイバッファは困難な質問を受け入れ、後続のステップでそのBCQ/NCQバリアントを再出力することで、その効果を増幅させます。各困難な x は、元の形式で \bar{r}_x \geq 0.5 に達する(「卒業」する)まで複数回の露出が必要となる場合があるためです。advantage 推定器はREINFORCE++の二段階バリアントを用います。グループごとの平均を引き、次に非自明なグループ全体でバッチ正規化し、標準的なPPOのclipped surrogateに適用します。アルゴリズム的にGRPOからの変更は局所的であり、困難な質問の検出器、BCQのために受け入れ時のみ教師を呼び出す二つのプロンプト書き換え関数、そして再定式化されたプロンプトを後続の訓練バッチに再注入するバッファから構成されます。
結果
著者らは、0.8B、2B、4B、9Bの学生スケールにおいてQwen3.5でZPPOを具体化し、27Bの教師を用いて77Kのマルチモーダルデータセット上でVLMとしてpost-trainingを実施しました。
最も明確なメカニズムの証拠は2Bにおける卒業曲線であり、受け入れられた後に卒業した困難な質問の累積数を、受け入れ時のロールアウト精度に対して、ZPPOと同じリプレイバッファを付加したGRPOとを比較して示しています。ZPPOは実質的により多くの困難な質問を卒業させており、受け入れ時精度がゼロに近づくほど差が広がります——これはまさに、バニラGRPOがゼロのadvantageを見て、バッファ単体では助けにならない領域です。
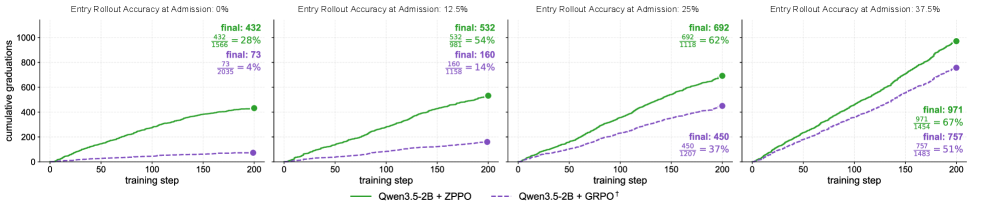
これにより、リプレイの寄与とBCQ/NCQの寄与が切り分けられます。バッファ単体では全不正解グループを救うことができません。なぜなら gradient が依然としてゼロだからです。再定式化こそが、それらの質問を訓練可能なインスタンスに変換します。
制限と未解決の問題
報酬は正誤のみ(ルールベースの完全一致と自由記述項目に対するLLM-as-judge)であり、ZPPOは推論能力を対象としており、安全性や公平性は対象外で、Qwen3.5の事前訓練のバイアスを受け継いでいます。BCQは受け入れた困難な質問ごとに少なくとも一つの正答を得るための教師アクセスを必要とするため、教師のコストは困難なセットのサイズに比例してスケールします。NCQは教師不要ですが、失敗モードの集約が情報を持つためには学生の誤ったロールアウトが十分多様であることを前提としています。\bar{r}_x < 0.5 の閾値はstd最大化によって正当化されていますが、スイープはされていません。BCQ候補の匿名化は、長さやスタイルが出所を漏らさないことに依存しており——これは経験的な仮定であり検証する価値があります。小規模な学生が推論によってではなく教師のスタイルを検出することで識別をショートカットする可能性があるためです。卒業のメトリクスは2Bで報告されており、スケールごとの卒業ダイナミクスとBCQとNCQのアブレーションは、ここで示した抜粋には掲載されていません。
なぜこれが重要か
ZPPOは、教師の情報がどこに入力されるか(プロンプト、勾配の外)と何が更新を駆動するか(学生自身のロールアウト、オンポリシー)との間に明確な分離を提供します。このデカップリングは、RLVRが小規模な学生に対して失敗する正確な病理——全不正解グループ——に対処しながら、教師のトラジェクトリ注入が引き起こすオフポリシードリフトを再導入せず、GRPOスタイルのパイプラインへの小規模なドロップイン変更によって実現します。
Source: https://arxiv.org/abs/2606.18216
ACE-Ego-0: 自己中心的な人間データとロボットデータをVLA事前学習に統合する
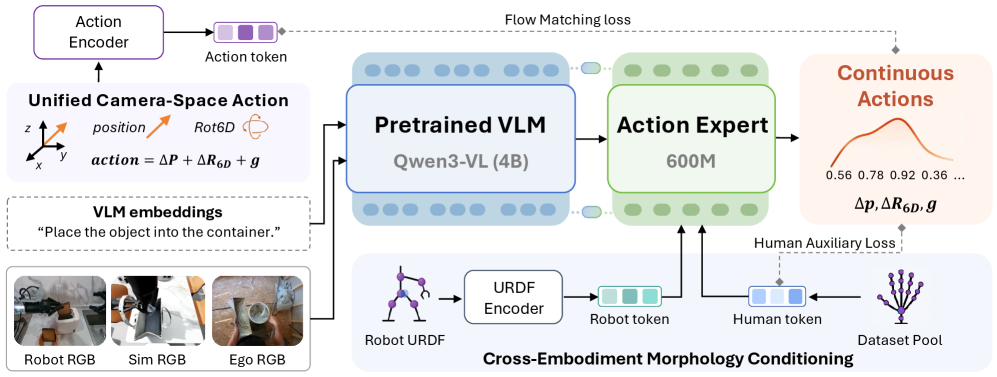
Vision-Language-Actionモデルは身体化データとともにスケールしますが、遠隔操作によるロボットの軌跡データは高コストです。自己中心的(egocentric)な人間の映像は豊富に存在し、ロボットが学習すべき操作行動と同様の内容を含んでいます。しかし、共同学習を阻む4つのミスマッチが存在します:行動空間(手 vs. エンドエフェクタ)、身体構造の運動学、制御周波数、そしてラベルの信頼性(回帰による疑似行動 vs. センサーで記録されたグラウンドトゥルース)です。ACE-Ego-0は、これらすべてのソースを吸収する単一のVLA事前学習レシピを提案します。具体的には、(i) 行動を共有カメラフレームインターフェースに射影し、(ii) 形態トークン(morphology tokens)を条件として与え、(iii) ノイズの多い人間の教師信号を補助ヘッド(auxiliary head)を介してダウンウェイトします。
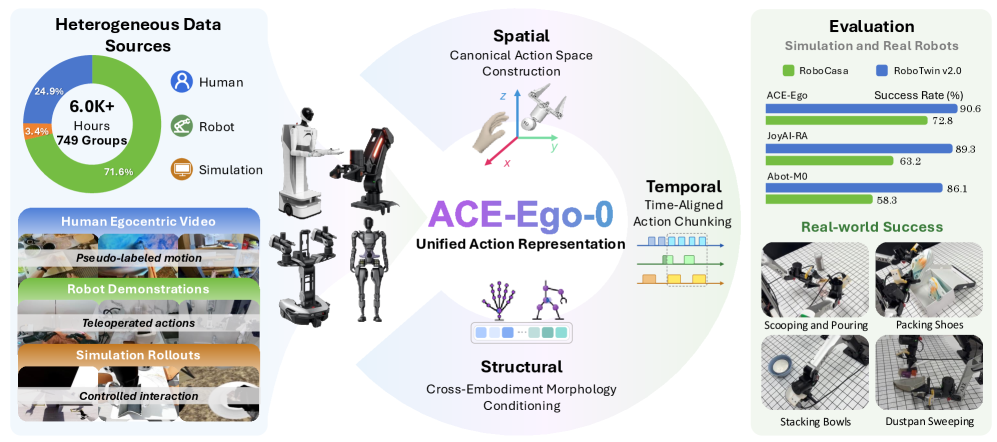
統一行動表現
第一の貢献は、プラットフォーム固有の座標系慣習を排除する標準行動空間です。すべてのエンドエフェクタ姿勢は、較正された外部パラメータ R_{\mathrm{cam}\leftarrow s}, t_{\mathrm{cam}\leftarrow s} を用いてヘッドカメラフレームで表現されます:
p_{\mathrm{cam}} = R_{\mathrm{cam}\leftarrow s}\, p_s + t_{\mathrm{cam}\leftarrow s}, \qquad R_{\mathrm{cam},ee} = R_{\mathrm{cam}\leftarrow s}\, R_{s,ee}.
姿勢の向きにはZhouらの連続6Dパラメタリゼーションを使用し、グリッパーコマンドとアームごとのアクティビティフラグを連結して統一された両腕行動ベクトルを構成します。行動が視覚観測と同じフレームに存在するため、ポリシーはワールドからカメラへの変換を学習する必要がなく、新たな身体構造はひとつの外部パラメータとURDF由来の形態トークンを入れ替えるだけで統合できます。実行時には逆変換によって実行フレームを復元します:
\hat{p}_s = R_{\mathrm{cam}\leftarrow s}^{\top}(\hat{p}_{\mathrm{cam}} - t_{\mathrm{cam}\leftarrow s}), \qquad \hat{R}_{s,ee} = R_{\mathrm{cam}\leftarrow s}^{\top}\hat{R}_{\mathrm{cam},ee},
ここで6D回転は逆変換の前にGram–Schmidt法によって再構成されます。
構造的な異質性(ヒューマノイドAgiBot G1、単腕車輪型Galaxea R1Lite、移動型両腕Galbot、および「人間代替」身体構造)は、各ソースのURDFから導出した形態トークンによって処理され、vision-language featuresとともにaction expertに入力されます。時間的な異質性(プラットフォーム間で10〜30 Hz)は、時間整合アクションチャンキング(time-aligned action chunking)によって解決され、チャンクは固定ステップ数ではなく固定の実時間ホライズンに対応します。
信頼性を考慮した学習
ロボットおよびシミュレーションのサンプルはセンサーに基づくラベルを持ち、主要なaction expertを直接教師あり学習します。単眼映像から回帰された人間の疑似行動は、スケール・接触・オクルージョンのある区間においてノイズが多くなります。ACE-Ego-0はこれらを補助損失ヘッドに転送します。この補助ヘッドはバックボーンを共有しますが、高分散のgradientによって主要なエキスパートのパラメータを汚染しません。補助目標はデータパイプラインによって信頼性が高いとフラグされた区間に教師信号を集中させます。これにより、人間の映像は表現的な事前情報(オブジェクトのアフォーダンス、運動の事前分布、言語グラウンディング)を提供しつつ、実行時の行動分布はロボットのデモンストレーションに固定されたままとなります。
データパイプライン
事前学習のプールは6,000時間を超え、AgiBot Alpha/Betaデモンストレーション、Galaxea R1Liteデータ、AgiBot DigitalWorldおよびRoboCasa Tabletopシミュレーション(GR1ヒューマノイド上での24タスク × 1,000エピソード)、および1,800時間超の自己収集Galbotデータを組み合わせています。自己中心的ブランチは、多段階パイプラインによって抽出された1,478時間の疑似行動ラベル付き操作映像を提供します:映像選択、単眼モーション再構成による手首軌跡と手の姿勢の復元、次にオクルージョンが多い区間や操作に関係しない区間を除外するための多段階品質管理、そして回復した手の姿勢を両腕行動スキーマにマッピングする処理を経ています。
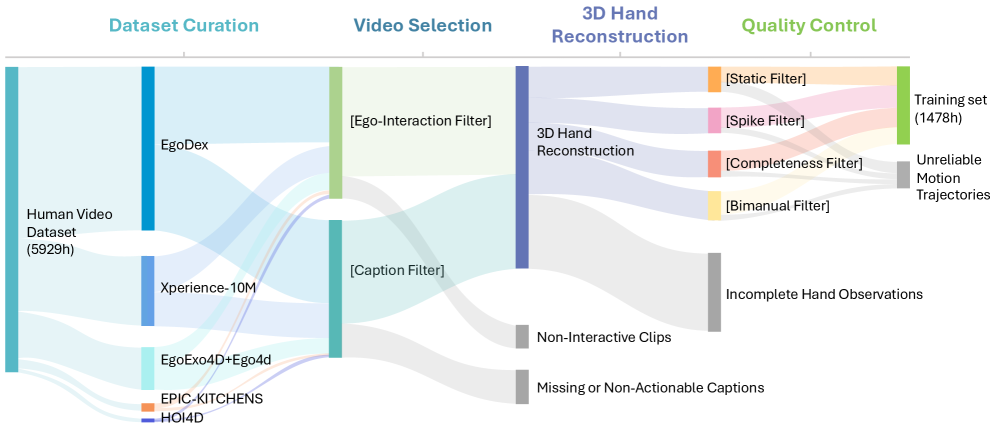
実験
評価は2つのシミュレーションスイートと1つの実機プラットフォームにまたがります:RoboCasa GR1 TableTop(ヒューマノイド卓上タスク24種)、RoboTwin 2.0(強いドメインランダム化を伴う両腕タスク50種)、そして6つの操作タスクを持つARX両腕実機ロボットです。RoboCasaのベースラインにはGR00T-N1.6、Qwen3PI、FLARE、ABot-M0、JoyAI-RA、DIALが含まれます;RoboTwin 2.0では \pi_{0.5}、Motus、LingBot-VLA、ABot-M0、JoyAI-RA、Hy-VLAとの比較が行われます。実機ロボットの比較にはfine-tuned \pi_{0.5} およびGR00T-N1.7を使用します。すべての評価はマルチタスクであり、成功率を報告します。提供されたセクションにはプロトコルの説明が記載されていますが、現在入手可能な抜粋では主要な数値は列挙されておらず、タスクごとの表(\pi_0を含む)は付録C.5に委ねられています。
制限と未解決の課題
このフレームワークは、学習時の標準化と実行時の逆変換の両方において正確なカメラ外部パラメータに依存しており、較正ミスは行動空間に直接バイアスをもたらします。単眼再構成による疑似行動の品質は依然として主要なノイズ源であり、信頼性を考慮した補助lossはそれを軽減するものの完全に除去するわけではありません——パイプラインレベルのフィルタリングを超えた明示的な不確実性推定はlossの重み付けに組み込まれていません。形態トークンは運動学をエンコードしますが動力学やアクチュエータの限界はエンコードしないため、制御帯域幅が大きく異なる身体構造への転移にはfine-tuningが依然として必要になる可能性があります。さらに、ヘッドカメラフレームの行動は安定した明確なヘッドカメラを前提としており、ヒューマノイドや自己中心的映像には自然ですが、固定された三人称視点のセットアップには不向きです。
なぜ重要なのか
ACE-Ego-0は、人間映像とロボットの共同事前学習を阻む異質性が大部分は表現の問題であることを示しています:カメラ空間の行動に形態トークンと時間整合チャンキングを加えることで、1,478時間の人間映像と約4,500時間の複数身体構造ロボット・シミュレーションデータを消費する単一インターフェースが実現されます。このレシピが付録の数値によって裏付けられれば、遠隔操作によらない教師信号でVLAをスケールするための具体的なテンプレートを提供することになります。
Source: https://arxiv.org/abs/2606.17200
GameCraft-Bench: エージェントはリアルなゲームエンジン上でプレイ可能なゲームをエンドツーエンドで構築できるか?
問題と動機
コーディングエージェントのベンチマークの多くは、孤立した関数・リポジトリへのパッチ・ユニットテストの合格率を評価しています。ゲーム生成はこの枠組みを打ち破るものです。「正解」の出力はテストを通過することではなく、起動可能なアーティファクトであり、そのランタイム上の振る舞い——シーングラフ、スクリプト、アセットのバインディング、入力処理、レンダリング、ゲームプレイループ——が自然言語による設計意図を総体として実現していることが求められます。著者らはエンドツーエンドのゲーム生成を次のように定式化しています。
x=(s,\mathcal{E})\ \longmapsto\ y=G,
ここで s はスペック(ルール、メカニクス、目標、プレゼンテーション)、\mathcal{E} は開発・ランタイム環境、G は生成されたゲームアーティファクトであり、観測可能なプレイヤーとゲームのインタラクションによって評価されます。著者らは、この設定のベンチマークが満たすべき三つの要件を主張しています。Engine Grounding(エージェントはサンドボックスではなく実際のエンジン内で動作しなければならない)、Artifact Completeness(スニペットではなく起動可能なプロジェクトを生成する)、Interactive Verification(静的なコード検査ではなく再現されたインタラクションによってスコアリングする)です。
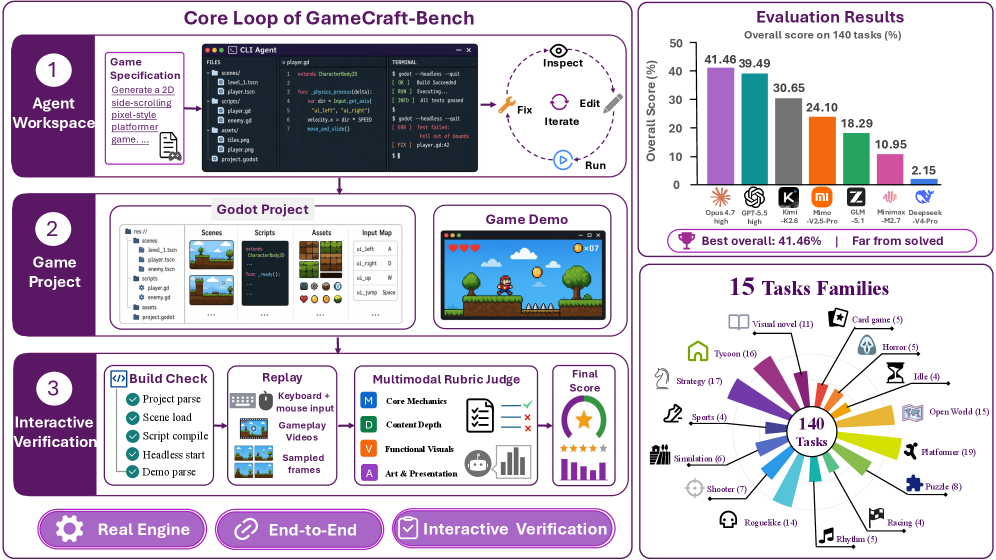
ベンチマークの構成
GameCraft-BenchはこのマッピングをGodot上で実現しています。各タスクは \tau=(s,\mathcal{E},\rho) であり、ルーブリック \rho はエージェントから隠蔽されます。環境は \mathcal{E}=(\mathcal{R},\mathcal{W},\mathcal{A},\mathcal{C}) と分解されます。Godotのランタイム・ツールチェーン \mathcal{R}、編集可能なワークスペース \mathcal{W}、共有リソースインターフェース \mathcal{A}、提出コントラクト \mathcal{C} です。エージェントは y=(G,\Pi)、すなわち完全なGodotプロジェクトと再生可能なインタラクショントレース \Pi=\{\pi_i\}_{i=1}^n を返す必要があります。検証器は \mathcal{R} 上で G を起動し、
O=\mathrm{Replay}_{\mathcal{R}}(G,\Pi),
を実行し、得られたゲームプレイ動画とサンプリングされたフレームをルーブリックに基づくマルチモーダルジャッジに入力します。重要な点として、トレースはアーティファクトの一部ではなく評価のための証拠です——これにより「ゲームが機能するか」と「エージェントが自身のデモを正しくスクリプト化したか」が分離されます。このスイートには15のゲームファミリー(プラットフォーマー、シューター、パズル、ストラテジースカーミッシュなど)にわたる140タスクが含まれます。

ルーブリックは四つの軸でスコアリングします。Mechanics(コアのゲームプレイルールが機能するか)、Depth(進行、状態、副次的システム)、Visuals(レンダリングの正確さ、UIの読みやすさ)、Art(スペックとのスタイル的一貫性)です。
結果
7種類のフロンティアコーディングエージェント構成を全140タスクで実行しました。Claude CodeにOpus-4.7-highとMiMo-V2.5-Pro、CodexにGPT-5.5-highとDeepSeek-V4-Pro、Kimi CodeにKimi-K2.6、Code BuddyにGLM-5.1とMiniMax-M2.7を使用しました。
| Harness | Model | Overall | Mechanics | Depth | Visuals | Art |
|---|---|---|---|---|---|---|
| Claude Code | Opus-4.7 high | 41.46 | 55.34 | 39.48 | 42.78 | 36.86 |
| Codex | GPT-5.5 high | 39.49 | 54.36 | 38.61 | 41.84 | 32.94 |
| Kimi Code | Kimi-K2.6 | 30.65 | 39.76 | 28.07 | 33.66 | 27.99 |
| Claude Code | MiMo-V2.5-Pro | 24.10 | 32.33 | 22.59 | 27.45 | 20.65 |
| Code Buddy | GLM-5.1 | 18.29 | 25.23 | 17.80 | 21.14 | 14.59 |
| Code Buddy | MiniMax-M2.7 | 10.95 | 14.27 | 9.92 | 14.92 | 8.85 |
| Codex | DeepSeek-V4-Pro | 2.15 | 2.25 | 1.69 | 1.97 | 2.63 |
最良のエージェントでも総合スコアは41.46%にとどまり、7構成中6つが40%未満となっています。CodexのDeepSeek-V4-Proは2.15%にまで崩壊しており、これは純粋な能力の差というよりも起動可能性・コントラクト遵守の失敗によるものと考えられます。全エージェントにわたって、MechanicsスコアはArtスコアを上回っており、エージェントは視覚的に一貫したプレゼンテーションを生成するよりも、認識可能なゲームプレイループを実装する方が信頼性が高いことを示唆しています。Depth軸はトップエージェントにおいてMechanicsを10〜16ポイント下回っており、副次的システム(進行、永続的な状態、バランスの取れた難易度)が系統的に実装不足であることを示しています。
診断的知見:デバッグシグナルとしてのレンダリングフィードバック
際立った分析として、エージェントがレンダリングされたゲームプレイを用いてループを閉じているかどうかを検証しています。多くの失敗(カメラのフレーミング、読めないHUD、崩れたレイアウト、意図したメカニクスが発動しないデモ)はソースコードや標準出力からは見えません。著者らはスクリーンショットヘルパーの呼び出しを各実行で計測しました。
- Kimi-K2.6:140タスクで2,998回のレンダリング画面検査(平均21.41、中央値19)、スクリーンショットを使用しなかったタスクは4件のみ。
- Opus-4.7:1,952回の検査(タスクあたり13.94回)。
- GPT-5.5:268回の検査(タスクあたり1.91回)。
あるStrategy-Skirmishのケースでは、Kimiはシーンを繰り返しレンダリングしてユニット配置のずれと選択ハイライトの欠如を検出し、グリッドとターンインジケーターにパッチを当てました。このパターンはゲーム生成を一発合成ではなく知覚に基づくイテレーションとして再定義します。注目すべき点として、GPT-5.5はKimiやOpusの約10分の1しかスクリーンショットを使用せずに総合スコア上位に近い成績を達成しており、視覚的デバッグと最終スコアの関係が単調ではないことを示唆しています——エンジンAPIに対するモデルの事前知識が、ある程度まで視覚的検証の代替として機能しているものと考えられます。
限界とオープンクエスチョン
このベンチマークはGodot専用であり、はるかに広いサーフェスAPIとアセットパイプラインを持つUnity/Unrealへの汎化は検証されていません。ルーブリックに基づくマルチモーダルジャッジングはジャッジモデルの失敗モードを引き継ぎますが、論文ではジャッジ間の一致度や人間との相関については報告されていません。提出コントラクトはエージェントが自身の再生トレースを生成することを要求しており、これはゲームプレイの正確さとエージェント自身のゲームのデモをスクリプト化する能力を混同させます。さらに、DeepSeek-V4-Proの2.15%という外れ値は、一部の構成においてコントラクト・起動可能性の失敗が能力の差を上回って支配的であることを示唆しており、独立した診断軸(例:起動可能性とルーブリックスコアの分離)が必要です。
なぜこれが重要か
GameCraft-Benchは、真にエンドツーエンドのエージェントタスクのクラスを運用可能な形で定義しています。成功の条件は、コードがテストを通過することではなく、実際のエンジンにおけるランタイムの振る舞いがオープンエンドな仕様に合致することです。41.46%という上限値とスクリーンショット使用量の分析は合わせて、現在のコーディングエージェントのボトルネックがコード合成よりも自身のアーティファクトに対するクローズドループ知覚にある可能性を示唆しています。
Source: https://arxiv.org/abs/2606.17861
Hacker News Signals
Qwen-Robot Suite: 物理世界インテリジェンスのための基盤モデルスイート
AlibabaのQwenチームが、ロボティクスおよび embodied AI を対象としたモデルスイートをリリースしました。このスイートは複数のコンポーネントで構成されています。まず、vision-language-action のための Qwen-VLo は、RGB観測と言語命令を入力として受け取り、低レベルのモーターコマンドを出力する統合マルチモーダルモデルです。次に、与えられた行動に対して将来の状態を予測するワールドモデルコンポーネント、そしてsim-to-real転送のためのツール群が含まれています。アーキテクチャは Qwen2.5-VL を拡張したもので、潜在表現を関節空間の軌道にマッピングする action-head レイヤーが追加されており、ロボットのデモンストレーションデータとウェブスケールのvision-language コーパスを混合したデータで学習されています。このアプローチは、操作ポリシー学習をシーケンスモデリング問題として扱うトレンドに沿ったものであり、行動トークンは固定またはfine-tuningされたVLMバックボーン上で自己回帰的に予測されるか、あるいは diffusion head を介して予測されます。主な主張としては、クロス embodiment 汎化(アーキテクチャを変更することなく、単一のチェックポイントを複数のロボット形態に展開可能)と、3D対応の視覚エンコーダによる空間推論の改善が挙げられています。ブログには具体的なベンチマーク数値(タスク成功率の表など)がほとんど掲載されておらず、独立した評価には限界があります。実用上重要な点として、モデルがオープンウェイトとして公開されているため、RT-2やOctoのような代替手段のようにAPIに依存することなく、研究室のロボティクススタックに直接利用できます。接触の多い操作、リアルタイム制御ループにおけるレイテンシ(多くのタスクでVLM推論の>100msは厳しい制約となります)、そしてfine-tuningに使用されたデモンストレーションデータの品質とライセンスに関しては、依然として未解決の問題が残っています。
Source: https://qwen.ai/blog?id=qwen-robotsuite
メモリ安全性 CVE の性質における Rust と C/C++ の違い
Jakub Beranek の投稿は、NVD データとケーススタディを基に、Rust および C/C++ コードベースにおけるメモリ安全性 CVE の分類を丁寧に行っています。この記事の核心的な主張は、単に「Rust はメモリ安全性に関するバグが少ない」ということではなく、残存するバグの性質が構造的に異なるという点にあります。C/C++ では、メモリ安全性 CVE は主に空間的な問題(バッファオーバーフロー、境界外読み書き)と時間的な問題(use-after-free、double-free)であり、これらは手動メモリ管理に起因しています。一方 Rust では、メモリ安全性 CVE は異なる領域に集中しています。すなわち、不正な不変条件の主張を含む unsafe ブロック、適切なライフタイムアノテーションなしに生ポインタが言語境界を越える FFI 境界エラー、そしてアロケーションサイズに影響する整数オーバーフロー・切り捨てのパスです。この投稿では、Rust の CVE はトリガーにアプリケーション固有のコンテキストをより多く必要とする傾向があり、古典的な C のバグのような汎用的なヒープスプレー技法では悪用できないことが指摘されています。
第二の区別として、Rust の型システムは特定のクラスの並行性バグ(データ競合)をほぼゼロに抑えますが、状態を破壊する unsafe 内のロジックエラーは依然としてメモリ非安全として現れうる点が挙げられます。定量的な観察として、本番環境での Rust コードベースにおける CVE 件数は unsafe のサーフェス量にほぼ比例しており、これは所有権モデルが実際に保証していることと一致しています。この投稿は適切に慎重な姿勢を保っており、Rust がメモリ安全性の脆弱性を完全に排除するとは主張せず、あくまでバグの分布を汎用的に悪用しにくいものへとシフトさせ、明示的にマークされたより小さなコードサーフェスの監査で済むことが多いバグへと移行させるに過ぎないと述べています。
Source: https://kobzol.github.io/rust/2026/06/15/how-memory-safety-cves-differ-between-rust-and-c-cpp.html
Show HN: 高解像度 Neural Cellular Automata
このプロジェクトは、Mordvintsev らの “Growing Neural Cellular Automata”(2020年)を起源とする Neural Cellular Automata(NCA)フレームワークを、より高い空間解像度へと拡張するものです。標準的な NCA は、メモリ使用量の二次的増加とスケール時の不安定性により、小さなグリッド(64×64 または 128×128)上で動作します。本実装はこれらの課題を以下の方法で解決しています:(1) グリッドをタイル分割し、重みを共有しながらパッチ単位でローカル更新ステップを実行することでメモリフットプリントを削減する;(2) 小さな摂動が伝播・増幅されやすい高解像度での学習を安定化するために、gradient clipping と正規化スキームを採用する;(3) 解像度に依らず固定された知覚カーネル(gradient 推定のための Sobel フィルタ)を適用する。更新則は標準的な形式に従っており、各セルの状態 s_t は s_{t+1} = s_t + f_\theta(P(s_t)) として更新されます。ここで P は知覚演算子、f_\theta は小規模な MLP です。本研究の意義は美的・技術的の両面にわたります――高解像度における NCA は低解像度では不可能なテクスチャレベルの細部を明らかにし、タイル分割アプローチは他のグリッドベースの学習済み動的システムにも適用可能な実践的手法です。ライブデモは WebGL/WASM を用いてブラウザ上で inference を実行しており、セルあたりの計算コストがリアルタイム実行に十分なほど小さいことを示しています。制限事項:タイル分割によりパッチの継ぎ目に境界アーティファクトが生じるためブレンドのヒューリスティクスが必要となる;低解像度バリアントと比較して学習の収束が遅い;また、ターゲットパターンは更新ダイナミクスのもとで安定を保つように慎重に設計する必要がある。
Source: https://cells2pixels.github.io/
Show HN: cuTile Rust: Rustによる安全でデータ競合のないGPUカーネル
NVIDIAのnvlabsが、GPUカーネルプログラミング向けCuTile C++タイリングライブラリ上のRust抽象化レイヤー「cuTile-rs」を公開しました。本ライブラリの中心的な貢献は、GPUメモリ階層をtype systemでエンコードすることにより、cooperative thread array(CTA)内のスレッド間のデータ競合をコンパイル時エラーにする点です。そのメカニズムはRustのownershipとlifetimeシステムを活用しています。共有メモリタイルは排他的または共有のborrow semanticsを持つ型付きリソースとして表現され、ライブラリのbarrier抽象はリソースの解放を同期ポイントと結び付けます。これにより、対応する__syncthreads()相当の処理が完了する前にタイルを読み込むことができなくなります。PTX/SASSレベルでは、生成されたコードは手書きのCUDAと等価であり、安全性の保証は純粋にRustの型レイヤーで実現されており、ランタイムオーバーヘッドはゼロです。本ライブラリはHopperおよびBlackwellアーキテクチャをターゲットとし、warpgroupレベルのmatrix multiply-accumulate(WGMMA)命令を安全なwrapperを通じて公開しています。これが重要な理由は、warpgroupプログラミングが非常に難しいことで知られているためです。async copyオペレーションとmma命令のbarrierに対する順序が誤っていると、大規模実行時に数値誤差としてのみ現れる、発見しにくい正確性バグの一般的な原因となります。なお、いくつかの制限が指摘されています。現在のAPI surfaceは限られており(密なmatmulとattentionライクなパターンは十分サポートされているが、疎または不規則なアクセスパターンにはunsafeへの降下が必要)、RustのGPUツールチェーンはCUDA Cと比較してまだ未成熟です(rustc-gpu/nvptx64ターゲットには既知のcodegen上の制限がある)。また、cuTileへの依存により、AMD/Intel GPUへの移植性は対応されていません。
Source: https://github.com/nvlabs/cutile-rs
GLM-5.2がArtificial Analysisにおけるオープンウェイトモデルのトップに
Zhipu AIのGLM-5.2が、MMLU、MATH、HumanEval、および推論タスクを集約し、レイテンシ正規化スコアリングを適用したArtificial Analysis Intelligence Indexのオープンウェイトモデル部門でトップに立ちました。このモデルはMoEアーキテクチャを採用しており、専門家の具体的な数は公開されていませんが、アクティブパラメータ数32Bの構成で提供されています。Artificial Analysisのリーダーボードでは、intelligence indexにおいてQwen2.5-72BおよびLlama-3.3-70Bを上回るスコアを示しつつ、A100ハードウェア上で競争力のあるtokens-per-secondスループットを維持しています。このindexの方法論では、品質タスクを70%の重みで評価し、レイテンシにペナルティを課すため、「高速だが精度が低い」モデルや「高精度だが低速な」モデルは、表面的な精度スコアが示すよりも低い順位に位置づけられます。GLM-5.2は特に中国語タスク(Zhipuの学習データ構成を考えれば当然といえます)およびコード生成において顕著な強みを示しており、HumanEval pass@1は80%台半ばと報告されています。注意点として、Artificial Analysis indexは一組織による複合メトリクスであり、コミュニティの合意によるベンチマークではありません。また、モデルの重みは公開されていますが、学習データやRLHFの手順はテクニカルレポートとして文書化されていません。HNのディスカッションでは、リーダーボードに最適化されたモデルが真の能力向上を示しているのか、それともベンチマークの飽和を示しているのかという議論と、32B MoEがコスト効率の高いセルフホスト構成に収まるかという実践的な問いが中心となっています(おおよその答えとしては、量子化を用いれば2x A100 80GBで可能とのことです)。
ヨーロッパは自国が保有するコンピュートでフロンティアAIモデルを訓練できるか?
euromeshリポジトリは、欧州の主権的なGPUコンピュート容量に関する体系的な分析であり、公開調達記録、各国AIイニシアチブの発表、およびスーパーコンピューティングセンターの機器目録から集約されています。その方法論は以下の通りです:GENCI(フランス)、CINECA(イタリア)、SURF(オランダ)、BSC(スペイン)などにおける既知のH100/A100クラスターを列挙し、インターコネクトのトポロジーを考慮した実効FLOPsを推定します(欧州の多くのクラスターはNVLinkではなくInfiniBand HDRを使用しており、大規模モデル訓練に必要な密結合が制限されます)。さらに、その合計値がGPT-4クラスのモデルを現実的な時間枠内で訓練するのに十分かどうかを計算します。概算の結果は厳しいものです:欧州の主権コンピュートは合計でおよそ50,000〜80,000 H100相当と推定されており、統一されたスケジューリングレイヤーを持たない15以上の機関に分散しています。5,000億パラメータの密なモデルを訓練するには約10^{25} FLOPsが必要であり、利用可能なクラスター全体で50%のMFUを仮定すると、数ヶ月にわたる実行が必要となります。さらに、拠点間のネットワーク遅延により、現在のツールではパイプライン並列処理を機関をまたいで実施することは事実上不可能です。このリポジトリは、データセンター間のネットワーク帯域幅(10〜100 Gbps対NVLinkドメイン内の3.2 Tbps)が、生のFLOP数ではなく真のボトルネックであることを指摘しています。EuroHPCの近日公開予定システム(JUPITERは1エクサFLOPを目標)が、従来の短期割り当てHPCモデルではなく長時間稼働のLLMジョブを許可するスケジューリングポリシーを採用するならば、その計算が変わり得るという点についても、議論の中で正確に言及されています。
Source: https://github.com/sammysltd/euromesh
SubQ 1.1 Small: テクニカルレポート
SubQ 1.1 Small は、パラメータ数10億未満の展開を目標とするコンパクトな言語モデルであり、アーキテクチャの設計判断とベンチマーク結果を網羅したテクニカルレポートが公開されています。このモデルは、効率化のためにいくつかの改良を施した標準的なdecoder-onlyのtransformerを採用しています。具体的には、KVキャッシュサイズを削減するために低グループ数のgrouped-query attention(GQA)、SwiGLU activation、そして embedding テーブルのサイズを縮小するためにより大規模なtokenizerから蒸留された語彙が使用されています。学習には二段階のレシピが採用されており、重複排除済みのWebコーパスを用いた大規模な事前学習、続いてDPOによる instruction fine-tuning が行われます。HellaSwag、ARC-Easy、Winogrande などのタスクにおける報告済みのベンチマーク数値は、10億パラメータ未満のクラス(SmolLM2、Qwen2.5-0.5B の範囲)の中で競争力を有していますが、推論負荷の高いタスクでは有意に大規模なモデルを超えるには至らないことがレポートの中で正直に述べられています。より興味深い技術的内容は量子化の挙動に関するものです。著者らは、4-bit GPTQによる量子化が集計ベンチマーク上の精度を1.5%未満しか低下させないことを報告しており、これは彼らの学習レシピによる比較的均一な重みのマグニチュード分布に起因するとしています。オンデバイス推論のターゲットとしては、ONNX/WebAssemblyを介したブラウザ上での実行と、int4のGGUFを介したマイクロコントローラへの展開が含まれます。レポートでは、主要なユースケースがオープンエンドな生成ではなく、検索拡張(retrieval augmentation)および分類タスクであることが率直に述べられており、これらの用途ではレイテンシの制約から10億パラメータ未満のモデルが実用的であり、より大規模なモデルは過剰スペックとなります。
Source: https://subq.ai/subq-1-1-small-technical-report
Ask HN: Has Anyone Replaced Claude/GPT with a Local Model for Daily Coding?
このスレッドは539件のコメントを集め、技術的なシグナル対ノイズ比が高い議論となっています。経験豊富な実践者たちの総意は次の通りです:ローカルモデルは7B〜32Bの範囲のモデル(Qwen2.5-Coder-32BとDeepSeek-Coder-V2-Liteが最も頻繁に挙げられる)を用いたオートコンプリートや単一ファイルの編集には実用的ですが、マルチファイルのリファクタリングやアーキテクチャの推論タスクでは、100k+トークン範囲でのコンテキストウィンドウ管理とinstruction-followingの品質においてフロンティアAPIが依然として優位であり、力不足となっています。ハードウェア要件についての議論では、Q4_K_M量子化の32Bモデルは24GB VRAM(RTX 4090または3090単体)に収まり、20〜40 tok/sを実現するとされており、インタラクティブな使用には許容範囲内とされています。OllamaとLlama.cppが主流のサービングスタックであり、Continue.devやAiderをエディタ統合レイヤーとして使用していると報告するコメント投稿者も複数います。レイテンシと品質のトレードオフが中心的な緊張点となっています:ローカル推論での20 tok/sは、特に長い補完において、Claudeの80+ tok/sのストリーミングと比較すると遅く感じられます。繰り返し指摘される点として、集計されたベンチマークスコアよりもタスクの種類の方が重要であるということがあります——ローカルモデルはボイラープレート、テスト生成、正規表現の構築をうまく処理できる一方で、大規模なコードベースをまたぐ複雑なデバッグでは依然として品質の差が見られます。コスト計算について:重度のAPI利用(月50〜100ドル程度)の場合、3090の投資回収期間は6〜12ヶ月ですが、プライバシーの観点(コードが外部に送信されない)が、独自のコードベースを扱う多くの回答者にとって、それとは独立した移行の動機となっています。
注目の新しいリポジトリ
VibeBench/VibeSearchBench
現実的な敵対的条件下における会話型情報検索エージェントを対象とした厳密な benchmark です。200のタスクは意図的に長期的な視野を持つよう設計されており、各タスクは意図的に曖昧なクエリから始まり、ペルソナ駆動型の段階的情報開示を通じて展開されます。つまり、エージェントは複数ターンにわたって明確化のための質問を行い、検索戦略を更新し続けなければなりません。この設計により、単一ターンの benchmark では完全に見落とされてしまう能力――曖昧さへの対処、能動的な情報探索、マルチホップな統合――がストレステストされます。
評価はQA benchmark に共通するスキーマ固定問題を回避しています。回答は知識グラフとして表現され、トリプレットレベルのF1でスコアリングされるため、部分点が構造的に意味を持ち、固定された回答スキーマへの依存もありません。「検証可能」な枠組みにより、各トリプレットをグラウンドトゥルースグラフと独立して照合できるため、スケールに対してヒューマンアノテーションのコストを現実的な水準に抑えることができます。
この benchmark は、印象的なデモが浅い検索能力を覆い隠してしまうような、雰囲気(vibe)に基づくエージェント評価への直接的な対抗として位置付けられています。RAGパイプライン、ツール拡張型LLM、またはマルチターン対話システムを構築する研究者にとって、これは原則に基づいた難易度の高いテストセットを提供します。リリースから数日以内に1000以上のスターを獲得したことは、実務家たちがまさにこのような構造的・敵対的・マルチターン型の検索 benchmark を待ち望んでいたことを示しています。
Source: https://github.com/VibeBench/VibeSearchBench
CodeBendKit/codeseek
人間向けのIDEではなく、AIコーディングエージェントによる利用を想定して設計されたコードインテリジェンスのプリミティブを提供するRust製CLIです。コアパイプラインは7つの言語にわたるコールグラフを構築し(tree-sitterまたは類似のASTツールを活用)、dense embedding、BM25スタイルのsparse転置インデックス、およびスコアのマージにReciprocal Rank Fusion(RRF)を組み合わせたハイブリッド検索インデックスを構成します。さらにオプションとして上位のrerankerステージも備えています。このスタックは本番環境のセマンティック検索システムで使われているものと同じretrieverアーキテクチャを、リポジトリ規模のコードナビゲーションに適用したものです。
ネイティブの出力形式はModel Context Protocol(MCP)ツールであり、Claude CodeおよびCodex CLIがコールグラフのトラバースやハイブリッドコード検索を、grepへのシェルアウトではなく構造化されたtool callとして直接呼び出せるようになっています。コンパイル済みのRustとして提供されるため、大規模なコードベースでも1秒未満でインデックスクエリが完了し、エージェントがタスクごとに多数の逐次的なretrieval callを行う場合に有効です。
このプロジェクトは、単純なファイル連結を超えた構造的なコードベース理解が必要なエージェント型コーディングワークフローを構築しようとしている方にとって実用的です。特にリファクタリング、依存関係のトレース、ファイルをまたいだシンボル解決などのユースケースに適しています。
Source: https://github.com/CodeBendKit/codeseek
perplexityai/bumblebee
Perplexity AIが開発した読み取り専用スキャナーで、インストール済みパッケージ・ブラウザ/エディタ拡張機能・開発者ツールのディスク上のメタデータを列挙し、そのインベントリをソフトウェアサプライチェーン侵害の既知データベースと照合します。読み取り専用という制約はアーキテクチャ上の意図的な設計であり、このツールは状態を一切変更しないため、CIや本番ビルドマシン上でも副作用のリスクなしに安全に実行できます。
このツールが対処する脅威モデルは具体的です。dependency confusion攻撃、タイポスクワットされたパッケージ、侵害された拡張機能は、開発者環境における重大な攻撃対象領域となっています(XZ utils、npmのsocket.io-parserインシデント、悪意あるVS Code拡張機能など)。Bumblebeeは、開発者がアドバイザリを手動で追跡することに頼るのではなく、体系的な監査を提供します。
フルSASTツールではなく開発者エンドポイントスキャナーとして設計されており、サプライチェーンへの露出(何がインストールされているか、バージョンは何か、既知の不正リストに登録されているかどうか)に絞って焦点を当てています。この狭いスコープにより、false positiveの発生率を低く抑えています。初日に4400以上のスターを獲得していることからも、開発者ツールにおけるこの種のターゲット絞り込まれたサプライチェーンの可視化に対する需要が明らかに高いことがわかります。
Source: https://github.com/perplexityai/bumblebee
omnigent-ai/omnigent
Claude Code、OpenAI Codex、およびユーザー定義エージェントといった異種AIコーディングエージェントに対して、統一された抽象化レイヤーを提供するメタハーネスです。これらのエージェントを共通インターフェース経由で操作でき、タスクオーケストレーションのロジックを書き直すことなく、実行時の切り替えや並列組み合わせが可能です。単純なルーティングを超えた主要なアーキテクチャ上の追加要素として、ポリシーの強制とサンドボックス化が挙げられます。オペレーターはエージェントが実行を許可されるアクションに対する制約を指定でき、各エージェント内部のガードレールに依存するのではなく、ハーネスレベルで強制されます。
協調的なマルチユーザーセッションモデルは技術的に興味深い点があります。複数のクライアントが同一のライブエージェントセッションをリアルタイムで観察・操作できるため、人間による監視ワークフロー(一人が記述し、別の一人が監査する)や、エージェント同士がペアで協働するパターンが実現します。
異なるタスクにわたって複数のエージェントタイプを運用する組織にとって、その価値は運用面にあります。単一の統合ポイントにより、エージェント固有の配管処理の表面積が削減されます。ポリシーレイヤーは、現行のエージェントデプロイメントにおけるエージェントごとのサンドボックス化が存在しないか、独自実装を必要とするという実際のギャップに対処しています。初期段階での牽引力(3200以上のスター)は、チームがこの種のマルチエージェントガバナンスレイヤーを積極的に求めていることを示しています。
Source: https://github.com/omnigent-ai/omnigent
amElnagdy/guard-skills
AIコーディングエージェントパイプラインに組み込み可能な、品質ゲート「スキル」のコレクションです。LLMが生成するコード・テスト・ドキュメントにおける典型的な失敗パターンを検出するための構造化チェック群です。「linter」ではなく「スキル」という位置づけは意図的なもので、人間が事後的に実行するためではなく、エージェント自身が自己評価ステップとして呼び出すことを想定して設計されています。
対象とする失敗パターンは、AIコードジェネレータが陥りやすいものに特化しています。すなわち、一見正しそうに見えて実は誤っているテストアサーション、存在しないAPIシグネチャのhallucination、実装から乖離したドキュメント、そして表面的なチェックは通過しながらエッジケースを見落とす浅いテストカバレッジです。静的linterが構文エラーや型エラーを捉えるのに対し、これらのガードはエージェント出力層におけるセマンティックな正確性を標的にしています。
実用的なデプロイパターンは、ワンショットの後処理としてではなく、エージェント型コーディングループ(生成→ガード→修正)の一ステップとして組み込む形です。これは、Claude CodeやCodexのワークフローといったプロダクション向けエージェントハーネスが採用しつつある構造と一致しています。AIコーディングをCIに統合するチームが、コンパイルや既存のlintルールを超えた機械的に検証可能な品質基準を求める場合に有用です。
Source: https://github.com/amElnagdy/guard-skills
packyme/privacy-filter
アプリケーションコードとLLM APIの間で透過的なプロキシとして機能するGoサービスで、リクエストがネットワーク境界を越える前にミリ秒レイテンシでPIIおよびシークレットの検出・除去を行います。ミリ秒レイテンシというパフォーマンスの主張は、数百ミリ秒の追加と大幅なコスト増を招く第二のLLM呼び出しではなく、ルールベースおよびパターンマッチングアプローチ(regex、コンパイル済みモデルを用いたNER、または類似手法)を採用していることを示唆しています。
脅威モデルは明快です。開発者がAPIキー、認証情報、氏名、メールアドレス、その他の規制対象データをクラウドLLMエンドポイントへのプロンプトに意図せず含めてしまうというリスクを対象としています。ゲートウェイアーキテクチャを採用しているため、アプリケーションコードの変更は不要で、リクエストはネットワーク層でインターセプトされ、スクラビング処理が施されます。
並行処理の効率性と低いGCオーバーヘッドを活かすためにGoで実装されており、高スループットサービスにおけるサイドカーまたはインプロセスライブラリとしての利用に適しています。PackyCodeによる本番環境でのデプロイの実績は、実世界での検証の証左となっています。LLM呼び出しを本番サービスに統合しているGDPR、HIPAA、またはSOC 2要件の対象チームにとって、これはほとんどのLLM SDK統合が完全に見落としている具体的なコンプライアンスのギャップに対処するものです。
Source: https://github.com/packyme/privacy-filter
1ove9/antenna-forge
AIによる最適化と実際の電磁シミュレーションをループ内に組み込んだアンテナ逆設計ツールです。具体的には、NEC2(モーメント法、ワイヤーアンテナに広く用いられる)とopenEMS(FDTDベースのフルウェーブシミュレーション)を使用しています。ここでの逆設計とは、既知のジオメトリをシミュレートするという順問題ではなく、目標とするRF性能特性(利得パターン、インピーダンス、帯域幅)を指定し、それを満たすアンテナのジオメトリ空間をオプティマイザーが探索することを意味します。
デュアルシミュレーター方式は注目に値します。NEC2は高速でワイヤー/モノポール形状に適している一方、openEMSは基板効果を含むより複雑な3D構造を扱えるため、このツールはより広いアンテナ設計空間にわたって有用です。AIコンポーネントは最適化ループを駆動していると考えられます。EMシミュレーターは微分不可能であるため、勾配フリーの手法(進化的アルゴリズム、Bayesian optimization)が用いられている可能性が高いです。
ブラウザ内のplaygroundは、ローカルへのNEC2/openEMSのインストールなしに実験したいRFエンジニアにとって、参入障壁を大幅に下げます。アンテナ設計は信頼性の高い結果を得るために物理シミュレーションが不可欠な領域であるため、サロゲートのみのアプローチではなく実際のシミュレーターをループ内に保持することは、正しいエンジニアリング上の選択です。
Source: https://github.com/1ove9/antenna-forge
ATOM00blue/machine-learning-library
厳選・構造化された923件のML学習リソースのコーパスです。391件のarXiv論文、474件の講義資料(Stanford、MIT、Karpathy、fast.ai)、58件の解説記事を含み、すべてMarkdownに正規化されてプロヴェナンスメタデータが保持されています。正規化のステップがここでの実質的なエンジニアリング作業であり、PDF、ノートブック、HTMLの講義ノートをクリーンなMarkdownへ変換し、一貫したfrontmatterを付与することで、生のPDFでは実現できないプログラマティックなユースケースが可能になります。
このフォーマットの選択によって、3つの具体的なユースケースが実現されます。(1) Obsidianでの人間による学習:トピックごとに整理されたノートのグラフビューにより、ナビゲーション可能な構造が得られます。(2) RAGコーパス:メタデータ付きのクリーンなMarkdownにより、信頼性の高いチャンキングと検索が可能になります。(3) fine-tuningデータセット:データセットカードとアトリビューションにプロヴェナンスの追跡が必要であるため、これが実現されます。トピックの整理により分類体系が定まり、人間および自動化された両方のコンテキストで検索品質の向上に寄与します。
生のarXivスクレイピングに対する優位性は、キュレーションと正規化にあります。すでに誰かが選別(単なる新着順ではなく教育的品質によるフィルタリング)とフォーマット変換(LaTeXレンダリングのアーティファクト除去、エンコーディング問題の修正)を済ませています。MLコンテンツを対象にドメイン固有のRAGシステムや合成学習データパイプラインを立ち上げようとしている研究者にとって、これはコーパスをゼロから構築するよりもはるかに少ない労力で始められる出発点となります。
Source: https://github.com/ATOM00blue/machine-learning-library