デイリーAIダイジェスト — 2026-06-10
arXiv ハイライト
Flow-DPPO: フローマッチングモデルのための発散近位方策最適化
問題
フローマッチングモデルのRL fine-tuning(Flow-GRPO、Flow-CPS、GRPO-Guard)は、KステップのデノイジングプロセスをMDPとして扱い、PPOの比率クリッピングによる信頼領域を継承しています:
r_k(\theta) = \frac{\pi_\theta({\bm a}_k\mid {\bm s}_k)}{\pi_{\theta_{\mathrm{old}}}({\bm a}_k\mid {\bm s}_k)},\quad \mathrm{clip}(r_k, 1-\epsilon, 1+\epsilon).
著者らは、これがフローモデルに対して構造的に誤りであると主張しています。ステップごとの方策はガウス分布(SDEサンプラーが予測された速度の周辺に固定分散のノイズを注入する)であるため、\pi_{\theta_{\mathrm{old}}}と\pi_\thetaの間の真のKLが閉形式で利用可能です。比率クリッピングはその発散のシングルサンプル確率的推定値を代理として使用しており、これは高分散です:サンプリングされた行動に依存して、同じ真のKLが[1-\epsilon, 1+\epsilon]の内側にも外側にも比率を生じさせる可能性があります。結果として、一部の軌道領域は過剰に制約され(発散が小さいときにgradientがマスクされる)、他の領域は過少に制約されます(発散が大きいときにgradientが許容される)。
手法
著者らはまず、フロー固有の信頼領域の基礎を確立します。終端報酬R({\bm x}_0,{\bm c})を持つ割引なし有限ホライズンMDPに対し、定理1は正確な性能差として次式を与えます:
J(\pi_\theta) - J(\pi_{\theta_{\mathrm{old}}}) = L'_{\theta_{\mathrm{old}}}(\pi_\theta) - \Delta(\pi_{\theta_{\mathrm{old}}},\pi_\theta),
代理関数は
L'_{\theta_{\mathrm{old}}}(\pi_\theta) = \mathbb{E}_{\tau\sim\pi_{\theta_{\mathrm{old}}}}\!\left[R\sum_{k=1}^{K-1}\!\left(\tfrac{\pi_\theta}{\pi_{\theta_{\mathrm{old}}}} - 1\right)\right]
です。定理2は残差を最大TV項で上界します:J(\pi_\theta) - J(\pi_{\theta_{\mathrm{old}}}) \geq L'_{\theta_{\mathrm{old}}}(\pi_\theta) - 2\xi(K-1)(K-2)\,D_{\mathrm{TV}}^{\max}(\pi_{\theta_{\mathrm{old}}}\|\pi_\theta)^2、ここで\xi=\max|R|です。これにより、比率制約ではなくステップごとの発散制約が正当化されます。
デノイジングステップkにおけるSDE更新は、平均\mu_\theta, \mu_{\theta_{\mathrm{old}}}と共有スカラー分散\sigma_k^2 Iを持つガウス分布であるため、ステップごとのKLは正確かつ低コストに計算できます:
D_{\mathrm{KL}}(\pi_{\theta_{\mathrm{old}}}\|\pi_\theta) = \frac{\|\mu_\theta - \mu_{\theta_{\mathrm{old}}}\|^2}{2\sigma_k^2}.
Flow-DPPOは比率クリッピングを非対称発散マスクで置き換えます。トークンkのgradientは、(a) ステップごとのKLが閾値\deltaを超え、かつ(b) 提案された更新が\pi_\thetaを\pi_{\theta_{\mathrm{old}}}からさらに遠ざける場合にのみ抑制されます。KLが\deltaを超えていても、gradientが信頼領域に向かって引き戻す方向であれば、更新は保持されます。これはPPOの非対称クリッピング(比率を1に向かって戻すgradientを保持する)の自然な類似ですが、ノイズの多い比率ではなく、決定論的で分散のない発散シグナルに適用されます。
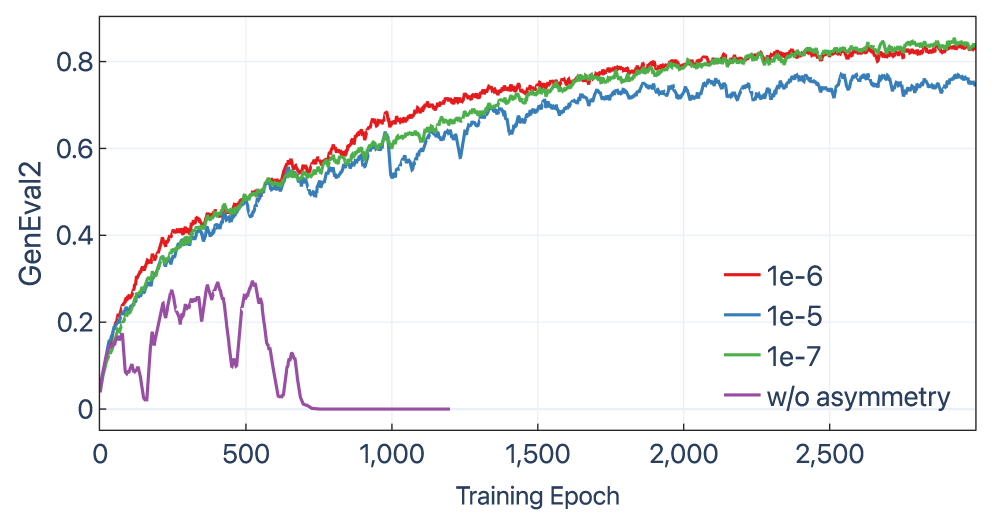
図3のアブレーションはこの非対称性を分離して示しています:「更新が遠ざかるか否か」の条件を除去すると学習が崩壊し、対称KLゲーティングは非対称バリアントより性能が劣ります。
結果
実験ではSD3.5-medium、FLUX2-klein-base-9B、FLUX.1-devをバックボーンとして使用し、GenEval2(ドメイン内、学習プロンプト20k、評価プロンプト800)を最適化しつつ、壊滅的忘却を検出するためにPickScore/CLIP/HPSv2をOODで追跡しています。
SD3.5-mediumでのマルチ報酬fine-tuning(GenEval2スコア): - 事前学習済み:12.4 - Flow-GRPO:39.9、Flow-CPS:44.6、GRPO-Guard:47.8、Diffusion-NFT:42.5 - Flow-DPPO:48.1、Flow-DPPO+CPS:51.6
FLUX2-klein-base-9Bではその差がさらに広がります: - Flow-GRPO:46.8、Flow-CPS:47.1、GRPO-Guard:49.0、Diffusion-NFT:47.3 - Flow-DPPO:57.7、Flow-DPPO+CPS:55.2
重要なことに、OODメトリクスも同時に改善しています。FLUX2-9BにおいてFlow-DPPO+CPSはPickScore 26.15(ドメイン内)および22.97(OOD)を達成し、Flow-GRPOの25.61 / 22.62と比較して優れており、HPSv2は0.427 / 0.370対0.412 / 0.357です。FLUX2-9Bにおける単一報酬の学習曲線(図2)では、Flow-DPPOがOODのCLIP/PickScore/HPSv2を維持または改善する一方で、ベースラインはそれらを劣化させており、これは緩い信頼領域下での報酬ハッキングの典型的なシグネチャです。
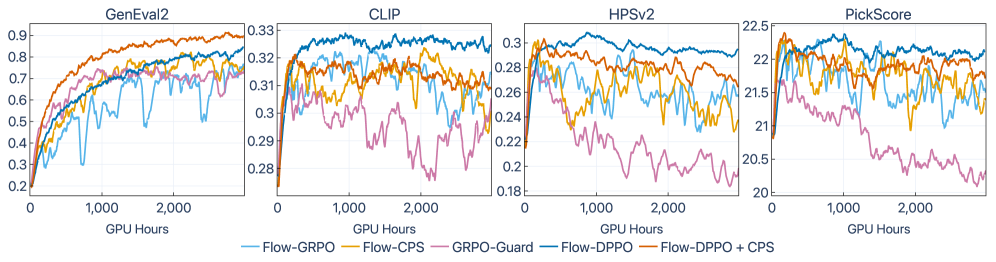
定性的には(図1)、Flow-DPPOはFLUX.1-devにおけるGRPOスタイルのベースラインと同等かそれ以上の構成的精度を達成しつつ、テクスチャ/品質の劣化が目に見えて少なく、これはKL制御の厳密さと一致しています。

限界と未解決の問題
正確KLのトリックは、ステップごとの方策が既知の分散を持つガウス分布であることに依拠しており、これはここで使用されるSDEサンプラーには当てはまりますが、任意の確率的サンプラーや離散トークンの自己回帰ヘッドには当てはまりません。定理2の上界は(K-1)(K-2)でスケールするため、発散閾値\deltaはデノイジングステップ数に依存すべきであることが示唆されますが、論文ではこのスケーリングを経験的に特徴付けていません。非対称マスクは追加のハイパーパラメータ(閾値)を導入しており、その報酬スケールやバックボーンに対する感度は十分にアブレーションされていません。また、「遠ざかる」基準は一次近似で計算されており、より大きな学習率での二次補正が重要かどうかは未解決です。
なぜ重要か
比率クリッピングは、真の方策KLの計算が難解な離散行動PPOから継承されました。フローモデルはその前提を破っており、ステップごとのガウス構造により正確なKLが自明に計算可能となるため、ノイズの多い比率を代理として使用することは厳密に劣ります。Flow-DPPOはこれを活用したシンプルなドロップイン代替手法であり、ドメイン内報酬とOOD汎化の両方で一貫した改善が見られることから、現在のフロー-RLパイプラインの多くは、PPOを過度に忠実に模倣することで性能を無駄にしていることが示唆されます。
Source: https://arxiv.org/abs/2606.11025
LLM RLにおける発散正則化の再考
LLMのpost-training RLは構造的にoff-policyです:rolloutエンジンとtrainingエンジンは数値的に乖離しており(BF16 vs FP8、カーネルの違い、MoEルーティングの非決定性)、ポリシーはミニバッチをまたいで古くなっていきます。そのため、trust-regionの制御が不可欠です。PPO/GRPOはr_t = \pi(y_t|s_t)/\mu(y_t|s_t)に対するimportance-ratioのclippingによってこれを実現しますが、語彙が長い尾を持つ分布の場合、|r_t - 1|は実際の分布的シフトの代理指標として不適切です:\mu(y_t|s_t) = 10^{-4}の稀なトークンはr_t = 5を取り得る一方で全変動への寄与は無視できるほど小さく、一方\mu(y_t|s_t) = 0.5の一般的なトークンが0.6へシフトするとr_t = 1.2でありながら絶対的な確率質量の変化はずっと大きくなります。DPPOは絶対確率シフトに対するバイナリマスクへの切り替えによってこれを修正しましたが、マスクは不連続です:trust regionの外側にある境界付近のトークンはgradientがゼロになり、修正的な引き戻しが生じません。本論文はDRPOを提案し、DPPOの幾何学的構造を維持しながらマスクを滑らかな二次正則化項で置き換えます。
バイナリTVマスクから二次ペナルティへ
出発点はBinary-TVの代理指標D_t^{\text{Bin-TV}} = |\pi(y_t|s_t) - \mu(y_t|s_t)| = \mu(y_t|s_t)\,|r_t - 1|です。DPPOの閾値D_t^{\text{Bin-TV}} \le \deltaは、トークンに適応的なratio境界と等価です。
|r_t - 1| \le \frac{\delta}{\mu(y_t|s_t)},
すなわち、稀なトークンにはより広いratio許容範囲が与えられ、一般的なトークンにはより厳しい許容範囲が与えられます。これをPPOスタイルのclipped surrogateに代入するとDPPOが定義されます。DRPOはその代わりに以下のように書きます。
\mathcal{L}_{\text{DRPO}}(x,\pi) = \mathbb{E}_{y\sim\mu(\cdot|x)}\!\left[\sum_{t=1}^{|y|} r_t \hat{A}_t - \frac{|\hat{A}_t|}{2\delta}\,\mu(y_t|s_t)\,(r_t-1)^2\right].
重要な設計上の選択は、二次項における\mu(y_t|s_t)の係数です。これがなければ、正則化項の均衡点は|r_t - 1|を固定値に固定します(SPOの幾何学)。これがあることで、均衡点は絶対確率シフト\mu|r_t - 1|を固定し、まさにBinary-TVのtrust regionと一致します。gradientは次のようになります。
\nabla \mathcal{L}_{\text{DRPO}} = \mathbb{E}\left[\sum_t \left(1 - \operatorname{sign}(\hat{A}_t(r_t-1))\frac{D_t^{\text{Bin-TV}}}{\delta}\right) r_t \hat{A}_t \nabla \log\pi(y_t|s_t)\right],
したがって、各トークンのpolicy-gradientへの寄与は、連続的な重みw_t \in (-\infty, 2]によってスケーリングされます。この重みは、トークンが境界に近づくにつれて滑らかに減衰し、有害な方向でD_t^{\text{Bin-TV}} = \deltaにおいてゼロになり、その先では符号が反転します——DPPOが欠く修正的な引き戻しを提供します。
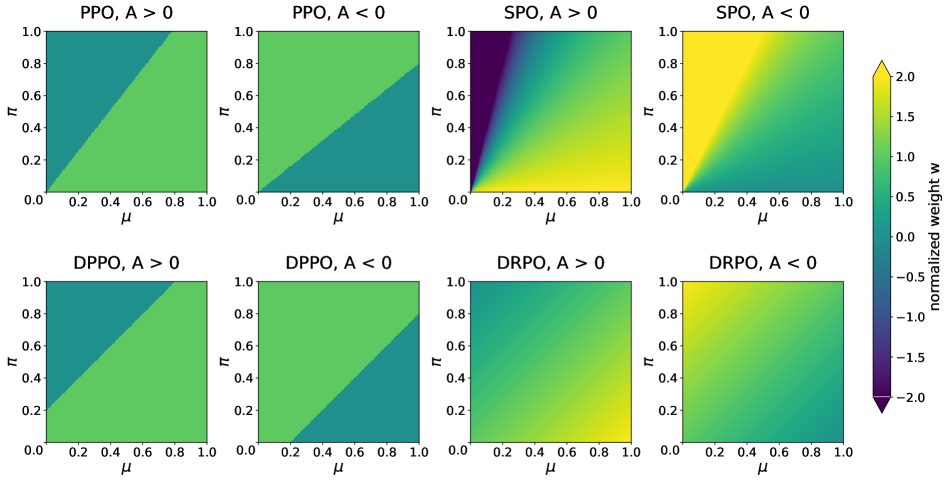
上記の重みの曲面は4つの方式を対比しています:SPOの重みは\muが小さいときに無制限に増大し(ratioの病理)、PPO/DPPOは鋭い不連続性を示す一方、DRPOは両引数において有界かつ連続です。
長い尾を持つ\muが重要な理由
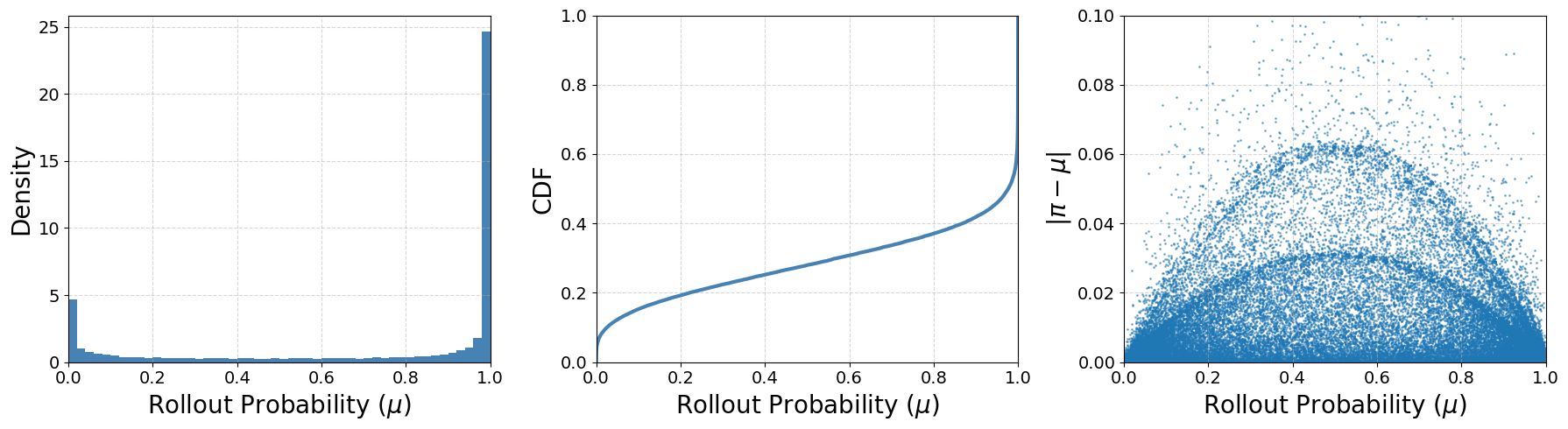
実験的に、Qwen3-30B-A3B-Baseからサンプリングされたトークンの7.8%が\mu(y_t|s_t) \le 0.01を持ちます。これらのトークンに対して、実際の確率シフトが微小であっても|r_t - 1|は高い分散を持つため、ratio-basedのtrust regionはそれらを過度にペナルティを課す(稀だが有用なトークンの探索を抑制する)か、clip-higherの緩和を用いると大多数のトークンを制御不足にするかのいずれかになります。
実験
DRPOはQwen3-4B-Base、Qwen3-30B-A3B-Base、Qwen3.5-35B-A3B-BaseでDAP 13K数学サブセットを用いて評価され、さらにDeepSeek-R1-Distill-Qwen-1.5BがAIME 2024/2025(16サンプル平均)上の1,460問のサニティセットで評価されます。Qwen3-30B-A3B-Baseについては、FP8-rolloutとFP8-E2E(trainingとrolloutの両方にFP8を使用)も追加テストしており、これはtraining-inferenceのミスマッチを悪化させます——MoEにとっては特に深刻です。ハイパーパラメータ:GRPOのclip-higherは(\epsilon_{\text{low}}, \epsilon_{\text{high}}) = (0.2, 0.28)、DPPOは\delta = 0.15、SPOとDRPOの閾値は12.5。
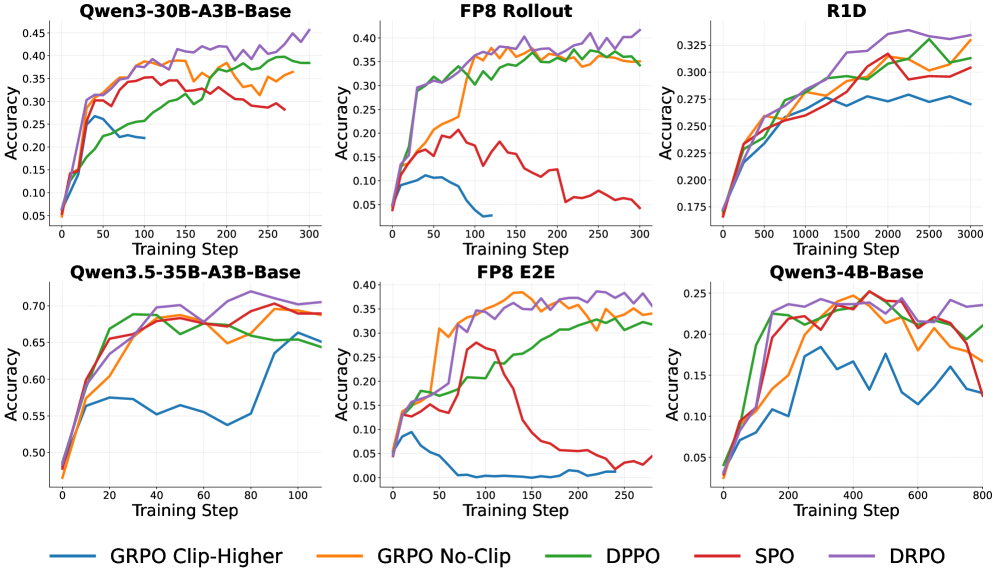
3つの知見が際立っています。第一に、ratio-basedの手法(GRPO、SPO)はFP8下で不安定であり頻繁にcollapseします。これは|r_t-1|が発散の代理指標として不適切であることと一致しています。第二に、ハードマスク手法(GRPO、DPPO)は安定している場合でもsmooth対応手法に比べて性能が低下します:DPPOはQwen3-30B-A3B-Baseで安定して学習しますが、DRPOよりも収束が遅く最終精度も低くなります。第三に、非正則化surrogateはtrust regionなしで時々最良の結果を示しますが、6設定中3つで性能が低下します——Qwen3-4B-Baseの実行では精度が0.25から0.17に下がります。DRPOはすべての6設定においてすべてのbaselineと同等以上の性能を示します。
限界と未解決の問題
本論文は本質的にはルールベースの報酬を用いた数学RLにおける正則化項のablationであり、検証不可能な報酬、RLHF選好モデリング、エージェント的な設定での結果は示されていません。閾値\delta(またはSPO同等の12.5)はグローバルにチューニングされており、幾何学的な議論は推定TVに結びついたトークンごとの適応的な\deltaがさらに有効である可能性を示唆しています。二次ペナルティは(r_t - 1)において対称です——\hat{A}_t > 0と\hat{A}_t < 0の非対称性に合わせた非対称なバリアントは未探索のままです。最後に、「誘導されたgradientの形式が名目上の発散よりも重要である」という結びの言葉は、目的関数レベルからKL/JSを出発点とする標準的な実践に疑問を呈しており、より体系的な理論的考察が必要です。
なぜ重要か
DRPOは、LLM RLの安定性を静かに損なっていた混乱を明確にします:制約すべき正しい対象はimportance ratioではなく絶対確率シフトであり、その制約はハードマスクではなく滑らかなgradient再重み付けによって実施されるべきです。二次ペナルティにおける\mu(y_t|s_t)係数は小さな変更ですが大きな効果をもたらします——これはSPOスタイルのratio均衡をTVスタイルの確率シフト均衡に変換するものであり、MoEモデルのFP8エンドツーエンド学習を実用的なものにします。
Source: https://arxiv.org/abs/2606.09821
推論はどのように流れるか?LLMにおける強化学習のためのAttention誘導情報フローの追跡
問題
LLMのRL後学習におけるトークンレベルのcredit assignmentは、通常一様です:GRPOとその派生手法は、軌跡内のすべてのトークンに同じadvantageを割り当てており、決定的な推論ステップを通常のformatting処理やfiller(穴埋めトークン)と混同しています。近年の研究では、点ごとのヒューリスティクス(entropy、gradient norm、max attention、mutual correlation)によって「重要な」トークンの重みを増やそうとしていますが、これらは影響が生成全体にどのように伝播するかという大域的な構造を無視しています。問題は、プロンプトから最終的な答えへと実際に情報を運ぶトークンを特定できるか、そしてRL時にそれらを強調することで測定可能な改善が得られるかどうかです。
手法:FlowTracer
FlowTracerは、推論をattention誘導DAG上の線形影響伝播プロセスとして扱い、保存された答え目標フローを抽出します。
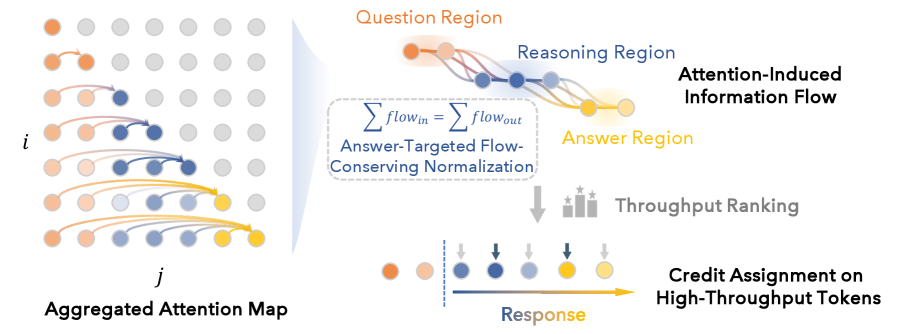
生の影響グラフ。 生成された系列 (x_1,\dots,x_T) に対して、時間順のDAG \mathcal{G}=(V,E) を構築し、すべての i<k に対してエッジ i\to k を張り、重みを
W_{ik} := a(x_k, x_i) \ge 0,
とします。ここで a(\cdot,\cdot) は、目標 k から源 i への(層・ヘッド全体での平均による)集約attentionです。重要なのは、W が確率的カーネルではなく非負の線形演算子として扱われる点です:x_i における1単位の影響が x_k に W_{ik} の割合を届け、\sum_{k>i} W_{ik}=1 という制約はありません。
生のattentionの2つの病理。 (1) Attentionはin-degree(\sum_{i<k} W_{ik} = 1)について正規化されていますが、out-degreeについては正規化されていないため、前向き伝播はトポロジーのみに起因してシグナルを増幅または減衰させます。(2) ほとんどのパスは答えとは無関係で、fillerや破棄された中間仮説で終端します。
Doob-h変換的な再重み付け。 FlowTracerはエッジを再重み付けし、答え領域に到達するパスのみが質量を持ち、中間トークンでの局所的なフロー保存(入力質量=出力質量、超源/超シンクを除く)が成立するようにします。これは、マルコフ過程を目標集合への到達に条件付けるh変換に類似しており、ここでは答えスパンで終端することに条件付けた線形影響フローを実現します。再重み付け後、グラフは答えを支持するルートのみをエンコードします。
前向き伝播とスループット。 プロンプト上の超源から1単位のフローを注入し、答え上の超シンクへルーティングします。各トークンのスループット——そのノードを通過する総質量——がそのcreditスコアです。高スループットのトークンは、問題と答えを接続する「推論バックボーン」を形成し、低スループットのトークンはformattingとfillerです。
RLへの統合。 FlowTracerはフローを連続的な重みとして使用するのではなく、ハードマスクに変換します:スループット上位40%のトークンを選択し、そのGRPOサロゲートに \gamma_{\text{flow}} = 1.5 を乗じます。セクション5.1のアブレーションがこの選択を正当化しています:スループットはheavy-tailedであるため、raw-flowによる再重み付けは外れ値を増幅させ;SigmoidやLog1pの圧縮は改善しますが、ハードTop-kマスクよりもパフォーマンスが低いままです。累積フロー閾値も固定トークン比率より悪く、質量集中によってカバレッジが過小または過大になります。
結果
Qwen3-Baseを使った数学的推論において、FlowTracerはGRPOおよび5つすべてのcredit-assignmentベースライン(Random、Entropy、Gradient、Correlation、Attention)を1Kおよび8Kコンテキストの両方で上回ります。
Qwen3-4B-Base、AIME24/25・AMC23・MATH500・OlympiadBenchの平均: - GRPO:37.1(1K)/ 44.8(8K) - Attention(最強ベースライン):38.6 / 47.2 - FlowTracer:39.4 / 48.6 ——GRPOに対してそれぞれ+2.2および+3.8
ベンチマーク別では、GRPOに対する8Kでの最大の改善はAIME25(+5.8、16.1→21.9)とAMC23(+4.8、57.6→62.4)です。
Qwen3-8B-Base、同じ平均: - GRPO:39.4 / 50.3 - Attention:41.3 / 50.9 - FlowTracer:43.4 / 52.5 ——GRPOに対して+4.0および+2.1
注目すべき1Kでの改善:AIME24 9.3→13.0(+3.7)、AIME25 7.3→11.8(+4.5)、AMC23 59.1→65.6(+6.5)。
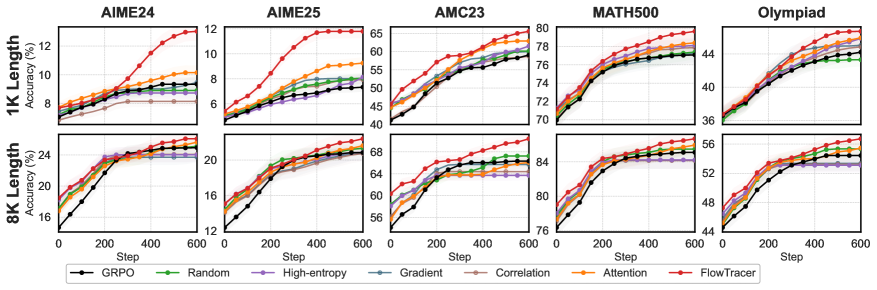
トレーニングカーブは、FlowTracerが早期にGRPOおよびAttentionベースラインから分離し、600ステップを通じてそのギャップを維持していることを示しており、targeted credit assignmentが単なる最終チェックポイントの成果ではないことを示唆しています。
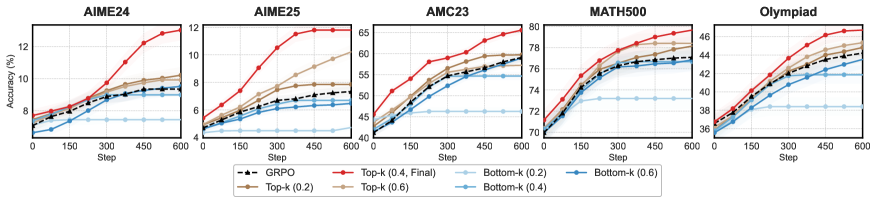
重要なことに、Top-k対Bottom-kのアブレーションは、フロー信号そのものが、単なるスパース化ではなく改善をもたらしていることを確認しています:低フロートークンを強調することは、すべての選択比率において高フロートークンを強調することを一貫して下回ります。
限界と未解決の問題
- Doob-h変換的な再重み付けと前向き伝播は、完全な軌跡にわたるattentionパスを必要とします;長いコンテキストでは O(T^2) のDAGと集約コストは無視できません。本論文はステップあたりの実時間オーバーヘッドを報告していません。
- 層・ヘッド全体での平均によるattentionの集約は、潜在的に関連性のある異質性を捨てています——最近の解釈可能性研究は、特定のヘッドが不均衡な因果的重みを持つことを示唆しています。
- ハードTop-40% / \gamma_{\text{flow}}=1.5 のレシピは数学問題に対して経験的に調整されており、同じハイパーパラメータがコーディングやエージェント型RLに転用できるかどうかは不明です。
- 影響としてのattentionは既知の近似であり、gradient-based attributionが特定されたバックボーンを検証または否定する可能性があります。
- process-reward-modelアプローチとの比較がありません。そちらは、loss重み付けの側ではなく報酬の側から同じcredit-assignment問題に取り組んでいます。
なぜ重要か
FlowTracerは、トークンレベルのcredit assignmentを、トークンごとのヒューリスティクスではなく、attention DAG上のグローバルなフロー問題として再定式化し、答えへの到達に条件付けることで、報酬、rolloutポリシー、オプティマイザーを変えることなく、数学ベンチマーク全体の平均でGRPOを2〜4ポイント改善する使用可能なバックボーンシグナルが得られることを示しています。これは、モデル内部の構造的シグナルを慎重に使用すること(大きさではなくランク)が、RLの fine-tuning において一様なトークン重み付けを置き換えられるという、明快なデモンストレーションです。
Source: https://arxiv.org/abs/2606.10646
Kwai Keye-VL-2.0 技術レポート
問題と動機
時間単位の長尺動画理解は、MLLM に対して三つの軸でストレスをかけます:超長トークン列(数万〜数十万のvision token)、フレーム間の高い冗長性、そして二乗コストの attention です。Keye-VL-2.0-30B-A3B はこれらの課題を、DeepSeek Sparse Attention(DSA)を GQA ベースのマルチモーダルアーキテクチャに適応させた 30B パラメータの MoE バックボーン(3B 活性化)で解決しようとしており、per-token の計算量を現実的な範囲に保ちながら 256K コンテキストのロスレス処理を主張しています。本モデルは、長尺動画・エージェント・推論ベンチマークにおいて Qwen3-VL、InternVL3.5、GPT-5-mini に対するオープンソースの競合として位置付けられています。
アーキテクチャ
四つのコンポーネントで構成されています:Keye-VL-1.5 から継承した SigLIP-400M-384-14 ViT、MLP projector、Qwen3-30B-A3B-Thinking-2507 MoE LLM、そして sparse attention モジュールです。長尺動画に対して重要なアーキテクチャ上の選択が二つあります:
Native-resolution ViT。 入力はオリジナルのアスペクト比を保持し、可変解像度に対応するため絶対学習可能位置 embedding が補間されます。これにより、dynamic tiling(InternVL3、MiniCPM-V)が引き起こすグローバル構造の損傷を回避し、NaViT/Qwen3.5/Kimi-2.5 の路線を踏襲します。OCR、チャート、動画内の小領域証拠に対しては、固定解像度の事前学習を再利用するよりも幾何情報を保持する方が重要です。
GQA 互換の DSA。 DSA は dense MQA 向けに導入されたものですが、著者らはグローバルな MQA ベースのインデックスパスとグループ化された GQA 集約を組み合わせることで、グループごとに sparse top-k トークン選択を行いながら LLM が使用する KV cache レイアウトをそのまま保持しています。インデクサはすべての過去トークンを低コストにスコアリング(単一ヘッド)し、GQA は選択されたサブセットにのみ attention します。位置 t におけるクエリグループ g について、模式的に示すと:
\mathcal{S}_t = \text{TopK}_k\!\left(q_t^{\text{idx}} \cdot K^{\text{idx}}\right),\quad o_t^{(g)} = \text{Softmax}\!\left(\tfrac{Q_t^{(g)} K_{\mathcal{S}_t}^\top}{\sqrt{d}}\right) V_{\mathcal{S}_t}
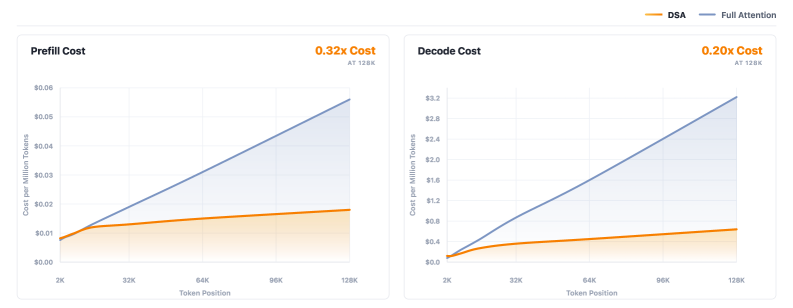
これにより KV-cache の GQA 形状が保たれ、単純な DSA-on-GQA ポートが必要とする KV の重複を回避できます。インデクサおよびグループ化 sparse attention 向けのカスタムカーネルが、同一の H800 価格条件のもとで長尺動画の prefill およびデコードコストを dense attention と比較して実質的に削減することが報告されています。
学習パイプライン
事前学習は四段階のカリキュラム(Figure 2)で構成されています:Stage 0 では ViT と LLM を凍結した状態で projector のみを画像テキストキャプションおよびインターリーブデータで学習し、Stage 1 では 32K コンテキストですべてを解凍し、Stage 2 では 64K に拡張してタスク固有のデータ(OCR、VQA、STEM、GUI、grounding、カウント、コード、ツール使用、検索)を注入し、Stage 3 では長尺動画・複数ページ文書・複数文書入力・長尺エージェント軌跡を用いて 256K まで拡張します。

動画の教師信号は、シーン分解による dense caption に大きく依存しています:各クリップをタイムスタンプ付きのシーンに分割し、シーンごとの dense caption とグローバルな概要を付与することで、知覚と grounding の両目標に対して整合した時間的・テキスト的信号を提供します。

ポスト学習は、(i) 約 500B トークンのコーパスに対する SFT(言語能力を保持するため約 40% はテキストのみとし、残りを動画・知覚・推論・エージェント・長コンテキストデータに分配)と、(ii) Context-RL および Video-RL と組み合わせた Cross-Modal Multi-Teacher On-Policy Distillation(MOPD)から構成されます。MOPD は、on-policy rollout を用いて複数の専門家教師から密なトークンレベル logit を MoE 学生に蒸留します。著者らはこれを、標準的なマルチタスク SFT が異質な教師を混在させる際に生じる破滅的な忘却への対処策として位置付けています。動画データの一部は、手がかりとなる区間を伴う多肢選択形式でフォーマットされており、モデルは <think> ステージ内で回答と根拠となるスパン [[mm, mm], ...] の両方を生成しなければならず、グローバルな事前知識ではなく証拠の局在化へと誘導されます。
インフラストラクチャ
学習スタックは非自明であり、貢献の一部を成しています。ExtraIO は、非同期かつ水平にスケーラブルなサービスを介して動画デコード・フレームサンプリングを学習から切り離します。ViT と LM は同一の GPU グループに配置されますが、独立した並列シャーディングを使用し(ViT を LM PP0 に固定するのではなく)、recompute-or-offload により ViT の活性化メモリをほぼゼロに近づけます。二段階のロードバランシングが、可変長・長尺動画サンプルから生じる分散を処理します。カスタム DSA カーネルは prefill とデコードの両方を対象としています。
結果
本論文は、動画理解・コーディング・エージェントツール使用・数学/科学推論・instruction following・汎用 VLM タスクにわたって、Qwen3.5、InternVL3.5、GPT-5-mini、Qwen3-VL との比較を行っています。長尺動画の評価には Video-MME-v2(平均精度に加えてグループベースの (N/4)^2 スコアを使用)、LongVideoBench、MLVU、Video-MME(字幕なし)が用いられています。Figure 5 の概要では、活性化パラメータスケール(3B 活性 / 30B 合計)において Keye-VL-2.0 が比較表の複数の行でトップに立っていることが示されていますが、提供されたスニペットにはベンチマークごとのスカラー値が記載されておらず、アーキテクチャ上の主な主張はロスレス 256K 処理であり、dense attention のベースラインでは切り捨てか二乗コストのいずれかを払わざるを得ないとされています。
限界と未解決の問題
提供されているセクションにはベンチマークごとの数値差分が記載されていないため、品質を固定した場合の DSA 対 dense の主張を外部から検証することは困難です。「ロスレス 256K」は dense の 256K ベースラインに対して定量的に示されているのではなく、主張されているに過ぎません。標準的な SFT 蒸留に対する MOPD の改善効果は、抜粋の中でアブレーションによって単独で検証されていません。Qwen3-30B-A3B-Thinking および Keye-VL-1.5 の ViT への依存により、改善効果が強力な上流コンポーネントと絡み合っています。最後に、GQA-DSA ポートは独立したインデクサヘッドを導入しており、その学習安定性や top-k の選択(k、局所性バイアス、再現ウィンドウ)についてはここでは詳述されていません。
この研究が重要な理由
これは DeepSeek Sparse Attention を GQA ベースのマルチモーダルモデルに適応させた最初の報告であり、時間単位の動画に対する具体的な I/O および並列性エンジニアリングと対になっています。ロスレス 256K の主張が独立した評価で支持されれば、GQA KV-cache レイアウト(これが支配的なデプロイ形態です)を捨てずに MLLM のコンテキストをスケールさせるための実践的なレシピを提供することになります。
Source: https://arxiv.org/abs/2606.10651
Role-Agent: デュアルロール進化によるLLMエージェントのブートストラッピング
問題設定
インタラクティブタスクにおけるRL을用いたLLMエージェントの訓練には、構造的なボトルネックが二つあります。第一に、環境からのフィードバックは一般にスパースかつトラジェクトリレベルであり、エピソード終端の二値成功シグナル(例:ALFWorld、WebShop)では中間の行動に対するクレジット割り当てが行われません。第二に、タスク分布が静的であるため、カリキュラムがエージェントの現在の失敗パターンに適応できず、エージェントはすでに解けるタスクに繰り返し遭遇する一方、一貫して失敗するタスクを十分に探索できません。報酬を密化したりタスクを多様化したりするために合成環境を構築することは、コストが高く脆弱です。
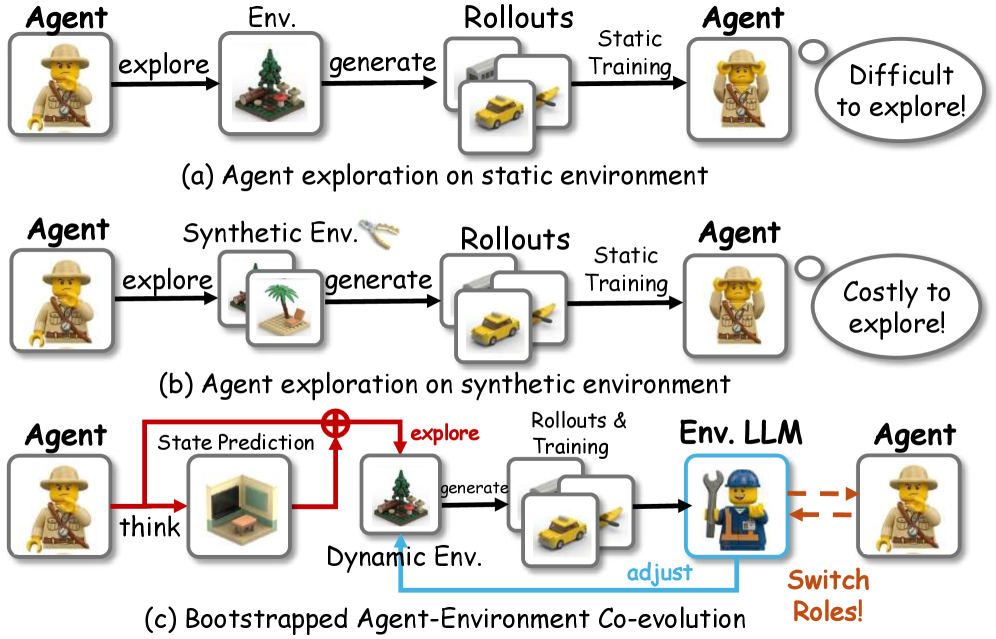
Role-Agentは、一つのLLMがポリシーと環境モデルの両方を担い、二つのロールが訓練を通じて共進化できるという考え方を提案しています。
手法
設定は標準的なスパース報酬MDP、すなわちトラジェクトリ \bm{\tau}=\{(\bm{s}_t,\bm{a}_t,r_t)\}_{t=1}^T を \pi_\theta(\bm{a}_t|\bm{s}_t,\bm{x}) によって生成し、実際の環境からトラジェクトリレベルの報酬 \mathcal{R}^E(\bm{\tau}_i) を得るものです。Role-Agentはこのループの上に二つのコンポーネントを重ねます。
World-In-Agent(WIA):状態予測によるプロセス報酬。 行動 \bm{a}_t を生成する際、エージェントはプロンプトによって次の H ステップの環境状態 \hat{\bm{s}}_{t+1},\dots,\hat{\bm{s}}_{t+H} も予測します。実際のロールアウト後、予測された状態がグランドトゥルースの状態 \bm{s}_{t+1},\dots,\bm{s}_{t+H} と比較され、そのアラインメントスコアがステップごとのプロセス報酬として使われます。具体的には、トラジェクトリレベルのアドバンテージに加えて状態レベルのアドバンテージが与えられるため、policy gradient は世界モデルが崩れたタイムステップにおいてクレジット・ブレームを受け取ります。直感的には、自分の行動の結果を予測できるエージェントは環境を意識した推論を行っているということであり、予測と観測のアラインメントは外部アノテーションを必要としない自己教師あり密シグナルです。
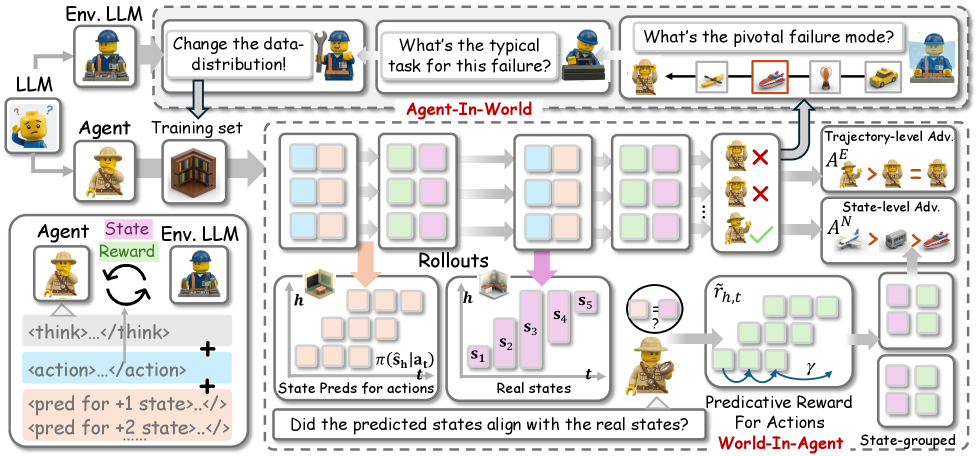
Agent-In-World(AIW):失敗駆動カリキュラム。 ロールアウトのバッチ \mathcal{T}=\{\bm{\tau}_i\} の後、LLMは「環境」としての役割に切り替わり、失敗したトラジェクトリを検査して失敗パターンのテキスト記述(例:サブゴール分解の誤り、前提条件の見落とし、検索のミスマッチ)を生成します。これらの失敗記述子をクエリとして用い、タスクプールから類似の失敗パターンを持つ追加の訓練タスクを検索し、次のバッチの分布を弱点に向けて再形成します。これは、固定された難易度スケジュールではなく、エージェント自身のエラー分析から誘導されるカリキュラムです。
この二つの要素はループを閉じます。WIAは密なステップごとのクレジットを提供することで、エージェントが個々のミスから実際に学習できるようにし、AIWはWIAのgradientが作用できる失敗パターンのインスタンスを次のバッチにより多く含めるようにします。訓練には、WIAの状態レベルアドバンテージで補強されたトラジェクトリレベルアドバンテージ \mathcal{R}^E(\bm{\tau}_i) を用いた標準的なpolicy-gradient更新が使われます。
結果
本論文は三つのタスクファミリーで評価を行っています:ALFWorld(具現化された家庭環境)、WebShop(118万商品を対象とするインタラクティブeコマース)、シングルホップ(NQ、TriviaQA、PopQA)およびマルチホップ(HotpotQA、2WikiMultiHopQA、MuSiQue、Bamboogle)にまたがる検索拡張QAです。報告された主要な数値は、これらのベンチマーク全体で強いベースラインに対して平均4%以上の改善です。
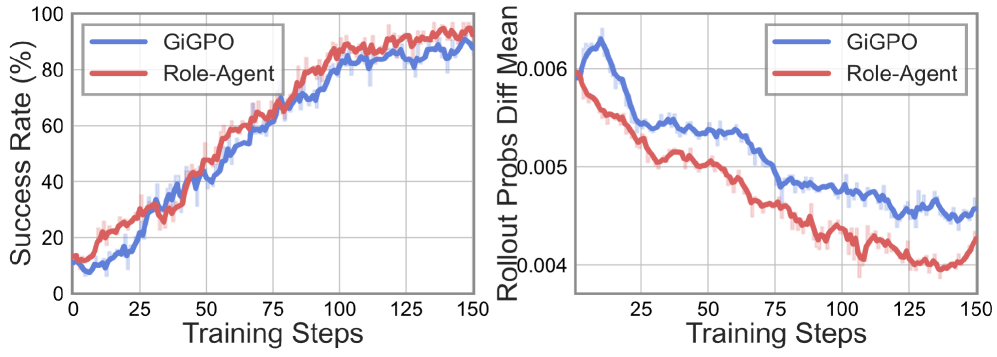
ALFWorldのダイナミクスプロットが最も診断的です。検証成功率はベースラインより速く、より高いプラトーまで上昇し、右パネルでは訓練時と推論時のロールアウト間のギャップが縮小していることが示されています。すなわち、WIAの予測アラインメント報酬は、訓練時にteacher-forcedまたはフィルタリングされたトラジェクトリを使用する場合にエージェントRLを悩ませる訓練・推論の分布ミスマッチを軽減しています。
限界と未解決の問題
本論文として提示された内容では完全には解決されていない問題がいくつかあります。
- 報酬ハッキングのリスク。 同一のモデルを行動と状態予測アラインメントのスコアリングの両方に使うと、自明に満たせる次状態(例:現在の状態のコピー、低エントロピーな記述の予測)を予測するインセンティブが生じます。本論文では、実際の状態との比較以外に、安全策(スコアラーの固定、プロンプトコンテキストの分離、グランドトゥルース観測に対するキャリブレーション)の詳細は述べられていません。
- 失敗パターンクラスタリングの品質。 AIWは、LLMが識別力のある失敗記述子を生成することと、関連する変形例を取得できる十分に密なリトリーバルプールに依存しています。タスクプールが限られたベンチマーク(例:Bamboogleの小規模なセット)では、カリキュラム再形成は機能不全に陥る可能性が高いです。
- ホライズン H のトレードオフ。 予測ホライズンが長いほど密なシグナルが得られますが、モデル誤差が蓄積されます。H の選択とその感度は、示されている抜粋では明らかにされていません。
- 「平均>4%」の汎用性。 集計された改善は、向上が一つのレジーム(例:ALFWorld)に偏っているのか、報酬スパース性のプロファイルが大きく異なるシングルホップQA・マルチホップQA・WebShopにわたって分散しているのかを隠しています。
なぜ重要か
Role-Agentは、モデルベースRLとLLMが出会って以来浮上してきたアイデアの明快な具体化です。すなわち、単一のモデルが環境を十分に模倣してプロセス報酬を生成でき、かつ自身の失敗を診断できるなら、有能なエージェントを訓練するために外部の密報酬環境や手作りのカリキュラムは不要だという考え方です。経験的なシグナル、すなわちALFWorldにおける訓練・推論ロールアウトギャップの縮小と、異種ベンチマーク全体にわたる一貫した平均改善は、このself-play的な共進化が、エージェントのpost-trainingに向けたRLHF式アノテーションやコストの高いシミュレータ構築に対して実用的な代替手段であることを示唆しています。
Source: https://arxiv.org/abs/2606.10917
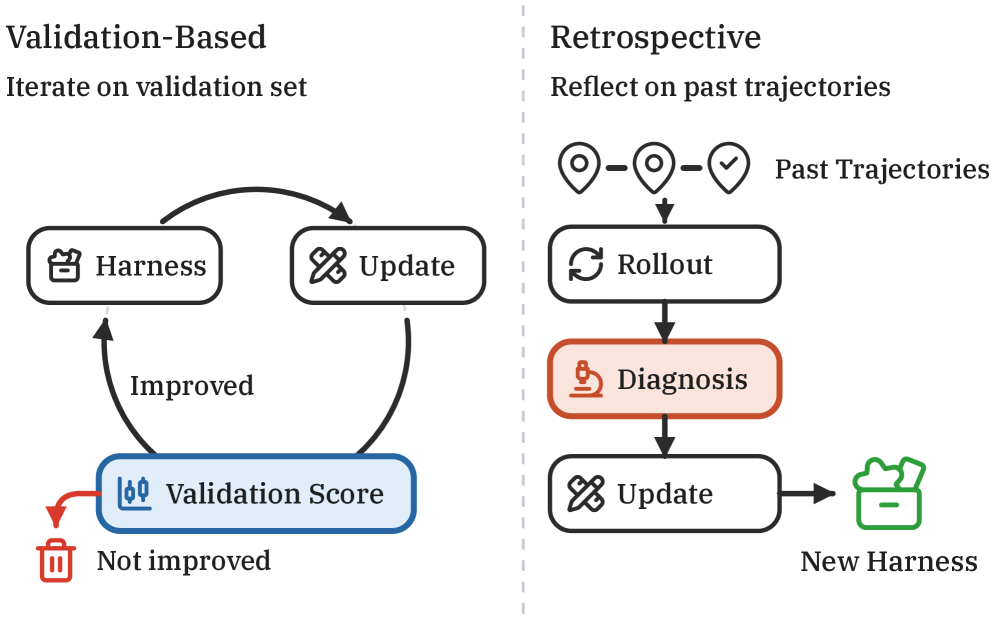
Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
問題設定
実際のエージェント展開では軌跡(trajectory)が蓄積されますが、最適化の対象となるラベル付き検証セットを持つことはほとんどありません。既存のharness最適化手法——エージェントのツール、スキル、プロンプトを反復的に改良する手法——は通常、採点済みの検証分割へのアクセスを前提としていますが、これは本番環境では非現実的です。本論文は、エージェントが過去のrolloutのみを用いて(正解ラベルなしで)自己教師的にharnessを改善できるかどうかを問います。
形式的には、harness h(ツール、プロンプト、スキル)とタスク t が与えられたとき、エージェントは軌跡 \tau = \mathrm{solve}(h, t) を生成します。最適化の目標は
h^\star = \arg\max_{h'}\; \mathbb{E}_{t,\, \tau \sim \mathrm{solve}(h', t)}\,[U(t, \tau)],
であり、U は直接評価できない潜在的な効用です。RHOは U の代わりに、同一バックボーンが同一タスク上の軌跡を比較するself-preferenceの推定器 \mathrm{rank}(t, \tau_1, \dots, \tau_m) ——軌跡間のペアワイズ比較——を用います。
手法
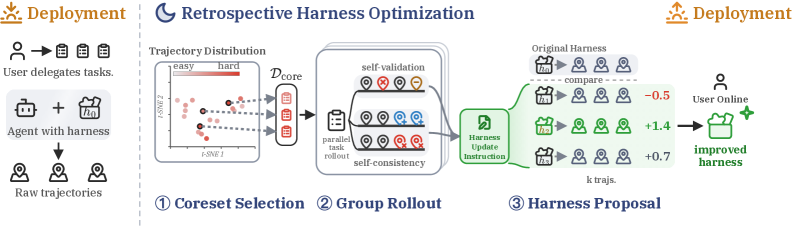
RHOは、外部の採点器なしに単一のバックボーン(ここではCodexエージェント経由のGPT-5.5)のみで駆動される、シングルラウンド・3段階パイプラインです。
Stage 1: Coresetの選択。 言語モデルのjudgeが過去の各軌跡 \tau_i に対して難易度スコア r_i を付与し、テキスト形式の診断を出力します。診断結果はembeddingされ、ペアワイズのコサイン類似度 S_{i,j} が計算されます。RHOはカーネルが
K = \mathrm{diag}(\widetilde{r})\, S\, \mathrm{diag}(\widetilde{r}), \qquad \widetilde{r}_i = \left(\frac{\max(r_i, \epsilon)}{\max_j \max(r_j, \epsilon)}\right)^{\alpha}, \quad \alpha = \frac{\theta}{2(1-\theta)}
であるDeterminantal Point Process(DPP)を用いて軌跡をランク付けします。指数 \alpha は難易度と多様性のトレードオフを制御し、\theta=1 では純粋に難易度でランク付け、\theta=0 では純粋に多様性でランク付けされます。本手法では \theta=0.7、k=10 を使用します。貪欲なDPP選択によって \mathcal{D}_{\mathrm{core}} が選ばれます。
Stage 2: グループrollout。 coresetの各タスクを現在のharness h_0 のもとで G=3 回並列に解き直します。タスクごとに2種類の診断シグナルが抽出されます。self-validationランキング(軌跡内のエラー解析)とself-consistencyランキング(失敗モードを示す可能性のある軌跡間の不一致)です。rolloutの1つが下流の比較のためのベースライン \tau_t^{(0)} として固定されます。
Stage 3: Best-of-N harness提案。 診断シグナルを条件として、オプティマイザは N=3 個の候補harnessを生成します。各候補が実行され、そのrolloutが同一のself-preferenceランカーを用いてベースラインとペアワイズで比較されます。rolloutが最も好まれた候補が h^\star として保持されます。
重要な設計上のポイントとして、harnessは実行可能なスクリプト(ツール)、スキルファイル(採点器・環境の特異性の記録)、命令ファイル(手続き的ルール)を含む設定可能なワークスペースフォルダです。オプティマイザは新しいツールを記述でき、単にメモリに追記するだけではありません——これはDynamic Cheatsheet、ReasoningBank、Sleep-time Computeといったメモリ拡張ベースラインよりも厳密に大きな行動空間です。
結果
ベースエージェントは高い推論努力設定のGPT-5.5を用いたCodexです。ベンチマークはSWE-Bench Pro(リポジトリレベルのSWE)、Terminal-Bench 2(実行可能な採点器を持つCLI)、GAIA-2(非同期知識作業)にまたがります。各ベンチマークは、RHOのシードとして使用される軌跡セットとホールドアウトテストセットに分割されます。
主な結果として、RHOの単一ラウンドがSWE-Bench Proの合格率を59%から78%へと——検証採点なしで——絶対値19ポイント向上させました。3つのベンチマークすべてにわたって、RHOは一貫した改善をもたらした一方、フィードバックフリーの3つのベースライン(Dynamic Cheatsheet、ReasoningBank、Sleep-time Compute)は、同等のエージェント呼び出し予算でより小さく一貫性の低い改善にとどまりました。著者らはこのギャップを、(i) より広い編集空間——メモリだけでなくツールとスキルの追加——と、(ii) 候補harnessに対するペアワイズself-preferenceの安定化効果に帰しています。
生成されたスキルファイルのほとんどは採点器・環境の回避策(例:過去に失敗を引き起こした既知の特異性)であり、RHOの改善が抽象的な推論パターンではなく、各ドメインの評価サーフェスをエージェントが学習することから主に得られていることを示唆しています。
限界と未解決の問題
- Self-preferenceはバックボーンのバイアスを継承します。あるドメインでランカーが冗長だが誤った軌跡を系統的に好む場合、RHOはそのモードに向けて最適化してしまいます。これを検出するための外部アンカーは存在しません。
- 報告されているのは単一の最適化ラウンドのみです。マルチラウンドのダイナミクス、self-rankerに対するreward hacking、harnesのドリフトは特徴付けられていません。
- coresetサイズ k=10、G=3、N=3 は固定されており、これら(および \theta=0.7)に対する感度は本文中で示されていません。
- スキルファイルには採点器の特異性が蓄積されるため、SWE-Bench Proでの改善がどの程度ベンチマーク固有のキャリブレーションを反映しているのか、あるいは転用可能な能力を反映しているのかという疑問が生じます。ベンチマーク間の転移研究がこれを明らかにするでしょう。
- 本手法は信頼できるself-validationが可能なフロンティア級のバックボーンに依存しており、より弱いモデルでの結果は報告されていません。
なぜこれが重要か
RHOは、十分に強力なバックボーンが自身のrolloutをランク付けすることで検証フィードバックのギャップの有用な部分を埋めることができ、ラベル付きデータなしでエージェントの展開を自己改善システムへと変えられることを示しています。1回の振り返りパスによるSWE-Bench Proでの59%から78%への跳躍は十分に大きく、self-preferenceバイアスが監視されることを条件として、harness自己最適化が本番エージェントループの現実的な構成要素となりえます。
Source: https://arxiv.org/abs/2606.05922
MemDreamer: 階層的グラフメモリとエージェント的検索機構による知覚と推論の分離を通じた長時間動画理解
問題
数時間にわたる動画理解は、エンドツーエンドVLMにおける二つの複合的な失敗モードによってボトルネックが生じています。すなわち、トークン爆発(1 fps・フレームあたり256 tokenで1時間の動画を処理すると約9.2 \times 10^5 tokenになる)と、attention dilution(関連するフレームが無関係なコンテキストに埋もれてしまう現象)です。既存の対策として、一様なサブサンプリング、token圧縮、スライディングウィンドウによる要約が挙げられますが、これらはいずれも細粒度の時空間的証拠を破棄してしまい、さらに同一のモデルに知覚(フレームに何が写っているか)と推論(どの証拠がクエリに答えるか)の両方を強いることになります。MemDreamerの主張は、これらを分離すべきだというものです。すなわち、知覚フェーズのパスで動画を構造化されたメモリに蒸留し、推論フェーズではエージェントが必要なものだけを取得するという設計です。
手法
MemDreamerは2段階のプラグアンドプレイなパイプラインです。
Hierarchical Graph Memory (HGM). 動画はインクリメンタルにストリーミングされ、三層のトップダウン構造に抽象化されます。
- 基礎グラフ G_0 = (V_0, E_0):ノード v \in V_0 はクリップレベルのフレームに基づいたエンティティ・イベントであり、エッジは空間的(共起、相対位置)、時間的(先後関係、継続時間)、因果的(行動 \to 効果)の三種類の関係をエンコードします。各ノードはmultimodal embeddingとテキスト記述子を保持します。
- 時間的連続性と意味的類似性によるクラスタリングで G_0 のサブグラフを集約した、シーン・エピソードノードの中間層。
- 中間層のグループを要約するナラティブレベルの抽象(章・テーマ)のトップ層。
層間のエッジは包含(親子)リンクであり、層内エッジは論理的構造を保持します。構築はインクリメンタルに行われ、入力される各クリップが V_0 を拡張し、影響を受けるサブツリーのみの再クラスタリングをトリガーするため、メモリ構築コストは動画の長さに対してほぼ線形にスケールします。
エージェント的ツール拡張検索. 推論時には、推論LLMがHGMに対してObservation-Reason-Action(ORA)ループを実行し、以下のようなツール群を使用します。
navigate(tier, node_id)— 階層を上下に移動する。search(query, tier)— 指定した層内でのセマンティックなノード検索。traverse(node_id, edge_type)— 空間・時間・因果エッジを辿る。inspect(node_id)— 葉ノードのグラウンドされたフレーム・領域を取得する。
各ORAステップでは、観測(ツール出力)がエージェントコンテキストに追記され、エージェントは answer を発行するまで推論トレースと次の行動を出力し続けます。重要なのは、取得されたノードのみが推論コンテキストに入力され、動画全体は入力されない点です。論文によれば、推論コンテキストはフルコンテキスト取り込みの約2%に制限されており、これがattention dilutionに直接対処しています。
この分離は次のように要約できます。
P(a \mid V, q) \;=\; \sum_{S \subseteq \text{HGM}(V)} \pi_\theta(S \mid q,\,\text{HGM}(V))\, p_\phi(a \mid S, q),
ここで \text{HGM}(V) は動画ごとに一度構築され(知覚)、\pi_\theta は取得サブグラフ S に対するエージェントポリシー、p_\phi は S のみを条件とする推論器です。実際には、エージェントがコミットした単一のトラジェクトリで和を近似します。
結果
四つの主要な長時間動画ベンチマーク全体でフレームワークはSOTAに達しており、人間の専門家との差を3.7ポイントにまで縮めたという主要な主張があります。最も有益なablationはコンテキストバジェット比較であり、フルコンテキストベースラインが取り込むtokenの約2%に推論を制限することで、そのベースラインに対して絶対精度で12.5ポイントの向上が得られています。これが知覚・推論分離の中心的な実証的証拠であり、「コンテキストが少ないほど精度が高い」という結果は、支配的な失敗モードが情報の欠如ではなくattention dilutionであることと整合しています。
統計解析から得られた二次的な知見として、VLMの純粋な論理推論ベンチマークのスコアとHGMと組み合わせた場合の長時間動画理解スコアの間に、強い正の線形相関があることが示されています。これは、知覚がメモリにオフロードされると、長時間動画QAがグラフ上のマルチホップシンボリック推論に帰着し、推論モデルの進歩が直接転用できることを示唆しています。
限界とオープンな問題
- HGMの品質は、エンティティ・関係、特に因果エッジの抽出に用いる知覚モデルに上界されます。動画からの因果抽出は依然として不安定であり、知覚モデルを差し替えた場合の感度については詳細が報告されていません。
- エージェント的検索は可変のレイテンシをもたらし、エージェントのツール使用能力に依存します。エージェントがループしたり早期に終了したりする場合の失敗モードは特性化されていません。
- 「フルコンテキストの2%」という比較は、二つの効果を混在させています。すなわち、コンテキストの小ささと、構造化された(グラフから取得された)コンテキストの効果です。これを分離するには、例えば階層なしの密な検索によって2%のフレームを選択するベースラインが必要です。
- 3.7ポイントの人間とのギャップはベンチマーク固有のものです。複数の因果エッジを組み合わせる必要がある長末尾の時間的・因果的質問でエラーが集中しやすいと考えられますが、質問タイプ別の詳細な分析が必要です。
- メモリ構築コストが償却されるのは、同一の動画が複数回クエリされる場合のみです。シングルクエリのストリーミングでは、フルコンテキストやtoken圧縮手法の方がまだ好ましい場合があります。
なぜ重要か
構造化された階層的メモリを介して知覚と推論を分離することで、長時間動画理解をグラフに基づくマルチホップ推論に変換できます。これはattention dilutionを回避するとともに、推論LLMの進歩を動画QAの向上に直接転用することを可能にします。2%のコンテキストバジェットで12.5ポイントの向上という結果は、数時間にわたる動画においては、より長いコンテキストウィンドウではなく構造に対する検索こそが適切な帰納バイアスであるという強力な証拠です。
Source: https://arxiv.org/abs/2606.07512
Hacker News Signals
FrontierCode:実際にコードをマージするかどうかを測定するeval
Cognition AIのFrontierCodeベンチマークは、コーディングevalにおける特定のギャップに対処しています。SWE-benchのような既存のベンチマークは、エージェントがテストをパスするdiffを生成できるかどうかを測定するものであり、生成されたコードがマージに足る本番品質かどうかを測定するものではありません。この区別は重要です。なぜなら、テストをパスすることは必要条件ではあっても十分条件ではないからです——ソリューションが期待出力をハードコードしたり、テストケースを削除したり、微妙なリグレッションを導入したり、技術的にはハーネスを満たしながらも読めないスパゲッティコードを生成したりする可能性があります。
FrontierCodeは実際のリポジトリからタスクを構築し、より豊富なルーブリックで提出物を評価します。すなわち、実装が既存の規約に従っているか、明示的にテストされていないエッジケースを処理しているか、不必要な複雑さを避けているか、周囲のコードとクリーンに統合されているかという点を評価します。このevalでは、人間のエンジニアの判断をground truthシグナルとして使用します——レビュアーは同僚の成果物に対するのと同じ基準を適用し、そのPRを実際に承認するかどうかを評価します。
機械的なセットアップとしては、非自明なマルチファイル編集を必要とするタスクをサンプリングし、エージェントのソリューションをまず自動テストにかけ(必要ではあるが十分ではないゲーティング)、その後サバイバーを人間によるレビューにルーティングします。この二段階パイプラインにより、明らかに壊れた提出物にレビュアーの時間を無駄遣いすることを避けつつ、最終的な指標が実際のマージ準備状況を反映することを保証します。
実際的な意義として、FrontierCodeのベンチマークスコアは、同一モデルに対するpass@kテストベースのevalよりも大幅に低くなっており、これは現在のリーダーボードの数値がデプロイ準備状況を過大評価していることを示唆しています。「テストがパスする」と「自分ならマージする」の間のギャップは、AIが生成したコードによる技術的負債の蓄積を定量化するものです——このコストはCIの失敗ではなく、メンテナンス負荷として現れます。
未解決の問題としては、人間レビュアー間の評価者間信頼性、スタイルと正確性に関する意見の相違をどう扱うか、そしてスケールでのコスト削減のためにトレーニングされたreward modelを使ってevalを部分的に自動化できるかどうかが挙げられます。
Source: https://cognition.ai/blog/frontier-code
FPGAにおけるKolmogorov-Arnold Networksを用いた超高速機械学習
本稿では、素粒子物理学検出器における超低遅延推論のために開発されたHigh-Level SynthesisワークフローであるHLS4MLを用いて、Kolmogorov-Arnold Networks(KAN)をFPGA上に実装する方法を探ります。主な魅力は、KANがMLPの「行列演算後に活性化」という構造を、学習可能な一変数スプライン関数をエッジに持つ形に置き換えている点にあり、これはFPGAのルックアップテーブルとより自然にマッピングできます。
アーキテクチャの変換は以下のように行われます。各KANエッジはB-splineの基底展開を計算します:入力 x が与えられると、エッジの出力は \sum_i c_i B_i(x) となります。ここで B_i はB-splineの基底関数、c_i は学習済み係数です。FPGA上では、各基底関数の評価はLUTまたはBRAMのルックアップとなり、重み付き和は小さなアキュムレータチェーンで実現されます。いずれもFPGAプリミティブの観点から低コストです。一方、MLP層は行列演算にDSP48乗算器を必要とし、これは希少なリソースです。
実装はHLS4MLの既存のスプラインプリミティブを使用し、KAN層の構造をラップして合成可能なVHDL/Verilogを生成します。Xilinx Ultrascale+上でのレイテンシベンチマークでは、推論が数十ナノ秒のオーダーを示しており、これはコライダー実験におけるLevel-1トリガーの要件と一致しており、同等の精度を持つMLPと比べてDSPの使用量も少なくなっています。
トレードオフとして、DSPではなくLUTとBRAMへのリソース負荷が増加します。スプラインが多用される小規模モデルではこれは有利ですが、大規模なネットワークではLUTの枯渇がボトルネックになります。また、KANの学習はMLPの学習よりも遅く不安定であるため、推論時のFPGA効率の向上は、オフライン学習ステップのコスト増大を伴うとも指摘されています。
これはニッチですが技術的に洗練されたアプローチです:FPGAを汎用アクセラレータとして扱うのではなく、新しいアーキテクチャクラスの構造的特性を活用してFPGAのリソース異種性を利用しています。
Source: https://aarushgupta.io/posts/kan-fpga/
macOS Container Machines
AppleのGitHub上のcontainerプロジェクトに、Virtualization.frameworkを基盤として軽量なLinux VMをmacOS上にプロビジョニングするcontainer machineサブコマンドが追加されました。container-machine.mdのドキュメントには、そのアーキテクチャが説明されています。各マシンはAlpineベースの最小限のLinuxゲストであり、コンテナのライフサイクル管理のためにホストへgRPC APIを公開する軽量なinitが動作しています。ホスト側のCLIはこのAPIと通信し、コンテナの作成・起動・停止・execを行います。
重要な技術的選択が、本プロジェクトをDocker Desktopと差別化しています。macOS側に常駐するデーモンプロセスは存在せず、VMそのものがデーモンとして機能し、ホストのCLIはvsock(virtioソケット)チャネルを介して接続します。vsockはネットワークインターフェースの設定を必要としないVM-ホスト間通信プリミティブを提供するため、Docker Desktopでポートフォワーディングの問題を引き起こすNATレイヤーの複雑さが排除されます。VM内部のコンテナネットワーキングは標準的なLinuxブリッジを使用し、ホストからコンテナへのトラフィックはvsockフォワーディングされたAPIを通じて、またはポートマッピングによって公開されます。
ファイルシステムの共有には、AppleのVirtualization.frameworkがネイティブにサポートするLinuxのvirtioベースのファイルシステムプロトコルであるvirtiofが使用されています。そのため、パフォーマンス特性は、旧来のVMベースのDockerセットアップで使用されていた9pプロトコルと比較して、ネイティブに近いものとなっています。
マシンイメージは再現可能であり、containerバイナリと並んでバージョン管理されています。これにより、VM環境は変更可能な永続的VMではなくinfrastructure-as-codeとして扱われます。この設計は、内部のLinux VMに変更が蓄積されていくDocker Desktop環境で一般的な状態ドリフトの問題を回避します。
未解決の課題としては、マルチマシントポロジーの扱い方(compose的なユースケースに関連)、Apple SiliconにおけるDocker Desktopと比較したオーバーヘッドのプロファイル、およびvsockベースのアプローチがデータパイプラインコンテナのような高帯域幅ワークロードに対してスループットの上限を課すかどうかが挙げられます。
Source: https://github.com/apple/container/blob/main/docs/container-machine.md
Grep さえあれば十分か?Agent ハーネスの選択がAgentic Searchの性能を左右する
このarXiv論文は、コーディングや検索タスクを担うagentに与えられる検索ツールが、基盤となるLLMそのものよりも性能を左右するかどうかという問いに取り組んでいます。実験的な結論は「yes」であり、しかもその影響度はこれまで十分に認識されていなかったほど大きなものです。著者らはいくつかのagentフレームワークを検索負荷の高いタスクで評価し、grep/ASTベースの厳密検索とembeddingベースのsemantic searchを入れ替えると、タスク成功率が同一ハーネス内でのモデル間差異を上回る幅で変化することを示しています。
そのメカニズムは、agentがどのように失敗するかに起因します。agentic loopにおけるLLMは、自身が見つけると予期している語彙に構文的に近いクエリを発行しがちです。これがgrepの強みです。一方、semantic searchはagentが用語のギャップを埋める必要がある場面で有効ですが、偽陽性(false positive)を引き起こしてマルチステップの推論チェーンを破綻させることがあります。論文では「最初の検索結果における検索精度(search precision at first result)」を計測してタスク完了率と相関させており、軌跡の早い段階での高精度な検索がタスク成功の支配的な予測因子であることを示しています。
論文ではさらに、著者らが「ハーネス・ロックイン(harness lock-in)」と呼ぶ現象を特徴づけています。これは、ある検索インターフェースでトレーニングまたはプロンプティングされたagentが、インターフェースが変わると性能が低下するという現象であり、基盤となるデータが同一であっても起こります。この結果は、agentが汎用的な検索戦略ではなく、検索ツール固有のアフォーダンスを学習していることを示唆しています。
副次的な知見として、検索ツールを増やすこと(grep + semantic + ASTナビゲーションをすべて同時に使用すること)が一様に性能を向上させるわけではないことも示されています。ツールの選択肢が多すぎるagentは、ツール選択に費やす軌跡ステップ数が増加し、結果のばらつきも大きくなります。これは「ツール過多コスト(tool proliferation tax)」と言えます。
システム設計への示唆として、検索ツールの選択はagentのデプロイにおける一級のハイパーパラメータとして扱われるべきであり、後付けの考慮事項であってはならないという点が挙げられます。また、ベンチマーク設計においても、モデルとツール構成の貢献を混同して集約するリーダーボードではなく、ハーネスで層別化した評価が求められることを本論文は主張しています。
Source: https://arxiv.org/abs/2605.15184
Apple Core AI フレームワーク
AppleのCoreAIは、SDKレベルで表面化した新しい統合フレームワークであり、これまで分散していたML推論パス(CoreML、ANEスケジューリング、オンデバイスモデル管理)を単一のAPIサーフェスに統合します。開発者向けドキュメントには、モデルのメタデータおよび現在のハードウェアの可用性に基づいて適切なコンピューティングバックエンド(ANE、GPU、CPU)にディスパッチする標準化された perform(_:) async メソッドを持つ Model プロトコルが記載されています。
技術的に最も注目すべき追加機能は AdaptableModel であり、ベースモデルの重みをアプリケーションに公開することなく、adapter(LoRAスタイルの重みデルタ注入)を通じたオンデバイスfine-tuningをサポートします。adapterの重みはアプリケーションのサンドボックスに保存され、ベースモデルはシステムが管理するストアに置かれます。このアーキテクチャはプライバシー境界を強制しながらパーソナライゼーションを実現します。ベースモデルはアプリのアドレス空間にマッピングされることがないため、悪意あるアプリによる抽出が不可能です。
また、GenerativeModel という抽象化も提供されており、AsyncSequenceを介したバックプレッシャー処理を備えたストリーミングトークン生成インターフェースを実現しています。これにより、Swiftアプリケーションがバックエンドが量子化されたオンデバイスモデルであるかプロキシされたクラウドエンドポイントであるかを意識することなく、テキスト生成を標準的な方法で利用できます。この抽象化は呼び出し側に対して透過的です。
スケジューリングの詳細についてはドキュメントの記述が乏しく、プロセスをまたいだ複数のCoreAIモデルリクエストがANEでどのように調停されるか、またはバックグラウンドのfine-tuningパス実行中に優先度の高いフォアグラウンド推論リクエストが到着した場合のプリエンプション遅延がどの程度かはまだ明確ではありません。複数のアプリが同時にCoreAIを使用した場合のAシリーズチップ上でのリソース競合の挙動は、未解決のエンジニアリング課題です。
これは能力の飛躍というよりもインフラ整備の取り組み——断片化したAPIサーフェスの統一——ですが、統合されたインフラこそがサードパーティ開発者がAppleデバイス群全体で信頼性の高いオンデバイスML機能を提供できるようにする基盤となります。
Source: https://developer.apple.com/documentation/coreai/
Grit: エージェントを用いたGitのRustによる書き直し
GitButlerのGritプロジェクトは、GitのコアをRustで書き直す試みであり、その実装の大部分を人間が一行一行書くのではなく、LLMコーディングエージェントが担うという点に特徴があります。このブログ投稿は、大規模なエージェント支援システムプログラミングから何が見えてくるかについて、率直に語っています。
技術的な内容としては、Gitのデータモデル(オブジェクト、ref、packfile、index)が互換性を保つため同一のオンディスクフォーマットに対して再実装されています。Rustによるこの実装が目標とするAPIカバレッジはlibgit2レベルであり、CLIの完全な置き換えではありません。チームはgitoxideをリファレンスおよび部分的な依存として利用しているため、ゼロから始めているわけではありません。
より興味深いエンジニアリング上の知見はエージェント固有の観察にあります。エージェントは自己完結していて仕様が明確なサブ問題、たとえば特定のオブジェクト型パーサーの実装、デルタエンコード・デコードルーティンの作成、仕様に基づくプロパティベーステストスイートの生成などに対してはうまく機能します。一方で、モジュール境界をまたぐ横断的な関心事、すなわちモジュール境界をまたいだ不変条件の維持、Rustの所有権グラフを通じたエラー型変更の伝播、コードベース全体をコンテキストとして保持しながら行う必要のあるアーキテクチャ上の意思決定といった場面では、予測可能な形で失敗します。
この投稿では、人間のエンジニアがインターフェースの契約とモジュール境界、すなわちRustにおける型シグネチャとtrait定義を書き、エージェントが実装を埋めるというワークフローが説明されています。こうすることでRustの型システムがエージェントのエラーを機械的に検出する検証レイヤーとして機能し、人間によるレビューの負担が「全行が正しいか」ではなく「インターフェースは意味をなすか」という確認に絞られます。
これは特定の言語の型システムの特性に根ざした、人間とエージェントの具体的な役割分担の説明であり、AIを活用したコーディングに関する議論の多くと比べて、より技術的な根拠を持っています。
Source: https://blog.gitbutler.com/true-grit
AppleがGoogle Geminiモデルを中核とした新しいAIアーキテクチャを公開
WWDC 2026の資料を通じて明らかになったこのアーキテクチャの開示では、Apple Intelligenceの改訂されたバックエンドが説明されています。具体的には、レイテンシおよびプライバシーに敏感なリクエストに対してデバイス上での推論(CoreAI/ANE経由で動作するApple独自の3Bクラスのモデルを使用)を行い、デバイス上の能力閾値を超えるリクエストに対してはGoogle Geminiモデルへのクラウドエスカレーションを行う構成です。これは以前のアーキテクチャ、すなわちAppleが独自に訓練したサーバーサイドモデルをクラウド層として使用するPrivate Cloud Computeインフラを置き換えるものです。
技術的に興味深いのはルーティングロジックです。このシステムはリクエストを2つの軸で分類します。センシティビティ(デバイス外に出すべきでない個人データが含まれるか)と能力(デバイス上のモデルが許容できる品質でこれを処理できるか)です。高センシティビティのリクエストは品質の低下に関わらずデバイス上に留まります。低センシティビティかつ高複雑性のリクエストは、Appleが運用するAPIプロキシ経由でGeminiにエスカレーションされ、そのプロキシが転送前に識別可能なメタデータを除去するというプライバシー上の特性が明示されています。このプロキシアーキテクチャが決意ある攻撃者に対して実質的なプライバシー保証を提供できるかどうかは、まだ公開されていない実装の詳細に依存します。
デバイス上のモデル層は構造的に変化していません。パラメータ数3B、INT4量子化、ANE上でスケジューリングされ、典型的な補完に対してレイテンシターゲットは50〜100msの範囲です。変更はクラウドフォールバックのみです。
Appleが行うエンジニアリングのトレードオフは以下の通りです。フロンティアモデルの能力をGoogleにアウトソーシングすることで、大規模なサーバーサイドモデルを運用するためのインフラ投資を回避できます。しかし、直接の競合他社へのサプライチェーン依存を生み出し、「デバイスから外に出ない」という主張よりも明確に成立させにくいプライバシーの論拠を抱えることになります。技術的に優れた構成を持つPrivate Cloud Computeの認証モデルは、サードパーティのクラウドプロバイダーには直接的には適用できません。
Source: https://www.macrumors.com/2026/06/08/apple-reveals-new-ai-architecture/
AIロックスター開発者の後始末
この投稿は、積極的なAI支援による機能開発期間の後にコードベースを保守するという実践者の体験談であり、そこから技術的な観察を抽出する価値があります。
繰り返し見られるパターン:AIが生成したコードは、既存の抽象化を無視したり重複させたりしながら、局所的には正しいソリューションを生み出す傾向があります。著者は、日付フォーマット、HTTPリトライロジック、入力バリデーションなど、同一ユーティリティの複数の並列実装を発見したことを記録しています。これは、各呼び出し時のエージェントが既存の実装を見つけて再利用するための十分なコンテキストを持っていなかったか、既存の実装がretrievalによって表面化されなかったためです。これはモデルの品質の問題であると同時に、RAG/context windowの問題でもあります。
第二のパターン:エージェントが生成するエラーハンドリングは浅いです。例外を飲み込むtry/catchブロック、空のコレクションをサイレントに返すfallback、そしてasync境界を越えたエラー状態の伝播の欠如が見られます。テストは通常ハッピーパスを検証するため、これらはテストの失敗を引き起こしません。そのため、潜在的な信頼性の技術的負債として蓄積されていきます。
この投稿では、体系的なレビュープロセスについて説明しています:静的解析ツール(言及されている具体的なものは、カスタムルールを適用したESLintとTypeScriptのstrict-nullチェックパス)を実行して、エージェントがベースラインを上回る割合で生成する問題のカテゴリを表面化させるというものです。これは、AI固有のlintingルールセット——人間のプログラマーの失敗モードではなく、コード生成の失敗モードに合わせてチューニングされたもの——が、実践的な緩和レイヤーになり得ることを示唆しています。
メタな観察として、エージェントが開発ループに入るとコード速度とコード品質が乖離し、そのギャップはコミット速度やテストの合格率には現れず、レビューの徹底度と長期的な保守コストにのみ現れるということです。これは測定の問題です:開発者の生産性を評価するために使われる指標が、蓄積されつつある負債を捉えられていないのです。
Source: https://www.codingwithjesse.com/blog/rockstar-developers/
注目の新しいリポジトリ
anthropics/defending-code-reference-harness
Anthropicによる、防御的利用を目的とした攻撃的セキュリティスキルのリファレンスコレクションです。脅威モデリング、静的・動的スキャン、脆弱性トリアージ、パッチ生成をカバーしています。このリポジトリはハーネスとして構成されており、個々のスキルモジュールを組み合わせて自律的なスキャンパイプラインを構築し、コードベースに向けてステップごとの人間の介入なしに実行できます。各スキルは独立してカスタマイズ可能なため、チームはオーケストレーションのスキャフォールディングを維持しながら、独自のスキャナーや社内トリアージのヒューリスティクスに差し替えることができます。この設計は、Claudeクラスのモデルと構造化されたtool-useループを組み合わせるパターンを反映しており、スキルが構造化された発見事項を出力し、トリアージスキルが深刻度と悪用可能性でフィルタリングし、パッチスキルが修正案を提案するという流れになっています。実用的に注目すべきはホワイトボックス・スキャンのパスで、コンパイル済みアーティファクトではなくソースを取り込みます。ハーネスはCI統合のためのフックも公開しています。LLMを活用したコードレビューの大規模導入を評価しているセキュリティエンジニアリングチームにとって、単なるAPIラッパーではなく、具体的で実用的な出発点となります。5,000以上のスター獲得は、自律スキャンパターンに対するコミュニティの高い関心を示しています。
Source: https://github.com/anthropics/defending-code-reference-harness
hadriansecurity/OpenHack
OpenHackは、ソースコードを起点としたホワイトボックスセキュリティレビューのために設計された、軽量なファイルベースのワークスペースです。GUIをラップしたりデータベースバックエンドを必要とするのではなく、プレーンファイルで動作します。発見事項、メモ、コードアノテーションはバージョン管理ツールがネイティブに理解できるディレクトリ構造の中に格納されます。「ソースガイド型」というフレーミングは、レビューのフローがブラックボックスHTTPファジングではなくソースコードのエントリポイントから始まることを意味しており、ワークフローをデータフロー・制御フロー分析に向けてシフトさせます。このツールは、手動監査においてカバレッジを追跡する低摩擦な環境を求めるセキュリティエンジニアを対象としています。関数をレビュー済みとしてマークし、特定の行に発見事項を紐付け、レポートをエクスポートする機能を備えています。すべてがテキストとファイルで構成されているため、grep、ripgrep、および静的解析パイプラインと自然に組み合わせられます。クラウド依存もテレメトリも存在しません。SaaSツールの利用が禁止されているセンシティブなコードベースに対してセキュリティアセスメントを行うチームにとって、ファイルベースモデルは真のアーキテクチャ上の優位性となります。このプロジェクトはまだ初期段階ですが、その設計思想——最小限の状態、コンポーザブル、監査可能——により拡張が容易です。
Source: https://github.com/hadriansecurity/OpenHack
wanghuan9/skill-manager (SkillDock)
SkillDock は、AIスキルおよびModel Context Protocol (MCP) サーバー向けのパッケージマネージャースタイルのツールです。このツールが解決しようとしているコアな問題は、急増するLLMのtool-useプラグインエコシステムに対するライフサイクル管理の欠如です。すなわち、スキルのインストール、バージョン固定、アップデート、またはローカルの変更をアップストリームの変更と比較(diff)するための標準化された手段が存在しないという問題です。SkillDock は、各スキルやMCPサーバーをGitで追跡されるアーティファクトとして扱うことで、このギャップを埋めます。技術的に興味深い点は「Git-aware update」メカニズムです。これはローカルの作業ツリーをアップストリームのリモートと比較し、ローカルのカスタマイズとアップストリームの変更との間のコンフリクトを検出し、選択的にアップデートを適用します。これはスキルのペイロードに対する git fetch + git merge に相当する操作です。これにより、スキルをフォークしてカスタマイズしているチームがアップデート時に変更を気づかずに失うことがなくなり、アップストリームのセキュリティパッチはマージ前にレビューできるようになります。MCPサーバー管理の側面では、サーバーの登録、設定、およびプロセスのライフサイクル管理を担います。多くのtool-use integrationを持つマルチエージェントパイプラインを運用している場合、SkillDock は手動のファイル管理やアドホックなスクリプトでは対処しにくい実際の運用上の複雑さを解消します。
Source: https://github.com/wanghuan9/skill-manager
Liu-Ming-Yu/alpha-forge
Alpha Forgeは、システマティックトレーディング向けのagentic AI オペレーティングシステムを標榜しています。技術的な構造は、データ取り込み、シグナル生成、バックテスト、注文管理を、構成可能かつオーケストレーションされたステージとして調整するエージェントループを中心に構築されています。「オペレーティングシステム」という枠組みは、エージェント間でのリソーススケジューリングを意味しており、複数のアルファ生成戦略を同時に実行し、計算資源を競い合い、ライブまたはシミュレーション上のパフォーマンス指標に基づいてプロモートまたは終了させることができます。実用的には、クオンツファイナンスにおける研究から本番環境へのデプロイメントパイプラインのための足場を提供しています。研究者が高レベルの仕様でシグナルを定義すると、エージェントがfeature engineering、ハイパーパラメータ探索、ウォークフォワード検証を担当し、システムはアイデアからデプロイされた戦略までの系譜を追跡します。agentic レイヤーにより、手動介入なしにバックテストのフィードバックに応じてシグナルを反復的に改良する能力が加わります。163スターとまだ初期段階にあり、ライブトレーディングへの本番対応には相当の堅牢化が必要になりますが、システマティック戦略開発のための研究プラットフォームとしてはアーキテクチャに一貫性があります。
Source: https://github.com/Liu-Ming-Yu/alpha-forge
Tejas-TA/predikit
Predikitは、学習済みMLモデルとLLMベースのエージェントの間に存在する統合のギャップを解消することを目的としています。問題は具体的です:sklearnパイプライン、PyTorchモデル、またはXGBoostリグレッサーを呼び出す必要があるエージェントは、現状ではそれらのモデルを呼び出し可能なツールとして公開するための手書きのラッパーコードを必要とします。Predikitは宣言的なブリッジを提供します――モデルとその入力スキーマを登録するだけで、Predikitがtool-use互換のインターフェース(関数呼び出しAPIおよびMCPスタイルのツール定義と互換)を自動的に生成します。型の強制変換、入力バリデーション、レスポンスのシリアライゼーションを処理します。これによりボイラープレートが排除され、さらに重要なことに、エージェントに公開されるスキーマがモデルが実際に期待するものと一致することが保証されるため、サイレントな型不一致エラーが減少します。このライブラリはモデル側(定義されたシグネチャを持つ任意のPython callableが対象)およびエージェント側(出力が標準的なtool-callレスポンスフォーマットに準拠)の双方においてフレームワーク非依存であるように見えます。より大規模なエージェントシステムの構成要素として予測モデルをデプロイするMLエンジニアにとって、これは完全なMLOpsプラットフォームを必要とせず、特定の繰り返し発生するペインポイントを解決する、目的に特化したユーティリティです。
Source: https://github.com/Tejas-TA/predikit
rpamis/comet
Cometは、エージェント駆動のワークフローを対象とした、フェーズガード付き自動化ハーネスであり、初期アイデアの取得からアーカイブまでの一連のプロセスをカバーします。「フェーズガード」設計がこのシステムの核心的な機械的アイデアです:ワークフローの各ステージ(仕様策定、計画立案、実行、レビュー、アーカイブ)には明示的な入出力条件が設定されており、次のフェーズが起動する前にそれらの条件を満たす必要があります。これにより、エージェントが検証ステップをスキップしたり、計画が一貫していない状態で実行を開始したりすることを防ぎます——この問題は、単純なエージェントパイプラインでよく見られる失敗パターンです。Cometはこれらのフェーズゲートを中心にスキル構成を構造化しており、個々のエージェントスキルは生の関数として呼び出されるのではなく、事前・事後条件チェックとともに登録されます。ハーネスはフェーズをまたいで状態を追跡するため、再開可能性が実現されています:実行フェーズが失敗した場合、それ以前のフェーズを再実行することなくリトライが可能です。このプロジェクトは、ソフトウェアエンジニアリングおよびビジネスプロセス自動化のユースケースをターゲットとしているようです。1,000以上のスターを獲得しており、相当数の採用実績があります。フェーズガードの抽象化は、監査可能性とロールバックが重要となる長期的なエージェントタスク全般において、独立して有用な概念です。
Source: https://github.com/rpamis/comet
boona13/image-extender
Image Extender は、画像をあらゆる方向に元の境界を超えて拡張するアウトペインティングのためのオープンソースWebアプリケーションです。このパイプラインには、技術的に注目すべき3つの独立したコンポーネントがあります。第一に、生成的補完にはGemini(OpenRouter経由でアクセス)を使用しており、品質の上限はGeminiのインペインティング能力によって決まります。第二に、シームブレンディングには単純なアルファ合成ではなくPoisson blendingを使用しています。Poisson blendingはシーム領域上でLaplace方程式の系を解いて境界をまたぐgradientフィールドを均等化し、可視的なエッジのない測光的に一貫した遷移を生成します。第三に、リクエストごとに3つの候補拡張を生成してピッカーを提示します。これはdiffusion的な生成の確率論的な性質を活用するシンプルながら効果的な方法であり、サンプル間の分散が十分に大きいため、3つのバリアントのうち1つは通常より優れています。スタックは画像処理の数学をPythonバックエンドで処理する標準的なWebアプリです。ローカルGPUなしでアウトペインティングが必要で、SaaSのブラックボックスではなく監査可能なオープンソースのコードベースを望むユーザーにとって、これは実行可能な選択肢です。
Source: https://github.com/boona13/image-extender
DaoyuanLi2816/can-i-finetune-this
このツールは、fine-tuning の実行に数時間を費やす前に、特定の Hugging Face モデルが推論および学習の両方において GPU VRAM に収まるかどうかを判定するという、実践的な事前チェックの問題を解決します。このエスティメータはモデルの識別子と GPU のスペックを受け取り、モデルの重み(対象の dtype)、optimizer の状態(Adam は各パラメータに対して fp32 のモーメントテンソルを2つ保持するため、fp32 でおよそパラメータ数の 3 \times バイトが必要)、gradient バッファ、および指定バッチサイズにおける activation メモリを考慮してメモリ要件を計算します。full fine-tuning、LoRA、または QLoRA が実行可能かどうか、また必要な量子化レベル(4-bit、8-bit、bf16)がどれかを出力します。計算は標準的な算出方式に従っており、P パラメータを持ち dtype 幅が w バイトのモデルに対して、基本的な重みのメモリは Pw となり、Adam による full fine-tuning では fp32 でおよそ 12P バイトが追加されます。このツールは、Hub から取得したモデルの実際の config に基づいてこれらの計算を自動化します。小規模で特化したユーティリティではありますが、特に共有クラスタリソース上でジョブを起動する前に実行不可能な設定を検出することで節約できる時間は確かなものがあります。個々の研究者にとっても、fine-tuning パイプラインにおける CI ステップとしても有用です。
Source: https://github.com/DaoyuanLi2816/can-i-finetune-this