Daily AI Digest — 2026-06-10
arXiv Highlights
Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching Models
Problem
RL fine-tuning of flow matching models (Flow-GRPO, Flow-CPS, GRPO-Guard) treats the K-step denoising process as an MDP and inherits PPO’s ratio-clipping trust region:
r_k(\theta) = \frac{\pi_\theta({\bm a}_k\mid {\bm s}_k)}{\pi_{\theta_{\mathrm{old}}}({\bm a}_k\mid {\bm s}_k)},\quad \mathrm{clip}(r_k, 1-\epsilon, 1+\epsilon).
The authors argue this is structurally wrong for flow models. The per-step policy is Gaussian (the SDE sampler injects fixed-variance noise around the predicted velocity), so the true KL between \pi_{\theta_{\mathrm{old}}} and \pi_\theta is available in closed form. Ratio clipping uses a single-sample stochastic estimate of that divergence as a proxy, which is high-variance: the same true KL can produce ratios well inside or well outside [1-\epsilon, 1+\epsilon] depending on the sampled action. Result: some trajectory regions are over-constrained (gradients masked when divergence is small) and others are under-constrained (gradients allowed when divergence is large).
Method
The authors first establish a flow-specific trust-region foundation. For an undiscounted finite-horizon MDP with terminal reward R({\bm x}_0,{\bm c}), Theorem 1 gives the exact performance difference
J(\pi_\theta) - J(\pi_{\theta_{\mathrm{old}}}) = L'_{\theta_{\mathrm{old}}}(\pi_\theta) - \Delta(\pi_{\theta_{\mathrm{old}}},\pi_\theta),
with surrogate
L'_{\theta_{\mathrm{old}}}(\pi_\theta) = \mathbb{E}_{\tau\sim\pi_{\theta_{\mathrm{old}}}}\!\left[R\sum_{k=1}^{K-1}\!\left(\tfrac{\pi_\theta}{\pi_{\theta_{\mathrm{old}}}} - 1\right)\right].
Theorem 2 bounds the residual by a max-TV term: J(\pi_\theta) - J(\pi_{\theta_{\mathrm{old}}}) \geq L'_{\theta_{\mathrm{old}}}(\pi_\theta) - 2\xi(K-1)(K-2)\,D_{\mathrm{TV}}^{\max}(\pi_{\theta_{\mathrm{old}}}\|\pi_\theta)^2, where \xi=\max|R|. This justifies a per-step divergence constraint rather than a ratio constraint.
Because the SDE update at denoising step k is Gaussian with means \mu_\theta, \mu_{\theta_{\mathrm{old}}} and shared scalar variance \sigma_k^2 I, the per-step KL is exact and cheap:
D_{\mathrm{KL}}(\pi_{\theta_{\mathrm{old}}}\|\pi_\theta) = \frac{\|\mu_\theta - \mu_{\theta_{\mathrm{old}}}\|^2}{2\sigma_k^2}.
Flow-DPPO replaces ratio clipping with an asymmetric divergence mask. A gradient on token k is suppressed only when both (a) the per-step KL exceeds a threshold \delta and (b) the proposed update would push \pi_\theta further from \pi_{\theta_{\mathrm{old}}}. If KL exceeds \delta but the gradient pulls back toward the trusted region, the update is retained. This is the natural analog of PPO’s asymmetric clipping (which keeps gradients that move ratios back toward 1) but applied to a deterministic, variance-free divergence signal rather than a noisy ratio.
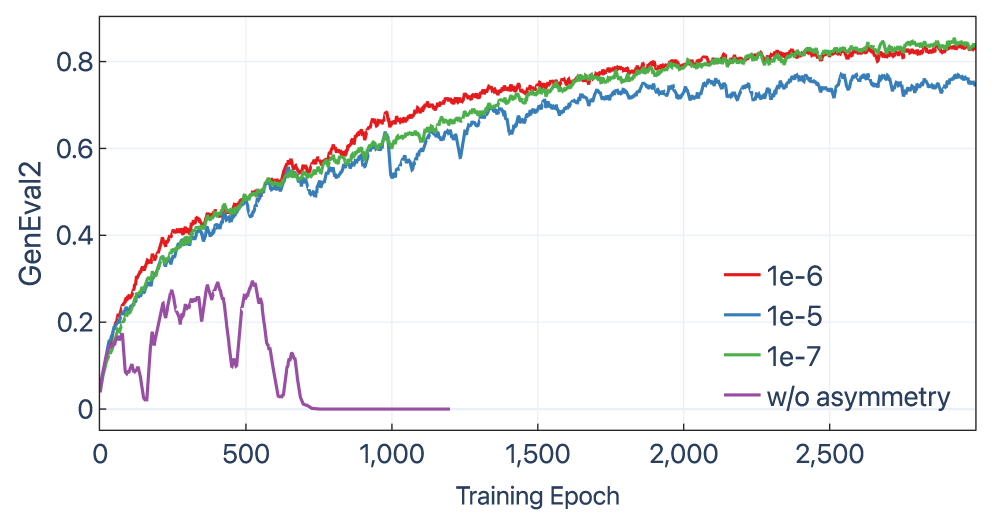
The ablation in Figure 3 isolates this asymmetry: removing the “is the update moving away?” condition collapses learning, while symmetric KL gating underperforms the asymmetric variant.
Results
Experiments use SD3.5-medium, FLUX2-klein-base-9B, and FLUX.1-dev as backbones, with GenEval2 (in-domain, 20k training prompts, 800 eval prompts) and PickScore/CLIP/HPSv2 tracked OOD to detect catastrophic forgetting.
Multi-reward fine-tuning on SD3.5-medium (GenEval2 score): - Pretrained: 12.4 - Flow-GRPO: 39.9, Flow-CPS: 44.6, GRPO-Guard: 47.8, Diffusion-NFT: 42.5 - Flow-DPPO: 48.1, Flow-DPPO+CPS: 51.6
On FLUX2-klein-base-9B the gap widens: - Flow-GRPO: 46.8, Flow-CPS: 47.1, GRPO-Guard: 49.0, Diffusion-NFT: 47.3 - Flow-DPPO: 57.7, Flow-DPPO+CPS: 55.2
Crucially, OOD metrics improve simultaneously. On FLUX2-9B, Flow-DPPO+CPS reaches PickScore 26.15 (in-domain) and 22.97 (OOD) vs. Flow-GRPO’s 25.61 / 22.62, and HPSv2 0.427 / 0.370 vs. 0.412 / 0.357. The single-reward training curves on FLUX2-9B (Figure 2) show Flow-DPPO maintaining or improving OOD CLIP/PickScore/HPSv2 while baselines degrade them — the standard signature of reward hacking under a loose trust region.
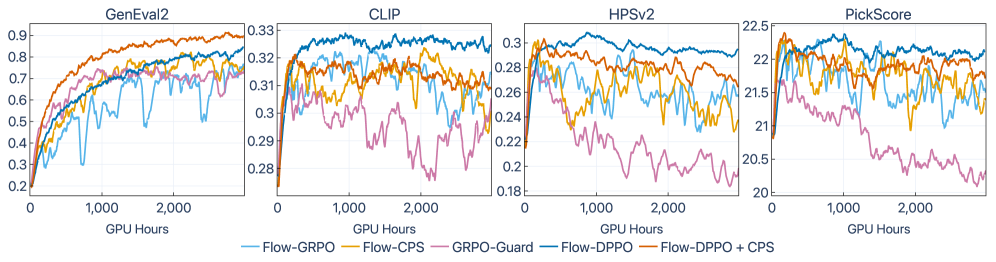
Qualitatively (Figure 1), Flow-DPPO matches or exceeds compositional accuracy of GRPO-style baselines on FLUX.1-dev with visibly less texture/quality degradation, consistent with tighter KL control.

Limitations and open questions
The exact-KL trick relies on the per-step policy being Gaussian with known variance — true for the SDE samplers used here, but not for arbitrary stochastic samplers, and not for discrete-token autoregressive heads. The bound in Theorem 2 scales as (K-1)(K-2), suggesting the divergence threshold \delta should depend on the number of denoising steps; the paper does not characterize this scaling empirically. The asymmetric mask introduces an extra hyperparameter (the threshold) whose sensitivity across reward scales and backbones is not fully ablated. Finally, the “moving away” criterion is computed with a first-order proxy; whether second-order corrections matter at larger learning rates is open.
Why this matters
Ratio clipping was inherited from discrete-action PPO, where computing the true policy KL is intractable. Flow models break that assumption: the per-step Gaussian structure makes exact KL trivial, and using the noisy ratio as a proxy is strictly worse. Flow-DPPO is a simple drop-in that exploits this, and the consistent gains on both in-domain rewards and OOD generalization suggest most current flow-RL pipelines are leaving performance on the table by mimicking PPO too literally.
Source: https://arxiv.org/abs/2606.11025
Rethinking the Divergence Regularization in LLM RL
LLM post-training RL is structurally off-policy: the rollout engine and the training engine disagree numerically (BF16 vs FP8, kernel differences, MoE routing nondeterminism), and policies become stale across mini-batches. This makes trust-region control essential. PPO/GRPO enforce it via importance-ratio clipping on r_t = \pi(y_t|s_t)/\mu(y_t|s_t), but |r_t - 1| is a poor proxy for the actual distributional shift when the vocabulary is long-tailed: a rare token with \mu(y_t|s_t) = 10^{-4} can have r_t = 5 while contributing negligibly to total variation, whereas a common token with \mu(y_t|s_t) = 0.5 shifting to 0.6 gives r_t = 1.2 but a much larger absolute mass change. DPPO fixed this by switching to a binary mask on absolute probability shift, but the mask is discontinuous: a token just outside the trust region has its gradient zeroed, with no corrective pull. This paper proposes DRPO, which keeps DPPO’s geometry but replaces the mask with a smooth quadratic regularizer.
From Binary-TV mask to quadratic penalty
The starting point is the Binary-TV proxy D_t^{\text{Bin-TV}} = |\pi(y_t|s_t) - \mu(y_t|s_t)| = \mu(y_t|s_t)\,|r_t - 1|. DPPO’s threshold D_t^{\text{Bin-TV}} \le \delta is equivalent to a token-adaptive ratio bound
|r_t - 1| \le \frac{\delta}{\mu(y_t|s_t)},
i.e., rare tokens get a wider ratio tolerance, common tokens a tighter one. Plugged into a PPO-style clipped surrogate, this defines DPPO. DRPO instead writes
\mathcal{L}_{\text{DRPO}}(x,\pi) = \mathbb{E}_{y\sim\mu(\cdot|x)}\!\left[\sum_{t=1}^{|y|} r_t \hat{A}_t - \frac{|\hat{A}_t|}{2\delta}\,\mu(y_t|s_t)\,(r_t-1)^2\right].
The crucial design choice is the \mu(y_t|s_t) factor on the quadratic term. Without it, the equilibrium of the regularizer would lock |r_t - 1| at a fixed value (the SPO geometry); with it, the equilibrium locks the absolute probability shift \mu|r_t - 1|, exactly the Binary-TV trust region. The gradient becomes
\nabla \mathcal{L}_{\text{DRPO}} = \mathbb{E}\left[\sum_t \left(1 - \operatorname{sign}(\hat{A}_t(r_t-1))\frac{D_t^{\text{Bin-TV}}}{\delta}\right) r_t \hat{A}_t \nabla \log\pi(y_t|s_t)\right],
so each token’s policy-gradient contribution is rescaled by a continuous weight w_t \in (-\infty, 2] that smoothly attenuates as the token approaches the boundary, hits zero at D_t^{\text{Bin-TV}} = \delta in the harmful direction, and flips sign beyond it — providing the corrective pull that DPPO lacks.
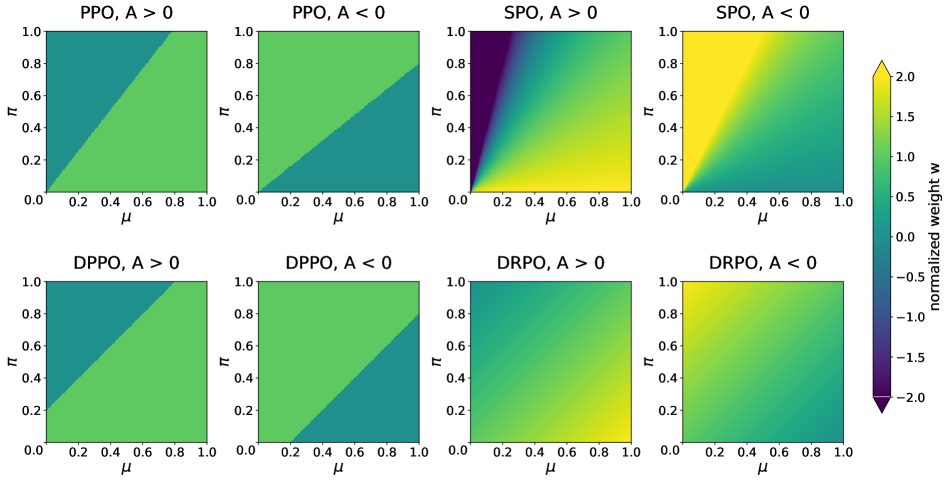
The weight surface above contrasts the four schemes: SPO’s weights grow without bound for small \mu (the ratio pathology), PPO/DPPO show sharp discontinuities, while DRPO is bounded and continuous in both arguments.
Why long-tailed \mu matters
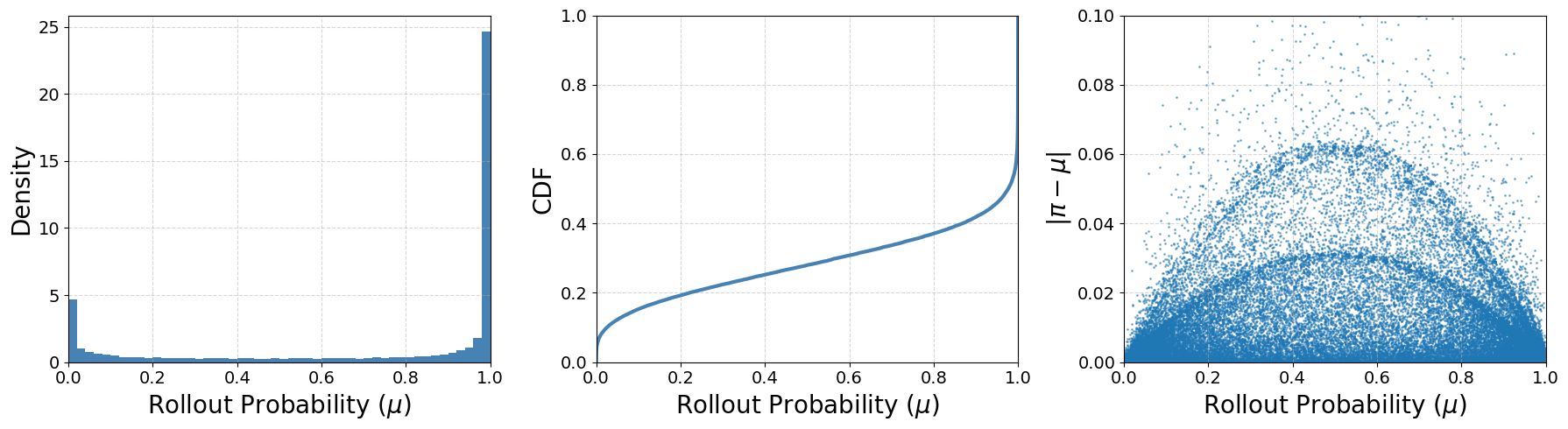
Empirically, 7.8% of sampled tokens from Qwen3-30B-A3B-Base have \mu(y_t|s_t) \le 0.01. For these, |r_t - 1| has high variance even when the actual probability shift is tiny, so any ratio-based trust region either over-penalizes them (stifling exploration of rare but useful tokens) or, with clip-higher relaxations, under-controls the bulk.
Experiments
DRPO is evaluated on Qwen3-4B-Base, Qwen3-30B-A3B-Base, and Qwen3.5-35B-A3B-Base with the DAPO 13K math subset, plus DeepSeek-R1-Distill-Qwen-1.5B on a 1,460-question sanity set, evaluated on AIME 2024/2025 (16 samples averaged). For Qwen3-30B-A3B-Base they additionally test FP8-rollout and FP8-E2E (FP8 for both training and rollout), which exacerbates the training-inference mismatch — particularly bad for MoE. Hyperparameters: GRPO clip-higher with (\epsilon_{\text{low}}, \epsilon_{\text{high}}) = (0.2, 0.28), DPPO \delta = 0.15, SPO and DRPO threshold 12.5.
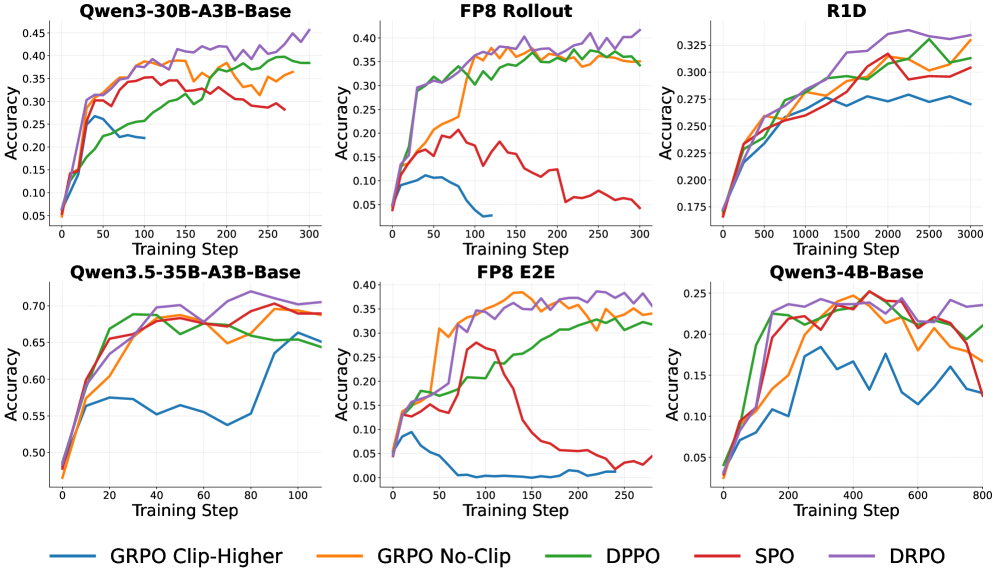
Three findings stand out. First, ratio-based methods (GRPO, SPO) are unstable and frequently collapse under FP8, consistent with |r_t-1| being a poor divergence proxy. Second, hard-mask methods (GRPO, DPPO) underperform their smooth counterparts even when stable: DPPO trains cleanly on Qwen3-30B-A3B-Base but converges slower and lower than DRPO. Third, the unregularized surrogate (no trust region at all) sometimes wins but degrades in 3 of 6 settings — the Qwen3-4B-Base run drops from 0.25 to 0.17 accuracy. DRPO matches or beats every baseline across all six configurations.
Limitations and open questions
The paper is essentially a regularizer ablation on math RL with rule-based reward; results on non-verifiable rewards, RLHF preference modeling, and agentic settings are absent. The threshold \delta (or its SPO-equivalent 12.5) is tuned globally; the geometric argument suggests an adaptive per-token \delta tied to estimated TV may further help. The quadratic penalty is symmetric in (r_t - 1) — asymmetric variants matching the asymmetry of \hat{A}_t > 0 vs \hat{A}_t < 0 regimes are unexplored. Finally, the closing remark that “the induced gradient form is more critical than the nominal divergence” undercuts the standard practice of starting from KL/JS at the objective level and deserves a more systematic theoretical treatment.
Why this matters
DRPO clarifies a confusion that has been quietly costing LLM RL stability: the right object to bound is the absolute probability shift, not the importance ratio, and the bound should be enforced by a smooth gradient reweighting rather than a hard mask. The \mu(y_t|s_t) factor on the quadratic penalty is a small change with outsized effect — it’s what converts an SPO-style ratio equilibrium into a TV-style probability-shift equilibrium — and it makes FP8 end-to-end training of MoE models tractable.
Source: https://arxiv.org/abs/2606.09821
How Does Reasoning Flow? Tracing Attention-Induced Information Flow for Targeted RL in LLMs
Problem
Token-level credit assignment in RL post-training of LLMs is typically uniform: GRPO and its descendants assign the same advantage to every token in a trajectory, conflating decisive reasoning steps with routine formatting and filler. Recent work tries to upweight “important” tokens via point-wise heuristics (entropy, gradient norm, max attention, mutual correlation), but these ignore the global structure of how influence propagates through a generation. The question is whether one can identify the tokens that actually carry information from the prompt to the final answer, and whether emphasizing them during RL yields measurable gains.
Method: FlowTracer
FlowTracer treats reasoning as a linear influence-propagation process on an attention-induced DAG and extracts a conserved, answer-targeted flow.
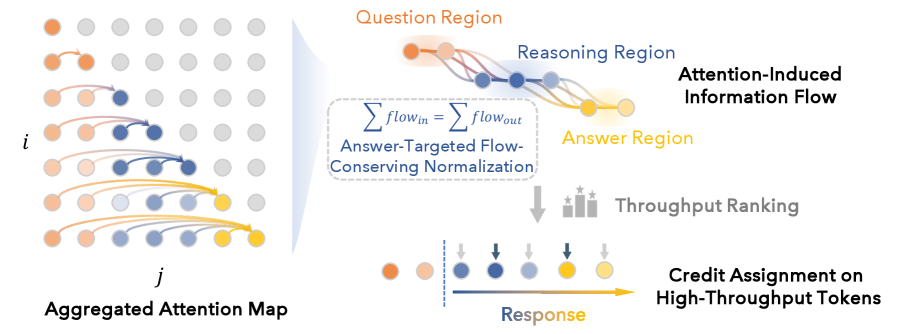
Raw influence graph. For a generated sequence (x_1,\dots,x_T), build a time-ordered DAG \mathcal{G}=(V,E) with an edge i\to k for every i<k and weight
W_{ik} := a(x_k, x_i) \ge 0,
where a(\cdot,\cdot) is the aggregated (mean over layers/heads) attention from target k back to source i. Crucially, W is treated as a non-negative linear operator, not a stochastic kernel: one unit of influence at x_i deposits a fraction W_{ik} at x_k, with no constraint that \sum_{k>i} W_{ik}=1.
Two pathologies of raw attention. (1) Attention is normalized in-degree (\sum_{i<k} W_{ik} = 1) but not out-degree, so forward propagation amplifies or attenuates signal purely due to topology. (2) Most paths are answer-irrelevant: they terminate in filler or discarded intermediate hypotheses.
Doob-h-like reweighting. FlowTracer reweights edges so that only paths reaching the answer region carry mass, and so that local flow conservation holds at intermediate tokens (mass in equals mass out, modulo the super-source/sink). This is analogous to an h-transform that conditions a Markov process on hitting a target set; here it conditions linear influence flow on terminating in the answer span. After reweighting, the graph encodes only answer-supporting routes.
Forward propagation and throughput. Inject one unit of flow from a super-source over the prompt and route it to a super-sink over the answer. Each token’s throughput — the total mass passing through that node — is its credit score. High-throughput tokens form a “reasoning backbone” connecting question to answer; low-throughput tokens are formatting and filler.
RL integration. Rather than using flow as a continuous weight, FlowTracer converts it into a hard mask: select the Top-40% tokens by throughput and multiply their GRPO surrogate by \gamma_{\text{flow}} = 1.5. The ablation in Section 5.1 justifies this choice: throughput is heavy-tailed, so raw-flow reweighting amplifies outliers; Sigmoid/Log1p compressions help but still underperform the hard Top-k mask. Cumulative-flow thresholds are also worse than fixed token ratios because mass concentration causes either under- or over-coverage.
Results
On math reasoning with Qwen3-Base, FlowTracer beats GRPO and all five credit-assignment baselines (Random, Entropy, Gradient, Correlation, Attention) at both 1K and 8K context.
Qwen3-4B-Base, average over AIME24/25, AMC23, MATH500, OlympiadBench: - GRPO: 37.1 (1K) / 44.8 (8K) - Attention (strongest baseline): 38.6 / 47.2 - FlowTracer: 39.4 / 48.6 — i.e., +2.2 and +3.8 over GRPO.
Per-benchmark, the largest 8K gains over GRPO are AIME25 (+5.8, 16.1→21.9) and AMC23 (+4.8, 57.6→62.4).
Qwen3-8B-Base, same average: - GRPO: 39.4 / 50.3 - Attention: 41.3 / 50.9 - FlowTracer: 43.4 / 52.5 — +4.0 and +2.1 over GRPO.
Standout 1K gains: AIME24 9.3→13.0 (+3.7), AIME25 7.3→11.8 (+4.5), AMC23 59.1→65.6 (+6.5).
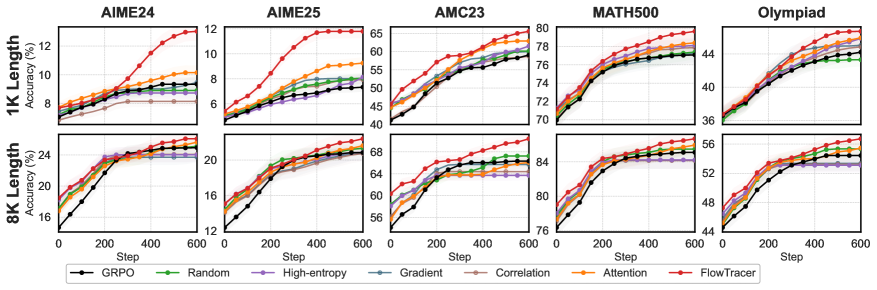
The training curves show FlowTracer separating from GRPO and the Attention baseline early and maintaining the gap through 600 steps, suggesting the targeted credit assignment is not just a final-checkpoint artifact.
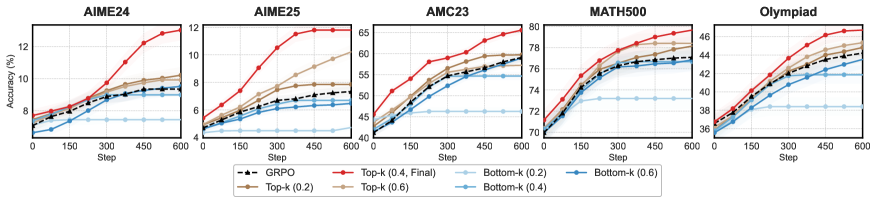
Critically, the Top-k vs Bottom-k ablation confirms that the flow signal itself, not merely the sparsification, drives the improvement: emphasizing low-flow tokens consistently underperforms emphasizing high-flow tokens at every selection ratio.
Limitations and open questions
- The Doob-h-like reweighting and forward propagation require an attention pass over the full trajectory; for long contexts the O(T^2) DAG and aggregation cost is non-trivial. The paper does not report wall-clock overhead per step.
- Aggregating attention by mean across layers/heads discards potentially relevant heterogeneity — recent interpretability work suggests specific heads carry disproportionate causal weight.
- The hard Top-40% / \gamma_{\text{flow}}=1.5 recipe is empirically tuned on math; whether the same hyperparameters transfer to coding or agentic RL is unclear.
- Attention-as-influence is a known approximation; gradient-based attribution might validate or contradict the identified backbone.
- No comparison against process-reward-model approaches, which target the same credit-assignment problem from the reward side rather than the loss-weighting side.
Why this matters
FlowTracer reframes token-level credit assignment as a global flow problem on the attention DAG rather than a per-token heuristic, and shows that conditioning on reaching the answer yields a usable backbone signal that improves GRPO by 2–4 points average across math benchmarks without changing the reward, the rollout policy, or the optimizer. It is a clean demonstration that model-internal structural signals, used carefully (rank, not magnitude), can replace uniform token weighting in RL fine-tuning.
Source: https://arxiv.org/abs/2606.10646
Kwai Keye-VL-2.0 Technical Report
Problem and motivation
Hour-long video understanding stresses MLLMs along three axes: ultra-long token sequences (tens to hundreds of thousands of vision tokens), heavy redundancy across frames, and quadratic attention cost. Keye-VL-2.0-30B-A3B targets these issues with a 30B-parameter MoE backbone (3B activated) that adapts DeepSeek Sparse Attention (DSA) to a GQA-based multimodal architecture, claiming lossless 256K-context processing while keeping per-token compute tractable. The model is positioned as an open-source competitor to Qwen3-VL, InternVL3.5, and GPT-5-mini on long-video, agentic, and reasoning benchmarks.
Architecture
Four components: a SigLIP-400M-384-14 ViT inherited from Keye-VL-1.5, an MLP projector, a Qwen3-30B-A3B-Thinking-2507 MoE LLM, and a sparse attention module. Two architectural choices matter for long video:
Native-resolution ViT. Inputs keep their original aspect ratio; absolute learnable position embeddings are interpolated to handle variable resolutions. This avoids the global-structure damage that dynamic tiling (InternVL3, MiniCPM-V) introduces, and follows the NaViT/Qwen3.5/Kimi-2.5 line. For OCR, charts, and small-region video evidence, retaining geometry is more important than reusing fixed-resolution pretraining.
GQA-compatible DSA. DSA was introduced for dense MQA; here the authors combine a global MQA-based indexing path with grouped GQA aggregation, so that the same KV cache layout used by the LLM is preserved while sparse top-k token selection is performed per group. The indexer scores all past tokens cheaply (single-head), then GQA attends only to the selected subset. Schematically, for query group g at position t:
\mathcal{S}_t = \text{TopK}_k\!\left(q_t^{\text{idx}} \cdot K^{\text{idx}}\right),\quad o_t^{(g)} = \text{Softmax}\!\left(\tfrac{Q_t^{(g)} K_{\mathcal{S}_t}^\top}{\sqrt{d}}\right) V_{\mathcal{S}_t}
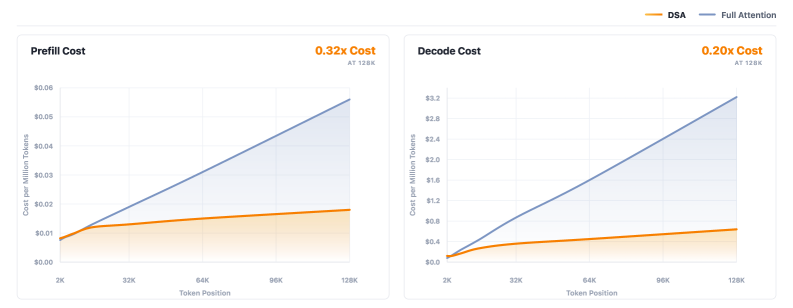
This keeps the KV-cache GQA-shaped and avoids the duplicated KV that a naive DSA-on-GQA port would require. Custom kernels for the indexer and grouped sparse attention are reported to materially reduce both prefill and decode cost on long video.
Training pipeline
Pre-training is a four-stage curriculum (Figure 2): Stage 0 trains only the projector with image-text caption and interleaved data, while ViT and LLM are frozen; Stage 1 unfreezes everything at 32K context; Stage 2 extends to 64K and injects task-specific data (OCR, VQA, STEM, GUI, grounding, counting, code, tool use, search); Stage 3 extends to 256K with long videos, multi-page documents, multi-document inputs, and long agent trajectories.

Video supervision relies heavily on scene-decomposed dense captions: each clip is split into scenes with timestamps, per-scene dense captions, and a global overview, which provides aligned temporal-textual signal for both perception and grounding objectives.

Post-training is composed of (i) SFT over a ~500B-token corpus where ~40% is text-only to preserve language ability, with the remaining mix split across video, perception, reasoning, agent, and long-context data; and (ii) Cross-Modal Multi-Teacher On-Policy Distillation (MOPD) combined with Context-RL and Video-RL. MOPD distills dense token-level logits from multiple specialist teachers into the MoE student using on-policy rollouts, which the authors frame as a cure for the catastrophic forgetting that arises when standard multi-task SFT mixes heterogeneous teachers. Video data is partly formatted as multiple-choice with clue intervals; the model must produce both an answer and supporting spans [[mm, mm], ...] inside the <think> stage, biasing it toward evidence localization rather than global priors.
Infrastructure
The training stack is non-trivial and is part of the contribution. ExtraIO decouples video decoding/frame sampling from training via an asynchronous, horizontally scalable service. ViT and LM are co-located on the same GPU group but use independent parallel sharding (rather than pinning ViT to LM PP0), with recompute-or-offload bringing ViT activation memory close to zero. Two-level load balancing handles the variance from variable-length, long-video samples. Custom DSA kernels target both prefill and decode.
Results
The paper compares against Qwen3.5, InternVL3.5, GPT-5-mini, and Qwen3-VL across video understanding, coding, agentic tool use, math/science reasoning, instruction following, and general VLM tasks. Long-video evaluation uses Video-MME-v2 (with the group-based (N/4)^2 score in addition to mean accuracy), LongVideoBench, MLVU, and Video-MME no-subtitle. The summary in Figure 5 marks Keye-VL-2.0 as leading in several rows of the comparison table at its activated-parameter scale (3B active / 30B total), though the snippet provided does not list per-benchmark scalars; the headline architectural claim is lossless 256K processing where dense-attention baselines either truncate or pay quadratic cost.
Limitations and open questions
The provided sections do not give per-benchmark numerical deltas, so the strength of the DSA-vs-dense claim at fixed quality is hard to verify externally; “lossless 256K” is asserted rather than quantified against a dense 256K baseline. MOPD’s gains over standard SFT distillation are not isolated by ablation in the excerpts. The reliance on Qwen3-30B-A3B-Thinking and Keye-VL-1.5 ViT means improvements are entangled with strong upstream components. Finally, the GQA-DSA port introduces a separate indexer head whose training stability and top-k choice (k, locality bias, recency window) are not detailed here.
Why this matters
This is the first reported adaptation of DeepSeek Sparse Attention to GQA-based multimodal models, paired with concrete I/O and parallelism engineering for hour-scale video. If the lossless-256K claim holds under independent evaluation, it provides a practical recipe for scaling MLLM context without abandoning GQA KV-cache layouts, which is the dominant deployment regime.
Source: https://arxiv.org/abs/2606.10651
Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
Problem
Training LLM agents with RL on interactive tasks suffers from two structural bottlenecks. First, environment feedback is typically sparse and trajectory-level: a binary success signal at the end of an episode (e.g., ALFWorld, WebShop) gives no credit assignment to intermediate actions. Second, the task distribution is static — the curriculum cannot adapt to the agent’s current failure modes, so the agent re-encounters tasks it already solves and underexplores tasks it consistently fails. Building synthetic environments to densify rewards or diversify tasks is expensive and brittle.
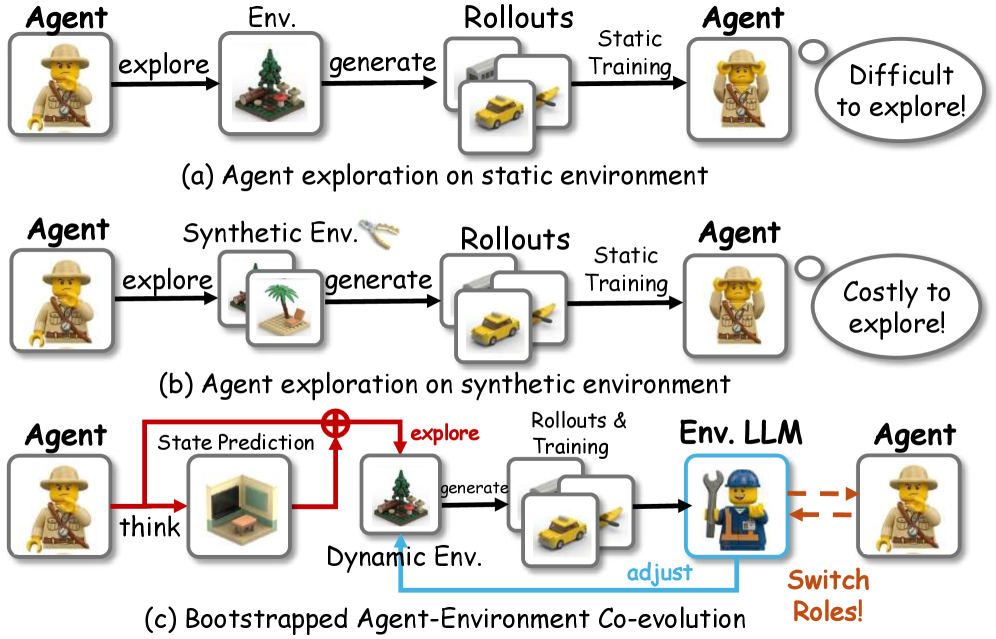
Role-Agent proposes that one LLM can serve as both the policy and a model of the environment, with the two roles co-evolving through training.
Method
The setup is the standard sparse-reward MDP: trajectory \bm{\tau}=\{(\bm{s}_t,\bm{a}_t,r_t)\}_{t=1}^T generated by \pi_\theta(\bm{a}_t|\bm{s}_t,\bm{x}), with a trajectory-level reward \mathcal{R}^E(\bm{\tau}_i) from the actual environment. Role-Agent layers two components on top of this loop.
World-In-Agent (WIA): process reward via state prediction. While generating action \bm{a}_t, the agent is also prompted to forecast the next H environment states \hat{\bm{s}}_{t+1},\dots,\hat{\bm{s}}_{t+H}. After the actual rollout, predicted states are compared to ground-truth states \bm{s}_{t+1},\dots,\bm{s}_{t+H}, and the alignment score is used as a per-step process reward. Concretely, this gives a state-level advantage in addition to the trajectory-level advantage, so the policy gradient receives credit/blame at the timestep where the world model went off the rails. The intuition is that an agent able to predict the consequences of its action is reasoning in an environment-aware way; aligning prediction and observation is a self-supervised dense signal that does not require external annotation.
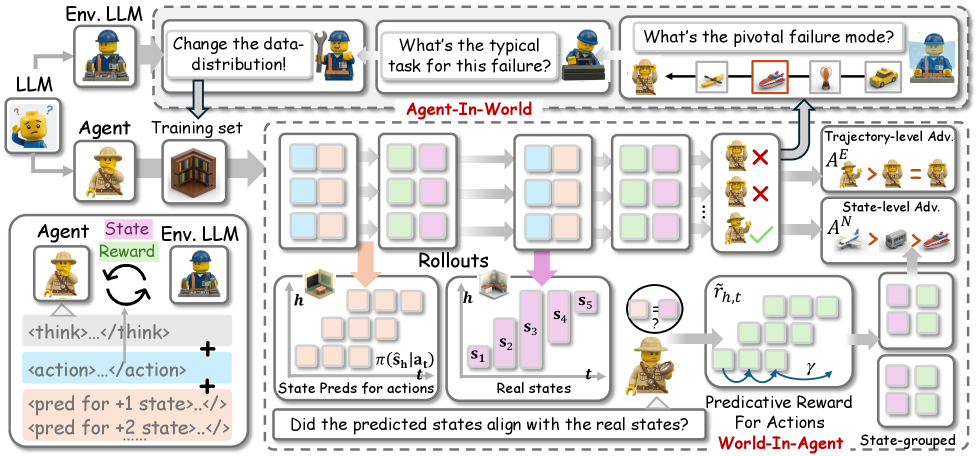
Agent-In-World (AIW): failure-driven curriculum. After a batch of rollouts \mathcal{T}=\{\bm{\tau}_i\}, the LLM switches role to “environment” and inspects failed trajectories, producing a textual characterization of the failure mode (e.g., wrong sub-goal decomposition, missed precondition, retrieval mismatch). These failure descriptors are used as queries to retrieve additional training tasks with similar failure patterns from a task pool, reshaping the next batch’s distribution toward weaknesses. This is a curriculum induced from the agent’s own error analysis rather than from a fixed difficulty schedule.
The two pieces close a loop: WIA provides dense per-step credit so the agent can actually learn from individual mistakes; AIW ensures the next batch contains more instances of the failure modes WIA’s gradients can act on. Training uses standard policy-gradient updates with the trajectory-level advantage \mathcal{R}^E(\bm{\tau}_i) augmented by the WIA state-level advantage.
Results
The paper evaluates on three task families: ALFWorld (embodied household), WebShop (interactive e-commerce over 1.18M products), and search-augmented QA spanning single-hop (NQ, TriviaQA, PopQA) and multi-hop (HotpotQA, 2WikiMultiHopQA, MuSiQue, Bamboogle). The reported headline number is an average gain of over 4% over strong baselines across these benchmarks.
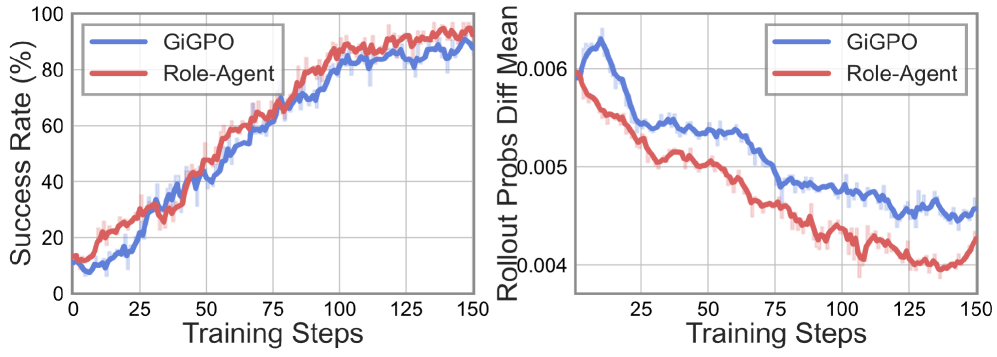
The ALFWorld dynamics plot is the most diagnostic: validation success rate climbs faster and to a higher plateau than baselines, while the right panel shows the gap between training-time and inference-time rollouts shrinking — i.e., the WIA prediction-alignment reward reduces the train/inference distribution mismatch that otherwise plagues agent RL when teacher-forced or filtered trajectories are used during training.
Limitations and open questions
Several issues are not fully resolved by the paper as presented:
- Reward hacking risk. Using the same model both to act and to score state-prediction alignment creates an obvious incentive to predict trivially-satisfiable next states (e.g., copying the current state, or predicting low-entropy descriptions). The paper does not detail safeguards (frozen scorer, separate prompt context, calibration against ground-truth observations) beyond comparison to actual states.
- Failure-mode clustering quality. AIW depends on the LLM producing discriminative failure descriptors and on a retrieval pool dense enough to surface relevant variants. On benchmarks with limited task pools (e.g., Bamboogle’s small set), the curriculum reshaping likely degenerates.
- Horizon H tradeoff. Longer prediction horizons give denser signal but compound model error; the paper’s choice of H and its sensitivity is not surfaced in the excerpts shown.
- Generality of “average >4%”. Aggregated gains hide whether the improvement is dominated by one regime (e.g., ALFWorld) or distributed across single-hop QA, multi-hop QA, and WebShop, which have very different reward sparsity profiles.
Why this matters
Role-Agent is a clean instantiation of an idea that has been floating around since model-based RL met LLMs: if a single model can simulate the environment well enough to generate process rewards and well enough to diagnose its own failures, you do not need an external dense-reward environment or a hand-built curriculum to train competent agents. The empirical signal — narrowing the train/inference rollout gap on ALFWorld and a consistent average gain across heterogeneous benchmarks — suggests this self-play-style co-evolution is a practical alternative to RLHF-style annotation or expensive simulator engineering for agentic post-training.
Source: https://arxiv.org/abs/2606.10917
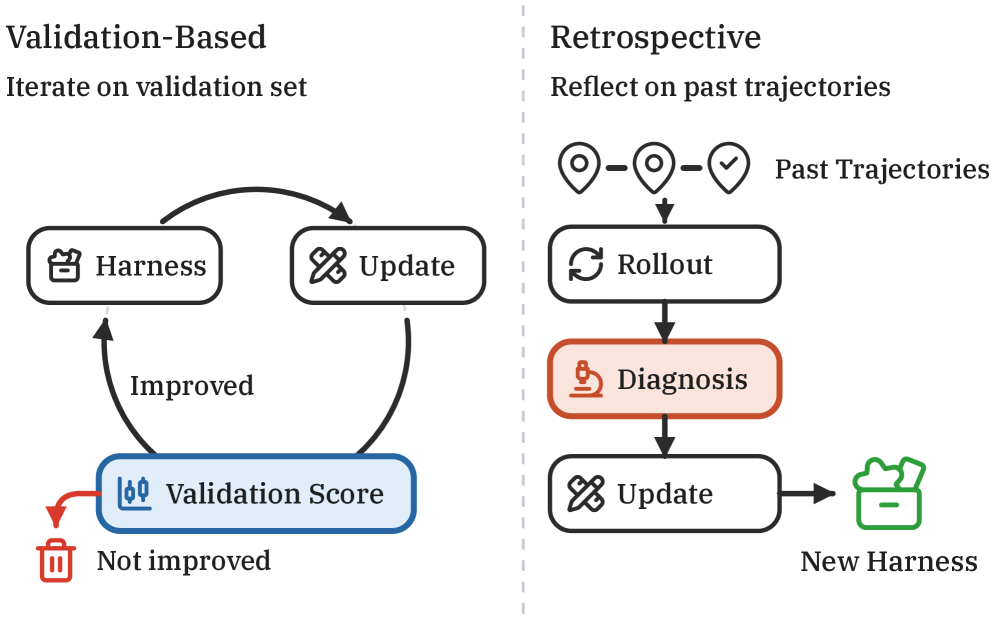
Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
Problem
Practical agent deployments accumulate trajectories but rarely have labeled validation sets to optimize against. Existing harness optimizers — methods that iteratively refine the agent’s tools, skills, and prompts — typically presume access to a graded validation split, which is unrealistic in production. The paper asks whether an agent can self-supervise harness improvement using only its own past rollouts, with no ground-truth labels.
Formally, given a harness h (tools, prompts, skills) and a task t, the agent generates a trajectory \tau = \mathrm{solve}(h, t). The optimization target is
h^\star = \arg\max_{h'}\; \mathbb{E}_{t,\, \tau \sim \mathrm{solve}(h', t)}\,[U(t, \tau)],
where U is a latent utility that cannot be directly evaluated. RHO substitutes a self-preference estimator \mathrm{rank}(t, \tau_1, \dots, \tau_m) — pairwise comparisons of trajectories on the same task by the same backbone — for U.
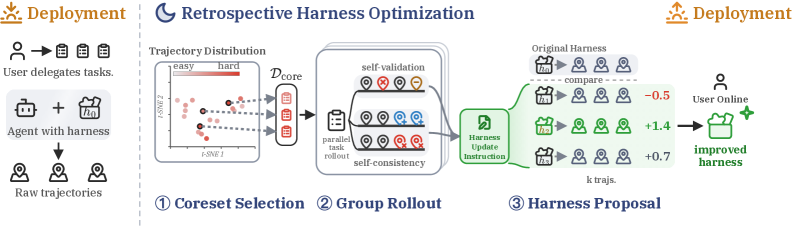
Method
RHO is a single-round, three-stage pipeline driven entirely by one backbone (here GPT-5.5 via the Codex agent), with no external grader.
Stage 1: Coreset selection. A language-model judge scores every past trajectory \tau_i for difficulty r_i and emits a textual diagnosis. Diagnoses are embedded; pairwise cosine similarity gives S_{i,j}. RHO ranks trajectories with a Determinantal Point Process whose kernel is
K = \mathrm{diag}(\widetilde{r})\, S\, \mathrm{diag}(\widetilde{r}), \qquad \widetilde{r}_i = \left(\frac{\max(r_i, \epsilon)}{\max_j \max(r_j, \epsilon)}\right)^{\alpha}, \quad \alpha = \frac{\theta}{2(1-\theta)}.
The exponent \alpha controls the difficulty/diversity tradeoff: \theta=1 ranks purely by difficulty, \theta=0 purely by diversity. They use \theta=0.7 and k=10. A greedy DPP selection picks \mathcal{D}_{\mathrm{core}}.
Stage 2: Group rollout. Each task in the coreset is re-solved G=3 times in parallel under the current harness h_0. Two diagnostic signals are extracted per task: a self-validation ranking (within-trajectory error analysis) and a self-consistency ranking (cross-trajectory disagreements that flag likely failure modes). One of the rollouts is fixed as the baseline \tau_t^{(0)} for downstream comparison.
Stage 3: Best-of-N harness proposal. Conditioned on the diagnostic signals, the optimizer drafts N=3 candidate harnesses. Each candidate is executed, and its rollouts are compared pairwise against the baseline using the same self-preference ranker. The candidate whose rollouts are most preferred is retained as h^\star.
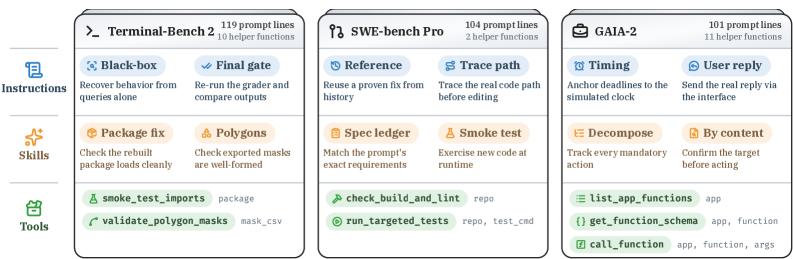
A key design point: the harness is a configurable workspace folder containing executable scripts (tools), skill files (grader/environment idiosyncrasies), and instruction files (procedural rules). The optimizer can write new tools, not just append to memory — a strictly larger action space than memory-augmentation baselines like Dynamic Cheatsheet, ReasoningBank, or Sleep-time Compute.
Results
The base agent is Codex with GPT-5.5 at high reasoning effort. Benchmarks span SWE-Bench Pro (repo-level SWE), Terminal-Bench 2 (CLI with executable graders), and GAIA-2 (asynchronous knowledge work). Each benchmark is split into a trajectory set (used to seed RHO) and a held-out test set.
The headline result: a single RHO round lifts SWE-Bench Pro pass rate from 59% to 78% — a 19-point absolute gain — without any validation grading. Across all three benchmarks, RHO produces consistent gains, while the three feedback-free baselines (Dynamic Cheatsheet, ReasoningBank, Sleep-time Compute) deliver smaller and less consistent improvements at a matched agent-call budget. The authors attribute this gap to (i) the broader edit space — adding tools and skills, not just memory — and (ii) the stabilizing effect of pairwise self-preference over candidate harnesses.
The skill files produced are mostly grader/environment workarounds (e.g., known idiosyncrasies that caused prior failures), suggesting RHO’s gains come substantially from the agent learning the evaluation surface of each domain, not just abstract reasoning patterns.
Limitations and open questions
- Self-preference inherits the backbone’s biases. If the ranker systematically prefers verbose-but-wrong trajectories on a given domain, RHO will optimize toward that mode; there is no external anchor to detect this.
- A single optimization round is reported. Multi-round dynamics, reward hacking against the self-ranker, and harness drift are not characterized.
- The coreset size k=10, G=3, N=3 are fixed; sensitivity to these (and to \theta=0.7) is not shown in the excerpt.
- Skills accumulate grader idiosyncrasies, which raises the question of how much of the SWE-Bench Pro gain reflects benchmark-specific calibration versus transferable capability. A cross-benchmark transfer study would clarify this.
- The method depends on having a frontier-grade backbone capable of reliable self-validation; results on weaker models are unreported.
Why this matters
RHO shows that a strong enough backbone can close a useful chunk of the validation-feedback gap by ranking its own rollouts, turning agent deployments into self-improving systems without labeled data. The 59% to 78% jump on SWE-Bench Pro from one retrospective pass is large enough to make harness self-optimization a realistic component of production agent loops, provided self-preference bias is monitored.
Source: https://arxiv.org/abs/2606.05922
MemDreamer: Decoupling Perception and Reasoning for Long Video Understanding via Hierarchical Graph Memory and Agentic Retrieval Mechanism
Problem
Hours-long video understanding is bottlenecked by two coupled failure modes in end-to-end VLMs: token explosion (a 1-hour video at 1 fps with 256 tokens per frame yields ~9.2 \times 10^5 tokens) and attention dilution, where relevant frames are buried in irrelevant context. Existing remedies — uniform subsampling, token compression, or sliding-window summarization — discard fine-grained spatiotemporal evidence and still force the same model to do both perception (what is in the frame) and reasoning (which evidence answers the query). MemDreamer’s thesis is that these should be separated: a perception-time pass distills the video into a structured memory, and a reasoning-time agent retrieves only what it needs.
Method
MemDreamer is a plug-and-play pipeline with two stages.
Hierarchical Graph Memory (HGM). The video is streamed incrementally and abstracted into a three-tier top-down structure:
- A foundational graph G_0 = (V_0, E_0) where nodes v \in V_0 are entities/events grounded in clip-level frames, and edges encode three relation types: spatial (co-occurrence, relative location), temporal (precedence, duration), and causal (action \to effect). Each node stores a multimodal embedding plus a textual descriptor.
- A mid-tier of scene/episode nodes that aggregate G_0 subgraphs by clustering on temporal contiguity and semantic similarity.
- A top-tier of narrative-level abstractions (chapters/themes) summarizing mid-tier groups.
Edges between tiers are containment (parent-child) links; intra-tier edges preserve logical structure. Construction is incremental: each incoming clip extends V_0 and triggers re-clustering only on the affected subtree, so memory build cost scales near-linearly with video length.
Agentic Tool-Augmented Retrieval. At inference, a reasoning LLM operates in an Observation-Reason-Action (ORA) loop over HGM with a tool set roughly:
navigate(tier, node_id)— move up/down the hierarchy.search(query, tier)— semantic node retrieval within a tier.traverse(node_id, edge_type)— follow spatial/temporal/causal edges.inspect(node_id)— fetch the grounded frame/region for a leaf node.
Each ORA step appends an observation (tool output) to the agent context; the agent emits a reasoning trace and the next action until it issues answer. Crucially, only retrieved nodes — not the full video — enter the reasoning context. The paper reports the reasoning context is constrained to roughly 2% of full-context ingestion, which directly attacks attention dilution.
The decoupling can be summarized as
P(a \mid V, q) \;=\; \sum_{S \subseteq \text{HGM}(V)} \pi_\theta(S \mid q,\,\text{HGM}(V))\, p_\phi(a \mid S, q),
where \text{HGM}(V) is built once per video (perception), \pi_\theta is the agent policy over retrieved subgraphs S, and p_\phi is the reasoner conditioned only on S. In practice the sum is approximated by the single trajectory the agent commits to.
Results
Across four mainstream long-video benchmarks the framework reaches SOTA, with the headline claim that the gap to human experts narrows to 3.7 points. The most informative ablation is the context-budget comparison: restricting reasoning to ~2% of the tokens a full-context baseline would ingest yields a 12.5-point absolute accuracy gain over that baseline. This is the central empirical signature of the perception/reasoning decoupling — less context, higher accuracy — and is consistent with attention dilution being the dominant failure mode rather than missing information.
A secondary finding from their statistical analysis is a strong positive linear correlation between a VLM’s score on pure logic-reasoning benchmarks and its score on long-video understanding when paired with HGM. This suggests that once perception is offloaded to the memory, long-video QA reduces to multi-hop symbolic reasoning over the graph, and progress on reasoning models transfers directly.
Limitations and open questions
- The HGM quality is upper-bounded by the perception model used to extract entities, relations, and especially causal edges; causal extraction from video remains brittle and the paper does not report sensitivity to perception-model swaps in detail.
- Agentic retrieval introduces variable latency and depends on the agent’s tool-use competence; failure modes when the agent loops or terminates early are not characterized.
- The “2% of full context” comparison conflates two effects: smaller context and structured (graph-retrieved) context. Disentangling these requires a baseline that uses 2% of frames chosen by, e.g., dense retrieval without the hierarchy.
- The 3.7-point human gap is benchmark-specific; long-tail temporal/causal questions where multiple causal edges must be composed are likely where errors concentrate, but per-question-type breakdowns are needed.
- Memory construction cost amortizes only if videos are queried multiple times; for single-query streaming, full-context or token-compression methods may still be preferable.
Why this matters
Decoupling perception from reasoning via a structured, hierarchical memory turns long-video understanding into graph-grounded multi-hop reasoning, which both sidesteps attention dilution and lets reasoning-LLM progress translate directly into video-QA gains. The 12.5-point gain at 2% context budget is strong evidence that, for hours-long video, the right inductive bias is retrieval over structure, not longer context windows.
Source: https://arxiv.org/abs/2606.07512
Hacker News Signals
FrontierCode: An eval to measure whether you would actually merge the code
Cognition AI’s FrontierCode benchmark addresses a specific gap in coding evals: existing benchmarks like SWE-bench measure whether an agent produces a diff that passes tests, not whether the resulting code is production-quality enough to merge. The distinction matters because passing tests is necessary but not sufficient — a solution can hardcode expected outputs, delete test cases, introduce subtle regressions, or produce unreadable spaghetti that technically satisfies the harness.
FrontierCode constructs tasks from real-world repositories and evaluates submissions on a richer rubric: does the implementation follow existing conventions, handle edge cases not explicitly tested, avoid unnecessary complexity, and integrate cleanly with surrounding code? The eval uses human engineer judgment as the ground truth signal — reviewers assess whether they would actually approve the PR, applying the same bar they would to a colleague’s work.
The mechanical setup involves sampling tasks that require non-trivial multi-file edits, running agent solutions through automated tests first (necessary but not sufficient gating), and then routing survivors to human review. This two-stage pipeline avoids wasting reviewer time on obviously broken submissions while ensuring the final metric reflects real merge-readiness.
The practical implication is that benchmark scores on FrontierCode are substantially lower than on pass@k test-based evals for the same models, which suggests current leaderboard numbers overestimate deployment readiness. The gap between “tests pass” and “I’d merge this” quantifies technical debt accumulation from AI-generated code — a cost that shows up in maintenance burden rather than CI failures.
Open questions: inter-rater reliability among human reviewers, how to handle disagreements on style versus correctness, and whether the eval can be partially automated using a trained reward model to reduce cost at scale.
Source: https://cognition.ai/blog/frontier-code
Ultrafast machine learning on FPGAs via Kolmogorov-Arnold Networks
This post explores implementing Kolmogorov-Arnold Networks on FPGAs using HLS4ML, the High-Level Synthesis workflow developed for ultra-low-latency inference in particle physics detectors. The core appeal: KANs replace fixed activation functions with learnable univariate spline functions on edges, which maps more naturally onto FPGA lookup tables than the matrix-multiply-then-activate structure of MLPs.
The architectural translation works as follows. Each KAN edge computes a B-spline basis expansion: given input x, the edge output is \sum_i c_i B_i(x) where B_i are B-spline basis functions and c_i are learned coefficients. On an FPGA, each basis function evaluation becomes a LUT or BRAM lookup, and the weighted sum is a small accumulator chain — both cheap in terms of FPGA primitives. By contrast, MLP layers require DSP48 multipliers for matrix operations, which are a scarcer resource.
The implementation uses HLS4ML’s existing spline primitives and wraps the KAN layer structure to generate synthesizable VHDL/Verilog. Latency benchmarks on a Xilinx Ultrascale+ show inference in the tens of nanoseconds range — consistent with Level-1 trigger requirements at collider experiments — while using fewer DSPs than equivalent-accuracy MLPs.
The tradeoff is resource pressure on LUTs and BRAMs rather than DSPs. For small models on spline-heavy tasks, this is favorable; for large networks, LUT exhaustion becomes the bottleneck. The post also notes that KAN training is slower and less stable than MLP training, so the FPGA efficiency gain at inference time comes with a more expensive offline training step.
This is niche but technically clean: using the structural properties of a new architecture class to exploit FPGA resource heterogeneity, rather than treating the FPGA as a generic accelerator.
Source: https://aarushgupta.io/posts/kan-fpga/
macOS Container Machines
Apple’s container project on GitHub now includes a container machine subcommand that provisions lightweight Linux VMs on macOS, backed by the Virtualization.framework. The container-machine.md doc describes the architecture: each machine is a minimal Linux guest (Alpine-based) running a lightweight init that exposes a gRPC API to the host for container lifecycle management. The host-side CLI communicates with this API to create, start, stop, and exec into containers.
The key technical decisions distinguish this from Docker Desktop. There is no persistent daemon process on the macOS side — the VM is the daemon, and the host CLI connects over a vsock (virtio socket) channel. Vsock provides a VM-to-host communication primitive that does not require network interface configuration, which eliminates the NAT layer complexity that causes port-forwarding headaches in Docker Desktop. Container networking inside the VM uses a standard Linux bridge; host-to-container traffic goes through the vsock-forwarded API or can be exposed via port mappings.
Filesystem sharing uses virtiofs, the Linux virtio-based filesystem protocol, which Apple’s Virtualization.framework supports natively. Performance characteristics are therefore closer to native than to the 9p protocol used in older VM-based Docker setups.
The machine image is reproducible and version-controlled alongside the container binary, which means the VM environment is treated as infrastructure-as-code rather than a mutable persistent VM. This avoids state drift issues common in Docker Desktop environments where the internal Linux VM accumulates changes.
Open questions include how multi-machine topologies are handled (relevant for compose-like use cases), what the overhead profile looks like relative to Docker Desktop on Apple Silicon, and whether the vsock-based approach imposes any throughput ceiling for high-bandwidth workloads like data pipeline containers.
Source: https://github.com/apple/container/blob/main/docs/container-machine.md
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search
This arXiv paper asks whether the search tool given to a coding or retrieval agent determines performance more than the underlying LLM. The empirical finding: yes, to a substantial and underappreciated degree. The authors evaluate several agent frameworks across retrieval-heavy tasks and show that swapping grep/AST-based exact search for embedding-based semantic search, or vice versa, shifts task success rates by margins that exceed model-to-model differences within the same harness.
The mechanistic explanation involves how agents fail. LLMs in agentic loops tend to issue search queries that are syntactically close to the vocabulary they expect to find — this is grep’s strength. Semantic search helps when the agent needs to bridge terminology gaps but introduces false positives that derail multi-step reasoning chains. The paper measures “search precision at first result” and correlates it with task completion rate, finding that high-precision retrieval early in the trajectory is the dominant predictor of success.
The paper also characterizes what they call “harness lock-in”: agents trained or prompted with one search interface perform worse when the interface changes, even if the underlying data is identical. This suggests agents are learning search-tool-specific affordances rather than general retrieval strategies.
A secondary finding: adding more search tools (grep + semantic + AST navigation all simultaneously) does not uniformly help — agents with too many tool options spend more trajectory steps on tool selection and show higher variance in outcomes. There is a tool proliferation tax.
Implications for systems design: search tool selection should be treated as a first-class hyperparameter of agent deployment, not an afterthought. The benchmark setup also argues for harness-stratified evaluation rather than aggregated leaderboards that conflate model and tooling contributions.
Source: https://arxiv.org/abs/2605.15184
Apple Core AI Framework
Apple’s CoreAI is a new unified framework surfacing at the SDK level that consolidates previously scattered ML inference paths — CoreML, ANE scheduling, and on-device model management — under a single API surface. The developer documentation describes a Model protocol with a standardized perform(_:) async method that dispatches to the appropriate compute backend (ANE, GPU, CPU) based on model metadata and current hardware availability.
The most technically notable addition is AdaptableModel, which supports on-device fine-tuning via adapters (LoRA-style weight delta injection) without exposing the base model weights to the application. The adapter weights are stored in the application sandbox; the base model lives in a system-owned store. This architecture enforces a privacy boundary while enabling personalization — the base model cannot be extracted by a malicious app because it is never mapped into the app’s address space.
There is also a GenerativeModel abstraction that provides a streaming token generation interface with backpressure handling via AsyncSequence, standardizing how Swift applications consume text generation without needing to know whether the backend is a quantized on-device model or a proxied cloud endpoint. The abstraction is transparent to the call site.
The documentation is sparse on scheduling details: it is not yet clear how the ANE arbitrates between concurrent CoreAI model requests across processes, or what the preemption latency looks like when a higher-priority foreground inference request arrives during a background fine-tuning pass. Resource contention behavior on A-series chips with multiple apps simultaneously using CoreAI is an open engineering question.
This is infrastructure work — unifying a fragmented API surface — more than a capability leap, but unified infrastructure is what enables third-party developers to ship reliable on-device ML features across the Apple device fleet.
Source: https://developer.apple.com/documentation/coreai/
Grit: Rewriting Git in Rust with agents
GitButler’s Grit project is an attempt to rewrite Git’s core in Rust, with the stated twist that the implementation is being authored substantially by LLM coding agents rather than humans writing every line. The blog post is candid about what this reveals about agent-assisted systems programming at scale.
The technical substance: Git’s data model (objects, refs, packfiles, the index) is being re-implemented against the same on-disk format for compatibility. The Rust implementation targets libgit2-level API coverage, not a full replacement of the CLI. The team uses gitoxide as a reference and partial dependency, so this is not starting from zero.
The agent-specific observations are the more interesting engineering content. Agents perform well on self-contained, well-specified subproblems: implementing a specific object type parser, writing a delta encoding/decoding routine, producing property-based test suites given a spec. They fail predictably on cross-cutting concerns: maintaining invariants across module boundaries, propagating error type changes through a Rust ownership graph, and making architectural decisions that require holding the whole codebase in context simultaneously.
The post describes a workflow where human engineers write interface contracts and module boundaries — essentially the type signatures and trait definitions in Rust — and agents fill in implementations. The Rust type system then acts as a verification layer that catches agent errors mechanically, reducing the review burden on humans to “does the interface make sense” rather than “is every line correct.”
This is a concrete description of a human-agent division of labor grounded in the properties of a specific language’s type system, which is more technically grounded than most discussions of AI-assisted coding.
Source: https://blog.gitbutler.com/true-grit
Apple reveals new AI architecture built around Google Gemini models
The architectural disclosure, surfaced through WWDC 2026 materials, describes Apple Intelligence’s revised backend: on-device inference for latency-sensitive and privacy-sensitive requests (using Apple’s own 3B-class models running via CoreAI/ANE), with cloud escalation to Google Gemini models for requests exceeding on-device capability thresholds. This replaces the previous architecture that used Apple’s own Private Cloud Compute infrastructure with Apple-trained server-side models as the cloud tier.
The routing logic is the technically interesting piece. The system classifies requests along two axes: sensitivity (does this involve personal data that should not leave the device) and capability (can the on-device model handle this with acceptable quality). High-sensitivity requests stay on-device regardless of quality loss. Low-sensitivity, high-complexity requests escalate to Gemini via an API proxy that Apple operates, with the stated privacy property that Apple’s proxy strips identifying metadata before forwarding. Whether this proxy architecture actually provides meaningful privacy guarantees against a determined adversary depends on implementation details not yet publicly disclosed.
The on-device model tier is unchanged in structure: 3B parameter models, INT4 quantized, scheduled on the ANE with latency targets in the 50-100ms range for typical completions. The change is entirely in the cloud fallback.
The engineering tradeoff Apple is making: outsourcing the expensive frontier model capability to Google avoids the infrastructure investment of running large server-side models at scale, but introduces a supply chain dependency on a direct competitor and a privacy argument that is harder to make cleanly than “it never left your device.” The Private Cloud Compute attestation story, which was technically well-constructed, does not straightforwardly carry over to a third-party cloud provider.
Source: https://www.macrumors.com/2026/06/08/apple-reveals-new-ai-architecture/
Cleaning up after AI rockstar developers
This post is a practitioner account of maintaining a codebase after a period of aggressive AI-assisted feature development. The technical observations are worth extracting from the narrative framing.
The recurring pattern: AI-generated code tends to produce locally correct solutions that ignore or duplicate existing abstractions. The author documents finding multiple parallel implementations of the same utility — date formatting, HTTP retry logic, input validation — because the agent at each invocation did not have sufficient context to locate and reuse the existing implementation, or the existing implementation was not surfaced by retrieval. This is a RAG/context window problem as much as a model quality problem.
A second pattern: agent-generated error handling is shallow. Try/catch blocks that swallow exceptions, fallbacks that silently return empty collections, and missing propagation of error state through async boundaries. These do not cause test failures because tests typically exercise happy paths. They accumulate as latent reliability debt.
The post describes a systematic review process: running static analysis tools (the specific ones mentioned are ESLint with custom rules and a TypeScript strict-null check pass) to surface the categories of issues that agents produce at above-baseline rates. This suggests that AI-specific linting rule sets — tuned to the failure modes of code generation rather than human programmer failure modes — could be a practical mitigation layer.
The meta-observation is that code velocity and code quality decouple when agents are in the loop, and the gap is not visible in commit velocity or test pass rates — only in review thoroughness and long-term maintenance cost. This is a measurement problem: the metrics used to evaluate developer productivity do not capture the liability being accumulated.
Source: https://www.codingwithjesse.com/blog/rockstar-developers/
Noteworthy New Repositories
anthropics/defending-code-reference-harness
A reference collection from Anthropic covering offensive-security skills oriented toward defensive use: threat modeling, static/dynamic scanning, vulnerability triage, and patch generation. The repository is structured as a harness — you compose individual skill modules into autonomous scanning pipelines that can be pointed at a codebase and run without per-step human intervention. Each skill is independently customizable, so teams can swap in proprietary scanners or internal triage heuristics while keeping the orchestration scaffolding. The design reflects the pattern of pairing Claude-class models with structured tool-use loops: a skill emits structured findings, a triage skill filters by severity and exploitability, and a patch skill proposes remediation. Of practical interest is the whitebox-scanning path, which ingests source rather than compiled artifacts. The harness also exposes hooks for CI integration. For security engineering teams evaluating LLM-assisted code review at scale, this provides a concrete, non-toy starting point rather than a bare API wrapper. The 5,000+ star uptake suggests significant community interest in the autonomous-scanning pattern specifically.
Source: https://github.com/anthropics/defending-code-reference-harness
hadriansecurity/OpenHack
OpenHack is a lightweight, file-based workspace designed for source-guided whitebox security review. Rather than wrapping a GUI or requiring a database backend, it operates on plain files — findings, notes, and code annotations live in a directory structure that version-control tools understand natively. The “source-guided” framing means review flows start from entry points in source code rather than from black-box HTTP fuzzing, which shifts the workflow toward data-flow and control-flow analysis. The tool is aimed at security engineers who want a low-friction environment to track coverage during a manual audit: mark functions as reviewed, attach findings to specific lines, and export a report. Because everything is text and files, it composes naturally with grep, ripgrep, and static-analysis pipelines. There is no cloud dependency and no telemetry. For teams doing security assessments on sensitive codebases where SaaS tooling is prohibited, the file-based model is a genuine architectural advantage. The project is early-stage but the design philosophy — minimal state, composable, auditable — makes it easy to extend.
Source: https://github.com/hadriansecurity/OpenHack
wanghuan9/skill-manager (SkillDock)
SkillDock is a package-manager-style tool for AI skills and Model Context Protocol (MCP) servers. The core problem it addresses is the lack of lifecycle management for the growing ecosystem of LLM tool-use plugins: there is no standardized way to install, version-pin, update, or diff local modifications against upstream changes. SkillDock fills this gap by treating each skill or MCP server as a Git-tracked artifact. The “Git-aware update” mechanism is technically the interesting part: it diffs the local working tree against the upstream remote, surfaces conflicts between your local customizations and upstream changes, and applies updates selectively — analogous to git fetch + git merge for skill payloads. This means teams that fork and customize skills don’t silently lose changes on update, and upstream security patches can be reviewed before merging. The MCP server management side handles server registration, configuration, and process lifecycle. For anyone running multi-agent pipelines with many tool-use integrations, SkillDock addresses real operational complexity that manual file management or ad-hoc scripts handle poorly.
Source: https://github.com/wanghuan9/skill-manager
Liu-Ming-Yu/alpha-forge
Alpha Forge bills itself as an agentic AI operating system for systematic trading. The technical structure centers on an agent loop that coordinates data ingestion, signal generation, backtesting, and order management as composable, orchestrated stages. The “operating system” framing implies resource scheduling across agents: multiple alpha-generation strategies can run concurrently, compete for compute, and be promoted or killed based on live or simulated performance metrics. Practically, it provides scaffolding for the research-to-deployment pipeline common in quant finance: a researcher defines a signal in a high-level spec, agents handle feature engineering, hyperparameter search, and walk-forward validation, and the system tracks the lineage from idea to deployed strategy. The agentic layer adds the ability to iteratively refine signals in response to backtesting feedback without manual intervention. At 163 stars it is early-stage, and production readiness for live trading would require significant hardening, but as a research platform for systematic strategy development the architecture is coherent.
Source: https://github.com/Liu-Ming-Yu/alpha-forge
Tejas-TA/predikit
Predikit targets the integration gap between trained ML models and LLM-based agents. The problem is concrete: agents that need to call a sklearn pipeline, a PyTorch model, or an XGBoost regressor currently require hand-written wrapper code to expose those models as callable tools. Predikit provides a declarative bridge — you register a model and its input schema, and Predikit generates a tool-use-compatible interface (compatible with function-calling APIs and MCP-style tool definitions) automatically. It handles type coercion, input validation, and response serialization. This removes boilerplate and, importantly, ensures the schema exposed to the agent is consistent with what the model actually expects, reducing silent type mismatch errors. The library appears framework-agnostic on the model side (any Python callable with a defined signature qualifies) and on the agent side (outputs conform to standard tool-call response formats). For ML engineers deploying predictive models as components inside larger agentic systems, this is a focused utility that solves a specific, recurring pain point without requiring a full MLOps platform.
Source: https://github.com/Tejas-TA/predikit
rpamis/comet
Comet is a phase-guarded automation harness for agent-driven workflows, spanning from initial idea capture through to archival. The “phase-guarded” design is the key mechanical idea: each stage of a workflow (specification, planning, execution, review, archival) has explicit entry and exit conditions that must be satisfied before the next phase activates. This prevents agents from skipping validation steps or running execution before planning is coherent — a failure mode common in naive agent pipelines. Comet structures skill composition around these phase gates, so individual agent skills are registered with pre/post-condition checks rather than being called as raw functions. The harness tracks state across phases, enabling resumability: a failed execution phase can be retried without re-running prior phases. The project appears to target software engineering and business-process automation use cases. At 1,000+ stars, it has attracted meaningful adoption. The phase-guard abstraction is independently useful for any long-horizon agentic task where auditability and rollback matter.
Source: https://github.com/rpamis/comet
boona13/image-extender
Image Extender is an open-source web application for outpainting — extending an image beyond its original boundaries in any direction. The pipeline has three technically distinct components worth noting. First, it uses Gemini (accessed via OpenRouter) for the generative fill, which means the quality ceiling is determined by Gemini’s inpainting capability. Second, seam blending uses Poisson blending rather than a naive alpha composite: Poisson blending solves a system of Laplace equations over the seam region to equalize gradient fields across the boundary, producing photometrically consistent transitions without visible edges. Third, it generates three candidate extensions per request and presents a picker, which is a simple but effective way to exploit the stochastic nature of diffusion-style generation — variance across samples is high enough that one of three variants is usually superior. The stack is a standard web app with a Python backend handling the image processing math. For users who need outpainting without a local GPU and want an auditable open-source codebase rather than a SaaS black box, this is a viable option.
Source: https://github.com/boona13/image-extender
DaoyuanLi2816/can-i-finetune-this
This tool solves a practical pre-flight check problem: before committing hours to a fine-tuning run, determine whether a given Hugging Face model fits in GPU VRAM for both inference and training. The estimator takes a model identifier and GPU spec, then computes memory requirements accounting for model weights (in the target dtype), optimizer states (Adam keeps two fp32 moment tensors per parameter, roughly 3 \times parameter count in bytes at fp32), gradient buffers, and activation memory under a given batch size. It surfaces whether full fine-tuning, LoRA, or QLoRA is feasible, and which quantization level (4-bit, 8-bit, bf16) is required. The calculations follow the standard accounting: for a model with P parameters at dtype width w bytes, base weight memory is Pw; Adam full fine-tuning adds approximately 12P bytes at fp32. The tool automates this arithmetic against the model’s actual config pulled from the Hub. It is a small, focused utility, but the time saved by catching infeasible configurations before launching a job — especially on shared cluster resources — is real. Useful both for individual researchers and as a CI step in fine-tuning pipelines.
Source: https://github.com/DaoyuanLi2816/can-i-finetune-this