デイリーAIダイジェスト — 2026-06-08
arXiv ハイライト
Socratic-SWE: トレースから導出されたAgent Skillによる自己進化型コーディングエージェント
問題設定
SWEエージェントのスケールアップにおけるボトルネックは、計算資源やモデル容量ではなく、タスクの供給にあります。現在主流の合成データレシピ――バグ注入、AST変換、テスト摂動――は、設計時に固定されたタスク分布を生成し、現在のソルバーの失敗モードとは統計的に独立しています。ソルバーが改善されるにつれ、これらのタスクの限界価値は低下します。なぜなら、その大部分はモデルがすでに克服した失敗モードを標的としており、一方で残余の困難なケース(状態追跡バグ、複数ファイルにまたがるリファクタリング、環境連動エラー)は依然として過少表現されているからです。Socratic-SWEは、このカリキュラムギャップ問題に対してループを閉じることで対処します:ソルバー自身の過去のロールアウトが、次ラウンドのタスクのソース分布となります。
手法
このフレームワークは、トレースマイニング、skill蒸留、タスク合成、報酬整合フィルタリングという4つの連結したステージで構成され、ラウンド t = 1, \dots, T にわたって反復されます。
トレースマイニング。 \mathcal{T}_t = \{(q_i, \tau_i, r_i)\} をラウンド t における(タスク、軌跡、結果)タプルの集合とします。軌跡にはツール呼び出し、編集、テスト実行が含まれます。成功・失敗した両方のトレースが保持されます。失敗は負のテンプレートを、成功は修復パターンを提供します。
Skill蒸留。 トレースはクラスタリングされ、構造化された agent skill s_k = (\text{symptom}, \text{root\_cause}, \text{repair\_pattern}, \text{diagnostic\_steps}) に要約されます。skillは本質的に型付きスキーマです。例えば「リファクタリング後のスライス境界におけるオフバイワン → テストが境界入力を通じて検出 → n を n+1 に置換することでスライス式を修正」のようなものです。skillは特定のリポジトリファイルを超えてトレースを汎化します。これがSocratic的な操作です――トレースをスカラー報酬の証拠として利用するのではなく、フレームワークはモデルにトレースが失敗または成功した理由を明示的に表現させ、その表現をジェネレータの事前分布として再利用します。
タスク合成。 各skill s_k に対して、フレームワークは実際のリポジトリをサンプリングし、s_k を具体化した修復を意図する候補タスク q' を生成します。合成は実際のコードに根ざしています:ジェネレータは対象ファイル/関数を選択し、skillの症状と整合する編集を適用し、元の(未編集の)コードが通過し編集済みコードが失敗するテストを生成します――これは標準的なSWE-benchのタスク構造ですが、摂動が汎用的なミューテーション演算子ではなく s_k に条件付けられています。
バリデーションと報酬。 2つのフィルターがタスクを保持します。(1) 実行ベースのバリデーション:タスクはコンパイルが通り、失敗テストは壊れたコードで失敗し、保留された参照修正では通過しなければなりません。(2) ソルバー勾配整合:候補 q' は以下によってスコアリングされます。
R(q') = \alpha \cdot \mathbb{P}[\text{Solver}_t \text{ fails}] \cdot \mathbb{P}[\text{Solver}_t \text{ can plausibly recover}] - \beta \cdot \text{redundancy}(q', \mathcal{T}_t),
ここで第1の因子は q' が勾配が有益な難易度帯(自明でも不可能でもない)に位置することを強制し、冗長性項はすでに習得済みのトレースとの重複にペナルティを与えます。具体的には、\text{Solver}_t を q' 上で K 回ロールアウトし、pass rateを測定することで整合性を推定します。pass rateがおおよそ [0.1, 0.6] のタスクが保持されます。
保持されたセット \mathcal{D}_{t+1} はソルバーのfine-tuningに使用されます(成功した修復軌跡に対するSFT、成功・失敗ロールアウト間の preference signal を含む)。更新された \text{Solver}_{t+1} は新たなトレースを生成し、ループが閉じます――skillバンクは事前に固定されるのではなく、エージェントとともに進化します。
結果
abstractでは、SWE-bench Verified、SWE-bench Lite、SWE-bench Pro、Terminal-Bench(提供されたテキストでは省略)における評価が報告されています。機構設計は、Socratic-SWEを静的合成データベースラインから区別する2つの経験的な特徴を予測します:(i) 1ラウンドで飽和するのではなく、ラウンドをまたいで単調に改善すること、および (ii) カリキュラムが残余の失敗モードに能力を集中させるため、LiteよりもPro(より困難な分割)で大きな改善が得られること。完全な結果テーブルなしでは正確なpass@1の数値を引用できません。方法論的な主張――トレース条件付きタスク生成が、計算量を揃えた比較においてミューテーションベースの生成を上回る――が、本論文が答えようとしている中心的な実証的問いです。
限界とオープンな問題
このデザインにはいくつかの固有の問題があります。第1に、skill collapse:蒸留ステップが少数の高頻度skillを生成した場合、カリキュラムが狭まり、エージェントは少数の修復テンプレートに過学習します。冗長性ペナルティはこれを緩和しますが解決はしません。skillバンクに対する多様性の事前分布を設定する方がよりクリーンでしょう。第2に、ソルバー勾配整合に対するreward hacking:目標難易度帯に位置するタスクが必ずしも有用とは限りません――一部は単に曖昧または不十分な仕様であり、ソルバーは対象skillとは無関係な理由で「失敗」します。第3に、実行ベースのバリデーションは弱いオラクルである:合成された失敗テストを通過する修正が意図した修復でない場合があり、退化した解がSFTデータに伝播する可能性があります。第4に、実際のSWE-benchタスクからの分布シフト:合成タスクはエージェント自身のトレースに条件付けられており、それ自体が特定のタスク分布で収集されたものです。これにより、カリキュラムが現実的な開発者のワークフローから乖離するクローズドなエコーチェンバーが生じるリスクがあります。最後に、フレームワークはコストが高く、各ラウンドにトレース生成、skill蒸留(LLM呼び出し)、候補生成、Kサンプルバリデーション、SFTが必要です。そのため、ラウンドあたりの実時間コストは相当なものであり、ベースラインとの比較は計算量を揃えなければ意味をなしません。
なぜ重要か
トレースから導出されたカリキュラムは、訓練分布をモデルの現在の弱点の関数とします。これは、タスク難易度が高次元であり、静的なミューテーション演算子が失敗モードの薄い断片しかカバーしないエージェント的ドメインにおける正しい帰納バイアスです。検証可能な報酬が存在するがタスク供給がボトルネックとなっているツール使用、ウェブナビゲーション、定理証明など、他のエージェントドメインにわたる自己進化型訓練のテンプレートとなり得ます。
Source: https://arxiv.org/abs/2606.07412
あなたのUnEmbedding行列は、テキストEmbeddingのための秘密のFeature Lensである
Decoder-only LLMは強力なzero-shotの推論器ですが、そのままではEncoder性能が低く、プールされたhidden statesはMTEBにおいて専用のembedderより劣ります。本論文はその機械的な原因のひとつを診断します――unembedding行列 W_U \in \mathbb{R}^{|V|\times d} は、高頻度かつ意味的に空のトークン(句読点、冠詞、BOS/EOSなど)をresidual streamに書き込むことだけを目的とした低次元部分空間を含んでいます――そして、その部分空間を閉形式の射影によって除去します。
診断:異方性と頻度バイアスの交差
logit lensをプールされたテキストembedding h に直接適用し、\mathrm{softmax}(W_U h) を計算すると、Qwen、Llama、Mistralのいずれにおいても、上位のデコードトークンが高頻度な間投詞によって支配されていることが分かります。
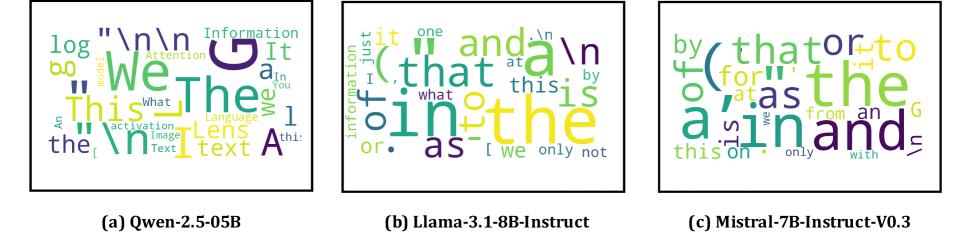
著者らはこれを、LLM表現のよく知られた異方性と結びつけています。つまり、embeddingは狭いコーンにクラスタリングされており、そのコーンの方向が、W_U が高頻度トークンを出力するために使用する方向と一致しているのです。これを明確にするために、著者らは学習コーパスの経験的なunigram分布 \pi にデコードされる「セントロイド」hidden state h^\star を逆算し、その後「Logit Spectroscopy」を実行します――W_U に対するSVDで W_U = U\Sigma V^\top を求め、各右特異方向 v_i について、h^\star を v_i に射影することでデコード分布が高頻度トークンにどれだけシフトするかを調べます。得られた \Delta\pi プロファイルはスペクトルの端に集中しています。
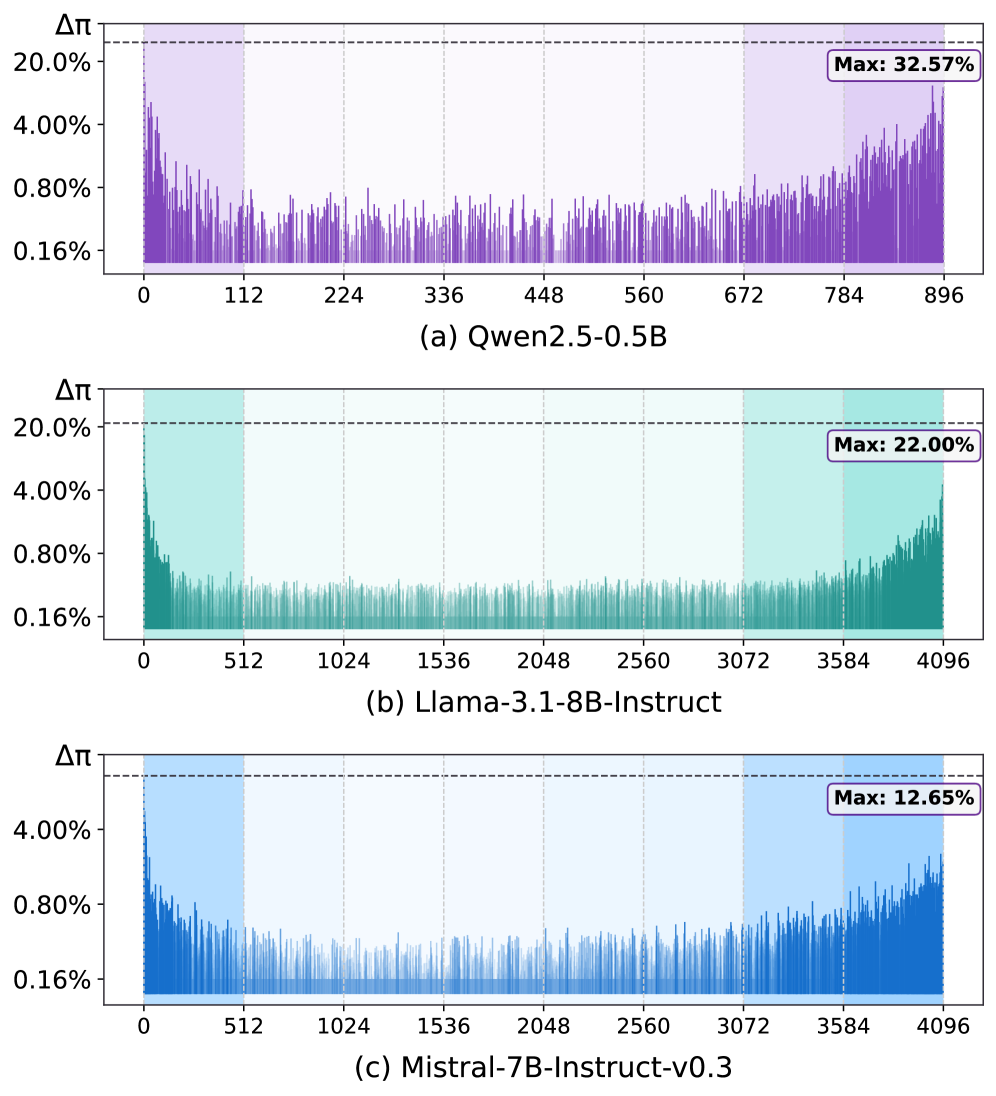
V のエッジ方向の小さな集合が、頻度トークンの質量の大部分を占めています。これをエッジスペクトル部分空間 V_E \in \mathbb{R}^{d \times k} と呼びます。
EmbedFilter:射影による除去
EmbedFilterはinference時に適用される単一の線形写像です:
\tilde h = (I - V_E V_E^\top)\, h.
V_E は、h^\star 上での \Delta\pi への寄与でランク付けされた W_U の上位 k 個の特異方向から構築されます。学習も、ラベルも、contrastiveなペアも不要です――filterは W_U だけから、モデルごとに一度計算されます。
\tilde h は (d-k) 次元の部分空間に存在するため、著者らはこれを無償の次元削減に組み込んでいます。\tilde h = Q z(Q \in \mathbb{R}^{d\times (d-k)} は正規直交)と書けば、すべての内積が保存されるため、retrievalインデックスは \tilde h の代わりに z を保存できます。\tau パラメータは出力次元を d/\tau にスケールし、処理の積極性を制御します。
\tilde h に対してlogit lensを再適用すると、上位6個のデコードトークンに、入力に実際に含まれる内容語が現れるようになります。
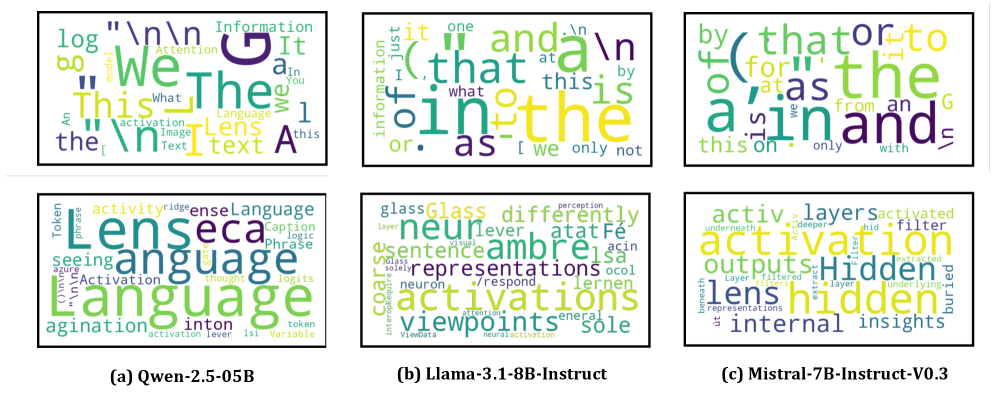
定量的な結果
MTEB(STS、Classification、Clustering、PairClass、Reranking、Retrieval、Summarizationにわたる49データセット)において、EmbedFilterは2種類の標準的なzero-shot LLM-encoderプロトコルであるPromptEOLとECHOの上に積み重ねられています:
- Qwen2.5-0.5B + PromptEOL:\tau=2 で 50.07 → 54.57 (+9.0%);\tau=4 で 53.47;\tau=8 で 51.43。Retrievalは 27.31 → 34.73、STSは 63.04 → 69.48 に向上。
- Qwen2.5-0.5B + ECHO:\tau=2 で 46.03 → 52.55 (+14.1%)。STS 63.98 → 70.77;PairClass 55.54 → 66.35;Retrieval 18.15 → 29.65。
- Llama-3.1-8B-Instruct + PromptEOL:\tau=2 で 55.13 → 56.79 (+3.0%)、Retrieval 25.45 → 29.69。
- Llama-3.1-8B-Instruct + ECHO:\tau=2 で 53.52 → ≥+?(STS 70.43 → 74.41;Clustering 38.89 → 42.64)。
重要なのは、\tau=8(すなわち8倍小さいインデックス)においても改善が維持されていることで、Qwen+ECHOは依然としてfull次元のベースラインに対して+7.4%の改善を示しています。改善が最も大きいのは小規模なQwen-0.5BモデルとECHO(より頻度バイアスが大きい)であり、ベースラインがすでに強いLlama-8B+PromptEOLでは最小です――これは、filteringが生のembeddingがエッジスペクトル方向に最も汚染されているときに最も効果的であるという仮説と一致しています。
限界と未解決の問題
- V_E はunigram事前分布から逆算したセントロイドhidden state h^\star を通じて選択されます。k の選択(およびタスクごとの最適な k)は、\Delta\pi のelbow以外には原理的な規則が与えられていません。
- すべての改善はzero-shot LLM encoderに対するものであり、学習中に暗黙的に頻度バイアスに対処するE5-MistralやNV-Embedのようなcontrastive fine-tunedなembedderとの比較はありません。EmbedFilterがそのようなfine-tuningと組み合わさるのか、あるいはそれに吸収されるのかは不明です。
- Summarizationの列では時折性能が低下します(Qwen+PromptEOL:\tau=2 で 27.30 → 27.12)。これは、フィルタリングされた部分空間が特定のタスクに対して何らかのシグナルを持っていることを示唆しています。
- この分析は V_E をunigram頻度と結びつけていますが、事前学習におけるトークン頻度とembeddingデコード方向における頻度は、すべてのモデルで必ずしも一致しません。また、因果的な介入(W_U からこれらの方向を除いて学習すること)は試みられていません。
なぜこれが重要か
本論文は、mechanistic-interpretabilityのツール――W_U に適用されたlogit lens――を、MTEBスコアを改善しながらインデックスサイズを削減する、学習不要の実用的な後処理器へと転換しています。また、LLM embeddingにおける異方性を、汎用的な幾何学的病理としてではなく、decoderの頻度事前分布に結びついた特定の識別可能な部分空間として再解釈しており、これは将来のembedding手法にとってより明確なターゲットとなります。
Source: https://arxiv.org/abs/2606.07502
SoCRATES: Towards Reliable Automated Evaluation of Proactive LLM Mediation across Domains and Socio-cognitive Variations
問題設定
LLM調停者の評価は、交渉者や討論者の評価よりも困難です。調停とは、対話が進むにつれて状態(感情、隠れた選好、文化的フレーミング)が変化する多ターンの軌跡に対する第三者介入だからです。既存のテストベッドは三つの病理を抱えています。第一に、通常は取引型交渉(CaSiNo、CraigslistBargain、KODIS)のような一つないし二つの専門家が作成したドメインのみをカバーしており、条件を指定しない単一ドメインの実行で成功率が80〜90%に膨れ上がっています。第二に、主に紛争当事者の戦略的姿勢のみを変化させており、感情的反応性や文化的アイデンティティといった直交する社会認知軸を無視しています。第三に、すべての対話ターンをすべてのトピックに対してスコアリングするため、トピック外の雑談がトピックごとのクレジット割り当てを汚染します。SoCRATESはこれら三点すべてを対象とします。
手法
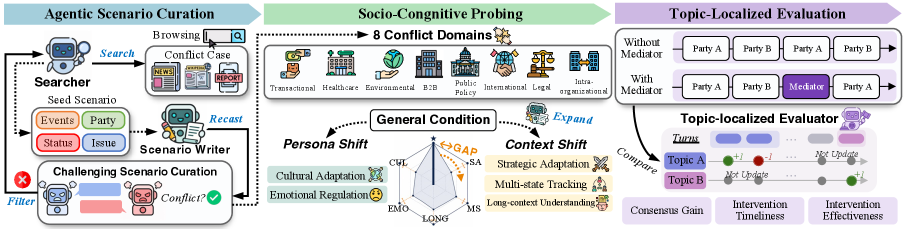
シナリオは s = (\mathcal{B}, \mathcal{P}, \mathcal{T}, \mathcal{W}) として形式化されます。ここで \mathcal{B} は背景情報(履歴、事前のコミットメント、戦略的姿勢)、\mathcal{P} = \{p_1,\dots,p_n\} は紛争当事者(各自がプライベートプロファイル——目標、代替案、トピックごとの立場、ペルソナ \pi_i、選好 w_i ——を持つLLMエージェント)、\mathcal{T}=\{T_1,\dots,T_k\} はトピックごとに離散的な選択肢集合を持つトピック集合(移動が自由テキストではなく選択肢のシフトとして観測可能)、そして \mathcal{W} はトピックにわたって合計100となる重みベクトルを各当事者に割り当てます。調停者はLLMエージェントであり、共有された入力(\mathcal{B}、\mathcal{T}、対話履歴)のみを参照し、各当事者のターンに介入/スキップの二値判断と発話を出力します——隠れたペルソナと選好を対話から推論しなければならず、調停は明示的な社会認知タスクとなっています。
パイプラインは三段階で構成されます。
- エージェントによるシナリオキュレーション:実際の公開紛争から八つのドメイン(取引型、法的、組織内、など)にまたがるシナリオをシードとして生成し、エンティティを匿名化します。
- 社会認知プロービング:s の一つの構成要素を一度に五つの軸(戦略的姿勢、当事者構成、履歴の長さ、感情的反応性、文化的アイデンティティ)に沿って摂動させます。ペルソナ軸はフロート型の強度スカラーでパラメータ化されます(強度レベル \{0, 0.33, 0.66, 1\} で検証済み)。
- トピック局所化評価:各トピック T_j について、T_j を明確に前進させるターンのみをスコアリングし、トピック外のノイズを排除します。合意獲得量、介入の適時性、介入の有効性という三つの指標が報告されます。
ペルソナの制御可能性は、A/Bの反応性ペアを用いて検証されます。二つの強度レベルをサンプリングし、第三の参照ペルソナを固定した上で、人間がより反応性の高い側を選択します。シミュレータ1つあたり160ペアで、Krippendorffの \alpha = 0.75 を達成し、DeepSeek-V3.2が七つのシミュレータの中で最上位にランクされ、フロートスカラーが順序付けられた振る舞いを生成することが確認されました。
トピック局所化評価器は、軌跡レベルでの専門家判断との間にPearson r = 0.823、結果レベルで 0.801 を達成しており、非専門家ベースラインの 0.331 / 0.527、ProMediateの 0.372 / 0.432 と比較して優れています。軌跡レベルのアライメントはターンごとのベースラインの2倍以上を達成しています。
ベンチマーキング結果
八つの調停者(GPT-5.4-mini、Gemini-3.1-Flash-Lite、Gemma-4-26B-A4B、Qwen3-30B、Solar-Pro-3、Nemotron3-120B、DeepSeek-V3.2、Qwen3-235B)がそれぞれ40シナリオ × 15条件 = 600実行で評価され、調停なしのベースラインとペアリングされた合計4,800実行が行われました。
主要な知見:
- 平均合意獲得量は34.4が上限であり、上位層30.7〜34.4と下位層15.7〜21.0という明確な二峰性の分布が見られます。最も強力な調停者でさえ、調停なしの合意ギャップの約三分の一しか埋められておらず、単一ドメインの先行研究で報告されている解決率80〜90%をはるかに下回っています。
- 商用モデルが優位に立ち、スケールはランクを決定しません。 GPT-5.4-miniとGemini-3.1-Flash-Liteは最良のオープンソースモデルを1.1〜2.5ポイント上回り、8ドメイン中6ドメインで勝利しています。Qwen3内ではスケールが有効(235Bは30Bの獲得量をほぼ二倍にする)ですが、Nemotron-3-120Bは法的ドメインおよび組織内ドメインで、推論ベンチマークスコアが同等の小さいGemma4-26Bに後れを取っています。
- モデル間の差よりもドメインの差の方が大きいです。 ドメインごとの平均は41.3(取引型)から16.6(組織内)まで幅があります。容易な側のドメインはまさに既存ベンチマークが集中している領域であり、先行研究が調停能力を過大評価している強力な証拠となっています。
- 適時性 \neq 有効性。 Solar-Pro-3とQwen3-30Bは最も適時に介入しながら合意獲得量では低くランクされており、頻繁に発話しても対話を前進させていません。一方、介入の有効性は合意獲得量と連動しています。
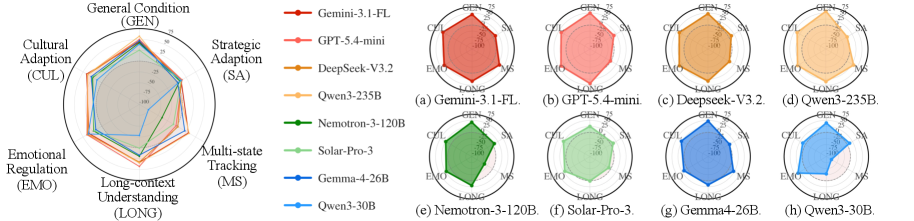
五つの社会認知軸にまたがる適応(図2)は、軸ごとにパフォーマンスが大きく変動することを示しており、図3は戦略的姿勢、感情的反応性、文化的アイデンティティについて、摂動なしの一般条件からのシフトを分解しています。ここでは複数の調停者について負のデルタが支配的です。

限界と未解決の問題
紛争当事者自体がLLMエージェントであるため、反応性に焦点を当てたペルソナ忠実性の検証(\alpha = 0.75)は文化的・当事者構成軸を完全にはカバーできず、著者らはその点で先行研究の検証に依存しています。トピックを選択肢集合に離散化することで観測可能性は得られますが、表現の柔軟性を犠牲にしており、実際の調停では選択肢の創出が伴うことが多いです。八つのドメインは広範ですが、依然としてシードからLLMがキュレーションしたものであり、結果指標は合意を測定するものの、合意の耐久性や公平性は測定していません。商用モデルの優位性が対話的推論に関する学習データに由来するのか、社会的トーンのヒューリスティックに関するRLHFに由来するのかは未検証のままです。
なぜこれが重要か
SoCRATESは二つの具体的な貢献をします。一つは、専門家との r = 0.82 のアライメントを持つトピック局所化評価器をメトリクスとして再利用可能な形で提供することです。もう一つは、単一ドメインの調停ベンチマークがLLMの社会的適応能力を大幅に過大評価しているという証拠を示すことです——ドメインと社会認知的変動が導入された場合、最強のフロンティアモデルでさえ合意ギャップの約33%しか埋められません。調停エージェントの進歩は、生の能力スケーリングではなく、社会的適応にあります。
Source: https://arxiv.org/abs/2606.05563
分解型ビジュアルプロキシによる直接的3D対応オブジェクト挿入
問題設定
現在のdiffusionベースのオブジェクト挿入手法は、このタスクを参照画像を条件とするmasked inpaintingとして扱います。すなわち、M を二値領域マスクとして p(I_{out}\mid I_{ref}, I_{bg}, M) を最大化する定式化です。この定式化には、挿入されたオブジェクトの3Dポーズを明示的に制御する手段がありません。実用上、ユーザーは「椅子を30°回転させて後ろに傾ける」といった指定ができず、モデルはデータの事前分布と文脈に基づいてもっともらしいポーズを選択します。指定された幾何学的レイアウトを遵守する必要があるECサイト、バーチャルステージング、あるいはあらゆるコンポジットパイプラインにとって、これは大きな制約となります。
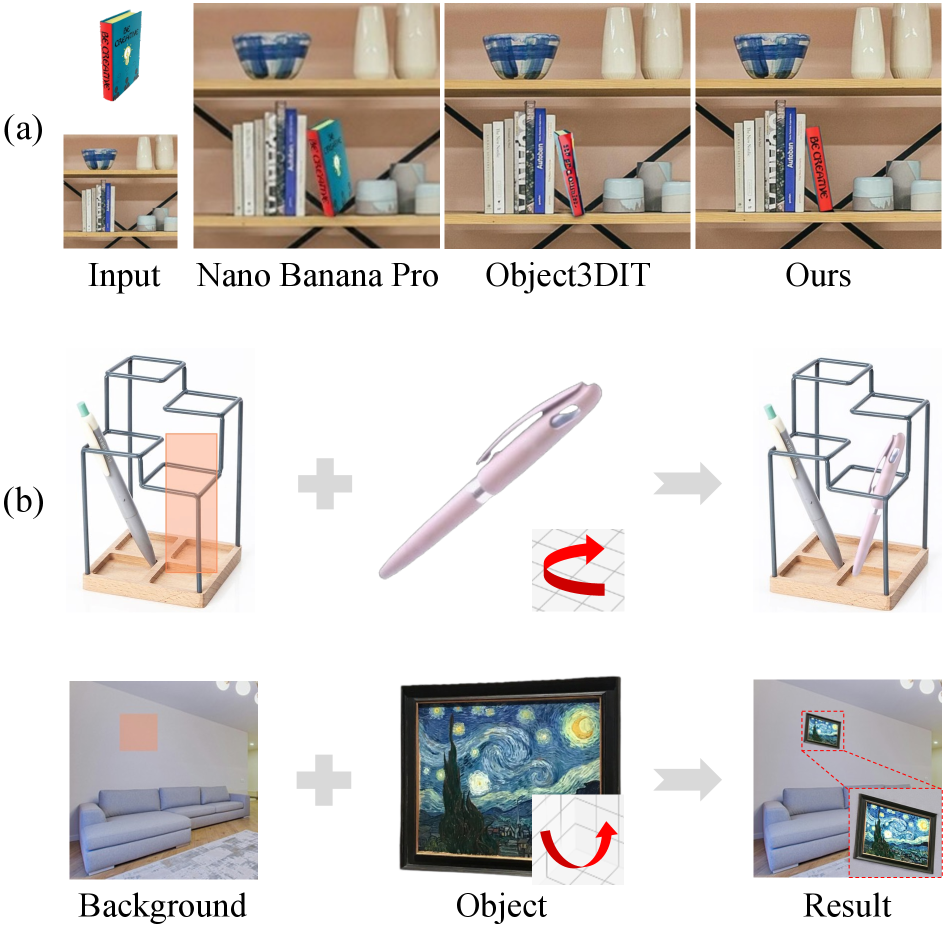
DIRECTは、この問題を6自由度ポーズ制約 \boldsymbol{\xi}\in\mathfrak{se}(3) のもとでの条件付き生成として再定式化し、(i) 参照画像のアイデンティティ、(ii) ユーザー指定のポーズ、(iii) ターゲットシーンとの測光的調和、の3つを同時に満たします。
手法
パイプラインは、2Dの参照画像を3Dプロキシ \mathcal{P} に変換し(本論文のセットアップではoff-the-shelfの画像→3Dモデルであるものを使用)、そのプロキシをユーザーが \mathfrak{se}(3) 操作できるように公開し、その後密なRGB幾何画像 I_{geo} として再レンダリングします。生成は以下のように定式化されます。
I_{out}\sim p_{\theta}(I\mid \underbrace{I_{ref}}_{\text{Appearance}}, \underbrace{I_{geo}}_{\text{Geometry}}, \underbrace{\Psi(I_{bg})}_{\text{Context}}, M),
ここで、frozen状態のFLUX.1-Fill-devバックボーン上に、分解型LoRAパスウェイを通じた3つの構造的に分離されたguidanceシグナルが入力されます。各adapterのrankは128です。この分割には実質的な意味があります。I_{ref} は高周波テクスチャ/アイデンティティを持ちますが空間的配置は持たず、I_{geo} は正確な幾何学情報を持ちますが単一視点3D再構成のアーティファクトによってテクスチャ品質が低下しており、\Psi(I_{bg}) はハーモナイゼーションのためにシーンレベルの照明/セマンティクスを提供します。
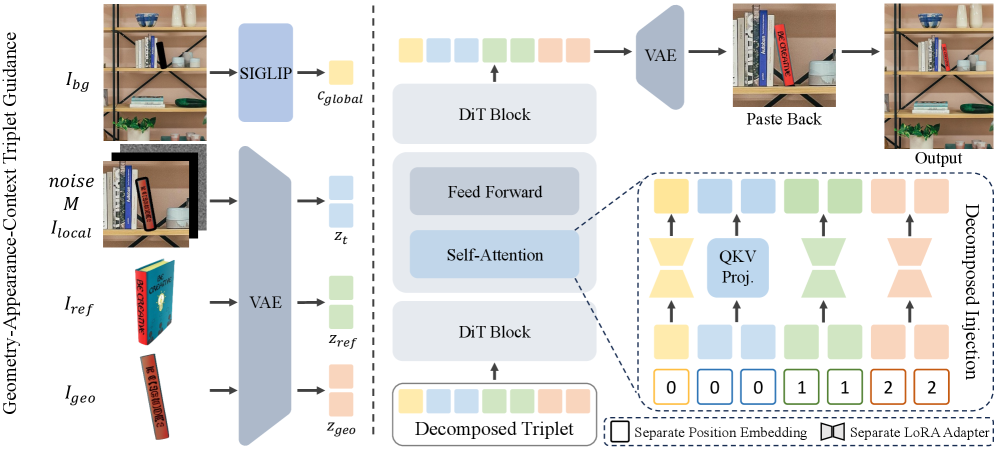
特筆すべき2つの非自明な設計選択があります。
depth/normalの代わりにRGB幾何画像を使用。 対称なオブジェクト(マグカップ、ほぼ正面から見た椅子など)は、反対の向きでもほぼ同一のdepthおよびnormalマップを生成するため、depthを条件とするモデルは「左向き」と「右向き」を区別できません。テクスチャ付きプロキシをRGBにレンダリングすることで、向きを曖昧さなく識別するための意味的なサーフェスの手がかり(ハンドル、ロゴ、非対称なマーキングなど)が得られます。

depth/normalの条件付けは対称なポーズを区別できないが、RGBプロキシはポーズのセマンティクスを保持する。 元の参照画像の再入力。 プロキシレンダラー(TRELLIS)がテクスチャをぼかすため、I_{geo} のみを条件とした場合は出力がぼけてしまいます。外観パスウェイが I_{ref} から高周波なアイデンティティ情報を補い、幾何学パスウェイがレイアウトを決定するという、「何か」と「どこに/どのような向きで」のクリーンな因数分解を実現します。
学習は、MVImgNet(実世界のマルチビュー)と自動化パイプラインで合成されたSA-1Bペアを組み合わせたキュレーション済みハイブリッドデータセット上で2段階で進行します。第1段階は4×A100でバッチサイズ4、200kステップ実行し、第2段階は8×A100でバッチサイズ8、40kステップ実行します。AdamW、\beta_1=0.9、\beta_2=0.999、学習率 1\times 10^{-4} を使用します。参照のdropout確率0.1により外観シグナルに対するCFGが可能となり、inference時はEulerサンプラーで28ステップ、CFGスケール2.0を使用します。
ポーズ忠実度のメトリクスであるMatching Error(ME)は最も有益な新たな指標です。生成されたオブジェクトのマスク領域とリサイズされた I_{geo} の間でMASt3Rによる密な対応点が確立され、マッチしたピクセルの平均誤差が報告されます。これは、単にもっともらしいオブジェクトを生成しているかどうかではなく、生成が幾何学的条件を遵守しているかを直接測定します。
結果
評価セットは200ペア(MVImgNetから100、手動検証済みSA-1Bから100)で、学習データから除外されています。6つのメトリクス(PSNR、SSIM、LPIPS、CLIP-I、DINO、ME)を評価します。ベースラインは、3Dポーズ編集器(Object3DIT)または画像→3Dレンダラー(TRELLIS)と強力な2D挿入器(SDベースではAnyDoor、FLUXベースではInsertAnything)をカスケード接続することで構築されます。
報告されているSDベースのObject3DIT†+AnyDoorベースラインの部分的な数値はPSNR 19.24、SSIM 0.7…であり、DIRECTはSDおよびFLUXバックボーンの両方において全6メトリクスで一貫して最良の結果を達成します(表の全行は入手可能なテキストでは省略されていますが、主要な主張は全メトリクスでの優位性です)。機械的に意味のある結果はMEに関するものです。カスケードされたベースラインは3Dエディタのポーズ実現と2D挿入器の再解釈の両方からエラーが蓄積されますが、DIRECTの単一モデルによるRGBプロキシ条件付けはそのループを閉じます。
制限と未解決の問題
- ポーズ忠実度は変換されたプロキシの品質にボトルネックがあります。TRELLISや現在の画像→3D手法が失敗するカテゴリ—薄い構造体、透明なオブジェクト、関節を持つオブジェクト—では、I_{geo} が幾何学的guidanceを誤った方向に導く可能性があります。
- このフレームワークはポーズを指定しますが、物理的なもっともらしさ(前景のシーン要素との接触、支持、オクルージョンの順序)については推論しません。マスク M は依然としてユーザーが描く必要があります。
- 評価はカスタムのMEメトリクスによる200ペアで行われており、論文をまたがる比較にはこのメトリクスの採用が必要となります。また、ベンチマークにおけるポーズの分布は特徴付けられていません。
- 3つのパスウェイにわたるLoRA rank 128は重量級であり、どのパスウェイがMEやアイデンティティメトリクスに最も貢献するかを分離したablationは、提供されているテキストには記載されていません。
- 学習データの品質は自動化されたSA-1B合成パイプラインに依存しており、そのパイプラインの失敗モードによるバイアスが残存している可能性があります。
重要性
挿入を外観/幾何学/コンテキストのチャンネルに分解し、ユーザーが操作した3Dプロキシのテクスチャ付きRGBレンダリングを使用するアプローチは、ベースモデルを再学習させることなくdiffusionベースのコンポジットに6自由度のポーズ制御を追加するための、クリーンで実装可能なレシピです。また、レンダリングされたプロキシに対するMatching Errorを、挿入タスクにおける参照不要のポーズ忠実度メトリクスとして利用可能なものとして確立します。
Source: https://arxiv.org/abs/2606.06601
ツールが失敗したとき:LLMエージェントにおける動的リプランニングと異常回復のベンチマーク
問題
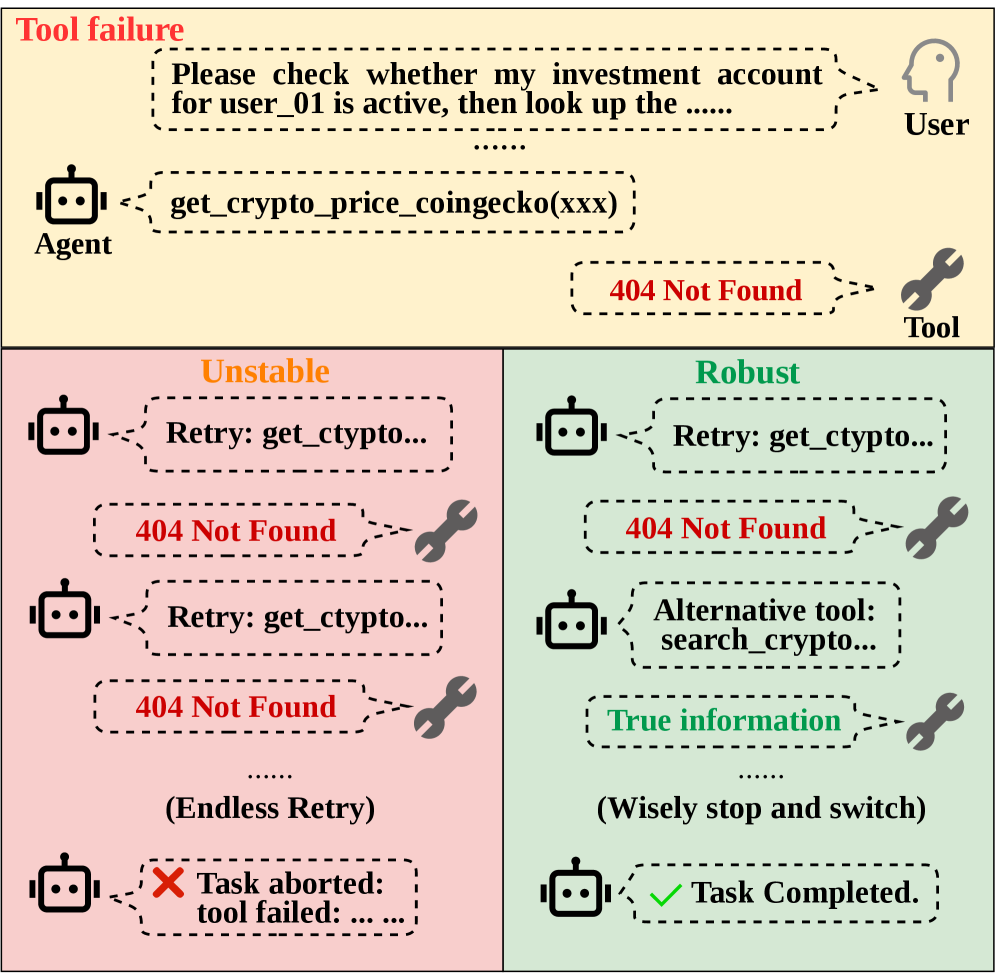
Tool-Integrated Reasoning(TIR)ベンチマークは、すべてのAPI呼び出しが期待されたペイロードを返す「ハッピーパス」においてエージェントを評価することがほとんどです。しかし実際の本番環境はそのように振る舞いません。ツールはレートリミットに引っかかり、古いまたは意味的に誤った出力を返し、非推奨化され、あるいはエラーコードとして明示されない形で壊れることがあります。そのため、既存のリーダーボードは、既知のプランを実行する能力と壊れたプランから回復する能力という、全く異なる2つの能力を混同しており、一度もリプランニングを迫られたことのないエージェントに有利な評価をしています。ToolMazeは、トポロジー的に多様なタスク全体でツールの挙動を系統的に摂動させ、エージェントが回復するかそれともリトライループに陥るかを測定することで、これらを切り離そうとする試みです。
手法
ToolMazeは、タスクの複雑度 \mathcal{C} と摂動モード \mathcal{P} からなる2次元グリッドでエージェントを評価します。
ツールコーパス。 270個の手作業でキュレーションされたツールからなり、それぞれ(i)機能カテゴリ — Source(例:get_weather)、Processor(例:temperature_converter)、Action(例:send_email、終端ノード) — と(ii)6つのドメイン(金融、旅行、オフィス、ショッピング、IoT、汎用)のいずれかにタグ付けされています。ドメインラベルはDAGサンプリングを制約しており、例えば旅行タスクが株価照会とメール送信をチェーンしないようになっています。
タスク構成。 タスクはコーパス上のDAGとしてサンプリングされ、すべての正しい形式のDAGには少なくとも1つのSourceと1つのActionが含まれ、オプションでProcessorがその間を橋渡しするという構造的不変条件を持ちます。4つの複雑度ティア \mathcal{C}1–\mathcal{C}4 は、トポロジー的な深さと分岐係数をスケールします。
摂動の分類体系。 失敗は 2\times 2 の形式で整理されます:
- 明示的vs.暗黙的:明示的失敗はエラー文字列を表面化させる;暗黙的失敗は構文的には正しいが意味的に破損した出力を返す(より難しいケース)。
- 一時的vs.永続的:一時的失敗はリトライで解消される;永続的失敗はそのツールを回避したリプランニングが必要となる。
これにより \mathcal{P}1–\mathcal{P}4 が得られます。この組み合わせ構造によって、系統的なリプランニング(暗黙的な破損を検出してツールを切り替える)と盲目的なリトライ(明示的・一時的な場合にのみ機能する)を分離することが可能になります。
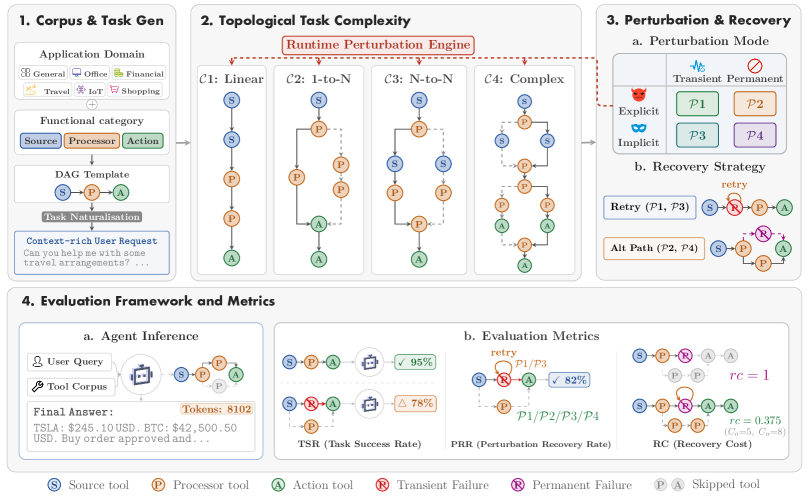
メトリクス。 3つの主要スコア:クリーンな実行下でのTask Success Rate(TSR)、摂動が注入されたことを条件としたPerturbation Recovery Rate(PRR)、および回復中に費やされた余分なツール呼び出しやトークンを捉えるRecovery Cost(RC)。TSRとは別にPRRを報告することがこの手法における中心的な工夫であり、基礎的な能力から回復スキルを切り離します。
結果
評価は、独自のフロンティアモデル(GPT-5.5、Gemini-3.1-Pro-Preview、Claude-Sonnet-4-6)とオープンウェイトモデル(GLM-5.1、Deepseek-V4-Pro、MiniMax-M2.7、Qwen3.5-35B-A3B、Qwen3.5-397B-A17B、Qwen3.6-27B)の両方をカバーしています。
主要な知見:
暗黙的な意味論的失敗が支配的な失敗モードである。 暗黙的摂動下でのPRRは明示的摂動に対して約 37% 低下します。エージェントは正しい形式のツール出力を過度に信頼し、破損した中間値を検証なしにDAGを通じて伝播させます。アンカーとなるエラー文字列がないため、リプランニングはトリガーされません。
トポロジー的な複雑度が試行錯誤的な崩壊を引き起こす。 \mathcal{C} が \mathcal{C}1 から \mathcal{C}4 へと増加するにつれ、TSRとPRRの両方が劣化し、エージェントは代替手段を探すのではなく同じ壊れたノードへの繰り返し呼び出しに陥るようになります。

ヒントプロンプティングの効果は不均一である。 エージェントにツール失敗を考慮するよう指示するプロンプト(図3の実線)は、低複雑度では性能をわずかに向上させますが、\mathcal{C}4 においてはそのギャップが縮まります。これは、ヒントが本物の検証ルーチンを実装するのではなく、表面的な挙動にバイアスをかけているだけであることと一致しています。
フォールトトレランスはベース能力よりもスケールしにくい。 最も重要な定量的主張:モデルのスケールが増大するにつれて、基本的なTSRはPRRよりも約 3.66倍 速く向上します。したがって、リプランニングはタスク実行と同じスケーリングの軌跡上にはなく、より大きなモデルは壊れたプランを修正することよりも、プランを実行することにおいてはるかに速く向上します。
限界と未解決の問題
ツールコーパスは手作業で構築されシミュレートされたものであり、実際のAPIは相関した失敗(例:地域的な障害が複数のツールに連鎖する)を示しますが、これはToolMazeではモデル化されていません。2x2摂動分類体系は粗く、部分的な劣化(例:古いが妥当に見えるデータ)は暗黙的・一時的と暗黙的・永続的の間に位置します。3.66倍のスケーリング比率は異質なモデルセットから導出されているため、学習データ、RLHF手法、ツール使用に関するpost-trainingの交絡因子をきれいに分離することはできません。さらに、このベンチマークは回復をスコアリングしますが、一部の暗黙的失敗のケースでは正しい挙動となりうる、適切に較正された棄権を報酬として与えません。
なぜ重要か
ToolMazeは、本番エージェントシステムがすでに制約条件と認識していることを測定するための明確な軸を提供します。それは、10個のツールがすべて機能しているときにチェーンできるかどうかではなく、そのうちの1つが静かに嘘をついていることに気づけるかどうかです。3.66倍のスケーリングギャップは、このギャップを埋めるためには次の事前学習ランを待つのではなく、検証モデル、出力のクロスチェック、または回復をターゲットとしたRLシグナルなど、明示的なリプランニング機構が必要であることを示唆しています。
Source: https://arxiv.org/abs/2606.05806
GENEB: ゲノムモデルの比較が困難な理由
ゲノム基盤モデルは共通の評価基盤なしに急増してきました。論文ごとに互いに交わらないタスクサブセット(Nucleotide Transformer ベンチマーク、GUE、BEND、Genomic Benchmarks、アドホックな TF binding の分割)を報告し、異なる fine-tuning プロトコルを使用し、異なるメトリクスを選択しています。その結果、スケーリング、トークン化(BPE vs. k-mer vs. 単一ヌクレオチド)、またはアーキテクチャ(Transformer vs. Mamba vs. HyenaDNA)に関する主張は、文献から直接判断することができません。
ゲノム基盤モデル論文間の引用グラフはまばらで断絶しており、ほとんどのモデルは少数の独自の先行モデルとのみ比較を行っており、推移的なランキングが存在しません。GENEBは、1つの probing プロトコルのもとで13の機能カテゴリにわたる100タスクにおいて40の凍結ゲノム FMを評価することで、この問題を解消しようとしています。
プロトコル
GENEBは各事前学習済みエンコーダを凍結し、1-shot、10-shot、およびフルデータの体制において、5つの固定シード \{13, 17, 42, 123, 997\} で平均化したシーケンス embedding に対してロジスティック回帰 probe(max_iter=1000)を適合させます。報告されるメトリクスは Matthews 相関係数であり、
\mathrm{MCC} = \frac{TP \cdot TN - FP \cdot FN}{\sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}},
クラス不均衡に対するロバスト性のために選択されています。10^5 配列を超えるタスクはサブサンプリングされます。著者らは GenomeOcean の embedding を用いて、MCC がこの閾値を超えると安定することを実験的に確認しています。2つのロバスト性チェックが報告されています:非線形(MLP)probing はランキングを保持し(Appendix E.1)、few-shot の結論は L2 正則化強度に対して非感応的です(Appendix E.2)。マクロ平均およびミクロ平均のランキングは \rho = 0.988 で一致しており(Appendix E.4)、報告された集約的な記述は重み付けのアーティファクトではありません。
probing のみの設計は意図的なものです:これは、「基盤モデル」の汎用性に関するほとんどの主張が暗黙的に対象とする fine-tuning 能力やヘッド設計から表現品質を切り離します。コストとして、有用な構造が線形読み出しよりも深い層に存在するモデルの性能を probing は過小評価します。MLP チェックはこれを部分的に対処しますが、ヘッドを調整したフル fine-tune との比較はスコープ外となっています。
結果
スケーリングは有意だが疎な関係。 40モデルにわたる \log_{10}(\text{params}) とフルショットのマクロ MCC 間のスピアマン相関は \rho = 0.565(p < 0.001)であり、ドメインミスマッチの外れ値である Evo-1-131k(原核生物のみの事前学習)を除外すると \rho = 0.685 に上昇します。
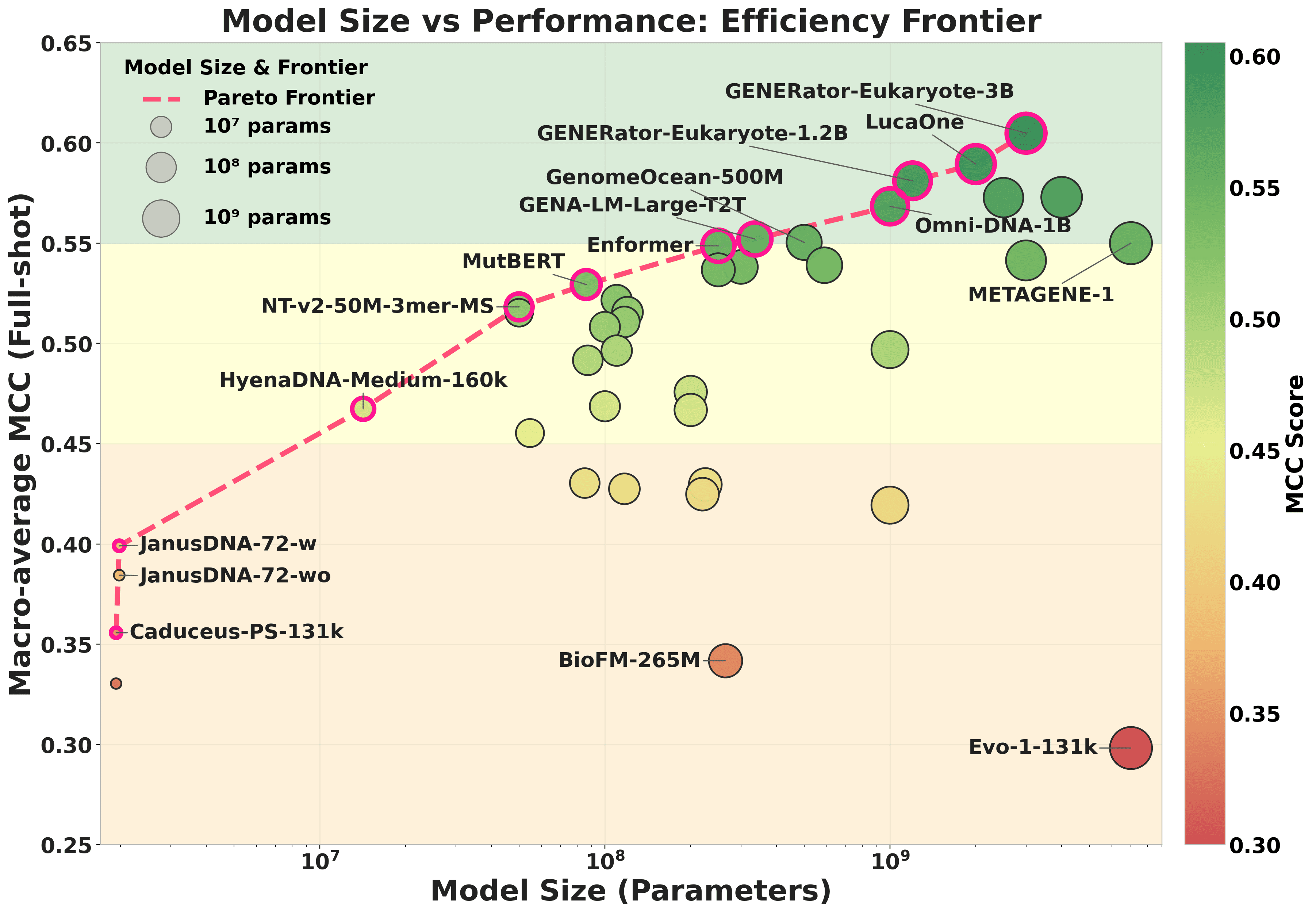
Pareto フロンティアは、フロンティアを大きく下回る大規模モデルがいくつかあることを示しています。ドメイン内の36モデル(原核生物、微生物、植物特有の事前学習を除く)の中で、著者らは少なくとも 5\times 小さいモデルが集約 MCC でより大きなモデルを上回る31の事例を発見しています。代表的な例として、MutBERT(86M、Transformer エンコーダ)は 11.6\times のサイズ差にもかかわらず eccDNAMamba(1B、Mamba SSM)を +0.110 マクロ MCC で上回っています。したがって、\log(\text{params}) はランク分散の約半分を説明し、アーキテクチャ × 事前学習コーパスのアライメントが残りの多くを説明しています。
カテゴリごとのスケーリングは異なる。 表1は \log_{10}(\text{params}) とマクロ MCC 間のカテゴリ内スピアマン \rho を報告しています。スケーリングは13カテゴリ中11カテゴリで有意(p < 0.05)であり、DNA メチル化の \rho = 0.345 からヒストン修飾の \rho = 0.579 までの範囲にあり、種分類は \rho = 0.304 で非有意となっています。この示唆するところは、長距離クロマチン状態の手がかりを伴うタスクは、局所的な配列モチーフ(例:メチル化コンテキストウィンドウ)が支配するタスクや小規模で既に捉えられている系統発生的シグナル(種)が支配するタスクよりも、スケールから多くの恩恵を受けるということです。
集約リーダーボードは不安定。 カテゴリヒートマップは実用的な結果を具体的に示しています。
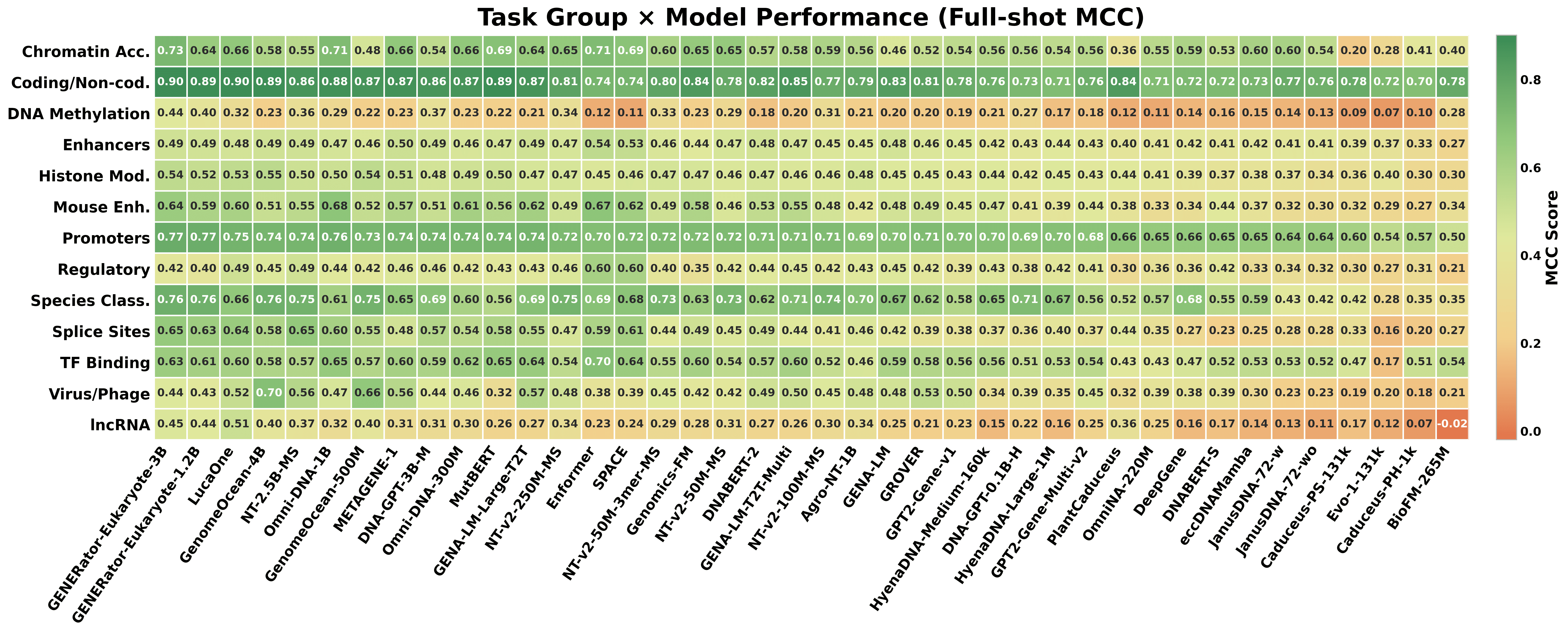
集約で最上位にランクされたモデルでさえ、すべてのカテゴリで最良というわけではなく、中位ランクのモデルが特定のカテゴリ(例:regulatory、viral、plant lncRNA)でトップに立つことがあります。したがって、特定の下流タスクに対して集約リーダーボードからモデルを選択することは系統的に最適でありません。カテゴリを考慮したモデル選択が GENEB の推奨される使用法となっています。
制限と未解決の問題
このベンチマークは probing のみで凍結表現を対象とするため、線形分離可能な構造は弱いが fine-tuned 性能が強いモデルは実際よりも悪く見えます。また、ロジスティック回帰 probe は非線形多様体をコンパクトにエンコードする表現にもペナルティを与えます。MLP probe のロバスト性チェックは助けになりますが、集約のみで報告されています。タスクスイートは真核生物に偏っており、真核生物の中でもヒトに偏っているため、非モデル生物および微生物の設定が過少に表現されています(これが Evo-1-131k が適切に特化したものとしてではなく、外れ値として見える理由です)。プロトコルは長コンテキストモデリングを個別に評価しておらず、10^5 配列を超えるタスクはサブサンプリングされ、有効コンテキスト長を揃えた制御比較はありません。最後に、1ショット体制あたり 40 \times 100 = 4000 の probe 適合があることを考えると、カテゴリ別の主張に対する多重比較補正は抜粋中に詳述されていません。
未解決の問題:(i)アーキテクチャ対スケールのトレードオフはヘッド fine-tuning を経ても残るのか、それとも消滅するのか?(ii)スケールを制御した後の残差を駆動する事前学習コーパスの軸(分類学的幅、リピートマスキング、regulatory エンリッチメント)はどれか?(iii)カテゴリ異質性のどれほどがトークナイザーの粒度(単一ヌクレオチド vs. BPE vs. 6-mer)によって説明されるか?
この研究の意義
GENEBは、集約的な「最良のゲノム基盤モデル」という主張が適切に定義されていないことを実証的に示しています:ランキングはカテゴリによって大きく変動し、スケールは集約シグナルの約 \rho \approx 0.6 分を獲得し、11\times 小さい適切にアライメントされたモデルが1Bパラメータの不一致モデルを上回ることがあります。実践者にとって、これはカテゴリを考慮したモデル選択が必須であることを意味します。モデル開発者にとっては、次の性能向上がさらなるパラメータ数の桁の増加よりも、事前学習コーパスとトークナイザー設計から得られる可能性が高いことを意味しています。
Source: https://arxiv.org/abs/2606.04525
dots.tts テクニカルレポート
dots.tts は、Xiaohongshu と SJTU X-LANCE が開発した 20 億パラメータの連続自己回帰型 TTS foundation model です。本システムは、連続潜在自己回帰型 TTS に繰り返し現れる障害モード、すなわち AR ループが高次元の音響潜在変数に直接回帰しなければならない長いロールアウト中のドリフトと不安定性を標的としています。その貢献として、予測に適した潜在変数のための AudioVAE、全履歴条件付きの AR flow-matching head、報酬不要の自己修正型 post-training ステージ、そして低レイテンシ推論のための CFG-aware MeanFlow distillation が挙げられます。
アーキテクチャ
バックボーンは表現学習と自己回帰モデリングを分離しています。個別に学習された凍結済みの AudioVAE が、48 kHz モノラル音声を 25 Hz での 128 次元潜在変数にマッピングします(時間方向に 1920\times ダウンサンプル)。デコーダには BigVGAN スタイルを採用しています。AR バックボーンは、セマンティックエンコーダ、事前学習済みテキスト LLM から初期化された LLM、および自己回帰 flow-matching head(AR-FM)の 3 つのコンポーネントで構成されます。
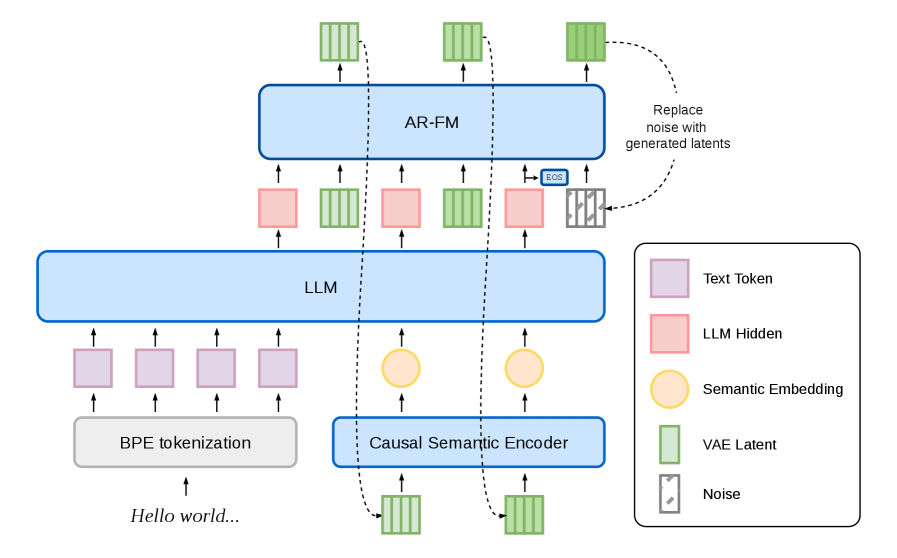
LLM は BPE テキストトークンと 6.25 Hz の音響セマンティックストリームをインターリーブして入力とし、各音声ステップにつき 1 つの隠れ状態 h_n を出力します。AR-FM head は h_n を条件として、次の 4 フレーム分の 25 Hz VAE 潜在変数パッチ Z_n \in \mathbb{R}^{4\times 128} を生成します。重要なのは、生成されたパッチが生の潜在変数として LLM にフィードバックされないことです。代わりに、パッチは AudioVAE の学習から再利用されたセマンティックエンコーダを通じて再射影され、単一の 6.25 Hz セマンティック embedding が生成され、それが LLM の次ステップの入力となります。著者らは、このセマンティックのみのフィードバックが連続 AR ロールアウトの安定化に不可欠であることを報告しており、生の VAE 潜在変数を LLM にフィードバックすると長い生成が不安定になることが示されています。
2 つの動作モードがサポートされています。テキストをプレフィックスとするプレーンな TTS モードと、低レイテンシストリーミングのための 1 テキストトークンと 1 音声ステップを交互に処理する 1T1A インターリービングモードです。
全履歴条件付き AR flow-matching head
AR-FM head は音響生成器です。標準的な flow-matching TTS head は各パッチを現在の LLM 隠れ状態のみを条件として生成するため、パッチ境界をまたいだ音響的連続性が制限されます。dots.tts では代わりに、C = (h_1, \ldots, h_N) を LLM 隠れ状態(ブロックサイズ 1)、Z = (Z_1, \ldots, Z_N) を潜在パッチ(ブロックサイズ L=4)として、全シーケンス [C \mid Z] 上でブロック因果 transformer を動作させます。学習時はブロック因果マスクを使用し、Z_n の各トークンが C_{1:n} および Z_{1:n-1} の全体に加えて自身のブロックに attention できるようにします。推論時は KV caching によって全履歴を左側に保持し、ステップ n では (h_n, Z_n) のみを追加します。RoPE の position ID は絶対時間に揃えられています。
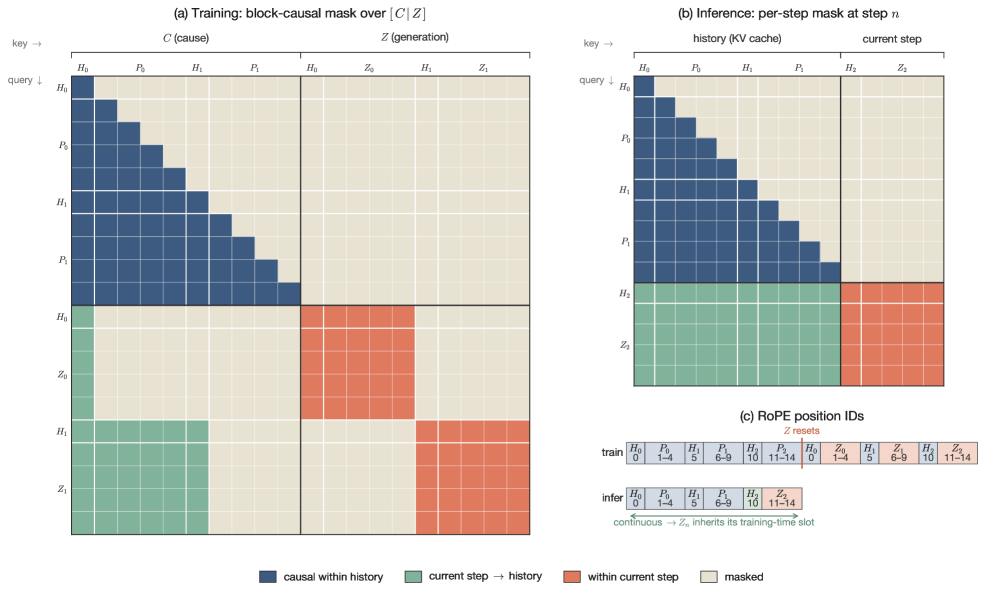
この全履歴条件付けにより、Z_n 上の flow-matching ODE がすべての事前生成音響に依存できるようになり、パッチ境界の不連続性と蓄積ドリフトが軽減されます。
報酬不要の自己修正型 post-training
教師あり flow-matching の事前学習後、AR-FM head は報酬モデルを使わずに post-training されます。この手続きでは head を自身のロールアウトに曝露させ、ドリフトしたプレフィックスからクリーンなターゲットを回帰するよう学習させます。これは実質的にロールアウトのデノイジングステップであり、teacher-forced flow matching に固有の学習と推論のギャップを解消するものです。セマンティックのみのフィードバックパスと組み合わせることで、これが連続 AR における誤差の蓄積に対する本システムの主たる解答となっています。
推論の高速化
低レイテンシ展開のために、head は CFG-aware MeanFlow distillation によって蒸留され、classifier-free guidance と多ステップ ODE を少数の関数評価に集約します。
データと結果
バックボーンは 150 万時間の音声(フィルタリング後 120 万時間)で学習されており、社内の中国語・英語データに加えて厳選されたオープンな ASR/TTS コーパスと少量のキャプション対付きセットから構成されます。前処理では、英語・その他言語に Whisper-Large-v3 を、北京語に Paraformer を使用し、クロス ASR 一貫性、実効帯域幅推定、UTMOS、クリップ内 x-vector 分散をフィルタとして適用しています。
Seed-TTS-Eval において、dots.tts は zh / en / zh-hard でそれぞれ WER 0.94% / 1.30% / 6.60%、SIM スコア 81.0 / 77.1 / 79.5 を報告しており、3 分割の平均でベストであると主張しています。著者らはさらに、MiniMax-Speech 多言語テストセット、CV3-Eval(クロスリンガル音声クローニング)、EmergentTTS-Eval(表現力)においてオープンソース SOTA を達成したと報告していますが、これらのベンチマークの具体的な数値は抜粋には含まれていません。
限界と未解決の問題
本報告書では、提供されているセクションにアブレーション研究を通じた 3 つの貢献(AudioVAE の目的関数、全履歴条件付け、自己修正型 post-training)それぞれの限界寄与を定量化していないため、Seed-TTS での改善がデータ規模によるものかアーキテクチャの選択によるものかは不明確です。セマンティックのみのフィードバックパスは実用的な安定化手法ですが、AR ループから音響的詳細を捨ててしまうため、非常に長いコンテキストにわたる韻律制御のボトルネックとなるかどうかは未解決です。zh-hard における 6.60% の WER は絶対値として依然高い水準にあります。また、多目的 AudioVAE のレシピ(第 2.2 節)と正確な自己修正目的関数は抜粋に詳述されておらず、レポートのみからの再現性が制限されています。
この研究の意義
連続潜在自己回帰型 TTS は、理論的な忠実性において優れているにもかかわらず、安定性において離散トークン系のシステムに遅れをとってきました。dots.tts は、予測に適した VAE、全履歴 flow-matching、ロールアウト対応の post-training を組み合わせることで、連続 AR システムがオープンソース規模で競争力のある Seed-TTS WER/SIM を達成できることを示しており、連続トークンのアプローチを実用的な TTS foundation model として実現可能なものにしています。
Source: https://arxiv.org/abs/2606.07080
Hacker News Signals
Tokenomics: エージェント型ソフトウェアエンジニアリングにおけるトークン消費の定量化
Source: https://arxiv.org/abs/2601.14470
SWE-benchのエコシステムから生まれた論文で、エージェント型コーディングパイプラインの全ライフサイクルにわたるトークン消費をプロファイリングしています。中心的な問いは「固定されたトークン予算が与えられた場合、それは実際にどこへ消費されるのか——コンテキスト検索、計画立案、コード生成、テスト実行フィードバック、re-rankingのどこか?」というものです。著者らはSWE-bench Verifiedのタスク上で動作するいくつかのエージェント型フレームワーク(ClaudeおよびGPT-4oをベースに構築されたものを含む)に計測機器を組み込み、パイプラインの各ステージ別にトークン消費を分解しています。
主要な知見として、コンテキストのロード——関連するリポジトリファイルをプロンプトに詰め込む処理——が全トークン使用量を支配しており、コードが1行も生成される前に予算の60〜80%を消費することが多いという点が挙げられます。コード生成そのものが占める割合はごく僅かです。本論文では「token efficiency」指標として「100万トークンあたりの解決済みissue数」を導入しており、これによってコスト調整済みの性能でアーキテクチャを比較することができます。ファイルを丸ごと詰め込むナイーブな retrieval-augmented アプローチは、スニペットレベルあるいはシンボルレベルの検索と比較して効率が著しく低いことが示されています。また著者らは、re-rankingや自己修復ループ(テストを実行して失敗をフィードバックする処理)はトークンコストが高い一方で、トークン当たりの限界リターンも高く——初期コンテキストを拡張するよりもROIが優れている——ことを示しています。
システム構築者への実践的な示唆は、ボトルネックが生成品質ではなくコンテキストのキュレーションにあるという点です。過剰な検索(over-retrieval)が主要な非効率の原因であり、各ターンで同じボイラープレートを再エンコードするマルチターンループにおいてその影響は複利的に積み重なります。本論文では、構造化された表現(例えば生ソースコードではなくシンボルグラフ)を用いることで、検索のrecallを犠牲にすることなくコンテキストのフットプリントを大幅に削減できる可能性があると提案しています。
限界点としては、分析が特定のベンチマークタスクに紐付いており、実世界のリポジトリの多様性やタスクの長さの分布を反映していない可能性があることが挙げられます。また、トークナイザーの違いによってモデルプロバイダー間でトークン数が大きく異なるため、モデル間の比較にはノイズが生じます。
Linearがなぜこれほど速いのか:技術的な詳細分析
Source: https://performance.dev/how-is-linear-so-fast-a-technical-breakdown
プロジェクト管理アプリ「Linear」のクライアントサイドパフォーマンスについて、詳細なリバースエンジニアリングとアーキテクチャ分析を行った記事です。知覚的な軽快さを説明するいくつかの具体的な手法が取り上げられています。
中心的なメカニズムは、WebAssembly(具体的には wa-sqlite や類似のバインディング)を介してブラウザ上で完全に動作するインメモリSQLiteデータベースです。すべての読み取りはUIスレッドの観点からローカルかつ同期的に行われ、クエリのためにサーバーへの往復レイテンシが発生しません。アプリはユーザーデータの完全なローカルレプリカを保持し、カスタムの同期プロトコルを介してインクリメンタルに同期します。これは「local-first」アーキテクチャパターンですが、高い工学的厳密さをもって実装されています。
書き込みはオプティミスティックに行われます。UIの状態はユーザーアクションに対して即座に更新され、ミューテーションはバックグラウンドでサーバー同期のためにキューに入れられます。コンフリクト解決は、エンティティの種類に応じてlast-write-winsまたはベクタークロックスキームに従います。同期レイヤーはフルドキュメント置換ではなくログ構造のデルタフォーマットを使用しており、帯域幅を低く抑え、オフライン後の再接続を低コストにします。
レンダリング側では、アプリはReactを使用しつつも、積極的なmemoizationと長いissueバックログに対する仮想化リストを活用しています。特筆すべきは、SQLiteレイヤーによって派生ビュー(フィルタリング・ソートされたissueリスト)がJavaScript配列操作ではなくインメモリストアに対する実際のSQLクエリとして計算される点で、大規模なデータセットに対してより高速であり、正確性の検証も容易です。
この分析ではさらに、(webビュー上に構築された)LinearのElectron的なデスクトップアプリが、ナビゲーション間でWASM SQLiteを永続化できることから恩恵を受けており、ブラウザのタブをリフレッシュした際に生じるコールドスタートのコストを回避できる点も指摘されています。
未解決の問題はスケーリングです。完全なローカルレプリカは典型的なチーム規模では良好に機能しますが、ユーザーごとのデータ量の上限が重要になります。この記事では、非常に大きなワークスペースを持つユーザーやマルチ組織アクセスをLinearがどのように処理するかについては十分に論じられていません。
Zeroserve: eBPFでスクリプティング可能なゼロコンフィグWebサーバー
Source: https://su3.io/posts/introducing-zeroserve
Zeroserveは、eBPFを主要な拡張機構として公開する最小構成のHTTPサーバーです。ユーザー空間に組み込まれたプラグインAPIやスクリプト言語を用いるのではなく、リクエスト処理ロジックはeBPFプログラムとして記述され、サーバーの処理パイプラインにアタッチされ、カーネルの検証済みVM上で実行されます。
アーキテクチャとしては、Nginxが「フェーズ」と呼ぶものに類似したフックポイント(例:post-parse、pre-response)にeBPFプログラムをアタッチします。各フックは、BPF mapのルックアップを通じてアクセス可能なリクエストメタデータ(メソッド、パス、キーバリューペアとしてのヘッダー)を含むコンテキスト構造体を受け取ります。レスポンスはeBPFプログラムから直接ショートサーキットすることが可能であり、単純なケース(静的リダイレクト、ヘルスチェック、レートリミットによる拒否)ではユーザー空間に入ることなくレスポンスが生成されます。これが主要なパフォーマンス上の主張、すなわち一般的なファストパスにおけるカーネルバイパスの根拠です。
「ゼロコンフィグ」という主張は、サーバーが設定ファイルなしで起動することを意味します。すべての挙動は起動後にbpf()システムコールを通じて注入されるため、BPFオブジェクトをロードできる任意のオーケストレーションレイヤーと組み合わせて利用できます。作者はプログラムのロードとピン留めを行うための小規模なユーザー空間ライブラリを提供しています。
ここで動作するeBPFプログラムは、標準的なカーネルベリファイアの制約(無制限ループの禁止、スタックの制限、任意メモリアクセスの禁止)のもとで実行されます。これにより表現力は制限される一方で、安全性が確保されます。複雑なロジック(データベースルックアップ、テンプレートレンダリング)には依然としてユーザー空間コンポーネントが必要であり、eBPFはルーティングとフィルタリングの層を担当します。
これは、カーネルネットワーキング(生パケット向けのXDP/TC)とユーザー空間のHTTPフレームワークの中間という設計上の位置づけとして興味深いものです。ソケット層より上、従来のWebフレームワークより下に位置し、カーネルに近い状態を保ちながらHTTPレベルのセマンティクスを捉えます。主要な未解決の問題は、ほとんどのワークロードにおいてeBPFの複雑さによるオーバーヘッドが単純なユーザー空間ルーターと比較して見合うかどうか、そしてロジックがカーネルとユーザー空間に分散している場合のデバッグと可観測性がどのように機能するかという点です。
Sem: コード理解のための新しいプリミティブ — Git上のエンティティ層
Source: https://ataraxy-labs.github.io/sem/
Semは、生のgit履歴とIDEレベルの言語サーバーの間に位置するレイヤーを提案します。具体的には、コードエンティティ(関数、型、モジュール)を時系列で追跡し、永続的かつクエリ可能なストアとして管理するものです。基本単位はファイルのdiffではなく、リネームやリファクタリングを経ても安定したアイデンティティを持つセマンティックエンティティです。
コアデータモデルは、エンティティのアイデンティティ(名前・囲むスコープ・構造的シグネチャの組み合わせから導出)から、各バージョンのタイムラインへのマッピングを保持します。各バージョンはgitコミットに紐付けられています。これは精神的にはgit log -Sがテキストに対して行うことに近いですが、パース済みのASTノードを対象として動作します。関数がリネームされたり別ファイルへ移動されたりした場合、semはAST diffに対する類似度ヒューリスティックによってアイデンティティの連続性を維持しようとし、ファイルレベルのgitが見てしまう「削除+新規作成」という誤った解釈を回避します。
クエリインターフェースは次のようなことを可能にします:「コミットYの時点で関数Xを呼び出しているすべての呼び出し元を表示する」「これら二つのタグ間で構造体Zの型シグネチャに何が変わったか」「このバグ修正と同じコミットで変更されたすべてのエンティティを探す」などです。これらは生のgit + grepで効率的に回答することが困難です。なぜなら、ファイルをまたぎ、コミットをまたいだセマンティックなjoinが必要だからです。
実装にはtree-sitterを使用して言語非依存なパースを実現しており、言語ごとのプラグイン不要で、tree-sitter grammarが存在する任意の言語をサポートします。コミット間のエンティティアイデンティティはgit logのトラバーサル時にインクリメンタルに計算され、ローカルのSQLiteデータベースに格納されます。
LSPとの違いは重要です:LSPはファイルスナップショット単位でステートレスであり、履歴の概念を持ちません。Semは履歴を最優先にします。git blameのようなツールとの違いは、粒度がサブファイル(エンティティレベル)であり、かつ連続性のトラッキングが構造的な変更を扱える点にあります。制限事項としては、大規模なリファクタリングに対するアイデンティティヒューリスティックの脆弱性と、大規模リポジトリにおけるブートストラップコストが挙げられます。
Symbolica 2.0: PythonとRustのためのプログラマブルシンボル
Source: https://symbolica.io/posts/symbolica_2_0_release/
Symbolicaは、Rustで実装され、Pythonバインディングを持つ数式処理システム(CAS)であり、式が日常的に数百万の項を含む高エネルギー物理計算をターゲットとしています。バージョン2.0では、プログラマブルな記号操作を中心とした複数の機能が追加されています。
コアデータ構造は、カスタムのhash-consed項木を用いた多変数多項式および有理関数のコンパクトな表現です。項はソートされた重複排除形式で格納されており、正規化が手続きではなく構造的な性質となっています。これにより、完全な簡略化パスを経ずとも、大きな式における等価性チェックが効率的に行えます。
2.0の目玉機能は「条件付きパターンマッチング」です。これは、パターンがマッチした部分式に対して任意のRust/Pythonの述語を持てる項書き換えシステムです。構文的なマッチングを超えており、「1/2より大きい有理数である任意の部分式にマッチする」といったルールを記述して変換を適用することができます。パターン言語は、ワイルドカード、シーケンスパターン(任意個数の引数にマッチ)、および名前付きキャプチャをサポートしています。
もう一つの主要な追加機能は、ある点周りのローラン級数展開のためのSeries型であり、係数の遅延評価をサポートしています。指定された打ち切り次数に必要な項のみが計算される仕組みです。これは、小さなパラメータで展開し、最初の数次のみを必要とする物理計算において重要です。
パフォーマンスは主要な設計目標であり、2.0リリースでは、改良されたZippelおよびスパース多変数GCDアルゴリズムにより、多項式GCDと因数分解のベンチマークにおいて1.x比で3〜10倍の高速化が達成されたと報告されています。PythonバインディングはPyO3を使用しており、大きなオーバーヘッドなしに完全なAPIを公開しています。
Symbolicaは商用利用が無料ではないため、sympyやFORMと比較して普及が制限されます。未解決の問題は、FORM(素粒子物理学のデファクトスタンダード)に対するパフォーマンス上の優位性が、エコシステムの慣性を乗り越えるのに十分かどうかという点です。
Open Code Review: AI搭載のコードレビューCLIツール
Source: https://github.com/alibaba/open-code-review
Alibabaのopen-code-reviewは、LLM APIをラップしたCLIツールであり(設定可能;デフォルトはQwenだがOpenAI互換エンドポイントもサポート)、プルリクエストのレビューを自動化します。技術的な核心は、レビュープロンプトの構築方法とモデルへの送信内容にあります。
本ツールはgit diffを呼び出して指定されたコミット範囲またはPRのパッチを抽出し、コンテキスト制限内に収めるためのチャンキング戦略を適用します。具体的には、まずファイル境界でdiffを分割し、単一ファイルのdiffが閾値を超える場合はhunk境界でさらに分割します。各チャンクは独立してレビューされ、結果は集約されます。この手法により、diffをhunkの途中で切り捨てるという一般的な失敗パターンを回避しています。
プロンプトエンジニアリングには構造化出力のリクエストが含まれており、モデルはseverity(blocking/warning/info)、ファイル、行範囲、カテゴリ(例:security、performance、correctness、style)、説明といったフィールドを持つJSONスキーマ形式でレビューを出力するよう指示されます。CLIはseverityやカテゴリでフィルタリングし、GitHub APIを介したGitHub PRコメント形式またはプレーンテキストとして出力をフォーマットできます。
「context injection」機能も備えており、追加ファイル(例:プロジェクト固有のスタイルガイド、アーキテクチャドキュメント)をレビュープロンプトの先頭に背景情報として付加することができます。これはseparatorを用いた単純な結合によって処理されており、retrieval-augmentedではありません。コンテキストファイル全体が毎回含まれます。
セキュリティ上の注意点として、本ツールはデフォルトでdiffを外部APIエンドポイントに送信します。内部コードベースに使用する場合は、セルフホストモデルを利用するか、エンドポイントをプライベートデプロイメントに慎重に設定する必要があります。
主な制限として、チャンクを独立してレビューするアプローチではファイル間のコンテキストが失われる点が挙げられます。インターフェースの変更とそのすべての実装が別々のチャンクでレビューされると、チャンクをまたがる一貫性の問題を見逃す可能性があります。また、チャンク間での重複コメントの重複排除も粗雑です。
Redis 8.8: 新しい配列データ構造、レートリミッター、パフォーマンス改善
Source: https://redis.io/blog/announcing-redis-8-8/
Redis 8.8 では、注目すべき3つの追加機能が導入されています。1つ目はネイティブの Array データ型で、O(1) のインデックスアクセスを持つ密な順序付きシーケンスです。これはこれまでのギャップを埋めるものです。Redis にはリスト(連結リストのセマンティクス、O(N) インデックス)、ソート済みセット(スコア順、O(log N))、ストリームがありましたが、真の O(1) ランダムアクセスを持つフラットな配列は存在していませんでした。実装では連続したメモリレイアウトにキャパシティ・長さのヘッダーを用い、realloc スタイルの成長戦略と通常の Redis メモリアロケーターフックを採用しています。インデックスアクセスパターンがランダムな時系列バッファや固定サイズのスライディングウィンドウなどのユースケースに適しています。
2つ目の追加機能は、組み込みのレートリミッターコマンド RATELIMIT.THROTTLE です。これは GCRA(generic cell rate algorithm、仮想スケジューリングを伴うリーキーバケットとも呼ばれる)を実装しています。このコマンドはアトミックであり、単一のキーに対して動作し、キャパシティ、補充レート、要求トークン数を引数として受け取り、リクエストが許可されるかどうか、残余キャパシティ、リセット時刻を返します。これにより Lua スクリプトで GCRA を実装するという一般的なパターンが置き換えられ、高速(Lua インタープリターのオーバーヘッドなし)かつセマンティクスが明確になるという利点があります。
8.8 のパフォーマンス改善には、読み書きのシステムコールをスレッド間でより積極的に分離する I/O スレッドモデルの刷新が含まれており、混在した読み書きワークロード下でのヘッドオブラインブロッキングを低減します。アナウンスに引用されたベンチマークでは、高接続数における pipeline 化された混在ワークロードで 15〜25% のスループット改善が示されています。
このリリースでは、LFU エビクションのための OBJECT FREQ の精度も改善されており、より高分解能なカウンターの減衰関数への切り替えが行われています。
注目すべき欠如点として、大規模デプロイにおける共通の課題であるマルチテナンシーやクラスターリバランシングの改善については、依然として進展が見られません。また、GCRA レートリミッターはキー単位で動作するため、キーをまたいだグローバルなレート制限にはアプリケーションレベルでの調整が引き続き必要です。
Python JITプロジェクトに開発一時停止が要請される
Python Steering Councilは、copy-and-patch JITコンパイラ(CPython 3.13に実験的に導入)に対して、活発な開発を一時停止するよう要請しました。アナウンス自体は簡潔ですが、その技術的な背景は相当に複雑です。
Brandt Bucherが設計したcopy-and-patch JITは、各バイトコード命令に対してテンプレートのマシンコードスタブを事前コンパイルし、実行時にそれらを「コピーしてパッチする」——つまりオペランドのアドレスや定数を埋め込む——ことでネイティブコードシーケンスを組み立てます。IRも、レジスタアロケータも、オプティマイザも必要とせず、本質的には高速なテンプレートのインスタンス生成器です。このデザインはメンテナビリティを考慮して選択されており、既存の特殊化適応型インタープリタの命令セットから直接コードを生成し、同じバイトコードセマンティクスを再利用します。
問題は、このJITが実際には意味のある高速化をもたらしていないことです。CPython 3.13のベンチマークでは、標準ベンチマークスイートにおいてJITが提供する改善は約1〜5%にとどまり、一部のワークロードではリグレッションも見られます。根本的な問題は、copy-and-patchが命令の境界をまたいだ最適化なしにコードを生成している点にあります——インライン化も、デッドコード削除も、テンプレートに組み込まれた以上のレジスタ割り当ても行われません。各テンプレートは個別には正しいものの、その組み合わせは最適化されていないのです。
Steering Councilの懸念は、JITがプラットフォームごとのコード生成サポートを必要とし、ビルドシステムを複雑化させているという継続的なメンテナンスコストに対して、それに見合うパフォーマンスの向上が得られていないことにあるようです。今回の一時停止はキャンセルではなく、Councilはより明確なロードマップを求めています。
より深い技術的な問題は、適切なIR(PyPyのRPythonやMLIRベースのアプローチのような)を備えた、より野心的なJITがCPythonの開発モデルの中で実現可能かどうかという点です。copy-and-patchアプローチは意図的に最小限のスコープで設計されており、コミュニティは今後、根本的により高い能力を持つものへ投資するか、CPythonのパフォーマンス上限はインタープリタのアーキテクチャによって規定されるものとして受け入れるか、という選択に直面しています。
注目の新規リポジトリ
perplexityai/bumblebee
インストール済みパッケージ、IDE拡張機能、CLIツール、および関連する設定ファイルといった開発者環境のメタデータを対象とした、読み取り専用のセキュリティスキャナーです。主な懸念事項はソフトウェアサプライチェーンの侵害、すなわち悪意あるパッケージ、タイポスクワッティングされたライブラリ、または公開開示後も開発者マシン上に残存するバックドア入り拡張機能です。Bumblebeeはパッケージマネージャー(npm、pip、cargoなど)および拡張機能レジストリを横断してディスク上のアーティファクトを列挙し、既知の侵害済み識別子のデータベースと照合します。この際、ファイルシステムへの変更は一切行いません。読み取り専用という制約は意図的な設計上の選択であり、CI環境での実行、インシデント対応中、あるいは副作用が許容されない共有ビルドマシン上でも安全に使用できます。Perplexity AIが社内で開発したツールであるため、このスキャナーは開発サプライチェーンをスケールで保護する上での実際の運用上の懸念を反映しています。このツールはインシデント後のトリアージにおいて特に有用であり、CVEや侵害されたパッケージ名が与えられた場合に、オペレーターが開発者ワークステーションやCIランナーのフリート全体を対象に被害状況をスキャンできます。メタデータのみを対象とするスコープにより、高速な動作を実現するとともに、フルSASTで発生しがちな誤検知の余地を排除しています。osqueryやsyftといったツールと並べて、多層防御パイプラインに自然に組み込める構成です。
Source: https://github.com/perplexityai/bumblebee
amElnagdy/guard-skills
コーディングエージェントのパイプラインに組み込むことを想定した、品質ゲート用「スキル」のコレクションです。LLMがループ内でツールを呼び出しながらコードを生成するワークフローを想定しています。課題は、LLMが生成するコードが特徴的かつ再現性のある形で失敗する点にあります(存在しないimportのハルシネーション、エラーハンドリングの欠如、常にパスするテストスタブ、実装とドキュメントコメントのズレなど)。Guard-skillsは、こうした失敗パターンを検出するデテクターを、エージェントやオーケストレーターが出力をコミットする前に呼び出せる、組み合わせ可能なチェックとして実装しています。各スキルは独立したバリデーターであり、入出力のコントラクトが明確に定義されているため、LangChain、AutoGen、あるいはカスタムのtool-callループなどのフレームワークへ容易に組み込むことができます。カバレッジの範囲は、構文とimportの検証、テスト品質のヒューリスティクス(無意味なアサーションやカバレッジの見せかけの検出)、ドキュメントの一貫性チェックにわたります。このプロジェクトは、AIが生成した成果物を信頼できない外部入力と同様の懐疑心をもって扱うべきという考え方を明確に打ち出しています。SWE-agentや社内のコード生成パイプラインを構築するチームにとって、このプロジェクトは既存の空白を埋めるものです。ほとんどのエージェントフレームワークには、「コンパイルが通るか」以上の構造化された生成後品質レイヤーが存在しないからです。生成ステップごとに実行しても大きなレイテンシオーバーヘッドが生じない、軽量な設計となっています。
Source: https://github.com/amElnagdy/guard-skills
1ove9/antenna-forge
実際の電磁シミュレータをループに組み込んだ、MLによる逆アンテナ設計システムです。ユーザーが目標とするSパラメータまたは放射パターンを指定すると、それに一致するアンテナ形状をシステムが探索します。重要な技術的詳細として、順モデルがサロゲートニューラルネットワークではなく、実際のNEC2(Numerical Electromagnetics Code)およびopenEMS(有限差分時間領域法)シミュレーションが探索中に呼び出される点が挙げられます。これにより計算コストを代償に物理的な忠実性が保たれます。AIコンポーネントは逆問題を担当し、網羅的なシミュレーションスイープを行わずに形状空間を効率的に探索します。その手法は、Bayesian optimizationや、高コストなフルウェーブ評価前の安価な事前フィルタリングのための学習済みサロゲートによるものと考えられます。ブラウザ上で動作するplaygroundにより、ローカルへのシミュレータインストールなしで実験が可能です。NEC2やopenEMSのセットアップには相当な手間がかかるため、これは非常に有用です。特定の周波数帯やフォームファクタ向けにカスタムアンテナを試作するRFエンジニアや研究者にとって、標準的な設計では不十分な場面において本システムは重要な意味を持ちます。電磁モデルの正確性が絶対条件である場合には、エンドツーエンドのニューラル近似ではなく、学習ベースの探索と物理的に精密なシミュレーションを組み合わせるアプローチが適切なトレードオフと言えます。
Source: https://github.com/1ove9/antenna-forge
gi-dellav/zerostack
Rustで実装された最小構成のcoding agentであり、メモリフットプリントの最小化とスループットの最大化を明示的な設計目標としています。ほとんどのcoding agentはPythonベースであり、インタープリタのオーバーヘッド、GCプレッシャー、大規模な依存ツリーといったランタイムコストは対話的な用途では許容範囲ですが、多数のagentインスタンスを並列に実行する際にはボトルネックとなります。これはSWE-bench形式の評価ハーネスやCIに統合された自動修復において一般的なパターンです。Zerostackはそのニッチをターゲットとしており、コード生成およびtool-callループを予測可能なリソース消費で駆動できる、小さくて自己完結したバイナリです。Rustによる実装により、アロケーションパターンを厳密に制御でき、agentループにおけるレイテンシ測定を歪める可能性のあるガベージコレクションの停止を回避できます。アーキテクチャは標準的なagentループ(LLM call → tool dispatch → observation → repeat)に従っていますが、スタンドアロン製品としてではなく、より大きなシステムへの組み込みを念頭に設計されています。同一マシン上に数十〜数百のagentワーカーを共存させる必要がある場合や、agentランタイム自体がコンテナサイドカーやエッジデバイスのような制約された環境に収まらなければならない場合など、インフラ構築に携わる方に関連する内容です。
Source: https://github.com/gi-dellav/zerostack
tastyeffectco/sandboxd
Kubernetesやクラウドコントロールプレーンなしでシングルコマンドから、公開アクセス可能なプレビューURLを持つ隔離された開発環境をプロビジョニングするセルフホスト型サンドボックスデーモンです。コンテナ化されたワークスペースを立ち上げ、リバースプロキシルーティングを処理してサンドボックスごとのURLを生成します。これは進行中の作業の共有、ライブURLに対するエンドツーエンドテストの実行、あるいはエージェント型コーディングセッション中にコーディングエージェントがインタラクションできるアドレス可能なHTTPエンドポイントの提供といった用途に有用です。Kubernetesを不要とする制約は重要な意味を持ちます。比較可能なほとんどのツール(セルフホスト版のGitpod、Coder)は大きな運用オーバーヘッドを伴うためです。Sandboxdは小規模チームおよび「SaaSファクトリー」——多数の短命な環境を素早く立ち上げるラピッドプロトタイピング工房——を対象としています。エージェント型コーディングの観点では、プログラム的にサンドボックスを作成し、エージェントをそのURLに向け、終了後にティアダウンするという一連の流れが、tool-callのパターンにきれいに適合します。シングルコマンドのUXは、実際の隔離レイヤーとしてDocker Composeまたは軽量なコンテナランタイムを使用していることを示唆しています。完全なプラットフォームというよりはインフラのグルーとして有用ですが、フルVM型サンドボックスと比べてセキュリティ境界が薄いというトレードオフがあります。
Source: https://github.com/tastyeffectco/sandboxd
SouravRoy-ETL/duckle
ローカルファーストなビジュアルETL/ELTパイプラインデザイナーで、データフローグラフをSQLにコンパイルしてDuckDB上で実行します。ユーザーはデスクトップGUIのドラッグ&ドロップでパイプラインを構築し、バックエンドが生成したSQLをDuckDBがインプロセスで実行します。つまり、外部データベース、ネットワーク、オーケストレーションサービスは一切不要です。コンパイルターゲットがPython/Sparkコードではなく平易なSQLであるという点が、このアーキテクチャ上の重要な設計判断です。出力は監査可能で、バージョン管理でき、移植性も高く、パイプラインはgitフレンドリーなディレクトリ構造のSQLファイルとして保存されます。DuckDBのカラム型エンジンは、ローカルのParquet、CSV、JSONファイルに対する分析ワークロードを十分な効率で処理するため、中小規模のデータ変換ジョブの多くは分散システムを必要としません。デスクトップアプリという形態(おそらくTauriまたはElectronがローカルのDuckDBインスタンスをラップする構成)により、スタック全体がオンマシンで完結します。想定ユーザーは、dbt+データウェアハウスの運用コストや、クラウドETLサービスのプライバシー上の懸念を避けつつ、ビジュアルパイプラインデザイナーの利便性を求めるデータエンジニアやアナリストです。DatassetteやEvidenceといったツールと並ぶ、より広範なローカルデータスタックムーブメントとの親和性も高いです。
Source: https://github.com/SouravRoy-ETL/duckle
ongridio/ongrid
インフラのオブザーバビリティデータに接続し、メッセージングプラットフォーム(Slack、Telegram、Lark、DingTalk)を通じてインターフェースを公開する運用AIエージェントです。このエージェントはインフラの状態——ログ、メトリクス、トポロジーグラフ——を取り込み、根本原因について推論し、チャットスレッドの自然言語コマンドをトリガーとして修復処置を実行できます。マルチプラットフォームのメッセージングサポートは、地域によって異なる実際のエンタープライズ展開パターンを反映しています。技術的な実質はtool-callレイヤーにあります。エージェントはインフラAPIへの読み取りアクセス(クラウドプロバイダーAPI、Kubernetes、モニタリングシステム)と修復アクションのための書き込みアクセスが必要であり、慎重な権限設計が求められます。「インフラを理解する」というフレーミングは、リソースタグとAPIの列挙からトポロジーまたは依存関係グラフを構築する何らかの仕組みを示唆しており、連鎖的な障害を診断する際にサービス間の関係についてLLMにコンテキストを与えると考えられます。エンジニアリング上の興味深い問題は信頼性です。本番インフラへのエージェント的な修復処置には、保守的なアクションポリシーとロールバックの基本操作が必要です。これはPagerDutyのAI機能やincident.ioのAutopilotと同じ領域に位置しますが、より広いメッセージングプラットフォームをサポートするセルフホスト可能なオープンソースの選択肢として差別化されています。
Source: https://github.com/ongridio/ongrid
nodiuus/nocturne
x86-64 PEバイナリを対象としたバイナリ間コード仮想化ツールです。コード仮想化は強力な難読化技術であり、選択されたbasic blockや関数をネイティブのx86-64から取り出し、バイナリに注入されたカスタム仮想マシン用のバイトコードとして再エンコードします。リバースエンジニアはこれにより、馴染みのあるx86パターンではなく、既存のツールサポートが存在しない新規ISAに直面することになります。Nocturneはこの変換を自動化します。具体的には、PEのパース、コード領域の選択、中間表現へのlift、カスタムVM ISAの定義(パターンマッチングに対抗するためランダム化可能なオペコードマッピングを持つ)、VMバイトコードの生成、そして注入されたインタープリタを呼び出すよう元のバイナリをパッチ適用するという処理を行います。難しさはx86-64の全命令空間にわたる正確性にあります。フラグ、呼び出し規約、間接制御フロー、例外処理などが該当します。商用の仮想化保護ツール(VMProtect、Themida)は長年のバグ修正の蓄積がありますが、オープンソース実装はセキュリティ研究、仮想化ベースの保護の仕組みの理解、および逆難読化ツールの開発に有用です。x86-64 PEというスコープにより、対象範囲は扱いやすいものに保たれています。仮想化ベースの保護を理解・解除する必要があるマルウェア解析研究者やCTFプレイヤー、また商用ライセンスなしに軽量なソフトウェア保護が必要な開発者にも関連します。