Daily AI Digest — 2026-06-08
arXiv Highlights
Socratic-SWE: Self-Evolving Coding Agents via Trace-Derived Agent Skills
Problem
Training SWE agents at scale is bottlenecked by task supply, not by compute or model capacity. The dominant synthetic-data recipes — bug injection, AST mutation, test perturbation — produce a task distribution that is fixed at design time and statistically independent of the current solver’s failure modes. As the solver improves, the marginal value of these tasks drops because most of them target failure modes the model has already covered, while the residual hard cases (state-tracking bugs, multi-file refactors, environment-coupled errors) remain underrepresented. Socratic-SWE attacks this curriculum-gap problem by closing the loop: the solver’s own historical rollouts become the source distribution for the next round of tasks.
Method
The framework has four coupled stages — trace mining, skill distillation, task synthesis, and reward-aligned filtering — iterated over rounds t = 1, \dots, T.
Trace mining. Let \mathcal{T}_t = \{(q_i, \tau_i, r_i)\} be the set of (task, trajectory, outcome) tuples from round t. Trajectories include tool calls, edits, and test executions. Both successful and failed traces are kept; failures provide negative templates and successes provide repair patterns.
Skill distillation. Traces are clustered and summarized into structured agent skills s_k = (\text{symptom}, \text{root\_cause}, \text{repair\_pattern}, \text{diagnostic\_steps}). A skill is essentially a typed schema: e.g., “off-by-one in slice boundary after refactor → test reveals via boundary input → fix replaces n with n+1 in slice expression.” Skills generalize the trace beyond the specific repository file. This is the Socratic move — instead of using traces as scalar reward evidence, the framework forces the model to articulate why a trace failed or succeeded, then reuses that articulation as a generator prior.
Task synthesis. For each skill s_k, the framework samples a real repository and generates a candidate repair task q' whose intended fix instantiates s_k. Synthesis is grounded in actual code: the generator selects a target file/function, applies an edit consistent with the skill’s symptom, and produces failing tests that the original (unedited) code passes and the edited code fails — the standard SWE-bench task structure, but with the perturbation conditioned on s_k rather than on a generic mutation operator.
Validation and reward. Two filters retain tasks. (1) Execution-based validation: the task must compile, the failing test must fail on the broken code and pass on a held-out reference fix. (2) Solver-gradient alignment: candidate q' is scored by
R(q') = \alpha \cdot \mathbb{P}[\text{Solver}_t \text{ fails}] \cdot \mathbb{P}[\text{Solver}_t \text{ can plausibly recover}] - \beta \cdot \text{redundancy}(q', \mathcal{T}_t),
where the first factor enforces that q' lies in the difficulty band where gradients are informative (not trivial, not impossible) and the redundancy term penalizes overlap with already-mastered traces. Concretely the alignment is estimated by sampling K rollouts of \text{Solver}_t on q' and measuring pass rate; tasks with pass rate in roughly [0.1, 0.6] are retained.
The retained set \mathcal{D}_{t+1} is used to fine-tune the solver (SFT on successful repair trajectories, with a preference signal between successful and failed rollouts). The updated \text{Solver}_{t+1} then generates fresh traces, and the loop closes — the skill bank evolves with the agent rather than being fixed a priori.
Results
The abstract reports evaluations on SWE-bench Verified, SWE-bench Lite, SWE-bench Pro, and Terminal-Bench (truncated in the provided text). The mechanism design predicts two empirical signatures that distinguish Socratic-SWE from static synthetic-data baselines: (i) monotone improvement across rounds rather than saturation after one round, and (ii) larger gains on the harder splits (Pro) than on Lite, because the curriculum concentrates capacity on residual failure modes. Without the full results table I cannot cite exact pass@1 numbers; the methodological claim — that trace-conditioned task generation outperforms mutation-based generation under matched compute — is the central empirical question the paper is set up to answer.
Limitations and open questions
Several issues are intrinsic to this design. First, skill collapse: if the distillation step produces a small number of high-frequency skills, the curriculum narrows and the agent overfits to a few repair templates. The redundancy penalty mitigates but does not solve this; a diversity prior over the skill bank would be cleaner. Second, reward hacking on solver-gradient alignment: tasks landing in the target difficulty band are not necessarily useful — some are simply ambiguous or underspecified, and the solver “fails” for reasons unrelated to the targeted skill. Third, execution-based validation is a weak oracle: a fix that passes the synthesized failing test may not be the intended repair, allowing degenerate solutions to propagate into SFT data. Fourth, distribution shift from real SWE-bench tasks: synthesized tasks are conditioned on the agent’s own traces, which were themselves collected on a particular task distribution; this risks a closed echo chamber where the curriculum drifts away from realistic developer workflows. Finally, the framework is expensive — each round requires trace generation, skill distillation (LLM calls), candidate generation, K-sample validation, and SFT — so the per-round wall-clock cost is substantial and the comparison to baselines must be compute-matched to be meaningful.
Why this matters
Trace-derived curricula make the training distribution a function of the model’s current weaknesses, which is the right inductive bias for agentic domains where task difficulty is high-dimensional and static mutation operators cover only a thin slice of failure modes. If the empirical gains hold under compute-matched comparisons, this is a template for self-evolving training across other agent domains — tool use, web navigation, theorem proving — where verifiable rewards exist but task supply is the bottleneck.
Source: https://arxiv.org/abs/2606.07412
Your UnEmbedding Matrix is Secretly a Feature Lens for Text Embeddings
Decoder-only LLMs are strong zero-shot reasoners but weak off-the-shelf encoders: pooled hidden states underperform dedicated embedders on MTEB. This paper diagnoses one mechanical cause — the unembedding matrix W_U \in \mathbb{R}^{|V|\times d} contains a low-dimensional subspace whose sole job is to write high-frequency, semantically empty tokens (punctuation, articles, BOS/EOS) into the residual stream — and removes it with a closed-form projection.
The diagnosis: anisotropy meets frequency bias
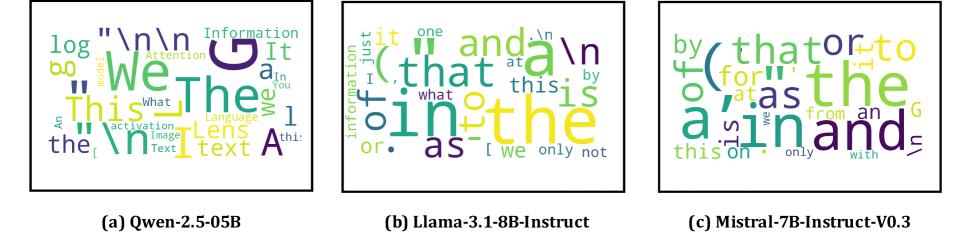
Applying the logit lens directly to a pooled text embedding h via \mathrm{softmax}(W_U h) shows the top-decoded tokens are dominated by frequent fillers across Qwen, Llama, and Mistral.
The authors connect this to the well-known anisotropy of LLM representations: embeddings cluster in a narrow cone, and the cone direction happens to be the one W_U uses to emit frequent tokens. To make this precise they reverse-engineer a “centroid” hidden state h^\star that decodes to the empirical unigram distribution \pi of the training corpus, then perform “Logit Spectroscopy” — an SVD on W_U giving W_U = U\Sigma V^\top — and ask, for each right-singular direction v_i, how much projecting h^\star onto v_i shifts the decoded distribution toward high-frequency tokens. The resulting \Delta\pi profile is concentrated at the spectral edges.
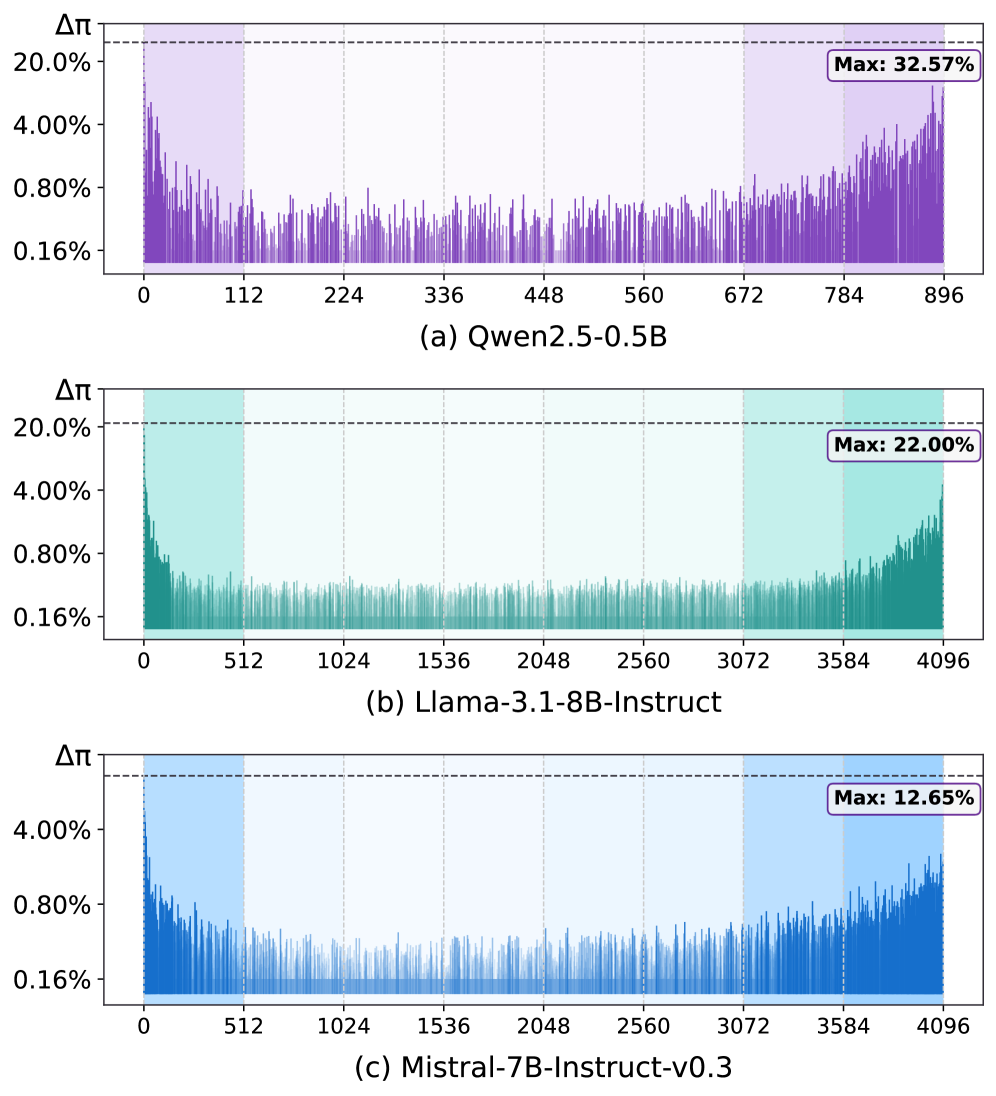
A small set of edge directions of V accounts for the bulk of frequency-token mass. Call this the edge spectrum subspace V_E \in \mathbb{R}^{d \times k}.
EmbedFilter: project it out
EmbedFilter is a single linear map applied at inference:
\tilde h = (I - V_E V_E^\top)\, h.
V_E is built from the top-k singular directions of W_U ranked by their contribution to \Delta\pi on h^\star. No training, no labels, no contrastive pairs — the filter is computed once per model from W_U alone.
Because \tilde h lives in a (d-k)-dimensional subspace, the authors fold this into a free dimensionality reduction: writing \tilde h = Q z with Q \in \mathbb{R}^{d\times (d-k)} orthonormal preserves all inner products, so retrieval indexes can store z instead of \tilde h. The \tau parameter controls aggressiveness, scaling output dim to d/\tau.
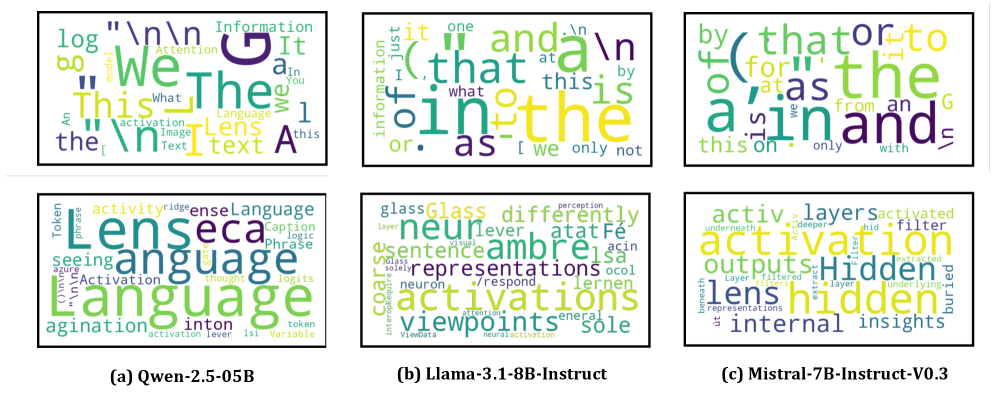
Re-running the logit lens on \tilde h shows the top-6 decoded tokens now contain content words literally present in the input.
Quantitative results
On MTEB (49 datasets across STS, Classification, Clustering, PairClass, Reranking, Retrieval, Summarization), EmbedFilter is layered on top of two standard zero-shot LLM-encoder protocols, PromptEOL and ECHO:
- Qwen2.5-0.5B + PromptEOL: 50.07 → 54.57 at \tau=2 (+9.0%); 53.47 at \tau=4; 51.43 at \tau=8. Retrieval jumps 27.31 → 34.73; STS 63.04 → 69.48.
- Qwen2.5-0.5B + ECHO: 46.03 → 52.55 (+14.1%) at \tau=2. STS 63.98 → 70.77; PairClass 55.54 → 66.35; Retrieval 18.15 → 29.65.
- Llama-3.1-8B-Instruct + PromptEOL: 55.13 → 56.79 (+3.0%) at \tau=2, with Retrieval 25.45 → 29.69.
- Llama-3.1-8B-Instruct + ECHO: 53.52 → ≥+? at \tau=2 (STS 70.43 → 74.41; Clustering 38.89 → 42.64).
Crucially, gains hold even at \tau=8 (i.e., 8x smaller index), where Qwen+ECHO still improves +7.4% over the full-dimensional baseline. The gains are largest on the smaller Qwen-0.5B model and on ECHO (which is more frequency-biased), and smallest on Llama-8B+PromptEOL where the baseline is already strong — consistent with the hypothesis that filtering helps most when the raw embedding is most contaminated by edge-spectrum directions.
Limitations and open questions
- V_E is selected via the centroid hidden state h^\star, itself reverse-engineered from the unigram prior; the choice of k (and the per-task optimal k) is not given a principled rule beyond the elbow in \Delta\pi.
- All gains are over zero-shot LLM encoders; there is no comparison to contrastively fine-tuned embedders like E5-Mistral or NV-Embed, which already address frequency bias implicitly during training. It is unclear whether EmbedFilter composes with such fine-tuning or is subsumed by it.
- The Summarization column occasionally regresses (Qwen+PromptEOL: 27.30 → 27.12 at \tau=2), suggesting the filtered subspace does carry some signal for certain tasks.
- The analysis ties V_E to unigram frequency, but token frequency in pretraining and frequency in the embedding decoding direction need not coincide for all models; a causal intervention (training without these directions in W_U) is not attempted.
Why this matters
The paper turns a mechanistic-interpretability tool — the logit lens applied to W_U — into a practical, training-free post-processor that simultaneously improves MTEB scores and shrinks index size. It also reframes anisotropy in LLM embeddings as not a generic geometric pathology but a specific, identifiable subspace tied to the decoder’s frequency prior, which is a cleaner target for future embedding methods.
Source: https://arxiv.org/abs/2606.07502
SoCRATES: Towards Reliable Automated Evaluation of Proactive LLM Mediation across Domains and Socio-cognitive Variations
Problem
Evaluating LLM mediators is harder than evaluating negotiators or debaters: mediation is a third-party intervention into a multi-turn trajectory whose state (emotions, hidden preferences, cultural framing) shifts as the dialogue progresses. Existing testbeds suffer from three pathologies. First, they cover one or two expert-authored domains, typically transactional bargaining (CaSiNo, CraigslistBargain, KODIS), inflating success rates to 80–90% on unconditioned single-domain runs. Second, they vary mainly the strategic posture of disputants, ignoring orthogonal socio-cognitive axes such as emotional reactivity or cultural identity. Third, they score every dialogue turn against every topic, so off-topic chatter pollutes per-topic credit assignment. SoCRATES targets all three.
Method
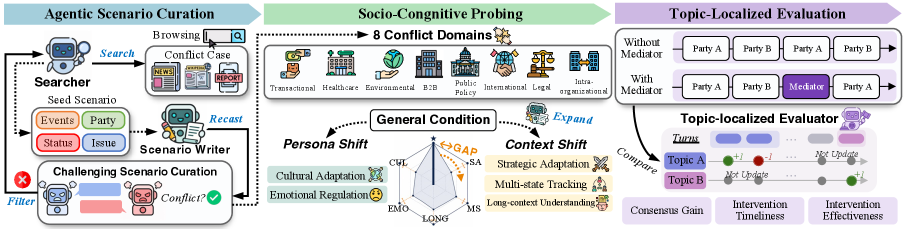
A scenario is formalized as s = (\mathcal{B}, \mathcal{P}, \mathcal{T}, \mathcal{W}) where \mathcal{B} is the background (history, prior commitments, strategic posture), \mathcal{P} = \{p_1,\dots,p_n\} are the disputing parties (each an LLM agent with a private profile: objective, fallback, per-topic stance, persona \pi_i, and preferences w_i), \mathcal{T}=\{T_1,\dots,T_k\} is a topic set with discrete option sets per topic (so movement is observable as an option shift, not free text), and \mathcal{W} assigns each party a weight vector summing to 100 over topics. The mediator is an LLM agent that sees only shared input (\mathcal{B}, \mathcal{T}, dialogue history) and at each party turn emits a binary intervene/skip decision plus an utterance — it must infer hidden personas and preferences from dialogue, making mediation an explicit social-cognition task.
The pipeline has three stages:
- Agentic scenario curation seeds scenarios from real public disputes across eight domains (transactional, legal, intra-organizational, etc.), anonymizing entities.
- Socio-cognitive probing perturbs one component of s at a time along five axes: strategic posture, party composition, history length, emotional reactivity, and cultural identity. Persona axes are parameterized by a float intensity scalar (validated at levels \{0, 0.33, 0.66, 1\}).
- Topic-localized evaluation: for each topic T_j, only the turns that demonstrably advance T_j are scored, eliminating off-topic noise. Three metrics are reported: consensus gain, intervention timeliness, intervention effectiveness.
Persona controllability is checked via A/B reactiveness pairs: two intensity levels are sampled and a third reference persona is held fixed; humans pick the more reactive side. With 160 pairs per simulator and Krippendorff’s \alpha = 0.75, DeepSeek-V3.2 ranked highest among seven simulators, confirming the float scalar produces ordered behavior.
The topic-localized evaluator achieves Pearson r = 0.823 with expert judgments at the trajectory level and 0.801 at the outcome level, versus 0.331 / 0.527 for a non-expert baseline and 0.372 / 0.432 for ProMediate. Trajectory-level alignment more than doubles the per-turn baseline.
Benchmarking results
Eight mediators (GPT-5.4-mini, Gemini-3.1-Flash-Lite, Gemma-4-26B-A4B, Qwen3-30B, Solar-Pro-3, Nemotron3-120B, DeepSeek-V3.2, Qwen3-235B) were each run on 40 scenarios × 15 conditions = 600 runs, totaling 4,800 runs paired with no-mediator baselines.
Headline findings:
- Average consensus gain caps at 34.4, with a clean bimodal split: top tier 30.7–34.4, bottom tier 15.7–21.0. Even the strongest mediator closes only roughly one-third of the unmediated consensus gap — far below the 80–90% resolution rates reported in single-domain prior work.
- Proprietary leads, scale doesn’t order the field. GPT-5.4-mini and Gemini-3.1-Flash-Lite beat the best open-source by 1.1–2.5 points and win 6/8 domains. Within Qwen3, scale helps (235B nearly doubles 30B’s gain), but Nemotron-3-120B trails the smaller Gemma4-26B on Legal and Intra-organizational despite comparable reasoning-benchmark scores.
- Domain matters more than the model gap. Per-domain means span 41.3 (Transactional) down to 16.6 (Intra-organizational). The easy end is exactly where existing benchmarks concentrate — strong evidence that prior work overstates mediation ability.
- Timeliness \neq effectiveness. Solar-Pro-3 and Qwen3-30B intervene most timely yet rank low on consensus gain — they speak often without moving the dialogue. Intervention effectiveness, by contrast, tracks consensus gain.
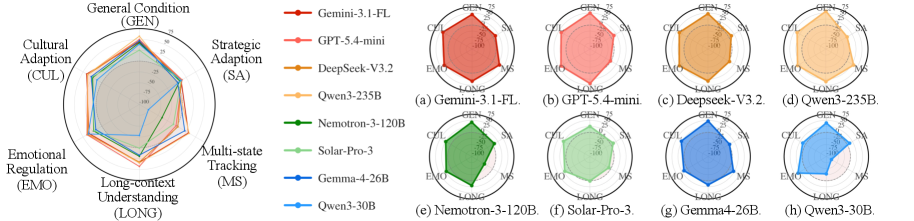
Adaptation across the five socio-cognitive axes (Figure 2) shows performance varies sharply per axis, and Figure 3 decomposes the shift relative to the unperturbed general condition for strategic posture, emotional reactivity, and cultural identity, where negative deltas dominate for several mediators.

Limitations and open questions
The disputants are themselves LLM agents, so persona fidelity validation (focused on reactiveness with \alpha = 0.75) does not fully cover cultural and party-composition axes — the authors lean on prior validations there. Topic discretization into option sets buys observability at the cost of expressive flexibility; real mediation often involves option invention. The eight domains are broad but still LLM-curated from seeds, and outcome metrics measure consensus, not durability or fairness of the agreement. Whether the proprietary edge reflects training data on dialogic reasoning or RLHF on social-tone heuristics remains untested.
Why this matters
SoCRATES makes two concrete contributions: a topic-localized evaluator with r = 0.82 expert alignment that is reusable as a metric, and evidence that single-domain mediation benchmarks are massively overestimating LLM social-adaptation ability — the best frontier model closes only ~33% of the consensus gap once domain and socio-cognitive variation are introduced. Progress on mediator agents lies in social adaptation, not raw capability scaling.
Source: https://arxiv.org/abs/2606.05563
Direct 3D-Aware Object Insertion via Decomposed Visual Proxies
Problem
Current diffusion-based object insertion methods treat the task as masked inpainting conditioned on a reference image: maximize p(I_{out}\mid I_{ref}, I_{bg}, M) where M is a binary region mask. This formulation has no explicit handle on the inserted object’s 3D pose. Practically, users cannot specify “rotate the chair 30° and tilt it back” — the model picks a plausible pose driven by data priors and context. For e-commerce, virtual staging, or any compositing pipeline that needs to honor a specified geometric layout, this is a hard limitation.
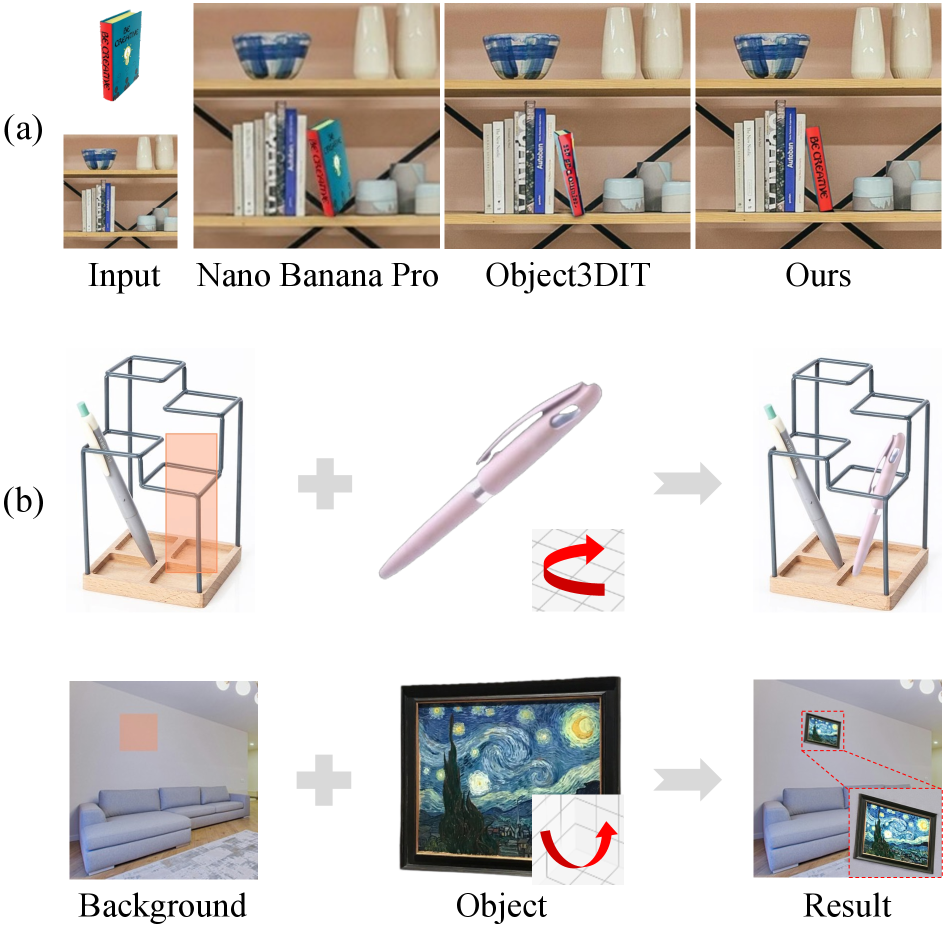
DIRECT reframes the problem as conditional generation under a 6-DoF pose constraint \boldsymbol{\xi}\in\mathfrak{se}(3), jointly satisfying (i) reference identity, (ii) user-specified pose, and (iii) photometric harmony with the target scene.
Method
The pipeline lifts the 2D reference into a 3D proxy \mathcal{P} (using an off-the-shelf image-to-3D model, TRELLIS in their setup), exposes that proxy to the user for \mathfrak{se}(3) manipulation, then re-renders it into a dense RGB geometry image I_{geo}. Generation is then formulated as
I_{out}\sim p_{\theta}(I\mid \underbrace{I_{ref}}_{\text{Appearance}}, \underbrace{I_{geo}}_{\text{Geometry}}, \underbrace{\Psi(I_{bg})}_{\text{Context}}, M),
with three structurally separated guidance signals fed through decomposed LoRA pathways on top of a frozen FLUX.1-Fill-dev backbone. Rank is 128 for each adapter. The split is doing real work: I_{ref} carries high-frequency texture/identity but no spatial arrangement; I_{geo} carries precise geometry but is texturally degraded by single-view 3D reconstruction artifacts; \Psi(I_{bg}) provides scene-level lighting/semantics for harmonization.
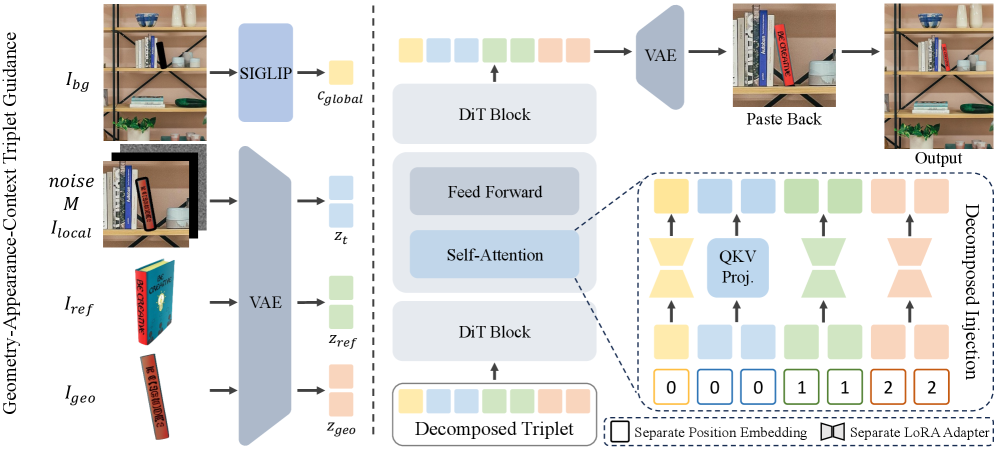
Two non-obvious design choices are worth flagging:
RGB geometry instead of depth/normal. Symmetric objects (mugs, chairs viewed near front) produce nearly identical depth and normal maps in opposite orientations, so a depth-conditioned model cannot disambiguate “facing left” vs “facing right.” Rendering the textured proxy to RGB carries semantic surface cues (handles, logos, asymmetric markings) that disambiguate orientation.

Depth/normal conditioning collapses symmetric pose; RGB proxy retains pose semantics. Re-injecting the original reference. Since the proxy renderer (TRELLIS) blurs textures, conditioning solely on I_{geo} produces blurry outputs. The appearance pathway re-supplies high-frequency identity from I_{ref} while the geometry pathway dictates layout — a clean factoring of “what” vs “where/how oriented.”
Training proceeds in two stages on a curated hybrid dataset combining MVImgNet (real multi-view) and SA-1B pairs synthesized through an automated pipeline. Stage one runs 200k steps on 4×A100, batch 4; stage two runs 40k steps on 8×A100, batch 8. AdamW, \beta_1=0.9, \beta_2=0.999, lr 1\times 10^{-4}. Reference dropout probability 0.1 enables CFG over the appearance signal; inference uses Euler with 28 steps and CFG scale 2.0.
The pose-fidelity metric, Matching Error (ME), is the most informative addition: dense MASt3R correspondences are established between the generated object’s masked region and the resized I_{geo}, and the average matched-pixel error is reported. This directly measures whether the generation respects the geometric condition rather than merely producing a plausible object.
Results
The evaluation set is 200 pairs (100 MVImgNet, 100 manually verified SA-1B), held out from training. Six metrics: PSNR, SSIM, LPIPS, CLIP-I, DINO, ME. Baselines are constructed by cascading a 3D pose-editor (Object3DIT) or an image-to-3D renderer (TRELLIS) with a strong 2D inserter (AnyDoor for SD-based, InsertAnything for FLUX-based).
The reported partial number for the SD-based Object3DIT†+AnyDoor baseline is PSNR 19.24, SSIM 0.7…, while DIRECT consistently achieves the best across all six metrics under both SD and FLUX backbones (the table’s full row is truncated in the available text but the headline claim is uniform dominance). The mechanically meaningful result is on ME: cascaded baselines accumulate error from both the 3D editor’s pose realization and the 2D inserter’s reinterpretation, whereas DIRECT’s single-model RGB-proxy conditioning closes that loop.
Limitations and open questions
- Pose fidelity is bottlenecked by the quality of the lifted proxy. Categories where TRELLIS (or any current image-to-3D) fails — thin structures, transparent objects, articulated objects — will produce I_{geo} that misleads geometry guidance.
- The framework specifies pose but does not reason about physical plausibility (contact, support, occlusion ordering with foreground scene elements). The mask M still has to be drawn by the user.
- Evaluation is on 200 pairs with a custom ME metric; cross-paper comparisons will require this metric to be adopted, and the pose distribution in the benchmark is not characterized.
- LoRA rank 128 across three pathways is heavy; an ablation isolating which pathway contributes most to ME vs identity metrics is not summarized in the provided text.
- Training data quality depends on the automated SA-1B synthesis pipeline; bias from that pipeline’s failure modes likely persists.
Why this matters
Decomposing insertion into appearance / geometry / context channels and using a textured-RGB rendering of a user-manipulated 3D proxy is a clean, implementable recipe for adding 6-DoF pose control to diffusion-based compositing without retraining the base model. It also establishes Matching Error against a rendered proxy as a usable, reference-free pose-fidelity metric for insertion tasks.
Source: https://arxiv.org/abs/2606.06601
When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
Problem
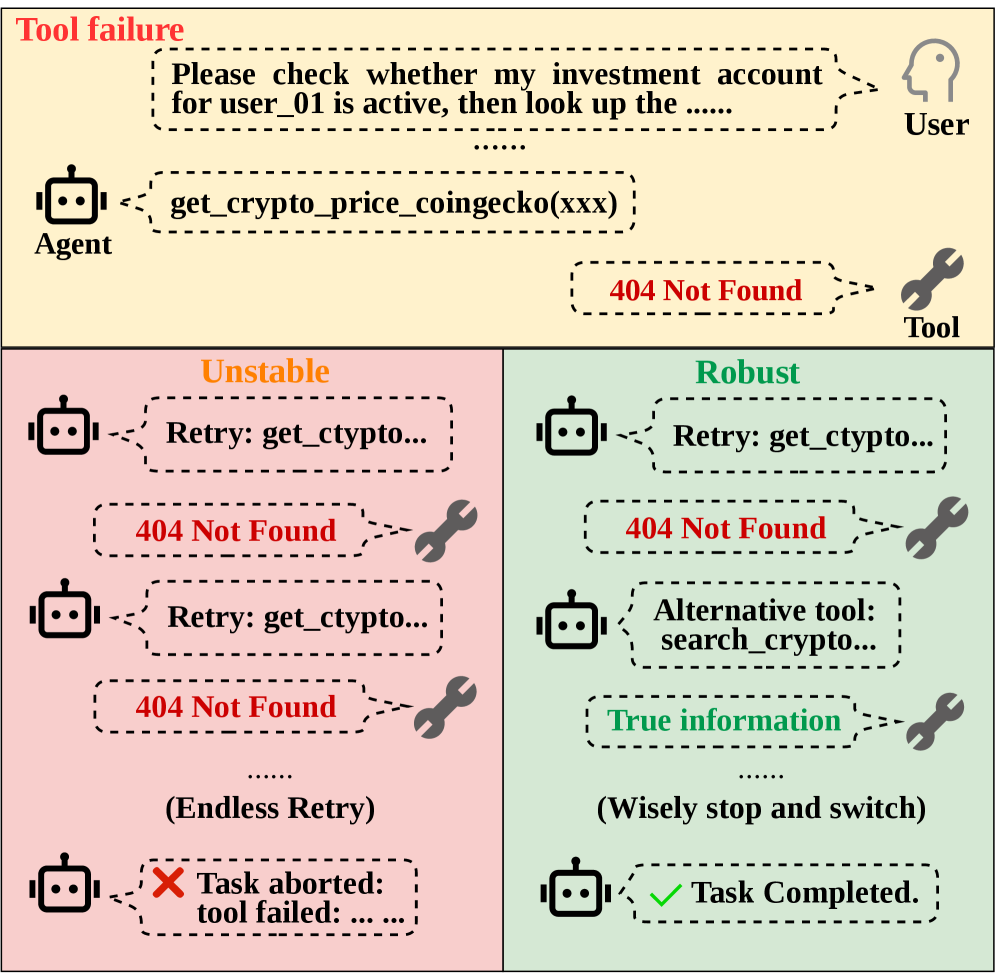
Tool-Integrated Reasoning (TIR) benchmarks predominantly score agents on “happy paths” where every API call returns the expected payload. Production deployments do not behave this way: tools rate-limit, return stale or semantically wrong outputs, deprecate, or break in ways that are not advertised through error codes. Existing leaderboards therefore conflate two very different competencies — executing a known plan and recovering from a broken one — and reward agents that have never had to replan. ToolMaze is an attempt to disentangle these by systematically perturbing tool behavior across topologically varied tasks and measuring whether agents recover or collapse into retry loops.
Method
ToolMaze evaluates agents on a 2D grid: task complexity \mathcal{C} and perturbation mode \mathcal{P}.
Tool corpus. 270 hand-curated tools, each tagged with (i) a functional category — Source (e.g., get_weather), Processor (e.g., temperature_converter), Action (e.g., send_email, terminal node) — and (ii) one of six domains (Financial, Travel, Office, Shopping, IoT, General). Domain labels constrain DAG sampling so that, e.g., a Travel task will not chain a stock-price lookup into an email send.
Task construction. Tasks are sampled as DAGs over the corpus, with the structural invariant that every well-formed DAG contains at least one Source and one Action, optionally bridged by Processors. Four complexity tiers \mathcal{C}1–\mathcal{C}4 scale the topological depth and branching factor.
Perturbation taxonomy. Failures form a 2\times 2:
- Explicit vs. Implicit: explicit failures surface an error string; implicit failures return syntactically valid but semantically corrupted outputs (the harder case).
- Transient vs. Permanent: transient failures resolve on retry; permanent failures require replanning around the tool.
This yields \mathcal{P}1–\mathcal{P}4. The combinatorial structure is what allows separation of systematic replanning (detect implicit corruption, switch tool) from blind retry (which works only for explicit-transient).
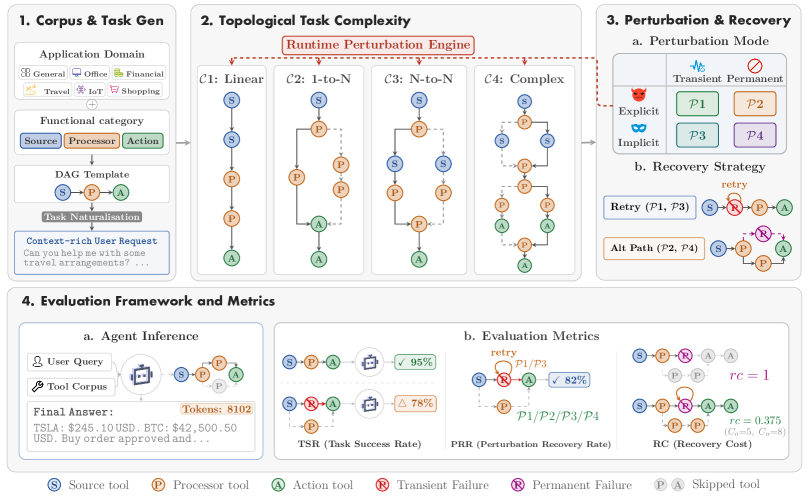
Metrics. Three primary scores: Task Success Rate (TSR) under clean execution, Perturbation Recovery Rate (PRR) measuring success conditional on a perturbation being injected, and Recovery Cost (RC) capturing extra tool calls or tokens spent during recovery. Reporting PRR separately from TSR is the central methodological move — it isolates the recovery skill from base competence.
Results
Evaluations cover both proprietary frontier models (GPT-5.5, Gemini-3.1-Pro-Preview, Claude-Sonnet-4-6) and open-weight models (GLM-5.1, Deepseek-V4-Pro, MiniMax-M2.7, Qwen3.5-35B-A3B, Qwen3.5-397B-A17B, Qwen3.6-27B).
Headline findings:
Implicit semantic failures are the dominant failure mode. PRR drops by approximately 37% under implicit perturbations relative to explicit ones. Agents over-trust well-formed tool outputs, propagating corrupted intermediate values through the DAG without verification. Without an error string to anchor on, no replanning is triggered.
Topological complexity induces trial-and-error collapse. As \mathcal{C} increases from \mathcal{C}1 to \mathcal{C}4, both TSR and PRR degrade, with agents becoming trapped in repeated calls to the same broken node rather than searching for alternatives.

Hint prompting helps unevenly. A prompt that instructs the agent to consider tool failure (solid lines in Figure 3) raises performance modestly at low complexity but the gap narrows at \mathcal{C}4, consistent with hints biasing surface behavior rather than installing a real verification routine.
Fault-tolerance scales worse than base capability. The most consequential quantitative claim: as model scale grows, basic TSR improves roughly 3.66× faster than PRR. Replanning is therefore not on the same scaling trajectory as task execution — bigger models get better at executing plans much faster than they get better at fixing broken ones.
Limitations and open questions
The tool corpus is hand-built and simulated; real APIs exhibit correlated failures (e.g., regional outages cascading across tools) that ToolMaze does not model. The 2x2 perturbation taxonomy is coarse — partial degradations (e.g., outdated but plausible data) sit awkwardly between implicit-transient and implicit-permanent. The 3.66× scaling ratio is derived from a heterogeneous model set, so confounds between training data, RLHF recipes, and tool-use post-training cannot be cleanly separated. Finally, the benchmark scores recovery but does not reward calibrated abstention, which may be the correct behavior in some implicit-failure cases.
Why this matters
ToolMaze provides a clean axis along which to measure something that production agent systems already know is the binding constraint: not whether the agent can chain ten tools when they all work, but whether it notices when one of them silently lies. The 3.66× scaling gap suggests that closing this gap requires explicit replanning machinery — verifier models, output cross-checking, or RL signals targeting recovery — rather than waiting for the next pretraining run.
Source: https://arxiv.org/abs/2606.05806
GENEB: Why Genomic Models Are Hard to Compare
Genomic foundation models have proliferated without a shared evaluation substrate. Different papers report on disjoint task subsets (Nucleotide Transformer benchmarks, GUE, BEND, Genomic Benchmarks, ad hoc TF-binding splits), use different fine-tuning protocols, and select different metrics. As a result, claims about scaling, tokenization (BPE vs. k-mer vs. single-nucleotide), or architecture (Transformer vs. Mamba vs. HyenaDNA) cannot be directly adjudicated from the literature.
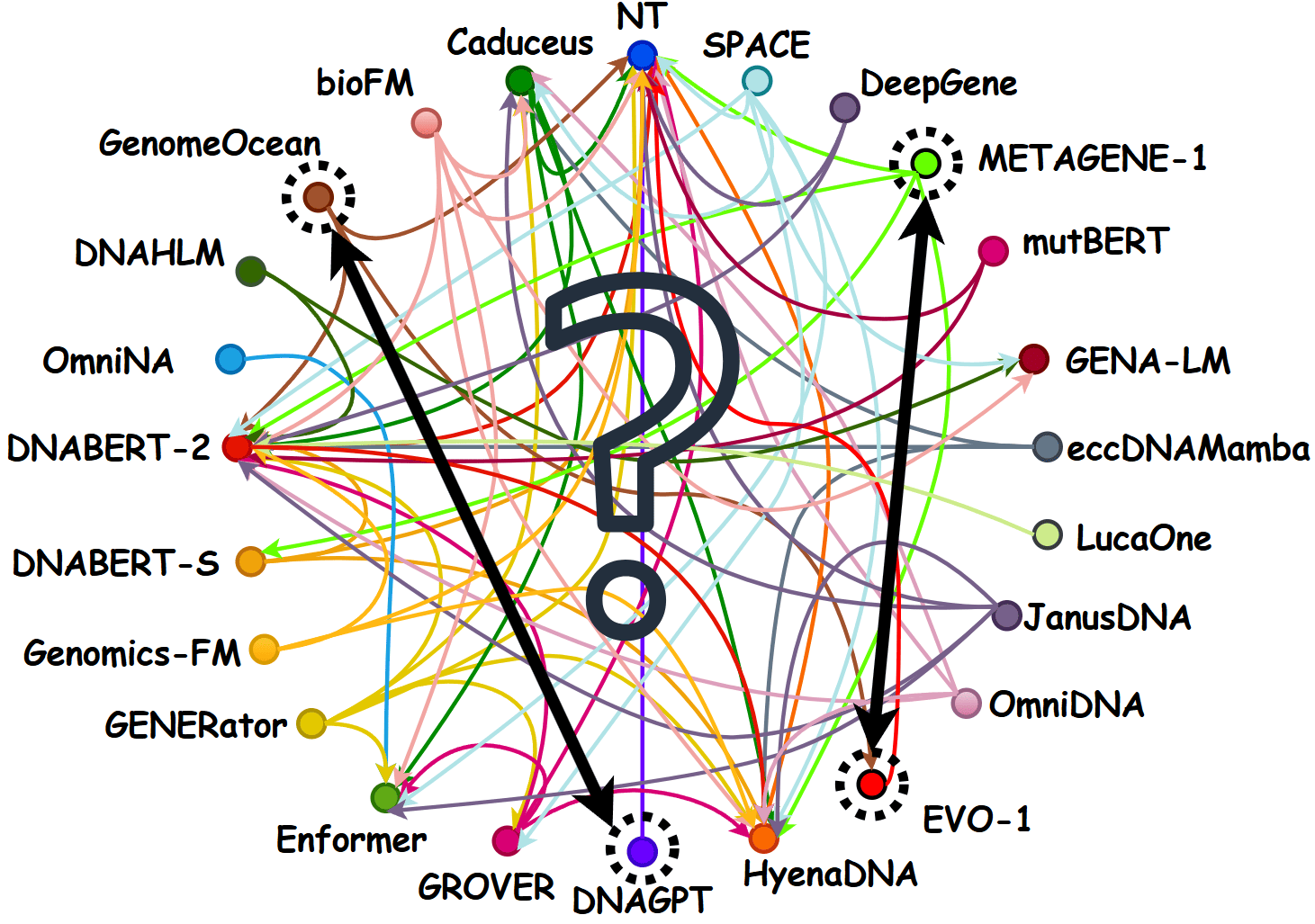
The citation graph among genomic foundation model papers is sparse and disconnected: most models compare against a small, idiosyncratic subset of predecessors, leaving no transitive ranking. GENEB attempts to close this by evaluating 40 frozen genomic FMs on 100 tasks across 13 functional categories under one probing protocol.
Protocol
GENEB freezes each pretrained encoder and fits a logistic regression probe (max_iter=1000) on sequence embeddings, in 1-shot, 10-shot, and full-data regimes, averaged over five fixed seeds \{13, 17, 42, 123, 997\}. The reported metric is Matthews correlation coefficient,
\mathrm{MCC} = \frac{TP \cdot TN - FP \cdot FN}{\sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}},
chosen for class-imbalance robustness. Tasks above 10^5 sequences are subsampled; the authors empirically check on GenomeOcean embeddings that MCC stabilizes past this threshold. Two robustness checks are reported: non-linear (MLP) probing preserves rankings (Appendix E.1), and few-shot conclusions are insensitive to the L2 regularization strength (Appendix E.2). Macro- and micro-averaged rankings agree at \rho = 0.988 (Appendix E.4), so the reported aggregate statements are not artifacts of weighting.
The probing-only design is deliberate: it isolates representation quality from fine-tuning capacity and head design, which is what most claims about “foundation model” generality implicitly target. The cost is that probing underestimates models whose useful structure lives deeper than a linear readout — the MLP check partially addresses this, but a head-tuned full-fine-tune comparison is out of scope.
Findings
Scaling is significant but loose. Spearman correlation between \log_{10}(\text{params}) and full-shot macro-MCC across the 40 models is \rho = 0.565 (p < 0.001), rising to \rho = 0.685 once Evo-1-131k (prokaryotic-only pretraining) is excluded as a domain-mismatch outlier.
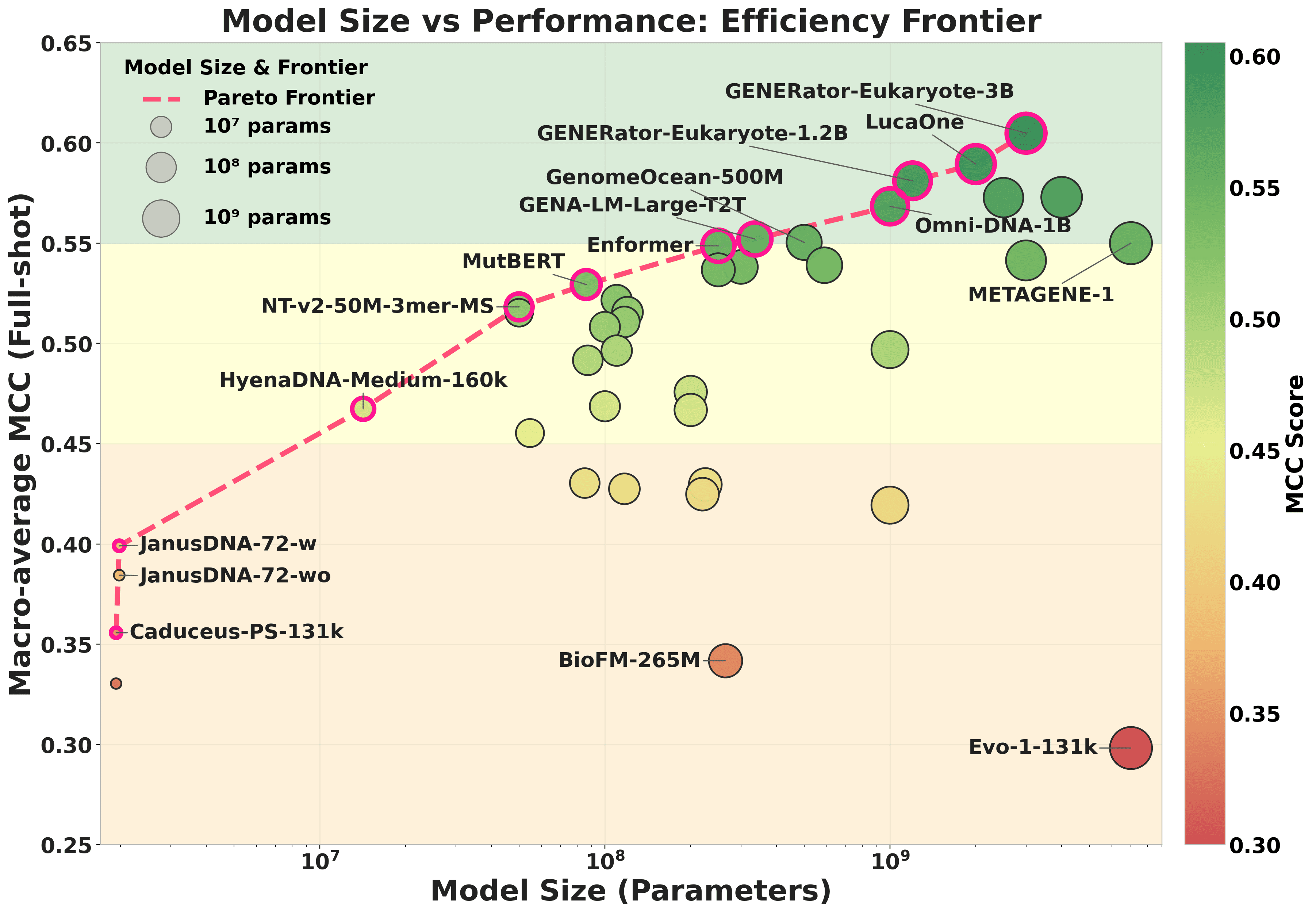
The Pareto frontier shows several large models well below it. Among the 36 in-domain models (excluding prokaryote-, microbe-, and plant-specific pretraining), the authors find 31 instances where a model at least 5\times smaller beats a larger counterpart in aggregate MCC. The headline example: MutBERT (86M, Transformer encoder) outperforms eccDNAMamba (1B, Mamba SSM) by +0.110 macro-MCC despite an 11.6\times size gap. So \log(\text{params}) explains roughly half the rank variance, and architecture × pretraining corpus alignment explains much of the rest.
Per-category scaling varies. Table 1 reports within-category Spearman \rho between \log_{10}(\text{params}) and macro-MCC. Scaling is significant (p < 0.05) in 11 of 13 categories, ranging from \rho = 0.345 for DNA methylation to \rho = 0.579 for histone modifications, with species classification non-significant at \rho = 0.304. The implication: tasks involving long-range chromatin-state cues benefit more from scale than tasks dominated by local sequence motifs (e.g., methylation context windows) or by phylogenetic signal already captured at small scale (species).
Aggregate leaderboards are unstable. The category heatmap makes the practical consequence concrete.
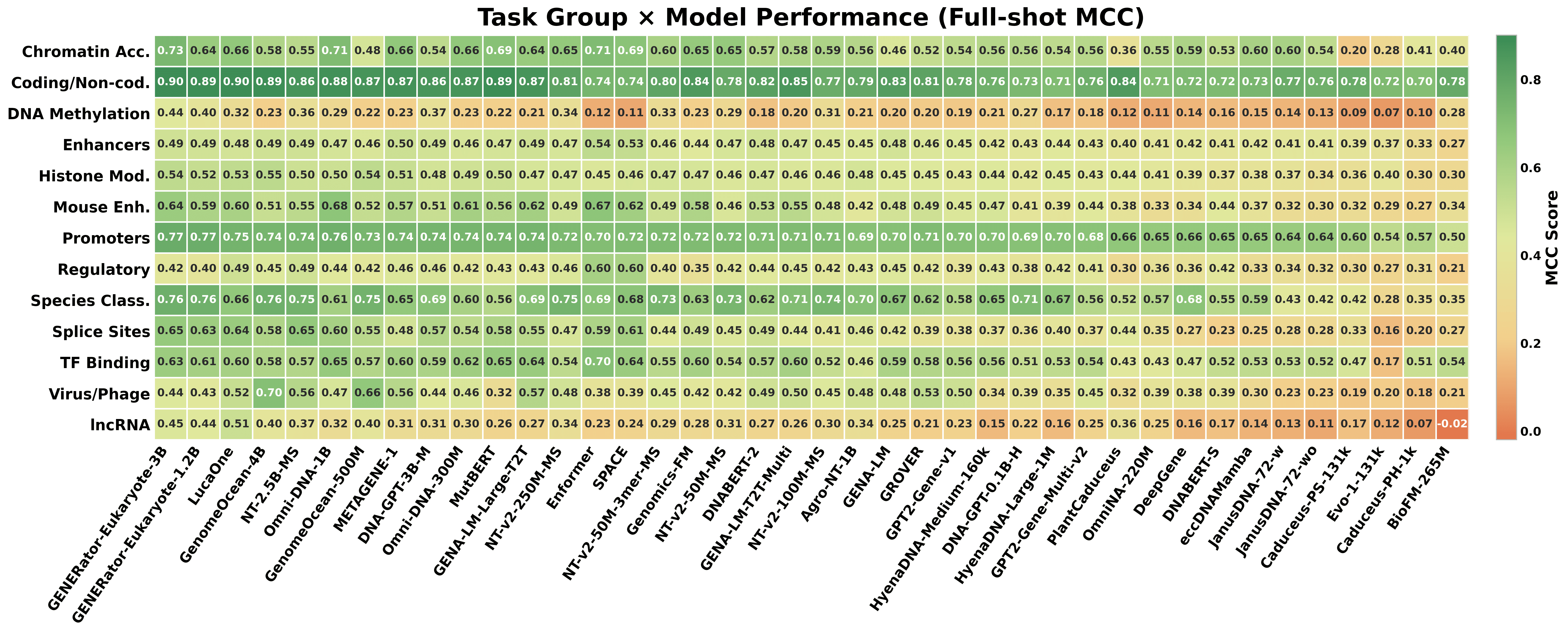
Even the top-ranked aggregate model is not the best in every category, and mid-ranked models can lead specific categories (e.g., regulatory, viral, plant lncRNA). Selecting a model from an aggregate leaderboard for a specific downstream task is therefore systematically suboptimal — category-aware selection is the recommended use of GENEB.
Limitations and open questions
The benchmark is probing-only and frozen-representation: a model with weak linearly separable structure but strong fine-tuned performance will look worse than it is. Logistic-regression probes also penalize representations that encode non-linear manifolds compactly; the MLP-probe robustness check helps but is reported only in aggregate. The task suite is skewed toward eukaryotic, and within eukaryotes toward human, leaving non-model-organism and microbial settings under-represented (which is why Evo-1-131k looks anomalous rather than appropriately specialized). The protocol does not separately credit long-context modeling: tasks above 10^5 sequences are subsampled, and there is no controlled comparison at matched effective context length. Finally, with 40 \times 100 = 4000 probe fits per shot regime, multiple-comparison corrections on per-category claims are not detailed in the excerpt.
Open questions: (i) does the architecture-vs-scale tradeoff survive head fine-tuning, or does it collapse? (ii) which pretraining-corpus axes (taxonomic breadth, repeat masking, regulatory enrichment) drive the residual after controlling for scale? (iii) how much of the category heterogeneity is explained by tokenizer granularity (single-nucleotide vs. BPE vs. 6-mer)?
Why this matters
GENEB makes the empirical case that aggregate “best genomic foundation model” claims are not well-defined: rankings shift sharply by category, scale buys \rho \approx 0.6-worth of aggregate signal, and an 11\times smaller well-aligned model can beat a 1B-parameter mismatched one. For practitioners, this means category-aware model selection is mandatory; for model developers, it means the next gain is more likely to come from pretraining-corpus and tokenizer design than from another order of magnitude of parameters.
Source: https://arxiv.org/abs/2606.04525
dots.tts Technical Report
dots.tts is a 2B-parameter continuous autoregressive TTS foundation model from Xiaohongshu and SJTU X-LANCE. The system targets a recurring failure mode of continuous-latent autoregressive TTS: drift and instability during long rollouts when the AR loop must regress directly on high-dimensional acoustic latents. The contributions are an AudioVAE designed for prediction-friendly latents, an AR flow-matching head with full-history conditioning, a reward-free self-corrective post-training stage, and CFG-aware MeanFlow distillation for low-latency inference.
Architecture
The backbone decouples representation learning from autoregressive modeling. A separately trained, frozen AudioVAE maps 48 kHz mono speech into a 128-d latent at 25 Hz (a 1920\times temporal downsample) with a BigVGAN-style decoder. The AR backbone has three pieces: a semantic encoder, an LLM initialized from a pretrained text LLM, and an autoregressive flow-matching head (AR-FM).
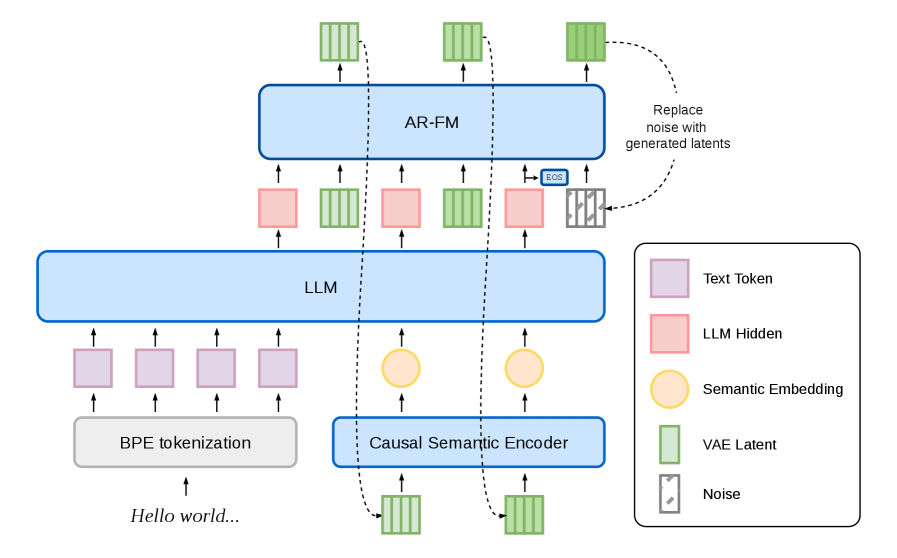
The LLM consumes interleaved BPE text tokens and a 6.25 Hz audio-semantic stream, emitting one hidden state per audio step h_n. The AR-FM head conditions on h_n to generate the next patch of four 25 Hz VAE-latent frames Z_n \in \mathbb{R}^{4\times 128}. Crucially, generated patches are not fed back to the LLM as raw latents. Instead, the patch is reprojected through the semantic encoder reused from AudioVAE training to produce a single 6.25 Hz semantic embedding, which becomes the LLM’s next-step input. The authors report this semantic-only feedback is necessary to stabilize continuous-AR rollouts; feeding the raw VAE latent back into the LLM destabilizes long generations.
Two operating modes are supported: a plain TTS mode where text is a prefix, and a 1T1A interleaving for low-latency streaming where one text token alternates with one audio step.
AR flow-matching head with full-history conditioning
The AR-FM head is the acoustic generator. Standard flow-matching TTS heads regenerate each patch conditioned only on the current LLM hidden state, which limits acoustic continuity across patch boundaries. dots.tts instead runs a block-causal transformer over the entire sequence [C \mid Z], where C = (h_1, \ldots, h_N) are LLM hidden states (block size 1) and Z = (Z_1, \ldots, Z_N) are latent patches (block size L=4). Training uses a block-causal mask so each token in Z_n attends to all of C_{1:n} and Z_{1:n-1} plus its own block. At inference, KV caching keeps the entire history on the left and only (h_n, Z_n) is appended at step n, with RoPE position IDs aligned to absolute time.
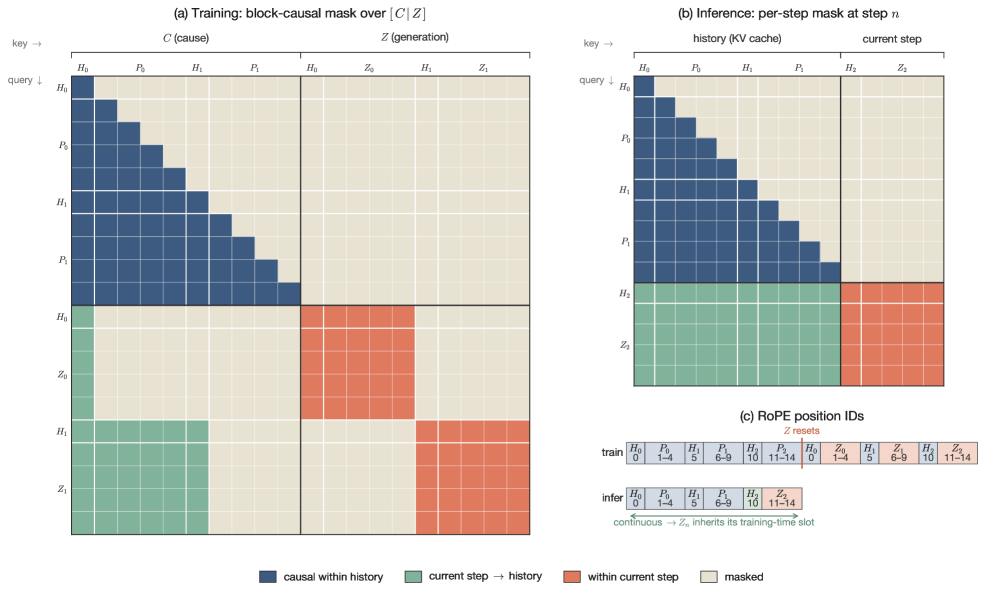
This full-history conditioning lets the flow-matching ODE on Z_n depend on all prior generated acoustics, reducing patch-boundary discontinuity and accumulating drift.
Reward-free self-corrective post-training
After supervised flow-matching pretraining, the AR-FM head is post-trained without reward models. The procedure exposes the head to its own rollouts and trains it to regress the clean target from drifted prefixes, effectively a denoising-of-rollouts step that closes the train/inference gap inherent to teacher-forced flow matching. Combined with the semantic-only feedback path, this is the system’s main answer to compounding error in continuous AR.
Inference acceleration
For low-latency deployment the head is distilled with CFG-aware MeanFlow distillation, collapsing classifier-free guidance and the multi-step ODE into a small number of function evaluations.
Data and results
The backbone is trained on 1.5M hours of audio (1.2M hours after filtering) drawn from in-house Chinese/English plus curated open ASR/TTS corpora and a small caption-paired set. Preprocessing uses Whisper-Large-v3 for English/other languages and Paraformer for Mandarin, with cross-ASR consistency, effective-bandwidth estimation, UTMOS, and intra-clip x-vector variance as filters.
On Seed-TTS-Eval, dots.tts reports WERs of 0.94% / 1.30% / 6.60% on zh / en / zh-hard with SIM scores 81.0 / 77.1 / 79.5, claimed as best average across the three splits. The authors further report consistent open-source SOTA on the MiniMax-Speech multilingual test set, CV3-Eval (cross-lingual voice cloning), and EmergentTTS-Eval (expressiveness), though specific numbers for those benchmarks are not included in the excerpts.
Limitations and open questions
The report does not quantify the marginal contribution of each of the three innovations (AudioVAE objectives, full-history conditioning, self-corrective post-training) via ablation in the provided sections, so it is unclear how much of the Seed-TTS gains come from data scale versus architectural choices. The semantic-only feedback path is a practical stability fix but discards acoustic detail from the AR loop; whether that bottlenecks prosodic control over very long contexts is open. The 6.60% WER on zh-hard remains high in absolute terms. Finally, the multi-objective AudioVAE recipe (Section 2.2) and the exact self-corrective objective are not detailed in the excerpts, limiting reproducibility from the report alone.
Why this matters
Continuous-latent autoregressive TTS has lagged discrete-token systems on stability despite better theoretical fidelity. dots.tts demonstrates that with a prediction-friendly VAE, full-history flow-matching, and rollout-aware post-training, a continuous-AR system can hit competitive Seed-TTS WER/SIM at open-source scale, making the continuous-token route viable for production TTS foundation models.
Source: https://arxiv.org/abs/2606.07080
Hacker News Signals
Tokenomics: Quantifying Where Tokens Are Used in Agentic Software Engineering
Source: https://arxiv.org/abs/2601.14470
A paper from the SWE-bench ecosystem that profiles token consumption across the full lifecycle of agentic coding pipelines. The core question: given a fixed token budget, where does it actually go — context retrieval, planning, code generation, test execution feedback, re-ranking? The authors instrument several agentic frameworks (including ones built on Claude and GPT-4o) running on SWE-bench Verified tasks and break down token spend by pipeline stage.
Key findings are that context loading — stuffing relevant repository files into the prompt — dominates total token usage, often consuming 60-80% of the budget before a single line of code is generated. Code generation itself is a small fraction. The paper introduces a “token efficiency” metric: resolved issues per million tokens, which lets you compare architectures on cost-adjusted performance. Naive retrieval-augmented approaches that stuff full files are dramatically less efficient than snippet-level or symbol-level retrieval. The authors also show that re-ranking and self-repair loops (running tests and feeding back failures) have high token cost but also high marginal return per token — better ROI than expanding initial context.
The practical implication for system builders: the bottleneck is not generation quality but context curation. Over-retrieval is the main inefficiency, and it compounds in multi-turn loops where each turn re-encodes the same boilerplate. The paper suggests that structured representations (e.g., symbol graphs rather than raw source) could substantially reduce the context footprint without sacrificing retrieval recall.
Limitations include that the analysis is tied to specific benchmark tasks that may not reflect real-world repository diversity or task length distributions. Token counts also vary significantly across model providers due to tokenizer differences, making cross-model comparisons noisy.
How Linear Is So Fast: A Technical Breakdown
Source: https://performance.dev/how-is-linear-so-fast-a-technical-breakdown
A detailed reverse-engineering and architecture analysis of the Linear project management app’s client-side performance. The piece covers several concrete techniques that collectively explain the perceived snappiness.
The central mechanism is an in-memory SQLite database running entirely in the browser via WebAssembly (specifically the wa-sqlite or similar binding). All reads are local and synchronous from the UI thread’s perspective — no round-trip latency to a server for queries. The app maintains a full local replica of the user’s data, synchronized incrementally via a custom sync protocol. This is the “local-first” architecture pattern, but executed with significant engineering rigor.
Writes are optimistic: UI state updates immediately on user action, and the mutation is queued for server sync in the background. Conflict resolution follows a last-write-wins or vector-clock scheme depending on entity type. The sync layer uses a log-structured delta format rather than full-document replacement, which keeps bandwidth low and makes reconnect-after-offline cheap.
On the rendering side, the app uses React but with aggressive memoization and virtualized lists for long issue backlogs. Crucially, the SQLite layer means derived views (filtered, sorted issue lists) are computed via actual SQL queries against the in-memory store rather than JavaScript array operations, which is faster for large datasets and easier to reason about correctness.
The analysis also notes that Linear’s Electron-like desktop app (built on a web view) benefits from having the WASM SQLite persist across navigations, avoiding the cold-start cost that browser tab refreshes incur.
The open question is scaling: full local replica works well for typical team sizes, but per-user data volume bounds matter. The piece does not fully address how Linear handles users with very large workspaces or multi-org access.
Zeroserve: A Zero-Config Web Server You Can Script with eBPF
Source: https://su3.io/posts/introducing-zeroserve
Zeroserve is a minimal HTTP server that exposes eBPF as the primary extension mechanism. Rather than a plugin API or scripting language embedded in userspace, request handling logic is written as eBPF programs that are attached to the server’s processing pipeline and executed in the kernel’s verified VM.
The architecture attaches eBPF programs at hook points analogous to what Nginx calls “phases” — e.g., post-parse, pre-response. Each hook receives a context struct with request metadata (method, path, headers as key-value pairs) accessible via BPF map lookups. Responses can be short-circuited directly from the eBPF program, which means for simple cases (static redirects, health checks, rate-limit rejections) the response is generated without ever entering userspace. This is the primary performance argument: kernel bypass for the common fast path.
The “zero-config” claim means the server starts without a configuration file; all behavior is injected via bpf() syscalls after startup, making it composable with any orchestration layer that can load BPF objects. The author provides a small userspace library to load and pin programs.
eBPF programs here run under the standard kernel verifier constraints — no unbounded loops, limited stack, no arbitrary memory access — which both limits expressiveness and provides safety. Complex logic (database lookups, template rendering) still needs a userspace component; eBPF handles the routing and filtering tier.
This is interesting as a design point in the space between kernel networking (XDP/TC for raw packets) and userspace HTTP frameworks. It sits above the socket layer but below a traditional web framework, catching HTTP-level semantics while staying close to the kernel. The main open question is whether the eBPF complexity overhead is worth it versus a simple userspace router for most workloads, and how debugging and observability work when logic is split across kernel and userspace.
Sem: New Primitive for Code Understanding — Entities on Top of Git
Source: https://ataraxy-labs.github.io/sem/
Sem proposes a layer between raw git history and IDE-level language servers: a persistent, queryable store of code entities (functions, types, modules) tracked through time. The fundamental unit is not a file diff but a semantic entity with a stable identity across renames and refactors.
The core data model maintains a mapping from entity identity (derived from a combination of name, enclosing scope, and structural signature) to a timeline of versions, each anchored to a git commit. This is similar in spirit to what git log -S does for text, but operating on parsed AST nodes. When a function is renamed or moved to another file, sem attempts to maintain identity continuity via a similarity heuristic on the AST diff, avoiding the false “deleted + created” interpretation that file-level git sees.
The query interface exposes things like: “show me all callers of function X as of commit Y,” “what changed in the type signature of struct Z between these two tags,” or “find all entities that were modified in the same commit as this bug fix.” These are hard to answer efficiently with raw git + grep because they require cross-file, cross-commit semantic joins.
The implementation uses tree-sitter for language-agnostic parsing, which means it supports any language with a tree-sitter grammar without per-language plugins. Entity identity across commits is computed incrementally on git log traversal and stored in a local SQLite database.
The distinction from LSP is important: LSPs are stateless per-file-snapshot and have no notion of history. Sem is history-first. The distinction from tools like git blame is that the granularity is sub-file (entity level) and the continuity tracking handles structural changes. Limitations include the identity heuristic’s fragility under large refactors and the bootstrapping cost on large repositories.
Symbolica 2.0: Programmable Symbols for Python and Rust
Source: https://symbolica.io/posts/symbolica_2_0_release/
Symbolica is a computer algebra system (CAS) implemented in Rust with Python bindings, targeting high-energy physics computations where expressions routinely contain millions of terms. Version 2.0 adds several capabilities centered on programmable symbolic manipulation.
The core data structure is a compact representation of multivariate polynomials and rational functions using a custom hash-consed term tree. Terms are stored in a sorted, deduplicated form that makes normalization a structural property rather than a procedure, which matters for equality checking in large expressions without full simplification passes.
The headline feature in 2.0 is “pattern matching with conditions” — a term-rewriting system where patterns can carry arbitrary Rust/Python predicates on matched subexpressions. This goes beyond syntactic matching; you can write rules like “match any subexpression that is a rational number greater than 1/2” and apply a transformation. The pattern language supports wildcards, sequence patterns (match any number of arguments), and named captures.
A second major addition is a Series type for Laurent series expansion around a point, with lazy evaluation of coefficients — only the terms needed for a given truncation order are computed. This is important for physics calculations where you expand in a small parameter and only need the first few orders.
Performance is a primary design goal; the 2.0 release cites 3-10x speedups on polynomial GCD and factorization benchmarks versus 1.x due to improved Zippel and sparse multivariate GCD algorithms. The Python bindings use PyO3 and expose the full API without significant overhead.
Symbolica is not free for commercial use, which limits its adoption compared to sympy or FORM. The open question is whether the performance advantages over FORM (the de facto standard in particle physics) are sufficient to overcome ecosystem inertia.
Open Code Review: An AI-Powered Code Review CLI Tool
Source: https://github.com/alibaba/open-code-review
Alibaba’s open-code-review is a CLI tool that wraps LLM APIs (configurable; defaults to Qwen but supports OpenAI-compatible endpoints) to automate pull request review. The technical substance is in how it constructs the review prompt and what it sends to the model.
The tool invokes git diff to extract the patch for a given commit range or PR, then applies a chunking strategy to stay within context limits: diffs are split at file boundaries first, then at hunk boundaries if a single file’s diff exceeds a threshold. Each chunk is reviewed independently, and results are aggregated. This avoids the common failure mode of truncating diffs mid-hunk.
The prompt engineering includes structured output requests: the model is asked to produce reviews in a JSON schema with fields for severity (blocking/warning/info), file, line range, category (e.g., security, performance, correctness, style), and explanation. Downstream, the CLI can filter by severity or category and format output for GitHub PR comments via the GitHub API or as plain text.
There is a “context injection” feature that lets you supply additional files (e.g., a project-specific style guide, an architecture document) as background context prepended to the review prompt. This is handled via a simple concatenation with a separator, not retrieval-augmented; the entire context file is included every time.
Security-relevant: the tool sends your diff to an external API endpoint by default. For internal codebases this requires either a self-hosted model or careful configuration of the endpoint to a private deployment.
The main limitation is the independent-chunk review approach loses cross-file context — a change to an interface and all its implementations reviewed in separate chunks may miss consistency issues that span the chunks. Deduplication of redundant comments across chunks is also rudimentary.
Redis 8.8: New Array Data Structure, Rate Limiter, Performance Improvements
Source: https://redis.io/blog/announcing-redis-8-8/
Redis 8.8 ships three notable additions. The first is a native Array data type — a dense, ordered sequence of values with O(1) index access. This fills a gap: Redis had lists (linked-list semantics, O(N) index), sorted sets (score-ordered, O(log N)), and streams, but no flat array with true O(1) random access. The implementation uses a contiguous memory layout with a capacity/length header, realloc-style growth, and the usual Redis memory allocator hooks. Use cases include time-series buffers and fixed-size sliding windows where index access patterns are random.
The second addition is a built-in rate limiter command, RATELIMIT.THROTTLE, implementing the generic cell rate algorithm (GCRA, also called the leaky bucket with virtual scheduling). The command is atomic and operates on a single key, taking capacity, fill rate, and requested tokens as arguments and returning whether the request is allowed plus remaining capacity and reset time. This replaces the common pattern of implementing GCRA in Lua scripts, with the advantage of being faster (no Lua interpreter overhead) and semantically clearer.
Performance improvements in 8.8 include a reworked I/O threading model that separates read and write syscalls more aggressively across threads, reducing head-of-line blocking under mixed read/write workloads. Benchmarks cited in the announcement show 15-25% throughput improvement on pipelined mixed workloads at high connection counts.
The release also improves OBJECT FREQ accuracy for LFU eviction by switching to a higher-resolution counter decay function.
Notably absent: any movement on multi-tenancy or improved cluster rebalancing, which remain common pain points for large deployments. The GCRA rate limiter also operates per-key, so cross-key or global rate limits still require application-level coordination.
Python JIT Project Was Asked to Pause Development
The Python Steering Council has asked the copy-and-patch JIT compiler (introduced experimentally in CPython 3.13) to pause active development. The announcement is terse but the technical context is substantial.
The copy-and-patch JIT, designed by Brandt Bucher, works by pre-compiling template machine code stubs for each bytecode instruction and then “copying and patching” them — filling in operand addresses and constants — at runtime to assemble native code sequences. It requires no IR, no register allocator, and no optimizer; it is essentially a fast template instantiator. This design was chosen for maintainability: it generates code directly from the existing specializing adaptive interpreter’s instruction set, reusing the same bytecode semantics.
The problem is that the JIT has not delivered meaningful speedups in practice. CPython 3.13 benchmarks show the JIT providing roughly 1-5% improvement on the standard benchmark suite, with regressions on some workloads. The core issue is that copy-and-patch generates code without optimization across instruction boundaries — there is no inlining, no dead code elimination, no register allocation beyond what the templates bake in. Each template is independently correct but the composition is not optimized.
The steering council’s concern appears to be the ongoing maintenance cost — the JIT requires per-platform code generation support and complicates the build system — without commensurate performance return. The pause is not a cancellation; the council is asking for a clearer roadmap.
The deeper technical question is whether a more ambitious JIT (with a proper IR, like PyPy’s RPython or a MLIR-based approach) is feasible within CPython’s development model. The copy-and-patch approach was explicitly scoped to be minimal; the community now faces whether to invest in something fundamentally more capable or accept that CPython’s performance ceiling is set by the interpreter’s architecture.
Noteworthy New Repositories
perplexityai/bumblebee
A read-only security scanner targeting developer-environment metadata: installed packages, IDE extensions, CLI tools, and related configuration files. The core concern is software supply-chain compromise — malicious packages, typosquatted libraries, or backdoored extensions that persist on developer machines long after public disclosure. Bumblebee enumerates on-disk artifacts across package managers (npm, pip, cargo, etc.) and extension registries, then cross-references findings against a database of known-compromised identifiers without making any mutations to the filesystem. The read-only constraint is a deliberate design choice: it makes the tool safe to run in CI, during incident response, or on shared build machines where side effects are unacceptable. Because it was built internally at Perplexity AI, the scanner reflects real operational concerns around securing the development supply chain at scale. The tool is particularly useful in post-incident triage — given a CVE or compromised package name, operators can sweep an entire fleet of developer workstations or CI runners for exposure. Its metadata-only scope keeps it fast and avoids the false-positive surface area of full SAST. A natural fit alongside tools like osquery or syft in a defense-in-depth pipeline.
Source: https://github.com/perplexityai/bumblebee
amElnagdy/guard-skills
A collection of quality-gate “skills” designed to be dropped into coding-agent pipelines — think LLM-driven code generation workflows where the agent calls tools in a loop. The problem: LLM-generated code fails in characteristic, repeatable ways (hallucinated imports, missing error handling, test stubs that always pass, doc-comment drift from implementation). Guard-skills encodes detectors for these failure modes as composable checks that the agent or orchestrator can invoke before committing output. Each skill is a standalone validator with a defined input/output contract, making them easy to wire into frameworks like LangChain, AutoGen, or custom tool-call loops. Coverage spans syntax and import validation, test quality heuristics (detecting vacuous assertions, coverage театр), and documentation consistency checks. The project is opinionated about treating AI-generated artifacts with the same skepticism as untrusted external input. For teams building SWE-agents or internal code-generation pipelines, this addresses a gap: most agent frameworks have no structured post-generation quality layer beyond “does it compile.” Lightweight enough to run on every generation step without significant latency overhead.
Source: https://github.com/amElnagdy/guard-skills
1ove9/antenna-forge
Inverse antenna design driven by ML with real electromagnetic simulators in the loop. The user specifies a target S-parameter or radiation pattern; the system searches over antenna geometry to match it. The critical technical detail is that the forward model is not a surrogate neural network — actual NEC2 (Numerical Electromagnetics Code) and openEMS (finite-difference time-domain) simulations are invoked during the search, preserving physical fidelity at the cost of compute. The AI component handles the inverse problem: navigating geometry space efficiently without exhaustive simulation sweeps, likely via Bayesian optimization or a learned surrogate for cheap pre-filtering before expensive full-wave evaluation. An in-browser playground lets users experiment without local simulator installation, which is non-trivial given NEC2 and openEMS setup friction. This matters for RF engineers and researchers prototyping custom antennas for specific frequency bands or form factors where standard designs are inadequate. Combining learned search with physics-accurate simulation rather than end-to-end neural approximation is the right trade-off when correctness of the electromagnetic model is non-negotiable.
Source: https://github.com/1ove9/antenna-forge
gi-dellav/zerostack
A minimal coding agent implemented in Rust, with the explicit design goal of minimizing memory footprint and maximizing throughput. Most coding agents are Python-based; the runtime overhead (interpreter, GC pressure, large dependency trees) is acceptable for interactive use but becomes a bottleneck when running many parallel agent instances — a common pattern in SWE-bench-style evaluation harnesses or CI-integrated automated repair. Zerostack targets that niche: a small, self-contained binary that can drive code-generation and tool-call loops with predictable resource consumption. The Rust implementation enables tight control over allocation patterns and avoids the garbage-collection pauses that can distort latency measurements in agentic loops. The architecture follows the standard agent loop (LLM call → tool dispatch → observation → repeat) but is engineered for embedding in larger systems rather than as a standalone product. Relevant for anyone building infrastructure where dozens or hundreds of agent workers need to coexist on the same machine, or where the agent runtime itself must fit inside a constrained environment like a container sidecar or edge device.
Source: https://github.com/gi-dellav/zerostack
tastyeffectco/sandboxd
A self-hosted sandbox daemon that provisions isolated development environments with publicly accessible preview URLs from a single command, without requiring Kubernetes or a cloud control plane. The implementation spins up containerized workspaces and handles reverse-proxy routing to generate per-sandbox URLs — useful for sharing in-progress work, running end-to-end tests against a live URL, or giving coding agents an addressable HTTP endpoint to interact with during agentic coding sessions. The no-Kubernetes constraint is meaningful: most comparable tools (Gitpod self-hosted, Coder) carry significant operational overhead. Sandboxd targets small teams and “SaaS factories” — rapid prototyping shops that spin up many short-lived environments. For agentic coding specifically, the ability to programmatically create a sandbox, point an agent at its URL, and teardown afterward fits cleanly into tool-call patterns. The single-command UX implies Docker Compose or a lightweight container runtime as the actual isolation layer. Useful as infrastructure glue rather than a complete platform, with the tradeoff that the security boundary is thinner than a full VM-based sandbox.
Source: https://github.com/tastyeffectco/sandboxd
SouravRoy-ETL/duckle
A local-first visual ETL/ELT pipeline designer that compiles dataflow graphs to SQL and executes them on DuckDB. The user builds pipelines via drag-and-drop in a desktop GUI; the backend emits SQL that DuckDB runs in-process, meaning no external database, no network, no orchestration service. The compilation target being plain SQL rather than Python/Spark code is the key architectural decision: the output is auditable, version-controllable, and portable — pipelines live as SQL files in a directory structure that is explicitly designed to be git-friendly. DuckDB’s columnar engine handles analytical workloads over local Parquet, CSV, or JSON files efficiently enough that many small-to-medium data transformation jobs never need a distributed system. The desktop-app form factor (likely Tauri or Electron wrapping a local DuckDB instance) keeps the entire stack on-machine. The target user is a data engineer or analyst who wants the convenience of a visual pipeline designer without the operational cost of dbt + a warehouse, or the privacy concerns of cloud ETL services. A natural complement to the broader local-data-stack movement alongside tools like Datasette and Evidence.
Source: https://github.com/SouravRoy-ETL/duckle
ongridio/ongrid
An operations AI agent that connects to infrastructure observability data and exposes its interface through messaging platforms (Slack, Telegram, Lark, DingTalk). The agent ingests infrastructure state — logs, metrics, topology graphs — reasons about root cause, and can execute remediations, all triggered by natural-language commands in a chat thread. The multi-platform messaging support reflects real enterprise deployment patterns in different geographies. The technical substance is in the tool-call layer: the agent needs read access to infrastructure APIs (cloud provider APIs, Kubernetes, monitoring systems) and write access for remediation actions, which requires careful permissioning. The “understands your infrastructure” framing implies some form of topology or dependency graph construction, likely from resource tags and API enumeration, that gives the LLM context about service relationships when diagnosing cascading failures. The interesting engineering question is reliability: agentic remediations on production infrastructure require conservative action policies and rollback primitives. This sits in the same space as PagerDuty’s AI features or incident.io’s Autopilot, but as a self-hostable open-source option with broader messaging platform support.
Source: https://github.com/ongridio/ongrid
nodiuus/nocturne
A binary-to-binary code virtualizer targeting x86-64 PE executables. Code virtualization is a strong obfuscation technique: selected basic blocks or functions are lifted out of native x86-64 and re-encoded as bytecode for a custom virtual machine that is injected into the binary. Reverse engineers then face a novel ISA with no existing tooling support rather than familiar x86 patterns. Nocturne automates this transformation: parse the PE, select code regions, lift to an intermediate representation, define a custom VM ISA (with randomizable opcode mappings to resist pattern matching), emit VM bytecode, and patch the original binary to call the injected interpreter. The difficulty is correctness across the full x86-64 surface area — flags, calling conventions, indirect control flow, exception handling. Production virtualizers (VMProtect, Themida) have years of bug-fixing behind them; an open-source implementation is useful for security research, understanding how virtualizer-based protections work, and developing deobfuscation tooling. The x86-64 PE scope keeps the target surface manageable. Relevant for malware analysis researchers and CTF players who need to understand or defeat virtualization-based protections, as well as developers who need lightweight software protection without commercial licensing.