デイリーAIダイジェスト — 2026-06-05
arXiv ハイライト
VideoKR: 知識・推論集約型動画理解に向けて
問題設定
既存の動画推論post-trainingコーパスおよびベンチマークは、測定を意図した能力を十分にテストできていません。フロンティアVLMは、VideoMMMU、MMVU、SciVideoBenchにおける多くの質問に対して、ランダムにサンプリングされた1フレームと質問テキストのみで回答可能です:GPT-5.2は3回試行の単一フレームプローブ条件でそれぞれ38.3%、49.7%、23.0%を達成しており、Claude-4.5-SonnetやQwen3-VL-235Bでも同様の数値が確認されています。すなわち、「知識集約型動画推論」ベンチマークの大部分は、image-VQAまたはテキストショートカットタスクとして解けてしまいます。訓練コーパスも同様の欠陥を抱えており、時間的 grounding が弱く、ドメインカバレッジが狭く、CoTがノイジーかつ浅いという問題があります。VideoKRはこのギャップの両端を対象として、145K本のCCライセンス専門ドメイン動画から構成される315Kサンプルのpost-trainingコーパスと、単一フレーム回答可能率が同一フロンティアモデルで9.5〜10.7%まで低下する2K件の専門家アノテーション付きベンチマーク(VideoKR-Eval)を提案します。
手法
構築パイプラインは半自動化されており、34名の大学院レベルのドメイン専門家がモデル生成ステップの全てを監査しています。
ドメイン知識バンク。 Subject → Course → Lecture → Knowledge Pointという4階層構造をトップダウンで構築します。著者らは主要大学のカリキュラムから自然科学・医療・人文社会科学・工学にわたる82科目を選定しました。各科目について専門家が4〜8個のコア学部科目をリストアップし、各科目についてシラバスを作成し、各講義についてLLMが知識ポイント(用語+段落定義)を提案し、専門家が検証します。このバンクは63,745個の知識ポイントを含み、動画選択とQAの grounding のための検索インデックスとして機能します。
動画収集とスキル指向QA合成。 動画はCCライセンスで知識ポイントにマッチングされます。QA合成は、単一フレーム検査ではなく継続的な動画理解を必要とする3つのコアスキルに条件付けされたスキル指向型です。

VideoKRコーパスの概要:CCライセンスの専門動画にgroundingされたスキル指向QAと、推論トレースが対応付けられたCoTサブセット。 各サンプルは対象スキルのもとで生成され、その後、難易度・多様性・信頼性について人間による監査が行われます。一部のサブセットにはCoT根拠(こちらも専門家が検証)が付加されます。公開分割はVideoKR-SFT-201K(根拠付き)とVideoKR-RL-114K(GRPOのための検証可能回答サブセット)です。

自然科学のSFTサンプル例:特定の動画エビデンスに紐付いた知識groundingされた chain of thought を示す。 Post-trainingパイプライン。 意図的に標準的な構成を採用しています:Qwen2.5-VL-7B-InstructおよびQwen3-VL-8B-InstructにおいてSFT → GRPOを実施します。SFTはVideoKR-SFT-201Kで1エポック実行し、GRPOはSFTチェックポイントからVideoKR-RL-114Kで1エポック実行します。GRPOのaccuracy rewardはVideo-R1に準拠し、open-endedにはROUGE、多肢選択にはExact Matchを使用します。両ステージともバッチサイズ32、最大4,096動画トークン、最大128フレームです。Qwen3-VL-8BについてはZero-RL変種(ベースに直接GRPOを適用)も評価されています。
VideoKR-Eval。 真の時間的エビデンスを必要とする専門家作成の多肢選択問題2,000件で構成され、ショートカット耐性を認証するために単一フレームプローブと合わせて評価されます(Qwen3-VL-235Bで10.1%、MMVUの45.2%と比較)。
結果
主要指標はVideoMMMU、MMVU、SciVideoBench、VideoKR-Evalにわたる知識集約型平均スコアです。
- Qwen2.5-VL-7B(16フレーム):VideoKRでのSFT+RLにより知識集約型平均スコアが41.9 → 46.6(+4.7)に向上し、Video-R1(+1.2)やVideoRFT(+1.4)を上回ります。データセット別では、MMVUが52.5 → 59.2、VideoKR-Evalが31.3 → 37.7に上昇します。汎用動画平均はほぼ横ばいです(59.1 → 60.1)。
- Qwen2.5-VL-7B(128フレーム):知識集約型平均41.9 → 46.6(+4.7)、VideoAuto-R1の44.3を上回ります。
- Qwen3-VL-8B(128フレーム):SFT+RLにより48.5 → 51.5(+3.0)となり、7/8Bスケールで最高の知識集約型平均スコアを達成し、Qwen3-VL-8B-Thinking(50.0)およびVideoAuto-R1(49.8)を超えます。VideoKR-Evalは39.0 → 45.3、MMVUは59.6 → 64.8に上昇します。
- ステージのアブレーション:Zero-RL(50.6)> SFT-only(49.2)であり、SFT+RL(51.5)が最良であり、SFT上のRLが最強の構成であり続けますが、RLのみでもSFTのみを超えており、検証可能報酬サブセットが根拠とは独立した推論シグナルを持つことが示唆されます。
- 汎用動画推論(Video-MME、MVBench、LongVideoBench)はQwen3-VL-8Bのベースから約0.5ポイント以内に保たれており(65.9 → 65.4)、大幅なドメイン特化コストは発生していません。
比較として、GPT-5.4とGemini 3 Proは知識集約型平均でそれぞれ71.3と69.0に達しており、post-trained 8Bモデルはオープンウェイトからそのギャップの相当な部分を埋めています。
限界と未解決の問題
パイプラインは34名の大学院レベルのアノテーターと約$70.4Kのモデル推論コストに依存しており、キュレーションステップの独立した再現を困難にしています。スキル分類は3スキルに固定されており、スキルのより細かい分解やスキルに対するカリキュラムスケジューリングが有効かどうかは未検証です。GRPOのrewardはROUGE/EMを使用しており、open-endedな科学的回答に対しては脆弱であり、RLのゲインはreward設計に制限されている可能性があります。VideoKR-Evalは多肢選択形式であるため、9.5〜10.7%の単一フレームフロアはショートカット耐性の上限であり、時間的 grounding の保証ではありません。さらに、汎用動画ベンチマークは概ね保持されている一方、Qwen3-VL-8BのSFT-onlyは汎用平均で3.6ポイント低下しており、RLなしでは根拠スタイルのSFTが汎用能力を損なう可能性があることが示唆されます。
重要性
本論文は、データ設計——知識バンクに grounding された、スキル条件付きの、専門家監査済みの、ショートカット耐性のある——が、7〜8Bスケールにおいて、RLアルゴリズムの改良よりも知識集約型動画ギャップを多く埋めるという明確かつ制御された主張を展開しています。また付随する単一フレーム監査は、「動画」ベンチマークが実際に動画を必要とするかどうかを検証するための安価な診断ツールを研究コミュニティに提供します。
Source: https://arxiv.org/abs/2606.05259
Reinforcement Learning によって未知言語翻訳のコンテキスト学習が引き出される
問題設定
極度に低リソース、あるいは未知の言語をLLMで翻訳する際、一般的には対訳データによる継続事前学習か、「文法書をコンテキストに含める」プロンプティング(例:MTOBによるKalamang翻訳)のいずれかに依存しています。どちらの手法も特定の言語に過適合する問題があります。継続学習は新しい言語に汎化せず、in-context learningは供給された文法を効果的に活用することなく、控えめな品質で頭打ちになります。著者らは目標をメタスキルとして再定義しています——辞書、対訳文、文法の抜粋からなる検索ベースの言語コンテキストを読み取り、それを翻訳に活用するというスキルです。そして、表面的なメトリクスに基づく結果指向のRLを少数の既知言語に対して適用することで、このスキルを訓練し、無関係な未知の言語に転移できるかどうかを問います。
手法
訓練コーパスは14の低リソース言語をカバーし、Seen(ロマンシュ語の変種であるPuter/ValladerとEnglishとペアを成す7つの雑多な言語)、Similar(Sursilvan→De、Surmiran→De——保留されたロマンシュ方言)、Unseen(Kalamang↔︎En、および4つのアウトオブドメインEn→X)に分割されています。訓練にはSeenデータのみを使用し、7,998のSimilarおよび750のKalamang対訳ペアは意図的に除外されています。
各プロンプトは5つのコンポーネントから構成されています(Table 1):ソース言語の言語・地理的プロファイル、翻訳方向とテスト文を含むタスク指示、LCSで検索された約20〜34件の辞書エントリ(ソーストークンあたり2件)、LCSで検索された3件または5件の対訳文ペア、2つの生の文法書抜粋、そしてステップバイステップのメタ言語的推論を要求するクロージング指示です。プロンプトの平均長は約2,800トークンです。
2つのバックボーン——Qwen3-4B-BaseとLlama-3.2-3B-Instruct——を、22のスコープ内方向について、SFT(金標準参照への交差エントロピー)またはchrFを報酬とするGRPO RLのいずれかで1エポック訓練しています。プロンプトとデコーディングはSFTとRLで同一であり、異なるのは教師信号のみです。SFTのバッチサイズは128、RLは64です。報酬信号は純粋に表面的なものであり——意味論的な評価、BLEURT型スコア、参照なしの判定器は一切使用しません——これが設計上の核心的な選択です。既知言語に対するchrFが、ポリシーをメモリ化されたレキシコンへの依存ではなく、コンテキストを真に参照する方向に押し向けると仮説されています。
結果
コンテキストのアブレーション(Table 4、Qwen3-4B-BaseでのRL)は、モデルが各コンポーネントを異なる形で学習して活用することを示しています。Romansh→De(Puter、Vallader)では、完全なコンテキストで0.5324 chrFに達し、辞書を除去すると0.4483(−8.4)、対訳文を除去すると0.5224(−1.0)、文法を除去すると0.5249(−0.5)に低下します。タスクのみ(コンテキストなし)の場合は0.4154まで崩壊します。Kalamangでは、対訳文コンポーネントについて様相が逆転します:En→Kal完全 = 0.3464、辞書なし = 0.2626(−8.4)、対訳文なし = 0.2733(−7.3)、文法なし = 0.3319(−1.5)です。つまり、ベースモデルが部分的に知識を持つRomanceの近傍言語に正書法が近い場合は辞書が支配的であり、ベースモデルが事前知識を持たないKalamangのような類型論的に孤立した言語では対訳文が支配的になります。文法の抜粋はchrFの下ではほとんど貢献しておらず、表面的な報酬が文法の記述する形態統語的現象に対して感度が低いことと整合しています。
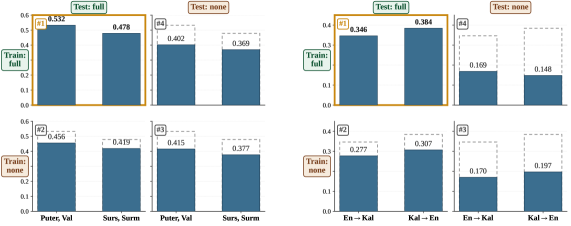
訓練・テスト間のコンテキスト不一致実験は、RLがコンテキスト活用ポリシーを学習しているのか、それとも単により優れた無条件翻訳器になっているのかを切り分けます。3つのテストグループすべてにおいて、テスト時に完全なコンテキストを与える(no/full)方が、完全なコンテキストで訓練してテスト時に除去する(full/no)よりも優れています:En→Kalではそのギャップは0.28対0.17 chrFです。したがって、改善はテスト時のプロンプトに付随しており、重みに内在化されていません——これはまさに著者らが目標とするメタスキルの振る舞いです。
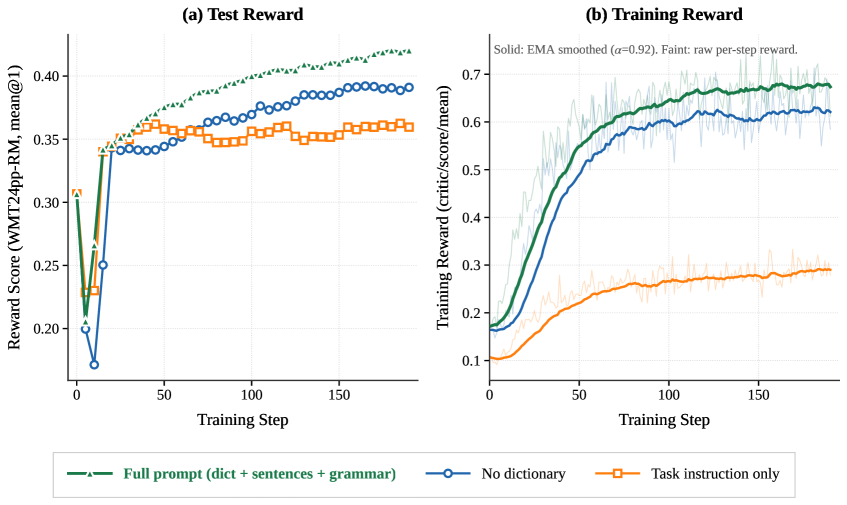
報酬曲線はプロンプトの豊富さによって明確に分離されており、完全構成が訓練全体を通じてchrF訓練報酬と保留されたWMT24++報酬の両方で支配的です。保留報酬は上昇し続けており——ポリシーが訓練言語でのchrFを単にハッキングしているわけではないことを示しています。論文中で参照されるより大きな実験表全体では、RLはSimilarおよびUnseenの分割においてSFTおよびICLを上回っています。SFTはSeenではRLに匹敵できますが転移では劣化しており、記憶化の仮説と整合しています。
限界
報酬はchrF、すなわち文字n-gramメトリクスであり、語彙的重複に対しては報酬を与えますが、形態論や語順に対しては弱いです。これが、文法のパッセージがほとんど何も貢献しない理由を説明しています——文法はchrFがスコアリングできない情報を符号化しています。評価言語数は数十にとどまり、真に未知のプローブとしてはKalamangが主要なものです。より広いアウトオブドメインのカバレッジは4言語にわたる400件のEn→Xテスト文に限定されています。検索パイプライン(LCSベースの辞書および文選択)はそれ自体が強い帰納バイアスであり、ポリシーはそれに依存しています。最後に、この結果はメタスキルが言語族を超えて転移することに依拠しており——Romansh→Kalamangでは奨励的ですが、類型論的体系性の研究は欠如しています。
なぜ重要か
これは、安価な表面的報酬を用いた結果指向のRLが、タスク固有の能力だけでなく、汎用的な「言語コンテキストを活用する」スキルを訓練できるという具体的な証拠です——GRPO-on-verifiable-rewardsのレシピを数学やコードを超えて、文書資料からの言語習得へと拡張するものです。このメタスキルがスケールするならば、検索可能な文法と辞書が存在することを条件に、言語固有の訓練データなしに、約7,000の言語のロングテールに向けた翻訳への道筋が示唆されます。
Source: https://arxiv.org/abs/2606.06428
Complexity-Balanced Diffusion Splitting
連続時間生成モデル(diffusion、flow matching)は、t \in [0,1] にわたる瞬時ベクトル場 v_t(x) を近似するために、単一のネットワーク v_\theta(x,t) を学習します。目標となる場はタイムライン上で性質が大きく変化します。t=1 付近ではデータ多様体の粗い構造へ向かう滑らかな収縮に近く、t=0 付近では細かい高周波の詳細を解像する必要があります。モノリシックなネットワークは、難易度に関わらず全ての時間領域に同一のFLOPを費やします。Complexity-Balanced Splitting(CBS)は、モノリシックなスケジュールを K 個の特化型サブネットワークで置き換え、それぞれが連続した時間区間を担当します。分割 \{0=t_0<t_1<\dots<t_K=1\} は、各セグメントが等しい近似負荷を持つように選択されます。
Barron境界から実用的なモニターへ
前提となるのはde Boorの等分布原理です。区分的近似において全誤差は最も誤差の大きいセグメントに支配されるため、最適な分割はセグメントごとの誤差を均等化します。CBSはこれをODE駆動の生成に適用します。ここでは、大域的なサンプリング誤差は軌跡に沿った局所打ち切り誤差の最大値によって規定されます。

等分布を実現するために、CBSは v_t のモデリング難易度を代理する時間ごとのモニター m(t) を必要とします。Section 3.1では、Barronの定理(Barron, 2002)からこれを導出しています。半径 r の領域上でスペクトル複雑度 C_f = \int \|\omega\| |\hat f(\omega)|\, d\omega を持つ目標 f に対して、n パラメータのネットワークが達成する誤差は
\varepsilon_{f_n} = \mathbb{E}_{p_t}[\|f-f_n\|^2] \le \frac{4 r^2 C_f^2}{n}
となります。潜在画像次元で C_{v_t} を直接推定することは扱いにくいため、著者らは場のDirichletエネルギー
E_D(v_t) = \tfrac{1}{2}\int \|\nabla_x v_t(x)\|^2 dx
を通じてこれを上界します。これはParsevalの等式により \frac{1}{2(2\pi)^d}\int \|\omega\|^2 \|\hat v_t(\omega)\|^2 d\omega と等しくなります。有効帯域幅に関するCauchy–Schwarzを適用すると C_{v_t}^2 \le K \cdot E_D(v_t) が得られ、代入することで計算可能なモニター
m(t) = K' \frac{E_D(v_t)}{n}
が得られます。すなわち、時刻 t における学習済みフローの空間的粗さを \nabla_x v_t のDirichletエネルギーで要約したものが、固定容量の学習器が被る時間ごとの近似誤差の原理的な上界となります。2番目のモニター(Sec. 3.2)はスペクトル的ではなく幾何的なものです。これはサンプリング軌跡 \ddot x(t) の曲率・加速度を測定し、v_t の積分曲線がどれだけ直線でないかを捉えます。直線的な軌跡は積分も fitting も容易ですが、高曲率の領域はより多くの容量を必要とします。2つのモニターは相補的です。一方は場を対象とし、もう一方はそれが誘導するフローを対象とします。どちらも同じ等分布アルゴリズムに組み込むことができます。
分割アルゴリズムとパイプライン
選択した m(t) を与えると、CBSは軽量な補助モデルから累積モニター M(t)=\int_0^t m(s)\,ds を計算します(展開グレードのジェネレータである必要がないため安価です)。分割は t_k = M^{-1}(k\, M(1)/K) によって定義され、各区間 [t_{k-1},t_k] が同一の積分負荷 M(1)/K を持つようになります。専門家 v_{\theta_k} は自身の区間に制限されたサンプルで学習され、推論時にはODEソルバーが t_k でネットワークを切り替えます。ヒューリスティックな時間分割も、分割境界に関する共同最適化も、高コストな探索も必要ありません。
実験設定
Section 4では3つの設定で評価が行われており、主要なテストベッドはScalable Interpolant Transformer(SiT)ファミリー(SiT-S、SiT-B、SiT-XL)をベースラインおよびCBSアンサンブルの構成要素として使用したImageNet-256の潜在生成です。事前学習済みオートエンコーダーの潜在空間で動作し、著者らは K 個の専門家によるCBS分割を、総パラメータ数またはステップごとのFLOPを揃えたモノリシックなSiTモデルと比較します。残りのサブセクションでは、K の増加に伴うスケーリング挙動(4.2)、網羅的探索によって得られた経験的最適解に対するCBS分割の精度(4.3)、Dirichletエネルギーモニターと軌跡加速度モニターの直接比較(4.4)、およびモニターの推定と分割計算のウォールクロックコスト(4.5)を対象としており、著者らはこれを展開ネットワークの学習コストに対して無視できると述べています。
限界と未解決の問題
提供されているセクションには最終的なFID/ISの数値、最適な K、または2つのモニターの相対的な性能が含まれていないため、CBSがオラクル分割にどれほど近づくかについての定量的な主張をここで再現することはできません。いくつかの概念的なギャップも残っています。Dirichlet境界は、ドメインに依存しており直接測定できない有効帯域幅 K に関するCauchy–Schwarzを通じて得られます。精度はスペクトルが仮定されたサポートにどれだけ近いかに依存します。ステップごとの推論コストは変わらず(専門家も依然としてtransformerです)、専門家がアダプターを通じてバックボーンを共有しない限りメモリは K に線形に増加します。これは自明な拡張です。このフレームワークは補助モデルのモニター推定が大きな専門家モデルに転移することを前提としています。これはDirichletエネルギーが学習器ではなく目標場の性質であるため妥当と思われますが、補助モデルと最終モデル間の分布シフトのもとでのストレステストは行われていません。最後に、近似誤差を等分布化することはサンプル品質誤差を等分布化することとは異なります。Figure 1の最大局所誤差ODE境界を通じた接続は示唆的ですが厳密ではありません。
なぜこれが重要か
CBSは、diffusion/flowモデルにおけるアドホックな時間分割ヒューリスティックを、Barronの定理に裏付けられた等分布原理で置き換え、t に沿った容量配分を測定可能なモニターの決定論的な関数に変換します。実験結果が理論を裏付けるならば、これは連続時間生成モデルにおいて固定パラメータ予算をより効率的に使用するためのドロップイン的な手法となります。
Source: https://arxiv.org/abs/2606.06477
自己進化型LLMエージェントにおける継続的経験内在化の再考
過去のインタラクション履歴をパラメトリックな重みに蒸留する自己進化型エージェントは、無制限のコンテキスト増大を伴わずに能力が複利的に向上することを期待させます。しかし本論文が示すのは、その逆の経験的現実です。すなわち、自己収集した軌跡に対してcontext-distillationを複数ラウンドにわたって反復すると、エージェントは単調な向上どころか段階的な能力崩壊を起こします。本研究の貢献は、この崩壊がなぜ生じるかを三つの軸——経験粒度、注入パターン、内在化レジーム——に沿って体系的に解剖し、安定性を回復するためのレシピを提示することにあります。
セットアップ
エージェントはReActに従い、五つのツール(Search、Visit、Python、Scholar、File Parser)を使用します。ステップ t において、ポリシー \pi_\theta は履歴 \mathcal{H}_{t-1} を条件として思考 \tau_t と行動 a_t \in \mathcal{A} を生成し、以下を得ます。
\mathcal{H}_T = (x, (\tau_1, a_1, o_1), \ldots, (\tau_T, a_T, o_T))
タスク報酬は r(\mathcal{H}_T) です。軌跡はDeepSeek-V4によって自然言語の経験プール \mathcal{E} = \{e_1, \ldots, e_N\} に要約され、その後学生モデル(Qwen3-4B-Instruct-2507およびQwen3-8B)の学習に再注入されます。継続的内在化は、収集・要約・蒸留のラウンドを反復する形で行われます。
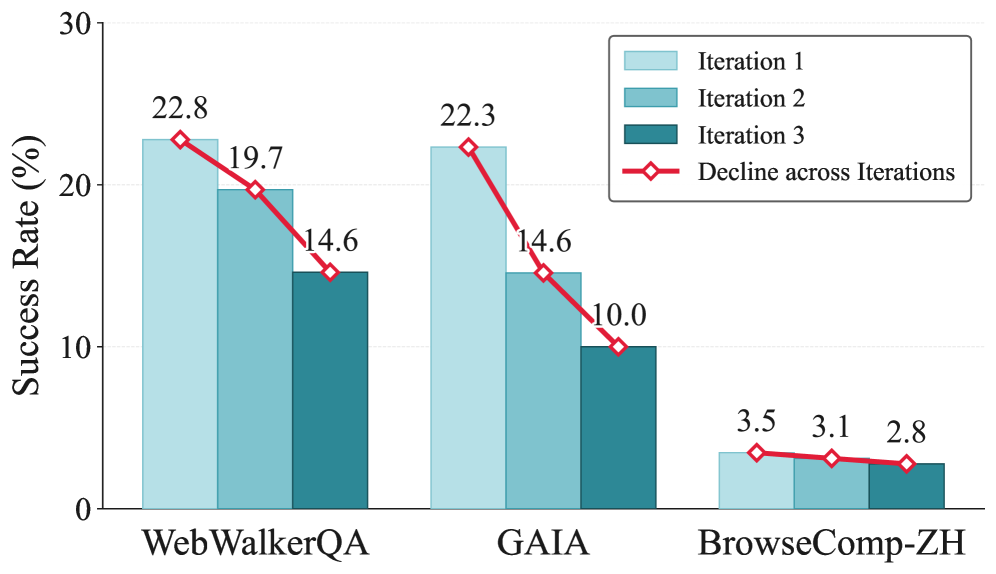
図1に示す崩壊パターンが中心的な現象です。すなわち、標準的なon-policy context-distillationは数回の反復後にベースモデルを下回る性能まで劣化し、より多くの自己経験が有益であるという暗黙の仮定に反します。
軸1: 経験粒度
第一の知見は、何が要約されるかがどれだけ要約されるかよりも重要であるということです。インスタンスレベルの経験は軌跡固有の痕跡——URL、数値、エンティティ文字列——を保持する一方で、原則レベルの経験は再利用可能な意思決定規則や失敗パターンを抽象化します。定量的には、著者らがサンプリングしたプールにおいて以下のことが示されています。
- インスタンスレベルの項目の74.4%が特定のURL/ドメインを含み、57.3%が具体的な数値を含み、93.9%がクエリまたはエンティティ固有の文字列を含む。
- 再利用可能な戦略的記述を含むインスタンスレベルの項目はわずか3.7%であるのに対し、原則レベルの項目では84.0%がそれを含む。
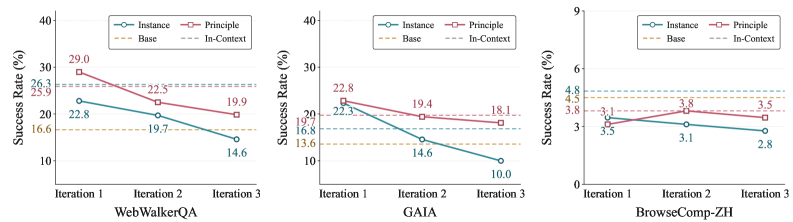
図2は、インスタンスレベルの経験が最初の反復で一時的な向上をもたらした後、反復が進むにつれてベースモデルを下回るまで低下することを示しています。一方、原則レベルの経験は反復を通じて安定しています。メカニズム的に説明すると、インスタンスレベルの蒸留は学生モデルを軌跡固有のアーティファクトに過学習させますが、それらのアーティファクトは後のラウンドで学生モデル自身が誘導する軌跡の分布とはもはや一致しません——これは自己進化に内在する共変量シフトの罠です。原則レベルの要約はこれらのローカルな特徴を除去し、新たな軌跡分布の下でも有効であり続ける規則を保持します。
軸2: 注入パターン
第二の軸は、学習中に経験が軌跡のどこに現れるかです。グローバル注入はすべての関連経験をシステム/コンテキストプレフィックスに連結し、抽象的なアドバイスと \mathcal{H}_T 全体との関連付けをモデルに内在化させます。ステップごとの注入は、各経験項目が実際に適用可能な中間的な意思決定状態 \mathcal{H}_{t-1} に合わせて整列させ、次の (\tau_t, a_t) をローカルに関連する原則に条件付けます。
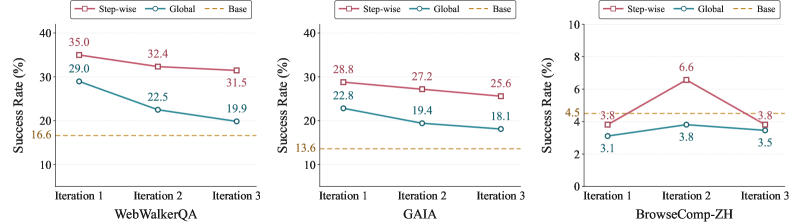
図3は、反復学習においてステップごとの注入がグローバル注入を大幅に上回り、長い水平線のツール使用においてそのギャップが広がることを示しています。解釈としては、長い軌跡はグローバル注入の下で信用割り当てシグナルを拡散させるため、学生モデルはある原則をそれが発火すべき特定の状態に結びつけることに失敗します。ステップごとの注入はこの結びつきを明示的にします。これはまさに、ツール使用の軌跡が異なる原則が適用される多くの意思決定ポイントを持つためです。
軸3: 内在化レジーム
第三の軸は、蒸留に使用される軌跡のソースに関するものです。On-policy context-distillationは、現在の学生モデルが \mathcal{E} を条件として生成した軌跡を学習に使用します。これは学生モデルの誤りを引き継ぎます。すなわち、低報酬または部分的に正しい軌跡はノイズの多いターゲットを生成し、反復が進むにつれてノイズが蓄積します。Off-policy context-distillationは代わりに、(報酬によってフィルタリングされた)高品質な教師の軌跡を教師信号として使用しつつ、原則レベルの経験をステップごとに注入します。著者らは——反復曲線もそれを支持しますが——このoff-policyレジームが大幅に安定した学習シグナルを提供すると主張しています。なぜなら、ターゲット分布が学生モデル自身の劣化とともにドリフトしないためです。On-policy蒸留はこの複数反復の設定において「本質的に不安定」であり、off-policyフィルタリングが自己強化的なエラーループを断ち切ります。
まとめ
複数回の反復的自己進化を乗り越えるレシピは以下の通りです。(i) 軌跡を戦略と失敗パターンを抽象化した原則レベルの経験に要約する、(ii) 経験が適用される意思決定状態においてステップごとに経験を注入する、(iii) 報酬フィルタリングされた教師の軌跡に対するoff-policy context-distillationで学習する。各軸は個別でも崩壊を軽減しますが、それらを組み合わせることで、Qwen3-4BおよびQwen3-8Bエージェントの反復を通じて継続的内在化をネガティブからネットポジティブに転換できます。
限界と未解決の問題
本研究ではDeepSeek-V4を要約器として使用しているため、原則/インスタンスの二分法はその要約器のプロンプティングの特性に部分的に依存しており、より小型の要約器が粒度の優位性を保持するかどうかは不明です。Off-policyレジームはより強力な教師へのアクセスに依存しており、学生モデルがすでにフロンティア近傍にある場合は適用性が制限されます。また、本論文は原則レベルの経験が冗長性や矛盾が支配的になる前にどれだけ蓄積できるかを定量化しておらず、数百のツール呼び出しを持つ軌跡——検索がボトルネックになる——にステップごとの注入がスケールするかどうかも検討されていません。最後に、失敗モード分析は経験的なものにとどまっており、on-policy反復がなぜ崩壊するかの形式的な説明(例えば、context-distillationに関する分布シフト境界の観点から)は欠落しています。
この研究が重要な理由
ほとんどの「自己進化型エージェント」パイプラインは、経験を重みに蒸留し直すことで能力が複利的に向上するという暗黙の仮定に基づいています。本論文はデフォルトのレシピが崩壊することを示し、継続的内在化が安定するか自己破壊的になるかを決定する三つの具体的な設計選択——粒度、注入箇所、off-policyフィルタリング——を特定しています。長期稼働するエージェントを構築する方々にとって、反復回数をスケールアップする前に調整すべきレバーはまさにこれらです。
Source: https://arxiv.org/abs/2606.04703
推論の影の価格:LLMに対する最適予算配分の経済的視点
問題設定
推論時スケーリング則によれば、クエリに対してより多くの推論トークンを割り当てることで精度が向上しますが、実際の運用では異種クエリストリームにわたるハードなトークン予算の制約下で動作します。均一な割り当ては、自明に解けるクエリや到底解決できないクエリに対してトークンを無駄遣いしますが、クエリごとの適応的な打ち切りには大域的な原理的基準が欠けています。本論文では、推論時の計算をリソース制約配分問題として定式化し、KKT条件から最適方策を導出し、ラグランジュ乗数を市場清算影価格(shadow price)として扱います。
経験的動機とユーティリティモデル
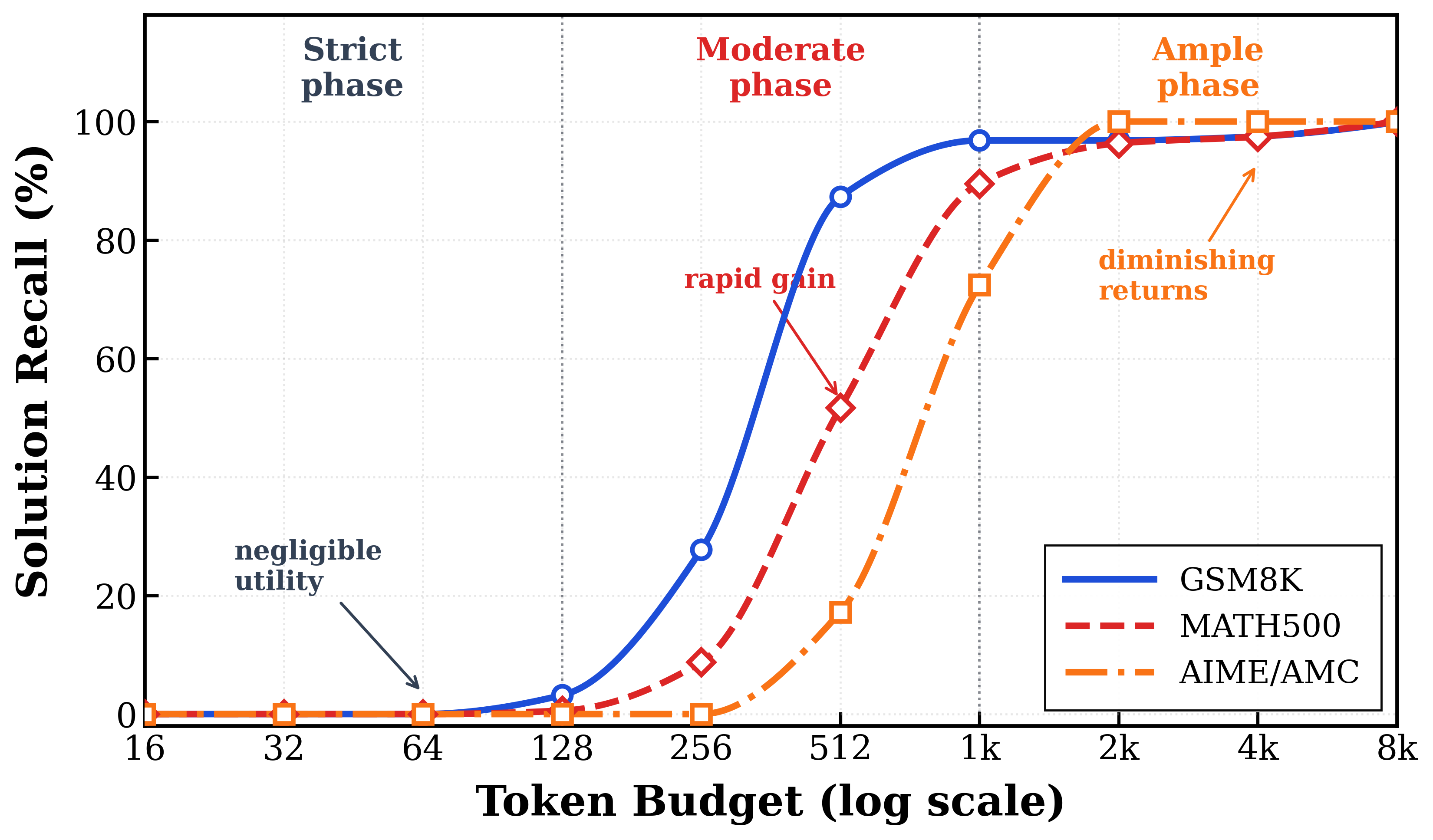
T=1.0(AIME-24ではN=50、GSM8KおよびMATH-500ではN=4)でQwen2.5-Math-7Bをサンプリングし、ロールアウトを長さでビン分けすると、3つのフェーズを持つ非単調なPass@1 vs. 長さ曲線が現れます:Strictフェーズ(出現閾値前はユーティリティ\approx 0)、Surgeフェーズ(急激な上昇)、Ampleフェーズ(収益の逓減または負の収益)です。
これにより、クエリごとのshifted-surgeユーティリティ関数が動機付けられます:
\phi_i(t) = \begin{cases} 0 & 0 \le t < \tau_i \\ \alpha_i(t-\tau_i)\,e^{-\beta_i(t-\tau_i)} & t \ge \tau_i \end{cases}
ここで、\tau_iは潜在的な出現閾値、\alpha_iは閾値を超えた後の初期限界ユーティリティ、\beta_iは減衰率です。経験的ロールアウトにこの形式をフィッティングした結果(下図の赤い曲線)は、ビンごとの正解数分布を概ね良好に追跡しています。
理論的最適解
\sum_i t_i \le B_{\text{total}}の制約下で\sum_i \phi_i(t_i)を最大化すると、ラグランジアン\mathcal{L} = \sum_i \phi_i(t_i) - \lambda(\sum_i t_i - B_{\text{total}})が得られます。定常性条件から影価格均等が導かれます:
\frac{\partial \phi_i(t_i^*)}{\partial t_i} = \lambda \quad \forall\, t_i^* > 0,
すなわち、資金を割り当てられた全クエリは等しい限界ユーティリティを持たなければなりません。\phi_iを微分すると、\Delta t = t_i - \tau_iに対して\alpha_i e^{-\beta_i \Delta t}(1-\beta_i \Delta t) = \lambdaが得られ、Lambert W関数によって閉形式の解を持ちます。クエリが合理的に放棄される(t_i^*=0)のは、その最大純余剰\phi_i(t_i^*) - \lambda t_i^*が負のとき、すなわち\lambda > \alpha_iのとき(\alpha_iが予約価格として機能するため)です。解決不能なクエリから解放されたトークンは、閾値付近にある解決可能なクエリに再配分されます。
CLEARアルゴリズム
CLEARはこの方策を3つのコンポーネントで実装しています:
- 閾値予測器。 GSM8K/MATH解の長さで学習したDeBERTa-v3-baseの回帰器f_\thetaが\hat\tau_i = \exp(f_\theta(s_i))を予測します。
- 大域パラメータ。 \alphaと\betaは、プロンプトから\beta_iを予測することは高分散であるため、クエリごとではなくバックボーンレベルの定数として扱われます。\betaは予算のプレッシャーに適応します:\beta = 1/\max(\epsilon,\bar B - \bar\tau)、ここで\bar Bはクエリごとの予算、\bar\tauは予測された閾値の平均です。
- 影価格ソルバー。 \lambdaに関する1次元の根探索により\sum_i t_i^*(\lambda) = B_{\text{total}}を強制します。ここでt_i^*(\lambda)はLambert-W閉形式解(\lambda \ge \alphaのとき放棄あり)です。
結果
評価には、Qwen2.5-Math-7B-InstructおよびQwen3-30B-A3B-Instructを使用し、クエリごとの予算256/512/1024/2048トークンで、4種類の合成500クエリストリーム(Balanced、Mostly-Easy、Mostly-Hard、U-Shaped)を用いています。
CLEAR (Lambert)は希少なリソース条件下でベースラインを凌駕します。予算256の場合:
- Balanced:14.6% vs. 3.0% Uniform(+11.6絶対値)、Oracle 19.0%。
- Mostly-Easy:33.0% vs. 9.0%(+24.0絶対値)、Oracle 42.2%。
- Mostly-Hard:6.2% vs. 1.0%(+5.2)、6\timesの相対的向上。
- U-Shaped:18.6% vs. 4.4%(+14.2)。
予算が増加するにつれ改善幅は単調に縮小し、2048トークンではほとんどのストリームでCLEARがUniformに匹敵します(例:Mostly-Easy 49.0% vs. 49.0%)。放棄が不要になるためです。単純なPredictor(\hat\tauによる比例配分)は低予算では実際にUniformを下回ります(例:Balanced-256で0.6%)。これは、影価格清算メカニズムなしのランキング単独では不十分であることを示しています。TALE-EP(トークン予算認識プロンプティング)も希少条件では同様に弱い結果となっています。HeuristicおよびAuction CLEARの変形はLambertソルバーに近づきますが、同等には達しません。
フェーズ遷移の分析では、予算が増えるにつれて放棄率がゼロに低下し、豊富なリソース条件ではCLEARがUniformに収束することが示されています。感度分析では、精度は絶対的な\alpha値に対してほぼ不変であることが示されており(最適な\lambda^*は線形にスケールする:\log\lambda^* \propto \log\alpha)、\alphaはゲージの自由度として機能します。配分の決定に重要なのは\lambda/\alphaの比率のみです。適応的な\betaルールは各ストリームにおける\beta感度の最適点付近に着地します。
限界
- \alpha,\betaは大域的なハイパーパラメータであり、実際のクエリごとの減衰率は大きく異なる可能性があり、モデルはこの分散を閾値予測器に押し込んでいます。
- 閾値予測はGSM8K/MATHの解の長さで学習されており、真の出現閾値のノイズの多い代理であり、数学以外の推論への汎化は未検証です。
- ストリームはオラクル難易度プールの合成混合であり、未知のクエリ到着統計やKVキャッシュ制約を伴うオンライン設定はモデル化されていません。
- ユーティリティ関数はパラメトリックなansatzであり、shifted-surge形状は経験的にはフィットしますが、モデル内部から導出されたものではなく、二値結果から連続ユーティリティへのマッピングはヒューリスティックです。
- 高予算では改善が消失するため、実用的なリソース条件は狭く、トークンが希少で難易度が異種の場合のサービングに限られます。
なぜこれが重要か
推論時の計算配分をKKT条件を通じて定式化することで、単一のスカラー値、すなわち影価格\lambdaが得られます。これは、どのクエリを放棄するかと残りのクエリにどれだけ費やすかを同時に決定し、クエリごとのヒューリスティックを大域的に一貫したルールに置き換えます。希少なリソース条件での3\timesの精度向上は、バッチレベルの経済的推論が、固定トークン予算下での本番LLMサービングに対する適切な抽象化であり、単なるクエリごとの適応的深度では不十分であることを示唆しています。
Source: https://arxiv.org/abs/2606.03092
OPRD: On-Policy Representation Distillation
On-policy distillation(OPD)は、学生モデル \pi_\theta を自身のロールアウト \hat{y}\sim\pi_\theta(\cdot\mid x) で学習させ、教師モデルの次トークン分布を一致させることで監督します。通常、reverse-KL Monte Carlo 推定量を用います。しかし、2つの構造的な問題が残っています。第一に、gradient は \sim 151K トークンの語彙(Qwen2.5)にわたる REINFORCE スタイルの推定量であるため、サンプリング分散は学習が進んでも減衰しません。top-k の代替手法でさえ、バイアスと分散のトレードオフを生じさせるだけで問題を根本的に解決しません。第二に、LM head W_{\text{head}} は低ランクで加法不変な射影 \mathbb{R}^d\to\mathbb{R}^{|\mathcal{V}|} であるため、\ker(W_{\text{head}}) に存在する教師の計算や softmax によって消去される情報は OPD には見えません。OPRD は、同じ on-policy トラジェクトリ上で監督を hidden state 空間に引き上げます。
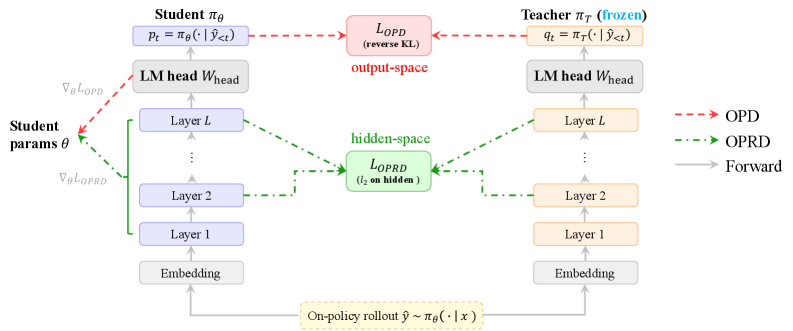
手法
\mathcal{L}_{\text{layer}}\subseteq\{1,\dots,L\} を蒸留対象のレイヤー集合、m_t\in\{0,1\} をロールアウト上の位置マスクとします。教師の表現 h_{T,t}^{(l)} と学生の表現 h_{\theta,t}^{(l)} に対して、OPRD は以下を最小化します。
\mathcal{L}_{\text{OPRD}}(\theta)=\mathbb{E}_{x,\hat{y}\sim\pi_\theta}\!\left[\frac{1}{|\mathcal{L}_{\text{layer}}|}\sum_{l\in\mathcal{L}_{\text{layer}}}\frac{1}{\sum_t m_t}\sum_{t=1}^{T} m_t\,\frac{1}{d}\bigl\|h_{\theta,t}^{(l)}-\mathrm{sg}\bigl(h_{T,t}^{(l)}\bigr)\bigr\|_2^2\right],
ここで \mathrm{sg}(\cdot) は教師側の stop-gradient を表し、1/d は hidden 幅にわたって正規化します。d_s\ne d_T の場合、学習可能な射影行列 W\in\mathbb{R}^{d_T\times d_s} が MSE の前に学生側をマッピングします。著者らのメインの設定では d_s=d_T=1536 であるため、W は省略されます。\mathcal{L}_{\text{layer}} の選択肢としては最終レイヤーのみ、全レイヤー、またはパリティに基づくサブセットなどが挙げられます。また \mathcal{P}(\hat{y}) は全トークン、あるいはプレフィックス・サフィックスとすることができます。
機械的な重要点として、loss の計算パスは LM head を一切経由しません。gradient は選択されたレイヤーの残差ストリームに直接流れます。これにより、(i) サンプルされた \log\pi の gradient を、サンプルあたり |\mathcal{L}_{\text{layer}}|\times|\mathcal{P}|\times d 個のスカラーを含む決定論的な dense gradient(top-k OPD と比較して桁違いに多い監督信号)に置き換えることができ、(ii) 蒸留のために [B,T,|\mathcal{V}|] の logits テンソルを具現化する必要がなくなります。これは |\mathcal{V}|\!\approx\!151K の場合、メモリの支配的な要因です。著者らはこれを2つの定理で裏付けています。一つは OPD の gradient に低減不可能な Monte Carlo 項が存在する一方、OPRD の gradient が決定論的であることを示す分散の上界、もう一つは LM head が hidden state の監督によって回収できる成分を捨てていることを示す情報ボトルネックの議論です。
実験
実験では、凍結された教師として JustRL-Deepseek-1.5B を、学生として DeepSeek-R1-Distill-Qwen-1.5B を使用します。どちらも Qwen2.5-1.5B のバックボーン(L=28、d=1536)であるため、hidden state の次元は一致しています。ベースラインは OPD top-1(サンプルトークンによる reverse KL)と OPD top-16 であり、OPRD とロールアウト、教師の forward 計算、および optimizer スケジュールを共有します。異なるのは監督の抽出点のみです。評価は AIME 2024、AIME 2025、および AIMO で Avg@16 を用いて行われます。
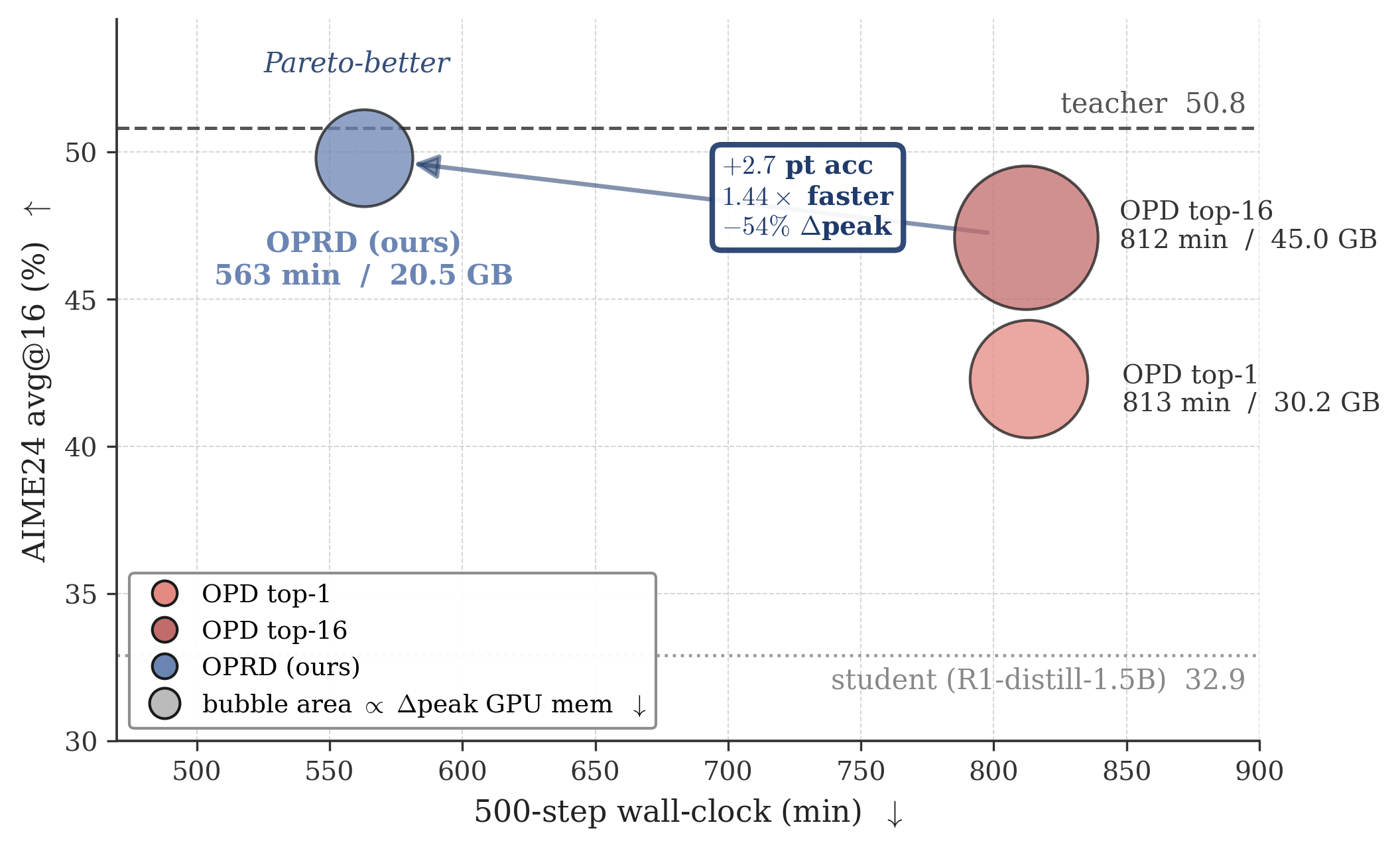
主要な結果として、8\times A100-80G FSDP による 500 ステップの optimizer 実行において、OPRD は Pareto 優位であることが示されています。OPRD は wall-clock 時間で 1.44\times 高速に学習し、top-k OPD と比較してアクター更新時のピーク GPU メモリを最大 54\% 削減しつつ、AIME24 Avg@16 でより高いスコアを達成しています。学習ダイナミクスを見ると、OPD top-1 と top-16 は3つのベンチマーク全てにおいて教師を大きく下回る水準で停滞または振動するのに対し、OPRD は継続的に改善し教師レベルの性能に近づいています。これは、決定論的な MSE gradient がサンプリングノイズによる後期の停滞を回避するという定理1の予測と一致しています。
副次的な効果として、応答長に関する以下の観察があります。
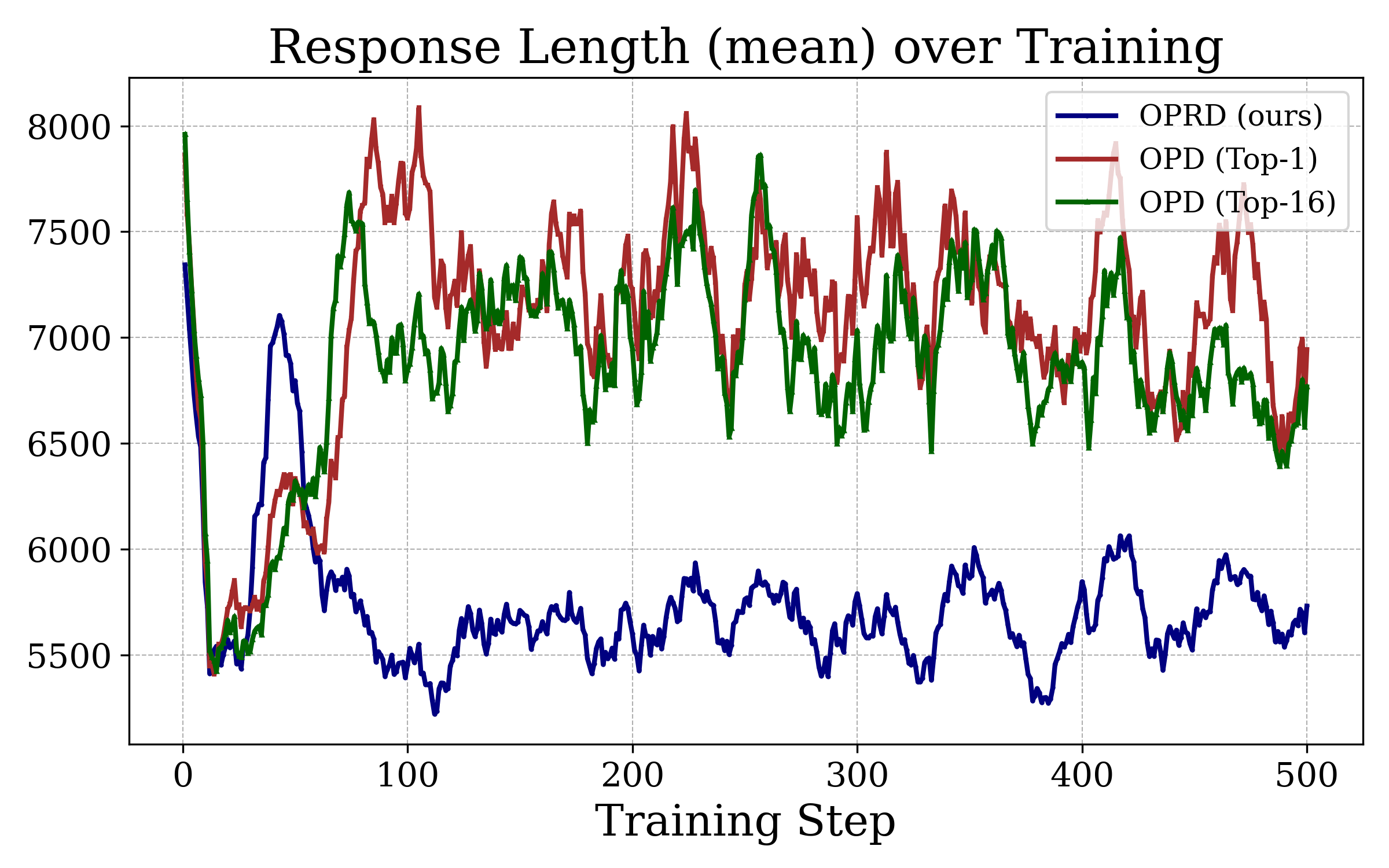
OPRD は応答あたり \sim 5{,}700 トークンに収束する一方、両方の OPD 変種は \sim 7{,}000 トークン前後で停滞します。精度が同等以上であることから、これは学習時の節約に加え、推論コストが実質的に \sim 19\% 削減されることを意味します。hidden state のアライメントにより、トークン確率のマッチングよりも忠実に教師の推論トラジェクトリが伝達されるためと考えられます。トークン確率のマッチングは冗長な回り道によっても満足され得ます。
限界と未解決の問題
最も強い結果はアーキテクチャが揃っている(d_s=d_T、同じバックボーンファミリー、同じトークナイザー)場合を前提としています。射影行列 W は幅の不一致には対応できますが、ファミリーをまたいだ蒸留やトークナイザーが異なる蒸留(例:Llama の学生、Qwen の教師)は評価されておらず、より複雑なアライメントが必要となります。異なる BPE の下では位置レベルのトークン対応が崩れるためです。\mathcal{L}_{\text{layer}} と \mathcal{P}(\hat{y}) の選択は設計上の調整可能なパラメータとして提示されていますが、提供されたセクション内で系統的なアブレーションは行われていません。最終レイヤーのみで十分か、全レイヤーのマッチングが必要かという問いは、メモリに関する議論に影響します。最後に、hidden 空間における MSE は強い制約です。これは学生を教師の特定の表現基底に押し込めるため、学生の容量が大幅に小さく内部の再パラメータ化が望ましい場合には問題になり得ます。理論は分散とボトルネックには対処していますが、この表現の硬直性に関するトレードオフには触れていません。
なぜこれが重要か
OPRD は、on-policy distillation が LM head を通じて監督を絞り込むことで教師の計算のほぼ全てを捨ててきた点を指摘し、ネットワークの早い段階に loss を移動させるだけで、サンプリング分散と大規模語彙によるメモリの膨張の両方を取り除けることを示しています。特に推論モデルの蒸留においては、教師と学生がバックボーンを共有することが多いため、これはほぼコストなしの置き換えであり、出力空間の OPD では埋めることのできない学生と教師のギャップを縮小します。
Source: https://arxiv.org/abs/2606.06021
ArcANE: ロールプレイ言語エージェントは適切なタイミングでキャラクターを維持できるか?
問題設定
ロールプレイ言語エージェント(RPLA)は通常、ある章においてキャラクターが知り得る事実を再現できるか、あるいは複数のターンにわたって安定したペルソナを維持できるか、という観点で評価されます。しかしこれらの評価枠組みはどちらも、文学的キャラクターの本質的な面白さ——価値観、恐れ、意思決定の方針が物語を通じて変化すること——を捉えきれていません。第一部のラスコーリニコフはエピローグのラスコーリニコフと同じように応答すべきではなく、どちらの応答も「キャラクターに即している」とスコアするベンチマークは、二つの異なる心理状態を混同してしまっています。より難しいのは反事実的プロンプト——原作テキストに登場しない状況——であり、この場合はretrieval-augmentedなコンテキストが何も取得できないため、エージェントは表面的な事実からではなく、フェーズ固有の心理から外挿しなければなりません。
ArcANE(Arc-Aware Narrative Evaluation)はまさにこのギャップを標的とします:エージェントはキャラクターのアークにおける適切なタイミングでキャラクターを維持できているか?
手法
このベンチマークは17の小説と80名の主要キャラクターを対象として自動構築されます。中心的な概念はCharacter Arcであり、物語をそのキャラクター固有の心理的軸(例:罪悪感、野望、信頼)に沿ったフェーズに分割したものです。形式的には、物語Nを持つキャラクターcのアークは以下の系列として定義されます。
A_c = \{(\phi_i, s_i, e_i, \psi_i)\}_{i=1}^{K}
ここで\phi_iはフェーズラベル、[s_i, e_i]はテキスト中のスパン、\psi_iはフェーズ条件付きの心理的記述(価値観、信念、支配的な感情)です。プローブは同一のシナリオqをすべてのフェーズiに対して提示するよう構築され、二つのレジームに分割されます:
- In-sourceシナリオ:小説が実際に描写しているか、そのフェーズにおいて強く示唆している状況。
- Out-of-sourceシナリオ:小説が決して探求しない反事実的な状況(例:キャラクターを無関係なジレンマに置く)。
(キャラクター、フェーズ、シナリオ)の各トリプルに対して、エージェントの応答r_{c,i,q}は単一のグローバルなペルソナではなく\psi_iとの整合性で判定されます。評価では六つのコンテキストモードと六つのモデルの組み合わせを比較します。コンテキストモードは推論時にRPLAが受け取る条件付け情報を変化させるもので、コンテキストなし、キャラクターサマリー、retrieved passages(小説へのRAG)、フルチャプターウィンドウ、伝記、および対象フェーズのCharacter Arc記述\psi_iが含まれます。
主要な実証的主張は、\psi_i——コンパクトなフェーズ固有の心理的プロンプト——への条件付けが他のすべてのコンテキスト戦略を上回り、N上のretrieval が関連するものを何も返せないout-of-sourceプローブにおいてその差が拡大する、というものです。
結果
六つのベースモデルすべてと六つのコンテキストモードすべてにわたって、Arc conditioningはすべてのモデルで最高性能のコンテキストでした。その優位性はout-of-sourceシナリオで最も大きく、このレジームではRAGおよびchapter-windowベースラインが最も劣化します——小説中に反事実的状況と一致するpassageが単純に存在しないためです。
著者らはその後、Arc条件付きのトラジェクトリでopen-weightバックボーンをfine-tuningし、ArcANE-8BとArcANE-32Bを作成しました。これらのモデルはフェーズ条件付き行動を内在化しており、out-of-sourceプローブでのArcの優位性がさらに広がっています。これはその利得が単なるpromptingのアーティファクトではなく、心理的フェーズの学習可能な表現に対応していることを示しています。In-sourceでの利得は小さく、retrievalとchapter contextがすでに十分な表面的シグナルを供給しているという仮説と整合しています;識別的なレジームは反事実的なものです。
限界と未解決問題
いくつかの点を指摘する価値があります。第一に、Character Arc自体がモデルによって抽出されるものです;もし抽出器がキャラクターを単一の心理的軸\psiに体系的に投影するならば、評価はそのバイアスを引き継ぎ、Arc条件付きのRPLAは小説の心理を反映するのではなく抽出器の語法に合わせているだけかもしれません。第二に、「\psi_iとの整合性」は自動で判定されます(おそらくLLM-as-judge)。これにより評価器と生成器の能力が結合し——Arc conditioningが有効なのは、判定器もアーク的に推論するためである可能性があります。第三に、ベンチマークは17の小説と80のキャラクターをカバーするにとどまり、文学的キャラクタータイプの多様性に対して小規模です;連載小説、アンサンブルキャスト、信頼できない語り手の構造は十分に表現されていません。第四に、フェーズは離散的として扱われていますが、多くのアークは連続的または非単調的(再発、退行)であり、分割\{[s_i, e_i]\}はこれらを過度に単純化している可能性があります。最後に、フェーズラベルや整合性判定について読者が同意するかどうかに関する人間の評価者によるキャリブレーションがabstractでは報告されていません。
未解決問題として:アークはNから事前計算するのではなく、インタラクション履歴からオンラインで推論できるか?Arc conditioningは小説全体を取り込める長コンテキストモデルとどのように組み合わせられるか?そして、Arc conditioningの優位性はマルチターンのロールプレイに移転するか——その場合、エージェント自身の以前のターンが条件付けの一部となり、トラジェクトリをフェーズから外してしまう可能性があります。
なぜこれが重要か
ArcANEはRPLA評価の枠組みを「エージェントはキャラクターが知っていることを知っているか」から「エージェントはキャラクターがその発展のこの時点で振る舞うように振る舞えるか」へと再定義し、コンパクトなフェーズ固有の心理的プロンプトが最も強力なコンテキストモードであり、retrievalが役に立たない反事実的シナリオ——実際にデプロイされたキャラクターエージェントが実際に動作するレジーム——に対して有用なfine-tuningシグナルであることを示しています。
Source: https://arxiv.org/abs/2606.05553
Hacker News Signals
Transformerは3つのprojectionを必要とするか?QKVバリアントの体系的研究
本論文は、attention機構における標準的なQ、K、Vのprojection構造が本当に必要なのか、それとも単なる慣習に過ぎないのかを問う、体系的な実証研究です。評価対象となる設計選択肢のグリッドは、Q/K/V間でのprojection共有、projectionの完全な除去、QとKの結合、value projectionの除去など多岐にわたります。各バリアントについて、一貫したスケールでモデルをスクラッチから学習し、下流のベンチマークで評価することで、各projectionの寄与を独立して分離しています。
主要な知見はいくつかの前提に疑問を呈しています。key projectionを除去してQ=Kと結合させると性能が顕著に低下しますが、value projectionの除去や共有は予想より低コストであり、いくつかの構成ではVに対して単一の共有projectionを用いても軽微な品質低下にとどまります。パラメータ予算を一定に保った場合、3つのprojectionを持つフルのattentionが常にPareto最適であるとは限りません。なぜなら、節約されたパラメータを他の箇所(例:より広いMLP層)に再配分できるからです。また本研究では、フルランクとno-projectionバリアントの中間点として、各projectionの低ランク分解についても検討しています。
メカニズム的な論拠として、QとKは異なる部分空間(ドット積のquery側とkey側)上で動作するため、区別可能な状態を保たなければならず、これらを結合するとattentionの選択性を生む非対称性が失われます。一方、value projectionは重み付け後の線形変換であり、feed-forwardサブレイヤーのoutput projectionとの冗長性が高くなっています。
これは効率的なアーキテクチャ探索において重要な意味を持ちます。V projectionを大きな損失なく除去または共有できるならば、小規模モデルはそれらのパラメータをより有効に活用できます。また、キャッシュされるKテンソルとVテンソルが縮小するため、推論時のKV cacheも削減されます。本論文は理論的な議論だけでなく具体的な実証的マップを提供しており、アーキテクチャのアブレーションを行う実務者が直接活用できるものとなっています。
制限事項:実験は中規模スケールで行われており、スケーリング則の相互作用によって10Bパラメータ以上では結論が変わる可能性があります。また、シングルタスクとマルチタスクのトレードオフについては十分に検討されていません。
Source: https://arxiv.org/abs/2606.04032
AnthropicによるAI駆動の脆弱性発見向けオープンソースフレームワーク
AnthropicはDefending Code Reference Harnessをリリースしました。これはLLM(具体的にはClaude)を用いてコードベースに対する自動脆弱性発見を行うためのフレームワークです。このリポジトリはコード解析パイプラインを構造化されたharnessで包んでおり、ソースファイルを取り込み、候補となるコード領域周辺のコンテキストウィンドウを構築し、セキュリティに特化したプロンプトでモデルを照会し、構造化された出力を実行可能な所見として解析します。
技術的な設計はいくつかの選択に基づいています。まず、コードはクロスリファレンスのコンテキストを保持した状態でチャンク化されており、モデルが孤立したスニペットではなく呼び出し先のシグネチャを参照できるよう、可能な限り関数コールグラフとインポートチェーンが含まれます。次に、プロンプト戦略として、所見を出力する前に脆弱性クラス(インジェクション、メモリ安全性、認証バイパス、ロジックエラー)について明示的に推論するようモデルに求め、セキュリティのセマンティクスに対する軽量なchain-of-thoughtとして機能します。第三に、harnessは構造化された出力スキーマ(深刻度、CWEカテゴリ、影響を受ける行の範囲、修正案)を強制することで、結果を後処理したり既存のissueトラッカーに取り込んだりすることが可能です。
リファレンス実装はC/C++とPythonを対象としていますが、チャンク化とシンボル解決モジュールを差し替えることで他の言語にも対応できる汎用的な設計になっています。また、同一のコードベースを複数のモデルやプロンプトのバリアントで並行実行する比較モードがあり、セキュリティタスクにおけるモデル能力のベンチマークに有用です。
注目すべきエンジニアリング上の詳細として、harnessはレート制限のバックオフ処理を行い、大規模リポジトリでのコスト超過を防ぐためにファイル単位でトークン消費量を追跡し、未レビューの差分のみを解析するトリアージモードをサポートしています。静的解析ツールの代替を目指すものではなく(形式的な健全性保証はありません)、パターンマッチングでは見逃されるセマンティクスレベルの問題を検出することで、それらを補完するよう設計されています。
未解決の問題として、大規模運用における誤検知率は明記されておらず、また既知のCVEに対する再現率を測定するためのground-truth評価harnessも提供されていません。
Source: https://github.com/anthropics/defending-code-reference-harness
AIが自己を構築するとき:Anthropicの再帰的自己改善に向けた進捗
Anthropicは、再帰的自己改善(RSI)——AIシステムが自身の能力開発を有意に加速させるシナリオ——に関する研究概要を公開しました。この投稿は論文ではなく、内部の知見をまとめ、問題空間を整理した技術的立場表明です。
中心的な技術的懸念は以下の点にあります。現代のMLパイプライン(データキュレーション、アーキテクチャ探索、ハイパーパラメータ最適化、評価設計、学習コード)は、それ自体がソフトウェアおよび研究タスクであり、有能なモデルが支援可能です。もしあるモデルの支援が、人間の研究者が行う場合よりも次世代モデルをより大きく改善し、そのサイクルが複利的に積み重なれば、RSIが実現します。この文書では、弱いRSI(AIが人間の研究者を補助するが、人間が制御を維持する。全体としてはプラスだが管理下にある状態)と強いRSI(各イテレーションにおける人間の介入を最小限に抑えつつ、AIがループを主導する状態)を区別しています。
システム論的な観点から、Anthropicはフィードバック遅延の問題を論じています。学習の実行には数週間を要するため、モデルが優れた学習改善案を生成したとしても、イテレーションサイクルは長くなります。評価設計、データフィルタリングスクリプト、学習インフラのバグ修正といった短いホライズンのタスクにおいて、現在のモデルが最も測定可能な貢献をもたらすと指摘されています。これはフィードバック信号が数か月ではなく数時間で得られるためです。
また、評価の困難さについても述べられています。モデルが提案したアーキテクチャの変更が本当に優れているかどうかを、フルの学習を実行する前にどのように判断するかという問題です。現在の手法では安価なプロキシ評価が用いられていますが、これらはスケール時に相関が崩れることが知られています。そのため、モデルの提案が方向性として正しい場合でも、ループにノイズが生じます。
安全性の観点からは、懸念されるのは能力の爆発的増大だけではありません。最適化圧力下でのRSIが、実際の目標では性能が低下するにもかかわらずプロキシ指標では高いスコアを記録するショートカットを発見してしまうという問題——開発ループ内部で生じる分布シフトの問題——も懸念されています。
技術的に薄い部分もあり、手法的な貢献というよりも問題の分類体系として有用です。現在のRSI率に関する定量的な主張は含まれていません。
Source: https://www.anthropic.com/institute/recursive-self-improvement
Uberの月額1,500ドルのAI上限は、AIツール価格設定の有用なシグナルである
Simon Willisonによる、Uberが従業員1人あたり月額1,500ドルのAIツール支出上限を設けているとの報告に関する分析は、AIツールベンダーが企業に対して現実的に請求できる価格をリバースエンジニアリングするためのレンズとして活用されています。技術的な内容はコスト構造の分解にあります。
1シートあたり月額1,500ドルという設定により、Uberは開発者の生産性向上がそのコストを上回るという賭けを暗黙的に行っています。Willisonの試算によると、現在のAPIの価格(モデルによってトークン100万件あたり約3〜15ドル)で月額1,500ドルは、開発者1人あたり月間約1億〜5億トークンに相当し、1日8時間の継続的なコーディング支援としては現実的であり、過剰でもありません。1シートあたりのSaaS価格(GitHub Copilotは月額約20ドル)とこの上限との乖離は2桁のオーダーであり、この上限が上限付きのSaaS製品ではなく、API直接利用の重量ユーザーを対象としていることを示唆しています。
より興味深い推論として、大企業が1シートあたり1,500ドルを支払う意思があるならば、agentic coding ツールを月額50〜100ドルで価格設定しているベンダーは、提供する価値を過小評価している可能性が高く、市場は価格発見フェーズにあると言えます。Willisonの見解では、この上限は支払い意欲の天井を示すものであり、下限を示すものではないとされていますが、現在のSaaS価格とその天井との乖離は、価格体系がまだ均衡に達していないことを示しています。
インフラの観点からは、この上限は企業が不透明な1シートあたりのSaaSから、上限を設定して監査可能な従量制のAPI消費へと移行しつつあることも示唆しています。これにより、アーキテクチャは「IDEプラグインに組み込まれたモデル」から「使用量会計機能を備えた内部APIエンドポイントとしてのモデル」へとシフトし、AIツールが社内でどのように展開・監視されるかに影響を与えます。
深い技術的内容はありませんが、コスト会計の分析は厳密であり、AI開発者向けツールの構築または評価を行うすべての人にとって実践的に有益な内容です。
Source: https://simonwillison.net/2026/Jun/3/uber-caps-usage/
Open Code Review – AlibabaによるAI駆動のコードレビューCLIツール
AlibabaのOpen Code ReviewはLLMの呼び出しをgitと統合された構造化コードレビューワークフローにラップするCLIツールです。ブランチまたはコミット範囲のdiffを取得し、プロジェクトレベルのコンテキストを含むファイルごとのレビュープロンプトを構築し、行番号にマッピングされた構造化コメントを出力します。出力はGitHub/GitLab PRへ各APIを通じて直接投稿することも、JSONとして利用することもできます。
技術的な設計にはいくつか注目すべき選択があります。コンテキストの注入は二層構造で処理されます。グローバルコンテキストドキュメント(プロジェクトのREADME、存在する場合はコーディング規約ファイル)はすべてのリクエストの先頭に付加され、ローカルコンテキストはdiffと軽量なASTパーサー(tree-sitterバックエンド)によって抽出された周辺の関数本体からファイルごとに構築されます。これにより、大規模なコードベースでファイル全体を送信することを避けつつ、diffのハンクをまたがる問題を検出するのに十分なセマンティックコンテキストを保持できます。
プロンプトテンプレートは固定スキーマでレスポンスを引き出すように設計されています。スキーマの内容は、issue種別(正確性、スタイル、セキュリティ、パフォーマンス、テストカバレッジ)、深刻度レベル、影響を受ける行の範囲、および修正案です。ツールはその後、文字列類似度ハッシュを使用してファイル間のほぼ同一の指摘を重複排除し、同じ定型的な観察でPRが埋め尽くされることを防ぎます。
モデルのサポートは設定可能で、デフォルトはOpenAI互換APIをターゲットとしていますが、アダプター層がHTTPインターフェースを抽象化しているため、OllamaやvLLM経由のローカルモデルも変更なしに動作します。トークンバジェット管理はファイルごとに設定可能な上限で処理され、サイズが大きすぎるファイルはdiffのみのコンテキストにフォールバックします。
CLIの設計はUnixの慣習に従っています。stdin/stdout互換、CI統合のための終了コード、オプションの --fail-on-severity フラグが備わっています。これにより、GitHub ActionsやPre-mergeフックへの組み込みが素直に行えます。
主な欠点:リポジトリ内に人間のレビュアーとの合意率や偽陽性率に関するベンチマークデータが存在しません。
Source: https://github.com/alibaba/open-code-review
セルフホスト型開発サンドボックス(プレビューURL付き、Docker・Go使用、Kubernetesなし)
tastyeffectcoのsandboxesリポジトリは、Goで記述された一時的な開発者サンドボックス環境をパブリックなプレビューURLとともに実装しています。使用するのはDockerのみで、Kubernetes・Nomad・GoランタイムとDocker APIが直接提供する範囲を超えたオーケストレーション層は一切必要ありません。
アーキテクチャはシンプルです。小さなGo HTTPサーバーがDockerコンテナのプール(サンドボックス1つにつき1コンテナ)を管理し、各コンテナは設定可能なベースイメージから起動されます。サンドボックスが作成されると、サーバーはワイルドカードDNSエントリ配下のサブドメインを割り当て、そのサブドメインをコンテナの公開ポートへルーティングするHTTPリバースプロキシをセットアップします。プロキシ層はGo標準ライブラリのhttputil.ReverseProxyで実装されており、サンドボックスごとのルーティング情報はインメモリマップに保存されます(フラットファイルへの永続化もオプションとして用意されています)。
プレビューURLの生成には、コンテナIDにマッピングされた短いランダムスラッグを使用します。TLSの処理は、GoサーバーのフロントエンドにCaddyまたはnginxのリバースプロキシを置いて終端し、ワイルドカードドメインのACME証明書発行を担当させます。設計ドキュメントでは、これにはAPIベースのワイルドカード証明書発行に対応したDNSプロバイダー(Let’s Encrypt DNS-01チャレンジ)が必要であると記されています。
ライフサイクル管理は最小限です。HTTPトラフィックの不在によって検出される設定可能なアイドルタイムアウト後に、コンテナは停止・削除されます。CPU/メモリのクォータ強制はDockerのネイティブcgroupが提供する範囲に限られるため、オペレーターはコンテナ起動時にリソース制約を設定します。
Kubernetesベースの同等ソリューションに対する優位点は運用上のシンプルさにあります。システム全体が単一のGoバイナリとDockerソケットのみで構成されます。同時に10〜50個のサンドボックスをホストする小規模なチームにとっては、大幅なインフラオーバーヘッドの削減につながります。トレードオフとして、ビンパッキング・マルチノードスケジューリング・オートスケーリングはいずれもサポートされず、すべてのサンドボックスは単一ホスト上で動作します。
社内開発ツールや、安価で隔離されたリーチャブルなコンテナを必要とするAIエージェント実行環境を構築しているチームに有益です。
Source: https://github.com/tastyeffectco/sandboxes
1995年風のドキュメントを書くようLLMをfine-tuningする
小規模なLLMをfine-tuningして、1990年代中頃のUnix manページやREADMEファイルのスタイル——簡潔で命令形、マーケティング言語なし、散文を最小限に抑えた——で技術ドキュメントを生成させる実践的な投稿です。技術的な核心はデータセット構築とfine-tuning手法にあります。
著者は歴史的なオープンソースドキュメントからデータセットをキュレーションしました。具体的には、GNUプロジェクトのmanページ、初期Linuxカーネルのドキュメント、BSDシステムのドキュメント、および1998年以前のソースアーカイブに含まれるREADMEファイルです。生のコーパスはメタデータを除去し、ホワイトスペースを正規化してクリーニングした後、より大きなモデルにプロンプトを与えて生成した合成命令プロンプト(“Write documentation for a function that does X”)と対応付けられました。これにより、教師あり fine-tuning 用の(命令文、1995年スタイルの出力)ペアが作成されます。
Fine-tuningはLoRAを用いて7Bパラメータのベースモデル(MistralまたはLlamaの派生モデル、投稿では若干曖昧)に対して行われました。LoRAのrankは16、alphaは32に設定され、QおよびV projectionに適用されました。トレーニングはおよそ8,000件のサンプルに対して3エポック実行され、cosine LRスケジュールとLoRAに典型的な比較的高い learning rate(2e-4)が使用されました。著者によれば、fine-tuned後のモデルは現代のLLMがデフォルトで使用する曖昧な表現(hedging language)、受動態、および機能を宣伝するような言い回しを確実に排除するとのことです。
興味深い技術的観察は否定的なものです。ベースモデルのRLHF fine-tuningは、アーキテクチャ自体よりもスタイルの変化に対して強く抵抗します。基礎的な補完能力は問題なく転移しますが、preference tuningによって組み込まれた「assistant voice」が低いLoRA rankでにじみ出てきます。rankを64に増やすとこのアーティファクトが大幅に軽減されたことから、RLHFのスタイル特徴は低ランク摂動が完全に上書きできる以上の多くの次元に分散していることが示唆されます。
実践的な示唆:小規模モデルへのスタイルのfine-tuningは有効ですが、preference tuningの慣性を克服するためには、タスクスキルのfine-tuningよりも高いLoRA rankが必要です。
Source: https://passo.uno/fine-tuning-docs-llm/
Launch HN: Expanse (YC P26) – 無駄なGPUキャパシティを解放する
Expanseは、遊休GPU容量の問題をターゲットにしています。クラウドプロバイダー、HPCクラスター、エンタープライズデータセンターには、オフピーク時間帯にアイドル状態または低稼働状態のGPUノードが存在しますが、予約システムが長時間実行ジョブ向けに設計されているため、短時間の突発的なコンピュートを必要とするワークロードからはそのキャパシティにアクセスできません。提案されているのは、このアイドル容量をMLの training および inference ワークロード向けにスケジューリング可能にするブローカーレイヤーです。
技術的な問題は単純ではありません。Spot/プリエンプティブルなGPUインスタンス(AWS Spot、GCP Spot VM)は存在しますが、粒度が粗く、可用性が予測しにくく、中断に耐えるためにワークロードのチェックポインティングが必要です。Expanseが掲げるアプローチは、異種キャパシティソース——オーナーと直接交渉した低稼働のオンプレミスクラスターを含む可能性もある——を統一APIで束ね、ワークロードを利用可能なウィンドウにマッチングするスケジューリングレイヤーを提供することです。
inference に関しては、コールドスタートのレイテンシオーバーヘッドをリクエストバッチ全体に分散させながら、その時点で最も安価な利用可能GPUへ短期リクエストをルーティングするという価値提案があります。training については、ワークロードレベルでのチェックポイント・レジューム対応が必要であり、フレームワークが定期的な状態シリアライゼーションフックによってこれを支援すると報告されています。
HNスレッドが提起しつつも十分に回答していない重要なエンジニアリング上の疑問は次の通りです:地理的に分散したキャパシティソースにまたがるジョブにおいて、ネットワークのローカリティはどのように扱われるか?inference ルーティングのコールドスタートのp99レイテンシオーバーヘッドはどの程度か?本質的にプリエンプティブルなリソース上でSLA保証はどのように提供されるか?
YCへの参加は初期段階であることを示唆しており、HNのディスカッションは、アグリゲーションレイヤーがSpotの直接購入に対して抽象化コストを正当化するだけの十分なマージンを生み出せるかどうかについて、適切な懐疑論を反映しています。コンセプト自体は妥当ですが、現時点では実装の詳細が乏しい状況です。
Source: HN thread (no external URL provided)
注目の新しいリポジトリ
huawei-csl/KVarN
KVarNは、vLLMとネイティブに統合されるKV-cache quantizationバックエンドであり、本番環境でのLLM推論においてコンテキスト長とバッチサイズを制限するメモリボトルネックを対象としています。核心となるアイデアは、attention cacheのkeyおよびvalueテンソルを低ビット表現(本リポジトリはサブ8ビットを目標)にquantizeすることであり、別途キャリブレーションパスを必要としません。quantizationパラメータはオンラインで導出されるため、デプロイメントは多段階パイプラインではなく、vLLMの設定における1つのフラグ変更で完結します。
実装はvLLMのpaged attentionおよびキャッシュ管理レイヤーにフックし、FP16によるKVストレージをquantize済みの等価物に置き換えながら、計算は高精度のまま維持します。トークンあたりのキャッシュフットプリントを3〜5倍削減することで、同一のGPUメモリバジェットで比例的に長いコンテキストまたは大きなバッチを収容できます。本プロジェクトはFP16ベースラインを超えるスループットを主張しており(メモリ帯域幅のプレッシャー軽減がdequantizationのオーバーヘッドを上回るためと考えられます)、標準ベンチマークではFP16レベルの精度を達成しています。
キャリブレーション不要という特性は重要です。多くのquantizationスキーム(GPTQ、AWQ)はスケールとゼロポイントを調整するために代表的なデータを必要としますが、KVarNはこれを回避します。これにより、キャリブレーションセットが少ないカスタムfine-tuneやドメイン固有モデルをデプロイするチームにとっての障壁が低下します。KV cacheが律速制約となる長コンテキストエージェントや高並列APIサービスを運用する方々に関連する成果です。
Source: https://github.com/huawei-csl/KVarN
Asymptote-Labs/agent-beacon
Agent Beaconは、LangSmithやWeights & Biases Weaveのようなクラウド中心のツールが埋められていないギャップを埋めるべく、ローカルAIエージェント専用のオブザーバビリティレイヤーとして位置づけられています。中核となる抽象概念は、エージェントランタイム(ツール呼び出し、LLM呼び出し、メモリの読み書き、サブプロセスの起動)を計装し、データをローカルマシン外に送出することなく構造化されたトレースを出力するエンドポイントテレメトリコレクターです。
アーキテクチャ的にはOpenTelemetryにインスパイアされたモデルに従っているように見えます。エージェントはスパンとイベントをローカルのコレクターデーモンに送信し、コレクターは軽量な組み込みストアにそれらを保存してクエリインターフェースを公開します。これにより、リモートバックエンドのレイテンシやプライバシーリスクを伴わずに、マルチステップのエージェントループ全体にわたるトレース相関が得られます。エージェントが特定のツールの分岐を選んだ理由やサブタスクで停止した原因のデバッグに有用です。
「初のオープンソース」という主張は、汎用的なLLMオブザーバビリティではなくローカルファースト・エージェント特化のテレメトリを対象とするという狭義においてはほぼ正確です。実用的なユースケースは、事後リプレイと構造化ロギングが必要なコーディングエージェント、自律パイプライン、CLIドリブンのワークフローです。インテグレーションは軽量で、任意のエージェントフレームワークを薄いSDKラッパーで包む形式です。クラウド依存なしに構造化されたイントロスペクションを必要とする、llama.cpp、Ollama、またはカスタムエージェントループ上で開発するチームに有用です。
Source: https://github.com/Asymptote-Labs/agent-beacon
intellicia-public/parastore
Parastoreは、合成消費者調査のためのシミュレーション環境です。ユーザーはアイソメトリック3D小売店舗レイアウトを描画し、LLMを搭載した顧客ペルソナを配置して、創発的な購買行動を観察できます。各ペルソナは人口統計属性、好み、予算制約によってパラメータ化されており、LLMはそのプロファイルと店舗の状態を条件として、逐次的な意思決定(ナビゲーション、商品検査、購入または放棄)を生成します。
技術的な興味の中心は、ペルソナ生成と意思決定ループにあります。スクリプト化された行動ツリーの代わりに、各エージェントは意思決定ポイントでLLMにクエリを発行し、商品属性・価格設定・棚配置に関する自然言語推論に基づいたアクションを生成します。これにより、本システムはLLMが生成した合成行動が実際の消費者データと相関するかどうかを評価するためのテストベッドとなっており、市場シミュレーションと合成データ生成における現在進行形の研究課題に対応しています。
アイソメトリック3Dフロントエンドは主に可視化・オーサリングツールであり、シミュレーションのコアはペルソナとLLMのインタラクションループです。研究者はこれを用いて、プラノグラムレイアウトのA/Bテストのプロトタイプ作成、異なるペルソナ分布における価格感度の研究、あるいは推薦モデルの学習用合成ショッピング軌跡の生成などに活用できます。主な限界として、実際の消費者に対するLLMの行動忠実度が未検証であり、グランドトゥルースのキャリブレーションが未解決の問題として残っています。行動シミュレーション研究のインフラとして興味深い取り組みです。
Source: https://github.com/intellicia-public/parastore
scheidydude/codeindex
Codeindexは、リポジトリ全体にわたる依存関係グラフを構築し、各ノードに対してblast-radius影響スコアを算出する静的解析ツールです。このスコアは、そのノードで変更が加えられた場合に影響を受ける下流のモジュール、ファイル、または関数の数を定量化するものです。これは、コーディングエージェントやLLMベースのPRレビュアーが編集を提案・適用する前にリスク範囲について推論する必要があるAI支援開発ワークフローにおいて、直接的に有用です。
依存関係グラフの構築はクロスファイル・クロスパッケージの参照を処理し、インポート、呼び出し、または継承関係をエッジとして表現する有向グラフを生成します。blast-radiusスコアリングは、このグラフ上の到達可能性メトリクスから導出されているようであり、あるノードのスコアはその推移的依存セットのサイズまたは重み付けされた重要度を反映します。スコアの高いノードは高リスクな変更点としてフラグが立てられます。
出力はプログラム的に利用可能であるため、LLMプロンプトへのコンテキスト注入(「この関数はblast-radiusスコアが0.87であり、43件の下流呼び出し元に影響する」)やCIパイプラインのゲーティングに適しています。Cursor、GitHub Copilot、またはカスタムコーディングエージェントを使用するチームにとって、この種の構造的メタデータは、単純なコードベースへのRAGアプローチに欠けているものそのものです。言語サポートとスコアリング関数の具体的な内容が、採用前に評価すべき主要な点となります。セマンティック検索ツールを置き換えるのではなく、それらを補完するものです。
Source: https://github.com/scheidydude/codeindex
tastyeffectco/sandboxes
このプロジェクトは、自己ホスト型のエフェメラルな開発サンドボックス環境を提供するもので、プレビューURLの自動プロビジョニング機能を備えており、コーディングエージェントや迅速なSaaSプロトタイピングのユースケースを対象としています。重要な設計上の制約は「Kubernetesを使わない」という点であり、スタックはフルオーケストレーションレイヤーではなく、軽量なコンテナまたはプロセス分離(おそらくDocker Composeまたは類似のもの)を用いたシングルコマンドで起動します。
各サンドボックスは独立したファイルシステムとネットワーク名前空間を持ち、プレビューURL機構がリバースプロキシを処理することで、サンドボックス内で動作する開発サーバーが安定した外部URLを通じて即座にアクセス可能になります。これはVercelやRailwayが提供するものと類似していますが、完全な自己ホスト型です。この点はコーディングエージェントにとって重要です。コードを生成・実行するエージェントは、ホスト環境を汚染することなく、Webhook、OAuthフロー、またはAPI統合のテストのためにネットワークアクセスを備えた実行場所を必要とするためです。
「SaaSファクトリー」というフレーミングは、エージェントが多数の並列プロトタイプを立ち上げるワークフローを指しています。シングルコマンドのセットアップと低いインフラオーバーヘッドにより、単一のVMや開発者のワークステーション上でもこれが現実的に実現可能となります。マネージド代替手段と比較した主なトレードオフは、運用責任(オートスケーリングなし、初期セットアップ以降のマネージドTLSローテーションなし)と、分離要件が中程度であるという暗黙の前提です。ローカルのエージェントパイプラインや自己ホスト型CIを運用するチームにとって、これはKubernetesの複雑さとまったく分離がない状態との間の実質的なギャップを埋めるものです。
Source: https://github.com/tastyeffectco/sandboxes
PentesterFlow/agent
PentesterFlow は、攻撃的セキュリティ操作のためのターミナルネイティブなエージェント型フレームワークです。標準的なペネトレーションテストツール(nmap、nikto、sqlmap、metasploit モジュール等)を LLM 駆動のプランナーの背後にラップし、ターゲット仕様を解釈して攻撃計画を生成し、ツールを順次実行して出力を解析し、発見結果に基づいて反復します。自然言語の指示によって駆動される、偵察から exploit までの完全なループを実現します。
このエージェント型アーキテクチャは、高レベルの目標(「このウェブアプリケーションを評価せよ」)をサブタスクに分解するプランニングコンポーネント、サブタスクを CLI 呼び出しにマッピングするツールディスパッチ層、そして構造化されていないツール出力から構造化された発見結果(オープンポート、CVE、認証情報)を抽出してプランナーのコンテキストにフィードバックする出力解析コンポーネントで構成されます。これにより、実務者が現在手動で閉じているループを自動化します。
AutoRecon のようなポイントツールと比較すると、LLM プランナーは適応的な意思決定を付加します。初期スキャンで特定のサービスバージョンが判明した場合、エージェントは固定のプレイブックを実行するのではなく、関連する exploit や列挙パスを動的に選択できます。明らかな制限事項として、ツール選択におけるハルシネーションのリスク、セキュリティコンテキストについて確実に推論できる高性能な LLM バックエンドの必要性、および自律的な exploit ツールの法的・倫理的なリスク領域が挙げられます。人間の監督なしに本番環境のレッドチーミングで使用するよりも、研究プラットフォームや制御されたラボ環境での利用に最も適しています。
Source: https://github.com/PentesterFlow/agent
ajsai47/backdoor
Backdoorは、Claude Code(Anthropicのターミナル向けコーディングエージェント)のLLM API呼び出しを、Anthropic APIに縛られることなく、DeepSeek、Groq、Ollama、OpenRouter、あるいはOpenAI互換の任意のエンドポイントといった任意のバックエンドへルーティングできる、薄いプロバイダルーティングシムです。この仕組みは、Claude Codeが行うAPI呼び出しを横断的に捕捉し、ターゲットプロバイダのプロトコルへ変換することで、認証・エンドポイントルーティング・リクエスト/レスポンスのフォーマット差異を吸収します。
技術的には単純明快ですが、実用上は大きな意義があります。Claude Codeのagentループ・tool-use処理・コンテキスト管理は高品質に設計されており、ユーザーはそのループをより安価なモデルやローカルホストのモデルに対して実行したいと考えています。シムアプローチを採用することで、Claude CodeのUXとscaffoldingをそのまま活かしながら、コストやプライバシーに関するトレードオフを自由に選択できます。たとえばローカルのOllamaインスタンスに対して実行すれば、APIコストをゼロにでき、コードを外部サーバーに一切送信せずに済みます。
主要な技術的課題は忠実性(fidelity)です。Claude CodeはAnthropic固有の機能(extended thinking、特定のtool-callフォーマット、prompt caching)を利用している可能性が高く、これらがすべてのバックエンドにクリーンにマッピングされるわけではありません。Backdoorがこれらの不一致をどのように処理するか——gracefulにdegradeするか、それとも壊れるか——が実際の使い勝手を左右します。オープンウェイトモデル上でagentループの品質が維持されるかを評価したい開発者や、データレジデンシー要件を持つ開発者にとって、これは有用な脱出口となります。
Source: https://github.com/ajsai47/backdoor
gonemedia/aipointer
AIPointerは、クロスプラットフォーム(macOS、Windows、Linux)対応のスクリーンオーバーレイアシスタントです。ホットキーを押すとスクリーンショットをキャプチャし、vision対応のLLMに送信して、現在のアプリケーションを離れることなくレスポンスをオーバーレイとして表示します。ワークフローは次のとおりです:ホットキーを押し続け、表示中の画面内容について音声または小さなテキスト入力で質問し、画面上にオーバーレイとして回答を受け取り、そして閉じる、という流れです。ブラウザやチャットインターフェースへのコンテキストスイッチは一切不要です。
実装には、グローバルホットキーリスナー、各OSに適したスクリーンショットキャプチャAPI、そしてOpenRouter・Anthropic・OpenAI・GeminiなどのvisionLLMバックエンドが使用されています。ローカルファースト・自前キー持ち込み方式を採用しているため、認証情報や画面内容がプロジェクトのサーバーを経由することはなく、APIコールはクライアントから選択したプロバイダーへ直接送信されます。
技術的な核心は、クロスプラットフォームのスクリーンショットおよびオーバーレイパイプラインにあります。マルチモニター環境での正確なディスプレイキャプチャ、HiDPIスケーリングへの対応、そしてベースとなるアプリケーションの入力フォーカスを妨げない、閉じることができるオーバーレイのレンダリングが求められます。これらは3つのプラットフォームすべてで非自明な課題です。ユースケースとしては、コーディング中のクイックドキュメント参照、使い慣れないアプリケーションのUI要素の説明、コピー&ペーストができないコンテンツに対するOCRとクエリのワークフローなどが挙げられます。主な制約はレイテンシです。vision APIのラウンドトリップはプロバイダーや画像サイズによって1〜5秒かかるため、連続した素早いクエリには適していません。