Daily AI Digest — 2026-06-05
arXiv Highlights
VideoKR: Towards Knowledge- and Reasoning-Intensive Video Understanding
Problem
Existing video-reasoning post-training corpora and benchmarks under-test what they claim to test. Frontier VLMs answer a large fraction of questions in VideoMMMU, MMVU, and SciVideoBench from a single randomly sampled frame plus the question text: GPT-5.2 hits 38.3%, 49.7%, and 23.0% respectively under three-trial single-frame probing, with similar numbers for Claude-4.5-Sonnet and Qwen3-VL-235B. That is, “knowledge-intensive video reasoning” benchmarks are largely solvable as image-VQA or text-shortcut tasks. Training corpora share the same flaw: weak temporal grounding, narrow domain coverage, and noisy or shallow CoT. VideoKR targets both ends of this gap with a 315K-example post-training corpus over 145K CC-licensed expert-domain videos and a 2K expert-annotated benchmark (VideoKR-Eval) where the single-frame answerability rate drops to 9.5–10.7% across the same frontier models.
Method
The construction pipeline is semi-automated with 34 graduate-level domain experts auditing every model-generated step.
Domain Knowledge Bank. A four-level hierarchy Subject → Course → Lecture → Knowledge Point is built top-down. The authors selected 82 subjects across Natural Sciences, Healthcare, Humanities/Social Sciences, and Engineering from top-university curricula. For each subject, experts list 4–8 core undergraduate courses; for each course, a syllabus; for each lecture, an LLM proposes knowledge points (term + paragraph definition), expert-validated. The bank contains 63,745 knowledge points and serves as the retrieval index for video selection and QA grounding.
Video collection and skill-oriented QA synthesis. Videos are CC-licensed and matched to knowledge points. QA synthesis is skill-conditioned on three core skills meant to require continuous video understanding rather than single-frame inspection.

Overview of the VideoKR corpus: skill-oriented QA grounded in CC-licensed expert videos, with a CoT subset paired to reasoning traces. Each example is generated under a target skill, then human-audited for difficulty, diversity, and reliability. A subset is augmented with CoT rationales (also expert-validated). The released splits are VideoKR-SFT-201K (with rationales) and VideoKR-RL-114K (verifiable-answer subset for GRPO).

A natural-science SFT example showing the knowledge-grounded chain of thought tied to specific video evidence. Post-training pipeline. Deliberately standard: SFT → GRPO on Qwen2.5-VL-7B-Instruct and Qwen3-VL-8B-Instruct. SFT runs one epoch on VideoKR-SFT-201K; GRPO runs one epoch on VideoKR-RL-114K from the SFT checkpoint. GRPO accuracy reward follows Video-R1: ROUGE for open-ended, Exact Match for multiple choice. Batch size 32 for both stages, max 4,096 video tokens, max 128 frames. A Zero-RL variant (GRPO directly on the base) is also evaluated for Qwen3-VL-8B.
VideoKR-Eval. 2,000 expert-written multiple-choice items requiring genuine temporal evidence, evaluated jointly with single-frame probing to certify shortcut resistance (10.1% for Qwen3-VL-235B, vs. 45.2% on MMVU).
Results
The headline number is the knowledge-intensive average over VideoMMMU, MMVU, SciVideoBench, and VideoKR-Eval.
- Qwen2.5-VL-7B (16-frame): SFT+RL on VideoKR moves the knowledge-intensive average from 41.9 → 46.6 (+4.7), versus Video-R1 (+1.2) and VideoRFT (+1.4). Per-dataset, MMVU rises 52.5 → 59.2 and VideoKR-Eval 31.3 → 37.7. General-video average is roughly flat (59.1 → 60.1).
- Qwen2.5-VL-7B (128-frame): knowledge-intensive average 41.9 → 46.6 (+4.7), beating VideoAuto-R1 at 44.3.
- Qwen3-VL-8B (128-frame): SFT+RL gives 48.5 → 51.5 (+3.0), the best knowledge-intensive average at the 7/8B scale, surpassing Qwen3-VL-8B-Thinking (50.0) and VideoAuto-R1 (49.8). VideoKR-Eval rises 39.0 → 45.3; MMVU 59.6 → 64.8.
- Ablation on stages: Zero-RL (50.6) > SFT-only (49.2), and SFT+RL (51.5) is best — RL on top of SFT remains the strongest configuration, but RL alone already exceeds SFT alone, suggesting the verifiable-reward subset carries reasoning signal independent of the rationales.
- General-video reasoning (Video-MME, MVBench, LongVideoBench) is held within ~0.5 points of the base on Qwen3-VL-8B (65.9 → 65.4), indicating no substantial domain-specialization tax.
For comparison, GPT-5.4 and Gemini 3 Pro reach 71.3 and 69.0 on the knowledge-intensive average; the post-trained 8B model closes a meaningful fraction of that gap from open weights.
Limitations and open questions
The pipeline depends on 34 graduate-level annotators and ~$70.4K of model-inference cost, which limits independent reproduction of the curation step. Skill taxonomy is fixed at three skills; whether finer skill decomposition or curriculum scheduling over skills would help is untested. The GRPO reward uses ROUGE/EM, which is brittle for open-ended scientific answers; the RL gains may be reward-shape-limited. VideoKR-Eval is multiple-choice, so the 9.5–10.7% single-frame floor is an upper bound on shortcut resistance, not a guarantee of temporal grounding. Finally, while general-video benchmarks are largely preserved, Qwen3-VL-8B SFT-only drops 3.6 points on the general average, suggesting rationale-style SFT can erode general capabilities absent RL.
Why this matters
The paper makes a clean, controlled case that data design — knowledge-bank-grounded, skill-conditioned, expert-audited, shortcut-resistant — closes more of the knowledge-intensive video gap than RL algorithm engineering at the 7–8B scale. The accompanying single-frame audit also gives the field a cheap diagnostic for whether a “video” benchmark actually requires video.
Source: https://arxiv.org/abs/2606.05259
Reinforcement Learning Elicits Contextual Learning of Unseen Language Translation
Problem
Translating extremely low-resource or unseen languages with LLMs typically relies on either continued pretraining on bilingual data or “grammar-book in-context” prompting (e.g., Kalamang via MTOB). Both overfit to specific languages: continued training does not generalize to new languages, and in-context learning saturates at modest quality without effectively exploiting the supplied grammar. The authors reframe the goal as a meta-skill — reading a retrieval-assembled linguistic context (dictionary, parallel sentences, grammar excerpts) and using it to translate. They ask whether outcome-based RL on a surface metric can train this skill on a small set of seen languages and transfer it to unrelated, unseen ones.
Method
The training corpus covers 14 low-resource languages partitioned into Seen (Romansh varieties Puter/Vallader plus seven misc. languages paired with English), Similar (Sursilvan→De, Surmiran→De — held-out Romansh dialects), and Unseen (Kalamang↔︎En, plus 4 OOD En→X). Only Seen data is used for training; the 7,998 Similar and 750 Kalamang parallel pairs that exist are deliberately excluded.
Each prompt is assembled from five components (Table 1): a linguistic/geographic profile of the source language, the task instruction with translation direction and test sentence, ~20–34 LCS-retrieved dictionary entries (2 per source token), 3 or 5 LCS-retrieved parallel sentence pairs, two raw grammar-book excerpts, and a closing instruction requesting step-by-step meta-linguistic reasoning. Average prompt length is ~2.8k tokens.
Two backbones — Qwen3-4B-Base and Llama-3.2-3B-Instruct — are trained one epoch on the 22 in-scope directions with either SFT (cross-entropy on the gold reference) or GRPO RL using chrF as reward. Prompts and decoding are identical across SFT and RL; only the supervision signal differs. SFT batch size 128, RL batch size 64. The reward signal is purely surface-level — no semantic, BLEURT-style, or reference-free judge — which is the central design choice: chrF on seen languages is hypothesized to push the policy toward genuinely consulting the context rather than memorizing lexicons.
Results
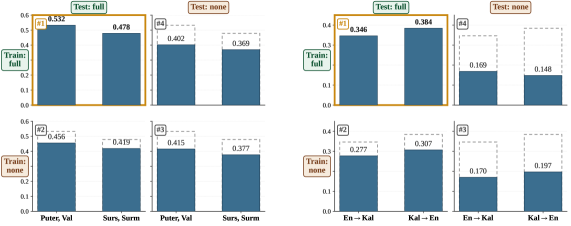
The context ablation (Table 4, RL on Qwen3-4B-Base) shows the model learns to use each component differentially. On Romansh→De (Puter, Vallader) the full context reaches 0.5324 chrF; removing the dictionary drops it to 0.4483 (−8.4), removing parallel sentences to 0.5224 (−1.0), and removing grammar to 0.5249 (−0.5). Task-only (no context) collapses to 0.4154. On Kalamang the picture inverts for the parallel-sentence component: En→Kal full = 0.3464, no-dict = 0.2626 (−8.4), no-sent = 0.2733 (−7.3), no-grammar = 0.3319 (−1.5). So dictionaries dominate when orthography is closer to a Romance neighbour the base model partially knows; parallel sentences dominate for a typologically isolated language like Kalamang where the base model has no priors. Grammar excerpts contribute little under chrF — consistent with surface reward being insensitive to the morphosyntactic phenomena grammars describe.
The train/test context-mismatch experiment isolates whether RL teaches a context-utilization policy or merely a better unconditional translator. Across all three test groups, swapping in full context at test time (no/full) outperforms training with full context but stripping it at test time (full/no): on En→Kal the gap is 0.28 vs. 0.17 chrF. The improvement is therefore attached to the test-time prompt, not internalized into weights — exactly the meta-skill behaviour the authors target.
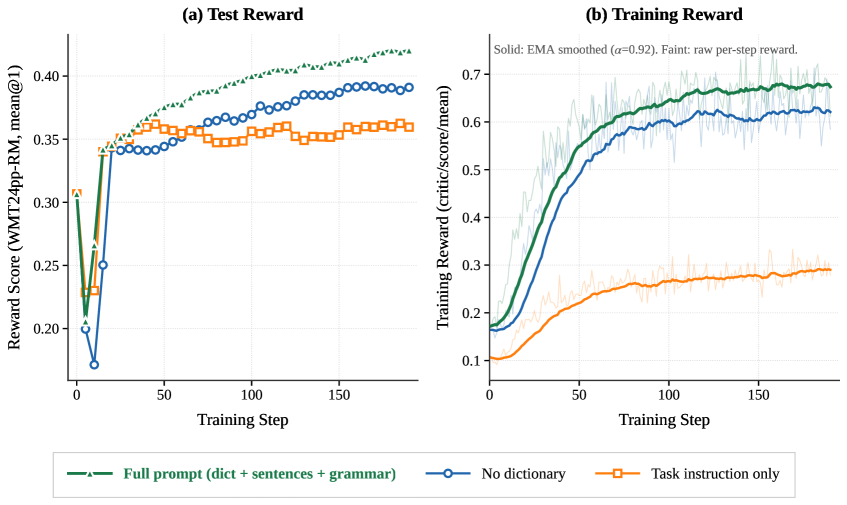
Reward curves show clean separation by prompt richness: the full configuration dominates throughout training on both the chrF training reward and a held-out WMT24++ reward, with the held-out reward continuing to rise — indicating the policy is not simply hacking chrF on training languages. Across the larger experimental table referenced in the paper, RL beats SFT and ICL on Similar and Unseen splits; SFT can match RL on Seen but degrades on transfer, consistent with the memorization hypothesis.
Limitations
The reward is chrF, a character-n-gram metric; it rewards lexical overlap and is weak on morphology and word order. This explains why grammar passages contribute almost nothing — they encode information chrF cannot score. Evaluation languages number in the tens, with Kalamang as the principal truly unseen probe; broader OOD coverage is limited to 400 En→X test sentences across 4 languages. The retrieval pipeline (LCS-based dictionary and sentence selection) is itself a strong inductive bias that the policy depends on. Finally, the result hinges on the meta-skill transferring across language families — encouraging on Romansh→Kalamang, but a typological systematicity study is absent.
Why this matters
This is concrete evidence that outcome-based RL with a cheap surface reward can train a generic “use the linguistic context” skill, not just task-specific competence — extending the GRPO-on-verifiable-rewards recipe beyond math and code into language acquisition from documentation. If the meta-skill scales, it suggests a path to translation for the long tail of ~7000 languages without per-language training data, conditional on a retrievable grammar and dictionary.
Source: https://arxiv.org/abs/2606.06428
Complexity-Balanced Diffusion Splitting
Continuous-time generative models (diffusion, flow matching) train a single network v_\theta(x,t) to approximate the instantaneous vector field v_t(x) across t \in [0,1]. The target field changes character dramatically along the timeline: near t=1 it resembles a smooth contraction toward the data manifold’s coarse structure, while near t=0 it must resolve fine, high-frequency detail. A monolithic network spends identical FLOPs on every regime regardless of difficulty. Complexity-Balanced Splitting (CBS) replaces the monolithic schedule with K specialized sub-networks, each responsible for a contiguous time interval, where the partition \{0=t_0<t_1<\dots<t_K=1\} is chosen so that every segment carries equal approximation burden.
From Barron bounds to a tractable monitor
The premise is de Boor’s equidistribution principle: in piecewise approximation, total error is dominated by the worst segment, so optimal partitions equalize per-segment error. CBS instantiates this for ODE-driven generation, where the global sampling error is governed by the maximum local truncation error along the trajectory.

To equidistribute, CBS needs a per-time monitor m(t) proxying the modeling difficulty of v_t. Section 3.1 derives this from Barron’s theorem (Barron, 2002): for a target f on a domain of radius r with spectral complexity C_f = \int \|\omega\| |\hat f(\omega)|\, d\omega, an n-parameter network achieves
\varepsilon_{f_n} = \mathbb{E}_{p_t}[\|f-f_n\|^2] \le \frac{4 r^2 C_f^2}{n}.
Directly estimating C_{v_t} in latent-image dimension is intractable, so the authors bound it via the field’s Dirichlet energy
E_D(v_t) = \tfrac{1}{2}\int \|\nabla_x v_t(x)\|^2 dx,
which by Parseval equals \frac{1}{2(2\pi)^d}\int \|\omega\|^2 \|\hat v_t(\omega)\|^2 d\omega. Applying Cauchy–Schwarz over an effective bandwidth gives C_{v_t}^2 \le K \cdot E_D(v_t), and substituting back yields the computable monitor
m(t) = K' \frac{E_D(v_t)}{n}.
Thus the spatial roughness of the learned flow at time t, summarized by the Dirichlet energy of \nabla_x v_t, is a principled upper bound on the per-time approximation error a fixed-capacity learner will incur. The second monitor (Sec. 3.2) is geometric rather than spectral: it measures the curvature/acceleration of sampling trajectories \ddot x(t), capturing how non-straight the integral curves of v_t are. Straight trajectories are easy to integrate and easy to fit; high-curvature regions demand more capacity. The two monitors are complementary — one targets the field, one targets its induced flow — and either can be plugged into the same equidistribution algorithm.
Splitting algorithm and pipeline
Given a chosen m(t), CBS computes the cumulative monitor M(t)=\int_0^t m(s)\,ds from a lightweight auxiliary model that estimates v_t (cheap because it does not need to be the deployment-grade generator). The partition is then defined by t_k = M^{-1}(k\, M(1)/K), so each interval [t_{k-1},t_k] carries identical integrated burden M(1)/K. A specialist v_{\theta_k} is trained on samples restricted to its interval; at inference, the ODE solver switches networks at t_k. No heuristic temporal splits, no joint optimization over partition boundaries, and no expensive search.
Experimental setup
Section 4 evaluates on three regimes; the headline testbed is ImageNet-256 latent generation using the Scalable Interpolant Transformer (SiT) family (SiT-S, SiT-B, SiT-XL) as both baselines and constituents of the CBS ensemble. Operating in the pre-trained autoencoder’s latent space, the authors compare a CBS partition of K specialists against monolithic SiT models matched in either total parameters or per-step FLOPs. The remaining subsections target: scaling behavior as K grows (4.2), tightness of CBS partitions versus the empirical optimum found by exhaustive search (4.3), head-to-head comparison of the Dirichlet-energy monitor against the trajectory-acceleration monitor (4.4), and the wall-clock cost of estimating the monitor and computing the split (4.5), which the authors describe as negligible relative to training the deployment networks.
Limitations and open questions
The provided sections do not include the final FID/IS numbers, the optimal K, or the relative performance of the two monitors, so quantitative claims about how close CBS comes to the oracle partition cannot be reproduced here. Several conceptual gaps remain. The Dirichlet bound passes through Cauchy–Schwarz over an effective bandwidth K that is domain-dependent and not directly measurable; tightness depends on how close the spectrum is to its assumed support. Per-step inference cost is unchanged (a specialist is still a transformer), but memory grows linearly in K unless specialists share a backbone with adapters — an obvious extension. The framework assumes that the auxiliary model’s monitor estimate transfers to the larger specialists; this is plausible because Dirichlet energy is a property of the target field, not the learner, but it has not been stress-tested under distribution shift between auxiliary and final models. Finally, equidistributing approximation error is not the same as equidistributing sample-quality error; the connection through Figure 1’s max-local-error ODE bound is suggestive but not tight.
Why this matters
CBS replaces ad hoc time-splitting heuristics in diffusion/flow models with an equidistribution principle backed by Barron’s theorem, turning capacity allocation along t into a deterministic function of a measurable monitor. If the empirical results bear out the theory, this is a drop-in way to spend a fixed parameter budget more efficiently in any continuous-time generative model.
Source: https://arxiv.org/abs/2606.06477
Rethinking Continual Experience Internalization for Self-Evolving LLM Agents
Self-evolving agents that distill prior interaction traces into parametric weights promise compounding improvement without unbounded context growth. The empirical reality, this paper shows, is the opposite: when context-distillation is iterated across multiple rounds of self-collected trajectories, agents undergo progressive capability collapse rather than monotonic gain. The contribution is a systematic dissection of why this happens along three axes — experience granularity, injection pattern, and internalization regime — and a recipe that recovers stability.
Setup
The agent follows ReAct with five tools (Search, Visit, Python, Scholar, File Parser). At step t, policy \pi_\theta produces a thought \tau_t and action a_t \in \mathcal{A} conditioned on history \mathcal{H}_{t-1}, yielding
\mathcal{H}_T = (x, (\tau_1, a_1, o_1), \ldots, (\tau_T, a_T, o_T))
with task reward r(\mathcal{H}_T). Trajectories are summarized via DeepSeek-V4 into a natural-language experience pool \mathcal{E} = \{e_1, \ldots, e_N\}, then re-injected into student training (Qwen3-4B-Instruct-2507 and Qwen3-8B). Continual internalization iterates collect-summarize-distill rounds.
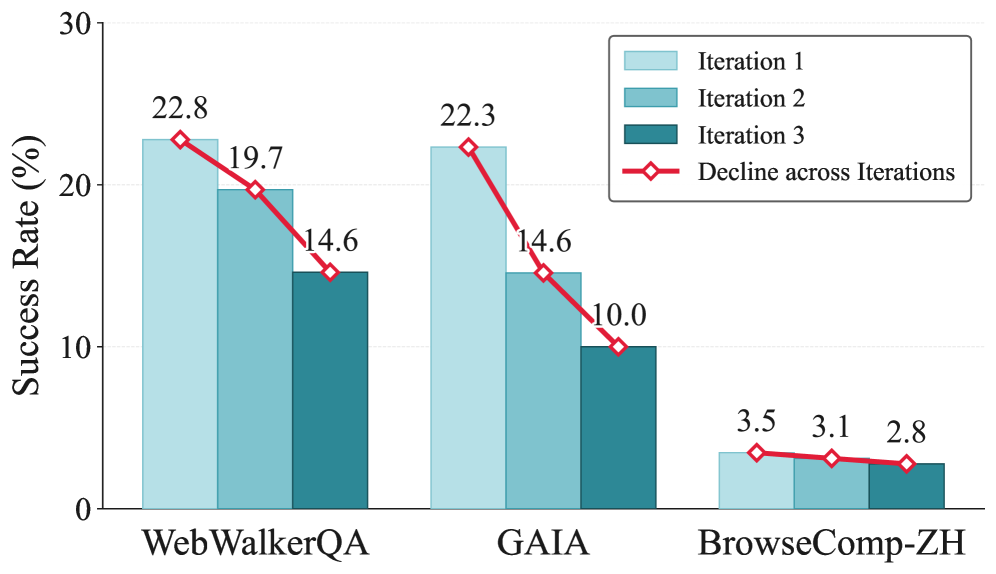
The collapse pattern in Figure 1 is the central phenomenon: standard on-policy context-distillation degrades below the base model after a few iterations, contradicting the implicit assumption that more self-experience helps.
Axis 1: Experience Granularity
The first finding is that what gets summarized matters more than how much. Instance-level experiences retain trajectory-specific traces — URLs, numerical values, entity strings — while principle-level experiences abstract reusable decision rules and failure patterns. Quantitatively, in the authors’ sampled pool:
- 74.4% of instance-level items contain specific URLs/domains, 57.3% contain concrete numbers, 93.9% contain query- or entity-specific strings.
- Only 3.7% of instance-level items contain reusable strategy-like statements, versus 84.0% of principle-level items.
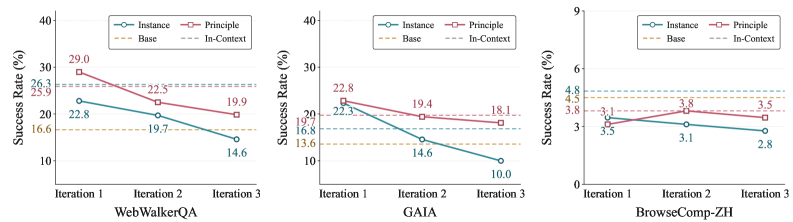
Figure 2 shows instance-level experience produces a transient first-iteration bump and then drops below the base model as iterations proceed; principle-level experience is durable across iterations. Mechanistically, instance-level distillation overfits the student to trajectory-local artifacts that no longer match the distribution of trajectories the student itself induces in later rounds — a covariate-shift trap intrinsic to self-evolution. Principle-level summaries strip these local features and retain rules that remain valid under new trajectory distributions.
Axis 2: Injection Pattern
The second axis is where in the trajectory the experience appears during training. Global injection concatenates all relevant experience into the system/context prefix, asking the model to internalize associations between abstract advice and the entire \mathcal{H}_T. Step-wise injection aligns each experience item with the intermediate decision state \mathcal{H}_{t-1} where it is actually applicable, conditioning the next (\tau_t, a_t) on the locally relevant principle.
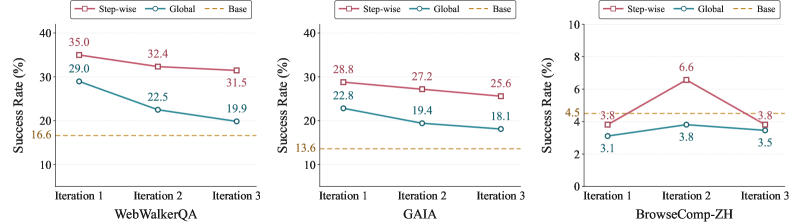
Figure 3 shows step-wise injection substantially outperforms global injection under iterative training, with the gap widening for long-horizon tool use. The interpretation: long trajectories diffuse the credit-assignment signal under global injection, so the student fails to bind a principle to the specific state where it should fire. Step-wise injection makes this binding explicit, which matters precisely because tool-use trajectories have many decision points where different principles apply.
Axis 3: Internalization Regime
The third axis concerns the source of trajectories used for distillation. On-policy context-distillation trains on trajectories the current student itself produces while conditioned on \mathcal{E}. This inherits the student’s mistakes: low-reward or partially-correct trajectories produce noisy targets, and as iterations proceed the noise compounds. Off-policy context-distillation instead uses high-quality teacher trajectories (filtered by reward) as the supervision target, while still injecting principle-level experience step-wise. The authors argue — and the iterative curves support — that this off-policy regime provides a substantially more stable training signal because the target distribution does not drift with the student’s own degradation. On-policy distillation is “inherently unstable” in this multi-iteration setting; off-policy filtering breaks the self-reinforcing error loop.
Putting it together
The recipe that survives multi-iteration self-evolution is: (i) summarize trajectories into principle-level experience that abstracts strategies and failure patterns, (ii) inject experience step-wise at the decision state where it applies, (iii) train via off-policy context-distillation on reward-filtered teacher trajectories. Each axis individually mitigates collapse; combining them is what converts continual internalization from net-negative to net-positive across iterations on Qwen3-4B and Qwen3-8B agents.
Limitations and open questions
The study uses DeepSeek-V4 as the summarizer, so the principle/instance dichotomy is partly a property of that summarizer’s prompting; whether smaller summarizers preserve the granularity advantage is unclear. The off-policy regime depends on access to a stronger teacher, which limits applicability when the student is already near-frontier. The paper does not quantify how much principle-level experience can accumulate before redundancy or contradiction dominates, nor whether step-wise injection scales to trajectories with hundreds of tool calls where retrieval becomes the bottleneck. Finally, the failure-mode analysis is empirical; a formal account of why on-policy iteration collapses (e.g., in terms of distribution shift bounds on context-distillation) is missing.
Why this matters
Most “self-evolving agent” pipelines tacitly assume that distilling experience back into weights compounds capability. This paper shows the default recipe collapses, and identifies three concrete design choices — granularity, injection locus, off-policy filtering — that determine whether continual internalization is stable or self-destructive. For anyone building long-running agents, these are the levers worth tuning before scaling iteration count.
Source: https://arxiv.org/abs/2606.04703
The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs
Problem
Inference-time scaling laws suggest that allocating more reasoning tokens to a query improves accuracy, but in practice deployment operates under hard token budgets across heterogeneous query streams. Uniform allocation wastes tokens on queries that are either trivially solvable or hopelessly out of reach, while per-query adaptive truncation lacks a principled global criterion. The paper poses inference-time compute as a constrained resource allocation problem and derives the optimal policy from KKT conditions, treating the Lagrange multiplier as a market-clearing shadow price.
Empirical motivation and utility model
Sampling Qwen2.5-Math-7B at T=1.0 (N=50 for AIME-24, N=4 for GSM8K and MATH-500) and binning rollouts by length reveals a non-monotone Pass@1 vs. length curve with three regimes: a Strict phase (utility \approx 0 before an emergence threshold), a Surge phase (rapid rise), and an Ample phase (diminishing or negative returns).
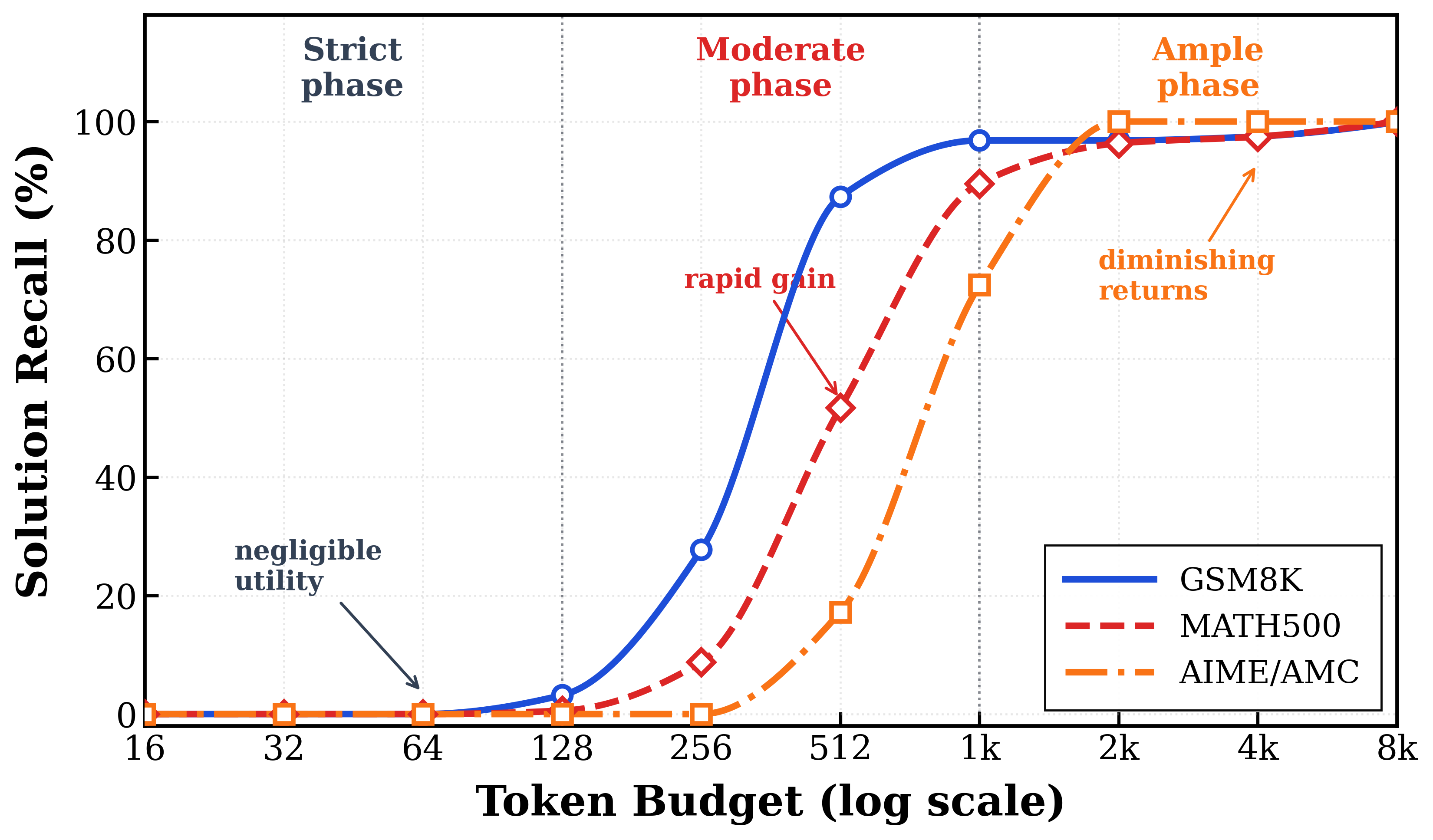
This motivates a per-query shifted-surge utility function:
\phi_i(t) = \begin{cases} 0 & 0 \le t < \tau_i \\ \alpha_i(t-\tau_i)\,e^{-\beta_i(t-\tau_i)} & t \ge \tau_i \end{cases}
where \tau_i is the latent emergence threshold, \alpha_i the initial marginal utility past threshold, and \beta_i the decay rate. Fitting this form to empirical rollouts (red curves below) tracks the bin-wise correct-count distributions reasonably well.
Theoretical optimum
Maximizing \sum_i \phi_i(t_i) s.t. \sum_i t_i \le B_{\text{total}} yields the Lagrangian \mathcal{L} = \sum_i \phi_i(t_i) - \lambda(\sum_i t_i - B_{\text{total}}). Stationarity gives shadow price parity:
\frac{\partial \phi_i(t_i^*)}{\partial t_i} = \lambda \quad \forall\, t_i^* > 0,
i.e., every funded query must have equal marginal utility. Differentiating \phi_i gives \alpha_i e^{-\beta_i \Delta t}(1-\beta_i \Delta t) = \lambda for \Delta t = t_i - \tau_i, which has closed form via the Lambert W function. A query is rationally abandoned (t_i^*=0) when its maximum net surplus \phi_i(t_i^*) - \lambda t_i^* is negative — equivalently, when \lambda > \alpha_i (since \alpha_i acts as a reservation price). Tokens freed from insolvent queries are reallocated to solvable ones near their thresholds.
CLEAR algorithm
CLEAR instantiates this policy with three components:
- Threshold predictor. A DeBERTa-v3-base regressor f_\theta trained on GSM8K/MATH solution lengths predicts \hat\tau_i = \exp(f_\theta(s_i)).
- Global parameters. \alpha and \beta are treated as backbone-level constants rather than per-query, since predicting \beta_i from a prompt is high-variance. \beta adapts to budget pressure: \beta = 1/\max(\epsilon,\bar B - \bar\tau) where \bar B is per-query budget and \bar\tau the mean predicted threshold.
- Shadow price solver. A 1-D root-find on \lambda enforces \sum_i t_i^*(\lambda) = B_{\text{total}}, where t_i^*(\lambda) is the Lambert-W closed form (with abandonment when \lambda \ge \alpha).
Results
Evaluation uses Qwen2.5-Math-7B-Instruct and Qwen3-30B-A3B-Instruct on four synthetic 500-query streams (Balanced, Mostly-Easy, Mostly-Hard, U-Shaped) at per-query budgets of 256/512/1024/2048 tokens.
CLEAR (Lambert) dominates baselines in scarce regimes. At budget 256:
- Balanced: 14.6% vs. 3.0% Uniform (+11.6 abs.), Oracle 19.0%.
- Mostly-Easy: 33.0% vs. 9.0% (+24.0 abs.), Oracle 42.2%.
- Mostly-Hard: 6.2% vs. 1.0% (+5.2), a 6\times relative gain.
- U-Shaped: 18.6% vs. 4.4% (+14.2).
Gains shrink monotonically with budget — at 2048 tokens CLEAR matches Uniform on most streams (e.g., Mostly-Easy 49.0% vs. 49.0%) since abandonment becomes unnecessary. The naive Predictor (proportional allocation by \hat\tau) actually underperforms Uniform at low budget (e.g., 0.6% on Balanced-256), indicating that ranking alone, without the shadow-price clearing mechanism, is insufficient. TALE-EP (token-budget-aware prompting) is similarly weak in scarcity. The Heuristic and Auction CLEAR variants approach but do not match the Lambert solver.
The phase-transition analysis shows abandonment rate falling to zero as budget grows; in the abundance regime CLEAR converges to Uniform. Sensitivity analysis indicates accuracy is approximately invariant to absolute \alpha (the optimal \lambda^* scales linearly: \log\lambda^* \propto \log\alpha), so \alpha acts as a gauge degree of freedom — only the ratio \lambda/\alpha matters for allocation decisions. The adaptive \beta rule lands near the \beta-sensitivity optimum on each stream.
Limitations
- \alpha,\beta are global hyperparameters; real per-query decay rates likely vary substantially, and the model conflates this variance into the threshold predictor.
- Threshold prediction is trained on GSM8K/MATH solution lengths, a noisy proxy for the true emergence threshold; generalization to non-math reasoning is untested.
- Streams are synthetic mixtures of an oracle-difficulty pool; online settings with unknown query arrival statistics and KV-cache constraints are not modeled.
- The utility function is a parametric ansatz — the shifted-surge shape fits empirically but is not derived from model internals, and the binary-outcome-to-continuous-utility mapping is heuristic.
- Gains vanish at high budget, so the practical regime is narrow: token-scarce serving with heterogeneous difficulty.
Why this matters
Framing inference-time compute allocation through KKT conditions yields a single scalar — the shadow price \lambda — that simultaneously decides which queries to abandon and how much to spend on the rest, replacing per-query heuristics with a globally consistent rule. The 3\times accuracy improvement in scarcity regimes suggests that batch-level economic reasoning, not just per-query adaptive depth, is the right abstraction for production LLM serving under fixed token budgets.
Source: https://arxiv.org/abs/2606.03092
OPRD: On-Policy Representation Distillation
On-policy distillation (OPD) trains a student \pi_\theta on its own rollouts \hat{y}\sim\pi_\theta(\cdot\mid x) and supervises it by matching the teacher’s next-token distribution, typically via a reverse-KL Monte Carlo estimator. Two structural problems remain. First, the gradient is a REINFORCE-style estimate over a \sim 151K-token vocabulary (Qwen2.5), so sampling variance does not decay with training; even top-k surrogates trade bias against variance without removing it. Second, the LM head W_{\text{head}} is a low-rank, additive-invariant projection \mathbb{R}^d\to\mathbb{R}^{|\mathcal{V}|}: any teacher computation that lives in \ker(W_{\text{head}}) or that the softmax washes out is invisible to OPD. OPRD lifts supervision back into the hidden-state space on the same on-policy trajectories.
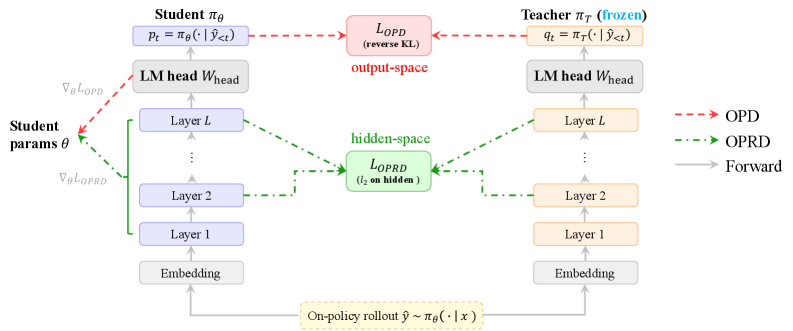
Method
Let \mathcal{L}_{\text{layer}}\subseteq\{1,\dots,L\} be the distilled layer set and m_t\in\{0,1\} a position mask over the rollout. With teacher representations h_{T,t}^{(l)} and student h_{\theta,t}^{(l)}, OPRD minimizes
\mathcal{L}_{\text{OPRD}}(\theta)=\mathbb{E}_{x,\hat{y}\sim\pi_\theta}\!\left[\frac{1}{|\mathcal{L}_{\text{layer}}|}\sum_{l\in\mathcal{L}_{\text{layer}}}\frac{1}{\sum_t m_t}\sum_{t=1}^{T} m_t\,\frac{1}{d}\bigl\|h_{\theta,t}^{(l)}-\mathrm{sg}\bigl(h_{T,t}^{(l)}\bigr)\bigr\|_2^2\right],
with \mathrm{sg}(\cdot) stop-gradient on the teacher and 1/d normalizing across hidden widths. When d_s\ne d_T, a learnable projector W\in\mathbb{R}^{d_T\times d_s} maps the student side before the MSE; in their main setup d_s=d_T=1536 so W is omitted. Choices for \mathcal{L}_{\text{layer}} include the last layer, all layers, or parity subsets; \mathcal{P}(\hat{y}) can be all tokens or a prefix/suffix.
The key mechanical point is that the loss path never touches the LM head: gradients flow directly into the residual stream at the chosen layers. This (i) replaces a sampled \log\pi gradient with a deterministic dense gradient carrying |\mathcal{L}_{\text{layer}}|\times|\mathcal{P}|\times d scalars per sample (orders of magnitude more supervision than top-k OPD), and (ii) avoids ever materializing the [B,T,|\mathcal{V}|] logits tensor for distillation—the dominant memory term at |\mathcal{V}|\!\approx\!151K. The authors back this with two theorems: a variance bound showing the OPD gradient has an irreducible Monte Carlo term while OPRD’s is deterministic, and an information-bottleneck argument showing the LM head discards components that hidden-state supervision recovers.
Experiments
The setup uses JustRL-Deepseek-1.5B as the frozen teacher and DeepSeek-R1-Distill-Qwen-1.5B as the student—both Qwen2.5-1.5B backbones (L=28, d=1536), so hidden states are dimensionally aligned. Baselines are OPD top-1 (sampled-token reverse KL) and OPD top-16, sharing rollouts, teacher forward, and optimizer schedule with OPRD; only the supervision extraction point differs. Evaluation is on AIME 2024, AIME 2025, and AIMO with Avg@16.
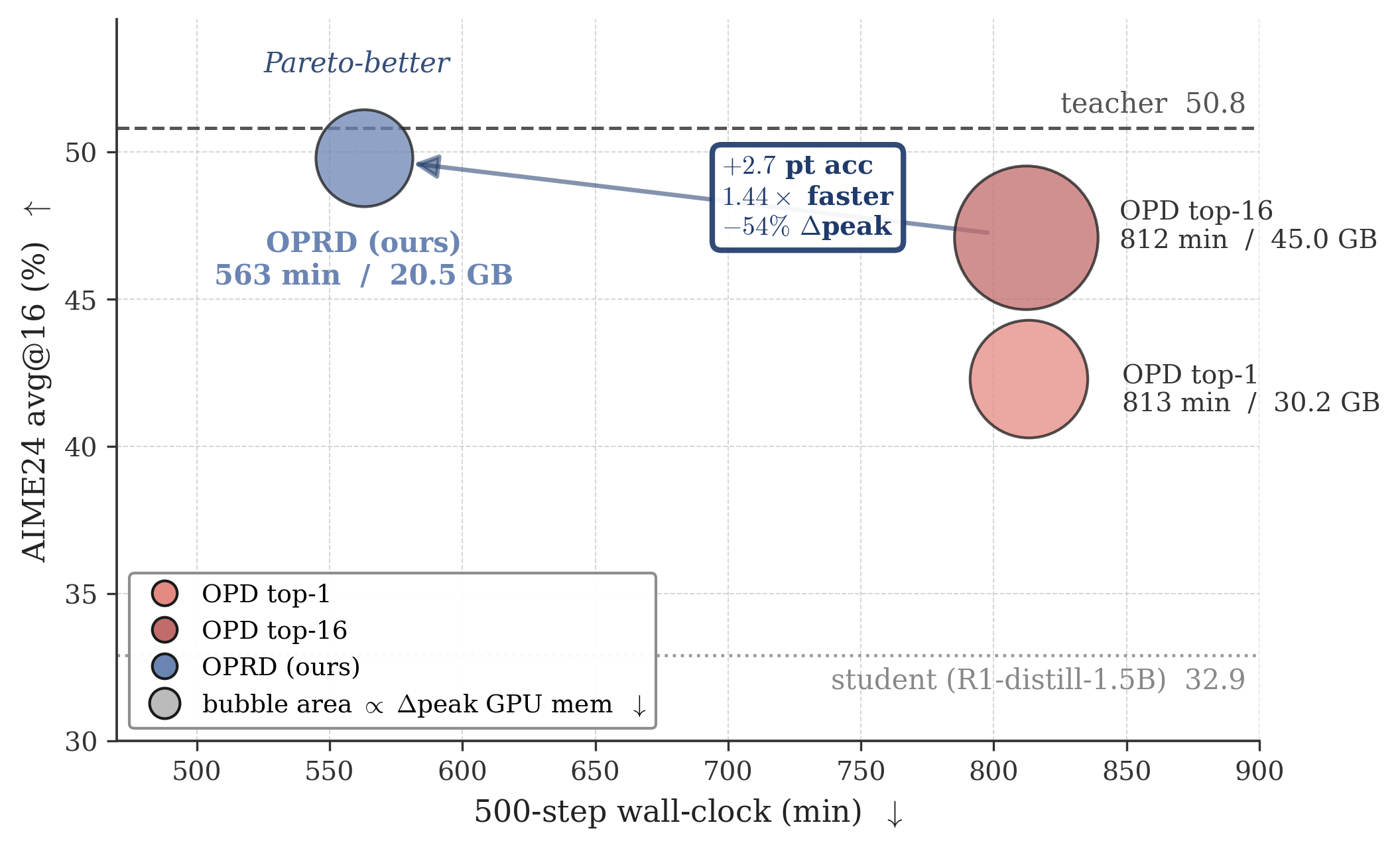
The headline result is Pareto dominance over 500 optimizer steps on 8\times A100-80G FSDP: OPRD trains 1.44\times faster wall-clock and reduces actor-update peak GPU memory by up to 54\% versus top-k OPD, while reaching higher AIME24 Avg@16. The training dynamics show that OPD top-1 and top-16 plateau or oscillate well below the teacher across all three benchmarks, whereas OPRD continues improving and approaches teacher-level performance—consistent with their Theorem 1 prediction that the deterministic MSE gradient avoids late-stage stagnation from sampling noise.
A secondary effect concerns response length:
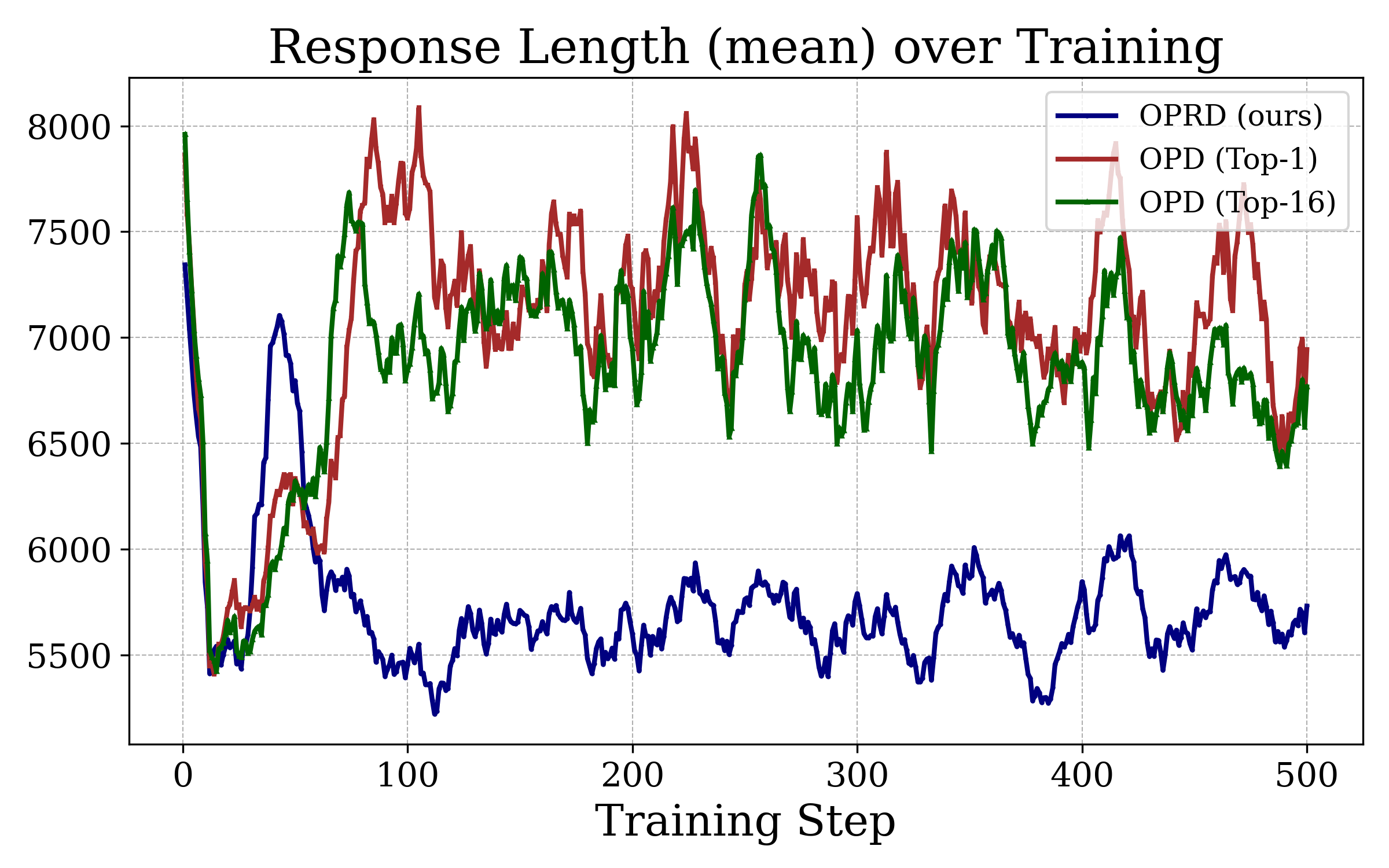
OPRD converges to \sim 5{,}700 tokens per response while both OPD variants plateau around \sim 7{,}000. Since accuracy is equal or higher, this is a real \sim 19\% reduction in inference cost on top of the training-time savings—plausibly because hidden-state alignment transfers the teacher’s reasoning trajectory more faithfully than token-probability matching, which can be satisfied by verbose detours.
Limitations and open questions
The strongest results assume aligned architectures (d_s=d_T, same backbone family, same tokenizer). The projector W handles width mismatch but cross-family or cross-tokenizer distillation (e.g., Llama student, Qwen teacher) is not evaluated and would require a more involved alignment—position-level token correspondence breaks under different BPEs. The choice of \mathcal{L}_{\text{layer}} and \mathcal{P}(\hat{y}) is presented as a design knob without a systematic ablation in the provided sections; whether last-layer-only suffices or full-layer matching is necessary affects the memory story. Finally, MSE in hidden space is a strong constraint: it forces the student into the teacher’s specific representational basis, which may be undesirable when student capacity is much smaller and an internal reparameterization would be preferable. The theory addresses variance and bottleneck but not this representational-rigidity tradeoff.
Why this matters
OPRD points out that on-policy distillation has been throwing away nearly all of the teacher’s computation by funneling supervision through the LM head, and that simply moving the loss earlier in the network removes both the sampling variance and the memory blow-up from large vocabularies. For reasoning-model distillation specifically—where teachers and students often share backbones—this is a near-free swap that closes the student–teacher gap that output-space OPD cannot.
Source: https://arxiv.org/abs/2606.06021
ArcANE: Do Role-Playing Language Agents Stay in Character at the Right Time?
Problem
Role-playing language agents (RPLAs) are typically evaluated on whether they reproduce facts a character would know at a given chapter, or whether they maintain a stable persona across turns. Both framings miss what makes literary characters interesting: their values, fears, and decision policies change across the narrative. A Raskolnikov in Part I should not respond like the Raskolnikov of the epilogue, and a benchmark that scores either response as “in character” conflates two different psychological states. The harder case is counterfactual prompts — scenarios that never appear in the source text — where retrieval-augmented contexts have nothing to retrieve and the agent must extrapolate from a phase-specific psychology rather than from surface facts.
ArcANE (Arc-Aware Narrative Evaluation) targets exactly this gap: does the agent stay in character at the right time in the character’s arc?
Method
The benchmark is automatically constructed over 17 novels and 80 principal characters. The central object is a Character Arc: a segmentation of the narrative into phases along a psychological axis specific to that character (e.g., guilt, ambition, trust). Formally, for character c with narrative N, the arc is a sequence
A_c = \{(\phi_i, s_i, e_i, \psi_i)\}_{i=1}^{K}
where \phi_i is a phase label, [s_i, e_i] is its span in the text, and \psi_i is a phase-conditional psychological description (values, beliefs, dominant affect). Probes are constructed so that the same scenario q is posed across all phases i, and split into two regimes:
- In-source scenarios: situations the novel actually depicts or strongly implies for that phase.
- Out-of-source scenarios: counterfactuals the novel never explores (e.g., placing the character in an unrelated dilemma).
For each (character, phase, scenario) triple, the agent’s response r_{c,i,q} is judged for alignment with \psi_i rather than with a single global persona. Evaluation compares six context modes crossed with six models. The context modes vary what conditioning the RPLA receives at inference: no context, character summary, retrieved passages (RAG over the novel), full chapter window, biography, and the Character Arc description \psi_i for the targeted phase.
The key empirical claim is that conditioning on \psi_i — a compact phase-specific psychological prompt — beats every other context strategy, and that the margin grows on out-of-source probes where retrieval over N returns nothing relevant.
Results
Across all six base models and all six context modes, Arc conditioning is the top-performing context on every model. The advantage is largest on out-of-source scenarios, which is the regime where RAG and chapter-window baselines degrade most — there is simply no passage in the novel that matches the counterfactual.
The authors then fine-tune open-weight backbones on Arc-conditioned trajectories to produce ArcANE-8B and ArcANE-32B. These models internalize the phase-conditional behavior so that the Arc advantage widens further on out-of-source probes, indicating that the gain is not merely a prompting artifact but corresponds to a learnable representation of psychological phase. In-source gains are smaller, consistent with the hypothesis that retrieval and chapter context already supply enough surface signal there; the discriminating regime is counterfactual.
Limitations and open questions
Several issues are worth flagging. First, Character Arcs are themselves model-extracted; if the extractor systematically projects characters onto a single psychological axis \psi, evaluation inherits that bias, and an Arc-conditioned RPLA may simply be matching the extractor’s idiom rather than the novel’s. Second, “alignment with \psi_i” is judged automatically (presumably LLM-as-judge), which couples evaluator and generator capabilities — Arc conditioning may help partly because the judge also reasons in arc terms. Third, the benchmark covers 17 novels and 80 characters, which is small relative to the diversity of literary character types; serial fiction, ensemble casts, and unreliable-narrator structures are underrepresented. Fourth, phases are treated as discrete; many arcs are continuous or non-monotonic (relapse, regression), and the segmentation \{[s_i, e_i]\} may oversimplify these. Finally, there is no human-rater calibration reported in the abstract for whether readers agree with the phase labels or with the alignment judgments.
Open questions: can arcs be inferred online from interaction history rather than precomputed from N? How does Arc conditioning compose with long-context models that can ingest entire novels? And does the Arc advantage transfer to multi-turn role-play, where the agent’s own prior turns become part of the conditioning and may pull the trajectory off-phase?
Why this matters
ArcANE reframes RPLA evaluation from “does the agent know what the character knows” to “does the agent behave as the character would at this point in their development”, and shows that a compact phase-conditional psychological prompt is both the strongest context mode and a useful fine-tuning signal — especially for counterfactual scenarios where retrieval is useless. That is the regime any deployed character agent actually operates in.
Source: https://arxiv.org/abs/2606.05553
Hacker News Signals
Do transformers need three projections? Systematic study of QKV variants
A systematic empirical study asking whether the standard Q, K, V projection structure in attention is necessary or merely conventional. The paper evaluates a grid of design choices: sharing projections across Q/K/V, removing projections entirely, tying Q and K, eliminating the value projection, and so on. For each variant the model is trained from scratch at consistent scale and evaluated on downstream benchmarks to isolate the contribution of each projection independently.
The key findings challenge some assumptions. Removing the key projection and tying Q=K degrades performance meaningfully, but removing or sharing the value projection is cheaper than expected — in several configurations a single shared projection for V incurs only minor quality loss. Full three-projection attention is not always Pareto-optimal when parameter budget is held fixed, because the saved parameters can be reallocated elsewhere (e.g., wider MLP layers). The study also examines low-rank factorizations of each projection as an intermediate point between full-rank and no-projection variants.
The mechanistic argument: Q and K must remain distinguishable because they operate on different subspaces (query-side vs. key-side of the dot-product), so tying them collapses the asymmetry that makes attention selective. The value projection by contrast is a post-weighting linear transform and is more redundant with the output projection in the feed-forward sublayer.
This matters for efficient architecture search. If V projections can be removed or shared without significant loss, small models can redirect those parameters more usefully, and inference-time KV cache is also reduced since cached K and V tensors shrink. The paper provides a concrete empirical map rather than theoretical argument alone, which makes it directly usable for practitioners doing architecture ablations.
Limitations: experiments are at moderate scale; scaling law interactions may shift conclusions at 10B+ parameters. Single-task vs. multi-task tradeoffs are not fully explored.
Source: https://arxiv.org/abs/2606.04032
Anthropic’s open-source framework for AI-powered vulnerability discovery
Anthropic released the Defending Code Reference Harness, a framework for using LLMs (specifically Claude) to perform automated vulnerability discovery on codebases. The repo provides a structured harness around a code analysis pipeline: it ingests source files, constructs context windows around candidate code regions, queries a model with security-focused prompts, and parses the structured output into actionable findings.
The technical design centers on a few choices. First, code is chunked with cross-reference context preserved — function call graphs and import chains are included where possible so the model sees callee signatures rather than isolated snippets. Second, the prompting strategy asks the model to reason about vulnerability classes (injection, memory safety, auth bypass, logic errors) explicitly before outputting findings, functioning as a lightweight chain-of-thought over security semantics. Third, the harness enforces a structured output schema (severity, CWE category, affected line range, suggested fix) so results can be post-processed or fed into existing issue trackers.
The reference implementation targets C/C++ and Python but the harness is generic enough to accommodate other languages by swapping the chunking and symbol-resolution modules. There is a comparison mode that runs the same codebase through multiple models or prompt variants side-by-side, which is useful for benchmarking model capability on security tasks.
Notable engineering detail: the harness handles rate-limit backoff, tracks token expenditure per file to avoid runaway costs on large repos, and supports a triage mode where only previously-unreviewed diffs are analyzed. It does not attempt to replace static analysis tools (no formal soundness guarantees) but is designed to complement them by catching semantic-level issues that pattern-matching misses.
Open questions: false-positive rate at scale is unstated; the framework provides no ground-truth eval harness to measure recall against known CVEs.
Source: https://github.com/anthropics/defending-code-reference-harness
When AI Builds Itself: Anthropic’s progress toward recursive self-improvement
Anthropic published a research overview on recursive self-improvement (RSI) — the scenario where an AI system meaningfully accelerates its own capability development. The post is not a paper but a technical position piece summarizing internal findings and framing the problem space.
The core technical concern: modern ML pipelines (data curation, architecture search, hyperparameter optimization, evaluation design, training code) are themselves software and research tasks that capable models can assist with. If a model’s assistance improves the next model more than human researchers would have, and that cycle compounds, you get RSI. The piece distinguishes between weak RSI (AI assists human researchers, net positive but human-controlled) and strong RSI (AI drives the loop with minimal human intervention in each iteration).
From a systems perspective, Anthropic discusses the feedback latency problem: training runs take weeks, so even if a model generates good training improvements, the iteration cycle is long. They note that shorter-horizon tasks — eval design, data filtering scripts, bug fixes in training infrastructure — are where current models provide the most measurable contribution, because the feedback signal arrives in hours rather than months.
The piece also addresses evaluation difficulty: how do you know if a model’s proposed architecture change is genuinely better before running the full training? Current practice involves cheaper proxy evals, but these have known correlation failures at scale. This makes the loop noisy even when the model’s suggestions are directionally correct.
Safety framing: the concern is not just capability explosion but that RSI under optimization pressure may find shortcuts that score well on proxies while degrading on the actual objective — a distributional shift problem internal to the development loop itself.
Technically thin in places; more useful as a problem taxonomy than as a methods contribution. No quantitative claims about current RSI rates.
Source: https://www.anthropic.com/institute/recursive-self-improvement
Uber’s $1,500/month AI limit is a useful signal for AI tool pricing
Simon Willison’s analysis of Uber’s reported $1,500/month per-employee cap on AI tooling spend uses it as a lens to reverse-engineer what AI tool vendors can realistically charge enterprises. The technical substance is in the cost structure decomposition.
At $1,500/month per seat, Uber is implicitly betting that developer productivity gains exceed that cost. Willison estimates that $1,500/month at current API pricing (roughly $3-15 per million tokens depending on model) corresponds to something like 100M-500M tokens/month per developer — which for continuous coding assistance at 8 hours/day is plausible but not excessive. The gap between per-seat SaaS pricing (GitHub Copilot at ~$20/month) and this ceiling is two orders of magnitude, which suggests the cap covers heavy API-direct usage rather than capped SaaS products.
The more interesting inference: if large enterprises are willing to pay $1,500/seat, vendors pricing agentic coding tools at $50-100/month are likely underpricing the value delivered, and the market is in a price discovery phase. Willison’s framing is that the cap reveals a willingness-to-pay ceiling, not a floor, but the gap between current SaaS pricing and that ceiling indicates the pricing regime has not equilibrated.
From an infrastructure standpoint, the cap also implies enterprises are moving away from opaque per-seat SaaS toward metered API consumption they can cap and audit. This shifts the architecture from “model embedded in IDE plugin” toward “model as internal API endpoint with usage accounting” — which has implications for how AI tooling is deployed and monitored internally.
No deep technical content here, but the cost accounting analysis is rigorous and practically relevant for anyone building or evaluating AI developer tooling.
Source: https://simonwillison.net/2026/Jun/3/uber-caps-usage/
Open Code Review – AI-powered code review CLI tool from Alibaba
Alibaba’s open-code-review is a CLI tool that wraps LLM calls into a structured code review workflow integrated with git. It diffs a branch or commit range, constructs per-file review prompts with project-level context, and outputs structured comments mapped to line numbers. The output can be posted directly to GitHub/GitLab PRs via their respective APIs or consumed as JSON.
The technical design has a few notable choices. Context injection is handled by a two-tier system: a global context document (project README, coding standards file if present) is prepended to every request, and a local context is constructed per-file from the diff plus the surrounding function bodies extracted by a lightweight AST parser (tree-sitter backed). This avoids sending entire files for large codebases while retaining enough semantic context to catch issues that span diff hunks.
The prompt template is structured to elicit responses in a fixed schema: issue type (correctness, style, security, performance, test coverage), severity level, affected line range, and a suggested fix. The tool then deduplicates near-identical findings across files using string similarity hashing to avoid spamming PRs with repeated boilerplate observations.
Model support is configurable; the default targets OpenAI-compatible APIs but the adapter layer abstracts the HTTP interface so local models via Ollama or vLLM work without modification. Token budget management is handled per-file with a configurable limit, and oversized files fall back to diff-only context.
The CLI design follows Unix conventions: stdin/stdout compatible, exit codes for CI integration, optional –fail-on-severity flag. This makes it straightforwardly composable in GitHub Actions or pre-merge hooks.
Main gap: no benchmark against human reviewer agreement or false-positive rate data in the repo.
Source: https://github.com/alibaba/open-code-review
Self-hosted dev sandboxes with preview URLs (Docker, Go, no Kubernetes)
The sandboxes repo from tastyeffectco implements ephemeral developer sandbox environments with public preview URLs, written in Go, using only Docker — no Kubernetes, no Nomad, no orchestration layer beyond what the Go runtime and Docker API provide directly.
The architecture is straightforward: a small Go HTTP server manages a pool of Docker containers (one per sandbox), each started from a configurable base image. When a sandbox is created, the server allocates a subdomain under a wildcard DNS entry and sets up an HTTP reverse proxy routing that subdomain to the container’s exposed port. The proxy layer is implemented with httputil.ReverseProxy from the Go standard library, with per-sandbox routing stored in an in-memory map (with optional persistence to a flat file).
Preview URL generation uses a short random slug mapped to the container ID. TLS is handled by terminating at a Caddy or nginx reverse proxy in front of the Go server, which handles ACME certificate issuance for the wildcard domain. The design document notes this requires a DNS provider with API-based wildcard cert issuance (Let’s Encrypt DNS-01 challenge).
Lifecycle management is minimal: containers are stopped and removed after a configurable idle timeout detected via HTTP traffic absence. There is no CPU/memory quota enforcement beyond what Docker’s native cgroup limits provide, so the operator sets resource constraints at container start time.
The value proposition over Kubernetes-based equivalents is operational simplicity: the entire system is a single Go binary plus a Docker socket. For a small team hosting 10-50 concurrent sandboxes, this eliminates substantial infrastructure overhead. The tradeoff is no bin-packing, no multi-node scheduling, and no auto-scaling — all sandboxes run on a single host.
Relevant for teams building internal dev tools or AI agent execution environments that need cheap, isolated, reachable containers.
Source: https://github.com/tastyeffectco/sandboxes
Fine-tuning an LLM to write docs like it’s 1995
A practitioner post on fine-tuning a small LLM to produce technical documentation in the style of mid-1990s Unix man pages and README files — terse, imperative, no marketing language, minimal prose. The technical substance is in the dataset construction and fine-tuning methodology.
The author curated a dataset from historical open-source documentation: GNU project man pages, early Linux kernel docs, BSD system documentation, and README files from source archives pre-dating 1998. The raw corpus was cleaned by stripping metadata and normalizing whitespace, then paired with synthetic instruction prompts (“Write documentation for a function that does X”) generated by prompting a larger model. This creates (instruction, 1995-style output) pairs for supervised fine-tuning.
Fine-tuning was done with LoRA on a 7B parameter base model (Mistral or Llama variant, the post is slightly ambiguous). The LoRA rank was set to 16 with alpha 32, applied to Q and V projections. Training ran for 3 epochs on roughly 8,000 examples, with a cosine LR schedule and a relatively high learning rate (2e-4) typical for LoRA. The author reports the fine-tuned model reliably drops hedging language, passive voice, and feature-marketing phrases that modern LLMs default to.
The interesting technical observation is negative: the base model’s RLHF fine-tuning resists the style shift more than the architecture does. The underlying completion capability transfers fine, but the “assistant voice” baked in by preference tuning bleeds through at low LoRA rank. Increasing rank to 64 substantially reduced this artifact, suggesting the RLHF style features are distributed across more dimensions than a low-rank perturbation can fully override.
Practical takeaway: style fine-tuning on small models works but requires higher LoRA rank than task-skill fine-tuning to overcome preference-tuning inertia.
Source: https://passo.uno/fine-tuning-docs-llm/
Launch HN: Expanse (YC P26) – Unlock Wasted GPU Capacity
Expanse targets the problem of stranded GPU capacity: cloud providers, HPC clusters, and enterprise data centers have GPU nodes that are idle or underutilized during off-peak windows, but that capacity is inaccessible to workloads requiring short-burst compute because reservation systems are designed for long-running jobs. The pitch is a brokerage layer that makes this idle capacity schedulable for ML training and inference workloads.
The technical problem is non-trivial. Spot/preemptible GPU instances exist (AWS Spot, GCP Spot VMs) but have coarse granularity, unpredictable availability, and require workload checkpointing to tolerate interruption. Expanse’s stated approach is to provide a unified API over heterogeneous capacity sources — potentially including underutilized on-premise clusters negotiated directly with owners — with a scheduling layer that matches workloads to available windows.
For inference specifically, the value proposition is routing short-horizon requests to whichever available GPU is cheapest at that moment, with the latency overhead of cold-start amortized over request batches. For training, the model requires checkpoint-resume support at the workload level, which the framework reportedly assists with via periodic state serialization hooks.
Key engineering questions that the HN thread raises but leaves largely unanswered: How is network locality handled when jobs span geographically distributed capacity sources? What is the p99 cold-start latency overhead for inference routing? How are SLA guarantees provided over inherently preemptible resources?
The YC affiliation suggests early-stage, and the HN discussion reflects appropriate skepticism about whether the aggregation layer adds enough margin over direct spot purchasing to justify the abstraction cost. The concept is sound; execution details are thin at this stage.
Source: HN thread (no external URL provided)
Noteworthy New Repositories
huawei-csl/KVarN
KVarN is a KV-cache quantization backend that integrates natively with vLLM, targeting the memory bottleneck that limits context length and batch size in production LLM inference. The core idea is to quantize key and value tensors in the attention cache to low-bit representations (the repo targets sub-8-bit) without requiring a separate calibration pass — the quantization parameters are derived online, making deployment a one-flag change in vLLM configuration rather than a multi-stage pipeline.
The implementation hooks into vLLM’s paged attention and cache management layers, replacing FP16 KV storage with quantized equivalents while keeping compute in higher precision. By shrinking per-token cache footprint 3-5x, the same GPU memory budget accommodates proportionally longer contexts or larger batches. The project claims throughput exceeding FP16 baseline (likely because reduced memory bandwidth pressure more than offsets dequantization overhead) and FP16-level accuracy on standard benchmarks.
The calibration-free property is significant: most quantization schemes (GPTQ, AWQ) need representative data to tune scales and zero-points; KVarN avoids this, lowering the barrier for teams deploying custom fine-tunes or domain-specific models where calibration sets are scarce. Relevant for anyone running long-context agents or high-concurrency API services where KV cache is the binding constraint.
Source: https://github.com/huawei-csl/KVarN
Asymptote-Labs/agent-beacon
Agent Beacon positions itself as an observability layer specifically for local AI agents — filling a gap left by cloud-centric tools like LangSmith or Weights & Biases Weave. The core abstraction is an endpoint telemetry collector that instruments agent runtimes (tool calls, LLM invocations, memory reads/writes, subprocess spawns) and emits structured traces without requiring data to leave the local machine.
Architecturally it appears to follow an OpenTelemetry-inspired model: agents emit spans and events to a local collector daemon, which stores them in a lightweight embedded store and exposes a query interface. This means you get trace correlation across multi-step agentic loops — useful for debugging why an agent chose a particular tool branch or stalled on a subtask — without the latency or privacy exposure of a remote backend.
The “first open-source” claim is mostly accurate in the narrow sense of targeting local-first, agent-specific telemetry rather than general LLM observability. The practical use case is coding agents, autonomous pipelines, and CLI-driven workflows where you need post-hoc replay and structured logging. Integration is lightweight: a thin SDK wrapper around the agent framework of choice. Useful for teams building on llama.cpp, Ollama, or custom agent loops who want structured introspection without cloud dependencies.
Source: https://github.com/Asymptote-Labs/agent-beacon
intellicia-public/parastore
Parastore is a simulation environment for synthetic consumer research: users draw an isometric 3D retail store layout, populate it with LLM-backed customer personas, and observe emergent shopping behavior. Each persona is parameterized with demographic attributes, preferences, and budget constraints, and the LLM generates sequential decision-making (navigation, product inspection, purchase or abandonment) conditioned on that profile and the store state.
The technical interest lies in the persona generation and decision loop. Rather than scripted behavior trees, each agent queries an LLM at decision points, producing actions grounded in natural-language reasoning about product attributes, pricing, and shelf placement. This makes the system a testbed for evaluating whether LLM-generated synthetic behavior correlates with real consumer data — a live research question in market simulation and synthetic data generation.
The isometric 3D frontend is primarily a visualization and authoring tool; the simulation core is the persona-LLM interaction loop. Researchers could use this to prototype A/B tests on planogram layouts, study price sensitivity under different persona distributions, or generate synthetic shopping trajectories for training recommendation models. The main limitation is that LLM behavioral fidelity to real consumers is unvalidated, making ground-truth calibration an open problem. Interesting as infrastructure for behavioral simulation research.
Source: https://github.com/intellicia-public/parastore
scheidydude/codeindex
Codeindex is a static analysis tool that builds a dependency graph across a repository and computes a blast-radius impact score for each node — quantifying how many downstream modules, files, or functions would be affected by a change at that point. This is directly useful in AI-assisted development workflows where a coding agent or LLM-based PR reviewer needs to reason about the risk surface of an edit before suggesting or applying it.
The dependency graph construction handles cross-file and cross-package references, producing a directed graph where edges represent import, call, or inheritance relationships. Blast-radius scoring appears to be derived from reachability metrics on this graph — a node’s score reflects the size or weighted importance of its transitive dependent set. High-score nodes are flagged as high-risk change points.
The output can be consumed programmatically, making it suitable for injecting context into LLM prompts (“this function has blast-radius score 0.87, touching 43 downstream callers”) or for gating CI pipelines. For teams using Cursor, GitHub Copilot, or custom coding agents, this kind of structural metadata is exactly what’s missing from naive RAG-over-codebase approaches. Language support and the specifics of the scoring function are the main things to evaluate before adopting. Complements semantic search tools rather than replacing them.
Source: https://github.com/scheidydude/codeindex
tastyeffectco/sandboxes
This project provides self-hosted, ephemeral development sandbox environments with automatically provisioned preview URLs, targeting the use case of coding agents and rapid SaaS prototyping. The key design constraint is no Kubernetes: the stack runs on a single command, using lightweight container or process isolation (likely Docker Compose or similar) rather than a full orchestration layer.
Each sandbox gets an isolated filesystem and network namespace, and the preview URL machinery handles reverse proxying so that a running dev server inside the sandbox is immediately accessible via a stable external URL — analogous to what Vercel or Railway provide, but entirely self-hosted. This matters for coding agents: an agent that generates and runs code needs a place to execute it with network access for testing webhooks, OAuth flows, or API integrations, without polluting the host environment.
The “SaaS factories” framing refers to workflows where agents spin up many parallel prototypes. The single-command setup and low infrastructure overhead make this practical on a single VM or developer workstation. The main trade-offs versus managed alternatives are operational responsibility (no autoscaling, no managed TLS rotation beyond initial setup) and the implicit assumption that isolation requirements are moderate. For teams running local agent pipelines or self-hosted CI, this fills a real gap between full Kubernetes complexity and no isolation at all.
Source: https://github.com/tastyeffectco/sandboxes
PentesterFlow/agent
PentesterFlow is a terminal-native agentic framework for offensive security operations. It wraps standard penetration testing tooling (nmap, nikto, sqlmap, metasploit modules, and similar) behind an LLM-driven planner that interprets a target specification, generates an attack plan, executes tools in sequence, parses their output, and iterates based on findings — a full recon-to-exploitation loop driven by natural language directives.
The agentic architecture involves a planning component that breaks a high-level objective (“assess this web application”) into subtasks, a tool-dispatch layer that maps subtasks to CLI invocations, and an output-parsing component that extracts structured findings (open ports, CVEs, credentials) from unstructured tool output to feed back into the planner’s context. This closes the loop that practitioners currently close manually.
Compared to point tools like AutoRecon, the LLM planner adds adaptive decision-making: if an initial scan reveals a specific service version, the agent can dynamically select relevant exploits or enumeration paths rather than running a fixed playbook. The obvious limitations are hallucination risk in tool selection, the need for a capable LLM backend to reason reliably about security context, and the legal/ethical surface area of autonomous exploitation tooling. Most useful as a research platform or in controlled lab environments rather than production red-teaming without human oversight.
Source: https://github.com/PentesterFlow/agent
ajsai47/backdoor
Backdoor is a thin provider-routing shim that lets Claude Code (Anthropic’s terminal coding agent) route its LLM API calls to arbitrary backends — DeepSeek, Groq, Ollama, OpenRouter, or any OpenAI-compatible endpoint — rather than being locked to the Anthropic API. The mechanism intercepts the API calls Claude Code makes and translates them to the target provider’s protocol, handling authentication, endpoint routing, and any necessary request/response format differences.
This is technically straightforward but practically significant: Claude Code’s agentic loop, tool-use handling, and context management are well-engineered, and users want to run that loop against cheaper or locally-hosted models. The shim approach means you get Claude Code’s UX and scaffolding with cost or privacy trade-offs of your choice. Running against a local Ollama instance, for example, eliminates API costs and keeps code off external servers entirely.
The main technical challenge is fidelity: Claude Code likely uses Anthropic-specific features (extended thinking, specific tool-call formats, prompt caching) that don’t map cleanly to all backends. How Backdoor handles these mismatches — whether it degrades gracefully or breaks — determines real-world usability. For developers who want to evaluate whether the agentic loop quality holds up on open-weight models, or who have data residency requirements, this is a useful escape hatch.
Source: https://github.com/ajsai47/backdoor
gonemedia/aipointer
AIPointer is a cross-platform (macOS, Windows, Linux) screen-overlay assistant that captures a screenshot on hotkey press, sends it to a vision-capable LLM, and renders the response as an overlay without leaving the current application. The workflow is: hold hotkey, ask a question verbally or via a small text input about visible screen content, receive answer overlaid on screen, dismiss. No context switching to a browser or chat interface.
The implementation uses a global hotkey listener, a screenshot capture API appropriate to each OS, and vision LLM backends via OpenRouter, Anthropic, OpenAI, or Gemini. The local-first, bring-your-own-key design means no credentials or screen content transit through the project’s servers — the API call goes directly from the client to the chosen provider.
The technical substance is in the cross-platform screenshot and overlay pipeline: capturing the correct display in multi-monitor setups, handling HiDPI scaling, and rendering a dismissable overlay that doesn’t interfere with the underlying application’s input focus. These are non-trivial on all three platforms. Use cases include quick documentation lookup while coding, explaining UI elements in unfamiliar applications, or OCR-and-query workflows on content that can’t be copy-pasted. The main constraint is latency: vision API round-trips add 1-5 seconds depending on provider and image size, making it unsuitable for rapid-fire queries.