Daily AI Digest — 2026-06-04
arXiv Highlights
Cosmos 3: Omnimodal World Models for Physical AI
Problem
Physical AI stacks today are fragmented: a VLM for perception, a separate video diffusion model for simulation/rollout, and a distinct policy network for action generation. Each component carries its own tokenizer, training corpus, and inductive biases, which makes joint reasoning over language, vision, audio, and motor commands brittle. The question Cosmos 3 attacks is whether a single backbone can subsume vision-language understanding, conditional video generation, world simulation (next-frame prediction conditioned on actions), and world-action models (policies conditioned on observations and instructions) without paying a quality tax on any of them. The claim is that an omnimodal world model — language, image, video, audio, and action in one autoregressive/diffusion-hybrid system — is the right factorization for embodied agents.
Method
Cosmos 3 is built around a Mixture-of-Transformers (MoT) architecture: per-modality expert blocks share attention but route through modality-specific FFNs and normalization, so that token streams from text, vision, audio, and action retain their native statistics while still attending across modalities. Concretely, given a sequence of mixed-modality tokens x_{1:T} with modality labels m_t \in \{\text{txt, img, vid, aud, act}\}, attention is dense across all tokens but the FFN at layer \ell is
h_t^{\ell+1} = h_t^\ell + \text{FFN}_{m_t}^\ell(\text{Attn}^\ell(h^\ell)_t),
so compute scales with active experts rather than total experts. This preserves a unified KV cache while giving each modality enough capacity for its own token distribution.
Tokenization is heterogeneous: text uses a BPE tokenizer; images and video frames are encoded by a continuous latent tokenizer (compatible with diffusion decoding) for generation tasks and by a discrete tokenizer for understanding tasks; audio is tokenized at frame rate; actions are discretized per-DoF. The model supports any-to-any input-output configurations by masking which positions are predicted vs. conditioned, which is what lets the same checkpoint serve as a VLM (text out, image in), a text-to-image/video model (vision out, text in), a world simulator (next video chunk conditioned on past video and actions), or a world-action model / policy (action out, conditioned on observation and instruction).
Training proceeds in stages. A large-scale pretraining phase mixes web-scale text, image-text, video-text, audio-text, and robotics trajectories. The objective combines next-token cross-entropy on discrete streams with a diffusion / flow-matching loss on continuous latent streams; for a continuous latent z with noise schedule \sigma_t, the loss is the standard
\mathcal{L}_{\text{flow}} = \mathbb{E}_{t, z, \epsilon}\big[\| v_\theta(z_t, t, c) - (\epsilon - z) \|^2\big],
while text and action heads use -\log p_\theta(x_t \mid x_{<t}, c). Post-training adds supervised fine-tuning on curated instruction and trajectory data, followed by preference optimization for generation quality and RL fine-tuning of the policy head on robotics tasks. Synthetic data — both generated trajectories and rendered worlds — is used heavily, and NVIDIA releases the curated synthetic datasets alongside checkpoints.
Results
The paper reports a single family of checkpoints evaluated across understanding and generation. On Artificial Analysis’s third-party leaderboards, the post-trained Cosmos 3 was ranked the best open-source Text-to-Image and best open-source Image-to-Video model at submission time. On RoboArena — a head-to-head policy benchmark for manipulation — Cosmos 3 was ranked the top policy model. Together these three rankings are notable because each is typically held by a specialist system (e.g., a dedicated diffusion image model, a dedicated video model, and a dedicated VLA policy); a unified backbone topping all three simultaneously is the central empirical claim. The technical report further argues that VLM benchmarks, world-simulation fidelity (next-frame prediction conditioned on actions), and audio-conditioned generation are competitive with specialist baselines, though the abstract does not enumerate per-benchmark numbers.
Limitations and open questions
Several caveats are worth flagging. First, “best open-source” rankings are time-stamped and the comparison set excludes closed frontier systems; the gap to those is not characterized in the abstract. Second, MoT shares attention across modalities, so long-horizon video plus action sequences will hit the usual quadratic cost — the report does not, from the abstract alone, settle whether inference latency is acceptable for closed-loop control at typical robot rates. Third, mixing diffusion-style continuous heads with autoregressive discrete heads in one model creates training-objective interference whose scaling behavior is poorly understood; the paper presumably ablates this but the trade-off curve will matter for downstream users. Fourth, RoboArena evaluates a finite task suite; generalization to long-horizon, contact-rich, or dexterous manipulation under distribution shift remains the standard open problem for VLAs. Finally, the release under OpenMDW-1.1 (https://openmdw.ai/license/1-1/) is permissive but data provenance for pretraining — particularly video — is the usual open question for models of this scale.
Why this matters
Cosmos 3 is a concrete data point that a single MoT backbone can simultaneously hold leaderboard positions in text-to-image, image-to-video, and robot policy evaluation, which undercuts the assumption that Physical AI needs separate perception, simulation, and control models. If the unification holds at scale, the engineering surface for embodied agents collapses substantially.
Source: https://arxiv.org/abs/2606.02800
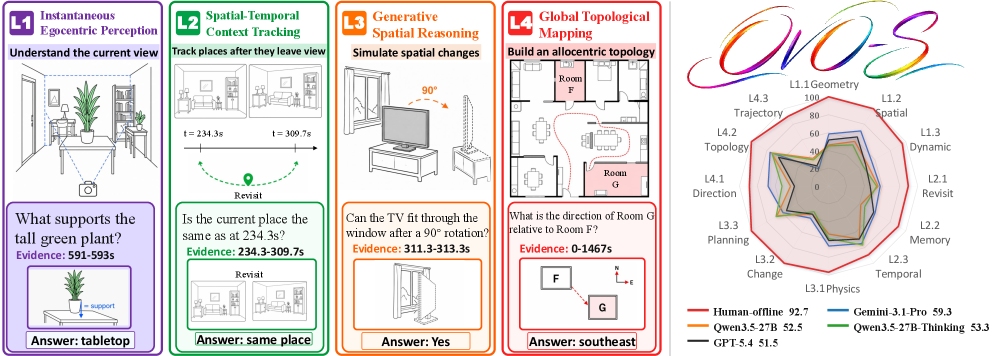
OVO-S-Bench: A Hierarchical Benchmark for Streaming Spatial Intelligence in Multimodal LLMs
Problem and motivation
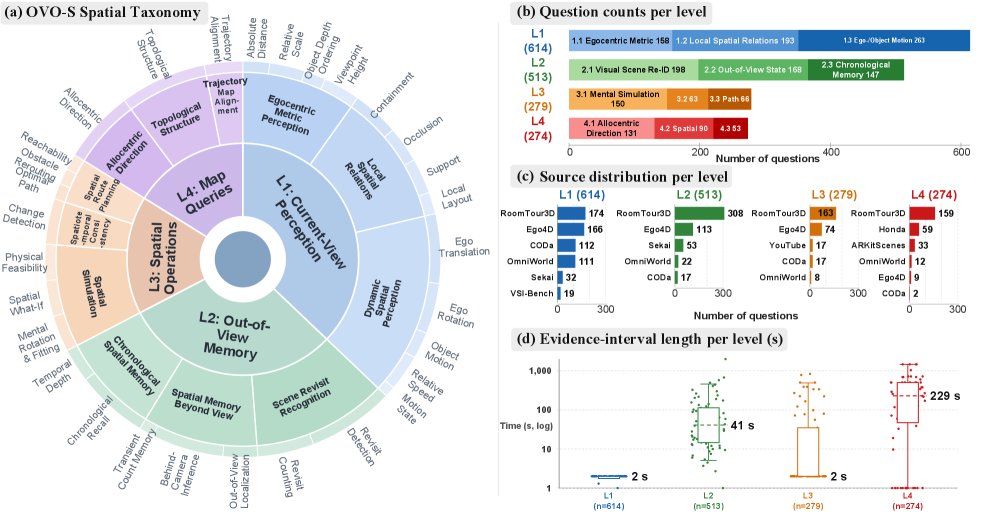
Embodied agents — robots, AR headsets, driving stacks — consume egocentric video as a causal stream and must answer spatial queries whose evidence may lie outside the current view. Existing video QA benchmarks evaluate offline over the full clip (allowing free re-scan) or focus on event recognition rather than spatial structure. Neither setting probes whether a multimodal LLM maintains a persistent, allocentric representation of the environment as frames arrive. OVO-S-Bench is a fully human-annotated benchmark (1,680 questions over 348 source videos, ~804 person-hours of multi-round QA across 12 annotators) targeting this gap. Each question has a query timestamp t_q and an evidence interval; at evaluation, the model only sees the prefix before t_q.
Taxonomy and protocol
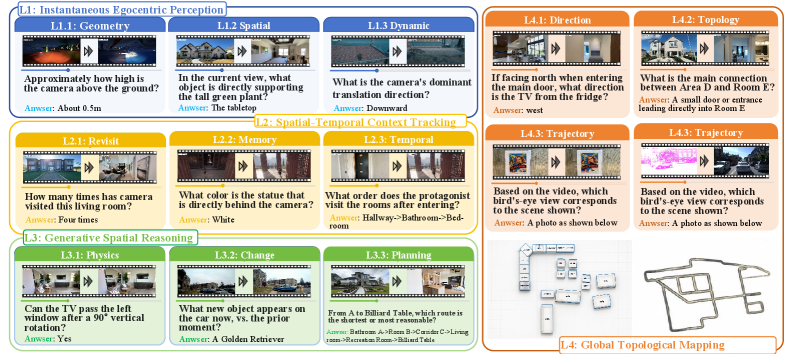
Questions are stratified into four levels reflecting increasing persistence and abstraction:
- L1 — Instantaneous Egocentric Perception: answerable from frames near t_q. Families: egocentric metric (distance, scale, clearance, viewpoint height), local spatial relations (containment, occlusion, support, visible layout), and dynamic perception (camera/object motion, relative speed).
- L2 — Spatiotemporal Context Tracking: the queried entity or relation is no longer in view; requires maintaining state across the prefix.
- L3 — Spatial Simulation and Reasoning: counterfactual or generative queries over the inferred scene (e.g., what would be visible from an alternate viewpoint).
- L4 — Allocentric Mapping: cross-viewpoint integration into a global, viewpoint-independent map (topology, room adjacency, route inference).
The streaming protocol truncates each video at t_q and feeds 128 uniformly sampled frames from the prefix together with the multiple-choice question. Native streaming architectures instead ingest at their published rate and are queried from the compressed state. This mirrors OVO-Bench and OST-Bench. Three controls anchor the leaderboard: a random baseline, a text-only baseline (GPT-5.4 given only question and options), and human raters under both streaming and offline protocols.
Main results
The benchmark covers 38 systems across seven families: proprietary MLLMs (GPT-5.4, Gemini-3.1-Pro/Flash-Lite, Grok-4.1-Fast), open-source backbones (InternVL-3.5, Qwen2.5/3/3.5-VL, Gemma-4, GLM-4.6V-Flash), streaming video MLLMs (Flash-VStream, StreamForest, StreamingVLM), token-compression/memory methods (InfiniPot-V, HERMES, FluxMem, StreamingTOM), spatially fine-tuned MLLMs (Spatial-MLLM, Cambrian-S\pmLFP, VST-SFT/RL, SenseNova-SI, Spatial-TTT), and embodied foundation models (Cosmos-Reason1, VeBrain, RynnBrain, RoboBrain2.5).
Headline numbers (overall multiple-choice accuracy):
- Human offline: 92.20; human streaming: 86.61.
- Best system, Gemini-3.1-Pro: 59.19 — a 27.4-point gap to streaming humans.
- GPT-5.4: 50.89; Gemini-3.1-Flash-Lite: 50.81; Grok-4.1-Fast: 43.73.
- Text-only GPT-5.4: 37.10; random: 31.33.
The L1→L4 breakdown for Gemini-3.1-Pro is 61.92 / 64.04 / 55.90 / 54.90, while humans (streaming) score 93.21 / 81.03 / 86.43 / 79.19. The largest absolute deficits sit at L3 (spatial simulation) and L4 (allocentric mapping): Gemini-3.1-Pro loses ~30 points to humans on L3 and ~24 on L4, with the L4.3 sub-task (image-option allocentric questions) collapsing to 22.64 vs. 71.70 for humans. The text-only baseline already reaches 38.85 on L3 and 35.53 on L4 — partly because L3 questions admit linguistic shortcuts and L4 has a constrained option distribution — which is a useful prior on how much each level genuinely requires vision.
Two qualitative findings stand out. First, streaming and spatially fine-tuned MLLMs underperform their own backbones: the inductive biases introduced by streaming token compression (InfiniPot-V, HERMES, FluxMem, StreamingTOM) and by spatial SFT/RL (Spatial-MLLM, VST-SFT/RL, SenseNova-SI) appear to damage the general visual reasoning that matters at L1–L2 without recovering enough on L3–L4. Second, the authors report (truncated in the abstract) that chain-of-thought provides limited or negative gains on spatial-streaming queries, consistent with prior reports that verbal reasoning fails to substitute for an internal map.
Limitations and open questions
The streaming protocol with 128 uniformly sampled prefix frames advantages models with strong long-context vision over true streaming architectures; it is not clear how much of the streaming-model deficit is methodological. L4.3 uses image options that some methods (e.g., InfiniPot-V) cannot ingest, leaving cross-comparison uneven. Multiple-choice format bounds the diagnostic resolution for L3 simulation, where free-form generation would expose richer failure modes. Finally, the benchmark does not directly test memory write/read primitives — only end-task accuracy — so it cannot adjudicate which memory representation (token cache, latent map, explicit scene graph) is the bottleneck.
Why this matters
OVO-S-Bench cleanly isolates the capability gap embodied agents actually need — building and querying a persistent allocentric map from a causal egocentric stream — and shows current MLLMs, including frontier proprietary models, are roughly 27 points below humans, with allocentric mapping as the dominant failure mode. Most strikingly, the streaming and spatially specialized systems regress relative to their general-purpose backbones, suggesting current spatial post-training and streaming compression strategies are net-negative on this axis.
Source: https://arxiv.org/abs/2606.03890
M^3Eval: Multi-Modal Memory Evaluation through Cognitively-Grounded Video Tasks
Problem
Long-form video benchmarks for multi-modal models predominantly probe perception and reasoning. They rarely isolate memory as a capability — what content is encoded, how faithfully it is retained, how it degrades under interference, and whether it can be re-bound to spatial/temporal sources. Without such probes, “long-context video” claims are difficult to falsify: a model can pass long-video QA by exploiting frame-level recency, captioning shortcuts, or single-stream salience without maintaining a coherent episodic representation.
M^3Eval addresses this by porting four canonical paradigms from cognitive psychology into controlled video tasks, each instrumented with metrics that name a specific failure mode rather than a single accuracy number.
Framework
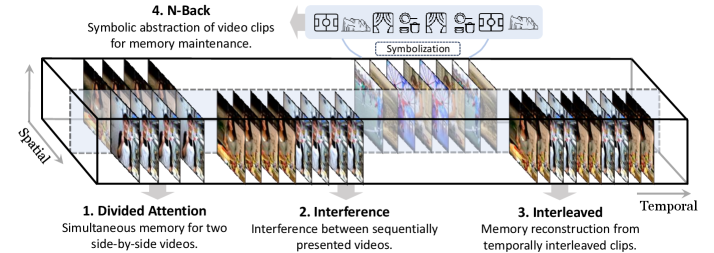
The benchmark spans a spatial–temporal–symbolic axis:
- Divided Attention (spatial encoding under concurrent streams): split-screen presentation of two semantically similar videos V_1, V_2, optionally with 10 uniformly spaced left/right swaps to test binding of content to location.
- Memory Interference (temporal): robustness to sequential similar distractors, modeled on retroactive/proactive interference.
- Interleaved Events (temporal reorganization): reconstructing event order from interleaved segments.
- N-Back (symbolic working memory): identity matching across temporal gaps of length N.
Each paradigm uses 4-way multiple choice with distractors hand-crafted to match a target failure mode, so chance is 25% and error types are diagnostic rather than aggregate.
Divided Attention: mechanics
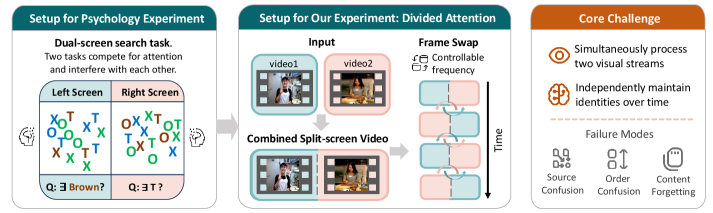
Two conditions are evaluated. In No swapping, V_1 is fixed left, V_2 fixed right; this isolates whether the model maintains disentangled representations under parallel input. In Swapping, the spatial assignment of (V_1,V_2) flips at 10 uniformly spaced timestamps, forcing the model to track content–location bindings rather than treating “left video” as a static stream.
Three question types target distinct failure modes:
- Source Identification — distractors attribute V_2 content to V_1 (source confusion).
- Order Understanding — distractors permute the temporal/causal sequence.
- Content Retention — distractors corrupt plot details of the target.
This factorization is the methodological core: source confusion isolates binding, order isolates temporal encoding, and retention isolates gist/detail recall. The same stimulus set is reused across the three metrics, so differences across columns reflect representational structure rather than item difficulty.
Quantitative results
Models tested: Gemini-3.1-Pro-Preview, GPT-5.4, Qwen3-VL-8B-Instruct, Qwen3.5-{4B,9B,27B}, InternVL3.5-8B, plus agentic systems VideoLucy and M3-Agent. Human reference is included.
On No swapping, humans reach 89.58 / 90.00 / 92.16 (%) on source/order/retention. The strongest model, Gemini-3.1-Pro-Preview, scores 62.50 / 52.50 / 49.02. GPT-5.4 sits at 27.08 / 35.00 / 47.06 — at chance on source identification. The Qwen3.5 family ranges from 18.75 (4B) to 41.67 (27B) on source identification, with 27B still 48 points below human. Open-source agents do not help: VideoLucy scores 16.67 / 42.50 / 37.25; M3-Agent 27.08 / 30.00 / 23.53.
Under Swapping, the largest degradation is concentrated on source identification: Gemini drops 25.00 points (62.50 → 37.50), Qwen3.5-9B drops 16.67 (35.42 → 18.75), Qwen3.5-27B drops 14.59 (41.67 → 27.08). Order Understanding and Content Retention are essentially unchanged or even improve marginally for some models (e.g., Gemini Content Retention +7.84, GPT-5.4 Source Identification +8.34, the latter likely a chance-level fluctuation given baseline 27.08). Humans show a much smaller, uniform decrement of about 5–8 points across all three metrics.
The dissociation is informative: swapping does not corrupt what happened or when it happened within a stream — it corrupts which stream owned it. This is the classic source-monitoring deficit, and it appears sharply in current VLMs while being mild in humans.
Attention-level diagnosis
The authors visualize attention maps in single-screen vs. split-screen settings. In single-video conditions, attention concentrates on the queried region; under split-screen, attention diffuses across both panels even when the question explicitly names the left video. The proposed mechanism is attention confusion across concurrent visual streams: the model fails to gate its tokens by spatial origin, so V_1 and V_2 tokens contribute jointly to retrieval. This suggests architectural rather than data fixes — e.g., explicit positional or stream-id conditioning, masked cross-stream attention, or hierarchical encoders that build per-stream summaries before fusion.
Limitations and open questions
- The benchmark uses 4-way MC with constructed distractors; absolute accuracies are sensitive to distractor calibration, and the small number of items per condition (humans evaluated on 40–51 questions per cell) makes single-point comparisons noisy. The aggregated patterns across paradigms are the more reliable signal.
- Attention visualizations support the confusion hypothesis qualitatively but do not establish causality; intervention experiments (forced single-stream masking) would be needed.
- Only the Divided Attention paradigm is reported in the provided sections; the headline claims about temporal source grounding being weaker than spatial, and limited symbolic memory in N-Back, rest on the full table set.
- Agentic pipelines (VideoLucy, M3-Agent) underperform their underlying VLMs on several cells, suggesting current memory-augmentation scaffolds do not address the binding problem and may even introduce information loss.
Why this matters
By decomposing “memory” into binding, ordering, retention, interference, and symbolic gap-bridging — and showing that current VLMs lose 15–25 points specifically on source binding when spatial layout is unstable — M^3Eval gives a falsifiable target for architectural work on long-video models. Multi-stream applications (driving, robotics, surveillance) depend exactly on the binding capacity that this benchmark shows is currently absent.
Source: https://arxiv.org/abs/2606.05008
Streaming Communication in Multi-Agent Reasoning
Multi-agent LLM systems typically follow a “generate-then-transfer” pattern: agent A_i produces its full reasoning trace, ships it to A_{i+1}, and only then does A_{i+1} begin work. End-to-end latency scales as \sum_i T_i where T_i is the per-agent generation time, and depth d becomes a hard latency multiplier. StreamMA argues that this is both unnecessary and counterproductive: streaming each reasoning step downstream as soon as it is emitted not only pipelines compute but, more surprisingly, raises task accuracy.
Setup and protocols
Let an agent’s reasoning be a sequence of steps s_1, s_2, \ldots, s_n. The paper formalizes three protocols:
- Single: one agent answers alone.
- Serial (standard multi-agent): A_{i+1} consumes the full chain s_{1:n}^{(i)} from A_i.
- Stream: A_{i+1} begins consuming s_k^{(i)} as soon as it is produced, executing concurrently with A_i.
The latency model under streaming reduces from \sum_i T_i toward \max_i T_i in the limit of perfect overlap. With per-step time \tau and n steps per agent across d agents, serial latency is d \cdot n \tau while stream latency approaches (n + d - 1)\tau, giving a speedup upper bound of
\text{Speedup} \le \frac{dn}{n + d - 1},
which approaches d for n \gg d. Token cost is essentially unchanged (each agent still emits its n steps), so the cost ratio is \approx 1 relative to serial.
Why streaming improves accuracy
The non-obvious claim is the effectiveness ordering. The authors model per-step correctness as non-uniform: early steps in a chain are empirically more reliable than later ones, because errors compound and late steps are conditioned on potentially flawed context. If p_k denotes the probability that step k is correct given correct prefix, then p_k is decreasing in k on hard problems. A downstream agent conditioned on the full chain s_{1:n} inherits the unreliable tail; an agent conditioned on a streamed prefix s_{1:k^\*} for some k^\* < n may avoid being misled by erroneous late steps.
In the streaming protocol, A_{i+1} does not wait for A_i’s tail — it begins reasoning from partial prefixes and effectively hedges against late-step errors. The closed-form analysis yields
\Pr[\text{Stream correct}] \ge \Pr[\text{Serial correct}] \ge \Pr[\text{Single correct}]
under the monotone-decreasing reliability assumption, with strict inequality when the tail-error probability is non-negligible. This is the first joint analysis covering latency, cost, and accuracy across the three protocols.
Empirical results
Evaluation spans eight benchmarks across mathematics (including HMMT 2026), science, and code, two frontier models (Claude Opus 4.6 and GPT-5.4), and three topologies (Chain, Tree, Graph). Headline numbers:
- Average improvement of +7.3 pp over the stronger of single/serial baselines.
- Maximum improvement of +22.4 pp on HMMT 2026 with Claude Opus 4.6-high.
- Gains hold across all three topologies, indicating the effect is not specific to linear chains; tree and graph aggregators also benefit when child agents stream to parents.
The latency reductions track the theoretical speedup bound; on deeper pipelines the wall-clock gain is roughly proportional to depth, while token cost stays within a few percent of serial.
Step-level scaling law
A secondary finding: increasing per-agent reasoning steps n consistently improves both single-agent and multi-agent performance, but the slope is steeper under streaming. Intuitively, longer chains offer streaming more opportunities to overlap and more prefix granularity for downstream agents to act on, while serial pipelines pay the full n\tau per agent without commensurate quality gains. This suggests step-count is a first-class scaling axis alongside model size and number of agents, with streaming as the protocol that lets you actually spend that budget without quadratic latency blowup.
Limitations and open questions
The analysis assumes monotone-decreasing per-step reliability, which holds on hard reasoning benchmarks but may fail when agents perform late-stage verification or self-correction — there, late steps are more reliable, and streaming would feed downstream agents premature conclusions. The protocol also assumes downstream agents can productively consume partial prefixes; in practice this requires either training or prompting for incremental input handling, and the paper does not deeply ablate prompt sensitivity. Synchronization overhead, backpressure when A_{i+1} outpaces A_i, and behavior under heterogeneous per-step latencies are mentioned but not exhaustively measured. Finally, the theoretical bounds assume independence of step-level errors across agents, which is optimistic for correlated failure modes (e.g., shared training data biases).
Open questions include: how to dynamically decide when to commit a streamed step versus revise it, whether speculative execution on partial prefixes (à la speculative decoding) compounds the speedup, and whether the step-level scaling law has a regime where it saturates or inverts.
Why this matters
Streaming reframes multi-agent latency from O(d) to nearly O(1) in agent depth without raising token cost, and the accuracy gain — driven by the simple observation that early reasoning steps are more trustworthy than late ones — is a free lunch that orthogonal latency-reduction work has missed. If the step-level scaling law generalizes, it reshapes how to spend inference budget in agentic systems.
Source: https://arxiv.org/abs/2606.05158
WebRISE: Requirement-Induced State Evaluation for MLLM-Generated Web Artifacts
Problem
Existing benchmarks for MLLM-generated web pages judge quality through local, static evidence: pixel similarity to a reference render, presence of specific DOM nodes, or scripted checkpoints along a fixed trajectory. This conflates “looks right” with “works right.” A page can render a login form that visually matches a target while the submit button is wired to nothing; conversely, a page with a different layout may correctly implement the required state machine. The authors argue that what determines whether a generated artifact is functional is its set of requirement-induced states and the transitions between them under user intent — properties that are implementation-agnostic but absent from current evaluation.

Method: Interaction Contract Graphs
WebRISE compiles each task’s natural-language requirement set R_\tau into an Interaction Contract Graph (ICG) G_\tau of observable states, transitions, and DOM/visual assertions. The same G_\tau is shared across five input modalities \mathcal{M}=\{\text{Text}, \text{Markdown}, \text{Sketch}, \text{Image}, \text{Video}\}, so for a fixed task \tau the model f_\theta produces h_{\theta,\tau}^m = f_\theta(x_\tau^m) as a self-contained HTML artifact (HTML+CSS+JS, no backend). Each transition is a tuple
t_j = (s_j^{\text{from}}, s_j^{\text{to}}, g_j, P_j, A_j^{\text{dom}}, A_j^{\text{vis}}),
where g_j is the natural-language goal handed to a contract-guided agent, P_j is a precondition set, and A_j^{\text{dom}}, A_j^{\text{vis}} are DOM-event and visual-postcondition assertions. The transition decomposition is the key design move: it localizes evidence to requirement-linked state changes rather than to a global DOM diff or a single screenshot.
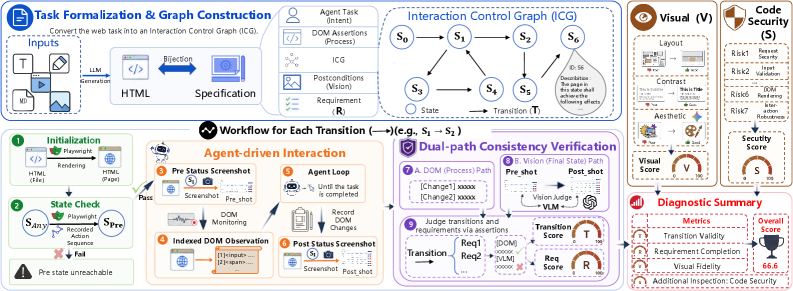
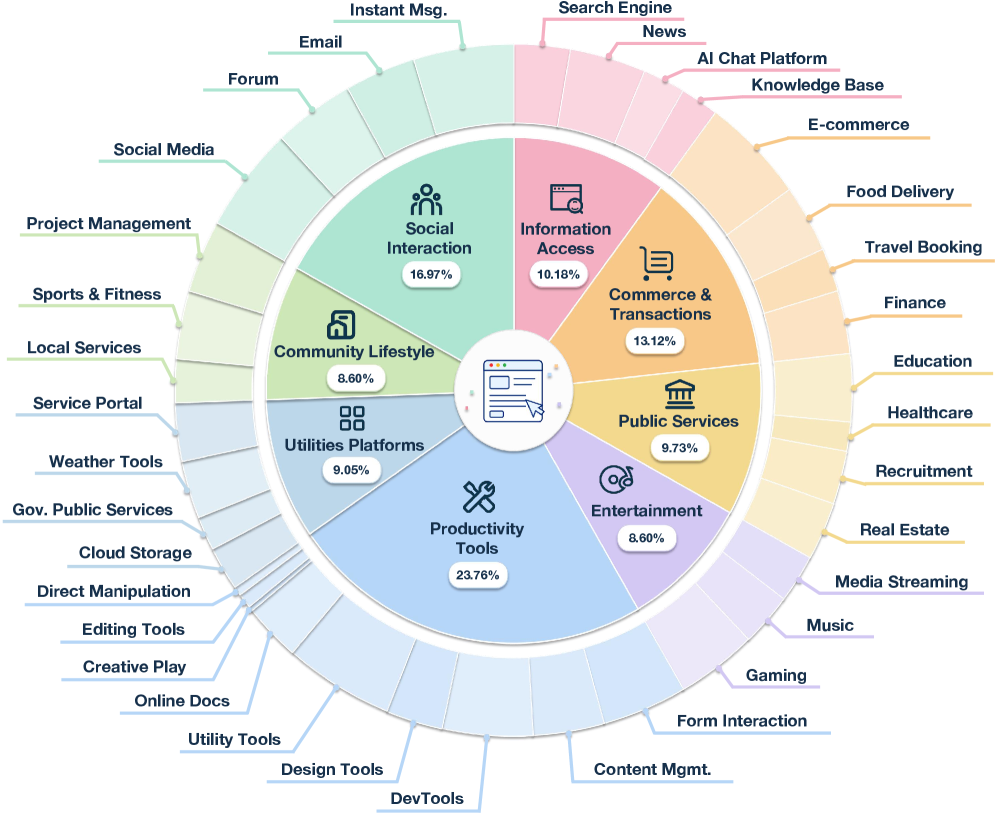
Evaluation (Algorithm 1) loads H in a real browser, restores s_j^{\text{from}} by replaying a cached trajectory \Pi, captures a pre-screenshot, checks P_j, then dispatches an agent with budget K to execute g_j. After a settle delay \Delta, it freezes the event log \mathcal{L} and scores DOM and visual oracles independently. A transition is Pass only if the source is reachable, the agent completes the action, and both oracles agree; on success, \Pi is updated with the trajectory to s_j^{\text{to}}, allowing branching graphs without re-deriving paths. The benchmark contains 442 tasks across 8 domains and 35 scenarios (Productivity Tools 23.76%, Social Interaction 16.97%, etc.), with 5,495 transitions and 5,271 requirement checks separating user-stated functions from implicit product-level constraints.
Results
Across 14 MLLMs (7 open-weight including Qwen3.5/3.6 family and Kimi K2.5/K2.6; 7 proprietary including GPT-5.4/5.5, Claude Opus 4.6/4.7, Gemini-3 Flash/3.1 Pro, Qwen3.6-Plus), even the strongest model reaches only 65.6% transition validity and 66.3% requirement coverage. The headline finding is the visual-behavior gap: Qwen3.6-35B-A3B on Markdown attains V=80.8 visual quality but only T=15.5 transition validity — a page that looks finished but barely runs. Visual fidelity is not a proxy for behavior.
Modality matters. Video specifications yield the strongest interaction signal, adding +10.6 pp implicit-requirement coverage over Text. This is consistent with the intuition that temporal demonstrations encode the intended state machine more directly than static text or screenshots, particularly for affordances the user did not state but expected (focus management, keyboard handling, error toasts). Implicit constraints, however, remain the dominant failure mode across all modalities.
The authors validate the ICG formulation against checkpoint-style evaluation via defect injection: ICG-based scoring detects injected state errors at 2–16× the rate of checkpoint evaluation. LLM-judge agreement with human verdicts is \kappa = 0.74.
Limitations
The judge layer remains susceptible to prompt sensitivity and API drift; the authors explicitly recommend reading scores as rank-orderings rather than absolute measurements, and release per-assertion verdicts to enable re-scoring. The ICGs encode regional product conventions from a single contributor pool, so the implicit-requirement set is not locale-neutral — applications targeting other markets need contract extensions. The protocol assumes single-page, backend-free artifacts; multi-page apps, persistent state, and network-dependent flows are out of scope. Finally, the contract-guided agent itself can fail to execute a goal g_j on a working page, conflating agent capability with artifact correctness; the budget K and replay cache \Pi mitigate but do not eliminate this.
Why this matters
WebRISE reframes web-generation evaluation from artifact matching to contract conformance, exposing that current MLLMs produce visually convincing but behaviorally incomplete pages — a gap that standard benchmarks structurally cannot see. The transition-level decomposition and 2–16× defect-detection improvement over checkpoint evaluation suggest ICGs should become the default substrate for any benchmark that claims to measure whether generated UIs work.
Source: https://arxiv.org/abs/2606.03220
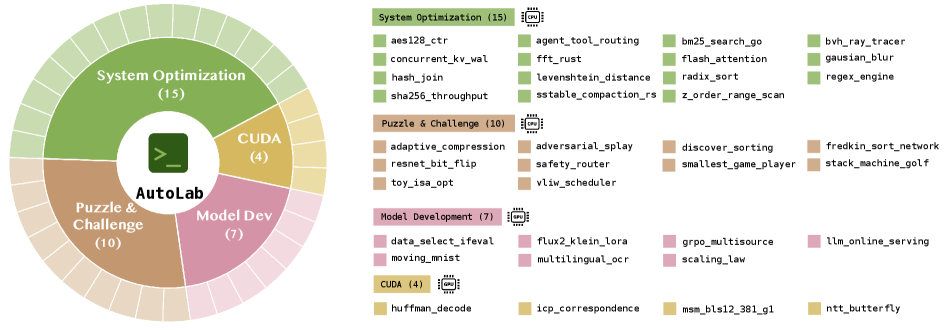
AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
Problem
Most agent benchmarks evaluate either single-turn answers or short-horizon trajectories spanning minutes. Real research and engineering, however, is iterative on the order of hours: propose, run, measure, refine. AutoLab targets this gap by measuring sustained closed-loop optimization where an agent is given a correct but suboptimal baseline and a wall-clock budget, and must improve a continuous performance metric. The hypothesis the authors validate empirically is that long-horizon persistence — repeated benchmark/edit/feedback cycles — dominates initial-attempt quality as a predictor of success.
Benchmark construction
AutoLab consists of 36 expert-curated tasks across four domains: system optimization, puzzles & challenges, model development, and CUDA kernel optimization. Each task is a tuple of (instruction, containerized environment with baseline code and a local eval script the agent may invoke, held-out verifier, hidden reference solution, wall-clock budget). References are required to beat baselines by a non-trivial margin — typically at least an order of magnitude on system-optimization tasks, and a clear statistical gain on model development.

Scoring is anchored at baseline (s=0) and reference (s=0.5), with values above 0.5 indicating super-reference performance. For order-of-magnitude metrics the authors use a log-stretch:
s(x) = \mathrm{clip}\!\left(\tfrac{1}{2} \cdot \frac{\log(m_{\mathcal{B}}/m(x))}{\log(m_{\mathcal{B}}/m_{\mathcal{R}})},\ 0,\ 1\right)
with a minimum-improvement gate that forces s=0 until the baseline is exceeded, eliminating credit for marginal noise. Higher-is-better metrics use the directional analogue. Verification is hack-resistant: the local script the agent calls during development is not the held-out verifier, so reward-hacked numbers do not transfer.
Models are ranked using three metrics over three independent rollouts: Avg@3 (typical), Best@3 (ceiling), and Dominance — a tournament-style head-to-head:
\mathrm{Dominance}(m)=\frac{1}{|\mathcal{T}|\cdot(|\mathcal{M}|-1)}\sum_{t\in\mathcal{T}}\sum_{\substack{o\in\mathcal{M}\\ o\neq m}}\!\Bigl(\mathbf{1}[s_{m,t}>s_{o,t}]+\tfrac{1}{2}\mathbf{1}[s_{m,t}=s_{o,t}]\Bigr).
Dominance ranges in [0,1] with 0.5 being average; it is robust to hardware variance and to a small number of high-leverage tasks.
Setup
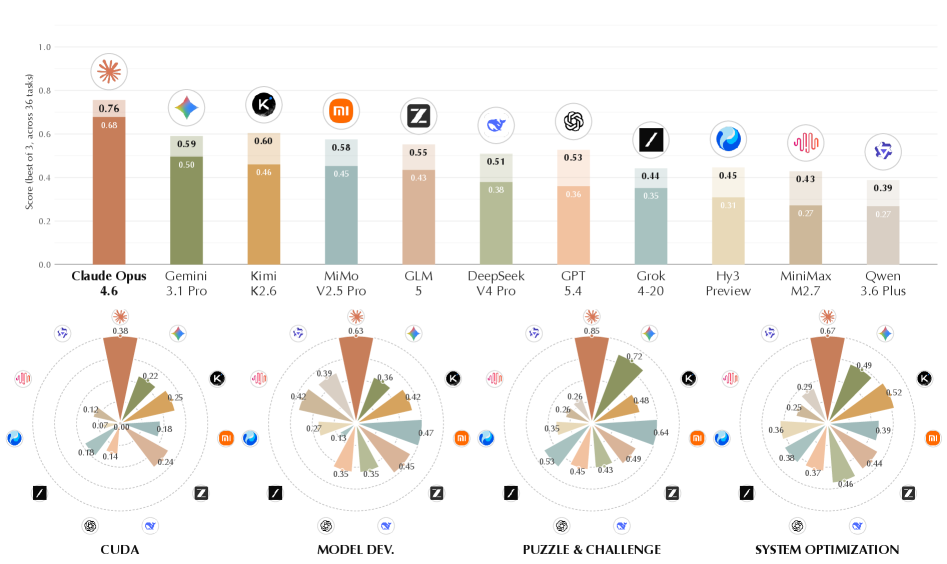
Seventeen models are evaluated, including proprietary flagships (claude-opus-4.6, gemini-3.1-pro, gpt-5.4, grok-4-20) and open-weight models above 200B parameters (qwen-3.6-plus, deepseek-v4-pro, glm-5, kimi-k2.6, hunyuan-3-preview, mimo-v2.5-pro, minimax-m2.7), plus older variants for ablation. The harness is Harbor with the terminus-2 agent (Section 4.3 includes a pilot with pi-mono and an optimized mini-swe-agent). CPU tasks run in a local Docker sandbox on a Ryzen 9950X / 64 GB workstation; GPU tasks run on Modal-provisioned H100s and L40S. Total compute: 2,544 wall-clock hours and 8.60 billion tokens.
Results
claude-opus-4.6 leads all four task categories on both Avg@3 and Best@3. The gap to other proprietary frontier models is large and is explained mechanistically by the cost analysis: gpt-5.4 and grok-4-20 cluster at markedly lower agent runtimes, terminating trials prematurely. Across models, Avg@3 correlates positively with both the average number of agent steps and average wall-clock runtime; the correlation with raw inference cost is weaker. Several open-weight models (notably deepseek-v4-flash and mimo-v2.5-pro) achieve competitive scores at substantially lower USD cost per task, indicating that pure long-horizon throughput, not necessarily peak per-token capability, drives benchmark performance.
The qualitative finding is that the dominant predictor of success is not the quality of the initial patch but the agent’s persistence in repeatedly benchmarking, editing, and incorporating empirical feedback. Models that early-stop — even when their first attempt is reasonable — leave most of the headroom on the table. The failure-mode breakdown in Figure 6 categorizes zero-score rollouts into four mutually exclusive classes (early termination, no improvement over baseline, broken modification, and infrastructure failures), with early termination dominant for several proprietary models.
Limitations and open questions
- Results are entangled with the terminus-2 harness; the Section 4.3 pi-mono and mini-swe-agent pilot suggests harness choice can shift rankings. (2) Models with <200B parameters are excluded, so the lower end of the capability/cost frontier is unmeasured. (3) The benchmark uses a fixed wall-clock budget per task; how scores scale with budget — i.e., whether weak models would catch up given more steps, or whether strong models saturate — is not characterized. (4) Hack-resistance relies on a held-out verifier, but for performance metrics like runtime and throughput the attack surface (e.g., precomputation, exploiting eval-script idiosyncrasies) is large; the paper claims resistance but does not quantify residual gaming. (5) The headline result that persistence dominates capability is partly an artifact of how proprietary models are tuned to terminate; it is unclear whether prompting or scaffolding alone closes the gap with claude-opus-4.6.
Why this matters
AutoLab makes the empirical case that on hour-scale closed-loop optimization, the binding constraint for current frontier models is iteration discipline rather than raw single-shot reasoning — several proprietary flagships fail by stopping early, not by producing weaker patches. This reframes “agent capability” evaluation around sustained empirical loops and provides a continuous, hack-resistant scoring scheme that resists saturation as models improve.
Source: https://arxiv.org/abs/2606.05080
Audio Interaction Model
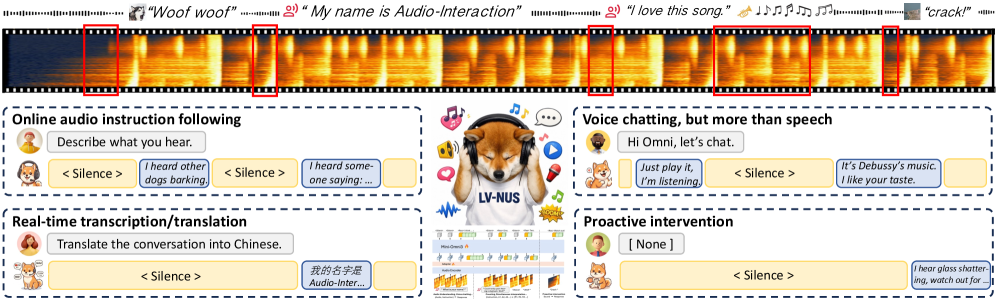
Current Large Audio Language Models (LALMs) operate as offline functions y = f(x, \mathcal{A}) over a complete utterance \mathcal{A} with a text instruction x, producing a single response after the full signal is observed. Streaming systems exist but are siloed: streaming ASR, simultaneous interpretation, or voice chat each live in separate models. This paper formalizes an Audio Interaction Model that fuses these regimes under a perceive–decide–respond loop, and instantiates it as Audio-Interaction trained with the SoundFlow framework on a new streaming corpus, StreamAudio-2M.
Problem formulation
The model consumes audio chunk-by-chunk and emits, at every step, both a binary intervention decision and (conditionally) a response token stream:
(d_t, r_t) = f(a_{\le t},\, d_{<t},\, r_{<t}),
where a_t is the current audio chunk, d_t \in \{\text{silent}, \text{respond}\} is the streaming intervention decision, and r_t is the generated response token. The contrast with the offline regime is shown in Figure 2: conventional LALMs wait for end-of-utterance, answer once, and specialize per task; Audio-Interaction continuously judges when to speak.
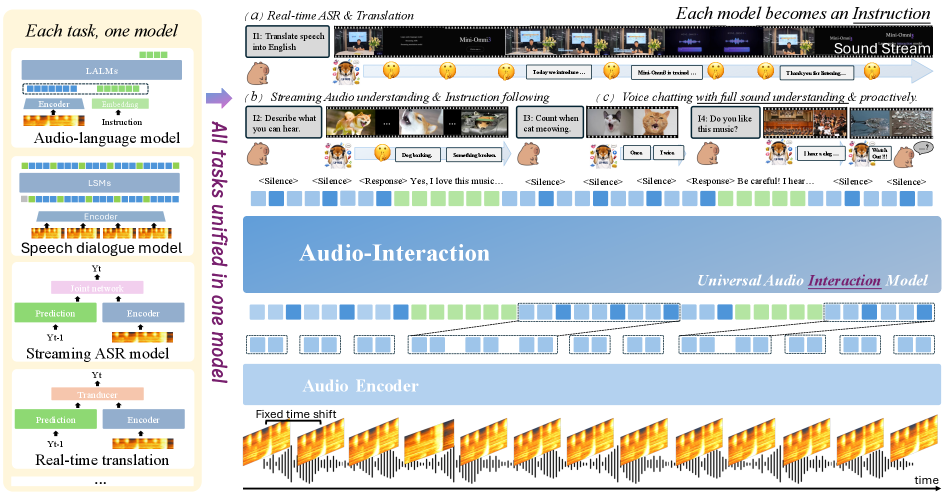
This single formulation subsumes a broad capability set: speech translation \to simultaneous interpretation (decide when enough source context has accumulated), dialogue \to open-domain audio discussion, audio understanding \to audio instruction following, and proactive assistance triggered purely by acoustic semantics with no textual prompt.
SoundFlow training
SoundFlow organizes audio signals, intermediate representations, and supervision into a single temporal sequence and jointly trains a language-modeling objective with a response-triggering objective (Figure 3). Concretely, at each streaming step the model is supervised both on whether to fire (d_t) and on the next response token when firing is the correct action. The reported training is “comprehension-aware,” meaning the trigger decision is conditioned on accumulated semantic state rather than purely acoustic VAD-style cues, which is what allows the same parameters to handle proactive intervention and simultaneous translation under one loss.
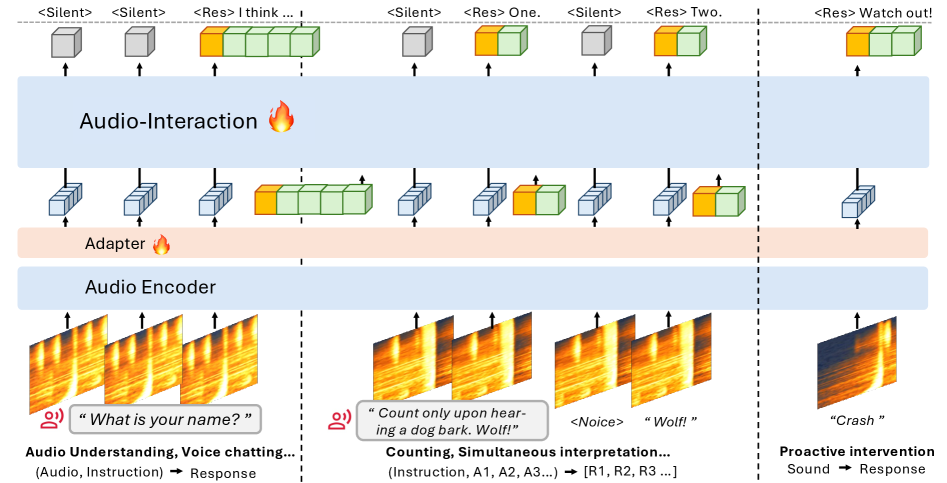
Deployment uses asynchronous low-latency inference, decoupling perception from response generation so that decoding a long answer does not stall ingestion of subsequent audio chunks — a necessary property for stable always-on operation.
StreamAudio-2M
Existing audio SFT corpora are essentially (clip, instruction, response) triplets (Kong et al. 2024; Chu et al. 2024), which presuppose a fixed boundary between input and response and therefore cannot teach the trigger. StreamAudio-2M is built streaming-native: each sample is a 3–15 turn heterogeneous interaction with interleaved events and sparse, context-dependent response cues. Scale is 2.6M items totaling 302k hours, partitioned across 7 major categories — Audio Agent, Proactive Respond, Voice Chatting, Streaming Audio Understanding, Following Music, Real-time ASR, Streaming Translation — and 28 sub-tasks. The sparsity of cues is what forces the model to learn d_t = \text{silent} as the high-prior default, mirroring how a human listener mostly does not interrupt.
The companion Proactive-Sound-Bench targets the qualitatively new capability: evaluating whether a model intervenes appropriately on the basis of audio semantics alone, with no explicit instruction. This is something none of MMAU, VoiceBench-style suites, or LibriSpeech can measure.
Evaluation
Audio-Interaction is benchmarked on 8 suites covering offline and streaming abilities: MMAU (Sound/Music/Speech understanding); the spoken-dialogue set AlpacaEval, SD-QA, Llama Questions, Web Questions following the VoiceBench protocol; LibriSpeech clean/other for ASR; CoVoST2 En\leftrightarrowZh for S2TT; and Proactive-Sound-Bench. The selected sections describe the experimental setting but do not enumerate score tables here, so the headline numerical claim available is the corpus scale (2.6M / 302k h / 28 sub-tasks) and the breadth of the evaluation surface — explicitly designed so that adding the streaming/trigger objective does not regress the offline tasks.
Limitations and open questions
The provided sections do not specify the backbone, audio tokenizer, chunk size, or trigger-head architecture, which are the central re-implementation details; nor do they quantify the offline–vs–online tradeoff. Three open questions follow naturally: (i) how is d_t calibrated so that the model neither over-interrupts nor misses cues — is it a thresholded logit, a separate classifier, or a learned action token in the LM vocabulary? (ii) how is asynchronous inference scheduled when long-form generation overlaps with new salient input (barge-in, mid-response retraction)? (iii) does Proactive-Sound-Bench reduce to event-detection plus instruction following, or does it require genuinely new capability? Without ablations isolating SoundFlow’s joint loss against a vanilla LM-only objective on the same corpus, it is also hard to attribute gains to the training framework versus the data.
Why this matters
Treating audio as a stream where the model itself decides when to speak is the right formulation for embodied assistants and any always-on agent, and it forces the trigger decision to be a first-class, supervised quantity rather than an external VAD. The 302k-hour streaming-native corpus and the proactive benchmark are the more durable contributions: they define what “online LALM” means as an evaluation target.
Source: https://arxiv.org/abs/2606.05121
Hacker News Signals
Gemma 4 12B: A unified, encoder-free multimodal model
Gemma 4 12B is Google’s latest open-weights model, notable for dropping the separate vision encoder entirely. Instead of a CLIP-style encoder feeding embeddings into a language model, the architecture processes image tokens directly through the same transformer stack that handles text, using a unified token space. This encoder-free design reduces architectural complexity and removes the encoder-decoder alignment problem that plagues two-tower multimodal systems.
The model supports a 128K context window and handles interleaved image-text inputs, multiple images per prompt, and video frames. At 12B parameters it fits in consumer GPU VRAM with quantization. Weights are released under the Gemma license (research and commercial use with restrictions).
The technical interest here is the encoder-free bet. Prior work like Fuyu-8B made this argument at smaller scale; Gemma 4 12B is a meaningful test of whether the approach holds at a size where encoder-based competitors like LLaVA-style models are well-optimized. The tradeoff is that the language model backbone must now learn spatial and visual representations without dedicated inductive biases from convolutions or ViT patch embeddings, relying entirely on scale and training data diversity. Whether this actually generalizes better or worse on fine-grained vision tasks (OCR, charts, spatial reasoning) is an open empirical question the release benchmarks only partially address.
HN discussion centers on the license restrictions (no use for training competing foundation models), the practical inference cost versus LLaVA-style alternatives, and how the architecture compares to the PaliGemma line which did use a SigLIP encoder.
Source: https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12b/
The ways we contain Claude across products
Anthropic’s engineering post describes the isolation and sandboxing layers used when Claude executes tool calls and agentic actions across products. The core problem: an LLM that can invoke tools, browse the web, write files, and call APIs creates a large attack surface for both accidental and adversarial misuse. The post covers four containment layers.
First, network isolation — tool-calling containers run without egress by default; external network access requires explicit allow-listing. Second, capability scoping — each deployment context receives a manifest of permitted tool types; Claude cannot invoke tools outside its declared scope even if a prompt requests it. Third, prompt injection mitigations — untrusted content from web pages or user-uploaded documents is structurally separated from system-prompt-level instructions, with heuristics to detect instruction injection in retrieved content. Fourth, action reversibility preference — the system is designed to prefer reversible over irreversible actions and to pause for confirmation before side-effecting operations above a configurable risk threshold.
The post is candid that these are defense-in-depth measures, not guarantees. Prompt injection in particular remains unsolved at the model level — the mitigations are structural (content tagging, retrieval sandboxing) rather than semantic. The confirmation-pause mechanism depends on accurate risk classification, which itself runs through Claude, creating a potential circularity.
From a systems perspective, the most technically interesting piece is the tool manifest architecture: treating capability scoping as a static declaration rather than a runtime check reduces the attack surface but requires careful API design to avoid manifest bypass through chained tool calls.
Source: https://www.anthropic.com/engineering/how-we-contain-claude
Elixir v1.20: Now a gradually typed language
Elixir 1.20 ships the first production-grade layer of its gradual type system, a multi-year effort building on set-theoretic types rather than the Hindley-Milner or bidirectional approaches common elsewhere. The type algebra uses union, intersection, and negation types as primitives, which maps naturally onto Elixir’s pattern-matching semantics and BEAM’s dynamic dispatch.
The key design constraint: Elixir cannot require type annotations on existing code. The system infers types from pattern matches, guards, and struct definitions, and uses those to issue warnings — not errors — on type violations. This is genuine gradual typing: untyped code interoperates transparently, and the type checker only activates where it has enough information to make confident claims.
Concretely, the checker now tracks types through function calls, identifies exhaustiveness failures in case expressions, and flags mismatched struct field access. The warnings are emitted at compile time, integrated with the existing mix compile pipeline. No new syntax is required for basic coverage; @type and @spec annotations from Dialyzer remain supported and feed into the new system.
The set-theoretic foundation matters because it handles union types that arise naturally from multi-clause functions and or-guards without the approximations Dialyzer requires. The theoretical underpinning is the work of Giuseppe Castagna on semantic subtyping, adapted for Elixir by José Valim and team. Full function-level type inference with annotation support is planned for subsequent releases.
HN discussion is largely positive, with notes on how this compares to Dialyzer’s success/pain history and whether the BEAM’s dynamic nature (hot code reloading, message passing) creates fundamental limits on what the type system can verify.
Source: https://elixir-lang.org/blog/2026/06/03/elixir-v1-20-0-released/
U of T researchers demonstrate AI worm could target any online device
The University of Toronto researchers demonstrate a self-replicating attack that exploits LLM-integrated applications. The threat model: a target system uses an LLM to process external content (emails, documents, web pages); the attacker embeds adversarial instructions in that content that cause the LLM to exfiltrate data and generate new payload-carrying outputs that infect downstream systems the target communicates with.
The mechanism is prompt injection combined with self-replication. The injected payload instructs the model to include a copy of the adversarial instructions in any response or forwarded content. In an email assistant scenario: infected email arrives, LLM processes it, LLM drafts replies or forwards containing the payload, recipients’ email assistants are compromised in turn. The “worm” label is apt — it spreads through the model’s normal output channels without requiring any traditional code execution vulnerability.
The practical severity depends heavily on the application’s tool permissions. A read-only summarization pipeline has low impact; an assistant with send-email, file-write, or API-call permissions is high impact. The containment layers described in the Anthropic post above are directly relevant here — network isolation and tool scoping limit blast radius, but they don’t prevent the replication vector itself.
The research contributes a concrete taxonomy of propagation paths and demonstrates working prototypes against GPT-4 and Gemini-based applications. The fundamental defense gap remains unsolved: distinguishing instruction from content is a semantic problem the model itself cannot reliably solve, and structural mitigations (tagging, sandboxing) reduce but do not eliminate attack surface.
Source: https://www.utoronto.ca/news/u-t-researchers-demonstrate-ai-worm-could-target-any-online-device
Writing Portable ARM64 Assembly (2023)
This post addresses a real portability gap: ARM64 assembly that runs on Linux/ELF with the System V ABI diverges from ARM64 assembly targeting macOS/Mach-O with Apple’s ABI variant, and both differ from Windows ARM64. The author documents the specific incompatibilities that bite cross-platform low-level code.
Key divergences covered: (1) Stack alignment requirements — macOS requires 16-byte stack alignment at all call sites, enforced by hardware on Apple Silicon; Linux is more permissive in practice. (2) Calling convention differences — Apple’s ABI reserves x18 as a platform register and must not be used by application code; the standard AAPCS64 only soft-reserves it. (3) Procedure linkage — on ELF targets, external function calls typically go through a PLT stub; on Mach-O, the pattern uses stubs in a separate section with a different stub format. (4) Local label syntax — gas and clang/llvm assemblers handle local labels differently across targets.
The recommended portability strategy is conditional assembly via preprocessor macros to abstract the platform-specific calling convention details, plus avoiding x18 entirely. The post includes concrete before/after examples for function prologues and epilogues.
This is practically relevant for anyone writing hand-optimized crypto, SIMD kernels, or JIT emitters that need to target multiple ARM64 platforms. The macOS/Linux divergence in particular catches developers who test on one platform and deploy on the other. The post is from 2023 but the underlying ABI differences remain current.
Source: https://ariadne.space/2023/04/12/writing-portable-arm-assembly.html
thunderbolt-ibverbs: We have InfiniBand at home
This post from Hellas AI documents building a high-bandwidth, low-latency interconnect for a small GPU cluster using Thunderbolt hardware combined with the InfiniBand Verbs (ibverbs) userspace API. The premise: dedicated InfiniBand NICs and switches are expensive; Thunderbolt 4 links provide 40 Gbps bandwidth and have PCIe-level latency since the protocol is fundamentally PCIe-over-cable.
The technical approach uses the thunderbolt-net kernel driver to expose Thunderbolt links as network interfaces, then runs RoCE (RDMA over Converged Ethernet) on top. The ibverbs API — originally designed for InfiniBand — works over RoCE, meaning NCCL and other RDMA-aware collective communication libraries can be used without modification. The result is that GPU-to-GPU transfers can bypass the CPU and kernel network stack via RDMA semantics on commodity Thunderbolt cables.
The measured numbers show meaningful latency improvement over standard TCP/IP over the same links, and bandwidth approaching the theoretical Thunderbolt limit for large transfers. The main limitation is topology: Thunderbolt daisy-chains support limited node counts and don’t provide the non-blocking fat-tree topologies that production InfiniBand deployments use. For a 2-8 node cluster doing model parallelism or parameter server workloads, this is a cost-effective alternative.
The post includes setup instructions for the kernel modules, ibverbs configuration, and NCCL environment variables. It is a solid example of extracting datacenter-class interconnect semantics from consumer hardware.
Source: https://blog.hellas.ai/blog/thunderbolt-ibverbs/
Gooey: A GPU-accelerated UI framework for Zig
Gooey is an early-stage UI toolkit written in Zig that renders entirely on the GPU using WebGPU (via the wgpu native library). The architecture is retained-mode: the application builds a widget tree, diffs it against the previous frame, and submits draw calls for changed regions. No HTML, no DOM, no system widget toolkit dependency.
The rendering pipeline uses signed-distance field (SDF) techniques for text and shape rendering, which allows resolution-independent rendering and smooth scaling without rasterizing at multiple sizes. Glyphs are stored as SDFs in a texture atlas; the fragment shader evaluates the SDF at pixel centers and applies antialiasing analytically. This is the same approach used by some game engines and terminals (e.g., Ghostty) for high-quality GPU text.
Zig’s comptime features are used for the widget system: widget types and their properties are resolved at compile time, reducing runtime dispatch overhead. The layout engine is an implementation of the flexbox algorithm, familiar from CSS but without the web platform baggage.
The project is pre-1.0 and the API surface is small. Current limitations include no accessibility tree, no IME support, and no system clipboard integration — all of which are hard platform-specific problems. The HN comments note that this occupies a similar niche to clay (the Zig-popular immediate-mode layout library) but with a retained-mode design and direct WebGPU backend rather than delegating rendering to the caller.
Interesting as both a Zig ecosystem data point and as an example of the ongoing trend toward application-layer GPU rendering bypassing system UI frameworks entirely.
Source: https://github.com/duanebester/gooey
QBE – Compiler Backend – 1.3
QBE is a small compiler backend (roughly 15K lines of C) intended as an alternative to LLVM for language implementers who need reasonable codegen quality without LLVM’s compile-time cost, API complexity, or binary size. Version 1.3 adds several backend improvements and bug fixes.
QBE defines its own SSA-form IR, similar in spirit to LLVM IR but significantly smaller in scope. The IR supports integer and floating-point types, aggregate types, and a flat memory model. From this IR, QBE generates x86-64, ARM64, and RISC-V assembly. Optimization passes are limited compared to LLVM — basic dead code elimination, copy propagation, and register allocation via a linear scan allocator — but sufficient to produce code that is typically within 20-30% of GCC -O1 output.
The value proposition is implementation simplicity: QBE is readable and hackable in a way LLVM is not. It has seen adoption in several hobby and research languages (Cproc, a C compiler; several ML-family experimental languages). The 1.3 release notes cover improved handling of aggregate return values on ARM64, corrections to the RISC-V calling convention implementation, and several correctness fixes in the register allocator.
The HN discussion raises the perennial question of when QBE is the right choice versus Cranelift (which targets similar use cases with a more industrial-strength register allocator and explicit WASM support) or simply targeting C as an IR. QBE’s answer is simplicity and auditability — the entire backend fits in a weekend’s reading.
Noteworthy New Repositories
chiennv2000/orthrus
Orthrus targets speculative decoding from a different angle: instead of a separate draft model, it uses a dual-view diffusion mechanism to generate candidate token sequences in parallel and then verifies them with the base LLM in a single forward pass. The “dual-view” framing means the system maintains two complementary representations of the partially decoded sequence — one autoregressive, one diffusion-based — and reconciles them to produce lossless output (identical distribution to greedy/sampling decoding from the original model). The claimed speedup comes from amortizing verification cost across multiple drafted tokens simultaneously, similar in spirit to Medusa or EAGLE but without requiring fine-tuning a separate head on the target model. The implementation appears to be PyTorch-based and targets standard HuggingFace-compatible LLMs. For practitioners who cannot modify model weights (API-constrained or production-frozen checkpoints), a training-free speculative method is genuinely useful. The lossless guarantee is the hard constraint that distinguishes it from approximate fast-decoding schemes. Worth examining the actual acceptance-rate math and wall-clock benchmarks on A100/H100 hardware before deployment. Open questions include how the diffusion view handles long-context KV cache and whether the dual-state overhead erodes gains on short sequences.
Source: https://github.com/chiennv2000/orthrus
UditAkhourii/adhd
ADHD implements Tree-of-Thought (ToT) reasoning as a composable skill for coding agents built on the Claude and Codex Agent SDKs. The core mechanism fans out multiple divergent reasoning branches under distinct “cognitive frames” (e.g., security-first, performance-first, simplicity-first), scores each branch on configurable heuristics, prunes branches whose scores fall below a threshold, and recursively deepens only the surviving paths. This is mechanically close to the BFS/DFS variants described in the original ToT paper, but wired directly into agent tool-call loops rather than sitting on top of a raw completion API. Pruning is explicit and early, which matters for cost control when each node involves a full agent step. The parallel fan-out is designed for problems where the solution space is genuinely multimodal — architecture decisions, algorithm selection, cross-domain synthesis — rather than single-path coding tasks. Built as a skill (a reusable callable unit in the SDK’s plugin model) rather than a standalone agent, so it composes with other skills in a pipeline. The main technical risk is that scoring functions are heuristic and domain-specific; without good scoring, the pruning degenerates into random truncation. Documentation on defining custom frame sets and score functions would determine real-world adoption.
Source: https://github.com/UditAkhourii/adhd
code-yeongyu/lazycodex
LazyCodex is an agent harness built specifically around OpenAI Codex, targeting the failure mode where Codex loses coherence on large, multi-file codebases. It addresses this with three subsystems: persistent project memory (structured summaries of file purposes, dependency graphs, and prior task outcomes stored between sessions), a planning layer that decomposes user intent into a sequenced task graph before any code is written, and a verification loop that runs tests and static analysis after each execution step and re-plans on failure. The “verified completion” framing means the agent does not report success until an automated check passes, not just until code is generated. This is architecturally similar to SWE-agent or Devin-style scaffolding but explicitly scoped to Codex as the underlying model. The project memory component is the most technically distinctive piece — maintaining a living summary of a codebase across sessions reduces the effective context window requirement and lets the agent handle repositories that exceed any single prompt. Key open questions: how memory is invalidated when files change externally, and whether the task graph planner handles cyclic dependencies (e.g., refactoring that affects tests that affect further refactoring).
Source: https://github.com/code-yeongyu/lazycodex
microsoft/intelligent-terminal
This is a fork of the open-source Windows Terminal (the standard Microsoft terminal emulator, written in C++/WinRT) with an embedded agent layer added directly to the shell UI. Rather than a separate chat panel, the agent integration is inline: it can observe command output, intercept stderr, suggest corrections, and execute follow-up commands within the same terminal session context. The technical distinction from existing shell-assistant tools (e.g., GitHub Copilot CLI, warp.dev) is that the agent has direct access to the terminal’s internal state — scrollback buffer, current directory, exit codes — without needing to parse screen-scraped text. This tight coupling enables more reliable context extraction than tools that sit outside the terminal process. Built on top of the existing Windows Terminal rendering engine (DirectWrite, DXGI) and input handling, so the base terminal performance is unaffected when the agent is idle. The integration targets the Windows AI Foundry / Azure OpenAI stack. Primary limitation: Windows-only by construction given the WinRT dependency, and the agent’s action space is currently constrained to text suggestions rather than full autonomous execution. Useful as a reference implementation for deep terminal-agent integration on the Windows platform.
Source: https://github.com/microsoft/intelligent-terminal
atomicstrata/atomicmemory
AtomicMemory provides a portable semantic memory layer for AI agents, designed to be framework-agnostic from the start. The core engine handles embedding-based storage and retrieval of memory chunks, with support for recency weighting, relevance scoring, and optional forgetting curves. On top of the engine sit multiple integration surfaces: a TypeScript SDK for direct programmatic use, framework adapters (targeting LangChain, LlamaIndex-style ecosystems), an MCP (Model Context Protocol) server so any MCP-compatible agent can use it as a tool, a CLI for inspection and debugging, and host plugins for embedding into specific environments. The portability pitch is real: by exposing both an MCP server and a TypeScript SDK, the same memory store can serve a Claude Desktop plugin, a custom Node.js agent, and a Python LangChain agent without duplicating storage. The semantic retrieval presumably uses a local vector index (likely HNSW or flat cosine over an embedding model), keeping it self-hostable without a cloud vector DB dependency. Key technical gaps to investigate: whether memories are namespaced per agent/user, how conflict resolution works when contradictory memories exist, and what embedding model is used by default and whether it is swappable.
Source: https://github.com/atomicstrata/atomicmemory
agentic-in/elephant-agent
Elephant Agent is framed around “Personal-Model First” architecture — the agent is designed to maintain a persistent, growing model of a specific user rather than operating statelessly across sessions. The “self-evolving” aspect refers to the agent updating its internal user model and behavioral policies based on interaction history, feedback signals, and task outcomes, without requiring explicit retraining of the underlying LLM. Mechanically, this likely involves a structured long-term memory store (the “elephant” metaphor), preference inference from implicit signals, and dynamic prompt construction that incorporates the accumulated user model at inference time. This is architecturally related to work on personalized agents and lifelong learning scaffolds, but positioned as a general-purpose personal assistant rather than a domain-specific tool. The repository is early-stage based on star count relative to description ambition; technical depth of the self-evolution mechanism — specifically whether it is truly adaptive or just accumulative memory retrieval — requires direct code inspection. The most interesting engineering question is how the agent handles contradictions between old and new user preferences and whether the user model has any interpretable structure beyond a flat memory log.
Source: https://github.com/agentic-in/elephant-agent
freestylefly/wesight
WeSight is a desktop AI agent workspace targeting developers who want to run multiple coding agents (Claude Code, OpenAI Codex, OpenClaw, Hermes) from a single UI without manually configuring each one. The “one-click setup” is the primary value proposition: it automates environment configuration, authentication, and routing so that a user can direct queries to different agents based on task type or preference without context-switching between tools. The custom LLM model routing layer is the technically interesting component — it presumably implements a dispatcher that classifies incoming tasks and forwards them to the most appropriate backend, similar in concept to mixture-of-agents routing but at the orchestration level rather than the inference level. Built as a desktop application (likely Electron or Tauri given the cross-platform positioning). The open-source nature means the routing logic is inspectable and customizable, which distinguishes it from closed orchestration products. Practical concerns: credential management for multiple API keys in a desktop app requires careful security design, and the routing heuristics will need tuning for non-obvious task boundaries. Useful for teams that want a unified agent workspace without vendor lock-in to a single provider’s IDE integration.
Source: https://github.com/freestylefly/wesight
MyuriKanao/src-hunter-skill
SRC Hunter is a Claude Code skill (a structured prompt/tool package for the Claude agent SDK) targeting offensive security researchers doing bug bounty, SRC (Security Response Center) submissions, and crowdsourced penetration testing. The technical content is substantial: 19 attack-class playbooks covering standard web and API vulnerability classes, 305 structured payloads organized by vulnerability type, 263 WAF and EDR bypass techniques, 2,887 real HackerOne case references, and statistical analysis of 88,636 WooYun (Chinese historical bug bounty platform) cases. The last two components are what differentiate this from a generic payload list — grounding the agent’s attack selection in historical case distributions means it can prioritize techniques by empirical success rate rather than theoretical completeness. Mechanically, the skill plugs into Claude Code’s tool-call loop: the agent uses the playbooks to structure its reconnaissance and exploitation reasoning, queries the payload library for concrete injection strings, and references bypass techniques when encountering filtering. The primary legal and ethical caveat is sharp: this tool is explicitly for authorized testing and research contexts. The WooYun statistical corpus is historically significant as a snapshot of Chinese web security vulnerability patterns from a now-defunct platform. Documentation is primarily in Chinese.