デイリーAIダイジェスト — 2026-05-27
arXiv ハイライト
SpatialBench: あなたのSpatial Foundation Modelはオールラウンドプレイヤーか?
Spatial foundation models(SFMs)— DUSt3R、MASt3R、VGGT、\pi^3、MapAnything、そしてDepth-Anythingファミリー — は、一般的にドメインごとの狭いbenchmark(室内向けのScanNet、自動運転向けのKITTI、オプティカルフロー向けのSintel)で評価されており、しばしば非決定的なフレームサンプリングが用いられています。このため、論文をまたいだ比較は信頼性に欠け、単一モデルが視点(egocentric、wrist)、動的性(静的シーンvs.動的シーン)、入力密度(1フレームから数百フレーム)、ハードウェア予算といった多様な条件にどれほど汎化できるかが不明瞭でした。SpatialBenchはこの問題に取り組み、19のデータセットと546シーンを単一の決定的プロトコルに統合し、4つの入力密度レジームのもとで5つのタスクスイートに対して6つのパラダイムにまたがる41モデルを評価しています。
Benchmarkの構築
すべての生データは、RGB、メトリック深度 D、カメラ-ワールド間の姿勢 T_{cw}、および内部パラメータ K からなるシーンごとのタプルに正規化されます。重要な設計上の選択は、各(シーン、視点密度)ペアを正確なフレームインデックスを指定したJSONレコードとして確定させることです。これにより、データの取り込みと評価が分離されます。すべての手法が同一の入力を受け取るため、AbsRel、AUC@30、ATE、F-scoreはすべての実行および論文間で直接比較可能です。
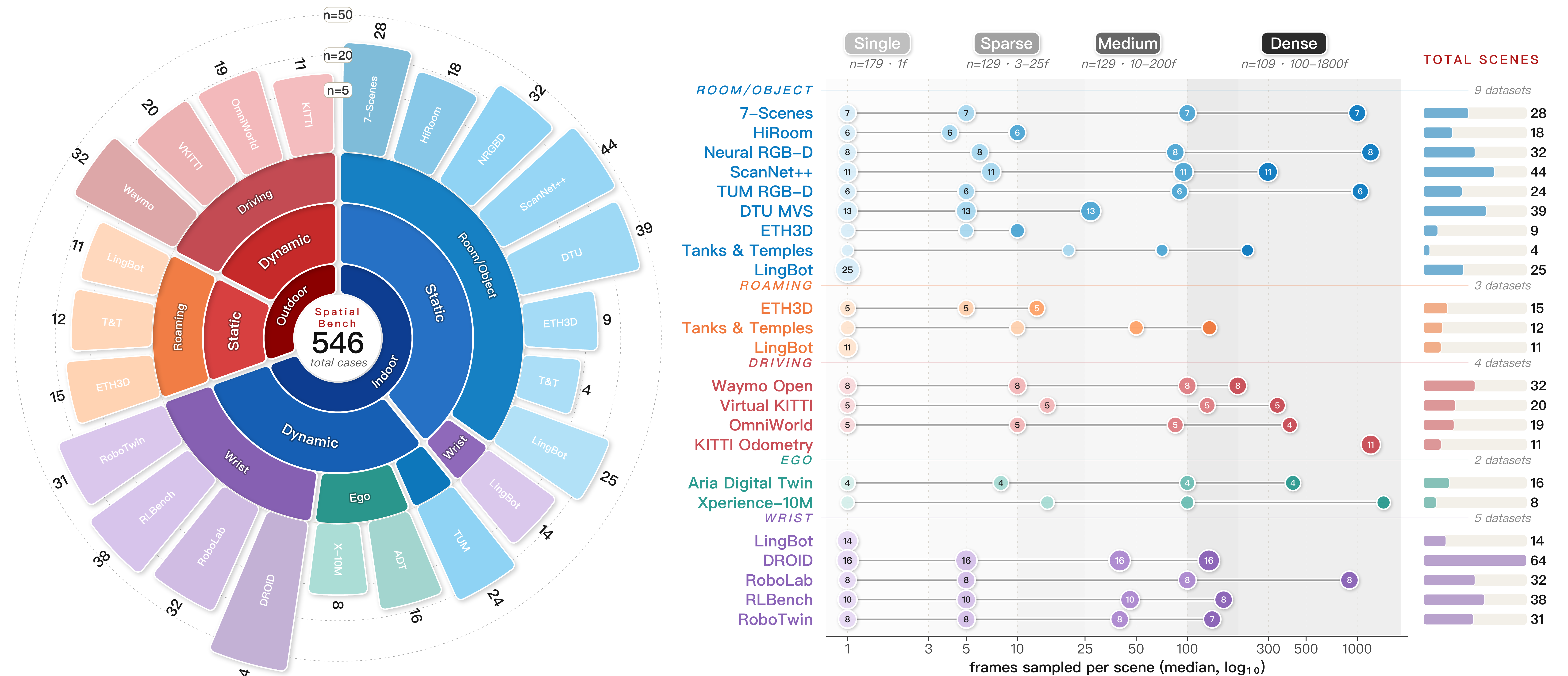
19のデータソースは、環境(室内/屋外)、動的性(静的/動的)、視点(通常/egocentric/wrist)、起源(実世界/合成)という4軸の分類体系にまたがっています。静的・実世界データは7-Scenes、DTU、NRGBD、ScanNet++、Tanks & Temples、ETH3Dから取得されており、動的・実世界データはTUM-Dynamic、DROID、Xperience、Waymo、KITTI-Odometryから、動的・合成データはADT、RLBench/Colosseum、RoboTwin、Robolab、Virtual KITTI 2、OmniWorld-Gameから取得されています。密度レジームはsingle-frame、sparse、medium、denseの4種類が報告されており、denseレジームでは大半の大型transformerでOOM(>140 GB)またはタイムアウト(>4時間/シーン)が発生します。
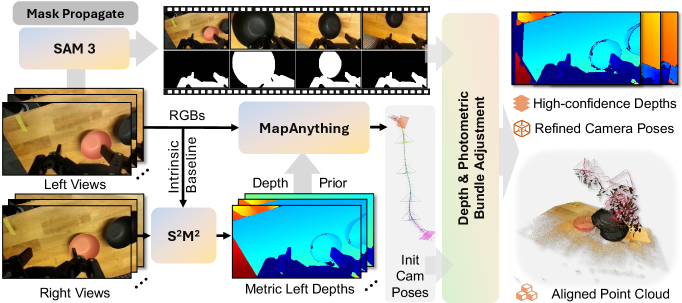
DROIDは、クリーンな真値ジオメトリを欠くwristビューのロボットデータセットですが、専用パイプラインで再構築されています。具体的には、信頼度フィルタリング付きの S^2M^2 によるステレオ深度、MapAnythingによる初期姿勢、SAM3によるグリッパー/接触マスク、そしてマスク済みRGBに対して姿勢を精緻化するbundle adjustmentが使用されています。
Depth-Anything-NextとDA-Next-5M
このbenchmarkにより明確なギャップが明らかになりました。既存のSFMsはegocentric・wristビューに対して低い性能を示しており、これらはembodiedアプリケーションで支配的であり、超近距離撮影、重いオクルージョン、積極的なego-motionを特徴としています。これを補うために、著者らはDA-Next-5Mをリリースしました。これは22Kシーンにわたる550万フレームからなり、主にegocentric/wristビューを含み、メトリック深度、内部パラメータ、外部パラメータを伴っています。シミュレーション部分は、背景、物体のスケール、色、wristカメラの配置にわたるdomain randomizationを使用しています。

Depth-Anything-Next(DA-Next)はこのコーパスで学習され(アーキテクチャの詳細は論文に委ねられています)、同一の評価ハーネスに統合されています。
結果
表1は、4つの密度レジームにわたるAbsRel(深度)、AUC@30(姿勢)、ATE(軌跡)、F-score(ジオメトリ)を報告しています。注目すべき数値を以下に示します。
- Single-frame AbsRel: DA-Nextは0.166を達成し、次点のend-to-end feed-forwardエントリと比べて54.9%の削減を実現しています。VGGTは0.184、FastVGGTは0.183、OmniVGGTは0.188、DA3ファミリーは0.333〜0.385の範囲、最適化ベースのDUSt3R/MASt3Rは0.385/0.456です。
- Sparse AbsRel: DA-Next 0.050(相対値−47.4%)、VGGT-Omega 0.077、\pi^3-X 0.084、AMB3R 0.088、\pi^3 0.092、DA3-Giant 0.095。SparseでのAUC@30:DA-Next 0.809、VGGT-Omega 0.803、DA3-Giant 0.785、DA3-Nested 0.779、\pi^3 0.742。
- Medium AbsRel: DA-Next 0.035(−59.3%)、VGGT-Omega 0.067、\pi^3-X 0.078、\pi^3 0.082、AMB3R 0.085。DA-NextのATE 1.442は最良値(\pi^3-Xの0.369)より+24.2%悪く、深度と姿勢のトレードオフを示しています。このモデルはメトリック深度に強く最適化されているものの、カメラ姿勢ヘッドはジオメトリ中心のアーキテクチャに及んでいません。
- Denseレジーム: 1 GBを超えるほぼすべてのtransformer(VGGT、MapAnything、OmniVGGT、\pi^3-X、AMB3R、DA3-Large/Giant/Nested、DA-Next)は>140 GBでOOMになります。生き残るのは、Fast3R、FastVGGT、\pi^3、DA3-Small/Base、およびstreaming/onlineメソッド(Spann3r、CUT3R、Point3R、Stream3R、StreamVGGT)のみです。denseでの生存者のうち、FastVGGTはAbsRel 0.130 / AUC@30 0.627 / ATE 9.984 / F 0.527を達成し、\pi^3は0.190 / 0.672 / 8.478 / 0.491を記録しています。
- レイテンシ(sparse、シーケンスあたり):MapAnythingおよびOmniVGGT 0.22秒、\pi^3 0.20秒、FastVGGT 0.24秒、VGGT 0.40秒、DA-Next 0.50秒、MonST3R 20.81秒。
Onlineメソッド(Spann3r、CUT3R、MonST3R、Point3R、Stream3R、StreamVGGT)はdense入力にクリーンにスケールできる唯一の手法ですが、精度面で大きなコストを払っています。例えばCUT3RはAbsRel平均0.223に対し、DA-Next sparseは0.050です。
制限と未解決の問題
このbenchmarkは「オールラウンド」を変化する密度とドメインのもとでの高いパフォーマンスと同一視していますが、現状のdenseレジームは方法論的な問いというよりも、メモリ競争の様相を呈しています。ほとんどのSOTAモデルは単純に実行できないため、denseリーダーボードは推論品質よりもアーキテクチャのコンパクトさを優遇する結果となっています。\pi^3-XとのDA-Nextの姿勢/ATE回帰は、学習データの混合が多視点的なジオメトリ整合性を犠牲にして深度に向けた表現を偏らせていることを示唆しています。SpatialBenchはまた、DROIDの S^2M^2 + BAの疑似真値に依存しており、これがwristビュー深度評価の忠実度に上限を設けています。最後に、41モデルが評価されていますが、プロトコルは再構築と姿勢のみをカバーしており、プランニング、マニピュレーション成功率、novel-view synthesis品質などの下流タスクはスコープ外です。
この研究の意義
決定論的かつクロスパラダイムの評価により、現在のSFMsの中に一様に最良のものは存在しないことが明らかになりました。小型モデルはdense入力にスケールできるが精度で劣り、大型transformerはmedium密度を超えるとOOMになり、深度が強いモデルは姿勢が弱い可能性があります。SpatialBenchとDA-Next-5Mは、embodied 3D知覚のための固定された評価基準と、不足していたデータレジーム(egocentric/wrist)をこの分野に提供します。
Source: https://arxiv.org/abs/2605.27367
MiniMax-M2シリーズ:最小の活性化パラメータで最大の実世界知性を解き放つ
MiniMax-M2は、静的なQAではなく長時間エージェント的デプロイを明確な設計目標とするsparse MoEファミリーです。フラッグシップモデルは総パラメータ数229.9B、トークンあたりの活性化パラメータ数9.8Bであり、設計上の主張は、小さな活性化フットプリントに加え、エージェントネイティブなデータパイプラインとツール使用軌跡向けに調整されたRLシステムを組み合わせることで、本番環境で実際に重要な作業負荷(コーディングエージェント、ディープサーチ、オフィス業務自動化)において密なフロンティアモデルに匹敵できるというものです。
アーキテクチャ
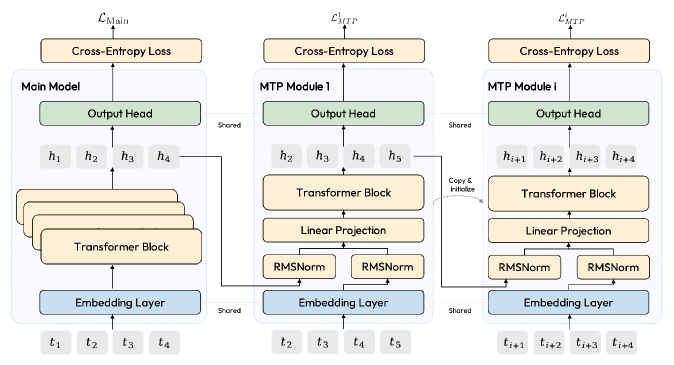
M2は62層のデコーダーのみのTransformerであり、隠れ次元3,072、語彙サイズ200,064トークンです。Attentionは48クエリヘッドと8 KVヘッドを持つGQA、全層にわたるfull attention、およびRoPEを採用しており、チームはスケール時のfull attentionを優先してMiniMax-Text-01のhybrid(linear/softmax)attentionを明示的に廃棄しています。MoE FFNは256個の細粒度expertを持ち、トークンあたり8個が活性化され、学習可能なexpertバイアスを伴うsigmoid gatingと、Wang et al. 2024に倣った補助loss不使用の負荷分散スキームを採用しています。Multi-Token Predictionヘッドはnext-token predictionと並行して学習され、後にweight copyingで拡張されることでマルチステップspeculative decodingをサポートします。
事前学習は29.2Tトークンを使用し、コード・数学・STEMのデータをアップサンプリングしています。コンテキストはステージごとに 8K \to 32K \to 192K と拡張され、短文のdecayデータ・自然に長いPDF・連結されたコード・テーマ別にパックされた文書を混合した9.3Tトークンのdecayフェーズを経ます。
エージェント的データパイプライン
post-trainingコーパスは、3つのコーディング領域(SWE、AppDev、ターミナル)とcoworkタスクにおける検証可能なエージェント的軌跡を中心に構築されています。SWEパイプラインはパーミッシブライセンスのGitHub PRをマイニングし、エージェント駆動のループを実行してPRごとのDocker環境を合成します。これは、ツールチェーンの協調が脆弱なコンパイル言語(Java/Go/Rust/C++)において特に重要です。PRはインテント(バグ修正・機能追加・リファクタリング・パフォーマンス・テスト)によってタグ付けされ、異なる報酬関数を適用できるようになっています。
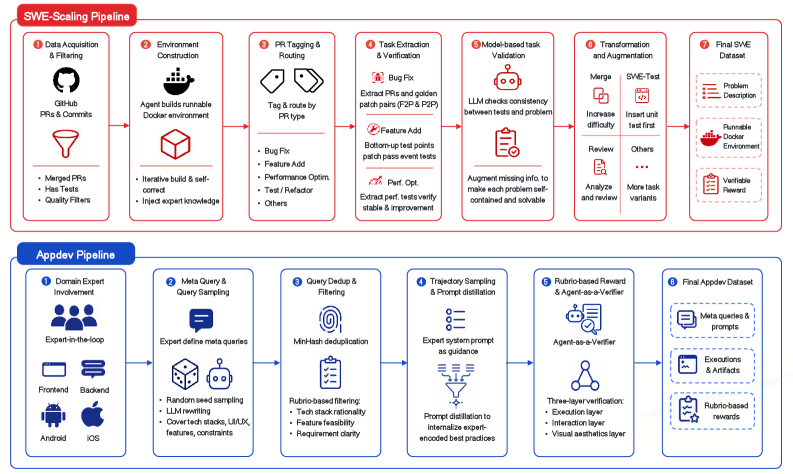
バグ修正の場合、有効性はgolden patchがFail-to-Pass(F2P)テストとPass-to-Pass(P2P)テストの両方を満たすことを要件とし、モデルエージェントはそれを再現しなければならず、P2Pは回帰を防ぎます。新しいコードを参照する新しいテストを伴う機能追加の場合、パイプラインはF2P/P2Pから実行可能な成果物の等価性評価へとシフトします。
インターリーブされた思考とRL
軌跡は以下のインターリーブされたシーケンスとしてモデル化されます:
\tau = (r_1, a_1, o_1, r_2, a_2, o_2, \ldots, r_T, a_T, o_T)
ここで各推論ブロック r_t は全過去履歴を条件としています。重要な点として、ターン t+1 で履歴に保持されるアシスタントメッセージはthinkingブロックを保持します:
\mathcal{H}_{t+1} = \mathcal{H}_t \oplus [\mathrm{assistant}(r_t, a_t)] \oplus [\mathrm{tool}(o_t)],
一方、\mathcal{H}_{t+1}^{(\text{drop})} = \mathcal{H}_t \oplus [\mathrm{assistant}(a_t)] \oplus [\mathrm{tool}(o_t)] というdropバリアントはターンごとに状態の再導出を強います。アブレーション実験により、持続性は期待される場所で最大の改善をもたらすことが示されており――マルチステップのディープサーチとSWEにおいて――Plan–Act–Reflectフレーミングと一致しています。
RLシステムであるForgeは、LLMをポリシーとして扱い、コンテキスト管理・メモリ・状態遷移を環境に外部化します。プロダクションエンジニアリング上の特筆事項として、可変長エージェントロールアウトのためのwindowed-FIFOスケジューリング、分岐した軌跡間でKVを共有するためのprefix-treeマージ、そして同一のトレーナーがwhite-box(logitレベル)とblack-box(APIのみ)の両エージェントを駆動できるよう訓練・推論・エージェントプロセスを厳密に分離することが挙げられています。SFTデータはドメイン報酬に対する大規模rejection samplingによって構築され、チャット・推論・コード・coworkにおけるインターリーブされた思考トレースを生成します。
評価
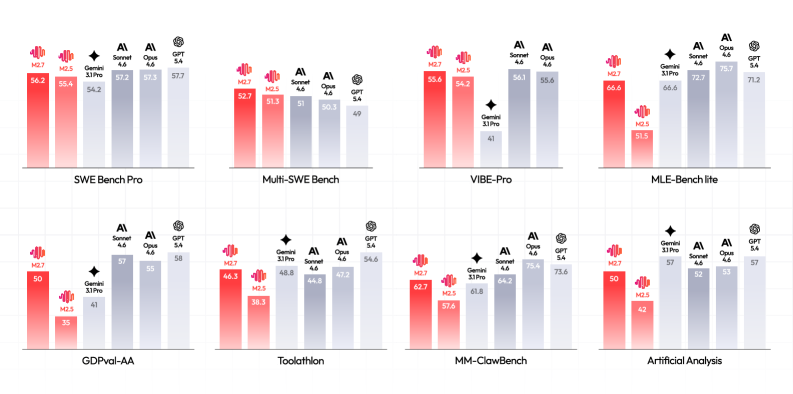
M2.7は、最大推論設定でClaude Opus 4.6、Claude Sonnet 4.6、GPT 5.4、Gemini 3.1 Proと比較評価されています。評価スイートは意図的に環境根拠型ベンチマークに偏っています:コーディングではSWE-bench Pro、SWE-bench Multilingual、Multi-SWE-bench、NL2Repo、Terminal-Bench 2.0、MLE Bench Lite;アプリ開発ではVIBE-ProとHyperTask;ディープリサーチではBrowseComp、Wide Search、RISE;オフィス業務ではGDPval-AA、Toolathlon、MEWC v2、Finance Modeling Pro;推論と知識ではAIME 2026、GPQA-Diamond、SciCode、IFBench、AA-LCR、HLE、MMLU-Proです。コーディングエージェントはClaude Codeスキャフォールド(GPT 5.4にはCodeX)を共有し、4試行の平均を取ります;Terminal-BenchはTerminus-2の下で2時間の実時間制限付き8 vCPU / 16 GBサンドボックスで実行されます。活性化パラメータ約10Bで、M2.7はこれらのブロック全体にわたってフロンティアのクローズドウェイトシステムに追随しており(図1)、M2.5からM2.7へのシリーズ内ギャップは最新のデータとRLイテレーションの貢献を分離するものとして報告されています。
限界と未解決の問題
本論文はいくつかの内部ベンチマーク(NL2Repo、VIBE-Pro、HyperTask、MM Claw、MEWC v2、Finance Modeling Pro、RISE)を前面に出しており、cowork主張の外部再現性が制限されています。M2.7における自己進化――訓練実行を自律的にデバッグし自身のスキャフォールドを編集すること――は、孤立したアブレーションを伴う測定された能力としてではなく、初期段階のステップとして提示されています。192KでのFull attentionを優先したhybrid attentionの廃棄は経験的に正当化されているものの、同等の計算量でのlinear-attentionベースラインとの比較分析は行われていません。最後に、活性化パラメータ数の見出し(9.8B)はサービング費用を過小評価しています:総パラメータ229.9Bは依然としてメモリフットプリントとルーティングオーバーヘッドを支配しています。
なぜこれが重要か
独立した再現実験においても数値が保たれるならば、M2はフルスタック――データパイプライン・インターリーブされた思考SFT・軌跡認識型RLシステム――がツール使用のために共同設計された場合、エージェントグレードのフロンティア能力が活性化パラメータ約10Bで達成可能であることを実証します。これは、デプロイ可能なエージェントのコストフロンティアを生のパラメータ数から環境とロールアウトインフラストラクチャへと再定義するものです。
Source: https://arxiv.org/abs/2605.26494
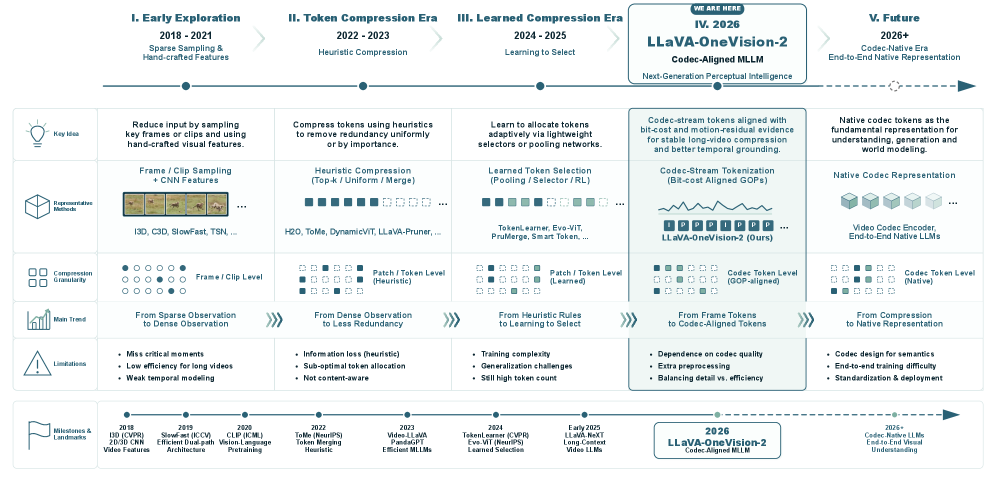
LLaVA-OneVision-2: 次世代知覚知能に向けて
問題
フレームサンプリング方式の動画MLLMは、経過時間(wall-clock time)に基づいて観測バジェットを割り当てます。この方式は、コンテンツが大部分において静的な場合には無駄が多く、識別に重要な証拠がサブ秒単位のイベント境界に存在する場合(時間的グラウンディング、細粒度の動作分類、繰り返しサイクルのカウントなど)には致命的な問題をもたらします。一様なGoP方式のサンプリングはすべての時間スロットを等しく情報量があるものとして扱いますが、実際には圧縮ビットストリームが、新規性(ひいては意味的なイベントコンテンツ)がどこに存在するかについての強い事前分布をすでに符号化しています。LLaVA-OneVision-2(LLaVA-OV-2)は、この信号を中心に動画トークン化ステップを再構成します。
手法
このモデルは、ネイティブ解像度処理のためのウィンドウattentionを備えたOneVision-Encoderバックボーン、軽量なVLコネクタ、および自己回帰型LMデコーダで構成される8Bクラスのビジョン言語モデル(VLM)です。codec-stream動画・一様サンプリング動画・静止画像という3つの入力モードが、単一のvisual-tokenインターフェースにマッピングされます。共有された3D RoPEがI/Pキャンバス、サンプリングフレーム、および画像トークンを1つの時空間座標系に配置し、group-visible attention maskによってどのトークンがどのトークンを参照するかを定義します(サンプリングフレーム/IPPPに対しては固定4スロットグループ、画像に対しては単一時間グループ、codec streamに対してはビットコスト適応型GoP ID)。
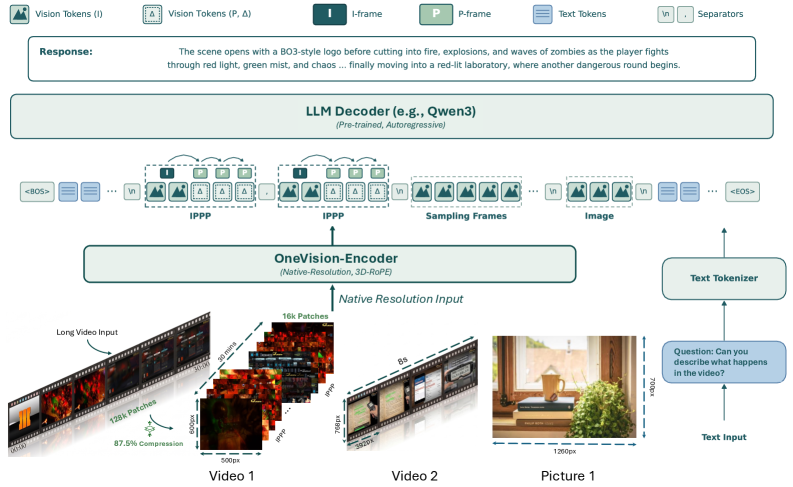
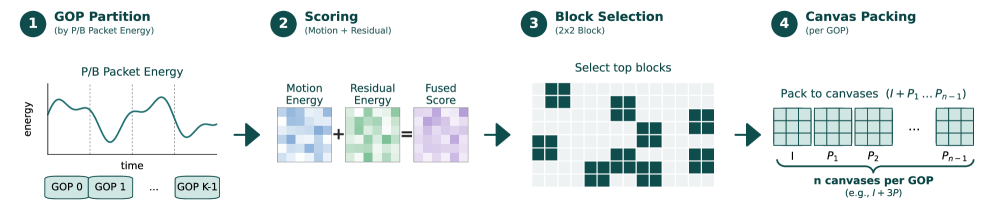
中心的な貢献はcodec-streamトークン化です。RGBにデコードして固定レートフレームをサンプリングする代わりに、モデルは圧縮ビットストリームを直接入力として受け取ります。
- ビットコストに基づく適応的GoP。 P/Bパケットのビットコストを用いてストリームを可変長GoP(Group of Pictures)に分割します。codecが予測コストを高く見積もった区間、すなわち新規性の高い区間は、それ自体のGoP境界を持ち、イベントを含むコンテンツにトークンを集中させます。
- 動き残差による空間的顕著性。 各GoP内で、動きベクトルと残差エネルギーが共同で 2{\times}2 パッチブロックをスコアリングします。高スコアのブロックが選択され、コンパクトなビジュアルキャンバスにパッキングされます:GoP毎に1つのアンカーI-キャンバスと、動き残差の証拠を持つ複数のP-キャンバスで構成されます。
- グループアライメントされたトークン。 各キャンバスのトークンはGoP IDを継承し、group-visible maskによってP-キャンバスはそのアンカーI-キャンバスを参照できます。これはcodecの依存構造を模倣しています。
学習はLLaVA-OneVision-1.5-8Bから初期化された4段階の漸進的レシピを使用し、各バッチにcodec-patchified動画を約50%、一様チャンクワイズ動画を約37.5%、画像を約12.5%の割合でインターリーブします。コーパスには、継承された8500万の画像テキスト中間学習セットと2200万の指示セット、FineVision(約2400万)、新たに公開された30s-Video-Caption-4.2M、800万クリップ/1041億トークンの再キャプション付き動画事前学習混合データセット、および3Dシーン・指差し・参照表現を対象とした400万サンプルの空間コーパスが含まれます。
結果
8Bクラスのベースライン(Qwen3-VL-8B、Keye-VL-1.5-8B、InternVL-3.5-8B、PLM-8B、LLaVA-OV-1.5-8B)との18タスクの動画平均において、LLaVA-OV-2はQwen3-VLの58.2に対して62.5を達成しました。差別化はcodec-streamトークン化が貢献するはずの箇所に集中しています。
- JumpScore(本論文が新たに提案した細粒度サイクルローカライゼーションベンチマーク。十分の一秒単位のサイクル開始ラベルを持つ189本の縄跳びクリップで構成):74.9(対Qwen3-VL 30.1、Keye-VL-1.5 39.6、InternVL-3.5 11.0、LLaVA-OV-1.5 2.1)。
- 時間的グラウンディング:t/Charades 53.5、t/ActivityNet 53.8、t/QVHighlights 66.4 — いずれも5〜35ポイント差でベストクラスを達成。
- トラッキング(J&F平均、4つのRVOSタスク):48.0(対Qwen3-VL 32.4、他は9以下)。DAVIS J&Fは次点の41.3に対して58.7。
- 空間推論平均(11タスク):63.5(対次点58.2)。TraceSpatial-3D 31.0対8.0、CrossPoint 61.9対26.9と、ロングテール空間タスクにおいて大きなマージンを示しています。
- 画像/文書平均:79.7。Qwen3-VLの80.7に後れを取るものの、V*-Bench(85.9)でトップを記録。
codecのアブレーションはそのメカニズムを分離して示しています。バックボーン・プロンプト・フレームバジェットを固定した状態で、codec入力はJumpScoreを6つのバジェットにわたる平均で37.9から55.2へ引き上げ(+17.3の絶対値改善)、3ベンチマークの時間的グラウンディング平均を35.5から45.2へ引き上げました(+9.7)。一様サンプリングがイベント境界を最も見逃しやすい低フレームバジェット時において、改善が最大となります:Charades-STAの4フレームでは、codecは42.4対17.4(一様)、QVHighlightsの16フレームでは51.5対24.9。長尺QAにおけるデルタは小さく厳密な単調性もありません(VideoMME-L-sub +1.2、LVBench +1.7、VideoEval-Pro +2.6)。これはcodecトークン化が時間的精度のために意味理解をトレードオフしていないことを確認するものです。
限界
codec表現はエンコーダのビット割り当てポリシーに依存しています。再エンコード・低ビットレート・または動きベクトル統計が劣化したスクリーンキャプチャコンテンツでは、顕著性信号が低下する可能性があります。JumpScoreは視覚的に明確に定義された単一の動作プリミティブ(縄が足の後ろを通る動作)を対象として構築されており、複数プリミティブの循環運動や非剛体の周期的イベントへの汎化は未検証です。画像/文書平均ではQwen3-VLに後れを取っており、codec/一様混合バッチの構成が高解像度文書モデリングを若干希薄化させている可能性を示唆しています。最後に、本論文では精度を揃えた条件下でのwall-clock時間やトークン数の効率を報告しておらず、「安定した長尺動画トークン圧縮」に関する計算コストの説明は不完全です。
意義
圧縮動画をデコードして再サンプリングするのではなく、ネイティブ入力として扱うことで、visual tokenバジェットをcodec自身の新規性推定と整合させることができます。イベントローカライズタスクにおける実験的な改善(JumpScore +17.3、QVHighlights@16 +26.6)は、フレームバジェットのスケーリングによって得られるものを上回っています。これは、データパイプラインにすでに存在する構造を活用することが、ブルートフォースのフレーム密度増加を上回る性能をもたらすという具体的な事例です。
Source: https://arxiv.org/abs/2605.25979
MobileMoE: オンデバイス Mixture of Experts のスケーリング
問題設定
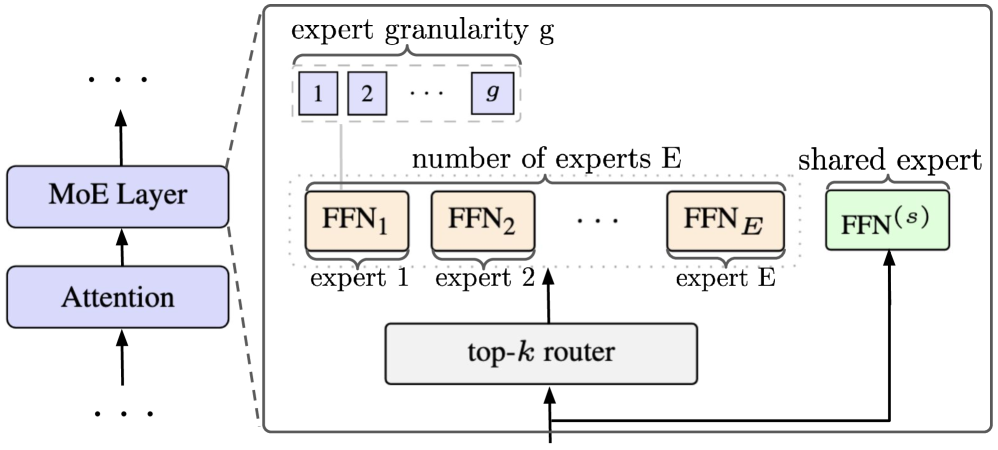
MoE はフロンティア規模の LM を席巻していますが、オンデバイス展開が主戦場となるアクティブパラメータ数 1B 未満の領域ではほとんど存在感がありません。大規模向けの経験則(DeepSeek-V3 の 256 experts top-8、Qwen3-MoE の 128 experts top-8、Mixtral の 8 experts top-2)は、モバイル DRAM(INT4 で約 5 GB 使用可能)とトークンあたりの計算量予算が学習 FLOP 最適性を上回る十億パラメータ未満の領域では何の指針も与えてくれません。MobileMoE が問いかけるのは、そのような制約のもとで (E, k, g, s) はメモリと計算量の両面において最適であるか、そして得られたモデルが同一 FLOPs でオンデバイスの強力な dense ベースラインを上回れるかという点です。
設計空間とベースバックボーン
MoE 層は次のようにパラメータ化されます。
\mathbf{y} = \sum_{i \in \text{Top-}gk} \text{router}_i(\mathbf{x}) \cdot \text{FFN}_i(\mathbf{x}) + \text{FFN}^{(s)}(\mathbf{x})
調整可能な要素は三つあります。スパース性 (E,k)、粒度 g(各 expert を幅 d_{\text{ff}}/g の g 個のサブ expert に分割し、gE 個の中から gk 個をアクティブにする)、および常時オンの共有 expert s です。バックボーンはオンデバイス dense の慣行(MobileLLM、MobileLLM-Pro)に従い、拡張率 d_{\text{ff}}/d_{\text{model}}=4、アスペクト比 d_{\text{model}}/n_l \approx 40(深く細い構造)、4 KV ヘッドの GQA、SwiGLU を採用しています。S(768/3072/20L、0.3B アクティブ)、M(1024/4096/26L、0.5B)、L(1280/5120/32L、0.9B)の三つのスケールで E \in \{1,2,4,8,16,32\}、g \in \{1,2,4,8,16\}、s \in \{\checkmark,\times\} を網羅的に探索しています。
オンデバイス スケーリング則
著者らは Chinchilla スタイルの法則を適合させており、(N_{\text{act}}, D) に変換済みの expert 数を加えています。
\frac{1}{\hat{E}} = \frac{1}{E - 1 + (\tfrac{1}{E_{\text{start}}} - \tfrac{1}{E_{\max}})^{-1}} + \frac{1}{E_{\max}},
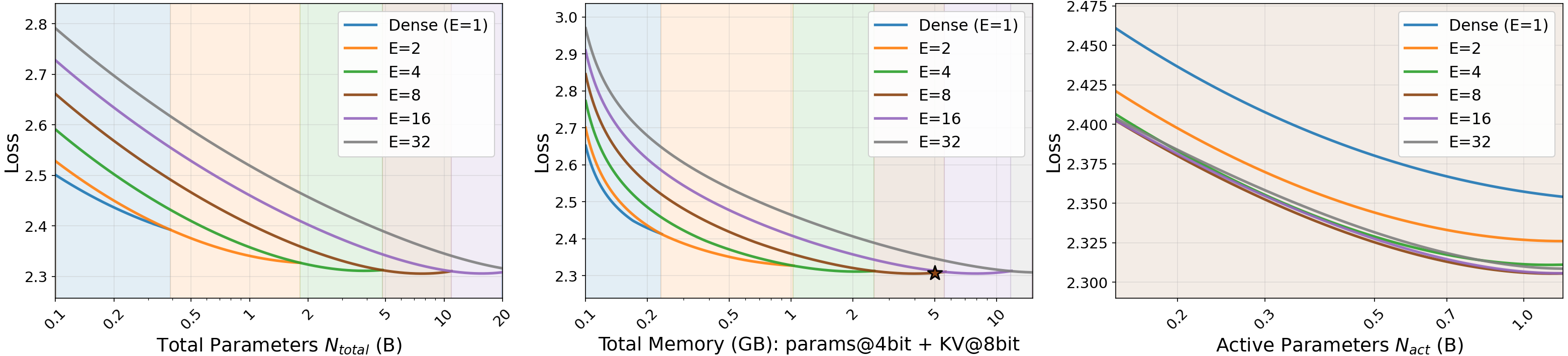
ここで E_{\text{start}}=1、E_{\max}=32 は N_{\text{act}} \in \{0.3, 0.5, 0.9\}B においてトータルパラメータ数が 5 GB INT4 モバイル DRAM 予算に収まるよう設定されています。フィッティングには curve_fit によるウォームスタートに続いて MSE に対する L-BFGS-B を使用し、アブレーションは最大約 500B トークンまで探索しています。以下の三つの知見が順次得られています(各ステップで直前の最適値を固定)。
- スパース性: E^\star = 8。固定 N_{\text{act}} のもとで loss は E の増加とともに減少しますが、トータルパラメータ数・メモリコストを考慮すると 8 を超えると改善が頭打ちになります。
- 粒度: g^\star = 8(すなわち 64 個の細粒度サブ expert、top-gk ルーティング)。
- 共有 expert: s = \checkmark が有効です。
アクティブパラメータ数・トータルパラメータ数・オンデバイスメモリ \mathcal{M} に関する Pareto 図では、5\times 10^{20} FLOP の学習予算のもとで E=8 の曲線が膝の部分に位置しています。
学習レシピ
オープンデータ(Dolma3 + MobileLLM のキュレーション済みミックス;ウェブ 62%、数学 11.6%、コード 10%、知識 10%、科学 6.4%)を用いた四段階構成です。
- PT: 約 6T トークン、ctx 2048、バッチサイズ 2048/3072(S,M / L)、ピーク LR 4\times 10^{-4}、0.1 までの cosine 減衰、drop-and-pad ディスパッチ、16〜32 H100 ノードで 3〜4 週間。
- MT: 約 500B トークン、ctx 8192、4\times 10^{-5} からの線形減衰。
- SFT: 約 126B トークン、dropless ディスパッチ、4\times 10^{-6} から 0 への cosine 減衰。
- QAT: 約 21B トークン、INT4 重み(グループ 32)、INT8 アクティベーション、INT4 embedding。
AdamW (\beta_1, \beta_2, \epsilon) = (0.9, 0.95, 10^{-15})、weight decay 0.1、gradient クリップ 1.0、BF16 重みと FP32 ルーター・オプティマイザ・gradients を全体を通して使用しています。
結果
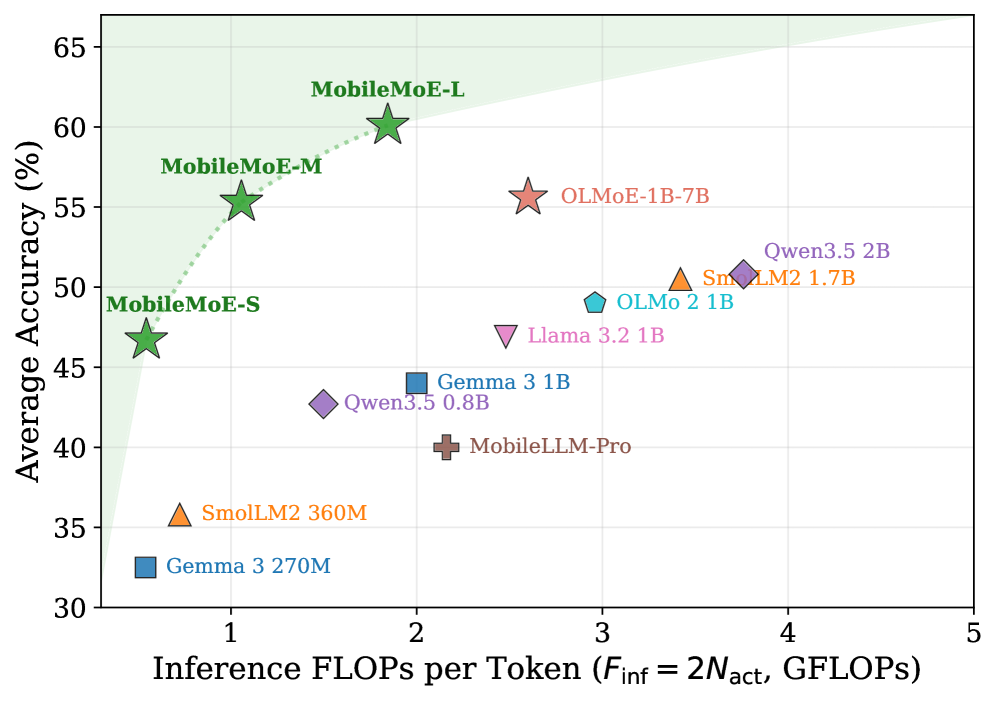
lm-eval による greedy decoding で評価した 14 の基礎ベンチマーク(HellaSwag、PIQA、SIQA、WinoGrande、MMLU、NQ、TriviaQA、ARC-C/E、OBQA、BoolQ、DROP、BBH、GSM8K)全体において、MobileMoE は主要な dense オンデバイス LLM(Gemma 3 270M/1B、SmolLM2 360M/1.7B、MobileLLM-Pro 1.1B、Llama 3.2 1B、OLMo 2 1B、Qwen3.5 0.8B/2B)に対して 2〜4× 少ない推論 FLOPs(F_{\text{inf}} = 2 N_{\text{act}})で同等以上の性能を達成し、OLMoE-1B-7B に対しては 最大 60% 少ないトータルパラメータ数で同等以上の性能を示しています。
学習後の expert 利用分析では、(i) タスク間の専門化——数学・コード・知識が 60 個の細粒度 expert の異なるサブセットをアクティブにすること——および (ii) PT → MT → SFT にかけての利用範囲の段階的な拡大が示されています。数学はコードや知識よりも広い expert セットをアクティブにしており、タスク条件付きの expert プリフェッチやプルーニングによってオンデバイスメモリをさらに削減できる可能性を示唆しています。
限界と未解決の問題
- スケーリング則のフィッティングでは E_{\max}=32 が 5 GB INT4 予算に紐付けられており、異なるメモリレジーム(例:8〜12 GB の高性能 NPU)では最適値がシフトする可能性がありますが、本論文ではそのフロンティアを特性評価していません。
- 探索は約 500B トークンまでに留まっており、最終モデルは約 6T トークンで学習されます。E^\star=8, g^\star=8 が 10 倍のデータ量でも最適であり続けるかは外挿であり、実測ではありません。
- 共有 expert とルーティング済み expert を組み合わせた場合の top-k および負荷分散 loss 係数については、抜粋中でアブレーションが行われていません。
- モバイル推論カーネルに関する主張(カスタム MoE カーネル、iPhone 16 Pro および Galaxy S25 への展開)は述べられていますが、実行時間の数値は提供されたセクションには含まれていません。
- INT4 重み / INT8 アクティベーション下でのルーティング:QAT は SFT 後に適用されますが、量子化に対する細粒度 expert の感度(粗粒度 expert との比較)は個別に特性評価されていません。
重要性
これは現実的なモバイルメモリと計算量制約のもとで MoE の設計選択を体系的に導出した初の研究であり、具体的な推奨——適度なスパース性(E=8)、高粒度(g=8)、共有 expert——に辿り着いており、精度を損なうことなく dense オンデバイスベースラインに対して 2〜4× の FLOP 削減を実現しています。推論カーネルの結果が実証されれば、十億パラメータ未満のアクティブ MoE はフロンティア専用のアーキテクチャではなく、オンデバイス LM のデフォルト選択肢として有力な候補となります。
Source: https://arxiv.org/abs/2605.27358
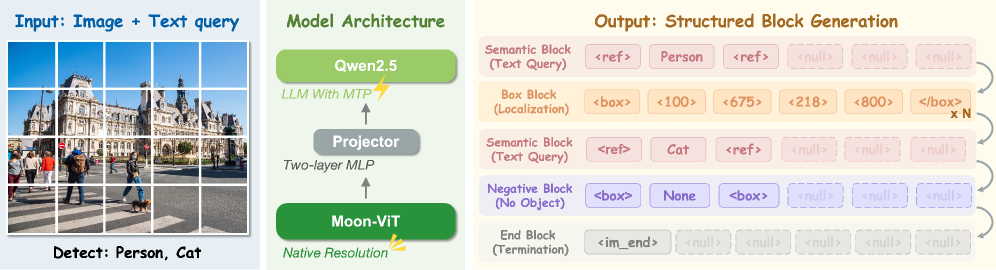
LocateAnything: Parallel Box DecodingによるFastかつ高品質なVision-Language Grounding
問題
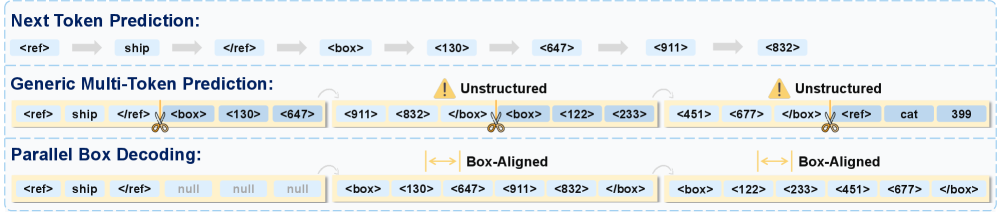
検出とgroundingを行う生成型VLMは、通常、各2次元ボックスを座標トークンのシーケンスとして(あるいはさらに悪い場合は桁ごとのテキストとして)シリアライズし、標準的なnext-token prediction(NTP)でデコードします。これに伴い二つの問題が生じます。第一に、ボックスを定義する4つの数値は幾何学的に結合されています(例:x_2 > x_1、アスペクト比の制約など)が、自己回帰的デコードはそれらを \prod_t P(c_t \mid c_{<t}) として因数分解するため、各座標をほぼ独立して学習し、誤差が蓄積されます。第二に、デコードのスループットはボックスあたりのトークン数とボックス数の積で制限されるため、密なシーン(LVIS、SKU110K)ではこれが支配的なコストになります。既存のmulti-token prediction(MTP)headは複数のトークンを一度にデコードしますが、ボックスのブロック構造を無視するため、幾何学的に一貫性のない出力を生成します。
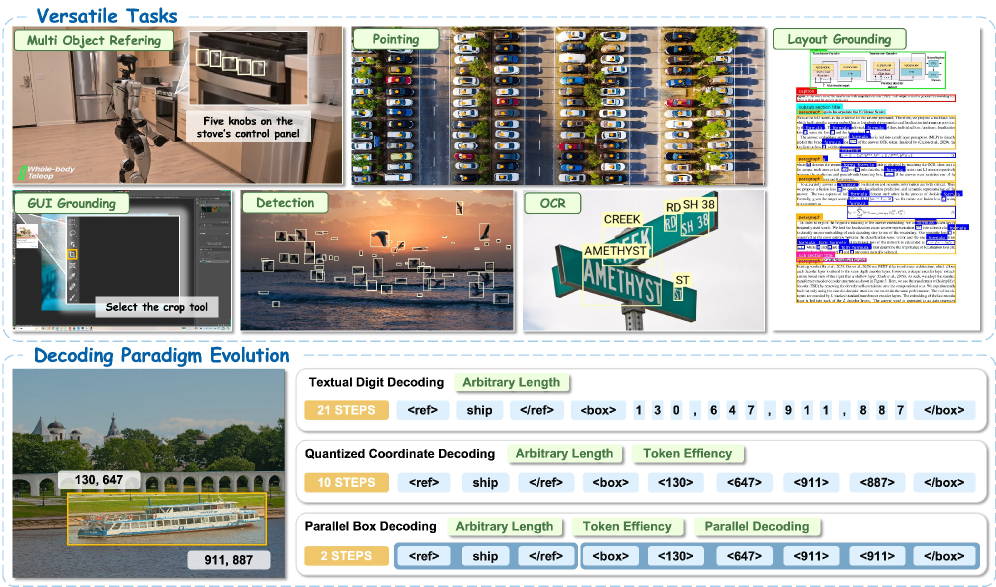
手法
LocateAnythingは標準的なVLMバックボーン — Moon-ViT vision encoder、MLP projector、Qwen2.5 LM — をネイティブ解像度で動作させつつ、座標トークンのNTPをParallel Box Decoding(PBD)による固定長ブロックに置き換えます。
ブロックベースの出力。 座標は [0, 1000] に正規化され、離散トークンに量子化されます(Pix2Seq/Rex-Omni方式)。出力は定長 L=6(4つの座標スロットに加え <box>/</box> 構造トークン、<null> によるパディング)のブロック列 \mathbf{B}=(b_1,\dots,b_N) に再編成されます。因数分解は
P(\mathbf{B}\mid \mathcal{Z},\mathcal{E})=\prod_{i=1}^{N}P(b_i \mid b_{<i},\mathcal{Z},\mathcal{E}),
となり、各 b_i はアトミックに予測されます — 6つのポジション全てがシーケンシャルにではなく、単一のforward stepでデコードされます。4種類のブロック型が小さな文法を形成します:Semanticブロック(言語的識別子、長い場合は複数ブロック)、Boxブロック(4つの量子化座標)、Negativeブロック(物体が存在しない場合)、Endブロック(終了)。
汎用MTPとの主要な相違点は、parallel headが幾何学的単位に整合していることです。k 個の将来トークンを予測する汎用MTPはボックスの境界を無視し、異なるオブジェクトにまたがるデコードチャンクを生成することで、図2に示すような不規則なパターンをもたらします。PBDはparallel slotを単一のボックスに制約するため、ボックス内の依存関係(4つの角点)は結合的にモデル化され、ボックス間の依存関係はブロックレベルで自己回帰的に保たれます。
学習。 検出/grounding データを含まない世界知識コーパスで最初にalignされたベースVLMの上で、2段階のSFTを実施します。Stage-1は精選されたデータセット(LocateAnything-Data)から1億3800万件のgrounding/detectionクエリを混合します。Stage-2は汎用データを20%に削減し、高IoU性能を向上させるために密オブジェクトのソース(MOT20Det、SKU110K)を重み付けします。学習目的は、semantic/制御トークンに対するNTPとboxブロックに対するブロックレベルMTPを組み合わせており、モデルは前のブロックを条件として4つの座標を並列に出力することを学習します。
推論。 ハイブリッドモードにより、完全並列ブロックデコード(最大スループット)とトークン単位デコード(最大ロバスト性)をオンデマンドで切り替えることができ、下流のキャリブレーションや制約付きデコードが必要な場合に有用です。
PBDのアーキテクチャ的貢献とデータスケールの貢献を分離するアブレーションのために、著者らはCOCOのみで再学習を行っています。
結果
LVIS(ゼロショット)およびCOCOにおいて、LocateAnything-3Bは以下の結果を報告しています:
- スループット(BPS、boxes/sec、MiMo-VL-7B = 1.0に正規化): 12.7(Rex-Omni-3Bの5.0、Qwen3-VL-4B/8B・OVIS2.5-2B・MiMo-VL-7B・Cosmos-Reason2-8Bのおよそ1.0〜1.3に対して)。最も近いVLM groundingスペシャリストの約2.5倍、標準VLMの約10倍。
- LVIS F1@IoU: 0.5 = 62.3、0.95 = 31.1、mean = 50.7。Rex-Omni-3B:64.3 / 20.7 / 46.9。SEED1.5-VL:65.6 / 19.5 / 46.7。本モデルは緩い閾値0.5では約2〜3ポイント劣るものの、IoU 0.95では約10ポイント上回っており、PBDの結合的な角点予測がボックスの幾何学的精度を向上させていることを示唆しています。
- COCO F1@IoU: 0.5 = 70.1、0.95 = 19.3、mean = 54.7。DINO-R50(mean 55.6)を上回り、はるかに重いDINO-Swin-Lのmean F1トレンドに匹敵しつつ、生成型のopen-vocabulary VLMであり続けます。IoU 0.95においてRex-Omni-3B(15.9)を上回り、Grounding DINO-Swin-T(23.0 — 特化型検出器として依然優れているが)にも迫ります。
両ベンチマークにわたるパターンは一貫しています:PBDは緩いIoUでの小さなrecallの低下と引き換えに、厳格なIoUで実質的な改善を達成し、2.5〜10倍のデコードスループットを実現します。
限界と未解決の問題
- 報告されているBPSは選択されたベースラインに対する相対的なスループットであり、絶対レイテンシ、バッチ効果、密な画像上のprefillコストは個別に示されていません。
- ブロック長は L=6 に固定されています。ポリゴンセグメンテーション、回転ボックス、3Dボックスなどのタスクでは異なる L が必要であり、アトミック単位が大きくなったり可変になったりした場合にPBDがどのようにスケールするかは論文に示されていません。
- 主要な数値については、1億3800万サンプルのデータエンジンがアーキテクチャとデータの貢献を混同しており、PBDを分離するのはCOCOのみのアブレーションに限られますが、その詳細は抜粋中に示されていません。
- 4つの座標の結合分布は、b_{<i} が与えられた条件付き独立なparallel head出力によってモデル化されます;これはブロック内の真に結合的な因数分解(例:ブロック内での自己回帰)より弱いです。極端なアスペクト比やオクルージョンの場合にこれが悪影響を及ぼすかどうかは不明です。
- IoU 0.5における緩い閾値でのRex-Omni/SEED1.5-VLとの差は、PBDが粗いrecallでは性能が低下する可能性を示唆しており、recallを重視するアプリケーションにはこのトレードオフが適さない場合があります。
重要性
座標トークンのシリアライズは生成型groundingのデフォルトとなっていましたが、ボックスの幾何学に対する帰納バイアスとしては不適切であり、推論のボトルネックでもあります。並列デコード単位を幾何学的アトムに整合させることで、VLMのopen-vocabulary・instruction-followingの利点を損なうことなくスループットを回復し、高IoUのlocalizationを実際に改善します — これにより、生成型検出器は厳格な閾値において特化型closed-set検出器との競争力を高めることができます。
Source: https://arxiv.org/abs/2605.27365
MobileGym: モバイルGUIエージェント研究のための検証可能かつ高並列シミュレーションプラットフォーム
問題
モバイルGUIエージェント研究は、相互に関連する二つの欠陥によって停滞してきました。(i) 一般的なコンシューマ向けアプリにおける決定論的・プログラム的な結果検証の欠如(そのため評価はフリーテキストマッチングや人手によるレビューに依存せざるを得ない)、および(ii) 実機または完全なAndroidエミュレータ上での並列ロールアウト実行にかかる法外なコスト(これにより意味のある規模でのオンラインRLが阻まれている)、という二点です。既存のエミュレータベースのベンチマークはAndroid内部をスループットのコストで再現しており、既存の静的データセットはランタイムを完全に回避することでインタラクションの忠実性を失っています。MobileGymは第三の選択肢を提唱します。すなわち、モバイルアプリのインタラクション表面をブラウザホスト型シミュレータで忠実に再現しつつ、すべての環境状態をスナップショット・フォーク・差分計算が可能な構造化JSONとして保持するというアプローチです。
手法
本プラットフォームはレイヤー化された状態モデル(図3)を中心に構築されています。読み取り主体のWorld Dataレイヤー(カタログ、連絡先、コンテンツコーパスなど)、環境ごとのRuntime Overlay(変更可能なセッション状態、下書き、一時的なアプリ状態)、そしてAndroid的なメカニズム——タスクスタック、キーボード、通知、権限、インテント、コンテンツ共有、バックキーのディスパッチ——を実装するOS Runtimeから構成されています。
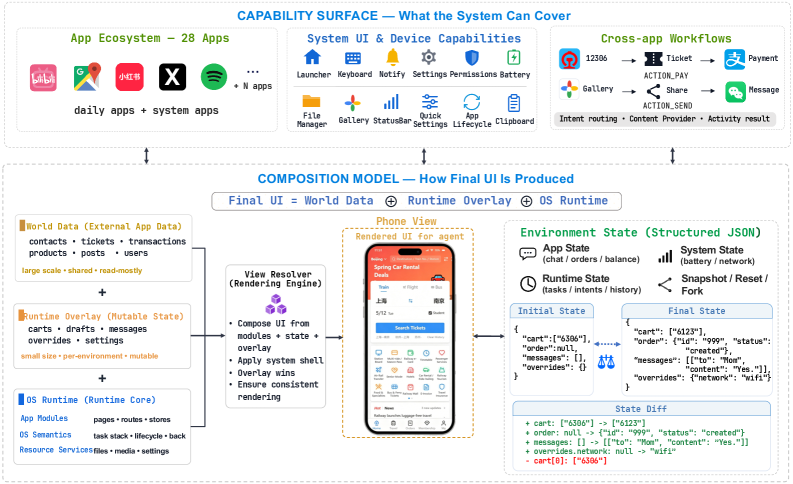
重要なのは、著者たちがピクセルレベルのAndroid忠実性やバックエンドの再現を目指していない点です。目標はエージェントから見えるインタラクション表面、すなわち視覚的なスクリーン、タッチ・タイピングの応答、ナビゲーション、クロスアプリの引き渡し、タスク関連の遷移です。これらすべてが構造化されたローカル状態の上でブラウザ内に実装されているため、環境全体が読み取り可能、書き込み可能、フォーク可能です。
これにより二つの運用上の特性が得られます。
- 状態差分による検証可能な結果。 タスクは、ロールアウト後のJSON状態を宣言的なゴール仕様と比較することで判定され、決定論的な判定結果とRLの報酬として利用可能な密な進捗シグナルを生成します。フリーテキストマッチングは構造化されたAnswerSheetプロトコルに置き換えられ、クエリスタイルのタスクにおける偽陰性の一般的な原因が排除されます。
- 高い並列性。 報告されているインスタンスごとのフットプリントはメモリ約400MB、コールドスタート約3秒であり、1サーバーあたり数百インスタンスを実行できます。JSON状態に対するスナップショット・リセット・フォーク操作により、ロールアウトの分岐が低コストで実現されます。
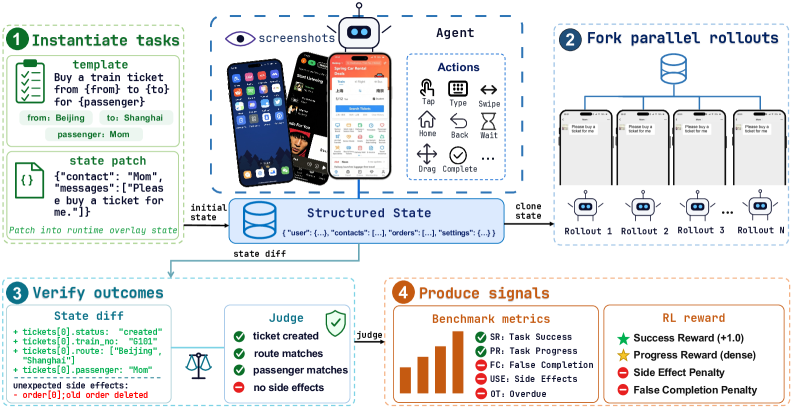
ベンチマーク層(MobileGym-Bench)はその上に構築されており、28アプリにわたる416のパラメータ化タスクテンプレート(テスト256、トレーニング160、厳密に非重複)を備えています。タスクは四つの直交軸に沿って分解されています。
- スコープ — S1(単一アプリ)、S2(2アプリ)、S3(\geq 3アプリ)。
- 目的 — operate(状態変更)、query(検索)、hybrid。
- 構成 — atomic、sequential、transfer(クロスアプリの引き渡し)、deep-dive(複数ステップのドリルダウン)。
- 難易度 — L1–L4、8つのリファレンスモデルに対して事後的にキャリブレーション。
各タスクには13タグの能力ボキャブラリから1〜4つのタグが付与されています。この直交分解が重要である理由は、以前の分類法(例:Mind2Webスタイル)ではアプリ数とサブタスク数が混在しており、軸ごとのアブレーションが不可能だったからです。
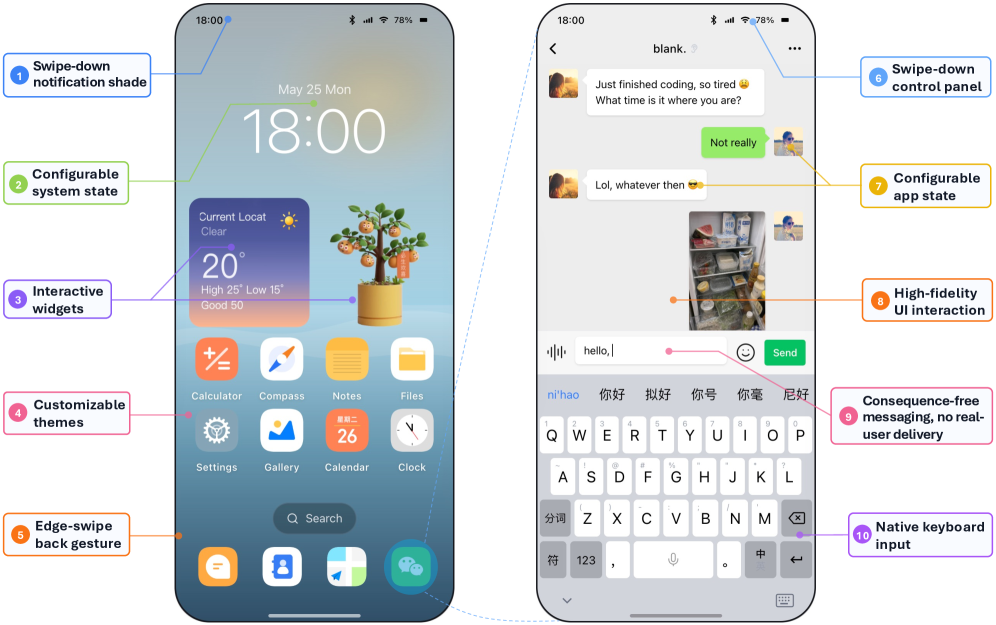
結果
256タスクのテストセットで9つのエージェントを評価しました。オープンソースモデルは4試行、プロプライエタリモデルは1試行(Gemini 3.1 Proは2試行)実施しました。主な数値は以下の通りです。
- 全体的なSR(成功率)の範囲:9.4%〜58.8%(6倍の開き)で、上位での飽和も下位での底打ちも見られません。
- Gemini 3.1 Pro:SR 58.8 ± 1.4 / PR 72.1;Doubao-Seed-2.0-Pro:52.0;Qwen3.6-Plus:45.7。
- オープンソースのGUIスペシャリストは低めに集中:AutoGLM-Phone-9B 20.0、UI-Venus-1.5-8B 15.4、GUI-Owl-1.5-8B-Think 15.1、UI-TARS-1.5-8B 13.8、Step-GUI-4B 12.9。汎用モデルのQwen3-VL-4B-Instructは9.4。
- 難易度の層別化は全9モデルで単調です。L1(n=20)ではすでにプロプライエタリとオープンソースが分離しており、3つのプロプライエタリモデルは97.5/100/100に対し、オープンソースは71.2〜86.2。L4(n=80)はフロンティアであり、Gemini 3.1 Proのみが21.9%を維持;次のプロプライエタリモデルは6.2%であり、すべてのオープンソースGUIスペシャリストは\leq 1.9%です。
- 診断は失敗を分解します:False Complete(FC)、Overdue Termination(OT)、Unexpected Side Effects(USE)。FCは全体的に高く(22.9〜39.6%)、モデルが状態差分ジャッジを満たさないまま頻繁に成功を宣言していることを示唆しており、これはフリーテキスト評価者には見えない失敗モードです。
Sim-to-Realのケーススタディでは、Qwen3-VL-4B-InstructへのGRPOが+12.8パーセントポイントの向上を報告しています(アブストラクトは文章途中で切れており、転移先の実機ベンチマークの詳細は不明ですが)、状態差分ジャッジからの報酬がシミュレータを超えて転移することが示されています。
制限とオープンクエスチョン
- 視覚的忠実性のギャップ。 UIはLLMが補助した再現であり、実際のアプリとはピクセルレベルの詳細が異なります。視覚的なグラウンディングタスクにおいてSim-to-Real転移にどの程度のコストがかかるかは、GRPOのケーススタディを超えては十分に定量化されていません。
- バックエンドのセマンティクスはシミュレートされたものであり、実際のものではありません。 ライブWebデータ、レコメンデーションフィード、またはサービス側のロジックに依存するタスクは忠実に表現できません。
- ジャッジのカバレッジ。 決定論的な状態差分判定は、ゴールが構造化状態スキーマで表現可能であることを前提としており、主観的または審美的な結果を持つタスクはこの契約の範囲外です。
- L4の天井。 ほとんどのモデルがL4でほぼゼロに近いスコアであるため、Gemini以外のクラスのシステムにとって、ベンチマークは現状フロンティアでほとんど勾配シグナルを提供していません。
- 能力タグの汎化。 13タグのボキャブラリとL1〜L4のキャリブレーションは8つのリファレンスモデルに基づいており、エージェントの能力が変化するにつれて再キャリブレーションが必要になります。
なぜこれが重要か
MobileGymは、エミュレータに縛られたロールアウトをフォーク可能なJSON状態に置き換え、フリーテキスト評価を決定論的な状態差分に置き換えることで、日常的なモバイルタスクにおけるオンラインRLを実現可能にします。この二つの欠けていたプリミティブこそが、GUIエージェントのトレーニングをオフライン軌跡に留め置いてきた根本的な原因でした。飽和なしに9つのモデル間でSRが6倍開いていることは、このベンチマークが次世代GUIエージェントの有用な識別器として機能し続けることを示唆しています。
Source: https://arxiv.org/abs/2605.26114
EvalVerse: プロフェッショナルな映像生成のためのパイプライン対応・専門家校正済みベンチマーキング
問題
現行の動画生成ベンチマーク(VBench、EvalCrafter、VADB、CineTechBench、UniVBench)は「出力は正しいか?」という観点、すなわちプロンプト追従性、基本的な時間的一貫性、単体の視覚品質を最適化の対象としており、「出力は優れた映画的表現か?」という観点はほとんど無視されています。美的・演出的・演技的・ポストプロダクション的な品質は、評価から抜け落ちているか、部分的にしかカバーされていません。foundation modelがネイティブ音声を伴うマルチショット・ナラティブ合成(Kling-v3-Omni、Seedance 2.0、HoloCine、LTX2)へと進化するにつれ、この評価ギャップは研究の進捗だけでなく、報酬シグナルの品質がポリシー品質を直接規定するRL/エージェント的なpost-trainingにおいてもボトルネックとなっています。EvalVerseは、評価を自動指標のチェックリストとしてではなく、主観的な映画的専門知識を体系的にデジタル化するプロセスとして扱うべきだと主張しています。
タクソノミーとデータセット
EvalVerseは、現在のモデルがエンド・ツー・エンドで合成を行うにもかかわらず、プロの映画制作ワークフローであるプリプロダクション・プロダクション・ポストプロダクションを軸に評価を体系化しています。このタクソノミーは、3つの制作ステージ、7つの映画的側面、18の主要次元、45のサブ次元、196の詳細な根拠(rationale)から構成されています。
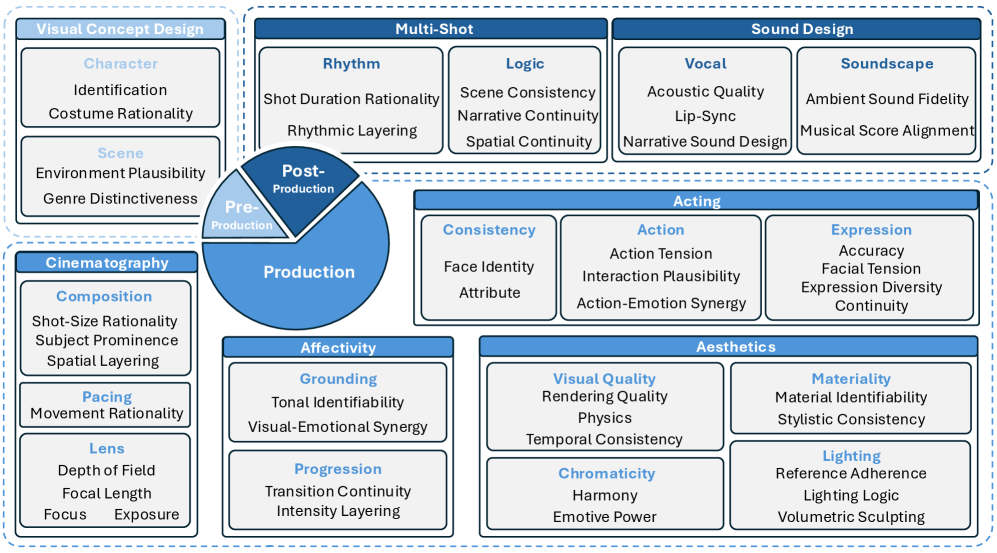
プリプロダクションでは「ビジュアルコンセプトデザイン」を評価します:キャラクター(識別可能性、衣装の合理性)とシーン(物理的・空間的論理に基づく環境の妥当性、スタイルの混在に対するジャンル識別性)。プロダクションは演技、撮影技法(構図、ペーシング、レンズ)、美的品質(視覚品質、色彩、照明、マテリアル性)、感情的喚起性(グラウンディング、プログレッション)に分かれます。ポストプロダクションはマルチショット(論理性、リズム)とサウンド(音声、サウンドスケープ)をカバーします。Table 2において先行する7つのベンチマークと比較すると、EvalVerseは列挙された14の次元すべてにわたって完全なカバレッジを持つ唯一のフレームワークです。
データエンジンは、プロの映画をキュレーションしたデータベースから「Real-to-Gen」テストペアを生成します。マルチモーダル知覚スイートが構造化されたメタデータ(カメラパラメータ、キャラクター属性、環境)を抽出し、続いて手動検証が行われます。サンプリングは確率的ではなく、9つの映画的次元にわたって比例的に行われます。Gemini 3.1 Proがメタデータと生のキャプションを映画的テストプロンプトに変換し、Nano Banana Proが被写体駆動(R2V)タスク向けの高忠実度参照画像を生成します。深度制御にはControlNetでfine-tuningされたモデルが使用されます。
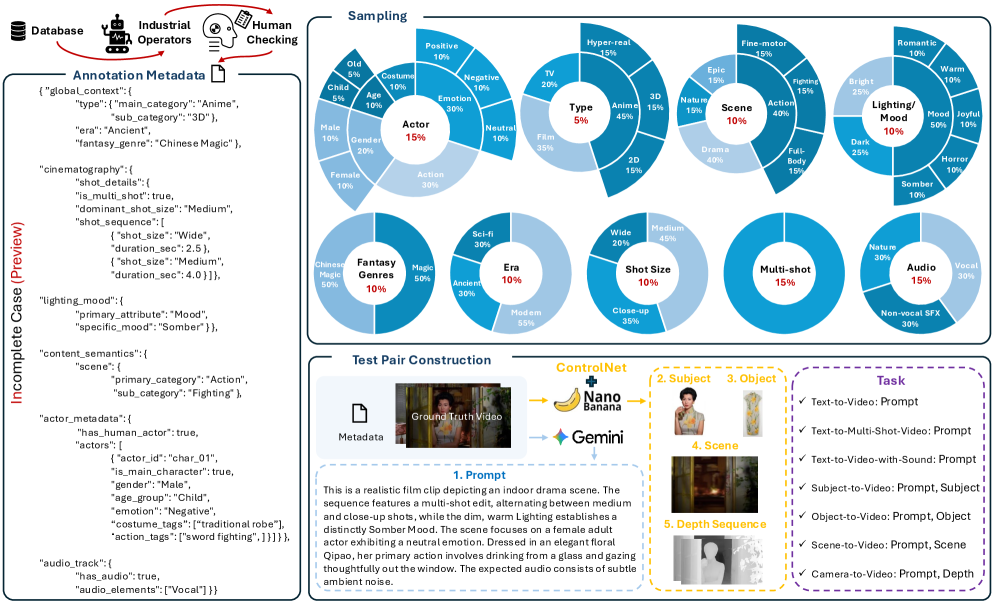
機械評価スイート
目的は専門家アノテーション \mathcal{H} を近似することです:
\mathbf{S} \approx \mathcal{H}(V, A, p, r), \quad V \in \mathbb{R}^{T \times H \times W \times C}, \; \mathbf{S} \in \mathbb{R}^{D}
パイプラインは2段階です。まず、特化した知覚オペレータのバンク \Phi = \{\phi_1, \dots, \phi_K\} が決定論的な証拠を抽出します:
E_{\text{prof}} = \bigcup_{k=1}^{K} \phi_k(V, A, p, r)
オペレータには、フレーム横断的な同一性追跡のためのDINOとInsightFace、意味的アンカリングのためのYOLO、音声・映像同期のためのSyncNet、音声感情のためのWhisperが含まれます。これにより、細粒度の時間的知覚や低レベル知覚タスクにおけるVLMの脆弱性として広く知られる問題を回避しています。次に、fine-tuningされたVLMが E_{\text{prof}} と196のrationalタクソノミーから引き出されたマルチ質問のrationaleを入力として受け取り、ステップ・バイ・ステップの推論を通じて次元ごとのスコアを生成します。
人間と機械の校正
校正は3層構造です:
- プロンプトレベル(Rationale置換) — VLMの知覚的到達範囲を超える抽象的なrationaleを反復的に置き換えます。
- 融合レベル(重み最適化) — 人間のアノテーションで学習した軽量MLPが、質問ごとのスコア、E_{\text{prof}} の証拠、VLM CoTの出力を混合する重みを学習し、オペレータのOOD失敗とVLM推論エラーを吸収します。
- パラメータレベル(知識注入) — 専門家データセットでのsupervised fine-tuningにより、汎用VLMを映画的報酬モデルへと変換します。
定量的結果
人間評価は3段階プロトコル(グラウンドトゥルース映像との識別的サイドバイサイドランキング、シニア映画製作者によるpass/fail QA、専門家による最終監査)を用い、クローズドソース(Kling-v3-Omni、Seedance 2.0、Happy Horse 1.0、Vidu-Q2-Pro、Hailuo 2.3)、オープンソース(Hunyuan 1.5 8.3B、LTX2 19B、Wan2.2 14B)、マルチショット/音声・映像専門(HoloCine 14B、MultiShotMaster 14B)を含む11のジェネレータを対象としています。
Table 3は次元ごとの機械対人間のペアワイズ勝率を報告しています。代表的なアライメントの例を挙げると:Consistencyでは、Seedance 2.0が0.79/0.81、Hailuo 2.3が0.90/0.70;Pacingでは、Hailuo 2.3が0.90/0.90、Seedance 2.0が0.81/0.75;Visual Qualityでは、Kling-v3-Omniが0.66/0.84、Happy Horse 1.0が0.68/0.78;Multi-Shot Logicでは、Happy Horse 1.0が0.80/0.88、HoloCineが0.45/0.75;Sound Vocalでは、Happy Horse 1.0が0.85/0.72。表全体を通じて、機械と人間の勝率は概ね一致しており、最大の残差は高度に主観的な次元に集中しています(Hailuo 2.3のキャラクター識別可能性:0.48/0.89;Hailuo 2.3のAffectivity Grounding:0.56/0.86)。これらはVLMの知覚的上限が依然として制約となっている領域です。ジェネレータ間では、Happy Horse 1.0、Seedance 2.0、Kling-v3-Omniがプロダクションステージの大半の次元を支配しており、LTX2とHoloCineはマルチショット/ネイティブ音声のニッチ領域でリードしています;MultiShotMasterはマルチショット特化にもかかわらず広範に低いパフォーマンス(しばしば勝率0.05〜0.25)を示しています。
限界と未解決の問題
このフレームワークはプロンプトおよび参照画像の合成にGemini 3.1 ProとNano Banana Proに依存しており、パイプラインの出力はこれらのプロプライエタリなシステムに紐付けられています。fusion-MLPは汎化の対象となる専門家アノテーション自体で学習されており、preference dataの過学習とjudge-modelの結託に関する標準的な懸念が生じます。いくつかの次元(マルチショットのLogic/Rhythm、Sound)は、それらをサポートする少数のモデルのサブセットでのみ評価されているため、クロスモデル比較は部分的なものにとどまります。さらに、オペレータスイートは固定されたセットであり、そのカバレッジ外の失敗モード(例:微妙な連続性エラー、ナラティブ因果関係)は依然としてVLMの推論に完全に依存しており、モデル更新とともに校正がずれていく可能性があります。
なぜ重要か
動画モデルのRLポストトレーニングが次のフロンティアであるならば、報酬品質が決定的な制約となります。そして現行のベンチマークは「良い」映画とは何かを十分に規定できていません。EvalVerseはドメインに根ざしたタクソノミーと、次元ごとのランキングが専門家の判断と高い一致を示す校正済みのVLM+オペレータ型judgeを提供しており、単なるリーダーボードではなく映画グレードのRLHFにおける実用的な報酬バックボーンとなる可能性を持っています。
Source: https://arxiv.org/abs/2605.23271
Hacker News Signals
LLMにおける睡眠様の記憶固定化メカニズム
Source: https://arxiv.org/abs/2605.26099
本論文は、生物学的神経系における睡眠段階の記憶固定化に類似した、訓練時の固定化フェーズを提案しています。中心的な問題として、逐次データで訓練されたLLMは壊滅的忘却に悩まされており、標準的な継続学習の緩和策(EWC、replay buffer)は計算オーバーヘッドを生じさせるか、あるいは古いデータへのアクセスを必要とします。
このメカニズムは、新規データに対するgradientの更新を定期的に中断し、代わりにオフラインの「固定化パス」を実行することで機能します。この固定化パスでは、モデル自身がサンプリングによって生成した合成サンプルを内部的に再生し、表現の変化の度合いに応じた重み付けを行います。鍵となる量は、現在のモデルの出力分布と凍結された「固定化前」チェックポイントとのKLダイバージェンスであり、パラメータ空間のどの部分が最も大きくドリフトしたかを特定するために使用されます。その後、パラメータは合成再生セットで推定されたFisher情報に比例して選択的に正則化されます。
形式的には、固定化lossは以下を加算します:
\mathcal{L}_{\text{cons}} = \lambda \sum_i F_i (\theta_i - \theta_i^*)^2
ここで、F_iは合成再生シーケンスに対する対角Fisher推定値、\theta^*は固定化前のスナップショットです。これはEWC方式ですが、F_iが保留タスクデータではなく自己生成データで推定されるという重要な違いがあり、元の訓練コーパスが利用できない設定でも適用可能です。
実験では、ナイーブなfine-tuningベースラインと比較して、以前に学習したタスクの保持率が15〜30%向上すること(保留タスクベンチマークのperplexityで測定)が示されており、固定化のオーバーヘッドは総訓練計算量の10%未満です。本手法は、コーディング、数学的推論、instruction-followingタスクにわたる逐次fine-tuningでテストされています。
限界として、自己生成再生データはモデルがすでに苦手とするタスクでは品質が低くなり得るため、フィードバックループが生じます。また、Fisher対角は大規模なtransformerの重み行列に対して粗い近似であり、さらに本手法は〜7Bパラメータを超えるスケールではテストされていません。
この研究が重要な理由
replay dataへのアクセスなしでの継続学習は、デプロイされたfine-tuningワークフローにおける実際的な要件です。以前のデータを保存する必要のない安価な自己蒸留メカニズムは、本番LLM適応パイプラインに直接活用できます。
人類の料理知識のすべてを2メガバイトに圧縮する
Source: https://arxiv.org/abs/2605.22391
本論文はデータ圧縮・知識表現に関する研究です。著者らは、レシピ、食材の代替ルール、調理技術の説明など、広範な料理知識のコーパスを2 MBのアーティファクトに符号化し、推論時にニューラルネットワークを使わずクエリ可能にすることを試みています。フレームワークは情報理論的なものです。すなわち、極端な圧縮からあるドメインの実用的知識をどれだけ復元できるか、という問いを立てています。
手法は複数のステップを組み合わせています。まず、大規模なレシピコーパスを解析・正規化し、構造化された中間表現(食材・分量・技術・手順)に変換します。次に、文法ベースの圧縮スキームを適用します。繰り返し出現するサブシーケンス(例:「玉ねぎが透き通るまで炒める」)を、ドメイン固有のトークン化を用いたLempel-Zivの変種によって共有辞書に組み込みます。さらに、食材の代替グラフとフレーバーペアリングのメタデータを圧縮された隣接構造として格納します。
2 MBという数値は、この構造化表現の最終的なgzip圧縮バイナリから得られます。展開後のアーティファクトは約40 MBです。クエリは、学習済みモデルではなく小規模な決定論的ルックアップエンジンで処理され、「インテリジェンス」は完全に符号化スキーマの中に存在します。
評価は定性的であり、レシピ再構成によって行われます。食材リストが与えられると、システムはもっともらしい技術シーケンスを取得します。著者らは、テストクエリの約70%が「料理的に一貫した」応答を返したと報告していますが(人間のアノテーターによる評価)、評価プロトコルは厳密ではありません。
技術的な関心は料理アプリケーションよりも圧縮アーキテクチャにあります。具体的には、手続き的テキストに対してジェネリック圧縮よりも高い圧縮率を達成するドメイン固有の文法誘導です。同じコーパスに対してジェネリックなgzipを適用すると約12 MBのアーティファクトが生成されますが、構造化アプローチは手続き的冗長性を利用することで2 MBを実現しています。
限界も大きく、一貫性指標は主観的であり、西洋料理以外のカバレッジは薄く、分量のスケーリングや食事制限に関する推論には対応していません。
なぜこれが重要か
ドメイン固有の手続き的テキスト圧縮への文法誘導アプローチは、ジェネリックな圧縮器よりもはるかに積極的に構造的冗長性を利用できる、他の命令が多いドメイン(組立マニュアル、実験プロトコルなど)にも転用可能です。
DeepSeek Reasonix: 高いキャッシュ効率と低コストを実現するDeepSeekネイティブコーディングエージェント
Source: https://esengine.github.io/DeepSeek-Reasonix/
Reasonixは、DeepSeekのAPIを中心に構築されたオープンソースのコーディングエージェントであり、積極的なpromptキャッシュとコンテキスト再利用によってトークンコストを最小化するよう最適化されています。技術的な核心は、エージェントのロジック自体よりもキャッシュアーキテクチャにあります。
基本的な観察として、DeepSeekのAPIはpromptのprefix部分のキャッシュヒットに対して大幅に割引されたレート(同社のティアでは約10倍安価)を適用しています。Reasonixは、システムprompt、ツール定義、チェックポイントまでの会話履歴をキャッシュ可能なprefixとして固定し、新しいターンの内容のみをキャッシュされていないsuffixとして追加するよう、すべてのエージェントターンを構造化しています。これには慎重なシリアライズが必要です。キャッシュをヒットさせるためにはprefixが呼び出し間でバイト単位で同一でなければならず、ツール定義、システム命令、および過去のアシスタントターンを決定論的にレンダリングする必要があります——タイムスタンプなし、UUIDノンスなし、順序の変動なしです。
エージェントループ自体は標準的なReActパターン(推論→行動(ツール呼び出し:シェル、ファイル読み書き、検索)→観察→繰り返し)に従っています。非標準的なのは「コンテキスト圧縮」ステップです。キャッシュされていないsuffixが設定可能なトークン予算を超えた場合、エージェントは中間ツール出力を圧縮された観察文字列に要約し、それを新たな固定prefixに組み込んで新しいキャッシュチェックポイントを作成します。これにより、キャッシュ効率を維持しつつ、コンテキストが無制限に増大するのを防ぎます。
実装はPythonで行われており、DeepSeekのOpenAI互換エンドポイントと統合されています。また、毎ターン完全なコンテキストを送信するナイーブなステートレスエージェントと比較して、マルチターンのコーディングタスクにおいて60〜80%のコスト削減を報告しています。ベンチマークタスクにはSWE-bench-liteスタイルのリポジトリ編集が含まれます。
制限事項として、prefixに少しでも変更があるとキャッシュが無効化されて節約効果が完全に失われるため、promptの反復に対してシステムが脆弱です。また、このワークフローはDeepSeek固有のキャッシュセマンティクスに依存しており、他のプロバイダーのものとは異なります。
なぜこれが重要か
promptのprefixキャッシュは、ほとんどのエージェントフレームワークでは十分に活用されていません。Reasonixは、プロバイダーのキャッシュ境界に沿ってエージェントの状態を構造化することが、大きなコスト上の意味を持つ一級のエンジニアリング上の関心事であることを示しています。
Rosalind: ラップトップ上でゲノム全体のパイプラインを実行するRust製ゲノミクスツールキット
Source: https://github.com/logannye/rosalind
Rosalindは、アライメント・バリアントコール・品質管理といったホールゲノムシーケンシング解析タスクを対象としたRustライブラリです。クラスターなしでコモディティハードウェア上での動作を想定して設計されており、エンジニアリング上の焦点はRustの所有権モデルとRayonベースのスレッドプールによるメモリ効率と並列性に置かれています。
このツールキットは、いくつかのコアなバイオインフォマティクスアルゴリズムをSafe Rustでゼロから実装しています:参照ゲノムのインデックス構築のためのBWT/FM-index、ショートリード用のバンド付きSmith-Watermanアライナー、そしてpileupモデルを用いた基本的なハプロタイプ対応バリアントコーラーです。FM-indexの構築は注目に値します:O(n) 時間で動作するprefix-doublingサフィックス配列構築(SA-ISバリアント)を使用しており、ヒト参照ゲノムのインデックス(約3 GB)を6 GB未満のRAMに収めることで、16 GBのラップトップでの利用を可能にしています。
並列処理はリードバッチレベルで行われます:FASTQファイルはチャンクに分割され、Rayonが利用可能なコア全体にアライメントジョブをディスパッチします。アライナーに共有可変状態が存在しないこと(各リードは独立している)はRustの所有権規則にそのままマッピングでき、著者はデータ競合がゼロであるため手動の同期が一切不要であったと述べています。
提示されているパフォーマンスの数値:ヒトゲノムの30xカバレッジWGSリードのアライメントは、16 GB RAMを搭載したM2 MacBook Pro上で約45分かかります。これは同ハードウェア上のBWA-MEM2の約15分と比較したものです。3倍の差はBWA-MEM2のSIMD最適化されたseed chainingによるものであり、Rosalindはまだこれを実装していないため、想定の範囲内です。
バリアントコールは「研究品質」と説明されています——pileupコーラーはGATK HaplotypeCallerの統計モデルを持たないため、臨床用途での実用には至っていません。
制限事項:SIMDアクセラレーションはまだなく、構造バリアントのサポートもなく、バリアントコーラーのindelに対する精度はGIABのようなゴールドスタンダードの真値セットに対してベンチマークされていません。
なぜこれが重要なのか
読みやすく依存関係の少ないRust製ゲノミクスライブラリは、バイオインフォマティクスをより大規模なRustアプリケーションに組み込む際の障壁を下げるとともに、この分野を支配しているC/C++コードベースよりも優れた教育的基盤として機能します。
Go 1.24におけるHTTP/2 Cleartext サーバーの利用
Source: https://www.clarityboss.com/blog/go-http2-cleartext-h2c-cloud-run
HTTP/2 Cleartext(h2c)はTLSなしのHTTP/2であり、TLSの終端がingressレイヤーで行われるサービスメッシュやロードバランサーからバックエンドへの通信で利用されます。GoのstandArd libraryであるnet/httpはデフォルトでTLS上のみHTTP/2を有効にするため、h2cを有効にするにはgolang.org/x/net/http2/h2cを明示的に使用する必要があります。
本記事では、Go 1.24で必要な具体的な記述方法を説明しています:
h2s := &http2.Server{}
handler := h2c.NewHandler(mux, h2s)
server := &http.Server{Addr: ":8080", Handler: handler}
server.ListenAndServe()h2c.NewHandlerラッパーはコネクションのアップグレードハンドシェイク(PRI * HTTP/2.0プリフェース)をインターセプトし、h2cコネクションに対してはhttp2.Serverインスタンスに処理を委譲しつつ、通常のリクエストに対してはHTTP/1.1にフォールバックします。このラッパーがない場合、GoのHTTPサーバーはh2cコネクションを暗黙のうちにHTTP/1.1へダウングレードしてしまいます。これは、h2cを送信するGoogle Cloud Runの内部ロードバランサーの背後にデプロイする際に、気づきにくい障害モードとなります。
また、Cloud Run固有の要件についても記載されています:バックエンドコンテナに対してHTTP/1.1ではなくh2cを使用するようフロントエンドに指示するため、gcloud run deployコマンドで--use-http2フラグを設定する必要があります。これを行わないと、サーバーがh2cをサポートしていても多重化の恩恵が失われます。
実際的な意義として、h2cはロードバランサーからバックエンドへの単一TCPコネクション上でリクエストの多重化を可能にし、高QPSサービスにおけるコネクションのオーバーヘッドを削減します。本記事の簡易ベンチマークでは、コネクション数がO(同時リクエスト数)からO(1)へ減少することが計測されています。
本記事が埋めている技術的なギャップは、Goのドキュメントにh2cのダウングレード動作が明確に説明されていない点、およびCloud Runのフラグがリファレンスドキュメントの奥深くに埋もれている点です。
なぜこれが重要か
h2cはクラウドネイティブスタックにおけるgRPCおよびHTTP/2の標準バックエンドプロトコルです。Goのオプトイン動作を理解することで、TLSを終端するインフラの背後にデプロイする際のパフォーマンスの暗黙的な低下を防ぐことができます。
アウトソーシングとローカルAIの組み合わせは、近くフロンティアラボへのAPI利用より経済的になる
本稿はコスト構造に関する議論を展開しています。多くのソフトウェア開発タスクにおいて、オフショア労働力とローカルで動作するオープンウェイトモデルを組み合わせることで、1〜2年以内にフロンティアプロバイダー(GPT-4o、Claude 3.5 Sonnetなど)へのAPIコストを下回るようになるという主張です。その技術的な核心はコストの分解にあります。
著者は開発ワークフローを「仕様策定 → コード生成 → レビュー → テスト」としてモデル化しています。大規模なコード生成におけるフロンティアAPIのコストは、GPT-4oの価格体系を用いた典型的なプロンプト・補完比のトークン数に基づき、本番コード1,000行あたり2〜8ドルと試算されています。これに対して、4x H100ノード(スポット価格で約10ドル/時間、スループット約500トークン/秒)上で70Bパラメータのオープンウェイトモデル(例:Llama 3.3 70BまたはQwen 2.5 Coder 72B)を継続的に稼働させた場合の償却コストは、1,000行あたり約0.20〜0.60ドルと計算されており、継続的なワークロードに対して5〜15倍のコスト削減が見込めます。
「アウトソーシング」コンポーネントは、人間が介在するレビュー層を指します。コストの低い地域にいる人間のレビュアーが、フロンティアモデルとローカルモデルのコスト差よりも低い費用でローカルモデルの出力を検証・修正できるという論理であり、ローカルモデルが失敗するタスクの末端部分も担うとされています。
本稿はモデル品質の差異を厳密にベンチマークしているわけではなく、HumanEvalおよびSWE-benchの数値を引用して70Bモデルがコーディングタスクにおいてはgpt-4oの70〜80%の性能を示すとし、そのギャップは人間によるレビューで対処可能と仮定しています。これが最も脆弱な仮定です。失敗モードの分布は平均的な性能よりも重要であり、コード生成における末端的な失敗(セキュリティバグ、微妙な論理エラー)は、時間的なプレッシャー下での人間によるレビューが最も見落としやすいものでもあります。
この議論は、スコープが明確に定義された高ボリュームかつ低クリティカリティのコード生成タスクに対しては方向性として妥当です。ただし、複雑なアーキテクチャ設計や低レイテンシが求められるインタラクティブなユースケースには当てはまりません。
なぜこれが重要か
コストの算数は丁寧に行う価値があります。本稿では、チームが自分たちのトークン使用量とレビュー人件費に照らし合わせて損益分岐点を見つけるための、パラメータを調整可能な再現性のあるモデルが提示されています。
Gitで追跡する書籍制作パイプラインを構築した
この記事では、物理的な書籍のための文書制作パイプラインについて説明しています。InDesignとWordをプレーンテキストかつバージョン管理されたツールチェーンに置き換えたものです。技術スタックは以下の通りです:Gitで管理されたMarkdownソースファイル、フォーマット変換のためのPandoc、レイアウト固有の処理(画像配置、キャプション番号付け、脚注フォーマット)を担うPandoc用カスタムLuaフィルター、そしてPDF生成の最終レンダリングバックエンドとしてのLaTeX/XeLaTeXです。
主要な設計上の判断は検討に値します。PandocのASTは、MarkdownやTeXを直接前処理・後処理するのではなく、Luaフィルターを通じて操作されます。これにより変換処理が合成可能でテスト可能な状態に保たれます。著者が実装したフィルターは以下のものです:章をまたいで一貫した図・表番号を実現するクロスリファレンスの解決、印刷版とデジタル版の切り替えのための条件付きコンテンツブロック、そして特定のLaTeX環境にマッピングされるコールアウトボックス用のカスタムブロックタイプです。
ビルドシステムはMakefileで構成されており、make pdf を実行するとフィルターチェーンを伴うPandocが走ってXeLaTeXソースを生成し、その後参照解決のために xelatex が2回呼び出されます。Markdown上のGit diffは人間が読める形式であるため、意味のあるバージョン履歴とプルリクエスト形式の編集レビューが可能になります。これはバイナリ形式の .docx や .indd ファイルでは実現不可能なことです。
著者が指摘する非自明な問題が一つあります:印刷向けの精密な組版制御(ウィドウ・オーファン制御、手動改ページのヒント)は、Markdown内にインラインでPandoc rawのLaTeXブロックとして記述されており、コンテンツとプレゼンテーションのきれいな分離を損なうという点です。これはテキストから印刷物へのパイプラインに内在する本質的なトレードオフです。
フォントの処理はXeLaTeXのネイティブOpenTypeサポートを通じて行われており、pdflatexでよく見られるフォント埋め込みの問題を排除しています。
制限事項として、このパイプラインはLaTeXのデバッグに慣れていることを前提とし、複雑なレイアウト(段組み、精密な画像回り込み)はビジュアルツールと比較して依然として難しい点が挙げられます。
なぜこれが重要か
Luaフィルター + Pandoc + XeLaTeXのパターンは、プロフェッショナルな文書制作に対する成熟した再現可能なアプローチであり、より多くの技術系著者が採用すべきものです。この記事は移植可能なアーキテクチャを備えた具体的な実証例となっています。
Rustの言語性能
Source: https://github.com/yugr/rust-slides
これはシステムエンジニアリングの観点からRustの性能特性を扱ったスライドデッキ(PDF)であり、Rustの抽象化がオーバーヘッドをもたらす箇所とその考え方に焦点を当てています。内容は典型的なRustの性能に関する記事よりも密度が高いです。
主なトピック:
ゼロコスト抽象化とその限界。 LLVMのインライン展開深度制限により、Iteratorチェーンが同等のCのループと比較して最適でないコード生成を行うケースを示しています。対処法はホットパスにあるイテレータアダプタへの#[inline(always)]の適用、または明示的なループへのフォールバックです。
境界チェック。 RustはスライスインデックスアクセスにGCC/Clangが範囲解析によってしばしば省略する境界チェックを挿入します。ループをイテレータを使う形に再構成する(コンパイラが範囲内であることを証明できる)ことで、チェックが除去されCと同等のスループットが回復されるパターンを示しています。構造上安全性を保証できるケースでは、unsafe { slice.get_unchecked(i) }についても適切な注意事項とともに解説されています。
モノモーフィゼーションのコスト。 ジェネリック関数は具体的な型ごとにモノモーフィズされるため、バイナリサイズが増加し命令キャッシュを圧迫する可能性があります。スライドではfn foo<T: Trait>(x: T)(モノモーフィズ)とfn foo(x: &dyn Trait)(動的ディスパッチ)をスケール時のicacheの挙動という観点で比較しています。
アロケータの挙動。 Rustのデフォルトグローバルアロケータ(jemallacはRust 1.32でシステムアロケータに置き換えられました)がボトルネックになりうる点について、#[global_allocator]属性を通じてmimallocやjemallocに差し替える方法を解説しており、アロケーション負荷の高いワークロードで10〜30%のスループット向上を示すベンチマーク数値も提示されています。
LLVMバックエンドの問題。 rustc/LLVMがGCCではベクトル化できるループを自動ベクトル化できないケースを複数示しており、std::simd(ポータブルSIMD)や明示的なintrinsicsを使った回避策を紹介しています。
スライドは実践的であり、曖昧な主張ではなく具体的なベンチマーク数値を引用しています。
なぜこれが重要なのか
Rustの性能モデルはしばしば無条件に「Cと同等」と説明されますが、このデッキはRustのコードが期待より遅い場合に実務者が必要とする具体的な失敗パターンと対処法を提供しています。
注目の新しいリポジトリ
chiennv2000/orthrus
Orthrusは、speculative decodingとデュアルビュー拡散機構を組み合わせることで、LLM推論のロスレス高速化を目指しています。中心的なアイデアは、トークン列の2つの相補的な表現——前向き自己回帰ビューとmasked-diffusionビュー——を維持し、両者の合意を利用して出力分布を変えることなく候補トークンを受理または棄却することです。これは標準的なspeculative decoding(別途ドラフトモデルを必要とする)とは異なり、diffusion headがベースモデルと共同で学習されるため、ミスマッチによるペナルティが軽減されます。「ロスレス」という主張は、受理されたトークンの分布が元のモデルのgreedy出力またはサンプリング出力と証明可能な意味で同一であることを意味します。実装はPyTorchで行われており、並列diffusionステップにはCUDAレベルのバッチ処理が用いられています。デュアルビューアーキテクチャはパラメータのオーバーヘッドをわずかに増加させますが、2つのビューが合意した場合に1回のforward passで複数のトークンを回収でき、品質を損なうことなく実際の処理速度の向上をもたらします。ドラフトモデルの維持コストがボトルネックとなっているプロダクション推論スタックや、厳密な出力忠実性を保ちながら非自己回帰的な高速化を追求する研究に関連しています。初期ベンチマークでは標準的な生成タスクにおいて有意なスループット向上が示唆されていますが、実際の性能向上はシーケンスのエントロピーとハードウェアのメモリ帯域幅に依存します。
Source: https://github.com/chiennv2000/orthrus
raiyanyahya/how-to-train-your-gpt
教育目的のエンドツーエンドGPT実装で、インラインコメントを通じてあらゆるアーキテクチャおよび学習上の決定を明示的に示すことを目的としています。このコードベースは、トークン化(スクラッチからのBPE)、transformer ブロック(multi-head self-attention、positional encoding、layer norm の配置)、学習ループ(AdamW、学習率のウォームアップとコサイン減衰、gradient clipping)、そして推論(温度サンプリング、top-k、top-p)を順を追って解説しています。Hugging Face からのインポートは一切なく、依存ライブラリは NumPy と PyTorch のみです。Karpathy の nanoGPT(自明な比較対象)との違いは、説明的なアノテーションの密度にあります。すべての tensor の reshape、すべてのマスキング操作、すべてのハイパーパラメータの選択に対して、何をしているかだけでなくなぜそうするかを説明するコメントが付いています。リポジトリは、読者が教科書の一章を読み進めるように線形にたどれる構成になっています。講座資料を作成する教育者、論文から transformer を学んだものの実装上のギャップを埋めたい実務者、そして細部を省略しないリファレンスを必要としているエンジニアのオンボーディングに役立ちます。プロダクション規模での使用を意図したものではなく、その価値は完全に可読性と説明の正確さにあります。
Source: https://github.com/raiyanyahya/how-to-train-your-gpt
UditAkhourii/adhd
ADHDは、Claude Agent SDK上に構築されたコーディングエージェント向けのTree-of-Thought(ToT)推論スキルを実装しています。技術的なアーキテクチャは、最初の問題文から並列ブランチへと展開し、各ブランチはそれぞれ異なる認知フレーム(例:adversarial、第一原理、アナロジーベース)のもとで評価されます。各ブランチは、coherence・novelty・feasibilityといった設定可能なルーブリックでスコアリングされ、枝刈り閾値を下回るブランチは深化される前に終了させられます。生き残ったブランチには、詳細化のための追加計算予算が割り当てられます。これは構造的に、均一な価値関数ではなく異種ヒューリスティックを用いた beam search に類似しており、すべてのブランチが同一の局所最適解に収束するリスクを低減します。枝刈り戦略こそが、これを単純な並列プロンプティングと区別するものです。すなわち、終端状態を待つのではなく、中間スコアに基づいて計算量をゲートする点が特徴です。SDK との統合により、このスキルはカスタムのオーケストレーション用グルーコードなしに、他のClaude エージェントツールと組み合わせて使用できます。主なユースケースは、大規模かつ仕様が不十分な解空間を持つ問題、すなわちアーキテクチャの意思決定・研究のフレーミング・クロスドメインデザインなど、single chain-of-thought パスでは非自明なパスを確実に見逃してしまうケースです。リポジトリには各認知フレーム向けのプロンプトテンプレートと、ドメインごとにチューニング可能なスコアリングルーブリックが含まれています。
Source: https://github.com/UditAkhourii/adhd
agentic-in/elephant-agent
Elephant Agent は「Personal Model First」アーキテクチャというコンセプトを中心に構築された、自己進化型のパーソナルAIエージェントです。このエージェントは、ユーザーの好み・コンテキスト・過去のインタラクションに関する永続的かつ構造化されたメモリを蓄積し、基盤モデルの汎用的な事前知識のみに依存するのではなく、そのメモリをプライマリな条件付けシグナルとして使用します。自己進化のメカニズムは、エージェントがメモリストアを定期的に振り返り、矛盾や古くなった信念を特定してその内部状態表現を更新する「リフレクション・パス」によって実現されています。これは標準的なRAGパイプラインよりも、生涯学習システムの精神に近い設計です。クエリ時にコンテキストを検索するのではなく、エージェントはユーザーの圧縮されたワールドモデルを継続的に維持します。実装では、エピソード記憶にはベクターストレージを、安定した好みの表現には構造化されたkey-value表現を組み合わせて使用しているようです。このアーキテクチャは、継続学習における標準的な未解決問題——ユーザーコンテキストの壊滅的忘却、情報損失を伴わないメモリの圧縮、永続的なパーソナルデータのプライバシー境界——を提起しています。ゼロショット汎化よりもセッション間の継続性が重要となる、パーソナル生産性ツールへの応用として有望です。
Source: https://github.com/agentic-in/elephant-agent
MyuriKanao/src-hunter-skill
SRC(セキュリティレスポンスセンター)およびバグバウンティのコンテキストにおける脆弱性調査を対象としたClaude Codeのskillです。技術的な内容は充実しており、SSRF・IDOR・XXE・デシリアライゼーションなどのカテゴリをカバーする19の構造化された攻撃プレイブック、脆弱性クラスごとに整理された305の構造化ペイロード、263のWAFおよびEDRバイパステクニックのドキュメント、さらに2つの大規模ケースデータベース(実際のHackerOneレポート2,887件と、WooYunの88,636件から抽出された統計的パターン)が含まれています。このskillはClaude Codeのtool-useインターフェースと統合されており、エージェントがターゲットのリコネサンス出力に基づいてプレイブックを選択・シーケンスできるようになっています。バイパスコーパスは特に注目すべき内容で、通常はブログ記事やプライベートメモに散在している経験的な回避知識をエンコードしています。セキュリティリサーチの観点から見ると、WooYunデータセットのアグリゲーションは、西洋のバグバウンティプログラムで主流となっているものとは異なる技術スタックを持つ中国市場のターゲットに対する有用な事前情報となります。本番環境でのエンゲージメントで使用する前にペイロードを監査することを推奨します。ここでの価値は、新規のゼロデイではなく、既知のテクニックの構造化された列挙にあります。責任ある使用には、対象組織からの許可が必要です。
Source: https://github.com/MyuriKanao/src-hunter-skill
python-telegramBot/ai-auto-trading
VoltAgentフレームワーク上に構築されたTypeScript/Node.jsの仮想通貨取引ボットで、BinanceおよびGate.ioのRESTおよびWebSocket APIをターゲットにしています。アーキテクチャはマルチストラテジー構成であり、平均回帰・モメンタム・LLMを活用したシグナル生成をそれぞれ独立したモジュールで実装し、ポジション上限・ドローダウンストップ・Kelly比率によるサイジングを各ストラテジー横断的に適用するリスク管理レイヤーを備えています。LLMコンポーネントはマーケットコメンタリーおよびオンチェーンシグナルを取り込み、生の取引シグナルを直接生成するのではなく、ストラテジーのウェイトを調整する方向性バイアススコアを出力します。これは言語モデルに直接の発注権限を与えることを避けた、合理的な設計上の選択です。Telegram連携により、リアルタイムの取引通知が提供されるとともに、再デプロイを必要とせずにチャットコマンドでパラメータ調整が可能です。TypeScriptの型付けの厳密さはここで重要な意味を持ちます。取引所APIのレスポンスが完全に型付けされているため、動的型付けの取引ボットで歴史的にサイレントな損失を引き起こしてきたデシリアライゼーションエラーを検出できます。主なエンジニアリング上のリスクはレイテンシです。高メッセージ量下でのNode.jsイベントループの競合が注文執行を遅延させる可能性があります。このリポジトリは、特にバックテスト基盤のドキュメントが存在しないことを考慮すると、プロダクションレディなデプロイメントとしてではなく、個人用取引システムを構築するための構造化されたスタート地点として扱うのが最善です。
Source: https://github.com/python-telegramBot/ai-auto-trading
thinkpixelIab/polymarket-ai-trading
Polymarketの CLOB(Central Limit Order Book)APIを対象とした予測市場トレーディングシステムで、Node/Expressバックエンド、SQLiteによる永続化、Dockerデプロイメント、そしてExpress経由で提供されるダッシュボード(オプションでRender/Vercelホスティング対応)を備えたフルスタック構成です。トレーディングロジックは2つの戦略を組み合わせています:GPTベースの確率予測(モデルに市場の質問に対する確信度を問い合わせ、その確信度を現在の市場価格と比較して誤った価格設定を特定する)と、歴史的に安定した市場に対するmean reversionです。推定されたedgeをもとにKelly criterionによるポジションサイジングが適用されています。資本リスクなしに戦略を検証できるペーパートレードモードは注目すべき機能で、実際のCLOB価格に対して仮想的なフィルを記録することで、現実的なスリッページの推定が可能になっています。SQLiteは市場状態、取引履歴、モデルの予測を永続化するために使用されており、デプロイメントのフットプリントを最小限に抑えています。GPT予測アプローチには既知のキャリブレーション問題があります:言語モデルは争点となっている質問に対して50%のアンカーに偏りがちであり、また学習のカットオフにより急速に変化するイベントへの対応に限界があります。このリポジトリは、一貫して利益を生むシステムというよりも、研究・実験プラットフォームであることを率直に認めています。
Source: https://github.com/thinkpixelIab/polymarket-ai-trading
gonemedia/aipointer
AIPointerは、クロスプラットフォーム(macOS、Windows、Linux)対応の画面認識AIオーバーレイです。インタラクションモデルはホットキートリガー方式を採用しており、設定可能なキーを押しながら質問を入力すると、ツールがスクリーンショットをキャプチャし、そのクエリとともにvision対応モデル(OpenRouter、Anthropic、OpenAI、またはGemini。いずれもユーザー提供のAPIキーを使用)に送信し、現在のアプリケーションを離れることなくオーバーレイとしてレスポンスを表示します。実装には仮想フレームバッファではなくプラットフォームごとのネイティブスクリーンショットAPIを使用しており、これによりレイテンシを低く抑えつつ、アクセシビリティAPIに伴うパーミッション処理のオーバーヘッドを回避しています。ローカルファースト、BYO-key(自前のAPIキーを持ち込む)、テレメトリなし、という設計により、データがサードパーティのリレーを経由することはなく、スクリーンショットはユーザーのマシンから選択したモデルプロバイダーのAPIへ直接送信されます。実用的な観点では、UI要素の素早い意味確認、画面上の可視コンテキストに基づいたドキュメント参照、そして画面表示と質問が密接に結びついたデバッグセッションにおいて特に有用です。OSレベルのAI統合(Apple Intelligence、Windows Copilot)と比較すると、AIPointerはモデルとAPIキーを完全にユーザーが制御できる一方、手動でのホットキー操作が必要となります。3つのターゲット間でスクリーンショットおよびオーバーレイAPIが大きく異なるため、クロスプラットフォーム対応の実現は技術的に容易ではありません。