Daily AI Digest — 2026-05-27
arXiv Highlights
SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
Spatial foundation models (SFMs) — DUSt3R, MASt3R, VGGT, \pi^3, MapAnything, and the Depth-Anything family — are typically reported on narrow per-domain benchmarks (ScanNet for indoor, KITTI for driving, Sintel for flow), often with non-deterministic frame sampling. This makes cross-paper comparisons unreliable and obscures how well a single model generalizes across viewpoints (egocentric, wrist), dynamics (static vs. moving scenes), input density (1 to hundreds of frames), and hardware budgets. SpatialBench addresses this by unifying 19 datasets and 546 scenes into a single deterministic protocol and evaluating 41 models across 6 paradigms on 5 task suites under 4 input-density regimes.
Benchmark construction
All raw data is normalized into a per-scene tuple of RGB, metric depth D, camera-to-world poses T_{cw}, and intrinsics K. The key design choice is that each (scene, view-density) pair is committed to a JSON record specifying exact frame indices. This decouples ingestion from evaluation: every method consumes identical inputs, so AbsRel, AUC@30, ATE, and F-score are directly comparable across runs and papers.
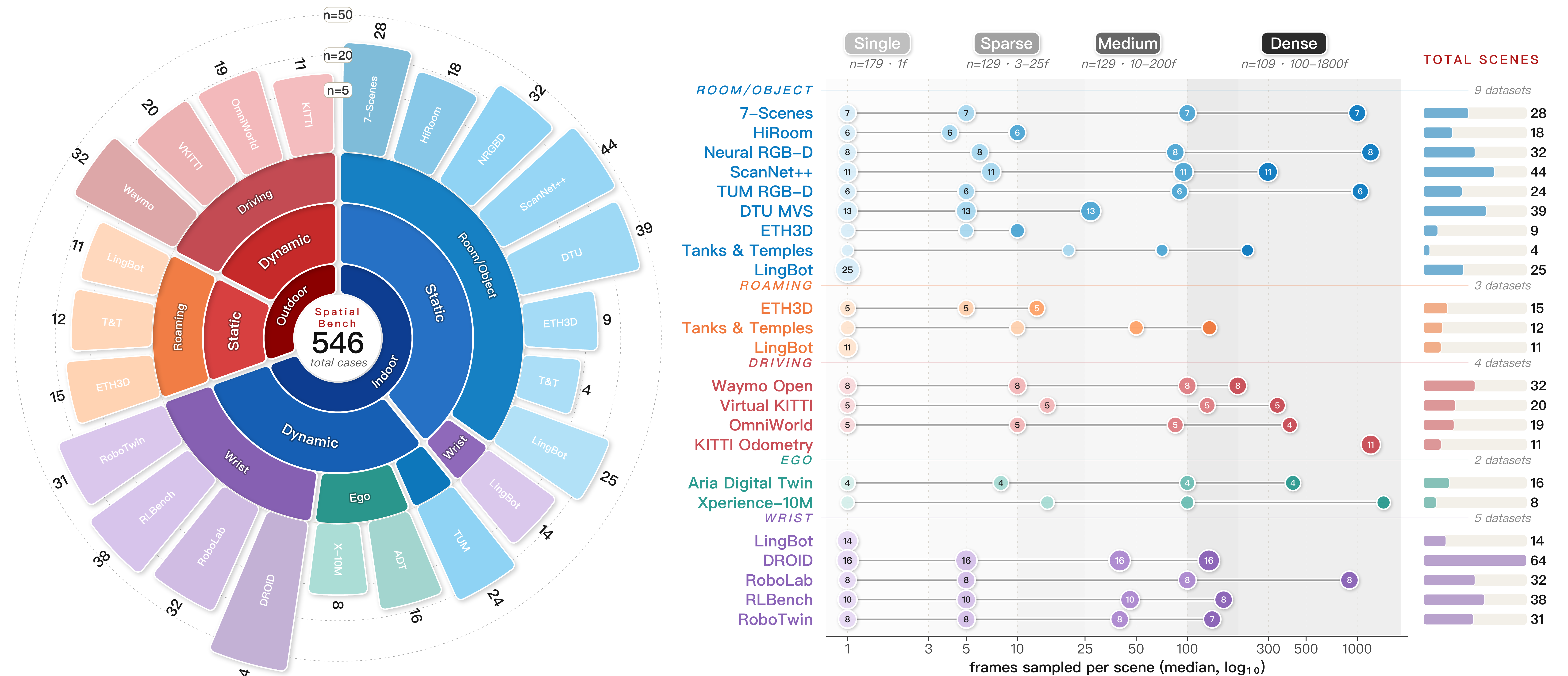
The 19 sources span a four-axis taxonomy: environment (indoor/outdoor), dynamics (static/dynamic), viewpoint (normal/egocentric/wrist), and origin (real/synthetic). Static-real comes from 7-Scenes, DTU, NRGBD, ScanNet++, Tanks & Temples, and ETH3D; dynamic-real from TUM-Dynamic, DROID, Xperience, Waymo, KITTI-Odometry; dynamic-synthetic from ADT, RLBench/Colosseum, RoboTwin, Robolab, Virtual KITTI 2, and OmniWorld-Game. Four density regimes — single-frame, sparse, medium, dense — are reported, with the dense regime triggering OOM (>140 GB) or timeout (>4 h/scene) on most large transformers.
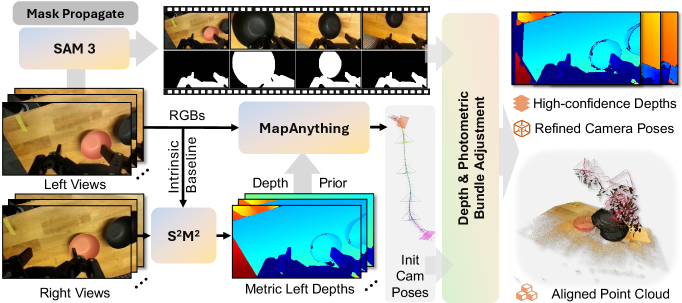
DROID, a wrist-view robot dataset lacking clean ground-truth geometry, is rebuilt with a dedicated pipeline: stereo depth from S^2M^2 with confidence filtering, initial pose from MapAnything, gripper/contact masks via SAM3, and bundle adjustment refining poses against the masked RGBs.
Depth-Anything-Next and DA-Next-5M
The benchmark exposes a clear gap: existing SFMs perform poorly on egocentric and wrist views, which dominate embodied applications and feature ultra-close-range capture, heavy occlusion, and aggressive ego-motion. To plug this, the authors release DA-Next-5M — 5.5M frames over 22K scenes, mostly egocentric/wrist — with metric depth, intrinsics, and extrinsics. Simulation portions use domain randomization over background, object scale, color, and wrist camera placement.

Depth-Anything-Next (DA-Next) is then trained on this corpus (architecture details deferred to the paper) and integrated into the same evaluation harness.
Results
Table 1 reports AbsRel (depth), AUC@30 (pose), ATE (trajectory), and F-score (geometry) across the four density regimes. Numbers worth fixing in mind:
- Single-frame AbsRel: DA-Next reaches 0.166, a 54.9% reduction over the next end-to-end feed-forward entry. VGGT sits at 0.184, FastVGGT at 0.183, OmniVGGT at 0.188; the DA3 family ranges 0.333–0.385; optimization-based DUSt3R/MASt3R are 0.385/0.456.
- Sparse AbsRel: DA-Next 0.050 (−47.4% relative), VGGT-Omega 0.077, \pi^3-X 0.084, AMB3R 0.088, \pi^3 0.092, DA3-Giant 0.095. AUC@30 in sparse: DA-Next 0.809, VGGT-Omega 0.803, DA3-Giant 0.785, DA3-Nested 0.779, \pi^3 0.742.
- Medium AbsRel: DA-Next 0.035 (−59.3%), VGGT-Omega 0.067, \pi^3-X 0.078, \pi^3 0.082, AMB3R 0.085. DA-Next ATE 1.442 is +24.2% worse than the best (\pi^3-X at 0.369), revealing a depth-vs-pose tradeoff: the model is strongly tuned for metric depth but its camera-pose head trails geometry-centric architectures.
- Dense regime: nearly every >1 GB transformer (VGGT, MapAnything, OmniVGGT, \pi^3-X, AMB3R, DA3-Large/Giant/Nested, DA-Next) hits OOM at >140 GB. Only Fast3R, FastVGGT, \pi^3, DA3-Small/Base, and the streaming/online methods (Spann3r, CUT3R, Point3R, Stream3R, StreamVGGT) survive. Among survivors at dense, FastVGGT achieves AbsRel 0.130 / AUC@30 0.627 / ATE 9.984 / F 0.527; \pi^3 posts 0.190 / 0.672 / 8.478 / 0.491.
- Latency (sparse, per-sequence): MapAnything and OmniVGGT 0.22 s, \pi^3 0.20 s, FastVGGT 0.24 s, VGGT 0.40 s, DA-Next 0.50 s, MonST3R 20.81 s.
Online methods (Spann3r, CUT3R, MonST3R, Point3R, Stream3R, StreamVGGT) are the only ones that scale to dense inputs cleanly but pay a steep accuracy cost: e.g. CUT3R averages AbsRel 0.223 vs. DA-Next sparse 0.050.
Limitations and open questions
The benchmark equates “all-round” with strong performance under shifting density and domain, but the dense regime is currently a memory contest more than a methodological one — most SOTA models simply cannot run, so the dense leaderboard rewards architectural compactness rather than reasoning quality. DA-Next’s pose/ATE regression vs. \pi^3-X suggests its training mixture biases representations toward depth at the cost of multi-view geometric consistency. SpatialBench also relies on S^2M^2 + BA pseudo-GT for DROID, which puts an upper bound on wrist-view depth evaluation fidelity. Finally, although 41 models are evaluated, the protocol only covers reconstruction and pose; downstream tasks such as planning, manipulation success, or novel-view synthesis quality are out of scope.
Why this matters
Deterministic, cross-paradigm evaluation exposes that no current SFM is uniformly best: small models scale to dense inputs but trail on accuracy, large transformers OOM past medium density, and depth-strong models can be pose-weak. SpatialBench plus DA-Next-5M give the field a fixed yardstick and a missing data regime (egocentric/wrist) for embodied 3D perception.
Source: https://arxiv.org/abs/2605.27367
The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
MiniMax-M2 is a sparse MoE family explicitly designed for long-horizon agentic deployment rather than static QA. The flagship has 229.9B total parameters with 9.8B activated per token, and the design thesis is that a small activation footprint, paired with agent-native data pipelines and an RL system tuned for tool-using trajectories, can match dense frontier models on the workloads that actually matter in production: coding agents, deep search, and office task automation.
Architecture
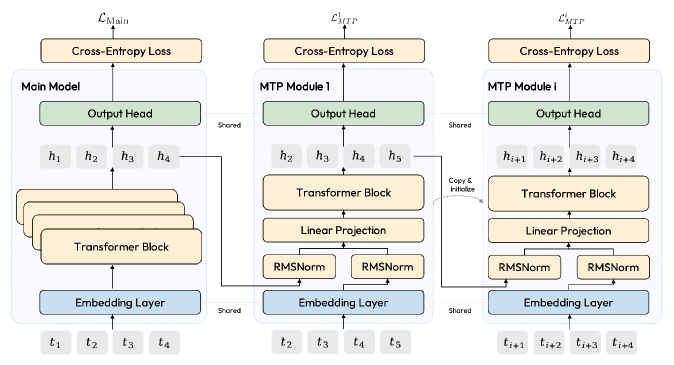
M2 is a 62-layer decoder-only Transformer with hidden dimension 3,072 and a 200,064-token vocabulary. Attention uses GQA with 48 query heads and 8 KV heads, full attention at every layer, and RoPE; the team explicitly abandons the hybrid (linear/softmax) attention of MiniMax-Text-01 in favor of full attention at scale. The MoE FFN has 256 fine-grained experts with 8 active per token, sigmoid gating with learnable expert biases, and an auxiliary-loss-free load-balancing scheme following Wang et al. 2024. A Multi-Token Prediction head is trained alongside next-token prediction and later expanded by weight copying to support multi-step speculative decoding.
Pre-training uses 29.2T tokens with up-sampled code, math, and STEM. Context is extended in stages 8K \to 32K \to 192K, with a 9.3T-token decay phase mixing short-text decay data, naturally long PDFs, concatenated code, and thematically packed documents.
Agentic data pipelines
The post-training corpus is built around verifiable agentic trajectories in three coding regimes (SWE, AppDev, terminal) plus cowork tasks. The SWE pipeline mines permissively-licensed GitHub PRs, then runs an agent-driven loop to synthesize per-PR Docker environments — particularly important for compiled languages (Java/Go/Rust/C++) where toolchain coordination is brittle. PRs are tagged by intent (bug fix, feature, refactor, perf, test) so that distinct reward functions can be applied.
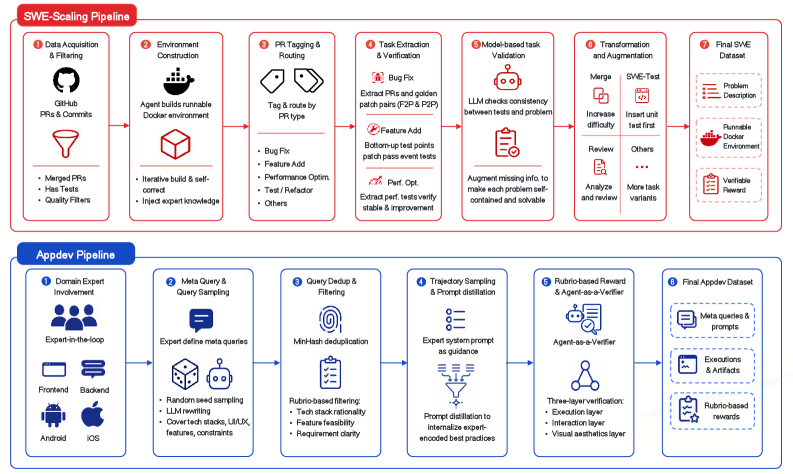
For bug fixes, validity requires a golden patch to satisfy both Fail-to-Pass (F2P) and Pass-to-Pass (P2P) tests; the model agent must then reproduce that, with P2P guarding against regressions. For feature additions, where new tests reference new code, the pipeline shifts away from F2P/P2P toward executable artifact equivalence.
Interleaved thinking and RL
Trajectories are modeled as interleaved sequences
\tau = (r_1, a_1, o_1, r_2, a_2, o_2, \ldots, r_T, a_T, o_T)
where each reasoning block r_t is conditioned on the full prior history. Crucially, the assistant message kept in history at turn t+1 retains the thinking block:
\mathcal{H}_{t+1} = \mathcal{H}_t \oplus [\mathrm{assistant}(r_t, a_t)] \oplus [\mathrm{tool}(o_t)],
versus the dropped variant \mathcal{H}_{t+1}^{(\text{drop})} = \mathcal{H}_t \oplus [\mathrm{assistant}(a_t)] \oplus [\mathrm{tool}(o_t)] that forces re-derivation of state every turn. Ablations show persistence yields the largest gains exactly where it should — multi-step deep search and SWE — consistent with the Plan–Act–Reflect framing.
The RL system, Forge, treats the LLM as the policy and externalizes context management, memory, and state transitions into the environment. Production engineering items called out: windowed-FIFO scheduling for variable-length agent rollouts, prefix-tree merging to share KV across branched trajectories, and a strict decoupling of training, inference, and agent processes so the same trainer can drive white-box (logit-level) and black-box (API-only) agents. SFT data is built by large-scale rejection sampling against domain rewards, producing interleaved-thinking traces in chat, reasoning, code, and cowork.
Evaluation
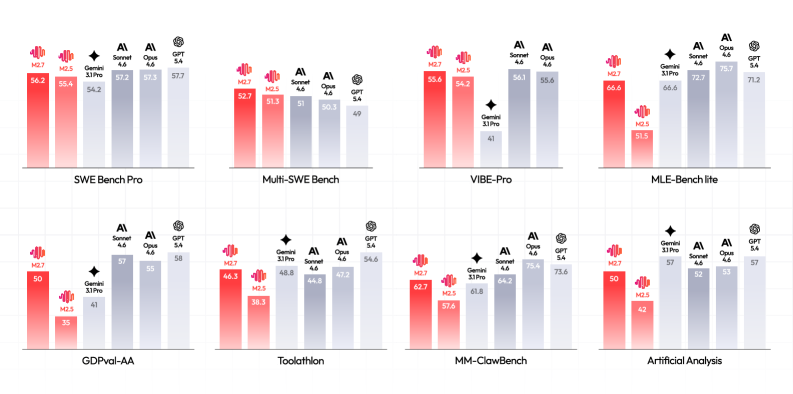
M2.7 is benchmarked against Claude Opus 4.6, Claude Sonnet 4.6, GPT 5.4, and Gemini 3.1 Pro, all in maximal reasoning configurations. The evaluation suite is deliberately skewed toward environment-grounded benchmarks: SWE-bench Pro, SWE-bench Multilingual, Multi-SWE-bench, NL2Repo, Terminal-Bench 2.0, MLE Bench Lite for coding; VIBE-Pro and HyperTask for app dev; BrowseComp, Wide Search, and RISE for deep research; GDPval-AA, Toolathlon, MEWC v2, and Finance Modeling Pro for office work; and AIME 2026, GPQA-Diamond, SciCode, IFBench, AA-LCR, HLE, and MMLU-Pro for reasoning and knowledge. Coding agents share a Claude Code scaffold (CodeX for GPT 5.4), with 4-trial averaging; Terminal-Bench runs in an 8 vCPU / 16 GB sandbox with a 2 hour wall-clock cap under Terminus-2. With ~10B activated parameters, M2.7 tracks frontier closed-weight systems across these blocks (Figure 1), and the within-series gap from M2.5 to M2.7 is reported to isolate the contribution of the latest data and RL iterations.
Limitations and open questions
The paper foregrounds several internal benchmarks (NL2Repo, VIBE-Pro, HyperTask, MM Claw, MEWC v2, Finance Modeling Pro, RISE), which limits external reproducibility of the cowork claims. Self-evolution at M2.7 — autonomously debugging training runs and editing its own scaffold — is presented as an early step rather than a measured capability with isolated ablations. The decision to drop hybrid attention in favor of full attention at 192K is justified empirically but not analyzed against linear-attention baselines at matched compute. Finally, the activation count headline (9.8B) understates serving cost: 229.9B total parameters still dominate memory footprint and routing overhead.
Why this matters
If the numbers hold under independent replication, M2 demonstrates that agent-grade frontier capability is reachable at ~10B activated parameters when the full stack — data pipelines, interleaved-thinking SFT, and a trajectory-aware RL system — is co-designed for tool use. That reframes the cost frontier for deployable agents away from raw parameter count toward environment and rollout infrastructure.
Source: https://arxiv.org/abs/2605.26494
LLaVA-OneVision-2: Towards Next-Generation Perceptual Intelligence
Problem
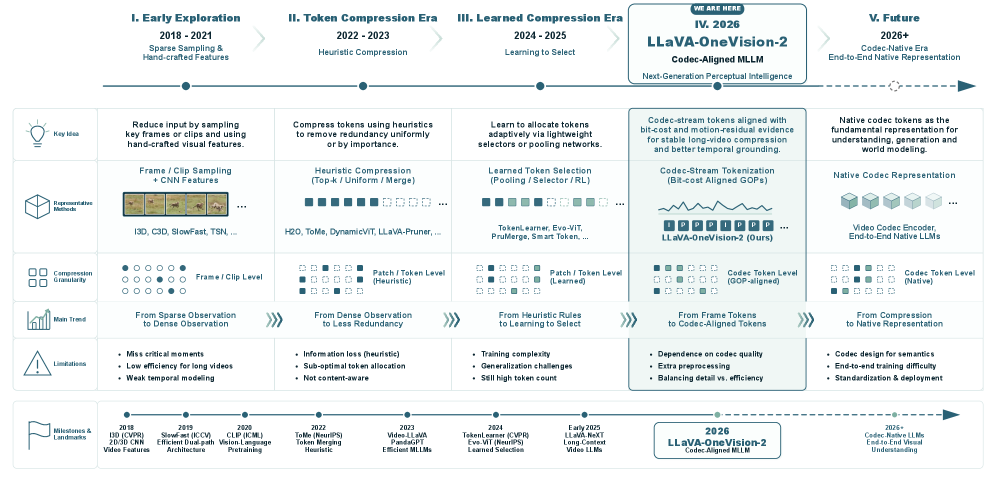
Frame-sampling video MLLMs allocate observation budget by elapsed wall-clock time. This is wasteful when content is mostly static and catastrophic when discriminative evidence lives at sub-second event boundaries — temporal grounding, fine-grained motion classification, repeated-cycle counting. Uniform GoP-style sampling treats all temporal slots as equally informative, while in practice the compressed bit-stream already encodes a strong prior over where novelty (and therefore semantic event content) lives. LLaVA-OneVision-2 (LLaVA-OV-2) reorganizes the video tokenization step around this signal.
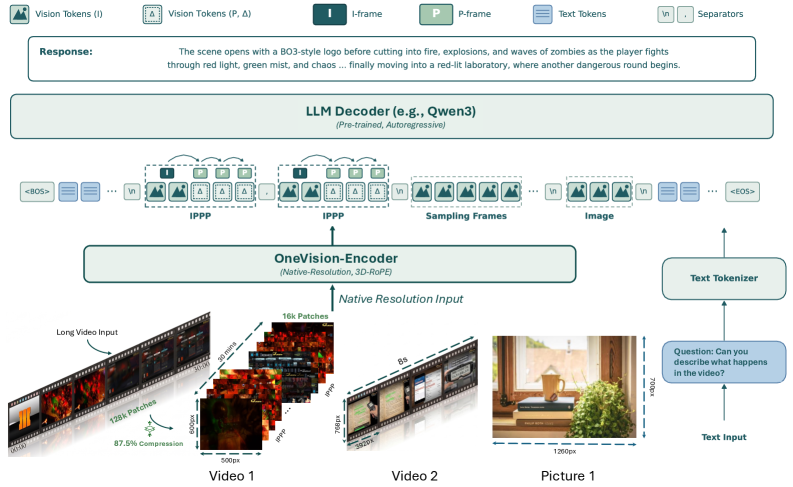
Method
The model is an 8B-class VLM built on the OneVision-Encoder backbone with windowed attention for native-resolution processing, a lightweight VL connector, and an autoregressive LM decoder. Three input modes — codec-stream video, uniformly sampled video, and static images — are mapped into a single visual-token interface. A shared 3D RoPE places I/P canvases, sampled frames, and image tokens in one spatiotemporal coordinate system, and group-visible attention masks define which tokens see each other (fixed 4-slot groups for sampled-frame/IPPP, single-temporal group for images, bit-cost-adaptive GoP ids for codec streams).
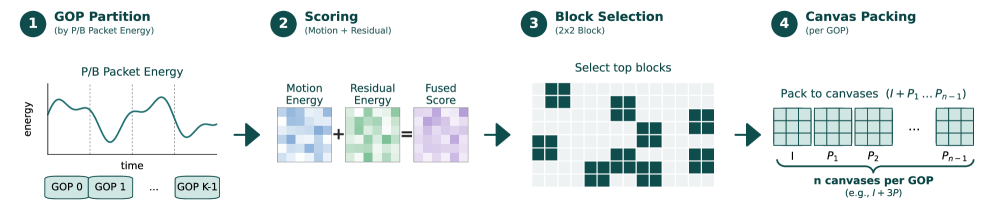
The central contribution is codec-stream tokenization. Rather than decoding to RGB and sampling fixed-rate frames, the model consumes the compressed bitstream directly:
- Adaptive GoPs from bit-cost. P/B packet bit-cost is used to partition the stream into variable-length GoPs. High-bit-cost intervals — those the codec found expensive to predict, i.e. high-novelty — receive their own GoP boundaries, concentrating tokens on event-bearing content.
- Motion-residual spatial saliency. Within each GoP, motion vectors and residual energy jointly score 2{\times}2 patch blocks. High-score blocks are selected and packed into compact visual canvases: one anchor I-canvas per GoP plus several P-canvases carrying motion-residual evidence.
- Group-aligned tokens. Each canvas’s tokens inherit a GoP id; group-visible masks let P-canvases attend to their anchor I-canvas, mirroring codec dependency structure.
Training uses a four-stage progressive recipe initialized from LLaVA-OneVision-1.5-8B, with each batch interleaving ~50% codec-patchified video, ~37.5% uniform chunk-wise video, and ~12.5% images. The corpora include the inherited 85M image–text mid-training set and 22M instruction set, FineVision (~24M), a newly released 30s-Video-Caption-4.2M, an 8M-clip / 104.1B-token re-captioned video pretraining mixture, and a 4M-sample spatial corpus covering 3D scenes, pointing, and referring expressions.
Results
On the 18-task video average across 8B-class baselines (Qwen3-VL-8B, Keye-VL-1.5-8B, InternVL-3.5-8B, PLM-8B, LLaVA-OV-1.5-8B), LLaVA-OV-2 reaches 62.5 vs Qwen3-VL’s 58.2. The differentiation concentrates exactly where codec-stream tokenization should help:
- JumpScore (the paper’s new fine-grained cycle-localization benchmark, 189 jump-rope clips with decimal-second cycle-start labels): 74.9 vs Qwen3-VL 30.1, Keye-VL-1.5 39.6, InternVL-3.5 11.0, LLaVA-OV-1.5 2.1.
- Temporal grounding: t/Charades 53.5, t/ActivityNet 53.8, t/QVHighlights 66.4 — all best-in-class by 5–35 points.
- Tracking (J&F avg, 4 RVOS tasks): 48.0 vs Qwen3-VL 32.4 and the rest below 9. DAVIS J&F is 58.7 vs 41.3 next-best.
- Spatial reasoning average (11 tasks): 63.5 vs 58.2 next-best, with TraceSpatial-3D 31.0 vs 8.0 and CrossPoint 61.9 vs 26.9 indicating sizable margins on the long-tail spatial tasks.
- Image/document average: 79.7, behind Qwen3-VL’s 80.7 but leading on V*-Bench (85.9).
The codec ablation isolates the mechanism. Holding backbone, prompts, and frame budget fixed, codec inputs lift JumpScore from an average 37.9 to 55.2 across six budgets (+17.3 absolute), and lift the three-benchmark temporal-grounding average from 35.5 to 45.2 (+9.7). Gains are largest at low frame budgets, where uniform sampling most often misses event boundaries: at 4 frames on Charades-STA, codec scores 42.4 vs 17.4 uniform; on QVHighlights at 16 frames, 51.5 vs 24.9. On long-form QA the deltas are smaller and not strictly monotonic (VideoMME-L-sub +1.2, LVBench +1.7, VideoEval-Pro +2.6), confirming that codec tokenization does not trade off semantic understanding for temporal precision.
Limitations
The codec representation is tied to the encoder’s bit allocation policy: re-encoded, low-bitrate, or screen-capture content with degenerate motion-vector statistics likely degrades the saliency signal. JumpScore is constructed around a single visually well-defined motion primitive (rope-behind-legs); whether the gains transfer to multi-primitive cyclic motion or non-rigid periodic events is untested. The image/document average trails Qwen3-VL, suggesting the codec/uniform mixed-batch composition mildly dilutes high-resolution document modeling. Finally, the paper does not report wall-clock or token-count efficiency under matched accuracy, so the compute story behind “stable long-video token compression” is partial.
Why this matters
Treating compressed video as the native input — rather than decoding and re-sampling — aligns the visual token budget with the codec’s own novelty estimate, and the empirical gains on event-localized tasks (+17.3 JumpScore, +26.6 QVHighlights@16) are larger than what scaling frame budgets buys. This is a concrete case where exploiting structure already present in the data pipeline outperforms brute-force frame density.
Source: https://arxiv.org/abs/2605.25979
MobileMoE: Scaling On-Device Mixture of Experts
Problem
MoE has dominated frontier-scale LMs but is largely absent below 1B active parameters, where on-device deployment lives. The standard rules of thumb at scale (DeepSeek-V3’s 256 experts top-8, Qwen3-MoE’s 128 experts top-8, Mixtral’s 8 experts top-2) give no guidance for the sub-billion regime, where mobile DRAM (~5 GB usable at INT4) and per-token compute budgets dominate over training-FLOP optimality. MobileMoE asks: under those constraints, what (E, k, g, s) is jointly memory- and compute-optimal, and can the resulting model beat strong dense on-device baselines at matched FLOPs?
Design space and base backbone
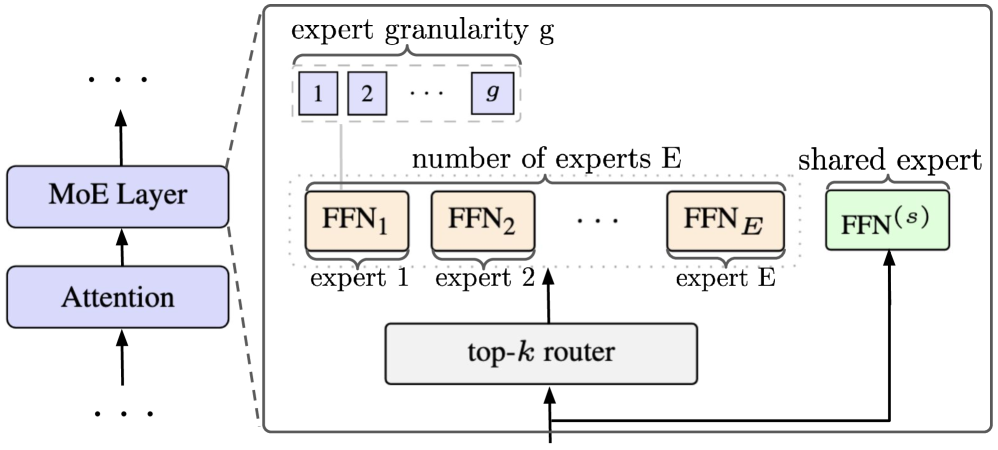
The MoE layer is parameterized as
\mathbf{y} = \sum_{i \in \text{Top-}gk} \text{router}_i(\mathbf{x}) \cdot \text{FFN}_i(\mathbf{x}) + \text{FFN}^{(s)}(\mathbf{x})
with three knobs: sparsity (E,k), granularity g (each expert split into g sub-experts of width d_{\text{ff}}/g, activating gk of gE experts), and a shared always-on expert s. The backbone follows on-device dense practice (MobileLLM, MobileLLM-Pro): expansion ratio d_{\text{ff}}/d_{\text{model}}=4, aspect ratio d_{\text{model}}/n_l \approx 40 (deep and narrow), GQA with 4 KV heads, SwiGLU. Three scales — S (768/3072/20L, 0.3B active), M (1024/4096/26L, 0.5B), L (1280/5120/32L, 0.9B) — sweep E \in \{1,2,4,8,16,32\}, g \in \{1,2,4,8,16\}, s \in \{\checkmark,\times\}.
On-device scaling law
The authors fit a Chinchilla-style law that augments (N_{\text{act}}, D) with a transformed expert count
\frac{1}{\hat{E}} = \frac{1}{E - 1 + (\tfrac{1}{E_{\text{start}}} - \tfrac{1}{E_{\max}})^{-1}} + \frac{1}{E_{\max}},
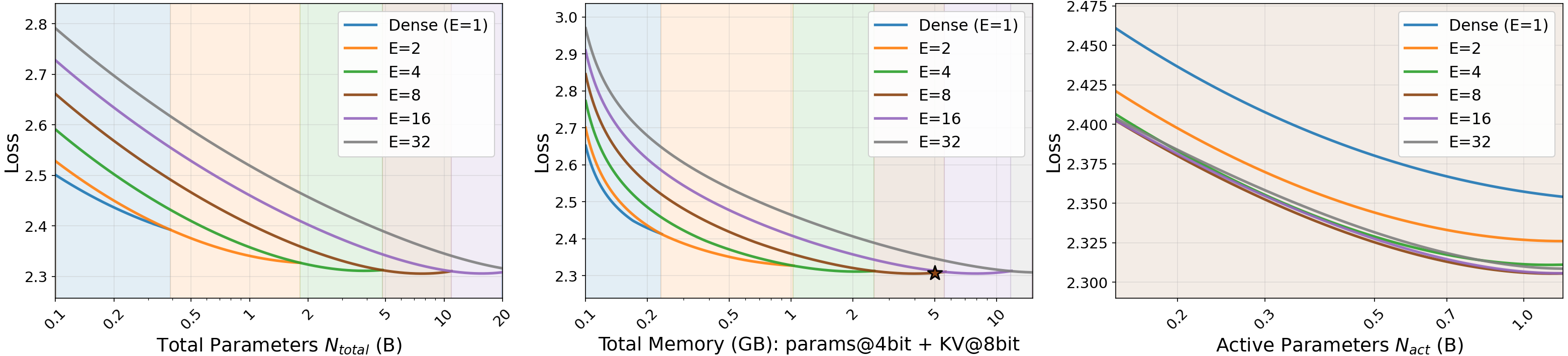
with E_{\text{start}}=1, E_{\max}=32 chosen so total parameters fit a 5 GB INT4 mobile DRAM budget at N_{\text{act}} \in \{0.3, 0.5, 0.9\}B. Fitting uses curve_fit warm-start then L-BFGS-B on MSE; ablations sweep up to ~500B tokens. Three findings emerge sequentially (each fixing the prior optimum):
- Sparsity: E^\star = 8. Loss decreases with E at fixed N_{\text{act}} but flattens beyond 8 once total-parameter / memory cost is included.
- Granularity: g^\star = 8 (so 64 fine sub-experts, top-gk routing).
- Shared expert: s = \checkmark helps.
The Pareto picture in active vs. total parameters vs. on-device memory \mathcal{M} shows the E=8 curve sitting at the knee under a 5\times 10^{20} FLOP training budget.
Training recipe
Four stages, all on open data (Dolma3 + MobileLLM curated mix; web 62%, math 11.6%, code 10%, knowledge 10%, science 6.4%):
- PT: ~6T tokens, ctx 2048, batch 2048/3072 (S,M / L), peak LR 4\times 10^{-4}, cosine to 0.1, drop-and-pad dispatch, 3–4 weeks on 16–32 H100 nodes.
- MT: ~500B tokens, ctx 8192, linear decay from 4\times 10^{-5}.
- SFT: ~126B tokens, dropless dispatch, cosine from 4\times 10^{-6} to 0.
- QAT: ~21B tokens, INT4 weights (group 32), INT8 activations, INT4 embeddings.
AdamW (\beta_1, \beta_2, \epsilon) = (0.9, 0.95, 10^{-15}), weight decay 0.1, grad clip 1.0, BF16 weights with FP32 router/optimizer/grads throughout.
Results
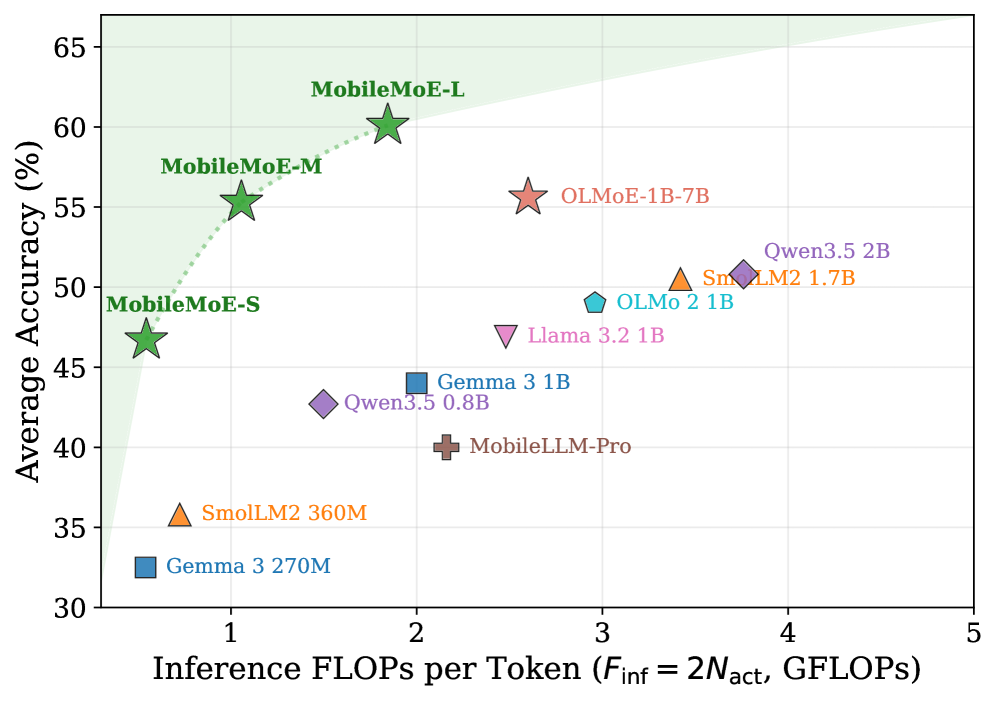
Across 14 foundational benchmarks (HellaSwag, PIQA, SIQA, WinoGrande, MMLU, NQ, TriviaQA, ARC-C/E, OBQA, BoolQ, DROP, BBH, GSM8K) evaluated via lm-eval with greedy decoding, MobileMoE matches or exceeds leading dense on-device LLMs (Gemma 3 270M/1B, SmolLM2 360M/1.7B, MobileLLM-Pro 1.1B, Llama 3.2 1B, OLMo 2 1B, Qwen3.5 0.8B/2B) at 2–4× fewer inference FLOPs (F_{\text{inf}} = 2 N_{\text{act}}), and matches or surpasses OLMoE-1B-7B with up to 60% fewer total parameters.
Expert utilization analysis post-training shows (i) cross-task specialization — math, code, and knowledge activate distinct subsets of the 60 fine-grained experts — and (ii) progressive broadening of utilization from PT → MT → SFT. Math activates a wider expert set than code or knowledge, suggesting task-conditional expert prefetching or pruning could shave on-device memory further.
Limitations and open questions
- The scaling-law fit uses E_{\max}=32 tied to a 5 GB INT4 budget; under different memory regimes (e.g., higher-end NPUs with 8–12 GB) the optimum likely shifts and the paper does not characterize that frontier.
- Sweeps go to ~500B tokens, while final models train on ~6T; whether E^\star=8, g^\star=8 remain optimal at 10× more data is extrapolated, not measured.
- Top-k for the shared+routed mix and load-balancing loss coefficients are not ablated in the excerpt.
- The mobile inference kernel claims (custom MoE kernel, iPhone 16 Pro and Galaxy S25 deployment) are stated but the wall-clock numbers are not in the provided sections.
- Routing under INT4 weights / INT8 activations: QAT is applied after SFT, but the sensitivity of fine-grained experts to quantization (compared to coarse experts) is not separately characterized.
Why this matters
This is the first systematic derivation of MoE design choices under realistic mobile memory and compute constraints, and it lands on a concrete recommendation — moderate sparsity (E=8), high granularity (g=8), shared expert — that delivers 2–4× FLOP savings over dense on-device baselines without losing accuracy. If the inference-kernel results hold up, sub-billion-active MoE becomes a credible default for on-device LMs rather than a frontier-only architecture.
Source: https://arxiv.org/abs/2605.27358
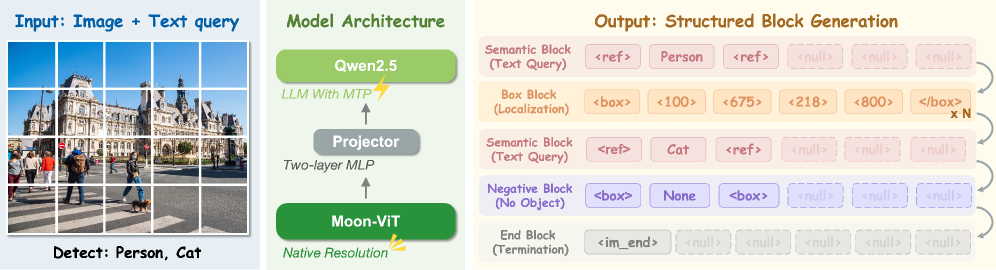
LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
Problem
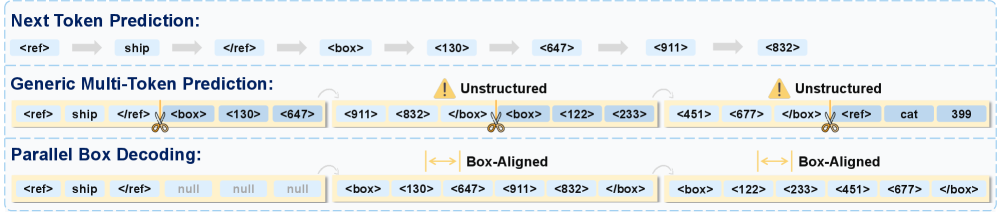
Generative VLMs that perform detection and grounding typically serialize each 2D box as a sequence of coordinate tokens (or worse, digit-by-digit text), then decode them under standard next-token prediction (NTP). Two issues follow. First, the four numbers defining a box are geometrically coupled (e.g., x_2 > x_1, aspect ratio constraints), but autoregressive decoding factorizes them as \prod_t P(c_t \mid c_{<t}), learning each coordinate largely independently and accumulating errors. Second, decoding throughput is bounded by the number of tokens per box times the number of boxes; on dense scenes (LVIS, SKU110K) this becomes the dominant cost. Existing multi-token prediction (MTP) heads decode several tokens at once but ignore the block structure of a box, producing inconsistent geometry.
Method
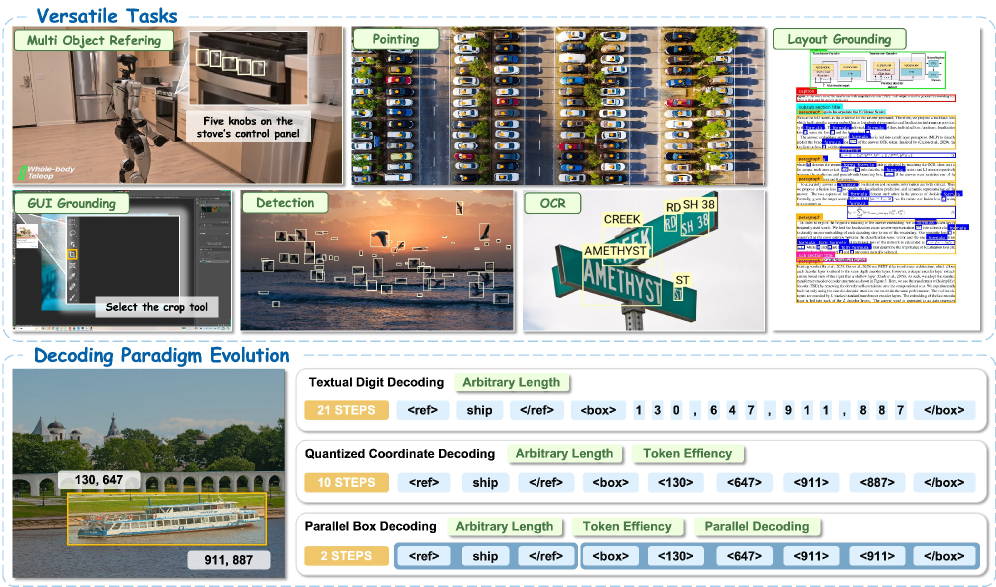
LocateAnything keeps a standard VLM backbone — Moon-ViT vision encoder, MLP projector, Qwen2.5 LM — operating at native resolution, but replaces coordinate-token NTP with Parallel Box Decoding (PBD) over fixed-length blocks.
Block-based output. Coordinates are normalized to [0,1000] and quantized into discrete tokens (à la Pix2Seq/Rex-Omni). Outputs are reorganized into a sequence of blocks \mathbf{B}=(b_1,\dots,b_N) with constant length L=6 (four coordinate slots plus <box>/</box> structural tokens; padding via <null>). The factorization is
P(\mathbf{B}\mid \mathcal{Z},\mathcal{E})=\prod_{i=1}^{N}P(b_i \mid b_{<i},\mathcal{Z},\mathcal{E}),
with each b_i predicted atomically — all six positions are decoded in a single forward step rather than sequentially. Four block types form a small grammar: Semantic blocks (linguistic identity, multi-block if long), Box blocks (the four quantized coordinates), Negative blocks (object absent), and End blocks (termination).
The key distinction from generic MTP is that the parallel head is aligned to the geometric unit. Generic MTP predicting k future tokens ignores box boundaries and produces decoded chunks that straddle different objects, yielding the irregular patterns shown in Figure 2. PBD instead constrains the parallel slot to a single box, so intra-box dependencies (the four corners) are modeled jointly while inter-box dependencies remain autoregressive at the block level.
Training. A two-stage SFT on top of a base VLM that is first aligned on world-knowledge corpora (no detection/grounding data). Stage-1 mixes 138M grounding/detection queries from a curated dataset (LocateAnything-Data). Stage-2 reduces general data to 20% and upweights dense-object sources (MOT20Det, SKU110K) to push high-IoU performance. The training objective combines NTP for semantic/control tokens with block-level MTP for box blocks, so the model learns to emit four coordinates in parallel conditional on prior blocks.
Inference. A hybrid mode allows switching between fully parallel block decoding (max throughput) and per-token decoding (max robustness) on demand, useful when downstream calibration or constrained decoding is needed.
For ablations isolating the architectural contribution of PBD from the data-scale contribution, the authors retrain on COCO only.
Results
On LVIS (zero-shot) and COCO, LocateAnything-3B reports:
- Throughput (BPS, boxes/sec, normalized to MiMo-VL-7B = 1.0): 12.7, versus 5.0 for Rex-Omni-3B and ≈1.0–1.3 for Qwen3-VL-4B/8B, OVIS2.5-2B, MiMo-VL-7B, Cosmos-Reason2-8B. ~2.5× over the closest VLM grounding specialist and ~10× over standard VLMs.
- LVIS F1@IoU: 0.5 = 62.3, 0.95 = 31.1, mean = 50.7. Rex-Omni-3B: 64.3 / 20.7 / 46.9. SEED1.5-VL: 65.6 / 19.5 / 46.7. The model sacrifices ~2–3 points at the loose 0.5 threshold but gains ~10 points at IoU 0.95, suggesting PBD’s joint corner prediction tightens box geometry.
- COCO F1@IoU: 0.5 = 70.1, 0.95 = 19.3, mean = 54.7. Beats DINO-R50 (55.6 mean) and matches the much heavier DINO-Swin-L on mean F1 trends, while remaining a generative open-vocabulary VLM. At IoU 0.95 it surpasses Rex-Omni-3B (15.9) and Grounding DINO-Swin-T (23.0 — still ahead, but with a specialized detector).
The pattern across both benchmarks is consistent: PBD trades a small amount of recall at loose IoU for substantial gains at strict IoU, while delivering 2.5–10× decoding throughput.
Limitations and open questions
- The reported BPS is a relative throughput against a chosen baseline; absolute latency, batch effects, and prefill cost on dense images are not broken out here.
- Block length is fixed at L=6. Tasks like polygon segmentation, oriented boxes, or 3D boxes need different L, and the paper does not show how PBD scales when the atomic unit is larger or variable.
- The 138M-sample data engine confounds architectural and data contributions for the main numbers; only COCO-only ablations isolate PBD, and these are not detailed in the excerpt.
- Joint distribution over the four coordinates is modeled by parallel head outputs that are conditionally independent given b_{<i}; this is weaker than truly joint factorization (e.g., autoregressive within the block). Whether this hurts in extreme aspect-ratio or occlusion cases is unclear.
- Drop at loose IoU 0.5 vs Rex-Omni/SEED1.5-VL suggests PBD may underperform on coarse recall; the trade-off may not suit recall-driven applications.
Why this matters
Coordinate-token serialization has been the default for generative grounding, but it is a poor inductive bias for box geometry and the dominant inference bottleneck. Aligning the parallel decoding unit to the geometric atom recovers throughput without giving up the open-vocabulary, instruction-following advantages of VLMs, and actually improves high-IoU localization — making generative detectors closer to competitive with specialized closed-set detectors at strict thresholds.
Source: https://arxiv.org/abs/2605.27365
MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research
Problem
Mobile GUI agent research has been bottlenecked by two coupled deficits: (i) lack of deterministic, programmatic outcome verification on everyday consumer apps, which forces evaluation to rely on free-text matching or human review, and (ii) the prohibitive cost of running parallel rollouts on real devices or full Android emulators, which blocks online RL at any meaningful scale. Existing emulator-backed benchmarks reproduce Android internals at the cost of throughput; existing static datasets sidestep the runtime entirely and lose interaction fidelity. MobileGym argues for a third option: faithfully reproduce the interaction surface of mobile apps in a browser-hosted simulator, while keeping all environment state as structured JSON that can be snapshotted, forked, and diffed.
Method
The platform is built around a layered state model (Figure 3): a read-mostly World Data layer (e.g., catalogs, contacts, content corpora), a per-environment Runtime Overlay (mutable session state, drafts, transient app state), and an OS Runtime that implements Android-like mechanisms — task stacks, keyboard, notifications, permissions, intents, content sharing, and back-key dispatch.
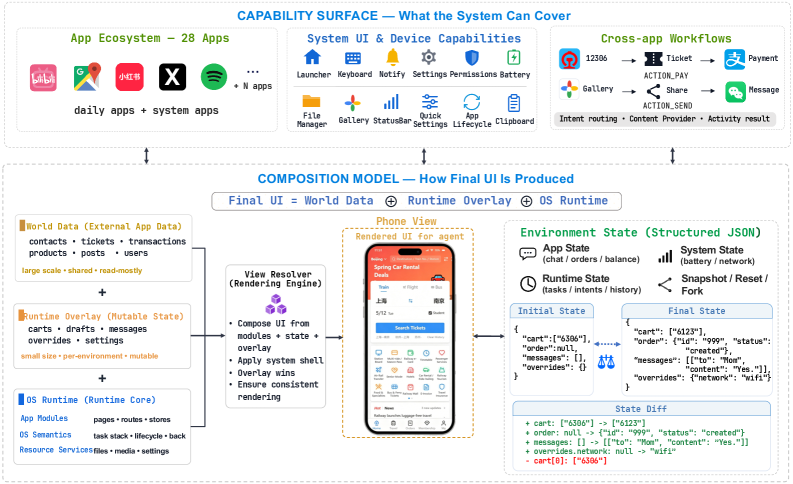
Crucially, the authors do not aim for pixel-level Android fidelity or backend reproduction. The target is the agent-visible interaction surface: visual screens, touch/typing responses, navigation, cross-app handoffs, and task-relevant transitions. Because all of this is implemented in the browser over structured local state, the entire environment is readable, writable, and forkable.
This buys two operational properties:
- Verifiable outcomes via state diff. A task is judged by comparing post-rollout JSON state against a declarative goal specification, producing a deterministic verdict and a dense progress signal usable as RL reward. Free-text matching is replaced by a structured AnswerSheet protocol, eliminating a common source of false negatives in query-style tasks.
- High parallelism. Reported per-instance footprint is roughly 400 MB memory and ~3 s cold start, with hundreds of instances per server. Snapshot/reset/fork on JSON state makes rollout branching cheap.
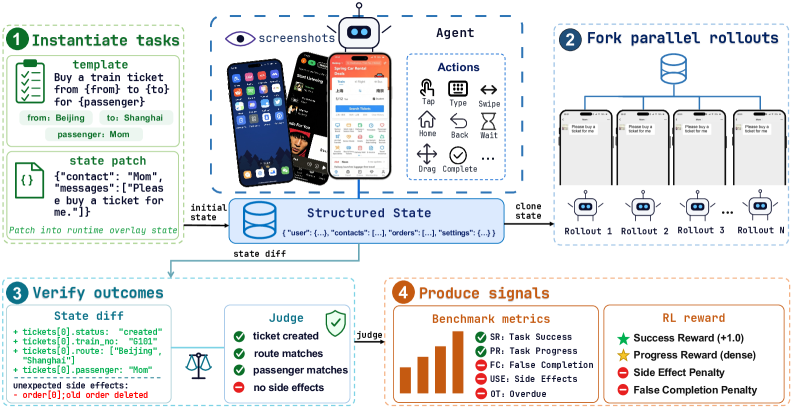
The benchmark layer (MobileGym-Bench) sits on top with 416 parameterized task templates (256 test, 160 train, strictly disjoint) over 28 apps. Tasks are factored along four orthogonal axes:
- Scope — S1 (single-app), S2 (two-app), S3 (\geq 3 apps).
- Objective — operate (state-changing), query (retrieval), hybrid.
- Composition — atomic, sequential, transfer (cross-app handoff), deep-dive (multi-step drill-down).
- Difficulty — L1–L4, calibrated post-hoc against eight reference models.
Each task carries 1–4 tags from a 13-tag capability vocabulary. The orthogonal factoring matters because prior taxonomies (e.g., Mind2Web-style) conflate app-count with subtask-count, making per-axis ablation impossible.
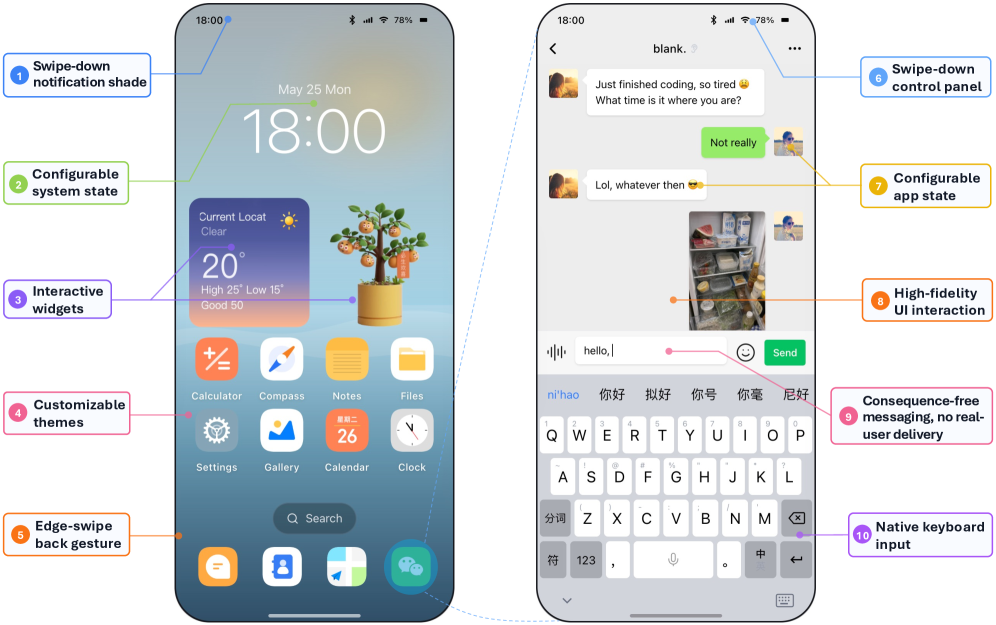
Results
Nine agents were evaluated on the 256-task test set, with open-source models run 4 trials and proprietary models 1 trial (2 for Gemini 3.1 Pro). Headline numbers:
- Overall SR range: 9.4%–58.8% (a 6× spread), with no saturation at the top or floor at the bottom.
- Gemini 3.1 Pro: 58.8 ± 1.4 SR / 72.1 PR; Doubao-Seed-2.0-Pro: 52.0; Qwen3.6-Plus: 45.7.
- Open-source GUI specialists cluster low: AutoGLM-Phone-9B 20.0, UI-Venus-1.5-8B 15.4, GUI-Owl-1.5-8B-Think 15.1, UI-TARS-1.5-8B 13.8, Step-GUI-4B 12.9. The generalist Qwen3-VL-4B-Instruct sits at 9.4.
- Difficulty stratification is monotone for all 9 models. L1 (n=20) already separates proprietary from open-source: 97.5/100/100 for the three proprietary models vs. 71.2–86.2 for open-source. L4 (n=80) is the frontier: only Gemini 3.1 Pro retains 21.9%; the next proprietary model is at 6.2%, and all open-source GUI specialists are \leq 1.9%.
- Diagnostics decompose failures: False Complete (FC), Overdue Termination (OT), Unexpected Side Effects (USE). FC is high across the board (22.9–39.6%), suggesting models frequently declare success without satisfying the state-diff judge — a failure mode invisible to free-text evaluators.
The Sim-to-Real case study reports GRPO on Qwen3-VL-4B-Instruct gaining +12.8 percentage points (abstract is truncated mid-sentence; the full transfer target is presumably a real-device benchmark), demonstrating that rewards from the state-diff judge transfer beyond the simulator.
Limitations and open questions
- Visual fidelity gap. UIs are LLM-assisted reproductions and differ in pixel-level detail from real apps; how much sim-to-real transfer this costs for vision-heavy grounding tasks is not fully quantified beyond the GRPO case study.
- Backend semantics are simulated, not real. Tasks that depend on live web data, recommendation feeds, or service-side logic cannot be expressed faithfully.
- Judge coverage. Deterministic state-diff judging assumes the goal is expressible in the structured state schema; tasks with subjective or aesthetic outcomes fall outside this contract.
- L4 ceiling. With most models scoring near zero on L4, the benchmark currently provides little gradient signal at the frontier for non-Gemini-class systems.
- Generalization of capability tags. The 13-tag vocabulary and L1–L4 calibration are anchored to eight reference models; recalibration will be needed as agent capabilities shift.
Why this matters
MobileGym makes online RL on everyday mobile tasks tractable by replacing emulator-bound rollouts with forkable JSON state and replacing free-text evaluation with deterministic state diffs — the two missing primitives that have kept GUI agent training stuck on offline trajectories. The 6× SR spread across 9 models without saturation suggests it will remain a useful discriminator for the next iteration of GUI agents.
Source: https://arxiv.org/abs/2605.26114
EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation
Problem
Current video-generation benchmarks (VBench, EvalCrafter, VADB, CineTechBench, UniVBench) optimize for “is the output correct?” — prompt-following, basic temporal consistency, isolated visual quality — and largely ignore “is the output good cinema?” Aesthetic, directorial, acting, and post-production qualities are either absent or only partially covered. As foundation models move from short clips toward multi-shot narrative synthesis with native audio (Kling-v3-Omni, Seedance 2.0, HoloCine, LTX2), the evaluation gap becomes a bottleneck for both research progress and RL/agentic post-training, where reward signal quality directly determines policy quality. EvalVerse argues that evaluation should be treated as the systematic digitization of subjective cinematic expertise rather than as a checklist of automatic metrics.
Taxonomy and dataset
EvalVerse organizes evaluation around the professional filmmaking workflow — Pre-Production, Production, Post-Production — even though current models synthesize end-to-end. The taxonomy contains 3 production stages, 7 cinematic aspects, 18 main dimensions, 45 sub-dimensions, and 196 granular rationales.
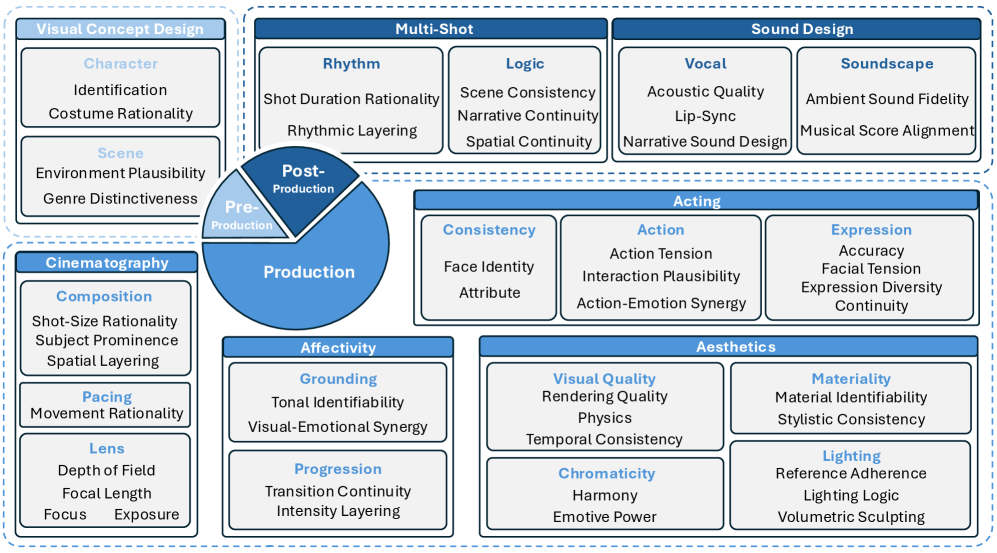
Pre-Production audits “Visual Concept Design”: Character (Identifiability, Costume Rationality) and Scene (Environment Plausibility under physical/spatial logic, Genre Distinctiveness against stylistic mixing). Production splits into Acting, Cinematography (Composition, Pacing, Lens), Aesthetics (Visual Quality, Chromaticity, Lighting, Materiality), and Affectivity (Grounding, Progression). Post-Production covers Multi-Shot (Logic, Rhythm) and Sound (Vocal, Soundscape). Compared against the seven prior benchmarks in Table 2, EvalVerse is the only framework with full coverage across all 14 listed dimensions.
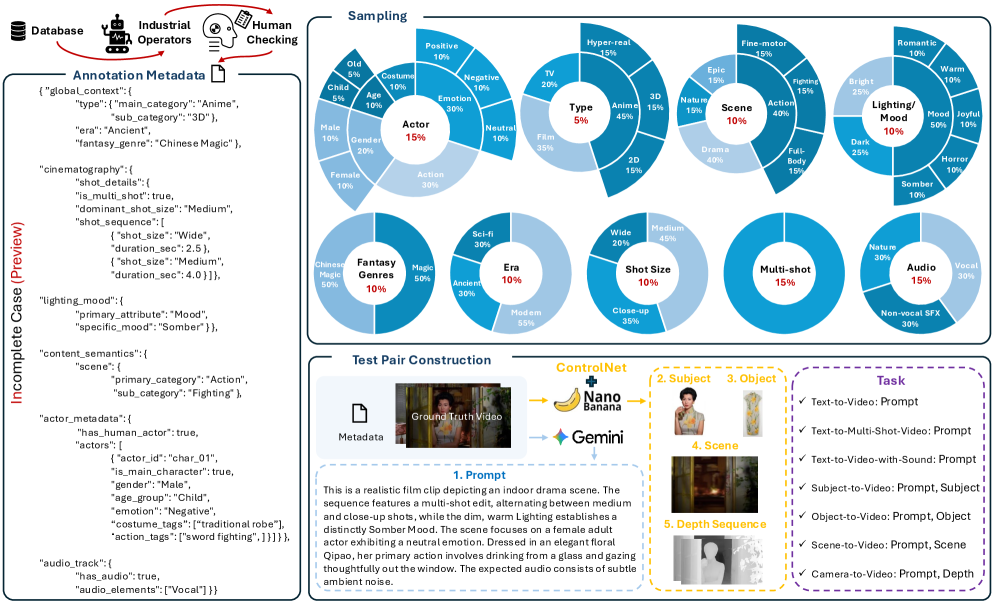
The data engine produces “Real-to-Gen” test pairs from a curated database of professional films. A multi-modal perception suite extracts structured metadata (camera parameters, character attributes, environments), followed by manual verification. Sampling is proportional across 9 cinematic dimensions rather than stochastic. Gemini 3.1 Pro converts metadata + raw captions into cinematic test prompts; Nano Banana Pro produces high-fidelity reference images for subject-driven (R2V) tasks; depth controls come from a ControlNet-tuned model.
Machine evaluation suite
The objective is to approximate expert annotation \mathcal{H}:
\mathbf{S} \approx \mathcal{H}(V, A, p, r), \quad V \in \mathbb{R}^{T \times H \times W \times C}, \; \mathbf{S} \in \mathbb{R}^{D}
The pipeline is two-stage. First, a bank of specialized perception operators \Phi = \{\phi_1, \dots, \phi_K\} extracts deterministic evidence:
E_{\text{prof}} = \bigcup_{k=1}^{K} \phi_k(V, A, p, r)
Operators include DINO and InsightFace for cross-frame identity tracking, YOLO for semantic anchoring, SyncNet for audio-visual sync, and Whisper for speech emotion. This sidesteps the well-known fragility of VLMs on fine-grained temporal and low-level perception tasks. Second, a fine-tuned VLM ingests E_{\text{prof}} together with multi-question rationales drawn from the 196-rationale taxonomy and produces dimension-wise scores via step-by-step reasoning.
Human–machine calibration
Calibration is three-tiered:
- Prompt-Level (Rationale Replacement) — abstract rationales beyond VLM perceptual reach are iteratively replaced.
- Fusion-Level (Weight Optimization) — a lightweight MLP trained on human annotations learns weights mixing per-question scores, E_{\text{prof}} evidence, and VLM CoT outputs, absorbing operator OOD failures and VLM reasoning errors.
- Parameter-Level (Knowledge Injection) — supervised fine-tuning on the expert dataset converts a generic VLM into a cinematic reward model.
Quantitative results
Human evaluation uses a three-stage protocol (discriminative side-by-side ranking against ground-truth video, senior-filmmaker pass/fail QA, expert final audit) covering 11 generators including closed-source (Kling-v3-Omni, Seedance 2.0, Happy Horse 1.0, Vidu-Q2-Pro, Hailuo 2.3), open-source (Hunyuan 1.5 8.3B, LTX2 19B, Wan2.2 14B), and multi-shot/audio-visual specialists (HoloCine 14B, MultiShotMaster 14B).
Table 3 reports machine vs. human pairwise win-ratios per dimension. A few representative alignments: on Consistency, Seedance 2.0 scores 0.79/0.81 and Hailuo 2.3 0.90/0.70; on Pacing, Hailuo 2.3 reaches 0.90/0.90 and Seedance 2.0 0.81/0.75; on Visual Quality, Kling-v3-Omni 0.66/0.84 and Happy Horse 1.0 0.68/0.78; on Multi-Shot Logic, Happy Horse 1.0 0.80/0.88 and HoloCine 0.45/0.75; on Sound Vocal, Happy Horse 1.0 0.85/0.72. Across the table, machine and human win ratios track closely, with the largest residuals concentrated on highly subjective dimensions (Character identifiability for Hailuo 2.3: 0.48/0.89; Affectivity Grounding for Hailuo 2.3: 0.56/0.86) where VLM perceptual ceilings remain limiting. Among generators, Happy Horse 1.0, Seedance 2.0, and Kling-v3-Omni dominate most production-stage dimensions; LTX2 and HoloCine lead within their multi-shot/audio-native niches; MultiShotMaster underperforms broadly (often 0.05–0.25 win ratio) despite multi-shot specialization.
Limitations and open questions
The framework relies on Gemini 3.1 Pro and Nano Banana Pro for prompt and reference synthesis — pipeline outputs are tied to these proprietary systems. The fusion-MLP is trained on the very expert annotations it must generalize from, raising standard concerns about preference-data overfitting and judge-model collusion. Several dimensions (Multi-Shot Logic/Rhythm, Sound) are evaluated only on the small subset of models supporting them, so cross-model comparison there is partial. Finally, the operator suite is a fixed set; failure modes outside its coverage (e.g., subtle continuity errors, narrative causality) still depend entirely on VLM reasoning, where calibration drifts with model updates.
Why this matters
If RL post-training of video models is the next frontier, reward quality is the binding constraint, and current benchmarks underspecify what “good” cinema means. EvalVerse provides a domain-grounded taxonomy and a calibrated VLM-plus-operator judge whose per-dimension rankings track expert judgment closely, making it a plausible reward backbone for cinematic-grade RLHF rather than just a leaderboard.
Source: https://arxiv.org/abs/2605.23271
Hacker News Signals
A sleep-like consolidation mechanism for LLMs
Source: https://arxiv.org/abs/2605.26099
The paper proposes a training-time consolidation phase analogous to sleep-stage memory consolidation in biological neural systems. The core problem: LLMs trained on sequential data suffer from catastrophic forgetting, and standard continual learning mitigations (EWC, replay buffers) either impose computational overhead or require access to old data.
The mechanism works by periodically interrupting gradient updates on new data and instead running an offline “consolidation pass” that replays internally generated synthetic samples — produced by the model itself via sampling — weighted by a measure of representational change. The key quantity is a KL divergence between the current model’s output distribution and a frozen “pre-consolidation” checkpoint, used to identify which parts of the parameter space drifted most. Parameters are then selectively regularized proportional to their Fisher information estimated on the synthetic replay set.
Formally, the consolidation loss adds:
\mathcal{L}_{\text{cons}} = \lambda \sum_i F_i (\theta_i - \theta_i^*)^2
where F_i is the diagonal Fisher estimate on the synthetically replayed sequences and \theta^* is the pre-consolidation snapshot. This is EWC-style, but with the crucial difference that F_i is estimated on self-generated data rather than held-out task data, making it applicable in settings where the original training corpus is unavailable.
Experiments show retention of previously learned tasks improves by 15–30% (measured by perplexity on held-out task benchmarks) relative to naive fine-tuning baselines, with consolidation overhead under 10% of total training compute. The method is tested on sequential fine-tuning across coding, math reasoning, and instruction-following tasks.
Limitations: the self-generated replay data can be low-quality for tasks where the model is already weak, creating a feedback loop. Fisher diagonal is a crude approximation for large transformer weight matrices, and the method has not been tested at scales above ~7B parameters.
Why this matters
Continual learning without replay data access is a practical requirement for deployed fine-tuning workflows; a cheap self-distillation mechanism that does not require storing prior data is directly useful for production LLM adaptation pipelines.
All of human cooking compressed into 2 megabytes
Source: https://arxiv.org/abs/2605.22391
This paper is a data compression / knowledge representation exercise: the authors attempt to encode a broad corpus of culinary knowledge — recipes, ingredient substitution rules, technique descriptions — into a 2 MB artifact that can be queried without a neural network at inference time. The framing is information-theoretic: how much of a domain’s actionable knowledge is recoverable from extreme compression?
The approach combines several steps. First, a large recipe corpus is parsed and normalized into a structured intermediate representation (ingredient, quantity, technique, sequence). Second, a grammar-based compression scheme is applied: recurring sub-sequences (e.g., “sauté onions until translucent”) are factored into a shared dictionary using a variant of Lempel-Ziv with domain-specific tokenization. Third, ingredient substitution graphs and flavor pairing metadata are stored as compressed adjacency structures.
The 2 MB figure comes from the final gzip-compressed binary of this structured representation. Decompressed, the artifact is ~40 MB. Querying is done via a small deterministic lookup engine rather than any learned model — the “intelligence” is entirely in the encoding schema.
Evaluation is qualitative and via recipe reconstruction: given an ingredient list, the system retrieves a plausible technique sequence. The authors report ~70% of test queries return a “culinarily coherent” response as rated by human annotators, though the rating protocol is not rigorous.
The technical interest lies more in the compression architecture than the culinary application: the domain-specific grammar induction that achieves better-than-generic compression ratios on procedural text. Generic gzip on the same corpus produces a ~12 MB artifact; the structured approach gets to 2 MB by exploiting procedural redundancy.
Limitations are significant: the coherence metric is subjective, coverage of non-Western cuisines is thin, and the system handles no quantity scaling or dietary constraint reasoning.
Why this matters
The grammar-induction approach to domain-specific procedural text compression is transferable to other instruction-heavy domains (assembly manuals, lab protocols) where structured redundancy can be exploited far more aggressively than generic compressors allow.
DeepSeek Reasonix: DeepSeek native coding agent with high caching and low cost
Source: https://esengine.github.io/DeepSeek-Reasonix/
Reasonix is an open-source coding agent built specifically around DeepSeek’s API, optimized to minimize token cost through aggressive prompt caching and context reuse. The technical substance is in the caching architecture rather than the agent logic itself.
The core observation: DeepSeek’s API charges a significantly reduced rate for cache hits on the prefix portion of prompts (~10x cheaper in their tier). Reasonix structures every agentic turn so that the system prompt, tool definitions, and conversation history up to a checkpoint are frozen as the cacheable prefix, and only the new turn’s content is appended as the uncached suffix. This requires careful serialization: the prefix must be byte-identical across calls to hit the cache, which means tool definitions, system instructions, and prior assistant turns must be rendered deterministically — no timestamps, no UUID nonces, no ordering variation.
The agent loop itself follows a standard ReAct pattern: reason, act (call a tool — shell, file read/write, search), observe, repeat. What is non-standard is the “context compaction” step: when the uncached suffix grows beyond a configurable token budget, the agent summarizes intermediate tool outputs into a compressed observation string and rolls that into a new frozen prefix, creating a new cache checkpoint. This prevents unbounded context growth while preserving cache efficiency.
The implementation is in Python, integrates with DeepSeek’s OpenAI-compatible endpoint, and reports cost reductions of 60–80% on multi-turn coding tasks compared to a naive stateless agent that sends full context each turn. Benchmark tasks include SWE-bench-lite style repository edits.
Limitations: cache invalidation on any prefix change wipes the savings entirely, so the system is brittle to prompt iteration. It also ties the workflow to DeepSeek’s specific caching semantics, which differ from other providers.
Why this matters
Prompt-prefix caching is underutilized in most agentic frameworks; Reasonix demonstrates that structuring agent state around provider cache boundaries is a first-class engineering concern with large cost implications.
Rosalind: A genomics toolkit in Rust running whole-genome pipelines on a laptop
Source: https://github.com/logannye/rosalind
Rosalind is a Rust library targeting whole-genome sequencing analysis tasks — alignment, variant calling, quality control — designed to run on commodity hardware without a cluster. The engineering focus is on memory efficiency and parallelism via Rust’s ownership model and Rayon-based thread pools.
The toolkit implements several core bioinformatics algorithms from scratch in safe Rust: a BWT/FM-index construction for reference genome indexing, a banded Smith-Waterman aligner for short reads, and a basic haplotype-aware variant caller using a pileup model. The FM-index construction is worth noting: it uses a prefix-doubling suffix array construction (SA-IS variant) that runs in O(n) time and fits a human reference genome index (~3 GB) in under 6 GB RAM, enabling use on a 16 GB laptop.
Parallelism is at the read-batch level: FASTQ files are chunked, and Rayon dispatches alignment jobs across available cores. The lack of shared mutable state in the aligner (each read is independent) maps cleanly onto Rust’s ownership rules, and the author notes zero data races required no manual synchronization.
Performance numbers given: aligning 30x coverage WGS reads (human genome) takes approximately 45 minutes on an M2 MacBook Pro with 16 GB RAM, compared to ~15 minutes for BWA-MEM2 on the same hardware. The 3x gap is expected given BWA-MEM2’s SIMD-optimized seed chaining, which Rosalind does not yet implement.
Variant calling is described as “research quality” — the pileup caller lacks the statistical models of GATK HaplotypeCaller, so it is not production-ready for clinical use.
Limitations: no SIMD acceleration yet, no structural variant support, and the variant caller’s accuracy on indels is not benchmarked against gold-standard truth sets like GIAB.
Why this matters
A readable, dependency-light Rust genomics library lowers the barrier to embedding bioinformatics into larger Rust applications and serves as a cleaner teaching substrate than the C/C++ codebases that dominate the field.
Using HTTP/2 Cleartext for a server in Go 1.24
Source: https://www.clarityboss.com/blog/go-http2-cleartext-h2c-cloud-run
HTTP/2 Cleartext (h2c) is HTTP/2 without TLS, used in service-mesh and load-balancer-to-backend communication where TLS termination happens at the ingress layer. Go’s standard library net/http enables HTTP/2 only over TLS by default; enabling h2c requires explicit use of golang.org/x/net/http2/h2c.
The post walks through the specific incantation required in Go 1.24:
h2s := &http2.Server{}
handler := h2c.NewHandler(mux, h2s)
server := &http.Server{Addr: ":8080", Handler: handler}
server.ListenAndServe()The h2c.NewHandler wrapper intercepts the connection upgrade handshake (the PRI * HTTP/2.0 preface) and delegates to the http2.Server instance for h2c connections while falling back to HTTP/1.1 for standard requests. Without this wrapper, Go’s HTTP server silently downgrades h2c connections to HTTP/1.1, which is a non-obvious failure mode when deploying behind Google Cloud Run’s internal load balancer, which does send h2c.
The post also documents the Cloud Run-specific requirement: setting the --use-http2 flag in the gcloud run deploy command to instruct the frontend to use h2c rather than HTTP/1.1 toward the backend container. Without it, multiplexing benefits are lost even if the server supports h2c.
Practical implication: h2c enables request multiplexing over a single TCP connection from the load balancer to the backend, reducing connection overhead for high-QPS services. The post measures connection count dropping from O(concurrent requests) to O(1) in a simple benchmark.
The technical gap filled here is that Go’s documentation does not clearly explain the h2c downgrade behavior, and the Cloud Run flag is buried in the reference docs.
Why this matters
h2c is the standard backend protocol for gRPC and HTTP/2 in cloud-native stacks; understanding Go’s opt-in behavior prevents silent performance regressions when deploying behind TLS-terminating infrastructure.
Outsourcing plus local AI will soon become more economical vs. frontier labs
The post makes a cost-structure argument: for many software development tasks, combining offshore labor with locally-run open-weight models will undercut API costs to frontier providers (GPT-4o, Claude 3.5 Sonnet, etc.) within 1-2 years. The technical substance lies in the cost decomposition.
The author models a development workflow as: specification → code generation → review → test. Frontier API costs for code generation at scale are estimated at $2–8 per 1,000 lines of production code (based on token counts for typical prompt/completion ratios with GPT-4o pricing). Against this, the author computes the amortized cost of running a 70B parameter open-weight model (e.g., Llama 3.3 70B or Qwen 2.5 Coder 72B) on a 4x H100 node (~$10/hr spot, ~500 tokens/sec throughput): approximately $0.20–0.60 per 1,000 lines, a 5–15x cost reduction for sustained workloads.
The “outsourcing” component is the human-in-the-loop review layer: the argument is that a human reviewer in a lower-cost geography can verify and patch local-model output for less than the delta between frontier and local model cost, while handling the tail of tasks where the local model fails.
The post does not benchmark model quality differences rigorously — it cites HumanEval and SWE-bench numbers showing 70B models at 70–80% of GPT-4o performance on coding tasks, and assumes the gap is handleable by human review. This is the weakest assumption: the failure mode distribution matters more than average performance, and tail failures in code generation (security bugs, subtle logic errors) are precisely what human review is least reliable at catching under time pressure.
The argument is directionally sound for well-scoped, high-volume, lower-criticality code generation tasks. It does not hold for complex architectural work or latency-sensitive interactive use cases.
Why this matters
The cost arithmetic is worth doing carefully; the post provides a replicable model that teams can parameterize against their own token usage and review labor costs to find their crossover point.
I built a Git-tracked book production pipeline
The post describes a document production pipeline for a physical book that replaces InDesign and Word with a plain-text, version-controlled toolchain. The technical stack: Markdown source files tracked in Git, Pandoc for format conversion, a custom Lua filter for Pandoc to handle layout-specific concerns (image placement, caption numbering, footnote formatting), and LaTeX/XeLaTeX as the final rendering backend for PDF generation.
The key engineering decisions are worth examining. Pandoc’s AST is manipulated via Lua filters rather than pre/post-processing the Markdown or TeX directly; this keeps transformations composable and testable. The author writes filters for: cross-reference resolution (figure/table numbering consistent across chapters), conditional content blocks (print vs. digital edition toggling), and custom block types for callout boxes that map to specific LaTeX environments.
The build system is a Makefile: make pdf runs Pandoc with the filter chain, producing a XeLaTeX source, then invokes xelatex twice for reference resolution. Git diffs on Markdown are human-readable, enabling meaningful version history and pull-request-style editorial review — something impossible with binary .docx or .indd files.
The author notes one non-trivial problem: precise typographic control for print (widow/orphan control, manual page break hints) is expressed as Pandoc raw LaTeX blocks inline in the Markdown, which breaks the clean separation of content and presentation. This is an inherent tension in any text-to-print pipeline.
Font handling is done via XeLaTeX’s native OpenType support, eliminating the font-embedding issues common with pdflatex.
Limitations: the pipeline requires comfort with LaTeX debugging, and complex layouts (multi-column, precise image wrapping) remain difficult compared to a visual tool.
Why this matters
The Lua filter + Pandoc + XeLaTeX pattern is a mature, reproducible approach to professional document production that more technical authors should adopt; the post is a concrete existence proof with transferable architecture.
Performance of Rust Language
Source: https://github.com/yugr/rust-slides
This is a slide deck (PDF) covering Rust’s performance characteristics from a systems engineering perspective, focused on where Rust’s abstractions impose overhead and how to reason about it. The content is denser than typical Rust performance posts.
Key topics covered:
Zero-cost abstractions and their limits. The slides demonstrate cases where Iterator chains produce suboptimal codegen compared to equivalent C loops due to inlining depth limits in LLVM. The fix is #[inline(always)] on iterator adapters in hot paths, or falling back to explicit loops.
Bounds checking. Rust inserts bounds checks on slice indexing that GCC/Clang often elide via range analysis. The slides show a pattern where restructuring loops to use iterators (which the compiler can prove in-bounds) eliminates the checks, recovering C-equivalent throughput. For cases where safety can be established by construction, unsafe { slice.get_unchecked(i) } is discussed with appropriate caveats.
Monomorphization cost. Generic functions are monomorphized per concrete type, increasing binary size and potentially blowing instruction cache. The slides compare fn foo<T: Trait>(x: T) (monomorphized) vs. fn foo(x: &dyn Trait) (dynamic dispatch) in terms of icache behavior at scale.
Allocator behavior. Rust’s default global allocator (jemalloc was replaced by the system allocator in Rust 1.32) can be a bottleneck; the slides cover swapping in mimalloc or jemalloc via the #[global_allocator] attribute, with benchmark numbers showing 10–30% throughput gains for allocation-heavy workloads.
LLVM backend issues. Several cases where rustc/LLVM fails to auto-vectorize loops that GCC vectorizes, with workarounds using std::simd (portable SIMD) or explicit intrinsics.
The slides are practical and cite specific benchmark numbers rather than making vague claims.
Why this matters
Rust’s performance model is often described as “C-equivalent” without qualification; this deck provides the concrete failure modes and mitigations that practitioners need when Rust code is slower than expected.
Noteworthy New Repositories
chiennv2000/orthrus
Orthrus targets lossless acceleration of LLM inference by combining speculative decoding with a dual-view diffusion mechanism. The core idea is to maintain two complementary representations of the token sequence — a forward autoregressive view and a masked-diffusion view — and use agreement between them to accept or reject candidate tokens without changing the output distribution. This is distinct from standard speculative decoding (which requires a separate draft model) because the diffusion head is trained jointly with the base model, reducing the mismatch penalty. The “lossless” claim means the accepted token distribution is provably identical to greedy or sampled output from the original model. Implementation is in PyTorch with CUDA-level batching for the parallel diffusion steps. The dual-view architecture adds modest parameter overhead but can recover multiple tokens per forward pass when the two views agree, yielding wall-clock speedups without quality regression. Relevant for production inference stacks where speculative decoding’s draft-model maintenance cost is a bottleneck, and for research into non-autoregressive acceleration that preserves exact output fidelity. Early benchmarks suggest meaningful throughput gains on standard generation tasks, though real-world gains will depend on sequence entropy and hardware memory bandwidth.
Source: https://github.com/chiennv2000/orthrus
raiyanyahya/how-to-train-your-gpt
A pedagogical, end-to-end GPT implementation aimed at making every architectural and training decision explicit through inline comments. The codebase walks through tokenization (BPE from scratch), the transformer block (multi-head self-attention, positional encodings, layer norm placement), the training loop (AdamW, learning-rate warmup and cosine decay, gradient clipping), and inference (temperature sampling, top-k, top-p). Nothing is imported from Hugging Face — dependencies are NumPy and PyTorch only. What distinguishes this from Karpathy’s nanoGPT (the obvious comparison) is the density of explanatory annotation: every tensor reshape, every masking operation, and every hyperparameter choice has a comment explaining the why, not just the what. The repository is structured so a reader can follow it linearly as a textbook chapter. Useful for instructors building course material, for practitioners who learned transformers from papers and want to close implementation gaps, and for onboarding engineers who need a reference that doesn’t elide details. Not intended for production scale; the value is entirely in readability and correctness of explanation.
Source: https://github.com/raiyanyahya/how-to-train-your-gpt
UditAkhourii/adhd
ADHD implements a Tree-of-Thought (ToT) reasoning skill for coding agents built on the Claude Agent SDK. The technical architecture fans out from an initial problem statement into parallel branches, each evaluated under a distinct cognitive frame (e.g., adversarial, first-principles, analogy-based). Each branch is scored on a configurable rubric — coherence, novelty, feasibility — and branches that fall below a pruning threshold are terminated before being deepened. Survivors receive additional compute budget for elaboration. This is structurally similar to beam search with heterogeneous heuristics rather than a uniform value function, which reduces the risk of all branches collapsing to the same local optimum. The pruning strategy is what separates this from naive parallel prompting: it gates compute on intermediate scores rather than waiting for terminal states. The SDK integration means the skill composes with other Claude agent tools without custom orchestration glue. Primary use case is problems with large, underspecified solution spaces — architecture decisions, research framing, cross-domain design — where a single chain-of-thought pass reliably misses non-obvious paths. The repository includes prompt templates for each cognitive frame and scoring rubrics that can be tuned per domain.
Source: https://github.com/UditAkhourii/adhd
agentic-in/elephant-agent
Elephant Agent is a self-evolving personal AI agent built around the concept of a “Personal Model First” architecture — the agent accumulates a persistent, structured memory of the user’s preferences, context, and past interactions, and uses that memory as the primary conditioning signal rather than relying solely on a foundation model’s generic priors. The self-evolution mechanism involves periodic reflection passes where the agent reviews its memory store, identifies inconsistencies or outdated beliefs, and updates its internal state representation. This is closer in spirit to lifelong learning systems than to standard RAG pipelines: rather than retrieving context at query time, the agent continuously maintains a compressed world model of the user. The implementation appears to use a combination of vector storage for episodic memory and structured key-value representations for stable preferences. The architecture raises standard open questions in continual learning — catastrophic forgetting of user context, memory compaction without information loss, and privacy boundaries for persistent personal data. Potentially useful for personal productivity tooling where session-to-session continuity matters more than zero-shot generalization.
Source: https://github.com/agentic-in/elephant-agent
MyuriKanao/src-hunter-skill
A Claude Code skill targeting vulnerability research in SRC (Security Response Center) and bug bounty contexts. The technical content is substantial: 19 structured attack playbooks covering categories such as SSRF, IDOR, XXE, and deserialization; 305 structured payloads organized by vulnerability class; 263 documented WAF and EDR bypass techniques; and two large case databases — 2,887 real HackerOne reports and statistical patterns extracted from 88,636 WooYun cases. The skill integrates with Claude Code’s tool-use interface, allowing the agent to select and sequence playbooks based on target reconnaissance output. The bypass corpus is particularly notable because it encodes empirical evasion knowledge that is typically scattered across blog posts and private notes. From a security research standpoint, the WooYun dataset aggregation is a useful prior for Chinese-market targets with different tech stacks than those dominant in Western bug bounty programs. Researchers should audit the payloads before use in live engagements; the value here is structured enumeration of known techniques rather than novel zero-days. Responsible use requires authorization from the target organization.
Source: https://github.com/MyuriKanao/src-hunter-skill
python-telegramBot/ai-auto-trading
A TypeScript/Node.js crypto trading bot built on the VoltAgent framework, targeting Binance and Gate.io via their REST and WebSocket APIs. The architecture is multi-strategy: separate modules implement mean reversion, momentum, and LLM-assisted signal generation, with a risk management layer that enforces position limits, drawdown stops, and Kelly-fraction sizing across strategies. The LLM component ingests market commentary and on-chain signals to produce directional bias scores that modulate strategy weights rather than generating raw trade signals directly — a reasonable design choice that avoids giving a language model direct order authority. Telegram integration provides real-time trade notifications and allows parameter adjustment via chat commands without redeployment. The TypeScript typing discipline is relevant here: exchange API responses are fully typed, which catches deserialization errors that have historically caused silent losses in dynamically typed trading bots. The main engineering risk is latency: Node.js event loop contention under high message volume can delay order execution. The repository is best treated as a structured starting point for building a personal trading system rather than a production-ready deployment, particularly given the absence of documented backtesting infrastructure.
Source: https://github.com/python-telegramBot/ai-auto-trading
thinkpixelIab/polymarket-ai-trading
A prediction market trading system targeting Polymarket’s CLOB (Central Limit Order Book) API, with a full stack: Node/Express backend, SQLite persistence, Docker deployment, and a dashboard served via Express with optional Render/Vercel hosting. The trading logic combines two strategies: GPT-based probability forecasting (the model is queried for its credence on a market question and that credence is compared against the current market price to identify mispricing) and mean reversion on historically stable markets. Kelly criterion sizing is applied to position sizing given estimated edge. The paper trading mode is a notable feature for strategy validation without capital risk — the system logs hypothetical fills against real CLOB prices, enabling realistic slippage estimation. SQLite is used to persist market state, trade history, and model forecasts, which keeps the deployment footprint minimal. The GPT forecasting approach faces a known calibration problem: language models tend toward the 50% anchor on contested questions, and their training cutoff limits freshness on fast-moving events. The repository is honest about this being a research and experimentation platform rather than a consistently profitable system.
Source: https://github.com/thinkpixelIab/polymarket-ai-trading
gonemedia/aipointer
AIPointer is a cross-platform (macOS, Windows, Linux) screen-aware AI overlay. The interaction model is hotkey-triggered: hold a configurable key, type a question, and the tool captures a screenshot, sends it along with the query to a vision-capable model (OpenRouter, Anthropic, OpenAI, or Gemini, with user-supplied API keys), and renders the response as an overlay without leaving the current application. The implementation uses native screenshot APIs per platform rather than a virtual framebuffer, which keeps latency low and avoids the permission overhead of accessibility APIs. The local-first, BYO-key, no-telemetry design means no data transits a third-party relay — the screenshot goes directly from the user’s machine to the chosen model provider’s API. Practically, this is most useful for quick disambiguation of UI elements, documentation lookups grounded in visible context, and debugging sessions where the question is tightly coupled to what is on screen. Compared to OS-level AI integrations (Apple Intelligence, Windows Copilot), AIPointer gives the user full model and key control at the cost of requiring manual hotkey invocation. The cross-platform scope is technically non-trivial given the divergence in screenshot and overlay APIs across the three targets.