デイリーAIダイジェスト — 2026-05-25
arXiv ハイライト
LLMs as Noisy Channels: A Shannon Perspective on Model Capacity and Scaling Laws
問題設定
既存のscaling law — Kaplan et al.のべき乗則およびChinchillaの加法形式 — は、N(パラメータ数)とD(トークン数)に対してlossが単調に減少することを予測します。しかし実験的には、この単調性が成立しないいくつかのレジームが存在します:catastrophic overtraining、量子化後の性能劣化、そして追加のpretrainingトークンやパラメータがdownstreamの性能を悪化させるbasinを形成するSFTのloss景観です。
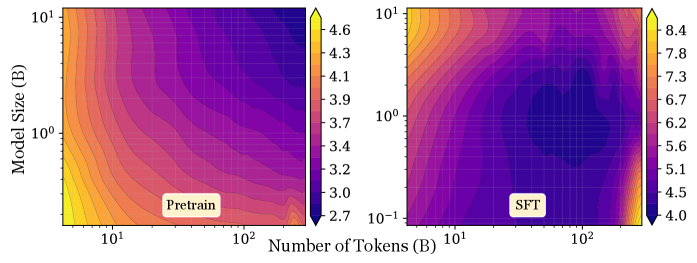
この図は、失敗モードを具体的に示しています:pretrainingの曲面は(N, D)に対して単調減少しますが、SFTの曲面はbasinを形成します — 固定したNにおいてある臨界的なDを超えると、downstream lossが再び上昇します。L = A N^{-\alpha} + B D^{-\beta} + Eの形のべき乗則はこの幾何学的構造を表現できません。なぜなら、各項はそれぞれの引数に対して単調であるからです。
手法
著者らはLLMの学習をGaussianチャネル上の伝送問題として再定式化します。Shannon–Hartley容量は次の式で表されます:
C = B \log_2\left(1 + \frac{S}{\mathcal{N}}\right),
ここでBは帯域幅、Sは信号電力、\mathcal{N}はノイズ電力です。彼らはB \mapsto N(表現帯域幅はパラメータ数に従って増大)、S \mapsto D(トークンによって供給される情報量)と対応付け、ノイズがデータ依存成分(Dに比例してスケールする破損、ラベルノイズ、摂動)とDおよびNを結合する交互作用項(例:ノイズに対するキャパシティのoverfitting)の両方を持つと仮定します。
これにより、Shannon Scaling Lawが導出されます:
C_{\text{LLM}} = a N^{\alpha} \log_2\!\left(1 + \frac{b D^{\beta}}{c (DN)^{\gamma} + d D^{\delta} + e}\right) \quad (6)
ここには9つの正の fitting 定数が含まれます。分子b D^\betaはデータが寄与する有用な信号を表し、分母はDNおよびD単独で超線形に増大するノイズ源をまとめたものです。固定したNにおいて\beta > \gamma + 1のとき、SNRは単調に増加します。一方\gammaまたは\deltaが支配的になると、SNRはピークに達した後低下し、U字型を形成します。\log_2のラッパーは容量をa N^\alpha×log-SNRで上から抑えるため、パラメータ数が厳密な上限を設定します。
6パラメータの簡略版はb, d, eを除いた形(fitにおいて一貫して無視できる)です:
C_{\text{Simpl}} = a N^{\alpha} \log_2\!\left(1 + \frac{D^{\beta}}{c (DN)^{\gamma} + D^{\delta}}\right) \quad (12)
fittingにはscipy.optimize.curve_fitを用い、Pythia(160M–12B、2kから140kステップのチェックポイント)およびOLMo2(1B/7B/13B/32Bのstage-1チェックポイント)に対して適用しています。摂動としては、SNR 40〜10 dBでのactivationへの加法的Gaussianノイズ、2/3/4ビットのGPTQ量子化、およびTRLのSFTTrainerによる数学・QA・コードへのSFTが含まれます。
著者らはまた、情報理論的な動機付けなしに非単調性だけで十分かを検証するため、2つのChinchilla拡張 — Symmetric(a N^\alpha/D^\beta + b D^\beta/N^\alpha + c)とAsymmetric — をベースラインとして導入しています。
結果
このlawによって予測されるU字型は実験的にも観察されます。Gaussianノイズを増大させると、Pythiaの(N, D) lossの等高線は単調な勾配から閉じたbasinへと変形します:

定量的には、表5がPythiaおよびOLMo2における各ノイズレベルでのR^2を報告しています。完全版lawはPythiaで平均R^2 = 0.9656 \pm 0.03、OLMo2で0.9646 \pm 0.05を達成しています。6パラメータの簡略版はそれぞれ0.9541と0.9630を維持しています。「Pareto Front」列 — 各ノイズレベルで最良のベースライン(Chinchilla、OpenAI、QiD、Law of Precision、Symmetric、Asymmetric)— はPythiaで平均0.9400、OLMo2で0.9566となっています。
basinが最も鋭くなる高ノイズレジームでは差が拡大します:PythiaのSNR 10 dBにおいて、簡略Shannon lawはR^2 = 0.9092を達成したのに対し、最良ベースラインは0.8322であり、完全版lawは0.9555に達しています。12 dBでは完全版lawが0.9234を記録し、ベースラインは曲率をfitできていません。OLMo2の10 dBでは完全版lawとベースラインが共に約0.87まで低下しており、非常に低いSNRではbasinの幾何学的構造がShannon parameterizationの柔軟性すら超えることを示唆しています。
限界と未解決の問題
S \mapsto D、B \mapsto Nという対応付けはヒューリスティックです:情報理論的には、Dは信号電力よりもチャネルの使用回数に近く、\log_2の形式は尤度モデルから導出されたものではなく類推によって導入されています。9つの自由定数を持つため、このlawはQiDやLaw of Precisionと同程度の表現能力を有しており、優位性は主に関数形式にあり、簡潔さにあるわけではありません。実験はpost-hoc摂動下でのpretraining lossとSFT lossを測定するものであり、fitting後のSNRをデータ分布の測定可能な特性や最適化器のノイズに結びつける結果はまだ得られていません。scaling lawの最も有用なテストである、fittingした(N, D)グリッドを超えた外挿は、単一の摂動レベルでのみ報告されています。10 dBにおけるOLMo2の崩壊は、ノイズ項c(DN)^\gamma + dD^\deltaが、摂動とアーキテクチャ固有の失敗モードとの相互作用が生じるレジームを過小指定していることを示唆しています。
なぜこれが重要か
べき乗則のscalingは、overtraining、低ビット量子化、SFTによる性能回帰といった今日の実用的な懸念を支配する非単調な挙動を扱うことができません。Chinchilla型の分子を\log_2(1 + \text{SNR})の内側に包むことは、高ノイズ時に原理的なbasinを生み出し、fitを一貫して改善する最小限の修正であり、まさにcompute配分において予測が重要となる状況に対応しています。
Source: https://arxiv.org/abs/2605.23901
SkillOpt: 自己進化するエージェントスキルのための戦略的最適化
問題
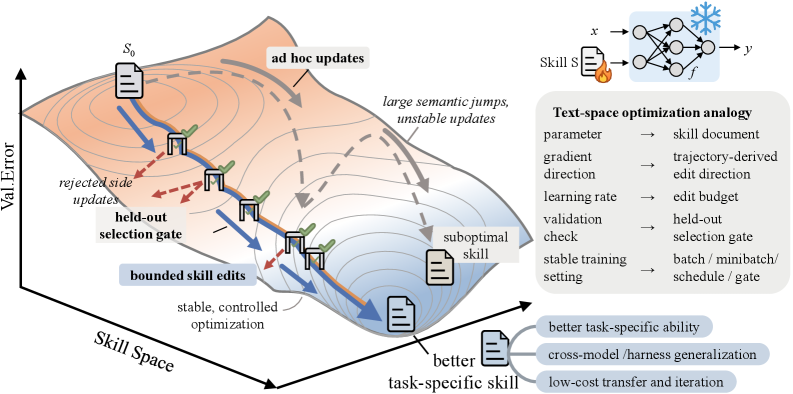
エージェントの「スキル」—— 自然言語による手続き的ポリシーであり、凍結されたモデルのコンテキストの先頭に追加されるもの —— は、通常、手作業で作成されるか、LLMによるワンショット生成か、もしくはアドホックな自己修正ループによって改良されます。これらのアプローチはいずれも、スキル構築をweight空間の学習と同等の規律を持つ最適化問題として扱っていません。すなわち、学習率に相当するもの、validation gate、棄却ステップのメモリ、エポックの概念が存在しないのです。その実証的な帰結として、スキルの「進化」が初期化時の性能を単調に改善することに頻繁に失敗しています。SkillOptはスキル文書 s を凍結されたエージェントの外部状態として再定式化し、制御可能なテキスト空間オプティマイザーで学習します。
手法
設定はテキストに転置された標準的なERMです。ターゲットモデル M、ハーネス h、タスク x に対し、ロールアウトは以下を返します。
(\tau(s), r(s)) = h(M, x, s), \quad r(s) \in [0,1].
分割 D_{\mathrm{tr}}, D_{\mathrm{sel}}, D_{\mathrm{test}} が与えられたとき、候補スキル \mathcal{C}(D_{\mathrm{tr}}) は D_{\mathrm{tr}} 上で学習することによって生成され、以下によって選択されます。
s^\star_{\mathrm{sel}} = \arg\max_{s \in \mathcal{C}(D_{\mathrm{tr}})} \frac{1}{|D_{\mathrm{sel}}|}\sum_{x \in D_{\mathrm{sel}}} r(s),
テストの報告はホールドアウト分割に対して行われます。
オプティマイザーは、M のweightに触れない独立した(フロンティアスケールの)LLMです。各ステップは以下の通りです。
- ロールアウトバッチ。 M が現在のスキル s_t を用いて D_{\mathrm{tr}} のミニバッチタスクを実行し、スコア付きの軌跡を生成します。
- リフレクション。 オプティマイザーは成功例と失敗例の両方を取り込み、単一のスキル文書に対する有界な型付き編集のセット ——
add、delete、replace—— を提案します。この境界はテキスト的な学習率として機能し、信頼領域に類似した形でステップあたりの差分の大きさを制限します。 - マージとランク付け。 提案された編集は重複が排除され(スキルハッシュがキャッシュされます)、エポックをまたいでスケジュールされた編集バジェットのもとでランク付けされます。
- Validation gate。 マージされた候補 s' は、その D_{\mathrm{sel}} 上の平均スコアが現在の最良スコアを厳密に上回る場合にのみ採用されます。棄却された編集は破棄されず、後続の提案においてオプティマイザーが負の証拠として条件付けるエポックローカルな棄却ステップバッファーに入ります。
- スロー/メタ更新。 エポックをまたいで、M を変更することなく、棄却および採用された軌跡にわたってより長い時間軸のレッスンをメタステップが蒸留します。
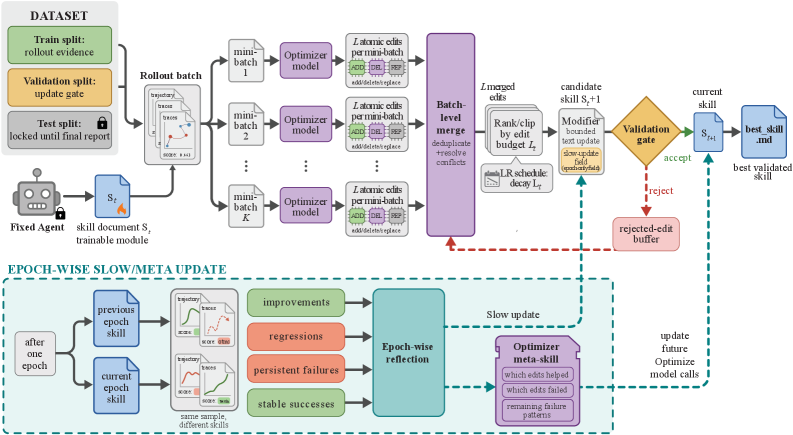
主要な規律的コミットメント —— 有界な編集(学習率)、validationゲート付き採用(各ステップのearly stopping)、棄却ステップバッファー(負サンプルメモリ)、エポック単位のスロー更新(momentum/メタ)、ハッシュベースの重複排除 —— により、このループはweightに対するSGDと同様の再現性を持ちます。一方、デプロイコストは静的スキルと同一です。best_skill.md のみがエクスポートされるため、推論時の追加モデル呼び出しはゼロです。
結果
評価は、異なるエージェントレジームにストレスをかけるために選ばれた6つのベンチマークにわたっています。SearchQA(シングルラウンドQA)、DocVQA、LiveMathematicianBench(MCQ)、OfficeQA(マルチターンツールループ、最大24コール)、SpreadsheetBench(openpyxl/pandas ランタイムを使用したマルチラウンドコード生成、最大30ターン)、ALFWorld(体化型、最大50ステップ)です。GPTファミリーとQwenファミリーから7つのターゲットモデルが、3つのハーネス(direct chat、Codex、Claude Code)にわたってテストされ、52の(モデル、ベンチマーク、ハーネス)セルを生成します。分割は決定論的(\mathtt{split\_seed=42})であり、テストスコアは分離されたホールドアウトデータに対するものです。
主要な主張:SkillOptは52のセルすべてで最良または同率最良であり、手書きの人間スキル、ワンショットLLMスキル、Trace2Skill、TextGrad、GEPA、EvoSkillというすべてのベースラインを各セルで上回っています。提供されたテキストのアブストラクトはGPT固有のデルタについては切り取られていますが、フロンティアスケールでの支配を示しています。
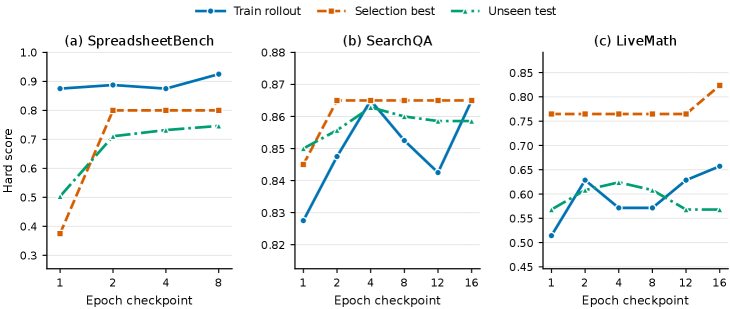
エポックチェックポイントにわたる軌跡分析 —— 学習ロールアウト、selection-best、ホールドアウトテストスコアを報告 —— により、validationゲート付きチェックポイントが汎化することが確認されます。D_{\mathrm{sel}} によって優先されるチェックポイントは、SpreadsheetBench、SearchQA、LiveMathにわたって D_{\mathrm{test}} 上で一貫して競争力があり、このゲートが単にselection分割に過学習しているわけではないことを示しています。
限界と未解決の問題
- オプティマイザー自体がフロンティアLLMであるため、デプロイコストはゼロであっても学習時のコストは無視できません。論文における「どの程度のコストで」という問いは認識されていますが、提供された抜粋では採用された編集あたりのオプティマイザー呼び出しバジェットを定量化していません。
- 「最良または同率最良」は弱い順序付けであり、最強のテキストオプティマイザーベースラインであるGEPAおよびEvoSkillに対する勝利の大きさは、提供されたセクションからは確認できません。
- 厳密なvalidationゲート付き採用は保守的であり、単一の有界な編集では厳密な改善が得られないプラトー領域で停滞する可能性があります。これはマルチステップの軌跡では改善できる場合でも同様です。棄却ステップバッファーだけでそのようなプラトーから脱出するのに十分かどうかは不明です。
- スキルはスカラースコアで評価されており、多目的スキル最適化(例:精度対ツール呼び出し回数)は対処されていません。
- 同じスキルに対するハーネスをまたいだ汎化 —— すなわち、direct chat下で最適化されたスキルがCodexに転移するかどうか —— は、各(モデル、ベンチマーク、ハーネス)セルが独立して評価されているものの、提供された抜粋では報告されていません。
なぜ重要か
スキル文書を学習可能な外部状態として扱い、学習率の境界、validation gate、負サンプルバッファーを備えることで、プロンプト/スキルエンジニアリングをクラフトから再現可能な最適化手続きへと変換し、推論時のオーバーヘッドをゼロに抑えます。52/52の主張がスケールにおいて成立するならば、fine-tuningなしで凍結されたエージェントを適応させるための原則的なデフォルト手法を提供します。
Source: https://arxiv.org/abs/2605.23904
Diffusion Transformerにおけるクロスレイヤー情報ルーティングの再考
Diffusion Transformer(DiT)はほぼあらゆる軸——tokenizer、attention variant、conditioning機構、学習目標、latent VAE——において改良が重ねられてきましたが、residual stream自体はオリジナルのエンコーダTransformerからそのまま引き継がれています。本論文は、単位係数residualはdiffusion生成に適していないと主張し、drop-in置換として学習済み・timestep条件付きアグリゲータ(Diffusion-Adaptive Routing、DAR)を提案しています。
診断:h_{l+1}=h_l+f_l(h_l;t) の何が問題か
著者らはSiT-XL/2(28ブロック、600Kイテレーション、4096枚のImageNetサンプル)に計測処理を施し、hidden state z_k のブロックごとの3種類の統計量を測定しています:forward \mathrm{RMS}(z_k)、backward \mathrm{RMS}(\partial\mathcal{L}/\partial z_k)、および連続するコサイン類似度 \cos(z_k,z_{k+1}) です。
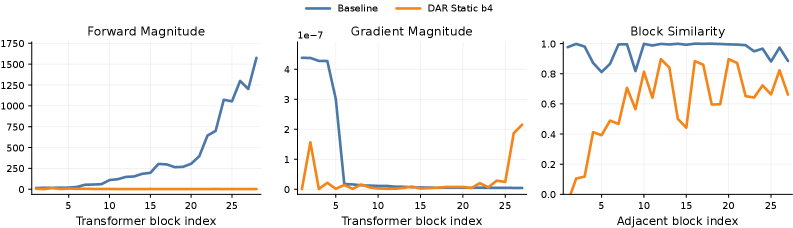
深さ方向に単調な3つの病理が浮かび上がります:
- forward magnitudeの膨張。 \mathrm{RMS}(z_k) はブロック1での \sim 15.5 からブロック28での \sim 1576 へと、おおよそ 100\times 増大します。各サブレイヤーは入力に単位RMS正規化を適用するため、深いサブレイヤーはストリームへのpost-normの影響をゼロ以外に保つために、ますます大きなraw outputを出力しなければなりません。これはLLMで以前に報告されたPreNorm希釈効果であり、現在DiTに対して定量化されています。
- backward gradientの減衰。 最初の5ブロックにおけるgradient RMSは 5\times 10^{-7} 程度であり、残りのスタック全体でさらに1桁以上低下し、ほぼゼロに近づきます。加算的residualには、深さ方向にgradient massを再分配する機構が存在しません。
- ブロック単位の冗長性。 深いスタック全体でトークンごとの \cos(z_k,z_{k+1})>0.9 が成立しており、隣接する深いブロックがほぼ同一の表現を計算していることを示し、容量の無駄遣いを意味します。
式(1)を展開すると h_l = h_0 + \sum_{i=0}^{l-1} f_i(h_i;t)、すなわちすべての過去のサブレイヤーが l や t によらず係数1で寄与することがわかります。モデルは特定のdenoisingステージにおいて特定の過去の表現を取り出すための調整手段を持っていません。
timestep軸はそもそも活用されているか?
DiTはテキストTransformerと異なり、入力分布が t とともに滑らかに変化します。著者らは、ベースラインが暗黙的にtimestep依存の混合を必要としているかどうかを検証するために、各historical residual sourceに計測専用のスカラーゲート(1に初期化)を取り付け、forward passの数値を変えずに、\partial\mathcal{L}/\partial \text{gate} を反実仮想的なsource importanceとして読み出します。
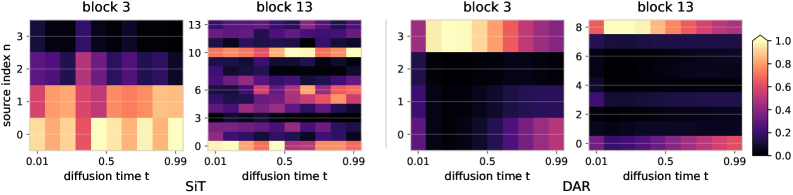
ベースラインはrouterを一切学習していないにもかかわらず、その反実仮想的なimportance mapは t に沿って系統的に変化し、しかも浅い位置と深い位置で異なるパターンを示します。これが、ルーティングを固定ではなく学習済みかつtimestep適応型にする経験的な動機です。
手法:Diffusion-Adaptive Routing
DARは式(1)を、サブレイヤー出力の履歴に対する学習可能な非逐次的アグリゲーションに置き換えます。具体的には、各ブロック l がsoftmaxルーティング重み \alpha_{i\to l}(t)(ソース i<l に対して、拡散タイムステップで条件付け)を保持し、running sumではなくhistoricalなサブレイヤー出力の混合として入力を構成します。
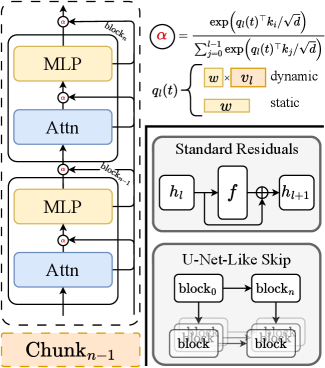
機構的に重要な3つの性質があります:
- 学習可能性。 ルーティング係数はパラメータであり、式(2)の単位係数の事前分布を破ることで、深いブロックが任意の過去のソースを減衰または増幅させることができます。
- timestep適応性。 \alpha_{i\to l} は t の関数であり、図3で観察された反実仮想的な構造と一致します。
- 非逐次性。 アグリゲーションは加算ではなく(softmax正規化された)混合であり、これがmagnitude膨張の病理に直接対処します——構成上、スタッキングによる単調なRMS爆発は生じません。
セクション3の診断は、チャンクサイズ S=4(ソースを4サブレイヤーのチャンクにグループ化)の静的DAR variantについても報告されており、timestep適応性がなくてもアグリゲーション形式だけで膨張・gradient減衰・冗長性が軽減されることを示唆しています。
DARはdrop-inのresidual置換として提示されているため、直交するDiT拡張と組み合わせることができます;著者らは特にREPA [yu2025repa]との組み合わせをREPAのオリジナル設定で検証しています。
結果
SiT recipleを固定したImageNet 256\times 256 において:
- 品質。 DARはSiT-XL/2を 2.11 FID 改善します(7.56 vs. 9.67)。
- 効率性。 DARはSiT-XL/2ベースラインの収束FIDに 8.75\times 少ない学習イテレーションで到達します。
- 互換性。 DARはREPAのオリジナル学習設定下でREPAと組み合わせ可能であり、その効果がrepresentation-alignmentの目的と冗長ではないことを示しています。
限界と未解決の問題
診断セクションでは単一の学習期間(600Kイテレーション)と単一のアーキテクチャスケール(XL/2)のみが報告されています。100\times のforward膨張が、より長い学習、より大きなモデル、あるいは代替の正規化(例:SiameseNorm)において持続するか飽和するかは示されていません。\alpha_{i\to l}(t) の正確な関数形、そのパラメータコスト、およびすべてのサブレイヤー出力をキャッシュすることによる推論オーバーヘッドは、提供されたセクションでは要約されていません;非常に深いDiTでは、O(L^2) のsource-mixingのフットプリントが無視できなくなる可能性があります。DARの効果がより高解像度のtext-to-image DiT、timestepとソースの結合が異なり得るvideo DiT、あるいはSiT以外のflow-matching variantに転移するかどうかはまだ検証されていません。最後に、反実仮想ゲート分析はベースライン周りの局所線形化であり、ベースラインがtimestep依存ルーティングを必要としているだろうことを示すものの、DARの特定のsoftmaxパラメタリゼーションが最適であることを示すものではありません。
この研究の意義
residual streamはDiT研究が手をつけてこなかった唯一のTransformerコンポーネントであり、本論文はそれがdiffusionに対して実際に誤調整されているという直接的な経験的証拠を提供しています:magnitudeが爆発し、gradientが消失し、隣接する深いブロックが処理を重複させます。drop-inのresidual置換による2.11 FIDの低下と 8.75\times の学習イテレーション高速化は、クロスレイヤールーティングがattentionやconditioningの選択と同等の、過小評価されていた設計軸であることを示唆しています。
Source: https://arxiv.org/abs/2605.20708
RankE: End-to-End Post-Training for Discrete Text-to-Image Generation with Decoder Co-Evolution
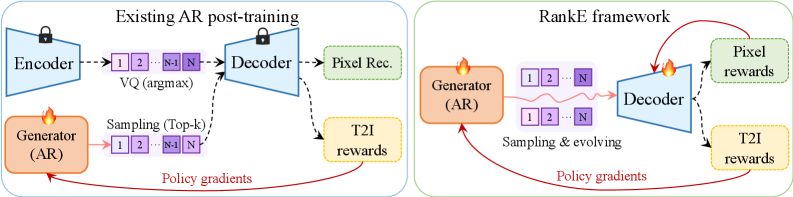
問題
離散型自己回帰(AR)T2Iスタックは、凍結されたVQトークナイザー/デコーダー D_\phi と、コードブックインデックスを出力するARポリシー \pi_\theta(z\mid y) を組み合わせており、それらのインデックスは x=D_\phi(z) を通じてピクセルに変換されます。Post-training(CLIPやHPSv2報酬を用いたRLHFスタイルのアライメント)はこれまで \pi_\theta にのみ適用され、D_\phi は手つかずのままでした。著者らはこのアプローチが安全ではないと主張します:報酬最適化によって \pi_\theta がドリフトするにつれ、生成されるトークン列の周辺分布が、デコーダーが逆変換するよう学習した経験的分布から乖離していくからです。著者らはこれをLatent Covariate Shift(LCS)と呼び、これがよく知られた病理として現れることを示しています――報酬は上昇する一方、デコードされた画像の忠実度は低下します。
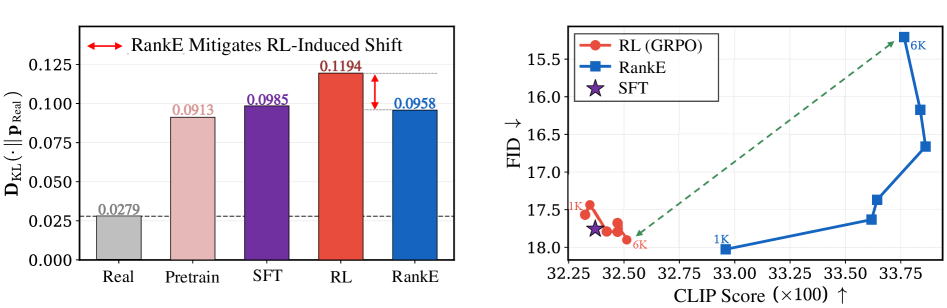
Figure 1はLCSを定量化しています:凍結されたトークナイザーで5,000枚の実MS-COCO画像をエンコードし、ポリシーが誘起するトークン分布と実画像のトークン分布のKLを測定し、2つの独立した実データ分割間の「Real–Real」KLを自然変動のフロアとして設定しています。このシフトは事前学習→SFT→標準RLへと単調に増大し、RankEはそれをフロアに近い水準まで引き戻します――RLが収束するころには、デコーダーは多様体外のコードを変換するよう求められているのです。
手法
RankEは以下の結合目的関数を定式化します:
\max_{\theta,\phi}\;\mathbb{E}_{y\sim\mathcal{D},\,z\sim\pi_\theta(\cdot\mid y)}\!\left[r(D_\phi(z),\,y)\right].
z のカテゴリカルサンプリングとVQのストレートスルー量子化器が勾配の経路を遮断するため、r の勾配は \phi には流れますが \theta には流れません。RankEはこれをバイアスのかかった緩和(Gumbel、デコーダーを通じたREINFORCEなど)で補うのではなく、それぞれのパラメータ空間に自然な形で更新を交互に行うことで結合問題を解き、この交互更新を単一の正則化目的関数に対するGeneralized EMの手続きとして捉えています。
具体的には(Figure 3):
Stage 1 — Policy Alignment。 \phi を凍結した状態で、\theta はランキングベースの報酬(CLIPまたはHPSv2)によるGRPOで更新され、EMA参照ポリシー \pi_{\bar\theta} に対するKLペナルティで正則化されます: \mathcal{L}_\theta = -\mathbb{E}\!\left[A(z,y)\log\pi_\theta(z\mid y)\right] + \beta\,\mathrm{KL}(\pi_\theta\,\Vert\,\pi_{\bar\theta}). これは標準的なRLHFの半分に相当しますが、それ単独ではまさにLCSを引き起こします。
Stage 2 — Decoder Adaptation。 \theta を凍結した状態で、デコーダー \phi は現在のポリシーからサンプリングされたロールアウトに対して同じランキング目的関数を最大化するよう更新され、固有のパラメータ空間における安定性アンカー(決定論的レンダラーにとってKLは意味をなさないため、元のデコーダーに対する再構成/特徴アンカー)で正則化されます。これにより D_\phi は新しいトークン分布を正しくデコードする方向に引き寄せられながら、報酬ハッキングされたアーティファクトへの崩壊を防ぎます。
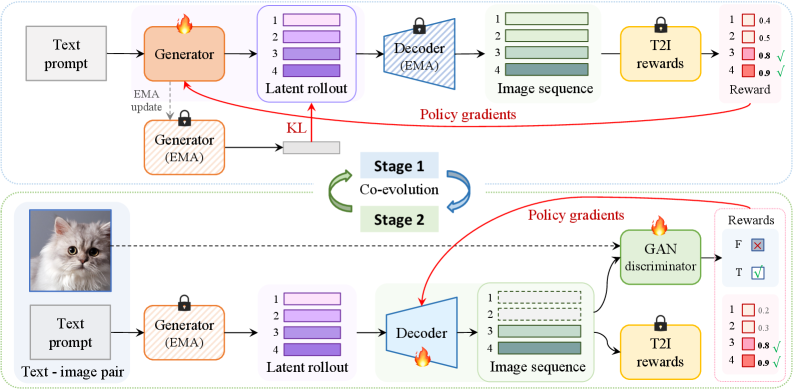
この交互実行が、微分不可能なギャップを越えて報酬情報を伝播させるものです:各Stage-2ステップは最新の \pi_\theta が出力するコード分布に D_\phi を適応させるため、次のStage-1ステップはそのサンプルを忠実にレンダリングできるデコーダーに対して最適化を行うことができます。
結果
2つのバックボーンが使用されています:LlamaGen-XL(775M)とJanus-Pro-1Bです。ベースラインはBase、同一のキュレーションコーパスに対するSFT、そしてStd. RL(CLIPまたはHPSv2報酬によるGRPO、凍結デコーダー)であり、最後のものが制御された比較となっています――報酬、データ、計算量がRankEと完全に一致しており、異なるのはdecoder co-evolutionのみです。
アブストラクトおよびFigure 1の主な知見:LlamaGen-XLにおいて、標準RLはCLIPスコアを改善する一方でデコードされた画像品質を低下させます(提供データではアブストラクトがこの文で切れています)。RankEはこの忠実度とアライメントのトレードオフを解消し、Figure 1のLCS-KLがReal–Realフロアに近い水準に戻りながらも、アライメント報酬は引き続き向上します。Section 4.3はメトリクスの改善をLCS仮説に結び付けるメカニズムの検証として位置づけられており、Section 4.4は2つのステージとそのアンカーに対するアブレーションを行っています。
限界と今後の課題
- このフレームワークは離散AR + VQデコーダースタックに特化しており、連続トークンARモデルやunified diffusion-decoderハイブリッドには対応していません――それらではアライメントのボトルネックが異なる形をとります(VAEに対するREPA-Eを参照)。
- Stage-2のアンカーはパラメータ空間に適した形で説明されていますが、本論文のデータは正確な関数形(知覚的?ピクセル?凍結デコーダーに対するfeature matching?)を確定しておらず、そのウェイトが忠実度とアライメントのknobを制御する可能性があり、著者らはそれを特性評価すべきでしょう。
- 評価されたバックボーンは2つ、報酬モデルも2つのみです;報酬自体が強力な知覚モデル(例:generative discriminator)である場合にdecoder co-evolutionが有効かどうかは未解決です。
- GEM解釈は示唆的ですが、現実的なアンカー選択のもとで結合目的関数が単調に改善されることは、引用された論文の抜粋では証明されていません。
- 通常最もメモリを要するモジュールであるデコーダーをRL中に学習することの計算オーバーヘッドは、提供されたセクションでは直接報告されていません。
なぜ重要か
離散AR T2Iのpost-trainingはLMからRLHF-on-policyのテンプレートを引き継いでいますが、テキストと異なりここでの「デコーダー」は特定のトークン分布に対して学習された非可逆なレンダラーです。RankEの診断――ポリシーのみのRLが暗黙のうちにコードをデコーダーの学習多様体から外してしまうという指摘――は、今日アライメントされているVQベースの生成システムほぼすべてに当てはまります。そして交互co-evolutionのレシピは、量子化を通じた微分を必要としないクリーンでドロップイン可能な解決策です。
Source: https://arxiv.org/abs/2605.21195
事前学習を超えたMuonの再考:VLAとRLVRにおけるスペクトル的失敗と高域通過による解決策
問題
Muonの行列符号更新 \mathrm{msign}(\mathbf{M}) = \mathbf{U}\mathbf{V}^\top は、Newton–Schulz(NS)反復によって近似されます。その形式は \mathbf{X} \leftarrow a\mathbf{X} + b\mathbf{X}\mathbf{X}^\top\mathbf{X} + c\mathbf{X}(\mathbf{X}^\top\mathbf{X})^2, \quad (a,b,c)=(3.4445,-4.7750,2.0315) であり、事前正規化されたモメンタムのすべての特異値を1に近づけます。この一様なスペクトル白色化はLLMの事前学習に適しています。なぜなら、すべての方向での探索が有益であるためです。しかし本論文は、この手法が2つの事後学習の状況で機能しなくなると主張しています。
VLA学習:アクションヘッドの勾配が本質的に低ランクであるケースです。有効ランク \mathrm{erank}(\mathbf{G}) = \exp(H(\mathbf{p}))(ただし p_i = \sigma_i / \sum_j \sigma_j)を用いると、著者らはVLA-Adapter / LIBERO Objectにおいてアクションモジュールのerankが3つのモジュール(視覚 > 言語 > 行動)の中で一貫して最小であり、学習ステップ全体を通じてモジュール間の分離が安定していることを示しています。
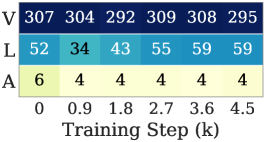
モジュールごとのerankと、アクションヘッドにおけるLRMuon・Muon・AdamWのコスト比較 スペクトル全体を1に引き上げると、純粋なノイズである末尾の方向が増幅されます(7次元のアクションベクトルは高ランクの更新を支持できません)。その結果、MuonはアクションモジュールにおいてAdamWより性能が劣ります。上位kの極因子 \mathbf{U}_k \mathbf{V}_k^\top への明示的なSVDによる切り捨てを行う低ランクMuon(LRMuon)は成功率を回復しますが、ステップごとのコストが大幅に増加します。
RLVR:勾配のSNRが低いケースです(GRPOのアドバンテージ \hat a_i = (R_i - \bar R)/(\mathrm{std}(R)+\epsilon) は、二値報酬においてグループ全員が正解または全員が不正解の場合にゼロに収束します)。また、モデルは事前学習中にすでにヘッドごとの特化を発達させています。白色化はその両方を損なわせます。ノイズが支配的な末尾方向を持ち上げるとともに、attention の鋭さ \beta_h = \|\mathbf{W}_Q^h\|_F\|\mathbf{W}_K^h\|_F/\sqrt{d_k} とヘッド出力の大きさを制御するヘッドごとのノルム構造を均質化してしまいます。
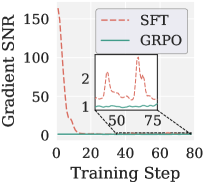
SFT対GRPOの勾配SNR、およびGRPO下でのMUATH500におけるMuonの性能低下
手法:Pionの高域通過NS
統一的な観察はスペクトル的なものです。どちらの状況においても、情報を持つ方向は少数の主要な特異値に集中しており、末尾はノイズです。Pionは一様な白色化をスペクトル高域通過に置き換えます。大きな \sigma_i は1の近くに保ち、小さな \sigma_i は0に向けて押し込みます。\mathbf{X} = \mathbf{U}\bm{\Sigma}\mathbf{V}^\top に対して1ステップのNSを適用すると \mathbf{X} \leftarrow \mathbf{U}\bigl(a\bm{\Sigma}+b\bm{\Sigma}^3+c\bm{\Sigma}^5\bigr)\mathbf{V}^\top と因数分解されるため、行列フィルタの設計はスカラー多項式 f(\sigma; a,b,c) = a\sigma + b\sigma^3 + c\sigma^5 を [0,1] 上で設計することに帰着します。単一の5次多項式では鋭いバンドエッジを実現できないため、Pionは k=5 回のNS反復を異なる係数を持つ2段階に分割します。
- Promotion f_p(k_p ステップ)、(a_p, b_p, c_p) = (1.875, -1.25, 0.375):順序を保ちながら特異値を単調に上昇させます。f_p(1)=1 および f_p'(1)=0 で固定されています。
- Suppression f_s(k_s = 5 - k_p ステップ)、(a_s, b_s, c_s) = (0, 2.5, -1.5):1付近の値はそのままにしつつ、小さな特異値を0に向けて急激に縮小させます。
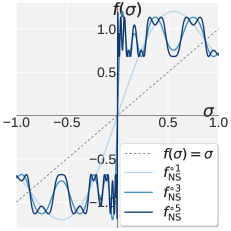
合成写像 f_s^{k_s} \circ f_p^{k_p} は、k_p \in \{0,\dots,5\} によって制御可能なカットオフを持つ高域通過を実現します。行列レベルのコストは変わりません。Muonと同じ形式の5回の行列積であり、SVDは不要です。RLVRに対してPionはヘッドごとのモード(Alg. 3)を使用します。各attention projectionをヘッド次元に沿って形状変換し、ヘッドごとに独立して高域通過NSを適用することで、行列全体の白色化によって消去されてしまう事前学習済みのヘッドごとのノルム異質性を保持します。付録GのPropositionはこれを具体的に示しています。Q/KのFrobeniusノルムがsoftmaxの逆温度 \beta_h を設定し、V/Oのスペクトルノルムが層出力へのヘッドの寄与とその勾配の大きさを上から抑えます。
結果
本論文の実験は、4つのLIBEROスイートとLIBERO-PlusにおけるVLA-Adapter(\ell_1回帰ヘッド)とVLANeXt(flow-matchingヘッド)、3つのDROIDの把持・配置タスクにおける \pi_{0.5} の実ロボットfine-tuning、そしてQwen3-1.7B / Qwen3-4Bを対象としたGRPO/GMPOによるRLVR(GSM8K、MATH500)を網羅しています。optimizerのレシピは一貫しています。その他の部分にはAdamW、V/Lの2D行列にはMuon、アクションの2D行列にはPion(VLA)、またはすべての2D行列にヘッドごとのPion(RLVR)を使用し、k_p \le 2(suppression優位)としています。
VLAの具体的なエビデンス:4.5kステップのLIBERO Objectにおいて(Fig. 1)、Muonはアクションモジュールでの性能がAdamWより劣る一方、LRMuonはそれを回復します。ただし、LRMuonのステップごとの正確なSVDはMuonと比較して総ウォールクロック時間を増大させます。VLA-Adapter / LIBERO Objectにおける1.5kステップでのPion対LRMuon(Fig. A1)は、Pionがすべての k \in \{1, 16, 64, 256\} においてLRMuonを上回る一方、ソフトスペクトルフィルタが固定の切り捨てランクの代わりにステップごと・層ごとに適応するため、Muonとほぼ同じステップごとのコストを実現することを示しています。RLVRのエビデンス(Fig. 2b)は、Qwen3-1.7BでのGRPO下においてMuonがMATH500でAdamWを下回って性能が低下することを確認しており、ヘッドごとのPionの動機付けとなっています。
限界
著者らは、Pionが降下方向が集中している状況向けに設計されており、一様な白色化のスペクトル的探索が望ましい挙動であるLLMの事前学習においてはMuonより性能が低下することが予想されると明示的に述べています。高域通過のカットオフは k_p \in \{0,\dots,5\} という離散的な形で、\sigma=0 と \sigma=1 における制約から導出された手動で固定された係数によって制御されます。MuonとPionの間を補間する適応的カットオフは未解決の課題です。Pionの多項式係数は層とステップにわたって固定されているため、層ごとのランク異質性は入力の事前正規化を通じて暗黙的にしか扱われません。逆方向のablationである低域通過Muon(付録L)は15個の係数すべてに対する数値的L-BFGS-Bフィッティングを必要とするため、より一般的なバンドフィルタには整った閉形式が存在しないことが示唆されます。
なぜこれが重要か
Muonの一様なスペクトル白色化は行列を考慮した最適化のデフォルトとしてますます扱われるようになっていますが、その帰納バイアス——末尾の増幅による探索——は、VLAのアクションヘッドとRLVRの事後学習を支配する低ランクまたは低SNRの勾配に対してはまったく逆効果です。Pionは、適切な調整パラメータがNS多項式そのものであることを示しています。2段階のpromotion-suppressionスケジュールはステップごとの余分なコストゼロで制御可能なスペクトル高域通過を実現し、ヘッドごとの適用は行列全体の直交化によって破壊されてしまうattentionの特化を保持します。
Source: https://arxiv.org/abs/2605.19282
Lens: 基盤テキスト-to-画像モデルにおける訓練効率の再考
Lensは、基盤T2I訓練の計算効率フロンティアを狙った38億パラメータのtext-to-image diffusion modelです。主要な主張は、Z-Image(6B)が使用する訓練計算量の約19.3%で、OneIG・GenEval・LongText・CVTGにおいてパラメータ数最大800億のオープンソースモデルと同等以上の性能を達成するというものです。論文はこれをパラメータ数以外の二つのレバーに帰しています:gradient stepあたりの情報密度の最大化、および収束を加速するアーキテクチャの選択です。
データ:密なキャプションと混合解像度バッチ
事前訓練コーパスのLens-800Mは、公開実世界データ・公開合成データ・非公開テキストリッチコンテンツ(ポスター、スライド、デザインアセット)・ランダム化された背景上の合成レンダリングテキストという四つのソースから構築されています。九段階のクリーニングパイプラインは、解像度フィルタリング(<384^2を除去)・NSFWクラシフィケーション(fine-tuned EVA)・審美性フィルタリング(Aesthetic Predictor v2.5、閾値3)・透かし検出(fine-tuned SigLIP2)・ラプラシアン分散による鮮明度フィルタリング・グレースケールヒストグラム上のShannonエントロピーフィルタリング・HSV Vチャネル輝度フィルタリング・FAISSを用いたコサイン類似度>0.985でのCLIP ViT-L/14による近重複除去を適用します。その結果、約8億枚の画像が得られます。
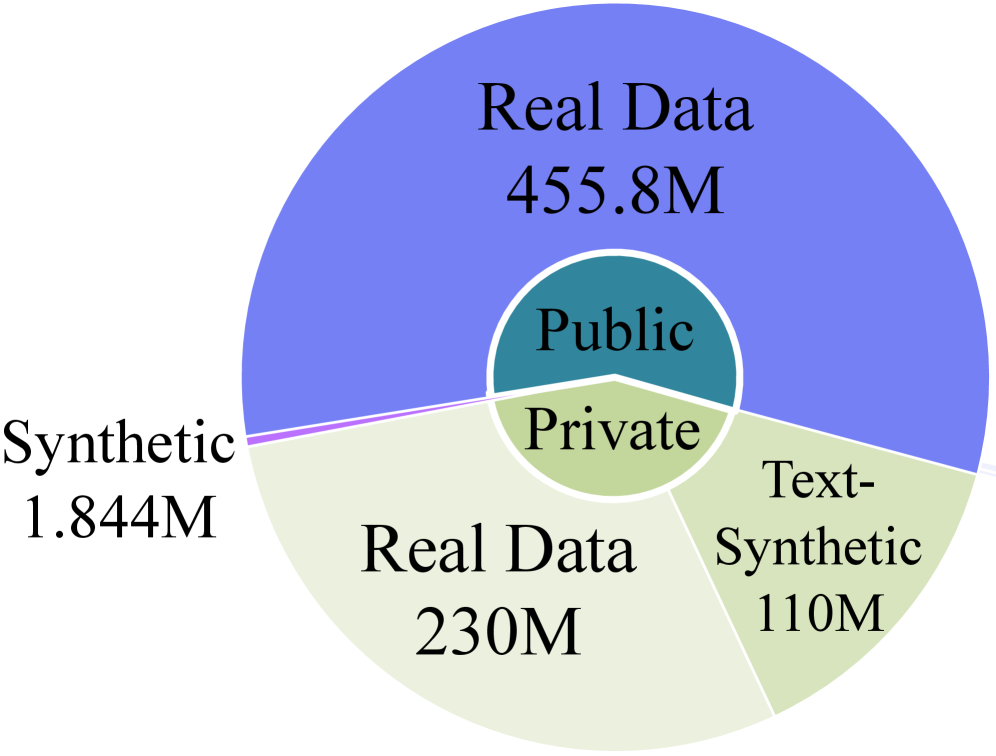
重要な取り組みは、ノイズの多いalt-textをGPT-4.1生成の長いキャプション(1画像あたり平均約109単語)に置き換えることです(Figure 3c)。その際、多言語レンダリングを保持するために画像内テキストを元の言語で保存します。短く曖昧なキャプションは、条件付きp(x \mid c)の学習ではなく曖昧性解消にモデルの容量を費やさせるという主張があり、また長いキャプションはユーザーがデプロイ時に構成的なプロンプトを発行するため訓練-推論ギャップも縮小するとされています。キャプションは多解像度・多アスペクト比バッチングと組み合わせることで、固定正方形訓練よりも各最適化ステップがより広い視覚的多様体をカバーします。
アーキテクチャと訓練レシピ
収束加速器として二つのアーキテクチャ上の選択が強調されています:テキスト特徴とより線形的に整合したlatentを生成するsemantic VAE(論文のFigure 5におけるVAEアブレーションで正当化されている)、および最適化速度を改善しつつ英語のみのキャプション訓練にもかかわらず多言語汎化をもたらす強力な言語エンコーダです。パイプラインには、手作業で設計された報酬ルーブリックを用いたキュレーションされたLens-RL-8Kデータセット上のRL後訓練が含まれ、その後classifier-free guidanceなしで動作する4ステップ生成器であるLens-Turboへのfew-step distillationが行われます。
結果
Table 2で報告されている四つのbenchmarkにおいて、Lens(20ステップ)とLens-Turbo(4ステップ)は以下の成績を示します:
- OneIG (EN/ZH): Lens 0.557 / 0.525、Lens-Turbo 0.554 / 0.519。これはZ-Image 6B(0.546 / 0.535 EN/ZH分割 — LensはENで勝ち、ZHでわずかに負け)およびQwen-Image 20BのEN(0.539)を上回ります。FLUX.2-Klein 9Bは0.532 / 0.430です。
- GenEval: Lens 0.930、Lens-Turbo 0.914 — いずれもLongCat-Image 6B(0.870)・Qwen-Image 20B(0.868)・Z-Image(0.840)を上回ります。Lens-Turboは4ステップながら、この構成的benchmarkにおてリストされた全てのオープンソースモデルを超えます。
- LongText (EN): Lens 0.937;Nano Banana 2.0(商用、0.981)とGPT Image 1(0.956)のみが上位です。LensはQwen-Image 20B(0.943)をわずかに上回ります。
- CVTG: Lens-TurboはNED 0.889・CLIP 0.965を達成し、最強のオープンソース数値であり、Z-Image(0.867 / 0.937)およびQwen-Image(0.829 / 0.930)を上回ります。20ステップのLensは0.869 / 0.951を報告しています。
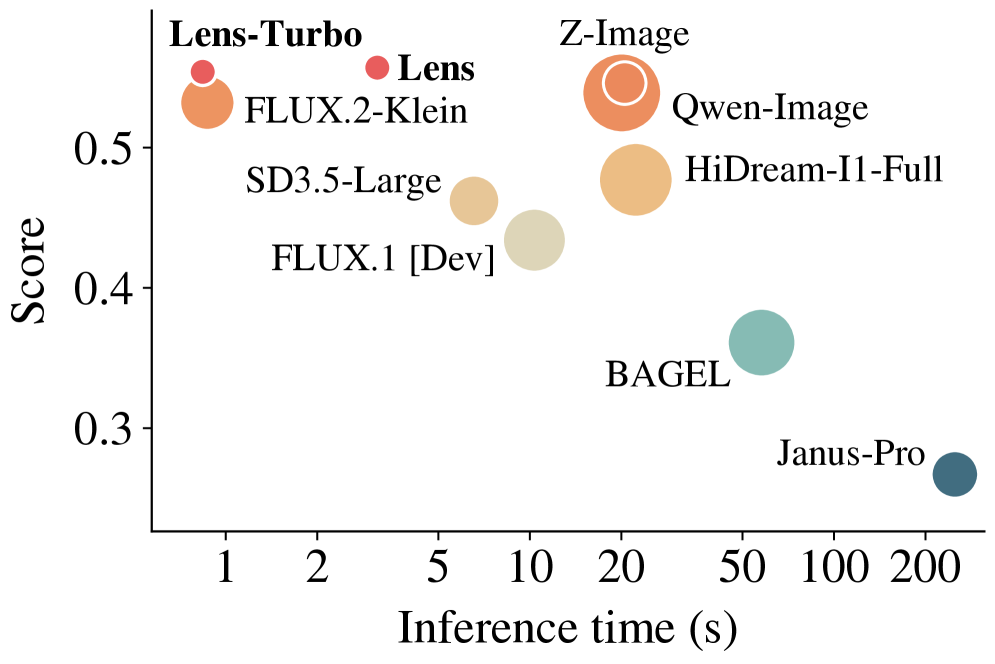
ParetoプロットはEfficiencyの主張を具体的に示しています:LensはHunyuan-Image-3.0(80B)・Qwen-Image(20B)・HiDream-I1-Full(17B)に対して左上領域を占め、一方Lens-Turboの4ステップ推論は、同等以上の品質において20ステップの競合モデルよりも大幅に低い実時間コストに位置します。

限界と未解決の問題
論文は、19.3%計算量という主張に対して(i)109単語キャプション・(ii)semantic VAE・(iii)言語エンコーダの選択・(iv)多解像度バッチングそれぞれの寄与を切り分けた制御されたアブレーションを公開していません — この主張はマッチしたバジェットによる再現ではなく、Z-Imageの報告バジェットに対して行われています。また、8億スケールでのGPT-4.1キャプション付与は「訓練計算量」の計算から除外された相当な一時的アノテーションコストを課しており、キャプション生成FLOPsを償却した場合にEfficiencyの主張が成立するかどうかは不明です。中国語のOneIG結果(0.525)はQwen-Image(0.548)およびZ-Image(0.535)に劣っており、多言語エンコーダにもかかわらず英語のみのキャプション訓練が非ラテン文字生成に残存コストをもたらすことが示唆されています。最後に、RL報酬ルーブリックとLens-RL-8Kのキュレーション基準は概略のみ記述されており、最終的なLens-Turboの数値に対するRLとdistillationの寄与は分離されていません。
なぜ重要か
このレシピが再現可能であれば、現在のオープンソースT2I訓練はパラメータ数ではなくキャプション品質とバッチあたりの情報密度によって大きくボトルネックされており、密な教師信号を持つ38億パラメータモデルが6–20Bのbaselineを凌駕できることが示唆されます。これはスケーリングの議論を再構成します:データセットアノテーション計算量(VLMキャプション付与)は、モデルスケール計算量の補完物であるだけでなく、その代替となり得るのです。
Source: https://arxiv.org/abs/2605.21573
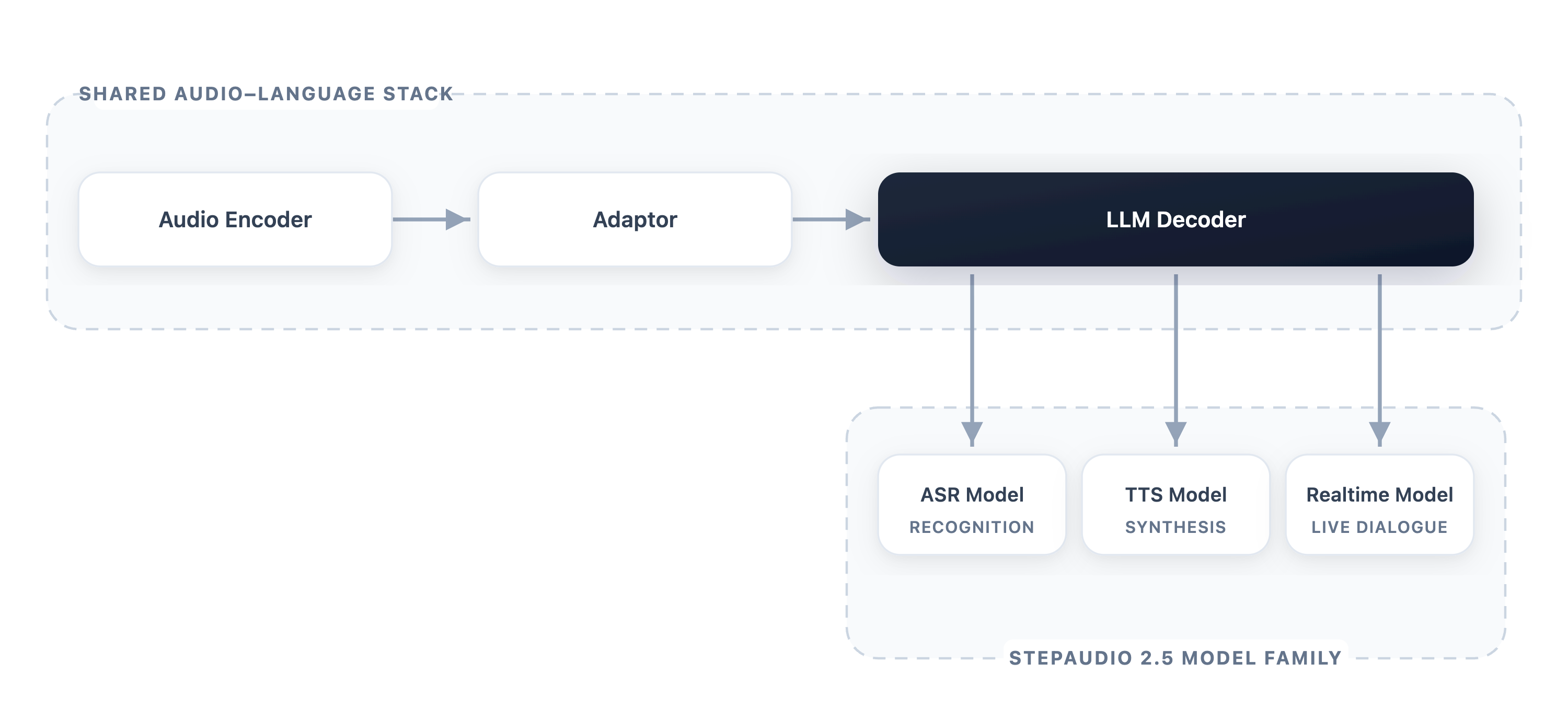
StepAudio 2.5 技術レポート
StepAudio 2.5 は、従来は個別に専門化されていた三つの領域、すなわち ASR・TTS・リアルタイム音声対話を、単一のバックボーンから統合的に扱う audio-language 基盤モデルです。その前提は、テキストと音声が共有された表現空間に共存すれば、タスクの専門化は「運用レジーム」、すなわちデータ構築・最適化目標(具体的にはタスクごとに調整された RLHF)・デコード制約へと還元されるというものです。本レポートの貢献は新しいアーキテクチャというよりも、一つのモデルが各軸において専門特化システムに匹敵あるいは凌駕できるようにする、規律あるpost-trainingレシピにあります。
共有バックボーン
アーキテクチャは現在標準的なencoder–adapter–LLM-decoderスタックです。凍結された audio encoder が音響 embedding を生成し、軽量な adapter がそれを decoder の隠れ空間に射影し、テキストで初期化された LLM decoder がテキストトークンと新たに導入された音声トークンの両方を含む統合トークン系列に対して動作します。この非対称性は意図的なもので、encoder が音響的抽象化を担い、decoder が意味論・指示追従・生成を担います。これにより、出力モダリティが異なる三つの下流システムがパラメータの大部分を共有できるようになっています。
pretraining に供給するデータエンジンも共有されています。生の音声は SED および VAD を経て非音声が除去され、セグメントはマージおよび再セグメントされて意味的に完結したベースサンプルへと変換されます。各サンプルは音質・合成音声検出・話者数についてアノテーションが付与されます。二つの ASR モデルが文字起こしと言語識別を行い、WER・編集距離・発話速度に基づくクロスバリデーションが実施されます。サンプルは言語・長さ・意味品質スコア・音質スコアによって格付けされ、pretraining の各ステージが選択的に各ティアをサンプリングできるようになっています。
検証付き MTP による ASR 専門化
ASR ブランチは共有バックボーンを維持しつつ、投機的デコードのための五ブランチ Multi-Token-Prediction (MTP) ヘッドを追加します。位置 t において、メインブランチが x_{t+1} を予測し、h 番目の MTP ブランチが h\in\{1,\dots,5\} に対して x_{t+1+h} を予測するため、各 forward ステップで 6 トークンの候補が得られます。重要なのは、MTP はあくまで高速化のための primitive として扱われるという点です。推論時には候補がトークンごとに自己回帰的パスと照合・検証され、最初の不一致で受理されるプレフィクスが打ち切られます。これにより、greedy AR デコードとの完全な等価性が保たれます。
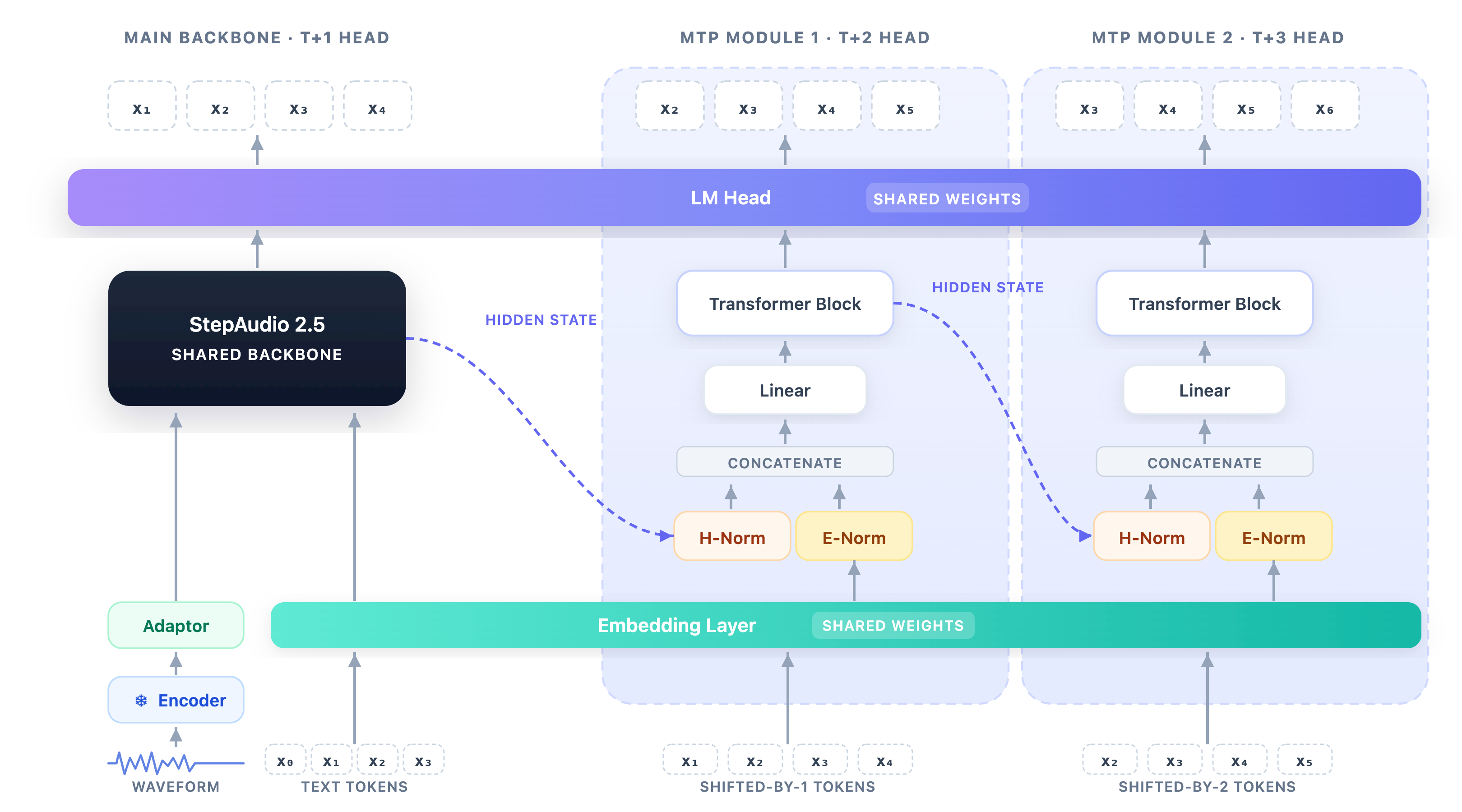
各 MTP ブロックは、前のブランチの隠れ状態とシフトされたトークン embedding を入力とし、正規化・結合を経て decoder 幅に射影し、decoder スタイルの Transformer ブロックを実行します。各新規ブロック内の Transformer 層は、言語的な事前知識を継承するために最終 decoder 層から初期化されます。embedding および LM head はメインブランチと共有されます。
学習はステージ制で行われます。まず SFT によりベースラインとなる AR 認識モデルを収束させます(32K トークンのパックシーケンス、encoder 凍結、SpecAugment スタイルの時間/周波数マスキング、10K ステップ、ピーク LR 2\times 10^{-5}、バッチサイズ 32、コサインスケジュールで 1\times 10^{-6} まで減衰)。次に、凍結ブランチのアライメントフェーズにて embedding および LM head を固定したまま MTP ブロックのみを LR 2\times 10^{-4} で学習します。最後に、joint calibration でバックボーンとブランチ間のミスマッチを低減するため、adapter と decoder を LR 2\times 10^{-5} で解凍して学習します。位置 t における目的関数はブランチの重みを指数的に減衰させ、逐次依存性を反映します:
w_h = \frac{\alpha^{h-1}}{\sum_{j=1}^{H}\alpha^{j-1}}, \quad H=5,\ \alpha=0.9,
\mathcal{L}_t = \mathrm{CE}(p_t, x_{t+1}) + \sum_{h=1}^{H} w_h\,\mathrm{CE}(p_{t,h}, x_{t+1+h}).
長時間音声向けのデータパイプラインは、クリップ単位の文字起こしからセッションレベルの精緻化へと移行し、精度とクリップ間の一貫性を維持します。
純粋な next-token prediction としての TTS
TTS ブランチでは encoder–adapter を完全に除去し、LLM のみを使用します。音声トークンは外国語として扱われ、合成は統合語彙上での next-token prediction として再定式化されることで、アライメント問題は単一の LM 内でのテキスト↔︎音声トークンのマッピング学習へと還元されます。SFT は二段階で行われます。まず大規模なゼロショット音声クローニングを global instruction supervision(話者・スタイル・韻律の粗い制御)で行い、次に高品質な社内データを用いてグローバルおよびインライン両方の指示による発話・セグメントレベルの細かな制御を学習します。
RLHF により、複雑あるいは抽象的な指示へのアライメントがさらに強化されます。Generative Reward Model (GRM) r_\phi は、同一プロンプト x に対する \pi_\theta からの候補 y を高品質な参照 y^* と対比してスコアリングし、ペアワイズなスカラーを生成します:
r_{hf}(x,y,y^*) = s\big(r_\phi(x,y,y^*)\big),
ここで s(\cdot) は報酬整形変換です。参照アンカー型の設計により、生の音質スコアで学習する際の絶対スケールの不安定性が回避されます。
リアルタイム専門化
リアルタイムブランチはアーキテクチャを同一のまま使用しますが、ライブの音声インタラクション特有の四つの問題に取り組みます:ターンをまたいだ会話的一貫性・対抗的入力に対するペルソナの一貫性・言語外情報への感度(ためらい・笑い・ペーシング)・自然さなどグラウンドトゥルースのない属性に対する報酬のスパース性です。学習レシピは三段階で構成されます:音声中心の mid-training(基盤 pretraining から継承され、音声に根ざした知覚と長文推論を提供)・マルチステージ SFT・RLHF です。特筆すべき点として、decoder は応答を出力する前に明示的な潜在推論トレースを生成しますが、これはリアルタイム学習を通じて保持されます。
制限と未解決の問題
本レポート(抜粋の範囲内)では、示されたセクション内に ASR の WER・TTS の MOS/CER・リアルタイムの遅延に関する直接比較の数値が示されていないため、専門特化システムに匹敵あるいは凌駕するという中心的な主張を具体的な値で確認することはできません。いくつかの設計上の選択についても正当化が部分的にしか行われていません。MTP における H=5 と \alpha=0.9 の選択・GRM の報酬における s(\cdot) の形式・ASR および Realtime では encoder を維持しながら TTS では完全に除去するという決定などがその例として挙げられます。参照アンカー型 GRM に依拠していることで、TTS の品質は参照データの入手可能性および GRM の人間的選好への較正によって上限が定まります。
この研究が重要な理由
単一の audio-language スタックがアーキテクチャの分岐なしにデータと RLHF のみで ASR・TTS・リアルタイム対話へと専門化できるとすれば、三つの独立した本番システムを維持する運用コストは消失し、共有バックボーンの改善があらゆる場所に波及します。また、verified-MTP レシピは、正確性を犠牲にすることなく任意の AR 音声デコーダを高速化するためのクリーンなテンプレートでもあります。
Source: https://arxiv.org/abs/2605.23463
Hacker News シグナル
制約の減衰:バックエンドコード生成におけるLLMエージェントの脆弱性
Source: https://arxiv.org/abs/2605.06445
本論文は、LLMベースのコーディングエージェントにおける「制約の減衰(constraint decay)」と呼ばれる障害モードを調査しています。エージェントワークフローが長くなるにつれて——ツール呼び出しが増え、コンテキストが拡大し、中間的な推論ステップが増加するにつれて——モデルはタスクの開始時に指定された制約を徐々に忘れるか、あるいは違反するようになります。バックエンドコード生成タスク(スキーマ設計、API実装、データベースクエリ)には、型安全性、認証要件、レート制限といったハードな制約が含まれており、それらは生成されたアーティファクト全体にわたってグローバルに保持されなければならないため、この問題は重要です。
著者らは、明示的かつ検証可能な制約を持つバックエンドコーディングタスクのベンチマークを構築し、ワークフローの深さの関数として制約の遵守率を測定しました。中心的な知見は、制約充足がエージェントのステップ数に対してほぼ単調に劣化するというものであり、その劣化は一様ではないという点です。プロンプトの早い段階で言及された制約は、生成ステップに近い位置で言及された制約よりも速く減衰し、これは長いコンテキストを持つ transformerにおける「lost-in-the-middle」現象と一致しています。
そのメカニズムは単純な忘却とは異なります。制約がattentionによって復元可能な場合(すなわち、技術的にはまだコンテキスト内に存在する場合)でも、エージェントはそれを適用することに失敗します。これは、問題の本質が純粋なコンテキストウィンドウの問題ではなく、反復的なツール使用の軌跡が元の指示の顕著性を希薄化させることにあることを示唆しています。Retrieval-augmented constraint injection(各エージェントステップで制約の要約を再挿入する手法)は減衰を部分的に緩和しますが、レイテンシを増加させ、かつ完全には解消されません。
定量的には、マルチステップタスクにおける遵守率は、難易度の高い制約カテゴリ(セキュリティ関連の制約が最も保持率が低い部類に入ります)においてシングルショットのベースラインと比較して30〜50パーセントポイント低下します。より大規模なモデルは減衰速度が遅いものの、影響を免れるわけではありません。
未解決の問題はアーキテクチャ的なものです。明示的な制約メモリモジュール、形式検証ループ、または構造化出力スキーマが、プロンプトエンジニアリング単独よりも強力な保証を提供できるかどうかという点が問われています。
なぜこれが重要か
制約の減衰は、本番のコードパイプラインにおけるエージェントの真剣な活用を損なう、具体的かつ測定可能な障害モードです。この研究は、信頼性の問題をモデルの能力の問題としてではなく、ワークフロー設計の問題として再定義しています。
Perceptual Image Codec: 実用的な学習型画像圧縮において何が重要か
Source: https://apple.github.io/ml-pico/
AppleのML-PICOは、学習型画像圧縮において、PSNRやMS-SSIMといった歪み指標ではなく、低ビットレートにおける知覚品質を実際に向上させる設計上の選択肢を検証した研究です。このコーデックは標準的なhyperprior/因子化エントロピーモデルアーキテクチャ上に構築されており、論文では知覚的損失関数、discriminatorアーキテクチャ、エントロピーモデルの容量、デコーダネットワークの深さそれぞれの寄与を切り分けるための系統的なablationを実施しています。
中心的な知見は、知覚的損失の選択が他のすべての要因を支配するという点です。LPIPS風のVGG feature lossを使用すると目に見えるテクスチャの幻覚アーティファクトが生じますが、より大規模なvision foundation model(DINOなど)に基づく損失に置き換えることで、知覚的な鮮明さを保ちながら構造的なアーティファクトを大幅に低減できます。patch discriminatorを用いた adversarial training もさらなる改善をもたらしますが、feature lossの選択に比べると二次的な効果です。
エントロピー側については、デコーダの表現力が十分であれば、エントロピーモデルを中程度の容量以上にスケールしても収穫逓減になることが示されています。これは、パラメータ予算の大部分をエントロピーモデルに割り当てる近年の研究への反論となっています。
定量的には、ML-PICOは0.05〜0.15 bppにおいてdiffusionベースのコーデック(HiFiCの各変種やCDCなど)と競争力のあるFIDおよびKIDスコアを達成しつつ、デバイスクラスのハードウェア上で実用的なデコード速度を実現しています。これはdiffusionベースのコーデックには主張できないことです。PSNRは設計上競争力を持たせていませんが、それが本研究で意識的に行われているトレードオフです。
実用上の限界として、知覚的な改善は非常に低いビットレートで最も顕著であり、中程度のレート(0.2 bpp超)では後処理を施した古典的なコーデックがそのギャップの大半を埋めてしまいます。また、テキストや医療画像のようにピクセル単位の正確な復元が求められるコンテンツに対しては、幻覚と忠実度のトレードオフは未解決のままです。
なぜこれが重要か
学習型コーデックは実用展開に近づいていますが、PSNRを品質と同一視する実務者からの信頼という問題に直面しています。本研究は実務者向けにablationに基づく明確な指針を提供するとともに、foundation modelの知覚的損失が今や圧縮における基幹インフラになっていることを明確に示しています。
DeepSeek Reasonix: 高いキャッシュ効率と低コストを実現するネイティブコーディングエージェント
Source: https://esengine.github.io/DeepSeek-Reasonix/
Reasonixは、DeepSeek-R1/V3をラップしたオープンソースのコーディングエージェントであり、長時間のエージェントセッションにおけるコストを最小化するため、DeepSeek APIのプロンプトキャッシュセマンティクスを明示的に活用するよう設計されています。中心的な技術的洞察は、DeepSeekがKVキャッシュから提供されるトークンに対して、新たに計算されるトークンよりも大幅に安い料金を設定しており、多くのコーディングエージェントフレームワークがキャッシュを無効化するような形でプロンプトを無自覚に再構築してしまうという点にあります。
本実装は、厳格なプレフィックス安定型プロンプト構造を強制することで高いキャッシュヒット率を達成しています。具体的には、システムプロンプト・リポジトリコンテキスト・会話履歴を常に固定順序でプロンプトの先頭に配置し、新しいユーザーターンのみを末尾に追記します。ツール呼び出しの結果は決定論的な追記専用フォーマットでシリアライズされます。これは、タイムスタンプを挿入したり、ツール結果をシャッフルしたり、コンテキストサマリーを再生成したりするフレームワークとは対照的であり、そういった操作はキャッシュのプレフィックスマッチングを破壊します。
Reasonixはさらに二層のコンテキスト管理戦略を実装しています。セッション全体を通じて安定した「コールド」プレフィックスと、現在の作業コンテキストとなる「ウォーム」サフィックスを分離し、コンテキスト上限に近づいた際にはコールド層ではなくウォーム層を刈り込む明示的なトランケーションロジックを備えています。これにより、計算コストの高いシステムコンテキストを常にキャッシュした状態に保ちます。
報告されているコスト削減効果は顕著であり、SWE-benchスタイルの評価における同等のタスク完了率を維持しつつ、同じタスクに対してナイーブなReActループエージェントと比較してコーディングセッションあたり約70〜80%のコスト削減を実現しています。キャッシュヒット時の応答が高速化されることで、レイテンシも改善されます。
このアプローチは、有利な価格差分を伴うプレフィックスキャッシュを公開しているプロバイダー(DeepSeek、および部分的にAnthropic)に特有のものです。すべてのプロバイダーに適用可能な汎用的な手法ではありません。
この研究が重要な理由
キャッシュを意識したプロンプトエンジニアリングは、最適化の軸として過小評価されています。Reasonixはこの手法を明示的かつ再現可能な形にしており、コストの差分は大規模にエージェントを運用するチームにとって無視できないほど大きなものです。
メモリはAIチップ部品コストのほぼ3分の2を占めるまでに拡大
Source: https://epoch.ai/data-insights/ai-chip-component-cost-shares
Epoch AIのデータ分析は、AIアクセラレータのBOM(部品表)構成の歴史的な変化を追跡しており、メモリ(主にHBMスタック)が現在、チップ部品コスト全体のおよそ60〜65%を占めるに至ったことを明らかにしています。これはpre-transformer時代と比べてはるかに大きな割合です。残りのコストはコンピュートダイ本体とパッケージング/インターコネクトに分配されています。
この要因はよく理解されています。transformer の inference および training は、実用的なほとんどのバッチサイズとシーケンス長においてメモリ帯域幅バウンドであり、コンピュートバウンドではありません。このため、ハードウェアベンダーはパッケージ上に直接搭載するHBMの容量を増大させてきました(H100:80 GB HBM3、B200:192 GB HBM3e)。HBMの生産はSK Hynix、Samsung、Micronに集中しており、歩留まりのスケーリングには限界があります。HBMのGB当たりコストは、3Dスタッキングプロセスやコンピュートダイとの高度な統合要件などの理由から、DRAMやNANDと同様の学習曲線をたどっていません。
この分析はinferenceのコスト構造に対して直接的な示唆を与えます。すなわち、GPUに支払うコストの大部分はFLOPsではなくメモリに対して支払われているということです。これは、メモリフットプリントを削減する手法(quantization、paged attention、利用率を向上させる speculative decoding など)が、FLOPsの節約効果が控えめであるにもかかわらず経済的に大きなインパクトをもたらす理由を部分的に説明しています。また、near-memoryおよびprocessing-in-memoryアーキテクチャへのベンダーの関心が高まっている理由も説明できます。
このデータはさらに、近い将来においてAIアクセラレータの供給を制約するボトルネックは、ロジックダイのファブキャパシティではなく、メモリの供給制約である可能性が高いことを示唆しています。
未解決の問いとしては、CXLアタッチトメモリや分解型メモリプーリングアーキテクチャが、HBMとより安価なDRAM階層のコスト差を、許容できない帯域幅ペナルティなしに活用できるかどうかという点が挙げられます。
この研究が重要な理由
チップのコスト構造を理解することは、インフラ調達の意思決定に役立ち、inference APIの価格動向を説明し、アーキテクチャ研究が最も高い経済的レバレッジを持つ領域を特定することに繋がります。
White Rabbit: 大規模分散システム向けサブナノ秒同期
Source: https://ohwr.org/projects/white-rabbit/
White Rabbit(WR)は、CERNで開発されたIEEE 1588(PTP)およびSynchronous Ethernet(SyncE)の拡張仕様であり、キロメートル規模の距離にわたる数百から数千ノードのネットワークにおいて、サブナノ秒の時刻同期を実現することを目標としています。CERNの加速器制御システム、KM3NeT ニュートリノ望遠鏡、および複数の重力波検出器のタイミングシステムに採用されています。
このプロトコルは、三つのメカニズムを組み合わせることで高精度を実現しています。第一に、SyncEが物理Ethernet層を通じて周波数リファレンスを伝搬し、すべてのスイッチクロックを共通のレートに同期させます。第二に、PTPv2のメッセージ交換により、カスタムFPGAのPHY/MAC層に直接実装されたピコ秒分解能のタイムスタンプハードウェアを用いてリンク遅延を計測します。第三に、TX/RXパスにおける異なるファイバー長や波長に起因する非対称な伝搬遅延を補正するため、リンクごとのキャリブレーション手順を実施します。
標準的なPTPと比較した際の主要な革新点は、ハードウェアタイムスタンプにあります。マイクロ秒単位のジッタを伴うソフトウェアタイムスタンプとは異なり、WRノードはクロックエッジ間を補間するfine-delay計測ユニットを用いて、パケットの到着・出発をハードウェアレベルでタイムスタンプし、10 ps以下の分解能を達成しています。WRPC(White Rabbit PTP Core)は、これを実装したオープンソースのFPGA IPコアです。
10ホップ、数キロメートルにわたるWRネットワークで実際に達成される精度は、同期オフセット <1 ns、ジッタ <1 ns であり、ソフトウェアPTP(〜1 µs)や衛星依存のないGPS規律発振器と比べて桁違いに優れています。ハードウェアおよびgatewareスタック全体がオープンハードウェア(CERN OHLライセンス)として公開されています。
制限事項:カスタムまたはWR対応のスイッチとNICが必要であり、汎用のEthernetハードウェアに後付けすることはできません。また、伝搬遅延の安定性が高いため、銅線よりもファイバーベースのネットワークの方が適しています。
この技術が重要な理由
分散システム(金融取引、5Gフロントホール、科学計測など)のタイミング要件がマイクロ秒を下回る水準へと進む中、WRはサブナノ秒同期が実運用においてどのような姿をとるかを示しています。また、オープンハードウェアとして公開されているため、CERN以外の環境でも再現可能です。
Claude はあなたのアーキテクトではない。そのふりをさせるのをやめよ
Source: https://www.hollandtech.net/claude-is-not-your-architect/
この投稿は、LLM をシステムアーキテクトとして使用することの失敗モードについて、技術的根拠に基づいた議論を展開しています。核心的な主張は、LLM はアーキテクチャ上もっともらしい出力——一見整合性があり、正しい用語を使用し、表面的なレビューをパスするような設計——を生成するものの、健全なアーキテクチャ上のトレードオフを行うために必要なシステムの運用コンテキストに関する因果モデルを持ち合わせていない、というものです。
識別された具体的な失敗パターンとして、LLM はシステムの実際の非機能要件に最適化された設計ではなく、レビュアーにとっての分かりやすさ(きれいな図、標準的なパターン)に最適化された設計を生成するという点があります。また、LLM は運用の歴史、チームの能力制約、あるいは経験豊富なアーキテクトが判断材料にするような既存の技術的負債について適切に推論できません。さらに、そのパターンが対象のスケールやチーム規模に適切かどうかに関わらず、業界標準のリファレンスアーキテクチャ(マイクロサービス、イベント駆動、CQRS)へ収束してしまいます。
著者は、LLM が真にレバレッジを発揮できるタスク(明確に仕様化されたアーキテクチャ内でのコード生成、ドキュメント作成、既知の制約内でのリファクタリング)と、LLM の出力が体系的に誤解を招くタスク(アーキテクチャ上の意思決定、キャパシティプランニング、分散状態における整合性モデルの選択)を区別しています。
この議論は LLM の推論における既知の問題と結びついています。つまり、モデルはアーキテクチャの選択を実際に制約する事後分析、インシデントレポート、あるいは混沌とした運用上の現実ではなく、理想化された条件でシステムがどのように構築されるかを説明するドキュメントやチュートリアルで学習されているという問題です。学習データの分布は楽観的なケースに偏っています。
実践的な推奨事項は、LLM を選択肢の列挙や自然言語でのトレードオフの明確化に活用することですが、すべてのアーキテクチャ上の出力は権威ある設計としてではなく、実際の運用上の制約に照らして批判的なレビューを要する第一草案の提案として扱うべきである、というものです。
なぜこれが重要か
この議論は Claude に限らず、設計の役割で使用されるあらゆる LLM に当てはまるものであり、一律の賛否ではなく、エンジニアリング組織における LLM の活用範囲を定めるための原則的な根拠を提供しています。
Jujutsu で Git の厳格さへの疲弊を克服する
Source: https://ikesau.co/blog/defeating-git-rigour-fatigue-with-jujutsu/
この記事では、Git から Jujutsu(jj)へのワークフロー移行について述べており、締め切りのプレッシャー下で開発者が規律あるコミット管理を断念してしまう原因となる具体的な UX の問題に焦点を当てています。技術的な核心は、jj のデータモデルが、Git の履歴をクリーンに保つことを認知的な負担にしている摩擦点をどのように排除するかにあります。
中心的な違いとして、jj にはインデックス/ステージングエリアがなく、detached HEAD 状態も存在しません。すべての作業ツリーの状態は自動的にコミットとなり、「現在のコミット」は明示的にプッシュされるまで常に変更可能です。これにより、「作業ツリーが汚れた状態でコンテキストスイッチが必要になる」という Git のワークフローパターン——stash、ブランチ作成、または WIP コミットの作成が必要となる——が、単に別のコミットへ移動するだけに集約されます。作業状態は自動的に保持されます。
jj split、jj absorb、jj rebase の各操作は、Git の同等機能には見られない形でファーストクラスかつコンフリクトセーフに実装されています。特に jj absorb は、各ファイル/ハンクを最後に変更したコミットに基づいて、作業ツリーの変更を適切な過去のコミットへ自動的に移動します——これは Git ではインタラクティブ rebase が必要な機械的な操作です。コンフリクトマーカーはコミットグラフ内に保存されるため、即時の解決を求められることなく、コンフリクトを抱えたままリベースして後から解決することが可能です。
著者の主張は、git の厳格さへの疲弊——プレッシャー下で rebase、squash、コミット整理をやめてしまう傾向——は規律の問題ではなくツールの問題だということです。jj は一般的なケースにおいて、履歴をクリーンに保つための操作コストをほぼゼロに近づけます。
注記されている制限事項として、jj の Git 互換バックエンドにより GitHub/GitLab との連携は可能ですが、メンタルモデルの転換(ステージングエリアの廃止、匿名ブランチ)には実質的な学習コストが伴います。また、すべての Git GUI が jj で管理されたリポジトリで正しく動作するわけではありません。
なぜこれが重要か
正しい行動への摩擦を減らす開発者ツールは、複利的な価値をもたらします。Jujutsu のモデルは、後付けのワークフロー慣習ではなく、永続的なイミュータブルスナップショットに基づくバージョン管理 UX の真の再設計です。
Launch HN: Runtime (YC P26) — チーム全員のためのサンドボックス化されたコーディングエージェント
Source: https://www.runtm.com/
Runtimeは、LLMコーディングエージェント向けにサンドボックス化された実行環境を提供するプロダクトです。非エンジニアのチームメンバーが、インフラ管理や共有システム上での信頼できないコード実行リスクを負うことなく、エージェント駆動のコード実行にアクセスできるようにするという、組織的な問題をターゲットにしています。
技術的な核心は隔離レイヤーにあります。各エージェントセッションは、ファイルシステムアクセスが制限されリソース上限が設けられた、ネットワーク分離済みのエフェメラルコンテナ上で動作します。このサンドボックス化は新規技術ではなく(確立されたコンテナおよびmicroVMのプリミティブ、おそらくgVisorやFirecracker相当の隔離技術に基づいています)、プロダクトとしてはこれをマルチエージェントオーケストレーションレイヤーおよび個人開発者ではなくチーム向けに設計されたパーミッションモデルと統合している点が特徴です。
パーミッションモデルこそが興味深い設計上の問題です。チームメンバーごとに、特定のデータソースからの読み取りは許可しつつ本番システムへの書き込みは禁止するエージェントの実行を認可したり、あらかじめ承認されたツールセットの実行は許可しつつ任意のシェルコマンドは禁止したりといった権限付与が必要になる場合があります。Runtimeはこうした制約を、ツール運用者がコンテナセキュリティを理解しなくても適用できるよう、実行サンドボックスの上位にポリシーレイヤーを実装しているようです。
LLM統合はプロバイダー非依存(主要なAPIプロバイダーをサポート)であり、エージェントフレームワークは新規のエージェントアーキテクチャではなく、薄いオーケストレーションレイヤーとして機能しているようです。差別化要因はAIレイヤーではなく、運用面とセキュリティサーフェスにあります。
YCローンチのディスカッションで挙がったオープンクエスチョンとしては、依存パッケージのインストールが必要なエージェント(コーディングタスクでよくある要件であり、イミュータブルなコンテナイメージと相反します)をサンドボックスがどのように扱うか、またI/O集約型のエージェントワークフローにおける隔離レイヤーのパフォーマンスオーバーヘッドはどの程度かといった点が挙げられています。
なぜこれが重要なのか
エンタープライズにおけるエージェント採用のボトルネックは、モデルの能力ではなく安全な実行と監査可能性にあります。エージェントではなくサンドボックスをプロダクトとして捉えるRuntimeのアプローチは、組織展開における正しい問題分解と言えます。
注目の新しいリポジトリ
usewhale/DeepSeek-Code-Whale
DeepSeekモデルを中心に構築された、ターミナルネイティブなAIコーディングエージェントです。主な技術的差別化ポイントは、prefix-cache最適化と1Mトークンコンテキストウィンドウのサポートです。prefix-cache最適化では、静的なシステムコンテキストprefixがリクエスト間で最大限に再利用されるようプロンプトを慎重に構造化することで、97%のライブキャッシュヒット率を実現すると主張しています。アーキテクチャには、外部ツールを接続するためのMCP(Model Context Protocol)ツール統合レイヤーと、ランタイム時に合成可能な再利用可能な高階動作(例:リファクタリングとテストのワークフロー)をユーザーが定義できる「Skills」拡張システムが含まれています。DeepSeekのAPIをネイティブにターゲットとしているため、汎用のOpenAI互換クライアントでは利用できないモデル固有の機能(FIM completion、キャッシュヘッダー)を活用できます。汎用レイヤーを経由せずにCLIエージェントを必要とする、DeepSeek inferenceをすでに運用しているチームに有用です。
Source: https://github.com/usewhale/DeepSeek-Code-Whale
ahammadmejbah/Awesome-Datasets-Hub
LLM研究およびfine-tuningに関連するデータセットを、タスクカテゴリ別に整理した体系的なカタログです。カテゴリとしては、医療AI、NLP、マルチモーダル学習、instruction tuning、chain-of-thought/推論、コード生成、評価 benchmarkが含まれます。本リポジトリの価値は新規データではなくキュレーションにあり、各エントリには出典、サイズ、ライセンス、および典型的なユースケースが記載されています。新しいfine-tuningや評価パイプラインを立ち上げようとしている実務者にとって、HuggingFace、PapersWithCode、ドメイン固有リポジトリに散在する情報を検索する手間を軽減します。instruction tuningおよび推論データセットのカバレッジは、現在のポスト学習アライメントへの注目を踏まえると特に有用です。本リポジトリはliving documentであるため、エントリの鮮度は継続的なメンテナンス上の課題となります。
Source: https://github.com/ahammadmejbah/Awesome-Datasets-Hub
ChristianJR19/grok-animus
任意のLLMバックエンド上に載せることで、状態を持ち継続的に進化する「コンパニオン」的な振る舞いを実現するために設計された、持続性・パーソナリティエンジンです。技術的には、構造化された長期記憶(エピソード記憶と意味記憶のストア)、インタラクション履歴に基づいて変化する可変パーソナリティベクター、そしてアイドル時間中に記憶の圧縮・再重み付けを行う低優先度の統合処理を実行する「夢」サブシステムを維持します。進化はfine-tuningではなく、パーソナリティパラメータの緩やかなドリフトとして実装されています。つまり、モデルの重みは凍結されたままですが、コンテキストと検索ポリシーが変化します。設計はモデル非依存であり、OpenAI互換またはローカルのLLMを差し込めるアダプターインターフェースを公開しています。これはRLHFによる完全なパーソナライゼーションに代わるアーキテクチャとして興味深いアプローチであり、重みの更新ではなく検索拡張型のコンテキストエンジニアリングによって見かけ上の行動的連続性を実現しています。
Source: https://github.com/ChristianJR19/grok-animus
mvm-sh/mvm
Goのために書かれたバイトコードインタプリタおよび仮想マシンで、Go固有のセマンティクスを超えた(“and beyond”)という野心的な目標を掲げています。設計はレジスタベースまたはスタックベースのVMモデル(言語ランタイムの実験的実装として典型的)に従っており、インタプリタの速度を重視しています。Go向けには、AOTコンパイルなしでGoコードを動的に実行できるため、コンパイル済みバイナリのロードが現実的でないプラグインシステム、スクリプティングレイヤー、サンドボックス実行環境などへの応用が考えられます。“beyond”というフレーミングは、より汎用的なIRまたは多言語フロントエンドターゲットを示唆していますが、現在の実装はGo中心のように見受けられます。Goホストアプリケーションへのembeddableなスクリプティングや、ユーザー提供のGoコードをサンドボックス化したいプロジェクトは、本プロジェクトをYaegi(より成熟しているものの既知のパフォーマンス上限がある)などの代替手段と比較検討することになるでしょう。
Source: https://github.com/mvm-sh/mvm
Evokoa/pgGraph
PostgreSQL上に直接構築されたグラフデータベースレイヤーであり、専用のグラフストアにデータを移行することなく、既存のリレーショナルスキーマをグラフセマンティクスでクエリできるようにします。実装にはPostgreSQLの再帰CTE、およびltree・隣接リスト表現を用いて頂点と辺をモデル化し、その上にグラフクエリインターフェースを公開しています。Neo4jやArangoDBといった専用グラフデータベースと比較した場合の利点は、データの重複がゼロであり、下層のPostgresインスタンスが持つ完全なACID保証を得られる点です。一方のトレードオフとして、大規模なグラフに対する深い探索は、ポインタチェイシングアクセスパターンに最適化されたネイティブグラフエンジンよりも低速になります。これは、グラフクエリがリレーショナルワークロードに対して副次的な位置づけにあるアプリケーション、あるいは運用上のシンプルさ(データベース一つ、バックアップ体制一つ)が純粋な探索性能を上回るケースにおいて、実用的な選択肢となります。
Source: https://github.com/Evokoa/pgGraph
entropyvortex/meta-llm-charter
コンパクトなシステムプロンプトフレームワークです。11個の運用ルールと1個のメタルールから構成されており、LLMコーディングエージェントをシニアエンジニアリング実践に関連する振る舞いへと制約するよう設計されています。具体的には、行動前の明示的な推論、最小差分の原則、コミット前のテスト規律、そして推測による解答ではなく曖昧さが生じた際のエスカレーションが挙げられます。メタルールは、エージェントが11個の基本ルール間で競合が発生した場合の対処方法を規定しています。これはポリシー仕様としてのprompt engineeringの一例であり、システムプロンプトを非公式な指示ではなく正式なチャーターとして扱っています。このドキュメントはコンテキスト予算内に収まるよう意図的にコンパクトに設計されつつも、包括性を保っています。予測可能で保守的な振る舞いを求め、最大限の自律性よりも安定性を重視する自律コーディングエージェントを展開するチームにとって、ベースラインまたはリファレンスとして有用です。
Source: https://github.com/entropyvortex/meta-llm-charter
Cmochance/codex-app-transfer
OpenAIのResponses API(Codex CLIが使用)をChat Completions APIフォーマットに変換するローカルHTTPプロキシです。これにより、Codex CLIがあらゆるOpenAI互換バックエンドへリクエストをルーティングできるようになり、特にKimi・DeepSeek・Zhipu GLM・Alibaba Bailianをターゲットとしています。この変換レイヤーは2つのAPIバージョン間のスキーマの差異を処理します(Responses APIはステートフルなセッション指向モデルを採用しているのに対し、Chat Completionsはステートレスです)。具体的には、ストリーミングイベント・tool callフォーマット・メッセージ構造のマッピングを行います。Responses APIはサードパーティプロバイダーによる実装がまだ広く普及しておらず、Codex CLIがそれをハードコードしているため、このツールは有用です。このゲートウェイをローカルで実行する場合、CLI自体に変更を加える必要はありません。アーキテクチャはリクエスト・レスポンス変換ミドルウェアを持つ標準的なリバースプロキシであり、軽量なGoまたはNodeサービスとして実装されていると考えられます。
Source: https://github.com/Cmochance/codex-app-transfer
av/facts
あいまいな散文的仕様書を、AIコーディングエージェントが参照・検証できる機械可読な「facts(事実)」に置き換えることを目指した開発ツールキットです。核となるアイデアは、ふわっとした自然言語仕様がエージェント支援開発におけるハルシネーションやスコープの逸脱の主要因であるという考えに基づいており、要件を構造化された反証可能なアサーションとしてエンコードすることで、エージェントはテストに使える明確なオラクルを得ることができます。このツールキットは、factsを定義し、それらをテストケースや受入基準に紐付け、生成ループにおいて検証を第一級のステップとする形でエージェントのコンテキストに供給するためのプリミティブを提供します。これはLLMエージェントを形式仕様に基づかせることに関する現在進行中の研究と繋がっており、AIが生成したコードが表面的なレビューは通過するものの暗黙の不変条件に違反するケースが頻発するチームにとって、実践的に重要な取り組みです。
Source: https://github.com/av/facts