Daily AI Digest — 2026-05-25
arXiv Highlights
LLMs as Noisy Channels: A Shannon Perspective on Model Capacity and Scaling Laws
Problem
Existing scaling laws — Kaplan et al.’s power law and Chinchilla’s additive form — predict monotonic loss reduction in N (parameters) and D (tokens). Empirically, several regimes break this monotonicity: catastrophic overtraining, post-quantization degradation, and SFT loss landscapes that exhibit a basin where additional pretraining tokens or parameters worsen downstream performance.
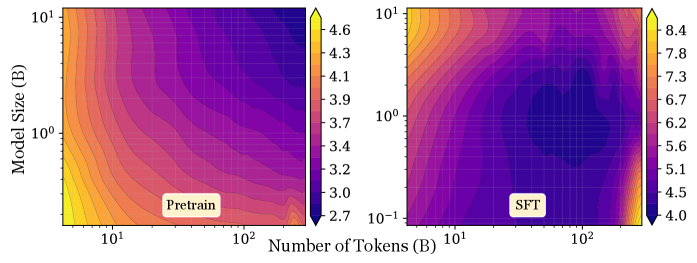
The figure makes the failure mode concrete: the pretraining surface is monotonically decreasing in (N, D), but the SFT surface forms a basin — past a critical D at fixed N, downstream loss climbs again. No power law of the form L = A N^{-\alpha} + B D^{-\beta} + E can express this geometry, because every term is monotone in each argument.
Method
The authors recast LLM training as transmission over a Gaussian channel. The Shannon–Hartley capacity is
C = B \log_2\left(1 + \frac{S}{\mathcal{N}}\right),
with bandwidth B, signal power S, and noise power \mathcal{N}. They map B \mapsto N (representational bandwidth grows with parameters), S \mapsto D (information delivered by tokens), and posit that noise has both a data-dependent component (corruption, label noise, perturbations scaling with D) and an interaction term coupling D and N (e.g., overfitting capacity to noise).
This yields the Shannon Scaling Law:
C_{\text{LLM}} = a N^{\alpha} \log_2\!\left(1 + \frac{b D^{\beta}}{c (DN)^{\gamma} + d D^{\delta} + e}\right) \quad (6)
with nine positive fitted constants. The numerator b D^\beta is the useful signal contributed by data; the denominator collects noise sources that grow super-linearly in DN and in D alone. When \beta > \gamma + 1 at fixed N, the SNR rises monotonically; when \gamma or \delta dominate, SNR peaks and then falls, producing the U-shape. The \log_2 wrapper bounds capacity above by a N^\alpha times log-SNR, so parameters set a hard ceiling.
A 6-parameter simplified variant drops b, d, e (consistently negligible in fits):
C_{\text{Simpl}} = a N^{\alpha} \log_2\!\left(1 + \frac{D^{\beta}}{c (DN)^{\gamma} + D^{\delta}}\right) \quad (12)
Fitting uses scipy.optimize.curve_fit on Pythia (160M–12B, checkpoints from 2k to 140k steps) and OLMo2 (1B/7B/13B/32B stage-1 checkpoints). Perturbations include additive Gaussian noise on activations at SNRs of 40–10 dB, GPTQ quantization at 2/3/4 bits, and SFT on math, QA, and code via TRL’s SFTTrainer.
The authors also introduce two Chinchilla extensions as baselines — Symmetric (a N^\alpha/D^\beta + b D^\beta/N^\alpha + c) and Asymmetric — to test whether non-monotonicity alone, without an information-theoretic motivation, is sufficient.
Results
The U-shape predicted by the law materializes empirically. Under increasing Gaussian noise, Pythia’s (N, D) loss contours deform from monotone gradients into closed basins:

Quantitatively, Table 5 reports R^2 on Pythia and OLMo2 across noise levels. The full law averages R^2 = 0.9656 \pm 0.03 on Pythia and 0.9646 \pm 0.05 on OLMo2. The simplified 6-parameter form retains 0.9541 and 0.9630 respectively. The “Pareto Front” column — the best baseline at each noise level (Chinchilla, OpenAI, QiD, Law of Precision, Symmetric, Asymmetric) — averages 0.9400 on Pythia and 0.9566 on OLMo2.
The gap widens in high-noise regimes where the basin is sharpest: at 10 dB SNR on Pythia, the simplified Shannon law reaches R^2 = 0.9092 versus 0.8322 for the best baseline; the full law reaches 0.9555. At 12 dB the full law scores 0.9234 versus baselines that cannot fit the curvature. On OLMo2 at 10 dB the full law and baseline collapse together (~0.87), suggesting at very low SNR the basin geometry exceeds even the Shannon parameterization’s flexibility.
Limitations and open questions
The mapping S \mapsto D, B \mapsto N is heuristic: information-theoretically, D is closer to channel uses than to signal power, and the \log_2 form is imported by analogy rather than derived from a likelihood model. With nine free constants the law has comparable capacity to QiD and Law of Precision, so the win is primarily in functional form, not parsimony. The experiments measure pretraining loss under post-hoc perturbations and SFT loss; no result yet ties the fitted SNR to a measurable property of the data distribution or of the optimizer’s noise. Extrapolation beyond the fitted (N, D) grid — the most useful test of a scaling law — is reported only at a single perturbation level. The 10 dB OLMo2 collapse hints that the noise term c(DN)^\gamma + dD^\delta underspecifies regimes where perturbation interacts with architecture-specific failure modes.
Why this matters
Power-law scaling cannot accommodate the non-monotone behavior that now dominates practical concerns — overtraining, low-bit quantization, and SFT-induced regression. Wrapping the Chinchilla-style numerator inside \log_2(1 + \text{SNR}) is the minimal modification that produces a principled basin and consistently improves fits at high noise, which is precisely where prediction matters for compute allocation.
Source: https://arxiv.org/abs/2605.23901
SkillOpt: Executive Strategy for Self-Evolving Agent Skills
Problem
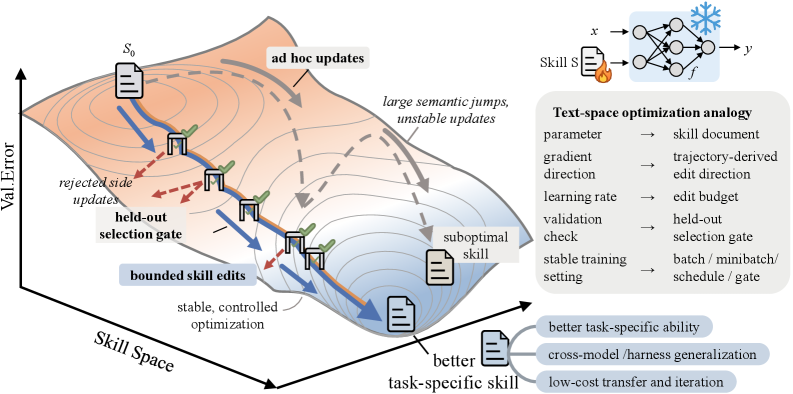
Agent “skills” — natural-language procedural policies prepended to a frozen model’s context — are typically authored by hand, generated one-shot from an LLM, or refined by ad-hoc self-revision loops. None of these treats skill construction as an optimization problem with the discipline of weight-space training: there is no learning-rate analogue, no validation gate, no rejected-step memory, no notion of an epoch. The empirical consequence is that skill “evolution” frequently fails to monotonically improve over its initialization. SkillOpt reframes the skill document s as the external state of a frozen agent and trains it with a controllable text-space optimizer.
Method
The setup is standard ERM transposed to text. For target model M, harness h, task x, a rollout returns
(\tau(s), r(s)) = h(M, x, s), \quad r(s) \in [0,1].
Given splits D_{\mathrm{tr}}, D_{\mathrm{sel}}, D_{\mathrm{test}}, candidate skills \mathcal{C}(D_{\mathrm{tr}}) are produced by training on D_{\mathrm{tr}} and selected via
s^\star_{\mathrm{sel}} = \arg\max_{s \in \mathcal{C}(D_{\mathrm{tr}})} \frac{1}{|D_{\mathrm{sel}}|}\sum_{x \in D_{\mathrm{sel}}} r(s),
with test reporting on the held-out split.
The optimizer is a separate (frontier-scale) LLM that does not touch M’s weights. Each step:
- Rollout batch. M executes a minibatch of D_{\mathrm{tr}} tasks with current skill s_t, producing scored trajectories.
- Reflection. The optimizer ingests both successes and failures and proposes a bounded set of typed edits —
add,delete,replace— on the single skill document. The bound functions as a textual learning rate: it caps the diff magnitude per step, analogous to a trust region. - Merge and rank. Proposed edits are de-duplicated (skill hashes are cached) and ranked under an edit budget scheduled across epochs.
- Validation gate. The merged candidate s' is accepted only if its mean score on D_{\mathrm{sel}} strictly exceeds that of the current best. Rejected edits are not discarded — they enter an epoch-local rejected-step buffer that the optimizer conditions on as negative evidence in subsequent proposals.
- Slow/meta update. Across epochs, a meta step distills longer-horizon lessons across rejected and accepted trajectories without modifying M.
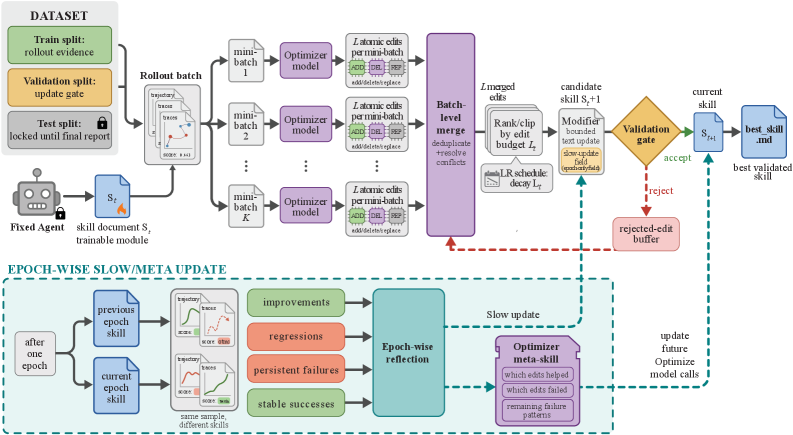
The key disciplinary commitments — bounded edits (learning rate), validation-gated acceptance (early stopping on each step), rejected-step buffer (negative-sample memory), epoch-wise slow update (momentum/meta), and hash-based deduplication — give the loop the same reproducibility properties as SGD on weights, while keeping deployment cost identical to a static skill: zero extra inference-time model calls, since only best_skill.md is exported.
Results
Evaluation spans six benchmarks chosen to stress different agent regimes: SearchQA (single-round QA), DocVQA, LiveMathematicianBench (MCQ), OfficeQA (multi-turn tool loops, up to 24 calls), SpreadsheetBench (multi-round codegen with openpyxl/pandas runtime, up to 30 turns), and ALFWorld (embodied, up to 50 steps). Seven target models from the GPT and Qwen families are tested across three harnesses (direct chat, Codex, Claude Code), yielding 52 (model, benchmark, harness) cells. Splits are deterministic (\mathtt{split\_seed=42}); test scores are on disjoint held-out data.
The headline claim: SkillOpt is best or tied in all 52 cells, beating per-cell every baseline among hand-written human skills, one-shot LLM skills, Trace2Skill, TextGrad, GEPA, and EvoSkill. The abstract is truncated in the provided text on the GPT-specific delta but indicates dominance at frontier scale.
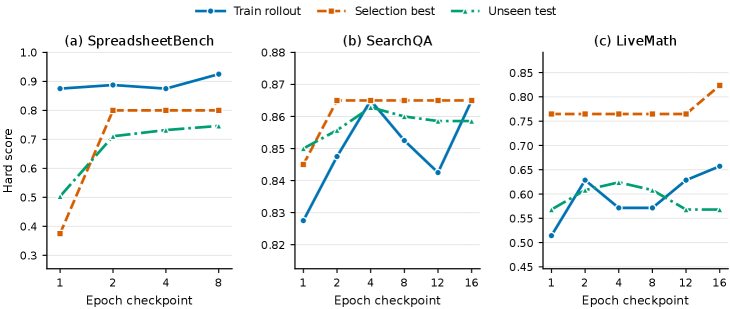
Trajectory analysis across epoch checkpoints — reporting training rollout, selection-best, and held-out test scores — confirms that the validation-gated checkpoint generalizes: the checkpoint preferred by D_{\mathrm{sel}} is consistently competitive on D_{\mathrm{test}} across SpreadsheetBench, SearchQA, and LiveMath, indicating the gate is not merely overfitting to the selection split.
Limitations and open questions
- The optimizer is itself a frontier LLM; training-time cost is non-trivial, even though deployment cost is zero. The paper’s “at what cost” question is acknowledged but the excerpt does not quantify optimizer-call budgets per accepted edit.
- “Best or tied” is a weak ordering; the magnitude of wins over GEPA and EvoSkill (the strongest text-optimizer baselines) is not visible from the provided sections.
- Strict validation-gated acceptance is conservative — it can stall in plateau regions where no single bounded edit yields a strict improvement, even when a multi-step trajectory would. Whether the rejected-step buffer alone is sufficient to escape such plateaus is unclear.
- Skills are scalar-scored; multi-objective skill optimization (e.g., accuracy vs. tool-call count) is not addressed.
- Generalization across harnesses for the same skill — i.e., whether a skill optimized under direct chat transfers to Codex — is not reported in the provided excerpt, though each (model, benchmark, harness) cell is evaluated independently.
Why this matters
Treating the skill document as trainable external state — with learning-rate bounds, a validation gate, and a negative-sample buffer — turns prompt/skill engineering from a craft into a reproducible optimization procedure that adds zero inference-time overhead. If the 52/52 claim holds at scale, it provides a principled default for adapting frozen agents without fine-tuning.
Source: https://arxiv.org/abs/2605.23904
Rethinking Cross-Layer Information Routing in Diffusion Transformers
Diffusion Transformers (DiTs) have been remodeled along nearly every axis — tokenizer, attention variant, conditioning mechanism, training objective, latent VAE — but the residual stream itself has been imported wholesale from the original encoder Transformer. This paper argues that the unit-coefficient residual is a poor fit for diffusion generation and proposes a learned, timestep-conditioned aggregator (Diffusion-Adaptive Routing, DAR) as a drop-in replacement.
Diagnosis: what is wrong with h_{l+1}=h_l+f_l(h_l;t)
The authors instrument SiT-XL/2 (28 blocks, 600K iters, 4096 ImageNet samples) and measure three per-block statistics of the hidden state z_k: forward \mathrm{RMS}(z_k), backward \mathrm{RMS}(\partial\mathcal{L}/\partial z_k), and consecutive cosine similarity \cos(z_k,z_{k+1}).
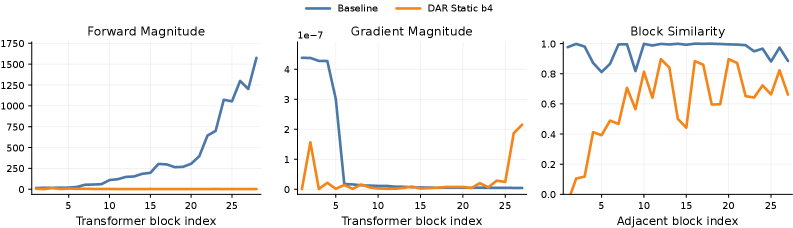
Three pathologies emerge, all monotone in depth:
- Forward magnitude inflation. \mathrm{RMS}(z_k) grows from \sim 15.5 at block 1 to \sim 1576 at block 28 — roughly 100\times. Because each sublayer applies unit-RMS normalization at its input, deep sublayers must emit ever-larger raw outputs simply to keep nonzero post-norm influence on the stream. This is the PreNorm dilution effect previously documented in LLMs, now quantified for DiTs.
- Backward gradient decay. Gradient RMS at the first five blocks is around 5\times 10^{-7} and falls by more than an order of magnitude across the remaining stack, hovering near zero. The additive residual offers no mechanism to redistribute gradient mass across depth.
- Block-wise redundancy. Per-token \cos(z_k,z_{k+1})>0.9 across the deep stack — neighboring deep blocks compute nearly the same representation, indicating wasted capacity.
Unrolling Eq. (1) gives h_l = h_0 + \sum_{i=0}^{l-1} f_i(h_i;t), i.e. every prior sublayer enters with coefficient 1, regardless of l or t. The model has no knob to retrieve a specific earlier representation at a specific denoising stage.
Is the timestep axis even being used?
DiTs differ from text Transformers precisely because the input distribution shifts smoothly with t. The authors test whether the baseline implicitly wants timestep-dependent mixing by attaching measurement-only scalar gates (initialized to 1) on each historical residual source, leaving the forward pass numerically unchanged, and reading out \partial\mathcal{L}/\partial \text{gate} as the counterfactual source importance.
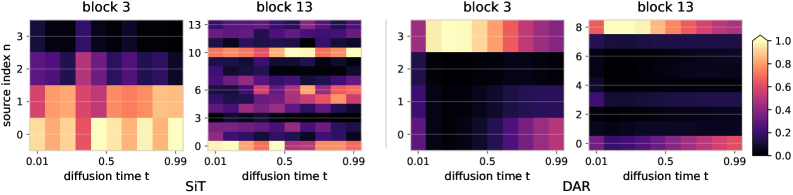
Even though the baseline never trains a router, its counterfactual importance map varies systematically along t, and differently at shallow vs. deep locations. This is the empirical motivation for making the routing both learned and timestep-adaptive rather than fixed.
Method: Diffusion-Adaptive Routing
DAR replaces Eq. (1) with a learnable, non-incremental aggregation over the history of sublayer outputs. Concretely, each block l maintains softmax routing weights \alpha_{i\to l}(t) over sources i<l, conditioned on the diffusion timestep, and forms its input as a mixture of historical sublayer outputs rather than a running sum.
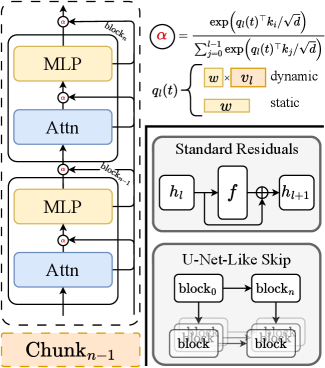
Three properties matter mechanically:
- Learnable. Routing coefficients are parameters, breaking the unit-coefficient prior of Eq. (2) and letting deep blocks attenuate or amplify any earlier source.
- Timestep-adaptive. \alpha_{i\to l} is a function of t, matching the counterfactual structure observed in Fig. 3.
- Non-incremental. Aggregation is a (softmax-normalized) mixture, not an addition, which directly addresses the magnitude-inflation pathology — by construction no monotone RMS blow-up arises from stacking.
The diagnostics in Section 3 are also reported for a static DAR variant with chunk size S=4 (sources grouped into chunks of 4 sublayers), suggesting that even without timestep adaptivity the aggregation form alone reduces inflation, gradient decay, and redundancy.
DAR is presented as a drop-in residual replacement, so it composes with orthogonal DiT enhancements; the authors specifically combine it with REPA [yu2025repa] using REPA’s original configuration.
Results
On ImageNet 256\times 256 with the SiT recipe held fixed:
- Quality. DAR improves SiT-XL/2 by 2.11 FID (7.56 vs. 9.67).
- Efficiency. DAR matches the converged FID of the SiT-XL/2 baseline using 8.75\times fewer training iterations.
- Compatibility. DAR stacks with REPA under REPA’s original training configuration, indicating the gain is not redundant with representation-alignment objectives.
Limitations and open questions
The diagnostic section reports a single training horizon (600K iters) and a single architecture scale (XL/2). It is not shown whether the 100\times forward inflation persists or saturates with longer training, larger models, or alternative normalizations (e.g. SiameseNorm). The exact functional form of \alpha_{i\to l}(t), its parameter cost, and inference overhead from caching all sublayer outputs are not summarized in the provided sections; for very deep DiTs the O(L^2) source-mixing footprint could become non-trivial. Whether DAR’s gains transfer to text-to-image DiTs at higher resolution, to video DiTs where the timestep-source coupling may differ, and to flow-matching variants beyond SiT remains to be tested. Finally, the counterfactual-gate analysis is a local linearization around the baseline; it shows the baseline would want timestep-dependent routing, not that the specific softmax parameterization in DAR is optimal.
Why this matters
The residual stream is the one component of the Transformer that DiT research has left untouched, and this paper provides direct empirical evidence that it is actively miscalibrated for diffusion: magnitudes explode, gradients vanish, and adjacent deep blocks duplicate work. A 2.11 FID drop and 8.75\times training-iteration speedup from a drop-in residual replacement suggests cross-layer routing is an undervalued design axis on par with attention or conditioning choices.
Source: https://arxiv.org/abs/2605.20708
RankE: End-to-End Post-Training for Discrete Text-to-Image Generation with Decoder Co-Evolution
Problem
Discrete autoregressive T2I stacks pair a frozen VQ tokenizer/decoder D_\phi with an AR policy \pi_\theta(z\mid y) that emits codebook indices, which are then rendered to pixels via x=D_\phi(z). Post-training (RLHF-style alignment with CLIP or HPSv2 rewards) has so far been applied only to \pi_\theta, leaving D_\phi untouched. The authors argue this is unsafe: as \pi_\theta drifts under reward optimization, the marginal distribution of token sequences it produces diverges from the empirical distribution the decoder was trained to invert. They name this Latent Covariate Shift (LCS) and show it manifests as a familiar pathology — reward goes up, decoded image fidelity goes down.
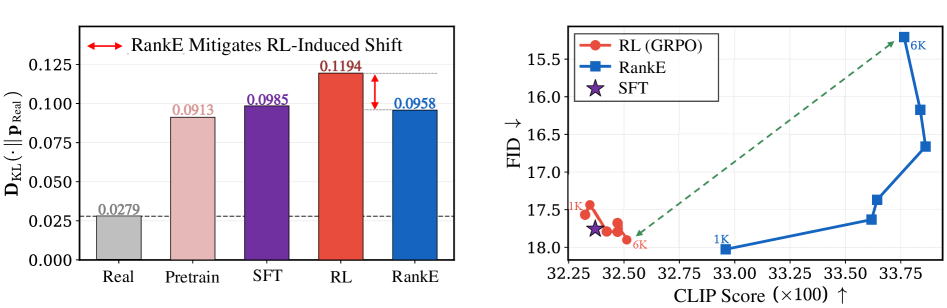
Figure 1 quantifies LCS by encoding 5,000 real MS-COCO images with the frozen tokenizer and measuring KL between the policy-induced token distribution and the real one, with a “Real–Real” KL between two independent real splits as a natural-variance floor. The shift grows monotonically through pre-training → SFT → standard RL, and RankE pulls it back down toward the floor — the decoder is being asked to render off-manifold codes by the time RL converges.
Method
RankE formalizes the joint objective
\max_{\theta,\phi}\;\mathbb{E}_{y\sim\mathcal{D},\,z\sim\pi_\theta(\cdot\mid y)}\!\left[r(D_\phi(z),\,y)\right].
The categorical sampling of z and the VQ straight-through quantizer break the gradient path: gradients of r flow into \phi but not into \theta. Rather than patch this with a biased relaxation (Gumbel, REINFORCE through the decoder, etc.), RankE solves the joint problem by alternating updates, each in the form natural to its parameter space, and viewing the alternation as a Generalized EM procedure on a single regularized objective.
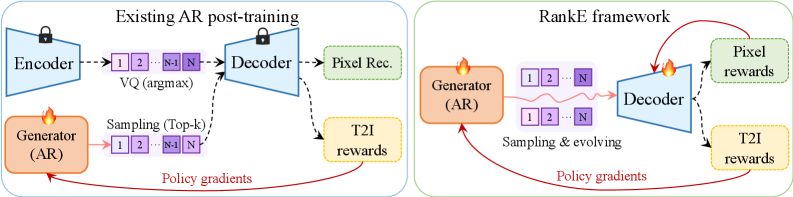
Concretely (Figure 3):
Stage 1 — Policy Alignment. With \phi frozen, \theta is updated by GRPO on a ranking-based reward (CLIP or HPSv2), regularized by a KL penalty against an EMA reference policy \pi_{\bar\theta}: \mathcal{L}_\theta = -\mathbb{E}\!\left[A(z,y)\log\pi_\theta(z\mid y)\right] + \beta\,\mathrm{KL}(\pi_\theta\,\Vert\,\pi_{\bar\theta}). This is the standard RLHF half — and on its own it is exactly what produces LCS.
Stage 2 — Decoder Adaptation. With \theta frozen, the decoder \phi is updated to maximize the same ranking objective on rollouts sampled from the current policy, regularized by a stability anchor in its native parameter space (a reconstruction/feature anchor against the original decoder, since KL is meaningless for a deterministic renderer). This pulls D_\phi toward correctly decoding the new token distribution while preventing collapse onto reward-hacked artifacts.
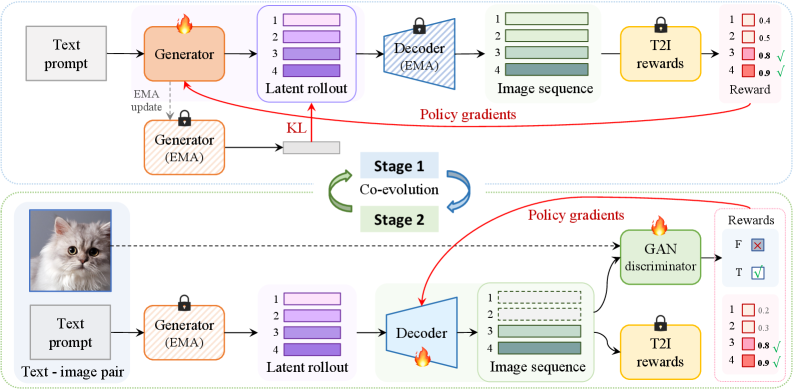
The interleaving is what propagates reward information across the non-differentiable gap: each Stage-2 step adapts D_\phi to whatever code distribution the latest \pi_\theta emits, so the next Stage-1 step optimizes against a decoder that actually renders its samples faithfully.
Results
Two backbones are used: LlamaGen-XL (775M) and Janus-Pro-1B. Baselines are Base, SFT on the same curated corpus, and Std. RL (GRPO with CLIP or HPSv2 reward, frozen decoder) — the last is the controlled comparison since reward, data, and compute match RankE exactly; only decoder co-evolution differs.
The headline finding from the abstract and Figure 1: on LlamaGen-XL, standard RL improves CLIP score but degrades decoded image quality (the abstract is truncated at this sentence in the provided data). RankE breaks this fidelity–alignment trade-off, with the LCS-KL in Figure 1 returning close to the Real–Real floor while alignment rewards continue to improve. Section 4.3 is positioned as a mechanism check tying the metric improvements back to the LCS hypothesis, and Section 4.4 ablates the two stages and their anchors.
Limitations and open questions
- The framework is specialized to discrete AR + VQ-decoder stacks; it does not address continuous-token AR models or unified diffusion-decoder hybrids, where the alignment bottleneck takes a different form (cf. REPA-E for VAEs).
- Stage-2 anchoring is described in parameter-space-appropriate terms but the paper data here does not pin down the exact functional form (perceptual? pixel? feature-matching against the frozen decoder?), and its weight likely controls a fidelity–alignment knob the authors should characterize.
- Only two backbones and two reward models are evaluated; whether decoder co-evolution helps when the reward is itself a strong perceptual model (e.g., a generative discriminator) is open.
- The GEM interpretation is suggestive but the paper does not, in the excerpted material, prove monotone improvement of the joint objective under realistic anchor choices.
- Compute overhead of training the decoder during RL — typically the heaviest module — is not directly reported in the provided sections.
Why this matters
Discrete AR T2I post-training has inherited the RLHF-on-policy template from LMs, but unlike text the “decoder” here is a learned, lossy renderer that was trained on a specific token distribution. RankE’s diagnosis — that policy-only RL silently moves codes off the decoder’s training manifold — applies to essentially every VQ-based generative system being aligned today, and the alternating co-evolution recipe is a clean, drop-in fix that doesn’t require differentiating through quantization.
Source: https://arxiv.org/abs/2605.21195
Rethinking Muon Beyond Pretraining: Spectral Failures and High-Pass Remedies for VLA and RLVR
Problem
Muon’s matrix-sign update \mathrm{msign}(\mathbf{M}) = \mathbf{U}\mathbf{V}^\top, approximated via Newton–Schulz (NS) iteration of the form \mathbf{X} \leftarrow a\mathbf{X} + b\mathbf{X}\mathbf{X}^\top\mathbf{X} + c\mathbf{X}(\mathbf{X}^\top\mathbf{X})^2, \quad (a,b,c)=(3.4445,-4.7750,2.0315), forces every singular value of the pre-normalized momentum toward 1. This uniform spectral whitening is well-suited to LLM pretraining, where exploration along every direction is useful. The paper argues it breaks down in two post-pretraining regimes:
VLA training, where the action head’s gradient is intrinsically low-rank. Using effective rank \mathrm{erank}(\mathbf{G}) = \exp(H(\mathbf{p})) with p_i = \sigma_i / \sum_j \sigma_j, the authors show that on VLA-Adapter / LIBERO Object the action module’s erank is consistently the smallest of the three modules (vision > language > action), with stable inter-module separation across training steps.
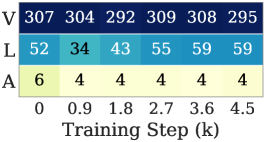
Per-module erank and the cost of LRMuon vs. Muon vs. AdamW on the action head. Lifting the entire spectrum to 1 amplifies tail directions that are pure noise (the seven-dim action vector cannot support a high-rank update), and Muon underperforms AdamW on the action module. Low-rank Muon (LRMuon), which truncates to a top-k polar factor \mathbf{U}_k \mathbf{V}_k^\top via explicit SVD, recovers the success rate but at substantially higher per-step cost.
RLVR, where gradients have low SNR (the GRPO advantage \hat a_i = (R_i - \bar R)/(\mathrm{std}(R)+\epsilon) on binary rewards collapses to zero whenever a group is all-correct or all-wrong) and the model has already developed per-head specialization during pretraining. Whitening corrupts both: it lifts noise-dominated tail directions and homogenizes per-head norm structure that controls attention sharpness \beta_h = \|\mathbf{W}_Q^h\|_F\|\mathbf{W}_K^h\|_F/\sqrt{d_k} and head output magnitude.
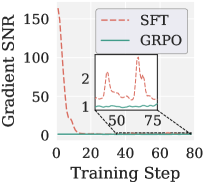
SFT vs. GRPO gradient SNR, and Muon’s regression on MATH500 under GRPO.
Method: Pion’s high-pass NS
The unifying observation is spectral: in both regimes the informative direction concentrates in a few leading singular values, while the tail is noise. Pion replaces uniform whitening with a spectral high-pass: keep large \sigma_i near 1, drive small \sigma_i toward 0. Because a single NS step on \mathbf{X} = \mathbf{U}\bm{\Sigma}\mathbf{V}^\top factors as \mathbf{X} \leftarrow \mathbf{U}\bigl(a\bm{\Sigma}+b\bm{\Sigma}^3+c\bm{\Sigma}^5\bigr)\mathbf{V}^\top, designing the matrix filter reduces to designing the scalar polynomial f(\sigma; a,b,c) = a\sigma + b\sigma^3 + c\sigma^5 on [0,1]. A single quintic cannot produce a sharp band edge, so Pion splits the k=5 NS iterations into two stages with distinct coefficients:
- Promotion f_p (k_p steps), (a_p, b_p, c_p) = (1.875, -1.25, 0.375): monotonically pushes singular values upward while preserving order, anchored by f_p(1)=1 and f_p'(1)=0.
- Suppression f_s (k_s = 5 - k_p steps), (a_s, b_s, c_s) = (0, 2.5, -1.5): sharply contracts small singular values toward 0 while leaving values near 1 fixed.
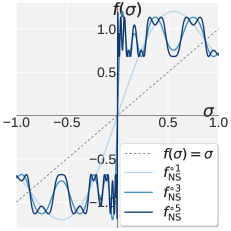
The composed map f_s^{k_s} \circ f_p^{k_p} realizes a high-pass with controllable cutoff via k_p \in \{0,\dots,5\}. The matrix-level cost is unchanged: 5 matmuls of the same form as Muon, no SVD. For RLVR, Pion uses a per-head mode (Alg. 3): each attention projection is reshaped along the head dimension and the high-pass NS is applied independently per head, preserving pretrained per-head norm heterogeneity that whole-matrix whitening would erase. The proposition in Appendix G makes this concrete: Q/K Frobenius norms set the softmax inverse temperature \beta_h, and V/O spectral norms bound the head’s contribution to the layer output and its gradient magnitude.
Results
The paper’s experimental matrix covers VLA-Adapter (\ell_1-regression head) and VLANeXt (flow-matching head) on the four LIBERO suites plus LIBERO-Plus, real-robot finetuning of \pi_{0.5} on three DROID grasp-and-place tasks, and RLVR with GRPO/GMPO on Qwen3-1.7B / Qwen3-4B (GSM8K, MATH500). The optimizer recipe is consistent: AdamW elsewhere, Muon on V/L 2D matrices, Pion on action 2D matrices (VLA) or per-head Pion on all 2D matrices (RLVR), with k_p \le 2 (suppression-dominant).
Concrete VLA evidence: on LIBERO Object at 4.5k steps (Fig. 1), Muon underperforms AdamW on the action module while LRMuon recovers — but LRMuon’s per-step exact SVD inflates total wall-clock time relative to Muon. Pion vs. LRMuon on VLA-Adapter / LIBERO Object at 1.5k steps (Fig. A1) shows Pion exceeds LRMuon at every k \in \{1, 16, 64, 256\} while matching Muon’s per-step cost almost exactly, since the soft spectral filter adapts per-step and per-layer instead of using a fixed truncation rank. RLVR evidence (Fig. 2b) confirms Muon regresses below AdamW on MATH500 under GRPO with Qwen3-1.7B, motivating per-head Pion.
Limitations
The authors are explicit that Pion is designed for regimes with concentrated descent directions and is expected to underperform Muon on LLM pretraining, where uniform whitening’s spectral exploration is the desired behavior. The high-pass cutoff is controlled discretely by k_p \in \{0,\dots,5\} with hand-pinned coefficients derived from constraints at \sigma=0 and \sigma=1; an adaptive cutoff that interpolates between Muon and Pion remains open. Pion’s polynomial coefficients are fixed across layers and steps, so layer-wise rank heterogeneity is handled only implicitly via the input pre-normalization. The reverse-ablation Low-pass Muon (Appendix L) requires numerical L-BFGS-B fitting of all 15 coefficients, suggesting that more general band filters do not admit clean closed forms.
Why this matters
Muon’s uniform spectral whitening is increasingly treated as a default for matrix-aware optimization, but its inductive bias — exploration via tail amplification — is exactly wrong for low-rank or low-SNR gradients, which dominate VLA action heads and RLVR post-training. Pion shows that the right knob is the NS polynomial itself: a two-stage promotion-suppression schedule yields a controllable spectral high-pass at zero extra per-step cost, and per-head application preserves attention specialization that whole-matrix orthogonalization destroys.
Source: https://arxiv.org/abs/2605.19282
Lens: Rethinking Training Efficiency for Foundational Text-to-Image Models
Lens is a 3.8B-parameter text-to-image diffusion model that targets the compute-efficiency frontier of foundation T2I training. The headline claim is that with roughly 19.3% of the training compute used by Z-Image (6B), Lens matches or exceeds open-source models up to 80B parameters on OneIG, GenEval, LongText, and CVTG. The paper attributes this to two levers beyond parameter count: maximizing information density per gradient step, and architectural choices that accelerate convergence.
Data: dense captions and mixed-resolution batches
The pre-training corpus, Lens-800M, is built from four sources — public real-world data, public synthetic data, private text-heavy content (posters, slides, design assets), and synthetic rendered text on randomized backgrounds. A nine-stage cleaning pipeline applies resolution filtering (<384^2 removed), NSFW classification (fine-tuned EVA), aesthetic filtering (Aesthetic Predictor v2.5, threshold 3), watermark detection (fine-tuned SigLIP2), Laplacian-variance clarity filtering, Shannon-entropy filtering on grayscale histograms, HSV V-channel luminance filtering, and CLIP ViT-L/14 near-duplicate removal at cosine similarity >0.985 via FAISS. The result is ~800M images.
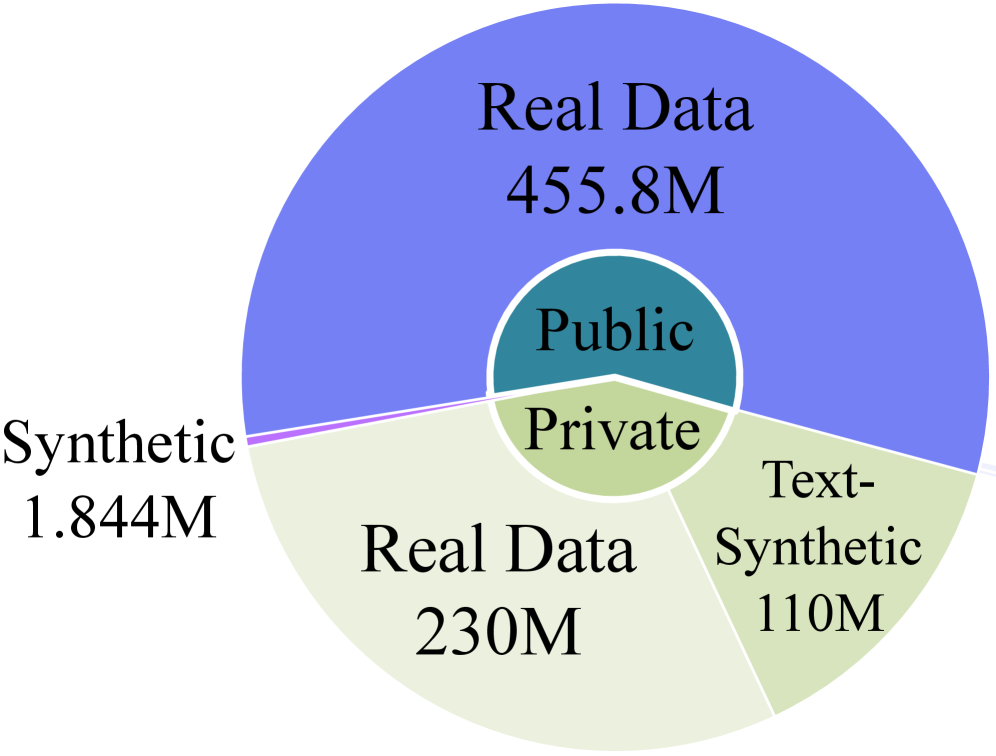
The critical move is replacing noisy alt-text with GPT-4.1-generated long captions averaging ~109 words per image (Figure 3c), while preserving in-image text in its original language to retain multilingual rendering. The argument is that short, ambiguous captions force the model to spend capacity on disambiguation rather than learning the conditional p(x \mid c), and that long captions also close the train–inference gap because users issue compositional prompts at deployment. Captions are paired with multi-resolution, multi-aspect-ratio batching so each optimization step covers a broader visual manifold than fixed-square training.
Architecture and training recipe
Two architectural choices are emphasized as convergence accelerators: a semantic VAE producing latents that are more linearly aligned with text features (justified by the VAE ablation in Figure 5 of the paper), and a strong language encoder that both improves optimization speed and yields multilingual generalization despite English-only caption training. The pipeline includes RL post-training on the curated Lens-RL-8K dataset with hand-designed reward rubrics, followed by few-step distillation into Lens-Turbo, a 4-step generator that operates without classifier-free guidance.
Results
On the four benchmarks reported in Table 2, Lens (20-step) and Lens-Turbo (4-step) deliver:
- OneIG (EN/ZH): Lens 0.557 / 0.525, Lens-Turbo 0.554 / 0.519. This beats Z-Image 6B (0.546 / 0.535 EN/ZH split — Lens wins EN, loses ZH narrowly) and Qwen-Image 20B on EN (0.539). FLUX.2-Klein 9B sits at 0.532 / 0.430.
- GenEval: Lens 0.930, Lens-Turbo 0.914 — both above LongCat-Image 6B (0.870), Qwen-Image 20B (0.868), and Z-Image (0.840). Lens-Turbo at 4 steps still exceeds every listed open-source model on this compositional benchmark.
- LongText (EN): Lens 0.937; only Nano Banana 2.0 (commercial, 0.981) and GPT Image 1 (0.956) score higher. Lens beats Qwen-Image 20B (0.943) marginally.
- CVTG: Lens-Turbo achieves NED 0.889 and CLIP 0.965, the strongest open-source numbers, surpassing Z-Image (0.867 / 0.937) and Qwen-Image (0.829 / 0.930). Lens at 20 steps reports 0.869 / 0.951.
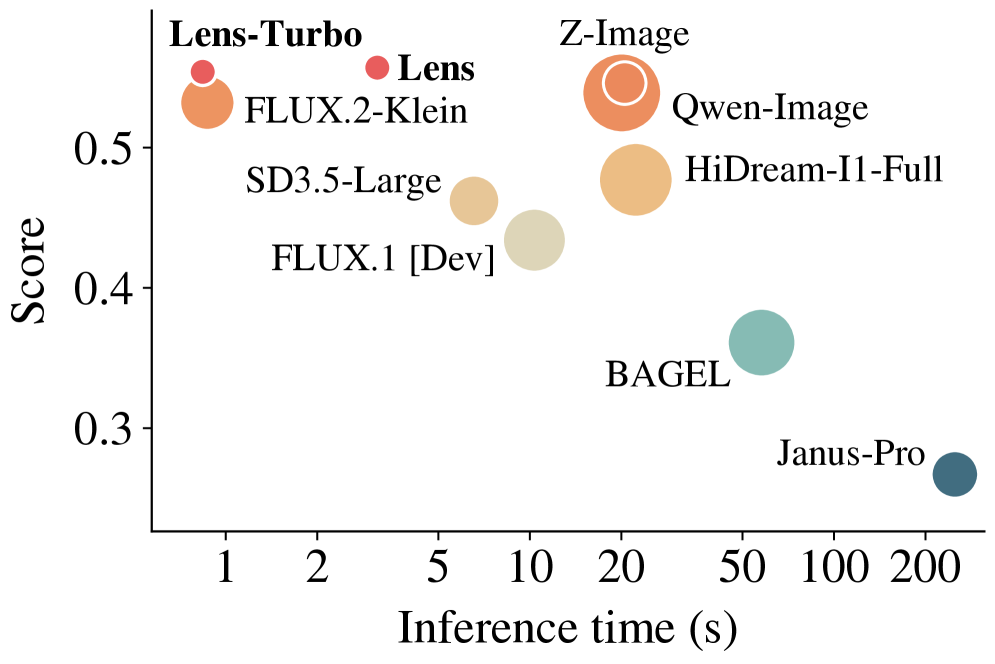
The Pareto plot makes the efficiency claim concrete: Lens occupies the upper-left region against Hunyuan-Image-3.0 (80B), Qwen-Image (20B), and HiDream-I1-Full (17B), while Lens-Turbo’s 4-step inference puts it at substantially lower wall-clock cost than 20-step competitors at comparable or higher quality.

Limitations and open questions
The paper does not release a controlled ablation that isolates the contributions of (i) the 109-word captions, (ii) the semantic VAE, (iii) the language encoder choice, and (iv) multi-resolution batching with respect to the 19.3%-compute claim — the claim is made against Z-Image’s reported budget rather than via a matched-budget reproduction. GPT-4.1 captioning at 800M scale also imposes a substantial one-time annotation cost that is excluded from the “training compute” accounting; whether the efficiency story holds when caption-generation FLOPs are amortized in is unclear. The Chinese OneIG result (0.525) trails Qwen-Image (0.548) and Z-Image (0.535), suggesting English-only caption training has a residual cost on non-Latin-script generation despite the multilingual encoder. Finally, the RL reward rubrics and Lens-RL-8K curation criteria are described only at a high level; the contribution of RL versus distillation to the final Lens-Turbo numbers is not separated.
Why this matters
If the recipe replicates, it suggests current open-source T2I training is heavily bottlenecked by caption quality and per-batch information density rather than parameter count, and that a 3.8B model with dense supervision can dominate 6–20B baselines. This reframes the scaling discussion: dataset annotation compute (VLM captioning) is a substitute for, not just a complement to, model-scale compute.
Source: https://arxiv.org/abs/2605.21573
StepAudio 2.5 Technical Report
StepAudio 2.5 is a unified audio-language foundation that targets three traditionally specialized regimes — ASR, TTS, and realtime spoken dialogue — from a single backbone. The premise is that once text and audio inhabit a shared representational space, task specialization reduces to “operational regimes”: data construction, optimization targets (specifically task-tailored RLHF), and decoding constraints. The report’s contribution is less a new architecture than a disciplined post-training recipe that lets one model match or exceed specialist systems on each axis.
Shared backbone
The architecture is the now-standard encoder–adapter–LLM-decoder stack: a frozen audio encoder produces acoustic embeddings, a lightweight adapter projects them into the decoder’s hidden space, and a text-initialized LLM decoder operates over a unified token sequence containing both text tokens and newly introduced audio tokens. The asymmetry is intentional — the encoder handles acoustic abstraction, the decoder owns semantics, instruction following, and generation. This is what allows the three downstream systems to share the bulk of parameters even when their output modality differs.
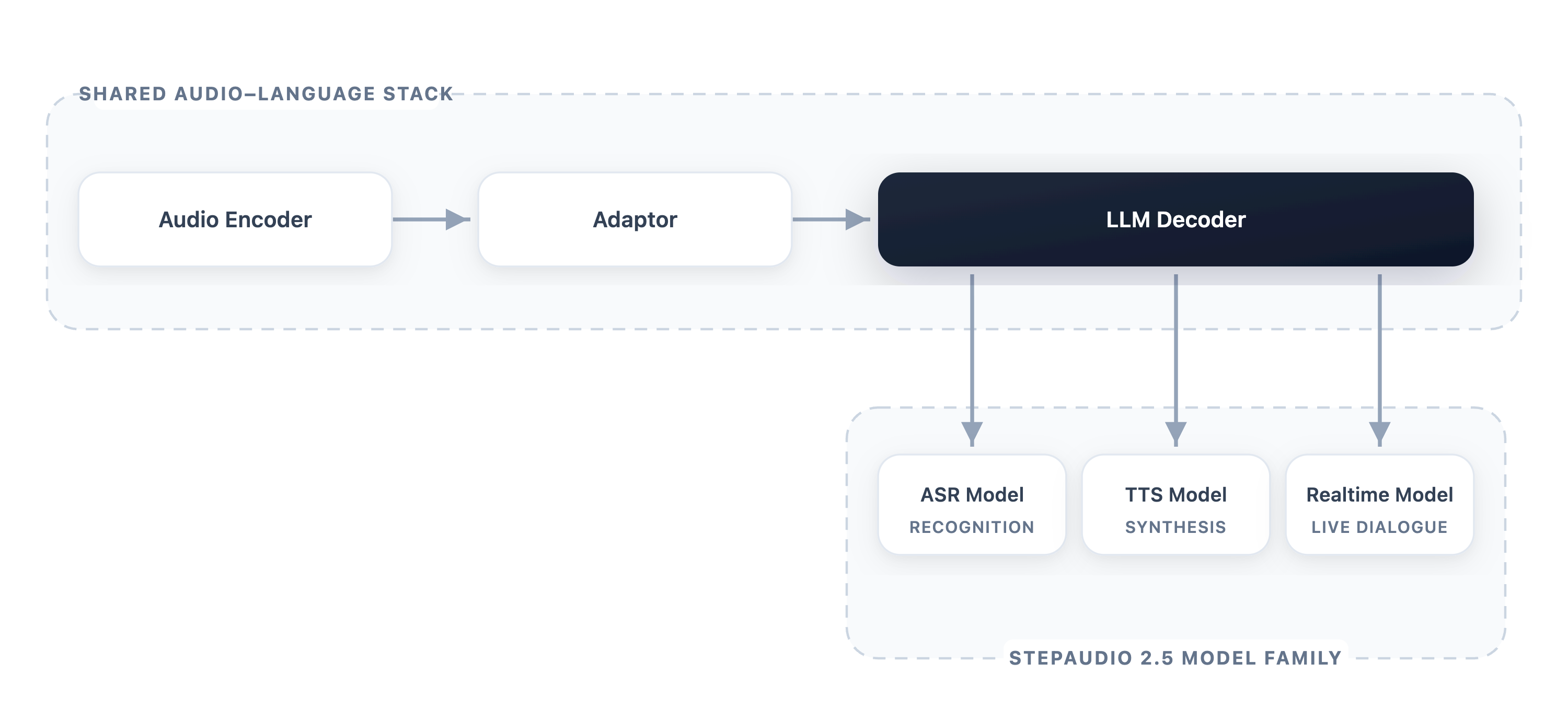
The data engine that feeds pretraining is also shared. Raw audio passes through SED and VAD to drop non-speech, segments are merged and re-segmented into semantically complete base samples, and each sample is annotated for audio quality, synthetic-voice detection, and speaker count. Dual ASR models transcribe and identify language, with cross-validation on WER, edit distance, and speech rate. Samples are then graded by language, duration, semantic-quality score, and audio-quality score so that pretraining stages can sample tiers selectively.
ASR specialization with verified MTP
The ASR branch keeps the shared backbone and adds a five-branch Multi-Token-Prediction (MTP) head for speculative decoding. At position t, the main branch predicts x_{t+1} and the h-th MTP branch predicts x_{t+1+h} for h\in\{1,\dots,5\}, so each forward step yields a 6-token proposal. Crucially, MTP is treated as an acceleration primitive only: at inference the proposal is verified token-by-token against the autoregressive path, and the first disagreement truncates the accepted prefix. This preserves exact equivalence to greedy AR decoding.
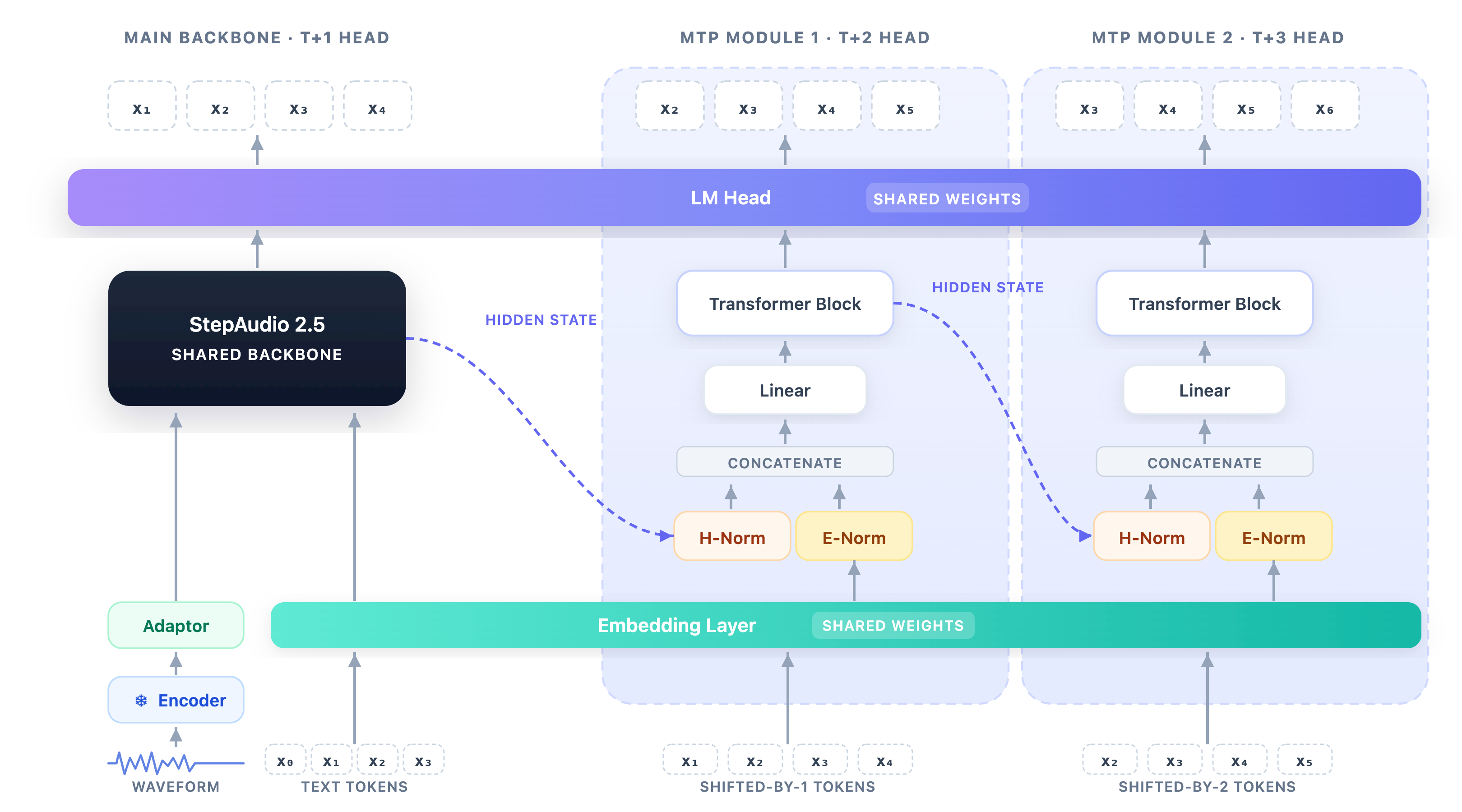
Each MTP block ingests the previous branch’s hidden state plus a shifted token embedding, normalizes and concatenates them, projects back to decoder width, and runs a decoder-style Transformer block. The Transformer layer in each new block is initialized from the last decoder layer to inherit a linguistic prior; embeddings and the LM head are shared with the main branch.
Training is staged. SFT first converges a baseline AR recognizer (32K-token packed sequences, frozen encoder, SpecAugment-style time/frequency masking, 10K steps, peak LR 2\times 10^{-5}, batch 32, cosine to 1\times 10^{-6}). Then frozen-branch alignment trains only the MTP blocks at LR 2\times 10^{-4}, leaving embeddings and LM head fixed. Finally, joint calibration unfreezes the adapter and decoder at LR 2\times 10^{-5} to reduce backbone–branch mismatch. The objective at position t exponentially decays branch weights to reflect serial dependency:
w_h = \frac{\alpha^{h-1}}{\sum_{j=1}^{H}\alpha^{j-1}}, \quad H=5,\ \alpha=0.9,
\mathcal{L}_t = \mathrm{CE}(p_t, x_{t+1}) + \sum_{h=1}^{H} w_h\,\mathrm{CE}(p_{t,h}, x_{t+1+h}).
The long-form data pipeline transitions from per-clip transcription to session-level refinement to keep accuracy and cross-clip consistency.
TTS as pure next-token prediction
The TTS branch removes the encoder–adapter entirely and uses only the LLM. Audio tokens are treated as a foreign language; synthesis is reformulated as next-token prediction over the joint vocabulary, so the alignment problem reduces to learning a text↔︎audio-token mapping inside a single LM. SFT proceeds in two stages: large-scale zero-shot voice cloning with global instruction supervision (coarse control over speaker, style, prosody), then high-quality in-house data with both global and inline instructions for utterance- and segment-level fine-grained control.
RLHF then sharpens alignment under complex or abstract instructions. A Generative Reward Model (GRM) r_\phi scores a candidate y from \pi_\theta against a high-quality reference y^* for the same prompt x, producing a pairwise scalar:
r_{hf}(x,y,y^*) = s\big(r_\phi(x,y,y^*)\big),
where s(\cdot) is a reward-shaping transform. The reference-anchored design sidesteps the absolute-scale instability of training on raw audio quality scores.
Realtime specialization
The realtime branch shares the architecture verbatim but tackles four problems specific to live spoken interaction: conversational coherence across turns, persona consistency under adversarial inputs, paralinguistic sensitivity (hesitation, laughter, pacing), and reward sparsity for attributes like naturalness with no ground truth. The training recipe has three stages: audio-centric mid-training (inherited from foundation pretraining, providing audio-grounded perception and long-form reasoning), multi-stage SFT, and RLHF. Notably the decoder produces an explicit latent reasoning trace before emitting a response, which is preserved through realtime training.
Limitations and open questions
The report (as excerpted) does not provide head-to-head ASR WER, TTS MOS/CER, or realtime latency numbers in the sections shown, so the central claim of matching or exceeding specialists cannot be checked against specific values here. Several design choices also remain only partially justified: the choice of H=5 and \alpha=0.9 for MTP, the form of s(\cdot) in the GRM reward, and the decision to drop the encoder entirely for TTS while keeping it for ASR and Realtime. The reliance on a reference-anchored GRM means TTS quality is upper-bounded by reference availability and the GRM’s calibration to human preference.
Why this matters
If a single audio-language stack can be specialized into ASR, TTS, and realtime dialogue purely through data and RLHF — without architectural divergence — the operational cost of maintaining three separate production systems collapses, and improvements to the shared backbone propagate everywhere. The verified-MTP recipe is also a clean template for accelerating any AR speech decoder without sacrificing exactness.
Source: https://arxiv.org/abs/2605.23463
Hacker News Signals
Constraint Decay: The Fragility of LLM Agents in Back End Code Generation
Source: https://arxiv.org/abs/2605.06445
The paper investigates a failure mode called “constraint decay” in LLM-based coding agents: as agentic workflows grow longer — more tool calls, more context, more intermediate reasoning steps — models progressively forget or violate constraints specified at the start of the task. This matters because backend code generation tasks (schema design, API implementation, database queries) carry hard constraints (type safety, auth requirements, rate limits) that must hold globally across generated artifacts.
The authors constructed a benchmark of backend coding tasks with explicit, verifiable constraints and measured compliance as a function of workflow depth. The core finding is that constraint satisfaction degrades roughly monotonically with the number of agent steps, and the degradation is not uniform: constraints mentioned early in the prompt decay faster than those mentioned proximal to the generation step, consistent with the lost-in-the-middle phenomenon in long-context transformers.
The mechanism is distinct from simple forgetting. Even when the constraint is recoverable via attention (i.e., it is still technically in context), agents fail to apply it — suggesting the issue is in how iterative tool-use trajectories dilute the salience of original instructions rather than a pure context-window problem. Retrieval-augmented constraint injection (re-inserting constraint summaries at each agent step) partially mitigates decay but introduces latency and does not eliminate it.
Quantitatively, compliance on multi-step tasks drops by 30-50 percentage points relative to single-shot baselines on the harder constraint categories (security-related constraints being among the worst retained). Larger models show slower decay rates but are not immune.
The open question is architectural: whether explicit constraint memory modules, formal verification loops, or structured output schemas can provide stronger guarantees than prompt engineering alone.
Why this matters
Constraint decay is a concrete, measurable failure mode that undermines any serious use of agents in production code pipelines. It reframes the reliability problem as a workflow-design issue, not just a model-capability issue.
Perceptual Image Codec: What Matters in Practical Learned Image Compression
Source: https://apple.github.io/ml-pico/
Apple’s ML-PICO work examines which design choices in learned image compression actually move the needle for perceptual quality at low bitrates, as opposed to distortion metrics like PSNR or MS-SSIM. The codec is built on a standard hyperprior/factorized entropy model architecture but the paper performs systematic ablations to isolate the contributions of: the perceptual loss function, the discriminator architecture, the entropy model capacity, and the decoder network depth.
The central finding is that the choice of perceptual loss dominates all other factors. Using a LPIPS-style VGG feature loss produces visible texture hallucination artifacts; replacing it with a loss derived from a larger vision foundation model (DINO or similar) significantly reduces structured artifacts while preserving perceptual sharpness. Adversarial training with a patch discriminator adds further benefit but is secondary to the feature loss choice.
On the entropy side, the paper finds that scaling the entropy model beyond a moderate capacity yields diminishing returns once the decoder is expressive enough — a counterpoint to recent work that pushes most parameter budget into the entropy model.
Quantitatively, ML-PICO achieves competitive FID and KID scores against diffusion-based codecs (e.g., HiFiC variants, CDC) at 0.05–0.15 bpp, while running at practical decode speeds on device-class hardware — something diffusion-based codecs cannot claim. PSNR is not competitive by design, which is the honest tradeoff being made.
Practical limitations: the perceptual gains are most visible at very low bitrates; at moderate rates (>0.2 bpp) classical codecs with post-processing close most of the gap. The hallucination-vs-fidelity tradeoff remains unsolved for content requiring pixel-accurate reconstruction (text, medical imagery).
Why this matters
Learned codecs are approaching deployment but face a credibility problem with practitioners who conflate PSNR with quality. This work provides a clear ablation-based recipe for practitioners and highlights that foundation model perceptual losses are now load-bearing infrastructure in compression.
DeepSeek Reasonix: Native Coding Agent with High Caching and Low Cost
Source: https://esengine.github.io/DeepSeek-Reasonix/
Reasonix is an open-source coding agent wrapper around DeepSeek-R1/V3 that is explicitly engineered around the DeepSeek API’s prompt caching semantics to minimize cost in long agentic sessions. The core technical insight is that DeepSeek charges significantly less for tokens served from the KV cache than for freshly computed tokens, and most coding agent frameworks naively reconstruct prompts in ways that defeat caching.
The implementation achieves high cache hit rates by enforcing a strict prefix-stable prompt structure: system prompt, repository context, and conversation history are always placed at the head of the prompt in a fixed order, and only the new user turn is appended. Tool call results are serialized in a deterministic, append-only format. This is in contrast to frameworks that inject timestamps, shuffle tool results, or regenerate context summaries, all of which break prefix matching in the cache.
Reasonix also implements a two-tier context management strategy: a persistent “cold” prefix (stable across the session) and a “warm” suffix (current working context), with explicit truncation logic that prunes the warm tier rather than the cold tier when approaching context limits. This keeps the expensive-to-compute system context permanently cached.
The reported cost reduction is substantial — roughly 70-80% lower cost per coding session compared to a naive ReAct-loop agent on the same tasks, with comparable task completion rates on SWE-bench-style evals. Latency also improves because cache hits return faster.
The approach is specific to providers that expose prefix caching with a favorable pricing differential (DeepSeek, and to a lesser extent Anthropic). It is not a general technique across all providers.
Why this matters
Cache-aware prompt engineering is underappreciated as an optimization axis. Reasonix makes the technique explicit and reproducible, and the cost differential is large enough to matter for any team running agents at scale.
Memory Has Grown to Nearly Two-Thirds of AI Chip Component Costs
Source: https://epoch.ai/data-insights/ai-chip-component-cost-shares
Epoch AI’s data analysis tracks the historical shift in bill-of-materials composition for AI accelerators, finding that memory (HBM stacks primarily) now accounts for roughly 60-65% of total chip component cost, up from a much smaller fraction in the pre-transformer era. The remaining cost is split between the compute die itself and packaging/interconnect.
The driver is well-understood: transformer inference and training are memory-bandwidth-bound, not compute-bound, for most practical batch sizes and sequence lengths. This pushed hardware vendors to integrate increasing amounts of HBM directly on-package (H100: 80 GB HBM3, B200: 192 GB HBM3e), and HBM production is concentrated among SK Hynix, Samsung, and Micron, with limited yield scaling. The cost per GB of HBM has not followed the same learning curve as DRAM or NAND, partly due to the 3D stacking process and the tight integration requirements with the compute die.
The analysis has direct implications for the cost structure of inference: a large fraction of what you pay for a GPU is paying for memory, not FLOPs. This partially explains why techniques that reduce memory footprint (quantization, paged attention, speculative decoding that improves utilization) have outsized economic impact relative to their modest FLOPs savings. It also explains vendor interest in near-memory and processing-in-memory architectures.
The data also implies that memory supply constraints, not fab capacity for logic dies, are likely to be the binding constraint on AI accelerator supply through the near term.
Open question: whether CXL-attached memory or disaggregated memory pooling architectures can arbitrage the cost differential between HBM and cheaper DRAM tiers without unacceptable bandwidth penalties.
Why this matters
Understanding chip cost structure informs infrastructure procurement decisions, explains pricing dynamics for inference APIs, and identifies where architectural research has the highest economic leverage.
White Rabbit: Sub-Nanosecond Synchronization for Large Distributed Systems
Source: https://ohwr.org/projects/white-rabbit/
White Rabbit (WR) is an extension of IEEE 1588 (PTP) and Synchronous Ethernet (SyncE) developed at CERN, targeting sub-nanosecond time synchronization across networks with hundreds to thousands of nodes spanning kilometer-scale distances. It is used in the CERN accelerator control system, the KM3NeT neutrino telescope, and several gravitational wave detector timing systems.
The protocol achieves its precision by combining three mechanisms. First, SyncE propagates a frequency reference through the physical Ethernet layer, disciplining all switch clocks to a common rate. Second, PTPv2 message exchange measures link delay with picosecond-resolution timestamping hardware implemented directly in the PHY/MAC layer of custom FPGAs. Third, a per-link calibration procedure accounts for asymmetric propagation delays caused by different fiber lengths and wavelengths on the TX/RX paths.
The key innovation relative to standard PTP is the hardware timestamping: rather than software timestamps with microsecond jitter, WR nodes timestamp packet arrival and departure at the hardware level using fine-delay measurement units that interpolate between clock edges, achieving resolution below 10 ps. The WRPC (White Rabbit PTP Core) is an open-source FPGA IP core implementing this.
Typical achieved accuracy across a 10-hop, multi-kilometer WR network is <1 ns synchronization offset and <1 ns jitter — orders of magnitude better than software PTP (~1 µs) or GPS-disciplined oscillators without the satellite dependency. The entire hardware and gateware stack is open hardware (CERN OHL license).
Limitations: requires custom or WR-compatible switches and NICs; cannot be retrofitted onto commodity Ethernet hardware; fiber-based networks work better than copper due to more stable propagation delay.
Why this matters
As distributed systems (financial trading, 5G fronthaul, scientific instrumentation) push timing requirements below microsecond thresholds, WR demonstrates what sub-nanosecond sync looks like in production — and the open hardware availability makes it reproducible outside CERN.
Claude Is Not Your Architect. Stop Letting It Pretend
Source: https://www.hollandtech.net/claude-is-not-your-architect/
The post makes a technically grounded argument about the failure mode of using LLMs as system architects rather than as implementation accelerators. The core claim is that LLMs generate architecturally plausible outputs — designs that look coherent, use correct terminology, and pass a surface-level review — but lack the causal model of a system’s operational context needed to make sound architectural tradeoffs.
The specific failure patterns identified: LLMs produce designs that optimize for comprehensibility to a reviewer (clean diagrams, standard patterns) rather than for the actual non-functional requirements of the system; they cannot reason about operational history, team capability constraints, or existing technical debt in ways that would inform an experienced architect; and they converge toward industry-standard reference architectures (microservices, event-driven, CQRS) regardless of whether those patterns are appropriate for the scale and team size in question.
The author distinguishes between tasks where LLMs add genuine leverage (code generation within a well-specified architecture, documentation, refactoring within known constraints) and tasks where the LLM’s output is systematically misleading (architectural decision-making, capacity planning, selecting consistency models for distributed state).
The argument connects to a known issue in LLM reasoning: models are trained on documentation and tutorials that describe how systems are built in idealized conditions, not on postmortems, incident reports, or the messy operational realities that actually constrain architecture choices. The training distribution is biased toward the optimistic case.
The practical recommendation is to use LLMs to enumerate options and articulate tradeoffs in natural language, but to treat all architectural outputs as first-draft proposals requiring critical review against actual operational constraints — not as authoritative designs.
Why this matters
The argument applies beyond Claude to any LLM used in design roles, and it provides a principled basis for scoping LLM use in engineering organizations rather than a blanket endorsement or rejection.
Defeating Git Rigour Fatigue with Jujutsu
Source: https://ikesau.co/blog/defeating-git-rigour-fatigue-with-jujutsu/
The post describes a workflow migration from Git to Jujutsu (jj), focusing on the specific UX problems that cause developers to abandon disciplined commit hygiene under deadline pressure. The technical substance is in how jj’s data model eliminates the friction points that make clean Git history a cognitive burden.
The central difference: jj has no index/staging area and no detached HEAD state. Every working-tree state is automatically a commit, and the “current commit” is always mutable until explicitly pushed. This means that the Git workflow pattern of “I have dirty working tree and need to context-switch” — which requires stashing, branching, or creating a WIP commit — collapses to simply navigating to a different commit; the working state is preserved automatically.
The jj split, jj absorb, and jj rebase operations are first-class and conflict-safe in a way Git’s equivalents are not. Specifically, jj absorb automatically moves working-tree changes into the appropriate prior commit based on which commit last touched each file/hunk — a mechanical operation that would require interactive rebase in Git. Conflict markers are stored in the commit graph rather than requiring immediate resolution, allowing you to rebase through conflicts and resolve them later.
The author’s argument is that git rigour fatigue — the tendency to stop rebasing, squashing, or organizing commits when under pressure — is not a discipline problem but a tooling problem. jj reduces the per-operation cost of history cleanliness to near zero in the common cases.
Limitations noted: jj’s Git-compatible backend means it works with GitHub/GitLab, but the mental model shift (no staging area, anonymous branches) has a real learning curve. Not all Git GUIs work correctly with jj-managed repos.
Why this matters
Developer tooling that reduces friction for correct behavior has compounding value. Jujutsu’s model is a genuine rethink of version control UX grounded in persistent immutable snapshots rather than bolted-on workflow conventions.
Launch HN: Runtime (YC P26) — Sandboxed Coding Agents for Everyone on a Team
Source: https://www.runtm.com/
Runtime is a product that provides sandboxed execution environments for LLM coding agents, targeting the organizational problem of giving non-engineer team members access to agent-driven code execution without requiring them to manage infrastructure or risk executing untrusted code on shared systems.
The technical core is an isolation layer: each agent session runs in an ephemeral, network-segmented container with constrained filesystem access and resource limits. The sandboxing is not novel technology (it builds on established container and microVM primitives, likely gVisor or Firecracker-class isolation), but the product integrates this with a multi-agent orchestration layer and a permission model designed for teams rather than individual developers.
The permission model is the interesting design problem. Different team members may be authorized to run agents that read from certain data sources but not write to production systems, or may be allowed to run pre-approved tool sets but not arbitrary shell commands. Runtime apparently implements a policy layer on top of the execution sandbox that enforces these constraints without requiring the tool operators to understand container security.
The LLM integration is provider-agnostic (supports major API providers) and the agent framework appears to be a thin orchestration layer rather than a novel agent architecture. The differentiation is in the operations and security surface, not the AI layer.
Open questions from the YC launch discussion: how the sandbox handles agents that need to install dependencies (a common requirement for coding tasks that conflicts with immutable container images), and what the performance overhead of the isolation layer is for I/O-intensive agent workflows.
Why this matters
The bottleneck for enterprise agent adoption is not model capability but safe execution and auditability. Runtime’s approach of treating the sandbox as the product rather than the agent is the correct decomposition for organizational deployment.
Noteworthy New Repositories
usewhale/DeepSeek-Code-Whale
A terminal-native AI coding agent built specifically around DeepSeek models. The main technical differentiators are its prefix-cache optimization, which claims a 97% live cache hit rate by carefully structuring prompts so that the static system-context prefix is maximally reused across requests, and support for DeepSeek’s 1M-token context window. The architecture includes an MCP (Model Context Protocol) tool integration layer for attaching external tools and a “Skills” extension system that lets users define reusable higher-order behaviors (e.g., refactor-and-test workflows) composable at runtime. Because it targets DeepSeek’s API natively, it can exploit model-specific features (FIM completion, caching headers) that a generic OpenAI-compatible client would miss. Useful for teams already running DeepSeek inference who want a CLI agent without proxying through a generic layer.
Source: https://github.com/usewhale/DeepSeek-Code-Whale
ahammadmejbah/Awesome-Datasets-Hub
A structured catalog of datasets relevant to LLM research and fine-tuning, organized by task category: medical AI, NLP, multimodal learning, instruction tuning, chain-of-thought/reasoning, code generation, and evaluation benchmarks. The value is in curation rather than novel data — each entry includes provenance, size, licensing, and typical use case. For practitioners standing up a new fine-tuning or evaluation pipeline, this reduces the otherwise scattered search across HuggingFace, PapersWithCode, and domain-specific repositories. Coverage of instruction-tuning and reasoning datasets is particularly relevant given the current emphasis on post-training alignment. The repo is a living document, so recency of entries is an ongoing maintenance concern.
Source: https://github.com/ahammadmejbah/Awesome-Datasets-Hub
ChristianJR19/grok-animus
A persistence and personality engine designed to sit on top of any LLM backend and produce stateful, evolving “companion” behavior. Technically, it maintains structured long-term memory (episodic and semantic stores), a mutable personality vector that shifts based on interaction history, and a “dream” subsystem that runs low-priority consolidation passes to compress and reweight memories during idle periods. Evolution is implemented as slow drift in personality parameters over time rather than fine-tuning — the model weights stay frozen, but the context and retrieval policy change. The design is model-agnostic: it exposes an adapter interface so any OpenAI-compatible or local LLM can be plugged in. This is architecturally interesting as an alternative to full RLHF personalization — achieving apparent behavioral continuity through retrieval-augmented context engineering rather than weight updates.
Source: https://github.com/ChristianJR19/grok-animus
mvm-sh/mvm
A bytecode interpreter and virtual machine written for Go, with stated ambitions beyond Go-specific semantics (“and beyond”). The design follows a register-based or stack-based VM model (typical for language runtime experiments) with a focus on interpreter speed. For Go specifically, this enables dynamic execution of Go code without AOT compilation, which has applications in plugin systems, scripting layers, and sandboxed execution environments where loading a compiled binary is impractical. The “beyond” framing suggests a more general IR or a multi-language front-end target, though the current implementation appears Go-centric. Projects needing embeddable scripting in a Go host application, or wanting to sandbox user-supplied Go code, would evaluate this against alternatives like Yaegi (which is more mature but has known performance ceilings).
Source: https://github.com/mvm-sh/mvm
Evokoa/pgGraph
A graph database layer built directly on PostgreSQL, allowing existing relational schemas to be queried with graph semantics without migrating data to a dedicated graph store. The implementation uses PostgreSQL’s recursive CTEs and/or ltree/adjacency list representations to model vertices and edges, and exposes a graph query interface over them. The advantage over purpose-built graph databases (Neo4j, ArangoDB) is zero data duplication and full ACID guarantees from the underlying Postgres instance. The trade-off is that deep traversals on large graphs will be slower than native graph engines optimized for pointer-chasing access patterns. This is a practical choice for applications where graph queries are secondary to relational workloads, or where operational simplicity (one database, one backup regime) outweighs raw traversal performance.
Source: https://github.com/Evokoa/pgGraph
entropyvortex/meta-llm-charter
A compact system-prompt framework — eleven operational rules plus one meta-rule — designed to constrain LLM coding agents toward behaviors associated with senior engineering practice: explicit reasoning before action, minimal diff principle, test-before-commit discipline, and escalation on ambiguity rather than hallucinated solutions. The meta-rule governs how the agent should handle conflicts between the eleven base rules. This is an instance of prompt engineering as policy specification, treating the system prompt as a formal charter rather than informal instructions. The document is intentionally compact to fit within context budgets while remaining comprehensive. Useful as a baseline or reference for teams deploying autonomous coding agents who want predictable, conservative behavior rather than maximal autonomy.
Source: https://github.com/entropyvortex/meta-llm-charter
Cmochance/codex-app-transfer
A local HTTP proxy that translates OpenAI’s Responses API (used by the Codex CLI) into the Chat Completions API format, enabling Codex CLI to route requests to any OpenAI-compatible backend — specifically targeting Kimi, DeepSeek, Zhipu GLM, and Alibaba Bailian. The translation layer handles schema differences between the two API versions (Responses API uses a stateful, session-oriented model; Chat Completions is stateless), mapping streaming events, tool call formats, and message structures. This is useful because the Responses API is not yet widely implemented by third-party providers, and Codex CLI hard-codes it. Running this gateway locally requires no changes to the CLI itself. The architecture is a standard reverse-proxy with request/response transformation middleware, likely implemented as a lightweight Go or Node service.
Source: https://github.com/Cmochance/codex-app-transfer
av/facts
A development toolkit aimed at replacing vague, prose-heavy specifications with machine-readable, verifiable “facts” that AI coding agents can act on and check against. The core idea is that fluffy natural-language specs are a primary source of hallucination and scope drift in agent-assisted development — by encoding requirements as structured, falsifiable assertions, the agent has an unambiguous oracle to test against. The toolkit provides primitives for defining facts, linking them to test cases or acceptance criteria, and feeding them into agent context in a way that makes verification a first-class step in the generation loop. This connects to ongoing research on grounding LLM agents in formal specifications, and is practically relevant for teams where AI-generated code frequently passes superficial review but violates unstated invariants.
Source: https://github.com/av/facts