デイリーAIダイジェスト — 2026-05-15
arXiv ハイライト
シンプルかつ統一されたスケーリングによるオリンピック推論における金メダルレベルの達成
問題と動機
フロンティア推論モデルは、すでにオリンピック問題の多くにおいて正しい最終解答を導き出せますが、オリンピックの採点は証明ベースです。正しい数値を得ていても、正当化されていないステップ、見落とされたケース、または論理的な誤りが含まれていれば、ゼロ点になり得ます。解答を復元する能力と証明の信頼性との間のギャップこそが、本論文が取り組む中心的な問題です。著者らは、post-trainedされた推論バックボーン(P1-30B-A3B)をSU-01という証明グレードのソルバーへと変換する統一されたレシピを提案し、IMO 2025、USAMO 2026、IPhO 2024/2025において金メダルレベルの性能を報告しています。
パイプライン
学習レシピはSFT、二段階RL、test-time scalingの3つのステージから成り、それぞれ異なる失敗モードに対処しています。
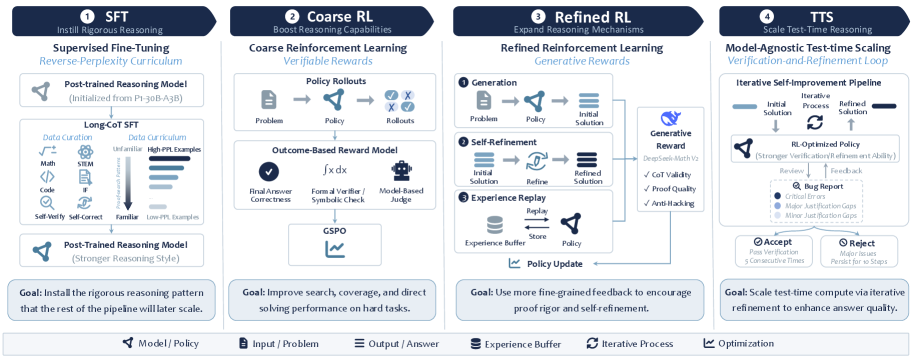
逆パープレキシティカリキュラムによるSFT。 P1-30B-A3Bから出発することで、instruction-followingと幅広い科学的能力が保持されるため、SFTは能力の再構築ではなく推論のパターンの整形に焦点を当てています。プロンプトはEvan Chenのオリンピックノート、数知密フォーラム、AoPS、オンライン競技数学書籍、および難易度\geq 6のDeepMath問題から取得し、NaturalReasoning、Nemotron-Instruction-Following-Chat-v1、Eurus-2-RL-Data、OpenCodeReasoning-2と混合することで狭い特化を防いでいます。DeepSeek-V3.2-Speciale が長形式の軌跡を生成し、8,192トークン以下のもののみを保持し、教師信号を清潔に保つために明示的な打ち切りを除去しています。直接解法に加えて、キュレーターは自己検証および自己改良トレースを合成しており、DeepSeekは自身の解法を検査し、バグレポートを書き、それを改良します。最終的な混合物には338Kの軌跡が含まれています。

二段階RL。 別のプロンプトプール(重複除去、デコンタミネーション、難易度のためのrejection samplingを経て、検証可能なもの8,967件、検証不可能なもの16,287件)が2つのRLフェーズを駆動します。Coarse RLは検証可能な報酬(RLVR)を使用して、SFTで整形されたポリシー上での直接解法を回復・増幅します。Refined RLは続いて、証明指向プロンプト(人手評価の証明によるOPCコーパスを含む)に対して生成的・証明品質の報酬を最適化し、自己改良プロンプトとexperience replayを用いて、稀な成功した困難問題のロールアウトを利用可能な状態に保ちます。RLの合計は30B-A3B MoEバックボーン上でおよそ200ステップです。
Test-time scaling。 推論はHuang and Yang(2025)の精神に沿ったsolve–verify–refineループに従います。ソルバープロンプトは証明の厳密性を優先し、改良ステップは弱いステップを修復し、検証プロンプトは構造化されたバグレポートを生成し、判定ステップは受理、棄却、またはキューへの再追加を行います。ループは、候補が繰り返しチェックのもとで検証に通過するまで繰り返されます。学習済みポリシーは100Kトークンを超える軌跡においてもコヒーレントな状態を維持しており、これがバジェットをドリフトに無駄にすることなく活用可能にしている要因です。
定量的結果
最も有益な分析は、AnswerBench(最終解答の正確性)対ProofBench-BasicおよびProofBench-Advanced(採点された証明)の段階的分解です。
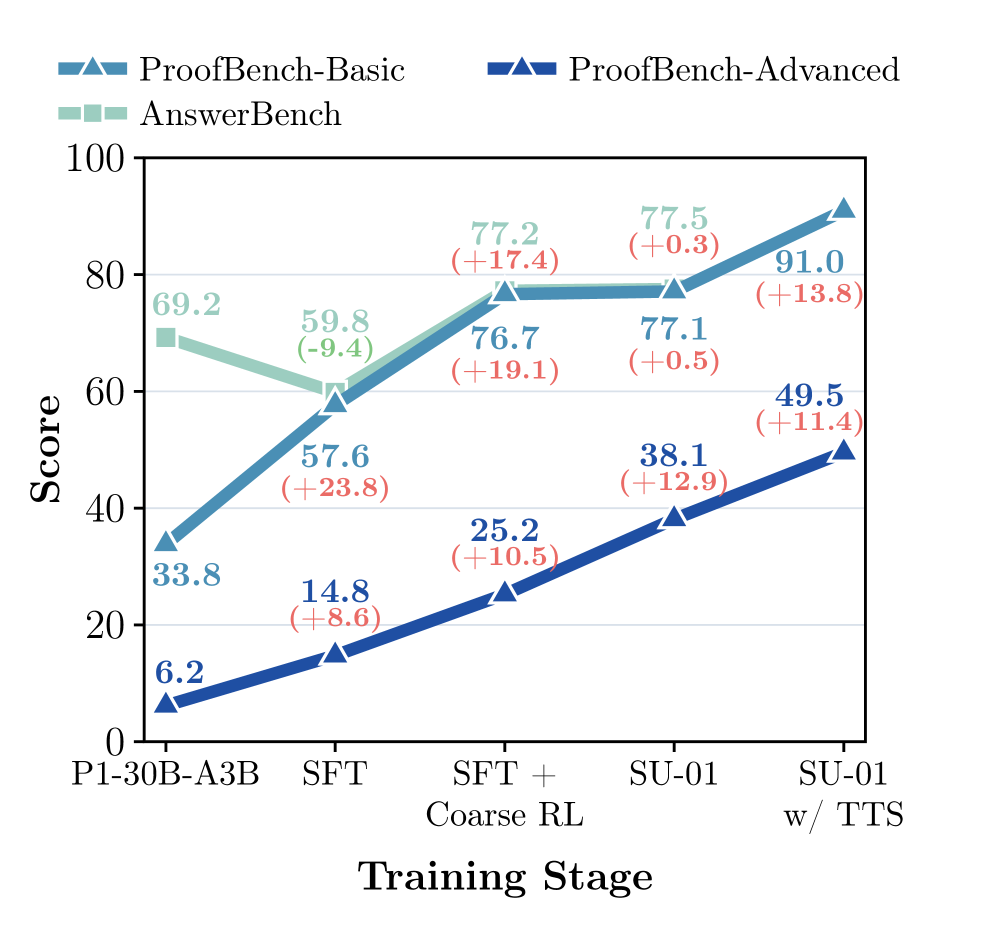
- P1-30B-A3Bベースライン:AnswerBench 69.2、ProofBench-Basic 33.8、ProofBench-Advanced 6.2。証明のギャップは深刻です。
- SFT後:AnswerBenchは59.8に低下しますが(モデルが短い解答の復元を証明探索と交換するため)、ProofBench-Basicは57.6、Advancedは14.8へと大幅に上昇します。
- Coarse RL後:AnswerBench 77.2、ProofBench-Basic 76.7、Advanced 25.2 — RLVRがSFTで定着した行動を、厳密性を損なうことなくより強い解法へとスケールさせています。
- Refined RL後(SU-01):AnswerBench 77.5、ProofBench-Basic 77.1、Advanced 38.1。利得は困難な証明問題に集中しており、これはまさに生成的証明報酬が効果を発揮すべき領域です。
- TTSを加えると:ProofBench-Basic 91.0、Advanced 49.5。
解答検証可能なベンチマークでは、SU-01はAnswerBench 77.5%、AMO-Bench 59.8%、AIME 2025/2026 94.6%/93.3%、FrontierScience-Olympiad総合 61.5%(物理 62.5、化学 69.4、生物 25.0)に達しています。Qwen3.6-35B-A3Bと競争力があり(平均77.4対77.3)、Nemotron-Cascade-2(71.8)、GLM-4.7-Flash(72.0)、Gemma-4-31B(70.9)を上回っています。主要な主張であるIMO 2025、USAMO 2026、IPhO 2024/2025における金メダルレベルの性能は、公式競技ファミリーで報告されています。
限界と未解決の問題
このレシピはスケール面では保守的(~340K SFT軌跡、~200 RLステップ)ですが、軌跡と検証合成のための強力な独自教師モデル(DeepSeek-V3.2-Speciale)に大きく依存しており、このような教師モデルなしでのアプローチの下限は不明確です。逆パープレキシティカリキュラムは主張されていますが、本論文の記述では機械的に詳細が不足しています。TTSを用いてもProofBench-Advancedは49.5にとどまり、高度な証明の半数以上が不完全なままです。また、FrontierScienceにおける化学・生物のカバレッジは不均一で(生物 25.0%)、証明厳密性の挙動が科学分野全体に均一に汎化していないことを示唆しています。さらに、TTSループの検証器はモデル自身であるため、欠陥のある証明が自己検証を決定的に通過してしまう失敗モードは定量化されていません。
重要性
本論文は、解答精度と証明厳密性は分離可能な軸であるという明確なアブレーションを提供しており、それぞれ異なる教師信号を必要とすることを示しています。前者には検証可能な報酬が、後者には生成的・証明報酬と自己改良が必要です。段階的な数値(Advanced ProofBench 6.2 → 14.8 → 25.2 → 38.1 → 49.5)は、フロンティアスケールのみに限らず、適度でかつ完全に記述されたパイプラインによる30B MoEからオリンピックグレードの証明構築が到達可能であることを示す、最も明快な公表済みの証拠です。
Source: https://arxiv.org/abs/2605.13301
SANA-WM: ハイブリッド線形 Diffusion Transformer による効率的な分スケール世界モデリング
問題設定
分単位の長さで720p映像を合成できるカメラ制御可能な世界モデルは、これまでLingBot-WorldやHY-WorldPlayのような産業規模の学習(膨大な計算資源、非公開データ、大規模なパラメータ数)を必要としてきました。主な障壁は、(i) 60秒・720pのクリップが生成する潜在系列に対するsoftmax attentionの二乗コスト、(ii) 連続6-DoF軌跡への正確かつ高レートな条件付け、(iii) ベースとなる生成器が小規模で限られたデータで学習された場合の忠実度の維持、の三点です。SANA-WMは、60秒・720p・シングルGPU推論を目標とする2.6BパラメータのオープンモデルであRり、メトリックスケールのポーズラベルを付与した約213Kの公開クリップのみを用いて、64台のH100で15日間学習されています。

手法
ハイブリッド線形/softmax DiT。 バックボーンは d_{\text{model}}=2240、20ヘッドの20ブロックDiTです。15ブロックにはフレームワイズのGated DeltaNet(GDN)という線形 attention の再帰機構を使用し、残りの5ブロック(層 \{3,7,11,15,19\})には線形スキャンでは捉えられないグローバルな依存関係を補完するために完全なsoftmax attentionを使用します。GDNのフレームごとの状態は、時間軸にわたる O(N^2) のsoftmaxを O(N) のメモリで置き換えるため、961フレームの潜在系列を扱いやすくしています。カスタムのfused Tritonカーネルがスキャンとゲーティングを実装しており、FlashAttention方式のsoftmaxカーネルと比較してwall-clock時間を競争力あるレベルに抑えています。
カメラ条件付け。 すべてのブロックはデュアルレートのカメラ条件付けを持ちます:UCPE(unified camera positional encoding)のattention項と、Plückerー座標のミキシングパスです。Plücker光線は6-DoF軌跡の密なピクセルごとの幾何学的encodingを提供し、フレームレベルのポーズトークンとよく組み合わさります。一方、UCPEは粗い軌跡情報をattentionに直接注入します。キャプションは意図的にシーン静的な内容—「左にパン」や「前進」といったトークンを含まず、物体・レイアウト・外観の記述のみ—とすることで、動作制御をポーズブランチに強制し、テキストエンコーダが軌跡の監督情報を漏洩できないようにしています。
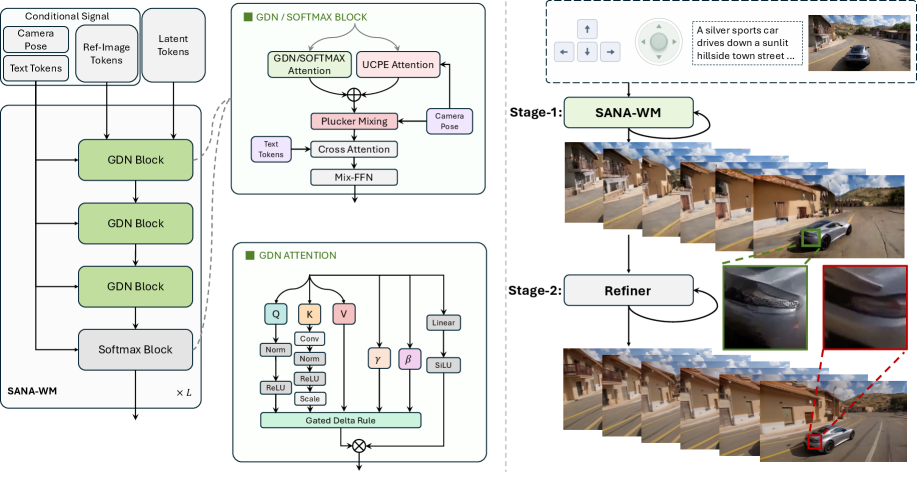
段階的学習。 ステージ1では、元のVAEをLTX2-VAE(潜在チャネル数 C=128)に置き換えることで、ST-DC-AEより 2.0\times、Wan2.1-VAEより 8.0\times 小さい表現を実現します。パッチ化層と出力投影層を再初期化し、フルモデルのfine-tuningを50kステップ実施します。ステージ2では、事前学習済みSANA-Videoの重みを短いクリップ上でハイブリッドGDN–softmax構造に移植します。ステージ3では、時間軸に沿ったContext-Parallelシャーディングを用いてflow matchingにより961フレーム(60秒)のシーケンスに拡張し、デュアルブランチのカメラ制御を有効にします。ステージ4では、自己回帰ロールアウトのためのチャンク因果バリアントをfine-tuningし、4ステップのself-forcing蒸留を適用します。デプロイ時には、softmax層にattention-sinkトークンとローカル時間窓を追加し、ロールアウト長に対してメモリとチャンクあたりのレイテンシが一定になるようにします—これはシングルGPU上でのストリーミング分スケール生成に不可欠です。
2段階生成。 長尺映像refinerをステージ1の出力に適用し、60秒にわたって蓄積する時間的不整合とテクスチャの劣化を修復します。
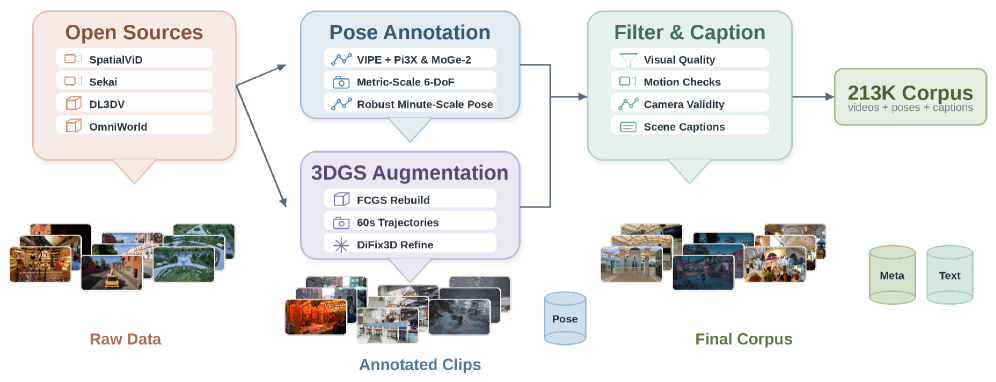
データパイプライン。 SANA-WMは7つのオープンソースから再アノテーションされた212,975クリップを使用し、メトリックスケールの6-DoFポーズが付与されています。アノテーターはVIPEを拡張し、深度バックエンドをPi3X(長シーケンス一貫性のある深度推定)とMoGe-2(フレームごとのメトリックスケール)に置き換え、さらにフレームごとの内部パラメータ最適化を追加しています。DL3DVの静止撮影は、FCGS 3D Gaussian Splattingをフィッティングし、長いカメラパスをレンダリングし、DiFix3Dでスプラッティングアーティファクトを除去することで(14,881クリップ拡張)、1分間の軌跡に変換されています。カメラ固有のフィルタリングとして、視野角・焦点距離の一貫性・ポーズの滑らかさ・スケール変動を考慮したものが適用されています。
結果
報告されている主要な数値は効率性を重視したものです:学習にはメトリックスケールのポーズ監督付き公開クリップ約213Kのみを使用し、64台のH100で約15日間で完了し、推論では60秒・720pのクリップをシングルGPU上で生成します。著者らは、いずれも大幅に大規模で非公開データで学習されたLingBot-WorldおよびHY-WorldPlayと同等の品質を主張しています。データ内訳は、SpatialVID-HQの10秒クリップ158,369件、ネイティブDL3DVの10秒5,691件、3DGS精製済みDL3DVの60秒14,881件、OmniWorldの60秒1,720件、Sekai-Gameの60秒合成3,560件、Sekai Walking-HQの60秒実写9,767件、MiraDataの60秒実写18,987件となっています。
限界と未解決の課題
提供されたセクションにはヘッドツーヘッドの定量的評価表(FVD、カメラ軌跡誤差、VBench)が含まれていないため、同等性の主張は現時点では定性的なものにとどまります。実際にSANA-WMが産業規模のベースラインにどこまで近いかは付録レベルの数値が示すことになります。ハイブリッドブロックスケジュール(softmaxとして \{3,7,11,15,19\} を選択)はヒューリスティックに決定されたようであり、softmaxブロックの配置数についてのアブレーション研究は示されていません。4ステップのself-forcing蒸留は双方向の教師と比較して測定可能な忠実度の低下をもたらす可能性があり、自己回帰のチャンク因果バリアントはattention sinkにもかかわらず分スケールのロールアウトにわたる露出バイアスのリスクを引き継ぎます。さらに、インターネット動画におけるポーズ精度は、特に強い動的コンテンツのもとでモノキュラー手がかりによるメトリックスケール推定が脆弱となるPi3X/MoGe-2/VIPEの失敗ケースによって制限されます。
重要性
SANA-WMは、線形 attention スキャンとスパースsoftmaxブロック、メトリックポーズアノテーションパイプラインを組み合わせることで、分スケールのポーズ制御可能な720p世界モデリングが学術的な計算資源(64台のH100、15日間、213Kの公開クリップ)で実現可能であることを示しています。同等性の主張が定量的に成立するならば、世界モデル研究をフロンティアラボのデータやハードウェア予算から切り離す信頼性の高いオープンベースラインとなり得ます。
Source: https://arxiv.org/abs/2605.15178
Darwin Family: MRI-Trust加重進化的マージによる言語モデル推論のトレーニング不要なスケーリング
問題
フロンティア推論モデルは通常、強力なベースチェックポイントの上に高コストなRLまたは蒸留パイプラインを経て得られます。Darwin Familyは、勾配更新なしに、既存のfine-tunedチェックポイントを重み空間で再結合することで、そのような利得を回復または超えられるかどうかを問います。本論文は、潜在的な推論能力は共有ベースの公開されているシブリングモデル群の中にすでにエンコードされており、ボトルネックはテンソル単位の再結合において均一平均化やTIESスタイルのマージを悩ます破壊的干渉を回避する原理的なメカニズムであると主張します。
手法
Darwinは、共有ベース \theta_{\text{base}} から派生した2つの親チェックポイント \theta_A, \theta_B を仮定し、\theta_A = \theta_{\text{base}} + \Delta_A、\theta_B = \theta_{\text{base}} + \Delta_B と分解します。マージカーネルはタスクベクトルのテンソル単位の凸結合です:
\theta_M(T) = \theta_{\text{base}}(T) + (1 - r_{\text{final}}(T))\,\Delta_A(T) + r_{\text{final}}(T)\,\Delta_B(T).
新規性は r_{\text{final}}(T) の決定方法にあります。2つのシグナルが生成され、調整されます。
Model-layer Response Importance(MRI)。 各テンソル T について、MRIはハイブリッドな診断事前分布です:
\mathrm{MRI}(T) = \alpha\,\mathrm{Static}(T) + (1-\alpha)\,\mathrm{Probe}(T), \quad \alpha=0.5.
静的項は T の正規化エントロピー、分散、および上限付き \ell_2 ノルムを集約します。プローブ項は、小規模な推論キャリブレーションセット対汎用プロンプトにおける活性化のコサイン距離を測定し、推論負荷下で機能が変化するテンソルを特定します。MRI由来の比率は
r_{\mathrm{MRI}}(T) = \frac{\mathrm{MRI}_B(T)}{\mathrm{MRI}_A(T)+\mathrm{MRI}_B(T)},
すなわち、機能的に顕著なテンソルを持つ親の方に重みを置くソフトな事前分布です。
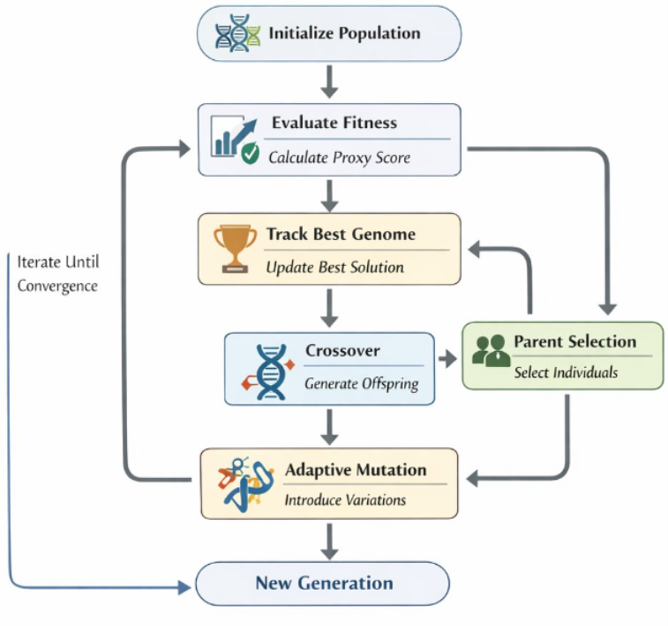
Genomeと進化的探索。 独立して、14次元の適応的マージgenomeがブロックおよびコンポーネントレベルの混合係数(attention Q/K/V/O、MLP up/gate/down、embedding、normsなど)をエンコードします。プロキシ適合度評価、トーナメント選択、交叉、適応的突然変異を伴う標準的な (\mu+\lambda) スタイルの進化ループがこれらのgenomeを進化させます(図3)。
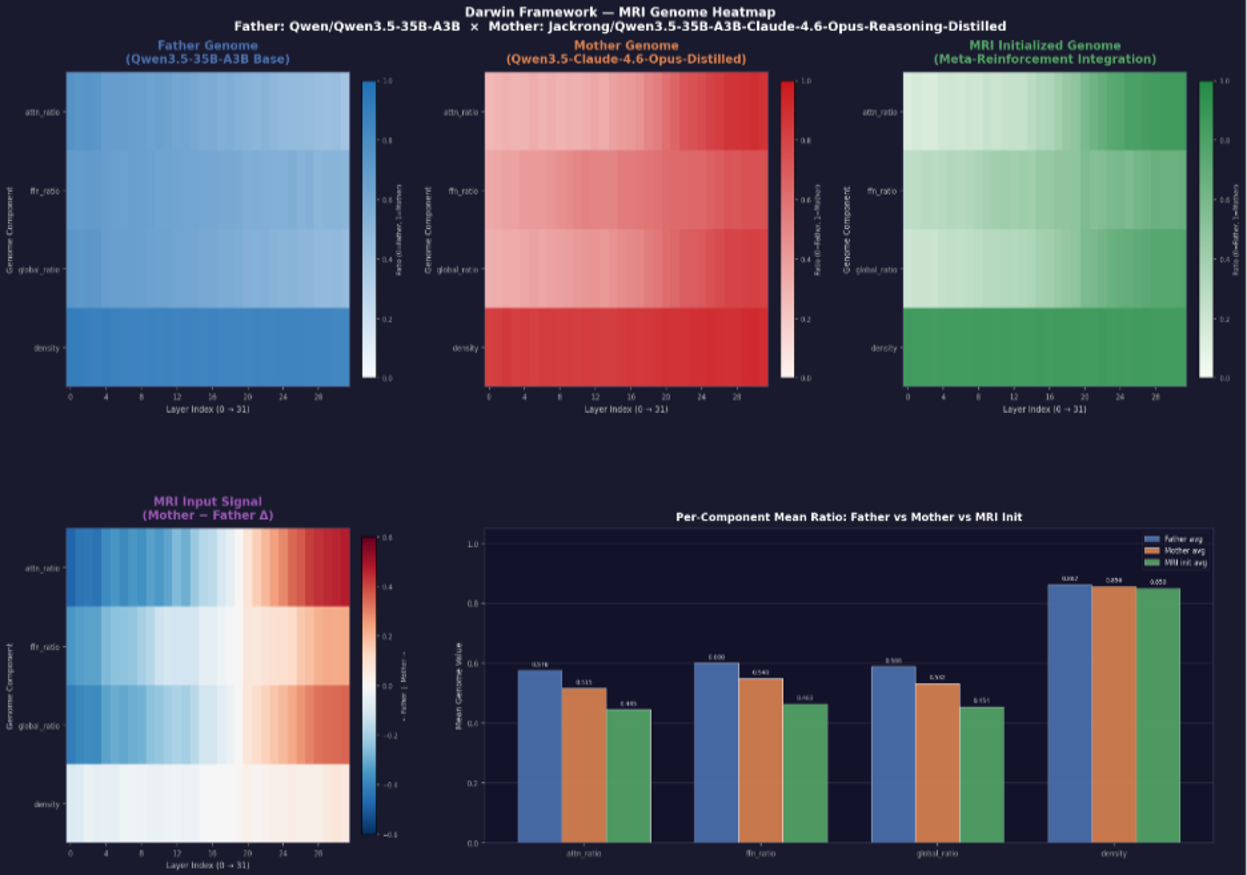
MRI-Trust Fusion。 学習可能なスカラーtrust パラメータ \tau が診断事前分布 r_{\mathrm{MRI}} とgenome由来の比率 r_{\mathrm{gene}} をブレンドして r_{\mathrm{final}} を生成します。経験的に、\tau はスケールを超えて \tau \approx 0.35\text{--}0.55 に収束し、どちらのシグナルも支配的になりません。MRI事前分布は初期集団を構造化し(図2は親とそれらの差分シグナルに対してMRI初期化されたgenomeのヒートマップを示します)、進化がその周りを洗練させます。著者らはこれが、診断なしの進化的マージよりも高速な収束と高いピークの両方を説明すると主張します。
Architecture Mapper。 異種の親(例:Transformer + Mamba)に対して、アライメントモジュールがアーキテクチャをまたいでテンソルをマッピングし、再結合が適切に定義されるようにします。これにより、Transformer-Mambaのトレーニング不要なマージが可能になります。
全体のパイプラインは図1にまとめられています。

マージカーネル自体はDARE-TIESです。著者らはlinear、SLERP、DARE-TIESを比較し、linearはタスク干渉に脆弱であり、SLERPは早期には滑らかだがピークが低く、DARE-TIESがdrop-and-rescaleによってパラメータの競合を緩和するため全構成において優位であることを確認しました。
結果
フラッグシップモデルであるDarwin-27B-OpusはGPQA Diamondで86.9%を達成し、85.5%(Father、ベース)、86.2%(Mother、推論蒸留済み)、単純平均/SLERPの86.1%を上回ります。本論文は2026-04-22時点で評価された1,252モデル中第6位のランクを報告しています。9つのベンチマークスイート全体(表1)において、Darwin-27B-Opusはすべてのベンチマークで両親を上回る成果を示します:ARC-Challenge 0.779対最良の親0.740、CommonsenseQA 0.783対0.776、HellaSwag 0.870対0.864、MMLU 0.776対0.782(motherに対してわずかに後退)、TriviaQA 0.722対0.718。全体平均は 0.786 \pm 0.040 であり、最強の親の \sim 0.776 および単純平均/SLERPの \sim 0.775 を上回ります。
診断なしの進化的マージと比較して、Darwinはより高いピーク精度と実行全体でのより低い分散を示し、MRIガイドによる初期化に帰因されます。再帰的な多世代進化(Darwin子孫の再マージ)は単調な改善を維持することが報告されており、クロスアーキテクチャのTransformer-Mambaの実験は実現可能性を確立していますが、そのアブレーションの詳細な数値は抜粋されたセクションには含まれていません。
限界と未解決の問題
- 共有ベースの仮定は \Delta 分解に不可欠です。Architecture Mapperは異種性を扱いますが、そのアライメント品質は提供されたテキスト内では定量化されていません。
- motherに対するGPQAの改善は絶対値では控えめ(0.7ポイント)であり、MMLUはわずかに後退します。ヘッドラインのランキングは制御された比較ではなくリーダーボードの構成に敏感です。
- MRIのプローブ項はキャリブレーションセットに依存しており、そのサイズと分布に対する感度は抜粋部分では未検討です。
- 進化的探索中のプロキシ適合度の詳細は示されていません。推論ベンチマークは通常高コストな評価を必要とし、プロキシと真の相関はこのクラスの手法において既知の失敗モードです。
- 探索自体のFLOPsに合わせた実際にfine-tunedされた推論モデルとの比較がありません。
なぜこれが重要か
診断ガイドによる重み空間の再結合が、GPQA Diamondのような難しいベンチマークにおいて勾配訓練された推論モデルとのギャップを真に埋められるなら、現在のフロンティアモデルにおける「推論能力」の非自明な割合がすでに既存のチェックポイントから線形アクセス可能であることを示唆し、さらなる訓練ではなく慎重なテンソル単位の混合がそれを顕在化させるのに十分であることを意味します。これは、ポスト訓練を既存のモデルエコシステムに対する探索問題として再定義するものです。
Source: https://arxiv.org/abs/2605.14386
Causal Forcing++: スケーラブルな少ステップ自己回帰拡散蒸留によるリアルタイムインタラクティブ動画生成
問題設定
リアルタイムインタラクティブ動画生成(ゲームスタイルのワールドモデル、アバター、制御可能なロールアウト)には、ストリーミング・低レイテンシ・フレームレベルの自己回帰(AR)デコーディングが必要です。AR拡散蒸留における現在の最先端手法——CausVid、Self Forcing、Causal Forcing——は、主にチャンク単位(チャンクあたり3枚の潜在フレーム)の4ステップ体制で検証されてきました。これは密なインタラクションループには粗すぎますし、チャンクごとのサンプリングコストも無視できません。著者らは、真に攻撃的な体制——フレーム単位ARかつフレームあたり1〜2サンプリングステップ——への拡張に取り組みます。
ボトルネックとなるのは、よく理解されている最終的な敵対的スコアマッチング段階(asymmetric DMD)ではなく、DMDが非常に敏感に依存する少ステップ学生の初期化です。既知の3つの初期化手法はいずれも、フレーム単位・1〜2ステップ生成への移行に耐えられません。
既存の初期化がなぜ失敗するか
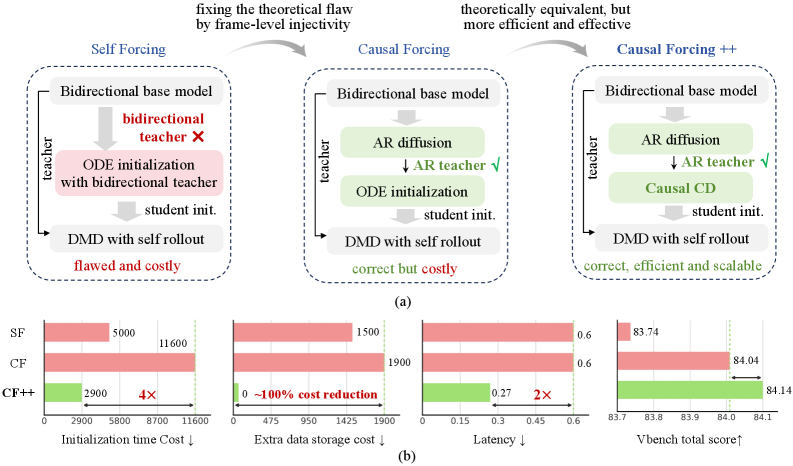
著者らは3つの選択肢を列挙し、それぞれがこの体制において異なる理由で破綻することを示します。
- 双方向teacherからのODE蒸留(CausVid、Self Forcing)。これはフレームレベルの単射性に違反します。同一のノイズ付きフレーム \mathbf{x}_t^i が異なる将来のコンテキストの下で複数のクリーンフレームに対応するため、ODEマッチングは \mathbb{E}[\mathbf{x}_0^i \mid \mathbf{x}_t^i, \mathbf{x}_t^{<i}, t], へと崩壊します。これはぼやけた非ARターゲットであり、ARフローマップではありません。誤差は自己ロールアウト中に蓄積されます。
- 少ステップ蒸留をスキップし、多ステップARテacher を直接実行する(LiveAvatar、WorldPlay)。アーキテクチャ上は整合していますが、1〜2ステップの実行ができません。
- ARテachからの因果的ODE蒸留(Causal Forcing)。理論的には正しいですが、学習データごとに完全なPF-ODE軌跡を事前計算する必要があり、コストが高くスケールが困難です。

Self Forcing流の初期化はチャンク単位4ステップの時点ですでに崩壊し、フレーム単位4ステップでさらに悪化し、フレーム単位1ステップでは壊滅的に破綻します。
手法:因果一貫性蒸留
著者らはStage 2における因果的ODE蒸留を、因果一貫性蒸留(causal CD)に置き換えます。どちらも同じAR条件付きフローマップ、すなわち (\mathbf{x}_t^i, \mathbf{x}_t^{<i}, t) からクリーンフレームへの写像を目標としますが、監督方法が異なります。
- 因果的ODE蒸留は、teacherが生成した完全なPF-ODE軌跡のエンドポイントに対してstudentを回帰させるため、多ステップ軌跡の保存が必要です。
- 因果CDは、単一のオンラインteacherオイラーステップを用いて隣接タイムステップ間の自己一貫性を強制します。具体的には、隣接する離散化時刻 t_n > t_{n-1} に対して、 \mathcal{L}_{\text{causal CD}} = \mathbb{E}\big\| f_\theta(\mathbf{x}_{t_n}^i, \mathbf{x}_{t_n}^{<i}, t_n) - f_{\theta^-}(\hat{\mathbf{x}}_{t_{n-1}}^i, \mathbf{x}_{t_{n-1}}^{<i}, t_{n-1}) \big\|_2^2, ここで \hat{\mathbf{x}}_{t_{n-1}}^i はARテacherの1回のオイラーステップ、\theta^- はEMAコピーです。これにより軌跡の保存が不要になり、最適化がローカルになり、フレームレベルの単射性に必要なAR条件付けとの互換性も維持されます。
完全なパイプラインはCausal Forcingの3段階を保持します。(1) teacher-forcing AR拡散学習、(2) 少ステップ初期化(今回は因果CD)、(3) 自己ロールアウトを伴うasymmetric DMD。ベースモデルはWan2.1-1.3Bを 480\times832、81フレーム、フレーム単位ARで使用します。Stage 2では48の離散化タイムステップ、二乗ノルムloss、オイラーソルバーを使用します。Stage 3は4ステップ(t=1, 0.9375, 0.8333, 0.625)、2ステップ(t=1, 0.8333)、1ステップで学習します。ASDに倣い、Stage 3では最初の潜在フレームに引き続き4ステップを使用し、続く20枚の潜在フレームに2または1ステップを使用します——これは定常状態のレイテンシを増大させずに難しいウォームアップフレームを吸収する実用的な選択です。Stage 3のスコアモデルにはWan2.1-14Bを使用し、それ以外はすべて1.3Bです。学習:バッチサイズ64でStage 1/2/3それぞれ20K/5K/1Kステップ;Stage 1〜2にはOpenVid(80K)、Stage 3にはVidProMを使用します。
結果
Figure 1によれば、Causal Forcing++はCausal Forcingと比べてStage 2の学習コストを 4\times 削減し、軌跡の事前計算パイプラインを排除し、推論レイテンシを50%低減し、VBenchスコアを改善しています。

定性的には、CF++は同じバックボーン上でCausVidとSelf Forcingを明確に上回りながらCausal Forcingに匹敵あるいは凌駕しており——さらに重要なことに、双方向teacherの初期化が崩壊するフレーム単位1〜2ステップの設定においても品質を維持しています。
限界と未解決の問題
本論文の証拠は単一のバックボーン(Wan2.1-1.3B/14B)の固定解像度に集中しており、より大きなモデルや異なるDiTファミリへの転移は検証されていません。1ステップおよび2ステップのStage 3は依然として最初の潜在フレームに対して4ステップのウォームアップに依存しているため、真に均一な1ステップロールアウトは実証されていません。因果CDは一貫性モデル特有の病理(離散化数、EMAスケジュール、ソルバー選択への感度)を引き継いでいますが、本論文は48タイムステップとオイラーを固定しており、アブレーションを行っていません。アクション条件付きワールドモデルの結果は主張されていますが、本稿で引用した箇所では詳述されていません。最後に、asymmetric DMD段階では14BのスコアモデルおよびStage 2のコストが削減されているにもかかわらず、学習時のデプロイコストは依然として相当なものです。
重要性
少ステップAR拡散はインタラクティブで制御可能な動画モデルへの実用的な経路であり、ボトルネックは敵対的fine-tuningから初期化へと静かにシフトしています。軌跡ベースのODE蒸留を、AR単射性を保持するローカルな一貫性目的関数に置き換えることで、フレーム単位1〜2ステップ蒸留が標準的なハードウェア上で実現可能になり、より困難なリアルタイム体制の体系的研究への道が開かれます。
Source: https://arxiv.org/abs/2605.15141
DiffusionOPD: 拡散モデルにおけるOn-Policy Distillationの統一的視点
問題設定
テキストから画像を生成する拡散モデルのRLによる後学習(DDPO、DPOK、FlowGRPO、DiffusionNFT、GRPO-Guard)は、単一タスクのレシピ——報酬を一つ選んで最適化する——に収束しています。マルチタスクの後学習は未解決の問題です。異種の報酬(構成的正確さ、OCR忠実度、審美性、選好スコア)に対する同時最適化は、gradient interferenceおよび報酬の不均衡に悩まされます。異なる報酬はスケールが互いに異なり、飽和する速度も異なります。Cascade RL(各報酬を順番にfine-tuneする手法)は脆弱であり、以前の目標を忘れてしまいます。著者らはこの問題を蒸留として再定式化しています。各タスクに対してそれぞれの報酬に最も適したアルゴリズムを用いてタスク専用の教師モデルを学習し、on-policy distillation(OPD)によって一つの生徒モデルに統合します。OPDはLLMに対して用いられてきましたが、連続状態の拡散モデルに対しては正式に導出されていませんでした。
手法
LLMの場合、OPDは生徒 \pi_\theta から完全なシーケンスをサンプリングし、生徒が訪問したprefixにおいて教師 \pi^\star にマッチさせます。シーケンスレベルのreverse KLは、各ステップのカテゴリカルKLへと正確に分解されます。
\mathcal{L}_{\text{OPD}}^{\text{LLM}}(\theta) = \mathbb{E}_{x\sim\pi_\theta}\!\left[\sum_{t=1}^T \mathrm{KL}\bigl(\pi_\theta(\cdot\mid x_{<t})\,\|\,\pi^\star(\cdot\mid x_{<t})\bigr)\right].
離散語彙に対する内側のKLは閉形式で得られるため、疎な結果報酬の代わりに密な各トークンの解析的な監督信号が得られます。
本研究の貢献は、これを連続状態の拡散モデルへと拡張したことにあります。逆向き過程を、遷移 p_\theta(x_{t-1}\mid x_t) および p^\star(x_{t-1}\mid x_t) を持つマルコフ連鎖として扱います。SDE(確率的)およびODE(決定論的平均)のどちらのパラメータ化に対しても、予測された速度/スコアによってパラメータ化されたガウス(または退化ガウス)の各ステップカーネルが得られます。生徒のロールアウト軌跡に沿った各ステップのreverse KLは、閉形式の平均マッチング lossへと収束します。
\mathcal{L}_{\text{OPD}}^{\text{diff}}(\theta) = \mathbb{E}_{x_t \sim p_\theta}\!\left[\sum_t \tfrac{1}{2\sigma_t^2}\|\mu_\theta(x_t,t) - \mu^\star(x_t,t)\|_2^2\right],
この式はSDEおよびODEサンプラーの両方をカバーします(ODEの極限は \sigma_t\!\to\!0 に対応し、平均マッチングのみとなります)。これはLLMのOPDにおける各トークンのKLの拡散モデル版であり、密で各ステップの解析的なgradientが生徒自身のロールアウトに沿って計算されます。advantage推定、重要度比、clippingは一切不要です。著者らは、これがFlowGRPOやGRPO-Guardで用いられるPPO/GRPOスタイルのスコア関数gradientよりも分散が低く、適用範囲が広いと主張し(また実験的に示し)ています。
学習パイプラインは以下の通りです。
- K 個の専門教師モデルを学習します。各教師は自身の報酬に対して、最も性能の良いRLアルゴリズムで学習されます(GenEvalにはDiffusionNFT、OCRおよびPickScore + ClipScore + HPSv2.1の複合審美性にはGRPO-Guard)。
- 上記の各ステップ平均マッチングKLを教師全体について合計し、LoRAの生徒モデルへと蒸留します。蒸留中の軌跡分布は生徒のロールアウトによって決定されます。
ベースモデルはSD3.5-Mediumを512×512で使用し、LoRA(\alpha=64、r=32)と40ステップの一次ODEエバリュエーターを用います。これはDiffusionNFTのセットアップに準拠しています。
結果
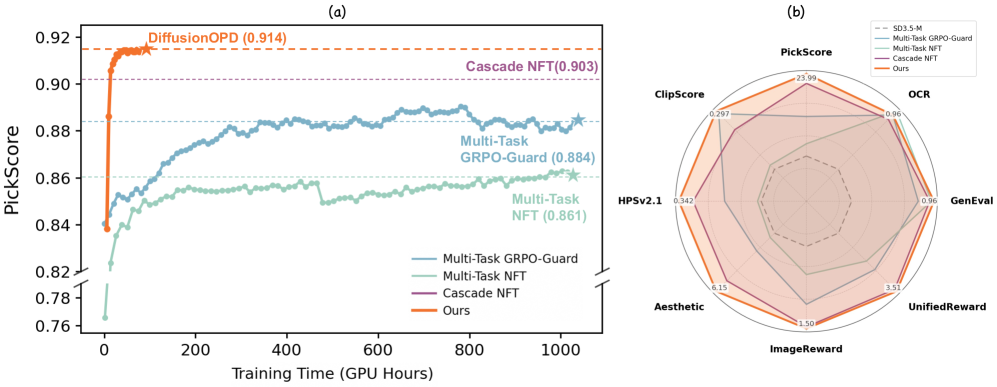
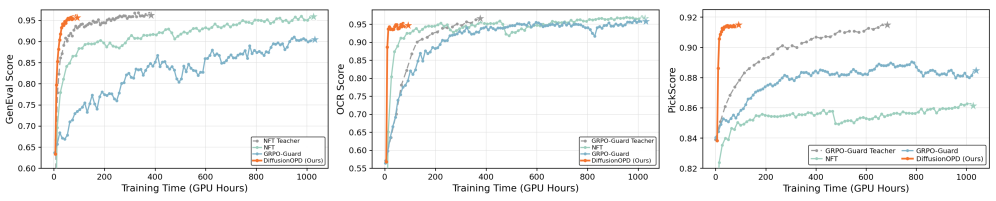
最も注目すべき数値は、8つの指標(GenEval、OCR、PickScore、ClipScore、HPSv2.1、Aesthetic、ImageReward、UnifiedReward)にわたるmin-max正規化平均です。
- DiffusionOPD: 0.929
- Cascade NFT: 0.851
- Multi-Task GRPO-Guard: 0.763
- Multi-Task NFT: 0.715
- SD3.5-M + CFG: 0.484
DiffusionOPDはすべての指標において最高スコアに並ぶかそれを上回ります。GenEval 0.96(GenEval教師と同率)、OCR 0.94(OCR教師の0.93を上回る)、Aesthetic 6.15(Aes教師の6.22に対して)、HPSv2.1 0.342、ImageReward 1.50、UnifiedReward 3.50。重要な点として、生徒モデルは各専門家の報酬に対してそれぞれの専門教師と同等の性能を達成しており——各タスクにおける性能劣化がなく——それらを一つにまとめることに成功しています。
もう一つの軸は実際の計算コストです。Multi-Task GRPO-Guardは129.86時間、Multi-Task NFTは128.42時間、Cascade NFTは約148.49時間を要します。DiffusionOPDは85.75時間(教師モデルの最大学習時間。Aes教師が支配的)+ 11.26時間のOPDステップ = エンドツーエンドで97.01時間であり、さらに教師モデルは並列学習が可能です。教師の学習を並列処理として扱う場合、OPDステップ自体は共同RLベースラインと比較しておよそ11倍低コストです。
定性的には、マルチタスクRLのベースラインはいずれか一方の教師の失敗モードを引き継ぐ傾向があります。Multi-Task NFTはグリフをきれいに描画しますが審美的な豊かさが失われ、GRPO-Guardは審美性を保持しますが構成的正確さが劣化します。一方、OPDの生徒モデルは構成的、テキスト的、審美的な基準を同時に満たす画像を生成します。

限界と未解決の問題
- 閉形式の各ステップKLはガウス(またはDirac)の逆向きカーネルに依存しており、カーネルが非ガウスとなるconsistency modelや少数ステップで蒸留されたサンプラーへの拡張は導出されていません。
- すべての教師が同一のベースモデルSD3.5-Mを共有しており、異なるバックボーン(異なる潜在空間、異なるスケジューラー)から構築された教師モデルを蒸留する場合については扱われていません。
- 本手法は各報酬に対して強力な専門家を学習できることを前提としています。報酬自体が十分に最適化されていない場合(例:3D一貫性、長文テキストのレンダリング)、性能の上限は教師モデルによって決まります。
- K 個の教師の数や、競合する報酬(例:審美性 vs. 厳格なプロンプト遵守)に対して性能がどのようにスケールするかについての分析はありません。
- PPOスタイルのgradientと比較した分散削減の主張は実験的に支持されていますが、形式的な上界は理想化されたガウスカーネルの設定に対するものにとどまります。
重要性
DiffusionOPDは、拡散モデルのマルチ報酬後学習を、扱いにくい共同RL問題から、解析的でサンプラー非依存の各ステップKLを用いたモジュール型蒸留へと変換します。各専門家の報酬を回復しながら、実際の計算時間をおよそ25〜35%削減し、正規化平均を0.85(Cascade NFT)から0.93へと向上させています。また、LLMのOPDと拡散モデルの関係を明確化するという点でも意義があります。すなわち、生徒のロールアウトに沿ったreverse KLという同じ原理が、離散的な場合にはトークンレベルのKLを、連続的な場合には平均マッチングを導出します。
Source: https://arxiv.org/abs/2605.15055
Self-Distilled Agentic Reinforcement Learning
エージェント型 RL におけるトラジェクトリレベルの報酬は弱い監督信号しか提供しません:複数ターンのロールアウトの末尾にある単一のスカラー値が、数百の推論・行動トークンにわたってクレジットを割り当てなければなりません。On-Policy Self-Distillation(OPSD)は、単一ターンの設定においてこの問題に対処するため、特権的なコンテキスト(例:参照回答)を持つ teacher ブランチを student と並列に実行し、トークンごとの logit を distillation します。OPSD をマルチターンエージェントにそのまま適用すると、本論文で特定された2つの理由から失敗します:(i) ターンをまたいだ分布ドリフトの累積が teacher シグナルを不安定化させる、(ii) 特権的なコンテキストが正解ではなく取得したスキルである場合、取得したスキルが無関係または誤適用されているために teacher が正しい student トークンを棄却してしまう可能性がある。SDAR(Self-Distilled Agentic RL)は最適化のバックボーンとして GRPO を維持しつつ、正負の teacher-student ギャップを非対称に扱うゲート付き補助 loss として OPSD を追加します。
セットアップと不安定性
マルチターントラジェクトリを y=(y_1,\dots,y_T)\sim\pi_\theta(\cdot\mid x) として平坦化します。位置 t における student コンテキストは s_t=(x,y_{<t}) であり、teacher は s_t^+=(x,c^+,y_{<t})(ここで c^+ は訓練時のみ利用可能な特権的コンテキスト)を参照します。エージェント型タスクでは、c^+ は取得したスキル、すなわちコンパクトな構造化デモンストレーションです。4つの取得戦略(UCB、Keyword Matching、Full、Random)を比較しており、UCB はスキルを以下によりスコアリングします:
\mathrm{score}(e) = \bar r(e) + c\sqrt{\tfrac{\ln N_{\mathrm{ucb}}}{n(e)}}.
ゲーティングの動機は実験的に示されています。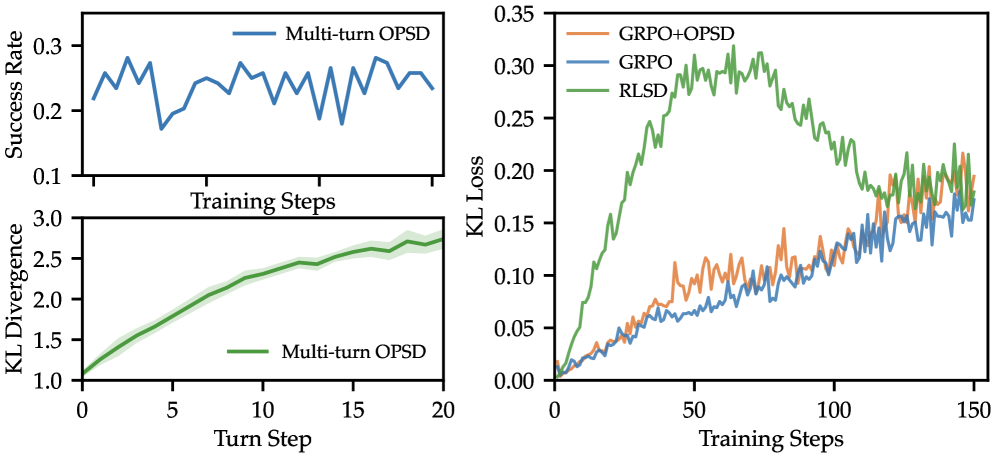 単純なマルチターン OPSD は KL の爆発とパフォーマンスの崩壊を示し、RLSD スタイルの組み合わせでは制御不能な KL の増大が見られます。これはまさに SDAR が抑制するよう設計された失敗モードです。
単純なマルチターン OPSD は KL の爆発とパフォーマンスの崩壊を示し、RLSD スタイルの組み合わせでは制御不能な KL の増大が見られます。これはまさに SDAR が抑制するよう設計された失敗モードです。
非対称性の根拠は teacher-student ギャップ分析に基づいています。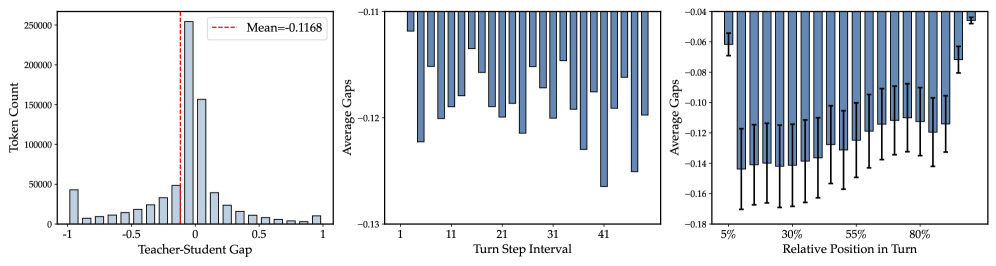 ギャップの分布は重裾であり対称ではありません:多くのトークンが小さいまたは負のギャップ(teacher が student に同意しない)を受け取りますが、これはターンの後半や各ターンの冒頭付近に集中しており、特権的なスキルコンテキストが誤誘導しやすい箇所です。これらのトークンを正のギャップトークンと同じ distillation ウェイトで扱うとノイズが混入します。
ギャップの分布は重裾であり対称ではありません:多くのトークンが小さいまたは負のギャップ(teacher が student に同意しない)を受け取りますが、これはターンの後半や各ターンの冒頭付近に集中しており、特権的なスキルコンテキストが誤誘導しやすい箇所です。これらのトークンを正のギャップトークンと同じ distillation ウェイトで扱うとノイズが混入します。
SDAR の目標関数
g_t = \log\pi_{\theta^+}(y_t\mid s_t^+) - \log\pi_\theta(y_t\mid s_t) を detach されたトークンごとの teacher-student ギャップとします。SDAR は g_t を sigmoid ゲート \sigma(\beta g_t) に通すことで、正のギャップトークン(teacher が支持)には増幅された distillation 圧力を与え、負のギャップトークン(teacher が棄却、おそらく誤って)には student 自身の正しい予測から遠ざけるのではなく、ソフトに減衰させます。全体の loss は以下のとおりです:
\mathcal{L}_{\text{SDAR}} = \mathcal{L}_{\text{GRPO}} + \lambda \, \mathbb{E}_t\!\left[\sigma(\beta g_t)\, \mathrm{KL}\!\big(\pi_{\theta^+}(\cdot\mid s_t^+)\,\|\,\pi_\theta(\cdot\mid s_t)\big)\right].
GRPO が主要なオプティマイザとして残り、OPSD は補助的かつゲート付きです。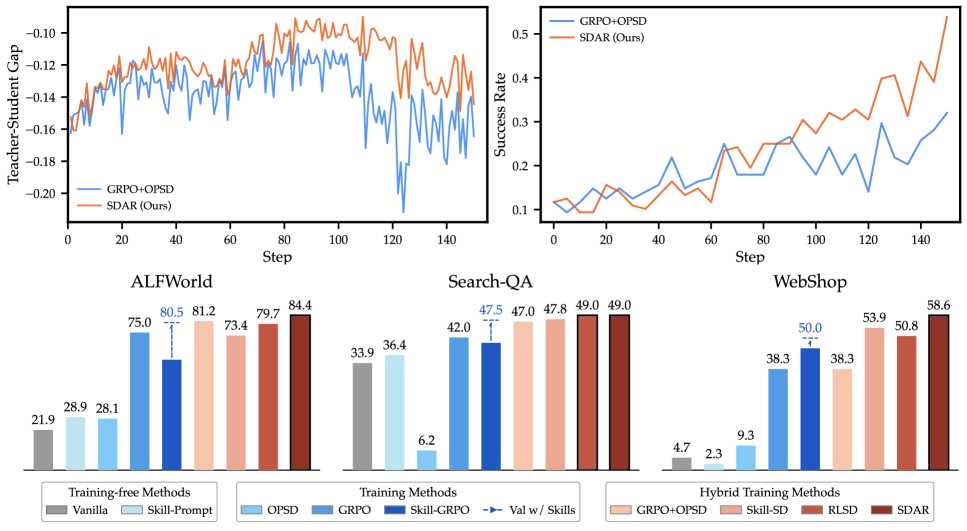 distillation 項がゲートなしで対称的に適用される GRPO+OPSD と対照的であり、これが前述の不安定性の原因です。
distillation 項がゲートなしで対称的に適用される GRPO+OPSD と対照的であり、これが前述の不安定性の原因です。
結果
ALFWorld、WebShop、Search-QA にわたる Qwen2.5 および Qwen3 バックボーンにおいて、SDAR は GRPO に対して以下の改善を達成します:
- +9.4%(ALFWorld)
- +7.0%(Search-QA:NQ、TriviaQA、PopQA、HotpotQA、2Wiki、MuSiQue、Bamboogle の平均)
- +10.2%(WebShop accuracy:先行研究に合わせた128タスク検証スライス)
重要なのは、SDAR が単純な GRPO+OPSD で見られた発散を回避している点です:補助 loss がトークンレベルのシグナルを提供し続ける間も、KL は訓練全体を通じて有界に保たれます。取得戦略(UCB、KM、Full、Random)にわたるロバスト性スイープは、c^+ の精度が低い場合でもゲーティングメカニズムが緩やかに劣化することを示唆しています。負のギャップ減衰が悪いスキルを吸収し、ポリシーを汚染させないのです。
限界と未解決の課題
このフレームワークには依然として利用可能なスキルライブラリと取得メカニズムが必要であり、完全なコールドスタートエージェント型タスク(デモなし)下でのパフォーマンスは評価されていません。ゲートは固定の \beta を使用しており、student の能力が変化する中でアダプティブまたは学習可能なゲートが有効かどうかは未解決です。teacher ブランチはトークンあたりの forward 計算を2倍にするため、長いホライズンでは無視できないコストとなります。理論的には、非対称な扱いが gradient にバイアスをもたらします。これは適切な KL 最小化ではなく、ゲート付き目標関数の不動点の挙動は解析されていません。最後に、評価は検証可能な報酬を持つテキストベースの環境に限定されており、よりスパースまたはノイジーな検証器を持つ環境(確率的出力を伴うツール使用、不安定なテスト下でのコード実行)への転移は未検証です。
この研究の重要性
SDAR は、マルチターンエージェントにおいてトラジェクトリレベルの RL とトークンレベルの distillation を、単純な組み合わせを悩ませてきた不安定性なしに組み合わせるための洗練されたレシピです。detach された teacher-student ギャップに対する非対称 sigmoid ゲートは小さな機械的変更ですが、脆弱な補助 loss をロバストなものに変換します。また、3つのベンチマークファミリーにわたる GRPO に対する一貫した約7〜10%の改善は、ゲーティングの原則が特定のスキル取得設定を超えて汎化することを示唆しています。
Source: https://arxiv.org/abs/2605.15155
MemLens: 大規模視覚言語モデルにおけるマルチモーダル長期記憶のベンチマーク評価
問題設定
長期的なマルチモーダルアシスタントは、多数のセッションにまたがって画像・キャプション・過去のターンを記憶する必要があります。このための構造的アプローチとして主に二つのファミリーが存在します:(i) インターリーブされたトランスクリプト全体を入力とするlong-context LVLMs と、(ii) 過去のターンをテキストまたはベクトルストアに圧縮してクエリ時に検索するmemory-augmented agentsです。既存のメモリベンチマークはテキストのみを対象としたもの(LoCoMo、LongMemEval)か、画像を単なる装飾として扱っており、回答のために画像内容が厳密には必要とされないものに限られていました。その結果、「メモリ」スコアはテキストのみのショートカットによって水増しされやすく、制御されたコンテキスト長においてマルチモーダルな根拠を真に必要とする問題での二つのファミリーの比較も行われてきませんでした。
MemLensは視覚的な根拠付けを強制し、コンテキスト長を独立変数として固定することで、二つのファミリーを対等に比較できるよう設計されています。
ベンチマークの構築
MemLensは、五つのメモリ能力にまたがるマルチセッション会話上の789問で構成されています:
- 情報抽出 — 単一の過去ターンから事実を復元する。
- マルチセッション推論 — 複数のセッションにわたって証拠を統合する。
- 時間的推論 — イベントの順序付けや日付特定を行う。
- 知識更新 — 後のセッションで上書きされた事実を追跡する。
- 回答拒否 — 証拠が存在しないまたは削除された場合に回答を控える。
各問題は4つのコンテキスト長:32K、64K、128K、256Kトークンで構成されています。設計上の重要な選択はクロスモーダルトークンカウント方式です。画像は各モデル固有の視覚トークナイザーのレートを用いてトークンコストに変換されており、トランスクリプトに含まれる画像と単語の比率に関わらず「32Kトークン」が同一の総プリフィルバジェットを意味するようになっています。この正規化がなければ、画像を256トークンとしてエンコードするシステムは1024トークンを使用するシステムと比べて実効的なトランスクリプトが大幅に短くなり、「コンテキスト長」の比較が無意味になってしまいます。
MemLensが本当に画像を必要とすることを検証するため、著者らはimage-ablation studyを実施しています。トランスクリプトから証拠画像を除去してフロンティアLVLMsに再クエリを行った結果、証拠に画像が含まれる80.4%の問題において、二つのフロンティアLVLMsの精度は2%未満に低下しました。これが核心的な主張です——ベンチマークの大多数の問題はテキストのショートカットでは解けず、メモリスコアは実際の視覚的記憶を反映しています。
手法:測定対象
各(モデル、問題、コンテキスト長)のトリプルに対し、メトリクスはゴールド回答に対するexact-match精度であり、回答拒否アイテムは証拠が存在しない場合にモデルが回答を控えるかどうかで採点されます。二つのシステムクラスを評価しています:
- 27のlong-context LVLMs(クローズドおよびオープン)。それぞれ目標トークンバジェットまでのインターリーブされたトランスクリプト全体を入力として受け取り、一回のforward passで回答します。したがって、性能は位置的汎化、コンテキスト深部の小さな視覚領域へのattention、および内部圧縮(例:sliding-windowやtoken-droppingスキーム)に依存します。
- 7つのmemory-augmented agents。これらは会話をターンごとに取り込み、外部ストア(典型的にはテキストサマリーに加えて画像キャプションまたはembedding)に書き込み、テスト時には少数のアイテムを短いプロンプトに検索します。視覚的忠実性はストレージステップが保持する内容によって上限が決まります。
この分割により、二つの失敗モードを切り離すことができます:read-time degradation(long-contextモデルがLの増大に伴って精度が低下すること)と、write-time compression loss(agentsがサマライズ時に視覚的詳細を破棄すること)です。
結果
二つの主要な知見が際立っています。
第一に、long-context LVLMsは短いコンテキストでは優位に立つものの、長さに伴い性能が低下します。フロンティアモデルは32Kでは証拠画像に直接attendできるため、直接的な視覚的根拠付けによって高い精度を達成します。コンテキストが256Kに向かって増大するにつれ、全体的に精度が大幅に低下します——いわゆる「lost-in-the-middle」パターンであり、画像ごとのトークンフットプリントが大きいため証拠がattentionの届きにくい位置に押しやられることで悪化します。
第二に、memory-augmented agentsは長さに対して安定していますが、視覚的には弱いです。検索コストがトランスクリプト長でスケールしないため、精度は32Kから256Kにかけてほぼ横ばいです。しかし、テキストサマリーが破棄してしまう細粒度の視覚的内容(数、属性、空間関係)を必要とする問題に対して系統的に失敗します。image-ablationの結果はその上限を定量化しています:ストレージがテキストのみのagentは、80.4%の画像必須サブセットにおいて2%未満のフロアを引き継ぎます。
五つの能力別の内訳も示唆に富んでいます。知識更新と時間的推論のアイテムはlong-context LVLMsにとって最も難しく、単一のスパンを検索するのではなく離れたターン間の情報統合が必要なためです。回答拒否の精度は過信を明らかにしています:多くのモデルは根拠となる画像が削除されても回答を捏造しており、現在のLVLMsにおける「メモリ」が証拠の不在に対して十分に較正されていないことを示しています。
限界と未解決の問題
ベンチマークはキュレートされた回答に対するexact-matchであるため、部分的な評価が反映されず、言い回しに敏感です。クロスモーダルのトークンバジェットは各モデルのトークナイザーに依存するため、大きく異なる視覚エンコーダ間の比較では、トークンコストがコンテキスト圧力の公正な代理指標であるという暗黙の仮定が含まれます。agentの評価は使用する特定のメモリアーキテクチャに依存しており、テキストと並行して画像パッチやVQコードを格納するハイブリッドagentは原理的に視覚的忠実性のギャップを埋めることができ、MemLensはその自然なテストベッドとなります。また、256Kは数ヶ月にわたってメモリを蓄積するデプロイされたアシスタントと比べて短く、テスト範囲を超えた外挿は検証されていません。
意義
MemLensは、コンテキスト長をモダリティ公平な形で一定に保ち、画像に根拠付けられた想起を強制する初めてのベンチマークであり、明確なトレードオフを浮き彫りにしています:long-context LVLMsは視覚的忠実性は高いものの長さのスケーリングが劣り、memory agentsは長さのスケーリングには強いものの視覚的忠実性が劣ります。非テキスト的な視覚メモリを持つagent——明らかな次のシステム——は、このベンチマークでは逃げ場がありません。
Source: https://arxiv.org/abs/2605.14906
Hacker News Signals
「アイドル」がアイドルでないとき:Linuxカーネルの最適化がQUICのバグになった経緯
CloudflareによるQUIC接続のデススパイラルに関するポストモーテムです。このデススパイラルは、SO_RCVTIMEOソケットオプションとカーネルのbusy-poll / NAPIアイドル最適化との予期しない相互作用によって引き起こされました。UDPソケットがbusy-pollモードにある場合、カーネルはソケットのタイムアウトが満了していなくても即座にEAGAINを返すことがあります。これは、「アイドル」検出パスがタイムアウト機構を短絡させてしまうためです。QUICのloss-recoveryタイマーは正確なタイムアウトセマンティクスに依存しており、recvmsgがデータなしで早期に返ると、QUICスタックはこれをタイムアウトイベントと解釈して再送をトリガーします。負荷がかかっている状態では、これがフィードバックループを生み出します。すなわち、偽の再送が負荷を増大させ、偽のEAGAIN返却の頻度が上がり、さらに再送が増加するというデススパイラルです。原因が特定されれば修正は単純です。busy-pollソケットでSO_RCVTIMEOを使用するのをやめてタイムアウトをユーザー空間で実装するか、対象ソケットのbusy-pollを無効にするかのいずれかです。興味深いエンジニアリング上の教訓は、NAPI busy-pollがスリープせずカーネル内でスピンすることでレイテンシを削減するために導入されたものの、ユーザー空間に公開するコントラクトがブロッキングI/Oの提供するものと微妙に異なるという点です。具体的には、busy-pollソケット上のrecvmsgは、タイムアウトが発火したからではなく、pollエポックが終了したためにEAGAINを返すことがあります。この違いはman 7 socketに明確に記載されていません。この投稿は、あるカーネル層で追加されたパフォーマンス最適化が、上位層のプロトコルスタックに組み込まれた前提を侵害しうることを示す好例です。Linux上でloss-recoveryのタイミングにSO_RCVTIMEOを使用しているQUIC実装はすべて、この相互作用を監査すべきです。
Source: https://blog.cloudflare.com/quic-death-spiral-fix/
arXiv の新方針:ハルシネーション参考文献に対する1年間の投稿禁止
arXiv は、AI によってハルシネーションされた参考文献——実在しない論文への引用——を含む論文を投稿した場合、1年間の投稿禁止措置を取ると発表しました。この方針は、LLM を用いた執筆が広まって以来、測定可能なレベルで頻発するようになった特定の失敗モード、すなわち捏造されているにもかかわらず一見もっともらしく見え、人間による簡易チェックをすり抜けてしまう引用を対象としています。執行の仕組みとしては、モデレーターまたはコミュニティメンバーが疑わしい参考文献にフラグを立て、その後 arXiv スタッフが書誌データベースと照合して確認するという手順を取ります。ハルシネーションと確認された参考文献が1件でも存在すれば禁止措置が発動されます。また、この方針は意図的な捏造と LLM の不注意な使用を区別しておらず、それが最も議論を呼んでいる点です。
この問題の技術的背景はよく理解されています。科学論文テキストで学習された自己回帰型言語モデルは、引用文字列(著者名、発行年、タイトル、掲載誌)の表層的な形式を学習しており、特に学習分布が疎なニッチな分野や学際的なトピックにおいて、一貫性があるように見えても実在しないエントリを生成することがあります。この方針は検証の責任を全面的に著者に課すものです。
批判派は、真に見落としが生じたケースに対して1年間の禁止は不均衡だと指摘しています。LLM に参考文献のフォーマットを依頼したものの各エントリの確認を怠った研究者が、意図的に捏造した引用を投稿した研究者と同じペナルティを受けることになります。一方、支持派は、投稿数の多さを考えると、これより軽い制裁では十分な抑止力にならないと主張しています。
より広い意味での示唆として、各投稿先は参考文献を自動検証するパイプラインを整備する必要があるということが挙げられます。Semantic Scholar や CrossRef の API を用いれば、解決できない DOI やタイトルを原理的にはフラグ立てできますが、現時点ではこれらは arXiv の投稿ワークフローに統合されていません。
Source: https://twitter.com/tdietterich/status/2055000956144935055
Apple M5における初の公開macOSカーネルメモリ破壊exploit
Apple Silicon M5上のカーネルメモリ破壊脆弱性に対する公開exploitがリリースされました。このwriteupでは、カーネルサブシステムにおける型混同(type confusion)または境界外書き込み(out-of-bounds write)について詳述しており(具体的なCVEおよび影響を受けるコンポーネントはpost内に記載されています)、非特権のローカル攻撃者がカーネルコード実行を達成できることが示されています。Apple Siliconにおいてこれが特に重要な意味を持つのは、カーネルがPointer Authentication (PAC)が施行されたEL1で動作しているためです。制御フローハイジャックの前提条件としてPACのバイパスが必要であり、使用された手法——別の情報漏洩プリミティブと連鎖させることで署名済みポインタを偽造またはリークする——は、現在のPACバイパス技術の水準を示しています。このexploit chainは特にM5をターゲットとしている点で注目に値します。従来の公開exploitは、緩和策がより弱いか異なっていた旧世代のマイクロアーキテクチャをターゲットとしていました。M5のメモリサブシステムおよびIOMMU構成はM1/M2とは異なっており、writeupではexploitに適応が必要だった理由についても論じています。システムセキュリティの観点から、公開proof-of-conceptの価値はAppleにパッチを強制し、防御側がexploitプリミティブを理解できるようにする点にあります。このリリースではexploitの信頼性(成功率、exploitation までの時間)もベンチマークされており、安定性に関する懸念についても議論されています——メモリを予測不可能に破壊するカーネルexploitは、確実な兵器化が困難です。このpostはARMv8.3+ハードウェア上でのPACバイパス手法の参考資料として機能するほど技術的に詳細です。影響を受けるmacOSバージョンのユーザーは、関連するセキュリティアップデートを適用する必要があります。M5搭載機に対するパッチの状況についてもwriteup内で言及されています。
Source: https://blog.calif.io/p/first-public-kernel-memory-corruption
Show HN: ベンチマークでランク付けされた、あなたのハードウェアに最適なローカル LLM を見つける
whichllm は小規模なオープンソースツールで、ハードウェアの仕様(GPU VRAM、CPU RAM、コンピュート能力)を入力すると、そのハードウェアで実際に動作し使用可能な速度で実行できるモデルに限定して、benchmark スコア順にランク付けされたローカル実行可能な LLM のリストを返します。技術的な核心はランキング手法にあります。このツールは、公開されている benchmark スコア(MMLU、HumanEval、MT-Bench など)と、一般的な quantization レベル(Q4_K_M、Q5_K_M、Q8_0、fp16)に対して経験的に導出されたメモリ使用量の推定値を組み合わせ、ランキングの前に実行可能性フィルターを計算します。利用可能な VRAM を超えるモデルは除外され、収まるモデルは複合 benchmark スコアによってランク付けされます。この複合スコアはタスクカテゴリをまたいだ加重平均であり、設定によって変更可能です。
このツールが解決する主なエンジニアリング上の課題は、公開されている benchmark リーダーボードが特定の quantization レベルにおけるメモリと性能のトレードオフを考慮していないという点です。そのためユーザーは、OOM を引き起こすか、実用的な速度で動作しないモデルを頻繁にダウンロードしてしまいます。現在のツールは、新しいモデルがリリースされるたびに手動で更新しなければならない静的な YAML ファイルからモデルのメタデータを取得しており、これが明白なスケーリング上の限界となっています。HuggingFace のメタデータと llama.cpp の benchmark 実行結果をスクレイピングする自動化パイプラインの方が保守性は高いでしょう。ハードウェアの入力は現在手動ですが、nvidia-smi / rocm-smi / Metal API を通じた自動検出の追加は容易です。評価や fine-tuning のためにローカル inference を実行している研究者にとって、このツールは「リーダーボードがある」と「自分のマシンで動くものがある」という間の実質的なギャップを埋めるものです。
Source: https://github.com/Andyyyy64/whichllm
新たなNginxのエクスプロイト
Nginx-Riftの開示では、nginxのリクエスト処理パスにおける脆弱性について説明しています。このリポジトリには、問題を実証するPoCが含まれており、細工されたHTTPリクエストを介して到達可能なメモリ安全性のバグ(境界外読み取りまたは書き込み)であると見られています。防御者にとって最も重要な技術的詳細は攻撃対象領域です。この脆弱性はコアHTTP/1.xまたはHTTP/2パース層(正確なコンポーネントについては開示内容を参照してください)に存在しており、公開されたnginxインスタンスにリクエストを送信できる任意のクライアントから、認証なしで到達可能であることを意味します。深刻度は、メモリ破壊がコード実行に悪用可能かどうか、あるいは情報漏洩やサービス拒否に限定されるかによって異なります。リポジトリ内のPoCは、少なくともワーカープロセスを混乱させるnullデリファレンスまたはヒープ破壊を示す、安定したクラッシュを実証しています。Nginxのアーキテクチャはある程度の隔離を提供しており、ワーカープロセスは非特権ユーザーとして動作し、クラッシュが発生してもマスタープロセスを停止させることなくワーカーが再起動されます。しかし、リモートから悪用可能なクラッシュは依然としてDoSベクターであり、破壊がwrite primitiveとして利用可能である場合、その隔離は不十分です。この開示は、リポジトリに記録された責任ある開示のタイムラインに従っています。インターネットに面した環境でnginxを運用しているオペレーターは、影響を受けるバージョン範囲を確認し、直ちにパッチを適用するか、提供されている設定による緩和策を適用すべきです。より広い観点から見ると、CベースのHTTPサーバーにおけるメモリ非安全性が繰り返し再発見されるというパターンは、メモリ安全な言語への書き直しの動機付けとなり続けています。nginxのメンテナーであるF5は、ApacheのHttpdの取り組みに相当するRustへの書き直しをまだ発表していません。
Source: https://github.com/DepthFirstDisclosures/Nginx-Rift
オンタリオ州の監査で、医師向けAI診療記録ツールが基本的な事実を日常的に誤ることが判明
オンタリオ州の監督機関が実施した監査では、AIを活用したアンビエント文書化ツール——臨床での診察場面を聴取してSOAPノートや診察サマリーを自動生成するシステム——を対象に調査を行い、系統的な事実誤りが発見されました。具体的には、誤った薬剤名、不正確な用量、誤帰属された症状、でっち上げられた所見などが確認されています。この技術的な障害モードは、MLの観点からは予測可能なものです。これらのシステムは一般的に、Whisperクラスのスピーチ認識(ASR)パイプラインをfine-tuningしたものがLLMによる要約層へと繋がる構造をとっています。誤りは両段階から伝播します。ASRは音声的に類似した薬剤名を混同し(「metformin」対「metoprolol」など、これは既知かつ文書化された問題です)、LLMによる要約層は、構造化された記録テンプレートを埋めるよう促された際に、文字起こしに存在しない詳細をhallucinationします。監査では、レビューされた記録の無視できない割合において誤りが見つかりましたが、臨床リスクを定量化するために必要な、薬剤リストのような特定フィールドにおける正確な偽陽性率については、報道においてground truthを決定するための監査方法論が十分に説明されていません。臨床上の賭け金は高く、退院サマリーの薬剤名が誤っていれば、その後の処置で有害事象を引き起こす可能性があります。根本的な問題は、これらのツールが十分な人間によるレビューなしに導入されているという点にあります。医師はAIが生成した記録に、すべてのフィールドを確認することなくサインオフしており、その背景には、採用を動機づけた効率化のメリットがすべての文章を確認しなければならなくなると消えてしまうという事情があります。これはモデルの品質問題であると同時に、導入体制とインセンティブの問題でもあります。監査は必須のレビューワークフローを推奨していますが、低信頼度フィールドを強調表示するツールが整備されない限り、レビューの負担は表面的なものにとどまる可能性が高いでしょう。
Claude Codeが大規模コードベースでどのように機能するか
AnthropicのエンジニアリングブログにおけるClaude Codeの大規模コードベース戦略に関する記事では、プロジェクト全体の理解を維持しながらcontext limitの範囲内に収めるために、このツールが使用する具体的な手法を解説しています。核心的な課題は、大規模コードベースが実用的なcontext windowをはるかに超えるため、システムは取り込むのではなく検索・取得しなければならないという点にあります。説明されているアプローチは複数のメカニズムを組み合わせています。すなわち、すべてのファイルを全文読み込むことなくシンボルテーブルやコールグラフを抽出するtree-sitterベースの構造解析、ファイル内容を読む前にgrep・find・LSPスタイルのクエリを使うようモデルに指示するsearch-firstワークフロー、そしてファイルを開く前に高レベルのタスク分解を行うプランニングフェーズ(これにより検索が探索的ではなく目的指向になります)が挙げられます。また、記事ではCLAUDE.mdという慣習についても説明しています。これはリポジトリレベルのmarkdownファイルであり、アーキテクチャの決定事項・直感的でない慣習・注意が必要なコードベースの領域についてモデルに永続的なコンテキストを与えるために作者が管理するものです。これは本質的に手動でキュレーションされた検索ドキュメントであり、多くの一般的なケースにおいてセマンティック検索の必要性を回避します。どこから始めるかに関するガイダンス(CLAUDE.mdを読み、次に関連するエントリポイントを読み、その後importをlazilyにたどる)は、学習されたポリシーではなく経験的に導き出されたワークフローを反映しています。注目すべき欠落点として、長いセッション中にファイルが変更された場合にClaude Codeがstaleなコンテキストをどう扱うかという議論がありません。これはアクティブなコードベースにおける実際的な問題です。この記事は評価的というより規範的な性格を持っており、推奨されるワークフローが単純な全コンテキスト読み込みやRAGアプローチと比べてタスク成功率を実際に向上させるかどうかについて、アブレーションデータは提供されていません。
Source: https://claude.com/blog/how-claude-code-works-in-large-codebases-best-practices-and-where-to-start
AIがあなたのコードを書くなら、なぜPythonを使うのか?
この投稿は、Pythonを選択する従来の理由——読みやすい構文、高速なイテレーション、充実したエコシステム、低い参入障壁——はいずれも主として人間の作者にとっての利点であり、LLMが実際に作者となる場合は関連する評価基準が変化する、と主張しています。この議論には検討に値する実質的な技術的内容が含まれています。Pythonの動的型付けとランタイムセマンティクスは、LLMが生成したPythonコードの静的検証を難しくします。つまり、実行前に型エラーを検出するコンパイラが存在せず、コンパイルステップの欠如によってバグが実行時に表面化し、しばしば本番環境で発覚します。RustやGoのような静的型付けのコンパイル言語をLLMが対象とする場合、コンパイラが生成コードの自動検証器として機能するため、生成時により多くのエラーが検出されるでしょう。これは正当な指摘であり——Rustと組み合わせて使用されるLLMコーディングアシスタントでは、コードが実行される前により高い割合のバグが検出されています。反論としては、Pythonのエコシステムの豊富さによりLLMの学習分布がより充実しており、一般的でない言語と比べてPythonではより精度の高い生成が可能になるという点が挙げられます。また、イテレーションループに関する議論もあります。たとえ人間がコードを書かないとしても、コードを実行し、エラートレースを読み、修正を指示するのは人間であり、Pythonの高速なフィードバックループはこの監督的役割においても依然として価値を持ちます。この記事では、LLMの観点からトークンコストがゼロである場合に言語レベルの冗長性(Java、C++)が実際に有益かどうかにも触れていますが、この点は解決されていません。LLM支援開発における言語選択の問題は真に未解決であり、実証的な研究に値します。
Source: https://medium.com/@NMitchem/if-ai-writes-your-code-why-use-python-bf8c4ba1a055
注目の新しいリポジトリ
browser-use/browser-harness
LLMがCSSセレクタやXPathのような脆弱なセレクタに依存せずにWebブラウザを操作できるよう設計された、自己修復型のブラウザ自動化レイヤーです。核心となるアイデアは、DOM操作が失敗した場合(要素が見つからない、レイアウトがシフトした、参照が古くなったなど)に、ハーネスが自動的にページコンテキストを再クエリし、セマンティックマッチングを用いてターゲット要素を再特定し、ハードエラーを出す代わりにリトライするというものです。これは生のPlaywright/Seleniumラッパーとは本質的に異なります。固定セレクタを記録するのではなく、ハーネスは現在のDOM状態のライブセマンティックインデックスを維持し、実行時に要素参照を解決します。
内部的にはPlaywright経由でChromiumをラップし、LLMに対して構造化されたアクション空間(click、type、scroll、extract、navigate)を公開するとともに、圧縮されたDOMスナップショットをコンテキストとしてフィードバックします。自己修復ループは失敗時に軽量な再識別パスを実行し、期待される要素の視覚的・構造的特徴を現在の候補と比較します。これにより、ページが更新されたりA/Bテストが発火した際に多くのLLMブラウザエージェントを悩ませる脆弱性が軽減されます。
このリポジトリは、ページ構造の安定性が保証されない環境で自律型WebエージェントやRPAの代替を構築する開発者を対象としています。ターゲットサイトが頻繁に変更される場合、生のブラウザツールコールよりも有用です。Pythonベース、MITに近いライセンス、12k以上のスターを持ち、実際に広く採用されていることが伺えます。主な制限として、セマンティック再識別が失敗したアクションごとにレイテンシを追加すること、またcanvasやshadow DOMを持つ複雑なSPAでは依然として問題が生じることが挙げられます。
Source: https://github.com/browser-use/browser-harness
facex-engine/facex
WebAssemblyに完全コンパイルされた顔分析スタック全体を、サーバーへのラウンドトリップを一切介さずにブラウザのクライアントサイドで動作させるプロジェクトです。パイプラインは5つのタスクをカバーしています:顔検出、576点の3D顔面メッシュ推定、顔認識(embedding抽出)、活性検知/なりすまし防止、そして笑顔検出です。5つのモデルはすべてWASMモジュールとしてバンドルされており、デバイスからデータが一切外部に送出されることなく、エンドユーザーのCPU(または利用可能な場合はWebGL/WebGPU経由のGPU)上で推論が実行されます。
576点の3Dメッシュは、MediaPipeの468点Face Meshよりも明らかに高密度であり、より精細な変形制御を必要とするARアプリケーションに関連するカスタムアーキテクチャまたは拡張トポロジーを示唆しています。anti-spoofモジュールは技術的に興味深い要素です:リプレイ攻撃・印刷攻撃の検出器を純粋にクライアントサイドで動作させることは、ダウンロードバジェットによるモデルサイズ制約を考えると容易ではなく、積極的な量子化または知識蒸留の適用が示唆されます。
アーキテクチャの選択(TensorFlow.jsやONNX Runtime WebではなくWASM)により、Pythonバックエンドを必要とせずにブラウザ間で予測可能なパフォーマンスが実現され、医療・本人確認・オフラインキオスク展開など、プライバシーに敏感なアプリケーションへの適用が可能です。Apache 2.0ライセンスにより商用利用の障壁も排除されています。現時点でスター数152と初期段階ではありますが、技術的なスコープは明確に定義されています。主要な未解決事項として、標準ベンチマーク(LFW、IJB-C)における認識精度の数値、およびミドルレンジのモバイルデバイスにおける推論レイテンシが挙げられます。
Source: https://github.com/facex-engine/facex
cosmicstack-labs/mercury-agent
Mercuryは、CLIまたはTelegramインターフェースから24時間365日の運用を想定して設計された、持続的かつ常時稼働のAI agentランタイムです。設計上の2つの際立った選択として、権限強化ツールとトークンバジェットが挙げられます。権限強化とは、各ツール(ファイルシステムアクセス、シェル実行、ネットワーク呼び出し)が明示的なケイパビリティ宣言を持つことを意味し、agentは宣言されたスコープ外のツールを呼び出すことができないため、prompt injectionや暴走したtool callsの被害範囲を縮小できます。トークンバジェットはハードな会計レイヤーを追加し、各タスクにコンテキストの使用上限を割り当てることで、長時間稼働の自律セッションにわたってAPIコストが無制限に累積するのを防ぎます。
マルチチャネルアクセス(CLI + Telegram)により、プロセスを再起動することなく人間のオペレーターがagentを監視・誘導できます。これは、割り込み機能が必要な夜間や背景で動作するジョブに関連します。説明文中の「soul-driven」というフレーミングは、セッションをまたいで行動の一貫性を維持する永続的なペルソナ/メモリレイヤーを指しているものと思われますが、そのレイヤーの技術的な実装の詳細は公開ドキュメントには十分に記載されていません。
2,200スターという数字は、相応の注目を集めていることを示しています。実用的なユースケースは、cron-job-plus-scriptパイプラインを、推論を通じて例外ケースを処理できるLLM agentに置き換えることです。常時稼働agentにおける主なリスクはツールの権限モデルにあります。つまり、OSレベルでそれらのケイパビリティ宣言がどのように強制される(プロセス分離、サンドボックス化)かという点が、依然として重要な未解決の問題です。
Source: https://github.com/cosmicstack-labs/mercury-agent
thClaws/thClaws
クラウド依存なしにローカルかつ自律的な実行を重視した、Rustネイティブのエージェントハーネスプラットフォームです。「マルチプロバイダー」とは、統一されたプロバイダートレイトを通じて複数のLLMバックエンド(OpenAI互換API、ローカルのOllamaなど)を抽象化し、エージェントのロジックを変更することなく推論エンドポイントを切り替えられることを意味します。「設計による主権性(sovereign by design)」というポジショニングは技術的なスタンスであり、テレメトリなし・アカウント不要・データが機外に出ないことを保証します。
ハーネスをPythonではなくRustで構築することは、エージェントランタイムとして意味のある利点をもたらします。多数の並行ツール実行スレッドを管理する際のメモリオーバーヘッドの低減、並列サブエージェントタスクのための安全な並行プリミティブ、そしてインタープリタへの依存なしに動作する単一のコンパイル済みバイナリが挙げられます。トレードオフとしては、Pythonと比較してLLMクライアントライブラリのエコシステムが小さい点がありますが、OpenAI互換のHTTPインターフェースによってこの問題は緩和されています。
このプラットフォームは、オンプレミスでエージェントを構築・デプロイしたい開発者をターゲットとしているようです。エアギャップ環境、エッジハードウェア、あるいはPythonのランタイムオーバーヘッドや依存関係チェーンが好ましくない状況が対象となります。915スターを獲得しており、セルフホストAIコミュニティで支持を集めています。未解決の問いはツールDSLに集中しており、複雑なツールグラフやエージェント間の委譲がどのように表現されるか、また再現可能な実行のためのシリアライズ可能なワークフロー形式が存在するかどうかが焦点となっています。
Source: https://github.com/thClaws/thClaws
opensquilla/opensquilla
OpenSquillaはトークン効率を目標としています——より大きなコンテキストを単純に投入するのではなく、消費トークンあたりのタスク完了品質を高めることを目指しています。「higher intelligence density」というフレーミングは、単なるプロンプト圧縮ではなく、コンテキストの組み立てと刈り込みに関する構造的な変更を示唆しています。想定されるメカニズムとしては、会話履歴の階層的な要約、関連するメモリチャンクの選択的な検索、そして冗長なLLMの応答を削減する構造化出力フォーマットなどが挙げられます。
このプロジェクトは、主要な最適化軸をコスト・品質比に置くエージェントフレームワークとして自らを位置づけています。これは、APIの利用コストが実際の予算項目となる本番環境のデプロイにおいて、実用的に重要な制約です。この点が、機能の幅広さや使いやすさを最適化するフレームワークとの差別化要因となっています。
758スターを獲得しており、プロジェクトの認知度は高まっています。技術的な核心となる問いは、「intelligence density」をどのように測定するか——すなわち、同じトークン予算がナイーブなエージェントループと比較してより良い成果をもたらすことを示すベンチマークまたはタスクスイートが何であるか——という点です。WebArenaやGAIAのような標準的なベンチマークにおけるトークン消費量対タスク成功率を示したablationが公開されていない限り、効率性の主張を検証することは困難です。オープンソースであるという性質上、コンテキスト管理のロジックは監査可能であり、各LLMへの呼び出しに何が含まれ、どこでトークンが消費されているかを正確に把握したいチームにとって価値があります。
Source: https://github.com/opensquilla/opensquilla
chekusu/wanman
Wanmanは、人間を能動的な指示者ではなく明示的にオブザーバーの役割へと移行させるマルチエージェントオーケストレーションランタイムです。設計のメタファーとして日本のワンマン列車運行を採用しており、乗客が運行に介入することなく単一の自動化された車掌が全ルートを管理するシステムに対応しています。実際には、ランタイムが複数のローカルエージェントプロセスを調整し、エージェント間でタスクをルーティングし、アーティファクトの受け渡しを処理し、実行状態を管理する一方で、人間はマイクロマネジメントではなくモニタリングに徹します。
技術的な本質はエージェントマトリックスを中心に展開します。これは、複数の特化したエージェントランタイム(それぞれが異なるモデルやツールセットで動作する可能性がある)が定義されたメッセージパッシングインターフェースを通じて通信するトポロジーです。アーティファクト(ファイル、構造化データ、中間結果)は会話コンテキストから再構築されるのではなく、エージェント間で受け渡されるファーストクラスオブジェクトとして扱われます。これによりトークンのオーバーヘッドが削減され、エージェント間の状態が明示的になります。
ローカルでの実行は意図的な設計判断であり、エージェントの調整はすべてユーザーのマシン上で行われることで、クラウドオーケストレーションのレイテンシを回避しデータをローカルに保持します。「オブザーバーロール」の設計には実際の工学的含意があります。すなわち、システムは堅牢な障害検知とエスカレーションロジックを備え、ルーティンなエラーで不必要なアラートを発することなく、真に人間の介入を要する問題を浮かび上がらせる必要があります。スター数547と初期段階にありますが、そのアーキテクチャの概念は単純な逐次エージェントチェーンとは明確に差別化されています。
Source: https://github.com/chekusu/wanman
regent-vcs/re_gent
Re_gent は、AIコーディングエージェントのセッションにバージョン管理のセマンティクスを適用するプロジェクトです。解決しようとしているコアの問題は、コーディングエージェントがファイル編集・ツール呼び出し・意思決定の連鎖を行う際、その過程が現状では不透明かつ不可逆である点にあります。エージェントが誤った方向に進んでしまった場合、復旧には手動での調査とロールバックが必要になります。Re_gent はエージェントの状態をバージョン管理されたグラフとして追跡し、Git がソースコードを管理するのと同様に、エージェントの実行履歴に対してブランチ・チェックポイント・diff・ロールバック操作を可能にします。
これはアーキテクチャ的に非自明な設計です。エージェントの状態には、ファイルの差分だけでなく、会話のコンテキスト・ツール呼び出し履歴・中間生成物・意思決定ポイントも含まれます。エージェントに有用なバージョン管理システムは、これらすべてを整合性のある形でスナップショットし、選択的な復元を可能にする必要があります。本プロジェクトはおそらく、ファイル状態に対するcopy-on-writeセマンティクスと、各ノードにおけるLLMインタラクションの明示的なログ記録を備えた、エージェント状態のDAGを実装しているものと考えられます。
自律的なコーディングワークフローにおける実用的価値は高いです。エージェントにリファクタリングを試みさせ、危険な変更の前にチェックポイントを作成し、結果を観察してアプローチが誤っていればチェックポイントにロールバックする、という一連の操作を手動での編集取り消しなしに行うことができます。スター数501と、本プロジェクトはまだ初期段階にあります。未解決の主な問題としては、コンテキスト状態(トークン履歴)をどのように効率的に保存・復元するか、そしてロールバック時に復元されたコンテキストを実際にLLMへ再入力するのか、それともファイル状態の復元にとどまるのかという点が挙げられます。
Source: https://github.com/regent-vcs/re_gent
chorus-codes/chorus
Chorusは、コードの意思決定に対してマルチLLMピアレビューを実装するツールであり、成果物をリリースする前に2〜4つの追加LLMインスタンスを招集してそのコードを批評します。このワークフローは既存のCLIツールと統合されており、ユーザーは自分のコーディングエージェントやエディタをそのまま使用し、Chorusはそこにレビューゲートを追加します。このゲートは、異なるモデル(例:GPT-4o、Claude、Gemini、ローカルのLlamaバリアント)から独立した評価を収集し、そのフィードバックを統合します。
技術的な根拠は、品質シグナルとしてのアンサンブル不一致にあります。異なるアーキテクチャと学習分布を持つ複数のモデルが、独立したプロンプトによって同一の懸念点に収束した場合、その懸念は単一モデルのhallucination よりも本物である可能性が高いと考えられます。レビュアー間の意見の相違は、人間による判断が必要な曖昧な設計上の決定を浮き彫りにします。これはCIパイプラインで複数の静的解析ツールを使用することに類似しており、それぞれが異なるfalse-positiveのプロファイルを持ち、その共通部分が高い信頼性を示します。
「自分のCLIを持ち込む」統合モデルにより、ChorusはフルIDEの代替ではなくミドルウェアとして機能し、導入の摩擦を低減しています。466スターを獲得しており、一定の支持を得ています。主な実用上の制限はコストとレイテンシです。4つのLLMコールを直列または並列で招集すると、レビューサイクルごとに実質的な時間とAPIコストが追加されます。このツールの価値提案は、コードの変更がそのオーバーヘッドを正当化するほど重要な場合に成立するため、行単位の編集よりもPRレベルのレビューに適しています。