Daily AI Digest — 2026-05-15
arXiv Highlights
Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
Problem and motivation
Frontier reasoning models can already produce correct final answers on a large fraction of olympiad problems, but olympiad grading is proof-based: a solution with the right number can still score zero if it contains an unjustified step, a missing case, or a logical fallacy. The gap between answer-recovery ability and proof reliability is the central object this paper attacks. The authors propose a unified recipe that turns a post-trained reasoning backbone (P1-30B-A3B) into a proof-grade solver, named SU-01, and report gold-medal-level performance on IMO 2025, USAMO 2026, and IPhO 2024/2025.
The pipeline
The training recipe has three stages — SFT, two-stage RL, and test-time scaling — each targeting a distinct failure mode.
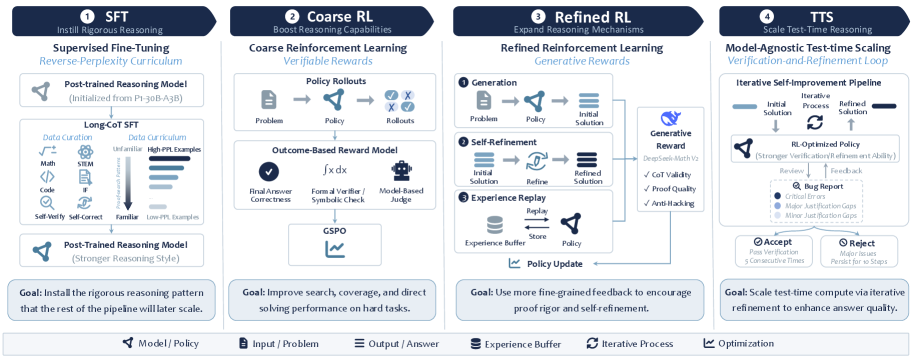
SFT with a reverse-perplexity curriculum. Starting from P1-30B-A3B preserves instruction-following and broad scientific competence, so SFT focuses on reshaping the pattern of reasoning rather than rebuilding capability. Prompts are drawn from Evan Chen’s olympiad notes, the Shuzhimi Forum, AoPS, online competition books, and DeepMath problems with difficulty \geq 6, mixed with NaturalReasoning, Nemotron-Instruction-Following-Chat-v1, Eurus-2-RL-Data, and OpenCodeReasoning-2 to prevent narrow specialization. DeepSeek-V3.2-Speciale generates long-form trajectories; only those under 8,192 tokens are retained, with explicit truncation removal to keep the supervised signal clean. Beyond direct solutions, the curators synthesize self-verification and self-refinement traces — DeepSeek inspects its own solution, writes a bug report, and refines it. The final mixture has 338K trajectories.

Two-stage RL. A separate prompt pool (8,967 verifiable, 16,287 non-verifiable, after dedup, decontamination, and rejection sampling for difficulty) drives two RL phases. Coarse RL uses verifiable rewards (RLVR) to recover and amplify direct solving on the SFT-shaped policy. Refined RL then optimizes against generative/proof-quality rewards on proof-oriented prompts (including the OPC corpus of human-evaluated proofs), with self-refinement prompts and experience replay to keep rare successful hard-problem rollouts available. Total RL is roughly 200 steps on a 30B-A3B MoE backbone.
Test-time scaling. Inference follows a solve–verify–refine loop in the spirit of Huang and Yang (2025): the solver prompt prioritizes proof rigor; the refinement step repairs weak steps; a verification prompt produces a structured bug report; a verdict step accepts, rejects, or requeues. Loops repeat until the candidate passes verification under repeated checks. The trained policy remains coherent on trajectories exceeding 100K tokens, which is what makes the budget usable rather than wasted on drift.
Quantitative results
The most informative analysis is the staged decomposition of AnswerBench (final-answer correctness) versus ProofBench-Basic and ProofBench-Advanced (graded proofs).
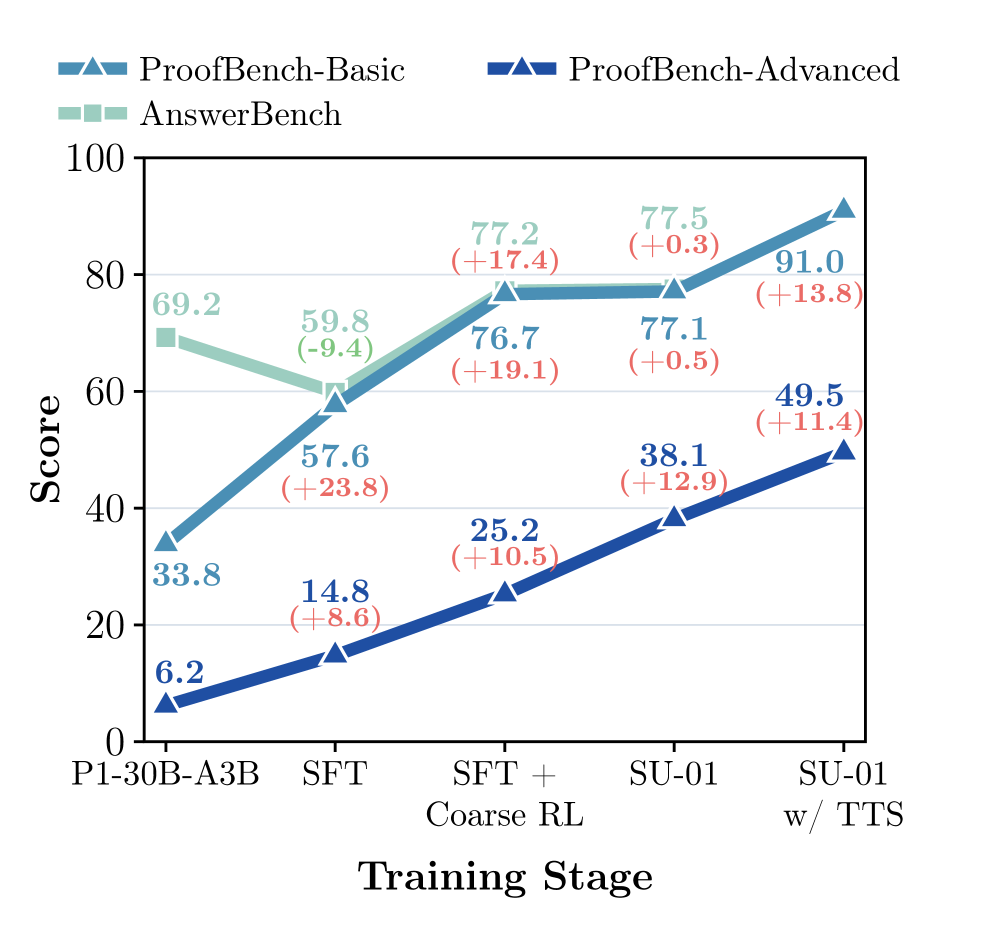
- P1-30B-A3B baseline: AnswerBench 69.2, ProofBench-Basic 33.8, ProofBench-Advanced 6.2. The proof gap is severe.
- After SFT: AnswerBench drops to 59.8 (the model trades short answer recovery for proof-search), but ProofBench-Basic jumps to 57.6 and Advanced to 14.8.
- After Coarse RL: AnswerBench 77.2, ProofBench-Basic 76.7, Advanced 25.2 — RLVR scales the SFT-installed behavior into stronger solving without erasing rigor.
- After Refined RL (SU-01): AnswerBench 77.5, ProofBench-Basic 77.1, Advanced 38.1. Gains concentrate on hard proof problems, exactly where generative proof rewards should help.
- With TTS: ProofBench-Basic 91.0, Advanced 49.5.
On answer-verifiable benchmarks, SU-01 reaches AnswerBench 77.5%, AMO-Bench 59.8%, AIME 2025/2026 94.6%/93.3%, and FrontierScience-Olympiad 61.5% overall (Physics 62.5, Chemistry 69.4, Biology 25.0). It is competitive with Qwen3.6-35B-A3B (avg 77.4 vs 77.3) and ahead of Nemotron-Cascade-2 (71.8), GLM-4.7-Flash (72.0), and Gemma-4-31B (70.9). The headline claim — gold-medal-level performance on IMO 2025, USAMO 2026, IPhO 2024/2025 — is reported in the official-competition family.
Limitations and open questions
The recipe is conservative in scale (~340K SFT trajectories, ~200 RL steps) but leans heavily on a strong proprietary teacher (DeepSeek-V3.2-Speciale) for trajectory and verification synthesis; the floor of this approach without such a teacher is unclear. The reverse-perplexity curriculum is asserted but mechanically underspecified in the excerpt. ProofBench-Advanced at 49.5 (with TTS) still leaves more than half of advanced proofs incomplete, and chemistry/biology coverage on FrontierScience is uneven (biology 25.0%), suggesting the proof-rigor behavior does not generalize uniformly across science domains. Finally, the TTS loop’s verifier is the model itself; the failure mode where a flawed proof passes self-verification deterministically is not quantified.
Why this matters
This paper provides a clean ablation that answer accuracy and proof rigor are separable axes, and that they require different supervision: verifiable rewards for the former, generative/proof rewards plus self-refinement for the latter. The staged numbers (Advanced ProofBench 6.2 → 14.8 → 25.2 → 38.1 → 49.5) are the cleanest published evidence that olympiad-grade proof construction is reachable from a 30B MoE with a modest, fully-described pipeline rather than only at frontier scale.
Source: https://arxiv.org/abs/2605.13301
SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
Problem
Camera-controllable world models that synthesize minute-long, 720p video have so far required industrial-scale training (LingBot-World, HY-WorldPlay), with prohibitive compute, undisclosed data, and large parameter counts. The core obstacles are (i) the quadratic cost of softmax attention over the latent sequences induced by 60-second 720p clips, (ii) accurate, high-rate conditioning on continuous 6-DoF trajectories, and (iii) preserving fidelity when the base generator is small and trained on limited data. SANA-WM is a 2.6B-parameter open model targeting this regime: 60s, 720p, single-GPU inference, trained on 64 H100s in 15 days using only ~213K public clips with metric-scale pose labels.

Method
Hybrid linear/softmax DiT. The backbone is a 20-block DiT with d_{\text{model}}=2240 and 20 heads. Fifteen blocks use frame-wise Gated DeltaNet (GDN), a linear-attention recurrence; the remaining five blocks at layers \{3,7,11,15,19\} use full softmax attention to recover global dependencies that linear scans miss. GDN’s per-frame state replaces the O(N^2) softmax with O(N) memory across the time axis, which is what makes 961-frame latent sequences tractable. Custom fused Triton kernels implement the GDN scan and gating to keep wall-clock competitive with FlashAttention-style softmax kernels.
Camera conditioning. Every block carries dual-rate camera conditioning: a UCPE (unified camera positional encoding) attention term plus a Plücker-coordinate mixing path. Plücker rays give a dense per-pixel geometric encoding of the 6-DoF trajectory that combines well with frame-level pose tokens, while UCPE injects coarse trajectory information directly into attention. Captions are deliberately scene-static — descriptions of objects, layout, and appearance with no “pan left”/“move forward” tokens — so that motion control is forced through the pose branch and the text encoder cannot leak trajectory supervision.
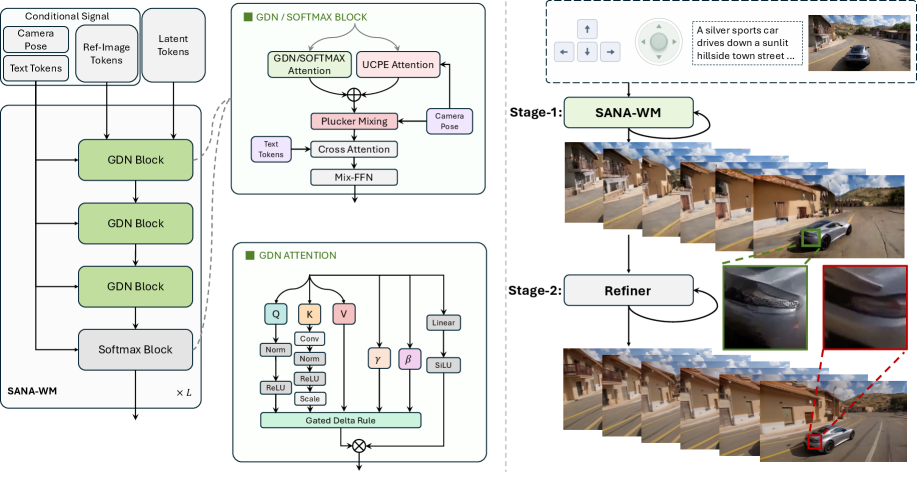
Progressive training. Stage 1 swaps the original VAE for LTX2-VAE with C=128 latent channels, giving 2.0\times smaller representations than ST-DC-AE and 8.0\times smaller than Wan2.1-VAE; the patchify and output projection are reinitialized and full-model fine-tuning runs for 50k steps. Stage 2 ports the pre-trained SANA-Video weights into the hybrid GDN–softmax structure on short clips. Stage 3 extends to 961-frame (60s) sequences with Context-Parallel sharding along time, using flow matching, and turns on the dual-branch camera control. Stage 4 fine-tunes a chunk-causal variant for autoregressive rollout, then applies self-forcing distillation to four denoising steps. For deployment, attention-sink tokens and local temporal windows are added to softmax layers so memory and per-chunk latency are constant in rollout length — critical for streaming minute-scale generation on a single GPU.
Two-stage generation. A long-video refiner is applied to stage-1 outputs to repair temporal inconsistencies and texture degradation that accumulate over 60s.
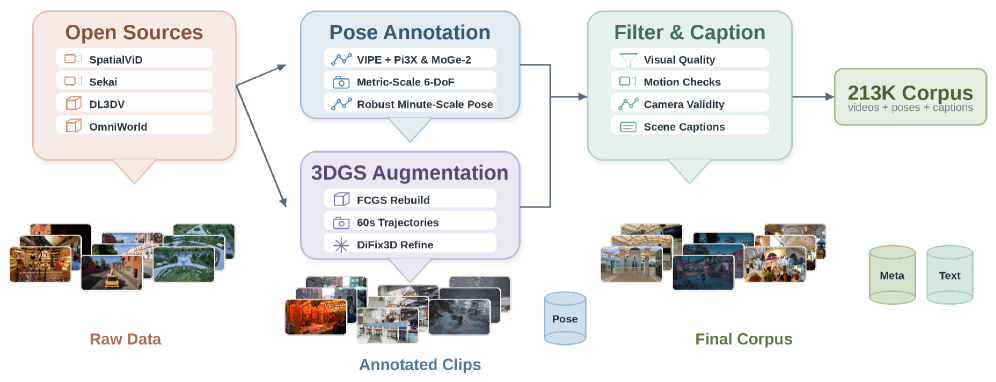
Data pipeline. SANA-WM uses 212,975 clips re-annotated with metric-scale 6-DoF poses across seven open sources. The annotator extends VIPE by replacing its depth backend with Pi3X (long-sequence-consistent depth) and MoGe-2 (per-frame metric scale), and adds per-frame intrinsic optimization. DL3DV static captures are converted into one-minute trajectories by fitting FCGS 3D Gaussian Splatting, rendering long camera paths, and applying DiFix3D to clean splatting artifacts (14,881 augmented clips). Camera-specific filters cover field of view, focal consistency, pose smoothness, and scale variation.
Results
The reported headline numbers are efficiency-centric: training uses only ~213K public clips with metric-scale pose supervision, completes in ~15 days on 64 H100s, and inference produces a 60s 720p clip on a single GPU. The authors claim quality parity with LingBot-World and HY-WorldPlay, both substantially larger and trained on closed data. The data table breaks down as 158,369 SpatialVID-HQ 10s clips, 5,691 native DL3DV 10s, 14,881 60s 3DGS-refined DL3DV, 1,720 OmniWorld 60s, 3,560 Sekai-Game 60s synthetic, 9,767 Sekai Walking-HQ 60s real, and 18,987 MiraData 60s real.
Limitations and open questions
The provided sections do not include head-to-head metric tables (FVD, camera-trajectory error, VBench), so the parity claim is qualitative here; the appendix-level numbers will determine how close SANA-WM actually sits to industrial baselines. The hybrid block schedule (\{3,7,11,15,19\} as softmax) appears chosen heuristically; ablations on softmax-block placement and count are not surfaced. The 4-step self-forcing distillation likely costs measurable fidelity versus the bidirectional teacher, and the autoregressive chunk-causal variant inherits exposure-bias risks over minute-scale rollouts despite attention sinks. Finally, pose accuracy on internet video is bounded by Pi3X/MoGe-2/VIPE failure modes, particularly under strong dynamic content where metric scale via monocular cues remains brittle.
Why this matters
SANA-WM shows that minute-scale, pose-controllable 720p world modeling is reachable at academic compute (64 H100s, 15 days, 213K public clips) by combining linear-attention scans with sparse softmax blocks and a metric-pose annotation pipeline. If the parity claims hold quantitatively, this is a credible open baseline that decouples world-model research from frontier-lab data and hardware budgets.
Source: https://arxiv.org/abs/2605.15178
Darwin Family: MRI-Trust-Weighted Evolutionary Merging for Training-Free Scaling of Language-Model Reasoning
Problem
Frontier reasoning models are typically obtained via expensive RL or distillation pipelines on top of strong base checkpoints. The Darwin Family asks whether one can instead recombine existing fine-tuned checkpoints in weight space to recover or exceed those gains, with no gradient updates. The paper claims that latent reasoning capabilities are already encoded across publicly available siblings of a shared base, and that the bottleneck is a principled mechanism for tensor-wise recombination that avoids the destructive interference plaguing uniform averaging or TIES-style merging.
Method
Darwin assumes two parent checkpoints \theta_A, \theta_B derived from a shared base \theta_{\text{base}}, decomposed as \theta_A = \theta_{\text{base}} + \Delta_A, \theta_B = \theta_{\text{base}} + \Delta_B. The merge kernel is a tensor-wise convex combination of task vectors:
\theta_M(T) = \theta_{\text{base}}(T) + (1 - r_{\text{final}}(T))\,\Delta_A(T) + r_{\text{final}}(T)\,\Delta_B(T).
The novelty is in how r_{\text{final}}(T) is determined. Two signals are produced and reconciled.
Model-layer Response Importance (MRI). For each tensor T, MRI is a hybrid diagnostic prior:
\mathrm{MRI}(T) = \alpha\,\mathrm{Static}(T) + (1-\alpha)\,\mathrm{Probe}(T), \quad \alpha=0.5.
The static term aggregates normalized entropy, variance, and capped \ell_2-norm of T. The probe term measures cosine distance between activations on a small reasoning calibration set vs. generic prompts, isolating tensors whose function shifts under reasoning load. The MRI-derived ratio is
r_{\mathrm{MRI}}(T) = \frac{\mathrm{MRI}_B(T)}{\mathrm{MRI}_A(T)+\mathrm{MRI}_B(T)},
i.e., a soft prior that weights toward whichever parent’s tensor is more functionally salient.
Genome and evolutionary search. Independently, a 14-dimensional adaptive merge genome encodes block- and component-level mixing coefficients (attention Q/K/V/O, MLP up/gate/down, embedding, norms, etc.). A standard (\mu+\lambda)-style evolutionary loop with proxy fitness evaluation, tournament selection, crossover, and adaptive mutation evolves these genomes (Figure 3).
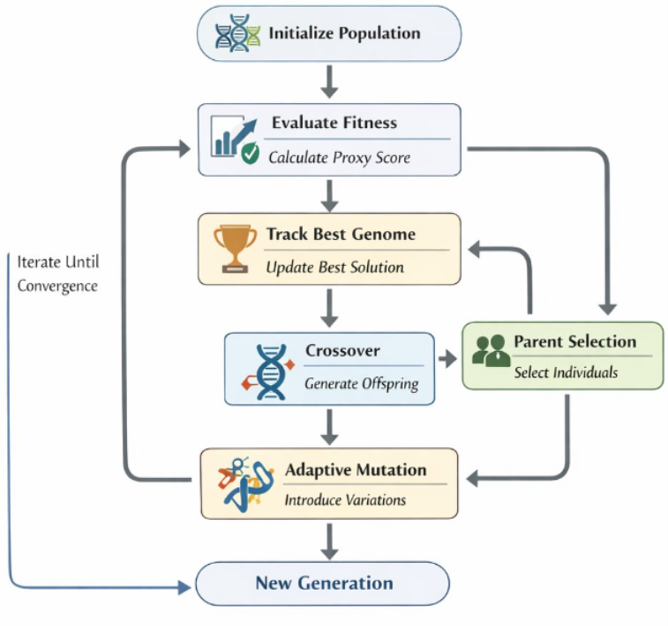
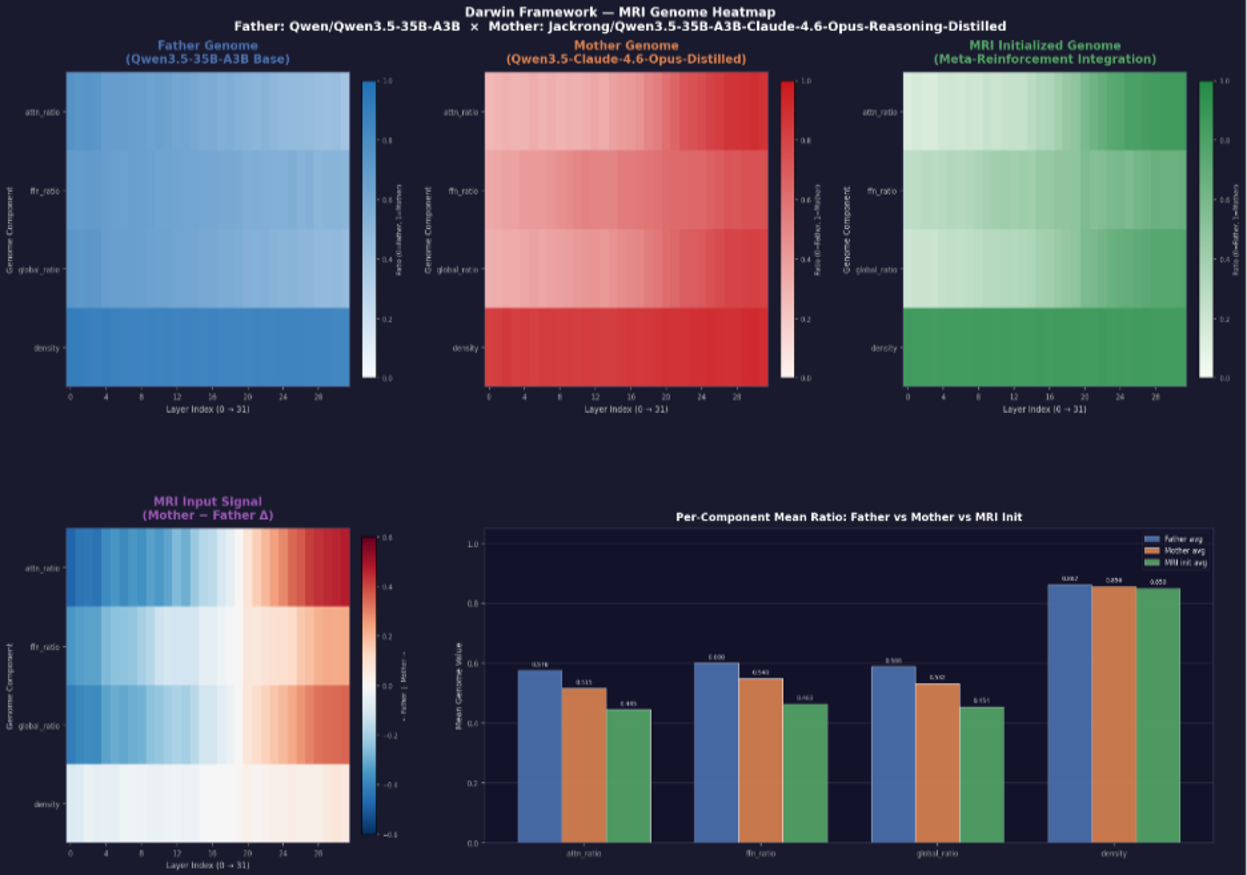
MRI-Trust Fusion. A learnable scalar trust parameter \tau blends the diagnostic prior r_{\mathrm{MRI}} with the genome-derived ratio r_{\mathrm{gene}} to yield r_{\mathrm{final}}. Empirically \tau converges to \tau \approx 0.35\text{--}0.55 across scales — neither signal dominates. The MRI prior structures the initial population (Figure 2 shows the heatmap of MRI-initialized genomes against the parents and their differential signal), and evolution refines around it, which the authors argue explains both faster convergence and higher peaks than diagnostic-free evolutionary merging.
Architecture Mapper. For heterogeneous parents (e.g., Transformer + Mamba), an alignment module maps tensors across architectures so that recombination is well-defined; this enables a Transformer-Mamba training-free merge.
The full pipeline is summarized in Figure 1.

The merge kernel itself is DARE-TIES; the authors compared linear, SLERP, and DARE-TIES, finding linear susceptible to task interference and SLERP smoother early but lower peak, with DARE-TIES dominating across configurations because its drop-and-rescale mitigates parameter conflicts.
Results
Flagship Darwin-27B-Opus on GPQA Diamond reaches 86.9%, vs. 85.5% (Father, base) and 86.2% (Mother, reasoning-distilled), and 86.1% for simple averaging / SLERP. The paper reports rank #6 of 1,252 evaluated models as of 2026-04-22. Across the nine-benchmark suite (Table 1), Darwin-27B-Opus posts gains over both parents on every benchmark: ARC-Challenge 0.779 vs. 0.740 (best parent), CommonsenseQA 0.783 vs. 0.776, HellaSwag 0.870 vs. 0.864, MMLU 0.776 vs. 0.782 (slight regression vs. mother), TriviaQA 0.722 vs. 0.718. Overall average is 0.786 \pm 0.040 vs. \sim 0.776 for the strongest parent and \sim 0.775 for simple averaging/SLERP.
Compared to evolutionary merging without diagnostics, Darwin shows higher peak accuracy and lower variance across runs, attributed to MRI-guided initialization. Recursive multi-generation evolution (re-merging Darwin offspring) is reported to retain monotone improvements, and the cross-architecture Transformer-Mamba experiment establishes feasibility, though detailed numbers for that ablation are not in the excerpted sections.
Limitations and open questions
- The shared-base assumption is critical for the \Delta decomposition; the Architecture Mapper handles heterogeneity but its alignment quality is not quantified in the provided text.
- GPQA gains over the mother are modest in absolute terms (0.7 points), and MMLU regresses slightly; the headline ranking is sensitive to leaderboard composition rather than a controlled comparison.
- The probe term in MRI depends on a calibration set; sensitivity to its size and distribution is unaddressed in the excerpts.
- Proxy fitness during evolutionary search is not detailed; reasoning benchmarks typically require expensive evaluation, and proxy-true correlation is a known failure mode for this class of methods.
- No comparison against actually fine-tuned reasoning models matched for FLOPs of the search itself.
Why this matters
If diagnostic-guided weight-space recombination genuinely closes the gap to gradient-trained reasoning models on hard benchmarks like GPQA Diamond, it implies that a non-trivial fraction of “reasoning capability” in current frontier models is already linearly accessible from existing checkpoints, and that careful per-tensor mixing — not more training — is sufficient to expose it. That reframes post-training as a search problem over an existing model ecosystem.
Source: https://arxiv.org/abs/2605.14386
Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation
Problem
Real-time interactive video generation (game-style world models, avatars, controllable rollouts) needs streaming, low-latency, frame-level autoregressive (AR) decoding. The current state of the art in AR diffusion distillation — CausVid, Self Forcing, Causal Forcing — has been validated mostly in the chunk-wise (3 latent frames per chunk) 4-step regime. That is too coarse for tight interaction loops, and the per-chunk sampling cost is non-negligible. The authors push to the genuinely aggressive regime: frame-wise AR with 1–2 sampling steps per frame.
The bottleneck is not the final adversarial score-matching stage (asymmetric DMD), which is well understood, but the few-step student initialization that DMD is highly sensitive to. None of the three known initializations survives the move to frame-wise, 1–2-step generation.
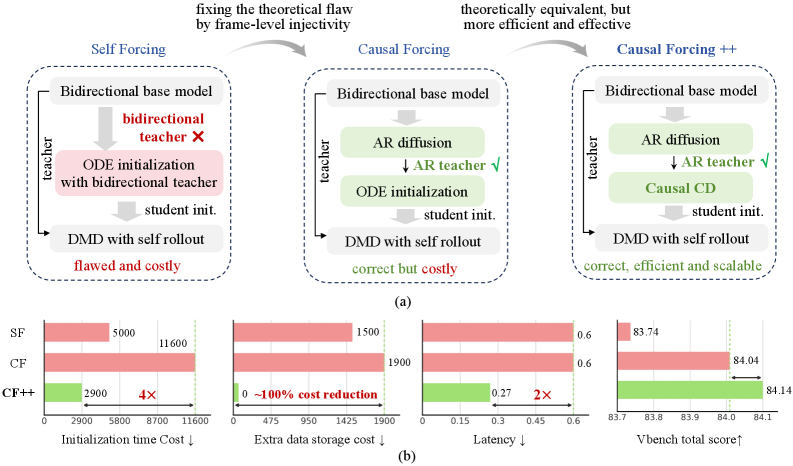
Why existing initializations fail
The authors enumerate three options and show each breaks for a different reason in this regime:
- ODE distillation from a bidirectional teacher (CausVid, Self Forcing). This violates frame-level injectivity: the same noisy frame \mathbf{x}_t^i corresponds to multiple clean frames under different future contexts, so ODE matching collapses toward \mathbb{E}[\mathbf{x}_0^i \mid \mathbf{x}_t^i, \mathbf{x}_t^{<i}, t], which is a blurred, non-AR target rather than the AR flow map. The error compounds during self-rollout.
- Skipping few-step distillation and running the multi-step AR teacher directly (LiveAvatar, WorldPlay). Architecturally aligned but cannot do 1–2 steps.
- Causal ODE distillation from an AR teacher (Causal Forcing). Theoretically correct but requires precomputing full PF-ODE trajectories per training datum — expensive and hard to scale.

The Self-Forcing-style initialization already collapses at chunk-wise 4-step, worsens at frame-wise 4-step, and breaks catastrophically at frame-wise 1-step.
Method: causal consistency distillation
The authors replace causal ODE distillation in Stage 2 with causal consistency distillation (causal CD). Both target the same AR-conditional flow map, i.e., the map taking (\mathbf{x}_t^i, \mathbf{x}_t^{<i}, t) to a clean frame, but the supervision differs:
- Causal ODE distillation regresses the student against the endpoint of a full PF-ODE trajectory generated by the teacher, requiring stored multi-step trajectories.
- Causal CD enforces self-consistency between adjacent timesteps using a single online teacher Euler step. Concretely, for adjacent discretized times t_n > t_{n-1}, \mathcal{L}_{\text{causal CD}} = \mathbb{E}\big\| f_\theta(\mathbf{x}_{t_n}^i, \mathbf{x}_{t_n}^{<i}, t_n) - f_{\theta^-}(\hat{\mathbf{x}}_{t_{n-1}}^i, \mathbf{x}_{t_{n-1}}^{<i}, t_{n-1}) \big\|_2^2, where \hat{\mathbf{x}}_{t_{n-1}}^i is one Euler step of the AR teacher and \theta^- is an EMA copy. This eliminates trajectory storage, makes the optimization local, and remains compatible with the AR conditioning required for frame-level injectivity.
The full pipeline keeps Causal Forcing’s three stages: (1) teacher-forcing AR diffusion training, (2) few-step initialization (now causal CD), (3) asymmetric DMD with self-rollout. The base model is Wan2.1-1.3B at 480\times832, 81 frames, frame-wise AR. Stage 2 uses 48 discretized timesteps, squared-norm loss, Euler solver. Stage 3 trains at 4-step (t=1, 0.9375, 0.8333, 0.625), 2-step (t=1, 0.8333), and 1-step. Following ASD, in Stage 3 the first latent frame still uses 4 steps while the subsequent 20 latent frames use 2 or 1 — a pragmatic choice that absorbs the harder warm-up frame without inflating steady-state latency. Stage 3 score models use Wan2.1-14B; everything else is 1.3B. Training: 20K/5K/1K steps for Stages 1/2/3 at batch size 64; OpenVid (80K) for Stages 1–2, VidProM for Stage 3.
Results
Per Figure 1, Causal Forcing++ reduces Stage 2 training cost by 4\times relative to Causal Forcing, eliminates the trajectory pre-computation pipeline, achieves 50% lower inference latency, and improves VBench scores.

Qualitatively, CF++ matches or exceeds Causal Forcing while clearly beating CausVid and Self Forcing on the same backbone — and crucially holds up in frame-wise 1–2-step settings where the bidirectional-teacher initializations collapse.
Limitations and open questions
The paper’s evidence centers on a single backbone (Wan2.1-1.3B/14B) at fixed resolution; transfer to larger models or different DiT families is not characterized. The 1-step and 2-step Stage 3 still leans on a 4-step warm-up for the first latent frame, so true uniform 1-step rollout is not demonstrated. Causal CD inherits consistency-model pathologies (sensitivity to discretization count, EMA schedule, solver choice); the paper fixes 48 timesteps and Euler without ablation. Action-conditioned world-model results are claimed but not detailed in the excerpts here. Finally, the asymmetric DMD stage uses a 14B score model, so deployment cost during training is still substantial even if Stage 2 is cheaper.
Why this matters
Few-step AR diffusion is the practical path to interactive, controllable video models, and the bottleneck has quietly shifted from the adversarial finetune to the initialization. Replacing trajectory-based ODE distillation with a local consistency objective that preserves AR injectivity makes frame-wise 1–2-step distillation tractable on standard hardware and clears the way for systematic study of harder real-time regimes.
Source: https://arxiv.org/abs/2605.15141
DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models
Problem
RL post-training of text-to-image diffusion models (DDPO, DPOK, FlowGRPO, DiffusionNFT, GRPO-Guard) has converged on a single-task recipe: pick one reward, optimize. Multi-task post-training is unsolved. Joint optimization across heterogeneous rewards (compositional correctness, OCR fidelity, aesthetics, preference scores) suffers from gradient interference and reward imbalance — different rewards have incompatible scales and saturate at different rates. Cascade RL (sequentially fine-tune on each reward) is brittle and forgets earlier objectives. The authors reframe the problem as distillation: train per-task teachers with the algorithm best suited to each reward, then merge them into one student via on-policy distillation (OPD), which has been used for LLMs but not formally derived for continuous-state diffusion.
Method
In the LLM case, OPD samples a full sequence from the student \pi_\theta and matches the teacher \pi^\star on student-visited prefixes. The sequence-level reverse KL decomposes exactly into per-step categorical KLs:
\mathcal{L}_{\text{OPD}}^{\text{LLM}}(\theta) = \mathbb{E}_{x\sim\pi_\theta}\!\left[\sum_{t=1}^T \mathrm{KL}\bigl(\pi_\theta(\cdot\mid x_{<t})\,\|\,\pi^\star(\cdot\mid x_{<t})\bigr)\right].
The discrete-vocabulary inner KL is closed-form, giving dense per-token analytic supervision instead of a sparse outcome reward.
The contribution is lifting this to continuous-state diffusion. Treat the reverse process as a Markov chain with transitions p_\theta(x_{t-1}\mid x_t) and p^\star(x_{t-1}\mid x_t). Both SDE (stochastic) and ODE (deterministic-mean) parameterizations yield Gaussian (or degenerate-Gaussian) per-step kernels parameterized by the predicted velocity/score. The per-step reverse KL along a student-rolled trajectory then collapses to a closed-form mean-matching loss:
\mathcal{L}_{\text{OPD}}^{\text{diff}}(\theta) = \mathbb{E}_{x_t \sim p_\theta}\!\left[\sum_t \tfrac{1}{2\sigma_t^2}\|\mu_\theta(x_t,t) - \mu^\star(x_t,t)\|_2^2\right],
where the same expression covers both SDE and ODE samplers (the ODE limit corresponds to \sigma_t\!\to\!0, mean-matching only). This is the diffusion analog of the per-token KL in LLM OPD: dense, per-step, analytic gradients computed along the student’s own rollout, with no advantage estimate, no importance ratio, and no clip. The authors argue (and empirically show) this has lower variance and broader applicability than PPO/GRPO-style score-function gradients used in FlowGRPO and GRPO-Guard.
The training pipeline:
- Train K specialized teachers, each on its own reward with whichever RL algorithm performs best (DiffusionNFT for GenEval; GRPO-Guard for OCR and the Aesthetics composite of PickScore + ClipScore + HPSv2.1).
- Distill into a single LoRA student via the per-step mean-matching KL above, summed across teachers, with student rollouts driving the trajectory distribution.
Base model is SD3.5-Medium at 512×512 with LoRA (\alpha=64, r=32) and a 40-step first-order ODE evaluator, matching the DiffusionNFT setup.
Results
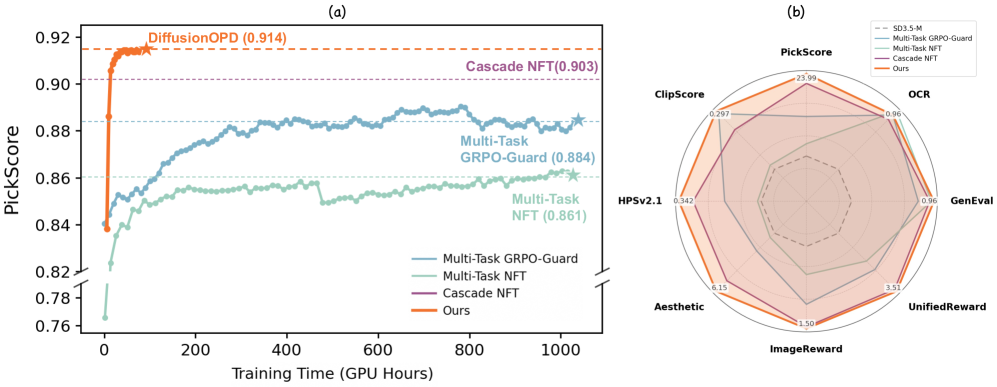
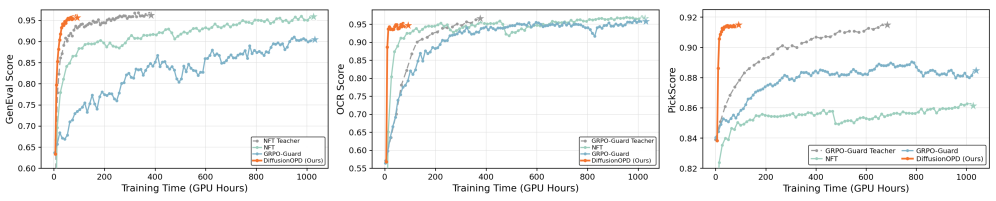
The headline number is the min-max-normalized average across eight metrics (GenEval, OCR, PickScore, ClipScore, HPSv2.1, Aesthetic, ImageReward, UnifiedReward).
- DiffusionOPD: 0.929
- Cascade NFT: 0.851
- Multi-Task GRPO-Guard: 0.763
- Multi-Task NFT: 0.715
- SD3.5-M + CFG: 0.484
DiffusionOPD wins or ties best on every metric: GenEval 0.96 (tied with the GenEval teacher), OCR 0.94 (vs. 0.93 for the OCR teacher), Aesthetic 6.15 (vs. 6.22 for the Aes teacher), HPSv2.1 0.342, ImageReward 1.50, UnifiedReward 3.50. Crucially the student matches each specialist on its own reward — no per-task regression — while uniting them.
Wall-clock cost is the other axis. Multi-Task GRPO-Guard takes 129.86 h, Multi-Task NFT 128.42 h, Cascade NFT ≈148.49 h. DiffusionOPD takes 85.75 h (max teacher training, dominated by the Aes teacher) + 11.26 h OPD = 97.01 h end-to-end, and the teachers can be trained in parallel. Treating teacher training as parallel work, the OPD stage itself is roughly 11× cheaper than the joint-RL baselines.
Qualitatively, multi-task RL baselines tend to inherit one teacher’s failure mode — Multi-Task NFT renders glyphs cleanly but loses aesthetic richness; GRPO-Guard preserves aesthetics but degrades compositional correctness — while the OPD student produces images that simultaneously satisfy compositional, textual, and aesthetic criteria.

Limitations and open questions
- The closed-form per-step KL relies on Gaussian (or Dirac) reverse kernels; extensions to consistency models or few-step distilled samplers, where the kernel is non-Gaussian, are not derived.
- All teachers share the same base SD3.5-M; distilling teachers built from different backbones (different latent spaces, different schedulers) is not addressed.
- The method assumes one can train a strong specialist per reward. For rewards that are themselves under-optimized (e.g., 3D consistency, long-text rendering) the ceiling is set by the teacher.
- No analysis of how performance scales with K teachers or with conflicting rewards (e.g., aesthetic vs. strict prompt adherence).
- The variance-reduction claim vs. PPO-style gradients is supported empirically but the formal bound is for the idealized Gaussian-kernel setting.
Why this matters
DiffusionOPD turns multi-reward post-training of diffusion models from a finicky joint-RL problem into modular distillation with an analytic, sampler-agnostic per-step KL — recovering each specialist’s reward while cutting wall-clock by ~25–35% and lifting the normalized average from 0.85 (Cascade NFT) to 0.93. It also clarifies the LLM-OPD/diffusion connection: the same reverse-KL-along-student-rollout principle produces token-level KL in the discrete case and mean-matching in the continuous case.
Source: https://arxiv.org/abs/2605.15055
Self-Distilled Agentic Reinforcement Learning
Trajectory-level rewards in agentic RL provide weak supervision: a single scalar at the end of a multi-turn rollout must credit-assign across hundreds of interleaved reasoning and action tokens. On-Policy Self-Distillation (OPSD) addresses this in single-turn settings by running a teacher branch with privileged context (e.g., reference answers) alongside the student, then distilling per-token logits. Naively porting OPSD to multi-turn agents fails for two reasons identified in this paper: (i) compounding distributional drift across turns destabilizes the teacher signal, and (ii) when the privileged context is retrieved skills rather than ground-truth answers, the teacher can reject correct student tokens because the retrieved skill is irrelevant or misapplied. SDAR (Self-Distilled Agentic RL) keeps GRPO as the optimization backbone and adds OPSD as a gated auxiliary loss that asymmetrically handles positive and negative teacher-student gaps.
Setup and instabilities
Flatten a multi-turn trajectory into y=(y_1,\dots,y_T)\sim\pi_\theta(\cdot\mid x). The student context at position t is s_t=(x,y_{<t}); the teacher sees s_t^+=(x,c^+,y_{<t}) where c^+ is privileged training-only context. For agentic tasks, c^+ is a retrieved skill — a compact structured demonstration. Four retrieval strategies are compared (UCB, Keyword Matching, Full, Random); UCB scores skills via
\mathrm{score}(e) = \bar r(e) + c\sqrt{\tfrac{\ln N_{\mathrm{ucb}}}{n(e)}}.
The motivation for gating is shown empirically. 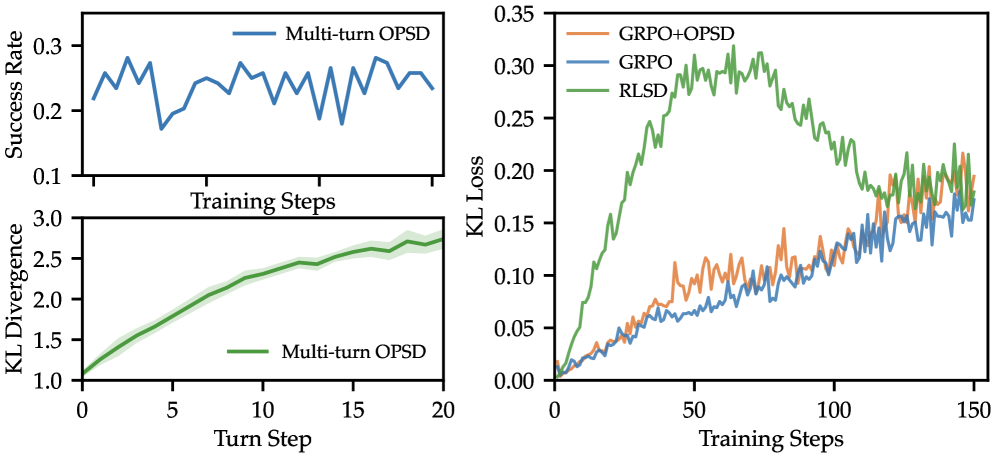 Plain multi-turn OPSD exhibits KL blowup and performance collapse, and an RLSD-style combination shows uncontrolled KL growth — exactly the failure mode SDAR is designed to suppress.
Plain multi-turn OPSD exhibits KL blowup and performance collapse, and an RLSD-style combination shows uncontrolled KL growth — exactly the failure mode SDAR is designed to suppress.
The asymmetry argument is grounded in a teacher-student gap analysis. 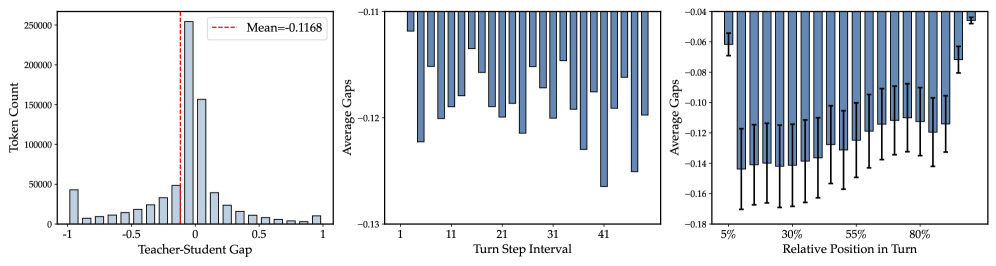 The gap distribution is heavy-tailed and not symmetric: many tokens receive small or negative gaps (teacher disagrees with student) concentrated at later turns and early in-turn positions, where the privileged skill context is most likely to mislead. Treating these tokens with the same distillation weight as positive-gap tokens injects noise.
The gap distribution is heavy-tailed and not symmetric: many tokens receive small or negative gaps (teacher disagrees with student) concentrated at later turns and early in-turn positions, where the privileged skill context is most likely to mislead. Treating these tokens with the same distillation weight as positive-gap tokens injects noise.
SDAR objective
Let g_t = \log\pi_{\theta^+}(y_t\mid s_t^+) - \log\pi_\theta(y_t\mid s_t) be the detached per-token teacher-student gap. SDAR maps g_t through a sigmoid gate \sigma(\beta g_t) so that positive-gap tokens (teacher endorses) receive amplified distillation pressure while negative-gap tokens (teacher rejects, possibly spuriously) are softly attenuated rather than pushing the student away from its own correct prediction. The total loss is
\mathcal{L}_{\text{SDAR}} = \mathcal{L}_{\text{GRPO}} + \lambda \, \mathbb{E}_t\!\left[\sigma(\beta g_t)\, \mathrm{KL}\!\big(\pi_{\theta^+}(\cdot\mid s_t^+)\,\|\,\pi_\theta(\cdot\mid s_t)\big)\right].
GRPO remains the primary optimizer; OPSD is auxiliary and gated. 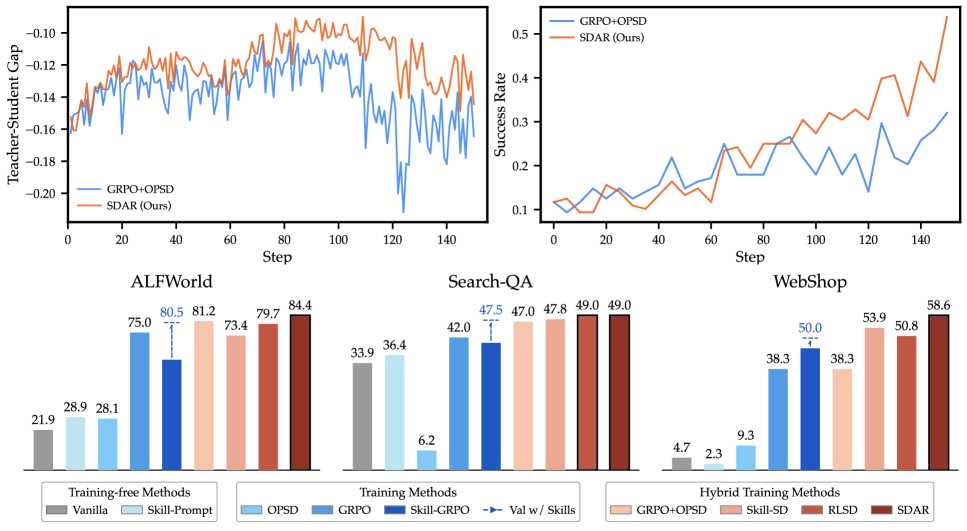 Contrast with GRPO+OPSD, where the distillation term is ungated and symmetrically applied — the source of the instability shown above.
Contrast with GRPO+OPSD, where the distillation term is ungated and symmetrically applied — the source of the instability shown above.
Results
On Qwen2.5 and Qwen3 backbones across ALFWorld, WebShop, and Search-QA, SDAR improves over GRPO by:
- +9.4% on ALFWorld,
- +7.0% on Search-QA (averaged over NQ, TriviaQA, PopQA, HotpotQA, 2Wiki, MuSiQue, Bamboogle),
- +10.2% on WebShop accuracy (128-task validation slice aligned with prior work).
Critically, SDAR avoids the divergence seen with naive GRPO+OPSD: KL stays bounded throughout training while the auxiliary loss continues to provide token-level signal. The robustness sweep over retrieval strategies (UCB, KM, Full, Random) suggests the gating mechanism degrades gracefully even when c^+ is low-fidelity — the negative-gap attenuation absorbs bad skills rather than letting them corrupt the policy.
Limitations and open questions
The framework still requires a usable skill library and a retrieval mechanism; performance under fully cold-start agentic tasks (no demonstrations) is not characterized. The gate uses a fixed \beta; whether an adaptive or learned gate would help under shifting student competence is open. The teacher branch doubles forward compute per token, a non-trivial cost at long horizons. Theoretically, the asymmetric treatment biases the gradient — it is not a proper KL minimization — and the fixed-point behavior of the gated objective is not analyzed. Finally, the evaluation is restricted to text-based environments with verifiable rewards; transfer to environments with sparser or noisier verifiers (tool-use with stochastic outputs, code execution under flaky tests) is untested.
Why this matters
SDAR is a clean recipe for combining trajectory-level RL with token-level distillation in multi-turn agents without the instability that has plagued naive combinations. The asymmetric sigmoid gate on detached teacher-student gaps is a small mechanical change that turns a brittle auxiliary loss into a robust one, and the consistent ~7-10% gains over GRPO across three benchmark families suggest the gating principle generalizes beyond the specific skills-retrieval setup.
Source: https://arxiv.org/abs/2605.15155
MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
Problem
Long-horizon multimodal assistants need to remember images, captions, and prior turns across many sessions. Two architectural families address this: (i) long-context LVLMs that ingest the full interleaved transcript, and (ii) memory-augmented agents that compress prior turns into a written or vector store and retrieve at query time. Existing memory benchmarks are either text-only (LoCoMo, LongMemEval) or treat images as decoration whose content is not strictly required to answer. As a result, “memory” scores can be inflated by text-only shortcuts, and the two families have never been compared on questions that genuinely require multimodal evidence at controlled context lengths.
MemLens is built to force visual grounding and to fix context length as an independent variable, so the two families can be compared head-to-head.
Benchmark construction
MemLens contains 789 questions over multi-session conversations spanning five memory abilities:
- Information extraction — recover a fact from a single past turn.
- Multi-session reasoning — combine evidence across sessions.
- Temporal reasoning — order or date events.
- Knowledge update — track a fact that is overwritten in a later session.
- Answer refusal — decline when the evidence is absent or removed.
Each question is instantiated at four context lengths: 32K, 64K, 128K, and 256K tokens. The key design choice is a cross-modal token-counting scheme: images are converted to a token cost using each model’s own visual tokenizer rate, so that “32K tokens” means the same total prefill budget regardless of how many images vs. words a transcript contains. Without this normalization, a system that encodes images at 256 tokens each would face a much shorter effective transcript than one that uses 1024 tokens per image, and “context length” comparisons would be meaningless.
To verify that MemLens really requires images, the authors run an image-ablation study: they remove the evidence images from the transcript and re-query frontier LVLMs. On the 80.4% of questions whose evidence includes images, two frontier LVLMs fall below 2% accuracy. That is the load-bearing claim — the benchmark is not solvable by text shortcuts on the majority of items, so memory scores reflect actual visual recall.
Method: what is being measured
For each (model, question, context length) triple the metric is exact-match accuracy against gold answers, with refusal items scored on whether the model abstains when evidence is absent. Two system classes are evaluated:
- 27 long-context LVLMs (closed and open). Each receives the full interleaved transcript up to the target token budget and answers in one forward pass. Performance therefore depends on positional generalization, attention to small visual regions deep in context, and any internal compression (e.g., sliding-window or token-dropping schemes).
- 7 memory-augmented agents. These ingest the conversation turn-by-turn, write to an external store (typically textual summaries plus image captions or embeddings), and at test time retrieve a small set of items into a short prompt. Visual fidelity here is bounded by what the storage step preserves.
The split lets one decouple two failure modes: read-time degradation (long-context models losing accuracy as L grows) versus write-time compression loss (agents discarding visual detail when summarizing).
Results
Two findings dominate.
First, long-context LVLMs win at short context but degrade with length. Frontier models do well at 32K because they directly attend to evidence images, achieving high accuracy via straightforward visual grounding. As context grows toward 256K, accuracy drops substantially across the board — the standard “lost-in-the-middle” pattern, exacerbated by the larger per-image token footprint that pushes evidence to less-attended positions.
Second, memory-augmented agents are length-stable but visually weak. Their accuracy is roughly flat from 32K to 256K because retrieval cost does not scale with transcript length, but they systematically fail on questions that need fine-grained visual content (counts, attributes, spatial relations) that a textual summary discards. The image-ablation result quantifies the ceiling: any agent whose storage is text-only inherits the sub-2% floor on the 80.4% image-required subset.
The five-ability breakdown is also informative. Knowledge-update and temporal-reasoning items are hardest for long-context LVLMs because they require integrating information across distant turns rather than retrieving a single span. Refusal accuracy reveals overconfidence: many models hallucinate answers when the supporting image has been removed, indicating that “memory” in current LVLMs is not well-calibrated against absence of evidence.
Limitations and open questions
The benchmark is exact-match on curated answers, which understates partial credit and is sensitive to phrasing. The cross-modal token budget depends on each model’s tokenizer; comparisons across very different visual encoders carry an implicit assumption that token cost is a fair proxy for context pressure. The agent evaluation depends on the specific memory architecture used; a hybrid agent that stores image patches or VQ codes alongside text could in principle close the visual-fidelity gap, and MemLens is the natural testbed for that. Finally, 256K is short relative to deployed assistants that accumulate memory over months; extrapolation beyond the tested range is not validated.
Why this matters
MemLens is the first benchmark that holds context length constant in a modality-fair way and forces image-grounded recall, exposing a clean tradeoff: long-context LVLMs have visual fidelity but poor length scaling, while memory agents have length scaling but poor visual fidelity. The obvious next system — an agent with a non-textual visual memory — has nowhere to hide on this benchmark.
Source: https://arxiv.org/abs/2605.14906
Hacker News Signals
When “idle” isn’t idle: how a Linux kernel optimization became a QUIC bug
Cloudflare’s post-mortem on a QUIC connection death spiral triggered by a Linux kernel behavior: the SO_RCVTIMEO socket option interacts unexpectedly with the kernel’s busy-poll / NAPI idle optimization. When a UDP socket is in busy-poll mode, the kernel can return EAGAIN immediately even when the socket timeout has not expired, because the “idle” detection path short-circuits the timeout machinery. QUIC’s loss-recovery timer relies on precise timeout semantics; when recvmsg returns early with no data, the QUIC stack interprets this as a timeout event and triggers retransmits. Under load, this produces a feedback loop: spurious retransmits increase load, which increases the rate of false EAGAIN returns, which increases retransmits further — the death spiral. The fix is straightforward once diagnosed: either avoid SO_RCVTIMEO on busy-poll sockets and implement timeouts in userspace, or disable busy-poll on the affected socket. The interesting engineering lesson is that NAPI busy-poll was introduced to reduce latency by spinning in the kernel rather than sleeping, but the contract it exposes to userspace is subtly different from what blocking I/O provides. Specifically, recvmsg on a busy-poll socket can return EAGAIN not because the timeout fired but because the poll epoch ended. This distinction is not clearly documented in man 7 socket. The post is a good example of how performance optimizations added at one kernel layer can violate assumptions baked into higher-layer protocol stacks. Any QUIC implementation using SO_RCVTIMEO for loss-recovery timing on Linux should audit this interaction.
Source: https://blog.cloudflare.com/quic-death-spiral-fix/
New arXiv policy: 1-year ban for hallucinated references
arXiv has announced that submitting a paper containing AI-hallucinated references — citations that do not correspond to real publications — will result in a one-year submission ban. The policy targets a specific failure mode that has become measurably common since LLM-assisted writing became widespread: fabricated but plausible-looking citations that pass casual human review. The enforcement mechanism requires moderators or community members to flag suspect references, after which arXiv staff verify against bibliographic databases. A single confirmed hallucinated reference triggers the ban; the policy does not distinguish between intentional fabrication and negligent LLM use, which is the most contentious aspect. The technical problem underlying this is well-understood: autoregressive language models trained on scientific text learn the surface form of citation strings (author, year, title, venue) and can generate coherent-looking but nonexistent entries, particularly for niche or interdisciplinary topics where the training distribution is sparse. The policy puts the verification burden squarely on authors. Critics note that the one-year ban is disproportionate for cases of genuine oversight — a researcher who asked an LLM to format references and failed to verify every entry faces the same penalty as one who knowingly submitted fabricated citations. Proponents argue that any weaker sanction would be insufficient deterrent given the volume of submissions. The broader implication is that venues will need automated reference-verification pipelines; tools like Semantic Scholar and CrossRef APIs can in principle flag non-resolving DOIs or titles, but this is not yet integrated into arXiv’s submission workflow.
Source: https://twitter.com/tdietterich/status/2055000956144935055
First public macOS kernel memory corruption exploit on Apple M5
A public exploit for a kernel memory corruption vulnerability on Apple Silicon M5 has been released. The writeup details a type confusion or out-of-bounds write in a kernel subsystem (the specific CVE and affected component are documented in the post) that allows an unprivileged local attacker to achieve kernel code execution. On Apple Silicon, this is particularly significant because the kernel runs at EL1 with Pointer Authentication (PAC) enforced; bypassing PAC is a prerequisite for control-flow hijacking, and the technique used — forging or leaking a signed pointer via a separate information disclosure primitive chained with the corruption — illustrates the current state of PAC bypass art. The exploit chain is notable for targeting M5 specifically; prior public exploits targeted older microarchitectures where mitigations were weaker or different. The M5’s memory subsystem and IOMMU configuration differ from M1/M2, and the writeup addresses why the exploit required adaptation. From a systems security standpoint, the value of a public proof-of-concept is that it forces Apple to patch and allows defenders to understand the exploit primitive. The release also benchmarks the reliability of the exploit (success rate, time to exploitation) and discusses stability concerns — kernel exploits that corrupt memory unpredictably are difficult to weaponize reliably. The post is technically detailed enough to serve as a reference for PAC bypass methodology on ARMv8.3+ hardware. Users on affected macOS versions should apply the relevant security update; the patch status relative to M5-equipped machines is addressed in the writeup.
Source: https://blog.calif.io/p/first-public-kernel-memory-corruption
Show HN: Find the best local LLM for your hardware, ranked by benchmarks
whichllm is a small open-source tool that takes your hardware specification (GPU VRAM, CPU RAM, compute capability) and returns a ranked list of locally runnable LLMs sorted by benchmark scores normalized to what will actually fit and run at usable speed on that hardware. The technical substance is in the ranking methodology: the tool uses a combination of published benchmark scores (MMLU, HumanEval, MT-Bench, etc.) and empirically derived memory-footprint estimates for common quantization levels (Q4_K_M, Q5_K_M, Q8_0, fp16) to compute a feasibility filter before ranking. Models that require more VRAM than available are excluded; those that fit are ranked by a composite benchmark score. The composite is a weighted average across task categories, which is configurable. The main engineering challenge this solves is that publicly available benchmark leaderboards do not account for the memory-vs-performance tradeoff at a given quantization level, and users frequently download models that either OOM or run too slowly to be useful. The tool currently pulls model metadata from a static YAML file that must be manually updated as new models are released, which is the obvious scaling limitation. An automated pipeline scraping HuggingFace metadata and llama.cpp benchmark runs would be more maintainable. The hardware input is currently manual rather than auto-detected, though auto-detection via nvidia-smi / rocm-smi / Metal API would be trivial to add. For researchers running local inference for evaluation or fine-tuning, this fills a genuine gap between “here is a leaderboard” and “here is what runs on my machine.”
Source: https://github.com/Andyyyy64/whichllm
New Nginx exploit
The Nginx-Rift disclosure describes a vulnerability in nginx’s request processing path. The repository contains a proof-of-concept demonstrating the issue, which appears to be a memory safety bug — an out-of-bounds read or write — reachable via a crafted HTTP request. The technical detail most relevant for defenders is the attack surface: the vulnerability is in the core HTTP/1.x or HTTP/2 parsing layer (the disclosure should be consulted for the exact component), meaning it is reachable without authentication from any client that can send a request to an exposed nginx instance. The severity depends on whether the memory corruption is exploitable for code execution or is limited to information disclosure or denial of service; the PoC in the repository demonstrates at minimum a reliable crash, indicating a null deref or heap corruption that disrupts the worker process. Nginx’s architecture provides some isolation — worker processes run as unprivileged users and a crash restarts the worker without taking down the master — but a remotely exploitable crash is still a DoS vector, and if the corruption is write-primitive-capable the isolation is insufficient. The disclosure follows a responsible-disclosure timeline that is documented in the repository. Operators running nginx in any internet-facing capacity should check the affected version range and patch or apply the provided configuration mitigation immediately. The broader pattern here — memory unsafety in C-based HTTP servers being repeatedly rediscovered — continues to motivate rewrites in memory-safe languages; nginx’s maintainer F5 has not announced a Rust rewrite equivalent to Apache’s Httpd efforts.
Source: https://github.com/DepthFirstDisclosures/Nginx-Rift
Ontario auditors find doctors’ AI note takers routinely blow basic facts
An audit conducted by Ontario’s oversight body examined AI-powered ambient documentation tools — systems that listen to clinical encounters and auto-generate SOAP notes or consultation summaries — and found systematic factual errors: wrong medications, incorrect dosages, misattributed symptoms, fabricated findings. The technical failure modes are predictable from an ML standpoint. These systems are generally fine-tuned speech-to-text pipelines (Whisper-class ASR) feeding into an LLM summarization layer. Errors propagate from both stages: ASR confuses phonetically similar drug names (a known, documented problem — “metformin” vs. “metoprolol”, etc.), and the LLM summarization layer hallucinates details not present in the transcript when prompted to fill structured note templates. The audit found errors in a non-trivial fraction of reviewed notes, though the exact false-positive rate for specific fields like medication lists is what would be needed to quantify clinical risk, and the audit methodology for determining ground truth is not fully described in the press coverage. The clinical stakes are high: an incorrect medication in a discharge summary can cause an adverse event downstream. The systemic problem is that these tools are being deployed with insufficient human review — physicians are signing off on AI-generated notes without verifying every field, partly because the efficiency gain that motivated adoption disappears if every sentence must be checked. This is a deployment and incentive problem as much as a model quality problem. The audit recommends mandatory review workflows, but absent tooling that highlights low-confidence fields, the review burden is likely to remain superficial.
How Claude Code works in large codebases
Anthropic’s engineering blog post on Claude Code’s large-codebase strategy covers the concrete techniques the tool uses to stay within context limits while maintaining enough project understanding to be useful. The core challenge is that large codebases far exceed any practical context window, so the system must retrieve rather than ingest. The described approach combines several mechanisms: tree-sitter-based structural parsing to extract symbol tables and call graphs without reading every file in full; a search-first workflow where the model is instructed to use grep, find, and LSP-style queries before reading file contents; and a planning phase where high-level task decomposition happens before any file is opened, so retrieval is directed rather than exploratory. The post also describes the CLAUDE.md convention — a repo-level markdown file that authors maintain to give the model persistent context about architecture decisions, non-obvious conventions, and areas of the codebase that require care. This is essentially a manually curated retrieval document that circumvents the need for semantic search in many common cases. The guidance on where to start (read the CLAUDE.md, then relevant entrypoints, then follow imports lazily) reflects an empirically derived workflow rather than a learned policy. One notable absence is any discussion of how Claude Code handles stale context when files change during a long session — a practical problem in active codebases. The post is prescriptive rather than evaluative; no ablation data is provided for whether the recommended workflows actually improve task success rate versus naive full-context or RAG approaches.
Source: https://claude.com/blog/how-claude-code-works-in-large-codebases-best-practices-and-where-to-start
If AI writes your code, why use Python?
The post argues that the conventional reasons to choose Python — readable syntax, fast iteration, large ecosystem, low barrier to entry — are all properties that primarily benefit the human author, and that if an LLM is doing the authoring, the relevant criteria shift. The argument has real technical content worth examining. Python’s dynamic typing and runtime semantics mean that LLM-generated Python code is harder to statically verify: no compiler catches type errors before execution, and the absence of a compile step means bugs surface at runtime, often in production. A statically typed, compiled language like Rust or Go would surface more errors at generation time if the LLM targets those languages, because the compiler acts as an automated verifier of the generated code. This is a genuine point — LLM coding assistants used with Rust see a higher fraction of bugs caught before the code ever runs. The counterargument is that Python’s ecosystem density means the LLM’s training distribution is richer, producing better-calibrated generations for Python than for less common languages. There is also the iteration loop argument: even if a human is not writing code, they are running it, reading error traces, and directing fixes — Python’s fast feedback loop still has value for this supervisory role. The piece also touches on whether language-level verbosity (Java, C++) is actually beneficial when token cost is zero from the LLM’s perspective; this is interesting but not resolved. The question of language choice under LLM-assisted development is genuinely open and worth empirical study.
Source: https://medium.com/@NMitchem/if-ai-writes-your-code-why-use-python-bf8c4ba1a055
Noteworthy New Repositories
browser-use/browser-harness
A self-healing browser automation layer designed to let LLMs drive web browsers without brittle CSS/XPath selectors. The core idea is that when a DOM interaction fails — element not found, layout shifted, stale reference — the harness automatically re-queries the page context, re-localizes the target element using semantic matching, and retries rather than hard-erroring. This is meaningfully different from raw Playwright/Selenium wrappers: instead of recording fixed selectors, the harness maintains a live semantic index of the current DOM state and resolves element references at execution time.
Under the hood it wraps Chromium via Playwright, exposes a structured action space (click, type, scroll, extract, navigate) to the LLM, and feeds back compressed DOM snapshots as context. The self-healing loop runs a lightweight re-identification pass on failure — comparing visual and structural features of the expected element against current candidates. This reduces the brittleness that plagues most LLM browser agents when pages update or A/B tests fire.
The repository targets developers building autonomous web agents or RPA replacements where page structure is not guaranteed stable. It is more useful than raw browser tool calls when the target sites change frequently. Python-based, MIT-adjacent, with 12k+ stars suggesting real adoption. The main limitation is that semantic re-identification adds latency per failed action, and complex SPAs with canvas or shadow DOM still pose problems.
Source: https://github.com/browser-use/browser-harness
facex-engine/facex
A complete face analysis stack compiled entirely to WebAssembly, running client-side in the browser with zero server round-trips. The pipeline covers five tasks: face detection, 576-point 3D facial mesh estimation, face recognition (embedding extraction), liveness/anti-spoofing, and smile detection. All five models are bundled as WASM modules, meaning inference executes on the end-user’s CPU (or GPU via WebGL/WebGPU if available) without any data leaving the device.
The 576-point 3D mesh is notably denser than MediaPipe’s 468-point Face Mesh, which suggests either a custom architecture or an extended topology — relevant for AR applications requiring finer deformation control. The anti-spoof module is the technically interesting inclusion: running a replay/print attack detector purely client-side is non-trivial given model size constraints imposed by download budgets, implying aggressive quantization or distillation.
The architecture choice (WASM over TensorFlow.js or ONNX Runtime Web) gives predictable performance across browsers without a Python backend, making it suitable for privacy-sensitive applications — medical, identity verification, or offline kiosk deployments. Apache 2.0 license removes commercial friction. At 152 stars it is early, but the technical scope is well-defined. Key open questions: what are the recognition accuracy numbers on standard benchmarks (LFW, IJB-C), and what is inference latency on a mid-range mobile device?
Source: https://github.com/facex-engine/facex
cosmicstack-labs/mercury-agent
Mercury is a persistent, always-on AI agent runtime designed for 24/7 operation from a CLI or Telegram interface. The two distinguishing design choices are permission-hardened tools and token budgets. Permission hardening means each tool (filesystem access, shell execution, network calls) carries an explicit capability declaration; the agent cannot invoke a tool outside its declared scope, reducing the blast radius of prompt injection or runaway tool calls. Token budgets add a hard accounting layer: each task is allocated a context spend limit, preventing unbounded API cost accumulation across long-running autonomous sessions.
Multi-channel access (CLI + Telegram) means the agent can be supervised or redirected by a human operator without restarting the process — relevant for overnight or background jobs where you want interrupt capability. The “soul-driven” framing in the description likely refers to a persistent persona/memory layer that maintains behavioral consistency across sessions, though the technical implementation details of that layer are not fully specified in public documentation.
At 2,200 stars it has meaningful traction. The practical use case is replacing cron-job-plus-script pipelines with an LLM agent that can handle exception cases through reasoning. The main risk in any always-on agent is the tool permission model — how those capability declarations are enforced (process isolation, sandboxing) at the OS level remains the critical open question.
Source: https://github.com/cosmicstack-labs/mercury-agent
thClaws/thClaws
A native Rust agent harness platform emphasizing local, sovereign execution without cloud dependency. “Multi-provider” means it abstracts over multiple LLM backends (OpenAI-compatible APIs, local Ollama, etc.) through a unified provider trait, letting users swap inference endpoints without changing agent logic. The “sovereign by design” positioning is a technical stance: no telemetry, no required accounts, no data leaving the machine.
Building the harness in Rust rather than Python gives meaningful advantages for an agent runtime: lower memory overhead when managing many concurrent tool execution threads, safe concurrency primitives for parallel sub-agent tasks, and a single compiled binary with no interpreter dependency. The tradeoff is a smaller ecosystem of LLM client libraries compared to Python, though the OpenAI-compatible HTTP interface mitigates this.
The platform appears to target developers who want to build and deploy agents on-premises — air-gapped environments, edge hardware, or situations where Python’s runtime overhead or dependency chain is undesirable. At 915 stars it is gaining traction in the self-hosted AI community. Open questions center on the tool DSL: how complex tool graphs and agent-to-agent delegation are expressed, and whether there is a serializable workflow format for reproducible runs.
Source: https://github.com/thClaws/thClaws
opensquilla/opensquilla
OpenSquilla targets token efficiency — achieving higher task completion quality per token spent rather than simply throwing larger context at problems. The “higher intelligence density” framing implies structural changes to how context is assembled and pruned rather than just prompt compression. Likely mechanisms include hierarchical summarization of conversation history, selective retrieval of relevant memory chunks, and structured output formats that reduce verbose LLM responses.
The project positions itself as an agent framework where the primary optimization axis is cost/quality ratio, which is a practically important constraint for production deployments where API spend is a real budget line. This differentiates it from frameworks optimizing for capability breadth or ease of use.
At 758 stars, the project is gaining visibility. The core technical question is how “intelligence density” is measured — what benchmark or task suite demonstrates that the same token budget yields better outcomes compared to a naive agent loop. Without published ablations showing token consumption versus task success rate on a standard benchmark (like WebArena or GAIA), the efficiency claim is hard to verify. The open-source nature means the context management logic is auditable, which is valuable for teams wanting to understand exactly what goes into each LLM call and where tokens are being spent.
Source: https://github.com/opensquilla/opensquilla
chekusu/wanman
Wanman is a multi-agent orchestration runtime that explicitly shifts the human into an observer role rather than an active director. The design metaphor — Japanese one-man train operation — maps onto a system where a single automated conductor manages the full route without passengers intervening in operations. In practice this means the runtime coordinates multiple local agent processes, routes tasks between them, handles artifact passing, and manages execution state, while the human monitors rather than micromanages.
The technical substance centers on the agent matrix: a topology where multiple specialized agent runtimes (each potentially running a different model or tool set) communicate through a defined message-passing interface. Artifacts (files, structured data, intermediate results) are first-class objects passed between agents rather than reconstructed from conversation context, which reduces token overhead and makes inter-agent state explicit.
Running locally is a deliberate choice — all agent coordination happens on the user’s machine, avoiding cloud orchestration latency and keeping data local. The “observer role” design has real engineering implications: the system needs robust failure detection and escalation logic to surface issues that genuinely require human intervention without crying wolf on routine errors. At 547 stars, it is early but the architectural concept is well-differentiated from simple sequential agent chains.
Source: https://github.com/chekusu/wanman
regent-vcs/re_gent
Re_gent applies version-control semantics to AI coding agent sessions. The core problem it addresses: coding agents make sequences of file edits, tool calls, and decisions that are currently opaque and irreversible — if the agent goes down a wrong path, recovery requires manual inspection and rollback. Re_gent tracks agent state as a versioned graph, allowing branch, checkpoint, diff, and rollback operations on agent execution history in the same way Git tracks source code.
This is architecturally non-trivial. Agent state includes not just file diffs but also the conversation context, tool call history, intermediate artifacts, and decision points. A useful version control system for agents needs to snapshot all of these coherently and allow selective restoration. The project likely implements a DAG of agent states with copy-on-write semantics for file state and explicit logging of LLM interactions at each node.
The practical value is high for autonomous coding workflows: you can let an agent attempt a refactor, checkpoint before a risky change, observe the result, and roll back to the checkpoint if the approach is wrong — without manually undoing edits. At 501 stars the project is early. Key open questions: how is context state (token history) stored and restored efficiently, and does rollback actually re-feed the restored context to the LLM or just restore file state?
Source: https://github.com/regent-vcs/re_gent
chorus-codes/chorus
Chorus implements multi-LLM peer review for code decisions by convening 2-4 additional LLM instances to critique a piece of work before it ships. The workflow integrates with existing CLI tools — you bring your own coding agent or editor, and Chorus adds a review gate that solicits independent assessments from different models (e.g., GPT-4o, Claude, Gemini, a local Llama variant) and synthesizes their feedback.
The technical rationale is ensemble disagreement as a quality signal: if multiple independently-prompted models with different architectures and training distributions converge on the same concern, that concern is more likely to be genuine than a single model’s hallucination. Divergence between reviewers surfaces ambiguous design decisions that warrant human judgment. This is analogous to using multiple static analyzers in a CI pipeline — each has different false-positive profiles, and the intersection is high-confidence.
The “bring your own CLI” integration model means Chorus acts as middleware rather than a full IDE replacement, which lowers adoption friction. At 466 stars it has traction. The main practical limitation is cost and latency: convening 4 LLM calls serially or in parallel adds real time and API spend to every review cycle. The value proposition holds when the code change is high-stakes enough to justify that overhead, making it better suited for PR-level review than line-by-line editing.