デイリーAIダイジェスト — 2026-05-08
arXiv ハイライト
RLはLLMに長期ホライズン推論を教えられるか?表現力が鍵である
問題設定
LLMのRLポストトレーニングにおける中心的な実証的問いは、トレーニングコストがタスク難易度に対してどのようにスケールするかという点です。先行研究では、問題の長さ・語彙・計画の深さ・論理構造といった軸が混在しており、何がRLを困難にするのかを切り分けることが難しい状況でした。本論文ではScaleLogicという合成的な論理推論生成器を導入し、二つの軸を分離します:証明の深さ D(ホライズン)と、論理的表現力(含意のみから始まり、連言・選言・否定・普遍量化を経て広がる一階論理のフラグメント)です。これらのパラメータを用いて、各表現力レベルにおいてRLトレーニングの計算量 T が目標精度に到達するまでに D に対してどのようにスケールするかを測定し、より表現力の高いトレーニングが実際のベンチマークへのより良い転移をもたらすかどうかを検証しています。
手法
各インスタンスは B 個の候補結論を持つ単一解答の選択式問題です。生成はバックワードに行われます:B 個のルートリテラルをサンプリングし、各リテラルを深さ D まで再帰的に証明木に展開します。各親ノードは子ノードを前提とする証明ステップの結論となります。各展開で導入される述語は新たに生成されるため、サブツリーごとに一意な導出が保証されます。証明木の一つはそのまま保持され、残り B-1 個は(i)一様サンプリングされた公理を一つ削除するか、(ii)公理中の一つのリテラルの極性を反転する(否定が論理に含まれる場合のみ)ことで改ざんされます。代替導出を作ることなく局所的な曖昧さを加えるために、ディストラクタールールが挿入されます。得られる二つの構造的パラメータ——分岐数 B と深さ D ——は、候補の混同しやすさと推論チェーンの長さを直接制御します。
表現力は、ルールスキーマで追加的な論理結合子を有効化することで変化させます:含意のみ(Horn節スタイルの「もし〜ならば」)、+\land、+\lor、+\neg、最後に +\forall(型付きエンティティに対する普遍量化)の順です。RLポストトレーニングはverlを用いたQwen3-4B(非thinkingモード)に対して実施され、GRPOをデフォルトとして使用しています。Qwen3-8Bや他のRLアルゴリズムへの複製実験は付録に記載されています。
中心的なスケーリングの主張は、表現力を固定した場合、目標精度に到達するために必要な計算量 T(D) が
T(D) = a \cdot D^{\gamma},
に従うというものであり、\gamma はその論理を特徴づける深さスケーリング指数です。
結果
べき乗則は全表現力設定において厳密に成立しており、R^2 > 0.99 を達成しています。決定的な比較は指数関数的な代替モデル T(D) = a \cdot e^{\gamma D} との比較であり、AIC差は全設定においてべき乗則を一貫して支持しています。
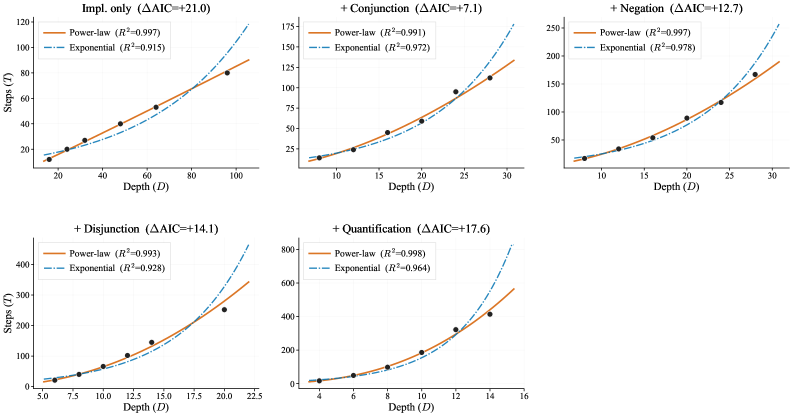
主要な知見は、\gamma が表現力と単調に増加し、含意のみの論理における \gamma \approx 1.04 から +Quantificationレベルでの \gamma \approx 2.60 に至るという点です。したがって、RLは推論ホライズンを拡張できる一方で、より豊かな論理では深さを1ステップ増やすごとの限界コストが超線形に増大します——量化が含まれる場合はおよそ D^{2.6}、Horn節フラグメントではほぼ線形です。これらの指数は計算量の測り方の選択に対して頑健です:T を生成トークン数・保持バッチ更新トークン数・トレーニングFLOPs T_{\text{FLOPs}} = 2N T_{\text{gen-tok}} + 6N T_{\text{upd-tok}}・実時間のいずれで置き換えても、べき乗則のfitと \gamma の順序関係は維持されます。
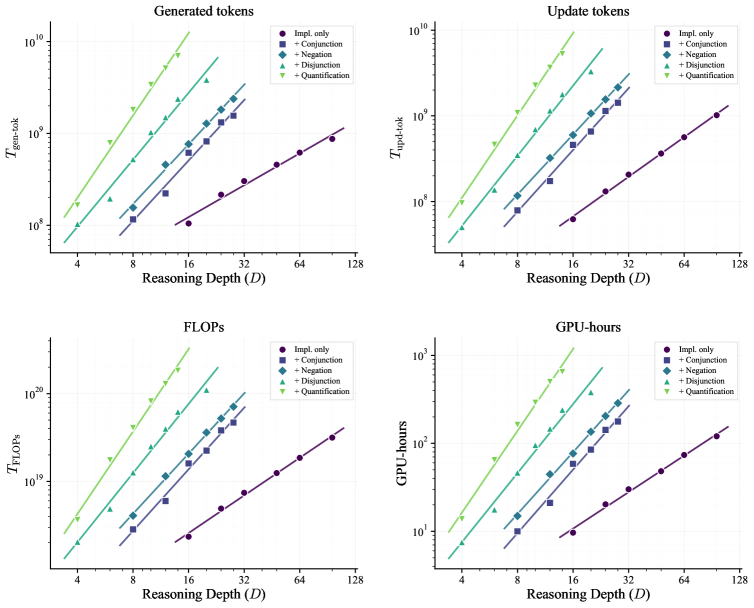
下流タスクへの転移については、より表現力の高いScaleLogic設定でトレーニングすることで、数学および一般推論ベンチマークにおいてより大きな改善が得られ——ベースモデルに対して最大+10.66ポイント——、表現力の低いトレーニングよりも少ない計算量で所定の精度レベルに到達できます。つまり表現力は単なる難易度パラメータではなく、転移の質を決定するものです。スケーリング挙動は複数のRLアルゴリズム(GRPO固有ではない)にわたっても成立しており、トレーニング中に見た深さを超えた深さへの非自明なOOD汎化も示されていますが、深さのギャップが広がるにつれ性能劣化が生じることも論文では報告されています。
限界と未解決の問い
- ScaleLogicは合成的であり、構造上証明が一意です。実際の推論では複数の有効な導出やノイズの多い前提が許容されており、T(D) の形状が変わる可能性があります。
- 実験はQwen3-4Bを中心とし、8Bへの拡張が一つあるのみです。\gamma がモデルスケール・基礎能力・事前学習データの構成にどう依存するかは特徴づけられていません——\gamma(N) スケーリング則が自然な次のステップとなるでしょう。
- 「表現力レベル」の選択は離散的な段階です。連続的な複雑性指標(例えば記述複雑性クラスや証明探索の分岐因子)があれば、\gamma を論理構造からfitするのではなく予測できるようになります。
- 下流転移の結果は励みになるものの、標準ベンチマーク上での測定であり、データ汚染や合成思考の連鎖との文体的な重複を排除することは困難です。
なぜ重要か
RLで深さ D に到達するための計算量が D^\gamma(\gamma は論理的表現力によって決まる)としてスケールするならば、「RLによる長期ホライズン推論」は単一の問題ではなく、基礎となる論理によってパラメータ化された問題の族です——そして \gamma \approx 1 と \gamma \approx 2.6 の差は、スケール上で扱いやすいか法外かの違いを意味します。また、より表現力の高い設定の方が単位計算量あたりの転移性能が高いため、合成カリキュラムは意図的に最大限の表現力を持つように設計すべきであることも示唆しています。
Source: https://arxiv.org/abs/2605.06638
Continuous Latent Diffusion Language Model
Cola DLM は、グローバルな意味計画とローカルなトークン実現を分離する階層的潜在変数言語モデルを提案しています。離散トークン上でdiffusionを実行するアプローチ(LLaDA、MDLMs)や、トークンごとの連続embeddingに対して実行するアプローチ(Plaid、SEDD方式の連続バリアント)とは異なり、Cola DLM は Text VAE を訓練して連続潜在変数 z_0 \in \mathbb{R}^d を取得し、flow matching によって連続正規化フロー(CNF)事前分布 p_\psi(z_0) を学習します。生成は以下のように因子分解されます。
p(x) = \int p_\theta(x\mid z_0)\, p_\psi(z_0)\, dz_0,
事前分布は、学習されたベクトル場 v_\psi のもとでの \mathcal{N}(0,I) の押し出し(pushforward)として実装されます:
z_1 \sim \mathcal{N}(0,I),\quad \tfrac{dz_t}{dt}=v_\psi(z_t,t),\quad z_0=\Phi^\psi_{0\leftarrow 1}(z_1).
潜在変数は B ブロックに分割され、ブロック因果分解 p_\psi(z_0)=p_\psi(z_0^{(1)})\prod_{b=2}^B p_\psi(z_0^{(b)}\mid z_0^{(<b)}) が適用されます。これはブロック因果 DiT によって実現されます。前置詞 x^{\mathrm{pre}} を条件とする生成では、まず前置詞を z^{\mathrm{pre}}\sim q_\phi(\cdot\mid x^{\mathrm{pre}}) にエンコードし、次に潜在空間において応答ブロックを自己回帰的にサンプリングします:\hat z_0^{(b)} = \Phi^\psi_{0\leftarrow 1}(\epsilon^{(b)}; z^{\mathrm{pre}}, \hat z_0^{(<b)})。その後 x^{\mathrm{res}}\sim p_\theta(\cdot\mid x^{\mathrm{pre}}, z^{\mathrm{pre}}, \hat z_0^{(1:B)}) としてデコードします。統一的なマルコフパス比較(付録 11)で精緻化された重要な概念的ポイントは、diffusion が観測に依存しない潜在変数上の 事前分布輸送 プロセスであり、トークン破損からの復元プロセスではないという点です。これこそがグローバルな意味的構造化と表面的な生成を分離するものです。
学習パイプライン
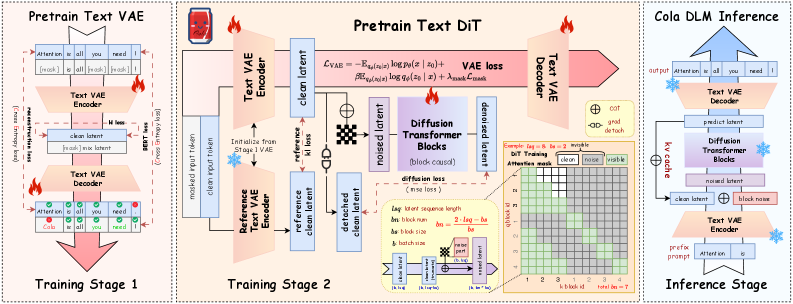
Stage 1 では、再構成 loss、補助的な BERT スタイルの目的関数、および KL 正則化項を用いて Text VAE を事前学習します。Stage 2 では、VAE とブロック因果 DiT を共同学習しながら、gradient 制御によってエンコーダ・デコーダの崩壊を防ぎつつ、flow matching によって事前分布を形成します。Flow matching の loss
\mathcal{L}_{\mathrm{FM}}(\psi) = \mathbb{E}\big[\|v_\psi(Z_t,t,c) - U^\star\|^2\big]
は条件付き平均速度を回帰します(命題 14.1)。論文では、これが モード探索型 密度推定量では ない ことを明示的に指摘しており、これが後述する PPL と品質の不一致の直接的な原因となっています。
理論的位置づけ
セクション 12 では、AR、LLaDA、Plaid、Cola DLM を母集団リスク分解
\text{risk} = H(p_{\mathrm{data}}) + \text{model mismatch} + \text{objective gap}
のもとで統一的に捉えています。Cola DLM については、ELBO が推論ギャップ \mathcal{G}^{\mathrm{infer}} = \mathbb{E}\,\mathrm{KL}(q_\phi(z_0\mid x)\|p_{\theta,\psi}(z_0\mid x))\ge 0 をもたらすため、AR に対する優位性は、潜在クラスがこのギャップ以上に低いミスマッチを持つ場合に限定されます。セクション 14 では、標準的な PPL 推定量 \mathcal{S}_{\mathrm{resp}}(x) が単一の事後潜在変数周辺の 局所的 スコアであり、真の周辺分布 p(x^{\mathrm{res}}\mid c)=\int p_\theta(x^{\mathrm{res}}\mid z,c)p_\psi(z\mid c)dz に対して NLL を系統的に過大評価することをさらに論じており、これが PPL ではなく精度で評価する判断の動機となっています。
潜在空間の幾何学とノイズスケジュール
セクション 13 では、反証可能な帰無仮説を検証しています。すなわち、潜在変数が独立したローカル次元の和であれば、最適な logSNR シフト \delta^\star は潜在次元 d に対して不変であるはずです(命題 13.2、\mathcal{J}_d(\delta)=a_d j(\delta)+b_d より)。しかし経験的にこれは棄却されます。
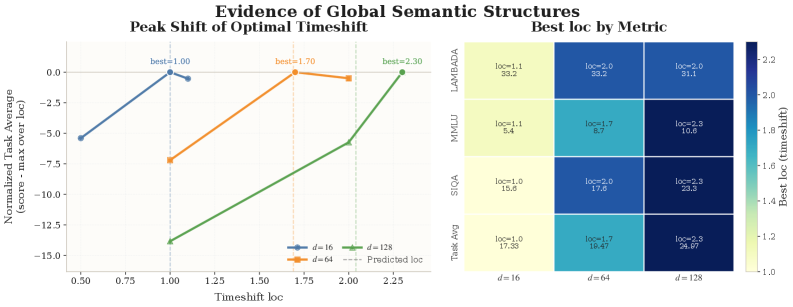
次元 d が大きいほど、より大きなシフト(すなわち高ノイズ・低SNR 領域に多くのスケジュールが割り当てられる)が系統的に好まれ、この傾向は評価指標全体にわたって安定しており、次元を超えた結合的な意味構造の存在を支持しています。セクション 15 では、シフト \lambda_\delta(t)=\lambda(t)+\delta を \alpha_{t,\delta}^2=\mathrm{sigmoid}(\lambda(t)+\delta) を介して生の時間ステップを logSNR 区間にリマッピングするものとして位置づけており、一様 t での学習は一様 \lambda での学習と等価ではないことを示しています。このシフトはラベル変換ではなく、意味的情報の再較正です。
実験結果
設定:OLMo 2 トークナイザー、500M VAE + 1.8B DiT(合計 ≈2B)を使用し、≈400M embedding + 1.8B バックボーンを持つ AR(LLaMA スタイル)および離散diffusion(LLaDA)ベースラインと比較しています。すべてのモデルは同一データ、シーケンス長 512、AdamW、学習率を 5k ステップで 1.5\times 10^{-4} にウォームアップし、1M ステップまでコサイン減衰で 1\times 10^{-5} に設定した条件で学習されています。評価は LAMBADA、MMLU、SIQA、SQuAD、Story Cloze、OBQA、RACE、HellaSwag を対象とした、厳密な文字列マッチングによる統一的な few-shot 生成評価です。
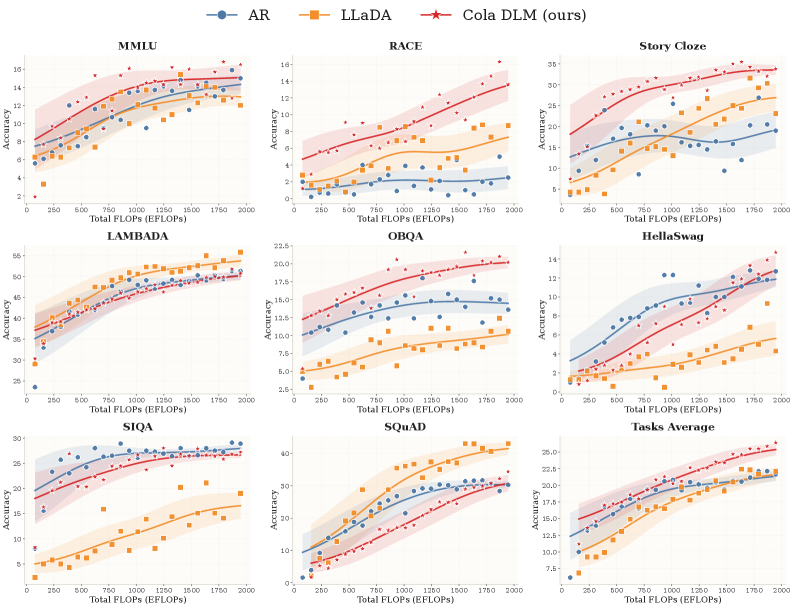
Cola DLM は良好なスケーリングを示し、同一の約 2B FLOPs バジェットプロトコルのもとで、8 つのベンチマークにわたるタスク平均で最良のスコアに達しています。著者らは、一部の多肢選択問題における絶対精度が低下していることを指摘しています。これは、プロトコルが尤度ランキングではなく生成的な解答を強制するためであり、非 AR モデルにとって既知の不利な点ですが、それでも比較を忠実なものにしています。
制限事項
PPL と品質の不一致は偶発的なものではなく構造的なものです。Flow matching は条件付き平均速度を学習し、局所的な ELBO スコアは事後分布の集中をニ重にペナルティ化するため、標準的な尤度指標はモデル選択や AR ベースラインとの比較に使用できません。ブロック因果 DiT は潜在レベルで粗い自己回帰バイアスを再導入しており、「非自己回帰」という主張はブロック内の並列性に限定されます。2B を超えた場合や同一データバジェットでのスケーリングは未検証であり、推論ギャップ \mathcal{G}^{\mathrm{infer}} がスケールとともに縮小するのか、それともゼロから有界なまま保たれるのかも不明です。デコードには v_\psi 上の ODE 積分と条件付きデコーダパスの両方が必要なため、同一品質での AR との実時間比較は提供されているセクションでは報告されていません。
なぜこれが重要か
Cola DLM は「diffusion を潜在事前分布輸送として捉え、トークン破損としては捉えない」という見方を明確に具体化したモデルであり、連続潜在テキストdiffusion が PPL では劣って見えながらも下流精度で AR に匹敵できる理由を説明する明示的な理論的機構(統一的なマルコフパス分解、ELBO 対 NLL ギャップ分析、logSNR シフト再較正)を備えています。スケールにおいて推論ギャップが真に小さいならば、これは非 AR テキストモデルへの信頼できる経路であり、連続マルチモーダル潜在変数への自然な拡張も期待できます。
Source: https://arxiv.org/abs/2605.06548
少ステップ拡散蒸留のための連続時間分布マッチング
問題設定
拡散/flowモデルのステップ蒸留は、Distribution Matching Distillation(DMD/DMD2)とConsistency Distillation(CD)という2つのパラダイムに収束しています。DMDはstudentとteacherの周辺分布間のreverse-KLを強制しますが、それはstudentのサンプリングスケジュールと一致する少数の事前定義された離散的な推論タイムステップ \{t_1,\dots,t_N\} においてのみです。このスパースなアンカリングと、reverse KLのmode-seekingな性質が組み合わさることで、過度に平滑化されたサンプルと視覚的なアーティファクトが生じており、先行研究ではこれを補助的なGAN discriminatorや報酬モデルで補正しています。一方CDは、PF-ODE軌跡全体を監督しますが、分布的忠実性よりもteacher軌跡マッチングによってデータ多様体に向けた出力のバイアスが生じる傾向があります。CDMは、DMDの分布的目的関数を連続時間に拡張することで、敵対的または報酬ベースの補助モジュールを不要にできるかどうかを問います。
手法
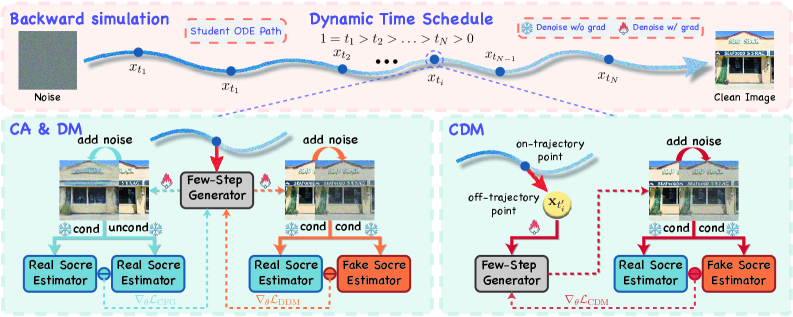
設定は、teacher \mathcal{D}_\phi から分離型DMD loss \mathcal{L}_{\mathrm{DMD}}=\mathcal{L}_{\mathrm{CA}}+\mathcal{L}_{\mathrm{DM}} によって蒸留される、velocity parameterized flow student \mathcal{D}_\theta(\mathbf{x}_t,t,\mathbf{c})=\mathbf{x}_t - t\, v_\theta(\mathbf{x}_t,t,\mathbf{c}) です。CA項は、正規化されたスコア差分を通じてclassifier-free guidance情報を再注入します:
\Delta_{\mathrm{ca}}^{\mathrm{real}} = w_\tau\,\alpha\,\bigl(\mathcal{D}_\phi(\mathbf{z}_\tau,\tau,\mathbf{c})-\mathcal{D}_\phi(\mathbf{z}_\tau,\tau,\varnothing)\bigr),\qquad w_\tau = \|\mathcal{D}_\phi(\mathbf{z}_\tau,\tau,\mathbf{c})-\mathcal{D}_\theta(\mathbf{x}_{t_i},t_i,\mathbf{c})\|_1^{-1},
DM項はfake-scoreネットワーク \mathcal{D}_\psi を用いた標準的なreverse-KLのsurrogateを持ちます。
CDMはこのベースラインを2つの軸に沿って修正します。
1. 動的連続スケジュール。 通常のDMD2/D-DMDは固定された推論グリッド \{t_1,\dots,t_N\} に沿ってのみ後ろ向きシミュレーションを行い、CA+DMを適用するアンカー i\sim\mathcal{U}\{1,\dots,N\} を1つサンプリングします。CDMはこれに対し、ランダムなスケジュール長 とアンカー位置をイテレーションごとにサンプリングします:アンカーは t\in(0,1] から一様にサンプリングされ、監督をデプロイ時のグリッドから切り離します。
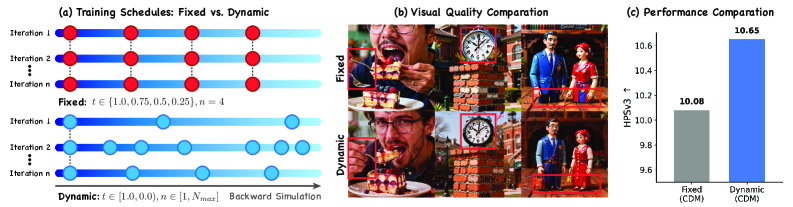
Figure 2(b)に示される実証的な主張は、厳密なアンカリングが少数のタイムステップにおけるvelocity fieldに過適合し、それ以外の場所では軌跡が十分に正則化されないというものです;一様な連続サンプリングはそのギャップを埋め、より細かいテクスチャをもたらします。
2. velocity外挿による連続時間アライメント。 ランダムなアンカーを用いても、監督はstudent自身の後ろ向きシミュレーションが訪れる点、すなわち軌跡上の潜在変数に留まります。CDMはさらに、現在のアンカー \mathbf{x}_{t_i} からstudentのvelocityに沿って摂動された時刻 t' へ外挿することにより、軌跡外の点を正則化し、合成潜在変数を生成します:
\tilde{\mathbf{x}}_{t'} = \mathbf{x}_{t_i} + (t'-t_i)\,v_\theta(\mathbf{x}_{t_i},t_i,\mathbf{c}),
そして (\tilde{\mathbf{x}}_{t'},t') においてDM目的関数を適用します。これにより、サンプリングされた軌跡に沿ってのみでなく (0,1] 全体にわたるvelocity fieldの一貫性が強制されます。これが、CDMが分布マッチングを放棄せずにCDの完全軌跡カバレッジをDMDフレームワークに取り込む仕組みです。
設計を動機づける有用な補助的観察として:\mathcal{L}_{\mathrm{DM}} のみを適用した場合、studentはCFG-augmentedな分布ではなくCFG-freeなteacher分布に収束します。これはDMが実際の分布的ドライバーであり、CAがguidanceを注入するために必要な直交的補正であることを示しています。

結果
実験はSD3-Mediumを用いて 1024\times1024 で行われ、2KのPickScore-testプロンプト(AES、PickScore、HPS v3、CLIP ViT-H-14)および1KのDPG-Benchプロンプトで評価されています。ベースラインにはHyper-SD、Flash、TDM、DMD2、D-DMDが含まれます。汎化性はLongcat-Imageへのパイプライン移植によって検証されています。選択された節では数値テーブル全体は列挙されていませんが、abstractと手法の記述において、CDMはDMD2および後続研究が視覚的品質のために依存していたGAN/報酬補助モジュールを取り除きつつ、同じ少ステップ設定(N が小さい、例えば1〜4ステップ)で動作するものとして位置づけられています。
限界と今後の課題
- 軌跡外の外挿は v_\theta に関して一次であり、|t'-t_i| が大きい場合、合成潜在変数は真のPF-ODE上の点から乖離し、正則化項はfake-scoreネットワークに分布外の入力でDMを評価させることになります。論文は引用された節において、|t'-t_i| をどの程度まで積極的に設定すると \mathcal{D}_\psi が不安定化するかを特徴づけていません。
- ランダムなスケジュール長はstudentが異なる数の後ろ向きステップで学習されることを意味しますが、デプロイ時は固定された N で使用されます;この学習/テストのミスマッチが非常に低い N(1〜2ステップ設定)においてコストをもたらすかどうかは論じられていません。
- DM-onlyの実験はstudentがCFG-freeなteacherにマッチすることを示しています;これは蒸留がCFGを崩壊させるという標準的な観察と整合しますが、CDMの品質上限が連続時間監督下でCA項がguidanceをいかによく再構成できるかに依存することも意味します。
- flow-matchingのteacher(SD3、Longcat-Image)のみが評価されており、\epsilon-predictionやv-prediction DDPMへの転用は暗示的に留まっています。
重要性
CDMは、アンカーをランダム化してvelocity外挿によって軌跡外の点に到達することで、DMDのreverse-KL目的関数を連続時間において密に適用できることを示し、consistency手法(完全軌跡、多様体アンカー型)と分布マッチング(スパース、分布的に正確)の間の概念的なギャップを埋めます。報告された品質が維持されるならば、DMD2スタイルのパイプラインに蓄積されてきたGAN/報酬の足場を取り除き、少ステップ蒸留を単一の分離されたCA+DM目的関数へと簡素化します。
Source: https://arxiv.org/abs/2605.06376
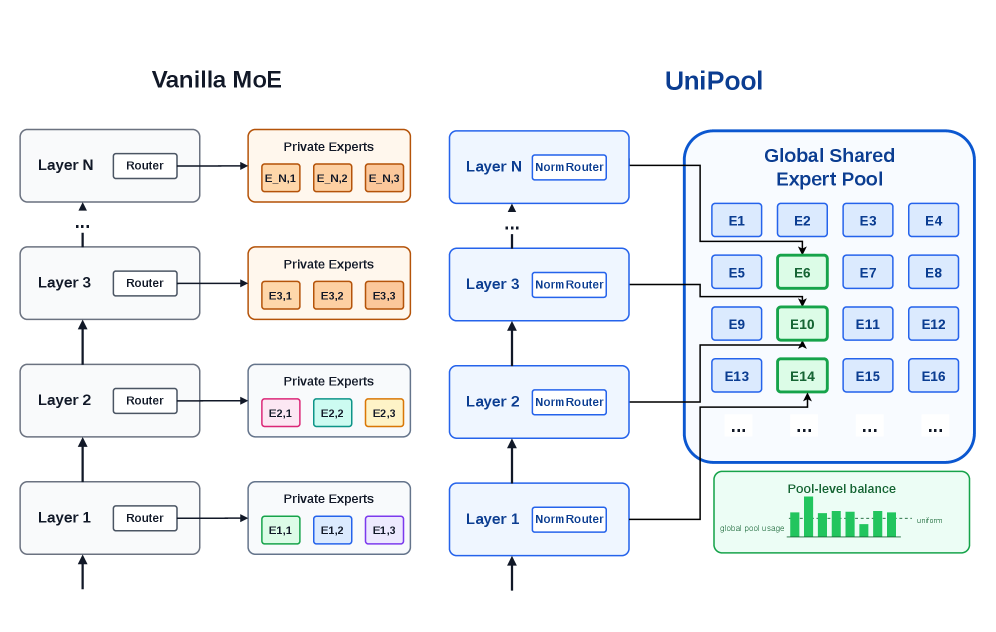
UniPool: Mixture-of-Experts のためのグローバル共有 Expert Pool
問題
標準的な MoE transformer では、expert の容量が深さに紐付けられています。L 層それぞれが E 個の expert のバンクを独自に保持するため、より深い層が実際に新たな容量を必要とするかどうかに関わらず、expert のパラメータ数は深さに対して線形に増加します。近年の知見は、深い層では新たな容量を必要としないことを示唆しています。Qwen および DeepSeek MoE における同一層の expert 重み行列は、ペアコサイン類似度が 0.9 を超える支配的な部分空間を共有しており、Qwen1.5-MoE、DeepSeek-V2-Lite、Qwen3-30B-A3B、および OLMoE において最も類似した同一層 expert に再ルーティングされたトークンは、最大 2\times のデコード高速化を達成しつつ精度を維持します。また、Mixtral 8x7B の expert のおよそ半数を枝刈りしても品質の低下は約 8% に留まり、冗長性は深い層に集中しています。
著者らはルーターレベルのプローブを追加しています。深い半分の層の一つについて、学習された top-k ルーターを一様ランダムな割り当てに置き換えるというものです。Qwen1.5-MoE、DeepSeek-V2-Lite、Qwen3-30B-A3B にわたって、下流タスクの平均精度はわずか 1.0〜1.6 ポイントしか低下しません(例:Qwen1.5-MoE: 67.92 → 66.29;Qwen3-30B-A3B: 73.02 → 72.06)。ルーター自体が専有の expert セットに対して鋭いパーティションを形成していないことを示しており、層ごとの所有権が各ブロックに同じ変換を独立して再発見させることを促していると考えられます。
手法
UniPool は層ごとの専有という概念を完全に排除します。L 個の互いに素な集合 \{e_{l,1},\ldots,e_{l,E}\} の代わりに、すべての層が単一のプール \mathcal{E}=\{e_1,\ldots,e_M\} にルーティングします。各層 l は自身のルーター r_l を保持します:
\text{FFN}_l(x) = \sum_{i \in \text{Top-}k(r_l(x))} g_{l,i}(x)\cdot e_i(x),
ここで e_i はすべての l にわたって共有されます。残差ストリームの統計が深さによって異なるため、ルーターは層ごとに独立して保持されますが、その下の FFN 計算は再利用されます。プールサイズ M は、通常の MoE の expert パラメータ予算に合わせて設定され、密結合相当のアクティブ FFN 計算量を維持します。
共有下での安定した学習のために、さらに 2 つの要素が必要です:
プールレベルの auxiliary loss。 標準的な層ごとの負荷分散 loss は、expert が共有されているため適切ではありません。層ごとのバランシング項は、特定の深さでは一部の expert が多用され他では使われないという自然なパターンを罰してしまいます。UniPool は代わりにすべての L 層にわたって利用率を集約し、プールレベルでバランシングを行うことで、どの expert もグローバルに無視されることなく、全層が全 expert を均一に使用することを強制しないようにします。
NormRouter。 softmax ルーターを、共有プールへのスパースでスケール安定な割り当てを生成する正規化スコアリングルールに置き換えます。ablation では、NormRouter を通常の MoE に単独で導入することはわずかに有害(loss +0.0058)ですが、共有とうまく組み合わさることが示されています。
ablation では中間的な共有スコープ G も検討しており、G=L は通常の MoE の層ごとの所有権に戻り、G=1 が完全な UniPool となります。G=6、4、2 の共有グループはいずれも通常の MoE より改善し、G\to 1 に向かうにつれて単調に性能が向上します。
結果
5 つの LLaMA スタイルのスケール(182M〜978M アクティブパラメータ、デフォルト 8E/top-1)で Pile の 30B トークンを用いて学習:
| スケール | 通常 MoE PPL | UniPool PPL |
|---|---|---|
| 182M | 6.9012 | 6.7058 |
| 469M | 6.0388 | 5.8334 |
| 650M | 5.7940 | 5.6186 |
| 830M | 5.6458 | 5.4320 |
| 978M | 5.5683 | 5.4736 |
UniPool はすべてのスケールで validation loss を改善しており、最大のギャップは 830M で見られます(loss 1.7309 → 1.6923;PPL 5.6458 → 5.4320)。
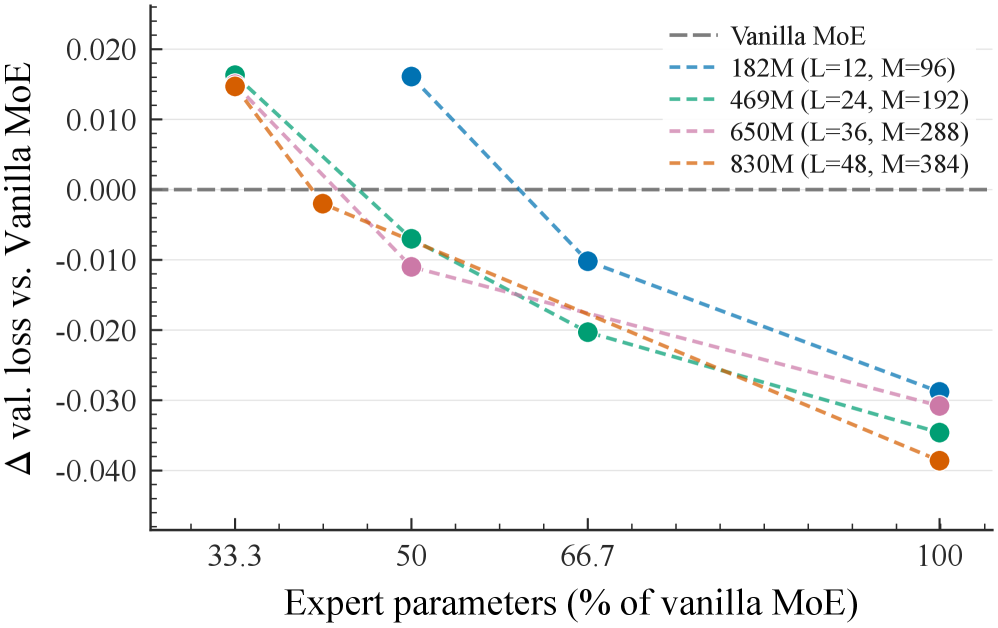
182M の ablation は各要素の寄与を分離しています。共有プールにおけるプールレベルの aux + softmax では −0.0137 の loss 改善、完全な UniPool(G=1)では −0.0288 となります。共有下でプール aux から層 aux に切り替えると符号が反転し(+0.0163)、auxiliary loss がプールレベルである必要があることを確認しています。
ルーティングが情報を持つようになる
共有が冗長性を特化へと変換することを示す最も明確な証拠は、Section 6.1 にあります。著者ら自身のモデルに対して深い半分のランダム化プローブを繰り返すと:
- 通常 MoE 469M:45.10 → 43.83(−1.3);978M:48.13 → 46.64(−1.5)。本番モデルのパターンと一致します。
- UniPool 469M:カーディナリティをそろえた top-8 ランダム化下で 47.16 → 43.10(−4.1);978M:48.35 → 44.25(−4.1)。
低下幅はほぼ 3 倍になります。すべての expert が L 層からの勾配シグナルを受け取り、すべての層が 1 つのプールをめぐって競合することで、生き残った expert は特化し、層ごとのルーターの選択がほぼ任意ではなく本質的な意味を持つようになります。
限界と未解決の問題
- スケールはアクティブパラメータ 978M および 30B トークンで頭打ちとなっており、フロンティアスケール(expert 予算がはるかに大きく、層ごとの冗長性が異なる振る舞いをする可能性がある)でギャップが持続するかは未検証です。
- すべての実験は単一のアーキテクチャファミリー(LLaMA スタイル、デフォルト 8E/top-1)を使用しています。shared-experts バリアント(DeepSeek スタイル)、fine-grained MoE、または top-2 ルーティングとの相互作用は特性評価されていません。
- プールレベルの auxiliary loss はグローバルな利用率をバランスさせますが、pool expert の小さなサブセットへの層崩壊を直接防ぐわけではありません。分析では利用率は報告されていますが、より長い学習下でのロングテールの振る舞いは示されていません。
- 推論時の配置:共有プールは expert 並列デプロイにおけるパラメータ局所性の前提を変えます。論文では現実的なサービング下での実行時間やメモリへの影響を定量化していません。
- ルーティングランダム化のメトリクスは示唆的ではありますが間接的です。回復された特化が解釈可能で異なる機能に対応するかどうかは未解決のままです。
なぜ重要か
UniPool は expert 容量を層ごとの割り当てではなくグローバルなアーキテクチャ予算として再定義し、expert パラメータ数と深さを切り離し、既知の冗長性という病理を再利用へと転換します。この結果がスケールで成立するならば、現在の MoE 設計は深さにおいてパラメータを系統的に過剰に割り当てており、深さで条件付けられたルーターを持つ単一の共有プールが厳密により優れたデフォルトであることを示唆しています。
Source: https://arxiv.org/abs/2605.06665
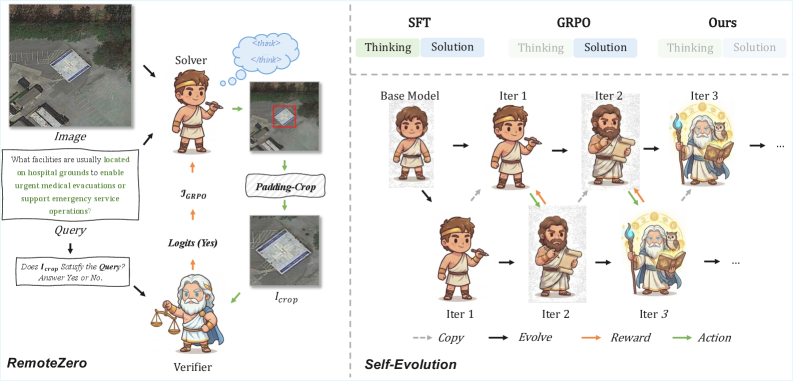
RemoteZero: ゼロ人手アノテーションによる地理空間推論
問題と動機
リモートセンシング画像上での地理空間推論は、自然言語クエリ(例:「港の入口に最も近い貯蔵タンク」)という不十分に指定されたクエリを、衛星画像上の正確なバウンディングボックスへと解決することを要求します。RemoteReasonerのような近年の推論強化型MLLMは、座標を出力する前に明示的なチェーン・オブ・ソートを生成しますが、これらのモデルの学習はGRPOにおけるIoUベースの報酬信号として使用される人手アノテーション済みボックスに依存しています。この「ロケーションボトルネック」により、利用可能なデータの大部分を占める大量のラベルなしリモートセンシング画像へのスケーリングが妨げられています。
RemoteZeroはボックス教師あり学習の要件を完全に排除します。動機となる非対称性は経験的なものです:主に画像とキャプションの alignment(P(\text{Text}|\text{Image}))で事前学習されたMLLMは強力なセマンティック検証器であり、切り取られた領域がクエリを満たすかどうかを信頼性高く判断できます。一方で、事前学習において細粒度の空間的回帰が十分に表現されていないため、座標の生成は比較的苦手です。本論文はこのギャップを利用します:モデルがすでに持っている識別器を用いて、モデルが欠いている生成器を監督するのです。
手法
設定は、画像 \mathcal{I} とクエリ \mathcal{Q} が与えられたとき、推論トレースとバウンディングボックス \mathbf{b} をサンプリングするポリシー \pi_\theta に対する標準的なGRPOです。本研究の貢献は報酬にあります。
既存の教師あり手法は外因的な幾何学的報酬 \mathcal{R}_{ext}(\mathbf{b}) = \text{IoU}(\mathbf{b}, \mathbf{b}_{gt}), を使用しており、ラベル付きの \mathbf{b}_{gt} が必要です。RemoteZeroはこれを内因的なセマンティック一貫性報酬 \mathcal{R}_{int}(\mathbf{b}) = V\!\left(\mathcal{T}(\mathcal{I}, \mathbf{b}),\, \mathcal{Q}\right), で置き換えます。ここで \mathcal{T} は \mathbf{b} から候補領域を抽出する決定論的なクロップ・パディング演算子であり、V はクロップが \mathcal{Q} に一致するかどうかの確信スコア s\in[0,1] を返す検証器MLLMです。
退化した解——検証器が存在を自明に確認するように画像全体を覆う \mathbf{b} を出力する——は、\mathcal{R}_{int} に面積ペナルティを加算することで対処し、ポリシーを最小限の十分な領域へと誘導します。全体のパイプラインを以下に示します。
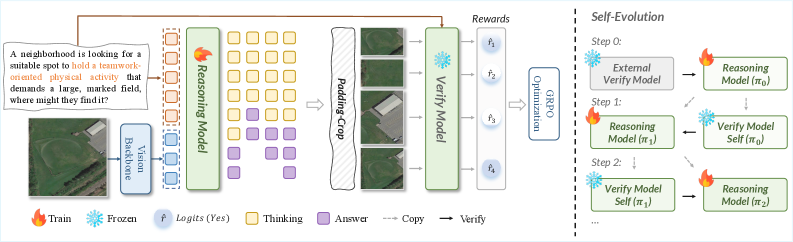
2つ目の貢献は反復的自己進化です。1回のGRPOラウンドの後、学習済みの(凍結された)ポリシー自体が次のラウンドの検証器になります。ポリシーの生成的グラウンディングが改善されることにより、クロップされた領域に対する検証モードで使用されるその識別器的な側面も改善されるため、報酬信号は外部ラベルなしに(原理的には)単調に鮮明化されます。これによりフレームワークはラベルなしリモートセンシング画像上のクローズドループへと変換されます。
具体的には、LoRA fine-tuningを施したQwen3-VL-8B-Instructを使用し、プロンプトごとに4サンプル、温度0.9でGRPO、学習率 5\times 10^{-6}、バッチサイズ6でgradient accumulation 8、10エポック、8 GPU上でbfloat16、DeepSpeed ZeRO-2を用います。最大シーケンス長は2048、画像は802,816ピクセルを上限とします。ラウンド0の検証器は、solverの初期化にも使用される同一のQwen3-VL-8Bベースモデルであり、識別的なプロンプト形式でクエリされます。
再実装のスケルトン
各学習ステップで、各 (\mathcal{I}, \mathcal{Q}) について:
- K=4 ロールアウト (\text{cot}_k, \mathbf{b}_k) \sim \pi_\theta をサンプリングする。
- アスペクト比を保持するパディングを用いてクロップ c_k = \mathcal{T}(\mathcal{I}, \mathbf{b}_k) を計算する。
- 検証器にクエリ:s_k = V(c_k, \mathcal{Q}) \in [0,1]。
- 報酬:r_k = s_k - \lambda \cdot \text{area}(\mathbf{b}_k)/\text{area}(\mathcal{I})。
- グループ相対的なアドバンテージ:K サンプルに対して A_k = (r_k - \mu_r)/\sigma_r。
- 参照ポリシーへのKLを用いて、A_k を使った (\text{cot}_k, \mathbf{b}_k) のトークンに対するPPO的なアップデート。
自己進化のために、ラウンド t の終了時に \pi_\theta のスナップショットを取得して凍結し、ラウンド t+1 における V として使用します。
結果
提供されているアブストラクトと実験セクションは見出しとなる数値を報告する前に切り取られており、本論文の主要な結果表は抜粋に含まれていません。機械的に確立されていること:学習は8 GPU上のLoRA adapterのみで実現可能であり、控えめな計算量を示唆しています。また、フレームワークはボックスアノテーションなしで動作します。内因的報酬が外因的なIoU教師あり学習に匹敵あるいは上回ることを検証するためには、標準的なリモートセンシンググラウンディングベンチマーク上でのRemoteReasonerおよびその他のIoU教師あり学習ベースラインとの定量的比較が必要ですが、これらはアブストラクトで言及されているものの、提供された抜粋には数値が含まれていません。
限界と未解決の問題
- 内因的報酬は検証器のバイアスを引き継ぎます。V が特定のクラスのクエリ(例:クロップをまたいだカウント、相対的な空間関係)を系統的に誤判断する場合、ポリシーはその誤りに対して最適化します。本論文では検証器のキャリブレーションや失敗モードについて議論されていません。
- 面積ペナルティの係数 \lambda は再現率(オブジェクトをカバーする)と精度(タイトなボックス)のトレードオフを制御しますが、抜粋にはアブレーションが示されていません。
- 自己進化は報酬ハッキングのリスクと、ポリシーと検証器が自信を持って誤った領域で共謀する退化した固定点のリスクをはらんでいます。凍結済み前ポリシースキームはこれを軽減しますが排除はしません;安定性分析や参照検証器へのKL制約があれば有益でしょう。
- クロップベースの検証はグローバルなコンテキストを破棄します。関係推論を要求するクエリ(「2つの橋の間にある建物」)では、クロップされた領域だけでは関係を検証するのに十分な証拠が含まれない場合があります。
- パディング演算子 \mathcal{T} が形状の事前分布を漏洩させる可能性があります(検証器が、中央に配置されたパディング済みクロップがポジティブを示すことを学習する可能性があります)。これにより、誤ったショートカットが生じます。
なぜ重要か
内因的なセマンティック検証がIoU教師あり学習の実行可能な代替となるならば、グラウンディングタスクにおけるGRPO型RLはアノテーションコストから切り離され、生の画像データとともにスケールします。識別器が生成器よりも強力であるという同一の非対称性は、視覚言語グラウンディング、文書理解、ツール使用の設定において広く適用可能であり、RemoteZeroのsolver-verifier-with-self-evolutionというレシピがリモートセンシングを超えて汎化することを示唆しています。
Source: https://arxiv.org/abs/2605.04451
MARBLE: Multi-Aspect Reward Balance for Diffusion RL
問題設定
テキスト-画像拡散モデルのRL fine-tuningは現在標準的な手法となっていますが、画像品質は本質的に多次元であり、プロンプト整合性、美的品質、OCR忠実度、構成的正確性、および人間の嗜好スコアをすべて同時に改善する必要があります。既存の選択肢はいずれも満足のいくものではありません:報酬ごとにスペシャリストを訓練する(統一モデルが存在せず、報酬間の転移も不可)、R(x) = \sum_k w_k R_k(x) によるスカラー化(スペシャリスト信号が十分に学習されない)、または手動でシーケンシャルなステージをスケジューリングする(脆弱であり、大規模なチューニングが必要)といった方法があります。
著者らは重み付き和による集約の失敗モードをサンプルレベルのスペシャリスト構造として特定しています:典型的なロールアウトバッチでは、ほとんどのサンプルは1つか2つの報酬次元に強いシグナルを持ち、残りの次元ではほぼゼロのシグナルしか持ちません。advantage を計算する前に報酬を平均化すると、情報を持たない次元からのノイズによって情報を持つ次元が希薄化されてしまいます。
手法
MARBLEはDiffusionNFT(Zheng et al., 2025)を基盤として構築されており、 \max_\theta\; \mathbb{E}_{x\sim\pi_\theta}[R(x)] - \beta_{\mathrm{KL}} D_{\mathrm{KL}}(\pi_\theta\|\pi_{\mathrm{ref}}) をノイズフリーのvelocity-matching lossによって最適化します: \ell(\theta; x, t) = r \cdot \mathcal{L}^+(\theta) + (1-r)\cdot \mathcal{L}^-(\theta), ここで r = \mathrm{clamp}\!\left(\tfrac{1}{2} + \tfrac{A(x)}{2A_{\max}}, 0, 1\right)、かつ \mathcal{L}^\pm(\theta) = \|v_\theta^\pm - v\|^2,\quad v_\theta^+ = (1-\beta)v^{\mathrm{old}} + \beta v_\theta,\; v_\theta^- = (1+\beta)v^{\mathrm{old}} - \beta v_\theta. 重要なのは、\mathcal{L}^+ と \mathcal{L}^- が advantage に依存しないという点であり、advantage はスカラーの補間係数 r を通じてのみ入力されます。
この構造的特性こそがMARBLEが活用するものです。\{R_k\} を単一の advantage に集約する代わりに、報酬ごとの advantage A_k(x)(バッチ内でz-score正規化)を計算し、報酬ごとの補間 r_k を形成し、報酬ごとのNFT loss \mathcal{L}_k(\theta) をインスタンス化します。各lossは独立したbackward passを通じて固有の gradient g_k = \nabla_\theta \mathcal{L}_k を生成します。その後、gradient harmonizationステップが \{g_k\} を、K 個のすべての目的を同時に改善する単一の降下方向 d に統合し、共有のLoRA adapterが d で更新されます。
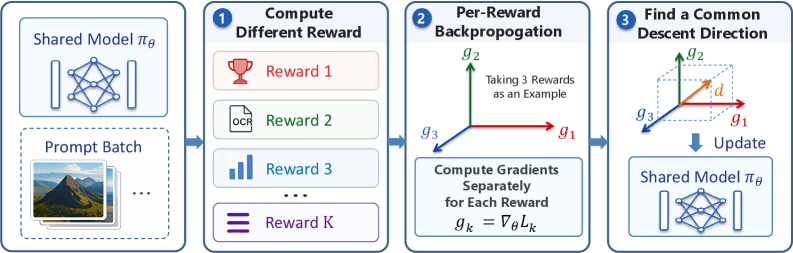
harmonizationはマルチタスクgradient surgeryコンポーネントです:目標は、競合を最小化する d を見つけること、例えばすべての g_k に対して非負の内積を持つベクトルを求めること(MGDA / PCGrad / CaGradの精神に倣って)です。これは、スカラー重みのチューニング問題とサンプル希薄化問題の両方を回避します。なぜなら各 g_k は報酬 k に対して実際に情報量の高いサンプル(高い |A_k| が r_k を0または1に押しやり、強い方向性シグナルを生成する)から計算され、同じサンプルが他の報酬に対して情報量があるかどうかには依存しないからです。
実験設定と結果
バックボーンはLoRA(rank 32, alpha 64)を搭載したStable Diffusion 3.5 Mediumで、AdamW、学習率 3\times 10^{-4}、16台のH200 GPUを使用します。5つの訓練報酬:PickScore、HPSv2、CLIPScore、OCR accuracy、GenEval。評価専用の保留報酬(訓練中には使用しない):Aesthetic Score、ImageReward、UniReward。
ベースライン:報酬ごとのFlowGRPOスペシャリスト、DiffusionNFT-sequential(手動スケジューリングされたステージ)、DiffusionNFT-simultaneous(スカラー化された重み付き和)。
提供されているセクションには完全な結果の表は記載されていませんが、実験設計は2つの主張を直接検証しています:(1) 単一のMARBLEモデルが5つの訓練報酬すべてにわたって報酬ごとのスペシャリストに匹敵または上回る性能を発揮すること、(2) 訓練混合またはそのスケジュールに過学習すると予想されるスカラー化またはシーケンシャルなマルチ報酬ベースラインよりも3つの保留報酬に対して汎化することです。
限界と未解決の問題
- harmonizationステップは本文の抜粋には明記されておらず、MGDA、PCGrad、CAGrad、またはカスタムルールのどれを選択するかによって収束挙動と計算コスト(各ステップで K 回のbackward passが必要であり、報酬数に対して線形にスケールする)が大きく異なります。
- K=5 は控えめな数です。K が増えるにつれて、共通の降下方向を見つけることはますます制約が厳しくなり、退化したケース(すべての内積が正となる d が存在しない場合)にはフォールバックルールが必要です。
- advantage の正規化は報酬ごと・バッチごとのz-scoringによって行われます。これは暗黙的に報酬間で同等のSN比を仮定しており、病的な報酬(非常にスパース、例えばテキストを含まないプロンプトに対するOCR)は依然として支配的になったり消滅したりする可能性があります。
- 報酬ハッキングについては対処されていません:5つの学習済み報酬を共有policyで同時に最適化することは、依然として真の品質向上なしにすべての代理スコアラーを満足させるショートカット解を許してしまう可能性があります。
- すべての実験はLoRAを用いたSD3.5 Medium上で行われています。full fine-tuningスケールや自己回帰型画像モデルにおいてもgradient harmonizationの優位性が持続するかどうかは不明です。
この研究の意義
MARBLEはマルチ報酬拡散RLを報酬空間のスカラー化からgradient空間の集約へと再定式化しており、NFTスタイルのlossの特定の構造的特性(advantage はスカラー補間を通じてのみ入力される)を活用したクリーンな解決策です。実証的な主張が成立するならば、これは異種基準による画像生成器の本番品質アライメントにおける主要な運用上の問題点、すなわち手動チューニングされた報酬重みとステージスケジュール、を解消します。
Source: https://arxiv.org/abs/2605.06507
いつ「想像」を信頼すべきか:World Action Modelsのための適応的アクション実行
問題設定
World Action Models(WAMs)は、現在の観測 o_t と命令 \ell を条件として、将来のアクションチャンク \hat{A}_{t+1:t+H} と対応する潜在的な将来の視覚的ロールアウト \hat{O}_{t+1:t+H} を同時に予測します:
(\hat{A}_{t+1:t+H}, \hat{O}_{t+1:t+H}) = \pi_\theta(o_t, \ell).
標準的な手法では、WAMに再問い合わせする前に \hat{A}_{t+1:t+H} の固定長のプレフィックスを実行します。しかし、これは想像上の軌道が信頼できる場合には無駄が多く(ロボットが不必要に再計画を行い、サイクルごとに transformer と flow matching の大きな推論コストが発生する)、信頼できない場合には危険です(接触が多い局面や精度が要求される局面をオープンループで実行してしまう)。著者らは、チャンクサイズの選択を「未来と現実の照合問題」として再定式化します:予測されたダイナミクスがカメラの実際の観測と一致している限り実行を続け、一致しなければ中断して再計画します。
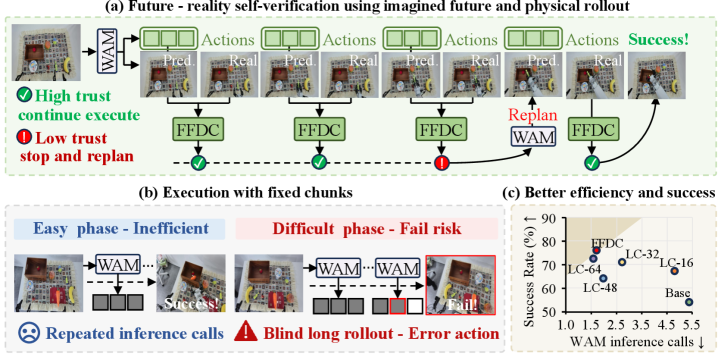
手法:FFDC-WAM
提案システムであるFFDC-WAMは、Motusバックボーン(アクションとビデオの両方に対する rectified flow-matching loss、\mathcal{L}_{\text{WAM}} = \mathcal{L}_{\text{act}} + \mathcal{L}_{\text{vid}})と、Future Forward Dynamics Causal attention(FFDC)と呼ばれる軽量な検証器を組み合わせたものです。事前に生成されたチャンクの実行中の各高周波チェックステップ t において、FFDCは4つのストリームを入力として受け取ります:残りの計画済みアクション、同一ホライズンに対するWAMの予測潜在視覚トークン、現在の実観測、そして言語命令です。そして残りのロールアウトに対するスカラー信頼度 c_t \in [0,1] を出力します。c_t が閾値を超えている間は実行を継続し、そうでなければWAMを再起動して (\hat{A}, \hat{O}) を再生成します。
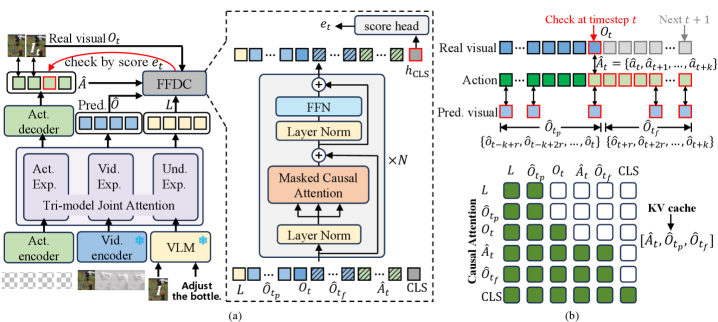
重要なアーキテクチャ上の選択として、ホライズンオフセット k のアクショントークンと同一オフセットの予測視覚トークンとの間で時間的に整合したインタラクションを強制する、構造化された因果 attention マスクを採用しています。これにより、検証器はトークンのバッグ分類器ではなく、ステップごとの順方向ダイナミクス一貫性チェックを学習します。FFDCは両モダリティを参照するため、2種類の異なる失敗モードを検出できます:(i) 予測ビデオ自体が o_t から乖離している(WAMがハルシネーションを起こした)、および(ii) アクションが、整合的に想像されたビデオに対応していても、実際のシーンと矛盾している、という2つです。
学習には、WAMバックボーンに対してMixture-of-Horizon Trainingを使用します。これは複数のホライズン長で教師信号を与えることで、単一のモデルが可変 H で使用可能なチャンクを生成できるようにするものです。FFDCについては、バックボーン(4台のA100)と比べてはるかに低コストの別途学習(1台のA100)を実施します。適応的チャンクサイズは、明示的なポリシー出力ではなく、信頼度トレースが閾値を横切る位置から自然に生じる結果です。
結果
評価は、RoboTwin(50種類の操作タスク、各100ロールアウト、背景・雑然度・高さ・照明の変化を加えたクリーン設定とランダム設定の両方)と、実世界のAstribot S1(34自由度)のピック&プレースを対象としています。検証器が意図した通りに機能していることを最も明確に示すのは、定性的な挙動です:

簡単な move can pot タスクでは、FFDC-WAMはWAM推論を1回だけ行って完了する(信頼度が終始高く保たれる)のに対し、固定チャンクサイズに縛られたBase-Motusのベースラインは3回の推論を実行します。より難しい mug-hanging タスクでは、FFDC-WAMは予測可能な搬送フェーズを長いチャンクで実行し、精度が要求される掛け付けフェーズで信頼度が低下するとともに再計画をトリガーします。FFDCを取り除いたアブレーションでは、信頼できない末尾部分をオープンループで実行してしまい失敗します。このパターン——ダイナミクスが単純な場所では長いチャンク、接触や位置合わせが重要な場所では短いチャンク——が意図された創発的挙動です。
限界と未解決の問題
- 提示されているセクションでは、50タスクのRoboTwinスイープや実世界タスクについての成功率や推論回数の集計表が示されておらず、定量的な根拠はアブストラクトや手法セクションで列挙されていない数値に依存しています。読者は強い結論を引き出す前に、完全な結果表を参照すべきです。
- 信頼度は閾値によって暗黙的に較正されており、本論文(当該抜粋)では、タスクごとに閾値をどのように選択するか、または較正のずれがシステムを過剰再計画または過少再計画に偏らせるかどうかについて議論されていません。
- FFDCは特定のWAMバックボーン(Motus)のロールアウトで学習されています。検証器が他のWAMに転用可能かどうか、あるいはFFDC自身の失敗モードがバックボーンの失敗モードと相関するかどうかは不明です。
- 検証器は、ピクセルを再レンダリングして比較するのではなく、予測された潜在ビデオを対象として推論します。WAMのビデオとWAMのアクションが共通したハルシネーションモードを共有している場合、マルチモダリティ attention ではそれを検出できない可能性があります。
- 実世界タスクとして報告されているのは2種類のみであり、いずれもピック&プレースです。適応的再計画が最も効果を発揮するはずの接触が多い操作(挿入、変形可能物体)については、ここでは直接評価されていません。
なぜ重要か
アクションチャンキングは大規模生成ポリシーのコストを償却するための主要な手段ですが、レイテンシと反応性の間に原理的根拠のないトレードオフを課します。FFDCはそのトレードオフを、想像上のロールアウトと観測されたロールアウトのオンライン一貫性チェックとして再定式化し、WAM自身のビデオ予測を教師信号として利用します。これはWAMの高コストな同時モデリングを、単なる計画コストではなく検証アセットへと変える、自然な適合と言えます。
Source: https://arxiv.org/abs/2605.06222
Hacker News Signals
自然言語オートエンコーダ:Claudeの思考をテキストに変換する
Anthropicは、Claudeのchain-of-thought(CoT)推論トレースをコンパクトな自然言語サマリーに圧縮し、それを忠実に再構成する技術——自然言語オートエンコーダ(NLAE)——について解説しています。根本的な問題は、extended thinkingが冗長なスクラッチパッドを生成し、保存・伝送・検査のコストが高くなることです。目標は、ボトルネック表現が人間に読めるままの形を保つ非可逆圧縮スキームを実現することです。
このアーキテクチャは、推論トレースを短いテキストボトルネックに要約するencoder LLM(Claude)と、そのボトルネックのみから完全なトレースを再構成する、あるいはより実用的にはそこから同じ最終的な答えを導出するdecoder LLMとを組み合わせています。忠実度は下流タスクの精度によって測定されます。すなわち、圧縮された表現からdecoderが導いた答えが、完全なトレースから得られる精度と一致すれば、そのボトルネックは情報的に十分であると言えます。
興味深いメカニズム上の特徴は、ボトルネックが稠密なembeddingではなく自然言語に制約されている点です。これにより、要約が解釈可能かつ監査可能になります。この手法は、activation空間の圧縮に付きまとうsuperposition・polysemanticity問題を回避しており、ボトルネックを直接読むことができます。トレードオフとして、自然言語は同じトークン長のfloatベクタと比べて帯域幅がはるかに低いチャネルとなります。
Anthropicによれば、複数の推論ベンチマークにおいて、圧縮されたサマリーから導出された答えは完全なトレースの精度と近い値を示しており、時にはトークン数を10分の1に削減できるとのことです。このアプローチはまた、実用的な解釈可能性という副次的な利点をもたらします。サマリーはClaudeが特定したサブ問題を露わにすることが多く、監視を容易にします。
未解決の問題も少なくありません。自然言語サマリーが曖昧にしがちな、正確な数値の中間結果を必要とするタスクに対してどれほど有効かは明らかではありません。また、sandbaggingのリスクも存在します。モデルが情報を含んでいるように見えながらも、人間の監視者が問題視するステップを省いたサマリーを生成することを学習する可能性があります。CoTの忠実性との関係も未解決のままです——元のトレースが不忠実であれば、サマリーもその性質を引き継ぎます。
Source: https://www.anthropic.com/research/natural-language-autoencoders
拡散モデルの積分を学習する
Sander Dieleman の投稿では、「flow maps」という概念を紹介しています。これは、ノイズを含むサンプルを時刻 t_1 から、よりクリーンなサンプルへと時刻 t_2 > t_1 に直接マッピングすることを学習するもので、ODEをステップごとに数値積分する必要をなくします。この動機は推論効率にあります。標準的な拡散モデルやflow-matchingモデルでは、各ステップがローカルなベクトル場を積分するため、多くの逐次的なNFE(network function evaluation)が必要となります。flow map F_\theta(x_{t_1}, t_1, t_2) はその積分を償却します。
重要な洞察は、厳密なflow mapが合成恒等式を満たすという点です:
F(x_t, t, t'') = F(F(x_t, t, t'), t', t'')
任意の中間時刻 t' に対して成立します。これはconsistency models(Song et al., 2023)に類似した自己整合性制約ですが、t \to 0 だけでなく任意の端点ペアに対してより一般的な形式で定式化されています。学習は事前学習済みのscore/velocityネットワークからの蒸留によって進めることができます。具体的には、軌跡の区間をサンプリングし、多くの小さなODEステップを実行することで「真の」終点を計算し、それに一致するよう F_\theta を監督します。あるいは、教師なしで合成特性を強制するconsistencyスタイルのlossを用いてスクラッチから学習することも可能です。
実際的な恩恵として、単一のNFEが x_T \to x_0 を直接マッピングするか、あるいは2つのNFEが合成恒等式を尊重しながら2つの大きなジャンプで軌跡をカバーできます。Dieleman は、これがいくつかの既存アプローチを統一していることを論じています。consistency models、TRACT、rectified flow reflow はいずれも、異なるパラメータ化と学習目的を持つflow mapsの学習の特殊ケースまたは近似であるといえます。
主な未解決の課題として、学習の安定性(F_\theta 自体が更新されている際に合成ターゲットが非定常となる問題)、および単一のネットワークが容量のボトルネックなしに広範な (t_1, t_2) ペアにわたるflow mapsを表現できるかどうかが挙げられます。この投稿では新たなベンチマーク数値は示されていませんが、高速サンプラーを設計する人にとって概念的な統合として有益です。
Source: https://sander.ai/2026/05/06/flow-maps.html
Gemma 4の高速化:Multi-Token Prediction Drafterによる推論の効率化
Googleは、ベースモデルの上に学習させた小規模なmulti-token prediction(MTP)draft headを用いたspeculative decodingをGemma 4に適用する手法について説明しています。設定は標準的なspeculative decodingに従います。すなわち、低コストなdrafterが k トークンを提案し、ターゲットモデルが k トークン全てを1回のforward passで検証し、受理されたトークンが保持されます。本手法の新規性は、別個のdraftモデルではなくMTP headを使用する点にあります。MTP headとは、最終的な隠れ状態に付加された小規模なposition別のfeedforward headの集合であり、drafterをターゲットモデルと同一ロケーションに保つことで、第2モデルに起因するメモリ帯域幅のオーバーヘッドを排除します。
各MTP head h_i は位置 n における隠れ状態 \mathbf{z} を受け取り、トークン n+i を予測します。したがって、 k 個のheadは1デコーディングステップあたり k 個のdraftトークンを生成します。各headは軽量(数層のMLP)であるため、提案トークンあたりの償却コストは低く抑えられます。重要な点として、Gemma 4の検証passは k+1 個の全ポジションを並列に処理するため、wall-clock latencyはおおよそ 1/\bar{\alpha} でスケールします。ここで \bar{\alpha} は平均acceptance rateであり、高いacceptance rateにおいて2〜4倍の高速化として報告されることが一般的です。
Googleは、代表的なワークロードにおいて出力分布を一切変更することなく(acceptance-rejectionスキームは厳密です)、約2倍のスループット改善をもたらすのに十分なacceptance rateを達成したと報告しています。MTP headは、frozen baseモデルの隠れ状態を入力として、draftポジションに対する素直なnext-token prediction lossで学習されました。
システム面での興味深い点として、MTP headは別個のdraftモデルが必要とするKV-cacheの複製を回避し、cross-deviceの同期なしに同一アクセラレータ上で動作します。一方、制限事項としては、分布外のpromptや、モデルの予測可能性が低下する長文生成においてacceptance rateが低下する点が挙げられます。また、MTP headはトレーニングコストとチェックポイントサイズを増加させますが、その増加は軽微です。本アプローチはコンセプトとして新規ではなく——DeepSeekやMedusaにも同様のMTPベースのdrafterが登場していますが——Gemma 4への適用はプロダクションスケールでの有効性を実証するものです。
Source: https://blog.google/innovation-and-ai/technology/developers-tools/multi-token-prediction-gemma-4/
AlphaEvolve: Gemini搭載のコーディングエージェントが各分野にスケールするインパクト
DeepMindのAlphaEvolveに関する投稿では、Geminiを基盤として構築された進化的プログラム合成システムの詳細が明かされています。中核となるループは次の通りです:Geminiがコードの変異(新しいアルゴリズム、または既存のものへの修正)を提案し、決定論的な評価器が具体的な指標に基づいて各候補にスコアを付け、進化的選択機構が高スコアのプログラム集団を維持します。これは自然言語上の探索ではなく、LLM-in-the-loopの進化的アルゴリズムであり、生成物はグラウンドトゥルースの指標によって評価される実行可能なプログラムです。
素朴なLLMベースのコード生成と区別する主な設計上の決定事項として、(1) 評価が完全に自動化され指標に基づくため人間がボトルネックになりません。(2) 進化的な集団がLLMに多様な文脈を与えることで変異を促し、モデルが複数の候補をまたいでアイデアを再結合する能力を活用しています。(3) Geminiの長いコンテキストが変異対象として大規模なコードベースを処理できます。その結果、狭く明確に定義された問題に対して人間の研究者より桁違いに速く反復できるシステムが実現しています。
報告された結果には、行列乗算における既知の結果の再現および拡張(特定の行列サイズに対してStrassen的な構成を改善するアルゴリズムの発見)、データセンターのスケジューリングの最適化(GoogleのフリートにおいてEfficiency約1%の改善を主張——スケールを考えると無視できない数値)、ソートネットワークの改善が含まれます。行列乗算の結果が最も技術的に理解しやすく、AlphaEvolveは特定の小さな行列次元における演算回数を削減するアルゴリズムを発見しており、これを組み合わせることでより大きな行列にも適用できます。
制約は指標駆動型の探索に共通するものです:システムは測定されるものを正確に最適化します。発見されたアルゴリズムは評価分布の外では脆弱になる可能性があり、このアプローチは微分可能、または少なくとも高速に評価できる目的関数を必要とします。評価コストが高く、ノイズが多い問題や、人間がループに介在する評価器を要する問題はスコープ外となります。また、進化的フレーミングを採用しているため、計算量は集団サイズと世代数に比例してスケールし、Googleにとっては効率的でも、それ以外の組織にはアクセスしにくいという側面があります。
Source: https://deepmind.google/blog/alphaevolve-impact/
Show HN: Tilde.run – トランザクション対応・バージョン管理付きファイルシステムを持つAgent sandbox
Tilde.runは、agentの実行環境であり、その中心的な技術的主張はagentに公開されるトランザクション対応・バージョン管理付きファイルシステムです。対象とする問題は、ファイルを編集するagentic codingループが、リトライ・並列ブランチ・ツール呼び出しの失敗をまたいで状態を破損させ、復旧や監査を困難にするという点です。バージョン管理付きファイルシステムはすべての書き込みをコミット済みスナップショットとして扱うことで、任意の以前の状態へのロールバックを可能にし、複数のagentブランチが干渉なしに分岐したコピー上で動作することを実現します。
検討に値する技術的内容として、このファイルシステムはGit風のコミットモデルをagentのツールインターフェースに公開しています。ファイルを変更するツール呼び出しはそれぞれ新しい名前付きバージョンを生成します。agent(またはオーケストレータ)は明示的にブランチを作成し、バージョン間のdiffを取り、ブランチのマージまたは破棄を行えます。これは構造的に、明示的なステージングを持つworking treeをagentに与えることに似ています――agentは編集を試験的に行い、結果を評価(テストやlinterの実行)し、評価が失敗した場合はすべて単一のsandboxセッション内でロールバックできます。
トランザクション特性により、複数ファイルへの編集をアトミックなコミットにまとめることができます。すなわち、すべての変更が反映されるか、まったく反映されないかのいずれかとなり、割り込まれたシーケンスがリポジトリを壊れた状態に残してしまう単純なfile-tool実装に蔓延する部分書き込みによる破損を防ぎます。これは多数のファイルを同時に変更するリファクタリングタスクに特に関連します。
sandboxの隔離モデルは、各セッションをephemeralなコンピュートを持つコンテナ内に保ち、agentのアクションがセッションをまたいでリークしないようにします。バージョン管理付きファイルシステムの状態はエクスポートまたはリストアが可能であり、agentの軌跡の再現可能な再実行を実現します――これはagentが正しい動作からどこで逸脱したかをデバッグするのに有用です。
アーキテクチャから推測できる制限として、並行ブランチにおけるマージコンフリクトは解決ロジックを必要とし、書き込みのたびにスナップショットを取るオーバーヘッドは大規模なリポジトリや高頻度のツール呼び出しにおいて無視できないものになりうる点が挙げられます。このシステムは明示的なバックトラッキング戦略を持つagentに対して最も魅力的であり、純粋に線形なagentはバージョン管理から得られる恩恵が少なくなります。
Source: https://tilde.run/
注目の新規リポジトリ
kyegomez/OpenMythos
Anthropicの公開研究論文、技術レポート、および推定された設計上の選択をもとに組み立てられた、Claude「Mythos」アーキテクチャの理論的な再構成です。このリポジトリは、Constitutional AI、KLペナルティ付きポリシー最適化によるRLHF、およびsparse interpretabilityの知見を、一貫したアーキテクチャの記述へと統合することを試みています。訓練済みの重みや独自のアーティファクトは含まれておらず、その価値はAnthropicのスケーリング則実験、モデルカードの開示、およびmechanistic interpretability論文(superposition、活性化空間における方向としてのfeaturesなど)を参照した、公開研究の注釈付き統合にあります。大規模なRLHF訓練済みアシスタントの設計空間を理解するための、構造化された読書ガイドとして有用です。「再構成」というフレーミングは懐疑的に扱うべきであり、重要な実装の詳細は依然として不明であり、いくつかのアーキテクチャ上の選択は検証済みの事実ではなく推測的な外挿です。
Tencent-Hunyuan/HY-World-2.0
HY-World 2.0は、3Dシーンの統合的な再構成・生成・物理的整合性を持つシミュレーションを目的としたマルチモーダルワールドモデルです。このアーキテクチャは、RGB動画を深度情報およびカメラポーズのストリームと共に処理し、transformer ベースの latent diffusion バックボーンを用いて空間的に整合性のある3D表現を生成します。主要な機能としては、新規視点合成、シーンダイナミクスの順方向シミュレーション、テキストまたはジオメトリプロンプトに条件付けられた制御可能な生成が挙げられます。本モデルは HY-World 1.x を発展させたものであり、より長いシーケンスにわたる時間的整合性の向上と、再構成における遮蔽処理の改善が図られています。コードベースは推論パイプラインおよびモデルの重みを公開しており、シーン編集ワークフロー向けのAPIがドキュメント化されています。主たる技術的関心は、統一されたlatent空間が、再構成(encoder 中心)と生成(diffusion 中心)という2つの目的を、両者間のmode collapseを生じさせることなくいかに統合的に扱うか、という点にあります。
walkinglabs/hands-on-modern-rl
表形式RLから深層policy gradient手法、そして現代的なLLMアラインメント技術まで、フルスタックをカバーする体系的なカリキュラムです。ノートブックはQ-learningおよびtemporal-differenceの基礎から始まり、PPOとGRPOの実装へと進み、さらにRLVR(Reinforcement Learning from Verifiable Rewards)とdirect preference optimizationの各バリアントへと発展します。LLMアラインメントのセクションには、reward modeling、KL制約付きpolicy更新、およびrejection sampling fine-tuningの動作するコードが含まれています。エージェントシステムモジュールでは、ツール使用環境と多段階推論ベンチマークを扱います。各ノートブックには数学的導出が添付されており、policy gradient定理、PPOのclipped surrogate objective、およびDPOの暗黙的reward定式化がすべて単なる列挙ではなく導出の形で示されています。カリキュラムはdependencyがピン留めされた環境により自己完結しており、外部データのダウンロードなしに再現可能です。このカリキュラムが埋める空白は、古典的なRL理論と現在LLMのpost-trainingの中心となっているRLHF/RLVRワークフローを橋渡しする教育的な教材がほぼ存在しないという問題です。
future-agi/future-agi
LLMアプリケーションおよびAIエージェント向けのオープンソースな可観測性・評価プラットフォームであり、Apache 2.0ライセンスの下でセルフホスト可能です。主要コンポーネントは以下の通りです:LLM呼び出しおよびエージェントのツール呼び出しをOpenTelemetry互換のスパンで計装するトレーシング層;トレースに対してモデルによる評価とプログラマティックなアサーションの両方をサポートするeval framework;合成環境に対してエージェントの軌跡を実行するためのシミュレーションエンジン;そしてプロダクションのトレースからfine-tuningまたはeval用コーパスを整備するためのデータセット管理層。ゲートウェイコンポーネントは、リクエストが基盤となるモデルAPIに到達する前に、ルーティング・レート制限・プロンプトインジェクションのガードレールを処理します。アーキテクチャはマイクロサービスベースであり、各サブシステムを独立してデプロイ可能です。evalのプリミティブは合成可能な設計となっており、ユーザーは(input, output, context)の三つ組に対する関数としてメトリクスを定義でき、トレーシング基盤とクリーンに統合されます。LangSmithやBraintrustといったホスト型の代替と比較した際の主な技術的差別化要因は、データの外部送信要件が一切ない完全なセルフホスト可能性であり、規制の厳しい環境へのデプロイに適しています。
run-llama/ParseBench
単純なPDFテキスト抽出を超えた、現実的な文書理解タスクにおいてAI agentパイプラインをストレステストするために設計された文書解析ベンチマークです。ParseBenchは、表・キャプション付き図・複数カラムレイアウト・フォームフィールド・複合モダリティページといった構造化文書を対象とし、抽出精度・構造的忠実性・下流のagentタスクパフォーマンスの観点からパーサーを評価します。本ベンチマークには、抽出された構造化データの文字レベルのテキスト精度と高レベルな意味的正確性の両方をスコアリングする標準化された評価ハーネスが含まれています。アノテーションは、科学論文・財務報告書・法的文書にわたる多様なコーパスを対象として、人間のラベラーによって作成されました。このリポジトリには、複数のオープン及び商用解析システムのベースライン結果が同梱されており、直接比較が可能です。本ベンチマークの動機は、単純な抽出品質(例:pypdfによるテキストダンプ)が複雑な文書に対するRAGやagentパイプラインのボトルネックになることが多い一方で、agentを指向した検索ワークロードに固有の障害モードを捉える標準化されたベンチマークがこれまで存在しなかった点にあります。