Daily AI Digest — 2026-05-08
arXiv Highlights
Can RL Teach Long-Horizon Reasoning to LLMs? Expressiveness Is Key
Problem
A central empirical question in RL post-training of LLMs is how training cost scales with task difficulty. Prior work mixes confounded axes (problem length, vocabulary, planning depth, logical structure), making it hard to isolate what makes RL hard. This paper introduces ScaleLogic, a synthetic logical-reasoning generator that decouples two axes: proof depth D (the horizon) and logical expressiveness (the fragment of first-order logic in use, from implication-only up through conjunction, disjunction, negation, and universal quantification). With these knobs, the authors measure how RL training compute T to reach a target accuracy scales with D at each expressiveness level, and whether more expressive training transfers better to real benchmarks.
Method
Each instance is a single-answer multiple-choice problem with B candidate conclusions. Generation is backward: sample B root literals, then recursively expand each into a proof tree to depth D, where every parent node is the conclusion of a proof step over its children as premises. Predicates introduced at each expansion are fresh, guaranteeing a unique derivation per subtree. One proof tree is left intact; the other B-1 are sabotaged by either (i) deleting one uniformly-sampled axiom or (ii) flipping the polarity of one literal in an axiom (only available when negation is in the logic). Distractor rules are inserted to add local ambiguity without creating alternative derivations. The resulting two structural knobs — branching B and depth D — directly control candidate confusability and chain length.
Expressiveness is varied by enabling additional connectives in the rule schemas: implication-only (Horn-style “if-then”), then +\land, +\lor, +\neg, and finally +\forall (universal quantification over typed entities). RL post-training is performed on Qwen3-4B (non-thinking) with verl, using GRPO as the default; replication on Qwen3-8B and other RL algorithms is in the appendix.
The central scaling claim is that, fixing expressiveness, the compute T(D) needed to reach a target accuracy follows
T(D) = a \cdot D^{\gamma},
with \gamma as the depth-scaling exponent characterizing that logic.
Results
The power law holds tightly: R^2 > 0.99 across all expressiveness settings. The decisive comparison is against an exponential alternative T(D) = a \cdot e^{\gamma D}; the AIC differences consistently favor the power law in every setting.
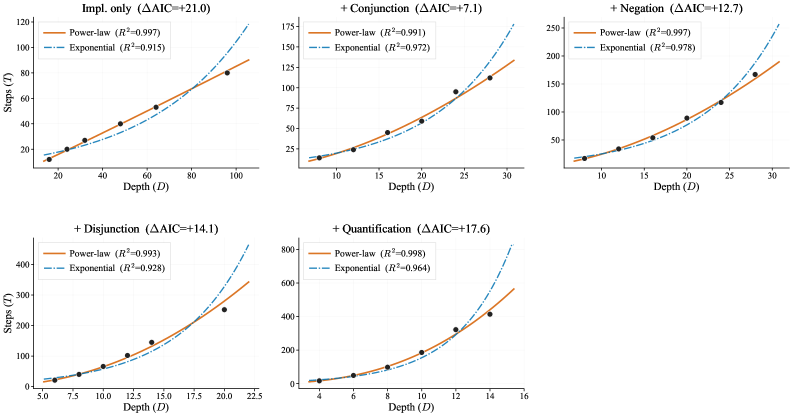
The key finding is that \gamma increases monotonically with expressiveness, from \gamma \approx 1.04 for implication-only logic up to \gamma \approx 2.60 at the +Quantification level. So while RL can extend reasoning horizons, the marginal cost of one more depth step grows superlinearly in richer logics — roughly D^{2.6} when quantification is in play, versus near-linear for Horn fragments. The exponents are robust to the choice of compute measure: when T is replaced by generated tokens, kept-batch update tokens, training FLOPs T_{\text{FLOPs}} = 2N T_{\text{gen-tok}} + 6N T_{\text{upd-tok}}, or wall-clock, the power-law fits and ordering of \gamma persist.
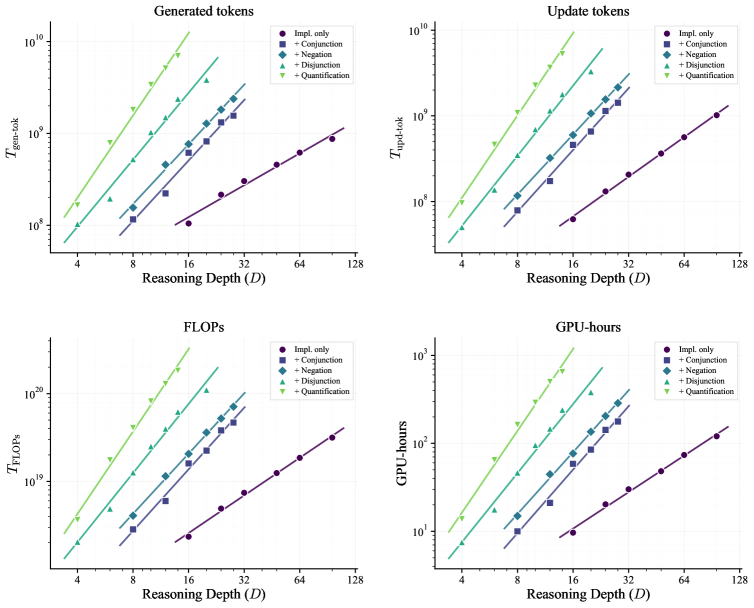
On downstream transfer, training in more expressive ScaleLogic settings yields larger gains on math and general reasoning benchmarks — up to +10.66 points over the base model — and reaches given accuracy levels with less compute than less expressive training. So expressiveness is not just a difficulty knob; it determines transfer quality. The scaling behavior also holds across multiple RL algorithms (not GRPO-specific) and shows non-trivial OOD generalization to depths beyond those seen in training, though the paper still reports degradation as the depth gap widens.
Limitations and open questions
- ScaleLogic is synthetic and proof-unique by construction; real reasoning admits multiple valid derivations and noisy premises, which may change the shape of T(D).
- Experiments center on Qwen3-4B with one extension to 8B; the dependence of \gamma on model scale, base capability, and pretraining data composition is not characterized — a \gamma(N) scaling law would be the natural next step.
- The choice of “expressiveness levels” is a discrete ladder; a continuous complexity measure (e.g., descriptive complexity class, or proof-search branching factor) would let one predict \gamma from logical structure rather than fit it.
- The downstream transfer result, while encouraging, is measured on standard benchmarks where contamination and stylistic overlap with synthetic chains-of-thought are hard to rule out.
Why this matters
If RL compute to reach depth D scales as D^\gamma with \gamma governed by logical expressiveness, then “long-horizon reasoning via RL” is not a single problem but a family parameterized by the underlying logic — and the gap between \gamma \approx 1 and \gamma \approx 2.6 is the difference between tractable and prohibitive at scale. It also suggests synthetic curricula should be deliberately maximally expressive, since those settings transfer better per unit compute.
Source: https://arxiv.org/abs/2605.06638
Continuous Latent Diffusion Language Model
Cola DLM proposes a hierarchical latent-variable language model that decouples global semantic planning from local token realization. Rather than running diffusion over discrete tokens (LLaDA, MDLMs) or over per-token continuous embeddings (Plaid, SEDD-style continuous variants), Cola DLM trains a Text VAE to obtain continuous latents z_0 \in \mathbb{R}^d and learns a continuous normalizing flow (CNF) prior p_\psi(z_0) via flow matching. Generation factorizes as
p(x) = \int p_\theta(x\mid z_0)\, p_\psi(z_0)\, dz_0,
with the prior implemented as the pushforward of \mathcal{N}(0,I) under a learned vector field v_\psi:
z_1 \sim \mathcal{N}(0,I),\quad \tfrac{dz_t}{dt}=v_\psi(z_t,t),\quad z_0=\Phi^\psi_{0\leftarrow 1}(z_1).
The latent is split into B blocks with a block-causal factorization p_\psi(z_0)=p_\psi(z_0^{(1)})\prod_{b=2}^B p_\psi(z_0^{(b)}\mid z_0^{(<b)}), which is enforced by a block-causal DiT. Conditional generation given a prefix x^{\mathrm{pre}} encodes the prefix to z^{\mathrm{pre}}\sim q_\phi(\cdot\mid x^{\mathrm{pre}}) and then samples response blocks autoregressively in latent space, \hat z_0^{(b)} = \Phi^\psi_{0\leftarrow 1}(\epsilon^{(b)}; z^{\mathrm{pre}}, \hat z_0^{(<b)}), before decoding x^{\mathrm{res}}\sim p_\theta(\cdot\mid x^{\mathrm{pre}}, z^{\mathrm{pre}}, \hat z_0^{(1:B)}). The crucial conceptual point, made precise in the unified Markov-path comparison (Appendix 11), is that the diffusion is a prior-transport process on an observation-independent latent, not a token-corruption recovery process; this is what separates global semantic organization from surface generation.
Training pipeline
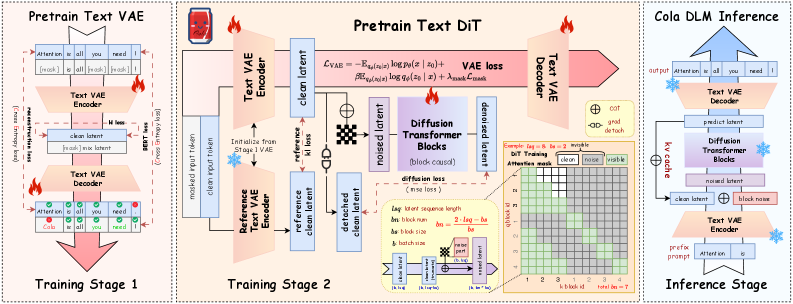
Stage 1 pretrains the Text VAE with a reconstruction loss, an auxiliary BERT-style objective, and a KL regularizer; Stage 2 jointly trains the VAE and the block-causal DiT with gradient control to keep the encoder/decoder from collapsing while flow matching shapes the prior. The flow-matching loss
\mathcal{L}_{\mathrm{FM}}(\psi) = \mathbb{E}\big[\|v_\psi(Z_t,t,c) - U^\star\|^2\big]
regresses the conditional mean velocity (Proposition 14.1), which the paper explicitly notes is not a mode-seeking density estimator — a direct cause of the PPL/quality mismatch discussed below.
Theoretical positioning
Section 12 unifies AR, LLaDA, Plaid, and Cola DLM under a population-risk decomposition
\text{risk} = H(p_{\mathrm{data}}) + \text{model mismatch} + \text{objective gap}.
For Cola DLM, the ELBO contributes an inference gap \mathcal{G}^{\mathrm{infer}} = \mathbb{E}\,\mathrm{KL}(q_\phi(z_0\mid x)\|p_{\theta,\psi}(z_0\mid x))\ge 0, so superiority over AR is conditional on the latent class having lower mismatch by more than this gap. Section 14 further argues that the standard PPL estimator \mathcal{S}_{\mathrm{resp}}(x) is a local score around a single posterior latent and systematically overestimates NLL relative to the true marginal p(x^{\mathrm{res}}\mid c)=\int p_\theta(x^{\mathrm{res}}\mid z,c)p_\psi(z\mid c)dz, motivating their decision to evaluate by accuracy rather than PPL.
Latent geometry and noise schedule
Section 13 tests a falsifiable null hypothesis: if the latent is a sum of independent local dimensions, the optimal logSNR shift \delta^\star should be invariant to latent dimension d (Proposition 13.2, since \mathcal{J}_d(\delta)=a_d j(\delta)+b_d). Empirically this is rejected.
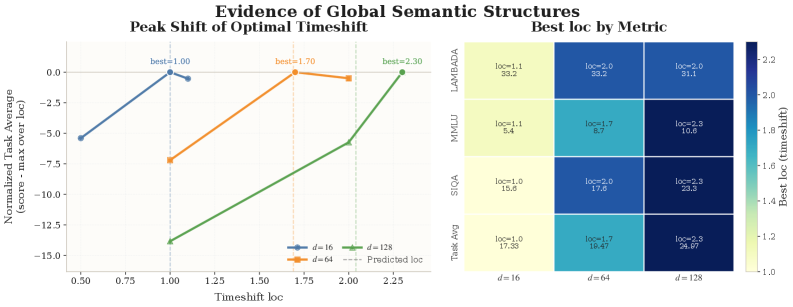
Larger d systematically prefers larger shifts (i.e., more of the schedule allocated to high-noise / low-SNR regions), and this preference is stable across evaluation metrics, supporting the existence of cross-dimensional joint semantic structure. Section 15 frames the shift \lambda_\delta(t)=\lambda(t)+\delta as remapping raw timesteps to logSNR intervals via \alpha_{t,\delta}^2=\mathrm{sigmoid}(\lambda(t)+\delta), so uniform-t training is not equivalent to uniform-\lambda training — the shift is a semantic information recalibration, not a label translation.
Experimental results
Setup: OLMo 2 tokenizer, 500M VAE + 1.8B DiT (≈2B total), compared against AR (LLaMA-style) and discrete diffusion (LLaDA) baselines with ≈400M embedding + 1.8B backbone, all trained on identical data with seq length 512, AdamW, lr warmed to 1.5\times 10^{-4} over 5k steps then cosine-decayed to 1\times 10^{-5} by 1M steps. Evaluation is unified few-shot generation with strict string matching on LAMBADA, MMLU, SIQA, SQuAD, Story Cloze, OBQA, RACE, HellaSwag.
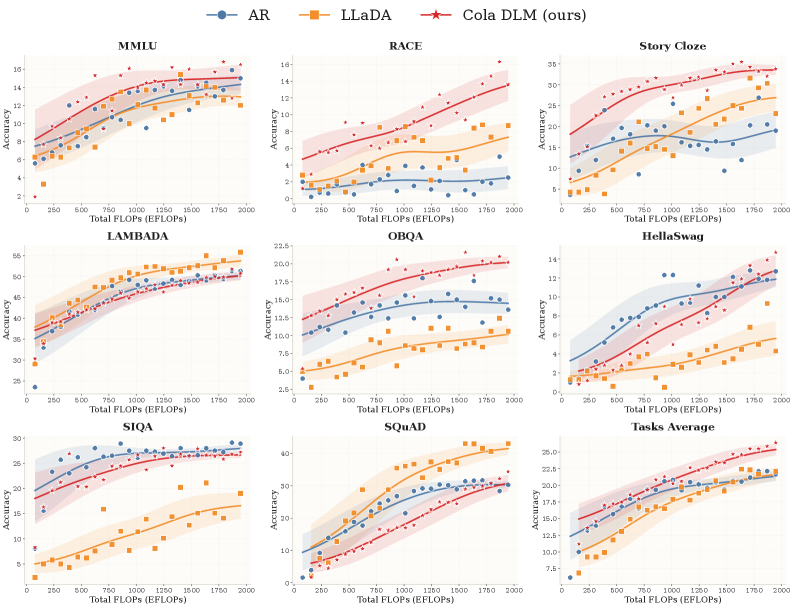
Cola DLM shows favorable scaling and reaches the best Task Average across the eight benchmarks under the matched ~2B FLOPs-budget protocol. The authors flag that absolute accuracy on some multiple-choice tasks is depressed because the protocol forces generative answering rather than likelihood ranking — a known disadvantage for non-AR models that nonetheless makes the comparison faithful.
Limitations
The PPL-quality mismatch is structural, not incidental: flow matching learns conditional-mean velocities, and the local ELBO score double-penalizes posterior concentration, so standard likelihood metrics cannot be used for model selection or comparison with AR baselines. The block-causal DiT reintroduces a coarse autoregressive bias at the latent level, which limits the “non-autoregressive” claim to within-block parallelism. Scaling beyond 2B and matched-data budgets is untested, as is whether the inference gap \mathcal{G}^{\mathrm{infer}} closes with scale or stays bounded away from zero. Decoding requires both an ODE integration over v_\psi and a conditional decoder pass, so wall-clock comparisons against AR at matched quality are not reported in the provided sections.
Why this matters
Cola DLM is a clean instantiation of the “diffusion as latent prior transport, not token corruption” view, with explicit theoretical machinery (unified Markov-path decomposition, ELBO-vs-NLL gap analysis, logSNR-shift recalibration) that explains why continuous-latent text diffusion can match AR on downstream accuracy while looking worse on PPL. If the inference gap is genuinely small at scale, this is a credible route to non-AR text models that also extend naturally to continuous multimodal latents.
Source: https://arxiv.org/abs/2605.06548
Continuous-Time Distribution Matching for Few-Step Diffusion Distillation
Problem
Step distillation for diffusion/flow models has converged on two paradigms: Distribution Matching Distillation (DMD/DMD2) and Consistency Distillation (CD). DMD enforces a reverse-KL between student and teacher marginals, but only at a small set of predefined discrete inference timesteps \{t_1,\dots,t_N\} that coincide with the student’s sampling schedule. This sparse anchoring, combined with the mode-seeking nature of reverse KL, produces over-smoothed samples and visible artifacts, which prior work patches with auxiliary GAN discriminators or reward models. CD by contrast supervises the entire PF-ODE trajectory but tends to bias outputs toward the data manifold via teacher-trajectory matching rather than distributional fidelity. CDM asks whether DMD’s distributional objective can be lifted to continuous time, eliminating the need for adversarial or reward-based crutches.
Method
The setup is a velocity-parameterized flow student \mathcal{D}_\theta(\mathbf{x}_t,t,\mathbf{c})=\mathbf{x}_t - t\, v_\theta(\mathbf{x}_t,t,\mathbf{c}), distilled from a teacher \mathcal{D}_\phi via the decoupled DMD loss \mathcal{L}_{\mathrm{DMD}}=\mathcal{L}_{\mathrm{CA}}+\mathcal{L}_{\mathrm{DM}}. The CA term reinjects classifier-free guidance information through a normalized score-difference
\Delta_{\mathrm{ca}}^{\mathrm{real}} = w_\tau\,\alpha\,\bigl(\mathcal{D}_\phi(\mathbf{z}_\tau,\tau,\mathbf{c})-\mathcal{D}_\phi(\mathbf{z}_\tau,\tau,\varnothing)\bigr),\qquad w_\tau = \|\mathcal{D}_\phi(\mathbf{z}_\tau,\tau,\mathbf{c})-\mathcal{D}_\theta(\mathbf{x}_{t_i},t_i,\mathbf{c})\|_1^{-1},
and the DM term carries the standard reverse-KL surrogate using a fake-score network \mathcal{D}_\psi.
CDM modifies this baseline along two axes.
1. Dynamic continuous schedule. Vanilla DMD2/D-DMD perform backward simulation only along the fixed inference grid \{t_1,\dots,t_N\}, then sample one anchor i\sim\mathcal{U}\{1,\dots,N\} at which to apply CA+DM. CDM instead samples a random schedule length and anchor positions per iteration: anchors are drawn uniformly from t\in(0,1], decoupling supervision from the deployment-time grid.
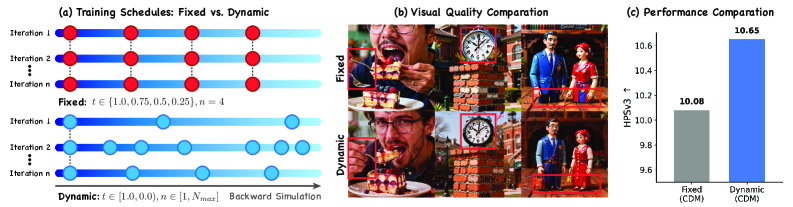
The empirical claim, visible in Figure 2(b), is that strict anchoring overfits the velocity field at a handful of timesteps and leaves the trajectory under-regularized elsewhere; uniform continuous sampling fills in the gaps and yields finer texture.
2. Continuous-time alignment via velocity extrapolation. Even with random anchors, supervision still falls on points the student’s own backward simulation visits — i.e., on-trajectory latents. CDM additionally regularizes off-trajectory points by extrapolating from the current anchor \mathbf{x}_{t_i} along the student’s velocity to a perturbed time t', generating a synthetic latent
\tilde{\mathbf{x}}_{t'} = \mathbf{x}_{t_i} + (t'-t_i)\,v_\theta(\mathbf{x}_{t_i},t_i,\mathbf{c}),
then applying the DM objective at (\tilde{\mathbf{x}}_{t'},t'). This forces consistency of the velocity field across (0,1] rather than only along sampled trajectories, which is the mechanism by which CDM imports CD’s full-trajectory coverage into the DMD framework without abandoning distribution matching.
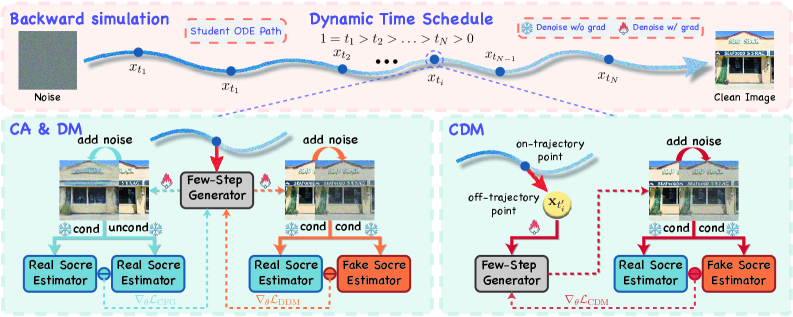
A useful auxiliary observation motivating the design: when only \mathcal{L}_{\mathrm{DM}} is applied, the student converges to the CFG-free teacher distribution rather than the CFG-augmented one, indicating that DM is the actual distributional driver and CA is the orthogonal correction needed to inject guidance.

Results
Experiments are on SD3-Medium at 1024\times1024, evaluated on 2K PickScore-test prompts (AES, PickScore, HPS v3, CLIP ViT-H-14) and 1K DPG-Bench prompts. Baselines include Hyper-SD, Flash, TDM, DMD2, and D-DMD. Generalization is verified by porting the pipeline to Longcat-Image. The selected sections do not enumerate the full numeric table, but the abstract and method position CDM as removing the GAN/reward auxiliary modules that DMD2 and follow-ups depended on for visual fidelity, while operating in the same few-step regime (N small, e.g. 1–4 steps).
Limitations and open questions
- The off-trajectory extrapolation is first-order in v_\theta; for large |t'-t_i| the synthetic latent diverges from any true PF-ODE point, and the regularizer effectively asks the fake-score network to evaluate DM on out-of-distribution inputs. The paper does not, in the excerpted sections, characterize how aggressive |t'-t_i| can be before destabilizing \mathcal{D}_\psi.
- Random schedule length means the student is trained under varying numbers of backward steps, but is deployed at a fixed N; whether this train/test mismatch costs anything at very low N (1–2 step regime) is not addressed.
- The DM-only experiment shows the student matches the CFG-free teacher; this is consistent with the standard observation that distillation collapses CFG, but it also means CDM’s quality ceiling is gated by how well the CA term reconstructs guidance under continuous-time supervision.
- Only flow-matching teachers (SD3, Longcat-Image) are evaluated; transfer to \epsilon-prediction or v-prediction DDPMs is left implicit.
Why this matters
CDM closes a conceptual gap between consistency methods (full-trajectory, manifold-anchored) and distribution matching (sparse, distributionally correct) by showing that DMD’s reverse-KL objective can be applied densely in continuous time once anchors are randomized and off-trajectory points are reached via velocity extrapolation. If the reported quality holds, it removes the GAN/reward scaffolding that has accumulated around DMD2-style pipelines, simplifying few-step distillation to a single decoupled CA+DM objective.
Source: https://arxiv.org/abs/2605.06376
UniPool: A Globally Shared Expert Pool for Mixture-of-Experts
Problem
Standard MoE transformers tie expert capacity to depth: each of the L layers maintains its own bank of E experts, so the expert parameter count grows linearly with depth regardless of whether deeper layers actually need fresh capacity. Recent evidence suggests they do not. Same-layer expert weight matrices in Qwen and DeepSeek MoEs share dominant subspaces with pairwise cosine similarity above 0.9; tokens re-routed to the most-similar same-layer expert in Qwen1.5-MoE, DeepSeek-V2-Lite, Qwen3-30B-A3B, and OLMoE preserve accuracy with up to 2\times decoding speedup; pruning roughly half of Mixtral 8x7B’s experts costs only ~8% relative quality, with redundancy concentrated in deep layers.
The authors add a router-level probe: replace one deep-half layer’s learned top-k router with uniform random assignment. Across Qwen1.5-MoE, DeepSeek-V2-Lite, and Qwen3-30B-A3B, average downstream accuracy drops only 1.0–1.6 points (e.g., Qwen1.5-MoE: 67.92 → 66.29; Qwen3-30B-A3B: 73.02 → 72.06). The router itself is not committing to a sharp partition over its private set, suggesting per-layer ownership encourages each block to independently rediscover the same transformations.
Method
UniPool drops layer-private ownership entirely. Instead of L disjoint sets \{e_{l,1},\ldots,e_{l,E}\}, all layers route into a single pool \mathcal{E}=\{e_1,\ldots,e_M\}. Each layer l keeps its own router r_l:
\text{FFN}_l(x) = \sum_{i \in \text{Top-}k(r_l(x))} g_{l,i}(x)\cdot e_i(x),
where e_i is shared across all l. Routers stay layer-specific because residual-stream statistics differ by depth, but the underlying FFN computations are reused. The pool size M is set to match the vanilla MoE expert-parameter budget while keeping dense-equivalent active FFN compute.
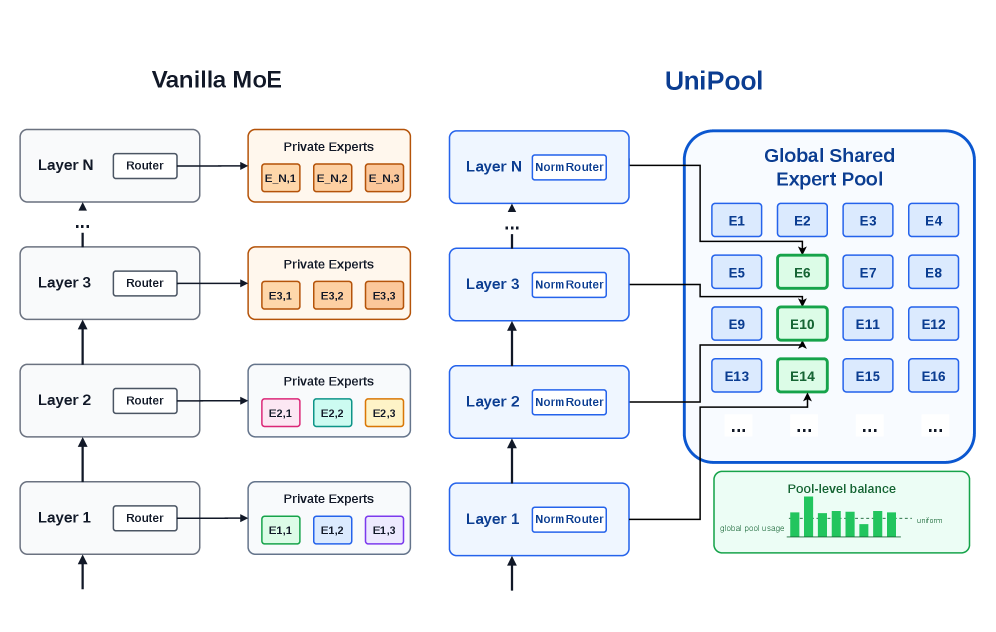
Two additional pieces are needed for stable training under sharing:
Pool-level auxiliary loss. A standard per-layer load-balancing loss is wrong here because experts are shared: a per-layer balancing term would punish the natural pattern where some experts get heavily used at certain depths and not others. UniPool instead aggregates utilization across all L layers and balances at the pool level, ensuring no expert is globally orphaned without forcing every layer to use every expert uniformly.
NormRouter. Replaces the softmax router with a normalized scoring rule that produces sparse, scale-stable assignments into the shared pool. The ablation shows that swapping NormRouter into vanilla MoE alone is mildly harmful (+0.0058 loss), but it composes well with sharing.
The ablation also examines intermediate sharing scope G, where G=L recovers vanilla MoE per-layer ownership and G=1 is full UniPool. Sharing groups of G=6, 4, 2 all improve over vanilla, with monotone gains as G\to 1.
Results
Trained on 30B tokens of the Pile across five LLaMA-style scales (182M–978M active params, default 8E/top-1):
| Scale | Vanilla MoE PPL | UniPool PPL |
|---|---|---|
| 182M | 6.9012 | 6.7058 |
| 469M | 6.0388 | 5.8334 |
| 650M | 5.7940 | 5.6186 |
| 830M | 5.6458 | 5.4320 |
| 978M | 5.5683 | 5.4736 |
UniPool improves validation loss at every scale, with the largest gap at 830M (loss 1.7309 → 1.6923; PPL 5.6458 → 5.4320).
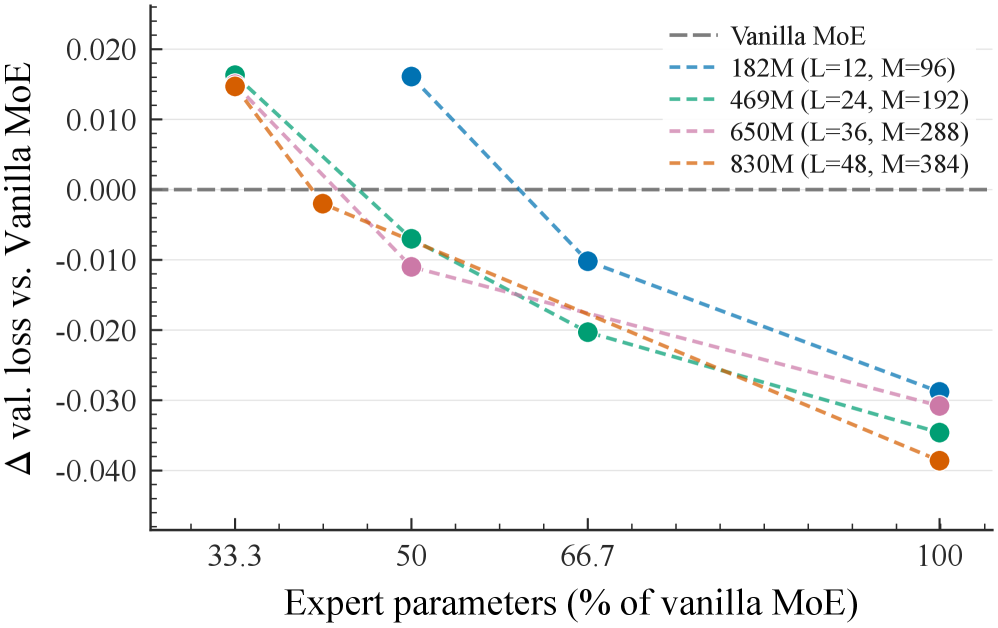
The 182M ablation isolates contributions: pool-level aux + softmax in a shared pool gives −0.0137 loss, full UniPool (G=1) gives −0.0288. Switching from pool aux to layer aux under sharing flips the sign (+0.0163), confirming the auxiliary loss must be pool-level.
Routing now carries information
The cleanest evidence that sharing converts redundancy into specialization is in Section 6.1. Repeating the deep-half randomization probe on the authors’ own models:
- Vanilla MoE 469M: 45.10 → 43.83 (−1.3); 978M: 48.13 → 46.64 (−1.5). Matches the production-model pattern.
- UniPool 469M: 47.16 → 43.10 (−4.1) under cardinality-matched top-8 randomization; 978M: 48.35 → 44.25 (−4.1).
The drop nearly triples. With every expert receiving gradient signal from L layers and all layers competing for one pool, surviving experts specialize, so the per-layer router’s choice becomes load-bearing rather than nearly arbitrary.
Limitations and open questions
- Scale tops out at 978M active params and 30B tokens; whether the gap persists at frontier scales (where total expert budget is much larger and per-layer redundancy could behave differently) is untested.
- All experiments use a single architecture family (LLaMA-style, 8E/top-1 default). Interaction with shared-experts variants (DeepSeek-style), fine-grained MoE, or top-2 routing is not characterized.
- The pool-level auxiliary loss balances global utilization but does not directly prevent layer collapse onto a small subset of pool experts; the analysis reports utilization but not long-tail behavior under longer training.
- Inference-time placement: the shared pool changes parameter-locality assumptions for expert-parallel deployment. The paper does not quantify wall-clock or memory implications under realistic serving.
- The routing-randomization metric is suggestive but indirect; whether the recovered specialization corresponds to interpretable, distinct functions remains open.
Why this matters
UniPool reframes expert capacity as a global architectural budget rather than a per-layer quota, decoupling expert-parameter count from depth and turning a known redundancy pathology into reuse. If the result holds at scale, it suggests current MoE designs systematically over-allocate parameters at depth, and that a single shared pool with depth-conditioned routers is a strictly better default.
Source: https://arxiv.org/abs/2605.06665
RemoteZero: Geospatial Reasoning with Zero Human Annotations
Problem and motivation
Geospatial reasoning over remote sensing imagery requires resolving an underspecified natural-language query (e.g., “the storage tank closest to the harbor entrance”) into a precise bounding box on a satellite image. Recent reasoning-augmented MLLMs such as RemoteReasoner produce explicit chains-of-thought before emitting coordinates, but training these models still depends on human-annotated boxes used as IoU-based reward signals in GRPO. This “location bottleneck” prevents scaling to the abundant unlabeled remote sensing imagery that constitutes the bulk of available data.
RemoteZero removes the box-supervision requirement entirely. The motivating asymmetry is empirical: an MLLM pre-trained predominantly on image-caption alignment (P(\text{Text}|\text{Image})) is a strong semantic verifier — it can reliably judge whether a cropped region satisfies a query — but a comparatively weak coordinate generator, since fine-grained spatial regression is underrepresented in pretraining. The paper exploits this gap: use the discriminator the model already has to supervise the generator the model lacks.
Method
The setup is standard GRPO on a policy \pi_\theta that, given image \mathcal{I} and query \mathcal{Q}, samples a reasoning trace and a bounding box \mathbf{b}. The contribution is the reward.
Existing supervised methods use the extrinsic geometric reward \mathcal{R}_{ext}(\mathbf{b}) = \text{IoU}(\mathbf{b}, \mathbf{b}_{gt}), which requires labeled \mathbf{b}_{gt}. RemoteZero replaces it with an intrinsic semantic consistency reward \mathcal{R}_{int}(\mathbf{b}) = V\!\left(\mathcal{T}(\mathcal{I}, \mathbf{b}),\, \mathcal{Q}\right), where \mathcal{T} is a deterministic crop-and-pad operator that extracts the candidate region from \mathbf{b}, and V is a verifier MLLM that returns a confidence score s\in[0,1] that the crop matches \mathcal{Q}.
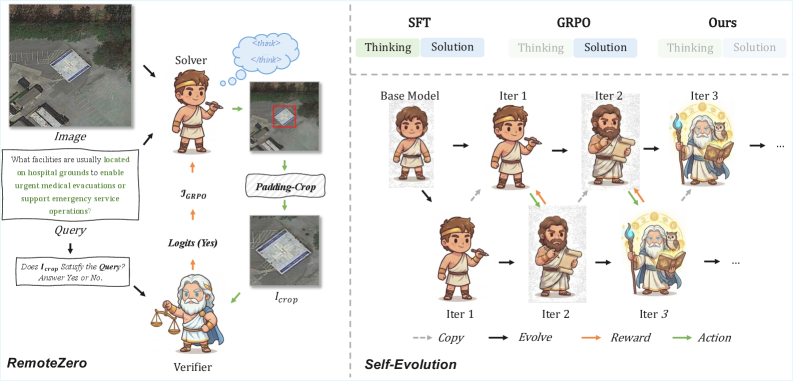
A degenerate solution — emit \mathbf{b} covering the entire image so the verifier trivially confirms presence — is handled with an area penalty added to \mathcal{R}_{int}, pushing the policy toward minimal sufficient regions. The full pipeline is shown below.
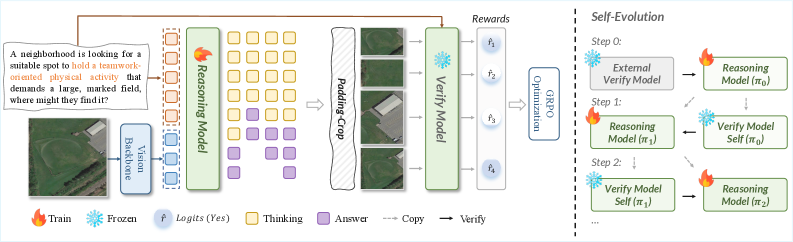
A second contribution is iterative self-evolution. After one GRPO round, the trained (frozen) policy itself becomes the verifier for the next round. Because the policy’s generative grounding has improved, its discriminative head — used in verification mode on cropped regions — also improves, so the reward signal sharpens monotonically (in principle) without any external labels. This converts the framework into a closed loop on unlabeled remote sensing imagery.
Concretely, instantiation uses Qwen3-VL-8B-Instruct with LoRA fine-tuning, GRPO with 4 samples per prompt at temperature 0.9, learning rate 5\times 10^{-6}, batch size 6 with gradient accumulation 8, 10 epochs, bfloat16 on 8 GPUs with DeepSpeed ZeRO-2. Maximum sequence length is 2048 and images are capped at 802,816 pixels. The verifier in round 0 is the same Qwen3-VL-8B base used as the solver init, queried in a discriminative prompt format.
Reimplementation skeleton
Per training step, for each (\mathcal{I}, \mathcal{Q}):
- Sample K=4 rollouts (\text{cot}_k, \mathbf{b}_k) \sim \pi_\theta.
- Compute crops c_k = \mathcal{T}(\mathcal{I}, \mathbf{b}_k) with padding to preserve aspect ratio.
- Query verifier: s_k = V(c_k, \mathcal{Q}) \in [0,1].
- Reward: r_k = s_k - \lambda \cdot \text{area}(\mathbf{b}_k)/\text{area}(\mathcal{I}).
- Group-relative advantage: A_k = (r_k - \mu_r)/\sigma_r over the K samples.
- PPO-style update on tokens of (\text{cot}_k, \mathbf{b}_k) using A_k with KL to reference policy.
For self-evolution, snapshot \pi_\theta at end of round t, freeze, and use as V in round t+1.
Results
The provided abstract and experimental section truncate before reporting headline numbers — the paper’s main result table is not included in the excerpt. What is established mechanically: training is feasible with only LoRA adapters on 8 GPUs, suggesting modest compute, and the framework operates without any box annotation. Quantitative comparisons against RemoteReasoner and other IoU-supervised baselines on standard remote sensing grounding benchmarks would be needed to validate that intrinsic reward matches or exceeds extrinsic IoU supervision; these are referenced in the abstract but the numbers are not in the supplied excerpt.
Limitations and open questions
- The intrinsic reward inherits the verifier’s biases. If V systematically misjudges a class of queries (e.g., counting, relative spatial relations across crops), the policy will optimize to those errors. The paper does not discuss verifier calibration or failure modes.
- The area penalty’s coefficient \lambda trades off recall (cover the object) against precision (tight box); no ablation is shown in the excerpt.
- Self-evolution risks reward hacking and degenerate fixed points where the policy and verifier collude on a confidently-wrong region. The frozen-previous-policy scheme mitigates but does not eliminate this; a stability analysis or KL constraint to a reference verifier would be informative.
- Crop-based verification discards global context. For queries requiring relational reasoning (“the building between the two bridges”), the cropped region alone may not contain enough evidence to verify the relation.
- The padding operator \mathcal{T} may leak shape priors (the verifier could learn that centered padded crops indicate positives), creating a spurious shortcut.
Why this matters
If intrinsic semantic verification is a viable substitute for IoU supervision, GRPO-style RL on grounding tasks decouples from annotation cost and scales with raw imagery. The same asymmetry — discriminator stronger than generator — applies broadly across vision-language grounding, document understanding, and tool-use settings, suggesting RemoteZero’s solver-verifier-with-self-evolution recipe generalizes beyond remote sensing.
Source: https://arxiv.org/abs/2605.04451
MARBLE: Multi-Aspect Reward Balance for Diffusion RL
Problem
RL fine-tuning of text-to-image diffusion models is now standard, but image quality is inherently multi-dimensional: prompt alignment, aesthetics, OCR fidelity, compositional correctness, and human-preference scores all need to improve jointly. Existing options are unsatisfying: train one specialist per reward (no unified model, no cross-reward transfer), scalarize via R(x) = \sum_k w_k R_k(x) (under-trains specialist signals), or hand-schedule sequential stages (brittle, requires extensive tuning).
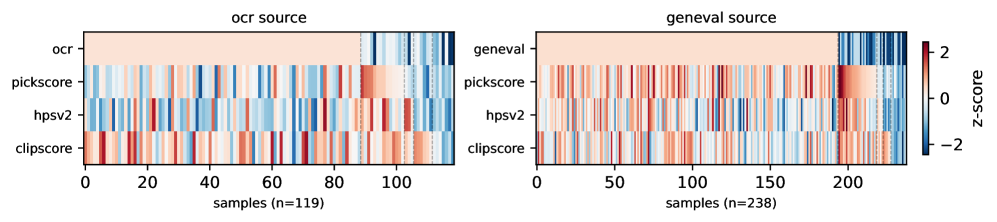
The authors identify the failure mode of weighted-sum aggregation as a sample-level specialist structure: in a typical rollout batch, most samples carry strong signal on one or two reward dimensions and near-zero signal on the rest. Averaging rewards before computing the advantage dilutes the informative dimensions with noise from uninformative ones.
Method
MARBLE builds on DiffusionNFT (Zheng et al., 2025), which optimizes \max_\theta\; \mathbb{E}_{x\sim\pi_\theta}[R(x)] - \beta_{\mathrm{KL}} D_{\mathrm{KL}}(\pi_\theta\|\pi_{\mathrm{ref}}) via a noise-free velocity-matching loss \ell(\theta; x, t) = r \cdot \mathcal{L}^+(\theta) + (1-r)\cdot \mathcal{L}^-(\theta), where r = \mathrm{clamp}\!\left(\tfrac{1}{2} + \tfrac{A(x)}{2A_{\max}}, 0, 1\right), and \mathcal{L}^\pm(\theta) = \|v_\theta^\pm - v\|^2,\quad v_\theta^+ = (1-\beta)v^{\mathrm{old}} + \beta v_\theta,\; v_\theta^- = (1+\beta)v^{\mathrm{old}} - \beta v_\theta. Crucially, \mathcal{L}^+ and \mathcal{L}^- are advantage-independent; the advantage enters only through the scalar interpolation coefficient r.
This structural property is what MARBLE exploits. Rather than collapsing \{R_k\} into a single advantage, it computes a per-reward advantage A_k(x) (z-score normalized within the batch), forms a per-reward interpolation r_k, and instantiates a per-reward NFT loss \mathcal{L}_k(\theta). Each loss yields its own gradient g_k = \nabla_\theta \mathcal{L}_k via a separate backward pass. A gradient harmonization step then combines \{g_k\} into a single descent direction d that improves all K objectives simultaneously, and the shared LoRA adapter is updated with d.
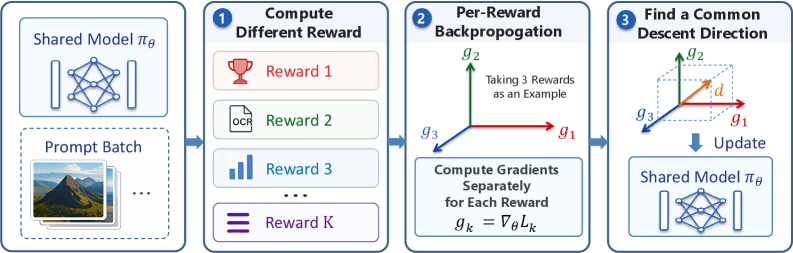
The harmonization is the multi-task gradient surgery component: the goal is to find d minimizing conflict, e.g., a vector with non-negative inner product against every g_k (in the spirit of MGDA / PCGrad / CAGrad). This sidesteps both the scalar-weight tuning problem and the sample-dilution problem, because each g_k is computed from samples actually informative for reward k (high |A_k| pushes r_k to 0 or 1, producing strong directional signal), independently of whether the same sample is informative for other rewards.
Setup and results
Backbone is Stable Diffusion 3.5 Medium with LoRA (rank 32, alpha 64), AdamW, lr 3\times 10^{-4}, 16 H200 GPUs. Five training rewards: PickScore, HPSv2, CLIPScore, OCR accuracy, GenEval. Held-out evaluation rewards (not seen during training): Aesthetic Score, ImageReward, UniReward.
Baselines: per-reward FlowGRPO specialists, DiffusionNFT-sequential (hand-scheduled stages), and DiffusionNFT-simultaneous (scalarized weighted sum).
The provided sections do not enumerate the full results table, but the experimental design directly tests two claims: (1) a single MARBLE model matches or exceeds per-reward specialists across all five trained rewards, and (2) it generalizes to the three held-out rewards better than scalarized or sequential multi-reward baselines, both of which are expected to overfit the training mixture or its schedule.
Limitations and open questions
- The harmonization step is not specified in the excerpt; the choice between MGDA, PCGrad, CAGrad, or a custom rule materially affects convergence behavior and compute (each step requires K backward passes, scaling linearly in the number of rewards).
- K=5 is modest. As K grows, finding a common descent direction becomes increasingly constrained; degenerate cases (no d with all positive inner products) require fallback rules.
- The advantage normalization is per-reward, per-batch via z-scoring. This implicitly assumes comparable signal-to-noise across rewards; pathological rewards (very sparse, e.g., OCR on prompts without text) may still dominate or vanish.
- Reward hacking is not addressed: jointly optimizing five learned rewards on a shared policy could still admit shortcut solutions that satisfy all surrogate scorers without genuine quality gains.
- All experiments are on SD3.5 Medium with LoRA. Whether the gradient-harmonization advantage persists at full fine-tuning scale or on autoregressive image models is unclear.
Why this matters
MARBLE reframes multi-reward diffusion RL from reward-space scalarization to gradient-space aggregation, a clean fix that exploits a specific structural property of NFT-style losses (advantage enters only through a scalar interpolation). If the empirical claims hold, this removes a major operational pain point — hand-tuned reward weights and stage schedules — for production-style alignment of image generators on heterogeneous criteria.
Source: https://arxiv.org/abs/2605.06507
When to Trust Imagination: Adaptive Action Execution for World Action Models
Problem
World Action Models (WAMs) jointly predict a future action chunk \hat{A}_{t+1:t+H} and the corresponding latent future visual rollout \hat{O}_{t+1:t+H} conditioned on the current observation o_t and instruction \ell:
(\hat{A}_{t+1:t+H}, \hat{O}_{t+1:t+H}) = \pi_\theta(o_t, \ell).
Standard practice executes a fixed prefix of \hat{A}_{t+1:t+H} before re-querying the WAM. This is wasteful when the imagined trajectory is reliable (the robot replans unnecessarily, paying a large transformer-plus-flow-matching inference cost each cycle) and dangerous when it is not (open-loop execution through contact-rich or precision-critical phases). The authors recast chunk-size selection as a future-reality verification problem: keep executing while predicted dynamics remain consistent with what the camera actually sees, abort and replan otherwise.
Method: FFDC-WAM
The system, FFDC-WAM, pairs a Motus backbone (rectified flow-matching losses for both action and video, \mathcal{L}_{\text{WAM}} = \mathcal{L}_{\text{act}} + \mathcal{L}_{\text{vid}}) with a lightweight verifier called Future Forward Dynamics Causal attention (FFDC). At each high-frequency check step t during execution of a previously generated chunk, FFDC consumes four streams: the remaining planned actions, the WAM’s predicted latent visual tokens for the same horizon, the current real observation, and the language instruction. It outputs a scalar confidence c_t \in [0,1] for the remaining rollout. Execution continues while c_t exceeds a threshold; otherwise the WAM is re-invoked to regenerate (\hat{A}, \hat{O}).
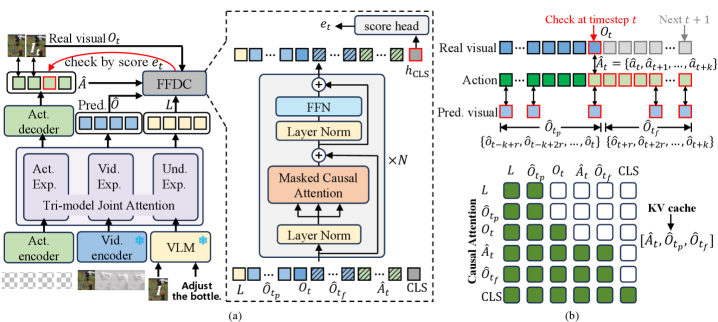
The key architectural choice is a structured causal attention mask that enforces temporally aligned interaction between the action token at horizon offset k and the predicted visual token at the same offset, so the verifier learns a per-step forward-dynamics consistency check rather than a bag-of-tokens classifier. Because FFDC sees both modalities, it can flag two distinct failure modes: (i) the predicted video itself drifts from o_t (the WAM hallucinated), and (ii) the actions, even if matched to a coherent imagined video, are inconsistent with the real scene.
Training uses Mixture-of-Horizon Training for the WAM backbone — supervising at multiple horizon lengths so a single model produces usable chunks at variable H — and a separate, much cheaper training pass for FFDC on a single A100 (vs. four A100s for the backbone). Adaptive chunk size is therefore not an explicit policy output but an emergent consequence of where the confidence trace crosses threshold.
Results
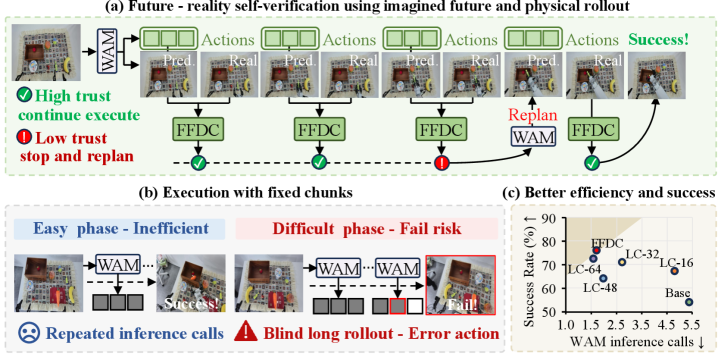
Evaluation covers RoboTwin (50 manipulation tasks, 100 rollouts each, with both clean and random settings introducing background, clutter, height, and lighting perturbations) and real-world Astribot S1 (34 DoF) pick-and-place. The qualitative behavior is the cleanest evidence that the verifier is doing what it claims:

On the easy move can pot task, FFDC-WAM finishes with a single WAM inference (confidence stays high throughout) while the Base-Motus baseline, locked to a fixed chunk size, performs three inferences. On the harder mug-hanging task, FFDC-WAM rides a long chunk through the predictable transport phase and then triggers replanning as confidence drops in the precision-critical hanging phase; the ablation that removes FFDC executes the unreliable tail open-loop and fails. This pattern — long chunks where dynamics are simple, short chunks where contact or alignment matters — is the intended emergent behavior.
Limitations and open questions
- The selected sections do not give aggregate success-rate or inference-count tables for the 50-task RoboTwin sweep or the real-world tasks; the quantitative case rests on numbers the abstract and method sections do not enumerate here. A reader should look to the full results tables before drawing strong conclusions about magnitude.
- Confidence is calibrated implicitly via a threshold; the paper does not (in these excerpts) discuss how the threshold is chosen per task or whether miscalibration biases the system toward over- or under-replanning.
- FFDC is trained on rollouts from a specific WAM backbone (Motus). Whether the verifier transfers to other WAMs, or whether its own failure modes correlate with the backbone’s, is unclear.
- The verifier reasons over predicted latent video rather than re-rendering and comparing pixels; if WAM video and WAM actions share a hallucinated mode, joint-modality attention may not detect it.
- Only two real-world tasks are reported, both pick-and-place; contact-rich manipulation (insertion, deformable objects) is the regime where adaptive replanning should pay off most, and is not directly evaluated here.
Why this matters
Action chunking is the dominant lever for amortizing the cost of large generative policies, but it imposes an unprincipled tradeoff between latency and reactivity. FFDC reframes that tradeoff as online consistency checking between an imagined and observed rollout, using the WAM’s own video prediction as the supervisory signal — a natural fit that turns the WAM’s expensive joint modeling into a verification asset rather than just a planning cost.
Source: https://arxiv.org/abs/2605.06222
Hacker News Signals
Natural Language Autoencoders: Turning Claude’s Thoughts into Text
Anthropic describes a technique for compressing Claude’s chain-of-thought (CoT) reasoning traces into compact natural-language summaries and reconstructing them faithfully — a natural language autoencoder (NLAE). The core problem: extended thinking produces verbose scratchpads that are expensive to store, transmit, and inspect. The goal is a lossy compression scheme where the bottleneck representation remains human-readable.
The architecture pairs an encoder LLM (Claude) that summarizes a reasoning trace into a short text bottleneck, and a decoder LLM that reconstructs the full trace or, more practically, produces the same final answer from that bottleneck alone. Fidelity is measured by downstream task accuracy: if the decoder reaching the same answer from the compressed representation matches accuracy from the full trace, the bottleneck is informationally sufficient.
The interesting mechanistic detail is that the bottleneck is constrained to natural language rather than a dense embedding, which forces the summarization to be interpretable and auditable. This sidesteps the superposition/polysemanticity problems that plague activation-space compression — you can read the bottleneck directly. The tradeoff is that natural language is a much lower-bandwidth channel than a float vector of the same token length.
Anthropic reports that on several reasoning benchmarks, answers derived from compressed summaries closely match full-trace accuracy, sometimes with 10x token reduction. The approach also surfaces a practical interpretability dividend: the summaries often expose which sub-problems Claude identified, making oversight easier.
Open questions are significant. It is unclear how well this holds for tasks requiring precise numerical intermediate results that natural language summaries tend to smear. There is also a sandbagging risk: a model could learn to produce summaries that look informative but omit the steps a human overseer would flag. The interaction with faithfulness of CoT remains unresolved — if the original trace is unfaithful, the summary inherits that property.
Source: https://www.anthropic.com/research/natural-language-autoencoders
Learning the Integral of a Diffusion Model
Sander Dieleman’s post introduces the concept of “flow maps” — learning a direct mapping from a noisy sample at time t_1 to a cleaner sample at time t_2 > t_1, bypassing the need to numerically integrate an ODE step-by-step. The motivation is inference efficiency: standard diffusion/flow-matching models require many sequential NFEs (network function evaluations) because each step integrates a local vector field. A flow map F_\theta(x_{t_1}, t_1, t_2) amortizes that integration.
The key insight is that the exact flow map satisfies a composition identity:
F(x_t, t, t'') = F(F(x_t, t, t'), t', t'')
for any intermediate t'. This is a self-consistency constraint analogous to consistency models (Song et al., 2023), but framed more generally for arbitrary endpoint pairs rather than just t \to 0. Training can proceed by distilling from a pre-trained score/velocity network: sample a trajectory segment, compute the “true” endpoint by running many small ODE steps, and supervise F_\theta to match it. Alternatively, one can train from scratch with a consistency-style loss that enforces the composition property without a teacher.
The practical payoff is that a single NFE maps x_T \to x_0 directly, or two NFEs can cover the trajectory in two large jumps while respecting the composition identity. Dieleman discusses how this unifies several existing approaches: consistency models, TRACT, and rectified flow reflow are all special cases or approximations of learning flow maps with different parameterizations and training objectives.
Key open challenges include training stability (the composition target is non-stationary when F_\theta is itself being updated) and whether a single network can represent flow maps over a wide range of (t_1, t_2) pairs without capacity bottlenecks. The post does not present new benchmark numbers, but the conceptual synthesis is useful for anyone designing fast samplers.
Source: https://sander.ai/2026/05/06/flow-maps.html
Accelerating Gemma 4: Faster Inference with Multi-Token Prediction Drafters
Google describes deploying speculative decoding for Gemma 4 using small multi-token prediction (MTP) draft heads trained on top of the base model. The setup is standard speculative decoding: a cheap drafter proposes k tokens, the target model verifies all k in a single forward pass, and accepted tokens are kept. The novelty is using MTP heads — a set of small per-position feedforward heads attached to the final hidden states — rather than a separate draft model, keeping the drafter co-located with the target and eliminating memory bandwidth overhead from a second model.
Each MTP head h_i takes the hidden state \mathbf{z} at position n and predicts token n+i, so k heads produce k draft tokens per decoding step. The heads are lightweight (a few MLP layers), so the amortized cost per proposed token is low. Crucially, the verification pass of Gemma 4 processes all k+1 positions in parallel, meaning wall-clock latency scales roughly as 1/\bar{\alpha} where \bar{\alpha} is the mean acceptance rate — commonly reported as 2-4x speedup at high acceptance rates.
Google reports acceptance rates high enough to yield approximately 2x throughput improvement on representative workloads without any change to output distribution (the acceptance-rejection scheme is exact). The MTP heads were trained with a straightforward next-token prediction loss on the draft positions, using the frozen base model’s hidden states as input.
The interesting systems angle is that MTP heads avoid the KV-cache duplication that a separate draft model requires and stay on the same accelerator without cross-device synchronization. Limitations: acceptance rates degrade on out-of-distribution prompts and long-form generation where the model becomes less predictable. MTP heads also add training cost and checkpoint size, though modestly. The approach is not novel in concept — similar MTP-based drafters appeared in DeepSeek and Medusa — but the Gemma 4 deployment validates it at production scale.
Source: https://blog.google/innovation-and-ai/technology/developers-tools/multi-token-prediction-gemma-4/
AlphaEvolve: Gemini-Powered Coding Agent Scaling Impact Across Fields
DeepMind’s AlphaEvolve post gives more detail on their evolutionary program synthesis system built on Gemini. The core loop: Gemini proposes code mutations (new algorithms or modifications to existing ones), a deterministic evaluator scores each candidate on a concrete metric, and an evolutionary selection mechanism maintains a population of high-scoring programs. This is an LLM-in-the-loop evolutionary algorithm, not a search over natural language — the artifacts are executable programs evaluated by ground-truth metrics.
The key design decisions that distinguish it from naive LLM-based code generation: (1) the evaluation is fully automated and metric-driven, removing human bottlenecks; (2) the evolutionary population gives the LLM diverse context to mutate from, exploiting the model’s ability to recombine ideas across candidates; (3) Gemini’s long context handles large codebases as mutation targets. The result is a system that iterates orders of magnitude faster than human researchers on narrow, well-specified problems.
Reported results include: recovering and extending known results in matrix multiplication (finding algorithms improving on Strassen-like constructions for specific matrix sizes), optimizing data center scheduling (claiming ~1% efficiency gain on Google’s fleet — non-trivial at scale), and improving sorting networks. The matrix multiplication results are the most technically legible — AlphaEvolve found algorithms reducing operation counts for specific small matrix dimensions, which can be composed for larger matrices.
The limitations are characteristic of any metric-driven search: the system optimizes exactly what is measured. Algorithms discovered may be brittle outside the evaluation distribution, and the approach requires a differentiable or at least fast-to-evaluate objective. Problems with expensive, noisy, or human-in-the-loop evaluators are outside scope. The evolutionary framing also means compute scales with population size and generation count — efficient for Google, less accessible otherwise.
Source: https://deepmind.google/blog/alphaevolve-impact/
Show HN: Tilde.run – Agent sandbox with a Transactional, Versioned Filesystem
Tilde.run is an agent execution environment whose central technical claim is a transactional, versioned filesystem exposed to the agent. The problem it targets: agentic coding loops that edit files can corrupt state across retries, parallel branches, or failed tool calls, making recovery and auditing difficult. A versioned filesystem treats every write as a committed snapshot, allowing rollback to any prior state and enabling multiple agent branches to operate on diverging copies without interference.
The technical substance worth examining: the filesystem exposes a Git-like commit model to the agent’s tool interface. Each tool call that mutates files produces a new named version. The agent (or orchestrator) can explicitly branch, diff between versions, and merge or discard branches. This is structurally similar to giving the agent a working tree with explicit staging — the agent can speculate on edits, evaluate results (run tests, linters), and roll back if the evaluation fails, all within a single sandbox session.
The transactional property means that multi-file edits can be grouped into atomic commits: either all changes land or none do, preventing partial-write corruption that plagues simple file-tool implementations where an interrupted sequence leaves the repo in a broken state. This is particularly relevant for refactoring tasks that touch many files simultaneously.
The sandbox isolation model keeps each session in a container with ephemeral compute, so agent actions cannot leak across sessions. The versioned filesystem state can be exported or restored, enabling reproducible reruns of agent trajectories — useful for debugging where exactly an agent diverged from correct behavior.
Limitations are inferrable from the architecture: merge conflicts in concurrent branches require resolution logic, and the overhead of snapshotting on every write may be non-trivial for large repositories or high-frequency tool calls. The system is most compelling for agents with explicit backtracking strategies; purely linear agents gain less from versioning.
Source: https://tilde.run/
Noteworthy New Repositories
kyegomez/OpenMythos
A theoretical reconstruction of the Claude “Mythos” architecture assembled from public Anthropic research papers, technical reports, and inferred design choices. The repo attempts to synthesize Constitutional AI, RLHF with KL-penalized policy optimization, and sparse interpretability findings into a coherent architectural description. It does not contain trained weights or proprietary artifacts; the value is in the annotated synthesis of published work — referencing Anthropic’s scaling laws experiments, model card disclosures, and mechanistic interpretability papers (superposition, features as directions in activation space). Useful as a structured reading guide for understanding the design space of large RLHF-trained assistants. Treat the “reconstructed” framing skeptically: significant implementation details remain unknown and several architectural choices are speculative extrapolations rather than verified facts.
Tencent-Hunyuan/HY-World-2.0
HY-World 2.0 is a multi-modal world model targeting joint reconstruction, generation, and physics-consistent simulation of 3D scenes. The architecture processes RGB video alongside depth and camera pose streams, using a transformer-based latent diffusion backbone to produce spatially coherent 3D representations. Key capabilities include novel view synthesis, forward simulation of scene dynamics, and controllable generation conditioned on text or geometry prompts. The model extends HY-World 1.x with improved temporal consistency across longer sequences and better handling of occlusion in reconstruction. The codebase exposes inference pipelines and model weights, with documented APIs for scene editing workflows. The primary technical interest is in how the unified latent space jointly handles the reconstruction (encoder-heavy) and generation (diffusion-heavy) objectives without mode collapse between the two regimes.
walkinglabs/hands-on-modern-rl
A structured curriculum covering the full stack from tabular RL through deep policy gradient methods to modern LLM alignment techniques. Notebooks progress from Q-learning and temporal-difference fundamentals through PPO and GRPO implementations, then into RLVR (Reinforcement Learning from Verifiable Rewards) and direct preference optimization variants. The LLM alignment section includes working code for reward modeling, KL-constrained policy updates, and rejection sampling fine-tuning. The agentic systems module covers tool-use environments and multi-step reasoning benchmarks. Mathematical derivations accompany each notebook — policy gradient theorems, the PPO clipped surrogate objective, and DPO’s implicit reward formulation are all derived rather than just stated. The curriculum is self-contained with dependency-pinned environments, making it reproducible without external data downloads. The gap this fills is the near-absence of pedagogical material that bridges classical RL theory and the RLHF/RLVR workflows now central to LLM post-training.
future-agi/future-agi
An open-source observability and evaluation platform for LLM applications and AI agents, self-hostable under Apache 2.0. The core components are: a tracing layer that instruments LLM calls and agent tool invocations via OpenTelemetry-compatible spans; an eval framework supporting both model-graded and programmatic assertions over traces; a simulation engine for running agent trajectories against synthetic environments; and a dataset management layer for curating fine-tuning or eval corpora from production traces. A gateway component handles routing, rate limiting, and prompt injection guardrails before requests reach underlying model APIs. The architecture is microservice-based, with each subsystem deployable independently. The eval primitives are composable — users define metrics as functions over (input, output, context) triples, which integrate cleanly with the tracing substrate. The main technical differentiator over hosted alternatives like LangSmith or Braintrust is full self-hostability with no data egress requirement, relevant for regulated deployments.
run-llama/ParseBench
A document parsing benchmark designed to stress-test AI agent pipelines on realistic document understanding tasks beyond simple PDF text extraction. ParseBench covers structured documents — tables, figures with captions, multi-column layouts, form fields, and mixed-modality pages — and evaluates parsers on extraction accuracy, structural fidelity, and downstream agent task performance. The benchmark includes a standardized evaluation harness that scores both character-level text accuracy and higher-level semantic correctness of extracted structured data. Annotations were produced by human labelers against a diverse corpus spanning scientific papers, financial filings, and legal documents. The repo ships baseline results for several open and commercial parsing systems, enabling direct comparison. The motivation is that naive extraction quality (e.g., pypdf text dump) frequently bottlenecks RAG and agent pipelines on complex documents, yet no standardized benchmark previously captured the failure modes specific to agent-oriented retrieval workloads.