デイリーAIダイジェスト — 2026-05-07
arXiv ハイライト
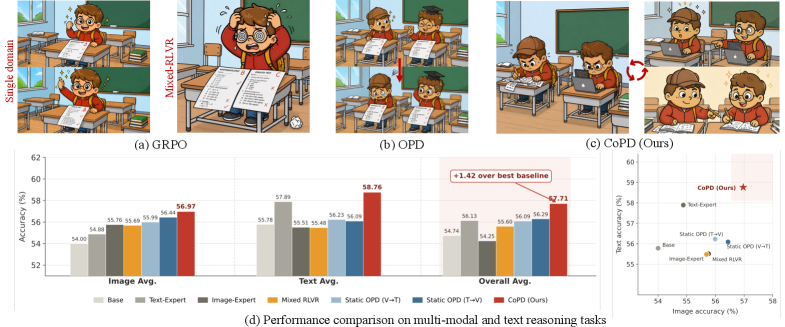
Co-Evolving Policy Distillation
複数の推論能力(テキスト、画像、動画)をRLVRのもとで単一のpolicyに統合しようとすると、構造的な緊張が生じます。すなわち、joint trainingはgradient conflictを引き起こし、一方でsequentialな「専門家訓練→distillation」パイプラインは教師と生徒の間でbehavioral patternのミスマッチに直面します。本論文はこの2つの失敗モードを形式化し、専門家が並列に訓練されながら互いにリアルタイムでdistillationを行うco-evolutionaryな代替手法を提案します。
能力損失の統一的な定量化
著者らは、任意の統合パラダイム \mathcal{P} を以下のようにモデル化します。
U_{\mathcal{P}} \approx a_{\mathcal{P}} \cdot X(D_1, D_2) + b_{\mathcal{P}},
ここで X は能力データセット全体にわたる最適化シグナルの総量、a_\mathcal{P}\in[0,1] は変換効率を表し、b_\mathcal{P}\le 0 は追加的な損失を表します。Mixed-data RLVRは a_{\text{mix}}=1 に設定されますが、divergenceコストを支払います。D_1 と D_2 から得られる各ステップのgradientが能力固有の次元で競合し、結果として
U_{\text{mix}} \approx X(D_1,D_2) - \Phi(D_1,D_2),\qquad \Phi>0
が得られます。これはよく知られたシーソー効果であり、一方の能力における向上が干渉によって部分的に打ち消されます。この現象は混合比に依存しません。Static OPDは \Phi を回避しますが a<1 という問題を抱えます。専門家が一度乖離してしまうと、生徒のon-policyロールアウトが教師のbehavioral supportを共有しなくなり、トークンレベルの監督が十分に吸収されなくなります。
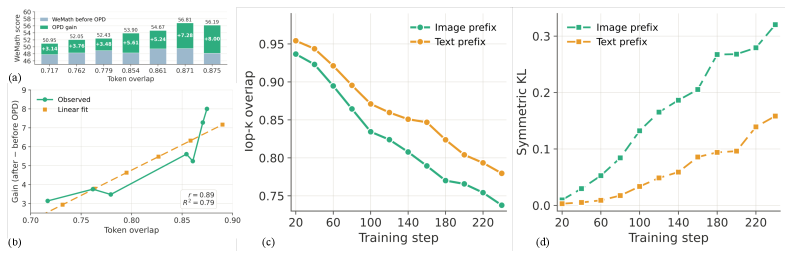
behavioral similarityの代理指標としてのtop-k overlap
パイロット研究では、「behavioral pattern gap」を共有ロールアウトにおける教師と生徒の分布間のtop-k トークンoverlapとして操作化しています。2つの経験的事実が明らかになります。(i)固定されたOPDステップからの利得は教師とのtop-k overlapにほぼ線形に比例して増加し、(ii)標準的なbranch-specific RLVRはこのoverlapを時間とともに低下させます。この示唆するところは、専門家が成熟してからdistillationを行うというスケジュールはまさに逆であるということです。そのころにはOPDを有効たらしめる性質そのものが損なわれているのです。
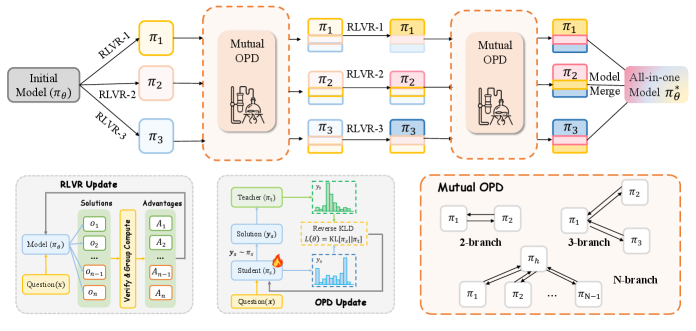
CoPD:RLVRと双方向OPDの交互適用
CoPDは同一の \pi_0 から K 個のブランチを初期化し、2つのフェーズを交互に繰り返します。
Branch-specific RLVR。 各ブランチ k は検証可能な報酬 r_k を用いて自身のデータセット \mathcal{D}_k 上でGRPOを実行します。
\mathcal{L}_{\text{RLVR}}^{(k)}(\theta_k) = \mathbb{E}_{x\sim \mathcal{D}_k}\!\left[\tfrac{1}{G}\sum_i \tfrac{1}{|y_i|}\sum_t \min\!\big(\rho_{i,t}^{(k)} \hat A_i^{\text{RL}}, \text{clip}(\rho_{i,t}^{(k)},1\!-\!\epsilon,1\!+\!\epsilon)\hat A_i^{\text{RL}}\big)\right].
これによりブランチ間に知識のギャップが生じます。
相互on-policy distillation。 次に各ブランチはon-policyロールアウトを生成し、もう一方のブランチからトークンレベルの監督を受けます。distillationは双方向であり、生徒サンプルは生徒自身から生成されるため、OPDが有効に機能する高overlapのレジームが維持されます。RLVRとOPDが短い間隔で交互に適用されるため、ブランチはbehavioralな観点で転移が機能不全に陥るほど乖離することがありません。
実験結果
実験ではQwen3-VL-4B-Instructを使用し、テキストデータはPolaris-53K、画像データはMMFineReason-123K、(3ブランチ実行の場合)フィルタリングされた動画サンプル40Kを用います。画像推論は7つのベンチマーク(MMMU、MMMU-Pro、MathVista、MathVision、ZeroBench、WeMath、MathVerse)で評価され、テキストはAIME24/25、HMMT25、MATH-500、Minervaで、動画はVideo-Holmes、MVBench、MMVU、VideoMathQAで評価されます。
本論文では、CoPDがドメイン固有のText-ExpertおよびImage-Expert、mixed RLVR、ならびにstatic OPDの両方向(V\toTおよびT\toV)を上回ることが報告されています。3ブランチの設定ではCoPDはMOPD(単一生徒への多教師distillation)を上回ります。特筆すべきは、統合されたCoPDモデルが単一ドメインの専門家をそれぞれ自身のベンチマークにおいて超えた点です。これは共進化が単に干渉を最小化するだけでなく、正のtransferを提供することの証左です。(abstractでは「大幅に上回る」ベースラインを強調しており、実験セクションではベンチマークが列挙されていますが、数値テーブル自体は抜粋には含まれていませんでした。)
限界と未解決問題
いくつかの問題が残されています。第一に、CoPDの計算コストはRLVRフェーズにおいてブランチ数にほぼ線形にスケールし、さらにOPDのコストが加わりますが、本論文ではmixed RLVRに対する厳密にFLOPsを合わせた比較が報告されていません。第二に、top-k overlap指標は経験的な代理指標であり、著者らはoverlapとOPD利得の間の線形fitを超えた理論的な裏付けを提供していません。第三に、同期スケジュール(RLVRとOPDをどの頻度で交互に行うか)はハイパーパラメータであり、その感度は抜粋において特徴付けられていません。第四に、3ブランチを超えたスケーラビリティ、およびデータ品質や報酬のスパース性が非常に非対称な能力への適用は未検証です。最後に、このフレームワークは各能力において検証可能な報酬を前提としており、検証可能な報酬とpreference設定が混在する場合への拡張は未解決です。
本研究の意義
CoPDは、多能力のpost-trainingを静的な「統合またはdistillation」問題から動的なco-training問題へと再定式化し、distillationがいつ機能するかを説明するconcreateなbehavioral similarityの診断指標(top-k overlap)を提供します。並列ブランチのパターンは、joint最適化のgradient conflictコストを支払うことなく、RLVRを多数のドメインにスケールするための有望なテンプレートとなります。
Source: https://arxiv.org/abs/2604.27083
RoundPipeによる複数コンシューマーGPU上での効率的なトレーニング
問題
コンシューマーGPUサーバー(例:8×RTX 4090、各24 GB、PCIe 4.0で32 GB/s、NVLinkなし)上でのLLMのfine-tuningは経済的に魅力的ですが、機械的には困難です。VRAMは逼迫しており、GPU間帯域幅はデータセンターのNVLink(200 GB/s)より一桁低くなっています。標準的なアプローチは、weights・gradients・optimizer states・activationsのCPUオフロードを伴うパイプライン並列(PP)です。PPはGPU間のトラフィックをステージ境界での小さなactivationテンソルに抑えられるためです。
問題は著者らが「weight binding」問題と呼ぶものです。既存のPPスケジュール(1F1B、ZB-H1、Looped BFSなど)では、N 個のGPU上でモデルを S = vN 個のステージに分割し、各ステージのweightsを1つのGPUに常駐させる必要があります。実際のLLMは均一ではなく、embedding/LM headステージは単一のtransformerブロックよりもはるかに重くなります。S を N の倍数に強制すると不均衡バブルが生じ、S を任意(例:4 GPU上で13ステージ)に設定すると、ステージ数の少ないGPUが重いGPUを待ってアイドル状態になるため構造的バブルが発生します。どちらにしても、スループットは最も遅いデバイスに制約されます。
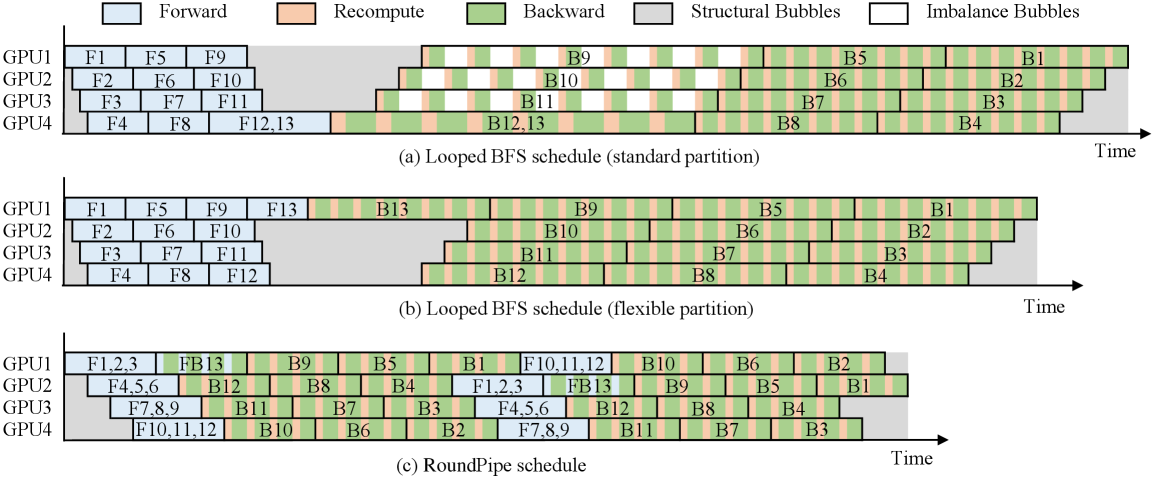
手法
重要な洞察は、完全なCPUオフロードを用いる場合、weightsはどのGPUにも固定されておらず、マイクロバッチごとにストリーミングされるという点です。そのためRoundPipeは、GPUをステートレスな実行ワーカーのプールとして扱い、ステージをデバイス上にラウンドロビン方式でディスパッチします。あるステージのforward・backwardは、ラウンドごとに異なるGPU上で実行される場合があります。GPUが長期的に保持する状態は、実行中に生成したactivations/gradientsのみです。
具体的には、S 個のステージと N 個のGPU(N \mid S の要件なし)に対して、RoundPipeはマイクロバッチウェーブごとに \lceil S/N \rceil ラウンドでパイプラインを実行します。非対称分割により、ステージサイズを実際のレイヤーコストに対応させることができ(LM headを独立したステージにすることが可能)、モデルが均一でない場合でもステージごとの実行時間がバランスされます。ラウンドロビンディスパッチにより、すべてのGPUがウェーブ全体でほぼ同等の総作業量を受け取ることが保証され、柔軟な分割が本来生じさせる構造的バブルが排除されます。
このシステムは、RayおよびveRL/HybridFlowのスタイルによるシングルコントローラーフレームワークとして構築されています。ユーザーはforward_backward()とoptimizerステップを呼び出す通常の逐次コードを記述し、コントローラー(ユーザーのスレッドで実行)がマイクロバッチを構成し、ステージをGPUワーカーにラウンドロビン順序で割り当て、依存関係を追跡します。GPUワーカーは非同期で実行し、別のoptimizerワーカーがホスト上でパラメータの非同期更新を実行します。実用上これを機能させる3つのサブシステムがあります:
優先度を考慮した転送スケジューリング。 PCIeがボトルネックです。各マイクロバッチには(a)ホストからGPUへのweightsの転送と(b)activationsの再計算または再読み込みが必要です。RoundPipeはこれらの転送を重要度順に並べることで、次のステージのweightsが計算開始前に到着し、H2Dコピーと計算が重なるようにします。レイヤーごとの再計算と再読み込みのトレードオフは、Figure 2のモデルから決定されます。
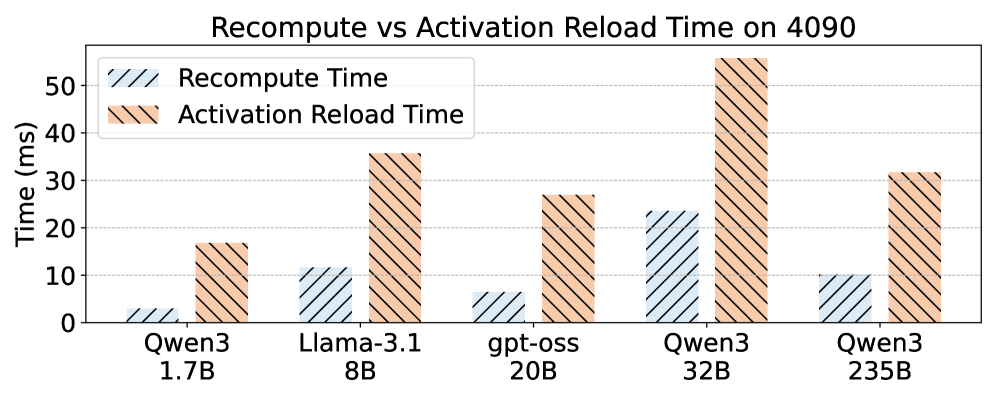
transformerレイヤーのactivationを再計算する場合と再読み込みする場合の理論的な時間 細粒度のイベントベース同期。 あるステージのforwardとbackwardがラウンドをまたいで異なるGPU上で実行される可能性があるため、単純なバリア同期では利得が失われてしまいます。RoundPipeは(マイクロバッチ、ステージ、方向)ごとにキー付けされた分散CUDAイベントを使用し、生産者と消費者が共有する特定のテンソルのみで同期するようにします。
非同期optimizer更新下でのパラメータ整合性。 optimizerがホスト上で並行して実行されるため、RoundPipeはあるステップ内のすべてのマイクロバッチが同じweightsを参照すること、およびgradient accumulationが正確であることを保証しなければなりません。これはweightバッファのバージョン管理と、関連するgradient書き込みの完了を条件としたoptimizerステップのゲーティングによって処理されます。
自動レイヤー分割。 プロファイラーがレイヤーごとのforward/backward時間とメモリを計測し、VRAMの制約のもとで最大ステージ時間を最小化する S ステージへの非対称分割を求めます。S は自由に選択でき(vN に制約されない)、これがLM headを独立したステージとして表現可能にする要因です。
結果
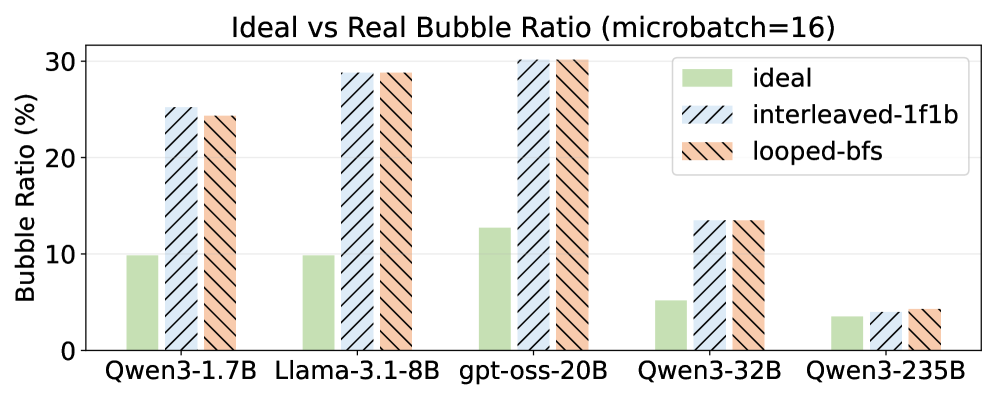
8×RTX 4090サーバー上で、RoundPipeは既存のPPベースラインに対して1.48〜2.16×のエンドツーエンドスループット向上を達成しています(論文のアブストラクトに記載された範囲であり、論文ではこれをweight-bindingバブルの排除によるものとしています)。バブル比率の分析(Figure 3)により、現実的な不均衡分割のもとでLoopedスケジュールが理想的なバランス分割時の理論値よりも大幅に高いバブル比率を示す一方で、RoundPipeはモデルの不均衡に関わらず近ゼロのバブルに近づくことが示されています。評価にはA800 NVLinkサーバー、シーケンス長スケーリング、GPU数スケーリングも含まれており、アブレーションによって各サブシステムへの寄与が明らかにされています。
限界と未解決の問題
この論文は積極的なCPUオフロードに依存しており、利得は転送スケジューリングが十分に重複した場合にPCIeが計算に追いつけることに依存するため、設計はactivation/weightのストリーミングが支配的なトレーニング体制に偏っています。非同期optimizerは同期SGD/Adamとの厳密な等価性に関する疑問を提起しています——バージョン管理はステールネスのコーナーケースを軽減しますが、完全には排除しません。ラウンドロビンディスパッチも均質なGPUを前提としており、混合ハードウェアサーバーでは負荷を考慮したバリアントが必要です。最後に、ヘッドラインの改善は範囲として報告されており、モデルごとの詳細な比較、および同じメモリバジェットでのZeRO-3+オフロードとの比較が次の自然なデータポイントとなります。
なぜこれが重要か
パイプラインスケジュールは、weightsがGPUに常駐しているという暗黙の前提のもとで設計されてきたため、S = vN という制約は自然に感じられました。weightsがホスト上に存在するようになると、その前提は根拠を失い、これを取り除くことでコンシューマーGPUによるLLMトレーニングを長らく悩ませてきた不均衡/構造的バブルの二項対立が解消されます。$25k の8×4090ボックス上での1.48〜2.16×の高速化は、その観察を真剣に受け止めた直接的な結果です。
Source: https://arxiv.org/abs/2604.27085
Length Value Model: トークンレベルの長さモデリングのためのスケーラブルなValue Pretraining
問題
トークン数は自己回帰的推論における基本通貨であり、レイテンシ、コスト、そしてchain-of-thoughtを介した推論品質を規定します。既存の長さ制御機構は粗いものです。それらは(i)目標長トークンや命令プレフィックスを条件として与え、モデルがその付近で停止することを期待する、(ii)事後的にトランケーションする、あるいは(iii)1回のロールアウトにつき1つのシグナルしか与えないシーケンスレベルの報酬でfine-tuningする、というものです。これらのいずれも、推論を継続すべきか、要約すべきか、あるいは終了すべきかを決定するために推論時コントローラが実際に必要とする、生成の残量に関するトークンごとの推定値を提供しません。
本論文はLength Value Model (LenVM)を提案します。これは残り長さの予測をvalue推定問題として定式化し、既存の生成トレースのみから導出される密なアノテーションフリーの教師信号を用いて学習します。
手法
軌跡を\tau = (s_0, a_0, s_1, a_1, \dots, s_T)とします。ここで各a_tは生成されたトークンであり、Tは(事前には未知の)終端ステップです。定数のトークンごとの報酬r_t = -c(c > 0)と割引率\gamma \in (0,1)を設定します。状態価値は以下のように表されます。
V(s_t) = \mathbb{E}\!\left[\sum_{k=0}^{T-t-1} \gamma^k r_{t+k}\right] = -c\,\mathbb{E}\!\left[\frac{1 - \gamma^{T-t}}{1 - \gamma}\right].
この表現は[-c/(1-\gamma), 0]で有界であり、期待残余ホライズン\mathbb{E}[T-t]について単調非増加であり、長さ推定値へと以下のように逆変換可能です。
\widehat{L}(s_t) = \log_\gamma\!\left(1 + \frac{(1-\gamma)\,V(s_t)}{c}\right).
この目標値の実用上の重要な主張は、(a) アノテーションフリーである——既存のトレースはいずれも割引和を通じて真のground-truth Vを与える、(b) 密である——すべてのトークンが学習シグナルとなる、(c) トレース分布のもとで不偏である、(d) pretraining規模のトークンバジェットへスケールする、という点です。
LenVMは transformer バックボーン上のvalue headとして実装され、モデルが生成した大規模なロールアウトコーパス上でV(s_t)をトークンごとに回帰するよう学習されます。推論時には、トークンごとの\widehat{L}が残り生成量の継続的に更新される推定値を提供し、これが制御シグナルとして用いられます——例えば、より短い補完へのデコーディングのバイアス付け、早期終了のゲーティング、またはトークンバジェットとの比較などに利用されます。
定数の負報酬を選択することは(例えばT-tを直接回帰するのとは異なり)重要な意味を持ちます。目標値を有界にすることで長いテールを持つ長さ分布での回帰が安定化し、割引率\gammaは近傍の終端が遠未来のトークンに対してどの程度の重みを持つかを制御します。生のT-tを回帰すると、長いトレースに対して非有界の損失が生じ、「残り50トークン」と「残り5000トークン」を線形に同一視してしまいます。割引価値はテールを圧縮します。
結果
主要な結果は、精密な長さマッチングとバジェット制約下での推論という2つの軸を対象としています。
LIFEBenchの厳密な長さマッチングにおいて、LenVMを7Bモデルに付加すると長さスコアは30.9から64.8へと向上します。本論文は同一の指標において、これがフロンティアのクローズドソースモデルを上回ると報告しています——これは、きめ細かなトークンレベルの長さ認識が非常に大規模なスケールでも自動的には獲得されない能力であるが、value headを通じて後付けで追加できることを示しています。
200生成トークンというハードバジェット下でのGSM8Kにおいて、LenVMで制御されたデコーディングは63%の精度を維持します。この結果が示す意図は、コントローラが均一にトランケーションするのではなく、価値推定値が終端まで依然として遠いと示す箇所にバジェットを費やすことで、chain-of-thoughtを適応的に圧縮できるというものです。本フレームワークは連続的なperformance/efficiencyトレードオフを露わにします。バジェットやコントローラが結論を強制するしきい値を変えることで、離散的なデコーディングモードを選択するのではなく、Paretoフロントを掃引することができます。
この手法はVLMsに対しても評価されており、value headの定式化がトークンレベルの軌跡のみに依存するため、モダリティに依存しないことが示唆されています。
限界と未解決の問題
いくつかの問題点は精査に値します。第一に、価値目標はデータ収集に使用したロールアウトポリシーに対してのみ不偏であり、デプロイ時のポリシーが乖離した場合(異なる温度、異なるプロンプト分布、RLHFによる更新)、Vはオフポリシーとなり\widehat{L}は偏ります。本論文はこのドリフトを定量的に特徴づけていません。第二に、定数報酬の設計はすべてのトークンを等コストとして扱うため、「残りトークン数」と「残り有用な計算量」を混同します——パディングを行うモデルと推論を行うモデルが同一に見えてしまいます。第三に、\gammaとcはテールの感度と近傍の解像度をトレードオフするハイパーパラメータですが、その選択基準は原理的に定められていません。第四に、コントローラの精度への影響は特定のバジェットで報告されていますが、サンプリング温度やself-consistency集約との相互作用は未探索です。最後に、LIFEBenchにおける厳密な長さマッチングの改善は劇的(30.9 → 64.8)ですが、このどれだけがステアビリティによるアーティファクトであるかは不明です——モデルに目標長を与え\widehat{L}を停止・継続シグナルとして使うことは、バジェット下でのオープンエンドな推論よりはるかに容易なタスクです。
この研究の意義
生成長をvalue functionとして再定式化することで、アノテーションなしに、そうでなければ直接最適化が難しい制御変数に対して密でスケーラブルな教師信号が得られます。LenVMスタイルのheadが標準的になれば、推論スタックはコストと品質のトレードオフに対する連続的なノブを獲得します。このトレードオフは現状では粗いmax-tokenのキャップとprompt engineeringによってのみ調整されています。
Source: https://arxiv.org/abs/2604.27039
Representation Fréchet Loss for Visual Generation
問題設定
実画像と生成画像の特徴分布間のFréchet距離(FD)は、生成モデルの主要な評価指標です(\phiがInception-v3の場合はFID)が、学習目的関数としての利用は非現実的と考えられてきました。その理由は構造的なものです:FDは分布的な量であり、(\boldsymbol{\mu}_g, \boldsymbol{\Sigma}_g)の安定した推定が必要で、Inception特徴の2048\times 2048共分散行列を確実に推定するには2048サンプルをはるかに超えるデータが必要となり、評価では通常50kサンプルが使用されます。1ステップあたり50kサンプルを通じた誤差逆伝播は実行不可能であり、一方で小バッチによるFD推定は偏りが大きく分散も高く、特に行列平方根の項 \mathrm{Tr}((\boldsymbol{\Sigma}_r\boldsymbol{\Sigma}_g)^{1/2}) において顕著です。本論文はこの障壁が幻想であると主張します:FD統計量の推定に使用する母集団サイズと、勾配が流れるバッチサイズを切り離すことができるのです。
手法:FD-loss
特徴量 \phi(\mathbf{x}) に当てはめた2つのガウス分布間のFDを再確認します:
\mathrm{FD}_\phi(\mathcal{R},\mathcal{G}) = \|\boldsymbol{\mu}_r-\boldsymbol{\mu}_g\|_2^2 + \mathrm{Tr}\!\left(\boldsymbol{\Sigma}_r+\boldsymbol{\Sigma}_g - 2(\boldsymbol{\Sigma}_r\boldsymbol{\Sigma}_g)^{1/2}\right).
核心的なトリックは、(\boldsymbol{\mu}_g,\boldsymbol{\Sigma}_g)を推定するために大きな生成母集団 \mathcal{G}_{\text{pop}}(例:50kのキャッシュ済み特徴量)を維持しつつ、勾配を持つのは現在の学習バッチ \mathcal{B}\subset\mathcal{G}_{\text{pop}}(例:1024サンプル)のみとすることです。概念的には以下のようになります:
# pseudocode
phi_batch = phi(generator(z_batch)) # gradient-bearing features
phi_pop = stop_grad(cache.update(phi_batch)) # large population, no grad
mu_g, Sigma_g = stats(concat(phi_batch, phi_pop))
loss = FD(mu_r, Sigma_r, mu_g, Sigma_g) # gradients flow only via phi_batchこれにより、母集団推定量はほぼ不偏かつフルランクとなり、1ステップあたりのコストはバッチスケールに抑えられます。(\boldsymbol{\mu}_r,\boldsymbol{\Sigma}_r)は実データセット上で一度だけ事前計算されます。行列平方根のトレースの勾配は、\boldsymbol{\Sigma}_gへのバッチ寄与に対する標準的な微分可能Lyapunov / SVDベースの定式化によって計算されます。
同じlossの形式は任意の表現 \phi(Inception、DINOv2、CLIP、SigLIPなど)に適用でき、\mathrm{FD}_\phiを学習シグナルとして与えます。著者らはさらに、表現固有の盲点に対して頑健な評価指標として、k=6個の特徴空間にわたる多表現集約 \mathrm{FDr}^k を提案しています。
重要なことに、FD-lossは後学習(post-training)目的関数です:事前学習済みの生成器を fine-tuning し、そのサンプルと実分布との間の \mathrm{FD}_\phi を最小化します。教師も敵対者も、サンプルごとのターゲットも存在しません。これにより、lossが出力における分布的一致のみを考慮するため、多ステップ生成器を直接1ステップ生成器に変換できます。

結果
クラス条件付きImageNet 256\times 256において、Inception表現下での1ステップpMF生成器のFD-loss後学習は、1 NFEでFID 0.72を達成しており、後学習モデルが蒸留していない多ステップ拡散ベースラインと同等またはそれ以上の性能を示しています。同じ手法により、多ステップ生成器であるJiT-Hを、敵対的学習や蒸留の教師なしで1-NFE生成器に変換しています(図1、下段)。
2番目の、より興味深い知見は \phi の選択に関するものです。異なる表現下でのpMF-B/16の後学習は、質的に異なるサンプルをもたらします。Inception学習モデルは最低FID(彼らの設定で0.81)を達成しますが、知覚的品質では現代の自己教師あり表現(DINOv2、SigLIP)で学習されたモデルに明らかに劣ります。後者はFIDでは悪化するものの、\mathrm{FDr}^6では良好なスコアを示します。

これはFIDが誤ったランキングを与えることの直接的な証拠です:最適化されるメトリクスが、どのアーティファクトが残存するかを決定します。多表現診断として \mathrm{FDr}^6 を使用することで、「良いFID」と「良いサンプル」の相関が解消されます。
本手法はクラス条件付きImageNetを超えて拡張されます。厳選された60k BLIP3o/GPT-4oの参照セットに対してFD-lossでStable Diffusion 3.5 Mediumを後学習することで、プロンプト忠実性を維持しながら参照分布の美的特性を継承する1-NFEのテキスト-画像生成モデルが得られます(56\timesのNFE削減)。

限界と未解決の問題
- 参照分布 (\boldsymbol{\mu}_r,\boldsymbol{\Sigma}_r) は固定されており、テキスト条件付き生成では、本手法は実質的に周辺分布を照合し、その参照がエンコードするバイアスを継承します(SD3.5の結果はスタイル転送であり、忠実なリアリズムではありません)。
- FDの根底にあるガウス仮定は残存し、高次の分布的構造はこのlossには見えません。現代の自己教師あり空間における特徴分布が十分にガウス的であるかどうかは分析されていません。
- 母集団キャッシュは陳腐化/更新のトレードオフを生み出しますが、これは実装依存であり、論文ではキャッシュサイズや更新頻度に対する感度を完全には特徴付けていません。
- 主要な結果はすべて強力な事前学習済み生成器の後学習です。FD-lossがゼロから競争力のある生成器を学習できるかどうかは未解決です。
- \mathrm{FDr}^k はより良いメトリクスとして提案されていますが、k個の表現の選択と重み付け自体が、操作可能な設計上の決定事項です。
重要性
推定器の母集団と勾配バッチを切り離すことで、FDは評価の気まぐれな指標から扱いやすい学習目的関数へと変わります。経験的な帰結(蒸留やGAN lossなしでの1-NFE ImageNet生成でFID 0.72)は、適切に選択された表現空間における分布照合lossが、現在の蒸留/一貫性/敵対的レシピの群れに対するより単純な代替手段となりうることを示唆しています。同様に重要なことは、異なる学習表現下でInception-FIDと知覚的品質が乖離することの実証が、単一表現FIDをフィールドのデフォルトのスコアボードから退場させる具体的な論拠となっていることです。
Source: https://arxiv.org/abs/2604.28190
MoCapAnything V2: 任意スケルトンに対するエンドツーエンドのモーションキャプチャ
問題
任意の(SMPL非準拠・非標準)スケルトンに対する単眼モーションキャプチャは、プロダクションアニメーションにおける実用上のボトルネックです。スタジオの各アセットは独自のボーン階層、レストポーズ、ローカル軸の規約を持っています。主流のアプローチは、パイプラインを (i) 3次元関節位置 \hat{p} \in \mathbb{R}^{J \times 3} を出力する学習済み Video-to-Pose ステージと、(ii) 関節回転 \hat{R} \in \mathrm{SO}(3)^J を復元する解析的逆運動学(IK)ステージに分解する形で構成されています。これには構造的な問題が二つあります。第一に、関節位置から回転は一意に定まりません:ボーン軸のツイストはエンドポイント位置からは観測不能であり、ツイスト自由度に沿ったいかなるIK解も恣意的なものになります。第二に、解析的IKは微分不可能であるため、アニメーション空間の loss からポーズ予測器へのgradient flowが遮断されます。その結果、Video-to-Pose モデルは、クリーンな回転に変換しやすいポーズを学習することも、回転の安定性のために位置誤差をトレードオフすることもできません。
MoCapAnything V2は両ステージを学習可能かつ同時訓練可能にするとともに、さらに重要な点として、ポーズから回転への問題が適切な定式化になるように再定式化します。
手法
核心となる観察は、p \mapsto R における曖昧性が確率的なものではなく構造的なものであるという点です:同一の関節位置が、異なるレストポーズおよび異なるローカル軸の規約のもとでは異なる回転に対応します。この写像は座標フレームに対してのみ一意に定義されるものであり、そのフレームはアセットごとに固有です。
著者らはこれを解決するために、Pose-to-Rotation ネットワークを、レストポーズ p_0 に加え、対象アセットから取得した 参照ポーズ-回転ペア (p_{\text{ref}}, R_{\text{ref}}) でコンディショニングする手法を採用しています。具体的には、回転予測器は次のように表されます:
\hat{R}_t = f_\theta\!\left(\hat{p}_t,\; p_0,\; p_{\text{ref}},\; R_{\text{ref}}\right),
ここで \hat{p}_t は Video-to-Pose バックボーンによるフレームごとの予測関節位置です。ペア (p_{\text{ref}}, R_{\text{ref}}) は二重の役割を果たします:それ自体では曖昧なツイスト自由度を固定し、かつ対象リグのローカル軸規約を暗黙的に伝達します(R_{\text{ref}} がそのリグのフレームで表現されているため)。レストポーズ p_0 はボーン長・階層のジオメトリを提供します。これらが組み合わさることで、不定な回帰問題が一意な目標を持つ条件付き問題へと変換されます。
f_\theta が微分可能であるため、パイプライン全体
\text{video} \xrightarrow{g_\phi} \hat{p} \xrightarrow{f_\theta} \hat{R}
は同時最適化が可能です。学習では、\hat{p} に対する位置 loss、\hat{R} に対する回転 loss(\mathrm{SO}(3) 上の測地線距離または6次元表現の回帰 loss)、および順運動学(FK)整合性項
\mathcal{L}_{\text{FK}} = \big\| \mathrm{FK}(\hat{R}, p_0) - p_{\text{gt}} \big\|^2
を組み合わせます。この項により、アニメーション空間の目的関数からのgradientが f_\theta を通じて g_\phi まで逆伝播します。これが、Video-to-Pose ステージが孤立した3D MPJPE を最小化するポーズではなく、対象リグに対して IK フレンドリーな ポーズを学習できるようになるメカニズムです。
新しいアセットへの推論時には、ユーザーが (p_0, p_{\text{ref}}, R_{\text{ref}})(通常はバインドポーズと単一のキーイングされたフレーム)を提供するだけでよく、再学習は不要です。参照フレームはテスト時に回転座標系を事実上キャリブレーションします。
結果
報告されているベンチマーク全体において、エンドツーエンドの定式化は、回転メトリクスにおいて分離された Video-to-Pose + 解析的IK のベースラインを上回りつつ、位置精度も維持しています。報告された改善幅はボーン軸ツイスト誤差において最も大きく、これはまさに解析的IKが構造的に盲点を抱える箇所です。(p_{\text{ref}}, R_{\text{ref}}) によるコンディショニングは必要不可欠であることが示されています:レストポーズまたは参照回転のいずれかを除去するアブレーションでは回転精度が大幅に低下し、特に参照回転の除去はツイスト自由度が高い関節(肩・股関節・手首)において最も大きな悪化をもたらします。同時訓練(FK整合性 loss を有効化)は、二つのネットワークを独立して訓練した場合と比較して位置・回転両方の誤差をさらに低減し、Video-to-Pose バックボーンが下流の回転要求に適応しているという主張を支持しています。
本システムは、学習分布と大きく異なるスケルトン(非人間型の生物や様式化されたキャラクター)に対して、対象リグからの単一の参照フレームのみを用い、アセットごとの fine-tuning なしに適用できることが実証されています。
限界と未解決の問題
参照ポーズ-回転ペアへの依存は、キャリブレーションの負担をユーザーに転嫁します:(p_{\text{ref}}, R_{\text{ref}}) の品質が回転品質を直接左右するにもかかわらず、退化した参照(例えば、参照フレーム自体がツイスト特異点上にある場合)については分析されていません。本手法は依然として正確な単眼3D関節推定に依存しており、Video-to-Pose ステージの奥行きおよびオクルージョンに起因する失敗モードを引き継ぎます。回転レベルでの時間的モデルは記述されていないため、フレーム間のツイスト整合性は \hat{p}_t の滑らかさにのみ依存していると考えられますが、これが高周波数動作(指や高速回転)に対して十分かどうかは不明です。最後に、本定式化は参照フレームとキャプチャシーケンス間でスケルトントポロジーが固定されていることを前提としており、モーフターゲットやトポロジーが変化するリグには対応できません。
重要性
任意スケルトンのモーションキャプチャは長年にわたり「関節を予測してからIK」という段階的アプローチに留まっており、ツイストの曖昧性は手作業によるクリーンアップで静かに吸収されてきました。曖昧性の背後にある座標系の欠落という構造を特定し、それを単一の参照ペア (p_{\text{ref}}, R_{\text{ref}}) で解消することで、ネットワークが実際にエンドツーエンドで解ける問題に変換されます。これは、標準的な人体テンプレートには決して一致しないプロダクションリグに対して正しい抽象化です。
Source: https://arxiv.org/abs/2604.28130
PhyCo: 生成モーションのための制御可能な物理的事前知識の学習
問題
事前学習済みのvideo diffusion modelは、もっともらしいテクスチャや短期的なモーションをレンダリングできますが、物理的制約を常に違反します:バウンドするオブジェクトは整合性のある反発係数を保存できず、滑るオブジェクトは摩擦を無視し、変形可能な物体は一貫性のない材料応答を示します。既存の物理認識型アプローチは、シミュレータをループに組み込むパイプライン(計算コストが高く、ジオメトリに依存する)か、あるいは印加力(Force-Prompting)のような単一属性を教師信号とするかのいずれかに依存しています。PhyCoは、シミュレータや推論時の明示的なジオメトリを使用することなく、摩擦・反発・変形・印加力という4つの物理的軸にわたって、連続的・解釈可能かつ構成的な制御を目標としています。
手法
PhyCoは、キュレーションされたシミュレーションデータセットと2段階の学習パイプラインを組み合わせています(Figure 2)。
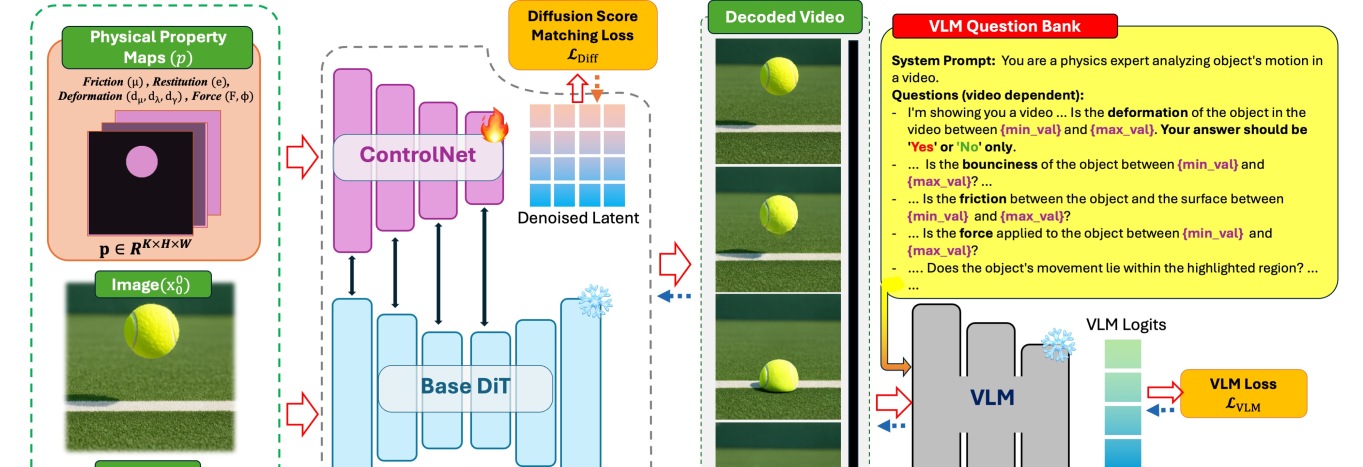
データセット。 Kubricを用いて、著者らは6つ(最終的には8つ)のシナリオにわたる100K以上のフォトリアリスティックなクリップを生成しています。それらのシナリオは、平面上のブロック、ボールと壁の反発、垂直バウンド、重力下のソフトボール、変形可能な物体への衝撃、プールテーブルでの複数ボールの衝突であり、オブジェクトの色、表面マテリアル、カメラ配置をランダム化し、Polyhaven テクスチャを用いた50のHDRI環境を使用しています(Figure 3)。重要なのは、各シーンが制御対象の属性がモーションにおいて明確に現れるように構成されている点です(PISAやForce-Promptingでも同様に指摘されている設計上の制約)。現在のdiffusion backboneの能力を超え、物理的なシグナルとは無関係な学習の分散を注入してしまうため、複雑な複数オブジェクトのダイナミクスは意図的に避けられています。

Stage 1 — 物理教師ありfine-tuning。 事前学習済みのDiT(Cosmos-Predict2)に、ピクセル位置合わせされた物理的特性マップをconditioningとして入力するControlNetブランチが追加されます。これらのマップは、関連するオブジェクト位置に摩擦・反発・変形・力ベクトルのスカラー値を配置する空間マスクです(Figure 4の白いブロブとして可視化されています)。モデルはこれらのマップを条件として標準的なdiffusion score-matching lossで学習されるため、ネットワークはシーンレベルの外観を記憶するのではなく、各特性の標準的な視覚的シグネチャをそのスカラー値と関連付けることを学習します。

Stage 2 — VLMガイド付き報酬最適化。 fine-tuningされたvision-language modelが、生成された各動画に対して物理に関する質問(例:「ボールは指定された反発係数で跳ね返ったか?」)でクエリされ、ControlNetでconditioningされたgeneratorへの報酬信号として逆伝播される微分可能なフィードバックを生成します。このステージは、単に定性的にもっともらしいモーションを生成するだけでなく、conditioningの値に対する定量的な遵守を強化します。
推論時には、特性マップとテキストのみが必要であり、物理エンジンも、メッシュも、点群も必要ありません。
結果
Physics-IQベンチマーク(固体力学・流体力学・光学・磁気学・熱力学;396本の参照動画)において、PhyCoは全カテゴリにわたってCosmos-Predict2、CogVideoX-I2V-5B、SVD-XT、LTX-Video、Force-Prompting、VLIPPを上回っています。これは学習とテストのフレーム数のミスマッチ(57フレームのクリップでの学習 vs. 120フレームのベンチマーク系列)があるにもかかわらず達成されています。
合成データでのアブレーション(Table 4)は、属性ごとの制御誤差を測定する、より機械論的なテストです:
| バリアント | FM ↓ | Fric. ↓ | FD (°) ↓ | Res. ↓ | Def. ↓ |
|---|---|---|---|---|---|
| Base (zero-shot) | 0.38 | 0.33 | 91.87 | 0.40 | 0.45 |
| Text-only fine-tuned | 0.31 | 0.30 | 40.35 | 0.31 | 0.14 |
| ControlNet (−VLM) | 0.33 | 0.24 | 38.05 | 0.28 | 0.14 |
| ControlNet (+VLM) | 0.28 | 0.20 | 22.53 | 0.16 | 0.10 |
力の方向誤差は 91.87°(実質的にランダム)から 22.53° へと低下し、ControlNetにVLM報酬を追加することで反発誤差が 0.31 から 0.16 へと半減しています。注目すべき点として、PhyCo データでのtext-only fine-tuningだけでも力の方向誤差を 40.35° まで削減できますが、ピクセル位置合わせconditioningの空間的精度には到達できません。
2AFC ユーザースタディもこれを裏付けています:CogVideoX-I2V-5Bとの比較では、PhyCo が摩擦で 95.5\%、反発で 100.0\%、変形で 82.2\%、力で 91.1\% の支持を獲得しています;Cosmos-Predict2Bとの比較ではそれぞれ 100.0\%、93.2\%、91.3\%、86.4\% を獲得しています。Force-Prompting(力のみ)との比較では、PhyCo が 71.7\% を獲得しています。PhyCo のtext-only fine-tuningバリアントは力において 58.7\% しか獲得できず、変形では負けており(56.8\% は境界線上;反発は 67.4\%)、これはControlNetの空間的conditioning——データセットだけでなく——が性能向上を牽引していることを確認しています。
限界
学習分布は、孤立した相互作用を持つ視覚的にクリーンで低クラッターのシーンに限定されており、複数オブジェクトの密なダイナミクスへの汎化は明示的にスコープ外であり、性能劣化が見込まれます。4つの物理的軸はスカラーの抽象化であり、異方性摩擦、粘弾性、破壊、流体相互作用はモデル化されていません。ピクセル位置合わせの特性マップは、ユーザー(または上流モジュール)がマスクを指定する必要があり、本論文ではマップノイズへの感度や、新規オブジェクトに対して特性マップをどのように作成すべきかを評価していません。57フレームの学習ホライズンも物理的整合性が保証される持続時間を制限しており、VLM報酬は物理クエリプロンプトがエンコードするバイアスを引き継ぎます。
重要性
PhyCo は、video diffusion における物理的制御可能性をシミュレータをループに組み込む推論から切り離すことができることを実証しています:スカラー特性マップ上のControlNet と VLMから導出された微分可能フィードバックの組み合わせにより、摩擦・反発・変形・力にわたって測定可能で構成的な制御が実現されます。このレシピ——標準的な視覚的シグネチャを分離する小規模で焦点を絞ったシミュレーションスイート、そしてVLMクリティックに対するRL的な精錬——は、生成モデルを他の構造化された事前知識に接地するための再利用可能なテンプレートです。
Source: https://arxiv.org/abs/2604.28169
ViPO: Visual Preference Optimization at Scale
問題設定
Preference optimization(DPOおよびその拡散モデル向け派生手法)は、視覚的生成モデルを人間の審美観に沿わせるための標準的手法となっていますが、LLMとは異なり、そのレシピはスケールとともに綺麗に機能するわけではありません。進歩を阻む二つの相互に絡み合ったボトルネックが存在します。第一に、公開されているpreference dataset(Pick-a-Pic、HPDv2)は構造的な意味でノイズが多く、「勝者」画像が審美的魅力においてはルーザーを上回っていても、プロンプトへの整合性や解剖学的正確さでは劣るケースが多々あります。このようなサンプルに対してDPOの対数比を単純に最大化すると、矛盾するgradientの方向にモデルが押し込まれます。第二に、データ自体が古くなっており、初期SD系モデルによる512〜768pxの出力であり、プロンプト分布にも偏りがあり、動画データはほぼ皆無です。本論文はこの両方を攻略します。すなわち、ノイズに頑健な目的関数(Poly-DPO)と、再構築されたデータセット(1024pxの画像ペア100万件、720p+の動画ペア30万件)を提案します。
手法:Poly-DPO
Diffusion-DPOの目的関数は、ノイズ除去軌跡上の扱いにくいpreference尤度を近似し、次の形のlossを与えます:
\mathcal{L}_{\text{DPO}} = -\mathbb{E}\left[\log \sigma\left(-\beta T\, \Delta_\theta\right)\right],
ここで \Delta_\theta = \big(\|\epsilon_\theta(x^w_t)-\epsilon^w\|^2 - \|\epsilon_{\text{ref}}(x^w_t)-\epsilon^w\|^2\big) - \big(\|\epsilon_\theta(x^l_t)-\epsilon^l\|^2 - \|\epsilon_{\text{ref}}(x^l_t)-\epsilon^l\|^2\big) は、固定された参照モデルに対して勝者 w とルーザー l の間の暗黙の報酬マージンを表します。相反するpreferenceが存在する場合、\Delta_\theta は次元間で符号が一致せず、sigmoidが飽和してノイズの多いペアのgradientが支配的になります。
Poly-DPOは、logitに多項式項を加えることで有効な信頼度を変調します:
\mathcal{L}_{\text{Poly-DPO}} = -\mathbb{E}\left[\log \sigma\left(-\beta T\, \Delta_\theta - \alpha (\beta T \Delta_\theta)^k\right)\right],
これは単一の指数・スケールのハイパーパラメータで制御されます(著者らは「2行の新しいコード」と強調しています)。多項式項はlossのランドスケープを再形成します。クリーンで一貫性のあるデータセットに対しては、確信度の高いペアのgradientを鋭くし、偏ったデータセットに対しては、過剰に確信を持って分類されてしまうペアの寄与を抑制し、モデルが矛盾するシグナルに過適合するのを防ぎます。幾何学的には、これは暗黙の報酬に対する信頼度を考慮した温度スケーリングであり、分類確率ではなくDPOのlogitに適用されるという点でfocal-loss風の重み付けに精神的に近いものです。

同一の関数形が、一つの指数を調整するだけで三つのレジーム(勝者優位、ルーザー優位、相反)をカバーできる点が、目的関数のファミリー自体を変更するIPO、KTO、SPOといった代替手法に対する実用的な利点です。
データセット:ViPO-Image-1M と ViPO-Video-300K
ViPO-Image-1Mは1024pxの画像ペア100万件を含み、FLUXとQwen-Imageにより生成され、五つのカテゴリ(一般的な審美性、プロンプト整合性、解剖学的正確さ、テキスト描画、スタイル)に整理されています。ViPO-Video-300KはWanVideoとSeedanceによる720p+の動画ペア30万件を三つのカテゴリにわたって提供しています。構築時にはカテゴリのカバレッジが均衡するよう明示的に設計されており、「簡単な」審美的preferenceがPick-a-Picを支配するようなランダムサンプリングとは対照的です。

ペアは、最先端の生成モデルからプロンプトごとに複数の候補をサンプリングし、カテゴリ固有のスコアラーでランク付けすることで生成されます(詳細なパイプラインは付録に記載)。設計上の重要な主張は、現世代のモデルを使用することで古いデータセットが持つ交絡因子が排除されるという点です。古いデータセットでは「勝者」が2024年の基準から見ても客観的に質が低く、alignmentシグナルが鈍化してしまいます。
結果
主要な実験はスケーリングのクリーンな評価を行っています。SD1.5、SDXL、SD3、SD3.5-Medium、FLUXにわたって、ViPO-Image-1MでPoly-DPOを用いて学習すると、データ量のスケールアップに伴ってwin rateが単調に向上します。これは、Pick-a-Pic-v2上のDiffusion-DPOが頭打ちになるか後退するのとは対照的です。
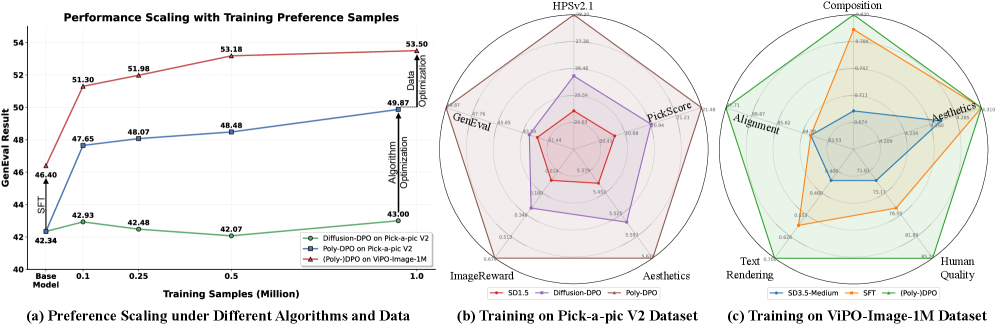
偏ったデータに対するストレステスト(SD1.5をPick-a-Pic-v2で学習)では、Poly-DPOはあらゆる評価次元——審美性、整合性、構造的品質——においてDiffusion-DPOを上回ります(図1b)。ViPO-Image-1Mで学習したSD3.5-Mediumでは、ノイズの多いデータに対する通常のDPOの失敗モードである「ある次元を別の次元と引き換えにする」という現象が見られず、全ての評価軸で均一に改善されています(図1c)。ViPO-Video-300Kで学習したWan2.1-T2V-1.3Bによる動画の結果も、同様の結論を時間的な設定へと拡張しています。
限界と未解決の問題
要旨が途中で切れており、提供されている抜粋には正確なwin rateの数値が含まれていないため、SPO/IPO/MaPOベースラインとの改善幅を提供テキストから正確に引用することはできません。多項式項はデータセットのノイズレベルに依存してその最適値が変化するハイパーパラメータを導入しますが、その原理的な推定方法は示されていません。パイプラインは依然として自動化されたスコアラーを用いてペアにラベルを付けており、それらの偏り(例えば、テキスト描画や解剖学的正確さにおけるHPSやPickScoreの失敗モード)を引き継ぎます。Poly-DPOが \beta チューニングの飽和レジームを超えた恩恵をもたらすのか、それとも単により良い有効 \beta スケジュールを再発見しているに過ぎないのかは、切り分けられていません。最後に、データセットはFLUX/Qwen-Image/WanVideo/Seedanceによって生成されているため、蒸留スタイルの上限がstudentに適用される可能性があります。
なぜ重要か
視覚的生成のpreference optimizationがLLMの軌跡に倣うためには、目的関数とデータの両方がノイズの下でも適切にスケールしなければなりません。ViPOは最小限の編集による目的関数の変更と、クリーンで大規模かつ高解像度のpreference corpusを提供します。この組み合わせこそが、DPOスタイルのalignmentを脆弱なfine-tuningのトリックではなく、画像・動画モデルにとって信頼できるスケーリングの軸とするために必要なものです。
Source: https://arxiv.org/abs/2604.24953
異種科学基盤モデルの協調
問題設定
エージェント型LLMシステムは言語をユニバーサルインターフェースとして扱うため、すべての推論をテキスト化された表現を通じて行う必要があります。これは、入力が非言語的モダリティ(時系列、表形式データ、分子構造、地理空間フィールド)に存在し、強力なドメイン特化型基盤モデル(FM)がすでに存在しながらもネイティブな言語APIを持たない科学的タスクには不向きです。本論文はこのギャップを形式化し、LLMが専門FMを後付けのツールとしてテキストシリアライゼーションの裏側に隠すのではなく、一級参加者として統括できるフレームワーク「Eywa」を提案します。
形式的には、タスクを \tau=(q,x,y^\star,\ell) とし、入力の因子分解を \mathcal{X}=\mathcal{X}_{\mathrm{lng}}\times\mathcal{X}_1\times\cdots\times\mathcal{X}_m, と定義します。ここで \mathcal{X}_k はFM F_k:\mathcal{X}_k\times\mathcal{U}_k\to\mathcal{O}_k のネイティブ入力空間です。エージェント型システム G は \mathbb{E}_{\tau}[\ell(G(q,x),y^\star)] を最小化します。LLMはポリシー A_{\mathrm{LLM}}:\mathcal{S}\to\Delta(\mathcal{M}) であり、何らかのテキスト射影を通じてのみ x_k を観測できます。このフレームワークはその情報損失を取り除くために構築されています。
手法
EywaAgent(FM–LLMの「Tsaheylu」結合)。 各ドメイン k に対して、Eywaはインターフェースペア (\phi_k,\psi_k) を定義します。
- \phi_k:\mathcal{S}\to\mathcal{U}_k — LLMのタスク状態 s を構造化されたFM呼び出し(データセットID、条件付き変数、ホライズン、ハイパーパラメータ)に変換するクエリコンパイラ。
- \psi_k:\mathcal{O}_k\to\mathcal{Z}_k — FMの生出力 o_k を構造化された言語消費可能なコンテキスト z_k(要約統計量、較正済み予測、ランク付き候補など)に変換するレスポンスアダプタ。
エンドツーエンドのループは以下の通りです。 \tau \xrightarrow{A_{\mathrm{LLM}}} s \xrightarrow{\phi_k} u_k \xrightarrow{F_k} o_k \xrightarrow{\psi_k} z_k \xrightarrow{A_{\mathrm{LLM}}} \hat{y}.
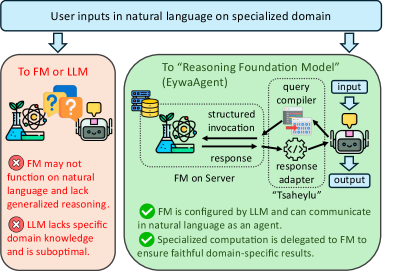
このインターフェースはModel Context Protocol上に実装されており、各 F_k は \mathcal{U}_k,\mathcal{O}_k に対して型付きスキーマを持つリモートサービスとして公開されます。MCPサーバーは x_k を取得し、F_k(x_k,u_k) を実行して構造化された o_k を返します。\psi_k はLLMコンテキストに付加される決定論的アダプタ(テンプレート化されたJSON-to-textおよび数値ダイジェスト処理)として実装されます。
EywaMAS。 単一エージェント設計をマルチエージェントシステム \mathcal{M}_{\mathrm{Eywa}}=(\mathcal{A},\mathcal{G}) に拡張します。ここで \mathcal{A} はトポロジー \mathcal{G} のもとで通常のLLMエージェントとEywaAgentを混在させます。状態・メッセージのダイナミクスは標準的な s_i^{(t)} = \mathrm{Update}_i(s_i^{(t-1)},m_{-i}^{(t)}),\quad m_i^{(t)}\sim A_i(s_i^{(t)}), であるため、既存のplanner/worker/summarizerアーキテクチャは、プロトコルを変更することなく、言語のみのワーカーをEywaAgentに置き換えるだけでアップグレードできます。すべてのエージェントがLLMである場合、EywaMASは従来のMASに帰着します。
EywaOrchestra。 プランナー主導のオーケストレーション層であり、固定トポロジーをエージェントプール上の構造化プランに置き換え、どのエージェントをどの順序で呼び出すかを動的に選択します。
結果
Eywabenchは物理・生命・社会科学にわたる9つのサブドメインをカバーし、テキスト・時系列・表形式のモダリティにまたがり、DeepPrinciple、MMLU-Pro、fev-bench、TabArenaから構築されています。
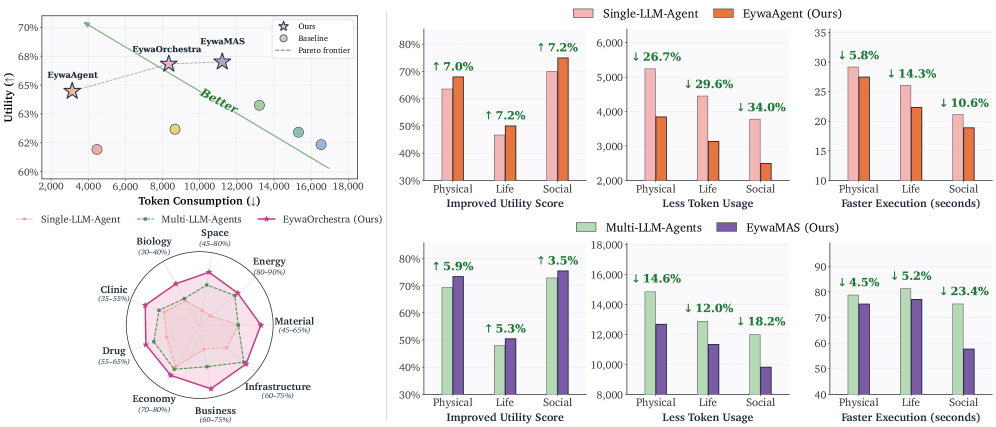
単一エージェント比較(全体的な有用性 / 時間 / トークン数):
- Single-LLM-Agent: 0.6154 / 25.22 s / 4469
- EywaAgent: 0.6558 / 22.78 s / 3137
サブドメインごとに、EywaAgentはすべてのサブドメインで有用性を向上させます。例えば、Energy 0.8202→0.8390、Space 0.5235→0.6123、Biology 0.3402→0.3718、Drug 0.6004→0.6199、Business 0.6528→0.7371となっています。数値推論がin-contextでエミュレートされる代わりにFMにオフロードされるため、トークン消費は約30%削減されます(4469→3137)。
マルチエージェント比較(全体的な有用性):
- Refine MAS: 0.6294(60.59 s / 8673トークン)
- Debate MAS: 0.6460(78.22 s / 13.6k–16.7kトークン)
- EywaAgent(単一エージェント)は0.6558ですでに両者を上回り、wall-clockで約3倍、トークン数で約3〜5倍の削減を実現しています。
Debateベースラインは時系列が多いドメイン(Biology 101.64 s、Economy 92.72 s)で高い効率コストを支払いながらも、それに見合った有用性の改善が得られておらず、言語のみの審議を増やしてもFMへの直接アクセスの代替にはならないことを示しています。
限界と未解決の問題
- 「ドメイン優位性」の仮定は公理的に扱われており、FMが誤較正されていたり分布外であったりする場合を検出するメカニズムをフレームワークは提供せず、LLMが o_k に疑問を呈する手段も限られています。
- アダプタ設計 (\phi_k,\psi_k) はFMごとに手動でエンジニアリングされています。数十の専門モデルへのスケールには学習済みまたは自動生成されたアダプタが必要になる可能性が高く、レスポンスアダプタ \psi_k は損失のあるボトルネックですが、論文ではその分析が行われていません。
- 提供されたセクションにおけるオーケストレーション評価は部分的であり、EywaOrchestraの計画ポリシーはregretや計画ホライズンの観点から特徴付けられていません。
- EywabenchはそのソースデータセットであるTabArenaおよびfev-benchと重複しており、LLMの事前学習に対するデータ汚染が制御されていません。
- FMの意見不一致、FMの障害モード、および敵対的な u_k 設定に対するロバスト性については検討されていません。
なぜ重要か
ほとんどの「科学的エージェント」研究では専門的な計算を脆弱なテキストによるツール使用を通じてルーティングしていますが、EywaはFMを型付きでMCP公開された呼び出し可能関数として形式化し、明示的なクエリ・レスポンスアダプタを持たせることで、それだけで大規模な言語のみのマルチエージェントスタックよりも低いトークン数とレイテンシコストでより高い有用性が得られることを示しています。この研究が開く興味深い研究領域は、LLMの審議をスケールさせることではなく、(\phi_k,\psi_k) をエンドツーエンドで学習することやFMの不確かさのもとでの推論です。
Source: https://arxiv.org/abs/2604.27351
Hacker News Signals
言語モデルにおける拒否応答は単一の方向によって媒介される
Source: https://arxiv.org/abs/2406.11717
本論文は、オープンウェイトの instruction-tuned LLM(Llama-3、Mistral、Gemma、Qwenなど)の広範なモデルにわたって拒否応答の挙動を因果的に媒介する、residual stream の活性化における一次元の線形部分空間を特定しています。中心的な発見は次の通りです:単一の方向 \hat{r} \in \mathbb{R}^d が存在し、推論中にすべての層にわたってすべての residual stream の活性化からこの方向を射影除去することで、汎用的な能力を測定可能な程度に劣化させることなく、拒否応答を確実に消去できます。
この方向は対比的平均差分によって特定されます:有害なプロンプトと無害なプロンプトに対する活性化を収集し、\hat{r} = \text{normalize}(\mu_\text{harmful} - \mu_\text{harmless}) を計算した後、すべての residual stream の位置において介入 \mathbf{x} \leftarrow \mathbf{x} - (\mathbf{x} \cdot \hat{r})\hat{r} を適用します。著者らはまた、この方向を逆向きに利用できることも示しており、\hat{r} のスケーリングされた倍数を活性化に加えると、モデルが無害なプロンプトを拒否するようになります。
補完的な発見として、単一の重み行列を標的とした直接的な重み編集によって拒否応答を誘発または除去できることが示されています:具体的には、attention 層の W_O に \alpha \hat{r} \hat{r}^\top を加算するというものです。これはランク1の編集であり、LoRAベースの jailbreak のような完全な fine-tune アプローチよりも解釈しやすいものです。
本研究は線形表現仮説に関する先行文献と接続しており、safety fine-tuning が分散した回路ではなく低次元の特徴を書き込むという経験的な裏付けを提供しています。これには実用的な含意(低コストな迂回手段の存在)と理論的な含意の両方があります:RLHF による alignment は非常に高次元の空間においてほぼ一次元の決定境界を符号化しているということです。著者らは JailbreakBench における拒否率をベンチマークとして示しており、MT-Bench の劣化を最小限に抑えながら、ablation 後に95%以上の攻撃成功率が得られることを示しています。限界として、この分析は活性化にアクセス可能なオープンウェイトモデルに限定されており、同じ方向が特徴レベルでアーキテクチャをまたいで汎化するのか、それとも機能的にのみ汎化するのかは不明です。
Alignment Whack-a-Mole: Fine-tuningによるLLMの著作権保護書籍の想起活性化
Source: https://github.com/cauchy221/Alignment-Whack-a-Mole-Code
このリポジトリは、著作権のあるテキストの再現を拒否するように安全性 alignment されたLLMが、軽量な fine-tuning によってそのテキストを想起させられることを示す研究に付随するものです。しかも、fine-tuning データがターゲットの書籍と全く無関係であっても同様の効果が生じます。「whack-a-mole(もぐら叩き)」というフレーミングは、alignment によって一つの望ましくない挙動を抑制すると別の挙動が不安定になり、fine-tuning によって抑制された能力が復元されるという本質的な問題を捉えています。
このメカニズムは、上記のrefusal-direction論文における線形表現の描像と一致しています。安全性 alignment は、residual stream 内の方向や抑制的な回路を通じて記憶されたコンテンツを抑制しますが、良性データに対する数回の gradient ステップによってモデルの activation 分布が十分に変化し、その抑制が部分的に解除されます。重要なのは、この効果が標的型攻撃を必要としない点です。instruction-following データに対する良性の fine-tuning であっても、ハリー・ポッター、グレート・ギャツビー、その他のテスト済みテキストの逐語的想起が再び可能になります。
評価プロトコルでは、正確な n-gram マッチ(n=50)とグラウンドトゥルースの文章に対する ROUGE-L を用いて逐語抽出率を測定し、ベースモデル、aligned モデル、fine-tuned-aligned モデルを比較しています。結果として、aligned モデルは抽出率を大幅に低下させますが、無関係な fine-tuning の 100〜500 gradient ステップによって抽出率はベースモデルのレベルに近づくことが示されています。
これが技術的に重要である理由は、post-training が「想起する」と「想起しない」の間に安定した分割を生み出せるという仮定に疑問を投げかけるからです。記憶は alignment に関わらずモデルの重みの中に存在しており、alignment はコンテンツを消去するのではなく、学習されたゲートを追加しているように見えます。著作権責任の観点からは、aligned モデルが学習データを再現しないと主張するAPIプロバイダーにとって重要な問題です。未解決の問いとしては、より大きなモデルがよりロバストに記憶を保持するか(それによりゲートの突破が容易になるか)、そして学習時の何らかの介入によってゲートするのではなく記憶されたコンテンツを実際に削除できるかどうかが挙げられます。
アルゴリズム採用におけるAIの自己優遇:実証的エビデンスと考察
Source: https://arxiv.org/abs/2509.00462
本論文は、LLMベースの採用システムが自己優遇を示すかどうかを検証します。具体的には、候補者の履歴書がAI支援によって生成・最適化されたことを示している場合、あるいは候補者が評価モデルの学習分布と相関する形でAI習熟度を示している場合に、システムが当該候補者を系統的に高く順位付けするかどうかを調べます。この問題が重要なのは、アルゴリズム採用がすでに大規模に導入されており、順位付けにおける系統的バイアスが法的・労働市場的な影響をもたらすためです。
実験設計には、制御された履歴書監査(resume audit)が用いられています。候補者の資格、AIシグナルとなる表現(例:GPT-4、Copilot、またはモデル固有のツールへの言及)、評価モデルの同一性を変化させた要因計画(factorial design)が採用されています。履歴書は複数のLLM(GPT-4o、Claude 3.5、Gemini 1.5 Pro、Llama 3)によってスコアリングされます。主な知見は、統計的に有意な自己優遇の存在です。すなわち、各モデルは、自身のエコシステムに関連するツールやワークフローに言及した履歴書に対して高いスコアを付与します。GPT-4oは、他のすべての要因を制御した上で、OpenAIのツールに言及した履歴書に対して、競合ツールに言及した同等の履歴書より約8〜12パーセンタイルポイント高いスコアを付与します。
想定されるメカニズムとして、インターネットデータで学習したLLMが暗黙的なブランド感情の連想を吸収しており、評価プロンプトがスコアリング時にこれらの連想を活性化するという説明が提示されています。これは単純なキーワードマッチングによるアーティファクトではなく、ツール名が言い換えられたり機能的に説明されたりした場合にも効果が持続します。
限界も相当大きく、履歴書監査研究は外部妥当性が限られており、実際の採用環境では人間によるレビューが介在するため効果量が小さくなる可能性があり、また特定の学習データへの因果帰属は行動実験のみからは不可能です。本論文はデバイアスの修正手法を提案していませんが、contrastive decodingや中立ベースラインに対するキャリブレーションが自然な候補として挙げられます。fine-tuningによる採用用途への特化が自己優遇を増幅させるか減衰させるかという問いは、未解決のまま残されています。
PyTorch Lightning AIトレーニングライブラリにShai-Hulud テーマのマルウェアが発見される
Source: https://semgrep.dev/blog/2026/malicious-dependency-in-pytorch-lightning-used-for-ai-training/
Semgrep のセキュリティチームは、PyTorch Lightning の依存ツリー内に悪意のあるパッケージを発見しました。このパッケージは、「Shai-Hulud」(砂虫)を参照するDuneをテーマにした変数名および関数名を使用しており、一般的なマルウェア文字列に対してチューニングされたパターンマッチング検出器を回避するための「珍しさによる難読化」として機能していたと見られます。
技術的な内容はサプライチェーン攻撃の亜種です。悪意のある依存パッケージはタイポスクワットまたは依存関係混乱(dependency-confusion)パッケージであり、インストール時にpost-installフック(setup.pyまたはpyproject.tomlのビルドスクリプト)を実行して任意のコードを走らせます。ペイロードのDuneテーマの命名は表面的なものに過ぎず、機能的な動作は標準的なinfostealer/remote-access-trojanの範疇です。すなわち、環境変数の外部流出(MLトレーニング環境では、APIキー、クラウド認証情報、Hugging Faceトークン、wandbシークレットが環境変数に含まれることが多い)、およびコールバックチャネルの確立が行われます。
ML特有の攻撃対象領域は特筆に値します。トレーニングジョブは通常、広範なIAMロールを持つクラウドVMまたはKubernetesポッド上で実行され、モデルレジストリへのアクセスや、S3/GCS/Azureストレージのシークレットを含む環境変数にもアクセスできます。侵害されたトレーニング環境では、1回のジョブ実行でモデルの重み、トレーニングデータ、および認証情報が流出する可能性があります。また、torch.hubやHugging Faceのfrom_pretrainedエコシステムは、設計上リモートコードを実行するため、追加の攻撃ベクトルとなります。
今回の検出は依存グラフの静的解析によって実現しました——SemgrepのルールがPOST-installの実行をフラグとして検出しました。緩和策としては、requirements.txtまたはpyproject.tomlで依存関係のハッシュをピン留めすること、ネットワーク隔離環境でインストールを実行すること、および実行前にsetup.py内のsubprocess/socketの呼び出しを監査することが挙げられます。より根本的な問題は、MLツールのエコシステムがそのセキュリティレビュープロセスよりも急速に成長しており、人気のあるトレーニングフレームワークが最小限の審査のもとで大規模な推移的依存ツリーを蓄積していることです。
IBM Granite 4.1 モデルファミリー
Source: https://research.ibm.com/blog/granite-4-1-ai-foundation-models
IBMのGranite 4.1リリースは、エンタープライズ向けオープンウェイトファミリーにおけるdenseバリアントおよびMoEバリアントを更新するものです。技術的に注目すべき点は、Granite 3.xと比較したアーキテクチャおよびトレーニングの変更点です。
Granite 4.1は、full attentionレイヤーとsliding-windowローカルattentionレイヤーを組み合わせたハイブリッドattentionアーキテクチャを採用しており、長いコンテキスト処理における二乗のattentionコストを削減しています。コンテキストウィンドウは128Kトークンまで拡張されています。MoEバリアント(Granite 4.1 MoE)は、ロードバランシング補助lossを伴うtop-k スパースルーティング機構を使用しており、これはMixtral以降の標準的な手法ですが、IBMは自社の内部ハードウェアターゲットにおける推論効率を特に考慮してエキスパートの粒度と数をチューニングしたと報告しています。
トレーニングデータの構成は、ほとんどのリリースよりも高いレベルで開示されています。ブログでは、コード、技術文書、エンタープライズデータドメインに重みを置いたミックスを使用し、ライセンス互換コンテンツを明示的にフィルタリングしたことが報告されています。これはエンタープライズのIPリスク上の理由から、IBMが一貫して強調してきた差別化要因です。instructバリアントは多段階パイプラインでトレーニングされており、キュレーションされた instruction データによるSFT、その後PPOベースのRLHFではなくDPOが適用されています。
報告されているベンチマーク数値には、MMLU(70Bクラスdenseモデル:約84%)、HumanEval(約78%)、および長文脈検索(128KでのNIAH:95%超のrecall)が含まれます。小型のdenseモデル(3B、8B)はオンデバイスおよびエッジデプロイメント向けに位置付けられており、コーディングタスクにおいてLlama 3.1 8Bと競合する性能を主張しています。
制限事項:このブログ投稿は技術レポートではないため、アーキテクチャのハイパーパラメータ、トレーニング計算量、および完全なベンチマーク手法は開示されていません。MoEのエキスパート数とルーティングの詳細は明記されていません。また、ハイブリッドattentionパターンが固定のインターリービング比率によって決定されているのか、あるいは学習によるものなのかも不明です。
LFM2-24B-A2B: LFM2アーキテクチャのスケールアップ
Source: https://www.liquid.ai/blog/lfm2-24b-a2b
Liquid AIのLFM2-24B-A2Bは、総パラメータ数24B、forward pass当たりのアクティブパラメータ数2Bのモデルであり、structured state-space model(SSM)layerとattention layerをハイブリッド構成で組み合わせたLFM2アーキテクチャをスケールアップしたものです。「A2B」という名称は、MoE sparse routingにおける2Bのアクティブパラメータ数を指しています。
LFM2アーキテクチャは、Liquid Foundation Model layer(linear recurrence / structured SSMファミリーの一変種であり、Mamba/S6やRWKV系の定式化に関連する)とgrouped-query attentionをインターリーブする構成を採用しています。このrecurrenceにより、recurrent stateが充填された後のSSM layerのステップごとの推論コストは O(1) となります。これが主要な動機であり、長いシーケンスをsub-quadraticなコストで処理できます。24B/2BのMoE構成はさらにsparse routingを重ねることで、大部分のパラメータをトークンごとに非アクティブな状態に保ち、FLOPsを2Bのdenseモデルに近い水準に抑えます。
報告されているベンチマーク結果は、標準的な評価において7B〜13BクラスのdenseモデルとMMUL ~72%、MATH ~58%で競争力のある性能を示しており、SSM recurrenceがアーキテクチャ上の優位性をもたらす長文脈タスクにおいて特に高い性能を示しています。スループットのベンチマークでは、シーケンス長>32Kにおいて同等の品質で7B dense transformerと比べてトークン/秒が2〜4倍向上すると主張されています。
主要な未解決の問題として以下が挙げられます。SSM-attentionハイブリッドはスケールアップ時に純粋なtransformerモデルでは回避できる学習不安定性を示すことがありますが、ブログではloss curveや学習安定性への介入については触れられていません。LFM layerの定式化はこの投稿では完全には仕様が開示されておらず、特定のSSM変種(S4、Mamba、GLA)との関係も明確にされていません。真に長距離の推論(単純な検索ではなく)を要するタスクでの評価が、SSMベースのアーキテクチャにとって意味のある試金石となります。重みは公開されており、独立したアーキテクチャ分析が可能です。
注目の新しいリポジトリ
atomicarchitects/equiformer_v3
Equiformer V3は、原子論的機械学習向けEquiformerV2アーキテクチャの第三世代であり、OC20やOC22などのベンチマークにおける分子特性予測および構造緩和タスクを対象としています。コア設計は、SO(3)の既約表現(irreps)上に構築されたSE(3)/E(3)-equivariantなgraph attentionを維持しており、角度基底関数として球面調和関数を使用し、相互作用の重みを条件付けるradialネットワークを備えています。V3では、attention機構とテンソル積縮約に対するアーキテクチャ上の改良が導入されており、equivarianceを保ちながらパラメータ効率を向上させています。ネットワークは原子グラフを処理し、各ノードはirrepsチャネル \bigoplus_l (2l+1) 次元成分に分解された特徴ベクトルを持ち、エッジは相対位置から導出された幾何学的embeddingを保持します。メッセージパッシングは構造上群のequivarianceを満たすように設計されており、力とエネルギーの予測が回転および反射に対して正しく変換されます。リポジトリには、訓練用config、事前学習済みチェックポイント、およびOpen Catalystデータセットに対する評価スクリプトが含まれています。EquiformerV2と比較して、V3はモデルの深さおよびシステムサイズに対してより良いスケーリング特性を目指しており、実行時間を支配するClebsch-GordanテンソL積の計算コストを削減しています。equivariantニューラルポテンシャルや材料科学向けfoundation modelに取り組む研究者にとって注目すべき成果です。
Source: https://github.com/atomicarchitects/equiformer_v3
future-agi/future-agi
Future-AGIは、LLMベースのパイプラインおよびエージェント向けのオープンソース評価・オブザーバビリティフレームワークです。技術的なコアは、モデル非依存の品質メトリクス群であり、事実整合性、指示追従、コンテキスト忠実性、ハルシネーション検出をカバーしており、ローカルまたはホスト型APIのいずれでも実行できます。メトリクスは、参照不要なLLM judgeと決定論的ヒューリスティックの組み合わせによって計算され、パイプラインステージをゲートするための閾値を設定可能です。このリポジトリは、任意のLangChain、LlamaIndex、または生のAPIコールグラフを計装するためのPython SDKを提供し、入出力トレースをキャプチャして非同期にスコアリングします。Pydanticベースのスキーマがトレース構造を定義しており、型付きインテグレーションおよびダウンストリームへの集計を可能にします。評価結果はダッシュボードに送られ、モデルバージョンやプロンプト変更にまたがるスコアドリフトのモニタリングに活用されます。また、このフレームワークはデータセットレベルのバッチ評価もサポートしており、テストセットがスコアリングされ、結果が構造化レポートとしてエクスポートされます。クローズドなオブザーバビリティ製品とは異なり、メトリクス計算コードは検査可能かつ拡張可能であり、ユーザーはシンプルなインターフェースに準拠したカスタム評価器を登録できます。主な制限として、judgeベースのメトリクスは基盤となるjudgeモデルのバイアスや能力の上限を引き継ぐ点が挙げられ、グラウンドトゥルースによるキャリブレーションデータは現時点でリポジトリに同梱されていません。
Source: https://github.com/future-agi/future-agi
Tisha-runwal/Personalized-Federated-Learning-for-Privacy–Preserving-and-Scalable-IoT-Driven-Smart-Healthcare
このリポジトリは、異種IoT健康モニタリングデバイスを対象とした個別化連合学習(pFL)システムを実装しています。コアアルゴリズムはper-FedAvgまたはローカル fine-tuning 連合学習の一変種であり、参加クライアント(個々の患者デバイスを表す)全体でFedAvgによりグローバルモデルを集約した後、各クライアントがプライベートなオンデバイスデータに対して少数のローカル gradient ステップでグローバルな重みを適応させます。この二段階アプローチは、センサーの分布や病理の有病率が患者間で大きく異なるヘルスケアIoTに固有の統計的不均一性に対処することを目的としています。プライバシーはアップロード前のローカル gradient 計算時における差分プライバシー(DP)ノイズ注入によって担保されており、プライバシー予算 (\epsilon, \delta) は設定可能です。コードベースには、集中パラメータ \alpha を用いたDirichlet割り当てによって標準的な健康データセット(例:MIMIC由来のバイタルサインやECGベンチマーク)をnon-IIDなクライアント分割に分割するシミュレーションインフラが含まれています。通信効率は集約前の gradient スパース化によって対処されています。本リポジトリには、トレーニングスクリプト、Flowerまたはカスタムコーディネーターによるクライアント/サーバーシミュレーション、およびグローバルと各クライアントの個別化精度の両方を計測する評価スクリプトが含まれています。シミュレートされるクライアント数を変化させたスケーラビリティ分析も含まれています。主な制限事項として、実験はシミュレーションのみであり実際の組み込みデプロイメントは行われていないこと、およびDP会計がより厳密なRDP境界ではなく基本的な合成則を用いていることが挙げられます。
FonaTech/Project_Chronos
Project Chronos は、分布シフト下における長期予測を志向した時系列forecasting frameworkです。アーキテクチャの中核は transformer encoder-decoderであり、learned temporal positional encodingを用いることで、embedding段階においてトレンド・季節性・残差分解を明示的に分離します。これはAutoformerやFEDformerに類似したアプローチを踏まえつつ、モジュール式のコンポーネント構造により分解戦略の差し替えを容易にしています。patchingストラテジーは、tokenization前に入力系列を非重複ウィンドウに分割することで、長いコンテキストにおける二次的なattentionコストを削減します。本frameworkは、点予測ではなくターゲット分布(GaussianまたはStudent-t)のパラメータを出力することで確率的forecastingをサポートし、proper scoring ruleによるキャリブレーション済み不確実性定量化を実現します。学習インフラにはカリキュラムスケジュールが含まれており、forecast horizonの長さを段階的に増加させることで、非常に長い予測ウィンドウにおけるgradient flowを安定化します。本リポジトリはmultivariate設定を対象とし、一般的な時系列データセット(ETT、Weather、Traffic)用のコネクタおよび汎用CSVローダーを備えています。設定はYAMLファイルを通じて管理され、モデルの深さ、patch size、分解タイプ、および分布のheadを制御します。評価スクリプトはMAE、MSE、CRPS、およびキャリブレーション指標を計算します。現在の主要な未解決課題は、同等のパラメータ数においてPatchTSTやiTransformerなどの既存ベースラインとの体系的なベンチマーク比較です。
Source: https://github.com/FonaTech/Project_Chronos
Dynamis-Labs/spectralquant
SpectralQuantは、ニューラルネットワークの重み行列のスペクトル解析と量子化のためのライブラリであり、モデル圧縮を純粋な大きさに基づく枝刈りではなく、数値線形代数の問題として定式化します。中核的な演算は重み行列の打ち切りSVD分解 W \approx U_k \Sigma_k V_k^\top であり、ランク k は特異値スペクトルに対する設定可能なエネルギー保持閾値によって各層ごとに決定されます。この低ランク近似は、保持された特異ベクトルおよび特異値の量子化と組み合わされており、ランクと数値精度の両方を同時に削減する2軸の圧縮スキームを実現します。本ライブラリには、事前学習済みモデルの特異値減衰プロファイルを解析するルーティンが含まれており、高速なスペクトル減衰を示す層(高い圧縮可能性)とフラットなスペクトルを示す層(低ランク近似に対する耐性が高い)を診断することができます。サポートされているバックエンドはPyTorchであり、分解後に nn.Linear 層をin-placeで置き換えるフックが提供されています。打ち切りによる精度損失を回復するためのpost-compression fine-tuningユーティリティも提供されています。本リポジトリには、標準的なvisionモデルおよびlanguageモデルに対する圧縮率と精度のトレードオフ曲線を計測したベンチマークが含まれています。既知の制限として、SVDベースのアプローチは全結合層およびattention projection層に対して最も効果的である一方、畳み込み層にはリシェイプのヒューリスティクスが必要であり、これが分解品質を低下させる場合があります。
Source: https://github.com/Dynamis-Labs/spectralquant
facebookresearch/neuroai
Facebook ResearchのNeuroAIリポジトリは、システム神経科学と人工知能の交差点に位置する計算ツールおよびモデル実装を収集しています。技術的な内容は二つの方向性にわたります:AIモデルのベンチマークと制約に神経データを活用すること、および神経計算に関する機能的仮説としてAIモデルを活用することです。本ライブラリは、神経集団記録とDNN中間活性化の間における表現類似性分析(RSA)およびcentered kernel alignment(CKA)をフィッティングするためのユーティリティを提供し、モデルの表現幾何学が脳領域の応答とどの程度一致するかを定量化します。また、タスク最適化されたニューラルネットワークモデル(例:腹側経路CNN、作業記憶のための回帰回路)の実装も含まれており、NeuralBenchやBrain-Score互換の評価インターフェースなど標準的な神経ベンチマーク向けデータローダーも備えています。予測性メトリクスは、モデル活性化から神経発火率へのlinear regressionまたはpartial least squaresマッピングを用いて計算され、保留試行に対するcross-validationも実施されます。AIから神経科学への方向性においては、大規模な事前学習済みvisionおよびlanguageモデルの創発的特性を調査するための分析ツールが同梱されており、例えば顔・物体・構文に選択的なユニットの局在化などが可能です。コードベースはモジュール化されており、神経データ処理、モデルのprobing、およびメトリクス計算は独立したサブパッケージに分離されています。制限点として、神経データ読み込みパイプラインのドキュメントは、特定の独自データセット形式への習熟を前提としています。