デイリーAIダイジェスト — 2026-06-15
arXiv ハイライト
APPO: Agentic Procedural Policy Optimization
問題設定
ツール使用LLMに対するAgentic RLでは、通常、粗い単位——軌跡全体、ツール呼び出しの境界、あるいは固定されたワークフローのステージ——にクレジットを付与します。これはツール呼び出しが構文的に明確であるため便利ですが、ツールを呼び出すかどうかという選択と、実際に下流の成功を左右するthinking spanの内部における多数の潜在的な推論決定とを混同してしまいます。高エントロピートークン(「意思決定点」の一般的な代理指標)で分岐する手法も信頼性に欠けます。高エントロピーはしばしば意味的に重要な分岐点ではなく、語彙的な代替(例:同義語、フォーマット)を反映しているためです。
著者らはこの問題を直接定量化しています。Tool-Starの54Kロールアウトを用いたパイロット研究では、エントロピー分布はヘビーテールですが、高エントロピートークンから再サンプリングされた分岐の精度はエントロピービン全体でほぼフラットである一方、高いBranching Scoreを持つ点から生成された分岐は下流の精度と強い相関を示しています。
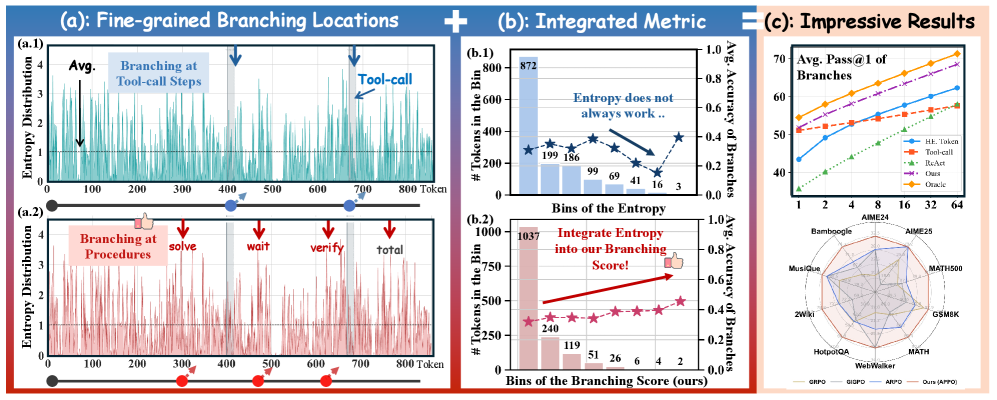
pass@kのパネルはさらに、BSベースの再サンプリングが、エントロピーベースおよびツール呼び出し境界ベースの再サンプリングよりも、オラクル(最も高い実験的精度を持つ点からの再サンプリング)をはるかに密接に追跡することを示しています。
手法
APPOは粗い分岐を、2つのコンポーネントを中心に構築された細粒度の手続きレベルの分岐およびクレジット付与に置き換えます。
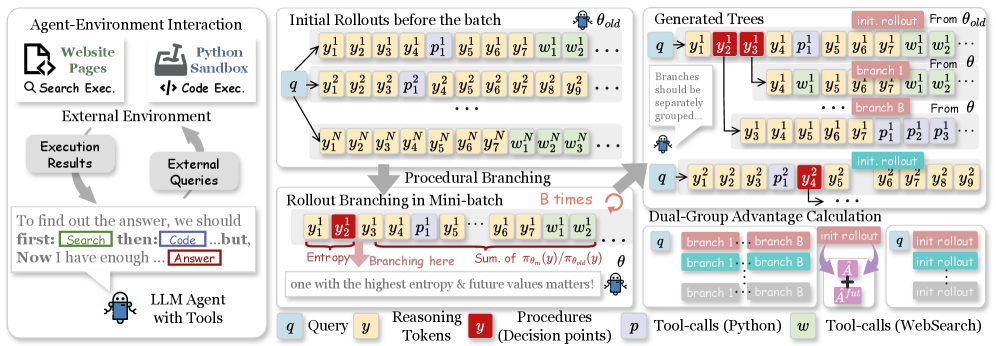
1. Branching Score (BS)。 ロールアウト内の候補トークン位置 t に対して、APPOは局所的な不確実性と未来認識シグナルを組み合わせます:t からの代替継続が、残りのシーケンスに対するpolicyの尤度をどの程度変化させるかを測定します。具体的には、エントロピー
H_t = -\sum_{j=1}^{|\mathcal{V}|} p_{t,j}\log p_{t,j},\quad \bm{p}_t = \mathrm{Softmax}(\bm{z}_t/\tau)
を、\pi_\theta の下で短い継続をサンプリングし、それらが軌跡の残りの部分に誘導する対数尤度を比較することで測定された尤度ゲイン項と融合させます。局所的な不確実性が高く、かつ下流の divergence も高い位置が意思決定点としてフラグ付けされます。これにより、高エントロピーだが不活性なトークン(例:句読点、交換可能なフレーズ)がフィルタリングされます。
2. 手続き的分岐とデュアルグループアドバンテージ。 標準的なagentic因数分解
P_\theta(\mathcal{G},y\mid x,T)=\prod_{t=1}^{T_a}[\pi_\theta(\mathcal{O}_t\mid \mathcal{G}_{<t},x;T)P_{env}(\mathcal{G}_t\mid \mathcal{O}_t,\mathcal{G}_{<t})]\prod_{t=1}^{T_b}\pi_\theta(\mathcal{O}_t\mid y_{<t},\mathcal{G},x;T),
の下での初期ロールアウトのバッチが与えられると、APPOはミニバッチ内のBS上位の位置を選択し、それらの位置から継続を再サンプリングします(ツール呼び出し境界からではなく)。元のロールアウトと分岐したロールアウトは、アドバンテージ推定に共同で使用される2つのグループを形成します。未来認識アドバンテージ項は、幾何学的な減衰 \gamma = 2^{-1/\tau}(\tau=32)を用いて終端報酬を各分岐に沿って伝播させ、分岐点からロールアウトの終端までの間に手続きレベルのクレジット付与を提供します。訓練には標準的なagentic RL目的関数
\max_{\pi_\theta}\,\mathbb{E}_{x\sim\mathcal{X},\,y\sim\pi_\theta(\cdot\mid x;T)}[r_\phi(x,y)] - \beta\,\mathbb{D}_{\mathrm{KL}}[\pi_\theta\,\|\,\pi_{\mathrm{ref}}]
を使用し、\beta=0(安定性のためKLを無効化)、バッチサイズ128、PPOミニバッチ16(8更新/ステップ)、ツール呼び出し出力はgradientからdetachされます。SFT初期化はARPOに従い、訓練はVeRLフレームワーク上で推論タスクに2エポック、検索タスクに5エポック実施されます。
結果
APPOは、vanilla RLベースライン(GRPO、Reinforce++、DAPO、GPPO、CISPO)、agentic RLベースライン(GIGPO、ARPO)、search agent(Search-o1、WebThinker)、および強力な参照モデル(QwQ、DeepSeek-R1、GPT-4o、o1-preview、Qwen3-32B)に対して、3つのベンチマークファミリーで評価されています:数学的推論(GSM8K、MATH、MATH500、AIME24/25)、マルチホップQA(HotpotQA、2Wiki、Musique、Bamboogle、WebWalker)、およびdeep-searchタスク(GAIA、HLE、Xbench)。評価指標はQAではF1、それ以外ではLLM-as-judgeによるpass@1(vLLM経由のQwen2.5-72B-Instruct)です。
4つのデータセットにわたるARPOとのpass@1〜pass@5分析が最も有益なアブレーションです。

APPOはpass@1だけでなくpass@k曲線全体を改善しており、これは細粒度の分岐がpolicyの推論経路の有効なカバレッジを拡大し、単一モードを鋭くするだけでなく——図1cのBS対エントロピー比較と一致しています——ことを示しています。
限界とオープンクエスチョン
- BSは短い継続を通じた位置ごとの尤度ゲイン推定を必要とするため、ステップあたりのコストは評価される候補分岐点の数に応じてスケールします。論文ではARPOに対する実際の計算オーバーヘッドは報告されていません。
- 減衰スケジュール \gamma=2^{-1/\tau}(\tau=32)は手動設定のハイパーパラメータであり、\tau およびBS融合の重みに対する感度は提供されたセクションでは詳述されていません。
- \beta=0 はKLアンカーを除去しており、著者らは安定性のためにこれが必要であると述べていますが、これは長期的な訓練においてdriftに関する疑問を生じさせます。
- 非QAタスクの評価はQwen2.5-72BによるLLM-as-judgeに依存しており、GAIAやHLEなどのdeep-searchベンチマークではjudgeモデルのバイアスが生じる可能性があります。
- この手法は短期的な尤度ゲインからの意味のあるシグナルを前提としています。報酬が高度に遅延しているか、BSの計算に使用されるホライゾンを超えてスパースなタスクでは、スコアがエントロピーに退化する可能性があります。
なぜこれが重要か
APPOは、エージェント軌跡における「意思決定点」がツール呼び出し境界と一致しておらず、エントロピーだけでは適切に識別できないという直観を実装化するものです。分岐とクレジット付与の両方を単一の細粒度かつ未来認識シグナルで置き換えることにより、長期ホライゾンのツール使用タスクにおける手続きレベルRLのためのより明確な基盤を提供します——粗いクレジット付与が持続的なボトルネックとなってきた設定において。
Source: https://arxiv.org/abs/2606.12384
HarnessX: 構成可能・適応的・進化可能なエージェントハーネスファウンドリ
問題設定
エージェントの性能はランタイムハーネス——プロンプト、ツール、メモリ、制御フロー——に依存しますが、ハーネスは依然として手作りかつ静的なままです。新しいモデルやタスクが登場するたびに専用のスキャフォールディングが必要となり、実行トレースが系統的な改善にリサイクルされることはほとんどありません。HarnessXは、ハーネスを型付き・置換可能・進化可能なオブジェクトとして具体化し、トレースがハーネスの編集とモデル訓練の両方を駆動するループを閉じることで、このギャップに対処します。
構成層
ハーネスはペア \mathcal{H}=(\mathcal{M},\mathcal{C}) として定義されます。ここで \mathcal{M} はモデル設定(main、judge、evaluator の各ロールを担うモデルとフォールバックポリシー)であり、\mathcal{C}=(\mathbf{P},\mathbf{S}) はモデルに依存しないハーネス設定です。\mathbf{P}:\mathcal{H}\!\mathit{ook}\to\mathrm{List}[\mathit{Processor}] は、8つのライフサイクルフック(task_start、step_start、before_model、after_model、before_tool、after_tool、step_end、task_end)それぞれを、明示的な変更許可コントラクトを持つ型付きプロセッサの順序付きリストにマッピングします(例:before_model は最後のユーザーコンテンツを変更し、ユーザーメッセージをちょうど1件追加できる;after_tool はツールの結果を上書きできる)。\mathbf{S} はツールレジストリ、トレーサー、ワークスペース、サンドボックスプロバイダー、プラグインリストなど、プロセッサ間で共有されるシングルトンスロットリソースを保持します。重要な点として、\mathcal{C} はシリアライズ可能・ハッシュ可能・置換可能であり、これがハーネスのプログラム的探索の前提条件となります。プロセッサは9次元の分類体系(モデル選択、コンテキスト組み立て、メモリ、ツールエコシステム、実行環境、評価/報酬、制御/安全、観測可能性、訓練ブリッジ)に沿って整理されており、ハーネス設定はフックの型とシングルトングループの制約に従う各 c_i\in\mathcal{C}_i のタプル \mathcal{H}=(c_1,\ldots,c_9) として表されます。
AEGIS: 記号的RLとしてのハーネス適応
AEGISはハーネスの進化を記号的アーティファクト上のMDPとして扱います:状態は設定 \mathcal{H}、行動は型付き編集、フィードバックはロールアウトからの(トレース、検証器報酬)ペアです。このマッピングは3つの病理——報酬ハッキング、壊滅的忘却、探索不足——を予測し、単一のメタエージェントによって駆動される4段階パイプラインの動機となります。
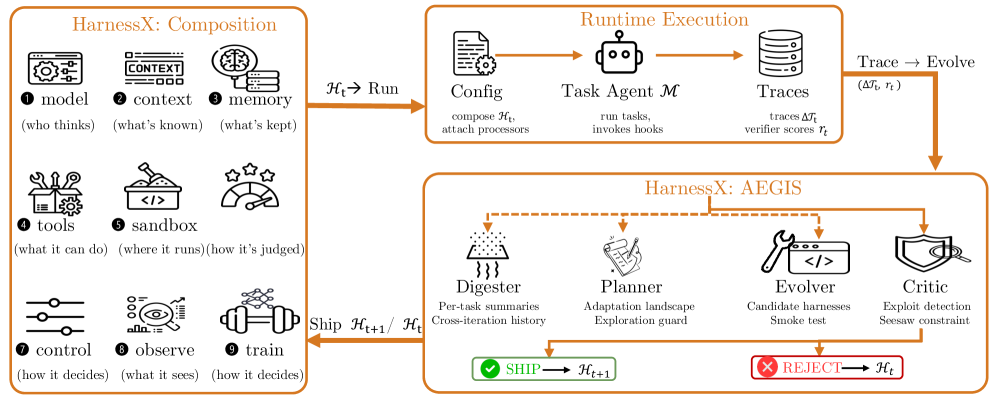
Digesterは1ラウンドのトレースを失敗クラスターに圧縮し、Plannerは候補となる編集を合成し、Evolverはそれらを (\mathbf{P},\mathbf{S}) 上の具体的な差分として具体化し、Criticはそれらを capability_evidence、predicted_impact、および attribution_signature(編集が発火した場合に次のラウンドで現れなければならないトレース特徴)を含む変更マニフェストに対して検証します。出荷された各編集は、t+1 におけるトレース特徴デルタに対して反証可能です。バリアント分離は、並行する候補をサンドボックス化してお互いのスロット状態を汚染しないようにすることで、安定したマルチバリアント進化を提供します。
GAIA / Sonnet 4.6の実例がこのループを説明しています:ラウンド9で成功率が77.7%から74.8%に後退し、DigesterはWikipediaのWebFetch呼び出し10件がそれぞれ0文字を返したことを観察しました(新しいWikipediaのフロントエンドがJSレンダリングパスを壊していた)。Evolverは複合編集(新しいツール+プロンプト追加+設定変更)を出荷し、これがそのランで最大の単一ラウンドゲインとなりました。
共進化
モデルを固定したままではハーネスの進化がスキャフォールディング上限に達し、ハーネスを固定したままではモデル訓練が訓練シグナル上限に達します。HarnessXは共有リプレイバッファ上の単一のイテレーション内で両方の更新を実行します。
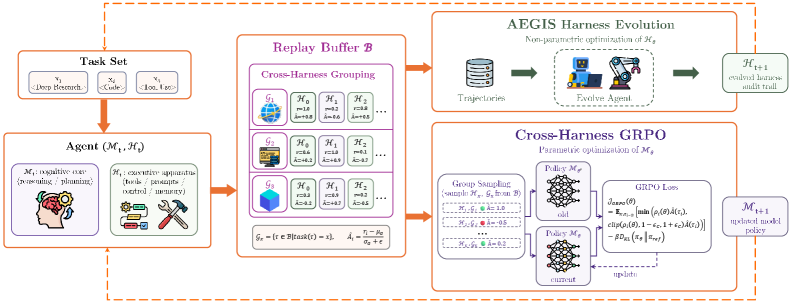
イテレーション t においてエージェント (\mathcal{M}_t,\mathcal{H}_t) はバッチ B_t をロールアウトし、観測可能性レイヤーが完全なトレース \tau_i を記録し、固定検証器がスカラー報酬 r_i を与えます(ハーネスバージョン間で報酬が比較可能であるために固定されており、これがクロスハーネスアドバンテージの要件です)。トレースは固定容量のFIFOバッファ \mathcal{B} に追加されます。クロスハーネスGRPO は同一タスクの軌跡をハーネスバージョンをまたいでグループ化し、グループ相対アドバンテージ \hat{A} を計算して、クリップされたGRPO目的関数を適用します。同じバッファ済みロールアウトがAEGISとGRPOの両方に供給されるため、モデルRLは追加のロールアウトコストを発生させません——これはハーネス進化のために生成されたデータに対するオフポリシー訓練です。
結果
5つのベンチマーク——GAIA(103タスク、完全一致)、ALFWorld(134、目標完了)、WebShop(100、属性一致)、\tau^3-Bench(3ドメイン、ルール遵守)、SWE-bench Verified(55、パッチ解決)——にわたり、HarnessXは最大 T=15 進化ラウンドおよび P=3 非生産的ラウンド後の早期停止で、平均+14.5%、最大+44.0%のゲインを報告しています。メタエージェントのトークン予算はベンチマークごとに合計1億〜1.75億です。ゲインはベースラインが低い場合に最も大きく、ハーネススキャフォールディングが弱いモデルの行動ギャップを最も容易に埋めるという主張と一致しています。
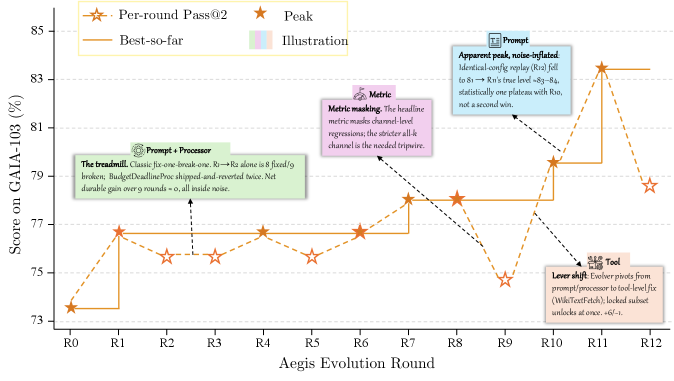
ベンチマークごとの詳細な分析は示唆に富んでいます。GAIAでは、失敗クラスターの内訳はブロックされたソース39%、推論33%、図/視覚11%、文書/表解析11%、スコープの曖昧さ6%であり、レバーの分布とモデル別レバーのヒートマップは進化が失敗の集中するところに集中していることを示しています。
限界
検証器は固定されており合理的に忠実でなければなりません——ハーネスバージョン間での報酬の比較可能性はクロスハーネスGRPOにとって構造的なものであり、オプションではありません。ベンチマークのサンプリングは控えめであり(例:SWE-bench Verifiedは55タスク、GAIAは103タスク)、15ラウンドの進化上限は漸近値を過小評価している可能性があります。このフレームワークは防御を主張するRL病理を継承していますが、その防御は(マニフェストゲート付き編集、バリアント分離という)アーキテクチャ的なものであり、証明可能な有界性を持つものではありません。ベンチマークあたり1億〜1.75億トークンの予算は無視できないものであり、モデルのfine-tuningのみに費やされる同等の計算との直接比較は行われていません。
なぜ重要か
ハーネスを型付き・置換可能なオブジェクトとして扱うことで、ランタイムインターフェースが第一級の最適化ターゲットとなり、RLへの操作的な対応関係がそれを探索するための原則的な根拠を与えます。経験的な主張——ハーネス進化とモデルRLが追加のロールアウトコストなしに単一の軌跡バッファを共有する——は実践的に興味深いものです:これは、エージェントベンチマークにおける進歩がモデルのスケーリングだけによらなくてもよいことを示唆しています。
Source: https://arxiv.org/abs/2606.14249
層をスキップするか繰り返すか?LLMにおけるProgram-of-Layersの学習
問題設定
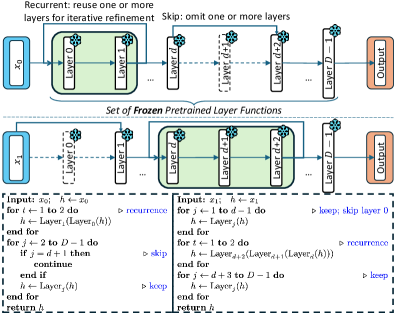
標準的なLLM推論は、入力の難易度に関わらず、D個のtransformerの層すべてを固定された順序で適用します。本論文では、この固定深度・固定順序のforward passがすべての入力に対して適切な計算であるか、あるいは同一の事前学習済み重みを用いた代替実行経路上に、より良い予測が存在するかどうかを問います。著者らはこれをprogram-of-layers(PoLar)として形式化しています。すなわち、各層 f_i:\mathbb{R}^{T\times d}\to\mathbb{R}^{T\times d} を呼び出し可能なモジュールとして扱い、推論プログラムを以下の系列として定義します。
\pi=(i_1,\ldots,i_K),\quad F_\pi=f_{i_K}\circ\cdots\circ f_{i_1},
ここで層のスキップや繰り返しが許容されます。ほとんどの入力に対して、\pi\neq(0,1,\ldots,D-1) となる複数の異なる \pi が正しい予測をもたらし、しばしば K<D となるという仮説を立てています。
存在の検証:診断ツールとしてのMCTS
この仮説を検証するために、著者らはDART-Math上でプログラムに対するMonte Carlo Tree Search(選択・展開・シミュレーション・バックプロパゲーション、展開演算子としてスキップと繰り返しを使用)を実行します。MCTSは代替プログラムが達成できることの上界を求めるオラクルとして純粋に使用されており、推論手法として用いるわけではありません。
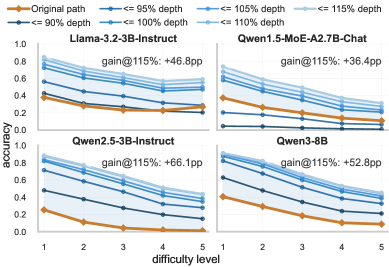
DM-1からDM-5にわたって、MCTSは D の90%という低い深度バジェット下でも標準forward passの精度に匹敵または超えるプログラムを発見し、115%では性能向上が拡大します。重要なのは、D より短い多くのプログラムが、元のモデルが誤答する入力に対して正解を出すことであり、これは固定forward passが(深度、精度)平面においてPareto最適でないことを示しています。
手法:PoLar予測ネットワーク
MCTSは推論時には計算コストが高すぎるため、PoLarはそれを1回の予測でプログラムを出力する軽量ネットワークに置き換えます。
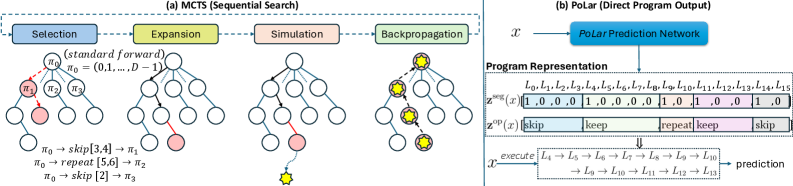
プログラムは2つの構造としてエンコードされます。
- Segmentation \mathbf{z}^{seg}(x)\in\{0,1\}^D:D 層を連続したpacked modules [s_j,s_{j+1}) に分割するバイナリ境界マスクで、最大セグメント長は K_{\max}=4 です。この上限は、有効なプログラムが短い連続セグメントによって支配されるというMCTSの知見によって正当化されます。
- Operations \mathbf{z}^{op}(x)\in\{\text{skip},\text{keep},\text{repeat}\}^D:セグメント開始位置においてのみ定義されます。セグメント [s_j,s_{j+1}) に対して:
\text{skip}:\emptyset,\quad \text{keep}:[s_j,\ldots,s_{j+1}-1],\quad \text{repeat}:[s_j,\ldots,s_{j+1}-1,s_j,\ldots,s_{j+1}-1].
演算子の語彙は意図的に最小限に抑えられています。MCTSのトレースから、セグメントあたり1回を超える再実行はほとんど効果がないことが示されているため、単一の repeat で十分です。必要に応じて、この語彙は repeat-k に自明な形で拡張できます。
ベースLLMは完全に凍結されており、訓練されるのは予測器のみです。推論時には、予測器に対するbeam searchがtop-k プログラムを生成し、サンプリングデコードのランダム性を排除したpass@k の類似物を提供します。多様性はトークンレベルの温度ではなく、計算経路から生まれます。
実験
モデル:LLaMA-3.2-3B-Instruct、Qwen1.5-MoE-A2.7B-Chat、Qwen2.5-3B-Instruct、Qwen3-8B(すべて凍結)。DART-Math(DM-1からDM-5、難易度別分割)でin-distributionの訓練・テストを実施。OOD評価では、DART-Mathの全データで訓練し、ASDiv、MAWPS、MMLU-Proのサブセット(数学、自然・社会科学、人文科学)でzero-shotテストを行います。
ベースラインは確率的出力手法(\tau=0 でのgreedy;\tau\in\{0.3,0.7,1.0\} でのサンプリング、best of k)と、内部計算に作用する動的深度・ルーティングアプローチ(DR.LLM、ShortGPT(静的プルーニング)、MindSkip、FlexiDepth)の両方にわたります。著者らは、PoLarが標準推論およびこれらの動的深度ベースラインに対してpass@k 精度を一貫して改善し、しばしば元のモデルより少ない層で実行しつつ、DART-Mathの分布から遠いASDiv、MAWPS、MMLU-Proの各サブジェクトでもOODにおける性能向上が持続することを報告しています。(ベンチマークごとの数値テーブルは実験セクションに記載されており、要旨レベルの主張は4つのモデルファミリにわたり、in-distributionおよびout-of-distributionの両設定で一貫性があるというものです。)
制約と未解決の問題
- 実験の範囲は数学的推論とMMIU-Proに限定されており、長文脈・コード・生成主体のタスクでの挙動は未検証です。
- K_{\max}=4 と単一の
repeat演算子は、本分布上のMCTS統計によって正当化されていますが、他のドメインではプログラム空間がより豊かな再帰(repeat-k)やより長いセグメントを必要とする可能性があります。 - プログラムに対するbeam searchはpass@k を提供しますが、k=1 のデプロイ時に1つのプログラムを選択することは予測器のキャリブレーションに依存します。top-1プログラムが誤りで、より深いbeamが正解である場合についての詳細な分析は本論文では行われていません。
- 各「モジュール」が何を計算するかの解釈可能性、および
repeatがresidual streamにおける反復的精緻化などの既知の現象に対応するかどうかは未解決のままです。 - ベースモデルの再訓練を行わないため、関数ライブラリは固定されています。層をプログラム予測器と共同適応させることでさらなる性能向上が期待できますが、それはtest-time onlyという前提を損なうことになります。
意義
PoLarはtest-time計算スケーリングを再定式化します。より多くのトークン(CoT、サンプリング)やより多くのパラメータを費やすのではなく、既存の層に対する異なる制御フローを費やすことで、事前学習済みtransformerが標準forward passで露わになるよりも豊かな有効な潜在計算のファミリを内包していることを示唆しています。この性能向上が数学的推論を超えて成立するならば、動的層プログラムは、計算を入力難易度に適応させるためのchain-of-thoughtおよびspeculative decodingに対して、安価かつ直交する軸となります。
Source: https://arxiv.org/abs/2606.06574
LoRA最適化におけるスケーリング係数の隠れた力
LoRAの更新式 \Delta W = \frac{\alpha}{r} BA には、実務家が通常、学習率 \eta に吸収される冗長なパラメータとして扱っているスケーリング係数 \alpha が含まれています。本論文は、この等価性が見かけ上のものに過ぎないと主張します。\alpha と \eta は異なる幾何学的対象に作用しており、\alpha の誤ったキャリブレーションこそが、LoRA が full fine-tuning(FFT)に対して性能が劣る実際の原因であると述べています。著者たちはこの非対称性を定量化し、それを説明するSignal-Drift分解を導出し、共同ハイパーパラメータ探索を行うことなくLoRAとFFTのギャップの大部分を埋めるリキャリブレーション手法 LoRA-\alpha を提案しています。
\alpha と \eta の間の経験的非対称性
Llama 3-1B / Tulu 3 上で (r, \eta, \alpha) に対する系統的なスイープを通じて、著者たちは \eta^*(r,\alpha) = \arg\min_\eta \mathcal{L}(r,\eta,\alpha) と対応する最小損失 \mathcal{L}^* を追跡しています。二つの規則性が浮かび上がります。第一に、「LoRAはFFTよりも \sim 10\times 大きな学習率を必要とする」というよく知られた通説は、小さな \alpha(例:\alpha=16)においてのみ成立するということです。\alpha が大きくなるにつれ、\eta^* は低下し、\mathcal{L}^* は単調に改善されます。
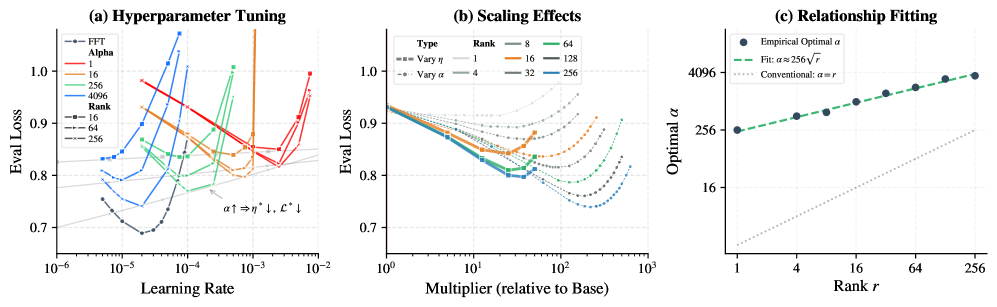
第二に、FFTのベースライン (\eta_{\text{FFT}}=2\times 10^{-5},\, \alpha_0=16) を出発点として、二つの直交する乗数 \mathcal{L}_\eta(m) = \mathcal{L}(r, m\eta_{\text{FFT}}, \alpha_0) と \mathcal{L}_\alpha(m) = \mathcal{L}(r, \eta_{\text{FFT}}, m\alpha_0) を追跡すると、\alpha スケーリングは不安定になる前にはるかに大きな m を許容し、\eta スケーリングよりも厳密に低い損失極小値に到達することが示されます。\eta スケーリングは早期にプラトーに達します。したがって、\alpha はステップサイズの代替物ではなく、損失ランドスケープそのものを変形させます。
Signal-Drift分解
これを説明するために、著者たちは双線形パラメタライゼーション \bm{w}(\bm{\theta}) = \mathrm{vec}(W_0 + \tfrac{\alpha}{r} BA) を用いて、LoRAの重み空間ステップとヘッセ行列を分解します:
\Delta\bm{w}_{\text{LoRA}} = \underbrace{J(\theta)\Delta\bm{\theta}}_{\Delta\bm{w}_{\text{Signal}}} + \underbrace{\tfrac{1}{2}\nabla^2_{\bm{\theta}}\bm{w}[\Delta\bm{\theta}, \Delta\bm{\theta}]}_{\Delta\bm{w}_{\text{Drift}}},
\mathcal{H}_{\text{LoRA}} = \underbrace{J(\theta)^\top \mathbf{H}_\ell J(\theta)}_{\mathcal{H}_{\text{Signal}}} + \underbrace{\sum_k g_k \nabla^2_{\bm{\theta}} w_k}_{\mathcal{H}_{\text{Drift}}}.
Signal項はタスクに整合した線形化であり、Drift項は BA の双線形性から生じるパラメタライゼーションのアーティファクトです。重要な点として、\Delta\bm{w}_{\text{Signal}} は \Delta\bm{\theta}(したがって \eta)に対して線形ですが、\Delta\bm{w}_{\text{Drift}} は \Delta\bm{\theta}(したがって \eta)に対して二次です。一方、\alpha によるスケーリングはヤコビアン自体を乗算するため、Driftを二次的に膨張させることなくSignalの曲率を増幅させます。
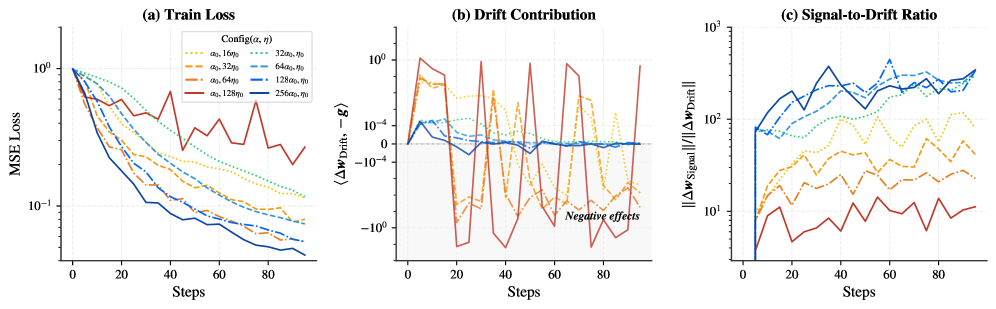
中央および右側のパネルが確認しているように、\eta スケーリングはドリフトの変動を急激に増加させsignal-to-drift比を悪化させる一方、\alpha スケーリングは相対的な観点でドリフトをほぼ一定に保ち、「純粋な」更新とより深いフィッティングをもたらします。
\alpha^* の r に対するサブ線形スケーリングと LoRA-\alpha
\alpha^*(r) = \arg\min_\alpha \mathcal{L}(r, \eta_{\text{FFT}}, \alpha) を定義すると、経験的なフィットはサブ線形であり、予想外に大きな係数を持つ平方根則 \alpha^* \approx C\sqrt{r} によってよく記述されます。標準的なヒューリスティクス(バニラLoRAでの \alpha = r、RsLoRAでの \alpha \propto \sqrt{r} だが定数が小さい)は 16\times~256\times 過小スケールです。
LoRA-\alpha は更新式を以下に置き換えます:
\Delta W = \frac{\alpha \cdot \alpha_{\text{base}}}{r} BA, \qquad \eta = \Theta(\eta_{\text{FFT}}),
曲率復元の役割(\alpha_{\text{base}})と残差チューニングパラメータ(\alpha、デフォルト 1、必要であれば [0.1,10] で探索)を分離します。\alpha_{\text{base}} に対する二つの処方:
- 経験的(LLMデフォルト): \alpha_{\text{base}} = 256\sqrt{r}。現代のLLMの均一な隠れ次元(d_{in}\sim 4096)を活用します。
- 解析的(層ごと): \alpha_{\text{base}} = \tfrac{1}{\sigma_A}\sqrt{r}。初期化時の期待タスク曲率をFFTと一致させることで導出されます。
最適化の安定性は \mathrm{tr}(\mathcal{H}) ではなく \lambda_{\max}(\mathcal{H}) によって支配されるため、経験的バージョンは解析的バージョンをわずかに超えます。
結果
DeBERTa-v3-base を用いたGLUE(rank 8、\eta=10^{-4})において、LoRA-\alpha は平均 87.97 を達成しており、バニラLoRAの 81.94、RsLoRAの 83.76、LoRAMの 86.44、FFTの 86.69 と比較して、スイープなしでFFTを上回っています。\alpha スイープあり(LoRA-\alpha^*)では平均が 89.09 まで上昇します。CoLAでの改善が最も顕著で、LoRAの 63.56、FFTの 67.26 に対して 70.89 を記録しています。
Llama 2-7B NLGベンチマーク(rank 16、\eta = 2\times 10^{-5})では、LoRA-\alpha は平均 35.81 を達成しており、LoRAの 29.37、LoRAMの 33.71 を上回っています。スイープありのLoRA-\alpha^* は 41.49 に達し、FFTの 44.57 に迫ります。rank 128では、LoRA-\alpha^* はFFTと同等(44.87 対 44.57)となり、GSM8K 59.97、MATH 11.74 でFFTと同等もしくはそれを超えています。デフォルトのLoRA-\alpha(スイープなし)は、rankを固定したすべてのヒューリスティクスを1~6ポイント上回り続けています。

この手法はflowマッチング目的関数を用いたFlux.1-12Bの diffusion fine-tuning にも転用可能であり、曲率復元の議論がクロスエントロピーに特有のものではないことが示唆されます。
限界と未解決の問題
平方根則の係数 C=256 は経験的なものであり、現在のLLMの隠れサイズに依存しています。d_{in} が大幅に小さいアーキテクチャでは再キャリブレーションが必要になる場合があります(解析的バリアントはこれに対処していますが、最適値を過小評価します)。トレースノルムとスペクトルノルムに基づく曲率マッチングの差異は認識されていますが、理論的には未解決のままです。Signal-Drift分解は二次テイラー展開であり、双線形曲率自体が変化する長期的なダイナミクスは分析されていません。最後に、量子化(QLoRA)との相互作用や、AdamW以外のオプティマイザ固有の挙動については未検証です。
なぜこれが重要か
これが正しければ、10年間にわたるLoRAのハイパーパラメータに関する通説は再定式化されます。「LoRAには大きな \eta が必要」というルールは過小スケールな \alpha に対する回避策であり、現在普及しているrankに依存したヒューリスティクスは1~2桁ずれているということになります。ほぼゼロコストの再キャリブレーション(\alpha_{\text{base}} = 256\sqrt{r})によってLoRAとFFTのギャップの大部分を埋めることができ、(\alpha, \eta) の共同スイープを実務家の作業から取り除くことができます。
Source: https://arxiv.org/abs/2606.12883
OmniDirector: クロスペアデータなしの汎用マルチショットカメラクローニング
問題設定
参照動画からカメラモーションをクローンして新たに生成した動画に適用することは、video diffusionにおける制御性の中核的な問題です。主要な2つのアプローチにはそれぞれ欠点があります。パラメトリック条件付け(Plückerembedding、生の R, t 系列)は、単一の連続ショットに対しては幾何学的に忠実ですが、外部パラメータが不連続であり内部モデルが変化し得る(例:魚眼レンズ、ドリーズーム)マルチショット入力では破綻します。もう一つの手法——同一のカメラ軌跡を異なるコンテンツ上で実現したクロスペアデータを合成する方法——は、特にカットを含む映画的なモーションにおいて、データ不足がボトルネックとなります。OmniDirectorは、(a) パラメトリックではなくビジュアルな表現を目指すことでモダリティ固有のエンコーダを必要とせずマルチモーダルDiTで処理でき、かつ(b) ショットをまたいで合成可能な表現の実現を目標としています。
手法
中心的なオブジェクトはカメラグリッドです:参照カメラ軌跡を、空の軸整列3Dワイヤーフレームの部屋を通る動きとして可視化した動画です。R_i \in SO(3)、t_i \in \mathbb{R}^3 を持つ参照ポーズ P=\{R_i, t_i\}_{i=1}^T が与えられると、著者らは \{t_i\} からシーンのバウンディングボックスを計算し、以下の式で床と天井を配置します:
y_{floor} = \overline{y} - \Delta h, \qquad y_{ceiling} = \overline{y} + \Delta h,
ここで \overline{y} はY軸方向のカメラ高さの平均であり、\Delta h は隣接ポーズ間の並進の中央値にスケールし、安定性のために下限が設けられています。2つのX–Z平面上に直交するグリッドラインがラスタライズされます。
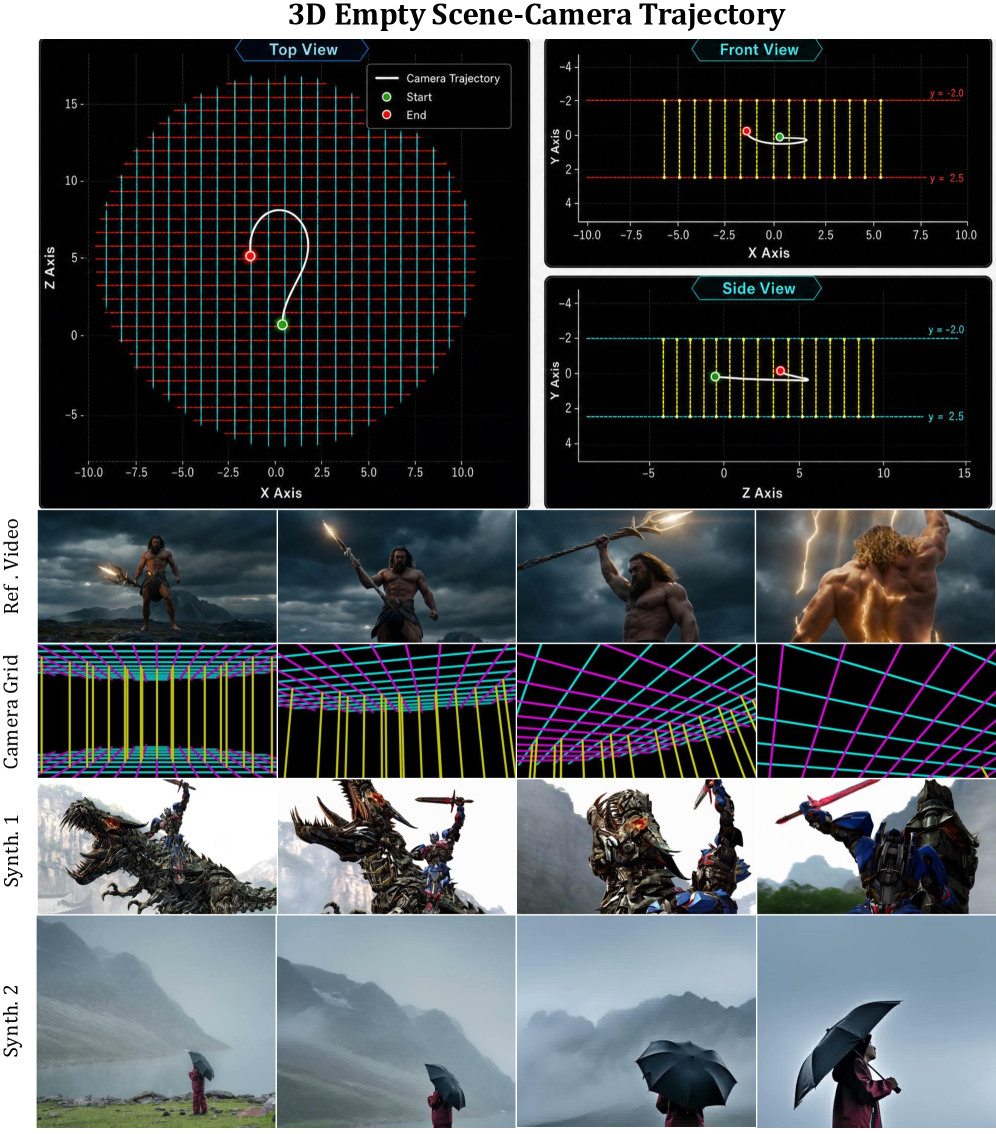
Y軸方向の奥行き手がかりのために、床と天井を完全に接続するのではなく、軌跡をX–Z平面に投影して c_{proj} を得て、KD木で d_{traj}(x,z) を計算し、以下のアニュラス上に垂直な壁セグメントを挿入します:
W = \{(x,z) \mid r < d_{traj}(x,z) < r + \delta\},
これによりカメラパスを囲むトンネルが形成されます。この静的なジオメトリを実際の \{R_i, t_i\} 系列を通じてレンダリングする(魚眼レンズに対するKannala–Brandtモデルや、ドリーズームに対する焦点距離スイープを含む実際の内部パラメータを使用)と、ピクセルがカメラモーションを視覚的にエンコードした動画 G が得られます。
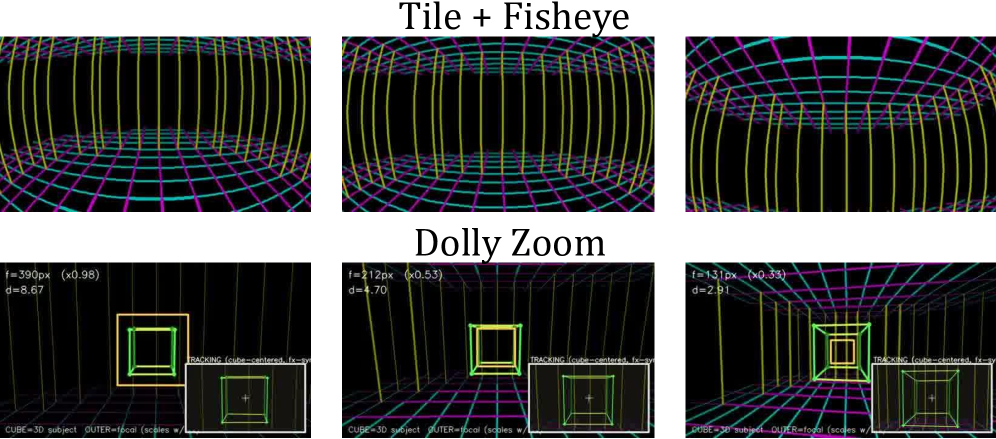
これが設計上の重要な選択です:G はただの動画であるため、マルチショット入力は自然に連結できます——各ショットは自身のポーズと内部パラメータを用いてグリッドをレンダリングし、カットはDiTがすでにモデル化を習得している通常のフレーム間変化として現れます。モデルは同一動画ペアから G \to \text{motion} のマッピングを学習するため、クロスペア(同一軌跡・異なるコンテンツ)データは不要です。
OmniDirectorは、MMDiT image-to-videoバックボーンをトリプレット \{G, I, T'\}——カメラグリッド G、参照画像 I、拡張テキストプロンプト T'——で条件付けします。3つすべてはシーケンス次元に沿ったトークン連結によって注入され、カメラグリッドのトークンはターゲット動画トークンと同じVAEエンコーダおよび位置スキームを共有するため、グリッドフレームと出力フレームの間の時空間的対応は暗黙的に確立されます。
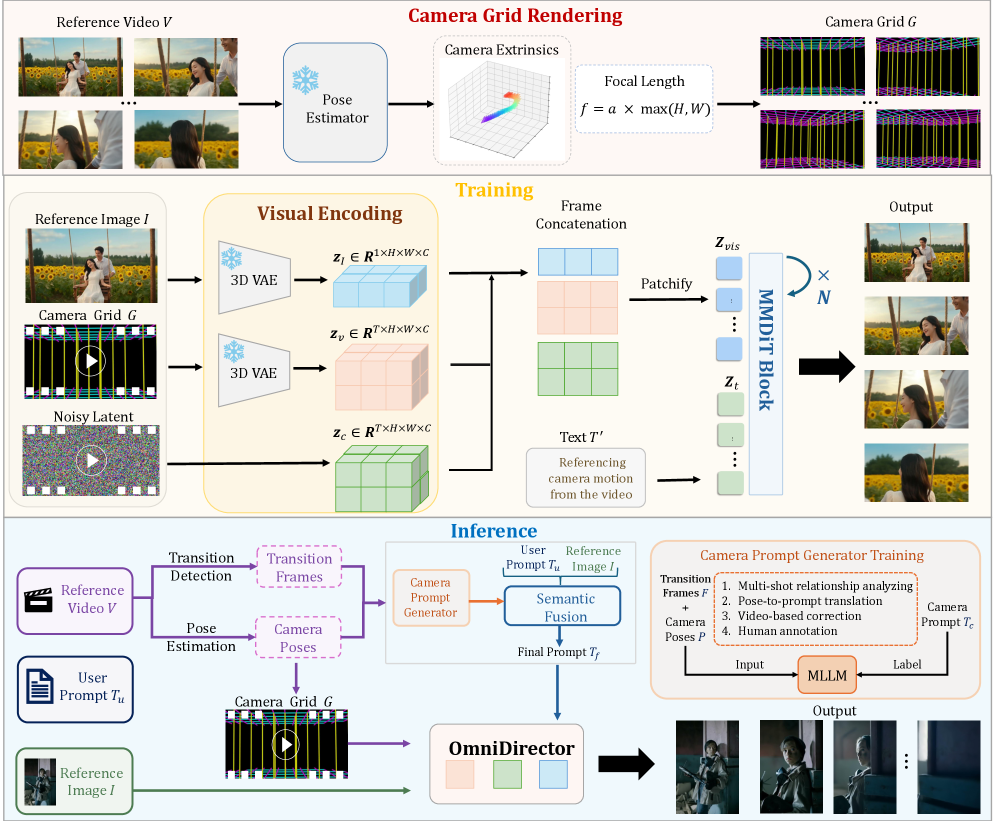
推論時には、階層的なPrompt Expansion(PE)Agentが制御信号を融合します:カメラグリッドをモーションのテキスト記述(パン、ドリー、カット種別)にパースし、ユーザーのコンテンツプロンプトおよび参照画像と整合させることで、視覚的条件と内部的に一貫した T' を生成します。学習には480pのインターネット動画180万本を使用し、10kステップ、バッチサイズ64、学習率 5 \times 10^{-5} で、グリッドのランダムリカラリングとポーズジッタをaugmentationとして適用します。
結果
カメラの忠実度はDPA-V3で抽出されたポーズを用いて測定され、スケール不変なRelative Rotation Error(RRE)およびRelative Translation Error(RTE)と、閾値付きの指標R-Pre(回転誤差 <4^\circ)およびT-Pre(並進方向誤差 <20^\circ)が計算されます。マルチショット評価では2つの遷移指標が導入されています:Tem-Pre(TransNet-V2でショット境界を検出し、参照の3フレーム以内であれば成功)およびSem-Pre(Gemini 3.1 Proで遷移タイプが一致するか検証)。参照動画のリーケージはフレームレベルおよびショットレベルでGeminiによって個別に定量化され、CamCloneMasterに対するGSBペアワイズスタディはカメラ、品質、およびナラティブの軸をカバーしています。該当セクションではこれらのプロトコルが説明されていますが、最終的な数値テーブルは列挙されておらず、アブストラクトの主要な主張は、パラメトリックおよびクロスペアのベースラインが劣化する複雑なマルチショット軌跡や特殊な内部パラメータに対して優れた制御性を有するというものです。
限界と未解決の問題
空の部屋のレンダリングはカメラ並進が規定する範囲を超えたシーンスケールの情報を破棄するため、絶対的なメトリックスケールは転送されず、相対的な軌跡形状のみが保持されます。このアプローチは評価に使用するポーズ推定器の誤差を引き継ぐため、著者らもこの点を認めてGemini/GSBを補完として追加しています。グリッド表現は学習解像度でレンダリングされる必要があり、非常に長いショットや極端な軌跡はバウンディングボックスの仮定を超える場合があります。さらに、PE AgentはシグナルのリコンサイルのためにexternalなLLMに依存しており、これにより制御性がそのモデルのgrounding能力に結び付けられてしまい、G と T' の間の不一致による失敗モードは提供されたセクションでは特徴付けられていません。
重要性
カメラ制御をパラメータから動画への変換ではなく、動画から動画への条件付けとして再定式化することで、クロスペアデータのボトルネックを回避し、カット・内部パラメータ・時間構造に対するDiTのネイティブな処理能力を継承します。同じトリック(バックボーンがすでに理解している動画として制御信号をレンダリングする)は他の幾何学的制御にも転用可能であると考えられます。
Source: https://arxiv.org/abs/2606.13432
記憶は検索されるのではなく再構成される:LLMエージェントのためのGraph Memory
問題
Memory-augmentedなLLMエージェントは一般的に、静的なretrieve-then-reasonパイプラインに従います:クエリ x が与えられると、ステートレスな retrieval policy \pi_p は固定されたメモリユニットの集合 \{v^{(1)},\dots,v^{(T)}\}=\pi_p(x) を返し、その後LLMはそれらに対して推論を行います。このデカップリングは、マルチホップクエリや時間的クエリにおいて失敗します。なぜなら、関連する証拠をクエリ単体から特定することができず、次に何を検索すべきかを知るためには推論の途中で蓄積された部分的な証拠が必要となるからです。
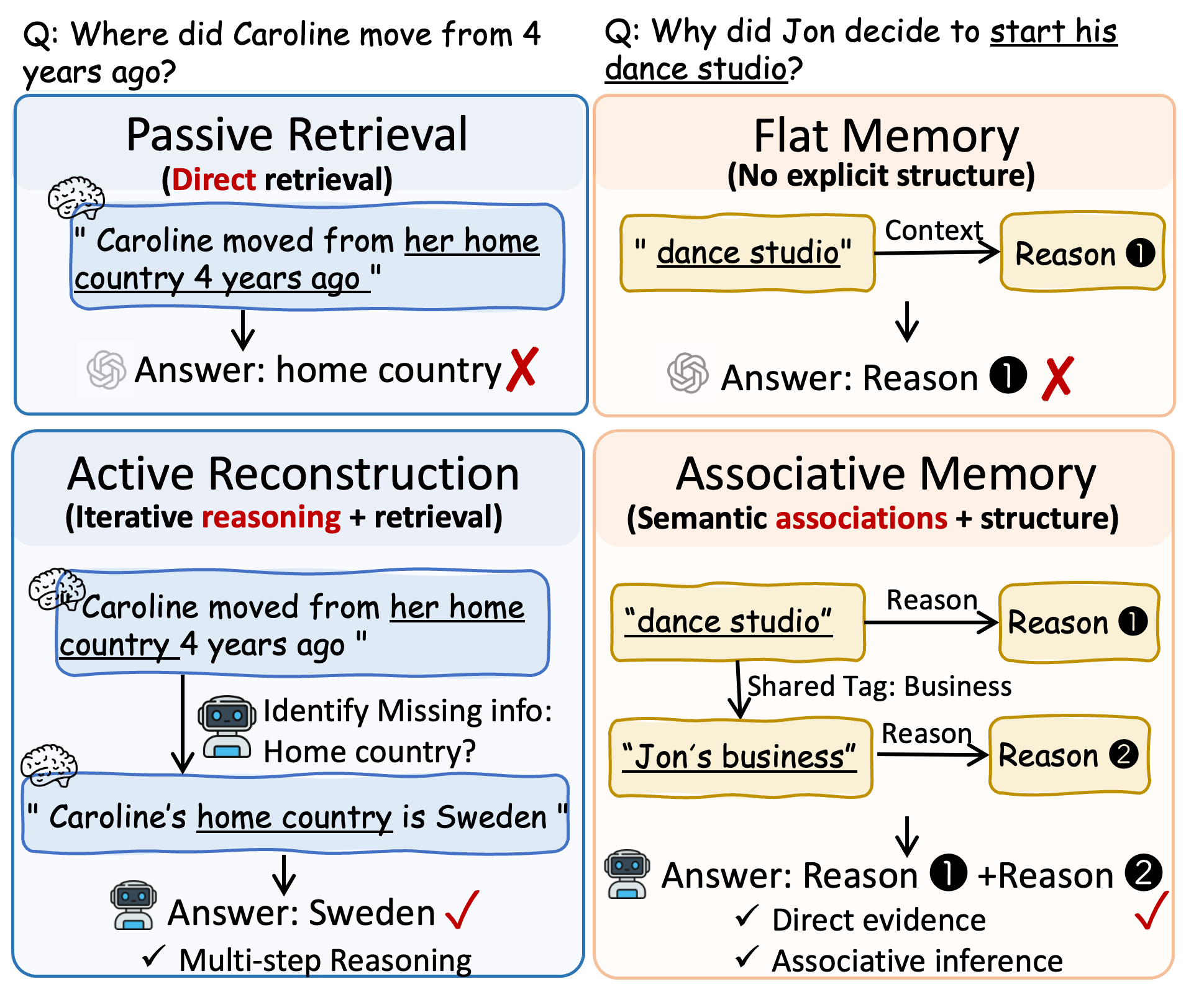
動機付けとなる例はこれを具体的に示しています:Nateがビデオゲームトーナメントに参加していた間、Carolineが何をしていたかを尋ねられた場合、パッシブ検索はNateのトーナメントに関するメモリを取得しますが、Carolineの活動には橋渡しができません。アクティブなpolicyは、まずトーナメントのメモリから時間的な手がかり(「7月」)を推論し、次にCarolineの7月の活動についてクエリを発行する必要があります。
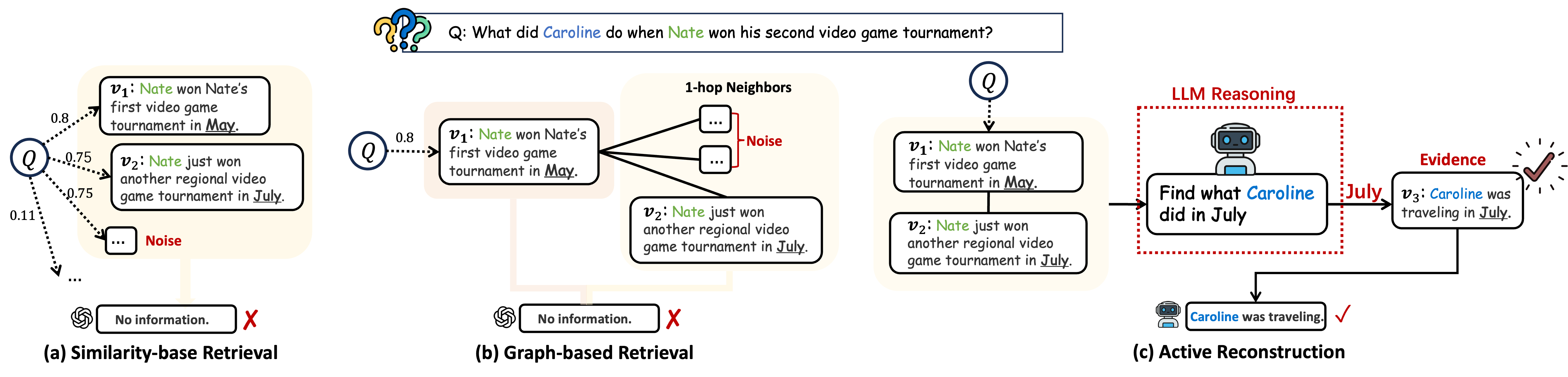
手法
MRAgentは検索をステートフルな逐次的意思決定プロセスとして再定式化します: v^{(t)} = \pi_a^{(t)}(x, S^{(t-1)}), \quad S^{(t)} = S^{(t-1)} \cup \{v^{(t)}\}.
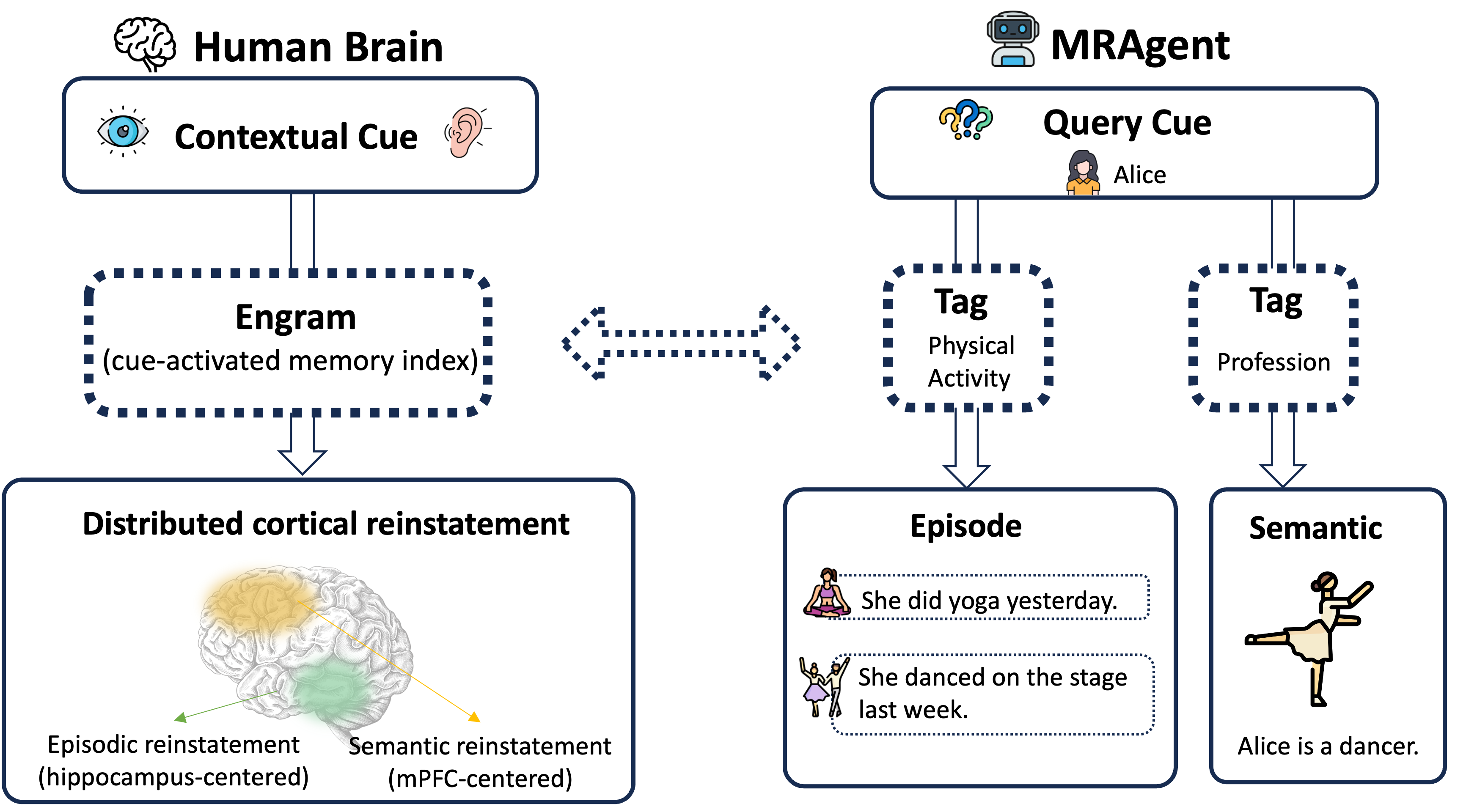
Cue–Tag–Contentグラフ。 メモリはヘテロジニアスグラフ \mathcal{M} = (\mathcal{C}, \mathcal{V}, \mathcal{R}) であり、cueノード c \in \mathcal{C}(細粒度なエンティティ・属性)、contentノード v \in \mathcal{V}(エピソード的・意味的メモリアイテム)、および型付き関係 \mathcal{R} \subseteq \mathcal{C} \times \mathcal{G} \times \mathcal{V} から構成され、各タグ g はcueとcontentユニット間の連想関係を要約します。構築は2フェーズで行われます:まずLLMが対話からcue、tag、contentユニットを抽出し、次に得られたトリプルからグラフが組み立てられます。
タグ層が重要な設計上の選択です。contentノード上での単純な n-hop展開は組み合わせ爆発を引き起こし、無関係なメモリでコンテキストが溢れかえります。タグは意味的な中間表現として機能し、エピソード的なコンテンツ全体を読むコストを支払う前に、LLMが安価にスコアリングと刈り込みを行えます。2段階アクセスを形式化する2つの誘導演算子は以下のとおりです: \phi_{c \to g}(c) \triangleq \{g \mid (c,g,\cdot) \in \mathcal{R}\}, \quad \phi_{(c,g) \to v}(c,g) \triangleq \{v \mid (c,g,v) \in \mathcal{R}\}.
アクティブ再構成。 ステップ t において、MRAgentは再構成状態 \mathcal{S}^{(t)} = (\mathcal{Z}^{(t)}, \mathcal{H}^{(t)}) を維持します。ここで \mathcal{Z}^{(t)} はアクティブな候補フロンティア(cue、tag、content)であり、\mathcal{H}^{(t)} は蓄積された証拠コンテキストです。LLMは \mathcal{H}^{(t)} を用いて、(i) \phi_{c \to g} を通じてどのcueを展開するかを選択し、(ii) 関連性によって得られたtagの集合を刈り込み、(iii) \phi_{(c,g) \to v} を通じてcontentを実体化し、(iv) 終了するか継続するかを判断します。このフレームワークは、インデックスによる検索ではなく、人間のエピソード記憶の構成的な見方を反映しています。
結果
LoCoMoにおいて、Claude-Sonnet-4.5を用いた場合、MRAgentは総合LLM-Judgeスコア88.32を達成しています。これに対し、最強のベースラインであるLangMemは78.61、Mem0は69.02であり、ベースラインに応じて約10〜19ポイントの絶対的な差があります。改善はアクティブな推論が最も重要なカテゴリで最大となっています:
- 時間的クエリ:J = 85.34 vs. 80.68(LangMem)、53.58(Mem0);F1 69.82 vs. 56.64
- オープンドメイン:J = 71.57 vs. 56.25(Mem0)、54.71(LangMem);F1 34.67 vs. 28.58
- マルチホップ:J = 90.19 vs. 75.88(Mem0);F1 56.72 vs. 48.66
- シングルホップ:J = 91.10 vs. 83.12(LangMem)
Gemini-2.5-Flashを用いても同様のパターンが見られます:総合J = 84.21 vs. 68.31(Mem0)であり、時間的JはJ = 61.68 → 80.37、オープンドメインJは41.66 → 68.75へと向上しています。アブストラクトにある「最大23%」の改善という主張は、カテゴリごとの最大デルタに対応しています(例:Geminiにおける時間的F1は58.19から67.66へ、オープンドメインJは41.66から68.75へ移動)。著者らは、contentの実体化前にタグレベルで刈り込みを行うことに起因するベースラインに対するトークンおよびランタイムコストの削減も報告していますが、具体的なコスト数値はここでは抜粋されていない後続のセクションに記載されています。
限界と未解決の課題
- メモリ構築はLLMによって抽出されたcueとtagに依存しており、\mathcal{R} の品質は抽出プロンプトに左右されますが、グラウンドトゥルースのグラフ構造に対するアブレーションは個別には行われていません。
- 再構成policyは推論時にLLM自体であるため、クエリごとのコストは探索の深さに応じてスケールします。論文のコストに関する主張はベースラインとの相対比較であり、絶対的なものではありません。
- アクティブループの終了基準はLLMによって判定されるものであり、学習されたものではありません。失敗モード(早期停止や無限展開)については特性評価が行われていません。
- 評価は対話ベンチマーク(LoCoMo、LongMemEval)に対するものであり、非会話的な長期的設定(コード、ツール使用トレース)への汎化は未検証です。
- 学習済みグラフ探索policy(例:GNNベースのretrieverや学習済みエージェント)との比較はなく、改善はプロンプトエンジニアリングによるベースラインに対するものです。
なぜこれが重要か
検索を推論と連動した意思決定プロセスとして扱うこと——生成の固定されたプレフィックスとしてではなく——は、エージェントメモリにとって構造的に異なるパラダイムであり、時間的・オープンドメインでの改善(しばしばJ > 20ポイント)は、現在のメモリシステムがストレージ表現よりも静的パイプラインによってボトルネックになっていることを示唆しています。Cue–Tag–Contentの分割は、LLM主導の制御下でマルチホップグラフ探索を実用的に保つための具体的な手法です。
Source: https://arxiv.org/abs/2606.06036
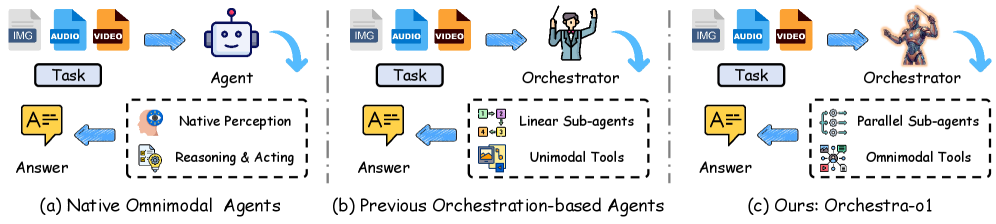
Orchestra-o1: オムニモーダルエージェントオーケストレーション
問題
マルチエージェントオーケストレーションフレームワークは、これまで主にテキストのみ、またはテキスト+画像の設定向けに構築されてきました。テキスト・画像・音声・動画を横断して推論する必要があるタスク――OmniGAIAに代表されるオムニモーダル領域――では、既存のオーケストレーターは以下の理由から性能が低下します。(a) タスク分解がモダリティを考慮していない、(b) サブエージェントが静的であり、対象となるモダリティの組み合わせに特化できない、(c) 多くのサブタスクがモダリティ間で独立しているにもかかわらず実行が逐次的である、という点です。その結果、強力なオムニモーダル基盤モデルがプリミティブとして利用可能な場合でも、異種入力に対する精度が低くなります。
手法
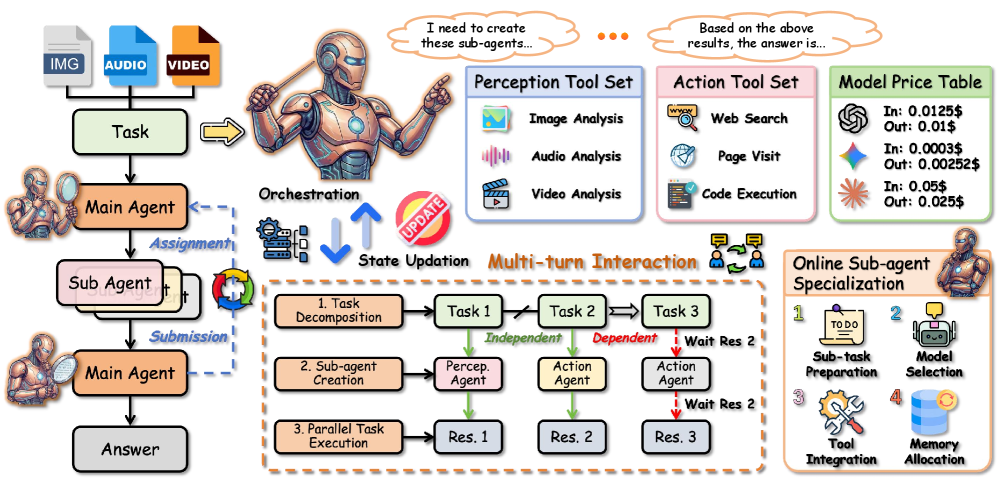
Orchestra-o1はオムニモーダルオーケストレーションをマルチラウンドの意思決定問題として定式化します。タスクは x=(q,\mathcal{M}) であり、\mathcal{M}=\{m_i\}_{i=1}^{N} は画像・音声・動画にわたります。オーケストレーターは、正解 a^* に対して R(\hat{a},a^*) を最大化する \hat{a} を出力しなければなりません。このフレームワークは、オムニモーダルなツールとモデルをラップするサブエージェントのプールの上に「メインエージェント」を配置し、3つの連携メカニズムを導入します。
モダリティを考慮したタスク分解。 メインエージェントは \mathcal{M} のモダリティシグネチャに基づいて分解を行い、必要なモダリティと期待される出力タイプをアノテーションとして付与したサブタスク \{s_j\} を生成します。これにより、例えば動画サブタスクと音声サブタスクを分割でき、単一のサブエージェントが十分に処理できない単一のマルチモーダルプロンプトに統合してしまうことを避けられます。
オンラインサブエージェント特化。 サブエージェントは固定された設定ではなく、ディスパッチ時にオーケストレーターがサブタスクのモダリティおよびトピックカテゴリに合わせてロール・ツールセット・promptをインスタンス化します。これが、固定された汎用サブエージェントを使用するAOrchestrastyleのフレームワークとの主な違いです。
サブタスクの並列実行。 モダリティをまたいで独立したサブタスクは並行して実行され、その結果は後続のラウンドでメインエージェントによって集約されます。
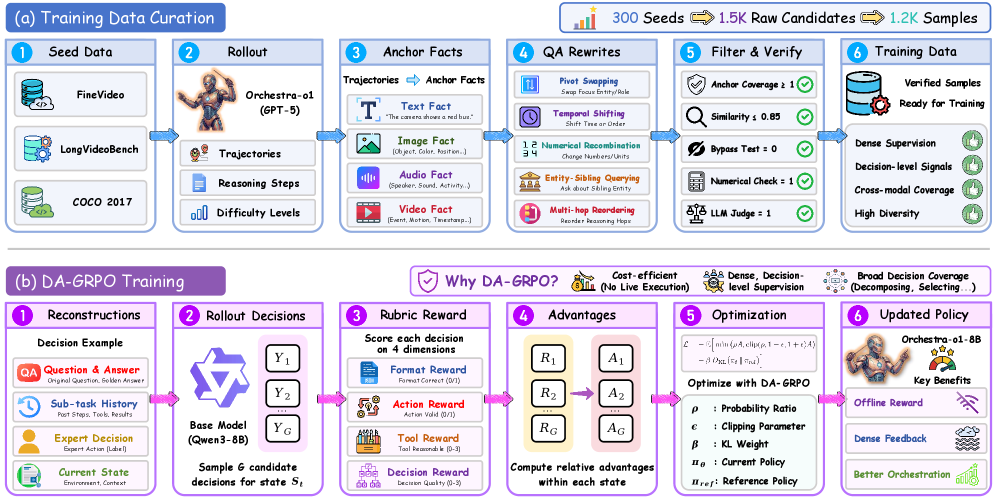
オープンソースのメインエージェントは2段階のレシピで学習されます。まずオムニモーダルタスクにおける成功したオーケストレーションのロールアウトから得られたキュレーション済み軌跡データセットを用い、次にGRPOの難易度考慮型バリアント(“DA-GRPO”)を適用します。DA-GRPOは標準的なGRPOのアドバンテージ正規化を修正し、難しいインスタンスの重みを大きくします。これにより、OmniGAIAにおけるロングテール問題、すなわちHardな例が通常ほとんど gradient を持たない問題に対処します。標準的なGRPO目的関数
\mathcal{J}_{\text{GRPO}}(\theta) = \mathbb{E}\Big[\frac{1}{G}\sum_{i=1}^{G}\min\big(r_i(\theta) A_i,\; \text{clip}(r_i(\theta),1\!-\!\epsilon,1\!+\!\epsilon) A_i\big)\Big] - \beta\,\mathrm{KL}(\pi_\theta\Vert\pi_{\text{ref}})
において、A_i はグループ正規化の前にインスタンス難易度係数によってスケール変換されます。これにより、Hardな項目に対する軌跡は、グループ内の報酬分散が小さい場合でも無視できない学習シグナルを保持します。
結果
OmniGAIAにおいて、Orchestra-o1は同等の計算量クラス内でオープンソース・プロプライエタリ両方のベースラインを上回ります。
オープンソースのエージェントモデルの中では、ReActを用いたネイティブオムニモーダルLLMは弱く、Qwen2.5-Omni-7Bは3.6%、Ming-Flash-Omni-100B-A6Bは8.3%、560BのLongCat-Flash-Omni-560B-A27Bは全体でわずか11.1%にとどまります。オーケストレーションなしの最強のオープンベースラインはOmniAtlas-Qwen3-30B-A3Bの20.8%です。Orchestra-o1-8Bは全体で30.0%を達成し、はるかに小さいバックボーンを使用しているにもかかわらず2位(OmniAtlas-Qwen3-30B-A3B)を9.2ポイント上回り、AOrchestrastyleのオープンソースオーケストレーションベースラインをabstractに記載の10.3%マージンで超えています。
カテゴリ別では、Orchestra-o1-8Bはオープンソースシステムの中で9カテゴリのうち7カテゴリでトップとなっており、Geo.(21.7 vs. 10.1)、History(37.9 vs. 29.9)、Art(45.5 vs. OmniAtlas-7Bの22.2)、Movie(38.5 vs. 11.5)、Science(38.9 vs. 27.8)などが含まれます。Finance(12.0 vs. OmniAtlas-Qwen3-30B-A3Bの32.0)のみ劣り、Sport(16.7)では同点です。
プロプライエタリなグループでは、GPT-5をバックボーンとしてインスタンス化したOrchestra-o1が全体で72.8%を達成し、Gemini-3-Proの62.5%、Gemini-3-Flashの51.7%、およびAOrchestra-GPT-5オーケストレーションベースラインの40.0%を超えます。AOrchestra-GPT-5との32.8ポイントの差は、基盤となるモデルを固定しているため、オーケストレーションメカニズム自体の貢献を示しています。カテゴリ別では、Orchestra-o1-GPT-5は全プロプライエタリベースラインと比べて9カテゴリのうち8カテゴリでトップであり、最も大きな向上はTech.(69.4 vs. Gemini-3-Proの59.2)とScience(73.1 vs. 42.3)で見られます。難易度別の分析では、Easy/Medium/Hardを通じて向上が維持されており、AOrchestrastyleとの効率比較では、より豊かな分解にもかかわらず並列実行パスによって実測時間コストが回収されることが示されています。
限界と未解決の問題
Financeにおける性能低下(12.0%)は、オンライン特化シグナルが常に有効とは限らないことを示唆しています――カテゴリがモダリティのルーティングではなくニッチなツール利用(例:定量的な検索)を必要とする場合、オーケストレーターは固定された専門家を下回ることがあります。学習レシピはキュレーション時に蒸留された成功軌跡に依存しており、DA-GRPOにおける失敗ケースのカバレッジは特性評価されていません。また、論文では3つのメカニズム(分解 vs. 特化 vs. 並列化)を分離したアブレーションが報告されておらず、それぞれの個別の貢献は定量化されていません。さらに、結果は単一のベンチマーク(OmniGAIA)でのみ報告されており、他のオムニモーダル評価スイートや長時間動画・ストリーミング音声を含む設定への転用は検証されていません。
なぜ重要か
オムニモーダルエージェントの精度を高めるのは、より強力なバックボーンだけでなく、オーケストレーションです。8BのOrchestra-o1はOmniGAIAにおいて560Bのネイティブオムニモーダルモデルをおよそ19ポイント上回り、GPT-5をオーケストレーションすることで同じモデルを用いた先行オーケストレーションフレームワークに対して32.8ポイントの向上をもたらします。これは、オムニモーダル能力をシステム設計の問題として再定式化するものであり、モダリティを考慮した分解とオンラインサブエージェント特化が第一級のレバーとなります。
Source: https://arxiv.org/abs/2606.13707
Hacker News Signals
M1 MaxコンピューターとローカルなMLモデルを使って669 GBのGoProビデオをインデックス化した
著者は、669 GBのGoPro映像からなる大規模な個人ビデオアーカイブに対して、クラウドへの依存なしにM1 Max上で完全なローカルMLパイプラインを実行しました。このパイプラインは複数のステージを組み合わせています:冗長な処理を避けるための一定サンプリングレートでのフレーム抽出、セマンティック検索を可能にするCLIPベースのフレームembedding、音声コンテンツ向けのWhisper方式の音声文字起こし、そしてコーパス全体をクエリ可能にするベクトルインデックス(おそらくFAISSまたは類似のもの)です。M1 Maxはこの用途に適した選択肢です:Neural Engineと統合メモリアーキテクチャにより、CLIP ViT-B/32以上のモデルが、ディスクリートGPU構成のPCIe帯域幅ボトルネックなしに許容できるスループットで動作します。ここでの興味深いエンジニアリング上のトレードオフはフレームサンプリング戦略です——疎すぎるとイベントを見逃し、密すぎるとembeddingのコストが支配的になります。669 GBの動画に対して1 fpsでもembeddingを保存すると数百万のベクトルが生成されるため、次元数とインデックス構造が重要になります。結果として、「木の近くでのスキー」や「夜のキャンプファイア」のようなクエリが、embedding空間でのコサイン類似度によってタイムスタンプに解決されるプライベートな検索可能ビデオアーカイブが実現します。このパターン——ローカルなCLIPとベクトルDBによる個人メディア管理——は、Apple Siliconマシンと根気さえあれば誰でも再現可能であり、それがこの取り組みが共感を呼ぶ理由です。より広い視点では、M1 Maxが備える32〜64 GBの統合メモリとNeural Engineの組み合わせにより、これまでクラウドでしか実現できなかったワークロードがコンシューマーハードウェア上で実行可能になっています。APIキーも不要、データがデバイスの外に出ることもなく、継続的なコストも発生しません。主な制限は、CLIPのゼロショット検索品質がドメイン固有のクエリや時間的に複雑なクエリで低下すること、そして個々のフレームではなく動きや時間的なシーケンスをクエリする明確な方法が存在しないことです。
Postgresにおいてスケーラブルな削除は DROP TABLE だけである
この記事は、本番環境での証拠をもとに、Postgresにおける行レベルのDELETEは多くのエンジニアが想定するようにスケールせず、大規模環境でスペースを確実に回収しテーブルの肥大化を防ぐ唯一の操作は、テーブル(またはパーティション)を丸ごと削除することだと主張しています。
根本的な問題はPostgresのMVCC実装にあります。DELETEはタプルを物理的に削除せず、古いタプルバージョンの xmax フィールドをセットするだけで、そのデッドタプルはVACUUMが処理するまで元の場所に残り続けます。大量削除、頻繁なデータ入れ替えのワークロード、時系列データの有効期限切れなど、削除が高頻度で発生する状況では、デッドタプルがautovacuumの処理能力を上回るペースで蓄積します。その結果がテーブル肥大化です。物理ファイルが増大し、インデックススキャンがより多くのページに触れるようになり、クエリプランが劣化します。テーブルを書き直すMANUAL VACUUM FULLを実行した場合でも、AccessExclusiveLock が必要となりテーブルがオフラインになります。
推奨されるパターンは、時間(または削除の述語でキーとなるもの)による宣言的パーティショニングと、古いパーティションに対する DROP TABLE または DETACH PARTITION + dropの組み合わせです。DROP TABLE はタプルレベルの処理という観点からO(1)であり、リレーションファイルとシステムカタログエントリをアトミックに削除し、MVCCクリーンアップの負担を伴いません。ALTER TABLE DETACH PARTITION CONCURRENTLY(Postgres 14以降で利用可能)を使えば、テーブル全体のロックなしにパーティションをデタッチでき、その後パーティションを独立して削除できます。
実践的な意味合いとして、保持ポリシー(30日以上前のログ、90日以上前のイベントなど)がある場合、正しいスキーマ設計は最初からタイムスタンプによるレンジパーティショニングを行うことであり、肥大化が現れてから後付けするものではありません。この記事は、インデックス付きのDELETEは「十分高速」だという一般的な思い込みに対する有益な反論となっています。追記が多く年齢でまとめて削除するワークロードにおいて、パーティション設計はオプションではなく、予測可能なパフォーマンスへの唯一の道筋です。
Source: https://planetscale.com/blog/the-only-scalable-delete
AI OSSツールのリポジトリが$7.3Mシードラウンド調達直後に一夜でアーカイブ化
TensorZeroは、構造化 inference、プロンプト管理、およびプロダクションシグナルに基づく fine-tuning のフィードバックループを備えたLLMアプリケーション構築フレームワークです。$7.3Mのシードラウンド直後にリポジトリが突然アーカイブ化されたことで、現在のAIツーリングの文脈における「オープンソース」の意味をめぐる活発な議論が巻き起こりました。
技術的な観点から、TensorZeroのコア設計は理解する価値があります。アプリケーションコードとLLM APIの間に位置する型付きゲートウェイとして機能し、リクエストには関数スキーマが付与され、レスポンスは出力型に対してバリデーションされ、入出力の両方がClickHouseバックエンドにログとして記録されます。フィードバック機構により、推論レコードに対してメトリクス(サムズアップ/ダウン、タスク完了シグナル、明示的なスコアなど)を付与することができ、それらは fine-tuning データセットの構築に利用されます。これはつまり、プロダクショントラフィックとモデル改善の間のループを、開発者がそのパイプラインを手動で構築することなく完結させるものです。設定は宣言的なTOML形式で、関数・そのバリアント(異なるプロンプトやモデル)・ルーティング/実験ロジックを記述します。
今回のアーカイブ化は、クローズドなライセンスまたはソース公開型ライセンスへの移行を示唆している可能性が高く、採用拡大を目的にオープンソース化した後、商業的価値の確保に向けて製品をゲート化するというインフラスタートアップの典型的な動きです。Hacker Newsでの議論の中心は信頼性の問題です。プロダクションシステムの依存関係としてフレームワークを採用した開発者は、その長期的な可用性に対する確証を必要としており、一夜でのアーカイブ化は、フォークや最後のコミットが引き続き利用可能だとしても、その信頼を損なうものです。この一件は「オープンコアベイト」懸念の典型的な事例と言えます。つまり、コミュニティを育てるためにパーミッシブなライセンスを使用し、ネットワーク効果が確立された後にリライセンスするという手法です。OSSのLLMインフラを評価するエンジニアにとって、この出来事は、依存関係を深く組み込む前にライセンス条項・コミットの頻度・メンテナーがVCの支援を受けているかどうかを確認することの重要性を改めて示しています。
Apple Foundation Models
Appleは、オンデバイスfoundation modelsに向けたパブリックAPIサーフェスをリリースし、Apple Foundation Modelsフレームワークとしてドキュメント化しています。Claudeプラットフォームのドキュメントページ(誤ったドキュメント化またはリダイレクトの副産物と思われます)はApple自身のSDKを指しています。このフレームワークは、テキスト生成、要約、構造化出力の抽出を含むタスクに向けて、Apple Silicon上でローカルに動作するモデルを公開しています。
技術的な内容として、これらのモデルはNeural Engineを使用してすべてオンデバイスで動作し、アプリと一緒に配布されるのではなくOSに統合されています。つまり、アプリバンドルにはモデルの重みが含まれません。APIはLanguageModelSessionを中心に構成されており、コンテキストと生成を管理します。構造化出力はファーストクラスの機能として扱われており、開発者はGenerableに準拠したSwiftの型を指定し、モデルはその型にデシリアライズ可能な出力を生成するよう制約されます。これはOpenAIの structured outputs と精神的には類似していますが、constrained decodingによってローカルで強制されます。ツール呼び出しはプロトコルベースのインターフェースを通じてサポートされています。
これらのモデルは、ベースのApple Siliconが持つメモリ制約に収まるよう量子化されています。報告されているパラメータ数は3B程度であり、AppleのオンデバイスMLの思想と一致しています。すなわち、他のフォアグラウンドタスクを劣化させることなく動作できる小ささを保ちながら、実用的なNLUおよび生成タスクには十分な大きさです。プライバシーがアーキテクチャ上の主要な動機であり、推論はデバイスの外に出ることなく、APIコール・レート制限・トークンあたりのコストも一切発生しません。
MLエンジニアにとって興味深い問いは、constrained decodingの実装です。Appleは、トライベースのトークンマスク、文法ガイドによる生成、あるいは事後的なバリデーションループのいずれを使用しているかについて詳細を公開していません。このフレームワークはSwift専用であり、クロスプラットフォームでの利用が制限されます。macOS 26およびiOS 26との統合により、デプロイターゲットは最新OSバージョンに限定されます。
Source: https://platform.claude.com/docs/en/cli-sdks-libraries/libraries/apple-foundation-models
zeroserveへのCaddy互換性追加:スループット3倍、レイテンシ70%削減
Zeroserveは、事前圧縮済みアセットを高スループット・低レイテンシで配信するために設計された静的ファイルサーバーです。本記事では、リバースプロキシのフロントエンドとしてCaddyを追加し、そのパフォーマンス差を計測した結果を報告しています。具体的には、従来の構成と比較して、スループットが約3倍向上し、レイテンシが70%低減しました。
技術的な説明の核心は、コネクションのハンドリングとTLSターミネーションにあります。CaddyはGoの標準ライブラリのcrypto/tlsを使った独自実装でTLSを処理し、HTTP/2およびHTTP/3(QUIC)の多重化を行い、コネクションプールを介してzeroserveへの持続的なアップストリーム接続を維持します。以前の構成では、TLSターミネーションがスタックのより下位で行われていたか、リクエストごとにコネクションのオーバーヘッドが発生していた可能性が高いです。TLSをCaddyにオフロードし、バックエンドへの持続的なコネクションプールを維持することで、リクエストあたりのオーバーヘッドが大幅に低減されます。
Zeroserveの設計思想は、事前にgzip、brotli、zstdで圧縮され、ディスクに保存されたファイルを配信することを中心としており、ランタイムでの圧縮を完全に回避し、CPUの代わりにディスクスペースを消費します。Caddyとの統合により、Accept-Encodingヘッダーに基づいた適切なContent-Encodingネゴシエーションが追加されるため、brotliをサポートするクライアントは、zeroserveがそのロジックを実装することなく.br形式のファイルを受け取れます。Caddyのfile_serverディレクティブにも同様の事前圧縮ファイル配信機能がありますが、zeroserveのアーキテクチャはメモリアロケーションの最小化と高速パス配信に特化しており、CaddyがプロトコルレベルのAの懸念を処理する場合において、より優れたバックエンドとなります。
レイテンシの70%低減は十分あり得る数値です。以前の構成がセッション再開やHTTP/2多重化なしでコネクションごとに同期的なTLSハンドシェイクを行っていた場合、そのオーバーヘッドはペイロードサイズが小さい場合に支配的になります。スループットの3倍向上は、ボトルネックが帯域幅ではなくコネクションの確立にあったことを示唆しています。本記事は、「専用プロキシにプロトコルの懸念事項を処理させ、バックエンドにはアプリケーションロジックのみを担当させる」という古典的なパターンの有益なケーススタディです。
Show HN: Trace – 通話中にフラグを立てられるオフラインMac会議文字起こしアプリ
Traceは、デバイス上の音声認識を使ってローカルで会議を文字起こしし、後で見返すために通話中の特定の瞬間にフラグを立てられるmacOSアプリケーションです。「オフライン」という制約が技術的な設計における核心的な選択であり、すべての音声処理はデバイス上で完結します。これにより、機密性の高い通話にクラウド文字起こしサービスを使うことを躊躇させるプライバシーへの懸念が解消されます。
技術スタックとしては、on-device認識オプションを使ったAppleのSFSpeechRecognizer、あるいはバンドルされたWhisperモデル(Apple Siliconにおけるこのユースケースではwhisper.cppが標準的な選択肢です)がほぼ確実に使用されています。通話中のフラグ付け機能は、摩擦の少いUIアクション——おそらくキーボードショートカットかメニューバーボタン——で実現されており、文字起こしストリームにタイムスタンプ付きのマーカーを挿入します。これにより、通話後のレビューでトランスクリプト全体をスクラブするのではなく、該当セグメントへ直接ジャンプできます。
macOSで通話の音声をキャプチャするには、AVFoundation経由でシステムオーディオをキャプチャするための画面録画権限が必要か、もしくはローカル側のみをキャプチャするマイク専用キャプチャが必要です。興味深いエンジニアリング上の問題は、通話の両側(ローカルマイク+スピーカー出力)をクリーンにキャプチャすることで、これには通常、仮想オーディオデバイス(BlackHoleが一般的なOSSソリューションです)か、macOS 12.3で導入された正規のシステムオーディオキャプチャ向けScreen Capture Kit APIの使用が必要です。
フラグ付け機能は、現実のワークフロー上のギャップに対処しています。現在の文字起こしツールは、読み通したり検索したりする必要のある大量のテキストを生成します。通話中にインラインでフラグを立てることで、高い重要度を持つ瞬間——意思決定、アクションアイテム、ユーザーがリアルタイムで重要だと認識した技術的な詳細——の構造化されたインデックスが作成されます。制限事項は精度の問題です。デバイス上のWhisperまたはSFSpeechRecognizerの品質は、アクセント、専門用語、話者の重複によって低下し、キャプチャの時点で修正する簡単な方法はありません。
Source: https://traceapp.info
Show HN: Paca – 人間とAIの協働のための軽量Jira代替ツール
Pacaは、人間のコントリビューターと並んでAIエージェントをコラボレーターとして明示的かつファーストクラスでサポートする、ミニマルなプロジェクト管理ツールです。その基本的な考え方は、JiraやLinear、GitHub Issuesといった既存ツールが作業を人間から人間へのタスクの受け渡しとしてモデル化しているのに対し、AIエージェントがコードの記述・テストの実行・PRの作成といったタスクをますます実行するようになっている現状では、ツール側もエージェントをWebhookによる自動化の後付けとしてではなく、ファーストクラスのアクターとして扱うべきだというものです。
技術的な実装としては、RustまたはTypeScriptのバックエンド(詳細はリポジトリを参照)に、人間がUIを通じて、エージェントがプログラム的にアクセスする形で利用されることを想定した、クリーンなRESTまたはGraphQL APIを備えています。タスクのアサイニーは人間のユーザーとエージェントのアイデンティティのいずれにも設定できます。設計上の重要な問いは、エージェントの進捗をどのように表現するかという点です。人間はカードを「進行中」から「完了」へ手動で移動しますが、エージェントはサブタスクを完了するたびに状態をアトミックに更新する必要があり、そのためにはデータモデルがより細粒度の状態遷移と自動化された監査証跡をサポートしている必要があります。
Jiraに対する「軽量」というポジショニングは、主に設定の煩雑さの削減に関するものです。カスタムワークフローも複雑なパーミッション階層もなく、完全なJira設定のオーバーヘッドがそのメリットを上回るような小規模チームやプロジェクトに適しています。AIを活用したワークフローにおける技術的な賭けとして興味深いのは、構造化されたタスク分解です。エージェントにタスクをアサインする場合、エージェントが自律的に行動するために十分なコンテキストがタスクの説明に含まれている必要があり、これはチケット内の暗黙的な属人的知識を減らし、より構造化されたacceptance criteriaの方向へ向かう圧力となります。Pacaのテンプレートとフィールドスキーマはおそらくこれを強制するでしょう。一方で限界もあります。AIの統合は、実際にAPIを読み取って作業を実行するエージェントオーケストレーション層の品質に依存します。PacaはCoordinationの基盤を提供しますが、エージェント自体は提供しないのです。
Source: https://github.com/Paca-AI/paca
AIはコードであり、プロンプトによって賢くなることはできない
The Registerのこの記事は、LLMがコンパイルされ、重み付けされ、固定された決定論的なアーティファクトであり、プロンプティングとは能力を増幅するメカニズムではなく、検索とフレーミングのメカニズムに過ぎないと主張しています。「プロンプトエンジニアリングは魔法だ」というユーザーの広範な信念が、潜在的な能力を引き出すことと新たな能力を生み出すことを混同しているというのがその論旨です。
技術的な主張は擁護可能です:学習済みモデルの重みは固定された関数 f_\theta: \mathcal{X} \to \mathcal{Y} をエンコードしています。プロンプティングはその関数に提示される入力分布を変化させます。つまり、モデルがうまく処理できる入力空間の領域にクエリを配置することで出力品質を向上させることができます(chain-of-thoughtがその最も明確な例であり、モデルが生成する中間的な推論トークンに条件付けできる能力を活用します)。しかし、\theta にエンコードされた能力を超えることはできません。モデルがある問題を解くための知識や推論構造を持っていなければ、どんなプロンプトを使っても回復することはできません。これは、実際に f_\theta を変更または拡張するfine-tuning、RLHF、または retrieval augmentationとは異なります。
「AIはコードである」というフレーミングは、擬人化への有効な是正となります。あるモデルのバージョンは固定された振る舞いを持つリリースアーティファクトであり、更新には会話ではなく再学習が必要です。実践的な含意として、モデルの失敗のデバッグはソフトウェアのデバッグと同様に扱うべきだということです。つまり、その失敗が能力の上限(モデルがそれをできない)なのか、検索の失敗(モデルは能力を持っているが入力のフレーミングがそれを引き出せていない)なのか、あるいは分布のミスマッチ(クエリが分布外である)なのかを特定する必要があります。これらにはそれぞれ異なる対処法があります。
この記事はやや言い過ぎな面もあるかもしれません。emergentな振る舞いやchain-of-thoughtは、単純なプロンプティングでは見逃してしまう非自明な潜在的推論をプロンプティングが引き出せることを示しています。しかし、プロンプトが「AIを賢くする」という俗説に対する核心的な反論は、技術的に健全です。
注目の新しいリポジトリ
Shiyao-Huang/awesome-agent-evolution
自己進化するAIエージェントの設計空間を網羅した、構造化されたサーベイおよびエビデンスマップです。このリポジトリは、文献を5つの軸で整理しています:メモリアーキテクチャ(エピソード記憶・意味記憶・パラメトリック記憶)、スキル獲得と転移、ハーネス/スキャフォールド設計、評価 benchmark、そしてマルチエージェントスウォーム協調です。単なる論文リストではなく、エージェントが時間をかけて自身の振る舞いをどのように修正するかについての分類体系を構築しており、prompt レベルの自己改善、fine-tuning ループ、ツール使用の進化を明確に区別しています。エージェントの自律性、継続学習、あるいはLLMベースの計画システムに取り組む研究者にとって、文献の入口として有用です。エビデンスマップ形式を採用しているため、各主張が特定の引用文献と結びついており、アーキテクチャ上の選択の実証的根拠を追跡しやすくなっています。完全な再学習なしにエージェントが能力を蓄積できる設計を考えている場合、本リポジトリは合理的な出発点となります。収録文献は2023〜2024年の研究に偏っていますが、これはちょうど当該分野が最も急速に発展している時期に対応しています。
Source: https://github.com/Shiyao-Huang/awesome-agent-evolution
myccarl/ai-shortVideo-pipeline
FastAPI オーケストレーション層を中心に構築され、Spring Boot API ゲートウェイをバックエンドとする、AI 生成ショート動画のエンドツーエンド本番パイプラインです。アーキテクチャはマルチモデル failover(プライマリの diffusion モデルや TTS モデルが利用不可の場合、リクエストを代替モデルにルーティング)と、高負荷時のカスケード障害を防ぐサーキットブレーカーパターンを実装しています。メータリングフックにより、モデル呼び出し全体にわたってリクエストごとのコスト計算が可能です。品質面では、フレーム間の意味的一貫性を維持するための prompt anchoring、生成されたフレームと元のプロンプト間の CLIP ベースの一貫性スコアリング、そしてドリフトが検出された際に音声と映像を再同期する AV sync 自動修復ステップが含まれています。オブザーバビリティはフルスタックで対応しており、分散トレーシング、構造化ログ、およびメトリクスがリクエストパス全体に組み込まれています。これは、AI 動画生成を使い捨てスクリプトとしてではなく、適度な本番スケールで運用する必要がある方にとって、非自明なシステム設計といえます。
Source: https://github.com/myccarl/ai-shortVideo-pipeline
leiting-eric/DailyBrief
GitHubトレンドリポジトリ、X(Twitter)のホット記事、金融市場データという23のデータソースを集約し、統合されたコンテンツをLLMに渡して中国語サマリーを生成する、自動化された日次ブリーフィングシステムです。集約レイヤーは異種APIをまたいだソースの正規化を担います。市場データは単なる価格表示にとどまらず、テクニカル分析モジュールが各種指標を計算し、テキスト形式のコメンタリーを生成します。デプロイメントはローカル実行とGitHub Actionsのスケジュールワークフローの両方に対応しており、永続的なサーバーインフラを一切必要とせずにパイプラインが動作します。LLMによるサマリー生成ステップでは、冗長な合成ではなく簡潔かつ事実に基づいた出力に調整されたpromptテンプレートを使用しています。サードパーティのニュースレターサービスに頼ることなく、技術シグナルと市場シグナルのパーソナライズされた日次ダイジェストを求める研究者やエンジニアにとって、このシステムは組み合わせ可能なベースを提供します。マルチソース設計により、薄いアダプターを実装するだけでデータソースの追加や入れ替えが容易に行えます。
Source: https://github.com/leiting-eric/DailyBrief
2417467487-hub/WorldCupROI
ワールドカップの試合データに特化したスポーツスポンサーシップ・インテリジェンス・プラットフォームです。コアとなる価値提案は、試合イベントシグナル(ゴール、カード、構造化テキストとして捉えられた試合の流れの変化)をスポンサーシップ意思決定における下流のROI予測に結びつける点にあります。このシステムは実際のソースから得られるテキストシグナル(ライブの試合フィードまたは試合後のレポートと思われるもの)を取り込み、点推定ではなく信頼区間を出力する不確実性を考慮した予測モデルを実行し、スポンサーに対してシナリオベースの推薦(例:異なる試合結果の軌跡におけるブランドの露出度)を提供します。不確実性の定量化はシステムに後付けで追加されたものではなく、アーキテクチャ上で明示的に組み込まれており、これは結果のばらつきが中心的なビジネスリスクとなるドメインにおいて正しい設計方針です。シナリオ推薦レイヤーは確率的な出力をスポンサーが実行可能な意思決定へと変換します。これは構造化予測と意思決定支援をスポーツアナリティクスに応用した、狭くも技術的に整合性のとれたアプリケーションであり、試合結果の分類ではなくブランドROI指標に明示的に焦点を当てることで、汎用的なベッティングモデルとは一線を画しています。
Source: https://github.com/2417467487-hub/WorldCupROI
cobusgreyling/loop-engineering
Addy OsmaniとBoris Chernyのエージェントシステムに関する論考にインスパイアされた、人間とAIエージェントのループを設計するためのパターンライブラリおよびツールセットです。このリポジトリには3つのCLIツールが含まれています:既存のエージェントワークフローを分析して失敗モードや非効率を特定する loop-audit、意見を持った構造で新しいループベースのプロジェクトをscaffoldingする loop-init、そして実行前に提案されたループ設計のトークンと計算コストを見積もる loop-cost です。概念的なコアは、エージェントのオーケストレーションを単なるプロンプトの連鎖としてではなく、明示的なフィードバックサイクルを持つエンジニアリングの一分野として捉えることにあります。パターンは、ループをいつ抜け出すか、人間のチェックポイントをどのように組み込むか、そして複数のイテレーションにわたってエージェントがタスクに集中し続けられるようにプロンプトをどのように構造化するか、といった内容をカバーしています。スターターとして、一般的なループトポロジー(単一エージェントのリトライ、マルチエージェントのハンドオフ、批評と改訂)の最小限の動作例が提供されています。場当たり的なエージェントスクリプトから、保守可能でコスト管理されたエージェントシステムへと移行したいエンジニアに役立ちます。
Source: https://github.com/cobusgreyling/loop-engineering
gykim80/perfectpixel-studio
生成AIを使ってゲームですぐに使えるキャラクタースプライトシートを生成するデスクトップアプリケーションです。Wails(Goバックエンド、Reactフロントエンド)で構築されており、単一のテキストプロンプトを入力することで、8方向の向きと100以上のアクションクラスをカバーするスプライトを生成します――2D RPGやトップダウン型ゲームアセットの標準的な要件を満たしています。Goバックエンドはモデルへの API呼び出しと画像後処理(グリッドの組み立てやフレームの正規化など)を担当し、ReactフロントエンドはCanvasベースのプレビューを提供します。8方向・マルチアクションという制約は技術的に容易ではなく、数十枚の生成画像にわたってキャラクターの同一性を保つ必要があります――以前のフレームへのコンディショニングなしに標準的な diffusion を用いると、一貫性のない結果が生じてしまいます。このリポジトリでは、スタイルを固定したプロンプティングと、場合によっては ControlNet や IP-Adapter によるコンディショニングを組み合わせることでこの問題に対処していると推測されますが、正確なメカニズムはソースコードで確認する価値があります。インディゲーム開発者にとっての価値は、手作業のピクセルアートに数週間かかる作業を自動化されたパイプラインへと圧縮できる点にあります。
Source: https://github.com/gykim80/perfectpixel-studio
withkynam/vibecode-pro-max-kit
Claude CodeとOpenAI Codexを対象とした、仕様駆動型の開発ハーネスです。このツールが解決しようとする中心的な問題は「context rot」、すなわちLLMコーディングエージェントが会話履歴の増大に伴いコードベースへの一貫した理解を失っていく現象です。その解決策として、プロジェクト仕様・アーキテクチャ上の意思決定・累積されたフィーチャーの状態を構造化された形式でモデルのcontext windowの外部に保存し、リクエストごとに関連するフラグメントを選択的に注入する、永続的かつ自己改善型のcontextメモリ層を採用しています。このシステムは作業を12の専門エージェント(planner、coder、reviewer、test writerなど)と32のスキル(一般的なサブタスク向けの再利用可能なpromptテンプレート)に分解します。自己改善という側面においては、メモリストアが各フィーチャーの完了後に、計画された内容ではなく実際にリリースされた内容に基づいて更新されます。このアーキテクチャはMemGPT方式の外部メモリと類似していますが、汎用的な会話ではなくソフトウェアエンジニアリングのワークフローに特化しています。設計上スタック非依存であり、ハーネスは対象プロジェクトで使用されるいかなる言語やフレームワークもラップします。
Source: https://github.com/withkynam/vibecode-pro-max-kit
alchaincyf/fanbox
AIを活用したコーディングセッション向けの、ローカルIDE隣接型コックピットUIです。レイアウトは3パネル構成で、左側にファイルブラウザ、右側にコマンド/エージェントターミナル、中央にdiffを中心とした変更ビューアを配置しています。中央パネルが実質的な貢献の核心であり、エージェントによるすべてのファイル変更をリアルタイムで構造化されたdiffとして表示するため、開発者は別途gitツールに切り替えることなく変更内容を監査できます。これは現在のエージェント型コーディングツールにおける実際のユーザビリティ上のギャップに対応しています。Claude CodeやCodexのようなエージェントは素早く変更を加えるため、実際に何が修正されたかを追跡しにくくなりがちです。ターミナルパネルは生のシェルとしてではなく、エージェントに直接コマンドを発行するよう設計されていますが、両者の境界は設定可能です。vibe-coding(AIを活用した高速開発)インターフェースとして構築されていますが、基盤となるdiffストリーミングアーキテクチャは、コミット前に複数のAIによるファイル変更を段階的にレビューする必要があるあらゆるワークフローにも適用できます。