Daily AI Digest — 2026-06-15
arXiv Highlights
APPO: Agentic Procedural Policy Optimization
Problem
Agentic RL for tool-using LLMs typically attaches credit to coarse units — entire trajectories, tool-call boundaries, or fixed workflow stages. This is convenient because tool calls are syntactically obvious, but it conflates the choice of whether to call a tool with the many latent reasoning decisions inside thinking spans that actually determine downstream success. Methods that branch at high-entropy tokens (a popular proxy for “decision points”) are also unreliable: high entropy often reflects lexical alternatives (e.g., synonyms, formatting) rather than semantically pivotal forks.
The authors quantify this directly. In the pilot study on Tool-Star’s 54K rollouts, the entropy distribution is heavy-tailed but the accuracy of branches resampled from high-entropy tokens is essentially flat across entropy bins, while branches generated from points with high Branching Score correlate strongly with downstream accuracy.
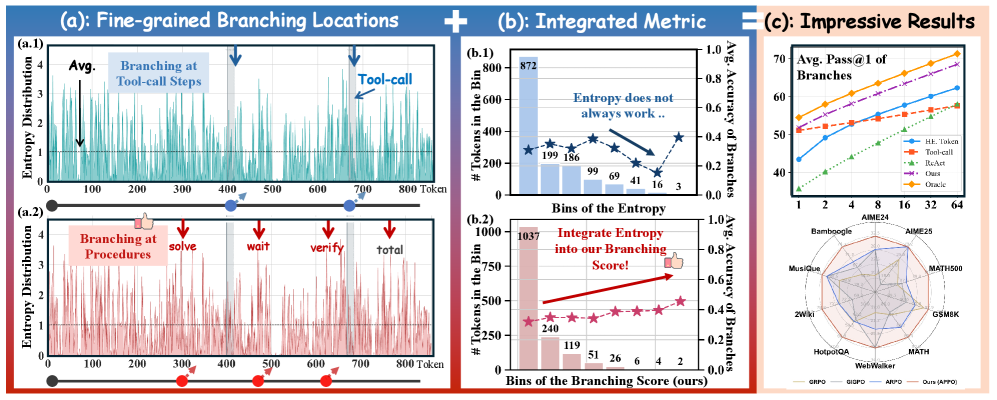
The pass@k panel further shows that BS-based resampling tracks the oracle (resample from points with highest empirical accuracy) much more tightly than entropy-based or tool-call-boundary resampling.
Method
APPO replaces coarse branching with fine-grained, procedure-level branching and credit assignment, built around two components.
1. Branching Score (BS). For a candidate token position t in a rollout, APPO combines local uncertainty with a future-aware signal: how much do alternative continuations from t change the policy’s likelihood over the remaining sequence? Concretely, entropy
H_t = -\sum_{j=1}^{|\mathcal{V}|} p_{t,j}\log p_{t,j},\quad \bm{p}_t = \mathrm{Softmax}(\bm{z}_t/\tau)
is fused with a likelihood-gain term measured by sampling short continuations under \pi_\theta and comparing their induced log-likelihood on the remainder of the trajectory. Positions with both high local uncertainty and high downstream divergence are flagged as decision points. This filters out high-entropy-but-inert tokens (e.g., punctuation, interchangeable phrasing).
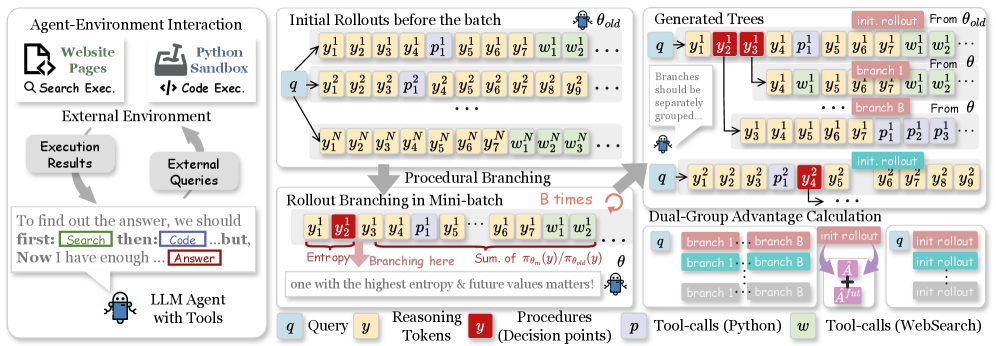
2. Procedural branching and dual-group advantage. Given a batch of initial rollouts under the standard agentic factorization
P_\theta(\mathcal{G},y\mid x,T)=\prod_{t=1}^{T_a}[\pi_\theta(\mathcal{O}_t\mid \mathcal{G}_{<t},x;T)P_{env}(\mathcal{G}_t\mid \mathcal{O}_t,\mathcal{G}_{<t})]\prod_{t=1}^{T_b}\pi_\theta(\mathcal{O}_t\mid y_{<t},\mathcal{G},x;T),
APPO selects top-BS positions inside the mini-batch and resamples continuations from those positions (rather than from tool-call boundaries). The original rollouts and the branched rollouts form two groups used jointly for advantage estimation. A future-aware advantage term then propagates terminal reward back along each branch with a geometric decay \gamma = 2^{-1/\tau} and \tau=32, providing procedure-level credit assignment between the branch point and the end of the rollout. Training uses the standard agentic RL objective
\max_{\pi_\theta}\,\mathbb{E}_{x\sim\mathcal{X},\,y\sim\pi_\theta(\cdot\mid x;T)}[r_\phi(x,y)] - \beta\,\mathbb{D}_{\mathrm{KL}}[\pi_\theta\,\|\,\pi_{\mathrm{ref}}]
with \beta=0 (KL disabled for stability), batch size 128, PPO mini-batch 16 (8 updates/step), and tool-call outputs detached from gradients. SFT initialization follows ARPO; training runs 2 epochs on reasoning and 5 on search tasks on the VeRL framework.
Results
APPO is evaluated against vanilla RL baselines (GRPO, Reinforce++, DAPO, GPPO, CISPO), agentic RL baselines (GIGPO, ARPO), search agents (Search-o1, WebThinker), and strong reference models (QwQ, DeepSeek-R1, GPT-4o, o1-preview, Qwen3-32B) on three benchmark families: math reasoning (GSM8K, MATH, MATH500, AIME24/25), multi-hop QA (HotpotQA, 2Wiki, Musique, Bamboogle, WebWalker), and deep-search tasks (GAIA, HLE, Xbench). Metrics are F1 for QA and LLM-as-judge pass@1 (Qwen2.5-72B-Instruct via vLLM) elsewhere.
The pass@1–pass@5 analysis against ARPO across four datasets is the most informative ablation.

APPO improves not just pass@1 but the entire pass@k curve, indicating that fine-grained branching expands the policy’s effective coverage of reasoning paths rather than merely sharpening a single mode — consistent with the BS-vs-entropy comparison in Figure 1c.
Limitations and open questions
- BS requires per-position likelihood-gain estimation via short continuations, so the per-step cost scales with the number of candidate branch points evaluated; the paper does not report wall-clock overhead relative to ARPO.
- The decay schedule \gamma=2^{-1/\tau} with \tau=32 is a hand-set hyperparameter; sensitivity to \tau and to the BS fusion weights is not detailed in the provided sections.
- \beta=0 removes the KL anchor, which the authors note is needed for stability; this raises questions about drift over longer training horizons.
- Evaluation relies on LLM-as-judge with Qwen2.5-72B for non-QA tasks, which can introduce judge-model biases on deep-search benchmarks like GAIA and HLE.
- The method assumes a meaningful signal from short-horizon likelihood gains; for tasks where reward is highly delayed or sparse beyond the horizon used to compute BS, the score may degrade to entropy.
Why this matters
APPO operationalizes the intuition that “decision points” in agent trajectories are not aligned with tool-call boundaries and are not well-identified by entropy alone. By replacing both branching and credit assignment with a single fine-grained, future-aware signal, it provides a cleaner substrate for procedure-level RL on long-horizon tool-use tasks — a setting where coarse credit assignment has been a persistent bottleneck.
Source: https://arxiv.org/abs/2606.12384
HarnessX: A Composable, Adaptive, and Evolvable Agent Harness Foundry
Problem
Agent performance depends on the runtime harness — prompts, tools, memory, and control flow — yet harnesses remain hand-crafted and static. Each new model or task requires bespoke scaffolding, and execution traces are rarely recycled into systematic improvement. HarnessX targets this gap by reifying the harness as a typed, substitutable, and evolvable object, then closing a loop in which traces drive both harness edits and model training.
Composition layer
A harness is a pair \mathcal{H}=(\mathcal{M},\mathcal{C}), where \mathcal{M} is a model configuration (which model fills the main, judge, evaluator roles plus fallback policy) and \mathcal{C}=(\mathbf{P},\mathbf{S}) is a model-independent harness configuration. \mathbf{P}:\mathcal{H}\!\mathit{ook}\to\mathrm{List}[\mathit{Processor}] maps each of eight lifecycle hooks (task_start, step_start, before_model, after_model, before_tool, after_tool, step_end, task_end) to an ordered list of typed processors with explicit permitted-modification contracts (e.g. before_model may modify last user content and append exactly one user message; after_tool may overwrite the tool result). \mathbf{S} holds singleton slot resources — tool registry, tracer, workspace, sandbox provider, plugin list — shared across processors. Crucially, \mathcal{C} is serializable, hashable, and substitutable, which is the precondition for programmatic search over harnesses. Processors are organized along a nine-dimensional taxonomy (model selection, context assembly, memory, tool ecosystem, execution environment, evaluation/reward, control/safety, observability, training bridge), so a harness configuration is a tuple \mathcal{H}=(c_1,\ldots,c_9) with each c_i\in\mathcal{C}_i subject to hook-type and singleton-group constraints.
AEGIS: harness adaptation as symbolic RL
AEGIS treats harness evolution as an MDP over symbolic artifacts: states are configurations \mathcal{H}, actions are typed edits, and feedback is the (trace, verifier-reward) pair from rollout. This mapping predicts three pathologies — reward hacking, catastrophic forgetting, under-exploration — which motivate a four-stage pipeline driven by a single meta-agent.
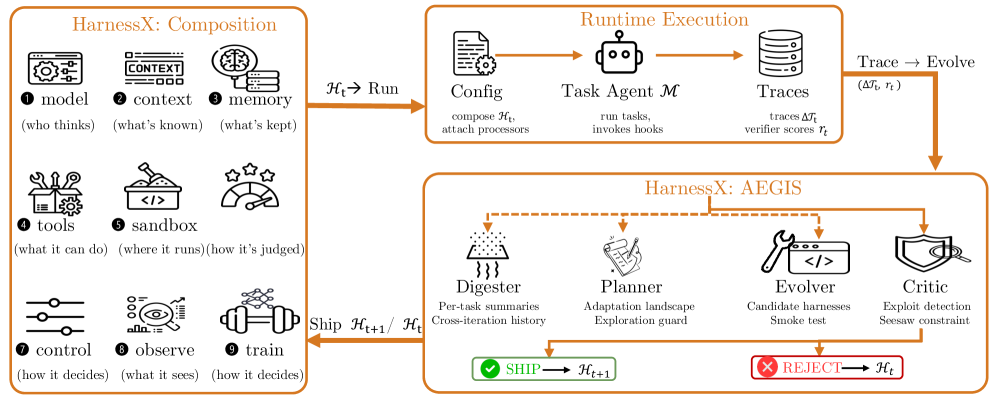
The Digester compresses a round of traces into failure clusters; the Planner synthesizes candidate edits; the Evolver materializes them as concrete diffs over (\mathbf{P},\mathbf{S}); the Critic checks them against a change manifest containing capability_evidence, predicted_impact, and an attribution_signature — a trace feature that must appear in the next round if the edit fired. Each shipped edit is therefore falsifiable against trace-feature deltas at t+1. Variant isolation provides stable multi-variant evolution by sandboxing concurrent candidates so they cannot pollute each other’s slot state.
A worked GAIA / Sonnet 4.6 example illustrates the loop: round 9 regressed success from 77.7% to 74.8%; the Digester observed that ten Wikipedia WebFetch calls returned 0 chars (the new Wikipedia frontend breaks the JS-rendering path); the Evolver shipped a composite edit (new tool + prompt addition + config change) that became the largest single-round gain in that run.
Co-evolution
With the model frozen, harness evolution hits a scaffolding ceiling; with the harness frozen, model training hits a training-signal ceiling. HarnessX runs both updates within one iteration over a shared replay buffer.
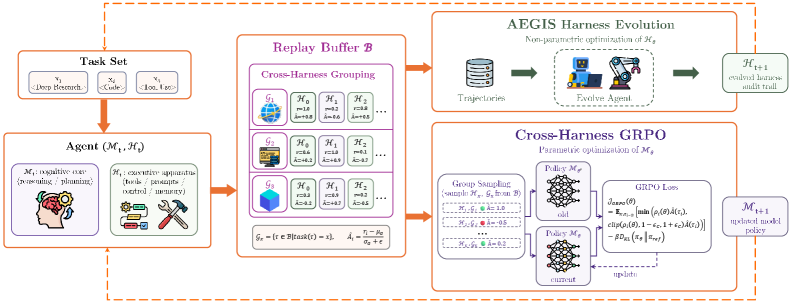
At iteration t the agent (\mathcal{M}_t,\mathcal{H}_t) rolls out batch B_t; the observability layer logs full traces \tau_i; a fixed verifier yields scalar rewards r_i (held fixed so that rewards are comparable across harness versions, a requirement for the cross-harness advantage). Traces are appended to a fixed-capacity FIFO buffer \mathcal{B}. Cross-harness GRPO groups trajectories of the same task across harness versions and computes group-relative advantages \hat{A}, then applies a clipped GRPO objective. Because the same buffered rollouts feed both AEGIS and GRPO, model RL incurs no additional rollout cost — it is off-policy training over data produced for harness evolution.
Results
Across five benchmarks — GAIA (103 tasks, exact match), ALFWorld (134, goal completion), WebShop (100, attribute match), \tau^3-Bench (3 domains, rule compliance), and SWE-bench Verified (55, patch resolution) — HarnessX reports an average gain of +14.5%, up to +44.0%, with up to T=15 evolution rounds and early stopping after P=3 unproductive rounds. Meta-agent token budgets are 100M–175M total per benchmark. Gains are largest where baselines are lowest, consistent with the claim that harness scaffolding most readily closes behavioral gaps for weaker models.
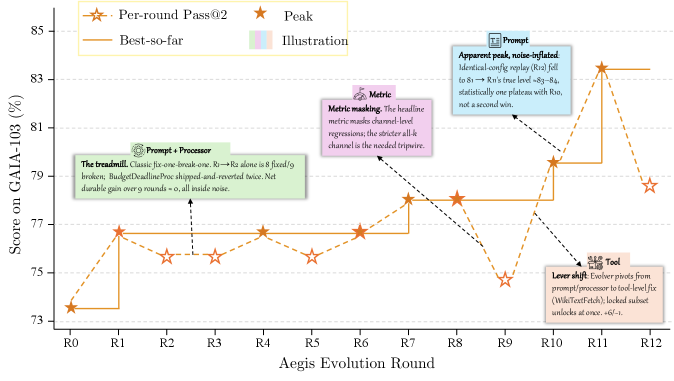
Per-benchmark anatomy is revealing. On GAIA, failure clusters break down as blocked-source 39%, reasoning 33%, figure/visual 11%, document/table parsing 11%, scope ambiguity 6%; the lever distribution and model-by-lever heatmap show evolution concentrating where failure mass concentrates.
Limitations
The verifier must be fixed and reasonably faithful — comparability of rewards across harness versions is structural, not optional, for cross-harness GRPO. The benchmarks sample modestly (e.g. 55 SWE-bench Verified tasks, 103 GAIA tasks), and 15-round evolution caps may understate asymptotes. The framework inherits known RL pathologies it claims to defend against, but the defenses are architectural (manifest-gated edits, variant isolation) rather than provably bounded. Token budgets in the 100M–175M range per benchmark are non-trivial and not directly compared against equivalent compute spent on model fine-tuning alone.
Why this matters
Treating the harness as a typed, substitutable object makes the runtime interface a first-class optimization target, and the operational mirror to RL gives a principled basis for searching it. The empirical claim — that harness evolution and model RL share a single trajectory buffer with no extra rollout cost — is the practically interesting one: it suggests progress on agent benchmarks need not come from model scaling alone.
Source: https://arxiv.org/abs/2606.14249
Skip a Layer or Loop It? Learning Program-of-Layers in LLMs
Problem
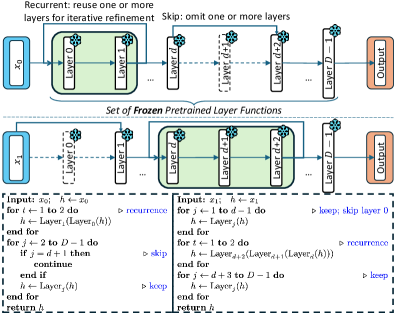
Standard LLM inference applies all D transformer layers in fixed order, regardless of input difficulty. The paper asks whether this fixed-depth, fixed-order forward pass is the right computation for every input, or whether better predictions exist along alternative execution paths through the same pretrained weights. The authors formalize this as a program-of-layers (PoLar): treating each layer f_i:\mathbb{R}^{T\times d}\to\mathbb{R}^{T\times d} as a callable module, an inference program is a sequence
\pi=(i_1,\ldots,i_K),\quad F_\pi=f_{i_K}\circ\cdots\circ f_{i_1},
allowed to skip or repeat layers. The conjecture is that for most inputs, multiple distinct \pi\neq(0,1,\ldots,D-1) produce correct predictions — and often with K<D.
Existence: MCTS as a diagnostic
To verify the conjecture, the authors run Monte Carlo Tree Search over programs (selection/expansion/simulation/backprop, with skip and repeat as expansion operators) on DART-Math. MCTS is used purely as an oracle to bound what alternative programs achieve, not as an inference method.
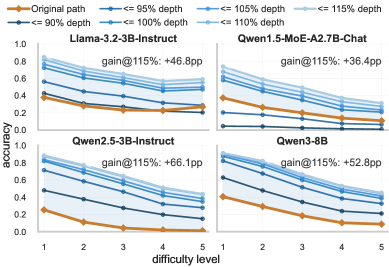
Across DM-1 to DM-5, MCTS finds programs that match or exceed standard forward-pass accuracy under depth budgets as low as 90% of D, and gains grow at 115%. Crucially, many programs shorter than D correctly answer inputs the original model gets wrong, demonstrating that the fixed forward pass is not Pareto-optimal in the (depth, accuracy) plane.
Method: PoLar prediction network
MCTS is intractable at inference time, so PoLar replaces it with a lightweight network that emits a program in one shot.
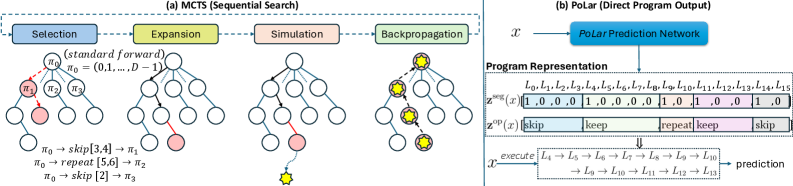
The program is encoded as two structures:
- Segmentation \mathbf{z}^{seg}(x)\in\{0,1\}^D: a binary boundary mask partitioning the D layers into contiguous packed modules [s_j,s_{j+1}), with maximum segment length K_{\max}=4. The cap is justified by the MCTS finding that valid programs are dominated by short contiguous segments.
- Operations \mathbf{z}^{op}(x)\in\{\text{skip},\text{keep},\text{repeat}\}^D, defined only at segment-start positions. Per segment [s_j,s_{j+1}):
\text{skip}:\emptyset,\quad \text{keep}:[s_j,\ldots,s_{j+1}-1],\quad \text{repeat}:[s_j,\ldots,s_{j+1}-1,s_j,\ldots,s_{j+1}-1].
The operator vocabulary is intentionally minimal: MCTS traces show that more than one re-execution per segment rarely helps, so a single repeat suffices. The vocabulary trivially extends to repeat-k if needed.
The base LLM is fully frozen; only the predictor is trained. At inference, beam search over the predictor produces top-k programs, giving a pass@k analog without sampling decoding randomness — diversity comes from computational paths, not from token-level temperature.
Experiments
Models: LLaMA-3.2-3B-Instruct, Qwen1.5-MoE-A2.7B-Chat, Qwen2.5-3B-Instruct, Qwen3-8B, all frozen. In-distribution training/testing on DART-Math (DM-1 to DM-5, per-difficulty splits). OOD evaluation trains on the union of DART-Math and tests zero-shot on ASDiv, MAWPS, and MMLU-Pro subsets (math, natural/social sciences, humanities).
Baselines span both stochastic-output methods (greedy at \tau=0; sampling at \tau\in\{0.3,0.7,1.0\}, best of k) and dynamic-depth/routing approaches that operate on internal computation: DR.LLM, ShortGPT (static pruning), MindSkip, FlexiDepth. The authors report that PoLar consistently improves pass@k accuracy over standard inference and these dynamic-depth baselines, frequently while executing fewer layers than the original model, and gains persist OOD on ASDiv, MAWPS, and MMLU-Pro subjects far from DART-Math’s distribution. (Per-benchmark numerical tables are in the experiments section; the abstract-level claim is consistency across four model families and across in- and out-of-distribution sets.)
Limitations and open questions
- The empirical scope is mathematical reasoning and MMLU-Pro; behavior on long-context, code, or generation-heavy tasks is unverified.
- K_{\max}=4 and a single-
repeatoperator are justified by MCTS statistics on this distribution; for other domains the program space may need richer recurrence (repeat-k) or longer segments. - Beam search over programs gives pass@k, but selecting one program at k=1 deployment depends on the predictor’s calibration; the paper does not deeply analyze when the top-1 program is wrong while a deeper beam is right.
- Interpretability of what each “module” computes — and whether
repeatcorresponds to known phenomena like iterative refinement in residual streams — remains open. - No retraining of the base model means the function library is fixed; co-adapting layers with the program predictor could likely yield further gains but defeats the test-time-only premise.
Why this matters
PoLar reframes test-time compute scaling: rather than spending more tokens (CoT, sampling) or more parameters, it spends a different control flow over existing layers, suggesting that pretrained transformers contain a richer family of valid latent computations than the standard forward pass exposes. If the gains hold beyond math reasoning, dynamic layer programs become a cheap, orthogonal axis to chain-of-thought and speculative decoding for adapting compute to input difficulty.
Source: https://arxiv.org/abs/2606.06574

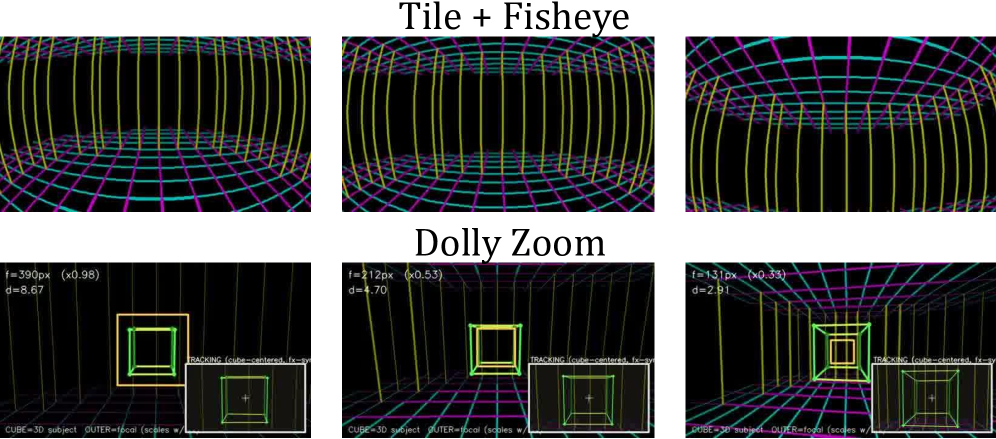
OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data
Problem
Cloning camera motion from a reference video into a newly generated video is a core controllability problem for video diffusion. Two dominant strategies have shortcomings. Parametric conditioning (Plücker embeddings, raw R, t sequences) is geometrically faithful for a single continuous take but breaks under multi-shot inputs where the extrinsics are discontinuous and the intrinsic model can change (e.g., fisheye, dolly zoom). The alternative — synthesizing cross-paired data where the same camera trajectory is realized over different content — is bottlenecked by data scarcity, particularly for cinematographic motions involving cuts. OmniDirector targets a representation that is (a) visual rather than parametric, so it can be consumed by a multimodal DiT without modality-specific encoders, and (b) compositional across shots.
Method
The central object is the camera grid: a video that visualizes the reference camera trajectory as motion through an empty, axis-aligned 3D wireframe room. Given reference poses P=\{R_i, t_i\}_{i=1}^T with R_i \in SO(3), t_i \in \mathbb{R}^3, the authors compute a scene bounding box from \{t_i\} and place a floor and ceiling at
y_{floor} = \overline{y} - \Delta h, \qquad y_{ceiling} = \overline{y} + \Delta h,
where \overline{y} is the mean camera height along Y and \Delta h scales with the median inter-pose translation, lower-bounded for stability. Orthogonal grid lines are rasterized on the two X–Z planes.
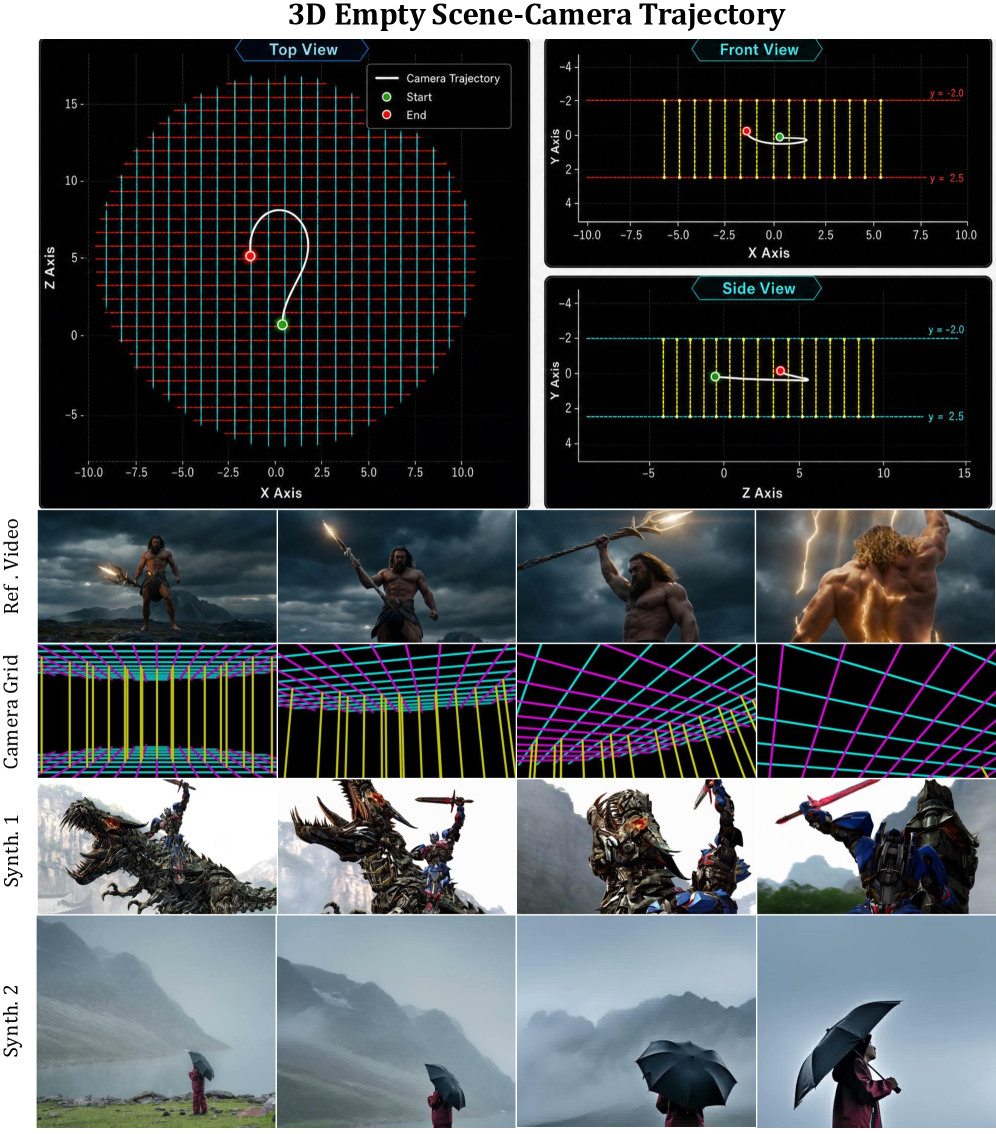
For Y-axis depth cues, rather than fully connecting floor and ceiling, the trajectory is projected onto X–Z to get c_{proj}, a KD-tree gives d_{traj}(x,z), and vertical wall segments are inserted on an annulus
W = \{(x,z) \mid r < d_{traj}(x,z) < r + \delta\},
producing a tunnel surrounding the camera path. Rendering this static geometry through the actual \{R_i, t_i\} sequence (with the actual intrinsics, including Kannala–Brandt for fisheye or focal-length sweeps for dolly zoom) yields a video G whose pixels encode the camera motion visually.
This is the key design choice: because G is just a video, multi-shot inputs concatenate naturally — each shot renders its own grid using its own poses and intrinsics, and cuts appear as ordinary frame-to-frame changes that the DiT already knows how to model. There is no need for cross-paired (same-trajectory, different-content) data because the model learns the mapping G \to \text{motion} from same-video pairs.
OmniDirector conditions an MMDiT image-to-video backbone on the triplet \{G, I, T'\}: the camera grid G, a reference image I, and an expanded text prompt T'. All three are injected via token concatenation along the sequence dimension; the camera grid tokens share the same VAE encoder and positional scheme as the target video tokens, so spatial-temporal correspondence between grid frames and output frames is implicit.
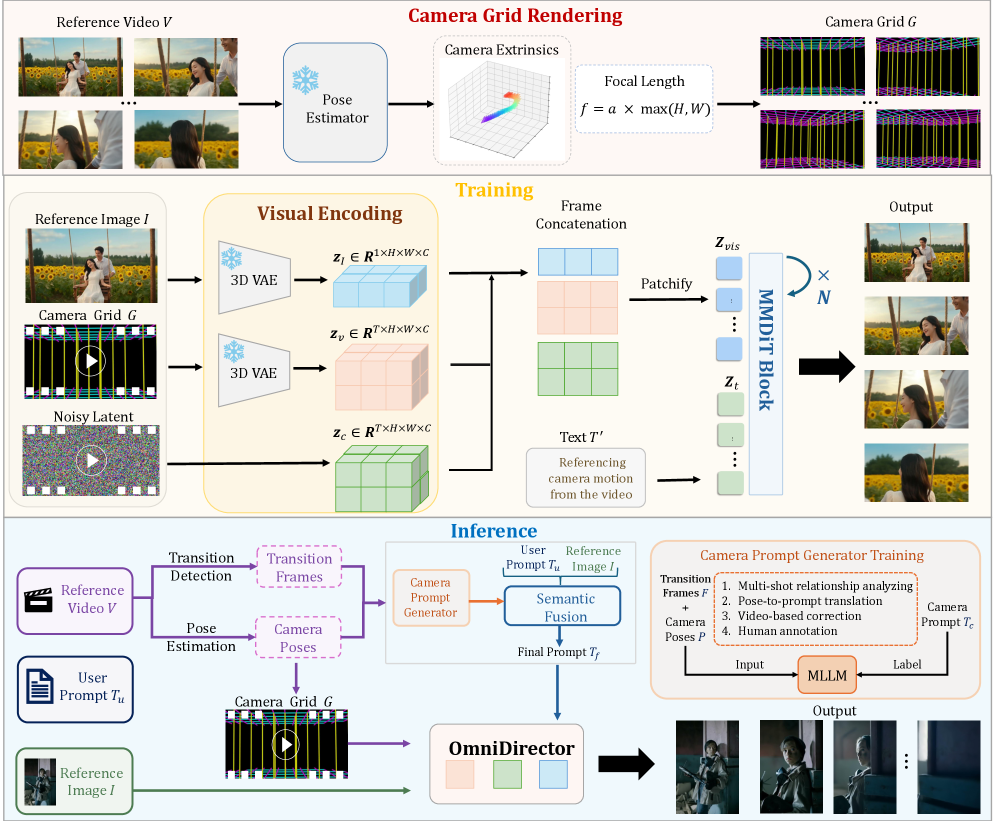
At inference, a hierarchical Prompt Expansion (PE) Agent fuses control signals: it parses the camera grid into a textual description of motion (pan, dolly, cut type) and reconciles it with the user’s content prompt and reference image, producing T' that is internally consistent with the visual conditions. Training uses 1.8M internet videos at 480p, 10k steps, batch 64, lr 5 \times 10^{-5}, with random recoloring of the grid and pose jitter as augmentations.
Results
Camera fidelity is measured with DPA-V3-extracted poses, computing scale-invariant Relative Rotation Error (RRE) and Relative Translation Error (RTE), with thresholded variants R-Pre (<4^\circ rotation) and T-Pre (<20^\circ translation direction). For multi-shot evaluation, two transition metrics are introduced: Tem-Pre (TransNet-V2 detects shot boundaries; success if within 3 frames of reference) and Sem-Pre (Gemini 3.1 Pro verifies transition type matches). Reference-video leakage is separately quantified at frame and shot level by Gemini, and a GSB pairwise study against CamCloneMaster covers camera, quality, and narrative axes. The selected sections describe these protocols but do not enumerate the final numerical tables; the headline claims in the abstract are superior controllability across complex multi-shot trajectories and special intrinsics where parametric and cross-paired baselines degrade.
Limitations and open questions
The empty-room rendering discards scene scale beyond what camera translations bound, so absolute metric scale is not transferred — only relative trajectory shape. The approach inherits errors from the pose estimator used for evaluation (the authors acknowledge this and add Gemini/GSB to compensate). The grid representation must be rendered at training resolution; very long takes or extreme trajectories may exceed the bounding-box assumption. Finally, the PE Agent depends on an external LLM for signal reconciliation, which couples controllability to that model’s grounding ability, and the failure modes of disagreement between G and T' are not characterized in the provided sections.
Why this matters
Recasting camera control as video-to-video conditioning — rather than parameter-to-video — sidesteps the cross-paired data bottleneck and inherits the DiT’s native handling of cuts, intrinsics, and temporal structure. The same trick (render the control signal as a video the backbone already understands) is likely transferable to other geometric controls.
Source: https://arxiv.org/abs/2606.13432
Memory is Reconstructed, Not Retrieved: Graph Memory for LLM Agents
Problem
Memory-augmented LLM agents typically follow a static retrieve-then-reason pipeline: given a query x, a stateless retrieval policy \pi_p returns a fixed set of memory units \{v^{(1)},\dots,v^{(T)}\}=\pi_p(x), after which the LLM reasons over them. This decoupling fails on multi-hop and temporal queries, where the relevant evidence cannot be identified from the query alone — partial evidence accumulated mid-reasoning is needed to know what to retrieve next.
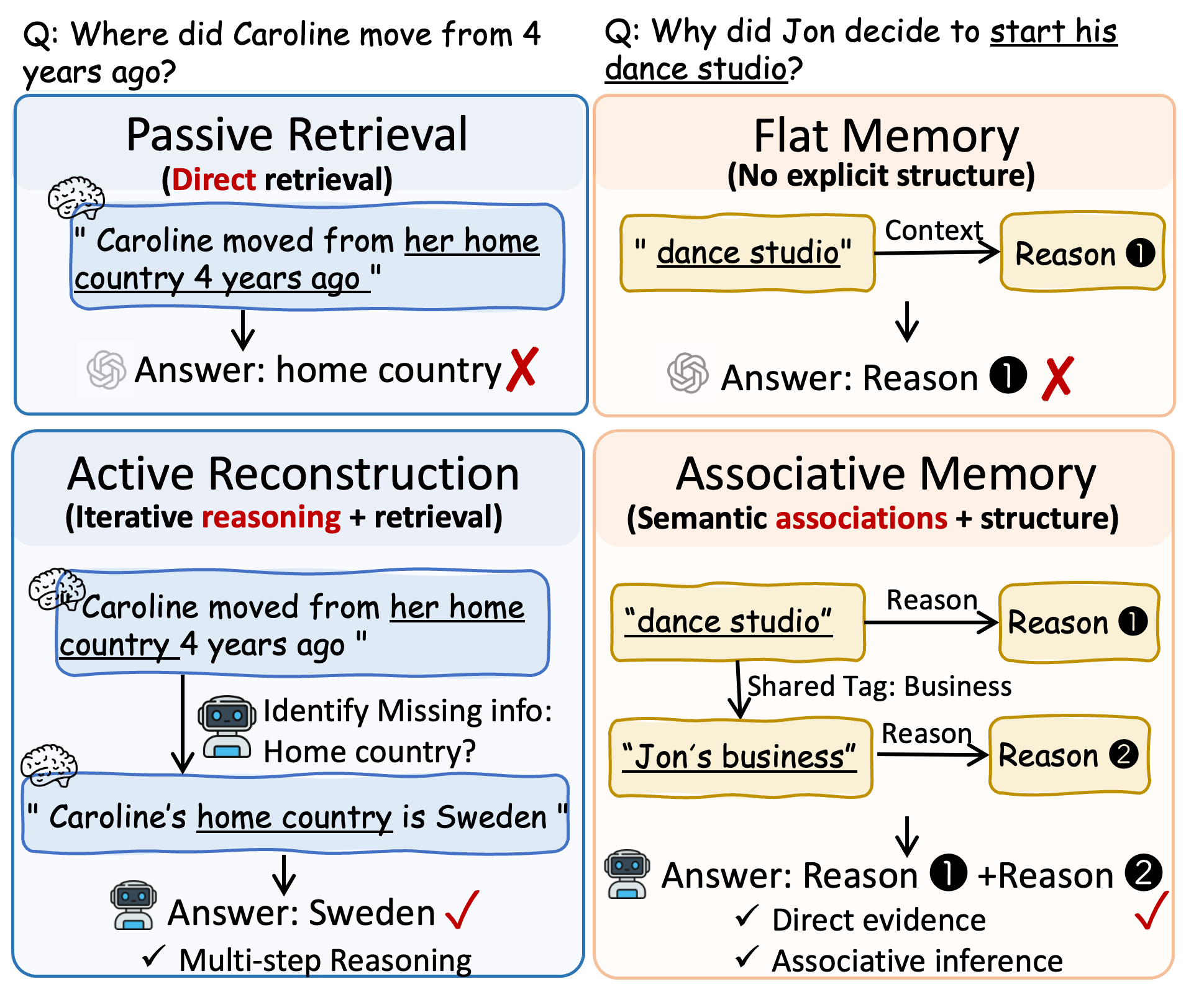
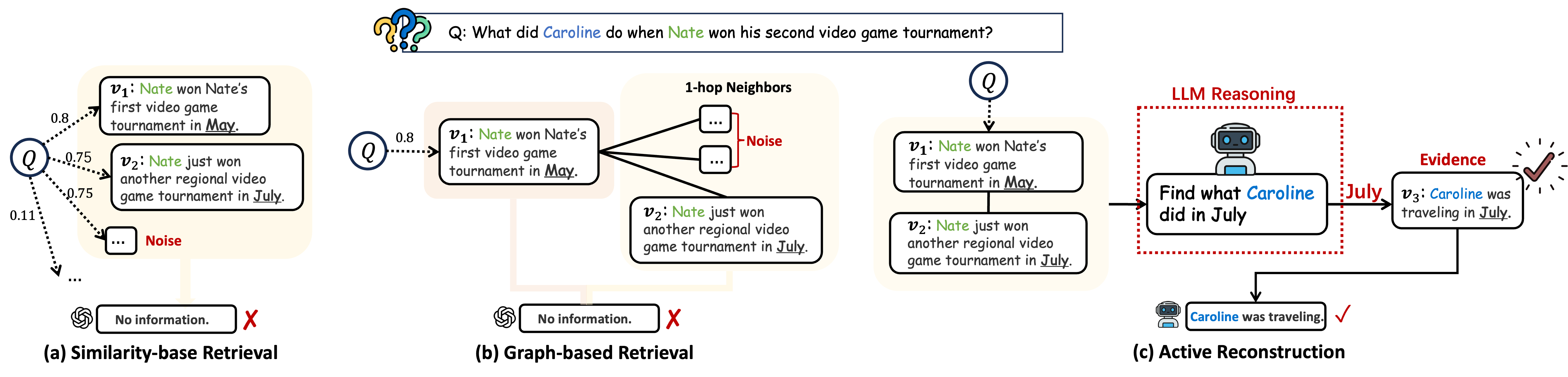
The motivating example makes this concrete: asked what Caroline did while Nate was at video game tournaments, passive retrieval pulls memories about Nate’s tournaments but cannot bridge to Caroline’s activities; an active policy must first infer the temporal cue (“July”) from the tournament memories and then query for Caroline’s July activities.
Method
MRAgent reformulates retrieval as a stateful sequential decision process: v^{(t)} = \pi_a^{(t)}(x, S^{(t-1)}), \quad S^{(t)} = S^{(t-1)} \cup \{v^{(t)}\}.
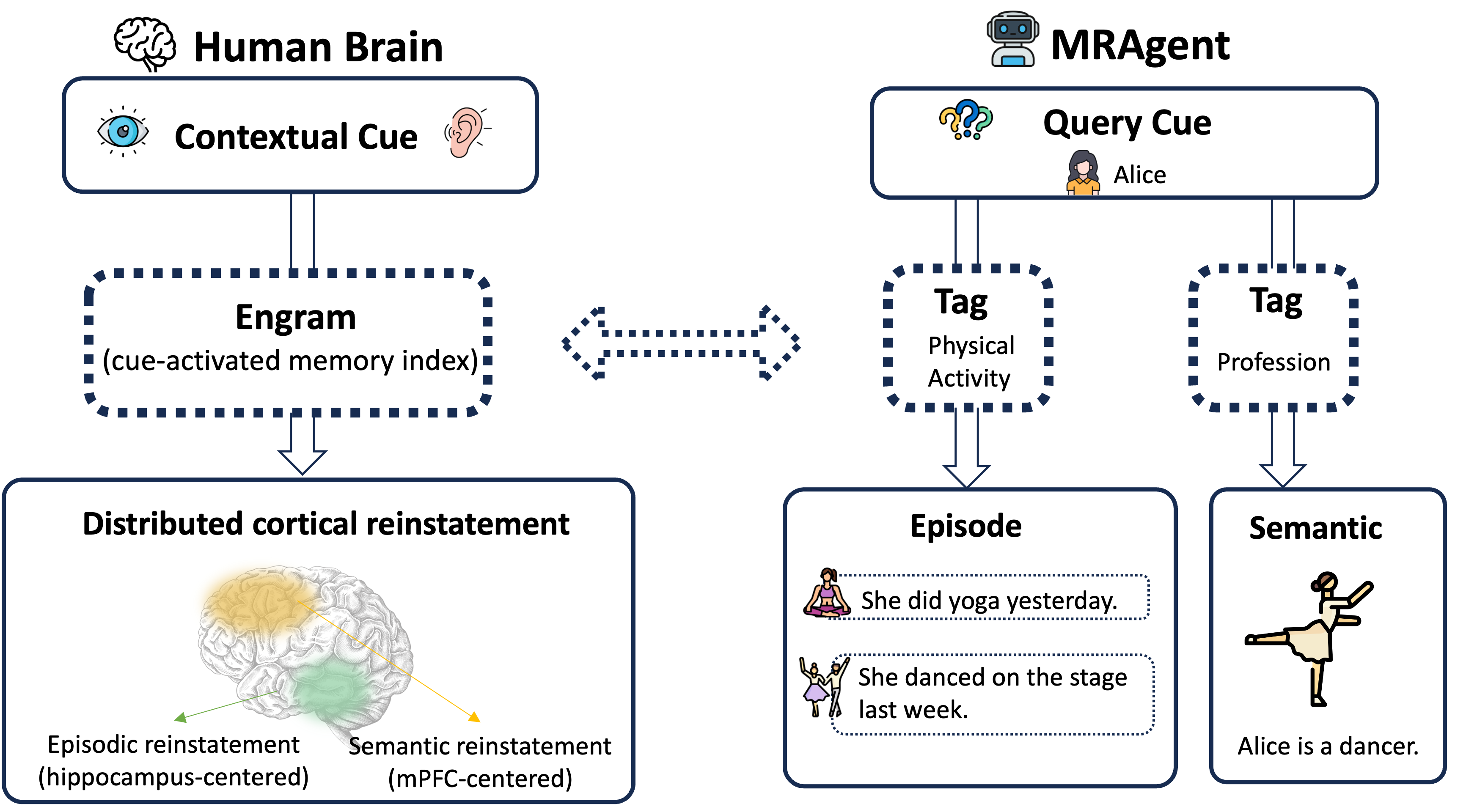
Cue–Tag–Content graph. Memory is a heterogeneous graph \mathcal{M} = (\mathcal{C}, \mathcal{V}, \mathcal{R}) with cue nodes c \in \mathcal{C} (fine-grained entities/attributes), content nodes v \in \mathcal{V} (episodic/semantic memory items), and typed relations \mathcal{R} \subseteq \mathcal{C} \times \mathcal{G} \times \mathcal{V} where each tag g summarizes the associative relation between a cue and a content unit. Construction is two-phase: an LLM extracts cues, tags, and content units from dialogues, then a graph is assembled from the resulting triples.
The tag layer is the key design choice. Naive n-hop expansion over content nodes blows up combinatorially and floods the context with irrelevant memories. Tags act as semantic intermediates that the LLM can score and prune cheaply before paying the cost of reading full episodic content. Two induced operators formalize the two-stage access: \phi_{c \to g}(c) \triangleq \{g \mid (c,g,\cdot) \in \mathcal{R}\}, \quad \phi_{(c,g) \to v}(c,g) \triangleq \{v \mid (c,g,v) \in \mathcal{R}\}.
Active reconstruction. At step t, MRAgent maintains a reconstruction state \mathcal{S}^{(t)} = (\mathcal{Z}^{(t)}, \mathcal{H}^{(t)}) where \mathcal{Z}^{(t)} is the active candidate frontier (cues, tags, contents) and \mathcal{H}^{(t)} is the accumulated evidence context. The LLM uses \mathcal{H}^{(t)} to (i) select which cues to expand via \phi_{c \to g}, (ii) prune the resulting tag set by relevance, (iii) materialize content via \phi_{(c,g) \to v}, and (iv) decide whether to terminate or continue. The framing mirrors a constructive view of human episodic memory rather than indexed lookup.
Results
On LoCoMo, with Claude-Sonnet-4.5, MRAgent reaches an overall LLM-Judge score of 88.32 vs. 78.61 for the strongest baseline (LangMem) and 69.02 for Mem0 — a ~10–19 point absolute gap depending on baseline. The improvement is largest on the categories where active reasoning matters most:
- Temporal: J = 85.34 vs. 80.68 (LangMem), 53.58 (Mem0); F1 69.82 vs. 56.64.
- Open-domain: J = 71.57 vs. 56.25 (Mem0), 54.71 (LangMem); F1 34.67 vs. 28.58.
- Multi-hop: J = 90.19 vs. 75.88 (Mem0); F1 56.72 vs. 48.66.
- Single-hop: J = 91.10 vs. 83.12 (LangMem).
With Gemini-2.5-Flash the pattern holds: overall J = 84.21 vs. 68.31 (Mem0), with temporal J jumping from 61.68 → 80.37 and open-domain J from 41.66 → 68.75. The headline “up to 23%” gain in the abstract corresponds to the largest per-category deltas (e.g., temporal F1 on Gemini moves from 58.19 to 67.66, open-domain J from 41.66 to 68.75). The authors also report reductions in token and runtime cost relative to baselines, attributed to tag-level pruning before content materialization, though the specific cost numbers live in later sections not excerpted here.
Limitations and open questions
- Memory construction relies on LLM-extracted cues and tags; quality of \mathcal{R} depends on extraction prompts and is not separately ablated against ground-truth graph structure.
- The reconstruction policy is itself an LLM at inference; per-query cost scales with traversal depth, and the paper’s cost claim is relative to baselines rather than absolute.
- Termination criteria for the active loop are LLM-judged rather than learned; failure modes (early stopping, infinite expansion) are not characterized.
- Evaluation is on dialogue benchmarks (LoCoMo, LongMemEval); generalization to non-conversational long-horizon settings (code, tool use traces) is untested.
- No comparison to learned graph traversal policies (e.g., GNN-based retrievers or trained agents); the gain is over prompt-engineered baselines.
Why this matters
Treating retrieval as a decision process interleaved with reasoning — rather than a fixed prefix to generation — is a structurally different paradigm for agent memory, and the temporal/open-domain gains (often >20 points J) suggest current memory systems are bottlenecked by the static pipeline more than by storage representation. The Cue–Tag–Content split is a practical recipe for keeping multi-hop graph traversal tractable under LLM-driven control.
Source: https://arxiv.org/abs/2606.06036
Orchestra-o1: Omnimodal Agent Orchestration
Problem
Multi-agent orchestration frameworks have largely been built for text-only or text+image settings. When tasks require jointly reasoning over text, images, audio, and video — the omnimodal regime exemplified by OmniGAIA — existing orchestrators degrade because (a) task decomposition is not modality-aware, (b) sub-agents are static and cannot specialize to the modality mix at hand, and (c) execution is serialized despite many sub-tasks being independent across modalities. The result is poor accuracy on heterogeneous inputs even when strong omnimodal foundation models are available as primitives.
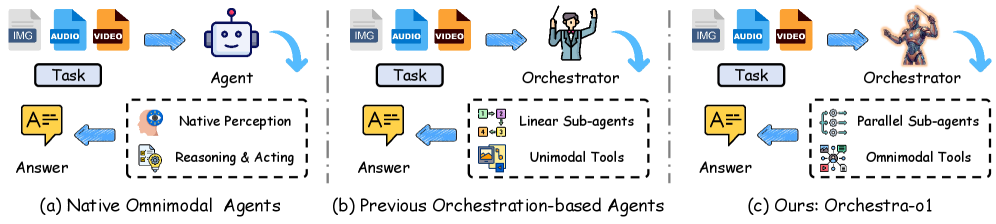
Method
Orchestra-o1 formulates omnimodal orchestration as a multi-round decision problem. A task is x=(q,\mathcal{M}) with \mathcal{M}=\{m_i\}_{i=1}^{N} ranging over images, audios, and videos; the orchestrator must produce \hat{a} maximizing R(\hat{a},a^*) against ground truth a^*. The framework places a “main agent” on top of a pool of sub-agents that wrap omnimodal tools and models, and introduces three coupled mechanisms:
Modality-aware task decomposition. The main agent conditions decomposition on the modality signature of \mathcal{M}, producing sub-tasks \{s_j\} each annotated with the modalities required and the expected output type. This allows, e.g., a video sub-task and an audio sub-task to be split rather than collapsed into a single multimodal prompt that no single sub-agent handles well.
Online sub-agent specialization. Sub-agents are not fixed configurations; at dispatch time the orchestrator instantiates a sub-agent’s role, tool set, and prompt to match the sub-task’s modality and topical category. This is the key difference from AOrchestra-style frameworks, which use a fixed cast of generalist sub-agents.
Parallel sub-task execution. Independent sub-tasks across modalities are executed concurrently, with results aggregated by the main agent in subsequent rounds.
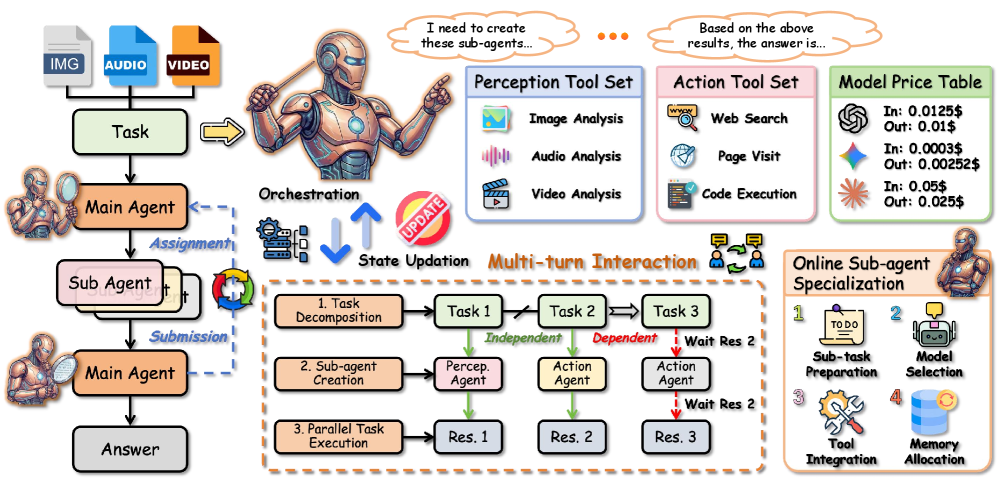
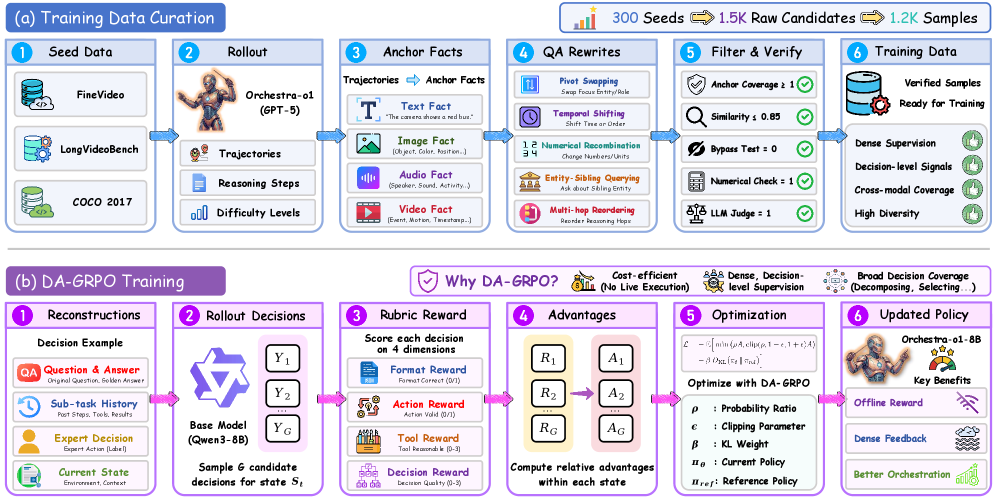
The open-source main agent is trained with a two-stage recipe: a curated trajectory dataset from successful orchestration rollouts on omnimodal tasks, followed by a difficulty-aware variant of GRPO (“DA-GRPO”). DA-GRPO modifies the standard GRPO advantage normalization to upweight harder instances, addressing the long tail in OmniGAIA where Hard examples otherwise contribute negligible gradient. The standard GRPO objective
\mathcal{J}_{\text{GRPO}}(\theta) = \mathbb{E}\Big[\frac{1}{G}\sum_{i=1}^{G}\min\big(r_i(\theta) A_i,\; \text{clip}(r_i(\theta),1\!-\!\epsilon,1\!+\!\epsilon) A_i\big)\Big] - \beta\,\mathrm{KL}(\pi_\theta\Vert\pi_{\text{ref}})
is used with A_i rescaled by an instance-difficulty factor before group normalization, so trajectories on Hard items retain non-trivial signal even when the in-group reward variance is small.
Results
On OmniGAIA, Orchestra-o1 dominates both open-source and proprietary baselines within its compute class.
Among open-source agentic models, native omnimodal LLMs under ReAct are weak: Qwen2.5-Omni-7B reaches 3.6%, Ming-Flash-Omni-100B-A6B reaches 8.3%, and the 560B LongCat-Flash-Omni-560B-A27B only 11.1% overall. The strongest non-orchestrated open baseline is OmniAtlas-Qwen3-30B-A3B at 20.8%. Orchestra-o1-8B reaches 30.0% overall, beating the second-best (OmniAtlas-Qwen3-30B-A3B) by 9.2 absolute points despite using a much smaller backbone, and exceeding AOrchestra’s open-source orchestration baseline by the headline 10.3% margin reported in the abstract.
Per-category, Orchestra-o1-8B leads on 7 of 9 categories among open-source systems, including Geo. (21.7 vs. 10.1), History (37.9 vs. 29.9), Art (45.5 vs. 22.2 for OmniAtlas-7B), Movie (38.5 vs. 11.5), and Science (38.9 vs. 27.8). It underperforms only on Finance (12.0 vs. 32.0 for OmniAtlas-Qwen3-30B-A3B) and ties on Sport (16.7).
In the proprietary group, Orchestra-o1 instantiated with GPT-5 as the backbone reaches 72.8% overall, exceeding Gemini-3-Pro at 62.5%, Gemini-3-Flash at 51.7%, and the AOrchestra-GPT-5 orchestration baseline at 40.0%. The 32.8-point gap over AOrchestra-GPT-5 isolates the contribution of the orchestration mechanism itself, since the underlying model is held fixed. Category-wise, Orchestra-o1-GPT-5 leads on 8 of 9 categories versus all proprietary baselines, with the largest gains in Tech. (69.4 vs. 59.2 for Gemini-3-Pro) and Science (73.1 vs. 42.3). Difficulty-stratified analysis shows the gains hold across Easy/Medium/Hard, and the efficiency comparison against AOrchestra indicates the parallel execution pathway recovers wall-clock cost despite the richer decomposition.
Limitations and open questions
The Finance regression (12.0%) suggests that the online specialization signal is not always informative — when a category requires niche tool use (e.g., quantitative retrieval) rather than modality routing, the orchestrator can underperform a fixed specialist. The training recipe relies on successful trajectories distilled at curation time; failure-mode coverage in DA-GRPO is not characterized. The paper does not report ablations isolating the three mechanisms (decomposition vs. specialization vs. parallelism), so their individual contributions remain unquantified. Finally, results are reported on a single benchmark (OmniGAIA); transfer to other omnimodal evaluation suites and to settings with longer videos or streaming audio is untested.
Why this matters
Orchestration, not just stronger backbones, drives omnimodal agent accuracy: an 8B Orchestra-o1 beats a 560B native omnimodal model by ~19 points on OmniGAIA, and orchestrating GPT-5 yields a 32.8-point gain over a prior orchestration framework using the same model. This reframes omnimodal capability as a system-design problem where modality-aware decomposition and online sub-agent specialization are first-class levers.
Source: https://arxiv.org/abs/2606.13707
Hacker News Signals
I indexed 669 GB of my GoPro videos using my M1 Max computer and local ML models
The author ran a full local ML pipeline over a large personal video archive — 669 GB of GoPro footage — entirely on an M1 Max without cloud dependencies. The pipeline combines several stages: frame extraction at some sampling rate to avoid redundant processing, CLIP-based embedding of frames to enable semantic search, likely whisper-style audio transcription for spoken content, and a vector index (probably FAISS or similar) to make the whole corpus queryable. The M1 Max is a reasonable target for this: its Neural Engine and unified memory architecture let models like CLIP ViT-B/32 or larger run with acceptable throughput without the PCIe bandwidth bottleneck of discrete GPU setups. The interesting engineering tension here is frame sampling strategy — too sparse and you miss events, too dense and embedding costs dominate. Storing embeddings for 669 GB of video at even 1 fps would yield millions of vectors, so dimensionality and index structure matter. The result is a private, searchable video archive where queries like “skiing near trees” or “campfire at night” resolve to timestamps via cosine similarity in the embedding space. This pattern — local CLIP + vector DB for personal media — is reproducible by anyone with an Apple Silicon machine and patience, which is why it resonates. The broader point is that the M1 Max’s combination of 32–64 GB unified memory and the Neural Engine makes previously cloud-gated workloads viable on consumer hardware. No API keys, no data leaving the device, no recurring cost. The main limitation is that CLIP’s zero-shot retrieval quality degrades on domain-specific or temporally complex queries, and there is no obvious way to query motion or temporal sequences rather than individual frames.
The only scalable delete in Postgres is DROP TABLE
This post argues, with production evidence, that row-level DELETE in Postgres does not scale in the way most engineers assume — and that the only operation that reliably reclaims space and avoids table bloat at scale is dropping the table (or partition) entirely.
The core issue is Postgres’s MVCC implementation. A DELETE does not remove a tuple; it sets the xmax field on the old tuple version, leaving dead tuples in-place until VACUUM processes them. At high delete volume — bulk deletes, churn-heavy workloads, time-series data expiry — dead tuples accumulate faster than autovacuum can process them. The result is table bloat: the physical file grows, index scans touch more pages, and query plans degrade. Even running manual VACUUM FULL, which rewrites the table, requires an AccessExclusiveLock and takes the table offline.
The recommended pattern is declarative partitioning by time (or whatever the delete predicate keys on), combined with DROP TABLE or DETACH PARTITION + drop on the old partition. DROP TABLE is O(1) from the perspective of tuple-level work — it removes the relation file and system catalog entries atomically, with no MVCC cleanup burden. ALTER TABLE DETACH PARTITION CONCURRENTLY (available since Postgres 14) allows detaching a partition without a full table lock, after which the partition can be dropped independently.
The practical implication: if you have a retention policy — logs older than 30 days, events older than 90 days — the correct schema design is range partitioning on the timestamp from the start, not retrofitting it after bloat appears. The post is a useful corrective to the common assumption that DELETE with an index is “fast enough.” For append-heavy, delete-by-age workloads, partition design is not optional — it is the only path to predictable performance.
Source: https://planetscale.com/blog/the-only-scalable-delete
AI OSS tool repo goes archived over night after raising $7.3M Seed
TensorZero is a framework for building LLM applications with structured inference, prompt management, and a feedback loop for fine-tuning based on production signals. The repo’s sudden archival shortly after a $7.3M seed round triggered significant discussion about what “open source” means in the current AI tooling landscape.
Technically, TensorZero’s core design is worth understanding. It sits between application code and LLM APIs as a typed gateway: requests carry a function schema, responses are validated against output types, and both inputs and outputs are logged to a ClickHouse backend. The feedback mechanism allows attaching metrics (thumbs up/down, task completion signals, explicit scores) to inference records, which are then used to construct fine-tuning datasets — essentially closing the loop between production traffic and model improvement without requiring the developer to build that pipeline manually. The configuration is declarative TOML specifying functions, their variants (different prompts or models), and routing/experimentation logic.
The archival likely signals a pivot to a closed or source-available license, a common trajectory for infrastructure startups that open-source to drive adoption then gate the product to capture commercial value. The HN discussion centers on trust: developers who build production systems on a dependency need confidence in its long-term availability, and an overnight archive — even if a fork or the last commit remains usable — undermines that. The episode is a clean example of the “open core bait” concern: use permissive licensing to grow a community, then relicense once network effects are established. For engineers evaluating OSS LLM infrastructure, this reinforces the value of checking license terms, commit cadence, and whether the maintainer has VC backing before embedding a dependency deeply.
Apple Foundation Models
Apple has released a public API surface for its on-device foundation models, documented under the Apple Foundation Models framework. The Claude platform documentation page (likely misdocumented or a redirect artifact) points to Apple’s own SDK. The framework exposes the models running locally on Apple Silicon for tasks including text generation, summarization, and structured output extraction.
The technical substance: the models run entirely on-device using the Neural Engine and are integrated into the OS rather than shipped with apps, meaning app bundles do not include model weights. The API is structured around LanguageModelSession, which manages context and generation. Structured output is a first-class feature — developers specify a Swift type conforming to Generable and the model is constrained to produce output that deserializes to that type, similar in spirit to OpenAI’s structured outputs but enforced locally via constrained decoding. Tool calling is supported through a protocol-based interface.
The models are quantized to fit within the memory constraints of even base Apple Silicon configurations. Reported parameter counts suggest these are in the 3B range, consistent with Apple’s on-device ML philosophy — small enough to run without degrading other foreground tasks, large enough for practical NLU and generation tasks. Privacy is the primary architectural motivation: inference never leaves the device, there are no API calls, no rate limits, no cost per token.
For ML engineers, the interesting question is the constrained decoding implementation — Apple has not published details on whether they use a trie-based token mask, grammar-guided generation, or a post-hoc validation loop. The framework is Swift-only, which limits cross-platform usage. Integration with macOS 26 and iOS 26 means deployment targets are gated to the latest OS versions.
Source: https://platform.claude.com/docs/en/cli-sdks-libraries/libraries/apple-foundation-models
Caddy compatibility for zeroserve: 3x throughput and 70% lower latency
Zeroserve is a static file server designed for high-throughput, low-latency serving of pre-compressed assets. This post documents adding Caddy as a reverse proxy frontend and measuring the performance delta: approximately 3x throughput increase and 70% reduction in latency compared to the previous setup.
The technical explanation centers on connection handling and TLS termination. Caddy handles TLS with its own implementation (using the Go standard library’s crypto/tls), HTTP/2 and HTTP/3 (QUIC) multiplexing, and persistent upstream connections to zeroserve via a connection pool. The previous configuration likely had TLS termination happening further down the stack or per-request connection overhead. By offloading TLS to Caddy and keeping a persistent pool of connections to the backend, the per-request overhead drops substantially.
Zeroserve’s design is oriented around serving files that are pre-compressed (gzip, brotli, zstd) and stored on disk — it avoids runtime compression entirely, trading disk space for CPU. The Caddy integration adds proper Content-Encoding negotiation based on Accept-Encoding headers, so clients that support brotli get the .br variant without zeroserve needing to implement that logic. Caddy’s file_server directive has similar pre-compressed file serving, but zeroserve’s architecture focuses on minimal allocations and fast path serving, making it a better backend when Caddy handles the protocol-level concerns.
The 70% latency reduction is plausible: if the previous setup was doing synchronous TLS handshakes per connection without session resumption or HTTP/2 multiplexing, the overhead would dominate at low payload sizes. The 3x throughput gain suggests the bottleneck was connection setup rather than bandwidth. The post is a useful case study in the classic “let a purpose-built proxy handle protocol concerns, let the backend handle only application logic” pattern.
Show HN: Trace – Offline Mac meeting transcripts you can flag mid-call
Trace is a macOS application that transcribes meetings locally using on-device speech recognition and lets users flag moments during a call for later review. The “offline” constraint is the defining technical choice: all audio processing stays on-device, which addresses the privacy concern that makes many users unwilling to use cloud transcription services for confidential calls.
The technical stack almost certainly uses Apple’s SFSpeechRecognizer with the on-device recognition option, or alternatively a bundled Whisper model (whisper.cpp being the standard choice for this use case on Apple Silicon). The mid-call flagging mechanism is a low-friction UI action — likely a keyboard shortcut or menu bar button — that timestamps a marker in the transcript stream, allowing the user to jump directly to that segment in post-call review rather than scrubbing through the full transcript.
Audio capture on macOS for calls requires either screen recording permission (to capture system audio via AVFoundation) or microphone-only capture if only capturing the local side. The interesting engineering problem is capturing both sides of a call (local mic + speaker output) cleanly, which typically requires either a virtual audio device (BlackHole is the common OSS solution) or using the Screen Capture Kit API introduced in macOS 12.3 for legitimate system audio capture.
The flagging feature addresses a real workflow gap: current transcription tools produce a wall of text that requires reading or searching. Inline flags during the call create a structured index of high-signal moments — decisions, action items, technical details the user knew were important in real time. The limitation is accuracy: on-device Whisper or SFSpeechRecognizer quality degrades with accents, technical vocabulary, and overlapping speakers, and there is no easy path to correction at the moment of capture.
Source: https://traceapp.info
Show HN: Paca – Lightweight Jira alternative for human-AI collaboration
Paca is a minimal project management tool with explicit first-class support for AI agents as collaborators alongside human contributors. The framing is that existing tools like Jira, Linear, and GitHub Issues model work as human-to-human task handoffs, and as AI agents increasingly execute tasks (writing code, running tests, filing PRs), the tooling should treat them as first-class actors rather than bolting on automation via webhooks.
Technically, the implementation is a Rust or TypeScript backend (the repo would clarify) with a clean REST or GraphQL API designed to be consumed by both humans via a UI and agents via programmatic access. Tasks have assignees that can be either human users or agent identities. The key design question is how agent progress is represented: a human moves a card from “in progress” to “done” manually, but an agent should update state atomically as it completes subtasks, which requires the data model to support finer-grained state transitions and automated audit trails.
The “lightweight” positioning relative to Jira is largely about reduced configuration surface — no custom workflows, no complex permission hierarchies — which makes it appropriate for small teams or projects where the overhead of full Jira configuration exceeds its benefit. For AI-augmented workflows, the interesting technical bet is on structured task decomposition: if an agent is assigned a task, it needs enough context in the task description to act autonomously, which pushes toward more structured acceptance criteria and less implicit tribal knowledge in tickets. Paca’s templates and field schema likely enforce this. The limitation is that the AI integration is only as good as the agent orchestration layer that actually reads the API and executes work — Paca provides the coordination surface but not the agents themselves.
Source: https://github.com/Paca-AI/paca
AI is code – and can’t be prompted into being smarter
This piece from The Register argues that LLMs are deterministic artifacts — compiled, weighted, fixed — and that prompting is a retrieval and framing mechanism, not a capability amplification mechanism. The argument is that widespread user belief in “prompt engineering as magic” conflates eliciting latent capability with creating new capability.
The technical claim is defensible: a trained model’s weights encode a fixed function f_\theta: \mathcal{X} \to \mathcal{Y}. Prompting changes the input distribution presented to that function — it can improve output quality by placing the query in a region of input space the model handles well (chain-of-thought being the clearest example, exploiting the model’s ability to condition on intermediate reasoning tokens it generates). But it cannot exceed the capability encoded in \theta. If the model lacks the knowledge or reasoning structure to solve a problem, no prompt recovers it. This is distinct from fine-tuning, RLHF, or retrieval augmentation, which actually modify or extend f_\theta.
The “AI is code” framing is a useful corrective to anthropomorphization. A model version is a release artifact with fixed behavior; updates require retraining, not conversation. The practical implication is that debugging model failures should be treated like debugging software: identify whether the failure is a capability ceiling (the model cannot do this), a retrieval failure (the model has the capability but the input framing doesn’t elicit it), or a distribution mismatch (the query is out-of-distribution). These have different remedies.
The piece probably overstates the case slightly — emergent behaviors and chain-of-thought do show that prompting can unlock non-trivial latent reasoning that naive prompting misses. But the core argument against the folk theory that prompts “make the AI smarter” is technically sound.
Noteworthy New Repositories
Shiyao-Huang/awesome-agent-evolution
A structured survey and evidence map covering the design space of self-evolving AI agents. The repo organizes literature across five axes: memory architectures (episodic, semantic, parametric), skill acquisition and transfer, harness/scaffold designs, evaluation benchmarks, and multi-agent swarm coordination. Rather than a flat paper list, it attempts a taxonomy of how agents modify their own behavior over time — distinguishing prompt-level self-improvement, fine-tuning loops, and tool-use evolution. Useful as a literature entry point for researchers working on agent autonomy, continual learning, or LLM-based planning systems. The evidence map format means each claim is tied to a specific citation, making it easier to trace the empirical basis for architectural choices. If you are designing an agent that needs to accumulate capabilities without full retraining, this is a reasonable starting index. Coverage skews toward 2023-2024 work, which is where the field is currently moving fastest.
Source: https://github.com/Shiyao-Huang/awesome-agent-evolution
myccarl/ai-shortVideo-pipeline
An end-to-end production pipeline for AI-generated short video, built around a FastAPI orchestration layer backed by a Spring Boot API gateway. The architecture implements multi-model failover (if a primary diffusion or TTS model is unavailable, requests route to alternates) and a circuit breaker pattern to prevent cascade failures under load. Metering hooks allow per-request cost accounting across model calls. On the quality side, the pipeline includes prompt anchoring to maintain semantic consistency across frames, CLIP-based consistency scoring between generated frames and the original prompt, and an AV sync auto-rescue step that realigns audio and video when drift is detected. Observability is full-stack: distributed tracing, structured logging, and metrics are wired through the entire request path. This is a non-trivial systems design for anyone who needs to run AI video generation at modest production scale rather than as a one-off script.
Source: https://github.com/myccarl/ai-shortVideo-pipeline
leiting-eric/DailyBrief
An automated daily briefing system that aggregates 23 data sources — GitHub trending repositories, X (Twitter) hot articles, and financial market data — then pipes the combined content through an LLM to produce Chinese-language summaries. The aggregation layer handles source normalization across heterogeneous APIs. Market data is not just price-quoted; a technical analysis module computes indicators and generates textual commentary. Deployment targets both local execution and GitHub Actions scheduled workflows, meaning the pipeline runs without any persistent server infrastructure. The LLM summarization step uses prompt templates tuned for concise, factual output rather than verbose synthesis. For researchers or engineers who want a personalized daily digest of technical and market signals without relying on a third-party newsletter service, this provides a composable base. The multi-source design makes it straightforward to add or swap data sources by implementing a thin adapter.
Source: https://github.com/leiting-eric/DailyBrief
2417467487-hub/WorldCupROI
A sports sponsorship intelligence platform focused on World Cup match data. The core value proposition is connecting match event signals — goals, cards, momentum shifts captured as structured text — to downstream ROI prediction for sponsorship decisions. The system ingests real-source text signals (likely live match feeds or post-match reports), runs uncertainty-aware prediction models that produce confidence intervals rather than point estimates, and outputs scenario-based recommendations for sponsors (e.g., brand visibility under different match outcome trajectories). Uncertainty quantification is architecturally explicit rather than bolted on, which is the right design for a domain where variance in outcomes is the central business risk. The scenario recommendation layer translates probabilistic outputs into actionable sponsor decisions. This is a narrow but technically coherent application of structured prediction and decision support to sports analytics, distinct from generic betting models by its explicit focus on brand ROI metrics rather than match outcome classification.
Source: https://github.com/2417467487-hub/WorldCupROI
cobusgreyling/loop-engineering
A patterns library and toolset for designing human-AI-agent loops, inspired by Addy Osmani’s and Boris Cherny’s writing on agentic systems. The repo ships three CLI tools: loop-audit for analyzing existing agent workflows and identifying failure modes or inefficiency, loop-init for scaffolding new loop-based projects with opinionated structure, and loop-cost for estimating token and compute costs of proposed loop designs before execution. The conceptual core is treating agent orchestration as an engineering discipline with explicit feedback cycles, not just prompt chaining. Patterns cover when to break out of a loop, how to inject human checkpoints, and how to structure prompts so that agents remain on-task across multiple iterations. Starters provide minimal working examples of common loop topologies (single-agent retry, multi-agent handoff, critique-and-revise). Useful for engineers who want to move from ad-hoc agent scripts to maintainable, cost-accountable agentic systems.
Source: https://github.com/cobusgreyling/loop-engineering
gykim80/perfectpixel-studio
A desktop application for generating game-ready character sprite sheets using generative AI. Built with Wails (Go backend, React frontend), it takes a single text prompt and produces sprites covering 8 directional orientations and over 100 action classes — the standard requirement for 2D RPG or top-down game assets. The Go backend handles model API calls and image post-processing (likely grid assembly and frame normalization); the React frontend provides a canvas-based preview. The 8-direction, multi-action constraint is technically non-trivial because it requires consistent character identity across dozens of generated images — standard diffusion without conditioning on prior frames produces incoherent results. The repo presumably addresses this through a combination of style-locked prompting and possibly ControlNet or IP-Adapter conditioning, though the exact mechanism is worth examining in the source. For indie game developers, the value is collapsing what would be weeks of manual pixel art into an automated pipeline.
Source: https://github.com/gykim80/perfectpixel-studio
withkynam/vibecode-pro-max-kit
A spec-driven development harness targeting Claude Code and OpenAI Codex. The central problem it addresses is context rot — LLM coding agents losing coherent understanding of a codebase as conversation history grows. The solution is a persistent, self-improving context memory layer that stores project specifications, architectural decisions, and accumulated feature state in structured form outside the model’s context window, then selectively injects relevant fragments per request. The system decomposes work across 12 specialized agents (e.g., planner, coder, reviewer, test writer) and 32 skills (reusable prompt templates for common sub-tasks). The self-improving aspect means the memory store is updated after each completed feature based on what actually shipped, not just what was planned. This is architecturally similar to MemGPT-style external memory but oriented toward software engineering workflows rather than general conversation. Stack-agnostic by design; the harness wraps whatever language/framework the underlying project uses.
Source: https://github.com/withkynam/vibecode-pro-max-kit
alchaincyf/fanbox
A local IDE-adjacent cockpit UI for AI-assisted coding sessions. The layout is a three-panel design: file browser on the left, command/agent terminal on the right, and a diff-centric change viewer in the center. The center panel is the substantive contribution — it surfaces every file modification made by an agent as a structured diff in real time, so the developer can audit changes without switching to a separate git tool. This addresses a genuine usability gap in current agentic coding tools: agents like Claude Code or Codex make changes quickly, and it is easy to lose track of what was actually modified. The terminal panel is designed to issue commands to agents directly rather than being a raw shell, though the boundary between the two is configurable. Built as a vibe-coding (rapid AI-assisted development) interface, but the underlying diff-streaming architecture is applicable to any workflow where multiple AI-initiated file changes need to be reviewed incrementally before commit.