デイリーAIダイジェスト — 2026-06-11
arXiv ハイライト
Manifold Power Iterationによる Mixture-of-Experts Routerの再設計
問題設定
sparse MoE layerにおいて、router R \in \mathbb{R}^{E \times d} は s_i = \langle x, R_{[i]} \rangle によってトークンを各expertに対してスコアリングします。ここで R_{[i]} は重み行列 W_*^i を持つexpert i のproxyとして機能します。標準的な学習済みrouterには、R_{[i]} を W_*^i の幾何学的構造に結びつける構造的制約が存在しません。各行はgatedされた出力に対するdownstreamのgradientを通じて間接的にのみ形成されます。著者らはこれが誤ったinductive biasであると主張します。すなわち、R_{[i]} が W_*^i を単一ベクトルで要約することを意図しているならば、行列論的に最適な選択(Eckart–Young定理)は W_*^i の主右特異ベクトルであるべきです。本論文は、各学習ステップで R_{[i]} をこの方向へ明示的に駆動するrouterのパラメータ化を提案します。
手法:Manifold Power Iteration (MPI)
目的はRayleigh商の最大化です。
\max_{R_{[i]}} \; \phi(W_*^i, R_{[i]}) = \frac{\|R_{[i]} W_*^i\|_2^2}{\|R_{[i]}\|_2^2}.
各ステップですべてのexpertに対して厳密なSVDを行うことは計算上非現実的です。代わりにMPIは、W_*^i {W_*^i}^\top に対するpower iterationを1ステップ適用し、続いてunit-norm多様体上へのretractionを行う「Power-then-Retract」更新を使用します。具体的には、各forward passにおいてgatingに使用される実効的なrouter行を次のように計算します。
R'_{[i]} = \mathrm{Retract}\!\left( R_{[i]} W_*^i {W_*^i}^\top \right),
ここで \mathrm{Retract}(\cdot) は安定性のために \|R'_{[i]}\|_2 = 1 を強制します。gating logitはその後通常通り \langle x, R'_{[i]} \rangle として計算されます。router行の計算のみが変更されるため、MPIはdrop-inの修正として機能します。W_*^i {W_*^i}^\top に対するpower iterationの標準的な収束性により、このmapの繰り返し適用によって R_{[i]} は W_*^i の主右特異ベクトルへと収束し、ステップごとのretractionによってnormの発散を防ぎます。著者らは(実際には W_*^i の代わりにgate-projection W_g^i を使用することを注記し)、1ステップのiterationで十分であると述べています。10回のiterationに増やすとスループットが5%低下し、pretraining lossが0.002〜0.003上昇し、downstream accuracyが1.39ポイント低下することから、積極的なalignmentがroutingダイナミクスを不安定化させることが示唆されます。
実験結果
著者らは、cosineスタイルのprojectionによってalignmentの主張を直接検証しています。
\lambda = \frac{\|R'_{[i]} W_g^i\|_2}{\|R'_{[i]}\|_2 \, \|W_g^i\|_2} \in [0,1].
1BモデルのLayer 12層全体において、通常のMoEは \lambda \in [0.22, 0.37](典型的には約0.25)を示す一方、MPIは \lambda \in [0.62, 0.70] を示します。これは主特異方向とのalignmentが約2〜3倍強化されていることを意味し、このパラメータ化が動機付けで規定した目標を達成していることの直接的な証拠となっています。
1Bスケールで100BのpretrainingトークンにおいてMPIは、4種類のoptimizer(AdamW、Muon、およびそれらのHyperball変種であるAdamH、MuonH)全体にわたって収束性とdownstreamの平均性能を改善しており、optimizer非依存性が示されています。MuonHを代表例として用いると、MPIはpretraining lossを0.013削減します。
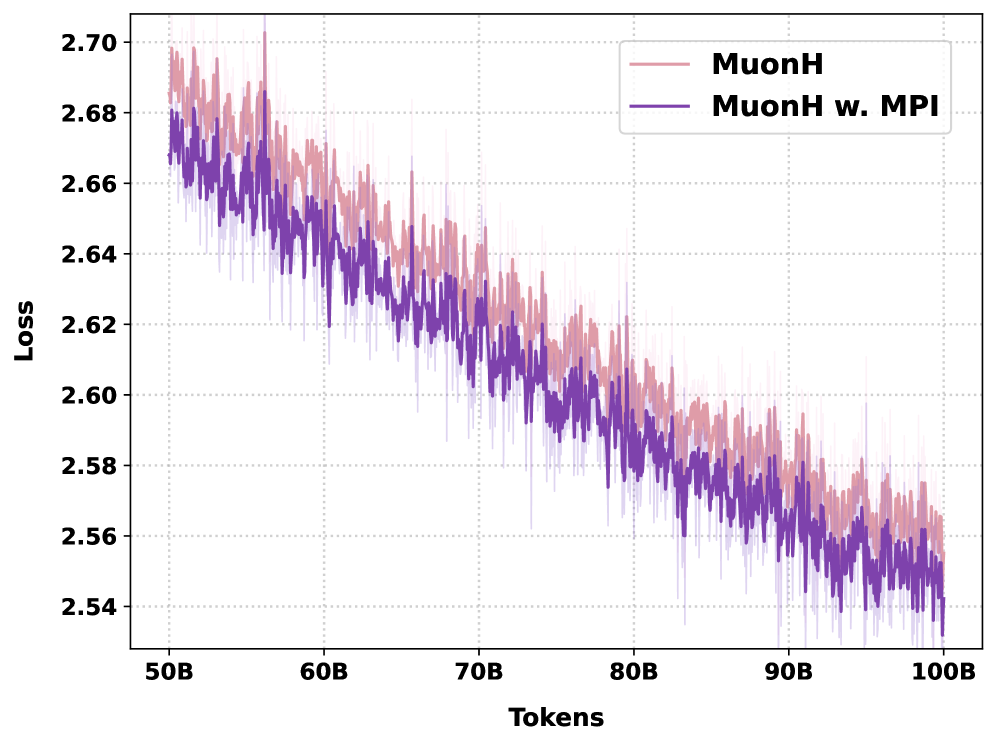
この恩恵はスケールアップしても持続します。11Bパラメータにおいて、MPIはpretrainingの全軌跡を通じて一貫したlossのギャップとdownstreamの優位性を維持しており、alignmentのpriorがモデルの容量に吸収されないことを示しています。
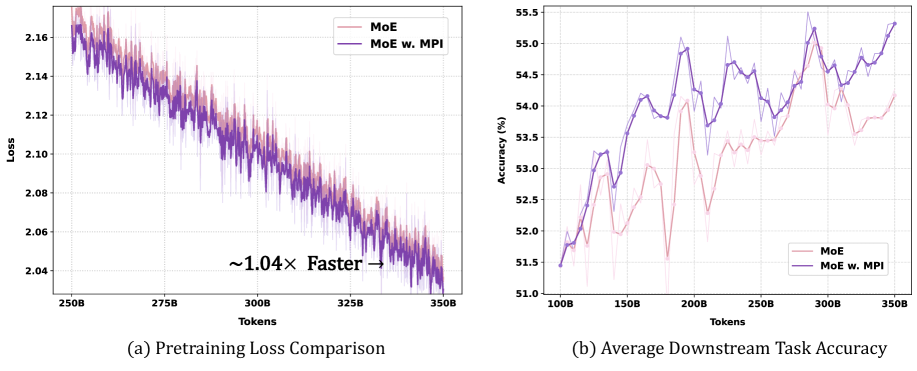
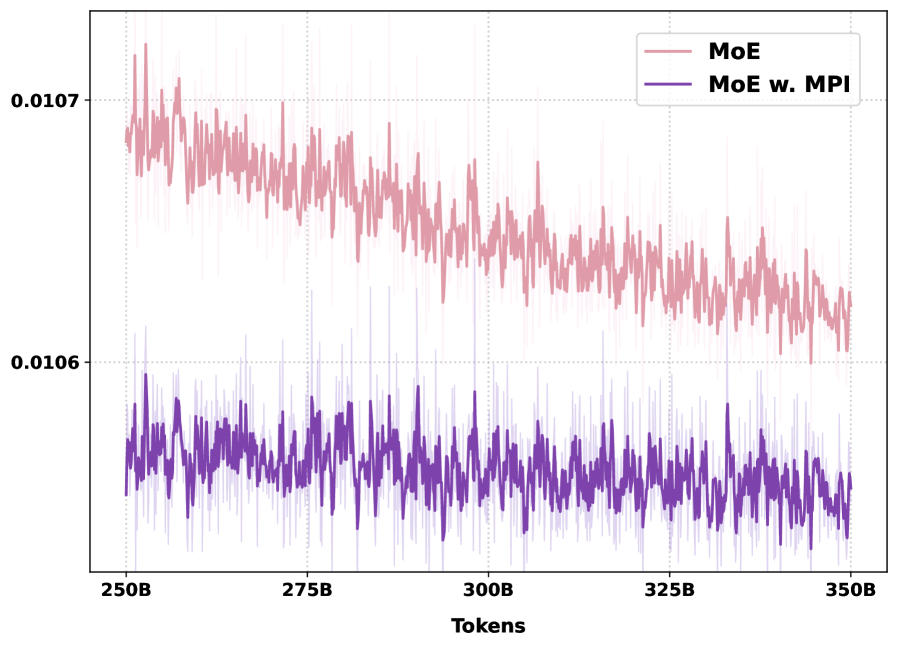
MPIは標準的なauxiliary objectiveとも互換性があります。3BにおけるLoad balancing lossの曲線は適切な挙動を示しており、MPIがroutingを少数のexpertに集中させないことを示しています。
1B/50Bトークンにおいてrouter z-loss(\beta = 0.001、Zoph et al. 2022)と組み合わせると、lossやgradientの異常なしにdownstreamでさらに0.68ポイントの向上が得られます。MPIはrouter行の計算のみを変更し、gating-weightのpathwayを保持するため、他のほとんどのrouter修正と直交的に組み合わせることができます。
限界と未解決の問題
- alignmentメトリック \lambda はper-expertのprojectionのlayer平均として報告されており、per-expertの分散や一部のexpertが依然として低いalignmentのままであるかどうかは特性評価されていません。
- 正当化はEckart–Youngの直観に依拠していますが、token–expertの親和性は入力分布の関数であり、W_*^i のスペクトルだけに依存するわけではありません。主特異方向が実際に不適切なproxyとなる場合(例えば、有用な部分空間のrankが1より大きいexpertや、入力統計が強く異方的な場合)の分析は行われていません。
- W_*^i の選択は W_g^i(SwiGLUスタイルFFNのgate projection)に集約されており、W_p^i や W_o^i、あるいはその組み合わせを使用することが重要かどうかは未解決のままです。
- 実験的には1回のiterationで十分ですが、10回のiterationで観察される不安定化はメカニズム的に分析されていません。これは完全なalignmentがroutingにおける有益な探索ノイズを除去することを示している可能性があります。
- 推論時の挙動:R'_{[i]} は現在のexpert重みに依存するため、routerは固定されたパラメータセットではありません。ストレージ・推論の詳細(重みが固定された後に R' を事前計算するかどうか)を明確にする価値があります。
この研究の意義
MPIはMoE routingに原理的な構造的prior(router行がそれぞれのexpertの主特異方向を追跡する)を、ほぼゼロの計算オーバーヘッドで与え、1Bから11Bにわたって複数のoptimizerにおいて実証的な改善をもたらします。これはrouterを自由浮動する学習済み行列から、expertの幾何学的構造に結合した制約付き推定器へと再定式化するものであり、expertのpruning、merging、upcyclingと生産的に相互作用する可能性の高い方向性です。
Source: https://arxiv.org/abs/2606.12397
スカラー報酬を超えて:推論をスコア分布に内在化する
問題
テキストから画像へのpost-trainingにおけるreward modelは、主観的な視覚的選好を通常スカラーまたはペアワイズlogitに圧縮してしまいます。これにより、重要な2つの構造が過度に圧縮されます:(a) ルーブリックビン間の順序的不確実性(3.5は1.0よりも4.0に近い)、および (b) 境界的なケースを曖昧さなく判断するために人間のアノテーターが使用するルーブリック条件付き推論です。推論ベースの生成的reward modelはこのシグナルの一部を回復しますが、拡散生成器のRL fine-tuningにおいてクエリするコストが高すぎるうえ、直接的な最適化ターゲットとして扱いにくい微分不可能なテキスト出力を生成します。著者らは、(i) 推論を伴うルーブリック整合スコア分布に対してトレーニングされ、(ii) ReFL方式のbackpropagationに適したコンパクトで微分可能なスカラー/分布予測器としてデプロイできるreward modelを目標としています。
アノテーションとルーブリック
アノテーションは4つの次元(テキストと画像の整合性、リアリズム、美観、物理的妥当性)をカバーし、それぞれ9段階の0.5刻みスケール \hat{s}\in\{1.0,1.5,\dots,5.0\} でスコア付けされ、5つのルーブリックビンとビンごとに15〜20個の較正サンプルで固定されます。著者らはコンテキスト不一致問題を指摘しています:文書全体をエンコードするには約 4\times 5\times 15\times 1024 \approx 3.07\times 10^{5} 個の画像トークンが必要であり、これはデプロイ可能なVLMのコンテキストをはるかに超えており、またアノテーターは同一プロンプトの比較を観察しますが、ポイントワイズreward modelはこれを観察しません。このことが、長いin-contextキャリブレーションではなく、スコア分布および同一プロンプトのスコアギャップに対する直接的な監督を動機付けています。
手法
教師VLM q_\theta(s\mid p, I, d, \rho) は推論トレース \rho を生成し、次にルーブリックビン上の分布をQ-Align方式のスコアヘッドでデコードします。デプロイされるスカラーは期待値
\mu_\theta(p, I, d, \rho) = \sum_{s\in\mathcal{S}} s\, q_\theta(s\mid p, I, d, \rho)
です。教師モデル(Qwen3.5-27B)は Group-wise Direct Score Optimization (GDSO) によってトレーニングされます:各選好タプル (p, I_w, I_l, \hat{s}_w, \hat{s}_l, d) に対し、\pi_{\theta_{\text{old}}} から各サイドにつき G 個のロールアウトをサンプリングし、推論 \rho_{j,i}、分布 q_{j,i}、期待スコア \mu_{j,i} にデコードします。目的関数は、(a) グループベースラインに対して \mu_{j,i} から導出された報酬を用いるGRPO方式のpolicy gradient、(b) |\mu_{j,i} - \hat{s}_j| にペナルティを与え q_{j,i} を \hat{s}_j 周りの順序的ソフトラベルに向かわせるポイントワイズ項、(c) スコアギャップ \mu_w - \mu_l が \hat{s}_w - \hat{s}_l を追跡するよう強制するペアワイズ項を組み合わせたものです。ポイントワイズ/ペアワイズlossは信頼スケール \alpha_{\text{pt}}, \alpha_{\text{pw}} で重み付けされた \lambda_{\text{pt}}, \lambda_{\text{pw}} によって調整され、反復スキームは N 回の外部ステップごとに \pi_{\text{ref}} \leftarrow \pi_\theta をリフレッシュします。
学生モデル(Qwen3.5-9B)は推論トレースを省略し、Reasoning-Internalized Score Distillation (RISD) によって q_\phi(s\mid p, I, d) を直接学習します:教師の推論条件付き分布へのKLダイバージェンス、および同一のポイントワイズ/ペアワイズスコア・ギャップlossを使用します。推論時、学生モデルは1回のforward passで分布と微分可能なスカラーを出力します。
結果
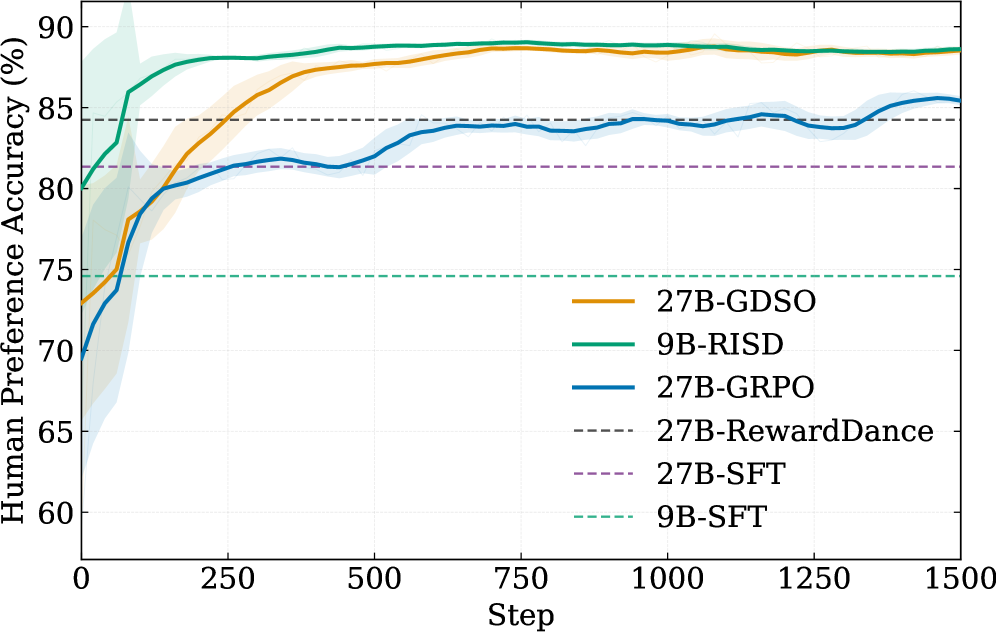
PLCC、SRCC、HPA、マージンHPA(|\hat{s}_a-\hat{s}_b|>0.5 のペア)を用いた保留済み内部テストセットにおける結果:
- 27B教師モデル。 ゼロショットベースライン:PLCC 0.6301、HPA 0.7438。SFT:0.6458 / 0.8135。RewardDance(事後蒸留CoT):0.6667 / 0.8425。平均分布報酬を用いたGRPO:0.7200 / 0.8604。GDSO:PLCC 0.7620、SRCC 0.7132、HPA 0.8956、マージンHPA 0.9885 — ゼロショット比でPLCC +0.1319、HPA +0.1518の向上であり、SFTおよびGRPOアブレーションの両方に対して明確な差を示し、policy gradientだけでなく明示的なポイントワイズ+ペアワイズ分布監督の寄与を切り分けています。
- 9B学生モデル。 ゼロショットは弱い(PLCC 0.3411、HPA 0.6563)。SFTとRewardDanceはPLCC 0.53/0.52に到達。ゼロから学習したGDSO:0.6341 / 0.8395。RISD:PLCC 0.7391、SRCC 0.6882、HPA 0.8864、マージンHPA 0.9801。これはパラメータ数がおよそ 1/3 であり推論時に推論トレースを出力しないにもかかわらず、27B教師モデルの選好精度をほぼ完全に回復しています(HPA:0.8864 対 0.8956)。
RISDの学生モデルは同じラベルでトレーニングされた9B GDSOモデルを明確に上回り(PLCC +0.105、HPA +0.047)、教師の推論条件付き分布が生ラベルからのスカラー+ギャップ監督では回復できない情報を含んでいることの証拠となっています。
微分可能なシグナルとしてのZ-Rewardの使用
学生モデルの期待スコア \mu_\phi(p, I, d) をReFL方式の直接報酬backpropagationループに組み込み、4つの次元にわたって集約します:R(p, I) = \mathcal{A}(\{\mu_\phi(p, I, d)\}_d)。これによって \nabla_\psi R をデノイザーを通じて伝播させます。10k回のイテレーションにわたる検証報酬カーブはすべての4次元(整合性、リアリズム、美観、物理的妥当性)で単調に上昇し、SFTベースラインとの定性的比較では構成上および物理的妥当性のエラーが減少しています。

限界
評価は内部テストセットに限定されており、公開ベンチマークの数値(例:GenAI-Bench、ImageReward、HPDv2)は報告されていないため、既存のreward modelとの絶対的な比較は困難です。分布 q_\theta はペアごとに1つのルーブリック較正スコアとギャップ制約からトレーニングされており、サンプルごとのアノテーター分布からではないため、高次モーメントの較正は暗黙的です。ポイントワイズ/ペアワイズの重み \lambda_{\text{pt}}, \lambda_{\text{pw}}, \alpha_{\text{pt}}, \alpha_{\text{pw}} は本稿中でアブレーションされておらず、4次元の集約 \mathcal{A} はタスク依存のまま残されており、これはT2IにおけるマルチオブジェクティブRLHFの既知の失敗モード(一軸でのreward hacking)です。RISDはまた教師の推論条件付き分布が適切に較正されていることを前提としており、教師のエラーは継承されます。
なぜこれが重要か
報酬をスカラーではなくルーブリック整合分布として扱うことで、拡散モデルのfine-tuningに対してより密なトレーニングターゲット(順序的ソフトラベル+ギャップ制約)とより密な最適化シグナル(ビン上の微分可能な期待値)の両方が得られます。同時に、推論をコンパクトなポイントワイズモデルに蒸留することで、CoT型の報酬判定器のデプロイコストが排除されます。27Bの推論教師モデルと同等の選好精度を達成した9B RISDの結果は、視覚的reward modelにおける適切な役割分担が「推論を推論時に用いる」ことではなく「推論をトレーニングシグナルとして用いる」ことであることを示唆しています。
Source: https://arxiv.org/abs/2606.09076
サブ二次アーキテクチャについて:応用から原理へ
問題設定
線形 attention スタイルのシーケンス演算子(Mamba-2、Gated DeltaNet、xLSTM)はいずれも有界な状態で \mathcal{O}(T) の推論を実現することを謳っていますが、タスクが非自明な状態追跡や累積構造を持つ場合にどの設計選択が実際に重要であるかについての統制された比較が、この分野には欠けています。本論文は二つのことを行います:(1) コード事前学習、コード蒸留、時系列基盤モデル(TSFM)事前学習において、一致したレシピのもとで三つの演算子をベンチマークする;(2) それらを gated-linear-attention の記法のもとで統一し、観察されたギャップの原因となるゲート機構を特定する。
統一的な定式化
三つのモデルはいずれも行列状態 \bm{C}_t \in \mathbb{R}^{D_{qk}\times D_v} 上の以下の形式の漸化式です:
\bm{C}_t = \bm{G}_t \,\bm{C}_{t-1} + \bm{k}_t \otimes \bm{v}_t, \qquad \bm{h}_t = \bm{q}_t \bm{C}_t,
状態遷移 \bm{G}_t の構造において異なります:
- Mamba-2:スカラー(または対角)減衰 \bm{G}_t = \alpha_t \bm{I}、\alpha_t \in (0,1)。
- Gated DeltaNet:ランク1の Householder スタイル補正 \bm{G}_t = \alpha_t(\bm{I} - \beta_t \bm{k}_t \bm{k}_t^\top)、固有値は [0,1](Grazzi et al. のパラメータ化では [-1,1])に制約。
- xLSTM(mLSTM):独立した入力ゲート i_t と忘却ゲート f_t が状態に乗算される形式 \bm{C}_t = f_t \bm{C}_{t-1} + i_t\,\bm{k}_t\otimes \bm{v}_t。両ゲートは符号関係に制約がなく、書き込みの大きさを減衰とは独立に変調できます。
著者らはハードウェア効率の良い学習のためにチャンクワイズ形式
\bm{H}_{[n]} = (\bm{Q}_{[n]}\bm{K}_{[n]}^\top \odot \bm{M})\bm{V}_{[n]} + \bm{Q}_{[n]}\bm{C}_{(n-1)C}
を使用しており、これは全演算子で同一であるため、品質のギャップはゲート機構に起因するものであり、カーネルには起因しません。
実験的なパターン
ベンチマークでは400Mパラメータの層間ハイブリッドを使用しています:全24層のうち3層がsoftmax-attention(xLSTM[7:1] = non-attention バジェット内で 6 mLSTM + 1 attention + 1 sLSTM スタイルの再帰)であり、Nemotron-CC-Code-v1 で20Bおよび100Bトークンで学習し、さらに Nemotron-CC-Code と FineWeb-Edu の混合データでも学習しています。
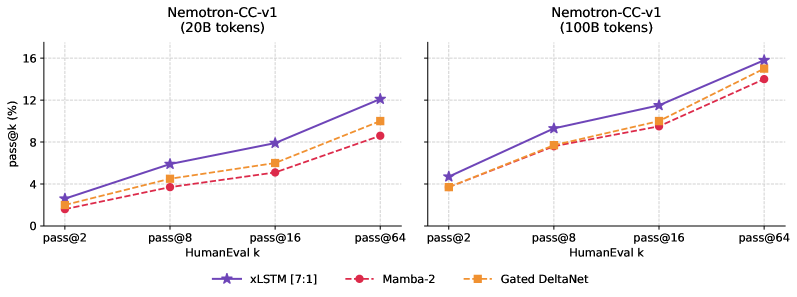
xLSTM ハイブリッドは、両方のデータスケールにわたって k\in\{2,8,16,64\} の HumanEval pass@k でリードしており、最も大きなギャップは20Bトークン時に見られます;100Bトークン時にはギャップは縮まりますが、順位は保たれます。推論・常識問題(HellaSwag、PIQA、ARC-E/C、WinoGrande)でも同じ方向の結果が示されますが、マージンは小さく、これらのベンチマークが長距離状態に対してそれほど感度が高くないことと整合しています。
TSFM の事前学習については、著者らは5つのパラメータスケールを探索し、GIFT-Eval 上でMASEとCRPSを報告しています。
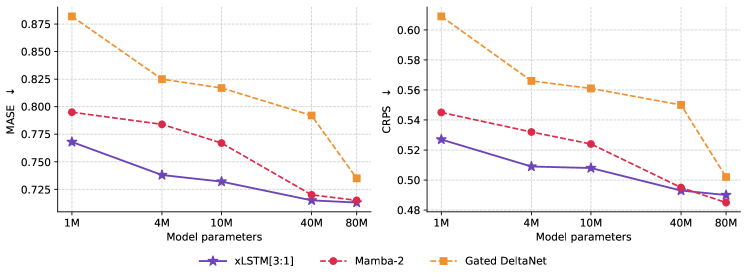
xLSTM は両指標において全スケールでパレート最適であり、パラメータが増えるにつれてギャップは縮まりますが逆転しません。同じ順位関係はコード蒸留実験(Section 2.2)においても再現されます。
合成的な状態追跡診断
メカニズムを特定するために、著者らは長さ128で学習し、A^nB^n、A^nB^nC^n、Majority、Parity、\mathbb{Z}_5 モジュラー算術、および S_3 の語問題において長さ512および2048(4\times および 16\times)に外挿します。
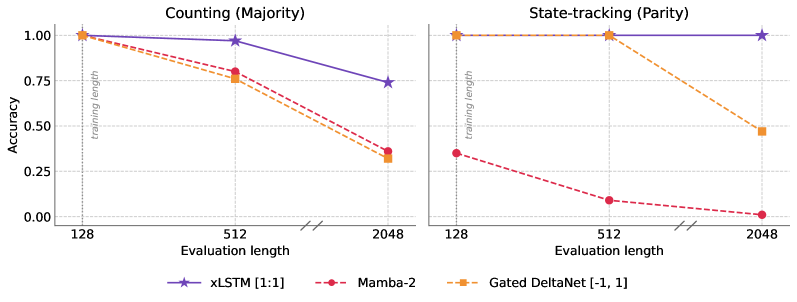
Figure 4 の具体的な数値:
- xLSTM[1:1] は両タスクで長さ汎化できる唯一の設定であり、全長において最高のMajority精度を持ち、2048まで完全なParity精度を達成しています。
- 標準的な非負固有値パラメータ化の Gated DeltaNet はparityを全く表現できません。
- Gated DeltaNet_{[-1,1]}(Grazzi et al., 2025)は分布内ではparityを解くものの、長さ2048では 0.47(チャンスレベル)まで劣化し、負の固有値拡張が表現可能性は修正するが安定性は修正しないことを示しています。
- Mamba-2は評価されたいかなる長さでもいずれのタスクも解くことができません。
解釈:Mamba-2のスカラー減衰はチャンネルごとの書き込み/消去を実行できません;Gated DeltaNet のランク1補正はキーに整合した上書きを実行しますが、制約された固有値が [0,1] ではparity不可能にし、[-1,1] ではparityを許容するが長いシーケンスで数値的なドリフトが蓄積します;xLSTM の独立した入力/忘却ゲートとスタビライザー・ノーマライザーのペアが 16\times 外挿を生き延びる有界かつ符号フレキシブルな累積を実現します。
限界
ハイブリッドは三つの softmax-attention 層を保持しているため、再帰演算子への帰属は部分的なものとなっています――softmax 層が再帰の弱点をマスクする可能性があります。400M スケールでは $$10B パラメータ時に順位が保たれるかどうかは未解決です;Figure 2 における100Bトークン時のギャップの縮小は、データが帰納的バイアスを部分的に代替し得ることを示唆しています。合成タスクは二つの軸(累積、parity スタイルの状態)を分離していますが、DeltaNet 系が通常強い連想想起やコピーについては評価していません。実時間やメモリの比較は報告されておらず、xLSTM のゲート機構(二つの追加スカラーゲートと指数スタビライザー機構)のスループットコストは定量化されていません。
なぜ重要か
これは、コードや時系列における下流の性能向上を、アーキテクチャのブランディングではなく、測定可能な特性――有界かつ符号フレキシブルな状態補正――に結びつける、明確な統制比較です。サブ二次演算子の設計者への示唆は具体的です:状態遷移 \bm{G}_t における固有値スペクトルと書き込み/消去チャンネルの独立性がレバーであり、それらを [0,1] やスカラー減衰に制約することは実質的な容量損失であり、事前学習 loss が気づくはるか前に合成 parity タスクによって可視化されます。
Source: https://arxiv.org/abs/2606.12364
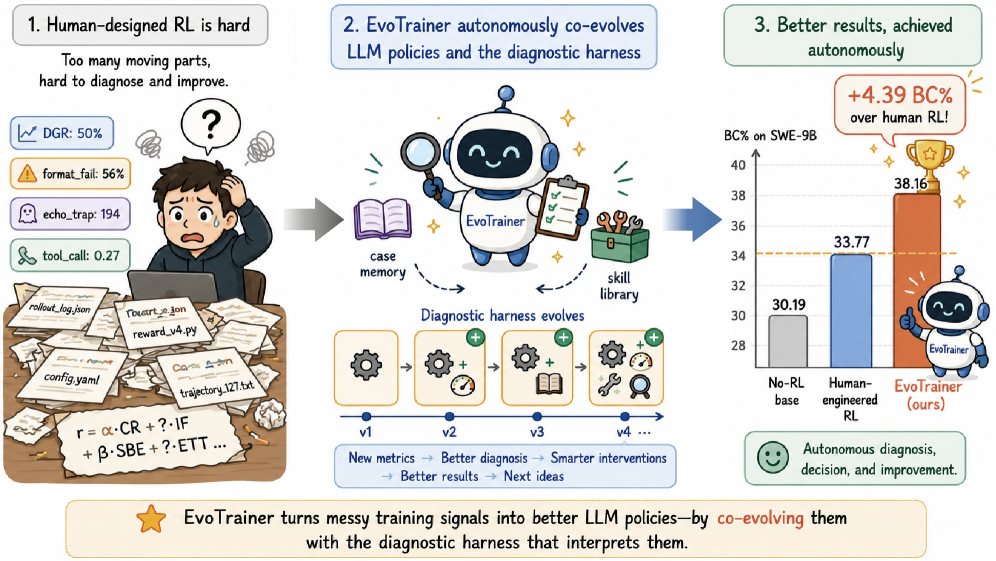
EvoTrainer: 自律的エージェント強化学習のためのLLMポリシーと訓練ハーネスの共進化
問題設定
自律的なLLM訓練システムは通常、探索をレシピ最適化として定式化します。コントローラがハイパーパラメータ、データミックス、あるいは報酬のバリアントを提案し、各実行を解釈する診断・評価パイプラインである訓練ハーネスは固定されたままです。エージェント型RLにおいて、これは重大な制限となります。長期的なトラジェクトリ(ツール使用、マルチステップのSWE編集)は、異なる失敗モードを混同してしまうようなスパースなスカラー報酬へと折りたたまれてしまいます。報酬をハッキングするエージェント、トラジェクトリの途中でクラッシュするエージェント、問題をクリーンに解決するエージェントは、静的なハーネスにとってはすべて区別不可能になる可能性があります。EvoTrainerの主張は、ハーネス自体もポリシーと同期して進化しなければならないというものです。そうでなければコントローラは、スコアを向上させるが病的なバージョンを昇格させてしまうからです。
手法
EvoTrainerは、自律的な訓練を、状態上における証拠条件付きのバージョン遷移の系列として定式化します。
\mathcal{T}_i = (v_i, h_i, \mathcal{A}_i, d_i, \Delta_i, \omega_i),
ここで、v_iはポリシーバージョン、h_iは現在の診断ハーネス、\mathcal{A}_i = \{\text{metrics}, \text{rollouts}, \text{configs}, \text{logs}, \text{diffs}\}は実行アーティファクト、d_iはハーネスが生成した診断、\Delta_iは提案された介入、\omega_i \in \{\text{improve}, \text{regress}, \text{mixed}, \text{insufficient}\}はラベル付けされた結果を表します。重要なのは、4値の結果空間により、実行を二値のkeep/rejectに還元することを防いでいる点です。脆弱な報酬を持つスコア向上バージョンや、有害な介入を露わにした退行ブランチは、それぞれ異なる証拠タイプとして保持されます。
アーキテクチャ(図2)は3つの結合ループで構成されています。
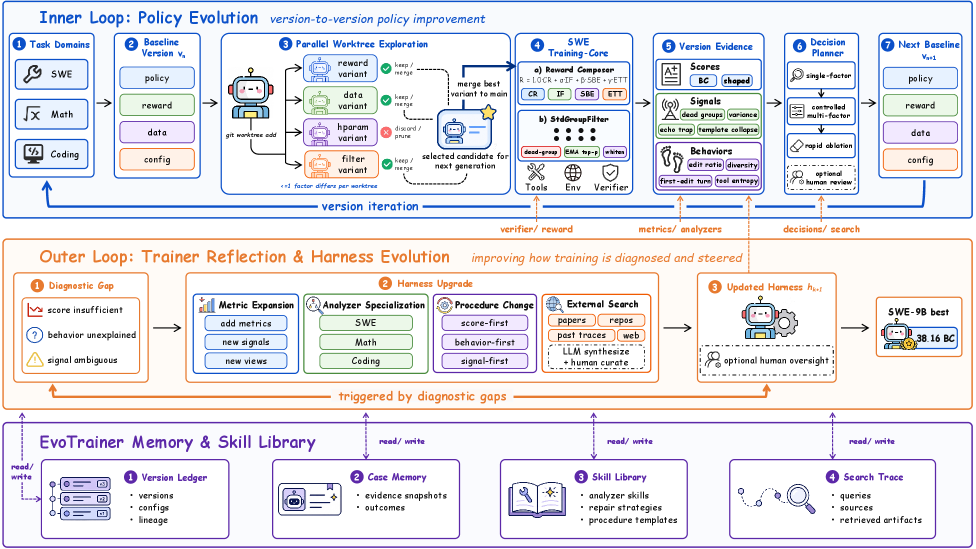
- ポリシー自己進化(上部ループ): 制御された探索が、介入\Delta_i(報酬シェーピング、カリキュラム変更、スキャフォールド編集)を通じてv_iからv_{i+1}を生成します。各候補が訓練・ロールアウトされ、アーティファクトがh_iに渡されて診断が行われます。
- ハーネス進化(中部ループ): 現在の診断が\omega_iクラス間を識別できない場合、たとえば高報酬のロールアウトが後にテストスキャフォールドを悪用していたことが判明した場合などに、診断コード自体が修正されます。修正された診断はアーティファクトアーカイブ\{\mathcal{A}_j\}_{j \le i}に対してバックテストされます。つまり、新しい診断は採用される前に、既知の良好・不良ラベルを遡及的に回復しなければなりません。
- 永続的メモリ(下部レイヤー): 成功した介入は、失敗モードのシグネチャをキーとする再利用可能なスキルとして抽象化されます。これにより、後続の探索がゼロから再開するのではなく、過去の証拠に条件付けた提案を行えるようになります。
図2の「training-core」パネルは、Dockerサンドボックス内のエージェント–ツールトラジェクトリを隠されたfail-to-passテストでスコアリングするSWEに対してこれを具体化しています。
結果
3つの評価ドメインは、単一ターンの検証可能タスクから長期的なエージェント的インタラクションまでをカバーしています。
- 数学: 6,429件のBigMath-Hardの問題で訓練(AIME 2024 P5との重複を除去)し、Avg@8のもと78問題(AIME 2024、AIME 2025、CNMO 2024)で評価。
- コーディング: 11,897件のTACO検証済み問題で訓練し、汚染を避けるために以前に公開されたアイテムを除外したLiveCodeBench-v6のAtCoder Beginner Contest 175問題で評価。これによりOODプロトコルを実現。
- SWE: 8,622件のswe-rebench-v6インスタンスで訓練し、凍結されたツールスキャフォールドと隠されたfail-to-passテストを使用して77件のホールドアウトPythonインスタンスで評価。バグカバレッジパーセント(BC%)を指標として使用。
最も注目される数値は長期的なエージェント型SWEにおけるもので、EvoTrainerはSWE-9BにおいてヒューマンエンジニアリングされたRLベースラインを+4.39 BC%上回ります(図1)。
昇格パス上のバージョンごとのトラジェクトリ(図3)は、ドメイン間で質的に異なる探索ダイナミクスを示しています。SWE-9BとSWE-4Bは、最終的に保持されたバージョンに至るまでいくつかの非単調な落ち込みを示しており、これはハーネスが初期のスコア向上が無効なトラジェクトリに起因するブランチを棄却していることと一致します。数学とコーディングのトラジェクトリはより滑らかであり、単一ターンの検証可能な報酬がすでに静的ハーネスに必要なシグナルのほとんどを提供していることを示唆しています。
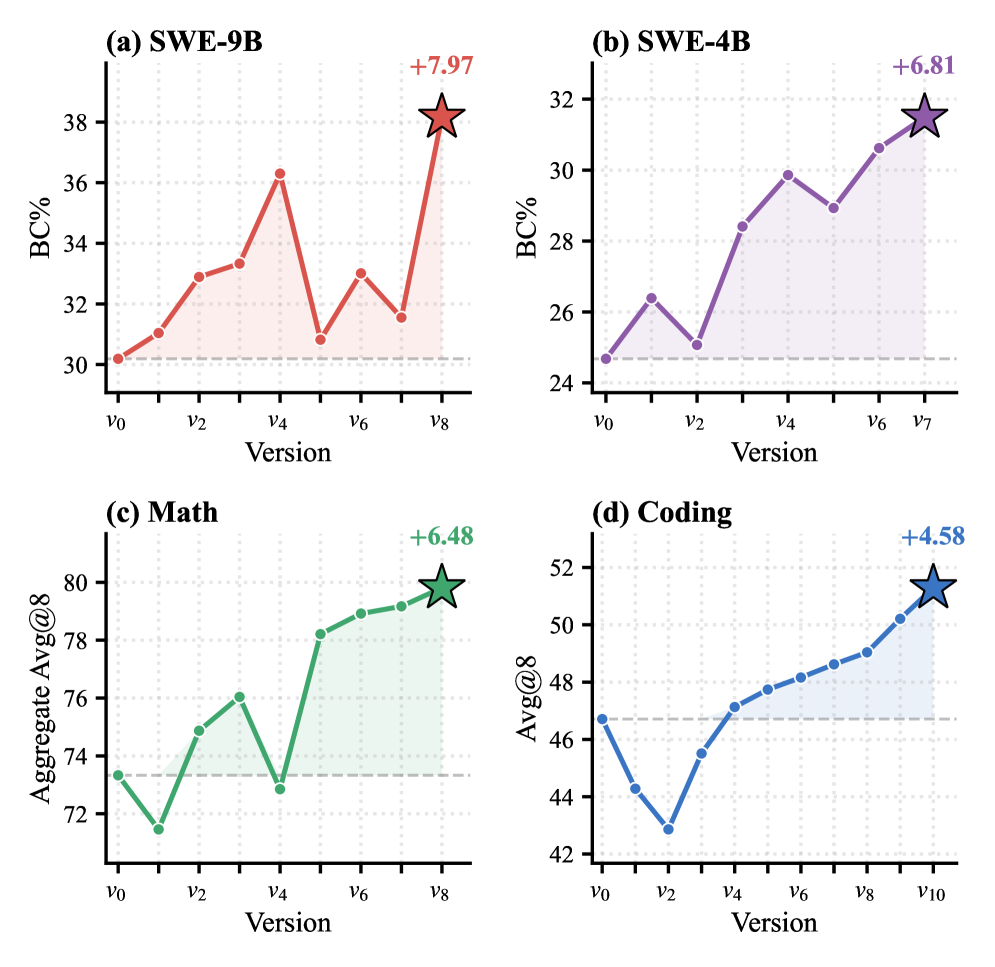
トラジェクトリ分析では、著者が強調する2つの定性的知見も報告されています。(i) 保持された戦略はドメイン間で分岐します。つまり、スキルライブラリはドメイン汎用ではなく特化していきます。(ii) 進化する診断は、無効な高スコアブランチが昇格するのを実証的に防いでおり、これがハーネス共進化の中心的な正当化根拠となっています。
限界と未解決問題
本論文は条件ごとに自律的トラジェクトリを単一シードで報告しているため、コントローラの確率的探索に対する分散は定量化されていません。図3がバージョンごとの非単調曲線を示していることを考えると、最終保持バージョンにおける実行間の分散は重大である可能性があります。SWE-9Bにおける+4.39 BC%の向上は最大の改善であり、見出しとなる結果ですが、数学とコーディングにおける絶対的な差は提供されたセクションには記載されていません。ハーネス進化メカニズムはアーティファクトアーカイブに対するバックテストに依存しており、新しい診断を過去のラベルとの一貫性に向けてバイアスさせます。これが真に新規な失敗モードを抑制するような保守性をもたらすかどうかは未解決問題です。最後に、コントローラと診断ハーネス自体がLLM駆動であり、固定ハーネスのレシピ探索と比較した共進化のコストは、抜粋されたセクションでは特徴付けられていません。
重要性
ほとんどの自律RLコントローラは訓練ハーネスをグラウンドトゥルースとして扱い、レシピのみを探索します。これはまさに、報酬ハッキングやサイレントなエージェント失敗が最も検出しにくいレジームです。EvoTrainerの証拠によれば、診断レイヤーの共進化が最も重要となるのは長期的なSWEにおいてであり、単一ターンの検証可能タスクでは最も重要性が低いことがわかります。これは、ハーネスの脆弱性が実際に問題となる場所を示す有用な実証的マップです。
Source: https://arxiv.org/abs/2606.03108
Embodied-R1.5: Embodied Foundation Modelsによる物理的知性の進化
Embodied-R1.5は、Qwen3-VL-8B-Instructをベースに構築された80億パラメータのEmbodied Foundation Model(EFM)であり、従来は独立していた3つの能力ファミリー — 空間認知、タスク計画・修正、ポインティング・軌跡グラウンディング — を単一の自己回帰ポリシーに統合しています。その動機は明快です。VLMプランナー+グラウンディングモデル+エラー検出器のカスケードスタックは、各インターフェースで情報を失い、マルチエージェントのオーケストレーションを必要とします。単一のモデルが3つの役割を担えば、修正器はプランナーの推論コンテキストとグラウンダーの空間状態を直接参照でき、システムの性能は基盤モデルの規模に応じて単調に向上します。
能力の分類とアーキテクチャ
著者らはEFM問題を、知覚→判断→実行のチェーンとして配置された3つの次元に分解しています(図2参照)。
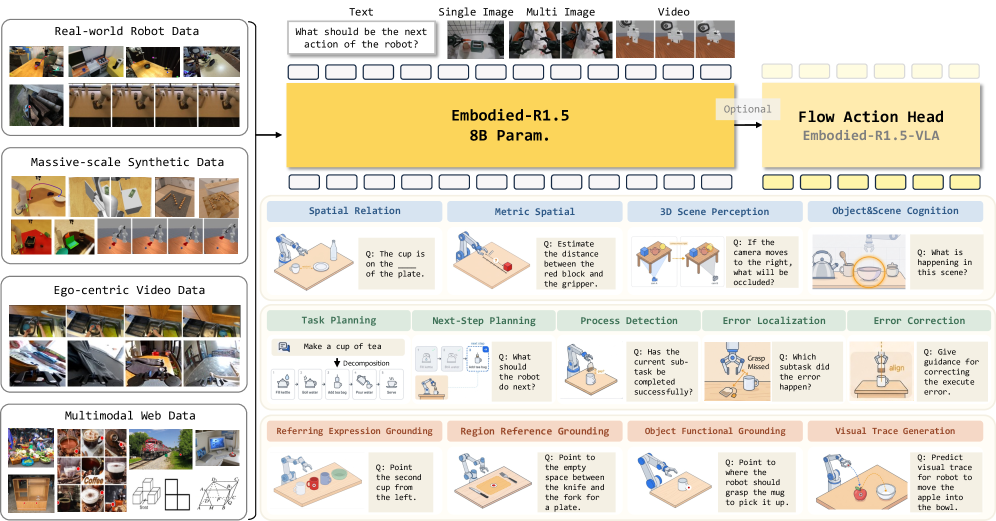
- 認知・空間推論:空間関係、メトリック推論(距離、空き空間のサイズ推定)、単眼深度とクロスビュージオメトリ、ロボット中心のシーン認知。
- 計画・修正:長期的な分解、次ステップのロールアウト、3段階のエラーチェーン(検出→局在化→修正)。
- ポインティング・位置特定:2Dポインティング、物体機能部位グラウンディング(OFG)、視覚軌跡グラウンディング(VTG)。
自然言語、点座標、軌跡トークン列を含むすべての出力は、単一の因果 LM 目標のもとでトークンとして生成されます。軽量なflow-matchingアクションエキスパートを付加することで、本モデルはVLAへ拡張できます。
データ:3つの自動化パイプライン、〜150億トークン
学習コーパスは34のデータセットを集約し、文書化されたカバレッジのギャップを補うための3つの独自パイプラインで補強されています。
- パイプライン1 — ER1.5-Spatial(〜20Kサンプル):Fractal/BridgeData V2/DROIDのRGBフレームから再構成した3Dセマンティックシーングラフ。このパイプラインはMoGe-2メトリック単眼ジオメトリ、Grounded-SAMオープン語彙セグメンテーション、RANSACグラウンドプレーンアライメントを連結し、空間QAをプログラム的に合成します。VLM-3RやCambrian-Sのような部屋スケールのデータセットでは補えないテーブルトップ操作のギャップを解消します。
- パイプライン2 — ER1.5-Correction(〜80万サンプル):2つの軸(計画失敗 vs. 実行失敗 × 検出/局在化/修正)に沿った失敗アノテーションで、6種類のQAタイプを生成します。計画失敗には5つの摂動演算子(省略、冗長、入れ替え、物体誤り、行動置換)を使用し、実行失敗にはManiSkill/GEMBenchにおけるビデオ切り捨て、説明置換、物理エンジン摂動を組み合わせます。
- パイプライン3 — Affordance and Trajectory:ポインティングとVTGを対象とします。
学習
ステージ1は、統合された150億トークンのコーパスに対する1エポックの全パラメータSFTです。AdamW、bf16、コサイン減衰と10%ウォームアップによるピーク学習率 2\times10^{-6}、グローバルバッチサイズ512、コンテキスト長8192トークン。具身化された視覚分布がウェブ事前学習から大きく乖離しているため、ビジョンエンコーダはフリーズせずに学習します。
ステージ2は検証可能な報酬を用いたRFTであり、ポインティングのIoU報酬と修正テキスト報酬のような異種タスク間のgradient競合を軽減するため、マルチタスクバランシングレシピを採用しています。ポインティングはRLから最も恩恵を受けますが、その報酬が座標に対する幾何学的メトリックにより密に検証可能であるためです。
PGCクローズドループ自律制御
単一のEmbodied-R1.5インスタンスが、プランナー、グラウンダー、修正器という3つの役割のもとで呼び出され、FIFOの画像・ステータスメモリバッファを共有します(図3)。
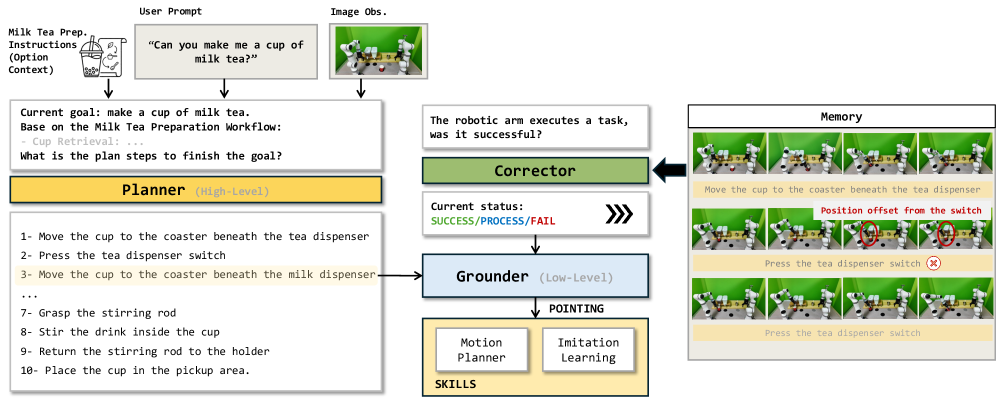
プランナーは指示を分解し、各サブタスク完了後に再計画を行います。グラウンダーはポインティングプリミティブを適応的に組み合わせます(例:スイッチの位置特定にOFGを使用し、押下軌跡にVTGを使用)。修正器は非同期クエリとして実行され、{SUCCESS, PROCESS, FAIL}を返し、失敗時に再計画をトリガーします。重要なのは、ハーネスにヒューリスティックなロジックが一切含まれておらず、すべての判断が共有モデルから生成されるため、エラー帰属がシリアライゼーションの損失なくプランナーの推論とグラウンダーのジオメトリの両方を参照できる点です。
定量的結果
Embodied Planning & Correction(表1、4つのベンチマーク)において:
- Embodied-R1.5の平均スコアは65.3であり、GPT-5.4の53.8、Mimo-Embodiedの54.1、Qwen3-VL-8Bの54.2、Gemini-Robotics-ER-1.5の41.3を上回ります。
- ベンチマーク別:RoboVQA 61.0、EgoPlan-2 53.8、Cosmos-Reason 69.3、RoboFAC 77.2(後者はGPT-5.4の70.1に対して+7の絶対値向上)。
24ベンチマークからなる完全なembodied VLMスイート全体では、16/24ベンチマークでSOTAを報告しています。操作ベンチマークスイートでは、EFMを小規模なアクションエキスパートヘッド付きのVLAへfine-tuningすることで、4つの操作スイートにおいて \pi_{0.5} を上回りました。注目すべき点は、内在化された具身化推論がVLA蒸留に必要なアクションデータ量を削減するということです。ゼロショット実機ロボット実験では、PGCのもとでの命令追従、道具アフォーダンス、長期的操作をカバーしています。
著者らはまた、EmbodiedEvalKitもリリースしています。これは4層の評価フレームワーク(データ、推論、パーシング、評価)であり、25以上のベンチマークと20以上のモデルにわたって座標規則(1000正規化、絶対ピクセルなど)を正規化します。これは、従来の具身化研究がアドホックなパーサーや非重複サブセットを使用していたことによる再現性の問題を解決します。
限界と未解決の問題
- PGCメモリモジュールは固定レートのFIFOバッファであり、より長期的なタスクには階層型または検索ベースのメモリが必要になる可能性があると著者らも認めています。
- 修正器の非同期クエリ頻度と低レベルコントローラのレートとの関係は明確にされておらず、実際の展開におけるレイテンシと精度のトレードオフは未解決のままです。
- マルチタスクRL競合については言及されていますが、バランシングレシピの詳細は付録に委ねられており、RFTフェーズの再現性はその詳細に依存します。
- \pi_{0.5} とのVLA fine-tuning比較では「少量のデータ」が使用されていますが、正確なデータスケーリング曲線があれば、どの程度の利得がEFM事前知識によるものか、データセットの重複によるものかを明確にできます。
- すべてのグラウンディングは2Dピクセル空間であり、深度・3D学習データを使用しているにもかかわらず、実行可能な出力は点と2Dトレースにとどまり、直接的な3Dポインティングが精密操作の精度向上に寄与するかどうかは未解決です。
なぜこれが重要か
プランナー、グラウンダー、修正器の役割を包含し、大多数のembodiedベンチマークでGPT-5.4とGemini-Robotics-ER-1.5を上回りながら、強力なVLA初期化としても機能する単一の80億パラメータモデルは、マルチエージェントカスケードではなく能力の統合こそが具身化知性のスケーリングにおける正しい方向性であることを示す具体的な証拠です。付随するEmbodiedEvalKitと失敗認識型修正データパイプラインは、この分野が欠いていた再利用可能なインフラストラクチャです。
Source: https://arxiv.org/abs/2606.11324
仮説ツリーの精緻化による汎用的自律研究に向けて
自律的最適化(Autonomous Optimization; AO)とは、エージェントがステップレベルの人間監督なしに研究成果物を反復的に編集し、ホールドアウトされたメトリクスを改善させる枠組みですが、標準的なエージェントループの弱点を露わにします。すなわち、一時的な試行が累積的な知識へと統合されないという問題です。本論文では、永続的な仮説ツリー(Hypothesis Tree)を中心的な状態として持つコーディネーター・エグゼキューター型フレームワーク「Arbor」を紹介します。この状態は、著者らが仮説ツリー精緻化(Hypothesis Tree Refinement; HTR)と呼ぶ手続きによって精緻化されます。
問題設定
著者らはAOをタプル \mathcal{P}=(\mathcal{M}_0,\mathcal{O},\mathcal{E}_{\mathrm{dev}},\mathcal{E}_{\mathrm{test}}) として定式化します。ここで \mathcal{M}_0 は変更可能な成果物(典型的にはコードベースとデータ)、\mathcal{O} はメトリクスの方向性を指定し、2つの評価器はそのObjectiveを異なるエビデンス上でインスタンス化します。エージェントは探索中に \mathcal{E}_{\mathrm{dev}} を自由に参照できますが、\mathcal{E}_{\mathrm{test}} をオラクルとして使用することはできません。成果物レベルの目標は
\mathcal{M}^{\star}=\arg\max_{\mathcal{M}'\in\mathcal{A}} S_{\mathrm{test}}(\mathcal{M}'),
と表されます。ここで \mathcal{A} はdevフィードバックのみを用いてエージェントが生成した候補の集合です。この分離は重要です。\mathcal{E}_{\mathrm{dev}} の特性に過学習した候補はAOの解とは見なされません。また、これは設計上の問題を再定式化します。すなわち、ノイズの多い代理指標上での探索をいかに配分しながら、転移した変更のみを受理するかという問いです。
Arborの3つの設計要件
Arborは、著者らがいかなるAOシステムも満たすべきと主張する3つの制約を基盤として構築されています。
- 整合性を伴う分岐(Branching with coherence)。 複数の妥当な仮説が非構造的なログとしてではなく、フロンティアとして共存しなければなりません。
- 局所的実行を伴うグローバル戦略(Global strategy with local execution)。 戦略的決定は複数実行をまたいだエビデンスに依存しますが、実装には短いホライズンのコード編集とデバッグが必要です。これらは分離されるべきです。
- ホールドアウト受理を伴う探索(Exploration with held-out admission)。 Devフィードバックが探索を駆動しますが、成果物の昇格には \mathcal{E}_{\mathrm{test}} への転移が必要です。
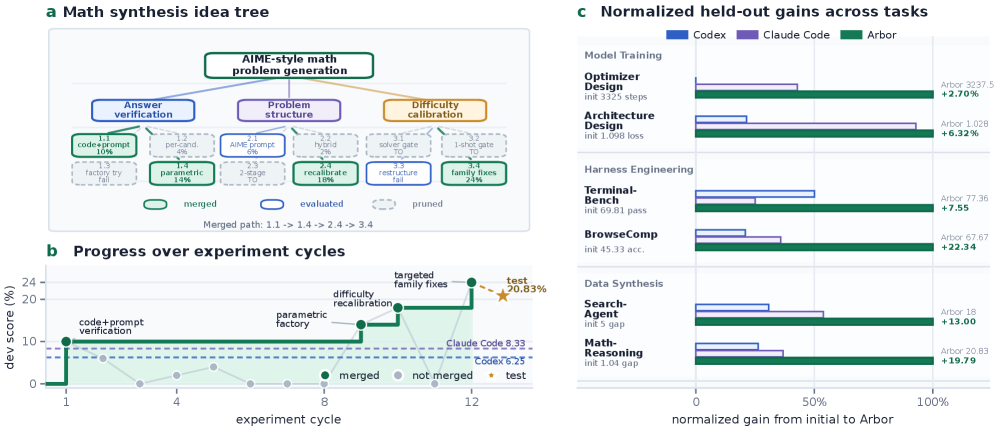
手法:HTR
永続的な状態は、4つのオブジェクトを結びつけるノードからなるツリーです。具体的には、仮説(提案された変更の自然言語による記述)、それを実現する成果物のバージョン(コードのworktree)、評価エビデンス(\mathcal{E}_{\mathrm{dev}} からのスコアとログ)、そして将来の決定に影響を与えるべき蒸留されたインサイトです。長命なコーディネーターがこのツリーをグローバルに所有します。コーディネーターはフロンティアを検査し、精緻化を提案し、有望なリーフを選択し、返されたエビデンスを統合し、インサイトを上方に伝播させ(これにより、ある兄弟ブランチが別の場所で発見された失敗モードから恩恵を受けられます)、ブランチを継続・剪定・統合するかを決定します。
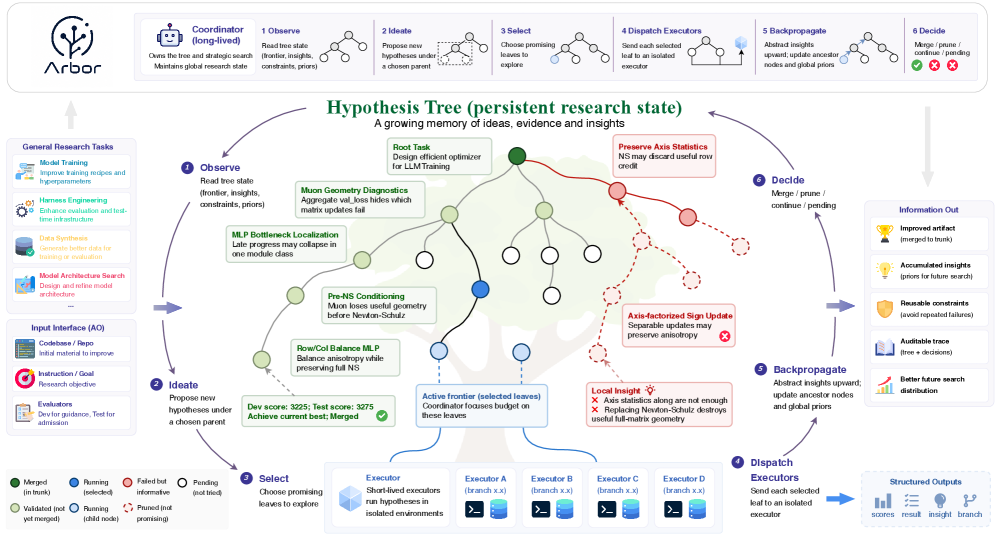
短命なエグゼキューターは、隔離されたworktree内で選択された仮説をテストし、スカラースコア、事実的な結果、蒸留されたインサイト、および成果物への参照といったコンパクトなレポートをコーディネーターに返します。重要な点は、低レベルの実行トレース(コンパイラエラー、デバッグの試み、評価器のstderr)はエグゼキューター内に留まり、コーディネーターのコンテキストを汚染しないことです。これにより、結果から仮説への帰属が保たれます。
ホールドアウトマージゲートは、devドリブンの探索と稼働中の「最良成果物」の間に位置します。候補はdevでの改善が \mathcal{E}_{\mathrm{test}} 上でも転移した場合にのみ昇格されます。これがArborが探索的進歩と検証済みの進歩を区別するメカニズムであり、上記のAO目標の操作的なアナログです。
タスクと結果
AOスイートは既存のベンチマークを基に構築されたモデル訓練タスクを含みます。オプティマイザー設計タスクはNanoGPT-Benchを使用し、公式のチューニング済みMuonオプティマイザーを \mathcal{M}_0 とします。devの評価器は標準ベンチマークであり、testの評価器はエージェントのオプティマイザーを2つのホールドアウトシードで再実行し、目標とする検証lossに達するまでの平均ステップ数を報告します。アーキテクチャ設計タスクはKarpathyのautoresearchベンチマークを使用し、エージェントは固定された時間バジェット内でLLM訓練コードベースを修正し、同様に2つのホールドアウトシードで平均化されます。
Figure 1(c)はすべてのタスクにわたる正規化されたホールドアウト改善量を報告し、Figure 1(b)はMath-Reasoning Data Synthesisの実行におけるdevスコアの推移を示しており、HTRが目指す累積的なパターンを実証しています。すなわち、改善はi.i.d.のランダムな改善としてではなく、インサイトの伝播に結びついたクラスターとして現れています。
本論文はさらに2つの汎用性の形式を評価しています(Figure 3)。(a) コントローラー、評価器バジェット、タスクアダプターを固定したまま LLM バックボーンを交換する場合、および (b) BrowseComp上で発展させた検索ハーネスをフリーズし、それをタスク固有のさらなるチューニングなしにホールドアウト検索エージェントタスクに適用する場合です。いずれも、Arborが生成する成果物がバックボーンではなくハーネスの特性であるかどうかを検証します。
制限事項と未解決の問い
提供されているセクションはAOの設定とフレームワークを記述していますが、メカニズムのレベルでいくつかの問いを未解決のまま残しています。マージゲートの統計的な信頼性は \mathcal{E}_{\mathrm{test}} の分散に依存しており、わずか2シードの平均化(NanoGPTおよびautoresearchタスクのように)は転移テストとしては弱いものです。インサイト伝播ステップはHTRの根幹をなす要素ですが、その正確な表現、兄弟インサイト間の矛盾の解決方法、および陳腐化したインサイトの廃棄方法は抜粋中では仕様が示されていません。計算量の計上(コーディネーターの決定ごとのエグゼキューター実行回数、タスクあたりの合計wall-clock時間)も、このアプローチをより単純なバンディット型や進化的ベースラインと正面から比較するために必要です。最後に、このフレームワークは安価で実行可能な \mathcal{E}_{\mathrm{dev}} を前提としており、評価に人間の判断や長い訓練ランを要するタスクではエグゼキューターバジェットの仮定にストレスがかかります。
なぜこれが重要か
AOは「エージェントがホールドアウトメトリクスのもとで研究成果物を改善する」ことを十分に明確に定式化し、システム間の比較を可能にします。そしてArborは正しい軸を単離しています。すなわち、明示的なインサイト伝播を伴う耐久性のある構造化された研究状態です。これは自律研究を単に長いエージェントループとして扱うのではありません。HTR式の累積状態が転移検証済みメトリクスにおいてフラットな試行錯誤を真に上回るならば、それはエージェント的研究をプロンプトエンジニアリングから探索プロセス設計へとシフトさせるものです。
Source: https://arxiv.org/abs/2606.11926
DeNovoSWE: スクラッチからリポジトリ全体を生成するための長期ホライゾン環境のスケーリング
問題
ほとんどのコードエージェント学習データは、局所的なissue解決を対象としています。SWE-Benchスタイルのインスタンスは、既存のリポジトリ内の少数のファイルを既存のテストに対して修正するものです。次のレジーム — 仕様からリポジトリ全体を合成すること — は、検証可能かつ実行可能なリポジトリスケールの生成タスクが乏しいため、ほとんど監督されていません。このようなデータを手動で作成することは現実的ではありません。各インスタンスには、(i) 実装を完全に制約するのに十分な情報を持つドキュメントのアーティファクト、(ii) 仕様を実際にテストするテストスイート、(iii) エージェントが生成したリポジトリをエンドツーエンドでビルド・評価できるサンドボックス環境、が必要です。DeNovoSWEは、この課題に対して自動化されたパイプラインで取り組み、4,818件のdoc-to-repoインスタンスを生成し、それらを使ってエージェントをBeyondSWE-Doc2Repoで5.8%から47.2%へと向上させます。
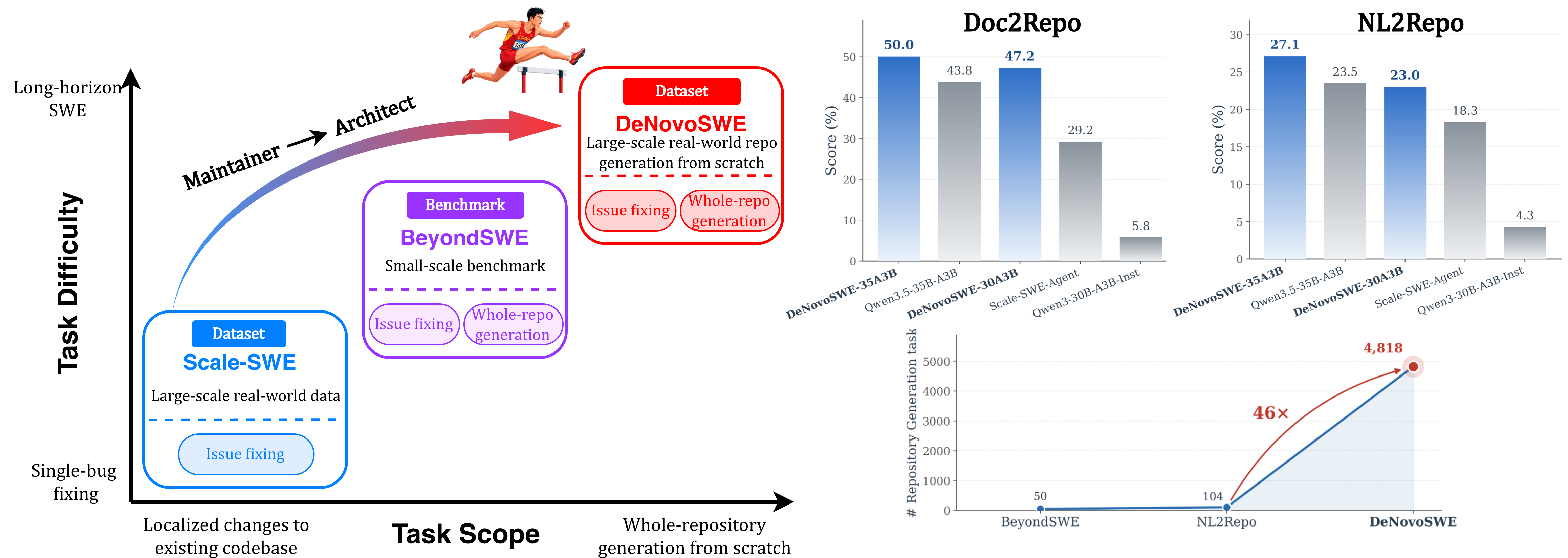
手法
構築パイプラインはdoc-to-repoタスクを逆転させます。合格するテストスイートを持つ実際のリポジトリから出発し、エージェントがそのドキュメントだけを読んで、同じテストを通過する実装を再構築できるほど豊富なドキュメントを生成します。システムは反復的なcritic-repairループを伴う分割統治スキーマに従います。
分割フェーズ。 各ソースリポジトリに対して2つの並行トラックが動作します:
- リポジトリ能力のパーティショニング。 overview-writerエージェントがグローバルなサマリーを生成し、capability-writerエージェントがリポジトリを機能的な能力にセグメント化して、各能力に実装ユニット(モジュール、クラス、関数、パブリックAPI)を割り当てます。各能力は最終ドキュメントの1つの章になります。
- リポジトリプロファイリング。 ユニットテストスイートが実行され、ランタイムトレースが収集されます。関数・クラスはdirect(テストファイルからインポート、インスタンス化、または呼び出されるもの)、core indirect、non-core indirectに分類されます。直接コンポーネントは完全なインポートパス、パブリックAPIシグネチャ、I/O動作を含めて文書化する必要があります。これらを不十分に仕様化すると、生成されたリポジトリがテスト不能になるためです。
LLM-as-judgeが能力マップとプロファイリング出力を整合させ、能力レベルのターゲットを生成します。
統治フェーズ。 各能力に対して、Draft → Critic → Repairループがドキュメントを生成します。criticは省略箇所(APIサーフェスの欠落、依存関係コントラクトの欠落、曖昧な動作)を特定し、repairエージェントが修正します。出力はマージされ、ゴールデン環境 — 正確な依存関係がプリインストールされ、ネットワークが制限されたサンドボックス — に投入されます。そこでソフトウェアエージェントがドキュメントからリポジトリを再生成しようとし、元のテストスイートに対してスコアリングされます。この構築ループのエージェントモジュールにはGPT-5.4/5.5が使用されています。
難易度を考慮したトラジェクトリフィルタリング。 トラジェクトリは次のようにスコアリングされます:
\text{score} = \frac{N_{\text{passed}}}{N_{\text{total}}}.
固定カットオフ(例:0.95)はトラジェクトリの品質とタスクの難易度を混同します。難しいリポジトリはほぼ完璧なロールアウトをほとんど生成できず、簡単なリポジトリはどのような緩い閾値でも弱いトラジェクトリを許容してしまいます。著者らは3つのシグナルからインスタンスごとの難易度スコアを構築します:構造的シグナル e_i \in \mathbb{Z}_{\ge 0}(スコープ内の実行可能なPython LOC)と2つの独立した5段階のLLM判断 \ell_i^{(g)}, \ell_i^{(q)} \in \{1,\dots,5\}。ロールアウトを持つサブセット \mathcal{I}^\star 上で、経験的パスレート
s_i = \frac{1}{|\mathcal{R}_i|}\sum_{r \in \mathcal{R}_i} \text{score}(r)
が監督ターゲットとなります。適切に構成された難易度推定器は s_i と反相関するべきです。フィルタリング閾値はインスタンスごとに設定されます:簡単なインスタンスには厳しく、難しいインスタンスには緩く設定され、希少な高品質の難しいトラジェクトリを保持します。
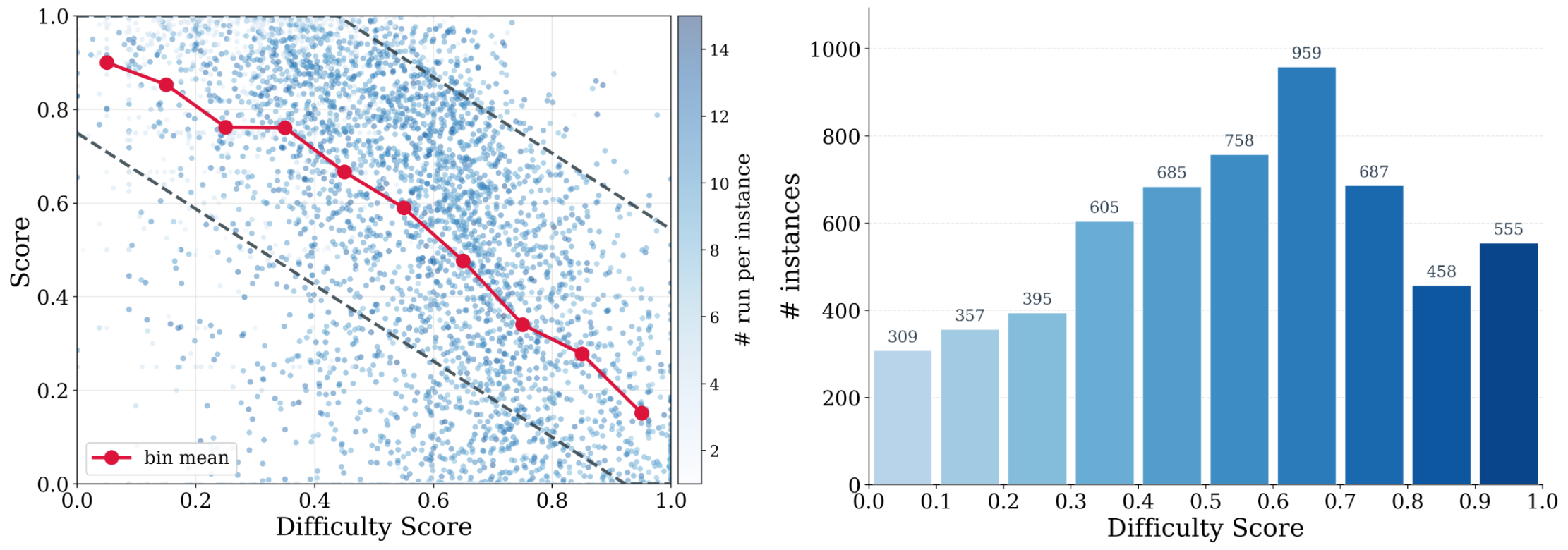
学習。 トラジェクトリはDeepSeek-V4-Pro HighをOpenHands/AweAgentスキャフォールディングで使用して生成されます:インスタンスあたり3ロールアウト、スコア1.0に達しなかったインスタンスには追加で3ロールアウトを実施します。難易度を考慮したフィルタリング後、約11kのトラジェクトリが残ります。SFTはQwen3-30B-A3B-Instruct(およびQwen3.5-35B-A3B)上で LR 1\text{e-}5、バッチサイズ128、ウォームアップ0.05、コンテキスト131,072で実行されます。lossは失敗したツール呼び出しおよびheredoc操作に対応するアシスタントターンでマスクされます — これは有用な詳細であり、これらは一般的な失敗モードであり、そのトークンがなければモデルが壊れたツール構文を模倣することを学んでしまいます。
結果
主要な数値:DeNovoSWEでQwen3-30B-A3Bをfine-tuningすることで、BeyondSWE-Doc2Repoが5.8%から47.2%へと、スクラッチからのリポジトリ合成を明示的にテストするために構築されたベンチマークで8倍の改善を達成しました。評価はベンチマークのゴールデン環境でBeyondSWEとNL2Repo-Benchの3試行平均で実施されます。データセット自体は4,818インスタンスを含み、学習セットは約11kのフィルタリング済みトラジェクトリを使用します。
限界と未解決の問題
- パイプラインはドキュメント合成と判断のためにGPT-5クラスのモデルに依存しており、データ品質はAPIコントラクトの捕捉における忠実性によって制限されます。criticステージのエラーは、テストスイートがたまたまそれを検出しないために「合格可能」な仕様-実装の不一致へと複合的に蓄積されます。
- 難易度キャリブレーションは1つのモデルファミリーからのロールアウトに固定されており、異なるジェネレーターにスケーリングする際に閾値が転移しない可能性があります。
- BeyondSWE-Doc2Repoの47.2%は飽和にはほど遠く、同じベンチマーク上でフロンティアのクローズドモデルとの直接比較は抜粋セクションには報告されていません。
- 失敗したツール呼び出しのlossマスキングヒューリスティックはノイズの多いシグナルを除去しますが、リカバリートラジェクトリに関する情報も除去します。明示的なエラーリカバリー監督が有効かどうかは未解決です。
- すべてのソースリポジトリはPythonであり、多言語スタック(ビルドシステム、ABI依存コード)への汎化はテストされていません。
なぜ重要か
リポジトリ全体の合成はissueレベルのSWEを超えた自然なスケーリング軸であり、ボトルネックは検証可能な学習データでした。DeNovoSWEは、自動化された分割統治パイプラインと難易度を考慮したフィルタリングにより、難しいdoc-to-repoベンチマークで30B MoEをほぼゼロからほぼ半分まで押し上げるのに十分なシグナルが得られることを示しており、制約はモデルではなくデータにあったことを示唆しています。
Source: https://arxiv.org/abs/2606.10728
Hacker News Signals
LLMは古典的なハイパーパラメータ最適化アルゴリズムを凌駕できるか?
Source: https://arxiv.org/abs/2603.24647
本論文は、LLMをハイパーパラメータ最適化(HPO)エージェントとして、古典的なベースライン — Bayesian optimization(TPE、GP-BO)、ランダムサーチ、CMA-ES — と比較ベンチマークしたものです。評価はHPO-Bおよびカスタムベンチマークから取得した表形式データとMLパイプラインのチューニングタスク群を対象としています。
実験の設定では、LLMをブラックボック最適化器として扱います。すなわち、(設定、性能)ペアの履歴をin-contextテキストとして受け取り、次に評価すべき設定を提案します。gradient信号もfine-tuningも行わず、純粋にfew-shotの逐次的意思決定に基づきます。評価対象のモデルはGPT-4、GPT-3.5、およびいくつかのオープンウェイト系モデルです。
結果はLLM陣営にとって厳しいものとなっています。大多数のベンチマークにおいて、古典的手法 — 特にTPEとGP-BO — が最終的な最良設定の品質とanytime性能の両面でLLMを上回っています。LLMは、事前学習でエンコードされた事前知識が問題領域と一致する低次元かつ構造が明確な探索空間において、ある程度競争力のある振る舞いを示します。一方、高次元空間や精密な数値推論を要するタスク(例:多くのオーダーにわたる学習率のチューニング)では、LLMの性能は著しく低下します。また、探索行動に一貫性がなく、原則に基づくacquisition functionのような推論を行うのではなく、序盤の良い結果を過度に活用するか、あるいはフレーミングがわずかに変わると逆に過剰な探索を行う傾向があります。
興味深い知見の一つとして、LLMは数値のプロンプト表現形式に対して敏感であることが挙げられます。lossをパーセンテージで表現するか生のfloat値で表現するかによって提案品質が測定可能な形で変化することが示されており、最適化の振る舞いが真の数値推論ではなく、部分的には表層的な形式に起因するアーティファクトである可能性を示唆しています。
また、本論文はコストの問題も指摘しています。GPT-4を用いた1回のHPOの実行は、同等のwall-clockバジェットでOptunaを実行するのと比べてオーダーが数桁異なるコストがかかる一方で、結果はさらに悪いものとなっています。
今後の課題としては、HPOトレースを用いたfine-tuningによりこのギャップを埋められるか否か、またLLMがスタンドアロンの最適化器としてではなくwarm-startの提案器として古典的手法を補完できるかどうかが挙げられます。本研究の結果は、構造化された数値最適化において原則に基づく確率的手法をLLMエージェントで置き換えることに対して、慎重な姿勢を促すものです。
DiffusionGemma: テキスト生成を4倍高速化
GoogleのDiffusionGemmaは、masked diffusion言語モデリングをGemmaアーキテクチャに適用することで、非自己回帰型テキスト生成アプローチを実現し、標準的なベンチマークにおいて同等の品質を保ちながら、比較可能な自己回帰型Gemmaモデルに対して約4倍のスループット向上を達成したと主張しています。
コアメカニズムはmasked diffusionです。学習時には、ノイズスケジュールに従ってトークンがマスクされ、モデルはマスクされていないコンテキストを条件として、破損したシーケンスから元のトークンを予測することを学習します。推論時は、完全にマスクされたシーケンスから生成を開始し、Tステップにわたって反復的にデノイズを行います。重要な点として、各ステップですべての位置を並列に洗練するため、Tはシーケンス長Lよりもはるかに小さくすることができます。生成コストは逐次的なO(L)ステップではなく、並列計算においてO(T \cdot L)でスケールしますが、実際にはT \ll Lであり、かつ現代のハードウェアが並列演算で飽和するため、実時間スループットが大幅に向上します。
4倍という数値は、T \approx 32{-}64のデノイズステップでのDiffusionGemmaと、同じシーケンス長での標準的なgreedy/beam decodingを用いた自己回帰型Gemmaを比較したものと考えられます。このモデルは標準的なGemma transformerバックボーンを使用しており、アーキテクチャの変更は最小限に抑えられています。主なエンジニアリング上の作業は、学習目標と推論ループの適応です。
注目すべき制限事項として、masked diffusionモデルは歴史的に自己回帰型モデルに対してperplexityおよびオープンエンドな生成品質で劣る傾向があり、特に長く一貫性のあるテキストにおいてその傾向が顕著です。4倍の高速化はスループットに焦点を当てたものであり、自己回帰型モデルがすでに高速である単一リクエストのサービング環境においては、レイテンシの改善には必ずしも結びつかない可能性があります。ブログ記事では、デプロイメントにおける重要なエンジニアリング上の判断基準となる品質対ステップ数のトレードオフ曲線についての詳細なablationが欠けています。また、このアプローチは既存の自己回帰型Gemmaチェックポイントを適応させるのではなく、再学習を必要とします。スループットを揃えた場合の品質差が実運用ユースケースにおいて許容できるかどうかは、ベンチマーク数値以上の検証を必要とする未解決の実証的問題です。
わずか€0.01の銀行振込で銀行AIエージェントが危険にさらされる可能性
Source: https://blue41.com/blog/how-we-helped-bunq-secure-their-financial-ai-assistant/
これは、セキュリティ調査の一環としてBunqのAI金融アシスタントで発見されたprompt injectionの脆弱性に関する実践的な開示報告です。攻撃ベクトルは、トランザクションメタデータを介した間接的なprompt injectionです。具体的には、攻撃者が細工された命令文を含む支払い説明を付与した€0.01の振込を実行し、被害ユーザーが取引履歴を照会した際にAIアシスタントがその内容を読み込む仕組みです。アシスタントはコンテキストウィンドウ全体を信頼された情報として扱うため、注入された命令に従ってしまいます。
技術的な核心は攻撃対象領域にあります。金融データを扱う現代のAIアシスタントは、信頼できないユーザー生成コンテンツ(取引の説明文、加盟店名、請求書テキスト)を取り込み、それをシステム命令と同一コンテキスト内に並べて提示しなければなりません。「データ」と「命令」の間にはハードウェア的またはcryptography的な境界は存在せず、すべてがトークンです。古典的なinjection対策(入力サニタイズ、出力エンコーディング)は、モデルが有用であるためにはコンテンツを意味的に処理する必要があるという点で、この脅威モデルにきれいにマッピングできません。
今回の調査で実証された影響には以下が含まれます。注入されたpromptがアシスタントにデータの要約と転送を指示することによるアカウント残高や取引履歴の外部漏洩、そしてアシスタントが振込起動のためのtool-use機能を持っていた場合のアクション実行の可能性です。€0.01というコストは、この攻撃をスケーラブルなものにしています。つまり、攻撃者は安価に数千人の潜在的被害者に対して無差別攻撃を仕掛けることができます。
議論された緩和策としては、コンテキスト内の階層的な信頼レベル(データプレーンのコンテンツを明示的にマーキングする)、信頼できないソースから取得したデータに対するinstruction-followingの制限、明示的な確認ステップを伴うサンドボックス化されたtool実行、および一般的な情報漏洩パターンに対するoutput filteringが挙げられています。しかし、これらのいずれも完全な防御策ではなく、脆弱性を排除するというよりも攻撃の敷居を高めるものに過ぎません。根本的な問題は、機密データへのアクセスと外部tool useを持つLLMベースのエージェントが、現在の大半のフレームワークに欠けているアーキテクチャ上の制約なしには、環境から任意のテキストを安全に取り込めないという点にあります。これは、機密データを扱うagentic systemsが古典的なアプリケーションセキュリティとは異なる脅威モデリングを必要とすることを具体的に示す好例です。
科学・工学のための関数解析入門
Source: https://arxiv.org/abs/1904.02539
本書は300ページ超の大学院レベルの講義ノートであり、PDE・数値手法・物理学への応用を明示的に志向した関数解析を扱っています。RudinやConwayに代表される純数学的な取り扱いとは一線を画しています。
扱われる内容は、距離空間・ノルム空間、Banach空間、Hilbert空間と正規直交基底、有界線形作用素とそのスペクトル、Hahn-Banachの定理・開写像定理、弱収束、コンパクト作用素、自己共役作用素のスペクトル理論、そして超関数とSobolev空間の入門にまで及びます。Sobolev空間の解説は、PDEの変分定式化を扱う実務家にとって特に有用であり、弱解が存在する理由や有限要素近似が収束する条件に関する関数解析的基盤を提供しています。
標準的な参考書との違いは、一貫した動機付けにあります。各抽象概念は、物理学や数値解析からの具体例とともに導入されます。楕円型PDEの適切性に中心的役割を果たすLax-Milgramの定理は導出された後、直ちにGalerkin法と結び付けられます。コンパクト自己共役作用素のスペクトル定理はSturm-Liouville問題と接続されます。超関数は、衝撃波解に現れる非滑らかな関数を微分する必要性を動機として導入されます。
ML研究者にとって、関数解析はカーネル法(RKHS理論)、operator learning(関数空間間の写像としてのneural operator)、正則化理論(Hilbert空間におけるTikhonov正則化)、および広いネットワークのmean-field・測度論的解析の基盤をなしています。例えばSobolevの埋め込み定理は、H^k(\Omega)内の関数がいつ連続になるかを制御するものであり、関数空間上のニューラルネットの近似理論に直接関係します。
本ノートは無料で公開されており、標準的な線形代数と実解析を前提とした自己完結した内容となっています。測度論的厳密さそのものを目的とせず、実用的な習熟度を必要とする応用数学・物理学・工学の博士課程1年生に適したレベルです。
Claude Desktopは起動のたびに1.8 GBのHyper-V VMを生成、チャットのみの用途でも同様
Source: https://github.com/anthropics/claude-code/issues/29045
技術的な問題の詳細:Windows上のClaude Desktopは、コード実行やエージェント機能を使用する意図がない場合でも、起動時にサイレントでフルHyper-V仮想マシンを立ち上げます。そのメモリフットプリントは約1.8 GBと報告されています。このVMはClaude Codeの統合機能に紐付いており、安全性の観点から隔離された実行環境(サンドボックス化されたシェル、ファイルシステムアクセスなど)を必要とします。問題は、遅延ロードやユーザーのオプトインによる制御が行われておらず、無条件に初期化される点です。
このVMはほぼ間違いなくWSL2/Hyper-V上で動作するLinuxゲストであり、Claude Codeがシェルコマンドやコードを実行するためのサンドボックス環境を提供しています。これ自体はセキュリティアーキテクチャとして合理的です。LLMエージェントによるコード実行はホストから隔離されるべきだからです。設計上の誤りは、無条件に初期化される点にあります。このサンドボックスはコード実行を必要とするセッションが開始された時点でのみインスタンス化されるべきであり、少なくともユーザーが明示的にオプトインできるトグルの裏側に配置されるべきです。
具体的な影響として、RAMが8〜16 GBのマシンでは、会話目的でClaude Desktopを起動したユーザーにとって、これは無視できないバックグラウンドの負担となります。また、Hyper-VはWindowsハイパーバイザープラットフォームの非互換性により、他のハイパーバイザー(特定の構成のVMware Workstation、旧バージョンのVirtualBoxなど)と競合します。そのため、一部のユーザーにとってはパフォーマンスの問題にとどまらず、完全な動作不能という深刻な事態を招きます。さらに、Claude Desktopの起動時間も大幅に延長されます。
エンジニアリングの観点からの適切な修正は、遅延初期化を採用することです。実行を必要とするツールをユーザーが呼び出したときにのみVMを起動し、理想的にはその際に視覚的なUI指標を表示すべきです。あるいは、Claude Code統合機能を必要としないユーザー向けに、完全に無効化できる設定フラグを提供することも有効です。このIssueのスレッドでは、こうした傾向がデスクトップAIアプリケーション全般にわたるより広い流れの一部であり、リソース消費に対するユーザーコントロールが不十分なまま、大きなシステムフットプリントを獲得しつつあると指摘されています。
Apache Burr: 信頼性の高いAIエージェントとアプリケーションの構築
Source: https://burr.apache.org/
Burrは、ステートフルなAIアプリケーションおよびエージェントを構築するためのPythonフレームワークであり、最近Apacheのインキュベーターに採択されました。中心的な抽象化はステートマシンです。アプリケーションは、遷移によって接続されたActionノードの有向グラフとして定義され、明示的なStateオブジェクトがノード間を受け渡されます。これは概念的にはLangGraphやAWS Step Functionsに近いですが、より限定的でオピニオネイテッドなAPIと組み込みの観測可能性を備えています。
主要な技術的設計方針として、stateはイミュータブルであり、可変のクラス属性に格納されるのではなく、グラフを通じて明示的に受け渡されます。各Actionはstateへの読み取りと書き込みを宣言するため、データフローの静的解析とデバッグの簡略化が可能です。遷移はガード条件付きエッジであり、ランタイムが条件を評価して次のノードを決定します。Actionは同期または非同期にでき、フレームワークは並列ファンアウトをサポートしています。
@action(reads=["query"], writes=["response"])
def call_llm(state: State) -> tuple[dict, State]:
result = llm.invoke(state["query"])
return {"response": result}, state.update(response=result)観測可能性の仕組みは差別化機能となっています。Burrはローカル UI(FastAPIを通じて提供)を同梱しており、すべてのstate遷移、入力、出力、およびタイミングを記録します。トレースは永続化および再生が可能であり、マルチステップのエージェント障害のデバッグにおける実際の課題に対処しています。永続化レイヤーはプラガブルなバックエンドをサポートしており(ローカルではSQLite、本番環境ではPostgres)。
LangGraphと比較すると、BurrはstateスキーマをよりExplicitに扱い、グラフDSL的な記述が少ないです。リトライロジックを含む素のPythonと比較すると、大きな依存関係を追加することなく構造をもたらします。Apacheのガバナンスモデルは、エンタープライズ展開に関連するサプライチェーンの信頼性を提供します。制限事項として、単純な線形チェーンでは通常の関数呼び出しで十分なところに概念的なオーバーヘッドが加わること、そしてLangChain周辺ツールと比較してプリビルドインテグレーションのエコシステムが小規模であることが挙げられます。また、ステートマシンモデルは定義時に制御フローグラフを列挙できることを前提としているため、高度に動的なエージェントトポロジーには扱いにくい面があります。
HelixDB: オブジェクトストレージ上に構築されたグラフデータベース
Source: https://github.com/HelixDB/helix-db/tree/main
HelixDBはRustで書かれたグラフデータベースであり、Neo4jやRocksDBバックエンドのグラフストアのようなローカルディスクファーストのアーキテクチャから脱却し、オブジェクトストレージ(S3互換バックエンド)を主要な永続化レイヤーとして採用しています。
ストレージモデルはグラフのトポロジー(隣接構造)とプロパティデータを分離し、それぞれをオブジェクトストア内の独立したオブジェクトとして格納します。ノードおよびエッジのレコードはシリアライズされ、UUIDから導出されたキーでアドレス指定されます。読み取りはキーによるオブジェクトの取得、すなわち実質的にはS3へのランダムアクセスGETリクエストを伴います。これはレイテンシ(リクエストあたり約10ms)の観点からはコストが高いものの、バイト単価は低く、容量はほぼ無制限にスケールします。そのため、このアーキテクチャはワーキングセットがローカルキャッシュレイヤーに収まり、クエリがグラフの広い範囲をコールド状態でトラバースする必要がないワークロードに最適化されています。
キャッシュ層(インメモリ、容量は設定可能)は繰り返しアクセスパターンを吸収し、コールドパスではオブジェクトストレージの全レイテンシが発生します。このトレードオフにより、HelixDBは分析用またはバッチ処理のグラフワークロードには適していますが、キャッシュミス率が高い低レイテンシトランザクショナルグラフクエリには不向きです。
クエリインターフェースはRust実行エンジンにコンパイルされるカスタムトラバーサルDSLを使用し、頂点・エッジのIDによるルックアップ、プロパティフィルタリング、述語プッシュダウンを伴うマルチホップトラバーサルといった標準的なグラフ操作をサポートしています。READMEに記載されているvector embedding サポートは、エンティティに関連するembeddingを持つRAGスタイルのアプリケーションでますます一般的になっているグラフ+ベクトルのハイブリッド検索パターンのために、近似最近傍探索を統合しています。
RustでビルドされS3をバックエンドとして使用することで、デプロイメントの運用が簡素化されます。ローカルディスクの管理、バックアップのオーケストレーション、ボリュームのプロビジョニングが不要です。耐久性はオブジェクトストアが担保します。未解決の問題は、キャッシュヒットが支配的なレジーム以外のクエリパターンにおいて、そのレイテンシプロファイルが専用グラフデータベースと競争力を持てるかどうかです。本プロジェクトは初期段階であり、現実的なトラバーサルワークロードにおけるJanusGraphやAmazon Neptuneとのベンチマーク比較はリポジトリに存在しません。
React CompilerをRustへ移植
Source: https://github.com/react/react/pull/36173
このプルリクエストは、これまでTypeScriptで実装されていたReact CompilerをRustで書き直す作業を開始するものです。React Compilerは自動メモ化を実行します。具体的には、ReactコンポーネントとhookのコードをStaticに解析してuseMemoおよびuseCallbackの呼び出しを挿入し、依存配列の手動管理なしに不要な再レンダリングを排除します。
現在のTypeScript実装は、BabelプラグインとしてまたはBundler(Vite、webpack、Next.js)に統合されたスタンドアロンのTransformとして動作しています。書き直しの動機はパフォーマンスです。TypeScriptコンパイラはJSランタイムのオーバーヘッドとシングルスレッド実行にボトルネックがあります。Rust実装ではファイル間の並列化が可能となり、RustベースのToolchain(Oxc、SWC、Rolldown)にネイティブ統合でき、これらのToolchainをすでに採用しているプロジェクトではBabel依存を排除できます。
このPRは現時点では主にScaffoldingの段階にあります。具体的には、CrateのStructureを確立し、TypeScript実装のHIR(High-Level Intermediate Representation)を踏襲するIR型をRustで定義し、新実装に対して既存のFixtureベースのテストスイートを実行するためのTest Harnessをセットアップしています。HIRはコンポーネントをScope解析付きのControl-Flow Graphとして表現しており、コンパイラのコアアルゴリズムはPropsやStateから派生した「Reactive」な値を特定し、最小限のメモ化境界を決定します。
移植における技術的な複雑さは単純な計算処理ではなく、コンパイラのセマンティック解析にあります。JavaScriptの参照等値セマンティクス、エイリアシング、およびReactのhookルールを正確にモデル化しなければなりません。メモ化における微妙な正確性のバグ(過剰なメモ化はStale Closureを引き起こし、不十分なメモ化は最適化を損なう)には広範なテストカバレッジが必要です。既存のFixtureスイートがこれを提供しており、PRは既存のテストをすべてPassすることをMergeの条件として明示的に設けています。
これはビルドパフォーマンスのためにJSToolchainコンポーネントをRustで書き直す広範なトレンド(Biome、Oxc、SWC、esbuild-rsの実験)に沿うものであり、大規模環境ではコンパイル時間が開発者体験における重大なコストとなっています。
注目すべき新しいリポジトリ
margelo/react-native-runtimes
React NativeのシングルJSスレッドはよく知られたボトルネックです。重い計算処理、大規模なJSONパース、複雑なビジネスロジックがUIをブロックしてしまいます。このライブラリは、メインruntimeと並行して独立したHermes VMインスタンスを起動することでこの問題を解決します。各インスタンスは独自のイベントループとメモリヒープを持ちます。WorkerはシンプルなAPIで作成でき、構造化メッセージパッシングを通じて通信し、任意のJSモジュールをインポートすることができます。各runtimeがWeb WorkerのシムではなくフルのHermesインスタンスであるため、メインスレッドと同じJIT/バイトコードコンパイル特性が得られ、実行モデルが劣化することはありません。実装はiOSとAndroid両方のネイティブレイヤーでJSI(JavaScript Interface)にフックしており、ブリッジのオーバーヘッドを最小限に抑えています。アーキテクチャ的には、ShopifyがカタログProcessingのオフロードに社内で使用しているものと類似しています。実用的なユースケースとしては、画像メタデータ処理、暗号化操作、ローカルML inferenceドライバー、バックグラウンド同期ロジックなどが挙げられます。react-native-workers(モダンなJSI以前の設計でシリアライゼーションが重いブリッジを使用)と比較して、よりクリーンで低レイテンシな設計となっています。layoutやrenderの最適化だけでは解消できないJSスレッドの飽和がプロファイリングで明らかになった場合には、評価する価値があります。
Source: https://github.com/margelo/react-native-runtimes
study8677/awesome-architecture
分散システムおよびAIネイティブなシステム設計のための、構造化されたバイリンガル(英語・中国語)リファレンスコーパスです。コンテンツは3層に整理されています:基礎的なパターン(コンセンサス、シャーディング、レプリケーション、キャッシュ無効化)を網羅する26本のチュートリアルドキュメント、再利用可能な25のアーキテクチャテンプレート(イベント駆動、CQRS、saga、sidecarなど)、そして本番環境のトレードオフを通じて設計上の意思決定を追跡する6本のエンドツーエンドケーススタディです。AIネイティブセクションは技術的に具体的で、RAGパイプラインアーキテクチャ(チャンキング戦略、ベクトルインデックスの選択、ハイブリッド検索)、コーディングエージェントのスキャフォールディング(ツール使用、メモリ、コンテキスト管理)、LLM serving インフラストラクチャを扱っています。抽象的な図ではなく、テンプレートにはレイテンシと一貫性のアノテーションを伴うコンポーネント分解が含まれています。バイリンガル形式は、言語の壁を越えて作業するチームや、アーキテクチャ用語がコミュニティ間でどのように翻訳されるかを追跡するうえで有用です。ライブラリではなく純粋なドキュメントですが、具体的なトレードオフの議論の密度が典型的な「awesome-X」リストとの差別化要素となっています。アプリケーション開発からインフラストラクチャやAIプラットフォームの役割に移行するエンジニアのオンボーディング資料として、あるいは設計レビュー時のチェックリストとして最も有用です。
Source: https://github.com/study8677/awesome-architecture
Evokoa/pgGraph
リレーショナルデータに対するグラフクエリを実現するには、一般的に専用のグラフデータベース(Neo4j、ArangoDB)への移行か、手書きの再帰的CTEが必要です。pgGraphは、独立したプロセスを必要とせず、PostgreSQLの上に直接グラフセマンティクスを追加します。Postgresの拡張インフラストラクチャを利用して標準テーブル上にグラフクエリレイヤーを公開し、外部キー関係と明示的に宣言されたエッジテーブルをグラフのエッジとして扱います。トラバーサルクエリ(BFS、DFS、最短経路、k-hopネイバーフッド)は、内部でWITH RECURSIVEまたはlateral joinを用いた最適化済みSQLにコンパイルされ、アプリケーションコードを経由したラウンドトリップを回避します。スキーマの宣言は軽量であり、既存のテーブルにアノテーションを付けるか、source/targetカラムを持つエッジテーブルを定義するだけで済みます。この拡張機能はC言語で実装されており(標準的なPG拡張モデル)、薄いSQL APIを提供します。これは、すでにPostgresを使用しており、グラフ的なアクセスパターン(ソーシャルグラフ、依存関係の解決、ナレッジグラフ、不正リング)を持つアプリケーションにとって有意義ですが、独立したグラフストアの運用上の複雑さを正当化できない場合に特に有効です。主な制約として、非常に深いトラバーサルは依然としてPostgresのクエリプランナーの限界に達する可能性があり、ネイティブグラフエンジンがポインタチェイシングストレージによって回避しているこの問題を克服できません。
Source: https://github.com/Evokoa/pgGraph
duncatzat/vigils
Rust(バックエンド)、Tauri(デスクトップシェル)、およびChrome Manifest V3 extensionで構築された、AIエージェントプロセス向けのローカルコントロールプレーンです。このアーキテクチャは、エージェントのツール呼び出しとブラウザ操作を実行前にインターセプトし、完全なコンテキストとともにユーザーへ承認または拒否を求めます。シークレット管理は第一級の関心事として扱われており、エージェントが認証情報パターン(APIキー、トークン、環境変数)に一致する文字列を送信しようとした際に検出し、それをブロックまたはリダクトします。Rustコアはプロセスの監視とポリシーエンジンを担い、TauriはElectronの重量感なしにネイティブUIを提供します。MV3 extensionはブラウザ側のエージェント操作(Playwright駆動または直接実行)にフックします。これはクラウドベースのエージェント可観測性プラットフォームとは異なり、テレメトリの外部送信なしにすべてがローカルで動作するため、エンタープライズやセキュリティに敏感なワークフローにおいて重要です。承認ワークフローは完全自動から完全監視まで設定可能であり、信頼されたアクションクラスに対してはルールベースのポリシーが適用されます。主な未解決課題は、手動承認が必要な場合に密なエージェントループへ導入されるレイテンシですが、非同期承認キューイングによって部分的に対処されています。
Source: https://github.com/duncatzat/vigils
trynullsec/nullsec-s1
生成されたコードや人間が記述したコードにおける脆弱性の自動発見とトリアージを目的とした、LLMベースのアプリケーションセキュリティシステムです。このアーキテクチャは「セキュリティネイティブ」と位置づけられており、汎用コーディングアシスタントにセキュリティプロンプトを後付けする形ではなく、セキュリティコーパス(CVEの説明、CWEタクソノミー、エクスプロイトパターン、OWASPカテゴリ)に特化した fine-tuning またはプロンプト設計が施されています。本システムはSASTスタイルの静的解析、依存関係の脆弱性マッピング、および修正パッチの生成をカバーしており、これらはすべて単一のLLMパイプラインを通じて実行されます。統合対象はCI/CDパイプラインおよびコードレビューワークフローです。実用上の差別化ポイントとして、既存のシグネチャを持たない新規の脆弱性パターンに対し、ルールベースのSASTツール(Semgrep、CodeQL)と比較して偽陽性率が低いと主張しています。ただし、LLMベースのセキュリティツールには自信満々な誤った評価を行うという既知の失敗モードがあるため、ベンチマーク手法が公開されるまでは懐疑的な姿勢が求められます。本リポジトリは初期段階にあり、近い将来における最も有益なユースケースは、自律的な本番環境での脆弱性発見というよりも、トリアージ支援と修正提案にとどまる可能性が高いと言えます。
Source: https://github.com/trynullsec/nullsec-s1
WantongC/journal-adapt-writing-skill
学術原稿は、文の複雑さ、ヘッジング表現の密度、引用の配置、セクション構成といったスタイル面でターゲットジャーナルの慣習と合致していない場合、デスクリジェクトや査読での減点を受けることが多くあります。このツールは、ターゲットジャーナルの掲載済み論文コーパスから慣習を自動的に抽出し、投稿原稿をセクションごとにそのスタイルに合わせて書き直します。パイプラインは以下の手順で構成されています:(1) 掲載済み論文のPDFを解析してスタイロメトリックな特徴と構造的パターンを抽出する;(2) ジャーナル固有のスタイルプロファイルを構築する;(3) LLM(バックエンドは設定可能)を使用して、科学的内容を保持しながら抽出した制約のもとで各セクションを書き直す。セクションごとに処理するアプローチは意図的なものであり、context windowを扱いやすい範囲に抑えつつ、著者が変更を逐次的にレビューできるようにするためです。Pythonで構築されており、標準的なPDF抽出とLLM APIコールを使用しています。制限事項はLLMベースの書き直しに本質的に伴うものであり、コンテンツのドリフトが生じる可能性があること、また小規模なコーパスから抽出されたスタイルプロファイルはノイズを含む場合があることが挙げられます。英語を母語としない研究者が特定性の高い投稿先を狙う場合や、ある研究分野の慣習から別の分野の慣習へ論文を適応させる場合に最も有用です。
Source: https://github.com/WantongC/journal-adapt-writing-skill
seochecks-ai/slopless
英語Markdownにおける低品質な文章パターンを検出するための、決定論的かつLLMを使用しないCLIおよびtextlintルールセットです。「Slop(スロップ)」は、具体的かつ監査可能なアンチパターンのリストとして定義されています。具体的には、フィラーフレーズ(“it is worth noting that”など)、hedge(曖昧化表現)の積み重ね、能動態が標準とされる文脈での受動態の過剰使用、AIに特徴的なn-gram(LLMの出力において人間のテクニカルライティングと比較して統計的に過剰に出現するフレーズ)、名詞化の連鎖、そして曖昧な強調表現が含まれます。ルールはtextlintプラグインとして実装されており、既存のlintパイプラインやCIワークフローと組み合わせて利用できます。この決定論的なアプローチは、LLMベースの文章品質ツールに対する意図的な対比として設計されています。すべてのフラグは、文書化された根拠を持つ具体的かつ検査可能なルールに対応しており、モデルの温度パラメータに起因する誤検知はなく、APIコストもゼロです。設定によりプロジェクトごとにカテゴリを無効化することも可能です(たとえば、正式な仕様書には不適切な受動態ルールなど)。ドキュメントチーム、テクニカルブロガー、または公開前にLLMが下書きしたテキストを取り込むパイプラインに対して、即座に有用です。ルールのコーパスが主要な資産であり、その品質は列挙されたパターンが実際の文章劣化をどれだけ的確に捉えているかに依存しており、これは継続的な実証的な問いです。