Daily AI Digest — 2026-06-11
arXiv Highlights
Redesign Mixture-of-Experts Routers with Manifold Power Iteration
Problem
In a sparse MoE layer, the router R \in \mathbb{R}^{E \times d} scores tokens against experts via s_i = \langle x, R_{[i]} \rangle, where R_{[i]} acts as a proxy for expert i with weight matrix W_*^i. The standard learned router has no structural constraint that ties R_{[i]} to the geometry of W_*^i; the row is only shaped indirectly via downstream gradients on the gated output. The authors argue this is the wrong inductive bias: if R_{[i]} is meant to summarize W_*^i in a single vector, the matrix-theoretically optimal choice (Eckart–Young) is the principal right-singular direction of W_*^i. The paper proposes a router parameterization that explicitly drives R_{[i]} toward this direction at each training step.
Method: Manifold Power Iteration (MPI)
The objective is to maximize the Rayleigh quotient
\max_{R_{[i]}} \; \phi(W_*^i, R_{[i]}) = \frac{\|R_{[i]} W_*^i\|_2^2}{\|R_{[i]}\|_2^2}.
Exact SVD on every expert per step is infeasible. Instead, MPI uses one step of power iteration on W_*^i {W_*^i}^\top followed by a retraction onto a unit-norm manifold — a “Power-then-Retract” update. Concretely, at each forward pass the effective router row used for gating is computed as
R'_{[i]} = \mathrm{Retract}\!\left( R_{[i]} W_*^i {W_*^i}^\top \right),
where \mathrm{Retract}(\cdot) enforces \|R'_{[i]}\|_2 = 1 for stability. Gating logits are then \langle x, R'_{[i]} \rangle as usual; only the router-row computation changes, so MPI is a drop-in modification. By the standard convergence of power iteration on W_*^i {W_*^i}^\top, repeated application of this map drives R_{[i]} toward the top right-singular vector of W_*^i, with the per-step retraction preventing norm blow-up. The authors note (substituting W_g^i — the gate-projection — for W_*^i in practice) that a single iteration per step suffices: increasing to 10 iterations costs 5% throughput, raises pretraining loss by 0.002–0.003, and drops downstream accuracy by 1.39 points, suggesting that aggressive alignment destabilizes routing dynamics.
Empirical results
The authors verify the alignment claim directly via the cosine-style projection
\lambda = \frac{\|R'_{[i]} W_g^i\|_2}{\|R'_{[i]}\|_2 \, \|W_g^i\|_2} \in [0,1].
Across the 12 layers of the 1B model, vanilla MoE yields \lambda \in [0.22, 0.37] (typically around 0.25), while MPI yields \lambda \in [0.62, 0.70] — roughly a 2–3× tighter alignment with the principal singular direction. This is direct evidence that the parameterization achieves what the motivation prescribes.
At 1B scale with 100B pretraining tokens, MPI improves convergence and downstream averages across four optimizers (AdamW, Muon, and their Hyperball variants AdamH, MuonH), showing it is optimizer-agnostic. Using MuonH as the representative, MPI cuts pretraining loss by 0.013.
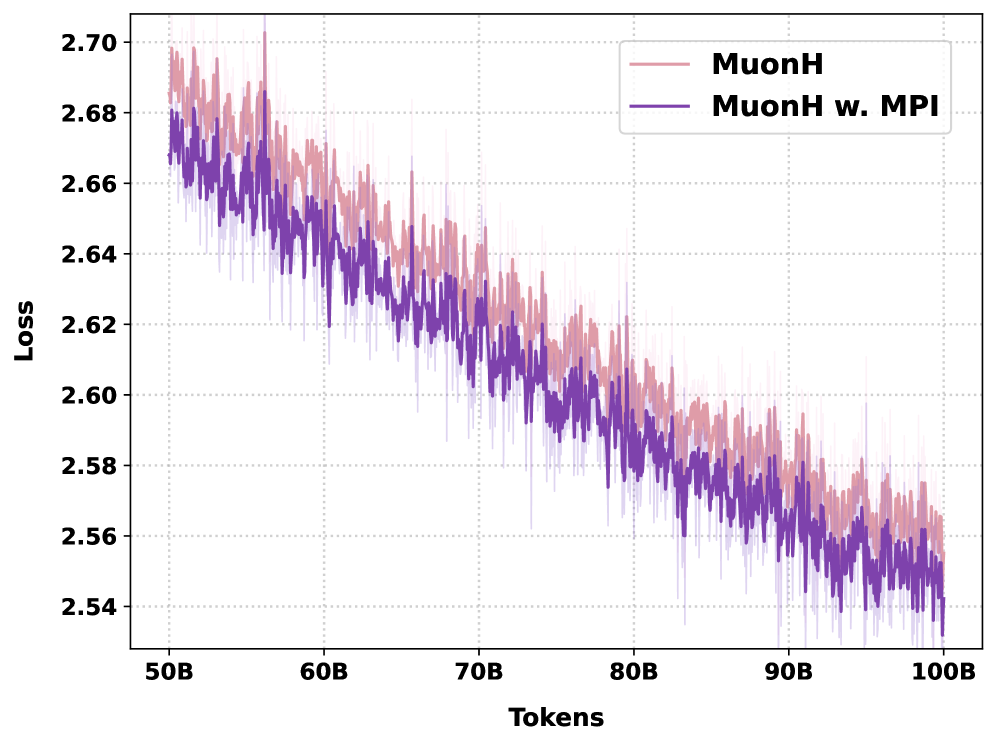
The benefit persists at scale. At 11B parameters, MPI maintains a consistent loss gap and downstream lead through the entire pretraining trajectory, indicating the alignment prior is not absorbed by capacity.
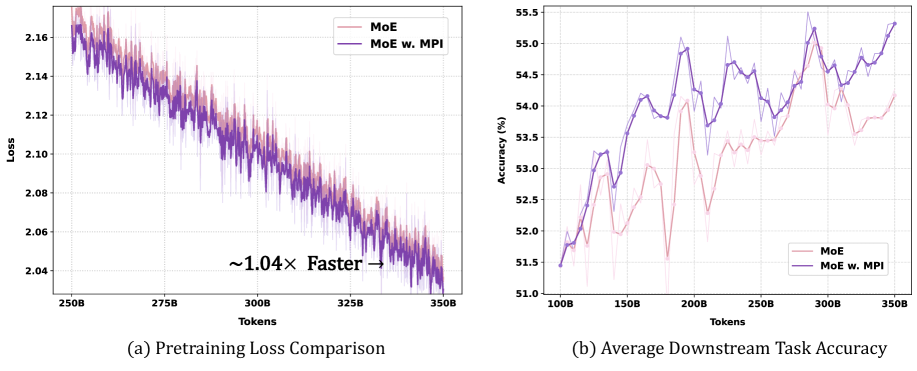
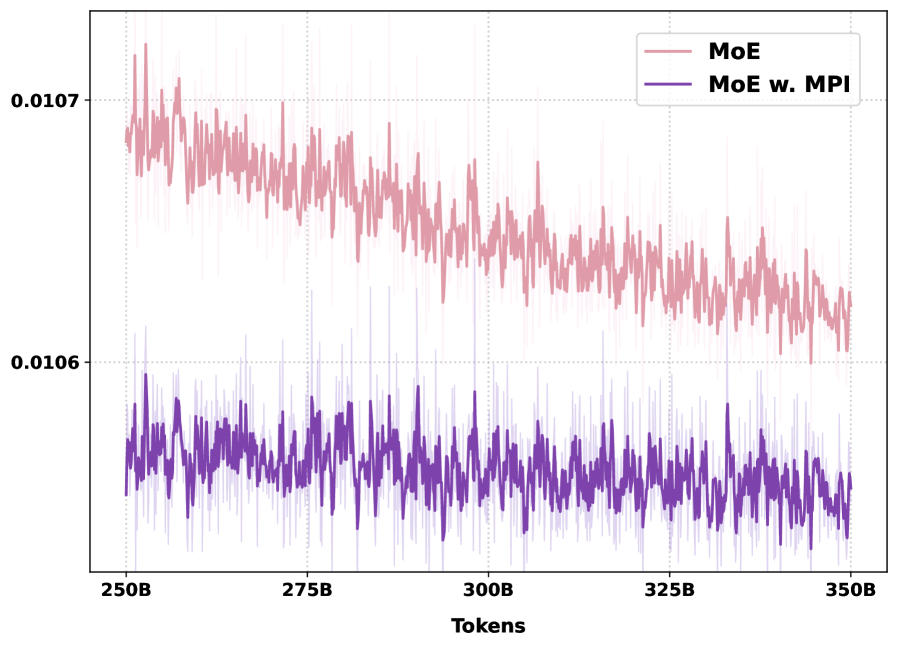
MPI is also compatible with the standard auxiliary objectives. Load balancing loss curves at 3B remain well-behaved, indicating MPI does not collapse routing onto a few experts.
Stacking with router z-loss (\beta = 0.001, Zoph et al. 2022) at 1B/50B tokens adds a further 0.68-point downstream gain with no loss or gradient anomalies. Because MPI changes only the router row computation and preserves the gating-weight pathway, it composes orthogonally with most other router modifications.
Limitations and open questions
- The alignment metric \lambda is reported as a layer-average of per-expert projections; the per-expert variance and whether some experts remain poorly aligned is not characterized.
- The justification leans on the Eckart–Young intuition, but token–expert affinity is a function of the input distribution, not just W_*^i’s spectrum. There is no analysis of when the principal singular direction is actually a poor proxy (e.g., experts whose useful subspace is rank > 1 or where input statistics are strongly anisotropic).
- Choice of W_*^i is collapsed to W_g^i (the gate projection of a SwiGLU-style FFN); whether using W_p^i or W_o^i, or a combination, would matter is left open.
- Single-iteration suffices empirically, but the destabilization observed at 10 iterations is not analyzed mechanistically — it could indicate that exact alignment removes useful exploration noise in routing.
- Inference-time behavior: since R'_{[i]} depends on current expert weights, the router is not a fixed parameter set; storage/inference details (whether R' is precomputed once weights freeze) are worth pinning down.
Why this matters
MPI gives MoE routing a principled structural prior — router rows track the dominant singular direction of their experts — at near-zero compute overhead and with empirical gains that hold from 1B to 11B and across optimizers. It reframes the router from a free-floating learned matrix into a constrained estimator coupled to expert geometry, a direction likely to interact productively with expert pruning, merging, and upcycling.
Source: https://arxiv.org/abs/2606.12397
Beyond Scalar Rewards by Internalizing Reasoning into Score Distributions
Problem
Reward models for text-to-image post-training typically collapse subjective visual preference into a scalar or a pairwise logit. This over-compresses two structures that matter: (a) ordinal uncertainty across rubric bins (a 3.5 is closer to a 4.0 than to a 1.0), and (b) the rubric-conditioned reasoning that human annotators use to disambiguate borderline cases. Reasoning-based generative reward models recover some of this signal but are too costly to query during RL fine-tuning of a diffusion generator and produce non-differentiable text outputs that are awkward as direct optimization targets. The authors target a reward model that (i) is trained against full rubric-aligned score distributions with reasoning, and (ii) deploys as a compact, differentiable scalar/distribution predictor suitable for ReFL-style backpropagation.
Annotation and rubric
Annotation covers four dimensions — text-image alignment, realism, aesthetics, physical plausibility — each scored on a 9-level half-point scale \hat{s}\in\{1.0,1.5,\dots,5.0\}, anchored by 5 rubric bins and 15-20 calibration exemplars per bin. The authors flag a context-mismatch problem: encoding the full document would require roughly 4\times 5\times 15\times 1024 \approx 3.07\times 10^{5} image tokens, far beyond a deployable VLM context, and annotators see same-prompt comparisons that a pointwise reward model never observes. This motivates direct supervision on score distributions and same-prompt score gaps rather than long in-context calibration.
Method
A teacher VLM q_\theta(s\mid p, I, d, \rho) produces a reasoning trace \rho then a distribution over rubric bins, decoded with a Q-Align-style score head. The deployed scalar is the expectation
\mu_\theta(p, I, d, \rho) = \sum_{s\in\mathcal{S}} s\, q_\theta(s\mid p, I, d, \rho).
The teacher (Qwen3.5-27B) is trained by Group-wise Direct Score Optimization (GDSO): for each preference tuple (p, I_w, I_l, \hat{s}_w, \hat{s}_l, d), G rollouts are sampled per side from \pi_{\theta_{\text{old}}}, decoded into reasoning \rho_{j,i}, distribution q_{j,i} and expected score \mu_{j,i}. The objective combines (a) a GRPO-style policy gradient using rewards derived from \mu_{j,i} versus group baselines, (b) a pointwise term penalizing |\mu_{j,i} - \hat{s}_j| and shaping q_{j,i} toward an ordinal soft label around \hat{s}_j, and (c) a pairwise term enforcing the score gap \mu_w - \mu_l to track \hat{s}_w - \hat{s}_l. The pointwise/pairwise losses are weighted by \lambda_{\text{pt}}, \lambda_{\text{pw}} with confidence scales \alpha_{\text{pt}}, \alpha_{\text{pw}}, and the iterative scheme refreshes \pi_{\text{ref}} \leftarrow \pi_\theta every N outer steps.
The student (Qwen3.5-9B) drops the reasoning trace and learns q_\phi(s\mid p, I, d) directly via Reasoning-Internalized Score Distillation (RISD): KL to the teacher’s reasoning-conditioned distribution plus the same pointwise/pairwise score and gap losses. At inference the student emits a distribution and a differentiable scalar in one forward pass.
Results
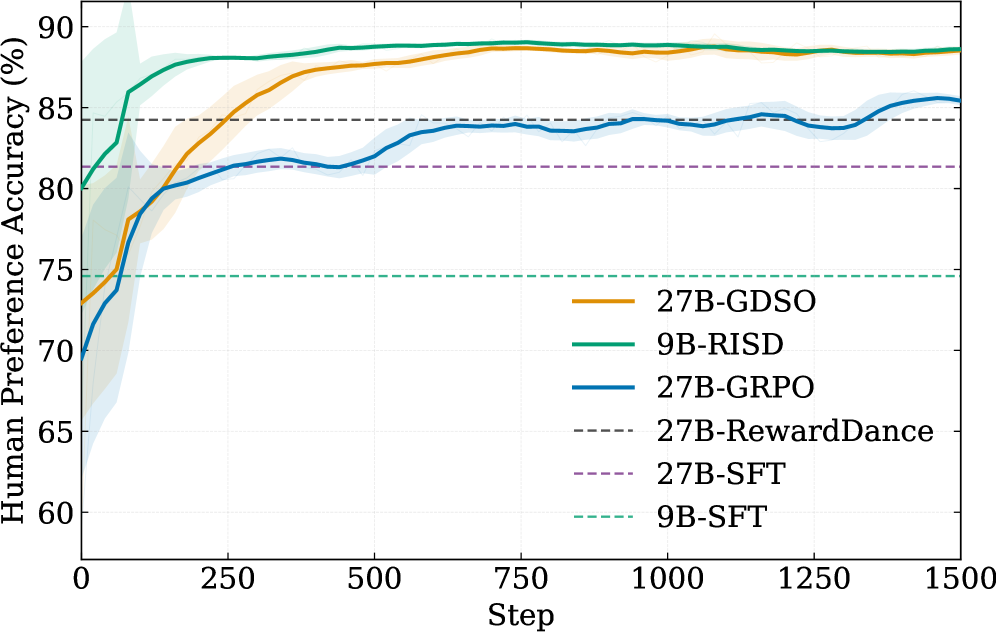
On the held-out internal test set with PLCC, SRCC, HPA and margin HPA (pairs with |\hat{s}_a-\hat{s}_b|>0.5):
- 27B teacher. Zero-shot baseline: PLCC 0.6301, HPA 0.7438. SFT: 0.6458 / 0.8135. RewardDance (post-hoc distilled CoT): 0.6667 / 0.8425. GRPO with mean-of-distribution reward: 0.7200 / 0.8604. GDSO: 0.7620 PLCC, 0.7132 SRCC, 0.8956 HPA, 0.9885 margin HPA — a +0.1319 PLCC and +0.1518 HPA gain over zero-shot, and clear margins over both SFT and the GRPO ablation, isolating the contribution of explicit pointwise + pairwise distribution supervision over policy gradient alone.
- 9B student. Zero-shot is weak (PLCC 0.3411, HPA 0.6563). SFT and RewardDance reach PLCC 0.53/0.52. GDSO from scratch: 0.6341 / 0.8395. RISD: 0.7391 PLCC, 0.6882 SRCC, 0.8864 HPA, 0.9801 margin HPA, recovering essentially all of the 27B teacher’s preference accuracy (0.8864 vs 0.8956 HPA) at roughly 1/3 parameters and without emitting reasoning at inference.
The RISD student strictly beats the 9B GDSO model trained on the same labels (+0.105 PLCC, +0.047 HPA), evidence that the teacher’s reasoning-conditioned distribution carries information beyond what scalar+gap supervision recovers from the raw labels.
Using Z-Reward as a differentiable signal
The student’s expected score \mu_\phi(p, I, d) is plugged into a ReFL-style direct reward backpropagation loop, aggregating across the four dimensions R(p, I) = \mathcal{A}(\{\mu_\phi(p, I, d)\}_d) and propagating \nabla_\psi R through the denoiser. Validation reward curves over 10k iterations rise monotonically on all four dimensions (alignment, realism, aesthetics, physical plausibility), and qualitative comparisons against the SFT baseline show fewer compositional and physical-plausibility errors.

Limitations
Evaluation is limited to an internal test set; no public benchmark numbers (e.g., GenAI-Bench, ImageReward, HPDv2) are reported, so absolute comparison to existing reward models is hard. The “distribution” q_\theta is trained from one rubric-calibrated score per pair plus gap constraints, not from per-sample annotator distributions, so its higher-moment calibration is implicit. The pointwise/pairwise weights \lambda_{\text{pt}}, \lambda_{\text{pw}}, \alpha_{\text{pt}}, \alpha_{\text{pw}} are not ablated in the excerpt, and the four-dimensional aggregation \mathcal{A} is left task-dependent — a known failure mode for multi-objective RLHF in T2I (reward hacking on one axis). RISD also assumes the teacher’s reasoning-conditioned distribution is well-calibrated; teacher errors will be inherited.
Why this matters
Treating the reward as a rubric-aligned distribution rather than a scalar gives both a denser training target (ordinal soft labels + gap constraints) and a denser optimization signal (a differentiable expectation over bins) for diffusion fine-tuning, while distilling reasoning into a compact pointwise model removes the deployment cost of CoT reward judges. The 9B RISD result matching a 27B reasoning teacher on preference accuracy suggests reasoning-as-training-signal, not reasoning-as-inference, is the right division of labor for visual reward models.
Source: https://arxiv.org/abs/2606.09076
On Subquadratic Architectures: From Applications to Principles
Problem
Linear-attention-style sequence operators (Mamba-2, Gated DeltaNet, xLSTM) all promise \mathcal{O}(T) inference with bounded state, but the field lacks a controlled comparison of which design choices actually matter when the task has nontrivial state-tracking or accumulation structure. The paper does two things: (1) benchmarks the three operators under matched recipes on code pretraining, code distillation, and time-series foundation-model (TSFM) pretraining; (2) unifies them under a gated-linear-attention notation and isolates the gating mechanism responsible for the observed gaps.
Unified formulation
All three models are recurrences over a matrix state \bm{C}_t \in \mathbb{R}^{D_{qk}\times D_v} of the form
\bm{C}_t = \bm{G}_t \,\bm{C}_{t-1} + \bm{k}_t \otimes \bm{v}_t, \qquad \bm{h}_t = \bm{q}_t \bm{C}_t,
differing in the structure of the state-transition \bm{G}_t:
- Mamba-2: scalar (or diagonal) decay \bm{G}_t = \alpha_t \bm{I} with \alpha_t \in (0,1).
- Gated DeltaNet: a rank-1 Householder-style correction \bm{G}_t = \alpha_t(\bm{I} - \beta_t \bm{k}_t \bm{k}_t^\top), eigenvalues constrained to [0,1] (or [-1,1] in the Grazzi et al. parameterization).
- xLSTM (mLSTM): independent input gate i_t and forget gate f_t multiplying the state, \bm{C}_t = f_t \bm{C}_{t-1} + i_t\,\bm{k}_t\otimes \bm{v}_t, with both gates unconstrained in sign relationships, allowing the write magnitude to be modulated independently of the decay.
The authors use the chunkwise form
\bm{H}_{[n]} = (\bm{Q}_{[n]}\bm{K}_{[n]}^\top \odot \bm{M})\bm{V}_{[n]} + \bm{Q}_{[n]}\bm{C}_{(n-1)C}
for hardware-efficient training, identical across operators, so any quality gap is attributable to the gating, not the kernel.
Empirical pattern
The benchmarks use 400M-parameter inter-layer hybrids: 24 layers total, 3 of which are softmax-attention (so xLSTM[7:1] = 6 mLSTM + 1 attention + 1 sLSTM-style recurrent within the non-attention budget), trained on Nemotron-CC-Code-v1 at 20B and 100B tokens, plus a Nemotron-CC-Code + FineWeb-Edu mix.
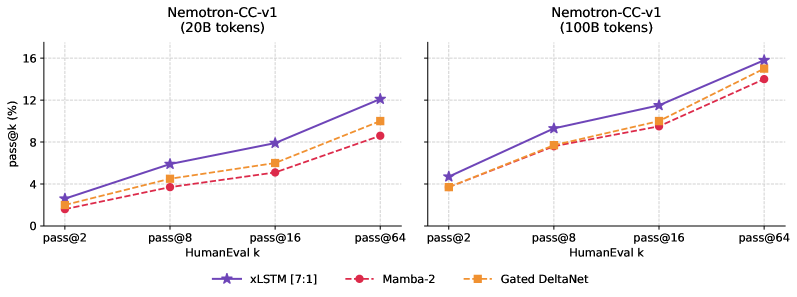
xLSTM hybrids lead on HumanEval pass@k for k\in\{2,8,16,64\} across both data scales, with the largest gap at 20B tokens; at 100B tokens the gap narrows but the ordering is preserved. Reasoning/commonsense (HellaSwag, PIQA, ARC-E/C, WinoGrande) shows the same direction with smaller margins, consistent with these benchmarks being less sensitive to long-range state.
For TSFM pretraining, the authors sweep five parameter scales and report MASE and CRPS on GIFT-Eval.
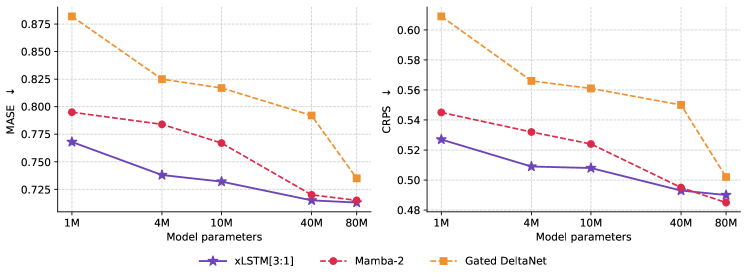
xLSTM is Pareto-best across scales on both metrics; the gap shrinks as parameters grow but does not invert. The same ordering reappears in code-distillation experiments (Section 2.2).
Synthetic state-tracking diagnostics
To pin down the mechanism, the authors train at length 128 and extrapolate to 512 and 2048 (4\times and 16\times) on A^nB^n, A^nB^nC^n, Majority, Parity, \mathbb{Z}_5 modular arithmetic, and word problems in S_3.
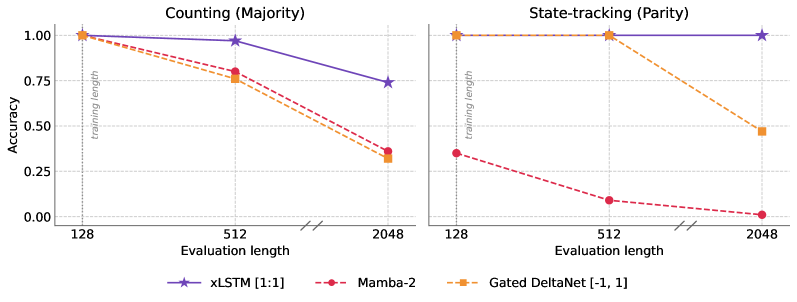
Concrete numbers from Figure 4:
- xLSTM[1:1] is the only configuration that length-generalizes on both tasks, with the highest Majority accuracy at every length and perfect Parity through 2048.
- Gated DeltaNet with the standard non-negative eigenvalue parameterization cannot represent parity at all.
- Gated DeltaNet_{[-1,1]} (Grazzi et al., 2025) solves parity in-distribution but degrades to 0.47 at length 2048 — chance-level — showing that the negative-eigenvalue extension fixes representability but not stability.
- Mamba-2 never solves either task at any evaluated length.
The interpretation: Mamba-2’s scalar decay cannot perform per-channel write/erase; Gated DeltaNet’s rank-1 correction performs key-aligned overwrite but its constrained eigenvalues either preclude parity (in [0,1]) or admit it but accumulate numerical drift over long sequences (in [-1,1]); xLSTM’s independent input/forget gates plus the stabilizer-normalizer pair give bounded, sign-flexible accumulation that survives 16\times extrapolation.
Limitations
Hybrids retain three softmax-attention layers, so the attribution to the recurrent operator is partial — a softmax layer can mask weaknesses in the recurrence. The 400M scale leaves open whether the ordering survives at $$10B parameters; the 100B-token narrowing in Figure 2 suggests data may partially substitute for inductive bias. The synthetic tasks isolate two axes (accumulation, parity-style state) but do not exercise associative recall or copy, where DeltaNet variants are typically strong. No wall-clock or memory comparison is reported, and the throughput cost of xLSTM’s gating (two additional scalar gates and exponential-stabilizer machinery) is not quantified.
Why this matters
This is a clean, matched-recipe comparison that ties downstream gains on code and time-series to a measurable property — bounded, sign-flexible state correction — rather than to architecture branding. The implication for designers of subquadratic operators is concrete: the eigenvalue spectrum and independence of write/erase channels in the state-transition \bm{G}_t are the levers, and constraining them to [0,1] or to scalar decays is a real capacity loss that synthetic parity tasks make visible long before pretraining loss does.
Source: https://arxiv.org/abs/2606.12364
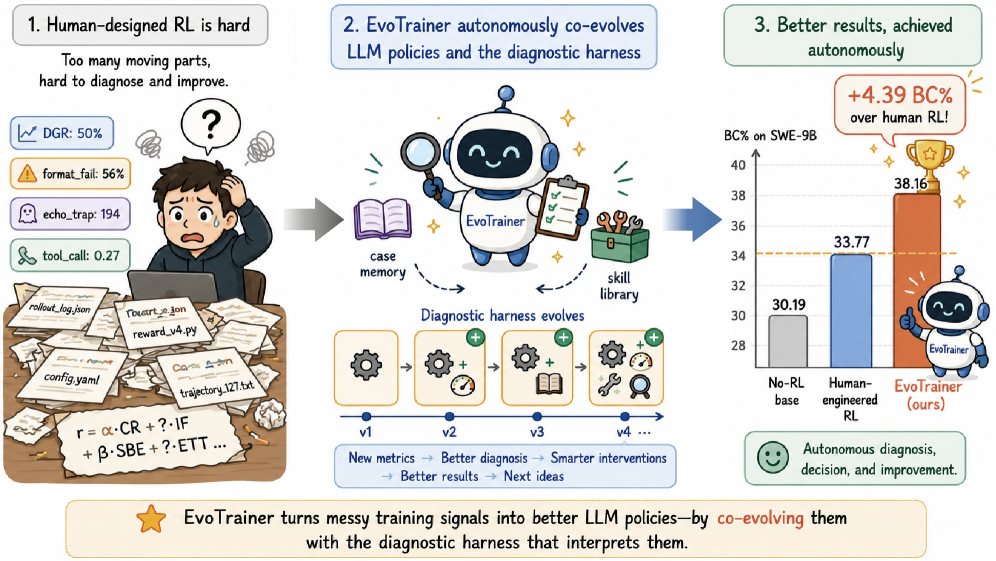
EvoTrainer: Co-Evolving LLM Policies and Training Harnesses for Autonomous Agentic Reinforcement Learning
Problem
Autonomous LLM training systems typically frame the search as recipe optimization: a controller proposes hyperparameters, data mixes, or reward variants, and the training harness — the diagnostic and evaluation pipeline that interprets each run — is held fixed. In agentic RL this is a significant limitation. Long-horizon trajectories (tool use, multi-step SWE edits) collapse into sparse scalar rewards that conflate distinct failure modes: an agent that hacks the reward, one that crashes mid-trajectory, and one that solves the problem cleanly may all be indistinguishable to a static harness. EvoTrainer’s claim is that the harness itself must evolve in lockstep with the policy, otherwise the controller will promote score-improving but pathological versions.
Method
EvoTrainer formulates autonomous training as a sequence of evidence-conditioned version transitions over states
\mathcal{T}_i = (v_i, h_i, \mathcal{A}_i, d_i, \Delta_i, \omega_i),
where v_i is the policy version, h_i is the current diagnostic harness, \mathcal{A}_i = \{\text{metrics}, \text{rollouts}, \text{configs}, \text{logs}, \text{diffs}\} are run artifacts, d_i is the harness-produced diagnosis, \Delta_i is the proposed intervention, and \omega_i \in \{\text{improve}, \text{regress}, \text{mixed}, \text{insufficient}\} is the labeled outcome. Crucially, the four-valued outcome space prevents the reduction of a run to a binary keep/reject — a score-improving version with a fragile reward, or a regressed branch that exposes a harmful intervention, are preserved as distinct evidence types.
The architecture (Figure 2) has three coupled loops:
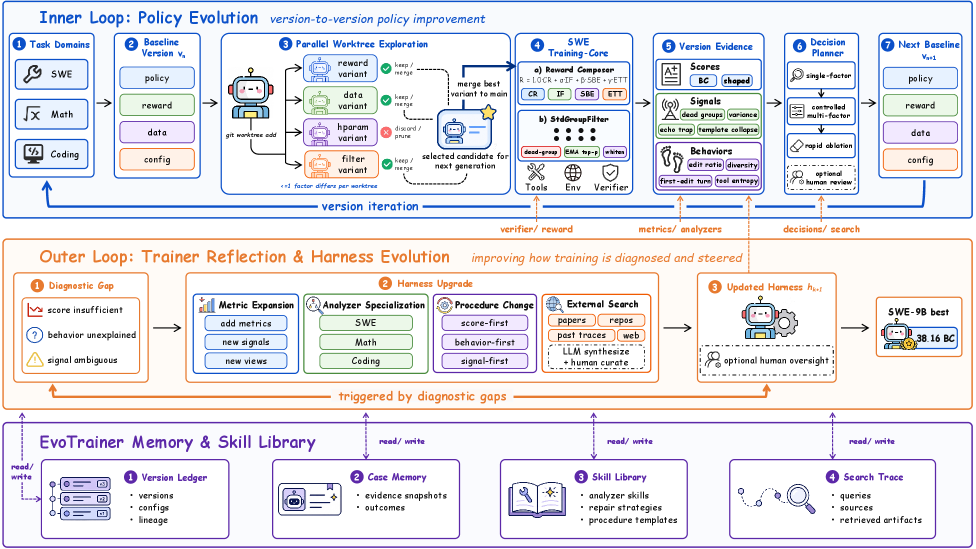
- Policy self-evolution (upper loop): controlled exploration produces v_{i+1} from v_i via intervention \Delta_i (reward shaping, curriculum changes, scaffold edits). Each candidate is trained, rolled out, and the artifacts are passed to h_i for diagnosis.
- Harness evolution (middle loop): the diagnostic code itself is revised when current diagnostics fail to discriminate among \omega_i classes — for example, when high-reward rollouts are later shown to exploit test scaffolding. Revised diagnostics are backtested on the artifact archive \{\mathcal{A}_j\}_{j \le i}, so a new diagnostic must retroactively recover known good/bad labels before being adopted.
- Persistent memory (bottom layer): successful interventions are abstracted into reusable skills keyed by failure-mode signatures, so later search can condition proposals on prior evidence rather than restart from scratch.
The “training-core” panel of Figure 2 instantiates this for SWE, where rollouts are agent–tool trajectories in Docker sandboxes scored by hidden fail-to-pass tests.
Results
The three evaluation domains span single-turn verifiable tasks to long-horizon agentic interaction:
- Math: trained on 6,429 BigMath-Hard problems (with the AIME 2024 P5 overlap removed), evaluated on 78 problems (AIME 2024, AIME 2025, CNMO 2024) under Avg@8.
- Coding: trained on 11,897 TACO-verified problems, evaluated on 175 LiveCodeBench-v6 AtCoder Beginner Contest problems with earlier-released items excluded to avoid contamination, giving an OOD protocol.
- SWE: trained on 8,622 swe-rebench-v6 instances, evaluated on 77 held-out Python instances using a frozen tool scaffold and hidden fail-to-pass tests, with bug-coverage percent (BC%) as the metric.
The headline number is on long-horizon agentic SWE: EvoTrainer exceeds the human-engineered RL baseline on SWE-9B by +4.39 BC% (Figure 1).
The per-version trajectories on the promoted path (Figure 3) show qualitatively different search dynamics across domains: SWE-9B and SWE-4B exhibit several non-monotonic dips before the final retained version, consistent with the harness rejecting branches whose initial score gains came from invalid trajectories; Math and Coding trajectories are smoother, suggesting that single-turn verifiable rewards already provide most of the signal a static harness would need.
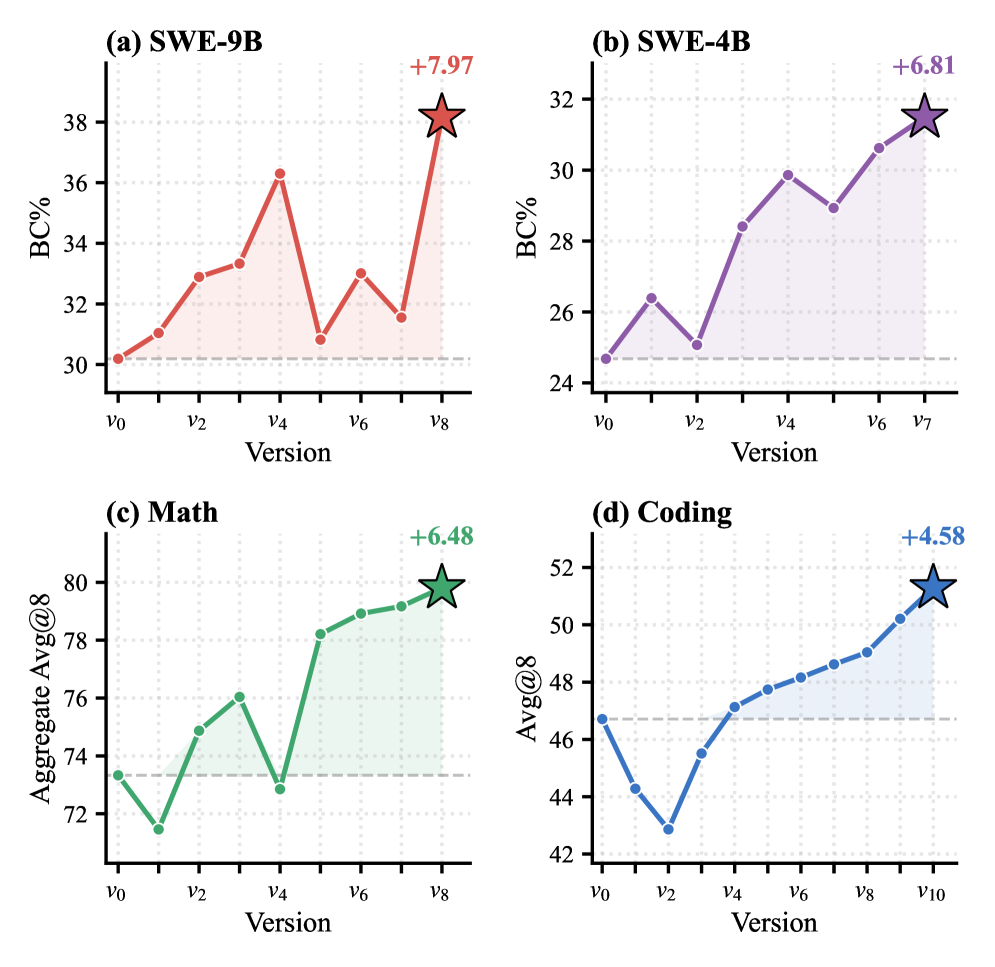
The trajectory analyses also report two qualitative findings the authors emphasize: (i) retained strategies diverge across domains — i.e., the skill library is not domain-general but specializes — and (ii) evolving diagnostics demonstrably prevent invalid high-scoring branches from being promoted, which is the central justification for harness co-evolution.
Limitations and open questions
The paper reports a single seed of the autonomous trajectory per condition, so variance over the controller’s stochastic search is not quantified; given that Figure 3 shows non-monotonic per-version curves, run-to-run variance in the final retained version is likely material. The +4.39 BC% gain on SWE-9B is the largest improvement and the headline result, but absolute differences on Math and Coding are not stated in the provided sections. The harness-evolution mechanism depends on backtesting against the artifact archive, which biases new diagnostics toward consistency with past labels — an open question is whether this introduces conservatism that suppresses genuinely novel failure modes. Finally, the controller and diagnostic harness are themselves LLM-driven; the cost of co-evolution relative to a fixed-harness recipe search is not characterized in the excerpted sections.
Why this matters
Most autonomous-RL controllers treat the training harness as ground truth and search only over recipes, which is exactly the regime where reward hacking and silent agentic failures are hardest to detect. EvoTrainer’s evidence that co-evolving the diagnostic layer matters most on long-horizon SWE — and least on single-turn verifiable tasks — is a useful empirical map of where harness fragility actually binds.
Source: https://arxiv.org/abs/2606.03108
Embodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models
Embodied-R1.5 is an 8B-parameter Embodied Foundation Model (EFM) built on Qwen3-VL-8B-Instruct that consolidates three traditionally siloed capability families — spatial cognition, task planning/correction, and pointing/trajectory grounding — into a single autoregressive policy. The motivation is straightforward: cascaded VLM-planner + grounding-model + error-detector stacks lose information at every interface and require multi-agent orchestration. If a single model carries all three roles, the corrector can directly read the planner’s reasoning context and the grounder’s spatial state, and the system scales monotonically with the underlying model.
Capability taxonomy and architecture
The authors decompose the EFM problem into three dimensions arranged as a perception→decision→execution chain (see Figure 2).
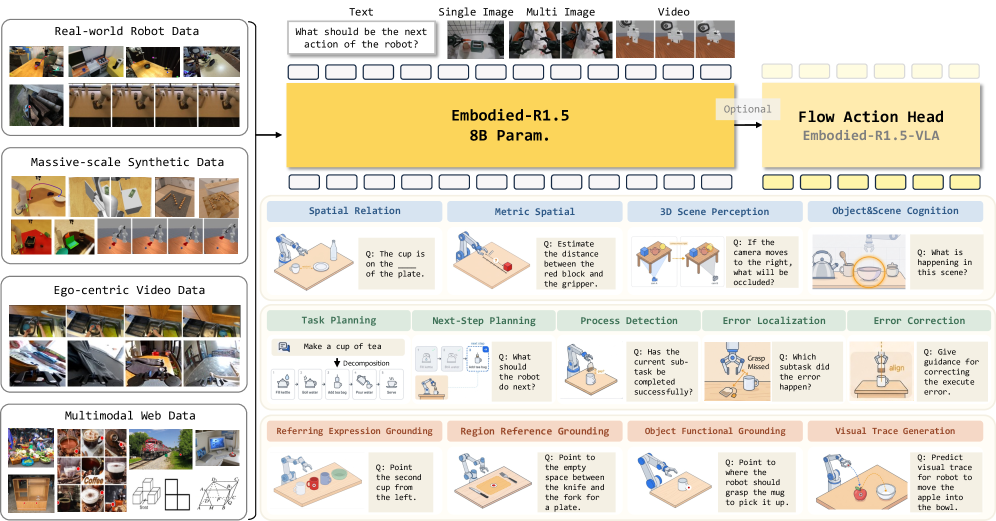
- Cognition & Spatial Reasoning: spatial relations, metric reasoning (distances, free-space sizing), monocular depth and cross-view geometry, and robot-centric scene cognition.
- Planning & Correction: long-horizon decomposition, next-step rollout, and a three-level error chain (detection → localization → correction).
- Pointing & Location: 2D pointing, object-functional-part grounding (OFG), and visual trajectory grounding (VTG).
All outputs — natural language, point coordinates, trajectory token sequences — are emitted as tokens under a single causal LM objective. The model can be extended to a VLA by attaching a lightweight flow-matching action expert.
Data: three automated pipelines, ~15B tokens
The training corpus aggregates 34 datasets and is supplemented by three proprietary pipelines targeting documented coverage gaps:
- Pipeline 1 — ER1.5-Spatial (~20K samples): 3D semantic scene graphs reconstructed from RGB frames in Fractal/BridgeData V2/DROID. The pipeline chains MoGe-2 metric monocular geometry, Grounded-SAM open-vocabulary segmentation, and RANSAC ground-plane alignment, then programmatically synthesizes spatial QA. This addresses the tabletop manipulation gap left by room-level datasets like VLM-3R and Cambrian-S.
- Pipeline 2 — ER1.5-Correction (~800K samples): failure annotations along two axes (planning vs. execution failure × detection/localization/correction), giving 6 QA types. Planning failures use five perturbation operators (omission, redundancy, swap, object error, action replacement); execution failures combine video truncation, description replacement, and physics-engine perturbation in ManiSkill/GEMBench.
- Pipeline 3 — Affordance and Trajectory for pointing and VTG.
Training
Stage 1 is full-parameter SFT on the unified 15B-token corpus for one epoch: AdamW, bf16, peak LR 2\times10^{-6} with cosine decay and 10% warmup, global batch 512, 8192-token context. The vision encoder is unfrozen because the embodied visual distribution diverges substantially from web pretraining.
Stage 2 is RFT with verifiable rewards, with a multi-task balanced recipe to mitigate gradient conflict between heterogeneous tasks (pointing IoU rewards vs. correction text rewards). Pointing benefits most from RL because its rewards are densely verifiable (geometric metrics on coordinates).
PGC closed-loop autonomy
A single Embodied-R1.5 instance is invoked under three roles — Planner, Grounder, Corrector — sharing a FIFO image/status memory buffer (Figure 3).
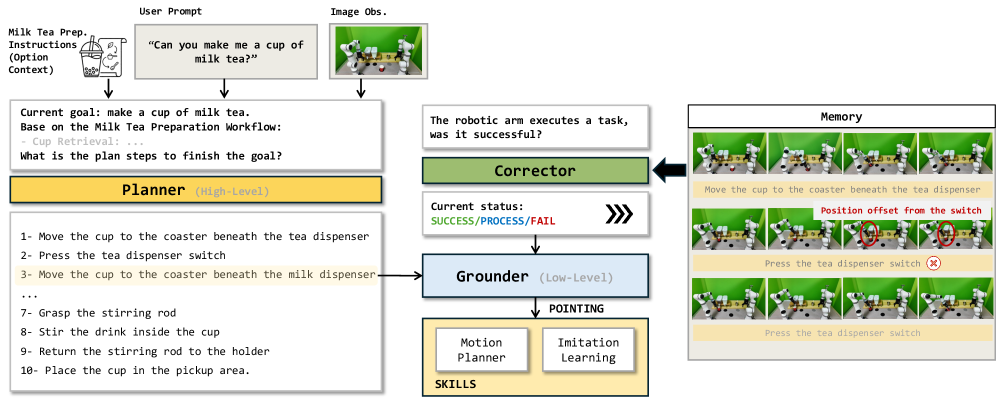
The Planner decomposes the instruction and re-plans after each sub-task; the Grounder adaptively composes pointing primitives (e.g. OFG to localize a switch, then VTG for the press trajectory); the Corrector runs as an asynchronous query returning {SUCCESS, PROCESS, FAIL} and triggers replanning on failure. Crucially, the harness contains no heuristic logic — all decisions come from the shared model, so error attribution sees both planner reasoning and grounder geometry without serialization loss.
Quantitative results
On Embodied Planning & Correction (Table 1, 4 benchmarks):
- Embodied-R1.5 averages 65.3, vs. GPT-5.4 53.8, Mimo-Embodied 54.1, Qwen3-VL-8B 54.2, Gemini-Robotics-ER-1.5 41.3.
- Per-benchmark: RoboVQA 61.0, EgoPlan-2 53.8, Cosmos-Reason 69.3, RoboFAC 77.2 (the latter a +7 absolute over GPT-5.4’s 70.1).
Across the full 24-benchmark embodied VLM suite the model reports SOTA on 16/24 benchmarks. On manipulation benchmark suites, fine-tuning the EFM into a VLA with a small action-expert head outperforms \pi_{0.5} on 4 manipulation suites — the headline being that internalized embodied reasoning reduces the action-data requirement for VLA distillation. Zero-shot real-robot experiments cover instruction following, tool affordance, and long-horizon manipulation under PGC.
The authors also release EmbodiedEvalKit, a four-layer evaluation framework (data, inference, parsing, evaluation) that normalizes coordinate conventions (1000-normalized, absolute pixel, etc.) across 25+ benchmarks and 20+ models — addressing a real reproducibility problem since prior embodied papers used ad-hoc parsers and non-overlapping subsets.
Limitations and open questions
- The PGC memory module is a fixed-rate FIFO buffer; longer-horizon tasks likely need hierarchical or retrieval-based memory, which the authors acknowledge.
- The Corrector’s asynchronous query frequency vs. low-level controller rate is not characterized; latency-accuracy tradeoffs in real deployment remain open.
- Multi-task RL conflict is mentioned but the balancing recipe details are deferred to the appendix; reproducibility of the RFT phase will hinge on those specifics.
- The VLA fine-tuning comparison to \pi_{0.5} uses “small amount of data” — exact data scaling curves would clarify how much of the gain is from EFM priors vs. dataset overlap.
- All grounding is 2D pixel-space; despite the depth/3D training data, the executable output is points and 2D traces, leaving open whether direct 3D pointing would help precision manipulation.
Why this matters
A single 8B model that subsumes planner, grounder, and corrector roles — and beats GPT-5.4 and Gemini-Robotics-ER-1.5 on the majority of embodied benchmarks while serving as a strong VLA initialization — is concrete evidence that capability unification, not multi-agent cascading, is the right axis for scaling embodied intelligence. The accompanying EmbodiedEvalKit and the failure-aware correction data pipeline are reusable infrastructure that the field has been missing.
Source: https://arxiv.org/abs/2606.11324
Toward Generalist Autonomous Research via Hypothesis-Tree Refinement
Autonomous optimization (AO) — letting an agent iteratively edit a research artifact to improve a held-out metric without step-level human supervision — exposes a weakness of standard agent loops: transient trials do not compose into cumulative knowledge. This paper introduces Arbor, a coordinator–executor framework whose central state is a persistent Hypothesis Tree, refined by a procedure the authors call Hypothesis Tree Refinement (HTR).
Problem setup
The authors formalize AO as a tuple \mathcal{P}=(\mathcal{M}_0,\mathcal{O},\mathcal{E}_{\mathrm{dev}},\mathcal{E}_{\mathrm{test}}), where \mathcal{M}_0 is the mutable artifact (typically a codebase plus data), \mathcal{O} specifies a metric direction, and the two evaluators instantiate that objective on different evidence. The agent may freely query \mathcal{E}_{\mathrm{dev}} during search but must not use \mathcal{E}_{\mathrm{test}} as an oracle. The artifact-level goal is
\mathcal{M}^{\star}=\arg\max_{\mathcal{M}'\in\mathcal{A}} S_{\mathrm{test}}(\mathcal{M}'),
where \mathcal{A} is the set of candidates the agent generated using only dev feedback. This separation is critical: a candidate that overfits idiosyncrasies of \mathcal{E}_{\mathrm{dev}} does not count as an AO solution. It also recasts the design problem: how do you allocate exploration on a noisy proxy while admitting changes only when they transfer?
Arbor’s three design requirements
Arbor is built around three constraints the authors argue any AO system must satisfy:
- Branching with coherence. Multiple plausible hypotheses must coexist as a frontier rather than as an unstructured log.
- Global strategy with local execution. Strategic decisions depend on cross-run evidence; implementation requires short-horizon code edits and debugging. These should be decoupled.
- Exploration with held-out admission. Dev feedback drives search, but artifact promotion requires transfer to \mathcal{E}_{\mathrm{test}}.
Method: HTR
The persistent state is a tree whose nodes bind together four objects: a hypothesis (natural-language statement of the proposed change), the artifact version that realizes it (a code worktree), the evaluation evidence (scores and logs from \mathcal{E}_{\mathrm{dev}}), and a distilled insight that should influence future decisions. A long-lived coordinator owns this tree globally: it inspects the frontier, proposes refinements, selects promising leaves, integrates returned evidence, propagates insights upward (so that a sibling branch can benefit from a failure mode discovered elsewhere), and decides whether to continue, prune, or merge a branch.
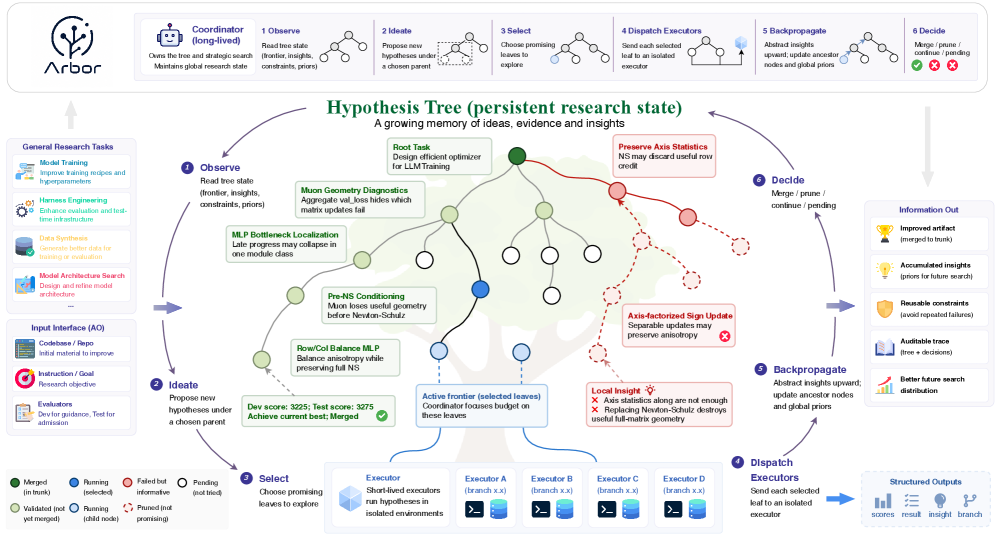
Short-lived executors test selected hypotheses in isolated worktrees and return compact reports — scalar scores, factual results, distilled insights, and artifact references — back to the coordinator. Crucially, low-level execution traces (compiler errors, debug attempts, evaluator stderr) stay inside the executor and never pollute the coordinator’s context, which preserves attribution from outcome to hypothesis.
A held-out merge gate sits between dev-driven exploration and the running “best artifact”: a candidate is promoted only when its dev gain transfers under \mathcal{E}_{\mathrm{test}}. This is the mechanism by which Arbor distinguishes exploratory progress from verified progress, and it is the operational analogue of the AO objective above.
Tasks and results
The AO suite includes model-training tasks built on existing benchmarks. Optimizer Design uses NanoGPT-Bench, with the official tuned Muon optimizer as \mathcal{M}_0; the dev evaluator is the standard benchmark and the test evaluator reruns the agent’s optimizer on two held-out seeds, reporting average step count to a target validation loss. Architecture Design uses Karpathy’s autoresearch benchmark, where the agent modifies an LLM training codebase under a fixed time budget, again averaged over two held-out seeds.
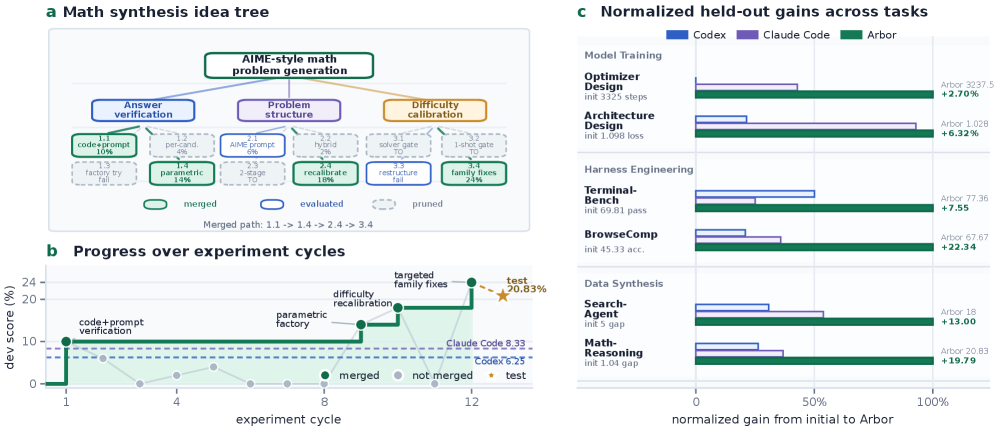
Figure 1(c) reports normalized held-out gains across all tasks, and Figure 1(b) shows a dev-score trajectory from a Math-Reasoning Data Synthesis run that demonstrates the cumulative pattern HTR aims to produce: improvements arrive in clusters tied to insight propagation, not as i.i.d. random improvements.
The paper also evaluates two forms of generality (Figure 3): (a) swapping the LLM backbone while keeping controller, evaluator budget, and task adapters fixed, and (b) freezing a search harness evolved on BrowseComp and applying it to held-out search-agent tasks without further task-specific tuning. Both probe whether the artifacts Arbor produces are properties of the harness rather than the backbone.
Limitations and open questions
The provided sections describe the AO setup and framework but leave several questions unresolved at the level of mechanism. The merge gate’s statistical reliability depends on the variance of \mathcal{E}_{\mathrm{test}} — averaging only two seeds (as in the NanoGPT and autoresearch tasks) is a weak transfer test. The insight-propagation step is the load-bearing element of HTR but its exact representation, how conflicts between sibling insights are resolved, and how stale insights are retired, are not specified in the excerpts. Compute accounting (how many executor runs per coordinator decision, total wall-clock per task) is also necessary before the approach can be compared head-to-head with simpler bandit-style or evolutionary baselines. Finally, the framework presumes a cheap, executable \mathcal{E}_{\mathrm{dev}}; tasks where evaluation requires human judgment or long training runs will stress the executor budget assumptions.
Why this matters
AO formalizes “an agent improves a research artifact under a held-out metric” cleanly enough to compare systems, and Arbor isolates the right axis — durable, structured research state with explicit insight propagation — rather than treating autonomous research as a longer agent loop. If HTR-style cumulative state genuinely outperforms flat trial-and-error on transfer-validated metrics, it shifts agentic research from prompt engineering toward search-process design.
Source: https://arxiv.org/abs/2606.11926
DeNovoSWE: Scaling Long-Horizon Environments for Generating Entire Repositories from Scratch
Problem
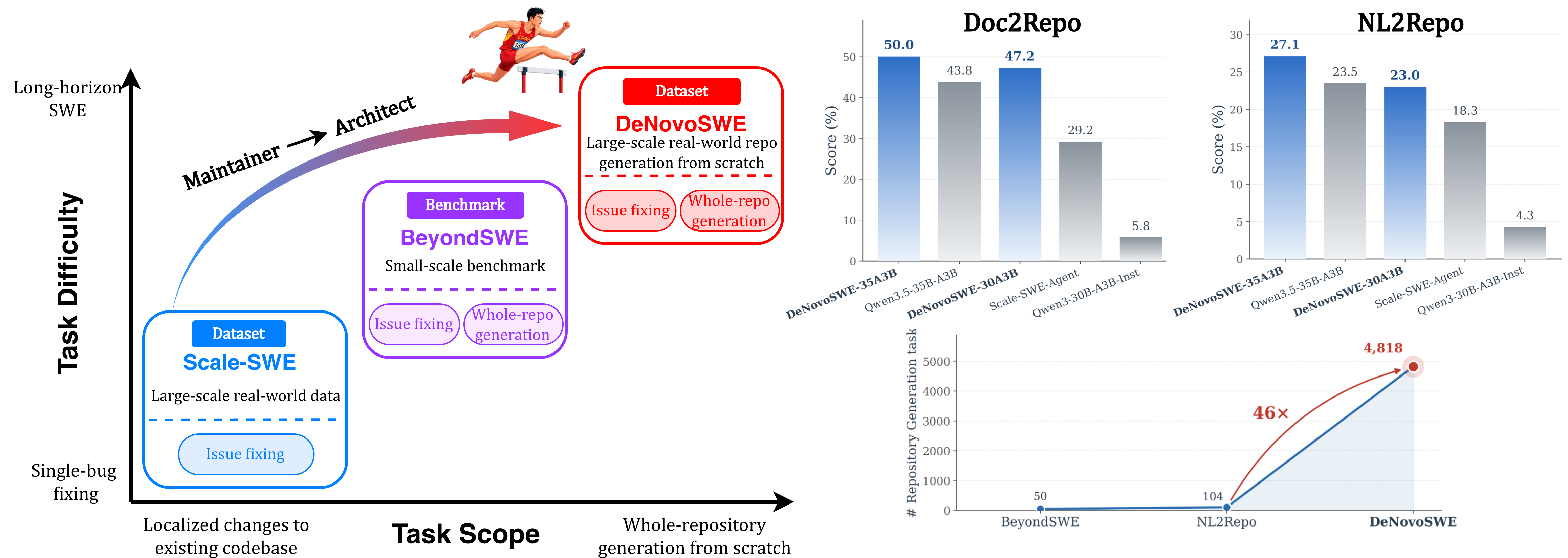
Most code-agent training data targets localized issue resolution: SWE-Bench-style instances modify a small number of files in an existing repository against pre-existing tests. The next regime — synthesizing a full repository from a specification — is largely unsupervised because verifiable, executable, repository-scale generation tasks are scarce. Producing such data manually is infeasible: each instance requires (i) a documentation artifact rich enough to fully constrain implementation, (ii) a test suite that actually exercises the spec, and (iii) a sandboxed environment in which an agent’s generated repository can be built and evaluated end-to-end. DeNovoSWE attacks this gap with an automated pipeline that emits 4,818 doc-to-repo instances and uses them to train an agent that goes from 5.8% to 47.2% on BeyondSWE-Doc2Repo.
Method
The construction pipeline reverses the doc-to-repo task: starting from real repositories with passing test suites, it generates documentation rich enough that an agent reading only the doc can reconstruct an implementation that passes those same tests. The system follows a divide-and-conquer schema with an iterative critic-repair loop.
Divide phase. Two concurrent tracks operate on each source repository:
- Repository ability partitioning. An overview-writer agent produces a global summary; a capability-writer agent then segments the repo into functional capabilities and assigns implementation units (modules, classes, functions, public APIs) to each. Each capability becomes a chapter in the final document.
- Repository profiling. The unit-test suite is executed and runtime traces collected. Functions/classes are partitioned into direct (imported, instantiated, or invoked from test files), core indirect, and non-core indirect. Direct components must be documented with full import paths, public API signatures, and I/O behavior, since under-specifying them makes the generated repo untestable.
An LLM-as-judge then aligns the capability map with the profiling output to produce per-capability targets. 
Conquer phase. For each capability, a Draft → Critic → Repair loop generates documentation. The critic identifies omissions (missing API surface, missing dependency contracts, ambiguous behavior); the repair agent revises. Outputs are merged and pushed into a golden environment — a sandbox with the exact dependencies pre-installed, network restricted — where a software agent attempts to regenerate the repository from the doc and is scored against the original test suite. GPT-5.4/5.5 power the agentic modules in this construction loop.
Difficulty-aware trajectory filtering. Trajectories are scored by
\text{score} = \frac{N_{\text{passed}}}{N_{\text{total}}}.
A fixed cutoff (e.g., 0.95) conflates trajectory quality with task difficulty: hard repos rarely yield near-perfect rollouts, while easy repos admit weak trajectories under any lenient threshold. The authors construct a per-instance difficulty score from three signals: a structural signal e_i \in \mathbb{Z}_{\ge 0} (executable Python LOC in scope) and two independent 5-point LLM judgments \ell_i^{(g)}, \ell_i^{(q)} \in \{1,\dots,5\}. On the subset \mathcal{I}^\star with rollouts, the empirical pass rate
s_i = \frac{1}{|\mathcal{R}_i|}\sum_{r \in \mathcal{R}_i} \text{score}(r)
is the supervision target; a well-formed difficulty estimator should anti-correlate with s_i. Filtering thresholds are then made instance-specific: stricter on easy instances, lenient on hard ones, preserving rare high-quality hard trajectories.
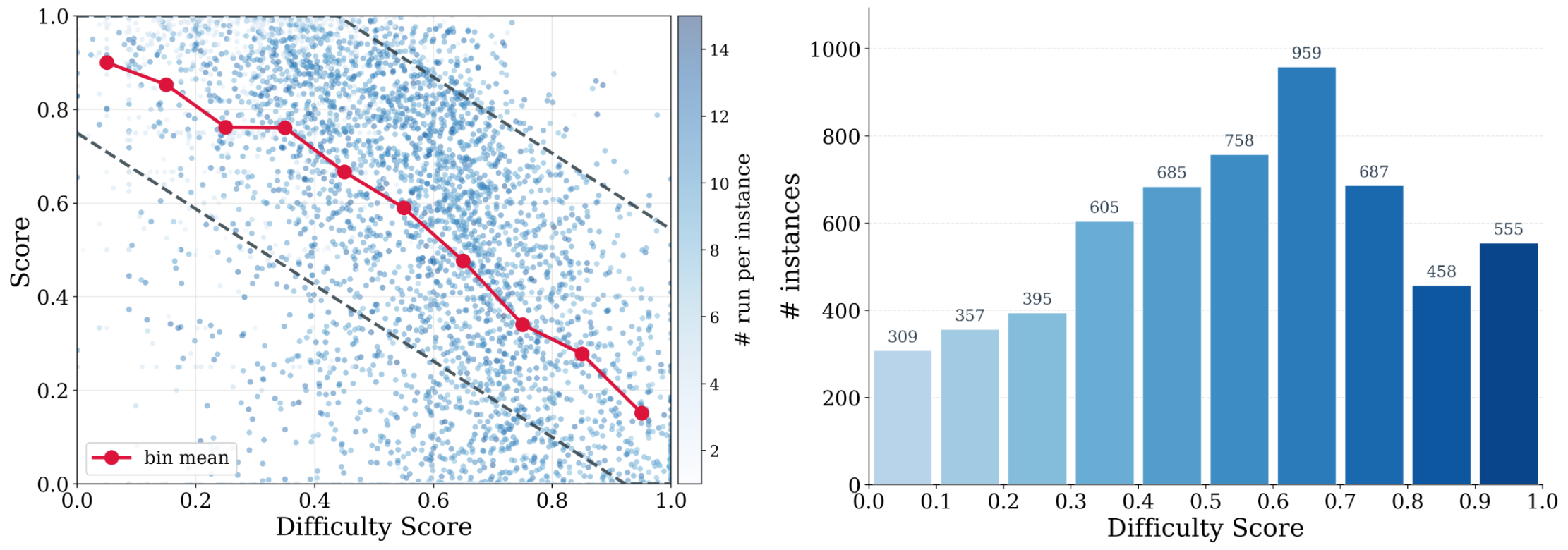
Training. Trajectories are generated with DeepSeek-V4-Pro High under OpenHands/AweAgent scaffolding: three rollouts per instance, plus three additional rollouts for instances that did not reach score 1.0. After difficulty-aware filtering, ~11k trajectories remain. SFT runs on Qwen3-30B-A3B-Instruct (and Qwen3.5-35B-A3B) at LR 1\text{e-}5, batch size 128, warmup 0.05, context 131,072. Loss is masked on assistant turns corresponding to failed tool invocations and heredoc operations — a useful detail, since these are common failure modes whose tokens would otherwise teach the model to imitate broken tool syntax.
Results
The headline number: fine-tuning Qwen3-30B-A3B on DeNovoSWE lifts BeyondSWE-Doc2Repo from 5.8% to 47.2%, an 8x improvement on a benchmark explicitly built to test from-scratch repository synthesis. Evaluation is conducted in the benchmark’s golden environment with three-trial averaging on BeyondSWE and NL2Repo-Bench. The dataset itself contains 4,818 instances; the trained set draws ~11k filtered trajectories.
Limitations and open questions
- The pipeline depends on GPT-5-class models for documentation synthesis and judging; data quality is bounded by their faithfulness in capturing API contracts. Errors in the critic stage will compound into spec-implementation mismatches that are nonetheless “passable” because the test suite happens to be silent on them.
- Difficulty calibration is anchored to rollouts from one model family; thresholds may not transfer when scaling to a different generator.
- BeyondSWE-Doc2Repo at 47.2% is far from saturation, and no head-to-head comparison against frontier closed models on the same benchmark is reported in the excerpted sections.
- Loss-masking heuristics for failed tool calls remove a noisy signal but also remove information about recovery trajectories; whether explicit error-recovery supervision would help is open.
- All source repos are Python; generalization to multi-language stacks (build systems, ABI-sensitive code) is untested.
Why this matters
Whole-repository synthesis is the natural scaling axis beyond issue-level SWE, and the bottleneck has been verifiable training data. DeNovoSWE shows that an automated divide-and-conquer pipeline plus difficulty-aware filtering yields enough signal to push a 30B MoE from near-zero to nearly half on a hard doc-to-repo benchmark, suggesting the data, not the model, was the binding constraint.
Source: https://arxiv.org/abs/2606.10728
Hacker News Signals
Can LLMs Beat Classical Hyperparameter Optimization Algorithms?
Source: https://arxiv.org/abs/2603.24647
The paper benchmarks LLMs as hyperparameter optimization (HPO) agents against classical baselines — Bayesian optimization (TPE, GP-BO), random search, and CMA-ES — across a suite of tabular and ML pipeline tuning tasks drawn from HPO-B and custom benchmarks.
The setup treats the LLM as a black-box optimizer: it receives the history of (configuration, performance) pairs as in-context text and proposes the next configuration to evaluate. No gradient signal, no fine-tuning; purely few-shot sequential decision-making. Models tested include GPT-4, GPT-3.5, and several open-weight variants.
Results are sobering for the LLM camp. On the majority of benchmarks, classical methods — particularly TPE and GP-BO — outperform LLMs in terms of final incumbent quality and anytime performance. LLMs show some competitive behavior on low-dimensional, well-structured search spaces where the prior encoded in pretraining happens to align with the problem domain. On higher-dimensional spaces or tasks requiring precise numerical reasoning (e.g., tuning learning rates across many orders of magnitude), LLMs degrade substantially. They also exhibit inconsistent exploration behavior: rather than principled acquisition-function-style reasoning, they tend to exploit early good results or, conversely, over-explore when framing shifts slightly.
One interesting finding: LLMs are sensitive to prompt formatting of numerical values. Representing losses as percentages versus raw floats measurably changes proposal quality, suggesting the optimization behavior is partly a surface-form artifact rather than genuine numerical reasoning.
The paper also flags cost: a single HPO run using GPT-4 costs orders of magnitude more than running Optuna for equivalent wall-clock budget, with worse results.
Open questions include whether fine-tuning on HPO traces could close the gap, and whether LLMs might complement classical methods as warm-start proposers rather than standalone optimizers. The results counsel against replacing principled probabilistic methods with LLM agents for structured numerical optimization.
DiffusionGemma: 4x Faster Text Generation
Google’s DiffusionGemma applies masked diffusion language modeling to the Gemma architecture, yielding a non-autoregressive text generation approach that claims roughly 4x throughput improvement over comparable autoregressive Gemma models at equivalent quality on standard benchmarks.
The core mechanism is masked diffusion: at training time, tokens are masked according to a noise schedule and the model learns to predict the original tokens from the corrupted sequence, conditioned on the unmasked context. At inference, generation begins from a fully masked sequence and iteratively denoises over T steps — critically, T can be much smaller than sequence length L, since each step refines all positions in parallel. The generation cost scales as O(T \cdot L) in parallel compute rather than O(L) sequential steps, but because T \ll L in practice and modern hardware saturates on parallel ops, wall-clock throughput improves substantially.
The 4x figure appears to come from comparing DiffusionGemma at T \approx 32{-}64 denoising steps against autoregressive Gemma with standard greedy/beam decoding at the same sequence length. The model uses the standard Gemma transformer backbone with minimal architectural changes; the main engineering work is adapting the training objective and inference loop.
Limitations worth noting: masked diffusion models historically lag autoregressive models on perplexity and open-ended generation quality, particularly for long, coherent text. The 4x speedup is throughput-focused and may not translate to latency improvements in single-request serving scenarios where autoregressive models are already fast. The blog post lacks detailed ablations on quality-vs-steps tradeoff curves, which would be the key engineering decision point for deployment. The approach also requires retraining rather than adapting existing autoregressive Gemma checkpoints. Whether the quality gap at matched throughput is acceptable for production use cases remains an open empirical question requiring more than benchmark numbers.
A €0.01 Bank Transfer Could Compromise a Banking AI Agent
Source: https://blue41.com/blog/how-we-helped-bunq-secure-their-financial-ai-assistant/
This is a practical disclosure of prompt injection vulnerabilities found in Bunq’s AI financial assistant during a security engagement. The attack vector is indirect prompt injection via transaction metadata: an attacker initiates a €0.01 transfer with a crafted payment description containing instruction text, which the AI assistant subsequently reads when the victim user queries their transaction history. The assistant, treating its context window as trusted, follows the injected instructions.
The technical substance is in the attack surface. Modern AI assistants over financial data must ingest untrusted user-generated content (transaction descriptions, merchant names, invoice text) and present it alongside system instructions in the same context. There is no hardware or cryptographic boundary between “data” and “instructions” — it is all tokens. Classical injection mitigations (input sanitization, output encoding) do not cleanly map to this threat model because the model must semantically process the content to be useful.
Demonstrated impact in the engagement included: exfiltrating account balance and transaction history by having the injected prompt instruct the assistant to summarize and forward data; potential for triggering actions if the assistant had tool-use capabilities for initiating transfers. The €0.01 cost makes this scalable — an attacker can carpet-bomb thousands of potential victims cheaply.
Mitigations discussed include: hierarchical trust levels in context (marking data-plane content explicitly), instruction-following restrictions on data retrieved from untrusted sources, sandboxed tool execution with explicit confirmation steps, and output filtering for common exfiltration patterns. None are complete defenses; they raise the bar rather than eliminate the vulnerability. The fundamental issue is that LLM-based agents with access to sensitive data and external tool use cannot safely ingest arbitrary text from their environment without architectural constraints that most current frameworks lack. This is a concrete illustration of why agentic systems over sensitive data require threat modeling distinct from classical application security.
An Introduction to Functional Analysis for Science and Engineering
Source: https://arxiv.org/abs/1904.02539
This is a graduate-level lecture note set (300+ pages) covering functional analysis with explicit orientation toward applications in PDEs, numerical methods, and physics — rather than the pure-mathematics treatment typical of Rudin or Conway.
The coverage spans: metric and normed spaces, Banach spaces, Hilbert spaces and orthonormal bases, bounded linear operators and their spectra, the Hahn-Banach and open mapping theorems, weak convergence, compact operators, spectral theory for self-adjoint operators, and an introduction to distributions and Sobolev spaces. The Sobolev space treatment is particularly useful for practitioners working with variational formulations of PDEs, as it provides the functional-analytic foundation for why weak solutions exist and when finite element approximations converge.
What distinguishes this from standard references is consistent motivational grounding: each abstraction is introduced alongside a concrete example from physics or numerics. The Lax-Milgram theorem, central to elliptic PDE well-posedness, is derived and immediately connected to Galerkin methods. The spectral theorem for compact self-adjoint operators is connected to Sturm-Liouville problems. Distributions are motivated through the need to differentiate non-smooth functions arising in shock solutions.
For ML researchers, functional analysis underpins kernel methods (RKHS theory), operator learning (neural operators as maps between function spaces), regularization theory (Tikhonov in Hilbert spaces), and the mean-field / measure-theoretic analysis of wide networks. The Sobolev embedding theorems, for instance, control when functions in H^k(\Omega) are continuous — directly relevant to approximation theory for neural nets on function spaces.
The notes are freely available and self-contained assuming standard linear algebra and real analysis. The level is appropriate for first-year PhD students in applied math, physics, or engineering who need working fluency rather than measure-theoretic rigor for its own sake.
Claude Desktop Spawns 1.8 GB Hyper-V VM on Every Launch, Even for Chat-Only Use
Source: https://github.com/anthropics/claude-code/issues/29045
The technical issue: Claude Desktop on Windows silently starts a full Hyper-V virtual machine at launch — reportedly ~1.8 GB memory footprint — regardless of whether the user intends to use any code execution or agentic features. This VM is tied to the Claude Code integration, which requires an isolated execution environment for safety reasons (sandboxed shell, file system access, etc.). The problem is that it is not lazy-loaded or gated on user opt-in; it initializes unconditionally.
The VM is almost certainly a Linux guest running under WSL2/Hyper-V, providing the sandboxed environment in which Claude Code executes shell commands and code. This is a reasonable security architecture: code execution from an LLM agent should be isolated from the host. The design error is unconditional initialization — the sandbox should be instantiated only when a session requiring code execution is started, or at minimum behind an explicit user opt-in toggle.
The concrete impact: on machines with 8-16 GB RAM, this is a significant background tax for users who launched Claude Desktop for conversational use. Hyper-V also conflicts with other hypervisors (VMware Workstation in certain configurations, older VirtualBox versions) due to the Windows hypervisor platform incompatibility, making this a hard breakage for some users, not just a performance complaint. Boot time for Claude Desktop is also meaningfully extended.
From an engineering standpoint, the right fix is deferred initialization: spawn the VM only when the user invokes a tool requiring execution, ideally with a visible UI indicator. Alternatively, provide a settings flag to fully disable Claude Code integration for users who do not need it. The issue thread notes this pattern follows a broader trend of desktop AI applications acquiring large system footprints with insufficient user control over resource consumption.
Apache Burr: Build Reliable AI Agents and Applications
Source: https://burr.apache.org/
Burr is a Python framework for building stateful AI applications and agents, recently accepted into the Apache incubator. The core abstraction is a state machine: applications are defined as directed graphs of Action nodes connected by transitions, with an explicit State object passed between nodes. This is conceptually close to LangGraph or AWS Step Functions but with a narrower, more opinionated API and built-in observability.
The key technical choices: state is immutable and explicitly threaded through the graph rather than stored in mutable class attributes. Each Action declares its reads and writes on state, enabling static analysis of data flow and simpler debugging. Transitions are guard-conditioned edges; the runtime evaluates conditions to determine next node. Actions can be synchronous or async, and the framework supports parallel fan-out.
@action(reads=["query"], writes=["response"])
def call_llm(state: State) -> tuple[dict, State]:
result = llm.invoke(state["query"])
return {"response": result}, state.update(response=result)The observability story is a differentiating feature: Burr ships a local UI (served via FastAPI) that records every state transition, inputs, outputs, and timing. Traces are persisted and replayable, which addresses a real pain point in debugging multi-step agent failures. The persistence layer supports pluggable backends (SQLite locally, Postgres for production).
Compared to LangGraph, Burr is more explicit about state schema and less graph-DSL-heavy; compared to raw Python with retry logic, it adds structure without a large dependency surface. The Apache governance model provides supply chain trust relevant to enterprise deployment. Limitations: the framework adds conceptual overhead for simple linear chains where a plain function call suffices, and the ecosystem of pre-built integrations is smaller than LangChain-adjacent tooling. The state machine model also assumes you can enumerate your control flow graph at definition time, which is awkward for highly dynamic agent topologies.
HelixDB: A Graph Database Built on Object Storage
Source: https://github.com/HelixDB/helix-db/tree/main
HelixDB is a graph database written in Rust that uses object storage (S3-compatible backends) as its primary persistence layer, departing from the local-disk-first architecture of systems like Neo4j or RocksDB-backed graph stores.
The storage model separates the graph topology (adjacency structure) from property data, storing each as independent objects in the object store. Node and edge records are serialized and addressed by UUID-derived keys. Reads involve fetching objects by key — effectively random-access GET requests to S3 — which is expensive in latency (~10ms per request) but cheap per byte and infinitely scalable in capacity. The architecture is therefore optimized for workloads where the working set fits in a local cache layer and queries do not require traversing large portions of the graph cold.
The caching tier (in-memory, with configurable capacity) absorbs repeated access patterns; the cold path pays full object-storage latency. This tradeoff makes HelixDB suitable for analytical or batch graph workloads but ill-suited for low-latency transactional graph queries where cache miss rates are high.
The query interface uses a custom traversal DSL compiled to a Rust execution engine, supporting standard graph operations: vertex/edge lookup by ID, property filtering, multi-hop traversal with predicate pushdown. The vector embedding support (noted in the README) integrates approximate nearest neighbor search for hybrid graph+vector retrieval patterns — increasingly common in RAG-style applications where entities have associated embeddings.
Being built in Rust with S3 as the backend makes deployment operationally simple: no local disk management, no backup orchestration, no volume provisioning. The object store handles durability. The open question is whether the latency profile is competitive with purpose-built graph databases for any query pattern outside the cache-hit-dominated regime. The project is early-stage; benchmarks against JanusGraph or Amazon Neptune on realistic traversal workloads are absent from the repository.
Port React Compiler to Rust
Source: https://github.com/react/react/pull/36173
This pull request initiates the work of rewriting the React Compiler — previously implemented in TypeScript — in Rust. The React Compiler performs automatic memoization: it statically analyzes React component and hook code to insert useMemo and useCallback calls, eliminating redundant re-renders without manual dependency array management.
The current TypeScript implementation runs as a Babel plugin or as a standalone transform integrated with bundlers (Vite, webpack, Next.js). The rewrite motivation is performance: the TypeScript compiler is bottlenecked by JS runtime overhead and single-threaded execution. A Rust implementation can be parallelized across files, integrated natively into Rust-based toolchains (Oxc, SWC, Rolldown), and eliminate the Babel dependency for projects already on those toolchains.
The PR is largely scaffolding at this stage: it establishes the crate structure, defines the IR types in Rust that mirror the TypeScript implementation’s HIR (high-level intermediate representation), and sets up the test harness to run the existing fixture-based test suite against the new implementation. The HIR represents components as control-flow graphs with scope analysis; the compiler’s core algorithm identifies “reactive” values — those derived from props or state — and determines the minimal memoization boundary.
The technical complexity in porting is not raw computation but the compiler’s semantic analysis: it must correctly model JavaScript’s reference equality semantics, aliasing, and the React rules of hooks. Subtle correctness bugs in memoization (over-memoizing causes stale closures; under-memoizing loses the optimization) require extensive test coverage. The existing fixture suite provides this, and the PR explicitly gates merge on passing all existing tests.
This fits the broader trend of JS toolchain components being rewritten in Rust (Biome, Oxc, SWC, esbuild-rs experiments) for build performance at scale, where compilation time is a significant developer experience cost.
Noteworthy New Repositories
margelo/react-native-runtimes
React Native’s single JS thread is a well-known bottleneck: heavy computation, large JSON parsing, or complex business logic blocks the UI. This library solves that by spinning up isolated Hermes VM instances alongside the main runtime, each with its own event loop and memory heap. Workers are created via a straightforward API, communicate via structured message passing, and can import arbitrary JS modules. Because each runtime is a full Hermes instance rather than a Web Worker shim, you get the same JIT/bytecode compilation characteristics as the main thread — no degraded execution model. The implementation hooks into JSI (JavaScript Interface) at the native layer for both iOS and Android, keeping the bridge overhead minimal. It is architecturally similar to what Shopify’s own apps use internally for offloading catalog processing. Practical use cases include image metadata processing, cryptographic operations, local ML inference drivers, and background sync logic. Compared to react-native-workers (which predates modern JSI and uses a serialization-heavy bridge), this is a cleaner, lower-latency design. Worth evaluating any time profiling reveals JS thread saturation that layout or render optimization alone cannot fix.
Source: https://github.com/margelo/react-native-runtimes
study8677/awesome-architecture
A structured, bilingual (English/Chinese) reference corpus for distributed and AI-native system design. Content is organized around three tiers: 26 tutorial documents covering foundational patterns (consensus, sharding, replication, cache invalidation), 25 reusable architecture templates (event-driven, CQRS, saga, sidecar, etc.), and 6 end-to-end case studies that trace design decisions through production trade-offs. The AI-native section is technically specific: it covers RAG pipeline architectures (chunking strategies, vector index selection, hybrid retrieval), coding agent scaffolding (tool use, memory, context management), and LLM serving infrastructure. Rather than abstract diagrams, templates include component breakdowns with latency and consistency annotations. The bilingual format makes it useful for teams working across language boundaries, or for tracing how architectural terminology translates between communities. Not a library — pure documentation — but the density of concrete trade-off discussion distinguishes it from typical “awesome-X” lists. Most useful as onboarding material for engineers moving from application development into infrastructure or AI platform roles, or as a checklist during design review.
Source: https://github.com/study8677/awesome-architecture
Evokoa/pgGraph
Graph queries against relational data typically require either migrating to a dedicated graph database (Neo4j, ArangoDB) or writing recursive CTEs by hand. pgGraph adds graph semantics directly on top of PostgreSQL without a separate process: it uses Postgres extension infrastructure to expose a graph query layer over standard tables, treating foreign-key relationships and explicitly declared edge tables as graph edges. Traversal queries (BFS, DFS, shortest path, k-hop neighborhood) are compiled into optimized SQL with WITH RECURSIVE or lateral joins under the hood, avoiding round-trips through application code. Schema declaration is lightweight — annotate existing tables or define edge tables with source/target columns. The extension is written in C (standard PG extension model) with a thin SQL API surface. This is meaningful for applications that already live in Postgres and have graph-shaped access patterns (social graphs, dependency resolution, knowledge graphs, fraud rings) but cannot justify operational complexity of a separate graph store. The main constraint is that very deep traversals will still hit Postgres query planner limits that a native graph engine avoids via pointer-chasing storage.
Source: https://github.com/Evokoa/pgGraph
duncatzat/vigils
A local control plane for AI agent processes, built with Rust (backend), Tauri (desktop shell), and a Chrome Manifest V3 extension. The architecture intercepts agent tool calls and browser actions before execution, presenting them to the user for approval or rejection with full context. Secret management is a first-class concern: the system detects when agents are about to transmit strings matching credential patterns (API keys, tokens, env vars) and blocks or redacts them. The Rust core handles process supervision and a policy engine; Tauri provides a native UI without Electron’s weight; the MV3 extension hooks into browser-side agent actions (Playwright-driven or direct). This is distinct from cloud-based agent observability platforms — everything runs locally with no telemetry egress, which matters for enterprise or security-sensitive workflows. The approval workflow is configurable from fully automatic to fully supervised, with rule-based policies for trusted action classes. The main open question is latency introduced into tight agent loops when manual approval is required, though async approval queuing partially addresses this.
Source: https://github.com/duncatzat/vigils
trynullsec/nullsec-s1
An LLM-based application security system targeting the automated discovery and triage of vulnerabilities in generated or human-written code. The architecture is “security-native” in that the model is fine-tuned or prompted specifically on security corpora (CVE descriptions, CWE taxonomy, exploit patterns, OWASP categories) rather than being a general coding assistant with security prompts bolted on. The system covers SAST-style static analysis, dependency vulnerability mapping, and generation of remediation patches — all driven through a single LLM pipeline. Integration targets CI/CD pipelines and code review workflows. The practical differentiator claim is lower false-positive rates compared to rule-based SAST tools (Semgrep, CodeQL) on novel vulnerability patterns that lack prior signatures. Skepticism is warranted until benchmark methodology is published: LLM-based security tools have a known failure mode of confident but incorrect assessments. The repo is early-stage; the most valuable near-term use case is likely triage assistance and remediation suggestion rather than autonomous vulnerability discovery in production.
Source: https://github.com/trynullsec/nullsec-s1
WantongC/journal-adapt-writing-skill
Academic manuscripts are frequently desk-rejected or penalized in review for stylistic mismatch with a target journal’s conventions — sentence complexity, hedging density, citation placement, section structure. This tool automates convention extraction from a corpus of published papers from a target journal, then rewrites a submitted manuscript section by section to match. The pipeline involves: (1) parsing PDFs of published papers to extract stylometric features and structural patterns; (2) building a journal-specific style profile; (3) using an LLM (configurable backend) to rewrite each section under the extracted constraints while preserving scientific content. The section-by-section approach is deliberate — it keeps context windows manageable and lets authors review changes incrementally. Built in Python, using standard PDF extraction and LLM API calls. Limitations are inherent to LLM-based rewriting: content drift is possible, and style profiles extracted from small corpora may be noisy. Most useful for non-native English writers targeting high-specificity venues, or for adapting a paper from one subfield’s conventions to another’s.
Source: https://github.com/WantongC/journal-adapt-writing-skill
seochecks-ai/slopless
A deterministic, LLM-free CLI and textlint rule set for detecting low-quality prose patterns in English Markdown. “Slop” is operationalized as a specific, auditable list of anti-patterns: filler phrases (“it is worth noting that”), hedge stacking, passive-voice overuse in contexts where active is standard, AI-characteristic n-grams (phrases statistically overrepresented in LLM output vs. human technical writing), nominalization chains, and vague intensifiers. Rules are implemented as textlint plugins, making them composable with existing lint pipelines and CI workflows. The deterministic approach is a deliberate contrast to LLM-based writing quality tools: every flag maps to a specific, inspectable rule with a documented rationale, no false positives from model temperature, and zero API cost. Configuration allows disabling categories per project (e.g., passive voice rules inappropriate for formal specifications). Most immediately useful for documentation teams, technical bloggers, or any pipeline that ingests LLM-drafted text before publication. The rule corpus is the primary asset — its quality depends on how well the enumerated patterns track actual prose degradation, which is an ongoing empirical question.