デイリーAIダイジェスト — 2026-06-09
arXiv ハイライト
SWE-Explore: コーディングエージェントのリポジトリ探索能力をベンチマークする
SWE-benchのようなリポジトリレベルのコーディングベンチマークは、エージェントを「解決済み/未解決」という二値の結果でスコアリングします。これにより、リポジトリのナビゲーション、コンテキスト取得、障害の局在化、パッチ合成という互いに異なる能力が一つの数値に集約されてしまい、失敗の原因特定やサブシステムの改善が困難になります。SWE-Exploreはこれらのうち最初の能力、すなわち探索能力を単独で評価します。具体的には、issue q とリポジトリスナップショット \mathcal{R} が与えられたとき、固定された行数予算のもとで関連するコード領域のランク付きリストを返すタスクであり、パッチの生成もグラウンドトゥルースへのアクセスも不要です。
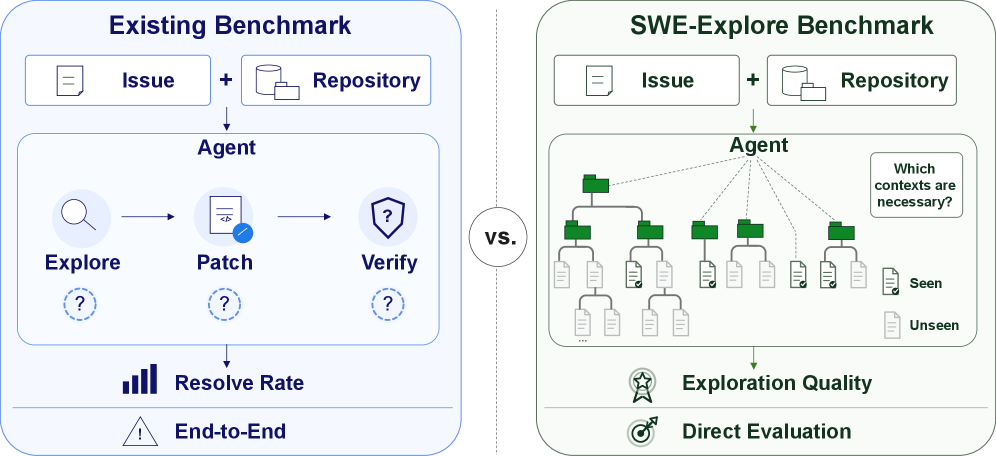
タスクとグラウンドトゥルース
エクスプローラーは以下の関数として定義されます。
f:(q,\mathcal{R}) \mapsto P=(r_1,r_2,\ldots,r_K), \qquad r_i=(p_i,s_i,e_i),
ここで各 r_i は(ファイルパス、開始行、終了行)の三つ組です。評価は、人手によるアノテーションやパッチのhunkではなく、軌跡(trajectory)に基づく教師信号に対して行われます。各インスタンスについて、著者はissueを正常に解決したエージェントの軌跡を取得し、読み取りアクション(ファイルのオープン、grep、範囲の閲覧)を抽出して、解決経路上で実際に参照された領域の「コア」集合 R_{\text{core}} と「オプショナル」なコンテキスト集合に集約します。独立して検証された軌跡から教師信号を蒸留することで、既知の問題を回避できます。すなわち、ゴールドパッチから導出されたグラウンドトゥルースは、issueの解決に実際に必要な補助的なコード(呼び出し元、テスト、設定ファイルなど)を過小に表現するという問題です。
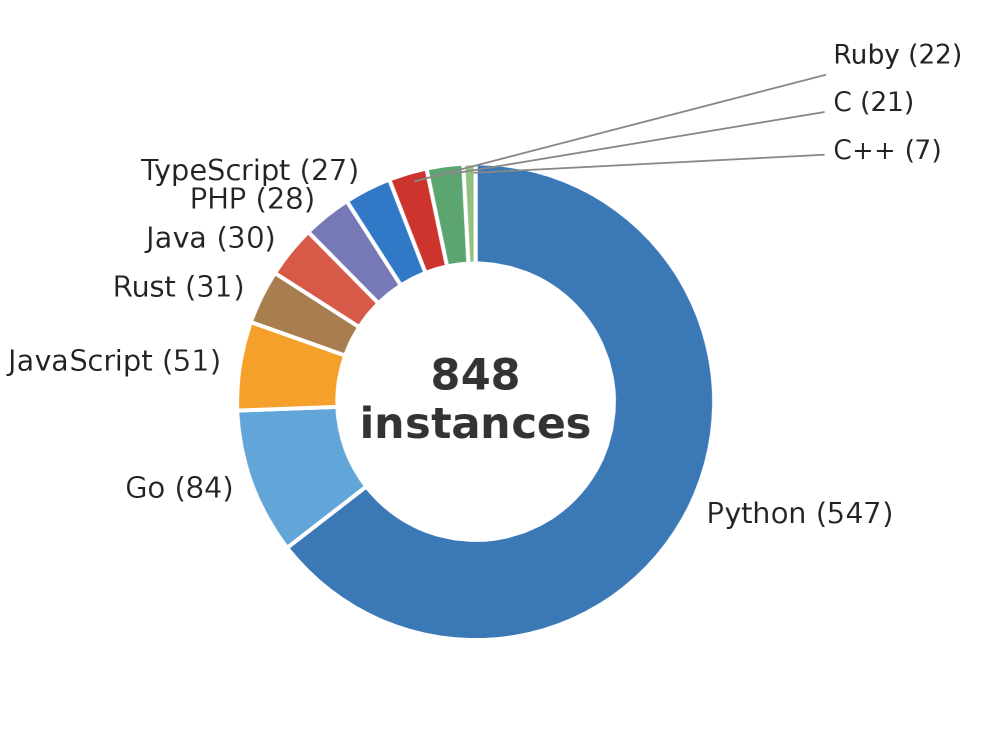
このベンチマークは203リポジトリ・10プログラミング言語にわたる848インスタンスを含み、SWE-bench系のスイートで主流であったPythonへの偏りを解消しています。
メトリクス
評価は三つの軸で行われます。(i) カバレッジ — 返された領域が R_{\text{core}} と行レベルでどれだけ重なるか、(ii) ランキング — 下流の修復LMがboundedなコンテキストを持つため、コア領域が P の早い位置に現れるかどうか、(iii) コンテキスト効率 — 消費した行数予算で正規化されたカバレッジであり、大きなファイルを丸ごと読み込むような振る舞いにペナルティを与えます。重要なのは、この評価がリポジトリの実行やパッチの生成を必要としないため、新しいエクスプローラーを低コストで差し込めることです。
また、標準的な評価ループには含まれない一回限りの方法論的チェックとして、著者は制限コンテキスト修復ブリッジを実行します。エクスプローラーが返した領域のみを固定の修復LMに入力し、解決率を測定するものです。これにより、上流のメトリクスが下流の修復と相関していることを、修復ノイズをエクスプローラーのスコアに組み込まずに検証できます。
評価対象のエクスプローラー
四つのファミリーがベンチマークされています。
- 上下限: Oracle(R_{\text{core}} を直接返す)とRandom(一様な領域サンプリング)。
- スパース検索: BM25、TF-IDF。
- dense検索: sentence transformerから蒸留した静的な単語embeddingリトリーバーであるPotionを用いたRAGパイプライン。
- エージェント型エクスプローラー: 汎用コーディングエージェント5種(Claude Code、Codex、OpenHands、Mini-SWE-Agent、AweAgent)と、局在化に特化した公開エージェント4種(AutoCodeRover、LocAgent、OrcaLoca、CoSIL)。
Oracleはさらにグラウンドトゥルース構築の検証にも使用されます。OracleのrepairブリッジによるPython解決率が高ければ、軌跡から蒸留された R_{\text{core}} が修復に十分であることが示され、教師信号が適切に構成されていることを確認できます。
ベンチマークが明らかにすること
このフレーミングが重要なのは、全体的なベンチマークでは分離できない失敗モードを切り離せるからです。適切なコンテキストが与えられれば正しいパッチを生成できるが、そのコンテキストを見つけられないエージェントは、SWE-bench上では、完璧に検索できるがパッチの品質が低いエージェントと区別がつきません。しかし、その改善策はまったく異なります。固定された行数予算のもとでカバレッジ、ランキング、コンテキスト効率をスコアリングすることで、SWE-Exploreは例えば「BM25に対するエージェントの改善が、より優れたナビゲーションによるものか、単により多くの行を読んだことによるものか」を問うことを可能にします。
選択されたセクションにはシステムごとの数値結果はまだ示されていませんが、abstractにはブリッジを通じてメトリクスが「下流の修復挙動を強く追跡する」と主張されており、四つのファミリー間には系統的なギャップが存在するとされています。これは、強力な汎用エージェントでさえ特化型の局在化エージェントと比べて探索が不十分であり、一方で特化型局在化エージェントはPython以外では脆弱になりうるという既存の観察と一致する結果です。
限界とオープンクエスチョン
軌跡から蒸留したグラウンドトゥルースは、成功した軌跡を生成したエージェントのバイアスを引き継ぎます。すなわち、代替的な解決経路が存在するとしても、いずれのソルバーも訪問しなかった領域は R_{\text{core}} に含まれません。また、行数予算の抽象化は、下流のコンシューマーがトークン制限のあるLMであることを前提としており、長期的なループの中で探索と編集を交互に行うエージェントは、その検索の動態ではなく、静的なランク付き出力のみで評価されます。さらに、修復ブリッジは単一の固定LMであるため、メトリクスが修復を追跡するという検証は、その修復モデルの失敗モードに条件付けられています。
なぜこれが重要か
サブタスクベンチマークは、「エージェントが機能した」から「どのコンポーネントを改善すべきかがわかる」へと研究分野を前進させる手段です。SWE-Exploreは、コーディングエージェント研究に対し、パイプラインの検索/ナビゲーション部分に向けた明確な行レベルのターゲットを提供します。多言語カバレッジと、ゴールドパッチのカバレッジ不足問題を回避した軌跡に基づく教師信号を備えています。
Source: https://arxiv.org/abs/2606.07297
On the Geometry of On-Policy Distillation
On-policy distillation(OPD)— studentが自身のrolloutをサンプリングし、そのrollout上でteacherのtoken-levelの分布と照合して学習する手法 — は、推論能力をより小さなLLMに転移するための主力手法となっています。本論文はパラメータ空間における構造的な問いを立てています:OPDは本質的に、異なる監督信号を用いたSFTなのか、より密な報酬を持つRLVRなのか、それとも幾何学的に異なる何かなのか? Qwen3ファミリーのチェックポイントに対する4種類のパラメータ空間診断およびtrajectory解析によって支持された答えは、第三の選択肢です。
SFTとRLVRの間にOPDを位置づける
著者らは、同一の数学プロンプト分布を共有するQwen3-8B SFTチェックポイントを起点とした3つのpost-trainingレジームを比較します。W_0をアンカー、\Delta W = W_+ - W_0をpost-trainingの更新量とします。4種類の診断が使用されます:
- bf16-aware更新スパース性。|\hat w_i - w_i| \le \eta \max(|w_i|,|\hat w_i|)(\eta = 10^{-3})の場合にw_iを変化なしとみなします;
- W_0とW_+の上位k部分空間における主角度回転;
- 特異値全体にわたるスペクトルドリフト;
- 更新マスクの局所化。可視な更新が主方向の重みに落ちるか、低マグニチュードの重みに落ちるかを問います。
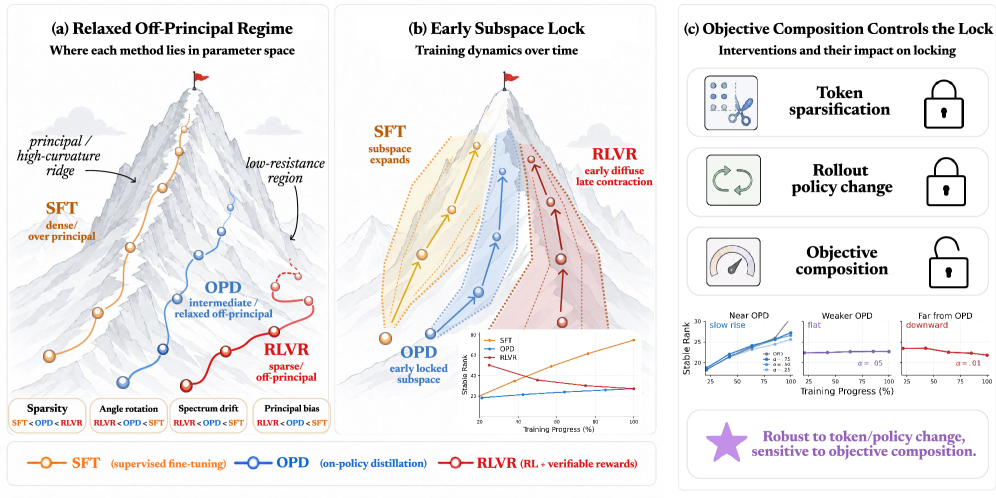
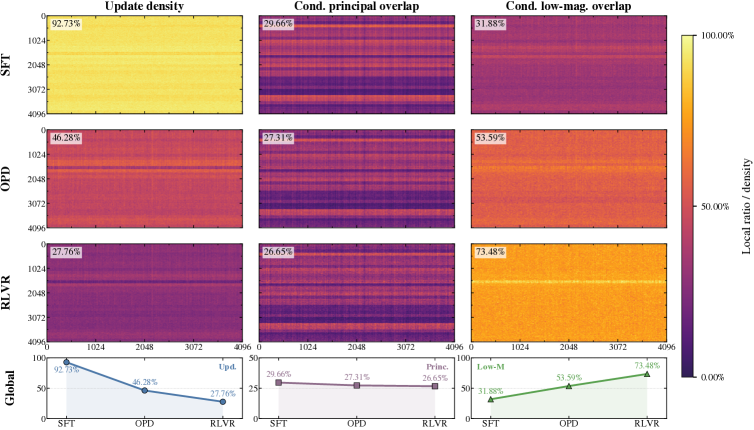
浮かび上がる描像(図1a)は「緩和されたoff-principal」レジームです:SFTは密でprincipal-alignedな更新を生成し、上位部分空間を回転させてスペクトルを再形成します;RLVRはスパースで強くoff-principalな更新を生成し、事前学習の幾何学を保存します;OPDはその中間に位置し、SFTより可視な重み変化が少なく、RLVRよりも幾何学的保存が弱くなっています。
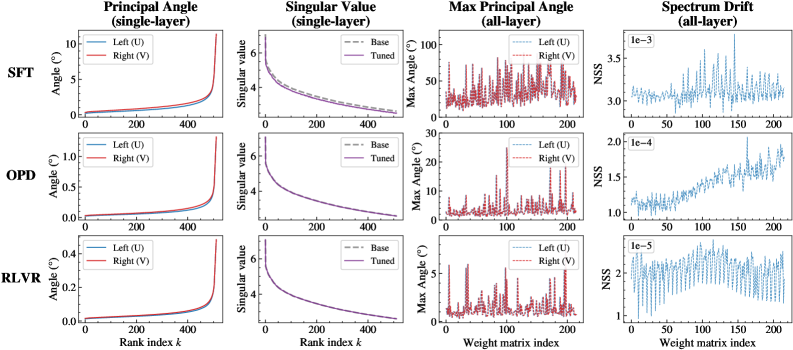
図2は主角度と特異値ドリフトのレベルでこれを具体化しています:SFTの回転曲線はランクインデックスkとともに急峻に上昇し、RLVRのそれは平坦を保ち、OPDのそれは一貫して中間に位置しますが、RLVRに近い傾向があります。図3の局所化分析はoff-principalバイアスを確認しています:OPDのbf16-visible更新は主要な重みを避け、低マグニチュードのエントリに集中しますが、RLVRほどの選択性はありません。
部分空間のロック
静的なエンドポイントの描像は、累積更新\Delta W_t = W_t - W_0を用いたtrajectory解析によって補完されます。鍵となる量はstable rankです:
\mathrm{srank}(\Delta W_t) = \frac{\|\Delta W_t\|_F^2}{\|\Delta W_t\|_{\mathrm{op}}^2},
これは解析された行列全体で平均されます。3つのtrajectoryが報告されています:
- SFT:学習が進むにつれてstable rankが成長し、更新部分空間が拡大します。
- RLVR:stable rankが低次元のエンドポイントに向かって収縮します。
- OPD:stable rankが早期に狭い低ランクバンドに入り、そこに留まり続けます。
したがってOPDは、SFTとRLVRの間の時間的補間ではなく、最初から低次元の更新チャネルにロックされます。OPDが単にWをほとんど動かさないという自明な説明を排除するために、著者らはFrobeniusノルムと特異値スペクトルのHill-tail推定値を追跡します。OPDはRLVRよりも実質的に大きなFrobenius更新を蓄積しながらも、比較可能なstable rankで終わり、そのHill-tailインデックスはSFTが急上昇しRLVRが下降する一方でわずかにしか変化しません。したがって低次元性は、更新のスケールではなく更新のスペクトル形状の性質です。
機能的な帰結は、OPDの早期に形成された更新部分空間に学習を制約することで検証されます:これはOPDの性能を保持しますが、SFTを大幅に劣化させます。早期にロックされた部分空間はOPDにとって機能的に十分ですが、SFTには表現力が不十分であり、OPDのロックされたチャネルが実際の学習が起きている場所であることの直接的な証拠となっています。
ロックを維持するもの
セクション5では、stable rankを監視しながら3つの候補ドライバーを摂動させています。
- トークンスパース化:上位KLトークンのみを保持するか、25%および50%の密度でランダムトークンを保持します。スパース化されたすべての変種はOPDのstable rankのtrajectoryに近く追従し、ランダム25%保持でさえスペクトル形状よりも更新スケールをより多く変化させます。したがってロックは高KLの「teaching」トークンの小さなセットに局所化されているわけではありません。
- Rolloutポリシー:rolloutをoff-policyにシフトすると更新ノルムは緩やかに増加しますが、stable rankのtrajectoryはon-policyのOPDとほぼ同一のままです。
- 目的関数の組み合わせ:OPDとRLVRを混合するとランクのダイナミクスが変化します。
したがってロックはランタイムの監督とデータソースの選択に対してロバストですが、lossの形式に対しては敏感です。これはrelaxed-Three-Gates解釈と整合しています:OPD目的関数自体が、どのトークンやrolloutがgradientを生成するかに依存せず、特定のスペクトルレジームを選択しています。
限界と未解決問題
この分析は相関的であり、一つのモデルファミリー(Qwen3、主にQwen3-8B)と数学ドメインに焦点を当てています。Stable rankはスペクトル形状の粗い要約であり、ロックされた部分空間がタスク固有の機能的方向と一致するのか、それとも単にloss landscapeにおける抵抗が低い方向と一致するのかは解決されていません。on-policy KL-to-teacher lossがスペクトル制限を生成するメカニズム — RLVRのverifier駆動スパース性とは対照的に — も未解明のままです。最後に、部分空間制約実験は十分性を示しているのであって必要性ではなく、同様の次元の代替的な低ランクチャネルもOPDをサポートできる可能性があります。
この研究の意義
OPDが機能的に十分でtoken-levelの監督とrolloutポリシーにほぼ非感受性である低次元のoff-principalチャネルで真に動作するならば、効率的なOPD実装 — 低ランクパラメタリゼーション、射影最適化器、あるいは部分空間制限fine-tuning — は品質損失なしに実現可能であるはずであり、またpost-training解析におけるSFT対RLの二分法は三レジームの見方に置き換えられるべきです。
Source: https://arxiv.org/abs/2606.07082
Latent Spatial Memory for Video World Models
長いカメラ軌跡にわたって生成フレームの3D一貫性を維持しようとするvideo world modelsは、一般的に明示的なRGBポイントクラウドキャッシュに依存しています。各conditioning stepでキャッシュはターゲットカメラにラスタライズされ、得られたRGB画像はdiffusion backboneに注入される前にVAEで再エンコードされます。このラスタライズ&エンコードの往復処理は、高解像度においてはVAEのエンコード/デコードがステップごとのコストを支配するため高コストであり、かつbackboneによって計算されたlatent featuresが各サイクルでピクセルから破棄・再構成されるため損失も伴います。Mirageはこれを、diffusion latent空間に完全に存在するキャッシュに置き換えることで、読み出し時のピクセル空間の迂回を排除します。
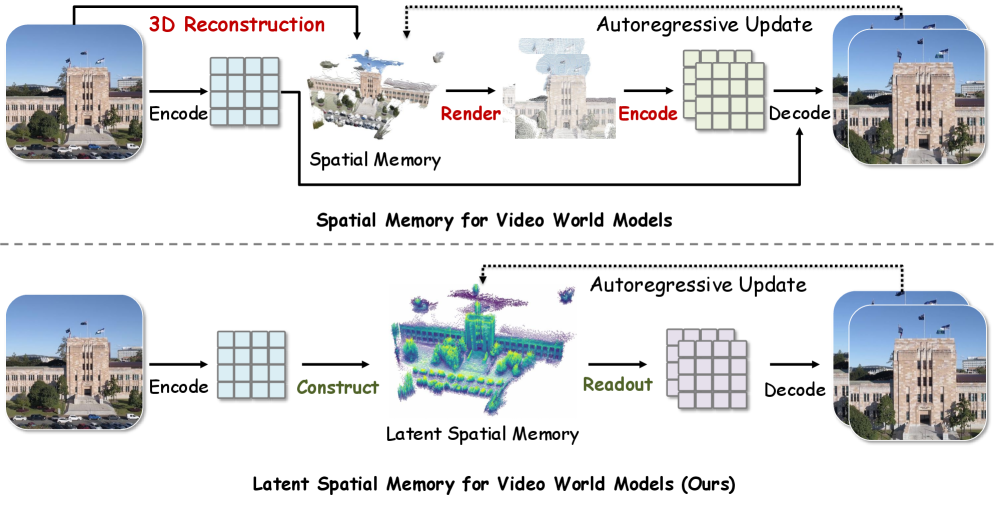
手法
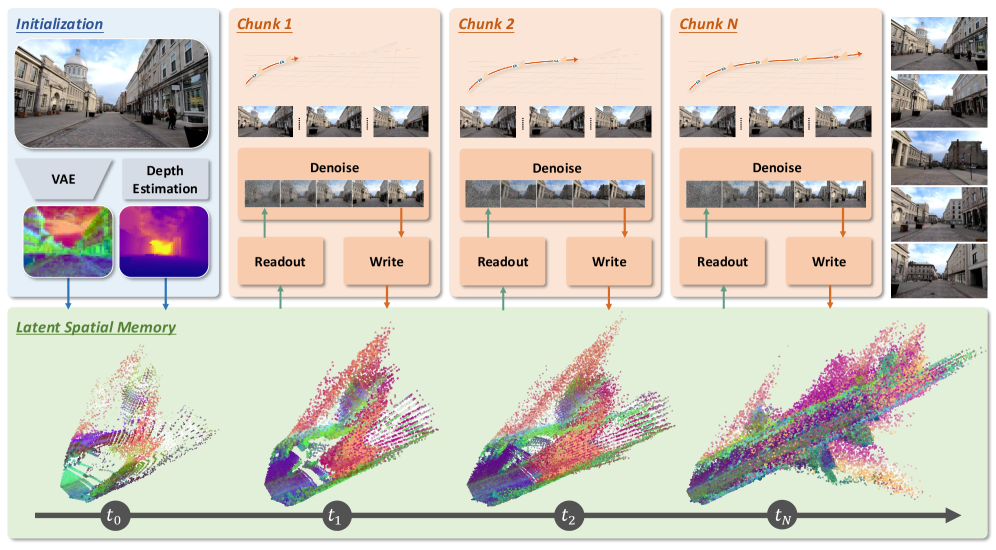
キャッシュ \mathcal{M} は3D点の集合であり、各点はRGBカラーではなく C=48 次元のlatent feature vectorを保持しています。初期化では、Wan2.2 VAE encoder \mathcal{E}(圧縮率 4\times 16\times 16)で最初のフレーム I^0 をエンコードし、単眼深度推定と既知のカメラの内部/外部パラメータを用いて各latent cellをワールド座標に逆投影します。深度 d を持つピクセル (u,v) における各latent cellは、カメラポーズで変換された3D点 X = K^{-1}[u,v,1]^\top d となり、(u,v) におけるlatent tokenが付与されます。
生成は9つのlatent frame(704\times 1280 の 33 RGBフレームに相当)にわたってチャンクごとに進行します。ターゲットチャンクに対して:
- Readout。 \mathcal{M} は latent 解像度 44\times 80 で各ターゲットカメラに投影され、ターゲットビューのlatent feature tensorを生成します(zバッファリングされ、空のセルはマスクされます)。
- Denoising。 このtensorはWan2.2-TI2V-5Bブロックから初期化されたControlNet方式のサイドブランチに入力され、diffusion backboneをconditioningします。学習にはターゲットフレームへのflow-matching objectiveを使用し、推論には40 UniPCステップを使用します。
- Update。 デコードされたチャンクが再エンコードされ、深度が再推定され、新しいlatent pointsが逆投影されて \mathcal{M} にマージされます。動的領域と空はマスクアウトされるため、静的なジオメトリのみがキャッシュに寄与します。
コスト削減の核心:従来のRGBキャッシュはサンプラー内部のすべてのconditioning stepでフル解像度 H\times W でラスタライズし、VAEでエンコードする必要があります。Mirageはチャンクごとにlatent解像度 H/s \times W/s(ここでは s=16)で一度だけラスタライズするため、キャッシュのフットプリントとreadoutの計算量をどちらも概ね s^2 倍削減します。ピクセル空間の演算はdenoisingループ内ではなく、チャンクレベルのupdateの際にのみ発生します。
結果
WorldScoreにおいて、MirageはAverage Scoreが 70.36 に達しており、Spatia(69.73)をわずかに上回り、最強のRGBポイントクラウドベースラインであるVoyager(66.08)を大幅に上回っています。コンポーネント別では、3D Consistency(92.21)、Photometric Consistency(93.95)、Style Consistency(96.91)、Object Control(74.17)でリードしています。Camera Controlは 55.36 であり、基盤となるvideo generatorsの 23〜38 を大きく上回っていますが、VoyagerのCamera Control(85.95)やInvisibleStitchのCamera Control(93.20)には及びません——明示的なジオメトリベースラインは一貫性と品質では劣るものの、厳密なカメラポーズへの追従において優位性を維持しています。Content Alignment(42.09)は中位であり、LucidDreamer(75.00)やVoyager(68.92)の方が高いスコアを示しており、latent cacheはセマンティックなプロンプト忠実度よりもジオメトリにより効果的であることが示唆されます。
効率性が最大の注目点です:rollout長がシングルH100上で増加するにつれて測定した結果、エンドツーエンドの生成が最大 10.57\times 高速化し、明示的な3Dベースラインと比較してキャッシュ読み出し1回あたりのピークメモリが 55\times 削減されます。RGBとlatentグリッドサイズの比率 s^2 = 256 がこれらの利得の根本的な源泉ですが、深度推定とチャンクレベルのupdateがピクセル空間に残るため、実際の高速化はそれより低くなります。

定性的には、RealEstate10K(深度とポーズを持つ屋内不動産映像)のみで学習しているにもかかわらず、Mirageは積極的なカメラ動作の下で屋外・自然シーンに汎化します。RGBポイントクラウドベースラインは、深度逆投影が信頼できない未知のレイアウトでテクスチャの伸張を示し、一方で基盤となるvideo generatorsは長いrolloutにわたってジオメトリ的にドリフトします。
制限と未解決の問題
latent cacheは深度推定器の失敗モードを引き継ぎます:深度が不正確だとlatent tokensが誤った3D座標に配置され、RGB空間のinpaintingとは異なり、キャッシュの内容が人間に解釈不可能であるため、こうしたエラーの診断が困難です。動的物体の取り扱いは粗いものがあります——動く領域はupdateから単純に除外されるため、モデルは再訪時に動く物体のメモリを維持できません。Camera controlの数値も明示的なジオメトリ手法に遅れており、サイドブランチのconditioningが直接ラスタライズされたRGBよりも弱いことを示しています。最後に、latent cacheは特定のVAEに紐付けられており、backbone間(または解像度間)でのメモリ転送には再エンコードが必要です。また、空のキャッシュセルを「補完」するためにdiffusion modelが使用するジオメトリckpointpriorは特徴付けられていません。
なぜこれが重要か
ピクセル空間ではなくlatent空間にメモリを保存することは、diffusion world modelsにとって自然な適合です:内部サンプリングループから冗長なエンコード/デコードの往復を取り除き、一貫性メトリクスを改善しながら桁違いの効率利得をもたらします。この結果は、3D一貫性を持つvideo generationを、再構成されたRGBシーンではなく、diffusion latentsに基づくジオメトリ的にインデックスされたfeature cachesの問題として再定義するものです。
Source: https://arxiv.org/abs/2606.09828
Echo-Memory: アクション世界モデルにおけるメモリの制御研究
アクション条件付き世界モデルは、最初のフレーム、テキストプロンプト、フレームごとのカメラ軌跡からチャンク分割された動画を生成します。これらモデルの主要な失敗は局所的な合成ではなくメモリにあります:カメラがある領域を離れて戻ってきたとき、顕著なオブジェクトとシーン構造が静かに変化してしまいます。既存のメモリ設計(生のコンテキストウィンドウ、学習済み圧縮器、空間キャッシュ、リカレント状態)は、各論文がメモリ機構を独自のバックボーン、リトリーバー、アクションエンコーディング、およびメトリクスと組み合わせているため、比較が困難です。Echo-Memoryはマッチドプロトコルによるアブレーション研究であり、単一のビデオ DiT、単一のオプティマイザー、単一のカメラアクションインターフェース、単一のサンプラー、単一の評価パイプラインを用いており、行をまたいで変化するのはメモリプロファイルのみです。
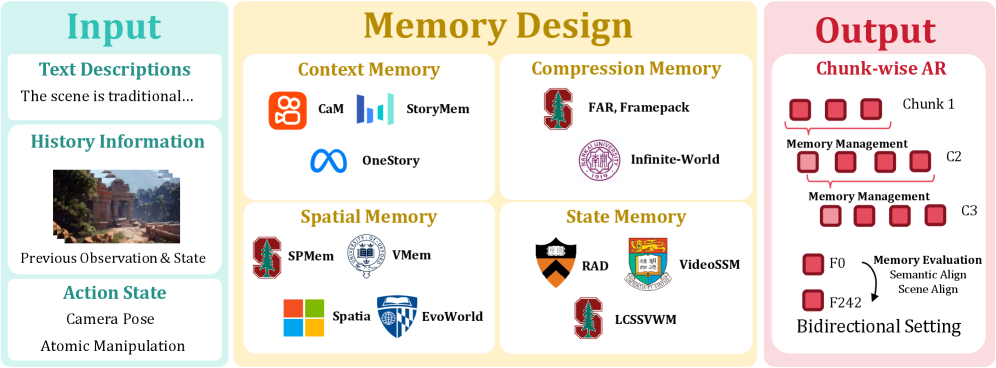
セットアップ
バックボーンは事前学習済みのビデオ diffusion transformer であり、対象フレームのみに制限された rectified-flow 回帰で学習されます:
\mathcal{L}(\theta)=\mathbb{E}_{t,\mathbf{x},\mathbf{c}}\,\|v_\theta(\mathbf{z}_t;t,\mathbf{c}_{\text{text}},\mathbf{c}_{\text{ctx}},\mathbf{c}_{\text{act}})-(\mathbf{z}_1-\mathbf{z}_0)\|_2^2.
各セグメントは 352\times640 の81フレームです。アクションは最初のフレームの参照座標系で表現された12次元の相対RT(回転9 + 並進3)です。メモリは \mathbf{c}_{\text{ctx}} を通じて組み込まれます。これは固定された視野ポリシーで取得された K 枚の過去フレームのフレームごとVAE潜在スタックであり、アンカー(現在のセグメントの開始点)は常に含まれ、取得されたフレームは10%の確率でドロップされます。全てのバリアントはAdamW(5\times10^{-5})、5kステップ、8×A100を共有します。変化するのは K\in\{1,5,20\} とメモリモジュールのみです。
この因子化により、先行研究が混在させていた4つの軸が切り離されます:容量(何個の過去トークンが保持されるか)、圧縮(どの程度積極的に要約されるか)、読み出し(ジェネレーターがどのようにクエリするか)、リカレンス(メモリが時間をまたいで更新される状態かどうか)。
メモリファミリー
- Context: K 枚の取得フレームのフレームごとVAEトークンを対象トークンに連結した生データ。容量は K に対して線形にスケールし、圧縮なし。
- Compression: 過去のトークンスタックをはるかに小さい重みのようなメモリにマッピングする学習済み演算子。積極的な圧縮で、リカレンスなし。
- Spatial: カメラポーズをキーとする2Dシーン要約を維持し、読み出しはフレームごとの attention ではなく幾何学的。
- State-Space: セグメントをまたいで伝播するSSMスタイルのリカレント状態。2つのバリアント:レガシーハイブリッドと、チャンクごとに状態を更新するブロックワイズバリアント。
3分岐評価
Echo-Memoryの第2の貢献は評価分類法です。Replay(GTカメラ軌跡、3つの生成チャンクにわたるPSNR/SSIM/LPIPS)はカメラ追従と局所的な忠実度を測定します。In-domain returnはGTに基づいた180°ループを使用し、往路/復路に沿ったミラーフレームを照合します。Open-domain returnは20のゲームスタイルプロンプト × 8枚のQwenで編集されたアイデンティティアンカー付き最初のフレーム(160フレームプール)を使用し、Qwen3-VL-30B-A3Bが重み 0.45\,s_{\text{appearance}}+0.25\,s_{\text{presence}}+0.20\,s_{\text{view}}+0.10\,s_{\text{scene}}([0,100] にリスケール)でスコアリングするコンパクトな45°の離脱/帰還プローブを採用します。ジャッジのサニティチェックにより、Claude Opus 4.6、GPT-5.5、および人間のアンカーがQwen3-VLと \Delta\le 3.1 以内に留まり、Pearson \rho\ge 0.93 であることが示されており、ジャッジの選択は行の順位を変えません。
replay 診断は固定GTトrajectoriesを用いて学習中に実行されます。著者たちは、スカラーの flow-matching loss はメモリの弱いプロキシであることを強調しています:ほぼ同一の loss を持つ2つの実行がチャンク境界で大きく分岐する可能性があります。

結果
ヘッドラインテーブルは分岐をまたいで勝者が逆転することを示しています。Replay PSNRではSpatial Memoryが最高(13.60)、Replay SSIM/LPIPSでは K{=}20 の生Context(0.449/0.496)が最高、open-domain VLMではブロックワイズState-Spaceが69.00で圧倒的に首位であり、Spatial(6.00)やI2Vベースライン(12.25)を大きく上回ります。
Contextファミリーの容量スイープが最も明確なシグナルです。アンカーのみのI2Vから K{=}5 に移行するとopen-domain VLMが12.25から50.75に上昇し、K{=}20 では58.63に達します。Replayメトリクス(R-P 10.03 → 11.92 → 12.54)の変化はずっと小さいです。生の履歴は主に意味的なreturnをもたらし、局所的なピクセル忠実度ではありません。これは圧縮されたメモリをI2Vだけでなく K{=}20 Contextの行に対してベンチマークすべきことを意味します。
さらに2つの逆転が診断的です。Spatial MemoryはReplay PSNRで勝利しますが、open-domain(6.00)で崩壊します:そのシーンキャッシュは可視領域の再構成を改善しますが、エクスカーション(迂回)を通じて特徴的なオブジェクトのアイデンティティを失います。ブロックワイズState-SpaceはReplay数値が弱い(R-P 9.59)ですが、意味的なreturnが最も強く、リカレント状態は局所的な再構成を犠牲にしてアイデンティティを保持します。Compression weight-onlyはopen-domain VLMで22.38を達成しますが、マッチドコンピュートでのContext K{=}5(50.75)を大きく下回り、現在の学習済み圧縮器は生のストレージに支配されていることを示しています。
限界と未解決の問題
この研究は一つのバックボーン(Wan-family DiT)、一つの取得ポリシー(固定FoV)、および相対RTアクションのみを固定しており、絶対アクションエンコーディングと学習済みリトリーバーはスコープ外です。Open-domainスコアリングは単一のVLMジャッジに依存しており、クロスジャッジチェックによって緩和されていますが排除はされていません。5kステップの予算は短いため、より長い学習での容量対圧縮の順位は不明です。ブロックワイズState-Spaceは意味的には勝利しますがreplay忠実度を犠牲にしており、これが本質的なものかチューニングの産物かは未解決です。replay とopen-domain returnの両方を同時に制するものはなく、支配的なメモリではなくパレートフロンティアの存在が示唆されます。
なぜこれが重要か
Echo-Memoryは、アクション世界モデルの論文が実際に報告する指標である「replay品質」がメモリを測定していないという反証可能な経験的主張を展開します。マッチドバックボーンとプロトコルにより、replayの順位は意味的なreturnに対して逆転し、生の K{=}20 contextは多くの圧縮メモリがアンダーパフォームする強いベースラインのままです。将来のメモリ機構は、局所的な軌跡PSNRではなく、離脱-帰還プローブで評価されるべきです。
Source: https://arxiv.org/abs/2606.09803
エンドツーエンドのコンテキスト圧縮をスケールで実現する
長コンテキスト推論はKV-cacheのメモリとprefillレイテンシに支配されており、いずれもコンテキスト長に対して線形に増加します。既存の対策は大きく二つの方向に分かれています:(i) 完全にprefillされたcacheに対して作用し、回避しようとしているprefillコストをそのまま引き継ぐpost-hoc KV-cache圧縮器(SnapKV、KVzip、Expected Attention、Attention Matching)、および(ii) 従来は大幅な精度低下を犠牲にしてシーケンスを短縮してきたencoder-decoderソフトトークン圧縮器です。本論文はencoder-decoderの方向を再検討し、制御されたアーキテクチャスイープを実施し、精度対TTFTのParetoフロンティアを支配できる十分なスケールでLatent Context Language Models(LCLMs)のファミリーを学習しています。
アーキテクチャ
LCLMは(encoder、adapter、decoder)の三つ組です。入力 x_{1:T} と圧縮率 N に対して、サイズ W のencoderウィンドウはシーケンスを I=\lceil T/W\rceil 個のチャンク w_i = x_{(i-1)W+1:\min(iW,T)} に分割します。各ウィンドウは隠れ状態 h^{(i)}_{1:|w_i|} にエンコードされ、次にpooling演算子が連続する N 個の状態を一つのlatentトークンに集約し、ウィンドウごとに M_i = \lceil |w_i|/N\rceil 個のlatentが生成されます。adapter a(\cdot) はencoderからdecoderの隠れ次元へ射影し、 s_{1:M} を生成します。decoderはこれを N\!M 個の生トークンの代わりに消費します。重要なのは、encoderウィンドウをバッチ処理できる点です(本論文ではencoderバッチサイズ128、W=1024、すなわち1回のバッチedエンコーダパスで131,072入力トークンを処理)。また、decoderは標準のKV cacheで動作するため、vLLM/SGLangおよびFlashAttentionは下流でそのまま適用できます。
アーキテクチャスイープは実践者にとって最も有益な貢献です。著者らは N=16 で38Bトークンを用いてQwen3-0.6B encoder/decoderペアをゼロからpre-trainし、pooling、attention mask、adapterの形状を変化させています。
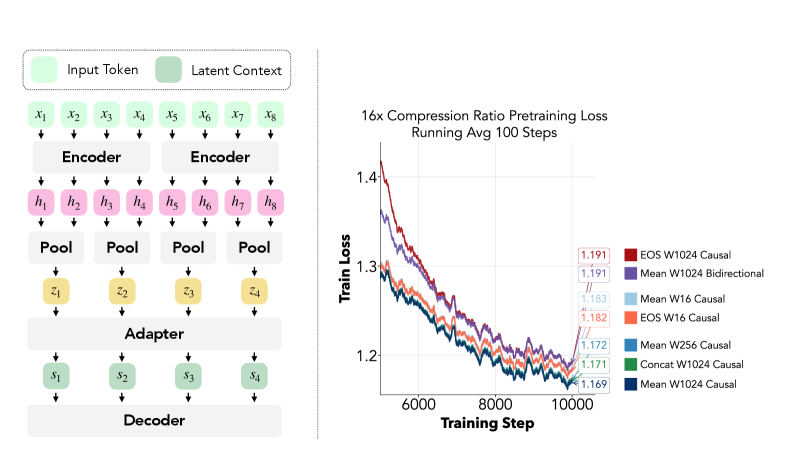
主要な発見:トークンベースのpooling(EOS/CLS)は、ICAE、AutoCompressor、および従来のソフトトークン研究のほとんどでデフォルトとして使われてきましたが、mean poolingと比べて一貫して劣っています。Concatenation pooling(N 個の隠れ状態を幅広いベクトルにスタックし、adapterで射影する)は小スケールではmeanと区別がつきませんが、スケールが拡大するにつれて差が生じます:低圧縮率(1{:}4)ではconcatenationが優り、高圧縮率(1{:}16)ではmeanが優り、コンテキストが長くなるにつれてその差は縮まります。これは、concatenationがmeanが捨ててしまう位置情報を保持するという直感と一致していますが、N が大きい場合はadapterの容量がボトルネックになります。
学習レシピ
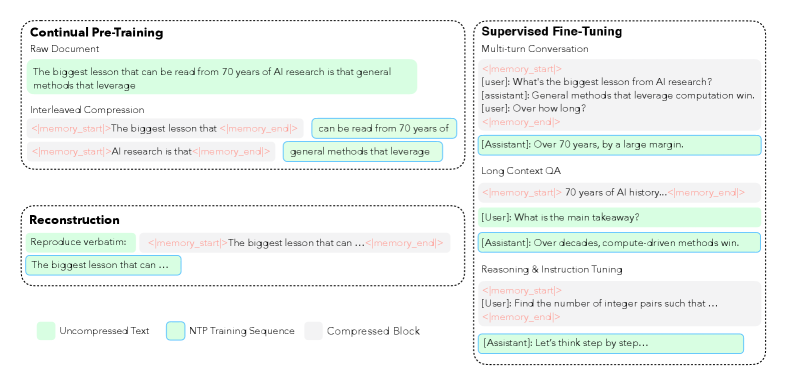
LCLMは、Qwen3-Embedding-0.6B(encoder)とQwen3-4B-Instruct-2507(decoder)からcontinual pre-trainingを行い、各圧縮率(N\in\{4,8,16\})について350Bトークン以上を使用します。三つのデータストリームがあります:
- インターリーブcontinual pre-training:各シーケンスを圧縮セグメントと非圧縮セグメントを交互に含む形式に分割し、next-token lossは非圧縮トークンのみに適用します。これは従来の「前半圧縮・後半trainable」という慣例(AutoCompressor、ICAE、CEPE)とは異なり、decoderがプレフィックスだけでなく任意の位置でlatentコンテキストを条件付けることを強制します。
- SFT:圧縮された長文書プロンプトを用いたfine-tuning。
- 補助的再構成:decoderにlatentから生のコンテキストを再現させることで、latentを逐語的な内容に固定します。
結果
同じQwen3-4B-Instruct-2507 decoderに対してRULERおよびLongBenchで評価したところ、LCLMsは単一のH200上での精度対TTFTにおいて新たなParetoフロンティアを確立しています。
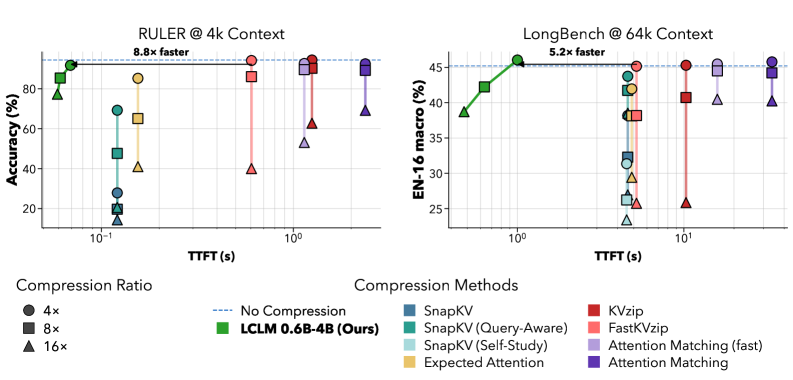
1{:}4、1{:}8、1{:}16 のLCLMsは、KVzip、FastKVzip、SnapKV、Expected Attention、Attention Matchingと同等以上の精度を達成しながら、厳密に高速に圧縮します。これはKV-cacheベースの手法がまず全コンテキストをprefillする必要があるのに対し、LCLMsはバッチ処理された短いウィンドウを通じてエンコーディングをamortizeするためです。ピークメモリの軸でも同様の順序が成立します:W=1024 ウィンドウのencoderアクティベーションは T に依存せず上限が定まる一方、KV圧縮器はプルーニング前に全cacheをマテリアライズする必要があります。
エージェントスキャフォールディング
latent表現がアドレス可能であるため、著者らは EXPAND(i) ツールを公開しており、これにより512トークンのチャンクのlatentをオンデマンドで生のトークンに置き換えられます。RULER NIAHタスクでは、エージェントは生の 16\times 圧縮モデルでは達成できない完全一致の精度を回復し、設定によっては非圧縮コンテキストと同等の結果を示します。このパターンは「latent空間でグローバルにスキャンし、トークン空間で選択的にズームイン」というもので、機能的には検索と類似していますが、検索インデックスが外部のembeddingストアではなくLCLM自身のlatentsへのattentionである点が異なります。
限界
decoderはQwen3-4B-Instruct-2507に固定されており、他のdecoderや大規模なdecoderへのencoderの転用可能性は実証されていません。16を超える圧縮率は探索されておらず、high-N の領域はまさにmean poolingの情報損失が最も影響を与えるべき場面です。再構成の目的関数はおそらく、抽象化を犠牲にして表層形式の忠実性にlatentをバイアスさせます。圧縮されたスパンにわたるマルチホップ推論を要求するタスク(RULERの変数追跡、マルチドキュメントQA)は、報告されたテーブルでLCLMsのKV-cache手法に対するマージンが最も縮まる場合です。最後に、エージェント的な EXPAND の評価はNIAHに限定されており、そこでの失敗モード(逐語的な検索)は展開操作に最も有利な設定となっています。
この研究の意義
これは、KV-cacheプルーニングを両方の軸で同時に説得力を持って上回るスケール(350Bトークン以上、4B decoder)で学習された初のencoder-decoderコンテキスト圧縮器であり、decoderのKV cache構造に手を加えないため標準的な推論エンジンとの互換性を維持しながらこれを実現しています。アーキテクチャに関する発見——トークンpoolingよりもmean/concat、プレフィックスのみのCPTよりもインターリーブCPT——は、ソフトトークン圧縮器を構築する誰にとっても即座に活用可能な知見です。
Source: https://arxiv.org/abs/2606.09659
CoVEBench: 動画編集モデルは複雑な指示を処理できるか?
問題設定
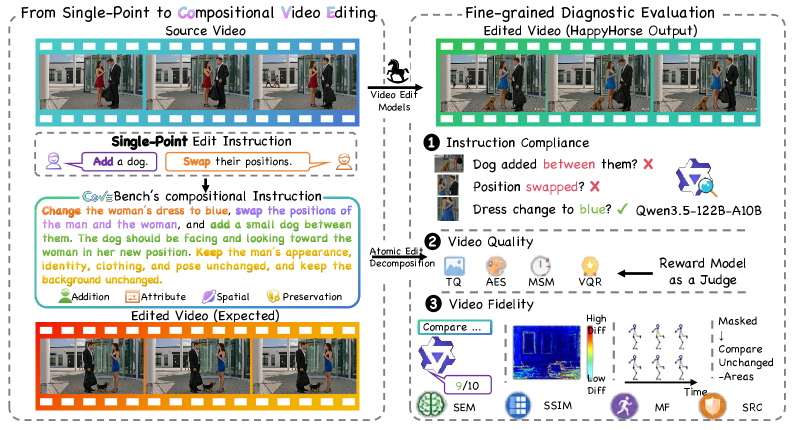
テキスト誘導型動画編集モデルは、通常、孤立した操作(オブジェクトの置換、スタイル変換、挿入など)に対してベンチマークが実施され、粗い大域的なメトリクス(CLIP類似度、フレームレベルのFID変種)で評価されています。実際のユーザープロンプトは合成的であり、それ以外のすべてを時空間的に保持しながら、被写体・動作・カメラを同時に変更するといった要求を含みます。既存のベンチマークは、モデルが要求されたすべての編集を実行したかどうか、未編集領域を誤って変更していないか、あるいは生成された動作が物理的に妥当かどうかを判別できません。CoVEBenchは、この合成的な編集の領域を対象とした診断ベンチマークです。
構成
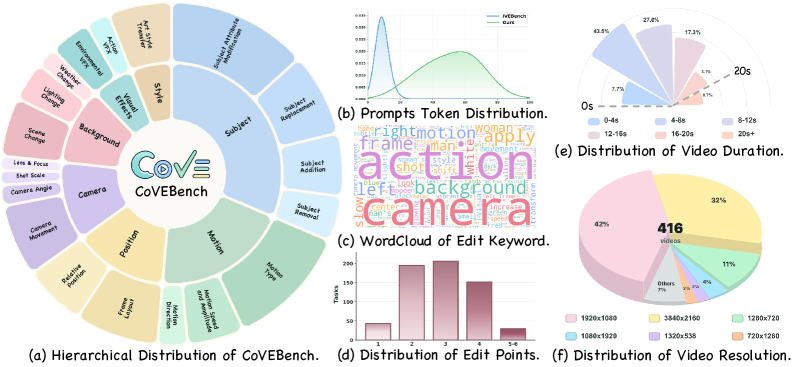
CoVEBenchは、416本のキュレーション済みソース動画(多様な長さと解像度)、626件の多点編集指示、および9,990件の細粒度チェックリスト項目を含んでいます。指示は原子的ではなく意図的に合成的に設計されており、195,625組のサンプリングされた指示ペアにわたるTF-IDF cosine similarityの平均値は0.0168(中央値0.0106)であり、プロンプトセット全体における語彙的冗長性が低いことを示しています。タクソノミーは、被写体・動作・属性・シーン・スタイル・カメラビューの編集にまたがっており、指示の分布は単一編集プロンプトよりも多重編集プロンプトに偏っています。
評価手法
評価マトリクスは、Instruction Compliance(指示遵守)、Video Quality(動画品質)、Video Fidelity(動画忠実度)の3軸で構成され、11のメトリクスを備えています。新規性の中核は、MLLM判定によるチェックリストであり、以下に分解されます。
- Multiple-choice questions(多肢選択問題): 編集前後の状態が競合する選択肢として提示され、正解の選択肢は指示の意図する結果と一致していなければなりません。
- Yes/No questions(二択問題): 要求された各動作が実行されたかどうか、および明らかに不自然なアーティファクトが現れていないかを確認します。
クエリは、Dual-Video形式(判定器がソースと編集済みクリップの両方を参照する形式;保存性の検証が必要な場合に使用)またはSingle-Video形式のいずれかを用います。チェックリストから導出された3つのスコアが実行と品質を分離します。
- IFS(Instruction Following Score): 視覚的品質を無視し、指示実行クエリの平均精度。
- VRS(Video Realism Score): リアリティ・アーティファクトクエリの平均精度。
- UAS(Union Accuracy Score): 編集タスクごとのスコアで、そのタスクの指示クエリとリアリティクエリの両方が正解の場合にのみ1となる論理積スコア。編集を実行しても非現実的な動画を生成したモデル、あるいは綺麗な動画を生成しても編集を省略したモデルをペナルティする仕組みです。
MLLMの判定器にはQwen3.5-122B-A10Bが使用されています。Video QualityはVisualQuality-R1(VQR)、Aesthetic Predictor v2.5(AES)、optical-flowベースのmotion smoothness(MSM)、DOVER++(TQ)を組み合わせています。Video FidelityはチェックリストベースのSemantic Consistency Score(SEM)、構造的忠実度のためのSSIM、CoTrackerの軌跡類似度(MF)、静的領域の一貫性のためのSAM2+DINOv2マスク特徴比較(SRC)を組み合わせています。UAS、VQR、SEMはそれぞれ3軸の全体的指標として指定されています。
結果
評価されたモデルは10件:InsV2V、VACE、Lucy Edit、ICVE、Ditto、Reco、OmniWeaving、Kiwi、HappyHorse1.0、Wan2.7です。3つの主要な観察が得られました。
指示遵守においてクローズドソース > オープンソース。 Wan2.7がUAS 56.89(IFS 82.02、VRS 79.97)でトップとなり、HappyHorse1.0がUAS 55.18(IFS 76.54、VRS 84.52)で続きます。最良のオープンソースモデルであるOmniWeavingは、競争力のあるIFS(57.18)にもかかわらず、UAS 30.14に留まり、クローズドソースの水準の約半分です。Kiwi(29.03)、Ditto(26.50)、Lucy(26.01)、ICVE(25.83)、ReCo(24.35)、InsV2V(14.61)、VACE(9.69)が後続します。
論理積がボトルネック。 すべてのモデルにおいて、UASはIFSおよびVRSの個別値を大幅に下回っています。例えば、Wan2.7のUAS 56.89に対してIFS 82.02、VRS 79.97という結果は、相当数の編集タスクにおいて動作は正しく行われても現実性が損なわれるか、あるいはその逆が起きていることを示唆しています。この差はより弱いモデルで拡大しており、VACEはIFS 22.92、VRS 41.35であるにもかかわらずUASはわずか9.69です。すべてのサブ編集が成功し、かつ結果が物理的に妥当なままである合成的な編集は稀です。
編集と保存のトレードオフ。 編集実行が強いほど、保存性が弱くなる傾向があります。Dittoは競争力のある実行スコア(IFS 49.45、VRS 60.69)を示しますが、SEMは58.02まで低下し、LucyのSEM 86.13やHappyHorse1.0の92.73を大きく下回ります。逆に、VACEは最高のSSIM(0.958)とMF(0.958クラスの軌跡類似度)を持ち、変更をほとんど行わないため保存性では高スコアを得る一方、実際の編集ではUAS 9.69と低評価です。SSIM値は(ICVEの0.288からLucyの0.762まで)広く分布しており、各モデルがピクセルをどの程度積極的に書き換えるかを反映しています。
限界とオープンクエスチョン
このベンチマークはMLLM判定器のバイアスを引き継いでいます。Qwen3.5は特定の視覚スタイルを系統的に優遇または不利に扱う可能性があり、チェックリスト構成の品質は外部から検証されていません。テストされたクローズドソースシステムは2件のみであるため、クローズドソース対オープンソースの一般化は示唆的なものに留まります。メトリクスセットは長時間にわたる編集の時間的一貫性を直接スコアリングせず(ほとんどのクリップは短時間)、SRCのマスクベースDINOv2比較はスタイル編集によって誘発されるグローバルな照明変化によって混乱する可能性があります。UASが大規模な人間の合成編集選好と相関するかどうかは、論文が完全に解決していない実証的な問いです。
重要性
CoVEBenchは、動画編集評価を実行と保存の論理積という観点から再定義し、個々のサブスキルが十分に見えても、現在のモデル(UAS 60未満の主要クローズドソースシステムを含む)が合成的なプロンプトを確実に処理できないことを明らかにしています。IFS/VRS/UASの分解は、メソッド開発者に対して、編集積極性・アーティファクト抑制・未編集領域のロックのどれに注力すべきかを判断するための実行可能な診断を提供します。
Source: https://arxiv.org/abs/2606.08415
LatentSkill: コンテキスト内のテキストスキルからLLMエージェントのための重みに埋め込まれた潜在スキルへ
問題
エージェントフレームワークは、繰り返し発生するサブタスクを達成する方法を記述した手続き型ドキュメントである「スキル」のテキストライブラリに依存する傾向が強まっています。これらのスキルは、すべての意思決定ステップでプロンプトに読み込まれます。このパターンには二つのコストがあります。プリフィルトークン数がスキルの数と長さに比例してスケールすること、そしてスキルの内容が平文で存在するため、抽出攻撃やprompt-injection攻撃にさらされることです。著者らは、スキルをオンデマンドでマウントされる重み空間モジュールにコンパイルできないかを問いかけます。これにより、スキルライブラリのモジュール性を維持しつつ、ステップごとのトークンオーバーヘッドを排除することを目指しています。
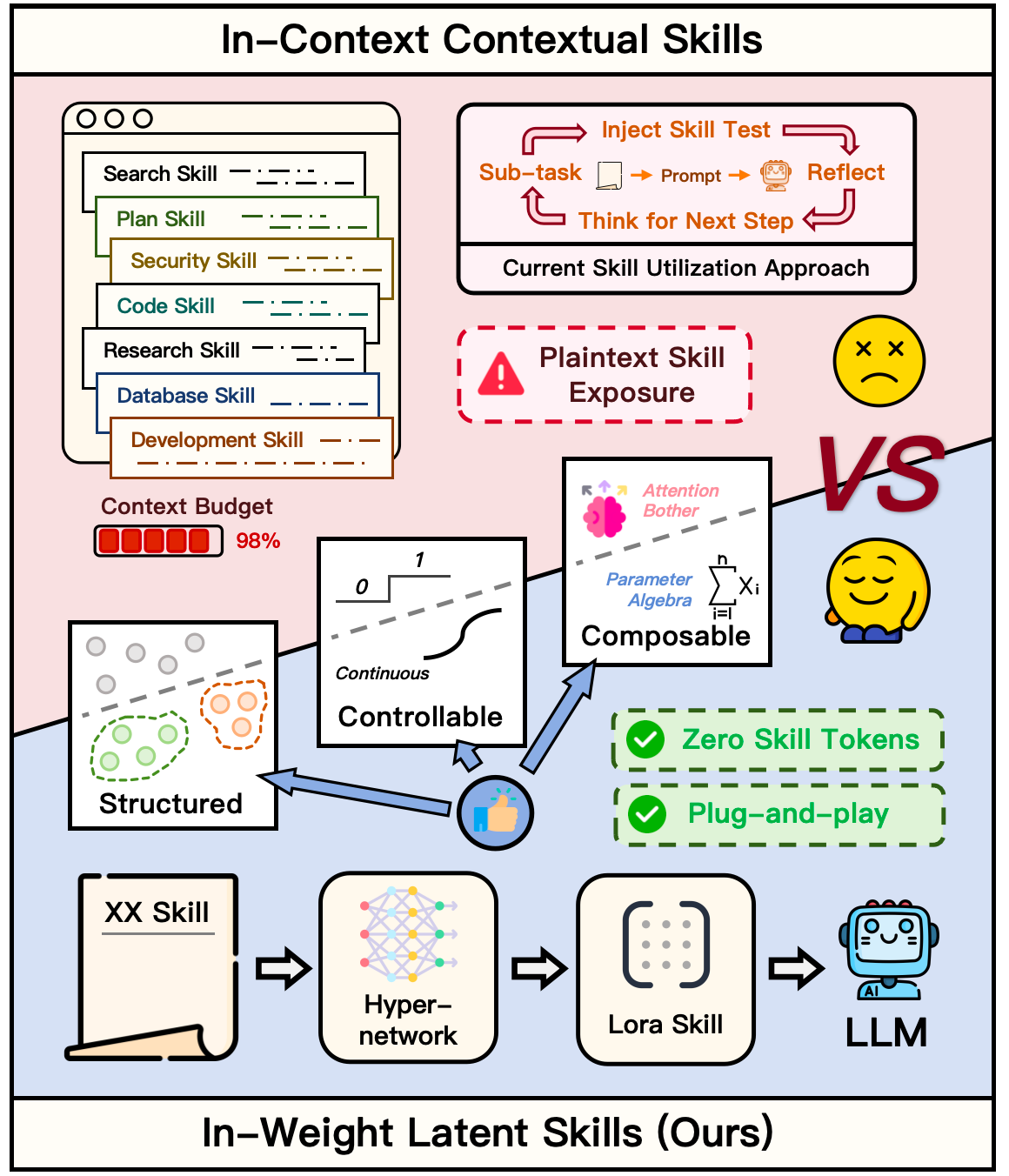
手法
LatentSkillはテキストによるコンディショニングをパラメータによるコンディショニングに置き換えます。凍結されたバックボーン M_\theta は、スキルドキュメント s を低ランクアダプターの集合にマッピングする学習済みスキルコンパイラ G_\phi(ハイパーネットワーク)が生成するLoRAアップデートによって拡張されます。
\Delta_s = G_\phi(s), \qquad p_{\theta,\phi}(y_t \mid h_t, s) = p_{\theta \oplus \alpha \Delta_s}(y_t \mid h_t).
各ターゲットモジュール m \in \mathcal{M} に対して、ハイパーネットワークは因子化されたアップデート \Delta W_s^{(m)} = B_s^{(m)} A_s^{(m)} を出力し、以下のようにマウントされます。
W' = W + \frac{\alpha}{r} B_s A_s,
ここで r はLoRAのランク、\alpha は推論時の注入強度です。マウント後、プロンプトにはスキルテキストが含まれず、タスク履歴 h_t のみが含まれます。
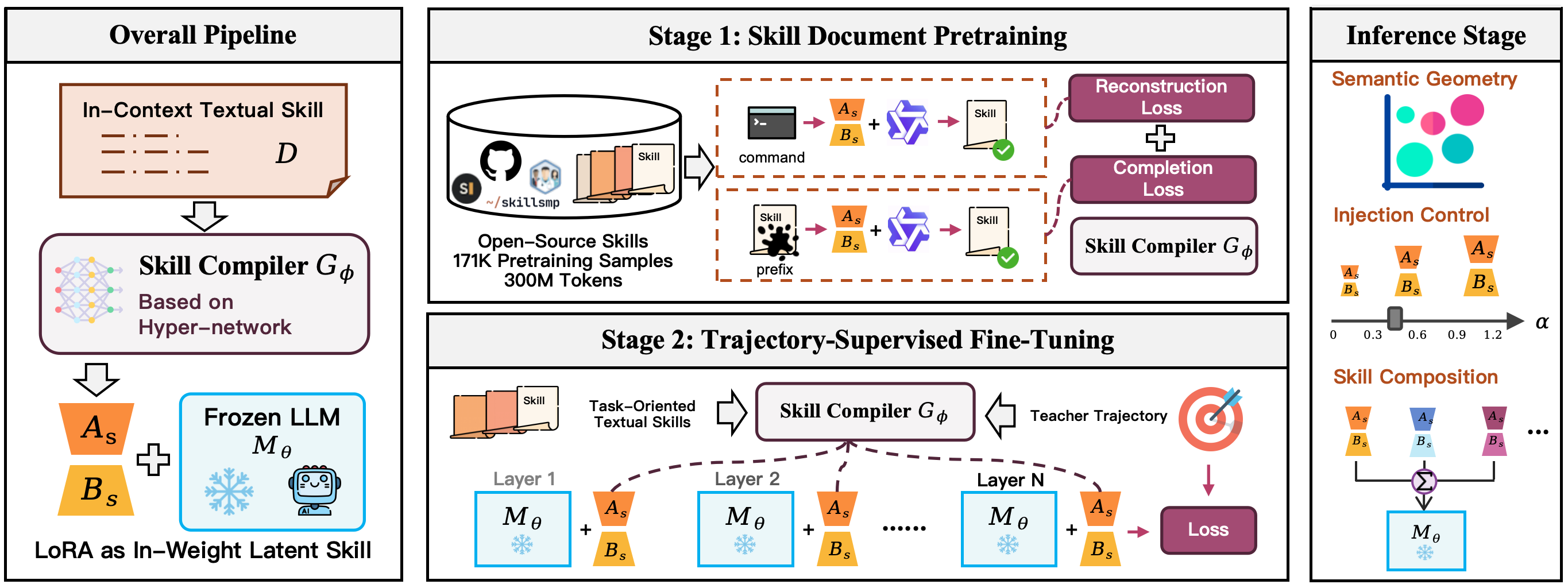
コンパイラの学習は二段階で進みます。まず、スキルドキュメント事前学習 により、ハイパーネットワークの出力アダプターを s でコンディショニングすることで凍結バックボーン上のスキルドキュメントのセマンティクスが再現されるよう整合させます(本質的にはドキュメントをLoRAの重みに蒸留します)。次に、トラジェクトリ教師あり fine-tuning ではエージェントのトラジェクトリを使用します。各 (s, h_t, y_t) トリプルに対して、マウントされた \Delta_s を通じて G_\phi に勾配が流れ、\log p_{\theta \oplus \alpha \Delta_s}(y_t \mid h_t) を最大化します。更新されるのは \phi のみで、\theta は凍結されたままです。推論時には、\alpha が注入強度を連続的に制御するノブとなり、異なるスキルのアダプターを整合されたコンポーネント上のパラメータ空間演算によって組み合わせることができます。
結果
ALFWorldにおいて、LatentSkillはコンテキスト内スキルベースラインと比較して、既見スプリットで+21.4ポイント、未見スプリットで+13.4ポイントの成功率向上を達成し、プリフィルトークンを64.1%削減しました。Search-QA(NQ + HotpotQAで学習し、OOD5データセットを含む7データセットで評価)では、Exact Matchが+3.0ポイント向上し、スキルトークンオーバーヘッドが72.2%低減されました。
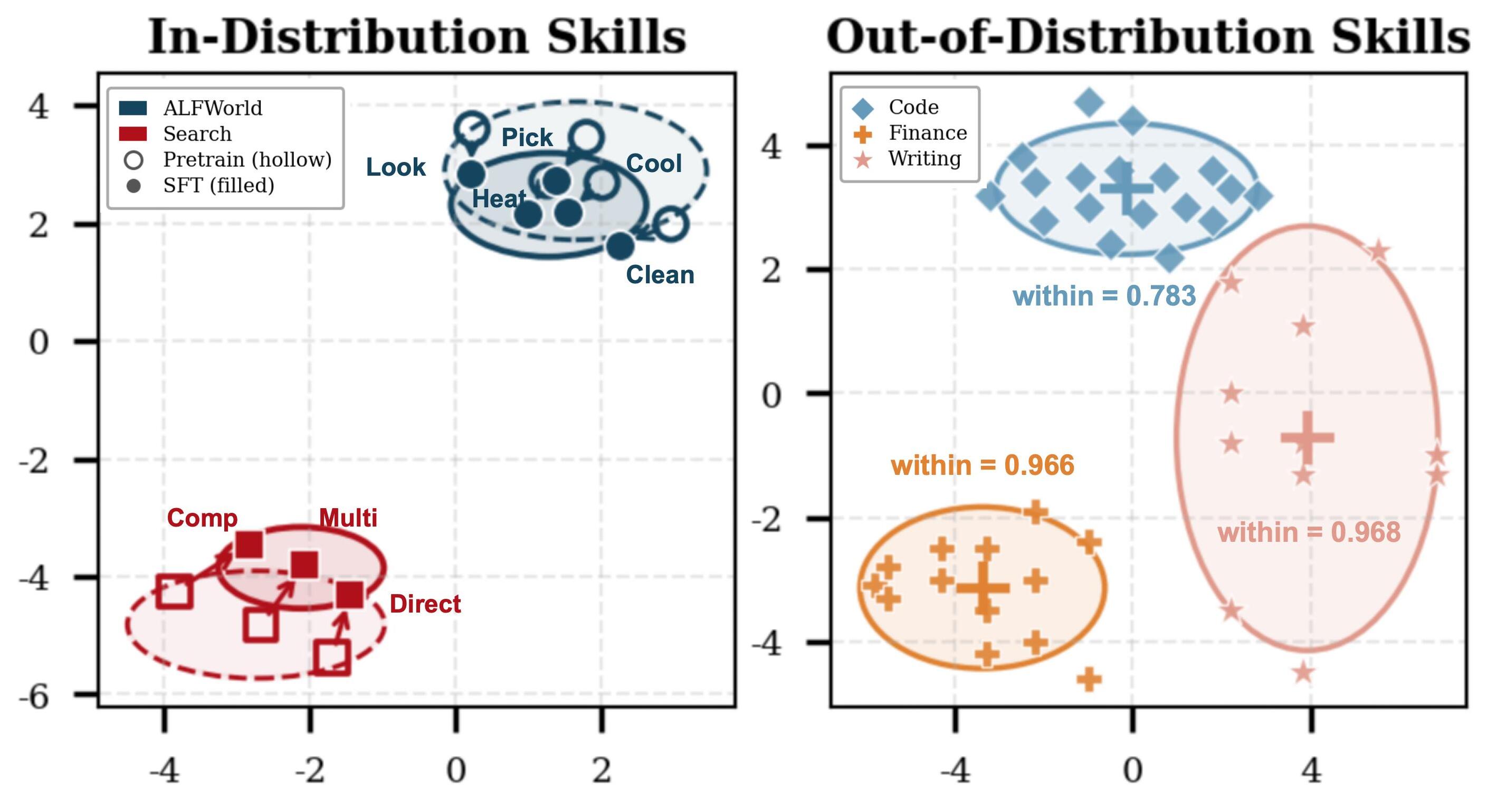
学習されたスキル幾何構造は体系化されています。生成されたLoRA重みのMDS可視化では、ドメイン内のALFWorldおよびSearchスキルが明確なクラスターを形成し、OODスキル(Code、Finance、Writing)がさらに分離していることが示されており、クラスター内のコサイン類似度の平均が高くなっています。これはハイパーネットワークの出力が任意の低損失アダプターではなく、重み空間においてセマンティクスに基づいて組織化された領域を占めていることを示しており、意味のある合成の前提条件となっています。
ロバスト性とセキュリティ
スキルテキストへの摂動に対する感度は、コンテキスト内プロンプティングよりも大幅に優れています。Paraphrase、Plaintext(Markdownを除去)、Reorder、Noiseの各条件下で、LatentSkillのALFWorldにおける平均成功率は70.7%であり、ベースラインの74.3%からわずか3.6ポイントの低下にとどまり、コンテキスト内スキルに対するマージンは17.2〜24.3ポイントの範囲となっています。PlaintextへのALFWorldにおける摂動では劣化がゼロであり、コンパイラが表面的なフォーマットではなくセマンティクスを捉えていることが示唆されます。
セキュリティ面での優位性はさらに顕著です。prompt-injection(Hijack)攻撃の下では、コンテキスト内スキルのALFWorldにおける成功率が52.9%から8.57%に崩壊する一方、LatentSkillは38.6%を維持します——スキルテキストがプロンプト内に存在しないため上書きされないからです。スキルの内容を再現しようとするExtract攻撃の下では、コンテキスト内スキルのSearch-QAにおける成功率が21.3%に低下しますが、潜在バリアントは29.3%を維持します。平文が単純に存在しないためです。
制限と未解決の問題
本論文は「スキルコンポーネントが整合されている場合の」構造化された幾何構造とパラメータ空間での合成を実証していますが、整合が失敗する場合や合成可能性がペアワイズ演算を超えてどのようにスケールするかは特徴付けられていません。学習にはスキルドメインごとのトラジェクトリデータが必要であり、全く新しいスキルカテゴリに対するゼロショットコンパイルの可能性という問題が生じます——OODのMDSは分離を示唆しますが、未見のスキルタイプに対するタスクパフォーマンスの測定には至っていません。ハイパーネットワーク自体がパラメータと一度限りのコンパイルコストを追加しますが、コンテキスト内スキルに対するキャッシュ戦略(KVキャッシュの再利用、プロンプト圧縮)とのトレードオフは直接比較されていません。ALFWorldにおけるHijack攻撃下でのロバスト性の数値(38.6%)は、クリーンな74.3%には程遠く、重み空間への格納は敵対的な劣化を軽減しますが排除はしません。
この研究が重要な理由
再利用可能なエージェントスキルをコンテキスト空間から重み空間に移すことは、プリフィルコスト、モジュール性、プロンプトレベルの攻撃対象面という、通常はトレードオフの関係にある三つの懸念を同時に解決するクリーンなアーキテクチャ上の転換です。ハイパーネットワークが生成するLoRAが信頼性高く合成可能なセマンティックマニフォールドを形成するなら、スキルライブラリは単なる検索されるテキストスニペットではなく、代数的構造を持つ第一級オブジェクトとなります。
Source: https://arxiv.org/abs/2606.06087
Hacker News Signals
なぜLinearはこれほど速いのか?技術的な詳細解説
Linearは、ほぼ瞬時のUIレスポンスで知られるプロジェクト管理ツールです。この解説では、そのような動作を実現するエンジニアリング上の選択を分解します。
コアアーキテクチャはローカルファースト・syncベースのモデルです。すべてのデータはクライアント上のインメモリストアに存在し(カスタムsyncエンジンの上に構築)、読み取り操作はネットワークに一切触れません。書き込みは即座にローカル状態へ楽観的に適用され、非同期で調整されます。これにより、従来のCRUDアプリにおける主要なレイテンシ源、すなわちレンダリング前のリクエスト/レスポンスのラウンドトリップが排除されます。
syncエンジンはoperational transforms(OT)またはCRDTに近い技術を使用して、並行編集を処理し、UIスレッドをブロックすることなくサーバー状態をマージします。クライアントはSQLiteライクな永続的ローカルデータベース(ブラウザではIndexedDBを使用)を維持するため、セッション復元後のコールドロードでもデータがすでにローカルに存在することから高速です。
レンダリングパフォーマンスはいくつかの層から生まれます。Linearはthereactを使用していますが、積極的なmemoizationと、画面外のアイテムのレンダリングを回避するvirtual listの実装を採用しています。ルーティング層はナビゲーションが確定する前にビューをpre-fetchするため、遷移が瞬時に見えます。また、コンポーネントをグローバル状態に過剰にサブスクライブさせるReactの一般的なアンチパターンを避けており、各コンポーネントは必要最小限のスライスのみをサブスクライブすることで、再レンダリングの範囲を縮小しています。
ネットワーク側では、更新はフルなJSONオブジェクトではなく、コンパクトなバイナリエンコードされたdeltaペイロードとして送信されます。WebSocket接続は永続的に保たれ、多重化されています。サーバーインフラはポーリングではなくクライアントへdelataをpushするよう設計されており、マルチデバイスsyncは数十ミリ秒で伝播します。
JavaScriptバンドルは積極的なcode splittingとtree shakingによって小さく保たれています。クリティカルなレンダリングパスでは重量級のサードパーティ依存を避けています。
最終的な効果として、ほとんどのインタラクションが同期的に感じられます。それはユーザーの視点からは実際にそうだからです——UIとローカルデータ層は同じ場所に存在し、ネットワークsyncはバックグラウンドのインフラに過ぎません。
Source: https://performance.dev/how-is-linear-so-fast-a-technical-breakdown
FrontierCode
Cognition AI(Devinの開発元)は、ソフトウェアエンジニアリングタスクの上位領域を対象としたベンチマークおよびそれに関連するモデル評価結果「FrontierCode」を公開しました。主張によれば、現在のフロンティアモデルは、大規模なコードベースの理解・長期的な計画立案・デバッグサイクルを必要とする複雑なマルチファイルの実世界コーディングタスクにおいて、依然として大きく失敗しているとのことです。これは単純な孤立した関数合成とは異なります。
このベンチマークは次のような要件を持つタスクで構成されています:(1) ゼロから書くのではなく既存のリポジトリをナビゲートすること、(2) 複数のコンポーネントにまたがり既存の抽象化への理解を必要とする機能を実装すること、(3) 明確な仕様の不一致ではなく間接的なエラーシグナル(テスト失敗・ランタイムクラッシュ)に基づいてデバッグを行うこと。
主要な技術的知見として、タスクの複雑度が増すにつれてパス率が急激に低下することが挙げられます。現在のモデルにおいて単純な単一関数の補完は高いパス率を示しますが、10ファイル以上の編集を正確に協調して行う必要があるタスクでは、最良のモデルであっても一桁台前半のパーセントにまで低下します。これはtransformerのコンテキスト利用における既知の失敗モードと一致しており、長い依存チェーンにわたってモデルがコヒーレンスを失い、局所的には妥当でも大域的には矛盾した編集を生成する傾向があります。
Cognition自身のエージェント(おそらくDevinのインフラを利用)はAPIのみのベースラインよりも高いスコアを達成しており、その要因としてエージェントのスキャフォールディング、すなわち反復的な実行・テストフィードバックループ・すべてのファイルをコンテキストに素朴に連結するのではなくリポジトリの状態を要約するワーキングメモリ機構を挙げています。
ベンチマークの方法論は実行ベースの評価を重視しており、LLM-as-judgeやBLEUスタイルの指標ではなく、解答がテストスイートをパスし既存のテストを壊さないことを条件としています。これはコーディングタスクにおいて正しいアプローチです。タスクは実際のイシュートラッカーを持つオープンソースリポジトリから収集されており、合成ベンチマークと比較してデータ汚染のリスクが低減されています。
暗示的な主張として、単純なタスクの差を縮めたペースでは、より困難なタスクにおける差をモデルのスケーリング単独では縮められていないこと、そしてエージェントアーキテクチャがベースモデルの能力とは独立して重要であることが挙げられます。
Source: https://cognition.ai/blog/frontier-code
数字なしの算術 – LLMが数学を行う仕組み
これは、transformerが算術を実行する際に使用する内部メカニズムを探るインタラクティブな記事であり、mechanistic interpretabilityをわかりやすく解説することを目的としています。焦点は、モデルが小さな整数の加算や乗算を行う際に、residual streamとattention layerで実際に何が起こっているかという点にあります。
中心的な知見は、モジュラー算術に関するNandaらの研究などの先行mechanistic interpretability研究と一致しており、transformerは記号的な桁操作に類するような方法で算術を実装していないというものです。その代わりに、数値は分散的なフーリエ的基底で表現されているように見えます。加算においては、個々のattention headが特定の周波数成分を取り出すことで、モデルは正弦波的な特徴を合成して a + b \pmod{N} を計算しているようです。出力位置におけるresidual streamはこれらの周波数成分の重ね合わせを保持しており、unembeddingのステップで最も近いトークンへの射影が行われます。
インタラクティブな要素により、読者は特定のオペランドの組み合わせに対してどのattention headが活性化するかを調べたり、オペランドが変化するにつれて出力トークン上のlogit分布がどのように変化するかを可視化したりすることができます。これにより、数値表現が記号的ではなく幾何学的であるという抽象的な主張が、具体的かつ検証可能なものとなります。
この記事が明らかにしている重要な制約として、これらのメカニズムは小規模でクリーンな算術タスク(一桁または二桁の加算)において研究されているという点があります。繰り上がりの伝播によって長距離依存が生じる多桁算術への一般化は、はるかに理解が進んでおらず、質的に異なる回路が関与しているか、あるいは完全に機能しなくなる可能性が高いと考えられます。これは、LLMが大きな数の算術において特有のエラー(繰り上がりの誤処理、学習分布外の数値への対応失敗)を犯す理由を説明するものでしょう。
この記事はLLMの数学能力を完全に説明すると主張しているわけではなく、ある狭い領域を特徴づけるものです。しかし、数値を桁の文字列としてではなく、学習された代数多様体上の点として捉えるというmechanisticな描像は、スケーリングだけでは算術の信頼性が自動的に改善されない理由を考える上での正しいフレームワークです。
Source: https://alvaro-videla.com/llm-arithmetic-internals/article_interactive/article.html
コード実行を引き起こす設定ファイル:サプライチェーンセキュリティの盲点
この投稿は、悪意あるパッケージよりも注目度が低いサプライチェーン攻撃の攻撃対象領域を体系的にまとめています。対象となるのは、パース時やプロジェクトの初期化時にコードをサイレントに実行してしまう設定ファイルです。
具体的な事例は示唆に富んでいます。[tool.setuptools.dynamic] セクションを含む pyproject.toml は、インストール時に評価される任意のPythonスクリプトを参照できます。.npmrc や各種JSツールの設定ファイルはライフサイクルスクリプトをトリガーできます。Jupyterノートブック(JSONファイル)は実行可能なセルを含んでおり、一部の環境ではファイルを開いただけで実行されます。Prettier、ESLintおよび類似ツールは設定ファイルに記述されたプラグインモジュールを読み込むため、侵害されたパッケージを指す .eslintrc.json が実行ベクターとなります。CMakeの CMakeLists.txt はconfigureの実行時に任意のCMakeスクリプト言語を実行します。
想定される脅威モデルは次の通りです。リポジトリに悪意ある設定ファイルを配置できた攻撃者(侵害された依存関係、プルリクエスト、またはCIアーティファクトを通じて)は、プロジェクトをクローンして初期化するあらゆる開発者またはCIシステム上でコード実行が可能になります。多くの場合、被害者が悪意あるコードを明示的に実行することすらありません。これは広く知られている npm install による悪意あるパッケージのシナリオとは異なります。なぜなら、設定ファイルを静的なデータとして扱うというメンタルモデルを迂回するからです。
議論されている緩和策は主にプロセスレベルのものです。設定ファイルの変更をコードと同じ厳密さでレビューすること、lockfileを使ってツールのバージョンを固定すること、依存関係のインストールを隔離された環境(コンテナ、サンドボックス化されたCI)で実行すること、そして設定スキーマを監査してデータと実行ディレクティブを区別することが挙げられます。「設定からコードを実行する」パターンはしばしば意図的な機能であるため、普遍的な技術的解決策は存在しません。
この投稿は、開発者環境やCIパイプラインの脅威モデリングにおける有用なリファレンスとなります。根本的な問題は、現代のビルドツールにおいて「データファイル」と「コードファイル」の区別が著しく曖昧になっていることにあります。
Source: https://safedep.io/config-files-that-run-code/
AIは減速している
この記事は、フロンティアLLMにおける意味のある能力向上のペースが2020〜2023年の時期と比較して減速しており、benchmark飽和とマーケティングの語りがその事実を覆い隠していると主張しています。
技術的な核心はいくつかの観察に基づいています。まず、ホールドアウトテストセットにおけるbenchmark測定上の進歩は続いていますが、benchmarkそのものが頻繁に飽和または汚染されているため、シグナルの質が低下しています。第二に、質的な能力の跳躍——モデルが「Xができない」から「確実にXができる」という閾値を越えるような種類の変化——が起きることは稀になっています。GPT-2からGPT-3への移行(emergent few-shot prompting)、GPT-3からInstructGPT(instruction following)、そしてGPT-4(専門資格試験における複雑な推論)への移行はそれぞれ明確なphase transitionを示していました。しかし最近のリリースは、新たなカテゴリの解放ではなく、既存の能力カテゴリの中での漸進的な改善にとどまっています。
第三に、computeのスケーリングは物理的・経済的な限界に直面しています。最大規模のトレーニングランは現在、データ品質(事前学習用のインターネットデータはほぼ使い尽くされている)、チップの入手可能性、そびえる規模でのinferenceの経済性によって制約されています。単純にスケールを拡大すれば次のphase transitionが生まれるという仮説は、2021年当時ほど経験的に裏付けられていません。
この記事は、これを「進歩が止まった」という主張と区別することに慎重です。post-trainingの技術(RLHF、RLVR、long-context fine-tuning)は引き続きデプロイされたモデルの挙動を意味深く改善し続けています。議論は具体的に、事前学習のスケーリングカーブの急勾配が平坦化したという点に向けられています。
考慮に値する反論としては、reasoning model(oシリーズ)がtest-time computeによって可能となった質的に新しい能力軸を表しているという点や、multimodalな能力が大幅に向上したという点があります。これらが著者が求めるようなphase transitionに相当するかどうかは、定義上の問題です。
Source: https://www.wheresyoured.at/ai-is-slowing-down
静かなナンバーズ・ステーション:19年間のGPS暗号技術を解読する
本記事は、GPS Navigation Message Authentication(NMA)システムの暗号技術的な歴史、具体的には暗号化されたM-codeシグナルと、展開されながらもほぼ20年間にわたって公式には文書化されなかった民間NMA(CNAV)認証メカニズムを再構築するものです。
技術的な核心は、GPSの制御セグメントがスプーフィングを防ぐために暗号認証された航法メッセージをブロードキャストしているという点にあります。民間向けの認証方式は、TESLA(Timed Efficient Stream Loss-tolerant Authentication)ベースのプロトコルを採用しています。すなわち、ハッシュチェーンはオフラインで計算され、各ブロードキャスト航法メッセージには、直前のタイムスロットでコミットされた鍵を用いて計算されたMACが含まれます。受信機はメッセージをバッファリングし、遅延してブロードキャストされる鍵を受信した後に検証を行います。これにより、受信機側に秘密鍵を保持させることなく非対称認証が実現されます。
本記事は、公式発表以前のシグナルキャプチャから研究者たちがどのようにして認証方式の構造を推測できたかを追跡しています。その手法は、ハッシュチェーンのリリースの規則性とメッセージ構造の統計解析を用いるものでした。ハッシュ関数とチェーンのパラメータは、観測された鍵リリースからリバースエンジニアリングすることが可能でした。
注目すべき点として、民間の受信機がこれを利用することが承認または指示されるよりも数年前からシステムがブロードキャストを行っていたことが挙げられます。つまり、認証インフラは一種の暗号的なナンバーズ・ステーションとして稼働しており、認証済みデータを、検証済みの受信者が存在しない状態で、あるいは機密扱いの軍事受信者に向けてブロードキャストし続けていたことになります。
セキュリティ上の含意は実際的なものです。GPSスプーフィングは依然として紛争環境における現実の脅威であり、NMAはその障壁を大幅に高めます。スプーフィングには、シグナルの偽造だけでなく、認証チェーンの破壊や過去の認証済みメッセージのリプレイ(フレッシュネスチェックで失敗します)が必要となるためです。リプレイ攻撃は依然として残存するリスクであり、独立した正確な時刻を維持できない受信機にとっては特に懸念されます。
Zig Structs of Arrays (2024)
この記事では、Zig における Struct of Arrays(SoA)データレイアウトパターンの実装を解説しています。このパターンは、パフォーマンスが要求されるアプリケーションにおいて SIMD フレンドリーかつキャッシュ効率の高いコードを書く上で重要です。
標準的な Array of Structs(AoS)レイアウトは、各要素のすべてのフィールドを連続して配置します:[{x, y, z}, {x, y, z}, ...]。多数の要素にわたって x フィールドだけを処理する場合、SIMD ロードは y や z のデータも読み込んでしまい、キャッシュ帯域幅を無駄に消費します。SoA はこれを逆転させます:{xs: [x, x, ...], ys: [y, y, ...], zs: [z, z, ...]} とすることで、単一フィールドのイテレーションが連続したメモリアクセスになります。
Zig の実装では comptime リフレクションを活用します。構造体型 T が与えられると、SoA ラッパーはコンパイル時に @typeInfo(T).Struct.fields を走査し、各フィールドをそのフィールドの型のスライスに置き換えた構造体を生成します。これはゼロコスト抽象化を実現します:生成された型は手書きしたものと完全に同一であり、メタプログラミングによる実行時オーバーヘッドはありません。
この記事ではアクセサ API についても取り上げています。インデックス i に対する「仮想的な」構造体の値を取得するには、各フィールドスライスのインデックス i を読み取って値を構築する必要がありますが、Zig の comptime ループによってこれを簡潔に生成できます。ミューテーションも対称的な形で処理されます。
実用上の懸念事項として、記事ではメモリアロケーションについても述べています。単純な実装ではフィールドごとに別々のスライスをアロケートするため、アロケータのオーバーヘッドが増大し、フィールド配列間のキャッシュローカリティが損なわれる可能性があります。より洗練されたバージョンでは、単一のバッキングバッファをアロケートしてそれを分割することで、各配列を物理的にメモリ上で近い位置に保ちます。
これは、データレイアウト最適化における C++ テンプレートメタプログラミングや Rust マクロの真の代替手段としての Zig の comptime を示す好例です。コードは読みやすく、生成されたレイアウトは検査可能です。
Source: https://andreashohmann.com/zig-struct-of-arrays/
小規模でハック可能なCUDA言語モデル実装
これは CUDA C で書かれた最小限の GPT 実装であり、フレームワークの抽象化を使うのではなく、低レベルのGPUカーネルを理解・改変したい開発者を対象としています。設計目標として明示されているのは、forward pass、backward pass、およびトレーニングループ全体が、CUDA と行列積のための BLAS ライクなライブラリ以外の外部依存なしに、少数のファイルに収まることです。
この実装は標準的な GPT-2 アーキテクチャをカバーしています:トークンおよび位置の embedding、因果マスクを伴うマルチヘッド self-attention、layer normalization、そしてGELU活性化を用いたフィードフォワードブロックです。attention および normalization のパスに関する CUDA カーネルは、cuDNN や cuBLAS を通じてではなく明示的に記述されており、そのため検査・改変が可能ですが、本番レベルのスループットには最適化されていません。
attention カーネルは flash attention のタイリングトリックを用いない素朴な O(n^2) attention を実装しており、教育的な実装としては適切ですが、シーケンス長に制限が生じます。backward pass カーネルは forward pass の構造を反映しており、リファレンス実装との比較による gradient の正確性検証に役立ちます。
実践者にとっての価値は、周辺のコードが最小限であれば、カスタム CUDA カーネルのデバッグが格段に容易になる点にあります。新規の attention バリアントや非標準の normalization スキームを実装している場合、PyTorch の内部にパッチを当てたり大規模フレームワークに対してカスタム CUDA 拡張を書いたりするよりも、改変のベースとなるクリーンなベースラインを持つ方がはるかに有用です。
制限事項はリポジトリ内に明示されています:mixed precision なし、tensor parallelism なし、大きいバッチサイズに向けた最適化されたメモリレイアウトなし。これは明示的にトレーニングフレームワークではなく、小規模での学習と実験のためのリファレンス実装です(小さいモデルサイズであれば、一般消費者向けの単一GPUに快適に収まる規模です)。
注目の新規リポジトリ
VibeBench/VibeSearchBench
単発の検索では対応しにくいタスク(曖昧なクエリ、情報が段階的に開示されるマルチターン対話、能動的な明確化要求)においてエージェント型検索システムを徹底的にテストすることを目的としたベンチマークです。200件の長期的な視野を持つタスクはペルソナ駆動型のユーザーシミュレータと組み合わされており、シミュレータは情報を段階的に開示することで、エージェントが「まだ何を知る必要があるか」を推論することを強制します。評価では、スキーマ依存のメトリクスを避けるため、正解文書からナレッジグラフを構築し、エージェントの応答から抽出された (subject, predicate, object) トリプルに基づくtriplet F1(適合率と再現率)で予測を採点します。これにより、文字列マッチングやembedding類似度によるスコアリングの脆弱性を回避しつつ、完全に検証可能かつ再現性のある評価を実現しています。このベンチマークは、一般的に単一の整形済みクエリと固定された回答文字列を前提とする既存のIR/QA評価の空白を埋めることを目的としています。マルチターンかつ不完全に指定された検索は、現実のエージェント的ユースケース(例:リサーチアシスタント、カスタマーサポート)に近いものですが、本ベンチマークのような厳密さでベンチマーク化されることはほとんどありませんでした。RAGパイプライン、ツール使用型LLM、またはユーザーモデルが検索モデルと同様に重要となる会話型検索エンジンを評価するすべての方にとって有用です。
Source: https://github.com/VibeBench/VibeSearchBench
deeplethe/forkd
AIエージェントのマイクロVM向けプロセスモデルランタイムであり、完全な仮想マシンに対してPOSIXの fork() セマンティクスを提供します。実装にはKVMによるハードウェア分離とcopy-on-writeスナップショットが使用されており、ウォーム状態の親VMから100個の子VMをスポーンする処理は約100 msで完了し、実行中のライブVMをブランチする操作(BRANCH オペレーション、実行途中の fork() に相当)は約150 msで完了します。CoWにより、子VMのメモリページは書き込みが発生するまで物理的には複製されないため、メモリのオーバーヘッドはVM数ではなく分岐後の差分に比例します。この設計は、複数の実行パスを同時に探索する必要があるエージェントのワークロード——投機的なツール呼び出し、並列仮説検証、失敗したアクション後のロールバックなど——をブランチごとにVMの完全な起動コストを支払わずに処理するという動機に基づいています。KVMの分離境界により、侵害されたあるいは誤動作する子VMが兄弟VMや親VMに影響を与えることができません。アーキテクチャ的には、汎用スナップショットを目的とするCRIUよりも、Firecracker方式のマイクロVMに近い設計ですが、APIはエージェントオーケストレーションを念頭に置いて構成されています。マルチエージェントサンドボックス、コード実行環境、あるいは状態のロールバックを低コストで実現する必要があるシステムを構築するすべての方に関連します。
Source: https://github.com/deeplethe/forkd
secureagentics/Adrian
LLMエージェントとそのツールインターフェースの間に位置するランタイムセキュリティレイヤーです。Adrianはツール呼び出しを実行前にインターセプトし、設定可能なポリシーに照らし合わせて評価します。対象とする脅威クラスは3種類あります:悪意あるツール利用(例:予期しないファイル削除や外部への情報漏洩呼び出し)、後続のエージェント動作を改変しうるツール出力に埋め込まれたprompt injection、そしてセッションを通じてエージェントのアクション分布が許可された運用範囲から逸脱するポリシードリフトです。インターセプトは同期的に行われ、Adrianが判定を下すまでエージェントはブロックされるため、許可なしにいかなるアクションも実行されません。ポリシードリフト検出は、セッション全体にわたる行動ベースラインを追跡し、統計的な逸脱を検出するものと考えられますが、その仕組みは完全には文書化されていません。このアーキテクチャは、エージェントがシェル、データベース書き込み、外部APIといった高い影響度を持つツールにアクセスできる本番環境のデプロイメントや、事後監査では不十分なケースに適しています。実行環境を制約するサンドボックスアプローチと比較して、Adrianはツール呼び出し自体のセマンティックレベルで動作するため、より細かい粒度でのallow/deny判断が可能です。主要な未解決の問題は、正当ではあるが通常とは異なるツール呼び出しシーケンスに対する偽陽性率です。
Source: https://github.com/secureagentics/Adrian
cellinlab/how-pi-agent-works
Pi Agentの内部アーキテクチャを技術的に解説したリポジトリで、コード付きの中国語で記述されています。このリポジトリは、会話型AIエージェントがどのように構成されているかを解剖しており、計画ループ、ツールディスパッチ、メモリ管理、LLMバックボーンと外部アクションエグゼキュータとのインターフェースを網羅しています。本番システムではなく主に教育目的で作られており、ユーザーのリクエストが意図分類、計画生成、ツール呼び出し、結果合成を経てどのように伝播するかを追った、注釈付きの実装スケッチとして構成されています。その価値は明示性にあります。ブラックボックスなフレームワークを指し示すのではなく、各段階での配線を示しており、独自のエージェントランタイムを構築する開発者や、特定のエージェントフレームワークがそのような設計判断を下す理由を理解しようとする開発者にとって有用です。中国語での記述は中国人開発者コミュニティを対象としていることを示唆していますが、コード自体は言語に関わらず読むことができます。このようなゼロからの再構築は、LangChainやAutoGenのような高レベルフレームワークに組み込まれた前提を監査する上で、また計画やメモリサブシステムへの変更を実験するための最小限のリファレンス実装を求める研究者にとって有用です。
Source: https://github.com/cellinlab/how-pi-agent-works
packyme/privacy-filter
LLM API呼び出しにおけるPIIおよびシークレット情報のリダクション(秘匿化)ゲートウェイを実装したGoライブラリおよびプロキシです。トークンがモデルに到達する前のリクエストパスで動作し、エンティティ認識とパターンマッチング(クレジットカード番号、APIキー、社会保障番号、メールアドレスなど)を実行し、検出された機密文字列をプレースホルダートークンで置換します。Go実装はミリ秒単位のレイテンシでのリダクションを目標としており、これはインタラクティブなLLM呼び出しに体感できる遅延を加えてはならない同期型ゲートウェイにとって適切な制約です。本ライブラリはPackyCodeにて本番環境にデプロイ済みであると説明されており、レイテンシに関する主張を裏付ける少なくとも一つの実世界での検証が存在します。コアとなるエンジニアリング上の課題はrecallとprecisionのバランスです。積極的なリダクションは情報漏洩リスクを低減しますが、モデルが必要とするコンテキストを破壊する恐れがあり、一方でリダクション不足では目的を果たせません。このリポジトリは、複合エンティティ(例:URL内に埋め込まれた名前)の扱い方、およびリダクションが後処理のために可逆的かどうかという観点から検討する価値があります。オンプレミスでのデプロイを行わずにユーザーデータをサードパーティのLLM APIに通すチームにとって、このような高速なインラインゲートウェイは実用的なコンプライアンスツールとなりますが、アプリケーションレベルでのデータ最小化の代替にはなりません。
Source: https://github.com/packyme/privacy-filter
AprilNEA/OpenLogi
HID++プロトコルを介してマウスやキーボードと通信する、Rustで書かれたネイティブかつローカルファーストなLogitech周辺機器マネージャーです。公式のLogitech Options+ソフトウェアおよびその必須クラウドアカウントを不要にします。ボタンのリマッピング、DPI設定、SmartShift(MX Masterシリーズデバイスの電磁スクロールホイール切り替え機能)をサポートしています。Rust実装は、本質的にHIDデバイス制御デーモンである本ソフトウェアにおける正確性と低オーバーヘッドを目標としており、ガベージコレクターによる停止なし、HIDレイヤーへの直接システムコール、バックグラウンドテレメトリープロセスなしを実現しています。HID++はUSB HID標準のLogitech独自拡張であり、レジスタベースのコマンドモデルを採用しています。これを正しく実装するにはリバースエンジニアリングされたプロトコルドキュメントが必要であり、本プロジェクトはSolaarやlibratbagが使用しているのと同じ資料群を参照していると思われます。「ローカルファースト」というコンセプトは実用上重要な意味を持ちます。公式ソフトウェアは機能の有効化やプロファイル同期のためにクラウドへ通信を行いますが、これはオフライン利用には不要であり、プライバシー上の懸念もあります。4,000以上のスターを獲得しており、ベンダーのソフトウェアスタックなしにSmartShiftサポートを必要とするLinuxおよびmacOS上のパワーユーザーの間で相当な支持を得ています。またRustのコードベースは、既存のPythonベースの代替手段と比較して、新しいデバイスサポートを追加するためのよりクリーンな基盤となっています。
Source: https://github.com/AprilNEA/OpenLogi
superloglabs/superlog
従来のログ集約およびアラート機能の上にAIエージェント層を追加したオブザーバビリティプラットフォームです。本システムは標準的なパイプラインを通じてログとメトリクスを取り込み、その後エージェントを実行して異常の診断と修復ステップの提案または実行を試みます。これがいわゆる「セルフヒール」という位置づけです。技術的に興味深い点は、エージェントがどのようにしてその行動を根拠づけるかにあります。具体的には、デプロイメントのコンテキスト(最近何が変更されたか)、サービストポロジー(何が何に依存しているか)、そして自動適用しても安全な修正と人間の承認が必要な修正を判断するポリシー層へのアクセスが必要です。これらのグラウンディング機構がなければ、ログを扱うLLMエージェントはもっともらしく聞こえるが誤った根本原因をハルシネーションしてしまいます。オープンソースとして公開されたことで、これらのグラウンディングコンポーネントを検査・修正することが可能になり、クローズドなAIOps製品との差別化点となっています。実用的には、アラートの量が多く、エージェントのアクションとしてエンコードできる十分に理解された修復プレイブック(サービスの再起動、デプロイメントのロールバック、レート制限の調整など)を持つチームにとって最も有用です。新規または複数システムにまたがる障害モードについては依然として人間の判断が必要となるため、その価値はルーティンな対処の自動化にあります。
Source: https://github.com/superloglabs/superlog
razr001/align-dev
AI コーディングアシスタントにコーディング規約を体系化・配布するためのツールレイヤーです。チームの慣習・パターン・制約を記述した構造化された自然言語ドキュメントである SKILL.md ファイルを生成し、リポジトリのルートに配置することで、Claude Code、Codex、Cursor、Copilot およびその他の類似エージェントがコンテキストとして参照できます。中心的な課題は、AI コーディングアシスタントがプロジェクト固有の慣習ではなく、母集団レベルのスタイルをデフォルトとして採用するため、機械的にはレビューを通過するものの、命名規則・エラー処理・コンポーネント構造など、リンターでは強制しにくい側面においてチームの規範から乖離したコードを生成してしまう点にあります。AlignDev は、既存のコードから慣習を抽出するか手動指定を受け付け、それを SKILL.md 形式にシリアライズする生成ワークフローを提供します。このアプローチは、コードベースに対する fine-tuning や RAG よりもシンプルであり、in-context でのインストラクションフォロイングに依拠しているため、エンコードできる慣習の詳細量には限界があるものの、異なるアシスタントバックエンド間で普遍的な互換性を保てます。主な制限は、SKILL.md の長さがコンテキストウィンドウに制約される点であり、サブシステム固有の慣習が多い複雑なコードベースでは、階層的またはモジュールスコープのバリアントが必要になる場合があります。