Daily AI Digest — 2026-06-09
arXiv Highlights
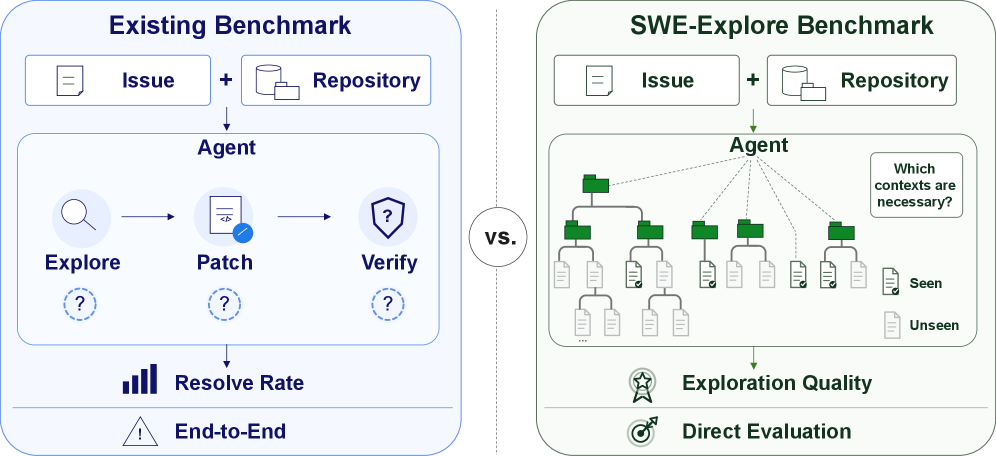
SWE-Explore: Benchmarking How Coding Agents Explore Repositories
Repository-level coding benchmarks like SWE-bench score agents on a binary resolved/unresolved outcome. That collapses several distinct competencies — repository navigation, context retrieval, fault localization, and patch synthesis — into one number, making it hard to attribute failures or improve subsystems. SWE-Explore isolates the first of these: given an issue q and a repository snapshot \mathcal{R}, return a ranked list of relevant code regions under a fixed line budget, with no patch required and no access to ground truth.
Task and ground truth
The explorer is a function
f:(q,\mathcal{R}) \mapsto P=(r_1,r_2,\ldots,r_K), \qquad r_i=(p_i,s_i,e_i),
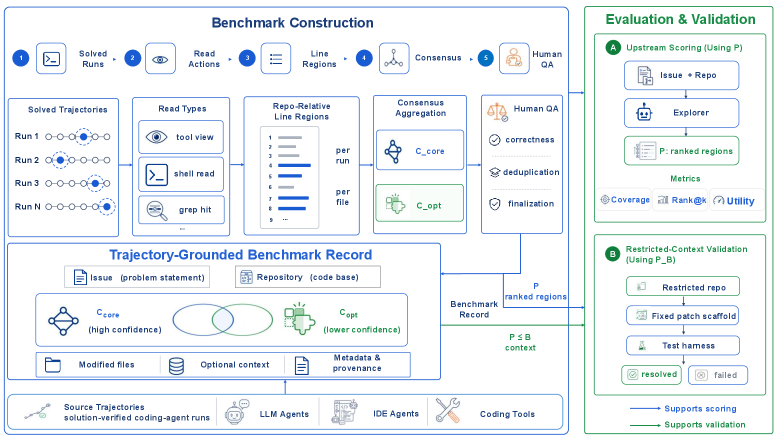
where each r_i is a (file path, start line, end line) triple. Evaluation happens against a trajectory-grounded supervision signal rather than human annotations or patch hunks. For each instance, the authors take agent trajectories that successfully resolved the issue, extract the read actions (file opens, greps, view ranges), and aggregate them into a “core” set R_{\text{core}} of regions actually consulted along the solution path, plus an “optional” context set. Distilling supervision from independently verified trajectories sidesteps a known pathology: ground truth derived from the gold patch underrepresents auxiliary code (callers, tests, configuration) that solving the issue actually requires reading.
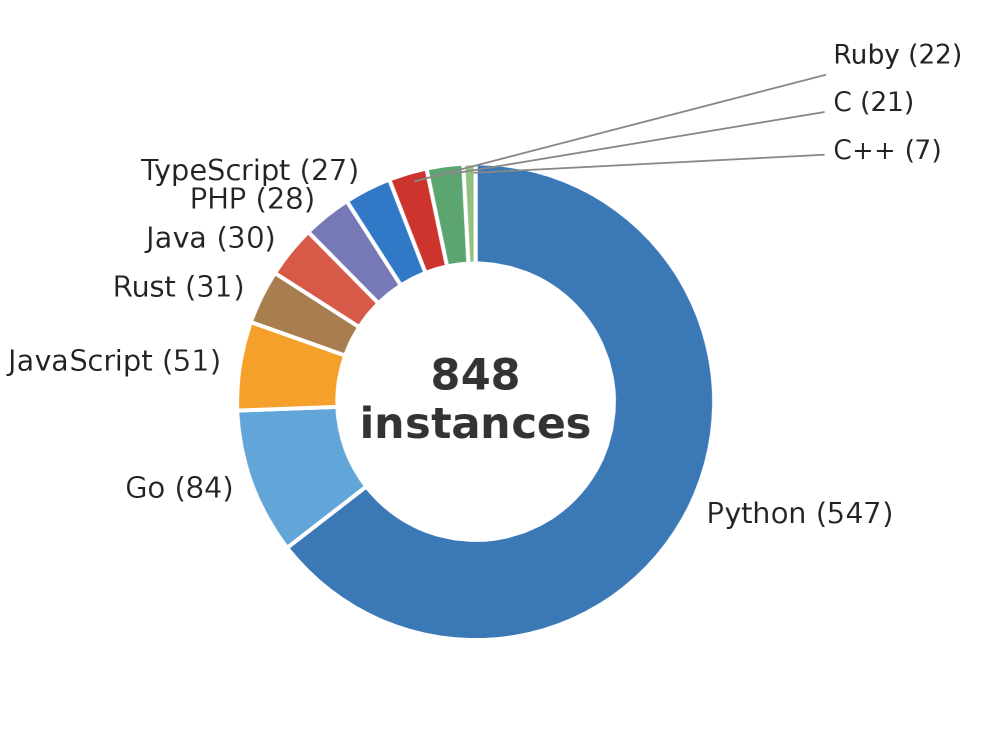
The benchmark contains 848 instances over 203 repositories and 10 programming languages, broadening the predominantly Python coverage of SWE-bench-style suites.
Metrics
Three axes are scored: (i) coverage — how much of R_{\text{core}} the returned regions overlap at the line level; (ii) ranking — whether core regions appear early in P, since downstream repair LMs have bounded context; and (iii) context-efficiency — coverage normalized by the line budget consumed, penalizing dumps of large files. Crucially, evaluation does not require running the repository or producing a patch, so a new explorer can be plugged in cheaply.
Separately, as a one-time methodological check (not part of the standard loop), the authors run a restricted-context repair bridge: feed only the explorer’s regions to a fixed repair LM and measure resolution. This validates that the upstream metrics correlate with downstream repair, without baking repair noise into the explorer score.
Explorers evaluated
Four families are benchmarked:
- Bounds: Oracle (returns R_{\text{core}} directly) and Random (uniform region sampling).
- Sparse retrieval: BM25, TF–IDF.
- Dense retrieval: a RAG pipeline using Potion, a static word-embedding retriever distilled from a sentence transformer.
- Agentic explorers: five general coding agents (Claude Code, Codex, OpenHands, Mini-SWE-Agent, AweAgent) and four published localization-specialized agents (AutoCodeRover, LocAgent, OrcaLoca, CoSIL).
Oracle additionally serves to validate ground-truth construction: if Oracle’s repair-bridge resolution rate is high, the trajectory-distilled R_{\text{core}} is genuinely sufficient for repair, confirming that the supervision is well-formed.
What the benchmark exposes
The framing matters because it disentangles failure modes that holistic benchmarks cannot. An agent that produces a correct patch given the right context but cannot find that context will look identical, on SWE-bench, to an agent that retrieves perfectly but patches poorly — yet the engineering remedies are entirely different. By scoring on coverage, ranking, and context-efficiency under a fixed line budget, SWE-Explore makes it possible to ask, e.g., whether an agent’s gains over BM25 come from better navigation or merely from reading more lines.
The selected sections do not yet enumerate per-system numerical results, but the abstract claims the metrics “strongly track downstream repair behavior” via the bridge, and that across the four families there are systematic gaps — a result consistent with prior observations that even strong general agents under-explore relative to specialized localizers, while specialized localizers can be brittle outside Python.
Limitations and open questions
Trajectory-distilled ground truth inherits the bias of whichever agents produced the successful trajectories: regions never visited by any solver are absent from R_{\text{core}}, even if alternative solution paths exist. The line-budget abstraction also assumes downstream consumers are token-bounded LMs; agents that interleave exploration with editing in long-horizon loops are evaluated only on the static ranked output, not on the dynamics of their search. Finally, the repair bridge is a single fixed LM, so the validation that metrics track repair is conditional on that repair model’s failure modes.
Why this matters
Sub-task benchmarks are how a field moves from “the agent worked” to “we know which component to improve.” SWE-Explore gives coding-agent research a clean, line-level target for the retrieval/navigation half of the pipeline, with multilingual coverage and trajectory-grounded supervision that avoids the gold-patch undercoverage problem.
Source: https://arxiv.org/abs/2606.07297
On the Geometry of On-Policy Distillation
On-policy distillation (OPD) — where a student samples its own rollouts and is trained against a teacher’s token-level distribution on those rollouts — has become a workhorse for transferring reasoning ability into smaller LLMs. This paper asks a structural question: in parameter space, is OPD essentially SFT with a different supervision signal, essentially RLVR with a denser reward, or something geometrically distinct? The answer, supported by four parameter-space diagnostics and trajectory analysis on Qwen3-family checkpoints, is the third.
Locating OPD between SFT and RLVR
The authors compare three post-training regimes anchored on the same Qwen3-8B SFT checkpoint with shared math prompt distribution. Let W_0 be the anchor and \Delta W = W_+ - W_0 the post-training update. Four diagnostics are used:
- bf16-aware update sparsity, treating w_i as unchanged if |\hat w_i - w_i| \le \eta \max(|w_i|,|\hat w_i|) with \eta = 10^{-3};
- principal-angle rotation between top-k subspaces of W_0 and W_+;
- spectral drift across singular values;
- update-mask localization, asking whether visible updates fall on principal-direction weights or on low-magnitude weights.
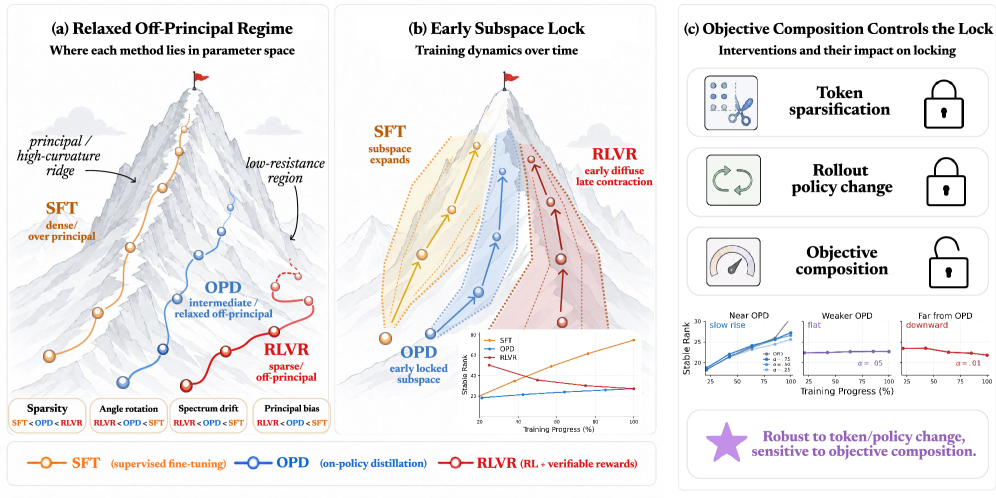
The picture that emerges (Figure 1a) is a “relaxed off-principal” regime: SFT produces dense, principal-aligned updates that rotate top subspaces and reshape the spectrum; RLVR produces sparse, strongly off-principal updates that preserve pretrained geometry; OPD sits between them — fewer visible weight changes than SFT, less geometric preservation than RLVR.
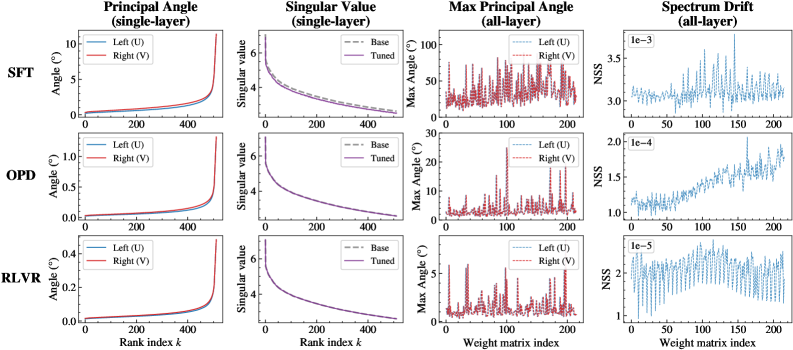
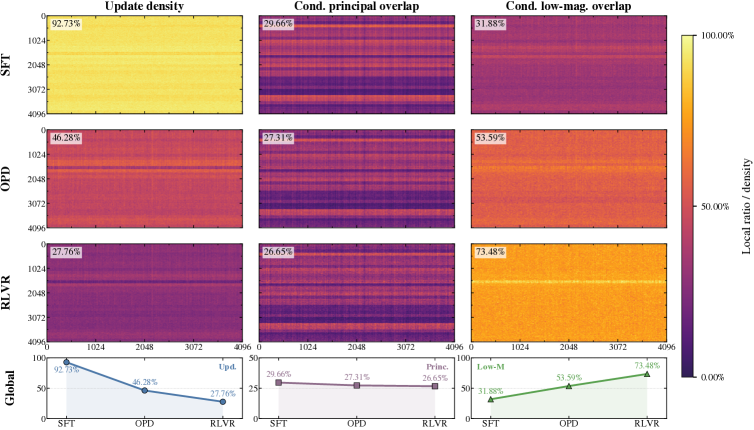
Figure 2 makes this concrete at the level of principal angles and singular-value drift: SFT’s rotation curves rise sharply with rank index k, RLVR’s stay flat, and OPD’s lie consistently between, but closer to RLVR. The localization analysis in Figure 3 confirms the off-principal bias: OPD’s bf16-visible updates avoid principal weights and concentrate on low-magnitude entries, but with less selectivity than RLVR.
Subspace locking
The static endpoint picture is supplemented by a trajectory analysis using cumulative updates \Delta W_t = W_t - W_0. The key quantity is stable rank,
\mathrm{srank}(\Delta W_t) = \frac{\|\Delta W_t\|_F^2}{\|\Delta W_t\|_{\mathrm{op}}^2},
averaged over analyzed matrices. Three trajectories are reported:
- SFT: stable rank grows as training proceeds — the update subspace expands.
- RLVR: stable rank contracts toward a low-dimensional endpoint.
- OPD: stable rank enters a narrow low-rank band early and stays there.
So OPD is not a temporal interpolation between SFT and RLVR; it locks into a low-dimensional update channel from the start. To rule out the trivial explanation that OPD simply moves W very little, the authors track Frobenius norms and Hill-tail estimates of singular-value spectra. OPD accumulates a substantially larger Frobenius update than RLVR yet ends with comparable stable rank, and its Hill-tail index evolves only mildly while SFT’s rises sharply and RLVR’s falls. The low-dimensionality is therefore a property of the update’s spectral shape, not its scale.
The functional consequence is tested by constraining training to the update subspace formed early in OPD: this preserves OPD performance but substantially degrades SFT. The early-locked subspace is functionally sufficient for OPD, but not expressive enough for SFT — direct evidence that OPD’s locked channel is where its learning actually happens.
What maintains the lock
Section 5 perturbs three candidate drivers while monitoring stable rank.
- Token sparsification: retain only top-KL tokens or random tokens at 25% and 50% density. All sparsified variants closely track the OPD stable-rank trajectory; even random 25% retention shifts update scale more than spectral shape. The lock is therefore not localized to a small set of high-KL “teaching” tokens.
- Rollout policy: shifting rollouts off-policy modestly increases update norm but leaves the stable-rank trajectory nearly identical to on-policy OPD.
- Objective composition: mixing OPD with RLVR changes the rank dynamics.
So the lock is robust to runtime supervision and data-source choices, but sensitive to the form of the loss. This is consistent with the relaxed-Three-Gates interpretation: the OPD objective itself selects a particular spectral regime, independent of which tokens or rollouts produce the gradient.
Limitations and open questions
The analysis is correlational and centered on one model family (Qwen3, primarily Qwen3-8B) and the math domain. Stable rank is a coarse summary of spectral shape; whether the locked subspace coincides with task-specific functional directions, or merely with directions of low resistance in the loss landscape, is not resolved. The mechanism by which an on-policy KL-to-teacher loss generates spectral confinement — as opposed to RLVR’s verifier-driven sparsity — is also left open. Finally, the subspace-constraint experiment shows sufficiency, not necessity: alternative low-rank channels of similar dimension may also support OPD.
Why this matters
If OPD genuinely operates in a low-dimensional, off-principal channel that is functionally sufficient and largely insensitive to token-level supervision and rollout policy, then efficient OPD implementations — low-rank parameterizations, projected optimizers, or subspace-restricted fine-tuning — should be tractable without quality loss, and the SFT-vs-RL dichotomy in post-training analysis should be replaced with a three-regime view.
Source: https://arxiv.org/abs/2606.07082
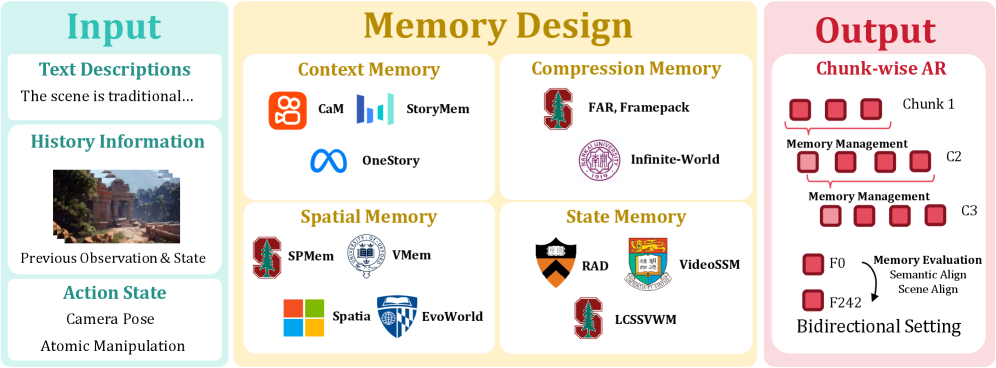
Latent Spatial Memory for Video World Models
Video world models that aim to keep generated frames 3D-consistent across long camera trajectories typically rely on an explicit RGB point cloud cache: at each conditioning step the cache is rasterized to the target camera, and the resulting RGB image is re-encoded through a VAE before being injected into a diffusion backbone. This rasterize-and-encode round trip is both expensive — VAE encode/decode dominates per-step cost at high resolution — and lossy, since the latent features computed by the backbone are discarded and reconstructed from pixels each cycle. Mirage replaces this with a cache that lives entirely in the diffusion latent space, eliminating the pixel-space detour during readout.
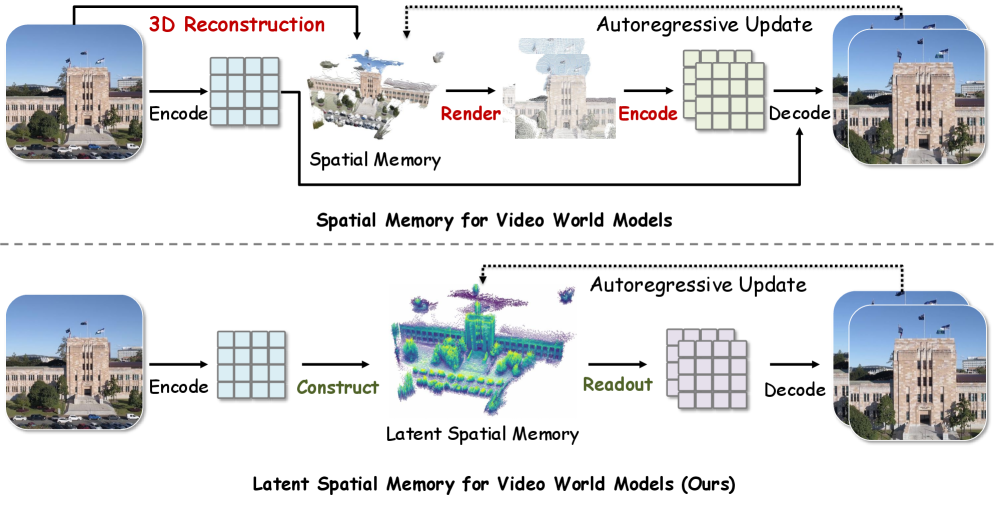
Method
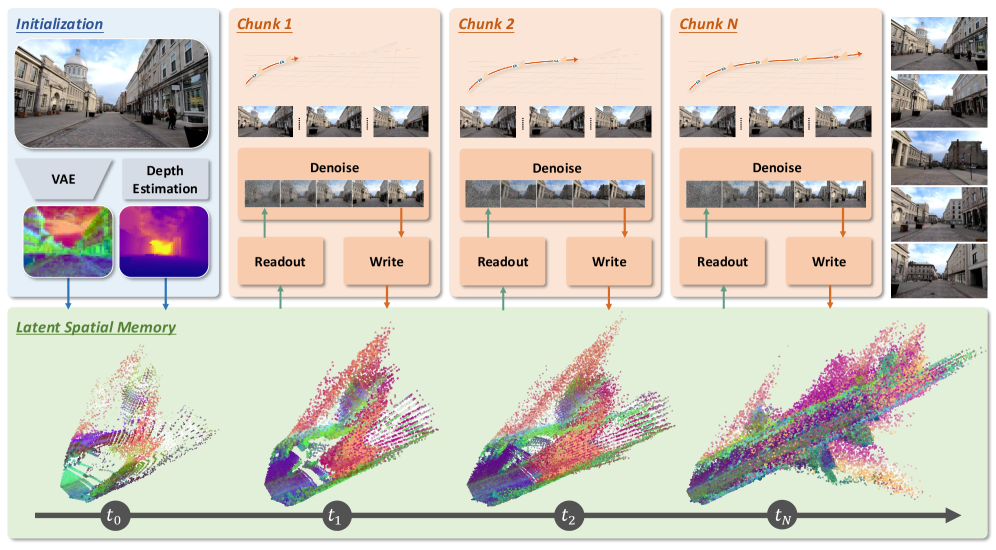
The cache \mathcal{M} is a set of 3D points, each carrying a C=48-dim latent feature vector rather than an RGB color. Initialization encodes the first frame I^0 with the Wan2.2 VAE encoder \mathcal{E} (compression 4\times 16\times 16) and back-projects each latent cell into world coordinates using a monocular depth estimate and the known camera intrinsics/extrinsics. Each latent cell at pixel (u,v) with depth d becomes a 3D point X = K^{-1}[u,v,1]^\top d transformed by the camera pose, attributed with the latent token at (u,v).
Generation proceeds chunk by chunk over nine latent frames (33 RGB frames at 704\times 1280). For a target chunk:
- Readout. \mathcal{M} is projected onto each target camera at latent resolution 44\times 80, producing a target-view latent feature tensor (z-buffered, with empty cells masked).
- Denoising. This tensor is fed into a ControlNet-style side branch initialized from the Wan2.2-TI2V-5B blocks, which conditions the diffusion backbone. Training uses the flow-matching objective on target frames; inference uses 40 UniPC steps.
- Update. The decoded chunk is re-encoded, depth is re-estimated, and the new latent points are back-projected and merged into \mathcal{M}. Dynamic regions and sky are masked out so that only static geometry contributes to the cache.
The key cost reduction: prior RGB caches must rasterize at full resolution H\times W then encode through the VAE for every conditioning step inside the sampler. Mirage rasterizes once per chunk at latent resolution H/s \times W/s (here s=16), shrinking both the cache footprint and the readout compute by roughly s^2. Pixel-space operations occur only during the chunk-level update, not inside the denoising loop.
Results
On WorldScore, Mirage reaches an Average Score of 70.36, slightly above Spatia (69.73) and substantially above the strongest RGB-point-cloud baseline Voyager (66.08). Component-wise it leads on 3D Consistency (92.21), Photometric Consistency (93.95), Style Consistency (96.91), and Object Control (74.17). Camera Control is 55.36, well above the foundation video generators (23–38) but below Voyager’s 85.95 and InvisibleStitch’s 93.20 — the explicit-geometry baselines retain an edge on strict camera-pose adherence even as they lose on consistency and quality. Content Alignment (42.09) is mid-pack; LucidDreamer (75.00) and Voyager (68.92) score higher, suggesting the latent cache helps geometry more than semantic prompt fidelity.
Efficiency is the headline: up to 10.57\times faster end-to-end generation and 55\times smaller peak memory for one cache read versus explicit 3D baselines, measured on a single H100 as rollout length grows. The s^2 = 256 ratio between RGB and latent grid sizes is the underlying source of these gains; the realized speedup is lower because depth estimation and the chunk-level update remain in pixel space.

Qualitatively, despite training only on RealEstate10K (indoor real-estate footage with depth and pose), Mirage generalizes to outdoor and natural scenes under aggressive camera motion. RGB point-cloud baselines exhibit stretched textures on unseen layouts where depth back-projection is unreliable, while foundation video generators drift geometrically over long rollouts.
Limitations and open questions
The latent cache inherits depth-estimator failure modes: incorrect depths place latent tokens at the wrong 3D coordinates, and unlike RGB-space inpainting these errors are harder to diagnose because the cache content is not human-interpretable. Dynamic-object handling is coarse — moving regions are simply excluded from the update, so the model cannot maintain memory of moving entities across re-visits. Camera-control numbers also lag explicit-geometry methods, indicating the side-branch conditioning is softer than direct rasterized RGB. Finally, the latent cache is tied to a specific VAE; transferring memory across backbones (or across resolutions) requires re-encoding, and the geometric prior the diffusion model uses to “fill in” empty cache cells is not characterized.
Why this matters
Storing memory in latent rather than pixel space is the natural fit for diffusion world models: it removes a redundant encode/decode round trip from the inner sampling loop and yields order-of-magnitude efficiency gains while improving consistency metrics. The result reframes 3D-consistent video generation as a problem of geometrically-indexed feature caches over diffusion latents rather than reconstructed RGB scenes.
Source: https://arxiv.org/abs/2606.09828
Echo-Memory: A Controlled Study of Memory in Action World Models
Action-conditioned world models generate chunked video from a first frame, a text prompt, and a per-frame camera trajectory. Their dominant failure is not local synthesis but memory: when the camera leaves a region and returns, salient objects and scene structure silently mutate. Prior memory designs (raw context windows, learned compressors, spatial caches, recurrent state) are difficult to compare because each paper bundles a memory mechanism with its own backbone, retriever, action encoding, and metric. Echo-Memory is a matched-protocol ablation: a single video DiT, single optimizer, single camera-action interface, single sampler, and single evaluation pipeline, with only the memory profile varying across rows.
Setup
The backbone is a pre-trained video diffusion transformer trained with rectified-flow regression restricted to the target frames,
\mathcal{L}(\theta)=\mathbb{E}_{t,\mathbf{x},\mathbf{c}}\,\|v_\theta(\mathbf{z}_t;t,\mathbf{c}_{\text{text}},\mathbf{c}_{\text{ctx}},\mathbf{c}_{\text{act}})-(\mathbf{z}_1-\mathbf{z}_0)\|_2^2.
Each segment is 81 frames at 352\times640. Actions are 12-dim relative RTs (9 rotation + 3 translation) expressed in the first-frame frame of reference. Memory enters through \mathbf{c}_{\text{ctx}}, a per-frame VAE latent stack of K historical frames retrieved by a fixed field-of-view policy, with the anchor (current segment start) always included and retrieved frames dropped 10% of the time. All variants share AdamW at 5\times10^{-5}, 5k steps, 8×A100. Only K\in\{1,5,20\} and the memory module change.
The factorization isolates four axes that prior work conflates: capacity (how many historical tokens are retained), compression (how aggressively they are summarized), read-out (how the generator queries them), and recurrence (whether memory is a state updated over time).
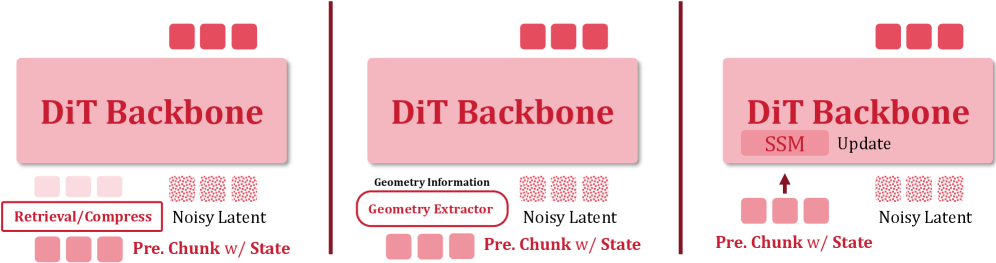
Memory families
- Context: raw per-frame VAE tokens for K retrieved frames concatenated to the target tokens. Capacity scales linearly in K; no compression.
- Compression: a learned operator that maps the historical token stack to a much smaller weight-like memory; aggressive compression, no recurrence.
- Spatial: maintains a 2D scene summary keyed by camera pose; read-out is geometric rather than per-frame attention.
- State-Space: an SSM-style recurrent state propagated across segments. Two variants: a legacy hybrid and a block-wise variant that updates the state per chunk.
Three-branch evaluation
Echo-Memory’s second contribution is the evaluation taxonomy. Replay (GT camera trajectory, PSNR/SSIM/LPIPS over 3 generated chunks) measures camera-following and local fidelity. In-domain return uses GT-backed 180° loops and matches mirrored frames along outgoing/returning legs. Open-domain return uses 20 game-style prompts × 8 Qwen-edited identity-anchored first frames (a 160-frame pool) with a compact 45° leave/return probe scored by Qwen3-VL-30B-A3B with weights 0.45\,s_{\text{appearance}}+0.25\,s_{\text{presence}}+0.20\,s_{\text{view}}+0.10\,s_{\text{scene}}, rescaled to [0,100]. A judge sanity check shows Claude Opus 4.6, GPT-5.5, and a human anchor stay within \Delta\le 3.1 of Qwen3-VL with Pearson \rho\ge 0.93, so judge choice does not reorder rows.
The replay diagnostic is run during training on fixed GT trajectories. The authors emphasize that the scalar flow-matching loss is a weak proxy for memory: two runs with near-identical loss can diverge sharply at chunk boundaries.

Results
The headline table inverts winners across branches. On Replay PSNR, Spatial Memory leads (13.60); on Replay SSIM/LPIPS, raw Context at K{=}20 leads (0.449/0.496); on open-domain VLM, block-wise State-Space dominates at 69.00, far above Spatial (6.00) and the I2V baseline (12.25).
The capacity sweep on the Context family is the cleanest signal. Moving from anchor-only I2V to K{=}5 raises open-domain VLM from 12.25 to 50.75; K{=}20 reaches 58.63. Replay metrics (R-P 10.03 → 11.92 → 12.54) move much less. Raw history primarily buys semantic return, not local pixel fidelity, which means compressed memories must be benchmarked against the K{=}20 Context row, not just I2V.
Two further inversions are diagnostic. Spatial Memory wins Replay PSNR but collapses on open-domain (6.00) — its scene cache improves visible-region reconstruction but loses distinctive object identity through an excursion. Block-wise State-Space has weak Replay numbers (R-P 9.59) but the strongest semantic return; the recurrent state preserves identity at the cost of local reconstruction. Compression weight-only achieves 22.38 open-domain VLM, well below Context K{=}5 at 50.75, indicating current learned compressors are dominated by raw storage at matched compute.
Limitations and open questions
The study fixes one backbone (Wan-family DiT), one retrieval policy (fixed FoV), and relative RT actions only; absolute action encodings and learned retrievers are out of scope. Open-domain scoring leans on a single VLM judge, mitigated but not eliminated by the cross-judge check. The 5k-step budget is short, so capacity-vs-compression rankings under longer training are unknown. Block-wise State-Space wins semantically but trades away replay fidelity; whether this is fundamental or a tuning artifact is open. No row simultaneously wins replay and open-domain return, suggesting a Pareto frontier rather than a dominant memory.
Why this matters
Echo-Memory makes a falsifiable empirical case that “replay quality” — the metric most action world model papers actually report — does not measure memory. With a matched backbone and protocol, replay rankings invert against semantic return, and raw K{=}20 context remains a strong baseline that most compressed memories underperform. Future memory mechanisms should be evaluated on leave-and-return probes, not on local trajectory PSNR.
Source: https://arxiv.org/abs/2606.09803
End-to-End Context Compression at Scale
Long-context inference is dominated by KV-cache memory and prefill latency, both linear in context length. Existing remedies fall into two camps: (i) post-hoc KV-cache compressors (SnapKV, KVzip, Expected Attention, Attention Matching) that operate on a fully prefilled cache and therefore inherit the prefill cost they aim to avoid, and (ii) encoder-decoder soft-token compressors that have historically traded substantial accuracy for shorter sequences. This paper revisits the encoder-decoder route, runs a controlled architecture sweep, and trains a family of Latent Context Language Models (LCLMs) at sufficient scale to dominate the accuracy-vs-TTFT Pareto frontier.
Architecture
An LCLM is a triple (encoder, adapter, decoder). For input x_{1:T} and compression ratio N, the encoder window of size W partitions the sequence into I=\lceil T/W\rceil chunks w_i = x_{(i-1)W+1:\min(iW,T)}. Each window is encoded into hidden states h^{(i)}_{1:|w_i|}, then a pooling operator collapses every N consecutive states into one latent token, giving M_i = \lceil |w_i|/N\rceil latents per window. An adapter a(\cdot) projects from encoder to decoder hidden dimension, producing s_{1:M} that the decoder consumes in place of N\!M raw tokens. Crucially, encoder windows can be batched (the paper uses encoder batch size 128 with W=1024, i.e. 131,072 input tokens per batched encoder pass), and the decoder still operates on a standard KV cache, so vLLM/SGLang and FlashAttention apply unchanged downstream.
The architecture sweep is the most useful contribution for practitioners. The authors pre-train Qwen3-0.6B encoder/decoder pairs from scratch on 38B tokens at N=16, varying pooling, attention masks, and adapter shapes.
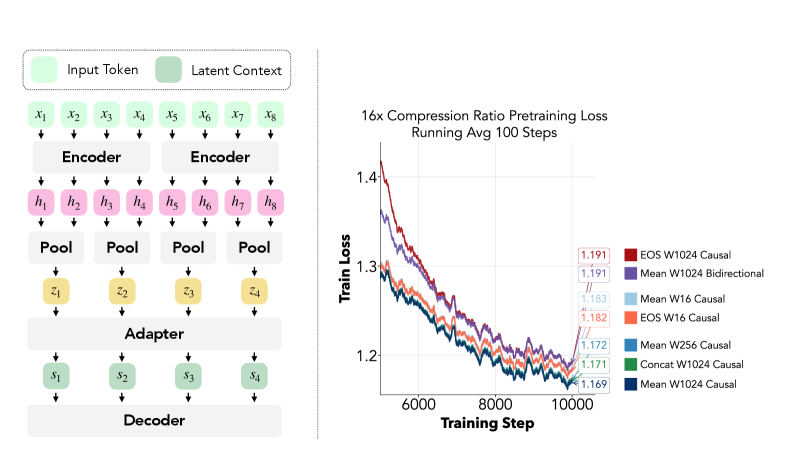
The headline finding: token-based pooling (EOS/CLS), the default in ICAE, AutoCompressor, and most prior soft-token work, is consistently worse than mean pooling. Concatenation pooling (stack the N hidden states into a wide vector and let the adapter project) is indistinguishable from mean at small scale but diverges at scale: concatenation wins at low compression ratios (1{:}4), mean wins at high ratios (1{:}16), and the gap closes as context grows. This is consistent with the intuition that concatenation preserves positional information that mean discards, but at high N the adapter capacity becomes the bottleneck.
Training recipe
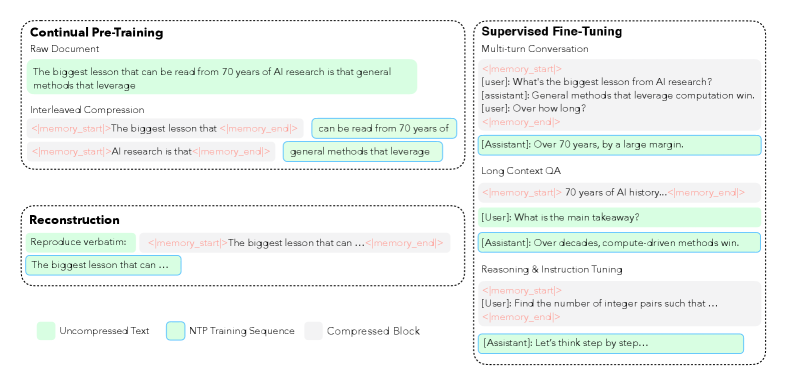
LCLMs are continually pre-trained from Qwen3-Embedding-0.6B (encoder) and Qwen3-4B-Instruct-2507 (decoder) on >350B tokens per compression ratio (N\in\{4,8,16\}), with three data streams:
- Interleaved continual pre-training: each sequence is split into alternating compressed and uncompressed segments, with next-token loss applied only on uncompressed tokens. This differs from the prior “first-half compressed, second-half trainable” convention (AutoCompressor, ICAE, CEPE) and forces the decoder to condition on latent context at arbitrary positions, not just the prefix.
- SFT on compressed long-document prompts.
- Auxiliary reconstruction: decoder is asked to reproduce raw context from latents, which anchors the latents to verbatim content.
Results
On RULER and LongBench against the same Qwen3-4B-Instruct-2507 decoder, LCLMs establish a new Pareto frontier in accuracy vs. TTFT on a single H200.
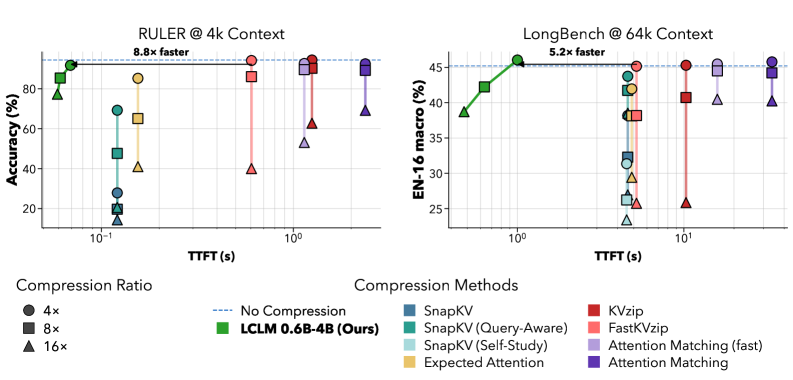
LCLMs at 1{:}4, 1{:}8, 1{:}16 achieve equivalent-or-higher accuracy than KVzip, FastKVzip, SnapKV, Expected Attention, and Attention Matching while compressing strictly faster, because KV-cache methods must first prefill the full context whereas LCLMs amortize encoding via batched short windows. The peak-memory axis follows the same ordering: encoder activations for a W=1024 window are bounded independent of T, while KV compressors must materialize the full cache before pruning.
Agent scaffolding
Because the latent representation is addressable, the authors expose an EXPAND(i) tool that swaps a 512-token chunk’s latents for its raw tokens on demand. On RULER NIAH tasks, the agent recovers exact-string accuracy that the raw 16\times compressed model cannot, in some settings matching uncompressed context. The pattern is “skim globally in latent space, zoom selectively in token space” - functionally analogous to retrieval, but with the retrieval index being the LCLM’s own attention over latents rather than an external embedding store.
Limitations
The decoder is fixed to Qwen3-4B-Instruct-2507; transferability of the encoder to other decoders or to larger decoders is not demonstrated. Compression ratios above 16 are not explored, and the high-N regime is exactly where mean pooling’s lossiness should hurt most. The reconstruction objective likely biases latents toward surface-form fidelity at the expense of abstraction; tasks requiring multi-hop reasoning over compressed spans (RULER variable tracking, multi-document QA) are precisely where LCLMs’ margin over KV-cache methods narrows in the reported tables. Finally, the agentic EXPAND evaluation is limited to NIAH, where the failure mode (verbatim retrieval) most favors expansion.
Why this matters
This is the first encoder-decoder context compressor trained at a scale (350B+ tokens, 4B decoder) where it convincingly beats KV-cache pruning on both axes simultaneously, and it does so while remaining compatible with stock inference engines because the decoder’s KV cache structure is untouched. The architecture findings - mean/concat over token pooling, interleaved CPT over prefix-only - are immediately actionable for anyone building soft-token compressors.
Source: https://arxiv.org/abs/2606.09659
CoVEBench: Can Video Editing Models Handle Complex Instructions?
Problem
Text-guided video editing models are typically benchmarked on isolated operations — replace an object, restyle, insert — and scored with coarse global metrics (CLIP similarity, frame-level FID variants). Real user prompts are compositional: simultaneously change subject, action, and camera while preserving everything else spatiotemporally. Existing benchmarks cannot tell whether a model executed all requested edits, whether it spuriously modified unedited regions, or whether the resulting motion is physically plausible. CoVEBench is a diagnostic benchmark targeting this compositional regime.
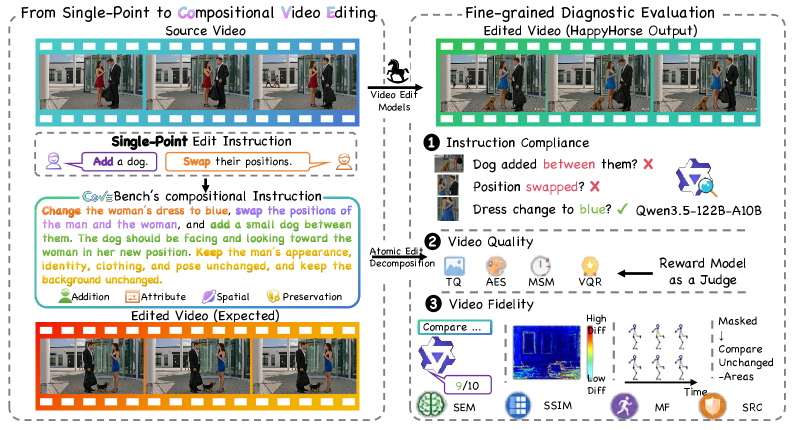
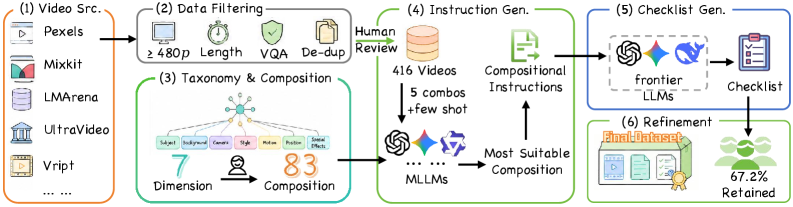
Construction
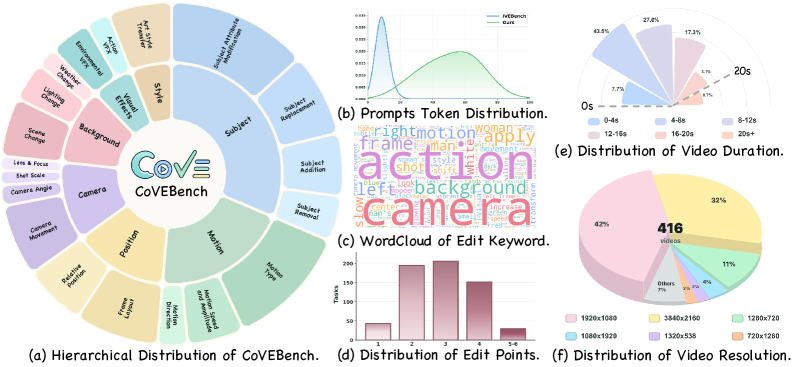
CoVEBench contains 416 curated source videos (varied duration and resolution), 626 multi-point editing instructions, and 9,990 fine-grained checklist items. Instructions are deliberately compositional rather than atomic, with TF-IDF cosine similarity across 195,625 sampled instruction pairs averaging 0.0168 (median 0.0106), indicating low lexical redundancy across the prompt set. The taxonomy spans subject, action, attribute, scene, style, and camera-view edits, and the instruction distribution is shifted toward multi-edit prompts rather than single-edit ones.
Evaluation methodology
The evaluation matrix has three axes — Instruction Compliance, Video Quality, and Video Fidelity — with 11 metrics. The novel core is the MLLM-judged checklist, decomposed into:
- Multiple-choice questions: pre-edit vs post-edit states are framed as competing options; the correct option must match the instruction’s intended outcome.
- Yes/No questions: probe whether each requested action was executed and whether obvious unnatural artifacts appeared.
Queries use either a Dual-Video format (judge sees source and edited clip; required when preservation must be verified) or Single-Video format. Three checklist-derived scores separate execution from quality:
- IFS (Instruction Following Score): mean accuracy over instruction-execution queries, ignoring visual quality.
- VRS (Video Realism Score): mean accuracy over realism/artifact queries.
- UAS (Union Accuracy Score): a per-edit task scores 1 only if both its instruction and realism queries are correct — a conjunction that punishes models that execute edits but produce implausible video, or produce clean video that omits edits.
Qwen3.5-122B-A10B serves as the MLLM judge. Video Quality combines VisualQuality-R1 (VQR), Aesthetic Predictor v2.5 (AES), optical-flow-based motion smoothness (MSM), and DOVER++ (TQ). Video Fidelity combines a checklist-based semantic consistency score (SEM), SSIM for structural fidelity, CoTracker trajectory similarity (MF), and SAM2+DINOv2 mask-feature comparison for static-region consistency (SRC). UAS, VQR, and SEM are designated the holistic indicators of the three axes.
Results
Ten models are evaluated: InsV2V, VACE, Lucy Edit, ICVE, Ditto, Reco, OmniWeaving, Kiwi, HappyHorse1.0, and Wan2.7. Three observations dominate:
Closed-source > open-source on compliance. Wan2.7 leads UAS at 56.89 (IFS 82.02, VRS 79.97); HappyHorse1.0 follows at UAS 55.18 (IFS 76.54, VRS 84.52). The best open-source model, OmniWeaving, reaches UAS 30.14 — roughly half the closed-source level — despite competitive IFS (57.18). Kiwi (29.03), Ditto (26.50), Lucy (26.01), ICVE (25.83), ReCo (24.35), InsV2V (14.61), and VACE (9.69) trail.
The conjunction is the bottleneck. Across all models, UAS is substantially below both IFS and VRS individually. For example, Wan2.7’s UAS of 56.89 versus IFS 82.02 and VRS 79.97 implies that on a sizable fraction of edits the model gets the action right but breaks realism, or vice versa. The gap widens for weaker models: VACE has IFS 22.92 and VRS 41.35 but UAS only 9.69. Compositional edits in which all sub-edits succeed and the result remains physically plausible are rare.
Edit–preservation trade-off. Stronger edit execution often correlates with weaker preservation. Ditto attains competitive execution scores (IFS 49.45, VRS 60.69) but SEM collapses to 58.02 — far below Lucy’s 86.13 or HappyHorse1.0’s 92.73. Conversely, VACE has the highest SSIM (0.958) and MF (0.958-class trajectory similarity) — it changes little, scoring well on preservation but poorly on actually doing the edit (UAS 9.69). SSIM ranges widely (ICVE 0.288 to Lucy 0.762), reflecting how aggressively each model rewrites pixels.
Limitations and open questions
The benchmark inherits MLLM-judge biases: Qwen3.5 may systematically reward or penalize particular visual styles, and checklist construction quality is not externally validated. Only two closed-source systems are tested, so the closed-vs-open generalization is suggestive rather than conclusive. The metric suite does not directly score temporal coherence of edits across long horizons (most clips are short), and SRC’s mask-based DINOv2 comparison can be confounded by global illumination shifts induced by style edits. Whether UAS correlates with human compositional-edit preference at scale is an empirical question the paper does not fully resolve.
Why this matters
CoVEBench reframes video-editing evaluation around the conjunction of execution and preservation, exposing that current models — including leading closed-source systems below 60 UAS — cannot reliably handle compositional prompts even when individual sub-skills look adequate. The IFS/VRS/UAS decomposition gives method developers an actionable diagnostic for whether to push on edit aggressiveness, artifact suppression, or unedited-region locking.
Source: https://arxiv.org/abs/2606.08415
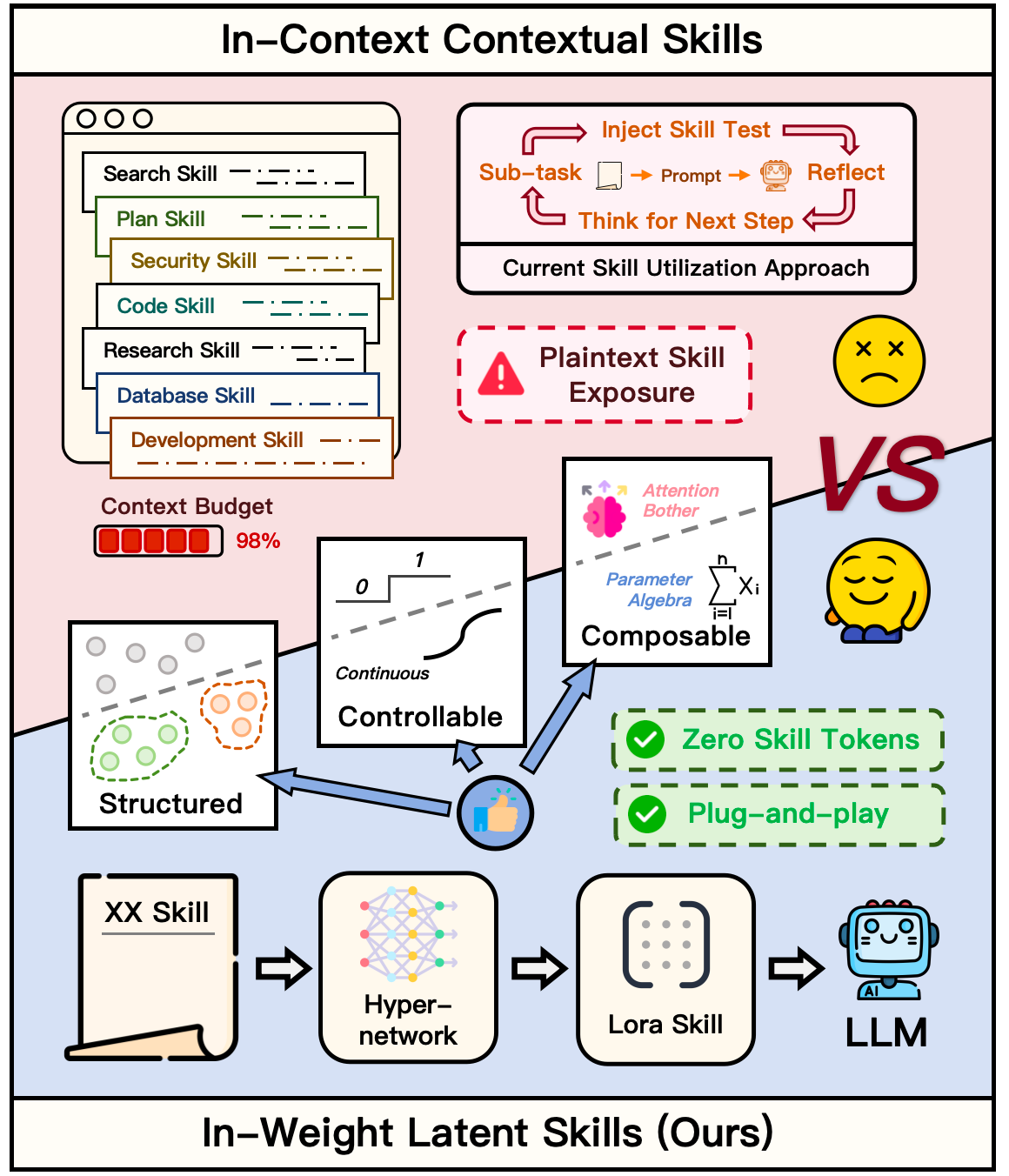
LatentSkill: From In-Context Textual Skills to In-Weight Latent Skills for LLM Agents
Problem
Agent frameworks increasingly rely on libraries of textual “skills” — procedural documents describing how to accomplish recurring subtasks — which are loaded into the prompt at every decision step. This pattern has two costs: prefill tokens scale with skill count and length, and the skill content sits in plaintext, exposing it to extraction and prompt-injection attacks. The authors ask whether skills can instead be compiled into weight-space modules that are mounted on demand, preserving the modularity of a skill library while removing per-step token overhead.
Method
LatentSkill replaces textual conditioning with parameter conditioning. A frozen backbone M_\theta is augmented by LoRA updates produced by a learned skill compiler G_\phi — a hypernetwork that maps a skill document s to a set of low-rank adapters:
\Delta_s = G_\phi(s), \qquad p_{\theta,\phi}(y_t \mid h_t, s) = p_{\theta \oplus \alpha \Delta_s}(y_t \mid h_t).
For each target module m \in \mathcal{M}, the hypernetwork emits a factored update \Delta W_s^{(m)} = B_s^{(m)} A_s^{(m)}, mounted as
W' = W + \frac{\alpha}{r} B_s A_s,
where r is the LoRA rank and \alpha is an inference-time injection strength. After mounting, the prompt no longer contains the skill text — only the task history h_t.
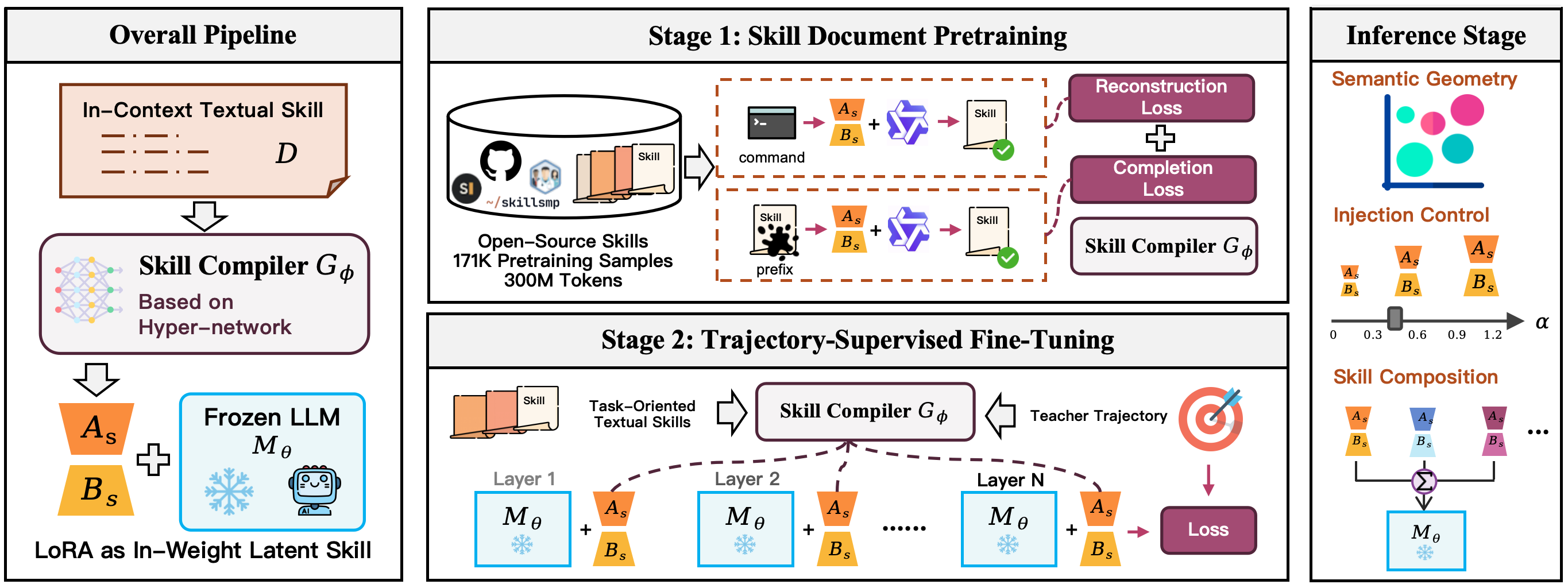
Training the compiler proceeds in two stages. First, skill document pretraining aligns the hypernetwork’s output adapters so that conditioning on s reproduces skill-document semantics on the frozen backbone (essentially distilling the document into LoRA weights). Second, trajectory-supervised fine-tuning uses agent trajectories: for each (s, h_t, y_t) triple, gradients flow through G_\phi via the mounted \Delta_s to maximize \log p_{\theta \oplus \alpha \Delta_s}(y_t \mid h_t). Only \phi is updated; \theta stays frozen. At inference, \alpha provides a continuous knob on injection strength, and adapters for different skills can be combined by parameter-space arithmetic on aligned components.
Results
On ALFWorld, LatentSkill improves success rate by +21.4 points on the seen split and +13.4 points on unseen over the in-context skill baseline, while using 64.1% fewer prefill tokens. On Search-QA (trained on NQ + HotpotQA, evaluated on seven datasets including five OOD), exact match rises by +3.0 points with 72.2% lower skill-token overhead.
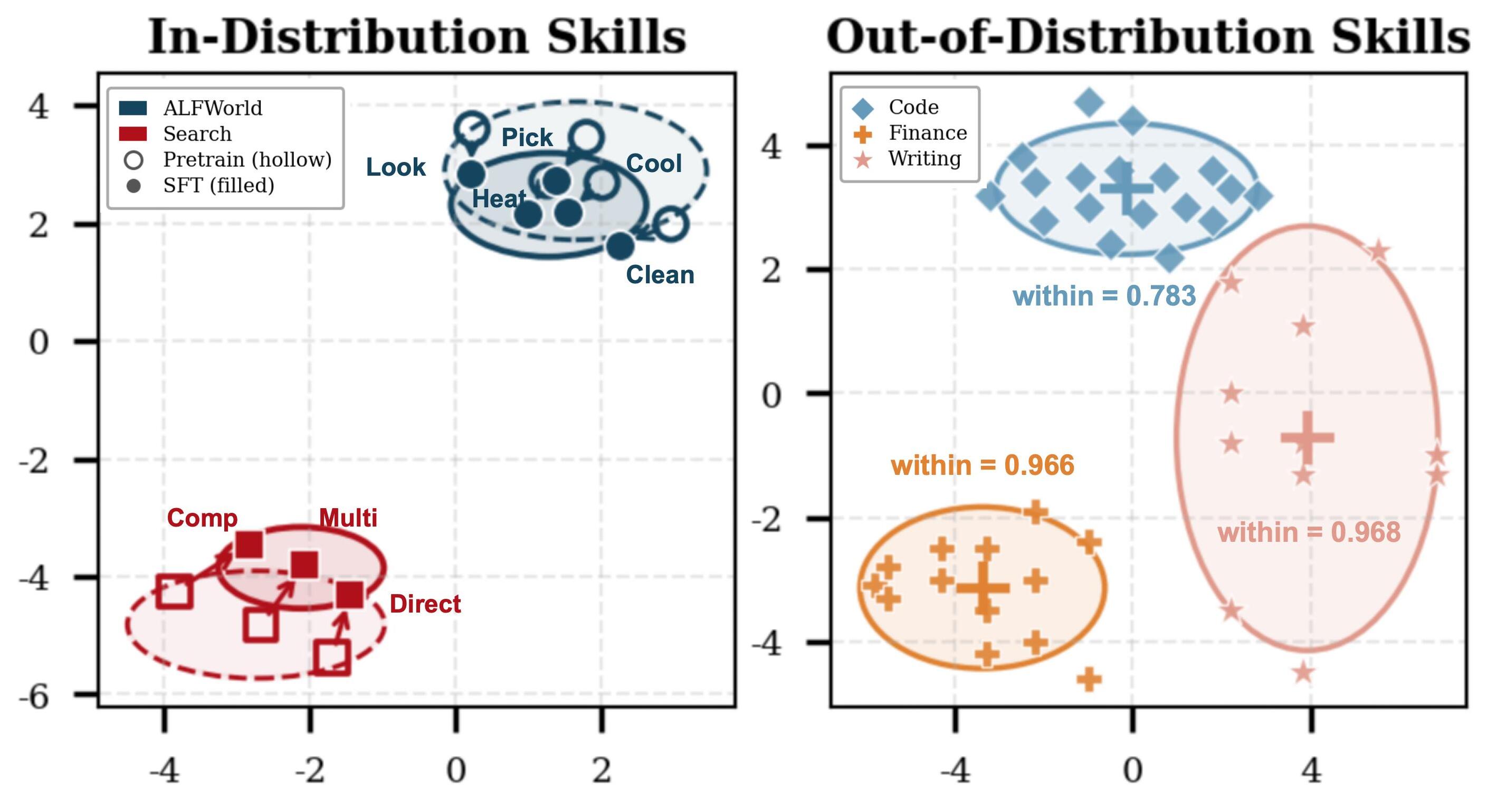
The learned skill geometry is structured. MDS visualizations of generated LoRA weights show in-domain ALFWorld and Search skills forming distinct clusters, and OOD skills (Code, Finance, Writing) further separating, with high mean intra-cluster cosine similarity. This indicates the hypernetwork outputs are not arbitrary low-loss adapters but occupy a semantically organized region of weight space — a precondition for meaningful composition.
Robustness and security
Sensitivity to skill-text perturbations is substantially better than in-context prompting. Under Paraphrase, Plaintext (Markdown stripped), Reorder, and Noise, LatentSkill’s average ALFWorld success is 70.7%, only 3.6 points below the base 74.3%, and its margin over in-context ranges from 17.2 to 24.3 points. Plaintext perturbation produces zero degradation on ALFWorld, suggesting the compiler captures semantics rather than surface formatting.
Security gains are sharper. Under prompt-injection (Hijack), in-context skill collapses from 52.9% to 8.57% on ALFWorld, while LatentSkill retains 38.6% — the skill text isn’t in the prompt to be overridden. Under Extract attacks attempting to reproduce skill content, in-context drops to 21.3% on Search-QA while the latent variant holds at 29.3%, since the plaintext is simply not there.
Limitations and open questions
The paper demonstrates structured geometry and parameter-space composition “when skill components are aligned,” but does not characterize when alignment fails or how compositionality scales beyond pairwise arithmetic. Training requires trajectory data per skill domain, raising the question of zero-shot compilation for entirely new skill categories — the OOD MDS suggests separation but stops short of measuring task performance on unseen skill types. The hypernetwork itself adds parameters and a one-time compilation cost; tradeoffs against caching strategies (KV cache reuse, prompt compression) for in-context skills are not directly compared. Robustness numbers under Hijack on ALFWorld (38.6%) are far from the clean 74.3%, so weight-space storage mitigates but does not eliminate adversarial degradation.
Why this matters
Moving reusable agent skills from context space to weight space is a clean architectural shift that simultaneously addresses prefill cost, modularity, and prompt-level attack surface — three concerns usually traded off against each other. If hypernetwork-generated LoRAs reliably form a composable semantic manifold, skill libraries become first-class objects with algebraic structure, not just text snippets to be retrieved.
Source: https://arxiv.org/abs/2606.06087
Hacker News Signals
How’s Linear so fast? A technical breakdown
Linear is a project management tool known for near-instant UI response. This breakdown dissects the engineering choices that produce that behavior.
The core architecture is a local-first, sync-based model. All data lives in an in-memory store on the client (built on top of a custom sync engine), so read operations never touch the network. Writes are applied optimistically to local state immediately and reconciled asynchronously. This eliminates the dominant latency source in conventional CRUD apps: the request/response round trip before rendering.
The sync engine uses operational transforms (OT) or CRDT-adjacent techniques to handle concurrent edits and merge server state without blocking the UI thread. The client maintains a persistent SQLite-like local database (via IndexedDB in the browser), so even cold loads after a session restore are fast because data is already local.
Rendering performance comes from several layers. Linear uses React but with aggressive memoization and a virtual list implementation that avoids rendering off-screen items. The routing layer pre-fetches views before navigation is committed, so transitions appear instantaneous. They also avoid the common React anti-pattern of over-subscribing components to global state; each component subscribes only to the minimal slice it needs, reducing re-render surface area.
On the network side, updates are sent as compact binary-encoded delta payloads rather than full JSON objects. WebSocket connections are kept persistent and multiplexed. The server infrastructure is designed to push deltas to clients rather than poll, so multi-device sync propagates in tens of milliseconds.
The JavaScript bundle is kept small through aggressive code splitting and tree shaking. They avoid heavyweight third-party dependencies in the critical render path.
The net effect is that most interactions feel synchronous because they are — from the user’s perspective, the UI and local data layer are co-located, and network sync is background infrastructure.
Source: https://performance.dev/how-is-linear-so-fast-a-technical-breakdown
FrontierCode
Cognition AI (makers of Devin) released a benchmark and associated model results called FrontierCode, targeting the upper end of software engineering tasks. The claim is that current frontier models still fail substantially on complex, multi-file, real-world coding tasks that require understanding large codebases, long-horizon planning, and debugging cycles — not just isolated function synthesis.
The benchmark is structured around tasks that require: (1) navigating an existing repository rather than writing from scratch, (2) implementing features that touch multiple components and require understanding of existing abstractions, (3) debugging where the error signal is indirect (test failures, runtime crashes) rather than a clear specification mismatch.
The key technical finding is that pass rates drop sharply as task complexity increases. Simple single-function completions see high pass rates on current models, but tasks requiring 10+ file edits coordinated correctly drop to low single-digit percentages even for the best available models. This is consistent with the known failure modes of transformer context utilization: models lose coherence over long dependency chains and tend to generate locally plausible but globally inconsistent edits.
Cognition’s own agent (presumably using Devin’s infrastructure) scores higher than API-only baselines, which they attribute to the agent scaffolding: iterative execution, test-feedback loops, and a working memory mechanism that summarizes repository state rather than naively concatenating all files into context.
The benchmark methodology emphasizes execution-based evaluation — a solution must pass the test suite and not break existing tests — rather than LLM-as-judge or BLEU-style metrics, which is the correct approach for coding tasks. Tasks are drawn from open-source repositories with real issue trackers, reducing contamination risk versus synthetic benchmarks.
The implicit argument is that raw model scaling is not closing the gap on these harder tasks at the rate it closed simpler ones, and that agent architecture matters independently of base model capability.
Source: https://cognition.ai/blog/frontier-code
Arithmetic Without Numbers – How LLMs Do Math
This is an interactive article that probes the internal mechanisms transformers use when performing arithmetic, aimed at making mechanistic interpretability accessible. The focus is on what actually happens in the residual stream and attention layers when a model adds or multiplies small integers.
The core finding, consistent with prior mechanistic interpretability work (e.g., Nanda et al. on modular arithmetic), is that transformers do not implement arithmetic via anything resembling symbolic digit manipulation. Instead, they appear to represent numbers in a distributed Fourier-like basis. For addition, the model seems to compute a + b \pmod{N} by composing sinusoidal features, where individual attention heads pick out specific frequency components. The residual stream at the output position carries a superposition of these frequency components, and the unembedding step projects onto the nearest token.
The interactive elements let readers probe which attention heads activate for specific operand pairs and visualize how the logit distribution over output tokens shifts as operands change. This makes the otherwise abstract claim — that numeric representations are geometric rather than symbolic — concrete and inspectable.
An important limitation the article surfaces: these mechanisms are studied on small, clean arithmetic tasks (single or double-digit addition). Generalization to multi-digit arithmetic, where carry propagation creates long-range dependencies, is much less understood and likely involves qualitatively different circuits or breaks down entirely, which would explain why LLMs make characteristic errors on large number arithmetic (mishandling carries, failing on numbers outside training distribution).
The article does not claim this fully explains LLM math ability; it characterizes one narrow regime. But the mechanistic picture it draws — numbers as points on a learned algebraic manifold, not as digit strings — is the right frame for thinking about why scaling alone does not automatically fix arithmetic reliability.
Source: https://alvaro-videla.com/llm-arithmetic-internals/article_interactive/article.html
Config Files That Run Code: Supply Chain Security Blindspot
This post catalogs a class of supply chain attack surface that gets less attention than malicious packages: configuration files that silently execute code during parsing or project initialization.
The concrete examples are instructive. pyproject.toml with a [tool.setuptools.dynamic] section can reference arbitrary Python scripts evaluated at install time. .npmrc and various JS tooling configs can trigger lifecycle scripts. Jupyter notebooks (JSON files) contain executable cells that run on open in some environments. Prettier, ESLint, and similar tools load plugin modules named in their config files — so a .eslintrc.json pointing at a compromised package is an execution vector. CMake CMakeLists.txt files execute arbitrary CMake scripting language on configure.
The threat model is: an attacker who can land a malicious config file in a repository (via compromised dependency, PR, or CI artifact) can get code execution on any developer or CI system that clones and initializes the project, often without the victim ever explicitly running the malicious code. This is distinct from the well-understood npm install malicious package scenario because it bypasses mental models that treat config as inert data.
The mitigations discussed are mostly process-level: review config changes with the same scrutiny as code, use lockfiles to pin tooling versions, run dependency installs in isolated environments (containers, sandboxed CI), and audit config schemas to distinguish data from execution directives. There is no universal technical fix because the “run code from config” pattern is often a deliberate feature.
The post is a useful reference for threat modeling developer environments and CI pipelines. The underlying issue is that the distinction between “data file” and “code file” has eroded substantially in modern build tooling.
Source: https://safedep.io/config-files-that-run-code/
AI is slowing down
This piece argues that the rate of meaningful capability improvement in frontier LLMs has decelerated relative to the 2020-2023 period, and that benchmark saturation and marketing narratives are obscuring this.
The technical substance centers on a few observations. First, benchmark-measured progress on held-out test sets continues, but the benchmarks themselves are frequently saturated or contaminated, so the signal is degraded. Second, qualitative capability jumps — the kind where a model crosses a threshold from “cannot do X” to “reliably does X” — have become rarer. The step from GPT-2 to GPT-3 (emergent few-shot prompting), or GPT-3 to InstructGPT (instruction following), or to GPT-4 (complex reasoning on professional exams) each represented a clear phase transition. Recent releases show incremental improvement within existing capability categories rather than new category unlocks.
Third, compute scaling is running into physical and economic limits. The largest training runs are now constrained by data quality (internet data is largely exhausted for pretraining), by chip availability, and by the economics of inference at scale. The hypothesis that simply scaling further will produce the next phase transition is less empirically supported than it was in 2021.
The post is careful to distinguish this from a claim that progress has stopped. Post-training techniques (RLHF, RLVR, long-context fine-tuning) continue to improve deployed model behavior meaningfully. The argument is specifically that the steepness of the pretraining scaling curve has flattened.
Counterarguments worth considering: reasoning models (o-series) represent a qualitatively new capability axis enabled by test-time compute, and multimodal capabilities have advanced substantially. Whether these constitute the kind of phase transitions the author is looking for is a definitional question.
Source: https://www.wheresyoured.at/ai-is-slowing-down
The Quiet Numbers Station: Decoding Nineteen Years of GPS Cryptography
This post reconstructs the cryptographic history of the GPS Navigation Message Authentication (NMA) system, specifically the encrypted M-code signal and the civil NMA (CNAV) authentication mechanism that was deployed but not publicly documented for nearly two decades.
The core technical story involves the GPS Control Segment broadcasting cryptographically authenticated navigation messages to prevent spoofing. The civil authentication scheme uses a Timed Efficient Stream Loss-tolerant Authentication (TESLA)-based protocol: a hash chain is computed offline, and each broadcast navigation message includes a MAC computed with a key that was committed to in a prior time slot. Receivers buffer messages and verify them once the delayed key is broadcast, providing asymmetric authentication without requiring a secret to be held on the receiver.
The post traces how researchers were able to infer the structure of the authentication scheme from signal captures before it was officially published, using the regularity of the hash chain releases and statistical analysis of the message structure. The hash function and chain parameters could be reverse-engineered from observed key releases.
A notable detail: the system was broadcasting for years before civilian receivers were authorized or instructed to use it, meaning the authentication infrastructure was operational as a kind of cryptographic numbers station — broadcasting authenticated data to no verified recipients, or to classified military ones.
The security implications are practical. GPS spoofing remains a live threat in contested environments; NMA raises the bar significantly because spoofing now requires not just signal forgery but breaking the authentication chain or replaying old authenticated messages (which fail freshness checks). Replay attacks remain a residual concern, especially for receivers that cannot maintain accurate time independently.
Zig Structs of Arrays (2024)
This post works through implementing the Struct of Arrays (SoA) data layout pattern in Zig, which is relevant for SIMD-friendly and cache-efficient code in performance-critical applications.
The standard Array of Structs (AoS) layout places all fields of each element contiguously: [{x, y, z}, {x, y, z}, ...]. When processing only the x field across many elements, a SIMD load pulls in y and z data as well, wasting cache bandwidth. SoA inverts this: {xs: [x, x, ...], ys: [y, y, ...], zs: [z, z, ...]}, so iterating over a single field is a contiguous memory access.
The Zig implementation leverages comptime reflection. Given a struct type T, the SoA wrapper iterates over @typeInfo(T).Struct.fields at compile time and generates a struct where each field is replaced by a slice of that field’s type. This produces zero-cost abstraction: the generated type is exactly what you would write by hand, with no runtime overhead from the metaprogramming.
The post also handles the accessor API — getting a “virtual” struct value for index i requires constructing a value by reading each field slice at index i, which Zig’s comptime loops can generate cleanly. Mutations are handled symmetrically.
One practical concern the post addresses is allocation: a naive implementation allocates a separate slice per field, hurting allocator overhead and potentially cache locality between field arrays. A more sophisticated version allocates a single backing buffer and partitions it, keeping the arrays physically close in memory.
This is a good demonstration of Zig’s comptime as a genuine alternative to C++ template metaprogramming or Rust macros for data layout optimization — the code is readable and the generated layout is inspectable.
Source: https://andreashohmann.com/zig-struct-of-arrays/
Tiny hackable CUDA language model implementation
This is a minimal GPT implementation in CUDA C, targeting developers who want to understand or modify the low-level GPU kernels rather than use a framework abstraction. The stated design goal is that the entire forward pass, backward pass, and training loop fit in a small number of files with no external dependencies beyond CUDA and a BLAS-like library for matrix multiplication.
The implementation covers the standard GPT-2 architecture: token and position embeddings, multi-head self-attention with causal masking, layer normalization, and a feedforward block with GELU activation. The CUDA kernels are written explicitly rather than through cuDNN or cuBLAS for the attention and normalization paths, which makes them inspectable and modifiable at the cost of not being optimized to production-level throughput.
The attention kernel implements the naive O(n^2) attention without flash attention’s tiling trick, which is appropriate for a pedagogical implementation but limits sequence length. The backward pass kernels mirror the forward pass structure, which is useful for verifying gradient correctness by comparison with reference implementations.
The value for a practitioner is that debugging a custom CUDA kernel is far easier when the surrounding code is minimal. If you are implementing a novel attention variant or a non-standard normalization scheme, having a clean baseline to modify is more useful than patching PyTorch internals or writing custom CUDA extensions against a large framework.
Limitations are explicit in the repo: no mixed precision, no tensor parallelism, no optimized memory layout for large batch sizes. This is explicitly not a training framework; it is a reference implementation for learning and experimentation at small scale (likely fits comfortably on a single consumer GPU for small model sizes).
Noteworthy New Repositories
VibeBench/VibeSearchBench
A benchmark designed to stress-test agentic search systems on tasks that resist single-shot retrieval: vague queries, multi-turn dialogue with progressive information disclosure, and proactive clarification requirements. The 200 long-horizon tasks are paired with persona-driven user simulators that release information incrementally, forcing an agent to reason about what it still needs to know. Evaluation avoids schema-dependent metrics by constructing a knowledge graph from ground-truth documents and scoring predictions via triplet F1 — precision and recall over (subject, predicate, object) triples extracted from agent responses. This sidesteps the fragility of string-match or embedding-similarity scoring while remaining fully verifiable and reproducible. The benchmark targets a gap in existing IR/QA evaluations, which typically assume a single well-formed query and a fixed answer string. Multi-turn, under-specified retrieval is closer to real agentic use (e.g., research assistants, customer support) but is rarely benchmarked with the rigor applied here. Useful for anyone evaluating RAG pipelines, tool-using LLMs, or conversational search engines where the user model is as important as the retrieval model.
Source: https://github.com/VibeBench/VibeSearchBench
deeplethe/forkd
A process-model runtime for AI agent microVMs that makes POSIX fork() semantics available to full virtual machines. The implementation uses KVM for hardware isolation and copy-on-write snapshots so that spawning 100 child VMs from a warm parent takes roughly 100 ms, and branching a live running VM (the BRANCH operation, analogous to fork() mid-execution) completes in about 150 ms. CoW means child memory pages are not physically duplicated until written, keeping memory overhead proportional to divergence rather than VM count. The design is motivated by agent workloads that need to explore multiple execution paths simultaneously — speculative tool calls, parallel hypothesis testing, or rollback after a failed action — without paying full VM boot cost per branch. The KVM isolation boundary ensures that a compromised or misbehaving child cannot affect siblings or the parent. This is architecturally closer to Firecracker-style microVMs than to container checkpointing (CRIU), but with an API shaped around agent orchestration rather than general-purpose snapshotting. Relevant to anyone building multi-agent sandboxes, code execution environments, or systems where state rollback needs to be cheap.
Source: https://github.com/deeplethe/forkd
secureagentics/Adrian
A runtime security layer that sits between an LLM agent and its tool interface. Adrian intercepts tool calls before execution and evaluates them against configurable policies, catching three distinct threat classes: malicious tool use (e.g., unexpected file deletion, exfiltration calls), prompt injection embedded in tool outputs that could redirect subsequent agent behavior, and policy drift where the agent’s action distribution shifts outside its authorized operational envelope over a session. The interception is synchronous — the agent blocks until Adrian renders a verdict — so no action executes without clearance. Policy drift detection presumably tracks a behavioral baseline across the session and flags statistical deviations, though the mechanism is not fully documented. The architecture is relevant to production deployments where agents have access to high-consequence tools (shell, database writes, external APIs) and where post-hoc audit is insufficient. Compared to sandboxing approaches (which constrain the execution environment), Adrian operates at the semantic level of the tool call itself, enabling finer-grained allow/deny decisions. The main open question is false positive rate on legitimate but unusual tool sequences.
Source: https://github.com/secureagentics/Adrian
cellinlab/how-pi-agent-works
A technical walkthrough of the internal architecture of Pi Agent, written in Chinese with code. The repository dissects how a conversational AI agent is structured — covering the planning loop, tool dispatch, memory management, and the interface between the LLM backbone and external action executors. It is primarily educational rather than a production system, organized as annotated implementation sketches that trace how a user request propagates through intent classification, plan generation, tool invocation, and result synthesis. The value is in the explicitness: rather than pointing to a black-box framework, it shows the wiring at each stage, making it useful for developers building their own agent runtimes or trying to understand why a specific agent framework makes the design choices it does. The Chinese-language framing suggests it targets the Chinese developer community, but the code is readable regardless. This kind of ground-up reconstruction is useful for auditing assumptions baked into higher-level frameworks like LangChain or AutoGen, and for researchers who want a minimal reference implementation to experiment with modifications to the planning or memory subsystems.
Source: https://github.com/cellinlab/how-pi-agent-works
packyme/privacy-filter
A Go library and proxy implementing a PII and secret redaction gateway for LLM API calls. It operates in the request path before tokens reach the model, performing entity recognition and pattern matching (credit card numbers, API keys, SSNs, email addresses, etc.) and replacing detected sensitive strings with placeholder tokens. The Go implementation targets millisecond-latency redaction, which is the right constraint for a synchronous gateway that must not add perceptible latency to interactive LLM calls. The library is described as production-deployed in PackyCode, providing at least one real-world validation of the latency claims. The core engineering challenge is recall-precision balance: aggressive redaction reduces leakage risk but can destroy context the model needs; under-redaction misses the point. The repo is worth examining for how it handles compound entities (e.g., a name embedded in a URL) and whether redaction is reversible for post-processing. For teams routing user data through third-party LLM APIs without on-premises deployment, a fast inline gateway of this kind is a practical compliance tool, though it is not a substitute for data minimization at the application level.
Source: https://github.com/packyme/privacy-filter
AprilNEA/OpenLogi
A native, local-first Logitech peripheral manager written in Rust that communicates with mice and keyboards via the HID++ protocol, eliminating the need for the official Logitech Options+ software and its mandatory cloud account. It supports button remapping, DPI configuration, and SmartShift (the electromagnetic scroll wheel switching feature on MX Master series devices). The Rust implementation targets correctness and low overhead for what is fundamentally a HID device control daemon — no garbage collector pauses, direct system calls to the HID layer, no background telemetry processes. HID++ is a Logitech-proprietary extension of the USB HID standard with a register-based command model; implementing it correctly requires reverse-engineered protocol documentation (the project likely draws on the same corpus used by Solaar and libratbag). The “local-first” framing matters practically: the official software phones home for feature activation and profile sync, which is unnecessary for offline use and a privacy concern. With 4,000+ stars, this has found a substantial audience among power users on Linux and macOS who need SmartShift support without the vendor software stack. The Rust codebase is also a cleaner base for adding new device support than the existing Python-based alternatives.
Source: https://github.com/AprilNEA/OpenLogi
superloglabs/superlog
An observability platform that adds an AI agent layer on top of conventional log aggregation and alerting. The system ingests logs and metrics through standard pipelines, then runs agents that attempt to diagnose anomalies and propose or execute remediation steps — the “self-heal” framing. The technical interest is in how the agent grounds its actions: it needs access to deployment context (what changed recently), service topology (what depends on what), and a policy layer that decides which fixes are safe to apply automatically versus which require human approval. Without those grounding mechanisms, an LLM agent operating on logs will hallucinate plausible-sounding but wrong root causes. The open-source release makes it possible to inspect and modify those grounding components, which distinguishes it from closed AIOps products. Practically, this is most useful for teams with high alert volume and well-understood remediation playbooks that can be encoded as agent actions — restarting a service, rolling back a deployment, adjusting a rate limit. Novel or multi-system failure modes will still require human judgment, so the value is in automating the routine tail.
Source: https://github.com/superloglabs/superlog
razr001/align-dev
A tooling layer for codifying and distributing coding standards to AI coding assistants. It generates a SKILL.md file — a structured natural-language document describing a team’s conventions, patterns, and constraints — that can be placed in a repository root and consumed as context by Claude Code, Codex, Cursor, Copilot, and similar agents. The core problem is that AI coding assistants default to population-level style rather than project-specific conventions, producing code that passes review mechanically but diverges from team norms in naming, error handling, component structure, and other dimensions that are hard to enforce via linters. AlignDev provides a generation workflow that extracts conventions from existing code or accepts manual specification, then serializes them into the SKILL.md format. The approach is simpler than fine-tuning or RAG over a codebase — it relies on in-context instruction following — which limits how much convention detail it can encode but keeps it universally compatible across different assistant backends. The main limitation is that SKILL.md length is bounded by context windows, and complex codebases with many subsystem-specific conventions may require hierarchical or module-scoped variants.