デイリーAIダイジェスト — 2026-06-02
arXiv ハイライト
Draft-OPD: 投機的デコーディングにおけるドラフトモデルのOn-Policy Distillation
問題設定
投機的デコーディングは、ターゲットモデル p_\theta と小型のドラフトモデル q_\phi を組み合わせて動作します。ドラフトモデルは K 個のトークン \hat{y}_{t+k}\sim q_\phi(\cdot\mid x_{<t},\hat{y}_{t:t+k-1}) を提案し、ターゲットモデルがそれらを並列に検証して、最長の有効なプレフィックスを受理します。高速化の程度は受理長 \tau によって決まり、これはドラフトモデルが実際に訪れる状態において q_\phi が p_\theta をどれだけ近似できているかに依存します。
現在のEAGLE3/DFlashスタイルのドラフトモデルは、ターゲットモデルが生成した軌跡に対するsupervised fine-tuningで学習されています。著者らは、このSFT目的関数がすぐに頭打ちになることを観察しており、テストデータにおける受理長はtraining lossが低下し続けても改善が止まります。
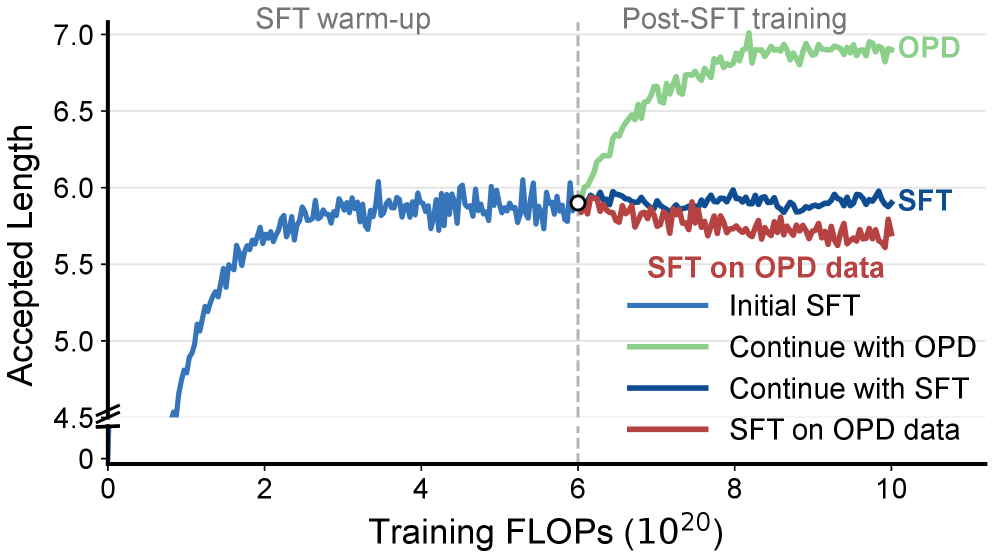
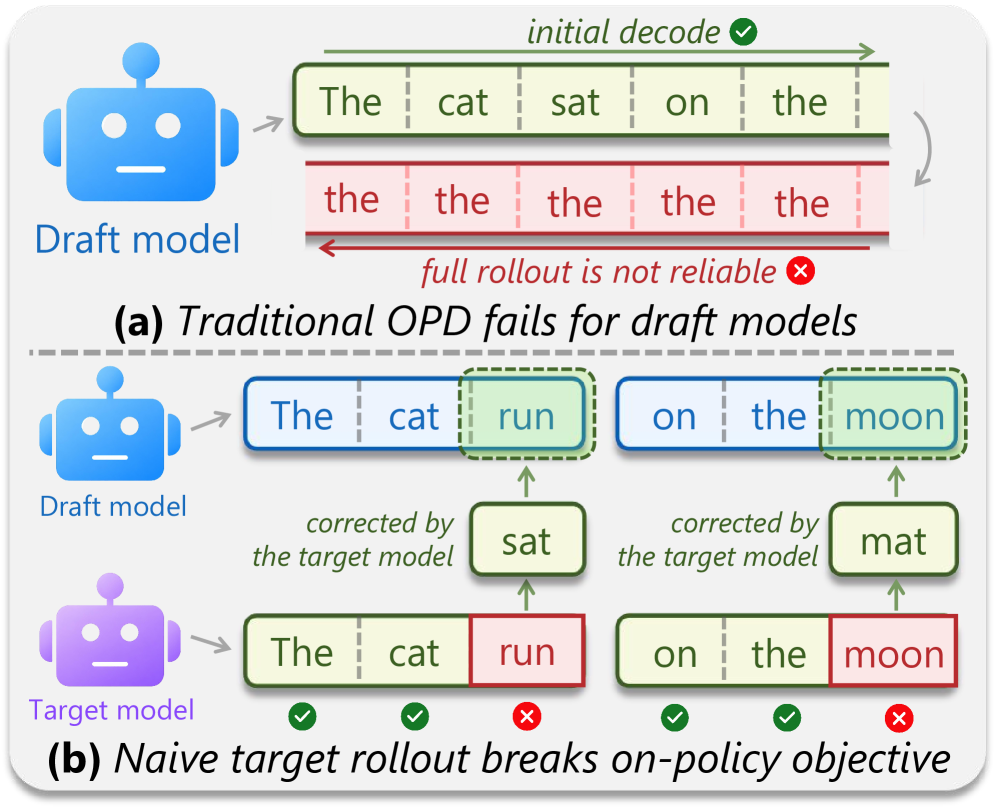
その原因は、標準的なオフライン学習と推論時の分布ミスマッチです。SFTは p_\theta から得られたプレフィックスに基づいて q_\phi を教師あり学習しますが、デコーディング時には q_\phi は自身のブロック提案を条件として動作します。自然な解決策はon-policy distillation(OPD)であり、ドラフトが誘起する状態の上で p_\theta が q_\phi を教師として指導します。しかし問題があります。ドラフトモジュールはターゲットのembeddingとLM headを共有しており、短いスパンを予測するよう学習されているため、単独の生成器ではありません。長い系列をロールアウトさせると退化した繰り返しサンプルが生成され、ターゲット支援によるロールアウトを使うと軌跡がターゲット分布に戻ってしまい、ドラフトが誤っている拒否トークンの位置における信号がちょうど失われます。
手法
Draft-OPDは、ロールアウトとon-policy教師信号の対象を分離することでこの問題を解決します。軌跡は通常の投機的デコーディングによって収集されるため、プレフィックス系列はターゲット品質になります。収集時に、ドラフトされた各ブロックの開始インデックスがアンカーとして記録されます。その後、学習では各アンカーからのドラフティングをリプレイします。アンカー状態から出発して、ドラフトモデルはブロックを再提案し、ターゲットモデルは同じ位置での分布を計算します。重要なのは、リプレイが元のドラフトの受理・拒否の両位置をカバーすることです。これにより、拒否された提案—最も有益な誤り信号—がlossに保持される一方で、周囲の文脈は依然として p_\theta に従います。
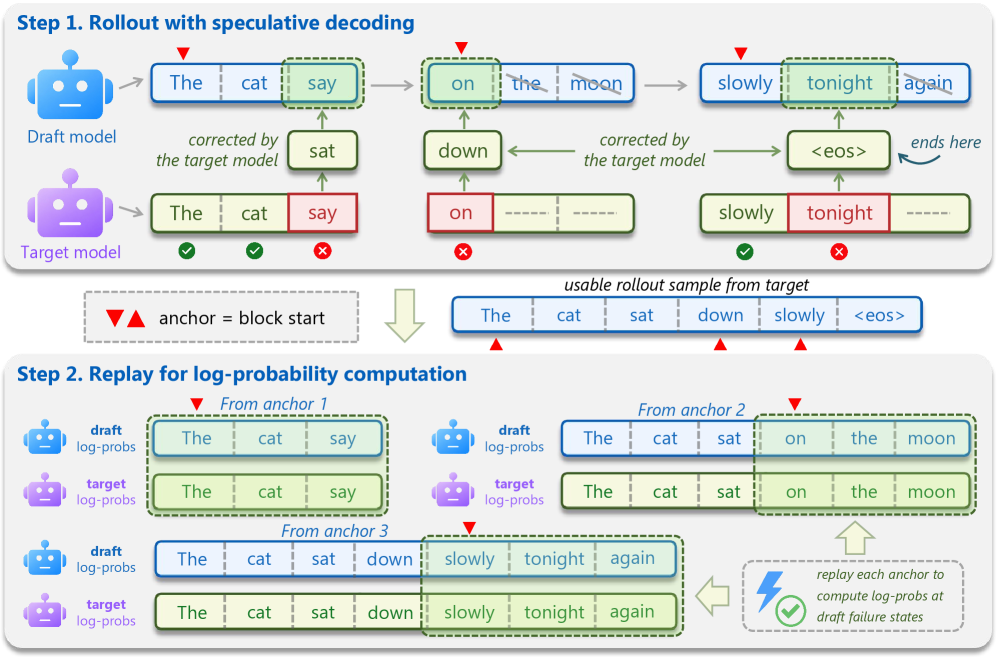
具体的には、各アンカー a に対してドラフトモデルが \hat{y}_{a:a+K-1}\sim q_\phi を展開し、lossは対応する位置でのターゲット分布に対するトークンレベルのdistillationです:
\mathcal{L}_{\text{Draft-OPD}} = \mathbb{E}_{a}\sum_{k=0}^{K-1} \mathrm{KL}\!\big(p_\theta(\cdot\mid x_{<a},\hat{y}_{a:a+k-1})\,\|\,q_\phi(\cdot\mid x_{<a},\hat{y}_{a:a+k-1})\big).
プレフィックス x_{<a} は投機的デコーディング(ターゲット品質)から得られますが、内部ブロック \hat{y}_{a:a+k-1} は q_\phi からサンプリングされるため、条件付け状態はデプロイ時と一致し、拒否位置でのteacher信号はマスクアウトされることなく保持されます。
結果
Qwen3-4BおよびQwen3-8Bを用いた実験では、数学(GSM8K、MATH-500、AIME25)、コード(MBPP、HumanEval、SWE-Lite)、チャット(MT-Bench)において、温度0および0.6、thinking modeのオン・オフの条件下で、Draft-OPDをEAGLE-3およびDFlashと比較しています。
主な平均高速化率(Table 1):
- Qwen3-4B、thinking on、T=0:EAGLE-3 4.41\times、DFlash 4.51\times、Draft-OPD 5.31\times(平均 \tau はDFlashの 5.51 に対して 5.96)
- Qwen3-8B、thinking on、T=0:4.58\times \to 4.67\times \to 5.36\times
- Qwen3-4B、thinking off、T=0:4.58\times \to 5.36\times \to 6.22\times、\tau=6.60
- Qwen3-8B、thinking off、T=0:4.99\times \to 5.69\times \to 6.49\times、\tau=6.57
改善は温度と推論モードにかかわらず一貫しており、Draft-OPDはDFlashに対して平均高速化率で約 0.7–0.9\times の向上、いくつかの設定では受理長で1ポイントの向上を達成しています。thinking off、T=0、Qwen3-8Bにおけるタスク別のハイライト:GSM8K 7.64\times(DFlash 6.81\times)、MATH-500 6.99\times(6.40\times)、HumanEval 6.02\times(5.64\times)。ドラフトモデルが通常苦手とするより難しいタスク(AIME25、SWE-Lite)での向上は絶対的な高速化率では小さいものの、方向性は一貫しています。Figure 1では、リプレイ機構なしにSFTデータをOPD収集データに置き換えただけの「OPD-as-SFT」ベースラインが受理長を積極的に低下させることも示されており、拒否トークンリプレイが実際に機能していることを裏付けています。
限界
リプレイステップでは、アンカーを保持し学習時にドラフトモデルを再実行する必要があるため、単純なSFTと比較して学習コストが増加します(論文ではオーバーヘッドの詳細は示されていません)。各アンカーでのteacher分布は再計算またはキャッシュが必要であり、キャッシュする場合は学習が固定されたターゲットのスナップショットに依存することになります。結果はQwen3ファミリーの最大30Bまでに限定されており、多量のRLHFが施されたモデルやさらに大規模なターゲットに対してDFlashとの差が広がるか縮まるかは不明です。また、本手法はターゲットの検証ルールが保持されるという標準的な投機的デコーディングの前提を引き継いでいるため、損失を許容するドラフト専用スキームには適用できません。さらに、分析は経験的なものであり、アンカーでの拒否トークン信号がターゲット単独の教師信号よりも厳密に優れたgradientをもたらす条件についての理論的な特徴付けはなされていません。
なぜ重要か
投機的デコーディングの高速化は、アーキテクチャよりもドラフトモデルの学習における学習・推論時の分布ミスマッチによってボトルネックが生じてきました。Draft-OPDは、自己回帰でないドラフトモジュールに対する適切なOPDの手法がフルロールアウトではなくアンカーベースのリプレイであることを示し、その洞察を検証器やターゲットを変更することなく強力なベースラインに対して約15–20%の追加エンドツーエンド高速化へと転換しています。
Source: https://arxiv.org/abs/2605.29343
VideoMLA: 分単位の自己回帰動画拡散のための低ランク潜在KV Cache
問題
長い自己回帰ロールアウトを実行するCausal動画拡散モデルは、固定サイズのスライディングウィンドウKV cacheに収束してきました。最近の研究では、ウィンドウを占めるトークンや位置エンコーディングの方法を調整してきましたが(CausVid、Self-Forcing、Rolling-Forcing、Infinity-RoPE)、per-headのKVレイアウトは密なままでした。そのレイアウトは、ストリーミングメモリとper-stepのレイテンシの主な要因となっています。Wan2.1-T2V-1.3Bでは、キャッシュされた各トークンのコストはレイヤーあたり2 n_h d_h = 3072スカラーです。数千の潜在トークンに30レイヤーを掛けた分単位のロールアウトでは、これが単一GPU上でのバッチサイズとコンテキスト長の制約となっています。
本論文では、DeepSeek-V2/V3のLLMで知られるMulti-Head Latent Attention (MLA)を動画拡散に移植するとともに、より興味深いこととして、言語モデルでMLAを動機付けたスペクトル的前提がここでは成立しないにもかかわらず、なぜMLAが機能するのかを説明しています。
手法
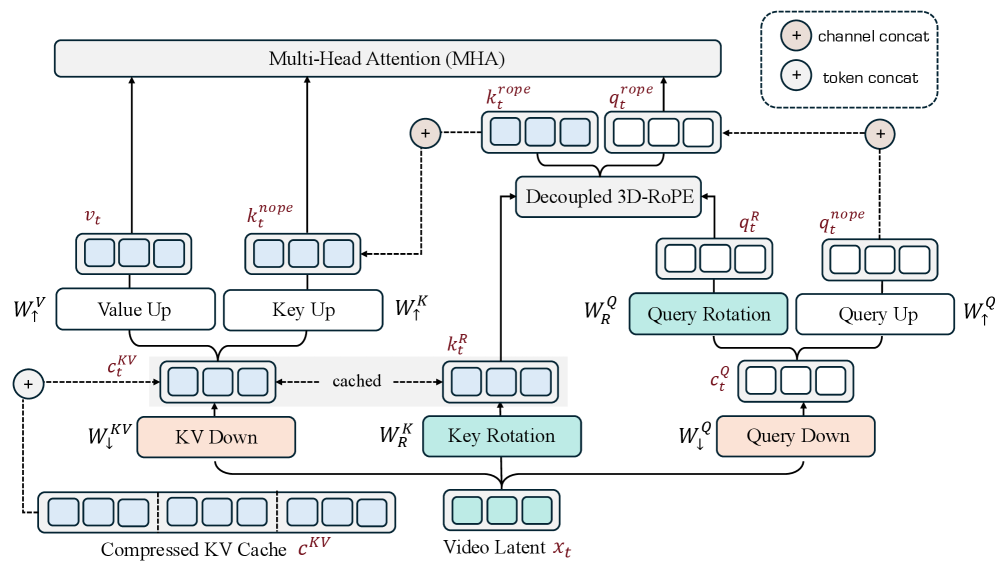
VideoMLAはWan2.1のバックボーン(30ブロック、d=1536、n_h=12、d_h=128)を維持し、self-attentionのみを置き換えます。per-headのkey次元は、content (NoPE) 部分とrotary部分に分割されます:d_h = d_h^{\mathrm{nope}} + d_h^{\mathrm{rope}} = 96 + 32。
各トークンx_t \in \mathbb{R}^{1536}は、cacheに2つのオブジェクトのみを書き込みます:
c_t^{KV} = W_\downarrow^{KV} x_t \in \mathbb{R}^{d_c}, \qquad k_t^R \in \mathbb{R}^{d_h^{\mathrm{rope}}}
ここでd_c=192です。分離された位置keyであるk_t^Rはヘッド間で共有され、最高周波数帯において(time, height, width)に対して(6,5,5)の複素数ペアを割り当てた3D-RoPEを使用します。per-headのkey/valueはオンザフライで再構成されます:
k_{t,h}^{\mathrm{nope}} = W_{\uparrow,h}^{K} c_t^{KV}, \qquad v_{t,h} = W_{\uparrow,h}^{V} c_t^{KV}.
queryのパスもこれを反映します:c_t^Q = W_\downarrow^Q x_t \in \mathbb{R}^{d_q}(d_q=768)、そしてq_{t,h}^{\mathrm{nope}} = W_{\uparrow,h}^Q c_t^Q。attention scoreは、NoPEの内積と共有RoPEの内積を組み合わせます(標準的なMLAの分離手法)。
per-tokenのcacheフットプリントは、レイヤーあたり3072からd_c + d_h^{\mathrm{rope}} = 224スカラーへと削減されます(13.7\times削減、per-token-per-layerで92.7%の節約)。学習は3段階のCausal Forcingパイプライン(Teacher Forcing、4ステップへのConsistency Distillation初期化、DMD)に従い、バッチサイズ128、learning rate 5\times 10^{-6}(TF)および2\times 10^{-6}(CD/DMD)、8\times B200上でbf16で実行されます。
MLAがここで機能する理由:スペクトルではなくランクバジェット
最も新規性の高い貢献は診断的なものです。LLMの文献では、事前学習済みの[W_K;W_V]がほぼ低ランクであり、d_cのボトルネックを通じて射影してもエネルギーの損失がわずかであるという主張でMLAが正当化されています。著者らはこれをWan2.1-T2V-1.3Bでテストし、逆の結果を見出しました。
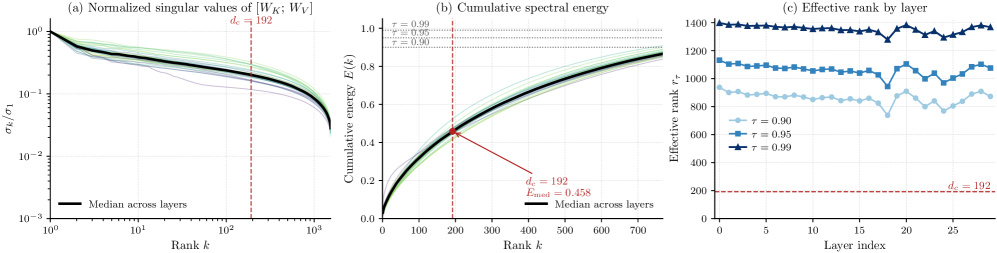
ナイーブなrank-192スペクトル近似では密なKVエネルギーの大部分が失われますが、VideoMLAはこのcacheサイズで生成品質を維持します。その解決策として:MLAは事前学習済みの演算子を近似するのではなく、それを新しい合成演算子で置き換えます。
M = \begin{bmatrix} W_\uparrow^K W_\downarrow^{KV} \\ W_\uparrow^V W_\downarrow^{KV} \end{bmatrix}
この演算子は構造的に最大d_cのランクに制約されています。学習された演算子は実質的にアーキテクチャのフルバジェットを使用します。
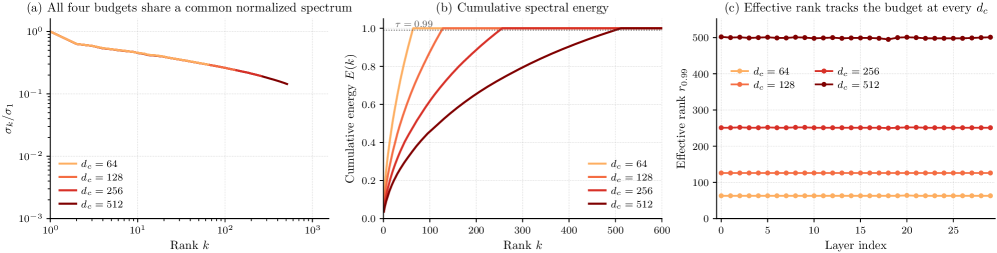
これはSVD初期化によるアーティファクトではないことが確認されています。ランダム初期化でも学習開始から同じほぼ飽和したランクに達し、学習によって低ランク解が発見されることも、スペクトルが崩壊することもありません。この論文を超えて有用な示唆として、MLAの成功はボトルネックによって課された最適化の幾何学に関するものであり、事前学習済み重みの性質ではないということです。これにより、MLAの適用可能性をソースモデルの低ランク診断から切り離すことができます。
定量的結果
- per-tokenのcache:レイヤーあたり224 vs 3072スカラー(13.7\times、92.7%)。
- サービング上の余裕:固定のB200メモリバジェット下で、d_c=192はdense MHAのOOMしないバッチサイズの8.0\timesを達成。
- ランク使用率:d_c \in \{64,128,256,512\}にわたってレイヤーごとの99%エネルギーランク\approx 0.98 d_c。
- 事前学習済み[W_K;W_V]:d_c=192での中央値スペクトルエネルギー45.8%;レイヤーあたりの実効ランク > 1300。
- 定性的評価:30秒のロールアウトでsubjectのidentityとシーン構造を維持;CausVid、Self-Forcing、Rolling-Forcing、Causal Forcing、Reward/Deep Forcing、LongLive、Infinity-RoPE、LongSANAとのhead-to-head比較。
抜粋されたExperimentsセクションにはFVD/VBenchの数値比較表が含まれていないため、ベースラインとの品質保持の程度はここでは定量化されていません。
限界とオープンな問題
- 提供されたテキストはベースラインスイープの標準的な動画品質指標(FVD、VBench、CLIPスコア)を省略しており、定性的なみの比較が最も弱い部分です。
- Wan2.1-1.3Bのみがテストされています。ボトルネックがランクを決定するという主張が、より大きなDiTや非causalなteacherに移転するかどうかは未解決です。
- d_h^{\mathrm{rope}}=32の割り当て(6,5,5)は手動で選択されており、空間軸対時間軸でのRoPEチャンネルバジェットの感度は抜粋では報告されていません。
- 学習パイプラインはCausal Forcingの蒸留に依存しており、MLAがDMDステージの再学習なしにpost-hocで後付けできるかどうかは不明です。
なぜこれが重要か
VideoMLAは分単位の自己回帰動画拡散に対してクリーンな13.7\timesのKV cache削減を実現し、さらに重要なこととして、MLAに関するスペクトル低ランクの説明を否定します:ボトルネックは実効ランクを露わにするのではなく、それを生み出すのです。この再解釈は、事前学習済みattentionがフルランクである(ほとんどのvision transformerがそうであるように)アーキテクチャにもMLAが一般化すべきであることを予測し、設計上の問いを「私のモデルは低ランクか?」から「どれだけのランクバジェットを確保できるか?」へとシフトさせます。
Source: https://arxiv.org/abs/2605.30351
NITP: Next Implicit Token Prediction for LLM Pre-training
問題
標準的なnext-token prediction(NTP)は、出力logitsに対するcross-entropyのみを通じてLLMを監督します。ここでの主張は、このシグナルが幾何学的に疎であるという点です。
\mathcal{L}_{\mathrm{NTP}} = -\mathbb{E}_x\Big[\log \frac{\exp(h_t^\top w_{x_{t+1}})}{\sum_{j\in\mathcal V}\exp(h_t^\top w_j)}\Big]
を通じたgradientは、ターゲットのembedding w_{x_{t+1}} と少数の高確率の候補に支配されるため、hidden state h_t \in \mathbb{R}^d に対する制約は実質的に単一の方向に沿ったものとなります。この部分空間に直交する h_t の成分はほとんど教師なしの状態にあり、著者らはこれが非等方的で縮退したhidden geometryを生み出し、汎化性能を制限すると主張しています。解決策は、単なる離散ラベルではなく、h_t に対する密なベクトル値のターゲットを追加することです。
手法
NITPは補助lossを加えます。これは位置 t における最終的なhidden stateに対して、次のトークンのidではなく、そのimplicitな表現、すなわち同じforward passから取得したトークン t+1 の浅い層のhidden state(stop-gradient付き)を予測するよう求めるものです。
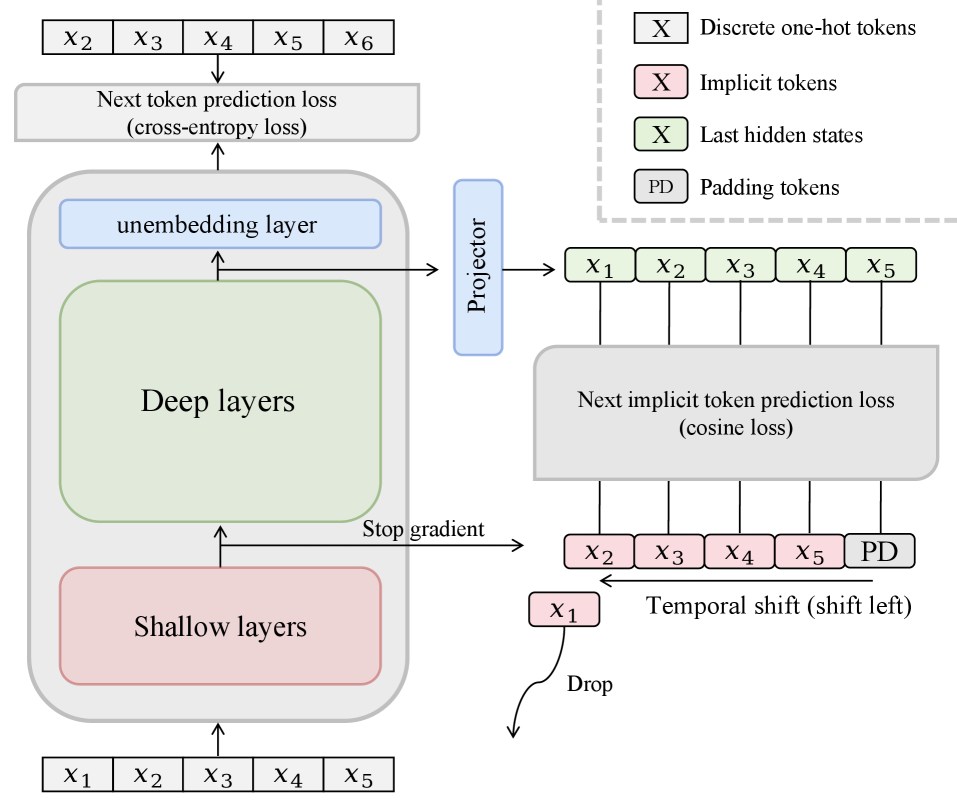
具体的には、h_t^{(L)} を最終層のhidden state、h_{t+1}^{(\ell)} を「セマンティックアンカー」として機能する浅い層(小さい \ell)のhidden stateとします。線形projector P が h_t^{(L)} をターゲット空間に写像し、補助lossはcosineを用いた目的関数となります。
\mathcal{L}_{\mathrm{NITP}} = 1 - \cos\!\big(P\, h_t^{(L)},\ \mathrm{sg}[h_{t+1}^{(\ell)}]\big),
全体の目的関数は \mathcal{L} = \mathcal{L}_{\mathrm{NTP}} + \lambda\, \mathcal{L}_{\mathrm{NITP}} です。設計上の重要な点が2つあります。
- ターゲットへのstop-gradient。 これがないと、両方のブランチが共に崩壊し(BYOLスタイルのcollapse risk)、また表現予測シグナルが浅い層に伝わり、本来持つべきでない役割を担わせてしまいます。
- 時間的シフト(t+1、t ではなく)。 同一トークン t の浅い表現を予測すると、深さ方向にわたる恒等写像に近い退化が生じます。次のトークンの浅い表現を予測することで、モデルは自身の入力を再構成するのではなく、予測的なセマンティック内容をencodeするよう強制されます。学習lossの曲線は、シフトありのバリアントが意味のある形で異なる、より低い値に収束することを示しています。
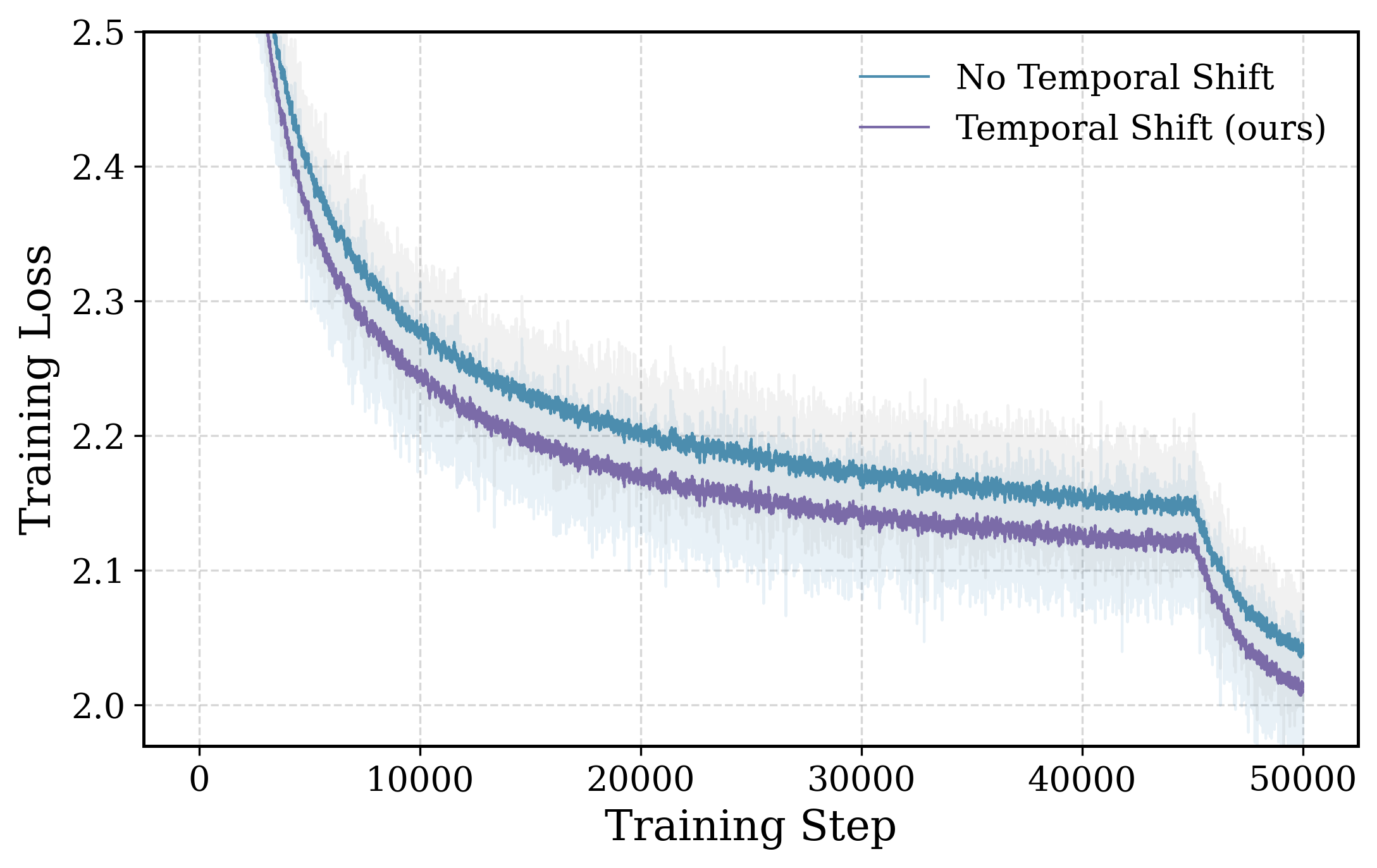
ターゲットはforward pass中に追加コストなしで生成されるため、1ステップあたりの計算オーバーヘッドは本質的に線形射影1回分とcosine lossのコストのみであり、transformerスタック全体に対して無視できる程度です。
論文で概略的に示された理論的主張は、cosine項が h_t の従来は拘束されていなかった方向を、安定した低分散のターゲットに結びつけることで制約するというものです。これにより最適化のlandscapeが正則化され、表現の分布がより等方的でコンパクトなgeometryに向かって押し進められ、NTPのみの学習が生み出すことが知られている非等方性が軽減されます。
結果
実験は0.5Bから3Bの dense modelと、9Bの DeepSeek-V2スタイルのMoE(144 experts、top-8 routing、~1B activated)を対象とし、8192コンテキストで330Bトークンをスクラッチから学習させています。9B MoEにおいて、NITPは以下の改善をもたらします。
- MMLU-Pro: +5.7% absolute
- C3: +6.4% absolute
- CommonsenseQA: +4.3% absolute
改善はより広範なベンチマーク一式(MMLU、C-Eval、Xiezhi、LAMBADA、ARC-C、Balanced COPA、BBH、AGIEval、GSM8k、LCBench)および dense スケール全体にわたって報告されており、改善が単一のベンチマークに依存した結果でなく、モデルサイズとともにスケールすることを示唆しています。
loss weightのablationは、\lambda に対して明確な内部最適値が存在することを示しています。
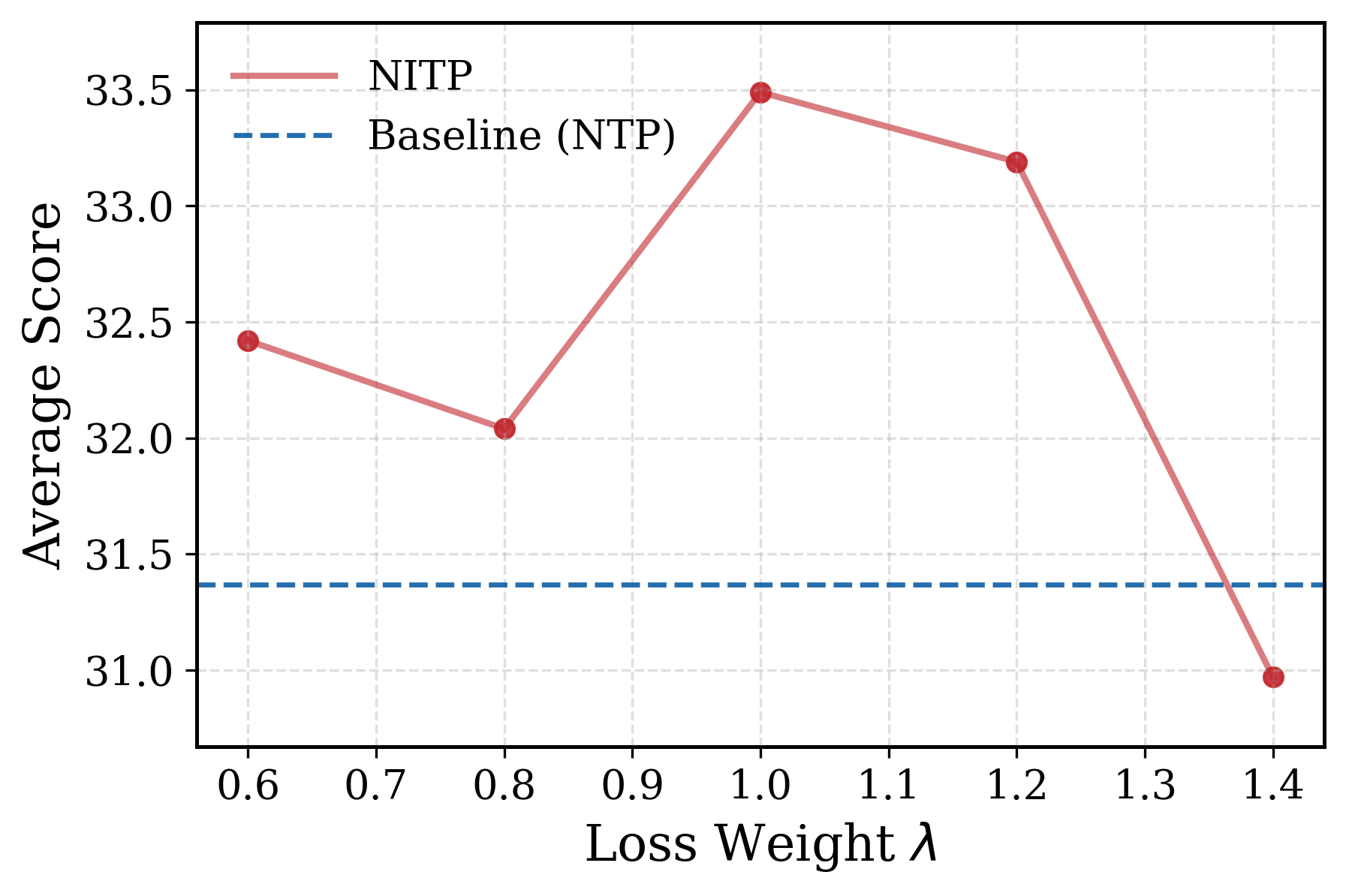
小さすぎると補助シグナルが無意味になり、大きすぎるとNTPと競合します。ターゲットに用いる浅い層の選択もablationされており、浅すぎるとtoken embedding(低セマンティックコンテンツ)に近づき、深すぎると予測層そのものに近づきます(ターゲットの情報漏洩 / collapse圧力)。
限界と未解決の問題
- ターゲットは同一モデルの浅い層の特徴です。これは便利ではありますが、ターゲットの品質をモデル自身の学習初期(特にpre-training序盤)の未成熟な浅い層に依存させることになります。EMAティーチャーや固定ティーチャーがより良い性能を示すかどうかについて、論文では深く分析されていません。
- cosine lossのみが報告されており、正規化空間でのL2や、より豊かなheadを持つJEPAスタイルのpredictorなど、自明な代替手法はablationされていません。
- 非等方性の低減に関する理論的議論は支持されていますが、実測された表現のgeometryメトリクス(例:本文中の明示的な等方性や effective rank の数値)と直接結びついていません。
- 評価はpre-trainingスケールでのfew-shot benchmark accuracyに限られており、instruction tuning / RLHF後の下流での挙動、calibrationや長文コンテキストへの影響は特定されていません。
- 最適な浅い層インデックスと \lambda はアーキテクチャとスケールごとに再調整が必要になる可能性があり、スケーリング則は示されていません。
この研究の意義
hidden stateに対するほぼゼロコストの補助目的関数が、9B-MoEスケールでのMMPLU-Proのような難しいベンチマークで数絶対ポイントの改善を安定的にもたらすならば、これはpre-trainingにおける最もコストの低い介入手法の一つとなります。また「自己蒸留」をteacher-studentのトリックとしてではなく、表現の正則化器として再定義するものです。さらに、h_t の拘束されていない方向というNTPのみのpre-trainingが性能を残したままにしている理由について、具体的かつ検証可能なメカニズムを提示しています。
Source: https://arxiv.org/abs/2605.24956
LVSA: 長尺動画 Diffusion のための Training-Free Sparse Attention
問題
Wan 2.1 や HunyuanVideo 1.5 のような Video diffusion transformer(DiT)は、推論計算のほぼ大半を時空間 self-attention に費やします。T 枚のlatentフレームとフレームあたり P = H_p W_p 個の空間パッチに対して N = T \cdot P トークンがあるとき、dense attention のコストは O(N^2 d) = O(T^2 P^2 d) となります。学習時のhorizonを超えて生成を延長すると、2つの問題が生じます:(i) レイテンシが許容できないほど増大し(Wan 2.1 1.3B の 720p で 6\times horizon にすると NPU 上で約500秒/イテレーションかかる;HunyuanVideo 1.5 は 2\times horizon で 80GB GPU のメモリが不足する)、(ii) positional embedding の外挿精度が低下するため、ほぼ静止したループのような「フリーズ」した品質劣化が生じます。既存の対処法は再学習を必要とする(高コストかつモデル固有)か、または固定グリッドのsparsityを用いることで周期的な時間的アーティファクトを引き起こすかのどちらかです。
手法
LVSA は、フレームごとの小さい attention セット \mathcal{A}(t) に対するトークンレベルの制限により、dense attention の総和を置き換えます:
\text{Attn}(q_{t,i}) = \sum_{\tau \in \mathcal{A}(t)} \sum_{p=0}^{P-1} \frac{\exp(q_{t,i} \cdot k_{\tau,p}/\sqrt{d})}{\sum_{\tau' \in \mathcal{A}(t)} \sum_{p'=0}^{P-1} \exp(q_{t,i} \cdot k_{\tau',p'}/\sqrt{d})} v_{\tau,p}.
クエリごとのコストは O(TPd) から O(|\mathcal{A}(t)| P d) に削減されます。この構成は2つのコンポーネントから成ります:
- Local window \mathcal{W}(t) = \{t' : \max(0, t-W) \le t' \le \min(T-1, t+W)\}:短距離の時間的コヒーレンスのために使用します。
- Periodic global anchors G = \{t : t \bmod T_{\text{per}} = 0\}:すべてのフレームがattendするもので、長距離のコンディショニングを提供します。
単純な選択肢——denoising ステップ全体で G を固定する——は、アンカーフレームが過剰なgradient massを受け取る固定グリッドバイアスを誘発し、反復的な時間的アーティファクトを生じさせます。LVSA はこれを rotating global anchors によって解消します:denoising ステップ s において、アンカーセット G^s は T を法として1ポジションずつシフトします。連続する任意の T_{\text{per}} ステップにわたって各フレームがちょうど1回グローバルアンカーとして機能し、時間的な優先位置を排除しつつ 1/T_{\text{per}} の密度を保ちます。
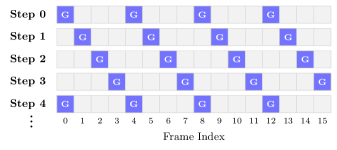
このパターンはステップごとに静的に既知のブロックスパースであるため、block-sparse FlashAttention の変種にきれいにマッピングできます。著者らは FlashInfer カーネル上に LVSA-FI 変種を実装し、さらに vLLM-Omni を通じて NPU 向けにも移植しています。本手法は training-free かつアーキテクチャに依存しません:Wan 2.1 1.3B/14B(single-stream、1D RoPE)と HunyuanVideo 1.5(dual-stream、3D RoPE)のいずれに対しても変更なしで動作します。
結果
GPU 上では、LVSA-FI は Wan 2.1 1.3B の 6\times horizon で最大 3.17\times、Wan 2.1 14B の 6\times horizon で 2.98\times、HunyuanVideo 1.5 の 1.5\times horizon で 3.33\times の高速化を達成し、いずれも dense attention との比較です。Wan 2.1 1.3B における他の長horizon手法との比較では、LVSA は RIFLEx より最大 2.41\times、UltraViCo より 3.27\times 高速です。高速化の倍率はhorizon長とともに単調に増加します。
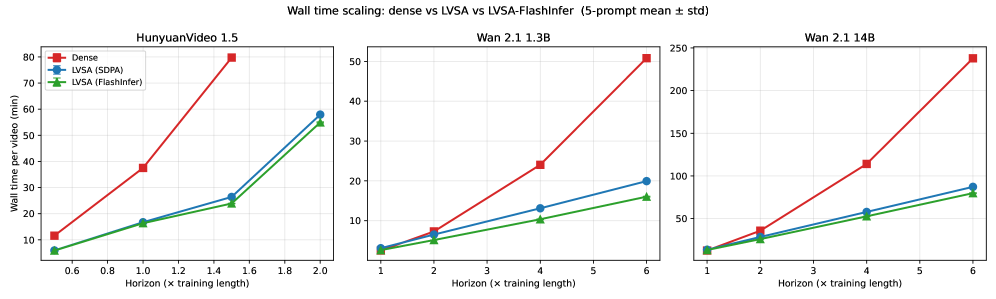
メモリ削減の定性的な効果として、LVSA-FI では HunyuanVideo 1.5 の 2\times horizon(257フレーム)が単一の 80GB GPU 上で実現可能になります。一方、dense attention ではメモリ不足となります。

NPU の結果(vLLM-Omni)も GPU の傾向を裏付けています。Wan 2.1 1.3B の 6\times horizon(481フレーム)において:480×832 で 2.17\times(47.76秒 vs 103.87秒)、720×1280 で 3.24\times(154.27秒 vs 499.47秒)。8基の NPU 上で Ulysses sequence parallelism を使用した Wan 2.2 A14B の 6\times、720×1280 では 2.71\times(108.90秒 vs 294.93秒)を達成します。短いhorizon(2\times)では、LVSA は dense より低速になる場合があります(Wan 2.1 1.3B の 480×832 で 0.93\times、Wan 2.2 A14B で 0.78\times)。これはウィンドウ+アンカーセットが T の無視できない割合をカバーし、カーネルのオーバーヘッドが支配的になるためです。クロスオーバーポイントはおよそ 4\times horizon 付近です。
限界と未解決の問題
論文では W と T_{\text{per}} をモデル間でどのように選択するか、また品質がこれらのハイパーパラメータに対してどの程度敏感であるかが明示されていません;ローテーションスケジュールは一様ですが、他の置換スケジュール(例:低不一致列)によってアーティファクトをさらに低減できる可能性があります。報告されている品質は VQeval 複合スコアによるものであり、人間による評価は実施されていません。ブロックスパースパターンは FlashInfer との相性は自然ですが、短いhorizonで dense より低速な挙動が示すように、タイルサイズが異なるハードウェアでは最適でない場合があります。最後に、本手法は時間次元のみをスパース化するものであり、空間トークンのスパース性は手つかずのまま残っており、さらなる圧縮の明確な軸となっています。arXiv 識別子(2605.31057)は異常に見えるため、確認する価値があります。
この研究が重要な理由
LVSA は、標準的な「global + window」sparse attention のレシピが、denoising ステップ全体でのアンカーのローテーションと組み合わせることで、再学習なしに事前学習済み video DiT の長horizon品質崩壊を解消するのに十分であることを示しています。これにより、長尺動画推論はモデルの再学習問題ではなくカーネルエンジニアリング問題となり、その効果はhorizonとともに拡大します——まさに dense attention が現実的でないレジームにおいて顕著です。
Source: https://arxiv.org/abs/2605.31057
ESPO: Early-Stopping Proximal Policy Optimization
問題設定
LLMの推論器をRL fine-tuningする際、軌跡の序盤で論理的な誤りが生じても、最大ホライズンまでロールアウトが続けられます。この失敗後のトークンは、(i) 正の報酬を得ることなく計算予算の大部分を消費し、(ii) advantage推定にノイズを注入します。すなわち、GAEは最終的な負の結果を何千ものトークンにわたって後ろ向きに伝播させ、実際には正しかった接頭部分にまで影響を与えます。標準的なPPO+outcome-rewardの設定は、ロールアウトのFLOPsを無駄にするとともに、クレジット割り当てが最も難しい箇所——疎な終端報酬を持つ長いchain-of-thought軌跡——において、まさにノイズの多いクレジット割り当てを生み出します。
ESPOはPPOの目的関数には手を加えず、代わりに軌跡の収集方法を変更します。サンプリング中にオンラインで失敗を検出し、打ち切りを行い、その打ち切り点を終端ペナルティを持つ吸収的失敗状態として扱います。概念的には、方策・批評器自身が誘導する終端ルールを持つ拡張MDPにおけるPPOであり、追加の報酬モデルや人手によるラベルは不要です。
手法
各デコードステップ t において、ESPOはロールアウトからすでに得られる2つの信号を使用します。
- サンプリングのlogitsから導出されるトークンレベルの代理後悔(surrogate regret)。具体的には、サンプリングされたトークンの対数確率と方策の最善の代替案との乖離を累積後悔 z_t(スムージングあり)として積算します。logitsはいずれにせよ生成中に計算されるため、追加のforward passは不要です。
- 批評器によるvalue-gate付き閾値 \beta \cdot \max(V_\phi(s_t), \varepsilon)。これはトリガーを、まだ期待されるリターンがどれだけ残っているかに適応させます。
軌跡は、スムージングされた累積後悔がvalue依存の閾値を超えた最初の t で打ち切られます。打ち切られた遷移は終端失敗報酬を伴う吸収状態として扱われ、PPOおよびGAEは打ち切られた軌跡に対して通常通り動作します。これにより、負のTD誤差は何千もの失敗後のトークンにわたって拡散するのではなく、検出された失敗ステップ付近に集中します。
批評器のwarmupスケジュールは、V_\phi のノイズが大きすぎて意味のある閾値を定義できない訓練初期において打ち切りを無効化します。warmupなしでは、\beta \cdot \max(V_\phi(s_t), \varepsilon) がランダム初期化された批評器の高い分散を引き継ぎ、有効な探索分岐に対しても偽の打ち切りを引き起こします。
結果
DAPO-Math-17kで訓練されたDeepSeek-R1-Distill-Qwen-7Bにおける結果:
- AIME 2024: 46.28% vs. PPO 45.25%
- AMC 2023: 85.83% vs. PPO 82.94%
- MATH-500: 87.42% vs. PPO 85.43%
- 累積ロールアウトトークン数20%超の削減
AIME24(avg@32)におけるablationは設計上の選択を個別に評価しています:
| バリアント | AIME24 | 累積トークン数 (M) | 平均トークン数 |
|---|---|---|---|
| (A) Full ESPO | 46.3 | 839.24 | 3278.30 |
| (B) warmupなし | 44.2 | 858.37 | 3353.03 |
| (C) terminal penaltyなし | 43.7 | 901.65 | 3522.09 |
| (D) value-onlyで停止 | 44.0 | 1090.05 | 4258.02 |
| (E) regret-onlyで停止 | 44.8 | 1086.51 | 4244.18 |
| (F) ランダム停止 | 42.4 | 855.59 | 3342.14 |
2つの知見が際立っています。第1に、regret信号とvalue gateの両方が必要であり、どちらか一方を除去すると(D、E)、約1.5〜2.3ポイントの損失が生じ、トークン節約の効果もほぼ消え、平均軌跡長が4200トークンを超えて戻ってしまいます。第2に、terminal failure penaltyの除去(C)はwarmupの除去(B)よりも悪化します。明示的な吸収ペナルティがなければ、GAEには打ち切りを失敗として位置づける根拠がなく、モデルは性能が低下(43.7)するとともに軌跡が長くなります(平均3522トークン)。ランダム停止(F)が最も弱く、節約効果が単なる長さ正則化のアーティファクトではないことが確認されます。
訓練ダイナミクスもこの図式を裏付けています。ESPO/Original(打ち切りがない場合にモデルが生成していたであろう長さ)はPPO/Originalに近い推移を示す一方、ESPO/Actual(打ち切り後の長さ)は大幅に低くなっています。すなわち、打ち切りは方策の自然な長さ分布を歪めることなく、無駄なサフィックスを除去します。ESPOはまた、訓練全体を通じてより高いactor entropyを維持し、PPO-on-LLMの設定で一般的な早期のentropy崩壊を緩和します。これは、失敗後のノイズのプルーニングが不良な接頭部分に対する過信勾配信号を低減するという主張と整合しています。批評器が鋭くなるにつれて、偽陽性率(実際には正しい軌跡が打ち切られる率)は訓練を通じて低下することが報告されています。
限界とオープンな問題
- 評価は検証可能なoutcome報酬を持つ数学推論のみが対象であり、代理後悔がより密なまたはノイズの多い報酬を持つタスク(コード、agentic tool use、オープンエンドな文書作成)において識別力を保てるかは未検証です。
- value-gate付き閾値は適切にキャリブレーションされた批評器に依存します。warmupのablation(B vs. A:2.1ポイント)は、手法がこれに対して実質的に敏感であることを示しています。value headなしで訓練されたモデル(GRPOスタイル)には、異なるゲーティング機構が必要です。
- terminal failure penaltyは固定スカラーであり、reward shapingおよびKL正則化との相互作用は特徴付けられていません。
- AIME24における報告の改善幅(約1ポイント)は小規模数学ベンチマークで典型的なノイズ幅の範囲内ですが、AMC23(+2.9)およびMATH500(+2.0)はより説得力があります。
- 内部ablationの範囲を超えた、長さペナルティベースラインや純粋に批評器のvalue値のみに基づく打ち切りとの比較はありません。
なぜ重要か
ESPOは「lossではなくデータ収集を修正する」というアプローチのクリーンな例です。誤った推論連鎖が方策自身のlogitsと批評器から検出可能であることを活用することで、精度とentropy保持を改善しながら、ロールアウトFLOPsの20%超を回収します。ロールアウトコストが訓練予算を支配する長いchain-of-thought RLにおいて、吸収的失敗状態を持つオンライン軌跡打ち切りは、他のPPO-on-LLMパイプラインにも汎化できる低リスクなドロップインの改善手法です。
Source: https://arxiv.org/abs/2605.29860
Crafter: 多様な入力から編集可能な科学的図形を生成するためのマルチエージェントハーネス
問題設定
科学的図形の生成は、これまでバックボーン問題として扱われてきました。すなわち、より強力な画像生成器を用いれば、より良い図形が得られると期待されてきたのです。しかし著者らは、この捉え方が誤っていると主張します。科学的図形は、離散的な意味論的コンポーネント(軸、ラベル付きボックス、矢印、パネル)の構造化された合成物であり、画像生成器は局所的かつ識別可能な形で失敗します。例えば、サブプロットのラベルの誤り、矢印の欠落、パネルの位置ずれなどが挙げられますが、これらはフリーテキストによるプロンプトの修正には適切に対応できません。既存の自動化手法は、テキストのみの入力から特定の図形タイプを対象とするもの(PaperBanana、AutoFigure)か、局所的な編集ができないラスター出力を生成するものに限られています。本論文は、必要なのは生成器の改善ではなく、生成器を包むハーネスという追加レイヤーであると提唱します。
ハーネスの抽象化
ハーネスは、共有の進化する仕様 \mathcal{S}(現在の計画、改訂履歴、過去の診断結果を保持する構造化レコード)を介した4つの役割からなるループです。
p_t = \mathcal{D}(\text{input}, \mathcal{S}_{t-1}), \quad a_t = \mathcal{E}(p_t), d_t = \mathcal{V}(a_t, \text{input}, \mathcal{S}_{t-1}), \quad \mathcal{S}_t = \mathcal{R}(d_t, \mathcal{S}_{t-1}).
デザイナー \mathcal{D} は計画を提案し、エグゼキュータ \mathcal{E} はそれをレンダリングし、ベリファイア \mathcal{V} はディレクティブな診断(各次元のスコア、特定された欠陥、修正案——スカラーの報酬ではありません)を出力し、リバイザー \mathcal{R} は \mathcal{S}_{t-1} に対して型付き編集を適用します。具体的には、レイアウト制約の追加、アーティファクトカテゴリの禁止、名前付き要素のリサイズなどが該当します。設計上の重要な選択は、\mathcal{R} がフリーテキストをプロンプトに追記するのではなく、構造化された操作を共有仕様に書き込むという点です。これにより、著者らがフリーテキスト修正ループの失敗モードとして特定するプロンプトの劣化を回避できます。ループは受理されるかバジェット T に達すると終了し、a^* = \arg\max_\tau \mathrm{score}(d_\tau) を返します。
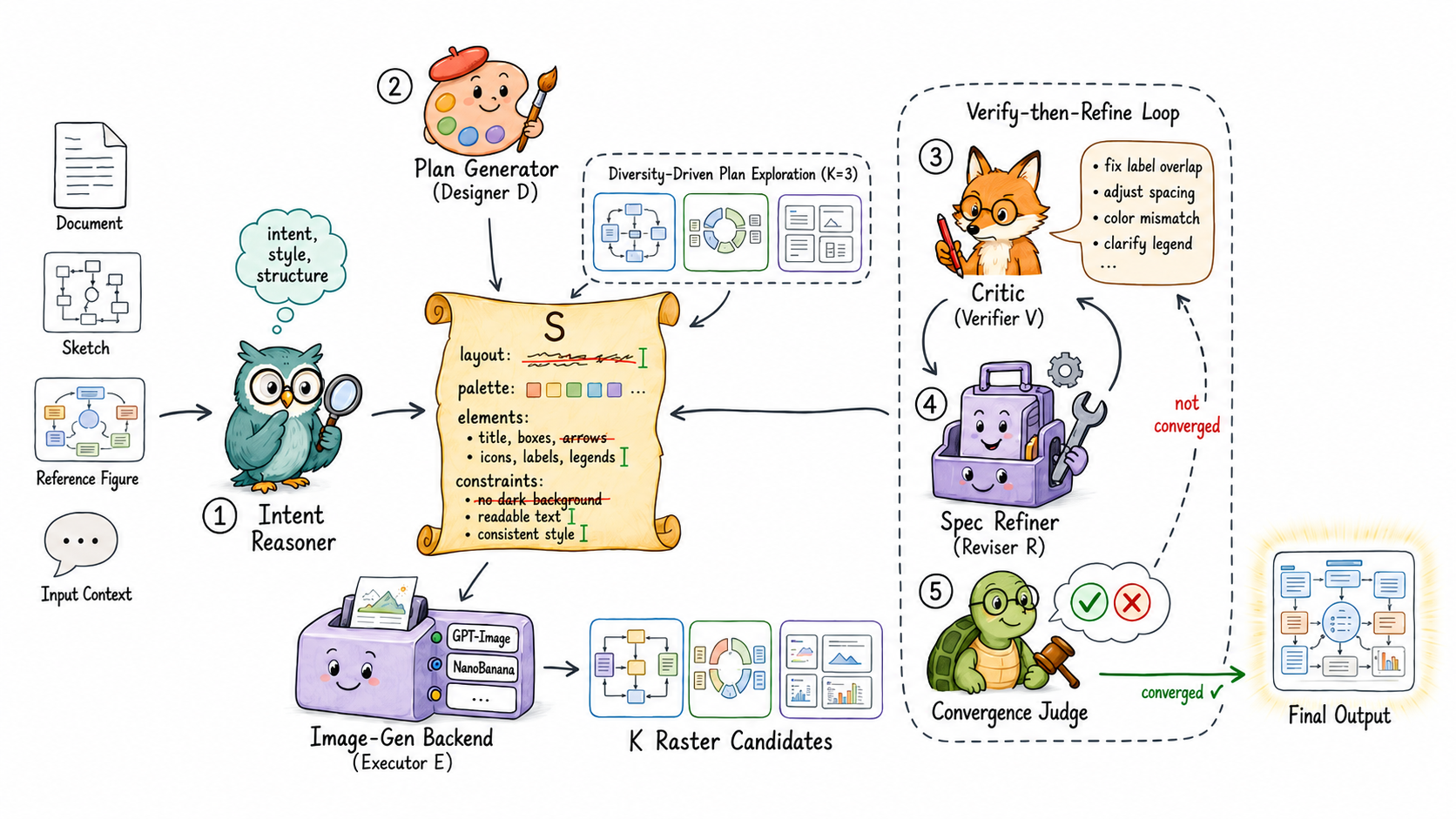
Crafterは、この枠組みを3つのメカニズムで具体化します。(1) 多様性駆動の計画探索:\mathcal{D} が各ラウンドで K 個の候補計画を提案することで、構造化レイアウトにおける出力の高い分散を緩和します。(2) 構造化された修正レイヤー:\mathcal{S} への型付き編集。(3) 多次元ディレクティブ批評家を用いた検証・再精緻化の反復。CraftEditorは同じループをラスター-ベクター変換に転用します。\mathcal{D} はSVGスケルトン生成器となり、\mathcal{E} は要素注入コードを実行し、\mathcal{V} は生成されたSVGに対するハイブリッド批評家として機能します。
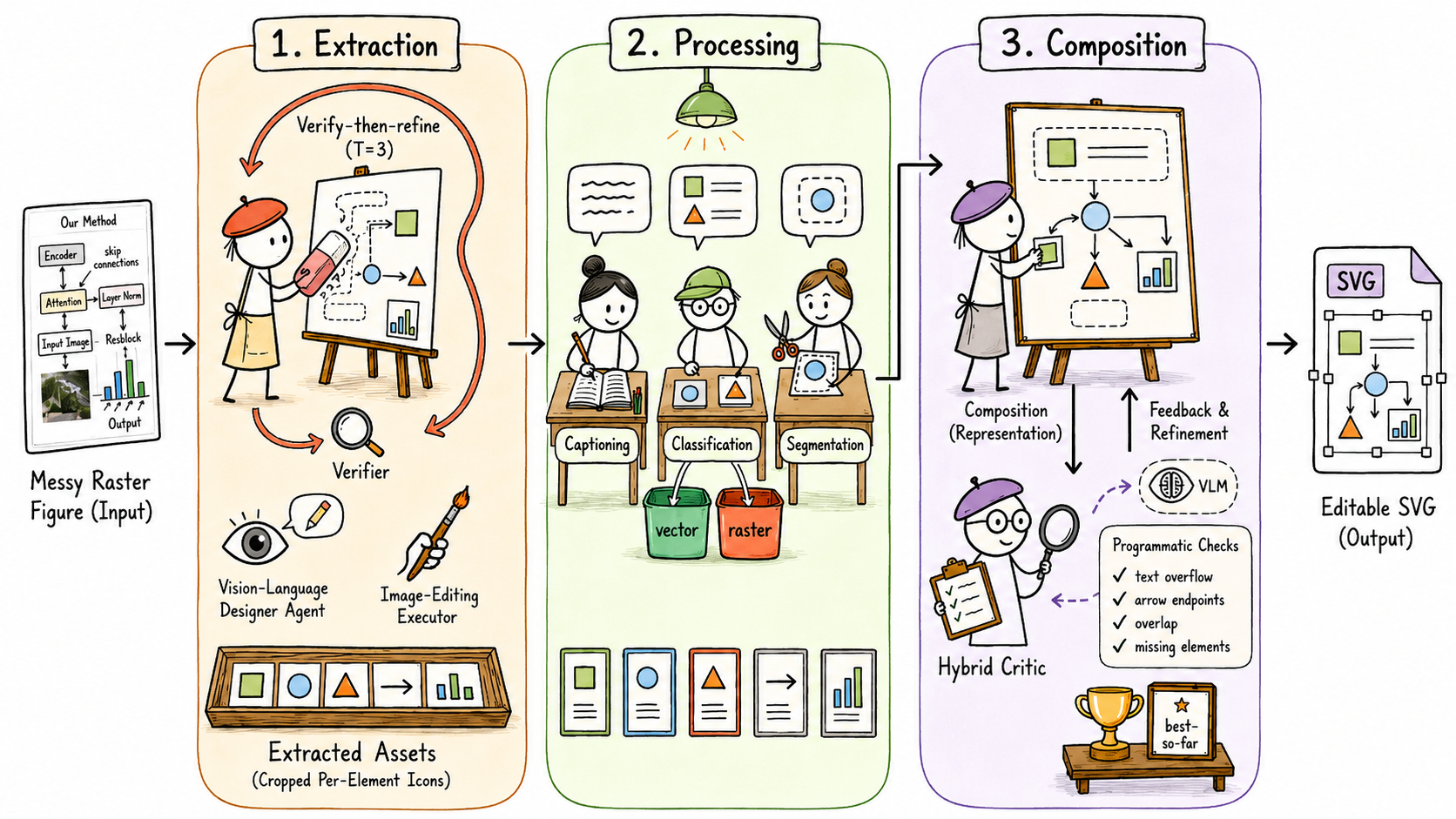
CraftEditorは編集可能性を3段階に分解します。Extraction(VLMデザイナーがkeep/deleteの計画を作成し、画像エディタがそれを実行し、\mathcal{V} が整理されたキャンバスを検証します)、Processing(各要素のキャプション付け、グラウンディング、分類)、そしてComposition(スケルトンSVGへの要素注入)です。
CraftBench
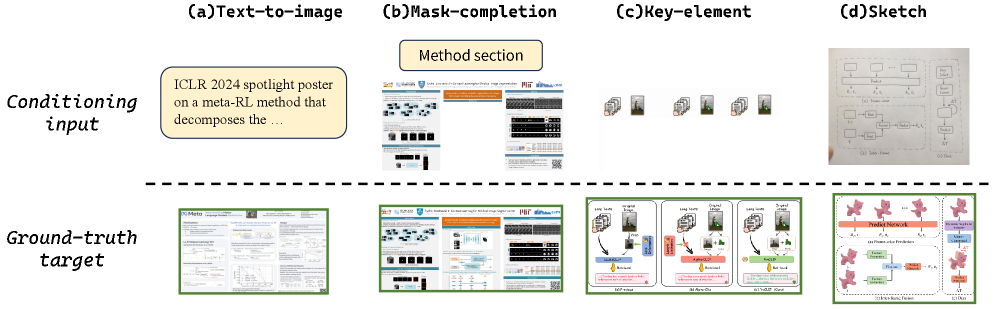
CraftBenchは、3種類の図形タイプと4種類の入力条件(text-to-image、mask-completion、key-element composition、sketch-conditioned)をカバーし、18の研究分野のarXivプレプリント、学会ポスター、研究ブログから選出された279個の精選サンプルで構成されています。パイプラインは、VLMコンテンツ分類、複雑度スコアリング、主張整合性検証によって553の候補を絞り込み、参照条件付きサンプルのそれぞれについて3名の大学院生アノテータが全員一致で承認する必要があります。
結果
すべてのエージェント手法は同一のバックボーン(Nano Banana 2)とVLMジャッジ(Gemini 3.1 Pro)を共有しているため、差異はオーケストレーションのみに起因します。PaperBanana-Benchにおいて、Crafter(Nano Banana 2)は総合スコア50.34を達成し、単体バックボーンの11.13(+39.21)およびPaperBanana(同バックボーン使用)の33.73(+16.61)を上回りました。Nano Banana Proを用いた場合、Crafterは50.00を達成し、単体の22.43(+27.57)およびPaperBanana/Proの35.96を上回りました。
より広範なCraftBenchでは、Crafter(Nano Banana 2)は総合スコア50.20を達成し、単体の19.90(+30.30)およびPaperBananaの28.00(+22.20)を上回りました。Crafter(Nano Banana Pro)は単体の22.40(+29.90)に対して52.30を達成しました。Proバックボーン使用時のCraftBenchにおけるタスク別スコアは、T2I 52.50、Mask 41.70、Sketch 73.80、KeyElement 33.30です。汎化能力の観点から最も顕著なのはPaperBananaベースラインです。そのバックボーンに対する向上幅は、PaperBanana-Benchの+22.60からCraftBenchでは+8.10へと縮小し、sketchタスクではバックボーンを下回っています。これはまさに、ハーネスが回避するよう設計された単一条件への過学習です。AutoFigureは両ベースラインでバックボーンに対して性能が低下しています(総合スコア1.37 / 2.20)。Crafterは、両ベースラインにおいてすべての次元・タスクで一様にバックボーンを上回る唯一の手法であり、すべての列で最良の値を達成しています。
限界と今後の課題
評価はVLM-as-judgeプロトコルに依存しており、人間によるターゲットに対する寛容なwin-rateを用いています。絶対的な数値はジャッジのバイアス(Gemini 3.1 Proが同系モデルの出力を評価すること)と絡み合っています。GPT-Image-2は、不安定性やsafety refusalにより、CraftBenchの279入力のうち260入力のみで有効な出力が得られ、比較が困難になっています。ハーネスは K 個の候補計画と T ラウンドの積に比例して推論コストが増大しますが、バックボーンから単純に KT 個の出力をサンプリングする場合との計算量を揃えたアブレーションは本稿では報告されていません。\mathcal{R} が使用する型付き編集の語彙——どの制約、禁止、リサイズが表現可能か——は本抄録では形式化されておらず、そのカバレッジが達成可能な修正の範囲を制限している可能性があります。最後に、CraftEditorのラスター-SVG変換の忠実度は、報告されている表では定量化されていません。
本研究の意義
本論文は、科学的図形の生成をオーケストレーション問題として再定式化し、型付き編集・ディレクティブ批評家ハーネスが、先行するエージェント型パイプラインが過学習を示す場面においても、図形タイプおよび入力条件をまたいで汎化することの直接的な証拠を提供しています。単体バックボークおよびエージェント型ベースライン双方に対して、すべての次元・タスクで一様な性能向上が得られるという結果は、より一般的な主張を支持しています。すなわち、構造化出力の生成においては、型付き仕様に修正を蓄積する方が、プロンプトに修正を蓄積するよりも優れているということです。
Source: https://arxiv.org/abs/2605.30611
TASTEの問題:エージェントベンチマークのカバレッジと難易度の改善
問題
LLMエージェント向けのツール使用ベンチマーク(特に \tau^2-Bench)は飽和しつつあります。フロンティアモデルは現在、タスクの大部分を解けるようになっていますが、ベンチマーク自体は自然言語シナリオを先に作成してからツール呼び出しにマッピングするという手順で構築されていました。この構築順序はカバレッジにバイアスをもたらします。人間が自然に思い描くシナリオは狭い範囲のツール使用パターンに集中してしまい、APIサーフェスの構文的に有効な組み合わせの大部分がテストされないまま残ります。従来の方法で新しいタスクを追加するのもコストがかかります――各シナリオには、手動による記述、オラクルポリシー、シミュレートされたユーザーゴール、検証ハーネスが必要です。
本論文はTASTE(Task Synthesis from Tool Sequence Evolution)を提案します。これはパイプラインを逆転させるものです。まず難しいツールシーケンスを生成し、カバレッジのためにクラスタリングし、その周辺にシナリオをインスタンス化してから、難易度のために進化させます。その成果物が \tau^c-Bench であり、\tau^2-Bench の3つのドメイン(airline、retail、telecom)をより困難に拡張したものです。
手法
中核となる技術的貢献は、大規模な離散組み合わせ空間上で有効なツールシーケンスをサンプリングするために使用されるAdaptive Contrastive n-gram (ACN)モデルです。単純に考えると、ツールセット \mathcal{T} 上の長さ L のシーケンス数は |\mathcal{T}|^L のスケールとなり、特定のドメインで一貫したマルチステップワークフローに対応するものはごく一部です(例えば、lookup_user の前に cancel_reservation を呼び出すことはできません)。TASTEは、候補シーケンスが妥当なドメインワークフローに対応するかどうかをスコアリングするLLMジャッジが提供する有効性ラベルを用いて、ACNに以下の条件付き確率をモデル化させます。
p(t_i \mid t_{i-n+1}, \dots, t_{i-1})
「contrastive」コンポーネントは有効・無効なシーケンスをそれぞれ正例・負例として使用し、「adaptive」とはLLMによって再評価された新たにサンプリングされたシーケンスで訓練プールを反復的に拡大することを指します。これにより、モデルのサポートが初期シードの分布を超えて広がります。この手法により、\tau^2-Bench のトレースで学習した単純なn-gramが既存の分布を再現してしまうという失敗モードを回避できます。
ACNサンプリングによって大量の有効な候補が生成された後、TASTEはツールシーケンスのembeddingに対してクラスタリングを適用し、各クラスターからメドイド・代表例を選択します。これがカバレッジ制御のノブとなっています。頻出パターンをオーバーサンプリングする代わりに、すべてのクラスターが1つのシードを提供します。
各シードシーケンスは次に完全なベンチマークタスクへとインスタンス化されます。LLMが以下を具体化します。(i) ツールシーケンスと整合するユーザーペルソナとゴール、(ii) そのシーケンスがオラクル解となるために必要なデータベース状態、(iii) 評価ルーブリック(最終状態チェックとアクションチェック)。最後に、反復的な難易度進化がタスクを変異させます――ディストラクターゴールの追加、曖昧なユーザー発話、より長い依存関係などを加え、参照エージェントの成功率が低下しつつもオラクルが解ける場合にのみ変異を保持します。これはEvol-Instructで使われているものと同じ難易度進化のアイデアですが、命令の複雑さのヒューリスティックではなくエージェントの通過率シグナルによって駆動されます。
結果
主な発見は、\tau^2-Bench をほぼ飽和させているモデルが \tau^c-Bench では大幅にスコアを落とすという点です。11組のエージェント/ユーザーLLMペアと3つのドメインにわたって、著者らは新しいベンチマークでの大きな絶対的性能低下を報告しつつ、タスクの有効性は高く維持されています(オラクルと人間によるスポットチェックが解けることを確認しています)。カバレッジ分析では、タスク数を揃えた場合に \tau^c-Bench が \tau^2-Bench よりも大幅に多くの異なるツールn-gramを扱っており、これがより長いあるいはノイズの多いプロンプトからではなく、広範なワークフローカバレッジによるものであることが示されています。
アブレーションは再実装にとって重要です。contrastiveシグナルを除去するとACNがシードの分布パターンに崩壊し、adaptive再訓練ループを除去すると低確率だが有効な組み合わせの探索が制限され、インスタンス化前のクラスタリングを除去すると頻出ツールペアに支配された冗長なタスクが生成されます。難易度進化は「より広いが簡単」と「より広くて難しい」のギャップをもたらすものです――これがなければカバレッジは改善されますが、通過率は \tau^2-Bench のレベルに近いまま留まります。
限界と未解決の問題
- LLMジャッジへの依存。 ACN訓練の有効性ラベルはLLMから得られます。ジャッジにおける系統的な盲点がシーケンス分布に伝播します。著者らはクロスチェックで緩和していますが、これは合成データパイプラインにおける既知の失敗モードです。
- n-gramの視野。 固定次数n-gramの条件付けは長距離依存性(例えばステップ2で使用したツールがステップ9を制約する場合)を捉えることができません。そのような構造を必要とするタスクはアンダーサンプリングされる可能性があります。ニューラルな自己回帰的な代替手法は単純ですが、ここでは未検討です。
- 難易度と現実性のトレードオフ。 進化はディストラクターや曖昧さを追加することで難易度を上げますが、一部の変異は敵対的だが非現実的な領域にドリフトするリスクがあります。論文では、進化したタスクが人間のアノテーターにとって実用的にどの程度現実的であり続けるかを定量化していません。
- ドメイン転移。 3つの対象ドメインはすべて \tau^2-Bench のインフラ(データベースバックのAPI、シミュレートされたユーザー)を共有しています。TASTEが確率的ツール、部分観測状態、または非APIアクション(ブラウジング、コード実行)を持つドメインに転移できるかどうかは未解決のままです。
- 飽和のタイムライン。 タスクが安価に生成できるため、\tau^c-Bench はモデルの改善に合わせて再生成できますが、これはリーダーボードの比較がバージョンに依存することも意味します。
なぜ重要か
エージェントベンチマークは手作業で書かれたシナリオにボトルネックがあり、この分野では能力の進歩に合わせてカバレッジと難易度を拡張するための原則的な方法が必要とされています。TASTEは、構築パイプラインを逆転させること――学習済み有効性モデルの下でまずツールシーケンスをサンプリングし、その周辺にシナリオを合成すること――が、より広く、かつより難しいベンチマークを同時に生み出すことを示しており、同じ仕組みを再実行して飽和を更新することができます。
Source: https://arxiv.org/abs/2605.28556
Hacker News Signals
Nvidia Cosmos 3
NvidiaのCosmos 3リリースは、物理AIワールドモデルプラットフォームを2つの主要な追加機能によって拡張しています。1つは状態記述から物理的に妥当なビデオの継続を生成するワールドモデル、もう1つはセンサー入力をロボットや車両の制御信号にマッピングするアクションモデルです。アーキテクチャは以前のCosmos tokenizerとdiffusion transformerバックボーン上に構築され、細粒度の物理conditioning(接触力、剛体力学、カメラのegomotion)のサポートが新たに追加されており、生成されたロールアウトがより長いホライズンにわたってニュートン力学の制約と整合性を保つようになっています。
アクションモデルのコンポーネントは、ワールドモデルの潜在空間上で動作するポリシーとして定式化されており、厳選されたロボットおよび自動運転車のデータセットを用いたimitation learningと、物理シミュレータのフィードバックを用いたRL fine-tuningの組み合わせで学習されています。Cosmos 3はまた、物理的推論を評価するための新しいベンチマークスイートも提供しており、タスクには未知の力の適用下での物体軌道の予測や、部分的な観測シーケンスから遮蔽されたジオメトリを推定するものが含まれます。
実用的な観点から、このリリースはsim-to-realギャップの問題を対象としています。多様かつ物理的に妥当な学習シナリオを生成することで、下流のロボットポリシーを比例した実世界のデータ収集なしに学習させることができます。モデルの重みはNvidiaデベロッパーポータルを通じて非商用研究ライセンスの下で公開されており、推論用のAPIアクセスも提供されています。
未解決の問題として、物理的整合性に関する主張は主に定性的なものに留まっており、定量的な誤差境界を伴う真のシミュレータロールアウトとの体系的な比較は提供されていません。学習分布(移動動作や運転に偏っている)外のマニピュレーションタスクへのアクションモデルの汎化性能については依然として不明確です。
暗号化された推論ブロブをいじり回す
Matthew Greenの投稿は、Anthropicの「暗号化推論」機能を解剖しています。この機能では、Claudeのextended thinkingトークンが、ユーザーには読めない不透明な暗号文ブロブとして送信されます。暗号工学的な問いは、これが意味のあるセキュリティ特性を提供しているのか、それとも見せかけに過ぎないのか、という点です。
Greenの分析は核心的な問題を特定しています。それは、Anthropicが鍵を管理しているということです。この暗号化はいかなる有用な意味においてもend-to-endではなく、ユーザーやサードパーティの中継インフラによる推論トレースの閲覧を防ぐに過ぎず、Anthropicは任意に復号できます。これはセキュリティ特性というより、「ユーザーからの機密性」と表現するほうが正確です。このスキームは(ブロブ構造の分析から)AES-GCMベースの対称暗号を使用しているように見え、鍵はAnthropicのインフラ外に出ることはありません。
次に彼は、これが推論の流出を試みるprompt injectionアタックへの防御になり得るかを検討しています。答えはほぼノーです。「推論を繰り返せ」と指示する敵対的なツール出力があれば、モデルは暗号化されたブロブではなく平文でそれを再現してしまうからです。暗号化はスクラッチパッドを受動的な検査から隠すだけであり、能動的な敵対的な引き出しからは保護しません。
この投稿はさらに、検証可能性という問題も提起しています。ユーザーは、暗号化されたブロブが実際に出力の根拠となった真正な推論に対応しており、事後的な合理化や空虚な計算ではないと信頼するよう求められます。推論トレースを出力に結びつけるzero-knowledge proofやcommitmentスキームがなければ、暗号化されたブロブには整合性の保証がありません。
これはAIの透明性に関するより広い問いにつながります。暗号化された推論は、セキュリティの言語をまとった製品機能(Anthropicの推論プロセスに対する競争上の堀)として提示されているということです。
Source: https://blog.cryptographyengineering.com/2026/05/29/fooling-around-with-encrypted-reasoning-blobs/
スタンフォード CS336 における AI エージェントのガイドライン
スタンフォードの CS336(Language Models from Scratch)が CLAUDE.md を公開しました。これは、課題1において Claude が学生向け AI アシスタントとして機能する際に与えられるシステムプロンプト/行動指針のドキュメントです。エンジニアリングの成果物として技術的に興味深く、エージェントに許可される行為と禁止される行為が明確に規定されています。
制約は厳格です。エージェントは、課題の構成要素を解くコードを書くこと、参照実装の詳細を開示すること、および解答を実質的に提供するような形で学生のコードをデバッグすることを明示的に禁じられています。一方で、概念の説明、関連ドキュメントへの誘導、課題仕様の明確化、および課題と無関係なツール(環境構築や無関係なインフラ問題のデバッグ)に関するサポートは許可されています。
また、メタ的な指示も含まれています。学生のリクエストが上記のルールに違反することを要求する場合、エージェントは暗黙的に拒否したり話をそらしたりするのではなく、その旨を明示的に伝えるべきとされています。これは拒否の挙動を明瞭に示そうとする具体的な試みです。
システム的な観点から見ると、これはハードな技術的制御ではなく自然言語ポリシーによる能力制限の一例です。モデルが解答コードを出力することを防ぐサンドボックスは存在せず、あるのは行動指針のみです。その有効性は、モデルが指示に従うかどうかに完全に依存しており、これは既知の脆弱な保証です。HN のディスカッションはこの緊張関係に大きく焦点を当てており、十分に粘り強い学生であれば、jailbreak や言い換えによって禁止された助けを引き出せる可能性が高く、名誉規程以外の強制メカニズムは存在しないと指摘されています。
このドキュメントは、教育現場や同様の制約された専門的な場面に LLM アシスタントを展開しようとしている方にとって有用な参考資料です。技術的な強制が依然としてソフトなものにとどまっているとはいえ、ポリシー設計の空間を明確に示しています。
Source: https://github.com/stanford-cs336/assignment1-basics/blob/main/CLAUDE.md
生物学者から盗んでHaskellのコンパイルを高速化する
この記事は、バイオインフォマティクスの配列アライメントアルゴリズムをGHCのコンパイル過程におけるCore中間表現内の共有機会発見の問題に応用したものです。
借用された具体的な生物学的手法は、BLASTやSmith-Watermanといったツールで使われている編集距離/動的計画法による近似文字列マッチングです。解決しようとしているコンパイラの問題は、Coreにおいて構造的に類似したサブ式を特定し、それらが構文的に同一でなくても重複排除またはCSE(共通部分式削除)を適用できるかを見極めることです。対象となる式は変数名、引数の順序、あるいはセマンティクスに影響しない細かな構造的差異によって異なっている場合があります。
鍵となる洞察は、GHC Coreの式をトークン列にシリアライズし、それらの列に対して近似マッチング(小さな編集距離を許容)を行うことで、厳密な構文マッチングでは見逃してしまう共有機会を発見できるというものです。使用されるDPテーブルは、Needleman-WunschアルゴリズムとほぼI同じ構造であり、Coreコンストラクタ間の意味的差異のコストを反映したカスタムスコアリング行列を用います。
著者は、後続のコンパイルステージにおける冗長な処理を削減することで、一部のベンチマークにおいて測定可能なコンパイル時間の短縮が得られたと報告しています。ただし、その数値はワークロードへの依存性が高く、アライメント自体が式の長さに対してO(mn)のオーバーヘッドを追加します。最も効果が高いのは、Template HaskellやレコードのボイラープレートなどI、繰り返し構造を持つ大量の生成コードです。
制限事項として、近似マッチングは偽の共有を特定してしまうリスクを伴います。すなわち、見た目は類似していても、代入後に型またはセマンティクスが異なる式を同一視してしまう可能性があります。この記事では、共有を確定する前に候補ペアを検証するための型検査パスが必要であることを認めています。
Streambed: PostgresのストリームをS3上のIcebergに変換、Postgresワイヤープロトコルをサポート
StreambedはGoで実装されたサービスで、Postgresの論理レプリケーション(WAL)を読み取り、変更ストリームをS3互換オブジェクトストレージ上のApache Icebergテーブル形式に書き込みます。最大の差別化ポイントは、Postgresワイヤープロトコルを話す点にあり、既存のPostgresクライアントが修正なしにStreambedに直接クエリできます。
アーキテクチャは3つのコンポーネントで構成されています。論理レプリケーションコンシューマはpgoutputプラグインを使ってPostgresに接続し、WALレコードを行レベルの変更イベント(before/afterイメージを含むINSERT/UPDATE/DELETE)にデコードしてメモリ上にバッファリングします。ライターコンポーネントはこれらのイベントをバッチ処理してParquetファイルをS3にコミットし、Icebergメタデータ(マニフェストファイル、スナップショットログ)をアトミックに更新します。クエリレイヤーはPostgresワイヤープロトコル(v3)を十分に実装し、シンプルなクエリを受け付けて、組み込みのクエリエンジンを介してIcebergのスキャン操作に変換します。
IcebergのインテグレーションによりCDCストリーム上でスナップショット分離とタイムトラベルクエリが可能になります。WAL自体がappend-onlyな構造であるため、任意の過去のスナップショット時点のテーブルを無償でクエリできます。
リポジトリに記載されている現在の制限事項として、DDL変更のサポートがない(スキーマ進化には手動介入が必要)、クエリレイヤーがSQLのサブセットしか処理できない(joinなし、aggregateも限定的)、高スループットなinsertワークロード下でのパフォーマンスがDebezium + Kafka + Flinkといった代替手段と比較されていないなどが挙げられています。Postgresワイヤープロトコルのサポートは部分的であり、prepared statementとCOPYプロトコルは実装されていません。
このツールは、フルCDCパイプライン(Debezium)とシンプルなpg-to-S3ダンプの間のニッチを埋めるもので、特にKafkaインフラなしにIcebergのオープンテーブルフォーマットを求めるチームに適しています。
Source: https://github.com/viggy28/streambed
Claude Opus 4.8
Anthropicは Claude Opus 4.8 をリリースしました。このモデルはフロンティア reasoning モデルとして位置づけられており、agentic なタスク完了能力の向上、長文脈の処理、そして事実に関する質問における hallucination 率の低減が図られています。モデルは200Kトークンのcontext windowをサポートし、「extended thinking」を導入しています。これはモデルが最終的な回答を生成する前に内部の reasoning トークンを生成するスクラッチパッド計算モードであり、それらのトークンはオプションでユーザーから隠すことができます(上記の encrypted reasoning に関する投稿を参照)。
Anthropicが報告した benchmark によると、Opus 4.8 は SWE-bench Verified(実際のGitHub issueに基づくソフトウェアエンジニアリングタスク)で72.5%を達成しており、リリース時点で公開 eval のトップかそれに近い位置に置かれることになります。GPQA(大学院レベルの科学的質問)では、extended thinking を有効にした場合に74.9%、無効の場合に68.2%を達成しており、スクラッチパッドモードの効果が定量的に示されています。
このモデルは特に agentic なユースケースを想定して位置づけられています。Anthropicはツール使用、マルチステップ計画、および長いタスク期間にわたって一貫した状態を維持する能力を強調しています。system prompt の処理も改訂され、複雑な複数部分からなる指示をより適切に尊重し、制約を暗黙のうちに無視しないようになっています。
HNのディスカッションは大規模(1,300件以上のコメント)であり、extended thinking 機能、価格設定(Opus 4.8 は Sonnet ティアのモデルと比較して大幅に高価)、そしてコーディングタスクにおける GPT-4o や Gemini Ultra との比較を中心に展開されています。複数の実務者が実際のデバッグタスクで以前のモデルを上回る性能を報告している一方、正確なツールコールのシーケンシングを必要とする agentic なワークフローで不安定な挙動が見られるという指摘もあります。
encrypted reasoning に関する論争(Greenの投稿を参照)はここでも直接関連しています。extended thinking トークンは不透明な blob として送信される可能性があり、Greenが分析した透明性に関する問題を提起しています。
Source: https://www.anthropic.com/news/claude-opus-4-8
Claude Codeにおける動的ワークフロー
AnthropicのClaude Codeは、動的ワークフロー(分岐、ループ、および条件付きタスクシーケンス)をサポートするようになりました。これらはモデルが静的な事前定義済みプランに従うのではなく、実行時に構築・実行するものです。この機能により、Claude Codeは中間結果に基づいて実行途中でタスクリストを再評価し、並列化可能なサブタスクにサブエージェントを生成し、失敗したステップを修正済みの戦略で再試行することができます。
機械的な観点では、ワークフローの表現はDAG(有向非巡回グラフ)であり、ノードはツール呼び出しまたはモデルの推論ステップ、エッジはデータ依存関係を持ちます。モデルはこのDAGを逐次的に生成します——グラフ全体を事前にプランするのではなく、各ノードが完了して結果を返すたびにグラフを拡張していきます。これはReActスタイルの実行に近いですが、フラットなアクションシーケンスではなく明示的な分岐構造を持つ点が異なります。
技術的に最も興味深い追加機能は並列実行能力です。モデルが独立したサブタスク(例:2つの別モジュールに対するテストの記述)を特定した場合、それらを並列動作するサブエージェントインスタンスにディスパッチし、結果を収集してマージすることができます。オーケストレーション層はサブエージェント間のコンテキスト分離と結果の集約を担います。
CI/CDおよび自律的なコーディングへの実践的な影響として、以前は逐次的なステップバイステップの指示が必要だった複雑な複数ファイルにまたがるリファクタリングを、単一の高レベルなゴールとして表現できるようになりました。モデルが分解とシーケンシングを処理します。失敗モードはエージェント型システムで想定される典型的なものです:上流のサブタスクが不正な出力を生成し、それを下流のタスクが検証なしに消費することで生じるカスケードエラー、および部分的な実行によってリポジトリが不整合な状態に変更された場合の回復困難性が挙げられます。
HNでの議論は実際の信頼性に焦点を当てています——具体的には、モデルが自己生成したワークフロー構造が、人間のチェックポイントなしに本番環境での使用に十分なほど堅牢かどうかという点です。
Source: https://claude.com/blog/introducing-dynamic-workflows-in-claude-code
GoのnetHTTP/httptrace を用いたHTTPリクエストのトレーシング
本記事は、Goの net/http/httptrace パッケージの実践的なウォークスルーです。このパッケージは、transportを変更したりクライアントをラップしたりすることなく、オブザーバビリティを目的としてHTTPクライアントの内部ステートマシンへのフックを提供します。
このパッケージは、ClientTrace 構造体をリクエストのcontextに添付することで機能します。この構造体には、リクエストライフサイクルの各遷移に対するオプションのコールバック関数が含まれています。具体的には、DNSの名前解決の開始・完了、コネクションの確立、TLSハンドシェイク、最初のバイトの送信、最初のバイトの受信、そしてコネクションの再利用と新規作成の区別です。コールバックはタイミング情報を受け取り、場合によっては実際に解決されたアドレスやTLS状態も受け取ります。
典型的なユースケースとしてレイテンシの診断が挙げられます。GotConn、WroteRequest、GotFirstResponseByte においてタイムスタンプを記録することで、リクエスト全体のレイテンシをDNSルックアップ、TCPダイヤル、TLSネゴシエーション、リクエストのシリアライゼーション、サーバー処理、レスポンス転送の各フェーズに分解できます。これはブラウザのDevToolsネットワークパネルが示すものと同じ分解方法であり、Goクライアントでプログラマティックにアクセスできるようになっています。
本記事では具体的な実装例を示しています。
trace := &httptrace.ClientTrace{
GotConn: func(info httptrace.GotConnInfo) {
log.Printf("conn reused: %v, idle: %v", info.Reused, info.WasIdle)
},
GotFirstResponseByte: func() {
log.Printf("TTFB: %v", time.Since(start))
},
}
req = req.WithContext(httptrace.WithClientTrace(req.Context(), trace))重要な制限として、httptrace はクライアント側のみをインスツルメントする点が挙げられます。サーバーの処理時間は、リクエスト書き込み完了から最初のレスポンスバイトまでの間隔として推測されますが、これはネットワークのRTTと実際のハンドラーのレイテンシを混同しています。分散トレーシングにおいては、OpenTelemetryのインスツルメンテーションを補完するものではありますが、その代替にはなりません。
注目の新リポジトリ
Kaelio/ktx
AIコーディング/アナリティクスエージェント(Claude Code、Codexなど)とデータソースの間に位置するコンテキストオーケストレーション層で、Model Context Protocol(MCP)を通じて公開されています。核心的なアイデアは、生のSQLやスキーマへの直接アクセスだけでは、エージェントが大規模に正確なデータクエリを実行するには不十分であるというもので、ktxはその上に三つのコンポーネントを追加します。すなわち、セマンティック層(カラムの別名、メトリクスの定義、ビジネスロジック)、スキルズレジストリ(エージェントが名前で呼び出せるパラメータ化されたクエリテンプレート)、そしてセッションをまたいでクエリパターンや修正を蓄積する永続メモリストアです。セマンティック層は、制御された語彙を提供することで、エージェントがカラム名を幻覚したりメトリクスを誤集計したりするのを防ぎます。スキルはバージョン管理されており、エージェントは自由形式のSQLを生成するのではなく名前付きプロシージャを呼び出すため、エラーの発生余地が縮小されます。メモリにより、エージェントは過去のユーザーによる修正や好まれるクエリ形式を想起できます。内部的にはMCPツールハンドラを登録するPythonサービスであり、エージェントは構造化されたツール記述を受け取り、型付きの結果を返します。クエリの正確性が重要で自由形式の生成では信頼性が低すぎるアナリティクスパイプラインにLLMエージェントを組み込むデータチームにとって有用です。
Source: https://github.com/Kaelio/ktx
Evokoa/pgGraph
既存のPostgreSQLデータベース上に、別途グラフエンジンを必要とせずにグラフクエリ機能を直接追加するツールです。このアプローチでは、ノードとエッジを通常のPostgresテーブルとして表現し、再帰的なCTEおよび標準的なSQL joinにコンパイルされるCypher風またはプロパティグラフ風のクエリインターフェースを提供します。これにより、データをPostgresから移行したり、Neo4jなどへのデュアルライトパイプラインを維持したりすることなく、最短経路・近傍クエリ・到達可能性といったグラフトラバーサルが実現できます。実装にはPostgres extensionと手続き型SQLが用いられており、グラフ固有の操作(例えば、幅優先探索はWITH RECURSIVEにコンパイルされます)を処理します。外部キーを自動的にイントロスペクトしてエッジ関係を推論できるため、導入時の摩擦が低減されます。主な価値提案は運用上のシンプルさにあります。新しいインフラが不要であり、既存のPostgresのRBACやバックアップがそのまま適用され、グラフクエリはリレーショナルフィルタと自然に組み合わせることができます。非常に大規模なグラフに対する深いトラバーサルでは、ネイティブのグラフエンジンほどのパフォーマンスは得られませんが、すでにPostgresに存在するデータセットに対する中程度の深さのクエリであれば、データベース内処理アプローチによってシリアライゼーションのオーバーヘッドを完全に回避できます。
Source: https://github.com/Evokoa/pgGraph
DaoyuanLi2816/can-i-finetune-this
指定したHugging Faceモデルがローカルのハードウェアでinferenceおよびfine-tuningのGPUメモリに収まるかどうかを答えるコマンドラインの推定ツールです。このツールはHub APIからモデルのメタデータ(パラメータ数、dtype、アーキテクチャ)を取得し、forward pass、backward pass、optimizer states、およびgradient checkpointingの各バリアントに対するピークメモリの推定値を計算します。メモリの内訳を明示的にモデル化しており、例えばAdamによるfull fine-tuningではoptimizer statesだけでfp32のパラメータメモリの 2 \times を消費し、mixed precisionとgradient checkpointingを組み合わせると計算式が変わります。LoRA/QLoRAのパスについても、削減された精度でロードされた凍結済みベース重みに加えて学習可能なアダプタパラメータを考慮することで推定が行われます。このツールは報告されたGPUのVRAMが十分かどうかを報告し、不十分な場合には実現可能にするための設定(量子化レベル、gradient checkpointing、batch size 1)を提案します。70B以上のチェックポイントをダウンロードした後、最初のforward passでOOMになる前に確認できる点で非常に有用です。実装はモデルのロードを一切行わない純粋なPythonであり、すべての推定は解析的に行われるため、数秒で実行できます。
Source: https://github.com/DaoyuanLi2816/can-i-finetune-this
anthropics/defending-code-reference-harness
Anthropicが公開した、Claudeをソフトウェアセキュリティのワークフローに統合するためのリファレンス実装です。このハーネスは4つのステージで構成されています:脅威モデリング(アーキテクチャの説明からSTRIDEまたはMITREにマッピングされた脅威ツリーを生成)、静的スキャン(既存のスキャナーをラップしてその結果をモデルにフィードしてトリアージ)、トリアージ(悪用可能性のコンテキストに基づいて発見内容の重複排除とランク付け)、そしてパッチ生成(確認された脆弱性に対するdiffの生成)です。各ステージは、独立して呼び出したり連鎖させたりできる、構成可能なスキルとして実装されています。自律的なスキャンハーネスはパイプライン全体をエンドツーエンドでラップしており、リポジトリのパスを与えるだけで、最小限の人手介入でシーケンス全体を実行します。カスタマイズ用のフックが明示的に提供されており、ユーザーは独自のスキャナーバックエンドへの置き換え、脅威モデリングスキーマの調整、またはトリアージプロンプトのオーバーライドが可能です。このプロジェクトは、AppSec自動化のためにClaudeを評価しているセキュリティチームや、LLMを活用した脆弱性修正のベンチマークを行う研究者を対象としているようです。すべてのスキルは型付きの入出力を持つ構造化されたプロンプトテンプレートとして定義されており、コアのオーケストレーションロジックを変更することなく、容易に適応・拡張できます。
Source: https://github.com/anthropics/defending-code-reference-harness
mkbhardwas12/pwned-deps
npm(package-lock.json)、PyPI(requirements.txt/poetry.lock)、Maven、Cargo、Goモジュール、RubyGemsに対応したロックファイル優先の依存関係脆弱性スキャナーです。「ロックファイル優先」とは、宣言されたバージョン範囲ではなくロックファイルから正確にピン留めされたバージョンを解決することを意味し、バージョンの曖昧さに起因する誤検知を排除します。脆弱性データはOSV(Open Source Vulnerabilities)データベースを主なソースとし、OSVにまだ登録されていないケースに対しては厳選されたフィードで補完されます。本プロジェクトは自身のリリース成果物に対してSLSA Level 3の来歴証明を主張しており、これはビルドパイプラインがソースコミットと公開バイナリを紐付ける署名済みアテステーションを生成することを意味します――ツールチェーン自体を監査する場合に関連します。CI integration はスキャン実行中のサプライチェーン干渉を防ぐため、ロックされたコンテナ内で動作します。結果はパイプラインのブロックやダッシュボードへの連携に適した構造化フォーマットで出力されます。pip-auditやnpm auditといったツールと比較して、複数エコシステムを単一ツールで扱うアプローチとロックされたコンテナによる実行モデルが主な差別化要因です。エコシステムごとのネイティブスキャナーを個別に実行するのが煩雑なポリグロットなモノレポに有用です。
Source: https://github.com/mkbhardwas12/pwned-deps
withkynam/vibecode-pro-max-kit
長期にわたるAI支援開発セッションにおけるcontext window劣化に対処するために設計された、構造化されたエージェントハーネスです。中核となるメカニズムはspec駆動型メモリシステムです。プロジェクトの状態は、構造化された仕様書(アーキテクチャの決定事項、機能コントラクト、未解決タスクなど)の集合として管理され、エージェントは生の会話履歴に依存するのではなく、これらの仕様書を読み書きします。context windowがオーバーフローしたり一貫性を失いそうになった場合、ハーネスはフルのチャットトランスクリプトではなくこれらの仕様書からエージェントのcontextを再構築(rehydrate)します。12エージェント・32スキル構成のアーキテクチャにより、作業は専門化されたサブエージェント(プランナー、コーダー、レビュアーなど)に分散され、各エージェントは狭いcontextスコープを持ちます。自己改善は、エージェントが実行中に学習した内容をもとに仕様書を更新するフィードバックループとして実装されており、将来のセッションはより豊富なベースラインから開始できます。Claude CodeおよびCodexとそれぞれのAPIを通じて互換性があります。解決しようとしている実際の問題——マルチセッションコーディングにおけるcontext rot——は現実に存在し、十分に記録されています。spec-as-memoryアプローチは合理的なエンジニアリング的対応ですが、30秒でオンボーディングできるという主張はプロジェクトの複雑さに照らして検証する必要があります。
Source: https://github.com/withkynam/vibecode-pro-max-kit
boona13/image-extender
アウトペインティング(画像を任意の方向に元の境界を超えて拡張する処理)のためのオープンソースWebアプリケーションです。生成バックエンドはOpenRouter経由でアクセスするGeminiを使用しているため、ローカルGPUは不要です。技術的に興味深いコンポーネントは継ぎ目ブレンディングのステップです。境界部分にモデルの生出力をそのまま使用するのではなく、Poissonブレンディングを適用して接合部における勾配場を調整し、単純な合成処理が引き起こす色の不連続性やエッジのアーティファクトを抑制します。Poissonブレンディングは、Dirichlet境界条件のもとでブレンド領域全体にわたってラプラシアン系 \nabla^2 f = \nabla^2 g を解き、境界値を一致させながら内部の勾配構造を保持します。このアプリはさらに3つの拡張候補を生成してユーザーに提示するため、1回の生成でモデルが不自然なまたはアーティファクトの多い結果を出力してしまう場合にも対処できます。Webインターフェースは任意の画像を受け付け、拡張方向と量をユーザーが指定でき、ブレンド済みの合成画像を返します。クラウド推論・Poissonポストプロセッシング・複数候補選択の組み合わせは、MLの専門知識を必要としない実用的なワークフローです。
Source: https://github.com/boona13/image-extender
hadriansecurity/OpenHack
Hadrian Securityがリリースした、ホワイトボックスセキュリティコードレビュー向けの軽量なファイルベースのワークスペース構造です。核となる設計思想は、スコープ定義・発見事項・メモ・エクスプロイトのスケッチといったすべてのレビュー成果物を、定義されたディレクトリスキーマ内のプレーンファイルとして管理する点にあり、データベースやSaaSプラットフォームを必要とせず、ワークスペースをバージョン管理・差分確認・共有できるようにしています。「ソースガイド型」とは、ブラックボックスによるプロービングではなく、実際のソースコードのレビューに特化していることを意味し、ワークスペースは発見事項をターゲットリポジトリのファイルパスと行番号に直接リンクさせます。ホワイトボックスに特化したアプローチにより、動的スキャナと比較して、データフロートレース・認証ロジックの監査・暗号の誤用検出といった、より精密な脆弱性分析が可能となります。レビュアーはファイルツリーに対して任意のエディタやスクリプトを使ってワークスペースを利用できます。またファイルベースのアプローチにより、ローカルファイルのコンテキストを操作するAIコーディングアシスタントとの統合も容易です。再現性・ポータビリティに優れた監査証跡を求めるセキュリティコンサルタントや、大規模な商用ツールを導入せずに構造化されたコードレビューを実施する内部レッドチームに有用です。