Daily AI Digest — 2026-06-02
arXiv Highlights
Draft-OPD: On-Policy Distillation for Speculative Draft Models
Problem
Speculative decoding pairs a target p_\theta with a small draft q_\phi: the drafter proposes K tokens \hat{y}_{t+k}\sim q_\phi(\cdot\mid x_{<t},\hat{y}_{t:t+k-1}), and the target verifies them in parallel, accepting the longest valid prefix. Acceleration is governed by the accepted length \tau, which depends on how well q_\phi approximates p_\theta on states the drafter actually visits.
Current EAGLE3/DFlash-style drafters are trained with supervised fine-tuning on target-generated trajectories. The authors observe that this SFT objective plateaus quickly — accepted length on test data stops improving even as training loss continues to decrease.
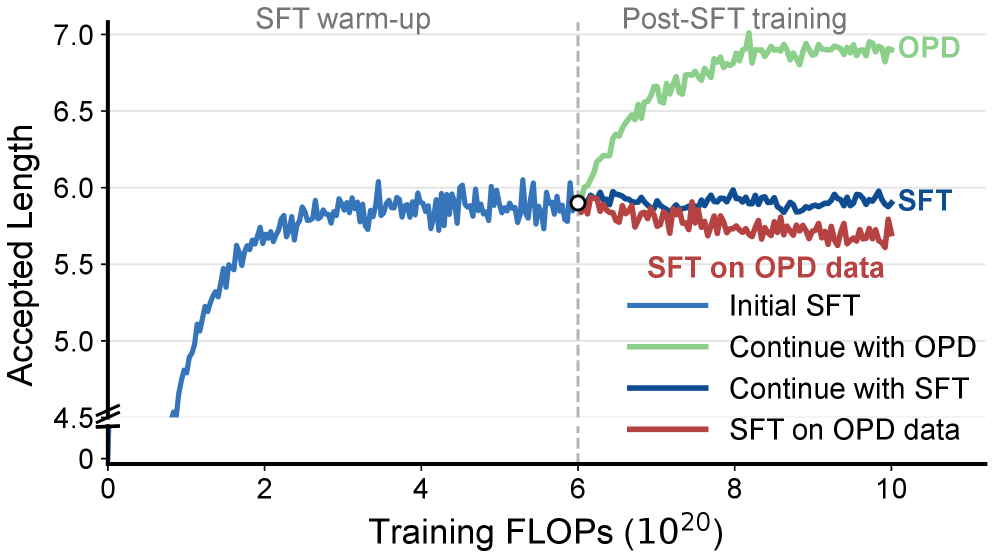
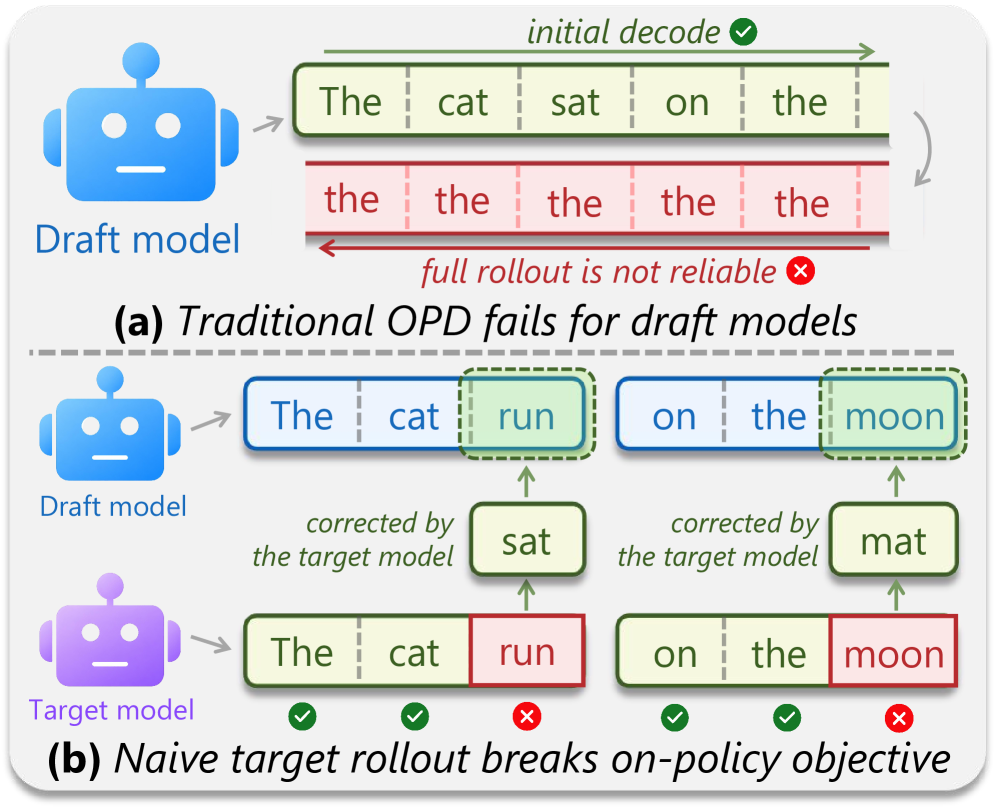
The cause is the standard offline-to-inference mismatch: SFT supervises q_\phi on prefixes drawn from p_\theta, but at decoding time q_\phi is conditioned on its own block proposals. The natural fix is on-policy distillation (OPD), where p_\theta supervises q_\phi on draft-induced states. The catch is that draft modules — which share the target’s embedding and LM head and are trained to predict short spans — are not standalone generators. Letting them roll out long sequences yields degenerate, repetitive samples; using target-assisted rollouts collapses the trajectory back to the target distribution and discards exactly the rejected-token positions where the drafter is wrong.
Method
Draft-OPD resolves this by decoupling rollout from the on-policy supervision target. Trajectories are collected with normal speculative decoding, so the prefix sequence is target-quality. During collection, the start index of every drafted block is recorded as an anchor. Training then replays drafting from each anchor: starting from the anchor state, the drafter re-proposes a block, and the target computes its distribution at the same positions. Critically, replay covers both accepted and rejected positions of the original draft, so the rejected proposals — the most informative error signal — are retained for the loss, while the surrounding context still follows p_\theta.
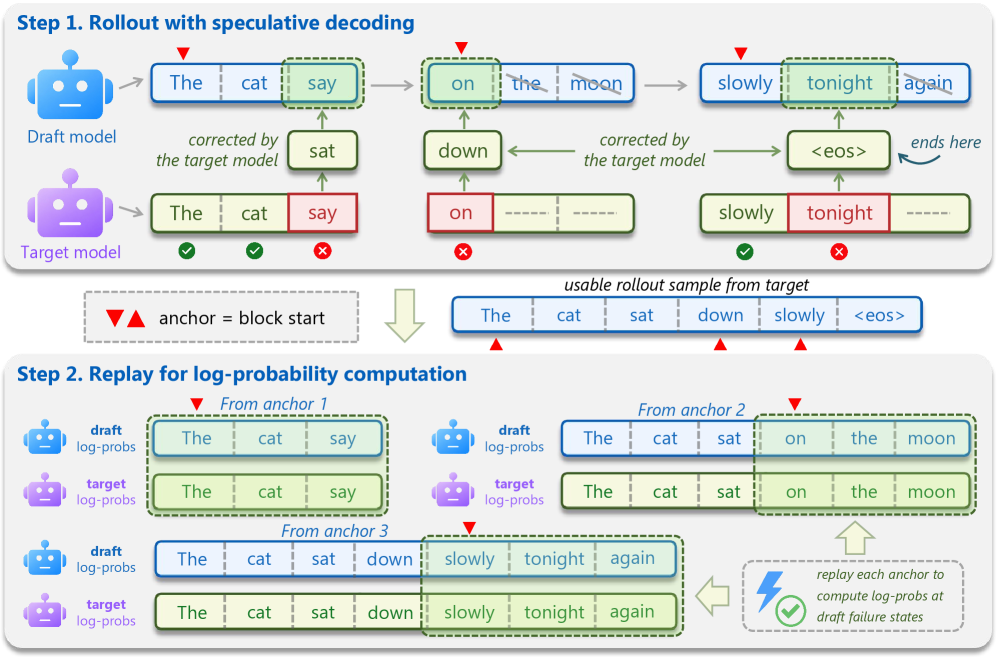
Concretely, for each anchor a the drafter unrolls \hat{y}_{a:a+K-1}\sim q_\phi, and the loss is a token-level distillation against the target distribution at matching positions:
\mathcal{L}_{\text{Draft-OPD}} = \mathbb{E}_{a}\sum_{k=0}^{K-1} \mathrm{KL}\!\big(p_\theta(\cdot\mid x_{<a},\hat{y}_{a:a+k-1})\,\|\,q_\phi(\cdot\mid x_{<a},\hat{y}_{a:a+k-1})\big).
Because the prefix x_{<a} comes from speculative decoding (target-quality) but the inner block \hat{y}_{a:a+k-1} is drawn from q_\phi, the conditioning state matches deployment, and the teacher signal at rejected positions is preserved rather than masked out.
Results
Experiments on Qwen3-4B and Qwen3-8B compare Draft-OPD against EAGLE-3 and DFlash across math (GSM8K, MATH-500, AIME25), code (MBPP, HumanEval, SWE-Lite), and chat (MT-Bench), at temperatures 0 and 0.6, with thinking mode on and off.
Selected mean speedups (Table 1):
- Qwen3-4B, thinking on, T=0: EAGLE-3 4.41\times, DFlash 4.51\times, Draft-OPD 5.31\times (mean \tau 5.96 vs 5.51 for DFlash).
- Qwen3-8B, thinking on, T=0: 4.58\times \to 4.67\times \to 5.36\times.
- Qwen3-4B, thinking off, T=0: 4.58\times \to 5.36\times \to 6.22\times, with \tau=6.60.
- Qwen3-8B, thinking off, T=0: 4.99\times \to 5.69\times \to 6.49\times, \tau=6.57.
The improvement is consistent across temperature and reasoning mode: Draft-OPD gains roughly 0.7–0.9\times in mean speedup over DFlash and a full point of accepted length on several settings. Per-task highlights at thinking-off, T=0, Qwen3-8B: GSM8K 7.64\times (DFlash 6.81\times), MATH-500 6.99\times (6.40\times), HumanEval 6.02\times (5.64\times). Gains on harder tasks where drafters typically struggle (AIME25, SWE-Lite) are smaller in absolute speedup but consistent in direction. Figure 1 also shows that simply replacing SFT data with OPD-collected data without the replay mechanism (the “OPD-as-SFT” baseline) actively degrades accepted length, supporting the claim that the rejected-token replay is doing real work.
Limitations
The replay step requires keeping anchors and re-running the drafter at training time, increasing training cost relative to plain SFT (the paper does not break down the overhead). The teacher distribution at each anchor must be recomputed or cached; if cached, this couples training to a fixed target snapshot. Results are confined to the Qwen3 family up to 30B; whether the gap over DFlash widens or narrows for heavily RLHF’d or much larger targets is unclear. The method also inherits the standard speculative-decoding assumption that the target’s verification rule is preserved, so it does not apply to lossy draft-only schemes. Finally, the analysis is empirical — there is no formal characterization of when the rejected-token signal at anchors provides a strictly better gradient than target-only supervision.
Why this matters
Speculative decoding gains have been bottlenecked less by architecture than by the train/inference distribution mismatch in drafter training. Draft-OPD shows that the right OPD recipe for non-autoregressive draft modules is anchor-based replay, not full rollout, and it converts that insight into ~15–20% additional end-to-end speedup over strong baselines without changing the verifier or the target.
Source: https://arxiv.org/abs/2605.29343
VideoMLA: Low-Rank Latent KV Cache for Minute-Scale Autoregressive Video Diffusion
Problem
Causal video diffusion models running long autoregressive rollouts have converged on fixed-size sliding-window KV caches. Recent work has tweaked which tokens occupy the window or how positions are encoded (CausVid, Self-Forcing, Rolling-Forcing, Infinity-RoPE), but the per-head KV layout has remained dense. That layout is the dominant contributor to streaming memory and per-step latency: for Wan2.1-T2V-1.3B, each cached token costs 2 n_h d_h = 3072 scalars per layer. At minute-scale rollouts with thousands of latent tokens times 30 layers, this is the binding constraint on batch size and context length on a single GPU.
This paper ports Multi-Head Latent Attention (MLA), known from DeepSeek-V2/V3 LLMs, to video diffusion, and — more interestingly — explains why it works despite the spectral premise that motivated MLA in language models being false here.
Method
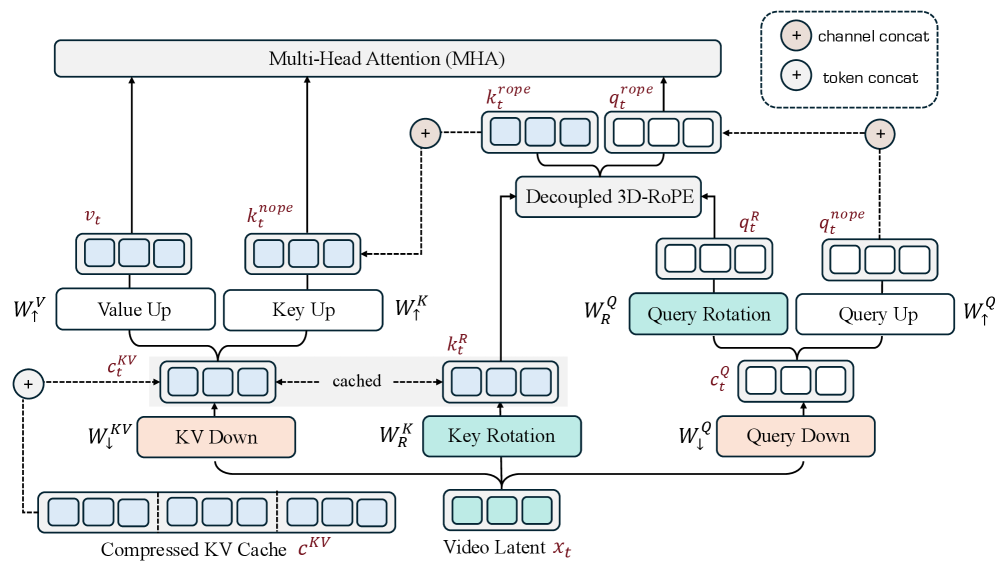
VideoMLA keeps the Wan2.1 backbone (30 blocks, d=1536, n_h=12, d_h=128) and replaces only self-attention. The per-head key dimension is split into a content (NoPE) part and a rotary part, d_h = d_h^{\mathrm{nope}} + d_h^{\mathrm{rope}} = 96 + 32.
Each token x_t \in \mathbb{R}^{1536} writes only two objects into the cache:
c_t^{KV} = W_\downarrow^{KV} x_t \in \mathbb{R}^{d_c}, \qquad k_t^R \in \mathbb{R}^{d_h^{\mathrm{rope}}}
with d_c=192. The decoupled positional key k_t^R is shared across heads and uses 3D-RoPE allocated (6,5,5) complex pairs over (time, height, width) on the highest-frequency bands. Per-head keys/values are reconstructed on the fly:
k_{t,h}^{\mathrm{nope}} = W_{\uparrow,h}^{K} c_t^{KV}, \qquad v_{t,h} = W_{\uparrow,h}^{V} c_t^{KV}.
The query path mirrors this: c_t^Q = W_\downarrow^Q x_t \in \mathbb{R}^{d_q} with d_q=768, then q_{t,h}^{\mathrm{nope}} = W_{\uparrow,h}^Q c_t^Q. Attention scores combine the NoPE inner product with the shared RoPE inner product — standard MLA decoupling.
Per-token cache footprint drops from 3072 to d_c + d_h^{\mathrm{rope}} = 224 scalars per layer — a 13.7\times reduction, or 92.7% per-token-per-layer savings. Training follows the three-stage Causal Forcing pipeline (Teacher Forcing, Consistency Distillation initialization to four steps, DMD), batch size 128, lr 5\times 10^{-6} for TF and 2\times 10^{-6} for CD/DMD, bf16 on 8\times B200.
Why MLA works here: rank budget, not spectrum
The most novel contribution is diagnostic. In LLM literature, MLA is justified by the claim that pretrained [W_K;W_V] is approximately low-rank, so projecting through a d_c-bottleneck loses little energy. The authors test this on Wan2.1-T2V-1.3B and find the opposite.
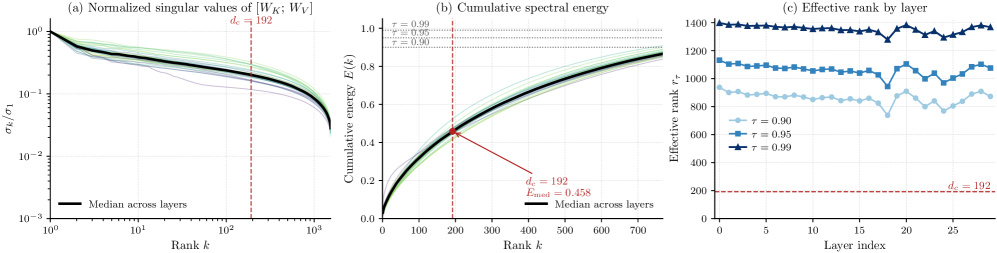
A naive rank-192 spectral approximation would discard the majority of the dense KV energy, yet VideoMLA preserves generation quality at this cache size. The resolution: MLA does not approximate the pretrained operator. It replaces it with a new composed operator
M = \begin{bmatrix} W_\uparrow^K W_\downarrow^{KV} \\ W_\uparrow^V W_\downarrow^{KV} \end{bmatrix}
constrained by construction to rank at most d_c. The learned operator uses essentially the full architectural budget.
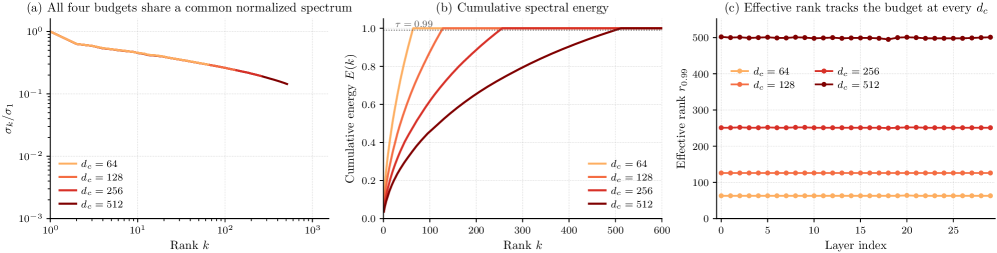
This is confirmed to not be an SVD-initialization artifact: random init reaches the same near-saturated rank from the start of training, and training neither discovers a lower-rank solution nor collapses the spectrum. The takeaway — useful beyond this paper — is that MLA’s success is about the optimization geometry imposed by the bottleneck, not a property of the pretrained weights. This decouples the applicability of MLA from low-rank diagnostics on the source model.
Quantitative results
- Per-token cache: 224 vs 3072 scalars/layer (13.7\times, 92.7%).
- Serving headroom: under a fixed B200 memory budget, d_c=192 gives 8.0\times the non-OOM batch size of dense MHA.
- Rank usage: layer-wise 99%-energy rank \approx 0.98 d_c across d_c \in \{64,128,256,512\}.
- Pretrained [W_K;W_V]: 45.8% median spectral energy at d_c=192; effective rank > 1300 per layer.
- Qualitative: 30s rollouts maintain subject identity and scene structure; head-to-head against CausVid, Self-Forcing, Rolling-Forcing, Causal Forcing, Reward/Deep Forcing, LongLive, Infinity-RoPE, LongSANA.
The Experiments section as excerpted does not include the FVD/VBench numerical comparison table, so the magnitude of quality preservation versus baselines is not quantified here.
Limitations and open questions
- The provided text omits standard video-quality metrics (FVD, VBench, CLIP scores) for the baseline sweep; the qualitative-only comparison is the weakest part.
- Only Wan2.1-1.3B is tested. Whether the bottleneck-determines-rank claim transfers to larger DiTs or non-causal teachers is open.
- The d_h^{\mathrm{rope}}=32 allocation (6,5,5) is hand-picked; sensitivity to RoPE channel budget across spatial vs temporal axes is not reported in the excerpt.
- The training pipeline depends on Causal Forcing distillation; whether MLA can be retrofitted post-hoc without DMD-stage retraining is unclear.
Why this matters
VideoMLA delivers a clean 13.7\times KV-cache reduction for minute-scale autoregressive video diffusion and, more importantly, falsifies the spectral-low-rank story for MLA: the bottleneck creates the effective rank rather than exposing it. That reframing predicts MLA should generalize to architectures where pretrained attention is full-rank — most vision transformers — and shifts the design question from “is my model low-rank?” to “how much rank budget can I afford?”
Source: https://arxiv.org/abs/2605.30351
NITP: Next Implicit Token Prediction for LLM Pre-training
Problem
Standard next-token prediction (NTP) supervises an LLM only through the cross-entropy on the output logits. The argument here is that this signal is geometrically sparse: the gradient through
\mathcal{L}_{\mathrm{NTP}} = -\mathbb{E}_x\Big[\log \frac{\exp(h_t^\top w_{x_{t+1}})}{\sum_{j\in\mathcal V}\exp(h_t^\top w_j)}\Big]
is dominated by the target embedding w_{x_{t+1}} and a small set of high-probability contenders, so the constraint on the hidden state h_t \in \mathbb{R}^d is effectively along a single direction. Components of h_t orthogonal to this subspace are essentially unsupervised, which the authors argue produces anisotropic, degenerate hidden geometry and limits generalization. The fix is to add a dense, vector-valued target for h_t rather than just a discrete label.
Method
NITP adds an auxiliary loss that asks the final hidden state at position t to predict not the next token’s id but its implicit representation: a shallow-layer hidden state of token t+1 taken from the same forward pass, with stop-gradient.
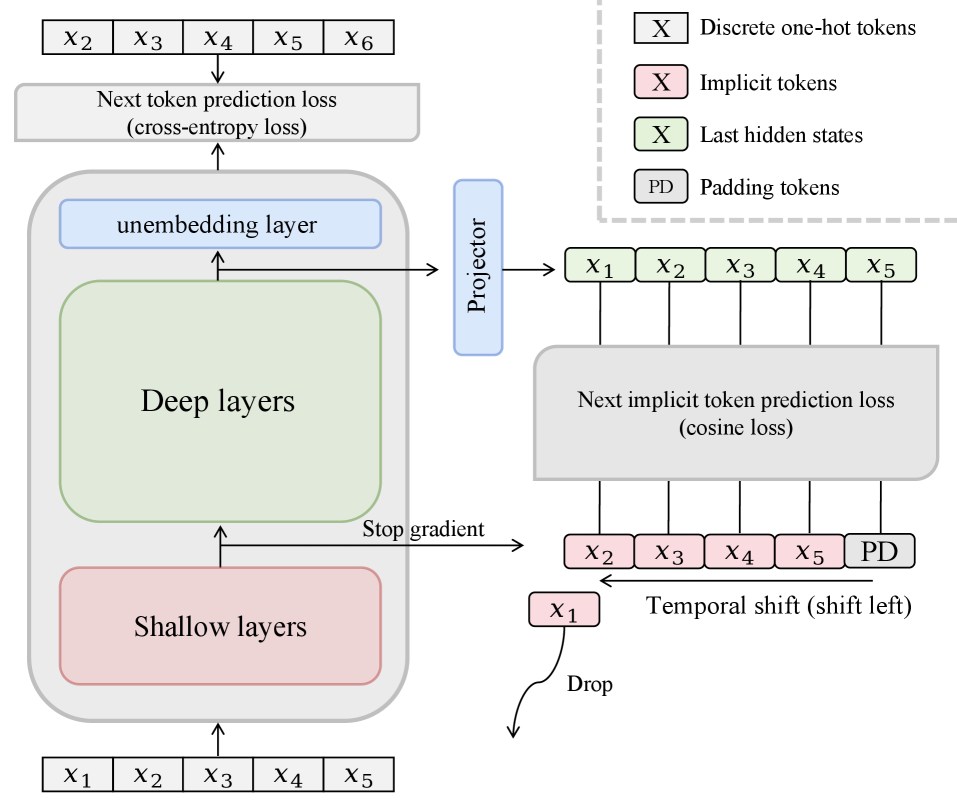
Concretely, let h_t^{(L)} be the last-layer hidden state and h_{t+1}^{(\ell)} a shallow-layer (small \ell) hidden state acting as a “semantic anchor”. A linear projector P maps h_t^{(L)} into the target space, and the auxiliary loss is a cosine objective:
\mathcal{L}_{\mathrm{NITP}} = 1 - \cos\!\big(P\, h_t^{(L)},\ \mathrm{sg}[h_{t+1}^{(\ell)}]\big),
with the total objective \mathcal{L} = \mathcal{L}_{\mathrm{NTP}} + \lambda\, \mathcal{L}_{\mathrm{NITP}}. Two design points matter:
- Stop-gradient on the target. Without it, both branches collapse jointly (BYOL-style collapse risk), and you also pollute the shallow layers with a representation-prediction signal they shouldn’t carry.
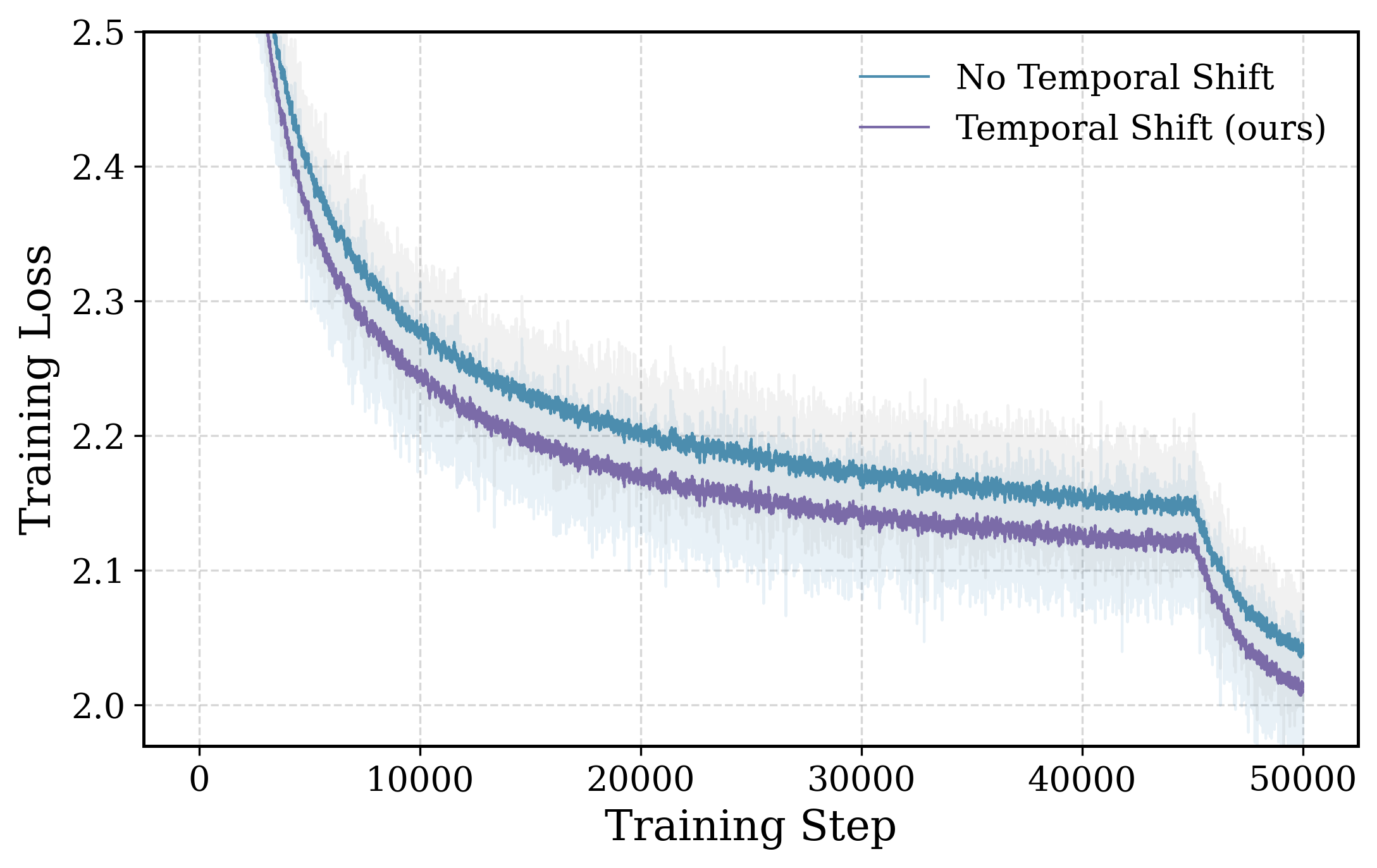
- Temporal shift (t+1, not t). Predicting the shallow representation of the same token t degenerates into an identity-like map across depth. Predicting the next token’s shallow representation forces the model to encode predictive semantic content rather than reconstruct its own input. The training-loss curves show that the shifted variant trains to a meaningfully different, lower regime.
The targets are produced for free during the forward pass, so per-step compute overhead is essentially the cost of one linear projection plus a cosine loss — negligible relative to the transformer stack.
The theoretical claim (sketched in the paper) is that the cosine term constrains the previously unconstrained directions of h_t by tying them to a stable, low-variance target. This regularizes the optimization landscape and pushes the representation distribution toward a more isotropic, compact geometry, mitigating the anisotropy that NTP-only training is known to produce.
Results
Experiments cover dense models from 0.5B to 3B and a 9B DeepSeek-V2-style MoE (144 experts, top-8 routing, ~1B activated), trained from scratch on 330B tokens at 8192 context. On the 9B MoE, NITP yields:
- MMLU-Pro: +5.7% absolute
- C3: +6.4% absolute
- CommonsenseQA: +4.3% absolute
Improvements are reported across the broader benchmark suite — MMLU, C-Eval, Xiezhi, LAMBADA, ARC-C, Balanced COPA, BBH, AGIEval, GSM8k, and LCBench — and across the dense scales, suggesting the gains are not a single-benchmark artifact and scale with model size.
The loss-weight ablation indicates a clear interior optimum for \lambda:
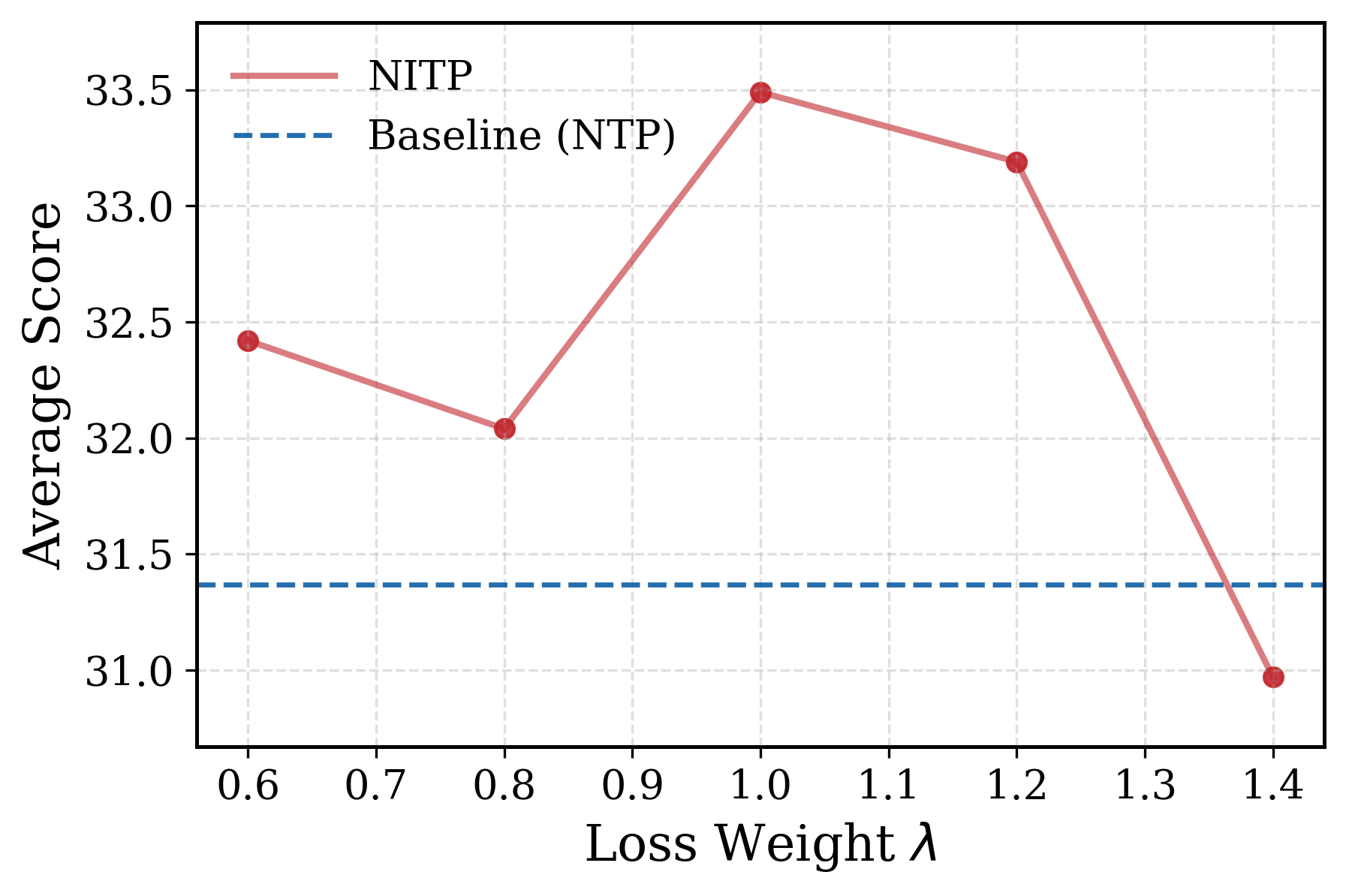
Too small and the auxiliary signal is irrelevant; too large and it competes with NTP. The shallow-layer choice for the target is also ablated — too shallow approaches token embeddings (low semantic content), too deep approaches the predictive layer itself (target leakage / collapse pressure).
Limitations and open questions
- The targets are the same model’s shallow features. This is convenient but couples target quality to the model’s own under-trained early layers, especially early in pre-training. The paper does not deeply analyze whether an EMA teacher or fixed teacher would do better.
- Only a cosine loss is reported; L2 in a normalized space, or a JEPA-style predictor with a richer head, are obvious alternatives that aren’t ablated.
- The theoretical argument about anisotropy reduction is supported but not directly tied to a measured representation-geometry metric (e.g., explicit isotropy or effective rank numbers in the main text).
- Evaluation is few-shot benchmark accuracy at pre-training scale; downstream behavior after instruction tuning / RLHF, and effect on calibration and long-context, are not characterized.
- The optimal shallow-layer index and \lambda may need re-tuning per architecture and scale; no scaling law is given.
Why this matters
If a near-zero-cost auxiliary objective on hidden states reliably adds several absolute points on hard benchmarks like MMLU-Pro at the 9B-MoE scale, it is one of the cheaper pre-training interventions on offer, and it reframes “self-distillation” as a representation regularizer rather than a teacher-student trick. It also gives a concrete, testable mechanism — under-constrained directions in h_t — for why NTP-only pre-training leaves performance on the table.
Source: https://arxiv.org/abs/2605.24956
LVSA: Training-Free Sparse Attention for Long Video Diffusion
Problem
Video diffusion transformers (DiTs) like Wan 2.1 and HunyuanVideo 1.5 spend the bulk of inference compute in spatio-temporal self-attention. With N = T \cdot P tokens for T latent frames and P = H_p W_p spatial patches per frame, dense attention costs O(N^2 d) = O(T^2 P^2 d). Two pathologies emerge when extending generation past the training horizon: (i) latency becomes prohibitive (a 6\times horizon on Wan 2.1 1.3B at 720p incurs ~500s/iter on NPU; HunyuanVideo 1.5 at 2\times horizon goes OOM on an 80GB GPU), and (ii) quality collapses to a “frozen” near-static loop because positional embeddings extrapolate poorly. Existing remedies either retrain (expensive, model-specific) or use fixed-grid sparsity that introduces periodic temporal artifacts.
Method
LVSA replaces the dense attention sum with a token-level restriction over a small per-frame attention set \mathcal{A}(t):
\text{Attn}(q_{t,i}) = \sum_{\tau \in \mathcal{A}(t)} \sum_{p=0}^{P-1} \frac{\exp(q_{t,i} \cdot k_{\tau,p}/\sqrt{d})}{\sum_{\tau' \in \mathcal{A}(t)} \sum_{p'=0}^{P-1} \exp(q_{t,i} \cdot k_{\tau',p'}/\sqrt{d})} v_{\tau,p}.
Per-query cost drops from O(TPd) to O(|\mathcal{A}(t)| P d). The construction has two components:
- Local window \mathcal{W}(t) = \{t' : \max(0, t-W) \le t' \le \min(T-1, t+W)\} for short-range temporal coherence.
- Periodic global anchors G = \{t : t \bmod T_{\text{per}} = 0\} that every frame attends to, providing long-range conditioning.
The naive choice — fixing G across denoising steps — induces a fixed-grid bias where the anchor frames receive disproportionate gradient mass, producing repetitive temporal artifacts. LVSA breaks this with rotating global anchors: at denoising step s, the anchor set G^s is shifted by one position modulo T. Over any T_{\text{per}} consecutive steps each frame serves as a global anchor exactly once, eliminating preferred temporal positions while preserving the 1/T_{\text{per}} density.
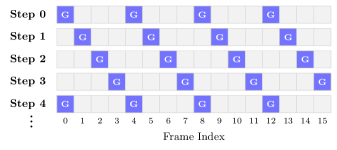
The pattern is block-sparse and known statically per step, so it maps cleanly onto block-sparse FlashAttention variants. The authors implement an LVSA-FI variant atop a FlashInfer kernel and additionally port the scheme to NPUs through vLLM-Omni. The method is training-free and architecture-agnostic: it works on Wan 2.1 1.3B/14B (single-stream, 1D RoPE) and HunyuanVideo 1.5 (dual-stream, 3D RoPE) without modification.
Results
On GPU, LVSA-FI yields up to 3.17\times speedup on Wan 2.1 1.3B at 6\times horizon, 2.98\times on Wan 2.1 14B at 6\times horizon, and 3.33\times on HunyuanVideo 1.5 at 1.5\times horizon, all relative to dense attention. Compared to other long-horizon methods on Wan 2.1 1.3B, LVSA is up to 2.41\times faster than RIFLEx and 3.27\times faster than UltraViCo. Speedups grow monotonically with horizon length.
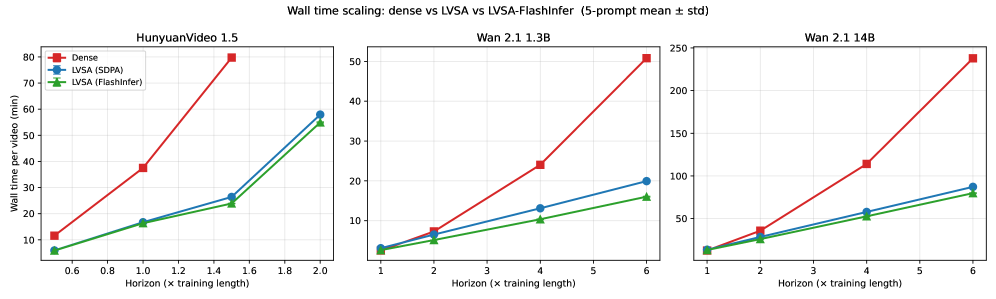
A qualitative consequence of memory reduction: HunyuanVideo 1.5 at 2\times horizon (257 frames) becomes feasible on a single 80GB GPU under LVSA-FI, whereas dense attention OOMs.

NPU results (vLLM-Omni) corroborate the GPU trend. For Wan 2.1 1.3B at 6\times horizon (481 frames): 2.17\times at 480×832 (47.76s vs 103.87s) and 3.24\times at 720×1280 (154.27s vs 499.47s). Wan 2.2 A14B with Ulysses sequence parallelism on 8 NPUs at 6\times, 720×1280 reaches 2.71\times (108.90s vs 294.93s). At short horizons (2\times), LVSA can be slower than dense (0.93\times on Wan 2.1 1.3B at 480×832, 0.78\times on Wan 2.2 A14B), because the window plus anchor set covers a non-trivial fraction of T and kernel overhead dominates. The crossover is around 4\times horizon.
Limitations and open questions
The paper does not specify how W and T_{\text{per}} are chosen across models, nor how sensitive quality is to these hyperparameters; the rotation schedule is uniform but other permutation schedules (e.g., low-discrepancy sequences) might further reduce artifacts. Reported quality is via VQeval composite scores; human evaluation is absent. The block-sparse pattern aligns naturally with FlashInfer but may be suboptimal on hardware with different tile sizes, as evidenced by the worse-than-dense behavior at small horizons. Finally, the method only sparsifies the temporal dimension; spatial token sparsity remains untouched, leaving a clear axis for further compression. The arXiv identifier (2605.31057) appears anomalous and worth verifying.
Why this matters
LVSA shows that the standard “global + window” sparse attention recipe, when combined with anchor rotation across denoising steps, is enough to break the long-horizon quality collapse in pretrained video DiTs without retraining. That makes long-video inference a kernel engineering problem rather than a model retraining one, and the gains compound with horizon — exactly the regime where dense attention is unaffordable.
Source: https://arxiv.org/abs/2605.31057
ESPO: Early-Stopping Proximal Policy Optimization
Problem
In RL fine-tuning of LLM reasoners, a trajectory that commits an early logical error is still rolled out to the maximum horizon. Those post-failure tokens (i) consume a large fraction of the compute budget without ever earning positive reward, and (ii) inject noise into advantage estimates: GAE smears the eventual negative outcome backward across thousands of tokens, including the prefix that was actually correct. The standard PPO + outcome-reward setup therefore wastes rollout FLOPs and produces noisy credit assignment exactly where credit assignment is hardest — long chain-of-thought trajectories with sparse terminal rewards.
ESPO leaves the PPO objective untouched and instead modifies trajectory collection: detect failure online during sampling, terminate, and treat the truncation point as an absorbing failure state with a terminal penalty. Conceptually this is PPO on an augmented MDP whose termination rule is induced by the policy/critic themselves, with no extra reward model or human labels.
Method
At each decoding step t, ESPO uses two signals already available from the rollout:
- A token-level surrogate regret derived from the sampling logits. Concretely, the deviation between the sampled token’s log-probability and the policy’s best alternative is accumulated into a cumulative regret z_t (with smoothing) — no extra forward pass is needed because logits are computed during generation anyway.
- A value-gated threshold from the critic, \beta \cdot \max(V_\phi(s_t), \varepsilon), which adapts the trigger to how much expected return is still on the table.
A trajectory is truncated at the first t where the smoothed cumulative regret exceeds the value-dependent threshold. The truncated transition is treated as absorbing with a terminal failure reward; PPO and GAE then run on the truncated trajectory normally, so the negative TD error is concentrated near the detected failure step rather than spread across thousands of post-failure tokens.
A critic warmup schedule disables truncation early in training, when V_\phi is too noisy to define a meaningful threshold. Without warmup, \beta \cdot \max(V_\phi(s_t), \varepsilon) inherits the high variance of a randomly initialized critic and triggers spurious truncations on valid exploratory branches.
Results
On DeepSeek-R1-Distill-Qwen-7B trained on DAPO-Math-17k:
- AIME 2024: 46.28% vs. PPO 45.25%
- AMC 2023: 85.83% vs. PPO 82.94%
- MATH-500: 87.42% vs. PPO 85.43%
20% reduction in cumulative rollout tokens.
The ablations on AIME24 (avg@32) isolate the design choices:
| Variant | AIME24 | Cum. Tokens (M) | Avg Tokens |
|---|---|---|---|
| (A) Full ESPO | 46.3 | 839.24 | 3278.30 |
| (B) w/o warmup | 44.2 | 858.37 | 3353.03 |
| (C) w/o terminal penalty | 43.7 | 901.65 | 3522.09 |
| (D) Value-only stop | 44.0 | 1090.05 | 4258.02 |
| (E) Regret-only stop | 44.8 | 1086.51 | 4244.18 |
| (F) Random stop | 42.4 | 855.59 | 3342.14 |
Two findings stand out. First, both the regret signal and the value gate are necessary: dropping either (D, E) loses ~1.5–2.3 points and roughly negates the token savings, with average trajectory length climbing back above 4200. Second, removing the terminal failure penalty (C) is worse than removing the warmup (B) — without the explicit absorbing penalty, GAE has nothing to anchor the truncation as a failure, and the model both performs worse (43.7) and rolls longer (3522 avg tokens). Random stopping (F) is the weakest, confirming that the savings are not just a length-regularization artifact.
The training dynamics reinforce this picture. ESPO/Original (the length the model would have produced absent truncation) tracks PPO/Original closely, while ESPO/Actual (post-truncation length) is substantially lower — i.e., truncation removes wasted suffix without distorting the policy’s natural length distribution. ESPO also maintains higher actor entropy throughout training, mitigating the premature entropy collapse common in PPO-on-LLM setups; this is consistent with the claim that pruning post-failure noise reduces overconfident gradient signals on bad prefixes. The false-positive rate (correct trajectories that get truncated anyway) is reported as decreasing over training as the critic sharpens.
Limitations and open questions
- All evaluation is on math reasoning with verifiable outcome rewards; whether the surrogate regret remains discriminative for tasks with denser or noisier rewards (code, agentic tool use, open-ended writing) is untested.
- The value-gated threshold depends on a well-calibrated critic; the warmup ablation (B vs. A: 2.1 points) shows the method is genuinely sensitive to this. Models trained without a value head (GRPO-style) would need a different gating mechanism.
- The terminal failure penalty is a fixed scalar; its interaction with reward shaping and KL regularization is not characterized.
- Reported gains on AIME24 (about 1 point) are within the noise band typical of small math benchmarks; AMC23 (+2.9) and MATH500 (+2.0) are more convincing.
- No comparison against length-penalty baselines or against truncating purely on critic value, beyond the internal ablation.
Why this matters
ESPO is a clean instance of “fix the data collection, not the loss”: by exploiting that wrong reasoning chains are detectable from the policy’s own logits and critic, it recovers >20% of rollout FLOPs while improving accuracy and entropy retention. For long-CoT RL where rollout cost dominates the training budget, online trajectory truncation with an absorbing failure state is a low-risk drop-in that should generalize to other PPO-on-LLM pipelines.
Source: https://arxiv.org/abs/2605.29860
Crafter: A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs
Problem
Scientific figure generation has been treated as a backbone problem: stronger image generators are expected to yield better figures. The authors argue this is misframed. Scientific figures are structured compositions of discrete semantic components (axes, labeled boxes, arrows, panels), and image generators fail in localized, identifiable ways — a mislabeled subplot, a missing arrow, a misaligned panel — that do not respond well to free-text prompt patching. Existing automation either targets one figure type from text-only input (PaperBanana, AutoFigure) or produces raster outputs that cannot be edited locally. The paper proposes that the missing layer is a harness around the generator, not a better generator.
The harness abstraction
The harness is a four-role loop over a shared evolving specification \mathcal{S} — a structured record holding the current plan, revision history, and prior diagnostics:
p_t = \mathcal{D}(\text{input}, \mathcal{S}_{t-1}), \quad a_t = \mathcal{E}(p_t), d_t = \mathcal{V}(a_t, \text{input}, \mathcal{S}_{t-1}), \quad \mathcal{S}_t = \mathcal{R}(d_t, \mathcal{S}_{t-1}).
The designer \mathcal{D} proposes plans, the executor \mathcal{E} renders them, the verifier \mathcal{V} emits a directive diagnostic (per-dimension scores, identified defects, suggested corrections — not a scalar reward), and the reviser \mathcal{R} applies typed edits to \mathcal{S}_{t-1}: add a layout constraint, ban an artifact category, resize a named element. The crucial design choice is that \mathcal{R} writes structured operations into a shared specification rather than appending free text to the prompt; this avoids the prompt degradation that the authors identify as a failure mode of free-text correction loops. The loop terminates on acceptance or budget T, returning a^* = \arg\max_\tau \mathrm{score}(d_\tau).
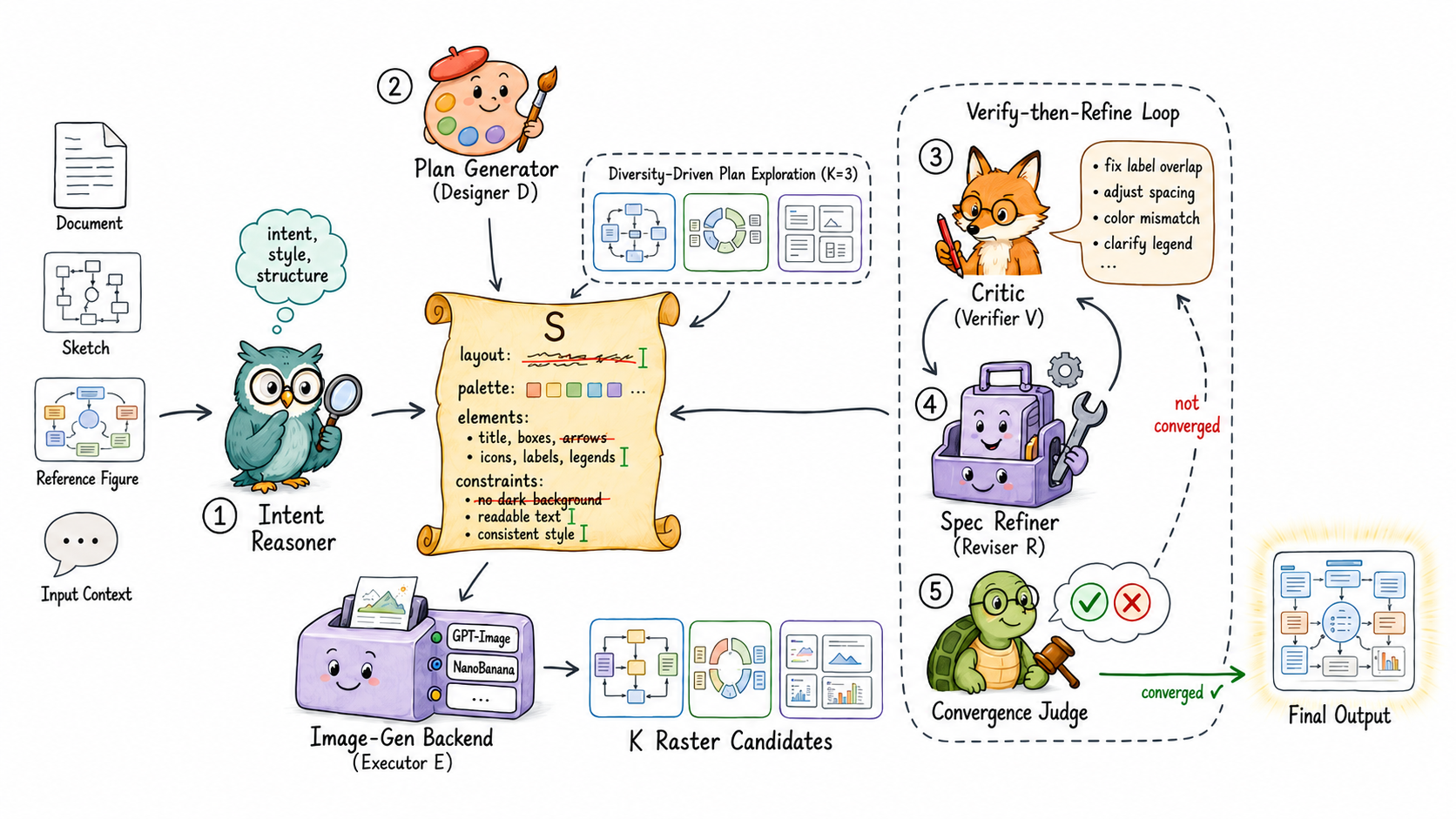
Crafter instantiates this with three mechanisms: (1) diversity-driven plan exploration, where \mathcal{D} proposes K candidate plans per round to mitigate high output variance on structured layouts; (2) a structured corrective layer (typed edits to \mathcal{S}); and (3) verify-then-refine iteration with a directive multi-dimensional critic. CraftEditor reuses the same loop for raster-to-vector conversion: \mathcal{D} becomes an SVG skeleton generator, \mathcal{E} executes element-injection code, and \mathcal{V} is a hybrid critic over the resulting SVG.
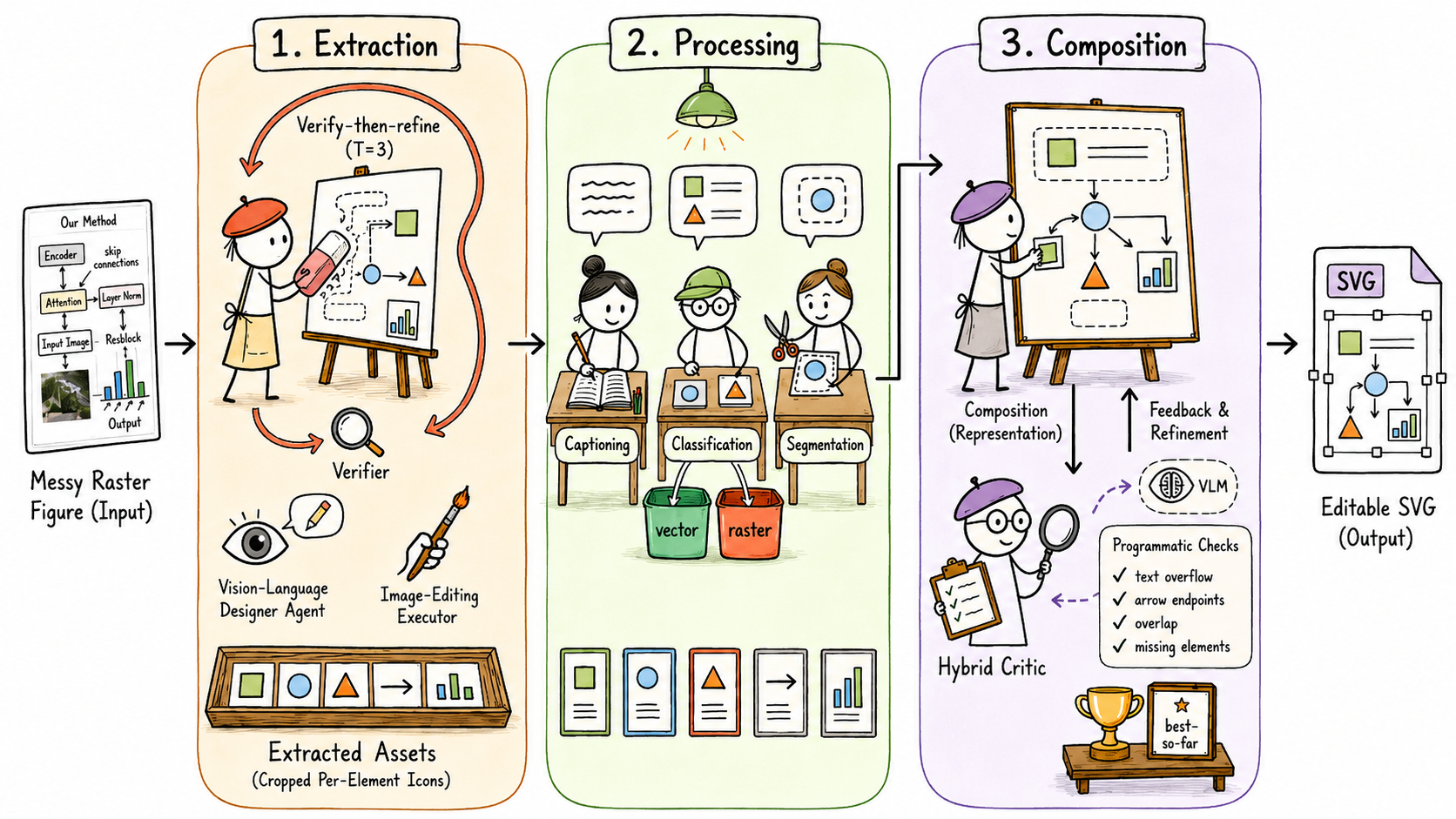
CraftEditor decomposes editability into Extraction (a VLM designer authors a keep/delete plan, an image editor executes it, and \mathcal{V} verifies the cleaned canvas), Processing (caption, ground, classify each element), and Composition (skeleton SVG plus injected elements).
CraftBench
CraftBench covers three figure types and four input conditions — text-to-image, mask-completion, key-element composition, and sketch-conditioned — for 279 curated samples drawn from arXiv preprints across 18 subject areas, conference posters, and research blogs. The pipeline filters 553 candidates via VLM content classification, complexity scoring, and claim-alignment verification; three graduate annotators must unanimously accept each reference-conditioned sample.
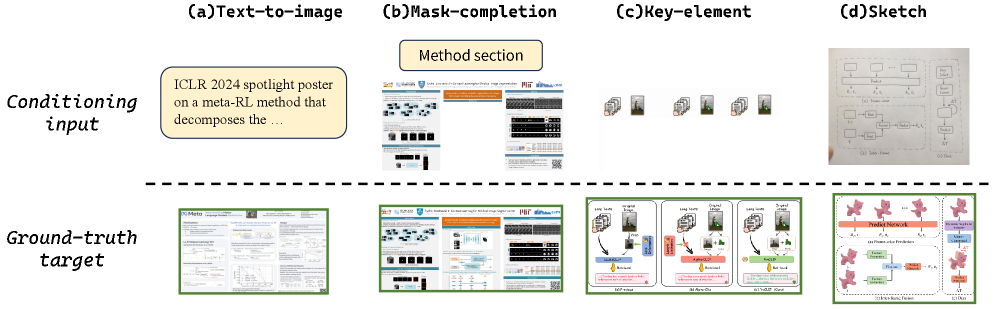
Results
All agentic methods share the same backbone (Nano Banana 2) and VLM judge (Gemini 3.1 Pro), so differences isolate orchestration. On PaperBanana-Bench, Crafter (Nano Banana 2) reaches 50.34 overall vs. 11.13 for the standalone backbone (+39.21) and 33.73 for PaperBanana on the same backbone (+16.61). With Nano Banana Pro, Crafter reaches 50.00 vs. 22.43 standalone (+27.57) and 35.96 for PaperBanana/Pro.
On the broader CraftBench, Crafter (Nano Banana 2) reaches 50.20 overall vs. 19.90 standalone (+30.30) and 28.00 for PaperBanana (+22.20). Crafter (Nano Banana Pro) reaches 52.30 vs. 22.40 standalone (+29.90). Per-task on CraftBench with the Pro backbone: T2I 52.50, Mask 41.70, Sketch 73.80, KeyElement 33.30. The generalization story is sharpest in the PaperBanana baseline: its lift over its backbone collapses from +22.60 on PaperBanana-Bench to +8.10 on CraftBench, and it falls below its backbone on the sketch task — exactly the single-condition overfitting the harness is designed to avoid. AutoFigure degrades against its backbone on both benchmarks (overall 1.37 / 2.20). Crafter is the only method that improves over its backbone uniformly across every dimension and every task on both benchmarks, and attains column-best in every column.
Limitations and open questions
The evaluation depends on a VLM-as-judge protocol with a lenient win-rate against human targets; absolute numbers are entangled with judge biases (Gemini 3.1 Pro judging outputs from a sister model). GPT-Image-2 produced valid outputs for only 260/279 CraftBench inputs due to instability and safety refusals, complicating its comparison. The harness multiplies inference cost by K candidate plans times T rounds, yet no compute-matched ablation against simply sampling KT outputs from the backbone is reported here. The typed-edit vocabulary used by \mathcal{R} — which constraints, bans, and resizes are expressible — is not formalized in the excerpt, and its coverage likely bounds achievable corrections. Finally, CraftEditor’s raster-to-SVG fidelity is not quantified in the reported tables.
Why this matters
The paper reframes scientific figure generation as an orchestration problem and provides direct evidence that a typed-edit, directive-critic harness generalizes across figure types and input conditions where prior agentic pipelines overfit. The result — uniform gains over both standalone and agentic baselines on every dimension and task — supports a more general claim that for structured-output generation, accumulating corrections in a typed specification beats accumulating them in a prompt.
Source: https://arxiv.org/abs/2605.30611
A Matter of TASTE: Improving Coverage and Difficulty of Agent Benchmarks
Problem
Tool-use benchmarks for LLM agents — notably \tau^2-Bench — are saturating. Frontier models now solve a large fraction of tasks, but the benchmarks themselves were constructed by writing natural-language scenarios first and then mapping them to tool calls. This construction order biases coverage: scenarios that humans naturally imagine collapse into a narrow band of tool-use patterns, leaving most syntactically valid combinations of an API surface untested. Adding new tasks the conventional way is also expensive — each scenario requires manual writing, oracle policies, simulated user goals, and verification harnesses.
The paper proposes TASTE (Task Synthesis from Tool Sequence Evolution), which inverts the pipeline: generate challenging tool sequences first, cluster them for coverage, instantiate scenarios around them, then evolve them for difficulty. The artifact is \tau^c-Bench, a harder extension of the three \tau^2-Bench domains (airline, retail, telecom).
Method
The core technical contribution is an Adaptive Contrastive n-gram (ACN) model used to sample valid tool sequences over a large discrete combinatorial space. Naively, the number of length-L sequences over a tool set \mathcal{T} scales as |\mathcal{T}|^L; only a tiny fraction correspond to coherent multi-step workflows in a given domain (e.g., one cannot cancel_reservation before lookup_user). TASTE trains the ACN to model the conditional
p(t_i \mid t_{i-n+1}, \dots, t_{i-1})
using validity labels supplied by an LLM judge that scores whether a candidate sequence corresponds to a plausible domain workflow. The “contrastive” component uses both valid and invalid sequences as positive/negative evidence, and “adaptive” refers to iteratively enlarging the training pool with newly sampled sequences re-judged by the LLM, so the model’s support expands beyond the initial seed distribution. This avoids the failure mode where a vanilla n-gram trained on \tau^2-Bench traces just reproduces the existing distribution.
After ACN sampling produces a large pool of valid candidates, TASTE applies clustering (over tool-sequence embeddings) and selects medoids/representatives from each cluster. This is the coverage-control knob: instead of oversampling common patterns, every cluster contributes one seed.
Each seed sequence is then instantiated into a full benchmark task: an LLM materializes (i) a user persona and goal consistent with the tool sequence, (ii) the database state required for the sequence to be the oracle solution, and (iii) the evaluation rubric (final-state checks plus action checks). Finally, iterative difficulty evolution mutates tasks — adding distractor goals, ambiguous user utterances, or longer dependencies — and retains mutations only if a reference agent’s success rate drops while the task remains solvable by an oracle. This is the same difficulty-evolution idea used in Evol-Instruct, but driven by agent-pass-rate signals rather than instruction-complexity heuristics.
Results
The headline finding is that models which nearly saturate \tau^2-Bench drop sharply on \tau^c-Bench. Across 11 agent/user LLM pairs and three domains, the authors report large absolute degradations on the new benchmark while keeping task validity high (oracle and human spot checks confirm solvability). Coverage analyses show \tau^c-Bench exercises substantially more distinct tool n-grams than \tau^2-Bench at matched task count, indicating the gain is from broader workflow coverage rather than just longer or noisier prompts.
The ablations matter for re-implementation: removing the contrastive signal collapses the ACN onto seed-distribution patterns; removing the adaptive retraining loop limits exploration of low-probability but valid combinations; removing clustering before instantiation produces redundant tasks dominated by frequent tool pairs. Difficulty evolution is responsible for the gap between “broader but easy” and “broader and hard” — without it, coverage improves but pass rates remain close to \tau^2-Bench levels.
Limitations and open questions
- LLM-judge dependence. Validity labels for ACN training come from an LLM; systematic blind spots in the judge propagate into the sequence distribution. The authors mitigate via cross-checks but this is a known failure mode for synthetic-data pipelines.
- n-gram horizon. Fixed-order n-gram conditioning cannot capture long-range dependencies (e.g., a tool used at step 2 constraining step 9). Tasks requiring such structure may be under-sampled. A neural autoregressive replacement is straightforward but unexplored here.
- Difficulty vs. realism trade-off. Evolution increases difficulty by adding distractors and ambiguity; some mutations risk drifting into adversarial-but-unrealistic territory. The paper does not quantify how often evolved tasks remain pragmatically realistic to a human annotator.
- Domain transfer. All three target domains share \tau^2-Bench infrastructure (database-backed APIs, simulated users). Whether TASTE transfers to domains with stochastic tools, partially observable state, or non-API actions (browsing, code execution) is open.
- Saturation timeline. Because tasks are produced cheaply, \tau^c-Bench can be regenerated as models improve; but this also means leaderboard comparisons are version-sensitive.
Why this matters
Agent benchmarks are bottlenecked by hand-authored scenarios, and the field needs a principled way to expand coverage and difficulty as capabilities advance. TASTE shows that inverting the construction pipeline — sample tool sequences first under a learned validity model, then synthesize scenarios around them — produces benchmarks that are simultaneously broader and harder, and the same machinery can be re-run to refresh saturation.
Source: https://arxiv.org/abs/2605.28556
Hacker News Signals
Nvidia Cosmos 3
Nvidia’s Cosmos 3 release extends their physical AI world model platform with two primary additions: a world model for generating physically plausible video continuations from state descriptions, and an action model that maps sensory inputs to robot or vehicle control signals. The architecture builds on their earlier Cosmos tokenizer and diffusion transformer backbone, now adding support for fine-grained physics conditioning — contact forces, rigid body dynamics, and camera egomotion — so generated rollouts remain consistent with Newtonian constraints over longer horizons.
The action model component is framed as a policy that operates over the latent space of the world model, trained with a combination of imitation learning on curated robot and autonomous vehicle datasets and RL fine-tuning using physics simulator feedback. Cosmos 3 also ships a new benchmark suite for evaluating physical reasoning: tasks include predicting object trajectories under novel force applications and inferring occluded geometry from partial observation sequences.
Practically, the release targets the sim-to-real gap problem. By generating diverse physically valid training scenarios, downstream robot policies can be trained without proportional real-world data collection. The model weights are available under a non-commercial research license via the Nvidia developer portal, with API access for inference.
Open questions: the physics consistency claims are largely qualitative; no systematic comparison against ground-truth simulator rollouts with quantified error bounds is provided. The action model’s generalization to manipulation tasks outside the training distribution (which skews toward locomotion and driving) remains unclear.
Fooling around with encrypted reasoning blobs
Matthew Green’s post dissects Anthropic’s “encrypted reasoning” feature, where Claude’s extended thinking tokens are transmitted as opaque ciphertext blobs that the user cannot read. The cryptographic engineering question is whether this provides any meaningful security property or is theater.
Green’s analysis identifies the core problem: Anthropic controls the keys. The encryption is not end-to-end in any useful sense — it prevents casual inspection of reasoning traces by users or third-party relay infrastructure, but Anthropic can decrypt at will. This is more accurately described as confidentiality-from-the-user than a security property. The scheme uses what appears to be symmetric encryption (AES-GCM based on blob structure analysis), with keys that never leave Anthropic’s infrastructure.
He then examines whether this could protect against prompt injection attacks that try to exfiltrate reasoning. The answer is mostly no: an adversarial tool output that says “repeat your reasoning” would cause the model to reproduce it in plaintext, not in the encrypted blob. The encryption only conceals the scratchpad from passive inspection, not from active adversarial elicitation.
The post also raises the question of verifiability: users are asked to trust that the encrypted blob actually corresponds to genuine reasoning that informed the output, rather than a post-hoc rationalization or an empty computation. Without a zero-knowledge proof or commitment scheme binding the reasoning trace to the output, the encrypted blob provides no integrity guarantee.
This connects to broader questions about AI transparency — encrypted reasoning is presented as a product feature (competitive moat for Anthropic’s reasoning process) dressed in security language.
Source: https://blog.cryptographyengineering.com/2026/05/29/fooling-around-with-encrypted-reasoning-blobs/
AI Agent Guidelines for CS336 at Stanford
Stanford’s CS336 (Language Models from Scratch) posted their CLAUDE.md — the system prompt / behavioral guidelines given to Claude when it acts as an AI assistant for students on assignment 1. The document is technically interesting as an engineering artifact: it specifies exactly what the agent is and is not permitted to do.
The constraints are strict. The agent is explicitly prohibited from writing code that solves assignment components, from revealing implementation details of reference solutions, and from debugging student code in ways that amount to writing the solution. It is permitted to explain concepts, point to relevant documentation, clarify assignment specifications, and help with non-assignment tooling (environment setup, debugging unrelated infrastructure issues).
The guidelines also include a meta-instruction: if a student’s request would require violating the above, the agent should say so explicitly rather than silently refusing or deflecting. This is a concrete attempt to make the refusal behavior legible.
From a systems perspective, this is an example of capability restriction via natural language policy rather than hard technical controls — there’s no sandbox preventing the model from outputting solution code, only behavioral instructions. The effectiveness depends entirely on the model following its instructions, which is a known-weak guarantee. The HN discussion focuses heavily on this tension: a sufficiently persistent student can likely extract prohibited help through jailbreaks or rephrasing, and there’s no enforcement mechanism beyond honor code.
The document is useful as a reference for anyone deploying LLM assistants in educational or similarly constrained professional contexts — it shows the policy design space clearly, even if the technical enforcement remains soft.
Source: https://github.com/stanford-cs336/assignment1-basics/blob/main/CLAUDE.md
Stealing from Biologists to Compile Haskell Faster
This post applies sequence alignment algorithms from bioinformatics to the problem of finding sharing opportunities in GHC’s Core intermediate representation during compilation.
The specific biological technique borrowed is approximate string matching via edit distance / dynamic programming, used in tools like BLAST and Smith-Waterman. The compiler problem being solved is identifying structurally similar subexpressions in Core that could be deduplicated or CSE’d (common subexpression eliminated) even when they are not syntactically identical — they may differ in variable names, argument order, or minor structural variations that don’t affect semantics.
The insight is that GHC Core expressions can be serialized into a token sequence, and approximate matching over those sequences (tolerating small edit distances) can find sharing opportunities that exact syntactic matching misses. The DP table used is essentially the same as Needleman-Wunsch with a custom scoring matrix reflecting the cost of semantic differences between Core constructors.
The author reports measurable compile-time reductions on some benchmarks by reducing redundant work in later compilation stages, though the numbers are highly workload-dependent and the technique adds its own overhead (the alignment itself is O(mn) in expression length). The sweet spot appears to be large generated code with repetitive structure — e.g., output from Template Haskell or record boilerplate.
Limitations: the approximate matching introduces the risk of identifying false sharing — expressions that look similar but have different types or semantics after substitution. The post acknowledges this requires a type-checking pass to validate candidate pairs before committing to sharing.
Streambed: Stream Postgres to Iceberg on S3, Supports Postgres Wire Protocol
Streambed is a Go service that reads Postgres logical replication (WAL) and writes the change stream into Apache Iceberg table format on S3-compatible object storage. The headline differentiator is that it speaks the Postgres wire protocol, meaning existing Postgres clients can query Streambed directly without modification.
The architecture has three components. A logical replication consumer connects to Postgres using the pgoutput plugin, decodes WAL records into row-level change events (INSERT/UPDATE/DELETE with before/after images), and buffers them in memory. A writer component batches these events and commits Parquet files to S3, updating the Iceberg metadata (manifest files, snapshot log) atomically. A query layer implements enough of the Postgres wire protocol (v3) to accept simple queries and translate them into Iceberg scan operations via an embedded query engine.
The Iceberg integration provides snapshot isolation and time-travel queries over the CDC stream — you can query the table as it existed at any prior snapshot, which the underlying WAL gives you for free since it’s an append-only structure.
Current limitations noted in the repo: no support for DDL changes (schema evolution requires manual intervention), the query layer only handles a subset of SQL (no joins, limited aggregates), and performance under high-throughput insert workloads hasn’t been benchmarked against alternatives like Debezium + Kafka + Flink. The Postgres wire protocol support is partial — prepared statements and COPY protocol are not implemented.
This fills a niche between full CDC pipelines (Debezium) and simpler pg-to-S3 dumps, particularly for teams that want Iceberg’s open table format without Kafka infrastructure.
Source: https://github.com/viggy28/streambed
Claude Opus 4.8
Anthropic released Claude Opus 4.8, positioned as a frontier reasoning model with improvements in agentic task completion, extended context handling, and reduced hallucination rates on factual queries. The model supports a 200K token context window and introduces “extended thinking” — a scratchpad computation mode where the model generates internal reasoning tokens before producing a final response, with those tokens optionally hidden from the user (see the encrypted reasoning post above).
Benchmarks reported by Anthropic show Opus 4.8 reaching 72.5% on SWE-bench Verified (software engineering tasks from real GitHub issues), which would place it at or near the top of public evals at release time. On GPQA (graduate-level science questions), the model achieves 74.9% with extended thinking enabled versus 68.2% without, quantifying the benefit of the scratchpad mode.
The model is notably positioned for agentic use cases: Anthropic emphasizes tool use, multi-step planning, and the ability to maintain coherent state across long task horizons. The system prompt handling has been revised to better respect complex, multi-part instructions without silently ignoring constraints.
The HN discussion is large (1300+ comments) and centers on the extended thinking feature, pricing (Opus 4.8 is substantially more expensive than Sonnet-tier models), and comparisons to GPT-4o and Gemini Ultra on coding tasks. Several practitioners report it outperforming prior models on real debugging tasks while others note inconsistent behavior on agentic workflows requiring precise tool call sequencing.
The encrypted reasoning controversy (see Green’s post) is directly relevant here: extended thinking tokens can be transmitted as opaque blobs, raising the transparency questions Green analyzed.
Source: https://www.anthropic.com/news/claude-opus-4-8
Dynamic Workflows in Claude Code
Anthropic’s Claude Code now supports dynamic workflows: branching, looping, and conditional task sequences that the model constructs and executes at runtime rather than following a static predefined plan. The feature allows Claude Code to re-evaluate its task list mid-execution based on intermediate results, spawn subagents for parallelizable subtasks, and retry failed steps with modified strategies.
Mechanically, the workflow representation is a DAG where nodes are tool calls or model inference steps and edges carry data dependencies. The model generates this DAG incrementally — it doesn’t plan the full graph upfront but extends it as each node completes and returns results. This is closer to ReAct-style execution than classical planning, but with explicit branching structure rather than a flat action sequence.
The parallel execution capability is the most technically interesting addition. When the model identifies independent subtasks (e.g., writing tests for two separate modules), it can dispatch them to concurrent subagent instances, collect results, and merge them. The orchestration layer handles context isolation between subagents and result aggregation.
Practical implications for CI/CD and autonomous coding: complex multi-file refactors that previously required sequential step-by-step instructions can now be expressed as a single high-level goal. The model handles decomposition and sequencing. The failure modes are the expected ones for agentic systems: cascading errors when an upstream subtask produces incorrect output that downstream tasks consume without validation, and difficulty recovering from states where partial execution has modified the repository in inconsistent ways.
The HN discussion focuses on reliability in practice — specifically whether the model’s self-generated workflow structure is robust enough for production use without human checkpoints.
Source: https://claude.com/blog/introducing-dynamic-workflows-in-claude-code
Tracing HTTP Requests with Go’s net/http/httptrace
This article is a practical walkthrough of Go’s net/http/httptrace package, which provides hooks into the HTTP client’s internal state machine for observability purposes — without modifying the transport or wrapping the client.
The package works by attaching a ClientTrace struct to a request’s context. The struct contains optional callback functions for each transition in the request lifecycle: DNS resolution start/done, connection establishment, TLS handshake, first byte sent, first byte received, and connection reuse versus new connection creation. The callbacks receive timing information and, in some cases, the actual resolved addresses or TLS state.
A canonical use case is diagnosing latency: by recording timestamps in GotConn, WroteRequest, and GotFirstResponseByte, you can decompose total request latency into DNS lookup, TCP dial, TLS negotiation, request serialization, server processing, and response transfer phases. This is the same decomposition that browser DevTools network panels show, now accessible programmatically in Go clients.
The article shows a concrete implementation:
trace := &httptrace.ClientTrace{
GotConn: func(info httptrace.GotConnInfo) {
log.Printf("conn reused: %v, idle: %v", info.Reused, info.WasIdle)
},
GotFirstResponseByte: func() {
log.Printf("TTFB: %v", time.Since(start))
},
}
req = req.WithContext(httptrace.WithClientTrace(req.Context(), trace))The key limitation is that httptrace instruments the client side only — server processing time is inferred as the gap between request write completion and first response byte, conflating network RTT and actual handler latency. For distributed tracing, this complements but does not replace OpenTelemetry instrumentation.
Noteworthy New Repositories
Kaelio/ktx
A context orchestration layer that sits between AI coding/analytics agents (Claude Code, Codex, etc.) and data sources, exposed via the Model Context Protocol (MCP). The core idea is that raw SQL or schema access is insufficient for agents to query data accurately at scale — ktx adds three components on top: a semantic layer (column aliases, metric definitions, business logic), a skills registry (parameterized query templates the agent can invoke by name), and a persistent memory store that accumulates query patterns and corrections across sessions. The semantic layer prevents agents from hallucinating column names or misaggregating metrics by providing a controlled vocabulary. Skills are versioned, so agents call named procedures rather than generating free-form SQL, reducing surface area for errors. Memory allows the agent to recall past user corrections and preferred query forms. Under the hood it is a Python service that registers MCP tool handlers; agents receive structured tool descriptions and return typed results. Useful for data teams embedding LLM agents into analytics pipelines where query correctness matters and free-form generation is too unreliable.
Source: https://github.com/Kaelio/ktx
Evokoa/pgGraph
Adds graph query capabilities directly on top of an existing PostgreSQL database without requiring a separate graph engine. The approach represents nodes and edges as ordinary Postgres tables and exposes a Cypher-like or property-graph query interface that compiles down to recursive CTEs and standard SQL joins. This means you get graph traversal — shortest paths, neighborhood queries, reachability — without migrating data out of Postgres or maintaining a dual-write pipeline to Neo4j or similar. The implementation uses Postgres extensions and procedural SQL to handle graph-specific operations (e.g., breadth-first search is compiled to WITH RECURSIVE). Foreign keys can be automatically introspected to infer edge relationships, lowering onboarding friction. The primary value proposition is operational simplicity: no new infrastructure, existing Postgres RBAC and backups apply, and graph queries compose naturally with relational filters. Performance will not match a native graph engine for deep traversals on very large graphs, but for moderate-depth queries on datasets already living in Postgres the in-database approach avoids serialization overhead entirely.
Source: https://github.com/Evokoa/pgGraph
DaoyuanLi2816/can-i-finetune-this
A command-line estimation tool that answers whether a given Hugging Face model will fit in GPU memory for both inference and fine-tuning, given local hardware. The tool fetches model metadata (parameter count, dtype, architecture) from the Hub API and computes peak memory estimates for forward pass, backward pass, optimizer states, and gradient checkpointing variants. It models the memory breakdown explicitly: for full fine-tuning with Adam, optimizer states alone consume 2 \times the parameter memory in fp32; with mixed precision and gradient checkpointing the formula changes accordingly. LoRA/QLoRA paths are also estimated by accounting for frozen base weights loaded at reduced precision plus trainable adapter parameters. The tool reports whether your reported GPU VRAM is sufficient, and if not, suggests configurations (quantization level, gradient checkpointing, batch size 1) that might make it feasible. This is useful before downloading a 70B+ checkpoint only to OOM during the first forward pass. Implementation is pure Python with no model loading — all estimates are analytic, so it runs in seconds.
Source: https://github.com/DaoyuanLi2816/can-i-finetune-this
anthropics/defending-code-reference-harness
An Anthropic-published reference implementation for integrating Claude into software security workflows. The harness covers four stages: threat modeling (generating STRIDE or MITRE-mapped threat trees from architecture descriptions), static scanning (wrapping existing scanners and feeding findings to the model for triage), triage (de-duplicating and ranking findings by exploitability context), and patch generation (producing diffs for confirmed vulnerabilities). Each stage is implemented as a composable skill that can be invoked independently or chained. The autonomous scanning harness wraps the pipeline end-to-end: given a repository path it runs the full sequence with minimal human intervention. Customization hooks are explicitly provided — users can substitute their own scanner backends, adjust the threat modeling schema, or override triage prompts. The project appears aimed at security teams evaluating Claude for AppSec automation, and at researchers benchmarking LLM-assisted vulnerability remediation. All skills are defined as structured prompt templates with typed inputs/outputs, making them easy to adapt or extend without modifying core orchestration logic.
Source: https://github.com/anthropics/defending-code-reference-harness
mkbhardwas12/pwned-deps
A lockfile-first dependency vulnerability scanner supporting npm (package-lock.json), PyPI (requirements.txt/poetry.lock), Maven, Cargo, Go modules, and RubyGems. “Lockfile-first” means it resolves exact pinned versions from lock files rather than declared ranges, eliminating false positives from version ambiguity. Vulnerability data comes from the OSV (Open Source Vulnerabilities) database supplemented by a curated feed for cases not yet in OSV. The project claims SLSA Level 3 provenance for its own release artifacts, meaning the build pipeline produces signed attestations linking source commits to published binaries — relevant if you are auditing your toolchain itself. The CI integration runs inside a locked container to prevent supply-chain interference during the scan itself. Results are emitted in a structured format suitable for blocking pipelines or feeding into dashboards. Compared to tools like pip-audit or npm audit, the multi-ecosystem single-tool approach and the locked-container execution model are the primary differentiators. Useful for polyglot monorepos where running separate ecosystem-native scanners is cumbersome.
Source: https://github.com/mkbhardwas12/pwned-deps
withkynam/vibecode-pro-max-kit
A structured agent harness designed to combat context window degradation in long-running AI-assisted development sessions. The core mechanism is a spec-driven memory system: the project state is maintained as a set of structured specification documents (architecture decisions, feature contracts, open tasks) that agents read and update rather than relying on raw conversation history. When the context window would otherwise overflow or lose coherence, the harness rehydrates the agent’s context from these specs rather than the full chat transcript. The 12-agent, 32-skill architecture distributes work across specialized sub-agents (planner, coder, reviewer, etc.) each with narrow context scope. Self-improvement is implemented as a feedback loop where agents update the spec documents based on what they learn during execution, so future sessions start from a richer baseline. Compatible with Claude Code and Codex via their respective APIs. The practical problem being solved — context rot in multi-session coding — is real and well-documented; the spec-as-memory approach is a reasonable engineering response, though the 30-second onboarding claim should be verified against project complexity.
Source: https://github.com/withkynam/vibecode-pro-max-kit
boona13/image-extender
An open-source web application for outpainting — extending an image beyond its original boundaries in any direction. The generative backend is Gemini accessed via OpenRouter, so no local GPU is required. The technically interesting component is the seam-blending step: rather than using the raw model output at the boundary, it applies Poisson blending to reconcile the gradient field at the join, suppressing color discontinuities and edge artifacts that naive compositing produces. Poisson blending solves a Laplacian system \nabla^2 f = \nabla^2 g over the blend region with Dirichlet boundary conditions, preserving interior gradient structure while matching boundary values. The app also generates three candidate extensions and presents them for selection, mitigating cases where the model produces an implausible or artifact-heavy result on a single draw. The web interface accepts arbitrary images, lets the user specify extension direction and amount, and returns the blended composite. The combination of cloud inference, Poisson post-processing, and multi-candidate selection is a practical workflow that requires no ML expertise to operate.
Source: https://github.com/boona13/image-extender
hadriansecurity/OpenHack
A lightweight, file-based workspace structure for whitebox security code review, released by Hadrian Security. The core design is that all review artifacts — scope definitions, findings, notes, exploit sketches — live as plain files in a defined directory schema, making the workspace versionable, diffable, and shareable without a database or SaaS platform. “Source-guided” means the tool is oriented toward reviewing actual source code rather than black-box probing: the workspace links findings directly to file paths and line numbers in the target repository. The whitebox focus enables more precise vulnerability analysis — data flow tracing, authentication logic audits, cryptographic misuse — compared to dynamic scanners. Reviewers can use the workspace with any editor or script against the file tree. The file-based approach also makes it straightforward to integrate with AI coding assistants that operate on local file contexts. Useful for security consultants who want a reproducible, portable audit trail, and for internal red teams running structured code reviews without committing to heavyweight commercial tooling.