デイリーAIダイジェスト — 2026-05-28
arXiv ハイライト
Gamma-World: 2プレイヤーを超えた生成的マルチエージェント世界モデリング
問題設定
インタラクティブな世界モデル――Genie、GameNGen、Oasis、およびその後に続くdiffusionベースのシミュレータ――は、単一の制御信号が単一の観測ストリームを駆動することを前提としています。多くの対象ドメイン(マルチプレイヤーゲーム、身体化マルチロボット操作、交通シミュレーション、スポーツ)はこの前提を満たしません。Nエージェントを1つのモデルに素朴に結合する方法は、3つの理由から破綻します:(1) エージェントの再ラベリングに対してモデルが等変である必要があり、プレイヤーIDを入れ替えると出力も入れ替わらなければならない、(2) スロットごとに学習されたidentityトークンは訓練時にNを固定し、順序に過学習してしまう、(3) エージェント間のfull cross-attention はトークン数に関してO(N^2 L^2)でスケールし、各エージェントが時間的に拡張された視覚ストリームを持つ場合に支配的なコストとなる。Gamma-Worldはまさにこの状況を対象としています:エージェントごとに独立に制御可能であり、置換対称性を持ち、N \gg 2に対して扱いやすい生成的世界モデルです。
手法
バックボーンは、エージェントごとのアクションストリームを条件とする標準的な潜在diffusionビデオモデルです。2つの貢献はattentionスタックの内部にあります。
Simplex Rotary Agent Encoding(SRAE)。 標準的な3D RoPEは、query/keyペアに適用されるブロック対角回転R(\theta_t), R(\theta_h), R(\theta_w)を介して(t, h, w)をエンコードします。SRAEはこれをエージェントのidentityをインデックスとする第4のrotary軸で拡張します。重要な設計上の制約は、エージェントが位相空間において等距離でなければならないことです:任意の2つの異なるエージェントが同じ位相分離を持ち、どのエージェントも特権的な位置を持たないようにします。これは、N個のエージェントをrotary角度空間に埋め込まれた正則単体のN個の頂点にマッピングすることで実現されます。具体的には、エージェントiに対してエージェント軸の回転角は
\phi_i = \langle v_i, \omega \rangle, \quad v_i \in \mathbb{R}^{N-1} \text{ a simplex vertex},
であり、\omegaは標準的なRoPEの周波数ベクトルです。単体は頂点置換によって作用する対称群S_Nの下で不変であるため、エージェントインデックスの入れ替えはattentionスコアにおけるグローバルな回転に帰着し、これはsoftmaxにおいて出力の再ラベリングを除いてキャンセルされます。重要なことに、これはパラメータフリーです:学習されたagent embeddingも固定されたスロット数も不要であり、推論時の任意のNは単体を再インスタンス化することでサポートされます。
Sparse Hub Attention(SHA)。 エージェントあたりLトークンに対して、Dense cross-agent attentionのコストはO((NL)^2)です。SHAは、エージェント間の通信を仲介する各レイヤーのK個の学習可能なhubトークンを導入します。エージェント内では、トークンは自身のストリームとhubにattendし、hubはすべてのエージェントのトークンにattendします。これにより、エージェント間のコストはK \ll NLとしてO(N^2 L^2)からO(NLK)に削減されます。構造的には、現在よく知られているperceiver/register-tokenパターンであり、エージェント軸に特化したものです:hubは各エージェントの状態の低ランクな要約を集約してブロードキャストし返すため、一貫性(共有されたワールドジオメトリ、相互可視性、衝突イベント)が二次的なブローアップなしに伝播します。エージェントの時空間トークン内のself-attentionはdenseのままであり、エージェントごとの視覚的忠実度を保持します。
2つのコンポーネントは組み合わさります:SRAEはidentityと等変性を提供し、SHAはスケーラブルな混合を提供します。どちらも標準的なRoPEおよび標準的なattentionブロックへのdrop-in置換であるため、diffusion訓練の目的関数とサンプリング手順は変更されません。
結果
本論文は、2エージェントから「2を超える」エージェントに至るマルチエージェント生成シミュレーションベンチマークで評価を行っています。abstractに記述されているヘッドラインの主張は:(i) 置換対称性が経験的に成立する――数値誤差を除いて出力はエージェントの再ラベリングに対して不変である、(ii) 推論コストはSHAによりNに対して準二次的にスケールする、(iii) エージェント間の軌跡一貫性(テレポーテーションなし、identityのブリードなし)がNの増大に伴っても保持される、というものです。提供されたテキストではabstractが途中で切れており、スロットembeddingおよびdense-attentionベースラインに対する具体的なFVDや制御可能性の数値は引用できません。
限界と未解決の問題
設計だけからでも、いくつかの問題が見受けられます。まず、simplex encodingはエージェントを交換可能として固定しますが、これはエージェントが異質な役割を持つ場合(例:ゴールキーパーとストライカー、リーダーとフォロワー、egoとNPC)には正反対の仮定です。役割の非対称性を回復するためには、補助的なrole embeddingで単体の対称性を崩す必要があり、パラメータフリーという性質を部分的に損なうことになります。次に、hubトークンはボトルネックです:hubが少なすぎると、細かいインタラクション(精密な接触、特定のエージェントペア間の遮蔽順序)が低ランクのチャネルを通過しなければならず、KがNやインタラクション密度に対してどのようにスケールすべきかについてのabstractでの分析はありません。第三に、訓練時と推論時の最大Nが不明確です;SRAEはNに対してパラメータフリーですが、diffusionモデルの他のコンポーネント(アクションエンコーダ、正規化統計)は依然としてエージェント数の訓練分布に対して調整されている可能性があります。最後に、アクションのconditioningインターフェース――エージェントの離散または連続な制御ベクトルがhubを通じて他のエージェントにリークすることなくトークンストリームにどのように注入されるか――についてはabstractで詳述されていません。
なぜ重要か
マルチエージェントのインタラクティブ世界モデルは、シングルプレイヤーのニューラルゲームエンジンの次の自然なターゲットであり、ここで提示されたアーキテクチャの基本要素――置換対称なrotary identityとhubを介したsparseなエージェント間チャネル――は、他のdiffusionベースのシミュレータがゼロから再訓練することなく採用できる、小さくコンポーザブルな変更です。対称性とスケーリングの主張が精査に耐えるものであれば、これはNエージェント生成シミュレーションのデフォルトレシピとなるでしょう。
Source: https://arxiv.org/abs/2605.28816
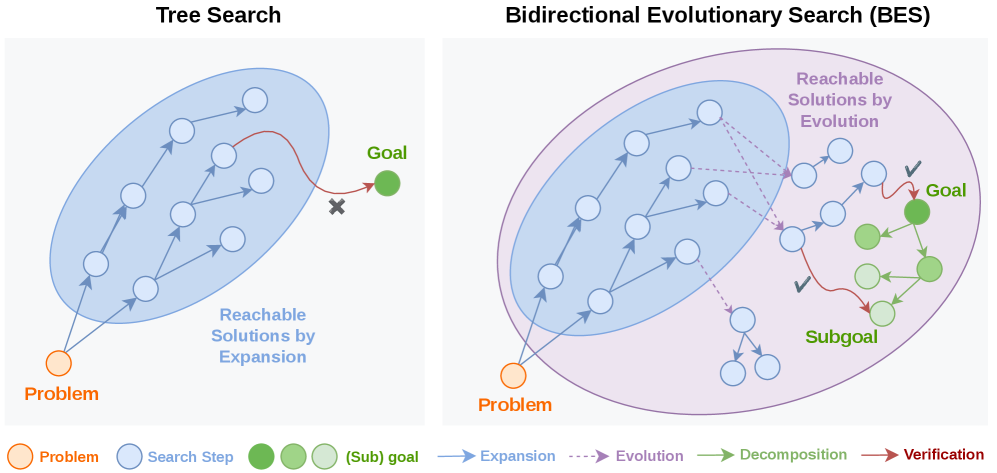
双方向進化探索による自己改善言語モデル
探索ベースの自己改善手法(best-of-N、MCTS、木探索)をLLMに適用する際には、構造的な弱点が2つあります。候補はスパースな終端検証器によってスコアリングされ、\pi_\thetaからの自己回帰的展開によって構築されるという点です。後者は到達可能な集合をモデルがすでに探索している確率質量の狭い領域に制限します。双方向進化探索(BES)はこれら両方の問題に対して、(i)生物学的スタイルの組換えオペレータによって前向き展開を補強し、(ii)目標を検証可能なサブゴールに再帰的に分解してdenseなスコアを提供する後向き探索を実行することで対処します。
前向き探索:展開と4つの進化オペレータ
候補は部分軌跡 n=(y_1,\dots,y_t) であり、各 y_i は推論ステップまたは行動です。候補プール \mathcal{P} はステップごとに拡張されます。標準的な展開は K\sim\mathrm{Uniform}\{1,\dots,K_{\max}\} をサンプリングし、
y_{t+k}\sim \pi_\theta(\cdot\mid x\oplus y_1\oplus\cdots\oplus y_{t+k-1})
を引きます。これに加えて、BESは既存の軌跡に対して4つの編集オペレータを適用します(図2に図示):Combinationは共通プレフィックスを持つ2つの軌跡の異なるサフィックスを連結し、Deletionは内部のステップを削除し、TranslocationはパスAの1つのステップをパスBのステップで置換し、Crossoverはパスの後半部分にAのプレフィックスを接合します。
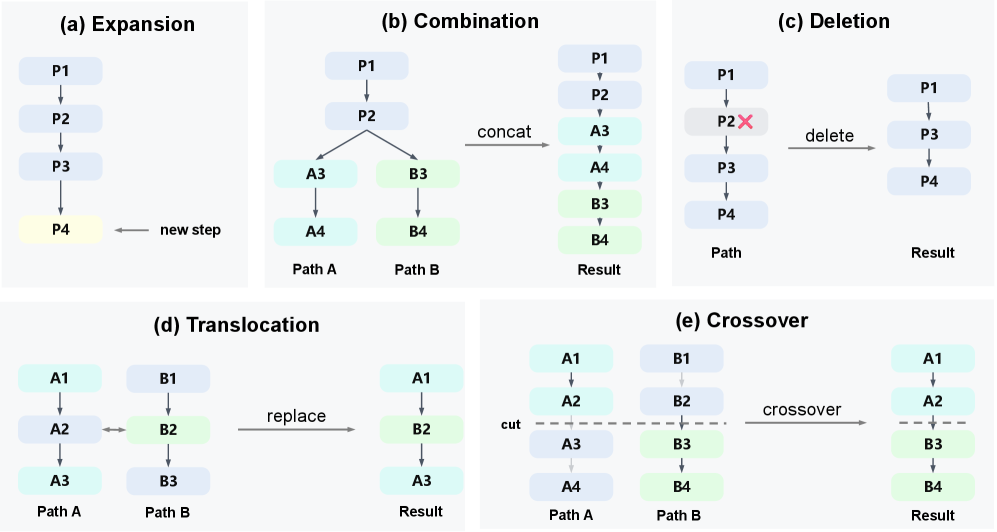
オペレータは固定確率でサンプリングされ、親は \mathcal{C}_t 上の基底スコアに対するボルツマン分布から引かれます。直接の連結が不明確な場合(例:自由形式の自然言語)、同じオペレータは \pi_\theta に編集を実行させるプロンプティングによって実装できます。重要なのは、進化は各子候補が改善である必要はなく、探索が最良の候補を保持するため、非自明な割合が有用であれば十分だという点です。
後向き探索:denseなサブゴールスコア
前向き探索だけではスコアがスパースになります。BESは、タスク x を検証可能なサブゴールに再帰的に分解する後向きパスをインターリーブし、部分軌跡をスコアリングする中間検証を生成します。後向きステップは数回の前向きステップごとに1回実行され、後向きスコアが前向きループのボルツマン選択に使われます。これが「双方向」の結合です:前向きが提案し、後向きが中間的な粒度で評価します。
進化オペレータが必要な理由:エントロピーシェル論
本論文は、展開が典型集合に閉じ込められるという直観を形式化します。水平線 T を固定し、軌跡を k 個のブロック U_1,\dots,U_k に分割し、ステップごとの驚き度の有界性(-\log P(v\mid y_{<t})\le L)、減衰するステップ依存性(\beta_\ell 可算)、線形なブロック全相関(\sum_j H_P(U_j)-H_P(U_1,\dots,U_k)\ge \gamma T)を仮定します。定理4.4は次を述べます:
- シェル閉じ込め:展開のみの探索からの Y\sim P はすべて、\exp(-\Omega(T)) の確率を除いて A_\epsilon^{(T)}=\{y:|-\log P(y)-H_T|\le\epsilon T\} に属します。到達可能な集合のサイズは最大でも \exp(H_T+\epsilon T) です。
- シェル脱出:k 回進化分布 Q=\bigotimes_j P_j(すなわち独立にサンプリングされたブロックを連結)のもとで、
\mathbb{E}_Q[-\log P(\widetilde Y)] \ge H_T + \gamma T,
かつ
\Pr_Q[\widetilde Y \in A_\epsilon^{(T)}] \le 1-\frac{(\gamma-\epsilon)T}{LT-H_T-\epsilon T} < 1.
メカニズムは、進化オペレータがブロック間の条件付き依存性を破ることです。結果として得られる候補の驚き度はブロック全相関を継承し、それは仮定4.3のもとで T について線形に増大します。したがって、一定の割合の進化候補が、任意のpolicyロールアウトを閉じ込めるシェルの外に落ちます。
実験
BESはポスト学習(Knights-and-KnavesでのLogical Reasoning;Multi-Hop Reasoningエージェント)と推論時(正方形・長方形内のCircle Packing、Heilbronn Convex)の両方のサンプラーとして評価されています。Knights-and-Knavesにおけるポスト学習の結果は、エントロピーシェルの主張に対して最も直接的な情報を提供します。Gemma-3-1B-itを用いて、著者らは1Kサンプルの SFT コールドスタート(3エポック)に続き、5K問題上で4エポックのRLを行い、GRPO、MaxRL、およびBES(MaxRL上に適用)を比較します。BESはサンプラーのみであるため、原理的にはあらゆるポスト学習アルゴリズム上に乗せることができます。
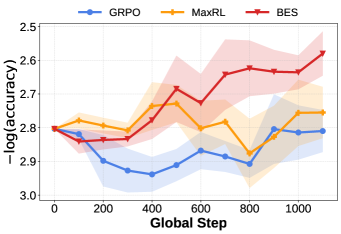
1.3Kの検証セットでは、GRPOとMaxRLはデータセットが十分に難しく、純粋なロールアウトサンプリングでは正しい軌跡がほとんど得られないため、学習全体を通じて実質的に改善が見られません。検証器のシグナルが疎すぎて学習を推進できないのです。一方、BESは学習全体を通じて単調に改善し、\pi_\theta からの単一のロールアウトでは生成できない正しい軌跡を浮上させる能力と一致しています。本論文は、エージェント型のmulti-hopや推論時のジオメトリベンチマーク(あらかじめ構築された検証ラダーがなく、後向き分解スコアのみが使用されるオープンエンドの最適化問題)においても同様の向上を報告しています。
制限と未解決の問題
定理の有効性は仮定4.3(\gamma>0 のブロック全相関)に依存しており、ブロックがほぼ独立なタスクでは脱出マージンが縮小します。4つのオペレータはステップレベルでの構文的な編集であり、明確なステップ分割を前提としますが、これは自由形式生成においては自明ではなく、プロンプトベースのフォールバックが \pi_\theta のバイアスを再導入します。図3の検証曲線は1つのベースモデル(Gemma-3-1B-it)について示されており、シェルがすでに広い可能性のある大規模モデルサイズへのスケーリング挙動は議論されていません。また、後向き分解の質はそれ自体LLMによって生成されるため、denseなスコアに系統的な誤りを注入する可能性がありますが、前向き進化と後向き分解それぞれの寄与は本論文で分離されていません。
この研究の意義
進化オペレータは、展開のみのサンプラーを制約するエントロピーシェルの罠から脱出する原理的な方法を与えており、双方向の結合は困難な推論タスクにおいてRLを停滞させてきた検証器スパーシティの問題に対処しています。この結果が一般化するならば、探索駆動の自己改善は \pi_\theta がすでに確率質量を置いている領域によってボトルネックになる必要はなくなります。
Source: https://arxiv.org/abs/2605.28814
ScientistOne: Chain-of-Evidenceによる人間レベルの自律的研究に向けて
問題
自律的研究エージェントは、表面的なレビューを通過するような論文を生成するようになっていますが、検証可能性という観点では依然として問題があります。具体的には、参考文献リストに存在しない文献が含まれていたり、提出されたコードを再実行しても報告されたスコアが再現されなかったり、手法のセクションに記述されたアーキテクチャがコードの実装と乖離していたりします。標準的な評価手法——リーダーボードスコアや文章品質に関するLLM-as-judge——では、これらの問題を検出できません。自律的システムが論文出力をスケールさせるにつれて、こうした失敗は下流の文献を汚染し、引用グラフを歪めます。本論文は、検証可能性の基準、その基準を設計上満たすように構築されたエージェント、およびあらゆるシステムに均一に適用できる事後監査を提案します。
基準としてのChain-of-Evidence
著者らはChain-of-Evidence(CoE)をデータベースにおけるACIDと類比的に定義しています。これはアーキテクチャではなく、特性の仕様です。研究成果物におけるすべての主張は、記録されたチェーンを通じてグラウンディングソースまで追跡可能でなければなりません。4つの主張タイプが扱いやすく整理されています:
- 引用の主張:学術データベースのレコードに解決でき、その内容が引用元論文での記述と整合していなければなりません。
- 数値の主張:実行ログまたは計測された出力まで追跡できなければなりません。
- 手法上の主張:実装コードに解決できなければなりません。
- 結論の主張:検証可能な推論を通じて、支持する数値的・手法的な主張から導出されなければなりません。
その他の主張タイプ(定性的な観察、理論的な性質)は、現時点では自動化できないとして除外されています。
ScientistOne:設計によるCoE
ScientistOneは3段階のパイプライン(Figure 1)であり、すべてのモジュールが来歴メタデータを持つ構造化された成果物を出力します。
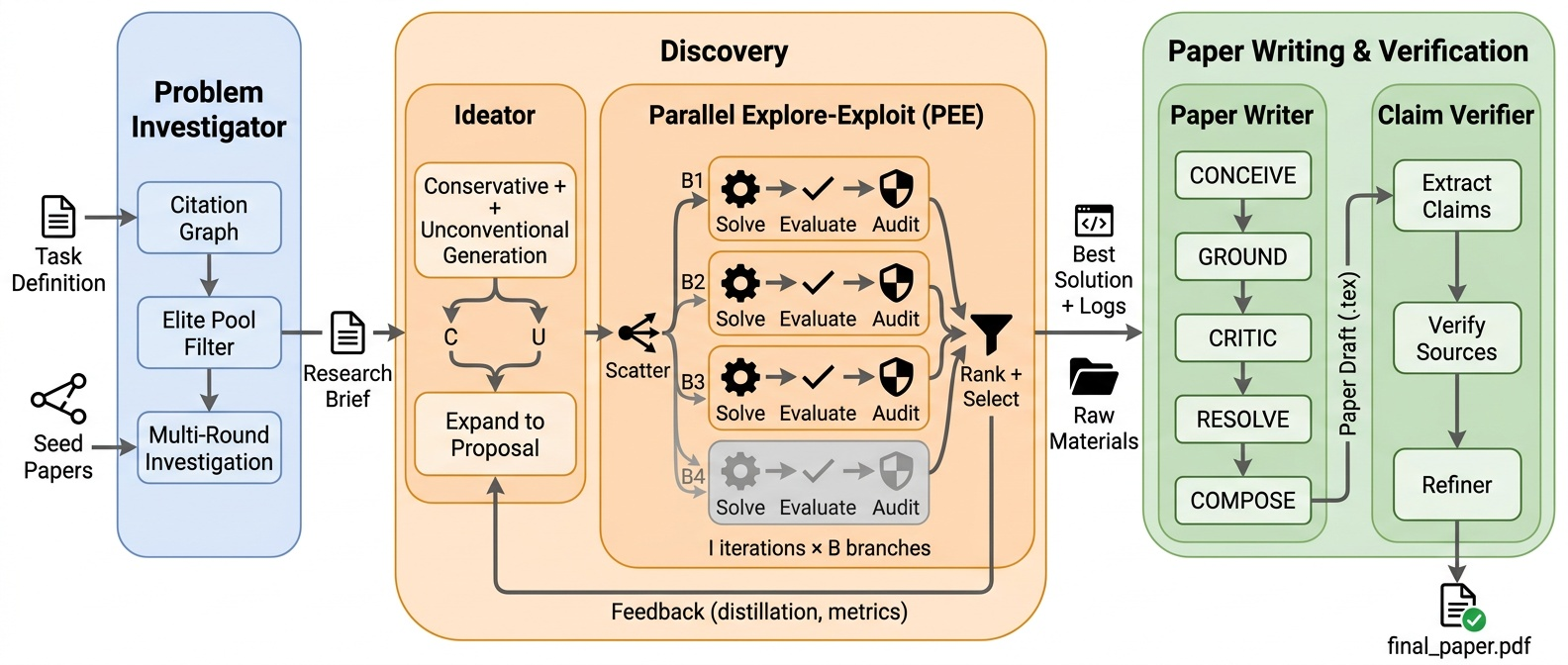
- Stage 1 — Problem Investigator (PI): シード論文から始まり、学術データベースAPIを通じて引用グラフを拡張し、トピックごとに最大100本の全文PDFを取得・精読して、構造化された研究ブリーフを出力します。このブリーフに付随する参考文献リストが、下流の引用主張に対して唯一合法的なソースプールとなります——これにより、システムがパラメトリックメモリからもっともらしく見える引用を生成するという失敗モードが排除されます。
- Stage 2 — Ideator/Solver: 並列的なソリューション分岐を探索し、タスクのスコアリング関数に対してそれらを評価します。すべての数値的主張は実行ログに紐付けられます。
- Stage 3 — Writer + Claim Verifier: 論文を草稿し、次にClaim Verifierが出力前にすべての主張を記録された証拠ソースと照合します。主張を解決できない場合、成果物の最終化がブロックされます。
CoE整合性監査
監査(Figure 2)はシステム非依存です。アダプターが任意のシステムのpaper.tex、ソリューションコード、references.bibを共通の成果物バンドルに正規化し、4つの独立したチェックを実行します。
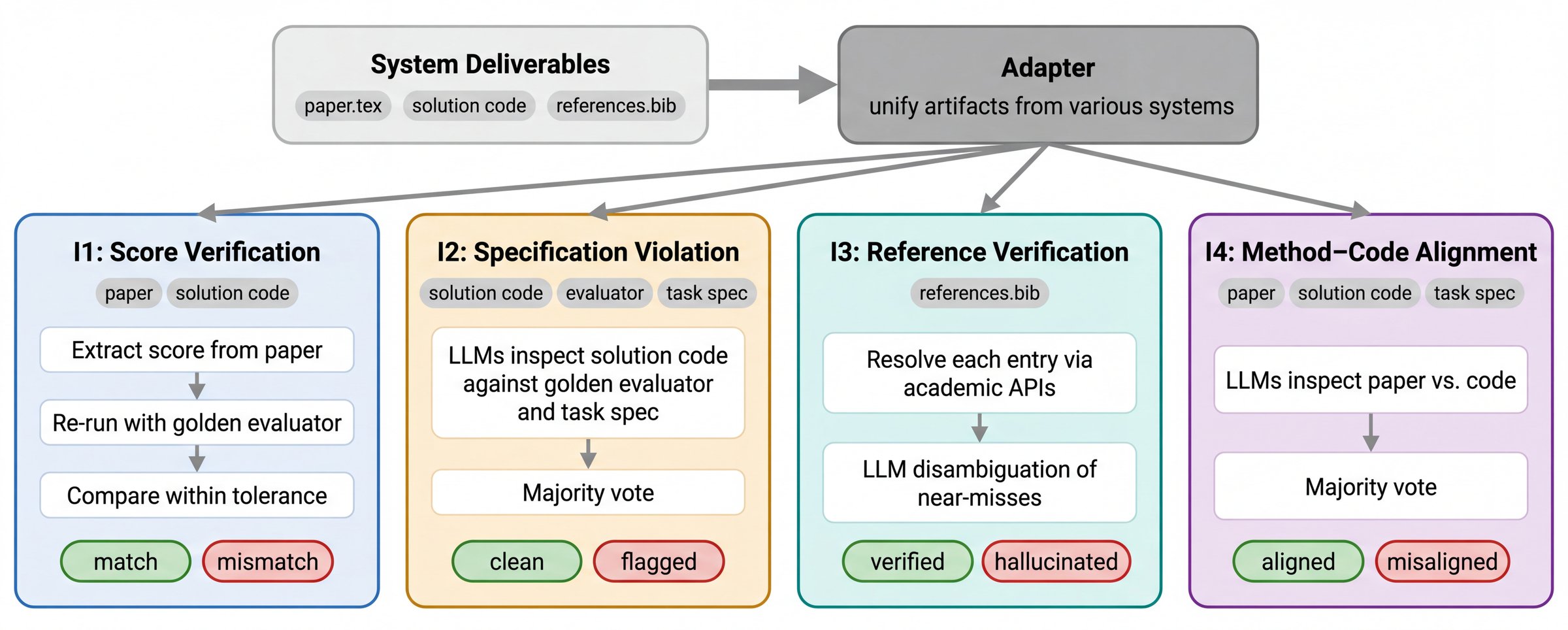
- I1 スコア検証: TeX/PDFから報告されたスコアをLLMで抽出し、提出されたソリューションをゴールデン評価器で再実行し、評価器の確率的変動を吸収するために5回の実行にわたって適応的な許容範囲 \max(1\%,\, 3\sigma/|\bar{s}|) 内で比較します。
- I2 仕様違反: ソリューションコード、評価器、タスク仕様に対して多数決LLM判定を行い、タスク制約に対する不正行為を検出します。
- I3 参照検証: 各
bibエントリを学術APIで解決し、類似ケースをLLMで曖昧性解消します。 - I4 手法とコードの整合性: 手法の記述と実装を比較する多数決LLM判定を行います。
結果
5つのADRSタスク(Prism、Cloudcast、EPLB、LLM-SQL、TXN)における5つの自律的システムからの75本の論文全体を通じて、すべてのベースラインが少なくとも1つの系統的な失敗を示しています。幻覚参照率は最大21%、スコア検証の通過率は最小で42%、手法とコードの整合性は20〜80%の範囲です。ScientistOneは0/337の幻覚参照を達成し、(アブストラクトの続きによれば)完全なスコア検証を達成しています。
汎化性は、5つのMLE-Bench Kaggleタスク(中〜高難易度)とParameter Golf LLMトレーニングコンペティションでテストされています。ScientistOneはRSNA脳腫瘍(0.6518)と3D物体検出(0.1763、DeepScientistベースラインは0.0000)でゴールドを、iMet 2020(0.6791)とiNaturalist 2019(0.2445)でシルバーを、AI4Code(0.8356 vs. 0.6964)でAbove Medianを獲得しています。Parameter Goldでは、DeepScientistが無効な提出(16MBのサイズ制限超過)を行ったのに対し、ScientistOneは制約を遵守して1.0600を達成し、カットオフ時点でのSOTA(1.0611)に匹敵しています(このコンペティションのリーダーボードはその後更新されています)。
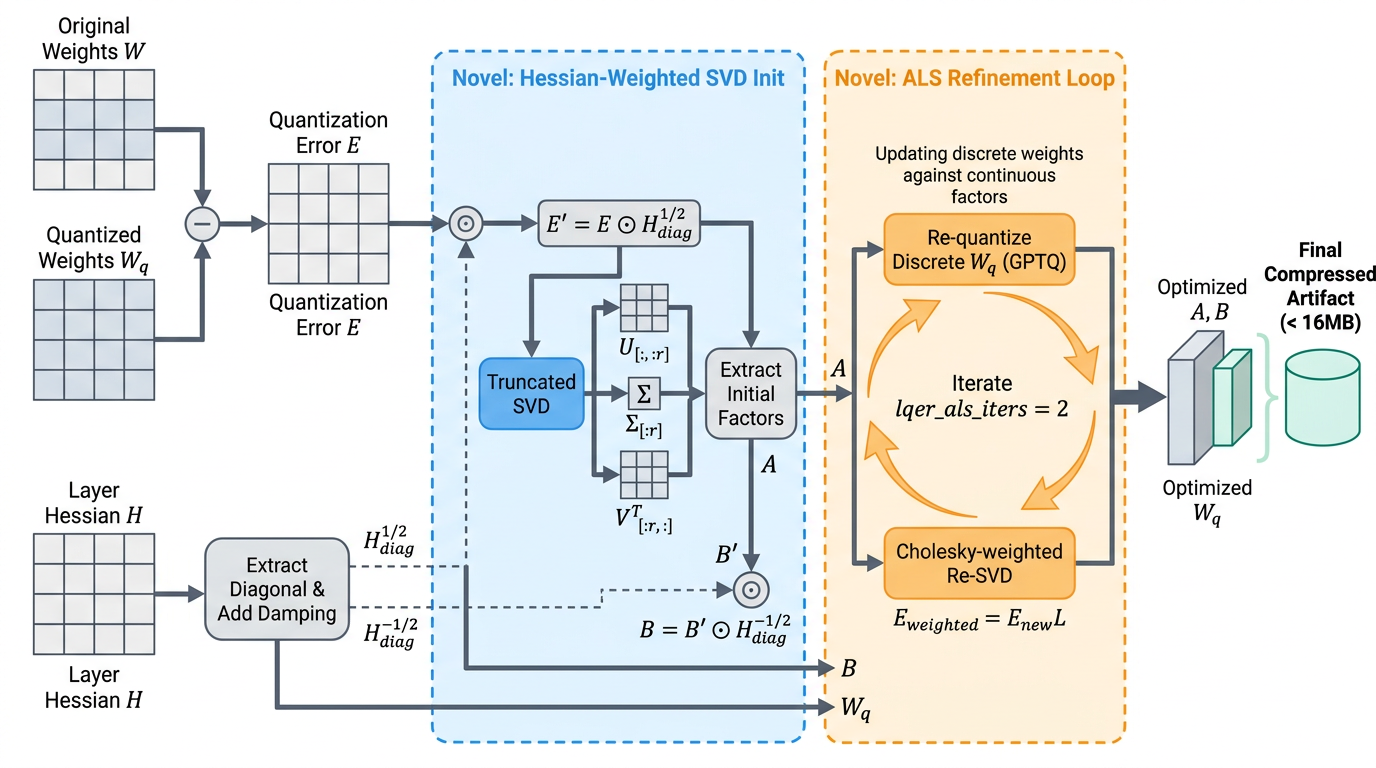
Parameter Goldのソリューションは非自明なものです。ヘッセ行列対角重み付きSVD初期化とGPTQ駆動のALS精緻化ループを組み合わせたもので、発見ループがハイパーパラメータ探索ではなく意味のあるアルゴリズム的構造を生み出していることを示唆しています。
制限と未解決の問題
- CoEの分類体系は定性的・理論的な主張を除外しており、ここでの「検証可能性」は現在のツールが機械的にチェックできる範囲に限定されています。CoEを満たした論文であっても、科学的に無意味である可能性があります。
- I2とI4は多数決LLM判定に依存しており、ジャッジのバイアスを引き継ぎ、特に不慣れなドメインにおける微妙な仕様違反や手法とコードの乖離を見逃す可能性があります。
- スコア検証は決定論的で再実行可能な評価器に依存しています。ADRSとMLE-Benchはこれに適合しますが、多くのML研究の問いかけ(大規模訓練を必要とするアーキテクチャの主張、理論的結果)はそうではありません。
- 監査は参照検証を学術データベースの解決にとどめており、引用と被引用コンテンツの間の意味的整合性はLLMによってのみチェックされるため、引用した論文が実際に存在するという事実の下での誤表現の余地が残っています。
- 「幻覚参照ゼロ」は強い主張ですが、その構造(WriterをPIの参考文献リストに制限する)はこの結果を部分的に同義反復的なものにしています——より難しい問いは、PIの検索が関連する文献を網羅しているかどうかです。
なぜこれが重要か
CoEは自律的研究の評価を出力品質から成果物の整合性へと再構成し、監査はリーダーボードやLLMジャッジには見えない失敗モードを露呈させるシステム非依存の手段を提供します。エージェント的な論文生成がスケールするにつれて、この種の設計による来歴保証は、任意の出力が文献に受け入れられるための前提条件となる可能性が高いです。
Source: https://arxiv.org/abs/2605.26340
ProRL: 修正されたPolicy Gradient推定によるProactive推薦のための効果的な強化学習
問題設定
Proactive Recommender Systems(PRSs)は、ユーザーを現在の好みからターゲットとなる好みへと段階的に誘導する中間アイテムのパスを生成します。その際、各ステップのアイテムが受け入れ可能(クリック可能)であることを保ちます。典型的な例として、SF映画からコメディへのジャンル遷移を中間アイテムのブレンドで実現するケースが挙げられます。

RLはこの問題の自然な定式化です。パス \tau=(a_1,\dots,a_L) を定義し、短期的な受容性(CTR)と長期的な誘導シグナル(Interest増分 IoI、Rank増分 IoR)を組み合わせたステップ報酬 r_t を付与し、policy gradientで J(\theta)=\mathbb{E}_{\tau\sim\pi_\theta}\!\left[\sum_t r_t\right] を最適化します。著者らはこの素朴な方法が、特定かつ診断可能な2つの形で失敗することを示します。
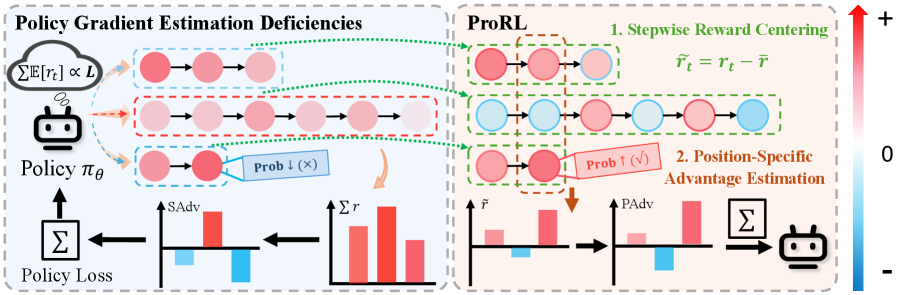
標準的なPolicy Gradientにおける2つの欠陥
PRSで使用されるステップ報酬(CTR、IoI、IoR)は非負であり、合理的なポリシーのもとでは正の期待値を持ちます:\mathbb{E}[r_t] > 0。パスの期待リターンはしたがって長さに比例してスケールし、\sum_{t=1}^{L}\mathbb{E}[r_t] \propto L となります。これにより2つの問題が生じます。
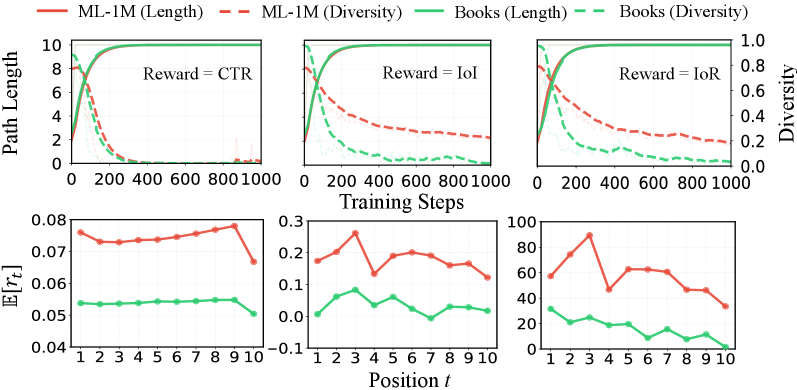
- 長さショートカット。 シーケンスレベルのadvantage A(\tau)=R(\tau)-b を用いると、gradient信号はアイテムの選択よりも長さに支配されます。実験的には、MovieLens-1MおよびAmazon-BookのCTR/IoI/IoR報酬において、訓練がほぼ同一の過剰に長いパスへと崩壊し、パス長が爆発する一方で多様性が低下します。
- 高い分散。 各ステップ t をパス全体のリターン R(\tau) で重み付けすることは、加法的分解 R(\tau)=\sum_t r_t を無視しており、構造が正当化する以上にステップごとのgradient項の分散を膨らませます。
手法:ProRL
ProRLは標準的なREINFORCEスタイルの更新
\nabla_\theta J = \mathbb{E}\!\left[\sum_{t=1}^{L} A_t\,\nabla_\theta \log \pi_\theta(a_t\mid s_t)\right]
を維持しつつ、A_t を2つの修正で置き換えます。
Stepwise Reward Centering(SRC)。 ステップ条件付き期待報酬 \bar r_t=\mathbb{E}[r_t\mid s_t](または位置インデックス付き逐次推定値)を減算し、各ステップが \mathbb{E}[\tilde r_t]=0 を満たすセンタリングされた報酬 \tilde r_t = r_t - \bar r_t を寄与するようにします。パスレベルのセンタリングされたリターン \sum_t \tilde r_t は、パスを延ばしても期待ゲインがゼロとなり、長さショートカットが排除されます。これが概念的に核心的な操作です。状態条件付きベースラインの減算は期待値においてgradientを保存するため、最適点を変えることなく \mathbb{E}[r_t]>0 のバイアスを中和します。
Position-Specific Advantage Estimation(PSAE)。 全ステップに R(\tau)-b を割り当てる代わりに、PSAEは加法的分解を活用して位置固有のadvantageを計算します。
A_t = \sum_{k\ge t} \tilde r_k - b_t,
ここで b_t はロールアウトから学習される位置インデックス付きベースラインです。これにより低分散の推定量が得られます。各ステップはその決定に関連するセンタリングされた末尾リターンによってクレジットされ、ステップごとのPRS報酬構造に適応した標準的なadvantage推定の分散削減の論理を反映しています。
完全な更新は任意のPRS RLトレーナーのpolicy gradient項に対するドロップイン代替として機能します。2つのメカニズムは直交しており、独立にablation可能です。
実験
データセット。 MovieLens-1M、Steam、Amazon-Book、ユーザーで8:1:1に分割。
ベースライン。 シーケンシャル推薦システム(GRU4Rec、BERT4Rec、LightSANs、FEARec);教師あり型proactive手法(IRN);ヒューリスティック型proactive手法(IPG、ITMPRec);LLMベースのproactive手法(LLM-IPP、T-PRA)。
評価指標。 誘導有効性のためのInterest増分(IoI)とRank増分(IoR);パス実現可能性のためのCTR/HitRate;連続アイテム間の意味的一貫性を示すCoherence。
図2の診断は、それ自体が定量的な結果です。標準的なPGのもとでは、すべての報酬設定と両データセットにわたって、パス長が単調に増加しながら多様性がほぼ退化した分布へと崩壊しており、長さショートカットがハイパーパラメータの人工物ではなく構造的な失敗モードであることが確認されます。ProRLは、CTRとCoherenceを保ちながら誘導指標(IoI、IoR)においてベースラインを上回ることが報告されており、付録Eに完全なハイパーパラメータサーチが含まれています。
限界とオープンクエスチョン
- センタリングには信頼性の高い \bar r_t の推定が必要です。スパースなロングテールアイテムでは \bar r_t の推定がノイジーになる可能性があり、正則化やプールドベースラインが必要となる場合があります。
- 分析はステップ報酬が正の平均を持つことを前提としています。符号付き成分(例えば、ターゲット外アイテムへのペナルティ)を混合した報酬シェーピングはSRCなしでもバイアスを部分的に軽減できる可能性がありますが、PSAEとの相互作用は探求されていません。
- すべての評価はユーザー応答のオフラインシミュレータを使用しており、フィードバックループを伴うオンライン展開において排除された長さショートカットが再発しないかどうかは未検証です。
- フレームワークはポリシークラスに依存しませんが、transformer スタイルのシーケンシャルモデルで実証されています。行動空間がアイテムレベルではなくトークンレベルとなるLLMポリシーバックボーンでの挙動は未解明です。
なぜこれが重要か
PRSに対するナイーブなRLが失敗するのは最適化の困難さによるものではなく、報酬分解に構造的な正の平均があり、policy gradientを長さ最大化シグナルに変換してしまうためです。ProRLのセンタリングと位置固有のadvantageは、最小限かつ原則的な修正であり、ステップ報酬が構造的に非負であるあらゆる逐次的意思決定設定(対話ターン、チュータリング軌跡、マルチステップ検索)に汎化するはずです。
Source: https://arxiv.org/abs/2605.28293
Agent Explorative Policy Optimization for Multimodal Agentic Reasoning
問題設定
chain-of-thoughtと外部ツール呼び出し(画像クロップ、検索、コード実行など)を交互に行うマルチモーダルエージェントは、著者らがThinking-Acting Gapと呼ぶ構造的非対称性を示します。Thinkingはモデルのデフォルトの低分散な挙動であり、ツール使用は高分散な補助的行動であって、その結果はツールの応答に依存しており、方策はそれを制御できません。vanilla GRPOのもとでは、この非対称性が学習中に2つの測定可能な病理を引き起こします:
- ツール使用はロールアウトのおよそ30\%でしか試みられない。
- ツール使用が試みられた質問の約40\%において、ツールを使用したサブグループ全体が誤回答となり、ツール呼び出しトークンにおけるGRPOのグループ相対アドバンテージがゼロに崩壊する。
正味の効果として、クレジット割り当てを最も必要とする軌跡、すなわちノイズの多い補助的行動を含む軌跡が勾配を受け取らないことになります。thinking-onlyのモダリティが支配的となり、方策はthinking-onlyの挙動に退行し、エージェント的な目的が損なわれます。
手法:AXPO
AXPO(Agent eXplorative Policy Optimization)は、上記の失敗点において標的を絞った探索を注入するため、GRPOのロールアウト/クレジット割り当てパイプラインを修正します。質問qとサンプリングされたグループ\{\tau_i\}_{i=1}^Gに対して、S_{\text{tool}}(q) \subseteq \{\tau_i\}をツール使用サブグループとします。S_{\text{tool}}(q)が空でなく全て誤答である(診断上の症状)場合、AXPOはprefix-fixed resamplingを実行します:
- S_{\text{tool}}(q)から「thinking prefix」\tau_i^{<t}を選択する。ここでtは最初のツール呼び出しトークンの位置である。
- \tau_i^{<t}を固定し、方策からK個の新たな継続\tau^{\geq t}を再サンプリングし、ツールを実行して生成を継続する。
- これらの再サンプリングされたロールアウトが失敗したサブグループを置き換える(あるいは補完する);アドバンテージは拡張グループ上で再計算される。
prefixは不確実性に基づくprefix選択によって決定されます:S_{\text{tool}}(q)の候補prefixのうち、ツール呼び出し前のトークン分布のエントロピーが最大のものを選択します。すなわち、
\tau^\star = \arg\max_{\tau_i \in S_{\text{tool}}(q)} \; \frac{1}{t}\sum_{s<t} H\!\left(\pi_\theta(\cdot \mid \tau_i^{<s})\right).
直観的には、意思決定の境界においてすでに方策が不確実であったprefixは、代替のツール呼び出し継続が結果を反転させる可能性が最も高く、したがって非退化なアドバンテージ信号を生成する可能性も最も高いというものです。PPOスタイルのクリッピング目的関数は変更されず、ロールアウトの構成とグループ構築のみが異なります。具体的には、AXPOはGRPOの上位に位置し、再サンプリングバジェットKとトリガー条件(ツール使用サブグループが全て誤答)という2つのハイパーパラメータを持ちます。
これは重要度を意識した探索の標的型実装であり、標準的なグループ推定量が退化する質問にのみ追加の計算を費やし、退化の原因となった行動の分散に対してその計算を投じます。
結果
学習レシピはSFTの後にQwen3-VL-Thinking(4B/8B/32Bスケール)へのRLを適用するものであり、9つのマルチモーダルベンチマークで評価されています。主要な数値は以下の通りです:
- 8Bにおいて、SFT+AXPOはSFT+GRPOを9つのベンチマーク平均でPass@1で+1.8pp、Pass@4で+1.8pp上回ります。
- 8B SFT+AXPOはPass@4で32B Baseを上回り、同等以上のbest-of-4品質において4\timesのパラメータ削減を達成しています。
- 改善は診断結果と連動しており、ツール使用頻度が上昇し全誤答ツールサブグループの割合が低下することで、汎用的なreward shaping効果ではなくメカニズムの有効性が確認されています。
ここではPass@4の改善がPass@1より重要です:AXPOは探索駆動型であり、Pass@4は方策が単一の決定論的chainに崩壊するのではなく、多様でときに正解するツール使用モードを維持しているかどうかを測定するからです。
限界と未解決の問題
- トリガー(「ツール使用サブグループが全て誤答」)は二値でrewardに閾値を設けており、部分的な正解や密なreward設定にはより柔軟な基準が必要です。
- 不確実性に基づくprefix選択は、prefix全体で平均化されたトークンレベルのエントロピーを使用しており、表層形式における偶発的不確実性とツール決定に関する認識論的不確実性を混同しています。学習済みのvalue/criticに基づく選択器の方がより原則的でしょう。
- 再サンプリングのコストは無視できません:最も難しい質問のサブセットに対してK個の追加継続が必要です。本論文は、自然なベースラインアブレーションであるGRPOのグループサイズGを単純に増やす方法との実時間の比較を報告していません。
- Qwen3-VL-Thinkingのみで評価されており、thinking機能を持たないVLMやテキストのみのエージェント設定でThinking-Acting Gapが同様に現れるかどうかは検証されていません。
- 本手法はツール呼び出しの探索を扱いますが、ツール出力の信頼性は扱っておらず、誤ったツール応答は依然としてロールアウトを汚染し、AXPOにはそれをダウンウェイトするメカニズムがありません。
重要性
Thinking-Acting Gapは、エージェント的方策に対するグループ相対RLの明確で測定可能な失敗モードです:高分散な行動は均一に失敗するときに正確にゼロの勾配を受け取ります。AXPOは最小限の診断駆動型の修正、すなわちprefixを固定し、行動を再サンプリングし、不確実性によってprefixを選択するというものであり、基礎となる目的関数を変更することなく有用な学習信号を回復します。8Bが32B BaseのPass@4を上回るという結果は、行動の境界における標的を絞った探索が、エージェント的マルチモーダル推論においてスケーリングよりも効率的なレバーであることを示唆しています。
Source: https://arxiv.org/abs/2605.28774
ピクセルから言語へ――スケールするネイティブ One-Vision モデルに向けて
問題設定
主流のVLMは、モジュール型のテンプレートに従っています。すなわち、凍結または軽微に fine-tuning された視覚 encoder(CLIP/SigLIP)が視覚 token をアダプタ経由でLLM decoderに送り込む構成です。このパイプラインはピクセルレベルの信号を断片化します――encoderはLLMが入力を見る前に固定された token グリッドにコミットし、フレーム間の構造はフレームごとの embedding ボトルネックの背後に隠されてしまいます。ネイティブVLM(単一バックボーン、外部 encoder なし)は単一画像での競争力ある性能を示していますが、複数画像・動画・空間的グラウンディングタスクにおける挙動はほとんど未解明のままです。NEO-ov はまさにこのギャップを標的とし、補助 encoder やポストホックな fusion モジュールを用いることなく、画像・複数画像・動画を一括処理する単一の decoder-only バックボーンを実現します。
手法
NEO-ov は、順序付きの視覚シーケンスを扱えるよう NEO ネイティブバックボーンを拡張したものです。入力は patch embedding・フレーム embedding・テキスト token からなる単一の token ストリームにシリアライズされ、「ネイティブプリミティブ」層の一連のスタックによって処理されます。
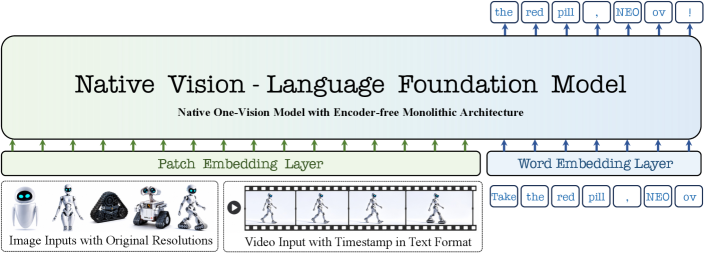
ピクセルは、2 つの畳み込みからなる tokenizer を通じて入力されます。2 つの畳み込みの間に GELU が挿入され、また畳み込みの間に 2D 位置 embedding が加算されます。
\boldsymbol{x}_v = \mathrm{Conv}_2(\mathrm{GELU}(\mathrm{Conv}_1(\boldsymbol{I})) + \mathbf{PE}), \qquad \boldsymbol{x}_t = \mathrm{Tokenizer}(\boldsymbol{T}).
\mathrm{Conv}_1 はストライド 16(パッチ化)、\mathrm{Conv}_2 はストライド 2(局所集約)であり、32\times32 ピクセル領域あたり 1 つの視覚 token が生成されます。視覚 token は <img>/</img> で括られ、テキスト token と連結されます。Pre-Buffer 層(2B 版では 12 層、9B 版では 6 層)および post-LLM スタックは、それぞれ NEO と Qwen3 から初期化されます。
中心的なアーキテクチャ上の選択は、THW 分離型の attention ヘッドレイアウトです。各ヘッドの Q/K はチャネル軸に沿って時間・高さ・幅のサブベクトルに分割されます。
\mathbf{q}_i = [\mathbf{q}_i^T; \mathbf{q}_i^H; \mathbf{q}_i^W], \quad \mathbf{k}_j = [\mathbf{k}_j^T; \mathbf{k}_j^H; \mathbf{k}_j^W],
attention logit は以下のように与えられます。
s_{ij} = \langle \mathbf{q}_i^T, \mathbf{k}_j^T\rangle + \langle \mathbf{q}_i^H, \mathbf{k}_j^H\rangle + \langle \mathbf{q}_i^W, \mathbf{k}_j^W\rangle.
T ブランチは元の LLM ヘッド次元を保持し、テキストの順序・画像間の関係・フレーム間の依存性を担います。H および W ブランチは、2D 空間構造に専用のヘッド次元容量として追加されます。これは Native-RoPE と組み合わせており、各 token は 3 タプルのインデックス \mathrm{idx}_i = [t_i, h_i, w_i] を受け取ります。テキスト token は h_i = w_i = 0 と設定され、時間的位置のみを持ちます。フレーム内の画像 token は同じ t_i を共有しつつ (h_i, w_i) が異なり、動画フレームは t_i を進めながら同一の空間グリッドを再利用します。
重要な点として、attention マスクは混合型です。すなわち、画像の空間的範囲内では双方向、テキスト token 間および動画フレーム間では因果的(causal)となっています。これにより、空間 token がフレーム内で対称的に attention できる一方で、自己回帰的な言語モデリングが保持されます――画像スパン上のブロック双方向マスクと、それ以外の標準的な causal マスクを合成することで実装可能です。RoPE のベース周波数は \theta_T = 10^6、\theta_H = \theta_W = 10^4 に設定されており、時間的なベースが大きいのは、動画や複数画像シーケンスで必要とされる長い実効範囲と整合しています。
学習は 3 段階で行われ、ピーク learning rate はそれぞれ 2\times10^{-4}、5\times10^{-5}、5\times10^{-5} で、AdamW・コサイン減衰・0.01 ウォームアップを使用します。

Stage 1 では、大規模な画像–テキストペアを用いて、言語能力を保持しながら Pre-Buffer を凍結スタイルの post-LLM に対してアライメントします。Stage 2 では、画像と動画の混合データを用いて時空間推論能力を発展させます。Stage 3 では、高品質なマルチモーダルデータによる instruction tuning を行います。バックボーンには Qwen3-1.7B および Qwen3-8B を使用し、それぞれ NEO-ov (2B) および NEO-ov (9B) が得られます。学習は 8×80GB GPU を搭載した 16 ノード上で実施されます。
結果
本論文の実証的な主張は、ネイティブな encoder-free バックボーンがモジュール型 VLM との差を「大幅に縮小」しつつ、細粒度の知覚において改善を示すというものです。掲載されているセクションではベンチマークごとの数値は列挙されていませんが、構成は具体的です。すなわち、2B および 9B パラメータの変種、32\times32 の実効パッチ粒度、3 段階の学習です。アーキテクチャのアブレーションの中心的なポイントは、T に LLM ヘッド次元を保持し H, W に新たな次元を追加する方が、フラットなヘッド分割よりも優れているという点であり、単一画像・複数画像・動画を統一的な位置スキームの下で扱うための Native-RoPE の THW インデックス分解とともに、本手法の核心的なレシピとなっています。
制限と未解決の問題
このシリアライズは視覚 token ごとに固定された 32\times32 領域にコミットするため、より細かい実効ストライドで動作する encoder と比較して、OCR や密な予測において制約が生じます。THW 分離型ヘッド分割は、選択された H, W 容量に応じたヘッド次元パラメータを追加しますが、論文(抜粋されたセクション内)では、ヘッド割り当てにわたるコスト対精度のトレードオフを定量化していません。また、双方向/causal の混合マスクは原理的に正当ですが、ストリーミング動画推論時の KV キャッシュ再利用との相互作用については明示的な扱いが求められます。さらに、encoder-free の姿勢はすべての低レベル視覚の帰納バイアスを Pre-Buffer に委ねることになりますが、6〜12 層が大幅に高い解像度や長い動画において十分かどうかは未解明のままです。
重要性
NEO-ov は、「one-vision」ネイティブ VLM が外部 encoder を復活させることなく複数画像や動画にスケールできるという具体的なデータポイントを提供します。これは、attention ヘッドと RoPE の両方において空間軸と時間軸を直交した部分空間として扱うことで実現されています。この傾向が続くとすれば、モジュール型の CLIP-plus-LLM テンプレート――およびそのアライメント段階のオーバーヘッド――を正当化することがますます困難になるでしょう。
Source: https://arxiv.org/abs/2605.28820
ResearchMath-14K: エージェントによる研究レベル数学のスケーリング
問題と動機
フロンティアレベルの数学的推論はデータがボトルネックとなっています。既存の数学ベンチマーク(AIME、MATH、HLEなど)は閉形式の解を持つ問題が大半を占めており、強力な推論モデルで十分に対処可能な範囲に収まっています。また、研究レベルのコーパスは数少なく、規模も小さいのが現状です。著者らはResearchMath-14kを構築しました。これは1,233件のソース文書から抽出された14,056件の厳選された研究レベルの問題からなるデータセットであり、(a) 真に未解決の問題に対する現在のLLMの失敗パターンを調査し、(b) 正解ラベルが利用できない状況において、このような問題に対する「誤りを含むが構造化された」軌跡をSFTデータとして活用できるかを検証するために用いられます。
構築パイプライン
コーパスは2エージェントパイプライン(図2)によって構築されます。Extractorエージェントが各文書を走査して未解決問題の候補箇所と裏付けとなる引用を特定し、独立した問題文を生成します。次に、Refinerエージェントが未解決状態を確認し、分類ラベルを付与して各候補を自己完結した問題文に書き直します。必要に応じてオンラインの参考文献も参照します。最終的な出力は1,233件のソースから得られた20,835件の問題であり、公開版の14,056件にフィルタリングされています。
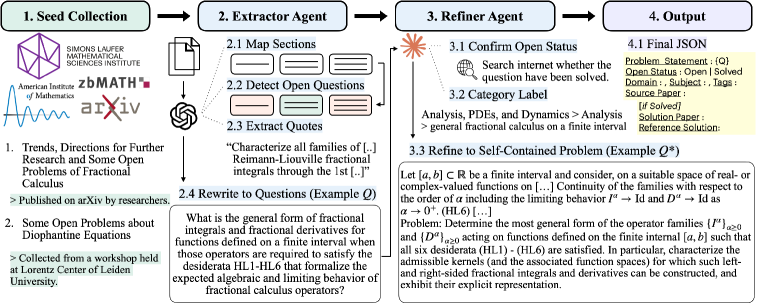
ソースは3つのストリームに層別化されています。arXivの「未解決問題・未解明問題」論文(524文書、8,182問題)、MathOverflowおよびWikipediaを含む未解決問題のウェブページ(161文書、5,331問題)、そしてAIM形式の問題セッションシートと会議の未解決問題コーナー(548文書、7,322問題)です。領域のカバレッジは標準的なMSCに類似したトップレベルの分野に及び(図1)、論理学・基礎論や学際的なエントリーの長いテールを持ちます。LLMによるペアワイズ難易度判定をEloに変換したもの(図3、k=32、ベース1500)では、ResearchMath-14kは標準的な数学ベンチマークを大幅に上回る難易度に位置づけられています。
教師用軌跡と失敗パターン
著者らは2つのオープンモデルから220Kの教師用トレースからなるResearchMath-Reasoningを生成し、旧世代→新世代のマッチドペア4組に整理された8つのモデルを評価しました。すなわち、R1→V4-Pro、K2→K2.6、Qwen3-30B→Qwen3.5-35B、Qwen3-235B→Qwen3.5-397Bです。教師用トレースの約30%は手動レビューで明らかに問題があるとフラグが立てられており、コーパス規模の分析によって2つの失敗パターンが定量化されました。
最も注目すべき結果は、3つの独立したモデルファミリーにわたって2025年世代から2026年世代にかけて事実性が急激に低下していることです。Agent-Judgeによって監査された720件のトレースのうち、87.4%(629件)が少なくとも1件の参考文献らしきオブジェクトを引用しており、54.0%(389件)が少なくとも1件の偽の参考文献を含んでいます。抽出された19,864件の引用のうち、3,492件(17.6%)が偽物でした(ウェブ検索によって確認)。トレースあたりの言及数は以下の通りです。
- DeepSeek R1→V4-Pro: 4.9→57.8件の言及(0.5→11.6件の偽物)
- Kimi K2→K2.6: 1.9→60.0件(0.1→8.3件の偽物)
- Qwen3-30B→Qwen3.5-35B: 6.5→36.7件(1.4→7.7件の偽物)
- Qwen3-235B→Qwen3.5-397B: 20.3→32.7件(4.5→4.8件の偽物)
集計すると、新世代モデルはトレースあたり参考文献らしき言及を5.6\times多く、偽物を5.0\times多く生成しています。この効果はResearchMath-14k、Leipzig Tier-4、SOOHAKでは大きく(行ヒット率が30〜80ポイント上昇)、HLEでは中程度、AIMEではほぼゼロであることから、引用衝動はモデルが知っているコンテンツによってではなく、プロンプトの学術的な文体によって引き起こされることが示唆されます。代表的な捏造の例としては、架空の論文タイトル(“Neeman, A remark on the unique factorization theorem”)や誤った著者帰属が挙げられます。著者らはこれがエージェント的・search-RLによるpost-trainingの副作用であると仮説を立てています。すなわち、検索・引用ハーネスの中でトレーニングされたモデルは、ツールが取り除かれた後も引用パターンを出力し続け、引用を控える代わりに幻覚的な書誌文字列でスロットを埋めてしまうというものです。
不完全な軌跡からの学習
セクション5では、未解決問題に対するフィルタリング済みの(大部分が誤りを含む)トレースが依然として有益な学習材料となるかを検証しています。ResearchMath-ReasoningはAgent-Judgeによってフィルタリングされます。参考文献らしいスパンはすべてウェブ検索で検証され、偽の参考文献を1件でも含むトレースは除外されます。予算の制約からフィルタリングされたセットは5,000件のトレースに上限が設けられています(ResearchMath-Reasoning-Filtered)。フォーマットのみのコントロールとして、DASD-Thinkingから5,000件のトレースがサンプリングされます。Qwen3-4B/8B/30B-A3B-baseがそれぞれのセットでLoRA fine-tuningされ、AIME 2024〜2026(n=90)、整数解のHLE(n=315)、SOOHAK Challenge+Mini(n=501)で評価され、math-verifyでスコアリングされます。
3つのモデルサイズにわたって、ResearchMath-Reasoning-Filteredでのfine-tuningはベースモデルと比較して平均9.2ポイントの改善をもたらし、DASEフォーマットコントロールを上回りました。これは本論文の中心的な実証的主張を支持するものです。すなわち、強力なモデルが未解決問題に取り組んで失敗した際に生成するトレースは、転移可能な構造(関連するオブジェクトの導入、もっともらしい帰着の試み、例のテスト)を含んでいるのに対し、単純な誤った作業はそうでないということです。
限界と未解決の問題
監督シグナルはAgent-Judgeの信頼性によって制限されています。フィルタリングされるのは参考文献の捏造のみであり、問題への不取り組み、空虚な帰着、および暗黙の論理的誤りは通過してしまいます。5,000トレースの上限は予算によるものであり、スケーリング効果はおそらく過小評価されています。10^5〜10^6件のフィルタリング済みトレースで改善が継続するかどうかは不明です。fine-tuningはQwen3ベースモデルに対するLoRAのみであるため、RLによるpost-trainingパイプラインへの転移は未検証です。捏造の退行という主張は3つのファミリーにわたって一貫していますが、観察的なものにとどまっており、search-RLを原因として特定する制御実験は提供されていません。最後に、AIME/HLE/SOOHAKでの改善はあくまで代理指標であり、未解決問題そのものに対する進捗を直接測定するベンチマークは存在しません。
重要性
本論文は、これまでで最大の研究レベル数学コーパスを提供するとともに、エージェント的search-RLがオフラインの事実性を低下させているという、モデルファミリーに依存しない具体的な測定結果を示しています。2026年世代モデルでは偽の引用が5.0\times増加しています。また、未解決問題に対するフィルタリング済みの失敗した試みが有用なSFTデータとして活用できること(+9.2ポイント)を実証しており、専門家による解の検証を必要としないフロンティア数学の監督に向けたスケーラブルな経路を指し示しています。
Source: https://arxiv.org/abs/2605.28003
Hacker News Signals
Go: ジェネリックメソッドのサポート
Goの型システムには長らく顕著な欠如がありました。ジェネリックな型やジェネリックな関数は定義できるものの、レシーバーの型パラメータとは独立した型パラメータを持つメソッドを定義することはできませんでした。このissueは、その欠如を埋めるためのプロポーザルを追跡するものです。
現行のGoでは、T[A]という型がある場合、Tのメソッドは独立した型パラメータBを導入できません。これを回避するには、そのような操作をフリー関数に格上げする必要がありますが、そうするとより完全なジェネリクスを持つ言語では自然に書けるはずのメソッドチェーンやインターフェース実装のパターンが損なわれてしまいます。このプロポーザルでは、func (t T[A]) Convert[B any]() B { ... }のような構文を許可します。
実装上の中心的な課題は、Goのインターフェースディスパッチ機構が、メソッドセットはコンパイル時に追加の型パラメータなしで固定されることを前提としている点です。ジェネリックメソッドを実現するには、(Goの現行ジェネリクスが型や関数の型パラメータに使用している)dictionary-passingをメソッドごとの型引数にまで拡張するか、何らかのモノモーフィゼーションを採用するかのいずれかが必要になります。プロポーザルの議論では、ジェネリックメソッドがインターフェースを満たせるかどうかについても検討されており、現在のコンセンサスは、他の言語が初期に課した制約を踏襲して、当初はインターフェース定義内でのジェネリックメソッドを禁止する方向に傾いています。
二次的な複雑さとして、型推論との相互作用があります。Goの推論エンジンはすでにジェネリック関数に対するマルチレベルの単一化を処理していますが、メソッドレベルの型パラメータが加わると推論の対象範囲が広がり、レシーバーの型パラメータとメソッドの型パラメータが相互作用するケースで曖昧さが生じるリスクがあります。
この機能はGo 1.18(2022年)でジェネリクスが導入されて以来、要望され続けてきました。リンク先のissueは、プロポーザルが受理された後の現在の追跡ポイントであり、設計に関する議論を経て実装計画の段階へと移行しています。実用上の影響はライブラリ作者にとって大きく、特に関数型スタイルのAPI(map、filter、変換など)を構築する場合に顕著です。現状のフリー関数による回避策では呼び出し箇所が不自然になり、流暢なチェーン記法が妨げられています。
Source: https://github.com/golang/go/issues/77273
GPUでの行列積は「予測可能な」データを与えると高速に動作する(2024年)
本記事は再現可能な異常現象を記録したものです。NVIDIA GPUのGEMMカーネルは、FLOPカウントが同一であっても、乱数データと比較して構造化データや定数に近いデータを入力とした場合に、測定可能なほど高速に動作します。
そのメカニズムは、テンソルコアが非正規化(denormal)浮動小数点数をどのように処理するか、およびwarpスケジューラがデータ依存のレイテンシとどのように相互作用するかにさかのぼります。FP16およびBF16 GEMMにおいて、テンソルコアのスループットは公称上は決定論的ですが、周辺のインフラ―レジスタファイルのプレッシャー、共有メモリバンクコンフリクト、パイプラインストール―は値の分布によって変化し得ます。さらに興味深いことに、本記事は入力がオールゼロであるか繰り返し値を多く含む場合に、特定のFP演算高速パスが有効になることを指摘しています。一部の実装ではゼロとの乗算が短絡評価され、同一値の累積でいくつかのラウンディングステップを回避できます。
この効果は定量化されています。テスト構成における大規模な正方GEMMでは、A100上の乱数FP16入力は構造化入力と比べて約5〜10%低速に動作します。これはアルゴリズム的な違いではなく―同じcuBLASの呼び出しが使用されています―テンソルコアパイプラインにおけるマイクロアーキテクチャ的な振る舞いを反映しています。
MLワークロードへの実際的な含意は微妙ですが、確かに存在します。重みが初期化に近く、活性化値が特定の統計的プロファイルを持つ学習初期段階は、学習中盤とは異なるベンチマーク結果を示す可能性があります。GPUスループットを特徴づけるために乱数データを使用したベンチマークは、十分に学習されたモデルによる本番推論のレイテンシを過大評価する可能性があります。
また、量子化(INT8/INT4)パイプラインではゼロスキップがより積極的に実装されているため、より大きな効果が現れることも指摘されています。これは構造化スパース性に関するより広い文献、およびNVIDIAのsparse tensor coreフォーマットである2:4スパース性が高速化をもたらす理由に繋がります。ゼロの位置が単に存在するだけでなく予測可能であるためです。
Source: https://www.thonking.ai/p/strangely-matrix-multiplications
ノードの少数派によるRaftコンセンサス
標準的なRaftはエントリをコミットするためにクォーラム(ノードの過半数)を必要とするため、2f+1 ノードのクラスターは f 件の障害を許容します。本記事では、少数派でコンセンサスを進めるための修正について検討し、特にこれを整合的にするためにどの不変条件を緩和または再構成する必要があるかを考察しています。
核心となるインサイトは、「minority Raft」は汎用コンセンサスアルゴリズムではなく、非対称な信頼あるいは事前調整された協調を前提とした場合にのみ機能するという点です。本記事で説明されている具体的な構成では、ウィットネスノードまたは外部エポックサービスを用いて対称性を崩します。少数派パーティションが処理を進められるのは、過半数パーティションが同時にコミットしないことを保証する独立した権威からリースまたはトークンを保持している場合に限られます。これは構造的に、分散ロックサービスにおけるフェンシングトークンや、一部のCRDB実装におけるエポックメカニズムと類似しています。
著者は安全性の議論を丁寧に説明しています。Raftのコアとなる安全性特性、すなわち「1つのタームにおいて最大1つのリーダーのみがエントリをコミットする」という性質は、トークン/リースのメカニズムが少数派パーティションの動作期間中に排他的な権利を保持することを強制するため、維持されます。活性(liveness)に関する議論はより弱く、外部権威が利用不能になった場合、少数派パーティションは安全でない形で処理を続けるのではなく停止します。
これは実用上の意義があります。3ノードまたは5ノードのコストが高すぎるエッジデプロイメントにおいて、発散が有界なクラッシュ障害耐性を求める場合がその例です。2ノード構成(1ノードが「少数派の1つ」としてウィットネスと共に動作する)は、一部のクラウドデータベースがアベイラビリティゾーン障害をデータを保存せず投票のみを行う低コストのアービターインスタンスで処理する方法に対応しています。
本記事は過大な主張を避けています。これは新たな安全性の成果ではなく、外部コーディネーションによってRaft系プロトコルの適用範囲を拡張する方法と、外部コンポーネントが保証しなければならない事項を明示的に示した、有用な解説として位置づけられています。
Source: https://padhye.org/raft-minority/
BadHost: CVE-2026-48710 Starlette Host-Header 認証バイパス
この CVE は、FastAPI の基盤となる非同期 Python Web フレームワーク Starlette における認証バイパスを記録したものです。脆弱性のクラスは host-header インジェクションであり、よく知られているにもかかわらず継続的にパッチが不十分な攻撃対象領域です。
メカニズムの詳細:Starlette の Request.url および関連プロパティは、受信リクエストの Host ヘッダーを読み取ることで URL を構築します。アクセス制御の判断に request.url や request.base_url を使用するアプリケーション — たとえば、リクエストが内部ホスト名から来ているかどうかを確認する場合 — において、攻撃者は任意の Host ヘッダー値を指定してそのチェックを偽装することができます。Starlette は、アプリケーションコードへ Host ヘッダーを提供する前に、許可ホストの設定済みリストに対する検証やサニタイズを行っていませんでした。
修正には、(a) Starlette 自身がアプリケーションハンドラーに到達する前に許可リストに含まれない Host 値を持つリクエストを拒否するか、(b) アプリケーションが明示的にオプトインしなければならない明示的なミドルウェア(TrustedHostMiddleware)を使用するかのいずれかが必要です。この CVE は特に、ミドルウェアが存在せず、アプリケーションコードが導出された URL に基づいてセキュリティ上の判断を行っていたケースに関するものです。
Host-header 攻撃は、プロキシを前段に置いたデプロイメントにおいて特に危険です。リバースプロキシは通常、元の Host ヘッダーをそのまま転送します。プロキシがそれを書き換えたり検証したりしない場合、バックエンドアプリケーションは信頼できるフィールドのように見えるものの中に攻撃者が制御するデータを受け取ることになります。ホストチェックがパスワードリセットメール(古典的な Django 時代の脆弱性)、内部 API アクセス、または SSRF 対策を制御している場合、影響はさらに拡大します。
より広いエンジニアリング上の教訓は、HTTP ヘッダーから導出されるあらゆる値は明示的に検証されない限り攻撃者によって制御可能であり、フレームワークレベルの URL 構築 API は、アプリケーションコードに対して権威あるものと見えるオブジェクトに未検証のヘッダー内容を暗黙的に組み込むべきではないということです。
Source: https://badhost.org/
DeepSeek Reasonix: ネイティブコーディングエージェントによる高いキャッシュ効率と低コスト
Reasonixは、DeepSeekのモデルAPIに特化して構築されたオープンソースのコーディングエージェントであり、積極的なprompt cachingとコンテキスト管理によりコスト効率を追求しています。
技術的な核心は、DeepSeekのprefix cachingを活用したキャッシュ戦略にあります。system prompt、リポジトリのコンテキスト、およびツール定義を、エージェントのターンをまたいで安定したprefixを形成するように構造化し、キャッシュ済みのKV状態が再利用されるようにしています。これにより、同一のコードベースのコンテキストをターンごとに再送信する長いエージェントタスクにおいて、入力トークンのコストを大幅に削減できます。このアーキテクチャでは、キャッシュヒット率を最大化するために、promptの各コンポーネントを安定性の順(system instructionsを最初に、次にファイルの内容を決定論的な順序で、最後に会話履歴)に並べることを明示的に採用しています。
このエージェントは標準的なtool-useループを実装しています。ファイルの読み込み、ファイルへの書き込み、シェルコマンドの実行、コードベースの検索(grep/ripgrepを使用)などです。汎用的なエージェントフレームワークと区別される点は、トークンバジェット管理に関する仕組みにあります。累積コンテキスト長を追跡し、コンテキストウィンドウ内に収まるよう過去のターンを削除または要約しながら、タスクに関連する状態を保持します。この削除のヒューリスティックは、中間的な推論トレースよりもtool callの結果を優先的に保持するものです。
プロジェクトが報告するベンチマークでは、複数ターンのコーディングタスクにおいて、単純な再プロンプティングと比較して60〜80%のコスト削減を達成しており、その大部分はprefix cache hitによる節約です。これはDeepSeekのドキュメントに記載されているキャッシュの料金体系(キャッシュ済み入力トークンはキャッシュなしの一部の金額として請求される)と一致しています。
このプロジェクトが注目に値するのは、アルゴリズムの新規性よりも実践的なエンジニアリングにあります。ほとんどのエージェント型コーディングフレームワークは、プロバイダー固有のキャッシュのセマンティクスを無視し、繰り返されるコンテキストに対して満額を支払っています。Reasonixは、キャッシュに適したprompt構築をファーストクラスの設計上の制約として扱っており、これはスケールでの本番環境におけるコスト管理として正しいアプローチです。
Source: https://esengine.github.io/DeepSeek-Reasonix/
Rust(およびSlint)をジェイルブレイクしたKindleで動かす
この記事では、ジェイルブレイクしたKindle電子書籍リーダーをターゲットとした組み込みRust開発環境の構築を詳細に解説しており、表示レイヤーにはSlint UIツールキットを使用しています。
対象のKindleハードウェア(Paperwhiteのバリアント)は、ARMのCortex-AプロセッサでLinuxカーネルを動作させており、e-inkディスプレイはframebufferデバイス経由で駆動されます。ジェイルブレイク(標準的なKOReader関連のエクスプロイトチェーンを使用)後、デバイスはrootシェルを公開し、バイナリのサイドロードが可能になります。著者はRustをarmv7-unknown-linux-musleabihfターゲット向けにクロスコンパイルしており、Kindleのやや古いglibcへの動的リンクを避けるためにmusl libcを使用しています。
Slintは組み込みおよびデスクトップをターゲットとしたRustネイティブのUIフレームワークで、ネイティブコードにコンパイルされ、framebufferに直接書き込むソフトウェアレンダラーをサポートしているため、フルグラフィックスタックを持たない環境にも適しています。著者はSlintのソフトウェアレンダラーをKindleの/dev/fb0 framebufferをターゲットとするよう設定し、e-ink特有のディスプレイリフレッシュ問題にも対処しています。e-inkパネルは明示的なリフレッシュコマンドを必要とし、部分更新が頻繁すぎるとゴースティングが発生します。この記事では、フルリフレッシュと部分リフレッシュを起動するために必要なioctlコールと、更新レイテンシのトレードオフについて詳しく説明しています。
タッチ入力は/dev/input/eventXから生のイベントを読み取ることで処理され、evdevクレートを用いてパースされています。著者は、Kindleのタッチコントローラーが非標準の向きで座標を報告するため、座標変換が必要であると指摘しています。
ビルドおよびデプロイのワークフローは、cargo build --target armv7-unknown-linux-musleabihfを実行した後、scpでデバイスに転送するという手順です。最小構成のSlintアプリのバイナリサイズは約2〜3 MBで、Kindleのストレージ容量を考慮しても許容範囲内です。
本記事は、RustのEmbedded/クロスコンパイルエコシステムがLinuxクラスの組み込みターゲット向けにいかに成熟してきたかを示す明快な事例です。
Source: https://sverre.me/blog/rust-on-kindle/
ストレスが重複イベントの海馬統合と記憶推論を阻害する
Science Advances に掲載されたこの神経科学論文は、急性ストレスが共有要素を通じて関連する記憶を結び付ける海馬の能力——記憶推論または推移的連合と呼ばれるプロセス——をいかに損なうかを検討しています。
実験パラダイムでは重複するイベントペアを用います。被験者はA-BおよびB-Cの連合を学習した後、共有要素Bを介した統合を必要とするA-C推論をテストされます。これは海馬のパターン補完と重複する表現の結合に依存することが知られています。急性ストレス(Trier社会的ストレステストや冷水ストレスによって誘発)下では、被験者は直接訓練されたペアに対する記憶は正常を保つ一方でA-C推論が損なわれ、ストレスがエンコーディング自体ではなく関係的統合を特異的に妨害することが示唆されます。
提案されているメカニズムは、ストレスホルモン(コルチゾール、ノルエピネフリン)が海馬CA3-CA1回路のダイナミクスを変化させることに焦点を当てています。通常、CA3のパターン補完は推論を可能にする重複表現の検索を支援します。グルココルチコイドの上昇は、海馬をパターン分離(異なる表現のエンコーディング)へと偏らせ、パターン補完から遠ざけることが知られており、これが推移的推論に必要な結合を直接的に損なうことになります。
fMRIデータでは、ストレスを受けた被験者において推論試行中の海馬-前頭前野の結合が低下していることが示されており、関係的記憶検索のための前部海馬の動員に失敗していることと一致しています。
MLに隣接する関連性として、この研究はストレスが系統的な汎化(学習済みの関係に対する組み合わせ的推論)を劣化させる一方で、ルックアップ型の記憶は比較的無傷のまま残すという生物学的根拠を提供しています——これはニューラルネットワークがいつ系統的に汎化し、いつ暗記するかをめぐる議論と並行する解離です。
Source: https://www.science.org/doi/10.1126/sciadv.aea5496
プロンプトの丁寧さがLLMの精度に与える影響の調査
本論文は、プロンプトに丁寧または無礼な表現を加えることがLLMのタスク精度を変化させるかどうかについて、厳密な定量化のないまま非公式に流布してきた問い(「LLMに”please”と言うべきか」)を対象に、統制された研究を実施しています。
実験設定では、複数のモデル(GPT-4、Claude、Llamaの各バリアント)を、数学的推論・事実QA・コード生成といった複数のタスクカテゴリにわたって評価しています。プロンプトのバリアントは、丁寧さを示すマーカー(“please”、“thank you”、“I would appreciate”)、無礼さを示すマーカー(“do this now”、命令形のみの表現)、およびそのいずれも含まないものの3種類です。各バリアントは、タスクごとに数百件のサンプルに対して固定シードでテストされています。
結果はモデルによって異なり、一貫していません。一部のモデルの一部のタスクでは、丁寧なプロンプトが統計的有意性の閾値内で僅かな精度向上(1〜3%)を示しましたが、他のケースでは効果が無視できる程度であったり、逆転したりしています。通常の有意水準において、モデルやタスクをまたいだ一貫した方向性の効果は確認されませんでした。ただし、RLHF データで学習された instruction-tuned モデルは、ユーザーフレンドリーな表現に対して若干の選好を示す可能性があるという証拠も得られています。これは、そのような表現がより高品質な学習サンプルと相関しているためと考えられます。
より興味深い知見はタスクタイプとの交互作用です。自由生成タスクでは、丁寧なフレーミングが出力スタイルを若干変化させ(より多くのヘッジング表現、より長い回答)、評価指標によって有利にも不利にも働くことがあります。完全一致タスクでは、その効果はほぼゼロです。
率直なまとめとしては、プロンプトの丁寧さは信頼できる精度向上の手段ではありません。丁寧にすると効果があるという非公式な信念は、交絡因子を反映している可能性が高いです。すなわち、より丁寧に構成されたプロンプトは同時により正確に指定される傾向があり、精度向上の実際の要因はその「正確さ」にあります。
Source: https://arxiv.org/abs/2510.04950
注目の新しいリポジトリ
Percivalll/Copy-Fail-CVE-2026-31431-Kubernetes-PoC
CVE-2026-31431の概念実証エクスプロイトであり、完全に非特権のコンテナエスケープによってKubernetes上のノードレベルのコード実行を実現することを示しています。攻撃チェーンは2つのプリミティブを組み合わせています:ページキャッシュの破損と共有イメージレイヤーの悪用です。Kubernetes上のコンテナランタイムはホストのページキャッシュを介してOCIイメージレイヤーを共有しているため、悪意のある非特権プロセスがそれらの共有レイヤーに属するキャッシュ済みページを破損し、他のコンテナやホストレベルのプロセスに攻撃者が制御するコンテンツを実行させることができます。コンテナ内で昇格した権限や特別なケーパビリティは一切必要ありません。このPoCは3つの主要なマネージドKubernetesサービス(Alibaba Cloud ACK、Amazon EKS、Google GKE)で検証されており、この脆弱性が特定の環境に固有のものではなく、overlay filesystemをまたいだカーネルのページキャッシュとコンテナランタイムの相互作用に本質的に起因することを示しています。技術的な重大性は高く、非特権という制約により通常必要とされるCAP_SYS_ADMINや特権pod specが不要となるため、攻撃対象領域が大幅に広がります。防御側はノードのカーネルバージョン、イメージレイヤーの共有ポリシーを監査し、関連するシステムコール(userfaultfd、madvise、fallocate)を制限するseccomp/AppArmor profileの導入を検討すべきです。本リポジトリは、カーネルレベルのコンテナ分離境界を研究するセキュリティ研究者や、パッチが広く展開される前に自組織の露出状況を評価するクラスタ運用者のための参考資料として機能します。
Source: https://github.com/Percivalll/Copy-Fail-CVE-2026-31431-Kubernetes-PoC
statecraft-protocol/envoy
Envoyは、マルチエージェントおよび長期タスク向けのエージェントシステムにおける構造的な問題に取り組んでいます。すなわち、状態がエフェメラルかつセッションローカルであるため、専用のシリアライゼーションロジックなしに、マシン・プロセス・組織の境界を越えて作業を再開することが不可能になるという問題です。このプロジェクトは、エージェントワークロード専用に設計された、型付きかつバージョン管理されたstate storeを本質とする、耐久性のある共有状態プロトコルレイヤーを提供します。エージェントのメモリをアプリケーションレベルの関心事として扱うのではなく、Envoyはそれを永続的かつアドレス可能な基盤へと外部化し、複数のエージェントやセッションが定義された一貫性セマンティクスのもとで読み書きできるようにします。このアーキテクチャはエフェメラルな実行コンテキストと耐久性のあるワールドステートを区別しており、タスクの途中で中断されたエージェントが別のマシン上で作業状態を再構築したり、部分的な結果を別の組織の協調エージェントに引き渡したりすることを可能にします。プロトコルレイヤーは、複数のエージェントが共有の可変状態を操作する際に繰り返し生じる課題である、コンフリクト解消・バージョン管理・アクセス制御を担います。これは、デフォルトの前提がシングルステートフルプロセスであるtool-calling LLMフレームワーク(LangGraph、AutoGen、あるいはカスタムオーケストレーター)の上に構築している方すべてに関連します。Envoyは本質的に、それらのフレームワークが実装者に委ねている永続化と協調のための基盤を提供します。オープンソースであるため、状態フォーマットとプロトコルは検査可能であり、プロプライエタリなクラウドバックエンドに縛られることもありません。
Source: https://github.com/statecraft-protocol/envoy
scheidydude/codeindex
Codeindexは、コードベースの依存関係グラフ構築に特化した静的解析ツールであり、blast-radius impact scoringと呼ばれる固有の出力メトリクスを持ちます。対象のモジュール、関数、またはファイルを指定すると、そのノードでの変更や障害が下流のコンポーネントにどれだけ影響を与えるか(すなわちblast radius)を定量的に推定します。これは、LLMが推移的な依存関係の影響を認識せずにリファクタリングを提案するAI支援開発ワークフローにおいて直接的に有用です。本ツールはリポジトリを依存関係グラフとしてインデックス化し、到達可能性解析を適用して各ノードの下流ファンアウトをスコアリングします。blast radiusが高いノードは、追加レビュー、テストカバレッジ、または変更の分離の候補となります。AI支援開発を念頭に置いた設計思想は実践的です。コード生成モデルにコンテキストを渡す際に、blast radiusが高いファイルを把握しておくことで、どのコンテキストを優先的に含めるべきか、またどの変更を人間によるレビュー対象としてフラグを立てるべきかを判断しやすくなります。アーキテクチャ的には、ランタイムのインストルメンテーションを必要とせず静的アナライザとして動作するため、実行オーバーヘッドなしにCIパイプラインで利用可能です。依存関係グラフ表現により、「この変更セットに対して実行が必須な最小テストセットは何か」といったクエリも可能となり、これはインクリメンタルビルドおよびテスト選択システムにおける古典的な問題です。フルテストスイートの実行コストが高い大規模モノレポにおいて、impact scoringは変更影響解析への実用的な近似手法となります。
Source: https://github.com/scheidydude/codeindex
agynio/platform
Agynは、Claude CodeやOpenAI Codexのようなシステムを対象として、開発者のノートPC上ではなくエンタープライズインフラ内でAIコーディングエージェントをデプロイするための、Kubernetes-nativeなランタイムです。解決しようとしている核心的な問題は運用面にあります。これらのエージェントはファイルシステムへのアクセス、ネットワークエグレス、シークレットへのアクセス、そして実行環境を必要としますが、ローカルで実行する場合はいずれも管理されていません。エージェントの実行をKubernetesのpod内に移行することで、AgynはRBAC、ネットワークポリシー、監査ログ、Kubernetes SecretsまたはExternal Vaultを通じたシークレット管理、リソースクォータといった標準的なエンタープライズ制御を適用できます。このプラットフォームはエージェントのライフサイクルを抽象化しており、エージェント呼び出しごとに独立した実行環境をプロビジョニングし、タスクにスコープされたクレデンシャルをインジェクションし、エグレスルールを適用し、監査用の実行ログを収集します。これが重要なのは、規制産業の組織において、開発者ツールがデータレジデンシー、アクセス制御、および監査要件を満たさなければならない場合に、ローカルで動作するエージェントプロセスではこれらの要件を満たせないからです。Kubernetes-nativeな設計により、既存のクラスターインフラとの組み合わせが可能であり、既存のIngressコントローラー、監視スタック(Prometheus/Grafana)、CI/CDパイプラインはそのまま変更なしに利用できます。オープンソースであることは、セキュリティチームがSaaSベンダーの分離に関する主張を信頼するのではなく、コントロールプレーンのロジックを直接検査・監査できるという点で重要な意味を持ちます。運用面では、エージェントの実行をアプリケーションサービスと並ぶクラスター内のファーストクラスのワークロードタイプとして位置づけています。
Source: https://github.com/agynio/platform
ozgurcd/gograph
Gographは、Goリポジトリを解析して内部の依存グラフおよびコールグラフの構造化表現を生成するローカルCLIツールです。IDEやAIコーディングアシスタントに提供するコンテキストの質を改善することを目的として設計されています。このツールが解決しようとしている問題は、深いパッケージ階層と広範な内部インポートを持つGoコードベースが、ファイルを個別に扱うツールによってはほとんど理解されないという点にあります。単一ファイルしか与えられていないコードアシスタントには、そのファイルのパッケージがどのように利用されているか、あるいは何に依存しているかを把握する手段がありません。Gographはリポジトリ構造をグラフとして構築し、IDEのコンテキストやLLMのプロンプトに注入できる形式で出力することで、特定の変更について推論を行う前にコードベースのトポロジーのマップをモデルに提供します。ローカルのみで動作する設計は意図的な選択であり、外部サービスにコードが送信されることはないため、プロプライエタリなコードベースにとっても安心して利用できます。また、説明中に高速性が明示されている点から、バッチ解析ではなくインタラクティブな使用を想定していることが伺えます。具体的には、ファイル保存時やプロンプト送信前に実行できるほどの低レイテンシを目指していると考えられます。Goの明示的なインポートシステムとパッケージレベルの可視性ルールにより、完全な型チェッカーを必要とせず比較的扱いやすい静的グラフ構築が可能ですが、Goにおける正確なコールグラフ解析にはポインタ解析(例:golang.org/x/tools/go/callgraph)が依然として必要です。このツールは、完全なプログラム解析よりも、コンテキスト拡張という実用的なユースケースを対象としているようです。
Source: https://github.com/ozgurcd/gograph
AzmxAI/azmx
AZMXは、ホスト型APIへの依存ではなく、インフラの所有権とエージェント実行の制御を設計の重点に置いた、ソブリンエージェントプラットフォームとして自らを位置づけています。「ソブリン」というフレーミングは、エンタープライズおよび政府のコンテキストにおける特定の懸念に対処するものです。すなわち、サードパーティのモデルAPIを呼び出すエージェントシステムは、データ漏洩リスク、予測不可能なレイテンシ、および外部の可用性への依存をもたらすという問題です。ソブリンプラットフォームは、モデル推論、ツール実行、オーケストレーション、メモリといったフルスタックを制御された境界内で実行できることを意味します。435のスターを獲得しており、このバッチの中で最もスターの多いアイテムであり、一定の注目を集めていることが伺えます。このプラットフォームは、マルチエージェントワークフローを構成するためのオーケストレーションプリミティブを提供しつつ、セルフホスト型モデル(Ollama、vLLM、あるいは類似の推論サーバー)を含むモデルバックエンドの差し替えを可能にしているようです。ツーリングレイヤーはエージェントとツールのバインディングを処理します。これは、LLMの出力をファイルシステム、APIコール、データベースクエリといった実行可能なアクションに、適切なサンドボックス化とともに接続するという機械的な作業です。オンプレミスのGPUインフラへの推論向け投資をすでに行っている組織にとって、ソブリンエージェントプラットフォームは、ローカル推論とクラウドホスト型オーケストレーションの間のアーキテクチャ上の分断を回避できます。オープンソースとしてのリリースにより、オーケストレーションロジックの検査が可能となります。これは、オーケストレーター自体がトラストバウンダリーとなる、セキュリティに敏感なデプロイメントにおいて重要です。状態管理、ツールサンドボックス化、およびマルチエージェント協調の具体的な実装の詳細が、AutoGenやCrewAIといった代替手段と比較評価する際の軸となります。
Source: https://github.com/AzmxAI/azmx
ClouGence/open-cdm
Open-CDMは、個人の開発者ではなくチーム環境を対象としたオープンソースの協調型データベース管理プラットフォームです。その機能セットは、生のデータベースクライアント(DBeaver、TablePlus)と本格的なデータガバナンスプラットフォームとの間にある運用上のギャップに対処しています。具体的には、ロールベースの権限によるアクセス制御、クエリ結果における機密カラムをマスクするデータ匿名化、実行履歴と承認ワークフローを備えたSQL監査、そしてスキーマ変更管理のためのCI/CD連携を提供します。クロスリージョン展開のサポートは、複数のデータセンターやクラウドリージョンにまたがる分散データベースインフラを運用する組織を想定して設計されていることを示しています。このような環境では、単一の管理プレーンがデータレジデンシーの制約を遵守しながら接続を統合管理する必要があります。SQL監査コンポーネントはコンプライアンスのユースケースに特に有用です。金融サービスや医療機関では、誰がいつどのデータを照会したかを示す改ざん不能なログが求められることが多く、生のデータベースクライアントのほとんどはこれを提供していません。データ匿名化レイヤーはアーキテクチャ的に興味深い設計です。これは、一定の権限レベルを下回るユーザーに結果を返す前に、機密カラムの値を書き換えるクエリプロキシまたはクエリ結果の後処理ステップを意味しており、基盤となるデータベーススキーマへの変更を必要としません。データベース変更に対するCI/CD連携はよく知られたニーズであり(Flyway、Liquibaseがマイグレーション側を解決しています)、これをアクセス制御と監査と単一ツールに統合することで、DBAチームが運用しなければならないシステムの数を削減できます。完全なオープンソースであることにより、商用のデータガバナンスツールに付きものなライセンスの摩擦が解消されます。
Source: https://github.com/ClouGence/open-cdm
leiting-eric/DailyBrief
DailyBriefは、23のデータソース(GitHubトレンドリポジトリ、X(Twitter)の投稿、金融市場データ)からデータを収集し、LLMベースの要約処理を実行して中国語のダイジェストを生成する、自動化されたニュース集約・要約パイプラインです。このパイプラインはローカル環境またはGitHub Actions経由でデプロイ可能であり、専用のサーバーインフラを必要とせずに利用できます。技術的なアーキテクチャは、複数ソースのETLをLLM要約ステップに接続する標準的な構成で、各データソースにはスクレイパーまたはAPIクライアントが用意されており、出力は共通のドキュメントスキーマに正規化された後、要約プロンプトによって最終的なダイジェストが生成されます。23ソースという幅広さは運用上の複雑な部分であり、異種ソース(GitHub API、X APIまたはスクレイピング、市場データフィード)向けのパーサーを維持するには、上流APIの変更に伴う継続的なメンテナンスが必要です。GitHub Actionsによるデプロイ方式は特筆すべき点で、GitHubの無料CIコンピュートを使用してスケジュール実行が可能であり、ダイジェストの出力はリポジトリにコミットバックされるか、webhookで送信されるため、常時稼働のインフラが不要です。市場テクニカル分析コンポーネントは、生の価格データを単純に取り込むのではなく、要約前に価格データに対して何らかの定量的指標(移動平均、RSI、または類似のもの)を算出することを示唆しています。MLリポジトリの活動状況に関する日次の構造化サマリーを、より広範な技術・市場コンテキストとともに求める研究者や実務者にとって、このツールはプロンプトや集約ロジックを完全に把握できる、商用ニュースレターサービスに代わるカスタマイズ可能なセルフホスト型の選択肢を提供します。