Daily AI Digest — 2026-05-28
arXiv Highlights
Gamma-World: Generative Multi-Agent World Modeling Beyond Two Players
Problem
Interactive world models — Genie, GameNGen, Oasis, and the diffusion-based simulators that followed — assume a single control signal driving a single observation stream. Many target domains (multiplayer games, embodied multi-robot manipulation, traffic simulation, sports) violate this. Naively concatenating N agents into one model breaks down for three reasons: (1) the model needs to remain equivariant under agent relabeling so that swapping player IDs swaps outputs, (2) per-slot learned identity tokens fix N at training time and overfit to ordering, and (3) full cross-agent attention scales as O(N^2 L^2) in tokens, which becomes the dominant cost when each agent contributes a temporally extended visual stream. Gamma-World targets exactly this regime: a generative world model that is independently controllable per agent, permutation-symmetric, and tractable for N \gg 2.
Method
The backbone is a standard latent-diffusion video model conditioned on per-agent action streams. The two contributions sit inside the attention stack.
Simplex Rotary Agent Encoding (SRAE). Standard 3D RoPE encodes (t, h, w) via block-diagonal rotations R(\theta_t), R(\theta_h), R(\theta_w) applied to query/key pairs. SRAE extends this with a fourth rotary axis indexing agent identity. The key design constraint is that agents must be equidistant in phase: any two distinct agents should have the same phase separation, so that no agent has a privileged position. This is achieved by mapping the N agents to the N vertices of a regular simplex embedded in the rotary angle space. Concretely, for agent i the agent-axis rotation angle is
\phi_i = \langle v_i, \omega \rangle, \quad v_i \in \mathbb{R}^{N-1} \text{ a simplex vertex},
with \omega the standard RoPE frequency vector. Because the simplex is invariant under the symmetric group S_N acting by vertex permutation, swapping agent indices reduces to a global rotation in attention scores, which cancels in the softmax up to relabeling of outputs. Crucially this is parameter-free: no learned agent embedding, no fixed slot count, and any N at inference is supported by re-instantiating the simplex.
Sparse Hub Attention (SHA). Dense cross-agent attention costs O((NL)^2) for L tokens per agent. SHA introduces K learnable hub tokens per layer that mediate inter-agent communication. Within an agent, tokens attend to their own stream plus the hubs; hubs attend to all agents’ tokens. This reduces cross-agent cost from O(N^2 L^2) to O(NLK) with K \ll NL. Structurally it is the now-familiar perceiver/register-token pattern, specialized to the agent axis: hubs aggregate a low-rank summary of each agent’s state and broadcast it back, so consistency (shared world geometry, mutual visibility, collision events) propagates without quadratic blowup. Self-attention within an agent’s spatiotemporal tokens remains dense, preserving per-agent visual fidelity.
The two pieces compose: SRAE provides identity and equivariance, SHA provides scalable mixing. Both are drop-in replacements for standard RoPE and standard attention blocks, so the diffusion training objective and sampling procedure are unchanged.
Results
The paper evaluates on multi-agent generative simulation benchmarks ranging from 2 to “beyond two” agents. The headline claims, as described in the abstract, are: (i) permutation symmetry holds empirically — outputs are invariant under agent relabeling up to numerical noise, (ii) inference cost scales sub-quadratically in N thanks to SHA, and (iii) trajectory consistency across agents (no teleportation, no identity bleed) is preserved as N grows. The abstract is truncated in the provided text and does not surface specific FVD or controllability numbers, so concrete deltas against per-slot-embedding and dense-attention baselines are not quotable here.
Limitations and open questions
Several issues are visible from the design alone. First, the simplex encoding fixes agents as exchangeable, which is exactly wrong when agents have heterogeneous roles (e.g., goalkeeper vs. striker, leader vs. follower, ego vs. NPC); recovering role asymmetry would require breaking the simplex symmetry with auxiliary role embeddings, partially defeating the parameter-free property. Second, hub tokens are a bottleneck: with too few hubs, fine-grained interactions (precise contact, occlusion ordering between specific agent pairs) must funnel through a low-rank channel, and there is no analysis in the abstract of how K should scale with N or with interaction density. Third, the maximum N at training versus inference is unclear; while SRAE is parameter-free in N, the diffusion model’s other components (action encoder, normalization statistics) may still be tuned to a training distribution of agent counts. Finally, the action conditioning interface — how an agent’s discrete or continuous control vector is injected into its token stream without leaking into others through the hubs — is not detailed in the abstract.
Why this matters
Multi-agent interactive world models are the natural next target after single-player neural game engines, and the architectural primitives here — a permutation-symmetric rotary identity and a hub-mediated sparse cross-agent channel — are the kind of small, composable changes that other diffusion-based simulators can adopt without retraining from scratch. If the symmetry and scaling claims hold up under scrutiny, this becomes a default recipe for N-agent generative simulation.
Source: https://arxiv.org/abs/2605.28816
Self-Improving Language Models with Bidirectional Evolutionary Search
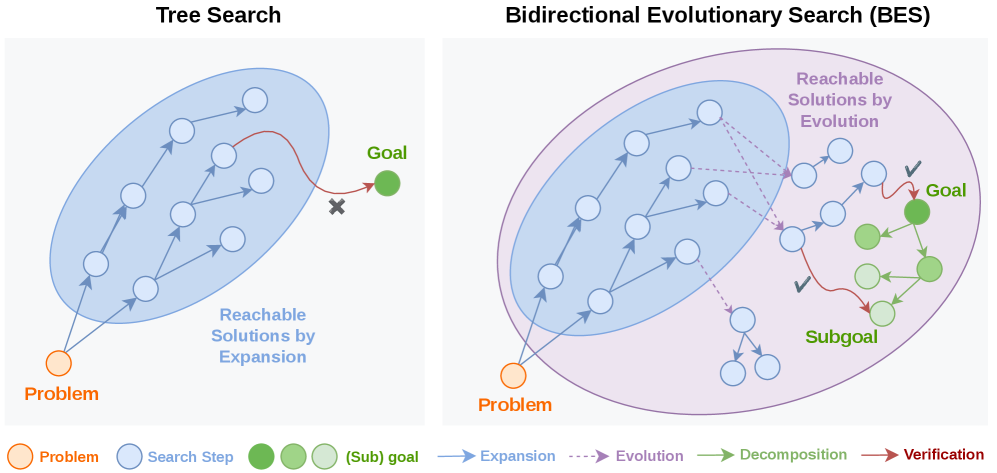
Search-based self-improvement (best-of-N, MCTS, tree search) has two structural weaknesses when applied to LLMs: candidates are scored by sparse terminal verifiers, and they are constructed by autoregressive expansion from \pi_\theta. The latter restricts the reachable set to a narrow region of probability mass — exactly the region the model already explores. Bidirectional Evolutionary Search (BES) attacks both issues by (i) augmenting forward expansion with biological-style recombination operators, and (ii) running a backward search that recursively decomposes the goal into checkable subgoals to provide dense scores.
Forward search: expansion plus four evolution operators
A candidate is a partial trajectory n=(y_1,\dots,y_t) where each y_i is a reasoning step or action. The candidate pool \mathcal{P} is grown step by step. Standard expansion samples K\sim\mathrm{Uniform}\{1,\dots,K_{\max}\} and draws
y_{t+k}\sim \pi_\theta(\cdot\mid x\oplus y_1\oplus\cdots\oplus y_{t+k-1}).
On top of this, BES applies four edit operators on existing trajectories (illustrated in Figure 2): Combination concatenates the distinct suffixes of two trajectories sharing a prefix; Deletion removes an interior step; Translocation replaces one step in path A with a step from path B; Crossover splices the prefix of A onto the tail of B.
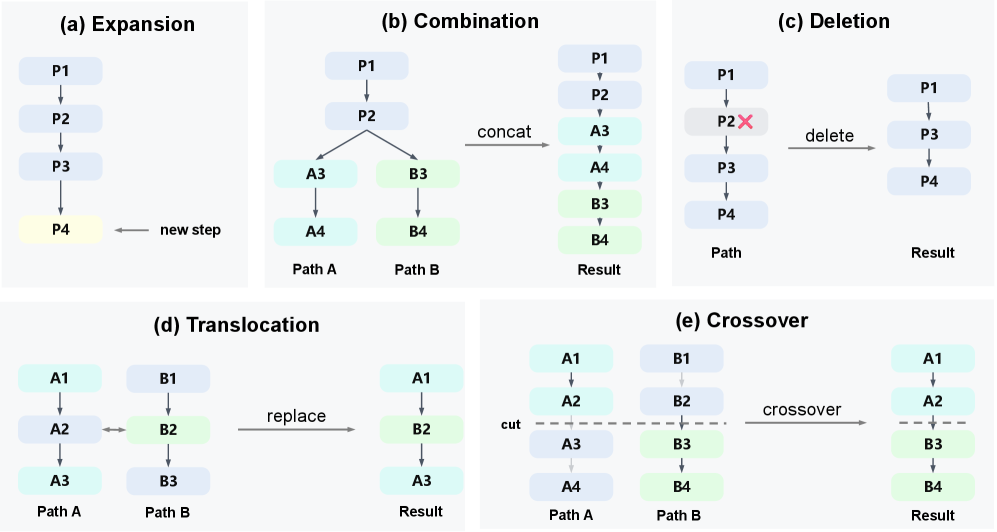
Operators are sampled with fixed probabilities; parents are drawn from a Boltzmann distribution over a base score over \mathcal{C}_t. When direct concatenation is ill-defined (e.g., free-form natural language), the same operators can be implemented by prompting \pi_\theta to perform the edit. Crucially, evolution does not require each child to be an improvement — only that a non-trivial fraction be useful, since the search retains the best candidates.
Backward search: dense subgoal scores
Forward search alone leaves the score sparse. BES interleaves a backward pass that recursively decomposes the task x into checkable subgoals, producing intermediate verifications that score partial trajectories. One backward step is run every several forward steps, and the backward score is what feeds the Boltzmann selection in the forward loop. This is the “bidirectional” coupling: forward proposes, backward grades at intermediate granularity.
Why evolution operators are necessary: entropy-shell argument
The paper formalizes the intuition that expansion is stuck in a typical set. Fix horizon T, partition trajectories into k blocks U_1,\dots,U_k, and assume bounded per-step surprise (-\log P(v\mid y_{<t})\le L), decaying step dependence (\beta_\ell summable), and linear block total correlation (\sum_j H_P(U_j)-H_P(U_1,\dots,U_k)\ge \gamma T). Theorem 4.4 then states:
- Shell confinement: every Y\sim P from expansion-only search lies in A_\epsilon^{(T)}=\{y:|-\log P(y)-H_T|\le\epsilon T\} except with probability \exp(-\Omega(T)). The reachable set has size at most \exp(H_T+\epsilon T).
- Shell escape: under the k-time evolution distribution Q=\bigotimes_j P_j (i.e., concatenating blocks sampled independently),
\mathbb{E}_Q[-\log P(\widetilde Y)] \ge H_T + \gamma T,
and
\Pr_Q[\widetilde Y \in A_\epsilon^{(T)}] \le 1-\frac{(\gamma-\epsilon)T}{LT-H_T-\epsilon T} < 1.
The mechanism is that evolution operators break inter-block conditional dependence; the resulting candidate’s surprise inherits the block total correlation, which grows linearly in T under Assumption 4.3. So a constant fraction of evolution candidates fall outside the shell that confines any policy rollout.
Experiments
BES is evaluated as a sampler for both post-training (Logical Reasoning on Knights-and-Knaves; Multi-Hop Reasoning agents) and inference (Circle Packing in square and rectangle, Heilbronn Convex). The post-training results on Knights-and-Knaves are the most directly informative for the entropy-shell claim. Using Gemma-3-1B-it, the authors do a 1K-example SFT cold start (3 epochs) followed by 4 epochs of RL on 5K problems, comparing GRPO, MaxRL, and BES (applied on top of MaxRL). BES is sampler-only, so it could in principle ride on any post-training algorithm.
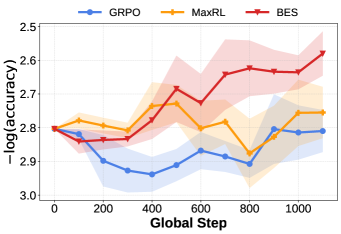
On the 1.3K validation set, GRPO and MaxRL show essentially no improvement across training because the dataset is hard enough that pure-rollout sampling rarely produces correct trajectories — the verifier signal is too sparse to drive learning. BES, by contrast, monotonically improves throughout training, consistent with its ability to surface correct trajectories that no single rollout from \pi_\theta would generate. The paper reports analogous gains on the agentic multi-hop and inference-time geometry benchmarks (open-ended optimization problems where there is no prebuilt verifier ladder, only the backward-decomposed scores).
Limitations and open questions
The theorem’s bite depends on Assumption 4.3 (\gamma>0 block total correlation); for tasks where blocks are nearly independent, the escape margin shrinks. The four operators are syntactic edits at the step level, which assumes a clean step segmentation — non-trivial for free-form generation, where the prompt-based fallback reintroduces \pi_\theta’s biases. The validation curve in Figure 3 is shown for one base model (Gemma-3-1B-it); scaling behavior at larger model sizes, where the shell may already be wider, is not addressed. Finally, backward decomposition quality is itself produced by an LLM and may inject systematic errors into the dense scores; the paper does not isolate the contribution of forward evolution vs. backward decomposition.
Why this matters
Evolution operators give a principled way out of the entropy-shell trap that bounds any expansion-only sampler, and the bidirectional coupling addresses the verifier-sparsity problem that has stalled RL on hard reasoning tasks. If the result generalizes, search-driven self-improvement need not be bottlenecked by what \pi_\theta already places mass on.
Source: https://arxiv.org/abs/2605.28814
ScientistOne: Towards Human-Level Autonomous Research via Chain-of-Evidence
Problem
Autonomous research agents now produce papers that pass surface-level review yet fail at verifiability: bibliographies contain references that do not exist, reported scores do not reproduce when the submitted code is re-run, and method sections describe architectures that diverge from what the code implements. Standard evaluation — leaderboard scores, LLM-as-judge on prose quality — does not catch any of this. As autonomous systems scale paper output, these failures pollute downstream literature and corrupt the citation graph. The paper proposes a verifiability standard, an agent designed to satisfy it by construction, and a post-hoc audit that applies uniformly across systems.
Chain-of-Evidence as a standard
The authors define Chain-of-Evidence (CoE) analogously to ACID for databases: a property specification, not an architecture. Every claim in a research artifact must be traceable through a recorded chain to a grounding source. Four claim types are made tractable:
- Citation claims: must resolve to a record in a scholarly database with content consistent with how the citing paper describes it.
- Numerical claims: must trace to an execution log or measured output.
- Methodological claims: must resolve to the implementing code.
- Conclusion claims: must derive from supporting numerical/methodological claims via verifiable reasoning.
Other claim types (qualitative observations, theoretical properties) are excluded as not currently automatable.
ScientistOne: CoE by construction
ScientistOne is a three-stage pipeline (Figure 1) where every module emits structured artifacts carrying provenance metadata.
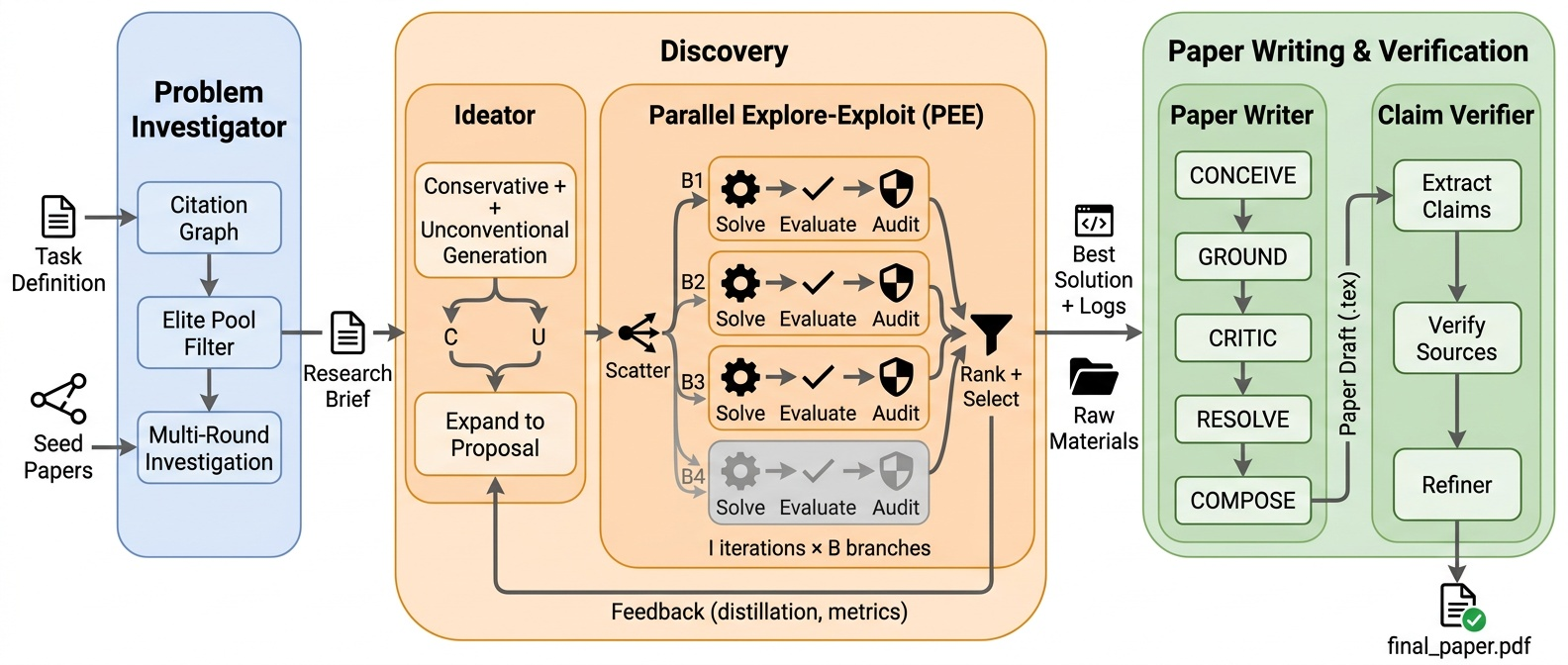
- Stage 1 — Problem Investigator (PI): Begins from seed papers, expands a citation graph through scholarly database APIs, retrieves and reads up to 100 full-text PDFs per topic, and emits a structured research brief. The bibliography accompanying the brief becomes the only legal source pool for citation claims downstream — eliminating the failure mode where systems generate plausible-looking citations from parametric memory.
- Stage 2 — Ideator/Solver: Explores parallel solution branches and evaluates them against the task’s scoring function; every numerical claim is anchored to an execution log.
- Stage 3 — Writer + Claim Verifier: Drafts the paper, then a Claim Verifier checks every claim against its recorded evidence source before emission. Failure to resolve a claim blocks the artifact from being finalized.
CoE Integrity Audit
The audit (Figure 2) is system-agnostic: an adapter normalizes any system’s paper.tex, solution code, and references.bib into a common artifact bundle, then runs four independent checks.
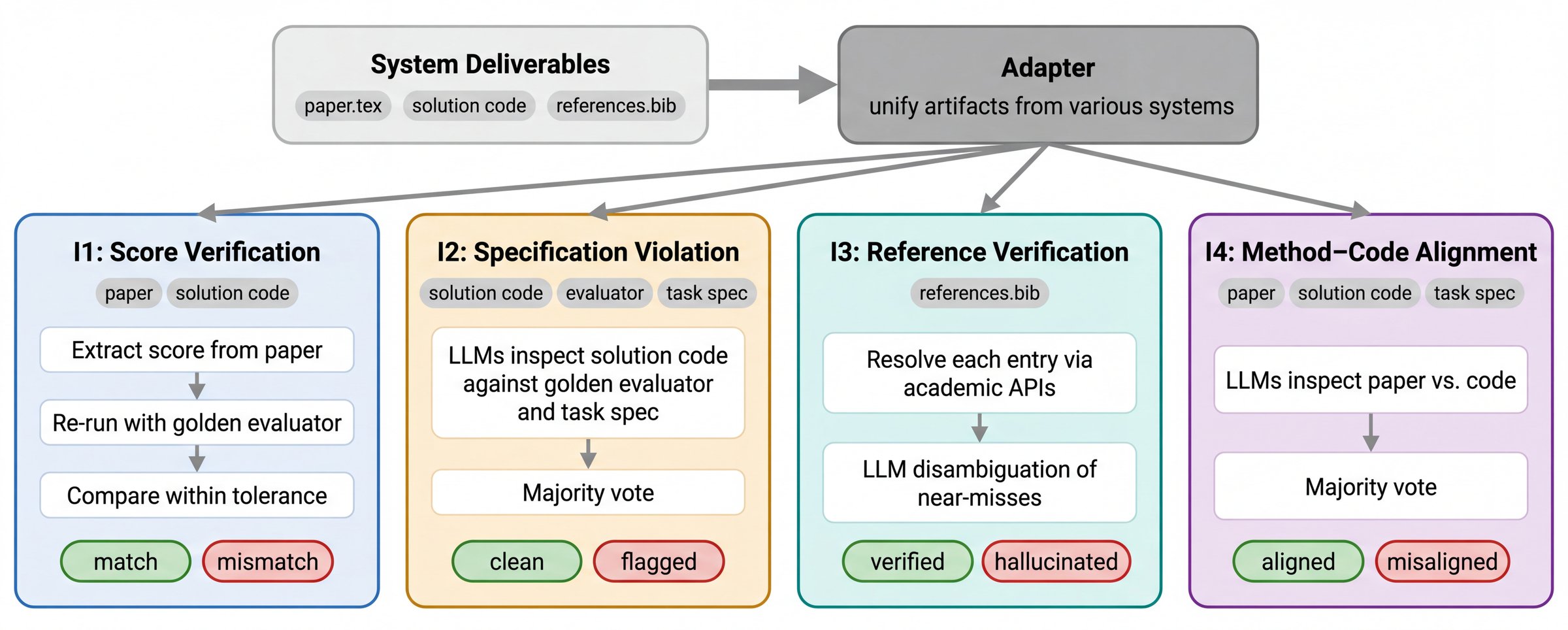
- I1 Score Verification: Extracts the reported score from TeX/PDF via LLM, re-runs the submitted solution on the golden evaluator, and compares within adaptive tolerance \max(1\%,\, 3\sigma/|\bar{s}|) over five runs to absorb evaluator stochasticity.
- I2 Specification Violation: Majority-vote LLM judgment over solution code, evaluator, and task spec to detect cheating against task constraints.
- I3 Reference Verification: Each
bibentry resolved through academic APIs with LLM disambiguation of near-misses. - I4 Method–Code Alignment: Majority-vote LLM judgment comparing method description to implementation.
Results
Across 75 papers from five autonomous systems on five ADRS tasks (Prism, Cloudcast, EPLB, LLM-SQL, TXN), every baseline exhibits at least one systematic failure: hallucinated reference rates up to 21%, score verification passing in as few as 42% of papers, and method-code alignment ranging 20–80%. ScientistOne achieves 0/337 hallucinated references and (per the abstract continuation) perfect score verification.
Generalization is tested on five MLE-Bench Kaggle tasks (Medium/High difficulty) and the Parameter Golf LLM-training competition. ScientistOne earns Gold on RSNA Brain Tumor (0.6518) and 3D Object Detection (0.1763, where the DeepScientist baseline scored 0.0000), Silver on iMet 2020 (0.6791) and iNaturalist 2019 (0.2445), and Above Median on AI4Code (0.8356 vs. 0.6964). On Parameter Golf, DeepScientist produced an invalid submission (16MB size limit exceeded); ScientistOne respected the constraint and achieved 1.0600, matching the SOTA-as-of-cutoff (1.0611) on a competition where the leaderboard has since advanced.
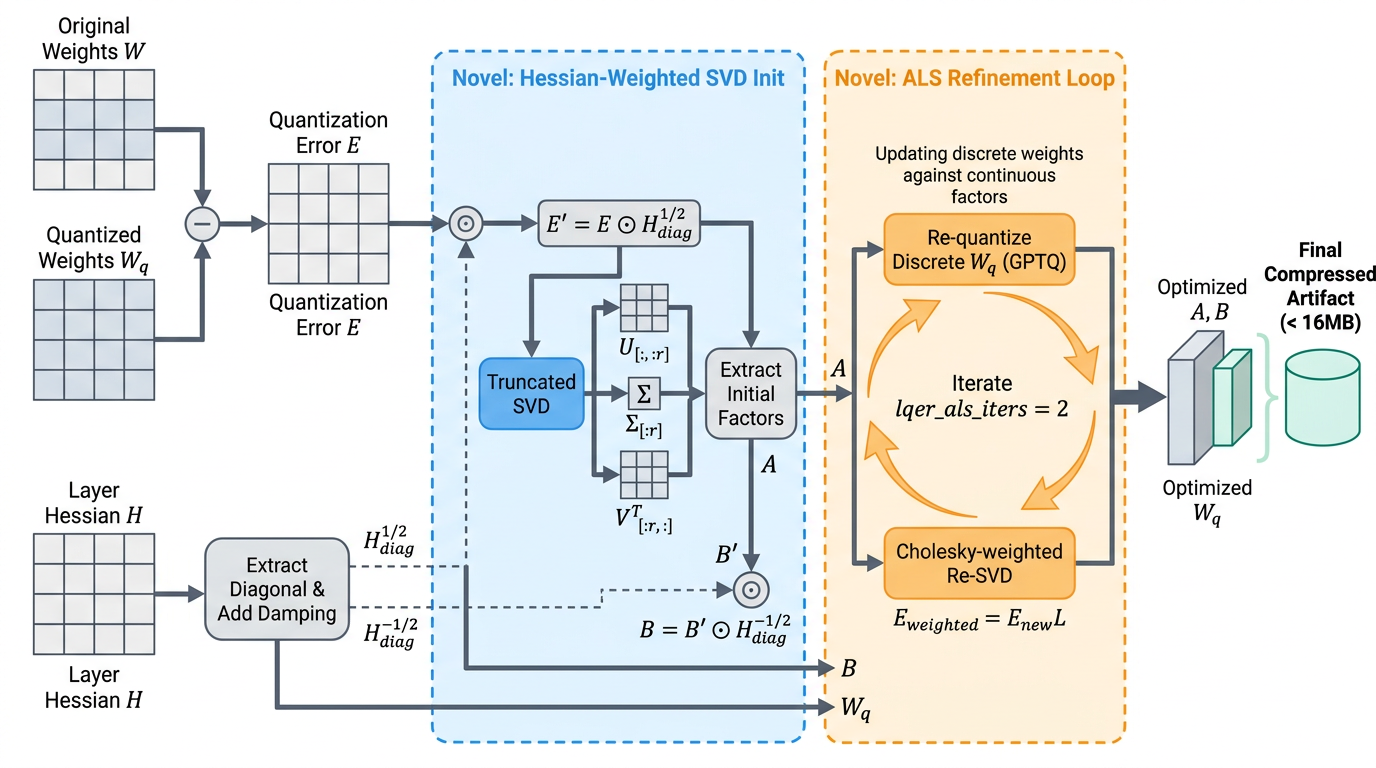
The Parameter Golf solution is non-trivial: a Hessian-diagonal-weighted SVD initialization composed with a GPTQ-driven ALS refinement loop, suggesting the discovery loop produces meaningful algorithmic structure rather than hyperparameter sweeps.
Limitations and open questions
- The CoE taxonomy excludes qualitative and theoretical claims; “verifiability” here is restricted to what current tooling can mechanically check. A paper can satisfy CoE and still be scientifically vacuous.
- I2 and I4 rely on majority-vote LLM judgment, which inherits the judge’s biases and may miss subtle specification violations or method-code drift, particularly in unfamiliar domains.
- Score verification depends on deterministic, re-runnable evaluators. ADRS and MLE-Bench fit; many ML research questions (architectural claims requiring large-scale training, theoretical results) do not.
- The audit caps reference verification at scholarly database resolution; semantic consistency between citation and cited content is checked only by LLM, leaving room for misrepresentation that the cited paper actually exists.
- “Zero hallucinated references” is a strong claim, but the construction (constrain Writer to PI’s bibliography) means the result is partly tautological — the harder question is whether PI’s retrieval covers the relevant literature.
Why this matters
CoE reframes evaluation of autonomous research from output quality to artifact integrity, and the audit gives a system-agnostic instrument that exposes failure modes invisible to leaderboards or LLM judges. As agentic paper-generation scales, this kind of provenance-by-construction is likely a prerequisite for any output to be admissible into the literature.
Source: https://arxiv.org/abs/2605.26340
ProRL: Effective Reinforcement Learning for Proactive Recommendation via Rectified Policy Gradient Estimation
Problem
Proactive Recommender Systems (PRSs) generate a path of intermediate items that gradually shift a user from current preferences toward a target preference, while keeping each step acceptable (clickable). The toy setup is a genre transition from Sci-Fi to Comedy via blended intermediate items.

RL is the natural formalism: define a path \tau=(a_1,\dots,a_L), attach step rewards r_t that combine short-term acceptance (CTR) with long-term guidance signals (Increment of Interest, IoI; Increment of Rank, IoR), and optimize J(\theta)=\mathbb{E}_{\tau\sim\pi_\theta}\!\left[\sum_t r_t\right] via policy gradient. The authors show this naive recipe fails in two specific, diagnosable ways.
Two deficiencies in the standard policy gradient
The step rewards used in PRS (CTR, IoI, IoR) are non-negative and have positive expectation under any reasonable policy: \mathbb{E}[r_t] > 0. The expected path return then scales with length, \sum_{t=1}^{L}\mathbb{E}[r_t] \propto L. Two consequences follow:
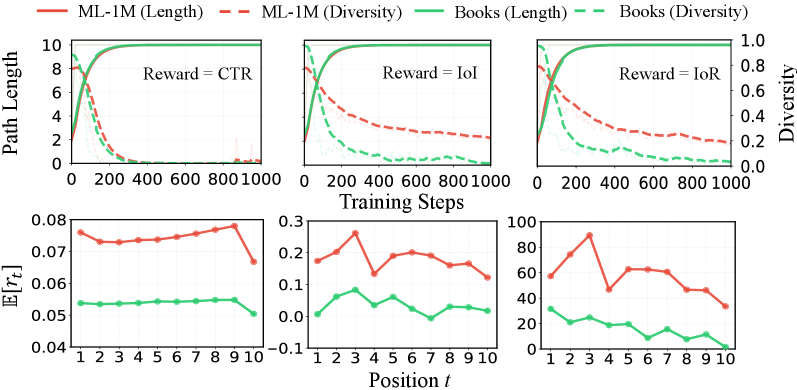
- Length shortcut. With sequence-level advantage A(\tau)=R(\tau)-b, the gradient signal is dominated by length rather than item choice. Empirically, training collapses to nearly identical overlong paths: path length explodes while diversity drops, across CTR/IoI/IoR rewards on both MovieLens-1M and Amazon-Book.
- High variance. Weighting every step t by the entire path return R(\tau) ignores the additive decomposition R(\tau)=\sum_t r_t, inflating the variance of the per-step gradient term beyond what the structure warrants.
Method: ProRL
ProRL keeps the standard REINFORCE-style update
\nabla_\theta J = \mathbb{E}\!\left[\sum_{t=1}^{L} A_t\,\nabla_\theta \log \pi_\theta(a_t\mid s_t)\right]
but replaces A_t with two rectifications.
Stepwise Reward Centering (SRC). Subtract a step-conditional expected reward \bar r_t=\mathbb{E}[r_t\mid s_t] (or a position-indexed running estimate), so each step contributes a centered reward \tilde r_t = r_t - \bar r_t with \mathbb{E}[\tilde r_t]=0. The path-level centered return \sum_t \tilde r_t then has zero expected gain from extending the path: any additional step contributes zero expected gradient mass, eliminating the length shortcut. This is the key conceptual move — it neutralizes the \mathbb{E}[r_t]>0 bias without changing the optimum, since subtracting a state-conditional baseline preserves the gradient in expectation.
Position-Specific Advantage Estimation (PSAE). Rather than assigning R(\tau)-b to every step, PSAE exploits the additive decomposition to compute a position-specific advantage
A_t = \sum_{k\ge t} \tilde r_k - b_t,
where b_t is a position-indexed baseline learned from rollouts. This yields a lower-variance estimator: each step is credited with the centered tail return relevant to its decision, mirroring the variance-reduction logic of standard advantage estimation but adapted to the per-step PRS reward structure.
The full update is a drop-in replacement for the policy gradient term in any PRS RL trainer; the two mechanisms are orthogonal and can be ablated independently.
Experiments
Datasets. MovieLens-1M, Steam, Amazon-Book, split 8:1:1 by user.
Baselines. Sequential recommenders (GRU4Rec, BERT4Rec, LightSANs, FEARec); supervised proactive (IRN); heuristic proactive (IPG, ITMPRec); LLM-based proactive (LLM-IPP, T-PRA).
Metrics. Increment of Interest (IoI) and Increment of Rank (IoR) for guidance effectiveness; CTR/HitRate for path feasibility; Coherence for semantic consistency between consecutive items.
The diagnostic in Figure 2 is itself a quantitative result: under standard PG, path length grows monotonically while diversity decays toward a near-degenerate distribution across all three reward configurations and both datasets, confirming that the length shortcut is not a hyperparameter artifact but a structural failure mode. ProRL is reported to outperform the baselines on guidance metrics (IoI, IoR) while preserving CTR and coherence; the paper’s Appendix E contains the full hyperparameter sweep.
Limitations and open questions
- Centering requires a reliable estimate of \bar r_t; for sparse long-tail items, \bar r_t estimates may be noisy and require regularization or pooled baselines.
- The analysis assumes step rewards have positive mean. Reward shaping that mixes signed components (e.g., penalties for off-target items) could partially mitigate the bias without SRC, but interactions with PSAE are not explored.
- All evaluation uses offline simulators of user response; whether the eliminated length shortcut survives in online deployment with feedback loops remains untested.
- The framework is agnostic to the policy class but is demonstrated on transformer-style sequential models; behavior with LLM-policy backbones (where action spaces are token-level rather than item-level) is open.
Why this matters
Naive RL on PRS does not fail because of optimization difficulty — it fails because the reward decomposition has a structural positive mean that converts policy gradient into a length-maximization signal. ProRL’s centering plus position-specific advantage is a minimal, principled fix that should generalize to any sequential-decision setting where step rewards are non-negative by construction (dialogue turns, tutoring trajectories, multi-step retrieval).
Source: https://arxiv.org/abs/2605.28293
Agent Explorative Policy Optimization for Multimodal Agentic Reasoning
Problem
Multimodal agents that interleave chain-of-thought with external tool calls (image crops, search, code execution, etc.) display a structural asymmetry the authors call the Thinking-Acting Gap. Thinking is the model’s default, low-variance behavior; tool use is a higher-variance auxiliary act whose outcome depends on the tool’s response, which the policy does not control. Under vanilla GRPO this asymmetry produces two measurable pathologies during training:
- Tool use is attempted on only roughly 30\% of rollouts.
- On about 40\% of questions where tool use is attempted, the entire tool-using subgroup is wrong, so the GRPO group-relative advantage at the tool-call tokens collapses to zero.
The net effect: precisely the trajectories that need credit assignment — those involving the noisy auxiliary action — receive no gradient. The thinking-only modality dominates and the policy regresses toward thinking-only behavior, undercutting the agentic objective.
Method: AXPO
AXPO (Agent eXplorative Policy Optimization) modifies the GRPO rollout/credit-assignment pipeline to inject targeted exploration at exactly the failure point above. For a question q with sampled group \{\tau_i\}_{i=1}^G, let S_{\text{tool}}(q) \subseteq \{\tau_i\} be the tool-using subgroup. If S_{\text{tool}}(q) is non-empty and all-wrong (the diagnostic symptom), AXPO performs prefix-fixed resampling:
- Choose a “thinking prefix” \tau_i^{<t} from S_{\text{tool}}(q), where t is the position of the first tool-call token.
- Freeze \tau_i^{<t} and resample K new continuations \tau^{\geq t} from the policy, executing the tool and continuing generation.
- These resampled rollouts replace (or augment) the failed subgroup; advantages are recomputed on the augmented group.
The prefix is selected by uncertainty-based prefix selection: among candidate prefixes in S_{\text{tool}}(q), pick the one whose pre-tool-call token distribution has highest entropy, i.e.
\tau^\star = \arg\max_{\tau_i \in S_{\text{tool}}(q)} \; \frac{1}{t}\sum_{s<t} H\!\left(\pi_\theta(\cdot \mid \tau_i^{<s})\right).
The intuition: prefixes where the policy was already uncertain at the decision boundary are the ones where alternative tool-call continuations are most likely to flip outcome and therefore most likely to produce a non-degenerate advantage signal. The PPO-style clipped objective is unchanged; only the rollout composition and group construction differ. Concretely, AXPO sits on top of GRPO with two hyperparameters: resample budget K and a trigger condition (all-wrong tool-using subgroup).
This is a targeted form of importance-aware exploration: it spends extra compute only on questions where the standard group estimator is degenerate, and it spends it on the action whose variance caused the degeneracy.
Results
The training recipe is SFT followed by RL on Qwen3-VL-Thinking at 4B/8B/32B scales, evaluated on nine multimodal benchmarks. Headline numbers:
- At 8B, SFT+AXPO beats SFT+GRPO by +1.8pp Pass@1 and +1.8pp Pass@4 averaged across the nine benchmarks.
- 8B SFT+AXPO surpasses 32B Base on Pass@4 — a 4\times parameter reduction at equal or better best-of-4 quality.
- Improvements track the diagnostic: tool-use frequency rises and the fraction of all-wrong tool subgroups drops, confirming the mechanism rather than a generic reward-shaping effect.
The Pass@4 gain matters more than Pass@1 here: AXPO is exploration-driven, and Pass@4 measures whether the policy maintains diverse, occasionally-correct tool-using modes rather than collapsing to a single deterministic chain.
Limitations and open questions
- The trigger (“all-wrong tool-using subgroup”) is binary and reward-thresholded; partial-credit or dense reward settings need a softer criterion.
- Uncertainty-based prefix selection uses token-level entropy averaged over the prefix; this conflates aleatoric uncertainty in surface form with epistemic uncertainty about the tool decision. A learned value/critic-based selector would be more principled.
- Resampling cost is non-trivial: K extra continuations on the hardest subset of questions. The paper does not report wall-clock parity vs. simply increasing GRPO group size G, which is the natural baseline ablation.
- Evaluated only on Qwen3-VL-Thinking; whether the Thinking-Acting Gap manifests identically in non-thinking VLMs or in text-only agentic settings is untested.
- The method addresses tool-call exploration but not tool-output reliability — a wrong tool response still poisons the rollout, and AXPO has no mechanism to down-weight it.
Why this matters
The Thinking-Acting Gap is a clean, measurable failure mode of group-relative RL on agentic policies: high-variance actions get zero gradient precisely when they fail uniformly. AXPO is a minimal, diagnostic-driven fix — fix the prefix, resample the action, select prefixes by uncertainty — that recovers a useful learning signal without changing the underlying objective. The 8B-beats-32B-Base Pass@4 result suggests targeted exploration at action boundaries is a more efficient lever than scaling for agentic multimodal reasoning.
Source: https://arxiv.org/abs/2605.28774
From Pixels to Words – Towards Native One-Vision Models at Scale
Problem
Mainstream VLMs follow a modular template: a frozen or lightly tuned vision encoder (CLIP/SigLIP) feeds visual tokens through an adapter into an LLM decoder. This pipeline fragments pixel-level signal — the encoder commits to a fixed token grid before the LLM ever sees the input, and cross-frame structure is hidden behind a per-frame embedding bottleneck. Native VLMs (single-backbone, no external encoder) have shown competitive single-image performance, but their behavior on multi-image, video, and spatial grounding tasks is largely uncharted. NEO-ov targets exactly this gap: a single decoder-only backbone that handles images, multi-image inputs, and video without auxiliary encoders or post-hoc fusion modules.
Method
NEO-ov extends the NEO native backbone to ordered visual sequences. Inputs are serialized into a single token stream consisting of patch embeddings, frame embeddings, and text tokens, processed by one stack of “native primitive” layers.
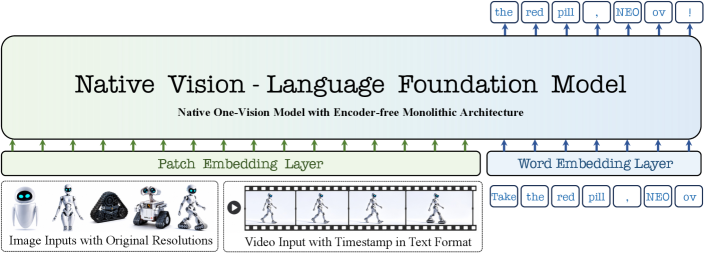
Pixels enter through a two-conv tokenizer with a GELU between them and a 2D positional embedding added between the convolutions:
\boldsymbol{x}_v = \mathrm{Conv}_2(\mathrm{GELU}(\mathrm{Conv}_1(\boldsymbol{I})) + \mathbf{PE}), \qquad \boldsymbol{x}_t = \mathrm{Tokenizer}(\boldsymbol{T}).
\mathrm{Conv}_1 has stride 16 (patchify), \mathrm{Conv}_2 has stride 2 (local aggregation), giving one visual token per 32\times32 pixel region. Visual tokens are bracketed by <img>/</img> and concatenated with text tokens. Pre-Buffer layers (12 for the 2B variant, 6 for the 9B) and the post-LLM stack are initialized from NEO and Qwen3 respectively.
The central architectural choice is a THW-decoupled attention head layout. Each head’s Q/K is split along the channel axis into temporal, height, and width sub-vectors:
\mathbf{q}_i = [\mathbf{q}_i^T; \mathbf{q}_i^H; \mathbf{q}_i^W], \quad \mathbf{k}_j = [\mathbf{k}_j^T; \mathbf{k}_j^H; \mathbf{k}_j^W],
with attention logit
s_{ij} = \langle \mathbf{q}_i^T, \mathbf{k}_j^T\rangle + \langle \mathbf{q}_i^H, \mathbf{k}_j^H\rangle + \langle \mathbf{q}_i^W, \mathbf{k}_j^W\rangle.
The T-branch retains the original LLM head dimension and carries textual order, cross-image relations, and cross-frame dependencies; the H and W branches are added head-dim capacity dedicated to 2D spatial structure. This is paired with Native-RoPE, where each token receives a 3-tuple index \mathrm{idx}_i = [t_i, h_i, w_i]. Text tokens set h_i = w_i = 0 and only carry temporal position; image tokens within a frame share a t_i but vary in (h_i, w_i); video frames advance t_i while reusing the same spatial grid.
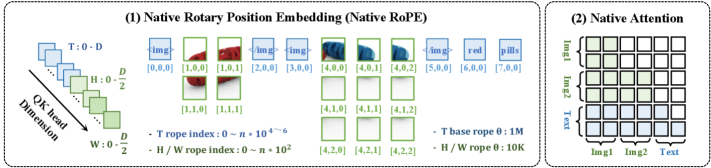
Crucially, the attention mask is mixed: bidirectional within an image’s spatial extent, causal across text tokens and across video frames. This preserves autoregressive language modeling while letting spatial tokens attend symmetrically inside a frame — implementable by composing a block-bidirectional mask on image spans with the standard causal mask elsewhere. RoPE base frequencies are set to \theta_T = 10^6, \theta_H = \theta_W = 10^4; the larger temporal base is consistent with the longer effective range needed for video and multi-image sequences.
Training follows three stages with peak LRs 2\times10^{-4}, 5\times10^{-5}, 5\times10^{-5} under AdamW, cosine decay, and 0.01 warm-up.

Stage 1 aligns the Pre-Buffer with the frozen-style post-LLM on large-scale image–text pairs while preserving language ability. Stage 2 trains on mixed image and video data to develop spatial-temporal reasoning. Stage 3 is instruction tuning on high-quality multimodal data. Backbones are Qwen3-1.7B and Qwen3-8B, yielding NEO-ov (2B) and NEO-ov (9B). Training runs on 16 nodes of 8×80GB GPUs.
Results
The paper’s empirical claim is that a native, encoder-free backbone “largely narrows the gap” to modular VLMs while improving fine-grained perception. The provided sections do not enumerate per-benchmark numbers, but the configuration is concrete: 2B and 9B parameter variants, 32\times32 effective patch granularity, and three-stage training. The architectural ablation centerpiece — that retaining the LLM head dim for T and adding fresh dims for H, W outperforms a flat head split — is the key recipe takeaway, alongside Native-RoPE’s THW index decomposition for unifying single-image, multi-image, and video regimes under one position scheme.
Limitations and open questions
The serialization commits to a fixed 32\times32 region per visual token, which constrains OCR and dense prediction relative to encoders that operate at finer effective strides. The decoupled THW head split adds head-dim parameters that scale with chosen H, W capacity; the paper does not (in the excerpted sections) characterize the cost vs. accuracy trade-off across head allocations. Finally, while the mixed bidirectional/causal mask is principled, its interaction with KV-cache reuse during streaming video inference deserves explicit treatment. The encoder-free posture also pushes all low-level visual inductive bias into the Pre-Buffer; whether 6–12 layers suffice at substantially higher resolutions or longer videos remains open.
Why this matters
NEO-ov is a concrete data point that “one-vision” native VLMs can be scaled to multi-image and video without resurrecting an external encoder, by treating spatial and temporal axes as orthogonal subspaces in both attention heads and RoPE. If the trend holds, the modular CLIP-plus-LLM template — and its alignment-stage overhead — becomes increasingly hard to justify.
Source: https://arxiv.org/abs/2605.28820
ResearchMath-14K: Scaling Research-Level Mathematics via Agents
Problem and motivation
Frontier mathematical reasoning is bottlenecked by data: existing math benchmarks (AIME, MATH, even HLE) are dominated by problems with closed-form answers that are well within the reach of strong reasoners, and the few research-level corpora are small. The authors construct ResearchMath-14k, 14,056 curated research-level problems extracted from 1,233 source documents, and use it to (a) probe the failure modes of current LLMs on genuinely open problems and (b) test whether wrong-but-structured trajectories on such problems can serve as SFT data when correctness labels are unavailable.
Construction pipeline
The corpus is built by a two-agent pipeline (Figure 2): an Extractor agent walks each document, locates candidate open-question spans together with supporting quotes, and emits standalone problem statements; a Refiner agent then checks open status, assigns a taxonomy label, and rewrites each candidate into a self-contained problem, optionally consulting online references. The raw output is 20,835 problems from 1,233 sources, filtered to the released 14,056.
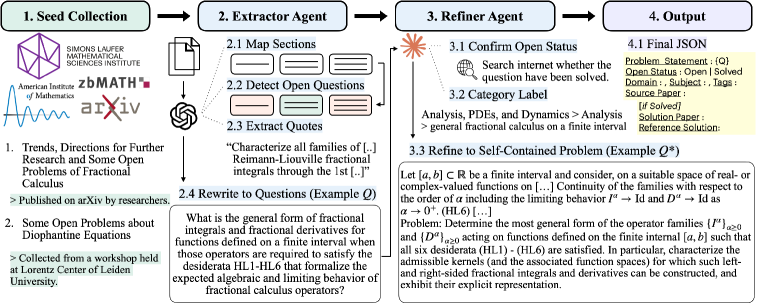
Sources are stratified into three streams: arXiv “open problems / unsolved” papers (524 documents, 8,182 problems), open-problem web pages including MathOverflow and Wikipedia (161 documents, 5,331 problems), and AIM-style problem-session sheets plus conference open-problem rounds (548 documents, 7,322 problems). Domain coverage spans the standard MSC-like top-level areas (Figure 1), with a long tail in logic/foundations and cross-disciplinary entries. Pairwise LLM difficulty judgments converted to Elo (Figure 3, k=32, base 1500) place ResearchMath-14k well above standard math benchmarks.
Teacher trajectories and failure modes
The authors generate ResearchMath-Reasoning, 220K teacher traces from two open models, and evaluate eight models grouped into four older→newer matched pairs: R1→V4-Pro, K2→K2.6, Qwen3-30B→Qwen3.5-35B, Qwen3-235B→Qwen3.5-397B. Roughly 30% of teacher traces are flagged as visibly problematic on manual review; the corpus-scale analysis then quantifies two failure modes.
The headline result is a sharp regression in factuality between the 2025 and 2026 generations across three independent model families. On 720 traces audited by an Agent-Judge, 87.4% (629) cite at least one reference-like object and 54.0% (389) contain at least one fake reference; of 19,864 extracted citations, 3,492 (17.6%) are fake (verified by web search). Per-trace mention counts:
- DeepSeek R1→V4-Pro: 4.9→57.8 mentions (0.5→11.6 fakes)
- Kimi K2→K2.6: 1.9→60.0 (0.1→8.3 fakes)
- Qwen3-30B→Qwen3.5-35B: 6.5→36.7 (1.4→7.7 fakes)
- Qwen3-235B→Qwen3.5-397B: 20.3→32.7 (4.5→4.8 fakes)
Aggregated, newer models produce 5.6\times more reference-like mentions per trace and 5.0\times more fakes. The effect is large on ResearchMath-14k, Leipzig Tier-4, and SOOHAK (row-hit rates rise 30–80 pp), modest on HLE, and near zero on AIME, suggesting the citation impulse is triggered by the academic register of the prompt rather than by content the model knows. Representative fabrications include invented paper titles (“Neeman, A remark on the unique factorization theorem”) and misattributed authors. The authors hypothesize this is a side effect of agentic / search-RL post-training: models trained inside a search-and-cite harness keep emitting citation patterns when the tool is removed, filling the slot with hallucinated bibliographic strings rather than abstaining.
Learning from imperfect traces
Section 5 tests whether filtered, mostly-incorrect traces on open problems still teach. ResearchMath-Reasoning is filtered with the Agent-Judge: every reference-like span is verified against web search, and any trace containing one fake reference is dropped. Budget caps the filtered set at 5,000 traces (ResearchMath-Reasoning-Filtered). As a format-only control, 5,000 traces are sampled from DASD-Thinking. Qwen3-4B/8B/30B-A3B-base are LoRA-fine-tuned on each set and evaluated on AIME 2024–2026 (n=90), integer-answer HLE (n=315), and SOOHAK Challenge+Mini (n=501), scored with math-verify.
Across the three model sizes, fine-tuning on ResearchMath-Reasoning-Filtered improves over the base models by 9.2 points on average, beating the DASD format-control. This supports the paper’s central empirical claim: a strong model attempting an open problem and failing produces traces with transferable structure (relevant objects introduced, plausible reductions attempted, examples tested), whereas naive wrong work does not.
Limitations and open questions
The supervision signal is bounded by Agent-Judge reliability: only reference fabrication is filtered, while non-attempts, vacuous reductions, and silent logical errors pass. The 5,000-trace cap is budget-driven and likely under-scales the effect; whether gains continue with 10^5–10^6 filtered traces is unknown. The fine-tuning is LoRA on Qwen3 base models only, so transfer to RL post-training pipelines is untested. The fabrication-regression claim, while consistent across three families, is observational; a controlled ablation isolating search-RL as the cause is not provided. Finally, AIME/HLE/SOOHAK gains are a proxy: there is no benchmark that directly measures progress on the open problems themselves.
Why this matters
The paper provides both the largest research-level math corpus to date and a concrete, family-agnostic measurement that agentic search-RL is degrading offline factuality, with 5.0\times more fake citations in 2026-generation models. It also demonstrates that filtered failed attempts on open problems are usable SFT data (+9.2 points), pointing to a scalable route for frontier-math supervision that does not require expert-verified solutions.
Source: https://arxiv.org/abs/2605.28003
Hacker News Signals
Go: Support for Generic Methods
Go’s type system has long had a notable gap: you can define generic types and generic functions, but you cannot define methods with their own type parameters distinct from the receiver’s type parameters. This issue tracks the proposal to close that gap.
In current Go, if you have a type T[A], a method on T cannot introduce an independent type parameter B. The workaround is to promote such operations to free functions, which breaks method chaining and interface satisfaction patterns that would be natural in languages with fuller generics. The proposal would allow syntax like func (t T[A]) Convert[B any]() B { ... }.
The core implementation challenge is that Go’s interface dispatch mechanism assumes method sets are fixed at compile time without additional type parameters. Generic methods would require either dictionary-passing (as Go’s current generics use for type parameters on types/functions) extended to per-method type arguments, or some form of monomorphization. The proposal discussion covers whether generic methods could satisfy interfaces — the current consensus leans toward disallowing generic methods in interface definitions initially, mirroring restrictions other languages imposed early on.
A secondary complication is the interaction with type inference. Go’s inference engine already handles multi-level unification for generic functions; adding method-level type parameters increases the inference surface and risks ambiguity in cases where the receiver’s type parameters and the method’s type parameters interact.
This has been a requested feature since generics shipped in Go 1.18 (2022). The linked issue is the active tracking point following an accepted proposal, meaning it has moved past the design debate into implementation planning. The practical impact is significant for library authors building functional-style APIs (maps, filters, transformations) where the current free-function workaround produces awkward call sites and prevents fluent chaining.
Source: https://github.com/golang/go/issues/77273
Matrix Multiplications on GPUs Run Faster When Given “Predictable” Data (2024)
This post documents a reproducible anomaly: GEMM kernels on NVIDIA GPUs run measurably faster when the input matrices contain structured or near-constant data compared to random data, even when the FLOP count is identical.
The mechanism traces to how tensor cores handle subnormal (denormal) floating-point values and how the warp scheduler interacts with data-dependent latency. For FP16 and BF16 GEMM, tensor core throughput is nominally deterministic, but the surrounding infrastructure — register file pressure, shared memory bank conflicts, and pipeline stalls — can vary based on value distribution. More interestingly, the post identifies that when inputs are all-zeros or have many repeated values, certain FP arithmetic fast-paths activate: multiplying by zero is short-circuited in some implementations, and accumulation of identical values can avoid some rounding steps.
The effect is quantified: random FP16 inputs on an A100 run roughly 5–10% slower than structured inputs for large square GEMMs in tested configurations. This is not algorithmic — the same cuBLAS call is used — but reflects microarchitectural behavior in the tensor core pipeline.
The practical implication for ML workloads is subtle but real. Early training, when weights are near initialization and activations have specific statistical profiles, may benchmark differently than mid-training. Benchmarks using random data to characterize GPU throughput may overestimate latency for production inference on well-trained models.
The post also notes that quantized (INT8/INT4) pipelines show larger effects because zero-skipping is more aggressively implemented. This connects to the broader literature on structured sparsity and why 2:4 sparsity (NVIDIA’s sparse tensor core format) produces speedups: the zero positions are predictable, not just present.
Source: https://www.thonking.ai/p/strangely-matrix-multiplications
Raft Consensus with a Minority of Nodes
Standard Raft requires a quorum — a majority of nodes — to commit entries, so a cluster of 2f+1 nodes tolerates f failures. This post explores a modification where consensus proceeds with a minority, specifically examining what invariants must be relaxed or restructured to make this coherent.
The key insight is that “minority Raft” is not a general-purpose consensus algorithm but works under an assumption of asymmetric trust or pre-arranged coordination. The specific construction described uses a witness node or external epoch service that breaks symmetry: a minority partition can proceed only if it holds a lease or token from a separate authority that guarantees the majority partition will not simultaneously commit. This is structurally similar to fencing tokens in distributed lock services or the epoch mechanism in some CRDB implementations.
The author walks through the safety argument carefully. The core Raft safety property — at most one leader per term commits entries — is preserved because the token/lease mechanism enforces that the minority partition holds an exclusive right during the interval it operates. The liveness argument is weaker: if the external authority is unavailable, the minority partition halts rather than proceeding unsafely.
This has practical relevance for edge deployments where three or five nodes are too expensive but you still want crash-fault tolerance with bounded divergence. The two-node case (one node proceeding as a “minority of one” with a witness) maps onto how some cloud databases handle availability zone failures with a low-cost arbiter instance that votes but doesn’t store data.
The post is careful not to overclaim — this is not a new safety result but a useful exposition of how external coordination can extend where Raft-like protocols operate, with explicit accounting of what the external component must guarantee.
Source: https://padhye.org/raft-minority/
BadHost: CVE-2026-48710 Starlette Host-Header Auth Bypass
This CVE documents an authentication bypass in Starlette, the async Python web framework underlying FastAPI. The vulnerability class is host-header injection, a well-known but persistently underpatched attack surface.
The mechanics: Starlette’s Request.url and related properties construct URLs by reading the Host header from the incoming request. If an application uses request.url or request.base_url for access control decisions — for example, checking whether a request is coming from an internal hostname — an attacker can supply an arbitrary Host header value to spoof that check. Starlette did not validate or sanitize the Host header against a configured list of allowed hosts before making it available to application code.
The fix requires either (a) Starlette itself rejecting requests with Host values not in an allowlist before they reach application handlers, or (b) explicit middleware (TrustedHostMiddleware) that applications must opt into. The CVE specifically concerns cases where the middleware was absent and application code made security decisions based on the derived URL.
Host-header attacks are particularly dangerous in proxy-fronted deployments. Reverse proxies typically forward the original Host header, and if the proxy does not rewrite or validate it, the backend application sees attacker-controlled data in what looks like a trusted field. The impact escalates when the host check gates password reset emails (classic Django-era vulnerability), internal API access, or SSRF mitigations.
The broader engineering lesson is that any value derived from HTTP headers is attacker-controlled unless explicitly validated, and framework-level URL construction APIs should not silently incorporate unvalidated header content into objects that appear authoritative to application code.
Source: https://badhost.org/
DeepSeek Reasonix: Native Coding Agent with High Caching and Low Cost
Reasonix is an open-source coding agent built specifically around DeepSeek’s model API, engineered for cost efficiency through aggressive prompt caching and context management.
The technical core is a caching strategy that exploits DeepSeek’s prefix caching: the system prompt, repository context, and tool definitions are structured to form a stable prefix across agent turns so that cached KV states are reused. This reduces input token costs substantially on long agentic tasks where the same codebase context is re-sent each turn. The architecture explicitly orders prompt components by stability (system instructions first, then file contents in deterministic order, then conversation history last) to maximize cache hit rate.
The agent implements a standard tool-use loop: read file, write file, execute shell command, search codebase (via grep/ripgrep). What distinguishes it from generic agent frameworks is the plumbing around token budget management — it tracks cumulative context length and prunes or summarizes earlier turns to stay within the context window while preserving task-relevant state. The pruning heuristic prioritizes retaining tool call results over intermediate reasoning traces.
Benchmarks reported by the project show cost reductions of 60–80% compared to naive re-prompting on multi-turn coding tasks, with the majority of savings from prefix cache hits. This aligns with DeepSeek’s documented cache pricing (cached input tokens are billed at a fraction of uncached).
The project is notable less for algorithmic novelty and more for practical engineering: most agentic coding frameworks ignore provider-specific caching semantics and pay full price for repeated context. Reasonix treats cache-friendly prompt construction as a first-class design constraint, which is the correct approach for production cost management at scale.
Source: https://esengine.github.io/DeepSeek-Reasonix/
Rust (and Slint) on a Jailbroken Kindle
This post details a full embedded Rust development setup targeting a jailbroken Kindle e-reader, using the Slint UI toolkit for the display layer.
The Kindle hardware in question (a Paperwhite variant) runs a Linux kernel on an ARM Cortex-A processor with an e-ink display driven via a framebuffer device. After jailbreak (using the standard KOReader-adjacent exploit chain), the device exposes a root shell and allows side-loading binaries. The author cross-compiles Rust for the armv7-unknown-linux-musleabihf target, using musl libc to avoid dynamic linking against the Kindle’s older glibc.
Slint is a Rust-native UI framework targeting embedded and desktop; it compiles to native code and supports a software renderer that writes directly to a framebuffer, making it suitable for environments without a full graphics stack. The author configures Slint’s software renderer to target the Kindle’s /dev/fb0 framebuffer and handles the e-ink-specific concern of display refresh: e-ink panels require explicit refresh commands and exhibit ghosting if partial updates are too frequent. The post documents the ioctl calls needed to trigger full vs. partial refresh and the tradeoffs in update latency.
Touch input is handled by reading raw events from /dev/input/eventX, parsed with the evdev crate. The author notes that the Kindle’s touch controller reports coordinates in a non-standard orientation requiring a transform.
The build and deployment workflow uses cargo build --target armv7-unknown-linux-musleabihf followed by scp to the device. Total binary size for a minimal Slint app is around 2–3 MB, acceptable for the Kindle’s storage.
This is a clean example of how the Rust embedded/cross-compilation ecosystem has matured for Linux-class embedded targets.
Source: https://sverre.me/blog/rust-on-kindle/
Stress Disrupts Hippocampal Integration of Overlapping Events and Memory Inference
This neuroscience paper in Science Advances examines how acute stress impairs the hippocampus’s ability to link related memories through shared elements — a process called memory inference or transitive association.
The paradigm uses overlapping event pairs: subjects learn A-B and B-C associations, then are tested on A-C inference, which requires integrating across the shared element B. This is known to depend on hippocampal pattern completion and the binding of overlapping representations. Under acute stress (induced via the Trier Social Stress Test or cold pressor), subjects show intact memory for directly trained pairs but impaired A-C inference, suggesting stress specifically disrupts relational integration rather than encoding per se.
The proposed mechanism centers on stress hormones (cortisol, norepinephrine) altering hippocampal CA3-CA1 circuit dynamics. Normally, CA3 pattern completion supports retrieval of overlapping representations that enable inference. Elevated glucocorticoids are known to bias the hippocampus toward pattern separation (encoding distinct representations) and away from pattern completion, which would directly impair the binding needed for transitive inference.
fMRI data show reduced hippocampal-prefrontal coupling during inference trials in stressed subjects, consistent with a failure to recruit the anterior hippocampus for relational memory retrieval.
The ML-adjacent relevance: this provides a biological grounding for why stress degrades systematic generalization (compositional reasoning over learned relations) while leaving lookup-style memory relatively intact — a dissociation that parallels debates about when neural networks generalize systematically vs. memorize.
Source: https://www.science.org/doi/10.1126/sciadv.aea5496
Investigating How Prompt Politeness Affects LLM Accuracy
This paper runs a controlled study on whether adding polite or rude phrasing to prompts changes LLM task accuracy, a question that has circulated informally (“say please to your LLM”) without rigorous quantification.
The experimental setup evaluates several models (GPT-4, Claude, Llama variants) across multiple task categories — math reasoning, factual QA, code generation — with prompt variants that add politeness markers (“please,” “thank you,” “I would appreciate”), rudeness markers (“do this now,” imperative-only phrasing), or neither. Each variant is tested with fixed seeds across hundreds of examples per task.
Results are mixed and model-dependent. For some models on some tasks, polite prompts show marginal accuracy gains (1–3%) that fall within statistical significance thresholds; for others the effect is negligible or reverses. The paper finds no consistent directional effect across models or tasks at conventional significance levels, though there is evidence that instruction-tuned models trained on RLHF data may exhibit slight preference for user-friendly phrasing because such phrasing correlates with higher-quality training examples.
The more interesting finding is task-type interaction: on open-ended generation tasks, polite framing slightly shifts output style (more hedging, longer responses) in ways that can help or hurt depending on the evaluation metric. For exact-match tasks the effect is near zero.
The honest summary: prompt politeness is not a reliable accuracy lever. The informal belief that it helps likely reflects confounding — more carefully composed prompts tend to be both polite and more precisely specified, and precision is the actual driver.
Source: https://arxiv.org/abs/2510.04950
Noteworthy New Repositories
Percivalll/Copy-Fail-CVE-2026-31431-Kubernetes-PoC
A proof-of-concept exploit for CVE-2026-31431, demonstrating a fully unprivileged container escape leading to node-level code execution on Kubernetes. The attack chain combines two primitives: page-cache corruption and shared image layer exploitation. Because container runtimes on Kubernetes share OCI image layers via the host’s page cache, a malicious unprivileged process can corrupt cached pages belonging to those shared layers, causing other containers — or host-level processes — to execute attacker-controlled content. No elevated privileges or special capabilities are required inside the container. The PoC has been validated on three major managed Kubernetes offerings: Alibaba Cloud ACK, Amazon EKS, and Google GKE, indicating the vulnerability is not environment-specific but rather inherent to how the container runtime interacts with the kernel’s page cache across overlay filesystems. The technical significance is high: the unprivileged constraint removes the usual prerequisite of CAP_SYS_ADMIN or privileged pod specs, making the attack surface substantially broader. Defenders should audit node kernel versions, image layer sharing policies, and consider seccomp/AppArmor profiles that restrict relevant syscalls (userfaultfd, madvise, fallocate). The repo serves as a reference for security researchers studying kernel-level container isolation boundaries and for cluster operators assessing exposure before patches are widely deployed.
Source: https://github.com/Percivalll/Copy-Fail-CVE-2026-31431-Kubernetes-PoC
statecraft-protocol/envoy
Envoy addresses a structural problem in multi-agent and long-horizon agentic systems: state is ephemeral and session-local, making it impossible to resume work across machines, processes, or organizational boundaries without bespoke serialization logic. The project provides a durable shared-state protocol layer — essentially a typed, versioned state store designed specifically for agent workloads. Rather than treating agent memory as an application-level concern, Envoy externalizes it into a persistent, addressable substrate that multiple agents or sessions can read from and write to with defined consistency semantics. The architecture distinguishes between ephemeral execution context and durable world state, allowing an agent interrupted mid-task to re-hydrate its working state on a different machine or hand off partial results to a collaborating agent in another organization. The protocol layer handles conflict resolution, versioning, and access control, which are the recurring pain points when multiple agents operate on shared mutable state. This is relevant to anyone building on top of tool-calling LLM frameworks (LangGraph, AutoGen, or custom orchestrators) where the default assumption is a single stateful process. Envoy essentially provides the persistence and coordination substrate that those frameworks leave to the implementer. The open-source nature means the state format and protocol are inspectable and not locked to a proprietary cloud backend.
Source: https://github.com/statecraft-protocol/envoy
scheidydude/codeindex
Codeindex is a static analysis tool focused on dependency graph construction for codebases, with a specific output metric called blast-radius impact scoring. Given a target module, function, or file, the tool computes a quantitative estimate of how many downstream components would be affected by a change or failure at that node — the blast radius. This is directly useful in AI-assisted development workflows where LLMs suggest refactors without awareness of transitive dependency consequences. The tool indexes the repository into a dependency graph, then applies reachability analysis to score each node by its downstream fan-out. High blast-radius nodes are candidates for extra review, test coverage, or change isolation. The framing around AI-assisted development is practical: when feeding context to a code-generation model, knowing which files have high blast radius helps prioritize what context to include and what changes to flag for human review. Architecturally, it appears to operate as a static analyzer rather than requiring runtime instrumentation, making it usable in CI pipelines without execution overhead. The dependency graph representation also enables queries like “what is the minimal set of tests I must run given this change set,” a classic problem in incremental build and test selection systems. For large monorepos where full test suite runs are expensive, impact scoring is a tractable approximation to change impact analysis.
Source: https://github.com/scheidydude/codeindex
agynio/platform
Agyn is a Kubernetes-native runtime for deploying AI coding agents — specifically targeting systems like Claude Code and OpenAI Codex — inside enterprise infrastructure rather than on developer laptops. The core problem it solves is operational: these agents require filesystem access, network egress, secret access, and execution environments, all of which are ungoverned when running locally. By moving agent execution into Kubernetes pods, Agyn can attach standard enterprise controls: RBAC, network policies, audit logging, secret management via Kubernetes Secrets or external vaults, and resource quotas. The platform abstracts the agent lifecycle — provisioning an isolated execution environment per agent invocation, injecting credentials scoped to the task, enforcing egress rules, and collecting execution logs for audit. This matters for organizations in regulated industries where developer tooling must satisfy data residency, access control, and audit requirements that a locally-running agent process simply cannot meet. The Kubernetes-native design means it composes with existing cluster infrastructure: existing ingress controllers, monitoring stacks (Prometheus/Grafana), and CI/CD pipelines apply without modification. The open-source posture is relevant because it allows security teams to inspect and audit the control plane logic directly, rather than trusting a SaaS vendor’s claims about isolation. Operationally, it positions agent execution as a first-class workload type in the cluster alongside application services.
Source: https://github.com/agynio/platform
ozgurcd/gograph
Gograph is a local CLI tool that analyzes Go repositories and generates structured representations of their internal dependency and call graphs, specifically designed to improve the context fed to IDEs and AI coding assistants. The problem it addresses is that Go codebases with deep package hierarchies and extensive internal imports are poorly understood by tools that treat files in isolation — a code assistant given a single file has no view of how that file’s packages are consumed or what it depends on. Gograph constructs the repository structure as a graph and outputs it in a format that can be injected into IDE context or LLM prompts, giving the model a map of the codebase topology before it reasons about any particular change. The local-only design is a deliberate choice: no code is sent to external services, which matters for proprietary codebases. Being fast is also explicit in the description, suggesting it is intended for interactive use rather than batch analysis — low enough latency to run on file save or before a prompt is submitted. Go’s explicit import system and package-level visibility rules make it comparatively tractable to static graph construction without needing a full type-checker, though precise call graph analysis in Go still requires pointer analysis (e.g., golang.org/x/tools/go/callgraph). The tool appears targeted at the practical use case of context augmentation rather than full program analysis.
Source: https://github.com/ozgurcd/gograph
AzmxAI/azmx
AZMX presents itself as a sovereign agent platform, meaning the design emphasis is on infrastructure ownership and control over agent execution rather than reliance on hosted APIs. The “sovereign” framing addresses a specific concern in enterprise and government contexts: agent systems that call out to third-party model APIs introduce data exfiltration risks, unpredictable latency, and dependency on external availability. A sovereign platform implies the ability to run the full stack — model inference, tool execution, orchestration, and memory — within a controlled perimeter. With 435 stars, it is the most-starred item in this batch, indicating some traction. The platform appears to provide orchestration primitives for composing multi-agent workflows while allowing model backends to be swapped, including self-hosted models (Ollama, vLLM, or similar inference servers). The tooling layer handles agent-to-tool binding, which is the mechanical work of connecting LLM output to executable actions — filesystem, API calls, database queries — with appropriate sandboxing. For organizations that have already invested in on-premises GPU infrastructure for inference, a sovereign agent platform avoids the architectural split between local inference and cloud-hosted orchestration. The open-source release enables inspection of the orchestration logic, which is important for security-sensitive deployments where the orchestrator itself is a trust boundary. The specific implementation details of state management, tool sandboxing, and multi-agent coordination are the axes on which this would be evaluated against alternatives like AutoGen or CrewAI.
Source: https://github.com/AzmxAI/azmx
ClouGence/open-cdm
Open-CDM is an open-source collaborative database management platform targeting team environments rather than individual developers. Its feature set addresses the operational gap between raw database clients (DBeaver, TablePlus) and full data governance platforms: it adds access control with role-based permissions, data anonymization for masking sensitive columns in query results, SQL auditing with execution history and approval workflows, and CI/CD integration for schema change management. The cross-regional deployment support indicates it is designed for organizations running distributed database infrastructure across multiple data centers or cloud regions, where a single-point management plane needs to federate connections while respecting data residency constraints. The SQL auditing component is particularly relevant for compliance use cases — financial services and healthcare organizations often require immutable logs of who queried what data and when, and most raw database clients do not provide this. The data anonymization layer is architecturally interesting: it implies a query proxy or result post-processing step that rewrites sensitive column values before returning them to users below a certain permission level, without requiring changes to the underlying database schema. CI/CD integration for database changes is a well-understood need (Flyway, Liquibase solve the migration side) but combining it with access control and audit in a single tool reduces the number of systems a DBA team must operate. Being fully open-source removes the licensing friction common in commercial data governance tools.
Source: https://github.com/ClouGence/open-cdm
leiting-eric/DailyBrief
DailyBrief is an automated news aggregation and summarization pipeline that pulls from 23 data sources — GitHub trending repositories, posts from X (Twitter), and financial market data — then runs LLM-based summarization to produce Chinese-language digests. The pipeline is deployable either locally or via GitHub Actions, making it usable without dedicated server infrastructure. The technical architecture is a standard multi-source ETL feeding into an LLM summarization step: each data source has a scraper or API client, outputs are normalized into a common document schema, and a summarization prompt produces the final digest. The 23-source breadth is the operationally complex part — maintaining parsers for heterogeneous sources (GitHub API, X API or scraping, market data feeds) requires ongoing maintenance as upstream APIs change. The GitHub Actions deployment path is notable: it allows the pipeline to run on a schedule using GitHub’s free CI compute, with digest output committed back to the repository or sent via webhook, requiring no always-on infrastructure. The market technical analysis component implies the pipeline also runs some quantitative indicators (moving averages, RSI, or similar) on price data before summarizing, rather than just ingesting raw price feeds. For researchers or practitioners who want a daily structured summary of ML repository activity alongside broader tech and market context, this provides a customizable, self-hosted alternative to commercial newsletter services, with full visibility into the prompts and aggregation logic.