デイリーAIダイジェスト — 2026-05-26
arXiv ハイライト
QUEST: 完全合成タスクによるフロンティア深層リサーチエージェントの訓練
問題設定
深層リサーチエージェント(Deep research agents)とは、Webコンテンツを反復的に検索・読解・統合し、根拠に基づいた長文回答を生成するシステムであり、現在はクローズドなシステム(OpenAI Deep Research、Gemini Deep Research、Perplexity Pro)が主流を占めています。オープンな実装は、短期的な事実検索(BrowseCompスタイル)または長文レポート作成のいずれか一方のタスクファミリーに過適合しがちで、両方を同時に扱えることは稀です。また、軌跡やルーブリック監督のために大量の人手アノテーションに依存することが多いです。本論文が取り組む未解決問題は、事実探索・引用根拠付け・レポート統合のすべてにおいて強力な、広範に有能なエージェントを、検証可能な報酬を持つ合成タスクのみを用いて作成できる単一のレシピが存在するか否かです。
QUESTは、8K個の合成タスクを用いた中間訓練・SFT・RLの統合パイプラインで訓練された、2B・8B・35Bパラメータスケールのエージェントファミリーを公開しています。
手法
中心的な貢献は、事実型タスクと統合型タスクの両方を包含する合成タスク生成のための統合ルーブリックツリーです。ルーブリックツリー T は、目標回答の階層的な分解であり、葉ノードは原子的かつ個別に検証可能なクレーム(エンティティ、日付、数値、引用要件、構造的制約など)です。タスク x、回答 y、ルーブリックツリー T(x) に対する報酬は次のように定義されます。
R(y, T) = \frac{1}{|L(T)|}\sum_{\ell \in L(T)} w_\ell \cdot \mathbb{1}[\text{verify}(\ell, y)],
ここで L(T) は葉ノードの集合、w_\ell は葉の重み、\text{verify} は決定論的またはLLMによる判定チェックです。各葉ノードが検証可能であるため、報酬は単一のエンドツーエンド正解シグナルと比較して密であり、同じ機構でBrowseCompスタイルの針探し問題(事実的な葉ノードが1つのツリー)と長文レポートタスク(構造的・引用的な葉ノードが数十あるツリー)の両方をカバーできます。
データパイプラインは以下の通りです。
- Webクロールからトピックをシードとして選び、LLMプランナーによってサブ質問に展開する。
- 各サブ質問について、実際のWebエビデンスを検索してクレームを根拠付け、取得ページで検証できないクレームは除外する。
- ルーブリックツリーを構成し、引用根拠の検証が可能なようにエビデンスURLを葉ノードに付与する。
- 難易度でフィルタリングする(ベースラインエージェントに対してrejection samplingを行い、ベースラインが失敗するタスクのみを残す)。
訓練は3段階から構成されます。
- 中間訓練(Mid-training): タスクレベルの監督を行う前に、フォーマットとツールスキーマを学習させるため、Webテキストと交互に合成ツール使用軌跡(検索・ブラウズ・スクラッチパッド操作)を用いた継続事前訓練を行う。
- SFT: 合成タスクを解く絞り込まれた教師軌跡に対するimitation学習。教師はツールループを実行するより強力なモデルであり、高い R を達成した軌跡のみを保持する。
- RL: R(y, T) を報酬として用いたGRPOスタイルのon-policy最適化。タスクごとに K 個のサンプル軌跡に対してgroup-relative advantageを計算し、value headを不要とする。
A_i = \frac{R_i - \mathrm{mean}(R_{1..K})}{\mathrm{std}(R_{1..K})}.
第二の貢献は組み込みコンテキスト管理です。長期的なエージェントはコンテキストウィンドウを使い切ってしまいますが、QUESTはモデルが明示的なsummarize/compressアクションを発行し、生のツール出力バッファとは別に構造化されたワーキングメモリを生成するよう訓練します。モデルは、いつ圧縮するか(監督におけるトークンバジェットのトリガー)と、何を保持するか(エンティティ、URL、ルーブリックの葉ノードに紐付いた部分的な回答)を学習します。推論時には、35Bモデルがネイティブコンテキストを超える長さのリサーチトレースを処理できるようになります。
結果
わずか8K個の合成タスクのみで、QUEST-35Bは評価されたベンチマーク群においてフロンティアのクローズドエージェントに匹敵するか、それを上回ると報告されています(ソースの要旨は途中で切れていますが、論文ではBrowseComp、GAIAスタイルの事実探索、ルーブリック採点によるレポート統合ベンチマークを対象としています)。クロススケールの傾向がより興味深い実験的主張であり、同じレシピが2Bおよび8Bの変種を同サイズのオープンベースラインと比較して大幅に向上させており、ルーブリックツリー報酬が大規模モデルの容量に特化したものではないことを示しています。
注目すべきアブレーションの結果は以下の通りです。
- 中間訓練を除去すると、ツール使用フォーマットの信頼性が崩壊し、RLの収束が損なわれる。
- ルーブリックツリーの分解を除去し(エンドツーエンドの合否のみを使用)、葉ノードレベルの密なシグナルを排除すると、RLの改善が大幅に減少する。
- コンテキスト管理を除去すると、軌跡が〜32Kトークンを超える長期タスクでの性能が頭打ちになる。
制限と未解決問題
- 検証器ループ: LLM検証器によって判定される葉ノードは、その検証器のバイアスを引き継ぎます。ルーブリックツリーによる訓練は、特に決定論的に検証できない「統合品質」葉ノードにおいて、判定者が受け入れるものに向けてGoodhartingするリスクがあります。
- 合成分布のカバレッジ: 固定されたシードプールから生成された8Kタスクは、敵対的なクエリや時間的に変化するクエリを過小表現する可能性があります。論文では、基盤となるWebが変化した場合の時系列シフト評価に対するロバスト性は報告されていません。
- 引用根拠付けは、取得コンテンツに対するクレームの含意ではなく、URLの一致によって検証されます。そのため、エージェントはトピック的には関連するが支持根拠にはならないURLを付与することで葉ノードを満たせてしまいます。
- ツール使用のリアリズム: 合成軌跡は適切に動作する検索APIを前提としています。実際の深層リサーチでは、ペイウォール・JSレンダリングページ・レート制限が発生しますが、これらは訓練には一切登場しません。
- 35Bモデルは依然としてSFT中に教師品質の軌跡を必要とするため、このレシピはより強力なモデルなしにはゼロからブートストラップできません。
重要性
ルーブリックツリーは「エージェントは良いレポートを書けたか」という混沌とした目標を、検証可能な葉ノードの構造化されたコレクションへと変換します。これはまさにRLが必要とする形式です。この結果が再現性を持つのであれば、フロンティアの深層リサーチ能力は、大規模な人手アノテーション軌跡ではなく、〜10^4 個の合成タスクと十分に強力な教師によって達成可能であることを示唆しており、ボトルネックをデータ収集から検証器の設計へと移行させます。
Source: https://arxiv.org/abs/2605.24218
ThriftAttention: 長コンテキストFP4 Attentionのための選択的混合精度
問題
Blackwell上のブロックスケールFP4 attention(例:SageAttention3)は長コンテキスト推論を高速化しますが、特にシーケンス長が増大するにつれて品質が低下します。標準的な対処法——一様に精度を引き上げる——は、FP4の効率の大部分を捨て去ることになります。本論文の中心的な観察は、FP4量子化誤差が(Q, K)ブロックグリッド全体で非常に不均一であるという点です。少数のブロックが出力誤差の大部分を支配しているため、選択的な混合精度スキームによってFP4に近いコストでFP16に近い品質を回復できます。
手法
標準的なattention o = \sum_j p_j v_j(ただし p_j = \mathrm{softmax}(q\cdot k_j/\sqrt{d}))を出発点とすると、FP4は各logitを\epsilon_jだけ摂動させます。出力の一次展開を行うと、
\delta o \approx \sum_j \frac{\partial o}{\partial s_j}\epsilon_j = \sum_j p_j (v_j - o)\,\epsilon_j,
したがって、
\|\delta o\| \le \sum_j |\epsilon_j|\cdot p_j \cdot \|v_j - o\|.
因子p_jはスコアに対して指数的であるため、attention weightが大きいブロックは確率質量をより多く引き寄せると同時に、出力における自身の量子化誤差を増幅させます。経験的には、これらは対角線付近のブロックおよび非初期のattention sinkです。
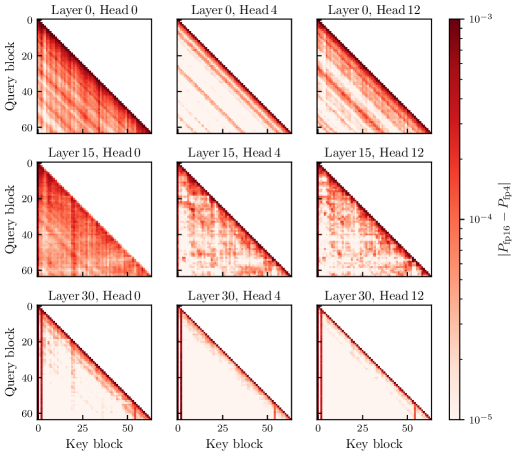
誤差マップは強いスパース性を確認しています。任意のヘッドにおいて、意味のある誤差が蓄積される(Q\text{-block}, K\text{-block})のペアはごく少数であり、そのパターンは対角局所性とsink列によって支配されています。
ThriftAttentionはこれをB_q = B_k = 64の2段階パイプラインで利用します。
- ブロック選択。 安価なヒューリスティックが、FP16で実行すべき重要な(Q,K)ブロックペアの少数のバジェットを識別します。残りのブロックはFP4で実行されます。
- オンラインsoftmaxマージによる混合精度attention。 FP16とFP4のパスはそれぞれのブロックセット上で計算され、標準的なオンラインsoftmaxの実行最大値・実行和のリダクションを通じて単一の出力に結合されます。これによりデータの2回目のパスは不要です。
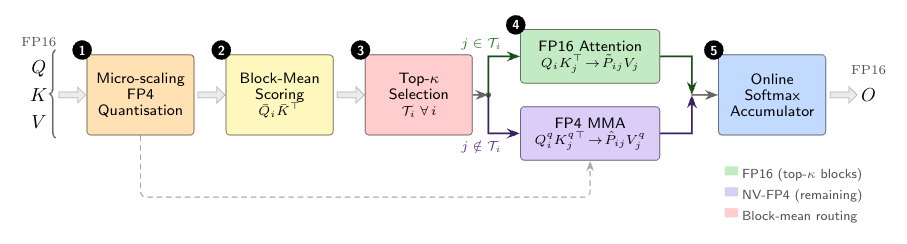
このマージは標準的なFlashAttentionスタイルのストリーミングリダクションであるため、FP16パスは選択されたブロックのみをマテリアライズすればよく、decode時のKVキャッシュのトラフィックはFP4部分によって支配されます。
結果
主要な動作点:(Q,K)ブロックのわずか5%のみをFP16で計算することで、平均してFP4からFP16へのNLLギャップの89.1%を回復します。
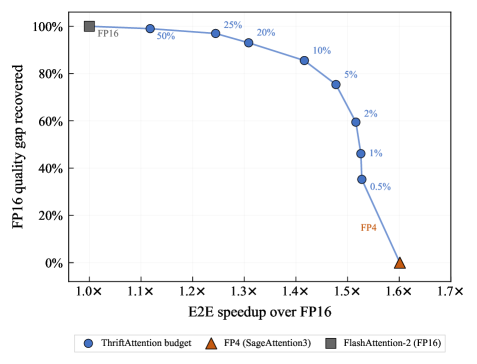
RTX PRO 6000(Blackwell)上でのB=1、n_\text{heads}=32、D=128、Qwen3-8Bによるカーネルおよびエンドツーエンドの測定結果:
- Prefillカーネル: FlashAttention-2(このGPUでサポートされる最速のベースライン)と比較して最大1.7\times。
- エンドツーエンドprefill: 131kコンテキストでFP16 attentionと比較して\sim1.2\times。
- Decodeカーネル: FlashAttention-2と比較して3\times~5.5\times、full FP4 attentionと比較してオーバーヘッドは最小限。
- エンドツーエンドdecode: Qwen3-8BにおいてFP16 attentionと比較して131kコンテキストでほぼ2\times。
decodeの優位性は直接的にKVキャッシュの帯域幅構造に由来します。ほとんどのブロックがFP4でストリームされるため、ロードされるトークンあたりのバイト数がFP8比で半減、FP16比で4分の1になります。FP16の少数ブロックは漸近的なメモリフットプリントを変えませんが、量子化誤差が\|\delta o\|を支配してしまうようなブロックをカバーします。
本論文はまた、HELMETにおける回復率のコンテキスト長スケーリングとPG-19上のNLL分析も報告しており、いずれも式(4)の上界と整合しています。Nが増大するにつれてより多くの位置が寄与しトークンあたりの誤差が蓄積されますが、支配的な項は少数のブロックに集中したままであり、固定5%のFP16バジェットでそれらを継続的に捕捉できます。
制限とオープンクエスチョン
- 選択ヒューリスティックはこの手法の核心ですが、abstractとSection 3ではそれを完全には規定しておらず、89.1%のギャップ回復——100%ではない——はヒューリスティックが依然として一部の高インパクトなブロックを見逃していることを示しています。スコアを考慮した、または2パスのセレクタによって残余ギャップを縮小できる可能性があります。
- 結果は主にQwen3-8Bと少数の長コンテキストベンチマーク上で報告されており、MoEモデル、KVヘッド数が非常に少ないGQA、およびより強いattention-sinkパターンを持つモデルにおける挙動は最適バジェットを変化させる可能性があります。
- すべての利得はFP4テンソルコアが存在するBlackwell(RTX PRO 6000)上で測定されており、Hopperまたはそれよりも古い世代ではFP4パスがエミュレーションに縮退します。
- 一次解析はブロック間での\epsilon_jの相互作用を無視しており、非常に積極的なFP4(小さいグループサイズ、外れ値が多いヘッド)の場合、線形化は最悪ケースの誤差を過小評価する可能性があります。
- 非常に長いコンテキスト($>256k)でのFP4行列積に対して相対的に、O(N/B_k)$のクエリごとスキャンですら非自明になる場合に、選択コストがどのようにスケールするかは不明確です。
なぜ重要か
ThriftAttentionは低ビットattentionを精度空間のスパース性問題として再定式化します。softmax Jacobian自体がどのブロックを高精度にする必要があるかを教えてくれ、そのセットは小さいのです。これは、一様FP4の品質崖なしにBlackwell上でエンドツーエンドの長コンテキストdecodeをおよそ2\times高速化するための、クリーンでドロップイン可能なパスであり、同じp_j(v_j - o)の議論は他の量子化attention schemeにも一般化できるはずです。
Source: https://arxiv.org/abs/2605.23081
自己回帰型動画生成のためのOn-Policy Adversarial Flow Distillation
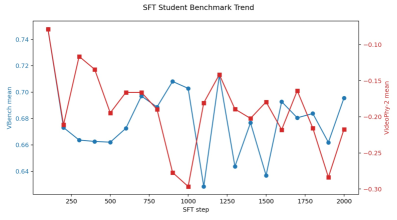
ブラックボックスの動画教師モデルを因果的自己回帰(AR)学生モデルに蒸留することは困難です。教師モデルはプロンプト条件付きの完成動画のみを出力し、スコア、潜在変数、denoising軌跡は公開しません。また、学生モデルは因果的であり、exposure biasを避けるために自身のロールアウト分布のもとで学習する必要があります。さらに、アーキテクチャ、モデル容量、サンプリングスケジュールも一般に異なります。こうした状況では標準的な手法は機能しません。教師動画に対するSFTはoff-policyであり、著者らが予備実験で示すように、SFTのステップ数が増えるにつれてVBenchおよびVideoPhy-2の指標において単調な改善どころか実際に性能が低下します。
スコアベースの分布マッチング(DMD、score distillation)は教師スコアなしには適用できません。純粋なadversarial imitationはロールアウトごとにサンプルレベルの信号が1つしか得られず、denoisingに対するステップごとのクレジットがありません。Adversarial Flow Distillation(AFD)はまさにこのギャップを埋めることを目的としています。
手法
\pi_T(x_0\mid y)をサンプリングのみの教師モデル、\pi_\thetaを速度場 f_\theta(x_t,t,y) を持つ因果的AR学生flowモデルとします。各ステップでは y\sim\mathcal{Y} をサンプリングし、教師に x_0^T を問い合わせ、現在の学生を自己回帰的な自己条件付きでロールアウトして \hat{x}_0 を得ます。
プロンプト条件付き時空間discriminator D_\phi(x_0,y)(VideoAlignから初期化し、LoRA(rank/alpha =256)で適応)は、教師サンプルを選好サンプルとして扱うBradley–Terryペアワイズlossで学習されます。
\mathcal{L}_D(\phi) = -\mathbb{E}_{(x_0^T,\hat{x}_0,y)}\,\log\sigma\!\left(D_\phi(x_0^T,y)-D_\phi(\hat{x}_0,y)\right).
これにより絶対的な報酬のキャリブレーションが不要になります。discriminatorは、適応的でbaseline減算済みの報酬を与えます。
r_\phi(\hat{x}_0,y)=\operatorname{sg}\!\left(D_\phi(\hat{x}_0,y)-b(y)\right),
ここで b(y) はプロンプトごとまたはバッチのbaseline(実装ではグローバル標準偏差正規化とプロンプトごとのEMAトラッキング、減衰率 \gamma=0.99、アドバンテージクリッピング上限 5.0 を使用)です。
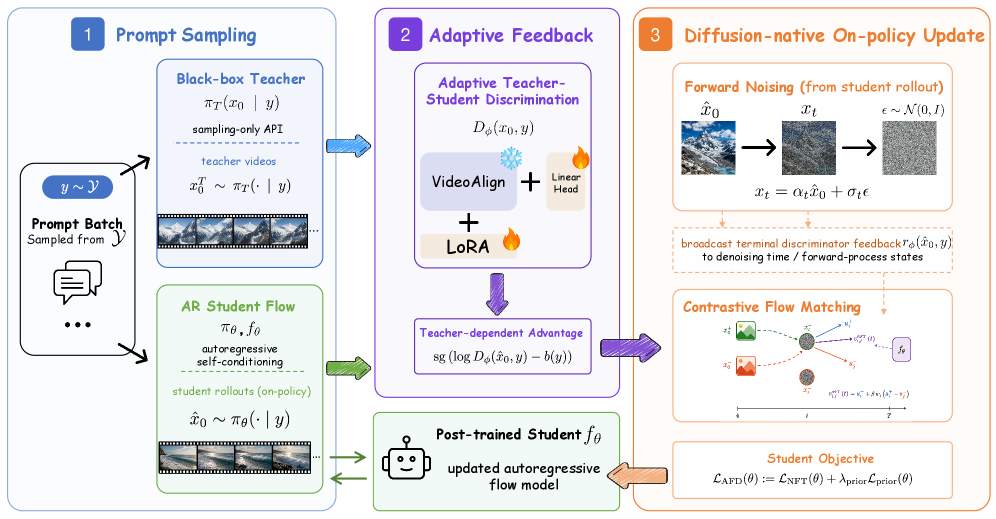
重要なステップは、このクリーンサンプル・サンプルレベルの信号を、DiffusionNFT方式の更新を通じて学生のdenoisingプロセス全体に渡る密な教師信号に変換することです。順方向プロセス x_t=\alpha_t x_0+\sigma_t\epsilon および順方向速度 v(x_0,\epsilon,t)=\dot\alpha_t x_0+\dot\sigma_t\epsilon のもとで、AFDは学生自身のノイズ付き状態を r_\phi によって重み付けし直し、傾けられたターゲット分布を生成します。
\pi^+(x_0\mid y)\propto \exp(\rho_\phi)\cdot \pi^{\text{old}}(x_0\mid y),
ここで \rho_\phi=\log D_\phi/(1-D_\phi) です。最適なdiscriminatorかつon-policyデータ(\pi^{\text{old}}=\pi_\theta)のもとでは \rho_\phi^*=\log\pi_T/\pi_\theta となり、\pi^+\propto\pi_T となります。学生のノイズ付き状態において \pi^+ に向けたflow-matchingの更新は、最適解において \pi_T からのon-policy逆KL蒸留と等価です。しかしこれは、教師スコアも、ステップのアライメントも、ARサンプラーを通じた逆連鎖のRLも必要とせず、純粋に順方向プロセスの速度ターゲットを通じて実現されます。
具体的には、AFDはflow matchingにおける教師サンプル項を、discriminatorから得られた重みを持つ重要度重み付きの学生サンプルで置き換えます。これにより、単一のブラックボックスサンプルレベルの信号から、各タイムステップ t に対する密な速度教師信号が得られます。これが本手法の中心的なメカニズム的貢献です。
実験設定と結果
学生モデル:Self-ForcingおよびCausal-Forcing ARビデオモデル(解像度 480\times 832)。教師モデル:Seedance 2.0(サンプリングAPIとしてのみアクセス)。継続的な適応にはVideoPhy-2から200プロンプトを使用し、教師モデルは同じプロンプトに対して問い合わせられます。学習はLoRAのみ(rank 256)、AdamW(\eta=10^{-5})、weight decay 10^{-4}、bfloat16、選択的正則化(補間係数 \beta=0.1、prior weight \lambda_{\text{prior}}=10^{-4})で行われます。
ベースライン:Base(事前学習済み)、教師動画に対するSFT、GAN(動画レベルのadversarialのみ、順方向プロセス更新なし)、スコアなしDMD(score項なしのDMDスキャフォールディング)。VBenchの次元はPhysics(時間的ちらつき、動きの滑らかさ、動的度合い、人物行動、空間的関係)とGeneral(残りの次元の平均)に分類され、ターゲットドメインの品質はVideoAlign-MQおよびVideoPhy-2-PCで評価されます。

定性的には、AFDはSFTが忠実度を損ない、GANがdenoisingを不十分にしか教師指導しない状況において、プロンプトのセマンティクスと基底モデルの視覚スタイルを保ちながら、学生モデルをより物理的に妥当な動き(流体の流れ、変形、接触など)へとシフトさせます。提供されているセクションでは、両ARファミリーにわたって、Base・SFT・GAN・スコアなしDMDと比較したPhysicsグループのVBench改善、VideoAlign-MQおよびVideoPhy-2-PCの改善がまとめられており、General VBenchは維持されています(数値テーブルは実験セクションで参照されていますが、本抜粋には再現されていません)。
限界と未解決の問題
逆KL蒸留との理論的等価性は、BTの最適解かつon-policyの極限においてのみ成立します。実際にはdiscriminatorは非定常であり、傾き \exp(\rho_\phi) は重い裾を持つため、アドバンテージクリップ上限 5.0 およびEMAトラッキングbaslineが必要です。本手法はdiscriminatorの帰納バイアス(本実装ではビデオアライメントモデル)を引き継ぐため、アライメントモデルが未見のモードを誤ってスコアリングする可能性があります。適応は物理ターゲットに対して200枚の教師動画のみを使用しており、スケーリング、教師とターゲットプロンプトセット間の分布シフト、学習ホライゾンより長いARロールアウトとの相互作用については検討されていません。また、本フレームワークは、利用可能な場合でも教師の部分的な情報(例:中間フレームやステップアライメントされた潜在変数)を活用しません。
重要性
AFDは、共進化するBradley–Terry discriminatorを密な順方向プロセスのflow targetに変換することで、完成サンプルのみを用いて商用のAPIのみのビデオ生成モデルを因果的AR学生モデルに蒸留するための原則的なレシピを提供します。これにより、SFTのoff-policyによる崩壊や純粋なadversarial trainingのスパースなクレジット割り当てを回避し、ARサンプラーを通じた誤差逆伝播なしにブラックボックス動画蒸留をon-policy逆KL最小化と接続します。
Source: https://arxiv.org/abs/2605.26105
Channel-wise Vector Quantization
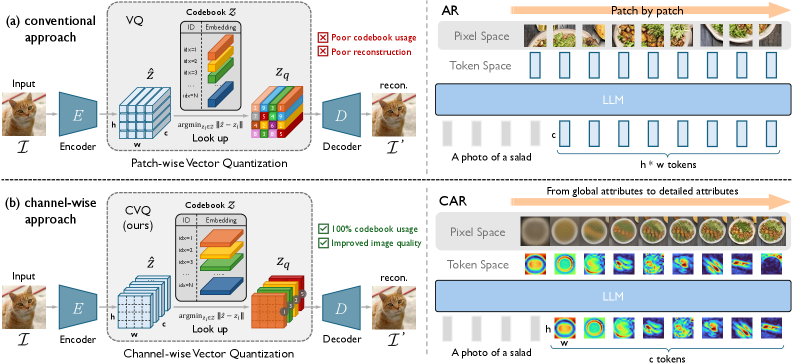
問題
VQベースの画像tokenizer(VQGANおよびその後継)は、潜在特徴マップ \mathbf{Z}\in\mathbb{R}^{h\times w\times c} を離散化する際、各空間的な 1\times 1\times c パッチベクトルを最近傍のコードブックエントリに割り当てます。この定式化には、二つの根強い失敗モードがあります。第一に、コードブック崩壊(codebook collapse):16,384エントリのコードブックでは、通常のVQGANはエントリのわずか4.5%しか使用しません。これは、自然画像には繰り返しや類似パッチが多く含まれており、それらが少数のクラスタ中心に集中してしまい、残りのエントリへのgradientが枯渇するためです。第二に、下流の自己回帰生成は、自然な因果構造を持たない2Dを1Dに変換したラスター順序を引き継いでしまいます。回避策(VQ-LCにおけるCLIP初期化コードブック、VQ-FCにおける分解lookup、回転トリック、残差量子化)は仕組みとパラメータを追加しますが、根本的な冗長性には部分的にしか対処できていません。
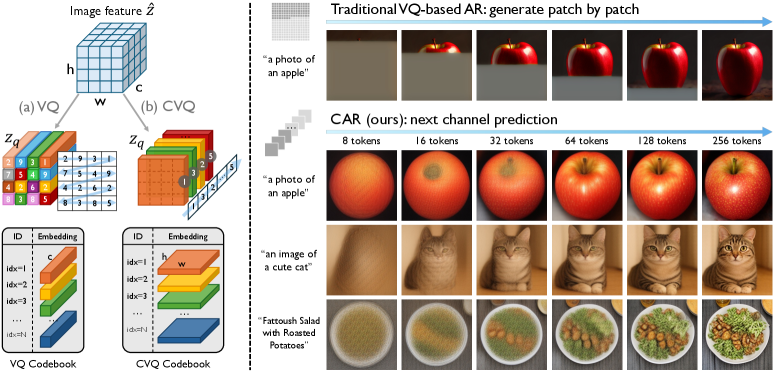
手法
CVQはスライスする軸を逆転させます。\mathbf{Z} を次元 c の h\times w 個のパッチベクトルとして扱う代わりに、次元 h\times w の c 個のチャネルスライスとして扱います。各チャネル \mathbf{z}^{(:,:,k)}\in\mathbb{R}^{h\times w\times 1} は独立してフラット化・量子化されます:
\mathbf{z}_q^{(:,:,k)} = \arg\min_{\mathbf{e}_n\in\mathcal{C}}\,\big\|\mathrm{vec}(\mathbf{z}^{(:,:,k)}) - \mathbf{e}_n\big\|_2^2,
ここで、単一の共有コードブック \mathcal{C}=\{\mathbf{e}_n\}_{n=1}^{N}、\mathbf{e}_n\in\mathbb{R}^{hw} が用いられます。画像あたりのトークン数は c(hw ではなく)となり、各トークンは局所的な空間パッチではなく、「視覚的詳細のレベル」——フル解像度のチャネルパターン——を索引付けします。
比較を公平に行うため、著者らは c = h\times w = 256 と設定しており、CVQとパッチワイズVQはlookup数、コードブックメモリ、ステップあたりの計算量が同一です。重要な非対称性は計算的なものではなく、統計的なものです。学習済みエンコーダのチャネルは異なる意味的因子(エッジ、色統計、テクスチャ周波数、物体部位)をエンコードする傾向があるため、異なる画像は異なるチャネルシグネチャを活性化しますが、画像内・画像間の異なるパッチは高度に冗長です。
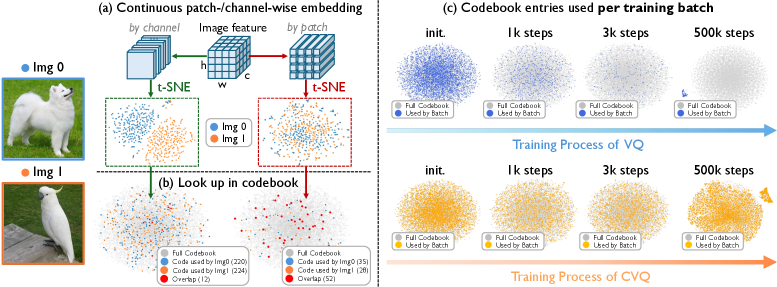
図4(a)は、視覚的には類似しているが意味的には異なる二つの画像のパッチembeddingのt-SNEが単一の雲として絡み合う様子を示しており、一方チャネルembeddingは明確に分離されたクラスタを形成しています。図4(c)は学習バッチごとにヒットしたコードブックエントリ数を追跡しており、パッチワイズVQは学習初期に少数の「外れ値」エントリに崩壊するのに対し、CVQはほぼ完全な利用率に近いところで飽和し、その状態を維持します。
CVQの上に、本論文はChannel-wise Autoregressive(CAR)生成器を構築しており、チャネルトークンを逐次的に予測します:p(t_1,\dots,t_c)=\prod_k p(t_k\mid t_{<k})。一般的なCNN/ViTエンコーダの前のチャネルは粗い大域的構造を、後のチャネルは細粒度の詳細を担うため、この順序はスケールピラミッドや多解像度コードブックを必要とせず、粗から細への生成軌跡を自然に再現します。
結果
ImageNet-1K val(256×256、100エポック、コードブック16,384、Adam \beta=(0.5,0.9)、lr 10^{-4})での再構成:
- 256トークン予算:通常のVQGANはコードブック使用率4.5%でrFID 4.84;SimVQは100%で2.63;CVQは補助lossなし・分解なし・事前学習特徴初期化なしで 100%使用率でrFID 2.60 を達成。
- 1024トークン予算:通常のVQGAN rFID 1.32 / PSNR 23.35 / 使用率2.8%;MoVQGAN rFID 1.05;VQ-LCは100kコードブックでrFID 1.29;CVQは16,384コードブックで rFID 0.88、PSNR 25.02、SSIM 0.723、使用率100% を達成。
100%の利用率は「余分な工夫なし」で達成されています——エントロピー正則化器なし、コードブックリセットなし、CLIP初期化なし、回転トリックなし。これは、コードブック崩壊が主に特徴マップを誤った軸でスライスすることによる結果であり、最近傍量子化固有の病理ではないことを示す、これまでで最も明確な証拠です。
CARを用いたtext-to-image生成において、本論文はDPG 86.7およびGenEval 0.79を報告しており、根本的に異なるトークン意味論を使用しながらパッチワイズARベースラインと競合する性能を示しています。
限界と未解決の問題
- 公平な比較のための c = hw という制約は便宜上のものであり任意です;c \ll hw(粗い「詳細レベル」が少数)や c \gg hw(細かいものが多数)の場合にCVQがどのようにスケールするかは、主要な表では特性評価されていません。
- チャネル順序はエンコーダによって所与のものとして扱われています。明示的な粗から細への順序を強制または学習すること(例:チャネルに対するPCAライクな目的関数)がCARをさらに改善するかどうかは未検討です。
- チャネルトークンは空間的局所性を欠くため、標準的な空間的帰納バイアス(局所attention、2D RoPE)は適用できず、ARtransformerはトークンごとに完全な大域的相互作用をモデル化する必要があります。
- 生成の数値(DPG 86.7、GenEval 0.79)は優秀ですが、最良のdiffusion T2Iシステムには及びません;同規模のAR T2Iモデルとの比較があれば、チャネルARがPareto改善なのかトレードオフなのかを明確にできるでしょう。
- 再構成は 256\times 256 で評価されており、hw が増大し一般にチャネル数が増大しない高解像度においてチャネルの意味論がどのように振る舞うかは、可変解像度に関する付録に委ねられています。
なぜこれが重要か
CVQは画像tokenizationを「画像のどこか」から「どの変動因子か」へと再定式化しており、そうすることで、補助的な工夫を一切用いることなく、同等の計算量においてrFIDを改善しながら、コードブック崩壊を第一級の問題として解消します。チャネルをトークンとして見る観点が大規模においても成立するならば、視覚コードブック、AR順序、およびtokenizerの幾何学と生成モデルの因果性の整合について、私たちの考え方を変えることになります。
Source: https://arxiv.org/abs/2605.26089
DVAO: Dynamic Variance-adaptive Advantage Optimization for Multi-reward Reinforcement Learning
問題設定
GRPOはPPOのvalue modelをgroup-relativeなadvantage推定に置き換えるものであり、LLMのpost-trainingにおいて魅力的なアプローチです。しかし実際には、アライメントの目的関数がスカラーであることはほとんどなく、数学的推論では精度と長さ制御を組み合わせ、ツール使用では呼び出し正確性とフォーマット準拠を組み合わせるなど、複数の要素が絡み合います。n個の報酬をGRPOに組み込む標準的な2つの方法は、いずれも問題を抱えています。
- Reward Combination (RC): 先に報酬を r_{\text{sum}} = \sum_k w_k r_k として合算し、1つのgroup-normalized advantage A_{\text{sum}} を計算する。
- Advantage Combination (AC): 目的関数ごとにgroup-normalized advantage A_k を計算し、固定の w_k を用いて A = \sum_k w_k A_k と組み合わせる。
本論文はどちらも満足なものでない理由を形式化し、variance-adaptiveなスキームを提案します。
RC vs. AC の分析
クエリ x_i に対して G 個のrolloutがある場合、\hat{\rho}_{kl}^{i} をグループ内における A_k と A_l の経験的相関とします。命題1は次を示します。
\frac{1}{G}\sum_{j=1}^{G}\bigl(A_{\text{sum}}^{(i,j)}\bigr)^2 \;\geq\; \frac{1}{G}\sum_{j=1}^{G}\Bigl(\sum_k w_k A_k^{(i,j)}\Bigr)^2,
ここで等号成立は全ての k\neq l について \hat{\rho}_{kl}=1 のときに限ります。GRPOのgradientはadvantageに対して線形であるため、目的関数が完全に相関していない場合、RCは期待二乗gradient normが厳密に大きくなり、これが経験的に不安定性として現れます。ACは大きさを抑制し、そのgradientは \nabla_\theta \mathcal{J}_{\text{GRPO}} = \sum_k w_k \nabla_\theta \mathcal{J}_{\text{GRPO},k} と分解されますが、静的な w_k は (i) 目的関数間の相関と (ii) 訓練中の各報酬の時間変動するsignal-to-noiseを無視してしまいます。
DVAO
DVAOは静的な w_k を、rolloutグループ内の各目的関数の経験的報酬分散から導出した重みに置き換えます。具体的には、プロンプト x_i における目的関数 k に対し、\hat{\sigma}_k^2(x_i) を G 個のrolloutにわたる r_k の分散とします。組み合わせたadvantageは \hat{\sigma}_k に比例した重みを使用するため、グループrolloutが良いトラジェクトリと悪いトラジェクトリを実際に区別できる目的関数(高分散、強い学習シグナル)はより大きな重みを受け取り、崩壊した、あるいはほぼ飽和した目的関数(低分散、標準化後はほぼノイズ)は抑制されます。本論文はこの構成が \mathbb{E}[A^2] を有界に保つことを証明し、ACの安定性上の利点を維持しながら、variance由来の重みが各 A_k のグループ内での共変動を暗黙的に考慮することによって、self-adaptiveな目的関数間の正則化を誘導することを示します。
GRPOの上に再実装するための具体的な手順は簡潔です。
for each prompt x_i:
sample G rollouts y_{i,1..G}
for each reward k:
compute r_k(x_i, y_{i,j})
A_k^{(i,j)} = (r_k - mean_j r_k) / std_j r_k
sigma_k_hat = std_j r_k
w_k(x_i) = f(sigma_k_hat) # variance-adaptive
A^{(i,j)} = sum_k w_k(x_i) * A_k^{(i,j)}
plug A^{(i,j)} into the GRPO clipped surrogateACからの本質的な違いは、w_k がグローバルなハイパーパラメータではなく、rollout統計のper-group・per-step関数となる点です。
実験
2つのタスクファミリーで評価が行われています。Qwen3-4B-BaseおよびQwen3-8B-Baseでの数学的推論では、報酬は精度と長さ制約であり、AIME-2024、AIME-2025、MATH500、OlympiadBench、AMC23で評価されます。Qwen2.5-3B/7B-Instructでのツール使用では、報酬は呼び出し正確性とフォーマット準拠であり、BFCL-v4で評価されます。ベースラインは単一報酬GRPO(r_{\text{acc}}のみ)、GRPO+RC、GRPO+AC、GDPOです。
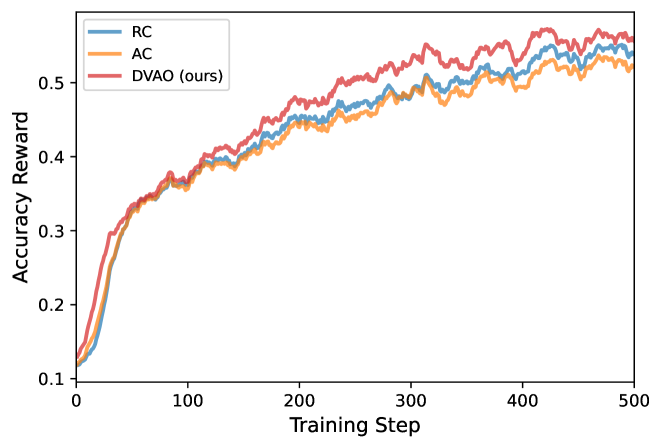
訓練ダイナミクスのプロットはDVAOの安定性に関する主張を裏付けています。4Bモデルでは、DVAOは精度報酬の平均をより高くかつ単調に維持しながら長さ報酬のstdを抑制し、平均応答長がドリフトすることなく目標範囲内に収まっています。
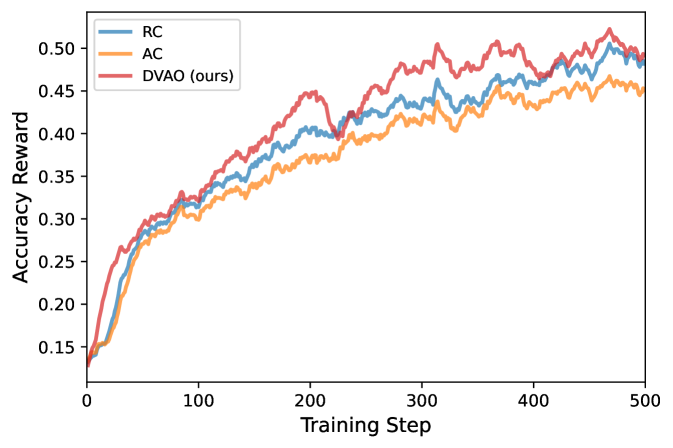
8Bでも同様のパターンが見られ、特にRCでは命題1が予測した大きなadvantage magnitudeがよりノイズの多い報酬カーブと積極的な長さ増加として現れています。
(提供された抜粋では最終的なベンチマーク数値は列挙されていませんが、主な主張は数学においてはAIME-2024/2025、MATH500、OlympiadBench、AMC23にわたる一貫した改善、ツール使用においてはBFCL-v4カテゴリにわたる改善、そして図1〜2で視覚的に確認できる定性的な安定性上の優位性です。)
限界と未解決の問題
- variance-adaptiveな重み付けは、グループ内報酬分散が学習シグナルの忠実な代理変数であることを前提としています。報酬ハッキングされた、あるいは飽和した目的関数は誤った理由で低分散を示すことがあり、その場合本手法はそれらを過小評価します。これはほぼ解決済みの目的関数に対しては望ましい挙動ですが、単に報酬を引き出すのが難しい場合には問題となります。
- \mathbb{E}[A^2] の有界性は解析的に証明されていますが、暗黙的な目的関数間の正則化がPPOスタイルのclipping rangeとどのように相互作用するかは特徴付けられていません。2つの安定化メカニズムが冗長であるか、あるいは一部のレジームで競合する可能性があります。
- 報告されているのは2目的関数設定(精度+長さ、正確性+フォーマット)のみです。n\geq 3 の報酬、特に反相関する目的関数(\hat{\rho}_{kl}<0)における挙動は、あらゆるvariance-adaptiveスキームにとってより興味深いストレステストとなります。
- \hat{\sigma}_k は少数サンプルの推定量であるため、G(グループサイズ)への感度は重要であり、本論文の安定性に関する議論はこの推定量が適切に条件付けられていることに依存しています。
なぜこれが重要か
Multi-reward RLHFは本番LLM訓練におけるデフォルトのレジームですが、研究コミュニティはこれまで手動調整したscalarizationの重みに静かに依存してきました。DVAOは原則に基づいた、ほぼコストのかからない代替手段を提供します。advantage magnitudeに対する証明可能な有界性を持つper-group variance由来の重み付けであり、静的な w_k の役割と、ACが見逃していた暗黙的な相関処理の両方を包含します。
Source: https://arxiv.org/abs/2605.25604
WBench: インタラクティブなビデオ世界モデル評価のための包括的なマルチターンベンチマーク
問題設定
インタラクティブなビデオ世界モデル — すなわち、
o_{t+1}\sim f_\theta(o_{t+1}\mid o_{\le t}, a_{\le t})
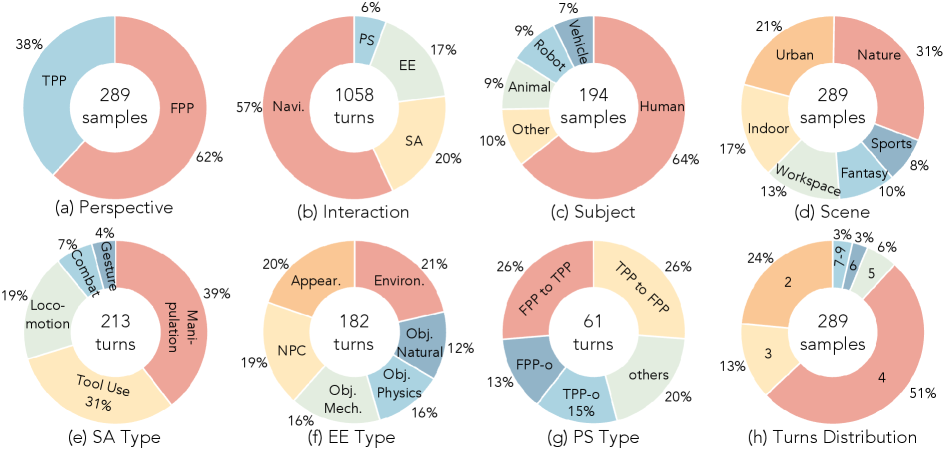
という形式の条件付き生成モデル — は、現在、テキスト駆動のビデオ生成モデル、カメラ制御モデル、および離散アクションによるゲームスタイルのモデルにまで広がっています。既存のベンチマーク(VBench、WorldScoreなど)は、視覚的品質や単一ターンのカメラ制御といった個別の軸をカバーするに過ぎず、ナビゲーション、被写体のアクション、イベント編集、視点切り替えを同時に評価する統一されたプロトコルは存在しませんでした。WBenchは、289ケース/1,058ターン、5つの評価次元、および人間の判断によって検証された22のサブメトリクスによって、この課題に取り組みます。
データセットの構築
各ケースは、入力を世界設定 \mathcal{W}(シーン、スタイル、視点、被写体)とインタラクションシーケンス \mathcal{I}=(a_0,\dots,a_{T-1}) に分解します。「設定優先」パイプラインにより、インタラクションが選択された世界内で物理的に実行可能であることが保証されます(例えば、天候編集には屋外シーンが必要であり、物体操作にはキッチンが必要です)。初期フレームはNano Banana 2とGPT-Image-1.5、および収集・撮影された画像から取得され、すべて手動で検証されています。シーン、スタイル、視点、被写体、および4つのインタラクションタイプという8つの軸にわたって層別サンプリングが適用されており、データセットの組成に示されるようなカバレッジが実現されています。
4つのインタラクションファミリーは、ナビゲーションに向けて統一されています。WBenchは8つのキーアクション(W/S/A/Dによる移動;矢印キーによる回転)を定義しており、同一の操作を一人称視点モードではカメラの動きに、三人称視点モードでは被写体の動きにマッピングします。ネイティブなテキスト、6自由度、または離散アクションのインターフェースを持つモデルは、この共通の制御アルファベットとの間で変換されるため、入力モダリティをまたいだ直接比較が可能です。
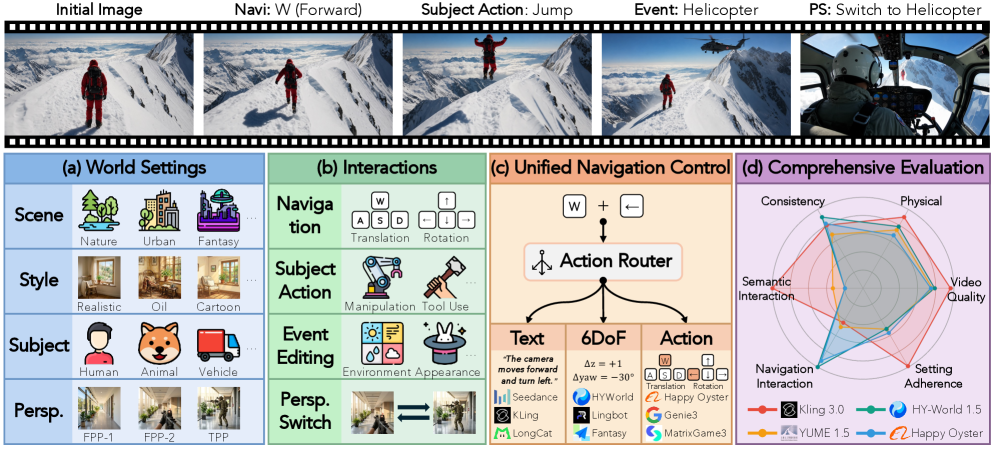
評価スイート
22のサブメトリクスは5つの次元にわたり、それぞれ [0,100] にリスケールされています。
- ビデオ品質: VBenchのaesthetic、imaging、flickering、dynamic-degree、motion-smoothnessメトリクス、およびパーセンタイル正規化されたHPSv3 reward。
- 設定遵守: (a) 最初から可視の要素と画面外に存在が期待される要素に分割されたシーンプロンプト、および(b) 外見と動作の事前知識に分割された被写体プロンプトに対するVLMスコアリング。
- インタラクション遵守: ナビゲーションは幾何学的に評価されます — MegaSaMによる各フレームのポーズが整列され、アクションシーケンスから導出された合成グラウンドトゥルース軌跡(一人称の回転 → 進行方向の変化;三人称の回転 → 周回運動)に対してアーク長リサンプリングが施されます。スコアは正規化されたATE(nATE)と反復アクションに対するターン間一貫性を組み合わせています。イベント編集と被写体アクションは、5つのバイナリチェック(変化検出、発生、完了、詳細精度、異常なし)を含むターンレベルのVLMを使用し、[0,5] のグレードを生成します。視点切り替えは、より厳格な連言的ルーブリック(遷移の可視性 ∧ ターゲットタイプの一貫性 ∧ 構造的適合性)を使用し、3つすべてが成立する場合のみカウントされます。
- 一貫性: 背景、空間的/ゲート付き空間的、セグメント、視点、被写体、幾何学的、および測光的安定性をカバーする8つのサブメトリクス。
- 物理的妥当性: 因果的忠実性と視覚的妥当性。
全体を通じて使用されるVLMバックボーンはdoubao-seed-2-0-lite-260215であり、すべてのサブメトリクスは人間の評価に対してキャリブレーションされています。
20モデルにわたる結果
158ケースのナビゲーション分割において、単一のモデルが支配的であることはありません。テキスト駆動モデルの中では、Seedance 1.5がビデオ品質で82.1をリード(グループ平均77.7)、Wan 2.7が設定遵守で91.4をリード、Kling 3.0がセマンティックインタラクションでリード(イベント編集81.4、被写体アクション85.6、視点切り替え55.0;グループ平均インタラクション73.1)、HY-Video 1.5が一貫性で87.4をリードし、LongCat-Videoが87.1で続いています。カメラ制御モデルはナビゲーションに優れており、HY-World 1.5はナビゲーションで87.5に達し、InSpatio-Worldは一貫性で88.4に達しますが、設定遵守では遅れを取っています(グループ平均69.4対テキスト駆動の81.6)。アクション条件付きのゲームスタイルモデル(Genie 3、Matrix-Game 3.0など)は最も高い生のdynamic-degreeスコア(約93〜98)を記録しますが、視点一貫性では崩壊しており(グループ平均37.3対テキスト駆動の74.7)、Matrix-Game 2.0は29.2、HY-GameCraftは17.9となっています。
視点切り替えは、大きな差をつけて最も難しいインタラクションです。グループ平均はテキスト駆動モデルで30.7であり、YUME 1.5は16.7、Kairos 3.0は13.3、Cosmos 2.5は20.0となっています。物理的妥当性も依然として弱く — 因果的忠実性の最高スコアはWan 2.7の83.3であり、Astraは48.3にまで崩壊しており、現在の世界モデルがマルチターンインタラクション下で基本的な動力学に違反していることを示しています。次元間の相関分析は、これらのトレードオフを定量化しています。
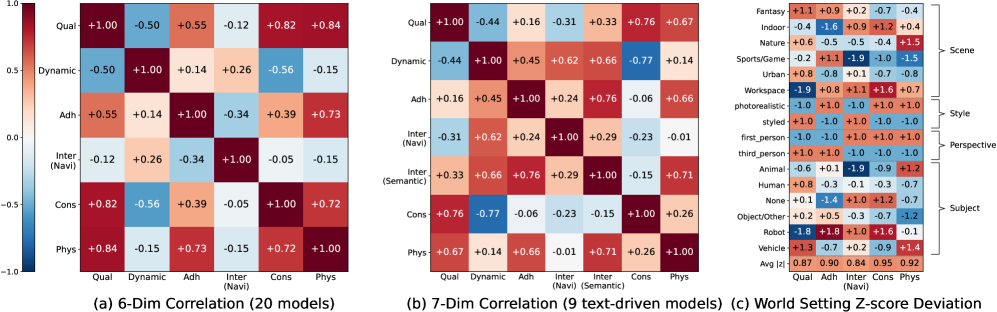
特筆すべき点として、設定ごとのZスコアマップは系統的な難易度パターンを示しています。様式化された/非現実的なレンダリングは設定遵守を容易にしますが物理的妥当性を損なう一方、複雑な屋外シーンはそのパターンを逆転させます。
限界と今後の課題
VLMベースのスコアリングはdoubaoバックボーンのバイアスを継承しており、メトリクスは人間の評価に対して検証されているものの、VLMバージョン間のドリフトがリーダーボードを変化させる可能性があります。ナビゲーションのグラウンドトゥルースは合成的なアクション対軌跡ルールから構築されているため、独自のアクションセマンティクス(例えば、可変ステップサイズ)を持つモデルは、アーク長正規化にもかかわらず不当にペナルティを受ける可能性があります。ベンチマークは289ケースしかなく、細粒度のサブセット比較に対する統計的検出力が限られており、視点切り替えは非常に厳格な連言的ルーブリックによって評価されるため、小さな検出失敗が支配的になります。最後に、アクション条件付きモデルはテキスト条件付き入力を必要とするイベント編集、被写体アクション、視点切り替えでは評価できないため、カバレッジのギャップが生じます。
この研究の意義
WBenchは、同一のマルチターンケースにおけるテキスト駆動、カメラ制御、アクション条件付きのインタラクティブなビデオモデルにわたる初めての公平な評価を提供し、単一軸のベンチマークでは見逃される具体的な弱点(視点切り替え、物理的妥当性、マルチターン一貫性)を明らかにしています。統一されたキーアクション制御アルファベットとポーズベースのナビゲーションスコアリングは、将来のあらゆる世界モデル評価において再利用可能なインフラストラクチャとなります。
Source: https://arxiv.org/abs/2605.25874
TriSplat: シミュレーション対応のFeed-Forward 3Dシーン再構成
Feed-forward 3D再構成はGaussian primitiveに収束しています。その理由は、ラスタライズのコストが低く、安定して学習できるからですが、GaussianはSurfaceを提供しません。物理シミュレータ、身体化エージェント、三角形を期待するレンダリングパイプラインといった下流の利用者は、通常、レンダリングされた深度からTSDF fusionやPoisson再構成を経由してメッシュを復元しますが、これは低速でロスが多く、それを生成したモデルとジオメトリを切り離してしまいます。TriSplatはGaussian primitiveを向き付きの三角形に置き換え、スパースなunposedビューから1回のforward passでポーズ(およびオプションでintrinsics)を含むシーン全体を予測します。メッシュはモデルの出力であり、事後的なアーティファクトではありません。
アーキテクチャとprimitive parameterization
エンコーダはDINOv2 backboneであり、2D RoPEとpixelごとの光線方向embeddingによって条件付けられた、intra-viewのself-attentionとcross-viewのjoint attentionをインターリーブするtransformer decoderを持ちます。3つのheadが並列に動作します:point head、camera head、primitive headです。
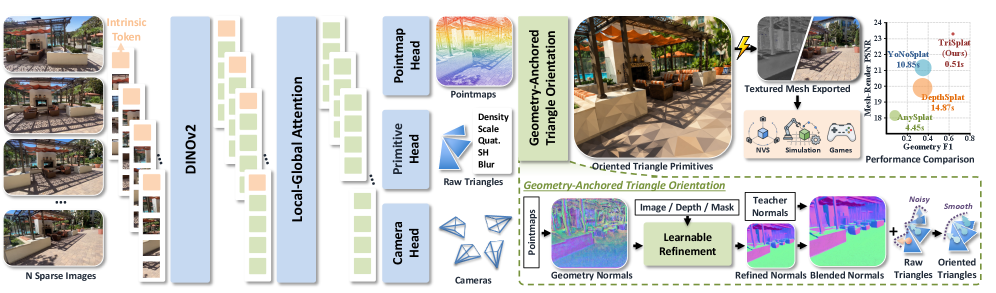
Point headはpixelごとに(u, v, z')を予測し、カメラフレーム内の3D点を次のように復元します:
\mathbf{p} = z \cdot (u, v, 1)^\top, \qquad z = \exp(z'),
これは横方向の座標と深度を乗法的に結合し、投影的画像モデルと整合しています。Camera headはdecoder tokenをmean-poolし、並進と3\times 3行列を回帰し、後者をSVD直交化によって\mathrm{SO}(3)に射影します。ゲージアンビギュイティを除去するためにポーズはview 1に対する相対値として表現され、scheduled samplingによって学習中にground-truthポーズ条件付けを減衰させることでテスト時の分布シフトを回避します。
Primitive headはpixelごとに、density logit、3つのscale logit、quaternion、SH係数、およびblurパラメータを出力します。入力RGBはpatch-embeddedされてprimitive featureに加算され、外観がheadへの短いパスを持つようにします。すべてのdense headは全解像度に達するためにpixel-shuffle upsamplingを使用します。
三角形自体は、canonical equilateral template \mathcal{T} \in \mathbb{R}^{3\times 3}から構築されます。Scale logitはsigmoidを通り、予測された深度とintrinsicsからのpixel footprintを使用してワールド単位に変換されます。頂点は次のように表されます:
\mathbf{v}_k = \mathbf{R}_c \, \mathbf{R}_n \, (\mathcal{T}_k \odot \mathbf{s}) + \mathbf{c},
ここで\mathbf{R}_nはジオメトリから導出されるタンジェントフレーム回転(自由に回帰されるものではない)であり、\mathbf{R}_cは予測されたカメラから世界座標への回転です。重要な設計上の選択として、\mathbf{R}_nは予測された点群マップから計算され、画像条件付きnormal headによって精緻化された法線から導出され、その後安定したローカルフレームに変換されます。向きを制約なしquaternionとして回帰すると、三角形が基礎となるSurfaceから傾いてしまいます。ジオメトリに向きを固定することで、三角形が由来するSurfaceに沿って配置されます。その後、三角形はtile-based sortingを持つ微分可能三角形ラスタライザに渡されます。三角形はエッジが鋭いため、学習にはプログレッシブなカリキュラム(blurパラメータがソフトからハードへの遷移を制御すると考えられる)を使用します。
定量的結果
6入力ビューを用いたRE10K上(表3)において、TriSplatはCD 0.190、F1 0.622、PSNR 24.69、SSIM 0.798、LPIPS 0.269を達成します。最も強力なpose-free GaussianベースラインであるYoNoSplat(CD 0.267、F1 0.443、PSNR 21.94)と比較すると、Chamfer距離が約29\%削減され、F1が+0.18、PSNRが+2.75 dB向上しています。MeshSplat(F1 0.340)やSurfelSplat(F1 0.154)などのSurface対応Gaussianバリアントは大幅に劣っており、SurfelSplatはこのメッシュexportプロトコルにおいて特に崩壊します(PSNR 11.18)。

DL3DVの定性的比較は、TSDF fusionされたGaussianパイプラインの失敗モードを明確に示しています:Surfaceが脱落し、ジオメトリが断片化し、シルエットが縮小します。TriSplatは6、12、24入力ビューにわたって一貫した三角形構造を維持します。

zero-shotのScanNet結果は最も印象的です。RE10Kのみで学習されたモデルをScanNet上で直接評価します(表4):TriSplatはAbsRel 0.188、AbsDiff 0.341、平均法線角度誤差27.9^\circ、および71.7\%のpixelが30^\circ以内という結果を達成します。次善のYoNoSplatは平均誤差54.1^\circ、30^\circ以内が41.0\%にとどまります。法線精度がほぼ倍増しており、これはアーキテクチャ上の事前知識と一致しています:ジオメトリに固定された向きにより、ネットワークは自由浮遊する属性としてではなく、予測された点群と整合する法線を生成することを強制されます。
制限と未解決の問題
論文のabstractは「mono-normal bootstrap」技術について文の途中で切れており、鋭いエッジを持つ三角形が崩壊せずに学習できるようにするための正確なウォームアップ手順はここでは完全に明示されていません。三角形のスケールはpixelごとの深度とintrinsic footprintに紐付けられているため、テクスチャのない領域では過剰テッセレーション、シルエットでは不十分なカバレッジが示唆されますが、より多くのビュー数でのDL3DVのレンダリングメトリクスがprimitive数のスケーリングを明確にするでしょう。この手法はまた、pixel単位で1つの三角形がSurfaceの妥当な分解であるという仮定を継承しています。薄い構造、透明または鏡面的なSurface、大きな平坦な領域については個別に分析されていません。最後に、ラスタライザは微分可能ですが、exportプロトコルと任意の下流シミュレータ(衝突クエリ、接触解決)との相互作用はベンチマークされていません。「シミュレーション対応」は測定された主張ではなく、表現上の主張にとどまっています。
この研究の重要性
primitive選択をラスタライズの利便性から切り離すことで、feed-forward 3Dネットワークが提供できるものが変わります:物理エンジンや身体化エージェントが使用可能なメッシュを生成する単一のforward passが実現でき、Gaussianパイプラインよりも大幅に優れたzero-shotの法線精度を持ちます。ジオメトリに固定された向きの事前知識が汎化するならば、それはSurface native primitiveこそが——Gaussianではなく——単なるnovel-view synthesisではなくインタラクションを対象とした再構成のデフォルトであるべきことを示唆しています。
Source: https://arxiv.org/abs/2605.26115
Hacker News Signals
White Rabbit – 大規模分散システム向けサブナノ秒同期
White Rabbit (WR) は、CERNおよびGSIが開発したオープンハードウェア・オープンファームウェアのIEEE 1588 (PTP) 拡張規格であり、数キロメートルにわたるネットワーク上で数千ノードをサブナノ秒精度・ピコ秒分解能で同期させることを目的としています。標準的なPTPが達成できる精度は約100 nsですが、WRは2つのメカニズムを組み合わせることで1 ns未満を実現しています。第一に、Synchronous Ethernet (SyncE) が物理層を通じて共通クロック周波数を配信し、PTPジッタの主要因を排除します。第二に、デジタルDMTD(Dual-Mixer Time Difference)回路がローカル発振器と回線クロック再生信号との間のクロックサイクル以下の位相オフセットを計測し、ソフトウェアサーボループにフィードバックしてローカル発振器を制御します。光ファイバの伝搬遅延は双方向で計測され、送受信経路で異なる波長(WRはTXとRXに1490/1310 nmの別々の波長を使用)を考慮した校正済み非対称性モデルにより分割されます。
リファレンスハードウェアはSPEC(Simple PCIe FMC Carrier)およびWR Switchであり、いずれも完全に公開されたKiCadの回路図とHDL(Xilinx Spartan-6上で合成可能)を備えています。ファームウェアはFPGA内のソフトコアLM32 CPU上で動作します。ハードウェア抽象化層からPTPデーモン(wr-daq として拡張されたPTPd)に至るまで、スタック全体がOpen Hardware Repositoryで公開されています。
導入実績としては、CERNの加速器複合施設(600ノード以上)、KM3NeT ニュートリノ望遠鏡、およびトレーサブルなUTC配信手段として利用している複数の国家計量機関が挙げられます。このプロトコルはIEEE 1588-2019においてHigh Accuracy profileとして採択されています。
技術的に興味深い点はDMTDにあります。GHzレートで直接位相を計測するのではなく、周波数がわずかにずれた2つの発振器で信号をミキシングダウンしてkHz帯のビート周波数に変換し、その低周波数で単純なカウンタが位相を計測します——低コストかつ高精度な手法です。未解決の課題としては、異種混在の光ファイバ設備への非対称性校正のスケーリング、および固定非対称性モデルが成立しない無線/RFリンクへのWRの適応が挙げられます。
Source: https://ohwr.org/projects/white-rabbit/
DeepSeek Reasonix – 高いキャッシュ効率と低コストを実現するDeepSeekネイティブコーディングエージェント
Reasonixは、DeepSeek-R1およびDeepSeek-V3を基盤とするコーディングエージェントのラッパーであり、DeepSeek APIの経済的特性——キャッシュヒット時のトークンコストが未キャッシュ時の約10分の1——に特化して設計されています。中核となる技術的な賭けは、プロジェクトのコンテキスト(ファイルツリー、コーディング規約、アーキテクチャ上の制約)を含む長く安定したシステムプロンプトをキャッシュに常駐させることで、リクエストあたりの償却コストを大幅に削減できるという考え方です。このエージェントは、大きなプレフィックスを不変のヘッダーとして維持し、可変の会話ターンのみをテールに追記することで、キャッシュヒットの対象面を最大化します。
ツール使用ループはReActスタイルの標準的なパターンに従っています。モデルが構造化されたツール呼び出し(ファイルの読み取り・書き込み、シェルコマンドの実行、grep)を出力し、ホストがそれらを実行し、結果を追記します。Reasonixはさらに「コンテキストバジェット」ヒューリスティックを追加しており、累積トークン使用量を追跡して閾値に近づくと、完了済みのステップを圧縮されたスクラッチパッドに要約してそれまでの生の履歴を置き換えます。これにより、プレフィックスの安定性を保ちながらコンテキストウィンドウのオーバーフローを防止します。
reasoning model(R1)に対しては、エージェントはchain-of-thoughtのトークンストリームを最終回答とは別に公開しており、下流のツールが推論トレースをログに記録しつつ、それを次のプロンプトにフィードバックしない(これにより非キャッシュのサフィックスが肥大化する)ようにしています。V3については、拡張的な推論を必要としないファイル編集に適した、より高速・低遅延なモードで動作します。
プロジェクトページに掲載されているベンチマークでは、中程度のリファクタリングタスクにおけるタスクあたりのコストは$0.01〜$0.05の範囲であるのに対し、同等のタスクをClaudeやGPT-4oで実行した場合は$0.20〜$0.50となっています。これは主に、DeepSeekのキャッシュ価格が積極的であり、かつプロンプト構造がそれを最大限に活用するよう調整されているためです。主な制限は、DeepSeek固有のキャッシュセマンティクスへの強い結合であり、他のプロバイダーに移植する場合はプレフィックス安定性戦略を根本から再考する必要があります。また、曖昧な複数ファイルにわたるリファクタリングにおいてR1が示す推論上の失敗もそのまま引き継ぎます。
Source: https://esengine.github.io/DeepSeek-Reasonix/
Gnutella: それを生み出した世界を超えて生き続けたプロトコル
この記事は、Gnutellaのプロトコル設計と、Napsterが訴訟によって消滅した数十年後もなぜGnutellaが機能し続けたのかについて、明快な技術的回顧録です。Gnutellaのオリジナル0.4仕様は、フラットで非構造化なP2Pオーバーレイでした。各ノードは少数のピアと接続し、クエリはTTLをデクリメントするQUERYメッセージによってネットワーク全体にフラッディングされます。レスポンスはリクエスト元に直接返されるのではなく、クエリの逆経路をたどって返送されます。TTL=7、分岐係数が約4の場合、単一クエリのメッセージ量はO(n)となり、ネットワークのスケールに伴って2000〜2001年に広く知られた帯域幅の爆発的増加を引き起こしました。
Gnutella 0.6はこの問題に対処するため、ultrapeers/leavesトポロジーを導入しました。接続性の高いノードの一部がultrapeersルーターとして機能し、leafノードはultrapeersへの2〜3接続のみを維持します。各leafは共有ファイルハッシュのBloom filterをultrapeersにプッシュすることで、クエリを満たせないleafをクエリルーティングがスキップできるようになります。これによりインデックスを集中化することなく、フラッディングを大幅に削減しました。
この記事が強調しているのは、Gnutellaが構造的に耐久性を持っていた理由です。召喚状を送れる中央サーバーが存在せず、メンバーシップレジストリもなく、週末に再実装できるほどシンプルなワイヤープロトコルを採用していました。プロトコルネゴシエーションはプレーンテキストのHTTPライクなハンドシェイクで、ファイアウォール越えにも適しています。拡張ヘッダー(X-Ultrapeer、X-Query-Routing)は旧来のクライアントとの互換性を壊すことなく追加されました。
今日において技術的に興味深いのは、Bloom filterベースのクエリルーティングです。これは現在のデータベースやネットワーキングで広く使われている分散近似メンバーシップ構造の先駆けと言えます。また、LimeWireの2010年の差止命令がネットワークを消滅させられなかったのは、プロトコル自体がすでにFrostwire、Phex、gtk-gnutellaなど多くの独立した実装として広く再実装されていたためだと指摘しています。リファレンス実装を多数の独立したコードベースに分散させたプロトコルは、事実上の検閲耐性を持つようになります。
Source: https://rickcarlino.com/notes/p2p/gnutella-explanation.html
Show HN: BPFプログラムをCではなくGoで書く
gobeeは、eBPFカーネルプログラムをGoのソースコードで記述し、標準的なclang/LLVM eBPFバックエンドに渡す前にCへトランスパイルする軽量フレームワークです。Go-to-Cトランスパイルのステップがこのプロジェクトの核心的な主張であり、標準のgo/astパッケージを使ってGoの制限されたサブセット(goroutineなし、GCなし、interfaceなし)をパースし、BPFマップのアクセサーやヘルパー関数呼び出しを適切に置換した等価なCコードを出力します。
これは、CiliumのeBPF-goやlibbpf-goのようなプロジェクトとはアーキテクチャ上根本的に異なります。それらのプロジェクトはカーネル側のBPFをCのまま維持し、ユーザースペースのローダーやマップ操作に対してのみGoバインディングを提供しています。gobeeの目標は、BPFの境界両側を単一言語で記述できる体験を実現することです。
トランスパイラーは代表的なBPFパターンに対応しています。bpf_map_lookup_elemによるマップルックアップ、per-CPU配列、perf eventの出力、kprobe/tracepointのアタッチメントなどです。BPFのverifierはヒープポインターを拒否するため、制限されたGoサブセットではスタックアロケーションのセマンティクスが強制されており、ヒープを必要とするGoの構文はトランスパイラーが静的に拒否します。固定サイズの配列や構造体はCへのマッピングが明確ですが、sliceやmapはサポートされていません。
技術的なリスクはverifierとの互換性にあります。LLVMのeBPFバックエンドは比較的安定していますが、BPF CO-RE(Compile Once, Run Everywhere)はclangがC型情報をもとに出力するBTFアノテーションに依存しています。カーネルバージョンをまたいだCO-REリロケーションを機能させるためには、トランスパイラーが正しいBTF互換の型宣言を出力する必要がありますが、現在のコードでそれが完全に対応されているかは明確ではありません。このプロジェクトはまだ初期段階にあり、Goを多用するチームにとっての主な価値は、CツールチェーンとのコンテキストスイッチングをGo一本化することで削減できる点にあります。代替案として、RustのAyaフレームワークはCの中間コードを使わずBPFバイトコードを直接生成するなど、この問題をより完全に解決しています。
Source: https://github.com/boratanrikulu/gobee
AIを使ってより良いコードをより時間をかけて書く
この投稿は、ある実践者による意図的なワークフローの転換についての記録です。LLMをスループット向上に使うのではなく、速度を犠牲にして品質向上のために使うというアプローチです。核心的な観察は、著者ループ内でのLLMを活用したコードレビュー――設計を書く前にモデルに批評を求めたり、初稿の後にエッジケースを列挙させたりすること――によって、以前ならPRレビューや本番環境まで生き残っていたような問題が表面化するというものです。
説明されているワークフローには、いくつかの具体的なステップがあります。書く前: 問題の記述をモデルに与え、仕様が不明確な要件や起こりうる障害モードを特定させます。書いている間: モデルを記憶を持つラバーダックとして使い、設計上の決定を説明しながら「見落としていることは何か」と問いかけます。書いた後: 実装をペーストして敵対的レビューを依頼し、スタイルに関する提案はせず、正確性・並行処理上の危険・エラー処理の漏れに集中するよう明示的に指示します。この最後のステップが最も信号対雑音比が高いと著者は報告しています――モデルは、明示的に探すよう促されると、チェックされていないエラーの戻り値やオフバイワンの条件を見つけることが驚くほど得意です。
この投稿はコストについても正直に述べています。このループを使うと、使わない場合よりも時間がかかり、モデルの提案の多くはノイズです。フィルタリングの負担はプログラマーにあります。また、モデルはより大きなコードベースの規約に設計が合っているかどうかを評価するのが苦手である、と著者は指摘しています。完全なコンテキストが欠けているためです――これはretrieval-augmentedなcoding agentsが部分的に対処しているものの、解消はされていない制限です。
暗示されている技術的な主張は、コーディングにおけるLLMの価値は品質と速度のトレードオフのフロンティア上で一様ではないというものです。現在のモデルは、自律的なコード生成器としてよりも、再現率は高いが適合率は低いチェッカーとして有用です。これは、SWE-benchのような研究の実証的な知見――実際のリポジトリタスクにおいてpass@kの性能は高いがpass@1は弱い――とも一致しています。
Source: https://nolanlawson.com/2026/05/25/using-ai-to-write-better-code-more-slowly/
GoからRustへの移行
これはRustコンサルティング会社であるcorrode.devによる体系的な移行ガイドであり、明らかな選択バイアスが存在しますが、技術的な内容はトレードオフについて詳細かつ誠実に記述されています。このガイドはGoの概念をRustの等価物に機械的なレベルでマッピングしています:goroutineはtokio::task::spawnまたはstd::threadへ、チャネルはtokio::sync::mpscまたはcrossbeamへ、interfaceはtraitへ、エラーの戻り値はResult<T, E>へ、そしてnilはOption<T>へ対応します。goroutineに関するセクションが最も詳細に掘り下げられており、GoのgoroutineスケジューラはプリエンプティブなランタイムによるM:N方式であるのに対し、Rust asyncは協調的であり明示的なexecutorを必要とします。並行処理を行うGoコードをRust asyncに移行するには、すべてのyieldポイントを明示的に特定する必要があり、それによってメンタルモデルが大幅に変化します。
ownershipシステムに最も多くの紙面が割かれています。GoのGCにより、ポインタを介してgoroutine間で可変状態を共有することは言語レベルでは問題ありません(データ競合はランタイムの問題であり、-raceフラグで検出されます)。Rustのborrow checkerは共有された可変参照をコンパイル時に拒否し、Arc<Mutex<T>>またはメッセージパッシングによる明示的な同期を強制します。このガイドは、これが単なる構文の変更ではなく、モジュールグラフ内のデータownershipの設計を見直す必要があることを正しく指摘しています。
実践的な移行のアドバイスとして、goroutineを持たない独立したユーティリティパッケージから始めること、インクリメンタルな移行中のブリッジとしてunsafeを控えめに使用すること、そしてハイブリッドフェーズ中のFFI境界にはcbindgen/cgoを使用することが挙げられています。また、このガイドは一括書き換えを推奨していません。
このガイドで欠けている点としては、ビルドの複雑さ(Rustのインクリメンタルなコンパイル時間は大規模なコードベースでは依然として苦痛を伴います)、一部の領域におけるエコシステムの成熟度のギャップ(例えばobservabilityツール)、そしてGoチームがborrow checkerを習得するための組織的なコストについての議論が挙げられます。これらが実際の移行における本当の摩擦点です。
Source: https://corrode.dev/learn/migration-guides/go-to-rust/
CVE-2026-28952: ClaudeによってApple macOS 26.5のカーネル脆弱性が発見される
このエントリが注目に値するのは、特定の脆弱性そのものというよりも、その帰属にあります。Appleのアドバイザリには技術的な詳細がほとんどなく、macOS 26.5で修正されたカーネルメモリ破壊の問題として記載されているに過ぎませんが、謝辞においてAnthropicのClaudeがこの欠陥を特定したとして言及されています。HNのスレッドでは、AIを活用した脆弱性調査が日常的になりつつあることを意味するとして、この点が議論の焦点となっています。
技術的な内容として推測できることとしては、Claudeはおそらくfuzzingや静的解析のループの中で使用されており、カーネルsyscall fuzzingのハーネスコードを生成するか、XNUソース(AppleがDarwinレイヤ向けにオープンソース化しているもの)のセマンティック解析を行っていたと考えられます。Apple siliconのカーネルにおけるメモリ破壊は、PAC(Pointer Authentication Codes)の存在により悪用が容易ではありません。PACはCPUレジスタに格納された鍵を使ってコードポインタおよびデータポインタに署名し、KTRR(Kernel Text Read-only Region)はランタイムでのカーネルテキストの改変を防止します。完全なexploit chainにはPACバイパスが必要であり、攻撃の難易度は大幅に上がります。
このCVEが2026年の名前空間に属することは、最近報告されたことを示唆しており、協調的な開示のタイムラインからは、AnthropicがAppleにproof of conceptを公開するのではなく、標準的なチャネルを通じて報告したことが窺えます。これは、セキュリティ研究者がAIツールを責任ある開示のパイプラインに組み込む方法と一致しています。モデルが候補を見つけ、人間が検証して報告するという流れです。
技術的に重要な点は、もしClaudeが人間が事前にターゲットを絞ったfuzzingロジックを記述することなくこれを特定したとすれば、フロンティアモデルが今やカーネルデータ構造の不変条件についてメモリ破壊の条件を指摘できる水準で推論できることを示唆しているということです。これが新規のセマンティック解析による発見なのか、既知の脆弱性クラスに対するパターンマッチングなのかについては、まだ公開されていません。より大きな未解決の問題は、Appleの自社セキュリティチームが今後の内部監査プロセスにLLMを活用したレビューをどのように組み込むかという点です。
Source: https://support.apple.com/en-us/127115
AI errno(2) の値
この投稿では、各種 LLM が POSIX errno 値テーブルをどの程度正確に把握しているかを体系的に実験的に検証しています。具体的には、EAGAIN、EWOULDBLOCK、EINPROGRESS といった標準エラーコードや、あまり一般的でないものも含めた整数値とセマンティクスを正しく述べられるかどうかを調べています。結果として、モデルは信頼性が低く一貫性に欠けることが明らかになりました。アーキテクチャ間での数値の混同(Linux x86-64、Linux ARM、macOS ではコードによって異なる割り当てがある)、EAGAIN と EWOULDBLOCK の混同(一部のプラットフォームでは別物だが、他では別名として扱われる)、そして確信に満ちた文章での errno 値のハルシネーションが頻繁に見られました。
技術的に興味深い知見は、これらの失敗がランダムではなく、まさにプラットフォーム依存である箇所や POSIX が実装に割り当てを委ねている箇所に集中しているという点です。モデルは複数プラットフォームのドキュメントをタグ付けなしに吸収し、推論時に平均化あるいはランダムに選択しているように見えます。主要なプラットフォーム全体で安定している値(EINVAL=22、ENOENT=2)については、モデルは確実に正解しています。一方、プラットフォーム間で可変なサブセットについては、精度が急激に低下します。
LLM を使ってシステムコードを書く際の実践的な示唆として、errno 値はモデルから取得したものをそのまま使用せず、必ずターゲットプラットフォームの <errno.h> に照らして検証すべきです。より本質的な問題は、これがより広範な失敗クラスの診断になっているという点です。同一のシンボルがプラットフォーム依存の数値セマンティクスを持つあらゆるドメイン(シグナル番号、ioctl 定数、ソケットオプションレベルなど)において、同様の信頼性の欠如が生じます。この投稿は、普遍的に見えるが実際にはそうでない数値定数に対して、モデルの信頼度キャリブレーションが特に不正確であることを思い起こさせる有益な内容です。投稿が暗示する推奨事項は、ABI レベルの定数については LLM の記憶を信頼するのではなく、常に権威ある情報源(man 3 errno、プラットフォームのヘッダファイル)を参照すべきということです。
注目の新しいリポジトリ
sno-ai/llmix
エージェントおよびツール使用ワークロードを対象としたLLM呼び出し向けの、プロダクションレベルのミドルウェア層です。既存のSDK(OpenAI、Anthropic、AI SDK、LiteLLM)を置き換えるのではなく、それらをラップした上で信頼性スタックを追加します。具体的には、設定可能なTTLによるキャッシュ、指数バックオフによるリトライ、モデルエンドポイントごとのサーキットブレーカー、そしてプール内でのAPIキーローテーションが含まれます。singleflightパターンにより進行中の同一リクエストを重複排除できるため、多数のエージェントスレッドが同じプロンプトを同時に発行する状況で特に効果を発揮します。
「MDA presets」(Model-Deployment-Alias)を使うと、名前付きの設定を定義し、呼び出し箇所を変更することなく基盤となるモデルをホットスワップできます。プロバイダーの性能が低下した際のA/Bテストやフォールバックルーティングに有用です。Python、TypeScript、Rustにわたる言語間の一貫性により、これら3つのいずれかで記述されたエージェントフレームワークが、同一の操作セマンティクスと設定スキーマを共有できます。
エンジニアリング上のトレードオフは合理的です。サーキットブレーカーはプロバイダーがレート制限をかけた際のカスケード障害を防ぎ、キーローテーションはアカウント間でクォータを分散し、singleflightは冗長なAPI費用を削減します。これらは個別には目新しいものではありませんが、一貫した動作を持つ単一のドロップイン層として3つのランタイムにまたがって組み合わさることで、現在ほとんどのチームが場当たり的に解決している実際の運用上のギャップに対処しています。
マルチエージェントパイプラインを大規模に運用しており、サービスごとにリトライロジックとキー管理を再実装することに疲弊しているのであれば、評価する価値があります。
Source: https://github.com/sno-ai/llmix
KevRojo/Dulus
フロンティアモデルを厳選されたシェル機能群に接続する、ターミナルネイティブなtool-calling LLM agentです。対応する機能はファイルの読み書き、任意のBash実行、リポジトリツリー全体へのregex grep、Webブラウジング、およびGit commitの作成です。アーキテクチャは標準的なReACtループに従っており、モデルがtool-call JSONを出力し、Dulusが対応するハンドラにディスパッチして結果をフィードバックし、モデルが完了を通知するまでこれを繰り返します。
類似プロジェクト(aider、Claude Code、OpenDevin)との差別化点として挙げられているのは、コストゼロのWebスクレイピング経路です。有料の検索APIではなく、公開されているAIチャットインターフェースを利用しているようです。これは実用的ではありますが脆弱な選択であり、AIチャットフロントエンドのスクレイピングはレート制限、CAPTCHA、および利用規約の変更に左右されます。Git統合により、エージェントは自然言語の仕様からターミナルを離れることなくコミット済みのdiffまで、一連のタスクを完結させることができます。
ツールのスコープは意図的に広く設計されており、Bash実行とWebアクセスの組み合わせは実質的に無制限のcomputeに相当するため、サンドボックス化とパーミッションのスコーピングは未解決の懸念事項です。現行リリースでは正式なサンドボックス機構はドキュメント化されていません。環境を自分でコントロールできるローカルの開発者自動化には適していますが、追加的な隔離措置なしにマルチテナントやCI環境で使用するには適切ではありません。
Source: https://github.com/KevRojo/Dulus
boratanrikulu/gobee
gobeeは、eBPF開発における実際のエルゴノミクス上の問題に取り組んでいます。必要とされるCの方言は低レベルであり、型安全性を欠き、ツールチェーン(clang、bpftool、libbpfヘッダー)の導入に摩擦が伴います。gobeeは、Goの制限されたサブセットを受け取り、有効なBPF Cを出力するトランスパイラを提供し、その後cilium/ebpfを用いて型付きGoバインディングを自動生成します。cilium/ebpfは、本番のeBPFプロジェクト(Cilium、Tetragon、Falco)でもすでに広く使用されているライブラリです。
サブセットの制限が必要なのは、BPFプログラムがヒープアロケーションなし・ループの有界性・512バイトのスタック制限を持つ、カーネル内の検証済みVMで動作するためです。gobeeはこれらの制約をGoのソースレベルで強制し、verifierによる拒否ではなくコンパイル時エラーとして通知します。生成されたバインディングはmapやprogramを強く型付けされたGo structとして公開し、生のcilium/ebpfコードをエラーが起きやすくしていた文字列ベースのmapアクセスを排除します。
トランスパイラアプローチは、Goコンパイラへの完全なBPFバックエンドの追加(これは現状存在しない)と比較してアーキテクチャ的にシンプルであり、カーネル側のコードをCとして提出前に確認できる状態に保ちます。主な制限は、サポートされるGoのサブセットが常に完全なGoのセマンティクスに追いつけないこと、および複雑なデータ構造では手動でCのshimが必要になる場合があることです。それでも、Go環境で書かれたネットワーク可観測性、トレーシング、セキュリティツールに対しては、eBPFの導入障壁を大幅に下げる効果があります。
Source: https://github.com/boratanrikulu/gobee
WantongC/journal-adapt-writing-skill
投稿先の学術誌の慣習に向けて学術論文のスタイル転換を行うツールです。ワークフローは次の通りです:特定の学術誌に掲載された論文のコーパスを入力し、構造的・言語的パターン(セクションの順序、ヘッジ表現の密度、引用箇所の配置、受動態・能動態の比率、専門用語)を抽出し、それらのパターンを投稿原稿へのリビジョンガイダンスとしてセクションごとに適用します。
このアプローチの枠組みは純粋な言い換えではなく文体計量的なものです。目的は表面的な書き換えではなく、投稿先が持つ暗黙の編集規範への整合であり、その規範はたとえば Nature Medicine とシステム系のカンファレンスプロシーディングスとの間では大きく異なります。これは正当な問題設定です。内容ではなくスタイルの不一致による不採録は珍しくなく、その慣習が明示的に文書化されることもほとんどありません。
技術的な実装は、fine-tuning ではなくスクレイピングしたコーパスから得たin-contextサンプルを用いたLLMプロンプティングを使用しているようです。これによりパイプラインの柔軟性は保たれますが、出力の品質は少数の例から分布の差異をモデルがどの程度内在化できるかに依存します。主な未解決の問題としては、信頼性の高いパターンを得るために学術誌ごとにどの程度の規模のコーパスが必要か、異質なスタイルを持つ学際的な学術誌にこのアプローチが対応できるか、そしてセクションごとの分解によってセクション横断的な一貫性が保たれるかどうかが挙げられます。それでも、複数の投稿先にまたがって執筆する研究者や、非母語の学術英語で執筆する研究者にとって、このツールは各媒体への深い手動による精通を必要とするタスクを操作可能なものにしています。
Source: https://github.com/WantongC/journal-adapt-writing-skill
seochecks-ai/slopless
英語Markdownにおける低品質な文章パターンを検出するための、決定論的・ルールベースのCLIおよびtextlintプラグインです。設計上の明示的な選択は決定論性にあります。LLMベースのライティングフィードバックとは異なり、フラグが立てられたすべてのトークンは定義済みのルールに対応しており、CIへの組み込みや再現可能なlintingパイプラインに適したツールとなっています。
対象とするパターン群——「prose slop」——は、LLMが生成するフィラー表現の語彙をカバーしています。中身のない強調語(“incredibly”、“leverage”、“seamlessly”)、曖昧な名詞化、冗長なヘッジング表現、使い古された接続フレーズなどが該当します。これらはまさに、事実として正確であっても人間の読者がAI生成テキストを見抜く際のシグナルとなるものです。
textlintのAST ベースのMarkdownパースを基盤として構築されたsloplessは、既存のtextlintエコシステムと統合でき、他のルール(文の長さ、受動態、読みやすさスコアなど)と組み合わせて使用できます。ルール定義は透過的であり上書き可能です。これは、特定のコンテキストで一部の用語を許可したいチーム(例:金融ドキュメントにおける動詞としての”leverage”)にとって重要な特性です。
実用的なユースケースとしては、ドキュメントリポジトリへのpre-commitフック、ブログコンテンツのPRチェック、あるいは人間のレビュアーが一次フィルタリングを求める編集パイプラインなどが挙げられます。制限はレキシコンベースのアプローチに本質的に伴うものです——フラグ対象の単語が正当に使用される場合の偽陽性、および特定の語彙として現れないslopパターン(例:循環的な定義、内容のない文)の検出不能性がその例です。完全なカバレッジを得るには、意味レベルのチェックと組み合わせることを推奨します。
Source: https://github.com/seochecks-ai/slopless
horang-labs/tessera
AIを活用したコーディングセッション向けに特化して設計されたワークスペースマネージャーです。非自明な規模のコードベース上で複数のエージェントとのやり取りを並行して実行する際に生じる、組織的なオーバーヘッドの問題に対処しています。コアのデータモデルは5階層で構成されています:ワークスペース(プロジェクトレベル)、コレクション(タスクのグループ化)、タブ、ペイン、そしてGit worktree — 最後の要素が主要な技術的差別化ポイントです。
各ペインまたはセッションを個別のGit worktreeにバインドすることで、Tesseraは複数のエージェントコーディングスレッドが同一リポジトリの隔離された作業ツリー上で同時に動作できるようにします。これにより、ブランチ切り替えのオーバーヘッドやセッション間の状態汚染が発生しません。これは、Claude Codeや類似ツールを使用する開発者が自然に望む並列化の形を反映しています:フィーチャーブランチ用のworktreeとバグ修正用のworktreeをそれぞれ用意し、それぞれが独自のエージェントコンテキストを持ちます。
UIはターミナルベース(ペイン/タブモデルから示唆される)でセッション永続的であるため、worktreeに紐づいたエージェントとの会話はターミナルを再起動しても保持されます。プロジェクト/コレクション階層は、過去のセッションとそれに関連するコード状態をアーカイブ・取得する手段を提供しており、数週間後に中断したタスクに戻る際に有用です。
主要なアーキテクチャ上の問いは、ペイン間でのコンテキスト管理方法です — エージェントの会話がリポジトリレベルのコンテキストを共有するか、完全に分離されるかという点です。完全な分離は安全ですが、タスク間の知識が失われます。共有コンテキストは結合度を高めます。大規模な並列エージェント支援開発を運用するチームにとって、注目に値するプロジェクトです。
Source: https://github.com/horang-labs/tessera
ajsai47/backdoor
Claude CodeのAPI呼び出しを任意のOpenAI互換エンドポイント(DeepSeek、Groq、Ollama、OpenRouter、およびOpenAIのchat completionsインターフェースを公開するその他のプロバイダー)に転送する薄い互換性shimです。Claude CodeはAnthropicのAPIにハードコードされていますが、backdoorはトランスポート層(ローカルプロキシまたは環境変数のオーバーライドと思われる)でインターセプトし、リクエストを設定されたバックエンドに変換・転送します。
実用上の価値はコストとレイテンシの柔軟性にあります。フロンティアレベルの性能が不要なタスクにおいては、DeepSeek-V3やOllamaを介してローカルにホストされたモデルは、Claude 3.5 Sonnetと比較してトークンあたりのコストが桁違いに安価です。また、ローカルのOllamaインスタンスに向けることで、機密性の高いコードベースに対して完全なオフライン運用も可能になります。
技術的なリスクはプロンプトフォーマットの不一致です。Claude Codeのシステムプロンプトおよびツール呼び出しスキーマはAnthropicのモデル向けにチューニングされており、オープンウェイトまたはサードパーティのモデルではこれらの扱いが異なる場合があり、ツール使用の信頼性の低下や不正な出力が生じる可能性があります。このshimはセマンティックな非互換性を修正することはできず、プロトコルレベルのものしか対処できません。対象モデルの指示追従性に応じて品質がばらつくことをユーザーは想定しておくべきです。
これは狭いスコープを持つ開発者向けの利便性ツールです。新規のアーキテクチャはありませんが、AnthropicのプライシングやデータルーティングなしにClaude Codeインターフェースを利用したい人々に対して、具体的なアクセス上の問題を解決します。
Source: https://github.com/ajsai47/backdoor
study8677/awesome-architecture
21種類のソフトウェアアーキテクチャパターンをビジュアルマップ形式で体系的にまとめたリファレンスコレクションです。LLM向けAPI gateway、RAGパイプラインアーキテクチャ、エージェントオーケストレーション、inference serving、ベクターデータベースの内部構造といったAI特有のインフラに関する項目を明示的にカバーしており、さらにイベント駆動型、マイクロサービス、CQRS、sagaといった古典的なパターンも網羅しています。各マップはダイアグラムにとどまらず、オープンソースのプロトタイプ実装へのリンクを備えています。
「アーキテクトのように考える」という教育的フレームは、スケーラビリティ・一貫性・フォールトトレランス・オブザーバビリティといった関心事を実装から切り離して解説する、言語非依存のシステム設計チュートリアルによって具現化されています。中国語と英語によるバイリンガル表示は主要読者層を反映したものですが、英語のみの読者にとっても有用性は損なわれません。
汎用的なawesome-listと比べてより実用的である点は、パターンダイアグラムと実際に動作するコードが結び付けられていることです。たとえばAI gatewayのマップでは、抽象的なルーティングやrate-limitingの概念が実際のプロキシ実装と接続されており、アーキテクチャ的思考とエンジニアリング実践の間のギャップを埋める役割を果たしています。
このフォーマットの限界として、静的なマップはツールの進化とともに陳腐化する点が挙げられます(特にinference servingやベクターDBの分野は変化が速い)。また、パターンの説明は必然的に高レベルにとどまります。このリポジトリは決定的なリファレンスとしてではなく、探索のための体系的な出発点として活用するのが最適です。古典的な分散システムのコンテンツと並んでAIインフラパターンが収録されていることは、現代のエンジニアリング現実を反映しています——これらの関心事は、システム設計面接や本番スタックにおいて共存することが増えています。