Daily AI Digest — 2026-05-26
arXiv Highlights
QUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks
Problem
Deep research agents — systems that iteratively search, read, and synthesize web content into grounded long-form answers — are dominated by closed systems (OpenAI Deep Research, Gemini Deep Research, Perplexity Pro). Open replications tend to overfit to one task family: either short-horizon fact lookup (BrowseComp-style) or long-form report writing, but rarely both, and they typically rely on heavy human annotation for trajectory or rubric supervision. The open question this paper addresses is whether a single recipe can produce a broadly capable agent — strong on fact seeking, citation grounding, and report synthesis — using only synthetic tasks with verifiable rewards.
QUEST releases a family of agents at 2B, 8B, and 35B parameter scales trained with a unified pipeline of mid-training, SFT, and RL on 8K synthetic tasks.
Method
The core contribution is a unified rubric tree for synthetic task generation that subsumes both factual and synthesis-style tasks. A rubric tree T is a hierarchical decomposition of a target answer where leaves are atomic, individually checkable claims (entity, date, numeric value, citation requirement, structural constraint, etc.). For a task x with answer y and rubric tree T(x), the reward is
R(y, T) = \frac{1}{|L(T)|}\sum_{\ell \in L(T)} w_\ell \cdot \mathbb{1}[\text{verify}(\ell, y)],
where L(T) are leaves, w_\ell are leaf weights, and \text{verify} is a deterministic or LLM-judged check. Because each leaf is verifiable, the reward is dense relative to a single end-to-end correctness signal, and the same machinery covers BrowseComp-style needle questions (a tree with one factual leaf) and long-form report tasks (trees with dozens of structural and citation leaves).
The data pipeline:
- Seed a topic from a web crawl, expand into sub-questions via an LLM planner.
- For each sub-question, ground claims by retrieving real web evidence; reject claims that cannot be verified against retrieved pages.
- Compose the rubric tree, attaching evidence URLs to leaves so citation grounding is checkable.
- Filter for difficulty (rejection sampling against a baseline agent — keep tasks the baseline fails).
Training has three stages:
- Mid-training: continued pretraining on synthetic tool-use trajectories (search, browse, scratchpad ops) interleaved with web text, to teach the format and tool schema before any task-level supervision.
- SFT: imitation on filtered teacher trajectories that solve the synthetic tasks. The teacher is an instrumented stronger model executing the tool loop; trajectories are kept only if they achieve high R.
- RL: GRPO-style on-policy optimization with R(y, T) as reward. Group-relative advantages are computed over K sampled trajectories per task, eliminating the value head:
A_i = \frac{R_i - \mathrm{mean}(R_{1..K})}{\mathrm{std}(R_{1..K})}.
A second contribution is built-in context management. Long-horizon agents blow through context windows; QUEST trains the model to emit explicit summarize/compress actions that produce a structured working memory, distinct from the raw tool-output buffer. The model learns when to compress (token-budget triggers in supervision) and what to retain (entities, URLs, partial answers tied to rubric leaves). At inference, this lets a 35B model handle research traces that exceed its native context.
Results
With only 8K synthesized tasks, QUEST-35B is reported to approach or surpass frontier closed agents on the evaluated benchmark mix (the abstract is truncated mid-sentence in the source, but the paper covers BrowseComp, GAIA-style fact seeking, and report-synthesis benchmarks with rubric-graded scoring). The cross-scale story is the more interesting empirical claim: the same recipe lifts the 2B and 8B variants substantially above same-size open baselines, indicating the rubric-tree reward is not specific to large-model capacity.
Ablation signal worth flagging:
- Removing mid-training collapses tool-use formatting reliability, hurting RL convergence.
- Removing the rubric-tree decomposition (using only end-to-end pass/fail) substantially reduces RL gains — the dense leaf-level signal is doing real work.
- Removing context management caps performance on long-horizon tasks where trajectories exceed ~32K tokens.
Limitations and open questions
- Verifier loops: leaves judged by an LLM verifier inherit that verifier’s biases. Rubric-tree training risks Goodharting toward whatever the judge accepts, especially for “synthesis quality” leaves that are not deterministically checkable.
- Synthetic distribution coverage: 8K tasks generated from a fixed seed pool may underrepresent adversarial or temporally-shifting queries. The paper does not report robustness to time-shifted evaluation where the underlying web has changed.
- Citation grounding is verified by URL match, not by claim entailment against retrieved content; an agent can satisfy the leaf by attaching a topical-but-non-supporting URL.
- Tool-use realism: synthetic trajectories assume a well-behaved search API. Real deep research involves paywalls, JS-rendered pages, and rate limits — none of which appear in training.
- The 35B model still requires teacher-quality trajectories during SFT, so the recipe is not bootstrappable from scratch without a stronger model.
Why this matters
Rubric trees turn the messy “did the agent write a good report” objective into a structured collection of verifiable leaves, which is precisely the form RL needs. If the result holds up, it suggests frontier deep-research capability is reachable with ~10^4 synthetic tasks plus a sufficiently strong teacher — not human-annotated trajectories at scale — and pushes the bottleneck from data collection to verifier design.
Source: https://arxiv.org/abs/2605.24218
ThriftAttention: Selective Mixed Precision for Long-Context FP4 Attention
Problem
Block-scaled FP4 attention on Blackwell (e.g. SageAttention3) accelerates long-context inference but degrades quality, especially as sequence length grows. The standard remedy — uniformly raise precision — discards most of the FP4 efficiency. The paper’s central observation is that FP4 quantisation error is highly non-uniform across the (Q, K) block grid: a small fraction of blocks dominate the output error, so a selective mixed-precision scheme can recover near-FP16 quality at near-FP4 cost.
Method
Starting from standard attention o = \sum_j p_j v_j with p_j = \mathrm{softmax}(q\cdot k_j/\sqrt{d}), FP4 perturbs each logit by \epsilon_j. A first-order expansion of the output gives
\delta o \approx \sum_j \frac{\partial o}{\partial s_j}\epsilon_j = \sum_j p_j (v_j - o)\,\epsilon_j,
so
\|\delta o\| \le \sum_j |\epsilon_j|\cdot p_j \cdot \|v_j - o\|.
The factor p_j is exponential in the score, so blocks with large attention weight both attract more probability mass and amplify their own quantisation error in the output. Empirically these are the near-diagonal blocks and non-initial attention sinks.
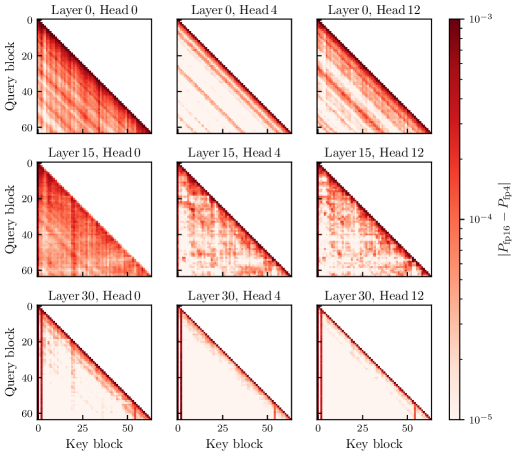
The error map confirms strong sparsity: in any given head, only a handful of (Q\text{-block}, K\text{-block}) pairs accumulate meaningful error, and the pattern is dominated by diagonal locality plus sink columns.
ThriftAttention exploits this with a two-stage pipeline using B_q = B_k = 64:
- Block selection. A cheap heuristic identifies a small budget of important (Q,K) block pairs that should run in FP16. The remaining blocks run in FP4.
- Mixed-precision attention with online softmax merge. FP16 and FP4 paths are computed on their respective block sets and combined into a single output through the standard online-softmax running-max / running-sum reduction, so no second pass over the data is needed.
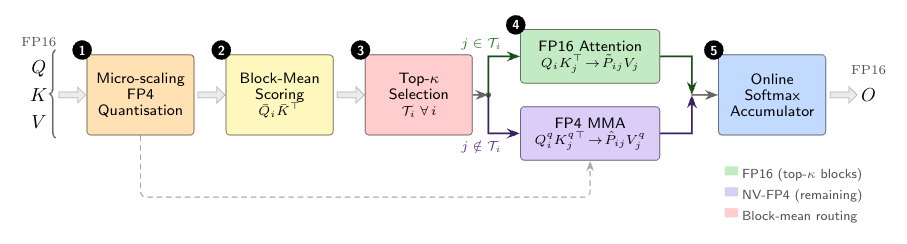
Because the merge is the standard FlashAttention-style streaming reduction, the FP16 path only needs to materialise the selected blocks, and KV-cache traffic during decode is dominated by the FP4 portion.
Results
The headline operating point: computing only 5% of (Q,K) blocks in FP16 recovers on average 89.1% of the FP4-to-FP16 NLL gap.
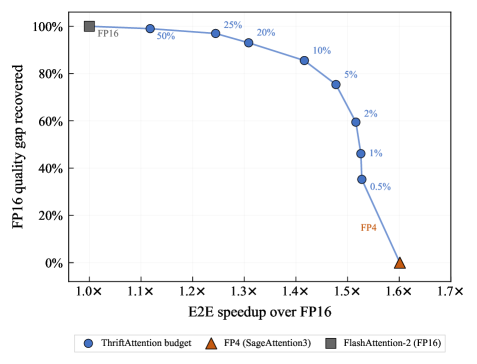
Kernel and end-to-end measurements on an RTX PRO 6000 (Blackwell), with B=1, n_\text{heads}=32, D=128, Qwen3-8B:
- Prefill kernel: up to 1.7\times over FlashAttention-2 (the fastest baseline supported on this GPU).
- End-to-end prefill: \sim1.2\times over FP16 attention at 131k context.
- Decode kernel: 3\times–5.5\times over FlashAttention-2, with minimal overhead vs full FP4 attention.
- End-to-end decode: nearly 2\times over FP16 attention at 131k context for Qwen3-8B.
The decode advantage comes directly from the KV-cache bandwidth structure: most blocks are streamed in FP4, halving (vs FP8) or quartering (vs FP16) the bytes per token loaded. The FP16 minority does not change the asymptotic memory footprint but does cover the blocks where quantisation error would otherwise dominate \|\delta o\|.
The paper also reports recovery scaling with context length on HELMET and an NLL analysis on PG-19, both consistent with the bound in (4): as N grows, more positions contribute and per-token error compounds, but the dominant terms remain concentrated in few blocks, so a fixed 5% FP16 budget continues to capture them.
Limitations and open questions
- The selection heuristic is the crux of the method; the abstract and Section 3 do not fully specify it, and 89.1% gap recovery — not 100% — indicates the heuristic still misses some high-impact blocks. A score-aware or two-pass selector might close the residual gap.
- Results are reported primarily on Qwen3-8B and a handful of long-context benchmarks; behaviour on MoE models, GQA with very small KV head counts, and models with stronger attention-sink patterns may shift the optimal budget.
- All gains are measured on Blackwell (RTX PRO 6000) where FP4 tensor cores exist; on Hopper or earlier the FP4 path collapses to emulation.
- The first-order analysis ignores interactions between \epsilon_j across blocks; for very aggressive FP4 (small group sizes, outlier-heavy heads) the linearisation may understate worst-case error.
- It is unclear how the selection cost scales for very long contexts ($>$256k) where even an O(N/B_k) per-query scan becomes non-trivial relative to the FP4 matmul.
Why this matters
ThriftAttention reframes low-bit attention as a sparsity problem in precision space: the softmax Jacobian itself tells you which blocks must be high-precision, and that set is small. This is a clean, drop-in path to roughly 2\times end-to-end long-context decoding on Blackwell without the quality cliff of uniform FP4, and the same p_j(v_j - o) argument should generalise to other quantised-attention schemes.
Source: https://arxiv.org/abs/2605.23081
On-Policy Adversarial Flow Distillation for Autoregressive Video Generation
Distilling a black-box video teacher into a causal autoregressive (AR) student is awkward: the teacher exposes only completed prompt-conditioned videos, no scores, latents, or denoising trajectories; the student is causal and must learn under its own rollout distribution to avoid exposure bias; and architectures, capacities, and sampling schedules typically differ. Standard tools fail in this regime. SFT on teacher videos is off-policy and, as the authors show in a preliminary scan, actually degrades the student over training steps on both VBench and VideoPhy-2 metrics rather than improving monotonically.
Score-based distribution matching (DMD, score distillation) is inapplicable without teacher scores. Pure adversarial imitation provides only a single sample-level signal per rollout, with no per-step credit for denoising. Adversarial Flow Distillation (AFD) targets exactly this gap.
Method
Let \pi_T(x_0\mid y) be a sampling-only teacher and \pi_\theta a causal AR student flow model with velocity field f_\theta(x_t,t,y). Each step samples y\sim\mathcal{Y}, queries the teacher for x_0^T, and rolls out the current student under autoregressive self-conditioning to obtain \hat{x}_0.
A prompt-conditioned spatiotemporal discriminator D_\phi(x_0,y) — initialized from VideoAlign and adapted with LoRA (rank/alpha =256) — is trained with a Bradley–Terry pairwise loss treating the teacher sample as preferred:
\mathcal{L}_D(\phi) = -\mathbb{E}_{(x_0^T,\hat{x}_0,y)}\,\log\sigma\!\left(D_\phi(x_0^T,y)-D_\phi(\hat{x}_0,y)\right).
This avoids absolute reward calibration. The discriminator yields an adaptive, baseline-subtracted reward
r_\phi(\hat{x}_0,y)=\operatorname{sg}\!\left(D_\phi(\hat{x}_0,y)-b(y)\right),
with b(y) a per-prompt or batch baseline (the implementation uses global-std normalization with per-prompt EMA tracking, decay \gamma=0.99, and advantage clipping at 5.0).
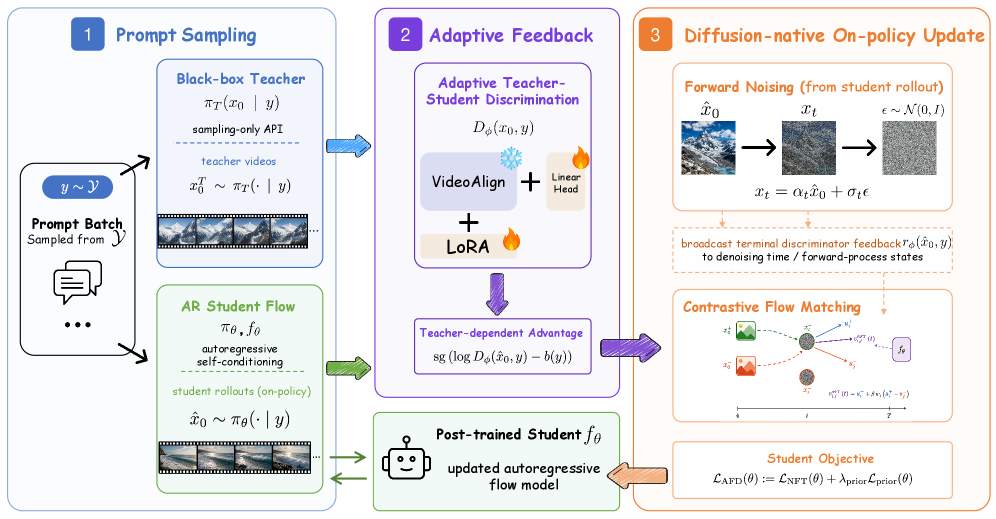
The key step is converting this clean-sample, sample-level signal into dense supervision over the student’s denoising process via a DiffusionNFT-style update. With forward process x_t=\alpha_t x_0+\sigma_t\epsilon and forward velocity v(x_0,\epsilon,t)=\dot\alpha_t x_0+\dot\sigma_t\epsilon, AFD reweights the student’s own noised states by r_\phi, producing a tilted target
\pi^+(x_0\mid y)\propto \exp(\rho_\phi)\cdot \pi^{\text{old}}(x_0\mid y),
where \rho_\phi=\log D_\phi/(1-D_\phi). Under the optimal discriminator and on-policy data (\pi^{\text{old}}=\pi_\theta), \rho_\phi^*=\log\pi_T/\pi_\theta, so \pi^+\propto\pi_T. The flow-matching update toward \pi^+ on the student’s noised states is, at optimality, equivalent to on-policy reverse-KL distillation from \pi_T — but realized purely through forward-process velocity targets, requiring no teacher score, no step alignment, and no reverse-chain RL through the AR sampler.
Concretely, AFD replaces the teacher-sample term in flow matching with importance-weighted student samples whose weights come from the discriminator. This gives dense per-t velocity supervision from a single black-box sample-level signal — the central mechanical contribution.
Experimental setup and results
Students: Self-Forcing and Causal-Forcing AR video models at 480\times 832. Teacher: Seedance 2.0 accessed only as a sampling API. Continual adaptation uses 200 prompts from VideoPhy-2, with the teacher queried on the same prompts. Training is LoRA-only (rank 256), AdamW at \eta=10^{-5}, weight decay 10^{-4}, bfloat16, with selective regularization (interpolation \beta=0.1, prior weight \lambda_{\text{prior}}=10^{-4}).
Baselines: Base (pretrained), SFT on teacher videos, GAN (video-level adversarial only, no forward-process update), and a score-free DMD (DMD scaffolding without the score term). VBench dimensions are split into Physics (temporal flickering, motion smoothness, dynamic degree, human action, spatial relationship) and General (mean of remaining dimensions); target-domain quality is assessed via VideoAlign-MQ and VideoPhy-2-PC.

Qualitatively, AFD shifts the student toward more physically plausible motion (fluid flow, deformation, contact) while preserving prompt semantics and the base model’s visual style — a regime where SFT collapses fidelity and GAN under-supervises denoising. The provided sections summarize Physics-grouped VBench gains together with VideoAlign-MQ and VideoPhy-2-PC improvements over Base, SFT, GAN, and score-free DMD across both AR families, with General VBench preserved (numerical tables are referenced in the experiments section but not reproduced in the excerpts here).
Limitations and open questions
The theoretical equivalence to reverse-KL distillation holds only at the BT optimum and in the on-policy limit; in practice the discriminator is non-stationary and the tilt \exp(\rho_\phi) is heavy-tailed, motivating the advantage clip at 5.0 and EMA-tracked baselines. The method inherits the discriminator’s inductive biases (here a video-alignment model), which can mis-score modes the alignment model never saw. Adaptation uses only 200 teacher videos for a physics target; scaling, distribution-shift between teacher and target prompt set, and interaction with longer AR rollouts than the training horizon are not addressed. The framework also does not exploit any partial teacher information (e.g., intermediate frames or step-aligned latents) when available.
Why this matters
AFD gives a principled recipe for distilling commercial, API-only video generators into causal AR students using only completed samples, by converting a co-evolving Bradley–Terry discriminator into dense forward-process flow targets. This sidesteps the off-policy collapse of SFT and the sparse credit assignment of pure adversarial training, and connects black-box video distillation to on-policy reverse-KL minimization without backpropagating through the AR sampler.
Source: https://arxiv.org/abs/2605.26105
Channel-wise Vector Quantization
Problem
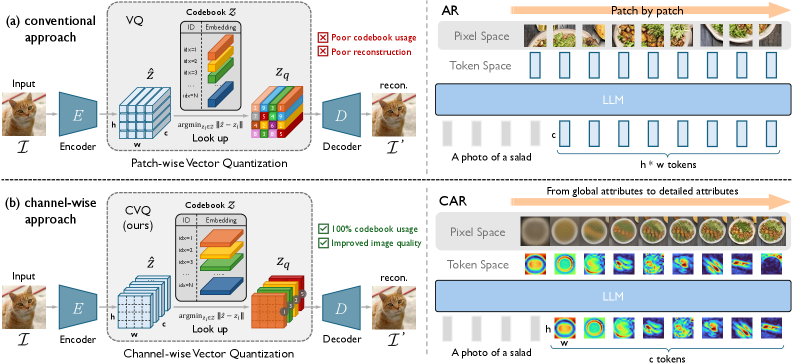
VQ-based image tokenizers (VQGAN and successors) discretize a latent feature map \mathbf{Z}\in\mathbb{R}^{h\times w\times c} by assigning each spatial 1\times 1\times c patch vector to its nearest codebook entry. This formulation has two persistent failure modes. First, codebook collapse: with a 16,384-entry codebook, vanilla VQGAN uses only 4.5% of entries, because natural images contain many repeated/similar patches that all snap to a small set of cluster centers, starving the rest of gradient. Second, downstream autoregressive generation inherits a 2D-as-1D raster ordering that has no natural causal structure. Workarounds (CLIP-initialized codebooks in VQ-LC, factorized lookups in VQ-FC, rotation tricks, residual quantization) add machinery and parameters but only partially address the underlying redundancy.
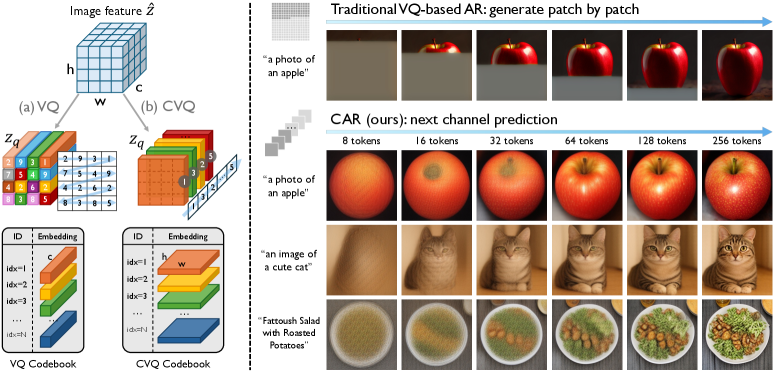
Method
CVQ inverts the slicing axis. Instead of treating \mathbf{Z} as h\times w patch vectors of dimension c, it treats it as c channel slices of dimension h\times w. Each channel \mathbf{z}^{(:,:,k)}\in\mathbb{R}^{h\times w\times 1} is flattened and quantized independently:
\mathbf{z}_q^{(:,:,k)} = \arg\min_{\mathbf{e}_n\in\mathcal{C}}\,\big\|\mathrm{vec}(\mathbf{z}^{(:,:,k)}) - \mathbf{e}_n\big\|_2^2,
with a single shared codebook \mathcal{C}=\{\mathbf{e}_n\}_{n=1}^{N}, \mathbf{e}_n\in\mathbb{R}^{hw}. The number of tokens per image becomes c (not hw), and each token now indexes a “level of visual detail” — a full-resolution channel pattern — rather than a localized spatial patch.
To keep the comparison apples-to-apples, the authors set c = h\times w = 256, so CVQ and patch-wise VQ have identical lookup count, codebook memory, and per-step compute. The asymmetry that matters is statistical, not computational. Channels of a learned encoder tend to encode different semantic factors (edges, color statistics, texture frequencies, object parts), so different images activate distinct channel signatures, whereas different patches within and across images are highly redundant.
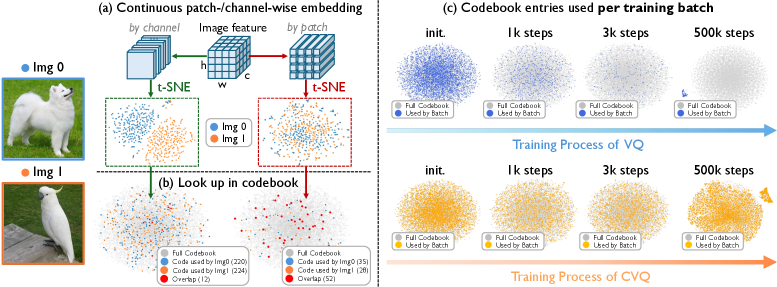
Figure 4(a) shows t-SNE of patch embeddings from two visually similar but semantically different images entangling into a single cloud, while channel embeddings form clearly separated clusters. Figure 4(c) tracks codebook entries hit per training batch: patch-wise VQ collapses to a small set of “outlier” entries within early training, while CVQ saturates near full utilization and stays there.
On top of CVQ, the paper builds a Channel-wise Autoregressive (CAR) generator that predicts channel tokens sequentially, p(t_1,\dots,t_c)=\prod_k p(t_k\mid t_{<k}). Because earlier channels of a typical CNN/ViT encoder carry coarse global structure and later channels carry fine-grained detail, this ordering reproduces a coarse-to-fine generation trajectory without needing scale pyramids or multi-resolution codebooks.
Results
Reconstruction on ImageNet-1K val (256×256, 100 epochs, codebook 16,384, Adam \beta=(0.5,0.9), lr 10^{-4}):
- 256-token budget: vanilla VQGAN gets rFID 4.84 with 4.5% codebook usage; SimVQ 2.63 at 100%; CVQ 2.60 at 100% with no auxiliary losses, factorization, or pretrained-feature initialization.
- 1024-token budget: vanilla VQGAN 1.32 rFID / 23.35 PSNR / 2.8% usage; MoVQGAN 1.05 rFID; VQ-LC 1.29 rFID with a 100k codebook; CVQ 0.88 rFID, 25.02 PSNR, SSIM 0.723, 100% usage with a 16,384 codebook.
The 100% utilization is reached “without bells and whistles” — no entropy regularizer, no codebook reset, no CLIP init, no rotation trick. This is the cleanest evidence to date that codebook collapse is largely a consequence of slicing the feature map along the wrong axis, not an inherent pathology of nearest-neighbor quantization.
For text-to-image generation with CAR, the paper reports DPG 86.7 and GenEval 0.79, competitive with patch-wise AR baselines while using a fundamentally different token semantics.
Limitations and open questions
- The constraint c = hw for fair comparison is convenient but arbitrary; how CVQ scales when c \ll hw (few coarse “detail levels”) or c \gg hw (many fine ones) is not characterized in the main tables.
- Channel ordering is taken as given by the encoder. Whether enforcing or learning an explicit coarse-to-fine ordering (e.g., via a PCA-like objective on channels) further helps CAR is unexplored.
- Channel tokens lack spatial locality, so standard spatial inductive biases (local attention, 2D RoPE) do not transfer; the AR transformer must model fully global interactions per token.
- Generation numbers (DPG 86.7, GenEval 0.79) are strong but trail the best diffusion T2I systems; the comparison to similarly-sized AR T2I models would clarify whether channel-AR is a Pareto improvement or a tradeoff.
- Reconstruction is evaluated at 256\times 256; how channel semantics behave at higher resolutions where hw grows and channel count typically does not is left to an appendix on variable resolution.
Why this matters
CVQ reframes image tokenization from “where in the image” to “which factor of variation,” and in doing so eliminates codebook collapse as a first-class problem with no auxiliary tricks while improving rFID at matched compute. If the channel-as-token view holds up at scale, it changes how we should think about visual codebooks, AR ordering, and the alignment between tokenizer geometry and generative model causality.
Source: https://arxiv.org/abs/2605.26089
DVAO: Dynamic Variance-adaptive Advantage Optimization for Multi-reward Reinforcement Learning
Problem
GRPO replaces PPO’s value model with a group-relative advantage estimate, which is attractive for LLM post-training. In practice, however, alignment objectives are rarely scalar: math reasoning combines accuracy with length-control, tool-use combines call correctness with format compliance, and so on. The two standard ways to fold n rewards into GRPO both have issues:
- Reward Combination (RC). Sum rewards first, r_{\text{sum}} = \sum_k w_k r_k, then compute one group-normalized advantage A_{\text{sum}}.
- Advantage Combination (AC). Compute per-objective group-normalized advantages A_k, then combine A = \sum_k w_k A_k with fixed w_k.
The paper formalizes why neither is satisfactory and proposes a variance-adaptive scheme.
Analysis of RC vs. AC
For a query x_i with G rollouts, let \hat{\rho}_{kl}^{i} be the empirical correlation between A_k and A_l within the group. Proposition 1 shows
\frac{1}{G}\sum_{j=1}^{G}\bigl(A_{\text{sum}}^{(i,j)}\bigr)^2 \;\geq\; \frac{1}{G}\sum_{j=1}^{G}\Bigl(\sum_k w_k A_k^{(i,j)}\Bigr)^2,
with equality iff \hat{\rho}_{kl}=1 for all k\neq l. Because the GRPO gradient is linear in the advantage, RC therefore yields strictly larger expected squared gradient norms whenever objectives are not perfectly correlated, which empirically manifests as instability. AC tames magnitudes — its gradient decomposes as \nabla_\theta \mathcal{J}_{\text{GRPO}} = \sum_k w_k \nabla_\theta \mathcal{J}_{\text{GRPO},k} — but the static w_k ignore (i) cross-objective correlations and (ii) the time-varying signal-to-noise of each reward during training.
DVAO
DVAO replaces the static w_k with weights derived from the empirical reward variance of each objective inside a rollout group. Concretely, for objective k on prompt x_i, let \hat{\sigma}_k^2(x_i) be the variance of r_k across the G rollouts. The combined advantage uses weights that scale with \hat{\sigma}_k, so objectives whose group rollouts actually distinguish good from bad trajectories (high variance, strong learning signal) receive more weight, while collapsed or near-saturated objectives (low variance, mostly noise after standardization) are suppressed. The paper proves that this construction keeps \mathbb{E}[A^2] bounded — preserving AC’s stability advantage — while inducing a self-adaptive cross-objective regularizer because the variance-derived weights implicitly account for how each A_k co-varies with the others within the group.
The mechanical recipe to reimplement is straightforward on top of GRPO:
for each prompt x_i:
sample G rollouts y_{i,1..G}
for each reward k:
compute r_k(x_i, y_{i,j})
A_k^{(i,j)} = (r_k - mean_j r_k) / std_j r_k
sigma_k_hat = std_j r_k
w_k(x_i) = f(sigma_k_hat) # variance-adaptive
A^{(i,j)} = sum_k w_k(x_i) * A_k^{(i,j)}
plug A^{(i,j)} into the GRPO clipped surrogateThe key conceptual departure from AC is that w_k becomes a per-group, per-step function of the rollout statistics rather than a global hyperparameter.
Experiments
Two task families are evaluated. For math reasoning on Qwen3-4B-Base and Qwen3-8B-Base, rewards are accuracy and a length constraint, evaluated on AIME-2024, AIME-2025, MATH500, OlympiadBench, and AMC23. For tool use on Qwen2.5-3B/7B-Instruct, rewards are call correctness and format compliance, evaluated on BFCL-v4. Baselines are single-reward GRPO (r_{\text{acc}} only), GRPO+RC, GRPO+AC, and GDPO.
The training-dynamics plots highlight DVAO’s stability claim. On the 4B model, DVAO maintains higher and more monotone accuracy-reward mean while keeping length-reward std contained, and its average response length stays inside the target band rather than drifting.
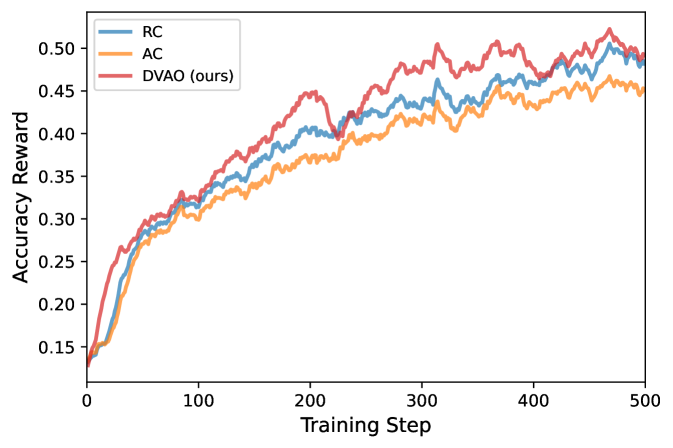
The same pattern holds at 8B, where RC in particular shows the larger advantage magnitudes predicted by Proposition 1 manifesting as noisier reward curves and more aggressive length growth.
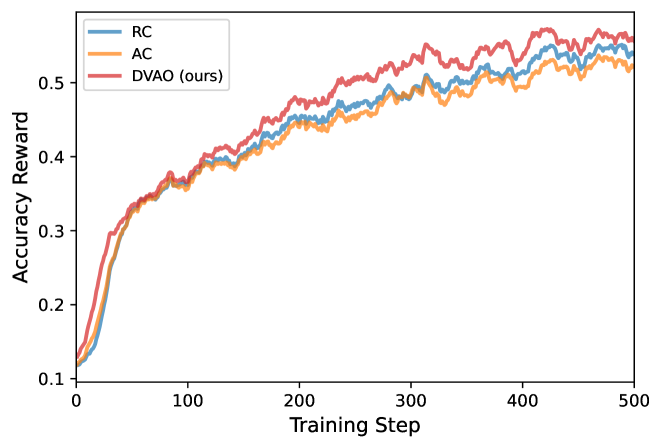
(The provided excerpt does not enumerate the final benchmark numbers; the headline claims are the consistent gains across AIME-2024/2025, MATH500, OlympiadBench, AMC23 for math and across BFCL-v4 categories for tool use, together with the qualitative stability advantage visible in Figures 1–2.)
Limitations and open questions
- The variance-adaptive weighting assumes within-group reward variance is a faithful proxy for learning signal. Reward-hacked or saturated objectives can have low variance for the wrong reasons; the method then under-weights them, which is the desired behavior on near-solved objectives but problematic if a reward is simply hard to elicit.
- The bound on \mathbb{E}[A^2] is established analytically, but the paper does not characterize how the implicit cross-objective regularization interacts with the PPO-style clipping range — the two stability mechanisms could be redundant or, in some regimes, conflicting.
- Only two-objective settings (accuracy+length, correctness+format) are reported. Behavior with n\geq 3 rewards, especially with anti-correlated objectives (\hat{\rho}_{kl}<0), is the more interesting stress test for any variance-adaptive scheme.
- Sensitivity to G (group size) is critical because \hat{\sigma}_k is a small-sample estimate; the paper’s stability arguments lean on this estimate being well-conditioned.
Why this matters
Multi-reward RLHF is the default regime for production LLM training, and the field has been quietly relying on hand-tuned scalarization weights. DVAO gives a principled, almost free replacement: a per-group variance-derived weighting with a provable bound on advantage magnitude that subsumes the role of static w_k and the implicit correlation handling that AC misses.
Source: https://arxiv.org/abs/2605.25604
WBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation
Problem
Interactive video world models — conditional generators of the form
o_{t+1}\sim f_\theta(o_{t+1}\mid o_{\le t}, a_{\le t})
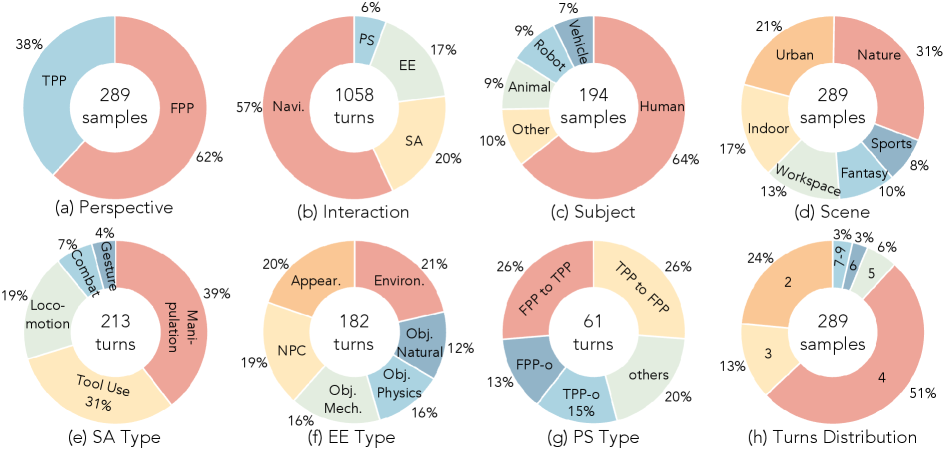
now span text-driven video generators, camera-controlled models, and discrete-action game-style models. Existing benchmarks (VBench, WorldScore, etc.) cover isolated axes such as visual quality or single-turn camera control, but no unified protocol evaluates multi-turn interactive behaviour across navigation, subject action, event editing, and perspective switching simultaneously. WBench addresses this with 289 cases / 1,058 turns, five evaluation dimensions, and 22 sub-metrics validated against human judgments.
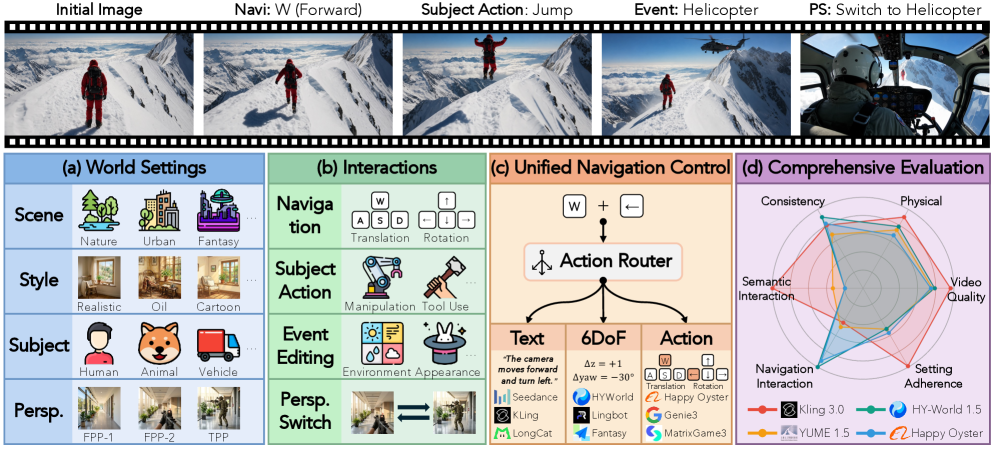
Construction
Each case factors inputs into a world setting \mathcal{W} (Scene, Style, Perspective, Subject) and an interaction sequence \mathcal{I}=(a_0,\dots,a_{T-1}). A “setting-first” pipeline forces interactions to be physically executable inside the chosen world (e.g., weather edits require outdoor scenes, manipulation requires a kitchen). Initial frames come from Nano Banana 2 and GPT-Image-1.5 plus collected/captured imagery, all manually verified. Stratified sampling is applied across eight axes — scene, style, perspective, subject, and the four interaction types — giving the coverage shown in the dataset composition.
The four interaction families are unified for navigation: WBench defines eight key actions (W/S/A/D translation; arrow-key rotation) that map the same control onto camera motion in first-person mode and onto subject motion in third-person mode. Models with native text, 6-DoF, or discrete-action interfaces are translated to/from this common control alphabet, allowing direct comparison across input modalities.
Evaluation suite
The 22 sub-metrics span five dimensions, each rescaled to [0,100]:
- Video quality: VBench’s aesthetic, imaging, flickering, dynamic-degree, and motion-smoothness metrics, plus a percentile-normalized HPSv3 reward.
- Setting adherence: VLM scoring of (a) scene prompt split into initially-visible vs. offscreen-but-expected elements, and (b) subject prompt split into appearance and motion priors.
- Interaction adherence: Navigation is graded geometrically — per-frame poses from MegaSaM are aligned and arc-length resampled against a synthetic ground-truth trajectory derived from the action sequence (first-person rotations → heading change; third-person rotations → orbital motion). Score combines normalized ATE (nATE) with cross-turn consistency for repeated actions. Event editing and subject action use a turn-level VLM with five binary checks (change detection, occurrence, completion, detail accuracy, anomaly absence) producing a [0,5] grade. Perspective switching uses a stricter conjunctive rubric (transition visibility ∧ target-type consistency ∧ structural compliance), counted only when all three hold.
- Consistency: eight sub-metrics covering background, spatial/gated-spatial, segment, perspective, subject, geometric, and photometric stability.
- Physics compliance: causal fidelity and visual plausibility.
The VLM backbone used throughout is doubao-seed-2-0-lite-260215; all sub-metrics were calibrated against human ratings.
Results across 20 models
On the 158-case navigation split, no single model dominates. Among text-driven models, Seedance 1.5 leads video quality at 82.1 (group avg 77.7), Wan 2.7 leads setting adherence at 91.4, Kling 3.0 leads semantic interaction (event editing 81.4, subject action 85.6, perspective switching 55.0; group avg interaction 73.1), and HY-Video 1.5 leads consistency at 87.4 with LongCat-Video close behind at 87.1. Camera-controlled models excel at navigation: HY-World 1.5 hits 87.5 navigation and InSpatio-World reaches 88.4 consistency, but they lag in setting adherence (group avg 69.4 vs. 81.6 for text-driven). Action-conditioned game-style models (Genie 3, Matrix-Game 3.0, etc.) post the best raw dynamic-degree scores (~93–98) but collapse on perspective consistency (group avg 37.3 vs. 74.7 text-driven), with Matrix-Game 2.0 at 29.2 and HY-GameCraft at 17.9.
Perspective switching is the hardest interaction by a large margin: group averages are 30.7 for text-driven models, with YUME 1.5 at 16.7, Kairos 3.0 at 13.3, and Cosmos 2.5 at 20.0. Physics compliance also remains weak — top causal-fidelity score is Wan 2.7 at 83.3, while Astra collapses to 48.3, indicating that current world models still violate basic dynamics under multi-turn interaction. The cross-dimension correlation analysis quantifies the trade-offs.
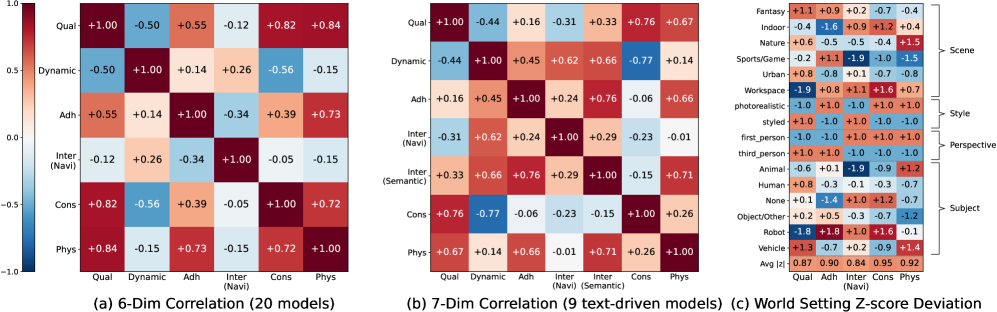
Notably, the per-setting Z-score map shows systematic difficulty patterns: stylized/non-realistic renderings ease setting adherence but hurt physics, while complex outdoor scenes invert that pattern.
Limitations and open questions
VLM-based scoring inherits biases from the doubao backbone; although metrics are validated against humans, drift across VLM versions could change leaderboards. The navigation ground truth is built from synthetic action-to-trajectory rules, so models with idiosyncratic action semantics (e.g., variable step size) may be unfairly penalized despite arc-length normalization. The benchmark has only 289 cases — limiting statistical power for fine-grained subset comparisons — and perspective switching is rated by such a strict conjunctive rubric that small detection failures dominate. Finally, action-conditioned models cannot be evaluated on event editing, subject action, or perspective switching since those require text-conditional inputs, leaving a coverage gap.
Why this matters
WBench gives the first apples-to-apples evaluation across text-driven, camera-controlled, and action-conditioned interactive video models on the same multi-turn cases, exposing concrete weaknesses (perspective switching, physics compliance, multi-turn consistency) that single-axis benchmarks miss. The unified key-action control alphabet and pose-based navigation scoring are reusable infrastructure for any future world-model evaluation.
Source: https://arxiv.org/abs/2605.25874
TriSplat: Simulation-Ready Feed-Forward 3D Scene Reconstruction
Feed-forward 3D reconstruction has converged on Gaussian primitives because they rasterize cheaply and train stably, but Gaussians do not give you a surface. Downstream consumers — physics simulators, embodied agents, rendering pipelines that expect triangles — typically recover meshes via TSDF fusion or Poisson reconstruction over rendered depth, which is slow, lossy, and decouples geometry from the model that produced it. TriSplat replaces the Gaussian primitive with an oriented triangle and predicts the full scene, including poses and (optionally) intrinsics, in one forward pass from sparse unposed views. The mesh is the model’s output, not a post-hoc artifact.
Architecture and primitive parameterization
The encoder is a DINOv2 backbone with a transformer decoder that interleaves intra-view self-attention and cross-view joint attention, conditioned by 2D RoPE and per-pixel ray-direction embeddings. Three heads run in parallel: a point head, a camera head, and a primitive head.
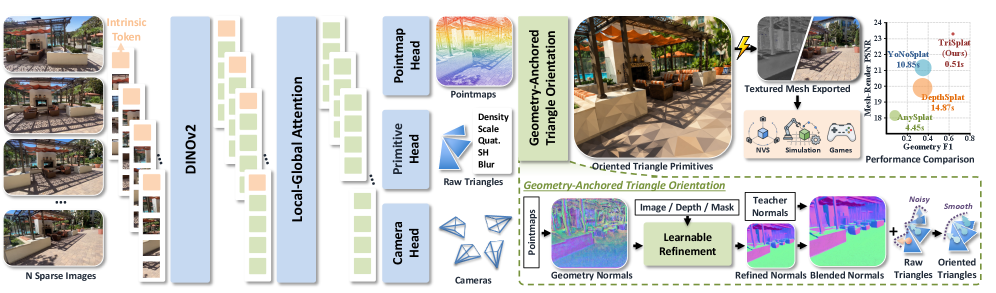
The point head predicts (u, v, z') per pixel and recovers the 3D point in the camera frame as
\mathbf{p} = z \cdot (u, v, 1)^\top, \qquad z = \exp(z'),
which couples lateral coordinates to depth multiplicatively and matches the projective image model. The camera head mean-pools decoder tokens, regresses a translation and a 3\times 3 matrix, and projects the latter onto \mathrm{SO}(3) via SVD orthogonalization. Poses are expressed relative to view 1 to remove gauge ambiguity, and scheduled sampling decays ground-truth pose conditioning during training to avoid test-time distribution shift.
The primitive head outputs density logit, three scale logits, a quaternion, SH coefficients, and a blur parameter per pixel; the input RGB is patch-embedded and added back into the primitive features so appearance has a short path to the head. All dense heads use pixel-shuffle upsampling to reach full resolution.
The triangle itself is built from a canonical equilateral template \mathcal{T} \in \mathbb{R}^{3\times 3}. Scale logits go through a sigmoid and are converted to world units using predicted depth and the pixel footprint from intrinsics. The vertex is
\mathbf{v}_k = \mathbf{R}_c \, \mathbf{R}_n \, (\mathcal{T}_k \odot \mathbf{s}) + \mathbf{c},
where \mathbf{R}_n is the tangent-frame rotation derived from geometry (not regressed freely), and \mathbf{R}_c is the predicted camera-to-world rotation. The key design choice is that \mathbf{R}_n comes from normals computed from the predicted point map and refined by an image-conditioned normal head, then converted into a stable local frame. Regressing orientation as an unconstrained quaternion would let triangles tilt away from the underlying surface; anchoring orientation to geometry keeps triangles flush with the surface they came from. Triangles are then fed to a differentiable triangle rasterizer with tile-based sorting. Because triangles are sharp-edged, training uses a progressive curriculum (the blur parameter likely controls a soft-to-hard transition).
Quantitative results
On RE10K with 6 input views (Table 3), TriSplat reaches CD 0.190, F1 0.622, PSNR 24.69, SSIM 0.798, LPIPS 0.269. Compared to the strongest pose-free Gaussian baseline YoNoSplat (CD 0.267, F1 0.443, PSNR 21.94), this is a \sim 29\% Chamfer reduction, +0.18 F1, and +2.75 dB. Surface-aware Gaussian variants like MeshSplat (F1 0.340) and SurfelSplat (F1 0.154) trail substantially; SurfelSplat in particular collapses on this mesh-export protocol (PSNR 11.18).

The DL3DV qualitative comparisons make the failure mode of TSDF-fused Gaussian pipelines explicit: surfaces drop out, geometry fragments, and silhouettes shrink. TriSplat keeps coherent triangle structure across 6, 12, and 24 input views.

The zero-shot ScanNet results are the most striking. Models trained only on RE10K are evaluated directly on ScanNet (Table 4): TriSplat achieves AbsRel 0.188, AbsDiff 0.341, mean normal angular error 27.9^\circ, and 71.7\% of pixels within 30^\circ. The next best, YoNoSplat, sits at 54.1^\circ mean error and 41.0\% within 30^\circ. The normal accuracy nearly doubles, which is consistent with the architectural prior: geometry-anchored orientation forces the network to produce normals that are coherent with the predicted point cloud rather than free-floating attributes.
Limitations and open questions
The paper’s abstract is truncated mid-sentence on the “mono-normal bootstrap” technique, so the precise warm-up procedure that lets sharp-edged triangles train without collapsing is not fully specified here. Triangle scale is tied to per-pixel depth and intrinsic footprint, which suggests over-tessellation in textureless regions and under-coverage at silhouettes — the rendering metrics on DL3DV at higher view counts would clarify how the primitive count scales. The method also inherits the assumption that one triangle per pixel is a reasonable surface decomposition; thin structures, transparent or specular surfaces, and large planar regions are not separately analyzed. Finally, the rasterizer is differentiable but the export protocol’s interaction with arbitrary downstream simulators (collision queries, contact resolution) is not benchmarked — “simulation-ready” remains a representational claim rather than a measured one.
Why this matters
Decoupling primitive choice from rasterization convenience changes what feed-forward 3D networks can deliver: a single forward pass that produces a mesh usable by physics engines and embodied agents, with substantially better zero-shot normals than Gaussian pipelines. If the geometry-anchored orientation prior generalizes, it suggests that surface-native primitives, not Gaussians, should be the default for reconstruction targeting interaction rather than just novel-view synthesis.
Source: https://arxiv.org/abs/2605.26115
Hacker News Signals
White Rabbit – sub-nanosecond synchronization for large distributed systems
White Rabbit (WR) is an open-hardware, open-firmware extension of IEEE 1588 (PTP) developed at CERN and GSI for synchronizing thousands of nodes across multi-kilometer networks with sub-nanosecond accuracy and picosecond precision. Standard PTP reaches ~100 ns; WR pushes to <1 ns by combining two mechanisms. First, Synchronous Ethernet (SyncE) distributes a common clock frequency over the physical layer, eliminating the dominant source of PTP jitter. Second, a digital DMTD (Dual-Mixer Time Difference) circuit measures sub-clock-cycle phase offsets between the local oscillator and the recovered line clock, feeding a software servo loop that disciplines the local oscillator. The fiber propagation delay is measured bidirectionally and split using a calibrated asymmetry model accounting for different wavelengths on TX and RX paths (WR uses separate 1490/1310 nm wavelengths for the two directions).
The reference hardware is the SPEC (Simple PCIe FMC Carrier) and the WR Switch, both with fully public KiCad schematics and HDL (synthesizable on Xilinx Spartan-6). The firmware runs on a soft-core LM32 CPU inside the FPGA. The entire stack — from hardware abstraction to the PTP daemon (PTPd extended as wr-daq) — is available on the Open Hardware Repository.
Deployments include CERN’s accelerator complex (600+ nodes), the KM3NeT neutrino telescope, and several national metrology institutes using it as a traceable UTC distribution method. The protocol has been adopted into IEEE 1588-2019 as the High Accuracy profile.
The interesting engineering is in the DMTD: rather than measuring phase directly at GHz rates, two oscillators slightly offset in frequency mix down the signal to a kHz-range beat frequency, then a simple counter measures phase at that low frequency — cheap and accurate. Open questions include scaling asymmetry calibration to heterogeneous fiber plants and adapting WR to wireless/RF links where the fixed-asymmetry model breaks down.
Source: https://ohwr.org/projects/white-rabbit/
DeepSeek Reasonix – DeepSeek native coding agent with high caching and low cost
Reasonix is a coding agent wrapper around DeepSeek-R1 and DeepSeek-V3 that is engineered specifically around the economics of the DeepSeek API, where prompt-cache hits cost roughly 10x less than uncached tokens. The core technical bet is that a long, stable system prompt containing project context — file trees, coding conventions, architectural constraints — will be cache-resident across calls, so amortized cost per request drops sharply. The agent maintains this large prefix as an immutable header and appends only the mutable conversation turn at the tail, maximizing the cache-hit surface.
The tool-use loop follows a standard ReAct-style pattern: the model emits structured tool calls (read file, write file, run shell command, grep), the host executes them, and results are appended. Reasonix adds a “context budget” heuristic: it tracks accumulated token usage and, when nearing a threshold, summarizes completed steps into a compressed scratchpad that replaces the raw history — keeping the prefix stable while preventing context-window overflow.
For the reasoning model (R1), the agent exposes the chain-of-thought token stream separately from the final answer, letting downstream tooling log reasoning traces without feeding them back into the next prompt (which would bloat the non-cached suffix). For V3, it operates in a faster, lower-latency mode suited for file edits that do not require extended reasoning.
Benchmarks on the project page show per-task costs in the $0.01–0.05 range for moderate refactoring tasks, compared to $0.20–0.50 for equivalent Claude or GPT-4o runs on the same tasks — primarily because DeepSeek’s cache pricing is aggressive and the prompt structure is tuned to exploit it. The main limitation is tight coupling to DeepSeek’s specific caching semantics; porting to another provider would require rethinking the prefix-stability strategy. It also inherits whatever reasoning failures R1 exhibits on ambiguous multi-file refactors.
Source: https://esengine.github.io/DeepSeek-Reasonix/
Gnutella: A Protocol Outliving the World That Created It
This post is a clean technical retrospective on Gnutella’s protocol design and why it remained functional decades after Napster was litigated out of existence. Gnutella’s original 0.4 spec was a flat, unstructured P2P overlay: every node connects to a small set of peers, and queries flood the network via TTL-decremented QUERY messages. Responses route back along the reverse path of the query, not directly to the requester. This is O(n) in message volume for a single query at TTL=7 and a branching factor of ~4, which caused the well-documented 2000–2001 bandwidth implosion as the network scaled.
Gnutella 0.6 introduced the ultrapeers/leaves topology to address this: a small fraction of well-connected nodes act as ultrapeer routers, while leaf nodes maintain only 2–3 connections to ultrapeers. Leaves push a Bloom filter of their shared file hashes to their ultrapeers, allowing query routing to skip leaves that cannot satisfy a query. This reduced flooding dramatically without centralizing the index.
The article highlights what made Gnutella structurally resilient: no central servers to subpoena, no membership registry, and a wire protocol simple enough to reimplement over a weekend. The protocol negotiation is plaintext HTTP-like handshake, making it firewall-traversal-friendly. Extension headers (X-Ultrapeer, X-Query-Routing) were added without breaking older clients.
What is technically interesting today is the Bloom-filter-based query routing — essentially a precursor to distributed approximate membership structures now common in databases and networking. The post also notes that LimeWire’s 2010 injunction didn’t kill the network because the protocol itself was already widely reimplemented in Frostwire, Phex, and gtk-gnutella. A protocol that distributes its own reference implementation into many independent codebases becomes de facto censorship-resistant.
Source: https://rickcarlino.com/notes/p2p/gnutella-explanation.html
Show HN: Write your BPF programs in Go, not C
gobee is a thin framework that lets you write eBPF kernel programs in Go source, transpiling them to C before passing to the standard clang/LLVM eBPF backend. The Go-to-C transpilation step is the substantive claim: the project parses a restricted subset of Go (no goroutines, no GC, no interfaces) using the standard go/ast package and emits equivalent C with BPF map accessors and helper function calls substituted appropriately.
This is architecturally different from projects like Cilium’s ebpf-go or libbpf-go, which keep kernel-side BPF in C and provide Go bindings only for the userspace loader and map interaction. gobee’s goal is a single-language authoring experience for both sides of the BPF boundary.
The transpiler handles the common BPF patterns: map lookups via bpf_map_lookup_elem, per-CPU arrays, perf event output, and kprobe/tracepoint attachment. The restricted Go subset enforces stack-allocation semantics because BPF’s verifier rejects heap pointers; the transpiler statically rejects any Go constructs that would require a heap. Fixed-size arrays and structs map cleanly to C; slices and maps do not and are unsupported.
The technical risk is verifier compatibility: LLVM’s eBPF backend is fairly stable but BPF CO-RE (Compile Once, Run Everywhere) relies on BTF annotations that clang emits based on C type information. The transpiler would need to emit correct BTF-compatible type declarations for CO-RE relocation to work across kernel versions — it is not clear from the current code that this is fully handled. The project is early-stage; the main value proposition for teams already heavily in Go is reducing context-switching between C toolchains. Alternative: Rust’s aya framework handles this more completely, generating BPF bytecode directly without a C intermediate.
Source: https://github.com/boratanrikulu/gobee
Using AI to write better code more slowly
The post is a practitioner’s account of a deliberate workflow inversion: instead of using LLMs to increase throughput, the author uses them to increase quality at the cost of speed. The core observation is that LLM-assisted code review in the authoring loop — asking the model to critique a design before writing it, or to enumerate edge cases after a first draft — surfaces issues that would previously have survived to PR review or production.
The workflow described has a few concrete steps. Before writing: prompt the model with the problem statement and ask it to identify underspecified requirements and likely failure modes. During: use the model as a rubber-duck with memory, narrating design decisions and asking “what am I missing.” After: paste the implementation and ask for adversarial review, specifically instructing the model not to suggest stylistic changes but to focus on correctness, concurrency hazards, and missing error handling. This last step is where the author reports the highest signal — models are surprisingly good at spotting unchecked error returns and off-by-one conditions when explicitly prompted to look for them.
The post is honest about costs: this takes longer than writing without the loop, and many model suggestions are noise. The filtering burden is on the programmer. The author also notes that models are poor at assessing whether a design fits a larger codebase’s conventions because they lack full context — a limitation that retrieval-augmented coding agents partially address but do not eliminate.
The implicit technical argument is that LLM value in coding is not uniform across the quality-speed tradeoff frontier; current models are more useful as a high-recall, low-precision checker than as an autonomous code generator. This matches empirical findings from studies like SWE-bench showing strong pass@k performance but weak pass@1 on real repository tasks.
Source: https://nolanlawson.com/2026/05/25/using-ai-to-write-better-code-more-slowly/
Migrating from Go to Rust
This is a structured migration guide from corrode.dev (a Rust consulting firm), so there is an obvious selection bias, but the technical content is detailed and honest about tradeoffs. The guide maps Go concepts to Rust equivalents at a mechanical level: goroutines to tokio::task::spawn or std::thread, channels to tokio::sync::mpsc or crossbeam, interfaces to traits, error returns to Result<T, E>, and nil to Option<T>. The section on goroutines is the most nuanced: Go’s goroutine scheduler is M:N with a preemptive runtime; Rust async is cooperative and requires an explicit executor. Migrating concurrent Go code to Rust async requires identifying every yield point explicitly, which changes the mental model substantially.
The ownership system gets the most attention. Go’s GC means sharing mutable state across goroutines via a pointer is fine at the language level (data races are a runtime concern caught by -race). Rust’s borrow checker rejects shared mutable references at compile time, forcing explicit synchronization via Arc<Mutex<T>> or message passing. The guide correctly notes this is not just a syntax change — it requires redesigning data ownership in the module graph.
Practical migration advice includes starting with isolated utility packages that have no goroutines, using unsafe sparingly as a bridge during incremental migration, and using cbindgen/cgo for FFI at the boundary during a hybrid phase. The guide recommends against big-bang rewrites.
Missing from the guide: discussion of build complexity (Rust’s incremental compile times are still painful for large codebases), the ecosystem maturity gap in some domains (observability tooling, for instance), and the organizational cost of ramping a Go team on the borrow checker. These are the real friction points in practice.
Source: https://corrode.dev/learn/migration-guides/go-to-rust/
CVE-2026-28952: Apple macOS 26.5 kernel vulnerability found by Claude
This entry is notable less for the specific vulnerability — Apple’s advisory is sparse on technical detail, listing it as a kernel memory corruption issue fixed in macOS 26.5 — and more for the attribution: Anthropic’s Claude is credited in the acknowledgments as having identified the flaw. The HN thread focuses on what this implies about AI-assisted vulnerability research becoming routine.
The technical substance that can be inferred: Claude was likely used in a fuzzing or static analysis loop, either generating harness code for kernel syscall fuzzing or performing semantic analysis of XNU source (which Apple open-sources for the Darwin layer). Memory corruption in the kernel on Apple silicon is non-trivial to exploit due to PAC (Pointer Authentication Codes), which signs code and data pointers using keys stored in CPU registers, and KTRR (Kernel Text Read-only Region) which prevents runtime kernel text modification. A full exploit chain requires a PAC bypass, raising the bar significantly.
The CVE being in the 2026 namespace suggests it was filed recently; the coordinated disclosure timeline implies Anthropic reported it to Apple through standard channels rather than publishing a proof of concept. This is consistent with how security researchers embed AI tools in responsible disclosure pipelines — the model finds candidates, humans validate and report.
What is technically significant: if Claude identified this without a human writing targeted fuzzing logic first, it suggests frontier models are now capable of reasoning about kernel data-structure invariants at a level sufficient to flag corruption conditions. Whether this was a novel semantic analysis finding or a pattern match against known vulnerability classes is not yet public. The broader open question is how Apple’s own security team will incorporate LLM-assisted review into their internal auditing process going forward.
Source: https://support.apple.com/en-us/127115
AI errno(2) values
This post runs a systematic empirical test of how well various LLMs know the POSIX errno value table — specifically, whether they can correctly state the integer values and semantics of standard error codes like EAGAIN, EWOULDBLOCK, EINPROGRESS, and the less common ones. The result is that models are unreliable and inconsistent: they frequently confuse numeric values across architectures (Linux x86-64 vs. Linux ARM vs. macOS have different assignments for some codes), conflate EAGAIN and EWOULDBLOCK (which are distinct on some platforms, aliased on others), and hallucinate errno values with confident prose.
The technically interesting finding is that the failures are not random — they cluster around precisely the cases that are genuinely platform-dependent or where POSIX leaves assignment to the implementation. Models appear to have absorbed documentation from multiple platforms without tagging it, then average or randomly select at inference time. For values that are stable across all major platforms (EINVAL=22, ENOENT=2), models are reliably correct. For the platform-variable subset, accuracy degrades sharply.
The practical implication for anyone using LLMs to write systems code: errno values should not be taken from a model without verification against the target platform’s <errno.h>. The deeper issue is that this is a diagnostic for a broader class of failure: any domain where the same symbol has platform-dependent numeric semantics (signal numbers, ioctl constants, socket option levels) will exhibit similar unreliability. The post is a useful reminder that model confidence calibration is particularly poor for numerical constants that look universal but are not. The recommendation implicit in the post is to always consult authoritative sources (man 3 errno, platform headers) rather than trusting LLM recall for ABI-level constants.
Noteworthy New Repositories
sno-ai/llmix
A production-grade middleware layer for LLM calls targeting agent and tool-use workloads. Rather than replacing your existing SDK (OpenAI, Anthropic, AI SDK, LiteLLM), llmix wraps it and adds a reliability stack: caching with configurable TTLs, exponential-backoff retries, circuit breakers per model endpoint, and API key rotation across a pool. The singleflight pattern deduplicates in-flight identical requests, which matters when many agent threads fire the same prompt concurrently.
The “MDA presets” (Model-Deployment-Alias) let you define named configurations and hot-swap the underlying model without changing call sites — useful for A/B testing or fallback routing when a provider degrades. Cross-language parity across Python, TypeScript, and Rust means agent frameworks written in any of the three can share the same operational semantics and configuration schema.
The engineering tradeoffs here are sensible: circuit breakers prevent cascade failures when a provider rate-limits; key rotation spreads quota across accounts; singleflight collapses redundant API spend. None of these are novel individually, but having them composed into a single drop-in layer with consistent behavior across three runtimes addresses a real operational gap that most teams currently solve ad hoc.
Worth evaluating if you are running multi-agent pipelines at scale and have grown tired of reinventing retry logic and key management in every service.
Source: https://github.com/sno-ai/llmix
KevRojo/Dulus
A terminal-native, tool-calling LLM agent that wires a frontier model to a curated set of shell capabilities: file read/write, arbitrary Bash execution, regex grep over a repository tree, web browsing, and Git commit authoring. The architecture follows the standard ReAct loop — the model emits tool-call JSON, Dulus dispatches to the corresponding handler, feeds the result back, and iterates until the model signals completion.
What distinguishes it from similar projects (aider, Claude Code, OpenDevin) is the claimed zero-cost web scraping path, apparently using publicly accessible chat interfaces rather than paid search APIs. That is a pragmatic but fragile choice: scraping AI chat frontends is subject to rate limits, CAPTCHAs, and ToS changes. The Git integration means the agent can take a task from natural-language spec all the way to a committed diff without leaving the terminal.
The tool surface is intentionally broad — Bash execution plus web access is essentially unrestricted compute, so sandboxing and permission scoping are open concerns. No formal sandboxing mechanism is documented in the current release. Suitable for local developer automation where you control the environment, less appropriate for multi-tenant or CI contexts without additional containment.
Source: https://github.com/KevRojo/Dulus
boratanrikulu/gobee
gobee addresses a genuine ergonomics problem in eBPF development: the required C dialect is low-level, lacks type safety, and the toolchain (clang, bpftool, libbpf headers) is friction-heavy. gobee provides a transpiler that accepts a restricted subset of Go and emits valid BPF C, then automatically generates typed Go bindings using cilium/ebpf — the same library already common in production eBPF projects (Cilium, Tetragon, Falco).
The subset restriction is necessary because BPF programs run in a verified in-kernel VM with no heap allocation, bounded loops, and a stack limit of 512 bytes. gobee enforces these constraints at the Go source level, giving compile-time errors rather than verifier rejections. Generated bindings expose maps and programs as strongly typed Go structs, eliminating the stringly-typed map access that makes raw cilium/ebpf code error-prone.
The transpiler approach is architecturally simpler than a full BPF backend in the Go compiler (which does not exist), and it keeps the kernel-side code inspectable as C before submission. The main limitation is that the supported Go subset will always lag behind full Go semantics, and complex data structures may require manual C shims. Still, for network observability, tracing, and security tooling written in Go shops, this meaningfully lowers the eBPF adoption barrier.
Source: https://github.com/boratanrikulu/gobee
WantongC/journal-adapt-writing-skill
A tool for style transfer of academic manuscripts toward target-venue conventions. The workflow: feed it a corpus of published papers from a specific journal, extract structural and linguistic patterns (section ordering, hedge density, citation placement, passive/active voice ratios, terminology), then apply those patterns as revision guidance to a submitted manuscript, section by section.
The framing is stylometric rather than purely paraphrastic — the goal is not surface rewriting but alignment with a venue’s implicit editorial norms, which vary substantially between, say, Nature Medicine and a systems conference proceedings. This is a legitimate problem: rejection due to style mismatch rather than content is common, and the conventions are rarely documented explicitly.
The technical implementation appears to use LLM prompting with in-context examples drawn from the scraped corpus, rather than fine-tuning, which keeps the pipeline flexible but means output quality depends on how well the model can internalize distributional differences from a few examples. Key open questions: how large a corpus is needed per journal to yield reliable patterns, whether the approach handles multi-disciplinary journals with heterogeneous style, and whether the section-by-section decomposition preserves cross-section coherence. Nonetheless, for researchers who write across multiple venues or in a non-native academic English register, this operationalizes a task that otherwise requires deep manual familiarity with each outlet.
Source: https://github.com/WantongC/journal-adapt-writing-skill
seochecks-ai/slopless
A deterministic, rule-based CLI and textlint plugin for detecting low-quality prose patterns in English Markdown. The explicit design choice is determinism: unlike LLM-based writing feedback, every flagged token maps to a defined rule, making the tool suitable for CI enforcement and reproducible linting pipelines.
The target pattern set — “prose slop” — covers the vocabulary of LLM-generated filler: hollow intensifiers (“incredibly,” “leverage,” “seamlessly”), vague nominalization, redundant hedging, and overused transition phrases. These are precisely the signals that make AI-generated text detectable to human readers even when factually correct.
Built on textlint’s AST-based Markdown parsing, slopless integrates with the existing textlint ecosystem and can be composed with other rules (sentence length, passive voice, readability scores). The rule definitions are transparent and overridable, which matters for teams that want to permit certain terms in specific contexts (e.g., “leverage” as a verb in finance docs).
Practical use cases: pre-commit hooks on documentation repos, PR checks on blog content, or editorial pipelines where a human reviewer wants a first-pass filter. The limitation is inherent to any lexicon-based approach — false positives on legitimate uses of flagged words, and no detection of slop patterns that don’t manifest as specific vocabulary (e.g., circular definitions, content-free sentences). Complement with a semantic-level check for full coverage.
Source: https://github.com/seochecks-ai/slopless
horang-labs/tessera
A workspace manager purpose-built for AI-assisted coding sessions, addressing the organizational overhead that emerges when running multiple concurrent agent interactions across a non-trivial codebase. The core data model has five levels: workspaces (project-level), collections (task groupings), tabs, panes, and Git worktrees — the last being the key technical differentiator.
By binding each pane or session to a separate Git worktree, Tessera allows multiple agent coding threads to operate on isolated working trees of the same repository simultaneously, without branch-switching overhead or state contamination between sessions. This mirrors how developers using Claude Code or similar tools naturally want to parallelize: one worktree for a feature branch, another for a bug fix, each with its own agent context.
The UI is terminal-based (implied by the pane/tab model) and session-persistent, so an agent conversation tied to a worktree survives terminal restarts. The project/collection hierarchy provides a way to archive and retrieve past sessions with their associated code state, which is useful when returning to an abandoned task weeks later.
The main architectural question is how context is managed across panes — whether agent conversations share repo-level context or are fully isolated. Full isolation is safer but loses cross-task knowledge; shared context introduces coupling. Worth watching for teams running parallel agent-assisted development at scale.
Source: https://github.com/horang-labs/tessera
ajsai47/backdoor
A thin compatibility shim that routes Claude Code’s API calls to arbitrary OpenAI-compatible endpoints: DeepSeek, Groq, Ollama, OpenRouter, and any other provider exposing the OpenAI chat completions interface. Claude Code is hardcoded to Anthropic’s API; backdoor intercepts at the transport layer (likely a local proxy or environment variable override) and translates or forwards requests to the configured backend.
The practical value is cost and latency flexibility: DeepSeek-V3 or a locally hosted model via Ollama is orders of magnitude cheaper per token than Claude 3.5 Sonnet for tasks where frontier capability is not required. It also enables fully offline operation for sensitive codebases when pointed at a local Ollama instance.
The technical risk is prompt-format mismatch. Claude Code’s system prompts and tool-call schemas are tuned for Anthropic’s models; open-weight or third-party models may handle these differently, producing degraded tool-use reliability or malformed outputs. The shim cannot fix semantic incompatibilities, only protocol ones. Users should expect variable quality depending on the target model’s instruction-following fidelity.
This is a developer convenience tool with a narrow scope — no novel architecture, but it solves a concrete access problem for anyone who wants the Claude Code interface without Anthropic’s pricing or data routing.
Source: https://github.com/ajsai47/backdoor
study8677/awesome-architecture
A structured reference collection covering 21 software architecture patterns as visual maps, with explicit coverage of AI-specific infrastructure: API gateways for LLMs, RAG pipeline architecture, agent orchestration, inference serving, and vector database internals, alongside classical patterns (event-driven, microservices, CQRS, saga). Each map links to open-source prototype implementations rather than stopping at diagrams.
The pedagogical framing — “think like an architect” — is operationalized through a language-agnostic system design tutorial that separates concerns (scalability, consistency, fault tolerance, observability) from implementation. The bilingual presentation (Chinese and English) reflects the primary audience but does not reduce utility for English-only readers.
What makes this more useful than a generic awesome-list is the connection between pattern diagrams and concrete runnable code. The AI gateway map, for instance, connects abstract routing and rate-limiting concepts to actual proxy implementations, which bridges the gap between architectural reasoning and engineering practice.
Limitations of the format: static maps go stale as tooling evolves (especially in the fast-moving inference serving and vector DB spaces), and the pattern descriptions are necessarily high-level. The repo is best used as a structured entry point for exploration rather than a definitive reference. The inclusion of AI infrastructure patterns alongside classical distributed systems content reflects current engineering reality, where these concerns increasingly coexist in the same system design interviews and production stacks.