デイリーAIダイジェスト — 2026-05-21
arXiv ハイライト
Mega-ASR: Towards In-the-wild^2 Speech Recognition via Scaling up Real-world Acoustic Simulation
問題設定
Qwen3-ASRやGemini-3-Proといった大規模音声言語モデルを含む現代のASRシステムは、複合的な実世界の音響歪み(例:残響の多い教会における遠距離音声と背景雑音の組み合わせ)に対して性能が急激に低下します。失敗の様式は単なるWERの上昇にとどまらず、重度の劣化下ではモデルが音響的根拠を失い、空の仮説を出力するか、音源とは無関係な流暢なテキストを幻覚として生成します。既存のロバスト性データセットは単一現象を個別に扱っており(NOIZEUS:雑音のみ、CHiME-4:雑音+遠距離、VOiCES:残響中心)、WER 4〜10%で飽和しているため、モデルが実際に破綻する領域をストレステストするには不十分です。著者らは「in-the-wild²」と呼ぶ領域——最先端システムのWERが30%を超える複合音響条件——を対象としています。
Voices-in-the-Wild-2M
このデータセットは、物理的な部屋シミュレーションではなくスペクトログラムレベルのコードベースシミュレーション(スケーラビリティを重視して選択)により構築されており、7種類の基本音響効果(雑音、遠距離、遮蔽、エコー&残響、録音、電子歪み、伝送ドロップアウト)を対象としています。各基本効果は手書きのスペクトルパイプラインであり、そのパラメータは当該現象の実世界録音上でQwen3-ASRをSFTフィッティングしてWER曲線を一致させることで反復的に較正されます。これらの基本効果は54種類のエージェント検証済み複合シナリオに組み合わされます。

その結果、平均WER 18.42%(ベンチスプリットにおけるQwen3-ASRベースライン ≈35%)の240万クリップが生成されます。既存コーパスとの比較:
| データセット | カバーする現象 | 規模 | WER |
|---|---|---|---|
| NOIZEUS | 雑音 | 1K | 9.45 |
| CHiME-4 | 雑音+遠距離 | 15K | 5.39 |
| VOiCES | 遠距離、E&R、録音、歪み | 1M | 8.94 |
| BERSt | E&R、録音 | 4.5K | 22.41 |
| Voices-in-the-Wild-2M | 全7種+ドロップアウト | 2M | 18.42 |
シミュレータの較正は実験的に検証されています:シミュレートされた基本効果上でのSFTは基本効果ごとの実テストセットに転移し(図3、左)、NOIZEUS 0dBにおける難易度サンプリングは自然分布に対して再バランスされています(図3、右)。
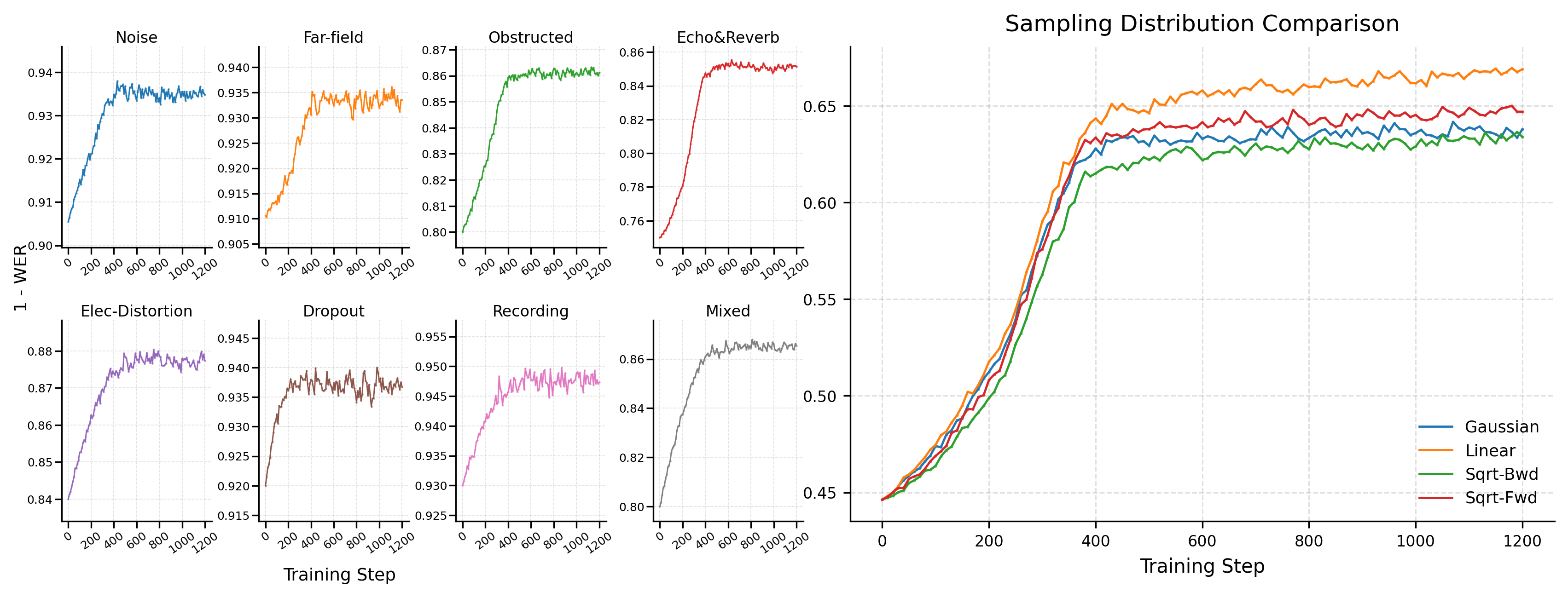
Mega-ASRの学習パイプライン
Qwen3-ASR-1.7B(エンコーダ+アライナ+LLMデコーダ)を基盤とし、2段階で構成されます。
A2S-SFT(Acoustic-to-Semantic Progressive SFT)。 著者らは中程度・高WER領域における2つの連関したボトルネックを診断しています:(i) エンコーダ・アライナが劣化した波形から信頼性の高い音響証拠を抽出できない、(ii) 証拠が部分的にしか信頼できない場合にLLMが意味的事前知識を活用できない。A2S-SFTは3つのフェーズで進行します:
- エンコーダとアライナのみを更新するWERグレード化されたカリキュラムで、学習プールを\text{WER}<30\% → <50\% → <70\%と段階的に拡大する。これにより、LLMに触れる前に音響知覚を段階的に構築します。
- 完全な\text{WER}<70\%プール上でのLLMのみのfine-tuning。信頼性の低い音響証拠のもとで意味的回復を活性化します。
- エンコーダ、アライナ、LLMの joint fine-tuning によるエンドツーエンドの整合。
DG-WGPO(Dual-Granularity WER-Gated Policy Optimization)。 A2S-SFTの初期化から、方策はk個の仮説を生成し、トークンレベルと文レベルのWER報酬を融合したスコアで評価します。粒度の重みはWER報酬の失敗を回避するために動的にゲーティングされます(文レベルWER単独では高WER領域でほぼ均一に低い報酬が与えられgradient信号が消滅し、トークンレベルWER単独では幻覚下でローカルな一致に対して過剰報酬が与えられます)。融合はロールアウトの実際のWER分布に基づいて変調されており、劣化スペクトル全体にわたって有用なgradientを供給します。
結果
逆境条件ベンチマーク上での結果(先行SOTAとの比較、おそらくQwen3-ASR-1.7B):
- VOiCES R4-B-F:45.69% WER(vs. 54.01%)
- NOIZEUS Sta-0:21.49%(vs. 29.34%)
- 複合Voices-in-the-Wild-Bench:オープンソース・クローズドソース両方のベースラインに対して30%超の相対WER削減
図1のレーダーチャートは、ロバスト性サブセットにおける改善がクリーン音声(LibriSpeech、CommonVoice22、FLEURS、AISHELL-1、WenetSpeech、VoxPopuli)で代償を払っていないことを示しています——回帰がないことを検証するために動的ルーティングLoRAのあり・なしが報告されています。
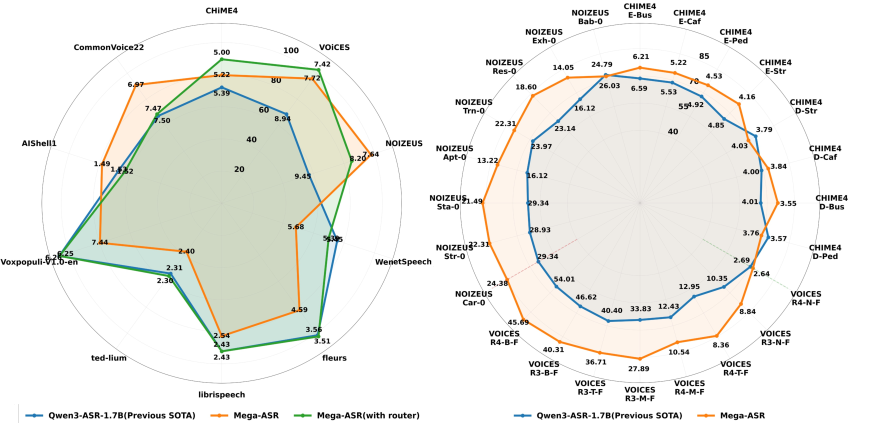
ケーススタディは定性的な失敗様式を定量化しています。Peak -5.2 dBの遠距離クリップにおいて:Qwen3-ASRは空の結果を返し(WER 100.0%)、Gemini-3-Proは流暢だが無関係な仮説を生成し(WER 86.1%)、Mega-ASRは参照テキストと一致します(WER 0.0%)。このパターンは雑音条件下および固有表現が多い発話でも繰り返されます。
限界と未解決問題
- 音響シミュレータは物理的なRIR畳み込みではなくスペクトログラムレベルで動作しており、較正はQwen3-ASRのWERを適合度信号として固定しているため、循環性のリスクがあります(シミュレータは評価対象のモデルファミリーを混乱させるように調整されており、そのモデルには見えない失敗様式を過小表現する可能性があります)。
- 54種類の複合シナリオはエージェントによって検証されており、クリップレベルでの物理的妥当性について人間が評価したものではありません。
- 「WERゲーティング」関数と粒度スケジュールは提供されているセクションでは詳細が示されておらず、再現性はこれらに依存しています。
- すべての改善は1.7Bの初期化に対して報告されており、意味的事前知識がより強く音響ボトルネックが支配的な7B以上のスケールでA2S-SFT+DG-WGPOが引き続き有効かどうかは未解決です。
- 凍結されたASRにフィードする専用の音声強調フロントエンド(例:拡散ベースのデノイザー)との比較はありません。
重要性
これはASRのロバスト性を既存ベンチマークの飽和点を超えて改善するための具体的なレシピです:複合的音響シミュレーションをスケールアップし、ナイーブな文レベルWER報酬が崩壊する高WER領域を生き延びるWERゲーテッドRL段階を伴う音響から意味へのカリキュラムで学習します。複合シナリオにおける30%超の相対WER削減は、ボトルネックがアーキテクチャではなくデータと最適化にあることを示唆しています。
Source: https://arxiv.org/abs/2605.19833
OScaR: LLMにおける極端なKV Cache量子化のためのオッカムの剃刀とその先へ
問題設定
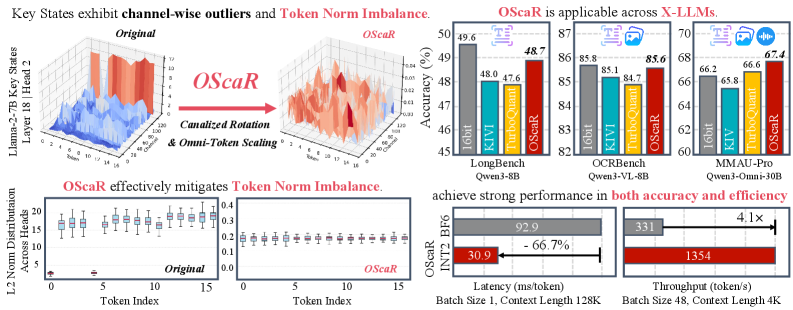
KV cacheのメモリは、長文コンテキストおよびマルチモーダルLLMの推論コストを支配しています。Keyテンソルはチャネル方向の外れ値を示すため、Key cacheのper-channel量子化が標準となっており、トークン次元をチャネル内で共有するscale/zero-pointは4〜8ビットでは良好に機能しますが、INT2では破綻します。本論文はその原因を特定します:小規模ながら一貫したサブセットのトークンが異常に低い\ell_2ノルムを持ち、単一のper-channelスケールがカバーしなければならないダイナミックレンジを拡大させるのです。著者らはこれをToken Norm Imbalance (TNI)と呼び、チャネル外れ値ではなくこれこそが極端な圧縮における制約要因であると指摘しています。
実験的・理論的診断
状態M\in\{Q,K,V\}における各トークンtとヘッドhについて、次のように計算します:
\mathcal{N}_t^{(M)} = \{\|\mathbf{t}_{t,h}^{(M)}\|_2 \mid h=1,\dots,H\}, \quad \|\mathbf{t}_{t,h}^{(M)}\|_2 = \sqrt{\sum_{j=1}^{d_h} (s_{t,h,j}^{(M)})^2}.
Llama-2-7B上でtにわたって\mathcal{N}_t^{(M)}を箱ひげ図で可視化すると、Q、K、Vで同時に非常に低いノルムを持つ、疎ながらも再現性のあるトークンの集合が現れます。これらはattention-sinkトークン(例:BOSトークンおよび高頻度な初期位置の少数のトークン)と一致しており、sinkが小さいvalue normを持ちながら大きなattention massを吸収するという先行研究の観察と整合しています。per-channelスケールは\Delta_c = (\max_t x_{t,c} - \min_t x_{t,c})/(2^b-1)として計算されるため、あるチャネルに沿った単一の低ノルム外れ値トークンがレンジを縮小させるわけではありませんが、高ノルムトークンのブロックが\Delta_cを大きくし、その結果としてb=2では低ノルムトークンの量子化がほぼ全ての情報を失います。
マルチモーダルモデルはこの問題をさらに深刻にします:ノルムの分散が広く、モダリティ(テキスト対画像対音声)が同一シーケンス内で異なるノルムの領域を形成し、さらに大きなノルムを持つ外れ値トークンが追加で現れます。したがって、モダリティをまたいで共有されるper-channelスケールは二重に不適合となります。
手法: OScaR
OScaR(Omni-Scaled Canalized Rotation)は、prefill/decoding時にオンラインで適用される、量子化前の二段階変換です。
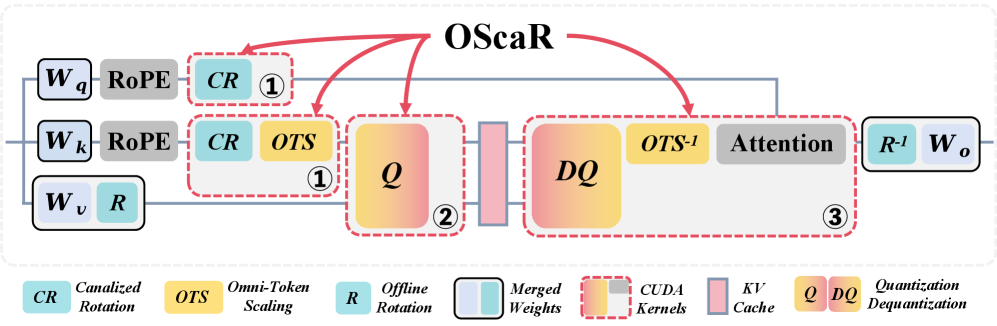
ステップ1 — Canalized Rotation。 Hadamard的な直交回転RをKのチャネル次元に沿って適用します(動的部分については単一のオンラインmatmulのコストで、先行する投影に吸収されます)。チャネル外れ値を抑制するために主に回転を行うQuaRot/RotateKVとは異なり、ここでの回転は「canalized」されており、チャネル方向の分散を均質化しながら、トークン方向のノルム構造を制御されたサブスペース上で保持するよう選択されます。これにより、次のステップがクリーンに作用できます。Rは直交行列であるため、\|K_t R\|_2 = \|K_t\|_2が成り立ち、ステップ2が作用するTNIの特性は変化しません。
ステップ2 — Omni-Token Scaling。 各トークンをそのノルムから導出されるper-tokenファクタ\alpha_tでリスケールします(本論文はアブレーション実験でいくつかの正規化のバリアントを検討しています);逆数\alpha_t^{-1}は下流のattention計算に折り込まれるため、この演算は完全精度では数学的に恒等変換です。スケーリング後、チャネル内のトークンの大きさは狭いバンドに圧縮され、これはまさにper-channel INT2量子化が忠実に機能する領域です。組み合わせた変換は次のように表されます:
\tilde{K}_t = \alpha_t \cdot (K_t R), \qquad \mathrm{Quant}_{\text{per-ch}}(\tilde{K}) \to \hat{K},
attention scoreは\mathrm{softmax}(Q (R^\top \mathrm{diag}(\alpha)^{-1} \hat{K}^\top)/\sqrt{d})として回復されます。RはHadamardであり\alphaは対角行列であるため、両者とも既存のカーネルに融合できます;著者らはCUDA実装を提供しています。
「Omni-」という名称は、マルチモーダルLLMにとって重要な、同一のスケーリングルールをモダリティをまたいで適用することを指しています。そこでは、naive per-channelスケールがテキスト・画像・音声トークンのクラスタにまたがって不整合を生じさせます。
結果
LongBench-EにおけるINT2・グループサイズ32での結果(TurboQuant+は2.5ビットという、より緩いバジェットを使用):
- Llama-3.1-8B: OScaRの平均は41.75で、FP16ベースライン(41.70)に匹敵し、KIVI(39.84)、OTT(40.74)、TurboQuant+(40.03)、QuaRot(37.94)、RotateKV(37.98)を上回ります。タスク別の顕著な改善例:GovReport 29.45 対 KIVIの24.41;MultiNews 5.68 対 KIVIの2.70;PassageRetrieval 44.46 対 FP16の43.57。
- Qwen3-8B: OScaRの平均は48.74 対 FP16の49.56で、次点のINT2手法(OTT)は48.21、QuaRotは40.13まで崩壊しています(TRECはQuaRot下では33.00まで低下するのに対し、OScaRでは72.00――回転のみの手法が一部タスクが依存するsink-token構造を損なうことの指標です)。
FP16との差は両モデルともINT2で1点未満であり、このビット幅では異例のことです。著者らはさらに、マルチモーダルモデルのOCRBench/DocVQAおよびQwen3-Omni-30B-A3BのMMAU-Proの結果と、セクション5.3および付録における効率性の測定結果(decoding高速化、スループット)も報告しています。
限界と未解決の問題
本論文は、提供されたセクションにおいてINT1やサブ2ビットの結果を報告しておらず、per-channelバンド自体が全く解像できない場合にOmni-Token Scalingで十分かどうかは不明です。per-tokenスケール\alpha_tは、\hat{K}と共にキャッシュされなければならない小さなper-tokenの状態を追加するため、グループサイズが小さい場合の2.5ビットベースラインとの正味のメモリ計算は精査に値します。\alpha_tの正規化の選択はアブレーションによって経験的に決定されており、閉形式の誤差境界からではありません。また、回転はHadamardであり学習済みではないため、両者とも原理的な扱いの余地が残されています。最後に、attention-sinkトークン自体は事前学習の脆弱なアーティファクトであり、sink抑制技術で学習されたモデルは異なるTNIプロファイルを示す可能性があり、再チューニングが必要となるかもしれません。
この研究の意義
TNIは、極端なKV量子化のボトルネックを、チャネル外れ値の問題(QuaRot、KIVI、RotateKVの背景にあるフレーミング)からトークンノルムの問題へと再定式化します。そして解決策は本質的に対角リスケールとHadamard回転であり、デプロイするのに十分安価です。グループ32のINT2でLongBenchのFP16に近いスコアを回復したことは、長文コンテキスト推論におけるlosslessなKV圧縮との残差ギャップのほとんどを埋めるものです。
Source: https://arxiv.org/abs/2605.19660
You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories
問題設定
RLVR(検証可能な報酬による強化学習、例えば数学に対するGRPO)は、LLMの推論能力を向上させる標準的なレシピとなっていますが、コストが高いという問題があります。具体的には、1.5B〜8Bパラメータのモデルに対して、検証器による advantage 推定を用いたロールアウト上で数百回の最適化ステップを必要とします。著者らはここで構造的な問いを立てています。すなわち、RLVRによって生成されるパラメータ軌跡 \{\theta_t\}_{t=0}^{T} の幾何学的構造はどのようなものか、そして軌跡の大部分をスキップできるほど予測可能かということです。著者らが与える答えは強力なものです。テンソルごとの重み差分軌跡は本質的にrank-1であり、ほぼ線形なスカラー係数を持ちます。したがって、将来のチェックポイントは短いプレフィックスから線形外挿により、追加の学習なしに予測できます。
手法
ネットワーク内の各テンソルについて、差分軌跡を以下のように定義します。 \Delta\theta_t = \theta_t - \theta_0, \quad t=1,\dots,T_{\text{obs}}. カットオフステップ T_{\text{cut}} までに観測された(ベクトル化された)差分を行列 M \in \mathbb{R}^{T_{\text{cut}} \times d} に積み上げ、SVD M = U\Sigma V^\top を計算します。第1右特異ベクトル \mathbf{v}_1 が支配的な更新方向を定義し、ステップごとのスカラー係数は以下の射影として得られます。 c_t = \langle \Delta\theta_t, \mathbf{v}_1 \rangle.
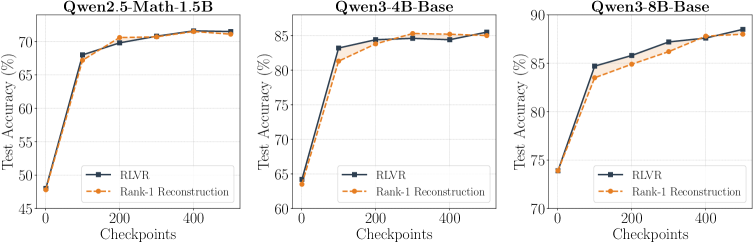
本手法を動機づける2つの実証的知見があります。第1に、各テンソルの完全な差分をrank-1近似 c_t \mathbf{v}_1 で置き換えても、テストした3つのモデルすべてにわたってMATHでの下流性能向上がほぼ完全に保たれます。
第2に、c_t は t に関してほぼ線形に変化します。最小二乗フィット c(t) = a t + b はQwen2.5-Math-1.5Bのほとんどのテンソルで R^2 > 0.98 を達成します。
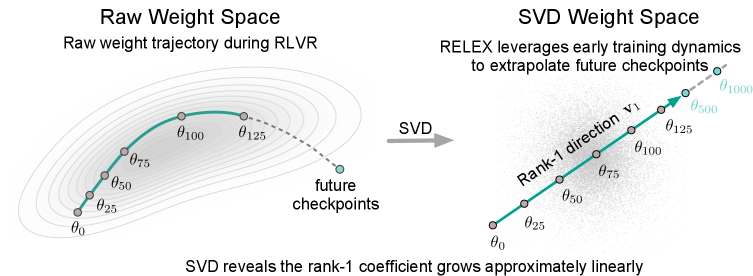
これら2つの事実により、RLVRチェックポイント予測は2ステップの手順(RELEX)に集約されます。
- T_{\text{cut}} ステップ(例:500ステップ中75または125ステップ)の短いプレフィックスだけRLVRを実行します。観測された差分行列のSVDからテンソルごとの \mathbf{v}_1 を計算します。
- 観測された差分を \mathbf{v}_1 に射影して \{c_t\} を得て、c(t)=at+b をフィットし、任意の将来ステップ T における予測チェックポイントを以下のようにテンソルごとに形成します。 \hat{\theta}_T = \theta_0 + (a T + b)\,\mathbf{v}_1
学習済みモデル不要、追加ロールアウト不要、T_{\text{cut}} 以降の検証器呼び出しも不要です。プレフィックスのRL実行に加わるコストは、テンソルごとの切り詰めSVDとスカラー線形回帰だけです。
結果
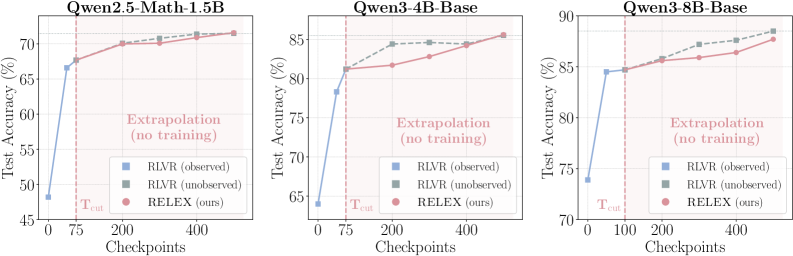
冒頭の図が主要な主張を要約しています。Qwen2.5-Math-1.5B、Qwen3-4B-Base、Qwen3-8B-Baseにわたって、RLVRステップの最初の約15%のみを使用して外挿されたチェックポイントが、MATHにおける対応するRLVRチェックポイントに匹敵するか、それを上回ります。
論文からの具体的な知見を以下に示します。
- 3つのモデルすべてが、プラトーに達するまでMATHに対してGRPOで500ステップ学習されており、ステップごとのチェックポイントが保存されています。RELEXは T_{\text{cut}}=75(学習の15%)という短いプレフィックスを使用します。
- 500ステップの完全な軌跡のrank-1再構成それ自体が、ベースモデルに対するMATH精度向上を本質的に保持します。これにより、rank-1部分空間が粗い近似にとどまらず、RLVRの更新のタスク関連成分を捉えていることが示されます。
- c_t の線形フィットはほとんどのテンソルで R^2 > 0.98 を達成しており、時間的外挿において線形(高次ではなく)が正当化されます。
- RELEXは観測窓を大きく超えて外挿でき、追加の学習コストなしにステップ1000(学習済みホライズンの2倍)までのチェックポイントを予測します。得られた重みは、ドメイン内のMATHとアウトオブドメインのベンチマーク(AIME 2025、AIME 2026、HMMT 2025、OlympiadBench、AMC 2023)の両方においてRLVRに匹敵するか、それを上回ります。
この結果が示唆することは、これらの数学分布に対するGRPOが重みの空間において、テンソルごとに一定速度で単一の方向に従う動作に近いことです。生の軌跡が曲線的に見えるのは、タスクに無関係な直交ノイズ成分に支配されているためです。
限界と未解決の問題
- 証拠は3つのQwenファミリーのベースモデルを用いたMATHに対するGRPOに限定されています。rank-1 + 線形構造が、コードに対するRL、エージェント的なツール使用、マルチタスク検証器の混合、または最適化の状況が異なる長いSFT/RLHFチェーン後のRLに対しても持続するかどうかは不明です。
- 「rank-1がほとんどの性能を捉える」という評価は精度で測定されており、方策分布については評価されていません。rank-1再構成の下でのRLVR方策へのKL、キャリブレーション、レアトークンの挙動はここでは特徴付けられていません。
- c_t の線形性は、方策が検証器の上限に近づくと崩れると考えられます。「ステップ1000まで」のRELEXの成功は、報酬がすでに飽和していることに依存している可能性が高く、真のRL軌跡が急激に向きを変えるレジームへ外挿しようとすれば失敗するでしょう。
- 分解はテンソルごとに行われており、テンソル間の結合については扱われていません。また、\mathbf{v}_1 が解釈可能かどうか(例えば、特定の attention ヘッドやMLPニューロンに整合しているかどうか)についても言及されていません。
- 自然な発展的研究の方向としては、発見された \mathbf{v}_1 を事後的な外挿のみに使うのではなく、RLオプティマイザ自体の内部でプレコンディショナーまたは制約として活用することが考えられます。
重要性
RLVRの fine-tuning 軌跡がこれほど低ランクで線形であるならば、これらのベンチマークに費やされたGRPOの計算の大部分は冗長です。短いプレフィックスとSVDによってエンドポイントを復元できます。これにより、安価な実践的レシピ(ステップ数の15%を実行し、残りを外挿する)が得られるとともに、数学に対する現在のRLVRはモデルの高次元的な容量を活用していないことが示唆されます。これは、より難しいRL目的やより豊かな報酬信号を設計するための定量的な目標を与えるものです。
Source: https://arxiv.org/abs/2605.21468
HRM-Text: スケーリングを超えた効率的なPretraining
問題設定
標準的なLLMのpretrainingは、計算規模と大量の生ウェブテキストのスケールを密接に結びつけています。HRM-Textは、根本的に異なるinductive bias――多重時間スケールのrecurrence――と、instruction dataに対するタスク完了型の目的関数を組み合わせることで、$1{,}500ドルの予算と40Bのユニークトークンを用いて競争力のある1Bパラメータモデルが実現できるかどうかを問います。動機付けのアナロジーは前頭頭頂ループ(frontoparietal loop)であり、遅い戦略的制御が速い実行を調節するというものです。技術的な問いは、これが言語モデリングにおいて安定して学習できるか、そして実際に同一FLOPsの条件下で優位性を発揮できるかという点にあります。
手法
バックボーンは、2つの結合モジュール H(遅い)と L(速い)を持つ階層的再帰モデル(Hierarchical Recurrent Model)です。フォワードパスはトークンembeddingから導出された z_H^0 と固定された z_L^0 から始まります。各外側サイクルでは L を3回更新した後に H を1回更新します。報告されている1B構成はH2L3であり、2 \times (3+1) = 8 モジュールステップ、すなわちフルコアの4 recursionsに相当します(H と L がそれぞれnon-embeddingパラメータの半分を保持するため)。線形headは最終的な H の状態から読み出しを行います。
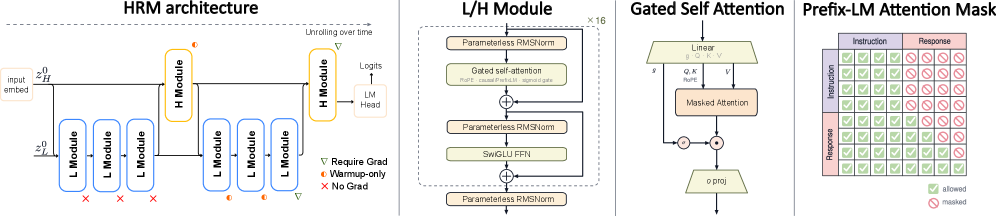
言語処理における深いrecurrenceを学習可能にする2つの安定化メカニズムを採用しています。
MagicNorm。 PreNormはidentityパス h_L = h_0 + \sum_l \text{Sublayer}(\cdot) を保持しますが、分散が深さとともに増大します。PostNormは分散を抑えますが、identityパスを破壊します。Recurrenceは同一変換を繰り返し適用するため、どちらの失敗モードも増幅されます。MagicNormは複数の内部PreNormブロックのスタックをモジュール出口で単一のnormで閉じます: z_n = \text{Norm}\!\left(z_{n-1} + \sum_{l=1}^{L} \text{Sublayer}_l(\text{Norm}(\cdot))\right). これは、フォワードホライズン N と打ち切りバックワードホライズン K \ll N の非対称性を利用しています。各recurrent出口で分散が再束縛される一方、短いバックワードウィンドウにおけるgradientは依然としてクリーンなresidualパスを参照できます。
Warmup deep credit assignment。 TBPTTは最初の段階では最後の2つのrecurrentステップのみにbackpropagateし、学習を通じて最後の5ステップまで徐々に拡張します。この K に関するカリキュラムが、トークンあたり実質8モジュール適用を持つモデルを発散なしに学習させる鍵です。
その他のコンポーネントは標準的でありながら簡略化されています:学習可能な \gamma を持たないパラメータなしのRMSNorm、SwiGLU、RoPE、およびsigmoid-gated multi-head attentionです。
pretrainingの目的関数は、完全なcausal LMではなくタスク完了型です。instructionと応答のペア (x_q, x_a) を連結し、NLLは応答部分のみで計算します(-\log P(x_a \mid x_q))。PrefixLMマスクにより x_q に対して双方向attention、x_a に対してcausal attentionを付与します。条件タグ(direct、cot、synth、noisy)を先頭に付けて出力スタイルを制御します。<think>...</think> 内のテキストは学習前に除去され、モデルがRLVR流の明示的なCoTに依存することを防ぎ、計算をrecurrenceに押し込みます。
コーパスはオープンなinstruction data(FLAN、Tasksource、SYNTH-rewritten Wikipedia、OpenMathInstruct2、NuminaMath、DMMath、Sudoku-Extremeなど)の176.5Bトークンです。SeqIOスタイルの層別サンプリングにより大規模ソースを上限設定(例:FLANでは5k docs/task、SYNTHでは10M)し、小規模ソースを 10\times アップサンプリングすることで、40Bのユニークトークンを60B合計で学習します。
結果
HRM-Text 1Bを40Bユニークトークンで学習した際の主要な数値は以下の通りです:MMLU 60.7、ARC-C 81.9、DROP 82.2、GSM8K 84.5、MATH 56.2、HellaSwag 63.4、Winogrande 72.4、BoolQ 86.2。学習は16 GPU上で1.9日間実施され、同程度のスコアを持つ2〜7BのオープンなFoundation modelと比較して、計算量は約96〜432\times、トークン数は100〜900\times 少ないと主張されています。
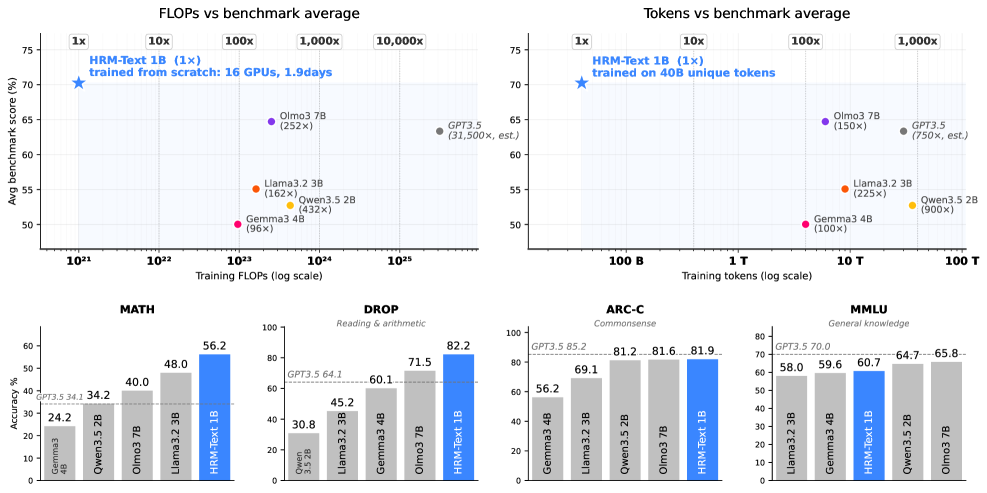
同一の学習FLOPs(1.0–1.1 \times 10^{21})の条件下では、HRM 1B(H2L3)はテストされたすべての代替手法を上回ります:4 recursionsのLooped Transformer 1B(MMLU 56.5、GSM8K 75.1、MATH 48.3)、r=7 のRINS 1B(56.1 / 77.7 / 48.9)、0.17Tトークンの1B Transformer(53.2 / 75.1 / 48.4)、3B deep Transformer(56.7 / 75.7 / 50.5)、3B wide Transformer(54.5 / 73.0 / 49.7)に対して優位です。deep Transformerベースラインが最も近い結果を示しており、これはHRMの優位性が部分的には有効深度の増大によるものであり、通常の深度スケーリングではこのトークン予算の下では完全に捉えられないことを示唆しています。
階層型対共有recurrenceのアブレーションはより明確です。TRM 1B(H2L1)は不安定な学習に終わり、MMLU 46.4、ARC-C 56.7、GSM8K 67.6に留まります。0.6Bでは同じH2L3スケジュールでHRMとTRMは同等(MMLU 56.87対56.88)ですが、1Bでは階層的でパラメータが独立したH/L変種のみが安定した学習を維持します。二重時間スケールはスケールにおいて必要であり、共有パラメータだけでは不十分です。
目的関数のアブレーションでは、PrefixLMを用いたresponse-only NLLが完全なcausal LMと比較して応答トークンのlossを低下させ、promptに対する層別のattention entropyを増加させることが示されており、これはプレフィックスの継続を記憶するのではなく、promptをより広く活用していることと一致しています。
限界
この比較には偏りがあります。HRM-Textは明示的なCoTを除去した高度にキュレーションされたinstruction/mathの混合データで学習されているのに対し、オープンモデルのベースラインは生ウェブテキストで学習後にpost-trainingが施されています。これを「pretraining」と呼ぶのは定義上の拡張解釈であり、スクラッチから学習したinstruction tuningに近いものです。また、MMULとGSM8KはOpenMathInstruct2やNuminaMathなどのソースからのデータ汚染に対しても脆弱であり、論文はデコンタミネーションについて報告していません。使用されたrecurrenceの深さ(4)は控えめであり、MagicNorm下でのHRMのスケーリング則は特徴付けられていません。最後に、単一チェックポイントによる報告と保留ウェブテキストに対するperplexityの欠如により、モデルがタスク分布を超えた一般的な言語モデリング能力を保持しているかどうかは不明なままです。
この研究の意義
より厳密な汚染管理のもとで結果が確認された場合、これは階層的recurrenceによる有効深度の増大と応答条件付き目的関数の組み合わせが、pretrainingのトークン数と計算量の1〜2桁分を代替できるという存在証明となります。これにより、学術規模の基礎研究における計算量とデータのフロンティアが再定義され、アーキテクチャと目的関数の設計がスケーリングの後付けではなく、第一級の変数として位置付けられます。
Source: https://arxiv.org/abs/2605.20613
言語モデルにおけるRLVRの学習不能現象
問題設定
GRPOを用いたRLVRは、LLMにおける推論を引き出すための標準的なレシピとなっていますが、例レベルの学習ダイナミクスはほとんど理解されていません。著者らは、鋭く再現性のある現象を記録しています:ベースモデルが最初に失敗する「難しい」例のうち、相当数のサブセットが、方策が正しいrolloutを時折生成する場合でさえも、GRPOの下で学習不能のままであるという現象です。これはロングテールの丸め誤差ではなく、RLVRが計算量にかかわらず達成できる上限を規定するものであり、通常のトリック(オーバーサンプリング、リプレイ、KL/クリップのチューニング)で覆い隠すことはできません。
セットアップと定義
ベースアルゴリズムは動的サンプリングを用いたGRPOです。検証可能な答え y^* を持つプロンプト x に対して、k 個のrolloutをサンプリングし、\mathbb{1}[y_i=y^*] で報酬を与え、advantageに標準化します:
\hat{A}_i = \frac{\mathbb{1}[y_i=y^*] - \mathrm{mean}(\cdot)}{\mathrm{std}(\cdot)},
そして \pi_{\text{ref}} に対するKLペナルティを伴うクリップされたPPOサロゲートを通じて最適化します。報酬分散がゼロのプロンプトは各ステップでフィルタリングされます。著者らは訓練セットを、訓練を通じて報酬が改善するかどうかに基づき、学習可能グループ \mathcal{D}_l と学習不能グループ \mathcal{D}_u に分割します。主な分析はMATH EasyにおけるQwen2.5-0.5BとMATH HardにおけるLlama-3.2-3B-Instructを用います。
自明な説明の排除
正のrolloutの希少性。 仮説1:\mathcal{D}_u は、任意のバッチで正しいrolloutが少なすぎるために失敗する。これをリプレイ付き強力なオーバーサンプリングスキーム(Algorithm 1)で検証します:4k 個のrolloutをサンプリングし、正例がちょうど k_{\text{pos}}=1、負例が k-1=7 となるように k 個にダウンサンプリングし、新鮮な正例が不足している場合はバッファリングされた正しいrollout(それぞれ最大2回)をリプレイします。これにより \mathcal{D}_l と \mathcal{D}_u の間で正/負の構成を強制的に均等化します。
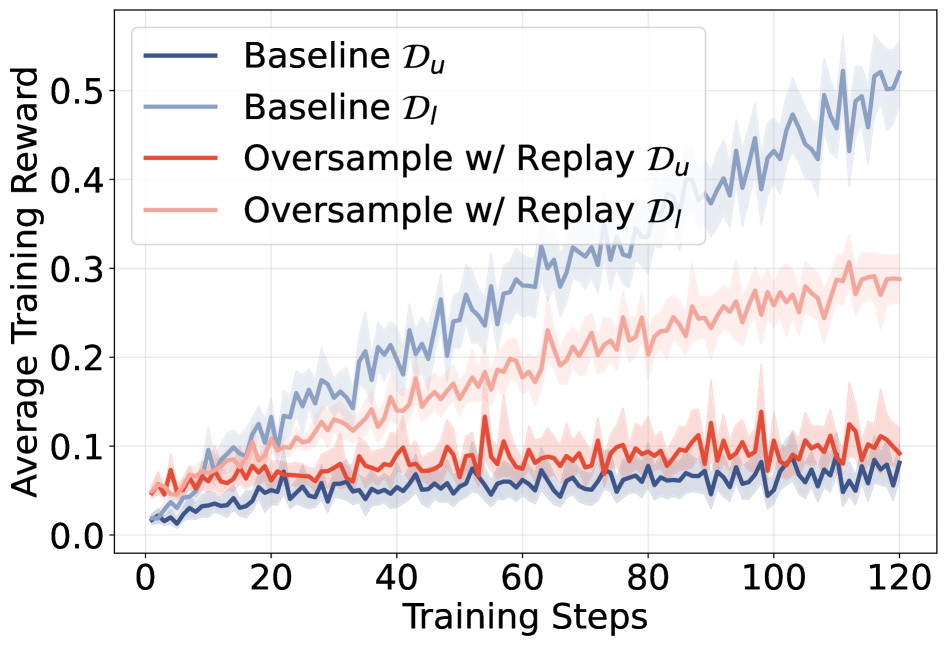
\mathcal{D}_l と \mathcal{D}_u の間の報酬ギャップは本質的に変わらず持続します。この介入は初期ステップで学習不能な報酬をわずかに引き上げますが、漸近的なギャップは保たれ、仮説1は棄却されます。
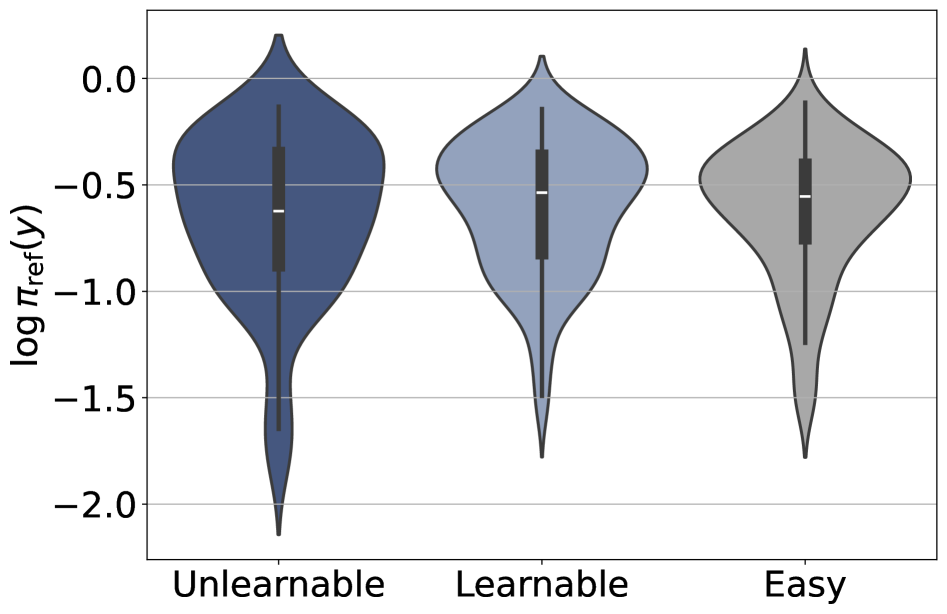
最適化の正則化器。 2つの候補:低尤度の正しいrolloutを抑制するKLペナルティと、その勾配をゼロにするPPOクリッピングです。\mathcal{D}_u 上の正しいrolloutの参照対数尤度の分布は \mathcal{D}_l 上の分布と重なっています——学習不能な例は \pi_{\text{ref}} の下で系統的にマニフォルド外にあるわけではありません。
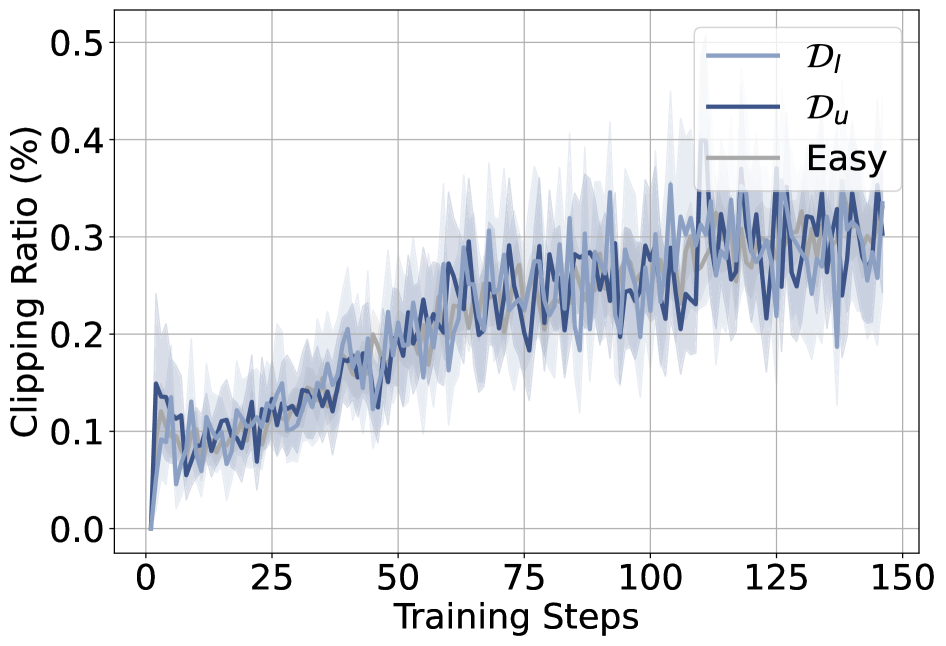
3つのグループ(学習可能、学習不能、容易)にわたるクリッピング比もほぼ同一であり、クリッピングが \mathcal{D}_u の更新を選択的に抑制しているわけではありません。
表現の病態としての学習不能性
最適化側の説明が排除されたため、著者らは勾配の幾何学に目を向けます。グループごとに100例に対して、初期方策から各1000個のrolloutをサンプリングし、正しいrolloutのみを保持し、例ごとのGRPO勾配を計算します——応答内のトークンにわたって平均化し、次に応答にわたって平均化します。これを扱いやすくするために、固定されたランダム初期化のLoRAアダプターを接続し、そのパラメータのみで微分します;0.5BモデルではLoRAベースの勾配類似度はフルパラメータの類似度を忠実に追跡します。ペアワイズコサイン類似度を、グループ内およびグループ間で比較します。
発見:学習不能な例は勾配の外れ値です。正しいrolloutの勾配は、他の例(他の学習不能な例を含む)の勾配との余弦類似度が低いです。学習可能な例は互いに勾配が強化し合うコヒーレントなクラスターを形成しますが、学習不能な例は軸外に位置するため、バッチの残りからの更新はそれらに転移せず、それら自身の(稀な、正しい)更新も逆に一般化しません。具体的には、方策が正しい思考の連鎖に偶然到達したとしても、そのrolloutにエンコードされた推論パターンは特異的であり——モデルが \mathcal{D}_l から同時に統合しているパターンと表現的な構造を共有していないことを意味します。\mathcal{D}_u 上の「正しい」rolloutの調査もこれを裏付けており、それらはモデルが圧縮できる推論ではなく、ショートカットや非一般化可能な連鎖を通じて y^* に到達することが多いです。
著者らはさらに、データ拡張(例:言い換え、代替解法のトレース)は \mathcal{D}_u とデータの残りとの勾配類似度を向上させないことを示しており、問題は表面的な形式の分散ではなく、例と方策の現在の特徴幾何学との間のより深い表現的ミスマッチであることを示しています。RLVRの勾配のみのフィードバックの中では、このミスマッチを修復するメカニズムは存在しません。
限界と未解決の問題
勾配分析は固定されたランダムLoRAを低次元プローブとして使用しています;フルパラメータ勾配との相関は0.5Bモデルのみで報告されており、スケールが大きくなると劣化する可能性があります。\mathcal{D}_l/\mathcal{D}_u への分割は、(x,y^*) の事前の性質ではなく訓練時の報酬軌跡によって操作的に定義されており、訓練前に学習不能性を予測することを困難にします。最後に、この論文は現象を診断するものであり、修正するものではありません:精選されたratioanleに対するSFT、訓練中の表現の手術、またはオフポリシー蒸留が \mathcal{D}_u の例を学習可能なものに変換できるかどうかは未解決のままです。
なぜこれが重要か
この結果はRLVRの上限を再定義します:それはrolloutサンプリング効率やKL/クリップのハイパーパラメータだけによって制限されるのではなく、例とベースモデルとの表現的な適合性制約によって制限されます。rolloutやリプレイバッファをスケールアップしてもこのギャップは縮まりません;難しい推論における意味のある進歩は、RLの目的関数ではなく表現を変える介入を必要とする可能性が高いです。
Source: https://arxiv.org/abs/2605.16787
Video2GUI: 汎用GUIエージェント事前学習のための大規模インタラクション軌跡の合成
問題
マルチモーダルLLM上に構築されたGUIエージェントは、学習データがボトルネックとなっています。既存の軌跡データセット(例:スクリーン録画ファームや人手によるアノテーション)はコストが高く、対応アプリケーションの範囲が狭く、10^5–10^6件の軌跡数を超えることはほとんどありません。その結果、汎化性能が低くなり、少数のオフィスソフトやECサイトで学習されたエージェントは、ロングテールのデスクトップやWebアプリケーションでは機能しません。本論文の主張は、オープンウェブにはすでに豊富なGUIデモンストレーション(チュートリアルやウォークスルー動画)が存在しており、十分に選択的な抽出パイプラインを用いれば、人手によるラベルなしでインターネット規模でそれらを収集できるというものです。
手法
Video2GUIは、ラベルなし動画メタデータを入力として、構造化されたエージェント軌跡 \tau = \{(s_t, a_t)\}_{t=1}^T を出力する粗から細へのフィルタリング・変換パイプラインです。ここで s_t はスクリーンショット的なフレーム、a_t \in \mathcal{A} はピクセル座標やテキストペイロードを伴うground化されたアクション(クリック、タイプ、スクロール、ドラッグ、キー操作)です。
このパイプラインは四つのステージで構成されます。
メタデータフィルタリング。 5億件の動画メタデータエントリを起点として、タイトル、説明文、タグ、チャンネル特徴に対する軽量な分類器が、GUIチュートリアルである可能性の高い候補を選択します。これにより、フレームをデコードする前に、無関係なコンテンツ(Vlog、ゲーム、音楽)の大部分が除外されます。
ビジュアルフィルタリング。 残った候補を低フレームレートでサンプリングし、デスクトップ/Web UIの視覚的統計(直線的なレイアウト、テキスト密度、カーソルの存在、ウィンドウのクローム)を確認するGUI対自然画像分類器に通します。UIフレーム割合の閾値を下回る動画は破棄されます。二段階目のパスでは、フェイスカムオーバーレイ、トーキングヘッドのイントロ、スライドのみのチュートリアルを検出して除去します。
軌跡抽出。 生き残った動画に対して、システムは以下を実行します。
- フレーム間でインタラクションポイントを局所化するためのカーソルトラッキング。
- カーソル周辺の視覚的変化(クリックフラッシュ、フォーカスリング、モーダルポップアップ、テキストキャレットの出現)を検出してアクション境界を推定するイベントセグメンテーション。
- セグメントを \{click, double-click, right-click, type, scroll, drag, hotkey\} に分類し、タイピングアクションに対してOCRでテキストペイロードを抽出する小規模VLMによるアクションタイピング。
- UIパーサーから復元された最近傍のUI要素バウンディングボックスにアクション座標をスナップし、(x, y, \text{element\_id}) タプルを生成するグラウンディング。
品質スコアリングと指示合成。 各軌跡は視覚的安定性、アクションセグメンテーション信頼度、OCR一貫性でスコア化されます。キャプショニングVLMが軌跡を条件として高レベルなタスク指示 g(およびステップごとの根拠)を生成し、grounding事前学習(s_t と参照表現が与えられた際に a_t の座標を予測する)と完全なアクション予測事前学習(g, s_{1:t}, a_{1:t-1} が与えられた際に a_t を予測する)の両方に使用可能な教師あり学習タプル (g, \{(s_t, a_t)\}) が得られます。
スケールで適用することで、WildGUIが得られます:1,500以上のアプリケーションとウェブサイトにまたがる1,200万件の軌跡であり、既存の公開コーパスよりもおよそ一桁広い範囲をカバーし、手作業による収集ではほとんど到達できない専門ソフトウェア(CAD、DAW、IDE、科学ツール)のロングテールも含みます。
事前学習と結果
Qwen2.5-VLとMiMo-VLは、grounding目標とアクション予測目標の混合を用いてWildGUIで継続事前学習され、その後標準的なGUIベンチマーク(参照表現に対するクリック精度を測定するgroundingタスク、およびエージェント軌跡のステップレベル精度を測定するアクションベンチマーク)で評価されました。
報告されたゲインはgroundingおよびアクションベンチマーク全体で5〜20%の絶対的な改善であり、事前学習済みモデルは同等のバックボーンサイズを使用する最先端ベースラインに匹敵するか、それを上回る性能を示しました。両バックボーンにわたるゲインの広がりは、改善がバックボーン固有ではなくデータ主導であることを示唆しており、アクションベンチマーク(純粋なgroundingよりも通常困難)における改善の大きさは、抽出された軌跡が要素の局所化シグナルだけでなく、有用な手続き的構造を含んでいることを示しています。
限界と未解決の課題
- アクションの忠実度。 カーソル軌跡の推論では隠れた状態を復元できません:視覚的フィードバックのないキーボードショートカット、コピー/ペースト、クリップボード経由のアクションは系統的に未検出になります。ドラッグと選択の区別はノイジーです。
- チュートリアルバイアス。 チュートリアル動画は理想化されたハッピーパスを描写します。このデータセットには、RLスタイルのfine-tuningが恩恵を受けるであろうエラー回復軌跡が含まれていない可能性があります。
- OCR依存のタイピングラベル。 タイプされたテキストは画面上のレンダリングから再構成されるため、パスワード、IMEによる文字入力、部分的な文字列入力は信頼性が低くなります。
- 解像度とアスペクト比のミスマッチ。 動画は様々な解像度で再エンコードされ、座標は正規化されますが、小さいUIターゲット(ツールバーアイコン)はラベルノイズに悩まされます。
- インタラクティブな検証なし。 ライブ環境で収集された軌跡とは異なり、a_t が実際に s_t \to s_{t+1} への遷移を引き起こすことを再現・検証する方法がありません。本論文では、ホールドアウトされた再現成功率メトリクスは報告されていません。
- ライセンス。 リリース計画はデータセットとパイプラインをカバーしますが、サードパーティのチュートリアル動画から派生したスクリーンショットの法的地位はアブストラクトでは議論されていません。
自然な次のステップは、ハッピーパスバイアスを補うために、WildGUI事前学習と小規模な環境グラウンドRLfine-tuningを組み合わせることです。
なぜ重要か
GUIエージェントはImageNet以前の初期視覚モデルと同様にデータ不足に悩まされており、Video2GUIはウェブをスクレイピングするという転換点となりうる手法であり、既存の5億件の動画シグナルをアノテーターなしで1,200万件のgrounded軌跡に変換します。5〜20%のゲインが独立した評価と再現検証で持続するならば、バックボーンの大型化ではなく、アプリケーションの広範な事前学習が、汎用的なコンピュータ使用エージェントに向けた近期的なレバーとなります。
Source: https://arxiv.org/abs/2605.14747
Uni-Edit: インテリジェントな編集は統合モデルチューニングのための汎用タスクである
問題
統合マルチモーダルモデル(UMM:画像理解・生成・編集を単一アーキテクチャで包含することを目指すもの)は、通常、異種タスクの混合によって学習されます。主流のレシピは、互いに分離したコーパス(理解向けのVQA+キャプショニング、生成向けのT2Iペア、編集向けの命令–編集トリプレット)に対する多段階カリキュラム学習であり、混合比率やlossの再重み付けを慎重に調整する必要があります。経験的には、これは相乗効果ではなくパレートのトレードオフをもたらします:生成性能の向上はVQA精度を損なう傾向があり、編集のfine-tuningはその両方を頻繁に低下させます。根本的な原因はタスク間の競合にあります。「画像を与えられた上で次のトークンを予測する」タスクと「テキストを条件としてピクセルをノイズ除去する」タスクからのgradientは、共有パラメータ上で異なる方向を向いており、編集は構造的な橋渡し役としてではなく、独立した第三の目的として扱われています。
Uni-Editはこの問題を再定式化します:3つの能力すべてを同時に必要とするような単一のタスクが存在し、それによって1つの学習ステージと1つのデータセットで3つすべてが改善できるのではないかというものです。著者らは、画像編集がまさにそのタスクであると主張しますが、それは編集の命令が理解を実際に機能させるほど十分に難しい場合に限られます。
手法
提案は2つのコンポーネントから構成されます:(1)インテリジェントな編集がUMMチューニングのための汎用タスクであるという主張、および(2)そのような命令を大規模に生成するデータ合成パイプラインです。
編集が適切な汎用タスクである理由。 標準的な編集の例はトリプレット (I_{\text{src}}, c, I_{\text{tgt}}) であり、c は命令、モデルは (I_{\text{src}}, c) を条件として I_{\text{tgt}} 上の生成lossを最小化します。c が単純な場合(例:「空を青くする」)、条件付けは局所的なテクスチャ・色変換に縮退し、理解はほとんど機能しません。解決策は、c に I_{\text{src}} に関する質問を埋め込み、その答えが編集内容を決定するために必要となるようにすることです。具体的には、命令は埋め込まれた質問とネストされた論理で構築されます:「女性が持っているオブジェクトを、彼女の靴の色に合った色のバージョンに置き換えてください」といった具合です。これを解くためには、モデルが(i)シーンを解析し、(ii)指示対象を特定し、(iii)属性について推論し、(iv)一貫した目標を合成する——すなわち、単一のforward/backwardパス内で理解の回路を使って生成の回路を駆動する——ことが求められます。
データ合成パイプライン。 既存の編集データセット(InstructPix2Pix、MagicBrush、UltraEditなど)は単純な命令を使用しているため、著者らはVQAデータをインテリジェントな編集ペアに変換する最初の自動化パイプラインを構築しました。このパイプラインはVQAソースから (I, q, a) を受け取り、以下を実行します:
- 質問 q と回答 a を用いて、質問が着目する I 内の根拠付けられた実体または属性を特定します。
- a に依存する実行内容を持つ編集仕様を生成します——例えば、「傘は何色ですか?」という質問と「赤」という回答は、「傘を現在の色の補色のものと交換する」という編集になります。
- 既製のエディタ/ジェネレータを使用してターゲット画像 I_{\text{tgt}} を合成し、VLMを通じて(a)規定された変更が存在すること、(b)無関係な領域が保持されていることを検証します。
- 必要に応じて、複数のVQA由来の述語を単一のネストされた命令に組み合わせ、推論の深さを増加させます。
結果として得られるコーパスUni-Edit-148kは、各命令が I_{\text{src}} に対する非自明な意味的依存性を持つ148kトリプレットを含んでいます。
学習。 UMMはUni-Edit-148k上で単一の編集目的で学習されます——独立したVQA lossも、独立したT2I lossも、カリキュラムも存在しません。統合モデルパラメータを \theta、I_{\text{tgt}} に対する標準的な条件付き生成lossを \mathcal{L}_{\text{edit}} とすると:
\mathcal{L}(\theta) = \mathbb{E}_{(I_{\text{src}}, c, I_{\text{tgt}}) \sim \mathcal{D}_{\text{Uni-Edit}}} \big[ \mathcal{L}_{\text{edit}}(\theta; I_{\text{src}}, c, I_{\text{tgt}}) \big].
c がVQAスタイルの推論を符号化し、I_{\text{tgt}} が生成を符号化しているため、\mathcal{L}_{\text{edit}} 単独からのgradientが両サブシステムに信号を伝播し、混合スケジュールを悩ませるタスク間干渉を排除するというのが主張の核心です。
結果
主要な経験的主張は、1つのタスク・1つのステージ・1つのデータセットが理解・生成・編集を同時に改善するというものです。報告された混合学習ベースラインに対する性能向上は、各能力の標準的なベンチマーク(理解向けのVQAスイート、生成向けのT2Iベンチマーク、編集ベンチマーク)全体で成立しています。重要なのは、編集のfine-tuningの後でも理解スコアが低下しない点です——これはほぼすべての先行統合チューニングレシピに共通する失敗モードであり——それどころか向上しており、インテリジェントな編集が必要な推論という観点からVQAの厳密な上位集合であるという仮説と一致しています。生成品質も向上しており、著者らはこれを、命令の表面形式ではなく細粒度のシーン意味論に合成ピクセルを根拠付けることをモデルが学習したためだと説明しています。
制限と未解決の問題
本アプローチは合成パイプラインの品質上限を引き継いでいます:ターゲット画像は既存のエディタによって生成されるため、アーティファクトやラベルノイズが伝播します。VLMによる検証はこれを軽減しますが、完全には排除できません。148kのスケールは混合学習コーパスと比較すると控えめであり、単一タスクのレシピが数百万スケールでも支配的であり続けるか、あるいは混合学習が追いつくかは未解決です。また、このフレームワークはベースUMMがすでに合理的なT2IおよびVQAの事前知識を持つことを前提としており、Uni-Edit単体でのゼロからの学習はいずれの能力もブートストラップできない可能性が高いです。最後に、「インテリジェント」は埋め込まれた質問とネストされた論理によって運用化されていますが、命令の難しさのより形式的な特徴付け(例:推論ステップ数、指示対象の曖昧さ)とそれが下流の性能向上とどのようにスケールするかを示すことで、本貢献の価値がより明確になるでしょう。
なぜ重要か
十分に豊かな単一タスクが統合モデルの多段階混合学習を代替できるなら、UMM開発のエンジニアリング表面は劇的に縮小します——混合比率も、ステージスケジュールも、タスクごとのデータキュレーションも不要になります。より広い原則として、能力は互いに独立して機能するタスクでバランスをとるのではなく、それらを同時に必要とするタスクを通じて共同学習されるべきであるという考え方は、タスク干渉が現在性能の上限となっているあらゆる統合モデルの設定において、ビジョンを超えて一般化する可能性があります。
Source: https://arxiv.org/abs/2605.21487
Hacker News Signals
Qwen3.7-Max: エージェントフロンティア
AlibabaのQwenチームは、エージェント的なワークロードに特化して位置づけられたdenseモデルであるQwen3.7-Maxをリリースしました。このアーキテクチャはQwen3シリーズをベースに構築されており、ツール呼び出し精度、マルチステップ推論、および長期タスクにわたる instruction following の改善が報告されています。このモデルは128Kのcontext windowをサポートしており、ツール使用やマルチターン計画タスクを含むいくつかのエージェント系ベンチマークにおいてGPT-4oを上回ると主張されています。特筆すべき点として、このリリースでは構造化出力の信頼性が強調されています。これは、下流のパーサーが不正なJSONや予期せぬスキーマの逸脱によって壊れるという、エージェントループ内で動作するLLMにおける慢性的な障害モードへの対処です。ブログ記事では、タスクの複雑さに応じて高速応答と拡張 chain-of-thought を切り替えられるハイブリッド思考モードが紹介されており、単純なサブタスクでの不必要なレイテンシを削減しつつ、必要な場面では推論の深さを維持することができます。このモデルはAPIおよびHugging Faceを通じて利用可能です。ツール拡張設定におけるグラウンディング品質や、retrieval-augmentedパイプラインと生のin-context stuffingとの比較において128Kコンテキストが実際にどの程度スケールするかについては、未解決の問いが残っています。
Source: https://qwen.ai/blog?id=qwen3.7
AIコーディングループにおける形式検証ゲート
この記事は、AIコーディングエージェントをよりスマートにすることよりも、特定の障害クラスをそもそも防ぐ強固な構造的制約を挿入する方が価値があると主張しています。核心的なアイデアは「構造的バックプレッシャー」です。すなわち、エージェントに対してより慎重になるようプロンプトで促す代わりに、不変条件が満たされるまで前進をブロックする形式的なゲート(型チェック、プロパティテスト、あるいは軽量なモデルチェッカー)を定義するというものです。ストリーム処理におけるバックプレッシャーとの類比は適切です。下流のコンシューマ(統合部分)が無制限に粗悪な出力を吸収するのではなく、出力がコントラクトを満たすまで生成を停止させる上流方向の圧力をかけるということです。著者は実践的な階層化を提案しています。(1) 最初のフィルタとしてコンパイラや型チェッカーによる構文・型ゲート、(2) 第二のゲートとしてユニットレベルのプロパティテスト、(3) オプションとして重要な不変条件に対する軽量な形式仕様チェック、という構成です。これらのチェックは安価で、合成可能であり、原則として言語に依存しないという点がポイントです。この記事は実装の詳細については軽めの扱いで、TLA+やAlloyのチェックを自動コーディングパイプラインに統合する具体的な実例はありません。しかし、アーキテクチャ的な直観は健全です。より深い含意は、エージェントの能力と形式的な正しさを保証するツールは補完的なものであり、代替関係にはないということです。より高性能なエージェントであっても、不変条件違反に対するハードストップから恩恵を受けます。限界としては、このアプローチは不変条件を安価に仕様化できることを前提としていますが、それ自体がしばしば困難な部分であるという点が挙げられます。
Source: https://reubenbrooks.dev/blog/structural-backpressure-beats-smarter-agents/
Stable Audio 3
Stability AIのStable Audio 3論文は、音楽・効果音・音声に対応した高品質な音声生成のためのlatent diffusion modelについて説明しています。このアーキテクチャは、variational autoencoderを用いて生の音声データを連続的なlatent空間に圧縮し、その後T5ファミリーのencoderを介してテキストプロンプトで条件付けしながら、それらのlatentに対してdiffusion transformer(DiT)を学習させます。主要な技術的貢献として、学習済みの時間的圧縮比を持つ1次元latent表現を使用することで、最大3分間の可変長音声生成に対応し、従来のシステムが抱えていた固定長制約を回避している点が挙げられます。本モデルは標準的なDDPMではなくflow matchingで学習されており、これにより推論ステップ数が削減され、同等のNFEバジェットにおけるサンプル品質が向上しています。条件付けは、テキストによる記述のほか、音声ベースのプロンプト(音声の継続によるスタイル転送)にも対応しています。評価にはテキストと音声のアライメントにCLAPスコア、品質評価にFrechet Audio Distance(FAD)が使用され、さらに人手による選好評価も実施されています。報告された結果は、Stable Audio 2と比較した改善を示しており、音楽生成ベンチマークにおいてMusicGenやAudioLDM2と競争力のある性能を達成しています。制限事項としては、長い生成物における時間的一貫性の欠如が散見されること、および細粒度なリズム構造に対する性能低下が挙げられます。コードおよびモデルの重みは、論文公開時点では完全にオープンにはなっていません。
Source: https://arxiv.org/abs/2605.17991
高速フーリエ変換がTransformerと出会う画像復元(2024年)
SFHformer(Spatial-Frequency Hybrid Transformer)は、単一のtransformerブロック内でローカルな空間的attention とグローバルな周波数領域推論を組み合わせることで、デノイズ・デブラリング・デレインといった画像復元タスクを対象としています。動機は明快です。純粋な空間的attentionはシーケンス長に対して二乗のコストがかかり、ウィンドウサイズを大きくしない限り局所的な構造しか捉えられません。一方、純粋な周波数領域手法(例えばFFTベースの畳み込み)はグローバルな周波数インタラクションを効率的に扱えますが、空間的局所性が失われます。SFHformerはこれに対処するため、特徴チャンネルを分割します。一方のブランチは空間パッチに対してウィンドウ化された self-attention を実行し、並列ブランチは2D FFTを適用して、軽量なMLPにより周波数空間でマグニチュードと位相を処理し、逆FFTによって再構成します。二つのブランチはチャンネル連結と学習済み射影によって融合されます。空間ブランチがローカルウィンドウを使用し、FFTブランチが O(N \log N) であることから、空間解像度に対する計算量はほぼ線形に抑えられます。標準的な復元ベンチマーク(GoPro deblurring、SIDD denoising、Rain100L)における結果では、SFHformerは同程度のパラメータ数においてRestormerおよびNAFNetと同等以上の性能を示しています。リポジトリにはトレーニング設定と事前学習済み重みが提供されています。未解決の問題として、境界領域でのウィンドウ化FFTによって生じる高周波エイリアシングアーティファクトに対して性能がどのようにスケールするか、また個別のトレーニングなしに学習済み周波数フィルタリングが異なる劣化タイプに対して汎化するかどうかという点が残されています。
Gemini 3.5 Flash
GoogleはGemini 3.5 Flashをリリースしました。これはGemini 3ファミリーにおけるレイテンシおよびコスト最適化モデルとして位置付けられています。技術的には、より大規模なGeminiモデルからのdistillationと、time-to-first-tokenの短縮およびドル当たりスループットの向上を実現するためのspeculative decodingの組み合わせに重点が置かれています。本モデルは100万トークンのコンテキストウィンドウをサポートしており、これが主要なアーキテクチャ上の特徴です。これにより、大規模なコードベース、法律文書、長尺な動画のトランスクリプトをチャンキングなしに単一コンテキストで処理することが可能になります。引用されているベンチマーク数値としては、「効率重視」の枠(GPT-4o-mini、Claude Haiku)に属する他のモデルと比較して、MMLU、HumanEval、MATHで高い性能を示しています。テキスト、画像、音声、動画のマルチモーダル入力をネイティブにサポートしています。100万トークンのコンテキストは技術的に興味深い点ですが、単純なattentionは二乗オーダーの計算量を必要とします。Googleは使用しているsparseまたはlinear attentionの具体的な実装を公開していませんが、以前のGeminiに関する研究ではring attentionおよびblockwise parallel attentionによる分散コンテキスト拡張が言及されていました。Flashモデルは API のみの提供です。実用上の制限事項としては、「100万トークンをサポートする」ことが、そのコンテキスト全体にわたって検索品質が均一であることを意味しないという点に通常通り注意が必要です。現在のほとんどのアーキテクチャでは、非常に長いコンテキストの中間部分においてempirical needle-in-haystackの性能が低下します。実際の本番環境での採用は、生のベンチマーク数値よりもコスト体系とレート制限によって決まることになるでしょう。
Source: https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-5/
Gemini Omni
Gemini Omni(一部のGoogle公式コミュニケーションではGemini 2.5 OmniまたはOmniケイパビリティティアとして言及される)は、Google DeepMindが開発したネイティブマルチモーダルモデルであり、モダリティ固有の前処理パイプラインを用いることなく、テキスト・画像・音声・動画をインターリーブした形式でエンド・ツー・エンドに処理するよう設計されています。アーキテクチャ上の主要な主張は、すべてのモダリティが共有シーケンスにトークン化され、単一のtransformerによって処理されるという点であり、個別のエンコーダが結合されたheadに入力するlate-fusionアプローチを回避しています。音声入力は、別個のASRシステムを経由させるのではなく、学習済み音声スペクトログラムtokenizerを介して処理されるため、韻律や準言語的特徴が保持されます。動画は、時間的位置encodingを伴うスパースなフレームシーケンスとして処理されます。本モデルはリアルタイムストリーミング入力をサポートしており、そのためにモダリティ境界をまたいだインクリメンタルattentionおよびKV-cacheの管理が必要とされます――これは非自明なシステム上の問題です。公開されているbenchmarkでは、video QA(EgoSchema、Video-MME)および音声理解タスクにおいて優れた性能が示されています。ライブデモでは、音声と動画を同時入力しながら低レイテンシで会話インタラクションが可能であることが強調されています。制限事項として、アーキテクチャの詳細はほとんど公開されていないこと、モデルはopen-weightではないこと、そしてAPI上のリアルタイムストリーミング性能は、負荷がかかった状況下では管理されたデモと大きく異なる可能性があることが挙げられます。
TLA+入門 LLM時代のための:プロンプトで勝利をつかむ
このチュートリアルは、LLMを検証オラクルとしてではなく、TLA+のスキャフォールディングツールとして活用することの実用的な利点を論じています。著者は、GPTクラスのモデルを用いて自然言語の記述から初期TLA+仕様を生成し、TLCモデルチェッカーをグランドトゥルースとして反復的に精緻化していくプロセスを丁寧に解説しています。そのワークフローは、システムを散文で記述し、仕様のドラフトを得て、TLCを実行し、エラートレースをLLMにフィードバックして修正させ、それを繰り返すというものです。核心的な洞察は、LLMがTLA+の構文的に煩雑な部分(ボイラープレート、集合論的表現、stuttering stepの定式化)には概ね対応できる一方で、安全性および活性プロパティの意味論的な正しさについては信頼性が低いという点です。まさにそこにTLCによるハードチェックの価値があります。本記事では、TLA+に必要となる核心的な概念として、初期状態の集合と次状態関係としての状態機械、状態述語としての不変条件、LTLによるテンポラルプロパティ、およびTLCが到達可能な状態空間上のBFSを用いて有界モデル検査を行う方法について解説しています。分散ロックプロトコルの具体的な例も丁寧に解説されています。正直に認められている限界としては、LLMは構文的な型検査を通過しつつも誤ったシステムモデルをエンコードする仕様を日常的に生成してしまうという点が挙げられており、仕様が過小仕様化されている場合には偽陽性のモデル検査通過を引き起こす可能性があります。本記事では、TLCでは処理できない一部のケースに対応できるApalache(シンボリックTLA+チェッカー)については扱っていません。
Source: https://emptysqua.re/blog/intro-to-tla-plus-for-the-llm-era/
AIエージェントによる分散システムのテスト
このリポジトリは、LLMベースのエージェントを用いて分散システムの障害注入と正確性テストを自動化する手法を探求しています。分散システムのテストは手動でのテスト構築にコストがかかり、カバレッジが本質的に不完全になりがちな領域です。このアプローチでは、テスト対象の分散システムを定義済みAPIを通じてアクセス可能なブラックボックスとして扱い、エージェントループを用いて(1)障害モードに関する仮説を生成し、(2)障害注入ハーネスを介してフォールト(ネットワーク分断、ノードクラッシュ、レイテンシ注入)を注入し、(3)指定された不変条件に対してシステムの挙動を観察し、(4)結果に基づいて反復するという手順を踏みます。このコードベースは、既存のカオスエンジニアリングプリミティブ(Chaos MonkeyやJepsenスタイルの注入に類似)を、どのフォールトを組み合わせてシーケンスするかを決定するLLMプランナーでラップしているようです。技術的な関心は状態空間カバレッジの問題にあります。ランダムな障害注入には稀な複数フォールトの相互作用を発見する点で既知の弱点があり、LLMによるガイド付き探索がプロンプトにエンコードされたシステム知識やドキュメントから取得した情報をもとに、より興味深いフォールトの組み合わせを優先的に探索できることが期待されています。制限事項も重大です。エージェントのフォールト選択は形式的な根拠を持たないためカバレッジの保証が存在せず、不変条件がどれだけ正確に指定されるかに大きく依存し、また形式的なスキャフォールディングなしではLLMによる分散システムのセマンティクス(線形化可能性、因果一貫性)に関する推論は信頼性が低いです。このリポジトリは初期段階であり、本番ツールというよりはプルーフオブコンセプトに近いものです。
Source: https://github.com/shenli/distributed-system-testing
注目の新規リポジトリ
ifixai-ai/iFixAi
LLMのalignmentプロパティを評価するための構造化された行動テストスイートです。本ライブラリは、fabrication(捏造)、manipulation(操作)、deception(欺瞞)、unpredictability(予測不能性)、opacity(不透明性)という5つの障害モードカテゴリにわたって32種類の adversarial probe を実行し、結果をレターグレードに集約します。テストランナーはプロバイダー非依存の設計となっており、OpenAI、Anthropic、AWS Bedrock、Azure OpenAI、Gemini向けのアダプターが用意されているため、同一の probe バッテリーをバックエンドを問わず変更なしに適用できます。
技術的に最も興味深い設計上の選択は、content-addressedマニフェストです。各テスト実行は、使用された正確なプロンプト、パラメータ、モデルバージョンのハッシュとともにシリアライズされ、過去の任意の評価をビット単位で同一に再現することが可能です。これは、回帰テストや、証明可能に同一の条件下で2つのモデルを比較する際に重要な意味を持ちます。
グレーディングパイプラインは標準的なAPIティアで5分以内に完了します。個々のテスト結果はカテゴリごとに公開されるため、チームは単一のスカラー値ではなく特定の障害モードにおける回帰を追跡できます。オープンソースとしてリリースされていることで、probe 自体が監査可能となっており、クローズドベンチマークには備わっていない特性です。
実用的なユースケースとしては、モデルバージョンやプロバイダーを切り替える際のalignment回帰を検出するためのCI統合が挙げられます。本ライブラリは包括的であることを主張しておらず、32件のテストはalignment問題空間のごく限られたサンプルに過ぎません。また、公開されている adversarial probe は最適化の対象となり得ます。
Source: https://github.com/ifixai-ai/iFixAi
jmerelnyc/Photo-agents
視覚に根ざしたメモリとランタイムスキル合成を中核に構築された、コンピュータ制御エージェントフレームワークです。エージェントはVLMを通じて画面を読み取り、階層型メモリアーキテクチャ(エピソード履歴、抽出済みファクト、作業コンテキスト)を維持し、未知のタスクに応じて新しいスキルルーティンを記述することができます。これらのスキルは再利用のために保存され、セッションごとに再導出する必要はありません。
階層型メモリ設計がこのフレームワークの中核的な貢献です。短期の作業コンテキストが中期のエピソードストアへと流れ込み、永続的なファクトは長期レイヤーへ昇格されます。これは認知的なメモリ階層を模倣しており、フラットな履歴を持つエージェントが長期的なタスクで直面するコンテキストウィンドウの爆発的な増大を回避します。スキル合成により、エージェントは人間がツールのラッパーを記述することなく新しい機能を自力で獲得できます。GUIのインタラクションを観察し、再利用可能な手順を抽出して、後の検索のためにインデックス付けします。
このフレームワークはデスクトップ自動化を対象としており、ブラウザ制御、ファイル管理、マルチアプリワークフローに対応しています。視覚的なグラウンディングにより、アクセシビリティAPIを必要とせずピクセルレベルの画面状態で動作するため、構造化されたUIツリーを公開していないアプリケーションに対しても堅牢に機能します。自己進化型スキルストアは最もリスクの高いコンポーネントであり、蓄積されたスキルがセッションをまたいでエラーを累積しないよう、検証が必要です。
Source: https://github.com/jmerelnyc/Photo-agents
alash3al/stash
LLMエージェント向けの永続的なメモリバックエンドで、Postgresを基盤とした単一の自己完結型バイナリとして配布されています。Stashはエージェントのメモリを3つの明示的な階層に構造化します:エピソード(タイムスタンプ付きのインタラクションシーケンス)、ファクト(世界やユーザーについて抽出された永続的な信念)、そしてワーキングコンテキスト(セッション内の短期的な状態)です。この3つはすべてModel Context Protocol(MCP)サーバーを通じてクエリ可能であり、MCP互換のエージェントフレームワークであればカスタムの統合コードなしに接続できます。
単一バイナリでのデプロイは、別途ベクターデータベース、オブジェクトストレージ、またはマネージドクラウドサービスを必要とするソリューションと比較して、運用上の大きな利点となります。Postgresが永続化、インデックス作成、およびトランザクション保証を担うため、別途管理すべきembeddingインデックスは存在しません。ただし、セマンティック検索が必要な場合は、スキーマでベクターカラムを利用することも可能です。
MCPインターフェースはread/writeの操作面を標準化しており、エージェントは生のSQLではなく型付きのメモリ操作を呼び出し、サーバー側でスキーマのマイグレーションと整合性を管理します。ファクト抽出とエピソード境界のロジックは、ドメイン固有のチューニングが最も必要になりやすい部分です。デフォルト設定は会話エージェントには機能しますが、複雑な状態を持つ長時間動作するタスクエージェントには調整が必要になる場合があります。
セルフホスト型で外部APIへの依存はなく、MITライセンスです。ベンダーロックインなしにエージェントメモリを実現したいチームにとって、合理的なデフォルト選択肢となります。
Source: https://github.com/alash3al/stash
shenli/distributed-system-testing
分散システムテストシナリオを対象としたエージェントスキル定義のコレクションです。ネットワーク分断の注入、コンセンサス不変条件の検証、レプリケーションラグの確認、マルチノード障害シナリオのオーケストレーションといったタスクのための、再利用可能なtool-callスキーマとpromptテンプレートをパッケージ化しています。こうしたテストは手動でスクリプトを書くと高コストになりがちですが、複数ステップにわたってシステム状態を推論できるエージェントを活用することで効率化できます。
各スキルはOpenAIスタイルのfunction callingをサポートするtool-calling APIと互換性のある構造化フォーマットに従っており、そのフォーマットをサポートするどのエージェントフレームワークにも組み込めます。各スキルは事前条件・実行アクション・事後条件アサーションをカプセル化しており、エージェントがスキルを連鎖させてマルチステップのテスト計画を構築するのに十分なセマンティック構造を提供しています。
実用上の価値は、非形式的なテストアイデア(「リーダー障害後にクラスターが回復することを確認する」など)と実行可能なテストシーケンスとのギャップを縮めることにあります。カスタムのカオススクリプトをゼロから書く代わりに、エージェントがスキルライブラリから構成要素を組み合わせられます。リポジトリはスター数143の初期段階にあり、スキルのカバレッジは現時点では限定的です。コンセンサスとレプリケーションのシナリオは存在しますが、ネットワークトポロジーの操作やストレージ層の障害については手薄な状態です。エージェント支援型カオスエンジニアリングパイプラインを構築するチームにとっての出発点として最も有用です。
Source: https://github.com/shenli/distributed-system-testing
beava-dev/beava
ストリーミング feature store に通常必要とされる Kafka と Flink のパイプラインを排除するために設計された、リアルタイム feature 計算レイヤーです。Beava はライブイベントを処理し、計算済みの feature をクエリ可能なストアに直接マテリアライズします。ストリーミングインフラの運用をチームに要求することなく、プロダクトの意思決定 feature(レコメンデーション、不正シグナル、パーソナライゼーショントリガー)に対してサブ秒のレイテンシを目標としています。
このアーキテクチャが賭けているのは、「ストリーミング」とラベル付けされたユースケースの大半は、実際には low-fanout なイベントから feature への変換であり、分散ログのスループット保証を必要としないという点です。これらをインプロセス、あるいは軽量なイベントバスを通じて処理することで、Beava はブローカー管理、コンシューマーグループの調整、およびステートフルなオペレーターのチェックポインティングという運用上のオーバーヘッドを取り除きます。
Feature の定義はイベントストリームに対する宣言的なルールとして表現され、ランタイムがウィンドウ集計、エンティティルックアップ、および feature サービングを担います。「product reflexes」というフレーミングはレイテンシに敏感なアクションを対象としており、直近 N 件のイベントから計算された feature は、そのイベントをトリガーした同一リクエストサイクル内で読み取り可能であるべきとされています。
主な制限はスケーラビリティです。Kafka を使わない設計は、分散ログが超えるために特化して構築されているスループットの上限までしか機能しません。高カーディナリティのイベントストリームやマルチコンシューマーの fan-out を持つチームはその上限に達するでしょう。厳しいレイテンシ要件を持つ小〜中規模のイベント量に対しては、運用上のフットプリントが大幅に簡素化されます。
Source: https://github.com/beava-dev/beava
lightseekorg/tokenspeed
生のトークン生成速度を競争軸に据えた、高スループットのLLM推論エンジンです。このプロジェクトは推論における遅延のクリティカルパス、すなわちprefillスループット、decodeスループット(tokens/sec)、およびtime-to-first-tokenを主なターゲットとし、これらの指標においてvLLMや類似エンジンを上回ることを明示的な目標としています。
リポジトリの説明から推察すると、このエンジンはcontinuous batching、ページドKV-cacheマネジメント、およびカーネルレベルの最適化(fused attention、量子化matmul)といった、競争力のある推論エンジンに共通の標準的な手法を採用していると考えられます。「speed of light」というフレーミングは、積極的なカーネルフュージョンに加え、speculative decodingやドラフトモデルを用いた高速化の可能性を示唆しています。
vLLMおよびTensorRT-LLMとの差別化要因を評価する上で重要なのは、ベンチマークの方法論です。スループットの数値はバッチサイズ、プロンプト長の分布、およびハードウェア構成に対して非常に敏感であるため、固定されたワークロードに対する再現可能なベンチマークがなければ、性能に関する主張は独立した検証を要します。
このプロジェクトはまだ初期段階にあるものの、1073スターを短期間で獲得しており、コミュニティが既存の推論エンジンのエコシステムに何らかのギャップを感じていることを示唆しています。おそらくデプロイの簡易性や特定のハードウェアターゲットへの対応が評価されているのでしょう。トークンスループットにボトルネックを抱え、vLLMの運用上の複雑さを負担に感じているセルフホスト型推論を大規模に運用するチームにとって、注目に値するプロジェクトです。
Source: https://github.com/lightseekorg/tokenspeed
FrankHui/paragents
並列LLMエージェントインスタンスを統合パネル上で実行するマルチエージェントセッションマネージャーで、エージェント間の権限モデリングおよびpreflight競合検出機能を備えています。本システムが解決しようとするコアな設計上の問題は、複数のエージェントが共有リソース(ファイルシステム、API、データベース)に対して同時並行で動作する際に、レースコンディションや競合する書き込みが発生するという点です。Paragentsはその実行前に調整レイヤーを追加します。
Preflight競合チェックは、各エージェントが実行しようとしているtool callsを検査し、同時に動作している他のエージェントが宣言したリソーススコープと照合することで、競合する操作が実行される前にフラグを立てるかブロックします。これは楽観的並行性制御(optimistic concurrency control)と精神的に類似したアプローチです。つまり、エージェントが意図する書き込みセットを宣言し、スケジューラーが競合するセッションを中断またはシリアライズします。
権限対応ツール(permission-aware tools)により、各エージェントセッションは明示的なケイパビリティの範囲内で動作します。あるエージェントがディレクトリへの読み書きアクセス権を持ち、別のエージェントが読み取り専用アクセスにとどまるといった設定が可能で、非協調的な変更を防ぎます。単一パネルUIはすべてのアクティブなセッション、現在のtool invocations、および競合の警告を一画面に表示するため、通常は不透明なマルチエージェントワークフローのデバッグに役立ちます。
このフレームワークは、複数の特化型エージェント(コード生成、テスト実行、ドキュメント生成など)が同一コードベースに対して同時に動作する開発者向けツールのシナリオに適しています。競合検出は必然的に保守的な設計となっており、アクセスパターンが重複していても実際には競合しないエージェント同士に対して誤検知を生じる場合があります。
Source: https://github.com/FrankHui/paragents
eggbrid2/mobileClaw
自律的な電話操作を実現するAndroidエージェントランタイムであり、VLMベースの画面読み取りとスキルルーティングシステム、およびMihomoベースのVPNワークフロー自動化のサポートを組み合わせています。このランタイムはピクセルレベルで動作し、vision-language modelを用いて画面の状態を解釈した上で、Androidのアクセシビリティ機能またはADBレイヤーを通じてアクション(タップ、スワイプ、テキスト入力)をディスパッチします。
アーキテクチャは、画面理解(スクリーンショットに対するVLM推論)、スキルルーティング(観測された状態を登録済みスキルハンドラに照合)、およびアクション実行の3つに分離されています。ミニアプリはルーティングテーブルに登録可能な軽量タスクモジュールであり、純粋なVLM駆動のアクション選択ではなく専用ロジックによって特定のアプリケーションフローを処理できます。これは柔軟性と信頼性の間における実用的なトレードオフです。
Mihomo VPN統合は最も特異なコンポーネントです。これにより、自動化ワークフローの一部としてプロキシ設定を通じたトラフィックルーティングが可能となり、地理的に制限されたアプリのテストや特定のネットワーク出口を必要とするワークフローの自動化に有用です。
このプロジェクトは、フルデスクトップクラスのエージェントフレームワークと制約のあるAndroid環境との間のギャップを埋めるものです。モバイルデバイス上でのVLM画面読み取りはレイテンシの制約を受けるため、スキルルーティングレイヤーはパフォーマンス上重要な役割を果たします。既知のフローはコストの高いVLM呼び出しをバイパスして直接実行されます。オープンなランタイムモデルにより、コアエージェントロジックを変更することなく、Pythonでカスタムスキルを登録することが可能です。