Daily AI Digest — 2026-05-21
arXiv Highlights
Mega-ASR: Towards In-the-wild^2 Speech Recognition via Scaling up Real-world Acoustic Simulation
Problem
Modern ASR systems — including large audio-language models like Qwen3-ASR and Gemini-3-Pro — degrade sharply on compositional real-world distortions (e.g., far-field speech in a reverberant church with background noise). The failure mode is not just elevated WER: under severe degradation, models lose acoustic grounding and either emit empty hypotheses or hallucinate fluent text unrelated to the source. Existing robustness datasets isolate single phenomena (NOIZEUS: noise only; CHiME-4: noise + far-field; VOiCES: reverb-centric) and saturate at WER 4–10%, which fails to stress the regime where models actually break. The authors target what they call “in-the-wild²” — compositional acoustic conditions where state-of-the-art systems exceed 30% WER.
Voices-in-the-Wild-2M
The dataset is built via spectrogram-level code-based simulation (chosen for tractable scale rather than physical room simulation) over seven atomic acoustic effects: noise, far-field, obstructed, echo&reverb, recording, electronic distortion, transmission dropout. Each atomic effect is a hand-written spectral pipeline whose parameters are iteratively calibrated by SFT-fitting Qwen3-ASR on real-world recordings of that phenomenon and matching its WER curve. The atoms are then composed into 54 agent-validated compound scenarios.

The result is 2.4M clips at average WER 18.42% (Qwen3-ASR baseline ≈35% on the bench split). Coverage relative to prior corpora:
| Dataset | Phenomena covered | Scale | WER |
|---|---|---|---|
| NOIZEUS | noise | 1K | 9.45 |
| CHiME-4 | noise+far | 15K | 5.39 |
| VOiCES | far, E&R, record, distort | 1M | 8.94 |
| BERSt | E&R, record | 4.5K | 22.41 |
| Voices-in-the-wild-2M | all 7 + drop | 2M | 18.42 |
The simulator calibration is validated empirically: SFT on simulated atoms transfers to real test sets per atom (Figure 3, left), and difficulty sampling on NOIZEUS 0dB is rebalanced relative to the natural distribution (Figure 3, right).
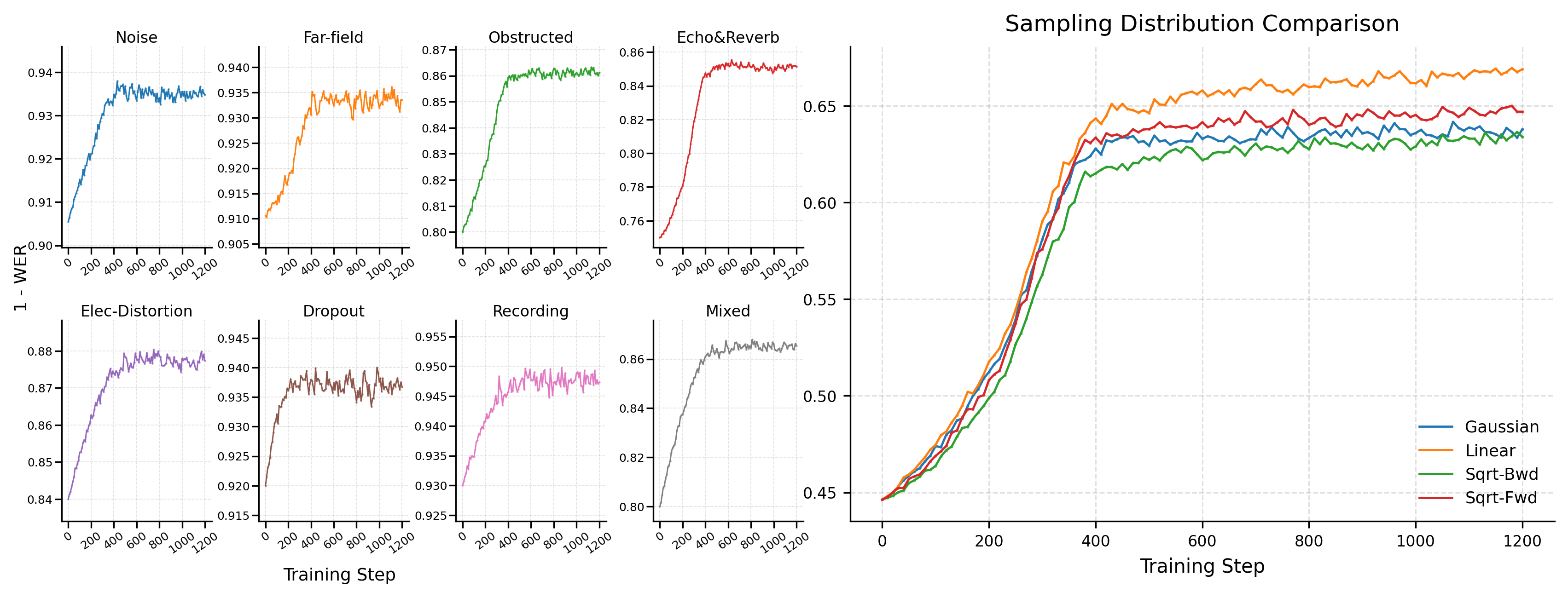
Mega-ASR training pipeline
Built on Qwen3-ASR-1.7B (encoder + aligner + LLM decoder). Two stages.
A2S-SFT (Acoustic-to-Semantic Progressive SFT). The authors diagnose two coupled bottlenecks at medium/high WER: (i) the encoder-aligner cannot extract reliable acoustic evidence from corrupted waveforms; (ii) the LLM cannot exploit its semantic prior when evidence is partially reliable. A2S-SFT proceeds in three phases:
- WER-graded curriculum updating only encoder + aligner, expanding the training pool from \text{WER}<30\% → <50\% → <70\%. This builds acoustic perception incrementally before the LLM is touched.
- LLM-only fine-tuning on the full \text{WER}<70\% pool, activating semantic recovery under unreliable acoustic evidence.
- Joint fine-tuning of encoder, aligner, and LLM for end-to-end alignment.
DG-WGPO (Dual-Granularity WER-Gated Policy Optimization). From the A2S-SFT init, the policy generates k hypotheses scored by a fused token-level + sentence-level WER reward, with the granularity weight gated dynamically to avoid WER-reward failure (sentence-WER alone gives near-uniform low rewards in high-WER regimes, killing gradient signal; token-WER alone over-rewards local matches under hallucination). The fusion is modulated based on the realized WER distribution of the rollouts, supplying useful gradients across the full degradation spectrum.
Results
On adverse-condition benchmarks (vs. prior SOTA, presumably Qwen3-ASR-1.7B):
- VOiCES R4-B-F: 45.69% WER vs. 54.01%.
- NOIZEUS Sta-0: 21.49% vs. 29.34%.
- Compound Voices-in-the-Wild-Bench: >30% relative WER reduction over both open- and closed-source baselines.
The radar in Figure 1 shows that gains on robustness subsets are not paid for on clean speech (LibriSpeech, CommonVoice22, FLEURS, AISHELL-1, WenetSpeech, VoxPopuli) — the dynamic routing LoRA is reported with/without to verify no regression.
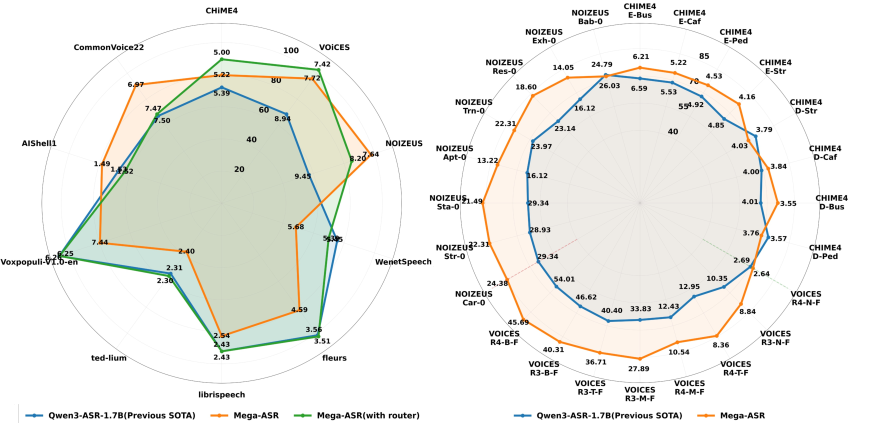
The case study quantifies the qualitative failure mode. On a Peak -5.2 dB far-field clip: Qwen3-ASR returns empty (WER 100.0%), Gemini-3-Pro fabricates a fluent but unrelated hypothesis (WER 86.1%), Mega-ASR matches the reference (WER 0.0%). The pattern repeats under noise and entity-heavy utterances.
Limitations and open questions
- The acoustic simulator operates at the spectrogram level rather than via physical RIR convolution; calibration is anchored to Qwen3-ASR’s WER as the fitness signal, which risks circularity (the simulator is tuned to confuse exactly the model family being evaluated, and may under-represent failure modes invisible to that model).
- 54 compound scenarios are agent-validated, not human-rated for physical plausibility at the per-clip level.
- The “WER-gated” gating function and granularity schedule are not specified in the provided sections; reproducibility hinges on these.
- All gains are reported relative to a 1.7B initialization; whether A2S-SFT + DG-WGPO continues to help at 7B+ scale, where semantic priors are stronger and the acoustic bottleneck dominates more, is open.
- No comparison with dedicated speech enhancement front-ends (e.g., diffusion-based denoisers) feeding a frozen ASR.
Why this matters
This is a concrete recipe for pushing ASR robustness past the saturation point of existing benchmarks: scale compositional acoustic simulation, then train along an acoustic-to-semantic curriculum with a WER-gated RL stage that survives the high-WER regime where naive sentence-WER rewards collapse. The 30%+ relative WER reduction on compound scenarios suggests that the bottleneck is not architectural but data- and optimization-shaped.
Source: https://arxiv.org/abs/2605.19833
OScaR: The Occam’s Razor for Extreme KV Cache Quantization in LLMs and Beyond
Problem
KV cache memory dominates inference cost for long-context and multi-modal LLMs. Per-channel quantization of the Key cache has become standard because Key tensors exhibit channel-wise outliers; sharing scale/zero-point across the token dimension within a channel works well at 4–8 bits but breaks down at INT2. The paper isolates why: a small but consistent subset of tokens has anomalously low \ell_2 norm, inflating the dynamic range that a single per-channel scale must cover. The authors term this Token Norm Imbalance (TNI) and identify it — not channel outliers — as the binding constraint at extreme compression.
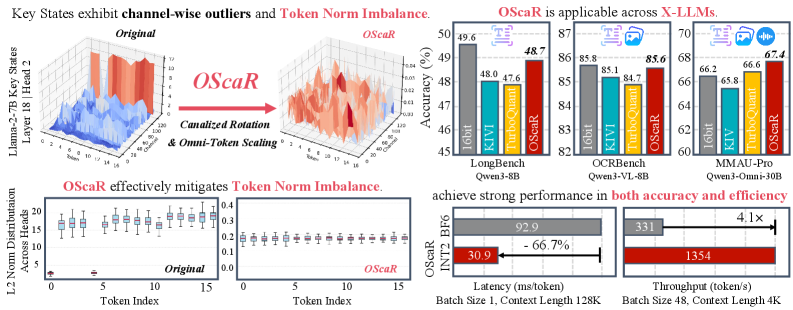
Empirical and theoretical diagnosis
For each token t and head h in state M\in\{Q,K,V\}, they compute
\mathcal{N}_t^{(M)} = \{\|\mathbf{t}_{t,h}^{(M)}\|_2 \mid h=1,\dots,H\}, \quad \|\mathbf{t}_{t,h}^{(M)}\|_2 = \sqrt{\sum_{j=1}^{d_h} (s_{t,h,j}^{(M)})^2}.
Boxplotting \mathcal{N}_t^{(M)} across t on Llama-2-7B reveals a sparse but reproducible set of tokens with very low norms across Q, K, and V simultaneously. These coincide with attention-sink tokens (e.g., the BOS token and a handful of high-frequency early positions), consistent with prior observations that sinks carry small value norms but absorb large attention mass. Because per-channel scales are computed as \Delta_c = (\max_t x_{t,c} - \min_t x_{t,c})/(2^b-1), a single low-norm outlier token along a channel does not shrink the range — but the block of high-norm tokens forces \Delta_c to be large, so quantization of the low-norm tokens loses essentially all signal at b=2.
Multi-modal models compound the problem: norm dispersion is wider, modalities (text vs. image vs. audio) form distinct norm regimes within the same sequence, and additional large-norm outlier tokens appear. A per-channel scale shared across modalities is therefore doubly mismatched.
Method: OScaR
OScaR (Omni-Scaled Canalized Rotation) is a two-step pre-quantization transform applied online during prefill/decoding.
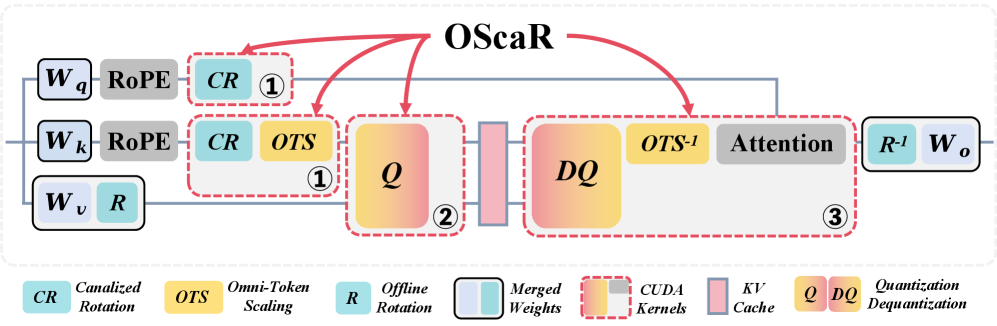
Step 1 — Canalized Rotation. A Hadamard-like orthogonal rotation R is applied along the channel dimension of K (and absorbed into the preceding projection at the cost of a single online matmul for the dynamic part). Unlike QuaRot/RotateKV, which rotate primarily to suppress channel outliers, the rotation here is “canalized” — chosen so that channel-wise variance is homogenized while token-wise norm structure is preserved on a controlled subspace, so that the next step can act on it cleanly. Because R is orthogonal, \|K_t R\|_2 = \|K_t\|_2, so the TNI signature on which Step 2 operates is unchanged.
Step 2 — Omni-Token Scaling. Each token is rescaled by a per-token factor \alpha_t derived from its norm (the paper considers several normalization variants in the ablations); the inverse \alpha_t^{-1} is folded into the attention computation downstream so the operation is mathematically a no-op at full precision. After scaling, the within-channel token magnitudes are compressed into a narrow band, which is exactly the regime where per-channel INT2 quantization is faithful. The combined transform is
\tilde{K}_t = \alpha_t \cdot (K_t R), \qquad \mathrm{Quant}_{\text{per-ch}}(\tilde{K}) \to \hat{K},
with attention scores recovered as \mathrm{softmax}(Q (R^\top \mathrm{diag}(\alpha)^{-1} \hat{K}^\top)/\sqrt{d}). Because R is Hadamard and \alpha is diagonal, both can be fused into existing kernels; the authors provide CUDA implementations.
The “Omni-” refers to the same scaling rule applying across modalities, which is critical for multi-modal LLMs where naive per-channel scales straddle text/image/audio token clusters.
Results
On LongBench-E at INT2 with group size 32 (TurboQuant+ uses 2.5-bit, a more lenient budget):
- Llama-3.1-8B: OScaR averages 41.75, matching the FP16 baseline (41.70) and beating KIVI (39.84), OTT (40.74), TurboQuant+ (40.03), QuaRot (37.94), and RotateKV (37.98). Notable per-task gains: GovReport 29.45 vs. KIVI’s 24.41; MultiNews 5.68 vs. KIVI’s 2.70; PassageRetrieval 44.46 vs. FP16’s 43.57.
- Qwen3-8B: OScaR averages 48.74 vs. FP16 49.56, with the next-best INT2 method (OTT) at 48.21 and QuaRot collapsing to 40.13 (TREC drops to 33.00 under QuaRot vs. 72.00 for OScaR — an indicator that rotation-only methods damage the sink-token structure that some tasks rely on).
The gap to FP16 is under 1 point on both models at INT2, which is unusual at this bit-width. The authors also report results on OCRBench/DocVQA for multi-modal models and MMAU-Pro for Qwen3-Omni-30B-A3B, plus efficiency measurements (decoding speedup, throughput) in Section 5.3 and the appendix.
Limitations and open questions
The paper does not, in the provided sections, report INT1 or sub-2-bit results, so it is unclear whether Omni-Token Scaling is sufficient when even the per-channel band cannot be resolved at all. The per-token scale \alpha_t adds a small per-token state that must be cached alongside \hat{K}; the net memory accounting versus 2.5-bit baselines deserves scrutiny when group size is small. The choice of normalization for \alpha_t is decided empirically via ablation rather than from a closed-form error bound, and the rotation is Hadamard rather than learned — both leave room for principled treatment. Finally, attention-sink tokens are themselves a fragile artifact of pretraining; a model trained with sink-suppression techniques may exhibit a different TNI profile and require re-tuning.
Why this matters
TNI reframes the bottleneck of extreme KV quantization from a channel-outlier problem (the framing behind QuaRot, KIVI, RotateKV) to a token-norm problem, and the fix is essentially a diagonal rescale plus a Hadamard rotation — cheap enough to deploy. Recovering near-FP16 LongBench scores at INT2 with group 32 closes most of the remaining gap to lossless KV compression for long-context inference.
Source: https://arxiv.org/abs/2605.19660
You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories
Problem
RLVR (reinforcement learning with verifiable rewards, e.g. GRPO on math) has become the standard recipe for boosting reasoning in LLMs, but it is expensive: hundreds of optimization steps over rollouts of a 1.5B–8B parameter model with verifier-driven advantage estimation. The authors ask a structural question: what is the geometry of the parameter trajectory \{\theta_t\}_{t=0}^{T} produced by RLVR, and is it predictable enough that most of the trajectory can be skipped? The answer they give is a strong one: the per-tensor weight delta trajectory is essentially rank-1 with a near-linear scalar coefficient, so future checkpoints can be linearly extrapolated from a short prefix without any further training.
Method
For each tensor in the network, define the delta trajectory \Delta\theta_t = \theta_t - \theta_0, \quad t=1,\dots,T_{\text{obs}}. Stack the (vectorized) deltas observed up to a cutoff step T_{\text{cut}} into a matrix M \in \mathbb{R}^{T_{\text{cut}} \times d} and take its SVD M = U\Sigma V^\top. The first right singular vector \mathbf{v}_1 defines the dominant update direction; the per-step scalar coefficient is the projection c_t = \langle \Delta\theta_t, \mathbf{v}_1 \rangle.
Two empirical findings drive the method. First, replacing each tensor’s full delta with its rank-1 approximation c_t \mathbf{v}_1 preserves essentially all downstream gain on MATH across all three models tested.
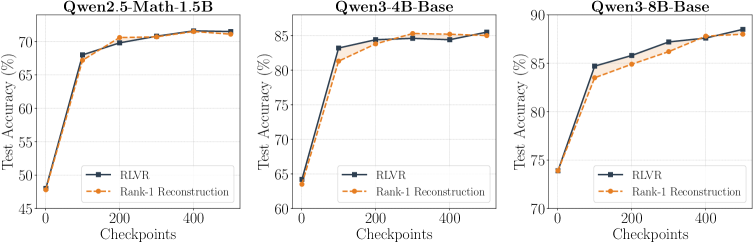
Second, c_t evolves nearly linearly in t: a least-squares fit c(t) = a t + b attains R^2 > 0.98 on most tensors of Qwen2.5-Math-1.5B.
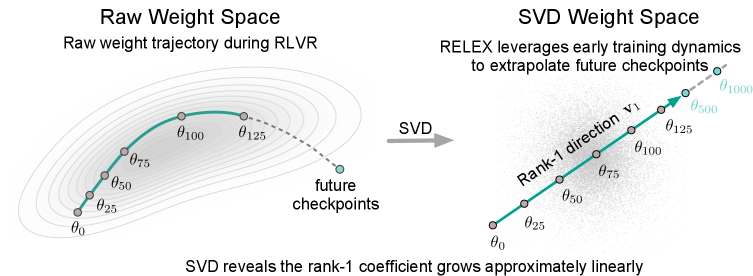
These two facts collapse RLVR checkpoint prediction into a two-step procedure (RELEX):
- Run RLVR for a short prefix of T_{\text{cut}} steps (e.g. 75 or 125 out of 500). Compute per-tensor \mathbf{v}_1 from SVD of the observed delta matrix.
- Project the observed deltas onto \mathbf{v}_1 to obtain \{c_t\}, fit c(t)=at+b, and form the predicted checkpoint at any future step T as \hat{\theta}_T = \theta_0 + (a T + b)\,\mathbf{v}_1 applied per tensor.
No learned model, no additional rollouts, no verifier calls beyond T_{\text{cut}}. The cost above the prefix RL run is one truncated SVD per tensor and a scalar linear regression.
Results
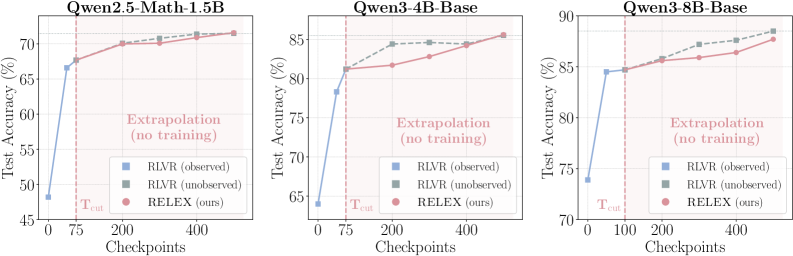
The teaser figure summarizes the headline claim: extrapolated checkpoints match or exceed the corresponding RLVR checkpoints on MATH across Qwen2.5-Math-1.5B, Qwen3-4B-Base, and Qwen3-8B-Base, using only the first ~15% of RLVR steps.
Concrete points from the paper:
- All three models are trained with GRPO on MATH for 500 steps until plateau, with per-step checkpoints. RELEX uses prefixes as short as T_{\text{cut}}=75 (15% of training).
- The rank-1 reconstruction of the full 500-step trajectory itself essentially preserves the MATH accuracy gain over the base model, establishing that the rank-1 subspace captures the task-relevant component of RLVR updates rather than only a coarse approximation.
- The linear fit of c_t achieves R^2 > 0.98 across most tensors, justifying linear (rather than higher-order) temporal extrapolation.
- RELEX extrapolates well past the observation window, predicting checkpoints up to step 1000 (twice the trained horizon) at no additional training cost, and the resulting weights match or exceed RLVR on both in-domain MATH and OOD benchmarks: AIME 2025, AIME 2026, HMMT 2025, OlympiadBench, AMC 2023.
The implication is that GRPO on these math distributions is, in weight space, doing something close to following a single direction at constant velocity per tensor; the curved appearance of the raw trajectory is dominated by orthogonal noise components that are not task-relevant.
Limitations and open questions
- The evidence is restricted to GRPO on MATH with three Qwen-family base models. It is unclear whether the rank-1 + linear structure persists for RL on code, agentic tool use, multi-task verifier mixes, or RL after long SFT/RLHF chains where the optimization landscape is different.
- “Rank-1 captures most performance” is measured on accuracy, not on the policy distribution; KL to the RLVR policy, calibration, and rare-token behavior under rank-1 reconstruction are not characterized here.
- Linearity of c_t presumably breaks once the policy approaches the verifier ceiling. RELEX’s success “up to step 1000” likely depends on the reward already being saturated; extrapolating into a regime where the true RL trajectory turns sharply would fail.
- The decomposition is per-tensor and does not address cross-tensor coupling. It is also silent on whether \mathbf{v}_1 is interpretable (e.g. aligned with specific attention heads or MLP neurons).
- A natural follow-up is to use the discovered \mathbf{v}_1 as a preconditioner or constraint inside the RL optimizer itself, rather than only as a post-hoc extrapolant.
Why this matters
If RLVR fine-tuning trajectories are this low-rank and this linear, then most of the GRPO compute spent on these benchmarks is redundant: a short prefix plus an SVD recovers the endpoint. This both gives a cheap practical recipe (run 15% of the steps, extrapolate the rest) and suggests that current RLVR on math is not exploiting the high-dimensional capacity of the model — a quantitative target for designing harder RL objectives or richer reward signals.
Source: https://arxiv.org/abs/2605.21468
HRM-Text: Efficient Pretraining Beyond Scaling
Problem
Standard LLM pretraining couples scale of compute with scale of raw web text. HRM-Text asks whether a fundamentally different inductive bias — multi-timescale recurrence — combined with a task-completion objective on instruction data can produce a competitive 1B-parameter model on a $1{,}500 budget and 40B unique tokens. The motivating analogy is the frontoparietal loop: slow strategic control modulating fast execution. The technical question is whether this can be made to train stably for language modeling and whether it actually wins under matched FLOPs.
Method
The backbone is a Hierarchical Recurrent Model with two coupled modules H (slow) and L (fast). A forward pass starts from z_H^0 derived from token embeddings and a fixed z_L^0. Each outer cycle runs three L updates followed by one H update; the reported 1B configuration is H2L3, giving 2 \times (3+1) = 8 module steps, equivalent to 4 recursions of the full core (since H and L each hold half the non-embedding parameters). A linear head reads from the final H state.
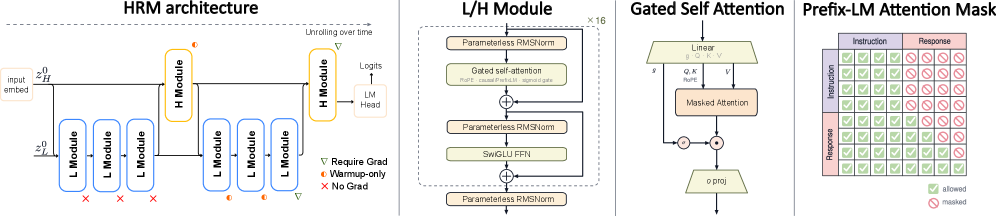
Two stabilization mechanisms make deep recurrence trainable on language:
MagicNorm. PreNorm preserves an identity path h_L = h_0 + \sum_l \text{Sublayer}(\cdot) but lets variance grow with depth; PostNorm bounds variance but breaks the identity path. Recurrence amplifies both failure modes because the same transformation is iterated. MagicNorm wraps a stack of internal PreNorm blocks with a single closing norm at the module exit: z_n = \text{Norm}\!\left(z_{n-1} + \sum_{l=1}^{L} \text{Sublayer}_l(\text{Norm}(\cdot))\right). This exploits the asymmetry between the forward horizon N and the truncated backward horizon K \ll N: variance is rebounded at each recurrent exit while gradients during the short backward window still see a clean residual path.
Warmup deep credit assignment. TBPTT initially backpropagates through only the last two recurrent steps, expanding to the last five over training. This curriculum on K is what lets a model with effectively 8 module applications per token train without divergence.
Other components are standard but stripped down: parameterless RMSNorm (no learnable \gamma), SwiGLU, RoPE, and sigmoid-gated multi-head attention.
The pretraining objective is task completion rather than full causal LM. Instruction–response pairs (x_q, x_a) are concatenated, NLL is computed only on the response, -\log P(x_a \mid x_q), and a PrefixLM mask gives bidirectional attention over x_q and causal attention over x_a. Condition tags (direct, cot, synth, noisy) are prepended to control output style; text inside <think>...</think> is stripped before training to prevent the model from leaning on RLVR-style explicit CoT and force computation into the recurrence.
The corpus is 176.5B tokens of open instruction data (FLAN, Tasksource, SYNTH-rewritten Wikipedia, OpenMathInstruct2, NuminaMath, DMMath, Sudoku-Extreme, etc.). SeqIO-style stratified sampling caps large sources (e.g., 5k docs/task in FLAN, 10M in SYNTH) and upsamples small ones 10\times, yielding 40B unique tokens trained for 60B total.
Results
The headline numbers for HRM-Text 1B trained on 40B unique tokens: 60.7 MMLU, 81.9 ARC-C, 82.2 DROP, 84.5 GSM8K, 56.2 MATH, 63.4 HellaSwag, 72.4 Winogrande, 86.2 BoolQ. Training ran 1.9 days on 16 GPUs, claimed at roughly 96–432\times less compute and 100–900\times fewer tokens than 2–7B open foundation models with comparable scores.
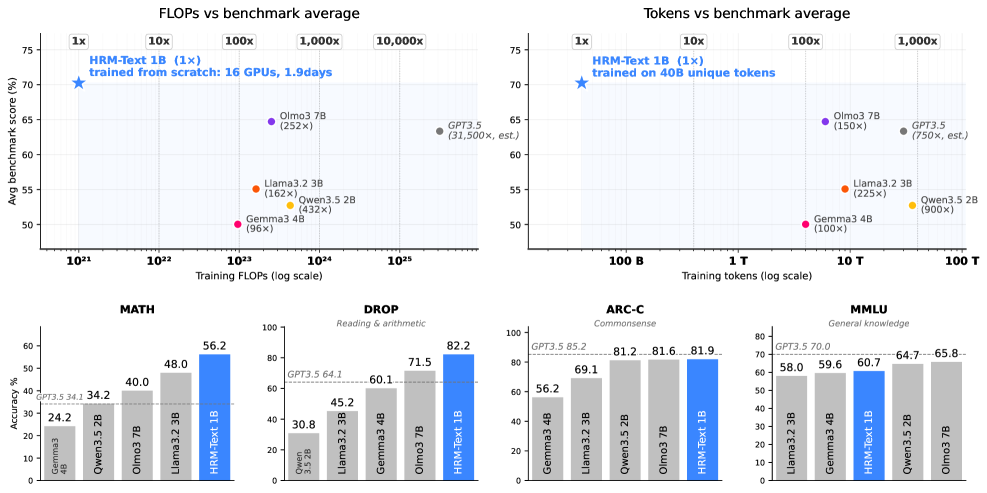
Under matched training FLOPs (1.0–1.1 \times 10^{21}), HRM 1B (H2L3) beats every alternative tested: vs. Looped Transformer 1B at 4 recursions (MMLU 56.5, GSM8K 75.1, MATH 48.3), RINS 1B with r=7 (56.1 / 77.7 / 48.9), a 1B Transformer at 0.17T tokens (53.2 / 75.1 / 48.4), a 3B deep Transformer (56.7 / 75.7 / 50.5), and a 3B wide Transformer (54.5 / 73.0 / 49.7). The deeper-Transformer baseline is the closest, which suggests HRM’s gain is partly an effective-depth gain that ordinary depth scaling does not fully capture under this token budget.
The hierarchical-vs-shared-recurrence ablation is more pointed. TRM 1B (H2L1) trains unstably and lands at MMLU 46.4, ARC-C 56.7, GSM8K 67.6. At 0.6B with the same H2L3 schedule, HRM and TRM tie (MMLU 56.87 vs. 56.88), but at 1B only the hierarchical, parameter-distinct H/L variant remains stable. Dual timescales appear necessary at scale; shared parameters are not enough.
The objective ablation shows response-only NLL with PrefixLM lowers response-token loss versus full causal LM and increases layerwise attention entropy on the prompt, consistent with broader prompt utilization rather than memorizing prefix continuations.
Limitations
The comparison is tilted: HRM-Text is trained on a heavily curated instruction/math mixture with explicit CoT removed, while the open-model baselines were trained on raw web text and then post-trained. Calling this “pretraining” is a definitional stretch — it is closer to scratch-trained instruction tuning. MMLU and GSM8K are also vulnerable to contamination from sources like OpenMathInstruct2 and NuminaMath; the paper does not report decontamination. The recurrence depth used (4) is modest, and scaling laws for HRM under MagicNorm are not characterized. Finally, single-checkpoint reporting and absent perplexity on held-out web text leave open whether the model retains general language modeling capability beyond the task distribution.
Why this matters
If the result holds under stricter contamination control, it is an existence proof that effective depth via hierarchical recurrence plus a response-conditioned objective can substitute for one-to-two orders of magnitude of pretraining tokens and compute. That reframes the compute/data frontier for academic-scale foundational research and makes architecture and objective design first-class variables again, not afterthoughts to scaling.
Source: https://arxiv.org/abs/2605.20613
The Unlearnability Phenomenon in RLVR for Language Models
Problem
RLVR with GRPO has become the standard recipe for eliciting reasoning in LLMs, but its learning dynamics at the example level are poorly understood. The authors document a sharp, reproducible phenomenon: among the “hard” examples a base model initially fails on, a substantial subset remains unlearnable under GRPO even when the policy occasionally produces correct rollouts. This is not a long-tail rounding error — it bounds what RLVR can achieve regardless of compute, and it cannot be papered over by the usual tricks (oversampling, replay, KL/clip tuning).
Setup and definitions
The base algorithm is GRPO with dynamic sampling. For each prompt x with verifiable answer y^*, k rollouts are sampled, rewarded with \mathbb{1}[y_i=y^*], and standardized to advantages
\hat{A}_i = \frac{\mathbb{1}[y_i=y^*] - \mathrm{mean}(\cdot)}{\mathrm{std}(\cdot)},
and optimized via the clipped PPO surrogate with a KL penalty against \pi_{\text{ref}}. Prompts with zero reward variance are filtered each step. The authors split the training set into a learnable group \mathcal{D}_l and an unlearnable group \mathcal{D}_u based on whether reward improves over training. The main analysis uses Qwen2.5-0.5B on MATH Easy and Llama-3.2-3B-Instruct on MATH Hard.
Ruling out the obvious explanations
Positive-rollout scarcity. Hypothesis 1: \mathcal{D}_u fails because too few rollouts are correct in any given batch. They test this with a strong oversampling-with-replay scheme (Algorithm 1): sample 4k rollouts, downsample to k such that exactly k_{\text{pos}}=1 is positive and k-1=7 are negative, replaying buffered correct rollouts (each at most twice) when fresh ones are insufficient. This forcibly equalizes the positive/negative composition between \mathcal{D}_l and \mathcal{D}_u.
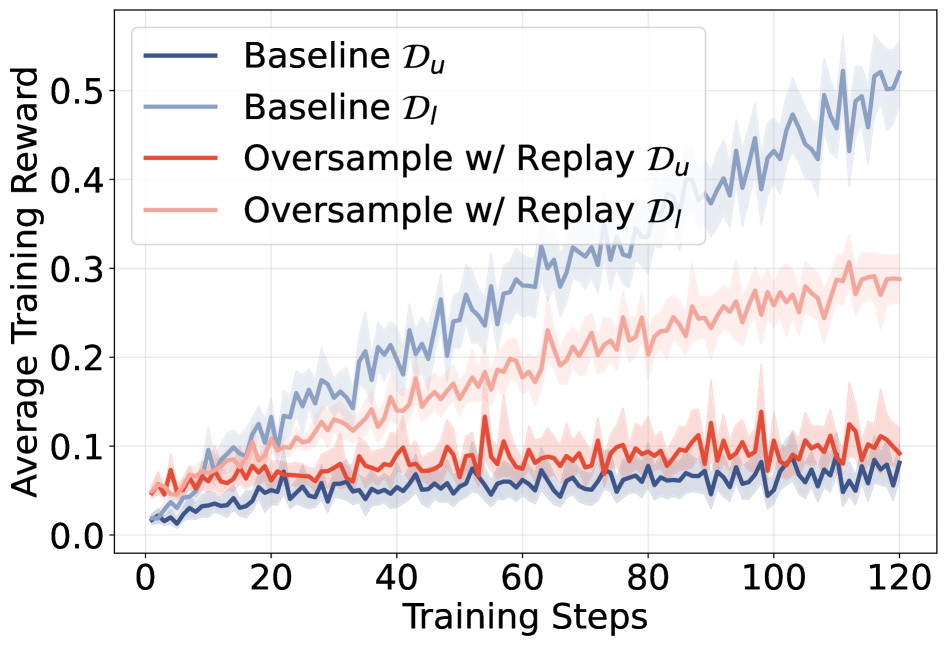
The reward gap between \mathcal{D}_l and \mathcal{D}_u persists essentially unchanged. The intervention does lift unlearnable rewards modestly in early steps but the asymptotic gap is preserved, falsifying Hypothesis 1.
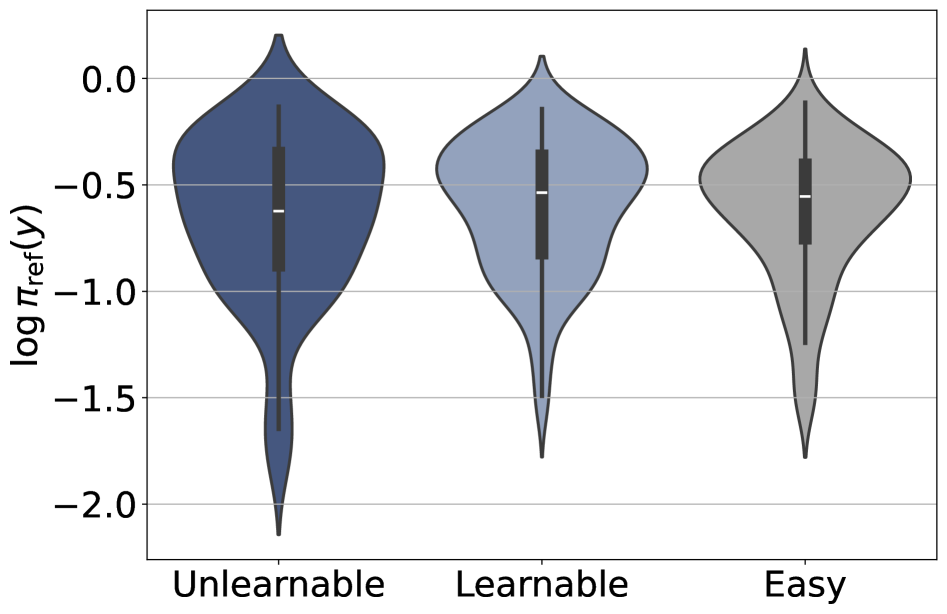
Optimization regularizers. Two candidates: KL penalty suppressing low-likelihood correct rollouts, and PPO clipping zeroing their gradient. The reference log-likelihood distribution of correct rollouts on \mathcal{D}_u overlaps the distribution on \mathcal{D}_l — unlearnable examples are not systematically off-manifold under \pi_{\text{ref}}.
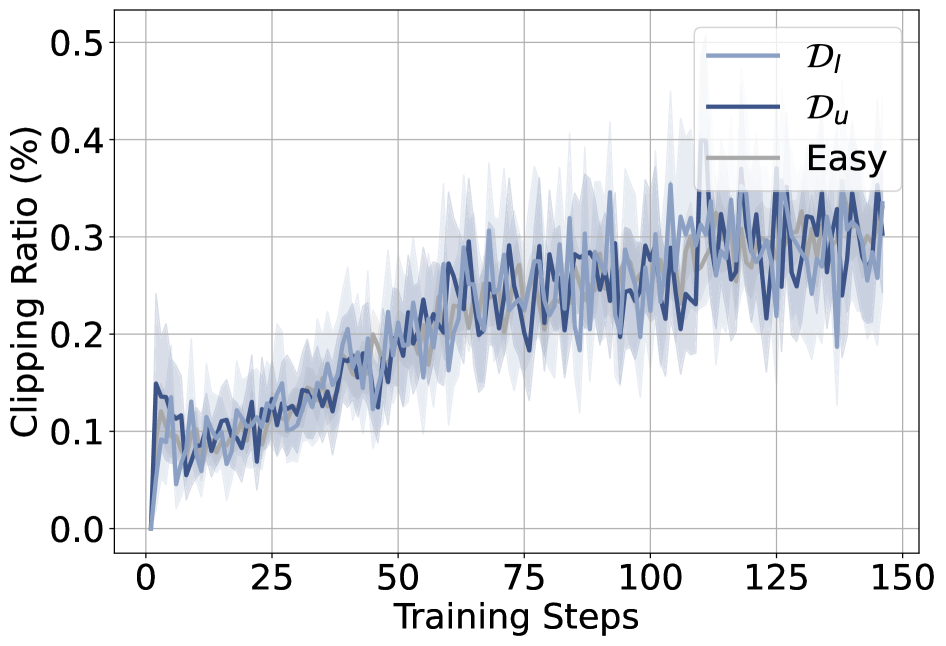
Clipping ratios across the three groups (learnable, unlearnable, easy) are also nearly identical, so clipping is not selectively muting \mathcal{D}_u updates.
Unlearnability as a representation pathology
With the optimization-side explanations excluded, the authors turn to gradient geometry. For 100 examples per group, they sample 1000 rollouts each from the initial policy, keep only correct rollouts, and compute the per-example GRPO gradient — averaging over tokens within a response, then over responses. To make this tractable they attach a fixed, randomly initialized LoRA adapter and differentiate only through its parameters; on the 0.5B model the LoRA-based gradient similarities track full-parameter similarities closely. Pairwise cosine similarities are then compared within and across groups.
The finding: unlearnable examples are gradient outliers. Their correct-rollout gradients have low cosine similarity with the gradients of other examples, including other unlearnable ones. Learnable examples form a coherent cluster whose gradients reinforce each other; unlearnable examples sit off-axis, so updates from the rest of the batch do not transfer to them, and their own (rare, correct) updates do not generalize back. Concretely, this means that even when the policy stumbles onto a correct chain-of-thought, the reasoning pattern encoded in that rollout is idiosyncratic — it does not share representational structure with the patterns the model is concurrently consolidating from \mathcal{D}_l. Inspection of the “correct” rollouts on \mathcal{D}_u corroborates this: they often reach y^* via shortcuts or non-generalizable chains rather than via reasoning the model can compress.
The authors further show that data augmentation (e.g., paraphrases, alternative solution traces) does not raise the gradient similarity of \mathcal{D}_u with the rest of the data, so the issue is not surface-form variance but a deeper representational mismatch between the example and the policy’s current feature geometry. Within RLVR’s gradient-only feedback, there is no mechanism to repair this mismatch.
Limitations and open questions
The gradient analysis depends on a fixed random LoRA as a low-dimensional probe; the correlation with full-parameter gradients is reported only for the 0.5B model and may degrade at scale. The split into \mathcal{D}_l/\mathcal{D}_u is operationally defined by training-time reward trajectories rather than by an a priori property of (x,y^*), which complicates predicting unlearnability before training. Finally, the paper diagnoses but does not fix the phenomenon: whether SFT on curated rationales, mid-training representation surgery, or off-policy distillation can convert \mathcal{D}_u examples into learnable ones is left open.
Why this matters
The result reframes RLVR’s ceiling: it is not bounded only by rollout sampling efficiency or KL/clip hyperparameters but by a representational compatibility constraint between examples and the base model. Scaling rollouts or replay buffers will not close this gap; meaningful progress on hard reasoning likely requires interventions that change the representation, not the RL objective.
Source: https://arxiv.org/abs/2605.16787
Video2GUI: Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining
Problem
GUI agents built on multimodal LLMs are bottlenecked by training data. Existing trajectory datasets (e.g., from screen recording farms or human annotators) are expensive, narrow in application coverage, and rarely exceed the 10^5–10^6 trajectory range. The result is poor generalization: agents trained on a handful of office suites or e-commerce sites fail on long-tail desktop and web applications. The paper’s claim is that the open web already contains a vast supply of grounded GUI demonstrations — tutorial and walkthrough videos — and that a sufficiently selective extraction pipeline can mine them at internet scale without human labels.
Method
Video2GUI is a coarse-to-fine filtering and conversion pipeline that ingests unlabeled video metadata and emits structured agent trajectories of the form \tau = \{(s_t, a_t)\}_{t=1}^T, where s_t is a screenshot-like frame and a_t \in \mathcal{A} is a grounded action (click, type, scroll, drag, key) with pixel coordinates or text payloads.
The pipeline has four stages:
Metadata filtering. Starting from 500M video metadata entries, lightweight classifiers over titles, descriptions, tags, and channel features select candidates likely to be GUI tutorials. This eliminates the bulk of irrelevant content (vlogs, gaming, music) before any frame is decoded.
Visual filtering. Remaining candidates are sampled at low frame rate and passed through a GUI-vs-natural-image classifier that checks for the visual statistics of desktop/web UIs (rectilinear layouts, text density, cursor presence, window chrome). Videos failing a UI-frame fraction threshold are discarded. A second pass detects and removes face-cam overlays, talking-head intros, and slide-only tutorials.
Trajectory extraction. For surviving videos, the system performs:
- Cursor tracking to localize interaction points across frames.
- Event segmentation by detecting visual deltas around the cursor (click flashes, focus rings, modal pop-ups, text caret appearance) to infer action boundaries.
- Action typing via a small VLM that classifies the segment into \{click, double-click, right-click, type, scroll, drag, hotkey\} and extracts text payloads via OCR for typing actions.
- Grounding by snapping the action coordinate to the nearest UI element bounding box recovered from a UI parser, yielding (x, y, \text{element\_id}) tuples.
Quality scoring and instruction synthesis. Each trajectory is scored for visual stability, action-segmentation confidence, and OCR consistency. A captioning VLM produces a high-level task instruction g (and per-step rationales) conditioned on the trajectory, giving supervised tuples (g, \{(s_t, a_t)\}) usable for both grounding pretraining (predict a_t’s coordinates given s_t and a referring expression) and full action-prediction pretraining (predict a_t given g, s_{1:t}, a_{1:t-1}).
Applied at scale, this yields WildGUI: 12M trajectories spanning >1,500 applications and websites — roughly an order of magnitude more breadth than prior public corpora, and with a long tail of professional software (CAD, DAWs, IDEs, scientific tools) that manual collection rarely reaches.
Pretraining and results
Qwen2.5-VL and MiMo-VL are continued-pretrained on WildGUI with a mixture of grounding and action-prediction objectives, then evaluated on standard GUI benchmarks (grounding tasks measuring click-accuracy on referring expressions, and action benchmarks measuring step-level accuracy on agent trajectories).
Reported gains are 5–20% absolute across grounding and action benchmarks, with the pretrained models matching or surpassing state-of-the-art baselines that use comparable backbone sizes. The breadth of the gain across both backbones suggests the improvement is data-driven rather than backbone-specific, and the magnitude of the improvement on action benchmarks (typically harder than pure grounding) indicates the extracted trajectories carry useful procedural structure, not just element-localization signal.
Limitations and open questions
- Action fidelity. Cursor-trajectory inference cannot recover hidden state: keyboard shortcuts without visual feedback, copy/paste, and clipboard-mediated actions are systematically under-detected. Drag distinctions vs. selection are noisy.
- Tutorial bias. Tutorial videos depict idealized happy paths. The dataset is unlikely to contain error-recovery trajectories, which are exactly what RL-style fine-tuning would benefit from.
- OCR-dependent typing labels. Typed text is reconstructed from on-screen rendering, so passwords, IME composition, and partial-string entry are unreliable.
- Resolution and aspect-ratio mismatch. Videos are re-encoded at varying resolutions; coordinates are normalized, but small UI targets (toolbar icons) suffer label noise.
- No interactive verification. Unlike trajectories collected in a live environment, there is no way to replay and validate that a_t actually transitions s_t \to s_{t+1}. The paper does not report a held-out replay-success metric.
- Licensing. The release plan covers the dataset and pipeline; the legal status of derived screenshots from third-party tutorial videos is not discussed in the abstract.
The natural follow-up is to combine WildGUI pretraining with smaller, environment-grounded RL fine-tuning to compensate for the happy-path bias.
Why this matters
GUI agents have been data-starved in the same way early vision models were before ImageNet — and Video2GUI is a plausible “scrape the web” inflection point, converting an existing 500M-video signal into 12M grounded trajectories without annotators. If the 5–20% gains hold up under independent evaluation and replay verification, breadth-of-applications pretraining (rather than larger backbones) is the near-term lever for general-purpose computer-use agents.
Source: https://arxiv.org/abs/2605.14747
Uni-Edit: Intelligent Editing Is A General Task For Unified Model Tuning
Problem
Unified Multimodal Models (UMMs) — single architectures intended to subsume image understanding, generation, and editing — are typically trained via heterogeneous task mixtures. The dominant recipe is multi-stage curriculum training over disjoint corpora (VQA + captioning for understanding, T2I pairs for generation, instruction–edit triplets for editing), with carefully tuned mixing ratios and loss reweighting. Empirically, this yields a Pareto trade-off rather than synergy: gains on generation tend to erode VQA accuracy, and editing finetuning frequently degrades both. The underlying reason is task conflict — the gradients from “predict next token given image” and “denoise pixels conditioned on text” point in different directions in shared parameters, and editing is treated as a third, separate objective rather than as a structural bridge.
Uni-Edit reframes the question: is there a single task whose optimal solution requires all three abilities simultaneously, so that one training stage on one dataset improves all three? The authors argue image editing is exactly that task — but only if the editing instructions are difficult enough to actually exercise understanding.
Method
The proposal has two components: (1) a claim that intelligent editing is a universal task for UMM tuning, and (2) a data synthesis pipeline that produces such instructions at scale.
Why editing is the right general task. A standard editing example is a triplet (I_{\text{src}}, c, I_{\text{tgt}}) where c is an instruction and the model minimizes a generative loss on I_{\text{tgt}} conditioned on (I_{\text{src}}, c). If c is simple (e.g., “make the sky blue”), the conditioning collapses to a localized texture/color transform — understanding is barely invoked. The fix is to make c encode a question about I_{\text{src}} whose answer is required to determine the edit. Concretely, instructions are constructed with embedded questions and nested logic: “replace the object the woman is holding with a [color matching her shoes] version of it.” Solving this forces the model to (i) parse the scene, (ii) identify referents, (iii) reason over attributes, and (iv) synthesize a coherent target — i.e., to use understanding circuits to drive generation circuits within a single forward/backward pass.
Data synthesis pipeline. Existing editing datasets (InstructPix2Pix, MagicBrush, UltraEdit, etc.) use simple instructions, so the authors build the first automated pipeline that converts VQA data into intelligent editing pairs. The pipeline takes (I, q, a) from VQA sources and:
- Uses the question q and answer a to identify a grounded entity or attribute in I that the question pivots on.
- Generates an edit specification whose execution depends on a — e.g., the question “what color is the umbrella?” with answer “red” becomes the edit “swap the umbrella with one of the complementary color of its current color.”
- Synthesizes the target image I_{\text{tgt}} using an off-the-shelf editor/generator and verifies via a VLM that (a) the prescribed change is present and (b) unrelated regions are preserved.
- Optionally composes multiple VQA-derived predicates into a single nested instruction, increasing reasoning depth.
The resulting corpus, Uni-Edit-148k, contains 148k triplets where each instruction has non-trivial semantic dependence on I_{\text{src}}.
Training. A UMM is trained on Uni-Edit-148k with a single editing objective — there is no separate VQA loss, no separate T2I loss, no curriculum. Letting \theta denote the unified model parameters and \mathcal{L}_{\text{edit}} the standard conditional generation loss on I_{\text{tgt}}:
\mathcal{L}(\theta) = \mathbb{E}_{(I_{\text{src}}, c, I_{\text{tgt}}) \sim \mathcal{D}_{\text{Uni-Edit}}} \big[ \mathcal{L}_{\text{edit}}(\theta; I_{\text{src}}, c, I_{\text{tgt}}) \big].
The claim is that because c encodes VQA-style reasoning and I_{\text{tgt}} encodes generation, gradients from \mathcal{L}_{\text{edit}} alone propagate signal into both subsystems, eliminating the inter-task interference that plagues mixed schedules.
Results
The headline empirical claim is that one task, one stage, one dataset jointly improves understanding, generation, and editing. Reported gains over mixed-training baselines hold across standard benchmarks for each capability (VQA suites for understanding, T2I benchmarks for generation, editing benchmarks for editing). Crucially, the understanding score does not regress after editing finetuning — the failure mode of nearly all prior unified-tuning recipes — and instead improves, consistent with the hypothesis that intelligent editing is a strict superset of VQA in terms of required reasoning. Generation quality also improves, which the authors attribute to the model learning to ground synthesized pixels in fine-grained scene semantics rather than in instruction surface form.
Limitations and open questions
The approach inherits the quality ceiling of its synthesis pipeline: target images are produced by existing editors, so artifacts and label noise propagate. Verification with a VLM filters but does not eliminate this. The 148k scale is modest relative to mixed-training corpora; whether the single-task recipe continues to dominate at multi-million scale, or whether mixed training catches up, is unresolved. The framework also assumes the base UMM already has reasonable T2I and VQA priors — pure-from-scratch training on Uni-Edit alone is unlikely to bootstrap either capability. Finally, “intelligent” is operationalized via embedded questions and nested logic; a more formal characterization of instruction difficulty (e.g., reasoning-step count, referent ambiguity) and its scaling with downstream capability gain would sharpen the contribution.
Why this matters
If a single, sufficiently rich task can replace multi-stage mixed training for unified models, the engineering surface of UMM development shrinks dramatically — no mixing ratios, no stage schedules, no per-task data curation. The broader principle, that capabilities should be co-trained via tasks that require them jointly rather than balanced via tasks that exercise them separately, is likely to generalize beyond vision to any unified-model setting where task interference currently caps performance.
Source: https://arxiv.org/abs/2605.21487
Hacker News Signals
Qwen3.7-Max: The Agent Frontier
Alibaba’s Qwen team released Qwen3.7-Max, a dense model positioned explicitly for agentic workloads. The architecture builds on the Qwen3 series with reported improvements in tool-calling accuracy, multi-step reasoning, and instruction following across long-horizon tasks. The model supports a 128K context window and is claimed to outperform GPT-4o on several agentic benchmarks including tool use and multi-turn planning tasks. Notably, the release emphasizes structured output reliability — a chronic failure mode for LLMs operating inside agent loops where downstream parsers break on malformed JSON or unexpected schema deviations. The blog post highlights a hybrid thinking mode where the model can toggle between fast response and extended chain-of-thought depending on task complexity, which reduces unnecessary latency on simple subtasks while preserving reasoning depth where needed. The model is available via API and through Hugging Face. Open questions remain around grounding quality in tool-augmented settings and how the 128K context scales in practice with retrieval-augmented pipelines versus raw in-context stuffing.
Source: https://qwen.ai/blog?id=qwen3.7
Formal Verification Gates for AI Coding Loops
This post argues that making AI coding agents smarter is less valuable than inserting hard structural constraints that prevent certain failure classes outright. The core idea is “structural backpressure”: instead of prompting the agent to be more careful, you define formal gates — type checks, property tests, or lightweight model checkers — that block forward progress until invariants hold. The analogy to backpressure in stream processing is apt: rather than having the consumer (downstream integration) absorb unbounded junk, you exert upstream pressure that halts generation until the output satisfies a contract. The author proposes layering this in practice: (1) syntax/type gates via the compiler or a type checker as the first filter, (2) unit-level property tests as a second gate, (3) optionally a lightweight formal spec check for critical invariants. The point is that these checks are cheap, composable, and language-agnostic in principle. The piece is light on implementation specifics — there is no worked example of integrating a TLA+ or Alloy check into an automated coding pipeline — but the architectural intuition is sound. The deeper implication is that agent capability and formal correctness tooling are complements, not substitutes: a more capable agent still benefits from hard stops on invariant violation. Limitation: the approach assumes you can specify the invariants cheaply, which is often the hard part.
Source: https://reubenbrooks.dev/blog/structural-backpressure-beats-smarter-agents/
Stable Audio 3
Stability AI’s Stable Audio 3 paper describes a latent diffusion model for high-quality audio generation supporting music, sound effects, and speech. The architecture uses a variational autoencoder to compress raw audio into a continuous latent space, then trains a diffusion transformer (DiT) over those latents conditioned on text prompts via a T5-family encoder. A key technical contribution is handling variable-length audio generation up to 3 minutes by using a 1D latent representation with a learned temporal compression ratio, avoiding the fixed-length constraints of earlier systems. The model is trained with flow matching rather than standard DDPM, which reduces the number of inference steps required and improves sample quality at equivalent NFE budgets. Conditioning supports both textual descriptions and audio-based prompts (style transfer via audio continuation). Evaluation uses CLAP scores for text-audio alignment and Frechet Audio Distance (FAD) for quality, along with human preference studies. Reported results show improvements over Stable Audio 2 and competitive performance against MusicGen and AudioLDM2 on music generation benchmarks. Limitations include occasional temporal incoherence in long generations and degraded performance on fine-grained rhythmic structure. The code and model weights are not fully open as of the paper release.
Source: https://arxiv.org/abs/2605.17991
When Fast Fourier Transform Meets Transformer for Image Restoration (2024)
SFHformer (Spatial-Frequency Hybrid Transformer) targets image restoration tasks — denoising, deblurring, deraining — by combining local spatial attention with global frequency-domain reasoning inside a single transformer block. The motivation is straightforward: pure spatial attention is quadratic in sequence length and captures only local structure unless window sizes are large, while pure frequency-domain methods (e.g., FFT-based convolutions) handle global frequency interactions efficiently but lose spatial locality. SFHformer addresses this by splitting feature channels: one branch runs windowed self-attention on spatial patches while a parallel branch applies 2D FFT, processes magnitude and phase in frequency space via lightweight MLPs, and reconstructs via inverse FFT. The two branches are fused via channel concatenation and a learned projection. Complexity is kept near-linear in spatial resolution because the spatial branch uses local windows and the FFT branch is O(N \log N). Results on standard restoration benchmarks (GoPro deblurring, SIDD denoising, Rain100L) show SFHformer competitive with or exceeding Restormer and NAFNet at similar parameter counts. The repository provides training configs and pretrained weights. Open question: how performance scales with high-frequency aliasing artifacts introduced by windowed FFT at boundary regions, and whether learned frequency filtering generalizes across corruption types without separate training.
Gemini 3.5 Flash
Google released Gemini 3.5 Flash, framed as a latency- and cost-optimized model in the Gemini 3 family. Technically, the emphasis is on distillation from larger Gemini models combined with speculative decoding to hit lower time-to-first-token and higher throughput per dollar. The model supports a 1M token context window, which is the headline architectural feature — enabling single-context processing of large codebases, legal documents, or long video transcripts without chunking. Benchmark numbers cited include strong performance on MMLU, HumanEval, and MATH relative to other models in the “efficient” tier (GPT-4o-mini, Claude Haiku). Multimodal inputs (text, image, audio, video) are supported natively. The 1M token context is technically interesting because naive attention is quadratic; Google has not publicly disclosed the exact sparse or linear attention variant used, though prior Gemini work referenced ring attention and blockwise parallel attention for distributed context extension. Flash models are API-only. Practical limitations include the usual caution that “supports 1M tokens” does not mean retrieval quality is uniform across that context — empirical needle-in-haystack performance degrades in the middle of very long contexts for most current architectures. The cost structure and rate limits will determine actual production adoption over raw benchmark numbers.
Source: https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-5/
Gemini Omni
Gemini Omni (also referred to in some Google communications as Gemini 2.5 Omni or a distinct “Omni” capability tier) is Google DeepMind’s native multimodal model designed for end-to-end processing of interleaved text, image, audio, and video without modality-specific preprocessing pipelines. The key architectural claim is that all modalities are tokenized into a shared sequence processed by a single transformer, avoiding late-fusion approaches where separate encoders feed into a combined head. Audio input is handled via a learned audio spectrogram tokenizer rather than routing through a separate ASR system, which preserves prosody and paralinguistic features. Video is processed as sparse frame sequences with temporal position encodings. The model supports real-time streaming input, which requires incremental attention and KV-cache management across modality boundaries — a non-trivial systems problem. Published benchmarks show strong performance on video QA (EgoSchema, Video-MME) and audio understanding tasks. The live demo emphasizes low-latency conversational interaction with simultaneous audio and video input. Limitations: the architecture details remain largely unpublished; the model is not open-weight; and real-time streaming performance in the API versus controlled demos may differ substantially under load.
Intro to TLA+ for the LLM Era: Prompt Your Way to Victory
This tutorial makes a practical argument for using LLMs as TLA+ scaffolding tools rather than as verification oracles. The author walks through using GPT-class models to generate initial TLA+ specifications from natural language descriptions, then iteratively refining them with the TLC model checker as the ground truth. The workflow is: describe the system in prose, get a draft spec, run TLC, feed back error traces to the LLM for repair, repeat. The key insight is that LLMs are decent at the syntactically annoying parts of TLA+ (boilerplate, set-theoretic expressions, stuttering step formulations) but unreliable on semantic correctness of safety and liveness properties — exactly where TLC provides a hard check. The post covers the core TLA+ concepts needed: state machines as sets of initial states and next-state relations, invariants as state predicates, temporal properties in LTL, and how TLC does bounded model checking via BFS over the reachable state space. A concrete example of a distributed lock protocol is worked through. The honest limitation acknowledged: LLMs routinely generate specs that type-check syntactically but encode the wrong system model, which can produce spuriously passing model checks if the spec is underspecified. The post does not address Apalache (the symbolic TLA+ checker) which handles some cases TLC cannot.
Source: https://emptysqua.re/blog/intro-to-tla-plus-for-the-llm-era/
Testing Distributed Systems with AI Agents
This repository explores using LLM-based agents to automate fault injection and correctness testing for distributed systems, a domain where manual test construction is expensive and coverage is inherently incomplete. The approach treats the distributed system under test as a black box accessible via a defined API, and uses an agent loop to (1) generate hypotheses about failure modes, (2) inject faults (network partitions, node crashes, latency injection) via a fault injection harness, (3) observe system behavior against specified invariants, and (4) iterate based on results. The codebase appears to wrap existing chaos engineering primitives (similar to Chaos Monkey / Jepsen-style injection) with an LLM planner that decides which faults to combine and sequence. The technical interest is in the state space coverage question: random fault injection has known weaknesses in finding rare multi-fault interactions, and the hope is that LLM-guided exploration can prioritize more interesting fault combinations based on system knowledge encoded in the prompt or retrieved from documentation. Limitations are significant: the agent’s fault selection is not formally grounded, so coverage guarantees are absent; the approach depends heavily on how precisely invariants are specified; and LLM reasoning about distributed system semantics (linearizability, causal consistency) is unreliable without formal scaffolding. The repo is early-stage and more proof-of-concept than production tooling.
Source: https://github.com/shenli/distributed-system-testing
Noteworthy New Repositories
ifixai-ai/iFixAi
A structured behavioral test suite for evaluating LLM alignment properties. The library runs 32 adversarial probes across five failure-mode categories — fabrication, manipulation, deception, unpredictability, and opacity — and aggregates results into a letter grade. The test runner is provider-agnostic, with adapters for OpenAI, Anthropic, AWS Bedrock, Azure OpenAI, and Gemini, so the same probe battery applies across backends without modification.
The most technically interesting design choice is the content-addressed manifest: each test run is serialized with a hash of the exact prompts, parameters, and model versions used, enabling bit-identical replay of any prior evaluation. This matters for regression testing and for comparing two models under provably identical conditions.
The grading pipeline completes in under five minutes on a standard API tier. Individual test results are exposed per-category so teams can track regressions on specific failure modes rather than a single scalar. The open-source release means the probes themselves are auditable — a property that closed benchmarks lack.
Practical use case: CI integration to catch alignment regressions when switching model versions or providers. The library does not claim to be comprehensive; 32 tests is a narrow sample of the alignment problem space, and adversarial probes that are public can be optimized against.
Source: https://github.com/ifixai-ai/iFixAi
jmerelnyc/Photo-agents
A computer-control agent framework built around vision-grounded memory and runtime skill synthesis. The agent reads the screen through a VLM, maintains a layered memory architecture (episodic history, extracted facts, working context), and can write new skill routines in response to novel tasks — storing them for reuse rather than re-deriving them each session.
The layered memory design is the core contribution: short-term working context feeds into a mid-term episode store, and durable facts are promoted to a long-term layer. This mirrors cognitive memory hierarchies and avoids the context-window blowup that flat-history agents suffer on long-horizon tasks. Skill synthesis means the agent can bootstrap new capabilities without a human writing tool wrappers — it observes a GUI interaction, extracts a reusable procedure, and indexes it for later retrieval.
The framework targets desktop automation: browser control, file management, multi-app workflows. Vision grounding means it operates on pixel-level screen state rather than requiring accessibility APIs, making it robust to applications that do not expose structured UI trees. The self-evolving skill store is the highest-risk component — accumulated skills need validation to avoid compounding errors across sessions.
Source: https://github.com/jmerelnyc/Photo-agents
alash3al/stash
A persistent memory backend for LLM agents, distributed as a single self-contained binary backed by Postgres. Stash structures agent memory into three explicit tiers: episodes (timestamped interaction sequences), facts (extracted durable beliefs about the world or user), and working context (short-lived in-session state). All three are queryable through a Model Context Protocol (MCP) server, meaning any MCP-compatible agent framework can attach to it without custom integration code.
The single-binary deployment is a meaningful operational advantage over solutions that require separate vector databases, object stores, or managed cloud services. Postgres handles persistence, indexing, and transactional guarantees; there is no separate embedding index to manage, though the schema can accommodate vector columns if semantic retrieval is needed.
The MCP interface standardizes the read/write surface: agents call typed memory operations rather than raw SQL, and the server handles schema migrations and consistency. The fact-extraction and episode-boundary logic is the part most likely to require domain tuning — the defaults work for conversational agents but may need adjustment for long-running task agents with complex state.
Self-hosted, no external API dependencies, MIT-licensed. A reasonable default for teams that want agent memory without vendor lock-in.
Source: https://github.com/alash3al/stash
shenli/distributed-system-testing
A collection of agent skill definitions targeting distributed-systems testing scenarios. The repository packages reusable tool-call schemas and prompt templates for tasks like injecting network partitions, validating consensus invariants, checking replication lag, and orchestrating multi-node fault scenarios — the kind of testing that is high-effort to script manually and benefits from an agent that can reason about system state across steps.
The skills follow a structured format compatible with tool-calling APIs, so they can be dropped into any agent framework that supports OpenAI-style function calling. Each skill encapsulates preconditions, the action it performs, and postcondition assertions, giving the agent enough semantic structure to chain skills into multi-step test plans.
The practical value is reducing the gap between informal test ideas (“check that the cluster recovers after leader failure”) and executable test sequences. Rather than writing bespoke chaos scripts, an agent can compose from the skill library. The repository is early-stage with 143 stars, and the skill coverage is currently narrow — consensus and replication scenarios are present, but network topology manipulation and storage-layer faults are sparse. Most useful as a starting point for teams building agent-assisted chaos engineering pipelines.
Source: https://github.com/shenli/distributed-system-testing
beava-dev/beava
A real-time feature computation layer designed to eliminate the Kafka-plus-Flink pipeline typically required for streaming feature stores. Beava processes live events and materializes computed features directly into a queryable store, targeting sub-second latency for product decision features (recommendations, fraud signals, personalization triggers) without requiring teams to operate streaming infrastructure.
The architectural bet is that most use cases labeled “streaming” are actually low-fanout event-to-feature transformations that do not need the throughput guarantees of a distributed log. By handling these in-process or through a lightweight event bus, Beava removes the operational overhead of broker management, consumer group coordination, and stateful operator checkpointing.
Feature definitions are expressed as declarative rules over event streams, with the runtime handling windowed aggregations, entity lookups, and feature serving. The “product reflexes” framing targets latency-sensitive actions: a feature computed from the last N events should be readable within the same request cycle that triggered the event.
The main limitation is scalability: the no-Kafka design works up to a throughput ceiling that a distributed log is specifically built to exceed. Teams with high-cardinality event streams or multi-consumer fan-out will hit the ceiling. For small-to-medium event volumes with tight latency requirements, this is a significantly simpler operational footprint.
Source: https://github.com/beava-dev/beava
lightseekorg/tokenspeed
A high-throughput LLM inference engine positioning itself on raw token generation speed. The project targets the latency-critical path in inference: prefill throughput, decode throughput (tokens/sec), and time-to-first-token, with the explicit goal of outperforming vLLM and similar engines on these metrics.
Based on the repository description, the engine likely employs continuous batching, paged KV-cache management, and kernel-level optimizations (fused attention, quantized matmuls) — the standard toolkit for competitive inference engines. The “speed of light” framing suggests aggressive kernel fusion and possibly speculative decoding or draft-model-based acceleration.
The key differentiator to evaluate against vLLM and TensorRT-LLM is benchmark methodology: throughput numbers are highly sensitive to batch size, prompt length distribution, and hardware configuration. Without reproducible benchmarks against a fixed workload, the performance claims require independent verification.
The project is early but has accumulated 1073 stars quickly, suggesting the community perceives a gap in the existing inference engine landscape — likely around deployment simplicity or specific hardware targets. Worth watching for teams running self-hosted inference at scale who are bottlenecked on token throughput and find vLLM’s operational complexity burdensome.
Source: https://github.com/lightseekorg/tokenspeed
FrankHui/paragents
A multi-agent session manager that runs parallel LLM agent instances in a unified panel, with cross-agent permission modeling and preflight conflict detection. The core design problem it addresses is that running multiple agents concurrently against shared resources (filesystems, APIs, databases) creates race conditions and conflicting writes — Paragents adds a coordination layer before execution.
Preflight conflict checks inspect the tool calls each agent intends to make, compare them against the declared resource scopes of concurrently running agents, and flag or block conflicting operations before they execute. This is similar in spirit to optimistic concurrency control: agents declare their intended write set, and the scheduler aborts or serializes conflicting sessions.
Permission-aware tools mean each agent session operates under an explicit capability envelope — one agent may have read/write access to a directory while another has read-only, preventing uncoordinated mutations. The single-panel UI surfaces all active sessions, their current tool invocations, and conflict warnings in one view, which is useful for debugging multi-agent workflows that are otherwise opaque.
The framework is well-suited to developer tooling scenarios where multiple specialized agents (code writer, test runner, documentation generator) operate on the same codebase concurrently. The conflict detection is necessarily conservative and may produce false positives on agents with overlapping but non-conflicting access patterns.
Source: https://github.com/FrankHui/paragents
eggbrid2/mobileClaw
An Android agent runtime for autonomous phone control, combining VLM-based screen reading with a skill routing system and support for Mihomo-based VPN workflow automation. The runtime operates at the pixel level using a vision-language model to interpret screen state, then dispatches actions (taps, swipes, text input) through Android’s accessibility or ADB layer.
The architecture separates screen understanding (VLM inference over screenshots), skill routing (matching observed state to a registered skill handler), and action execution. Mini-apps are lightweight task modules that can be registered into the routing table, allowing the agent to handle specific application flows with specialized logic rather than pure VLM-driven action selection — a practical compromise between flexibility and reliability.
Mihomo VPN integration is the most unusual component: it enables the agent to route traffic through proxy configurations as part of automated workflows, which is relevant for testing geographically restricted apps or automating workflows that require specific network egress.
The project fills a gap between full desktop-class agent frameworks and the constrained Android environment. VLM screen reading on a mobile device is latency-constrained, so the skill routing layer is important for performance — known flows bypass expensive VLM calls and execute directly. The open runtime model means custom skills can be registered in Python without modifying core agent logic.