デイリーAIダイジェスト — 2026-05-14
arXiv ハイライト
Asymmetric Flow Models
問題設定
ピクセル空間における flow matching では、ネットワークに対して速度 \bm{u} = \bm{\epsilon} - \bm{x}_0(ここで \bm{\epsilon} \in \mathbb{R}^D は等方ガウスノイズ)を予測させます。高次元ピクセルデータ(D が大きい場合)では、ノイズ項は本質的に非圧縮的です:自然画像が低次元多様体上に集中しているにもかかわらず、ネットワークは内部特徴量を通じてフルランクのガウスノイズを運ばなければなりません。これは容量の無駄遣いであり、内部表現を汚染します。これが、大規模スケールにおいて latent diffusion がピクセル diffusion を凌駕してきた理由の一つです。AsymFlow は、アーキテクチャや flow-matching loss を変更することなく、ターゲットのノイズ側を低ランク部分空間に制限できるかどうかを問いかけます。
手法
\bm{A} \in \mathbb{R}^{D \times r} が正規直交列を持ち、\bm{P} = \bm{A}\bm{A}^\mathrm{T} がランク-r 部分空間への直交射影行列であるとします。AsymFlow では、ネットワーク G_\theta に対して非対称速度
\bm{u}_{\mathrm{A}} \coloneqq \bm{P}\bm{\epsilon} - \bm{x}_0,
すなわちフルランクのデータ予測・低ランクのノイズ予測を行わせます。フルランクの速度は、部分空間とその補空間への分解によって解析的に復元されます:\bm{P}\hat{\bm{u}} = \bm{P}\hat{\bm{u}}_{\mathrm{A}} は直接得られ、一方 \mathrm{Im}(\bm{I} - \bm{P}) においてはノイズ成分が観測されないため、予測された \hat{\bm{x}}_0 = -(\bm{I}-\bm{P})\hat{\bm{u}}_{\mathrm{A}} の部分を用いた \bm{x}_0-to-\bm{u} の関係によって再構成されます。この復元は標準的な flow-matching loss に組み込まれるため、学習・サンプリングのパイプラインは変更されません。
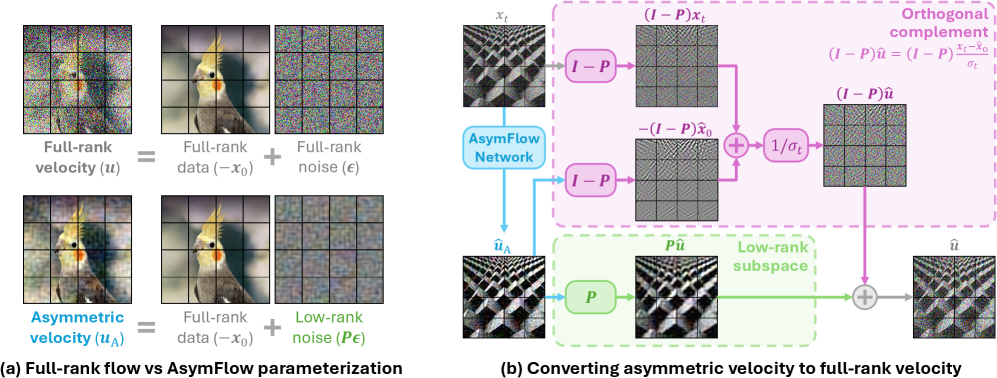
射影はパッチ単位で適用されます:DiT/JiT トークンの次元が D = 768 の場合、単一の \bm{A} \in \mathbb{R}^{768 \times r} がすべてのパッチトークンで共有されます。スクラッチからの学習では、\bm{A} は画像パッチの上位-r PCA 基底を用います。重要な点として、直交補空間の復元には予測された \bm{x}_0 成分のみを使用するため、t \to 0 付近で \bm{x}_0-to-\bm{u} 変換に必要な \sigma_{\min} クランプへの感度が低くなります。
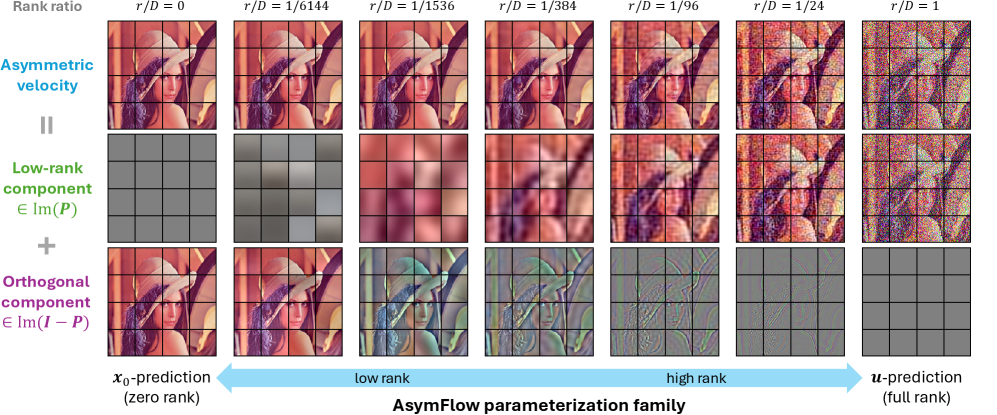
有用な再解釈として(Figure 3)、\bm{u}_{\mathrm{A}} = \bm{P}\bm{u} + (\bm{I}-\bm{P})(-\bm{x}_0) と分解できます:部分空間では \bm{u}-prediction のように振る舞い、補空間では \bm{x}_0-prediction のように振る舞います。r を変化させることで、完全な \bm{x}_0-prediction(r=0、JiT を復元)から完全な \bm{u}-prediction(r=D)まで滑らかに補間できます。
latent-to-pixel fine-tuning
同じ仕組みにより、事前学習済み latent flow モデルをピクセル空間へ厳密にリフトすることが可能です。\bm{z}_0 \in \mathbb{R}^d 上の latent モデル \hat{\bm{u}}_{\bm{z}} = G_\phi(\bm{z}_t, t) が与えられたとき、latent とピクセル空間の間でパッチ単位の線形写像 \bm{A} \in \mathbb{R}^{D \times d} を Procrustes 整合し、リフトされた低ランクのピクセル \bm{x}_0^{\mathrm{L}} \coloneqq \bm{A}\bm{z}_0 を定義します。すると
\bm{z}_t = \bm{A}^\mathrm{T} \bm{x}_t^{\mathrm{L}}, \qquad \bm{u}^{\mathrm{L}} = \bm{P}\bm{A}\bm{u}_{\bm{z}} + (\bm{I}-\bm{P})\frac{\bm{x}_t^{\mathrm{L}} + \bm{A}\bm{u}_{\bm{z}}}{\sigma_t},
となり、latent ODE は \bm{A}\,G_\phi(\bm{A}^\mathrm{T}\bm{x}_t^{\mathrm{L}}, t) によって実現されるランク-d のピクセル ODE と厳密に等価になります。射影 \bm{A}^\mathrm{T}、\bm{A} は G_\phi の入出力線形層に組み込まれ、初期化済みのピクセル AsymFlow が生成されます。このモデルのターゲットは \bm{u}_{\mathrm{A}} とは近似残差 \bm{x}_0 - \bm{x}_0^{\mathrm{L}} だけ異なります——これは構成上、低周波・低レベルのギャップに過ぎません。高レベルの構造は既に latent の軌跡から正しく得られているためです。したがって fine-tuning では、ピクセル生成を再学習するのではなく、テクスチャレベルの不一致を修正するだけで済みます。
結果
クラス条件付き ImageNet 256 \times 256 において、AsymFlow で r=8 として JiT-H/16 バックボーンを学習すると、953M パラメータ・363 GFLOPs で FID 1.57 を達成します。これは JiT-H/16 の 1.86、JiT-G/16(2B)の 1.82、PixelREPA-H/16 の 1.81、PixelDiT-XL/16 の 1.61、DeCo-XL/16 の 1.62 を上回り、表中の DiT/JiT スタイルの plain pixel transformer において最良の値です。
アブレーションにより各要素の寄与が明確になります。\sigma_{\min}=0.04 で 600 エポック学習した場合、AsymFlow(r=8)は FID 1.76 / IS 312.0 に対し、JiT は FID 1.90 / IS 300.8 となります。\sigma_{\min} クランプを除去すると、JiT は FID が 1.37 悪化(3.27 に)しますが、AsymFlow はわずか 0.52 の悪化(2.28 に)にとどまり、\bm{u} スタイルの予測を部分空間に限定することで低ノイズ時の数値的不安定性がほぼ解消されることが確認されます。ランクのスイープ(Figure 5)では、guided FID が r=0(JiT)から急激に低下し r=8 で最小となり、その後緩やかに悪化することが示されます;同一ランクのランダム部分空間より PCA 部分空間が優れており、正則化のみによる説明は排除されます。収束速度(Figure 6)も学習全体を通じて JiT より速くなっています。
text-to-image においては、FLUX.2 klein 9B から fine-tuning した AsymFlow が、ピクセル空間の生成モデル(AsymFLUX.2 klein)として、ピクセル T2I の最先端として報告されており、latent-to-pixel リフトによってほぼ整合した出発点が得られるため、fine-tuning では射影残差の修正のみを行えば済みます。
限界
パッチ単位の \bm{A} は線形かつ全トークンで共有されるため、空間的に不均一な構造(例えば高周波な微細領域)も平坦な領域と同じランク予算が割り当てられます。PCA 基底はデータ依存であり、データセットごとに再推定が必要です。最適ランクは小さく(D=768 のうち r=8)、スイープによって選択されますが、原理的な選択基準は示されていません。latent-to-pixel リフトは latent トークンとピクセルパッチの間のほぼ線形な関係を仮定していますが、非線形デコーダを持つ VAE に対してはこれは近似に過ぎません。FLOPs は報告されていますが、射影層による実測時間やメモリのオーバーヘッドは分析されていません。
重要性
AsymFlow は、flow matching におけるノイズ予測の負荷が高次元では大部分が無駄な容量であることを示し、ほぼ自明な再パラメータ化——\bm{\epsilon} をランク-8 の部分空間に射影し \bm{u} を解析的に復元する——によって、固定計算量でのピクセル空間 FID を改善し、かつ latent flow モデルからピクセル flow モデルへの厳密な橋渡しが実現されることを実証します。これは、学習済み意味論を破棄することなく、大規模な事前学習済み latent 生成モデルを直接ピクセル空間へ fine-tuning する初めての実用的なレシピです。
Source: https://arxiv.org/abs/2605.12964
MinT: 数百万のLLMの学習と推論のためのマネージドインフラストラクチャ
MinT (MindLab Toolkit) はモデリング論文ではなく、インフラストラクチャ論文です。これは、産業用LLMデプロイメントにおいてますます一般的になっているシナリオを対象としています。すなわち、少数の高価なベースモデルレプリカ(denseまたはMoE、1Tパラメータ以上を含む)が、訓練済みポリシーの大規模なカタログ——それぞれ典型的にはRLポスト学習(GRPOおよびその変種)または supervised fine-tuning によって生成されたLoRAアダプタ——をサポートしなければならない状況です。各ポリシーをマージされた完全なチェックポイントとして具体化するという単純なアプローチは、このスケールでは運用上実行不可能であり、本論文は、ポリシーを第一級のアドレス可能なオブジェクトとしてアダプタリビジョンで表現し、ベースモデルを常駐させたまま維持するサービス指向設計を主張しています。
問題の定式化
経済的な非対称性が核心にあります。フロンティアベースモデルは一度ロードされ、tensor並列およびexpert並列ワーカー全体にシャーディングされ、多数のポスト学習ジョブと多数の推論リクエストにわたって償却されます。ポリシー間で実際に変化するアーティファクトは、A \in \mathbb{R}^{r \times d}、B \in \mathbb{R}^{d \times r}(ここで r は1程度の小さい値をとりえる)を持つLoRAアダプタ \Delta W = BA です。rank-1の設定では、エクスポートされたアダプタはベースモデルサイズの1%未満です。MinTは、学習/推論パイプライン全体——ロールアウト、更新、エクスポート、評価、推論、ロールバック——が完全なチェックポイントではなくアダプタリビジョンのみを移動すべきであり、分散学習、推論、スケジューリング、データ移動をサービスインターフェースの背後に隠すべきであるという観察に基づいて構築されています。
システムの軸
本システムは、3つの直交する軸に沿ってスケーリングを整理しています。
Scale Up(スケールアップ)。 MinTは、LoRAベースのRLポスト学習をフロンティアスケールのdenseおよびMoEアーキテクチャに拡張します。著者らは、最近のフロンティアモデルで使用されているattentionの変種——Multi-head Latent Attention (MLA) および “DSA” attentionパス——ならびに総パラメータ数1T超の構成についてその実現可能性を検証しています。ここでの非自明なエンジニアリング上の内容は、LoRA注入点、並列性プラン、およびgradientルーティングを、attentionの変種とMoEを認識できるようにする必要があることです。すなわち、expertそれ自体がLoRA因子を持つことができ、アダプタシャードはベースモデルの既存のTP/EP/PPレイアウトと整合する必要があり、再シャッフルはできません。
Scale Down(スケールダウン)。 ロールアウトワーカー、トレーナー、評価器、サーバー間でエクスポートされるのはアダプタのみであるため、新しいポリシーを具体化するためのステップあたりのコストは劇的に削減されます。報告されている数値は具体的です。アダプタのみのハンドオフにより、4B denseモデルでは測定されたステップ時間が 18.3\times、30B MoEでは完全チェックポイントベースラインに対して 2.85\times 削減されます。さらに、並行マルチポリシーGRPO——共有の常駐ベースに対して複数のポリシーの更新を実行すること——は、ピークメモリを増加させることなく、ウォールタイムを 1.77\times(4B dense)および 1.45\times(30B MoE)短縮します。これは、主要なメモリ項がbaseの重みとKV cacheであり、rank-r アダプタではないためです。GRPOのステップあたりメモリがactivation、ロールアウト、および固定されたbaseによって支配されており、アダプタのgradientが各層あたり O(r(d_{\text{in}} + d_{\text{out}})) を追加するに過ぎないことを考えれば、これは期待通りの挙動です。
Scale Out(スケールアウト)。 第3の軸は、耐久性のあるポリシーのアドレス可能性をCPU/GPUのワーキングセットから分離します。ポリシーはレジストリ内の耐久性を持つ、名前付きのバージョン管理されたオブジェクトであり、その一部のみが任意の時点でCPU/GPUメモリにホットな状態として保持されます。tensor-parallel デプロイメントは、1つのベースに対して多数のアダプタを並行して提供し、アダプタスワップはリクエストの粒度で行われます。これは標準的な「多数のLoRA、1つのベース」推論パターン(cf. S-LoRA、Punica)ですが、学習側のライフサイクルと統合されており、新たにエクスポートされたリビジョンを同じインターフェースを通じてプロモート、A/B評価、推論、ロールバックすることができます。
パイプラインとしてのライフサイクル
MinTにおける作業単位は、ステージを移動するアダプタリビジョンです。ステージは、ロールアウト(軌道生成のために現在のアダプタを常駐ベースに対して使用する)、更新(GRPOまたはSFTステップによる新しいアダプタの生成)、エクスポート(レジストリへの書き込み)、評価(オフラインまたはシャドウトラフィック)、推論(ライブへのプロモート)、ロールバック(以前のリビジョンへの復元)から構成されます。すべてのステージがマージされたチェックポイントではなくアダプタを操作するため、データ移動コストはアダプタサイズによって制限され、スケジューリング問題はアダプタシャードをベースモデルレプリカに配置することに集約されます。これは、完全なチェックポイントスケジューリングと比較してはるかに小さいbin-packingインスタンスです。
制限と未解決の問題
Scale Outの説明のところで要旨が文の途中で切れているため、推論側の同時実行数とレイテンシの正確な数値はここでは得られません。示されている内容では、いくつかの問題が取り上げられていません。(i) 多数のアダプタが1つのベースレプリカ上でKV cacheとバッチattentionを共有する際のクロスポリシー干渉をMinTがどのように処理するか、(ii) rank選択が報告されたスピードアップとどのように相互作用するか——18.3\times という数値はおそらく低rankの場合であり、r が完全な fine-tuning に向けて増加するにつれてのカーブは示されていない、(iii) MoE expert レベルのアダプタ(per-expert LoRA)がサポートされているかどうか、およびそれらがexpert-parallelルーティングとどのように相互作用するか、(iv) ベースモデルのアップグレード時の挙動(アダプタ変換ステップが提供されない限り、依存するすべてのアダプタを無効化する)。1Tパラメータの検証は有望ですが、要旨ではそのスケールでの学習スループットや収束挙動を定量化していません。
なぜこれが重要か
ポスト学習カタログがベースモデルレプリカよりも速く成長し続けるならば、運用上のボトルネックは計算からチェックポイントのロジスティクスへと移行します。MinTは、——後から考えれば当然の——設計を形式化しています。すなわち、RLポスト学習と推論スタック全体にわたって、マージされたモデルではなくアダプタを通貨の単位として扱うことです。そして、少数のフロンティアベースに対して数百万のポリシーを推論することが具体的に実現可能であることを示す、ステップ時間の桁違いの削減を報告しています。
Source: https://arxiv.org/abs/2605.13779
AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation
問題設定
Consistency distillation(CD)は、video diffusionのサンプリングコストを数十NFEから数ステップへと劇的に削減することを可能にしてきましたが、テスト時のスケーリング特性に根本的な問題を抱えています。すなわち、ステップ数を増やすと品質が頭打ちになるか、むしろ劣化するという病理的な挙動を示します。その原因は構造的なものです。CDは確率フローODEの軌跡をconsistency軌跡で置き換えます。この軌跡の唯一の不変量はエンドポイントz_0であり、各ステップは学習済みのショートカットz_t \to z_0とそれに続く再ノイズ付加です。中間状態はもはや整合的なODE多様体上には存在しないため、オペレータを繰り返し適用してもサンプルは精緻化されず、累積した近似誤差が注入されるだけです。これは特にビデオの文脈で重要な問題となります。(i)実務者はレイテンシ予算に応じて1、2、4、または16 NFEで動作する単一モデルを求めており、(ii)因果的・ストリーミングなビデオ生成はすでに離散化誤差に加えてexposure biasの問題を抱えているからです。
AnyFlowは、エンドポイントではなくODE軌跡全体を対象とした初のビデオ蒸留フレームワークとして位置づけられており、蒸留済みモデルから単調な(少なくとも劣化しない)品質対NFE曲線を回復します。
手法
核心となるのは、エンドポイントconsistency f_\theta(z_t, t) \approx z_0から、任意の時刻ペア間のflow mapへのシフトです:
f_\theta(z_t, t, r) \approx z_r, \quad 0 \le r \le t \le 1.
flow mapを直接学習するのはコストが高く、任意の(t, r)に対する教師の目標z_rは直接得られません。利用可能なのは教師の瞬間速度場v_\phi(z_t, t)のみです。標準的なショートカット/flow mapアプローチではself-bootstrapping(短い学生ステップを2つ合成して長い1ステップを教師する)によりこれを処理しますが、これはオフポリシーです。すなわち、教師として機能する状態は、テスト時に学生が実際に訪れる状態とは異なります。
AnyFlowの貢献はFlow Map Backward Simulation(FMBS)です。サンプリングスケジュール1 = t_0 > t_1 > \dots > t_N = 0を与えたとき、完全な教師のEulerロールアウトをフォワード方向に実行して\{z_{t_i}\}を得た後、それをオンポリシーの目標として用いるショートカット遷移に分解します。具体的には、i < jを満たす任意のペア(t_i, t_j)について、ロールアウトのセグメント
z_{t_j} = z_{t_i} + \sum_{k=i}^{j-1}(t_{k+1}-t_k)\, v_\phi(z_{t_k}, t_k)
は、学生のflow map f_\theta(z_{t_i}, t_i, t_j)に対する、教師と整合した有効な目標となります。学生はサンプリングされた(i, j)ペアにわたって\|f_\theta(z_{t_i}, t_i, t_j) - z_{t_j}\|^2で回帰されます。z_{t_i}はクリーンな潜在変数の独立なフォワードノイズ付加ではなく教師によって生成されるため、学生は推論時に実際に遭遇する周辺分布で正確に教師されます。これがオンポリシー特性です。また、目標は二次的な数の教師呼び出しではなく、単一のロールアウトから取得されます。
このbackward simulationの観点は両方の極端なケースを包含しています。j = N(すなわちt_j = 0)のとき、目標は標準的なconsistencyエンドポイントに帰着し、j = i+1のときは単一ステップの速度マッチングに帰着します。学習では区間長を混合するため、結果として得られるオペレータは任意のステップ数で使用可能になります。
因果的・自己回帰的ビデオモデルに対しては、FMBSはさらにexposure biasにも対処します。学生自身(または教師)の軌跡上でロールアウトを実行し、次のセグメント遷移を教師することで、教師強制されたクリーンな履歴で学習するのではなく、テスト時の事前生成済みフレームの条件付け分布を模倣します。
結果
最も重要な定性的結果はテスト時スケーリング曲線です。CDのベースラインは2〜4 NFEを超えると特徴的な劣化を示すのに対し、AnyFlowの品質はNFEが増加するにつれて改善するか一定を保ち、極限では決定論的ODE教師に匹敵します。論文の概要では、AnyFlowがビデオ diffusionにおいてこれを達成した初のフレームワークであると報告されています。論文によれば、これは双方向および因果的ビデオ diffusion バックボーンの両方に対して成立し、低NFEでの離散化誤差の低減と高NFEでのexposure biasの改善が示されています。
(具体的なVBench / FVDの数値およびNFEごとの詳細は論文の実験テーブルに記載されています。ここで入手可能なアブストラクトは文中で途切れているため、スコアを創作することは控えます。方向性のある主張、すなわち劣化しないテスト時スケーリングおよびマッチしたNFEにおけるCDベースラインとの比較での因果生成品質の改善は、この手法が実現するよう設計されており、論文が実証を主張しているものです。)
限界と未解決の問題
- FMBSはトレーニング例ごとに完全な教師Eulerロールアウトを必要とするため、CDの2点ブートストラップよりも1ステップあたりのコストが高くなります。論文の効率性に関する主張は、このロールアウトを多くの(i,j)ペアにわたって償却することに基づいていますが、非常に長いビデオ(ロールアウトコストが支配的になる場合)においてこのトレードオフが依然として有利かどうかは不明です。
- flow mapは2次元の時間グリッド(t, r)上でパラメータ化されており、conditioning能力に負荷をかけます。特に遷移がほぼ恒等写像に近くなる対角線付近において、単一のネットワークが三角形全体をどれほどうまくカバーできるかは実証的な問題です。
- オンポリシーの教師は学生のロールアウトではなく教師のロールアウトを使用します。真のオンポリシー蒸留は学習中にf_\thetaの下でロールアウトを再実行し、テスト時の状態により忠実になりますが、移動する目標という問題が生じます。AnyFlowのFMBSは教師の周辺分布に対してオンポリシーであり、これは弱いですがより安定した概念です。
- このフレームワークは決定論的ODEサンプリングを対象としています。中程度のNFEでODEを上回ることのある確率的サンプラーは対象外です。
重要性
Any-step蒸留はデプロイメントにおける正しいフレーミングです。NFE予算にわたって緩やかに劣化する単一の蒸留済みビデオモデルがあれば、ステップ数に特化した複数の学生モデルを維持する必要がなくなります。蒸留の目標をエンドポイントconsistencyからflow map遷移へ移し、教師ロールアウトのbackward simulationによって欠落していた中間的な教師信号を補うことで、AnyFlowはODEサンプラーを魅力的にしていたテスト時スケーリング特性を回復します。
Source: https://arxiv.org/abs/2605.13724
Many-Shot CoT-ICL: In-Context Learningを真に学習させる
問題設定
Many-shot in-context learning(ICL)——多数(数十から数百)のデモンストレーションをプロンプトに与える手法——は、分類ベンチマークにおいてfine-tuningに匹敵する品質に近づくことが知られており、n(デモンストレーション数)に対して単調な性能向上が得られます。こうした証拠のほとんどは非推論タスクから得られたものです。本論文は、デモンストレーションにchain-of-thought(CoT)の根拠が含まれ、対象タスクが多段階推論である場合に、同様のスケーリング則が成立するかを問います。実証的な答えはノーです:標準的な「ショット数が多いほど良い」という経験則は破綻し、類似度ベースの検索は信頼性を失い、デモンストレーションの順序の影響が一次的な要因となります。著者らは、many-shot CoT-ICLをin-contextのテスト時学習として再解釈します——プロンプトが内部的な解法手順を形成する教師信号として機能するという観点から、具体的なデモンストレーション順序付けアルゴリズムを導出します。
CoT-ICLスケーリングの実証的解剖
最初の知見は、二つの軸に沿った明確な乖離です:タスクタイプ(分類 vs. 推論)とモデルタイプ(instruction-tuned vs. 推論訓練済み)。非推論LLM(Llama-3.1-8B-Instruct、Qwen2.5-7B/14B-Instruct)では、分類精度はnに対して滑らかに向上しますが、推論精度は不安定であり、CoTショット数を増やすにつれて劣化することも多いです。パラメータ規模を大きくするだけではこの問題は解決されず、Llama-3.3-70Bでも数学においてCoTデモンストレーションを追加することで性能が低下します。
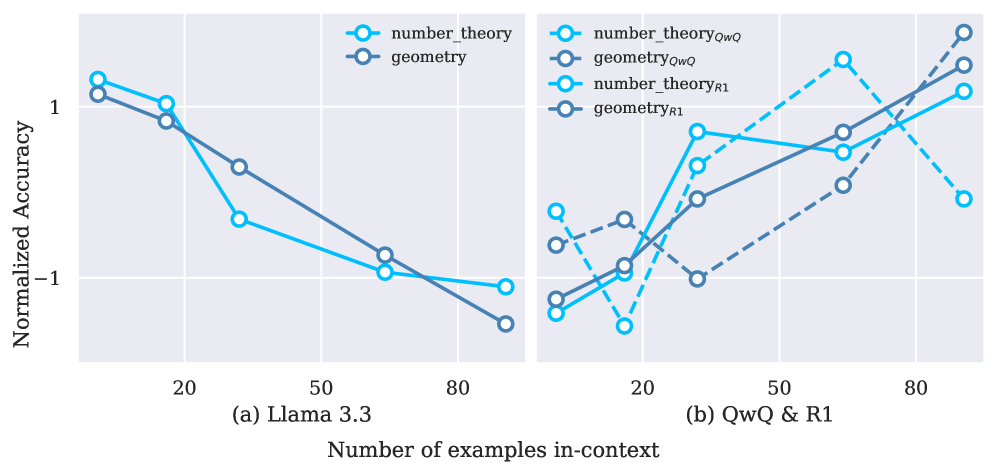
推論訓練済みモデルは質的に異なる振る舞いを示します。QwQ-32BとDeepSeek-R1(685B)は数学において明確な正のスケーリングを示し、Qwen3ファミリー(8B/14B)は推論データセット全体にわたってnに対して単調な性能向上を示します。これは「スケーリング能力」と「スケーリング活用」を分離するものです:推論時に長いCoTコンテキストを消費するよう明示的に訓練されたモデルのみが、CoTショット数の増加を精度向上に変換できるようです。
第二の知見は、標準的な検索レシピを否定するものです。意味的類似度検索(embeddingに基づくkNN)は非推論タスクでは有効ですが、推論では失敗します。なぜなら、入力の意味的類似度は手続き的適合性を予測することが難しいからです——表面的な形式が類似する二つの幾何問題が、無関係な導出を必要とする場合があります。第三の知見は順序スケーリングです:置換に対する分散がnとともに増大します。128ショットの場合、デモンストレーションの並び替えだけで精度が数ポイント変動します。
手順吸収:制御実験
最も強力なメカニズム的証拠は、幾何問題における手続き的破壊のアブレーション実験から得られます。著者らは、有効なデモンストレーション(x_i, C_i, y_i)と破壊されたデモンストレーション(x_i, C_0, y_i)——すべての根拠が最初のデモンストレーションのchain C_0で置き換えられたもの——を比較します。入力、最終回答、フォーマット、コンテキスト長は一定に保ち、x_iとその根拠の間の整合性のみを破壊します。
n=16では二つの設定はほぼ区別がつきません(Qwen3-8B:57.62 vs. 57.62;Qwen3-14B:66.17 vs. 67.01)。n=128ではギャップが開きます:Qwen3-8Bは67.01から65.76に、Qwen3-14Bは73.07から70.56に低下します。重要なのは、有効なデモンストレーションは破壊されたものよりも16→128スケーリングから大きな恩恵を得るということです——すなわち、大きなnの利益の多くは、より長いコンテキストの活性化や繰り返されるアンサーラベルではなく、根拠の手続き的内容から具体的に生じています。これが「in-contextテスト時学習」という枠組みの実証的な根拠となっています。
Curvilinear Demonstration Selection(CDS)
順序が重要であり、プロンプト全体にわたる手続き的滑らかさが安定性を支配するという観点から、著者らはCDSを提案します。各デモンストレーション\mathbf{d}_iを投影\mathbf{e}'を通じて\mathbf{e}_iにembeddingし、連続する変位ベクトルを
\mathbf{v}_t = \mathbf{e}'_{\pi(t)} - \mathbf{e}'_{\pi(t-1)},
と定義して、全ターニング角を最小化する置換\piを選択します:
\Theta(O) = \sum_{t=2}^{n-1} \arccos\!\left(\frac{\mathbf{v}_t \cdot \mathbf{v}_{t+1}}{\|\mathbf{v}_t\|\,\|\mathbf{v}_{t+1}\|}\right).
この目的関数はembedding空間における急激な方向変化を罰則化し、デモンストレーション集合を通る低曲率の軌跡を生成します。骨格的な実装は単純です:embeddingを投影し(例:PCA)、厳密な問題がTSPの変形であるためgreedyまたは2-optヒューリスティックで\min_\pi \Thetaを解きます。CDSは、推論に対して不十分であることが前節で示されたランダム順序付けとクエリへの類似度検索の両方を置き換えます。
著者らは幾何問題、数論、DetectiveQAにおいてQwen3-8B/14Bを用いてデモンストレーション予算全体にわたりCDSを評価します;本節では軌跡曲率と精度の相関を動機として報告し、完全な数値は実験付録に委ねられています。
限界と未解決の問題
破壊アブレーション実験は単一のタスク(幾何問題)と一つのモデルファミリー(Qwen3)に対してのみ実施されており、数学的推論を超えた「手順吸収」の一般性は未検証です。CDSの目的関数はヒューリスティックです——全ターニング角は多くの滑らかさ汎関数の一つに過ぎず、embeddingモデルと投影選択に依存しており、どちらも理論的な根拠はありません。本論文は、CDSによる性能向上が検索と組み合わさるかどうか、またクエリ条件付き選択を許可した場合に曲率と精度の相関が維持されるかどうかを明らかにしていません。最後に、「in-contextテスト時学習」は解釈的な枠組みとして提示されており、すでに示された順序感度と手順感度を超えた反証可能な予測を与えるものではありません。
なぜこれが重要か
標準的なmany-shot ICLの方法論——類似度で検索し、コンテキストに詰め込み、単調な性能向上を期待する——はCoT推論には転用できず、その破綻はスケールの問題ではなく構造的なものです。プロンプトを手順を誘導する教師信号として扱うことで、デモンストレーション設計を軌跡設計として再定式化します。これにより、実践者が長いコンテキストの推論プロンプトを構築する際に変えるべき具体的な指針(順序が重要、手続き的整合性が重要、類似度は重要ではない)が明確になります。
Source: https://arxiv.org/abs/2605.13511
Orthrus: デュアルビュー拡散による省メモリ並列トークン生成
問題設定
Autoregressiveなデコーディングはメモリ帯域幅がボトルネックとなります。K個の継続トークンを生成するにはK回の逐次的なforward passが必要であり、各passでKVキャッシュ全体を再読み込みします。拡散言語モデルはブロックを並列に出力することでこの直列依存を解消しますが、そのコストとしてサンプル品質の低下、ゼロから学習する高コスト、そしてAR分布に対する厳密な等価性保証の欠如を伴います。OrthrusはこのエンジニアリングBring課題に直接取り組みます。すなわち、AR分布を厳密に保ちながら、KVメモリを倍増させることなくK個の位置にわたってデコード遅延を分散させることは可能でしょうか。
手法
核となるアイデアは、単一のtransformer内での厳密な機能的分離です。事前学習済みARバックボーン\mathcal{M}_{\text{AR}}は凍結され、プロンプト\mathbf{x}_{1:t}から高忠実度のKV状態を構築するためにのみ使用されます。第2のattentionパス——拡散ヘッド——が独自のprojection (\mathbf{W}_{Q_{\text{diff}}}, \mathbf{W}_{K_{\text{diff}}}, \mathbf{W}_{V_{\text{diff}}})とともに各ブロックに組み込まれ、AR重みから初期化された後、その他すべてを固定したまま学習されます。学習可能なパラメータ数はモデル全体のおよそ16%です。
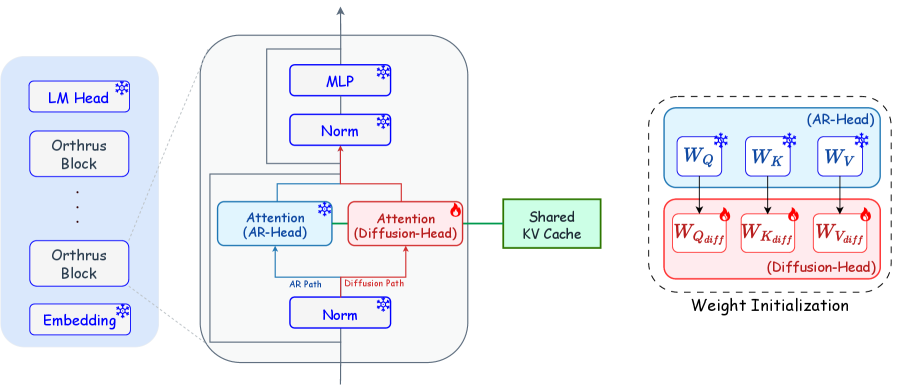
生成時には、まずARビューが\mathbf{x}_{1:t}に対して通常のprefillを行い、因果的な(\mathbf{K}_{\text{AR}}, \mathbf{V}_{\text{AR}})を生成して1つのアンカートークンをデコードします。次に拡散ビューが、そのアンカーとK-1個の<mask> embeddingを連結することで長さKの拡張ブロックを構築し、単一のforward passでネットワークに通します。各層において、拡散クエリはARキャッシュとマスクされたブロックの双方向自己表現の両方にわたってattentionを行います。
\mathbf{O}_{\text{diff}} = \text{Softmax}\!\left(\frac{\mathbf{Q}_{\text{diff}}\,[\mathbf{K}_{\text{AR}} \,\|\, \mathbf{K}_{\text{diff}}]^{\top}}{\sqrt{d_{\text{head}}}}\right)[\mathbf{V}_{\text{AR}} \,\|\, \mathbf{V}_{\text{diff}}],
ここで\mathbf{O}_{\text{diff}} \in \mathbb{R}^{K \times d_{\text{head}}}です。特筆すべき2つの帰結があります。第1に、過去のKVはその場で共有されます——拡散ビューはキャッシュに新たなK個の位置のみを追加するため、メモリオーバーヘッドはコンテキスト長に依存しません。第2に、ARのprojectionは変更されないため、ARビューの分布はビット単位で保持されます。これが推論時に使用される「厳密な合意メカニズム(exact consensus mechanism)」を正当化するものです(ARヘッドが各並列提案を因果分布と照合して再検証し、不一致を棄却します)。
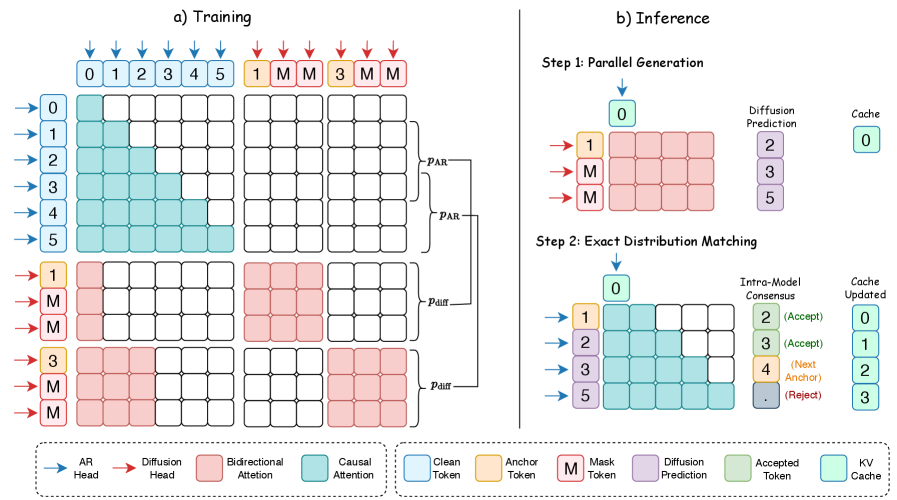
したがって学習は、拡散projectionのみに対するmasked-denoisingの目的関数に帰着します。ブロックを(アンカー、マスク)に破損し、ARのKVを所与として真のトークンを再構成するよう拡散ヘッドを学習させます。ARヘッドとそのKVが目標分布を明示的に定義しているため、バックボーンに対する別途のノイズスケジュールは不要です。
結果
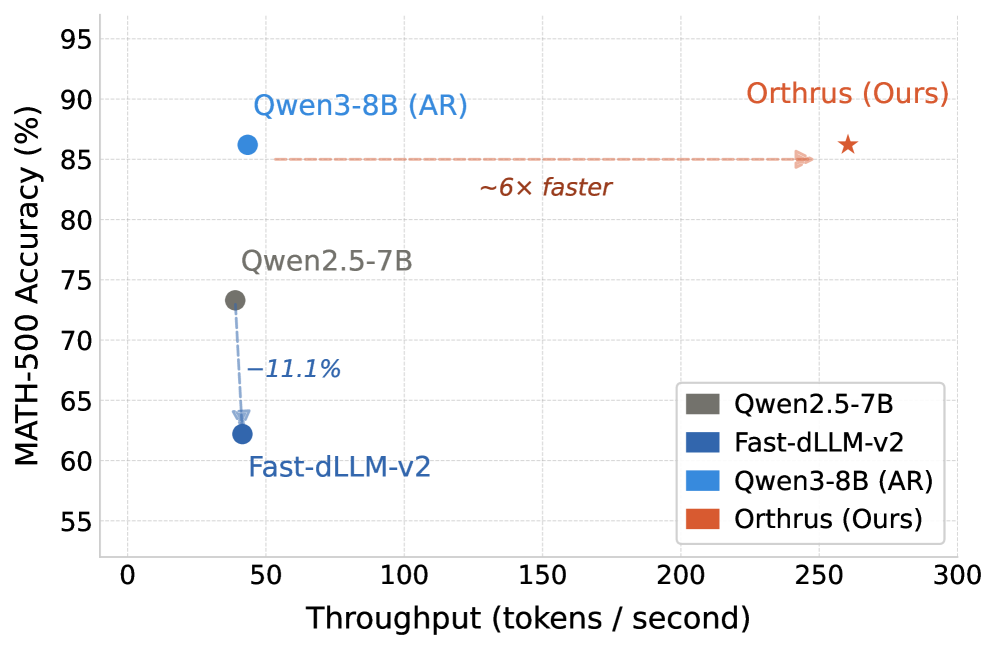
著者らはQwen3-1.7B/4B/8Bを対象として、すべてのサイズでARバックボーンを凍結した状態で評価を行います。Qwen3-8Bを用いたMATH-500では、OrthrusはARベースラインに対して厳密に無損失な精度のまま6×のスループット高速化を達成します——すなわち、合意メカニズムがARのサンプル分布を厳密に再現します——一方、同等の高速化を行ったFast-dLLM-v2では精度が大幅に劣化します。論文の主要な数値である7.8×は、最も有利な設定に対応しています。
ブロックサイズのアブレーションは、高速化の源泉を明確にします。Kブロック全体が既存のKVキャッシュに対して単一のforward passで処理されるため、pass当たりの遅延はKに対してほぼ一定です。K=4からK=32にスケールすると、1forward当たりのトークン数(TPF)が6.35に上昇し、遅延ペナルティなしに3.6×のスループット乗数をもたらすため、K=32がデフォルトとして採用されます。TPF < Kとなるのは想定内です。合意チェックが一部の並列提案を棄却するため、K=32では実際の受理率はおよそ6.35/32 \approx 0.20となります——つまり、高速化はK個すべてを受理することではなく、安価な並列提案と無視できない受理率の組み合わせから生じています。
限界と未解決の問題
- 「無損失」という主張はARの合意チェックに依存します。論文の定量的な高速化数値はMATH-500における棄却後の実効値ですが、長文・低構造な生成(対話、高エントロピーなコード)での受理率は報告されておらず、おそらくより低いと考えられます。
- 評価対象がQwen3のみに限定されています。異なるattentionパターン(GQA比率、sliding-window、MoE routing)を持つモデルに対して、16%の学習可能パラメータからなる拡散ヘッドが十分かどうかは未検証です。
- 拡散ヘッドはそれでも層ごとの計算量と第2のprojectionセットを追加します。メモリ帯域幅がボトルネックのハードウェアでは効果は実質的ですが、計算量がボトルネックの状況(小バッチ、短コンテキスト)では状況が逆転する可能性があります。
- Kが32を超えた場合に受理率がどのようにスケールするかの分析、および構造的に類似したspeculative decoding(draft+verify)との相互作用についての分析がありません。
重要性
Orthrusは並列デコーディングを、新たな事前学習体制ではなく凍結バックボーンのadapter問題として再定式化します。学習可能な拡散ヘッドをARモデル自身のKVキャッシュ経由でルーティングし、ARヘッドで検証することで、AR厳密出力と追加の過去KVメモリ不要を両立させた拡散スタイルのブロック並列性を実現します。数学ベンチマーク以外でも受理率が維持されるならば、「ドラフト」モデルが目標モデルそのものであるため、speculative decodingよりもクリーンなドロップイン代替となります。
Source: https://arxiv.org/abs/2605.12825
ノイズ追跡ペアによるRectified FlowのオフラインPreference Optimization
問題設定
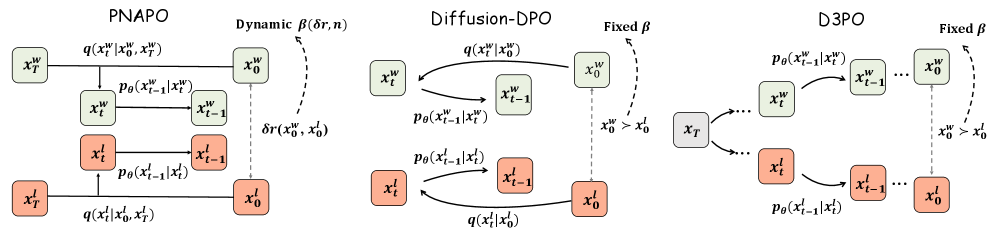
拡散モデルに対するDPOスタイルのアラインメントは、rectified flow(RF)と構造的なミスマッチを抱えています。標準的なpreferenceデータセットは (c, \boldsymbol{x}_0^w, \boldsymbol{x}_0^l)(プロンプト、勝者画像、敗者画像)のみを保存します。拡散モデルのDPO lossを計算するには逆軌跡に沿った中間潜在変数 \boldsymbol{x}_t が必要であり、Diffusion-DPOは \boldsymbol{\epsilon} \sim \mathcal{N}(0, I) として新たなフォワードノイズ \boldsymbol{x}_t = \alpha_t \boldsymbol{x}_0 + \sigma_t \boldsymbol{\epsilon} をサンプリングすることでこれを取得します。RFに対してこのアプローチは二重の意味で誤っています:(i) RF軌跡は特定の事前分布 \boldsymbol{x}_T によってインデックスされたほぼ直線であるため、独立にサンプリングされた \boldsymbol{\epsilon} は実際の生成パスに対応しなくなります;(ii) このミスマッチによる分散がgradientノイズを増大させ、収束を遅らせます。D3POのような代替手法は逆プロセスを反復的に実行することで軌跡を復元しますが、計算コストが高くなります。
手法:PNAPO
修正のアイデアは概念的にシンプルです――各画像を生成した事前ノイズを保存する――しかしデータスキーマとサロゲート目標の両方が変わります。PNAPOは標準的なトリプレットを6組 (c, \boldsymbol{x}_T^w, \boldsymbol{x}_0^w, \boldsymbol{x}_T^l, \boldsymbol{x}_0^l, \delta r) に置き換えます。
オフポリシーデータの構築。 プロンプトはDiffusionDBから取得し、Detoxifyでフィルタリング、JaccardおよびCLIPコサイン類似度(>0.8)で重複除去、100クラスターKNNリサンプリングによるリバランスを行い、2万件のプロンプトを生成します。各プロンプトに対して現在のRFモデルが独立にサンプリングした事前分布 \boldsymbol{x}_T^w, \boldsymbol{x}_T^l \sim \mathcal{N}(0,I) から、Euler離散サンプリング(50ステップ、guidance 1)を用いて2枚の画像を生成します。HPSv2.1が連続的なrewardギャップ
\delta r = r_\theta(\boldsymbol{x}_0^w) - r_\theta(\boldsymbol{x}_0^l)
を提供し、これが勝者・敗者のラベリングとpreferenceの強さの評価の両方に使われます。
直線補間によるRF整合サロゲート。 RFは \boldsymbol{x}_T から \boldsymbol{x}_0 へをほぼ直線的なパスで輸送するため、中間状態は再ノイズ化ではなく線形補間によって推定されます:
\boldsymbol{x}_t = (1-t)\,\boldsymbol{x}_0 + t\,\boldsymbol{x}_T,\quad t \in [0,1].
これにより軌跡が生成時に実際に使用した事前分布に固定され、\boldsymbol{\epsilon} の再サンプリングによる分散が排除され、DPO目標に対してより密なサロゲートが得られます。Figure 3はこれをDiffusion-DPOの確率的フォワードノイズ化およびD3POの反復逆ロールアウトと比較しています。
動的正則化。 標準的なDPOは参照モデルへのKLを制御する固定 \beta を使用します。PNAPOは(i) rewardギャップ \delta r および(ii) 学習ステップ n に基づいて正則化を変調します:\delta r が大きいペア(より明確なpreference)はより強くpushされ、スケジュールは n にわたってアニールされることで後期学習を安定化させます。この考え方の直感は、マージンの小さいペアはノイズの多いプロキシであり、マージンの大きいものほどポリシーを積極的に引っ張ることを許すべきではないというものです。
得られるフレームワークはRLフリーかつオフラインです:データは参照RFポリシーから一度生成され、適応的 \beta を持つ補間ベースDPO lossに対するgradient更新に再利用されます。
結果
実験ではFLUX.1-devとSD3-Mediumを使用し、8台のH800上でAdamW(学習率 1\text{e-}6)を用います;\beta = 2000(FLUXは 5000 を使用――なお、テーブルは2つのモデルに対して逆マッピングを報告しています)。評価にはHPDv2(3200プロンプト)とOPDv1(7459プロンプト)を用い、PickScore、HPSv2.1、ImageReward、LAION Aesthetic、CLIPでスコアリングし、GenEvalも使用します。
FLUX/HPDv2において、PNAPOはHPSv2.1 31.71(DPO 30.84、ベースFLUX 30.50に対して)、ImageReward 1.217(DPO 1.185に対して)、Aesthetic 6.475(6.307に対して)を達成します。FLUX/OPDv1では:HPSv2.1 32.10(DPO 30.79に対して)、Aesthetic 6.692(6.548に対して)、CLIP 36.89(36.19に対して)。SD3-Mも同じ順序を示し、例えばHPDv2のHPSv2.1はPNAPO 31.62、DPO 31.13、SFT 30.83となっています。基準手法のPNAPOに対するwin-rateは両モデルのほぼすべてのメトリクスで50%を下回ります(SFT-FLUXのHPSv2.1は88.4%と報告されていますが、これはテーブルのキャプション規則に従うとPNAPOのSFTに対するwin-rateであり、数値的にはPNAPOの方が高いスコアを示しています)。
より際立っているのは効率性の結果です。H800での報告された学習コスト:
- DPO-SD3 約249.6 GPU時間 vs PNAPO-SD3 約20.8 GPU時間(≈12倍)
- DPO-FLUX 約422.4 GPU時間 vs PNAPO-FLUX 約35.2 GPU時間(≈12倍)
この桁違いの削減は分散に関する議論と一致しています:軌跡が真の事前分布に固定されることで、ポリシーがrewardに向けて動くために必要なgradientステップ数が大幅に削減されます。

制限と未解決の問題
- 直線補間は理想化されたrectified flowに対してのみ厳密であり、学習済みRFモデルには残余の曲率が残るため、サロゲートにはバイアスが生じます――独立なフォワードノイズ化よりは小さいですが。本論文ではこのバイアスを定量化していません。
- rewardシグナルはHPSv2.1のみを使用しており、ラベリングと(部分的に)評価の両方に用いられるため、reward hackingとrewardモデルのoverfittingのリスクがあります;cross-rewardアブレーションは報告されていません。
- 動的 \beta スケジュールは \delta r とステップ n に基づいて説明されていますが、厳密な関数形式は掲載されたセクションには含まれておらず、その形状に対する感度は不明です。
- すべての改善はT2I RFモデルに対するものであり、事前ノイズ追跡がDDPMファミリーのモデル(軌跡が直線でない)に有効かどうかは未解決です。
- オフポリシーデータはモデル自身から生成されるため、反復的な自己改善によってrewardモデルのバイアスがラウンドをまたいで蓄積する可能性があります。
この研究の意義
Rectified flowの本質的な特性――直線的で事前分布にインデックスされた軌跡――が、拡散モデルから引き継いだpreferenceパイプラインによって捨て去られていました。勝者・敗者画像と並んで事前ノイズを保存し、\boldsymbol{x}_t = (1-t)\boldsymbol{x}_0 + t\boldsymbol{x}_T を使用するというデータスキーマの小さな変更が、約12倍の学習コスト削減と一貫したrewardモデルの改善をもたらします。これは、RFのアラインメントはDDPM-DPOから後付けで移植するのではなく、軌跡の同一性を中心に再設計すべきであることを示唆しています。
Source: https://arxiv.org/abs/2605.09433
LLM-Agentの時代におけるDAggerの再考
長期ホライゾンのLM agentは、模倣学習における馴染み深い病理に直面しています。初期の行動における1つの誤りが状態分布を教師の多様体から外れた方向へシフトさせ、それ以降の意思決定は学習中に学生が一度も見たことのない文脈から行われることになります。本論文は、post-trainingのランドスケープを2つの失敗モードのトレードオフとして捉えています。教師の軌跡に対するSupervised fine-tuning (SFT)はトークンごとに密な監督を提供しますが、学生に対して完全にoff-policyであるため、古典的なcovariate shiftの境界(後悔がホライゾンに対して二次的に増大する)を引き継ぎます。一方、検証可能な報酬を用いたRL(例:GRPO)はon-policyであり、そのミスマッチを回避しますが、提供されるのは終端の R(\tau,x)\in\{0,1\} のみであり、数十回のツール呼び出しにまたがる軌跡全体では弱いシグナルとなります。著者らはDataset Aggregation(DAgger)を自然な統合手法として再考します。ロールアウトは学生によって誘導された状態分布のもとで生成される一方、ラベルはより強力な教師から供給されます。
セットアップとアルゴリズム
マルチターンのagentは、プロンプト、過去の行動、環境からの観測を蓄積する状態 s_t \triangleq (x, a_{1:t-1}, o_{1:t-1}) によってモデル化されます。各ターンにおいて a_t \sim \pi(\cdot\mid s_t) および o_t \sim \mathrm{Env}(\cdot\mid x, a_{1:t}, o_{1:t-1}) であり、finish 行動が発生するか T_{\max} に達した時点で終了します。検証器は R(\tau,x)\in\{0,1\} を返します。SWE-Gymの場合、生成されたパッチが保留されたユニットテストを通過するかどうかです。
ここでのDAggerはトークンレベルではなく、ターンレベルの補間で動作します。各ロールアウトステップでは、行動ポリシーを混合分布からサンプリングします。 \pi_{\mathrm{behave}}(\cdot\mid s_t) = \beta\,\pi_e(\cdot\mid s_t) + (1-\beta)\,\pi_\theta(\cdot\mid s_t), すなわち確率 \beta で教師がターンを出力し、それ以外は学生が出力します。軌跡が展開された後、訪問されたすべての状態 s_t に対して教師 \pi_e に問い合わせを行い、目標行動 a_t^\star \sim \pi_e(\cdot\mid s_t) を生成します。学生は標準的なSFT lossによって更新されます。 \mathcal{L}(\theta) = -\mathbb{E}_{s_t \sim d^{\pi_{\mathrm{behave}}}}\big[\log \pi_\theta(a_t^\star \mid s_t)\big]. 2つの性質が導かれます。第一に、\beta \to 0 のとき、状態分布 d^{\pi_{\mathrm{behave}}} はデプロイ時の分布 d^{\pi_\theta} に近づき、学生は実際に遭遇する文脈で学習されるため、covariate shiftを直接的に解消します。第二に、監督は密なままです。各ターンで1つの終端スカラーではなく、教師の行動ラベルが得られます。
学生はQwen3-4B-Instruct-2507またはQwen3-8Bであり、教師はより大きなQwen3-Coder-30B-A3B-Instructです。学習には2,338件のSWE-Gymタスクを使用し、評価にはSWE-Gym Holdout(ドメイン内)の100インスタンスとSWE-Bench Verifiedの500タスクのうち466件を使用します(34件のMatplotlibインスタンスはDockerEnvironmentでビルドに失敗するため除外されており、著者らはこの除外による集計への影響が1%未満であると報告しています)。
実験的知見
4つのリサーチクエスチョンが実験を構成しています。SFT / GRPO / on-policy distillationと比較した全体的な有効性、同等の計算量における学習の安定性、covariate shiftの直接的な測定、そして定性的な行動の変化です。covariate shiftの診断は機構的に最も示唆に富んでいます。著者らは、学生自身が訪問した文脈で評価されたトークンレベルの逆KL D_{\mathrm{KL}}(\pi_\theta \| \pi_e) を測定しています。
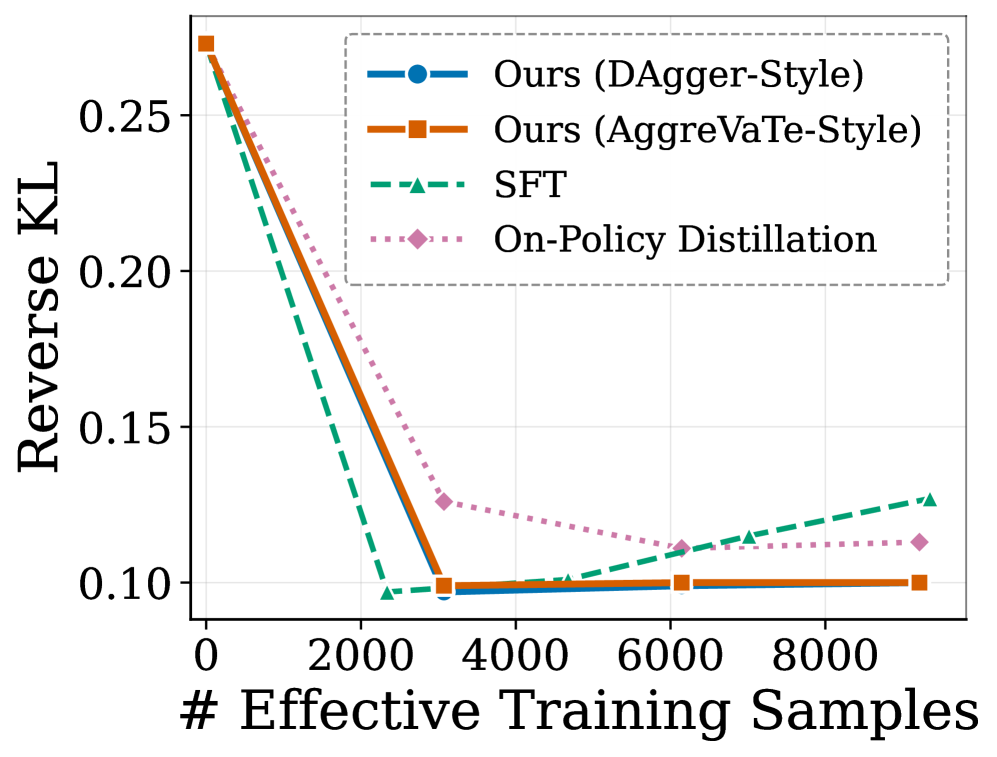
重要な比較は、学生自身の状態分布におけるSFTとDAggerの比較です。SFTは定義上、教師が訪問した状態において D_{\mathrm{KL}} を最小化しますが、それらはデプロイ時に遭遇する状態ではありません。図は、学生が訪問した文脈において、SFTモデルの教師からの乖離が、d^{\pi_\theta} のもとで教師を模倣するよう明示的に学習されたDAgger学習済み学生よりも大幅に高いままであることを示しています。これがcovariate shiftの実証的なシグネチャです。SFTの学習分布と評価分布が一致しておらず、その不一致がターンをまたいで累積していきます。
限界とオープンクエスチョン
いくつかの点が精査に値します。(1) DAggerは学生が訪問したすべての状態に対してオンラインで教師への問い合わせを必要とします。マルチターンのSWE-Gymロールアウト全体で30Bパラメータの教師を使用するのはコストがかかるため、GRPOとの同等計算量比較が最も重要な実験であり、計算量の正規化の詳細(教師の推論 vs. 学生のgradient step)がどの程度結果が一般化されるかを左右します。(2) 混合スケジュール \beta は自由なハイパーパラメータです。古典的なDAggerは \beta_t \to 0 へアニーリングしますが、確率的で分岐が多い行動空間を持つLM agentに最適なスケジュールは明らかにされていません。(3) 教師のラベルはそれ自体が確率的なサンプルであり、最適な行動ではありません。DAggerが意図的に生成する分布外の学生状態において教師が誤った場合、学生は検証器による訂正なしにそれらの誤りを引き継ぎます。教師ラベルに対する検証可能な報酬フィルタリングを組み合わせたハイブリッドアプローチは明らかな次のステップです。(4) 結果は1つの教師-学生ファミリーによるSWE-Gym / SWE-Bench Verifiedに限定されており、web agent、ツール利用のベンチマーク、または実行可能な検証器が存在しない設定への汎化は未解決のままです。
なぜこれが重要か
DAggerは、LM agentのpost-trainingをSFTとRLVRの陣営に分断している、密な監督とon-policyな状態分布のジレンマに対して原理的な答えを提供します。強力な教師と学生ポリシーのターンレベル混合としてこれを再定式化することは、明確な理論的正当性を持つ小さなアルゴリズム上の変更です。また、学生が訪問した文脈における逆KL診断は、あらゆるマルチターンagentパイプラインにおけるcovariate shiftの検出に有用で移転可能な手法です。
Source: https://arxiv.org/abs/2605.12913
Hacker News Signals
「アイドル」なのにアイドルでない:Linuxカーネルの最適化がQUICのバグになるまで
CloudflareがQUIC接続のデス・スパイラルに関するポストモーテムを公開し、その根本原因をSO_TIMESTAMPINGとLinuxカーネルの受信バッファ・コアレッシング・パスとのインタラクションに辿り着きました。UDPソケットがアイドル状態(パケットが到着していない状態)のとき、カーネルのGRO(Generic Receive Offload)レイヤーは、部分的に組み立てられたセグメントを即座にフラッシュするのではなく、CPU単位のキャッシュに保持することがあります。これは、さらに多くのパケットが到着してコアレッシングできるという前提に基づいており、パケットごとのオーバーヘッドを削減するための仕組みです。しかしQUICの下では、この動作がロス検出および輻輳制御タイマーと悪い形で干渉します。カーネルがACK誘発パケットの配送を十分に遅延させると、送信側のPTO(probe timeout)が発火して再送が行われます。その再送がさらにコアレッシングの遅延を引き起こし、接続は最小輻輳ウィンドウでのPTO駆動による再送を繰り返すデス・スパイラルに陥ります。接続は技術的には生きているにもかかわらず、スループットが事実上停止した状態になります。
修正には、SO_BUSY_POLLを設定するか、あるいはイベントループの各イテレーションでカーネル側のフラッシュを強制する形でEPOLLEXCLUSIVE付きのepollを使用することで、GROキャッシュを明示的にフラッシュする必要がありました。投稿ではudp_gro_receiveのコールパスを丁寧に解説し、(a)GROタイマーが発火するか、(b)同じフローに別のパケットが到着するか、(c)アプリケーションがbusy-pollヒントを通じて明示的にドレインするか、のいずれかが起きない限り、CPU単位のnapiキャッシュがフラッシュされない理由を説明しています。
より本質的な問題は、GROがTCPのセマンティクス、すなわちカーネルがコアレッシングの判断を両側で掌握しているという前提で設計されていた点にあります。QUICがUDP上で動作する場合、アプリケーション自身が信頼性を実装しなければならないため、TCPに対しては透過的だったカーネルレベルのバッチング最適化が、QUICレイヤーでは観測可能かつ危険なものになります。投稿では影響の規模も定量化しており、影響を受けた接続はQUICのidle-timeoutの境界でリカバリするかタイムアウトするかのいずれかが起きるまで、数十秒間デス・スパイラルに留まる可能性があるとしています。
Microsoft BitLocker – YellowKey ゼロデイエクスプロイト
YellowKeyの開示により、BitLockerのプリブート認証が、ブート時に接続されたUSBドライブ上に特定のファイルを配置することでバイパス可能であることが明らかになりました。技術的な主張は、Windows Boot Managerがリムーバブルメディア上のBCD(Boot Configuration Data)エントリを列挙する際に、攻撃者が用意したBCDを読み込ませることが可能であり、TPMがVMK(Volume Master Key)をアンシールする前に実行を別の場所へリダイレクトしたり整合性チェックを無効化したりできるというものです。
重要な点は、この攻撃がターゲットドライブへの物理的な改ざんやTPMのデキャッピングを一切必要としないことです。攻撃対象となるのはbootmgr.efi内のBCD解析コードであり、特定の構成下では、リムーバブルメディアからのBCDストアを信頼済みキーによる署名なしに処理してしまいます。Secure Bootの適用が不完全な場合――具体的には、DBX(禁止署名データベース)が更新されていない場合や、署名済みだが脆弱なブートローダーが依然として信頼されている場合――に、1回のブートサイクルの間だけ物理アクセスを持つ攻撃者がVMKを抽出できます。
この攻撃は、Dolos Groupをはじめとする研究者たちがかねてより調査してきた攻撃カテゴリに該当します。すなわち、TPMのみを使用するBitLocker構成(PIN・USBキーなし)は、TPMのアンシールを制御するPCR測定値を確立するために、UEFI Secure Bootからboot managerに至るチェーン全体に完全に依存しています。そのチェーン内にある署名済みコンポーネントがPCR値を誤って報告するよう誘導可能な場合、あるいはPCR測定が確定する前に実行されるBCD処理パスが存在する場合には、セキュリティモデルが破綻します。
現実的な緩和策は、プリブートPINを併用したBitLockerの使用と、脆弱なブートローダーバイナリを信頼しないよう更新されたSecure Boot DBXの適用です。ドメイン参加マシン上でのTPMのみの構成は、Microsoftがパッチ済みのbootmgrを提供するまで引き続き脆弱なままです。報道における「バックドア」という表現は正確ではなく、より正確にはOS起動前のBCDソース列挙における論理的な欠陥と言えます。
Interfaze: スケールにおける高精度を実現するために構築された新しいモデルアーキテクチャ
Interfazeのブログ記事では、「動的コンテキストルーティングを備えた階層的 mixture of experts」と呼ぶアーキテクチャを紹介していますが、実装の詳細は乏しい状況です。主張によれば、このモデルはトークン単位だけでなくコンテキストセグメント全体を特化したサブネットワークにルーティングし、ルーティングの判断を現在のトークンだけでなく全シーケンスの圧縮サマリーに基づいて行うことで、transformer の密な baseline と比較してパラメータあたりの精度を向上させるとされています。
セグメントまたは文書レベルでルーティングを行うというこのアーキテクチャ上のアイデアは、標準的なスパース MoE の既知の弱点に対処するものです。トークンレベルのルーティングはゲーティングの決定において長距離依存関係を無視するため、話題的に一貫したコンテンツが無関係なエキスパートに分割されてしまう可能性があります。グローバルなコンテキスト embedding を計算し(小規模な attention ベースのサマライザーを介して行われるようです)、それに基づいてルーターを条件付けることで、エキスパートの利用がより意味的に一貫したものになるとのことです。
このブログ記事はいくつかの推論およびコーディングタスクにおけるベンチマーク数値を提示しており、特定のサブセットにおいて GPT-4o および Claude 3.5 Sonnet を上回ると主張していますが、評価方法論は完全には開示されていません。プロンプトの構成、サンプリングパラメータ、あるいは比較対象のタスクが恣意的に選ばれたものかどうかについての詳細は示されていません。論文も、モデルの重みも、再現可能なアーティファクトへのリンクも存在しません。
HNのディスカッションでは適切な懐疑的見解が示されています。アーキテクチャの説明が曖昧であるため、真の新規性とマーケティング的な文言を区別することが難しいという指摘があります。セグメントレベルのルーティングというアイデアは、LongformerのグローバルなAttentionトークンや階層的なtransformerといった先行研究に前例があり、これが根本的に新しいアーキテクチャを構成するという主張には、ブログ記事が提供するもの以上の厳密なアブレーション実験が必要です。プレプリントや独立した評価が登場するまでは、投機的な技術的フレーミングを伴う製品発表として扱うべきです。
Source: https://interfaze.ai/blog/interfaze-a-new-model-architecture-built-for-high-accuracy-at-scale
Show HN: Statewright – AIエージェントを信頼性の高いものにするビジュアルステートマシン
Statewrightは、開発者がエージェントの制御フローを型付きトランジションを持つ明示的な有限状態機械(FSM)として定義し、そのFSMをLLMコール周囲のスキャフォールディングとして実行できるライブラリです。その価値提案はエンジニアリングレベルのものです。FSMは、定義時にすべての到達可能な状態を列挙できる形式モデルを提供するため、純粋にプロンプト駆動またはchain-of-thoughtエージェントでは困難な方法で、エージェントの動作を監査・テスト・制約することが可能になります。
実装はビジュアルエディタを使用しており、JSONまたはYAMLの状態グラフにエクスポートされます。実行時には、各状態にLLMコール、ツール呼び出し、または決定論的ハンドラを関連付けることができます。トランジションは、決定論的に(構造化出力のパースによって)または小規模な分類コールを通じて評価されるガードです。重要な制約は、エージェントがグラフに宣言されていない状態に遷移できないという点です。自由形式の「次のアクション」決定は存在せず、LLMの役割は現在の状態のパラメータを埋め、どの定義済みトランジションに従うかを通知することです。
これは本質的に「言語エージェントをマルコフ決定過程として捉える」フレーミングで提唱されているアプローチですが、研究成果としてではなく開発者ツールとして実装されています。本番エージェントにとっての実用的なメリットは、不透明なトークン補完のシーケンスではなく、名前付き状態にマッピングされた明示的な監査ログが得られることと、LLMレスポンスをモックすることでトランジショングラフに対して決定論的なユニットテストを記述できることです。
制限は表現力にあります。必要な状態の集合を事前に列挙できない、真にオープンエンドなプランニングを要するタスクは、固定されたFSMには自然にフィットしません。このライブラリは「動的状態拡張」によって部分的にこれに対処していますが、そのメカニズムは十分にドキュメント化されていません。適切にスコープが定められたワークフロー自動化(フォーム入力、マルチステップAPIオーケストレーション、カスタマーサービスルーティング)に対しては、非構造化エージェントループよりも合理的なエンジニアリングの選択肢です。
enum から文字列への変換コスト:C++26 reflection vs. 従来の方法
Vittorio Romeo のベンチマーク記事では、enum の値をその文字列名に変換する際のランタイムおよびコンパイル時のコストを、4 つのアプローチを用いて検証しています。対象は、手書きの switch 文、マクロ生成のルックアップテーブル(X-macros)、サードパーティライブラリ(magic_enum。コンパイラ固有の __PRETTY_FUNCTION__ / std::source_location ハックを用い、template のインスタンス化を介してコンパイル時に enum 名を取り出す)、そして C++26 の static reflection(std::meta 経由)です。
パフォーマンス上の問題は、主にコンパイル時に集中しています。magic_enum は template のインスタンス化数が爆発的に増加することで知られており、N 個の enumerator を持つ enum に対して、名前の抽出中に O(N) 個の関数 template をインスタンス化します。これにより、デフォルトでは N=128 前後でコンパイル時の制限に達し、大規模な enum ではビルド速度が目に見えて低下します。X-macro アプローチは文字列リテラルの連結以外にコンパイル時のオーバーヘッドはゼロですが、定義箇所でのマクロ規律の徹底が必要という侵襲的な制約があります。
std::meta::enumerators_of を用いた C++26 reflection は、クリーンな解決策を提供します。コンパイラが enum の enumerator をコンパイル時の std::meta::info 値の range として公開し、そこから std::meta::identifier_of を通じて名前を取得できます。これにより、template の爆発を起こすことなく、素直な constexpr 配列の構築が可能になります。
constexpr auto names = []<auto... Es>(std::integer_sequence<std::size_t, Es...>) {
return std::array{std::meta::identifier_of(Es)...};
}(/* std::meta::enumerators_of からの enumerator pack */);Romeo のベンチマークによると、reflection ベースのアプローチはランタイムで switch 文と同等のパフォーマンスを示し(いずれも境界チェック付き配列ルックアップにコンパイルされます)、N 個の template インスタンス化問題を解消し、定義箇所に依存しないよりクリーンなコードを生成します。主な制限はツールチェーンの対応状況であり、C++26 reflection には -freflection オプションを付けた最近の Clang または EDG ベースのコンパイラが必要で、GCC はまだ対応していません。
Source: https://vittorioromeo.com/index/blog/refl_enum_to_string.html
LinuxゲーミングがWindowsより高速化しているのは、Windows APIがLinuxカーネルの機能になりつつあるから
この記事では、Proton/Wine上でWindowsゲームを実行する際のオーバーヘッドを削減する2つの独立したカーネル開発について取り上げています。一つはFUTEX_WAITVシステムコール(5.16でマージ済み)、もう一つはより最近の6.14でランクインしたNT同期プリミティブ(ntsync)に関する取り組みです。
FUTEX_WAITVは、スレッドが複数のfutexのベクターに対して同時に待機できるようにするもので、WaitForMultipleObjectsのセマンティクスに直接対応します。以前、Wineは待機可能なオブジェクトごとに専用のカーネルスレッドを生成し、シグナルやeventfdを使ってウェイクアップを集約することでWaitForMultipleObjectsを実装していました。これは、フレームごとに数十もの同期オブジェクトを待機するゲームにとって、無視できないオーバーヘッドでした。
ntsyncはさらに踏み込んでおり、完全なNTカーネルオブジェクトモデル(NTセマンティクスを持つmutex、イベント、セマフォ)をioctlを備えたキャラクターデバイスとして実装しています。POSIXプリミティブでは直接表現できないNTセマンティクスの要点は、NT mutexがオーナー付きかつ再帰的であること、NTイベントがオートリセットとマニュアルリセットの両モードおよび特定のパルスセマンティクスを持つこと、そしてWAIT_ALLを指定したWaitForMultipleObjectsがすべてのオブジェクトをアトミックに取得するかまったく取得しないかのいずれかでなければならないことです。ntsyncはこれらをカーネル空間において、オブジェクトごとの状態をカーネルメモリで追跡するntsync_deviceとして実装しており、Wineは従来のユーザー空間エミュレーションパスの代わりに、単一のNTSYNC_IOC_WAIT_ANYまたはNTSYNC_IOC_WAIT_ALL ioctlを発行できるようになっています。
記事および関連するPhoronixのテスト結果によるベンチマーク数値は、同期処理の多いタイトルにおいてフレームタイム分散の測定可能な低減を示しています。フレームごとに短命なmutex取得を多用するゲームで最大の効果が得られており、一部タイトルでは10〜20%のスループット向上が報告されています。より広い含意としては、Protonの互換性の上限が、同期オーバーヘッドではなく、GPUドライバーとDirect3D変換品質によってますます規定されるようになってきているということです。
Bun を Rust で書き直す PR がマージされた
PR #30412 は、Bun の HTTP サーバー内部実装を Zig から Rust へ書き直したもので、具体的にはサーバーサイドのリクエスト/レスポンスのライフサイクルを扱う bun.http モジュールが対象です。Bun は Zig を使った代表的なプロジェクトとして知られているため、パフォーマンスクリティカルなサブシステムへの Rust 採用は、言語選択に対してイデオロギー的ではなくプラグマティックなスタンスをとっていることを示しており、注目に値します。
PR のディスカッションにおける技術的な根拠は、Rust の tokio エコシステムおよび非同期 HTTP ライブラリ(hyper、h2)の成熟度と、Zig の非同期 I/O の現状との比較に集約されます。Zig の async/await は再設計を待つ形で 0.12 でいったん言語から削除されており、構造化された非同期並行処理を必要とするプロジェクトは、独自のランタイムを実装するか、同期的なスレッドモデルを使用するかの選択を迫られています。既存の Zig 製 HTTP サーバーはカスタムのイベントループ統合を用いていましたが、Rust による書き直しでは tokio の実績あるエグゼキューターと hyper の HTTP/1.1 および HTTP/2 実装を直接活用できます。
相互運用の境界は C FFI レイヤーを通じて処理されており、Zig は extern "C" 関数経由で Rust 製 HTTP サーバーを呼び出し、Rust 側も同じ仕組みで JavaScript 実行のために Zig へコールバックします。この PR では、Rust クレートを静的ライブラリとしてコンパイルし、最終的な Bun バイナリにリンクする build.rs が追加されています。
HN のディスカッションでは、これがコードベース全体での Zig から Rust への移行を示すものかという当然の疑問が上がっています。Bun チームの回答は、この書き直しは HTTP サーバーにスコープを絞ったものであり、特定のライブラリの利用可能性に動機づけられたものであって、言語全体の切り替えではないというものです。より興味深いエンジニアリング上の問題は、FFI 境界がホットパスに計測可能なオーバーヘッドをもたらすかどうかという点ですが、パフォーマンスを動機とした書き直しとしては注目すべき欠落として、この PR には変更前後のベンチマークが含まれていません。
Show HN: RockboxファームウェアをベースにしたモダンなMusic Player Daemon
rockbox-zigは、RockboxオーディオファームウェアのPlaybackエンジンをネットワーク対応のMusicデーモンとして再実装したもので、コアとなるDSPおよびcodecレイヤーをZigに移植し、従来のMPDプロトコルをgRPC APIで置き換えています。RockboxのCodecライブラリは、固定小数点DSPを組み込みターゲット向けに最適化した上で、幅広いロスレスおよびロッシーフォーマット(FLAC、APE、Musepack、Speex、AAC、WavPack)をサポートしています。これをZigに移植することで、そのcodecの多様性を維持しながら、標準的なLinuxサーバーやデスクトップシステム上でバイナリをデプロイできるようになっています。
gRPCインターフェースは、元のMPDテキストプロトコルからの意図的な脱却です。.proto定義はPlayback制御、キュー管理、メタデータクエリを型付きRPCコールとして公開しており、行指向のテキストパーサーを実装することなく、gRPCをサポートする任意の言語でクライアントを構築することが容易になっています。本プロジェクトにはWeb UIクライアントとCLIが含まれています。
RockboxのCコードのZig移植は、大部分が機械的な変換です。ZigのCインターオプにより、@cImportを通じてオリジナルのRockbox Cを直接呼び出すことができるため、codecレイヤーの多くは真の書き直しではなく、ZigビルドシステムでコンパイルされたオリジナルのCコードです。Zigネイティブな部分はデーモンのインフラストラクチャ、すなわちイベントループ、gRPCサーバー(ZigのgRPCライブラリを使用)、およびALSA/PulseAudio/PipeWireバックエンドによるオーディオ出力です。
技術的に興味深い点は、FPUを搭載したプラットフォームでRockboxの固定小数点DSPを使用していることです。RockboxのDSPはARM7/ColdFireターゲット向けに浮動小数点演算を避けるよう設計されていました。x86-64上では固定小数点パスは等価な浮動小数点DSPより遅くなりますが、オーディオ再生においてはその差は無関係です。本プロジェクトは開発初期段階にあり、キューおよびプレイリストの状態管理はまだ再起動をまたいで永続化されません。
注目の新しいリポジトリ
samchon/ttsc
ttsc は、typescript-go(tsc の公式 Go 書き直し版)の上にプラグイン API を層として追加した、ドロップイン TypeScript コンパイララッパーです。主な価値は二点あります:(1) 後処理ステップとしてではなく、型チェッカー自身のパス内で動作するコンパイラ駆動の transform plugins であり、これにより別途 ts-morph のトラバーサルを行うことなく完全な型情報にアクセス可能な変換が実現できます;(2) TypeScript linter(ts-eslint のルールに類似)をコンパイルパイプラインに直接統合することで、ESLint を個別に実行する場合と比べて約 20 倍のスループット向上を謳っています。基盤となるコンパイラは Go で書かれネイティブバイナリにコンパイルされているため、コールドスタートおよびインクリメンタルリビルドのコストは Node.js 版 tsc に比べて大幅に低くなっています。プラグイン作者は型付きインターフェースを実装し、コンパイラの明確に定義されたフェーズにフックを登録します。型安全な実行とは、プラグインが生成あるいは変換したコードが盲目的にエミットされるのではなく、同じ型システムのパスによって再チェックされることを保証するものです。これは DTO バリデータや ORM スキーマ導出などのコード生成ユースケースに関連しており、既存の ttypescript や ts-patch のような解決策は Node.js コンパイラの内部にパッチを当てる形式のため、tsc のバージョンをまたいで壊れる可能性があります。非自明な TypeScript transform パイプラインを維持しているチームや、CI で大規模に lint を実行しているチームにとって、注目に値するプロジェクトです。
Source: https://github.com/samchon/ttsc
xataio/xata
Xataは、オープンソースのクラウドネイティブPostgresプラットフォームであり、2つの非標準プリミティブを中心に設計されています。それは、copy-on-writeによるデータベースのブランチングとスケール・トゥ・ゼロのコンピュートです。ブランチングはCoWストレージレイヤーを使用しているため、数ギガバイトのデータベースからブランチを作成しても処理は瞬時に完了し、ストレージのオーバーヘッドはデータセット全体のサイズではなく、差分となる書き込み量にのみ比例します。これはNeonのブランチングと同一のセマンティクスモデルであり、完全にオープンソース化されたスタックとして実装されています。スケール・トゥ・ゼロは、アイドル時にコンピュートを停止し、接続時に再開するもので、アクティブ時間あたりのコストが重要となるサーバーレスやプレビュー環境のワークロードをターゲットにしています。このプラットフォームは標準的なPostgres wireプロトコルを公開しているため、既存のドライバーやORMに変更は必要ありません。内部アーキテクチャはストレージとコンピュートを分離しており、これはクラウドネイティブデータベース(Aurora、Neon、AlloyDB)に共通するパターンですが、オープンソースとしてリリースされることで、オペレーターはマネージドサービスに縛られることなくフルスタックをセルフホストできます。オープンソース化直後に835スターを獲得したことは、セルフホスト可能なNeonの代替に対する需要を示しています。PRごとのエフェメラルなデータベース環境の構築、ステージングパイプライン、またはスキーマ・パー・テナントよりもブランチングによるテナント分離がアーキテクチャ的に優れているマルチテナントSaaSを構築しているチームに関連性があります。
Source: https://github.com/xataio/xata
bkywksj/knowledge-base
Tauri 2.x(Rustバックエンド)、React 19(フロントエンド)、SQLiteを単一ストレージ基盤として構築された、ローカルファースト型のパーソナル知識ベースデスクトップアプリケーションです。全文検索にはSQLiteのFTS5拡張を使用しており、外部の検索デーモンを一切必要とせずにプロセス内で検索が完結します。双方向リンクおよびナレッジグラフは、Markdown AST上でのリンク抽出パスを基盤として実装されており、グラフのエッジはSQLiteに格納されます。同期はデータベース全体の同期ではなく、ノート単位の粒度を中心に設計されており、スケジューラーがWebDAV・S3・ファイルシステム同期プロバイダーにわたってインクリメンタルな双方向調整を実行します。また、ライブラリ全体のZIPバックアップへのフォールバック機能も備えています。AIレイヤーはOpenAI互換エンドポイント、Ollama、および任意のカスタムプロバイダーをtool-callingフレームワーク経由でサポートしており、エージェントが単にテキストを生成するだけでなく、定義済みのツール(検索、ノート作成、ノートのリンク)を呼び出せる仕組みになっています。暗号化はvault抽象として実装されており、vault単位の鍵とPINによるhidden-notes機能を持ちます。インポートは.md・.txt・.pdf・.docxに対応し、文字コードの自動検出も行います。TauriとRustの採用により、バイナリのフットプリントが小さく、Electron方式のChromiumバンドルによるオーバーヘッドもありません。クラウド依存ゼロはマーケティング上の主張ではなく、真のアーキテクチャ的特性であり、すべてのデータパスはローカルで完結します。
Source: https://github.com/bkywksj/knowledge-base
mvm-sh/mvm
mvm はGoのソースコードを対象としたバイトコードインタープリタおよび仮想マシンであり、Go以外の言語への対応も将来の目標として掲げています。「高速インタープリタ」という位置づけが示す通り、go build を呼び出してネイティブコードを実行するのではなく、Goを内部バイトコードIRにコンパイルして実行する設計です。これにより、フルツールチェーンのコンパイルレイテンシを伴わずに、スクリプティング、プラグインのサンドボックス化、REPL形式の実行といったユースケースが実現できます。この設計空間は yaegi(TraefikのGoインタープリタ)やLua-in-Goのための gopherlua と同様ですが、組み込み優先のツールではなく汎用VMとして位置づけられています。「and beyond」という言語サポートのヒントは、複数のフロントエンド言語に対する共通バイトコードターゲット、もしくはカスタム文法による言語拡張の計画のどちらかを示唆しています。レジスタベースかスタックベースのVMか、GC戦略、ネイティブGoパッケージを呼び出すためのFFI、型システムがバイトコードレベルで強制されるかどうかといった主要な技術的疑問点はまだ十分に文書化されていませんが、これらこそが yaegi との競合軸となります。cgo や os/exec を使わない動的コードローディングが求められるGoサービスのプラグインアーキテクチャや、テスト実行のたびにフル再コンパイルがボトルネックとなるモノレポにおけるビルドシステムの高速化に関連する技術です。
Source: https://github.com/mvm-sh/mvm
awizemann/harness
Harnessは、iOS Simulator・macOSネイティブアプリ・Webアプリを対象としたLLM駆動の自動UIテストツールです。オペレーターは平易な言語でゴールを記述し(例:「ログインして新しいプロジェクトを作成する」)、エージェントループがそのゴールをUIアクションに変換し、accessibility APIまたはWebDriver経由でそれらを実行し、結果として得られる状態を観察しながら、ゴール達成または失敗まで処理を継続します。出力は合否の assertion ではなく、エージェントが詰まった箇所・リトライした箇所・失敗した箇所をまとめた「フリクションレポート」です。これは従来のスクリプトベースUIオートメーション(XCTest、Playwright)よりも探索的テストに近いアプローチです。技術スタックはmacOS 14+上のSwift 6であり、エージェントループにモダンなSwift並行処理モデル(async/await、structured concurrency)を活用し、ブリッジレイヤー不要でシミュレーターとのインタラクションにネイティブのXCTest/Accessibility APIを使用できます。LLM統合は、生のスクリーンショットではなくアプリのaccessibility階層を構造化入力としてモデルに渡す、vision-language modelまたはaccessibility-tree-as-contextアプローチに従っている可能性が高いですが、どちらのアプローチも考えられます。提供価値は、決定論的な assertion では表現しにくいものの、アプリを操作するユーザーには明らかなUXリグレッションを検出する点にあり、ユニットテストや integration test の代替ではなく補完的なツールとして位置づけられます。
Source: https://github.com/awizemann/harness
openlake-project/openlake
OpenLakeはGPUデータ投入のボトルネック、すなわちGPU演算が分散ストレージからのトレーニングデータ到着を待つ間アイドル状態になるという問題を解決することを目指しています。「GPUワークロード向けの超高効率ストレージ」というコンセプトは、深層学習パイプラインの特定のアクセスパターン、つまり大規模なシーケンシャルリード、多数のGPUワーカーからの高い並行性、ファイルあたりのメタデータオーバーヘッドの最小化を念頭に設計されたオブジェクトストアまたはファイルシステムを指しています。アーキテクチャには、ランダムアクセスではなくシーケンシャルスキャンに最適化されたカスタムストレージフォーマット、プリフェッチを考慮したスケジューリング、そしてデータパスにおけるCPU関与を削減するためのRDMAまたはGPUDirectサポートが含まれる可能性があります。「驚異的な速度」という主張は、様々なバッチサイズにおけるsamples/sec、bytes/secといった具体的なベンチマークにより、FUSEマウントされたS3、NFS、あるいはIBM Storage ScaleやNVIDIA Magnum IOといった専用の代替手段と比較して評価される必要があります。これはWebDataset、MosaicMLのStreamingDataset、Googleのtf.data serviceと同じ問題領域ですが、dataset APIではなくストレージレイヤーとして位置づけられています。I/Oスループットが演算ではなくボトルネックとなっている大規模事前学習を実行しているMLインフラチームに関連します。
Source: https://github.com/openlake-project/openlake
esengine/DeepSeek-Reasonix
DeepSeekモデルに特化して構築されたターミナルベースのAIコーディングエージェントであり、主要なエンジニアリング上の差別化要因はprefix-cacheの安定性にあります。DeepSeekのKV-cacheプレフィックスキャッシングは、プロンプトのプレフィックスがターン間で一定に保たれている場合に最も効率的に機能します。動的なコンテンツ(タイムスタンプ、ターンカウンター、可変コンテキスト)をシステムプロンプトの先頭に追加するエージェントは、キャッシュの局所性を壊し、すべてのリクエストでフルprefillコストが発生します。Reasonixは、システムプロンプトとツール定義を静的に保つよう設計されており、長いセッション全体でキャッシュヒット率を高く維持します。これにより、長いエージェントタスクを「実行したまま放置する」ことが現実的になり、トークンあたりのコストが膨らむことがありません。アーキテクチャは標準的なtool-callingエージェントループ(シェル・ファイル・コードツールを通じた観察・計画・実行)ですが、プロンプト構築の規律がコアとなる貢献です。2053スターを獲得しており、DeepSeekユーザーコミュニティで大きな支持を集めています。キャッシュの局所性を意識したプロンプトエンジニアリングが最重要課題となる、キャッシングプロキシ(例:SGLangのRadixAttentionやvLLMのprefix caching)を用いてDeepSeek推論をセルフホストしているチームにとって検討する価値があります。ターミナルインターフェースにより、ContinueやCursorといったWebベースの代替手段と比較して運用上のフットプリントを最小限に抑えています。
Source: https://github.com/esengine/DeepSeek-Reasonix
t8y2/dbx
dbx は、MySQL、PostgreSQL、SQLite、Redis、MongoDB、DuckDB、ClickHouse、SQL Server、およびその他のバックエンドをサポートする15 MBのクロスプラットフォームデータベースGUIクライアントです。小さなバイナリサイズが主要な技術的特徴であり、比較として、DBeaverのインストーラーは約100 MB、TablePlusも同程度です。これを実現するには、おそらく非Electronビルド(ネイティブUIツールキット、またはフルChromiumをバンドルしない最小限のWebViewラッパー)と慎重な依存関係の管理が必要です。リレーショナル(MySQL、Postgres、SQLite、SQL Server)、カラム指向(DuckDB、ClickHouse)、ドキュメント(MongoDB)、キーバリュー(Redis)といった異種バックエンドを単一クライアントでサポートするには、根本的に異なるワイヤープロトコル間でクエリ実行、結果スキーマ、メタデータ操作を正規化するドライバー抽象化レイヤーが必要です。1411というスター数は、同分野の重量級クライアント(DBeaver、TablePlus、DataGrip)に対する軽量でポータブルな代替手段への本物の需要を示しています。異種データスタックを単一のツールで扱いたい開発者、数百MBのインストールを避けたい場合、あるいはElectronベースのツールのインストールが制限されている環境において特に有用です。DuckDBとClickHouseのサポートは、GUIクエリツールによってCLIよりも反復作業の時間を節約できる、アナリティクス重視のワークフローにおいて特筆すべき点です。
Source: https://github.com/t8y2/dbx